mirror of
https://github.com/huggingface/trl.git
synced 2025-10-20 18:43:52 +08:00
Compare commits
109 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| d06b131097 | |||
| f3230902b1 | |||
| bbc7eeb29c | |||
| 163dae5579 | |||
| 64c8db2f9a | |||
| 25d4d81801 | |||
| 685620ac6c | |||
| 2b531b9223 | |||
| 4f7f73dd09 | |||
| c60c41688e | |||
| cbb98dabb1 | |||
| a86eaab8e8 | |||
| aa9770c6bd | |||
| 0fe603eca1 | |||
| 843c14574f | |||
| 009b82412f | |||
| 82c8f20601 | |||
| b56e8b3277 | |||
| 0161a8e602 | |||
| 6e34c5932b | |||
| e1531aa526 | |||
| cb6c45474a | |||
| fe55b440e7 | |||
| 431456732c | |||
| 9679d87012 | |||
| 099f0bf42b | |||
| 33f88ead0b | |||
| 7705daa672 | |||
| fe49697e66 | |||
| d1ad5405cb | |||
| 1e88b84ab9 | |||
| c39207460f | |||
| 61af5f26b6 | |||
| 7a89a43c3f | |||
| fead2c8c77 | |||
| b4bb12992e | |||
| b21baddc5c | |||
| 216c119fa9 | |||
| a2747acc0f | |||
| b61a4b95a0 | |||
| 5c5d7687d8 | |||
| 096f5e9da5 | |||
| 2a0ed3a596 | |||
| ff13c5bc6d | |||
| d3e05d6490 | |||
| fadffc22bc | |||
| d405c87068 | |||
| b46716c4f5 | |||
| ec8a5b7679 | |||
| 376d152d3f | |||
| ef57cddbc3 | |||
| 20111ad03a | |||
| a4793c2ede | |||
| 0ddf9f657f | |||
| 3138ef6f5a | |||
| a5b0414f63 | |||
| e174bd50a5 | |||
| 86c117404c | |||
| a94761a02c | |||
| 5fb5af7c34 | |||
| 25fa1bd880 | |||
| 6916e0d2df | |||
| 1704a864e7 | |||
| e547c392f9 | |||
| a31bad83fb | |||
| 31cc361d17 | |||
| ab453ec183 | |||
| 933c91cc66 | |||
| ffad0a19d0 | |||
| e0172fc8ec | |||
| dec9993129 | |||
| c85cdbdbd0 | |||
| e59cce9f81 | |||
| c60fd915c1 | |||
| 08f550674c | |||
| 52fecee883 | |||
| 3cfe194e34 | |||
| ad325152cc | |||
| 1f29725381 | |||
| 23a06c94b8 | |||
| 5c24d5bb2e | |||
| 503ac5d82c | |||
| ce37eadcfa | |||
| 160d0c9d6c | |||
| d1c7529328 | |||
| fc468e0f35 | |||
| 131e5cdd10 | |||
| bb4a9800fa | |||
| 3804a72e6c | |||
| a004b02c4a | |||
| 8b234479bc | |||
| cf20878113 | |||
| d8ae4d08c6 | |||
| a2749d9e0c | |||
| ed87942a47 | |||
| 734624274d | |||
| 237eb9c6a5 | |||
| 2672a942a6 | |||
| b5cce0d13e | |||
| 0b165e60bc | |||
| 404621f0f9 | |||
| 89df6abf21 | |||
| 9523474490 | |||
| 1620da371a | |||
| 9b60207f0b | |||
| a6ebdb6e75 | |||
| 9c3e9e43d0 | |||
| 0610711dda | |||
| 24627e9c89 |
3
.github/workflows/build_documentation.yml
vendored
3
.github/workflows/build_documentation.yml
vendored
@ -16,4 +16,5 @@ jobs:
|
||||
repo_owner: lvwerra
|
||||
version_tag_suffix: ""
|
||||
secrets:
|
||||
token: ${{ secrets.HUGGINGFACE_PUSH }}
|
||||
token: ${{ secrets.HUGGINGFACE_PUSH }}
|
||||
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
|
||||
33
.github/workflows/clear_cache.yml
vendored
Normal file
33
.github/workflows/clear_cache.yml
vendored
Normal file
@ -0,0 +1,33 @@
|
||||
name: "Cleanup Cache"
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: "0 0 * * *"
|
||||
|
||||
jobs:
|
||||
cleanup:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: Cleanup
|
||||
run: |
|
||||
gh extension install actions/gh-actions-cache
|
||||
|
||||
REPO=${{ github.repository }}
|
||||
|
||||
echo "Fetching list of cache key"
|
||||
cacheKeysForPR=$(gh actions-cache list -R $REPO | cut -f 1 )
|
||||
|
||||
## Setting this to not fail the workflow while deleting cache keys.
|
||||
set +e
|
||||
echo "Deleting caches..."
|
||||
for cacheKey in $cacheKeysForPR
|
||||
do
|
||||
gh actions-cache delete $cacheKey -R $REPO --confirm
|
||||
done
|
||||
echo "Done"
|
||||
env:
|
||||
GH_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
14
.github/workflows/delete_doc_comment.yml
vendored
14
.github/workflows/delete_doc_comment.yml
vendored
@ -1,13 +1,13 @@
|
||||
name: Delete dev documentation
|
||||
name: Delete doc comment
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
types: [ closed ]
|
||||
|
||||
workflow_run:
|
||||
workflows: ["Delete doc comment trigger"]
|
||||
types:
|
||||
- completed
|
||||
|
||||
jobs:
|
||||
delete:
|
||||
uses: huggingface/doc-builder/.github/workflows/delete_doc_comment.yml@main
|
||||
with:
|
||||
pr_number: ${{ github.event.number }}
|
||||
package: trl
|
||||
secrets:
|
||||
comment_bot_token: ${{ secrets.COMMENT_BOT_TOKEN }}
|
||||
12
.github/workflows/delete_doc_comment_trigger.yml
vendored
Normal file
12
.github/workflows/delete_doc_comment_trigger.yml
vendored
Normal file
@ -0,0 +1,12 @@
|
||||
name: Delete doc comment trigger
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
types: [ closed ]
|
||||
|
||||
|
||||
jobs:
|
||||
delete:
|
||||
uses: huggingface/doc-builder/.github/workflows/delete_doc_comment_trigger.yml@main
|
||||
with:
|
||||
pr_number: ${{ github.event.number }}
|
||||
27
.github/workflows/stale.yml
vendored
Normal file
27
.github/workflows/stale.yml
vendored
Normal file
@ -0,0 +1,27 @@
|
||||
name: Stale Bot
|
||||
|
||||
on:
|
||||
schedule:
|
||||
- cron: "0 15 * * *"
|
||||
|
||||
jobs:
|
||||
close_stale_issues:
|
||||
name: Close Stale Issues
|
||||
if: github.repository == 'lvwerra/trl'
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: Install requirements
|
||||
run: |
|
||||
pip install PyGithub
|
||||
- name: Close stale issues
|
||||
run: |
|
||||
python scripts/stale.py
|
||||
32
.github/workflows/tests.yml
vendored
32
.github/workflows/tests.yml
vendored
@ -7,28 +7,30 @@ on:
|
||||
branches: [ main ]
|
||||
|
||||
jobs:
|
||||
|
||||
check_code_quality:
|
||||
runs-on: ubuntu-latest
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: [3.9]
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
- uses: actions/checkout@v2
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install .[dev]
|
||||
- name: Check quality
|
||||
run: |
|
||||
make quality
|
||||
fetch-depth: 0
|
||||
submodules: recursive
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
- uses: pre-commit/action@v2.0.3
|
||||
with:
|
||||
extra_args: --all-files
|
||||
|
||||
tests:
|
||||
needs: check_code_quality
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: [3.7, 3.8, 3.9]
|
||||
python-version: ['3.8', '3.9', '3.10']
|
||||
os: ['ubuntu-latest', 'macos-latest', 'windows-latest']
|
||||
runs-on: ${{ matrix.os }}
|
||||
steps:
|
||||
@ -37,6 +39,10 @@ jobs:
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
cache: "pip"
|
||||
cache-dependency-path: |
|
||||
setup.py
|
||||
requirements.txt
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
|
||||
16
.github/workflows/upload_pr_documentation.yml
vendored
Normal file
16
.github/workflows/upload_pr_documentation.yml
vendored
Normal file
@ -0,0 +1,16 @@
|
||||
name: Upload PR Documentation
|
||||
|
||||
on:
|
||||
workflow_run:
|
||||
workflows: ["Build PR Documentation"]
|
||||
types:
|
||||
- completed
|
||||
|
||||
jobs:
|
||||
build:
|
||||
uses: huggingface/doc-builder/.github/workflows/upload_pr_documentation.yml@main
|
||||
with:
|
||||
package_name: trl
|
||||
secrets:
|
||||
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
|
||||
comment_bot_token: ${{ secrets.COMMENT_BOT_TOKEN }}
|
||||
42
.pre-commit-config.yaml
Normal file
42
.pre-commit-config.yaml
Normal file
@ -0,0 +1,42 @@
|
||||
repos:
|
||||
- repo: https://github.com/PyCQA/isort
|
||||
rev: 5.12.0
|
||||
hooks:
|
||||
- id: isort
|
||||
args:
|
||||
- --profile=black
|
||||
- --skip-glob=wandb/**/*
|
||||
- --thirdparty=wandb
|
||||
- repo: https://github.com/myint/autoflake
|
||||
rev: v1.4
|
||||
hooks:
|
||||
- id: autoflake
|
||||
args:
|
||||
- -r
|
||||
- --exclude=wandb,__init__.py
|
||||
- --in-place
|
||||
- --remove-unused-variables
|
||||
- --remove-all-unused-imports
|
||||
- repo: https://github.com/python/black
|
||||
rev: 22.3.0
|
||||
hooks:
|
||||
- id: black
|
||||
args:
|
||||
- --line-length=119
|
||||
- --target-version=py38
|
||||
- --exclude=wandb
|
||||
- repo: https://github.com/pycqa/flake8
|
||||
rev: 6.0.0
|
||||
hooks:
|
||||
- id: flake8
|
||||
args:
|
||||
- --ignore=E203,E501,W503,E128
|
||||
- --max-line-length=119
|
||||
|
||||
# - repo: https://github.com/codespell-project/codespell
|
||||
# rev: v2.1.0
|
||||
# hooks:
|
||||
# - id: codespell
|
||||
# args:
|
||||
# - --ignore-words-list=nd,reacher,thist,ths,magent,ba
|
||||
# - --skip=docs/css/termynal.css,docs/js/termynal.js
|
||||
@ -36,10 +36,15 @@ First you want to make sure that all the tests pass:
|
||||
make test
|
||||
```
|
||||
|
||||
Then before submitting your PR make sure the code quality follows the standards. You can run the following command to format and test:
|
||||
Then before submitting your PR make sure the code quality follows the standards. You can run the following command to format:
|
||||
|
||||
```bash
|
||||
make style && make quality
|
||||
make precommit
|
||||
```
|
||||
|
||||
Make sure to install `pre-commit` before running the command:
|
||||
```bash
|
||||
pip install pre-commit
|
||||
```
|
||||
|
||||
## Do you want to contribute to the documentation?
|
||||
|
||||
12
Makefile
12
Makefile
@ -1,15 +1,9 @@
|
||||
.PHONY: quality style test
|
||||
.PHONY: test precommit
|
||||
|
||||
check_dirs := examples tests trl
|
||||
|
||||
test:
|
||||
python -m pytest -n auto --dist=loadfile -s -v ./tests/
|
||||
|
||||
quality:
|
||||
black --check --line-length 119 --target-version py38 $(check_dirs)
|
||||
isort --check-only $(check_dirs)
|
||||
flake8 $(check_dirs)
|
||||
|
||||
style:
|
||||
black --line-length 119 --target-version py38 $(check_dirs)
|
||||
isort $(check_dirs)
|
||||
precommit:
|
||||
pre-commit run --all-files
|
||||
|
||||
91
README.md
91
README.md
@ -3,18 +3,38 @@
|
||||
</div>
|
||||
|
||||
# TRL - Transformer Reinforcement Learning
|
||||
> Train transformer language models with reinforcement learning.
|
||||
> Full stack transformer language models with reinforcement learning.
|
||||
|
||||
<p align="center">
|
||||
<a href="https://github.com/lvwerra/trl/blob/main/LICENSE">
|
||||
<img alt="License" src="https://img.shields.io/github/license/lvwerra/trl.svg?color=blue">
|
||||
</a>
|
||||
<a href="https://huggingface.co/docs/trl/index">
|
||||
<img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/trl/index.svg?down_color=red&down_message=offline&up_message=online">
|
||||
</a>
|
||||
<a href="https://github.com/lvwerra/trl/releases">
|
||||
<img alt="GitHub release" src="https://img.shields.io/github/release/lvwerra/trl.svg">
|
||||
</a>
|
||||
</p>
|
||||
|
||||
|
||||
## What is it?
|
||||
With `trl` you can train transformer language models with Proximal Policy Optimization (PPO). The library is built on top of the [`transformers`](https://github.com/huggingface/transformers) library by 🤗 Hugging Face. Therefore, pre-trained language models can be directly loaded via `transformers`. At this point most of decoder architectures and encoder-decoder architectures are supported.
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/TRL-readme.png">
|
||||
</div>
|
||||
|
||||
`trl` is a full stack library where we provide a set of tools to train transformer language models with Reinforcement Learning, from the Supervised Fine-tuning step (SFT), Reward Modeling step (RM) to the Proximal Policy Optimization (PPO) step. The library is built on top of the [`transformers`](https://github.com/huggingface/transformers) library by 🤗 Hugging Face. Therefore, pre-trained language models can be directly loaded via `transformers`. At this point most of decoder architectures and encoder-decoder architectures are supported. Refer to the documentation or the `examples/` folder for example code snippets and how to run these tools.
|
||||
|
||||
**Highlights:**
|
||||
- `PPOTrainer`: A PPO trainer for language models that just needs (query, response, reward) triplets to optimise the language model.
|
||||
- `AutoModelForCausalLMWithValueHead` & `AutoModelForSeq2SeqLMWithValueHead`: A transformer model with an additional scalar output for each token which can be used as a value function in reinforcement learning.
|
||||
- Example: Train GPT2 to generate positive movie reviews with a BERT sentiment classifier.
|
||||
|
||||
## How it works
|
||||
- [`SFTTrainer`](https://huggingface.co/docs/trl/sft_trainer): A light and friendly wrapper around `transformers` Trainer to easily fine-tune language models or adapters on a custom dataset.
|
||||
- [`RewardTrainer`](https://huggingface.co/docs/trl/reward_trainer): A light wrapper around `transformers` Trainer to easily fine-tune language models for human preferences (Reward Modeling).
|
||||
- [`PPOTrainer`](https://huggingface.co/docs/trl/trainer#trl.PPOTrainer): A PPO trainer for language models that just needs (query, response, reward) triplets to optimise the language model.
|
||||
- [`AutoModelForCausalLMWithValueHead`](https://huggingface.co/docs/trl/models#trl.AutoModelForCausalLMWithValueHead) & [`AutoModelForSeq2SeqLMWithValueHead`](https://huggingface.co/docs/trl/models#trl.AutoModelForSeq2SeqLMWithValueHead): A transformer model with an additional scalar output for each token which can be used as a value function in reinforcement learning.
|
||||
- [Examples](https://github.com/lvwerra/trl/tree/main/examples): Train GPT2 to generate positive movie reviews with a BERT sentiment classifier, full RLHF using adapters only, train GPT-j to be less toxic, [Stack-Llama example](https://huggingface.co/blog/stackllama), etc.
|
||||
|
||||
## How PPO works
|
||||
Fine-tuning a language model via PPO consists of roughly three steps:
|
||||
|
||||
1. **Rollout**: The language model generates a response or continuation based on query which could be the start of a sentence.
|
||||
@ -52,8 +72,59 @@ pip install -e .
|
||||
|
||||
## How to use
|
||||
|
||||
### Example
|
||||
This is a basic example on how to use the library. Based on a query the language model creates a response which is then evaluated. The evaluation could be a human in the loop or another model's output.
|
||||
### `SFTTrainer`
|
||||
|
||||
This is a basic example on how to use the `SFTTrainer` from the library. The `SFTTrainer` is a light wrapper around the `transformers` Trainer to easily fine-tune language models or adapters on a custom dataset.
|
||||
|
||||
```python
|
||||
# imports
|
||||
from datasets import load_dataset
|
||||
from trl import SFTTrainer
|
||||
|
||||
# get dataset
|
||||
dataset = load_dataset("imdb", split="train")
|
||||
|
||||
# get trainer
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
train_dataset=dataset,
|
||||
dataset_text_field="text",
|
||||
max_seq_length=512,
|
||||
)
|
||||
|
||||
# train
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
### `RewardTrainer`
|
||||
|
||||
This is a basic example on how to use the `RewardTrainer` from the library. The `RewardTrainer` is a wrapper around the `transformers` Trainer to easily fine-tune reward models or adapters on a custom preference dataset.
|
||||
|
||||
```python
|
||||
# imports
|
||||
from transformers import AutoModelForSequenceClassification, AutoTokenizer
|
||||
from trl import RewardTrainer
|
||||
|
||||
# load model and dataset - dataset needs to be in a specific format
|
||||
model = AutoModelForSequenceClassification.from_pretrained("gpt2")
|
||||
tokenizer = AutoTokenizer.from_pretrained("gpt2")
|
||||
|
||||
...
|
||||
|
||||
# load trainer
|
||||
trainer = RewardTrainer(
|
||||
model=model,
|
||||
tokenizer=tokenizer,
|
||||
train_dataset=dataset,
|
||||
)
|
||||
|
||||
# train
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
### `PPOTrainer`
|
||||
|
||||
This is a basic example on how to use the `PPOTrainer` from the library. Based on a query the language model creates a response which is then evaluated. The evaluation could be a human in the loop or another model's output.
|
||||
|
||||
```python
|
||||
# imports
|
||||
@ -78,7 +149,7 @@ query_txt = "This morning I went to the "
|
||||
query_tensor = tokenizer.encode(query_txt, return_tensors="pt")
|
||||
|
||||
# get model response
|
||||
response_tensor = respond_to_batch(model_ref, query_tensor)
|
||||
response_tensor = respond_to_batch(model, query_tensor)
|
||||
|
||||
# create a ppo trainer
|
||||
ppo_trainer = PPOTrainer(ppo_config, model, model_ref, tokenizer)
|
||||
@ -99,6 +170,8 @@ For a detailed example check out the example python script `examples/sentiment/s
|
||||
<p style="text-align: center;"> <b>Figure:</b> A few review continuations before and after optimisation. </p>
|
||||
</div>
|
||||
|
||||
Have a look at more examples inside [`examples/`](https://github.com/lvwerra/trl/tree/main/examples) folder.
|
||||
|
||||
## References
|
||||
|
||||
### Proximal Policy Optimisation
|
||||
|
||||
96
benchmark/benchmark.py
Normal file
96
benchmark/benchmark.py
Normal file
@ -0,0 +1,96 @@
|
||||
import argparse
|
||||
import math
|
||||
import os
|
||||
import shlex
|
||||
import subprocess
|
||||
import uuid
|
||||
from distutils.util import strtobool
|
||||
|
||||
|
||||
def parse_args():
|
||||
# fmt: off
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--command", type=str, default="",
|
||||
help="the command to run")
|
||||
parser.add_argument("--num-seeds", type=int, default=3,
|
||||
help="the number of random seeds")
|
||||
parser.add_argument("--start-seed", type=int, default=1,
|
||||
help="the number of the starting seed")
|
||||
parser.add_argument("--workers", type=int, default=0,
|
||||
help="the number of workers to run benchmark experimenets")
|
||||
parser.add_argument("--auto-tag", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
|
||||
help="if toggled, the runs will be tagged with git tags, commit, and pull request number if possible")
|
||||
parser.add_argument("--slurm-template-path", type=str, default=None,
|
||||
help="the path to the slurm template file (see docs for more details)")
|
||||
parser.add_argument("--slurm-gpus-per-task", type=int, default=1,
|
||||
help="the number of gpus per task to use for slurm jobs")
|
||||
parser.add_argument("--slurm-total-cpus", type=int, default=50,
|
||||
help="the number of gpus per task to use for slurm jobs")
|
||||
parser.add_argument("--slurm-ntasks", type=int, default=1,
|
||||
help="the number of tasks to use for slurm jobs")
|
||||
parser.add_argument("--slurm-nodes", type=int, default=None,
|
||||
help="the number of nodes to use for slurm jobs")
|
||||
args = parser.parse_args()
|
||||
# fmt: on
|
||||
return args
|
||||
|
||||
|
||||
def run_experiment(command: str):
|
||||
command_list = shlex.split(command)
|
||||
print(f"running {command}")
|
||||
fd = subprocess.Popen(command_list)
|
||||
return_code = fd.wait()
|
||||
assert return_code == 0
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parse_args()
|
||||
|
||||
commands = []
|
||||
for seed in range(0, args.num_seeds):
|
||||
commands += [" ".join([args.command, "--seed", str(args.start_seed + seed)])]
|
||||
|
||||
print("======= commands to run:")
|
||||
for command in commands:
|
||||
print(command)
|
||||
|
||||
if args.workers > 0 and args.slurm_template_path is None:
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
|
||||
executor = ThreadPoolExecutor(max_workers=args.workers, thread_name_prefix="cleanrl-benchmark-worker-")
|
||||
for command in commands:
|
||||
executor.submit(run_experiment, command)
|
||||
executor.shutdown(wait=True)
|
||||
else:
|
||||
print("not running the experiments because --workers is set to 0; just printing the commands to run")
|
||||
|
||||
# SLURM logic
|
||||
if args.slurm_template_path is not None:
|
||||
if not os.path.exists("slurm"):
|
||||
os.makedirs("slurm")
|
||||
if not os.path.exists("slurm/logs"):
|
||||
os.makedirs("slurm/logs")
|
||||
print("======= slurm commands to run:")
|
||||
with open(args.slurm_template_path) as f:
|
||||
slurm_template = f.read()
|
||||
slurm_template = slurm_template.replace("{{array}}", f"0-{len(commands) - 1}%{args.workers}")
|
||||
slurm_template = slurm_template.replace(
|
||||
"{{seeds}}", f"({' '.join([str(args.start_seed + int(seed)) for seed in range(args.num_seeds)])})"
|
||||
)
|
||||
slurm_template = slurm_template.replace("{{len_seeds}}", f"{args.num_seeds}")
|
||||
slurm_template = slurm_template.replace("{{command}}", args.command)
|
||||
slurm_template = slurm_template.replace("{{gpus_per_task}}", f"{args.slurm_gpus_per_task}")
|
||||
total_gpus = args.slurm_gpus_per_task * args.slurm_ntasks
|
||||
slurm_cpus_per_gpu = math.ceil(args.slurm_total_cpus / total_gpus)
|
||||
slurm_template = slurm_template.replace("{{cpus_per_gpu}}", f"{slurm_cpus_per_gpu}")
|
||||
slurm_template = slurm_template.replace("{{ntasks}}", f"{args.slurm_ntasks}")
|
||||
if args.slurm_nodes is not None:
|
||||
slurm_template = slurm_template.replace("{{nodes}}", f"#SBATCH --nodes={args.slurm_nodes}")
|
||||
else:
|
||||
slurm_template = slurm_template.replace("{{nodes}}", "")
|
||||
filename = str(uuid.uuid4())
|
||||
open(os.path.join("slurm", f"{filename}.slurm"), "w").write(slurm_template)
|
||||
slurm_path = os.path.join("slurm", f"{filename}.slurm")
|
||||
print(f"saving command in {slurm_path}")
|
||||
if args.workers > 0:
|
||||
run_experiment(f"sbatch {slurm_path}")
|
||||
16
benchmark/trl.slurm_template
Normal file
16
benchmark/trl.slurm_template
Normal file
@ -0,0 +1,16 @@
|
||||
#!/bin/bash
|
||||
#SBATCH --partition=dev-cluster
|
||||
#SBATCH --gpus-per-task={{gpus_per_task}}
|
||||
#SBATCH --cpus-per-gpu={{cpus_per_gpu}}
|
||||
#SBATCH --ntasks={{ntasks}}
|
||||
#SBATCH --mem-per-cpu=11G
|
||||
#SBATCH --output=slurm/logs/%x_%j.out
|
||||
#SBATCH --array={{array}}
|
||||
|
||||
{{nodes}}
|
||||
|
||||
seeds={{seeds}}
|
||||
seed=${seeds[$SLURM_ARRAY_TASK_ID % {{len_seeds}}]}
|
||||
|
||||
echo "Running task $SLURM_ARRAY_TASK_ID with seed: $seed"
|
||||
srun {{command}} --seed $seed
|
||||
@ -7,20 +7,32 @@
|
||||
title: Installation
|
||||
- local: customization
|
||||
title: Customize your training
|
||||
- local: logging
|
||||
title: Understanding logs
|
||||
title: Get started
|
||||
- sections:
|
||||
- local: models
|
||||
title: Model Classes
|
||||
- local: trainer
|
||||
title: Trainer Classes
|
||||
- local: reward_trainer
|
||||
title: Training your own reward model
|
||||
- local: sft_trainer
|
||||
title: Supervised fine-tuning
|
||||
- local: extras
|
||||
title: Extras - Better model output without reinforcement learning
|
||||
title: API
|
||||
- sections:
|
||||
- local: sentiment_tuning
|
||||
title: Sentiment Tuning
|
||||
- local: sentiment_tuning_peft
|
||||
- local: lora_tuning_peft
|
||||
title: Peft support - Low rank adaption of 8 bit models
|
||||
- local: summarization_reward_tuning
|
||||
title: Summarization Reward Tuning
|
||||
- local: detoxifying_a_lm
|
||||
title: Detoxifying a Language Model
|
||||
- local: using_llama_models
|
||||
title: Using LLaMA with TRL
|
||||
- local: multi_adapter_rl
|
||||
title: Multi Adapter RL (MARL) - a single base model for everything
|
||||
title: Examples
|
||||
|
||||
@ -2,6 +2,22 @@
|
||||
|
||||
At `trl` we provide the possibility to give enough modularity to users to be able to efficiently customize the training loop for their needs. Below are some examples on how you can apply and test different techniques.
|
||||
|
||||
## Run on multiple GPUs / nodes
|
||||
|
||||
We leverage `accelerate` to enable users to run their training on multiple GPUs or nodes. You should first create your accelerate config by simply running:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
Then make sure you have selected multi-gpu / multi-node setup. You can then run your training by simply running:
|
||||
|
||||
```bash
|
||||
accelerate launch your_script.py
|
||||
```
|
||||
|
||||
Refer to the [examples page](https://github.com/lvwerra/trl/tree/main/examples) for more details
|
||||
|
||||
## Use different optimizers
|
||||
|
||||
By default, the `PPOTrainer` creates a `torch.optim.Adam` optimizer. You can create and define a different optimizer and pass it to `PPOTrainer`:
|
||||
@ -63,7 +79,7 @@ optimizer = Lion(filter(lambda p: p.requires_grad, self.model.parameters()), lr=
|
||||
...
|
||||
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer, optimizer=optimizer)
|
||||
```
|
||||
We advice you to use the learning rate that you would use for `Adam` divided by 3 as pointed out [here](https://github.com/lucidrains/lion-pytorch#lion---pytorch). We observed an improvement when using this optimizer compared to classic Adam (check the full logs [here](https://wandb.ai/distill-bloom/trl/runs/lj4bheke?workspace=user-younesbelkada)):
|
||||
We advise you to use the learning rate that you would use for `Adam` divided by 3 as pointed out [here](https://github.com/lucidrains/lion-pytorch#lion---pytorch). We observed an improvement when using this optimizer compared to classic Adam (check the full logs [here](https://wandb.ai/distill-bloom/trl/runs/lj4bheke?workspace=user-younesbelkada)):
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-lion.png">
|
||||
@ -90,7 +106,7 @@ config = PPOConfig(**ppo_config)
|
||||
|
||||
# 2. Create optimizer
|
||||
optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate)
|
||||
lr_scheduler = lr_scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
|
||||
lr_scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
|
||||
|
||||
# 3. initialize trainer
|
||||
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer, optimizer=optimizer, lr_scheduler=lr_scheduler)
|
||||
@ -149,4 +165,33 @@ When training large models, you should better handle the CUDA cache by iterative
|
||||
|
||||
```python
|
||||
config = PPOConfig(..., optimize_cuda_cache=True)
|
||||
```
|
||||
```
|
||||
|
||||
## Use correctly DeepSpeed stage 3:
|
||||
|
||||
A small tweak need to be added to your training script to use DeepSpeed stage 3 correctly. You need to properly initialize your reward model on the correct device using the `zero3_init_context_manager` context manager. Here is an example adapted for the `gpt2-sentiment` script:
|
||||
|
||||
```python
|
||||
ds_plugin = ppo_trainer.accelerator.state.deepspeed_plugin
|
||||
if ds_plugin is not None and ds_plugin.is_zero3_init_enabled():
|
||||
with ds_plugin.zero3_init_context_manager(enable=False):
|
||||
sentiment_pipe = pipeline("sentiment-analysis", model="lvwerra/distilbert-imdb", device=device)
|
||||
else:
|
||||
sentiment_pipe = pipeline("sentiment-analysis", model="lvwerra/distilbert-imdb", device=device)
|
||||
```
|
||||
|
||||
## Use torch distributed
|
||||
torch.distributed package provides PyTorch natives method to distribute a network over several machines (mostly useful if there are several GPU nodes). It copies the model on each GPU, runs the forward and backward on each and then applies the mean of gradient of all GPUs for each one. If running torch 1.XX, you can call `torch.distributed.launch`, like
|
||||
|
||||
`python -m torch.distributed.launch --nproc_per_node=1 reward_summarization.py --bf16`
|
||||
|
||||
For torch 2.+ `torch.distributed.launch` is deprecated and one needs to run:
|
||||
`torchrun --nproc_per_node=1 reward_summarization.py --bf16`
|
||||
or
|
||||
`python -m torch.distributed.run --nproc_per_node=1 reward_summarization.py --bf16`
|
||||
|
||||
Note that using `python -m torch.distributed.launch --nproc_per_node=1 reward_summarization.py --bf16` with torch 2.0 ends in
|
||||
```
|
||||
ValueError: Some specified arguments are not used by the HfArgumentParser: ['--local-rank=0']
|
||||
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 194889) of binary: /home/ubuntu/miniconda3/envs/trl/bin/python
|
||||
```
|
||||
|
||||
72
docs/source/extras.mdx
Normal file
72
docs/source/extras.mdx
Normal file
@ -0,0 +1,72 @@
|
||||
# Extras: Alternative ways to get better model output without RL based fine-tuning
|
||||
|
||||
Within the extras module is the `best-of-n` sampler class that serves as an alternative method of generating better model output.
|
||||
As to how it fares against the RL based fine-tuning, please look in the `examples` directory for a comparison example
|
||||
|
||||
## Usage
|
||||
|
||||
To get started quickly, instantiate an instance of the class with a model, a length sampler, a tokenizer and a callable that serves as a proxy reward pipeline that outputs reward scores for input queries
|
||||
|
||||
```python
|
||||
|
||||
from transformers import pipeline, AutoTokenizer
|
||||
from trl import AutoModelForCausalLMWithValueHead
|
||||
from trl.core import LengthSampler
|
||||
from trl.extras import BestOfNSampler
|
||||
|
||||
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained(ref_model_name)
|
||||
reward_pipe = pipeline("sentiment-analysis", model=reward_model, device=device)
|
||||
tokenizer = AutoTokenizer.from_pretrained(ref_model_name)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
|
||||
# callable that takes a list of raw text and returns a list of corresponding reward scores
|
||||
def queries_to_scores(list_of_strings):
|
||||
return [output["score"] for output in reward_pipe(list_of_strings)]
|
||||
|
||||
best_of_n = BestOfNSampler(model, tokenizer, queries_to_scores, length_sampler=output_length_sampler)
|
||||
|
||||
|
||||
```
|
||||
|
||||
And assuming you have a list/tensor of tokenized queries, you can generate better output by calling the `generate` method
|
||||
|
||||
```python
|
||||
|
||||
best_of_n.generate(query_tensors, device=device, **gen_kwargs)
|
||||
|
||||
```
|
||||
The default sample size is 4, but you can change it at the time of instance initialization like so
|
||||
|
||||
```python
|
||||
|
||||
best_of_n = BestOfNSampler(model, tokenizer, queries_to_scores, length_sampler=output_length_sampler, sample_size=8)
|
||||
|
||||
```
|
||||
|
||||
The default output is the result of taking the top scored output for each query, but you can change it to top 2 and so on by passing the `n_candidates` argument at the time of instance initialization
|
||||
|
||||
```python
|
||||
|
||||
best_of_n = BestOfNSampler(model, tokenizer, queries_to_scores, length_sampler=output_length_sampler, n_candidates=2)
|
||||
|
||||
```
|
||||
|
||||
There is the option of setting the generation settings (like `temperature`, `pad_token_id`) at the time of instance creation as opposed to when calling the `generate` method.
|
||||
This is done by passing a `GenerationConfig` from the `transformers` library at the time of initialization
|
||||
|
||||
```python
|
||||
|
||||
from transformers import GenerationConfig
|
||||
|
||||
generation_config = GenerationConfig(min_length= -1, top_k=0.0, top_p= 1.0, do_sample= True, pad_token_id=tokenizer.eos_token_id)
|
||||
|
||||
best_of_n = BestOfNSampler(model, tokenizer, queries_to_scores, length_sampler=output_length_sampler, generation_config=generation_config)
|
||||
|
||||
best_of_n.generate(query_tensors, device=device)
|
||||
|
||||
```
|
||||
|
||||
Furthermore, at the time of initialization you can set the seed to control repeatability of the generation process and the number of samples to generate for each query
|
||||
|
||||
|
||||
29
docs/source/logging.mdx
Normal file
29
docs/source/logging.mdx
Normal file
@ -0,0 +1,29 @@
|
||||
# Logging
|
||||
|
||||
As reinforcement learning algorithms are historically challenging to debug, it's important to pay careful attention to logging.
|
||||
By default, the TRL [`PPOTrainer`] saves a lot of relevant information to `wandb` or `tensorboard`.
|
||||
|
||||
Upon initialization, pass one of these two options to the [`PPOConfig`]:
|
||||
```
|
||||
config = PPOConfig(
|
||||
model_name=args.model_name,
|
||||
log_with=`wandb`, # or `tensorboard`
|
||||
)
|
||||
```
|
||||
If you want to log with tensorboard, add the kwarg `project_kwargs={"logging_dir": PATH_TO_LOGS}` to the PPOConfig.
|
||||
|
||||
## PPO Logging
|
||||
|
||||
### Crucial values
|
||||
During training, many values are logged, here are the most important ones:
|
||||
|
||||
1. `env/reward_mean`,`env/reward_std`, `env/reward_dist`: the properties of the reward distribution from the "environment".
|
||||
2. `ppo/mean_scores`: The mean scores directly out of the reward model.
|
||||
3. `ppo/mean_non_score_reward`: The mean negated KL penalty during training (shows the delta between the reference model and the new policy over the batch in the step)
|
||||
|
||||
### Training stability parameters:
|
||||
Here are some parameters that are useful to monitor for stability (when these diverge or collapse to 0, try tuning variables):
|
||||
|
||||
1. `ppo/loss/value`: The value function loss -- will spike / NaN when not going well.
|
||||
2. `ppo/val/clipfrac`: The fraction of clipped values in the value function loss. This is often from 0.3 to 0.6.
|
||||
3. `objective/kl_coef`: The target coefficient with [`AdaptiveKLController`]. Often increases before numerical instabilities.
|
||||
143
docs/source/lora_tuning_peft.mdx
Normal file
143
docs/source/lora_tuning_peft.mdx
Normal file
@ -0,0 +1,143 @@
|
||||
# Examples of using peft with trl to finetune 8-bit models with Low Rank Adaption (LoRA)
|
||||
|
||||
The notebooks and scripts in this examples show how to use Low Rank Adaptation (LoRA) to fine-tune models in a memory efficient manner. Most of PEFT methods supported in peft library but note that some PEFT methods such as Prompt tuning are not supported.
|
||||
For more information on LoRA, see the [original paper](https://arxiv.org/abs/2106.09685).
|
||||
|
||||
Here's an overview of the `peft`-enabled notebooks and scripts in the [trl repository](https://github.com/lvwerra/trl/tree/main/examples):
|
||||
|
||||
| File | Task | Description | Colab link |
|
||||
|---|---| --- |
|
||||
| [`gpt2-sentiment_peft.py`](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt2-sentiment_peft.py) | Sentiment | Same as the sentiment analysis example, but learning a low rank adapter on a 8-bit base model | |
|
||||
| [`cm_finetune_peft_imdb.py`](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/cm_finetune_peft_imdb.py) | Sentiment | Fine tuning a low rank adapter on a frozen 8-bit model for text generation on the imdb dataset. | |
|
||||
| [`merge_peft_adapter.py`](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/merge_peft_adapter.py) | 🤗 Hub | Merging of the adapter layers into the base model’s weights and storing these on the hub. | |
|
||||
| [`gpt-neo-20b_sentiment_peft.py`](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/gpt-neo-20b_sentiment_peft.py) | Sentiment | Sentiment fine-tuning of a low rank adapter to create positive reviews. | |
|
||||
| [`gpt-neo-1b_peft.py`](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neo-1b-multi-gpu/gpt-neo-1b_peft.py) | Sentiment | Sentiment fine-tuning of a low rank adapter to create positive reviews using 2 GPUs. | |
|
||||
| [`stack_llama/rl_training.py`](https://github.com/lvwerra/trl/blob/main/examples/stack_llama/scripts/rl_training.py) | RLHF | Distributed fine-tuning of the 7b parameter LLaMA models with a learned reward model and `peft`. | |
|
||||
| [`stack_llama/reward_modeling.py`](https://github.com/lvwerra/trl/blob/main/examples/stack_llama/scripts/reward_modeling.py) | Reward Modeling | Distributed training of the 7b parameter LLaMA reward model with `peft`. | |
|
||||
| [`stack_llama/supervised_finetuning.py`](https://github.com/lvwerra/trl/blob/main/examples/stack_llama/scripts/supervised_finetuning.py) | SFT | Distributed instruction/supervised fine-tuning of the 7b parameter LLaMA model with `peft`. | |
|
||||
|
||||
## Installation
|
||||
Note: peft is in active development, so we install directly from their Github page.
|
||||
Peft also relies on the latest version of transformers.
|
||||
|
||||
```bash
|
||||
pip install trl[peft]
|
||||
pip install bitsandbytes loralib
|
||||
pip install git+https://github.com/huggingface/transformers.git@main
|
||||
#optional: wandb
|
||||
pip install wandb
|
||||
```
|
||||
|
||||
Note: if you don't want to log with `wandb` remove `log_with="wandb"` in the scripts/notebooks. You can also replace it with your favourite experiment tracker that's [supported by `accelerate`](https://huggingface.co/docs/accelerate/usage_guides/tracking).
|
||||
|
||||
## How to use it?
|
||||
|
||||
Simply declare a `PeftConfig` object in your script and pass it through `.from_pretrained` to load the TRL+PEFT model.
|
||||
|
||||
```python
|
||||
from peft import LoraConfig
|
||||
from trl import AutoModelForCausalLMWithValueHead
|
||||
|
||||
model_id = "edbeeching/gpt-neo-125M-imdb"
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
model_id,
|
||||
peft_config=lora_config,
|
||||
)
|
||||
```
|
||||
And if you want to load your model in 8bit precision:
|
||||
```python
|
||||
pretrained_model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
config.model_name,
|
||||
load_in_8bit=True,
|
||||
peft_config=lora_config,
|
||||
)
|
||||
```
|
||||
... or in 4bit precision:
|
||||
```python
|
||||
pretrained_model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
config.model_name,
|
||||
peft_config=lora_config,
|
||||
load_in_4bit=True,
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
## Launch scripts
|
||||
|
||||
The `trl` library is powered by `accelerate`. As such it is best to configure and launch trainings with the following commands:
|
||||
|
||||
```bash
|
||||
accelerate config # will prompt you to define the training configuration
|
||||
accelerate launch scripts/gpt2-sentiment_peft.py # launches training
|
||||
```
|
||||
|
||||
## Using `trl` + `peft` and Data Parallelism
|
||||
|
||||
You can scale up to as many GPUs as you want, as long as you are able to fit the training process in a single device. The only tweak you need to apply is to load the model as follows:
|
||||
```python
|
||||
from peft import LoraConfig
|
||||
...
|
||||
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
pretrained_model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
config.model_name,
|
||||
peft_config=lora_config,
|
||||
)
|
||||
```
|
||||
And if you want to load your model in 8bit precision:
|
||||
```python
|
||||
pretrained_model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
config.model_name,
|
||||
peft_config=lora_config,
|
||||
load_in_8bit=True,
|
||||
)
|
||||
```
|
||||
... or in 4bit precision:
|
||||
```python
|
||||
pretrained_model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
config.model_name,
|
||||
peft_config=lora_config,
|
||||
load_in_4bit=True,
|
||||
)
|
||||
```
|
||||
Finally, make sure that the rewards are computed on correct device as well, for that you can use `ppo_trainer.model.current_device`.
|
||||
|
||||
## Naive pipeline parallelism (NPP) for large models (>60B models)
|
||||
|
||||
The `trl` library also supports naive pipeline parallelism (NPP) for large models (>60B models). This is a simple way to parallelize the model across multiple GPUs.
|
||||
This paradigm, termed as "Naive Pipeline Parallelism" (NPP) is a simple way to parallelize the model across multiple GPUs. We load the model and the adapters across multiple GPUs and the activations and gradients will be naively communicated across the GPUs. This supports `int8` models as well as other `dtype` models.
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-npp.png">
|
||||
</div>
|
||||
|
||||
### How to use NPP?
|
||||
|
||||
Simply load your model with a custom `device_map` argument on the `from_pretrained` to split your model across multiple devices. Check out this [nice tutorial](https://github.com/huggingface/blog/blob/main/accelerate-large-models.md) on how to properly create a `device_map` for your model.
|
||||
|
||||
Also make sure to have the `lm_head` module on the first GPU device as it may throw an error if it is not on the first device. As this time of writing, you need to install the `main` branch of `accelerate`: `pip install git+https://github.com/huggingface/accelerate.git@main` and `peft`: `pip install git+https://github.com/huggingface/peft.git@main`.
|
||||
|
||||
That all you need to do to use NPP. Check out the [gpt-neo-1b_peft.py](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neo-1b-multi-gpu/gpt-neo-1b_peft.py) example for a more details usage of NPP.
|
||||
|
||||
### Launch scripts
|
||||
|
||||
Although `trl` library is powered by `accelerate`, you should run your training script in a single process. Note that we do not support Data Parallelism together with NPP yet.
|
||||
|
||||
```bash
|
||||
python PATH_TO_SCRIPT
|
||||
```
|
||||
100
docs/source/multi_adapter_rl.mdx
Normal file
100
docs/source/multi_adapter_rl.mdx
Normal file
@ -0,0 +1,100 @@
|
||||
# Multi Adapter RL (MARL) - a single base model for everything
|
||||
|
||||
Here we present an approach that uses a single base model for the entire PPO algorithm - which includes retrieving the reference logits, computing the active logits and the rewards. This feature is experimental as we did not tested the convergence of the approach. We encourage the community to let us know if they potentially face into any issue.
|
||||
|
||||
## Requirements
|
||||
|
||||
You just need to install `peft` and optionally install `bitsandbytes` as well if you want to go for 8bit base models, for more memory efficient finetuning.
|
||||
|
||||
## Summary
|
||||
|
||||
You need to address this approach in three stages that we summarize as follows:
|
||||
|
||||
1- Train a base model on the target domain (e.g. `imdb` dataset) - this is the Supervised Fine Tuning stage - it can leverage the `SFTTrainer` from TRL.
|
||||
2- Train a reward model using `peft`. This is required in order to re-use the adapter during the RL optimisation process (step 3 below). We show an example of leveraging the `RewardTrainer` from TRL in [this example](https://github.com/lvwerra/trl/tree/main/examples/0-abstraction-RL/reward_modeling.py)
|
||||
3- Fine tune new adapters on the base model using PPO and the reward adapter. ("0 abstraction RL")
|
||||
|
||||
Make sure to use the same model (i.e. same architecure and same weights) for the stages 2 & 3.
|
||||
|
||||
## Quickstart
|
||||
|
||||
Let us assume you have trained your reward adapter on `llama-7b` model using `RewardTrainer` and pushed the weights on the hub under `trl-lib/llama-7b-hh-rm-adapter`.
|
||||
When doing PPO, before passing the model to `PPOTrainer` create your model as follows:
|
||||
|
||||
```python
|
||||
model_name = "huggyllama/llama-7b"
|
||||
rm_adapter_id = "trl-lib/llama-7b-hh-rm-adapter"
|
||||
|
||||
# PPO adapter
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
model_name,
|
||||
peft_config=lora_config,
|
||||
reward_adapter=rm_adapter_id,
|
||||
)
|
||||
|
||||
...
|
||||
trainer = PPOTrainer(
|
||||
model=model,
|
||||
...
|
||||
)
|
||||
|
||||
...
|
||||
```
|
||||
Then inside your PPO training loop, call the `compute_reward_score` method by accessing to the `model` attribute from `PPOTrainer`.
|
||||
|
||||
```python
|
||||
rewards = trainer.model.compute_reward_score(**inputs)
|
||||
```
|
||||
|
||||
## Advanced usage
|
||||
|
||||
### Control on the adapter name
|
||||
|
||||
If you are familiar with the `peft` library, you know that you can use multiple adapters inside the same model. What you can do is to train multiple adapters on the same base model to fine-tune on different policies.
|
||||
In this case, you want to have a control on the adapter name you want to activate back, after retrieving the reward. For that, simply pass the appropriate `adapter_name` to `ppo_adapter_name` argument when calling `compute_reward_score`.
|
||||
|
||||
```python
|
||||
adapter_name_policy_1 = "policy_1"
|
||||
rewards = trainer.model.compute_reward_score(**inputs, ppo_adapter_name=adapter_name_policy_1)
|
||||
...
|
||||
```
|
||||
|
||||
### Using 4-bit and 8-bit base models
|
||||
|
||||
For more memory efficient fine-tuning, you can load your base model in 8-bit or 4-bit while keeping the adapters in the default precision (float32).
|
||||
Just pass the appropriate arguments (i.e. `load_in_8bit=True` or `load_in_4bit=True`) to `AutoModelForCausalLMWithValueHead.from_pretrained` as follows (assuming you have installed `bitsandbytes`):
|
||||
```python
|
||||
model_name = "llama-7b"
|
||||
rm_adapter_id = "trl-lib/llama-7b-hh-rm-adapter"
|
||||
|
||||
# PPO adapter
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
model_name,
|
||||
peft_config=lora_config,
|
||||
reward_adapter=rm_adapter_id,
|
||||
load_in_8bit=True,
|
||||
)
|
||||
|
||||
...
|
||||
trainer = PPOTrainer(
|
||||
model=model,
|
||||
...
|
||||
)
|
||||
...
|
||||
```
|
||||
@ -19,30 +19,40 @@ The following code illustrates the steps above.
|
||||
# 0. imports
|
||||
import torch
|
||||
from transformers import GPT2Tokenizer
|
||||
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
|
||||
from trl.core import respond_to_batch
|
||||
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer
|
||||
|
||||
|
||||
# 1. load a pretrained model
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
|
||||
model_ref = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
|
||||
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
|
||||
model_ref = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
|
||||
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
# 2. initialize trainer
|
||||
ppo_config = {'batch_size': 1}
|
||||
ppo_config = {"batch_size": 1}
|
||||
config = PPOConfig(**ppo_config)
|
||||
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer)
|
||||
|
||||
# 3. encode a query
|
||||
query_txt = "This morning I went to the "
|
||||
query_tensor = tokenizer.encode(query_txt, return_tensors="pt")
|
||||
query_tensor = tokenizer.encode(query_txt, return_tensors="pt").to(model.pretrained_model.device)
|
||||
|
||||
# 4. generate model response
|
||||
response_tensor = respond_to_batch(model, query_tensor)
|
||||
response_txt = tokenizer.decode(response_tensor[0,:])
|
||||
generation_kwargs = {
|
||||
"min_length": -1,
|
||||
"top_k": 0.0,
|
||||
"top_p": 1.0,
|
||||
"do_sample": True,
|
||||
"pad_token_id": tokenizer.eos_token_id,
|
||||
"max_new_tokens": 20,
|
||||
}
|
||||
response_tensor = ppo_trainer.generate([item for item in query_tensor], return_prompt=False, **generation_kwargs)
|
||||
response_txt = tokenizer.decode(response_tensor[0])
|
||||
|
||||
# 5. define a reward for response
|
||||
# (this could be any reward such as human feedback or output from another model)
|
||||
reward = [torch.tensor(1.0)]
|
||||
reward = [torch.tensor(1.0, device=model.pretrained_model.device)]
|
||||
|
||||
# 6. train model with ppo
|
||||
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
|
||||
|
||||
61
docs/source/reward_trainer.mdx
Normal file
61
docs/source/reward_trainer.mdx
Normal file
@ -0,0 +1,61 @@
|
||||
# Reward Modeling
|
||||
|
||||
TRL supports custom reward modeling for anyone to perform reward modeling on their dataset and model.
|
||||
|
||||
## Expected dataset format
|
||||
|
||||
The reward trainer expects a very specific format for the dataset. Since the model will be trained to predict which sentence is the most relevant, given two sentences. We provide an example from the [`Anthropic/hh-rlhf`](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset below:
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/rlhf-antropic-example.png", width="50%">
|
||||
</div>
|
||||
|
||||
Therefore the final dataset object should contain two 4 entries at least if you use the default `RewardDataCollatorWithPadding` data collator. The entries should be named:
|
||||
|
||||
- `input_ids_chosen`
|
||||
- `attention_mask_chosen`
|
||||
- `input_ids_rejected`
|
||||
- `attention_mask_rejected`
|
||||
|
||||
The `j` and `k` suffixes are used to denote the two sentences in the paired dataset.
|
||||
|
||||
## Using the `RewardTrainer`
|
||||
|
||||
After standardizing your dataset, you can use the `RewardTrainer` as a classic HugingFace Trainer.
|
||||
You should pass an `AutoModelForSequenceClassification` model to the `RewardTrainer`.
|
||||
|
||||
### Leveraging the `peft` library to train a reward model
|
||||
|
||||
Just pass a `peft_config` in the key word arguments of `RewardTrainer`, and the trainer should automatically take care of converting the model into a PEFT model!
|
||||
|
||||
```python
|
||||
from peft import LoraConfig, task_type
|
||||
from transformers import AutoModelForSequenceClassification, AutoTokenizer, TrainingArguments
|
||||
from trl import RewardTrainer
|
||||
|
||||
model = AutoModelForSequenceClassification.from_pretrained("gpt2")
|
||||
peft_config = LoraConfig(
|
||||
task_type=TaskType.SEQ_CLS,
|
||||
inference_mode=False,
|
||||
r=8,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.1,
|
||||
)
|
||||
|
||||
...
|
||||
|
||||
trainer = RewardTrainer(
|
||||
model=model,
|
||||
args=training_args,
|
||||
tokenizer=tokenizer,
|
||||
train_dataset=dataset,
|
||||
peft_config=peft_config,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
```
|
||||
|
||||
## RewardTrainer
|
||||
|
||||
[[autodoc]] RewardTrainer
|
||||
@ -1,82 +0,0 @@
|
||||
# Examples of using peft and trl to finetune 8-bit models with Low Rank Adaption
|
||||
|
||||
The notebooks and scripts in this examples show how to fine-tune a model with a sentiment classifier (such as `lvwerra/distilbert-imdb`).
|
||||
|
||||
Here's an overview of the notebooks and scripts in the [trl repository](https://github.com/lvwerra/trl/tree/main/examples):
|
||||
|
||||
| File | Description | Colab link |
|
||||
|---|---| --- |
|
||||
| [`gpt2-sentiment_peft.py`](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt2-sentiment_peft.py) | Same as the sentiment analysis example, but learning a low rank adapter on a 8-bit base model | |
|
||||
| [`cm_finetune_peft_imdb.py`](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/cm_finetune_peft_imdb.py) | Fine tuning a Low Rank Adapter on a frozen 8-bit model for text generation on the imdb dataset. | |
|
||||
| [`merge_peft_adapter.py`](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/merge_peft_adapter.py) | Merging of the adapter layers into the base model’s weights and storing these on the hub. | |
|
||||
| [`gpt-neo-20b_sentiment_peft.py`](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/gpt-neo-20b_sentiment_peft.py) | Sentiment fine-tuning of a Low Rank Adapter to create positive reviews. | |
|
||||
| [`gpt-neo-1b_peft.py`](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neo-1b-multi-gpu/gpt-neo-1b_peft.py) | Sentiment fine-tuning of a Low Rank Adapter to create positive reviews using 2 GPUs. | |
|
||||
|
||||
## Installation
|
||||
Note: peft is in active development, so we install directly from their github page.
|
||||
Peft also relies on the latest version of transformers.
|
||||
|
||||
```bash
|
||||
pip install trl[peft]
|
||||
pip install bitsandbytes loralib
|
||||
pip install git+https://github.com/huggingface/transformers.git@main
|
||||
#optional: wandb
|
||||
pip install wandb
|
||||
```
|
||||
|
||||
Note: if you don't want to log with `wandb` remove `log_with="wandb"` in the scripts/notebooks. You can also replace it with your favourite experiment tracker that's [supported by `accelerate`](https://huggingface.co/docs/accelerate/usage_guides/tracking).
|
||||
|
||||
|
||||
## Launch scripts
|
||||
|
||||
The `trl` library is powered by `accelerate`. As such it is best to configure and launch trainings with the following commands:
|
||||
|
||||
```bash
|
||||
accelerate config # will prompt you to define the training configuration
|
||||
accelerate launch scripts/gpt2-sentiment_peft.py # launches training
|
||||
```
|
||||
|
||||
## Using `trl` + `peft` and Data Parallelism
|
||||
|
||||
You can scale up to as many GPUs as you want, as long as you are able to fit the training process in a single device. The only tweak you need to apply is to load the model as follows:
|
||||
```python
|
||||
from accelerate import Accelerator
|
||||
...
|
||||
|
||||
current_device = Accelerator().process_index
|
||||
|
||||
pretrained_model = AutoModelForCausalLM.from_pretrained(
|
||||
config.model_name, load_in_8bit=True, device_map={"": current_device}
|
||||
)
|
||||
```
|
||||
The reason behind `device_map={"": current_device}` is that when you set `"":device_number`, `accelerate` will set the entire model on the `device_number` device. Therefore this trick enables to set the model on the correct device for each process.
|
||||
|
||||
As the `Accelerator` object from `accelerate` will take care of initializing the distributed setup correctly.
|
||||
Make sure to initialize your accelerate config by specifying that you are training in a multi-gpu setup, by running `accelerate config` and make sure to run the training script with `accelerator launch your_script.py`.
|
||||
|
||||
Finally make sure that the rewards are computed on `current_device` as well.
|
||||
|
||||
## Naive pipeline parallelism (NPP) for large models (>60B models)
|
||||
|
||||
The `trl` library also supports naive pipeline parallelism (NPP) for large models (>60B models). This is a simple way to parallelize the model across multiple GPUs.
|
||||
This paradigm, termed as "Naive Pipeline Parallelism" (NPP) is a simple way to parallelize the model across multiple GPUs. We load the model and the adapters across multiple GPUs and the activations and gradients will be naively communicated across the GPUs. This supports `int8` models as well as other `dtype` models.
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-npp.png">
|
||||
</div>
|
||||
|
||||
### How to use NPP?
|
||||
|
||||
Simply load your model with a custom `device_map` argument on the `from_pretrained` to split your model across multiple devices. Check out this [nice tutorial](https://github.com/huggingface/blog/blob/main/accelerate-large-models.md) on how to properly create a `device_map` for your model.
|
||||
|
||||
Also make sure to have the `lm_head` module on the first GPU device as it may throw an error if it is not on the first device. As this time of writing, you need to install the `main` branch of `accelerate`: `pip install git+https://github.com/huggingface/accelerate.git@main` and `peft`: `pip install git+https://github.com/huggingface/peft.git@main`.
|
||||
|
||||
That all you need to do to use NPP. Check out the [gpt-neo-1b_peft.py](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neo-1b-multi-gpu/gpt-neo-1b_peft.py) example for a more details usage of NPP.
|
||||
|
||||
### Launch scripts
|
||||
|
||||
Although `trl` library is powered by `accelerate`, you should run your training script in a single process. Note that we do not support Data Parallelism together with NPP yet.
|
||||
|
||||
```bash
|
||||
python PATH_TO_SCRIPT
|
||||
```
|
||||
248
docs/source/sft_trainer.mdx
Normal file
248
docs/source/sft_trainer.mdx
Normal file
@ -0,0 +1,248 @@
|
||||
# Supervised Fine-tuning Trainer
|
||||
|
||||
Supervised fine-tuning (or SFT for short) is a crucial step in RLHF. In TRL we provide an easy-to-use API to create your SFT models and train them with few lines of code on your dataset.
|
||||
|
||||
## Quickstart
|
||||
|
||||
If you have a dataset hosted on the 🤗 Hub, you can easily fine-tune your SFT model using [`SFTTrainer`] from TRL. Let us assume your dataset is `imdb`, the text you want to predict is inside the `text` field of the dataset, and you want to fine-tune the `facebook/opt-350m` model.
|
||||
The following code-snippet takes care of all the data pre-processing and training for you:
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
from trl import SFTTrainer
|
||||
|
||||
dataset = load_dataset("imdb", split="train")
|
||||
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
train_dataset=dataset,
|
||||
dataset_text_field="text",
|
||||
max_seq_length=512,
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
Make sure to pass a correct value for `max_seq_length` as the default value will be set to `min(tokenizer.model_max_length, 1024)`.
|
||||
|
||||
You can also construct a model outside of the trainer and pass it as follows:
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
from datasets import load_dataset
|
||||
from trl import SFTTrainer
|
||||
|
||||
dataset = load_dataset("imdb", split="train")
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model,
|
||||
train_dataset=dataset,
|
||||
dataset_text_field="text",
|
||||
max_seq_length=512,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
The above snippets will use the default training arguments from the [`transformers.TrainingArguments`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) class. If you want to modify that, make sure to create your own `TrainingArguments` object and pass it to the [`SFTTrainer`] constructor as it is done on the [`supervised_finetuning.py` script](https://github.com/lvwerra/trl/blob/main/examples/stack_llama/scripts/supervised_finetuning.py) on the stack-llama example.
|
||||
|
||||
## Advanced usage
|
||||
|
||||
### Format your input prompts
|
||||
|
||||
For instruction fine-tuning, it is quite common to have two columns inside the dataset: one for the prompt & the other for the response.
|
||||
This allows people to format examples like [Stanford-Alpaca](https://github.com/tatsu-lab/stanford_alpaca) did as follows:
|
||||
```bash
|
||||
Below is an instruction ...
|
||||
|
||||
### Instruction
|
||||
{prompt}
|
||||
|
||||
### Response:
|
||||
{completion}
|
||||
```
|
||||
Let us assume your dataset has two fields, `question` and `answer`. Therefore you can just run:
|
||||
```python
|
||||
...
|
||||
def formatting_prompts_func(example):
|
||||
output_texts = []
|
||||
for i in range(len(example['question'])):
|
||||
text = f"### Question: {example['question'][i]}\n ### Answer: {example['answer'][i]}"
|
||||
output_texts.append(text)
|
||||
return output_texts
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model,
|
||||
train_dataset=dataset,
|
||||
formatting_func=formatting_prompts_func,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
To preperly format your input make sure to process all the examples by looping over them and returning a list of processed text. Check out a full example on how to use SFTTrainer on alpaca dataset [here](https://github.com/lvwerra/trl/pull/444#issue-1760952763)
|
||||
|
||||
### Packing dataset ([`ConstantLengthDataset`])
|
||||
|
||||
[`SFTTrainer`] supports _example packing_, where multiple short examples are packed in the same input sequence to increase training efficiency. This is done with the [`ConstantLengthDataset`] utility class that returns constant length chunks of tokens from a stream of examples. To enable the usage of this dataset class, simply pass `packing=True` to the [`SFTTrainer`] constructor.
|
||||
|
||||
```python
|
||||
...
|
||||
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
train_dataset=dataset,
|
||||
dataset_text_field="text",
|
||||
packing=True
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
Note that if you use a packed dataset and if you pass `max_steps` in the training arguments you will probably train your models for more than few epochs, depending on the way you have configured the packed dataset and the training protocol. Double check that you know and understand what you are doing.
|
||||
|
||||
#### Customize your prompts using packed dataset
|
||||
|
||||
If your dataset has several fields that you want to combine, for example if the dataset has `question` and `answer` fields and you want to combine them, you can pass a formatting function to the trainer that will take care of that. For example:
|
||||
|
||||
```python
|
||||
def formatting_func(example):
|
||||
text = f"### Question: {example['question']}\n ### Answer: {example['answer']}"
|
||||
return text
|
||||
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
train_dataset=dataset,
|
||||
packing=True,
|
||||
formatting_func=formatting_func
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
You can also customize the [`ConstantLengthDataset`] much more by directly passing the arguments to the [`SFTTrainer`] constructor. Please refer to that class' signature for more information.
|
||||
|
||||
### Control over the pretrained model
|
||||
|
||||
You can directly pass the kwargs of the `from_pretrained()` method to the [`SFTTrainer`]. For example, if you want to load a model in a different precision, analoguous to
|
||||
|
||||
```python
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.bfloat16)
|
||||
|
||||
```python
|
||||
...
|
||||
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
train_dataset=dataset,
|
||||
dataset_text_field="text",
|
||||
torch_dtype=torch.bfloat16,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
Note that all keyword arguments of `from_pretrained()` are supported.
|
||||
|
||||
### Training adapters
|
||||
|
||||
We also support a tight integration with 🤗 PEFT library so that any user can conveniently train adapters and share them on the Hub instead of training the entire model
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
from trl import SFTTrainer
|
||||
from peft import LoraConfig
|
||||
|
||||
dataset = load_dataset("imdb", split="train")
|
||||
|
||||
peft_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
"EleutherAI/gpt-neo-125m",
|
||||
train_dataset=dataset,
|
||||
dataset_text_field="text",
|
||||
peft_config=peft_config
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
Note that in case of training adapters, we manually add a saving callback to automatically save the adapters only:
|
||||
```python
|
||||
class PeftSavingCallback(TrainerCallback):
|
||||
def on_save(self, args, state, control, **kwargs):
|
||||
checkpoint_path = os.path.join(args.output_dir, f"checkpoint-{state.global_step}")
|
||||
kwargs["model"].save_pretrained(checkpoint_path)
|
||||
|
||||
if "pytorch_model.bin" in os.listdir(checkpoint_path):
|
||||
os.remove(os.path.join(checkpoint_path, "pytorch_model.bin"))
|
||||
```
|
||||
If you want to add more callbacks, make sure to add this one as well to properly save the adapters only during training.
|
||||
```python
|
||||
...
|
||||
|
||||
callbacks = [YourCustomCallback(), PeftSavingCallback()]
|
||||
|
||||
trainer = SFTTrainer(
|
||||
"EleutherAI/gpt-neo-125m",
|
||||
train_dataset=dataset,
|
||||
dataset_text_field="text",
|
||||
torch_dtype=torch.bfloat16,
|
||||
peft_config=peft_config,
|
||||
callbacks=callbacks
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
### Training adapters with base 8 bit models
|
||||
|
||||
For that you need to first load your 8bit model outside the Trainer and pass a `PeftConfig` to the trainer. For example:
|
||||
|
||||
```python
|
||||
...
|
||||
|
||||
peft_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
"EleutherAI/gpt-neo-125m",
|
||||
load_in_8bit=True,
|
||||
device_map="auto",
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model,
|
||||
train_dataset=dataset,
|
||||
dataset_text_field="text",
|
||||
torch_dtype=torch.bfloat16,
|
||||
peft_config=peft_config,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Best practices
|
||||
|
||||
Pay attention to the following best practices when training a model with that trainer:
|
||||
|
||||
- [`SFTTrainer`] always pads by default the sequences to the `max_seq_length` argument of the [`SFTTrainer`]. If none is passed, the trainer will retrieve that value from the tokenizer. Some tokenizers do not provide default value, so there is a check to retrieve the minimum between 2048 and that value. Make sure to check it before training.
|
||||
- For training adapters in 8bit, you might need to tweak the arguments of the `prepare_model_for_int8_training` method from PEFT, hence we advise users to use `prepare_in_int8_kwargs` field, or create the `PeftModel` outside the [`SFTTrainer`] and pass it.
|
||||
- For a more memory-efficient training using adapters, you can load the base model in 8bit, for that simply add `load_in_8bit` argument when creating the [`SFTTrainer`], or create a base model in 8bit outside the trainer and pass it.
|
||||
- If you create a model outside the trainer, make sure to not pass to the trainer any additional keyword arguments that are relative to `from_pretrained()` method.
|
||||
|
||||
## SFTTrainer
|
||||
|
||||
[[autodoc]] SFTTrainer
|
||||
|
||||
## ConstantLengthDataset
|
||||
|
||||
[[autodoc]] trainer.ConstantLengthDataset
|
||||
@ -2,6 +2,7 @@
|
||||
|
||||
At TRL we support PPO (Proximal Policy Optimisation) with an implementation that largely follows the structure introduced in the paper "Fine-Tuning Language Models from Human Preferences" by D. Ziegler et al. [[paper](https://arxiv.org/pdf/1909.08593.pdf), [code](https://github.com/openai/lm-human-preferences)].
|
||||
The Trainer and model classes are largely inspired from `transformers.Trainer` and `transformers.AutoModel` classes and adapted for RL.
|
||||
We also support a `RewardTrainer` that can be used to train a reward model.
|
||||
|
||||
## PPOConfig
|
||||
|
||||
@ -11,6 +12,10 @@ The Trainer and model classes are largely inspired from `transformers.Trainer` a
|
||||
|
||||
[[autodoc]] PPOTrainer
|
||||
|
||||
## RewardTrainer
|
||||
|
||||
[[autodoc]] RewardTrainer
|
||||
|
||||
## set_seed
|
||||
|
||||
[[autodoc]] set_seed
|
||||
|
||||
160
docs/source/using_llama_models.mdx
Normal file
160
docs/source/using_llama_models.mdx
Normal file
@ -0,0 +1,160 @@
|
||||
# Using LLaMA models with TRL
|
||||
|
||||
We've begun rolling out examples to use Meta's LLaMA models in `trl` (see [Meta's LLaMA release](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) for the original LLaMA model).
|
||||
|
||||
## Efficient training strategies
|
||||
|
||||
Even training the smallest LLaMA model requires an enormous amount of memory. Some quick math: in bf16, every parameter uses 2 bytes (in fp32 4 bytes) in addition to 8 bytes used, e.g., in the Adam optimizer (see the [performance docs](https://huggingface.co/docs/transformers/perf_train_gpu_one#optimizer) in Transformers for more info). So a 7B parameter model would use `(2+8)*7B=70GB` just to fit in memory and would likely need more when you compute intermediate values such as attention scores. So you couldn’t train the model even on a single 80GB A100 like that. You can use some tricks, like more efficient optimizers of half-precision training, to squeeze a bit more into memory, but you’ll run out sooner or later.
|
||||
|
||||
Another option is to use Parameter-Efficient Fine-Tuning (PEFT) techniques, such as the [`peft`](https://github.com/huggingface/peft) library, which can perform low-rank adaptation (LoRA) on a model loaded in 8-bit.
|
||||
For more on `peft` + `trl`, see the [docs](https://huggingface.co/docs/trl/sentiment_tuning_peft).
|
||||
|
||||
Loading the model in 8bit reduces the memory footprint drastically since you only need one byte per parameter for the weights (e.g. 7B LlaMa is 7GB in memory).
|
||||
Instead of training the original weights directly, LoRA adds small adapter layers on top of some specific layers (usually the attention layers); thus, the number of trainable parameters is drastically reduced.
|
||||
|
||||
In this scenario, a rule of thumb is to allocate ~1.2-1.4GB per billion parameters (depending on the batch size and sequence length) to fit the entire fine-tuning setup.
|
||||
This enables fine-tuning larger models (up to 50-60B scale models on a NVIDIA A100 80GB) at low cost.
|
||||
|
||||
Now we can fit very large models into a single GPU, but the training might still be very slow.
|
||||
The simplest strategy in this scenario is data parallelism: we replicate the same training setup into separate GPUs and pass different batches to each GPU.
|
||||
With this, you can parallelize the forward/backward passes of the model and scale with the number of GPUs.
|
||||
|
||||
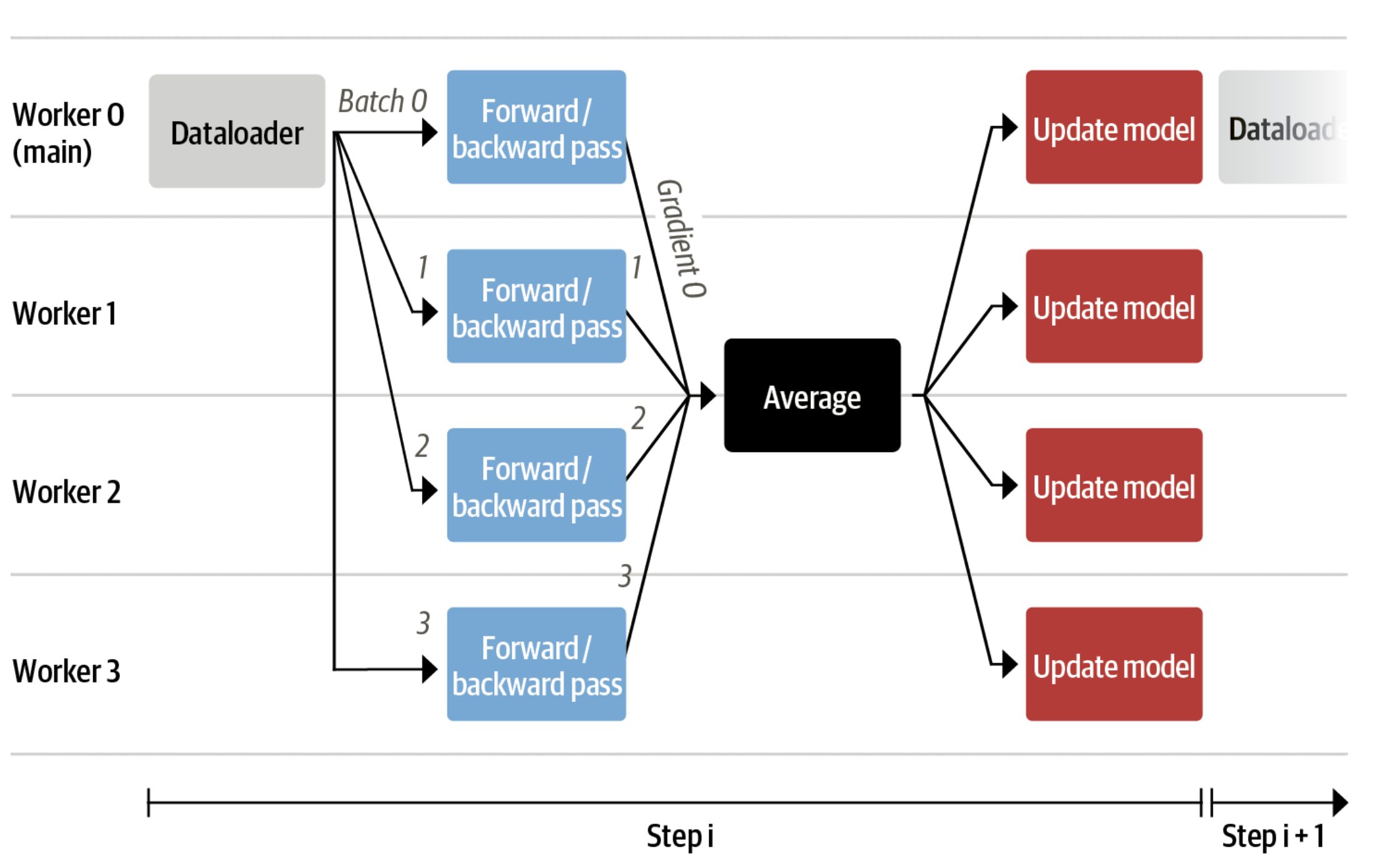
|
||||
|
||||
We use either the `transformers.Trainer` or `accelerate`, which both support data parallelism without any code changes, by simply passing arguments when calling the scripts with `torchrun` or `accelerate launch`. The following runs a training script with 8 GPUs on a single machine with `accelerate` and `torchrun`, respectively.
|
||||
|
||||
```bash
|
||||
accelerate launch --multi_gpu --num_machines 1 --num_processes 8 my_accelerate_script.py
|
||||
torchrun --nnodes 1 --nproc_per_node 8 my_torch_script.py
|
||||
```
|
||||
|
||||
## Supervised fine-tuning
|
||||
|
||||
Before we start training reward models and tuning our model with RL, it helps if the model is already good in the domain we are interested in.
|
||||
In our case, we want it to answer questions, while for other use cases, we might want it to follow instructions, in which case instruction tuning is a great idea.
|
||||
The easiest way to achieve this is by continuing to train the language model with the language modeling objective on texts from the domain or task.
|
||||
The [StackExchange dataset](https://huggingface.co/datasets/HuggingFaceH4/stack-exchange-preferences) is enormous (over 10 million instructions), so we can easily train the language model on a subset of it.
|
||||
|
||||
There is nothing special about fine-tuning the model before doing RLHF - it’s just the causal language modeling objective from pretraining that we apply here.
|
||||
To use the data efficiently, we use a technique called packing: instead of having one text per sample in the batch and then padding to either the longest text or the maximal context of the model, we concatenate a lot of texts with a EOS token in between and cut chunks of the context size to fill the batch without any padding.
|
||||
|
||||
|
||||
|
||||
With this approach the training is much more efficient as each token that is passed through the model is also trained in contrast to padding tokens which are usually masked from the loss.
|
||||
If you don't have much data and are more concerned about occasionally cutting off some tokens that are overflowing the context you can also use a classical data loader.
|
||||
|
||||
The packing is handled by the `ConstantLengthDataset` and we can then use the `Trainer` after loading the model with `peft`. First, we load the model in int8, prepare it for training, and then add the LoRA adapters.
|
||||
|
||||
```python
|
||||
# load model in 8bit
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
args.model_path,
|
||||
load_in_8bit=True,
|
||||
device_map={"": Accelerator().local_process_index}
|
||||
)
|
||||
model = prepare_model_for_int8_training(model)
|
||||
|
||||
# add LoRA to model
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
model = get_peft_model(model, config)
|
||||
```
|
||||
|
||||
We train the model for a few thousand steps with the causal language modeling objective and save the model.
|
||||
Since we will tune the model again with different objectives, we merge the adapter weights with the original model weights.
|
||||
|
||||
**Disclaimer:** due to LLaMA's license, we release only the adapter weights for this and the model checkpoints in the following sections.
|
||||
You can apply for access to the base model's weights by filling out Meta AI's [form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform) and then converting them to the 🤗 Transformers format by running this [script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py).
|
||||
Note that you'll also need to install 🤗 Transformers from source until the `v4.28` is released.
|
||||
|
||||
Now that we have fine-tuned the model for the task, we are ready to train a reward model.
|
||||
|
||||
## Reward modeling and human preferences
|
||||
|
||||
In principle, we could fine-tune the model using RLHF directly with the human annotations.
|
||||
However, this would require us to send some samples to humans for rating after each optimization iteration.
|
||||
This is expensive and slow due to the number of training samples needed for convergence and the inherent latency of human reading and annotator speed.
|
||||
|
||||
A trick that works well instead of direct feedback is training a reward model on human annotations collected before the RL loop.
|
||||
The goal of the reward model is to imitate how a human would rate a text. There are several possible strategies to build a reward model: the most straightforward way would be to predict the annotation (e.g. a rating score or a binary value for “good”/”bad”).
|
||||
In practice, what works better is to predict the ranking of two examples, where the reward model is presented with two candidates `(y_k, y_j)` for a given prompt `x` and has to predict which one would be rated higher by a human annotator.
|
||||
|
||||
With the StackExchange dataset, we can infer which of the two answers was preferred by the users based on the score.
|
||||
With that information and the loss defined above, we can then modify the `transformers.Trainer` by adding a custom loss function.
|
||||
|
||||
```python
|
||||
class RewardTrainer(Trainer):
|
||||
def compute_loss(self, model, inputs, return_outputs=False):
|
||||
rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]
|
||||
rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]
|
||||
loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()
|
||||
if return_outputs:
|
||||
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
|
||||
return loss
|
||||
```
|
||||
|
||||
We utilize a subset of a 100,000 pair of candidates and evaluate on a held-out set of 50,000. With a modest training batch size of 4, we train the Llama model using the LoRA `peft` adapter for a single epoch using the Adam optimizer with BF16 precision. Our LoRA configuration is:
|
||||
|
||||
```python
|
||||
peft_config = LoraConfig(
|
||||
task_type=TaskType.SEQ_CLS,
|
||||
inference_mode=False,
|
||||
r=8,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.1,
|
||||
)
|
||||
```
|
||||
As detailed in the next section, the resulting adapter can be merged into the frozen model and saved for further downstream use.
|
||||
|
||||
## Reinforcement Learning from Human Feedback
|
||||
|
||||
With the fine-tuned language model and the reward model at hand, we are now ready to run the RL loop. It follows roughly three steps:
|
||||
|
||||
1. Generate responses from prompts,
|
||||
2. Rate the responses with the reward model,
|
||||
3. Run a reinforcement learning policy-optimization step with the ratings.
|
||||
|
||||
The Query and Response prompts are templated as follows before being tokenized and passed to the model:
|
||||
|
||||
```bash
|
||||
Question: <Query>
|
||||
|
||||
Answer: <Response>
|
||||
```
|
||||
|
||||
The same template was used for SFT, RM and RLHF stages.
|
||||
Once more, we utilize `peft` for memory-efficient training, which offers an extra advantage in the RLHF context.
|
||||
Here, the reference model and policy share the same base, the SFT model, which we load in 8-bit and freeze during training.
|
||||
We exclusively optimize the policy's LoRA weights using PPO while sharing the base model's weights.
|
||||
|
||||
```python
|
||||
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
|
||||
question_tensors = batch["input_ids"]
|
||||
|
||||
# sample from the policy and to generate responses
|
||||
response_tensors = ppo_trainer.generate(
|
||||
question_tensors,
|
||||
return_prompt=False,
|
||||
length_sampler=output_length_sampler,
|
||||
**generation_kwargs,
|
||||
)
|
||||
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
|
||||
|
||||
# Compute sentiment score
|
||||
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
|
||||
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
|
||||
rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs]
|
||||
|
||||
# Run PPO step
|
||||
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
|
||||
# Log stats to Wandb
|
||||
ppo_trainer.log_stats(stats, batch, rewards)
|
||||
```
|
||||
|
||||
For the rest of the details adn evaluation, please refer to our [blog post on StackLLaMA](https://huggingface.co/blog/stackllama).
|
||||
@ -1,16 +1,6 @@
|
||||
# Sentiment Examples
|
||||
|
||||
The notebooks and scripts in this examples show how to fine-tune a model with a sentiment classifier (such as `lvwerra/distilbert-imdb`).
|
||||
|
||||
Here's an overview of the notebooks and scripts:
|
||||
|
||||
| File | Description |
|
||||
|---|---|
|
||||
| `notebooks/gpt2-sentiment.ipynb` | Fine-tune GPT2 to generate positive movie reviews. |
|
||||
| `notebooks/gpt2-sentiment-control.ipynb` | Fine-tune GPT2 to generate movie reviews with controlled sentiment. |
|
||||
| `scripts/gpt2-sentiment.py` | Same as the notebook, but easier to use to use in mutli-GPU setup. |
|
||||
| `scripts/t5-sentiment.py` | Same as GPT2 script, but for a Seq2Seq model (T5). |
|
||||
# Examples
|
||||
|
||||
_The best place to learn about examples in TRL is our [docs page](https://huggingface.co/docs/trl/index)!_
|
||||
|
||||
## Installation
|
||||
|
||||
@ -19,48 +9,24 @@ pip install trl
|
||||
#optional: wandb
|
||||
pip install wandb
|
||||
```
|
||||
Note: if you don't want to log with `wandb` remove `log_with="wandb"` in the scripts/notebooks.
|
||||
You can also replace it with your favourite experiment tracker that's [supported by `accelerate`](https://huggingface.co/docs/accelerate/usage_guides/tracking).
|
||||
|
||||
Note: if you don't want to log with `wandb` remove `log_with="wandb"` in the scripts/notebooks. You can also replace it with your favourite experiment tracker that's [supported by `accelerate`](https://huggingface.co/docs/accelerate/usage_guides/tracking).
|
||||
## Accelerate Config
|
||||
For all the examples, you'll need to generate an `Accelerate` config with:
|
||||
|
||||
|
||||
## Launch scripts
|
||||
|
||||
The `trl` library is powered by `accelerate`. As such it is best to configure and launch trainings with the following commands:
|
||||
|
||||
```bash
|
||||
```shell
|
||||
accelerate config # will prompt you to define the training configuration
|
||||
accelerate launch scripts/gpt2-sentiment.py # launches training
|
||||
```
|
||||
|
||||
# Summarization Example
|
||||
|
||||
The script in this example show how to train a reward model for summarization, following the OpenAI Learning to Summarize from Human Feedback [paper](https://arxiv.org/abs/2009.01325). We've validated that the script can be used to train a small GPT2 to get slightly over 60% validation accuracy, which is aligned with results from the paper. The model is [here](https://huggingface.co/Tristan/gpt2_reward_summarization).
|
||||
Then, it is encouraged to launch jobs with `accelerate launch`!
|
||||
|
||||
Here's an overview of the files:
|
||||
## Categories
|
||||
The examples are currently split over the following categories:
|
||||
|
||||
| File | Description |
|
||||
|---|---|
|
||||
| `scripts/reward_summarization.py` | For tuning the reward model. |
|
||||
| `scripts/ds3_reward_summarization_example_config.json` | Can be used with the reward model script to scale it up to arbitrarily big models that don't fit on a single GPU. |
|
||||
|
||||
|
||||
## Installation
|
||||
|
||||
```bash
|
||||
pip install trl
|
||||
pip install evaluate
|
||||
# optional: deepspeed
|
||||
pip install deepspeed
|
||||
```
|
||||
|
||||
```bash
|
||||
# If you want your reward model to follow the Learning to Summarize from Human Feedback paper closely, then tune a GPT model on summarization and then instantiate the reward model
|
||||
# with it. In other words, pass in the name of your summarization-finetuned gpt on the hub, instead of the name of the pretrained gpt2 like we do in the following examples of how
|
||||
# to run this script.
|
||||
|
||||
# Example of running this script with the small size gpt2 on a 40GB A100 (A100's support bf16). Here, the global batch size will be 64:
|
||||
python -m torch.distributed.launch --nproc_per_node=1 reward_summarization.py --bf16
|
||||
|
||||
# Example of running this script with the xl size gpt2 on 16 40GB A100's. Here the global batch size will still be 64:
|
||||
python -m torch.distributed.launch --nproc_per_node=16 reward_summarization.py --per_device_train_batch_size=1 --per_device_eval_batch_size=1 --gradient_accumulation_steps=4 --gpt_model_name=gpt2-xl --bf16 --deepspeed=ds3_reward_summarization_example_config.json
|
||||
```
|
||||
**1: [Sentiment](https://github.com/lvwerra/trl/tree/main/examples/sentiment)**: Fine-tune a model with a sentiment classification model.
|
||||
**2: [StackOverflow](https://github.com/lvwerra/trl/tree/main/examples/stack_llama)**: Perform the full RLHF process (fine-tuning, reward model training, and RLHF) on StackOverflow data.
|
||||
**3: [summarization](https://github.com/lvwerra/trl/tree/main/examples/summarization)**: Recreate OpenAI's [Learning to Summarize paper](https://proceedings.neurips.cc/paper/2020/file/1f89885d556929e98d3ef9b86448f951-Paper.pdf).
|
||||
**4: [toxicity](https://github.com/lvwerra/trl/tree/main/examples/toxicity)**: Fine-tune a model to reduce the toxicity of its generations.
|
||||
write about best-of-n as an alternative rlhf
|
||||
**5: [best-of-n sampling](https://github.com/lvwerra/trl/tree/main/examples/best_of_n_sampling)**: Comparative demonstration of best-of-n sampling as a simpler (but relatively expensive) alternative to RLHF
|
||||
|
||||
16
examples/best_of_n_sampling/README.md
Normal file
16
examples/best_of_n_sampling/README.md
Normal file
@ -0,0 +1,16 @@
|
||||
# Best-of-n sampling as an alternative to RLHF
|
||||
|
||||
Paraphrasing from [OpenAI's blog post on best-of-n sampling](https://openai.com/research/measuring-goodharts-law)
|
||||
|
||||
With `RLHF` we try to optimize w.r.t to a proxy objective. `RLHF` is not the only way to do this.
|
||||
One of the many other ways is `best-of-n sampling`. It is simple to implement and competitive to `RLHF` in some cases.
|
||||
That said, `best-of-n sampling` is expensive when it comes to inference time compute.
|
||||
|
||||
The included notebook compares reward-model scores of prompt based responses from
|
||||
1. a base model (`gpt2-imdb`)
|
||||
2. `RLHF` tuned model based on this base-model
|
||||
3. the base-model again from which we sample n responses to each prompt, score them and take the best scored one AKA the `best-of-n sampled` model
|
||||
|
||||
|
||||
|
||||
|
||||
648
examples/best_of_n_sampling/notebooks/best_of_n.ipynb
Normal file
648
examples/best_of_n_sampling/notebooks/best_of_n.ipynb
Normal file
@ -0,0 +1,648 @@
|
||||
{
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 0,
|
||||
"metadata": {
|
||||
"colab": {
|
||||
"provenance": []
|
||||
},
|
||||
"kernelspec": {
|
||||
"name": "python3",
|
||||
"display_name": "Python 3"
|
||||
},
|
||||
"language_info": {
|
||||
"name": "python"
|
||||
},
|
||||
"accelerator": "GPU",
|
||||
"gpuClass": "standard"
|
||||
},
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"\n",
|
||||
"**Best-of-n sampling as an alternative to RLHF**\n",
|
||||
"\n",
|
||||
"This notebook compares reward-model scores of prompt based responses from \n",
|
||||
"1. a base model (`gpt2-imdb`)\n",
|
||||
"2. `RLHF` tuned model based on this base-model \n",
|
||||
"3. the base-model again from which we sample n responses to each prompt, score them and take the best scored one AKA the `best-of-n sampled` model\n",
|
||||
"\n"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "WQpNapZNWuXP"
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"Import dependencies\n"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "Lo98lkdP66_x"
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"source": [
|
||||
"%pip install transformers trl"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "vDA6qayz692w"
|
||||
},
|
||||
"execution_count": null,
|
||||
"outputs": []
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"import pandas as pd\n",
|
||||
"from transformers import pipeline, AutoTokenizer\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"\n",
|
||||
"from trl import AutoModelForCausalLMWithValueHead\n",
|
||||
"from trl.core import LengthSampler\n",
|
||||
"\n",
|
||||
"device = 0 if torch.cuda.is_available() else \"cpu\""
|
||||
],
|
||||
"metadata": {
|
||||
"id": "M1s_iNm773hM"
|
||||
},
|
||||
"execution_count": 2,
|
||||
"outputs": []
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"Various constants"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "Y7hyrIrO8tcY"
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"source": [
|
||||
"ref_model_name = \"lvwerra/gpt2-imdb\"\n",
|
||||
"model_name = \"lvwerra/gpt2-imdb-pos-v2\"\n",
|
||||
"reward_model = \"lvwerra/distilbert-imdb\"\n",
|
||||
"\n",
|
||||
"N_BEST_OF = 4"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "MqS3OM6Q8x6g"
|
||||
},
|
||||
"execution_count": 3,
|
||||
"outputs": []
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"Models and tokenizers "
|
||||
],
|
||||
"metadata": {
|
||||
"id": "c1YcXeElg6or"
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"source": [
|
||||
"model = AutoModelForCausalLMWithValueHead.from_pretrained(model_name)\n",
|
||||
"\n",
|
||||
"ref_model = AutoModelForCausalLMWithValueHead.from_pretrained(ref_model_name)\n",
|
||||
"\n",
|
||||
"reward_pipe = pipeline(\"sentiment-analysis\", model=reward_model, device=device)\n",
|
||||
"\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(ref_model_name)\n",
|
||||
"\n",
|
||||
"tokenizer.pad_token = tokenizer.eos_token\n",
|
||||
"\n",
|
||||
"# cuda-ize models\n",
|
||||
"model.cuda()\n",
|
||||
"ref_model.cuda()"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "b855NrL181Hh"
|
||||
},
|
||||
"execution_count": null,
|
||||
"outputs": []
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"Dataset building"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "Z1Cz0gCFhZYJ"
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"source": [
|
||||
"def build_dataset(tokenizer, dataset_name=\"imdb\", input_min_text_length=2, input_max_text_length=8):\n",
|
||||
" # load imdb with datasets\n",
|
||||
" ds = load_dataset(dataset_name, split=\"train\")\n",
|
||||
" ds = ds.rename_columns({\"text\": \"review\"})\n",
|
||||
" ds = ds.filter(lambda x: len(x[\"review\"]) > 200, batched=False)\n",
|
||||
"\n",
|
||||
" input_size = LengthSampler(input_min_text_length, input_max_text_length)\n",
|
||||
"\n",
|
||||
" def tokenize(sample):\n",
|
||||
" sample[\"input_ids\"] = tokenizer.encode(sample[\"review\"])[: input_size()]\n",
|
||||
" sample[\"query\"] = tokenizer.decode(sample[\"input_ids\"])\n",
|
||||
" return sample\n",
|
||||
"\n",
|
||||
" ds = ds.map(tokenize, batched=False)\n",
|
||||
" ds.set_format(type=\"torch\")\n",
|
||||
" return ds\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"dataset = build_dataset(tokenizer)"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "LqLVEp5p_8XM"
|
||||
},
|
||||
"execution_count": null,
|
||||
"outputs": []
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"source": [
|
||||
"gen_kwargs = {\"min_length\": -1, \"top_k\": 0.0, \"top_p\": 1.0, \"do_sample\": True, \"pad_token_id\": tokenizer.eos_token_id}\n",
|
||||
"sent_kwargs = {\"top_k\": None, \"function_to_apply\": \"none\", \"batch_size\": 16}"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "AqA2McjMAxNw"
|
||||
},
|
||||
"execution_count": 6,
|
||||
"outputs": []
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"source": [
|
||||
"output_min_length = 4\n",
|
||||
"output_max_length = 16\n",
|
||||
"output_length_sampler = LengthSampler(output_min_length, output_max_length)\n",
|
||||
"\n",
|
||||
"#### get a batch from the dataset\n",
|
||||
"bs = 16\n",
|
||||
"output_data = dict()\n",
|
||||
"dataset.set_format(\"pandas\")\n",
|
||||
"df_batch = dataset[:].sample(bs)\n",
|
||||
"output_data[\"query\"] = df_batch[\"query\"].tolist()\n",
|
||||
"query_tensors = df_batch[\"input_ids\"].tolist()\n",
|
||||
"\n",
|
||||
"# :: [Resp]\n",
|
||||
"response_tensors_ref, response_tensors = [], []\n",
|
||||
"# :: [[Resp]]\n",
|
||||
"response_tensors_best_of = []"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "L_q4qs35AxcR"
|
||||
},
|
||||
"execution_count": 7,
|
||||
"outputs": []
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"\n",
|
||||
"Generation using various models"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "QVfpyHnZBLKY"
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"source": [
|
||||
"for i in range(bs):\n",
|
||||
" gen_len = output_length_sampler()\n",
|
||||
"\n",
|
||||
" query = torch.tensor(query_tensors[i])\n",
|
||||
"\n",
|
||||
" output = ref_model.generate(query.unsqueeze(dim=0).to(device), max_new_tokens=gen_len, **gen_kwargs).squeeze()\n",
|
||||
" response_tensors_ref.append(tokenizer.decode(output))\n",
|
||||
"\n",
|
||||
" output = model.generate(query.unsqueeze(dim=0).to(device), max_new_tokens=gen_len, **gen_kwargs).squeeze()\n",
|
||||
" response_tensors.append(tokenizer.decode(output))\n",
|
||||
"\n",
|
||||
" # generating copies of the same query for the Best-of-n sampling\n",
|
||||
" queries = query.repeat((N_BEST_OF, 1))\n",
|
||||
" output = ref_model.generate(queries.to(device), max_new_tokens=gen_len, **gen_kwargs).squeeze()\n",
|
||||
" response_tensors_best_of.append(tokenizer.batch_decode(output))"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "-imZ7uEFBNbw"
|
||||
},
|
||||
"execution_count": 8,
|
||||
"outputs": []
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"Scoring"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "Jp5FC0Y5h_Sf"
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"source": [
|
||||
"scores_ref = [output[0][\"score\"] for output in reward_pipe(response_tensors_ref, **sent_kwargs)]\n",
|
||||
"scores = [output[0][\"score\"] for output in reward_pipe(response_tensors, **sent_kwargs)]\n",
|
||||
"scores_best_of = []\n",
|
||||
"for i, response in enumerate(response_tensors_best_of):\n",
|
||||
" # base_score = scores_ref[i]\n",
|
||||
" scores_best_of.append(torch.tensor([output[0][\"score\"] for output in reward_pipe(response, **sent_kwargs)]))"
|
||||
],
|
||||
"metadata": {
|
||||
"id": "PyDbbAQ0F_h7"
|
||||
},
|
||||
"execution_count": null,
|
||||
"outputs": []
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"source": [
|
||||
"output_data[\"response (ref)\"] = response_tensors_ref\n",
|
||||
"output_data[\"scores (ref)\"] = scores_ref\n",
|
||||
"output_data[\"response (RLHF)\"] = response_tensors\n",
|
||||
"output_data[\"scores (RLHF)\"] = scores\n",
|
||||
"output_data[\"response (best_of)\"] = [\n",
|
||||
" response_tensors_best_of[i][a.argmax().item()] for i, a in enumerate(scores_best_of)\n",
|
||||
"]\n",
|
||||
"output_data[\"scores (best_of)\"] = [a.max().item() for a in scores_best_of]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# store results in a dataframe\n",
|
||||
"df_results = pd.DataFrame(output_data)\n",
|
||||
"df_results"
|
||||
],
|
||||
"metadata": {
|
||||
"colab": {
|
||||
"base_uri": "https://localhost:8080/",
|
||||
"height": 682
|
||||
},
|
||||
"id": "nA1GDNJEiGm-",
|
||||
"outputId": "1389c686-0751-4304-dea2-b71fd68748e1"
|
||||
},
|
||||
"execution_count": 10,
|
||||
"outputs": [
|
||||
{
|
||||
"output_type": "execute_result",
|
||||
"data": {
|
||||
"text/plain": [
|
||||
" query \\\n",
|
||||
"0 I'm a pretty old \n",
|
||||
"1 One of the most \n",
|
||||
"2 Okay, as \n",
|
||||
"3 Watching \"Kro \n",
|
||||
"4 Seriously what were they thinking? \n",
|
||||
"5 OK Hollywood \n",
|
||||
"6 \"Bend It \n",
|
||||
"7 While the premise behind The House \n",
|
||||
"8 Well let me go \n",
|
||||
"9 Vijay Krishna Acharya \n",
|
||||
"10 Watching this movie made me \n",
|
||||
"11 There are probably \n",
|
||||
"12 Meryl Stre \n",
|
||||
"13 I thought I read somewhere that \n",
|
||||
"14 Good movie, very \n",
|
||||
"15 It was agonizing \n",
|
||||
"\n",
|
||||
" response (ref) scores (ref) \\\n",
|
||||
"0 I'm a pretty old kid, well, with lots of girl 1.179652 \n",
|
||||
"1 One of the most psychologically devastating as... 2.477277 \n",
|
||||
"2 Okay, as ruthless as they are, even their leve... 1.466462 \n",
|
||||
"3 Watching \"Kroger\" (1915- 0.186047 \n",
|
||||
"4 Seriously what were they thinking? It ain't go... 1.010697 \n",
|
||||
"5 OK Hollywood goes into a total game of audio, ... 0.934041 \n",
|
||||
"6 \"Bend It, Luther, Dodge, Church Goes to Rome w... 0.039218 \n",
|
||||
"7 While the premise behind The House of Dracula ... -0.079306 \n",
|
||||
"8 Well let me go...I don't want to movie it. I'm... 1.015246 \n",
|
||||
"9 Vijay Krishna Acharya Sawai (Elverling). She was 0.341506 \n",
|
||||
"10 Watching this movie made me poorly appreciate ... 1.574047 \n",
|
||||
"11 There are probably more but if you had never s... -0.047099 \n",
|
||||
"12 Meryl Streep's version of 0.373884 \n",
|
||||
"13 I thought I read somewhere that the Lord had c... 0.091776 \n",
|
||||
"14 Good movie, very funny, acting is very good.<|... 2.408837 \n",
|
||||
"15 It was agonizing, and it made me wonder 1.240262 \n",
|
||||
"\n",
|
||||
" response (RLHF) scores (RLHF) \\\n",
|
||||
"0 I'm a pretty old lady, and I loved this movie ... 2.218363 \n",
|
||||
"1 One of the most Antibiotic Apps I have seen in 2.145479 \n",
|
||||
"2 Okay, as I enjoyed the movie. It's added bonus... 2.239827 \n",
|
||||
"3 Watching \"Kroven\". The film has a 1.044690 \n",
|
||||
"4 Seriously what were they thinking? It's a very... 2.753088 \n",
|
||||
"5 OK Hollywood shoot, and this is a classic. Som... 2.517364 \n",
|
||||
"6 \"Bend It all\" is a sophisticated, drawing and ... 2.583935 \n",
|
||||
"7 While the premise behind The House Intelligenc... 0.205217 \n",
|
||||
"8 Well let me go through everything says it's a ... 2.727040 \n",
|
||||
"9 Vijay Krishna Acharya is a perfect performance... 2.563642 \n",
|
||||
"10 Watching this movie made me sleep better. It w... 1.690222 \n",
|
||||
"11 There are probably random man only recently wh... 0.398258 \n",
|
||||
"12 Meryl Streitz, who is 0.085154 \n",
|
||||
"13 I thought I read somewhere that my thoughts, a... 1.833734 \n",
|
||||
"14 Good movie, very much fuzz and logical based w... 2.325996 \n",
|
||||
"15 It was agonizing because it was truly fun to 0.969669 \n",
|
||||
"\n",
|
||||
" response (best_of) scores (best_of) \n",
|
||||
"0 I'm a pretty old, stinking,acting kinda chick ... 2.016955 \n",
|
||||
"1 One of the most memorable performances of this... 2.676944 \n",
|
||||
"2 Okay, as I put it in such a negative mood, it ... 1.478424 \n",
|
||||
"3 Watching \"Kro\" is an entertainment craze 1.389495 \n",
|
||||
"4 Seriously what were they thinking? It was stil... 2.523514 \n",
|
||||
"5 OK Hollywood pay and the freaky set-up of this... 1.634765 \n",
|
||||
"6 \"Bend It 9\"/\"Zara Pephoto\") and an honest, rea... 2.557210 \n",
|
||||
"7 While the premise behind The House of Dracula ... 1.676889 \n",
|
||||
"8 Well let me go though, alive in this ever grow... 2.652859 \n",
|
||||
"9 Vijay Krishna Acharya adeptly emerges, and the... 2.308076 \n",
|
||||
"10 Watching this movie made me curious: what did ... 0.950836 \n",
|
||||
"11 There are probably too many documentaries in s... 1.142725 \n",
|
||||
"12 Meryl Streep performed an awe 1.932498 \n",
|
||||
"13 I thought I read somewhere that The Odd Couple... 0.475951 \n",
|
||||
"14 Good movie, very well polished, nicely written... 2.820022 \n",
|
||||
"15 It was agonizing, poignant, and worst of 2.058277 "
|
||||
],
|
||||
"text/html": [
|
||||
"\n",
|
||||
" <div id=\"df-f55eb9dc-030e-4d67-8f1c-6f797f325376\">\n",
|
||||
" <div class=\"colab-df-container\">\n",
|
||||
" <div>\n",
|
||||
"<style scoped>\n",
|
||||
" .dataframe tbody tr th:only-of-type {\n",
|
||||
" vertical-align: middle;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe tbody tr th {\n",
|
||||
" vertical-align: top;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe thead th {\n",
|
||||
" text-align: right;\n",
|
||||
" }\n",
|
||||
"</style>\n",
|
||||
"<table border=\"1\" class=\"dataframe\">\n",
|
||||
" <thead>\n",
|
||||
" <tr style=\"text-align: right;\">\n",
|
||||
" <th></th>\n",
|
||||
" <th>query</th>\n",
|
||||
" <th>response (ref)</th>\n",
|
||||
" <th>scores (ref)</th>\n",
|
||||
" <th>response (RLHF)</th>\n",
|
||||
" <th>scores (RLHF)</th>\n",
|
||||
" <th>response (best_of)</th>\n",
|
||||
" <th>scores (best_of)</th>\n",
|
||||
" </tr>\n",
|
||||
" </thead>\n",
|
||||
" <tbody>\n",
|
||||
" <tr>\n",
|
||||
" <th>0</th>\n",
|
||||
" <td>I'm a pretty old</td>\n",
|
||||
" <td>I'm a pretty old kid, well, with lots of girl</td>\n",
|
||||
" <td>1.179652</td>\n",
|
||||
" <td>I'm a pretty old lady, and I loved this movie ...</td>\n",
|
||||
" <td>2.218363</td>\n",
|
||||
" <td>I'm a pretty old, stinking,acting kinda chick ...</td>\n",
|
||||
" <td>2.016955</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>1</th>\n",
|
||||
" <td>One of the most</td>\n",
|
||||
" <td>One of the most psychologically devastating as...</td>\n",
|
||||
" <td>2.477277</td>\n",
|
||||
" <td>One of the most Antibiotic Apps I have seen in</td>\n",
|
||||
" <td>2.145479</td>\n",
|
||||
" <td>One of the most memorable performances of this...</td>\n",
|
||||
" <td>2.676944</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>2</th>\n",
|
||||
" <td>Okay, as</td>\n",
|
||||
" <td>Okay, as ruthless as they are, even their leve...</td>\n",
|
||||
" <td>1.466462</td>\n",
|
||||
" <td>Okay, as I enjoyed the movie. It's added bonus...</td>\n",
|
||||
" <td>2.239827</td>\n",
|
||||
" <td>Okay, as I put it in such a negative mood, it ...</td>\n",
|
||||
" <td>1.478424</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>3</th>\n",
|
||||
" <td>Watching \"Kro</td>\n",
|
||||
" <td>Watching \"Kroger\" (1915-</td>\n",
|
||||
" <td>0.186047</td>\n",
|
||||
" <td>Watching \"Kroven\". The film has a</td>\n",
|
||||
" <td>1.044690</td>\n",
|
||||
" <td>Watching \"Kro\" is an entertainment craze</td>\n",
|
||||
" <td>1.389495</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>4</th>\n",
|
||||
" <td>Seriously what were they thinking?</td>\n",
|
||||
" <td>Seriously what were they thinking? It ain't go...</td>\n",
|
||||
" <td>1.010697</td>\n",
|
||||
" <td>Seriously what were they thinking? It's a very...</td>\n",
|
||||
" <td>2.753088</td>\n",
|
||||
" <td>Seriously what were they thinking? It was stil...</td>\n",
|
||||
" <td>2.523514</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>5</th>\n",
|
||||
" <td>OK Hollywood</td>\n",
|
||||
" <td>OK Hollywood goes into a total game of audio, ...</td>\n",
|
||||
" <td>0.934041</td>\n",
|
||||
" <td>OK Hollywood shoot, and this is a classic. Som...</td>\n",
|
||||
" <td>2.517364</td>\n",
|
||||
" <td>OK Hollywood pay and the freaky set-up of this...</td>\n",
|
||||
" <td>1.634765</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>6</th>\n",
|
||||
" <td>\"Bend It</td>\n",
|
||||
" <td>\"Bend It, Luther, Dodge, Church Goes to Rome w...</td>\n",
|
||||
" <td>0.039218</td>\n",
|
||||
" <td>\"Bend It all\" is a sophisticated, drawing and ...</td>\n",
|
||||
" <td>2.583935</td>\n",
|
||||
" <td>\"Bend It 9\"/\"Zara Pephoto\") and an honest, rea...</td>\n",
|
||||
" <td>2.557210</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>7</th>\n",
|
||||
" <td>While the premise behind The House</td>\n",
|
||||
" <td>While the premise behind The House of Dracula ...</td>\n",
|
||||
" <td>-0.079306</td>\n",
|
||||
" <td>While the premise behind The House Intelligenc...</td>\n",
|
||||
" <td>0.205217</td>\n",
|
||||
" <td>While the premise behind The House of Dracula ...</td>\n",
|
||||
" <td>1.676889</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>8</th>\n",
|
||||
" <td>Well let me go</td>\n",
|
||||
" <td>Well let me go...I don't want to movie it. I'm...</td>\n",
|
||||
" <td>1.015246</td>\n",
|
||||
" <td>Well let me go through everything says it's a ...</td>\n",
|
||||
" <td>2.727040</td>\n",
|
||||
" <td>Well let me go though, alive in this ever grow...</td>\n",
|
||||
" <td>2.652859</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>9</th>\n",
|
||||
" <td>Vijay Krishna Acharya</td>\n",
|
||||
" <td>Vijay Krishna Acharya Sawai (Elverling). She was</td>\n",
|
||||
" <td>0.341506</td>\n",
|
||||
" <td>Vijay Krishna Acharya is a perfect performance...</td>\n",
|
||||
" <td>2.563642</td>\n",
|
||||
" <td>Vijay Krishna Acharya adeptly emerges, and the...</td>\n",
|
||||
" <td>2.308076</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>10</th>\n",
|
||||
" <td>Watching this movie made me</td>\n",
|
||||
" <td>Watching this movie made me poorly appreciate ...</td>\n",
|
||||
" <td>1.574047</td>\n",
|
||||
" <td>Watching this movie made me sleep better. It w...</td>\n",
|
||||
" <td>1.690222</td>\n",
|
||||
" <td>Watching this movie made me curious: what did ...</td>\n",
|
||||
" <td>0.950836</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>11</th>\n",
|
||||
" <td>There are probably</td>\n",
|
||||
" <td>There are probably more but if you had never s...</td>\n",
|
||||
" <td>-0.047099</td>\n",
|
||||
" <td>There are probably random man only recently wh...</td>\n",
|
||||
" <td>0.398258</td>\n",
|
||||
" <td>There are probably too many documentaries in s...</td>\n",
|
||||
" <td>1.142725</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>12</th>\n",
|
||||
" <td>Meryl Stre</td>\n",
|
||||
" <td>Meryl Streep's version of</td>\n",
|
||||
" <td>0.373884</td>\n",
|
||||
" <td>Meryl Streitz, who is</td>\n",
|
||||
" <td>0.085154</td>\n",
|
||||
" <td>Meryl Streep performed an awe</td>\n",
|
||||
" <td>1.932498</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>13</th>\n",
|
||||
" <td>I thought I read somewhere that</td>\n",
|
||||
" <td>I thought I read somewhere that the Lord had c...</td>\n",
|
||||
" <td>0.091776</td>\n",
|
||||
" <td>I thought I read somewhere that my thoughts, a...</td>\n",
|
||||
" <td>1.833734</td>\n",
|
||||
" <td>I thought I read somewhere that The Odd Couple...</td>\n",
|
||||
" <td>0.475951</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>14</th>\n",
|
||||
" <td>Good movie, very</td>\n",
|
||||
" <td>Good movie, very funny, acting is very good.<|...</td>\n",
|
||||
" <td>2.408837</td>\n",
|
||||
" <td>Good movie, very much fuzz and logical based w...</td>\n",
|
||||
" <td>2.325996</td>\n",
|
||||
" <td>Good movie, very well polished, nicely written...</td>\n",
|
||||
" <td>2.820022</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>15</th>\n",
|
||||
" <td>It was agonizing</td>\n",
|
||||
" <td>It was agonizing, and it made me wonder</td>\n",
|
||||
" <td>1.240262</td>\n",
|
||||
" <td>It was agonizing because it was truly fun to</td>\n",
|
||||
" <td>0.969669</td>\n",
|
||||
" <td>It was agonizing, poignant, and worst of</td>\n",
|
||||
" <td>2.058277</td>\n",
|
||||
" </tr>\n",
|
||||
" </tbody>\n",
|
||||
"</table>\n",
|
||||
"</div>\n",
|
||||
" <button class=\"colab-df-convert\" onclick=\"convertToInteractive('df-f55eb9dc-030e-4d67-8f1c-6f797f325376')\"\n",
|
||||
" title=\"Convert this dataframe to an interactive table.\"\n",
|
||||
" style=\"display:none;\">\n",
|
||||
" \n",
|
||||
" <svg xmlns=\"http://www.w3.org/2000/svg\" height=\"24px\"viewBox=\"0 0 24 24\"\n",
|
||||
" width=\"24px\">\n",
|
||||
" <path d=\"M0 0h24v24H0V0z\" fill=\"none\"/>\n",
|
||||
" <path d=\"M18.56 5.44l.94 2.06.94-2.06 2.06-.94-2.06-.94-.94-2.06-.94 2.06-2.06.94zm-11 1L8.5 8.5l.94-2.06 2.06-.94-2.06-.94L8.5 2.5l-.94 2.06-2.06.94zm10 10l.94 2.06.94-2.06 2.06-.94-2.06-.94-.94-2.06-.94 2.06-2.06.94z\"/><path d=\"M17.41 7.96l-1.37-1.37c-.4-.4-.92-.59-1.43-.59-.52 0-1.04.2-1.43.59L10.3 9.45l-7.72 7.72c-.78.78-.78 2.05 0 2.83L4 21.41c.39.39.9.59 1.41.59.51 0 1.02-.2 1.41-.59l7.78-7.78 2.81-2.81c.8-.78.8-2.07 0-2.86zM5.41 20L4 18.59l7.72-7.72 1.47 1.35L5.41 20z\"/>\n",
|
||||
" </svg>\n",
|
||||
" </button>\n",
|
||||
" \n",
|
||||
" <style>\n",
|
||||
" .colab-df-container {\n",
|
||||
" display:flex;\n",
|
||||
" flex-wrap:wrap;\n",
|
||||
" gap: 12px;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .colab-df-convert {\n",
|
||||
" background-color: #E8F0FE;\n",
|
||||
" border: none;\n",
|
||||
" border-radius: 50%;\n",
|
||||
" cursor: pointer;\n",
|
||||
" display: none;\n",
|
||||
" fill: #1967D2;\n",
|
||||
" height: 32px;\n",
|
||||
" padding: 0 0 0 0;\n",
|
||||
" width: 32px;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .colab-df-convert:hover {\n",
|
||||
" background-color: #E2EBFA;\n",
|
||||
" box-shadow: 0px 1px 2px rgba(60, 64, 67, 0.3), 0px 1px 3px 1px rgba(60, 64, 67, 0.15);\n",
|
||||
" fill: #174EA6;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" [theme=dark] .colab-df-convert {\n",
|
||||
" background-color: #3B4455;\n",
|
||||
" fill: #D2E3FC;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" [theme=dark] .colab-df-convert:hover {\n",
|
||||
" background-color: #434B5C;\n",
|
||||
" box-shadow: 0px 1px 3px 1px rgba(0, 0, 0, 0.15);\n",
|
||||
" filter: drop-shadow(0px 1px 2px rgba(0, 0, 0, 0.3));\n",
|
||||
" fill: #FFFFFF;\n",
|
||||
" }\n",
|
||||
" </style>\n",
|
||||
"\n",
|
||||
" <script>\n",
|
||||
" const buttonEl =\n",
|
||||
" document.querySelector('#df-f55eb9dc-030e-4d67-8f1c-6f797f325376 button.colab-df-convert');\n",
|
||||
" buttonEl.style.display =\n",
|
||||
" google.colab.kernel.accessAllowed ? 'block' : 'none';\n",
|
||||
"\n",
|
||||
" async function convertToInteractive(key) {\n",
|
||||
" const element = document.querySelector('#df-f55eb9dc-030e-4d67-8f1c-6f797f325376');\n",
|
||||
" const dataTable =\n",
|
||||
" await google.colab.kernel.invokeFunction('convertToInteractive',\n",
|
||||
" [key], {});\n",
|
||||
" if (!dataTable) return;\n",
|
||||
"\n",
|
||||
" const docLinkHtml = 'Like what you see? Visit the ' +\n",
|
||||
" '<a target=\"_blank\" href=https://colab.research.google.com/notebooks/data_table.ipynb>data table notebook</a>'\n",
|
||||
" + ' to learn more about interactive tables.';\n",
|
||||
" element.innerHTML = '';\n",
|
||||
" dataTable['output_type'] = 'display_data';\n",
|
||||
" await google.colab.output.renderOutput(dataTable, element);\n",
|
||||
" const docLink = document.createElement('div');\n",
|
||||
" docLink.innerHTML = docLinkHtml;\n",
|
||||
" element.appendChild(docLink);\n",
|
||||
" }\n",
|
||||
" </script>\n",
|
||||
" </div>\n",
|
||||
" </div>\n",
|
||||
" "
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"execution_count": 10
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
40
examples/hello_world.py
Normal file
40
examples/hello_world.py
Normal file
@ -0,0 +1,40 @@
|
||||
# 0. imports
|
||||
import torch
|
||||
from transformers import GPT2Tokenizer
|
||||
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer
|
||||
|
||||
|
||||
# 1. load a pretrained model
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
|
||||
model_ref = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
|
||||
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
# 2. initialize trainer
|
||||
ppo_config = {"batch_size": 1}
|
||||
config = PPOConfig(**ppo_config)
|
||||
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer)
|
||||
|
||||
# 3. encode a query
|
||||
query_txt = "This morning I went to the "
|
||||
query_tensor = tokenizer.encode(query_txt, return_tensors="pt").to(model.pretrained_model.device)
|
||||
|
||||
# 4. generate model response
|
||||
generation_kwargs = {
|
||||
"min_length": -1,
|
||||
"top_k": 0.0,
|
||||
"top_p": 1.0,
|
||||
"do_sample": True,
|
||||
"pad_token_id": tokenizer.eos_token_id,
|
||||
"max_new_tokens": 20,
|
||||
}
|
||||
response_tensor = ppo_trainer.generate([item for item in query_tensor], return_prompt=False, **generation_kwargs)
|
||||
response_txt = tokenizer.decode(response_tensor[0])
|
||||
|
||||
# 5. define a reward for response
|
||||
# (this could be any reward such as human feedback or output from another model)
|
||||
reward = [torch.tensor(1.0, device=model.pretrained_model.device)]
|
||||
|
||||
# 6. train model with ppo
|
||||
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
|
||||
194
examples/multi-adapter-rl/reward_modeling.py
Normal file
194
examples/multi-adapter-rl/reward_modeling.py
Normal file
@ -0,0 +1,194 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
|
||||
from transformers import (
|
||||
AutoModelForSequenceClassification,
|
||||
AutoTokenizer,
|
||||
BitsAndBytesConfig,
|
||||
HfArgumentParser,
|
||||
TrainingArguments,
|
||||
)
|
||||
|
||||
from trl import RewardTrainer
|
||||
|
||||
|
||||
########################################################################
|
||||
# This is a fully working simple example to use trl's RewardTrainer.
|
||||
#
|
||||
# This example fine-tunes any causal language model (GPT-2, GPT-Neo, etc.)
|
||||
# by using the RewardTrainer from trl, we will leverage PEFT library to finetune
|
||||
# adapters on the model.
|
||||
#
|
||||
########################################################################
|
||||
|
||||
|
||||
# Define and parse arguments.
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
"""
|
||||
These arguments vary depending on how many GPUs you have, what their capacity and features are, and what size model you want to train.
|
||||
"""
|
||||
|
||||
local_rank: Optional[int] = field(default=-1, metadata={"help": "Used for multi-gpu"})
|
||||
|
||||
per_device_train_batch_size: Optional[int] = field(default=4)
|
||||
per_device_eval_batch_size: Optional[int] = field(default=1)
|
||||
gradient_accumulation_steps: Optional[int] = field(default=1)
|
||||
learning_rate: Optional[float] = field(default=2e-5)
|
||||
weight_decay: Optional[int] = field(default=0.001)
|
||||
max_seq_length: Optional[int] = field(default=512)
|
||||
model_name: Optional[str] = field(
|
||||
default="huggyllama/llama-7b",
|
||||
metadata={
|
||||
"help": "The model that you want to train from the Hugging Face hub. E.g. gpt2, gpt2-xl, bert, etc."
|
||||
},
|
||||
)
|
||||
dataset_name: Optional[str] = field(
|
||||
default="Anthropic/hh-rlhf",
|
||||
metadata={"help": "The preference dataset to use."},
|
||||
)
|
||||
use_4bit: Optional[bool] = field(
|
||||
default=True,
|
||||
metadata={"help": "Activate 4bit precision base model loading"},
|
||||
)
|
||||
use_nested_quant: Optional[bool] = field(
|
||||
default=False,
|
||||
metadata={"help": "Activate nested quantization for 4bit base models"},
|
||||
)
|
||||
bnb_4bit_compute_dtype: Optional[str] = field(
|
||||
default="bfloat16",
|
||||
metadata={"help": "Compute dtype for 4bit base models"},
|
||||
)
|
||||
bnb_4bit_quant_type: Optional[str] = field(
|
||||
default="nf4",
|
||||
metadata={"help": "Quantization type fp4 or nf4"},
|
||||
)
|
||||
num_train_epochs: Optional[int] = field(
|
||||
default=1,
|
||||
metadata={"help": "The number of training epochs for the reward model."},
|
||||
)
|
||||
|
||||
gradient_checkpointing: Optional[bool] = field(
|
||||
default=True,
|
||||
metadata={"help": "Enables gradient checkpointing."},
|
||||
)
|
||||
optim: Optional[str] = field(
|
||||
default="adamw_hf",
|
||||
metadata={"help": "The optimizer to use."},
|
||||
)
|
||||
lr_scheduler_type: Optional[str] = field(
|
||||
default="linear",
|
||||
metadata={"help": "The lr scheduler"},
|
||||
)
|
||||
|
||||
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
|
||||
def create_and_prepare_model(args):
|
||||
bnb_config = BitsAndBytesConfig(
|
||||
load_in_4bit=args.use_4bit,
|
||||
bnb_4bit_quant_type=args.bnb_4bit_quant_type,
|
||||
bnb_4bit_compute_dtype=getattr(torch, args.bnb_4bit_compute_dtype),
|
||||
bnb_4bit_use_double_quant=args.use_nested_quant,
|
||||
)
|
||||
|
||||
# TODO: make it more userfriendly
|
||||
device_map = {"": 0}
|
||||
|
||||
model = AutoModelForSequenceClassification.from_pretrained(
|
||||
args.model_name, quantization_config=bnb_config, device_map=device_map
|
||||
)
|
||||
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=args.gradient_checkpointing)
|
||||
|
||||
# we add `score` to the list of modules to save to
|
||||
# correctly save the score head.
|
||||
peft_config = LoraConfig(
|
||||
lora_alpha=32, lora_dropout=0.05, bias="none", task_type="SEQ_CLS", modules_to_save=["score"]
|
||||
)
|
||||
|
||||
model = get_peft_model(model, peft_config)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(script_args.model_name, use_auth_token=True)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
return model, tokenizer
|
||||
|
||||
|
||||
def create_and_prepare_dataset(args, tokenizer, num_proc=12):
|
||||
dataset = load_dataset(args.dataset_name, split="train[:1%]")
|
||||
original_columns = dataset.column_names
|
||||
|
||||
def preprocess_function(examples):
|
||||
new_examples = {
|
||||
"input_ids_chosen": [],
|
||||
"attention_mask_chosen": [],
|
||||
"input_ids_rejected": [],
|
||||
"attention_mask_rejected": [],
|
||||
}
|
||||
for chosen, rejected in zip(examples["chosen"], examples["rejected"]):
|
||||
tokenized_chosen = tokenizer(
|
||||
chosen, truncation=True, padding="max_length", max_length=script_args.max_seq_length
|
||||
)
|
||||
tokenized_rejected = tokenizer(
|
||||
rejected, truncation=True, padding="max_length", max_length=script_args.max_seq_length
|
||||
)
|
||||
|
||||
new_examples["input_ids_chosen"].append(tokenized_chosen["input_ids"])
|
||||
new_examples["attention_mask_chosen"].append(tokenized_rejected["attention_mask"])
|
||||
new_examples["input_ids_rejected"].append(tokenized_chosen["input_ids"])
|
||||
new_examples["attention_mask_rejected"].append(tokenized_rejected["attention_mask"])
|
||||
|
||||
return new_examples
|
||||
|
||||
dataset = dataset.map(preprocess_function, batched=True, num_proc=num_proc, remove_columns=original_columns)
|
||||
return dataset
|
||||
|
||||
|
||||
def main():
|
||||
model, tokenizer = create_and_prepare_model(script_args)
|
||||
dataset = create_and_prepare_dataset(script_args, tokenizer)
|
||||
|
||||
training_args = TrainingArguments(
|
||||
output_dir="./output",
|
||||
per_device_train_batch_size=script_args.per_device_train_batch_size,
|
||||
learning_rate=script_args.learning_rate,
|
||||
optim=script_args.optim,
|
||||
max_steps=1,
|
||||
lr_scheduler_type=script_args.lr_scheduler_type,
|
||||
gradient_accumulation_steps=script_args.gradient_accumulation_steps,
|
||||
save_steps=1,
|
||||
gradient_checkpointing=script_args.gradient_checkpointing,
|
||||
)
|
||||
|
||||
trainer = RewardTrainer(
|
||||
model=model,
|
||||
args=training_args,
|
||||
tokenizer=tokenizer,
|
||||
train_dataset=dataset,
|
||||
max_length=script_args.max_seq_length,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
116
examples/multi-adapter-rl/rl_finetuning.py
Normal file
116
examples/multi-adapter-rl/rl_finetuning.py
Normal file
@ -0,0 +1,116 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from datasets import load_dataset
|
||||
from peft import LoraConfig
|
||||
from tqdm import tqdm
|
||||
from transformers import LlamaTokenizer
|
||||
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer
|
||||
from trl.core import LengthSampler
|
||||
|
||||
|
||||
rm_adapter_id = "trl-lib/llama-7b-hh-rm-adapter"
|
||||
model_name = "huggyllama/llama-7b"
|
||||
dataset_name = "Anthropic/hh-rlhf"
|
||||
|
||||
input_min_text_length = 6
|
||||
input_max_text_length = 12
|
||||
|
||||
|
||||
def create_and_prepare_dataset(tokenizer):
|
||||
dataset = load_dataset(dataset_name, split="train[:1%]")
|
||||
|
||||
input_size = LengthSampler(input_min_text_length, input_max_text_length)
|
||||
|
||||
def tokenize(example):
|
||||
text_size = input_size()
|
||||
example["input_ids"] = tokenizer.encode(example["chosen"])[:text_size]
|
||||
example["query"] = tokenizer.decode(example["input_ids"])
|
||||
return example
|
||||
|
||||
dataset = dataset.map(tokenize, batched=False)
|
||||
dataset.set_format("torch")
|
||||
return dataset
|
||||
|
||||
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
model_name,
|
||||
load_in_8bit=True,
|
||||
device_map={"": 0},
|
||||
peft_config=lora_config,
|
||||
reward_adapter=rm_adapter_id,
|
||||
)
|
||||
tokenizer = LlamaTokenizer.from_pretrained(model_name)
|
||||
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
dataset = create_and_prepare_dataset(tokenizer)
|
||||
|
||||
|
||||
def collator(data):
|
||||
return dict((key, [d[key] for d in data]) for key in data[0])
|
||||
|
||||
|
||||
config = PPOConfig(
|
||||
model_name=model_name,
|
||||
learning_rate=1e-5,
|
||||
batch_size=8,
|
||||
mini_batch_size=2,
|
||||
gradient_accumulation_steps=2,
|
||||
optimize_cuda_cache=True,
|
||||
)
|
||||
|
||||
ppo_trainer = PPOTrainer(
|
||||
config,
|
||||
model,
|
||||
ref_model=None,
|
||||
tokenizer=tokenizer,
|
||||
dataset=dataset,
|
||||
data_collator=collator,
|
||||
)
|
||||
|
||||
generation_kwargs = {
|
||||
"top_k": 0.0,
|
||||
"top_p": 1.0,
|
||||
"do_sample": True,
|
||||
"pad_token_id": tokenizer.pad_token_id,
|
||||
}
|
||||
|
||||
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
|
||||
question_tensors = batch["input_ids"]
|
||||
|
||||
response_tensors = ppo_trainer.generate(
|
||||
question_tensors,
|
||||
return_prompt=False,
|
||||
**generation_kwargs,
|
||||
)
|
||||
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
|
||||
|
||||
# Compute reward score
|
||||
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
|
||||
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt").to(ppo_trainer.accelerator.device)
|
||||
raw_rewards = ppo_trainer.model.compute_reward_score(**inputs)
|
||||
rewards = [raw_rewards[i, -1, 1] for i in range(len(raw_rewards))] # take last token
|
||||
|
||||
# Run PPO step
|
||||
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
|
||||
ppo_trainer.log_stats(stats, batch, rewards)
|
||||
23
examples/sentiment/README.md
Normal file
23
examples/sentiment/README.md
Normal file
@ -0,0 +1,23 @@
|
||||
# Sentiment Examples
|
||||
|
||||
The notebooks and scripts in this examples show how to fine-tune a model with a sentiment classifier (such as `lvwerra/distilbert-imdb`).
|
||||
|
||||
Here's an overview of the notebooks and scripts:
|
||||
|
||||
| File | Description |
|
||||
|---|---|
|
||||
| `notebooks/gpt2-sentiment.ipynb` | Fine-tune GPT2 to generate positive movie reviews. |
|
||||
| `notebooks/gpt2-sentiment-control.ipynb` | Fine-tune GPT2 to generate movie reviews with controlled sentiment. |
|
||||
| `scripts/gpt2-sentiment.py` | Same as the notebook, but easier to use to use in mutli-GPU setup. |
|
||||
| `scripts/t5-sentiment.py` | Same as GPT2 script, but for a Seq2Seq model (T5). |
|
||||
|
||||
## Launch scripts
|
||||
|
||||
The `trl` library is powered by `accelerate`. As such it is best to configure and launch trainings with the following commands:
|
||||
|
||||
```bash
|
||||
accelerate config # will prompt you to define the training configuration
|
||||
accelerate launch scripts/gpt2-sentiment.py # launches training
|
||||
```
|
||||
|
||||
|
||||
@ -73,6 +73,7 @@
|
||||
"import pandas as pd\n",
|
||||
"from random import choices\n",
|
||||
"import matplotlib.pyplot as plt\n",
|
||||
"\n",
|
||||
"tqdm.pandas()\n",
|
||||
"\n",
|
||||
"from datasets import load_dataset\n",
|
||||
@ -95,22 +96,15 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"sentiment_pipe_kwargs = {\n",
|
||||
" \"top_k\": None, \n",
|
||||
" \"function_to_apply\": \"none\"\n",
|
||||
"}\n",
|
||||
"sentiment_pipe_kwargs = {\"top_k\": None, \"function_to_apply\": \"none\"}\n",
|
||||
"\n",
|
||||
"config = PPOConfig(\n",
|
||||
" model_name=\"lvwerra/gpt2-imdb\",\n",
|
||||
" steps=51200,\n",
|
||||
" learning_rate=1.41e-5,\n",
|
||||
" remove_unused_columns=False,\n",
|
||||
" log_with=\"wandb\"\n",
|
||||
" model_name=\"lvwerra/gpt2-imdb\", steps=51200, learning_rate=1.41e-5, remove_unused_columns=False, log_with=\"wandb\"\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"txt_in_len = 5\n",
|
||||
"txt_out_len = 20\n",
|
||||
"seed = 1\n"
|
||||
"seed = 1"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -201,13 +195,13 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# create the dataset \n",
|
||||
"# \n",
|
||||
"dataset = load_dataset('imdb', split='train')\n",
|
||||
"dataset = dataset.rename_columns({'text': 'review', 'label': 'sentiment'})\n",
|
||||
"# create the dataset\n",
|
||||
"#\n",
|
||||
"dataset = load_dataset(\"imdb\", split=\"train\")\n",
|
||||
"dataset = dataset.rename_columns({\"text\": \"review\", \"label\": \"sentiment\"})\n",
|
||||
"# make sure the comments are are at least 500 and trim to 1000\n",
|
||||
"dataset = dataset.filter(lambda x: len(x[\"review\"])>500, batched=False)\n",
|
||||
"dataset = dataset.map(lambda x:{\"review\":x['review'][:1000]}, batched=False)\n",
|
||||
"dataset = dataset.filter(lambda x: len(x[\"review\"]) > 500, batched=False)\n",
|
||||
"dataset = dataset.map(lambda x: {\"review\": x[\"review\"][:1000]}, batched=False)\n",
|
||||
"\n",
|
||||
"dataset"
|
||||
]
|
||||
@ -241,11 +235,15 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"dataset = dataset.map(lambda x:{\"input_ids\": gpt2_tokenizer.encode(' '+x['review'], return_tensors=\"pt\")[0, :txt_in_len]}, batched=False)\n",
|
||||
"dataset = dataset.map(lambda x:{\"query\": gpt2_tokenizer.decode(x[\"input_ids\"])}, batched=False)\n",
|
||||
"dataset = dataset.map(\n",
|
||||
" lambda x: {\"input_ids\": gpt2_tokenizer.encode(\" \" + x[\"review\"], return_tensors=\"pt\")[0, :txt_in_len]},\n",
|
||||
" batched=False,\n",
|
||||
")\n",
|
||||
"dataset = dataset.map(lambda x: {\"query\": gpt2_tokenizer.decode(x[\"input_ids\"])}, batched=False)\n",
|
||||
"dataset = dataset[:20480]\n",
|
||||
"\n",
|
||||
"from datasets import Dataset\n",
|
||||
"\n",
|
||||
"dataset = Dataset.from_dict(dataset)\n",
|
||||
"dataset.set_format(\"pytorch\")"
|
||||
]
|
||||
@ -355,7 +353,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"ppo_trainer = PPOTrainer(config, gpt2_model, gpt2_model_ref, gpt2_tokenizer, dataset, data_collator=collator)\n"
|
||||
"ppo_trainer = PPOTrainer(config, gpt2_model, gpt2_model_ref, gpt2_tokenizer, dataset, data_collator=collator)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -373,7 +371,7 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"if ppo_trainer.accelerator.num_processes == 1:\n",
|
||||
" device = 0 if torch.cuda.is_available() else \"cpu\" # to avoid a `pipeline` bug\n",
|
||||
" device = 0 if torch.cuda.is_available() else \"cpu\" # to avoid a `pipeline` bug\n",
|
||||
"else:\n",
|
||||
" device = ppo_trainer.accelerator.device\n",
|
||||
"sentiment_pipe = pipeline(\"sentiment-analysis\", \"lvwerra/distilbert-imdb\", device=device)"
|
||||
@ -404,7 +402,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"text = 'this movie was really bad!!'\n",
|
||||
"text = \"this movie was really bad!!\"\n",
|
||||
"output = sentiment_pipe(text, **sentiment_pipe_kwargs)\n",
|
||||
"output"
|
||||
]
|
||||
@ -427,7 +425,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"text = 'this movie was really good!!'\n",
|
||||
"text = \"this movie was really good!!\"\n",
|
||||
"output = sentiment_pipe(text, **sentiment_pipe_kwargs)\n",
|
||||
"output"
|
||||
]
|
||||
@ -450,7 +448,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"text = 'this movie was a documentary'\n",
|
||||
"text = \"this movie was a documentary\"\n",
|
||||
"output = sentiment_pipe(text, **sentiment_pipe_kwargs)\n",
|
||||
"output"
|
||||
]
|
||||
@ -472,7 +470,7 @@
|
||||
" positive_logits = []\n",
|
||||
" for out in outputs:\n",
|
||||
" for element in out:\n",
|
||||
" if element[\"label\"]==\"POSITIVE\":\n",
|
||||
" if element[\"label\"] == \"POSITIVE\":\n",
|
||||
" positive_logits.append(torch.tensor(element[\"score\"]))\n",
|
||||
" return positive_logits"
|
||||
]
|
||||
@ -511,8 +509,8 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"ctrl_str = ['[negative]', '[neutral]', '[positive]']\n",
|
||||
"device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\") # this should be handled by accelerate\n",
|
||||
"ctrl_str = [\"[negative]\", \"[neutral]\", \"[positive]\"]\n",
|
||||
"device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\") # this should be handled by accelerate\n",
|
||||
"ctrl_tokens = dict((s, gpt2_tokenizer.encode(s, return_tensors=\"pt\").squeeze().to(device)) for s in ctrl_str)"
|
||||
]
|
||||
},
|
||||
@ -559,14 +557,14 @@
|
||||
" task [positive]: reward = logit\n",
|
||||
" \"\"\"\n",
|
||||
" for i in range(len(logit)):\n",
|
||||
" if task[i]=='[negative]':\n",
|
||||
" if task[i] == \"[negative]\":\n",
|
||||
" logit[i] = -logit[i]\n",
|
||||
" elif task[i]=='[neutral]':\n",
|
||||
" logit[i] = -2*torch.abs(logit[i])+4\n",
|
||||
" elif task[i]=='[positive]':\n",
|
||||
" elif task[i] == \"[neutral]\":\n",
|
||||
" logit[i] = -2 * torch.abs(logit[i]) + 4\n",
|
||||
" elif task[i] == \"[positive]\":\n",
|
||||
" pass\n",
|
||||
" else:\n",
|
||||
" raise ValueError('task has to be in [0, 1, 2]!')\n",
|
||||
" raise ValueError(\"task has to be in [0, 1, 2]!\")\n",
|
||||
" return logit"
|
||||
]
|
||||
},
|
||||
@ -611,7 +609,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"pos_logit_to_reward(torch.Tensor([4,4,4]), ctrl_str)"
|
||||
"pos_logit_to_reward(torch.Tensor([4, 4, 4]), ctrl_str)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -631,7 +629,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"pos_logit_to_reward(torch.Tensor([-4,-4,-4]), ctrl_str)"
|
||||
"pos_logit_to_reward(torch.Tensor([-4, -4, -4]), ctrl_str)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -668,14 +666,14 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"generation_kwargs = {\n",
|
||||
" \"min_length\":-1,\n",
|
||||
" \"min_length\": -1,\n",
|
||||
" \"top_k\": 0.0,\n",
|
||||
" \"top_p\": 1.0,\n",
|
||||
" \"do_sample\": True,\n",
|
||||
" \"pad_token_id\": gpt2_tokenizer.eos_token_id,\n",
|
||||
" \"max_new_tokens\": txt_out_len,\n",
|
||||
" \"eos_token_id\": -1\n",
|
||||
"}\n"
|
||||
" \"eos_token_id\": -1,\n",
|
||||
"}"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -698,7 +696,6 @@
|
||||
"4. Get sentiments for query/responses from BERT\n",
|
||||
"5. Optimize policy with PPO using the (query, response, reward) triplet\n",
|
||||
"6. Log all the training statistics\n",
|
||||
|
||||
"\n",
|
||||
"**Training time**\n",
|
||||
"\n",
|
||||
@ -724,11 +721,14 @@
|
||||
"source": [
|
||||
"for epoch in range(2):\n",
|
||||
" for batch in tqdm(ppo_trainer.dataloader):\n",
|
||||
" logs, game_data, = dict(), dict()\n",
|
||||
" \n",
|
||||
" (logs, game_data,) = (\n",
|
||||
" dict(),\n",
|
||||
" dict(),\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" #### prepend a random control token\n",
|
||||
" task_list = choices(ctrl_str, k=config.batch_size)\n",
|
||||
" game_data['query'] = [t+q for t,q in zip(task_list, batch['query'])]\n",
|
||||
" game_data[\"query\"] = [t + q for t, q in zip(task_list, batch[\"query\"])]\n",
|
||||
" query_tensors = [torch.cat((ctrl_tokens[t], input_ids)) for t, input_ids in zip(task_list, batch[\"input_ids\"])]\n",
|
||||
"\n",
|
||||
" #### get response from gpt2\n",
|
||||
@ -736,21 +736,21 @@
|
||||
" for query in query_tensors:\n",
|
||||
" response = ppo_trainer.generate(query, **generation_kwargs)\n",
|
||||
" response_tensors.append(response.squeeze()[-txt_out_len:])\n",
|
||||
" game_data['response'] = [gpt2_tokenizer.decode(r.squeeze()) for r in response_tensors]\n",
|
||||
" game_data[\"response\"] = [gpt2_tokenizer.decode(r.squeeze()) for r in response_tensors]\n",
|
||||
"\n",
|
||||
" #### sentiment analysis\n",
|
||||
" texts = [q + r for q,r in zip(batch['query'], game_data['response'])]\n",
|
||||
" texts = [q + r for q, r in zip(batch[\"query\"], game_data[\"response\"])]\n",
|
||||
" logits = extract_pipe_output(sentiment_pipe(texts, **sentiment_pipe_kwargs))\n",
|
||||
" rewards = pos_logit_to_reward(logits, task_list)\n",
|
||||
"\n",
|
||||
" #### Run PPO training \n",
|
||||
" #### Run PPO training\n",
|
||||
" t = time.time()\n",
|
||||
" stats = ppo_trainer.step(query_tensors, response_tensors, rewards)\n",
|
||||
"\n",
|
||||
" for cs in ctrl_str:\n",
|
||||
" key = 'env/reward_'+cs.strip('[]')\n",
|
||||
" stats[key] = np.mean([r.cpu().numpy() for r, t in zip(rewards, task_list) if t==cs])\n",
|
||||
" ppo_trainer.log_stats(stats, game_data, rewards)\n"
|
||||
" key = \"env/reward_\" + cs.strip(\"[]\")\n",
|
||||
" stats[key] = np.mean([r.cpu().numpy() for r, t in zip(rewards, task_list) if t == cs])\n",
|
||||
" ppo_trainer.log_stats(stats, game_data, rewards)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -803,12 +803,11 @@
|
||||
],
|
||||
"source": [
|
||||
"for ctrl_s in ctrl_str:\n",
|
||||
" plt.hist([r for r, t in zip(logs['env/reward_dist'], task_list) if t==ctrl_s],\n",
|
||||
" density=True,\n",
|
||||
" alpha=0.5,\n",
|
||||
" label=ctrl_s)\n",
|
||||
"plt.legend(loc='best')\n",
|
||||
"plt.title('reward distribution')\n",
|
||||
" plt.hist(\n",
|
||||
" [r for r, t in zip(logs[\"env/reward_dist\"], task_list) if t == ctrl_s], density=True, alpha=0.5, label=ctrl_s\n",
|
||||
" )\n",
|
||||
"plt.legend(loc=\"best\")\n",
|
||||
"plt.title(\"reward distribution\")\n",
|
||||
"plt.grid(True)\n",
|
||||
"plt.show()"
|
||||
]
|
||||
@ -827,8 +826,8 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"gpt2_model.save_pretrained('gpt2-imdb-ctrl')\n",
|
||||
"gpt2_tokenizer.save_pretrained('gpt2-imdb-ctrl')"
|
||||
"gpt2_model.save_pretrained(\"gpt2-imdb-ctrl\")\n",
|
||||
"gpt2_tokenizer.save_pretrained(\"gpt2-imdb-ctrl\")"
|
||||
]
|
||||
}
|
||||
],
|
||||
|
||||
@ -63,6 +63,7 @@
|
||||
"import torch\n",
|
||||
"from tqdm import tqdm\n",
|
||||
"import pandas as pd\n",
|
||||
"\n",
|
||||
"tqdm.pandas()\n",
|
||||
"\n",
|
||||
"from transformers import pipeline, AutoTokenizer\n",
|
||||
@ -91,11 +92,7 @@
|
||||
" log_with=\"wandb\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"sent_kwargs = {\n",
|
||||
" \"return_all_scores\": True,\n",
|
||||
" \"function_to_apply\": \"none\",\n",
|
||||
" \"batch_size\": 16\n",
|
||||
"}"
|
||||
"sent_kwargs = {\"return_all_scores\": True, \"function_to_apply\": \"none\", \"batch_size\": 16}"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -105,6 +102,7 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import wandb\n",
|
||||
"\n",
|
||||
"wandb.init()"
|
||||
]
|
||||
},
|
||||
@ -149,13 +147,13 @@
|
||||
"source": [
|
||||
"def build_dataset(config, dataset_name=\"imdb\", input_min_text_length=2, input_max_text_length=8):\n",
|
||||
" \"\"\"\n",
|
||||
" Build dataset for training. This builds the dataset from `load_dataset`, one should \n",
|
||||
" Build dataset for training. This builds the dataset from `load_dataset`, one should\n",
|
||||
" customize this function to train the model on its own dataset.\n",
|
||||
" \n",
|
||||
"\n",
|
||||
" Args:\n",
|
||||
" dataset_name (`str`): \n",
|
||||
" dataset_name (`str`):\n",
|
||||
" The name of the dataset to be loaded.\n",
|
||||
" \n",
|
||||
"\n",
|
||||
" Returns:\n",
|
||||
" dataloader (`torch.utils.data.DataLoader`):\n",
|
||||
" The dataloader for the dataset.\n",
|
||||
@ -163,19 +161,19 @@
|
||||
" tokenizer = AutoTokenizer.from_pretrained(config.model_name)\n",
|
||||
" tokenizer.pad_token = tokenizer.eos_token\n",
|
||||
" # load imdb with datasets\n",
|
||||
" ds = load_dataset(dataset_name, split='train')\n",
|
||||
" ds = ds.rename_columns({'text': 'review'})\n",
|
||||
" ds = ds.filter(lambda x: len(x[\"review\"])>200, batched=False)\n",
|
||||
" ds = load_dataset(dataset_name, split=\"train\")\n",
|
||||
" ds = ds.rename_columns({\"text\": \"review\"})\n",
|
||||
" ds = ds.filter(lambda x: len(x[\"review\"]) > 200, batched=False)\n",
|
||||
"\n",
|
||||
" input_size = LengthSampler(input_min_text_length, input_max_text_length)\n",
|
||||
"\n",
|
||||
" def tokenize(sample):\n",
|
||||
" sample[\"input_ids\"] = tokenizer.encode(sample[\"review\"])[:input_size()]\n",
|
||||
" sample[\"input_ids\"] = tokenizer.encode(sample[\"review\"])[: input_size()]\n",
|
||||
" sample[\"query\"] = tokenizer.decode(sample[\"input_ids\"])\n",
|
||||
" return sample\n",
|
||||
"\n",
|
||||
" ds = ds.map(tokenize, batched=False)\n",
|
||||
" ds.set_format(type='torch')\n",
|
||||
" ds.set_format(type=\"torch\")\n",
|
||||
" return ds"
|
||||
]
|
||||
},
|
||||
@ -187,6 +185,7 @@
|
||||
"source": [
|
||||
"dataset = build_dataset(config)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def collator(data):\n",
|
||||
" return dict((key, [d[key] for d in data]) for key in data[0])"
|
||||
]
|
||||
@ -252,7 +251,7 @@
|
||||
"source": [
|
||||
"device = ppo_trainer.accelerator.device\n",
|
||||
"if ppo_trainer.accelerator.num_processes == 1:\n",
|
||||
" device = 0 if torch.cuda.is_available() else \"cpu\" # to avoid a `pipeline` bug\n",
|
||||
" device = 0 if torch.cuda.is_available() else \"cpu\" # to avoid a `pipeline` bug\n",
|
||||
"sentiment_pipe = pipeline(\"sentiment-analysis\", model=\"lvwerra/distilbert-imdb\", device=device)"
|
||||
]
|
||||
},
|
||||
@ -281,7 +280,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"text = 'this movie was really bad!!'\n",
|
||||
"text = \"this movie was really bad!!\"\n",
|
||||
"sentiment_pipe(text, **sent_kwargs)"
|
||||
]
|
||||
},
|
||||
@ -303,7 +302,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"text = 'this movie was really good!!'\n",
|
||||
"text = \"this movie was really good!!\"\n",
|
||||
"sentiment_pipe(text, **sent_kwargs)"
|
||||
]
|
||||
},
|
||||
@ -321,13 +320,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"gen_kwargs = {\n",
|
||||
" \"min_length\":-1,\n",
|
||||
" \"top_k\": 0.0,\n",
|
||||
" \"top_p\": 1.0,\n",
|
||||
" \"do_sample\": True,\n",
|
||||
" \"pad_token_id\": tokenizer.eos_token_id\n",
|
||||
"}"
|
||||
"gen_kwargs = {\"min_length\": -1, \"top_k\": 0.0, \"top_p\": 1.0, \"do_sample\": True, \"pad_token_id\": tokenizer.eos_token_id}"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -370,16 +363,16 @@
|
||||
"\n",
|
||||
"\n",
|
||||
"generation_kwargs = {\n",
|
||||
" \"min_length\":-1,\n",
|
||||
" \"min_length\": -1,\n",
|
||||
" \"top_k\": 0.0,\n",
|
||||
" \"top_p\": 1.0,\n",
|
||||
" \"do_sample\": True,\n",
|
||||
" \"pad_token_id\": tokenizer.eos_token_id\n",
|
||||
" \"pad_token_id\": tokenizer.eos_token_id,\n",
|
||||
"}\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):\n",
|
||||
" query_tensors = batch['input_ids']\n",
|
||||
" query_tensors = batch[\"input_ids\"]\n",
|
||||
"\n",
|
||||
" #### Get response from gpt2\n",
|
||||
" response_tensors = []\n",
|
||||
@ -388,14 +381,14 @@
|
||||
" generation_kwargs[\"max_new_tokens\"] = gen_len\n",
|
||||
" response = ppo_trainer.generate(query, **generation_kwargs)\n",
|
||||
" response_tensors.append(response.squeeze()[-gen_len:])\n",
|
||||
" batch['response'] = [tokenizer.decode(r.squeeze()) for r in response_tensors]\n",
|
||||
" batch[\"response\"] = [tokenizer.decode(r.squeeze()) for r in response_tensors]\n",
|
||||
"\n",
|
||||
" #### Compute sentiment score\n",
|
||||
" texts = [q + r for q,r in zip(batch['query'], batch['response'])]\n",
|
||||
" texts = [q + r for q, r in zip(batch[\"query\"], batch[\"response\"])]\n",
|
||||
" pipe_outputs = sentiment_pipe(texts, **sent_kwargs)\n",
|
||||
" rewards = [torch.tensor(output[1][\"score\"]) for output in pipe_outputs]\n",
|
||||
"\n",
|
||||
" #### Run PPO step \n",
|
||||
" #### Run PPO step\n",
|
||||
" stats = ppo_trainer.step(query_tensors, response_tensors, rewards)\n",
|
||||
" ppo_trainer.log_stats(stats, batch, rewards)"
|
||||
]
|
||||
@ -414,7 +407,7 @@
|
||||
"\n",
|
||||
"One can observe how the model starts to generate more positive outputs after a few optimisation steps.\n",
|
||||
"\n",
|
||||
"> Note: Investigating the KL-divergence will probably show that at this point the model has not converged to the target KL-divergence, yet. To get there would require longer training or starting with a higher inital coefficient."
|
||||
"> Note: Investigating the KL-divergence will probably show that at this point the model has not converged to the target KL-divergence, yet. To get there would require longer training or starting with a higher initial coefficient."
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -685,31 +678,33 @@
|
||||
"game_data = dict()\n",
|
||||
"dataset.set_format(\"pandas\")\n",
|
||||
"df_batch = dataset[:].sample(bs)\n",
|
||||
"game_data['query'] = df_batch['query'].tolist()\n",
|
||||
"query_tensors = df_batch['input_ids'].tolist()\n",
|
||||
"game_data[\"query\"] = df_batch[\"query\"].tolist()\n",
|
||||
"query_tensors = df_batch[\"input_ids\"].tolist()\n",
|
||||
"\n",
|
||||
"response_tensors_ref, response_tensors = [], []\n",
|
||||
"\n",
|
||||
"#### get response from gpt2 and gpt2_ref\n",
|
||||
"for i in range(bs):\n",
|
||||
" gen_len = output_length_sampler()\n",
|
||||
" output = ref_model.generate(torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device),\n",
|
||||
" max_new_tokens=gen_len, **gen_kwargs).squeeze()[-gen_len:]\n",
|
||||
" output = ref_model.generate(\n",
|
||||
" torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device), max_new_tokens=gen_len, **gen_kwargs\n",
|
||||
" ).squeeze()[-gen_len:]\n",
|
||||
" response_tensors_ref.append(output)\n",
|
||||
" output = model.generate(torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device),\n",
|
||||
" max_new_tokens=gen_len, **gen_kwargs).squeeze()[-gen_len:]\n",
|
||||
" output = model.generate(\n",
|
||||
" torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device), max_new_tokens=gen_len, **gen_kwargs\n",
|
||||
" ).squeeze()[-gen_len:]\n",
|
||||
" response_tensors.append(output)\n",
|
||||
"\n",
|
||||
"#### decode responses\n",
|
||||
"game_data['response (before)'] = [tokenizer.decode(response_tensors_ref[i]) for i in range(bs)]\n",
|
||||
"game_data['response (after)'] = [tokenizer.decode(response_tensors[i]) for i in range(bs)]\n",
|
||||
"game_data[\"response (before)\"] = [tokenizer.decode(response_tensors_ref[i]) for i in range(bs)]\n",
|
||||
"game_data[\"response (after)\"] = [tokenizer.decode(response_tensors[i]) for i in range(bs)]\n",
|
||||
"\n",
|
||||
"#### sentiment analysis of query/response pairs before/after\n",
|
||||
"texts = [q + r for q,r in zip(game_data['query'], game_data['response (before)'])]\n",
|
||||
"game_data['rewards (before)'] = [output[1][\"score\"] for output in sentiment_pipe(texts, **sent_kwargs)]\n",
|
||||
"texts = [q + r for q, r in zip(game_data[\"query\"], game_data[\"response (before)\"])]\n",
|
||||
"game_data[\"rewards (before)\"] = [output[1][\"score\"] for output in sentiment_pipe(texts, **sent_kwargs)]\n",
|
||||
"\n",
|
||||
"texts = [q + r for q,r in zip(game_data['query'], game_data['response (after)'])]\n",
|
||||
"game_data['rewards (after)'] = [output[1][\"score\"] for output in sentiment_pipe(texts, **sent_kwargs)]\n",
|
||||
"texts = [q + r for q, r in zip(game_data[\"query\"], game_data[\"response (after)\"])]\n",
|
||||
"game_data[\"rewards (after)\"] = [output[1][\"score\"] for output in sentiment_pipe(texts, **sent_kwargs)]\n",
|
||||
"\n",
|
||||
"# store results in a dataframe\n",
|
||||
"df_results = pd.DataFrame(game_data)\n",
|
||||
@ -767,10 +762,10 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print('mean:')\n",
|
||||
"print(\"mean:\")\n",
|
||||
"display(df_results[[\"rewards (before)\", \"rewards (after)\"]].mean())\n",
|
||||
"print()\n",
|
||||
"print('median:')\n",
|
||||
"print(\"median:\")\n",
|
||||
"display(df_results[[\"rewards (before)\", \"rewards (after)\"]].median())"
|
||||
]
|
||||
},
|
||||
@ -843,8 +838,8 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"model.save_pretrained('gpt2-imdb-pos-v2', push_to_hub=True)\n",
|
||||
"tokenizer.save_pretrained('gpt2-imdb-pos-v2', push_to_hub=True)"
|
||||
"model.save_pretrained(\"gpt2-imdb-pos-v2\", push_to_hub=True)\n",
|
||||
"tokenizer.save_pretrained(\"gpt2-imdb-pos-v2\", push_to_hub=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@ -17,9 +17,9 @@ from typing import Optional
|
||||
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
|
||||
from peft import LoraConfig
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, HfArgumentParser, pipeline
|
||||
from transformers import AutoTokenizer, HfArgumentParser, pipeline
|
||||
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer, set_seed
|
||||
from trl.core import LengthSampler
|
||||
@ -51,7 +51,7 @@ from trl.core import LengthSampler
|
||||
# the training parameters, and the PPO parameters.
|
||||
# Check the default arguments in the `PPOConfig` class for more details.
|
||||
# If you want to log with tensorboard, add the kwarg
|
||||
# `accelerator_kwargs={"logging_dir": PATH_TO_LOGS}` to the PPOConfig.
|
||||
# `project_kwargs={"logging_dir": PATH_TO_LOGS}` to the PPOConfig.
|
||||
|
||||
|
||||
# Define and parse arguments.
|
||||
@ -63,7 +63,7 @@ class ScriptArguments:
|
||||
|
||||
# NOTE: gpt2 models use Conv1D instead of Linear layers which are not yet supported in 8 bit mode
|
||||
# models like gpt-neo* models are more suitable
|
||||
model_name: Optional[str] = field(default="EleutherAI/gpt-neox-20b", metadata={"help": "the model name"})
|
||||
model_name: Optional[str] = field(default="edbeeching/gpt-neo-1.3B-imdb", metadata={"help": "the model name"})
|
||||
log_with: Optional[str] = field(default=None, metadata={"help": "use 'wandb' to log with wandb"})
|
||||
learning_rate: Optional[float] = field(default=1.41e-5, metadata={"help": "the learning rate"})
|
||||
merge_model_adapter: Optional[bool] = field(default=False, metadata={"help": "the learning rate"})
|
||||
@ -162,16 +162,15 @@ lora_config = LoraConfig(
|
||||
)
|
||||
|
||||
# Now let's build the model, the reference model, and the tokenizer.
|
||||
pretrained_model = AutoModelForCausalLM.from_pretrained(
|
||||
config.model_name, load_in_8bit=True, device_map="balanced", max_memory={0: "800MB", 1: "800MB"}
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
config.model_name,
|
||||
load_in_8bit=True,
|
||||
device_map="balanced",
|
||||
max_memory={0: "800MB", 1: "800MB"},
|
||||
peft_config=lora_config,
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
|
||||
|
||||
pretrained_model = prepare_model_for_int8_training(pretrained_model)
|
||||
pretrained_model = get_peft_model(pretrained_model, lora_config)
|
||||
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(pretrained_model)
|
||||
|
||||
print_trainable_parameters(model)
|
||||
|
||||
# GPT-2 tokenizer has a pad token, but it is not eos_token by default. We need to set it to eos_token.
|
||||
|
||||
@ -5,6 +5,6 @@ can find out more in our [blogpost](https://huggingface.co/blog/trl-peft).
|
||||
|
||||
Overall there were three key steps and training scripts:
|
||||
|
||||
1. **cm_finetune_peft_imdb.py** - Fine tuning a Low Rank Adapter on a frozen 8-bit model for text generation on the imdb dataset.
|
||||
1. **clm_finetune_peft_imdb.py** - Fine tuning a Low Rank Adapter on a frozen 8-bit model for text generation on the imdb dataset.
|
||||
2. **merge_peft_adapter.py** - Merging of the adapter layers into the base model’s weights and storing these on the hub.
|
||||
3. **gpt-neo-20b_sentiment_peft.py** - Sentiment fine-tuning of a Low Rank Adapter to create positive reviews.
|
||||
|
||||
@ -59,9 +59,7 @@ if tokenizer.pad_token_id is None:
|
||||
|
||||
|
||||
if "gpt-neox" in model_args.model_name_or_path:
|
||||
model = prepare_model_for_int8_training(
|
||||
model, output_embedding_layer_name="embed_out", layer_norm_names=["layer_norm", "layernorm"]
|
||||
)
|
||||
model = prepare_model_for_int8_training(model, output_embedding_layer_name="embed_out")
|
||||
else:
|
||||
model = prepare_model_for_int8_training(model)
|
||||
|
||||
|
||||
@ -51,7 +51,7 @@ from trl.core import LengthSampler
|
||||
# the training parameters, and the PPO parameters.
|
||||
# Check the default arguments in the `PPOConfig` class for more details.
|
||||
# If you want to log with tensorboard, add the kwarg
|
||||
# `accelerator_kwargs={"logging_dir": PATH_TO_LOGS}` to the PPOConfig.
|
||||
# `project_kwargs={"logging_dir": PATH_TO_LOGS}` to the PPOConfig.
|
||||
|
||||
|
||||
# Define and parse arguments.
|
||||
|
||||
@ -60,11 +60,20 @@ class ScriptArguments:
|
||||
model_name: Optional[str] = field(default="lvwerra/gpt2-imdb", metadata={"help": "the model name"})
|
||||
log_with: Optional[str] = field(default=None, metadata={"help": "use 'wandb' to log with wandb"})
|
||||
learning_rate: Optional[float] = field(default=1.41e-5, metadata={"help": "the learning rate"})
|
||||
mini_batch_size: Optional[int] = field(default=16, metadata={"help": "the PPO minibatch size"})
|
||||
batch_size: Optional[int] = field(default=256, metadata={"help": "the batch size"})
|
||||
mini_batch_size: Optional[int] = field(default=128, metadata={"help": "the PPO minibatch size"})
|
||||
batch_size: Optional[int] = field(default=128, metadata={"help": "the batch size"})
|
||||
gradient_accumulation_steps: Optional[int] = field(
|
||||
default=1, metadata={"help": "the number of gradient accumulation steps"}
|
||||
)
|
||||
early_stopping: Optional[bool] = field(default=False, metadata={"help": "whether to early stop"})
|
||||
kl_penalty: Optional[str] = field(
|
||||
default="kl",
|
||||
metadata={
|
||||
"help": "kl penalty options: 'kl': model_logp - ref_logp, 'abs': abs(kl) and 'mse': mean squared error mse(kl)."
|
||||
},
|
||||
)
|
||||
target_kl: Optional[float] = field(default=0.1, metadata={"help": "kl target for early stopping"})
|
||||
seed: Optional[int] = field(default=0, metadata={"help": "the random seed"})
|
||||
|
||||
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
@ -77,6 +86,10 @@ config = PPOConfig(
|
||||
mini_batch_size=script_args.mini_batch_size,
|
||||
batch_size=script_args.batch_size,
|
||||
gradient_accumulation_steps=script_args.gradient_accumulation_steps,
|
||||
early_stopping=script_args.early_stopping,
|
||||
target_kl=script_args.target_kl,
|
||||
kl_penalty=script_args.kl_penalty,
|
||||
seed=script_args.seed,
|
||||
)
|
||||
|
||||
|
||||
@ -160,22 +173,15 @@ generation_kwargs = {
|
||||
"top_p": 1.0,
|
||||
"do_sample": True,
|
||||
"pad_token_id": tokenizer.eos_token_id,
|
||||
"max_new_tokens": 32,
|
||||
}
|
||||
output_min_length = 4
|
||||
output_max_length = 16
|
||||
output_length_sampler = LengthSampler(output_min_length, output_max_length)
|
||||
|
||||
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
|
||||
query_tensors = batch["input_ids"]
|
||||
|
||||
# Get response from gpt2
|
||||
response_tensors = []
|
||||
for query in query_tensors:
|
||||
gen_len = output_length_sampler()
|
||||
generation_kwargs["max_new_tokens"] = gen_len
|
||||
response = ppo_trainer.generate(query, **generation_kwargs)
|
||||
response_tensors.append(response.squeeze()[-gen_len:])
|
||||
batch["response"] = [tokenizer.decode(r.squeeze()) for r in response_tensors]
|
||||
response_tensors = ppo_trainer.generate(query_tensors, return_prompt=False, **generation_kwargs)
|
||||
batch["response"] = tokenizer.batch_decode(response_tensors)
|
||||
|
||||
# Compute sentiment score
|
||||
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
|
||||
|
||||
@ -16,11 +16,10 @@ from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
|
||||
from peft import LoraConfig
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, HfArgumentParser, pipeline
|
||||
from transformers import AutoTokenizer, HfArgumentParser, pipeline
|
||||
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer, set_seed
|
||||
from trl.core import LengthSampler
|
||||
@ -56,7 +55,7 @@ tqdm.pandas()
|
||||
# the training parameters, and the PPO parameters.
|
||||
# Check the default arguments in the `PPOConfig` class for more details.
|
||||
# If you want to log with tensorboard, add the kwarg
|
||||
# `accelerator_kwargs={"logging_dir": PATH_TO_LOGS}` to the PPOConfig.
|
||||
# `project_kwargs={"logging_dir": PATH_TO_LOGS}` to the PPOConfig.
|
||||
|
||||
|
||||
# Define and parse arguments.
|
||||
@ -141,11 +140,18 @@ def collator(data):
|
||||
# set seed before initializing value head for deterministic eval
|
||||
set_seed(config.seed)
|
||||
|
||||
# Now let's build the main base model! We'll use the `AutoModelForCausalLM` class and load the model in 8 bit mode.
|
||||
current_device = Accelerator().process_index
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
pretrained_model = AutoModelForCausalLM.from_pretrained(
|
||||
config.model_name, load_in_8bit=True, device_map={"": current_device}
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
config.model_name,
|
||||
load_in_8bit=True,
|
||||
peft_config=lora_config,
|
||||
)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
|
||||
@ -168,20 +174,7 @@ def print_trainable_parameters(model):
|
||||
)
|
||||
|
||||
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
pretrained_model = prepare_model_for_int8_training(pretrained_model, layer_norm_names=[])
|
||||
pretrained_model = get_peft_model(pretrained_model, lora_config)
|
||||
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(pretrained_model)
|
||||
print_trainable_parameters(model)
|
||||
model.train()
|
||||
|
||||
# GPT-2 tokenizer has a pad token, but it is not eos_token by default. We need to set it to eos_token.
|
||||
# only for this model.
|
||||
@ -194,7 +187,7 @@ ppo_trainer = PPOTrainer(config, model, ref_model=None, tokenizer=tokenizer, dat
|
||||
# to the same device as the PPOTrainer.
|
||||
device = ppo_trainer.accelerator.device
|
||||
if ppo_trainer.accelerator.num_processes == 1:
|
||||
device = current_device if torch.cuda.is_available() else "cpu" # to avoid a `pipeline` bug
|
||||
device = model.current_device if torch.cuda.is_available() else "cpu" # to avoid a `pipeline` bug
|
||||
sentiment_pipe = pipeline("sentiment-analysis", model="lvwerra/distilbert-imdb", device=device)
|
||||
|
||||
# We then define the arguments to pass to the `generate` function. These arguments
|
||||
@ -220,13 +213,10 @@ for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
|
||||
model.gradient_checkpointing_disable()
|
||||
model.pretrained_model.config.use_cache = True
|
||||
# Get response from Causal LM
|
||||
response_tensors = []
|
||||
for query in query_tensors:
|
||||
gen_len = output_length_sampler()
|
||||
generation_kwargs["max_new_tokens"] = gen_len
|
||||
response = ppo_trainer.generate(query, **generation_kwargs)
|
||||
response_tensors.append(response.squeeze()[-gen_len:])
|
||||
batch["response"] = [tokenizer.decode(r.squeeze()) for r in response_tensors]
|
||||
response_tensors = ppo_trainer.generate(
|
||||
query_tensors, return_prompt=False, length_sampler=output_length_sampler, **generation_kwargs
|
||||
)
|
||||
batch["response"] = tokenizer.batch_decode(response_tensors)
|
||||
|
||||
# Compute sentiment score
|
||||
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
|
||||
|
||||
@ -144,14 +144,11 @@ output_length_sampler = LengthSampler(output_min_length, output_max_length)
|
||||
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
|
||||
query_tensors = batch["input_ids"]
|
||||
|
||||
# Get response from gpt2
|
||||
response_tensors = []
|
||||
for query in query_tensors:
|
||||
gen_len = output_length_sampler()
|
||||
generation_kwargs["max_new_tokens"] = gen_len
|
||||
response = ppo_trainer.generate(query, **generation_kwargs)
|
||||
response_tensors.append(response.squeeze())
|
||||
batch["response"] = [tokenizer.decode(r[1:].squeeze()) for r in response_tensors]
|
||||
# Get response from t5
|
||||
response_tensors = ppo_trainer.generate(
|
||||
query_tensors, return_prompt=False, length_sampler=output_length_sampler, **generation_kwargs
|
||||
)
|
||||
batch["response"] = tokenizer.batch_decode([r[1:] for r in response_tensors])
|
||||
|
||||
# Compute sentiment score
|
||||
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
|
||||
|
||||
18
examples/stack_llama/scripts/README.md
Normal file
18
examples/stack_llama/scripts/README.md
Normal file
@ -0,0 +1,18 @@
|
||||
# RLHF pipeline for the creation of StackLLaMa: a Stack exchange llama-7b model.
|
||||
There were three main steps to the training process:
|
||||
1. Supervised fine-tuning of the base llama-7b model to create llama-7b-se:
|
||||
- `torchrun --nnodes 1 --nproc_per_node 8 examples/stack_llama/scripts/supervised_finetuning.py --model_path=<LLAMA_MODEL_PATH> --streaming --no_gradient_checkpointing --learning_rate 1e-5 --max_steps 5000 --output_dir ./llama-se`
|
||||
2. Reward modeling using dialog pairs from the SE dataset using the llama-7b-se to create llama-7b-se-rm:
|
||||
- `torchrun --nnodes 1 --nproc_per_node 8 examples/stack_llama/scripts/reward_modeling.py --model_name=<LLAMA_SE_MODEL>`
|
||||
3. RL fine-tuning of llama-7b-se with the llama-7b-se-rm reward model:
|
||||
- `accelerate launch --multi_gpu --num_machines 1 --num_processes 8 examples/stack_llama/scripts/rl_training.py --log_with=wandb --model_name=<LLAMA_SE_MODEL> --reward_model_name=<LLAMA_SE_RM_MODEL> --adafactor=False --tokenizer_name=<LLAMA_TOKENIZER> --save_freq=100 --output_max_length=128 --batch_size=8 --gradient_accumulation_steps=8 --batched_gen=True --ppo_epochs=4 --seed=0 --learning_rate=1.4e-5 --early_stopping=True --output_dir=llama-se-rl-finetune-128-8-8-1.4e-5_adam`
|
||||
|
||||
|
||||
LoRA layers were using at all stages to reduce memory requirements.
|
||||
At each stage the peft adapter layers were merged with the base model, using:
|
||||
```shell
|
||||
python examples/stack_llama/scripts/merge_peft_adapter.py --adapter_model_name=XXX --base_model_name=YYY --output_name=ZZZ
|
||||
```
|
||||
Note that this script requires `peft>=0.3.0`.
|
||||
|
||||
For access to the base llama-7b model, please see Meta's [release](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) and [request form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform).
|
||||
47
examples/stack_llama/scripts/merge_peft_adapter.py
Normal file
47
examples/stack_llama/scripts/merge_peft_adapter.py
Normal file
@ -0,0 +1,47 @@
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
from peft import PeftConfig, PeftModel
|
||||
from transformers import AutoModelForCausalLM, AutoModelForSequenceClassification, AutoTokenizer, HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
"""
|
||||
The name of the Casual LM model we wish to fine with PPO
|
||||
"""
|
||||
|
||||
adapter_model_name: Optional[str] = field(default=None, metadata={"help": "the model name"})
|
||||
base_model_name: Optional[str] = field(default=None, metadata={"help": "the model name"})
|
||||
output_name: Optional[str] = field(default=None, metadata={"help": "the model name"})
|
||||
|
||||
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
assert script_args.adapter_model_name is not None, "please provide the name of the Adapter you would like to merge"
|
||||
assert script_args.base_model_name is not None, "please provide the name of the Base model"
|
||||
assert script_args.base_model_name is not None, "please provide the output name of the merged model"
|
||||
|
||||
peft_config = PeftConfig.from_pretrained(script_args.adapter_model_name)
|
||||
if peft_config.task_type == "SEQ_CLS":
|
||||
# peft is for reward model so load sequence classification
|
||||
model = AutoModelForSequenceClassification.from_pretrained(
|
||||
script_args.base_model_name, num_labels=1, torch_dtype=torch.bfloat16
|
||||
)
|
||||
else:
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
script_args.base_model_name, return_dict=True, torch_dtype=torch.bfloat16
|
||||
)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(script_args.base_model_name)
|
||||
|
||||
# Load the Lora model
|
||||
model = PeftModel.from_pretrained(model, script_args.adapter_model_name)
|
||||
model.eval()
|
||||
|
||||
model = model.merge_and_unload()
|
||||
|
||||
model.save_pretrained(f"{script_args.output_name}")
|
||||
tokenizer.save_pretrained(f"{script_args.output_name}")
|
||||
model.push_to_hub(f"{script_args.output_name}", use_temp_dir=False)
|
||||
300
examples/stack_llama/scripts/reward_modeling.py
Normal file
300
examples/stack_llama/scripts/reward_modeling.py
Normal file
@ -0,0 +1,300 @@
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
import evaluate
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from datasets import load_dataset
|
||||
from peft import LoraConfig, TaskType, get_peft_model
|
||||
from transformers import (
|
||||
AutoModelForSequenceClassification,
|
||||
AutoTokenizer,
|
||||
HfArgumentParser,
|
||||
PreTrainedTokenizerBase,
|
||||
Trainer,
|
||||
TrainerCallback,
|
||||
TrainingArguments,
|
||||
)
|
||||
from transformers.utils import PaddingStrategy
|
||||
|
||||
|
||||
# Define and parse arguments.
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
"""
|
||||
These arguments vary depending on how many GPUs you have, what their capacity and features are, and what size model you want to train.
|
||||
"""
|
||||
|
||||
local_rank: Optional[int] = field(default=-1, metadata={"help": "Used for multi-gpu"})
|
||||
resume_from_checkpoint: Optional[bool] = field(
|
||||
default=False,
|
||||
metadata={"help": "If you want to resume training where it left off."},
|
||||
)
|
||||
deepspeed: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "Path to deepspeed config if using deepspeed. You may need this if the model that you want to train doesn't fit on a single GPU."
|
||||
},
|
||||
)
|
||||
per_device_train_batch_size: Optional[int] = field(default=4)
|
||||
per_device_eval_batch_size: Optional[int] = field(default=1)
|
||||
gradient_accumulation_steps: Optional[int] = field(default=1)
|
||||
learning_rate: Optional[float] = field(default=2e-5)
|
||||
weight_decay: Optional[float] = field(default=0.001)
|
||||
model_name: Optional[str] = field(
|
||||
default="gpt2",
|
||||
metadata={
|
||||
"help": "The model that you want to train from the Hugging Face hub. E.g. gpt2, gpt2-xl, bert, etc."
|
||||
},
|
||||
)
|
||||
tokenizer_name: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The tokenizer for your model, if left empty will use the default for your model",
|
||||
},
|
||||
)
|
||||
bf16: Optional[bool] = field(
|
||||
default=True,
|
||||
metadata={
|
||||
"help": "This essentially cuts the training time in half if you want to sacrifice a little precision and have a supported GPU."
|
||||
},
|
||||
)
|
||||
num_train_epochs: Optional[int] = field(
|
||||
default=1,
|
||||
metadata={"help": "The number of training epochs for the reward model."},
|
||||
)
|
||||
train_subset: Optional[int] = field(
|
||||
default=100000,
|
||||
metadata={"help": "The size of the subset of the training data to use"},
|
||||
)
|
||||
eval_subset: Optional[int] = field(
|
||||
default=50000,
|
||||
metadata={"help": "The size of the subset of the eval data to use"},
|
||||
)
|
||||
gradient_checkpointing: Optional[bool] = field(
|
||||
default=False,
|
||||
metadata={"help": "Enables gradient checkpointing."},
|
||||
)
|
||||
optim: Optional[str] = field(
|
||||
default="adamw_hf",
|
||||
metadata={"help": "The optimizer to use."},
|
||||
)
|
||||
lr_scheduler_type: Optional[str] = field(
|
||||
default="linear",
|
||||
metadata={"help": "The lr scheduler"},
|
||||
)
|
||||
max_length: Optional[int] = field(default=512)
|
||||
eval_first_step: Optional[bool] = field(
|
||||
default=False,
|
||||
metadata={"help": "Whether to run eval after the first step"},
|
||||
)
|
||||
|
||||
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
# Load the human stack-exchange-paired dataset for tuning the reward model.
|
||||
train_dataset = load_dataset("lvwerra/stack-exchange-paired", data_dir="data/reward", split="train")
|
||||
if script_args.train_subset > 0:
|
||||
train_dataset = train_dataset.select(range(script_args.train_subset))
|
||||
eval_dataset = load_dataset("lvwerra/stack-exchange-paired", data_dir="data/evaluation", split="train")
|
||||
if script_args.eval_subset > 0:
|
||||
eval_dataset = eval_dataset.select(range(script_args.eval_subset))
|
||||
# Define the training args. Needs to be done before the model is loaded if you are using deepspeed.
|
||||
model_name_split = script_args.model_name.split("/")[-1]
|
||||
output_name = (
|
||||
f"{model_name_split}_peft_stack-exchange-paired_rmts__{script_args.train_subset}_{script_args.learning_rate}"
|
||||
)
|
||||
|
||||
training_args = TrainingArguments(
|
||||
output_dir=output_name,
|
||||
learning_rate=script_args.learning_rate,
|
||||
per_device_train_batch_size=script_args.per_device_train_batch_size,
|
||||
per_device_eval_batch_size=script_args.per_device_eval_batch_size,
|
||||
num_train_epochs=script_args.num_train_epochs,
|
||||
weight_decay=script_args.weight_decay,
|
||||
evaluation_strategy="steps",
|
||||
eval_steps=500,
|
||||
save_strategy="steps",
|
||||
save_steps=500,
|
||||
gradient_accumulation_steps=script_args.gradient_accumulation_steps,
|
||||
gradient_checkpointing=script_args.gradient_checkpointing,
|
||||
deepspeed=script_args.deepspeed,
|
||||
local_rank=script_args.local_rank,
|
||||
remove_unused_columns=False,
|
||||
label_names=[],
|
||||
bf16=script_args.bf16,
|
||||
logging_strategy="steps",
|
||||
logging_steps=10,
|
||||
optim=script_args.optim,
|
||||
lr_scheduler_type=script_args.lr_scheduler_type,
|
||||
)
|
||||
# Load the value-head model and tokenizer.
|
||||
tokenizer_name = script_args.tokenizer_name if script_args.tokenizer_name is not None else script_args.model_name
|
||||
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name, use_auth_token=True)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
|
||||
peft_config = LoraConfig(
|
||||
task_type=TaskType.SEQ_CLS,
|
||||
inference_mode=False,
|
||||
r=8,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.1,
|
||||
)
|
||||
|
||||
model = AutoModelForSequenceClassification.from_pretrained(
|
||||
script_args.model_name, num_labels=1, torch_dtype=torch.bfloat16
|
||||
)
|
||||
model = get_peft_model(model, peft_config)
|
||||
model.print_trainable_parameters()
|
||||
|
||||
# Need to do this for gpt2, because it doesn't have an official pad token.
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
model.config.pad_token_id = tokenizer.eos_token_id
|
||||
model.config.use_cache = not script_args.gradient_checkpointing
|
||||
num_proc = 24 # Can adjust to be higher if you have more processors.
|
||||
original_columns = train_dataset.column_names
|
||||
|
||||
|
||||
# Turn the dataset into pairs of post + summaries, where text_j is the preferred question + answer and text_k is the other.
|
||||
# Then tokenize the dataset.
|
||||
def preprocess_function(examples):
|
||||
new_examples = {
|
||||
"input_ids_j": [],
|
||||
"attention_mask_j": [],
|
||||
"input_ids_k": [],
|
||||
"attention_mask_k": [],
|
||||
}
|
||||
for question, response_j, response_k in zip(examples["question"], examples["response_j"], examples["response_k"]):
|
||||
tokenized_j = tokenizer("Question: " + question + "\n\nAnswer: " + response_j, truncation=True)
|
||||
tokenized_k = tokenizer("Question: " + question + "\n\nAnswer: " + response_k, truncation=True)
|
||||
|
||||
new_examples["input_ids_j"].append(tokenized_j["input_ids"])
|
||||
new_examples["attention_mask_j"].append(tokenized_j["attention_mask"])
|
||||
new_examples["input_ids_k"].append(tokenized_k["input_ids"])
|
||||
new_examples["attention_mask_k"].append(tokenized_k["attention_mask"])
|
||||
|
||||
return new_examples
|
||||
|
||||
|
||||
# preprocess the dataset and filter out QAs that are longer than script_args.max_length
|
||||
train_dataset = train_dataset.map(
|
||||
preprocess_function,
|
||||
batched=True,
|
||||
num_proc=num_proc,
|
||||
remove_columns=original_columns,
|
||||
)
|
||||
train_dataset = train_dataset.filter(
|
||||
lambda x: len(x["input_ids_j"]) <= script_args.max_length and len(x["input_ids_k"]) <= script_args.max_length
|
||||
)
|
||||
|
||||
eval_dataset = eval_dataset.map(
|
||||
preprocess_function,
|
||||
batched=True,
|
||||
num_proc=num_proc,
|
||||
remove_columns=original_columns,
|
||||
)
|
||||
eval_dataset = eval_dataset.filter(
|
||||
lambda x: len(x["input_ids_j"]) <= script_args.max_length and len(x["input_ids_k"]) <= script_args.max_length
|
||||
)
|
||||
|
||||
|
||||
# We need to define a special data collator that batches the data in our j vs k format.
|
||||
@dataclass
|
||||
class RewardDataCollatorWithPadding:
|
||||
tokenizer: PreTrainedTokenizerBase
|
||||
padding: Union[bool, str, PaddingStrategy] = True
|
||||
max_length: Optional[int] = None
|
||||
pad_to_multiple_of: Optional[int] = None
|
||||
return_tensors: str = "pt"
|
||||
|
||||
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
|
||||
features_j = []
|
||||
features_k = []
|
||||
for feature in features:
|
||||
features_j.append(
|
||||
{
|
||||
"input_ids": feature["input_ids_j"],
|
||||
"attention_mask": feature["attention_mask_j"],
|
||||
}
|
||||
)
|
||||
features_k.append(
|
||||
{
|
||||
"input_ids": feature["input_ids_k"],
|
||||
"attention_mask": feature["attention_mask_k"],
|
||||
}
|
||||
)
|
||||
batch_j = self.tokenizer.pad(
|
||||
features_j,
|
||||
padding=self.padding,
|
||||
max_length=self.max_length,
|
||||
pad_to_multiple_of=self.pad_to_multiple_of,
|
||||
return_tensors=self.return_tensors,
|
||||
)
|
||||
batch_k = self.tokenizer.pad(
|
||||
features_k,
|
||||
padding=self.padding,
|
||||
max_length=self.max_length,
|
||||
pad_to_multiple_of=self.pad_to_multiple_of,
|
||||
return_tensors=self.return_tensors,
|
||||
)
|
||||
batch = {
|
||||
"input_ids_j": batch_j["input_ids"],
|
||||
"attention_mask_j": batch_j["attention_mask"],
|
||||
"input_ids_k": batch_k["input_ids"],
|
||||
"attention_mask_k": batch_k["attention_mask"],
|
||||
"return_loss": True,
|
||||
}
|
||||
return batch
|
||||
|
||||
|
||||
# Define the metric that we'll use for validation.
|
||||
accuracy = evaluate.load("accuracy")
|
||||
|
||||
|
||||
def compute_metrics(eval_pred):
|
||||
predictions, _ = eval_pred
|
||||
# Here, predictions is rewards_j and rewards_k.
|
||||
# We want to see how much of the time rewards_j > rewards_k.
|
||||
predictions = np.argmax(predictions, axis=0)
|
||||
labels = np.zeros(predictions.shape)
|
||||
return accuracy.compute(predictions=predictions, references=labels)
|
||||
|
||||
|
||||
class RewardTrainer(Trainer):
|
||||
# Define how to compute the reward loss. We use the InstructGPT pairwise logloss: https://arxiv.org/abs/2203.02155
|
||||
def compute_loss(self, model, inputs, return_outputs=False):
|
||||
rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]
|
||||
rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]
|
||||
loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()
|
||||
if return_outputs:
|
||||
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
|
||||
return loss
|
||||
|
||||
|
||||
# Train the model, woohoo.
|
||||
trainer = RewardTrainer(
|
||||
model=model,
|
||||
args=training_args,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
compute_metrics=compute_metrics,
|
||||
data_collator=RewardDataCollatorWithPadding(tokenizer=tokenizer, max_length=script_args.max_length),
|
||||
)
|
||||
|
||||
|
||||
if script_args.eval_first_step:
|
||||
|
||||
class EvaluateFirstStepCallback(TrainerCallback):
|
||||
def on_step_end(self, args, state, control, **kwargs):
|
||||
if state.global_step == 1:
|
||||
control.should_evaluate = True
|
||||
|
||||
trainer.add_callback(EvaluateFirstStepCallback())
|
||||
|
||||
trainer.train(script_args.resume_from_checkpoint)
|
||||
|
||||
print("Saving last checkpoint of the model")
|
||||
model.save_pretrained(output_name + "_peft_last_checkpoint")
|
||||
264
examples/stack_llama/scripts/rl_training.py
Normal file
264
examples/stack_llama/scripts/rl_training.py
Normal file
@ -0,0 +1,264 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from peft import LoraConfig
|
||||
from tqdm import tqdm
|
||||
from transformers import Adafactor, AutoTokenizer, HfArgumentParser, pipeline
|
||||
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer, set_seed
|
||||
from trl.core import LengthSampler
|
||||
|
||||
|
||||
tqdm.pandas()
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
"""
|
||||
The name of the Casual LM model we wish to fine with PPO
|
||||
"""
|
||||
|
||||
# NOTE: gpt2 models use Conv1D instead of Linear layers which are not yet supported in 8 bit mode
|
||||
# models like gpt-neo* models are more suitable.
|
||||
model_name: Optional[str] = field(default="", metadata={"help": "the model name"})
|
||||
tokenizer_name: Optional[str] = field(default="", metadata={"help": "the tokenizer name"})
|
||||
reward_model_name: Optional[str] = field(default="", metadata={"help": "the reward model name"})
|
||||
log_with: Optional[str] = field(default=None, metadata={"help": "use 'wandb' to log with wandb"})
|
||||
learning_rate: Optional[float] = field(default=1.41e-5, metadata={"help": "the learning rate"})
|
||||
output_max_length: Optional[int] = field(default=128, metadata={"help": "maximum length for generation"})
|
||||
mini_batch_size: Optional[int] = field(default=1, metadata={"help": "the PPO minibatch size"})
|
||||
batch_size: Optional[int] = field(default=32, metadata={"help": "the batch size"})
|
||||
ppo_epochs: Optional[int] = field(default=4, metadata={"help": "the number of ppo epochs"})
|
||||
gradient_accumulation_steps: Optional[int] = field(
|
||||
default=4, metadata={"help": "the number of gradient accumulation steps"}
|
||||
)
|
||||
adafactor: Optional[bool] = field(default=False, metadata={"help": "whether to use the adafactor optimizer"})
|
||||
early_stopping: Optional[bool] = field(default=False, metadata={"help": "whether to early stop"})
|
||||
target_kl: Optional[float] = field(default=0.1, metadata={"help": "kl target for early stopping"})
|
||||
reward_baseline: Optional[float] = field(
|
||||
default=0.0,
|
||||
metadata={"help": "a baseline value that is subtracted from the reward"},
|
||||
)
|
||||
batched_gen: Optional[bool] = field(default=False, metadata={"help": "whether to use the batched text gen"})
|
||||
save_freq: Optional[int] = field(default=None, metadata={"help": "n steps to save the model"})
|
||||
output_dir: Optional[str] = field(default="runs/", metadata={"help": "n steps to save the model"})
|
||||
seed: Optional[int] = field(default=0, metadata={"help": "the seed"})
|
||||
steps: Optional[int] = field(default=20000, metadata={"help": "number of epochs"})
|
||||
init_kl_coef: Optional[float] = field(
|
||||
default=0.2,
|
||||
metadata={"help": "Initial KL penalty coefficient (used for adaptive and linear control)"},
|
||||
)
|
||||
|
||||
adap_kl_ctrl: Optional[bool] = field(default=True, metadata={"help": "Use adaptive KL control, otherwise linear"})
|
||||
|
||||
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args: ScriptArguments = parser.parse_args_into_dataclasses()[0]
|
||||
reward_model_name = script_args.reward_model_name
|
||||
dataset_name = "lvwerra/stack-exchange-paired"
|
||||
config = PPOConfig(
|
||||
steps=script_args.steps,
|
||||
model_name=script_args.model_name,
|
||||
learning_rate=script_args.learning_rate,
|
||||
log_with=script_args.log_with,
|
||||
batch_size=script_args.batch_size,
|
||||
mini_batch_size=script_args.mini_batch_size,
|
||||
gradient_accumulation_steps=script_args.gradient_accumulation_steps,
|
||||
optimize_cuda_cache=True,
|
||||
early_stopping=script_args.early_stopping,
|
||||
target_kl=script_args.target_kl,
|
||||
ppo_epochs=script_args.ppo_epochs,
|
||||
seed=script_args.seed,
|
||||
init_kl_coef=script_args.init_kl_coef,
|
||||
adap_kl_ctrl=script_args.adap_kl_ctrl,
|
||||
)
|
||||
|
||||
train_dataset = load_dataset("lvwerra/stack-exchange-paired", data_dir="data/rl", split="train")
|
||||
train_dataset = train_dataset.select(range(100000))
|
||||
# We then define the arguments to pass to the sentiment analysis pipeline.
|
||||
# We set `return_all_scores` to True to get the sentiment score for each token.
|
||||
sent_kwargs = {
|
||||
"return_all_scores": True,
|
||||
"function_to_apply": "none",
|
||||
"batch_size": 16,
|
||||
"truncation": True,
|
||||
}
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(script_args.tokenizer_name)
|
||||
# GPT-2 tokenizer has a pad token, but it is not eos_token by default. We need to set it to eos_token.
|
||||
# only for this model.
|
||||
|
||||
if getattr(tokenizer, "pad_token", None) is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
|
||||
# Below is an example function to build the dataset. In our case, we use the IMDB dataset
|
||||
# from the `datasets` library. One should customize this function to train the model on
|
||||
# its own dataset.
|
||||
def build_dataset(
|
||||
tokenizer,
|
||||
dataset_name="lvwerra/stack-exchange-paired",
|
||||
):
|
||||
"""
|
||||
Build dataset for training. This builds the dataset from `load_dataset`, one should
|
||||
customize this function to train the model on its own dataset.
|
||||
|
||||
Args:
|
||||
dataset_name (`str`):
|
||||
The name of the dataset to be loaded.
|
||||
|
||||
Returns:
|
||||
dataloader (`torch.utils.data.DataLoader`):
|
||||
The dataloader for the dataset.
|
||||
"""
|
||||
|
||||
# load imdb with datasets
|
||||
ds = load_dataset(dataset_name, data_dir="data/rl", split="train")
|
||||
original_columns = ds.column_names
|
||||
num_proc = 24
|
||||
|
||||
def preprocess_function(examples):
|
||||
new_examples = {
|
||||
"query": [],
|
||||
"input_ids": [],
|
||||
}
|
||||
for question in examples["question"]:
|
||||
query = "Question: " + question + "\n\nAnswer: "
|
||||
tokenized_question = tokenizer(query, truncation=True)
|
||||
new_examples["query"].append(query)
|
||||
new_examples["input_ids"].append(tokenized_question["input_ids"])
|
||||
|
||||
return new_examples
|
||||
|
||||
ds = train_dataset.map(
|
||||
preprocess_function,
|
||||
batched=True,
|
||||
num_proc=num_proc,
|
||||
remove_columns=original_columns,
|
||||
)
|
||||
ds = ds.filter(lambda x: len(x["input_ids"]) < 512, batched=False)
|
||||
|
||||
ds.set_format(type="torch")
|
||||
return ds
|
||||
|
||||
|
||||
# We retrieve the dataloader by calling the `build_dataset` function.
|
||||
dataset = build_dataset(tokenizer)
|
||||
|
||||
|
||||
def collator(data):
|
||||
return dict((key, [d[key] for d in data]) for key in data[0])
|
||||
|
||||
|
||||
# set seed before initializing value head for deterministic eval
|
||||
set_seed(config.seed)
|
||||
|
||||
# Now let's build the model, the reference model, and the tokenizer.
|
||||
current_device = Accelerator().local_process_index
|
||||
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
config.model_name,
|
||||
load_in_8bit=True,
|
||||
device_map={"": current_device},
|
||||
peft_config=lora_config,
|
||||
)
|
||||
|
||||
optimizer = None
|
||||
if script_args.adafactor:
|
||||
optimizer = Adafactor(
|
||||
filter(lambda p: p.requires_grad, model.parameters()),
|
||||
scale_parameter=False,
|
||||
relative_step=False,
|
||||
warmup_init=False,
|
||||
lr=config.learning_rate,
|
||||
)
|
||||
# We then build the PPOTrainer, passing the model, the reference model, the tokenizer
|
||||
ppo_trainer = PPOTrainer(
|
||||
config,
|
||||
model,
|
||||
ref_model=None,
|
||||
tokenizer=tokenizer,
|
||||
dataset=dataset,
|
||||
data_collator=collator,
|
||||
optimizer=optimizer,
|
||||
)
|
||||
|
||||
# We then build the sentiment analysis pipeline, passing the model name and the
|
||||
# sentiment analysis pipeline arguments. Let's also make sure to set the device
|
||||
# to the same device as the PPOTrainer.
|
||||
device = ppo_trainer.accelerator.device
|
||||
if ppo_trainer.accelerator.num_processes == 1:
|
||||
device = 0 if torch.cuda.is_available() else "cpu" # to avoid a ` pipeline` bug
|
||||
sentiment_pipe = pipeline(
|
||||
"sentiment-analysis",
|
||||
model=reward_model_name,
|
||||
device_map={"": current_device},
|
||||
model_kwargs={"load_in_8bit": True},
|
||||
tokenizer=tokenizer,
|
||||
return_token_type_ids=False,
|
||||
)
|
||||
|
||||
# We then define the arguments to pass to the `generate` function. These arguments
|
||||
# are passed to the `generate` function of the PPOTrainer, which is a wrapper around
|
||||
# the `generate` function of the trained model.
|
||||
generation_kwargs = {
|
||||
# "min_length": -1,
|
||||
"top_k": 0.0,
|
||||
"top_p": 1.0,
|
||||
"do_sample": True,
|
||||
"pad_token_id": tokenizer.pad_token_id,
|
||||
"eos_token_id": 100_000,
|
||||
}
|
||||
output_min_length = 32
|
||||
output_max_length = script_args.output_max_length
|
||||
output_length_sampler = LengthSampler(output_min_length, output_max_length)
|
||||
|
||||
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
|
||||
if epoch >= config.total_ppo_epochs:
|
||||
break
|
||||
|
||||
question_tensors = batch["input_ids"]
|
||||
|
||||
response_tensors = ppo_trainer.generate(
|
||||
question_tensors,
|
||||
return_prompt=False,
|
||||
length_sampler=output_length_sampler,
|
||||
**generation_kwargs,
|
||||
)
|
||||
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
|
||||
|
||||
# Compute sentiment score
|
||||
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
|
||||
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
|
||||
rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs]
|
||||
|
||||
# Run PPO step
|
||||
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
|
||||
ppo_trainer.log_stats(stats, batch, rewards)
|
||||
|
||||
if script_args.save_freq and epoch and epoch % script_args.save_freq == 0:
|
||||
ppo_trainer.save_pretrained(script_args.output_dir + f"step_{epoch}")
|
||||
208
examples/stack_llama/scripts/supervised_finetuning.py
Normal file
208
examples/stack_llama/scripts/supervised_finetuning.py
Normal file
@ -0,0 +1,208 @@
|
||||
import argparse
|
||||
import os
|
||||
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from peft import LoraConfig
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, logging, set_seed
|
||||
|
||||
from trl import SFTTrainer
|
||||
from trl.trainer import ConstantLengthDataset
|
||||
|
||||
|
||||
"""
|
||||
Fine-Tune Llama-7b on SE paired dataset
|
||||
"""
|
||||
|
||||
|
||||
def get_args():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--model_path", type=str, default="")
|
||||
parser.add_argument("--dataset_name", type=str, default="lvwerra/stack-exchange-paired")
|
||||
parser.add_argument("--subset", type=str, default="data/finetune")
|
||||
parser.add_argument("--split", type=str, default="train")
|
||||
parser.add_argument("--size_valid_set", type=int, default=4000)
|
||||
parser.add_argument("--streaming", action="store_true")
|
||||
parser.add_argument("--shuffle_buffer", type=int, default=5000)
|
||||
|
||||
parser.add_argument("--seq_length", type=int, default=1024)
|
||||
parser.add_argument("--max_steps", type=int, default=10000)
|
||||
parser.add_argument("--batch_size", type=int, default=4)
|
||||
parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
|
||||
parser.add_argument("--eos_token_id", type=int, default=49152)
|
||||
|
||||
parser.add_argument("--learning_rate", type=float, default=1e-4)
|
||||
parser.add_argument("--lr_scheduler_type", type=str, default="cosine")
|
||||
parser.add_argument("--num_warmup_steps", type=int, default=100)
|
||||
parser.add_argument("--weight_decay", type=float, default=0.05)
|
||||
|
||||
parser.add_argument("--local_rank", type=int, default=0)
|
||||
parser.add_argument("--no_fp16", action="store_false")
|
||||
parser.add_argument("--bf16", action="store_true", default=False)
|
||||
parser.add_argument("--no_gradient_checkpointing", action="store_false", default=False)
|
||||
parser.add_argument("--seed", type=int, default=0)
|
||||
parser.add_argument("--num_workers", type=int, default=None)
|
||||
parser.add_argument("--output_dir", type=str, default="./checkpoints")
|
||||
parser.add_argument("--log_freq", default=1, type=int)
|
||||
parser.add_argument("--eval_freq", default=1000, type=int)
|
||||
parser.add_argument("--save_freq", default=1000, type=int)
|
||||
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
def chars_token_ratio(dataset, tokenizer, nb_examples=400):
|
||||
"""
|
||||
Estimate the average number of characters per token in the dataset.
|
||||
"""
|
||||
total_characters, total_tokens = 0, 0
|
||||
for _, example in tqdm(zip(range(nb_examples), iter(dataset)), total=nb_examples):
|
||||
text = prepare_sample_text(example)
|
||||
total_characters += len(text)
|
||||
if tokenizer.is_fast:
|
||||
total_tokens += len(tokenizer(text).tokens())
|
||||
else:
|
||||
total_tokens += len(tokenizer.tokenize(text))
|
||||
|
||||
return total_characters / total_tokens
|
||||
|
||||
|
||||
def print_trainable_parameters(model):
|
||||
"""
|
||||
Prints the number of trainable parameters in the model.
|
||||
"""
|
||||
trainable_params = 0
|
||||
all_param = 0
|
||||
for _, param in model.named_parameters():
|
||||
all_param += param.numel()
|
||||
if param.requires_grad:
|
||||
trainable_params += param.numel()
|
||||
print(
|
||||
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
|
||||
)
|
||||
|
||||
|
||||
def prepare_sample_text(example):
|
||||
"""Prepare the text from a sample of the dataset."""
|
||||
text = f"Question: {example['question']}\n\nAnswer: {example['response_j']}"
|
||||
return text
|
||||
|
||||
|
||||
def create_datasets(tokenizer, args):
|
||||
dataset = load_dataset(
|
||||
args.dataset_name,
|
||||
data_dir=args.subset,
|
||||
split=args.split,
|
||||
use_auth_token=True,
|
||||
num_proc=args.num_workers if not args.streaming else None,
|
||||
streaming=args.streaming,
|
||||
)
|
||||
if args.streaming:
|
||||
print("Loading the dataset in streaming mode")
|
||||
valid_data = dataset.take(args.size_valid_set)
|
||||
train_data = dataset.skip(args.size_valid_set)
|
||||
train_data = train_data.shuffle(buffer_size=args.shuffle_buffer, seed=args.seed)
|
||||
else:
|
||||
dataset = dataset.train_test_split(test_size=0.005, seed=args.seed)
|
||||
train_data = dataset["train"]
|
||||
valid_data = dataset["test"]
|
||||
print(f"Size of the train set: {len(train_data)}. Size of the validation set: {len(valid_data)}")
|
||||
|
||||
chars_per_token = chars_token_ratio(train_data, tokenizer)
|
||||
print(f"The character to token ratio of the dataset is: {chars_per_token:.2f}")
|
||||
|
||||
train_dataset = ConstantLengthDataset(
|
||||
tokenizer,
|
||||
train_data,
|
||||
formatting_func=prepare_sample_text,
|
||||
infinite=True,
|
||||
seq_length=args.seq_length,
|
||||
chars_per_token=chars_per_token,
|
||||
)
|
||||
valid_dataset = ConstantLengthDataset(
|
||||
tokenizer,
|
||||
valid_data,
|
||||
formatting_func=prepare_sample_text,
|
||||
infinite=False,
|
||||
seq_length=args.seq_length,
|
||||
chars_per_token=chars_per_token,
|
||||
)
|
||||
return train_dataset, valid_dataset
|
||||
|
||||
|
||||
def run_training(args, train_data, val_data):
|
||||
print("Loading the model")
|
||||
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
train_data.start_iteration = 0
|
||||
|
||||
print("Starting main loop")
|
||||
|
||||
training_args = TrainingArguments(
|
||||
output_dir=args.output_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=args.max_steps,
|
||||
eval_steps=args.eval_freq,
|
||||
save_steps=args.save_freq,
|
||||
logging_steps=args.log_freq,
|
||||
per_device_train_batch_size=args.batch_size,
|
||||
per_device_eval_batch_size=args.batch_size,
|
||||
learning_rate=args.learning_rate,
|
||||
lr_scheduler_type=args.lr_scheduler_type,
|
||||
warmup_steps=args.num_warmup_steps,
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
||||
gradient_checkpointing=not args.no_gradient_checkpointing,
|
||||
fp16=not args.no_fp16,
|
||||
bf16=args.bf16,
|
||||
weight_decay=args.weight_decay,
|
||||
run_name="llama-7b-finetuned",
|
||||
report_to="wandb",
|
||||
ddp_find_unused_parameters=False,
|
||||
)
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
args.model_path, load_in_8bit=True, device_map={"": Accelerator().process_index}
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=model,
|
||||
args=training_args,
|
||||
train_dataset=train_data,
|
||||
eval_dataset=val_data,
|
||||
peft_config=lora_config,
|
||||
packing=True,
|
||||
)
|
||||
|
||||
print_trainable_parameters(trainer.model)
|
||||
|
||||
print("Training...")
|
||||
trainer.train()
|
||||
|
||||
print("Saving last checkpoint of the model")
|
||||
trainer.model.save_pretrained(os.path.join(args.output_dir, "final_checkpoint/"))
|
||||
|
||||
|
||||
def main(args):
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.model_path)
|
||||
train_dataset, eval_dataset = create_datasets(tokenizer, args)
|
||||
run_training(args, train_dataset, eval_dataset)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = get_args()
|
||||
assert args.model_path != "", "Please provide the llama model path"
|
||||
|
||||
set_seed(args.seed)
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
|
||||
logging.set_verbosity_error()
|
||||
|
||||
main(args)
|
||||
32
examples/summarization/README.md
Normal file
32
examples/summarization/README.md
Normal file
@ -0,0 +1,32 @@
|
||||
# Summarization Examples
|
||||
|
||||
The script in this example show how to train a reward model for summarization, following the OpenAI Learning to Summarize from Human Feedback [paper](https://arxiv.org/abs/2009.01325). We've validated that the script can be used to train a small GPT2 to get slightly over 60% validation accuracy, which is aligned with results from the paper. The model is [here](https://huggingface.co/Tristan/gpt2_reward_summarization).
|
||||
|
||||
Here's an overview of the files:
|
||||
|
||||
| File | Description |
|
||||
|---|---|
|
||||
| `scripts/reward_summarization.py` | For tuning the reward model. |
|
||||
| `scripts/ds3_reward_summarization_example_config.json` | Can be used with the reward model script to scale it up to arbitrarily big models that don't fit on a single GPU. |
|
||||
|
||||
|
||||
## Installation
|
||||
|
||||
```bash
|
||||
pip install trl
|
||||
pip install evaluate
|
||||
# optional: deepspeed
|
||||
pip install deepspeed
|
||||
```
|
||||
|
||||
```bash
|
||||
# If you want your reward model to follow the Learning to Summarize from Human Feedback paper closely, then tune a GPT model on summarization and then instantiate the reward model
|
||||
# with it. In other words, pass in the name of your summarization-finetuned gpt on the hub, instead of the name of the pretrained gpt2 like we do in the following examples of how
|
||||
# to run this script.
|
||||
|
||||
# Example of running this script with the small size gpt2 on a 40GB A100 (A100's support bf16). Here, the global batch size will be 64:
|
||||
python -m torch.distributed.launch --nproc_per_node=1 reward_summarization.py --bf16
|
||||
|
||||
# Example of running this script with the xl size gpt2 on 16 40GB A100's. Here the global batch size will still be 64:
|
||||
python -m torch.distributed.launch --nproc_per_node=16 reward_summarization.py --per_device_train_batch_size=1 --per_device_eval_batch_size=1 --gradient_accumulation_steps=4 --gpt_model_name=gpt2-xl --bf16 --deepspeed=ds3_reward_summarization_example_config.json
|
||||
```
|
||||
7
examples/toxicity/README.md
Normal file
7
examples/toxicity/README.md
Normal file
@ -0,0 +1,7 @@
|
||||
# De-detoxifying language models
|
||||
|
||||
To run this code, do the following:
|
||||
|
||||
```shell
|
||||
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file {CONFIG} examples/toxicity/scripts/gpt-j-6b-toxicity.py --log_with wandb
|
||||
```
|
||||
@ -55,7 +55,7 @@ tqdm.pandas()
|
||||
# the training parameters, and the PPO parameters.
|
||||
# Check the default arguments in the `PPOConfig` class for more details.
|
||||
# If you want to log with tensorboard, add the kwarg
|
||||
# `accelerator_kwargs={"logging_dir": PATH_TO_LOGS}` to the PPOConfig.
|
||||
# `project_kwargs={"logging_dir": PATH_TO_LOGS}` to the PPOConfig.
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
"""
|
||||
@ -67,11 +67,15 @@ class ScriptArguments:
|
||||
model_name: Optional[str] = field(default="ybelkada/gpt-j-6b-sharded-bf16", metadata={"help": "the model name"})
|
||||
log_with: Optional[str] = field(default=None, metadata={"help": "use 'wandb' to log with wandb"})
|
||||
learning_rate: Optional[float] = field(default=(1.47e-5) * 2, metadata={"help": "the learning rate"})
|
||||
mini_batch_size: Optional[int] = field(default=1, metadata={"help": "the PPO minibatch size"})
|
||||
batch_size: Optional[int] = field(default=256, metadata={"help": "the batch size"})
|
||||
mini_batch_size: Optional[int] = field(default=4, metadata={"help": "the PPO minibatch size"})
|
||||
batch_size: Optional[int] = field(default=16, metadata={"help": "the batch size"})
|
||||
gradient_accumulation_steps: Optional[int] = field(
|
||||
default=1, metadata={"help": "the number of gradient accumulation steps"}
|
||||
)
|
||||
model_save_path: Optional[str] = field(
|
||||
default="./gpt-j-6B-detoxified-long-context-26-shl-1e4-final",
|
||||
metadata={"help": "the path to save the model"},
|
||||
)
|
||||
|
||||
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
@ -81,6 +85,7 @@ config = PPOConfig(
|
||||
model_name=script_args.model_name,
|
||||
learning_rate=script_args.learning_rate,
|
||||
log_with=script_args.log_with,
|
||||
ppo_epochs=100,
|
||||
mini_batch_size=script_args.mini_batch_size,
|
||||
batch_size=script_args.batch_size,
|
||||
gradient_accumulation_steps=script_args.gradient_accumulation_steps,
|
||||
@ -199,12 +204,12 @@ output_min_length = 20
|
||||
output_max_length = 30
|
||||
output_length_sampler = LengthSampler(output_min_length, output_max_length)
|
||||
|
||||
model_save_path = "/mnt/disks/younes-disk/models/gpt-j-6B-detoxified-long-context-26-shl-1e4-final"
|
||||
model_save_path = script_args.model_save_path
|
||||
|
||||
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
|
||||
query_tensors = batch["input_ids"]
|
||||
|
||||
# Get response from gpt2
|
||||
# Get response from the policy model
|
||||
response_tensors = []
|
||||
for query in query_tensors:
|
||||
gen_len = output_length_sampler()
|
||||
|
||||
@ -3,3 +3,4 @@ torch>=1.4.0
|
||||
tqdm
|
||||
transformers
|
||||
accelerate
|
||||
peft>=0.3.0
|
||||
|
||||
60
scripts/stale.py
Normal file
60
scripts/stale.py
Normal file
@ -0,0 +1,60 @@
|
||||
# Copyright 2023 The HuggingFace Team, the AllenNLP library authors. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
Script to close stale issue. Taken in part from the AllenNLP repository.
|
||||
https://github.com/allenai/allennlp.
|
||||
"""
|
||||
import os
|
||||
from datetime import datetime as dt
|
||||
|
||||
from github import Github
|
||||
|
||||
|
||||
LABELS_TO_EXEMPT = [
|
||||
"good first issue",
|
||||
"good second issue",
|
||||
"feature request",
|
||||
]
|
||||
|
||||
|
||||
def main():
|
||||
g = Github(os.environ["GITHUB_TOKEN"])
|
||||
repo = g.get_repo("lvwerra/trl")
|
||||
open_issues = repo.get_issues(state="open")
|
||||
|
||||
for issue in open_issues:
|
||||
comments = sorted([comment for comment in issue.get_comments()], key=lambda i: i.created_at, reverse=True)
|
||||
last_comment = comments[0] if len(comments) > 0 else None
|
||||
if (
|
||||
last_comment is not None
|
||||
and last_comment.user.login == "github-actions[bot]"
|
||||
and (dt.utcnow() - issue.updated_at).days > 7
|
||||
and (dt.utcnow() - issue.created_at).days >= 30
|
||||
and not any(label.name.lower() in LABELS_TO_EXEMPT for label in issue.get_labels())
|
||||
):
|
||||
issue.edit(state="closed")
|
||||
elif (
|
||||
(dt.utcnow() - issue.updated_at).days > 23
|
||||
and (dt.utcnow() - issue.created_at).days >= 30
|
||||
and not any(label.name.lower() in LABELS_TO_EXEMPT for label in issue.get_labels())
|
||||
):
|
||||
issue.create_comment(
|
||||
"This issue has been automatically marked as stale because it has not had "
|
||||
"recent activity. If you think this still needs to be addressed "
|
||||
"please comment on this thread.\n\n"
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@ -9,7 +9,3 @@ line_length = 119
|
||||
lines_after_imports = 2
|
||||
multi_line_output = 3
|
||||
use_parentheses = True
|
||||
|
||||
[flake8]
|
||||
ignore = E203, E501, W503
|
||||
max-line-length = 119
|
||||
7
setup.py
7
setup.py
@ -54,9 +54,10 @@ To create the package for pypi.
|
||||
Then push the change with a message 'set dev version'
|
||||
"""
|
||||
|
||||
from setuptools import setup, find_packages
|
||||
from setuptools import find_packages, setup
|
||||
|
||||
__version__ = "0.4.1" # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)
|
||||
|
||||
__version__ = "0.4.7" # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)
|
||||
|
||||
REQUIRED_PKGS = [
|
||||
"torch>=1.4.0",
|
||||
@ -68,7 +69,7 @@ REQUIRED_PKGS = [
|
||||
EXTRAS = {
|
||||
"test": ["parameterized", "pytest", "pytest-xdist", "accelerate", "peft"],
|
||||
"peft": ["peft>=0.2.0"],
|
||||
"dev": ["parameterized", "pytest", "pytest-xdist", "black", "isort", "flake8>=3.8.3", "peft>=0.2.0"],
|
||||
"dev": ["parameterized", "pytest", "pytest-xdist", "pre-commit", "peft>=0.2.0"],
|
||||
}
|
||||
|
||||
setup(
|
||||
|
||||
98
tests/test_best_of_n_sampler.py
Normal file
98
tests/test_best_of_n_sampler.py
Normal file
@ -0,0 +1,98 @@
|
||||
import unittest
|
||||
|
||||
import torch
|
||||
from transformers import AutoTokenizer, GenerationConfig
|
||||
|
||||
from trl import AutoModelForCausalLMWithValueHead
|
||||
from trl.core import LengthSampler
|
||||
from trl.extras import BestOfNSampler
|
||||
|
||||
|
||||
def queries_to_scores(list_of_strings):
|
||||
return [torch.rand(1).item() for _ in list_of_strings]
|
||||
|
||||
|
||||
class BestOfNSamplerTester(unittest.TestCase):
|
||||
"""
|
||||
Tests the BestOfNSampler class
|
||||
"""
|
||||
|
||||
ref_model_name = "trl-internal-testing/dummy-GPT2-correct-vocab"
|
||||
output_length_sampler = LengthSampler(2, 6)
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(ref_model_name)
|
||||
tokenizer = AutoTokenizer.from_pretrained(ref_model_name)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
output_length_sampler = LengthSampler(2, 6)
|
||||
|
||||
def test_different_input_types(self):
|
||||
r"""
|
||||
Tests if the different input types normalizer works
|
||||
"""
|
||||
|
||||
generation_config = GenerationConfig(
|
||||
min_length=-1,
|
||||
top_k=0.0,
|
||||
top_p=1.0,
|
||||
do_sample=True,
|
||||
pad_token_id=self.tokenizer.eos_token_id,
|
||||
)
|
||||
|
||||
output_length_sampler = LengthSampler(2, 6)
|
||||
|
||||
best_of_n = BestOfNSampler(
|
||||
self.model,
|
||||
self.tokenizer,
|
||||
queries_to_scores,
|
||||
length_sampler=output_length_sampler,
|
||||
generation_config=generation_config,
|
||||
)
|
||||
|
||||
queries = ["hello world", "goodbye world"]
|
||||
tokenized_queries = [self.tokenizer.encode(query) for query in queries]
|
||||
|
||||
various_queries_formats = [
|
||||
(tokenized_queries[0], 1),
|
||||
(tokenized_queries, 2),
|
||||
(torch.tensor(tokenized_queries[1]), 1),
|
||||
([torch.tensor(query) for query in tokenized_queries], 2),
|
||||
]
|
||||
|
||||
for q, expected_length in various_queries_formats:
|
||||
results = best_of_n.generate(q)
|
||||
self.assertIsInstance(results, list)
|
||||
assert len(results) == expected_length
|
||||
|
||||
def test_different_sample_sizes_and_n_candidates_values(self):
|
||||
r"""
|
||||
Tests different sample sizes and n_candidates values
|
||||
"""
|
||||
generation_config = GenerationConfig(
|
||||
min_length=-1,
|
||||
top_k=0.0,
|
||||
top_p=1.0,
|
||||
do_sample=True,
|
||||
pad_token_id=self.tokenizer.eos_token_id,
|
||||
)
|
||||
|
||||
output_length_sampler = LengthSampler(6, 10)
|
||||
|
||||
for sample_value, n_candidates_values, expected in [
|
||||
(4, 2, 2),
|
||||
(10, 3, 3),
|
||||
(6, 4, 4),
|
||||
]:
|
||||
best_of_n = BestOfNSampler(
|
||||
self.model,
|
||||
self.tokenizer,
|
||||
queries_to_scores,
|
||||
length_sampler=output_length_sampler,
|
||||
generation_config=generation_config,
|
||||
sample_size=sample_value,
|
||||
n_candidates=n_candidates_values,
|
||||
)
|
||||
|
||||
queries = ["hello world", "troll the world"]
|
||||
tokenized_queries = [self.tokenizer.encode(query) for query in queries]
|
||||
results = best_of_n.generate(tokenized_queries)
|
||||
for result in results:
|
||||
assert len(result) == expected
|
||||
9
tests/test_e2e.py
Normal file
9
tests/test_e2e.py
Normal file
@ -0,0 +1,9 @@
|
||||
import subprocess
|
||||
|
||||
|
||||
def test_hello_world():
|
||||
subprocess.run(
|
||||
"python examples/hello_world.py",
|
||||
shell=True,
|
||||
check=True,
|
||||
)
|
||||
@ -30,6 +30,7 @@ ALL_CAUSAL_LM_MODELS = [
|
||||
"trl-internal-testing/tiny-random-BloomForCausalLM",
|
||||
"trl-internal-testing/tiny-random-GPT2LMHeadModel",
|
||||
"trl-internal-testing/tiny-random-CodeGenForCausalLM-sharded",
|
||||
# "trl-internal-testing/tiny-random-LlamaForCausalLM", uncomment on the next transformers release
|
||||
]
|
||||
|
||||
ALL_SEQ2SEQ_MODELS = [
|
||||
|
||||
@ -25,7 +25,7 @@ from trl import AutoModelForCausalLMWithValueHead, is_peft_available
|
||||
if is_peft_available():
|
||||
from peft import get_peft_model, LoraConfig
|
||||
|
||||
from .testing_utils import require_peft
|
||||
from .testing_utils import require_bitsandbytes, require_peft
|
||||
|
||||
|
||||
@require_peft
|
||||
@ -80,6 +80,51 @@ class PeftModelTester(unittest.TestCase):
|
||||
nb_trainable_params = sum(p.numel() for p in non_peft_model.parameters() if p.requires_grad)
|
||||
self.assertEqual(nb_trainable_params, 99578)
|
||||
|
||||
def test_create_peft_model_from_config(self):
|
||||
r"""
|
||||
Simply creates a peft model and checks that it can be loaded.
|
||||
"""
|
||||
trl_model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
self.causal_lm_model_id, peft_config=self.lora_config
|
||||
)
|
||||
# Check that the number of trainable parameters is correct
|
||||
nb_trainable_params = sum(p.numel() for p in trl_model.parameters() if p.requires_grad)
|
||||
self.assertEqual(nb_trainable_params, 10273)
|
||||
|
||||
causal_lm_model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id)
|
||||
trl_model = AutoModelForCausalLMWithValueHead.from_pretrained(causal_lm_model, peft_config=self.lora_config)
|
||||
# Check that the number of trainable parameters is correct
|
||||
nb_trainable_params = sum(p.numel() for p in trl_model.parameters() if p.requires_grad)
|
||||
self.assertEqual(nb_trainable_params, 10273)
|
||||
|
||||
@require_bitsandbytes
|
||||
def test_create_bnb_peft_model_from_config(self):
|
||||
r"""
|
||||
Simply creates a peft model and checks that it can be loaded.
|
||||
"""
|
||||
from bitsandbytes.nn import Linear8bitLt
|
||||
|
||||
trl_model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
self.causal_lm_model_id, peft_config=self.lora_config, load_in_8bit=True
|
||||
)
|
||||
# Check that the number of trainable parameters is correct
|
||||
nb_trainable_params = sum(p.numel() for p in trl_model.parameters() if p.requires_grad)
|
||||
self.assertEqual(nb_trainable_params, 10273)
|
||||
self.assertTrue(
|
||||
trl_model.pretrained_model.model.gpt_neox.layers[0].mlp.dense_h_to_4h.__class__ == Linear8bitLt
|
||||
)
|
||||
|
||||
causal_lm_model = AutoModelForCausalLM.from_pretrained(
|
||||
self.causal_lm_model_id, load_in_8bit=True, device_map="auto"
|
||||
)
|
||||
trl_model = AutoModelForCausalLMWithValueHead.from_pretrained(causal_lm_model, peft_config=self.lora_config)
|
||||
# Check that the number of trainable parameters is correct
|
||||
nb_trainable_params = sum(p.numel() for p in trl_model.parameters() if p.requires_grad)
|
||||
self.assertEqual(nb_trainable_params, 10273)
|
||||
self.assertTrue(
|
||||
trl_model.pretrained_model.model.gpt_neox.layers[0].mlp.dense_h_to_4h.__class__ == Linear8bitLt
|
||||
)
|
||||
|
||||
def test_save_pretrained_peft(self):
|
||||
r"""
|
||||
Check that the model can be saved and loaded properly.
|
||||
@ -118,3 +163,46 @@ class PeftModelTester(unittest.TestCase):
|
||||
# check all the weights are the same
|
||||
for p1, p2 in zip(model.named_parameters(), model_from_pretrained.named_parameters()):
|
||||
self.assertTrue(torch.allclose(p1[1], p2[1]), msg=f"{p1[0]} != {p2[0]}")
|
||||
|
||||
def test_load_pretrained_peft(self):
|
||||
r"""
|
||||
Check that the model saved with peft class interface can be loaded properly.
|
||||
"""
|
||||
causal_lm_model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id)
|
||||
pretrained_model = get_peft_model(causal_lm_model, self.lora_config)
|
||||
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(pretrained_model)
|
||||
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
pretrained_model.save_pretrained(tmp_dir)
|
||||
model_from_pretrained = AutoModelForCausalLMWithValueHead.from_pretrained(tmp_dir)
|
||||
|
||||
# check that the files `adapter_model.bin` and `adapter_config.json` are in the directory
|
||||
self.assertTrue(
|
||||
os.path.isfile(f"{tmp_dir}/adapter_model.bin"),
|
||||
msg=f"{tmp_dir}/adapter_model.bin does not exist",
|
||||
)
|
||||
self.assertTrue(
|
||||
os.path.exists(f"{tmp_dir}/adapter_config.json"),
|
||||
msg=f"{tmp_dir}/adapter_config.json does not exist",
|
||||
)
|
||||
|
||||
# check all the weights are the same
|
||||
for p1, p2 in zip(model.named_parameters(), model_from_pretrained.named_parameters()):
|
||||
if p1[0] not in ["v_head.summary.weight", "v_head.summary.bias"]:
|
||||
self.assertTrue(torch.allclose(p1[1], p2[1]), msg=f"{p1[0]} != {p2[0]}")
|
||||
|
||||
def test_continue_training_peft_model(self):
|
||||
r"""
|
||||
Load peft and checks that it can continue training.
|
||||
"""
|
||||
causal_lm_model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id)
|
||||
pretrained_model = get_peft_model(causal_lm_model, self.lora_config)
|
||||
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
pretrained_model.save_pretrained(tmp_dir)
|
||||
# set is_trainable to True
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(tmp_dir, is_trainable=True)
|
||||
# Check that the number of trainable parameters is correct
|
||||
nb_trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
|
||||
self.assertEqual(nb_trainable_params, 10273)
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import copy
|
||||
import fnmatch
|
||||
import gc
|
||||
import re
|
||||
@ -105,7 +105,6 @@ class PPOTrainerTester(unittest.TestCase):
|
||||
set_seed(42)
|
||||
cls._token = CI_HUB_USER_TOKEN
|
||||
cls._api = HfApi(endpoint=CI_HUB_ENDPOINT)
|
||||
cls._api.set_access_token(CI_HUB_USER_TOKEN)
|
||||
HfFolder.save_token(CI_HUB_USER_TOKEN)
|
||||
|
||||
# model_id
|
||||
@ -680,6 +679,47 @@ class PPOTrainerTester(unittest.TestCase):
|
||||
f"Parameter {name} has a gradient larger than max_grad_norm",
|
||||
)
|
||||
|
||||
def test_ppo_trainer_kl_penalty(self):
|
||||
dummy_dataset = self._init_dummy_dataset()
|
||||
|
||||
log_probs = torch.Tensor([[0.5, 0.2, 0.1], [0.6, 0.2, 0.1]])
|
||||
ref_log_probs = torch.Tensor([[0.4, 0.3, 0.0], [0.7, 0.1, 0.3]])
|
||||
|
||||
ppo_trainer = PPOTrainer(
|
||||
config=self.ppo_config,
|
||||
model=self.gpt2_model,
|
||||
ref_model=None,
|
||||
tokenizer=self.gpt2_tokenizer,
|
||||
dataset=dummy_dataset,
|
||||
)
|
||||
|
||||
expected_output = torch.Tensor([[0.1000, -0.1000, 0.1000], [-0.1000, 0.1000, -0.2000]])
|
||||
self.assertTrue(torch.allclose(ppo_trainer._kl_penalty(log_probs, ref_log_probs), expected_output))
|
||||
|
||||
self.ppo_config.kl_penalty = "abs"
|
||||
ppo_trainer = PPOTrainer(
|
||||
config=self.ppo_config,
|
||||
model=self.gpt2_model,
|
||||
ref_model=None,
|
||||
tokenizer=self.gpt2_tokenizer,
|
||||
dataset=dummy_dataset,
|
||||
)
|
||||
|
||||
expected_output = torch.Tensor([[0.1000, 0.1000, 0.1000], [0.1000, 0.1000, 0.2000]])
|
||||
self.assertTrue(torch.allclose(ppo_trainer._kl_penalty(log_probs, ref_log_probs), expected_output))
|
||||
|
||||
self.ppo_config.kl_penalty = "mse"
|
||||
ppo_trainer = PPOTrainer(
|
||||
config=self.ppo_config,
|
||||
model=self.gpt2_model,
|
||||
ref_model=None,
|
||||
tokenizer=self.gpt2_tokenizer,
|
||||
dataset=dummy_dataset,
|
||||
)
|
||||
|
||||
expected_output = torch.Tensor([[0.0050, 0.0050, 0.0050], [0.0050, 0.0050, 0.0200]])
|
||||
self.assertTrue(torch.allclose(ppo_trainer._kl_penalty(log_probs, ref_log_probs), expected_output))
|
||||
|
||||
@require_peft
|
||||
@mark.peft_test
|
||||
def test_peft_model_ppo_trainer(self):
|
||||
@ -740,6 +780,98 @@ class PPOTrainerTester(unittest.TestCase):
|
||||
else:
|
||||
self.assertTrue(param.grad is None, f"Parameter {name} has a gradient")
|
||||
|
||||
@require_peft
|
||||
@mark.peft_test
|
||||
def test_peft_model_ppo_adapter_rm_trainer(self):
|
||||
from peft import LoraConfig, get_peft_model
|
||||
from transformers import AutoModelForCausalLM, AutoModelForSequenceClassification
|
||||
|
||||
dummy_inputs = torch.LongTensor([[1, 2, 3, 4, 5], [1, 2, 3, 4, 5]])
|
||||
rm_lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="SEQ_CLS",
|
||||
)
|
||||
|
||||
reward_model = AutoModelForSequenceClassification.from_pretrained(self.model_id)
|
||||
reward_model = get_peft_model(reward_model, rm_lora_config)
|
||||
dummy_optim = torch.optim.Adam(filter(lambda p: p.requires_grad, reward_model.parameters()), lr=1e-3)
|
||||
|
||||
previous_rm_logits = reward_model(dummy_inputs).logits
|
||||
loss = previous_rm_logits.mean()
|
||||
loss.backward()
|
||||
|
||||
dummy_optim.step()
|
||||
reward_model.eval()
|
||||
|
||||
original_rm_logits = reward_model(dummy_inputs).logits
|
||||
|
||||
with tempfile.TemporaryDirectory() as tmpdirname:
|
||||
reward_model.save_pretrained(tmpdirname)
|
||||
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
gpt2_model = AutoModelForCausalLM.from_pretrained(self.model_id)
|
||||
|
||||
# this line is very important
|
||||
def make_inputs_require_grad(module, input, output):
|
||||
output.requires_grad_(True)
|
||||
|
||||
gpt2_model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
|
||||
|
||||
peft_model = get_peft_model(gpt2_model, lora_config)
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
peft_model,
|
||||
reward_adapter=tmpdirname,
|
||||
)
|
||||
|
||||
dummy_dataset = self._init_dummy_dataset()
|
||||
self.ppo_config.batch_size = 2
|
||||
self.ppo_config.mini_batch_size = 1
|
||||
|
||||
ppo_trainer = PPOTrainer(
|
||||
config=self.ppo_config,
|
||||
model=model,
|
||||
ref_model=None,
|
||||
tokenizer=self.gpt2_tokenizer,
|
||||
dataset=dummy_dataset,
|
||||
)
|
||||
|
||||
self.assertTrue(ppo_trainer.ref_model is None)
|
||||
|
||||
dummy_dataloader = ppo_trainer.dataloader
|
||||
|
||||
# train model with ppo
|
||||
for query_tensor, response_tensor in dummy_dataloader:
|
||||
# define a reward for response
|
||||
# (this could be any reward such as human feedback or output from another model)
|
||||
reward = [torch.tensor(1.0), torch.tensor(0.0)]
|
||||
# train model by running a step twice
|
||||
_ = ppo_trainer.step([q for q in query_tensor], [r for r in response_tensor], reward)
|
||||
|
||||
ppo_trainer.model.train()
|
||||
ppo_trainer.model.gradient_checkpointing_enable()
|
||||
_ = ppo_trainer.step([q for q in query_tensor], [r for r in response_tensor], reward)
|
||||
break
|
||||
|
||||
new_logits = ppo_trainer.model.compute_reward_score(dummy_inputs)
|
||||
self.assertTrue(not torch.allclose(previous_rm_logits, new_logits[:, -1, :]))
|
||||
self.assertTrue(torch.allclose(original_rm_logits, new_logits[:, -1, :]))
|
||||
|
||||
# check gradients
|
||||
for name, param in model.named_parameters():
|
||||
if ("lora" in name or "v_head" in name) and ("reward" not in name):
|
||||
self.assertTrue(param.grad is not None, f"Parameter {name} has a no gradient")
|
||||
else:
|
||||
self.assertTrue(param.grad is None, f"Parameter {name} has a gradient")
|
||||
|
||||
@unittest.skip("Fix by either patching `whomai()` to work in the staging endpoint or use a dummy prod user.")
|
||||
def test_push_to_hub(self):
|
||||
REPO_NAME = "test-ppo-trainer"
|
||||
@ -845,3 +977,124 @@ class PPOTrainerTester(unittest.TestCase):
|
||||
self.assertTrue(param.grad is not None, f"Parameter {name} has a no gradient")
|
||||
else:
|
||||
self.assertTrue(param.grad is None, f"Parameter {name} has a gradient")
|
||||
|
||||
def test_generation(self):
|
||||
dummy_dataset = self._init_dummy_dataset()
|
||||
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
|
||||
tokenizer = AutoTokenizer.from_pretrained("gpt2")
|
||||
|
||||
ppo_trainer = PPOTrainer(
|
||||
config=self.ppo_config,
|
||||
model=model,
|
||||
ref_model=None,
|
||||
tokenizer=tokenizer,
|
||||
dataset=dummy_dataset,
|
||||
)
|
||||
|
||||
input_texts = ["this is a test", "this is another, longer test"]
|
||||
|
||||
generation_kwargs = {"do_sample": False, "max_new_tokens": 4, "pad_token_id": tokenizer.eos_token_id}
|
||||
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
model_inputs = [tokenizer(txt, return_tensors="pt").input_ids.squeeze() for txt in input_texts]
|
||||
|
||||
generations_batched = ppo_trainer.generate(model_inputs, batch_size=2, **generation_kwargs)
|
||||
generations_batched = tokenizer.batch_decode(generations_batched)
|
||||
|
||||
generations_single = [ppo_trainer.generate(inputs, **generation_kwargs).squeeze() for inputs in model_inputs]
|
||||
generations_single = tokenizer.batch_decode(generations_single)
|
||||
|
||||
self.assertEqual(generations_single, generations_batched)
|
||||
|
||||
def test_grad_accumulation(self):
|
||||
dummy_dataset = self._init_dummy_dataset()
|
||||
|
||||
torch.manual_seed(0)
|
||||
gpt2_model = AutoModelForCausalLMWithValueHead.from_pretrained(self.model_id, summary_dropout_prob=0.0)
|
||||
gpt2_model_clone = copy.deepcopy(gpt2_model)
|
||||
|
||||
self.ppo_config.mini_batch_size = 2
|
||||
self.ppo_config.ppo_epochs = 1
|
||||
|
||||
ppo_trainer = PPOTrainer(
|
||||
config=self.ppo_config,
|
||||
model=gpt2_model,
|
||||
ref_model=None,
|
||||
tokenizer=self.gpt2_tokenizer,
|
||||
dataset=dummy_dataset,
|
||||
)
|
||||
|
||||
dummy_dataloader = ppo_trainer.dataloader
|
||||
|
||||
# train model with ppo
|
||||
for query_tensor, response_tensor in dummy_dataloader:
|
||||
# define a reward for response
|
||||
# (this could be any reward such as human feedback or output from another model)
|
||||
reward = [torch.tensor(1.0), torch.tensor(1.0)]
|
||||
# train model by running a step twice
|
||||
_ = ppo_trainer.step([q for q in query_tensor], [r for r in response_tensor], reward)
|
||||
break
|
||||
|
||||
model_grad = gpt2_model.v_head.summary.weight.grad.clone()
|
||||
|
||||
self.ppo_config.gradient_accumulation_steps = 2
|
||||
self.ppo_config.mini_batch_size = 1
|
||||
|
||||
ppo_trainer = PPOTrainer(
|
||||
config=self.ppo_config,
|
||||
model=gpt2_model_clone,
|
||||
ref_model=None,
|
||||
tokenizer=self.gpt2_tokenizer,
|
||||
dataset=dummy_dataset,
|
||||
)
|
||||
|
||||
dummy_dataloader = ppo_trainer.dataloader
|
||||
|
||||
# train model with ppo
|
||||
for query_tensor, response_tensor in dummy_dataloader:
|
||||
# define a reward for response
|
||||
# (this could be any reward such as human feedback or output from another model)
|
||||
reward = [torch.tensor(1.0), torch.tensor(1.0)]
|
||||
# train model by running a step twice
|
||||
_ = ppo_trainer.step([q for q in query_tensor], [r for r in response_tensor], reward)
|
||||
break
|
||||
|
||||
model_grad_acc = gpt2_model_clone.v_head.summary.weight.grad.clone()
|
||||
self.assertTrue(torch.allclose(model_grad_acc, model_grad, rtol=1e-3, atol=1e-3))
|
||||
|
||||
@unittest.skip("Fix by either patching `whomai()` to work in the staging endpoint or use a dummy prod user.")
|
||||
def test_push_to_hub_if_best_reward(self):
|
||||
REPO_NAME = "test-ppo-trainer"
|
||||
repo_id = f"{CI_HUB_USER}/{REPO_NAME}"
|
||||
|
||||
dummy_dataset = self._init_dummy_dataset()
|
||||
|
||||
push_to_hub_if_best_kwargs = {"repo_id": repo_id}
|
||||
|
||||
ppo_config = PPOConfig(
|
||||
batch_size=2,
|
||||
mini_batch_size=1,
|
||||
log_with=None,
|
||||
push_to_hub_if_best_kwargs=push_to_hub_if_best_kwargs,
|
||||
compare_steps=1,
|
||||
)
|
||||
|
||||
ppo_trainer = PPOTrainer(
|
||||
config=ppo_config,
|
||||
model=self.gpt2_model,
|
||||
ref_model=self.gpt2_model_ref,
|
||||
tokenizer=self.gpt2_tokenizer,
|
||||
dataset=dummy_dataset,
|
||||
)
|
||||
|
||||
dummy_dataloader = ppo_trainer.dataloader
|
||||
# train model with ppo
|
||||
for query_tensor, response_tensor in dummy_dataloader:
|
||||
# define a reward for response
|
||||
# (this could be any reward such as human feedback or output from another model)
|
||||
reward = [torch.tensor(1.0), torch.tensor(0.0)]
|
||||
# train model
|
||||
_ = ppo_trainer.step([q for q in query_tensor], [r for r in response_tensor], reward)
|
||||
break
|
||||
|
||||
262
tests/test_reward_trainer.py
Normal file
262
tests/test_reward_trainer.py
Normal file
@ -0,0 +1,262 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import tempfile
|
||||
import unittest
|
||||
|
||||
import torch
|
||||
from datasets import Dataset
|
||||
from transformers import AutoModelForSequenceClassification, AutoTokenizer, EvalPrediction, TrainingArguments
|
||||
|
||||
from trl import RewardTrainer
|
||||
from trl.trainer import compute_accuracy
|
||||
|
||||
from .testing_utils import require_peft
|
||||
|
||||
|
||||
class RewardTrainerTester(unittest.TestCase):
|
||||
@classmethod
|
||||
def setUpClass(cls):
|
||||
cls.model_id = "trl-internal-testing/dummy-GPT2-correct-vocab"
|
||||
cls.model = AutoModelForSequenceClassification.from_pretrained(cls.model_id)
|
||||
cls.tokenizer = AutoTokenizer.from_pretrained(cls.model_id)
|
||||
cls.tokenizer.pad_token = cls.tokenizer.eos_token
|
||||
|
||||
def test_accuracy_metrics(self):
|
||||
dummy_eval_predictions = EvalPrediction(torch.FloatTensor([[0.1, 0.9], [0.9, 0.1]]), torch.LongTensor([0, 0]))
|
||||
accuracy = compute_accuracy(dummy_eval_predictions)
|
||||
self.assertEqual(accuracy["accuracy"], 0.5)
|
||||
|
||||
def test_reward_trainer(self):
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
per_device_train_batch_size=2,
|
||||
max_steps=3,
|
||||
remove_unused_columns=False,
|
||||
gradient_accumulation_steps=4,
|
||||
learning_rate=9e-1,
|
||||
evaluation_strategy="steps",
|
||||
)
|
||||
|
||||
# fmt: off
|
||||
dummy_dataset_dict = {
|
||||
"input_ids_chosen": [
|
||||
torch.LongTensor([0, 1, 2,]),
|
||||
torch.LongTensor([1, 2]),
|
||||
torch.LongTensor([0, 1, 2,]),
|
||||
torch.LongTensor([1, 2]),
|
||||
],
|
||||
"attention_mask_chosen": [
|
||||
torch.LongTensor([1, 1, 1]),
|
||||
torch.LongTensor([1, 0]),
|
||||
torch.LongTensor([1, 1, 1]),
|
||||
torch.LongTensor([1, 0]),
|
||||
],
|
||||
"input_ids_rejected": [
|
||||
torch.LongTensor([0, 2,]),
|
||||
torch.LongTensor([1, 2, 0]),
|
||||
torch.LongTensor([0, 2,]),
|
||||
torch.LongTensor([1, 2, 0]),
|
||||
],
|
||||
"attention_mask_rejected": [
|
||||
torch.LongTensor([1, 1]),
|
||||
torch.LongTensor([1, 1, 0]),
|
||||
torch.LongTensor([1, 1]),
|
||||
torch.LongTensor([1, 1, 1]),
|
||||
],
|
||||
}
|
||||
# fmt: on
|
||||
dummy_dataset = Dataset.from_dict(dummy_dataset_dict)
|
||||
|
||||
trainer = RewardTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
tokenizer=self.tokenizer,
|
||||
train_dataset=dummy_dataset,
|
||||
eval_dataset=dummy_dataset,
|
||||
)
|
||||
|
||||
previous_trainable_params = {n: param.clone() for n, param in trainer.model.named_parameters()}
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
|
||||
# check the params have changed
|
||||
for n, param in previous_trainable_params.items():
|
||||
new_param = trainer.model.get_parameter(n)
|
||||
# check the params have changed - ignore 0 biases
|
||||
if param.sum() != 0:
|
||||
self.assertFalse(torch.equal(param, new_param))
|
||||
|
||||
preds = trainer.predict(dummy_dataset)
|
||||
self.assertEqual(preds.predictions.shape, (4, 2))
|
||||
|
||||
@require_peft
|
||||
def test_reward_trainer_peft(self):
|
||||
import peft
|
||||
from peft import LoraConfig, TaskType
|
||||
|
||||
peft_version = peft.__version__
|
||||
|
||||
peft_config = LoraConfig(
|
||||
task_type=TaskType.SEQ_CLS,
|
||||
inference_mode=False,
|
||||
r=8,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.1,
|
||||
)
|
||||
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
per_device_train_batch_size=2,
|
||||
max_steps=6,
|
||||
remove_unused_columns=False,
|
||||
gradient_accumulation_steps=2,
|
||||
learning_rate=9e-1,
|
||||
evaluation_strategy="steps",
|
||||
)
|
||||
|
||||
# fmt: off
|
||||
dummy_dataset_dict = {
|
||||
"input_ids_chosen": [
|
||||
torch.LongTensor([0, 1, 2,]),
|
||||
torch.LongTensor([1, 2]),
|
||||
torch.LongTensor([0, 1, 2,]),
|
||||
torch.LongTensor([1, 2]),
|
||||
],
|
||||
"attention_mask_chosen": [
|
||||
torch.LongTensor([1, 1, 1]),
|
||||
torch.LongTensor([1, 0]),
|
||||
torch.LongTensor([1, 1, 1]),
|
||||
torch.LongTensor([1, 0]),
|
||||
],
|
||||
"input_ids_rejected": [
|
||||
torch.LongTensor([0, 2,]),
|
||||
torch.LongTensor([1, 2, 0]),
|
||||
torch.LongTensor([0, 2,]),
|
||||
torch.LongTensor([1, 2, 0]),
|
||||
],
|
||||
"attention_mask_rejected": [
|
||||
torch.LongTensor([1, 1]),
|
||||
torch.LongTensor([1, 1, 0]),
|
||||
torch.LongTensor([1, 1]),
|
||||
torch.LongTensor([1, 1, 1]),
|
||||
],
|
||||
}
|
||||
# fmt: on
|
||||
dummy_dataset = Dataset.from_dict(dummy_dataset_dict)
|
||||
|
||||
trainer = RewardTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
tokenizer=self.tokenizer,
|
||||
train_dataset=dummy_dataset,
|
||||
eval_dataset=dummy_dataset,
|
||||
peft_config=peft_config,
|
||||
)
|
||||
previous_trainable_params = {}
|
||||
previous_non_trainable_params = {}
|
||||
|
||||
# due to a change in the way the modules to save are dealt in PEFT.
|
||||
trainable_params_name = ["lora", "score"] if peft_version < "0.3.0" else ["lora", "modules_to_save"]
|
||||
|
||||
# check gradients are not None
|
||||
for n, param in trainer.model.named_parameters():
|
||||
if any([t in n for t in trainable_params_name]):
|
||||
previous_trainable_params[n] = param.clone()
|
||||
else:
|
||||
previous_non_trainable_params[n] = param.clone()
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
|
||||
# check the params have changed
|
||||
for n, param in previous_trainable_params.items():
|
||||
new_param = trainer.model.get_parameter(n)
|
||||
self.assertFalse(torch.allclose(param, new_param, atol=1e-12, rtol=1e-12))
|
||||
|
||||
# check the non trainable params have not changed
|
||||
for n, param in previous_non_trainable_params.items():
|
||||
new_param = trainer.model.get_parameter(n)
|
||||
self.assertTrue(torch.allclose(param, new_param, atol=1e-12, rtol=1e-12))
|
||||
|
||||
preds = trainer.predict(dummy_dataset)
|
||||
self.assertEqual(preds.predictions.shape, (4, 2))
|
||||
|
||||
def test_reward_trainer_assert_value_error(self):
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
per_device_train_batch_size=2,
|
||||
max_steps=1,
|
||||
remove_unused_columns=False,
|
||||
)
|
||||
|
||||
dummy_dataset_dict = {
|
||||
# fmt: off
|
||||
"input_ids_b": [
|
||||
torch.LongTensor([0, 1, 2,]),
|
||||
torch.LongTensor([1, 2]),
|
||||
torch.LongTensor([0, 1, 2,]),
|
||||
torch.LongTensor([1, 2]),
|
||||
],
|
||||
"attention_mask_c": [
|
||||
torch.LongTensor([1, 1, 1]),
|
||||
torch.LongTensor([1, 0]),
|
||||
torch.LongTensor([1, 1, 1]),
|
||||
torch.LongTensor([1, 0]),
|
||||
],
|
||||
"input_ids_f": [
|
||||
torch.LongTensor([0, 2,]),
|
||||
torch.LongTensor([1, 2, 0]),
|
||||
torch.LongTensor([0, 2,]),
|
||||
torch.LongTensor([1, 2, 0]),
|
||||
],
|
||||
"attention_mask_g": [
|
||||
torch.LongTensor([1, 1]),
|
||||
torch.LongTensor([1, 1, 0]),
|
||||
torch.LongTensor([1, 1]),
|
||||
torch.LongTensor([1, 1, 1]),
|
||||
],
|
||||
# fmt: on
|
||||
}
|
||||
dummy_dataset = Dataset.from_dict(dummy_dataset_dict)
|
||||
|
||||
trainer = RewardTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
tokenizer=self.tokenizer,
|
||||
train_dataset=dummy_dataset,
|
||||
)
|
||||
|
||||
with self.assertRaises(ValueError):
|
||||
trainer.train()
|
||||
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
per_device_train_batch_size=2,
|
||||
max_steps=1,
|
||||
remove_unused_columns=True,
|
||||
)
|
||||
|
||||
with self.assertWarns(UserWarning):
|
||||
trainer = RewardTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
tokenizer=self.tokenizer,
|
||||
train_dataset=dummy_dataset,
|
||||
)
|
||||
524
tests/test_sft_trainer.py
Normal file
524
tests/test_sft_trainer.py
Normal file
@ -0,0 +1,524 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import os
|
||||
import tempfile
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
from datasets import Dataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
|
||||
|
||||
from trl import SFTTrainer
|
||||
from trl.import_utils import is_peft_available
|
||||
from trl.trainer import ConstantLengthDataset, DataCollatorForCompletionOnlyLM
|
||||
|
||||
from .testing_utils import require_peft
|
||||
|
||||
|
||||
def formatting_prompts_func(example):
|
||||
text = f"### Question: {example['question']}\n ### Answer: {example['answer']}"
|
||||
return text
|
||||
|
||||
|
||||
def formatting_prompts_func_batched(example):
|
||||
output_text = []
|
||||
for i, question in enumerate(example["question"]):
|
||||
text = f"### Question: {question}\n ### Answer: {example['answer'][i]}"
|
||||
output_text.append(text)
|
||||
return output_text
|
||||
|
||||
|
||||
if is_peft_available():
|
||||
from peft import LoraConfig, PeftModel
|
||||
|
||||
|
||||
class SFTTrainerTester(unittest.TestCase):
|
||||
r""" """
|
||||
|
||||
@classmethod
|
||||
def setUpClass(cls):
|
||||
cls.model_id = "trl-internal-testing/dummy-GPT2-correct-vocab"
|
||||
cls.model = AutoModelForCausalLM.from_pretrained(cls.model_id)
|
||||
cls.tokenizer = AutoTokenizer.from_pretrained(cls.model_id)
|
||||
cls.tokenizer.pad_token = cls.tokenizer.eos_token
|
||||
cls.dummy_dataset = Dataset.from_dict(
|
||||
{
|
||||
"question": [
|
||||
"Does llamas know how to code?",
|
||||
"Does llamas know how to fly?",
|
||||
"Does llamas know how to talk?",
|
||||
"Does llamas know how to code?",
|
||||
"Does llamas know how to fly?",
|
||||
"Does llamas know how to talk?",
|
||||
"Does llamas know how to swim?",
|
||||
],
|
||||
"answer": [
|
||||
"Yes, llamas are very good at coding.",
|
||||
"No, llamas can't fly.",
|
||||
"Yes, llamas are very good at talking.",
|
||||
"Yes, llamas are very good at coding.",
|
||||
"No, llamas can't fly.",
|
||||
"Yes, llamas are very good at talking.",
|
||||
"No, llamas can't swim.",
|
||||
],
|
||||
"text": [
|
||||
"### Question: Does llamas know how to code?\n ### Answer: Yes, llamas are very good at coding.",
|
||||
"### Question: Does llamas know how to fly?\n ### Answer: No, llamas can't fly.",
|
||||
"### Question: Does llamas know how to talk?\n ### Answer: Yes, llamas are very good at talking.",
|
||||
"### Question: Does llamas know how to code?\n ### Answer: Yes, llamas are very good at coding.",
|
||||
"### Question: Does llamas know how to fly?\n ### Answer: No, llamas can't fly.",
|
||||
"### Question: Does llamas know how to talk?\n ### Answer: Yes, llamas are very good at talking.",
|
||||
"### Question: Does llamas know how to swim?\n ### Answer: No, llamas can't swim.",
|
||||
],
|
||||
}
|
||||
)
|
||||
|
||||
cls.train_dataset = ConstantLengthDataset(
|
||||
cls.tokenizer,
|
||||
cls.dummy_dataset,
|
||||
dataset_text_field=None,
|
||||
formatting_func=formatting_prompts_func,
|
||||
seq_length=16,
|
||||
num_of_sequences=16,
|
||||
)
|
||||
|
||||
cls.eval_dataset = ConstantLengthDataset(
|
||||
cls.tokenizer,
|
||||
cls.dummy_dataset,
|
||||
dataset_text_field=None,
|
||||
formatting_func=formatting_prompts_func,
|
||||
seq_length=16,
|
||||
num_of_sequences=16,
|
||||
)
|
||||
|
||||
def test_constant_length_dataset(self):
|
||||
formatted_dataset = ConstantLengthDataset(
|
||||
self.tokenizer,
|
||||
self.dummy_dataset,
|
||||
dataset_text_field=None,
|
||||
formatting_func=formatting_prompts_func,
|
||||
)
|
||||
|
||||
self.assertTrue(len(formatted_dataset) == len(self.dummy_dataset))
|
||||
self.assertTrue(len(formatted_dataset) > 0)
|
||||
|
||||
for example in formatted_dataset:
|
||||
self.assertTrue("input_ids" in example)
|
||||
self.assertTrue("labels" in example)
|
||||
|
||||
self.assertTrue(len(example["input_ids"]) == formatted_dataset.seq_length)
|
||||
self.assertTrue(len(example["labels"]) == formatted_dataset.seq_length)
|
||||
|
||||
decoded_text = self.tokenizer.decode(example["input_ids"])
|
||||
self.assertTrue(("Question" in decoded_text) and ("Answer" in decoded_text))
|
||||
|
||||
def test_sft_trainer(self):
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=4,
|
||||
eval_steps=2,
|
||||
save_steps=2,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model_id,
|
||||
args=training_args,
|
||||
train_dataset=self.train_dataset,
|
||||
eval_dataset=self.eval_dataset,
|
||||
packing=True,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
self.assertIsNotNone(trainer.state.log_history[0]["eval_loss"])
|
||||
|
||||
self.assertTrue("pytorch_model.bin" in os.listdir(tmp_dir + "/checkpoint-2"))
|
||||
|
||||
def test_sft_trainer_uncorrect_data(self):
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=2,
|
||||
eval_steps=1,
|
||||
save_steps=1,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
with self.assertRaises(ValueError):
|
||||
_ = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.dummy_dataset,
|
||||
packing=True,
|
||||
)
|
||||
|
||||
# This should work
|
||||
_ = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.dummy_dataset,
|
||||
formatting_func=formatting_prompts_func,
|
||||
packing=True,
|
||||
)
|
||||
|
||||
# This should not work as well
|
||||
with self.assertRaises(ValueError):
|
||||
_ = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.dummy_dataset,
|
||||
formatting_func=formatting_prompts_func,
|
||||
packing=False,
|
||||
)
|
||||
|
||||
# but this shpuld work
|
||||
_ = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.dummy_dataset,
|
||||
formatting_func=formatting_prompts_func_batched,
|
||||
packing=False,
|
||||
)
|
||||
|
||||
def test_sft_trainer_with_model_num_train_epochs(self):
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=2,
|
||||
eval_steps=1,
|
||||
save_steps=1,
|
||||
num_train_epochs=2,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.train_dataset,
|
||||
eval_dataset=self.eval_dataset,
|
||||
packing=True,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
self.assertIsNotNone(trainer.state.log_history[0]["eval_loss"])
|
||||
|
||||
self.assertTrue("pytorch_model.bin" in os.listdir(tmp_dir + "/checkpoint-2"))
|
||||
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=2,
|
||||
save_steps=1,
|
||||
num_train_epochs=2,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.dummy_dataset,
|
||||
dataset_text_field="text",
|
||||
max_seq_length=16,
|
||||
num_of_sequences=16,
|
||||
packing=True,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
|
||||
self.assertTrue("pytorch_model.bin" in os.listdir(tmp_dir + "/checkpoint-2"))
|
||||
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=2,
|
||||
save_steps=1,
|
||||
num_train_epochs=2,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.dummy_dataset,
|
||||
dataset_text_field="text",
|
||||
max_seq_length=16,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
|
||||
self.assertTrue("pytorch_model.bin" in os.listdir(tmp_dir + "/checkpoint-1"))
|
||||
|
||||
def test_sft_trainer_with_model(self):
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=2,
|
||||
eval_steps=1,
|
||||
save_steps=1,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.train_dataset,
|
||||
eval_dataset=self.eval_dataset,
|
||||
packing=True,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
self.assertIsNotNone(trainer.state.log_history[0]["eval_loss"])
|
||||
|
||||
self.assertTrue("pytorch_model.bin" in os.listdir(tmp_dir + "/checkpoint-2"))
|
||||
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=2,
|
||||
save_steps=1,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.dummy_dataset,
|
||||
dataset_text_field="text",
|
||||
max_seq_length=16,
|
||||
num_of_sequences=16,
|
||||
packing=True,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
|
||||
self.assertTrue("pytorch_model.bin" in os.listdir(tmp_dir + "/checkpoint-2"))
|
||||
|
||||
# with formatting_func + packed
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=2,
|
||||
save_steps=1,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.dummy_dataset,
|
||||
formatting_func=formatting_prompts_func,
|
||||
max_seq_length=16,
|
||||
num_of_sequences=16,
|
||||
packing=True,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
|
||||
self.assertTrue("pytorch_model.bin" in os.listdir(tmp_dir + "/checkpoint-2"))
|
||||
|
||||
# with formatting_func + packed
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=2,
|
||||
save_steps=1,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.dummy_dataset,
|
||||
formatting_func=formatting_prompts_func_batched,
|
||||
max_seq_length=16,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
|
||||
self.assertTrue("pytorch_model.bin" in os.listdir(tmp_dir + "/checkpoint-2"))
|
||||
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=2,
|
||||
save_steps=1,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.dummy_dataset,
|
||||
dataset_text_field="text",
|
||||
max_seq_length=16,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
|
||||
self.assertTrue("pytorch_model.bin" in os.listdir(tmp_dir + "/checkpoint-1"))
|
||||
|
||||
def test_data_collator_completion_lm(self):
|
||||
response_template = "### Response:\n"
|
||||
data_collator = DataCollatorForCompletionOnlyLM(response_template, tokenizer=self.tokenizer, mlm=False)
|
||||
|
||||
text = """\n\n### Instructions:\nHello all this should be masked\n\n### Response:\nI have not been masked correctly."""
|
||||
encoded_text = self.tokenizer(text)
|
||||
encoded_text["input_ids"] = encoded_text["input_ids"]
|
||||
|
||||
examples = [encoded_text]
|
||||
|
||||
batch = data_collator(examples)
|
||||
labels = batch["labels"]
|
||||
last_pad_idx = np.where(labels == -100)[1][-1]
|
||||
result_text = self.tokenizer.decode(batch["input_ids"][0, last_pad_idx + 1 :])
|
||||
self.assertTrue(result_text == "I have not been masked correctly.")
|
||||
|
||||
def test_sft_trainer_infinite_with_model(self):
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=5,
|
||||
eval_steps=1,
|
||||
save_steps=1,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.train_dataset,
|
||||
eval_dataset=self.eval_dataset,
|
||||
packing=True,
|
||||
max_seq_length=500,
|
||||
)
|
||||
|
||||
self.assertTrue(trainer.train_dataset.infinite)
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
self.assertIsNotNone(trainer.state.log_history[0]["eval_loss"])
|
||||
|
||||
# make sure the trainer did 5 steps
|
||||
self.assertTrue("pytorch_model.bin" in os.listdir(tmp_dir + "/checkpoint-5"))
|
||||
|
||||
def test_sft_trainer_infinite_with_model_epochs(self):
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
num_train_epochs=1,
|
||||
per_device_train_batch_size=2,
|
||||
save_strategy="epoch",
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model,
|
||||
args=training_args,
|
||||
train_dataset=self.train_dataset,
|
||||
eval_dataset=self.eval_dataset,
|
||||
packing=True,
|
||||
max_seq_length=500,
|
||||
)
|
||||
|
||||
self.assertFalse(trainer.train_dataset.infinite)
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
|
||||
# make sure the trainer did 5 steps
|
||||
self.assertTrue("pytorch_model.bin" in os.listdir(tmp_dir + "/checkpoint-4"))
|
||||
|
||||
@require_peft
|
||||
def test_peft_sft_trainer(self):
|
||||
with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
training_args = TrainingArguments(
|
||||
output_dir=tmp_dir,
|
||||
dataloader_drop_last=True,
|
||||
evaluation_strategy="steps",
|
||||
max_steps=4,
|
||||
eval_steps=2,
|
||||
save_steps=2,
|
||||
per_device_train_batch_size=2,
|
||||
)
|
||||
|
||||
peft_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=self.model_id,
|
||||
args=training_args,
|
||||
train_dataset=self.train_dataset,
|
||||
eval_dataset=self.eval_dataset,
|
||||
peft_config=peft_config,
|
||||
packing=True,
|
||||
)
|
||||
|
||||
self.assertTrue(isinstance(trainer.model, PeftModel))
|
||||
|
||||
trainer.train()
|
||||
|
||||
self.assertIsNotNone(trainer.state.log_history[-1]["train_loss"])
|
||||
self.assertIsNotNone(trainer.state.log_history[0]["eval_loss"])
|
||||
|
||||
self.assertTrue("adapter_model.bin" in os.listdir(tmp_dir + "/checkpoint-2"))
|
||||
self.assertTrue("adapter_config.json" in os.listdir(tmp_dir + "/checkpoint-2"))
|
||||
self.assertTrue("pytorch_model.bin" not in os.listdir(tmp_dir + "/checkpoint-2"))
|
||||
@ -27,6 +27,17 @@ def require_peft(test_case):
|
||||
return test_case
|
||||
|
||||
|
||||
def require_bitsandbytes(test_case):
|
||||
"""
|
||||
Decorator marking a test that requires bitsandbytes. Skips the test if bitsandbytes is not available.
|
||||
"""
|
||||
try:
|
||||
import bitsandbytes # noqa: F401
|
||||
except ImportError:
|
||||
test_case = unittest.skip("test requires bitsandbytes")(test_case)
|
||||
return test_case
|
||||
|
||||
|
||||
def require_torch_multi_gpu(test_case):
|
||||
"""
|
||||
Decorator marking a test that requires multiple GPUs. Skips the test if there aren't enough GPUs.
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
# flake8: noqa
|
||||
|
||||
__version__ = "0.4.1"
|
||||
__version__ = "0.4.7"
|
||||
|
||||
from .core import set_seed
|
||||
from .extras import BestOfNSampler
|
||||
from .import_utils import is_peft_available
|
||||
from .models import (
|
||||
AutoModelForCausalLMWithValueHead,
|
||||
@ -10,4 +11,4 @@ from .models import (
|
||||
PreTrainedModelWrapper,
|
||||
create_reference_model,
|
||||
)
|
||||
from .trainer import PPOConfig, PPOTrainer
|
||||
from .trainer import DataCollatorForCompletionOnlyLM, PPOConfig, PPOTrainer, RewardTrainer, SFTTrainer
|
||||
|
||||
16
trl/extras/__init__.py
Normal file
16
trl/extras/__init__.py
Normal file
@ -0,0 +1,16 @@
|
||||
# flake8: noqa
|
||||
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from .best_of_n_sampler import BestOfNSampler
|
||||
117
trl/extras/best_of_n_sampler.py
Normal file
117
trl/extras/best_of_n_sampler.py
Normal file
@ -0,0 +1,117 @@
|
||||
from typing import Any, Callable, List, Optional, Union
|
||||
|
||||
import torch
|
||||
from transformers import GenerationConfig, PreTrainedTokenizer, PreTrainedTokenizerFast
|
||||
|
||||
from ..core import set_seed
|
||||
from ..models import SUPPORTED_ARCHITECTURES, PreTrainedModelWrapper
|
||||
|
||||
|
||||
class BestOfNSampler(object):
|
||||
def __init__(
|
||||
self,
|
||||
model: PreTrainedModelWrapper,
|
||||
tokenizer: Union[PreTrainedTokenizer, PreTrainedTokenizerFast],
|
||||
queries_to_scores: Callable[[List[str]], List[float]],
|
||||
length_sampler: Any,
|
||||
sample_size: int = 4,
|
||||
seed: Optional[int] = None,
|
||||
n_candidates: int = 1,
|
||||
generation_config: Optional[GenerationConfig] = None,
|
||||
) -> None:
|
||||
r"""
|
||||
Initialize the sampler for best-of-n generation
|
||||
|
||||
Args:
|
||||
model (`PreTrainedModelWrapper`):
|
||||
The pretrained model to use for generation
|
||||
tokenizer (`PreTrainedTokenizer` or `PreTrainedTokenizerFast`):
|
||||
Tokenizer associated with the pretrained model
|
||||
queries_to_scores (`Callable[[List[str]], List[float]]`):
|
||||
Callable that takes a list of generated texts and returns the associated reward scores
|
||||
length_sampler (`Any`):
|
||||
Sampler used to sample the length of the generated text
|
||||
sample_size (`int`):
|
||||
Number of samples to generate for each query
|
||||
seed (`int`, *optional*):
|
||||
Random seed used to control generation
|
||||
n_candidates (`int`):
|
||||
Number of candidates to return for each query
|
||||
generation_config (`GenerationConfig`, *optional*):
|
||||
Generation config passed to the underlying model's `generate` method.
|
||||
See `GenerationConfig` (https://huggingface.co/docs/transformers/v4.29.1/en/main_classes/text_generation#transformers.GenerationConfig) for more details
|
||||
"""
|
||||
if seed is not None:
|
||||
set_seed(seed)
|
||||
|
||||
if not isinstance(tokenizer, (PreTrainedTokenizer, PreTrainedTokenizerFast)):
|
||||
raise ValueError(
|
||||
f"tokenizer must be a PreTrainedTokenizer or PreTrainedTokenizerFast, got {type(tokenizer)}"
|
||||
)
|
||||
if not isinstance(model, (SUPPORTED_ARCHITECTURES)):
|
||||
raise ValueError(
|
||||
f"model must be a PreTrainedModelWrapper, got {type(model)} - supported architectures are: {SUPPORTED_ARCHITECTURES}"
|
||||
)
|
||||
|
||||
self.model = model
|
||||
self.tokenizer = tokenizer
|
||||
|
||||
self.queries_to_scores = queries_to_scores
|
||||
self.length_sampler = length_sampler
|
||||
self.gen_config = generation_config
|
||||
self.sample_size = sample_size
|
||||
self.n_candidates = n_candidates
|
||||
|
||||
def generate(
|
||||
self,
|
||||
tokenized_query: Union[List[int], torch.Tensor, List[torch.Tensor], List[List[int]]],
|
||||
skip_special_tokens: bool = True,
|
||||
device: Optional[Union[str, torch.device]] = None,
|
||||
**generation_kwargs,
|
||||
) -> List[List[str]]:
|
||||
r"""
|
||||
Generate the best of n samples for input queries
|
||||
|
||||
Args:
|
||||
tokenized_query (`List[int]` or `torch.Tensor` or `List[torch.Tensor]` or `List[int]`):
|
||||
represents either a single tokenized query (a single tensor or a list of integers) or a batch of tokenized queries (a list of tensors or a list of lists of integers)
|
||||
skip_special_tokens (`bool`):
|
||||
Whether to remove the special tokens from the output
|
||||
device (`str` or `torch.device`, *optional*):
|
||||
The device on which the model will be loaded
|
||||
**generation_kwargs (`dict`, *optional*):
|
||||
Additional keyword arguments passed along to the underlying model's `generate` method.
|
||||
This is used to override generation config
|
||||
|
||||
Returns:
|
||||
List[List[str]]: A list of lists of generated texts
|
||||
"""
|
||||
queries = None
|
||||
|
||||
if isinstance(tokenized_query, torch.Tensor) and tokenized_query.ndim == 1:
|
||||
queries = tokenized_query.unsqueeze(0)
|
||||
elif isinstance(tokenized_query, List):
|
||||
element_type = type(tokenized_query[0])
|
||||
if element_type == int:
|
||||
queries = torch.tensor(tokenized_query).unsqueeze(0)
|
||||
elif element_type == torch.Tensor:
|
||||
queries = [tensor.reshape((1, -1)) for tensor in tokenized_query]
|
||||
else:
|
||||
queries = [torch.tensor(query).reshape((1, -1)) for query in tokenized_query]
|
||||
|
||||
result = []
|
||||
|
||||
for query in queries:
|
||||
queries = query.repeat((self.sample_size, 1))
|
||||
output = self.model.generate(
|
||||
queries.to(device),
|
||||
max_new_tokens=self.length_sampler(),
|
||||
generation_config=self.gen_config,
|
||||
**generation_kwargs,
|
||||
).squeeze()
|
||||
output = self.tokenizer.batch_decode(output, skip_special_tokens=skip_special_tokens)
|
||||
scores = torch.tensor(self.queries_to_scores(output))
|
||||
output = [output[i] for i in scores.topk(self.n_candidates).indices]
|
||||
result.append(output)
|
||||
|
||||
return result
|
||||
@ -12,11 +12,13 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
from copy import deepcopy
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from accelerate import Accelerator
|
||||
from huggingface_hub import hf_hub_download
|
||||
from transformers import PreTrainedModel
|
||||
|
||||
@ -24,10 +26,24 @@ from ..import_utils import is_peft_available
|
||||
|
||||
|
||||
if is_peft_available():
|
||||
from peft import PeftConfig, PeftModel, PeftModelForCausalLM, PeftModelForSeq2SeqLM
|
||||
from peft import (
|
||||
LoraConfig,
|
||||
PeftConfig,
|
||||
PeftModel,
|
||||
PeftModelForCausalLM,
|
||||
PeftModelForSeq2SeqLM,
|
||||
PromptLearningConfig,
|
||||
get_peft_model,
|
||||
prepare_model_for_int8_training,
|
||||
)
|
||||
from peft.peft_model import set_peft_model_state_dict
|
||||
|
||||
|
||||
LAYER_PATTERNS = ["transformer.h.{layer}", "model.decoder.layers.{layer}", "gpt_neox.layers.{layer}"]
|
||||
LAYER_PATTERNS = [
|
||||
"transformer.h.{layer}",
|
||||
"model.decoder.layers.{layer}",
|
||||
"gpt_neox.layers.{layer}",
|
||||
"model.layers.{layer}",
|
||||
]
|
||||
|
||||
|
||||
class PreTrainedModelWrapper(nn.Module):
|
||||
@ -47,6 +63,7 @@ class PreTrainedModelWrapper(nn.Module):
|
||||
transformers_parent_class = None
|
||||
supported_args = None
|
||||
supported_modules = ("v_head",)
|
||||
supported_rm_modules = ("score",)
|
||||
supported_pretrained_model_architectures = (
|
||||
(PreTrainedModel)
|
||||
if not is_peft_available()
|
||||
@ -60,6 +77,7 @@ class PreTrainedModelWrapper(nn.Module):
|
||||
self.config = pretrained_model.config
|
||||
self.prepare_inputs_for_generation = pretrained_model.prepare_inputs_for_generation
|
||||
self.is_loaded_in_8bit = getattr(pretrained_model, "is_loaded_in_8bit", False)
|
||||
self.is_loaded_in_4bit = getattr(pretrained_model, "is_loaded_in_4bit", False)
|
||||
self.is_sequential_parallel = False
|
||||
|
||||
if hasattr(pretrained_model, "gradient_checkpointing_disable"):
|
||||
@ -88,52 +106,114 @@ class PreTrainedModelWrapper(nn.Module):
|
||||
Additional keyword arguments passed along to the underlying model's
|
||||
`from_pretrained` method. We also pre-process the kwargs to extract
|
||||
the arguments that are specific to the `transformers.PreTrainedModel`
|
||||
class and the arguments that are specific to trl models.
|
||||
class and the arguments that are specific to trl models. The kwargs
|
||||
also support `prepare_model_for_int8_training` arguments from
|
||||
`peft` library.
|
||||
"""
|
||||
if kwargs is not None:
|
||||
trl_model_args, pretrained_kwargs = cls._split_kwargs(kwargs)
|
||||
peft_config = kwargs.pop("peft_config", None)
|
||||
reward_adapter = kwargs.pop("reward_adapter", None)
|
||||
is_trainable = kwargs.pop("is_trainable", False)
|
||||
trl_model_args, pretrained_kwargs, peft_quantization_kwargs = cls._split_kwargs(kwargs)
|
||||
else:
|
||||
peft_config = None
|
||||
is_trainable = False
|
||||
trl_model_args = {}
|
||||
pretrained_kwargs = {}
|
||||
peft_quantization_kwargs = {}
|
||||
|
||||
if reward_adapter is not None and not isinstance(reward_adapter, str):
|
||||
raise ValueError(
|
||||
"The `reward_adapter` argument should be a string representing the name of local path or the Hub id to the Reward Modeling adapter."
|
||||
)
|
||||
|
||||
is_peft_model = False
|
||||
|
||||
current_device = cls._get_current_device()
|
||||
if isinstance(pretrained_model_name_or_path, str):
|
||||
is_loaded_in_8bit = pretrained_kwargs["load_in_8bit"] if "load_in_8bit" in pretrained_kwargs else False
|
||||
is_loaded_in_4bit = pretrained_kwargs["load_in_4bit"] if "load_in_4bit" in pretrained_kwargs else False
|
||||
else:
|
||||
is_loaded_in_8bit = getattr(pretrained_model_name_or_path, "is_loaded_in_8bit", False)
|
||||
is_loaded_in_4bit = getattr(pretrained_model_name_or_path, "is_loaded_in_4bit", False)
|
||||
|
||||
if (is_loaded_in_8bit or is_loaded_in_4bit) and "device_map" not in pretrained_kwargs:
|
||||
# warn users
|
||||
logging.warning(
|
||||
"The `device_map` argument is not provided. We will override the device_map argument."
|
||||
" to set the entire"
|
||||
" model on the current device. If you want to set the model on multiple devices, please provide"
|
||||
" a custom `device_map` argument."
|
||||
)
|
||||
pretrained_kwargs["device_map"] = {"": current_device}
|
||||
|
||||
if is_peft_available() and peft_config is not None and not isinstance(peft_config, PeftConfig):
|
||||
raise ValueError("The `peft_config` argument should be an instance of `peft.PeftConfig` class.")
|
||||
|
||||
# First, load the pre-trained model using the parent-class
|
||||
# either `AutoModelForCausalLM` or `AutoModelForSeq2SeqLM`
|
||||
if isinstance(pretrained_model_name_or_path, str):
|
||||
if is_peft_available():
|
||||
try:
|
||||
peft_filename = hf_hub_download(pretrained_model_name_or_path, "adapter_config.json")
|
||||
# If there is a trained peft adapter in the hub, load its config.
|
||||
remote_adapter_config = hf_hub_download(pretrained_model_name_or_path, "adapter_config.json")
|
||||
except: # noqa
|
||||
peft_filename = None
|
||||
remote_adapter_config = None
|
||||
else:
|
||||
peft_filename = None
|
||||
remote_adapter_config = None
|
||||
|
||||
# Dealing with `peft` case:
|
||||
# 1- check if `adapter_config` has been saved in the hub or locally
|
||||
# 2- if yes, load the `peft` config
|
||||
# 3- use the config to load the `transformers` model and then load the `peft` model
|
||||
if (
|
||||
os.path.exists(pretrained_model_name_or_path)
|
||||
and ("adapter_config.json" in os.listdir(pretrained_model_name_or_path) or peft_filename is not None)
|
||||
and is_peft_available()
|
||||
):
|
||||
if peft_filename is not None:
|
||||
peft_config = PeftConfig.from_pretrained(peft_filename)
|
||||
local_adapter_present = os.path.exists(os.path.join(pretrained_model_name_or_path, "adapter_config.json"))
|
||||
|
||||
if (local_adapter_present or remote_adapter_config is not None) and is_peft_available():
|
||||
if peft_config is not None:
|
||||
logging.warning(
|
||||
"`peft_config` argument ignored since a peft config file was found in "
|
||||
f"{pretrained_model_name_or_path}"
|
||||
)
|
||||
|
||||
# Load the trained peft adapter config
|
||||
if local_adapter_present:
|
||||
trained_adapter_config = PeftConfig.from_pretrained(pretrained_model_name_or_path)
|
||||
else:
|
||||
peft_config = PeftConfig.from_pretrained(pretrained_model_name_or_path)
|
||||
trained_adapter_config = PeftConfig.from_pretrained(remote_adapter_config)
|
||||
|
||||
# Load the pretrained base model
|
||||
pretrained_model = cls.transformers_parent_class.from_pretrained(
|
||||
peft_config.base_model_name_or_path, *model_args, **pretrained_kwargs
|
||||
trained_adapter_config.base_model_name_or_path, *model_args, **pretrained_kwargs
|
||||
)
|
||||
|
||||
pretrained_model = PeftModel.from_pretrained(pretrained_model, pretrained_model_name_or_path)
|
||||
# Wrap the pretrained model with the trained peft adapter
|
||||
pretrained_model = PeftModel.from_pretrained(
|
||||
pretrained_model, pretrained_model_name_or_path, is_trainable=is_trainable
|
||||
)
|
||||
logging.info("Trained peft adapter loaded")
|
||||
else:
|
||||
pretrained_model = cls.transformers_parent_class.from_pretrained(
|
||||
pretrained_model_name_or_path, *model_args, **pretrained_kwargs
|
||||
)
|
||||
|
||||
if peft_config is not None:
|
||||
# Initialize a new peft adapter with the given config
|
||||
if is_loaded_in_8bit or is_loaded_in_4bit:
|
||||
pretrained_model = prepare_model_for_int8_training(
|
||||
pretrained_model,
|
||||
**peft_quantization_kwargs,
|
||||
)
|
||||
pretrained_model = get_peft_model(pretrained_model, peft_config)
|
||||
logging.info("peft adapter initialised")
|
||||
|
||||
elif isinstance(pretrained_model_name_or_path, cls.supported_pretrained_model_architectures):
|
||||
pretrained_model = pretrained_model_name_or_path
|
||||
|
||||
if peft_config is not None and isinstance(pretrained_model, PreTrainedModel):
|
||||
# Initialize a new peft adapter with the given config
|
||||
if is_loaded_in_8bit or is_loaded_in_4bit:
|
||||
pretrained_model = prepare_model_for_int8_training(
|
||||
pretrained_model,
|
||||
**peft_quantization_kwargs,
|
||||
)
|
||||
pretrained_model = get_peft_model(pretrained_model, peft_config)
|
||||
logging.info("peft adapter initialised")
|
||||
else:
|
||||
raise ValueError(
|
||||
"pretrained_model_name_or_path should be a string or a PreTrainedModel, "
|
||||
@ -143,11 +223,17 @@ class PreTrainedModelWrapper(nn.Module):
|
||||
if is_peft_available():
|
||||
if isinstance(pretrained_model, PeftModel):
|
||||
is_peft_model = True
|
||||
# for backward compatibility
|
||||
if hasattr(pretrained_model, "active_peft_config") and isinstance(
|
||||
pretrained_model.active_peft_config, PromptLearningConfig
|
||||
):
|
||||
raise ValueError("PromptLearningConfig is not supported for PPO training.")
|
||||
# Then, create the full model by instantiating the wrapper class
|
||||
model = cls(pretrained_model, **trl_model_args)
|
||||
|
||||
# if resume_training, load the state_dict again - this is ok since the
|
||||
# state_dict is removed from the model after loading it.
|
||||
is_resuming_training = True
|
||||
if isinstance(pretrained_model_name_or_path, str):
|
||||
filename = os.path.join(pretrained_model_name_or_path, "pytorch_model.bin")
|
||||
sharded_index_filename = os.path.join(pretrained_model_name_or_path, "pytorch_model.bin.index.json")
|
||||
@ -161,45 +247,87 @@ class PreTrainedModelWrapper(nn.Module):
|
||||
if os.path.exists(sharded_index_filename):
|
||||
index_file_name = sharded_index_filename
|
||||
else:
|
||||
index_file_name = hf_hub_download(
|
||||
pretrained_model_name_or_path, "pytorch_model.bin.index.json"
|
||||
)
|
||||
try:
|
||||
index_file_name = hf_hub_download(
|
||||
pretrained_model_name_or_path, "pytorch_model.bin.index.json"
|
||||
)
|
||||
except ValueError: # not continue training, do not have v_head weight
|
||||
is_resuming_training = False
|
||||
logging.warning(
|
||||
f"A {type(pretrained_model)} model is loaded from '{pretrained_model_name_or_path}', "
|
||||
f"and no v_head weight is found. This IS expected if you are not resuming PPO training."
|
||||
)
|
||||
# load json
|
||||
with open(index_file_name, "r") as f:
|
||||
index = json.load(f)
|
||||
# check filename with `v_head` or any known extra module:
|
||||
files_to_download = set()
|
||||
for k, v in index["weight_map"].items():
|
||||
if any([module in k for module in cls.supported_modules]):
|
||||
files_to_download.add(v)
|
||||
is_shared = True
|
||||
|
||||
if is_shared:
|
||||
# download each file and add it to the state_dict
|
||||
state_dict = {}
|
||||
for shard_file in files_to_download:
|
||||
filename = hf_hub_download(pretrained_model_name_or_path, shard_file)
|
||||
state_dict.update(torch.load(filename, map_location="cpu"))
|
||||
else:
|
||||
state_dict = torch.load(filename, map_location="cpu")
|
||||
if is_resuming_training:
|
||||
with open(index_file_name, "r") as f:
|
||||
index = json.load(f)
|
||||
# check filename with `v_head` or any known extra module:
|
||||
files_to_download = set()
|
||||
for k, v in index["weight_map"].items():
|
||||
if any([module in k for module in cls.supported_modules]):
|
||||
files_to_download.add(v)
|
||||
is_shared = True
|
||||
if is_resuming_training:
|
||||
if is_shared:
|
||||
# download each file and add it to the state_dict
|
||||
state_dict = {}
|
||||
for shard_file in files_to_download:
|
||||
filename = hf_hub_download(pretrained_model_name_or_path, shard_file)
|
||||
state_dict.update(torch.load(filename, map_location="cpu"))
|
||||
else:
|
||||
state_dict = torch.load(filename, map_location="cpu")
|
||||
|
||||
else:
|
||||
state_dict = pretrained_model_name_or_path.state_dict()
|
||||
|
||||
model.is_peft_model = is_peft_model
|
||||
|
||||
model.post_init(state_dict=state_dict)
|
||||
model.current_device = current_device
|
||||
|
||||
if is_resuming_training:
|
||||
model.post_init(state_dict=state_dict)
|
||||
|
||||
if not is_peft_model and reward_adapter is not None:
|
||||
raise ValueError("reward_adapter can only be used with a PeftModel. ")
|
||||
elif is_peft_model and reward_adapter is not None:
|
||||
model.add_and_load_reward_modeling_adapter(reward_adapter)
|
||||
model.supports_rm_adapter = True
|
||||
else:
|
||||
model.supports_rm_adapter = False
|
||||
|
||||
return model
|
||||
|
||||
@classmethod
|
||||
def _get_current_device(cls):
|
||||
r"""
|
||||
Get the current device using the `Accelerate` object - We just return the
|
||||
process index of the `Accelerate` object to handle corner cases when running scripts
|
||||
in distributed setups.
|
||||
|
||||
Returns:
|
||||
current_device (`int`):
|
||||
The current device index.
|
||||
"""
|
||||
dummy_accelerator = Accelerator()
|
||||
current_device = dummy_accelerator.process_index
|
||||
return current_device if torch.cuda.is_available() else "cpu"
|
||||
|
||||
@classmethod
|
||||
def _split_kwargs(cls, kwargs):
|
||||
"""
|
||||
Separate the kwargs from the arguments that we support inside
|
||||
`supported_args` and the ones that we don't.
|
||||
"""
|
||||
check_peft_kwargs = False
|
||||
|
||||
if is_peft_available():
|
||||
from peft import prepare_model_for_int8_training
|
||||
|
||||
check_peft_kwargs = True
|
||||
|
||||
supported_kwargs = {}
|
||||
unsupported_kwargs = {}
|
||||
peft_kwargs = {}
|
||||
|
||||
for key, value in kwargs.items():
|
||||
if key in cls.supported_args:
|
||||
@ -207,7 +335,13 @@ class PreTrainedModelWrapper(nn.Module):
|
||||
else:
|
||||
unsupported_kwargs[key] = value
|
||||
|
||||
return supported_kwargs, unsupported_kwargs
|
||||
if check_peft_kwargs:
|
||||
if key in prepare_model_for_int8_training.__code__.co_varnames:
|
||||
peft_kwargs[key] = value
|
||||
if key in unsupported_kwargs:
|
||||
unsupported_kwargs.pop(key)
|
||||
|
||||
return supported_kwargs, unsupported_kwargs, peft_kwargs
|
||||
|
||||
def push_to_hub(self, *args, **kwargs):
|
||||
r"""
|
||||
@ -239,7 +373,7 @@ class PreTrainedModelWrapper(nn.Module):
|
||||
Keyword arguments passed along to the underlying model's
|
||||
`save_pretrained` method.
|
||||
"""
|
||||
state_dict = kwargs.pop("state_dict", None)
|
||||
state_dict = kwargs.get("state_dict")
|
||||
if state_dict is None:
|
||||
state_dict = self.state_dict()
|
||||
kwargs["state_dict"] = state_dict
|
||||
@ -268,6 +402,82 @@ class PreTrainedModelWrapper(nn.Module):
|
||||
"""
|
||||
raise NotImplementedError
|
||||
|
||||
def add_and_load_reward_modeling_adapter(self, adapter_model_id, adapter_name="reward_model_adapter"):
|
||||
r"""
|
||||
Add and load a reward modeling adapter. This method can only be used if the
|
||||
model is a `PeftModel` and if you have initialized the model with the `reward_modeling_adapter_id`
|
||||
argument, pointing to the id of the reward modeling adapter. The latest needs also to contain the
|
||||
score head in order to produce the reward.
|
||||
"""
|
||||
filename = os.path.join(adapter_model_id, "adapter_model.bin")
|
||||
if not os.path.exists(filename):
|
||||
try:
|
||||
local_filename = hf_hub_download(adapter_model_id, "adapter_model.bin")
|
||||
except: # noqa
|
||||
raise ValueError(
|
||||
"Could not find adapter model in the Hub, make sure you have the correct adapter model id."
|
||||
)
|
||||
else:
|
||||
local_filename = filename
|
||||
|
||||
adapter_state_dict = torch.load(local_filename, map_location="cpu")
|
||||
rm_adapter_peft_config = LoraConfig.from_pretrained(adapter_model_id)
|
||||
|
||||
for score_name_candidate in self.supported_rm_modules:
|
||||
if any([score_name_candidate in name for name in adapter_state_dict.keys()]):
|
||||
score_name = score_name_candidate
|
||||
# we have found the correct head name and can break
|
||||
break
|
||||
|
||||
score_dict = {}
|
||||
copy_adapter_state_dict = adapter_state_dict.copy()
|
||||
|
||||
for name, _ in copy_adapter_state_dict.items():
|
||||
if score_name in name:
|
||||
key_name = ".".join(name.split(".")[-1:])
|
||||
score_dict[key_name] = adapter_state_dict.pop(name).to(self._get_current_device())
|
||||
|
||||
self.pretrained_model.add_adapter(adapter_name, rm_adapter_peft_config)
|
||||
self.rm_adapter_name = adapter_name
|
||||
|
||||
num_labels, hidden_dim = score_dict["weight"].shape
|
||||
has_bias = any(["bias" in name for name in adapter_state_dict.keys()])
|
||||
|
||||
self.score = nn.Linear(hidden_dim, num_labels, bias=has_bias).to(self._get_current_device())
|
||||
self.score.load_state_dict(score_dict)
|
||||
|
||||
# load the adapter to the model
|
||||
set_peft_model_state_dict(self.pretrained_model, adapter_state_dict, adapter_name=adapter_name)
|
||||
|
||||
def compute_reward_score(self, input_ids, attention_mask=None, ppo_adapter_name="default", **kwargs):
|
||||
r"""
|
||||
Computes the reward score for a given input. The method has first to enable the adapter
|
||||
and then compute the reward score. After that the model disables the reward modeling
|
||||
adapter and enables the default ppo adapter again.
|
||||
"""
|
||||
if not self.supports_rm_adapter:
|
||||
raise ValueError("This model does not support reward modeling adapter.")
|
||||
|
||||
# enable rm adapter
|
||||
self.pretrained_model.set_adapter(self.rm_adapter_name)
|
||||
self.pretrained_model.eval()
|
||||
|
||||
base_model_output = self.pretrained_model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
output_hidden_states=True,
|
||||
return_dict=True,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
last_hidden_states = base_model_output.hidden_states[-1]
|
||||
scores = self.score(last_hidden_states)
|
||||
|
||||
self.pretrained_model.set_adapter(ppo_adapter_name)
|
||||
self.pretrained_model.train()
|
||||
|
||||
return scores
|
||||
|
||||
|
||||
def create_reference_model(
|
||||
model: PreTrainedModelWrapper, num_shared_layers: int = None, pattern: str = None
|
||||
@ -334,4 +544,7 @@ def create_reference_model(
|
||||
param = ref_model.get_parameter(param_name)
|
||||
param.requires_grad = False
|
||||
|
||||
if pattern is not None and len(unshared_param_list) == 0:
|
||||
logging.warning("Pattern passed or found, but no layers matched in the model. Check for a typo.")
|
||||
|
||||
return ref_model.eval()
|
||||
|
||||
@ -101,7 +101,7 @@ class AutoModelForCausalLMWithValueHead(PreTrainedModelWrapper):
|
||||
Additional keyword arguments, that are passed to the `ValueHead` class.
|
||||
"""
|
||||
super().__init__(pretrained_model)
|
||||
v_head_kwargs, _ = self._split_kwargs(kwargs)
|
||||
v_head_kwargs, _, _ = self._split_kwargs(kwargs)
|
||||
|
||||
if not any(hasattr(self.pretrained_model, attribute) for attribute in self.lm_head_namings):
|
||||
raise ValueError("The model does not have a language model head, please use a model that has one.")
|
||||
@ -157,10 +157,13 @@ class AutoModelForCausalLMWithValueHead(PreTrainedModelWrapper):
|
||||
Additional keyword arguments, that are passed to the wrapped model.
|
||||
"""
|
||||
kwargs["output_hidden_states"] = True # this had already been set in the LORA / PEFT examples
|
||||
kwargs["past_key_values"] = past_key_values
|
||||
|
||||
if self.is_peft_model and self.pretrained_model.active_peft_config.peft_type == "PREFIX_TUNING":
|
||||
kwargs.pop("past_key_values")
|
||||
|
||||
base_model_output = self.pretrained_model(
|
||||
input_ids=input_ids,
|
||||
past_key_values=past_key_values,
|
||||
attention_mask=attention_mask,
|
||||
**kwargs,
|
||||
)
|
||||
@ -279,7 +282,7 @@ class AutoModelForSeq2SeqLMWithValueHead(PreTrainedModelWrapper):
|
||||
|
||||
def __init__(self, pretrained_model, **kwargs):
|
||||
super().__init__(pretrained_model)
|
||||
v_head_kwargs, _ = self._split_kwargs(kwargs)
|
||||
v_head_kwargs, _, _ = self._split_kwargs(kwargs)
|
||||
self.is_encoder_decoder = True
|
||||
|
||||
if not self._has_lm_head():
|
||||
@ -392,9 +395,12 @@ class AutoModelForSeq2SeqLMWithValueHead(PreTrainedModelWrapper):
|
||||
attention_mask=None,
|
||||
**kwargs,
|
||||
):
|
||||
kwargs["past_key_values"] = past_key_values
|
||||
if self.is_peft_model and self.pretrained_model.active_peft_config.peft_type == "PREFIX_TUNING":
|
||||
kwargs.pop("past_key_values")
|
||||
|
||||
base_model_output = self.pretrained_model(
|
||||
input_ids=input_ids,
|
||||
past_key_values=past_key_values,
|
||||
attention_mask=attention_mask,
|
||||
output_hidden_states=True, # We force the model to output hidden states
|
||||
**kwargs,
|
||||
|
||||
@ -16,10 +16,12 @@
|
||||
|
||||
# There is a circular import in the PPOTrainer if we let isort sort these
|
||||
# isort: off
|
||||
from .utils import AdaptiveKLController, FixedKLController
|
||||
from .utils import AdaptiveKLController, FixedKLController, ConstantLengthDataset, DataCollatorForCompletionOnlyLM
|
||||
|
||||
# isort: on
|
||||
|
||||
from .base import BaseTrainer
|
||||
from .ppo_config import PPOConfig
|
||||
from .ppo_trainer import PPOTrainer
|
||||
from .reward_trainer import RewardTrainer, compute_accuracy
|
||||
from .sft_trainer import SFTTrainer
|
||||
|
||||
@ -11,145 +11,183 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import logging
|
||||
import os
|
||||
import subprocess
|
||||
import warnings
|
||||
from dataclasses import dataclass
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
import numpy as np
|
||||
import requests
|
||||
|
||||
from ..core import flatten_dict
|
||||
|
||||
|
||||
def autotag() -> str:
|
||||
wandb_tag = ""
|
||||
logging.info("autotag feature is enabled")
|
||||
try:
|
||||
git_tag = subprocess.check_output(["git", "describe", "--tags"]).decode("ascii").strip()
|
||||
wandb_tag = f"{git_tag}"
|
||||
logging.info(f"identified git tag: {git_tag}")
|
||||
except subprocess.CalledProcessError:
|
||||
return wandb_tag
|
||||
|
||||
git_commit = subprocess.check_output(["git", "rev-parse", "--verify", "HEAD"]).decode("ascii").strip()
|
||||
try:
|
||||
# if the current branch is not main, try find the PR number
|
||||
git_branch = subprocess.check_output(["git", "rev-parse", "--abbrev-ref", "HEAD"]).decode("ascii").strip()
|
||||
if git_branch != "main":
|
||||
# try finding the pull request number on github
|
||||
prs = requests.get(f"https://api.github.com/search/issues?q=repo:lvwerra/trl+is:pr+{git_commit}")
|
||||
if prs.status_code == 200:
|
||||
prs = prs.json()
|
||||
if len(prs["items"]) > 0:
|
||||
pr = prs["items"][0]
|
||||
pr_number = pr["number"]
|
||||
wandb_tag += f",pr-{pr_number}"
|
||||
logging.info(f"identified github pull request: {pr_number}")
|
||||
else:
|
||||
logging.info("current branch is main, not searching for pull request")
|
||||
except Exception as e:
|
||||
logging.warning(f"Automatic autotag failed with the following error: {e}")
|
||||
|
||||
return wandb_tag
|
||||
|
||||
|
||||
@dataclass
|
||||
class PPOConfig(object):
|
||||
"""
|
||||
Configuration class for PPOTrainer
|
||||
|
||||
Args:
|
||||
model_name (`str`, *optional*, defaults to `None`):
|
||||
Name of model to use - used only for tracking purposes
|
||||
steps (`int`, *optional*, defaults to 20000):
|
||||
Number of training steps
|
||||
learning_rate (`float`, *optional*, defaults to 1.41e-5):
|
||||
Adam learning rate
|
||||
adap_kl_ctrl (`bool`, *optional*, defaults to True):
|
||||
Use adaptive KL control, otherwise linear
|
||||
init_kl_coef (`float`, *optional*, defaults to 0.2):
|
||||
Initial KL penalty coefficient (used for adaptive and linear control)
|
||||
target (`float`, *optional*, defaults to 6):
|
||||
Target KL value for adaptive KL control
|
||||
horizon (`float`, *optional*, defaults to 10000):
|
||||
Horizon for adaptive KL control
|
||||
gamma (`float`, *optional*, defaults to 1):
|
||||
Gamma parameter for advantage calculation
|
||||
lam (`float`, *optional*, defaults to 0.95):
|
||||
Lambda parameter for advantage calculation
|
||||
cliprange (`float`, *optional*, defaults to 0.2):
|
||||
Range for clipping in PPO policy gradient loss
|
||||
cliprange_value (`float`, *optional*, defaults to 0.2):
|
||||
Range for clipping values in loss calculation
|
||||
vf_coef (`float`, *optional*, defaults to 0.1):
|
||||
Scaling factor for value loss
|
||||
batch_size (`int`, *optional*, defaults to 256):
|
||||
Number of samples per optimisation step
|
||||
forward_batch_size (`int`, *optional*, defaults to 16):
|
||||
Number of samples forward passed through model at a time
|
||||
mini_batch_size (`int`, *optional*, defaults to 1):
|
||||
Number of samples optimized inside PPO together
|
||||
gradient_accumulation_steps (`int`, *optional*, defaults to 1):
|
||||
The number of gradient accumulation steps
|
||||
ppo_epochs (`int`, *optional*, defaults to 4):
|
||||
Number of optimisation epochs per batch of samples
|
||||
remove_unused_columns (`bool`, *optional*, defaults to True):
|
||||
Remove unused columns from the dataset if `datasets.Dataset` is used
|
||||
log_with (`str`, *optional*, defaults to `None`):
|
||||
Log with either "wandb" or "tensorboard", check
|
||||
https://huggingface.co/docs/accelerate/usage_guides/tracking for more details
|
||||
accelerator_kwargs (`dict`, *optional*, defaults to {}):
|
||||
Keyword arguments for the accelerator (e.g. `logging_dir`)
|
||||
tracker_kwargs (`dict`, *optional*, defaults to {}):
|
||||
Keyword arguments for the tracker (e.g. wandb_project)
|
||||
tracker_project_name (`str`, *optional*, defaults to "trl"):
|
||||
Name of project to use for tracking
|
||||
max_grad_norm (`float`, *optional*, defaults to `None`):
|
||||
Maximum gradient norm for gradient clipping
|
||||
seed (`int`, *optional*, defaults to 0):
|
||||
Seed value for random generations
|
||||
optimize_cuda_cache (`bool`, *optional*, defaults to `False`):
|
||||
Optimize CUDA cache for slightly more memory-effcient training
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model_name: Optional[str] = None,
|
||||
steps: Optional[int] = 20000,
|
||||
learning_rate: Optional[float] = 1e-5,
|
||||
adap_kl_ctrl: Optional[bool] = True,
|
||||
init_kl_coef: Optional[float] = 0.2,
|
||||
target: Optional[float] = 6,
|
||||
horizon: Optional[float] = 10000,
|
||||
gamma: Optional[float] = 1,
|
||||
lam: Optional[float] = 0.95,
|
||||
cliprange: Optional[float] = 0.2,
|
||||
cliprange_value: Optional[float] = 0.2,
|
||||
vf_coef: Optional[float] = 0.1,
|
||||
batch_size: Optional[int] = 256,
|
||||
forward_batch_size: Optional[int] = None,
|
||||
mini_batch_size: Optional[int] = 1,
|
||||
gradient_accumulation_steps: Optional[int] = 1,
|
||||
ppo_epochs: Optional[int] = 4,
|
||||
remove_unused_columns: Optional[bool] = True,
|
||||
log_with: Optional[str] = None,
|
||||
tracker_kwargs: Optional[dict] = {},
|
||||
accelerator_kwargs: Optional[dict] = {},
|
||||
tracker_project_name: Optional[str] = "trl",
|
||||
max_grad_norm: Optional[float] = None,
|
||||
seed: Optional[int] = 0,
|
||||
optimize_cuda_cache: Optional[bool] = False,
|
||||
):
|
||||
self.model_name = model_name
|
||||
self.steps = steps
|
||||
self.learning_rate = learning_rate
|
||||
self.adap_kl_ctrl = adap_kl_ctrl
|
||||
self.init_kl_coef = init_kl_coef
|
||||
self.target = target
|
||||
self.horizon = horizon
|
||||
self.gamma = gamma
|
||||
self.lam = lam
|
||||
self.cliprange = cliprange
|
||||
self.cliprange_value = cliprange_value
|
||||
self.vf_coef = vf_coef
|
||||
self.batch_size = batch_size
|
||||
if forward_batch_size is not None:
|
||||
task_name: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={"help": "Name of task to use - used only for tracking purposes"},
|
||||
)
|
||||
model_name: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={"help": "Name of model to use - used only for tracking purposes"},
|
||||
)
|
||||
steps: Optional[int] = field(default=20000, metadata={"help": "Number of training steps"})
|
||||
learning_rate: Optional[float] = field(default=1e-5, metadata={"help": "Adam learning rate"})
|
||||
adap_kl_ctrl: Optional[bool] = field(default=True, metadata={"help": "Use adaptive KL control, otherwise linear"})
|
||||
init_kl_coef: Optional[float] = field(
|
||||
default=0.2,
|
||||
metadata={"help": "Initial KL penalty coefficient (used for adaptive and linear control)"},
|
||||
)
|
||||
kl_penalty: Optional[str] = field(
|
||||
default="kl",
|
||||
metadata={
|
||||
"help": "kl penalty options: 'kl': model_logp - ref_logp, 'abs': abs(kl) and 'mse': mean squared error mse(kl)."
|
||||
},
|
||||
)
|
||||
target: Optional[float] = field(default=6, metadata={"help": "Target KL value for adaptive KL control"})
|
||||
horizon: Optional[float] = field(default=10000, metadata={"help": "Horizon for adaptive KL control"})
|
||||
gamma: Optional[float] = field(default=1, metadata={"help": "Gamma parameter for advantage calculation"})
|
||||
lam: Optional[float] = field(default=0.95, metadata={"help": "Lambda parameter for advantage calculation"})
|
||||
cliprange: Optional[float] = field(
|
||||
default=0.2, metadata={"help": "Range for clipping in PPO policy gradient loss"}
|
||||
)
|
||||
cliprange_value: Optional[float] = field(
|
||||
default=0.2, metadata={"help": "Range for clipping values in loss calculation"}
|
||||
)
|
||||
vf_coef: Optional[float] = field(default=0.1, metadata={"help": "Scaling factor for value loss"})
|
||||
batch_size: Optional[int] = field(default=256, metadata={"help": "Number of samples per optimisation step"})
|
||||
forward_batch_size: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={"help": "Number of samples forward passed through model at a time"},
|
||||
)
|
||||
mini_batch_size: Optional[int] = field(
|
||||
default=1, metadata={"help": "Number of samples optimized inside PPO together"}
|
||||
)
|
||||
gradient_accumulation_steps: Optional[int] = field(
|
||||
default=1, metadata={"help": "The number of gradient accumulation steps"}
|
||||
)
|
||||
ppo_epochs: Optional[int] = field(
|
||||
default=4,
|
||||
metadata={"help": "Number of optimisation epochs per batch of samples"},
|
||||
)
|
||||
remove_unused_columns: Optional[bool] = field(
|
||||
default=True,
|
||||
metadata={"help": "Remove unused columns from the dataset if `datasets.Dataset` is used"},
|
||||
)
|
||||
log_with: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "Log with either 'wandb' or 'tensorboard', check https://huggingface.co/docs/accelerate/usage_guides/tracking for more details"
|
||||
},
|
||||
)
|
||||
tracker_kwargs: Optional[dict] = field(
|
||||
default_factory=dict,
|
||||
metadata={"help": "Keyword arguments for the tracker (e.g. wandb_project)"},
|
||||
)
|
||||
accelerator_kwargs: Optional[dict] = field(
|
||||
default_factory=dict,
|
||||
metadata={"help": "Keyword arguments for the accelerator"},
|
||||
)
|
||||
project_kwargs: Optional[dict] = field(
|
||||
default_factory=dict,
|
||||
metadata={"help": "Keyword arguments for the accelerator project config (e.g. `logging_dir`)"},
|
||||
)
|
||||
tracker_project_name: Optional[str] = field(
|
||||
default="trl", metadata={"help": "Name of project to use for tracking"}
|
||||
)
|
||||
max_grad_norm: Optional[float] = field(
|
||||
default=None, metadata={"help": "Maximum gradient norm for gradient clipping"}
|
||||
)
|
||||
seed: Optional[int] = field(default=0, metadata={"help": "Seed value for random generations"})
|
||||
optimize_cuda_cache: Optional[bool] = field(
|
||||
default=False,
|
||||
metadata={"help": "Optimize CUDA cache for slightly more memory-efficient training"},
|
||||
)
|
||||
early_stopping: Optional[bool] = field(
|
||||
default=False, metadata={"help": "Whether to stop the PPO optimization loop early is the KL too high"}
|
||||
)
|
||||
target_kl: Optional[float] = field(
|
||||
default=0.1, metadata={"help": "Stop early if we exceed this value by over 50%"}
|
||||
)
|
||||
push_to_hub_if_best_kwargs: Optional[dict] = field(
|
||||
default_factory=dict,
|
||||
metadata={"help": "Keyword arguments for pushing model to the hub during training (e.g. repo_id)"},
|
||||
)
|
||||
compare_steps: Optional[int] = field(
|
||||
default=1,
|
||||
metadata={"help": "Number of steps between comparison of the current reward with the best seen so far"},
|
||||
)
|
||||
ratio_threshold: Optional[float] = field(
|
||||
default=10.0, metadata={"help": "Skip mini-batches with high PPO ratios that can cause loss spikes"}
|
||||
)
|
||||
|
||||
def __post_init__(self):
|
||||
if self.forward_batch_size is not None:
|
||||
warnings.warn(
|
||||
"Note that using `forward_batch_size` is deprecated, use `mini_batch_size` instead. By setting it you overwrite `mini_batch_size` which affects both the batch size during forward passes and also the mini batch size for PPO optimization."
|
||||
)
|
||||
self.mini_batch_size = forward_batch_size
|
||||
else:
|
||||
self.mini_batch_size = mini_batch_size
|
||||
self.gradient_accumulation_steps = gradient_accumulation_steps
|
||||
self.ppo_epochs = ppo_epochs
|
||||
self.remove_unused_columns = remove_unused_columns
|
||||
self.seed = seed
|
||||
self.mini_batch_size = self.forward_batch_size
|
||||
|
||||
self.log_with = log_with
|
||||
# check if wandb is installed
|
||||
if self.log_with == "wandb":
|
||||
# raise error if wandb is not installed
|
||||
try:
|
||||
import wandb # noqa: F401
|
||||
|
||||
existing_wandb_tag = os.environ.get("WANDB_TAGS", "")
|
||||
wandb_tag = autotag()
|
||||
if len(wandb_tag) > 0:
|
||||
if len(existing_wandb_tag) > 0:
|
||||
os.environ["WANDB_TAGS"] = ",".join([existing_wandb_tag, wandb_tag])
|
||||
else:
|
||||
os.environ["WANDB_TAGS"] = wandb_tag
|
||||
logging.info(f"the following tags will be used for wandb logging: {os.environ['WANDB_TAGS']}")
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"Please install wandb to use wandb logging. You can do this by running `pip install wandb`."
|
||||
)
|
||||
|
||||
self.tracker_kwargs = tracker_kwargs
|
||||
self.accelerator_kwargs = accelerator_kwargs
|
||||
self.tracker_project_name = tracker_project_name
|
||||
self.optimize_cuda_cache = optimize_cuda_cache
|
||||
self.max_grad_norm = max_grad_norm
|
||||
|
||||
self.total_ppo_epochs = int(np.ceil(steps / batch_size))
|
||||
self.total_ppo_epochs = int(np.ceil(self.steps / self.batch_size))
|
||||
assert self.kl_penalty in ["kl", "abs", "mse"]
|
||||
|
||||
def to_dict(self):
|
||||
output_dict = {}
|
||||
|
||||
@ -14,17 +14,25 @@
|
||||
import inspect
|
||||
import os
|
||||
import time
|
||||
import typing
|
||||
import warnings
|
||||
from typing import List, Optional, Union
|
||||
from typing import Callable, List, Optional, Union
|
||||
|
||||
import datasets
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
from accelerate.utils import ProjectConfiguration
|
||||
from datasets import Dataset
|
||||
from huggingface_hub import whoami
|
||||
from packaging import version
|
||||
from requests.exceptions import HTTPError
|
||||
from torch.optim import Adam
|
||||
from transformers import DataCollatorForLanguageModeling, PreTrainedTokenizer, PreTrainedTokenizerFast
|
||||
from transformers import (
|
||||
DataCollatorForLanguageModeling,
|
||||
PreTrainedTokenizer,
|
||||
PreTrainedTokenizerBase,
|
||||
PreTrainedTokenizerFast,
|
||||
)
|
||||
|
||||
from ..core import (
|
||||
WANDB_PADDING,
|
||||
@ -106,7 +114,7 @@ class PPOTrainer(BaseTrainer):
|
||||
transformer model with a casual language modelling head. Check the documentation of `PreTrainedModelWrapper`
|
||||
for more details. If no reference model is provided, the trainer will create a reference model with the same
|
||||
architecture as the model to be optimized with shared layers.
|
||||
**tokenizer** (`Union[PreTrainedTokenizer, PreTrainedTokenizerFast]`) -- Tokenizer to be used for encoding the
|
||||
**tokenizer** (`PreTrainedTokenizerBase`) -- Tokenizer to be used for encoding the
|
||||
data. Check the documentation of `transformers.PreTrainedTokenizer` and
|
||||
`transformers.PreTrainedTokenizerFast` for more details.
|
||||
**dataset** (Union[`torch.utils.data.Dataset`, `datasets.Dataset`], *optional*) -- PyTorch dataset or Hugging
|
||||
@ -127,11 +135,11 @@ class PPOTrainer(BaseTrainer):
|
||||
self,
|
||||
config: PPOConfig = None,
|
||||
model: PreTrainedModelWrapper = None,
|
||||
ref_model: PreTrainedModelWrapper = None,
|
||||
tokenizer: Union[PreTrainedTokenizer, PreTrainedTokenizerFast] = None,
|
||||
ref_model: Optional[PreTrainedModelWrapper] = None,
|
||||
tokenizer: PreTrainedTokenizerBase = None,
|
||||
dataset: Optional[Union[torch.utils.data.Dataset, Dataset]] = None,
|
||||
optimizer: Optional[torch.optim.Optimizer] = None,
|
||||
data_collator=None,
|
||||
data_collator: Optional[typing.Callable] = None,
|
||||
num_shared_layers: Optional[int] = None,
|
||||
lr_scheduler: Optional[torch.optim.lr_scheduler._LRScheduler] = None,
|
||||
):
|
||||
@ -145,9 +153,9 @@ class PPOTrainer(BaseTrainer):
|
||||
Hugging Face transformer model with a value head.
|
||||
ref_model (`PreTrainedModelWrapper`):
|
||||
Hugging Face transformer model with a casual language modelling head. Used for KL penalty
|
||||
tokenizer (`transformers.PreTrainedTokenizer`):
|
||||
tokenizer (`transformers.PreTrainedTokenizerBase`):
|
||||
Hugging Face tokenizer
|
||||
dataset (Union[`torch.utils.data.Dataset`, `datasets.Dataset`], *optional*):
|
||||
dataset (Optional[Union[`torch.utils.data.Dataset`, `datasets.Dataset`]]):
|
||||
PyTorch dataset or Hugging Face dataset. If a Hugging Face dataset is passed, the dataset
|
||||
will be preprocessed by removing the columns that are not used by the model. If none is passed,
|
||||
a warning will be raised in a multi-GPU setting.
|
||||
@ -169,9 +177,9 @@ class PPOTrainer(BaseTrainer):
|
||||
# Step 0: check positional arguments validity
|
||||
if not isinstance(config, PPOConfig):
|
||||
raise ValueError(f"config must be a PPOConfig, got {type(config)}")
|
||||
if not isinstance(tokenizer, (PreTrainedTokenizer, PreTrainedTokenizerFast)):
|
||||
if not isinstance(tokenizer, (PreTrainedTokenizerBase)):
|
||||
raise ValueError(
|
||||
f"tokenizer must be a PreTrainedTokenizer or PreTrainedTokenizerFast, got {type(tokenizer)}"
|
||||
f"tokenizer must be a PreTrainedTokenizerBase like a PreTrainedTokenizer or a PreTrainedTokenizerFast, got {type(tokenizer)}"
|
||||
)
|
||||
if not isinstance(model, (SUPPORTED_ARCHITECTURES)):
|
||||
raise ValueError(
|
||||
@ -181,10 +189,16 @@ class PPOTrainer(BaseTrainer):
|
||||
self.accelerator = Accelerator(
|
||||
log_with=config.log_with,
|
||||
gradient_accumulation_steps=config.gradient_accumulation_steps,
|
||||
project_config=ProjectConfiguration(**config.project_kwargs),
|
||||
**config.accelerator_kwargs,
|
||||
)
|
||||
|
||||
is_using_tensorboard = config.log_with is not None and config.log_with == "tensorboard"
|
||||
|
||||
self.accelerator.init_trackers(
|
||||
config.tracker_project_name, config=config.to_dict(), init_kwargs=config.tracker_kwargs
|
||||
config.tracker_project_name,
|
||||
config=dict(trl_ppo_trainer_config=config.to_dict()) if not is_using_tensorboard else config.to_dict(),
|
||||
init_kwargs=config.tracker_kwargs,
|
||||
)
|
||||
|
||||
self.model = model
|
||||
@ -216,7 +230,7 @@ class PPOTrainer(BaseTrainer):
|
||||
self.tokenizer = tokenizer
|
||||
|
||||
if dataset is not None and not (isinstance(dataset, torch.utils.data.Dataset) or isinstance(dataset, Dataset)):
|
||||
raise ValueError("dataloader must be a torch.utils.data.Dataset or datasets.Dataset")
|
||||
raise ValueError("dataset must be a torch.utils.data.Dataset or datasets.Dataset")
|
||||
elif dataset is None:
|
||||
warnings.warn(
|
||||
"No dataset is provided. Make sure to set config.batch_size to the correct value before training.",
|
||||
@ -228,9 +242,9 @@ class PPOTrainer(BaseTrainer):
|
||||
self.dataloader = self.prepare_dataloader(self.dataset, data_collator)
|
||||
elif self.dataset is None and self.accelerator.num_processes > 1:
|
||||
warnings.warn(
|
||||
"No dataset is provided. In a multi-GPU setting, this will lead to an error. You should",
|
||||
" prepare your dataloader yourself with `dataloader = ppo_trainer.accelerator.prepare(dataloader)`",
|
||||
" and using `torch.utils.data.DataLoader`, or pass a dataset to the `PPOTrainer`. Please ",
|
||||
"No dataset is provided. In a multi-GPU setting, this will lead to an error. You should"
|
||||
" prepare your dataloader yourself with `dataloader = ppo_trainer.accelerator.prepare(dataloader)`"
|
||||
" and using `torch.utils.data.DataLoader`, or pass a dataset to the `PPOTrainer`. Please "
|
||||
" refer to the documentation for more details.",
|
||||
UserWarning,
|
||||
)
|
||||
@ -265,16 +279,36 @@ class PPOTrainer(BaseTrainer):
|
||||
else:
|
||||
self.kl_ctl = FixedKLController(self.config.init_kl_coef)
|
||||
|
||||
# Safety checkers for DS integration
|
||||
is_deepspeed_used = self.accelerator.distributed_type == "DEEPSPEED" and hasattr(
|
||||
self.accelerator.state, "deepspeed_plugin"
|
||||
)
|
||||
|
||||
(
|
||||
self.model,
|
||||
self.ref_model,
|
||||
self.optimizer,
|
||||
self.data_collator,
|
||||
self.dataloader,
|
||||
self.lr_scheduler,
|
||||
) = self.accelerator.prepare(
|
||||
self.model, self.ref_model, self.optimizer, self.data_collator, self.dataloader, self.lr_scheduler
|
||||
self.model, self.optimizer, self.data_collator, self.dataloader, self.lr_scheduler
|
||||
)
|
||||
if is_deepspeed_used:
|
||||
# 8 bit models are already set on the correct device
|
||||
if not self.is_peft_model and not (
|
||||
getattr(self.ref_model.pretrained_model, "is_loaded_in_8bit", False)
|
||||
or getattr(self.ref_model.pretrained_model, "is_loaded_in_4bit", False)
|
||||
):
|
||||
# DS integration only allows for single model and as `ref_model` is only used for
|
||||
# `KL devergence loss`,i.e, in eval model, just have it be on the respective device and
|
||||
# there is no need to pass it to the `accelerator.prepare` call
|
||||
self.ref_model = self.ref_model.to(self.accelerator.device)
|
||||
|
||||
# this hack seems to be needed for DS stage 3 to work
|
||||
if self.accelerator.state.deepspeed_plugin.zero_stage == 3:
|
||||
self.model.train()
|
||||
else:
|
||||
self.ref_model = self.accelerator.prepare(self.ref_model)
|
||||
|
||||
# In a distributed setup, only logging needs to be performed on the main process
|
||||
# check: https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html
|
||||
@ -284,6 +318,14 @@ class PPOTrainer(BaseTrainer):
|
||||
# init the current step
|
||||
self.current_step = 0
|
||||
|
||||
# init variables for pushing model to hub
|
||||
if config.push_to_hub_if_best_kwargs:
|
||||
if "repo_id" not in config.push_to_hub_if_best_kwargs:
|
||||
raise ValueError("You have to specify repo_id in order to push the model to the hub!")
|
||||
self.push_to_hub_kwargs = config.push_to_hub_if_best_kwargs
|
||||
self.compare_step = 0
|
||||
self.highest_reward = torch.tensor(-float("inf"))
|
||||
|
||||
# post process for PP
|
||||
if not getattr(self.model, "is_sequential_parallel", False):
|
||||
self.current_device = self.accelerator.device
|
||||
@ -357,7 +399,14 @@ class PPOTrainer(BaseTrainer):
|
||||
else:
|
||||
return dataset.remove_columns(ignored_columns)
|
||||
|
||||
def generate(self, query_tensor: torch.Tensor, **generation_kwargs):
|
||||
def generate(
|
||||
self,
|
||||
query_tensor: Union[torch.Tensor, List[torch.Tensor]],
|
||||
length_sampler: Callable = None,
|
||||
batch_size: int = 4,
|
||||
return_prompt: bool = True,
|
||||
**generation_kwargs,
|
||||
):
|
||||
"""
|
||||
Generate response with the model given the query tensor.
|
||||
call the `generate` method of the model.
|
||||
@ -367,15 +416,95 @@ class PPOTrainer(BaseTrainer):
|
||||
A tensor of shape (`batch_size`, `seq_len`) containing query tokens.
|
||||
generation_kwargs (dict[str, Any]):
|
||||
Keyword arguments for generation.
|
||||
length_sampler (`Callable`, *optional*):
|
||||
Callable that returns the number of newly generated tokens.
|
||||
batch_size (`int`, *optional):
|
||||
Batch size used for generation, defaults to `4`.
|
||||
return_prompt (`bool`, *optional*):
|
||||
If set to `False` the prompt is not returned but only the newly generated tokens, defaults to `True`.
|
||||
|
||||
Returns:
|
||||
`torch.LongTensor`: A tensor of shape (`batch_size`, `gen_len`) containing response tokens.
|
||||
"""
|
||||
response = self.accelerator.unwrap_model(self.model).generate(
|
||||
input_ids=query_tensor.unsqueeze(dim=0), **generation_kwargs
|
||||
)
|
||||
|
||||
return response
|
||||
if isinstance(query_tensor, List):
|
||||
return self._generate_batched(
|
||||
query_tensor,
|
||||
length_sampler=length_sampler,
|
||||
batch_size=batch_size,
|
||||
return_prompt=return_prompt,
|
||||
**generation_kwargs,
|
||||
)
|
||||
|
||||
else:
|
||||
if length_sampler is not None:
|
||||
generation_kwargs["max_new_tokens"] = length_sampler()
|
||||
response = self.accelerator.unwrap_model(self.model).generate(
|
||||
input_ids=query_tensor.unsqueeze(dim=0), **generation_kwargs
|
||||
)
|
||||
|
||||
if not return_prompt and not self.is_encoder_decoder:
|
||||
return response[:, query_tensor.shape[0] :]
|
||||
return response
|
||||
|
||||
def _generate_batched(
|
||||
self,
|
||||
query_tensors: List[torch.Tensor],
|
||||
length_sampler: Callable = None,
|
||||
batch_size: int = 4,
|
||||
return_prompt: bool = True,
|
||||
pad_to_multiple_of: int = None,
|
||||
remove_padding: bool = True,
|
||||
**generation_kwargs,
|
||||
):
|
||||
outputs = []
|
||||
|
||||
padding_side_default = self.tokenizer.padding_side
|
||||
if not self.is_encoder_decoder:
|
||||
self.tokenizer.padding_side = "left"
|
||||
|
||||
# in case we have fewer examples than bs
|
||||
batch_size = min(len(query_tensors), batch_size)
|
||||
|
||||
for i in range(0, len(query_tensors), batch_size):
|
||||
if length_sampler is not None:
|
||||
generation_kwargs["max_new_tokens"] = length_sampler()
|
||||
|
||||
# prevent overflow if query tensors are not even multiple of bs
|
||||
end_index = min(len(query_tensors), i + batch_size)
|
||||
|
||||
batch = query_tensors[i:end_index]
|
||||
batch_mask = [torch.ones_like(element) for element in batch]
|
||||
inputs = {"input_ids": batch, "attention_mask": batch_mask}
|
||||
|
||||
padded_inputs = self.tokenizer.pad(
|
||||
inputs,
|
||||
padding=True,
|
||||
max_length=None,
|
||||
pad_to_multiple_of=pad_to_multiple_of,
|
||||
return_tensors="pt",
|
||||
).to(self.current_device)
|
||||
|
||||
generations = self.accelerator.unwrap_model(self.model).generate(**padded_inputs, **generation_kwargs)
|
||||
|
||||
for generation, mask in zip(generations, padded_inputs["attention_mask"]):
|
||||
if not self.is_encoder_decoder:
|
||||
output = generation[(1 - mask).sum() :] # remove padding
|
||||
else:
|
||||
output = generation
|
||||
|
||||
if not return_prompt and not self.is_encoder_decoder:
|
||||
output = output[(mask).sum() :] # remove prompt
|
||||
|
||||
if remove_padding and self.tokenizer.eos_token_id in output:
|
||||
pad_mask = output == self.tokenizer.eos_token_id
|
||||
pad_start = torch.nonzero(pad_mask, as_tuple=False)[0, 0].item()
|
||||
output = output[: pad_start + 1] # keep the eos token at the end
|
||||
|
||||
outputs.append(output)
|
||||
|
||||
self.tokenizer.padding_side = padding_side_default
|
||||
return outputs
|
||||
|
||||
def _step_safety_checker(
|
||||
self,
|
||||
@ -403,7 +532,7 @@ class PPOTrainer(BaseTrainer):
|
||||
if not isinstance(tensor_list, list):
|
||||
raise ValueError(f"{name} must be a list of tensors - got {type(tensor_list)}")
|
||||
if not isinstance(tensor_list[0], torch.Tensor):
|
||||
raise ValueError(f"Elements in {name} must tensors - got {type(tensor_list[0])}")
|
||||
raise ValueError(f"Elements in {name} must be tensors - got {type(tensor_list[0])}")
|
||||
if batch_size is not None and len(tensor_list) != batch_size:
|
||||
raise ValueError(
|
||||
f"Batch size ({batch_size}) does not match number of examples - but got {len(tensor_list)} for: {name}"
|
||||
@ -448,6 +577,17 @@ class PPOTrainer(BaseTrainer):
|
||||
|
||||
queries, responses, scores = self._step_safety_checker(bs, queries, responses, scores)
|
||||
|
||||
# if we want to push best model to the hub
|
||||
if hasattr(self, "highest_reward"):
|
||||
if self.compare_step % self.config.compare_steps == 0:
|
||||
curr_mean_reward = torch.tensor(scores).mean()
|
||||
# if the best reward ever seen
|
||||
if curr_mean_reward > self.highest_reward:
|
||||
self.highest_reward = curr_mean_reward
|
||||
# push model to hub
|
||||
self.push_to_hub(**self.push_to_hub_kwargs)
|
||||
self.compare_step += 1
|
||||
|
||||
timing = dict()
|
||||
t0 = time.time()
|
||||
|
||||
@ -500,11 +640,12 @@ class PPOTrainer(BaseTrainer):
|
||||
rewards, non_score_reward = self.compute_rewards(scores, all_logprobs, ref_logprobs, masks)
|
||||
timing["time/ppo/compute_rewards"] = time.time() - t
|
||||
|
||||
# upcast to float32 to avoid dataset issues
|
||||
mini_batch_dict = {
|
||||
"queries": queries,
|
||||
"responses": responses,
|
||||
"logprobs": all_logprobs,
|
||||
"values": values,
|
||||
"logprobs": all_logprobs.to(torch.float32),
|
||||
"values": values.to(torch.float32),
|
||||
"rewards": rewards,
|
||||
"masks": masks,
|
||||
}
|
||||
@ -530,24 +671,37 @@ class PPOTrainer(BaseTrainer):
|
||||
|
||||
t = time.time()
|
||||
all_stats = []
|
||||
early_stop = False
|
||||
for _ in range(self.config.ppo_epochs):
|
||||
for batch in mini_batch_dataloader:
|
||||
if early_stop:
|
||||
break
|
||||
|
||||
for i, batch in enumerate(mini_batch_dataloader):
|
||||
with self.accelerator.accumulate(self.model):
|
||||
model_inputs = {k: batch[k] for k in model_inputs_names}
|
||||
logprobs, logits, vpreds, _ = self.batched_forward_pass(
|
||||
self.model, batch["queries"], batch["responses"], model_inputs
|
||||
self.model, batch["queries"], batch["responses"], model_inputs, return_logits=True
|
||||
)
|
||||
if (i % self.config.gradient_accumulation_steps) == 0:
|
||||
self.optimizer.zero_grad()
|
||||
|
||||
train_stats = self.train_minibatch(
|
||||
batch["logprobs"],
|
||||
batch["values"],
|
||||
batch["rewards"],
|
||||
logprobs,
|
||||
logits,
|
||||
vpreds,
|
||||
batch["masks"],
|
||||
)
|
||||
|
||||
train_stats = self.train_minibatch(
|
||||
batch["logprobs"],
|
||||
batch["values"],
|
||||
batch["rewards"],
|
||||
logprobs,
|
||||
logits,
|
||||
vpreds,
|
||||
batch["masks"],
|
||||
)
|
||||
all_stats.append(train_stats)
|
||||
all_stats.append(train_stats)
|
||||
|
||||
if self.config.early_stopping:
|
||||
policykl = train_stats["policy/policykl"]
|
||||
early_stop = self._early_stop(policykl)
|
||||
if early_stop:
|
||||
break
|
||||
|
||||
timing["time/ppo/optimize_step"] = time.time() - t
|
||||
|
||||
@ -567,6 +721,8 @@ class PPOTrainer(BaseTrainer):
|
||||
train_stats=train_stats,
|
||||
kl_coef=self.kl_ctl.value,
|
||||
masks=masks,
|
||||
queries=queries,
|
||||
responses=responses,
|
||||
)
|
||||
# Gather/Reduce stats from all processes
|
||||
if self.is_distributed:
|
||||
@ -591,6 +747,41 @@ class PPOTrainer(BaseTrainer):
|
||||
|
||||
return stats
|
||||
|
||||
def _early_stop(self, policykl):
|
||||
r"""
|
||||
Handles the early stopping logic. If the policy KL is greater than the target KL, then the gradient is zeroed and
|
||||
the optimization step is skipped.
|
||||
This also handles the multi-gpu case where the policy KL is averaged across all processes.
|
||||
|
||||
Args:
|
||||
policy_kl (torch.Tensor):
|
||||
the policy KL
|
||||
|
||||
Returns:
|
||||
`bool`: whether to early stop or not
|
||||
"""
|
||||
early_stop = False
|
||||
if not self.config.early_stopping:
|
||||
return early_stop
|
||||
|
||||
if not self.is_distributed and policykl > 1.5 * self.config.target_kl:
|
||||
self.optimizer.zero_grad()
|
||||
early_stop = True
|
||||
elif self.is_distributed:
|
||||
import torch.distributed as dist
|
||||
|
||||
# Wait for all processes to finish
|
||||
dist.barrier()
|
||||
|
||||
# all gather the policykl
|
||||
dist.all_reduce(policykl, dist.ReduceOp.SUM)
|
||||
policykl /= self.accelerator.num_processes
|
||||
|
||||
if policykl > 1.5 * self.config.target_kl:
|
||||
self.optimizer.zero_grad()
|
||||
early_stop = True
|
||||
return early_stop
|
||||
|
||||
def gather_stats(self, stats):
|
||||
"""
|
||||
Gather stats from all processes. Useful in the context of distributed training.
|
||||
@ -644,6 +835,7 @@ class PPOTrainer(BaseTrainer):
|
||||
queries: torch.Tensor,
|
||||
responses: torch.Tensor,
|
||||
model_inputs: dict,
|
||||
return_logits: bool = False,
|
||||
):
|
||||
"""
|
||||
Calculate model outputs in multiple batches.
|
||||
@ -653,6 +845,8 @@ class PPOTrainer(BaseTrainer):
|
||||
List of tensors containing the encoded queries, shape (`batch_size`, `query_length`)
|
||||
responses (`torch.LongTensor`):
|
||||
List of tensors containing the encoded responses, shape (`batch_size`, `response_length`)
|
||||
return_logits (`bool`, *optional*, defaults to `False`):
|
||||
Whether to return all_logits. Set to `False` if logits are not needed to reduce memory consumption.
|
||||
Returns:
|
||||
(tuple):
|
||||
- all_logprobs (`torch.FloatTensor`): Log probabilities of the responses,
|
||||
@ -696,20 +890,20 @@ class PPOTrainer(BaseTrainer):
|
||||
start += attention_mask[j, :].nonzero()[0]
|
||||
end = start + len(response_batch[j])
|
||||
|
||||
if len(logprobs[j, start:end]) < 2:
|
||||
raise ValueError("Responses are too short. Make sure they are at least 4 tokens long.")
|
||||
|
||||
masks[j, :start] = 0
|
||||
masks[j, end:] = 0
|
||||
|
||||
all_logits.append(logits)
|
||||
if return_logits:
|
||||
all_logits.append(logits)
|
||||
else:
|
||||
del logits
|
||||
all_values.append(values)
|
||||
all_logprobs.append(logprobs)
|
||||
all_masks.append(masks)
|
||||
|
||||
return (
|
||||
torch.cat(all_logprobs),
|
||||
torch.cat(all_logits)[:, :-1],
|
||||
torch.cat(all_logits)[:, :-1] if return_logits else None,
|
||||
torch.cat(all_values)[:, :-1],
|
||||
torch.cat(all_masks)[:, :-1],
|
||||
)
|
||||
@ -748,7 +942,6 @@ class PPOTrainer(BaseTrainer):
|
||||
"""
|
||||
loss_p, loss_v, train_stats = self.loss(old_logprobs, values, rewards, logits, vpreds, logprobs, mask)
|
||||
loss = loss_p + loss_v
|
||||
self.optimizer.zero_grad()
|
||||
self.accelerator.backward(loss)
|
||||
|
||||
if self.config.max_grad_norm is not None:
|
||||
@ -781,15 +974,30 @@ class PPOTrainer(BaseTrainer):
|
||||
"""
|
||||
rewards, non_score_rewards = [], []
|
||||
for score, logprob, ref_logprob, mask in zip(scores, logprobs, ref_logprobs, masks):
|
||||
kl = logprob - ref_logprob
|
||||
# compute KL penalty (from difference in logprobs)
|
||||
kl = self._kl_penalty(logprob, ref_logprob)
|
||||
non_score_reward = -self.kl_ctl.value * kl
|
||||
non_score_rewards.append(non_score_reward)
|
||||
reward = non_score_reward.clone()
|
||||
last_non_masked_index = mask.nonzero()[-1]
|
||||
|
||||
# reward is preference model score + KL penalty
|
||||
reward[last_non_masked_index] += score
|
||||
rewards.append(reward)
|
||||
return torch.stack(rewards), torch.stack(non_score_rewards)
|
||||
|
||||
def _kl_penalty(self, logprob: torch.FloatTensor, ref_logprob: torch.FloatTensor) -> torch.FloatTensor:
|
||||
if self.config.kl_penalty == "kl":
|
||||
return logprob - ref_logprob
|
||||
|
||||
if self.config.kl_penalty == "abs":
|
||||
return (logprob - ref_logprob).abs()
|
||||
|
||||
if self.config.kl_penalty == "mse":
|
||||
return 0.5 * (logprob - ref_logprob).square()
|
||||
|
||||
raise NotImplementedError
|
||||
|
||||
def loss(
|
||||
self,
|
||||
old_logprobs: torch.FloatTensor,
|
||||
@ -807,9 +1015,9 @@ class PPOTrainer(BaseTrainer):
|
||||
old_logprobs (`torch.FloatTensor`):
|
||||
Log probabilities of the model, shape (`batch_size`, `response_length`)
|
||||
values (`torch.FloatTensor`):
|
||||
Values of the value head, shape (`batch_size`, `hidden_dim`)
|
||||
Values of the value head, shape (`batch_size`, `response_length`)
|
||||
rewards (`torch.FloatTensor`):
|
||||
Rewards from the reward model, shape (`batch_size`)
|
||||
Rewards from the reward model, shape (`batch_size`, `response_length`)
|
||||
logits (`torch.FloatTensor`):
|
||||
Logits of the model, shape (`batch_size`, `response_length`, `vocab_size`)
|
||||
v_pred (`torch.FloatTensor`):
|
||||
@ -842,20 +1050,32 @@ class PPOTrainer(BaseTrainer):
|
||||
vf_losses1 = (vpreds - returns) ** 2
|
||||
vf_losses2 = (vpredclipped - returns) ** 2
|
||||
vf_loss = 0.5 * masked_mean(torch.max(vf_losses1, vf_losses2), mask)
|
||||
vf_clipfrac = masked_mean(torch.gt(vf_losses2, vf_losses1).double(), mask)
|
||||
vf_clipfrac = masked_mean(torch.gt(vf_losses2, vf_losses1).float(), mask)
|
||||
|
||||
ratio = torch.exp(logprobs - old_logprobs)
|
||||
|
||||
pg_losses = -advantages * ratio
|
||||
pg_losses2 = -advantages * torch.clamp(ratio, 1.0 - self.config.cliprange, 1.0 + self.config.cliprange)
|
||||
|
||||
pg_loss = masked_mean(torch.max(pg_losses, pg_losses2), mask)
|
||||
pg_clipfrac = masked_mean(torch.gt(pg_losses2, pg_losses).double(), mask)
|
||||
pg_clipfrac = masked_mean(torch.gt(pg_losses2, pg_losses).float(), mask)
|
||||
|
||||
loss = pg_loss + self.config.vf_coef * vf_loss
|
||||
|
||||
avg_ratio = masked_mean(ratio, mask).item()
|
||||
if avg_ratio > self.config.ratio_threshold:
|
||||
warnings.warn(
|
||||
f"The average ratio of batch ({avg_ratio:.2f}) exceeds threshold {self.config.ratio_threshold:.2f}. Skipping batch."
|
||||
)
|
||||
pg_loss = pg_loss * 0.0
|
||||
vf_loss = vf_loss * 0.0
|
||||
loss = loss * 0.0
|
||||
|
||||
entropy = masked_mean(entropy_from_logits(logits), mask)
|
||||
|
||||
approxkl = 0.5 * masked_mean((logprobs - old_logprobs) ** 2, mask)
|
||||
policykl = masked_mean(old_logprobs - logprobs, mask)
|
||||
|
||||
return_mean, return_var = masked_mean(returns, mask), masked_var(returns, mask)
|
||||
value_mean, value_var = masked_mean(values, mask), masked_var(values, mask)
|
||||
|
||||
@ -902,7 +1122,19 @@ class PPOTrainer(BaseTrainer):
|
||||
mean_kl = kl_list.mean()
|
||||
mean_entropy = (-data["logprobs"] * mask).sum(axis=-1).mean()
|
||||
|
||||
mean_non_score_reward = masked_mean(data["non_score_reward"], mask)
|
||||
mean_non_score_reward = masked_mean(
|
||||
data["non_score_reward"], mask
|
||||
) # non_score_reward is size `batch_size`, `response_length`
|
||||
mean_scores = torch.stack(data["scores"]).mean() # scores is size `batch_size`
|
||||
std_scores = torch.stack(data["scores"]).std()
|
||||
|
||||
if mean_kl.item() < -1.0:
|
||||
# warn users
|
||||
warnings.warn(
|
||||
f"KL divergence is starting to become negative: {mean_kl.item():.2f} - this might be a precursor for failed training."
|
||||
" sometimes this happens because the generation kwargs are not correctly set. Please make sure"
|
||||
" that the generation kwargs are set correctly, or review your training hyperparameters."
|
||||
)
|
||||
|
||||
stats = {
|
||||
"objective/kl": mean_kl,
|
||||
@ -912,8 +1144,21 @@ class PPOTrainer(BaseTrainer):
|
||||
"objective/kl_coef": kl_coef,
|
||||
"objective/entropy": mean_entropy,
|
||||
"ppo/mean_non_score_reward": mean_non_score_reward,
|
||||
"ppo/mean_scores": mean_scores,
|
||||
"ppo/std_scores": std_scores,
|
||||
}
|
||||
|
||||
# Log text properties
|
||||
query_lens = torch.tensor([len(query) for query in data["queries"]], dtype=torch.float)
|
||||
response_lens = torch.tensor([len(response) for response in data["responses"]], dtype=torch.float)
|
||||
|
||||
stats["tokens/queries_len_mean"] = torch.mean(query_lens).cpu().numpy().item()
|
||||
stats["tokens/queries_len_std"] = torch.std(query_lens).cpu().numpy().item()
|
||||
stats["tokens/queries_dist"] = query_lens.cpu().numpy()
|
||||
stats["tokens/responses_len_mean"] = torch.mean(response_lens).cpu().numpy().item()
|
||||
stats["tokens/responses_len_std"] = torch.std(response_lens).cpu().numpy().item()
|
||||
stats["tokens/responses_dist"] = response_lens.cpu().numpy()
|
||||
|
||||
for k, v in data["train_stats"].items():
|
||||
stats[f"ppo/{k}"] = torch.mean(v, axis=0)
|
||||
stats["ppo/val/var_explained"] = 1 - stats["ppo/val/error"] / stats["ppo/returns/var"]
|
||||
@ -975,6 +1220,10 @@ class PPOTrainer(BaseTrainer):
|
||||
logs["env/reward_std"] = torch.std(rewards).cpu().numpy().item()
|
||||
logs["env/reward_dist"] = rewards.cpu().numpy()
|
||||
|
||||
logs["env/reward_mean"] = torch.mean(rewards).cpu().numpy().item()
|
||||
logs["env/reward_std"] = torch.std(rewards).cpu().numpy().item()
|
||||
logs["env/reward_dist"] = rewards.cpu().numpy()
|
||||
|
||||
if self.config.log_with == "tensorboard":
|
||||
# update the current step
|
||||
self.current_step += 1
|
||||
@ -998,10 +1247,16 @@ class PPOTrainer(BaseTrainer):
|
||||
path (`str`): The path to save the model card to.
|
||||
model_name (`str`, *optional*): The name of the model, defaults to `TRL Model`.
|
||||
"""
|
||||
try:
|
||||
user = whoami()["name"]
|
||||
# handle the offline case
|
||||
except HTTPError:
|
||||
warnings.warn("Cannot retrieve user information assuming you are running in offline mode.")
|
||||
return
|
||||
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
|
||||
user = whoami()["name"]
|
||||
model_card_content = MODEL_CARD_TEMPLATE.format(model_name=model_name, model_id=f"{user}/{path}")
|
||||
with open(os.path.join(path, "README.md"), "w", encoding="utf-8") as f:
|
||||
f.write(model_card_content)
|
||||
|
||||
210
trl/trainer/reward_trainer.py
Normal file
210
trl/trainer/reward_trainer.py
Normal file
@ -0,0 +1,210 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import warnings
|
||||
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from datasets import Dataset
|
||||
from transformers import DataCollator, PreTrainedModel, PreTrainedTokenizerBase, Trainer, TrainingArguments
|
||||
from transformers.trainer_callback import TrainerCallback
|
||||
from transformers.trainer_pt_utils import nested_detach
|
||||
from transformers.trainer_utils import EvalPrediction
|
||||
|
||||
from ..import_utils import is_peft_available
|
||||
from .utils import PeftSavingCallback, RewardDataCollatorWithPadding
|
||||
|
||||
|
||||
if is_peft_available():
|
||||
from peft import PeftModel, get_peft_model
|
||||
|
||||
|
||||
def compute_accuracy(eval_pred) -> Dict[str, float]:
|
||||
predictions, labels = eval_pred
|
||||
# Here, predictions is rewards_chosen and rewards_rejected.
|
||||
# We want to see how much of the time rewards_chosen > rewards_rejected.
|
||||
predictions = np.argmax(predictions, axis=1)
|
||||
|
||||
accuracy = np.array(predictions == labels, dtype=float).mean().item()
|
||||
return {"accuracy": accuracy}
|
||||
|
||||
|
||||
class RewardTrainer(Trainer):
|
||||
r"""
|
||||
The RewardTrainer can be used to train your custom Reward Model. It is a subclass of the
|
||||
`transformers.Trainer` class and inherits all of its attributes and methods. It is recommended to use
|
||||
an `AutoModelForSequenceClassification` as the reward model. The reward model should be trained on a dataset
|
||||
of paired examples, where each example is a tuple of two sequences. The reward model should be trained to
|
||||
predict which example in the pair is more relevant to the task at hand.
|
||||
|
||||
The reward trainer expects a very specific format for the dataset. The dataset should contain two 4 entries at least
|
||||
if you don't use the default `RewardDataCollatorWithPadding` data collator. The entries should be named
|
||||
- `input_ids_chosen`
|
||||
- `attention_mask_chosen`
|
||||
- `input_ids_rejected`
|
||||
- `attention_mask_rejected`
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model: Union[PreTrainedModel, nn.Module] = None,
|
||||
args: TrainingArguments = None,
|
||||
data_collator: Optional[DataCollator] = None,
|
||||
train_dataset: Optional[Dataset] = None,
|
||||
eval_dataset: Optional[Union[Dataset, Dict[str, Dataset]]] = None,
|
||||
tokenizer: Optional[PreTrainedTokenizerBase] = None,
|
||||
model_init: Optional[Callable[[], PreTrainedModel]] = None,
|
||||
compute_metrics: Optional[Callable[[EvalPrediction], Dict]] = None,
|
||||
callbacks: Optional[List[TrainerCallback]] = None,
|
||||
optimizers: Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None),
|
||||
preprocess_logits_for_metrics: Optional[Callable[[torch.Tensor, torch.Tensor], torch.Tensor]] = None,
|
||||
max_length: Optional[int] = None,
|
||||
peft_config: Optional[Dict] = None,
|
||||
):
|
||||
"""
|
||||
Initialize RewardTrainer.
|
||||
|
||||
Args:
|
||||
model (`transformers.PreTrainedModel`):
|
||||
The model to train, preferably an `AutoModelForSequenceClassification`.
|
||||
args (`transformers.TrainingArguments`):
|
||||
The arguments to use for training.
|
||||
data_collator (`transformers.DataCollator`):
|
||||
The data collator to use for training. If None is specified, the default data collator (`RewardDataCollatorWithPadding`) will be used
|
||||
which will pad the sequences to the maximum length of the sequences in the batch, given a dataset of paired sequences.
|
||||
train_dataset (`datasets.Dataset`):
|
||||
The dataset to use for training.
|
||||
eval_dataset (`datasets.Dataset`):
|
||||
The dataset to use for evaluation.
|
||||
tokenizer (`transformers.PreTrainedTokenizerBase`):
|
||||
The tokenizer to use for training. This argument is required if you want to use the default data collator.
|
||||
model_init (`Callable[[], transformers.PreTrainedModel]`):
|
||||
The model initializer to use for training. If None is specified, the default model initializer will be used.
|
||||
compute_metrics (`Callable[[transformers.EvalPrediction], Dict]`, *optional* defaults to `compute_accuracy`):
|
||||
The metrics to use for evaluation. If no metrics are specified, the default metric (`compute_accuracy`) will be used.
|
||||
callbacks (`List[transformers.TrainerCallback]`):
|
||||
The callbacks to use for training.
|
||||
optimizers (`Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR]`):
|
||||
The optimizer and scheduler to use for training.
|
||||
preprocess_logits_for_metrics (`Callable[[torch.Tensor, torch.Tensor], torch.Tensor]`):
|
||||
The function to use to preprocess the logits before computing the metrics.
|
||||
max_length (`int`, defaults to `None`):
|
||||
The maximum length of the sequences in the batch. This argument is required if you want to use the default data collator.
|
||||
peft_config (`Dict`, defaults to `None`):
|
||||
The PEFT configuration to use for training. If you pass a PEFT configuration, the model will be wrapped in a PEFT model.
|
||||
"""
|
||||
if not is_peft_available() and peft_config is not None:
|
||||
raise ValueError(
|
||||
"PEFT is not installed and you passed a `peft_config` in the trainer's kwargs, please install it to use the PEFT models"
|
||||
)
|
||||
elif is_peft_available() and peft_config is not None:
|
||||
model = get_peft_model(model, peft_config)
|
||||
|
||||
if is_peft_available() and callbacks is None and isinstance(model, PeftModel):
|
||||
callbacks = [PeftSavingCallback()]
|
||||
|
||||
if compute_metrics is None:
|
||||
compute_metrics = compute_accuracy
|
||||
|
||||
if data_collator is None:
|
||||
if tokenizer is None:
|
||||
raise ValueError(
|
||||
"max_length or a tokenizer must be specified when using the default RewardDataCollatorWithPadding"
|
||||
)
|
||||
if max_length is None:
|
||||
warnings.warn(
|
||||
"When using RewardDataCollatorWithPadding, you should set `max_length` in the RewardTrainer's init"
|
||||
" it will be set to `512` by default, but you should do it yourself in the future.",
|
||||
UserWarning,
|
||||
)
|
||||
max_length = 512
|
||||
data_collator = RewardDataCollatorWithPadding(tokenizer, max_length=max_length)
|
||||
|
||||
if args.remove_unused_columns:
|
||||
args.remove_unused_columns = False
|
||||
# warn users
|
||||
warnings.warn(
|
||||
"When using RewardDataCollatorWithPadding, you should set `remove_unused_columns=False` in your TrainingArguments"
|
||||
" we have set it for you, but you should do it yourself in the future.",
|
||||
UserWarning,
|
||||
)
|
||||
|
||||
self.use_reward_data_collator = True
|
||||
else:
|
||||
self.use_reward_data_collator = False
|
||||
super().__init__(
|
||||
model,
|
||||
args,
|
||||
data_collator,
|
||||
train_dataset,
|
||||
eval_dataset,
|
||||
tokenizer,
|
||||
model_init,
|
||||
compute_metrics,
|
||||
callbacks,
|
||||
optimizers,
|
||||
preprocess_logits_for_metrics,
|
||||
)
|
||||
|
||||
def compute_loss(
|
||||
self,
|
||||
model: Union[PreTrainedModel, nn.Module],
|
||||
inputs: Dict[str, Union[torch.Tensor, Any]],
|
||||
return_outputs=False,
|
||||
) -> Union[torch.Tensor, Tuple[torch.Tensor, Dict[str, torch.Tensor]]]:
|
||||
if not self.use_reward_data_collator:
|
||||
raise NotImplementedError(
|
||||
"compute_loss is only implemented for RewardDataCollatorWithPadding, please implement your own compute_loss method if you are using a custom data collator"
|
||||
)
|
||||
rewards_chosen = model(input_ids=inputs["input_ids_chosen"], attention_mask=inputs["attention_mask_chosen"])[0]
|
||||
rewards_rejected = model(
|
||||
input_ids=inputs["input_ids_rejected"], attention_mask=inputs["attention_mask_rejected"]
|
||||
)[0]
|
||||
loss = -nn.functional.logsigmoid(rewards_chosen - rewards_rejected).mean()
|
||||
if return_outputs:
|
||||
return loss, {"rewards_chosen": rewards_chosen, "rewards_rejected": rewards_rejected}
|
||||
return loss
|
||||
|
||||
def prediction_step(
|
||||
self,
|
||||
model: Union[PreTrainedModel, nn.Module],
|
||||
inputs: Dict[str, Union[torch.Tensor, Any]],
|
||||
prediction_loss_only: bool,
|
||||
ignore_keys: Optional[List[str]] = None,
|
||||
) -> Tuple[Optional[torch.Tensor], Optional[torch.Tensor], Optional[torch.Tensor]]:
|
||||
inputs = self._prepare_inputs(inputs)
|
||||
if ignore_keys is None:
|
||||
if hasattr(self.model, "config"):
|
||||
ignore_keys = getattr(self.model.config, "keys_to_ignore_at_inference", [])
|
||||
else:
|
||||
ignore_keys = []
|
||||
|
||||
with torch.no_grad():
|
||||
loss, logits_dict = self.compute_loss(model, inputs, return_outputs=True)
|
||||
|
||||
if prediction_loss_only:
|
||||
return (loss, None, None)
|
||||
|
||||
loss = loss.detach()
|
||||
logits = tuple(v for k, v in logits_dict.items() if k not in ignore_keys)
|
||||
logits = nested_detach(logits)
|
||||
# Stack accepted against rejected, mean over logits
|
||||
# and softmax to get preferences between accepted and rejected to sum to 1
|
||||
logits = torch.stack(logits).mean(dim=2).softmax(dim=0).T
|
||||
|
||||
labels = torch.zeros(logits.shape[0])
|
||||
|
||||
return loss, logits, labels
|
||||
294
trl/trainer/sft_trainer.py
Normal file
294
trl/trainer/sft_trainer.py
Normal file
@ -0,0 +1,294 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import warnings
|
||||
from typing import Callable, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from datasets import Dataset
|
||||
from transformers import (
|
||||
AutoModelForCausalLM,
|
||||
AutoTokenizer,
|
||||
DataCollator,
|
||||
DataCollatorForLanguageModeling,
|
||||
PreTrainedModel,
|
||||
PreTrainedTokenizerBase,
|
||||
Trainer,
|
||||
TrainingArguments,
|
||||
)
|
||||
from transformers.trainer_callback import TrainerCallback
|
||||
from transformers.trainer_utils import EvalPrediction
|
||||
|
||||
from ..import_utils import is_peft_available
|
||||
from .utils import ConstantLengthDataset, DataCollatorForCompletionOnlyLM, PeftSavingCallback
|
||||
|
||||
|
||||
if is_peft_available():
|
||||
from peft import PeftConfig, PeftModel, get_peft_model, prepare_model_for_int8_training
|
||||
|
||||
|
||||
class SFTTrainer(Trainer):
|
||||
r"""
|
||||
Class definition of the Supervised Finetuning Trainer (SFT Trainer).
|
||||
This class is a wrapper around the `transformers.Trainer` class and inherits all of its attributes and methods.
|
||||
The trainer takes care of properly initializing the PeftModel in case a user passes a `PeftConfig` object.
|
||||
|
||||
Args:
|
||||
model (Union[`transformers.PreTrainedModel`, `nn.Module`, `str`]):
|
||||
The model to train, can be a `PreTrainedModel`, a `torch.nn.Module` or a string with the model name to
|
||||
load from cache or download. The model can be also converted to a `PeftModel` if a `PeftConfig` object is
|
||||
passed to the `peft_config` argument.
|
||||
args (Optional[`transformers.TrainingArguments`]):
|
||||
The arguments to tweak for training. Please refer to the official documentation of `transformers.TrainingArguments`
|
||||
for more information.
|
||||
data_collator (Optional[`transformers.DataCollator`]):
|
||||
The data collator to use for training.
|
||||
train_dataset (Optional[`datasets.Dataset`]):
|
||||
The dataset to use for training. We recommend users to use `trl.trainer.ConstantLengthDataset` to create their dataset.
|
||||
eval_dataset (Optional[Union[`datasets.Dataset`, Dict[`str`, `datasets.Dataset`]]]):
|
||||
The dataset to use for evaluation. We recommend users to use `trl.trainer.ConstantLengthDataset` to create their dataset.
|
||||
tokenizer (Optional[`transformers.PreTrainedTokenizer`]):
|
||||
The tokenizer to use for training. If not specified, the tokenizer associated to the model will be used.
|
||||
model_init (`Callable[[], transformers.PreTrainedModel]`):
|
||||
The model initializer to use for training. If None is specified, the default model initializer will be used.
|
||||
compute_metrics (`Callable[[transformers.EvalPrediction], Dict]`, *optional* defaults to `compute_accuracy`):
|
||||
The metrics to use for evaluation. If no metrics are specified, the default metric (`compute_accuracy`) will be used.
|
||||
callbacks (`List[transformers.TrainerCallback]`):
|
||||
The callbacks to use for training.
|
||||
optimizers (`Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR]`):
|
||||
The optimizer and scheduler to use for training.
|
||||
preprocess_logits_for_metrics (`Callable[[torch.Tensor, torch.Tensor], torch.Tensor]`):
|
||||
The function to use to preprocess the logits before computing the metrics.
|
||||
peft_config (`Optional[PeftConfig]`):
|
||||
The PeftConfig object to use to initialize the PeftModel.
|
||||
dataset_text_field (`Optional[str]`):
|
||||
The name of the text field of the dataset, in case this is passed by a user, the trainer will automatically create a
|
||||
`ConstantLengthDataset` based on the `dataset_text_field` argument.
|
||||
formatting_func (`Optional[Callable]`):
|
||||
The formatting function to be used for creating the `ConstantLengthDataset`.
|
||||
max_seq_length (`Optional[int]`):
|
||||
The maximum sequence length to use for the `ConstantLengthDataset` and for automaticallty creating the Dataset. Defaults to `512`.
|
||||
infinite (`Optional[bool]`):
|
||||
Whether to use an infinite dataset or not. Defaults to `False`.
|
||||
num_of_sequences (`Optional[int]`):
|
||||
The number of sequences to use for the `ConstantLengthDataset`. Defaults to `1024`.
|
||||
chars_per_token (`Optional[float]`):
|
||||
The number of characters per token to use for the `ConstantLengthDataset`. Defaults to `3.6`. You can check how this is computed in the
|
||||
stack-llama example: https://github.com/lvwerra/trl/blob/08f550674c553c36c51d1027613c29f14f3676a5/examples/stack_llama/scripts/supervised_finetuning.py#L53.
|
||||
packing (`Optional[bool]`):
|
||||
Used only in case `dataset_text_field` is passed. This argument is used by the `ConstantLengthDataset` to pack the sequences
|
||||
of the dataset.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model: Union[PreTrainedModel, nn.Module, str] = None,
|
||||
args: TrainingArguments = None,
|
||||
data_collator: Optional[DataCollator] = None,
|
||||
train_dataset: Optional[Dataset] = None,
|
||||
eval_dataset: Optional[Union[Dataset, Dict[str, Dataset]]] = None,
|
||||
tokenizer: Optional[PreTrainedTokenizerBase] = None,
|
||||
model_init: Optional[Callable[[], PreTrainedModel]] = None,
|
||||
compute_metrics: Optional[Callable[[EvalPrediction], Dict]] = None,
|
||||
callbacks: Optional[List[TrainerCallback]] = None,
|
||||
optimizers: Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None),
|
||||
preprocess_logits_for_metrics: Optional[Callable[[torch.Tensor, torch.Tensor], torch.Tensor]] = None,
|
||||
peft_config: Optional[Dict] = None,
|
||||
dataset_text_field: Optional[str] = None,
|
||||
packing: Optional[bool] = False,
|
||||
formatting_func: Optional[Callable] = None,
|
||||
max_seq_length: Optional[int] = None,
|
||||
infinite: Optional[bool] = False,
|
||||
num_of_sequences: Optional[int] = 1024,
|
||||
chars_per_token: Optional[float] = 3.6,
|
||||
):
|
||||
if isinstance(model, str):
|
||||
warnings.warn(
|
||||
"You passed a model_id to the SFTTrainer. This will automatically create an "
|
||||
"`AutoModelForCausalLM` or a `PeftModel` (if you passed a `peft_config`) for you."
|
||||
)
|
||||
|
||||
if packing and data_collator is not None and isinstance(data_collator, DataCollatorForCompletionOnlyLM):
|
||||
raise ValueError(
|
||||
"You passed a `DataCollatorForCompletionOnlyLM` to the SFTTrainer. This is not compatible with the `packing` argument."
|
||||
)
|
||||
|
||||
if is_peft_available() and peft_config is not None:
|
||||
if not isinstance(peft_config, PeftConfig):
|
||||
raise ValueError(
|
||||
"If you want to use the PeftModel, you need to pass a PeftConfig object to the SFTTrainer."
|
||||
f" and you passed a {type(peft_config)}."
|
||||
)
|
||||
|
||||
if not isinstance(model, PeftModel):
|
||||
if not isinstance(model, PreTrainedModel):
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model,
|
||||
)
|
||||
|
||||
if getattr(model, "is_loaded_in_8bit", False) or getattr(model, "is_loaded_in_4bit", False):
|
||||
model = prepare_model_for_int8_training(model)
|
||||
|
||||
model = get_peft_model(model, peft_config)
|
||||
|
||||
if callbacks is None:
|
||||
callbacks = [PeftSavingCallback]
|
||||
elif not isinstance(model, (PreTrainedModel, PeftModel)):
|
||||
model = AutoModelForCausalLM.from_pretrained(model)
|
||||
|
||||
if tokenizer is None:
|
||||
tokenizer = AutoTokenizer.from_pretrained(model.config._name_or_path)
|
||||
if getattr(tokenizer, "pad_token", None) is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
if max_seq_length is None:
|
||||
# to overcome some issues with broken tokenizers
|
||||
max_seq_length = min(tokenizer.model_max_length, 1024)
|
||||
|
||||
warnings.warn(
|
||||
f"You didn't pass a `max_seq_length` argument to the SFTTrainer, this will default to {max_seq_length}"
|
||||
)
|
||||
|
||||
if not packing:
|
||||
if dataset_text_field is None and formatting_func is None:
|
||||
raise ValueError(
|
||||
"You passed `packing=False` to the SFTTrainer, but you didn't pass a `dataset_text_field` or `formatting_func` argument."
|
||||
)
|
||||
|
||||
if data_collator is None:
|
||||
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
|
||||
|
||||
if train_dataset is not None:
|
||||
train_dataset = self._prepare_dataset(
|
||||
train_dataset,
|
||||
tokenizer,
|
||||
packing,
|
||||
dataset_text_field,
|
||||
max_seq_length,
|
||||
formatting_func,
|
||||
infinite,
|
||||
num_of_sequences,
|
||||
chars_per_token,
|
||||
)
|
||||
if eval_dataset is not None:
|
||||
eval_dataset = self._prepare_dataset(
|
||||
eval_dataset,
|
||||
tokenizer,
|
||||
packing,
|
||||
dataset_text_field,
|
||||
max_seq_length,
|
||||
formatting_func,
|
||||
infinite,
|
||||
num_of_sequences,
|
||||
chars_per_token,
|
||||
)
|
||||
|
||||
super().__init__(
|
||||
model=model,
|
||||
args=args,
|
||||
data_collator=data_collator,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
tokenizer=tokenizer,
|
||||
model_init=model_init,
|
||||
compute_metrics=compute_metrics,
|
||||
callbacks=callbacks,
|
||||
optimizers=optimizers,
|
||||
preprocess_logits_for_metrics=preprocess_logits_for_metrics,
|
||||
)
|
||||
|
||||
if self.args.max_steps > 0 and packing:
|
||||
warnings.warn(
|
||||
"You passed `packing=True` to the SFTTrainer, and you are training your model with `max_steps` strategy. The dataset will be iterated until the `max_steps` are reached."
|
||||
)
|
||||
self.train_dataset.infinite = True
|
||||
elif self.args.max_steps == -1 and packing:
|
||||
self.train_dataset.infinite = False
|
||||
|
||||
def _prepare_dataset(
|
||||
self,
|
||||
dataset,
|
||||
tokenizer,
|
||||
packing,
|
||||
dataset_text_field,
|
||||
max_seq_length,
|
||||
formatting_func,
|
||||
infinite,
|
||||
num_of_sequences,
|
||||
chars_per_token,
|
||||
):
|
||||
if dataset is None:
|
||||
raise ValueError("The dataset should not be None")
|
||||
|
||||
# check if torch dataset / dataloader and do nothing
|
||||
if isinstance(dataset, (torch.utils.data.IterableDataset, torch.utils.data.Dataset, ConstantLengthDataset)):
|
||||
return dataset
|
||||
|
||||
if not packing:
|
||||
return self._prepare_non_packed_dataloader(
|
||||
tokenizer, dataset, dataset_text_field, max_seq_length, formatting_func
|
||||
)
|
||||
|
||||
if dataset_text_field is not None or formatting_func is not None:
|
||||
if tokenizer is None:
|
||||
raise ValueError(
|
||||
"You need to pass a tokenizer when using the SFT Trainer when passing a `dataset_text_field`."
|
||||
)
|
||||
|
||||
return ConstantLengthDataset(
|
||||
tokenizer,
|
||||
dataset,
|
||||
dataset_text_field=dataset_text_field,
|
||||
formatting_func=formatting_func,
|
||||
seq_length=max_seq_length,
|
||||
infinite=infinite,
|
||||
num_of_sequences=num_of_sequences,
|
||||
chars_per_token=chars_per_token,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
)
|
||||
|
||||
raise ValueError(
|
||||
"You need to pass a `dataset_text_field` or `formatting_func` argument to the SFTTrainer if you want to use the `ConstantLengthDataset`."
|
||||
)
|
||||
|
||||
def _prepare_non_packed_dataloader(
|
||||
self, tokenizer, dataset, dataset_text_field, max_seq_len, formatting_func=None
|
||||
):
|
||||
use_formatting_func = formatting_func is not None and dataset_text_field is None
|
||||
self._dataset_sanity_checked = False
|
||||
|
||||
# Inspired from: https://huggingface.co/learn/nlp-course/chapter7/6?fw=pt
|
||||
def tokenize(element):
|
||||
outputs = tokenizer(
|
||||
element[dataset_text_field] if not use_formatting_func else formatting_func(element),
|
||||
truncation=True,
|
||||
padding=False,
|
||||
max_length=max_seq_len,
|
||||
return_overflowing_tokens=False,
|
||||
return_length=False,
|
||||
)
|
||||
|
||||
if use_formatting_func and not self._dataset_sanity_checked:
|
||||
if not isinstance(formatting_func(element), list):
|
||||
raise ValueError(
|
||||
"The `formatting_func` should return a list of processed strings since it can lead to silent bugs."
|
||||
)
|
||||
else:
|
||||
self._dataset_sanity_checked = True
|
||||
|
||||
return {"input_ids": outputs["input_ids"], "attention_mask": outputs["attention_mask"]}
|
||||
|
||||
tokenized_dataset = dataset.map(tokenize, batched=True, remove_columns=dataset.column_names)
|
||||
|
||||
return tokenized_dataset
|
||||
@ -11,7 +11,16 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import os
|
||||
import random
|
||||
import warnings
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from torch.utils.data import IterableDataset
|
||||
from transformers import DataCollatorForLanguageModeling, PreTrainedTokenizerBase, TrainerCallback
|
||||
|
||||
|
||||
class AdaptiveKLController:
|
||||
@ -40,3 +49,250 @@ class FixedKLController:
|
||||
|
||||
def update(self, current, n_steps):
|
||||
pass
|
||||
|
||||
|
||||
class DataCollatorForCompletionOnlyLM(DataCollatorForLanguageModeling):
|
||||
"""
|
||||
Data collator used for completion tasks. It ensures that all the tokens of the labels are set to an 'ignore_index'
|
||||
up to the prompt response template tokens ('response_template'). This ensure that the loss is only
|
||||
calculated on the completion of the reponse.
|
||||
|
||||
Args:
|
||||
response_template (`str`): the template form that indicates the start of the response, typically something like
|
||||
'### Response:\n'
|
||||
mlm (`bool`, *optional*, defaults to `False`): Whether or not to use masked language modeling in the underlying
|
||||
`DataCollatorForLanguageModeling` class. Note that this option currently has no effect but is present
|
||||
for flexibility and backwards-compatibility.
|
||||
ignore_index (`int`, *optional*, defaults to `-100`):
|
||||
The index to use to ignore the initial tokens with
|
||||
"""
|
||||
|
||||
def __init__(self, response_template: str, *args, mlm: bool = False, ignore_index: int = -100, **kwargs):
|
||||
super().__init__(*args, mlm=mlm, **kwargs)
|
||||
self.response_template = response_template
|
||||
self.ignore_index = ignore_index
|
||||
|
||||
def torch_call(self, examples: List[Union[List[int], Any, Dict[str, Any]]]) -> Dict[str, Any]:
|
||||
batch = super().torch_call(examples)
|
||||
|
||||
# The prompt ends with the response key plus a newline. We encode this and then try to find it in the
|
||||
# sequence of tokens. This should just be a single token.
|
||||
response_token_ids = self.tokenizer.encode(self.response_template, add_special_tokens=False)
|
||||
|
||||
labels = batch["labels"].clone()
|
||||
|
||||
for i in range(len(examples)):
|
||||
response_token_ids_start_idx = None
|
||||
|
||||
for idx in np.where(batch["labels"][i] == response_token_ids[0])[0]:
|
||||
# `response_token_ids` is `'### Response:\n'`, here we are just making sure that the token IDs match
|
||||
if response_token_ids == examples[i]["input_ids"][idx : idx + len(response_token_ids)]:
|
||||
response_token_ids_start_idx = idx
|
||||
|
||||
if response_token_ids_start_idx is None:
|
||||
raise RuntimeError(
|
||||
f'Could not find response key {response_token_ids} in token IDs {batch["labels"][i]}'
|
||||
)
|
||||
|
||||
response_token_ids_end_idx = response_token_ids_start_idx + len(response_token_ids)
|
||||
|
||||
# Make pytorch loss function ignore all tokens up through the end of the response key
|
||||
labels[i, :response_token_ids_end_idx] = self.ignore_index
|
||||
|
||||
batch["labels"] = labels
|
||||
|
||||
return batch
|
||||
|
||||
|
||||
@dataclass
|
||||
class RewardDataCollatorWithPadding:
|
||||
r"""
|
||||
Reward DataCollator class that padds the inputs to the maximum length of the batch.
|
||||
Args:
|
||||
tokenizer (`PreTrainedTokenizerBase`):
|
||||
The tokenizer used for encoding the data.
|
||||
padding (`Union[bool, str, `PaddingStrategy`]`, `optional`, defaults to `True`):
|
||||
padding_strategy to pass to the tokenizer.
|
||||
max_length (`Optional[int]`, `optional`, defaults to `None`):
|
||||
The maximum length of the sequence to be processed.
|
||||
pad_to_multiple_of (`Optional[int]`, `optional`, defaults to `None`):
|
||||
If set will pad the sequence to a multiple of the provided value.
|
||||
return_tensors (`str`, `optional`, defaults to `"pt"`):
|
||||
The tensor type to use.
|
||||
"""
|
||||
tokenizer: PreTrainedTokenizerBase
|
||||
padding: Union[bool, str] = True
|
||||
max_length: Optional[int] = None
|
||||
pad_to_multiple_of: Optional[int] = None
|
||||
return_tensors: str = "pt"
|
||||
|
||||
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
|
||||
features_chosen = []
|
||||
features_rejected = []
|
||||
for feature in features:
|
||||
# check if the keys are named as expected
|
||||
if (
|
||||
"input_ids_chosen" not in feature
|
||||
or "input_ids_rejected" not in feature
|
||||
or "attention_mask_chosen" not in feature
|
||||
or "attention_mask_rejected" not in feature
|
||||
):
|
||||
raise ValueError(
|
||||
"The features should include `input_ids_chosen`, `attention_mask_chosen`, `input_ids_rejected` and `attention_mask_rejected`"
|
||||
)
|
||||
|
||||
features_chosen.append(
|
||||
{
|
||||
"input_ids": feature["input_ids_chosen"],
|
||||
"attention_mask": feature["attention_mask_chosen"],
|
||||
}
|
||||
)
|
||||
features_rejected.append(
|
||||
{
|
||||
"input_ids": feature["input_ids_rejected"],
|
||||
"attention_mask": feature["attention_mask_rejected"],
|
||||
}
|
||||
)
|
||||
batch_chosen = self.tokenizer.pad(
|
||||
features_chosen,
|
||||
padding=self.padding,
|
||||
max_length=self.max_length,
|
||||
pad_to_multiple_of=self.pad_to_multiple_of,
|
||||
return_tensors=self.return_tensors,
|
||||
)
|
||||
batch_rejected = self.tokenizer.pad(
|
||||
features_rejected,
|
||||
padding=self.padding,
|
||||
max_length=self.max_length,
|
||||
pad_to_multiple_of=self.pad_to_multiple_of,
|
||||
return_tensors=self.return_tensors,
|
||||
)
|
||||
batch = {
|
||||
"input_ids_chosen": batch_chosen["input_ids"],
|
||||
"attention_mask_chosen": batch_chosen["attention_mask"],
|
||||
"input_ids_rejected": batch_rejected["input_ids"],
|
||||
"attention_mask_rejected": batch_rejected["attention_mask"],
|
||||
"return_loss": True,
|
||||
}
|
||||
return batch
|
||||
|
||||
|
||||
class ConstantLengthDataset(IterableDataset):
|
||||
"""
|
||||
Iterable dataset that returns constant length chunks of tokens from stream of text files.
|
||||
The dataset also formats the text before tokenization with a specific format that is provided
|
||||
by the user.
|
||||
|
||||
Args:
|
||||
tokenizer (`transformers.PreTrainedTokenizer`):
|
||||
The processor used for proccessing the data.
|
||||
dataset (`dataset.Dataset`):
|
||||
Dataset with text files.
|
||||
dataset_text_field (`str`, **optional**):
|
||||
Name of the field in the dataset that contains the text. Used only if `formatting_func` is `None`.
|
||||
formatting_func (`Callable`, **optional**):
|
||||
Function that formats the text before tokenization. Usually it is recommended to have follows a certain
|
||||
pattern such as `"### Question: {question}\n ### Answer: {answer}\n"`
|
||||
infinite (`bool`, *optional*, defaults to `False`):
|
||||
If True the iterator is reset after dataset reaches end else stops.
|
||||
seq_length (`int`, *optional*, defaults to `1024`):
|
||||
Length of token sequences to return.
|
||||
num_of_sequences (`int`, *optional*, defaults to `1024`):
|
||||
Number of token sequences to keep in buffer.
|
||||
chars_per_token (`int`, *optional*, defaults to `3.6`):
|
||||
Number of characters per token used to estimate number of tokens in text buffer.
|
||||
eos_token_id (`int`, *optional*, defaults to `0`):
|
||||
Id of the end of sequence token if the passed tokenizer does not have an EOS token.
|
||||
shuffle ('bool', *optional*, defaults to True)
|
||||
Shuffle the examples before they are returned
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
tokenizer,
|
||||
dataset,
|
||||
dataset_text_field=None,
|
||||
formatting_func=None,
|
||||
infinite=False,
|
||||
seq_length=1024,
|
||||
num_of_sequences=1024,
|
||||
chars_per_token=3.6,
|
||||
eos_token_id=0,
|
||||
shuffle=True,
|
||||
):
|
||||
self.tokenizer = tokenizer
|
||||
|
||||
if tokenizer.eos_token_id is None:
|
||||
warnings.warn(
|
||||
"The passed tokenizer does not have an EOS token. We will use the passed eos_token_id instead which corresponds"
|
||||
f" to {eos_token_id}. If this is not the correct EOS token, make sure to pass the correct eos_token_id."
|
||||
)
|
||||
|
||||
self.concat_token_id = tokenizer.eos_token_id if tokenizer.eos_token_id else eos_token_id
|
||||
self.dataset = dataset
|
||||
self.seq_length = seq_length
|
||||
self.infinite = infinite
|
||||
self.current_size = 0
|
||||
self.max_buffer_size = seq_length * chars_per_token * num_of_sequences
|
||||
self.shuffle = shuffle
|
||||
if formatting_func is None:
|
||||
self.formatting_func = lambda x: x[dataset_text_field]
|
||||
else:
|
||||
self.formatting_func = formatting_func
|
||||
|
||||
if formatting_func is not None:
|
||||
formatting_func_signature = formatting_func.__code__.co_varnames
|
||||
if len(formatting_func_signature) > 1:
|
||||
warnings.warn(
|
||||
"The passed formatting_func has more than one argument. Usually that function should have a single argument `example`"
|
||||
" which corresponds to the dictonnary returned by each element of the dataset. Make sure you know what you are doing."
|
||||
)
|
||||
|
||||
def __len__(self):
|
||||
return len(self.dataset)
|
||||
|
||||
def __iter__(self):
|
||||
iterator = iter(self.dataset)
|
||||
more_examples = True
|
||||
while more_examples:
|
||||
buffer, buffer_len = [], 0
|
||||
while True:
|
||||
if buffer_len >= self.max_buffer_size:
|
||||
break
|
||||
try:
|
||||
buffer.append(self.formatting_func(next(iterator)))
|
||||
buffer_len += len(buffer[-1])
|
||||
except StopIteration:
|
||||
if self.infinite:
|
||||
iterator = iter(self.dataset)
|
||||
warnings.warn("The dataset reached end and the iterator is reset to the start.")
|
||||
else:
|
||||
more_examples = False
|
||||
break
|
||||
tokenized_inputs = self.tokenizer(buffer, truncation=False)["input_ids"]
|
||||
all_token_ids = []
|
||||
for tokenized_input in tokenized_inputs:
|
||||
all_token_ids.extend(tokenized_input + [self.concat_token_id])
|
||||
examples = []
|
||||
for i in range(0, len(all_token_ids), self.seq_length):
|
||||
input_ids = all_token_ids[i : i + self.seq_length]
|
||||
if len(input_ids) == self.seq_length:
|
||||
examples.append(input_ids)
|
||||
if self.shuffle:
|
||||
random.shuffle(examples)
|
||||
for example in examples:
|
||||
self.current_size += 1
|
||||
yield {
|
||||
"input_ids": torch.LongTensor(example),
|
||||
"labels": torch.LongTensor(example),
|
||||
}
|
||||
|
||||
|
||||
class PeftSavingCallback(TrainerCallback):
|
||||
def on_save(self, args, state, control, **kwargs):
|
||||
if args.should_save:
|
||||
checkpoint_path = os.path.join(args.output_dir, f"checkpoint-{state.global_step}")
|
||||
kwargs["model"].save_pretrained(checkpoint_path)
|
||||
|
||||
if "pytorch_model.bin" in os.listdir(checkpoint_path):
|
||||
os.remove(os.path.join(checkpoint_path, "pytorch_model.bin"))
|
||||
|
||||
Reference in New Issue
Block a user