mirror of
https://github.com/huggingface/trl.git
synced 2025-11-12 01:04:41 +08:00
Compare commits
146 Commits
v0.12.2
...
v0.14-rele
| Author | SHA1 | Date | |
|---|---|---|---|
| 49711efab9 | |||
| 801582ec24 | |||
| ed14ed9043 | |||
| 4659ad916f | |||
| 1123bd0f51 | |||
| 55a329e9f0 | |||
| 4720656654 | |||
| 807046b7d7 | |||
| 317d2d477b | |||
| aeb03cf1a9 | |||
| 2578e95023 | |||
| 6f99f42f72 | |||
| d14f7f3eb2 | |||
| 8e65825d4c | |||
| 5e4d7be0e1 | |||
| f34b70a32e | |||
| 0e216f7411 | |||
| 59c201433c | |||
| 40c238395e | |||
| a1d2955116 | |||
| 887c1f3fa3 | |||
| 949db2357e | |||
| fe4b5efe4e | |||
| a9b54a852e | |||
| d4222a1e08 | |||
| a5c88d6c75 | |||
| b6a084c46e | |||
| d9f056862f | |||
| 3d2c1e49b1 | |||
| 5fd78367ae | |||
| 0f5ffad26e | |||
| 88514d51e3 | |||
| 76837e82b9 | |||
| 35553930da | |||
| fd4b283b82 | |||
| 1b1140aa69 | |||
| 4c7eb6fe29 | |||
| 564fc86759 | |||
| 3215a1c586 | |||
| cdc16f3ac6 | |||
| 2ecd53ad77 | |||
| 5877786b5a | |||
| 57d9a97394 | |||
| 751fb1d84b | |||
| edabe0a2d8 | |||
| abfffc510b | |||
| ed7de87dc7 | |||
| beb892bfe0 | |||
| f2d42fa0c2 | |||
| d6a7e9d6f5 | |||
| 451677203d | |||
| 2f25f54ab9 | |||
| a50124dd3a | |||
| 1d23ecc36f | |||
| 52d213173f | |||
| d9ee2fd202 | |||
| 763738f457 | |||
| aed5da580e | |||
| 99451b421a | |||
| 5239b9462d | |||
| 8fb267ff1e | |||
| 2e1adbb6ff | |||
| b668048fe1 | |||
| 8c49ea39ec | |||
| 88ad1a099c | |||
| 9908dda6d9 | |||
| 5e204e1eaa | |||
| 82cfeb8930 | |||
| 0fe73a8af5 | |||
| 33fb9efc43 | |||
| f68d11f9f9 | |||
| aeca63774f | |||
| 117c6d4b52 | |||
| 6d4ed070f1 | |||
| cd7156fb34 | |||
| ca850be0a2 | |||
| 179ba53671 | |||
| e3e171a26b | |||
| b3aff441ff | |||
| efc687db62 | |||
| f2e362656c | |||
| c9c4f18039 | |||
| 460e780265 | |||
| 7ba118a229 | |||
| 6a05feff02 | |||
| 2f72f47191 | |||
| 9410874787 | |||
| 9c5388b69e | |||
| b02189aaa5 | |||
| 52201d3c18 | |||
| 9ff79a65e3 | |||
| 9001a8682c | |||
| f6f42651e2 | |||
| 148b592313 | |||
| d6a8f2c2f6 | |||
| 8d9cfaafeb | |||
| 94e4135a17 | |||
| ac267781ec | |||
| 2c6e0d9705 | |||
| e1d781353b | |||
| a34e9bf84f | |||
| c10cc8995b | |||
| 9368dccef6 | |||
| 43df3a485a | |||
| baee06f2e8 | |||
| bbd8cbb720 | |||
| 4f937c7629 | |||
| 16fa13ce72 | |||
| 453db5cd79 | |||
| ee3cbe1946 | |||
| 17e8060984 | |||
| 163695e85c | |||
| 672c96546d | |||
| bdeb117320 | |||
| 6578fdc101 | |||
| a0066f47f8 | |||
| 5626806aef | |||
| bb0afc2459 | |||
| 066fc37bd3 | |||
| b80c1a6fb8 | |||
| b5eabbeb07 | |||
| cbf9abcd07 | |||
| 6f8fe59aeb | |||
| 1293f37c5f | |||
| e7870dd5d6 | |||
| 21d5baf338 | |||
| 76dbb1a576 | |||
| b8c9d9c7bc | |||
| 623963126b | |||
| 2d24d35013 | |||
| dde20b23cf | |||
| 015321e135 | |||
| 454f36d951 | |||
| 9b7f9f3519 | |||
| 518e29ca9c | |||
| ac7b6cfdfa | |||
| 0238d96c6f | |||
| c86b51cd12 | |||
| ac77c09223 | |||
| 7f2ccbe3a2 | |||
| 74e20cbbbc | |||
| 27b9e3a93f | |||
| dc2b8b9e90 | |||
| 5e90682836 | |||
| 3b439967f4 | |||
| 2f34a161cd |
76
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
76
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@ -7,36 +7,7 @@ body:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this bug report! 🤗
|
||||
|
||||
Before you submit your bug report:
|
||||
|
||||
- If it is your first time submitting, be sure to check our [bug report guidelines](https://github.com/huggingface/trl/blob/main/CONTRIBUTING.md#did-you-find-a-bug)
|
||||
|
||||
- type: textarea
|
||||
id: system-info
|
||||
attributes:
|
||||
label: System Info
|
||||
description: Please share your system info with us. You can run the command `trl env` and copy-paste its output below.
|
||||
placeholder: trl version, transformers version, platform, python version, ...
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: checkboxes
|
||||
id: information-scripts-examples
|
||||
attributes:
|
||||
label: Information
|
||||
description: 'The problem arises when using:'
|
||||
options:
|
||||
- label: "The official example scripts"
|
||||
- label: "My own modified scripts"
|
||||
|
||||
- type: checkboxes
|
||||
id: information-tasks
|
||||
attributes:
|
||||
label: Tasks
|
||||
description: "The tasks I am working on are:"
|
||||
options:
|
||||
- label: "An officially supported task in the `examples` folder"
|
||||
- label: "My own task or dataset (give details below)"
|
||||
🚩 If it is your first time submitting, be sure to check our [bug report guidelines](https://github.com/huggingface/trl/blob/main/CONTRIBUTING.md#did-you-find-a-bug)
|
||||
|
||||
- type: textarea
|
||||
id: reproduction
|
||||
@ -50,18 +21,47 @@ body:
|
||||
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
|
||||
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
|
||||
|
||||
placeholder: |
|
||||
Steps to reproduce the behavior:
|
||||
value: |
|
||||
```python
|
||||
from trl import ...
|
||||
|
||||
1.
|
||||
2.
|
||||
3.
|
||||
```
|
||||
|
||||
outputs:
|
||||
|
||||
```
|
||||
Traceback (most recent call last):
|
||||
File "example.py", line 42, in <module>
|
||||
...
|
||||
```
|
||||
|
||||
- type: textarea
|
||||
id: expected-behavior
|
||||
id: system-info
|
||||
attributes:
|
||||
label: System Info
|
||||
description: |
|
||||
Please provide information about your system: platform, Python version, PyTorch version, Transformers version, devices, TRL version, ...
|
||||
You can get this information by running `trl env` in your terminal.
|
||||
|
||||
placeholder: Copy-paste the output of `trl env`
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: checkboxes
|
||||
id: terms
|
||||
attributes:
|
||||
label: Expected behavior
|
||||
description: "A clear and concise description of what you would expect to happen."
|
||||
label: Checklist
|
||||
description: |
|
||||
Before submitting, please confirm that you've completed each of the following.
|
||||
If an item doesn't apply to your issue, check it anyway to show you've reviewed it.
|
||||
options:
|
||||
- label: "I have checked that my issue isn't already filed (see [open issues](https://github.com/huggingface/trl/issues?q=is%3Aissue))"
|
||||
required: true
|
||||
- label: "I have included my system information"
|
||||
required: true
|
||||
- label: "Any code provided is minimal, complete, and reproducible ([more on MREs](https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/creating-and-highlighting-code-blocks))"
|
||||
required: true
|
||||
- label: "Any code provided is properly formatted in code blocks, (no screenshot, [more on code blocks](https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/creating-and-highlighting-code-blocks))"
|
||||
required: true
|
||||
- label: "Any traceback provided is complete"
|
||||
required: true
|
||||
|
||||
15
.github/workflows/issue_auto_labeller.yml
vendored
Normal file
15
.github/workflows/issue_auto_labeller.yml
vendored
Normal file
@ -0,0 +1,15 @@
|
||||
name: "Hugging Face Issue Labeler"
|
||||
on:
|
||||
issues:
|
||||
types: opened
|
||||
|
||||
jobs:
|
||||
triage:
|
||||
runs-on: ubuntu-latest
|
||||
permissions:
|
||||
issues: write
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: August-murr/auto-labeler@main
|
||||
with:
|
||||
hf-api-key: ${{ secrets.CI_HF_API_TOKEN }}
|
||||
8
.github/workflows/tests.yml
vendored
8
.github/workflows/tests.yml
vendored
@ -65,7 +65,7 @@ jobs:
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: Results with ${{ matrix.python-version }} on ${{ matrix.os }} with lastest dependencies
|
||||
title: Results with Python ${{ matrix.python-version }} on ${{ matrix.os }} with lastest dependencies
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
@ -97,7 +97,7 @@ jobs:
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: Results with ${{ matrix.python-version }} on ${{ matrix.os }} with dev dependencies
|
||||
title: Results with Python 3.12 on ubuntu-latest with dev dependencies
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
@ -126,7 +126,7 @@ jobs:
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: Results with ${{ matrix.python-version }} on ${{ matrix.os }} without optional dependencies
|
||||
title: Results with Python 3.12 on ubuntu-latest without optional dependencies
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
@ -158,6 +158,6 @@ jobs:
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: Results with ${{ matrix.python-version }} on ${{ matrix.os }} with minimum versions
|
||||
title: Results with Python 3.12 on ubuntu-latest with minimum versions
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
45
.github/workflows/tests_latest.yml
vendored
Normal file
45
.github/workflows/tests_latest.yml
vendored
Normal file
@ -0,0 +1,45 @@
|
||||
name: Tests latest TRL release with dev dependencies
|
||||
|
||||
on:
|
||||
schedule:
|
||||
- cron: '0 0 * * *' # Runs daily at midnight UTC
|
||||
|
||||
workflow_dispatch:
|
||||
|
||||
env:
|
||||
TQDM_DISABLE: 1
|
||||
CI_SLACK_CHANNEL: ${{ secrets.CI_PUSH_MAIN_CHANNEL }}
|
||||
|
||||
jobs:
|
||||
tests:
|
||||
name: Tests latest TRL release with dev dependencies
|
||||
runs-on: 'ubuntu-latest'
|
||||
steps:
|
||||
- name: Git checkout
|
||||
uses: actions/checkout@v4
|
||||
with: { ref: v0.14-release }
|
||||
- name: Set up Python 3.12
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.12'
|
||||
cache: "pip"
|
||||
cache-dependency-path: |
|
||||
setup.py
|
||||
requirements.txt
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install -U git+https://github.com/huggingface/accelerate.git
|
||||
python -m pip install -U git+https://github.com/huggingface/datasets.git
|
||||
python -m pip install -U git+https://github.com/huggingface/transformers.git
|
||||
python -m pip install ".[dev]"
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
make test
|
||||
- name: Post to Slack
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: Results of latest TRL with Python 3.12 on ubuntu-latest with dev dependencies
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
3
.gitignore
vendored
3
.gitignore
vendored
@ -143,6 +143,3 @@ checklink/cookies.txt
|
||||
nbs/wandb/
|
||||
examples/notebooks/wandb/
|
||||
wandb/
|
||||
|
||||
# cli scripts that are symlinked from `examples/scripts`
|
||||
trl/commands/scripts/
|
||||
@ -31,4 +31,4 @@ keywords:
|
||||
- pytorch
|
||||
- transformers
|
||||
license: Apache-2.0
|
||||
version: 0.11.1
|
||||
version: 0.13
|
||||
|
||||
207
CONTRIBUTING.md
207
CONTRIBUTING.md
@ -33,12 +33,12 @@ For something slightly more challenging, you can also take a look at the [Good S
|
||||
Before you start contributing make sure you have installed all the dev tools:
|
||||
|
||||
```bash
|
||||
make dev
|
||||
pip install -e .[dev]
|
||||
```
|
||||
|
||||
## Fixing outstanding issues
|
||||
|
||||
If you notice an issue with the existing code and have a fix in mind, feel free to [start contributing](#create-a-pull-request) and open a Pull Request!
|
||||
If you notice an issue with the existing code and have a fix in mind, feel free to [start contributing](#submitting-a-pull-request-pr) and open a Pull Request!
|
||||
|
||||
## Submitting a bug-related issue or feature request
|
||||
|
||||
@ -152,7 +152,7 @@ Follow these steps to start contributing:
|
||||
4. Set up a development environment by running the following command in a conda or a virtual environment you've created for working on this library:
|
||||
|
||||
```bash
|
||||
$ make dev
|
||||
$ pip install -e .[dev]
|
||||
```
|
||||
|
||||
(If TRL was already installed in the virtual environment, remove
|
||||
@ -256,3 +256,204 @@ That's how `make test` is implemented (without the `pip install` line)!
|
||||
|
||||
You can specify a smaller set of tests to test only the feature
|
||||
you're working on.
|
||||
|
||||
### Default values guidelines
|
||||
|
||||
1. **Use defaults when appropriate**:
|
||||
|
||||
Provide default values unless the parameter's value varies significantly by use case. For example, datasets or models should not have defaults, but parameters like `learning_rate` should.
|
||||
|
||||
2. **Prioritize proven defaults**:
|
||||
|
||||
Default values should align with those recommended in the original paper or method. Alternatives require strong evidence of superior performance in most cases.
|
||||
|
||||
3. **Ensure safety and predictability**:
|
||||
|
||||
Defaults must be safe, expected and reliable. Avoid settings that could lead to surprising outcomes, such as excessive memory usage or poor performance in edge cases.
|
||||
|
||||
4. **Balance consistency and flexibility**:
|
||||
|
||||
Aim for consistent defaults across similar functions or methods. However, consistency should not be preferred to point 2 or 3.
|
||||
|
||||
5. **Opt-in for new features**:
|
||||
|
||||
Do not enable new features or improvements (e.g., novel loss functions) by default. Users should explicitly opt-in to use these.
|
||||
|
||||
### Writing documentation
|
||||
|
||||
High-quality documentation is crucial for maintaining a project that is easy to use, understand, and extend. When adding new features, ensure they are thoroughly documented to maintain consistency and clarity throughout the project.
|
||||
|
||||
To illustrate what good documentation looks like, here’s an example of a well-documented function:
|
||||
|
||||
````python
|
||||
def replicate_str(string: str, n: int, sep: str = " ") -> str:
|
||||
r"""
|
||||
Replicate a string `n` times with a separator.
|
||||
|
||||
Args:
|
||||
string (`str`):
|
||||
String to replicate.
|
||||
n (`int`):
|
||||
Number of times to replicate the string.
|
||||
sep (`str`, *optional*, defaults to `" "`):
|
||||
Separator to use between each replication.
|
||||
|
||||
Returns:
|
||||
`str`: The replicated string.
|
||||
|
||||
Examples:
|
||||
```python
|
||||
>>> replicate_str("hello", 3)
|
||||
"hello hello hello"
|
||||
>>> replicate_str("hello", 3, sep=", ")
|
||||
"hello, hello, hello"
|
||||
```
|
||||
"""
|
||||
return sep.join([string] * n)
|
||||
````
|
||||
|
||||
* **Line Wrapping:** Applied a consistent line wrap at column 120 to improve readability.
|
||||
* **Definite Articles:** Removed definite articles where possible to streamline language. (Eg: Changed "The string to replicate" to "String to replicate")
|
||||
* **Type Annotations:**
|
||||
* Always include type definitions, indicating if a parameter is optional and specifying the default value.
|
||||
* Note that `Optional` means that the value can be `None`, and `*optional*` means that it is not required for the user to pass a value.
|
||||
E.g., for arguments that can't be `None` and aren't required:
|
||||
|
||||
```python
|
||||
foo (`int`, *optional*, defaults to `4`):
|
||||
```
|
||||
|
||||
For arguments that can be `None` and are required:
|
||||
|
||||
```python
|
||||
foo (`Optional[int]`):
|
||||
```
|
||||
|
||||
for arguments that can be `None` and aren't required:
|
||||
|
||||
```python
|
||||
foo (`Optional[int]`, *optional*, defaults to `None`):
|
||||
```
|
||||
|
||||
* **String Defaults:**
|
||||
* Ensured that default string values are wrapped in double quotes:
|
||||
|
||||
```python
|
||||
defaults to `"foo"`
|
||||
```
|
||||
|
||||
* **Dictionary Typing:**
|
||||
* Replaced generic `dict` type hints with more explicit `dict[str, Any]` to clarify expected key-value pairs.
|
||||
* **Default Value Formatting:**
|
||||
* Consistently surrounded default values with backticks for improved formatting:
|
||||
|
||||
```python
|
||||
defaults to `4`
|
||||
```
|
||||
|
||||
* **Sub-sectioning:** When the number of arguments is large, consider breaking them into sub-sections for better readability.
|
||||
|
||||
```python
|
||||
def calculate_statistics(data: list[float], precision: int = 2, include_variance: bool = False) -> dict[str, float]:
|
||||
r"""
|
||||
Calculates basic statistics for a given dataset.
|
||||
|
||||
Args:
|
||||
> Data inputs
|
||||
|
||||
data (`list[float]`):
|
||||
A list of numerical values to analyze.
|
||||
|
||||
> Configuration parameters
|
||||
|
||||
precision (`int`, *optional*, defaults to `2`):
|
||||
Number of decimal places to round the results.
|
||||
include_variance (`bool`, *optional*, defaults to `False`):
|
||||
Whether to include the variance of the dataset in the results.
|
||||
|
||||
Returns:
|
||||
`dict[str, float]`:
|
||||
A dictionary containing calculated statistics such as mean, median, and optionally variance.
|
||||
"""
|
||||
...
|
||||
```
|
||||
|
||||
### Deprecation and backward compatibility
|
||||
|
||||
Our approach to deprecation and backward compatibility is flexible and based on the feature’s usage and impact. Each deprecation is carefully evaluated, aiming to balance innovation with user needs.
|
||||
|
||||
When a feature or component is marked for deprecation, its use will emit a warning message. This warning will include:
|
||||
|
||||
- **Transition Guidance**: Instructions on how to migrate to the alternative solution or replacement.
|
||||
- **Removal Version**: The target version when the feature will be removed, providing users with a clear timeframe to transition.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
warnings.warn(
|
||||
"The `Trainer.foo` method is deprecated and will be removed in version 0.14.0. "
|
||||
"Please use the `Trainer.bar` class instead.",
|
||||
FutureWarning,
|
||||
)
|
||||
```
|
||||
|
||||
The deprecation and removal schedule is based on each feature's usage and impact, with examples at two extremes:
|
||||
|
||||
- **Experimental or Low-Use Features**: For a feature that is experimental or has limited usage, backward compatibility may not be maintained between releases. Users should therefore anticipate potential breaking changes from one version to the next.
|
||||
|
||||
- **Widely-Used Components**: For a feature with high usage, we aim for a more gradual transition period of approximately **5 months**, generally scheduling deprecation around **5 minor releases** after the initial warning.
|
||||
|
||||
These examples represent the two ends of a continuum. The specific timeline for each feature will be determined individually, balancing innovation with user stability needs.
|
||||
|
||||
### Working with warnings
|
||||
|
||||
Warnings play a critical role in guiding users toward resolving potential issues, but they should be used thoughtfully to avoid unnecessary noise. Unlike logging, which provides informational context or operational details, warnings signal conditions that require attention and action. Overusing warnings can dilute their importance, leading users to ignore them entirely.
|
||||
|
||||
#### Definitions
|
||||
|
||||
- **Correct**: An operation is correct if it is valid, follows the intended approach, and aligns with the current best practices or guidelines within the codebase. This is the recommended or intended way to perform the operation.
|
||||
- **Supported**: An operation is supported if it is technically valid and works within the current codebase, but it may not be the most efficient, optimal, or recommended way to perform the task. This includes deprecated features or legacy approaches that still work but may be phased out in the future.
|
||||
|
||||
#### Choosing the right message
|
||||
|
||||
- **Correct → No warning**:
|
||||
If the operation is fully valid and expected, no message should be issued. The system is working as intended, so no warning is necessary.
|
||||
|
||||
- **Correct but deserves attention → No warning, possibly a log message**:
|
||||
When an operation is correct but uncommon or requires special attention, providing an informational message can be helpful. This keeps users informed without implying any issue. If available, use the logger to output this message. Example:
|
||||
|
||||
```python
|
||||
logger.info("This is an informational message about a rare but correct operation.")
|
||||
```
|
||||
|
||||
- **Correct but very likely a mistake → Warning with option to disable**:
|
||||
In rare cases, you may want to issue a warning for a correct operation that’s very likely a mistake. In such cases, you must provide an option to suppress the warning. This can be done with a flag in the function. Example:
|
||||
|
||||
```python
|
||||
def my_function(foo, bar, _warn=True):
|
||||
if foo == bar:
|
||||
if _warn:
|
||||
warnings.warn("foo and bar are the same, this is likely a mistake. Ignore this warning by setting `_warn=False`.")
|
||||
# Do something
|
||||
```
|
||||
|
||||
- **Supported but not correct → Warning**:
|
||||
If the operation is technically supported but is deprecated, suboptimal, or could cause future issues (e.g., conflicting arguments), a warning should be raised. This message should be actionable, meaning it must explain how to resolve the issue. Example:
|
||||
|
||||
```python
|
||||
def my_function(foo, bar):
|
||||
if foo and bar:
|
||||
warnings.warn("Both `foo` and `bar` were provided, but only one is allowed. Ignoring `foo`. Please pass only one of these arguments.")
|
||||
# Do something
|
||||
```
|
||||
|
||||
- **Not supported → Exception**:
|
||||
If the operation is invalid or unsupported, raise an exception. This indicates that the operation cannot be performed and requires immediate attention. Example:
|
||||
|
||||
```python
|
||||
def my_function(foo, bar):
|
||||
if foo and bar:
|
||||
raise ValueError("Both `foo` and `bar` were provided, but only one is allowed. Please pass only one of these arguments.")
|
||||
```
|
||||
|
||||
By following this classification, you ensure that warnings, information, and exceptions are used appropriately, providing clear guidance to the user without cluttering the system with unnecessary messages.
|
||||
|
||||
6
Makefile
6
Makefile
@ -5,12 +5,6 @@ check_dirs := examples tests trl
|
||||
ACCELERATE_CONFIG_PATH = `pwd`/examples/accelerate_configs
|
||||
COMMAND_FILES_PATH = `pwd`/commands
|
||||
|
||||
|
||||
dev:
|
||||
[ -L "$(pwd)/trl/commands/scripts" ] && unlink "$(pwd)/trl/commands/scripts" || true
|
||||
pip install -e ".[dev]"
|
||||
ln -s `pwd`/examples/scripts/ `pwd`/trl/commands
|
||||
|
||||
test:
|
||||
python -m pytest -n auto --dist=loadfile -s -v --reruns 5 --reruns-delay 1 --only-rerun '(OSError|Timeout|HTTPError.*502|HTTPError.*504||not less than or equal to 0.01)' ./tests/
|
||||
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
# TRL - Transformer Reinforcement Learning
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl_banner_dark.png" alt="TRL Banner">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl_banner_dark.png" alt="TRL Banner">
|
||||
</div>
|
||||
|
||||
<hr> <br>
|
||||
@ -198,7 +198,7 @@ If you want to contribute to `trl` or customize it to your needs make sure to re
|
||||
```bash
|
||||
git clone https://github.com/huggingface/trl.git
|
||||
cd trl/
|
||||
make dev
|
||||
pip install -e .[dev]
|
||||
```
|
||||
|
||||
## Citation
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
# This script runs an SFT example end-to-end on a tiny model using different possible configurations
|
||||
# but defaults to QLoRA + PEFT
|
||||
OUTPUT_DIR="test_dpo/"
|
||||
MODEL_NAME="trl-internal-testing/tiny-random-LlamaForCausalLM"
|
||||
MODEL_NAME="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
|
||||
DATASET_NAME="trl-internal-testing/hh-rlhf-helpful-base-trl-style"
|
||||
MAX_STEPS=5
|
||||
BATCH_SIZE=2
|
||||
@ -35,7 +35,7 @@ CMD="""
|
||||
accelerate launch $EXTRA_ACCELERATE_ARGS \
|
||||
--num_processes $NUM_GPUS \
|
||||
--mixed_precision 'fp16' \
|
||||
`pwd`/examples/scripts/dpo.py \
|
||||
`pwd`/trl/scripts/dpo.py \
|
||||
--model_name_or_path $MODEL_NAME \
|
||||
--dataset_name $DATASET_NAME \
|
||||
--output_dir $OUTPUT_DIR \
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
# This script runs an SFT example end-to-end on a tiny model using different possible configurations
|
||||
# but defaults to QLoRA + PEFT
|
||||
OUTPUT_DIR="test_sft/"
|
||||
MODEL_NAME="trl-internal-testing/tiny-random-LlamaForCausalLM"
|
||||
MODEL_NAME="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
|
||||
DATASET_NAME="stanfordnlp/imdb"
|
||||
MAX_STEPS=5
|
||||
BATCH_SIZE=2
|
||||
@ -36,7 +36,7 @@ CMD="""
|
||||
accelerate launch $EXTRA_ACCELERATE_ARGS \
|
||||
--num_processes $NUM_GPUS \
|
||||
--mixed_precision 'fp16' \
|
||||
`pwd`/examples/scripts/sft.py \
|
||||
`pwd`/trl/scripts/sft.py \
|
||||
--model_name $MODEL_NAME \
|
||||
--dataset_name $DATASET_NAME \
|
||||
--output_dir $OUTPUT_DIR \
|
||||
|
||||
@ -5,21 +5,55 @@
|
||||
title: Installation
|
||||
- local: quickstart
|
||||
title: Quickstart
|
||||
- local: clis
|
||||
title: Get started with Command Line Interfaces (CLIs)
|
||||
title: Getting started
|
||||
- sections:
|
||||
- local: dataset_formats
|
||||
title: Dataset Formats
|
||||
- local: how_to_train
|
||||
title: PPO Training FAQ
|
||||
- local: use_model
|
||||
title: Use Trained Models
|
||||
- local: customization
|
||||
title: Customize the Training
|
||||
title: Training FAQ
|
||||
- local: logging
|
||||
title: Understanding Logs
|
||||
title: Get started
|
||||
title: Conceptual Guides
|
||||
- sections:
|
||||
- sections: # Sort alphabetically
|
||||
- local: clis
|
||||
title: Command Line Interface (CLI)
|
||||
- local: customization
|
||||
title: Customizing the Training
|
||||
- local: reducing_memory_usage
|
||||
title: Reducing Memory Usage
|
||||
- local: speeding_up_training
|
||||
title: Speeding Up Training
|
||||
- local: use_model
|
||||
title: Using Trained Models
|
||||
title: How-to guides
|
||||
- sections:
|
||||
- local: deepspeed_integration
|
||||
title: DeepSpeed
|
||||
- local: liger_kernel_integration
|
||||
title: Liger Kernel
|
||||
- local: peft_integration
|
||||
title: PEFT
|
||||
- local: unsloth_integration
|
||||
title: Unsloth
|
||||
title: Integrations
|
||||
- sections:
|
||||
- local: example_overview
|
||||
title: Example Overview
|
||||
- local: community_tutorials
|
||||
title: Community Tutorials
|
||||
- local: sentiment_tuning
|
||||
title: Sentiment Tuning
|
||||
- local: using_llama_models
|
||||
title: Training StackLlama
|
||||
- local: detoxifying_a_lm
|
||||
title: Detoxifying a Language Model
|
||||
- local: learning_tools
|
||||
title: Learning to Use Tools
|
||||
- local: multi_adapter_rl
|
||||
title: Multi Adapter RLHF
|
||||
title: Examples
|
||||
- sections:
|
||||
- sections: # Sorted alphabetically
|
||||
- local: alignprop_trainer
|
||||
title: AlignProp
|
||||
- local: bco_trainer
|
||||
@ -34,6 +68,8 @@
|
||||
title: Online DPO
|
||||
- local: gkd_trainer
|
||||
title: GKD
|
||||
- local: grpo_trainer
|
||||
title: GRPO
|
||||
- local: kto_trainer
|
||||
title: KTO
|
||||
- local: nash_md_trainer
|
||||
@ -42,6 +78,8 @@
|
||||
title: ORPO
|
||||
- local: ppo_trainer
|
||||
title: PPO
|
||||
- local: prm_trainer
|
||||
title: PRM
|
||||
- local: reward_trainer
|
||||
title: Reward
|
||||
- local: rloo_trainer
|
||||
@ -65,20 +103,6 @@
|
||||
title: Data Utilities
|
||||
- local: text_environments
|
||||
title: Text Environments
|
||||
- local: script_utils
|
||||
title: Script Utilities
|
||||
title: API
|
||||
- sections:
|
||||
- local: example_overview
|
||||
title: Example Overview
|
||||
- local: sentiment_tuning
|
||||
title: Sentiment Tuning
|
||||
- local: lora_tuning_peft
|
||||
title: Training with PEFT
|
||||
- local: detoxifying_a_lm
|
||||
title: Detoxifying a Language Model
|
||||
- local: using_llama_models
|
||||
title: Training StackLlama
|
||||
- local: learning_tools
|
||||
title: Learning to Use Tools
|
||||
- local: multi_adapter_rl
|
||||
title: Multi Adapter RLHF
|
||||
title: Examples
|
||||
|
||||
@ -7,7 +7,7 @@
|
||||
If your reward function is differentiable, directly backpropagating gradients from the reward models to the diffusion model is significantly more sample and compute efficient (25x) than doing policy gradient algorithm like DDPO.
|
||||
AlignProp does full backpropagation through time, which allows updating the earlier steps of denoising via reward backpropagation.
|
||||
|
||||
<div style="text-align: center"><img src="https://align-prop.github.io/reward_tuning.png"/></div>
|
||||
<div style="text-align: center"><img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/reward_tuning.png"/></div>
|
||||
|
||||
|
||||
## Getting started with `examples/scripts/alignprop.py`
|
||||
@ -62,7 +62,7 @@ embedding_model = Accelerator().prepare_model(self.embedding_model)
|
||||
embedding_func = partial(embed_prompt, model=embedding_model)
|
||||
```
|
||||
|
||||
Set `prompt_sample_size` to defined how many prompts are selected to train the UDM classifier and start the training with the provided embedding function:
|
||||
Set `prompt_sample_size` to define how many prompts are selected to train the UDM classifier and start the training with the provided embedding function:
|
||||
|
||||
```py
|
||||
training_args = BCOConfig(
|
||||
@ -97,4 +97,4 @@ To scale how much the auxiliary loss contributes to the total loss, use the hype
|
||||
|
||||
## BCOConfig
|
||||
|
||||
[[autodoc]] BCOConfig
|
||||
[[autodoc]] BCOConfig
|
||||
@ -14,4 +14,8 @@
|
||||
|
||||
## LogCompletionsCallback
|
||||
|
||||
[[autodoc]] LogCompletionsCallback
|
||||
[[autodoc]] LogCompletionsCallback
|
||||
|
||||
## MergeModelCallback
|
||||
|
||||
[[autodoc]] MergeModelCallback
|
||||
@ -4,8 +4,15 @@ You can use TRL to fine-tune your Language Model with Supervised Fine-Tuning (SF
|
||||
|
||||
Currently supported CLIs are:
|
||||
|
||||
- `trl sft`: fine-tune a LLM on a text/instruction dataset
|
||||
- `trl dpo`: fine-tune a LLM with DPO on a preference dataset
|
||||
#### Training commands
|
||||
|
||||
- `trl dpo`: fine-tune a LLM with DPO
|
||||
- `trl grpo`: fine-tune a LLM with GRPO
|
||||
- `trl kto`: fine-tune a LLM with KTO
|
||||
- `trl sft`: fine-tune a LLM with SFT
|
||||
|
||||
#### Other commands
|
||||
|
||||
- `trl chat`: quickly spin up a LLM fine-tuned for chatting
|
||||
- `trl env`: get the system information
|
||||
|
||||
@ -23,7 +30,7 @@ We also recommend you passing a YAML config file to configure your training prot
|
||||
|
||||
```yaml
|
||||
model_name_or_path:
|
||||
trl-internal-testing/tiny-random-LlamaForCausalLM
|
||||
Qwen/Qwen2.5-0.5B
|
||||
dataset_name:
|
||||
stanfordnlp/imdb
|
||||
report_to:
|
||||
@ -58,7 +65,7 @@ Follow the basic instructions above and run `trl sft --output_dir <output_dir> <
|
||||
trl sft --model_name_or_path facebook/opt-125m --dataset_name stanfordnlp/imdb --output_dir opt-sft-imdb
|
||||
```
|
||||
|
||||
The SFT CLI is based on the `examples/scripts/sft.py` script.
|
||||
The SFT CLI is based on the `trl/scripts/sft.py` script.
|
||||
|
||||
### Direct Policy Optimization (DPO)
|
||||
|
||||
@ -81,7 +88,7 @@ trl dpo --model_name_or_path facebook/opt-125m --output_dir trl-hh-rlhf --datase
|
||||
```
|
||||
|
||||
|
||||
The DPO CLI is based on the `examples/scripts/dpo.py` script.
|
||||
The DPO CLI is based on the `trl/scripts/dpo.py` script.
|
||||
|
||||
|
||||
#### Custom preference dataset
|
||||
@ -117,8 +124,6 @@ Besides talking to the model there are a few commands you can use:
|
||||
- `save` or `save {SAVE_NAME}`: save the current chat and settings to file by default to `./chat_history/{MODEL_NAME}/chat_{DATETIME}.yaml` or `{SAVE_NAME}` if provided
|
||||
- `exit`: closes the interface
|
||||
|
||||
The default examples are defined in `examples/scripts/config/default_chat_config.yaml` but you can pass your own with `--config CONFIG_FILE` where you can also specify the default generation parameters.
|
||||
|
||||
## Getting the system information
|
||||
|
||||
You can get the system information by running the following command:
|
||||
29
docs/source/community_tutorials.md
Normal file
29
docs/source/community_tutorials.md
Normal file
@ -0,0 +1,29 @@
|
||||
# Community Tutorials
|
||||
|
||||
Community tutorials are made by active members of the Hugging Face community that want to share their knowledge and expertise with others. They are a great way to learn about the library and its features, and to get started with core classes and modalities.
|
||||
|
||||
# Language Models
|
||||
|
||||
| Task | Class | Description | Author | Tutorial | Colab |
|
||||
| ----------------------- | --------------- | ---------------------------------------------------------------------------------------- | -------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Instruction tuning | [`SFTTrainer`] | Fine-tuning Google Gemma LLMs using ChatML format with QLoRA | [Philipp Schmid](https://huggingface.co/philschmid) | [Link](https://www.philschmid.de/fine-tune-google-gemma) | [](https://colab.research.google.com/github/philschmid/deep-learning-pytorch-huggingface/blob/main/training/gemma-lora-example.ipynb) |
|
||||
| Structured Generation | [`SFTTrainer`] | Fine-tuning Llama-2-7B to generate Persian product catalogs in JSON using QLoRA and PEFT | [Mohammadreza Esmaeilian](https://huggingface.co/Mohammadreza) | [Link](https://huggingface.co/learn/cookbook/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format) | [](https://colab.research.google.com/github/huggingface/cookbook/blob/main/notebooks/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format.ipynb) |
|
||||
| Preference Optimization | [`DPOTrainer`] | Align Mistral-7b using Direct Preference Optimization for human preference alignment | [Maxime Labonne](https://huggingface.co/mlabonne) | [Link](https://mlabonne.github.io/blog/posts/Fine_tune_Mistral_7b_with_DPO.html) | [](https://colab.research.google.com/github/mlabonne/llm-course/blob/main/Fine_tune_a_Mistral_7b_model_with_DPO.ipynb) |
|
||||
| Preference Optimization | [`ORPOTrainer`] | Fine-tuning Llama 3 with ORPO combining instruction tuning and preference alignment | [Maxime Labonne](https://huggingface.co/mlabonne) | [Link](https://mlabonne.github.io/blog/posts/2024-04-19_Fine_tune_Llama_3_with_ORPO.html) | [](https://colab.research.google.com/drive/1eHNWg9gnaXErdAa8_mcvjMupbSS6rDvi) |
|
||||
| Instruction tuning | [`SFTTrainer`] | How to fine-tune open LLMs in 2025 with Hugging Face | [Philipp Schmid](https://huggingface.co/philschmid) | [Link](https://www.philschmid.de/fine-tune-llms-in-2025) | [](https://colab.research.google.com/github/philschmid/deep-learning-pytorch-huggingface/blob/main/training/fine-tune-llms-in-2025.ipynb) |
|
||||
|
||||
<Youtube id="cnGyyM0vOes" />
|
||||
|
||||
# Vision Language Models
|
||||
|
||||
| Task | Class | Description | Author | Tutorial | Colab |
|
||||
| --------------- | -------------- | ---------------------------------------------------------------------------- | ------------------------------------------------------ | -------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Visual QA | [`SFTTrainer`] | Fine-tuning Qwen2-VL-7B for visual question answering on ChartQA dataset | [Sergio Paniego](https://huggingface.co/sergiopaniego) | [Link](https://huggingface.co/learn/cookbook/fine_tuning_vlm_trl) | [](https://colab.research.google.com/github/huggingface/cookbook/blob/main/notebooks/en/fine_tuning_vlm_trl.ipynb) |
|
||||
| Visual QA | [`SFTTrainer`] | Fine-tuning SmolVLM with TRL on a consumer GPU | [Sergio Paniego](https://huggingface.co/sergiopaniego) | [Link](https://huggingface.co/learn/cookbook/fine_tuning_smol_vlm_sft_trl) | [](https://colab.research.google.com/github/huggingface/cookbook/blob/main/notebooks/en/fine_tuning_smol_vlm_sft_trl.ipynb) |
|
||||
| SEO Description | [`SFTTrainer`] | Fine-tuning Qwen2-VL-7B for generating SEO-friendly descriptions from images | [Philipp Schmid](https://huggingface.co/philschmid) | [Link](https://www.philschmid.de/fine-tune-multimodal-llms-with-trl) | [](https://colab.research.google.com/github/philschmid/deep-learning-pytorch-huggingface/blob/main/training/fine-tune-multimodal-llms-with-trl.ipynb) |
|
||||
| Visual QA | [`DPOTrainer`] | PaliGemma 🤝 Direct Preference Optimization | [Merve Noyan](https://huggingface.co/merve) | [Link](https://github.com/merveenoyan/smol-vision/blob/main/PaliGemma_DPO.ipynb) | [](https://colab.research.google.com/github/merveenoyan/smol-vision/blob/main/PaliGemma_DPO.ipynb) |
|
||||
| Visual QA | [`DPOTrainer`] | Fine-tuning SmolVLM using direct preference optimization (DPO) with TRL on a consumer GPU | [Sergio Paniego](https://huggingface.co/sergiopaniego) | [Link](https://huggingface.co/learn/cookbook/fine_tuning_vlm_dpo_smolvlm_instruct) | [](https://colab.research.google.com/github/huggingface/cookbook/blob/main/notebooks/en/fine_tuning_vlm_dpo_smolvlm_instruct.ipynb) |
|
||||
|
||||
## Contributing
|
||||
|
||||
If you have a tutorial that you would like to add to this list, please open a PR to add it. We will review it and merge it if it is relevant to the community.
|
||||
@ -75,7 +75,7 @@ While training and evaluating we record the following reward metrics:
|
||||
|
||||
### Simple Preference Optimization (SimPO)
|
||||
|
||||
The [SimPO](https://huggingface.co/papers/2405.14734) method is also implemented in the [`CPOTrainer`]. SimPO is an alternative loss that adds a reward margin, allows for length normalization, and does not use BC regularization. To use this loss, we can use SimPO easily by turning on `loss_type="simpo"` and `cpo_alpha=0` in the [`CPOConfig`].
|
||||
The [SimPO](https://huggingface.co/papers/2405.14734) method is also implemented in the [`CPOTrainer`]. SimPO is an alternative loss that adds a reward margin, allows for length normalization, and does not use BC regularization. To use this loss, we can use SimPO easily by turning on `loss_type="simpo"` and `cpo_alpha=0.0` in the [`CPOConfig`].
|
||||
|
||||
### CPO-SimPO
|
||||
|
||||
@ -134,7 +134,7 @@ Read more about 8-bit model loading in `transformers` [here](https://huggingface
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
from trl import DPOConfig, DPOTrainer
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
@ -1,15 +1,29 @@
|
||||
## Data Utilities
|
||||
# Data Utilities
|
||||
|
||||
## is_conversational
|
||||
|
||||
[[autodoc]] is_conversational
|
||||
|
||||
## apply_chat_template
|
||||
|
||||
[[autodoc]] apply_chat_template
|
||||
|
||||
## maybe_apply_chat_template
|
||||
|
||||
[[autodoc]] maybe_apply_chat_template
|
||||
|
||||
## extract_prompt
|
||||
|
||||
[[autodoc]] extract_prompt
|
||||
|
||||
## maybe_extract_prompt
|
||||
|
||||
[[autodoc]] maybe_extract_prompt
|
||||
|
||||
## unpair_preference_dataset
|
||||
|
||||
[[autodoc]] unpair_preference_dataset
|
||||
|
||||
## maybe_unpair_preference_dataset
|
||||
|
||||
[[autodoc]] maybe_unpair_preference_dataset
|
||||
@ -77,6 +77,18 @@ This guide provides an overview of the dataset formats and types supported by ea
|
||||
"label": False}</code></pre>
|
||||
</td>
|
||||
</tr>
|
||||
</tr>
|
||||
<td>Stepwise supervision</td>
|
||||
<td>
|
||||
<pre><code>{"prompt": "Which number is larger, 9.8 or 9.11?",
|
||||
"completions": ["The fractional part of 9.8 is 0.8.",
|
||||
"The fractional part of 9.11 is 0.11.",
|
||||
"0.11 is greater than 0.8.",
|
||||
"Hence, 9.11 > 9.8."],
|
||||
"labels": [True, True, False, False]}</code></pre>
|
||||
</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
### Formats
|
||||
@ -87,9 +99,11 @@ The standard dataset format typically consists of plain text strings. The column
|
||||
|
||||
```python
|
||||
# Language modeling
|
||||
example = {"text": "The sky is blue."}
|
||||
language_modeling_example = {"text": "The sky is blue."}
|
||||
# Preference
|
||||
example = {"chosen": "The sky is blue.", "rejected": "The sky is green."}
|
||||
preference_example = {"prompt": "The sky is", "chosen": " blue.", "rejected": " green."}
|
||||
# Unpaired preference
|
||||
unpaired_preference_example = {"prompt": "The sky is", "completion": " blue.", "label": True}
|
||||
```
|
||||
|
||||
#### Conversational
|
||||
@ -104,18 +118,17 @@ messages = [
|
||||
]
|
||||
```
|
||||
|
||||
Just like standard datasets, the columns in conversational datasets vary depending on the task. For instance, a preference dataset would include columns like `"chosen"` and `"rejected"` to compare responses:
|
||||
Just like standard datasets, the columns in conversational datasets vary depending on the task. Below are examples of conversational dataset formats for different tasks:
|
||||
|
||||
```python
|
||||
example = {
|
||||
"chosen": [
|
||||
{"role": "user", "content": "What color is the sky?"},
|
||||
{"role": "assistant", "content": "It is blue."},
|
||||
],
|
||||
"rejected": [
|
||||
{"role": "user", "content": "What color is the sky?"},
|
||||
{"role": "assistant", "content": "It is green."},
|
||||
],
|
||||
# Prompt-completion
|
||||
prompt_completion_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"completion": [{"role": "assistant", "content": "It is blue."}]}
|
||||
# Preference
|
||||
preference_example = {
|
||||
"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"chosen": [{"role": "assistant", "content": "It is blue."}],
|
||||
"rejected": [{"role": "assistant", "content": "It is green."}],
|
||||
}
|
||||
```
|
||||
|
||||
@ -128,7 +141,13 @@ Conversational datasets are useful for training chat models, but must be convert
|
||||
A language modeling dataset consists of a column `"text"` (or `"messages"` for conversational datasets) containing a full sequence of text.
|
||||
|
||||
```python
|
||||
# Standard format
|
||||
language_modeling_example = {"text": "The sky is blue."}
|
||||
# Conversational format
|
||||
language_modeling_example = {"messages": [
|
||||
{"role": "user", "content": "What color is the sky?"},
|
||||
{"role": "assistant", "content": "It is blue."}
|
||||
]}
|
||||
```
|
||||
|
||||
#### Prompt-only
|
||||
@ -136,9 +155,14 @@ language_modeling_example = {"text": "The sky is blue."}
|
||||
In a prompt-only dataset, only the initial prompt (the question or partial sentence) is provided under the key `"prompt"`. The training typically involves generating the completion based on this prompt, where the model learns to continue or complete the given input.
|
||||
|
||||
```python
|
||||
# Standard format
|
||||
prompt_only_example = {"prompt": "The sky is"}
|
||||
# Conversational format
|
||||
prompt_only_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}]}
|
||||
```
|
||||
|
||||
For examples of prompt-only datasets, refer to the [Prompt-only datasets collection](https://huggingface.co/collections/trl-lib/prompt-only-datasets-677ea25245d20252cea00368).
|
||||
|
||||
<Tip>
|
||||
|
||||
While both the prompt-only and language modeling types are similar, they differ in how the input is handled. In the prompt-only type, the prompt represents a partial input that expects the model to complete or continue, while in the language modeling type, the input is treated as a complete sentence or sequence. These two types are processed differently by TRL. Below is an example showing the difference in the output of the `apply_chat_template` function for each type:
|
||||
@ -170,21 +194,41 @@ apply_chat_template(lm_example, tokenizer)
|
||||
A prompt-completion dataset includes a `"prompt"` and a `"completion"`.
|
||||
|
||||
```python
|
||||
# Standard format
|
||||
prompt_completion_example = {"prompt": "The sky is", "completion": " blue."}
|
||||
# Conversational format
|
||||
prompt_completion_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"completion": [{"role": "assistant", "content": "It is blue."}]}
|
||||
```
|
||||
|
||||
For examples of prompt-completion datasets, refer to the [Prompt-completion datasets collection](https://huggingface.co/collections/trl-lib/prompt-completion-datasets-677ea2bb20bbb6bdccada216).
|
||||
|
||||
#### Preference
|
||||
|
||||
A preference dataset is used for tasks where the model is trained to choose between two or more possible completions to the same prompt. This dataset includes a `"prompt"`, a `"chosen"` completion, and a `"rejected"` completion. The model is trained to select the `"chosen"` response over the `"rejected"` response.
|
||||
Some dataset may not include the `"prompt"` column, in which case the prompt is implicit and directly included in the `"chosen"` and `"rejected"` completions. We recommend using explicit prompts whenever possible.
|
||||
|
||||
```python
|
||||
# explicit prompt
|
||||
preference_example = {"prompt": "The sky is", "chosen": " blue.", "rejected": " green."} # recommended
|
||||
# implicit prompt
|
||||
# Standard format
|
||||
## Explicit prompt (recommended)
|
||||
preference_example = {"prompt": "The sky is", "chosen": " blue.", "rejected": " green."}
|
||||
# Implicit prompt
|
||||
preference_example = {"chosen": "The sky is blue.", "rejected": "The sky is green."}
|
||||
|
||||
# Conversational format
|
||||
## Explicit prompt (recommended)
|
||||
preference_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"chosen": [{"role": "assistant", "content": "It is blue."}],
|
||||
"rejected": [{"role": "assistant", "content": "It is green."}]}
|
||||
## Implicit prompt
|
||||
preference_example = {"chosen": [{"role": "user", "content": "What color is the sky?"},
|
||||
{"role": "assistant", "content": "It is blue."}],
|
||||
"rejected": [{"role": "user", "content": "What color is the sky?"},
|
||||
{"role": "assistant", "content": "It is green."}]}
|
||||
```
|
||||
|
||||
For examples of preference datasets, refer to the [Preference datasets collection](https://huggingface.co/collections/trl-lib/preference-datasets-677e99b581018fcad9abd82c).
|
||||
|
||||
Some preference datasets can be found with [the tag `dpo` on Hugging Face Hub](https://huggingface.co/datasets?other=dpo). You can also explore the [librarian-bots' DPO Collections](https://huggingface.co/collections/librarian-bots/direct-preference-optimization-datasets-66964b12835f46289b6ef2fc) to identify preference datasets.
|
||||
|
||||
#### Unpaired preference
|
||||
@ -192,9 +236,30 @@ Some preference datasets can be found with [the tag `dpo` on Hugging Face Hub](h
|
||||
An unpaired preference dataset is similar to a preference dataset but instead of having `"chosen"` and `"rejected"` completions for the same prompt, it includes a single `"completion"` and a `"label"` indicating whether the completion is preferred or not.
|
||||
|
||||
```python
|
||||
# Standard format
|
||||
unpaired_preference_example = {"prompt": "The sky is", "completion": " blue.", "label": True}
|
||||
# Conversational format
|
||||
unpaired_preference_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"completion": [{"role": "assistant", "content": "It is blue."}],
|
||||
"label": True}
|
||||
```
|
||||
|
||||
For examples of unpaired preference datasets, refer to the [Unpaired preference datasets collection](https://huggingface.co/collections/trl-lib/unpaired-preference-datasets-677ea22bf5f528c125b0bcdf).
|
||||
|
||||
#### Stepwise supervision
|
||||
|
||||
A stepwise (or process) supervision dataset is similar to an [unpaired preference](#unpaired-preference) dataset but includes multiple steps of completions, each with its own label. This structure is useful for tasks that need detailed, step-by-step labeling, such as reasoning tasks. By evaluating each step separately and providing targeted labels, this approach helps identify precisely where the reasoning is correct and where errors occur, allowing for targeted feedback on each part of the reasoning process.
|
||||
|
||||
```python
|
||||
stepwise_example = {
|
||||
"prompt": "Which number is larger, 9.8 or 9.11?",
|
||||
"completions": ["The fractional part of 9.8 is 0.8, while the fractional part of 9.11 is 0.11.", "Since 0.11 is greater than 0.8, the number 9.11 is larger than 9.8."],
|
||||
"labels": [True, False]
|
||||
}
|
||||
```
|
||||
|
||||
For examples of stepwise supervision datasets, refer to the [Stepwise supervision datasets collection](https://huggingface.co/collections/trl-lib/stepwise-supervision-datasets-677ea27fd4c5941beed7a96e).
|
||||
|
||||
## Which dataset type to use?
|
||||
|
||||
Choosing the right dataset type depends on the task you are working on and the specific requirements of the TRL trainer you are using. Below is a brief overview of the dataset types supported by each TRL trainer.
|
||||
@ -205,12 +270,14 @@ Choosing the right dataset type depends on the task you are working on and the s
|
||||
| [`CPOTrainer`] | [Preference (explicit prompt recommended)](#preference) |
|
||||
| [`DPOTrainer`] | [Preference (explicit prompt recommended)](#preference) |
|
||||
| [`GKDTrainer`] | [Prompt-completion](#prompt-completion) |
|
||||
| [`GRPOTrainer`] | [Prompt-only](#prompt-only) |
|
||||
| [`IterativeSFTTrainer`] | [Unpaired preference](#unpaired-preference) |
|
||||
| [`KTOTrainer`] | [Unpaired preference](#unpaired-preference) or [Preference (explicit prompt recommended)](#preference) |
|
||||
| [`NashMDTrainer`] | [Prompt-only](#prompt-only) |
|
||||
| [`OnlineDPOTrainer`] | [Prompt-only](#prompt-only) |
|
||||
| [`ORPOTrainer`] | [Preference (explicit prompt recommended)](#preference) |
|
||||
| [`PPOTrainer`] | Tokenized language modeling |
|
||||
| [`PRMTrainer`] | [Stepwise supervision](#stepwise-supervision) |
|
||||
| [`RewardTrainer`] | [Preference (implicit prompt recommended)](#preference) |
|
||||
| [`SFTTrainer`] | [Language modeling](#language-modeling) |
|
||||
| [`XPOTrainer`] | [Prompt-only](#prompt-only) |
|
||||
@ -224,12 +291,12 @@ For more information on how to work with conversational datasets, refer to the [
|
||||
|
||||
## Working with conversational datasets in TRL
|
||||
|
||||
Conversational datasets are increasingly common, especially for training chat models. However, TRL trainers (except [`SFTTrainer`]) don't support conversational datasets in their raw format. These datasets must first be converted into a standard format.
|
||||
Conversational datasets are increasingly common, especially for training chat models. However, some TRL trainers don't support conversational datasets in their raw format. (For more information, see [issue #2071](https://github.com/huggingface/trl/issues/2071).) These datasets must first be converted into a standard format.
|
||||
Fortunately, TRL offers tools to easily handle this conversion, which are detailed below.
|
||||
|
||||
### Converting a conversational dataset into a standard dataset
|
||||
|
||||
TRL trainers do not support conversational datasets in their raw format. To use them, you need to convert them into a standard dataset format using a chat template. This template is provided by the tokenizer of the model you use.
|
||||
To convert a conversational dataset into a standard dataset, you need to _apply a chat template_ to the dataset. A chat template is a predefined structure that typically includes placeholders for user and assistant messages. This template is provided by the tokenizer of the model you use.
|
||||
|
||||
For detailed instructions on using chat templating, refer to the [Chat templating section in the `transformers` documentation](https://huggingface.co/docs/transformers/en/chat_templating).
|
||||
|
||||
@ -338,14 +405,15 @@ This section provides example code to help you convert between different dataset
|
||||
|
||||
For simplicity, some of the examples below do not follow this recommendation and use the standard format. However, the conversions can be applied directly to the conversational format without modification.
|
||||
|
||||
| From \ To | Language modeling | Prompt-completion | Prompt-only | Preference with implicit prompt | Preference | Unpaired preference |
|
||||
| ------------------------------- | ----------------------------------------------------------------------- | ----------------------------------------------------------------------- | ----------------------------------------------------------------- | --------------------------------------------------------- | --------------------------------------------------------- | ------------------------------------------------------------------------- |
|
||||
| Language modeling | N/A | N/A | N/A | N/A | N/A | N/A |
|
||||
| Prompt-completion | [🔗](#from-prompt-completion-to-language-modeling-dataset) | N/A | [🔗](#from-prompt-completion-to-prompt-only-dataset) | N/A | N/A | N/A |
|
||||
| Prompt-only | N/A | N/A | N/A | N/A | N/A | N/A |
|
||||
| Preference with implicit prompt | [🔗](#from-preference-with-implicit-prompt-to-language-modeling-dataset) | [🔗](#from-preference-with-implicit-prompt-to-prompt-completion-dataset) | [🔗](#from-preference-with-implicit-prompt-to-prompt-only-dataset) | N/A | [🔗](#from-implicit-to-explicit-prompt-preference-dataset) | [🔗](#from-preference-with-implicit-prompt-to-unpaired-preference-dataset) |
|
||||
| Preference | [🔗](#from-preference-to-language-modeling-dataset) | [🔗](#from-preference-to-prompt-completion-dataset) | [🔗](#from-preference-to-prompt-only-dataset) | [🔗](#from-explicit-to-implicit-prompt-preference-dataset) | N/A | [🔗](#from-preference-to-unpaired-preference-dataset) |
|
||||
| Unpaired preference | [🔗](#from-unpaired-preference-to-language-modeling-dataset) | [🔗](#from-unpaired-preference-to-prompt-completion-dataset) | [🔗](#from-unpaired-preference-to-prompt-only-dataset) | N/A | N/A | N/A |
|
||||
| From \ To | Language modeling | Prompt-completion | Prompt-only | Preference with implicit prompt | Preference | Unpaired preference | Stepwise supervision |
|
||||
| ------------------------------- | ----------------------------------------------------------------------- | ----------------------------------------------------------------------- | ----------------------------------------------------------------- | --------------------------------------------------------- | --------------------------------------------------------- | ------------------------------------------------------------------------- | -------------------- |
|
||||
| Language modeling | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
|
||||
| Prompt-completion | [🔗](#from-prompt-completion-to-language-modeling-dataset) | N/A | [🔗](#from-prompt-completion-to-prompt-only-dataset) | N/A | N/A | N/A | N/A |
|
||||
| Prompt-only | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
|
||||
| Preference with implicit prompt | [🔗](#from-preference-with-implicit-prompt-to-language-modeling-dataset) | [🔗](#from-preference-with-implicit-prompt-to-prompt-completion-dataset) | [🔗](#from-preference-with-implicit-prompt-to-prompt-only-dataset) | N/A | [🔗](#from-implicit-to-explicit-prompt-preference-dataset) | [🔗](#from-preference-with-implicit-prompt-to-unpaired-preference-dataset) | N/A |
|
||||
| Preference | [🔗](#from-preference-to-language-modeling-dataset) | [🔗](#from-preference-to-prompt-completion-dataset) | [🔗](#from-preference-to-prompt-only-dataset) | [🔗](#from-explicit-to-implicit-prompt-preference-dataset) | N/A | [🔗](#from-preference-to-unpaired-preference-dataset) | N/A |
|
||||
| Unpaired preference | [🔗](#from-unpaired-preference-to-language-modeling-dataset) | [🔗](#from-unpaired-preference-to-prompt-completion-dataset) | [🔗](#from-unpaired-preference-to-prompt-only-dataset) | N/A | N/A | N/A | N/A |
|
||||
| Stepwise supervision | [🔗](#from-stepwise-supervision-to-language-modeling-dataset) | [🔗](#from-stepwise-supervision-to-prompt-completion-dataset) | [🔗](#from-stepwise-supervision-to-prompt-only-dataset) | N/A | N/A | [🔗](#from-stepwise-supervision-to-unpaired-preference-dataset) | N/A |
|
||||
|
||||
### From prompt-completion to language modeling dataset
|
||||
|
||||
@ -521,6 +589,14 @@ dataset = unpair_preference_dataset(dataset)
|
||||
'label': True}
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Keep in mind that the `"chosen"` and `"rejected"` completions in a preference dataset can be both good or bad.
|
||||
Before applying [`unpair_preference_dataset`], please ensure that all `"chosen"` completions can be labeled as good and all `"rejected"` completions as bad.
|
||||
This can be ensured by checking absolute rating of each completion, e.g. from a reward model.
|
||||
|
||||
</Tip>
|
||||
|
||||
### From preference to language modeling dataset
|
||||
|
||||
To convert a preference dataset into a language modeling dataset, remove the rejected, concatenate the prompt and the chosen into the `"text"` column.
|
||||
@ -654,9 +730,17 @@ dataset = unpair_preference_dataset(dataset)
|
||||
'label': True}
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Keep in mind that the `"chosen"` and `"rejected"` completions in a preference dataset can be both good or bad.
|
||||
Before applying [`unpair_preference_dataset`], please ensure that all `"chosen"` completions can be labeled as good and all `"rejected"` completions as bad.
|
||||
This can be ensured by checking absolute rating of each completion, e.g. from a reward model.
|
||||
|
||||
</Tip>
|
||||
|
||||
### From unpaired preference to language modeling dataset
|
||||
|
||||
To convert an unpaired preference dataset into a language modeling dataset, concatenate the prompt and the completion into the `"text"` column, and remove the prompt, completion and label columns.
|
||||
To convert an unpaired preference dataset into a language modeling dataset, concatenate prompts with good completions into the `"text"` column, and remove the prompt, completion and label columns.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
@ -670,7 +754,7 @@ dataset = Dataset.from_dict({
|
||||
def concatenate_prompt_completion(example):
|
||||
return {"text": example["prompt"] + example["completion"]}
|
||||
|
||||
dataset = dataset.map(concatenate_prompt_completion).remove_columns(["prompt", "completion", "label"])
|
||||
dataset = dataset.filter(lambda x: x["label"]).map(concatenate_prompt_completion).remove_columns(["prompt", "completion", "label"])
|
||||
```
|
||||
|
||||
```python
|
||||
@ -680,7 +764,7 @@ dataset = dataset.map(concatenate_prompt_completion).remove_columns(["prompt", "
|
||||
|
||||
### From unpaired preference to prompt-completion dataset
|
||||
|
||||
To convert an unpaired preference dataset into a prompt-completion dataset, remove the label columns.
|
||||
To convert an unpaired preference dataset into a prompt-completion dataset, filter for good labels, then remove the label columns.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
@ -691,7 +775,7 @@ dataset = Dataset.from_dict({
|
||||
"label": [True, True, False, False],
|
||||
})
|
||||
|
||||
dataset = dataset.remove_columns(["label"])
|
||||
dataset = dataset.filter(lambda x: x["label"]).remove_columns(["label"])
|
||||
```
|
||||
|
||||
```python
|
||||
@ -720,6 +804,107 @@ dataset = dataset.remove_columns(["completion", "label"])
|
||||
{'prompt': 'The sky is'}
|
||||
```
|
||||
|
||||
### From stepwise supervision to language modeling dataset
|
||||
|
||||
To convert a stepwise supervision dataset into a language modeling dataset, concatenate prompts with good completions into the `"text"` column.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["Blue light", "Water"],
|
||||
"completions": [[" scatters more in the atmosphere,", " so the sky is green."],
|
||||
[" forms a less dense structure in ice,", " which causes it to expand when it freezes."]],
|
||||
"labels": [[True, False], [True, True]],
|
||||
})
|
||||
|
||||
def concatenate_prompt_completions(example):
|
||||
completion = "".join(example["completions"])
|
||||
return {"text": example["prompt"] + completion}
|
||||
|
||||
dataset = dataset.filter(lambda x: all(x["labels"])).map(concatenate_prompt_completions, remove_columns=["prompt", "completions", "labels"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'text': 'Blue light scatters more in the atmosphere, so the sky is green.'}
|
||||
```
|
||||
|
||||
### From stepwise supervision to prompt completion dataset
|
||||
|
||||
To convert a stepwise supervision dataset into a prompt-completion dataset, join the good completions and remove the labels.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["Blue light", "Water"],
|
||||
"completions": [[" scatters more in the atmosphere,", " so the sky is green."],
|
||||
[" forms a less dense structure in ice,", " which causes it to expand when it freezes."]],
|
||||
"labels": [[True, False], [True, True]],
|
||||
})
|
||||
|
||||
def join_completions(example):
|
||||
completion = "".join(example["completions"])
|
||||
return {"completion": completion}
|
||||
|
||||
dataset = dataset.filter(lambda x: all(x["labels"])).map(join_completions, remove_columns=["completions", "labels"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': 'Blue light', 'completion': ' scatters more in the atmosphere, so the sky is green.'}
|
||||
```
|
||||
|
||||
### From stepwise supervision to prompt only dataset
|
||||
|
||||
To convert a stepwise supervision dataset into a prompt-only dataset, remove the completions and the labels.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["Blue light", "Water"],
|
||||
"completions": [[" scatters more in the atmosphere,", " so the sky is green."],
|
||||
[" forms a less dense structure in ice,", " which causes it to expand when it freezes."]],
|
||||
"labels": [[True, False], [True, True]],
|
||||
})
|
||||
|
||||
dataset = dataset.remove_columns(["completions", "labels"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': 'Blue light'}
|
||||
```
|
||||
|
||||
### From stepwise supervision to unpaired preference dataset
|
||||
|
||||
To convert a stepwise supervision dataset into an unpaired preference dataset, join the completions and merge the labels.
|
||||
|
||||
The method for merging the labels depends on the specific task. In this example, we use the logical AND operation. This means that if the step labels indicate the correctness of individual steps, the resulting label will reflect the correctness of the entire sequence.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["Blue light", "Water"],
|
||||
"completions": [[" scatters more in the atmosphere,", " so the sky is green."],
|
||||
[" forms a less dense structure in ice,", " which causes it to expand when it freezes."]],
|
||||
"labels": [[True, False], [True, True]],
|
||||
})
|
||||
|
||||
def merge_completions_and_labels(example):
|
||||
return {"prompt": example["prompt"], "completion": "".join(example["completions"]), "label": all(example["labels"])}
|
||||
|
||||
dataset = dataset.map(merge_completions_and_labels, remove_columns=["completions", "labels"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': 'Blue light', 'completion': ' scatters more in the atmosphere, so the sky is green.', 'label': False}
|
||||
```
|
||||
|
||||
## Vision datasets
|
||||
|
||||
Some trainers also support fine-tuning vision-language models (VLMs) using image-text pairs. In this scenario, it's recommended to use a conversational format, as each model handles image placeholders in text differently.
|
||||
@ -6,16 +6,16 @@
|
||||
|
||||
| Before | After DDPO finetuning |
|
||||
| --- | --- |
|
||||
| <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/pre_squirrel.png"/></div> | <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/post_squirrel.png"/></div> |
|
||||
| <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/pre_crab.png"/></div> | <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/post_crab.png"/></div> |
|
||||
| <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/pre_starfish.png"/></div> | <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/post_starfish.png"/></div> |
|
||||
| <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/pre_squirrel.png"/></div> | <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/post_squirrel.png"/></div> |
|
||||
| <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/pre_crab.png"/></div> | <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/post_crab.png"/></div> |
|
||||
| <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/pre_starfish.png"/></div> | <div style="text-align: center"><img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/post_starfish.png"/></div> |
|
||||
|
||||
|
||||
## Getting started with Stable Diffusion finetuning with reinforcement learning
|
||||
|
||||
The machinery for finetuning of Stable Diffusion models with reinforcement learning makes heavy use of HuggingFace's `diffusers`
|
||||
library. A reason for stating this is that getting started requires a bit of familiarity with the `diffusers` library concepts, mainly two of them - pipelines and schedulers.
|
||||
Right out of the box (`diffusers` library), there isn't a `Pipeline` nor a `Scheduler` instance that is suitable for finetuning with reinforcement learning. Some adjustments need to made.
|
||||
library. A reason for stating this is that getting started requires a bit of familiarity with the `diffusers` library concepts, mainly two of them - pipelines and schedulers.
|
||||
Right out of the box (`diffusers` library), there isn't a `Pipeline` nor a `Scheduler` instance that is suitable for finetuning with reinforcement learning. Some adjustments need to be made.
|
||||
|
||||
There is a pipeline interface that is provided by this library that is required to be implemented to be used with the `DDPOTrainer`, which is the main machinery for fine-tuning Stable Diffusion with reinforcement learning. **Note: Only the StableDiffusion architecture is supported at this point.**
|
||||
There is a default implementation of this interface that you can use out of the box. Assuming the default implementation is sufficient and/or to get things moving, refer to the training example alongside this guide.
|
||||
@ -26,7 +26,7 @@ For a more detailed look into the interface and the associated default implement
|
||||
|
||||
Note that the default implementation has a LoRA implementation path and a non-LoRA based implementation path. The LoRA flag enabled by default and this can be turned off by passing in the flag to do so. LORA based training is faster and the LORA associated model hyperparameters responsible for model convergence aren't as finicky as non-LORA based training.
|
||||
|
||||
Also in addition, there is the expectation of providing a reward function and a prompt function. The reward function is used to evaluate the generated images and the prompt function is used to generate the prompts that are used to generate the images.
|
||||
Also in addition, there is the expectation of providing a reward function and a prompt function. The reward function is used to evaluate the generated images and the prompt function is used to generate the prompts that are used to generate the images.
|
||||
|
||||
## Getting started with `examples/scripts/ddpo.py`
|
||||
|
||||
7
docs/source/deepspeed_integration.md
Normal file
7
docs/source/deepspeed_integration.md
Normal file
@ -0,0 +1,7 @@
|
||||
# DeepSpeed Integration
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Section under construction. Feel free to contribute!
|
||||
|
||||
</Tip>
|
||||
@ -45,7 +45,7 @@ When doing PPO, it is very important to design the problem efficiently so that t
|
||||
|
||||
### Pre-processing the dataset
|
||||
|
||||
The dataset consist of prompts and their continuations, and each of them has an associated `toxicity` score.
|
||||
The dataset consists of prompts and their continuations, and each of them has an associated `toxicity` score.
|
||||
|
||||
A `prompt` example:
|
||||
```
|
||||
@ -83,7 +83,7 @@ As a compromise between the two we took for a context window of 10 to 15 tokens
|
||||
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-long-vs-short-context.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl-long-vs-short-context.png">
|
||||
</div>
|
||||
|
||||
### How to deal with OOM issues
|
||||
@ -101,15 +101,15 @@ and the optimizer will take care of computing the gradients in `bfloat16` precis
|
||||
- Use shared layers: Since PPO algorithm requires to have both the active and reference model to be on the same device, we have decided to use shared layers to reduce the memory footprint of the model. This can be achieved by specifying `num_shared_layers` argument when calling the `create_reference_model()` function. For example, if you want to share the first 6 layers of the model, you can do it like this:
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-shared-layers.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl-shared-layers.png">
|
||||
</div>
|
||||
|
||||
```python
|
||||
ref_policy = create_reference_model(model, num_shared_layers=6)
|
||||
trainer = PPOTrainer(..., ref_policy=ref_policy)
|
||||
ref_model = create_reference_model(model, num_shared_layers=6)
|
||||
trainer = PPOTrainer(..., ref_model=ref_model)
|
||||
```
|
||||
|
||||
In the example above this means that the model have the 4 first layers frozen (i.e. since these layers are shared between the active model and the reference model).
|
||||
In the example above this means that the model has the 4 first layers frozen (i.e. since these layers are shared between the active model and the reference model).
|
||||
|
||||
- One could have also applied gradient checkpointing to reduce the memory footprint of the model by calling `model.pretrained_model.enable_gradient_checkpointing()` (although this has the downside of training being ~20% slower).
|
||||
|
||||
@ -124,13 +124,13 @@ We have decided to keep 3 models in total that correspond to our best models:
|
||||
We have used different learning rates for each model, and have found out that the largest models were quite hard to train and can easily lead to collapse mode if the learning rate is not chosen correctly (i.e. if the learning rate is too high):
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-collapse-mode.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl-collapse-mode.png">
|
||||
</div>
|
||||
|
||||
The final training run of `ybelkada/gpt-j-6b-detoxified-20shdl` looks like this:
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-gpt-j-final-run-2.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl-gpt-j-final-run-2.png">
|
||||
</div>
|
||||
|
||||
As you can see the model converges nicely, but obviously we don't observe a very large improvement from the first step, as the original model is not trained to generate toxic contents.
|
||||
@ -138,7 +138,7 @@ As you can see the model converges nicely, but obviously we don't observe a very
|
||||
Also we have observed that training with larger `mini_batch_size` leads to smoother convergence and better results on the test set:
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-gpt-j-mbs-run.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl-gpt-j-mbs-run.png">
|
||||
</div>
|
||||
|
||||
## Results
|
||||
@ -159,7 +159,7 @@ We report the toxicity score of 400 sampled examples, compute its mean and stand
|
||||
|
||||
<div class="column" style="text-align:center">
|
||||
<figure>
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-final-barplot.png" style="width:80%">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl-final-barplot.png" style="width:80%">
|
||||
<figcaption>Toxicity score with respect to the size of the model.</figcaption>
|
||||
</figure>
|
||||
</div>
|
||||
@ -167,7 +167,7 @@ We report the toxicity score of 400 sampled examples, compute its mean and stand
|
||||
Below are few generation examples of `gpt-j-6b-detox` model:
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-toxicity-examples.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl-toxicity-examples.png">
|
||||
</div>
|
||||
|
||||
The evaluation script can be found [here](https://github.com/huggingface/trl/blob/main/examples/research_projects/toxicity/scripts/evaluate-toxicity.py).
|
||||
@ -176,7 +176,7 @@ The evaluation script can be found [here](https://github.com/huggingface/trl/blo
|
||||
|
||||
The results are quite promising, as we can see that the models are able to reduce the toxicity score of the generated text by an interesting margin. The gap is clear for `gpt-neo-2B` model but we less so for the `gpt-j-6B` model. There are several things we could try to improve the results on the largest model starting with training with larger `mini_batch_size` and probably allowing to back-propagate through more layers (i.e. use less shared layers).
|
||||
|
||||
To sum up, in addition to human feedback this could be a useful additional signal when training large language models to ensure there outputs are less toxic as well as useful.
|
||||
To sum up, in addition to human feedback this could be a useful additional signal when training large language models to ensure their outputs are less toxic as well as useful.
|
||||
|
||||
### Limitations
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# DPO Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=dpo,trl)
|
||||
[](https://huggingface.co/models?other=dpo,trl) [](https://github.com/huggingface/smol-course/tree/main/2_preference_alignment)
|
||||
|
||||
## Overview
|
||||
|
||||
@ -59,7 +59,7 @@ accelerate launch train_dpo.py
|
||||
|
||||
Distributed across 8 GPUs, the training takes approximately 3 minutes. You can verify the training progress by checking the reward graph. An increasing trend in the reward margin indicates that the model is improving and generating better responses over time.
|
||||
|
||||

|
||||

|
||||
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-DPO) performs, you can use the [TRL Chat CLI](clis#chat-interface).
|
||||
|
||||
@ -112,12 +112,12 @@ For a complete example of fine-tuning a vision-language model, refer to the scri
|
||||
|
||||
## Example script
|
||||
|
||||
We provide an example script to train a model using the DPO method. The script is available in [`examples/scripts/dpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo.py)
|
||||
We provide an example script to train a model using the DPO method. The script is available in [`trl/scripts/dpo.py`](https://github.com/huggingface/trl/blob/main/trl/scripts/dpo.py)
|
||||
|
||||
To test the DPO script with the [Qwen2 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) on the [UltraFeedback dataset](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized), run the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch examples/scripts/dpo.py \
|
||||
accelerate launch trl/scripts/dpo.py \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
|
||||
--dataset_name trl-lib/ultrafeedback_binarized \
|
||||
--num_train_epochs 1 \
|
||||
@ -150,6 +150,7 @@ The DPO algorithm supports several loss functions. The loss function can be set
|
||||
| `"sppo_hard"` | The [SPPO](https://huggingface.co/papers/2405.00675) authors claim that SPPO is capable of solving the Nash equilibrium iteratively by pushing the chosen rewards to be as large as 1/2 and the rejected rewards to be as small as -1/2 and can alleviate data sparsity issues. The implementation approximates this algorithm by employing hard label probabilities, assigning 1 to the winner and 0 to the loser. |
|
||||
| `"aot"` or `loss_type="aot_pair"` | The [AOT](https://huggingface.co/papers/2406.05882) authors propose to use Distributional Preference Alignment Via Optimal Transport. Traditionally, the alignment algorithms use paired preferences at a sample level, which does not ensure alignment on the distributional level. AOT, on the other hand, can align LLMs on paired or unpaired preference data by making the reward distribution of the positive samples stochastically dominant in the first order on the distribution of negative samples. Specifically, `loss_type="aot"` is appropriate for paired datasets, where each prompt has both chosen and rejected responses; `loss_type="aot_pair"` is for unpaired datasets. In a nutshell, `loss_type="aot"` ensures that the log-likelihood ratio of chosen to rejected of the aligned model has higher quantiles than that ratio for the reference model. `loss_type="aot_pair"` ensures that the chosen reward is higher on all quantiles than the rejected reward. Note that in both cases quantiles are obtained via sorting. To fully leverage the advantages of the AOT algorithm, it is important to maximize the per-GPU batch size. |
|
||||
| `"apo_zero"` or `loss_type="apo_down"` | The [APO](https://huggingface.co/papers/2408.06266) method introduces an "anchored" version of the alignment objective. There are two variants: `apo_zero` and `apo_down`. The `apo_zero` loss increases the likelihood of winning outputs while decreasing the likelihood of losing outputs, making it suitable when the model is less performant than the winning outputs. On the other hand, `apo_down` decreases the likelihood of both winning and losing outputs, but with a stronger emphasis on reducing the likelihood of losing outputs. This variant is more effective when the model is better than the winning outputs. |
|
||||
| `"discopop"` | The [DiscoPOP](https://huggingface.co/papers/2406.08414) paper uses LLMs to discover more efficient offline preference optimization losses. In the paper the proposed DiscoPOP loss (which is a log-ratio modulated loss) outperformed other optimization losses on different tasks (IMDb positive text generation, Reddit TLDR summarization, and Alpaca Eval 2.0). |
|
||||
|
||||
### Label smoothing
|
||||
|
||||
@ -277,6 +278,6 @@ dpo_trainer = DPOTrainer(
|
||||
|
||||
[[autodoc]] DPOConfig
|
||||
|
||||
## PreferenceCollator
|
||||
## DataCollatorForPreference
|
||||
|
||||
[[autodoc]] trainer.dpo_trainer.PreferenceCollator
|
||||
[[autodoc]] trainer.dpo_trainer.DataCollatorForPreference
|
||||
@ -31,23 +31,19 @@ Then, it is encouraged to launch jobs with `accelerate launch`!
|
||||
|
||||
# Maintained Examples
|
||||
|
||||
|
||||
Scripts can be used as examples of how to use TRL trainers. They are located in the [`trl/scripts`](https://github.com/huggingface/trl/blob/main/trl/scripts) directory. Additionally, we provide examples in the [`examples/scripts`](https://github.com/huggingface/trl/blob/main/examples/scripts) directory. These examples are maintained and tested regularly.
|
||||
|
||||
| File | Description |
|
||||
| ----------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| [`examples/scripts/alignprop.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/alignprop.py) | This script shows how to use the [`AlignPropTrainer`] to fine-tune a diffusion model. |
|
||||
| [`examples/scripts/bco.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/bco.py) | This script shows how to use the [`KTOTrainer`] with the BCO loss to fine-tune a model to increase instruction-following, truthfulness, honesty and helpfulness using the [openbmb/UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset. |
|
||||
| [`examples/scripts/chat.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/chat.py) | This script allows you to load and use a model as a chatbot. |
|
||||
| [`examples/scripts/cpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/cpo.py) | This script shows how to use the [`CPOTrainer`] to fine-tune a model to increase helpfulness and harmlessness using the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset. |
|
||||
| [`examples/scripts/ddpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ddpo.py) | This script shows how to use the [`DDPOTrainer`] to fine-tune a stable diffusion model using reinforcement learning. |
|
||||
| [`examples/scripts/dpo_vlm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo_vlm.py) | This script shows how to use the [`DPOTrainer`] to fine-tune a Vision Language Model to reduce hallucinations using the [openbmb/RLAIF-V-Dataset](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset) dataset. |
|
||||
| [`examples/scripts/dpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo.py) | This script shows how to use the [`DPOTrainer`] to fine-tune a stable to increase helpfulness and harmlessness using the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset. |
|
||||
| [`examples/scripts/kto.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/kto.py) | This script shows how to use the [`KTOTrainer`] to fine-tune a model. |
|
||||
| [`examples/scripts/orpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/orpo.py) | This script shows how to use the [`ORPOTrainer`] to fine-tune a model to increase helpfulness and harmlessness using the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset. |
|
||||
| [`examples/scripts/ppo/ppo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ppo/ppo.py) | This script shows how to use the [`PPOTrainer`] to fine-tune a model to improve its ability to continue text with positive sentiment or physically descriptive language |
|
||||
| [`examples/scripts/ppo/ppo_tldr.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ppo/ppo_tldr.py) | This script shows how to use the [`PPOTrainer`] to fine-tune a model to improve its ability to generate TL;DR summaries. |
|
||||
| [`examples/scripts/reward_modeling.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/reward_modeling.py) | This script shows how to use the [`RewardTrainer`] to train a reward model on your own dataset. |
|
||||
| [`examples/scripts/sft.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py) | This script shows how to use the [`SFTTrainer`] to fine-tune a model or adapters into a target dataset. |
|
||||
| [`examples/scripts/sft_vlm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/sft_vlm.py) | This script shows how to use the [`SFTTrainer`] to fine-tune a Vision Language Model in a chat setting. The script has only been tested with [LLaVA 1.5](https://huggingface.co/llava-hf/llava-1.5-7b-hf), [LLaVA 1.6](https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf), and [Llama-3.2-11B-Vision-Instruct](https://huggingface.co/meta-llama/Llama-3.2-11B-Vision-Instruct) models so users may see unexpected behaviour in other model architectures. |
|
||||
|
||||
Here are also some easier-to-run colab notebooks that you can use to get started with TRL:
|
||||
|
||||
254
docs/source/grpo_trainer.md
Normal file
254
docs/source/grpo_trainer.md
Normal file
@ -0,0 +1,254 @@
|
||||
# GRPO Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=grpo,trl)
|
||||
|
||||
## Overview
|
||||
|
||||
TRL supports the GRPO Trainer for training language models, as described in the paper [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300) by [Zhihong Shao](https://huggingface.co/syhia), [Peiyi Wang](https://huggingface.co/peiyiwang89), [Qihao Zhu](https://huggingface.co/zqh11), Runxin Xu, [Junxiao Song](https://huggingface.co/haha-point), Mingchuan Zhang, Y. K. Li, Y. Wu, [Daya Guo](https://huggingface.co/guoday).
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
> Mathematical reasoning poses a significant challenge for language models due to its complex and structured nature. In this paper, we introduce DeepSeekMath 7B, which continues pre-training DeepSeek-Coder-Base-v1.5 7B with 120B math-related tokens sourced from Common Crawl, together with natural language and code data. DeepSeekMath 7B has achieved an impressive score of 51.7% on the competition-level MATH benchmark without relying on external toolkits and voting techniques, approaching the performance level of Gemini-Ultra and GPT-4. Self-consistency over 64 samples from DeepSeekMath 7B achieves 60.9% on MATH. The mathematical reasoning capability of DeepSeekMath is attributed to two key factors: First, we harness the significant potential of publicly available web data through a meticulously engineered data selection pipeline. Second, we introduce Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO.
|
||||
|
||||
This post-training method was contributed by [Quentin Gallouédec](https://huggingface.co/qgallouedec).
|
||||
|
||||
## Quick start
|
||||
|
||||
This example demonstrates how to train a model using the GRPO method. We train a [Qwen 0.5B Instruct model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) with the prompts from the [TLDR dataset](https://huggingface.co/datasets/trl-lib/tldr) (completion column is ingored!). You can view the data in the dataset here:
|
||||
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/tldr/embed/viewer/default/train?row=0"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
Below is the script to train the model.
|
||||
|
||||
```python
|
||||
# train_grpo.py
|
||||
from datasets import load_dataset
|
||||
from trl import GRPOConfig, GRPOTrainer
|
||||
|
||||
dataset = load_dataset("trl-lib/tldr", split="train")
|
||||
|
||||
# Define the reward function, which rewards completions that are close to 20 characters
|
||||
def reward_len(completions, **kwargs):
|
||||
return [abs(20 - len(completion)) for completion in completions]
|
||||
|
||||
training_args = GRPOConfig(output_dir="Qwen2-0.5B-GRPO", logging_steps=10)
|
||||
trainer = GRPOTrainer(
|
||||
model="Qwen/Qwen2-0.5B-Instruct",
|
||||
reward_funcs=reward_len,
|
||||
args=training_args,
|
||||
train_dataset=dataset,
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
Execute the script using the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch train_grpo.py
|
||||
```
|
||||
|
||||
Distributed across 8 GPUs, the training takes approximately 1 day.
|
||||
|
||||

|
||||
|
||||
## Looking deeper into the GRPO method
|
||||
|
||||
GRPO is an online learning algorithm, meaning it improves iteratively by using the data generated by the trained model itself during training. The intuition behind GRPO objective is to maximize the advantage of the generated completions, while ensuring that the model remains close to the reference policy. To understand how GRPO works, it can be broken down into four main steps: **Generating completions**, **computing the advantage**, **estimating the KL divergence**, and **computing the loss**.
|
||||
|
||||

|
||||
|
||||
### Generating completions
|
||||
|
||||
At each training step, we sample a batch of prompts and generate a set of \\( G \\) completions for each prompt (denoted as \\( o_i \\)).
|
||||
|
||||
### Computing the advantage
|
||||
|
||||
For each of the \\( G \\) sequences, we compute the reward using a reward model. To align with the comparative nature of reward models—typically trained on datasets of comparisons between outputs for the same question—the advantage is calculated to reflect these relative comparisons. It is normalized as follows:
|
||||
|
||||
$$\hat{A}_{i,t} = \frac{r_i - \text{mean}(\mathbf{r})}{\text{std}(\mathbf{r})}$$
|
||||
|
||||
This approach gives the method its name: **Group Relative Policy Optimization (GRPO)**.
|
||||
|
||||
### Estimating the KL divergence
|
||||
|
||||
KL divergence is estimated using the approximator introduced by [Schulman et al. (2020)](http://joschu.net/blog/kl-approx.html). The approximator is defined as follows:
|
||||
|
||||
$$\mathbb{D}_{\text{KL}}\left[\pi_\theta \|\pi_{\text{ref}}\right] = \frac{\pi_{\text{ref}}(o_{i,t} \mid q, o_{i,<t})}{\pi_\theta(o_{i,t} \mid q, o_{i,<t})} - \log \frac{\pi_{\text{ref}}(o_{i,t} \mid q, o_{i,<t})}{\pi_\theta(o_{i,t} \mid q, o_{i,<t})} - 1,
|
||||
$$
|
||||
|
||||
### Computing the loss
|
||||
|
||||
The objective is to maximize the advantage while ensuring that the model remains close to the reference policy. Consequently, the loss is defined as follows:
|
||||
|
||||
$$
|
||||
\mathcal{L}_{\text{GRPO}}(\theta) = -\frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left[ \frac{\pi_\theta(o_{i,t} \mid q, o_{i,< t})}{\left[\pi_\theta(o_{i,t} \mid q, o_{i,< t})\right]_{\text{no grad}}} \hat{A}_{i,t} - \beta \mathbb{D}_{\text{KL}}\left[\pi_\theta \| \pi_{\text{ref}}\right] \right],
|
||||
$$
|
||||
|
||||
where the first term represents the scaled advantage and the second term penalizes deviations from the reference policy through KL divergence.
|
||||
|
||||
In the original paper, this formulation is generalized to account for multiple updates after each generation by leveraging the **clipped surrogate objective**:
|
||||
|
||||
$$
|
||||
\mathcal{L}_{\text{GRPO}}(\theta) = - \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left[ \min \left( \frac{\pi_\theta(o_{i,t} \mid q, o_{i,< t})}{\pi_{\theta_{\text{old}}}(o_{i,t} \mid q, o_{i,< t})} \hat{A}_{i,t}, \, \text{clip}\left( \frac{\pi_\theta(o_{i,t} \mid q, o_{i,< t})}{\pi_{\theta_{\text{old}}}(o_{i,t} \mid q, o_{i,< t})}, 1 - \epsilon, 1 + \epsilon \right) \hat{A}_{i,t} \right) - \beta \mathbb{D}_{\text{KL}}\left[\pi_\theta \| \pi_{\text{ref}}\right] \right],
|
||||
$$
|
||||
|
||||
where \\(\text{clip}(\cdot, 1 - \epsilon, 1 + \epsilon) \\) ensures that updates do not deviate excessively from the reference policy by bounding the policy ratio between \\( 1 - \epsilon \\) and \\( 1 + \epsilon \\).
|
||||
In TRL though, as in the original paper, we only do one update per generation, so we can simplify the loss to the first form.
|
||||
|
||||
## Logged metrics
|
||||
|
||||
The GRPO Trainer logs the following metrics:
|
||||
|
||||
- `completion_length`: The average completion length.
|
||||
- `reward/{reward_func_name}`: The reward computed by each reward function.
|
||||
- `reward`: The average reward.
|
||||
- `reward_std` : The average standard deviation within reward groups.
|
||||
- `kl` : The average KL divergence between the model and the reference model calculated on completions.
|
||||
|
||||
## Customization
|
||||
|
||||
## Speed up training with vLLM-powered generation
|
||||
|
||||
Generation is often the main bottleneck that makes training slow with online methods. To accelerate generation, you can use [vLLM](https://github.com/vllm-project/vllm), a library that enables fast generation. To enable it, pass `use_vllm=True` in the training arguments.
|
||||
|
||||
```python
|
||||
from trl import GRPOConfig
|
||||
|
||||
training_args = GRPOConfig(..., use_vllm=True)
|
||||
```
|
||||
|
||||
For more information, see [Speeding up training with vLLM](speeding_up_training#vllm-for-fast-generation-in-online-methods).
|
||||
|
||||
### Using a custom reward function
|
||||
|
||||
The [`GRPOTrainer`] supports using custom reward functions instead of dense reward models. To ensure compatibility, your reward function must satisfy the following requirements:
|
||||
|
||||
1. **Input arguments**:
|
||||
- The function must accept the following as keyword arguments:
|
||||
- `prompts` (contains the prompts),
|
||||
- `completions` (contains the generated completions),
|
||||
- All columns names (but `prompt`) that the dataset may have. For example, if the dataset contains a column named `ground_truth`, the function will be called with `ground_truth` as a keyword argument.
|
||||
|
||||
The easiest way to comply with this requirement is to use `**kwargs` in the function signature.
|
||||
- Depending on the dataset format, the input will vary:
|
||||
- For [standard format](dataset_formats#standard), `prompts` and `completions` will be lists of strings.
|
||||
- For [conversational format](dataset_formats#conversational), `prompts` and `completions` will be lists of message dictionaries.
|
||||
|
||||
2. **Return value**: The function must return a list of floats. Each float represents the reward corresponding to a single completion.
|
||||
|
||||
#### Example 1: Reward longer completions
|
||||
|
||||
Below is an example of a reward function for a standard format that rewards longer completions:
|
||||
|
||||
```python
|
||||
def reward_func(completions, **kwargs):
|
||||
"""Reward function that gives higher scores to longer completions."""
|
||||
return [float(len(completion)) for completion in completions]
|
||||
```
|
||||
|
||||
You can test it as follows:
|
||||
|
||||
```python
|
||||
>>> prompts = ["The sky is", "The sun is"]
|
||||
>>> completions = [" blue.", " in the sky."]
|
||||
>>> print(reward_func(prompts=prompts, completions=completions))
|
||||
[6.0, 12.0]
|
||||
```
|
||||
|
||||
#### Example 2: Reward completions with specific format
|
||||
|
||||
Below is an example of a reward function that checks if the completion has a specific format. This example is inspired by the _format reward_ function used in the paper [DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning](https://huggingface.co/papers/2501.12948).
|
||||
It is designed for conversational format, where prompts and completions consist of structured messages.
|
||||
|
||||
```python
|
||||
import re
|
||||
|
||||
def format_reward_func(completions, **kwargs):
|
||||
"""Reward function that checks if the completion has a specific format."""
|
||||
pattern = r"^<think>.*?</think><answer>.*?</answer>$"
|
||||
completion_contents = [completion[0]["content"] for completion in completions]
|
||||
matches = [re.match(pattern, content) for content in completion_contents]
|
||||
return [1.0 if match else 0.0 for match in matches]
|
||||
```
|
||||
|
||||
You can test this function as follows:
|
||||
|
||||
```python
|
||||
>>> prompts = [
|
||||
... [{"role": "assistant", "content": "What is the result of (1 + 2) * 4?"}],
|
||||
... [{"role": "assistant", "content": "What is the result of (3 + 1) * 2?"}],
|
||||
... ]
|
||||
>>> completions = [
|
||||
... [{"role": "assistant", "content": "<think>The sum of 1 and 2 is 3, which we multiply by 4 to get 12.</think><answer>(1 + 2) * 4 = 12</answer>"}],
|
||||
... [{"role": "assistant", "content": "The sum of 3 and 1 is 4, which we multiply by 2 to get 8. So (3 + 1) * 2 = 8."}],
|
||||
... ]
|
||||
>>> format_reward_func(prompts=prompts, completions=completions)
|
||||
[1.0, 0.0]
|
||||
```
|
||||
|
||||
#### Example 3: Reward completions based on a reference
|
||||
|
||||
Below is an example of a reward function that checks if the is correct. This example is inspired by the _accuracy reward_ function used in the paper [DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning](https://huggingface.co/papers/2501.12948).
|
||||
This example is designed for [standard format](dataset_formats#standard), where the dataset contains a column named `ground_truth`.
|
||||
|
||||
```python
|
||||
import re
|
||||
|
||||
def reward_func(completions, ground_truth, **kwargs):
|
||||
# Regular expression to capture content inside \boxed{}
|
||||
matches = [re.search(r"\\boxed\{(.*?)\}", completion) for completion in completions]
|
||||
contents = [match.group(1) if match else "" for match in matches]
|
||||
# Reward 1 if the content is the same as the ground truth, 0 otherwise
|
||||
return [1.0 if c == gt else 0.0 for c, gt in zip(contents, ground_truth)]
|
||||
```
|
||||
|
||||
You can test this function as follows:
|
||||
|
||||
```python
|
||||
>>> prompts = ["Problem: Solve the equation $2x + 3 = 7$. Solution:", "Problem: Solve the equation $3x - 5 = 10$."]
|
||||
>>> completions = [r" The solution is \boxed{2}.", r" The solution is \boxed{6}."]
|
||||
>>> ground_truth = ["2", "5"]
|
||||
>>> reward_func(prompts=prompts, completions=completions, ground_truth=ground_truth)
|
||||
[1.0, 0.0]
|
||||
```
|
||||
|
||||
#### Passing the reward function to the trainer
|
||||
|
||||
To use your custom reward function, pass it to the `GRPOTrainer` as follows:
|
||||
|
||||
```python
|
||||
from trl import GRPOTrainer
|
||||
|
||||
trainer = GRPOTrainer(
|
||||
reward_funcs=reward_func,
|
||||
...,
|
||||
)
|
||||
```
|
||||
|
||||
If you have multiple reward functions, you can pass them as a list:
|
||||
|
||||
```python
|
||||
from trl import GRPOTrainer
|
||||
|
||||
trainer = GRPOTrainer(
|
||||
reward_funcs=[reward_func1, reward_func2],
|
||||
...,
|
||||
)
|
||||
```
|
||||
|
||||
and the reward will be computed as the sum of the rewards from each function.
|
||||
|
||||
Note that [`GRPOTrainer`] supports multiple reward functions of different types. See the parameters documentation for more details.
|
||||
|
||||
## GRPOTrainer
|
||||
|
||||
[[autodoc]] GRPOTrainer
|
||||
|
||||
## GRPOConfig
|
||||
|
||||
[[autodoc]] GRPOConfig
|
||||
@ -18,7 +18,7 @@ When training RL models, optimizing solely for reward may lead to unexpected beh
|
||||
However, the RL model being optimized against the reward model may learn patterns that yield high reward but do not represent good language. This can result in extreme cases where the model generates texts with excessive exclamation marks or emojis to maximize the reward. In some worst-case scenarios, the model may generate patterns completely unrelated to natural language yet receive high rewards, similar to adversarial attacks.
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/kl-example.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/kl-example.png">
|
||||
<p style="text-align: center;"> <b>Figure:</b> Samples without a KL penalty from <a href="https://huggingface.co/papers/1909.08593">https://huggingface.co/papers/1909.08593</a>. </p>
|
||||
</div>
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl_banner_dark.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl_banner_dark.png">
|
||||
</div>
|
||||
|
||||
# TRL - Transformer Reinforcement Learning
|
||||
@ -7,11 +7,9 @@
|
||||
TRL is a full stack library where we provide a set of tools to train transformer language models with Reinforcement Learning, from the Supervised Fine-tuning step (SFT), Reward Modeling step (RM) to the Proximal Policy Optimization (PPO) step.
|
||||
The library is integrated with 🤗 [transformers](https://github.com/huggingface/transformers).
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/TRL-readme.png">
|
||||
</div>
|
||||
## Learn
|
||||
|
||||
Check the appropriate sections of the documentation depending on your needs:
|
||||
Learn post-training with TRL and other libraries in 🤗 [smol course](https://github.com/huggingface/smol-course).
|
||||
|
||||
## API documentation
|
||||
|
||||
@ -38,28 +36,39 @@ Check the appropriate sections of the documentation depending on your needs:
|
||||
<div class="mt-10">
|
||||
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5">
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/dpo_vlm">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/dpo_vlm/thumbnail.png" alt="thumbnail">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/dpo_vlm/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on July 10, 2024</p>
|
||||
<p class="text-gray-700">Preference Optimization for Vision Language Models with TRL</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/rlhf">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/120_rlhf/thumbnail.png" alt="thumbnail">
|
||||
<p class="text-gray-700">Illustrating Reinforcement Learning from Human Feedback</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/trl-peft">
|
||||
<img src="https://github.com/huggingface/blog/blob/main/assets/133_trl_peft/thumbnail.png?raw=true" alt="thumbnail">
|
||||
<p class="text-gray-700">Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/stackllama">
|
||||
<img src="https://github.com/huggingface/blog/blob/main/assets/138_stackllama/thumbnail.png?raw=true" alt="thumbnail">
|
||||
<p class="text-gray-700">StackLLaMA: A hands-on guide to train LLaMA with RLHF</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/dpo-trl">
|
||||
<img src="https://github.com/huggingface/blog/blob/main/assets/157_dpo_trl/dpo_thumbnail.png?raw=true" alt="thumbnail">
|
||||
<p class="text-gray-700">Fine-tune Llama 2 with DPO</p>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/putting_rl_back_in_rlhf_with_rloo">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/putting_rl_back_in_rlhf_with_rloo/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on June 12, 2024</p>
|
||||
<p class="text-gray-700">Putting RL back in RLHF</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/trl-ddpo">
|
||||
<img src="https://github.com/huggingface/blog/blob/main/assets/166_trl_ddpo/thumbnail.png?raw=true" alt="thumbnail">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/166_trl_ddpo/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on September 29, 2023</p>
|
||||
<p class="text-gray-700">Finetune Stable Diffusion Models with DDPO via TRL</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/dpo-trl">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/157_dpo_trl/dpo_thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on August 8, 2023</p>
|
||||
<p class="text-gray-700">Fine-tune Llama 2 with DPO</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/stackllama">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/138_stackllama/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on April 5, 2023</p>
|
||||
<p class="text-gray-700">StackLLaMA: A hands-on guide to train LLaMA with RLHF</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/trl-peft">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/133_trl_peft/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on March 9, 2023</p>
|
||||
<p class="text-gray-700">Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/rlhf">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/120_rlhf/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on December 9, 2022</p>
|
||||
<p class="text-gray-700">Illustrating Reinforcement Learning from Human Feedback</p>
|
||||
</a>
|
||||
</div>
|
||||
</div>
|
||||
39
docs/source/installation.md
Normal file
39
docs/source/installation.md
Normal file
@ -0,0 +1,39 @@
|
||||
# Installation
|
||||
You can install TRL either from PyPI or from source:
|
||||
|
||||
## PyPI
|
||||
Install the library with pip or [uv](https://docs.astral.sh/uv/):
|
||||
|
||||
<hfoptions id="install">
|
||||
<hfoption id="uv">
|
||||
|
||||
uv is a fast Rust-based Python package and project manager. Refer to [Installation](https://docs.astral.sh/uv/getting-started/installation/) for installation instructions), .
|
||||
|
||||
```bash
|
||||
uv pip install trl
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="pip">
|
||||
|
||||
```bash
|
||||
pip install trl
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## Source
|
||||
You can also install the latest version from source. First clone the repo and then run the installation with `pip`:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/trl.git
|
||||
cd trl/
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
If you want the development install you can replace the pip install with the following:
|
||||
|
||||
```bash
|
||||
pip install -e ".[dev]"
|
||||
```
|
||||
@ -1,24 +0,0 @@
|
||||
# Installation
|
||||
You can install TRL either from pypi or from source:
|
||||
|
||||
## pypi
|
||||
Install the library with pip:
|
||||
|
||||
```bash
|
||||
pip install trl
|
||||
```
|
||||
|
||||
### Source
|
||||
You can also install the latest version from source. First clone the repo and then run the installation with `pip`:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/trl.git
|
||||
cd trl/
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
If you want the development install you can replace the pip install with the following:
|
||||
|
||||
```bash
|
||||
pip install -e ".[dev]"
|
||||
```
|
||||
@ -1,11 +1,17 @@
|
||||
# Judges
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
TRL Judges is an experimental API which is subject to change at any time.
|
||||
|
||||
</Tip>
|
||||
|
||||
TRL provides judges to easily compare two completions.
|
||||
|
||||
Make sure to have installed the required dependencies by running:
|
||||
|
||||
```bash
|
||||
pip install trl[llm_judge]
|
||||
pip install trl[judges]
|
||||
```
|
||||
|
||||
## Using the provided judges
|
||||
@ -46,34 +52,38 @@ judge.judge(
|
||||
) # Outputs: [0, 1]
|
||||
```
|
||||
|
||||
## BaseJudge
|
||||
## Provided judges
|
||||
|
||||
[[autodoc]] BaseJudge
|
||||
|
||||
## BaseRankJudge
|
||||
|
||||
[[autodoc]] BaseRankJudge
|
||||
|
||||
## BasePairwiseJudge
|
||||
|
||||
[[autodoc]] BasePairwiseJudge
|
||||
|
||||
## RandomRankJudge
|
||||
|
||||
[[autodoc]] RandomRankJudge
|
||||
|
||||
## RandomPairwiseJudge
|
||||
|
||||
[[autodoc]] RandomPairwiseJudge
|
||||
|
||||
## PairRMJudge
|
||||
### PairRMJudge
|
||||
|
||||
[[autodoc]] PairRMJudge
|
||||
|
||||
## HfPairwiseJudge
|
||||
### HfPairwiseJudge
|
||||
|
||||
[[autodoc]] HfPairwiseJudge
|
||||
|
||||
## OpenAIPairwiseJudge
|
||||
### OpenAIPairwiseJudge
|
||||
|
||||
[[autodoc]] OpenAIPairwiseJudge
|
||||
|
||||
### AllTrueJudge
|
||||
|
||||
[[autodoc]] AllTrueJudge
|
||||
|
||||
## Base classes
|
||||
|
||||
### BaseJudge
|
||||
|
||||
[[autodoc]] BaseJudge
|
||||
|
||||
### BaseBinaryJudge
|
||||
|
||||
[[autodoc]] BaseBinaryJudge
|
||||
|
||||
### BaseRankJudge
|
||||
|
||||
[[autodoc]] BaseRankJudge
|
||||
|
||||
### BasePairwiseJudge
|
||||
|
||||
[[autodoc]] BasePairwiseJudge
|
||||
@ -51,7 +51,7 @@ accelerate launch train_kto.py
|
||||
|
||||
Distributed across 8 x H100 GPUs, the training takes approximately 30 minutes. You can verify the training progress by checking the reward graph. An increasing trend in the reward margin indicates that the model is improving and generating better responses over time.
|
||||
|
||||

|
||||

|
||||
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-KTO) performs, you can use the [TRL Chat CLI](clis#chat-interface).
|
||||
|
||||
@ -80,12 +80,12 @@ In theory, the dataset should contain at least one chosen and one rejected compl
|
||||
|
||||
## Example script
|
||||
|
||||
We provide an example script to train a model using the KTO method. The script is available in [`examples/scripts/kto.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/kto.py)
|
||||
We provide an example script to train a model using the KTO method. The script is available in [`trl/scripts/kto.py`](https://github.com/huggingface/trl/blob/main/trl/scripts/kto.py)
|
||||
|
||||
To test the KTO script with the [Qwen2 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) on the [UltraFeedback dataset](https://huggingface.co/datasets/trl-lib/kto-mix-14k), run the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch examples/scripts/kto.py \
|
||||
accelerate launch trl/scripts/kto.py \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
|
||||
--dataset_name trl-lib/kto-mix-14k \
|
||||
--num_train_epochs 1 \
|
||||
@ -115,7 +115,7 @@ Each choice of `beta` has a maximum learning rate it can tolerate before learnin
|
||||
### Imbalanced data
|
||||
|
||||
The `desirable_weight` and `undesirable_weight` of the [`KTOConfig`] refer to the weights placed on the losses for desirable/positive and undesirable/negative examples.
|
||||
By default, they are both 1. However, if you have more of one or the other, then you should upweight the less common type such that the ratio of (`desirable_weight` \\(\times\\) number of positives) to (`undesirable_weight` \\(\times\\) number of negatives) is in the range 1:1 to 4:3.
|
||||
By default, they are both 1. However, if you have more of one or the other, then you should upweight the less common type such that the ratio of (`desirable_weight` \\(\times\\) number of positives) to (`undesirable_weight` \\(\times\\) number of negatives) is in the range 1:1 to 4:3.
|
||||
|
||||
## Logged metrics
|
||||
|
||||
@ -69,7 +69,7 @@ The rough idea is as follows:
|
||||
)
|
||||
```
|
||||
4. Then generate some data such as `tasks = ["\n\nWhat is 13.1-3?", "\n\nWhat is 4*3?"]` and run the environment with `queries, responses, masks, rewards, histories = env.run(tasks)`. The environment will look for the `<call>` token in the prompt and append the tool output to the response; it will also return the mask associated with the response. You can further use the `histories` to visualize the interaction between the model and the tool; `histories[0].show_text()` will show the text with color-coded tool output and `histories[0].show_tokens(tokenizer)` will show visualize the tokens.
|
||||

|
||||

|
||||
1. Finally, we can train the model with `train_stats = ppo_trainer.step(queries, responses, rewards, masks)`. The trainer will use the mask to ignore the tool output when computing the loss, make sure to pass that argument to `step`.
|
||||
|
||||
## Experiment results
|
||||
@ -102,7 +102,7 @@ python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--scan-history
|
||||
```
|
||||
|
||||
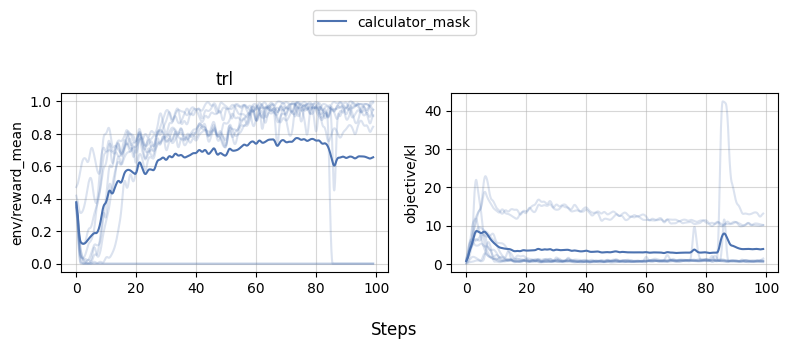
|
||||

|
||||
|
||||
As we can see, while 1-2 experiments crashed for some reason, most of the runs obtained near perfect proficiency in the calculator task.
|
||||
|
||||
@ -147,7 +147,7 @@ The frame of rackets for all sports was traditionally made of solid wood (later
|
||||
|
||||
We then basically deployed this snippet as a Hugging Face space [here](https://huggingface.co/spaces/vwxyzjn/pyserini-wikipedia-kilt-doc), so that we can use the space as a `transformers.Tool` later.
|
||||
|
||||
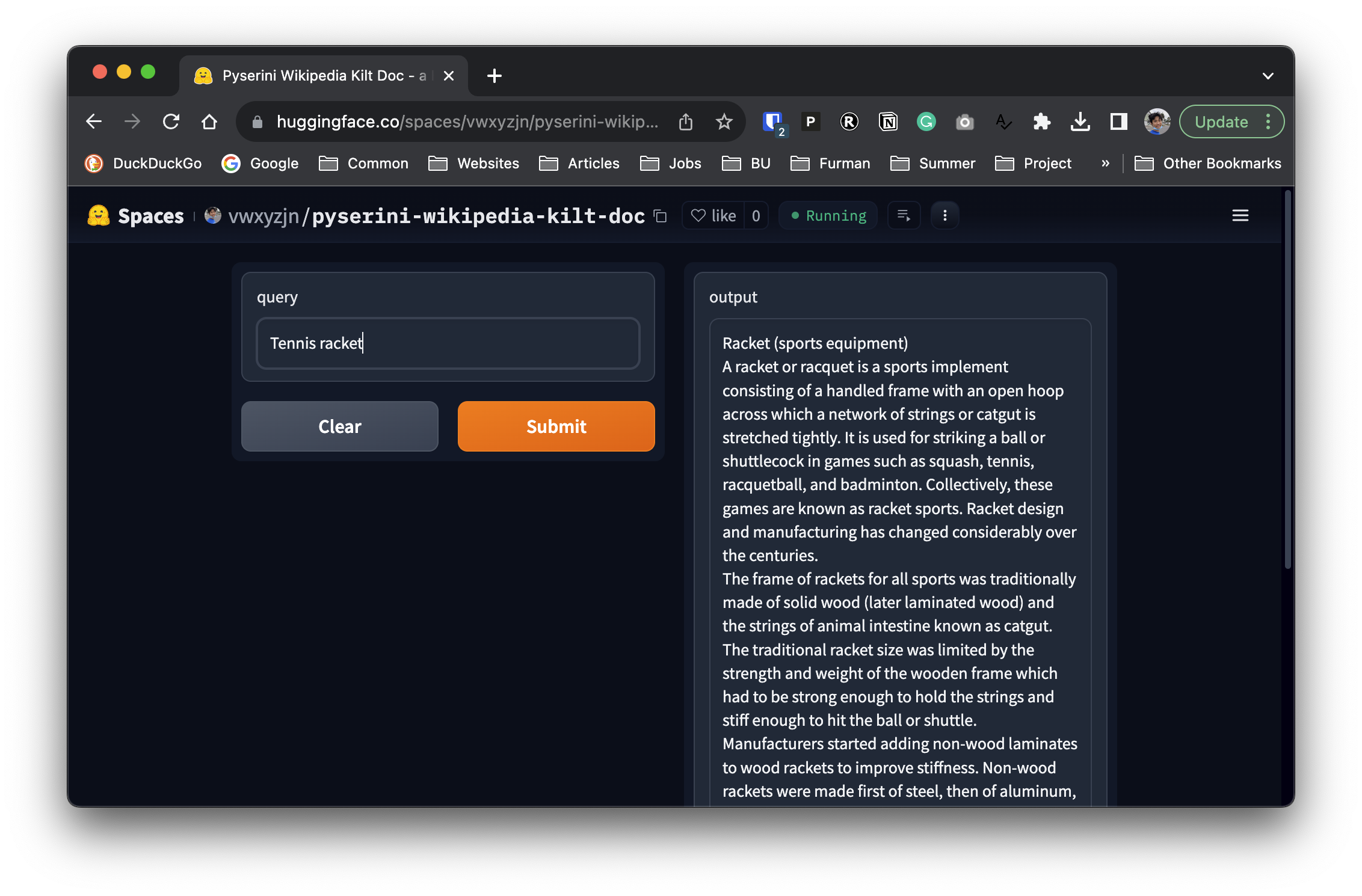
|
||||

|
||||
|
||||
### Experiment settings
|
||||
|
||||
@ -181,7 +181,7 @@ Q: """
|
||||
|
||||
Our experiments show that the agent can learn to use the wiki tool to answer questions. The learning curves would go up mostly, but one of the experiment did crash.
|
||||
|
||||
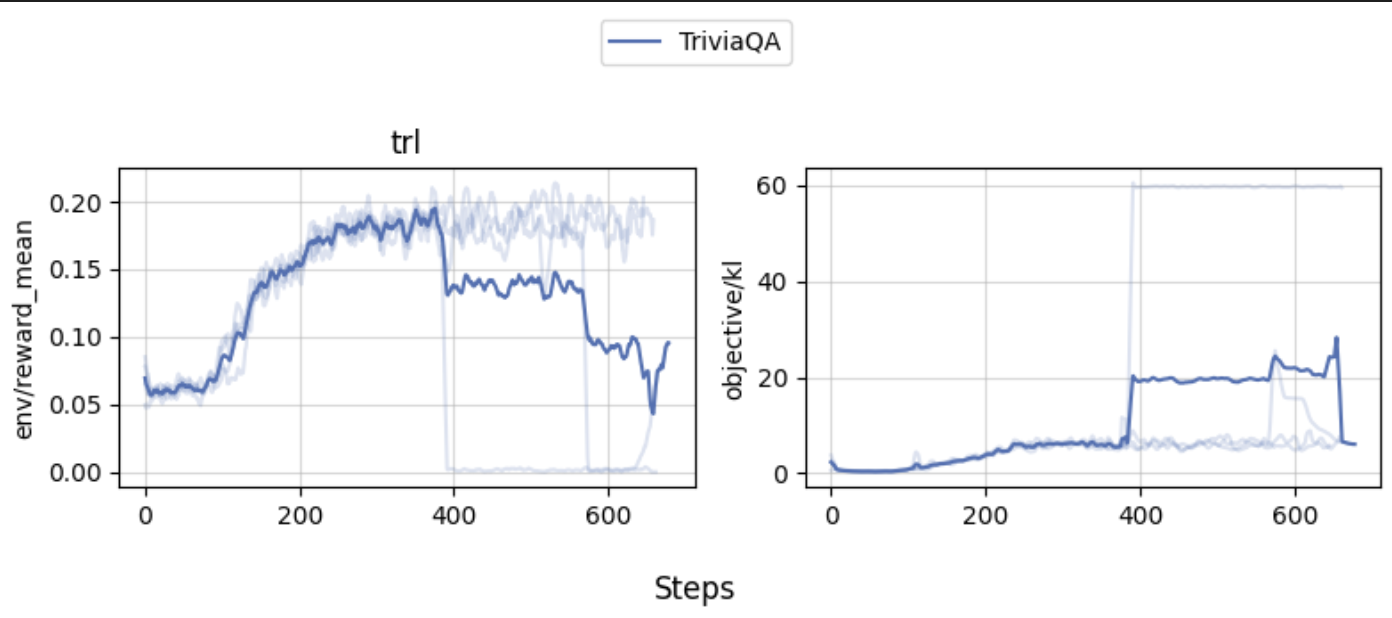
|
||||

|
||||
|
||||
Wandb report is [here](https://wandb.ai/costa-huang/cleanRL/reports/TriviaQA-Final-Experiments--Vmlldzo1MjY0ODk5) for further inspection.
|
||||
|
||||
@ -191,13 +191,13 @@ Note that the correct rate of the trained model is on the low end, which could b
|
||||
* **incorrect searches:** When given the question `"What is Bruce Willis' real first name?"` if the model searches for `Bruce Willis`, our wiki tool returns "Patrick Poivey (born 18 February 1948) is a French actor. He is especially known for his voice: he is the French dub voice of Bruce Willis since 1988.` But a correct search should be `Walter Bruce Willis (born March 19, 1955) is an American former actor. He achieved fame with a leading role on the comedy-drama series Moonlighting (1985–1989) and appeared in over a hundred films, gaining recognition as an action hero after his portrayal of John McClane in the Die Hard franchise (1988–2013) and other roles.[1][2]"
|
||||
|
||||
|
||||
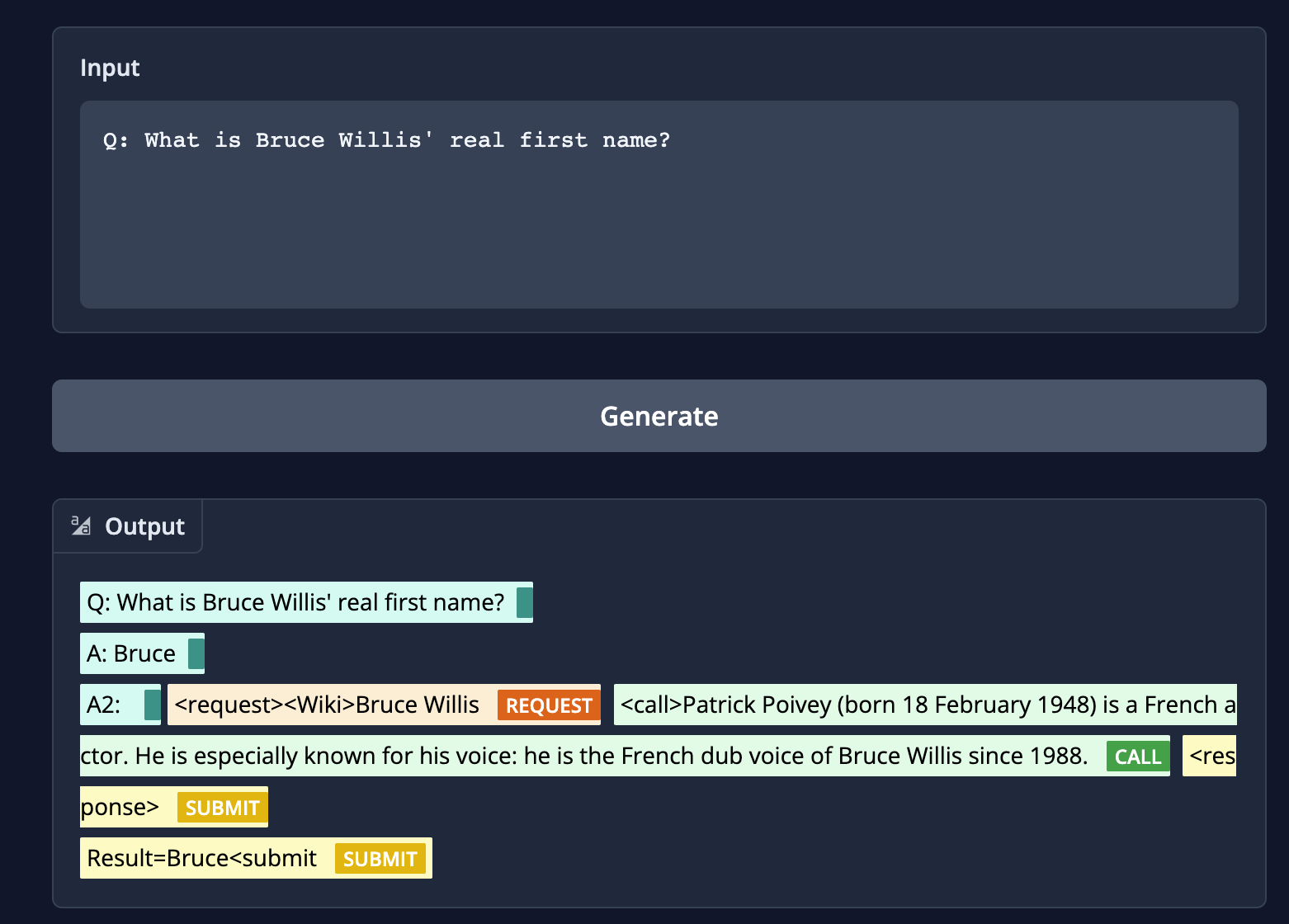
|
||||

|
||||
|
||||
* **unnecessarily long response**: The wiki tool by default sometimes output very long sequences. E.g., when the wiki tool searches for "Brown Act"
|
||||
* Our wiki tool returns "The Ralph M. Brown Act, located at California Government Code 54950 "et seq.", is an act of the California State Legislature, authored by Assemblymember Ralph M. Brown and passed in 1953, that guarantees the public's right to attend and participate in meetings of local legislative bodies."
|
||||
* [ToolFormer](https://huggingface.co/papers/2302.04761)'s wiki tool returns "The Ralph M. Brown Act is an act of the California State Legislature that guarantees the public's right to attend and participate in meetings of local legislative bodies." which is more succinct.
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
## (Early Experiments 🧪): solving math puzzles with python interpreter
|
||||
@ -230,4 +230,4 @@ Q: """
|
||||
|
||||
Training experiment can be found at https://wandb.ai/lvwerra/trl-gsm8k/runs/a5odv01y
|
||||
|
||||
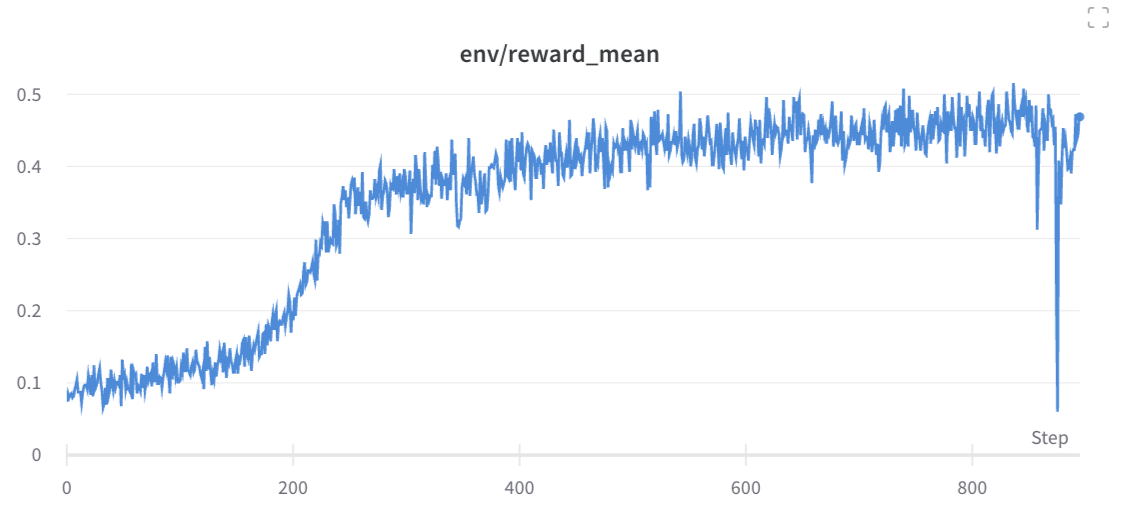
|
||||

|
||||
7
docs/source/liger_kernel_integration.md
Normal file
7
docs/source/liger_kernel_integration.md
Normal file
@ -0,0 +1,7 @@
|
||||
# Liger Kernel Integration
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Section under construction. Feel free to contribute!
|
||||
|
||||
</Tip>
|
||||
@ -111,7 +111,7 @@ trainer.add_callback(completions_callback)
|
||||
|
||||
This callback logs the model's generated completions directly to Weights & Biases.
|
||||
|
||||

|
||||

|
||||
|
||||
## Example script
|
||||
|
||||
|
||||
@ -51,7 +51,7 @@ accelerate launch train_online_dpo.py
|
||||
|
||||
Distributed across 8 GPUs, the training takes approximately 1 hour. You can verify the training progress by checking the reward graph. An increasing trend in both the reward for rejected and chosen completions indicates that the model is improving and generating better responses over time.
|
||||
|
||||

|
||||

|
||||
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-OnlineDPO) performs, you can use the [TRL Chat CLI](clis#chat-interface).
|
||||
|
||||
@ -110,7 +110,7 @@ trainer.add_callback(completions_callback)
|
||||
|
||||
This callback logs the model's generated completions directly to Weights & Biases.
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
## Example script
|
||||
@ -265,7 +265,7 @@ plt.tight_layout()
|
||||
plt.show()
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
The online DPO checkpoint gets increasingly more win rate as we scale up the model sizes. This is a good sign that the online DPO implementation is working as intended.
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# ORPO Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=orpo,trl)
|
||||
[](https://huggingface.co/models?other=orpo,trl) [](https://github.com/huggingface/smol-course/tree/main/2_preference_alignment)
|
||||
|
||||
## Overview
|
||||
|
||||
@ -54,7 +54,7 @@ accelerate launch train_orpo.py
|
||||
|
||||
Distributed across 8 GPUs, the training takes approximately 30 minutes. You can verify the training progress by checking the reward graph. An increasing trend in the reward margin indicates that the model is improving and generating better responses over time.
|
||||
|
||||

|
||||

|
||||
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-ORPO) performs, you can use the [TRL Chat CLI](clis#chat-interface).
|
||||
|
||||
|
||||
@ -118,7 +118,7 @@ The `trl` library also supports naive pipeline parallelism (NPP) for large model
|
||||
This paradigm, termed as "Naive Pipeline Parallelism" (NPP) is a simple way to parallelize the model across multiple GPUs. We load the model and the adapters across multiple GPUs and the activations and gradients will be naively communicated across the GPUs. This supports `int8` models as well as other `dtype` models.
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-npp.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl-npp.png">
|
||||
</div>
|
||||
|
||||
### How to use NPP?
|
||||
@ -140,5 +140,5 @@ python PATH_TO_SCRIPT
|
||||
You can easily fine-tune Llama2 model using `SFTTrainer` and the official script! For example to fine-tune llama2-7b on the Guanaco dataset, run (tested on a single NVIDIA T4-16GB):
|
||||
|
||||
```bash
|
||||
python examples/scripts/sft.py --output_dir sft_openassistant-guanaco --model_name meta-llama/Llama-2-7b-hf --dataset_name timdettmers/openassistant-guanaco --load_in_4bit --use_peft --per_device_train_batch_size 4 --gradient_accumulation_steps 2
|
||||
python trl/scripts/sft.py --output_dir sft_openassistant-guanaco --model_name meta-llama/Llama-2-7b-hf --dataset_name timdettmers/openassistant-guanaco --load_in_4bit --use_peft --per_device_train_batch_size 4 --gradient_accumulation_steps 2
|
||||
```
|
||||
@ -66,7 +66,7 @@ The logged metrics are as follows. Here is an example [tracked run at Weights an
|
||||
|
||||
To help you understand what your model is doing, we periodically log some sample completions from the model. Here is an example of a completion. In an example [tracked run at Weights and Biases](https://wandb.ai/huggingface/trl/runs/dd2o3g35), it looks like the following, allowing you to see the model's response at different stages of training. By default we generate `--num_sample_generations 10` during training, but you can customize the number of generations.
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
In the logs the sampled generations look like
|
||||
@ -210,7 +210,7 @@ The PPO checkpoint gets a 64.7% preferred rate vs the 33.0% preference rate of t
|
||||
|
||||
Metrics:
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
```bash
|
||||
|
||||
125
docs/source/prm_trainer.md
Normal file
125
docs/source/prm_trainer.md
Normal file
@ -0,0 +1,125 @@
|
||||
# PRM Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=prm,trl)
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
PRM Trainer is an experimental API which is subject to change at any time.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Overview
|
||||
|
||||
Process-supervised Reward Models (PRM) were proposed in [Solving math word problems with process- and outcome-based feedback](https://huggingface.co/papers/2211.14275) by Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
> Recent work has shown that asking language models to generate reasoning steps improves performance on many reasoning tasks. When moving beyond prompting, this raises the question of how we should supervise such models: outcome-based approaches which supervise the final result, or process-based approaches which supervise the reasoning process itself? Differences between these approaches might naturally be expected not just in final-answer errors but also in reasoning errors, which can be difficult to detect and are problematic in many real-world domains such as education. We run the first comprehensive comparison between process- and outcome-based approaches trained on a natural language task, GSM8K. We find that pure outcome-based supervision produces similar final-answer error rates with less label supervision. However, for correct reasoning steps we find it necessary to use processbased supervision or supervision from learned reward models that emulate process-based feedback. In total, we improve the previous best results from 16.8% → 12.7% final-answer error and 14.0% → 3.4% reasoning error among final-answer-correct solutions.
|
||||
|
||||
This post-training method was contributed by [Gaetan Lopez](https://github.com/gaetanlop), [Lewis Tunstall](https://huggingface.co/lewtun), [Quentin Gallouédec](https://huggingface.co/qgallouedec) and [Agustín Piqueres](https://huggingface.co/plaguss).
|
||||
|
||||
|
||||
## Quick start
|
||||
|
||||
This example demonstrates how to train a model using the PRM method. We use the [Qwen 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B) as the base model. We use the stepwise supervision data from the [Math Shepherd dataset](https://huggingface.co/datasets/trl-lib/math_shepherd). You can view the data in the dataset here:
|
||||
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/math_shepherd/embed/viewer/default/train?row=0"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
Below is the script to train the model:
|
||||
|
||||
```python
|
||||
# train_prm.py
|
||||
from datasets import load_dataset
|
||||
from trl import PRMConfig, PRMTrainer
|
||||
from transformers import AutoModelForTokenClassification, AutoTokenizer
|
||||
|
||||
model = AutoModelForTokenClassification.from_pretrained("Qwen/Qwen2-0.5B", num_labels=2)
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B")
|
||||
train_dataset = load_dataset("trl-lib/math_shepherd", split="train[:10%]")
|
||||
|
||||
training_args = PRMConfig(output_dir="Qwen2-0.5B-Reward-Math-Sheperd", logging_steps=10)
|
||||
trainer = PRMTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
Execute the script using the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch train_prm.py
|
||||
```
|
||||
|
||||
Distributed across 8 GPUs, the training takes approximately 1 hour.
|
||||
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-Reward-Math-Sheperd) performs, you can use the following script.
|
||||
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
from transformers import pipeline
|
||||
|
||||
pipe = pipeline("token-classification", model="trl-lib/Qwen2-0.5B-Reward-Math-Sheperd")
|
||||
dataset = load_dataset("trl-lib/math_shepherd")
|
||||
example = {
|
||||
"prompt": "Musa is the class teacher of a class of 45 students. He wants to split them into three groups by age. If a third of the class is under 11 years, and two-fifths are above 11 but under 13, how many students will be in the third group (13 years and above)?",
|
||||
"completions": [
|
||||
"Step 1: A third of the class is under 11 years because 11 - 1/3 = <<11-1/3=7>>7.",
|
||||
"Step 2: Two-fifths of the class are above 11 but under 13 because 2/5 * 11 = <<2/5*11=8>>8.",
|
||||
"Step 3: There are 45 students, so the third group will have 45 - 7 - 8 = <<45-7-8=20>>20 students. The answer is: 20",
|
||||
],
|
||||
"labels": [True, False, False],
|
||||
}
|
||||
|
||||
|
||||
separator = "\n" # It's important to use the same separator as the one used during training
|
||||
|
||||
for idx in range(1, len(example["completions"]) + 1):
|
||||
steps = example["completions"][0:idx]
|
||||
text = separator.join((example["prompt"], *steps)) + separator # Add a separator between the prompt and each steps
|
||||
pred_entity = pipe(text)[-1]["entity"]
|
||||
pred = {"LABEL_0": False, "LABEL_1": True}[pred_entity]
|
||||
label = example["labels"][idx - 1]
|
||||
print(f"Step {idx}\tPredicted: {pred} \tLabel: {label}")
|
||||
```
|
||||
|
||||
```text
|
||||
Step 1 Predicted: True Label: True
|
||||
Step 2 Predicted: False Label: False
|
||||
Step 3 Predicted: False Label: False
|
||||
```
|
||||
|
||||
It's a win!
|
||||
|
||||
## Expected dataset type
|
||||
|
||||
PRM requires a [stepwise supervision](dataset_formats#stepwise-supervision).
|
||||
The dataset should contain the following columns: `prompt`, `completions` and `labels`, where `completions` contains a list of reasoning steps and `labels` a list of booleans or floats indicating the correctness of each step.
|
||||
|
||||
The [`PRMTrainer`] only supports [standard](dataset_formats#standard) dataset format.
|
||||
|
||||
## Example script
|
||||
|
||||
We provide an example script to train a model using the PRM method. The script is available in [`examples/scripts/prm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/prm.py)
|
||||
|
||||
To use the PRM script with the [Qwen2 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B) on the [Math Shepherd dataset](https://huggingface.co/datasets/trl-lib/math_shepherd), run the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch examples/scripts/prm.py \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B \
|
||||
--dataset_name trl-lib/math_shepherd \
|
||||
--num_train_epochs 1 \
|
||||
--logging_steps 25 \
|
||||
--output_dir Qwen2-0.5B-Reward-Math-Sheperd
|
||||
```
|
||||
|
||||
## PRMTrainer
|
||||
|
||||
[[autodoc]] PRMTrainer
|
||||
|
||||
## PRMConfig
|
||||
|
||||
[[autodoc]] PRMConfig
|
||||
@ -9,7 +9,7 @@ Fine-tuning a language model via PPO consists of roughly three steps:
|
||||
3. **Optimization**: This is the most complex part. In the optimisation step the query/response pairs are used to calculate the log-probabilities of the tokens in the sequences. This is done with the model that is trained and a reference model, which is usually the pre-trained model before fine-tuning. The KL-divergence between the two outputs is used as an additional reward signal to make sure the generated responses don't deviate too far from the reference language model. The active language model is then trained with PPO.
|
||||
|
||||
The full process is illustrated in the following figure:
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl_overview.png"/>
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl_overview.png"/>
|
||||
|
||||
## Minimal example
|
||||
|
||||
133
docs/source/reducing_memory_usage.md
Normal file
133
docs/source/reducing_memory_usage.md
Normal file
@ -0,0 +1,133 @@
|
||||
# Reducing Memory Usage
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Section under construction. Feel free to contribute!
|
||||
|
||||
</Tip>
|
||||
|
||||
## Truncation
|
||||
|
||||
Sequence lengths in the dataset can vary widely. When data is batched, sequences are padded to match the longest one in the batch, which can cause high memory usage, even if most sequences are relatively short.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/why_you_should_truncate.png" alt="Truncation prompt completion" width="600"/>
|
||||
</div>
|
||||
|
||||
To reduce memory usage, it’s important to truncate sequences to a reasonable length. While TRL trainers truncate sequences by default, you may want to adjust the default truncation length to better align with your specific use case.
|
||||
|
||||
<hfoptions id="dpo">
|
||||
<hfoption id="DPO">
|
||||
|
||||
DPO truncation is applied first to the prompt and to the completion via the `max_prompt_length` and `max_completion_length` parameters. The `max_length` parameter is then used to truncate the resulting sequence.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/truncation_prompt_completion.png" alt="Truncation prompt completion" width="600"/>
|
||||
</div>
|
||||
|
||||
To set the truncation parameters, use the following code snippet:
|
||||
|
||||
```python
|
||||
from trl import DPOConfig
|
||||
|
||||
training_args = DPOConfig(..., max_prompt_length=..., max_length=...)
|
||||
```
|
||||
|
||||
You can also use the `max_completion_length` parameter to truncate the completion, though this is less common since the goal is typically to preserve the completion's full length whenever possible.
|
||||
|
||||
```python
|
||||
from trl import DPOConfig
|
||||
|
||||
training_args = DPOConfig(..., max_completion_length=...)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="SFT">
|
||||
|
||||
SFT truncation is applied to the input sequence via the `max_seq_length` parameter.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/truncation_input_ids.png" alt="Truncation input ids" width="600"/>
|
||||
</div>
|
||||
|
||||
To set the truncation parameter, use the following code snippet:
|
||||
|
||||
```python
|
||||
from trl import SFTConfig
|
||||
|
||||
training_args = SFTConfig(..., max_seq_length=...)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## Packing
|
||||
|
||||
<Tip>
|
||||
|
||||
This technique applies only to SFT.
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
[Truncation](#truncation) has several drawbacks:
|
||||
1. **Loss of information**: Key data at the end of a sequence may be discarded.
|
||||
2. **Choosing truncation length**: Too short loses data; too long undermines efficiency.
|
||||
|
||||
Packing, introduced in [Raffel et al., 2020](https://huggingface.co/papers/1910.10683), addresses these issues by grouping sequences instead of truncating. It concatenates and splits dataset sequences into the desired lengths.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/packing.png" alt="Packing" width="600"/>
|
||||
</div>
|
||||
|
||||
Packing eliminates padding, preserves all sequence information, and allows for flexible sequence lengths, making it a more efficient alternative to truncation. To enable packing, use `packing=True` in the [`SFTConfig`]:
|
||||
|
||||
```python
|
||||
from trl import SFTConfig
|
||||
|
||||
training_args = SFTConfig(..., packing=True, max_seq_length=512)
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Packing may cause batch contamination, where adjacent sequences influence one another. This can be problematic for some applications. For more details, see [#1230](https://github.com/huggingface/trl/issues/1230).
|
||||
|
||||
</Tip>
|
||||
|
||||
## Disabling model gathering for generation in online methods
|
||||
|
||||
When using DeepSpeed ZeRO-3, model weights are sharded across multiple GPUs. Online methods involve generating completions from the model as part of the training process. During this step, the model weights are temporarily gathered on a single GPU for generation. For very large models, this gathering can lead to out-of-memory (OOM) errors, as described in this issue: [#2250](https://github.com/huggingface/trl/issues/2250#issue-2598304204).
|
||||
|
||||
If you encounter this issue, you can disable the gathering of model weights for generation by setting the following parameter:
|
||||
|
||||
<hfoptions id="ds3_gather_for_generation">
|
||||
<hfoption id="Online DPO">
|
||||
|
||||
```python
|
||||
from trl import OnlineDPOConfig
|
||||
|
||||
training_args = OnlineDPOConfig(..., ds3_gather_for_generation=False)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="PPO">
|
||||
|
||||
```python
|
||||
from trl import PPOConfig
|
||||
|
||||
training_args = PPOConfig(..., ds3_gather_for_generation=False)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="RLOO">
|
||||
|
||||
```python
|
||||
from trl import RLOOConfig
|
||||
|
||||
training_args = RLOOConfig(..., ds3_gather_for_generation=False)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
This adjustment prevents model weights from being gathered, avoiding OOM errors, but it may result in slower generation speeds.
|
||||
@ -68,7 +68,7 @@ The logged metrics are as follows. Here is an example [tracked run at Weights an
|
||||
|
||||
To help you understand what your model is doing, we periodically log some sample completions from the model. Here is an example of a completion. In an example [tracked run at Weights and Biases](https://wandb.ai/huggingface/trl/runs/u2sqci34), it looks like the following, allowing you to see the model's response at different stages of training. By default we generate `--num_sample_generations 10` during training, but you can customize the number of generations.
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
In the logs the sampled generations look like
|
||||
@ -218,8 +218,8 @@ accelerate launch --config_file examples/accelerate_configs/deepspeed_zero2.yaml
|
||||
--num_ppo_epochs 2 \
|
||||
--num_mini_batches 2 \
|
||||
--learning_rate 3e-6 \
|
||||
--per_device_train_batch_size 8 \
|
||||
--gradient_accumulation_steps 8 \
|
||||
--per_device_train_batch_size 16 \
|
||||
--gradient_accumulation_steps 16 \
|
||||
--total_episodes 1000000 \
|
||||
--model_name_or_path EleutherAI/pythia-1b-deduped \
|
||||
--sft_model_path cleanrl/EleutherAI_pythia-1b-deduped__sft__tldr \
|
||||
@ -251,7 +251,7 @@ The RLOO checkpoint gets a 51.2% preferred rate vs the 33.0% preference rate of
|
||||
|
||||
Metrics:
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
```bash
|
||||
@ -269,6 +269,17 @@ python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--scan-history
|
||||
```
|
||||
|
||||
## Reinforce++
|
||||
|
||||
The [Reinforce++](https://hijkzzz.notion.site/reinforce-plus-plus) report by Jian Hu suggests several optimization tricks to enhance performance and stability of RLHF. They include:
|
||||
|
||||
- Clipping rewards: limiting reward values within a specific range to mitigate the impact of extreme rewards on model updates, thus preventing gradient explosion
|
||||
- Normalizing rewards: scaling rewards to have a mean of 0 and a standard deviation of 1, which helps in stabilizing the training process
|
||||
- Normalizing advantages: scaling advantages to have a mean of 0 and a standard deviation of 1, which helps in stabilizing the training process
|
||||
- Using token-level KL penalty that is defined as equation (1) of the report vs. sequence-level KL penalty (default)
|
||||
|
||||
These options are available via the appropriate arguments in the [`RLOOConfig`] class.
|
||||
|
||||
|
||||
## RLOOTrainer
|
||||
|
||||
@ -276,4 +287,4 @@ python -m openrlbenchmark.rlops_multi_metrics \
|
||||
|
||||
## RLOOConfig
|
||||
|
||||
[[autodoc]] RLOOConfig
|
||||
[[autodoc]] RLOOConfig
|
||||
|
||||
12
docs/source/script_utils.md
Normal file
12
docs/source/script_utils.md
Normal file
@ -0,0 +1,12 @@
|
||||
# Scripts Utilities
|
||||
|
||||
## ScriptArguments
|
||||
|
||||
[[autodoc]] ScriptArguments
|
||||
|
||||
## TrlParser
|
||||
|
||||
[[autodoc]] TrlParser
|
||||
- parse_args_and_config
|
||||
- parse_args_into_dataclasses
|
||||
- set_defaults_with_config
|
||||
@ -1,10 +1,10 @@
|
||||
# Supervised Fine-tuning Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=sft,trl)
|
||||
[](https://huggingface.co/models?other=sft,trl) [](https://github.com/huggingface/smol-course/tree/main/1_instruction_tuning)
|
||||
|
||||
Supervised fine-tuning (or SFT for short) is a crucial step in RLHF. In TRL we provide an easy-to-use API to create your SFT models and train them with few lines of code on your dataset.
|
||||
|
||||
Check out a complete flexible example at [`examples/scripts/sft.py`](https://github.com/huggingface/trl/tree/main/examples/scripts/sft.py).
|
||||
Check out a complete flexible example at [`trl/scripts/sft.py`](https://github.com/huggingface/trl/tree/main/trl/scripts/sft.py).
|
||||
Experimental support for Vision Language Models is also included in the example [`examples/scripts/sft_vlm.py`](https://github.com/huggingface/trl/tree/main/examples/scripts/sft_vlm.py).
|
||||
|
||||
## Quickstart
|
||||
@ -331,33 +331,38 @@ Note that all keyword arguments of `from_pretrained()` are supported.
|
||||
|
||||
### Training adapters
|
||||
|
||||
We also support tight integration with 🤗 PEFT library so that any user can conveniently train adapters and share them on the Hub instead of training the entire model
|
||||
We also support tight integration with 🤗 PEFT library so that any user can conveniently train adapters and share them on the Hub instead of training the entire model.
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
from trl import SFTConfig, SFTTrainer
|
||||
from peft import LoraConfig
|
||||
|
||||
dataset = load_dataset("stanfordnlp/imdb", split="train")
|
||||
dataset = load_dataset("trl-lib/Capybara", split="train")
|
||||
|
||||
peft_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
target_modules="all-linear",
|
||||
modules_to_save=["lm_head", "embed_token"],
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
"EleutherAI/gpt-neo-125m",
|
||||
"Qwen/Qwen2.5-0.5B",
|
||||
train_dataset=dataset,
|
||||
args=SFTConfig(output_dir="/tmp"),
|
||||
args=SFTConfig(output_dir="Qwen2.5-0.5B-SFT"),
|
||||
peft_config=peft_config
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> If the chat template contains special tokens like `<|im_start|>` (ChatML) or `<|eot_id|>` (Llama), the embedding layer and LM head must be included in the trainable parameters via the `modules_to_save` argument. Without this, the fine-tuned model will produce unbounded or nonsense generations. If the chat template doesn't contain special tokens (e.g. Alpaca), then the `modules_to_save` argument can be ignored or set to `None`.
|
||||
|
||||
|
||||
You can also continue training your `PeftModel`. For that, first load a `PeftModel` outside `SFTTrainer` and pass it directly to the trainer without the `peft_config` argument being passed.
|
||||
|
||||
### Training adapters with base 8 bit models
|
||||
@ -463,30 +468,30 @@ We included a utility function to create your model.
|
||||
|
||||
```python
|
||||
from trl import ModelConfig, SFTTrainer, get_kbit_device_map, get_peft_config, get_quantization_config
|
||||
model_config = ModelConfig(
|
||||
model_args = ModelConfig(
|
||||
model_name_or_path="facebook/opt-350m"
|
||||
attn_implementation=None, # or "flash_attention_2"
|
||||
)
|
||||
torch_dtype = (
|
||||
model_config.torch_dtype
|
||||
if model_config.torch_dtype in ["auto", None]
|
||||
else getattr(torch, model_config.torch_dtype)
|
||||
model_args.torch_dtype
|
||||
if model_args.torch_dtype in ["auto", None]
|
||||
else getattr(torch, model_args.torch_dtype)
|
||||
)
|
||||
quantization_config = get_quantization_config(model_config)
|
||||
quantization_config = get_quantization_config(model_args)
|
||||
model_kwargs = dict(
|
||||
revision=model_config.model_revision,
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
attn_implementation=model_config.attn_implementation,
|
||||
revision=model_args.model_revision,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
attn_implementation=model_args.attn_implementation,
|
||||
torch_dtype=torch_dtype,
|
||||
use_cache=False if training_args.gradient_checkpointing else True,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_config.model_name_or_path, **model_kwargs)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_args.model_name_or_path, **model_kwargs)
|
||||
trainer = SFTTrainer(
|
||||
...,
|
||||
model=model_config.model_name_or_path,
|
||||
peft_config=get_peft_config(model_config),
|
||||
model=model_args.model_name_or_path,
|
||||
peft_config=get_peft_config(model_args),
|
||||
)
|
||||
```
|
||||
|
||||
@ -497,7 +502,7 @@ NEFTune is a technique to boost the performance of chat models and was introduce
|
||||
> Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/neft-screenshot.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/neft-screenshot.png">
|
||||
</div>
|
||||
|
||||
To use it in `SFTTrainer` simply pass `neftune_noise_alpha` when creating your `SFTConfig` instance. Note that to avoid any surprising behaviour, NEFTune is disabled after training to retrieve back the original behaviour of the embedding layer.
|
||||
@ -522,7 +527,7 @@ trainer.train()
|
||||
We have tested NEFTune by training `mistralai/Mistral-7B-v0.1` on the [OpenAssistant dataset](https://huggingface.co/datasets/timdettmers/openassistant-guanaco) and validated that using NEFTune led to a performance boost of ~25% on MT Bench.
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-neftune-mistral-7b.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/trl-neftune-mistral-7b.png">
|
||||
</div>
|
||||
|
||||
Note however, that the amount of performance gain is _dataset dependent_ and in particular, applying NEFTune on synthetic datasets like [UltraChat](https://huggingface.co/datasets/stingning/ultrachat) typically produces smaller gains.
|
||||
@ -619,7 +624,7 @@ To learn more about Liger-Kernel, visit their [official repository](https://gith
|
||||
|
||||
Pay attention to the following best practices when training a model with that trainer:
|
||||
|
||||
- [`SFTTrainer`] always pads by default the sequences to the `max_seq_length` argument of the [`SFTTrainer`]. If none is passed, the trainer will retrieve that value from the tokenizer. Some tokenizers do not provide a default value, so there is a check to retrieve the minimum between 2048 and that value. Make sure to check it before training.
|
||||
- [`SFTTrainer`] always truncates by default the sequences to the `max_seq_length` argument of the [`SFTTrainer`]. If none is passed, the trainer will retrieve that value from the tokenizer. Some tokenizers do not provide a default value, so there is a check to retrieve the minimum between 1024 and that value. Make sure to check it before training.
|
||||
- For training adapters in 8bit, you might need to tweak the arguments of the `prepare_model_for_kbit_training` method from PEFT, hence we advise users to use `prepare_in_int8_kwargs` field, or create the `PeftModel` outside the [`SFTTrainer`] and pass it.
|
||||
- For a more memory-efficient training using adapters, you can load the base model in 8bit, for that simply add `load_in_8bit` argument when creating the [`SFTTrainer`], or create a base model in 8bit outside the trainer and pass it.
|
||||
- If you create a model outside the trainer, make sure to not pass to the trainer any additional keyword arguments that are relative to `from_pretrained()` method.
|
||||
75
docs/source/speeding_up_training.md
Normal file
75
docs/source/speeding_up_training.md
Normal file
@ -0,0 +1,75 @@
|
||||
# Speeding Up Training
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Section under construction. Feel free to contribute!
|
||||
|
||||
</Tip>
|
||||
|
||||
## vLLM for fast generation in online methods
|
||||
|
||||
Online methods such as GRPO or Online DPO require the model to generate completions, which is often a slow process and can significantly impact training time.
|
||||
To speed up generation, you can use [vLLM](https://github.com/vllm-project/vllm), a library that enables fast generation through, among other things, PagedAttention. TRL's online trainers support vLLM, greatly improving training speed.
|
||||
|
||||
To use [vLLM](https://github.com/vllm-project/vllm), first install it using:
|
||||
|
||||
```bash
|
||||
pip install vllm
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```bash
|
||||
pip install "trl[vllm]"
|
||||
```
|
||||
|
||||
<hfoptions id="vllm examples">
|
||||
<hfoption id="Online DPO">
|
||||
|
||||
Then, enable it by passing `use_vllm=True` in the training arguments.
|
||||
|
||||
```python
|
||||
from trl import OnlineDPOConfig
|
||||
|
||||
training_args = OnlineDPOConfig(..., use_vllm=True)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="GRPO">
|
||||
|
||||
Then, enable it by passing `use_vllm=True` in the training arguments.
|
||||
|
||||
```python
|
||||
from trl import GRPOConfig
|
||||
|
||||
training_args = GRPOConfig(..., use_vllm=True)
|
||||
```
|
||||
|
||||
The strategy here is to use a dedicated GPU for generation powered by vLLM, while using the remainder for training.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
When using vLLM, an additional GPU is required exclusively for generation. This means you need at least two available GPUs and must ensure that one remains unused by the trainer. To achieve this, run the training with `--num_processes <NUMBER_OF_GPUs - 1>`.
|
||||
|
||||
For example, if you have 4 GPUs, set `--num_processes 3` to allocate three GPUs for training while reserving one for generation.
|
||||
```bash
|
||||
accelerate launch --multi_gpu --num_processes 3 train_grpo.py
|
||||
```
|
||||
|
||||

|
||||
|
||||
</Tip>
|
||||
|
||||
You can further tune the vLLM configuration by setting a specific `vllm_device` and `vllm_gpu_memory_utilization` in the [`GRPOConfig`].
|
||||
|
||||
```python
|
||||
training_args = GRPOConfig(
|
||||
...,
|
||||
use_vllm=True,
|
||||
vllm_device="cuda:4",
|
||||
vllm_gpu_memory_utilization=0.7,
|
||||
)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
@ -3,7 +3,7 @@
|
||||
Text environments provide a learning ground for language agents. It allows a language model to use tools to accomplish a task such as using a Python interpreter to answer math questions or using a search index for trivia questions. Having access to tools allows language models to solve tasks that would be very hard for the models itself but can be trivial for the appropriate tools. A good example is arithmetics of large numbers that become a simple copy-paste task once you have access to a calculator.
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/textenv.png">
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/textenv.png">
|
||||
</div>
|
||||
|
||||
Let's dive into how text environments work and start with tools!
|
||||
@ -179,13 +179,13 @@ When the model interacts inside the `TextEnvironment` it can be useful to visual
|
||||
You can see that the prompt is highlighted in gray, whereas system segments such as query and tool responses are highlighted in green. All segments generated by the model are highlighted in blue and in addition to the pure text output the reward is displayed as additional text in plum. Here an example of `show_text`:
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/textenv_show_text.png" width=600>
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/textenv_show_text.png" width=600>
|
||||
</div>
|
||||
|
||||
Sometimes there can be tricky tokenization related issues that are hidden when showing the decoded text. Thus `TextHistory` also offers an option to display the same highlighting on the tokens directly with `show_tokens`:
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/textenv_show_tokens.png" width=800>
|
||||
<img src="https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/textenv_show_tokens.png" width=800>
|
||||
</div>
|
||||
|
||||
Note that you can turn on the colour legend by passing `show_legend=True`.
|
||||
|
||||
7
docs/source/unsloth_integration.md
Normal file
7
docs/source/unsloth_integration.md
Normal file
@ -0,0 +1,7 @@
|
||||
# Unsloth Integration
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Section under construction. Feel free to contribute!
|
||||
|
||||
</Tip>
|
||||
@ -19,7 +19,7 @@ Now we can fit very large models into a single GPU, but the training might still
|
||||
The simplest strategy in this scenario is data parallelism: we replicate the same training setup into separate GPUs and pass different batches to each GPU.
|
||||
With this, you can parallelize the forward/backward passes of the model and scale with the number of GPUs.
|
||||
|
||||
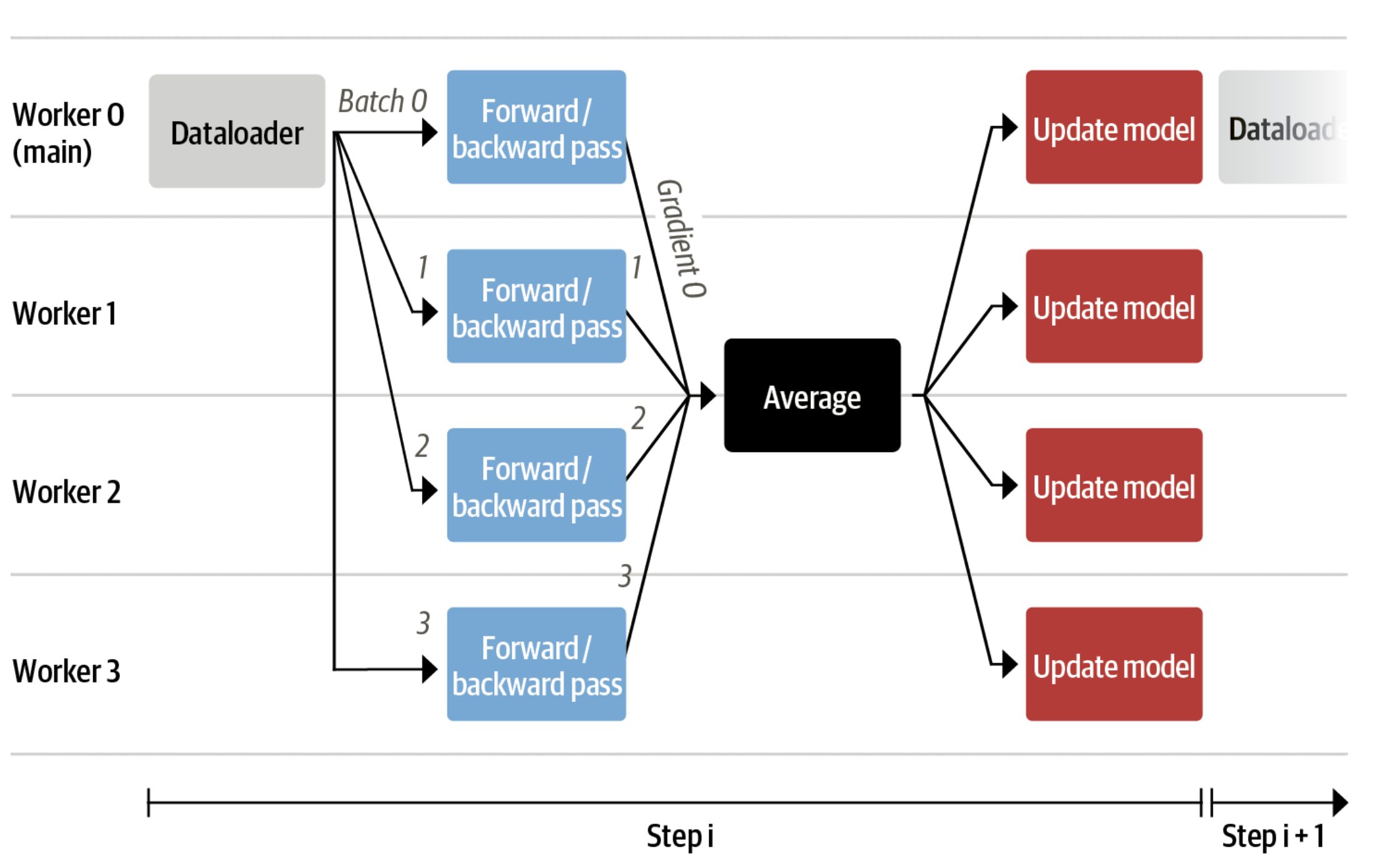
|
||||

|
||||
|
||||
We use either the `transformers.Trainer` or `accelerate`, which both support data parallelism without any code changes, by simply passing arguments when calling the scripts with `torchrun` or `accelerate launch`. The following runs a training script with 8 GPUs on a single machine with `accelerate` and `torchrun`, respectively.
|
||||
|
||||
@ -38,7 +38,7 @@ The [StackExchange dataset](https://huggingface.co/datasets/HuggingFaceH4/stack-
|
||||
There is nothing special about fine-tuning the model before doing RLHF - it’s just the causal language modeling objective from pretraining that we apply here.
|
||||
To use the data efficiently, we use a technique called packing: instead of having one text per sample in the batch and then padding to either the longest text or the maximal context of the model, we concatenate a lot of texts with a EOS token in between and cut chunks of the context size to fill the batch without any padding.
|
||||
|
||||
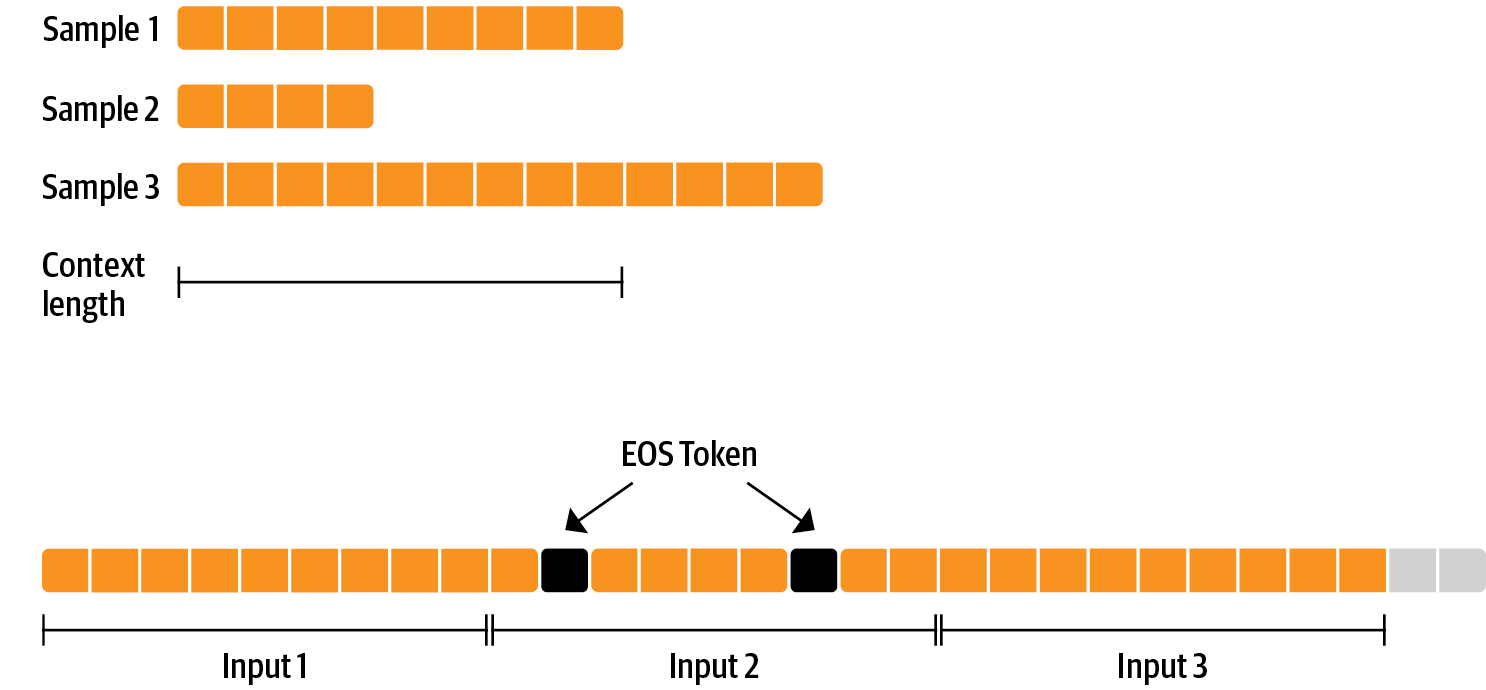
|
||||

|
||||
|
||||
With this approach the training is much more efficient as each token that is passed through the model is also trained in contrast to padding tokens which are usually masked from the loss.
|
||||
If you don't have much data and are more concerned about occasionally cutting off some tokens that are overflowing the context you can also use a classical data loader.
|
||||
@ -110,7 +110,7 @@ trainer.add_callback(completions_callback)
|
||||
|
||||
This callback logs the model's generated completions directly to Weights & Biases.
|
||||
|
||||

|
||||

|
||||
|
||||
## Example script
|
||||
|
||||
@ -7,7 +7,7 @@
|
||||
# CUDA_VISIBLE_DEVICES: 0
|
||||
|
||||
model_name_or_path:
|
||||
trl-internal-testing/tiny-random-LlamaForCausalLM
|
||||
Qwen/Qwen2.5-0.5B
|
||||
dataset_name:
|
||||
stanfordnlp/imdb
|
||||
report_to:
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -13,10 +13,11 @@
|
||||
# limitations under the License.
|
||||
|
||||
import re
|
||||
from dataclasses import dataclass
|
||||
from typing import Dict, List, Optional
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import ModelCard
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@ -30,13 +31,20 @@ class ScriptArguments:
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/hh-rlhf-helpful-base"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
dataset_num_proc (`int` or `None`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/hh-rlhf-helpful-base"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
push_to_hub: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Whether to push the dataset to the Hugging Face Hub."},
|
||||
)
|
||||
repo_id: str = field(
|
||||
default="trl-lib/hh-rlhf-helpful-base", metadata={"help": "Hugging Face repository ID to push the dataset to."}
|
||||
)
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None, metadata={"help": "Number of workers to use for dataset processing."}
|
||||
)
|
||||
|
||||
|
||||
def common_start(str1: str, str2: str) -> str:
|
||||
@ -51,7 +59,7 @@ def common_start(str1: str, str2: str) -> str:
|
||||
return "".join(common_chars)
|
||||
|
||||
|
||||
def extract_dialogue(example: str) -> List[Dict[str, str]]:
|
||||
def extract_dialogue(example: str) -> list[dict[str, str]]:
|
||||
# Extract the prompt, which corresponds to the common start of the chosen and rejected dialogues
|
||||
prompt_text = common_start(example["chosen"], example["rejected"])
|
||||
|
||||
@ -79,12 +87,40 @@ def extract_dialogue(example: str) -> List[Dict[str, str]]:
|
||||
prompt.append({"role": role, "content": content})
|
||||
|
||||
# Remove the prompt from the chosen and rejected dialogues
|
||||
chosen = [{"role": "assitant", "content": chosen_line}]
|
||||
chosen = [{"role": "assistant", "content": chosen_line}]
|
||||
rejected = [{"role": "assistant", "content": rejected_line}]
|
||||
|
||||
return {"prompt": prompt, "chosen": chosen, "rejected": rejected}
|
||||
|
||||
|
||||
model_card = ModelCard("""
|
||||
---
|
||||
tags: [trl]
|
||||
---
|
||||
|
||||
# HH-RLHF-Helpful-Base Dataset
|
||||
|
||||
## Summary
|
||||
|
||||
The HH-RLHF-Helpful-Base dataset is a processed version of [Anthropic's HH-RLHF](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset, specifically curated to train models using the [TRL library](https://github.com/huggingface/trl) for preference learning and alignment tasks. It contains pairs of text samples, each labeled as either "chosen" or "rejected," based on human preferences regarding the helpfulness of the responses. This dataset enables models to learn human preferences in generating helpful responses, enhancing their ability to assist users effectively.
|
||||
|
||||
## Data Structure
|
||||
|
||||
- **Format**: [Conversational](https://huggingface.co/docs/trl/main/dataset_formats#conversational)
|
||||
- **Type**: [Preference](https://huggingface.co/docs/trl/main/dataset_formats#preference)
|
||||
|
||||
Columns:
|
||||
- `"prompt"`: The user query.
|
||||
- `"chosen"`: A response deemed helpful by human evaluators.
|
||||
- `"rejected"`: A response considered less helpful or unhelpful.
|
||||
|
||||
This structure allows models to learn to prefer the _chosen_ response over the _rejected_ one, thereby aligning with human preferences in helpfulness.
|
||||
|
||||
## Generation script
|
||||
|
||||
The script used to generate this dataset can be found [here](https://github.com/huggingface/trl/blob/main/examples/datasets/hh-rlhf-helpful-base.py).
|
||||
""")
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
@ -94,3 +130,4 @@ if __name__ == "__main__":
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
model_card.push_to_hub(script_args.repo_id, repo_type="dataset")
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -12,10 +12,11 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import ModelCard
|
||||
from transformers import AutoTokenizer, HfArgumentParser
|
||||
|
||||
|
||||
@ -29,13 +30,22 @@ class ScriptArguments:
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/lm-human-preferences-descriptiveness"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
dataset_num_proc (`int` or `None`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/lm-human-preferences-descriptiveness"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
push_to_hub: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Whether to push the dataset to the Hugging Face Hub."},
|
||||
)
|
||||
repo_id: str = field(
|
||||
default="trl-lib/lm-human-preferences-descriptiveness",
|
||||
metadata={"help": "Hugging Face repository ID to push the dataset to."},
|
||||
)
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={"help": "Number of workers to use for dataset processing."},
|
||||
)
|
||||
|
||||
|
||||
# Edge cases handling: remove the cases where all samples are the same
|
||||
@ -55,6 +65,34 @@ def to_prompt_completion(example, tokenizer):
|
||||
return {"prompt": prompt, "chosen": chosen, "rejected": rejected}
|
||||
|
||||
|
||||
model_card = ModelCard("""
|
||||
---
|
||||
tags: [trl]
|
||||
---
|
||||
|
||||
# LM-Human-Preferences-Descriptiveness Dataset
|
||||
|
||||
## Summary
|
||||
|
||||
The LM-Human-Preferences-Descriptiveness dataset is a processed subset of [OpenAI's LM-Human-Preferences](https://github.com/openai/lm-human-preferences), focusing specifically on enhancing the descriptiveness of generated text. It contains pairs of text samples, each labeled as either "chosen" or "rejected," based on human preferences regarding the level of detail and vividness in the descriptions. This dataset enables models to learn human preferences in descriptive language, improving their ability to generate rich and engaging narratives.
|
||||
|
||||
## Data Structure
|
||||
|
||||
- **Format**: [Standard](https://huggingface.co/docs/trl/main/dataset_formats#standard)
|
||||
- **Type**: [Preference](https://huggingface.co/docs/trl/main/dataset_formats#preference)
|
||||
|
||||
Columns:
|
||||
- `"prompt"`: The text sample.
|
||||
- `"chosen"`: A version of the text with enhanced descriptiveness.
|
||||
- `"rejected"`: A version of the text with less descriptiveness.
|
||||
|
||||
This structure allows models to learn to prefer the _chosen_ response over the _rejected_ one, thereby aligning with human preferences in descriptive language.
|
||||
|
||||
## Generation script
|
||||
|
||||
The script used to generate this dataset can be found [here](https://github.com/huggingface/trl/blob/main/examples/datasets/lm-human-preferences-descriptiveness.py).
|
||||
""")
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
@ -79,3 +117,4 @@ if __name__ == "__main__":
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
model_card.push_to_hub(script_args.repo_id, repo_type="dataset")
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -12,10 +12,11 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import ModelCard
|
||||
from transformers import AutoTokenizer, HfArgumentParser
|
||||
|
||||
|
||||
@ -29,13 +30,22 @@ class ScriptArguments:
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/lm-human-preferences-sentiment"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
dataset_num_proc (`int` or `None`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/lm-human-preferences-sentiment"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
push_to_hub: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Whether to push the dataset to the Hugging Face Hub."},
|
||||
)
|
||||
repo_id: str = field(
|
||||
default="trl-lib/lm-human-preferences-sentiment",
|
||||
metadata={"help": "Hugging Face repository ID to push the dataset to."},
|
||||
)
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={"help": "Number of workers to use for dataset processing."},
|
||||
)
|
||||
|
||||
|
||||
def to_prompt_completion(example, tokenizer):
|
||||
@ -50,6 +60,34 @@ def to_prompt_completion(example, tokenizer):
|
||||
return {"prompt": prompt, "chosen": chosen, "rejected": rejected}
|
||||
|
||||
|
||||
model_card = ModelCard("""
|
||||
---
|
||||
tags: [trl]
|
||||
---
|
||||
|
||||
# LM-Human-Preferences-Sentiment Dataset
|
||||
|
||||
## Summary
|
||||
|
||||
The LM-Human-Preferences-Sentiment dataset is a processed subset of [OpenAI's LM-Human-Preferences](https://github.com/openai/lm-human-preferences), focusing specifically on sentiment analysis tasks. It contains pairs of text samples, each labeled as either "chosen" or "rejected," based on human preferences regarding the sentiment conveyed in the text. This dataset enables models to learn human preferences in sentiment expression, enhancing their ability to generate and evaluate text with desired emotional tones.
|
||||
|
||||
## Data Structure
|
||||
|
||||
- **Format**: [Standard](https://huggingface.co/docs/trl/main/dataset_formats#standard)
|
||||
- **Type**: [Preference](https://huggingface.co/docs/trl/main/dataset_formats#preference)
|
||||
|
||||
Columns:
|
||||
- `"prompt"`: The text sample.
|
||||
- `"chosen"`: A version of the text that conveys the desired sentiment.
|
||||
- `"rejected"`: A version of the text that does not convey the desired sentiment.
|
||||
|
||||
This structure allows models to learn to prefer the _chosen_ response over the _rejected_ one, thereby aligning with human preferences in sentiment expression.
|
||||
|
||||
## Generation script
|
||||
|
||||
The script used to generate this dataset can be found [here](https://github.com/huggingface/trl/blob/main/examples/datasets/lm-human-preferences-sentiment.py).
|
||||
""")
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
@ -72,3 +110,4 @@ if __name__ == "__main__":
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
model_card.push_to_hub(script_args.repo_id, repo_type="dataset")
|
||||
|
||||
170
examples/datasets/math_shepherd.py
Normal file
170
examples/datasets/math_shepherd.py
Normal file
@ -0,0 +1,170 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import re
|
||||
from dataclasses import dataclass, field
|
||||
from itertools import chain
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import ModelCard
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/math_shepherd"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`int` or `None`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Whether to push the dataset to the Hugging Face Hub."},
|
||||
)
|
||||
repo_id: str = field(
|
||||
default="trl-lib/math_shepherd",
|
||||
metadata={"help": "Hugging Face repository ID to push the dataset to."},
|
||||
)
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={"help": "Number of workers to use for dataset processing."},
|
||||
)
|
||||
|
||||
|
||||
def process_example(example):
|
||||
# Replace "ки" with "ⶻ" so that the size of the "input" matches the size of the "label"
|
||||
inputs = example["input"].replace("ки", "ⶻ")
|
||||
|
||||
# Find the indices of the "ⶻ" characters (that should match with the indexes of the "+" or "-" in the label)
|
||||
indexes = [m.start() for m in re.finditer("ⶻ", inputs)]
|
||||
|
||||
# Sanity that all indexes are either "+" or "-"
|
||||
assert all(example["label"][idx] in ["+", "-"] for idx in indexes)
|
||||
|
||||
# Get the labels
|
||||
labels = [example["label"][idx] == "+" for idx in indexes]
|
||||
|
||||
# Split the inputs into steps (caution, the first step is missing here, it is the prompt)
|
||||
steps = [inputs[i:j] for i, j in zip(chain([0], indexes), chain(indexes, [None]))]
|
||||
|
||||
# Remove the last step (single ⶻ)
|
||||
steps = steps[:-1]
|
||||
|
||||
# Get the prompt (first part) and completions (rest)
|
||||
prompt = steps[0]
|
||||
completions = steps[1:]
|
||||
|
||||
# Remove the heading "ⶻ" and the final whitespace from the completions
|
||||
assert all(completion.startswith("ⶻ") for completion in completions)
|
||||
completions = [completion[1:].strip() for completion in completions]
|
||||
|
||||
# At this point, we need to retrieve the first step from the prompt.
|
||||
# First, we handle particular cases (annotation error) where we have a first label before the end of the prompt.
|
||||
if prompt.startswith(
|
||||
(
|
||||
"Mr. Rocky",
|
||||
"Parker",
|
||||
"What is the smallest positive",
|
||||
" The Myth",
|
||||
"Let $\\mathbf{a}$",
|
||||
"Find the arithmetic",
|
||||
"Determine an ordered pair",
|
||||
"Determine the ordered pair",
|
||||
"At the Quill and Scroll stationery",
|
||||
"Round to the nearest",
|
||||
r"Calculate $\sqrt{10p}",
|
||||
r"Simplify $\sqrt{28x}",
|
||||
)
|
||||
):
|
||||
# Some spotted datasets errors where there is an annotation in the prompt: we remove it
|
||||
labels = labels[1:]
|
||||
|
||||
# Then we handle the general case: we get the first step from the prompt by looking for "Step 1:" or "step 1:" or
|
||||
# (less common) "?".
|
||||
elif "Step 1:" in prompt:
|
||||
prompt, first_step = prompt.split("Step 1:")
|
||||
first_step = "Step 1:" + first_step
|
||||
completions = [first_step.strip()] + completions
|
||||
elif "step 1:" in prompt:
|
||||
prompt, first_step = prompt.split("step 1:")
|
||||
first_step = "step 1:" + first_step
|
||||
completions = [first_step.strip()] + completions
|
||||
elif "?" in prompt:
|
||||
prompt, first_step = prompt.split("?")
|
||||
prompt = prompt + "?"
|
||||
completions = [first_step.strip()] + completions
|
||||
else:
|
||||
raise ValueError(f"Prompt can't be processed: {prompt}")
|
||||
|
||||
# Strip the prompt
|
||||
prompt = prompt.strip()
|
||||
|
||||
# Sanity check that the length of the completions is the same as the length of the labels
|
||||
assert len(completions) == len(labels)
|
||||
|
||||
return {"prompt": prompt, "completions": completions, "labels": labels}
|
||||
|
||||
|
||||
model_card = ModelCard("""
|
||||
---
|
||||
tags: [trl]
|
||||
---
|
||||
|
||||
# Math-Shepherd Dataset
|
||||
|
||||
## Summary
|
||||
|
||||
The Math-Shepherd dataset is a processed version of [Math-Shepherd dataset](peiyi9979/Math-Shepherd), designed to train models using the [TRL library](https://github.com/huggingface/trl) for stepwise supervision tasks. It provides step-by-step solutions to mathematical problems, enabling models to learn and verify each step of a solution, thereby enhancing their reasoning capabilities.
|
||||
|
||||
## Data Structure
|
||||
|
||||
- **Format**: [Standard](https://huggingface.co/docs/trl/main/dataset_formats#standard)
|
||||
- **Type**: [Stepwise supervision](https://huggingface.co/docs/trl/main/dataset_formats#stepwise-supervision)
|
||||
|
||||
Columns:
|
||||
- `"prompt"`: The problem statement.
|
||||
- `"completions"`: A list of reasoning steps generated to solve the problem.
|
||||
- `"labels"`: A list of booleans or floats indicating the correctness of each corresponding reasoning step.
|
||||
|
||||
This structure allows models to learn the correctness of each step in a solution, facilitating improved reasoning and problem-solving abilities.
|
||||
|
||||
## Generation script
|
||||
|
||||
The script used to generate this dataset can be found [here](https://github.com/huggingface/trl/blob/main/examples/datasets/math_shepherd.py).
|
||||
""")
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
dataset = load_dataset("peiyi9979/Math-Shepherd", split="train")
|
||||
|
||||
dataset = dataset.map(
|
||||
process_example,
|
||||
remove_columns=["input", "label", "task"],
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
)
|
||||
dataset = dataset.train_test_split(test_size=0.05, seed=42)
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
model_card.push_to_hub(script_args.repo_id, repo_type="dataset")
|
||||
157
examples/datasets/prm800k.py
Normal file
157
examples/datasets/prm800k.py
Normal file
@ -0,0 +1,157 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import ModelCard
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/prm800k"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`int` or `None`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Whether to push the dataset to the Hugging Face Hub."},
|
||||
)
|
||||
repo_id: str = field(
|
||||
default="trl-lib/prm800k",
|
||||
metadata={"help": "Hugging Face repository ID to push the dataset to."},
|
||||
)
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={"help": "Number of workers to use for dataset processing."},
|
||||
)
|
||||
|
||||
|
||||
def process_example(example):
|
||||
outputs = []
|
||||
prompt = example["question"]["problem"]
|
||||
|
||||
# Iterate through each step
|
||||
previous_completions = []
|
||||
previous_labels = []
|
||||
for step in example["label"]["steps"]:
|
||||
if step["completions"] is None and step["human_completion"] is None and step["chosen_completion"] is None:
|
||||
# happens sometimes
|
||||
break
|
||||
# Loop through completions
|
||||
for completion_idx, completion in enumerate(step["completions"]):
|
||||
# For every completion that are not chosen, we are in a terminal state, so we can add it to the list of outputs.
|
||||
if completion_idx != step["chosen_completion"]:
|
||||
content = completion["text"]
|
||||
completions = previous_completions[:] + [content]
|
||||
label = completion["rating"] == 1
|
||||
labels = previous_labels[:] + [label]
|
||||
outputs.append({"prompt": prompt, "completions": completions, "labels": labels})
|
||||
|
||||
# Now, exapand the previous completions and labels
|
||||
if step["chosen_completion"] is not None:
|
||||
chosen_completion = step["completions"][step["chosen_completion"]]
|
||||
label = chosen_completion["rating"] == 1
|
||||
elif step["human_completion"] is not None:
|
||||
chosen_completion = step["human_completion"]
|
||||
label = True
|
||||
else:
|
||||
break
|
||||
content = chosen_completion["text"]
|
||||
previous_completions.append(content)
|
||||
previous_labels.append(label)
|
||||
|
||||
# Last step: we are in a terminal state, so we can add it to the list of outputs
|
||||
outputs.append({"prompt": prompt, "completions": previous_completions, "labels": previous_labels})
|
||||
return outputs
|
||||
|
||||
|
||||
def process_batch(examples):
|
||||
outputs = []
|
||||
batch_size = len(examples["label"])
|
||||
for idx in range(batch_size):
|
||||
example = {k: v[idx] for k, v in examples.items()}
|
||||
outputs.extend(process_example(example))
|
||||
# list of dict to dict of list
|
||||
outputs = {k: [v[k] for v in outputs] for k in outputs[0]}
|
||||
return outputs
|
||||
|
||||
|
||||
model_card = ModelCard("""
|
||||
---
|
||||
tags: [trl]
|
||||
---
|
||||
|
||||
# PRM800K Dataset
|
||||
|
||||
## Summary
|
||||
|
||||
The PRM800K dataset is a processed version of [OpenAI's PRM800K](https://github.com/openai/prm800k), designed to train models using the [TRL library](https://github.com/huggingface/trl) for stepwise supervision tasks. It contains 800,000 step-level correctness labels for model-generated solutions to problems from the MATH dataset. This dataset enables models to learn and verify each step of a solution, enhancing their reasoning capabilities.
|
||||
|
||||
## Data Structure
|
||||
|
||||
- **Format**: [Standard](https://huggingface.co/docs/trl/main/dataset_formats#standard)
|
||||
- **Type**: [Stepwise supervision](https://huggingface.co/docs/trl/main/dataset_formats#stepwise-supervision)
|
||||
|
||||
Columns:
|
||||
- `"prompt"`: The problem statement.
|
||||
- `"completions"`: A list of reasoning steps generated to solve the problem.
|
||||
- `"labels"`: A list of booleans or floats indicating the correctness of each corresponding reasoning step.
|
||||
|
||||
This structure allows models to learn the correctness of each step in a solution, facilitating improved reasoning and problem-solving abilities.
|
||||
|
||||
## Generation script
|
||||
|
||||
The script used to generate this dataset can be found [here](https://github.com/huggingface/trl/blob/main/examples/datasets/prm800k.py).
|
||||
""")
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
data_files = {
|
||||
"train": "https://github.com/openai/prm800k/raw/refs/heads/main/prm800k/data/phase1_train.jsonl",
|
||||
"test": "https://github.com/openai/prm800k/raw/refs/heads/main/prm800k/data/phase1_test.jsonl",
|
||||
}
|
||||
dataset = load_dataset("json", data_files=data_files)
|
||||
|
||||
dataset = dataset.map(
|
||||
process_batch,
|
||||
batched=True,
|
||||
batch_size=10,
|
||||
remove_columns=[
|
||||
"labeler",
|
||||
"timestamp",
|
||||
"generation",
|
||||
"is_quality_control_question",
|
||||
"is_initial_screening_question",
|
||||
"question",
|
||||
"label",
|
||||
],
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
)
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
model_card.push_to_hub(script_args.repo_id, repo_type="dataset")
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -12,10 +12,11 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import features, load_dataset
|
||||
from huggingface_hub import ModelCard
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@ -29,13 +30,22 @@ class ScriptArguments:
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/rlaif-v"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
dataset_num_proc (`int` or `None`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/rlaif-v"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
push_to_hub: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Whether to push the dataset to the Hugging Face Hub."},
|
||||
)
|
||||
repo_id: str = field(
|
||||
default="trl-lib/rlaif-v",
|
||||
metadata={"help": "Hugging Face repository ID to push the dataset to."},
|
||||
)
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={"help": "Number of workers to use for dataset processing."},
|
||||
)
|
||||
|
||||
|
||||
def to_conversational(example):
|
||||
@ -50,6 +60,35 @@ def to_conversational(example):
|
||||
return {"prompt": prompt, "images": [example["image"]], "chosen": chosen, "rejected": rejected}
|
||||
|
||||
|
||||
model_card = ModelCard("""
|
||||
---
|
||||
tags: [trl]
|
||||
---
|
||||
|
||||
# RLAIF-V Dataset
|
||||
|
||||
## Summary
|
||||
|
||||
The RLAIF-V dataset is a processed version of the [openbmb/RLAIF-V-Dataset](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset#dataset-card-for-rlaif-v-dataset), specifically curated to train vision-language models using the [TRL library](https://github.com/huggingface/trl) for preference learning tasks. It contains 83,132 high-quality comparison pairs, each comprising an image and two textual descriptions: one preferred and one rejected. This dataset enables models to learn human preferences in visual contexts, enhancing their ability to generate and evaluate image captions.
|
||||
|
||||
## Data Structure
|
||||
|
||||
- **Format**: [Conversational](https://huggingface.co/docs/trl/main/dataset_formats#conversational)
|
||||
- **Type**: [Preference](https://huggingface.co/docs/trl/main/dataset_formats#preference)
|
||||
|
||||
Columns:
|
||||
- `"prompt"`: The task related to the image.
|
||||
- `"images"`: The image.
|
||||
- `"chosen"`: The preferred answer.
|
||||
- `"rejected"`: An alternative answer that was not preferred.
|
||||
|
||||
This structure allows models to learn to prefer the _chosen_ response over the _rejected_ one, thereby aligning with human preferences in visual tasks.
|
||||
|
||||
## Generation script
|
||||
|
||||
The script used to generate this dataset can be found [here](https://github.com/huggingface/trl/blob/main/examples/datasets/rlaif-v.py).
|
||||
""")
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
@ -71,3 +110,4 @@ if __name__ == "__main__":
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
model_card.push_to_hub(script_args.repo_id, repo_type="dataset")
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -12,10 +12,11 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import ModelCard
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@ -29,13 +30,22 @@ class ScriptArguments:
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/tldr"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
dataset_num_proc (`int` or `None`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/tldr"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
push_to_hub: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Whether to push the dataset to the Hugging Face Hub."},
|
||||
)
|
||||
repo_id: str = field(
|
||||
default="trl-lib/tldr",
|
||||
metadata={"help": "Hugging Face repository ID to push the dataset to."},
|
||||
)
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={"help": "Number of workers to use for dataset processing."},
|
||||
)
|
||||
|
||||
|
||||
def to_prompt_completion(example):
|
||||
@ -45,6 +55,33 @@ def to_prompt_completion(example):
|
||||
return {"prompt": prompt, "completion": completion}
|
||||
|
||||
|
||||
model_card = ModelCard("""
|
||||
---
|
||||
tags: [trl]
|
||||
---
|
||||
|
||||
# TL;DR Dataset
|
||||
|
||||
## Summary
|
||||
|
||||
The TL;DR dataset is a processed version of Reddit posts, specifically curated to train models using the [TRL library](https://github.com/huggingface/trl) for summarization tasks. It leverages the common practice on Reddit where users append "TL;DR" (Too Long; Didn't Read) summaries to lengthy posts, providing a rich source of paired text data for training summarization models.
|
||||
|
||||
## Data Structure
|
||||
|
||||
- **Format**: [Standard](https://huggingface.co/docs/trl/main/dataset_formats#standard)
|
||||
- **Type**: [Prompt-completion](https://huggingface.co/docs/trl/main/dataset_formats#prompt-completion)
|
||||
|
||||
Columns:
|
||||
- `"prompt"`: The unabridged Reddit post.
|
||||
- `"completion"`: The concise "TL;DR" summary appended by the author.
|
||||
|
||||
This structure enables models to learn the relationship between detailed content and its abbreviated form, enhancing their summarization capabilities.
|
||||
|
||||
## Generation script
|
||||
|
||||
The script used to generate this dataset can be found [here](https://github.com/huggingface/trl/blob/main/examples/datasets/tldr.py).
|
||||
""")
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
@ -65,3 +102,4 @@ if __name__ == "__main__":
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
model_card.push_to_hub(script_args.repo_id, repo_type="dataset")
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -12,10 +12,11 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import ModelCard
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@ -29,13 +30,22 @@ class ScriptArguments:
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/tldr-preference"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
dataset_num_proc (`int` or `None`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/tldr-preference"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
push_to_hub: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Whether to push the dataset to the Hugging Face Hub."},
|
||||
)
|
||||
repo_id: str = field(
|
||||
default="trl-lib/tldr-preference",
|
||||
metadata={"help": "Hugging Face repository ID to push the dataset to."},
|
||||
)
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={"help": "Number of workers to use for dataset processing."},
|
||||
)
|
||||
|
||||
|
||||
def to_preference(example):
|
||||
@ -56,6 +66,34 @@ def to_preference(example):
|
||||
return {"prompt": prompt, "chosen": chosen, "rejected": rejected}
|
||||
|
||||
|
||||
model_card = ModelCard("""
|
||||
---
|
||||
tags: [trl]
|
||||
---
|
||||
|
||||
# TL;DR Dataset for Preference Learning
|
||||
|
||||
## Summary
|
||||
|
||||
The TL;DR dataset is a processed version of Reddit posts, specifically curated to train models using the [TRL library](https://github.com/huggingface/trl) for preference learning and Reinforcement Learning from Human Feedback (RLHF) tasks. It leverages the common practice on Reddit where users append "TL;DR" (Too Long; Didn't Read) summaries to lengthy posts, providing a rich source of paired text data for training models to understand and generate concise summaries.
|
||||
|
||||
## Data Structure
|
||||
|
||||
- **Format**: [Standard](https://huggingface.co/docs/trl/main/dataset_formats#standard)
|
||||
- **Type**: [Preference](https://huggingface.co/docs/trl/main/dataset_formats#preference)
|
||||
|
||||
Columns:
|
||||
- `"prompt"`: The unabridged Reddit post.
|
||||
- `"chosen"`: The concise "TL;DR" summary appended by the author.
|
||||
- `"rejected"`: An alternative summary or response that was not selected.
|
||||
|
||||
This structure enables models to learn the relationship between detailed content and its abbreviated form, enhancing their summarization capabilities.
|
||||
|
||||
## Generation script
|
||||
|
||||
The script used to generate this dataset can be found [here](https://github.com/huggingface/trl/blob/main/examples/datasets/tldr_preference.py).
|
||||
""")
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
@ -70,3 +108,4 @@ if __name__ == "__main__":
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
model_card.push_to_hub(script_args.repo_id, repo_type="dataset")
|
||||
|
||||
@ -1,54 +0,0 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoTokenizer, HfArgumentParser
|
||||
|
||||
from trl.trainer.utils import SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
|
||||
"""
|
||||
python -i examples/datasets/tokenize_ds.py --model HuggingFaceH4/zephyr-7b-beta
|
||||
python -i examples/datasets/tokenize_ds.py --model gpt2
|
||||
"""
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
dataset_name: str = field(
|
||||
default="trl-internal-testing/hh-rlhf-helpful-base-trl-style", metadata={"help": "The dataset to load"}
|
||||
)
|
||||
model: str = field(default="gpt2", metadata={"help": "The model to use for tokenization"})
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None, metadata={"help": "The number of workers to use to tokenize the data"}
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
script_args = HfArgumentParser(ScriptArguments).parse_args_into_dataclasses()[0]
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
tokenizer = AutoTokenizer.from_pretrained(script_args.model)
|
||||
if tokenizer.chat_template is None:
|
||||
tokenizer.chat_template = SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
def process(row):
|
||||
row["chosen"] = tokenizer.apply_chat_template(row["chosen"], tokenize=False)
|
||||
row["rejected"] = tokenizer.apply_chat_template(row["rejected"], tokenize=False)
|
||||
return row
|
||||
|
||||
dataset = dataset.map(process, num_proc=script_args.dataset_num_proc)
|
||||
print(dataset["train"][0]["chosen"])
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -12,10 +12,11 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import ModelCard
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@ -29,13 +30,22 @@ class ScriptArguments:
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/ultrafeedback-prompt"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
dataset_num_proc (`int` or `None`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/ultrafeedback-prompt"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
push_to_hub: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Whether to push the dataset to the Hugging Face Hub."},
|
||||
)
|
||||
repo_id: str = field(
|
||||
default="trl-lib/ultrafeedback-prompt",
|
||||
metadata={"help": "Hugging Face repository ID to push the dataset to."},
|
||||
)
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={"help": "Number of workers to use for dataset processing."},
|
||||
)
|
||||
|
||||
|
||||
def to_unpaired_preference(example):
|
||||
@ -50,6 +60,30 @@ def drop_long_prompt(example):
|
||||
return True
|
||||
|
||||
|
||||
model_card = ModelCard("""
|
||||
---
|
||||
tags: [trl]
|
||||
---
|
||||
|
||||
# UltraFeedback - Prompts Dataset
|
||||
|
||||
## Summary
|
||||
|
||||
The UltraFeedback - Prompts dataset is a processed version of the [UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset for model evaluation on specific aspects like helpfulness, honesty, and instruction-following.
|
||||
|
||||
## Data Structure
|
||||
|
||||
- **Format**: [Conversational](https://huggingface.co/docs/trl/main/dataset_formats#conversational)
|
||||
- **Type**: [Prompt-only](https://huggingface.co/docs/trl/main/dataset_formats#prompt-only)
|
||||
|
||||
Column:
|
||||
- `"prompt"`: The input question or instruction provided to the model.
|
||||
|
||||
## Generation script
|
||||
|
||||
The script used to generate this dataset can be found [here](https://github.com/huggingface/trl/blob/main/examples/datasets/ultafeedback-prompt.py).
|
||||
""")
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
@ -66,3 +100,4 @@ if __name__ == "__main__":
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
model_card.push_to_hub(script_args.repo_id, repo_type="dataset")
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -12,10 +12,11 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import ModelCard
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@ -27,46 +28,61 @@ class ScriptArguments:
|
||||
Args:
|
||||
model_name (`str`, *optional*, defaults to `"gpt-3.5-turbo"`):
|
||||
Language model to target. Possible values are:
|
||||
|
||||
- `"alpaca-7b"`
|
||||
- `"bard"`
|
||||
- `"falcon-40b-instruct"`
|
||||
- `"gpt-3.5-turbo"` (default)
|
||||
- `"gpt-4"`
|
||||
- `"llama-2-13b-chat"`
|
||||
- `"llama-2-70b-chat"`
|
||||
- `"llama-2-7b-chat"`
|
||||
- `"mpt-30b-chat"`
|
||||
- `"pythia-12b"`
|
||||
- `"starchat"`
|
||||
- `"ultralm-13b"`
|
||||
- `"ultralm-65b"`
|
||||
- `"vicuna-33b"`
|
||||
- `"wizardlm-13b"`
|
||||
- `"wizardlm-70b"`
|
||||
- `"wizardlm-7b"`
|
||||
|
||||
aspect (`str`, *optional*, defaults to `"helpfulness"`):
|
||||
Aspect to target. Possible values are:
|
||||
|
||||
- `"helpfulness"` (default)
|
||||
- `"honesty"`
|
||||
- `"instruction-following"`
|
||||
- `"truthfulness"`
|
||||
|
||||
Aspect to target.
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/ultrafeedback-gpt-3.5-turbo-helpfulness"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
dataset_num_proc (`int` or `None`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
model_name: str = "gpt-3.5-turbo"
|
||||
aspect: str = "helpfulness"
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/ultrafeedback-gpt-3.5-turbo-helpfulness"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
model_name: str = field(
|
||||
default="gpt-3.5-turbo",
|
||||
metadata={
|
||||
"help": "Language model to target.",
|
||||
"choices": [
|
||||
"alpaca-7b",
|
||||
"bard",
|
||||
"falcon-40b-instruct",
|
||||
"gpt-3.5-turbo",
|
||||
"gpt-4",
|
||||
"llama-2-13b-chat",
|
||||
"llama-2-70b-chat",
|
||||
"llama-2-7b-chat",
|
||||
"mpt-30b-chat",
|
||||
"pythia-12b",
|
||||
"starchat",
|
||||
"ultralm-13b",
|
||||
"ultralm-65b",
|
||||
"vicuna-33b",
|
||||
"wizardlm-13b",
|
||||
"wizardlm-70b",
|
||||
"wizardlm-7b",
|
||||
],
|
||||
},
|
||||
)
|
||||
aspect: str = field(
|
||||
default="helpfulness",
|
||||
metadata={
|
||||
"help": "Aspect to target. Possible values are: 'helpfulness' (default), 'honesty', "
|
||||
"'instruction-following', 'truthfulness'.",
|
||||
"choices": ["helpfulness", "honesty", "instruction-following", "truthfulness"],
|
||||
},
|
||||
)
|
||||
push_to_hub: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Whether to push the dataset to the Hugging Face Hub."},
|
||||
)
|
||||
repo_id: str = field(
|
||||
default="trl-lib/ultrafeedback-gpt-3.5-turbo-helpfulness",
|
||||
metadata={"help": "Hugging Face repository ID to push the dataset to."},
|
||||
)
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={"help": "Number of workers to use for dataset processing."},
|
||||
)
|
||||
|
||||
|
||||
def to_unpaired_preference(example, model_name, aspect):
|
||||
@ -79,6 +95,32 @@ def to_unpaired_preference(example, model_name, aspect):
|
||||
return {"prompt": prompt, "completion": completion, "label": label}
|
||||
|
||||
|
||||
model_card = ModelCard("""
|
||||
---
|
||||
tags: [trl]
|
||||
---
|
||||
|
||||
# UltraFeedback GPT-3.5-Turbo Helpfulness Dataset
|
||||
|
||||
## Summary
|
||||
|
||||
The UltraFeedback GPT-3.5-Turbo Helpfulness dataset contains processed user-assistant interactions filtered for helpfulness, derived from the [openbmb/UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset. It is designed for fine-tuning and evaluating models in alignment tasks.
|
||||
|
||||
## Data Structure
|
||||
|
||||
- **Format**: [Conversational](https://huggingface.co/docs/trl/main/dataset_formats#conversational)
|
||||
- **Type**: [Unpaired preference](https://huggingface.co/docs/trl/main/dataset_formats#unpaired-preference)
|
||||
|
||||
Column:
|
||||
- `"prompt"`: The input question or instruction provided to the model.
|
||||
- `"completion"`: The model's response to the prompt.
|
||||
- `"label"`: A binary value indicating whether the response is sufficiently helpful.
|
||||
|
||||
## Generation script
|
||||
|
||||
The script used to generate this dataset can be found [here](https://github.com/huggingface/trl/blob/main/examples/datasets/ultafeedback.py).
|
||||
""")
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
@ -100,3 +142,4 @@ if __name__ == "__main__":
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
model_card.push_to_hub(script_args.repo_id, repo_type="dataset")
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<div style=\"text-align: center\">\n",
|
||||
"<img src='https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/gpt2_bert_training.png' width='600'>\n",
|
||||
"<img src='https://huggingface.co/datasets/trl-lib/documentation-images/resolve/main/gpt2_bert_training.png' width='600'>\n",
|
||||
"<p style=\"text-align: center;\"> <b>Figure:</b> Experiment setup to tune GPT2. The yellow arrows are outside the scope of this notebook, but the trained models are available through Hugging Face. </p>\n",
|
||||
"</div>\n",
|
||||
"\n",
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -13,7 +13,7 @@
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
from typing import Any, Optional, Union
|
||||
|
||||
import evaluate
|
||||
import numpy as np
|
||||
@ -236,7 +236,7 @@ class RewardDataCollatorWithPadding:
|
||||
pad_to_multiple_of: Optional[int] = None
|
||||
return_tensors: str = "pt"
|
||||
|
||||
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
|
||||
def __call__(self, features: list[dict[str, Any]]) -> dict[str, Any]:
|
||||
features_j = []
|
||||
features_k = []
|
||||
for feature in features:
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
@ -19,9 +20,9 @@ from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from peft import LoraConfig
|
||||
from tqdm import tqdm
|
||||
from transformers import Adafactor, AutoTokenizer, HfArgumentParser, pipeline
|
||||
from transformers import Adafactor, AutoTokenizer, HfArgumentParser, pipeline, set_seed
|
||||
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer, set_seed
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer
|
||||
from trl.core import LengthSampler
|
||||
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -15,7 +15,7 @@
|
||||
# 0. imports
|
||||
import os
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Dict, Optional
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
@ -109,9 +109,9 @@ def get_stack_exchange_paired(
|
||||
|
||||
The dataset is converted to a dictionary with the following structure:
|
||||
{
|
||||
'prompt': List[str],
|
||||
'chosen': List[str],
|
||||
'rejected': List[str],
|
||||
'prompt': list[str],
|
||||
'chosen': list[str],
|
||||
'rejected': list[str],
|
||||
}
|
||||
|
||||
Prompts are structured as follows:
|
||||
@ -126,7 +126,7 @@ def get_stack_exchange_paired(
|
||||
)
|
||||
original_columns = dataset.column_names
|
||||
|
||||
def return_prompt_and_responses(samples) -> Dict[str, str]:
|
||||
def return_prompt_and_responses(samples) -> dict[str, str]:
|
||||
return {
|
||||
"prompt": ["Question: " + question + "\n\nAnswer: " for question in samples["question"]],
|
||||
"chosen": samples["response_j"],
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -154,7 +154,7 @@ ppo_config = PPOConfig(
|
||||
optimize_cuda_cache=True,
|
||||
)
|
||||
|
||||
ppo_trainer = PPOTrainer(config=ppo_config, model=model, tokenizer=tokenizer, dataset=ds)
|
||||
ppo_trainer = PPOTrainer(args=ppo_config, model=model, tokenizer=tokenizer, dataset=ds)
|
||||
test_dataloader = ppo_trainer.accelerator.prepare(test_dataloader)
|
||||
|
||||
# text env
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -105,7 +105,7 @@ config = PPOConfig(
|
||||
seed=script_args.seed,
|
||||
optimize_cuda_cache=True,
|
||||
)
|
||||
ppo_trainer = PPOTrainer(config=config, model=model, tokenizer=tokenizer)
|
||||
ppo_trainer = PPOTrainer(args=config, model=model, tokenizer=tokenizer)
|
||||
dataset = load_dataset("mandarjoshi/trivia_qa", "rc", split="train")
|
||||
local_seed = script_args.seed + ppo_trainer.accelerator.process_index * 100003 # Prime
|
||||
dataset = dataset.shuffle(local_seed)
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
@ -24,9 +25,10 @@ from transformers import (
|
||||
HfArgumentParser,
|
||||
RobertaForSequenceClassification,
|
||||
RobertaTokenizer,
|
||||
set_seed,
|
||||
)
|
||||
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer, create_reference_model, set_seed
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer, create_reference_model
|
||||
from trl.core import LengthSampler
|
||||
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 metric-space, The HuggingFace Team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Total Batch size = 128 = 4 (num_gpus) * 8 (per_device_batch) * 4 (accumulation steps)
|
||||
Feel free to reduce batch size or increasing truncated_rand_backprop_min to a higher value to reduce memory usage.
|
||||
@ -36,20 +37,38 @@ from trl.models.auxiliary_modules import aesthetic_scorer
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
pretrained_model (`str`, *optional*, defaults to `"runwayml/stable-diffusion-v1-5"`):
|
||||
Pretrained model to use.
|
||||
pretrained_revision (`str`, *optional*, defaults to `"main"`):
|
||||
Pretrained model revision to use.
|
||||
hf_hub_model_id (`str`, *optional*, defaults to `"alignprop-finetuned-stable-diffusion"`):
|
||||
HuggingFace repo to save model weights to.
|
||||
hf_hub_aesthetic_model_id (`str`, *optional*, defaults to `"trl-lib/ddpo-aesthetic-predictor"`):
|
||||
Hugging Face model ID for aesthetic scorer model weights.
|
||||
hf_hub_aesthetic_model_filename (`str`, *optional*, defaults to `"aesthetic-model.pth"`):
|
||||
Hugging Face model filename for aesthetic scorer model weights.
|
||||
use_lora (`bool`, *optional*, defaults to `True`):
|
||||
Whether to use LoRA.
|
||||
"""
|
||||
|
||||
pretrained_model: str = field(
|
||||
default="runwayml/stable-diffusion-v1-5", metadata={"help": "the pretrained model to use"}
|
||||
default="runwayml/stable-diffusion-v1-5", metadata={"help": "Pretrained model to use."}
|
||||
)
|
||||
pretrained_revision: str = field(default="main", metadata={"help": "the pretrained model revision to use"})
|
||||
pretrained_revision: str = field(default="main", metadata={"help": "Pretrained model revision to use."})
|
||||
hf_hub_model_id: str = field(
|
||||
default="alignprop-finetuned-stable-diffusion", metadata={"help": "HuggingFace repo to save model weights to"}
|
||||
default="alignprop-finetuned-stable-diffusion", metadata={"help": "HuggingFace repo to save model weights to."}
|
||||
)
|
||||
hf_hub_aesthetic_model_id: str = field(
|
||||
default="trl-lib/ddpo-aesthetic-predictor",
|
||||
metadata={"help": "HuggingFace model ID for aesthetic scorer model weights"},
|
||||
metadata={"help": "Hugging Face model ID for aesthetic scorer model weights."},
|
||||
)
|
||||
hf_hub_aesthetic_model_filename: str = field(
|
||||
default="aesthetic-model.pth",
|
||||
metadata={"help": "HuggingFace model filename for aesthetic scorer model weights"},
|
||||
metadata={"help": "Hugging Face model filename for aesthetic scorer model weights."},
|
||||
)
|
||||
use_lora: bool = field(default=True, metadata={"help": "Whether to use LoRA."})
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -126,7 +126,7 @@ if __name__ == "__main__":
|
||||
if tokenizer.chat_template is None:
|
||||
model, tokenizer = setup_chat_format(model, tokenizer)
|
||||
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
|
||||
accelerator = Accelerator()
|
||||
embedding_model = AutoModel.from_pretrained(
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -12,357 +12,6 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import copy
|
||||
import json
|
||||
import os
|
||||
import pwd
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
from threading import Thread
|
||||
|
||||
import torch
|
||||
from rich.console import Console
|
||||
from rich.live import Live
|
||||
from rich.markdown import Markdown
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
|
||||
|
||||
from trl import TrlParser, init_zero_verbose
|
||||
from trl.commands.cli_utils import ChatArguments
|
||||
from trl.trainer.utils import get_quantization_config
|
||||
|
||||
|
||||
init_zero_verbose()
|
||||
|
||||
HELP_STRING = """\
|
||||
|
||||
**TRL CHAT INTERFACE**
|
||||
|
||||
The chat interface is a simple tool to try out a chat model.
|
||||
|
||||
Besides talking to the model there are several commands:
|
||||
- **clear**: clears the current conversation and start a new one
|
||||
- **example {NAME}**: load example named `{NAME}` from the config and use it as the user input
|
||||
- **set {SETTING_NAME}={SETTING_VALUE};**: change the system prompt or generation settings (multiple settings are separated by a ';').
|
||||
- **reset**: same as clear but also resets the generation configs to defaults if they have been changed by **set**
|
||||
- **save {SAVE_NAME} (optional)**: save the current chat and settings to file by default to `./chat_history/{MODEL_NAME}/chat_{DATETIME}.yaml` or `{SAVE_NAME}` if provided
|
||||
- **exit**: closes the interface
|
||||
"""
|
||||
|
||||
SUPPORTED_GENERATION_KWARGS = [
|
||||
"max_new_tokens",
|
||||
"do_sample",
|
||||
"num_beams",
|
||||
"temperature",
|
||||
"top_p",
|
||||
"top_k",
|
||||
"repetition_penalty",
|
||||
]
|
||||
|
||||
SETTING_RE = r"^set\s+[A-Za-z\s_]+=[A-Za-z\d\s.!\"#$%&'()*+,-/:<=>?@\[\]^_`{|}~]+(?:;\s*[A-Za-z\s_]+=[A-Za-z\d\s.!\"#$%&'()*+,-/:<=>?@\[\]^_`{|}~]+)*$"
|
||||
|
||||
|
||||
class RichInterface:
|
||||
def __init__(self, model_name=None, user_name=None):
|
||||
self._console = Console()
|
||||
if model_name is None:
|
||||
self.model_name = "assistant"
|
||||
else:
|
||||
self.model_name = model_name
|
||||
if user_name is None:
|
||||
self.user_name = "user"
|
||||
else:
|
||||
self.user_name = user_name
|
||||
|
||||
def stream_output(self, output_stream):
|
||||
"""Stream output from a role."""
|
||||
# This method is originally from the FastChat CLI: https://github.com/lm-sys/FastChat/blob/main/fastchat/serve/cli.py
|
||||
# Create a Live context for updating the console output
|
||||
text = ""
|
||||
self._console.print(f"[bold blue]<{self.model_name}>:")
|
||||
with Live(console=self._console, refresh_per_second=4) as live:
|
||||
# Read lines from the stream
|
||||
for i, outputs in enumerate(output_stream):
|
||||
if not outputs or i == 0:
|
||||
continue
|
||||
text += outputs
|
||||
# Render the accumulated text as Markdown
|
||||
# NOTE: this is a workaround for the rendering "unstandard markdown"
|
||||
# in rich. The chatbots output treat "\n" as a new line for
|
||||
# better compatibility with real-world text. However, rendering
|
||||
# in markdown would break the format. It is because standard markdown
|
||||
# treat a single "\n" in normal text as a space.
|
||||
# Our workaround is adding two spaces at the end of each line.
|
||||
# This is not a perfect solution, as it would
|
||||
# introduce trailing spaces (only) in code block, but it works well
|
||||
# especially for console output, because in general the console does not
|
||||
# care about trailing spaces.
|
||||
lines = []
|
||||
for line in text.splitlines():
|
||||
lines.append(line)
|
||||
if line.startswith("```"):
|
||||
# Code block marker - do not add trailing spaces, as it would
|
||||
# break the syntax highlighting
|
||||
lines.append("\n")
|
||||
else:
|
||||
lines.append(" \n")
|
||||
markdown = Markdown("".join(lines).strip(), code_theme="github-dark")
|
||||
# Update the Live console output
|
||||
live.update(markdown)
|
||||
self._console.print()
|
||||
return text
|
||||
|
||||
def input(self):
|
||||
input = self._console.input(f"[bold red]<{self.user_name}>:\n")
|
||||
self._console.print()
|
||||
return input
|
||||
|
||||
def clear(self):
|
||||
self._console.clear()
|
||||
|
||||
def print_user_message(self, text):
|
||||
self._console.print(f"[bold red]<{self.user_name}>:[/ bold red]\n{text}")
|
||||
self._console.print()
|
||||
|
||||
def print_green(self, text):
|
||||
self._console.print(f"[bold green]{text}")
|
||||
self._console.print()
|
||||
|
||||
def print_red(self, text):
|
||||
self._console.print(f"[bold red]{text}")
|
||||
self._console.print()
|
||||
|
||||
def print_help(self):
|
||||
self._console.print(Markdown(HELP_STRING))
|
||||
self._console.print()
|
||||
|
||||
|
||||
def get_username():
|
||||
return pwd.getpwuid(os.getuid())[0]
|
||||
|
||||
|
||||
def create_default_filename(model_name):
|
||||
time_str = time.strftime("%Y-%m-%d_%H-%M-%S")
|
||||
return f"{model_name}/chat_{time_str}.json"
|
||||
|
||||
|
||||
def save_chat(chat, args, filename):
|
||||
output_dict = {}
|
||||
output_dict["settings"] = vars(args)
|
||||
output_dict["chat_history"] = chat
|
||||
|
||||
folder = args.save_folder
|
||||
|
||||
if filename is None:
|
||||
filename = create_default_filename(args.model_name_or_path)
|
||||
filename = os.path.join(folder, filename)
|
||||
os.makedirs(os.path.dirname(filename), exist_ok=True)
|
||||
|
||||
with open(filename, "w") as f:
|
||||
json.dump(output_dict, f, indent=4)
|
||||
return os.path.abspath(filename)
|
||||
|
||||
|
||||
def clear_chat_history(system_prompt):
|
||||
if system_prompt is None:
|
||||
chat = []
|
||||
else:
|
||||
chat = [{"role": "system", "content": system_prompt}]
|
||||
return chat
|
||||
|
||||
|
||||
def parse_settings(user_input, current_args, interface):
|
||||
settings = user_input[4:].strip().split(";")
|
||||
settings = [(setting.split("=")[0], setting[len(setting.split("=")[0]) + 1 :]) for setting in settings]
|
||||
settings = dict(settings)
|
||||
error = False
|
||||
|
||||
for name in settings:
|
||||
if hasattr(current_args, name):
|
||||
try:
|
||||
if isinstance(getattr(current_args, name), bool):
|
||||
if settings[name] == "True":
|
||||
settings[name] = True
|
||||
elif settings[name] == "False":
|
||||
settings[name] = False
|
||||
else:
|
||||
raise ValueError
|
||||
else:
|
||||
settings[name] = type(getattr(current_args, name))(settings[name])
|
||||
except ValueError:
|
||||
interface.print_red(
|
||||
f"Cannot cast setting {name} (={settings[name]}) to {type(getattr(current_args, name))}."
|
||||
)
|
||||
else:
|
||||
interface.print_red(f"There is no '{name}' setting.")
|
||||
|
||||
if error:
|
||||
interface.print_red("There was an issue parsing the settings. No settings have been changed.")
|
||||
return current_args, False
|
||||
else:
|
||||
for name in settings:
|
||||
setattr(current_args, name, settings[name])
|
||||
interface.print_green(f"Set {name} to {settings[name]}.")
|
||||
|
||||
time.sleep(1.5) # so the user has time to read the changes
|
||||
return current_args, True
|
||||
|
||||
|
||||
def load_model_and_tokenizer(args):
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.model_name_or_path,
|
||||
revision=args.model_revision,
|
||||
trust_remote_code=args.trust_remote_code,
|
||||
)
|
||||
|
||||
torch_dtype = args.torch_dtype if args.torch_dtype in ["auto", None] else getattr(torch, args.torch_dtype)
|
||||
quantization_config = get_quantization_config(args)
|
||||
model_kwargs = dict(
|
||||
revision=args.model_revision,
|
||||
attn_implementation=args.attn_implementation,
|
||||
torch_dtype=torch_dtype,
|
||||
device_map="auto",
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
args.model_name_or_path, trust_remote_code=args.trust_remote_code, **model_kwargs
|
||||
)
|
||||
|
||||
if getattr(model, "hf_device_map", None) is None:
|
||||
model = model.to(args.device)
|
||||
|
||||
return model, tokenizer
|
||||
|
||||
|
||||
def parse_eos_tokens(tokenizer, eos_tokens, eos_token_ids):
|
||||
if tokenizer.pad_token_id is None:
|
||||
pad_token_id = tokenizer.eos_token_id
|
||||
else:
|
||||
pad_token_id = tokenizer.pad_token_id
|
||||
|
||||
all_eos_token_ids = []
|
||||
|
||||
if eos_tokens is not None:
|
||||
all_eos_token_ids.extend(tokenizer.convert_tokens_to_ids(eos_tokens.split(",")))
|
||||
|
||||
if eos_token_ids is not None:
|
||||
all_eos_token_ids.extend([int(token_id) for token_id in eos_token_ids.split(",")])
|
||||
|
||||
if len(all_eos_token_ids) == 0:
|
||||
all_eos_token_ids.append(tokenizer.eos_token_id)
|
||||
|
||||
return pad_token_id, all_eos_token_ids
|
||||
|
||||
|
||||
def chat_cli():
|
||||
parser = TrlParser(ChatArguments)
|
||||
|
||||
if "--config" not in sys.argv:
|
||||
sys.argv.append("--config")
|
||||
sys.argv.append(os.path.join(os.path.dirname(__file__), "config/default_chat_config.yaml"))
|
||||
args = parser.parse_args_and_config()[0]
|
||||
if args.examples is None:
|
||||
args.examples = {}
|
||||
|
||||
current_args = copy.deepcopy(args)
|
||||
|
||||
if args.user is None:
|
||||
user = get_username()
|
||||
else:
|
||||
user = args.user
|
||||
|
||||
model, tokenizer = load_model_and_tokenizer(args)
|
||||
generation_streamer = TextIteratorStreamer(tokenizer, skip_special_tokens=True, skip_prompt=True)
|
||||
|
||||
pad_token_id, eos_token_ids = parse_eos_tokens(tokenizer, args.eos_tokens, args.eos_token_ids)
|
||||
|
||||
interface = RichInterface(model_name=args.model_name_or_path, user_name=user)
|
||||
interface.clear()
|
||||
chat = clear_chat_history(current_args.system_prompt)
|
||||
while True:
|
||||
try:
|
||||
user_input = interface.input()
|
||||
|
||||
if user_input == "clear":
|
||||
chat = clear_chat_history(current_args.system_prompt)
|
||||
interface.clear()
|
||||
continue
|
||||
|
||||
if user_input == "help":
|
||||
interface.print_help()
|
||||
continue
|
||||
|
||||
if user_input == "exit":
|
||||
break
|
||||
|
||||
if user_input == "reset":
|
||||
interface.clear()
|
||||
current_args = copy.deepcopy(args)
|
||||
chat = clear_chat_history(current_args.system_prompt)
|
||||
continue
|
||||
|
||||
if user_input.startswith("save") and len(user_input.split()) < 2:
|
||||
split_input = user_input.split()
|
||||
|
||||
if len(split_input) == 2:
|
||||
filename = split_input[1]
|
||||
else:
|
||||
filename = None
|
||||
filename = save_chat(chat, current_args, filename)
|
||||
interface.print_green(f"Chat saved in {filename}!")
|
||||
continue
|
||||
|
||||
if re.match(SETTING_RE, user_input):
|
||||
current_args, success = parse_settings(user_input, current_args, interface)
|
||||
if success:
|
||||
chat = []
|
||||
interface.clear()
|
||||
continue
|
||||
|
||||
if user_input.startswith("example") and len(user_input.split()) == 2:
|
||||
example_name = user_input.split()[1]
|
||||
if example_name in current_args.examples:
|
||||
interface.clear()
|
||||
chat = []
|
||||
interface.print_user_message(current_args.examples[example_name]["text"])
|
||||
user_input = current_args.examples[example_name]["text"]
|
||||
else:
|
||||
interface.print_red(
|
||||
f"Example {example_name} not found in list of available examples: {list(current_args.examples.keys())}."
|
||||
)
|
||||
continue
|
||||
|
||||
chat.append({"role": "user", "content": user_input})
|
||||
|
||||
inputs = tokenizer.apply_chat_template(chat, return_tensors="pt", add_generation_prompt=True).to(
|
||||
model.device
|
||||
)
|
||||
attention_mask = torch.ones_like(inputs)
|
||||
generation_kwargs = dict(
|
||||
inputs=inputs,
|
||||
attention_mask=attention_mask,
|
||||
streamer=generation_streamer,
|
||||
max_new_tokens=current_args.max_new_tokens,
|
||||
do_sample=current_args.do_sample,
|
||||
num_beams=current_args.num_beams,
|
||||
temperature=current_args.temperature,
|
||||
top_k=current_args.top_k,
|
||||
top_p=current_args.top_p,
|
||||
repetition_penalty=current_args.repetition_penalty,
|
||||
pad_token_id=pad_token_id,
|
||||
eos_token_id=eos_token_ids,
|
||||
)
|
||||
|
||||
thread = Thread(target=model.generate, kwargs=generation_kwargs)
|
||||
thread.start()
|
||||
model_output = interface.stream_output(generation_streamer)
|
||||
thread.join()
|
||||
chat.append({"role": "assistant", "content": model_output})
|
||||
|
||||
except KeyboardInterrupt:
|
||||
break
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
chat_cli()
|
||||
################################################################################################
|
||||
# This file has been moved to https://github.com/huggingface/trl/blob/main/trl/scripts/chat.py #
|
||||
################################################################################################
|
||||
|
||||
@ -1,13 +0,0 @@
|
||||
examples:
|
||||
llama:
|
||||
text: There is a Llama in my lawn, how can I get rid of it?
|
||||
code:
|
||||
text: Write a Python function that integrates any Python function f(x) numerically over an arbitrary interval [x_start, x_end].
|
||||
helicopter:
|
||||
text: How many helicopters can a human eat in one sitting?
|
||||
numbers:
|
||||
text: Count to 10 but skip every number ending with an 'e'
|
||||
birds:
|
||||
text: Why aren't birds real?
|
||||
socks:
|
||||
text: Why is it important to eat socks after meditating?
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Run the CPO training script with the following command with some example arguments.
|
||||
In general, the optimal configuration for CPO will be similar to that of DPO:
|
||||
@ -63,16 +64,16 @@ from trl.trainer.utils import SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser((ScriptArguments, CPOConfig, ModelConfig))
|
||||
script_args, training_args, model_config = parser.parse_args_into_dataclasses()
|
||||
script_args, training_args, model_args = parser.parse_args_into_dataclasses()
|
||||
|
||||
################
|
||||
# Model & Tokenizer
|
||||
################
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code
|
||||
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code
|
||||
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
if tokenizer.pad_token is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
@ -80,7 +81,7 @@ if __name__ == "__main__":
|
||||
################
|
||||
# Dataset
|
||||
################
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
if tokenizer.chat_template is None:
|
||||
tokenizer.chat_template = SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
@ -93,7 +94,7 @@ if __name__ == "__main__":
|
||||
train_dataset=dataset[script_args.dataset_train_split],
|
||||
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
|
||||
processing_class=tokenizer,
|
||||
peft_config=get_peft_config(model_config),
|
||||
peft_config=get_peft_config(model_args),
|
||||
)
|
||||
|
||||
# train and save the model
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 metric-space, The HuggingFace Team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
python examples/scripts/ddpo.py \
|
||||
--num_epochs=200 \
|
||||
@ -40,20 +41,38 @@ from trl import DDPOConfig, DDPOTrainer, DefaultDDPOStableDiffusionPipeline
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
pretrained_model (`str`, *optional*, defaults to `"runwayml/stable-diffusion-v1-5"`):
|
||||
Pretrained model to use.
|
||||
pretrained_revision (`str`, *optional*, defaults to `"main"`):
|
||||
Pretrained model revision to use.
|
||||
hf_hub_model_id (`str`, *optional*, defaults to `"ddpo-finetuned-stable-diffusion"`):
|
||||
HuggingFace repo to save model weights to.
|
||||
hf_hub_aesthetic_model_id (`str`, *optional*, defaults to `"trl-lib/ddpo-aesthetic-predictor"`):
|
||||
Hugging Face model ID for aesthetic scorer model weights.
|
||||
hf_hub_aesthetic_model_filename (`str`, *optional*, defaults to `"aesthetic-model.pth"`):
|
||||
Hugging Face model filename for aesthetic scorer model weights.
|
||||
use_lora (`bool`, *optional*, defaults to `True`):
|
||||
Whether to use LoRA.
|
||||
"""
|
||||
|
||||
pretrained_model: str = field(
|
||||
default="runwayml/stable-diffusion-v1-5", metadata={"help": "the pretrained model to use"}
|
||||
default="runwayml/stable-diffusion-v1-5", metadata={"help": "Pretrained model to use."}
|
||||
)
|
||||
pretrained_revision: str = field(default="main", metadata={"help": "the pretrained model revision to use"})
|
||||
pretrained_revision: str = field(default="main", metadata={"help": "Pretrained model revision to use."})
|
||||
hf_hub_model_id: str = field(
|
||||
default="ddpo-finetuned-stable-diffusion", metadata={"help": "HuggingFace repo to save model weights to"}
|
||||
default="ddpo-finetuned-stable-diffusion", metadata={"help": "HuggingFace repo to save model weights to."}
|
||||
)
|
||||
hf_hub_aesthetic_model_id: str = field(
|
||||
default="trl-lib/ddpo-aesthetic-predictor",
|
||||
metadata={"help": "HuggingFace model ID for aesthetic scorer model weights"},
|
||||
metadata={"help": "Hugging Face model ID for aesthetic scorer model weights."},
|
||||
)
|
||||
hf_hub_aesthetic_model_filename: str = field(
|
||||
default="aesthetic-model.pth",
|
||||
metadata={"help": "HuggingFace model filename for aesthetic scorer model weights"},
|
||||
metadata={"help": "Hugging Face model filename for aesthetic scorer model weights."},
|
||||
)
|
||||
use_lora: bool = field(default=True, metadata={"help": "Whether to use LoRA."})
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,128 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
# Full training
|
||||
python examples/scripts/dpo.py \
|
||||
--dataset_name trl-lib/ultrafeedback_binarized \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
|
||||
--learning_rate 5.0e-7 \
|
||||
--num_train_epochs 1 \
|
||||
--per_device_train_batch_size 2 \
|
||||
--gradient_accumulation_steps 8 \
|
||||
--gradient_checkpointing \
|
||||
--logging_steps 25 \
|
||||
--eval_strategy steps \
|
||||
--eval_steps 50 \
|
||||
--output_dir Qwen2-0.5B-DPO \
|
||||
--no_remove_unused_columns
|
||||
|
||||
# LoRA:
|
||||
python examples/scripts/dpo.py \
|
||||
--dataset_name trl-lib/ultrafeedback_binarized \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
|
||||
--learning_rate 5.0e-6 \
|
||||
--num_train_epochs 1 \
|
||||
--per_device_train_batch_size 2 \
|
||||
--gradient_accumulation_steps 8 \
|
||||
--gradient_checkpointing \
|
||||
--logging_steps 25 \
|
||||
--eval_strategy steps \
|
||||
--eval_steps 50 \
|
||||
--output_dir Qwen2-0.5B-DPO \
|
||||
--no_remove_unused_columns \
|
||||
--use_peft \
|
||||
--lora_r 32 \
|
||||
--lora_alpha 16
|
||||
"""
|
||||
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
from trl import (
|
||||
DPOConfig,
|
||||
DPOTrainer,
|
||||
ModelConfig,
|
||||
ScriptArguments,
|
||||
TrlParser,
|
||||
get_kbit_device_map,
|
||||
get_peft_config,
|
||||
get_quantization_config,
|
||||
)
|
||||
from trl.trainer.utils import SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = TrlParser((ScriptArguments, DPOConfig, ModelConfig))
|
||||
script_args, training_args, model_config = parser.parse_args_and_config()
|
||||
|
||||
################
|
||||
# Model & Tokenizer
|
||||
###################
|
||||
torch_dtype = (
|
||||
model_config.torch_dtype
|
||||
if model_config.torch_dtype in ["auto", None]
|
||||
else getattr(torch, model_config.torch_dtype)
|
||||
)
|
||||
quantization_config = get_quantization_config(model_config)
|
||||
model_kwargs = dict(
|
||||
revision=model_config.model_revision,
|
||||
attn_implementation=model_config.attn_implementation,
|
||||
torch_dtype=torch_dtype,
|
||||
use_cache=False if training_args.gradient_checkpointing else True,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code, **model_kwargs
|
||||
)
|
||||
peft_config = get_peft_config(model_config)
|
||||
if peft_config is None:
|
||||
ref_model = AutoModelForCausalLM.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code, **model_kwargs
|
||||
)
|
||||
else:
|
||||
ref_model = None
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code
|
||||
)
|
||||
if tokenizer.pad_token is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
if tokenizer.chat_template is None:
|
||||
tokenizer.chat_template = SIMPLE_CHAT_TEMPLATE
|
||||
if script_args.ignore_bias_buffers:
|
||||
# torch distributed hack
|
||||
model._ddp_params_and_buffers_to_ignore = [
|
||||
name for name, buffer in model.named_buffers() if buffer.dtype == torch.bool
|
||||
]
|
||||
|
||||
################
|
||||
# Dataset
|
||||
################
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
|
||||
##########
|
||||
# Training
|
||||
################
|
||||
trainer = DPOTrainer(
|
||||
model,
|
||||
ref_model,
|
||||
args=training_args,
|
||||
train_dataset=dataset[script_args.dataset_train_split],
|
||||
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
|
||||
processing_class=tokenizer,
|
||||
peft_config=peft_config,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
if training_args.eval_strategy != "no":
|
||||
metrics = trainer.evaluate()
|
||||
trainer.log_metrics("eval", metrics)
|
||||
trainer.save_metrics("eval", metrics)
|
||||
|
||||
# Save and push to hub
|
||||
trainer.save_model(training_args.output_dir)
|
||||
if training_args.push_to_hub:
|
||||
trainer.push_to_hub(dataset_name=script_args.dataset_name)
|
||||
###############################################################################################
|
||||
# This file has been moved to https://github.com/huggingface/trl/blob/main/trl/scripts/dpo.py #
|
||||
###############################################################################################
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Usage:
|
||||
|
||||
@ -64,18 +65,16 @@ JUDGES = {"pair_rm": PairRMJudge, "openai": OpenAIPairwiseJudge, "hf": HfPairwis
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = TrlParser((ScriptArguments, OnlineDPOConfig, ModelConfig))
|
||||
script_args, training_args, model_config = parser.parse_args_and_config()
|
||||
script_args.gradient_checkpointing_kwargs = {"use_reentrant": True}
|
||||
script_args, training_args, model_args = parser.parse_args_and_config()
|
||||
training_args.gradient_checkpointing_kwargs = {"use_reentrant": True}
|
||||
|
||||
torch_dtype = (
|
||||
model_config.torch_dtype
|
||||
if model_config.torch_dtype in ["auto", None]
|
||||
else getattr(torch, model_config.torch_dtype)
|
||||
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
|
||||
)
|
||||
quantization_config = get_quantization_config(model_config)
|
||||
quantization_config = get_quantization_config(model_args)
|
||||
model_kwargs = dict(
|
||||
revision=model_config.model_revision,
|
||||
attn_implementation=model_config.attn_implementation,
|
||||
revision=model_args.model_revision,
|
||||
attn_implementation=model_args.attn_implementation,
|
||||
torch_dtype=torch_dtype,
|
||||
use_cache=False if training_args.gradient_checkpointing else True,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
@ -83,19 +82,19 @@ if __name__ == "__main__":
|
||||
)
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code, **model_kwargs
|
||||
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code, **model_kwargs
|
||||
)
|
||||
|
||||
if training_args.reward_model_path is not None:
|
||||
reward_model = AutoModelForSequenceClassification.from_pretrained(
|
||||
training_args.reward_model_path,
|
||||
num_labels=1,
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
**model_kwargs,
|
||||
)
|
||||
reward_tokenizer = AutoTokenizer.from_pretrained(
|
||||
training_args.reward_model_path,
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
truncation=True,
|
||||
truncation_side="left", # since we judge the completion, truncating left is more appropriate
|
||||
)
|
||||
@ -110,9 +109,9 @@ if __name__ == "__main__":
|
||||
judge = None
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path,
|
||||
model_args.model_name_or_path,
|
||||
padding_side="left",
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
**model_kwargs,
|
||||
)
|
||||
if tokenizer.chat_template is None:
|
||||
@ -120,7 +119,7 @@ if __name__ == "__main__":
|
||||
if tokenizer.pad_token_id is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
|
||||
trainer = OnlineDPOTrainer(
|
||||
model=model,
|
||||
@ -131,7 +130,7 @@ if __name__ == "__main__":
|
||||
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
|
||||
processing_class=tokenizer,
|
||||
reward_processing_class=reward_tokenizer,
|
||||
peft_config=get_peft_config(model_config),
|
||||
peft_config=get_peft_config(model_args),
|
||||
)
|
||||
|
||||
if training_args.eval_strategy != "no":
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
accelerate launch examples/scripts/dpo_vlm.py \
|
||||
--dataset_name HuggingFaceH4/rlaif-v_formatted \
|
||||
@ -44,43 +45,39 @@ from trl import (
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = TrlParser((ScriptArguments, DPOConfig, ModelConfig))
|
||||
script_args, training_args, model_config = parser.parse_args_and_config()
|
||||
script_args, training_args, model_args = parser.parse_args_and_config()
|
||||
|
||||
################
|
||||
# Model & Tokenizer
|
||||
################
|
||||
torch_dtype = (
|
||||
model_config.torch_dtype
|
||||
if model_config.torch_dtype in ["auto", None]
|
||||
else getattr(torch, model_config.torch_dtype)
|
||||
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
|
||||
)
|
||||
quantization_config = get_quantization_config(model_config)
|
||||
quantization_config = get_quantization_config(model_args)
|
||||
|
||||
model_kwargs = dict(
|
||||
revision=model_config.model_revision,
|
||||
attn_implementation=model_config.attn_implementation,
|
||||
revision=model_args.model_revision,
|
||||
attn_implementation=model_args.attn_implementation,
|
||||
torch_dtype=torch_dtype,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
model = AutoModelForVision2Seq.from_pretrained(
|
||||
model_config.model_name_or_path,
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
model_args.model_name_or_path,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
**model_kwargs,
|
||||
)
|
||||
peft_config = get_peft_config(model_config)
|
||||
peft_config = get_peft_config(model_args)
|
||||
if peft_config is None:
|
||||
ref_model = AutoModelForVision2Seq.from_pretrained(
|
||||
model_config.model_name_or_path,
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
model_args.model_name_or_path,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
**model_kwargs,
|
||||
)
|
||||
else:
|
||||
ref_model = None
|
||||
processor = AutoProcessor.from_pretrained(
|
||||
model_config.model_name_or_path,
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
do_image_splitting=False,
|
||||
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code, do_image_splitting=False
|
||||
)
|
||||
tokenizer = processor.tokenizer
|
||||
|
||||
@ -103,7 +100,7 @@ if __name__ == "__main__":
|
||||
################
|
||||
# Dataset
|
||||
################
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
|
||||
################
|
||||
# Training
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -47,14 +47,28 @@ Model win rate: 63.00%
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
model_name_or_path: str = field(metadata={"help": "The model name or path to the model to evaluate."})
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
model_name_or_path (`str`):
|
||||
Model name or path to the model to evaluate.
|
||||
judge_model (`str`, *optional*, defaults to `"meta-llama/Meta-Llama-3-70B-Instruct"`):
|
||||
Model name or path to the model to use as a judge. E.g., 'gpt-3.5-turbo-0125' or
|
||||
'meta-llama/Meta-Llama-3-70B-Instruct'.
|
||||
num_examples (`int` or `None`, *optional*, defaults to `None`):
|
||||
Number of examples to evaluate.
|
||||
"""
|
||||
|
||||
model_name_or_path: str = field(metadata={"help": "Model name or path to the model to evaluate."})
|
||||
judge_model: str = field(
|
||||
default="meta-llama/Meta-Llama-3-70B-Instruct",
|
||||
metadata={
|
||||
"help": "The model name or path to the model to use as a judge. E.g., 'gpt-3.5-turbo-0125', 'meta-llama/Meta-Llama-3-70B-Instruct'."
|
||||
"help": "Model name or path to the model to use as a judge. E.g., 'gpt-3.5-turbo-0125' or "
|
||||
"'meta-llama/Meta-Llama-3-70B-Instruct'."
|
||||
},
|
||||
)
|
||||
num_examples: Optional[int] = field(default=None, metadata={"help": "The number of examples to evaluate."})
|
||||
num_examples: Optional[int] = field(default=None, metadata={"help": "Number of examples to evaluate."})
|
||||
|
||||
|
||||
# Parse the arguments
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
# Full training:
|
||||
python examples/scripts/gkd.py \
|
||||
@ -63,17 +64,17 @@ from trl import (
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = TrlParser((ScriptArguments, GKDConfig, ModelConfig))
|
||||
script_args, training_args, model_config = parser.parse_args_and_config()
|
||||
script_args, training_args, model_args = parser.parse_args_and_config()
|
||||
|
||||
################
|
||||
# Model & Tokenizer
|
||||
################
|
||||
quantization_config = get_quantization_config(model_config)
|
||||
quantization_config = get_quantization_config(model_args)
|
||||
model_kwargs = dict(
|
||||
revision=model_config.model_revision,
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
attn_implementation=model_config.attn_implementation,
|
||||
torch_dtype=model_config.torch_dtype,
|
||||
revision=model_args.model_revision,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
attn_implementation=model_args.attn_implementation,
|
||||
torch_dtype=model_args.torch_dtype,
|
||||
use_cache=False if training_args.gradient_checkpointing else True,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
@ -81,10 +82,10 @@ if __name__ == "__main__":
|
||||
training_args.model_init_kwargs = model_kwargs
|
||||
|
||||
teacher_model_kwargs = dict(
|
||||
revision=model_config.model_revision,
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
attn_implementation=model_config.attn_implementation,
|
||||
torch_dtype=model_config.torch_dtype,
|
||||
revision=model_args.model_revision,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
attn_implementation=model_args.attn_implementation,
|
||||
torch_dtype=model_args.torch_dtype,
|
||||
use_cache=True,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
@ -92,9 +93,9 @@ if __name__ == "__main__":
|
||||
training_args.teacher_model_init_kwargs = teacher_model_kwargs
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path,
|
||||
revision=model_config.model_revision,
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
model_args.model_name_or_path,
|
||||
revision=model_args.model_revision,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
padding_side="left",
|
||||
)
|
||||
if tokenizer.pad_token is None:
|
||||
@ -103,7 +104,7 @@ if __name__ == "__main__":
|
||||
################
|
||||
# Dataset
|
||||
################
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
|
||||
with PartialState().local_main_process_first():
|
||||
dataset = dataset.map(
|
||||
@ -117,13 +118,13 @@ if __name__ == "__main__":
|
||||
# Training
|
||||
################
|
||||
trainer = GKDTrainer(
|
||||
model=model_config.model_name_or_path,
|
||||
model=model_args.model_name_or_path,
|
||||
teacher_model=training_args.teacher_model_name_or_path,
|
||||
args=training_args,
|
||||
train_dataset=dataset[script_args.dataset_train_split],
|
||||
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
|
||||
processing_class=tokenizer,
|
||||
peft_config=get_peft_config(model_config),
|
||||
peft_config=get_peft_config(model_args),
|
||||
)
|
||||
|
||||
if training_args.eval_strategy != "no":
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -16,7 +16,7 @@
|
||||
Run the KTO training script with the commands below. In general, the optimal configuration for KTO will be similar to that of DPO.
|
||||
|
||||
# Full training:
|
||||
python examples/scripts/kto.py \
|
||||
python trl/scripts/kto.py \
|
||||
--dataset_name trl-lib/kto-mix-14k \
|
||||
--model_name_or_path=trl-lib/qwen1.5-1.8b-sft \
|
||||
--per_device_train_batch_size 16 \
|
||||
@ -33,7 +33,7 @@ python examples/scripts/kto.py \
|
||||
--logging_first_step
|
||||
|
||||
# QLoRA:
|
||||
python examples/scripts/kto.py \
|
||||
python trl/scripts/kto.py \
|
||||
--dataset_name trl-lib/kto-mix-14k \
|
||||
--model_name_or_path=trl-lib/qwen1.5-1.8b-sft \
|
||||
--per_device_train_batch_size 8 \
|
||||
@ -91,7 +91,7 @@ if __name__ == "__main__":
|
||||
model, tokenizer = setup_chat_format(model, tokenizer)
|
||||
|
||||
# Load the dataset
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
|
||||
# Initialize the KTO trainer
|
||||
trainer = KTOTrainer(
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Usage:
|
||||
|
||||
@ -69,18 +70,16 @@ JUDGES = {"pair_rm": PairRMJudge, "openai": OpenAIPairwiseJudge, "hf": HfPairwis
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = TrlParser((ScriptArguments, NashMDConfig, ModelConfig))
|
||||
script_args, training_args, model_config = parser.parse_args_and_config()
|
||||
script_args.gradient_checkpointing_kwargs = {"use_reentrant": True}
|
||||
script_args, training_args, model_args = parser.parse_args_and_config()
|
||||
training_args.gradient_checkpointing_kwargs = {"use_reentrant": True}
|
||||
|
||||
torch_dtype = (
|
||||
model_config.torch_dtype
|
||||
if model_config.torch_dtype in ["auto", None]
|
||||
else getattr(torch, model_config.torch_dtype)
|
||||
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
|
||||
)
|
||||
quantization_config = get_quantization_config(model_config)
|
||||
quantization_config = get_quantization_config(model_args)
|
||||
model_kwargs = dict(
|
||||
revision=model_config.model_revision,
|
||||
attn_implementation=model_config.attn_implementation,
|
||||
revision=model_args.model_revision,
|
||||
attn_implementation=model_args.attn_implementation,
|
||||
torch_dtype=torch_dtype,
|
||||
use_cache=False if training_args.gradient_checkpointing else True,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
@ -88,17 +87,17 @@ if __name__ == "__main__":
|
||||
)
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code, **model_kwargs
|
||||
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code, **model_kwargs
|
||||
)
|
||||
ref_model = AutoModelForCausalLM.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code, **model_kwargs
|
||||
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code, **model_kwargs
|
||||
)
|
||||
|
||||
if training_args.reward_model_path is not None:
|
||||
reward_model = AutoModelForSequenceClassification.from_pretrained(
|
||||
training_args.reward_model_path,
|
||||
num_labels=1,
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
**model_kwargs,
|
||||
)
|
||||
else:
|
||||
@ -111,16 +110,14 @@ if __name__ == "__main__":
|
||||
judge = None
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path,
|
||||
padding_side="left",
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
model_args.model_name_or_path, padding_side="left", trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
if tokenizer.pad_token is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
if tokenizer.chat_template is None:
|
||||
tokenizer.chat_template = SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
|
||||
trainer = NashMDTrainer(
|
||||
model=model,
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Run the ORPO training script with the following command with some example arguments.
|
||||
In general, the optimal configuration for ORPO will be similar to that of DPO without the need for a reference model:
|
||||
@ -63,16 +64,16 @@ from trl.trainer.utils import SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser((ScriptArguments, ORPOConfig, ModelConfig))
|
||||
script_args, training_args, model_config = parser.parse_args_into_dataclasses()
|
||||
script_args, training_args, model_args = parser.parse_args_into_dataclasses()
|
||||
|
||||
################
|
||||
# Model & Tokenizer
|
||||
################
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code
|
||||
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code
|
||||
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
if tokenizer.pad_token is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
@ -80,7 +81,7 @@ if __name__ == "__main__":
|
||||
################
|
||||
# Dataset
|
||||
################
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
if tokenizer.chat_template is None:
|
||||
tokenizer.chat_template = SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
@ -93,7 +94,7 @@ if __name__ == "__main__":
|
||||
train_dataset=dataset[script_args.dataset_train_split],
|
||||
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
|
||||
processing_class=tokenizer,
|
||||
peft_config=get_peft_config(model_config),
|
||||
peft_config=get_peft_config(model_args),
|
||||
)
|
||||
|
||||
# train and save the model
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -14,6 +14,7 @@
|
||||
|
||||
import shutil
|
||||
|
||||
import torch
|
||||
from accelerate import PartialState
|
||||
from datasets import load_dataset
|
||||
from transformers import (
|
||||
@ -23,7 +24,15 @@ from transformers import (
|
||||
HfArgumentParser,
|
||||
)
|
||||
|
||||
from trl import ModelConfig, PPOConfig, PPOTrainer, ScriptArguments
|
||||
from trl import (
|
||||
ModelConfig,
|
||||
PPOConfig,
|
||||
PPOTrainer,
|
||||
ScriptArguments,
|
||||
get_kbit_device_map,
|
||||
get_peft_config,
|
||||
get_quantization_config,
|
||||
)
|
||||
from trl.trainer.utils import SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
|
||||
@ -60,37 +69,55 @@ accelerate launch --config_file examples/accelerate_configs/deepspeed_zero3.yaml
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser((ScriptArguments, PPOConfig, ModelConfig))
|
||||
script_args, training_args, model_config = parser.parse_args_into_dataclasses()
|
||||
script_args, training_args, model_args = parser.parse_args_into_dataclasses()
|
||||
# remove output_dir if exists
|
||||
shutil.rmtree(training_args.output_dir, ignore_errors=True)
|
||||
|
||||
################
|
||||
# Model & Tokenizer
|
||||
################
|
||||
torch_dtype = (
|
||||
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
|
||||
)
|
||||
quantization_config = get_quantization_config(model_args)
|
||||
model_kwargs = dict(
|
||||
revision=model_args.model_revision,
|
||||
attn_implementation=model_args.attn_implementation,
|
||||
torch_dtype=torch_dtype,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path,
|
||||
padding_side="left",
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
model_args.model_name_or_path, padding_side="left", trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
|
||||
if tokenizer.chat_template is None:
|
||||
tokenizer.chat_template = SIMPLE_CHAT_TEMPLATE
|
||||
value_model = AutoModelForSequenceClassification.from_pretrained(
|
||||
training_args.reward_model_path, trust_remote_code=model_config.trust_remote_code, num_labels=1
|
||||
training_args.reward_model_path, trust_remote_code=model_args.trust_remote_code, num_labels=1
|
||||
)
|
||||
reward_model = AutoModelForSequenceClassification.from_pretrained(
|
||||
training_args.reward_model_path, trust_remote_code=model_config.trust_remote_code, num_labels=1
|
||||
)
|
||||
ref_policy = AutoModelForCausalLM.from_pretrained(
|
||||
training_args.sft_model_path, trust_remote_code=model_config.trust_remote_code
|
||||
training_args.reward_model_path, trust_remote_code=model_args.trust_remote_code, num_labels=1
|
||||
)
|
||||
policy = AutoModelForCausalLM.from_pretrained(
|
||||
training_args.sft_model_path, trust_remote_code=model_config.trust_remote_code
|
||||
training_args.sft_model_path, trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
|
||||
peft_config = get_peft_config(model_args)
|
||||
if peft_config is None:
|
||||
ref_policy = AutoModelForCausalLM.from_pretrained(
|
||||
training_args.sft_model_path, trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
else:
|
||||
ref_policy = None
|
||||
|
||||
################
|
||||
# Dataset
|
||||
################
|
||||
dataset = load_dataset(script_args.dataset_name, split=script_args.dataset_train_split)
|
||||
dataset = load_dataset(
|
||||
script_args.dataset_name, name=script_args.dataset_config, split=script_args.dataset_train_split
|
||||
)
|
||||
eval_samples = 100
|
||||
train_dataset = dataset.select(range(len(dataset) - eval_samples))
|
||||
eval_dataset = dataset.select(range(len(dataset) - eval_samples, len(dataset)))
|
||||
@ -123,14 +150,15 @@ if __name__ == "__main__":
|
||||
# Training
|
||||
################
|
||||
trainer = PPOTrainer(
|
||||
config=training_args,
|
||||
args=training_args,
|
||||
processing_class=tokenizer,
|
||||
policy=policy,
|
||||
ref_policy=ref_policy,
|
||||
model=policy,
|
||||
ref_model=ref_policy,
|
||||
reward_model=reward_model,
|
||||
value_model=value_model,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
peft_config=peft_config,
|
||||
)
|
||||
trainer.train()
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -14,6 +14,7 @@
|
||||
|
||||
import shutil
|
||||
|
||||
import torch
|
||||
from accelerate import PartialState
|
||||
from datasets import load_dataset
|
||||
from transformers import (
|
||||
@ -23,16 +24,24 @@ from transformers import (
|
||||
HfArgumentParser,
|
||||
)
|
||||
|
||||
from trl import ModelConfig, PPOConfig, PPOTrainer, ScriptArguments
|
||||
from trl import (
|
||||
ModelConfig,
|
||||
PPOConfig,
|
||||
PPOTrainer,
|
||||
ScriptArguments,
|
||||
get_kbit_device_map,
|
||||
get_peft_config,
|
||||
get_quantization_config,
|
||||
)
|
||||
from trl.trainer.utils import SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
|
||||
"""
|
||||
python examples/scripts/ppo/ppo_tldr.py \
|
||||
--dataset_name trl-internal-testing/tldr-preference-sft-trl-style
|
||||
--dataset_name trl-internal-testing/tldr-preference-sft-trl-style \
|
||||
--dataset_test_split validation \
|
||||
--learning_rate 3e-6 \
|
||||
--output_dir models/minimal/ppo \
|
||||
--output_dir models/minimal/ppo_tldr \
|
||||
--per_device_train_batch_size 1 \
|
||||
--gradient_accumulation_steps 64 \
|
||||
--total_episodes 30000 \
|
||||
@ -41,11 +50,13 @@ python examples/scripts/ppo/ppo_tldr.py \
|
||||
--reward_model_path cleanrl/EleutherAI_pythia-1b-deduped__reward__tldr \
|
||||
--missing_eos_penalty 1.0 \
|
||||
--stop_token eos \
|
||||
--response_length 53
|
||||
--response_length 53 \
|
||||
--eval_strategy steps \
|
||||
--eval_steps 100
|
||||
|
||||
accelerate launch --config_file examples/accelerate_configs/deepspeed_zero2.yaml \
|
||||
examples/scripts/ppo/ppo_tldr.py \
|
||||
--dataset_name trl-internal-testing/tldr-preference-sft-trl-style
|
||||
--dataset_name trl-internal-testing/tldr-preference-sft-trl-style \
|
||||
--dataset_test_split validation \
|
||||
--output_dir models/minimal/ppo_tldr \
|
||||
--learning_rate 3e-6 \
|
||||
@ -57,43 +68,61 @@ accelerate launch --config_file examples/accelerate_configs/deepspeed_zero2.yaml
|
||||
--reward_model_path cleanrl/EleutherAI_pythia-1b-deduped__reward__tldr \
|
||||
--local_rollout_forward_batch_size 16 \
|
||||
--missing_eos_penalty 1.0 \
|
||||
--stop_token eos
|
||||
--stop_token eos \
|
||||
--eval_strategy steps \
|
||||
--eval_steps 100
|
||||
"""
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser((ScriptArguments, PPOConfig, ModelConfig))
|
||||
script_args, training_args, model_config = parser.parse_args_into_dataclasses()
|
||||
script_args, training_args, model_args = parser.parse_args_into_dataclasses()
|
||||
# remove output_dir if exists
|
||||
shutil.rmtree(training_args.output_dir, ignore_errors=True)
|
||||
|
||||
################
|
||||
# Model & Tokenizer
|
||||
################
|
||||
torch_dtype = (
|
||||
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
|
||||
)
|
||||
quantization_config = get_quantization_config(model_args)
|
||||
model_kwargs = dict(
|
||||
revision=model_args.model_revision,
|
||||
attn_implementation=model_args.attn_implementation,
|
||||
torch_dtype=torch_dtype,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path,
|
||||
padding_side="left",
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
model_args.model_name_or_path, padding_side="left", trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
|
||||
if tokenizer.chat_template is None:
|
||||
tokenizer.chat_template = SIMPLE_CHAT_TEMPLATE
|
||||
value_model = AutoModelForSequenceClassification.from_pretrained(
|
||||
training_args.reward_model_path, trust_remote_code=model_config.trust_remote_code, num_labels=1
|
||||
training_args.reward_model_path, trust_remote_code=model_args.trust_remote_code, num_labels=1
|
||||
)
|
||||
reward_model = AutoModelForSequenceClassification.from_pretrained(
|
||||
training_args.reward_model_path, trust_remote_code=model_config.trust_remote_code, num_labels=1
|
||||
)
|
||||
ref_policy = AutoModelForCausalLM.from_pretrained(
|
||||
training_args.sft_model_path, trust_remote_code=model_config.trust_remote_code
|
||||
training_args.reward_model_path, trust_remote_code=model_args.trust_remote_code, num_labels=1
|
||||
)
|
||||
policy = AutoModelForCausalLM.from_pretrained(
|
||||
training_args.sft_model_path, trust_remote_code=model_config.trust_remote_code
|
||||
training_args.sft_model_path, trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
|
||||
peft_config = get_peft_config(model_args)
|
||||
if peft_config is None:
|
||||
ref_policy = AutoModelForCausalLM.from_pretrained(
|
||||
training_args.sft_model_path, trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
else:
|
||||
ref_policy = None
|
||||
|
||||
################
|
||||
# Dataset
|
||||
################
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
train_dataset = dataset[script_args.dataset_train_split]
|
||||
eval_dataset = dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None
|
||||
|
||||
@ -130,14 +159,15 @@ if __name__ == "__main__":
|
||||
# Training
|
||||
################
|
||||
trainer = PPOTrainer(
|
||||
config=training_args,
|
||||
args=training_args,
|
||||
processing_class=tokenizer,
|
||||
policy=policy,
|
||||
ref_policy=ref_policy,
|
||||
model=policy,
|
||||
ref_model=ref_policy,
|
||||
reward_model=reward_model,
|
||||
value_model=value_model,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
peft_config=peft_config,
|
||||
)
|
||||
trainer.train()
|
||||
|
||||
|
||||
130
examples/scripts/prm.py
Normal file
130
examples/scripts/prm.py
Normal file
@ -0,0 +1,130 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Full training:
|
||||
python examples/scripts/prm.py \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
|
||||
--dataset_name trl-lib/prm800k \
|
||||
--output_dir Qwen2-0.5B-Reward \
|
||||
--per_device_train_batch_size 8 \
|
||||
--num_train_epochs 1 \
|
||||
--gradient_checkpointing True \
|
||||
--learning_rate 1.0e-5 \
|
||||
--logging_steps 25 \
|
||||
--eval_strategy steps \
|
||||
--eval_steps 50
|
||||
|
||||
LoRA:
|
||||
python examples/scripts/prm.py \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
|
||||
--dataset_name trl-lib/prm800k \
|
||||
--output_dir Qwen2-0.5B-Reward-LoRA \
|
||||
--per_device_train_batch_size 8 \
|
||||
--num_train_epochs 1 \
|
||||
--gradient_checkpointing True \
|
||||
--learning_rate 1.0e-4 \
|
||||
--logging_steps 25 \
|
||||
--eval_strategy steps \
|
||||
--eval_steps 50
|
||||
--use_peft \
|
||||
--lora_r 32 \
|
||||
--lora_alpha 16
|
||||
"""
|
||||
|
||||
import warnings
|
||||
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModelForTokenClassification, AutoTokenizer, HfArgumentParser
|
||||
|
||||
from trl import (
|
||||
ModelConfig,
|
||||
PRMConfig,
|
||||
PRMTrainer,
|
||||
ScriptArguments,
|
||||
get_kbit_device_map,
|
||||
get_peft_config,
|
||||
get_quantization_config,
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser((ScriptArguments, PRMConfig, ModelConfig))
|
||||
script_args, training_args, model_config = parser.parse_args_into_dataclasses()
|
||||
training_args.gradient_checkpointing_kwargs = dict(use_reentrant=False)
|
||||
|
||||
################
|
||||
# Model & Tokenizer
|
||||
################
|
||||
torch_dtype = (
|
||||
model_config.torch_dtype
|
||||
if model_config.torch_dtype in ["auto", None]
|
||||
else getattr(torch, model_config.torch_dtype)
|
||||
)
|
||||
quantization_config = get_quantization_config(model_config)
|
||||
model_kwargs = dict(
|
||||
revision=model_config.model_revision,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
use_cache=False if training_args.gradient_checkpointing else True,
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code, use_fast=True
|
||||
)
|
||||
model = AutoModelForTokenClassification.from_pretrained(
|
||||
model_config.model_name_or_path, num_labels=2, trust_remote_code=model_config.trust_remote_code, **model_kwargs
|
||||
)
|
||||
# Align padding tokens between tokenizer and model
|
||||
model.config.pad_token_id = tokenizer.pad_token_id
|
||||
|
||||
if model_config.use_peft and model_config.lora_task_type != "TOKEN_CLS":
|
||||
warnings.warn(
|
||||
"You are using a `task_type` that is different than `TOKEN_CLS` for PEFT. This will lead to silent bugs"
|
||||
" Make sure to pass --lora_task_type TOKEN_CLS when using this script with PEFT.",
|
||||
UserWarning,
|
||||
)
|
||||
|
||||
##############
|
||||
# Load dataset
|
||||
##############
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
|
||||
dataset = dataset.filter(lambda x: len(x["completions"]) > 0)
|
||||
|
||||
##########
|
||||
# Training
|
||||
##########
|
||||
trainer = PRMTrainer(
|
||||
model=model,
|
||||
processing_class=tokenizer,
|
||||
args=training_args,
|
||||
train_dataset=dataset[script_args.dataset_train_split],
|
||||
eval_dataset=dataset[script_args.dataset_test_split],
|
||||
peft_config=get_peft_config(model_config),
|
||||
)
|
||||
trainer.train()
|
||||
|
||||
############################
|
||||
# Save model and push to Hub
|
||||
############################
|
||||
trainer.save_model(training_args.output_dir)
|
||||
metrics = trainer.evaluate()
|
||||
trainer.log_metrics("eval", metrics)
|
||||
trainer.save_metrics("eval", metrics)
|
||||
|
||||
# Save and push to hub
|
||||
trainer.save_model(training_args.output_dir)
|
||||
if training_args.push_to_hub:
|
||||
trainer.push_to_hub(dataset_name=script_args.dataset_name)
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Full training:
|
||||
python examples/scripts/reward_modeling.py \
|
||||
@ -64,30 +65,28 @@ from trl import (
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser((ScriptArguments, RewardConfig, ModelConfig))
|
||||
script_args, training_args, model_config = parser.parse_args_into_dataclasses()
|
||||
script_args, training_args, model_args = parser.parse_args_into_dataclasses()
|
||||
training_args.gradient_checkpointing_kwargs = dict(use_reentrant=False)
|
||||
|
||||
################
|
||||
# Model & Tokenizer
|
||||
################
|
||||
torch_dtype = (
|
||||
model_config.torch_dtype
|
||||
if model_config.torch_dtype in ["auto", None]
|
||||
else getattr(torch, model_config.torch_dtype)
|
||||
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
|
||||
)
|
||||
quantization_config = get_quantization_config(model_config)
|
||||
quantization_config = get_quantization_config(model_args)
|
||||
model_kwargs = dict(
|
||||
revision=model_config.model_revision,
|
||||
revision=model_args.model_revision,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
use_cache=False if training_args.gradient_checkpointing else True,
|
||||
torch_dtype=torch_dtype,
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code, use_fast=True
|
||||
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code, use_fast=True
|
||||
)
|
||||
model = AutoModelForSequenceClassification.from_pretrained(
|
||||
model_config.model_name_or_path, num_labels=1, trust_remote_code=model_config.trust_remote_code, **model_kwargs
|
||||
model_args.model_name_or_path, num_labels=1, trust_remote_code=model_args.trust_remote_code, **model_kwargs
|
||||
)
|
||||
# Align padding tokens between tokenizer and model
|
||||
model.config.pad_token_id = tokenizer.pad_token_id
|
||||
@ -96,16 +95,17 @@ if __name__ == "__main__":
|
||||
if tokenizer.chat_template is None:
|
||||
model, tokenizer = setup_chat_format(model, tokenizer)
|
||||
|
||||
if model_config.use_peft and model_config.lora_task_type != "SEQ_CLS":
|
||||
if model_args.use_peft and model_args.lora_task_type != "SEQ_CLS":
|
||||
warnings.warn(
|
||||
"You are using a `task_type` that is different than `SEQ_CLS` for PEFT. This will lead to silent bugs"
|
||||
" Make sure to pass --lora_task_type SEQ_CLS when using this script with PEFT."
|
||||
" Make sure to pass --lora_task_type SEQ_CLS when using this script with PEFT.",
|
||||
UserWarning,
|
||||
)
|
||||
|
||||
##############
|
||||
# Load dataset
|
||||
##############
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
|
||||
##########
|
||||
# Training
|
||||
@ -116,7 +116,7 @@ if __name__ == "__main__":
|
||||
args=training_args,
|
||||
train_dataset=dataset[script_args.dataset_train_split],
|
||||
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
|
||||
peft_config=get_peft_config(model_config),
|
||||
peft_config=get_peft_config(model_args),
|
||||
)
|
||||
trainer.train()
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user