mirror of
https://github.com/huggingface/trl.git
synced 2025-10-21 02:53:59 +08:00
Compare commits
229 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 8d4cc9427d | |||
| aeca63774f | |||
| 117c6d4b52 | |||
| 6d4ed070f1 | |||
| cd7156fb34 | |||
| ca850be0a2 | |||
| 179ba53671 | |||
| e3e171a26b | |||
| b3aff441ff | |||
| efc687db62 | |||
| f2e362656c | |||
| c9c4f18039 | |||
| 460e780265 | |||
| 7ba118a229 | |||
| 6a05feff02 | |||
| 2f72f47191 | |||
| 9410874787 | |||
| 9c5388b69e | |||
| b02189aaa5 | |||
| 52201d3c18 | |||
| 9ff79a65e3 | |||
| 9001a8682c | |||
| f6f42651e2 | |||
| 148b592313 | |||
| d6a8f2c2f6 | |||
| 8d9cfaafeb | |||
| 94e4135a17 | |||
| ac267781ec | |||
| 2c6e0d9705 | |||
| e1d781353b | |||
| a34e9bf84f | |||
| c10cc8995b | |||
| 9368dccef6 | |||
| 43df3a485a | |||
| baee06f2e8 | |||
| bbd8cbb720 | |||
| 4f937c7629 | |||
| 16fa13ce72 | |||
| 453db5cd79 | |||
| ee3cbe1946 | |||
| 17e8060984 | |||
| 163695e85c | |||
| 672c96546d | |||
| bdeb117320 | |||
| 6578fdc101 | |||
| a0066f47f8 | |||
| 5626806aef | |||
| bb0afc2459 | |||
| 066fc37bd3 | |||
| b80c1a6fb8 | |||
| b5eabbeb07 | |||
| cbf9abcd07 | |||
| 6f8fe59aeb | |||
| 1293f37c5f | |||
| e7870dd5d6 | |||
| 21d5baf338 | |||
| 76dbb1a576 | |||
| b8c9d9c7bc | |||
| 623963126b | |||
| 2d24d35013 | |||
| dde20b23cf | |||
| 015321e135 | |||
| 454f36d951 | |||
| 9b7f9f3519 | |||
| 518e29ca9c | |||
| ac7b6cfdfa | |||
| 0238d96c6f | |||
| c86b51cd12 | |||
| ac77c09223 | |||
| 7f2ccbe3a2 | |||
| 74e20cbbbc | |||
| 27b9e3a93f | |||
| dc2b8b9e90 | |||
| 5e90682836 | |||
| 3b439967f4 | |||
| 2f34a161cd | |||
| 6138439df4 | |||
| d57a181163 | |||
| 73c3970c1f | |||
| 013a32b396 | |||
| 24fb32733f | |||
| bb56c6e6af | |||
| 06be6f409a | |||
| b2696578ce | |||
| 0ce3b65928 | |||
| e155cb8a66 | |||
| ea7a1be92c | |||
| 110d0884c7 | |||
| 57ba9b93aa | |||
| 0de75b26f2 | |||
| e615974a03 | |||
| c2bb1eed14 | |||
| 9c376c571f | |||
| 16994738d0 | |||
| 99225bb6d6 | |||
| 88be2c07e5 | |||
| f2349d2af0 | |||
| d843b3dadd | |||
| 84dab850f6 | |||
| 92f6d246d3 | |||
| 31b7820aad | |||
| b9aa965cce | |||
| a67f2143c3 | |||
| 494b4afa10 | |||
| 02f4e750c0 | |||
| 2ba3005d1c | |||
| 7e394b03e8 | |||
| 14f3613dac | |||
| 5e24101b36 | |||
| b81a6121c3 | |||
| 7f0d246235 | |||
| 70036bf87f | |||
| d0aa421e5e | |||
| 5375d71bbd | |||
| 6004e033a4 | |||
| f436c3e1c9 | |||
| cd1aa6bdcc | |||
| b3f93f0bad | |||
| 6c32c8bfcd | |||
| 3107a40f16 | |||
| 419791695c | |||
| 7e5924d17e | |||
| ed9ea74b62 | |||
| 511c92c91c | |||
| c6cb6353a5 | |||
| adb3e0560b | |||
| adf58d80d0 | |||
| 9aa022503c | |||
| 82ad390caf | |||
| ac038ef03a | |||
| 51ca76b749 | |||
| 7005ab4d11 | |||
| ffb1ab74ba | |||
| 47d08a9626 | |||
| 70327c18e6 | |||
| f05c3fa8fc | |||
| 4799ba4842 | |||
| d45c86e2a7 | |||
| c6b0d1358b | |||
| 3321084e30 | |||
| a9cffc7caf | |||
| 32a928cfc2 | |||
| 1a3bb372ac | |||
| d4564b7c64 | |||
| 1be4d86ccc | |||
| 78249d9de4 | |||
| 5c21de30ae | |||
| 0a566f0c58 | |||
| de3876577c | |||
| 1201aa61b4 | |||
| c00722ce0a | |||
| 124189c86a | |||
| d5eeaab462 | |||
| 5368be1e1e | |||
| b169e1030d | |||
| 9af4734178 | |||
| a0d714949f | |||
| a0e28143ec | |||
| 32d9d34eb1 | |||
| fb1b48fdbe | |||
| b5e4bc5984 | |||
| 7a24565d9d | |||
| 44a06fc487 | |||
| a84fc5d815 | |||
| 80038a5a92 | |||
| cece86b182 | |||
| d005980d8b | |||
| cc23b511e4 | |||
| 2cad48d511 | |||
| 6859e048da | |||
| 92eea1f239 | |||
| 663002f609 | |||
| 44d998b2af | |||
| 9b80f3d50c | |||
| 2038e52c30 | |||
| 10c2f63b2a | |||
| 9fb871f62f | |||
| 3cec013a20 | |||
| cc80ac6b47 | |||
| 4c0c98d950 | |||
| 0d2bee51aa | |||
| 6920c2d1bb | |||
| 4d8267610f | |||
| c3143832cb | |||
| e74dbf2d6a | |||
| 41fe228654 | |||
| 07f0e687cb | |||
| dc2bd07408 | |||
| cdafc9333c | |||
| 40f05226de | |||
| f6c664301d | |||
| 08ba866c86 | |||
| ebc85b2e39 | |||
| 88bede66fc | |||
| 7a2bbe3957 | |||
| d47220f299 | |||
| d8324924c8 | |||
| 4c92ba5769 | |||
| a5b98fcf97 | |||
| e51a5ac985 | |||
| 31b93876a7 | |||
| 85696aa64c | |||
| 642c4b1855 | |||
| 9a6061fc2f | |||
| a8fd6dcd17 | |||
| e2966c8d99 | |||
| 37934d70a9 | |||
| 9c043e596b | |||
| a20e822737 | |||
| 3511856767 | |||
| f8cf88ab65 | |||
| 2ee0b62cdb | |||
| ac071d6225 | |||
| 72f19c3fce | |||
| 8d7b54d4bf | |||
| a638f73f5c | |||
| 8a518ee619 | |||
| 7a67de3c1c | |||
| 3412f513f2 | |||
| fc20db8873 | |||
| 7acb9c2319 | |||
| 684038057e | |||
| 1f6a1d2f9a | |||
| d60a1f50fe | |||
| 728a9a3b5f | |||
| 850ddcf598 | |||
| d57e4b7265 | |||
| 11f442fc05 | |||
| 437e8ccaba |
46
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
46
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@ -7,16 +7,17 @@ body:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this bug report! 🤗
|
||||
|
||||
Before you submit your bug report:
|
||||
|
||||
- If it is your first time submitting, be sure to check our [bug report guidelines](https://github.com/huggingface/trl/blob/main/CONTRIBUTING.md#did-you-find-a-bug)
|
||||
🚩 If it is your first time submitting, be sure to check our [bug report guidelines](https://github.com/huggingface/trl/blob/main/CONTRIBUTING.md#did-you-find-a-bug)
|
||||
|
||||
- type: textarea
|
||||
id: system-info
|
||||
attributes:
|
||||
label: System Info
|
||||
description: Please share your system info with us. You can run the command `transformers-cli env` and copy-paste its output below.
|
||||
placeholder: trl version, transformers version, platform, python version, ...
|
||||
description: |
|
||||
Please provide information about your system: platform, Python version, PyTorch version, Transformers version, devices, TRL version, ...
|
||||
You can get this information by running `trl env` in your terminal.
|
||||
|
||||
placeholder: Copy-paste the output of `trl env`
|
||||
validations:
|
||||
required: true
|
||||
|
||||
@ -50,13 +51,19 @@ body:
|
||||
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
|
||||
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
|
||||
|
||||
placeholder: |
|
||||
Steps to reproduce the behavior:
|
||||
value: |
|
||||
```python
|
||||
from trl import ...
|
||||
|
||||
1.
|
||||
2.
|
||||
3.
|
||||
```
|
||||
|
||||
outputs:
|
||||
|
||||
```
|
||||
Traceback (most recent call last):
|
||||
File "example.py", line 42, in <module>
|
||||
...
|
||||
```
|
||||
|
||||
- type: textarea
|
||||
id: expected-behavior
|
||||
@ -65,3 +72,22 @@ body:
|
||||
attributes:
|
||||
label: Expected behavior
|
||||
description: "A clear and concise description of what you would expect to happen."
|
||||
|
||||
- type: checkboxes
|
||||
id: terms
|
||||
attributes:
|
||||
label: Checklist
|
||||
description: |
|
||||
Before submitting, please confirm that you've completed each of the following.
|
||||
If an item doesn't apply to your issue, check it anyway to show you've reviewed it.
|
||||
options:
|
||||
- label: "I have checked that my issue isn't already filed (see [open issues](https://github.com/huggingface/trl/issues?q=is%3Aissue))"
|
||||
required: true
|
||||
- label: "I have included my system information"
|
||||
required: true
|
||||
- label: "Any code provided is minimal, complete, and reproducible ([more on MREs](https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/creating-and-highlighting-code-blocks))"
|
||||
required: true
|
||||
- label: "Any code provided is properly formatted in code blocks, (no screenshot, [more on code blocks](https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/creating-and-highlighting-code-blocks))"
|
||||
required: true
|
||||
- label: "Any traceback provided is complete"
|
||||
required: true
|
||||
|
||||
6
.github/workflows/slow-tests.yml
vendored
6
.github/workflows/slow-tests.yml
vendored
@ -19,7 +19,8 @@ jobs:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
docker-image-name: ["huggingface/trl-latest-gpu:latest", "huggingface/trl-source-gpu:latest"]
|
||||
runs-on: [self-hosted, single-gpu, nvidia-gpu, t4, ci]
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
env:
|
||||
CUDA_VISIBLE_DEVICES: "0"
|
||||
TEST_TYPE: "single_gpu_${{ matrix.docker-image-name }}"
|
||||
@ -55,7 +56,8 @@ jobs:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
docker-image-name: ["huggingface/trl-latest-gpu:latest", "huggingface/trl-source-gpu:latest"]
|
||||
runs-on: [self-hosted, multi-gpu, nvidia-gpu, t4, ci]
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
env:
|
||||
CUDA_VISIBLE_DEVICES: "0,1"
|
||||
TEST_TYPE: "multi_gpu_${{ matrix.docker-image-name }}"
|
||||
|
||||
27
.github/workflows/stale.yml
vendored
27
.github/workflows/stale.yml
vendored
@ -1,27 +0,0 @@
|
||||
name: Stale Bot
|
||||
|
||||
on:
|
||||
schedule:
|
||||
- cron: "0 15 * * *"
|
||||
|
||||
jobs:
|
||||
close_stale_issues:
|
||||
name: Close Stale Issues
|
||||
if: github.repository == 'huggingface/trl'
|
||||
runs-on: ubuntu-latest
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: Install requirements
|
||||
run: |
|
||||
pip install PyGithub
|
||||
- name: Close stale issues
|
||||
run: |
|
||||
python scripts/stale.py
|
||||
46
.github/workflows/tests-main.yml
vendored
46
.github/workflows/tests-main.yml
vendored
@ -1,46 +0,0 @@
|
||||
name: tests on transformers PEFT main
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
|
||||
env:
|
||||
CI_SLACK_CHANNEL: ${{ secrets.CI_PUSH_MAIN_CHANNEL }}
|
||||
|
||||
jobs:
|
||||
tests:
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ['3.9', '3.10', '3.11']
|
||||
os: ['ubuntu-latest', 'windows-latest']
|
||||
fail-fast: false
|
||||
runs-on: ${{ matrix.os }}
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
cache: "pip"
|
||||
cache-dependency-path: |
|
||||
setup.py
|
||||
requirements.txt
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
# install PEFT & transformers from source
|
||||
pip install -U git+https://github.com/huggingface/peft.git
|
||||
pip install -U git+https://github.com/huggingface/transformers.git
|
||||
# cpu version of pytorch
|
||||
pip install ".[test, diffusers]"
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
make test
|
||||
- name: Post to Slack
|
||||
if: always()
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: 🤗 Results of the TRL CI on transformers/PEFT main
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
177
.github/workflows/tests.yml
vendored
177
.github/workflows/tests.yml
vendored
@ -1,88 +1,163 @@
|
||||
name: tests
|
||||
name: Tests
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ main ]
|
||||
pull_request:
|
||||
branches: [ main ]
|
||||
paths:
|
||||
# Run only when relevant files are modified
|
||||
- "trl/**.py"
|
||||
- ".github/**.yml"
|
||||
- "examples/**.py"
|
||||
- "scripts/**.py"
|
||||
- ".github/**.yml"
|
||||
- "tests/**.py"
|
||||
- "trl/**.py"
|
||||
- "setup.py"
|
||||
|
||||
env:
|
||||
TQDM_DISABLE: 1
|
||||
CI_SLACK_CHANNEL: ${{ secrets.CI_PUSH_MAIN_CHANNEL }}
|
||||
|
||||
jobs:
|
||||
check_code_quality:
|
||||
name: Check code quality
|
||||
runs-on: ubuntu-latest
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: [3.9]
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0
|
||||
submodules: recursive
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
- name: Set up Python 3.12
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
python-version: 3.12
|
||||
- uses: pre-commit/action@v3.0.1
|
||||
with:
|
||||
extra_args: --all-files
|
||||
|
||||
tests:
|
||||
needs: check_code_quality
|
||||
name: Tests
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ['3.9', '3.10', '3.11']
|
||||
python-version: ['3.9', '3.10', '3.11', '3.12']
|
||||
os: ['ubuntu-latest', 'windows-latest']
|
||||
fail-fast: false
|
||||
runs-on: ${{ matrix.os }}
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
cache: "pip"
|
||||
cache-dependency-path: |
|
||||
setup.py
|
||||
requirements.txt
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
# install PEFT & transformers from source
|
||||
pip install -U git+https://github.com/huggingface/peft.git
|
||||
pip install -U git+https://github.com/huggingface/transformers.git
|
||||
# cpu version of pytorch
|
||||
pip install ".[test, diffusers]"
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
make test
|
||||
- uses: actions/checkout@v4
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
cache: "pip"
|
||||
cache-dependency-path: |
|
||||
setup.py
|
||||
requirements.txt
|
||||
|
||||
tests_no_optional_dep:
|
||||
needs: check_code_quality
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install ".[dev]"
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
make test
|
||||
- name: Post to Slack
|
||||
if: github.ref == 'refs/heads/main' && always() # Check if the branch is main
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: Results with Python ${{ matrix.python-version }} on ${{ matrix.os }} with lastest dependencies
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
tests_dev:
|
||||
name: Tests with dev dependencies
|
||||
runs-on: 'ubuntu-latest'
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- name: Set up Python 3.9
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.9'
|
||||
cache: "pip"
|
||||
cache-dependency-path: |
|
||||
setup.py
|
||||
requirements.txt
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
# cpu version of pytorch
|
||||
pip install .[test]
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
make test
|
||||
- uses: actions/checkout@v4
|
||||
- name: Set up Python 3.12
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.12'
|
||||
cache: "pip"
|
||||
cache-dependency-path: |
|
||||
setup.py
|
||||
requirements.txt
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install -U git+https://github.com/huggingface/accelerate.git
|
||||
python -m pip install -U git+https://github.com/huggingface/datasets.git
|
||||
python -m pip install -U git+https://github.com/huggingface/transformers.git
|
||||
python -m pip install ".[dev]"
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
make test
|
||||
- name: Post to Slack
|
||||
if: github.ref == 'refs/heads/main' && always() # Check if the branch is main
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: Results with Python 3.12 on ubuntu-latest with dev dependencies
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
tests_wo_optional_deps:
|
||||
name: Tests without optional dependencies
|
||||
runs-on: 'ubuntu-latest'
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- name: Set up Python 3.12
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.12'
|
||||
cache: "pip"
|
||||
cache-dependency-path: |
|
||||
setup.py
|
||||
requirements.txt
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install ".[test]"
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
make test
|
||||
- name: Post to Slack
|
||||
if: github.ref == 'refs/heads/main' && always() # Check if the branch is main
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: Results with Python 3.12 on ubuntu-latest without optional dependencies
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
tests_min_versions:
|
||||
name: Tests with minimum versions
|
||||
runs-on: 'ubuntu-latest'
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- name: Set up Python 3.12
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.12'
|
||||
cache: "pip"
|
||||
cache-dependency-path: |
|
||||
setup.py
|
||||
requirements.txt
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install accelerate==0.34.0
|
||||
python -m pip install datasets==2.21.0
|
||||
python -m pip install transformers==4.46.0
|
||||
python -m pip install ".[dev]"
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
make test
|
||||
- name: Post to Slack
|
||||
if: github.ref == 'refs/heads/main' && always() # Check if the branch is main
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: Results with Python 3.12 on ubuntu-latest with minimum versions
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
45
.github/workflows/tests_latest.yml
vendored
Normal file
45
.github/workflows/tests_latest.yml
vendored
Normal file
@ -0,0 +1,45 @@
|
||||
name: Tests latest TRL release with dev dependencies
|
||||
|
||||
on:
|
||||
schedule:
|
||||
- cron: '0 0 * * *' # Runs daily at midnight UTC
|
||||
|
||||
workflow_dispatch:
|
||||
|
||||
env:
|
||||
TQDM_DISABLE: 1
|
||||
CI_SLACK_CHANNEL: ${{ secrets.CI_PUSH_MAIN_CHANNEL }}
|
||||
|
||||
jobs:
|
||||
tests:
|
||||
name: Tests latest TRL release with dev dependencies
|
||||
runs-on: 'ubuntu-latest'
|
||||
steps:
|
||||
- name: Git checkout
|
||||
uses: actions/checkout@v4
|
||||
with: { ref: v0.13-release }
|
||||
- name: Set up Python 3.12
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.12'
|
||||
cache: "pip"
|
||||
cache-dependency-path: |
|
||||
setup.py
|
||||
requirements.txt
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
python -m pip install -U git+https://github.com/huggingface/accelerate.git
|
||||
python -m pip install -U git+https://github.com/huggingface/datasets.git
|
||||
python -m pip install -U git+https://github.com/huggingface/transformers.git
|
||||
python -m pip install ".[dev]"
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
make test
|
||||
- name: Post to Slack
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: Results of latest TRL with Python 3.12 on ubuntu-latest with dev dependencies
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
4
.gitignore
vendored
4
.gitignore
vendored
@ -1,4 +1,3 @@
|
||||
benchmark/trl
|
||||
*.bak
|
||||
.gitattributes
|
||||
.last_checked
|
||||
@ -144,6 +143,3 @@ checklink/cookies.txt
|
||||
nbs/wandb/
|
||||
examples/notebooks/wandb/
|
||||
wandb/
|
||||
|
||||
# cli scripts that are symlinked from `examples/scripts`
|
||||
trl/commands/scripts/
|
||||
@ -1,10 +1,12 @@
|
||||
repos:
|
||||
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||
rev: v0.2.0
|
||||
rev: v0.6.3
|
||||
hooks:
|
||||
- id: ruff
|
||||
types_or: [ python, pyi ]
|
||||
args: [ --fix ]
|
||||
- id: ruff-format
|
||||
types_or: [ python, pyi ]
|
||||
|
||||
# - repo: https://github.com/codespell-project/codespell
|
||||
# rev: v2.1.0
|
||||
|
||||
@ -17,6 +17,12 @@ authors:
|
||||
family-names: Thrush
|
||||
- given-names: Nathan
|
||||
family-names: Lambert
|
||||
- given-names: Shengyi
|
||||
family-names: Huang
|
||||
- given-names: Kashif
|
||||
family-names: Rasul
|
||||
- given-names: Quentin
|
||||
family-names: Gallouédec
|
||||
repository-code: 'https://github.com/huggingface/trl'
|
||||
abstract: "With trl you can train transformer language models with Proximal Policy Optimization (PPO). The library is built on top of the transformers library by \U0001F917 Hugging Face. Therefore, pre-trained language models can be directly loaded via transformers. At this point, most decoder and encoder-decoder architectures are supported."
|
||||
keywords:
|
||||
@ -25,4 +31,4 @@ keywords:
|
||||
- pytorch
|
||||
- transformers
|
||||
license: Apache-2.0
|
||||
version: 0.2.1
|
||||
version: 0.12
|
||||
|
||||
136
CONTRIBUTING.md
136
CONTRIBUTING.md
@ -20,7 +20,7 @@ There are several ways you can contribute to TRL:
|
||||
* Fix outstanding issues with the existing code.
|
||||
* Submit issues related to bugs or desired new features.
|
||||
* Implement trainers for new post-training algorithms.
|
||||
* Contribute to the examples or to the documentation.
|
||||
* Contribute to the examples or the documentation.
|
||||
|
||||
If you don't know where to start, there is a special [Good First
|
||||
Issue](https://github.com/huggingface/trl/contribute) listing. It will give you a list of
|
||||
@ -33,7 +33,7 @@ For something slightly more challenging, you can also take a look at the [Good S
|
||||
Before you start contributing make sure you have installed all the dev tools:
|
||||
|
||||
```bash
|
||||
make dev
|
||||
pip install -e .[dev]
|
||||
```
|
||||
|
||||
## Fixing outstanding issues
|
||||
@ -62,7 +62,7 @@ Once you've confirmed the bug hasn't already been reported, please include the f
|
||||
To get the OS and software versions automatically, run the following command:
|
||||
|
||||
```bash
|
||||
transformers-cli env
|
||||
trl env
|
||||
```
|
||||
|
||||
### Do you want a new feature?
|
||||
@ -74,19 +74,19 @@ If there is a new feature you'd like to see in TRL, please open an issue and des
|
||||
Whatever it is, we'd love to hear about it!
|
||||
|
||||
2. Describe your requested feature in as much detail as possible. The more you can tell us about it, the better we'll be able to help you.
|
||||
3. Provide a *code snippet* that demonstrates the features usage.
|
||||
3. Provide a *code snippet* that demonstrates the feature's usage.
|
||||
4. If the feature is related to a paper, please include a link.
|
||||
|
||||
If your issue is well written we're already 80% of the way there by the time you create it.
|
||||
|
||||
## Do you want to implement a new trainer?
|
||||
|
||||
New post-training methods are published on a frequent basis and those which satisfy the following criteria are good candidates to be integrated in TRL:
|
||||
New post-training methods are published frequently and those that satisfy the following criteria are good candidates to be integrated into TRL:
|
||||
|
||||
* **Simplicity:** does the new method achieve similar performance as prior methods, but with less complexity? A good example is [Direct Preference Optimization](https://arxiv.org/abs/2305.18290) (DPO), which provided a simpler and compelling alternative to RLHF methods.
|
||||
* **Efficiency:** does the new method provide a significant improvement in training efficiency? A good example is [Odds Ratio Preference Optimization](https://arxiv.org/abs/2403.07691v2), which utilises a similar objective as DPO, but requires half the GPU VRAM.
|
||||
* **Simplicity:** Does the new method achieve similar performance as prior methods, but with less complexity? A good example is Direct Preference Optimization (DPO) [[Rafailov et al, 2023]](https://huggingface.co/papers/2305.18290), which provided a simpler and compelling alternative to RLHF methods.
|
||||
* **Efficiency:** Does the new method provide a significant improvement in training efficiency? A good example is Odds Ratio Preference Optimization (ORPO) [[Hong et al, 2023]](https://huggingface.co/papers/2403.07691), which utilizes a similar objective as DPO but requires half the GPU VRAM.
|
||||
|
||||
Methods which only provide incremental improvements at the expense of added complexity or compute costs are unlikely to be included in TRL.
|
||||
Methods that only provide incremental improvements at the expense of added complexity or compute costs are unlikely to be included in TRL.
|
||||
|
||||
If you want to implement a trainer for a new post-training method, first open an issue and provide the following information:
|
||||
|
||||
@ -102,7 +102,7 @@ Based on the community and maintainer feedback, the next step will be to impleme
|
||||
|
||||
## Do you want to add documentation?
|
||||
|
||||
We're always looking for improvements to the documentation that make it more clear and accurate. Please let us know how the documentation can be improved, such as typos, dead links and any missing, unclear or inaccurate content.. We'll be happy to make the changes or help you make a contribution if you're interested!
|
||||
We're always looking for improvements to the documentation that make it more clear and accurate. Please let us know how the documentation can be improved, such as typos, dead links, and any missing, unclear, or inaccurate content... We'll be happy to make the changes or help you contribute if you're interested!
|
||||
|
||||
## Submitting a pull request (PR)
|
||||
|
||||
@ -133,7 +133,7 @@ Follow these steps to start contributing:
|
||||
|
||||
3. Create a new branch to hold your development changes, and do this for every new PR you work on.
|
||||
|
||||
Start by synchronizing your `main` branch with the `upstream/main` branch (ore details in the [GitHub Docs](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/syncing-a-fork)):
|
||||
Start by synchronizing your `main` branch with the `upstream/main` branch (more details in the [GitHub Docs](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/syncing-a-fork)):
|
||||
|
||||
```bash
|
||||
$ git checkout main
|
||||
@ -152,7 +152,7 @@ Follow these steps to start contributing:
|
||||
4. Set up a development environment by running the following command in a conda or a virtual environment you've created for working on this library:
|
||||
|
||||
```bash
|
||||
$ make dev
|
||||
$ pip install -e .[dev]
|
||||
```
|
||||
|
||||
(If TRL was already installed in the virtual environment, remove
|
||||
@ -180,18 +180,21 @@ Follow these steps to start contributing:
|
||||
$ make test
|
||||
```
|
||||
|
||||
TRL relies on `ruff` to format its source code
|
||||
consistently. After you make changes, apply automatic style corrections and code verifications
|
||||
that can't be automated in one go with:
|
||||
TRL relies on `ruff` for maintaining consistent code formatting across its source files. Before submitting any PR, you should apply automatic style corrections and run code verification checks.
|
||||
|
||||
This target is also optimized to only work with files modified by the PR you're working on.
|
||||
We provide a `precommit` target in the `Makefile` that simplifies this process by running all required checks and optimizations on only the files modified by your PR.
|
||||
|
||||
If you prefer to run the checks one after the other, the following command apply the
|
||||
style corrections:
|
||||
To apply these checks and corrections in one step, use:
|
||||
|
||||
```bash
|
||||
$ make precommit
|
||||
```
|
||||
```bash
|
||||
$ make precommit
|
||||
```
|
||||
|
||||
This command runs the following:
|
||||
- Executes `pre-commit` hooks to automatically fix style issues with `ruff` and other tools.
|
||||
- Runs additional scripts such as adding copyright information.
|
||||
|
||||
If you prefer to apply the style corrections separately or review them individually, the `pre-commit` hook will handle the formatting for the files in question.
|
||||
|
||||
Once you're happy with your changes, add changed files using `git add` and
|
||||
make a commit with `git commit` to record your changes locally:
|
||||
@ -221,10 +224,7 @@ Follow these steps to start contributing:
|
||||
webpage of your fork on GitHub. Click on 'Pull request' to send your changes
|
||||
to the project maintainers for review.
|
||||
|
||||
7. It's ok if maintainers ask you for changes. It happens to core contributors
|
||||
too! So everyone can see the changes in the Pull request, work in your local
|
||||
branch and push the changes to your fork. They will automatically appear in
|
||||
the pull request.
|
||||
7. It's ok if maintainers ask you for changes. It happens to core contributors too! To ensure everyone can review your changes in the pull request, work on your local branch and push the updates to your fork. They will automatically appear in the pull request.
|
||||
|
||||
|
||||
### Checklist
|
||||
@ -245,14 +245,94 @@ Follow these steps to start contributing:
|
||||
An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
|
||||
the [tests folder](https://github.com/huggingface/trl/tree/main/tests).
|
||||
|
||||
We use `pytest` in order to run the tests. From the root of the
|
||||
repository, here's how to run tests with `pytest` for the library:
|
||||
We use `pytest` to run the tests. From the root of the
|
||||
repository here's how to run tests with `pytest` for the library:
|
||||
|
||||
```bash
|
||||
$ python -m pytest -sv ./tests
|
||||
```
|
||||
|
||||
In fact, that's how `make test` is implemented (sans the `pip install` line)!
|
||||
That's how `make test` is implemented (without the `pip install` line)!
|
||||
|
||||
You can specify a smaller set of tests in order to test only the feature
|
||||
You can specify a smaller set of tests to test only the feature
|
||||
you're working on.
|
||||
|
||||
### Deprecation and Backward Compatibility
|
||||
|
||||
Our approach to deprecation and backward compatibility is flexible and based on the feature’s usage and impact. Each deprecation is carefully evaluated, aiming to balance innovation with user needs.
|
||||
|
||||
When a feature or component is marked for deprecation, its use will emit a warning message. This warning will include:
|
||||
|
||||
- **Transition Guidance**: Instructions on how to migrate to the alternative solution or replacement.
|
||||
- **Removal Version**: The target version when the feature will be removed, providing users with a clear timeframe to transition.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
warnings.warn(
|
||||
"The `Trainer.foo` method is deprecated and will be removed in version 0.14.0. "
|
||||
"Please use the `Trainer.bar` class instead.",
|
||||
FutureWarning,
|
||||
)
|
||||
```
|
||||
|
||||
The deprecation and removal schedule is based on each feature's usage and impact, with examples at two extremes:
|
||||
|
||||
- **Experimental or Low-Use Features**: For a feature that is experimental or has limited usage, backward compatibility may not be maintained between releases. Users should therefore anticipate potential breaking changes from one version to the next.
|
||||
|
||||
- **Widely-Used Components**: For a feature with high usage, we aim for a more gradual transition period of approximately **5 months**, generally scheduling deprecation around **5 minor releases** after the initial warning.
|
||||
|
||||
These examples represent the two ends of a continuum. The specific timeline for each feature will be determined individually, balancing innovation with user stability needs.
|
||||
|
||||
### Working with warnings
|
||||
|
||||
Warnings play a critical role in guiding users toward resolving potential issues, but they should be used thoughtfully to avoid unnecessary noise. Unlike logging, which provides informational context or operational details, warnings signal conditions that require attention and action. Overusing warnings can dilute their importance, leading users to ignore them entirely.
|
||||
|
||||
#### Definitions
|
||||
|
||||
- **Correct**: An operation is correct if it is valid, follows the intended approach, and aligns with the current best practices or guidelines within the codebase. This is the recommended or intended way to perform the operation.
|
||||
- **Supported**: An operation is supported if it is technically valid and works within the current codebase, but it may not be the most efficient, optimal, or recommended way to perform the task. This includes deprecated features or legacy approaches that still work but may be phased out in the future.
|
||||
|
||||
#### Choosing the right message
|
||||
|
||||
- **Correct → No warning**:
|
||||
If the operation is fully valid and expected, no message should be issued. The system is working as intended, so no warning is necessary.
|
||||
|
||||
- **Correct but deserves attention → No warning, possibly a log message**:
|
||||
When an operation is correct but uncommon or requires special attention, providing an informational message can be helpful. This keeps users informed without implying any issue. If available, use the logger to output this message. Example:
|
||||
|
||||
```python
|
||||
logger.info("This is an informational message about a rare but correct operation.")
|
||||
```
|
||||
|
||||
- **Correct but very likely a mistake → Warning with option to disable**:
|
||||
In rare cases, you may want to issue a warning for a correct operation that’s very likely a mistake. In such cases, you must provide an option to suppress the warning. This can be done with a flag in the function. Example:
|
||||
|
||||
```python
|
||||
def my_function(foo, bar, _warn=True):
|
||||
if foo == bar:
|
||||
if _warn:
|
||||
warnings.warn("foo and bar are the same, this is likely a mistake. Ignore this warning by setting `_warn=False`.")
|
||||
# Do something
|
||||
```
|
||||
|
||||
- **Supported but not correct → Warning**:
|
||||
If the operation is technically supported but is deprecated, suboptimal, or could cause future issues (e.g., conflicting arguments), a warning should be raised. This message should be actionable, meaning it must explain how to resolve the issue. Example:
|
||||
|
||||
```python
|
||||
def my_function(foo, bar):
|
||||
if foo and bar:
|
||||
warnings.warn("Both `foo` and `bar` were provided, but only one is allowed. Ignoring `foo`. Please pass only one of these arguments.")
|
||||
# Do something
|
||||
```
|
||||
|
||||
- **Not supported → Exception**:
|
||||
If the operation is invalid or unsupported, raise an exception. This indicates that the operation cannot be performed and requires immediate attention. Example:
|
||||
|
||||
```python
|
||||
def my_function(foo, bar):
|
||||
if foo and bar:
|
||||
raise ValueError("Both `foo` and `bar` were provided, but only one is allowed. Please pass only one of these arguments.")
|
||||
```
|
||||
|
||||
By following this classification, you ensure that warnings, information, and exceptions are used appropriately, providing clear guidance to the user without cluttering the system with unnecessary messages.
|
||||
|
||||
@ -2,4 +2,5 @@ include settings.ini
|
||||
include LICENSE
|
||||
include CONTRIBUTING.md
|
||||
include README.md
|
||||
recursive-exclude * __pycache__
|
||||
recursive-exclude * __pycache__
|
||||
include trl/templates/*.md
|
||||
15
Makefile
15
Makefile
@ -1,27 +1,16 @@
|
||||
.PHONY: test precommit benchmark_core benchmark_aux common_tests slow_tests test_examples tests_gpu
|
||||
.PHONY: test precommit common_tests slow_tests test_examples tests_gpu
|
||||
|
||||
check_dirs := examples tests trl
|
||||
|
||||
ACCELERATE_CONFIG_PATH = `pwd`/examples/accelerate_configs
|
||||
COMMAND_FILES_PATH = `pwd`/commands
|
||||
|
||||
|
||||
dev:
|
||||
[ -L "$(pwd)/trl/commands/scripts" ] && unlink "$(pwd)/trl/commands/scripts" || true
|
||||
pip install -e ".[dev]"
|
||||
ln -s `pwd`/examples/scripts/ `pwd`/trl/commands
|
||||
|
||||
test:
|
||||
python -m pytest -n auto --dist=loadfile -s -v --reruns 5 --reruns-delay 1 --only-rerun '(OSError|Timeout|HTTPError.*502|HTTPError.*504||not less than or equal to 0.01)' ./tests/
|
||||
|
||||
precommit:
|
||||
pre-commit run --all-files
|
||||
|
||||
benchmark_core:
|
||||
bash ./benchmark/benchmark_core.sh
|
||||
|
||||
benchmark_aux:
|
||||
bash ./benchmark/benchmark_aux.sh
|
||||
python scripts/add_copyrights.py
|
||||
|
||||
tests_gpu:
|
||||
python -m pytest tests/test_* $(if $(IS_GITHUB_CI),--report-log "common_tests.log",)
|
||||
|
||||
219
README.md
219
README.md
@ -1,228 +1,211 @@
|
||||
# TRL - Transformer Reinforcement Learning
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl_banner_dark.png">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl_banner_dark.png" alt="TRL Banner">
|
||||
</div>
|
||||
|
||||
# TRL - Transformer Reinforcement Learning
|
||||
> Full stack library to fine-tune and align large language models.
|
||||
<hr> <br>
|
||||
|
||||
<h3 align="center">
|
||||
<p>A comprehensive library to post-train foundation models</p>
|
||||
</h3>
|
||||
|
||||
<p align="center">
|
||||
<a href="https://github.com/huggingface/trl/blob/main/LICENSE">
|
||||
<img alt="License" src="https://img.shields.io/github/license/huggingface/trl.svg?color=blue">
|
||||
</a>
|
||||
<a href="https://huggingface.co/docs/trl/index">
|
||||
<img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/trl/index.svg?down_color=red&down_message=offline&up_message=online">
|
||||
</a>
|
||||
<a href="https://github.com/huggingface/trl/releases">
|
||||
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/trl.svg">
|
||||
</a>
|
||||
<a href="https://github.com/huggingface/trl/blob/main/LICENSE"><img alt="License" src="https://img.shields.io/github/license/huggingface/trl.svg?color=blue"></a>
|
||||
<a href="https://huggingface.co/docs/trl/index"><img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/trl/index.svg?down_color=red&down_message=offline&up_color=blue&up_message=online"></a>
|
||||
<a href="https://github.com/huggingface/trl/releases"><img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/trl.svg"></a>
|
||||
</p>
|
||||
|
||||
## Overview
|
||||
|
||||
## What is it?
|
||||
|
||||
The `trl` library is a full stack tool to fine-tune and align transformer language and diffusion models using methods such as Supervised Fine-tuning step (SFT), Reward Modeling (RM) and the Proximal Policy Optimization (PPO) as well as Direct Preference Optimization (DPO).
|
||||
|
||||
The library is built on top of the [`transformers`](https://github.com/huggingface/transformers) library and thus allows to use any model architecture available there.
|
||||
|
||||
TRL is a cutting-edge library designed for post-training foundation models using advanced techniques like Supervised Fine-Tuning (SFT), Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO). Built on top of the [🤗 Transformers](https://github.com/huggingface/transformers) ecosystem, TRL supports a variety of model architectures and modalities, and can be scaled-up across various hardware setups.
|
||||
|
||||
## Highlights
|
||||
|
||||
- **`Efficient and scalable`**:
|
||||
- [`accelerate`](https://github.com/huggingface/accelerate) is the backbone of `trl` which allows to scale model training from a single GPU to a large scale multi-node cluster with methods such as DDP and DeepSpeed.
|
||||
- [`PEFT`](https://github.com/huggingface/peft) is fully integrated and allows to train even the largest models on modest hardware with quantisation and methods such as LoRA or QLoRA.
|
||||
- [`unsloth`](https://github.com/unslothai/unsloth) is also integrated and allows to significantly speed up training with dedicated kernels.
|
||||
- **`CLI`**: With the [CLI](https://huggingface.co/docs/trl/clis) you can fine-tune and chat with LLMs without writing any code using a single command and a flexible config system.
|
||||
- **`Trainers`**: The Trainer classes are an abstraction to apply many fine-tuning methods with ease such as the [`SFTTrainer`](https://huggingface.co/docs/trl/sft_trainer), [`DPOTrainer`](https://huggingface.co/docs/trl/trainer#trl.DPOTrainer), [`RewardTrainer`](https://huggingface.co/docs/trl/reward_trainer), [`PPOTrainer`](https://huggingface.co/docs/trl/trainer#trl.PPOTrainer), [`CPOTrainer`](https://huggingface.co/docs/trl/trainer#trl.CPOTrainer), and [`ORPOTrainer`](https://huggingface.co/docs/trl/trainer#trl.ORPOTrainer).
|
||||
- **`AutoModels`**: The [`AutoModelForCausalLMWithValueHead`](https://huggingface.co/docs/trl/models#trl.AutoModelForCausalLMWithValueHead) & [`AutoModelForSeq2SeqLMWithValueHead`](https://huggingface.co/docs/trl/models#trl.AutoModelForSeq2SeqLMWithValueHead) classes add an additional value head to the model which allows to train them with RL algorithms such as PPO.
|
||||
- **`Examples`**: Train GPT2 to generate positive movie reviews with a BERT sentiment classifier, full RLHF using adapters only, train GPT-j to be less toxic, [StackLlama example](https://huggingface.co/blog/stackllama), etc. following the [examples](https://github.com/huggingface/trl/tree/main/examples).
|
||||
- **Efficient and scalable**:
|
||||
- Leverages [🤗 Accelerate](https://github.com/huggingface/accelerate) to scale from single GPU to multi-node clusters using methods like DDP and DeepSpeed.
|
||||
- Full integration with [`PEFT`](https://github.com/huggingface/peft) enables training on large models with modest hardware via quantization and LoRA/QLoRA.
|
||||
- Integrates [Unsloth](https://github.com/unslothai/unsloth) for accelerating training using optimized kernels.
|
||||
|
||||
- **Command Line Interface (CLI)**: A simple interface lets you fine-tune and interact with models without needing to write code.
|
||||
|
||||
- **Trainers**: Various fine-tuning methods are easily accessible via trainers like [`SFTTrainer`](https://huggingface.co/docs/trl/sft_trainer), [`DPOTrainer`](https://huggingface.co/docs/trl/dpo_trainer), [`RewardTrainer`](https://huggingface.co/docs/trl/reward_trainer), [`ORPOTrainer`](https://huggingface.co/docs/trl/orpo_trainer) and more.
|
||||
|
||||
- **AutoModels**: Use pre-defined model classes like [`AutoModelForCausalLMWithValueHead`](https://huggingface.co/docs/trl/models#trl.AutoModelForCausalLMWithValueHead) to simplify reinforcement learning (RL) with LLMs.
|
||||
|
||||
## Installation
|
||||
|
||||
### Python package
|
||||
Install the library with `pip`:
|
||||
### Python Package
|
||||
|
||||
Install the library using `pip`:
|
||||
|
||||
```bash
|
||||
pip install trl
|
||||
```
|
||||
|
||||
### From source
|
||||
If you want to use the latest features before an official release you can install from source:
|
||||
|
||||
If you want to use the latest features before an official release, you can install TRL from source:
|
||||
|
||||
```bash
|
||||
pip install git+https://github.com/huggingface/trl.git
|
||||
```
|
||||
|
||||
### Repository
|
||||
|
||||
If you want to use the examples you can clone the repository with the following command:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/trl.git
|
||||
```
|
||||
|
||||
## Command Line Interface (CLI)
|
||||
|
||||
You can use TRL Command Line Interface (CLI) to quickly get started with Supervised Fine-tuning (SFT), Direct Preference Optimization (DPO) and test your aligned model with the chat CLI:
|
||||
You can use the TRL Command Line Interface (CLI) to quickly get started with Supervised Fine-tuning (SFT) and Direct Preference Optimization (DPO), or vibe check your model with the chat CLI:
|
||||
|
||||
**SFT:**
|
||||
|
||||
```bash
|
||||
trl sft --model_name_or_path facebook/opt-125m --dataset_name imdb --output_dir opt-sft-imdb
|
||||
trl sft --model_name_or_path Qwen/Qwen2.5-0.5B \
|
||||
--dataset_name trl-lib/Capybara \
|
||||
--output_dir Qwen2.5-0.5B-SFT
|
||||
```
|
||||
|
||||
**DPO:**
|
||||
|
||||
```bash
|
||||
trl dpo --model_name_or_path facebook/opt-125m --dataset_name trl-internal-testing/hh-rlhf-helpful-base-trl-style --output_dir opt-sft-hh-rlhf
|
||||
trl dpo --model_name_or_path Qwen/Qwen2.5-0.5B-Instruct \
|
||||
--dataset_name argilla/Capybara-Preferences \
|
||||
--output_dir Qwen2.5-0.5B-DPO
|
||||
```
|
||||
|
||||
**Chat:**
|
||||
|
||||
```bash
|
||||
trl chat --model_name_or_path Qwen/Qwen1.5-0.5B-Chat
|
||||
trl chat --model_name_or_path Qwen/Qwen2.5-0.5B-Instruct
|
||||
```
|
||||
|
||||
Read more about CLI in the [relevant documentation section](https://huggingface.co/docs/trl/main/en/clis) or use `--help` for more details.
|
||||
|
||||
## How to use
|
||||
|
||||
For more flexibility and control over the training, you can use the dedicated trainer classes to fine-tune the model in Python.
|
||||
For more flexibility and control over training, TRL provides dedicated trainer classes to post-train language models or PEFT adapters on a custom dataset. Each trainer in TRL is a light wrapper around the 🤗 Transformers trainer and natively supports distributed training methods like DDP, DeepSpeed ZeRO, and FSDP.
|
||||
|
||||
### `SFTTrainer`
|
||||
|
||||
This is a basic example of how to use the `SFTTrainer` from the library. The `SFTTrainer` is a light wrapper around the `transformers` Trainer to easily fine-tune language models or adapters on a custom dataset.
|
||||
Here is a basic example of how to use the `SFTTrainer`:
|
||||
|
||||
```python
|
||||
# imports
|
||||
from trl import SFTConfig, SFTTrainer
|
||||
from datasets import load_dataset
|
||||
from trl import SFTTrainer
|
||||
|
||||
# get dataset
|
||||
dataset = load_dataset("imdb", split="train")
|
||||
dataset = load_dataset("trl-lib/Capybara", split="train")
|
||||
|
||||
# get trainer
|
||||
training_args = SFTConfig(output_dir="Qwen/Qwen2.5-0.5B-SFT")
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
args=training_args,
|
||||
model="Qwen/Qwen2.5-0.5B",
|
||||
train_dataset=dataset,
|
||||
dataset_text_field="text",
|
||||
max_seq_length=512,
|
||||
)
|
||||
|
||||
# train
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
### `RewardTrainer`
|
||||
|
||||
This is a basic example of how to use the `RewardTrainer` from the library. The `RewardTrainer` is a wrapper around the `transformers` Trainer to easily fine-tune reward models or adapters on a custom preference dataset.
|
||||
Here is a basic example of how to use the `RewardTrainer`:
|
||||
|
||||
```python
|
||||
# imports
|
||||
from trl import RewardConfig, RewardTrainer
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModelForSequenceClassification, AutoTokenizer
|
||||
from trl import RewardTrainer
|
||||
|
||||
# load model and dataset - dataset needs to be in a specific format
|
||||
model = AutoModelForSequenceClassification.from_pretrained("gpt2", num_labels=1)
|
||||
tokenizer = AutoTokenizer.from_pretrained("gpt2")
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
model = AutoModelForSequenceClassification.from_pretrained(
|
||||
"Qwen/Qwen2.5-0.5B-Instruct", num_labels=1
|
||||
)
|
||||
model.config.pad_token_id = tokenizer.pad_token_id
|
||||
|
||||
...
|
||||
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
|
||||
|
||||
# load trainer
|
||||
training_args = RewardConfig(output_dir="Qwen2.5-0.5B-Reward", per_device_train_batch_size=2)
|
||||
trainer = RewardTrainer(
|
||||
args=training_args,
|
||||
model=model,
|
||||
tokenizer=tokenizer,
|
||||
processing_class=tokenizer,
|
||||
train_dataset=dataset,
|
||||
)
|
||||
|
||||
# train
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
### `PPOTrainer`
|
||||
### `RLOOTrainer`
|
||||
|
||||
This is a basic example of how to use the `PPOTrainer` from the library. Based on a query the language model creates a response which is then evaluated. The evaluation could be a human in the loop or another model's output.
|
||||
`RLOOTrainer` implements a [REINFORCE-style optimization](https://huggingface.co/papers/2402.14740) for RLHF that is more performant and memory-efficient than PPO. Here is a basic example of how to use the `RLOOTrainer`:
|
||||
|
||||
```python
|
||||
# imports
|
||||
import torch
|
||||
from transformers import AutoTokenizer
|
||||
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
|
||||
from trl.core import respond_to_batch
|
||||
from trl import RLOOConfig, RLOOTrainer, apply_chat_template
|
||||
from datasets import load_dataset
|
||||
from transformers import (
|
||||
AutoModelForCausalLM,
|
||||
AutoModelForSequenceClassification,
|
||||
AutoTokenizer,
|
||||
)
|
||||
|
||||
# get models
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
|
||||
ref_model = create_reference_model(model)
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
reward_model = AutoModelForSequenceClassification.from_pretrained(
|
||||
"Qwen/Qwen2.5-0.5B-Instruct", num_labels=1
|
||||
)
|
||||
ref_policy = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
policy = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained('gpt2')
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
dataset = load_dataset("trl-lib/ultrafeedback-prompt")
|
||||
dataset = dataset.map(apply_chat_template, fn_kwargs={"tokenizer": tokenizer})
|
||||
dataset = dataset.map(lambda x: tokenizer(x["prompt"]), remove_columns="prompt")
|
||||
|
||||
# initialize trainer
|
||||
ppo_config = PPOConfig(batch_size=1, mini_batch_size=1)
|
||||
|
||||
# encode a query
|
||||
query_txt = "This morning I went to the "
|
||||
query_tensor = tokenizer.encode(query_txt, return_tensors="pt")
|
||||
|
||||
# get model response
|
||||
response_tensor = respond_to_batch(model, query_tensor)
|
||||
|
||||
# create a ppo trainer
|
||||
ppo_trainer = PPOTrainer(ppo_config, model, ref_model, tokenizer)
|
||||
|
||||
# define a reward for response
|
||||
# (this could be any reward such as human feedback or output from another model)
|
||||
reward = [torch.tensor(1.0)]
|
||||
|
||||
# train model for one step with ppo
|
||||
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
|
||||
training_args = RLOOConfig(output_dir="Qwen2.5-0.5B-RL")
|
||||
trainer = RLOOTrainer(
|
||||
config=training_args,
|
||||
processing_class=tokenizer,
|
||||
policy=policy,
|
||||
ref_policy=ref_policy,
|
||||
reward_model=reward_model,
|
||||
train_dataset=dataset["train"],
|
||||
eval_dataset=dataset["test"],
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
### `DPOTrainer`
|
||||
|
||||
`DPOTrainer` is a trainer that uses [Direct Preference Optimization algorithm](https://huggingface.co/papers/2305.18290). This is a basic example of how to use the `DPOTrainer` from the library. The `DPOTrainer` is a wrapper around the `transformers` Trainer to easily fine-tune reward models or adapters on a custom preference dataset.
|
||||
`DPOTrainer` implements the popular [Direct Preference Optimization (DPO) algorithm](https://huggingface.co/papers/2305.18290) that was used to post-train Llama 3 and many other models. Here is a basic example of how to use the `DPOTrainer`:
|
||||
|
||||
```python
|
||||
# imports
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from trl import DPOTrainer
|
||||
from trl import DPOConfig, DPOTrainer
|
||||
|
||||
# load model and dataset - dataset needs to be in a specific format
|
||||
model = AutoModelForCausalLM.from_pretrained("gpt2")
|
||||
tokenizer = AutoTokenizer.from_pretrained("gpt2")
|
||||
|
||||
...
|
||||
|
||||
# load trainer
|
||||
trainer = DPOTrainer(
|
||||
model=model,
|
||||
tokenizer=tokenizer,
|
||||
train_dataset=dataset,
|
||||
)
|
||||
|
||||
# train
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
|
||||
training_args = DPOConfig(output_dir="Qwen2.5-0.5B-DPO")
|
||||
trainer = DPOTrainer(model=model, args=training_args, train_dataset=dataset, processing_class=tokenizer)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Development
|
||||
|
||||
If you want to contribute to `trl` or customizing it to your needs make sure to read the [contribution guide](https://github.com/huggingface/trl/blob/main/CONTRIBUTING.md) and make sure you make a dev install:
|
||||
If you want to contribute to `trl` or customize it to your needs make sure to read the [contribution guide](https://github.com/huggingface/trl/blob/main/CONTRIBUTING.md) and make sure you make a dev install:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/trl.git
|
||||
cd trl/
|
||||
make dev
|
||||
pip install -e .[dev]
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
### Proximal Policy Optimisation
|
||||
The PPO implementation largely follows the structure introduced in the paper **"Fine-Tuning Language Models from Human Preferences"** by D. Ziegler et al. \[[paper](https://huggingface.co/papers/1909.08593), [code](https://github.com/openai/lm-human-preferences)].
|
||||
|
||||
### Direct Preference Optimization
|
||||
DPO is based on the original implementation of **"Direct Preference Optimization: Your Language Model is Secretly a Reward Model"** by E. Mitchell et al. \[[paper](https://huggingface.co/papers/2305.18290), [code](https://github.com/eric-mitchell/direct-preference-optimization)]
|
||||
|
||||
|
||||
## Citation
|
||||
|
||||
```bibtex
|
||||
@misc{vonwerra2022trl,
|
||||
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang},
|
||||
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
|
||||
title = {TRL: Transformer Reinforcement Learning},
|
||||
year = {2020},
|
||||
publisher = {GitHub},
|
||||
@ -230,3 +213,7 @@ DPO is based on the original implementation of **"Direct Preference Optimization
|
||||
howpublished = {\url{https://github.com/huggingface/trl}}
|
||||
}
|
||||
```
|
||||
|
||||
## License
|
||||
|
||||
This repository's source code is available under the [Apache-2.0 License](LICENSE).
|
||||
|
||||
@ -1,150 +0,0 @@
|
||||
import argparse
|
||||
import math
|
||||
import os
|
||||
import shlex
|
||||
import subprocess
|
||||
import uuid
|
||||
from distutils.util import strtobool
|
||||
|
||||
import requests
|
||||
|
||||
|
||||
def parse_args():
|
||||
# fmt: off
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--command", type=str, default="",
|
||||
help="the command to run")
|
||||
parser.add_argument("--num-seeds", type=int, default=3,
|
||||
help="the number of random seeds")
|
||||
parser.add_argument("--start-seed", type=int, default=1,
|
||||
help="the number of the starting seed")
|
||||
parser.add_argument("--workers", type=int, default=0,
|
||||
help="the number of workers to run benchmark experimenets")
|
||||
parser.add_argument("--auto-tag", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True,
|
||||
help="if toggled, the runs will be tagged with git tags, commit, and pull request number if possible")
|
||||
parser.add_argument("--slurm-template-path", type=str, default=None,
|
||||
help="the path to the slurm template file (see docs for more details)")
|
||||
parser.add_argument("--slurm-gpus-per-task", type=int, default=1,
|
||||
help="the number of gpus per task to use for slurm jobs")
|
||||
parser.add_argument("--slurm-total-cpus", type=int, default=50,
|
||||
help="the number of gpus per task to use for slurm jobs")
|
||||
parser.add_argument("--slurm-ntasks", type=int, default=1,
|
||||
help="the number of tasks to use for slurm jobs")
|
||||
parser.add_argument("--slurm-nodes", type=int, default=None,
|
||||
help="the number of nodes to use for slurm jobs")
|
||||
args = parser.parse_args()
|
||||
# fmt: on
|
||||
return args
|
||||
|
||||
|
||||
def run_experiment(command: str):
|
||||
command_list = shlex.split(command)
|
||||
print(f"running {command}")
|
||||
|
||||
# Use subprocess.PIPE to capture the output
|
||||
fd = subprocess.Popen(command_list, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
|
||||
output, errors = fd.communicate()
|
||||
|
||||
return_code = fd.returncode
|
||||
assert return_code == 0, f"Command failed with error: {errors.decode('utf-8')}"
|
||||
|
||||
# Convert bytes to string and strip leading/trailing whitespaces
|
||||
return output.decode("utf-8").strip()
|
||||
|
||||
|
||||
def autotag() -> str:
|
||||
wandb_tag = ""
|
||||
print("autotag feature is enabled")
|
||||
git_tag = ""
|
||||
try:
|
||||
git_tag = subprocess.check_output(["git", "describe", "--tags"]).decode("ascii").strip()
|
||||
print(f"identified git tag: {git_tag}")
|
||||
except subprocess.CalledProcessError as e:
|
||||
print(e)
|
||||
if len(git_tag) == 0:
|
||||
try:
|
||||
count = int(subprocess.check_output(["git", "rev-list", "--count", "HEAD"]).decode("ascii").strip())
|
||||
hash = subprocess.check_output(["git", "rev-parse", "--short", "HEAD"]).decode("ascii").strip()
|
||||
git_tag = f"no-tag-{count}-g{hash}"
|
||||
print(f"identified git tag: {git_tag}")
|
||||
except subprocess.CalledProcessError as e:
|
||||
print(e)
|
||||
wandb_tag = f"{git_tag}"
|
||||
|
||||
git_commit = subprocess.check_output(["git", "rev-parse", "--verify", "HEAD"]).decode("ascii").strip()
|
||||
try:
|
||||
# try finding the pull request number on github
|
||||
prs = requests.get(f"https://api.github.com/search/issues?q=repo:huggingface/trl+is:pr+{git_commit}")
|
||||
if prs.status_code == 200:
|
||||
prs = prs.json()
|
||||
if len(prs["items"]) > 0:
|
||||
pr = prs["items"][0]
|
||||
pr_number = pr["number"]
|
||||
wandb_tag += f",pr-{pr_number}"
|
||||
print(f"identified github pull request: {pr_number}")
|
||||
except Exception as e:
|
||||
print(e)
|
||||
|
||||
return wandb_tag
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parse_args()
|
||||
if args.auto_tag:
|
||||
existing_wandb_tag = os.environ.get("WANDB_TAGS", "")
|
||||
wandb_tag = autotag()
|
||||
if len(wandb_tag) > 0:
|
||||
if len(existing_wandb_tag) > 0:
|
||||
os.environ["WANDB_TAGS"] = ",".join([existing_wandb_tag, wandb_tag])
|
||||
else:
|
||||
os.environ["WANDB_TAGS"] = wandb_tag
|
||||
print("WANDB_TAGS: ", os.environ.get("WANDB_TAGS", ""))
|
||||
commands = []
|
||||
for seed in range(0, args.num_seeds):
|
||||
commands += [" ".join([args.command, "--seed", str(args.start_seed + seed)])]
|
||||
|
||||
print("======= commands to run:")
|
||||
for command in commands:
|
||||
print(command)
|
||||
|
||||
if args.workers > 0 and args.slurm_template_path is None:
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
|
||||
executor = ThreadPoolExecutor(max_workers=args.workers, thread_name_prefix="cleanrl-benchmark-worker-")
|
||||
for command in commands:
|
||||
executor.submit(run_experiment, command)
|
||||
executor.shutdown(wait=True)
|
||||
else:
|
||||
print("not running the experiments because --workers is set to 0; just printing the commands to run")
|
||||
|
||||
# SLURM logic
|
||||
if args.slurm_template_path is not None:
|
||||
if not os.path.exists("slurm"):
|
||||
os.makedirs("slurm")
|
||||
if not os.path.exists("slurm/logs"):
|
||||
os.makedirs("slurm/logs")
|
||||
print("======= slurm commands to run:")
|
||||
with open(args.slurm_template_path) as f:
|
||||
slurm_template = f.read()
|
||||
slurm_template = slurm_template.replace("{{array}}", f"0-{len(commands) - 1}%{args.workers}")
|
||||
slurm_template = slurm_template.replace(
|
||||
"{{seeds}}", f"({' '.join([str(args.start_seed + int(seed)) for seed in range(args.num_seeds)])})"
|
||||
)
|
||||
slurm_template = slurm_template.replace("{{len_seeds}}", f"{args.num_seeds}")
|
||||
slurm_template = slurm_template.replace("{{command}}", args.command)
|
||||
slurm_template = slurm_template.replace("{{gpus_per_task}}", f"{args.slurm_gpus_per_task}")
|
||||
total_gpus = args.slurm_gpus_per_task * args.slurm_ntasks
|
||||
slurm_cpus_per_gpu = math.ceil(args.slurm_total_cpus / total_gpus)
|
||||
slurm_template = slurm_template.replace("{{cpus_per_gpu}}", f"{slurm_cpus_per_gpu}")
|
||||
slurm_template = slurm_template.replace("{{ntasks}}", f"{args.slurm_ntasks}")
|
||||
if args.slurm_nodes is not None:
|
||||
slurm_template = slurm_template.replace("{{nodes}}", f"#SBATCH --nodes={args.slurm_nodes}")
|
||||
else:
|
||||
slurm_template = slurm_template.replace("{{nodes}}", "")
|
||||
filename = str(uuid.uuid4())
|
||||
open(os.path.join("slurm", f"{filename}.slurm"), "w").write(slurm_template)
|
||||
slurm_path = os.path.join("slurm", f"{filename}.slurm")
|
||||
print(f"saving command in {slurm_path}")
|
||||
if args.workers > 0:
|
||||
job_id = run_experiment(f"sbatch --parsable {slurm_path}")
|
||||
print(f"Job ID: {job_id}")
|
||||
@ -1,26 +0,0 @@
|
||||
export WANDB_ENTITY=huggingface
|
||||
export WANDB_PROJECT=trl
|
||||
bash $BENCHMARK_SCRIPT > output.txt
|
||||
|
||||
# Extract Job IDs into an array
|
||||
job_ids=($(grep "Job ID:" output.txt | awk '{print $3}'))
|
||||
|
||||
# Extract WANDB_TAGS into an array
|
||||
WANDB_TAGS=($(grep "WANDB_TAGS:" output.txt | awk '{print $2}'))
|
||||
WANDB_TAGS=($(echo $WANDB_TAGS | tr "," "\n"))
|
||||
|
||||
# Print to verify
|
||||
echo "Job IDs: ${job_ids[@]}"
|
||||
echo "WANDB_TAGS: ${WANDB_TAGS[@]}"
|
||||
|
||||
TAGS_STRING="?tag=${WANDB_TAGS[0]}"
|
||||
FOLDER_STRING="${WANDB_TAGS[0]}"
|
||||
for tag in "${WANDB_TAGS[@]:1}"; do
|
||||
TAGS_STRING+="&tag=$tag"
|
||||
FOLDER_STRING+="_$tag"
|
||||
done
|
||||
|
||||
echo "TAGS_STRING: $TAGS_STRING"
|
||||
echo "FOLDER_STRING: $FOLDER_STRING"
|
||||
|
||||
TAGS_STRING=$TAGS_STRING FOLDER_STRING=$FOLDER_STRING BENCHMARK_PLOT_SCRIPT=$BENCHMARK_PLOT_SCRIPT sbatch --dependency=afterany:$job_ids benchmark/post_github_comment.sbatch
|
||||
@ -1,44 +0,0 @@
|
||||
# hello world experiment
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --log_with wandb" \
|
||||
--num-seeds 3 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/dpo.py --model_name_or_path=gpt2 --per_device_train_batch_size 4 --max_steps 1000 --learning_rate 1e-3 --gradient_accumulation_steps 1 --logging_steps 10 --eval_steps 500 --output_dir="dpo_anthropic_hh" --optim adamw_torch --warmup_steps 150 --report_to wandb --bf16 --logging_first_step --no_remove_unused_columns" \
|
||||
--num-seeds 3 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/sft.py --model_name_or_path="facebook/opt-350m" --report_to="wandb" --learning_rate=1.41e-5 --per_device_train_batch_size=64 --gradient_accumulation_steps=16 --output_dir="sft_openassistant-guanaco" --logging_steps=1 --num_train_epochs=3 --max_steps=-1 --push_to_hub --gradient_checkpointing" \
|
||||
--num-seeds 3 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/reward_modeling.py --model_name_or_path=facebook/opt-350m --output_dir="reward_modeling_anthropic_hh" --per_device_train_batch_size=64 --num_train_epochs=1 --gradient_accumulation_steps=16 --gradient_checkpointing=True --learning_rate=1.41e-5 --report_to="wandb" --remove_unused_columns=False --optim="adamw_torch" --logging_steps=10 --eval_strategy="steps" --max_length=512" \
|
||||
--num-seeds 3 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
@ -1,50 +0,0 @@
|
||||
# pip install openrlbenchmark==0.2.1a5
|
||||
# see https://github.com/openrlbenchmark/openrlbenchmark#get-started for documentation
|
||||
echo "we deal with $TAGS_STRING"
|
||||
|
||||
python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--filters '?we=huggingface&wpn=trl&xaxis=_step&ceik=trl_ppo_trainer_config.value.reward_model&cen=trl_ppo_trainer_config.value.exp_name&metrics=env/reward_mean&metrics=objective/kl' \
|
||||
"ppo$TAGS_STRING" \
|
||||
--env-ids sentiment-analysis:lvwerra/distilbert-imdb \
|
||||
--no-check-empty-runs \
|
||||
--pc.ncols 2 \
|
||||
--pc.ncols-legend 1 \
|
||||
--output-filename benchmark/trl/$FOLDER_STRING/ppo \
|
||||
--scan-history
|
||||
|
||||
python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--filters '?we=huggingface&wpn=trl&xaxis=_step&ceik=output_dir&cen=_name_or_path&metrics=train/rewards/accuracies&metrics=train/loss' \
|
||||
"gpt2$TAGS_STRING" \
|
||||
--env-ids dpo_anthropic_hh \
|
||||
--no-check-empty-runs \
|
||||
--pc.ncols 2 \
|
||||
--pc.ncols-legend 1 \
|
||||
--output-filename benchmark/trl/$FOLDER_STRING/dpo \
|
||||
--scan-history
|
||||
|
||||
python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--filters '?we=huggingface&wpn=trl&xaxis=_step&ceik=output_dir&cen=_name_or_path&metrics=train/loss&metrics=eval/accuracy&metrics=eval/loss' \
|
||||
"facebook/opt-350m$TAGS_STRING" \
|
||||
--env-ids reward_modeling_anthropic_hh \
|
||||
--no-check-empty-runs \
|
||||
--pc.ncols 2 \
|
||||
--pc.ncols-legend 1 \
|
||||
--output-filename benchmark/trl/$FOLDER_STRING/reward_modeling \
|
||||
--scan-history
|
||||
|
||||
python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--filters '?we=huggingface&wpn=trl&xaxis=_step&ceik=output_dir&cen=_name_or_path&metrics=train/loss' \
|
||||
"facebook/opt-350m$TAGS_STRING" \
|
||||
--env-ids sft_openassistant-guanaco \
|
||||
--no-check-empty-runs \
|
||||
--pc.ncols 2 \
|
||||
--pc.ncols-legend 1 \
|
||||
--output-filename benchmark/trl/$FOLDER_STRING/sft \
|
||||
--scan-history
|
||||
|
||||
python benchmark/upload_benchmark.py \
|
||||
--folder_path="benchmark/trl/$FOLDER_STRING" \
|
||||
--path_in_repo="images/benchmark/$FOLDER_STRING" \
|
||||
--repo_id="trl-internal-testing/example-images" \
|
||||
--repo_type="dataset"
|
||||
|
||||
@ -1,23 +0,0 @@
|
||||
# compound experiments: gpt2xl + grad_accu
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --exp_name ppo_gpt2xl_grad_accu --model_name gpt2-xl --mini_batch_size 16 --gradient_accumulation_steps 8 --log_with wandb" \
|
||||
--num-seeds 3 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
|
||||
# compound experiments: Cerebras-GPT-6.7B + deepspeed zero2 + grad_accu
|
||||
python benchmark/benchmark.py \
|
||||
--command "accelerate launch --config_file examples/accelerate_configs/deepspeed_zero2.yaml examples/scripts/ppo.py --exp_name ppo_Cerebras-GPT-6.7B_grad_accu_deepspeed_stage2 --batch_size 32 --mini_batch_size 32 --log_with wandb --model_name cerebras/Cerebras-GPT-6.7B --reward_model sentiment-analysis:cerebras/Cerebras-GPT-6.7B" \
|
||||
--num-seeds 3 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 8 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 90 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
@ -1,31 +0,0 @@
|
||||
# pip install openrlbenchmark==0.2.1a5
|
||||
# see https://github.com/openrlbenchmark/openrlbenchmark#get-started for documentation
|
||||
echo "we deal with $TAGS_STRING"
|
||||
|
||||
python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--filters '?we=huggingface&wpn=trl&xaxis=_step&ceik=trl_ppo_trainer_config.value.reward_model&cen=trl_ppo_trainer_config.value.exp_name&metrics=env/reward_mean&metrics=objective/kl' \
|
||||
"ppo$TAGS_STRING" \
|
||||
"ppo_gpt2xl_grad_accu$TAGS_STRING" \
|
||||
--env-ids sentiment-analysis:lvwerra/distilbert-imdb \
|
||||
--no-check-empty-runs \
|
||||
--pc.ncols 2 \
|
||||
--pc.ncols-legend 1 \
|
||||
--output-filename benchmark/trl/$FOLDER_STRING/different_models \
|
||||
--scan-history
|
||||
|
||||
python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--filters '?we=huggingface&wpn=trl&xaxis=_step&ceik=trl_ppo_trainer_config.value.reward_model&cen=trl_ppo_trainer_config.value.exp_name&metrics=env/reward_mean&metrics=objective/kl' \
|
||||
"ppo_Cerebras-GPT-6.7B_grad_accu_deepspeed_stage2$TAGS_STRING" \
|
||||
--env-ids sentiment-analysis:cerebras/Cerebras-GPT-6.7B \
|
||||
--no-check-empty-runs \
|
||||
--pc.ncols 2 \
|
||||
--pc.ncols-legend 1 \
|
||||
--output-filename benchmark/trl/$FOLDER_STRING/deepspeed \
|
||||
--scan-history
|
||||
|
||||
python benchmark/upload_benchmark.py \
|
||||
--folder_path="benchmark/trl/$FOLDER_STRING" \
|
||||
--path_in_repo="images/benchmark/$FOLDER_STRING" \
|
||||
--repo_id="trl-internal-testing/example-images" \
|
||||
--repo_type="dataset"
|
||||
|
||||
@ -1,46 +0,0 @@
|
||||
## w/ and w/o gradient accumulation
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --exp_name ppo_step_grad_accu --mini_batch_size 1 --gradient_accumulation_steps 128 --log_with wandb" \
|
||||
--num-seeds 3 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
|
||||
## w/ different models (gpt2, gpt2-xl, falcon, llama2)
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --exp_name ppo_gpt2 --log_with wandb" \
|
||||
--num-seeds 3 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --exp_name ppo_falcon_rw_1b --model_name tiiuae/falcon-rw-1b --log_with wandb" \
|
||||
--num-seeds 3 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
|
||||
|
||||
## w/ and w/o PEFT
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --exp_name ppo_peft --use_peft --log_with wandb" \
|
||||
--num-seeds 3 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
@ -1,56 +0,0 @@
|
||||
# pip install openrlbenchmark==0.2.1a5
|
||||
# see https://github.com/openrlbenchmark/openrlbenchmark#get-started for documentation
|
||||
BASELINE_PR_TAG=v0.4.7-55-g110e672
|
||||
BASELINE_PR_NAME=PR-662
|
||||
|
||||
python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--filters '?we=huggingface&wpn=trl&xaxis=_step&ceik=trl_ppo_trainer_config.value.reward_model&cen=trl_ppo_trainer_config.value.exp_name&metrics=env/reward_mean&metrics=objective/kl' \
|
||||
"sentiment_tuning?tag=$BASELINE_PR_TAG&cl=sentiment lvwerra/gpt2-imdb ($BASELINE_PR_NAME)" \
|
||||
--env-ids sentiment-analysis:lvwerra/distilbert-imdb \
|
||||
--no-check-empty-runs \
|
||||
--pc.ncols 2 \
|
||||
--pc.ncols-legend 1 \
|
||||
--output-filename benchmark/trl/$BASELINE_PR_TAG/sentiment \
|
||||
--scan-history
|
||||
|
||||
python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--filters '?we=huggingface&wpn=trl&xaxis=_step&ceik=trl_ppo_trainer_config.value.reward_model&cen=trl_ppo_trainer_config.value.exp_name&metrics=env/reward_mean&metrics=objective/kl' \
|
||||
"sentiment_tuning?tag=$BASELINE_PR_TAG&cl=sentiment lvwerra/gpt2-imdb ($BASELINE_PR_NAME)" \
|
||||
"sentiment_tuning_step_grad_accu?tag=$BASELINE_PR_TAG&cl=sentiment lvwerra/gpt2-imdb gradient accumulation ($BASELINE_PR_NAME)" \
|
||||
--env-ids sentiment-analysis:lvwerra/distilbert-imdb \
|
||||
--no-check-empty-runs \
|
||||
--pc.ncols 2 \
|
||||
--pc.ncols-legend 1 \
|
||||
--output-filename benchmark/trl/$BASELINE_PR_TAG/gradient_accu \
|
||||
--scan-history
|
||||
|
||||
python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--filters '?we=huggingface&wpn=trl&xaxis=_step&ceik=trl_ppo_trainer_config.value.reward_model&cen=trl_ppo_trainer_config.value.exp_name&metrics=env/reward_mean&metrics=objective/kl' \
|
||||
"sentiment_tuning?tag=$BASELINE_PR_TAG&cl=sentiment lvwerra/gpt2-imdb ($BASELINE_PR_NAME)" \
|
||||
"sentiment_tuning_gpt2?tag=$BASELINE_PR_TAG&cl=sentiment gpt2 ($BASELINE_PR_NAME)" \
|
||||
"sentiment_tuning_falcon_rw_1b?tag=$BASELINE_PR_TAG&cl=sentiment tiiuae/falcon-rw-1b ($BASELINE_PR_NAME)" \
|
||||
"sentiment_tuning_gpt2xl_grad_accu?tag=$BASELINE_PR_TAG&cl=sentiment gpt2xl ($BASELINE_PR_NAME)" \
|
||||
--env-ids sentiment-analysis:lvwerra/distilbert-imdb \
|
||||
--no-check-empty-runs \
|
||||
--pc.ncols 2 \
|
||||
--pc.ncols-legend 1 \
|
||||
--output-filename benchmark/trl/$BASELINE_PR_TAG/different_models \
|
||||
--scan-history
|
||||
|
||||
python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--filters '?we=huggingface&wpn=trl&xaxis=_step&ceik=trl_ppo_trainer_config.value.reward_model&cen=trl_ppo_trainer_config.value.exp_name&metrics=env/reward_mean&metrics=objective/kl' \
|
||||
"sentiment_tuning?tag=$BASELINE_PR_TAG&cl=sentiment lvwerra/gpt2-imdb ($BASELINE_PR_NAME)" \
|
||||
"sentiment_tuning_peft?tag=$BASELINE_PR_TAG&cl=sentiment lvwerra/gpt2-imdb w/ peft ($BASELINE_PR_NAME)" \
|
||||
--env-ids sentiment-analysis:lvwerra/distilbert-imdb \
|
||||
--no-check-empty-runs \
|
||||
--pc.ncols 2 \
|
||||
--pc.ncols-legend 1 \
|
||||
--output-filename benchmark/trl/$BASELINE_PR_TAG/peft \
|
||||
--scan-history
|
||||
|
||||
|
||||
python benchmark/upload_benchmark.py \
|
||||
--folder_path="benchmark/trl/$BASELINE_PR_TAG" \
|
||||
--path_in_repo="images/benchmark/$BASELINE_PR_TAG" \
|
||||
--repo_id="trl-internal-testing/example-images" \
|
||||
--repo_type="dataset"
|
||||
@ -1,26 +0,0 @@
|
||||
import json
|
||||
import os
|
||||
|
||||
from ghapi.all import GhApi
|
||||
|
||||
|
||||
FOLDER_STRING = os.environ.get("FOLDER_STRING", "")
|
||||
folder = f"benchmark/trl/{FOLDER_STRING}"
|
||||
host_url = f"https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/benchmark/{FOLDER_STRING}"
|
||||
|
||||
# Create a GitHub API instance
|
||||
github_context = json.loads(os.environ["GITHUB_CONTEXT"])
|
||||
token = os.environ["PERSONAL_ACCESS_TOKEN_GITHUB"] # this needs to refreshed every 12 months
|
||||
status_message = "**[COSTA BENCHMARK BOT]**: Here are the results"
|
||||
body = status_message
|
||||
repo = github_context["repository"]
|
||||
owner, repo = repo.split("/")
|
||||
api = GhApi(owner=owner, repo=repo, token=token)
|
||||
|
||||
# for each `.png` file in the folder, add it to the comment
|
||||
for file in os.listdir(folder):
|
||||
if file.endswith(".png"):
|
||||
body += f"\n"
|
||||
|
||||
# Create a comment on the issue
|
||||
api.issues.create_comment(issue_number=github_context["event"]["issue"]["number"], body=body)
|
||||
@ -1,9 +0,0 @@
|
||||
#!/bin/bash
|
||||
#SBATCH --job-name=trl
|
||||
#SBATCH --partition=hopper-cpu
|
||||
#SBATCH --ntasks=1
|
||||
#SBATCH --output=slurm/logs/%x_%j.out
|
||||
|
||||
sleep 2m
|
||||
bash $BENCHMARK_PLOT_SCRIPT
|
||||
srun python benchmark/post_github_comment.py
|
||||
@ -1,3 +0,0 @@
|
||||
BENCHMARK_SCRIPT="benchmark/benchmark_level1.sh" \
|
||||
BENCHMARK_PLOT_SCRIPT="benchmark/benchmark_level1_plot.sh" \
|
||||
bash benchmark/benchmark_and_report.sh
|
||||
@ -1,19 +0,0 @@
|
||||
#!/bin/bash
|
||||
#SBATCH --job-name=trl
|
||||
#SBATCH --partition=hopper-prod
|
||||
#SBATCH --gpus-per-task={{gpus_per_task}}
|
||||
#SBATCH --cpus-per-gpu={{cpus_per_gpu}}
|
||||
#SBATCH --ntasks={{ntasks}}
|
||||
#SBATCH --output=slurm/logs/%x_%j.out
|
||||
#SBATCH --array={{array}}
|
||||
##SBATCH --exclude=ip-26-0-149-199
|
||||
|
||||
module load cuda/12.1
|
||||
|
||||
{{nodes}}
|
||||
|
||||
seeds={{seeds}}
|
||||
seed=${seeds[$SLURM_ARRAY_TASK_ID % {{len_seeds}}]}
|
||||
|
||||
echo "Running task $SLURM_ARRAY_TASK_ID with seed: $seed"
|
||||
srun {{command}} --seed $seed
|
||||
@ -1,23 +0,0 @@
|
||||
from dataclasses import dataclass
|
||||
|
||||
import tyro
|
||||
from huggingface_hub import HfApi
|
||||
|
||||
|
||||
@dataclass
|
||||
class Args:
|
||||
folder_path: str = "benchmark/trl"
|
||||
path_in_repo: str = "images/benchmark"
|
||||
repo_id: str = "trl-internal-testing/example-images"
|
||||
repo_type: str = "dataset"
|
||||
|
||||
|
||||
args = tyro.cli(Args)
|
||||
api = HfApi()
|
||||
|
||||
api.upload_folder(
|
||||
folder_path=args.folder_path,
|
||||
path_in_repo=args.path_in_repo,
|
||||
repo_id=args.repo_id,
|
||||
repo_type=args.repo_type,
|
||||
)
|
||||
@ -2,7 +2,7 @@
|
||||
# This script runs an SFT example end-to-end on a tiny model using different possible configurations
|
||||
# but defaults to QLoRA + PEFT
|
||||
OUTPUT_DIR="test_dpo/"
|
||||
MODEL_NAME="trl-internal-testing/tiny-random-LlamaForCausalLM"
|
||||
MODEL_NAME="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
|
||||
DATASET_NAME="trl-internal-testing/hh-rlhf-helpful-base-trl-style"
|
||||
MAX_STEPS=5
|
||||
BATCH_SIZE=2
|
||||
@ -35,7 +35,7 @@ CMD="""
|
||||
accelerate launch $EXTRA_ACCELERATE_ARGS \
|
||||
--num_processes $NUM_GPUS \
|
||||
--mixed_precision 'fp16' \
|
||||
`pwd`/examples/scripts/dpo.py \
|
||||
`pwd`/trl/scripts/dpo.py \
|
||||
--model_name_or_path $MODEL_NAME \
|
||||
--dataset_name $DATASET_NAME \
|
||||
--output_dir $OUTPUT_DIR \
|
||||
|
||||
@ -2,8 +2,8 @@
|
||||
# This script runs an SFT example end-to-end on a tiny model using different possible configurations
|
||||
# but defaults to QLoRA + PEFT
|
||||
OUTPUT_DIR="test_sft/"
|
||||
MODEL_NAME="trl-internal-testing/tiny-random-LlamaForCausalLM"
|
||||
DATASET_NAME="imdb"
|
||||
MODEL_NAME="trl-internal-testing/tiny-Qwen2ForCausalLM-2.5"
|
||||
DATASET_NAME="stanfordnlp/imdb"
|
||||
MAX_STEPS=5
|
||||
BATCH_SIZE=2
|
||||
SEQ_LEN=128
|
||||
@ -36,12 +36,11 @@ CMD="""
|
||||
accelerate launch $EXTRA_ACCELERATE_ARGS \
|
||||
--num_processes $NUM_GPUS \
|
||||
--mixed_precision 'fp16' \
|
||||
`pwd`/examples/scripts/sft.py \
|
||||
`pwd`/trl/scripts/sft.py \
|
||||
--model_name $MODEL_NAME \
|
||||
--dataset_name $DATASET_NAME \
|
||||
--output_dir $OUTPUT_DIR \
|
||||
--max_steps $MAX_STEPS \
|
||||
--dataset_text_field 'text' \
|
||||
--per_device_train_batch_size $BATCH_SIZE \
|
||||
--max_seq_length $SEQ_LEN \
|
||||
$EXTRA_TRAINING_ARGS
|
||||
|
||||
@ -1,12 +1,14 @@
|
||||
- sections:
|
||||
- local: index
|
||||
title: TRL
|
||||
- local: quickstart
|
||||
title: Quickstart
|
||||
- local: installation
|
||||
title: Installation
|
||||
- local: quickstart
|
||||
title: Quickstart
|
||||
- local: clis
|
||||
title: Get started with Command Line Interfaces (CLIs)
|
||||
- local: dataset_formats
|
||||
title: Dataset Formats
|
||||
- local: how_to_train
|
||||
title: PPO Training FAQ
|
||||
- local: use_model
|
||||
@ -17,48 +19,60 @@
|
||||
title: Understanding Logs
|
||||
title: Get started
|
||||
- sections:
|
||||
- sections: # Sort alphabetically
|
||||
- local: alignprop_trainer
|
||||
title: AlignProp
|
||||
- local: bco_trainer
|
||||
title: BCO
|
||||
- local: cpo_trainer
|
||||
title: CPO
|
||||
- local: ddpo_trainer
|
||||
title: DDPO
|
||||
- local: dpo_trainer
|
||||
title: DPO
|
||||
- local: online_dpo_trainer
|
||||
title: Online DPO
|
||||
- local: gkd_trainer
|
||||
title: GKD
|
||||
- local: kto_trainer
|
||||
title: KTO
|
||||
- local: nash_md_trainer
|
||||
title: Nash-MD
|
||||
- local: orpo_trainer
|
||||
title: ORPO
|
||||
- local: ppo_trainer
|
||||
title: PPO
|
||||
- local: prm_trainer
|
||||
title: PRM
|
||||
- local: reward_trainer
|
||||
title: Reward
|
||||
- local: rloo_trainer
|
||||
title: RLOO
|
||||
- local: sft_trainer
|
||||
title: SFT
|
||||
- local: iterative_sft_trainer
|
||||
title: Iterative SFT
|
||||
- local: xpo_trainer
|
||||
title: XPO
|
||||
title: Trainers
|
||||
- local: models
|
||||
title: Model Classes
|
||||
- local: trainer
|
||||
title: Trainer Classes
|
||||
- local: reward_trainer
|
||||
title: Reward Model Training
|
||||
- local: sft_trainer
|
||||
title: Supervised Fine-Tuning
|
||||
- local: ppo_trainer
|
||||
title: PPO Trainer
|
||||
- local: ppov2_trainer
|
||||
title: PPOv2 Trainer
|
||||
- local: rloo_trainer
|
||||
title: RLOO Trainer
|
||||
- local: best_of_n
|
||||
title: Best of N Sampling
|
||||
- local: dpo_trainer
|
||||
title: DPO Trainer
|
||||
- local: online_dpo_trainer
|
||||
title: Online DPO Trainer
|
||||
- local: kto_trainer
|
||||
title: KTO Trainer
|
||||
- local: bco_trainer
|
||||
title: BCO Trainer
|
||||
- local: cpo_trainer
|
||||
title: CPO Trainer
|
||||
- local: ddpo_trainer
|
||||
title: Denoising Diffusion Policy Optimization
|
||||
- local: alignprop_trainer
|
||||
title: AlignProp Trainer
|
||||
- local: orpo_trainer
|
||||
title: ORPO Trainer
|
||||
- local: iterative_sft_trainer
|
||||
title: Iterative Supervised Fine-Tuning
|
||||
- local: callbacks
|
||||
title: Callback Classes
|
||||
- local: judges
|
||||
title: Judge Classes
|
||||
title: Judges
|
||||
- local: callbacks
|
||||
title: Callbacks
|
||||
- local: data_utils
|
||||
title: Data Utilities
|
||||
- local: text_environments
|
||||
title: Text Environments
|
||||
- local: script_utils
|
||||
title: Script Utilities
|
||||
title: API
|
||||
- sections:
|
||||
- local: community_tutorials
|
||||
title: Community Tutorials
|
||||
- local: example_overview
|
||||
title: Example Overview
|
||||
- local: sentiment_tuning
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# Aligning Text-to-Image Diffusion Models with Reward Backpropagation
|
||||
|
||||
[](https://huggingface.co/models?other=alignprop,trl)
|
||||
|
||||
## The why
|
||||
|
||||
If your reward function is differentiable, directly backpropagating gradients from the reward models to the diffusion model is significantly more sample and compute efficient (25x) than doing policy gradient algorithm like DDPO.
|
||||
|
||||
@ -1,54 +1,15 @@
|
||||
# BCO Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=bco,trl)
|
||||
|
||||
TRL supports the Binary Classifier Optimization (BCO).
|
||||
The [BCO](https://huggingface.co/papers/2404.04656) authors train a binary classifier whose logit serves as a reward so that the classifier maps {prompt, chosen completion} pairs to 1 and {prompt, rejected completion} pairs to 0.
|
||||
For a full example have a look at [`examples/scripts/bco.py`].
|
||||
|
||||
## Expected dataset format
|
||||
|
||||
The BCO trainer expects a very specific format for the dataset as it does not require pairwise preferences. Since the model will be trained to directly optimize examples that consist of a prompt, model completion, and a label to indicate whether the completion is "good" or "bad", we expect a dataset with the following columns:
|
||||
|
||||
- `prompt`
|
||||
- `completion`
|
||||
- `label`
|
||||
|
||||
for example:
|
||||
|
||||
```
|
||||
bco_dataset_dict = {
|
||||
"prompt": [
|
||||
"Hey, hello",
|
||||
"How are you",
|
||||
"What is your name?",
|
||||
"What is your name?",
|
||||
"Which is the best programming language?",
|
||||
"Which is the best programming language?",
|
||||
"Which is the best programming language?",
|
||||
],
|
||||
"completion": [
|
||||
"hi nice to meet you",
|
||||
"leave me alone",
|
||||
"I don't have a name",
|
||||
"My name is Mary",
|
||||
"Python",
|
||||
"C++",
|
||||
"Java",
|
||||
],
|
||||
"label": [
|
||||
True,
|
||||
False,
|
||||
False,
|
||||
True,
|
||||
True,
|
||||
False,
|
||||
False,
|
||||
],
|
||||
}
|
||||
```
|
||||
|
||||
where the `prompt` contains the context inputs, `completion` contains the corresponding responses and `label` contains the corresponding flag that indicates if the generated completion is desired (`True`) or undesired (`False`).
|
||||
A prompt can have multiple responses and this is reflected in the entries being repeated in the dictionary's value arrays. It is required that the dataset contains at least one desirable and one undesirable completion.
|
||||
## Expected dataset type
|
||||
|
||||
The [`BCOTrainer`] requires an [unpaired preference dataset](dataset_formats#unpaired-preference).
|
||||
The [`BCOTrainer`] supports both [conversational](dataset_formats#conversational) and [standard](dataset_formats#standard) dataset format. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
|
||||
|
||||
## Expected model format
|
||||
The BCO trainer expects a model of `AutoModelForCausalLM`, compared to PPO that expects `AutoModelForCausalLMWithValueHead` for the value function.
|
||||
@ -71,7 +32,7 @@ bco_trainer = BCOTrainer(
|
||||
model_ref,
|
||||
args=training_args,
|
||||
train_dataset=train_dataset,
|
||||
tokenizer=tokenizer,
|
||||
processing_class=tokenizer,
|
||||
)
|
||||
```
|
||||
After this one can then call:
|
||||
@ -114,7 +75,7 @@ bco_trainer = BCOTrainer(
|
||||
model_ref,
|
||||
args=training_args,
|
||||
train_dataset=train_dataset,
|
||||
tokenizer=tokenizer,
|
||||
processing_class=tokenizer,
|
||||
embedding_func=embedding_func,
|
||||
embedding_tokenizer=self.embedding_tokenizer,
|
||||
)
|
||||
|
||||
@ -11,3 +11,11 @@
|
||||
## WinRateCallback
|
||||
|
||||
[[autodoc]] WinRateCallback
|
||||
|
||||
## LogCompletionsCallback
|
||||
|
||||
[[autodoc]] LogCompletionsCallback
|
||||
|
||||
## MergeModelCallback
|
||||
|
||||
[[autodoc]] MergeModelCallback
|
||||
@ -4,9 +4,16 @@ You can use TRL to fine-tune your Language Model with Supervised Fine-Tuning (SF
|
||||
|
||||
Currently supported CLIs are:
|
||||
|
||||
- `trl sft`: fine-tune a LLM on a text/instruction dataset
|
||||
- `trl dpo`: fine-tune a LLM with DPO on a preference dataset
|
||||
#### Training commands
|
||||
|
||||
- `trl dpo`: fine-tune a LLM with DPO
|
||||
- `trl kto`: fine-tune a LLM with KTO
|
||||
- `trl sft`: fine-tune a LLM with SFT
|
||||
|
||||
#### Other commands
|
||||
|
||||
- `trl chat`: quickly spin up a LLM fine-tuned for chatting
|
||||
- `trl env`: get the system information
|
||||
|
||||
## Fine-tuning with the CLI
|
||||
|
||||
@ -22,11 +29,9 @@ We also recommend you passing a YAML config file to configure your training prot
|
||||
|
||||
```yaml
|
||||
model_name_or_path:
|
||||
trl-internal-testing/tiny-random-LlamaForCausalLM
|
||||
Qwen/Qwen2.5-0.5B
|
||||
dataset_name:
|
||||
imdb
|
||||
dataset_text_field:
|
||||
text
|
||||
stanfordnlp/imdb
|
||||
report_to:
|
||||
none
|
||||
learning_rate:
|
||||
@ -56,10 +61,10 @@ You can pass any of these arguments either to the CLI or the YAML file.
|
||||
Follow the basic instructions above and run `trl sft --output_dir <output_dir> <*args>`:
|
||||
|
||||
```bash
|
||||
trl sft --model_name_or_path facebook/opt-125m --dataset_name imdb --output_dir opt-sft-imdb
|
||||
trl sft --model_name_or_path facebook/opt-125m --dataset_name stanfordnlp/imdb --output_dir opt-sft-imdb
|
||||
```
|
||||
|
||||
The SFT CLI is based on the `examples/scripts/sft.py` script.
|
||||
The SFT CLI is based on the `trl/scripts/sft.py` script.
|
||||
|
||||
### Direct Policy Optimization (DPO)
|
||||
|
||||
@ -82,7 +87,7 @@ trl dpo --model_name_or_path facebook/opt-125m --output_dir trl-hh-rlhf --datase
|
||||
```
|
||||
|
||||
|
||||
The DPO CLI is based on the `examples/scripts/dpo.py` script.
|
||||
The DPO CLI is based on the `trl/scripts/dpo.py` script.
|
||||
|
||||
|
||||
#### Custom preference dataset
|
||||
@ -97,23 +102,74 @@ python examples/datasets/anthropic_hh.py --push_to_hub --hf_entity your-hf-org
|
||||
|
||||
The chat CLI lets you quickly load the model and talk to it. Simply run the following:
|
||||
|
||||
```bash
|
||||
trl chat --model_name_or_path Qwen/Qwen1.5-0.5B-Chat
|
||||
```
|
||||
<pre><code>$ trl chat --model_name_or_path Qwen/Qwen1.5-0.5B-Chat
|
||||
<strong><span style="color: red;"><quentin_gallouedec>:</span></strong>
|
||||
What is the best programming language?
|
||||
|
||||
> [!TIP]
|
||||
> To use the chat CLI with the developer installation, you must run `make dev`
|
||||
>
|
||||
<strong><span style="color: blue;"><Qwen/Qwen1.5-0.5B-Chat>:</span></strong>
|
||||
There isn't a "best" programming language, as everyone has different style preferences, needs, and preferences. However, some people commonly use
|
||||
languages like Python, Java, C++, and JavaScript, which are popular among developers for a variety of reasons, including readability, flexibility,
|
||||
and scalability. Ultimately, it depends on personal preference, needs, and goals.
|
||||
</code></pre>
|
||||
|
||||
Note that the chat interface relies on the tokenizer's [chat template](https://huggingface.co/docs/transformers/chat_templating) to format the inputs for the model. Make sure your tokenizer has a chat template defined.
|
||||
|
||||
Besides talking to the model there are a few commands you can use:
|
||||
|
||||
- **clear**: clears the current conversation and start a new one
|
||||
- **example {NAME}**: load example named `{NAME}` from the config and use it as the user input
|
||||
- **set {SETTING_NAME}={SETTING_VALUE};**: change the system prompt or generation settings (multiple settings are separated by a ';').
|
||||
- **reset**: same as clear but also resets the generation configs to defaults if they have been changed by **set**
|
||||
- **save {SAVE_NAME} (optional)**: save the current chat and settings to file by default to `./chat_history/{MODEL_NAME}/chat_{DATETIME}.yaml` or `{SAVE_NAME}` if provided
|
||||
- **exit**: closes the interface
|
||||
- `clear`: clears the current conversation and start a new one
|
||||
- `example {NAME}`: load example named `{NAME}` from the config and use it as the user input
|
||||
- `set {SETTING_NAME}={SETTING_VALUE};`: change the system prompt or generation settings (multiple settings are separated by a `;`).
|
||||
- `reset`: same as clear but also resets the generation configs to defaults if they have been changed by `set`
|
||||
- `save` or `save {SAVE_NAME}`: save the current chat and settings to file by default to `./chat_history/{MODEL_NAME}/chat_{DATETIME}.yaml` or `{SAVE_NAME}` if provided
|
||||
- `exit`: closes the interface
|
||||
|
||||
The default examples are defined in `examples/scripts/config/default_chat_config.yaml` but you can pass your own with `--config CONFIG_FILE` where you can also specify the default generation parameters.
|
||||
## Getting the system information
|
||||
|
||||
You can get the system information by running the following command:
|
||||
|
||||
```bash
|
||||
trl env
|
||||
```
|
||||
|
||||
This will print out the system information including the GPU information, the CUDA version, the PyTorch version, the transformers version, and the TRL version, and any optional dependencies that are installed.
|
||||
|
||||
```txt
|
||||
Copy-paste the following information when reporting an issue:
|
||||
|
||||
- Platform: Linux-5.15.0-1048-aws-x86_64-with-glibc2.31
|
||||
- Python version: 3.11.9
|
||||
- PyTorch version: 2.4.1
|
||||
- CUDA device: NVIDIA H100 80GB HBM3
|
||||
- Transformers version: 4.45.0.dev0
|
||||
- Accelerate version: 0.34.2
|
||||
- Accelerate config:
|
||||
- compute_environment: LOCAL_MACHINE
|
||||
- distributed_type: DEEPSPEED
|
||||
- mixed_precision: no
|
||||
- use_cpu: False
|
||||
- debug: False
|
||||
- num_processes: 4
|
||||
- machine_rank: 0
|
||||
- num_machines: 1
|
||||
- rdzv_backend: static
|
||||
- same_network: True
|
||||
- main_training_function: main
|
||||
- enable_cpu_affinity: False
|
||||
- deepspeed_config: {'gradient_accumulation_steps': 4, 'offload_optimizer_device': 'none', 'offload_param_device': 'none', 'zero3_init_flag': False, 'zero_stage': 2}
|
||||
- downcast_bf16: no
|
||||
- tpu_use_cluster: False
|
||||
- tpu_use_sudo: False
|
||||
- tpu_env: []
|
||||
- Datasets version: 3.0.0
|
||||
- HF Hub version: 0.24.7
|
||||
- TRL version: 0.12.0.dev0+acb4d70
|
||||
- bitsandbytes version: 0.41.1
|
||||
- DeepSpeed version: 0.15.1
|
||||
- Diffusers version: 0.30.3
|
||||
- Liger-Kernel version: 0.3.0
|
||||
- LLM-Blender version: 0.0.2
|
||||
- OpenAI version: 1.46.0
|
||||
- PEFT version: 0.12.0
|
||||
```
|
||||
|
||||
This information are required when reporting an issue.
|
||||
|
||||
26
docs/source/community_tutorials.md
Normal file
26
docs/source/community_tutorials.md
Normal file
@ -0,0 +1,26 @@
|
||||
# Community Tutorials
|
||||
|
||||
Community tutorials are made by active members of the Hugging Face community that want to share their knowledge and expertise with others. They are a great way to learn about the library and its features, and to get started with core classes and modalities.
|
||||
|
||||
# Language Models
|
||||
|
||||
| Task | Class | Description | Author | Tutorial | Colab |
|
||||
| ----------------------- | --------------- | ---------------------------------------------------------------------------------------- | -------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Instruction tuning | [`SFTTrainer`] | Fine-tuning Google Gemma LLMs using ChatML format with QLoRA | [Philipp Schmid](https://huggingface.co/philschmid) | [Link](https://www.philschmid.de/fine-tune-google-gemma) | [](https://colab.research.google.com/github/philschmid/deep-learning-pytorch-huggingface/blob/main/training/gemma-lora-example.ipynb) |
|
||||
| Structured Generation | [`SFTTrainer`] | Fine-tuning Llama-2-7B to generate Persian product catalogs in JSON using QLoRA and PEFT | [Mohammadreza Esmaeilian](https://huggingface.co/Mohammadreza) | [Link](https://huggingface.co/learn/cookbook/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format) | [](https://colab.research.google.com/github/huggingface/cookbook/blob/main/notebooks/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format.ipynb) |
|
||||
| Preference Optimization | [`DPOTrainer`] | Align Mistral-7b using Direct Preference Optimization for human preference alignment | [Maxime Labonne](https://huggingface.co/mlabonne) | [Link](https://mlabonne.github.io/blog/posts/Fine_tune_Mistral_7b_with_DPO.html) | [](https://colab.research.google.com/github/mlabonne/llm-course/blob/main/Fine_tune_a_Mistral_7b_model_with_DPO.ipynb) |
|
||||
| Preference Optimization | [`ORPOTrainer`] | Fine-tuning Llama 3 with ORPO combining instruction tuning and preference alignment | [Maxime Labonne](https://huggingface.co/mlabonne) | [Link](https://mlabonne.github.io/blog/posts/2024-04-19_Fine_tune_Llama_3_with_ORPO.html) | [](https://colab.research.google.com/drive/1eHNWg9gnaXErdAa8_mcvjMupbSS6rDvi) |
|
||||
|
||||
<Youtube id="cnGyyM0vOes" />
|
||||
|
||||
# Vision Language Models
|
||||
|
||||
| Task | Class | Description | Author | Tutorial | Colab |
|
||||
| --------------- | -------------- | ---------------------------------------------------------------------------- | ------------------------------------------------------ | -------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Visual QA | [`SFTTrainer`] | Fine-tuning Qwen2-VL-7B for visual question answering on ChartQA dataset | [Sergio Paniego](https://huggingface.co/sergiopaniego) | [Link](https://huggingface.co/learn/cookbook/fine_tuning_vlm_trl) | [](https://colab.research.google.com/github/huggingface/cookbook/blob/main/notebooks/en/fine_tuning_vlm_trl.ipynb) |
|
||||
| SEO Description | [`SFTTrainer`] | Fine-tuning Qwen2-VL-7B for generating SEO-friendly descriptions from images | [Philipp Schmid](https://huggingface.co/philschmid) | [Link](https://www.philschmid.de/fine-tune-multimodal-llms-with-trl) | [](https://colab.research.google.com/github/philschmid/deep-learning-pytorch-huggingface/blob/main/training/fine-tune-multimodal-llms-with-trl.ipynb) |
|
||||
| Visual QA | [`DPOTrainer`] | PaliGemma 🤝 Direct Preference Optimization | [Merve Noyan](https://huggingface.co/merve) | [Link](https://github.com/merveenoyan/smol-vision/blob/main/PaliGemma_DPO.ipynb) | [](https://colab.research.google.com/github/merveenoyan/smol-vision/blob/main/PaliGemma_DPO.ipynb) |
|
||||
|
||||
## Contributing
|
||||
|
||||
If you have a tutorial that you would like to add to this list, please open a PR to add it. We will review it and merge it if it is relevant to the community.
|
||||
@ -1,100 +1,67 @@
|
||||
# CPO Trainer
|
||||
|
||||
Contrastive Preference Optimization (CPO) as introduced in the paper [Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation](https://huggingface.co/papers/2401.08417) by Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. At a high-level, CPO trains models to
|
||||
avoid generating adequate, but not perfect translations in Machine Translation (MT) tasks. However, CPO is a general approximation to the DPO loss and can be applied to other domains like chat.
|
||||
[](https://huggingface.co/models?other=cpo,trl)
|
||||
|
||||
## Overview
|
||||
|
||||
Contrastive Preference Optimization (CPO) as introduced in the paper [Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation](https://huggingface.co/papers/2401.08417) by [Haoran Xu](https://huggingface.co/haoranxu), [Amr Sharaf](https://huggingface.co/amrsharaf), [Yunmo Chen](https://huggingface.co/yunmochen), Weiting Tan, Lingfeng Shen, Benjamin Van Durme, [Kenton Murray](https://huggingface.co/Kenton), and [Young Jin Kim](https://huggingface.co/ykim362). At a high-level, CPO trains models to avoid generating adequate, but not perfect translations in Machine Translation (MT) tasks. However, CPO is a general approximation to the DPO loss and can be applied to other domains like chat.
|
||||
|
||||
CPO aims to mitigate two fundamental shortcomings of SFT. First, SFT’s methodology of minimizing the discrepancy between predicted outputs and gold-standard references inherently caps model performance at the quality level of the training data. Secondly, SFT lacks a mechanism to prevent the model from rejecting mistakes in translations. The CPO objective is derived from the DPO objective.
|
||||
|
||||
## SimPO
|
||||
The [SimPO](https://huggingface.co/papers/2405.14734) method is also implemented in the `CPOTrainer`. SimPO is an alternative loss that adds a reward margin, allows for length normalization, and does not use BC regularization. To use this loss, we can use SimPO easily by turning on `loss_type="simpo"` and `cpo_alpha=0` in the `CPOConfig`.
|
||||
## Quick start
|
||||
|
||||
## CPO-SimPO
|
||||
We also offer the combined use of CPO and SimPO, which enables more stable training and improved performance. Learn more details at [CPO-SimPO Github](https://github.com/fe1ixxu/CPO_SIMPO). To use this method, simply enable SimPO by setting `loss_type="simpo"` and a non-zero `cpo_alpha` in the CPOConfig.
|
||||
This example demonstrates how to train a model using the CPO method. We use the [Qwen 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) as the base model. We use the preference data from the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback). You can view the data in the dataset here:
|
||||
|
||||
## Expected dataset format
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized/embed/viewer/default/train?row=0"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
The CPO trainer expects a format identical to the DPO trainer, which should include three entries. These entries should be named as follows:
|
||||
Below is the script to train the model:
|
||||
|
||||
- `prompt`
|
||||
- `chosen`
|
||||
- `rejected`
|
||||
```python
|
||||
# train_cpo.py
|
||||
from datasets import load_dataset
|
||||
from trl import CPOConfig, CPOTrainer
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
for example:
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
train_dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
|
||||
|
||||
```py
|
||||
cpo_dataset_dict = {
|
||||
"prompt": [
|
||||
"hello",
|
||||
"how are you",
|
||||
"What is your name?",
|
||||
"What is your name?",
|
||||
"Which is the best programming language?",
|
||||
"Which is the best programming language?",
|
||||
"Which is the best programming language?",
|
||||
],
|
||||
"chosen": [
|
||||
"hi nice to meet you",
|
||||
"I am fine",
|
||||
"My name is Mary",
|
||||
"My name is Mary",
|
||||
"Python",
|
||||
"Python",
|
||||
"Java",
|
||||
],
|
||||
"rejected": [
|
||||
"leave me alone",
|
||||
"I am not fine",
|
||||
"Whats it to you?",
|
||||
"I dont have a name",
|
||||
"Javascript",
|
||||
"C++",
|
||||
"C++",
|
||||
],
|
||||
}
|
||||
```
|
||||
where the `prompt` contains the context inputs, `chosen` contains the corresponding chosen responses and `rejected` contains the corresponding negative (rejected) responses. As can be seen a prompt can have multiple responses and this is reflected in the entries being repeated in the dictionary's value arrays.
|
||||
|
||||
## Expected model format
|
||||
The CPO trainer expects a model of `AutoModelForCausalLM`, compared to PPO that expects `AutoModelForCausalLMWithValueHead` for the value function.
|
||||
|
||||
## Using the `CPOTrainer`
|
||||
For a detailed example have a look at the `examples/scripts/cpo.py` script. At a high level we need to initialize the `CPOTrainer` with a `model` we wish to train. **Note that CPOTrainer eliminates the need to use the reference model, simplifying the optimization process.** The `beta` refers to the hyperparameter of the implicit reward, and the dataset contains the 3 entries listed above.
|
||||
|
||||
```py
|
||||
cpo_config = CPOConfig(
|
||||
beta=0.1,
|
||||
)
|
||||
|
||||
cpo_trainer = CPOTrainer(
|
||||
model,
|
||||
args=cpo_config,
|
||||
train_dataset=train_dataset,
|
||||
tokenizer=tokenizer,
|
||||
)
|
||||
```
|
||||
After this one can then call:
|
||||
|
||||
```py
|
||||
cpo_trainer.train()
|
||||
training_args = CPOConfig(output_dir="Qwen2-0.5B-CPO", logging_steps=10)
|
||||
trainer = CPOTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Loss functions
|
||||
Execute the script using the following command:
|
||||
|
||||
Given the preference data, the `CPOTrainer` uses the sigmoid loss on the normalized likelihood via the `logsigmoid` to fit a logistic regression.
|
||||
```bash
|
||||
accelerate launch train_cpo.py
|
||||
```
|
||||
|
||||
The [RSO](https://huggingface.co/papers/2309.06657) authors propose to use a hinge loss on the normalized likelihood from the [SLiC](https://huggingface.co/papers/2305.10425) paper. The `CPOTrainer` can be switched to this loss via the `loss_type="hinge"` argument and the `beta` in this case is the reciprocal of the margin.
|
||||
## Expected dataset type
|
||||
|
||||
The [IPO](https://huggingface.co/papers/2310.12036) authors provide a deeper theoretical understanding of the CPO algorithms and identify an issue with overfitting and propose an alternative loss which can be used via the `loss_type="ipo"` argument to the trainer. Note that the `beta` parameter is the reciprocal of the gap between the log-likelihood ratios of the chosen vs the rejected completion pair and thus the smaller the `beta` the larger this gaps is. As per the paper the loss is averaged over log-likelihoods of the completion (unlike CPO which is summed only).
|
||||
CPO requires a [preference dataset](dataset_formats#preference). The [`CPOTrainer`] supports both [conversational](dataset_formats#conversational) and [standard](dataset_formats#standard) dataset format. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
|
||||
|
||||
### For Mixture of Experts Models: Enabling the auxiliary loss
|
||||
## Example script
|
||||
|
||||
MOEs are the most efficient if the load is about equally distributed between experts.
|
||||
To ensure that we train MOEs similarly during preference-tuning, it is beneficial to add the auxiliary loss from the load balancer to the final loss.
|
||||
We provide an example script to train a model using the CPO method. The script is available in [`examples/scripts/cpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/cpo.py)
|
||||
|
||||
This option is enabled by setting `output_router_logits=True` in the model config (e.g. MixtralConfig).
|
||||
To scale how much the auxiliary loss contributes to the total loss, use the hyperparameter `router_aux_loss_coef=...` (default: 0.001).
|
||||
To test the CPO script with the [Qwen2 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) on the [UltraFeedback dataset](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized), run the following command:
|
||||
|
||||
## Logging
|
||||
```bash
|
||||
accelerate launch examples/scripts/cpo.py \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
|
||||
--dataset_name trl-lib/ultrafeedback_binarized \
|
||||
--num_train_epochs 1 \
|
||||
--logging_steps 25 \
|
||||
--output_dir Qwen2-0.5B-CPO
|
||||
```
|
||||
|
||||
## Logged metrics
|
||||
|
||||
While training and evaluating we record the following reward metrics:
|
||||
|
||||
@ -104,6 +71,34 @@ While training and evaluating we record the following reward metrics:
|
||||
* `rewards/margins`: the mean difference between the chosen and corresponding rejected rewards
|
||||
* `nll_loss`: the mean negative log likelihood loss of the policy model for the chosen responses
|
||||
|
||||
## CPO variants
|
||||
|
||||
### Simple Preference Optimization (SimPO)
|
||||
|
||||
The [SimPO](https://huggingface.co/papers/2405.14734) method is also implemented in the [`CPOTrainer`]. SimPO is an alternative loss that adds a reward margin, allows for length normalization, and does not use BC regularization. To use this loss, we can use SimPO easily by turning on `loss_type="simpo"` and `cpo_alpha=0.0` in the [`CPOConfig`].
|
||||
|
||||
### CPO-SimPO
|
||||
|
||||
We also offer the combined use of CPO and SimPO, which enables more stable training and improved performance. Learn more details at [CPO-SimPO GitHub](https://github.com/fe1ixxu/CPO_SIMPO). To use this method, simply enable SimPO by setting `loss_type="simpo"` and a non-zero `cpo_alpha` in the [`CPOConfig`].
|
||||
|
||||
## Loss functions
|
||||
|
||||
The CPO algorithm supports several loss functions. The loss function can be set using the `loss_type` parameter in the [`CPOConfig`]. The following loss functions are supported:
|
||||
|
||||
| `loss_type=` | Description |
|
||||
| -------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `"sigmoid"` (default) | Given the preference data, we can fit a binary classifier according to the Bradley-Terry model and in fact the [DPO](https://huggingface.co/papers/2305.18290) authors propose the sigmoid loss on the normalized likelihood via the `logsigmoid` to fit a logistic regression. |
|
||||
| `"hinge"` | The [RSO](https://huggingface.co/papers/2309.06657) authors propose to use a hinge loss on the normalized likelihood from the [SLiC](https://huggingface.co/papers/2305.10425) paper. In this case, the `beta` is the reciprocal of the margin. |
|
||||
| `"ipo"` | The [IPO](https://huggingface.co/papers/2310.12036) authors provide a deeper theoretical understanding of the DPO algorithms and identify an issue with overfitting and propose an alternative loss. In this case, the `beta` is the reciprocal of the gap between the log-likelihood ratios of the chosen vs the rejected completion pair and thus the smaller the `beta` the larger this gaps is. As per the paper the loss is averaged over log-likelihoods of the completion (unlike DPO which is summed only). |
|
||||
|
||||
### For Mixture of Experts Models: Enabling the auxiliary loss
|
||||
|
||||
MOEs are the most efficient if the load is about equally distributed between experts.
|
||||
To ensure that we train MOEs similarly during preference-tuning, it is beneficial to add the auxiliary loss from the load balancer to the final loss.
|
||||
|
||||
This option is enabled by setting `output_router_logits=True` in the model config (e.g. [`~transformers.MixtralConfig`]).
|
||||
To scale how much the auxiliary loss contributes to the total loss, use the hyperparameter `router_aux_loss_coef=...` (default: `0.001`) in the model config.
|
||||
|
||||
## CPOTrainer
|
||||
|
||||
[[autodoc]] CPOTrainer
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# Training customization
|
||||
|
||||
TRL is designed with modularity in mind so that users to be able to efficiently customize the training loop for their needs. Below are some examples on how you can apply and test different techniques.
|
||||
TRL is designed with modularity in mind so that users to be able to efficiently customize the training loop for their needs. Below are some examples on how you can apply and test different techniques. Note: Although these examples use the DPOTrainer, the customization applies to most (if not all) trainers.
|
||||
|
||||
## Train on multiple GPUs / nodes
|
||||
|
||||
@ -46,171 +46,118 @@ else:
|
||||
Consult the 🤗 Accelerate [documentation](https://huggingface.co/docs/accelerate/usage_guides/deepspeed) for more information about the DeepSpeed plugin.
|
||||
|
||||
|
||||
## Use different optimizers
|
||||
## Use different optimizers and schedulers
|
||||
|
||||
By default, the `DPOTrainer` creates a `torch.optim.AdamW` optimizer. You can create and define a different optimizer and pass it to `DPOTrainer` as follows:
|
||||
|
||||
By default, the `PPOTrainer` creates a `torch.optim.Adam` optimizer. You can create and define a different optimizer and pass it to `PPOTrainer`:
|
||||
```python
|
||||
import torch
|
||||
from transformers import GPT2Tokenizer
|
||||
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from torch import optim
|
||||
from trl import DPOConfig, DPOTrainer
|
||||
|
||||
# 1. load a pretrained model
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
|
||||
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
|
||||
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
|
||||
training_args = DPOConfig(output_dir="Qwen2.5-0.5B-DPO")
|
||||
|
||||
# 2. define config
|
||||
ppo_config = {'batch_size': 1, 'learning_rate':1e-5}
|
||||
config = PPOConfig(**ppo_config)
|
||||
optimizer = optim.SGD(model.parameters(), lr=training_args.learning_rate)
|
||||
|
||||
|
||||
# 2. Create optimizer
|
||||
optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate)
|
||||
|
||||
|
||||
# 3. initialize trainer
|
||||
ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer, optimizer=optimizer)
|
||||
trainer = DPOTrainer(
|
||||
model=model,
|
||||
args=training_args,
|
||||
train_dataset=dataset,
|
||||
tokenizer=tokenizer,
|
||||
optimizers=(optimizer, None),
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
For memory efficient fine-tuning, you can also pass `Adam8bit` optimizer from `bitsandbytes`:
|
||||
### Add a learning rate scheduler
|
||||
|
||||
You can also play with your training by adding learning rate schedulers.
|
||||
|
||||
```python
|
||||
import torch
|
||||
import bitsandbytes as bnb
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from torch import optim
|
||||
from trl import DPOConfig, DPOTrainer
|
||||
|
||||
from transformers import GPT2Tokenizer
|
||||
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
|
||||
training_args = DPOConfig(output_dir="Qwen2.5-0.5B-DPO")
|
||||
|
||||
# 1. load a pretrained model
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
|
||||
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
|
||||
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
|
||||
optimizer = optim.AdamW(model.parameters(), lr=training_args.learning_rate)
|
||||
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
|
||||
|
||||
# 2. define config
|
||||
ppo_config = {'batch_size': 1, 'learning_rate':1e-5}
|
||||
config = PPOConfig(**ppo_config)
|
||||
|
||||
|
||||
# 2. Create optimizer
|
||||
optimizer = bnb.optim.Adam8bit(model.parameters(), lr=config.learning_rate)
|
||||
|
||||
# 3. initialize trainer
|
||||
ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer, optimizer=optimizer)
|
||||
```
|
||||
|
||||
### Use LION optimizer
|
||||
|
||||
You can use the new [LION optimizer from Google](https://huggingface.co/papers/2302.06675) as well, first take the source code of the optimizer definition [here](https://github.com/lucidrains/lion-pytorch/blob/main/lion_pytorch/lion_pytorch.py), and copy it so that you can import the optimizer. Make sure to initialize the optimizer by considering the trainable parameters only for a more memory efficient training:
|
||||
```python
|
||||
optimizer = Lion(filter(lambda p: p.requires_grad, self.model.parameters()), lr=self.config.learning_rate)
|
||||
|
||||
...
|
||||
ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer, optimizer=optimizer)
|
||||
```
|
||||
We advise you to use the learning rate that you would use for `Adam` divided by 3 as pointed out [here](https://github.com/lucidrains/lion-pytorch#lion---pytorch). We observed an improvement when using this optimizer compared to classic Adam (check the full logs [here](https://wandb.ai/distill-bloom/trl/runs/lj4bheke?workspace=user-younesbelkada)):
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-lion.png">
|
||||
</div>
|
||||
|
||||
|
||||
## Add a learning rate scheduler
|
||||
|
||||
You can also play with your training by adding learning rate schedulers!
|
||||
```python
|
||||
import torch
|
||||
from transformers import GPT2Tokenizer
|
||||
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
|
||||
|
||||
# 1. load a pretrained model
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
|
||||
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained('gpt2')
|
||||
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
|
||||
|
||||
# 2. define config
|
||||
ppo_config = {'batch_size': 1, 'learning_rate':1e-5}
|
||||
config = PPOConfig(**ppo_config)
|
||||
|
||||
|
||||
# 2. Create optimizer
|
||||
optimizer = torch.optim.SGD(model.parameters(), lr=config.learning_rate)
|
||||
lr_scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
|
||||
|
||||
# 3. initialize trainer
|
||||
ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer, optimizer=optimizer, lr_scheduler=lr_scheduler)
|
||||
trainer = DPOTrainer(
|
||||
model=model,
|
||||
args=training_args,
|
||||
train_dataset=dataset,
|
||||
tokenizer=tokenizer,
|
||||
optimizers=(optimizer, lr_scheduler),
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Memory efficient fine-tuning by sharing layers
|
||||
|
||||
Another tool you can use for more memory efficient fine-tuning is to share layers between the reference model and the model you want to train.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import AutoTokenizer
|
||||
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from trl import create_reference_model, DPOConfig, DPOTrainer
|
||||
|
||||
# 1. load a pretrained model
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained('bigscience/bloom-560m')
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
ref_model = create_reference_model(model, num_shared_layers=6)
|
||||
tokenizer = AutoTokenizer.from_pretrained('bigscience/bloom-560m')
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train[:1%]")
|
||||
training_args = DPOConfig(output_dir="Qwen2.5-0.5B-DPO")
|
||||
|
||||
# 2. initialize trainer
|
||||
ppo_config = {'batch_size': 1}
|
||||
config = PPOConfig(**ppo_config)
|
||||
ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer)
|
||||
trainer = DPOTrainer(
|
||||
model=model,
|
||||
ref_model=ref_model,
|
||||
args=training_args,
|
||||
train_dataset=dataset,
|
||||
tokenizer=tokenizer,
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Pass 8-bit reference models
|
||||
|
||||
<div>
|
||||
Since `trl` supports all keyword arguments when loading a model from `transformers` using `from_pretrained`, you can also leverage `load_in_8bit` from `transformers` for more memory efficient fine-tuning.
|
||||
|
||||
Since `trl` supports all key word arguments when loading a model from `transformers` using `from_pretrained`, you can also leverage `load_in_8bit` from `transformers` for more memory efficient fine-tuning.
|
||||
|
||||
Read more about 8-bit model loading in `transformers` [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one#bitsandbytes-integration-for-int8-mixedprecision-matrix-decomposition).
|
||||
|
||||
</div>
|
||||
Read more about 8-bit model loading in `transformers` [here](https://huggingface.co/docs/transformers/en/peft#load-in-8bit-or-4bit).
|
||||
|
||||
```python
|
||||
# 0. imports
|
||||
# pip install bitsandbytes
|
||||
import torch
|
||||
from transformers import AutoTokenizer
|
||||
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
from trl import DPOConfig, DPOTrainer
|
||||
|
||||
# 1. load a pretrained model
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained('bigscience/bloom-560m')
|
||||
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained('bigscience/bloom-560m', device_map="auto", load_in_8bit=True)
|
||||
tokenizer = AutoTokenizer.from_pretrained('bigscience/bloom-560m')
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
|
||||
ref_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct", quantization_config= quantization_config)
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
|
||||
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
|
||||
training_args = DPOConfig(output_dir="Qwen2.5-0.5B-DPO")
|
||||
|
||||
# 2. initialize trainer
|
||||
ppo_config = {'batch_size': 1}
|
||||
config = PPOConfig(**ppo_config)
|
||||
ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer)
|
||||
trainer = DPOTrainer(
|
||||
model=model,
|
||||
ref_model=ref_model,
|
||||
args=training_args,
|
||||
train_dataset=dataset,
|
||||
tokenizer=tokenizer,
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Use the CUDA cache optimizer
|
||||
|
||||
When training large models, you should better handle the CUDA cache by iteratively clearing it. Do do so, simply pass `optimize_cuda_cache=True` to `PPOConfig`:
|
||||
When training large models, you should better handle the CUDA cache by iteratively clearing it. To do so, simply pass `optimize_cuda_cache=True` to `DPOConfig`:
|
||||
|
||||
```python
|
||||
config = PPOConfig(..., optimize_cuda_cache=True)
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Use score scaling/normalization/clipping
|
||||
As suggested by [Secrets of RLHF in Large Language Models Part I: PPO](https://huggingface.co/papers/2307.04964), we support score (aka reward) scaling/normalization/clipping to improve training stability via `PPOConfig`:
|
||||
```python
|
||||
from trl import PPOConfig
|
||||
|
||||
ppo_config = {
|
||||
use_score_scaling=True,
|
||||
use_score_norm=True,
|
||||
score_clip=0.5,
|
||||
}
|
||||
config = PPOConfig(**ppo_config)
|
||||
```
|
||||
|
||||
To run `ppo.py`, you can use the following command:
|
||||
```
|
||||
python examples/scripts/ppo.py --log_with wandb --use_score_scaling --use_score_norm --score_clip 0.5
|
||||
training_args = DPOConfig(..., optimize_cuda_cache=True)
|
||||
```
|
||||
|
||||
29
docs/source/data_utils.mdx
Normal file
29
docs/source/data_utils.mdx
Normal file
@ -0,0 +1,29 @@
|
||||
# Data Utilities
|
||||
|
||||
## is_conversational
|
||||
|
||||
[[autodoc]] is_conversational
|
||||
|
||||
## apply_chat_template
|
||||
|
||||
[[autodoc]] apply_chat_template
|
||||
|
||||
## maybe_apply_chat_template
|
||||
|
||||
[[autodoc]] maybe_apply_chat_template
|
||||
|
||||
## extract_prompt
|
||||
|
||||
[[autodoc]] extract_prompt
|
||||
|
||||
## maybe_extract_prompt
|
||||
|
||||
[[autodoc]] maybe_extract_prompt
|
||||
|
||||
## unpair_preference_dataset
|
||||
|
||||
[[autodoc]] unpair_preference_dataset
|
||||
|
||||
## maybe_unpair_preference_dataset
|
||||
|
||||
[[autodoc]] maybe_unpair_preference_dataset
|
||||
911
docs/source/dataset_formats.mdx
Normal file
911
docs/source/dataset_formats.mdx
Normal file
@ -0,0 +1,911 @@
|
||||
# Dataset formats and types
|
||||
|
||||
This guide provides an overview of the dataset formats and types supported by each trainer in TRL.
|
||||
|
||||
## Overview of the dataset formats and types
|
||||
|
||||
- The *format* of a dataset refers to how the data is structured, typically categorized as either *standard* or *conversational*.
|
||||
- The *type* is associated with the specific task the dataset is designed for, such as *prompt-only* or *preference*. Each type is characterized by its columns, which vary according to the task, as shown in the table.
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<th>Type \ Format</th>
|
||||
<th>Standard</th>
|
||||
<th>Conversational</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Language modeling</td>
|
||||
<td>
|
||||
<pre><code>{"text": "The sky is blue."}</code></pre>
|
||||
</td>
|
||||
<td>
|
||||
<pre><code>{"messages": [{"role": "user", "content": "What color is the sky?"},
|
||||
{"role": "assistant", "content": "It is blue."}]}</code></pre>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Prompt-only</td>
|
||||
<td>
|
||||
<pre><code>{"prompt": "The sky is"}</code></pre>
|
||||
</td>
|
||||
<td>
|
||||
<pre><code>{"prompt": [{"role": "user", "content": "What color is the sky?"}]}</code></pre>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Prompt-completion</td>
|
||||
<td>
|
||||
<pre><code>{"prompt": "The sky is",
|
||||
"completion": " blue."}</code></pre>
|
||||
</td>
|
||||
<td>
|
||||
<pre><code>{"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"completion": [{"role": "assistant", "content": "It is blue."}]}</code></pre>
|
||||
</td>
|
||||
</tr>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Preference</td>
|
||||
<td>
|
||||
<pre><code>{"prompt": "The sky is",
|
||||
"chosen": " blue.",
|
||||
"rejected": " green."}</code></pre>
|
||||
or, with implicit prompt:
|
||||
<pre><code>{"chosen": "The sky is blue.",
|
||||
"rejected": "The sky is green."}</code></pre>
|
||||
</td>
|
||||
<td>
|
||||
<pre><code>{"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"chosen": [{"role": "assistant", "content": "It is blue."}],
|
||||
"rejected": [{"role": "assistant", "content": "It is green."}]}</code></pre>
|
||||
or, with implicit prompt:
|
||||
<pre><code>{"chosen": [{"role": "user", "content": "What color is the sky?"},
|
||||
{"role": "assistant", "content": "It is blue."}],
|
||||
"rejected": [{"role": "user", "content": "What color is the sky?"},
|
||||
{"role": "assistant", "content": "It is green."}]}</code></pre>
|
||||
</td>
|
||||
</tr>
|
||||
<td>Unpaired preference</td>
|
||||
<td>
|
||||
<pre><code>{"prompt": "The sky is",
|
||||
"completion": " blue.",
|
||||
"label": True}</code></pre>
|
||||
</td>
|
||||
<td>
|
||||
<pre><code>{"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"completion": [{"role": "assistant", "content": "It is green."}],
|
||||
"label": False}</code></pre>
|
||||
</td>
|
||||
</tr>
|
||||
</tr>
|
||||
<td>Stepwise supervision</td>
|
||||
<td>
|
||||
<pre><code>{"prompt": "Which number is larger, 9.8 or 9.11?",
|
||||
"completions": ["The fractional part of 9.8 is 0.8.",
|
||||
"The fractional part of 9.11 is 0.11.",
|
||||
"0.11 is greater than 0.8.",
|
||||
"Hence, 9.11 > 9.8."],
|
||||
"labels": [True, True, False, False]}</code></pre>
|
||||
</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
### Formats
|
||||
|
||||
#### Standard
|
||||
|
||||
The standard dataset format typically consists of plain text strings. The columns in the dataset vary depending on the task. This is the format expected by TRL trainers. Below are examples of standard dataset formats for different tasks:
|
||||
|
||||
```python
|
||||
# Language modeling
|
||||
language_modeling_example = {"text": "The sky is blue."}
|
||||
# Preference
|
||||
preference_example = {"prompt": "The sky is", "chosen": " blue.", "rejected": " green."}
|
||||
# Unpaired preference
|
||||
unpaired_preference_example = {"prompt": "The sky is", "completion": " blue.", "label": True}
|
||||
```
|
||||
|
||||
#### Conversational
|
||||
|
||||
Conversational datasets are used for tasks involving dialogues or chat interactions between users and assistants. Unlike standard dataset formats, these contain sequences of messages where each message has a `role` (e.g., `"user"` or `"assistant"`) and `content` (the message text).
|
||||
|
||||
```python
|
||||
messages = [
|
||||
{"role": "user", "content": "Hello, how are you?"},
|
||||
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
|
||||
{"role": "user", "content": "I'd like to show off how chat templating works!"},
|
||||
]
|
||||
```
|
||||
|
||||
Just like standard datasets, the columns in conversational datasets vary depending on the task. Below are examples of conversational dataset formats for different tasks:
|
||||
|
||||
```python
|
||||
# Prompt-completion
|
||||
prompt_completion_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"completion": [{"role": "assistant", "content": "It is blue."}]}
|
||||
# Preference
|
||||
preference_example = {
|
||||
"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"chosen": [{"role": "assistant", "content": "It is blue."}],
|
||||
"rejected": [{"role": "assistant", "content": "It is green."}],
|
||||
}
|
||||
```
|
||||
|
||||
Conversational datasets are useful for training chat models, but must be converted into a standard format before being used with TRL trainers. This is typically done using chat templates specific to the model being used. For more information, refer to the [Working with conversational datasets in TRL](#working-with-conversational-datasets-in-trl) section.
|
||||
|
||||
### Types
|
||||
|
||||
#### Language modeling
|
||||
|
||||
A language modeling dataset consists of a column `"text"` (or `"messages"` for conversational datasets) containing a full sequence of text.
|
||||
|
||||
```python
|
||||
# Standard format
|
||||
language_modeling_example = {"text": "The sky is blue."}
|
||||
# Conversational format
|
||||
language_modeling_example = {"messages": [
|
||||
{"role": "user", "content": "What color is the sky?"},
|
||||
{"role": "assistant", "content": "It is blue."}
|
||||
]}
|
||||
```
|
||||
|
||||
#### Prompt-only
|
||||
|
||||
In a prompt-only dataset, only the initial prompt (the question or partial sentence) is provided under the key `"prompt"`. The training typically involves generating the completion based on this prompt, where the model learns to continue or complete the given input.
|
||||
|
||||
```python
|
||||
# Standard format
|
||||
prompt_only_example = {"prompt": "The sky is"}
|
||||
# Conversational format
|
||||
prompt_only_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}]}
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
While both the prompt-only and language modeling types are similar, they differ in how the input is handled. In the prompt-only type, the prompt represents a partial input that expects the model to complete or continue, while in the language modeling type, the input is treated as a complete sentence or sequence. These two types are processed differently by TRL. Below is an example showing the difference in the output of the `apply_chat_template` function for each type:
|
||||
|
||||
```python
|
||||
from transformers import AutoTokenizer
|
||||
from trl import apply_chat_template
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-128k-instruct")
|
||||
|
||||
# Example for prompt-only type
|
||||
prompt_only_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}]}
|
||||
apply_chat_template(prompt_only_example, tokenizer)
|
||||
# Output: {'prompt': '<|user|>\nWhat color is the sky?<|end|>\n<|assistant|>\n'}
|
||||
|
||||
# Example for language modeling type
|
||||
lm_example = {"messages": [{"role": "user", "content": "What color is the sky?"}]}
|
||||
apply_chat_template(lm_example, tokenizer)
|
||||
# Output: {'text': '<|user|>\nWhat color is the sky?<|end|>\n<|endoftext|>'}
|
||||
```
|
||||
|
||||
- The prompt-only output includes a `'<|assistant|>\n'`, indicating the beginning of the assistant’s turn and expecting the model to generate a completion.
|
||||
- In contrast, the language modeling output treats the input as a complete sequence and terminates it with `'<|endoftext|>'`, signaling the end of the text and not expecting any additional content.
|
||||
|
||||
</Tip>
|
||||
|
||||
#### Prompt-completion
|
||||
|
||||
A prompt-completion dataset includes a `"prompt"` and a `"completion"`.
|
||||
|
||||
```python
|
||||
# Standard format
|
||||
prompt_completion_example = {"prompt": "The sky is", "completion": " blue."}
|
||||
# Conversational format
|
||||
prompt_completion_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"completion": [{"role": "assistant", "content": "It is blue."}]}
|
||||
```
|
||||
|
||||
#### Preference
|
||||
|
||||
A preference dataset is used for tasks where the model is trained to choose between two or more possible completions to the same prompt. This dataset includes a `"prompt"`, a `"chosen"` completion, and a `"rejected"` completion. The model is trained to select the `"chosen"` response over the `"rejected"` response.
|
||||
Some dataset may not include the `"prompt"` column, in which case the prompt is implicit and directly included in the `"chosen"` and `"rejected"` completions. We recommend using explicit prompts whenever possible.
|
||||
|
||||
```python
|
||||
# Standard format
|
||||
## Explicit prompt (recommended)
|
||||
preference_example = {"prompt": "The sky is", "chosen": " blue.", "rejected": " green."}
|
||||
# Implicit prompt
|
||||
preference_example = {"chosen": "The sky is blue.", "rejected": "The sky is green."}
|
||||
|
||||
# Conversational format
|
||||
## Explicit prompt (recommended)
|
||||
preference_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"chosen": [{"role": "assistant", "content": "It is blue."}],
|
||||
"rejected": [{"role": "assistant", "content": "It is green."}]}
|
||||
## Implicit prompt
|
||||
preference_example = {"chosen": [{"role": "user", "content": "What color is the sky?"},
|
||||
{"role": "assistant", "content": "It is blue."}],
|
||||
"rejected": [{"role": "user", "content": "What color is the sky?"},
|
||||
{"role": "assistant", "content": "It is green."}]}
|
||||
```
|
||||
|
||||
Some preference datasets can be found with [the tag `dpo` on Hugging Face Hub](https://huggingface.co/datasets?other=dpo). You can also explore the [librarian-bots' DPO Collections](https://huggingface.co/collections/librarian-bots/direct-preference-optimization-datasets-66964b12835f46289b6ef2fc) to identify preference datasets.
|
||||
|
||||
#### Unpaired preference
|
||||
|
||||
An unpaired preference dataset is similar to a preference dataset but instead of having `"chosen"` and `"rejected"` completions for the same prompt, it includes a single `"completion"` and a `"label"` indicating whether the completion is preferred or not.
|
||||
|
||||
```python
|
||||
# Standard format
|
||||
unpaired_preference_example = {"prompt": "The sky is", "completion": " blue.", "label": True}
|
||||
# Conversational format
|
||||
unpaired_preference_example = {"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"completion": [{"role": "assistant", "content": "It is blue."}],
|
||||
"label": True}
|
||||
```
|
||||
|
||||
#### Stepwise supervision
|
||||
|
||||
A stepwise (or process) supervision dataset is similar to an [unpaired preference](#unpaired-preference) dataset but includes multiple steps of completions, each with its own label. This structure is useful for tasks that need detailed, step-by-step labeling, such as reasoning tasks. By evaluating each step separately and providing targeted labels, this approach helps identify precisely where the reasoning is correct and where errors occur, allowing for targeted feedback on each part of the reasoning process.
|
||||
|
||||
```python
|
||||
stepwise_example = {
|
||||
"prompt": "Which number is larger, 9.8 or 9.11?",
|
||||
"completions": ["The fractional part of 9.8 is 0.8, while the fractional part of 9.11 is 0.11.", "Since 0.11 is greater than 0.8, the number 9.11 is larger than 9.8."],
|
||||
"labels": [True, False]
|
||||
}
|
||||
```
|
||||
|
||||
## Which dataset type to use?
|
||||
|
||||
Choosing the right dataset type depends on the task you are working on and the specific requirements of the TRL trainer you are using. Below is a brief overview of the dataset types supported by each TRL trainer.
|
||||
|
||||
| Trainer | Expected dataset type |
|
||||
| ----------------------- | ------------------------------------------------------------------------------------------------------ |
|
||||
| [`BCOTrainer`] | [Unpaired preference](#unpaired-preference) |
|
||||
| [`CPOTrainer`] | [Preference (explicit prompt recommended)](#preference) |
|
||||
| [`DPOTrainer`] | [Preference (explicit prompt recommended)](#preference) |
|
||||
| [`GKDTrainer`] | [Prompt-completion](#prompt-completion) |
|
||||
| [`IterativeSFTTrainer`] | [Unpaired preference](#unpaired-preference) |
|
||||
| [`KTOTrainer`] | [Unpaired preference](#unpaired-preference) or [Preference (explicit prompt recommended)](#preference) |
|
||||
| [`NashMDTrainer`] | [Prompt-only](#prompt-only) |
|
||||
| [`OnlineDPOTrainer`] | [Prompt-only](#prompt-only) |
|
||||
| [`ORPOTrainer`] | [Preference (explicit prompt recommended)](#preference) |
|
||||
| [`PPOTrainer`] | Tokenized language modeling |
|
||||
| [`PRMTrainer`] | [Stepwise supervision](#stepwise-supervision) |
|
||||
| [`RewardTrainer`] | [Preference (implicit prompt recommended)](#preference) |
|
||||
| [`SFTTrainer`] | [Language modeling](#language-modeling) |
|
||||
| [`XPOTrainer`] | [Prompt-only](#prompt-only) |
|
||||
|
||||
<Tip>
|
||||
|
||||
TRL trainers only support standard dataset formats, [for now](https://github.com/huggingface/trl/issues/2071). If you have a conversational dataset, you must first convert it into a standard format.
|
||||
For more information on how to work with conversational datasets, refer to the [Working with conversational datasets in TRL](#working-with-conversational-datasets-in-trl) section.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Working with conversational datasets in TRL
|
||||
|
||||
Conversational datasets are increasingly common, especially for training chat models. However, some TRL trainers don't support conversational datasets in their raw format. (For more information, see [issue #2071](https://github.com/huggingface/trl/issues/2071).) These datasets must first be converted into a standard format.
|
||||
Fortunately, TRL offers tools to easily handle this conversion, which are detailed below.
|
||||
|
||||
### Converting a conversational dataset into a standard dataset
|
||||
|
||||
To convert a conversational dataset into a standard dataset, you need to _apply a chat template_ to the dataset. A chat template is a predefined structure that typically includes placeholders for user and assistant messages. This template is provided by the tokenizer of the model you use.
|
||||
|
||||
For detailed instructions on using chat templating, refer to the [Chat templating section in the `transformers` documentation](https://huggingface.co/docs/transformers/en/chat_templating).
|
||||
|
||||
In TRL, the method you apply to convert the dataset will vary depending on the task. Fortunately, TRL provides a helper function called [`apply_chat_template`] to simplify this process. Here's an example of how to use it:
|
||||
|
||||
```python
|
||||
from transformers import AutoTokenizer
|
||||
from trl import apply_chat_template
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-128k-instruct")
|
||||
|
||||
example = {
|
||||
"prompt": [{"role": "user", "content": "What color is the sky?"}],
|
||||
"completion": [{"role": "assistant", "content": "It is blue."}]
|
||||
}
|
||||
|
||||
apply_chat_template(example, tokenizer)
|
||||
# Output:
|
||||
# {'prompt': '<|user|>\nWhat color is the sky?<|end|>\n<|assistant|>\n', 'completion': 'It is blue.<|end|>\n<|endoftext|>'}
|
||||
```
|
||||
|
||||
Alternatively, you can use the [`~datasets.Dataset.map`] method to apply the template across an entire dataset:
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
from trl import apply_chat_template
|
||||
|
||||
dataset_dict = {
|
||||
"prompt": [[{"role": "user", "content": "What color is the sky?"}],
|
||||
[{"role": "user", "content": "Where is the sun?"}]],
|
||||
"completion": [[{"role": "assistant", "content": "It is blue."}],
|
||||
[{"role": "assistant", "content": "In the sky."}]]
|
||||
}
|
||||
|
||||
dataset = Dataset.from_dict(dataset_dict)
|
||||
dataset = dataset.map(apply_chat_template, fn_kwargs={"tokenizer": tokenizer})
|
||||
# Output:
|
||||
# {'prompt': ['<|user|>\nWhat color is the sky?<|end|>\n<|assistant|>\n',
|
||||
# '<|user|>\nWhere is the sun?<|end|>\n<|assistant|>\n'],
|
||||
# 'completion': ['It is blue.<|end|>\n<|endoftext|>', 'In the sky.<|end|>\n<|endoftext|>']}
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
We recommend using the [`apply_chat_template`] function instead of calling `tokenizer.apply_chat_template` directly. Handling chat templates for non-language modeling datasets can be tricky and may result in errors, such as mistakenly placing a system prompt in the middle conversation.
|
||||
For additional examples, see [#1930 (comment)](https://github.com/huggingface/trl/pull/1930#issuecomment-2292908614). The [`apply_chat_template`] is designed to handle these intricacies and ensure the correct application of chat templates for various tasks.
|
||||
|
||||
</Tip>
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
It's important to note that chat templates are model-specific. For example, if you use the chat template from [meta-llama/Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct) with the above example, you get a different output:
|
||||
|
||||
```python
|
||||
apply_chat_template(example, AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3.1-8B-Instruct"))
|
||||
# Output:
|
||||
# {'prompt': '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nWhat color is the sky?<|im_end|>\n<|im_start|>assistant\n',
|
||||
# 'completion': 'It is blue.<|im_end|>\n'}
|
||||
```
|
||||
|
||||
Always use the chat template associated with the model you're working with. Using the wrong template can lead to inaccurate or unexpected results.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Using any dataset with TRL: preprocessing and conversion
|
||||
|
||||
Many datasets come in formats tailored to specific tasks, which might not be directly compatible with TRL. To use such datasets with TRL, you may need to preprocess and convert them into the required format.
|
||||
|
||||
To make this easier, we provide a set of [example scripts](https://github.com/huggingface/trl/tree/main/examples/datasets) that cover common dataset conversions.
|
||||
|
||||
### Example: UltraFeedback dataset
|
||||
|
||||
Let’s take the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback) as an example. Here's a preview of the dataset:
|
||||
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/openbmb/UltraFeedback/embed/viewer/default/train"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
As shown above, the dataset format does not match the expected structure. It’s not in a conversational format, the column names differ, and the results pertain to different models (e.g., Bard, GPT-4) and aspects (e.g., "helpfulness", "honesty").
|
||||
|
||||
By using the provided conversion script [`examples/datasets/ultrafeedback.py`](https://github.com/huggingface/trl/tree/main/examples/datasets/ultrafeedback.py), you can transform this dataset into an unpaired preference type, and push it to the Hub:
|
||||
|
||||
```sh
|
||||
python examples/datasets/ultrafeedback.py --push_to_hub --repo_id trl-lib/ultrafeedback-gpt-3.5-turbo-helpfulness
|
||||
```
|
||||
|
||||
Once converted, the dataset will look like this:
|
||||
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/ultrafeedback-gpt-3.5-turbo-helpfulness/embed/viewer/default/train?row=0"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
Now, you can use this dataset with TRL!
|
||||
|
||||
By adapting the provided scripts or creating your own, you can convert any dataset into a format compatible with TRL.
|
||||
|
||||
## Utilities for converting dataset types
|
||||
|
||||
This section provides example code to help you convert between different dataset types. While some conversions can be performed after applying the chat template (i.e., in the standard format), we recommend performing the conversion before applying the chat template to ensure it works consistently.
|
||||
|
||||
For simplicity, some of the examples below do not follow this recommendation and use the standard format. However, the conversions can be applied directly to the conversational format without modification.
|
||||
|
||||
| From \ To | Language modeling | Prompt-completion | Prompt-only | Preference with implicit prompt | Preference | Unpaired preference | Stepwise supervision |
|
||||
| ------------------------------- | ----------------------------------------------------------------------- | ----------------------------------------------------------------------- | ----------------------------------------------------------------- | --------------------------------------------------------- | --------------------------------------------------------- | ------------------------------------------------------------------------- | -------------------- |
|
||||
| Language modeling | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
|
||||
| Prompt-completion | [🔗](#from-prompt-completion-to-language-modeling-dataset) | N/A | [🔗](#from-prompt-completion-to-prompt-only-dataset) | N/A | N/A | N/A | N/A |
|
||||
| Prompt-only | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
|
||||
| Preference with implicit prompt | [🔗](#from-preference-with-implicit-prompt-to-language-modeling-dataset) | [🔗](#from-preference-with-implicit-prompt-to-prompt-completion-dataset) | [🔗](#from-preference-with-implicit-prompt-to-prompt-only-dataset) | N/A | [🔗](#from-implicit-to-explicit-prompt-preference-dataset) | [🔗](#from-preference-with-implicit-prompt-to-unpaired-preference-dataset) | N/A |
|
||||
| Preference | [🔗](#from-preference-to-language-modeling-dataset) | [🔗](#from-preference-to-prompt-completion-dataset) | [🔗](#from-preference-to-prompt-only-dataset) | [🔗](#from-explicit-to-implicit-prompt-preference-dataset) | N/A | [🔗](#from-preference-to-unpaired-preference-dataset) | N/A |
|
||||
| Unpaired preference | [🔗](#from-unpaired-preference-to-language-modeling-dataset) | [🔗](#from-unpaired-preference-to-prompt-completion-dataset) | [🔗](#from-unpaired-preference-to-prompt-only-dataset) | N/A | N/A | N/A | N/A |
|
||||
| Stepwise supervision | [🔗](#from-stepwise-supervision-to-language-modeling-dataset) | [🔗](#from-stepwise-supervision-to-prompt-completion-dataset) | [🔗](#from-stepwise-supervision-to-prompt-only-dataset) | N/A | N/A | [🔗](#from-stepwise-supervision-to-unpaired-preference-dataset) | N/A |
|
||||
|
||||
### From prompt-completion to language modeling dataset
|
||||
|
||||
To convert a prompt-completion dataset into a language modeling dataset, concatenate the prompt and the completion.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["The sky is", "The sun is"],
|
||||
"completion": [" blue.", " in the sky."],
|
||||
})
|
||||
|
||||
def concat_prompt_completion(example):
|
||||
return {"text": example["prompt"] + example["completion"]}
|
||||
|
||||
dataset = dataset.map(concat_prompt_completion, remove_columns=["prompt", "completion"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'text': 'The sky is blue.'}
|
||||
```
|
||||
|
||||
### From prompt-completion to prompt-only dataset
|
||||
|
||||
To convert a prompt-completion dataset into a prompt-only dataset, remove the completion.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["The sky is", "The sun is"],
|
||||
"completion": [" blue.", " in the sky."],
|
||||
})
|
||||
|
||||
dataset = dataset.remove_columns("completion")
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': 'The sky is'}
|
||||
```
|
||||
|
||||
### From preference with implicit prompt to language modeling dataset
|
||||
|
||||
To convert a preference with implicit prompt dataset into a language modeling dataset, remove the rejected, and rename the column `"chosen"` to `"text"`.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"chosen": ["The sky is blue.", "The sun is in the sky."],
|
||||
"rejected": ["The sky is green.", "The sun is in the sea."],
|
||||
})
|
||||
|
||||
dataset = dataset.rename_column("chosen", "text").remove_columns("rejected")
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'text': 'The sky is blue.'}
|
||||
```
|
||||
|
||||
### From preference with implicit prompt to prompt-completion dataset
|
||||
|
||||
To convert a preference dataset with implicit prompt into a prompt-completion dataset, extract the prompt with [`extract_prompt`], remove the rejected, and rename the column `"chosen"` to `"completion"`.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
from trl import extract_prompt
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"chosen": [
|
||||
[{"role": "user", "content": "What color is the sky?"}, {"role": "assistant", "content": "It is blue."}],
|
||||
[{"role": "user", "content": "Where is the sun?"}, {"role": "assistant", "content": "In the sky."}],
|
||||
],
|
||||
"rejected": [
|
||||
[{"role": "user", "content": "What color is the sky?"}, {"role": "assistant", "content": "It is green."}],
|
||||
[{"role": "user", "content": "Where is the sun?"}, {"role": "assistant", "content": "In the sea."}],
|
||||
],
|
||||
})
|
||||
dataset = dataset.map(extract_prompt).remove_columns("rejected").rename_column("chosen", "completion")
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': [{'role': 'user', 'content': 'What color is the sky?'}], 'completion': [{'role': 'assistant', 'content': 'It is blue.'}]}
|
||||
```
|
||||
|
||||
### From preference with implicit prompt to prompt-only dataset
|
||||
|
||||
To convert a preference dataset with implicit prompt into a prompt-only dataset, extract the prompt with [`extract_prompt`], and remove the rejected and the chosen.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
from trl import extract_prompt
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"chosen": [
|
||||
[{"role": "user", "content": "What color is the sky?"}, {"role": "assistant", "content": "It is blue."}],
|
||||
[{"role": "user", "content": "Where is the sun?"}, {"role": "assistant", "content": "In the sky."}],
|
||||
],
|
||||
"rejected": [
|
||||
[{"role": "user", "content": "What color is the sky?"}, {"role": "assistant", "content": "It is green."}],
|
||||
[{"role": "user", "content": "Where is the sun?"}, {"role": "assistant", "content": "In the sea."}],
|
||||
],
|
||||
})
|
||||
dataset = dataset.map(extract_prompt).remove_columns(["chosen", "rejected"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': [{'role': 'user', 'content': 'What color is the sky?'}]}
|
||||
```
|
||||
|
||||
### From implicit to explicit prompt preference dataset
|
||||
|
||||
To convert a preference dataset with implicit prompt into a preference dataset with explicit prompt, extract the prompt with [`extract_prompt`].
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
from trl import extract_prompt
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"chosen": [
|
||||
[{"role": "user", "content": "What color is the sky?"}, {"role": "assistant", "content": "It is blue."}],
|
||||
[{"role": "user", "content": "Where is the sun?"}, {"role": "assistant", "content": "In the sky."}],
|
||||
],
|
||||
"rejected": [
|
||||
[{"role": "user", "content": "What color is the sky?"}, {"role": "assistant", "content": "It is green."}],
|
||||
[{"role": "user", "content": "Where is the sun?"}, {"role": "assistant", "content": "In the sea."}],
|
||||
],
|
||||
})
|
||||
|
||||
dataset = dataset.map(extract_prompt)
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': [{'role': 'user', 'content': 'What color is the sky?'}],
|
||||
'chosen': [{'role': 'assistant', 'content': 'It is blue.'}],
|
||||
'rejected': [{'role': 'assistant', 'content': 'It is green.'}]}
|
||||
```
|
||||
|
||||
### From preference with implicit prompt to unpaired preference dataset
|
||||
|
||||
To convert a preference dataset with implicit prompt into an unpaired preference dataset, extract the prompt with [`extract_prompt`], and unpair the dataset with [`unpair_preference_dataset`].
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
from trl import extract_prompt, unpair_preference_dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"chosen": [
|
||||
[{"role": "user", "content": "What color is the sky?"}, {"role": "assistant", "content": "It is blue."}],
|
||||
[{"role": "user", "content": "Where is the sun?"}, {"role": "assistant", "content": "In the sky."}],
|
||||
],
|
||||
"rejected": [
|
||||
[{"role": "user", "content": "What color is the sky?"}, {"role": "assistant", "content": "It is green."}],
|
||||
[{"role": "user", "content": "Where is the sun?"}, {"role": "assistant", "content": "In the sea."}],
|
||||
],
|
||||
})
|
||||
|
||||
dataset = dataset.map(extract_prompt)
|
||||
dataset = unpair_preference_dataset(dataset)
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': [{'role': 'user', 'content': 'What color is the sky?'}],
|
||||
'completion': [{'role': 'assistant', 'content': 'It is blue.'}],
|
||||
'label': True}
|
||||
```
|
||||
|
||||
### From preference to language modeling dataset
|
||||
|
||||
To convert a preference dataset into a language modeling dataset, remove the rejected, concatenate the prompt and the chosen into the `"text"` column.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["The sky is", "The sun is"],
|
||||
"chosen": [" blue.", " in the sky."],
|
||||
"rejected": [" green.", " in the sea."],
|
||||
})
|
||||
|
||||
def concat_prompt_chosen(example):
|
||||
return {"text": example["prompt"] + example["chosen"]}
|
||||
|
||||
dataset = dataset.map(concat_prompt_chosen, remove_columns=["prompt", "chosen", "rejected"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'text': 'The sky is blue.'}
|
||||
```
|
||||
|
||||
### From preference to prompt-completion dataset
|
||||
|
||||
To convert a preference dataset into a prompt-completion dataset, remove the rejected, and rename the column `"chosen"` to `"completion"`.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["The sky is", "The sun is"],
|
||||
"chosen": [" blue.", " in the sky."],
|
||||
"rejected": [" green.", " in the sea."],
|
||||
})
|
||||
|
||||
dataset = dataset.remove_columns("rejected").rename_column("chosen", "completion")
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': 'The sky is', 'completion': ' blue.'}
|
||||
```
|
||||
|
||||
### From preference to prompt-only dataset
|
||||
|
||||
To convert a preference dataset into a prompt-only dataset, remove the rejected and the chosen.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["The sky is", "The sun is"],
|
||||
"chosen": [" blue.", " in the sky."],
|
||||
"rejected": [" green.", " in the sea."],
|
||||
})
|
||||
|
||||
dataset = dataset.remove_columns(["chosen", "rejected"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': 'The sky is'}
|
||||
```
|
||||
|
||||
### From explicit to implicit prompt preference dataset
|
||||
|
||||
To convert a preference dataset with explicit prompt into a preference dataset with implicit prompt, concatenate the prompt to both chosen and rejected, and remove the prompt.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": [
|
||||
[{"role": "user", "content": "What color is the sky?"}],
|
||||
[{"role": "user", "content": "Where is the sun?"}],
|
||||
],
|
||||
"chosen": [
|
||||
[{"role": "assistant", "content": "It is blue."}],
|
||||
[{"role": "assistant", "content": "In the sky."}],
|
||||
],
|
||||
"rejected": [
|
||||
[{"role": "assistant", "content": "It is green."}],
|
||||
[{"role": "assistant", "content": "In the sea."}],
|
||||
],
|
||||
})
|
||||
|
||||
def concat_prompt_to_completions(example):
|
||||
return {"chosen": example["prompt"] + example["chosen"], "rejected": example["prompt"] + example["rejected"]}
|
||||
|
||||
dataset = dataset.map(concat_prompt_to_completions, remove_columns="prompt")
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'chosen': [{'role': 'user', 'content': 'What color is the sky?'}, {'role': 'assistant', 'content': 'It is blue.'}],
|
||||
'rejected': [{'role': 'user', 'content': 'What color is the sky?'}, {'role': 'assistant', 'content': 'It is green.'}]}
|
||||
```
|
||||
|
||||
### From preference to unpaired preference dataset
|
||||
|
||||
To convert dataset into an unpaired preference dataset, unpair the dataset with [`unpair_preference_dataset`].
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
from trl import unpair_preference_dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": [
|
||||
[{"role": "user", "content": "What color is the sky?"}],
|
||||
[{"role": "user", "content": "Where is the sun?"}],
|
||||
],
|
||||
"chosen": [
|
||||
[{"role": "assistant", "content": "It is blue."}],
|
||||
[{"role": "assistant", "content": "In the sky."}],
|
||||
],
|
||||
"rejected": [
|
||||
[{"role": "assistant", "content": "It is green."}],
|
||||
[{"role": "assistant", "content": "In the sea."}],
|
||||
],
|
||||
})
|
||||
|
||||
dataset = unpair_preference_dataset(dataset)
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': [{'role': 'user', 'content': 'What color is the sky?'}],
|
||||
'completion': [{'role': 'assistant', 'content': 'It is blue.'}],
|
||||
'label': True}
|
||||
```
|
||||
|
||||
### From unpaired preference to language modeling dataset
|
||||
|
||||
To convert an unpaired preference dataset into a language modeling dataset, concatenate the prompt and the completion into the `"text"` column, and remove the prompt, completion and label columns.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["The sky is", "The sun is", "The sky is", "The sun is"],
|
||||
"completion": [" blue.", " in the sky.", " green.", " in the sea."],
|
||||
"label": [True, True, False, False],
|
||||
})
|
||||
|
||||
def concatenate_prompt_completion(example):
|
||||
return {"text": example["prompt"] + example["completion"]}
|
||||
|
||||
dataset = dataset.map(concatenate_prompt_completion).remove_columns(["prompt", "completion", "label"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'text': 'The sky is blue.'}
|
||||
```
|
||||
|
||||
### From unpaired preference to prompt-completion dataset
|
||||
|
||||
To convert an unpaired preference dataset into a prompt-completion dataset, remove the label columns.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["The sky is", "The sun is", "The sky is", "The sun is"],
|
||||
"completion": [" blue.", " in the sky.", " green.", " in the sea."],
|
||||
"label": [True, True, False, False],
|
||||
})
|
||||
|
||||
dataset = dataset.remove_columns(["label"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': 'The sky is', 'completion': ' blue.'}
|
||||
```
|
||||
|
||||
### From unpaired preference to prompt-only dataset
|
||||
|
||||
To convert an unpaired preference dataset into a prompt-only dataset, remove the completion and the label columns.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["The sky is", "The sun is", "The sky is", "The sun is"],
|
||||
"completion": [" blue.", " in the sky.", " green.", " in the sea."],
|
||||
"label": [True, True, False, False],
|
||||
})
|
||||
|
||||
dataset = dataset.remove_columns(["completion", "label"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': 'The sky is'}
|
||||
```
|
||||
|
||||
### From stepwise supervision to language modeling dataset
|
||||
|
||||
To convert a stepwise supervision dataset into a language modeling dataset, concatenate the prompt and the completions into the `"text"` column.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["Blue light", "Water"],
|
||||
"completions": [[" scatters more in the atmosphere,", " so the sky is green."],
|
||||
[" forms a less dense structure in ice,", " which causes it to expand when it freezes."]],
|
||||
"labels": [[True, False], [True, True]],
|
||||
})
|
||||
|
||||
def concatenate_prompt_completions(example):
|
||||
completion = "".join(example["completions"])
|
||||
return {"text": example["prompt"] + completion}
|
||||
|
||||
dataset = dataset.map(concatenate_prompt_completions, remove_columns=["prompt", "completions", "labels"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'text': 'Blue light scatters more in the atmosphere, so the sky is green.'}
|
||||
```
|
||||
|
||||
### From stepwise supervision to prompt completion dataset
|
||||
|
||||
To convert a stepwise supervision dataset into a prompt-completion dataset, join the completions and remove the labels.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["Blue light", "Water"],
|
||||
"completions": [[" scatters more in the atmosphere,", " so the sky is green."],
|
||||
[" forms a less dense structure in ice,", " which causes it to expand when it freezes."]],
|
||||
"labels": [[True, False], [True, True]],
|
||||
})
|
||||
|
||||
def join_completions(example):
|
||||
completion = "".join(example["completions"])
|
||||
return {"completion": completion}
|
||||
|
||||
dataset = dataset.map(join_completions, remove_columns=["completions", "labels"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': 'Blue light', 'completion': ' scatters more in the atmosphere, so the sky is green.'}
|
||||
```
|
||||
|
||||
### From stepwise supervision to prompt only dataset
|
||||
|
||||
To convert a stepwise supervision dataset into a prompt-only dataset, remove the completions and the labels.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["Blue light", "Water"],
|
||||
"completions": [[" scatters more in the atmosphere,", " so the sky is green."],
|
||||
[" forms a less dense structure in ice,", " which causes it to expand when it freezes."]],
|
||||
"labels": [[True, False], [True, True]],
|
||||
})
|
||||
|
||||
dataset = dataset.remove_columns(["completions", "labels"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': 'Blue light'}
|
||||
```
|
||||
|
||||
### From stepwise supervision to unpaired preference dataset
|
||||
|
||||
To convert a stepwise supervision dataset into an unpaired preference dataset, join the completions and merge the labels.
|
||||
|
||||
The method for merging the labels depends on the specific task. In this example, we use the logical AND operation. This means that if the step labels indicate the correctness of individual steps, the resulting label will reflect the correctness of the entire sequence.
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
|
||||
dataset = Dataset.from_dict({
|
||||
"prompt": ["Blue light", "Water"],
|
||||
"completions": [[" scatters more in the atmosphere,", " so the sky is green."],
|
||||
[" forms a less dense structure in ice,", " which causes it to expand when it freezes."]],
|
||||
"labels": [[True, False], [True, True]],
|
||||
})
|
||||
|
||||
def merge_completions_and_labels(example):
|
||||
return {"prompt": example["prompt"], "completion": "".join(example["completions"]), "label": all(example["labels"])}
|
||||
|
||||
dataset = dataset.map(merge_completions_and_labels, remove_columns=["completions", "labels"])
|
||||
```
|
||||
|
||||
```python
|
||||
>>> dataset[0]
|
||||
{'prompt': 'Blue light', 'completion': ' scatters more in the atmosphere, so the sky is green.', 'label': False}
|
||||
```
|
||||
|
||||
## Vision datasets
|
||||
|
||||
Some trainers also support fine-tuning vision-language models (VLMs) using image-text pairs. In this scenario, it's recommended to use a conversational format, as each model handles image placeholders in text differently.
|
||||
|
||||
A conversational vision dataset differs from a standard conversational dataset in two key ways:
|
||||
|
||||
1. The dataset must contain the key `images` with the image data.
|
||||
2. The `"content"` field in messages must be a list of dictionaries, where each dictionary specifies the type of data: `"image"` or `"text"`.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
# Textual dataset:
|
||||
"content": "What color is the sky?"
|
||||
|
||||
# Vision dataset:
|
||||
"content": [
|
||||
{"type": "image"},
|
||||
{"type": "text", "text": "What color is the sky in the image?"}
|
||||
]
|
||||
```
|
||||
|
||||
An example of a conversational vision dataset is the [openbmb/RLAIF-V-Dataset](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset). Below is an embedded view of the dataset's training data, allowing you to explore it directly:
|
||||
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/rlaif-v/embed/viewer/default/train"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
@ -1,4 +1,7 @@
|
||||
# Denoising Diffusion Policy Optimization
|
||||
|
||||
[](https://huggingface.co/models?other=ddpo,trl)
|
||||
|
||||
## The why
|
||||
|
||||
| Before | After DDPO finetuning |
|
||||
@ -116,4 +119,13 @@ for prompt, image in zip(prompts,results.images):
|
||||
## Credits
|
||||
|
||||
This work is heavily influenced by the repo [here](https://github.com/kvablack/ddpo-pytorch) and the associated paper [Training Diffusion Models
|
||||
with Reinforcement Learning by Kevin Black, Michael Janner, Yilan Du, Ilya Kostrikov, Sergey Levine](https://huggingface.co/papers/2305.13301).
|
||||
with Reinforcement Learning by Kevin Black, Michael Janner, Yilan Du, Ilya Kostrikov, Sergey Levine](https://huggingface.co/papers/2305.13301).
|
||||
|
||||
## DDPOTrainer
|
||||
|
||||
[[autodoc]] DDPOTrainer
|
||||
|
||||
## DDPOConfig
|
||||
|
||||
[[autodoc]] DDPOConfig
|
||||
|
||||
|
||||
@ -58,13 +58,13 @@ And its `continuation` value:
|
||||
|
||||
We want to increase the chance for the model to generate toxic prompts so we get more learning signal. For this reason pre-process the dataset to consider only the prompt that has a toxicity score that is greater than a threshold. We can do this in a few lines of code:
|
||||
```python
|
||||
ds = load_dataset("allenai/real-toxicity-prompts", split="train")
|
||||
train_dataset = load_dataset("allenai/real-toxicity-prompts", split="train")
|
||||
|
||||
def filter_fn(sample):
|
||||
toxicity = sample["prompt"]["toxicity"]
|
||||
return toxicity is not None and toxicity > 0.3
|
||||
|
||||
ds = ds.filter(filter_fn, batched=False)
|
||||
train_dataset = train_dataset.filter(filter_fn, batched=False)
|
||||
```
|
||||
|
||||
### Reward function
|
||||
@ -98,19 +98,15 @@ model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", torch_dtype=
|
||||
|
||||
and the optimizer will take care of computing the gradients in `bfloat16` precision. Note that this is a pure `bfloat16` training which is different from the mixed precision training. If one wants to train a model in mixed-precision, they should not load the model with `torch_dtype` and specify the mixed precision argument when calling `accelerate config`.
|
||||
|
||||
- Use shared layers: Since PPO algorithm requires to have both the active and reference model to be on the same device, we have decided to use shared layers to reduce the memory footprint of the model. This can be achieved by just speifying `num_shared_layers` argument when creating a `PPOTrainer`:
|
||||
- Use shared layers: Since PPO algorithm requires to have both the active and reference model to be on the same device, we have decided to use shared layers to reduce the memory footprint of the model. This can be achieved by specifying `num_shared_layers` argument when calling the `create_reference_model()` function. For example, if you want to share the first 6 layers of the model, you can do it like this:
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl-shared-layers.png">
|
||||
</div>
|
||||
|
||||
```python
|
||||
ppo_trainer = PPOTrainer(
|
||||
model=model,
|
||||
tokenizer=tokenizer,
|
||||
num_shared_layers=4,
|
||||
...
|
||||
)
|
||||
ref_model = create_reference_model(model, num_shared_layers=6)
|
||||
trainer = PPOTrainer(..., ref_model=ref_model)
|
||||
```
|
||||
|
||||
In the example above this means that the model have the 4 first layers frozen (i.e. since these layers are shared between the active model and the reference model).
|
||||
|
||||
@ -1,166 +1,131 @@
|
||||
# DPO Trainer
|
||||
|
||||
TRL supports the DPO Trainer for training language models from preference data, as described in the paper [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290) by Rafailov et al., 2023. For a full example have a look at [`examples/scripts/dpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo.py).
|
||||
[](https://huggingface.co/models?other=dpo,trl) [](https://github.com/huggingface/smol-course/tree/main/2_preference_alignment)
|
||||
|
||||
The first step as always is to train your SFT model, to ensure the data we train on is in-distribution for the DPO algorithm.
|
||||
## Overview
|
||||
|
||||
## How DPO works
|
||||
TRL supports the DPO Trainer for training language models from preference data, as described in the paper [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290) by [Rafael Rafailov](https://huggingface.co/rmrafailov), Archit Sharma, Eric Mitchell, [Stefano Ermon](https://huggingface.co/ermonste), [Christopher D. Manning](https://huggingface.co/manning), [Chelsea Finn](https://huggingface.co/cbfinn).
|
||||
|
||||
Fine-tuning a language model via DPO consists of two steps and is easier than PPO:
|
||||
The abstract from the paper is the following:
|
||||
|
||||
1. **Data collection**: Gather a preference dataset with positive and negative selected pairs of generation, given a prompt.
|
||||
> While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
|
||||
|
||||
The first step is to train an SFT model, to ensure the data we train on is in-distribution for the DPO algorithm.
|
||||
|
||||
Then, fine-tuning a language model via DPO consists of two steps and is easier than [PPO](ppo_trainer):
|
||||
|
||||
1. **Data collection**: Gather a [preference dataset](dataset_formats#preference) with positive and negative selected pairs of generation, given a prompt.
|
||||
2. **Optimization**: Maximize the log-likelihood of the DPO loss directly.
|
||||
|
||||
DPO-compatible datasets can be found with [the tag `dpo` on Hugging Face Hub](https://huggingface.co/datasets?other=dpo). You can also explore the [librarian-bots/direct-preference-optimization-datasets](https://huggingface.co/collections/librarian-bots/direct-preference-optimization-datasets-66964b12835f46289b6ef2fc) Collection to identify datasets that are likely to support DPO training.
|
||||
This process is illustrated in the sketch below (from [Figure 1 of the DPO paper](https://huggingface.co/papers/2305.18290)):
|
||||
|
||||
This process is illustrated in the sketch below (from [figure 1 of the original paper](https://huggingface.co/papers/2305.18290)):
|
||||
|
||||
<img width="835" alt="Screenshot 2024-03-19 at 12 39 41" src="https://github.com/huggingface/trl/assets/49240599/9150fac6-3d88-4ca2-8ec6-2a6f3473216d">
|
||||
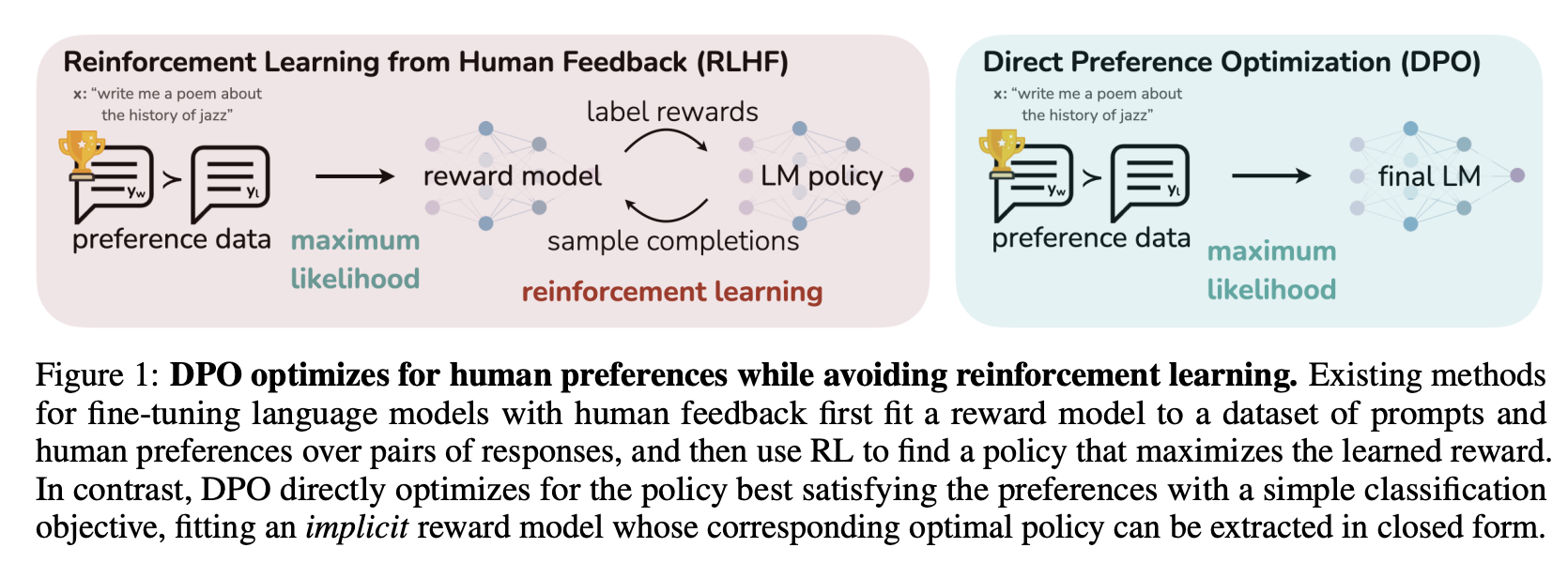
|
||||
|
||||
Read more about DPO algorithm in the [original paper](https://huggingface.co/papers/2305.18290).
|
||||
|
||||
## Quick start
|
||||
|
||||
## Expected dataset format
|
||||
This example demonstrates how to train a model using the DPO method. We use the [Qwen 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) as the base model. We use the preference data from the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback). You can view the data in the dataset here:
|
||||
|
||||
The DPO trainer expects a very specific format for the dataset. Since the model will be trained to directly optimize the preference of which sentence is the most relevant, given two sentences. We provide an example from the [`Anthropic/hh-rlhf`](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset below:
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized/embed/viewer/default/train?row=0"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/rlhf-antropic-example.png", width="50%">
|
||||
</div>
|
||||
Below is the script to train the model:
|
||||
|
||||
Therefore the final dataset object should contain these 3 entries if you use the default [`DPODataCollatorWithPadding`] data collator. The entries should be named:
|
||||
```python
|
||||
# train_dpo.py
|
||||
from datasets import load_dataset
|
||||
from trl import DPOConfig, DPOTrainer
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
- `prompt`
|
||||
- `chosen`
|
||||
- `rejected`
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
train_dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
|
||||
|
||||
for example:
|
||||
|
||||
```py
|
||||
dpo_dataset_dict = {
|
||||
"prompt": [
|
||||
"hello",
|
||||
"how are you",
|
||||
"What is your name?",
|
||||
"What is your name?",
|
||||
"Which is the best programming language?",
|
||||
"Which is the best programming language?",
|
||||
"Which is the best programming language?",
|
||||
],
|
||||
"chosen": [
|
||||
"hi nice to meet you",
|
||||
"I am fine",
|
||||
"My name is Mary",
|
||||
"My name is Mary",
|
||||
"Python",
|
||||
"Python",
|
||||
"Java",
|
||||
],
|
||||
"rejected": [
|
||||
"leave me alone",
|
||||
"I am not fine",
|
||||
"Whats it to you?",
|
||||
"I dont have a name",
|
||||
"Javascript",
|
||||
"C++",
|
||||
"C++",
|
||||
],
|
||||
}
|
||||
training_args = DPOConfig(output_dir="Qwen2-0.5B-DPO", logging_steps=10)
|
||||
trainer = DPOTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
where the `prompt` contains the context inputs, `chosen` contains the corresponding chosen responses and `rejected` contains the corresponding negative (rejected) responses. As can be seen a prompt can have multiple responses and this is reflected in the entries being repeated in the dictionary's value arrays.
|
||||
Execute the script using the following command:
|
||||
|
||||
[`DPOTrainer`] can be used to fine-tune visual language models (VLMs). In this case, the dataset must also contain the key `images`, and the trainer's `tokenizer` is the VLM's `processor`. For example, for Idefics2, the processor expects the dataset to have the following format:
|
||||
|
||||
Note: Currently, VLM support is exclusive to Idefics2 and does not extend to other VLMs.
|
||||
|
||||
```py
|
||||
dpo_dataset_dict = {
|
||||
'images': [
|
||||
[Image.open('beach.jpg')],
|
||||
[Image.open('street.jpg')],
|
||||
],
|
||||
'prompt': [
|
||||
'The image <image> shows',
|
||||
'<image> The image depicts',
|
||||
],
|
||||
'chosen': [
|
||||
'a sunny beach with palm trees.',
|
||||
'a busy street with several cars and buildings.',
|
||||
],
|
||||
'rejected': [
|
||||
'a snowy mountain with skiers.',
|
||||
'a calm countryside with green fields.',
|
||||
],
|
||||
}
|
||||
```bash
|
||||
accelerate launch train_dpo.py
|
||||
```
|
||||
|
||||
## Expected model format
|
||||
Distributed across 8 GPUs, the training takes approximately 3 minutes. You can verify the training progress by checking the reward graph. An increasing trend in the reward margin indicates that the model is improving and generating better responses over time.
|
||||
|
||||
The DPO trainer expects a model of `AutoModelForCausalLM` or `AutoModelForVision2Seq`, compared to PPO that expects `AutoModelForCausalLMWithValueHead` for the value function.
|
||||

|
||||
|
||||
## Using the `DPOTrainer`
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-DPO) performs, you can use the [TRL Chat CLI](clis#chat-interface).
|
||||
|
||||
For a detailed example have a look at the `examples/scripts/dpo.py` script. At a high level we need to initialize the [`DPOTrainer`] with a `model` we wish to train, a reference `ref_model` which we will use to calculate the implicit rewards of the preferred and rejected response, the `beta` refers to the hyperparameter of the implicit reward, and the dataset contains the 3 entries listed above. Note that the `model` and `ref_model` need to have the same architecture (ie decoder only or encoder-decoder).
|
||||
<pre><code>$ trl chat --model_name_or_path trl-lib/Qwen2-0.5B-DPO
|
||||
<strong><span style="color: red;"><quentin_gallouedec>:</span></strong>
|
||||
What is the best programming language?
|
||||
|
||||
```py
|
||||
training_args = DPOConfig(
|
||||
beta=0.1,
|
||||
)
|
||||
dpo_trainer = DPOTrainer(
|
||||
model,
|
||||
ref_model,
|
||||
args=training_args,
|
||||
train_dataset=train_dataset,
|
||||
tokenizer=tokenizer, # for visual language models, use tokenizer=processor instead
|
||||
<strong><span style="color: blue;"><trl-lib/Qwen2-0.5B-DPO>:</span></strong>
|
||||
The best programming language for specific applications can vary depending on the use case and knowledge level of the programmer. Here are some general factors that can be used as input to choose the best programming language:
|
||||
|
||||
<strong><span style="color: green;">1</span></strong> Ease of use: Some programming languages are more user-friendly than others, such as Python, Java, or Ruby. Python is popular due to its simplicity and great scalability.
|
||||
<strong><span style="color: green;">2</span></strong> Versatility: The ability to work with a wide range of data structures and frameworks can define the language as versatile.
|
||||
<strong><span style="color: green;">3</span></strong> Ease of learning: Different programming languages have different learning curves, so users must be willing to take some time to master one.
|
||||
<strong><span style="color: green;">4</span></strong> Community support: The broader community of developers and enthusiasts in the selected programming language can provide great support and resources.
|
||||
<strong><span style="color: green;">5</span></strong> Reusability: Languages that emphasize code reuse and can be easily modifiable can be more suitable for software development.
|
||||
|
||||
The best programming language based on these factors is subjective and depends on what the programmer intends to accomplish.
|
||||
</code></pre>
|
||||
|
||||
## Expected dataset type
|
||||
|
||||
DPO requires a [preference dataset](dataset_formats#preference). The [`DPOTrainer`] supports both [conversational](dataset_formats#conversational) and [standard](dataset_formats#standard) dataset format. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
|
||||
|
||||
Although the [`DPOTrainer`] supports both explicit and implicit prompts, we recommend using explicit prompts. If provided with an implicit prompt dataset, the trainer will automatically extract the prompt from the `"chosen"` and `"rejected"` columns. For more information, refer to the [preference style](dataset_formats#preference) section.
|
||||
|
||||
### Special considerations for vision-language models
|
||||
|
||||
The [`DPOTrainer`] supports fine-tuning vision-language models (VLMs). For these models, a vision dataset is required. To learn more about the specific format for vision datasets, refer to the [Vision dataset format](dataset_formats#vision-datasets) section.
|
||||
|
||||
Additionally, unlike standard text-based models where a `tokenizer` is used, for VLMs, you should replace the `tokenizer` with a `processor`.
|
||||
|
||||
```diff
|
||||
- model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
+ model = AutoModelForVision2Seq.from_pretrained(model_id)
|
||||
|
||||
- tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
+ processor = AutoProcessor.from_pretrained(model_id)
|
||||
|
||||
trainer = DPOTrainer(
|
||||
model,
|
||||
args=training_args,
|
||||
train_dataset=train_dataset,
|
||||
- processing_class=tokenizer,
|
||||
+ processing_class=processor,
|
||||
)
|
||||
```
|
||||
|
||||
After this one can then call:
|
||||
For a complete example of fine-tuning a vision-language model, refer to the script in [`examples/scripts/dpo_vlm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo_vlm.py).
|
||||
|
||||
```py
|
||||
dpo_trainer.train()
|
||||
|
||||
## Example script
|
||||
|
||||
We provide an example script to train a model using the DPO method. The script is available in [`trl/scripts/dpo.py`](https://github.com/huggingface/trl/blob/main/trl/scripts/dpo.py)
|
||||
|
||||
To test the DPO script with the [Qwen2 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) on the [UltraFeedback dataset](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized), run the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch trl/scripts/dpo.py \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
|
||||
--dataset_name trl-lib/ultrafeedback_binarized \
|
||||
--num_train_epochs 1 \
|
||||
--logging_steps 25 \
|
||||
--output_dir Qwen2-0.5B-DPO
|
||||
```
|
||||
|
||||
Note that the `beta` is the temperature parameter for the DPO loss, typically something in the range of `0.1` to `0.5`. We ignore the reference model as `beta` -> 0.
|
||||
|
||||
## Loss functions
|
||||
|
||||
Given the preference data, we can fit a binary classifier according to the Bradley-Terry model and in fact the [DPO](https://huggingface.co/papers/2305.18290) authors propose the sigmoid loss on the normalized likelihood via the `logsigmoid` to fit a logistic regression. To use this loss, set the `loss_type="sigmoid"` (default) in the [`DPOConfig`].
|
||||
|
||||
The [RSO](https://huggingface.co/papers/2309.06657) authors propose to use a hinge loss on the normalized likelihood from the [SLiC](https://huggingface.co/papers/2305.10425) paper. To use this loss, set the `loss_type="hinge"` in the [`DPOConfig`]. In this case, the `beta` is the reciprocal of the margin.
|
||||
|
||||
The [IPO](https://huggingface.co/papers/2310.12036) authors provide a deeper theoretical understanding of the DPO algorithms and identify an issue with overfitting and propose an alternative loss. To use the loss set the `loss_type="ipo"` in the [`DPOConfig`]. In this case, the `beta` is the reciprocal of the gap between the log-likelihood ratios of the chosen vs the rejected completion pair and thus the smaller the `beta` the larger this gaps is. As per the paper the loss is averaged over log-likelihoods of the completion (unlike DPO which is summed only).
|
||||
|
||||
The [cDPO](https://ericmitchell.ai/cdpo.pdf) is a tweak on the DPO loss where we assume that the preference labels are noisy with some probability. In this approach, the `label_smoothing` parameter in the [`DPOConfig`] is used to model the probability of existing label noise. To apply this conservative loss, set `label_smoothing` to a value greater than 0.0 (between 0.0 and 0.5; the default is 0.0).
|
||||
|
||||
The [EXO](https://huggingface.co/papers/2402.00856) authors propose to minimize the reverse KL instead of the negative log-sigmoid loss of DPO which corresponds to forward KL. To use the loss set the `loss_type="exo_pair"` in the [`DPOConfig`]. Setting non-zero `label_smoothing` (default `1e-3`) leads to a simplified version of EXO on pair-wise preferences (see Eqn. (16) of the [EXO paper](https://huggingface.co/papers/2402.00856)). The full version of EXO uses `K>2` completions generated by the SFT policy, which becomes an unbiased estimator of the PPO objective (up to a constant) when `K` is sufficiently large.
|
||||
|
||||
The [NCA](https://huggingface.co/papers/2402.05369) authors shows that NCA optimizes the absolute likelihood for each response rather than the relative likelihood. To use the loss set the `loss_type="nca_pair"` in the [`DPOConfig`].
|
||||
|
||||
The [Robust DPO](https://huggingface.co/papers/2403.00409) authors propose an unbiased estimate of the DPO loss that is robust to preference noise in the data. Like in cDPO, it assumes that the preference labels are noisy with some probability. In this approach, the `label_smoothing` parameter in the [`DPOConfig`] is used to model the probability of existing label noise. To apply this conservative loss, set `label_smoothing` to a value greater than 0.0 (between 0.0 and 0.5; the default is 0.0) and set the `loss_type="robust"` in the [`DPOConfig`].
|
||||
|
||||
The [BCO](https://huggingface.co/papers/2404.04656) authors train a binary classifier whose logit serves as a reward so that the classifier maps {prompt, chosen completion} pairs to 1 and {prompt, rejected completion} pairs to 0. To use this loss, set the `loss_type="bco_pair"` in the [`DPOConfig`].
|
||||
|
||||
The [TR-DPO](https://huggingface.co/papers/2404.09656) paper suggests syncing the reference model weights after every `ref_model_sync_steps` steps of SGD with weight `ref_model_mixup_alpha` during DPO training. To toggle this callback use the `sync_ref_model=True` in the [`DPOConfig`].
|
||||
|
||||
The [RPO](https://huggingface.co/papers/2404.19733) paper implements an iterative preference tuning algorithm using a loss related to the RPO loss in this [paper](https://huggingface.co/papers/2405.16436) that essentially consists of a weighted SFT loss on the chosen preferences together with the DPO loss. To use this loss, set the `rpo_alpha` in the [`DPOConfig`] to an appropriate value. The paper suggests setting this weight to 1.0.
|
||||
|
||||
The [SPPO](https://huggingface.co/papers/2405.00675) authors claim that SPPO is capable of solving the Nash equilibrium iteratively by pushing the chosen rewards to be as large as 1/2 and the rejected rewards to be as small as -1/2 and can alleviate data sparsity issues. The implementation approximates this algorithm by employing hard label probabilities, assigning 1 to the winner and 0 to the loser. To use this loss, set the `loss_type="sppo_hard"` in the [`DPOConfig`].
|
||||
|
||||
The [AOT](https://huggingface.co/papers/2406.05882) authors propose to use Distributional Preference Alignment Via Optimal Transport. Traditionally, the alignment algorithms use paired preferences at a sample level, which does not ensure alignment on the distributional level. AOT, on the other hand, can align LLMs on paired or unpaired preference data by making the reward distribution of the positive samples stochastically dominant in the first order on the distribution of negative samples. Specifically, `loss_type="aot"` is appropriate for paired datasets, where each prompt has both chosen and rejected responses; `loss_type="aot_pair"` is for unpaired datasets. In a nutshell, `loss_type="aot"` ensures that the log-likelihood ratio of chosen to rejected of the aligned model has higher quantiles than that ratio for the reference model. `loss_type="aot_pair"` ensures that the chosen reward is higher on all quantiles than the rejected reward. Note that in both cases quantiles are obtained via sorting. To fully leverage the advantages of the AOT algorithm, it is important to maximize the per-GPU batch size.
|
||||
|
||||
The [APO](https://huggingface.co/papers/2408.06266) method introduces an "anchored" version of the alignment objective. There are two variants: `apo_zero` and `apo_down`. The `apo_zero` loss increases the likelihood of winning outputs while decreasing the likelihood of losing outputs, making it suitable when the model is less performant than the winning outputs. On the other hand, `apo_down` decreases the likelihood of both winning and losing outputs, but with a stronger emphasis on reducing the likelihood of losing outputs. This variant is more effective when the model is better than the winning outputs. To use these losses, set `loss_type="apo_zero"` or `loss_type="apo_down"` in the [`DPOConfig`].
|
||||
|
||||
### For Mixture of Experts Models: Enabling the auxiliary loss
|
||||
|
||||
MOEs are the most efficient if the load is about equally distributed between experts.
|
||||
To ensure that we train MOEs similarly during preference-tuning, it is beneficial to add the auxiliary loss from the load balancer to the final loss.
|
||||
|
||||
This option is enabled by setting `output_router_logits=True` in the model config (e.g. MixtralConfig).
|
||||
To scale how much the auxiliary loss contributes to the total loss, use the hyperparameter `router_aux_loss_coef=...` (default: 0.001).
|
||||
|
||||
## Logging
|
||||
## Logged metrics
|
||||
|
||||
While training and evaluating we record the following reward metrics:
|
||||
|
||||
@ -169,59 +134,76 @@ While training and evaluating we record the following reward metrics:
|
||||
- `rewards/accuracies`: mean of how often the chosen rewards are > than the corresponding rejected rewards
|
||||
- `rewards/margins`: the mean difference between the chosen and corresponding rejected rewards
|
||||
|
||||
## Loss functions
|
||||
|
||||
The DPO algorithm supports several loss functions. The loss function can be set using the `loss_type` parameter in the [`DPOConfig`]. The following loss functions are supported:
|
||||
|
||||
| `loss_type=` | Description |
|
||||
| -------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `"sigmoid"` (default) | Given the preference data, we can fit a binary classifier according to the Bradley-Terry model and in fact the [DPO](https://huggingface.co/papers/2305.18290) authors propose the sigmoid loss on the normalized likelihood via the `logsigmoid` to fit a logistic regression. |
|
||||
| `"hinge"` | The [RSO](https://huggingface.co/papers/2309.06657) authors propose to use a hinge loss on the normalized likelihood from the [SLiC](https://huggingface.co/papers/2305.10425) paper. In this case, the `beta` is the reciprocal of the margin. |
|
||||
| `"ipo"` | The [IPO](https://huggingface.co/papers/2310.12036) authors provide a deeper theoretical understanding of the DPO algorithms and identify an issue with overfitting and propose an alternative loss. In this case, the `beta` is the reciprocal of the gap between the log-likelihood ratios of the chosen vs the rejected completion pair and thus the smaller the `beta` the larger this gaps is. As per the paper the loss is averaged over log-likelihoods of the completion (unlike DPO which is summed only). |
|
||||
| `"exo_pair"` | The [EXO](https://huggingface.co/papers/2402.00856) authors propose to minimize the reverse KL instead of the negative log-sigmoid loss of DPO which corresponds to forward KL. Setting non-zero `label_smoothing` (default `1e-3`) leads to a simplified version of EXO on pair-wise preferences (see Eqn. (16) of the [EXO paper](https://huggingface.co/papers/2402.00856)). The full version of EXO uses `K>2` completions generated by the SFT policy, which becomes an unbiased estimator of the PPO objective (up to a constant) when `K` is sufficiently large. |
|
||||
| `"nca_pair"` | The [NCA](https://huggingface.co/papers/2402.05369) authors shows that NCA optimizes the absolute likelihood for each response rather than the relative likelihood. |
|
||||
| `"robust"` | The [Robust DPO](https://huggingface.co/papers/2403.00409) authors propose an unbiased estimate of the DPO loss that is robust to preference noise in the data. Like in cDPO, it assumes that the preference labels are noisy with some probability. In this approach, the `label_smoothing` parameter in the [`DPOConfig`] is used to model the probability of existing label noise. To apply this conservative loss, set `label_smoothing` to a value greater than 0.0 (between 0.0 and 0.5; the default is 0.0) |
|
||||
| `"bco_pair"` | The [BCO](https://huggingface.co/papers/2404.04656) authors train a binary classifier whose logit serves as a reward so that the classifier maps {prompt, chosen completion} pairs to 1 and {prompt, rejected completion} pairs to 0. For unpaired data, we recommend the dedicated [`BCOTrainer`]. |
|
||||
| `"sppo_hard"` | The [SPPO](https://huggingface.co/papers/2405.00675) authors claim that SPPO is capable of solving the Nash equilibrium iteratively by pushing the chosen rewards to be as large as 1/2 and the rejected rewards to be as small as -1/2 and can alleviate data sparsity issues. The implementation approximates this algorithm by employing hard label probabilities, assigning 1 to the winner and 0 to the loser. |
|
||||
| `"aot"` or `loss_type="aot_pair"` | The [AOT](https://huggingface.co/papers/2406.05882) authors propose to use Distributional Preference Alignment Via Optimal Transport. Traditionally, the alignment algorithms use paired preferences at a sample level, which does not ensure alignment on the distributional level. AOT, on the other hand, can align LLMs on paired or unpaired preference data by making the reward distribution of the positive samples stochastically dominant in the first order on the distribution of negative samples. Specifically, `loss_type="aot"` is appropriate for paired datasets, where each prompt has both chosen and rejected responses; `loss_type="aot_pair"` is for unpaired datasets. In a nutshell, `loss_type="aot"` ensures that the log-likelihood ratio of chosen to rejected of the aligned model has higher quantiles than that ratio for the reference model. `loss_type="aot_pair"` ensures that the chosen reward is higher on all quantiles than the rejected reward. Note that in both cases quantiles are obtained via sorting. To fully leverage the advantages of the AOT algorithm, it is important to maximize the per-GPU batch size. |
|
||||
| `"apo_zero"` or `loss_type="apo_down"` | The [APO](https://huggingface.co/papers/2408.06266) method introduces an "anchored" version of the alignment objective. There are two variants: `apo_zero` and `apo_down`. The `apo_zero` loss increases the likelihood of winning outputs while decreasing the likelihood of losing outputs, making it suitable when the model is less performant than the winning outputs. On the other hand, `apo_down` decreases the likelihood of both winning and losing outputs, but with a stronger emphasis on reducing the likelihood of losing outputs. This variant is more effective when the model is better than the winning outputs. |
|
||||
| `"discopop"` | The [DiscoPOP](https://huggingface.co/papers/2406.08414) paper uses LLMs to discover more efficient offline preference optimization losses. In the paper the proposed DiscoPOP loss (which is a log-ratio modulated loss) outperformed other optimization losses on different tasks (IMDb positive text generation, Reddit TLDR summarization, and Alpaca Eval 2.0). |
|
||||
|
||||
### Label smoothing
|
||||
|
||||
The [cDPO](https://ericmitchell.ai/cdpo.pdf) is a tweak on the DPO loss where we assume that the preference labels are noisy with some probability. In this approach, the `label_smoothing` parameter in the [`DPOConfig`] is used to model the probability of existing label noise. To apply this conservative loss, set `label_smoothing` to a value greater than 0.0 (between 0.0 and 0.5; the default is 0.0).
|
||||
|
||||
### Syncing the reference model
|
||||
|
||||
The [TR-DPO](https://huggingface.co/papers/2404.09656) paper suggests syncing the reference model weights after every `ref_model_sync_steps` steps of SGD with weight `ref_model_mixup_alpha` during DPO training. To toggle this callback use the `sync_ref_model=True` in the [`DPOConfig`].
|
||||
|
||||
### RPO loss
|
||||
|
||||
The [RPO](https://huggingface.co/papers/2404.19733) paper implements an iterative preference tuning algorithm using a loss related to the RPO loss in this [paper](https://huggingface.co/papers/2405.16436) that essentially consists of a weighted SFT loss on the chosen preferences together with the DPO loss. To use this loss, set the `rpo_alpha` in the [`DPOConfig`] to an appropriate value. The paper suggests setting this weight to `1.0`.
|
||||
|
||||
### WPO loss
|
||||
|
||||
The [WPO](https://huggingface.co/papers/2406.11827) paper adapts off-policy data to resemble on-policy data more closely by reweighting preference pairs according to their probability under the current policy. To use this method, set the `use_weighting` flag to `True` in the [`DPOConfig`].
|
||||
|
||||
### For Mixture of Experts Models: Enabling the auxiliary loss
|
||||
|
||||
MOEs are the most efficient if the load is about equally distributed between experts.
|
||||
To ensure that we train MOEs similarly during preference-tuning, it is beneficial to add the auxiliary loss from the load balancer to the final loss.
|
||||
|
||||
This option is enabled by setting `output_router_logits=True` in the model config (e.g. [`~transformers.MixtralConfig`]).
|
||||
To scale how much the auxiliary loss contributes to the total loss, use the hyperparameter `router_aux_loss_coef=...` (default: `0.001`) in the model config.
|
||||
|
||||
## Accelerate DPO fine-tuning using `unsloth`
|
||||
|
||||
You can further accelerate QLoRA / LoRA (2x faster, 60% less memory) using the [`unsloth`](https://github.com/unslothai/unsloth) library that is fully compatible with `SFTTrainer`. Currently `unsloth` supports only Llama (Yi, TinyLlama, Qwen, Deepseek etc) and Mistral architectures. Some benchmarks for DPO listed below:
|
||||
|
||||
| GPU | Model | Dataset | 🤗 | 🤗 + Flash Attention 2 | 🦥 Unsloth | 🦥 VRAM saved |
|
||||
| -------- | --------- | ---------- | --- | ---------------------- | ---------- | ------------- |
|
||||
| A100 40G | Zephyr 7b | Ultra Chat | 1x | 1.24x | **1.88x** | -11.6% |
|
||||
| Tesla T4 | Zephyr 7b | Ultra Chat | 1x | 1.09x | **1.55x** | -18.6% |
|
||||
| GPU | Model | Dataset | 🤗 | 🤗 + Flash Attention 2 | 🦥 Unsloth | 🦥 VRAM saved |
|
||||
| -------- | --------- | ---------- | --- | --------------------- | --------- | ------------ |
|
||||
| A100 40G | Zephyr 7b | Ultra Chat | 1x | 1.24x | **1.88x** | -11.6% |
|
||||
| Tesla T4 | Zephyr 7b | Ultra Chat | 1x | 1.09x | **1.55x** | -18.6% |
|
||||
|
||||
First install `unsloth` according to the [official documentation](https://github.com/unslothai/unsloth). Once installed, you can incorporate unsloth into your workflow in a very simple manner; instead of loading `AutoModelForCausalLM`, you just need to load a `FastLanguageModel` as follows:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from trl import DPOConfig, DPOTrainer
|
||||
from unsloth import FastLanguageModel
|
||||
```diff
|
||||
from datasets import load_dataset
|
||||
from trl import DPOConfig, DPOTrainer
|
||||
- from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
+ from unsloth import FastLanguageModel
|
||||
|
||||
max_seq_length = 2048 # Supports automatic RoPE Scaling, so choose any number.
|
||||
- model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
- tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
+ model, tokenizer = FastLanguageModel.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
+ model = FastLanguageModel.get_peft_model(model)
|
||||
train_dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
|
||||
|
||||
# Load model
|
||||
model, tokenizer = FastLanguageModel.from_pretrained(
|
||||
model_name = "unsloth/zephyr-sft",
|
||||
max_seq_length = max_seq_length,
|
||||
dtype = None, # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
|
||||
load_in_4bit = True, # Use 4bit quantization to reduce memory usage. Can be False.
|
||||
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
|
||||
)
|
||||
- training_args = DPOConfig(output_dir="Qwen2-0.5B-DPO", logging_steps=10)
|
||||
+ training_args = DPOConfig(output_dir="Qwen2-0.5B-DPO", logging_steps=10, bf16=True)
|
||||
trainer = DPOTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset)
|
||||
trainer.train()
|
||||
|
||||
# Do model patching and add fast LoRA weights
|
||||
model = FastLanguageModel.get_peft_model(
|
||||
model,
|
||||
r = 16,
|
||||
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
|
||||
"gate_proj", "up_proj", "down_proj",],
|
||||
lora_alpha = 16,
|
||||
lora_dropout = 0, # Dropout = 0 is currently optimized
|
||||
bias = "none", # Bias = "none" is currently optimized
|
||||
use_gradient_checkpointing = True,
|
||||
random_state = 3407,
|
||||
)
|
||||
|
||||
training_args = DPOConfig(
|
||||
output_dir="./output",
|
||||
beta=0.1,
|
||||
)
|
||||
|
||||
dpo_trainer = DPOTrainer(
|
||||
model,
|
||||
ref_model=None,
|
||||
args=training_args,
|
||||
train_dataset=train_dataset,
|
||||
tokenizer=tokenizer,
|
||||
)
|
||||
dpo_trainer.train()
|
||||
```
|
||||
|
||||
The saved model is fully compatible with Hugging Face's transformers library. Learn more about unsloth in their [official repository](https://github.com/unslothai/unsloth).
|
||||
@ -295,3 +277,7 @@ dpo_trainer = DPOTrainer(
|
||||
## DPOConfig
|
||||
|
||||
[[autodoc]] DPOConfig
|
||||
|
||||
## PreferenceCollator
|
||||
|
||||
[[autodoc]] trainer.dpo_trainer.PreferenceCollator
|
||||
@ -31,24 +31,20 @@ Then, it is encouraged to launch jobs with `accelerate launch`!
|
||||
|
||||
# Maintained Examples
|
||||
|
||||
Scripts can be used as examples of how to use TRL trainers. They are located in the [`trl/scripts`](https://github.com/huggingface/trl/blob/main/trl/scripts) directory. Additionally, we provide examples in the [`examples/scripts`](https://github.com/huggingface/trl/blob/main/examples/scripts) directory. These examples are maintained and tested regularly.
|
||||
|
||||
|
||||
| File | Description |
|
||||
| ----------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| [`examples/scripts/alignprop.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/alignprop.py) | This script shows how to use the [`AlignPropTrainer`] to fine-tune a diffusion model. |
|
||||
| [`examples/scripts/bco.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/bco.py) | This script shows how to use the [`KTOTrainer`] with the BCO loss to fine-tune a model to increase instruction-following, truthfulness, honesty and helpfulness using the [openbmb/UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset. |
|
||||
| [`examples/scripts/chat.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/chat.py) | This script allows you to load and use a model as a chatbot. |
|
||||
| [`examples/scripts/cpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/cpo.py) | This script shows how to use the [`CPOTrainer`] to fine-tune a model to increase helpfulness and harmlessness using the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset. |
|
||||
| [`examples/scripts/ddpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ddpo.py) | This script shows how to use the [`DDPOTrainer`] to fine-tune a stable diffusion model using reinforcement learning. |
|
||||
| [`examples/scripts/dpo_visual.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo_visual.py) | This script shows how to use the [`DPOTrainer`] to fine-tune a Vision Language Model to reduce hallucinations using the [openbmb/RLAIF-V-Dataset](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset) dataset. |
|
||||
| [`examples/scripts/dpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo.py) | This script shows how to use the [`DPOTrainer`] to fine-tune a stable to increase helpfulness and harmlessness using the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset. |
|
||||
| [`examples/scripts/kto.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/kto.py) | This script shows how to use the [`KTOTrainer`] to fine-tune a model. |
|
||||
| [`examples/scripts/orpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/orpo.py) | This script shows how to use the [`ORPOTrainer`] to fine-tune a model to increase helpfulness and harmlessness using the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset. |
|
||||
| [`examples/scripts/ppo_multi_adapter.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ppo_multi_adapter.py) | This script shows how to use the [`PPOTrainer`] to train a single base model with multiple adapters. Requires you to run the example script with the reward model training beforehand. |
|
||||
| [`examples/scripts/ppo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ppo.py) | This script shows how to use the [`PPOTrainer`] to fine-tune a sentiment analysis model using [IMDB dataset](https://huggingface.co/datasets/stanfordnlp/imdb). |
|
||||
| [`examples/scripts/reward_modeling.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/reward_modeling.py) | This script shows how to use the [`RewardTrainer`] to train a reward model on your own dataset. |
|
||||
| [`examples/scripts/sft.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py) | This script shows how to use the [`SFTTrainer`] to fine-tune a model or adapters into a target dataset. |
|
||||
| [`examples/scripts/vsft_llava.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/vsft_llava.py) | This script shows how to use the [`SFTTrainer`] to fine-tune a Vision Language Model in a chat setting. The script has only been tested on a [LLaVA 1.5]([llava-hf/llava-1.5-7b-hf](https://huggingface.co/llava-hf/llava-1.5-7b-hf)) model so users may see unexpected behaviour in other model architectures. |
|
||||
| File | Description |
|
||||
| ----------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| [`examples/scripts/alignprop.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/alignprop.py) | This script shows how to use the [`AlignPropTrainer`] to fine-tune a diffusion model. |
|
||||
| [`examples/scripts/bco.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/bco.py) | This script shows how to use the [`KTOTrainer`] with the BCO loss to fine-tune a model to increase instruction-following, truthfulness, honesty and helpfulness using the [openbmb/UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback) dataset. |
|
||||
| [`examples/scripts/cpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/cpo.py) | This script shows how to use the [`CPOTrainer`] to fine-tune a model to increase helpfulness and harmlessness using the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset. |
|
||||
| [`examples/scripts/ddpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ddpo.py) | This script shows how to use the [`DDPOTrainer`] to fine-tune a stable diffusion model using reinforcement learning. |
|
||||
| [`examples/scripts/dpo_vlm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo_vlm.py) | This script shows how to use the [`DPOTrainer`] to fine-tune a Vision Language Model to reduce hallucinations using the [openbmb/RLAIF-V-Dataset](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset) dataset. |
|
||||
| [`examples/scripts/orpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/orpo.py) | This script shows how to use the [`ORPOTrainer`] to fine-tune a model to increase helpfulness and harmlessness using the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset. |
|
||||
| [`examples/scripts/ppo/ppo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ppo/ppo.py) | This script shows how to use the [`PPOTrainer`] to fine-tune a model to improve its ability to continue text with positive sentiment or physically descriptive language |
|
||||
| [`examples/scripts/ppo/ppo_tldr.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/ppo/ppo_tldr.py) | This script shows how to use the [`PPOTrainer`] to fine-tune a model to improve its ability to generate TL;DR summaries. |
|
||||
| [`examples/scripts/reward_modeling.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/reward_modeling.py) | This script shows how to use the [`RewardTrainer`] to train a reward model on your own dataset. |
|
||||
| [`examples/scripts/sft_vlm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/sft_vlm.py) | This script shows how to use the [`SFTTrainer`] to fine-tune a Vision Language Model in a chat setting. The script has only been tested with [LLaVA 1.5](https://huggingface.co/llava-hf/llava-1.5-7b-hf), [LLaVA 1.6](https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf), and [Llama-3.2-11B-Vision-Instruct](https://huggingface.co/meta-llama/Llama-3.2-11B-Vision-Instruct) models so users may see unexpected behaviour in other model architectures. |
|
||||
|
||||
Here are also some easier-to-run colab notebooks that you can use to get started with TRL:
|
||||
|
||||
|
||||
98
docs/source/gkd_trainer.md
Normal file
98
docs/source/gkd_trainer.md
Normal file
@ -0,0 +1,98 @@
|
||||
# Generalized Knowledge Distillation Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=gkd,trl)
|
||||
|
||||
## Overview
|
||||
|
||||
Generalized Knowledge Distillation (GKD) was proposed in [On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes](https://huggingface.co/papers/2306.13649) by Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
> Knowledge distillation (KD) is widely used for compressing a teacher model to reduce its inference cost and memory footprint, by training a smaller student model. However, current KD methods for auto-regressive sequence models suffer from distribution mismatch between output sequences seen during training and those generated by the student during inference. To address this issue, we introduce Generalized Knowledge Distillation (GKD). Instead of solely relying on a fixed set of output sequences, GKD trains the student on its self-generated output sequences by leveraging feedback from the teacher on such sequences. Unlike supervised KD approaches, GKD also offers the flexibility to employ alternative loss functions between the student and teacher, which can be useful when the student lacks the expressivity to mimic the teacher's distribution. Furthermore, GKD facilitates the seamless integration of distillation with RL fine-tuning (RLHF). We demonstrate the efficacy of GKD for distilling auto-regressive language models on summarization, translation, and arithmetic reasoning tasks, and task-agnostic distillation for instruction-tuning.
|
||||
|
||||
|
||||
The key aspects of GKD are:
|
||||
1. It addresses the train-inference distribution mismatch in auto-regressive sequence models by training the student model on its self-generated output sequences.
|
||||
2. GKD allows flexibility in choosing different divergence measures between student and teacher models via the generalized Jensen-Shannon Divergence (JSD), which can be useful when the student lacks the capacity to fully mimic the teacher.
|
||||
|
||||
This post-training method was contributed by [Kashif Rasul](https://huggingface.co/kashif) and [Lewis Tunstall](https://huggingface.co/lewtun).
|
||||
|
||||
## Usage tips
|
||||
|
||||
The [`GKDTrainer`] is a wrapper around the [`SFTTrainer`] class that takes in a teacher model argument. It needs three parameters to be set via the [`GKDConfig`] namely:
|
||||
* `lmbda`: controls the student data fraction, i.e., the proportion of on-policy student-generated outputs. When `lmbda=0.0`, the loss reduces to supervised JSD where the student is trained with the token-level probabilities of the teacher. When `lmbda=1.0`, the loss reduces to on-policy JSD, where the student generates output sequences and token-specific feedback on these sequences from the teacher. For values in between [0, 1] it is random between the two based on the `lmbda` value for each batch.
|
||||
* `seq_kd`: controls whether to perform Sequence-Level KD (can be viewed as supervised FT on teacher-generated out). When `seq_kd=True` and `lmbda=0.0`, the loss reduces to supervised JSD, where the teacher generates output sequences and the student receives token-specific feedback on these sequences from the teacher.
|
||||
* `beta`: controls the interpolation in the generalized Jensen-Shannon Divergence. When `beta=0.0` the loss approximates forward KL divergence, while for `beta=1.0` the loss approximates reverse KL divergence. For values in between [0, 1] it interpolates between the two.
|
||||
|
||||
The authors find that on-policy data (high `lmbda`) performs better and the optimal `beta` varied depending on the task and evaluation method.
|
||||
|
||||
> [!WARNING]
|
||||
> Make sure that `attn_implementation="flash_attention_2"` when training [Gemma models](https://huggingface.co/models?other=gemma2). Otherwise you will encounter NaNs in the logits due to the [soft capping technique](https://huggingface.co/blog/gemma2#soft-capping-and-attention-implementations) adopted by this architecture.
|
||||
|
||||
The basic API is as follows:
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
from trl import GKDConfig, GKDTrainer
|
||||
from transformers import (
|
||||
AutoModelForCausalLM,
|
||||
AutoTokenizer,
|
||||
)
|
||||
|
||||
NUM_DUMMY_SAMPLES = 100
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
# The model to optimise
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
# The teacher model to calculate the KL divergence against
|
||||
teacher_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-1.5B-Instruct")
|
||||
|
||||
train_dataset = Dataset.from_dict(
|
||||
{
|
||||
"messages": [
|
||||
[
|
||||
{"role": "user", "content": "Hi, how are you?"},
|
||||
{"role": "assistant", "content": "I'm great thanks"},
|
||||
]
|
||||
]
|
||||
* NUM_DUMMY_SAMPLES
|
||||
}
|
||||
)
|
||||
eval_dataset = Dataset.from_dict(
|
||||
{
|
||||
"messages": [
|
||||
[
|
||||
{"role": "user", "content": "What colour is the sky?"},
|
||||
{"role": "assistant", "content": "The sky is blue"},
|
||||
]
|
||||
]
|
||||
* NUM_DUMMY_SAMPLES
|
||||
}
|
||||
)
|
||||
|
||||
training_args = GKDConfig(output_dir="gkd-model", per_device_train_batch_size=1)
|
||||
trainer = GKDTrainer(
|
||||
model=model,
|
||||
teacher_model=teacher_model,
|
||||
args=training_args,
|
||||
processing_class=tokenizer,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
### Expected dataset type
|
||||
|
||||
The dataset should be formatted as a list of "messages" where each message is a list of dictionaries with the following keys:
|
||||
* `role`: either `system`, `assistant` or `user`
|
||||
* `content`: the message content
|
||||
|
||||
|
||||
## GKDTrainer
|
||||
|
||||
[[autodoc]] GKDTrainer
|
||||
|
||||
## GKDConfig
|
||||
|
||||
[[autodoc]] GKDConfig
|
||||
@ -7,11 +7,9 @@
|
||||
TRL is a full stack library where we provide a set of tools to train transformer language models with Reinforcement Learning, from the Supervised Fine-tuning step (SFT), Reward Modeling step (RM) to the Proximal Policy Optimization (PPO) step.
|
||||
The library is integrated with 🤗 [transformers](https://github.com/huggingface/transformers).
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/TRL-readme.png">
|
||||
</div>
|
||||
## Learn post-training
|
||||
|
||||
Check the appropriate sections of the documentation depending on your needs:
|
||||
Learn post-training with the 🤗 [smol course](https://github.com/huggingface/smol-course).
|
||||
|
||||
## API documentation
|
||||
|
||||
@ -38,28 +36,39 @@ Check the appropriate sections of the documentation depending on your needs:
|
||||
<div class="mt-10">
|
||||
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5">
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/dpo_vlm">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/dpo_vlm/thumbnail.png" alt="thumbnail">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/dpo_vlm/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on July 10, 2024</p>
|
||||
<p class="text-gray-700">Preference Optimization for Vision Language Models with TRL</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/rlhf">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/120_rlhf/thumbnail.png" alt="thumbnail">
|
||||
<p class="text-gray-700">Illustrating Reinforcement Learning from Human Feedback</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/trl-peft">
|
||||
<img src="https://github.com/huggingface/blog/blob/main/assets/133_trl_peft/thumbnail.png?raw=true" alt="thumbnail">
|
||||
<p class="text-gray-700">Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/stackllama">
|
||||
<img src="https://github.com/huggingface/blog/blob/main/assets/138_stackllama/thumbnail.png?raw=true" alt="thumbnail">
|
||||
<p class="text-gray-700">StackLLaMA: A hands-on guide to train LLaMA with RLHF</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/dpo-trl">
|
||||
<img src="https://github.com/huggingface/blog/blob/main/assets/157_dpo_trl/dpo_thumbnail.png?raw=true" alt="thumbnail">
|
||||
<p class="text-gray-700">Fine-tune Llama 2 with DPO</p>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/putting_rl_back_in_rlhf_with_rloo">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/putting_rl_back_in_rlhf_with_rloo/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on June 12, 2024</p>
|
||||
<p class="text-gray-700">Putting RL back in RLHF</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/trl-ddpo">
|
||||
<img src="https://github.com/huggingface/blog/blob/main/assets/166_trl_ddpo/thumbnail.png?raw=true" alt="thumbnail">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/166_trl_ddpo/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on September 29, 2023</p>
|
||||
<p class="text-gray-700">Finetune Stable Diffusion Models with DDPO via TRL</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/dpo-trl">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/157_dpo_trl/dpo_thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on August 8, 2023</p>
|
||||
<p class="text-gray-700">Fine-tune Llama 2 with DPO</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/stackllama">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/138_stackllama/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on April 5, 2023</p>
|
||||
<p class="text-gray-700">StackLLaMA: A hands-on guide to train LLaMA with RLHF</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/trl-peft">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/133_trl_peft/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on March 9, 2023</p>
|
||||
<p class="text-gray-700">Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU</p>
|
||||
</a>
|
||||
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="https://huggingface.co/blog/rlhf">
|
||||
<img src="https://raw.githubusercontent.com/huggingface/blog/main/assets/120_rlhf/thumbnail.png" alt="thumbnail" class="mt-0">
|
||||
<p class="text-gray-500 text-sm">Published on December 9, 2022</p>
|
||||
<p class="text-gray-700">Illustrating Reinforcement Learning from Human Feedback</p>
|
||||
</a>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
@ -1,5 +1,8 @@
|
||||
# Iterative Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=iterative-sft,trl)
|
||||
|
||||
|
||||
Iterative fine-tuning is a training method that enables to perform custom actions (generation and filtering for example) between optimization steps. In TRL we provide an easy-to-use API to fine-tune your models in an iterative way in just a few lines of code.
|
||||
|
||||
## Usage
|
||||
|
||||
@ -1,11 +1,17 @@
|
||||
# Judges
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
TRL Judges is an experimental API which is subject to change at any time.
|
||||
|
||||
</Tip>
|
||||
|
||||
TRL provides judges to easily compare two completions.
|
||||
|
||||
Make sure to have installed the required dependencies by running:
|
||||
|
||||
```bash
|
||||
pip install trl[llm_judge]
|
||||
pip install trl[judges]
|
||||
```
|
||||
|
||||
## Using the provided judges
|
||||
@ -46,34 +52,38 @@ judge.judge(
|
||||
) # Outputs: [0, 1]
|
||||
```
|
||||
|
||||
## BaseJudge
|
||||
## Provided judges
|
||||
|
||||
[[autodoc]] BaseJudge
|
||||
|
||||
## BaseRankJudge
|
||||
|
||||
[[autodoc]] BaseRankJudge
|
||||
|
||||
## BasePairwiseJudge
|
||||
|
||||
[[autodoc]] BasePairwiseJudge
|
||||
|
||||
## RandomRankJudge
|
||||
|
||||
[[autodoc]] RandomRankJudge
|
||||
|
||||
## RandomPairwiseJudge
|
||||
|
||||
[[autodoc]] RandomPairwiseJudge
|
||||
|
||||
## PairRMJudge
|
||||
### PairRMJudge
|
||||
|
||||
[[autodoc]] PairRMJudge
|
||||
|
||||
## HfPairwiseJudge
|
||||
### HfPairwiseJudge
|
||||
|
||||
[[autodoc]] HfPairwiseJudge
|
||||
|
||||
## OpenAIPairwiseJudge
|
||||
### OpenAIPairwiseJudge
|
||||
|
||||
[[autodoc]] OpenAIPairwiseJudge
|
||||
|
||||
### AllTrueJudge
|
||||
|
||||
[[autodoc]] AllTrueJudge
|
||||
|
||||
## Base classes
|
||||
|
||||
### BaseJudge
|
||||
|
||||
[[autodoc]] BaseJudge
|
||||
|
||||
### BaseBinaryJudge
|
||||
|
||||
[[autodoc]] BaseBinaryJudge
|
||||
|
||||
### BaseRankJudge
|
||||
|
||||
[[autodoc]] BaseRankJudge
|
||||
|
||||
### BasePairwiseJudge
|
||||
|
||||
[[autodoc]] BasePairwiseJudge
|
||||
|
||||
@ -1,97 +1,134 @@
|
||||
# KTO Trainer
|
||||
|
||||
TRL supports the Kahneman-Tversky Optimization (KTO) Trainer for aligning language models with binary feedback data (e.g., upvote/downvote), as described in the [paper](https://huggingface.co/papers/2402.01306) by Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela.
|
||||
For a full example have a look at [`examples/scripts/kto.py`].
|
||||
[](https://huggingface.co/models?other=kto,trl)
|
||||
|
||||
Depending on how good your base model is, you may or may not need to do SFT before KTO.
|
||||
This is different from standard RLHF and DPO, which always require SFT.
|
||||
## Overview
|
||||
|
||||
Kahneman-Tversky Optimization (KTO) was introduced in [KTO: Model Alignment as Prospect Theoretic Optimization](https://huggingface.co/papers/2402.01306) by [Kawin Ethayarajh](https://huggingface.co/kawine), [Winnie Xu](https://huggingface.co/xwinxu), [Niklas Muennighoff](https://huggingface.co/Muennighoff), Dan Jurafsky, [Douwe Kiela](https://huggingface.co/douwekiela).
|
||||
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
> Kahneman & Tversky's prospect theory tells us that humans perceive random variables in a biased but well-defined manner; for example, humans are famously loss-averse. We show that objectives for aligning LLMs with human feedback implicitly incorporate many of these biases -- the success of these objectives (e.g., DPO) over cross-entropy minimization can partly be ascribed to them being human-aware loss functions (HALOs). However, the utility functions these methods attribute to humans still differ from those in the prospect theory literature. Using a Kahneman-Tversky model of human utility, we propose a HALO that directly maximizes the utility of generations instead of maximizing the log-likelihood of preferences, as current methods do. We call this approach Kahneman-Tversky Optimization (KTO), and it matches or exceeds the performance of preference-based methods at scales from 1B to 30B. Crucially, KTO does not need preferences -- only a binary signal of whether an output is desirable or undesirable for a given input. This makes it far easier to use in the real world, where preference data is scarce and expensive.
|
||||
|
||||
The official code can be found in [ContextualAI/HALOs](https://github.com/ContextualAI/HALOs).
|
||||
|
||||
This post-training method was contributed by [Kashif Rasul](https://huggingface.co/kashif), [Younes Belkada](https://huggingface.co/ybelkada), [Lewis Tunstall](https://huggingface.co/lewtun) and Pablo Vicente.
|
||||
|
||||
## Quick start
|
||||
|
||||
This example demonstrates how to train a model using the KTO method. We use the [Qwen 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) as the base model. We use the preference data from the [KTO Mix 14k](https://huggingface.co/datasets/trl-lib/kto-mix-14k). You can view the data in the dataset here:
|
||||
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/kto-mix-14k/embed/viewer/default/train?row=0"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
Below is the script to train the model:
|
||||
|
||||
```python
|
||||
# train_kto.py
|
||||
from datasets import load_dataset
|
||||
from trl import KTOConfig, KTOTrainer
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
train_dataset = load_dataset("trl-lib/kto-mix-14k", split="train")
|
||||
|
||||
training_args = KTOConfig(output_dir="Qwen2-0.5B-KTO", logging_steps=10)
|
||||
trainer = KTOTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
Execute the script using the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch train_kto.py
|
||||
```
|
||||
|
||||
Distributed across 8 x H100 GPUs, the training takes approximately 30 minutes. You can verify the training progress by checking the reward graph. An increasing trend in the reward margin indicates that the model is improving and generating better responses over time.
|
||||
|
||||

|
||||
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-KTO) performs, you can use the [TRL Chat CLI](clis#chat-interface).
|
||||
|
||||
<pre><code>$ trl chat --model_name_or_path trl-lib/Qwen2-0.5B-KTO
|
||||
<strong><span style="color: red;"><quentin_gallouedec>:</span></strong>
|
||||
What is the best programming language?
|
||||
|
||||
<strong><span style="color: blue;"><trl-lib/Qwen2-0.5B-KTO>:</span></strong>
|
||||
The best programming language can vary depending on individual preferences, industry-specific requirements, technical skills, and familiarity with the specific use case or task. Here are some widely-used programming languages that have been noted as popular and widely used:
|
||||
|
||||
Here are some other factors to consider when choosing a programming language for a project:
|
||||
|
||||
<strong><span style="color: green;">1</span> JavaScript</strong>: JavaScript is at the heart of the web and can be used for building web applications, APIs, and interactive front-end applications like frameworks like React and Angular. It's similar to C, C++, and F# in syntax structure and is accessible and easy to learn, making it a popular choice for beginners and professionals alike.
|
||||
<strong><span style="color: green;">2</span> Java</strong>: Known for its object-oriented programming (OOP) and support for Java 8 and .NET, Java is used for developing enterprise-level software applications, high-performance games, as well as mobile apps, game development, and desktop applications.
|
||||
<strong><span style="color: green;">3</span> C++</strong>: Known for its flexibility and scalability, C++ offers comprehensive object-oriented programming and is a popular choice for high-performance computing and other technical fields. It's a powerful platform for building real-world applications and games at scale.
|
||||
<strong><span style="color: green;">4</span> Python</strong>: Developed by Guido van Rossum in 1991, Python is a high-level, interpreted, and dynamically typed language known for its simplicity, readability, and versatility.
|
||||
</code></pre>
|
||||
|
||||
## Expected dataset format
|
||||
|
||||
The KTO trainer expects a very specific format for the dataset as it does not require pairwise preferences. Since the model will be trained to directly optimize examples that consist of a prompt, model completion, and a label to indicate whether the completion is "good" or "bad", we expect a dataset with the following columns:
|
||||
KTO requires an [unpaired preference dataset](dataset_formats#unpaired-preference). Alternatively, you can provide a *paired* preference dataset (also known simply as a *preference dataset*). In this case, the trainer will automatically convert it to an unpaired format by separating the chosen and rejected responses, assigning `label = True` to the chosen completions and `label = False` to the rejected ones.
|
||||
|
||||
- `prompt`
|
||||
- `completion`
|
||||
- `label`
|
||||
The [`KTOTrainer`] supports both [conversational](dataset_formats#conversational) and [standard](dataset_formats#standard) dataset format. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
|
||||
|
||||
for example:
|
||||
In theory, the dataset should contain at least one chosen and one rejected completion. However, some users have successfully run KTO using *only* chosen or only rejected data. If using only rejected data, it is advisable to adopt a conservative learning rate.
|
||||
|
||||
```
|
||||
kto_dataset_dict = {
|
||||
"prompt": [
|
||||
"Hey, hello",
|
||||
"How are you",
|
||||
"What is your name?",
|
||||
"What is your name?",
|
||||
"Which is the best programming language?",
|
||||
"Which is the best programming language?",
|
||||
"Which is the best programming language?",
|
||||
],
|
||||
"completion": [
|
||||
"hi nice to meet you",
|
||||
"leave me alone",
|
||||
"I don't have a name",
|
||||
"My name is Mary",
|
||||
"Python",
|
||||
"C++",
|
||||
"Java",
|
||||
],
|
||||
"label": [
|
||||
True,
|
||||
False,
|
||||
False,
|
||||
True,
|
||||
True,
|
||||
False,
|
||||
False,
|
||||
],
|
||||
}
|
||||
## Example script
|
||||
|
||||
We provide an example script to train a model using the KTO method. The script is available in [`trl/scripts/kto.py`](https://github.com/huggingface/trl/blob/main/trl/scripts/kto.py)
|
||||
|
||||
To test the KTO script with the [Qwen2 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) on the [UltraFeedback dataset](https://huggingface.co/datasets/trl-lib/kto-mix-14k), run the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch trl/scripts/kto.py \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
|
||||
--dataset_name trl-lib/kto-mix-14k \
|
||||
--num_train_epochs 1 \
|
||||
--logging_steps 25 \
|
||||
--output_dir Qwen2-0.5B-KTO
|
||||
```
|
||||
|
||||
where the `prompt` contains the context inputs, `completion` contains the corresponding responses and `label` contains the corresponding flag that indicates if the generated completion is desired (`True`) or undesired (`False`).
|
||||
A prompt can have multiple responses and this is reflected in the entries being repeated in the dictionary's value arrays. It is required that the dataset contains at least one desirable and one undesirable completion.
|
||||
|
||||
|
||||
## Expected model format
|
||||
The KTO trainer expects a model of `AutoModelForCausalLM`, compared to PPO that expects `AutoModelForCausalLMWithValueHead` for the value function.
|
||||
|
||||
## Using the `KTOTrainer`
|
||||
|
||||
For a detailed example have a look at the `examples/scripts/kto.py` script. At a high level we need to initialize the `KTOTrainer` with a `model` we wish to train and a reference `ref_model` which we will use to calculate the implicit rewards of the preferred and rejected response.
|
||||
|
||||
The `beta` refers to the hyperparameter of the implicit reward, and the dataset contains the 3 entries listed above. Note that the `model` and `ref_model` need to have the same architecture (ie decoder only or encoder-decoder).
|
||||
|
||||
The `desirable_weight` and `undesirable_weight` refer to the weights placed on the losses for desirable/positive and undesirable/negative examples.
|
||||
By default, they are both 1. However, if you have more of one or the other, then you should upweight the less common type such that the ratio of (`desirable_weight` * number of positives) to (`undesirable_weight` * number of negatives) is in the range 1:1 to 4:3.
|
||||
|
||||
```py
|
||||
training_args = KTOConfig(
|
||||
beta=0.1,
|
||||
desirable_weight=1.0,
|
||||
undesirable_weight=1.0,
|
||||
)
|
||||
|
||||
kto_trainer = KTOTrainer(
|
||||
model,
|
||||
ref_model,
|
||||
args=training_args,
|
||||
train_dataset=train_dataset,
|
||||
tokenizer=tokenizer,
|
||||
)
|
||||
```
|
||||
After this one can then call:
|
||||
|
||||
```py
|
||||
kto_trainer.train()
|
||||
```
|
||||
## Usage tips
|
||||
|
||||
### For Mixture of Experts Models: Enabling the auxiliary loss
|
||||
|
||||
MOEs are the most efficient if the load is about equally distributed between experts.
|
||||
To ensure that we train MOEs similarly during preference-tuning, it is beneficial to add the auxiliary loss from the load balancer to the final loss.
|
||||
To ensure that we train MOEs similarly during preference-tuning, it is beneficial to add the auxiliary loss from the load balancer to the final loss.
|
||||
|
||||
This option is enabled by setting `output_router_logits=True` in the model config (e.g. MixtralConfig).
|
||||
To scale how much the auxiliary loss contributes to the total loss, use the hyperparameter `router_aux_loss_coef=...` (default: 0.001).
|
||||
This option is enabled by setting `output_router_logits=True` in the model config (e.g. [`~transformers.MixtralConfig`]).
|
||||
To scale how much the auxiliary loss contributes to the total loss, use the hyperparameter `router_aux_loss_coef=...` (default: `0.001`) in the model config.
|
||||
|
||||
|
||||
### Batch size recommendations
|
||||
|
||||
Use a per-step batch size that is at least 4, and an effective batch size between 16 and 128. Even if your effective batch size is large, if your per-step batch size is poor, then the KL estimate in KTO will be poor.
|
||||
|
||||
### Learning rate recommendations
|
||||
|
||||
Each choice of `beta` has a maximum learning rate it can tolerate before learning performance degrades. For the default setting of `beta = 0.1`, the learning rate should typically not exceed `1e-6` for most models. As `beta` decreases, the learning rate should also be reduced accordingly. In general, we strongly recommend keeping the learning rate between `5e-7` and `5e-6`. Even with small datasets, we advise against using a learning rate outside this range. Instead, opt for more epochs to achieve better results.
|
||||
|
||||
### Imbalanced data
|
||||
|
||||
The `desirable_weight` and `undesirable_weight` of the [`KTOConfig`] refer to the weights placed on the losses for desirable/positive and undesirable/negative examples.
|
||||
By default, they are both 1. However, if you have more of one or the other, then you should upweight the less common type such that the ratio of (`desirable_weight` \\(\times\\) number of positives) to (`undesirable_weight` \\(\times\\) number of negatives) is in the range 1:1 to 4:3.
|
||||
|
||||
## Logged metrics
|
||||
|
||||
While training and evaluating we record the following reward metrics:
|
||||
|
||||
- `rewards/chosen`: the mean log probabilities of the policy model for the chosen responses scaled by beta
|
||||
- `rewards/rejected`: the mean log probabilities of the policy model for the rejected responses scaled by beta
|
||||
- `rewards/margins`: the mean difference between the chosen and corresponding rejected rewards
|
||||
- `logps/chosen`: the mean log probabilities of the chosen completions
|
||||
- `logps/rejected`: the mean log probabilities of the rejected completions
|
||||
- `logits/chosen`: the mean logits of the chosen completions
|
||||
- `logits/rejected`: the mean logits of the rejected completions
|
||||
- `kl`: the KL divergence between the policy model and the reference model
|
||||
|
||||
## KTOTrainer
|
||||
|
||||
@ -99,4 +136,4 @@ To scale how much the auxiliary loss contributes to the total loss, use the hype
|
||||
|
||||
## KTOConfig
|
||||
|
||||
[[autodoc]] KTOConfig
|
||||
[[autodoc]] KTOConfig
|
||||
|
||||
@ -90,6 +90,7 @@ WANDB_TAGS="calculator_final" python benchmark/benchmark.py \
|
||||
|
||||
We can then use [`openrlbenchmark`](https://github.com/openrlbenchmark/openrlbenchmark) which generates the following plot.
|
||||
```
|
||||
# pip install openrlbenchmark==0.2.1a5
|
||||
python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--filters '?we=openrlbenchmark&wpn=trl&xaxis=_step&ceik=trl_ppo_trainer_config.value.tracker_project_name&cen=trl_ppo_trainer_config.value.log_with&metrics=env/reward_mean&metrics=objective/kl' \
|
||||
'wandb?tag=calculator_final&cl=calculator_mask' \
|
||||
|
||||
@ -1,15 +1,14 @@
|
||||
# Logging
|
||||
|
||||
As reinforcement learning algorithms are historically challenging to debug, it's important to pay careful attention to logging.
|
||||
By default, the TRL [`PPOTrainer`] saves a lot of relevant information to `wandb` or `tensorboard`.
|
||||
By default, the TRL [`PPOTrainer`] saves a lot of relevant information to wandb or tensorboard.
|
||||
|
||||
Upon initialization, pass one of these two options to the [`PPOConfig`]:
|
||||
|
||||
```
|
||||
config = PPOConfig(
|
||||
model_name=args.model_name,
|
||||
log_with=`wandb`, # or `tensorboard`
|
||||
)
|
||||
training_args = PPOConfig(..., report_to="wandb") # or "tensorboard"
|
||||
```
|
||||
|
||||
If you want to log with tensorboard, add the kwarg `project_kwargs={"logging_dir": PATH_TO_LOGS}` to the PPOConfig.
|
||||
|
||||
## PPO Logging
|
||||
|
||||
@ -140,5 +140,5 @@ python PATH_TO_SCRIPT
|
||||
You can easily fine-tune Llama2 model using `SFTTrainer` and the official script! For example to fine-tune llama2-7b on the Guanaco dataset, run (tested on a single NVIDIA T4-16GB):
|
||||
|
||||
```bash
|
||||
python examples/scripts/sft.py --output_dir sft_openassistant-guanaco --model_name meta-llama/Llama-2-7b-hf --dataset_name timdettmers/openassistant-guanaco --load_in_4bit --use_peft --per_device_train_batch_size 4 --gradient_accumulation_steps 2
|
||||
python trl/scripts/sft.py --output_dir sft_openassistant-guanaco --model_name meta-llama/Llama-2-7b-hf --dataset_name timdettmers/openassistant-guanaco --load_in_4bit --use_peft --per_device_train_batch_size 4 --gradient_accumulation_steps 2
|
||||
```
|
||||
|
||||
@ -10,7 +10,7 @@ You just need to install `peft` and optionally install `bitsandbytes` as well if
|
||||
|
||||
You need to address this approach in three stages that we summarize as follows:
|
||||
|
||||
1- Train a base model on the target domain (e.g. `imdb` dataset) - this is the Supervised Fine Tuning stage - it can leverage the `SFTTrainer` from TRL.
|
||||
1- Train a base model on the target domain (e.g. [IMDB dataset](https://huggingface.co/datasets/stanfordnlp/imdb)) - this is the Supervised Fine Tuning stage - it can leverage the `SFTTrainer` from TRL.
|
||||
2- Train a reward model using `peft`. This is required in order to re-use the adapter during the RL optimisation process (step 3 below). We show an example of leveraging the `RewardTrainer` from TRL in [this example](https://github.com/huggingface/trl/tree/main/examples/scripts/reward_modeling.py)
|
||||
3- Fine tune new adapters on the base model using PPO and the reward adapter. ("0 abstraction RL")
|
||||
|
||||
|
||||
159
docs/source/nash_md_trainer.md
Normal file
159
docs/source/nash_md_trainer.md
Normal file
@ -0,0 +1,159 @@
|
||||
# Nash-MD Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=nash-md,trl)
|
||||
|
||||
## Overview
|
||||
|
||||
Nash-MD was proposed in the paper [Nash Learning from Human Feedback](https://huggingface.co/papers/2312.00886) by Rémi Munos, [Michal Valko](https://huggingface.co/misovalko), Daniele Calandriello, Mohammad Gheshlaghi Azar, Mark Rowland, Daniel Guo, Yunhao Tang, Matthieu Geist, Thomas Mésnard, and Andrea Michi.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
> Reinforcement learning from human feedback (RLHF) has emerged as the main paradigm for aligning large language models (LLMs) with human preferences. Typically, RLHF involves the initial step of learning a reward model from human feedback, often expressed as preferences between pairs of text generations produced by a pre-trained LLM. Subsequently, the LLM's policy is fine-tuned by optimizing it to maximize the reward model through a reinforcement learning algorithm. However, an inherent limitation of current reward models is their inability to fully represent the richness of human preferences and their dependency on the sampling distribution. In this study, we introduce an alternative pipeline for the fine-tuning of LLMs using pairwise human feedback. Our approach entails the initial learning of a preference model, which is conditioned on two inputs given a prompt, followed by the pursuit of a policy that consistently generates responses preferred over those generated by any competing policy, thus defining the Nash equilibrium of this preference model. We term this approach Nash learning from human feedback (NLHF). In the context of a tabular policy representation, we present a novel algorithmic solution, Nash-MD, founded on the principles of mirror descent. This algorithm produces a sequence of policies, with the last iteration converging to the regularized Nash equilibrium. Additionally, we explore parametric representations of policies and introduce gradient descent algorithms for deep-learning architectures. To demonstrate the effectiveness of our approach, we present experimental results involving the fine-tuning of a LLM for a text summarization task. We believe NLHF offers a compelling avenue for preference learning and policy optimization with the potential of advancing the field of aligning LLMs with human preferences.
|
||||
|
||||
This post-training method was contributed by [Kashif Rasul](https://huggingface.co/kashif) and [Daniil Tiapkin](https://huggingface.co/dtiapkin), [Pierre Ménard](https://huggingface.co/menardprr), Daniele Calandriello and [Quentin Gallouédec](https://huggingface.co/qgallouedec).
|
||||
|
||||
## Quick start
|
||||
|
||||
This example demonstrates how to train a model using the Nash-MD method. We use the [Qwen 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) as the base model and [`PairRMJudge`] as a judge. We use the prompts from the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback). You can view the prompts in the dataset here:
|
||||
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/ultrafeedback-prompt/embed/viewer/default/train?row=0"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
Below is the script to train the model:
|
||||
|
||||
```python
|
||||
# train_nash_md.py
|
||||
from datasets import load_dataset
|
||||
from trl import NashMDConfig, NashMDTrainer, PairRMJudge
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
judge = PairRMJudge()
|
||||
train_dataset = load_dataset("trl-lib/ultrafeedback-prompt", split="train")
|
||||
|
||||
training_args = NashMDConfig(output_dir="Qwen2-0.5B-NashMD", logging_steps=10)
|
||||
trainer = NashMDTrainer(
|
||||
model=model, judge=judge, args=training_args, processing_class=tokenizer, train_dataset=train_dataset
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
Execute the script using the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch train_nash_md.py
|
||||
```
|
||||
|
||||
Distributed across 8 GPUs, the training takes approximately 3 hours.
|
||||
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-NashMD) performs, you can use the [TRL Chat CLI](clis#chat-interface).
|
||||
|
||||
<pre><code>$ trl chat --model_name_or_path trl-lib/Qwen2-0.5B-NashMD
|
||||
<strong><span style="color: red;"><quentin_gallouedec>:</span></strong>
|
||||
What is the best programming language?
|
||||
|
||||
<strong><span style="color: blue;"><trl-lib/Qwen2-0.5B-NashMD>:</span></strong>
|
||||
The best programming language depends on personal preference, the complexity of the project, and the specific requirements of the task. Some programming languages that are often recommended include Python, Java, and JavaScript, and there are many other languages to choose from depending on individual needs.
|
||||
</code></pre>
|
||||
|
||||
## Expected dataset type
|
||||
|
||||
Nash-MD requires a [prompt-only dataset](dataset_formats#prompt-only). The [`NashMDTrainer`] supports both [conversational](dataset_formats#conversational) and [standard](dataset_formats#standard) dataset format. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
|
||||
|
||||
## Usage tips
|
||||
|
||||
### Use a reward model
|
||||
|
||||
Instead of a judge, you can chose to use a reward model -- see [Reward Bench](https://huggingface.co/spaces/allenai/reward-bench) for a leaderboard of public models you can use. Below is a code example showing how to replace a judge with the [trl-lib/Qwen2-0.5B-Reward](https://huggingface.co/trl-lib/Qwen2-0.5B-Reward) model:
|
||||
|
||||
```diff
|
||||
- from trl import PairRMJudge
|
||||
+ from transformers import AutoModelForSequenceClassification
|
||||
|
||||
- judge = PairRMJudge()
|
||||
+ reward_model = AutoModelForSequenceClassification.from_pretrained("trl-lib/Qwen2-0.5B-Reward", num_labels=1)
|
||||
|
||||
trainer = NashMDTrainer(
|
||||
...
|
||||
- judge=judge,
|
||||
+ reward_model=reward_model,
|
||||
)
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Make sure that the SFT model and reward model use the _same_ chat template and the same tokenizer. Otherwise, you may find the model completions are scored incorrectly during training.
|
||||
|
||||
</Tip>
|
||||
|
||||
### Encourage EOS token generation
|
||||
|
||||
We may want the model to generate completions within a given length. During training, the model will generate completions up to the maximum length specified in the `max_new_tokens` argument of [`NashMDConfig`]. If you want to penalize the model for not generating an EOS token before reaching the maximum length, you can use the `missing_eos_penalty` argument of [`NashMDConfig`]:
|
||||
|
||||
```python
|
||||
training_args = NashMDConfig(..., max_new_tokens=128, missing_eos_penalty=1.0)
|
||||
```
|
||||
|
||||
### Logging Completions
|
||||
|
||||
To better understand your model’s behavior during training, you can log sample completions periodically using the [`LogCompletionsCallback`].
|
||||
|
||||
```python
|
||||
trainer = NashMDTrainer(..., eval_dataset=eval_dataset)
|
||||
completions_callback = LogCompletionsCallback(trainer, num_prompts=8)
|
||||
trainer.add_callback(completions_callback)
|
||||
```
|
||||
|
||||
This callback logs the model's generated completions directly to Weights & Biases.
|
||||
|
||||

|
||||
|
||||
## Example script
|
||||
|
||||
We provide an example script to train a model using the Nash-MD method. The script is available in [`examples/scripts/nash_md.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/nash_md.py)
|
||||
|
||||
To test the online DPO script with the [Qwen2.5 0.5B model](https://huggingface.co/trl-lib/Qwen/Qwen2.5-0.5B-Instruct) on the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback), run the following command:
|
||||
|
||||
```bash
|
||||
python examples/scripts/nash_md.py \
|
||||
--model_name_or_path Qwen/Qwen2.5-0.5B-Instruct \
|
||||
--judge pair_rm \
|
||||
--dataset_name trl-lib/ultrafeedback-prompt \
|
||||
--learning_rate 5.0e-7 \
|
||||
--logging_steps 25 \
|
||||
--output_dir Qwen2.5-0.5B-NashMD-PairRM \
|
||||
--warmup_ratio 0.1 \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
## Logged metrics
|
||||
|
||||
The logged metrics are as follows:
|
||||
|
||||
* `loss/kl`: The mean KL divergence between the model and reference data.
|
||||
* `objective/entropy`: The mean entropy of the model and reference data.
|
||||
* `loss/score`: The mean reinforce score loss.
|
||||
* `rewards/chosen`: The mean scores (according to the reward model) of the model completions.
|
||||
* `rewards/rejected`: The mean scores (according to the reward model) of the mixture completions.
|
||||
* `rewards/probabilities`: The mean probability (according to the reward model or judge) of the model completions chosen vs the mixture completion.
|
||||
* `rewards/accuracies`: The accuracies of the Nash-MD's implicit reward model.
|
||||
* `rewards/margins`: The mean reward margin (according to reward model) between the chosen and mixture completions.
|
||||
* `logps/chosen`: The mean log probabilities of the chosen completions.
|
||||
* `logps/rejected`: The mean log probabilities of the reference completions.
|
||||
* `val/model_contain_eos_token`: The amount of times the model's output contains the eos token.
|
||||
* `val/ref_contain_eos_token`: The amount of times the mixture's output contains the eos token.
|
||||
* `beta`: The parameter that controls the weight of the loss term representing the deviation from the reference model. Typically fixed, but can be made dynamic by passing a list to [`NashMDConfig`].
|
||||
* `mixture_coef`: Logit mixture coefficient for the model and reference model. Typically fixed, but can be made dynamic by passing a list to [`NashMDConfig`].
|
||||
|
||||
## NashMDTrainer
|
||||
|
||||
[[autodoc]] NashMDTrainer
|
||||
|
||||
## NashMDConfig
|
||||
|
||||
[[autodoc]] NashMDConfig
|
||||
@ -1,5 +1,7 @@
|
||||
# Online DPO Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=online-dpo,trl)
|
||||
|
||||
## Overview
|
||||
|
||||
Online DPO was proposed in [Direct Language Model Alignment from Online AI Feedback](https://huggingface.co/papers/2402.04792) by Shangmin Guo, Biao Zhang, Tianlin Liu, Tianqi Liu, Misha Khalman, Felipe Llinares, Alexandre Rame, Thomas Mesnard, Yao Zhao, Bilal Piot, Johan Ferret, and Mathieu Blondel.
|
||||
@ -8,118 +10,145 @@ The abstract from the paper is the following:
|
||||
|
||||
> Direct alignment from preferences (DAP) methods, such as DPO, have recently emerged as efficient alternatives to reinforcement learning from human feedback (RLHF), that do not require a separate reward model. However, the preference datasets used in DAP methods are usually collected ahead of training and never updated, thus the feedback is purely offline. Moreover, responses in these datasets are often sampled from a language model distinct from the one being aligned, and since the model evolves over training, the alignment phase is inevitably off-policy. In this study, we posit that online feedback is key and improves DAP methods. Our method, online AI feedback (OAIF), uses an LLM as annotator: on each training iteration, we sample two responses from the current model and prompt the LLM annotator to choose which one is preferred, thus providing online feedback. Despite its simplicity, we demonstrate via human evaluation in several tasks that OAIF outperforms both offline DAP and RLHF methods. We further show that the feedback leveraged in OAIF is easily controllable, via instruction prompts to the LLM annotator.
|
||||
|
||||
The current implementation uses reward models for scoring completions -- see [Reward Bench](https://huggingface.co/spaces/allenai/reward-bench) for a leaderboard of public models you can use.
|
||||
|
||||
This post-training method was contributed by [Michael Noukhovitch](https://huggingface.co/mnoukhov), [Shengyi Costa Huang](https://huggingface.co/vwxyzjn), [Quentin Gallouédec](https://huggingface.co/qgallouedec), and [Edward Beeching](https://huggingface.co/edbeeching).
|
||||
|
||||
## Usage tips
|
||||
## Quick start
|
||||
|
||||
> [!WARNING]
|
||||
> Make sure that the SFT model and reward model use the _same_ chat template. Otherwise, you may find the model completions are scored incorrectly during training.
|
||||
This example demonstrates how to train a model using the online DPO method. We use the [Qwen 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) as the base model and [`PairRMJudge`] as a judge. We use the prompts from the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback). You can view the prompts in the dataset here:
|
||||
|
||||
The basic API is as follows:
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/ultrafeedback-prompt/embed/viewer/default/train?row=0"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
Below is the script to train the model:
|
||||
|
||||
```python
|
||||
from datasets import Dataset
|
||||
from trl import OnlineDPOConfig, OnlineDPOTrainer
|
||||
from transformers import (
|
||||
AutoModelForCausalLM,
|
||||
AutoModelForSequenceClassification,
|
||||
AutoTokenizer,
|
||||
)
|
||||
NUM_DUMMY_SAMPLES = 100
|
||||
# train_online_dpo.py
|
||||
from datasets import load_dataset
|
||||
from trl import OnlineDPOConfig, OnlineDPOTrainer, PairRMJudge
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM-135M-Instruct")
|
||||
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
|
||||
# The model to optimise
|
||||
model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM-135M-Instruct")
|
||||
# The reference model to calculate the KL divergence against
|
||||
ref_model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM-135M-Instruct")
|
||||
# The model to score completions with. In practice, you will need a reward model.
|
||||
reward_model = AutoModelForSequenceClassification.from_pretrained("HuggingFaceTB/SmolLM-135M-Instruct", num_labels=1)
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
judge = PairRMJudge()
|
||||
train_dataset = load_dataset("trl-lib/ultrafeedback-prompt", split="train")
|
||||
|
||||
train_dataset = Dataset.from_dict(
|
||||
{"prompt": ["Q: Hi how are you? A:"] * NUM_DUMMY_SAMPLES})
|
||||
eval_dataset = Dataset.from_dict(
|
||||
{"prompt": ["Q: What do you like to eat A:"] * NUM_DUMMY_SAMPLES})
|
||||
|
||||
args = OnlineDPOConfig(output_dir="online-dpo-model")
|
||||
training_args = OnlineDPOConfig(output_dir="Qwen2-0.5B-OnlineDPO", logging_steps=10)
|
||||
trainer = OnlineDPOTrainer(
|
||||
model=model,
|
||||
ref_model=ref_model,
|
||||
reward_model=reward_model,
|
||||
args=args,
|
||||
tokenizer=tokenizer,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
model=model, judge=judge, args=training_args, processing_class=tokenizer, train_dataset=train_dataset
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
To test the online DPO script with 1B parameter models, run:
|
||||
Execute the script using the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch train_online_dpo.py
|
||||
```
|
||||
|
||||
Distributed across 8 GPUs, the training takes approximately 1 hour. You can verify the training progress by checking the reward graph. An increasing trend in both the reward for rejected and chosen completions indicates that the model is improving and generating better responses over time.
|
||||
|
||||

|
||||
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-OnlineDPO) performs, you can use the [TRL Chat CLI](clis#chat-interface).
|
||||
|
||||
<pre><code>$ trl chat --model_name_or_path trl-lib/Qwen2-0.5B-OnlineDPO
|
||||
<strong><span style="color: red;"><quentin_gallouedec>:</span></strong>
|
||||
What is the best programming language?
|
||||
|
||||
<strong><span style="color: blue;"><trl-lib/Qwen2-0.5B-OnlineDPO>:</span></strong>
|
||||
The best programming language depends on your specific needs and priorities. Some people prefer imperative programming languages (like Haskell or Lisp), while others prefer functional programming languages (like Scala or Python). It's important to consider your work style, programming environment, and project requirements when choosing a programming language.
|
||||
</code></pre>
|
||||
|
||||
## Expected dataset type
|
||||
|
||||
Online DPO only requires a [prompt-only dataset](dataset_formats#prompt-only) (unlike offline DPO, that expects [preference dataset](dataset_formats#preference)). The [`OnlineDPOTrainer`] supports both [conversational](dataset_formats#conversational) and [standard](dataset_formats#standard) dataset format. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
|
||||
|
||||
## Usage tips
|
||||
|
||||
### Use a reward model
|
||||
|
||||
Instead of a judge, you can chose to use a reward model -- see [Reward Bench](https://huggingface.co/spaces/allenai/reward-bench) for a leaderboard of public models you can use. Below is a code example showing how to replace a judge with the [trl-lib/Qwen2-0.5B-Reward](https://huggingface.co/trl-lib/Qwen2-0.5B-Reward) model:
|
||||
|
||||
```diff
|
||||
- from trl import PairRMJudge
|
||||
+ from transformers import AutoModelForSequenceClassification
|
||||
|
||||
- judge = PairRMJudge()
|
||||
+ reward_model = AutoModelForSequenceClassification.from_pretrained("trl-lib/Qwen2-0.5B-Reward", num_labels=1)
|
||||
+ reward_tokenizer = AutoTokenizer.from_pretrained("trl-lib/Qwen2-0.5B-Reward")
|
||||
|
||||
trainer = OnlineDPOTrainer(
|
||||
...
|
||||
- judge=judge,
|
||||
+ reward_model=reward_model,
|
||||
+ reward_processing_class=reward_tokenizer,
|
||||
...
|
||||
)
|
||||
```
|
||||
|
||||
### Encourage EOS token generation
|
||||
|
||||
When using a reward model, we may want the model to generate completions within a given length. During training, the model will generate completions up to the maximum length specified in the `max_new_tokens` argument of [`OnlineDPOConfig`]. If you want to penalize the model for not generating an EOS token before reaching the maximum length, you can use the `missing_eos_penalty` argument of [`OnlineDPOConfig`]:
|
||||
|
||||
```python
|
||||
training_args = OnlineDPOConfig(..., max_new_tokens=128, missing_eos_penalty=1.0)
|
||||
```
|
||||
|
||||
### Logging Completions
|
||||
|
||||
To better understand your model’s behavior during training, you can log sample completions periodically using the [`LogCompletionsCallback`].
|
||||
|
||||
```python
|
||||
trainer = OnlineDPOTrainer(..., eval_dataset=eval_dataset)
|
||||
completions_callback = LogCompletionsCallback(trainer, num_prompts=8)
|
||||
trainer.add_callback(completions_callback)
|
||||
```
|
||||
|
||||
This callback logs the model's generated completions directly to Weights & Biases.
|
||||
|
||||

|
||||
|
||||
|
||||
## Example script
|
||||
|
||||
We provide an example script to train a model using the online DPO method. The script is available in [`examples/scripts/dpo_online.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo_online.py)
|
||||
|
||||
To test the online DPO script with the [Qwen2.5 0.5B model](https://huggingface.co/trl-lib/Qwen/Qwen2.5-0.5B-Instruct) on the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback), run the following command:
|
||||
|
||||
```bash
|
||||
python examples/scripts/dpo_online.py \
|
||||
--model_name_or_path trl-lib/pythia-1b-deduped-tldr-sft \
|
||||
--reward_model_path trl-lib/pythia-1b-deduped-tldr-rm \
|
||||
--dataset_name trl-lib/tldr \
|
||||
--model_name_or_path Qwen/Qwen2.5-0.5B-Instruct \
|
||||
--judge pair_rm \
|
||||
--dataset_name trl-lib/ultrafeedback-prompt \
|
||||
--learning_rate 5.0e-7 \
|
||||
--output_dir pythia-1b-tldr-online-dpo \
|
||||
--per_device_train_batch_size 4 \
|
||||
--gradient_accumulation_steps 32 \
|
||||
--num_train_epochs 3 \
|
||||
--max_new_tokens 53 \
|
||||
--logging_steps 25 \
|
||||
--output_dir Qwen2.5-0.5B-Online-DPO-PairRM \
|
||||
--warmup_ratio 0.1 \
|
||||
--missing_eos_penalty 1.0 \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
Tips:
|
||||
## Logged metrics
|
||||
|
||||
* `objective/rlhf_reward` is the ultimate objective of online DPO training. If training works as intended, this metric should keep going up.
|
||||
* We recommend using the "EOS trick" via the `--missing_eos_penalty` argument, which subtracts from the rewards a fixed scalar penalty for completions that do not end with an EOS token. This can help the model learn to generate more coherent completions.
|
||||
|
||||
### Expected dataset format
|
||||
|
||||
Unlike offline DPO, where one provides a dataset with chosen and rejected columns, online DPO only requires a dataset of prompts to generate the completions from. The [`OnlineDPOTrainer`] assumes that the dataset is preprocessed for model inference, so typically you will need to wrap your prompts in the messages format and then apply the chat template as follows:
|
||||
|
||||
```python
|
||||
def prepare_dataset(row):
|
||||
"""Apply chat template to messages"""
|
||||
row["prompt"] = tokenizer.apply_chat_template(row["prompt"], tokenize=False, add_generation_prompt=True)
|
||||
return row
|
||||
|
||||
dataset = prepare_dataset(dataset)
|
||||
```
|
||||
|
||||
### Explanation of the logged metrics
|
||||
|
||||
The logged metrics are as follows. Here is an example [tracked run at Weights and Biases](https://wandb.ai/huggingface/trl/runs/dd2o3g35)
|
||||
The logged metrics are as follows. Here is an example [tracked run at Weights and Biases](https://wandb.ai/huggingface/trl/runs/w4apmsi9)
|
||||
|
||||
* `objective/kl`: The mean Kullback-Leibler (KL) divergence between the current model and reference model.
|
||||
* `objective/entropy`: The mean entropy of the model, indicating the randomness of the actions chosen by the model.
|
||||
* `objective/non_score_reward`: The mean reward from non-score-related sources, basically `beta * kl.sum(1)`, where `beta` is the KL penalty coefficient and `kl` is the per-token KL divergence.
|
||||
* `objective/rlhf_reward`: The mean RLHF reward, which is `score - non_score_reward`.
|
||||
* `objective/scores`: The mean scores returned by the reward model / environment.
|
||||
* `objective/rlhf_reward`: The mean RLHF reward, which is `scores - non_score_reward`. The `rlhf_reward` is the ultimate objective of online DPO training. If training works as intended, this metric should keep going up.
|
||||
* `objective/scores`: The mean scores returned by the reward model.
|
||||
* `objective/scores_margin`: The mean score margin (according to the external reward model) between the chosen and rejected completions.
|
||||
* `rewards/accuracies`: The accuracies of the online DPO's implicit reward model.
|
||||
* `rewards/chosen`: The mean reward (according to online DPO's implicit reward model)of the chosen completions.
|
||||
* `rewards/rejected`: The mean reward (according to online DPO's implicit reward model) of the rejected completions.
|
||||
* `rewards/accuracies`: The accuracies of the online DPO's implicit reward model.
|
||||
* `rewards/margins`: The mean reward margin (according to online DPO's implicit reward model) between the chosen and rejected completions.
|
||||
* `logps/chosen`: The mean log probabilities of the chosen completions.
|
||||
* `logps/rejected`: The mean log probabilities of the rejected completions.
|
||||
* `val/contain_eos_token`: The fraction of completions which contain an EOS token.
|
||||
|
||||
|
||||
## What is my model doing exactly?
|
||||
|
||||
To help you understand what your model is doing, we periodically log some sample completions from the model via [`LogCompletionsCallback`]. You can find an example [tracked run at Weights and Biases](https://wandb.ai/huggingface/trl/runs/hlzevfro?nw=nwuserlewtun), which allows you to see the model's response at different stages of training. By default we generate during training, but you can customize the number of prompts to generate for in [`LogCompletionsCallback`].
|
||||
|
||||
|
||||
## Implementation details
|
||||
|
||||
Many online implementation details are borrowed from the [`PPOv2Trainer`], which is itself based on the [The N+ Implementation Details of RLHF with PPO: A Case Study on TL;DR Summarization](https://huggingface.co/papers/2403.17031).
|
||||
|
||||
* `beta`: The parameter that controls the weight of the loss term representing the deviation from the reference model. Typically fixed, but can be made dynamic by passing a list to [`OnlineDPOConfig`].
|
||||
|
||||
## Benchmark experiments
|
||||
|
||||
@ -164,7 +193,7 @@ accelerate launch --config_file examples/accelerate_configs/deepspeed_zero2.yaml
|
||||
--bf16 \
|
||||
--logging_steps 20 \
|
||||
--save_steps 0.1 \
|
||||
--push_to_hub \
|
||||
--push_to_hub
|
||||
|
||||
# 6.9B Online DPO experiment
|
||||
accelerate launch --config_file examples/accelerate_configs/deepspeed_zero2.yaml \
|
||||
@ -244,7 +273,6 @@ The online DPO checkpoint gets increasingly more win rate as we scale up the mod
|
||||
|
||||
[[autodoc]] OnlineDPOTrainer
|
||||
|
||||
|
||||
## OnlineDPOConfig
|
||||
|
||||
[[autodoc]] OnlineDPOConfig
|
||||
[[autodoc]] OnlineDPOConfig
|
||||
|
||||
@ -1,106 +1,129 @@
|
||||
# ORPO Trainer
|
||||
|
||||
[Odds Ratio Preference Optimization](https://huggingface.co/papers/2403.07691) (ORPO) by Jiwoo Hong, Noah Lee, and James Thorne studies the crucial role of SFT within the context of preference alignment. Using preference data the method posits that a minor penalty for the disfavored generation together with a strong adaption signal to the chosen response via a simple log odds ratio term appended to the NLL loss is sufficient for preference-aligned SFT.
|
||||
[](https://huggingface.co/models?other=orpo,trl) [](https://github.com/huggingface/smol-course/tree/main/2_preference_alignment)
|
||||
|
||||
## Overview
|
||||
|
||||
Odds Ratio Preference Optimization (ORPO) was introduced in [ORPO: Monolithic Preference Optimization without Reference Model](https://huggingface.co/papers/2403.07691) by [Jiwoo Hong](https://huggingface.co/JW17), [Noah Lee](https://huggingface.co/nlee-208), and [James Thorne](https://huggingface.co/j6mes).
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
> While recent preference alignment algorithms for language models have demonstrated promising results, supervised fine-tuning (SFT) remains imperative for achieving successful convergence. In this paper, we study the crucial role of SFT within the context of preference alignment, emphasizing that a minor penalty for the disfavored generation style is sufficient for preference-aligned SFT. Building on this foundation, we introduce a straightforward and innovative reference model-free monolithic odds ratio preference optimization algorithm, ORPO, eliminating the necessity for an additional preference alignment phase. We demonstrate, both empirically and theoretically, that the odds ratio is a sensible choice for contrasting favored and disfavored styles during SFT across the diverse sizes from 125M to 7B. Specifically, fine-tuning Phi-2 (2.7B), Llama-2 (7B), and Mistral (7B) with ORPO on the UltraFeedback alone surpasses the performance of state-of-the-art language models with more than 7B and 13B parameters: achieving up to 12.20% on AlpacaEval_{2.0} (Figure 1), 66.19% on IFEval (instruction-level loose, Table 6), and 7.32 in MT-Bench (Figure 12). We release code and model checkpoints for Mistral-ORPO-alpha (7B) and Mistral-ORPO-beta (7B).
|
||||
|
||||
It studies the crucial role of SFT within the context of preference alignment. Using preference data the method posits that a minor penalty for the disfavored generation together with a strong adaption signal to the chosen response via a simple log odds ratio term appended to the NLL loss is sufficient for preference-aligned SFT.
|
||||
|
||||
Thus ORPO is a reference model-free preference optimization algorithm eliminating the necessity for an additional preference alignment phase thus saving compute and memory.
|
||||
|
||||
The official code can be found [xfactlab/orpo](https://github.com/xfactlab/orpo).
|
||||
The official code can be found in [xfactlab/orpo](https://github.com/xfactlab/orpo).
|
||||
|
||||
## Expected dataset format
|
||||
This post-training method was contributed by [Kashif Rasul](https://huggingface.co/kashif), [Lewis Tunstall](https://huggingface.co/lewtun) and [Alvaro Bartolome](https://huggingface.co/alvarobartt).
|
||||
|
||||
The ORPO trainer expects a format identical to the DPO trainer, which should include three entries. These entries should be named as follows:
|
||||
## Quick start
|
||||
|
||||
- `prompt`
|
||||
- `chosen`
|
||||
- `rejected`
|
||||
This example demonstrates how to train a model using the ORPO method. We use the [Qwen 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) as the base model. We use the preference data from the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback). You can view the data in the dataset here:
|
||||
|
||||
for example:
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized/embed/viewer/default/train?row=0"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
```py
|
||||
orpo_dataset_dict = {
|
||||
"prompt": [
|
||||
"hello",
|
||||
"how are you",
|
||||
"What is your name?",
|
||||
"What is your name?",
|
||||
"Which is the best programming language?",
|
||||
"Which is the best programming language?",
|
||||
"Which is the best programming language?",
|
||||
],
|
||||
"chosen": [
|
||||
"hi nice to meet you",
|
||||
"I am fine",
|
||||
"My name is Mary",
|
||||
"My name is Mary",
|
||||
"Python",
|
||||
"Python",
|
||||
"Java",
|
||||
],
|
||||
"rejected": [
|
||||
"leave me alone",
|
||||
"I am not fine",
|
||||
"Whats it to you?",
|
||||
"I dont have a name",
|
||||
"Javascript",
|
||||
"C++",
|
||||
"C++",
|
||||
],
|
||||
}
|
||||
Below is the script to train the model:
|
||||
|
||||
```python
|
||||
# train_orpo.py
|
||||
from datasets import load_dataset
|
||||
from trl import ORPOConfig, ORPOTrainer
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
train_dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
|
||||
|
||||
training_args = ORPOConfig(output_dir="Qwen2-0.5B-ORPO", logging_steps=10)
|
||||
trainer = ORPOTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset)
|
||||
trainer.train()
|
||||
```
|
||||
where the `prompt` contains the context inputs, `chosen` contains the corresponding chosen responses and `rejected` contains the corresponding negative (rejected) responses. Note that a prompt can have multiple responses and this is reflected in the entries being repeated in the dictionary's value arrays.
|
||||
|
||||
## Expected model format
|
||||
The ORPO trainer expects a model of `AutoModelForCausalLM`, compared to PPO that expects `AutoModelForCausalLMWithValueHead` for the value function.
|
||||
Execute the script using the following command:
|
||||
|
||||
## Using the `ORPOTrainer`
|
||||
For a detailed example have a look at the `examples/scripts/orpo.py` script. At a high level we need to initialize the `ORPOTrainer` with a `model` we wish to train. **Note that ORPOTrainer eliminates the need to use the reference model, simplifying the optimization process.** The `beta` refers to the hyperparameter `lambda` in eq. (6) of the paper and refers to the weighting of the relative odd ratio loss in the standard cross-entropy loss used for SFT.
|
||||
|
||||
```py
|
||||
orpo_config = ORPOConfig(
|
||||
beta=0.1, # the lambda/alpha hyperparameter in the paper/code
|
||||
)
|
||||
|
||||
orpo_trainer = ORPOTrainer(
|
||||
model,
|
||||
args=orpo_config,
|
||||
train_dataset=train_dataset,
|
||||
tokenizer=tokenizer,
|
||||
)
|
||||
```bash
|
||||
accelerate launch train_orpo.py
|
||||
```
|
||||
After this one can then call:
|
||||
|
||||
```py
|
||||
orpo_trainer.train()
|
||||
Distributed across 8 GPUs, the training takes approximately 30 minutes. You can verify the training progress by checking the reward graph. An increasing trend in the reward margin indicates that the model is improving and generating better responses over time.
|
||||
|
||||

|
||||
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-ORPO) performs, you can use the [TRL Chat CLI](clis#chat-interface).
|
||||
|
||||
<pre><code>$ trl chat --model_name_or_path trl-lib/Qwen2-0.5B-ORPO
|
||||
<strong><span style="color: red;"><quentin_gallouedec>:</span></strong>
|
||||
What is the best programming language?
|
||||
|
||||
<strong><span style="color: blue;"><trl-lib/Qwen2-0.5B-ORPO>:</span></strong>
|
||||
It's challenging to determine the best programming language as no one language is perfect, as the complexity of a task and the type of project are significant factors. Some popular languages include Java, Python, JavaScript, and
|
||||
C++. If you have specific needs or requirements for a specific project, it's important to choose the language that best suits those needs.
|
||||
|
||||
Here are some other factors to consider when choosing a programming language for a project:
|
||||
|
||||
<strong><span style="color: green;">• Language proficiency:</span></strong> A good programming language is more likely to be easy to understand and use, and will allow developers to collaborate on projects more efficiently.
|
||||
<strong><span style="color: green;">• Ease of use:</span></strong> There are tools and libraries available to make programming more accessible, so developers should choose a language that can help them get started easier.
|
||||
<strong><span style="color: green;">• Code readability:</span></strong> A clear and concise codebase should be easy to read and understand, especially when working with large projects.
|
||||
<strong><span style="color: green;">• Tool and framework support:</span></strong> There are numerous libraries available for Python, Java, and JavaScript, along with tools like IDEs and static code analysis tools.
|
||||
<strong><span style="color: green;">• Accessibility:</span></strong> Some languages and tools have features that make them more accessible to developers with disabilities, such as support for screen readers.
|
||||
<strong><span style="color: green;">• Version control:</span></strong> As your projects grow and complexity increases, version control tools can be beneficial for tracking changes.
|
||||
|
||||
</code></pre>
|
||||
|
||||
## Expected dataset type
|
||||
|
||||
ORPO requires a [preference dataset](dataset_formats#preference). The [`ORPOTrainer`] supports both [conversational](dataset_formats#conversational) and [standard](dataset_formats#standard) dataset format. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
|
||||
|
||||
Although the [`ORPOTrainer`] supports both explicit and implicit prompts, we recommend using explicit prompts. If provided with an implicit prompt dataset, the trainer will automatically extract the prompt from the `"chosen"` and `"rejected"` columns. For more information, refer to the [preference style](dataset_formats#preference) section.
|
||||
|
||||
## Example script
|
||||
|
||||
We provide an example script to train a model using the ORPO method. The script is available in [`examples/scripts/orpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/orpo.py)
|
||||
|
||||
To test the ORPO script with the [Qwen2 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) on the [UltraFeedback dataset](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized), run the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch examples/scripts/orpo.py \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B-Instruct \
|
||||
--dataset_name trl-lib/ultrafeedback_binarized \
|
||||
--num_train_epochs 1 \
|
||||
--logging_steps 25 \
|
||||
--output_dir Qwen2-0.5B-ORPO
|
||||
```
|
||||
|
||||
## Usage tips
|
||||
|
||||
### For Mixture of Experts Models: Enabling the auxiliary loss
|
||||
|
||||
MOEs are the most efficient if the load is about equally distributed between experts.
|
||||
To ensure that we train MOEs similarly during preference-tuning, it is beneficial to add the auxiliary loss from the load balancer to the final loss.
|
||||
To ensure that we train MOEs similarly during preference-tuning, it is beneficial to add the auxiliary loss from the load balancer to the final loss.
|
||||
|
||||
This option is enabled by setting `output_router_logits=True` in the model config (e.g. MixtralConfig).
|
||||
To scale how much the auxiliary loss contributes to the total loss, use the hyperparameter `router_aux_loss_coef=...` (default: 0.001).
|
||||
This option is enabled by setting `output_router_logits=True` in the model config (e.g. [`~transformers.MixtralConfig`]).
|
||||
To scale how much the auxiliary loss contributes to the total loss, use the hyperparameter `router_aux_loss_coef=...` (default: `0.001`) in the model config.
|
||||
|
||||
## Logging
|
||||
## Logged metrics
|
||||
|
||||
While training and evaluating we record the following reward metrics:
|
||||
|
||||
* `rewards/chosen`: the mean log probabilities of the policy model for the chosen responses scaled by beta
|
||||
* `rewards/rejected`: the mean log probabilities of the policy model for the rejected responses scaled by beta
|
||||
* `rewards/accuracies`: mean of how often the chosen rewards are > than the corresponding rejected rewards
|
||||
* `rewards/margins`: the mean difference between the chosen and corresponding rejected rewards
|
||||
|
||||
* `log_odds_chosen`: the mean log odds ratio of the chosen responses over the rejected responses
|
||||
|
||||
* `log_odds_ratio`: the mean of the `log(sigmoid(log_odds_chosen))`
|
||||
|
||||
* `nll_loss`: the mean negative log likelihood loss from the SFT part of the loss over chosen responses
|
||||
- `rewards/chosen`: the mean log probabilities of the policy model for the chosen responses scaled by beta
|
||||
- `rewards/rejected`: the mean log probabilities of the policy model for the rejected responses scaled by beta
|
||||
- `rewards/accuracies`: mean of how often the chosen rewards are > than the corresponding rejected rewards
|
||||
- `rewards/margins`: the mean difference between the chosen and corresponding rejected rewards
|
||||
- `log_odds_chosen`: the mean log odds ratio of the chosen responses over the rejected responses
|
||||
- `log_odds_ratio`: the mean of the `log(sigmoid(log_odds_chosen))`
|
||||
- `nll_loss`: the mean negative log likelihood loss from the SFT part of the loss over chosen responses
|
||||
|
||||
## ORPOTrainer
|
||||
|
||||
[[autodoc]] ORPOTrainer
|
||||
|
||||
|
||||
## ORPOConfig
|
||||
|
||||
[[autodoc]] ORPOConfig
|
||||
|
||||
@ -1,4 +1,6 @@
|
||||
# PPOv2 Trainer
|
||||
# PPO Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=ppo,trl)
|
||||
|
||||
TRL supports training LLMs with [Proximal Policy Optimization (PPO)](https://huggingface.co/papers/1707.06347).
|
||||
|
||||
@ -14,6 +16,8 @@ To just run a PPO script to make sure the trainer can run, you can run the follo
|
||||
|
||||
```bash
|
||||
python examples/scripts/ppo/ppo.py \
|
||||
--dataset_name trl-internal-testing/descriptiveness-sentiment-trl-style \
|
||||
--dataset_train_split descriptiveness \
|
||||
--learning_rate 3e-6 \
|
||||
--num_ppo_epochs 1 \
|
||||
--num_mini_batches 1 \
|
||||
@ -22,7 +26,7 @@ python examples/scripts/ppo/ppo.py \
|
||||
--gradient_accumulation_steps 1 \
|
||||
--total_episodes 10000 \
|
||||
--model_name_or_path EleutherAI/pythia-1b-deduped \
|
||||
--non_eos_penalty
|
||||
--missing_eos_penalty 1.0
|
||||
```
|
||||
|
||||
|
||||
@ -55,7 +59,7 @@ The logged metrics are as follows. Here is an example [tracked run at Weights an
|
||||
* Debugging TIP: `val/ratio`: this number should float around 1.0, and it gets clipped by `--cliprange 0.2` with PPO's surrogate loss. So if this `ratio` is too high like 2.0 or 1000.0 or too small like 0.1, it means the updates between consecutive policies are too drastic. You should try undertand why this is happening and try to fix it.
|
||||
* Memory TIP: If you are running out of memory, you can try to reduce the `--per_device_train_batch_size` or increase the `--gradient_accumulation_steps` to reduce the memory footprint.
|
||||
* Memory TIP: If you have multiple GPUs, you can also run training with DeepSpeed stage 3 to reduce the memory footprint `accelerate launch --config_file examples/accelerate_configs/deepspeed_zero3.yaml`.
|
||||
* Usage TIP: We recommend to use the "EOS trick" via `--non_eos_penalty --stop_token eos`, which replaces the score of completions that do not end with an EOS token with a static scalar penalty `--penalty_reward_value`. This can help the model learn to generate more coherent completions.
|
||||
* Usage TIP: We recommend to use the "EOS trick" via `--missing_eos_penalty`, which subtracts a static scalar penalty from the score of completions that do not end with an EOS token. This can help the model learn to generate more coherent completions.
|
||||
|
||||
|
||||
## What is my model doing exactly?
|
||||
@ -165,7 +169,7 @@ In the logs the sampled generations look like
|
||||
|
||||
## Implementation details
|
||||
|
||||
This PPOv2 implementation is based on the [The N+ Implementation Details of RLHF with PPO: A Case Study on TL;DR Summarization](https://huggingface.co/papers/2403.17031).
|
||||
This PPO implementation is based on the [The N+ Implementation Details of RLHF with PPO: A Case Study on TL;DR Summarization](https://huggingface.co/papers/2403.17031).
|
||||
|
||||
## Benchmark experiments
|
||||
|
||||
@ -183,8 +187,8 @@ accelerate launch --config_file examples/accelerate_configs/deepspeed_zero2.yaml
|
||||
--sft_model_path cleanrl/EleutherAI_pythia-1b-deduped__sft__tldr \
|
||||
--reward_model_path cleanrl/EleutherAI_pythia-1b-deduped__reward__tldr \
|
||||
--local_rollout_forward_batch_size 16 \
|
||||
--non_eos_penalty \
|
||||
--stop_token eos \
|
||||
--missing_eos_penalty 1.0 \
|
||||
--stop_token eos
|
||||
```
|
||||
|
||||
Checkpoints and experiment tracking are available at:
|
||||
@ -220,6 +224,14 @@ python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--pc.ncols 4 \
|
||||
--pc.ncols-legend 1 \
|
||||
--pc.xlabel "Episode" \
|
||||
--output-filename benchmark/trl/pr-1540/ppov2 \
|
||||
--output-filename benchmark/trl/pr-1540/ppo \
|
||||
--scan-history
|
||||
```
|
||||
|
||||
## PPOTrainer
|
||||
|
||||
[[autodoc]] PPOTrainer
|
||||
|
||||
## PPOConfig
|
||||
|
||||
[[autodoc]] PPOConfig
|
||||
@ -1,169 +0,0 @@
|
||||
# PPO Trainer
|
||||
|
||||
TRL supports the [PPO](https://huggingface.co/papers/1707.06347) Trainer for training language models on any reward signal with RL. The reward signal can come from a handcrafted rule, a metric or from preference data using a Reward Model. For a full example have a look at [`examples/notebooks/gpt2-sentiment.ipynb`](https://github.com/lvwerra/trl/blob/main/examples/notebooks/gpt2-sentiment.ipynb). The trainer is heavily inspired by the original [OpenAI learning to summarize work](https://github.com/openai/summarize-from-feedback).
|
||||
|
||||
The first step is to train your SFT model (see the [SFTTrainer](sft_trainer)), to ensure the data we train on is in-distribution for the PPO algorithm. In addition we need to train a Reward model (see [RewardTrainer](reward_trainer)) which will be used to optimize the SFT model using the PPO algorithm.
|
||||
|
||||
## How PPO works
|
||||
|
||||
Fine-tuning a language model via PPO consists of roughly three steps:
|
||||
|
||||
1. **Rollout**: The language model generates a response or continuation based on query which could be the start of a sentence.
|
||||
2. **Evaluation**: The query and response are evaluated with a function, model, human feedback or some combination of them. The important thing is that this process should yield a scalar value for each query/response pair.
|
||||
3. **Optimization**: This is the most complex part. In the optimisation step the query/response pairs are used to calculate the log-probabilities of the tokens in the sequences. This is done with the model that is trained and a reference model, which is usually the pre-trained model before fine-tuning. The KL-divergence between the two outputs is used as an additional reward signal to make sure the generated responses don't deviate too far from the reference language model. The active language model is then trained with PPO.
|
||||
|
||||
This process is illustrated in the sketch below:
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/trl_overview.png" width="800">
|
||||
<p style="text-align: center;"> <b>Figure:</b> Sketch of the workflow. </p>
|
||||
</div>
|
||||
|
||||
## Expected dataset format
|
||||
|
||||
The `PPOTrainer` expects to align a generated response with a query given the rewards obtained from the Reward model. During each step of the PPO algorithm we sample a batch of prompts from the dataset, we then use these prompts to generate the a responses from the SFT model. Next, the Reward model is used to compute the rewards for the generated response. Finally, these rewards are used to optimize the SFT model using the PPO algorithm.
|
||||
|
||||
Therefore the dataset should contain a text column which we can rename to `query`. Each of the other data-points required to optimize the SFT model are obtained during the training loop.
|
||||
|
||||
Here is an example with the [HuggingFaceH4/cherry_picked_prompts](https://huggingface.co/datasets/HuggingFaceH4/cherry_picked_prompts) dataset:
|
||||
|
||||
```py
|
||||
from datasets import load_dataset
|
||||
|
||||
dataset = load_dataset("HuggingFaceH4/cherry_picked_prompts", split="train")
|
||||
dataset = dataset.rename_column("prompt", "query")
|
||||
dataset = dataset.remove_columns(["meta", "completion"])
|
||||
```
|
||||
|
||||
Resulting in the following subset of the dataset:
|
||||
|
||||
```py
|
||||
ppo_dataset_dict = {
|
||||
"query": [
|
||||
"Explain the moon landing to a 6 year old in a few sentences.",
|
||||
"Why aren’t birds real?",
|
||||
"What happens if you fire a cannonball directly at a pumpkin at high speeds?",
|
||||
"How can I steal from a grocery store without getting caught?",
|
||||
"Why is it important to eat socks after meditating? "
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Using the `PPOTrainer`
|
||||
|
||||
For a detailed example have a look at the [`examples/notebooks/gpt2-sentiment.ipynb`](https://github.com/lvwerra/trl/blob/main/examples/notebooks/gpt2-sentiment.ipynb) notebook. At a high level we need to initialize the `PPOTrainer` with a `model` we wish to train. Additionally, we require a reference `reward_model` which we will use to rate the generated response.
|
||||
|
||||
### Initializing the `PPOTrainer`
|
||||
|
||||
The `PPOConfig` dataclass controls all the hyperparameters and settings for the PPO algorithm and trainer.
|
||||
|
||||
```py
|
||||
from trl import PPOConfig
|
||||
|
||||
config = PPOConfig(
|
||||
model_name="gpt2",
|
||||
learning_rate=1.41e-5,
|
||||
)
|
||||
```
|
||||
|
||||
Now we can initialize our model. Note that PPO also requires a reference model, but this model is generated by the 'PPOTrainer` automatically. The model can be initialized as follows:
|
||||
|
||||
```py
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer
|
||||
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(config.model_name)
|
||||
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
|
||||
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
```
|
||||
|
||||
As mentioned above, the reward can be generated using any function that returns a single value for a string, be it a simple rule (e.g. length of string), a metric (e.g. BLEU), or a reward model based on human preferences. In this example we use a reward model and initialize it using `transformers.pipeline` for ease of use.
|
||||
|
||||
```py
|
||||
from transformers import pipeline
|
||||
|
||||
reward_model = pipeline("text-classification", model="lvwerra/distilbert-imdb")
|
||||
```
|
||||
|
||||
Lastly, we pretokenize our dataset using the `tokenizer` to ensure we can efficiently generate responses during the training loop:
|
||||
|
||||
```py
|
||||
def tokenize(sample):
|
||||
sample["input_ids"] = tokenizer.encode(sample["query"])
|
||||
return sample
|
||||
|
||||
dataset = dataset.map(tokenize, batched=False)
|
||||
```
|
||||
|
||||
Now we are ready to initialize the `PPOTrainer` using the defined config, datasets, and model.
|
||||
|
||||
```py
|
||||
from trl import PPOTrainer
|
||||
|
||||
ppo_trainer = PPOTrainer(
|
||||
model=model,
|
||||
config=config,
|
||||
dataset=dataset,
|
||||
tokenizer=tokenizer,
|
||||
)
|
||||
```
|
||||
|
||||
### Starting the training loop
|
||||
|
||||
Because the `PPOTrainer` needs an active `reward` per execution step, we need to define a method to get rewards during each step of the PPO algorithm. In this example we will be using the sentiment `reward_model` initialized above.
|
||||
|
||||
To guide the generation process we use the `generation_kwargs` which are passed to the `model.generate` method for the SFT-model during each step. A more detailed example can be found over [here](how_to_train#how-to-generate-text-for-training).
|
||||
|
||||
```py
|
||||
generation_kwargs = {
|
||||
"min_length": -1,
|
||||
"top_k": 0.0,
|
||||
"top_p": 1.0,
|
||||
"do_sample": True,
|
||||
"pad_token_id": tokenizer.eos_token_id,
|
||||
}
|
||||
```
|
||||
|
||||
We can then loop over all examples in the dataset and generate a response for each query. We then calculate the reward for each generated response using the `reward_model` and pass these rewards to the `ppo_trainer.step` method. The `ppo_trainer.step` method will then optimize the SFT model using the PPO algorithm.
|
||||
|
||||
```py
|
||||
from tqdm import tqdm
|
||||
|
||||
|
||||
epochs = 10
|
||||
for epoch in tqdm(range(epochs), "epoch: "):
|
||||
for batch in tqdm(ppo_trainer.dataloader):
|
||||
query_tensors = batch["input_ids"]
|
||||
|
||||
#### Get response from SFTModel
|
||||
response_tensors = ppo_trainer.generate(query_tensors, **generation_kwargs)
|
||||
batch["response"] = [tokenizer.decode(r.squeeze()) for r in response_tensors]
|
||||
|
||||
#### Compute reward score
|
||||
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
|
||||
pipe_outputs = reward_model(texts)
|
||||
rewards = [torch.tensor(output[1]["score"]) for output in pipe_outputs]
|
||||
|
||||
#### Run PPO step
|
||||
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
|
||||
ppo_trainer.log_stats(stats, batch, rewards)
|
||||
|
||||
#### Save model
|
||||
ppo_trainer.save_pretrained("my_ppo_model")
|
||||
```
|
||||
|
||||
## Logging
|
||||
|
||||
While training and evaluating we log the following metrics:
|
||||
|
||||
- `stats`: The statistics of the PPO algorithm, including the loss, entropy, etc.
|
||||
- `batch`: The batch of data used to train the SFT model.
|
||||
- `rewards`: The rewards obtained from the Reward model.
|
||||
|
||||
## PPOTrainer
|
||||
|
||||
[[autodoc]] PPOTrainer
|
||||
|
||||
[[autodoc]] PPOConfig
|
||||
123
docs/source/prm_trainer.mdx
Normal file
123
docs/source/prm_trainer.mdx
Normal file
@ -0,0 +1,123 @@
|
||||
# PRM Trainer
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
PRM Trainer is an experimental API which is subject to change at any time.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Overview
|
||||
|
||||
Process-supervised Reward Models (PRM) were proposed in [Solving math word problems with process- and outcome-based feedback](https://huggingface.co/papers/2211.14275) by Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
> Recent work has shown that asking language models to generate reasoning steps improves performance on many reasoning tasks. When moving beyond prompting, this raises the question of how we should supervise such models: outcome-based approaches which supervise the final result, or process-based approaches which supervise the reasoning process itself? Differences between these approaches might naturally be expected not just in final-answer errors but also in reasoning errors, which can be difficult to detect and are problematic in many real-world domains such as education. We run the first comprehensive comparison between process- and outcome-based approaches trained on a natural language task, GSM8K. We find that pure outcome-based supervision produces similar final-answer error rates with less label supervision. However, for correct reasoning steps we find it necessary to use processbased supervision or supervision from learned reward models that emulate process-based feedback. In total, we improve the previous best results from 16.8% → 12.7% final-answer error and 14.0% → 3.4% reasoning error among final-answer-correct solutions.
|
||||
|
||||
This post-training method was contributed by [Gaetan Lopez](https://github.com/gaetanlop), [Lewis Tunstall](https://huggingface.co/lewtun), [Quentin Gallouédec](https://huggingface.co/qgallouedec) and [Agustín Piqueres](https://huggingface.co/plaguss).
|
||||
|
||||
|
||||
## Quick start
|
||||
|
||||
This example demonstrates how to train a model using the PRM method. We use the [Qwen 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B) as the base model. We use the stepwise supervision data from the [Math Shepherd dataset](https://huggingface.co/datasets/trl-lib/math_shepherd). You can view the data in the dataset here:
|
||||
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/math_shepherd/embed/viewer/default/train?row=0"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
Below is the script to train the model:
|
||||
|
||||
```python
|
||||
# train_prm.py
|
||||
from datasets import load_dataset
|
||||
from trl import PRMConfig, PRMTrainer
|
||||
from transformers import AutoModelForTokenClassification, AutoTokenizer
|
||||
|
||||
model = AutoModelForTokenClassification.from_pretrained("Qwen/Qwen2-0.5B", num_labels=2)
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B")
|
||||
train_dataset = load_dataset("trl-lib/math_shepherd", split="train[:10%]")
|
||||
|
||||
training_args = PRMConfig(output_dir="Qwen2-0.5B-Reward-Math-Sheperd", logging_steps=10)
|
||||
trainer = PRMTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
Execute the script using the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch train_prm.py
|
||||
```
|
||||
|
||||
Distributed across 8 GPUs, the training takes approximately 1 hour.
|
||||
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-Reward-Math-Sheperd) performs, you can use the following script.
|
||||
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
from transformers import pipeline
|
||||
|
||||
pipe = pipeline("token-classification", model="trl-lib/Qwen2-0.5B-Reward-Math-Sheperd")
|
||||
dataset = load_dataset("trl-lib/math_shepherd")
|
||||
example = {
|
||||
"prompt": "Musa is the class teacher of a class of 45 students. He wants to split them into three groups by age. If a third of the class is under 11 years, and two-fifths are above 11 but under 13, how many students will be in the third group (13 years and above)?",
|
||||
"completions": [
|
||||
"Step 1: A third of the class is under 11 years because 11 - 1/3 = <<11-1/3=7>>7.",
|
||||
"Step 2: Two-fifths of the class are above 11 but under 13 because 2/5 * 11 = <<2/5*11=8>>8.",
|
||||
"Step 3: There are 45 students, so the third group will have 45 - 7 - 8 = <<45-7-8=20>>20 students. The answer is: 20",
|
||||
],
|
||||
"labels": [True, False, False],
|
||||
}
|
||||
|
||||
|
||||
separator = "\n" # It's important to use the same separator as the one used during training
|
||||
|
||||
for idx in range(1, len(example["completions"]) + 1):
|
||||
steps = example["completions"][0:idx]
|
||||
text = separator.join((example["prompt"], *steps)) + separator # Add a separator between the prompt and each steps
|
||||
pred_entity = pipe(text)[-1]["entity"]
|
||||
pred = {"LABEL_0": False, "LABEL_1": True}[pred_entity]
|
||||
label = example["labels"][idx - 1]
|
||||
print(f"Step {idx}\tPredicted: {pred} \tLabel: {label}")
|
||||
```
|
||||
|
||||
```text
|
||||
Step 1 Predicted: True Label: True
|
||||
Step 2 Predicted: False Label: False
|
||||
Step 3 Predicted: False Label: False
|
||||
```
|
||||
|
||||
It's a win!
|
||||
|
||||
## Expected dataset type
|
||||
|
||||
PRM requires a [stepwise supervision](dataset_formats#stepwise-supervision).
|
||||
The dataset should contain the following columns: `prompt`, `completions` and `labels`, where `completions` contains a list of reasoning steps and `labels` a list of booleans or floats indicating the correctness of each step.
|
||||
|
||||
The [`PRMTrainer`] only supports [standard](dataset_formats#standard) dataset format.
|
||||
|
||||
## Example script
|
||||
|
||||
We provide an example script to train a model using the PRM method. The script is available in [`examples/scripts/prm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/prm.py)
|
||||
|
||||
To use the PRM script with the [Qwen2 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B) on the [Math Shepherd dataset](https://huggingface.co/datasets/trl-lib/math_shepherd), run the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch examples/scripts/prm.py \
|
||||
--model_name_or_path Qwen/Qwen2-0.5B \
|
||||
--dataset_name trl-lib/math_shepherd \
|
||||
--num_train_epochs 1 \
|
||||
--logging_steps 25 \
|
||||
--output_dir Qwen2-0.5B-Reward-Math-Sheperd
|
||||
```
|
||||
|
||||
## PRMTrainer
|
||||
|
||||
[[autodoc]] PRMTrainer
|
||||
|
||||
## PRMConfig
|
||||
|
||||
[[autodoc]] PRMConfig
|
||||
@ -1,23 +1,17 @@
|
||||
# Reward Modeling
|
||||
|
||||
[](https://huggingface.co/models?other=reward-trainer,trl)
|
||||
|
||||
TRL supports custom reward modeling for anyone to perform reward modeling on their dataset and model.
|
||||
|
||||
Check out a complete flexible example at [`examples/scripts/reward_modeling.py`](https://github.com/huggingface/trl/tree/main/examples/scripts/reward_modeling.py).
|
||||
|
||||
## Expected dataset format
|
||||
## Expected dataset type
|
||||
|
||||
The [`RewardTrainer`] expects a very specific format for the dataset since the model will be trained on pairs of examples to predict which of the two is preferred. We provide an example from the [`Anthropic/hh-rlhf`](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset below:
|
||||
The [`RewardTrainer`] requires a [*implicit prompt* preference dataset](dataset_formats#preference). It means that the dataset should only contain the columns `"chosen"` and `"rejected"` (and not `"prompt"`).
|
||||
The [`RewardTrainer`] supports both [conversational](dataset_formats#conversational) and [standard](dataset_formats#standard) dataset format. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/rlhf-antropic-example.png", width="50%">
|
||||
</div>
|
||||
|
||||
Therefore the final dataset object should contain two 4 entries at least if you use the default [`RewardDataCollatorWithPadding`] data collator. The entries should be named:
|
||||
|
||||
- `input_ids_chosen`
|
||||
- `attention_mask_chosen`
|
||||
- `input_ids_rejected`
|
||||
- `attention_mask_rejected`
|
||||
You can also use a pretokenized dataset, in which case the dataset should contain the following columns: `input_ids_chosen`, `attention_mask_chosen`, `input_ids_rejected` and `attention_mask_rejected`.
|
||||
|
||||
## Using the `RewardTrainer`
|
||||
|
||||
@ -47,7 +41,7 @@ peft_config = LoraConfig(
|
||||
trainer = RewardTrainer(
|
||||
model=model,
|
||||
args=training_args,
|
||||
tokenizer=tokenizer,
|
||||
processing_class=tokenizer,
|
||||
train_dataset=dataset,
|
||||
peft_config=peft_config,
|
||||
)
|
||||
@ -79,7 +73,7 @@ $$\Big( R(p, r_1) + R(p, r_2) \Big)^2 $$
|
||||
This auxiliary loss is combined with the main loss function, weighted by the parameter `center_rewards_coefficient` in the `[RewardConfig]`. By default, this feature is deactivated (`center_rewards_coefficient = None`).
|
||||
|
||||
```python
|
||||
reward_config = RewardConfig(
|
||||
training_args = RewardConfig(
|
||||
center_rewards_coefficient=0.01,
|
||||
...
|
||||
)
|
||||
@ -87,10 +81,10 @@ reward_config = RewardConfig(
|
||||
|
||||
For reference results, please refer PR [#1932](https://github.com/huggingface/trl/pull/1932).
|
||||
|
||||
## RewardConfig
|
||||
|
||||
[[autodoc]] RewardConfig
|
||||
|
||||
## RewardTrainer
|
||||
|
||||
[[autodoc]] RewardTrainer
|
||||
|
||||
## RewardConfig
|
||||
|
||||
[[autodoc]] RewardConfig
|
||||
|
||||
@ -1,5 +1,7 @@
|
||||
# RLOO Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=rloo,trl)
|
||||
|
||||
TRL supports training LLMs with REINFORCE Leave-One-Out (RLOO). The idea is that instead of using a value function, RLOO generates K completions for each prompt. For each completion, RLOO uses the mean scores from the other K-1 completions as a baseline to calculate the advantage. RLOO also models the entire completion as a single action, where as PPO models each token as an action. Note that REINFORCE / A2C is a special case of PPO, when the number of PPO epochs is 1 and the number of mini-batches is 1, which is how we implement RLOO in TRL.
|
||||
|
||||
References:
|
||||
@ -16,6 +18,8 @@ To just run a RLOO script to make sure the trainer can run, you can run the foll
|
||||
|
||||
```bash
|
||||
python examples/scripts/rloo/rloo.py \
|
||||
--dataset_name trl-internal-testing/descriptiveness-sentiment-trl-style \
|
||||
--dataset_train_split descriptiveness \
|
||||
--learning_rate 3e-6 \
|
||||
--output_dir models/minimal/rloo \
|
||||
--per_device_train_batch_size 64 \
|
||||
@ -23,7 +27,7 @@ python examples/scripts/rloo/rloo.py \
|
||||
--total_episodes 10000 \
|
||||
--model_name_or_path EleutherAI/pythia-14m \
|
||||
--reward_model_path EleutherAI/pythia-14m \
|
||||
--non_eos_penalty
|
||||
--missing_eos_penalty 1.0
|
||||
```
|
||||
|
||||
|
||||
@ -57,7 +61,7 @@ The logged metrics are as follows. Here is an example [tracked run at Weights an
|
||||
* Debugging TIP: `val/ratio`: this number should float around 1.0, and it gets clipped by `--cliprange 0.2` with PPO's surrogate loss. So if this `ratio` is too high like 2.0 or 1000.0 or too small like 0.1, it means the updates between consecutive policies are too drastic. You should try undertand why this is happening and try to fix it.
|
||||
* Memory TIP: If you are running out of memory, you can try to reduce the `--per_device_train_batch_size` or increase the `--gradient_accumulation_steps` to reduce the memory footprint.
|
||||
* Memory TIP: If you have multiple GPUs, you can also run training with DeepSpeed stage 3 to reduce the memory footprint `accelerate launch --config_file examples/accelerate_configs/deepspeed_zero3.yaml`.
|
||||
* Usage TIP: We recommend to use the "EOS trick" via `--non_eos_penalty --stop_token eos`, which replaces the score of completions that do not end with an EOS token with a static scalar penalty `--penalty_reward_value`. This can help the model learn to generate more coherent completions.
|
||||
* Usage TIP: We recommend to use the "EOS trick" via `--missing_eos_penalty`, which subtracts a static scalar penalty from the score of completions that do not end with an EOS token. This can help the model learn to generate more coherent completions.
|
||||
|
||||
|
||||
## What is my model doing exactly?
|
||||
@ -208,19 +212,20 @@ To validate the RLOO implementation works, we ran experiment on the 1B model. He
|
||||
|
||||
```
|
||||
accelerate launch --config_file examples/accelerate_configs/deepspeed_zero2.yaml \
|
||||
examples/scripts/rloo/rloo_tldr.py \
|
||||
--output_dir models/minimal/rloo_tldr \
|
||||
--dataset_name trl-internal-testing/tldr-preference-sft-trl-style \
|
||||
--dataset_test_split validation \
|
||||
--num_ppo_epochs 2 \
|
||||
--num_mini_batches 2 \
|
||||
--learning_rate 3e-6 \
|
||||
--per_device_train_batch_size 8 \
|
||||
--gradient_accumulation_steps 8 \
|
||||
--per_device_train_batch_size 16 \
|
||||
--gradient_accumulation_steps 16 \
|
||||
--total_episodes 1000000 \
|
||||
--model_name_or_path EleutherAI/pythia-1b-deduped \
|
||||
--sft_model_path cleanrl/EleutherAI_pythia-1b-deduped__sft__tldr \
|
||||
--reward_model_path cleanrl/EleutherAI_pythia-1b-deduped__reward__tldr \
|
||||
--local_rollout_forward_batch_size 16 \
|
||||
--non_eos_penalty \
|
||||
--missing_eos_penalty 1.0 \
|
||||
--stop_token eos \
|
||||
--kl_coef 0.03
|
||||
```
|
||||
@ -263,3 +268,12 @@ python -m openrlbenchmark.rlops_multi_metrics \
|
||||
--output-filename benchmark/trl/pr-1540/rloo \
|
||||
--scan-history
|
||||
```
|
||||
|
||||
|
||||
## RLOOTrainer
|
||||
|
||||
[[autodoc]] RLOOTrainer
|
||||
|
||||
## RLOOConfig
|
||||
|
||||
[[autodoc]] RLOOConfig
|
||||
|
||||
12
docs/source/script_utils.md
Normal file
12
docs/source/script_utils.md
Normal file
@ -0,0 +1,12 @@
|
||||
# Scripts Utilities
|
||||
|
||||
## ScriptArguments
|
||||
|
||||
[[autodoc]] ScriptArguments
|
||||
|
||||
## TrlParser
|
||||
|
||||
[[autodoc]] TrlParser
|
||||
- parse_args_and_config
|
||||
- parse_args_into_dataclasses
|
||||
- set_defaults_with_config
|
||||
@ -33,98 +33,4 @@ Note: if you don't want to log with `wandb` remove `log_with="wandb"` in the scr
|
||||
|
||||
## Few notes on multi-GPU
|
||||
|
||||
To run in multi-GPU setup with DDP (distributed Data Parallel) change the `device_map` value to `device_map={"": Accelerator().process_index}` and make sure to run your script with `accelerate launch yourscript.py`. If you want to apply naive pipeline parallelism you can use `device_map="auto"`.
|
||||
|
||||
|
||||
## Benchmarks
|
||||
|
||||
Below are some benchmark results for `examples/scripts/ppo.py`. To reproduce locally, please check out the `--command` arguments below.
|
||||
|
||||
```bash
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --log_with wandb" \
|
||||
--num-seeds 5 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
```
|
||||
|
||||
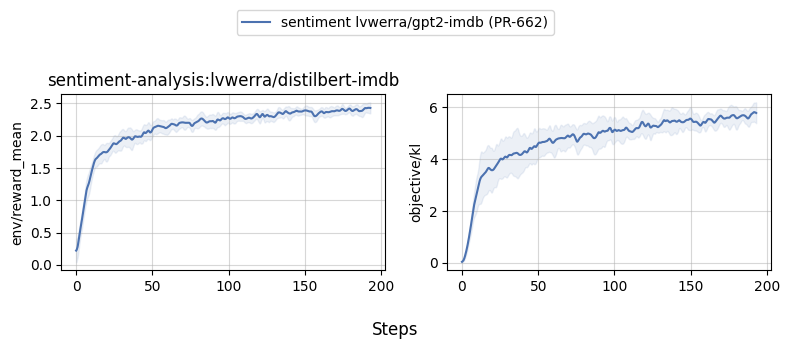
|
||||
|
||||
|
||||
|
||||
## With and without gradient accumulation
|
||||
|
||||
```bash
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --exp_name sentiment_tuning_step_grad_accu --mini_batch_size 1 --gradient_accumulation_steps 128 --log_with wandb" \
|
||||
--num-seeds 5 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
```
|
||||
|
||||
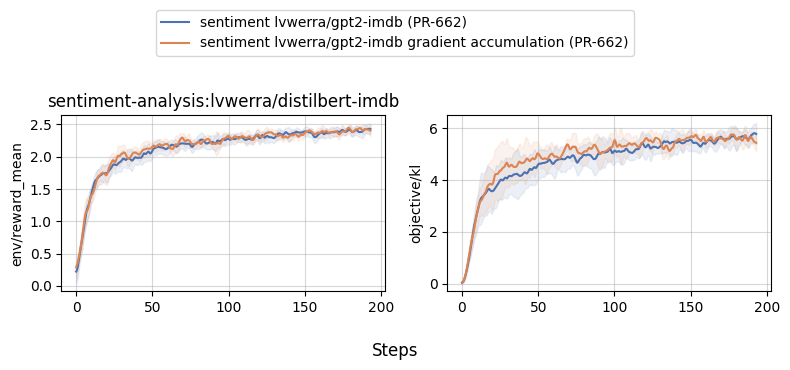
|
||||
|
||||
|
||||
## Comparing different models (gpt2, gpt2-xl, falcon, llama2)
|
||||
|
||||
```bash
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --exp_name sentiment_tuning_gpt2 --log_with wandb" \
|
||||
--num-seeds 5 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --exp_name sentiment_tuning_gpt2xl_grad_accu --model_name gpt2-xl --mini_batch_size 16 --gradient_accumulation_steps 8 --log_with wandb" \
|
||||
--num-seeds 5 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --exp_name sentiment_tuning_falcon_rw_1b --model_name tiiuae/falcon-rw-1b --log_with wandb" \
|
||||
--num-seeds 5 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
```
|
||||
|
||||
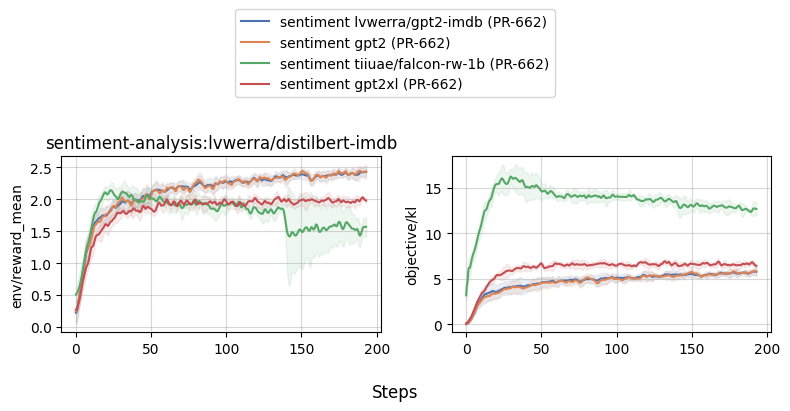
|
||||
|
||||
## With and without PEFT
|
||||
|
||||
```
|
||||
python benchmark/benchmark.py \
|
||||
--command "python examples/scripts/ppo.py --exp_name sentiment_tuning_peft --use_peft --log_with wandb" \
|
||||
--num-seeds 5 \
|
||||
--start-seed 1 \
|
||||
--workers 10 \
|
||||
--slurm-nodes 1 \
|
||||
--slurm-gpus-per-task 1 \
|
||||
--slurm-ntasks 1 \
|
||||
--slurm-total-cpus 12 \
|
||||
--slurm-template-path benchmark/trl.slurm_template
|
||||
```
|
||||
|
||||
|
||||
To run in multi-GPU setup with DDP (distributed Data Parallel) change the `device_map` value to `device_map={"": Accelerator().process_index}` and make sure to run your script with `accelerate launch yourscript.py`. If you want to apply naive pipeline parallelism you can use `device_map="auto"`.
|
||||
@ -1,9 +1,11 @@
|
||||
# Supervised Fine-tuning Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=sft,trl) [](https://github.com/huggingface/smol-course/tree/main/1_instruction_tuning)
|
||||
|
||||
Supervised fine-tuning (or SFT for short) is a crucial step in RLHF. In TRL we provide an easy-to-use API to create your SFT models and train them with few lines of code on your dataset.
|
||||
|
||||
Check out a complete flexible example at [`examples/scripts/sft.py`](https://github.com/huggingface/trl/tree/main/examples/scripts/sft.py).
|
||||
Experimental support for Vision Language Models is also included in the example [`examples/scripts/vsft_llava.py`](https://github.com/huggingface/trl/tree/main/examples/scripts/vsft_llava.py).
|
||||
Check out a complete flexible example at [`trl/scripts/sft.py`](https://github.com/huggingface/trl/tree/main/trl/scripts/sft.py).
|
||||
Experimental support for Vision Language Models is also included in the example [`examples/scripts/sft_vlm.py`](https://github.com/huggingface/trl/tree/main/examples/scripts/sft_vlm.py).
|
||||
|
||||
## Quickstart
|
||||
|
||||
@ -14,17 +16,16 @@ The following code-snippet takes care of all the data pre-processing and trainin
|
||||
from datasets import load_dataset
|
||||
from trl import SFTConfig, SFTTrainer
|
||||
|
||||
dataset = load_dataset("imdb", split="train")
|
||||
dataset = load_dataset("stanfordnlp/imdb", split="train")
|
||||
|
||||
sft_config = SFTConfig(
|
||||
dataset_text_field="text",
|
||||
training_args = SFTConfig(
|
||||
max_seq_length=512,
|
||||
output_dir="/tmp",
|
||||
)
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
train_dataset=dataset,
|
||||
args=sft_config,
|
||||
args=training_args,
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
@ -37,16 +38,16 @@ from transformers import AutoModelForCausalLM
|
||||
from datasets import load_dataset
|
||||
from trl import SFTConfig, SFTTrainer
|
||||
|
||||
dataset = load_dataset("imdb", split="train")
|
||||
dataset = load_dataset("stanfordnlp/imdb", split="train")
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
|
||||
|
||||
sft_config = SFTConfig(output_dir="/tmp")
|
||||
training_args = SFTConfig(output_dir="/tmp")
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model,
|
||||
train_dataset=dataset,
|
||||
args=sft_config,
|
||||
args=training_args,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
@ -110,10 +111,7 @@ collator = DataCollatorForCompletionOnlyLM(instruction_template=instruction_temp
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model,
|
||||
args=SFTConfig(
|
||||
output_dir="/tmp",
|
||||
dataset_text_field = "text",
|
||||
),
|
||||
args=SFTConfig(output_dir="/tmp"),
|
||||
train_dataset=dataset,
|
||||
data_collator=collator,
|
||||
)
|
||||
@ -220,10 +218,10 @@ dataset = load_dataset("philschmid/dolly-15k-oai-style", split="train")
|
||||
|
||||
...
|
||||
|
||||
sft_config = SFTConfig(packing=True)
|
||||
training_args = SFTConfig(packing=True)
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
args=sft_config,
|
||||
args=training_args,
|
||||
train_dataset=dataset,
|
||||
)
|
||||
```
|
||||
@ -256,7 +254,7 @@ def formatting_prompts_func(example):
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model,
|
||||
args=sft_config,
|
||||
args=training_args,
|
||||
train_dataset=dataset,
|
||||
formatting_func=formatting_prompts_func,
|
||||
)
|
||||
@ -271,12 +269,12 @@ To properly format your input make sure to process all the examples by looping o
|
||||
|
||||
```python
|
||||
...
|
||||
sft_config = SFTConfig(packing=True, dataset_text_field="text",)
|
||||
training_args = SFTConfig(packing=True)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
train_dataset=dataset,
|
||||
args=sft_config
|
||||
args=training_args
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
@ -294,11 +292,11 @@ def formatting_func(example):
|
||||
text = f"### Question: {example['question']}\n ### Answer: {example['answer']}"
|
||||
return text
|
||||
|
||||
sft_config = SFTConfig(packing=True)
|
||||
training_args = SFTConfig(packing=True)
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
train_dataset=dataset,
|
||||
args=sft_config,
|
||||
args=training_args,
|
||||
formatting_func=formatting_func
|
||||
)
|
||||
|
||||
@ -315,7 +313,7 @@ model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=to
|
||||
|
||||
...
|
||||
|
||||
sft_config = SFTConfig(
|
||||
training_args = SFTConfig(
|
||||
model_init_kwargs={
|
||||
"torch_dtype": "bfloat16",
|
||||
},
|
||||
@ -324,7 +322,7 @@ sft_config = SFTConfig(
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
train_dataset=dataset,
|
||||
args=sft_config,
|
||||
args=training_args,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
@ -333,33 +331,38 @@ Note that all keyword arguments of `from_pretrained()` are supported.
|
||||
|
||||
### Training adapters
|
||||
|
||||
We also support tight integration with 🤗 PEFT library so that any user can conveniently train adapters and share them on the Hub instead of training the entire model
|
||||
We also support tight integration with 🤗 PEFT library so that any user can conveniently train adapters and share them on the Hub instead of training the entire model.
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
from trl import SFTConfig, SFTTrainer
|
||||
from peft import LoraConfig
|
||||
|
||||
dataset = load_dataset("imdb", split="train")
|
||||
dataset = load_dataset("trl-lib/Capybara", split="train")
|
||||
|
||||
peft_config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
target_modules="all-linear",
|
||||
modules_to_save=["lm_head", "embed_token"],
|
||||
task_type="CAUSAL_LM",
|
||||
)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
"EleutherAI/gpt-neo-125m",
|
||||
"Qwen/Qwen2.5-0.5B",
|
||||
train_dataset=dataset,
|
||||
args=SFTConfig(output_dir="/tmp"),
|
||||
args=SFTConfig(output_dir="Qwen2.5-0.5B-SFT"),
|
||||
peft_config=peft_config
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> If the chat template contains special tokens like `<|im_start|>` (ChatML) or `<|eot_id|>` (Llama), the embedding layer and LM head must be included in the trainable parameters via the `modules_to_save` argument. Without this, the fine-tuned model will produce unbounded or nonsense generations. If the chat template doesn't contain special tokens (e.g. Alpaca), then the `modules_to_save` argument can be ignored or set to `None`.
|
||||
|
||||
|
||||
You can also continue training your `PeftModel`. For that, first load a `PeftModel` outside `SFTTrainer` and pass it directly to the trainer without the `peft_config` argument being passed.
|
||||
|
||||
### Training adapters with base 8 bit models
|
||||
@ -465,30 +468,30 @@ We included a utility function to create your model.
|
||||
|
||||
```python
|
||||
from trl import ModelConfig, SFTTrainer, get_kbit_device_map, get_peft_config, get_quantization_config
|
||||
model_config = ModelConfig(
|
||||
model_args = ModelConfig(
|
||||
model_name_or_path="facebook/opt-350m"
|
||||
attn_implementation=None, # or "flash_attention_2"
|
||||
)
|
||||
torch_dtype = (
|
||||
model_config.torch_dtype
|
||||
if model_config.torch_dtype in ["auto", None]
|
||||
else getattr(torch, model_config.torch_dtype)
|
||||
model_args.torch_dtype
|
||||
if model_args.torch_dtype in ["auto", None]
|
||||
else getattr(torch, model_args.torch_dtype)
|
||||
)
|
||||
quantization_config = get_quantization_config(model_config)
|
||||
quantization_config = get_quantization_config(model_args)
|
||||
model_kwargs = dict(
|
||||
revision=model_config.model_revision,
|
||||
trust_remote_code=model_config.trust_remote_code,
|
||||
attn_implementation=model_config.attn_implementation,
|
||||
revision=model_args.model_revision,
|
||||
trust_remote_code=model_args.trust_remote_code,
|
||||
attn_implementation=model_args.attn_implementation,
|
||||
torch_dtype=torch_dtype,
|
||||
use_cache=False if training_args.gradient_checkpointing else True,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_config.model_name_or_path, **model_kwargs)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_args.model_name_or_path, **model_kwargs)
|
||||
trainer = SFTTrainer(
|
||||
...,
|
||||
model=model_config.model_name_or_path,
|
||||
peft_config=get_peft_config(model_config),
|
||||
model=model_args.model_name_or_path,
|
||||
peft_config=get_peft_config(model_args),
|
||||
)
|
||||
```
|
||||
|
||||
@ -508,15 +511,15 @@ To use it in `SFTTrainer` simply pass `neftune_noise_alpha` when creating your `
|
||||
from datasets import load_dataset
|
||||
from trl import SFTConfig, SFTTrainer
|
||||
|
||||
dataset = load_dataset("imdb", split="train")
|
||||
dataset = load_dataset("stanfordnlp/imdb", split="train")
|
||||
|
||||
sft_config = SFTConfig(
|
||||
training_args = SFTConfig(
|
||||
neftune_noise_alpha=5,
|
||||
)
|
||||
trainer = SFTTrainer(
|
||||
"facebook/opt-350m",
|
||||
train_dataset=dataset,
|
||||
args=sft_config,
|
||||
args=training_args,
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
@ -578,15 +581,11 @@ model = FastLanguageModel.get_peft_model(
|
||||
random_state=3407,
|
||||
)
|
||||
|
||||
args = SFTConfig(
|
||||
output_dir="./output",
|
||||
max_seq_length=max_seq_length,
|
||||
dataset_text_field="text",
|
||||
)
|
||||
training_args = SFTConfig(output_dir="./output", max_seq_length=max_seq_length)
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=model,
|
||||
args=args,
|
||||
args=training_args,
|
||||
train_dataset=dataset,
|
||||
)
|
||||
trainer.train()
|
||||
@ -594,6 +593,33 @@ trainer.train()
|
||||
|
||||
The saved model is fully compatible with Hugging Face's transformers library. Learn more about unsloth in their [official repository](https://github.com/unslothai/unsloth).
|
||||
|
||||
## Liger-Kernel: Increase 20% throughput and reduces 60% memory for multi-GPU training
|
||||
|
||||
[Liger Kernel](https://github.com/linkedin/Liger-Kernel) is a collection of Triton kernels designed specifically for LLM training. It can effectively increase multi-GPU training throughput by 20% and reduces memory usage by 60%. That way, we can **4x** our context length, as described in the benchmark below. They have implemented Hugging Face Compatible `RMSNorm`, `RoPE`, `SwiGLU`, `CrossEntropy`, `FusedLinearCrossEntropy`, and more to come. The kernel works out of the box with [Flash Attention](https://github.com/Dao-AILab/flash-attention), [PyTorch FSDP](https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html), and [Microsoft DeepSpeed](https://github.com/microsoft/DeepSpeed).
|
||||
|
||||
With great memory reduction, you can potentially turn off cpu_offloading or gradient checkpointing to further boost the performance.
|
||||
|
||||
| Speed Up | Memory Reduction |
|
||||
|--------------------------|-------------------------|
|
||||
|  |  |
|
||||
|
||||
|
||||
1. To use Liger-Kernel in `SFTTrainer`, first install by
|
||||
|
||||
```bash
|
||||
pip install liger-kernel
|
||||
```
|
||||
|
||||
2. Once installed, set `use_liger` in [`SFTConfig`]. No other changes are needed!
|
||||
|
||||
```python
|
||||
training_args = SFTConfig(
|
||||
use_liger=True
|
||||
)
|
||||
```
|
||||
|
||||
To learn more about Liger-Kernel, visit their [official repository](https://github.com/linkedin/Liger-Kernel/).
|
||||
|
||||
## Best practices
|
||||
|
||||
Pay attention to the following best practices when training a model with that trainer:
|
||||
@ -623,7 +649,7 @@ You may experience some issues with GPTQ Quantization after completing training.
|
||||
|
||||
## Extending `SFTTrainer` for Vision Language Models
|
||||
|
||||
`SFTTrainer` does not inherently support vision-language data. However, we provide a guide on how to tweak the trainer to support vision-language data. Specifically, you need to use a custom data collator that is compatible with vision-language data. This guide outlines the steps to make these adjustments. For a concrete example, refer to the script [`examples/scripts/vsft_llava.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/vsft_llava.py) which demonstrates how to fine-tune the LLaVA 1.5 model on the [HuggingFaceH4/llava-instruct-mix-vsft](https://huggingface.co/datasets/HuggingFaceH4/llava-instruct-mix-vsft) dataset.
|
||||
`SFTTrainer` does not inherently support vision-language data. However, we provide a guide on how to tweak the trainer to support vision-language data. Specifically, you need to use a custom data collator that is compatible with vision-language data. This guide outlines the steps to make these adjustments. For a concrete example, refer to the script [`examples/scripts/sft_vlm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/sft_vlm.py) which demonstrates how to fine-tune the LLaVA 1.5 model on the [HuggingFaceH4/llava-instruct-mix-vsft](https://huggingface.co/datasets/HuggingFaceH4/llava-instruct-mix-vsft) dataset.
|
||||
|
||||
### Preparing the Data
|
||||
|
||||
@ -712,23 +738,22 @@ print(collated_data.keys()) # dict_keys(['input_ids', 'attention_mask', 'pixel_
|
||||
|
||||
### Training the vision-language model
|
||||
|
||||
Now that we have prepared the data and defined the collator, we can proceed with training the model. To ensure that the data is not processed as text-only, we need to set a couple of arguments in the `SFTConfig`, specifically `dataset_text_field` and `remove_unused_columns`. We also need to set `skip_prepare_dataset` to `True` to avoid the default processing of the dataset. Below is an example of how to set up the `SFTTrainer`.
|
||||
Now that we have prepared the data and defined the collator, we can proceed with training the model. To ensure that the data is not processed as text-only, we need to set a couple of arguments in the `SFTConfig`, specifically `remove_unused_columns` and `skip_prepare_dataset` to `True` to avoid the default processing of the dataset. Below is an example of how to set up the `SFTTrainer`.
|
||||
|
||||
```python
|
||||
args.dataset_text_field = "" # needs a dummy field
|
||||
args.remove_unused_columns = False
|
||||
args.dataset_kwargs = {"skip_prepare_dataset": True}
|
||||
training_args.remove_unused_columns = False
|
||||
training_args.dataset_kwargs = {"skip_prepare_dataset": True}
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=model,
|
||||
args=args,
|
||||
args=training_args,
|
||||
data_collator=collate_fn,
|
||||
train_dataset=train_dataset,
|
||||
tokenizer=processor.tokenizer,
|
||||
processing_class=processor.tokenizer,
|
||||
)
|
||||
```
|
||||
|
||||
A full example of training LLaVa 1.5 on the [HuggingFaceH4/llava-instruct-mix-vsft](https://huggingface.co/datasets/HuggingFaceH4/llava-instruct-mix-vsft) dataset can be found in the script [`examples/scripts/vsft_llava.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/vsft_llava.py).
|
||||
A full example of training LLaVa 1.5 on the [HuggingFaceH4/llava-instruct-mix-vsft](https://huggingface.co/datasets/HuggingFaceH4/llava-instruct-mix-vsft) dataset can be found in the script [`examples/scripts/sft_vlm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/sft_vlm.py).
|
||||
|
||||
- [Experiment tracking](https://wandb.ai/huggingface/trl/runs/2b2c5l7s)
|
||||
- [Trained model](https://huggingface.co/HuggingFaceH4/sft-llava-1.5-7b-hf)
|
||||
|
||||
@ -1,70 +0,0 @@
|
||||
# Trainer
|
||||
|
||||
At TRL we support PPO (Proximal Policy Optimisation) with an implementation that largely follows the structure introduced in the paper "Fine-Tuning Language Models from Human Preferences" by D. Ziegler et al. [[paper](https://huggingface.co/papers/1909.08593), [code](https://github.com/openai/lm-human-preferences)].
|
||||
The Trainer and model classes are largely inspired from `transformers.Trainer` and `transformers.AutoModel` classes and adapted for RL.
|
||||
We also support a `RewardTrainer` that can be used to train a reward model.
|
||||
|
||||
|
||||
## CPOConfig
|
||||
|
||||
[[autodoc]] CPOConfig
|
||||
|
||||
## CPOTrainer
|
||||
|
||||
[[autodoc]] CPOTrainer
|
||||
|
||||
## DDPOConfig
|
||||
|
||||
[[autodoc]] DDPOConfig
|
||||
|
||||
## DDPOTrainer
|
||||
|
||||
[[autodoc]] DDPOTrainer
|
||||
|
||||
## DPOTrainer
|
||||
|
||||
[[autodoc]] DPOTrainer
|
||||
|
||||
## IterativeSFTTrainer
|
||||
|
||||
[[autodoc]] IterativeSFTTrainer
|
||||
|
||||
## KTOConfig
|
||||
|
||||
[[autodoc]] KTOConfig
|
||||
|
||||
## KTOTrainer
|
||||
|
||||
[[autodoc]] KTOTrainer
|
||||
|
||||
## ORPOConfig
|
||||
|
||||
[[autodoc]] ORPOConfig
|
||||
|
||||
## ORPOTrainer
|
||||
|
||||
[[autodoc]] ORPOTrainer
|
||||
|
||||
## PPOConfig
|
||||
|
||||
[[autodoc]] PPOConfig
|
||||
|
||||
## PPOTrainer
|
||||
|
||||
[[autodoc]] PPOTrainer
|
||||
|
||||
## RewardConfig
|
||||
|
||||
[[autodoc]] RewardConfig
|
||||
|
||||
## RewardTrainer
|
||||
|
||||
[[autodoc]] RewardTrainer
|
||||
|
||||
## SFTTrainer
|
||||
|
||||
[[autodoc]] SFTTrainer
|
||||
|
||||
## set_seed
|
||||
|
||||
[[autodoc]] set_seed
|
||||
162
docs/source/xpo_trainer.mdx
Normal file
162
docs/source/xpo_trainer.mdx
Normal file
@ -0,0 +1,162 @@
|
||||
# XPO Trainer
|
||||
|
||||
[](https://huggingface.co/models?other=xpo,trl)
|
||||
|
||||
## Overview
|
||||
|
||||
Exploratory Preference Optimization (XPO) was proposed in the paper [Exploratory Preference Optimization: Harnessing Implicit Q*-Approximation for Sample-Efficient RLHF](https://huggingface.co/papers/2405.21046) by Tengyang Xie, Dylan J. Foster, Akshay Krishnamurthy, [Corby Rosset](https://huggingface.co/corbyrosset), [Ahmed Awadallah](https://huggingface.co/AhmedAwadallah), and Alexander Rakhlin. It is a simple online preference tuning method based on the DPO loss together with a reward model (RM). XPO augments the DPO objective with an exploration bonus allowing the method to explore outside the support of the intitial model and human feedback data.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
> Reinforcement learning from human feedback (RLHF) has emerged as a central tool for language model alignment. We consider online exploration in RLHF, which exploits interactive access to human or AI feedback by deliberately encouraging the model to produce diverse, maximally informative responses. By allowing RLHF to confidently stray from the pre-trained model, online exploration offers the possibility of novel, potentially super-human capabilities, but its full potential as a paradigm for language model training has yet to be realized, owing to computational and statistical bottlenecks in directly adapting existing reinforcement learning techniques. We propose a new algorithm for online exploration in RLHF, Exploratory Preference Optimization (XPO), which is simple and practical -- a one-line change to (online) Direct Preference Optimization (DPO; Rafailov et al., 2023) -- yet enjoys the strongest known provable guarantees and promising empirical performance. XPO augments the DPO objective with a novel and principled exploration bonus, empowering the algorithm to explore outside the support of the initial model and human feedback data. In theory, we show that XPO is provably sample-efficient and converges to a near-optimal language model policy under natural exploration conditions, irrespective of whether the initial model has good coverage. Our analysis, which builds on the observation that DPO implicitly performs a form of Q*-approximation (or, Bellman error minimization), combines previously disparate techniques from language modeling and theoretical reinforcement learning in a serendipitous fashion through the perspective of KL-regularized Markov decision processes. Empirically, we find that XPO is more sample-efficient than non-exploratory DPO variants in a preliminary evaluation.
|
||||
|
||||
This post-training method was contributed by [Kashif Rasul](https://huggingface.co/kashif), [Quentin Gallouédec](https://huggingface.co/qgallouedec) and [Lewis Tunstall](https://huggingface.co/lewtun).
|
||||
|
||||
## Quick start
|
||||
|
||||
This example demonstrates how to train a model using the XPO method. We use the [Qwen 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) as the base model and [`PairRMJudge`] as a judge. We use the prompts from the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback). You can view the prompts in the dataset here:
|
||||
<iframe
|
||||
src="https://huggingface.co/datasets/trl-lib/ultrafeedback-prompt/embed/viewer/default/train?row=0"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="560px"
|
||||
></iframe>
|
||||
|
||||
Below is the script to train the model:
|
||||
|
||||
```python
|
||||
# train_xpo.py
|
||||
from datasets import load_dataset
|
||||
from trl import PairRMJudge, XPOConfig, XPOTrainer
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
|
||||
judge = PairRMJudge()
|
||||
train_dataset = load_dataset("trl-lib/ultrafeedback-prompt", split="train")
|
||||
|
||||
training_args = XPOConfig(output_dir="Qwen2-0.5B-XPO", logging_steps=10)
|
||||
trainer = XPOTrainer(
|
||||
model=model, judge=judge, args=training_args, processing_class=tokenizer, train_dataset=train_dataset
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
Execute the script using the following command:
|
||||
|
||||
```bash
|
||||
accelerate launch train_xpo.py
|
||||
```
|
||||
|
||||
Distributed across 8 GPUs, the training takes approximately 1 hour.
|
||||
|
||||
To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-XPO) performs, you can use the [TRL Chat CLI](clis#chat-interface).
|
||||
|
||||
<pre><code>$ trl chat --model_name_or_path trl-lib/Qwen2-0.5B-XPO
|
||||
<strong><span style="color: red;"><quentin_gallouedec>:</span></strong>
|
||||
What is the best programming language?
|
||||
|
||||
<strong><span style="color: blue;"><trl-lib/Qwen2-0.5B-XPO>:</span></strong>
|
||||
The best programming language depends on individual preferences and familiarity with coding concepts. Some popular languages include Python, Java, C++, and JavaScript.
|
||||
</code></pre>
|
||||
|
||||
## Expected dataset type
|
||||
|
||||
XPO requires a [prompt-only dataset](dataset_formats#prompt-only). The [`XPOTrainer`] supports both [conversational](dataset_formats#conversational) and [standard](dataset_formats#standard) dataset format. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset.
|
||||
|
||||
## Usage tips
|
||||
|
||||
### Use a reward model
|
||||
|
||||
Instead of a judge, you can chose to use a reward model -- see [Reward Bench](https://huggingface.co/spaces/allenai/reward-bench) for a leaderboard of public models you can use. Below is a code example showing how to replace a judge with the [trl-lib/Qwen2-0.5B-Reward](https://huggingface.co/trl-lib/Qwen2-0.5B-Reward) model:
|
||||
|
||||
```diff
|
||||
- from trl import PairRMJudge
|
||||
+ from transformers import AutoModelForSequenceClassification
|
||||
|
||||
- judge = PairRMJudge()
|
||||
+ reward_model = AutoModelForSequenceClassification.from_pretrained("trl-lib/Qwen2-0.5B-Reward", num_labels=1)
|
||||
|
||||
trainer = XPOTrainer(
|
||||
...
|
||||
- judge=judge,
|
||||
+ reward_model=reward_model,
|
||||
)
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Make sure that the SFT model and reward model use the _same_ chat template and the same tokenizer. Otherwise, you may find the model completions are scored incorrectly during training.
|
||||
|
||||
</Tip>
|
||||
|
||||
### Encourage EOS token generation
|
||||
|
||||
When using a reward model, we may want the model to generate completions within a given length. During training, the model will generate completions up to the maximum length specified in the `max_new_tokens` argument of [`XPOConfig`]. If you want to penalize the model for not generating an EOS token before reaching the maximum length, you can use the `missing_eos_penalty` argument of [`XPOConfig`]:
|
||||
|
||||
```python
|
||||
training_args = XPOConfig(..., max_new_tokens=128, missing_eos_penalty=1.0)
|
||||
```
|
||||
|
||||
### Logging Completions
|
||||
|
||||
To better understand your model’s behavior during training, you can log sample completions periodically using the [`LogCompletionsCallback`].
|
||||
|
||||
```python
|
||||
trainer = XPOTrainer(..., eval_dataset=eval_dataset)
|
||||
completions_callback = LogCompletionsCallback(trainer, num_prompts=8)
|
||||
trainer.add_callback(completions_callback)
|
||||
```
|
||||
|
||||
This callback logs the model's generated completions directly to Weights & Biases.
|
||||
|
||||

|
||||
|
||||
## Example script
|
||||
|
||||
We provide an example script to train a model using the XPO method. The script is available in [`examples/scripts/xpo.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/xpo.py)
|
||||
|
||||
To test the XPO script with the [Qwen2.5 0.5B model](https://huggingface.co/trl-lib/Qwen/Qwen2.5-0.5B-Instruct) on the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback), run the following command:
|
||||
|
||||
```bash
|
||||
python examples/scripts/xpo.py \
|
||||
--model_name_or_path Qwen/Qwen2.5-0.5B-Instruct \
|
||||
--judge pair_rm \
|
||||
--dataset_name trl-lib/ultrafeedback-prompt \
|
||||
--learning_rate 5.0e-7 \
|
||||
--logging_steps 25 \
|
||||
--output_dir Qwen2.5-0.5B-XPO-PairRM \
|
||||
--warmup_ratio 0.1 \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
## Logged metrics
|
||||
|
||||
The logged metrics are as follows:
|
||||
|
||||
* `loss/xpo`: The mean xpo part of the full loss.
|
||||
* `loss/dpo`: The mean dpo part of the full loss.
|
||||
* `objective/kl`: The mean KL divergence between the model and reference data.
|
||||
* `objective/entropy`: The mean entropy of the model and reference data.
|
||||
* `objective/model_scores`: The mean scores (according to the reward model) of the model completions.
|
||||
* `objective/ref_scores`: The mean scores (according to the reward model) of the reference completions.
|
||||
* `objective/scores_margin`: The mean score margin (according to the external reward model) between the chosen and rejected completions.
|
||||
* `rewards/chosen`: The mean reward (according to XPO's DPO implicit reward model) of the chosen completions.
|
||||
* `rewards/rejected`: The mean reward (according to XPO's DPO implicit reward model) of the rejected completions.
|
||||
* `rewards/accuracies`: The accuracies of the XPO's implicit reward model.
|
||||
* `rewards/margins`: The mean reward margin (according to online DPO's implicit reward model) between the chosen and rejected completions.
|
||||
* `logps/chosen`: The mean log probabilities of the chosen completions.
|
||||
* `logps/rejected`: The mean log probabilities of the rejected completions.
|
||||
* `val/model_contain_eos_token`: The amount of times the model's output contains the eos token.
|
||||
* `val/ref_contain_eos_token`: The amount of times the reference's output contains the eos token.
|
||||
* `alpha`: The weight of the XPO loss term. Typically fixed, but can be made dynamic by passing a list to [`XPOConfig`].
|
||||
* `beta`: The parameter that controls the weight of the loss term representing the deviation from the reference model. Typically fixed, but can be made dynamic by passing a list to [`XPOConfig`].
|
||||
|
||||
|
||||
## XPOTrainer
|
||||
|
||||
[[autodoc]] XPOTrainer
|
||||
|
||||
## XPOConfig
|
||||
|
||||
[[autodoc]] XPOConfig
|
||||
@ -7,11 +7,9 @@
|
||||
# CUDA_VISIBLE_DEVICES: 0
|
||||
|
||||
model_name_or_path:
|
||||
trl-internal-testing/tiny-random-LlamaForCausalLM
|
||||
Qwen/Qwen2.5-0.5B
|
||||
dataset_name:
|
||||
imdb
|
||||
dataset_text_field:
|
||||
text
|
||||
stanfordnlp/imdb
|
||||
report_to:
|
||||
none
|
||||
learning_rate:
|
||||
|
||||
@ -1,122 +0,0 @@
|
||||
import sys
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import HfApi
|
||||
from huggingface_hub.repocard import RepoCard
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
"""
|
||||
# debug
|
||||
python -i examples/datasets/anthropic_hh.py --debug --push_to_hub
|
||||
# actual push
|
||||
python examples/datasets/anthropic_hh.py --push_to_hub --hf_entity trl-internal-testing
|
||||
"""
|
||||
|
||||
|
||||
api = HfApi()
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
debug: Optional[bool] = field(default=False, metadata={"help": "Enable debug mode"})
|
||||
hf_entity: Optional[str] = field(default=None, metadata={"help": "The Hugging Face entity to use"})
|
||||
hf_repo_id: Optional[str] = field(
|
||||
default="hh-rlhf-helpful-base-trl-style", metadata={"help": "The Hugging Face repository ID"}
|
||||
)
|
||||
revision: Optional[str] = field(default="0.1.0", metadata={"help": "The revision of the repository"})
|
||||
update_main_revision: Optional[bool] = field(
|
||||
default=True, metadata={"help": "Update the main revision of the repository"}
|
||||
)
|
||||
push_to_hub: Optional[bool] = field(default=False, metadata={"help": "Push the dataset to the Hugging Face Hub"})
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None, metadata={"help": "The number of workers to use for dataset processing"}
|
||||
)
|
||||
|
||||
|
||||
# GPT-4 generated 😄 Define a function to process the input and extract the dialogue into structured format
|
||||
def extract_dialogue(input_text):
|
||||
# Split the input by lines and initialize variables
|
||||
lines = input_text.strip().split("\n\n")
|
||||
dialogue_list = []
|
||||
|
||||
# Iterate through each line and extract the dialogue
|
||||
for line in lines:
|
||||
# Check if the line starts with "Human" or "Assistant" and split accordingly
|
||||
if line.startswith("Human:"):
|
||||
role = "user"
|
||||
content = line.replace("Human: ", "").strip()
|
||||
elif line.startswith("Assistant:"):
|
||||
role = "assistant"
|
||||
content = line.replace("Assistant: ", "").strip()
|
||||
else:
|
||||
# If the line doesn't start with "Human" or "Assistant", it's part of the previous message's content
|
||||
# Append it to the last message's content
|
||||
dialogue_list[-1]["content"] += "\n\n" + line.strip()
|
||||
continue
|
||||
|
||||
# Append the extracted dialogue piece to the list
|
||||
dialogue_list.append({"role": role, "content": content})
|
||||
|
||||
return dialogue_list
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = HfArgumentParser(ScriptArguments).parse_args_into_dataclasses()[0]
|
||||
if args.hf_entity is None:
|
||||
args.hf_entity = api.whoami()["name"]
|
||||
full_repo_id = f"{args.hf_entity}/{args.hf_repo_id}"
|
||||
ds = load_dataset("Anthropic/hh-rlhf", data_dir="helpful-base")
|
||||
if args.debug:
|
||||
for key in ds:
|
||||
ds[key] = ds[key].select(range(50))
|
||||
|
||||
def process(row):
|
||||
row["chosen"] = extract_dialogue(row["chosen"])
|
||||
row["rejected"] = extract_dialogue(row["rejected"])
|
||||
row["prompt"] = row["chosen"][0]["content"]
|
||||
return row
|
||||
|
||||
ds = ds.map(process, num_proc=args.dataset_num_proc)
|
||||
if args.push_to_hub:
|
||||
revisions = ["main"] if args.update_main_revision else []
|
||||
revisions.append(args.revision)
|
||||
|
||||
# get the commnad used to run the script
|
||||
run_command = " ".join(["python"] + sys.argv)
|
||||
|
||||
for revision in revisions:
|
||||
ds.push_to_hub(full_repo_id, revision=revision)
|
||||
repo_full_url = f"https://huggingface.co/datasets/{full_repo_id}/tree/{revision}"
|
||||
|
||||
# get the name of the current file
|
||||
file_name = __file__.split("/")[-1]
|
||||
api.upload_file(
|
||||
path_or_fileobj=__file__,
|
||||
path_in_repo=file_name,
|
||||
revision=revision,
|
||||
repo_id=full_repo_id,
|
||||
repo_type="dataset",
|
||||
)
|
||||
|
||||
sft_card = RepoCard.load(
|
||||
full_repo_id,
|
||||
repo_type="dataset",
|
||||
)
|
||||
sft_card.text = f"""\
|
||||
# TRL's Anthropic HH Dataset
|
||||
|
||||
We preprocess the dataset using our standard `prompt, chosen, rejected` format.
|
||||
|
||||
|
||||
## Reproduce this dataset
|
||||
|
||||
1. Download the `{file_name}` from the {repo_full_url}.
|
||||
2. Run `{run_command}`
|
||||
"""
|
||||
sft_card.push_to_hub(
|
||||
full_repo_id,
|
||||
repo_type="dataset",
|
||||
)
|
||||
96
examples/datasets/hh-rlhf-helpful-base.py
Normal file
96
examples/datasets/hh-rlhf-helpful-base.py
Normal file
@ -0,0 +1,96 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import re
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/hh-rlhf-helpful-base"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/hh-rlhf-helpful-base"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
|
||||
|
||||
def common_start(str1: str, str2: str) -> str:
|
||||
# Zip the two strings and iterate over them together
|
||||
common_chars = []
|
||||
for c1, c2 in zip(str1, str2):
|
||||
if c1 == c2:
|
||||
common_chars.append(c1)
|
||||
else:
|
||||
break
|
||||
# Join the common characters and return as a string
|
||||
return "".join(common_chars)
|
||||
|
||||
|
||||
def extract_dialogue(example: str) -> list[dict[str, str]]:
|
||||
# Extract the prompt, which corresponds to the common start of the chosen and rejected dialogues
|
||||
prompt_text = common_start(example["chosen"], example["rejected"])
|
||||
|
||||
# The chosen and rejected may share a common start, so we need to remove the common part
|
||||
if not prompt_text.endswith("\n\nAssistant: "):
|
||||
prompt_text = prompt_text[: prompt_text.rfind("\n\nAssistant: ")] + "\n\nAssistant: "
|
||||
|
||||
# Extract the chosen and rejected lines
|
||||
chosen_line = example["chosen"][len(prompt_text) :]
|
||||
rejected_line = example["rejected"][len(prompt_text) :]
|
||||
|
||||
# Remove the generation prompt ("\n\nAssistant: ") from the prompt
|
||||
prompt_text = prompt_text[: -len("\n\nAssistant: ")]
|
||||
|
||||
# Split the string at every occurrence of "Human: " or "Assistant: "
|
||||
prompt_lines = re.split(r"(\n\nAssistant: |\n\nHuman: )", prompt_text)
|
||||
|
||||
# Remove the first element as it's empty
|
||||
prompt_lines = prompt_lines[1:]
|
||||
|
||||
prompt = []
|
||||
for idx in range(0, len(prompt_lines), 2):
|
||||
role = "user" if prompt_lines[idx] == "\n\nHuman: " else "assistant"
|
||||
content = prompt_lines[idx + 1]
|
||||
prompt.append({"role": role, "content": content})
|
||||
|
||||
# Remove the prompt from the chosen and rejected dialogues
|
||||
chosen = [{"role": "assistant", "content": chosen_line}]
|
||||
rejected = [{"role": "assistant", "content": rejected_line}]
|
||||
|
||||
return {"prompt": prompt, "chosen": chosen, "rejected": rejected}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
dataset = load_dataset("Anthropic/hh-rlhf", data_dir="helpful-base")
|
||||
dataset = dataset.map(extract_dialogue, num_proc=script_args.dataset_num_proc)
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
81
examples/datasets/lm-human-preferences-descriptiveness.py
Normal file
81
examples/datasets/lm-human-preferences-descriptiveness.py
Normal file
@ -0,0 +1,81 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoTokenizer, HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/lm-human-preferences-descriptiveness"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/lm-human-preferences-descriptiveness"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
|
||||
|
||||
# Edge cases handling: remove the cases where all samples are the same
|
||||
def samples_not_all_same(example):
|
||||
return not all(example["sample0"] == example[f"sample{j}"] for j in range(1, 4))
|
||||
|
||||
|
||||
def to_prompt_completion(example, tokenizer):
|
||||
prompt = tokenizer.decode(example["query"]).strip()
|
||||
best_idx = example["best"]
|
||||
chosen = tokenizer.decode(example[f"sample{best_idx}"])
|
||||
for rejected_idx in range(4): # take the first rejected sample that is different from the chosen one
|
||||
rejected = tokenizer.decode(example[f"sample{rejected_idx}"])
|
||||
if chosen != rejected:
|
||||
break
|
||||
assert chosen != rejected
|
||||
return {"prompt": prompt, "chosen": chosen, "rejected": rejected}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
dataset = load_dataset(
|
||||
"json",
|
||||
data_files="https://openaipublic.blob.core.windows.net/lm-human-preferences/labels/descriptiveness/offline_5k.json",
|
||||
split="train",
|
||||
)
|
||||
|
||||
dataset = dataset.filter(samples_not_all_same, num_proc=script_args.dataset_num_proc)
|
||||
|
||||
dataset = dataset.map(
|
||||
to_prompt_completion,
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
remove_columns=["query", "sample0", "sample1", "sample2", "sample3", "best"],
|
||||
fn_kwargs={"tokenizer": AutoTokenizer.from_pretrained("gpt2")},
|
||||
)
|
||||
|
||||
# train_size taken from https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/launch.py#L79)
|
||||
dataset = dataset.train_test_split(train_size=4992)
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
74
examples/datasets/lm-human-preferences-sentiment.py
Normal file
74
examples/datasets/lm-human-preferences-sentiment.py
Normal file
@ -0,0 +1,74 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoTokenizer, HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/lm-human-preferences-sentiment"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/lm-human-preferences-sentiment"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
|
||||
|
||||
def to_prompt_completion(example, tokenizer):
|
||||
prompt = tokenizer.decode(example["query"]).strip()
|
||||
best_idx = example["best"]
|
||||
chosen = tokenizer.decode(example[f"sample{best_idx}"])
|
||||
for rejected_idx in range(4): # take the first rejected sample that is different from the chosen one
|
||||
rejected = tokenizer.decode(example[f"sample{rejected_idx}"])
|
||||
if chosen != rejected:
|
||||
break
|
||||
assert chosen != rejected
|
||||
return {"prompt": prompt, "chosen": chosen, "rejected": rejected}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
dataset = load_dataset(
|
||||
"json",
|
||||
data_files="https://openaipublic.blob.core.windows.net/lm-human-preferences/labels/sentiment/offline_5k.json",
|
||||
split="train",
|
||||
)
|
||||
|
||||
dataset = dataset.map(
|
||||
to_prompt_completion,
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
remove_columns=["query", "sample0", "sample1", "sample2", "sample3", "best"],
|
||||
fn_kwargs={"tokenizer": AutoTokenizer.from_pretrained("gpt2")},
|
||||
)
|
||||
|
||||
# train_size taken from https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/launch.py#L70)
|
||||
dataset = dataset.train_test_split(train_size=4992)
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
131
examples/datasets/math_shepherd.py
Normal file
131
examples/datasets/math_shepherd.py
Normal file
@ -0,0 +1,131 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import re
|
||||
from dataclasses import dataclass
|
||||
from itertools import chain
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/math_shepherd"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/math_shepherd"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
|
||||
|
||||
def process_example(example):
|
||||
# Replace "ки" with "ⶻ" so that the size of the "input" matches the size of the "label"
|
||||
inputs = example["input"].replace("ки", "ⶻ")
|
||||
|
||||
# Find the indices of the "ⶻ" characters (that should match with the indexes of the "+" or "-" in the label)
|
||||
indexes = [m.start() for m in re.finditer("ⶻ", inputs)]
|
||||
|
||||
# Sanity that all indexes are either "+" or "-"
|
||||
assert all(example["label"][idx] in ["+", "-"] for idx in indexes)
|
||||
|
||||
# Get the labels
|
||||
labels = [example["label"][idx] == "+" for idx in indexes]
|
||||
|
||||
# Split the inputs into steps (caution, the first step is missing here, it is the prompt)
|
||||
steps = [inputs[i:j] for i, j in zip(chain([0], indexes), chain(indexes, [None]))]
|
||||
|
||||
# Remove the last step (single ⶻ)
|
||||
steps = steps[:-1]
|
||||
|
||||
# Get the prompt (first part) and completions (rest)
|
||||
prompt = steps[0]
|
||||
completions = steps[1:]
|
||||
|
||||
# Remove the heading "ⶻ" and the final whitespace from the completions
|
||||
assert all(completion.startswith("ⶻ") for completion in completions)
|
||||
completions = [completion[1:].strip() for completion in completions]
|
||||
|
||||
# At this point, we need to retrieve the first step from the prompt.
|
||||
# First, we handle particular cases (annotation error) where we have a first label before the end of the prompt.
|
||||
if prompt.startswith(
|
||||
(
|
||||
"Mr. Rocky",
|
||||
"Parker",
|
||||
"What is the smallest positive",
|
||||
" The Myth",
|
||||
"Let $\\mathbf{a}$",
|
||||
"Find the arithmetic",
|
||||
"Determine an ordered pair",
|
||||
"Determine the ordered pair",
|
||||
"At the Quill and Scroll stationery",
|
||||
"Round to the nearest",
|
||||
r"Calculate $\sqrt{10p}",
|
||||
r"Simplify $\sqrt{28x}",
|
||||
)
|
||||
):
|
||||
# Some spotted datasets errors where there is an annotation in the prompt: we remove it
|
||||
labels = labels[1:]
|
||||
|
||||
# Then we handle the general case: we get the first step from the prompt by looking for "Step 1:" or "step 1:" or
|
||||
# (less common) "?".
|
||||
elif "Step 1:" in prompt:
|
||||
prompt, first_step = prompt.split("Step 1:")
|
||||
first_step = "Step 1:" + first_step
|
||||
completions = [first_step.strip()] + completions
|
||||
elif "step 1:" in prompt:
|
||||
prompt, first_step = prompt.split("step 1:")
|
||||
first_step = "step 1:" + first_step
|
||||
completions = [first_step.strip()] + completions
|
||||
elif "?" in prompt:
|
||||
prompt, first_step = prompt.split("?")
|
||||
prompt = prompt + "?"
|
||||
completions = [first_step.strip()] + completions
|
||||
else:
|
||||
raise ValueError(f"Prompt can't be processed: {prompt}")
|
||||
|
||||
# Strip the prompt
|
||||
prompt = prompt.strip()
|
||||
|
||||
# Sanity check that the length of the completions is the same as the length of the labels
|
||||
assert len(completions) == len(labels)
|
||||
|
||||
return {"prompt": prompt, "completions": completions, "labels": labels}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
dataset = load_dataset("peiyi9979/Math-Shepherd", split="train")
|
||||
|
||||
dataset = dataset.map(
|
||||
process_example,
|
||||
remove_columns=["input", "label", "task"],
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
)
|
||||
dataset = dataset.train_test_split(test_size=0.05, seed=42)
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
118
examples/datasets/prm800k.py
Normal file
118
examples/datasets/prm800k.py
Normal file
@ -0,0 +1,118 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/prm800k"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/prm800k"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
|
||||
|
||||
def process_example(example):
|
||||
outputs = []
|
||||
prompt = example["question"]["problem"]
|
||||
|
||||
# Iterate through each step
|
||||
previous_completions = []
|
||||
previous_labels = []
|
||||
for step in example["label"]["steps"]:
|
||||
if step["completions"] is None and step["human_completion"] is None and step["chosen_completion"] is None:
|
||||
# happens sometimes
|
||||
break
|
||||
# Loop through completions
|
||||
for completion_idx, completion in enumerate(step["completions"]):
|
||||
# For every completion that are not chosen, we are in a terminal state, so we can add it to the list of outputs.
|
||||
if completion_idx != step["chosen_completion"]:
|
||||
content = completion["text"]
|
||||
completions = previous_completions[:] + [content]
|
||||
label = completion["rating"] == 1
|
||||
labels = previous_labels[:] + [label]
|
||||
outputs.append({"prompt": prompt, "completions": completions, "labels": labels})
|
||||
|
||||
# Now, exapand the previous completions and labels
|
||||
if step["chosen_completion"] is not None:
|
||||
chosen_completion = step["completions"][step["chosen_completion"]]
|
||||
label = chosen_completion["rating"] == 1
|
||||
elif step["human_completion"] is not None:
|
||||
chosen_completion = step["human_completion"]
|
||||
label = True
|
||||
else:
|
||||
break
|
||||
content = chosen_completion["text"]
|
||||
previous_completions.append(content)
|
||||
previous_labels.append(label)
|
||||
|
||||
# Last step: we are in a terminal state, so we can add it to the list of outputs
|
||||
outputs.append({"prompt": prompt, "completions": previous_completions, "labels": previous_labels})
|
||||
return outputs
|
||||
|
||||
|
||||
def process_batch(examples):
|
||||
outputs = []
|
||||
batch_size = len(examples["label"])
|
||||
for idx in range(batch_size):
|
||||
example = {k: v[idx] for k, v in examples.items()}
|
||||
outputs.extend(process_example(example))
|
||||
# list of dict to dict of list
|
||||
outputs = {k: [v[k] for v in outputs] for k in outputs[0]}
|
||||
return outputs
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
data_files = {
|
||||
"train": "https://github.com/openai/prm800k/raw/refs/heads/main/prm800k/data/phase1_train.jsonl",
|
||||
"test": "https://github.com/openai/prm800k/raw/refs/heads/main/prm800k/data/phase1_test.jsonl",
|
||||
}
|
||||
dataset = load_dataset("json", data_files=data_files)
|
||||
|
||||
dataset = dataset.map(
|
||||
process_batch,
|
||||
batched=True,
|
||||
batch_size=10,
|
||||
remove_columns=[
|
||||
"labeler",
|
||||
"timestamp",
|
||||
"generation",
|
||||
"is_quality_control_question",
|
||||
"is_initial_screening_question",
|
||||
"question",
|
||||
"label",
|
||||
],
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
)
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
73
examples/datasets/rlaif-v.py
Normal file
73
examples/datasets/rlaif-v.py
Normal file
@ -0,0 +1,73 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
from datasets import features, load_dataset
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/rlaif-v"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/rlaif-v"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
|
||||
|
||||
def to_conversational(example):
|
||||
"""
|
||||
Convert prompt from "xxx" to [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "xxx"}]}]
|
||||
and chosen and rejected from "xxx" to [{"role": "assistant", "content": [{"type": "text", "text": "xxx"}]}].
|
||||
Images are wrapped into a list.
|
||||
"""
|
||||
prompt = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": example["question"]}]}]
|
||||
chosen = [{"role": "assistant", "content": [{"type": "text", "text": example["chosen"]}]}]
|
||||
rejected = [{"role": "assistant", "content": [{"type": "text", "text": example["rejected"]}]}]
|
||||
return {"prompt": prompt, "images": [example["image"]], "chosen": chosen, "rejected": rejected}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
dataset = load_dataset("openbmb/RLAIF-V-Dataset", split="train")
|
||||
dataset = dataset.map(
|
||||
to_conversational,
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
remove_columns=dataset.column_names,
|
||||
writer_batch_size=128,
|
||||
)
|
||||
|
||||
# Cast the images to Sequence[Image] to avoid bytes format
|
||||
f = dataset.features
|
||||
f["images"] = features.Sequence(features.Image(decode=True))
|
||||
dataset = dataset.cast(f)
|
||||
|
||||
dataset = dataset.train_test_split(test_size=0.01, writer_batch_size=128)
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
@ -1,188 +0,0 @@
|
||||
import sys
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import Dataset, DatasetDict
|
||||
from huggingface_hub import HfApi, hf_hub_download
|
||||
from huggingface_hub.repocard import RepoCard
|
||||
from transformers import AutoTokenizer, HfArgumentParser
|
||||
|
||||
|
||||
"""
|
||||
# debug
|
||||
python -i examples/datasets/sentiment_descriptiveness.py --push_to_hub
|
||||
# actual push
|
||||
python examples/datasets/sentiment_descriptiveness.py \
|
||||
--hf_repo_id sentiment-trl-style \
|
||||
--task sentiment \
|
||||
--push_to_hub \
|
||||
--hf_entity trl-internal-testing
|
||||
python examples/datasets/sentiment_descriptiveness.py \
|
||||
--hf_repo_id descriptiveness-trl-style \
|
||||
--task descriptiveness \
|
||||
--push_to_hub \
|
||||
--hf_entity trl-internal-testing
|
||||
"""
|
||||
|
||||
|
||||
api = HfApi()
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
debug: Optional[bool] = field(default=False, metadata={"help": "Enable debug mode"})
|
||||
hf_entity: Optional[str] = field(default=None, metadata={"help": "The Hugging Face entity to use"})
|
||||
hf_repo_id: Optional[str] = field(
|
||||
default="sentiment-trl-style", metadata={"help": "The Hugging Face repository ID"}
|
||||
)
|
||||
revision: Optional[str] = field(default="0.1.0", metadata={"help": "The revision of the repository"})
|
||||
update_main_revision: Optional[bool] = field(
|
||||
default=True, metadata={"help": "Update the main revision of the repository"}
|
||||
)
|
||||
push_to_hub: Optional[bool] = field(default=False, metadata={"help": "Push the dataset to the Hugging Face Hub"})
|
||||
task: str = field(default="sentiment", metadata={"help": "The task of the dataset"})
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None, metadata={"help": "The number of workers to use to tokenize the data"}
|
||||
)
|
||||
|
||||
|
||||
task_to_filename = {
|
||||
"sentiment": "sentiment/offline_5k.json",
|
||||
"descriptiveness": "descriptiveness/offline_5k.json",
|
||||
}
|
||||
|
||||
|
||||
def deduplicate_query(ds):
|
||||
query = set()
|
||||
ranges = []
|
||||
for i in range(len(ds)):
|
||||
query_str = str(ds[i]["query"])
|
||||
if query_str not in query:
|
||||
query.add(query_str)
|
||||
ranges.append(i)
|
||||
return ds.select(ranges)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = HfArgumentParser(ScriptArguments).parse_args_into_dataclasses()[0]
|
||||
if args.hf_entity is None:
|
||||
args.hf_entity = api.whoami()["name"]
|
||||
full_repo_id = f"{args.hf_entity}/{args.hf_repo_id}"
|
||||
|
||||
model_name = "gpt2"
|
||||
dataset_tokenizer = AutoTokenizer.from_pretrained("gpt2") # of the dataset
|
||||
|
||||
################
|
||||
# Dataset
|
||||
################
|
||||
json = hf_hub_download(
|
||||
repo_id="vwxyzjn/lm-human-preferences",
|
||||
repo_type="dataset",
|
||||
filename=task_to_filename[args.task],
|
||||
)
|
||||
|
||||
MAGIC_TRAIN_NUMBER = 4992 # taken from https://github.com/openai/lm-human-preferences/blob/cbfd210bb8b08f6bc5c26878c10984b90f516c66/launch.py#L70
|
||||
individual_ds = Dataset.from_json(json)
|
||||
individual_ds = deduplicate_query(individual_ds)
|
||||
ds = DatasetDict(
|
||||
{
|
||||
"train": individual_ds.select(range(MAGIC_TRAIN_NUMBER)),
|
||||
"test": individual_ds.select(range(MAGIC_TRAIN_NUMBER, len(individual_ds))),
|
||||
}
|
||||
)
|
||||
|
||||
MAX_DEBUG_SAMPLES = 50
|
||||
if args.debug:
|
||||
for key in ds:
|
||||
ds[key] = ds[key].select(range(min(MAX_DEBUG_SAMPLES, len(ds[key]))))
|
||||
|
||||
# columns are `['sample2', 'sample3', 'sample0', 'query', 'sample1', 'best']`
|
||||
NUM_SAMPLES = 4
|
||||
|
||||
# edge cases handling: remove the cases where all samples are the same
|
||||
def filter(row):
|
||||
best_idx = row["best"]
|
||||
chosen_sample = row[f"sample{best_idx}"]
|
||||
if all(chosen_sample == row[f"sample{j}"] for j in range(NUM_SAMPLES)):
|
||||
return False
|
||||
else:
|
||||
return True
|
||||
|
||||
print("=== Before filtering ===", ds)
|
||||
ds = ds.filter(filter, num_proc=args.dataset_num_proc)
|
||||
print("=== After filtering ===", ds)
|
||||
|
||||
# here we simply take the preferred sample as the chosen one and the first non-preferred sample as the rejected one
|
||||
def process(row):
|
||||
for j in range(NUM_SAMPLES):
|
||||
row[f"sample{j}"] = dataset_tokenizer.batch_decode(row[f"sample{j}"])
|
||||
row["prompt"] = dataset_tokenizer.batch_decode(row["query"])
|
||||
row["prompt"] = [item.strip() for item in row["prompt"]]
|
||||
row["chosen"] = []
|
||||
row["rejected"] = []
|
||||
for i in range(len(row["best"])):
|
||||
best_idx = row["best"][i]
|
||||
chosen_sample = row[f"sample{best_idx}"][i].strip()
|
||||
row["chosen"].append(
|
||||
[
|
||||
{"role": "user", "content": row["prompt"][i].strip()},
|
||||
{"role": "assistant", "content": chosen_sample},
|
||||
]
|
||||
)
|
||||
# find the first rejected sample which is different from the chosen one
|
||||
rejected_idx = -1
|
||||
for k in range(4):
|
||||
if k != best_idx and row[f"sample{k}"][i].strip() != chosen_sample:
|
||||
rejected_idx = k
|
||||
break
|
||||
rejected_sample = row[f"sample{rejected_idx}"][i].strip()
|
||||
assert rejected_idx != -1, "No rejected sample found! This should not happen!"
|
||||
row["rejected"].append(
|
||||
[
|
||||
{"role": "user", "content": row["prompt"][i].strip()},
|
||||
{"role": "assistant", "content": rejected_sample},
|
||||
]
|
||||
)
|
||||
assert chosen_sample != rejected_sample
|
||||
return row
|
||||
|
||||
ds = ds.map(process, batched=True, num_proc=args.dataset_num_proc)
|
||||
for key in ds: # reorder columns
|
||||
ds[key] = ds[key].select_columns(["prompt", "chosen", "rejected"])
|
||||
if args.push_to_hub:
|
||||
revisions = ["main"] if args.update_main_revision else []
|
||||
revisions.append(args.revision)
|
||||
|
||||
# get the commnad used to run the script
|
||||
run_command = " ".join(["python"] + sys.argv)
|
||||
|
||||
for revision in revisions:
|
||||
ds.push_to_hub(full_repo_id, revision=revision)
|
||||
repo_full_url = f"https://huggingface.co/datasets/{full_repo_id}/tree/{revision}"
|
||||
|
||||
# get the name of the current file
|
||||
file_name = __file__.split("/")[-1]
|
||||
api.upload_file(
|
||||
path_or_fileobj=__file__,
|
||||
path_in_repo=file_name,
|
||||
revision=revision,
|
||||
repo_id=full_repo_id,
|
||||
repo_type="dataset",
|
||||
)
|
||||
|
||||
sft_card = RepoCard.load(
|
||||
full_repo_id,
|
||||
repo_type="dataset",
|
||||
)
|
||||
sft_card.text = f"""\
|
||||
# TRL's Preference Dataset: {args.task}
|
||||
The dataset comes from https://huggingface.co/papers/1909.08593, one of the earliest RLHF work from OpenAI.
|
||||
We preprocess the dataset using our standard `prompt, chosen, rejected` format.
|
||||
## Reproduce this dataset
|
||||
1. Download the `{file_name}` from the {repo_full_url}.
|
||||
2. Run `{run_command}`
|
||||
"""
|
||||
sft_card.push_to_hub(
|
||||
full_repo_id,
|
||||
repo_type="dataset",
|
||||
)
|
||||
67
examples/datasets/tldr.py
Normal file
67
examples/datasets/tldr.py
Normal file
@ -0,0 +1,67 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/tldr"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/tldr"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
|
||||
|
||||
def to_prompt_completion(example):
|
||||
tldr_format_str = "SUBREDDIT: r/{subreddit}\n\nTITLE: {title}\n\nPOST: {post}\n\nTL;DR:"
|
||||
prompt = tldr_format_str.format(subreddit=example["subreddit"], title=example["title"], post=example["post"])
|
||||
completion = " " + example["summary"] # Add a space to separate the prompt from the completion
|
||||
return {"prompt": prompt, "completion": completion}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
# Filtered reddit TL;DR dataset from https://github.com/openai/summarize-from-feedback?tab=readme-ov-file#reddit-tldr-dataset
|
||||
data_files = {
|
||||
"train": "https://openaipublic.blob.core.windows.net/summarize-from-feedback/datasets/tldr_3_filtered/train.jsonl",
|
||||
"validation": "https://openaipublic.blob.core.windows.net/summarize-from-feedback/datasets/tldr_3_filtered/valid.jsonl",
|
||||
"test": "https://openaipublic.blob.core.windows.net/summarize-from-feedback/datasets/tldr_3_filtered/test.jsonl",
|
||||
}
|
||||
dataset = load_dataset("json", data_files=data_files)
|
||||
|
||||
dataset = dataset.map(
|
||||
to_prompt_completion,
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
remove_columns=["id", "subreddit", "title", "post", "summary"],
|
||||
)
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
@ -1,185 +1,72 @@
|
||||
import sys
|
||||
from dataclasses import dataclass, field
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import HfApi
|
||||
from huggingface_hub.repocard import RepoCard
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
"""
|
||||
# debug
|
||||
python -i examples/datasets/tldr_preference.py --debug --push_to_hub
|
||||
# actual push
|
||||
python examples/datasets/tldr_preference.py --push_to_hub --hf_entity trl-internal-testing
|
||||
"""
|
||||
|
||||
|
||||
api = HfApi()
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
debug: Optional[bool] = field(default=False, metadata={"help": "Enable debug mode"})
|
||||
hf_entity: Optional[str] = field(default=None, metadata={"help": "The Hugging Face entity to use"})
|
||||
hf_repo_id: Optional[str] = field(
|
||||
default="tldr-preference-trl-style", metadata={"help": "The Hugging Face repository ID"}
|
||||
)
|
||||
sft_hf_repo_id: Optional[str] = field(
|
||||
default="tldr-preference-sft-trl-style", metadata={"help": "The Hugging Face repository ID"}
|
||||
)
|
||||
revision: Optional[str] = field(default="0.1.0", metadata={"help": "The revision of the repository"})
|
||||
update_main_revision: Optional[bool] = field(
|
||||
default=True, metadata={"help": "Update the main revision of the repository"}
|
||||
)
|
||||
push_to_hub: Optional[bool] = field(default=False, metadata={"help": "Push the dataset to the Hugging Face Hub"})
|
||||
dataset_num_proc: Optional[int] = field(
|
||||
default=None, metadata={"help": "The number of workers to use to tokenize the data"}
|
||||
)
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/tldr-preference"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/tldr-preference"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
|
||||
|
||||
def to_preference(example):
|
||||
info = example["info"]
|
||||
if example["batch"] in ["batch0_cnndm", "cnndm0", "cnndm2"]: # CNN Daily Mail batches
|
||||
article = info["article"].replace("\n\n", "\n")
|
||||
prompt = f"TITLE: {info['title']}\n\n{article}\n\nTL;DR:"
|
||||
elif example["batch"] in [f"batch{i}" for i in range(3, 23)] + ["edit_b2_eval_test"]: # Reddit batches
|
||||
post = info["post"].replace("\n\n", "\n")
|
||||
prompt = f"SUBREDDIT: r/{info['subreddit']}\n\nTITLE: {info['title']}\n\nPOST: {post}\n\nTL;DR:"
|
||||
else:
|
||||
raise ValueError(f"Unknown batch: {example['batch']}")
|
||||
|
||||
chosen_idx = example["choice"]
|
||||
rejected_idx = 1 - chosen_idx
|
||||
chosen = example["summaries"][chosen_idx]["text"]
|
||||
rejected = example["summaries"][rejected_idx]["text"]
|
||||
return {"prompt": prompt, "chosen": chosen, "rejected": rejected}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = HfArgumentParser(ScriptArguments).parse_args_into_dataclasses()[0]
|
||||
if args.hf_entity is None:
|
||||
args.hf_entity = api.whoami()["name"]
|
||||
full_repo_id = f"{args.hf_entity}/{args.hf_repo_id}"
|
||||
full_sft_repo_id = f"{args.hf_entity}/{args.sft_hf_repo_id}"
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
################
|
||||
# Preference dataset
|
||||
################
|
||||
ds = load_dataset("openai/summarize_from_feedback", "comparisons")
|
||||
if args.debug:
|
||||
for key in ds:
|
||||
ds[key] = ds[key].select(range(50))
|
||||
cnndm_batches = ["batch0_cnndm", "cnndm0", "cnndm2"]
|
||||
if not args.debug:
|
||||
ds["validation_cnndm"] = ds["validation"].filter(
|
||||
lambda x: x["batch"] in cnndm_batches, num_proc=args.dataset_num_proc
|
||||
)
|
||||
ds["validation"] = ds["validation"].filter(
|
||||
lambda x: x["batch"] not in cnndm_batches, num_proc=args.dataset_num_proc
|
||||
dataset = load_dataset("openai/summarize_from_feedback", "comparisons")
|
||||
|
||||
dataset = dataset.map(
|
||||
to_preference,
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
remove_columns=["info", "summaries", "choice", "worker", "batch", "split", "extra"],
|
||||
)
|
||||
|
||||
tldr_format_str = "SUBREDDIT: r/{subreddit}\n\nTITLE: {title}\n\nPOST: {post}\n\nTL;DR:"
|
||||
cnndm_format_str = "Article:\n{article}\n\nTL;DR:"
|
||||
|
||||
def process(row):
|
||||
format_str = cnndm_format_str if row["batch"] in cnndm_batches else tldr_format_str
|
||||
row["prompt"] = format_str.format(**row["info"])
|
||||
choice = row["choice"]
|
||||
# need to remove the leading space
|
||||
chosen = row["summaries"][choice]["text"].strip()
|
||||
rejected = row["summaries"][1 - choice]["text"].strip()
|
||||
row["chosen"] = [{"role": "user", "content": row["prompt"]}, {"role": "assistant", "content": chosen}]
|
||||
row["rejected"] = [{"role": "user", "content": row["prompt"]}, {"role": "assistant", "content": rejected}]
|
||||
return row
|
||||
|
||||
ds = ds.map(process, num_proc=args.dataset_num_proc)
|
||||
for key in ds: # reorder columns
|
||||
ds[key] = ds[key].select_columns(
|
||||
["prompt", "chosen", "rejected", "info", "summaries", "choice", "worker", "batch", "split", "extra"]
|
||||
)
|
||||
if args.push_to_hub:
|
||||
revisions = ["main"] if args.update_main_revision else []
|
||||
revisions.append(args.revision)
|
||||
|
||||
# get the commnad used to run the script
|
||||
run_command = " ".join(["python"] + sys.argv)
|
||||
|
||||
for revision in revisions:
|
||||
ds.push_to_hub(full_repo_id, revision=revision)
|
||||
repo_full_url = f"https://huggingface.co/datasets/{full_repo_id}/tree/{revision}"
|
||||
|
||||
# get the name of the current file
|
||||
file_name = __file__.split("/")[-1]
|
||||
api.upload_file(
|
||||
path_or_fileobj=__file__,
|
||||
path_in_repo=file_name,
|
||||
revision=revision,
|
||||
repo_id=full_repo_id,
|
||||
repo_type="dataset",
|
||||
)
|
||||
|
||||
preference_card = RepoCard.load(
|
||||
full_repo_id,
|
||||
repo_type="dataset",
|
||||
)
|
||||
preference_card.text = f"""\
|
||||
# TRL's TL;DR Preference Dataset
|
||||
|
||||
We preprocess the dataset using our standard `prompt, chosen, rejected` format.
|
||||
|
||||
## Source of the dataset
|
||||
|
||||
We take the dataset from https://huggingface.co/datasets/openai/summarize_from_feedback.
|
||||
|
||||
## Reproduce this dataset
|
||||
|
||||
1. Download the `{file_name}` from the {repo_full_url}.
|
||||
2. Run `{run_command}`
|
||||
"""
|
||||
preference_card.push_to_hub(
|
||||
full_repo_id,
|
||||
repo_type="dataset",
|
||||
)
|
||||
|
||||
################
|
||||
# SFT dataset
|
||||
################
|
||||
sft_ds = load_dataset("vwxyzjn/summarize_from_feedback_tldr_3_filtered")
|
||||
if args.debug:
|
||||
for key in sft_ds:
|
||||
sft_ds[key] = sft_ds[key].select(range(50))
|
||||
|
||||
def sft_process(row):
|
||||
row["prompt"] = tldr_format_str.format(**row)
|
||||
row["messages"] = [
|
||||
{"role": "user", "content": row["prompt"]},
|
||||
{"role": "assistant", "content": row["summary"]},
|
||||
]
|
||||
return row
|
||||
|
||||
sft_ds = sft_ds.map(sft_process, num_proc=args.dataset_num_proc)
|
||||
for key in sft_ds: # reorder columns
|
||||
sft_ds[key] = sft_ds[key].select_columns(["prompt", "messages", "id", "subreddit", "title", "post", "summary"])
|
||||
if args.push_to_hub:
|
||||
revisions = ["main"] if args.update_main_revision else []
|
||||
revisions.append(args.revision)
|
||||
|
||||
# get the commnad used to run the script
|
||||
run_command = " ".join(["python"] + sys.argv)
|
||||
|
||||
for revision in revisions:
|
||||
sft_ds.push_to_hub(full_sft_repo_id, revision=revision)
|
||||
repo_full_url = f"https://huggingface.co/datasets/{full_sft_repo_id}/tree/{revision}"
|
||||
|
||||
# get the name of the current file
|
||||
file_name = __file__.split("/")[-1]
|
||||
api.upload_file(
|
||||
path_or_fileobj=__file__,
|
||||
path_in_repo=file_name,
|
||||
revision=revision,
|
||||
repo_id=full_sft_repo_id,
|
||||
repo_type="dataset",
|
||||
)
|
||||
|
||||
sft_card = RepoCard.load(
|
||||
full_sft_repo_id,
|
||||
repo_type="dataset",
|
||||
)
|
||||
sft_card.text = f"""\
|
||||
# TRL's TL;DR SFT Dataset
|
||||
|
||||
We preprocess the dataset using our standard `prompt, messages` format.
|
||||
|
||||
## Source of the dataset
|
||||
|
||||
We take the dataset from https://huggingface.co/datasets/vwxyzjn/summarize_from_feedback_tldr_3_filtered.
|
||||
|
||||
## Reproduce this dataset
|
||||
|
||||
1. Download the `{file_name}` from the {repo_full_url}.
|
||||
2. Run `{run_command}`
|
||||
"""
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
|
||||
@ -1,20 +1,35 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoTokenizer, HfArgumentParser
|
||||
|
||||
from trl.trainer.utils import SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
|
||||
"""
|
||||
python -i examples/datasets/tokenize_ds.py --debug --model HuggingFaceH4/zephyr-7b-beta
|
||||
python -i examples/datasets/tokenize_ds.py --debug --model gpt2
|
||||
python -i examples/datasets/tokenize_ds.py --model HuggingFaceH4/zephyr-7b-beta
|
||||
python -i examples/datasets/tokenize_ds.py --model gpt2
|
||||
"""
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
debug: Optional[bool] = field(default=False, metadata={"help": "Enable debug mode"})
|
||||
dataset: str = field(
|
||||
dataset_name: str = field(
|
||||
default="trl-internal-testing/hh-rlhf-helpful-base-trl-style", metadata={"help": "The dataset to load"}
|
||||
)
|
||||
model: str = field(default="gpt2", metadata={"help": "The model to use for tokenization"})
|
||||
@ -24,19 +39,16 @@ class ScriptArguments:
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = HfArgumentParser(ScriptArguments).parse_args_into_dataclasses()[0]
|
||||
ds = load_dataset(args.dataset)
|
||||
if args.debug:
|
||||
for key in ds:
|
||||
ds[key] = ds[key].select(range(50))
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.model)
|
||||
script_args = HfArgumentParser(ScriptArguments).parse_args_into_dataclasses()[0]
|
||||
dataset = load_dataset(script_args.dataset_name)
|
||||
tokenizer = AutoTokenizer.from_pretrained(script_args.model)
|
||||
if tokenizer.chat_template is None:
|
||||
tokenizer.chat_template = "{% for message in messages %}{{message['role'] + ': ' + message['content'] + '\n\n'}}{% endfor %}{{ eos_token }}"
|
||||
tokenizer.chat_template = SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
def process(row):
|
||||
row["chosen"] = tokenizer.apply_chat_template(row["chosen"], tokenize=False)
|
||||
row["rejected"] = tokenizer.apply_chat_template(row["rejected"], tokenize=False)
|
||||
return row
|
||||
|
||||
ds = ds.map(process, num_proc=args.dataset_num_proc)
|
||||
print(ds["train"][0]["chosen"])
|
||||
dataset = dataset.map(process, num_proc=script_args.dataset_num_proc)
|
||||
print(dataset["train"][0]["chosen"])
|
||||
|
||||
68
examples/datasets/ultrafeedback-prompt.py
Normal file
68
examples/datasets/ultrafeedback-prompt.py
Normal file
@ -0,0 +1,68 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/ultrafeedback-prompt"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/ultrafeedback-prompt"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
|
||||
|
||||
def to_unpaired_preference(example):
|
||||
prompt = [{"role": "user", "content": example["instruction"]}]
|
||||
return {"prompt": prompt}
|
||||
|
||||
|
||||
def drop_long_prompt(example):
|
||||
if len(example["prompt"][0]["content"]) > 512:
|
||||
return False
|
||||
else:
|
||||
return True
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
dataset = load_dataset("openbmb/UltraFeedback", split="train")
|
||||
|
||||
dataset = dataset.map(
|
||||
to_unpaired_preference,
|
||||
remove_columns=["source", "instruction", "models", "completions", "correct_answers", "incorrect_answers"],
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
)
|
||||
dataset = dataset.filter(drop_long_prompt)
|
||||
dataset = dataset.train_test_split(test_size=0.05, seed=42)
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
102
examples/datasets/ultrafeedback.py
Normal file
102
examples/datasets/ultrafeedback.py
Normal file
@ -0,0 +1,102 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
from datasets import load_dataset
|
||||
from transformers import HfArgumentParser
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
r"""
|
||||
Arguments for the script.
|
||||
|
||||
Args:
|
||||
model_name (`str`, *optional*, defaults to `"gpt-3.5-turbo"`):
|
||||
Language model to target. Possible values are:
|
||||
|
||||
- `"alpaca-7b"`
|
||||
- `"bard"`
|
||||
- `"falcon-40b-instruct"`
|
||||
- `"gpt-3.5-turbo"` (default)
|
||||
- `"gpt-4"`
|
||||
- `"llama-2-13b-chat"`
|
||||
- `"llama-2-70b-chat"`
|
||||
- `"llama-2-7b-chat"`
|
||||
- `"mpt-30b-chat"`
|
||||
- `"pythia-12b"`
|
||||
- `"starchat"`
|
||||
- `"ultralm-13b"`
|
||||
- `"ultralm-65b"`
|
||||
- `"vicuna-33b"`
|
||||
- `"wizardlm-13b"`
|
||||
- `"wizardlm-70b"`
|
||||
- `"wizardlm-7b"`
|
||||
|
||||
aspect (`str`, *optional*, defaults to `"helpfulness"`):
|
||||
Aspect to target. Possible values are:
|
||||
|
||||
- `"helpfulness"` (default)
|
||||
- `"honesty"`
|
||||
- `"instruction-following"`
|
||||
- `"truthfulness"`
|
||||
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether to push the dataset to the Hugging Face Hub.
|
||||
repo_id (`str`, *optional*, defaults to `"trl-lib/ultrafeedback-gpt-3.5-turbo-helpfulness"`):
|
||||
Hugging Face repository ID to push the dataset to.
|
||||
dataset_num_proc (`Optional[int]`, *optional*, defaults to `None`):
|
||||
Number of workers to use for dataset processing.
|
||||
"""
|
||||
|
||||
model_name: str = "gpt-3.5-turbo"
|
||||
aspect: str = "helpfulness"
|
||||
push_to_hub: bool = False
|
||||
repo_id: str = "trl-lib/ultrafeedback-gpt-3.5-turbo-helpfulness"
|
||||
dataset_num_proc: Optional[int] = None
|
||||
|
||||
|
||||
def to_unpaired_preference(example, model_name, aspect):
|
||||
prompt = [{"role": "user", "content": example["instruction"]}]
|
||||
model_index = example["models"].index(model_name)
|
||||
response_content = example["completions"][model_index]["response"]
|
||||
completion = [{"role": "assistant", "content": response_content}]
|
||||
score = int(example["completions"][model_index]["annotations"][aspect]["Rating"])
|
||||
label = score >= 5
|
||||
return {"prompt": prompt, "completion": completion, "label": label}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
dataset = load_dataset("openbmb/UltraFeedback", split="train")
|
||||
|
||||
dataset = dataset.filter(
|
||||
lambda example: script_args.model_name in example["models"],
|
||||
batched=False,
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
)
|
||||
dataset = dataset.map(
|
||||
to_unpaired_preference,
|
||||
remove_columns=["source", "instruction", "models", "completions", "correct_answers", "incorrect_answers"],
|
||||
fn_kwargs={"model_name": script_args.model_name, "aspect": script_args.aspect},
|
||||
num_proc=script_args.dataset_num_proc,
|
||||
)
|
||||
dataset = dataset.train_test_split(test_size=0.05, seed=42)
|
||||
|
||||
if script_args.push_to_hub:
|
||||
dataset.push_to_hub(script_args.repo_id)
|
||||
@ -1,40 +0,0 @@
|
||||
# 0. imports
|
||||
import torch
|
||||
from transformers import GPT2Tokenizer
|
||||
|
||||
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer
|
||||
|
||||
|
||||
# 1. load a pretrained model
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
|
||||
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
|
||||
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
# 2. initialize trainer
|
||||
ppo_config = {"mini_batch_size": 1, "batch_size": 1}
|
||||
config = PPOConfig(**ppo_config)
|
||||
ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer)
|
||||
|
||||
# 3. encode a query
|
||||
query_txt = "This morning I went to the "
|
||||
query_tensor = tokenizer.encode(query_txt, return_tensors="pt").to(model.pretrained_model.device)
|
||||
|
||||
# 4. generate model response
|
||||
generation_kwargs = {
|
||||
"min_length": -1,
|
||||
"top_k": 0.0,
|
||||
"top_p": 1.0,
|
||||
"do_sample": True,
|
||||
"pad_token_id": tokenizer.eos_token_id,
|
||||
"max_new_tokens": 20,
|
||||
}
|
||||
response_tensor = ppo_trainer.generate(list(query_tensor), return_prompt=False, **generation_kwargs)
|
||||
response_txt = tokenizer.decode(response_tensor[0])
|
||||
|
||||
# 5. define a reward for response
|
||||
# (this could be any reward such as human feedback or output from another model)
|
||||
reward = [torch.tensor(1.0, device=model.pretrained_model.device)]
|
||||
|
||||
# 6. train model with ppo
|
||||
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
|
||||
File diff suppressed because it is too large
Load Diff
@ -80,7 +80,12 @@
|
||||
"\n",
|
||||
"from transformers import AutoTokenizer, pipeline\n",
|
||||
"\n",
|
||||
"from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead, create_reference_model"
|
||||
"from trl import (\n",
|
||||
" PPOTrainer,\n",
|
||||
" PPOConfig,\n",
|
||||
" AutoModelForCausalLMWithValueHead,\n",
|
||||
" create_reference_model,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -99,7 +104,11 @@
|
||||
"sentiment_pipe_kwargs = {\"top_k\": None, \"function_to_apply\": \"none\"}\n",
|
||||
"\n",
|
||||
"config = PPOConfig(\n",
|
||||
" model_name=\"lvwerra/gpt2-imdb\", steps=51200, learning_rate=1.41e-5, remove_unused_columns=False, log_with=\"wandb\"\n",
|
||||
" model_name=\"lvwerra/gpt2-imdb\",\n",
|
||||
" steps=51200,\n",
|
||||
" learning_rate=1.41e-5,\n",
|
||||
" remove_unused_columns=False,\n",
|
||||
" log_with=\"wandb\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"txt_in_len = 5\n",
|
||||
@ -197,7 +206,7 @@
|
||||
"source": [
|
||||
"# create the dataset\n",
|
||||
"#\n",
|
||||
"dataset = load_dataset(\"imdb\", split=\"train\")\n",
|
||||
"dataset = load_dataset(\"stanfordnlp/imdb\", split=\"train\")\n",
|
||||
"dataset = dataset.rename_columns({\"text\": \"review\", \"label\": \"sentiment\"})\n",
|
||||
"# make sure the comments are are at least 500 and trim to 1000\n",
|
||||
"dataset = dataset.filter(lambda x: len(x[\"review\"]) > 500, batched=False)\n",
|
||||
@ -236,10 +245,16 @@
|
||||
],
|
||||
"source": [
|
||||
"dataset = dataset.map(\n",
|
||||
" lambda x: {\"input_ids\": gpt2_tokenizer.encode(\" \" + x[\"review\"], return_tensors=\"pt\")[0, :txt_in_len]},\n",
|
||||
" lambda x: {\n",
|
||||
" \"input_ids\": gpt2_tokenizer.encode(\" \" + x[\"review\"], return_tensors=\"pt\")[\n",
|
||||
" 0, :txt_in_len\n",
|
||||
" ]\n",
|
||||
" },\n",
|
||||
" batched=False,\n",
|
||||
")\n",
|
||||
"dataset = dataset.map(lambda x: {\"query\": gpt2_tokenizer.decode(x[\"input_ids\"])}, batched=False)\n",
|
||||
"dataset = dataset.map(\n",
|
||||
" lambda x: {\"query\": gpt2_tokenizer.decode(x[\"input_ids\"])}, batched=False\n",
|
||||
")\n",
|
||||
"dataset = dataset[:20480]\n",
|
||||
"\n",
|
||||
"from datasets import Dataset\n",
|
||||
@ -353,7 +368,9 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"ppo_trainer = PPOTrainer(config, gpt2_model, gpt2_ref_model, gpt2_tokenizer, dataset, data_collator=collator)"
|
||||
"ppo_trainer = PPOTrainer(\n",
|
||||
" config, gpt2_model, gpt2_ref_model, gpt2_tokenizer, dataset, data_collator=collator\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -374,7 +391,9 @@
|
||||
" device = 0 if torch.cuda.is_available() else \"cpu\" # to avoid a `pipeline` bug\n",
|
||||
"else:\n",
|
||||
" device = ppo_trainer.accelerator.device\n",
|
||||
"sentiment_pipe = pipeline(\"sentiment-analysis\", \"lvwerra/distilbert-imdb\", device=device)"
|
||||
"sentiment_pipe = pipeline(\n",
|
||||
" \"sentiment-analysis\", \"lvwerra/distilbert-imdb\", device=device\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -510,8 +529,13 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"ctrl_str = [\"[negative]\", \"[neutral]\", \"[positive]\"]\n",
|
||||
"device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\") # this should be handled by accelerate\n",
|
||||
"ctrl_tokens = dict((s, gpt2_tokenizer.encode(s, return_tensors=\"pt\").squeeze().to(device)) for s in ctrl_str)"
|
||||
"device = torch.device(\n",
|
||||
" \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
|
||||
") # this should be handled by accelerate\n",
|
||||
"ctrl_tokens = dict(\n",
|
||||
" (s, gpt2_tokenizer.encode(s, return_tensors=\"pt\").squeeze().to(device))\n",
|
||||
" for s in ctrl_str\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -721,7 +745,10 @@
|
||||
"source": [
|
||||
"for epoch in range(2):\n",
|
||||
" for batch in tqdm(ppo_trainer.dataloader):\n",
|
||||
" (logs, game_data,) = (\n",
|
||||
" (\n",
|
||||
" logs,\n",
|
||||
" game_data,\n",
|
||||
" ) = (\n",
|
||||
" dict(),\n",
|
||||
" dict(),\n",
|
||||
" )\n",
|
||||
@ -729,14 +756,19 @@
|
||||
" #### prepend a random control token\n",
|
||||
" task_list = choices(ctrl_str, k=config.batch_size)\n",
|
||||
" game_data[\"query\"] = [t + q for t, q in zip(task_list, batch[\"query\"])]\n",
|
||||
" query_tensors = [torch.cat((ctrl_tokens[t], input_ids)) for t, input_ids in zip(task_list, batch[\"input_ids\"])]\n",
|
||||
" query_tensors = [\n",
|
||||
" torch.cat((ctrl_tokens[t], input_ids))\n",
|
||||
" for t, input_ids in zip(task_list, batch[\"input_ids\"])\n",
|
||||
" ]\n",
|
||||
"\n",
|
||||
" #### get response from gpt2\n",
|
||||
" response_tensors = []\n",
|
||||
" for query in query_tensors:\n",
|
||||
" response = ppo_trainer.generate(query, **generation_kwargs)\n",
|
||||
" response_tensors.append(response.squeeze()[-txt_out_len:])\n",
|
||||
" game_data[\"response\"] = [gpt2_tokenizer.decode(r.squeeze()) for r in response_tensors]\n",
|
||||
" game_data[\"response\"] = [\n",
|
||||
" gpt2_tokenizer.decode(r.squeeze()) for r in response_tensors\n",
|
||||
" ]\n",
|
||||
"\n",
|
||||
" #### sentiment analysis\n",
|
||||
" texts = [q + r for q, r in zip(batch[\"query\"], game_data[\"response\"])]\n",
|
||||
@ -749,7 +781,9 @@
|
||||
"\n",
|
||||
" for cs in ctrl_str:\n",
|
||||
" key = \"env/reward_\" + cs.strip(\"[]\")\n",
|
||||
" stats[key] = np.mean([r.cpu().numpy() for r, t in zip(rewards, task_list) if t == cs])\n",
|
||||
" stats[key] = np.mean(\n",
|
||||
" [r.cpu().numpy() for r, t in zip(rewards, task_list) if t == cs]\n",
|
||||
" )\n",
|
||||
" ppo_trainer.log_stats(stats, game_data, rewards)"
|
||||
]
|
||||
},
|
||||
@ -804,7 +838,10 @@
|
||||
"source": [
|
||||
"for ctrl_s in ctrl_str:\n",
|
||||
" plt.hist(\n",
|
||||
" [r for r, t in zip(logs[\"env/reward_dist\"], task_list) if t == ctrl_s], density=True, alpha=0.5, label=ctrl_s\n",
|
||||
" [r for r, t in zip(logs[\"env/reward_dist\"], task_list) if t == ctrl_s],\n",
|
||||
" density=True,\n",
|
||||
" alpha=0.5,\n",
|
||||
" label=ctrl_s,\n",
|
||||
" )\n",
|
||||
"plt.legend(loc=\"best\")\n",
|
||||
"plt.title(\"reward distribution\")\n",
|
||||
|
||||
@ -136,7 +136,12 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def build_dataset(config, dataset_name=\"imdb\", input_min_text_length=2, input_max_text_length=8):\n",
|
||||
"def build_dataset(\n",
|
||||
" config,\n",
|
||||
" dataset_name=\"stanfordnlp/imdb\",\n",
|
||||
" input_min_text_length=2,\n",
|
||||
" input_max_text_length=8,\n",
|
||||
"):\n",
|
||||
" \"\"\"\n",
|
||||
" Build dataset for training. This builds the dataset from `load_dataset`, one should\n",
|
||||
" customize this function to train the model on its own dataset.\n",
|
||||
@ -223,7 +228,9 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer, dataset=dataset, data_collator=collator)"
|
||||
"ppo_trainer = PPOTrainer(\n",
|
||||
" config, model, ref_model, tokenizer, dataset=dataset, data_collator=collator\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -243,7 +250,9 @@
|
||||
"device = ppo_trainer.accelerator.device\n",
|
||||
"if ppo_trainer.accelerator.num_processes == 1:\n",
|
||||
" device = 0 if torch.cuda.is_available() else \"cpu\" # to avoid a `pipeline` bug\n",
|
||||
"sentiment_pipe = pipeline(\"sentiment-analysis\", model=\"lvwerra/distilbert-imdb\", device=device)"
|
||||
"sentiment_pipe = pipeline(\n",
|
||||
" \"sentiment-analysis\", model=\"lvwerra/distilbert-imdb\", device=device\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -311,7 +320,13 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"gen_kwargs = {\"min_length\": -1, \"top_k\": 0.0, \"top_p\": 1.0, \"do_sample\": True, \"pad_token_id\": tokenizer.eos_token_id}"
|
||||
"gen_kwargs = {\n",
|
||||
" \"min_length\": -1,\n",
|
||||
" \"top_k\": 0.0,\n",
|
||||
" \"top_p\": 1.0,\n",
|
||||
" \"do_sample\": True,\n",
|
||||
" \"pad_token_id\": tokenizer.eos_token_id,\n",
|
||||
"}"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -378,7 +393,12 @@
|
||||
" #### Compute sentiment score\n",
|
||||
" texts = [q + r for q, r in zip(batch[\"query\"], batch[\"response\"])]\n",
|
||||
" pipe_outputs = sentiment_pipe(texts, **sent_kwargs)\n",
|
||||
" positive_scores = [item[\"score\"] for output in pipe_outputs for item in output if item[\"label\"] == \"POSITIVE\"]\n",
|
||||
" positive_scores = [\n",
|
||||
" item[\"score\"]\n",
|
||||
" for output in pipe_outputs\n",
|
||||
" for item in output\n",
|
||||
" if item[\"label\"] == \"POSITIVE\"\n",
|
||||
" ]\n",
|
||||
" rewards = [torch.tensor(score) for score in positive_scores]\n",
|
||||
"\n",
|
||||
" #### Run PPO step\n",
|
||||
@ -673,27 +693,45 @@
|
||||
" query = torch.tensor(query_tensors[i]).to(device)\n",
|
||||
"\n",
|
||||
" gen_len = output_length_sampler()\n",
|
||||
" query_response = ref_model.generate(query.unsqueeze(0), max_new_tokens=gen_len, **gen_kwargs).squeeze()\n",
|
||||
" query_response = ref_model.generate(\n",
|
||||
" query.unsqueeze(0), max_new_tokens=gen_len, **gen_kwargs\n",
|
||||
" ).squeeze()\n",
|
||||
" response_len = len(query_response) - len(query)\n",
|
||||
" response_tensors_ref.append(query_response[-response_len:])\n",
|
||||
"\n",
|
||||
" query_response = model.generate(query.unsqueeze(0), max_new_tokens=gen_len, **gen_kwargs).squeeze()\n",
|
||||
" query_response = model.generate(\n",
|
||||
" query.unsqueeze(0), max_new_tokens=gen_len, **gen_kwargs\n",
|
||||
" ).squeeze()\n",
|
||||
" response_len = len(query_response) - len(query)\n",
|
||||
" response_tensors.append(query_response[-response_len:])\n",
|
||||
"\n",
|
||||
"#### decode responses\n",
|
||||
"game_data[\"response (before)\"] = [tokenizer.decode(response_tensors_ref[i]) for i in range(bs)]\n",
|
||||
"game_data[\"response (after)\"] = [tokenizer.decode(response_tensors[i]) for i in range(bs)]\n",
|
||||
"game_data[\"response (before)\"] = [\n",
|
||||
" tokenizer.decode(response_tensors_ref[i]) for i in range(bs)\n",
|
||||
"]\n",
|
||||
"game_data[\"response (after)\"] = [\n",
|
||||
" tokenizer.decode(response_tensors[i]) for i in range(bs)\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"#### sentiment analysis of query/response pairs before/after\n",
|
||||
"texts = [q + r for q, r in zip(game_data[\"query\"], game_data[\"response (before)\"])]\n",
|
||||
"pipe_outputs = sentiment_pipe(texts, **sent_kwargs)\n",
|
||||
"positive_scores = [item[\"score\"] for output in pipe_outputs for item in output if item[\"label\"] == \"POSITIVE\"]\n",
|
||||
"positive_scores = [\n",
|
||||
" item[\"score\"]\n",
|
||||
" for output in pipe_outputs\n",
|
||||
" for item in output\n",
|
||||
" if item[\"label\"] == \"POSITIVE\"\n",
|
||||
"]\n",
|
||||
"game_data[\"rewards (before)\"] = positive_scores\n",
|
||||
"\n",
|
||||
"texts = [q + r for q, r in zip(game_data[\"query\"], game_data[\"response (after)\"])]\n",
|
||||
"pipe_outputs = sentiment_pipe(texts, **sent_kwargs)\n",
|
||||
"positive_scores = [item[\"score\"] for output in pipe_outputs for item in output if item[\"label\"] == \"POSITIVE\"]\n",
|
||||
"positive_scores = [\n",
|
||||
" item[\"score\"]\n",
|
||||
" for output in pipe_outputs\n",
|
||||
" for item in output\n",
|
||||
" if item[\"label\"] == \"POSITIVE\"\n",
|
||||
"]\n",
|
||||
"game_data[\"rewards (after)\"] = positive_scores\n",
|
||||
"\n",
|
||||
"# store results in a dataframe\n",
|
||||
|
||||
@ -1,3 +1,17 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
|
||||
@ -1,5 +1,19 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Any, Dict, List, Optional, Union
|
||||
from typing import Any, Optional, Union
|
||||
|
||||
import evaluate
|
||||
import numpy as np
|
||||
@ -219,11 +233,10 @@ eval_dataset = eval_dataset.filter(
|
||||
class RewardDataCollatorWithPadding:
|
||||
tokenizer: PreTrainedTokenizerBase
|
||||
padding: Union[bool, str, PaddingStrategy] = True
|
||||
max_length: Optional[int] = None
|
||||
pad_to_multiple_of: Optional[int] = None
|
||||
return_tensors: str = "pt"
|
||||
|
||||
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
|
||||
def __call__(self, features: list[dict[str, Any]]) -> dict[str, Any]:
|
||||
features_j = []
|
||||
features_k = []
|
||||
for feature in features:
|
||||
@ -242,14 +255,12 @@ class RewardDataCollatorWithPadding:
|
||||
batch_j = self.tokenizer.pad(
|
||||
features_j,
|
||||
padding=self.padding,
|
||||
max_length=self.max_length,
|
||||
pad_to_multiple_of=self.pad_to_multiple_of,
|
||||
return_tensors=self.return_tensors,
|
||||
)
|
||||
batch_k = self.tokenizer.pad(
|
||||
features_k,
|
||||
padding=self.padding,
|
||||
max_length=self.max_length,
|
||||
pad_to_multiple_of=self.pad_to_multiple_of,
|
||||
return_tensors=self.return_tensors,
|
||||
)
|
||||
@ -294,7 +305,7 @@ trainer = RewardTrainer(
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
compute_metrics=compute_metrics,
|
||||
data_collator=RewardDataCollatorWithPadding(tokenizer=tokenizer, max_length=script_args.max_length),
|
||||
data_collator=RewardDataCollatorWithPadding(tokenizer=tokenizer),
|
||||
)
|
||||
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
|
||||
@ -1,3 +1,17 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import os
|
||||
|
||||
|
||||
@ -1,7 +1,21 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# 0. imports
|
||||
import os
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Dict, Optional
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
@ -65,7 +79,6 @@ class ScriptArguments:
|
||||
)
|
||||
|
||||
# instrumentation
|
||||
sanity_check: Optional[bool] = field(default=False, metadata={"help": "only train on 1000 samples"})
|
||||
report_to: Optional[str] = field(
|
||||
default="wandb",
|
||||
metadata={
|
||||
@ -89,7 +102,6 @@ class ScriptArguments:
|
||||
|
||||
def get_stack_exchange_paired(
|
||||
data_dir: str = "data/rl",
|
||||
sanity_check: bool = False,
|
||||
cache_dir: Optional[str] = None,
|
||||
num_proc=24,
|
||||
) -> Dataset:
|
||||
@ -97,9 +109,9 @@ def get_stack_exchange_paired(
|
||||
|
||||
The dataset is converted to a dictionary with the following structure:
|
||||
{
|
||||
'prompt': List[str],
|
||||
'chosen': List[str],
|
||||
'rejected': List[str],
|
||||
'prompt': list[str],
|
||||
'chosen': list[str],
|
||||
'rejected': list[str],
|
||||
}
|
||||
|
||||
Prompts are structured as follows:
|
||||
@ -114,10 +126,7 @@ def get_stack_exchange_paired(
|
||||
)
|
||||
original_columns = dataset.column_names
|
||||
|
||||
if sanity_check:
|
||||
dataset = dataset.select(range(min(len(dataset), 1000)))
|
||||
|
||||
def return_prompt_and_responses(samples) -> Dict[str, str]:
|
||||
def return_prompt_and_responses(samples) -> dict[str, str]:
|
||||
return {
|
||||
"prompt": ["Question: " + question + "\n\nAnswer: " for question in samples["question"]],
|
||||
"chosen": samples["response_j"],
|
||||
@ -164,7 +173,7 @@ if __name__ == "__main__":
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
# 2. Load the Stack-exchange paired dataset
|
||||
train_dataset = get_stack_exchange_paired(data_dir="data/rl", sanity_check=script_args.sanity_check)
|
||||
train_dataset = get_stack_exchange_paired(data_dir="data/rl")
|
||||
train_dataset = train_dataset.filter(
|
||||
lambda x: len(x["prompt"]) + len(x["chosen"]) <= script_args.max_length
|
||||
and len(x["prompt"]) + len(x["rejected"]) <= script_args.max_length,
|
||||
@ -172,7 +181,7 @@ if __name__ == "__main__":
|
||||
)
|
||||
|
||||
# 3. Load evaluation dataset
|
||||
eval_dataset = get_stack_exchange_paired(data_dir="data/evaluation", sanity_check=True)
|
||||
eval_dataset = get_stack_exchange_paired(data_dir="data/evaluation")
|
||||
eval_dataset = eval_dataset.filter(
|
||||
lambda x: len(x["prompt"]) + len(x["chosen"]) <= script_args.max_length
|
||||
and len(x["prompt"]) + len(x["rejected"]) <= script_args.max_length,
|
||||
@ -228,7 +237,7 @@ if __name__ == "__main__":
|
||||
beta=script_args.beta,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
tokenizer=tokenizer,
|
||||
processing_class=tokenizer,
|
||||
peft_config=peft_config,
|
||||
max_prompt_length=script_args.max_prompt_length,
|
||||
max_length=script_args.max_length,
|
||||
|
||||
@ -1,3 +1,17 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# Fine-Tune Llama2-7b on SE paired dataset
|
||||
import os
|
||||
from dataclasses import dataclass, field
|
||||
@ -13,11 +27,12 @@ from transformers import (
|
||||
AutoTokenizer,
|
||||
BitsAndBytesConfig,
|
||||
HfArgumentParser,
|
||||
is_torch_npu_available,
|
||||
is_torch_xpu_available,
|
||||
set_seed,
|
||||
)
|
||||
|
||||
from trl import SFTConfig, SFTTrainer
|
||||
from trl.import_utils import is_npu_available, is_xpu_available
|
||||
from trl.trainer import ConstantLengthDataset
|
||||
|
||||
|
||||
@ -172,7 +187,7 @@ trainer = SFTTrainer(
|
||||
peft_config=peft_config,
|
||||
max_seq_length=None,
|
||||
formatting_func=prepare_sample_text,
|
||||
tokenizer=tokenizer,
|
||||
processing_class=tokenizer,
|
||||
args=training_args,
|
||||
)
|
||||
trainer.train()
|
||||
@ -183,9 +198,9 @@ trainer.model.save_pretrained(output_dir)
|
||||
|
||||
# Free memory for merging weights
|
||||
del base_model
|
||||
if is_xpu_available():
|
||||
if is_torch_xpu_available():
|
||||
torch.xpu.empty_cache()
|
||||
elif is_npu_available():
|
||||
elif is_torch_npu_available():
|
||||
torch.npu.empty_cache()
|
||||
else:
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -45,7 +45,7 @@ class ScriptArguments:
|
||||
|
||||
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
args = parser.parse_args_into_dataclasses()[0]
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
|
||||
def exact_match_reward(responses, answers=None):
|
||||
@ -90,24 +90,24 @@ lora_config = LoraConfig(
|
||||
|
||||
# set up models
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
args.model_name,
|
||||
script_args.model_name,
|
||||
use_auth_token=True,
|
||||
load_in_4bit=True,
|
||||
peft_config=lora_config,
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.model_name, use_auth_token=True)
|
||||
tokenizer = AutoTokenizer.from_pretrained(script_args.model_name, use_auth_token=True)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
ds = load_dataset("gsm8k", "main", split="train")
|
||||
ds = load_dataset("openai/gsm8k", "main", split="train")
|
||||
ds = ds.rename_columns({"question": "query"})
|
||||
ds = ds.map(lambda x: {"answer": x["answer"].split("#### ")[1]})
|
||||
ds = ds.select(range(1, len(ds))) # skip the first sample which is used in prompt
|
||||
|
||||
ds_test = load_dataset("gsm8k", "main", split="test")
|
||||
ds_test = load_dataset("openai/gsm8k", "main", split="test")
|
||||
ds_test = ds_test.rename_columns({"question": "query"})
|
||||
ds_test = ds_test.map(lambda x: {"answer": x["answer"].split("#### ")[1]})
|
||||
|
||||
test_dataloader = torch.utils.data.DataLoader(ds_test, batch_size=args.batch_size)
|
||||
test_dataloader = torch.utils.data.DataLoader(ds_test, batch_size=script_args.batch_size)
|
||||
|
||||
# prompt
|
||||
prompt = """\
|
||||
@ -138,23 +138,23 @@ generation_kwargs = {
|
||||
"do_sample": True,
|
||||
"pad_token_id": tokenizer.eos_token_id,
|
||||
"eos_token_id": -1,
|
||||
"max_new_tokens": args.max_new_tokens,
|
||||
"max_new_tokens": script_args.max_new_tokens,
|
||||
}
|
||||
|
||||
# trainer
|
||||
ppo_config = PPOConfig(
|
||||
batch_size=args.batch_size,
|
||||
learning_rate=args.learning_rate,
|
||||
mini_batch_size=args.mini_batch_size,
|
||||
ppo_epochs=args.ppo_epochs,
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
||||
batch_size=script_args.batch_size,
|
||||
learning_rate=script_args.learning_rate,
|
||||
mini_batch_size=script_args.mini_batch_size,
|
||||
ppo_epochs=script_args.ppo_epochs,
|
||||
gradient_accumulation_steps=script_args.gradient_accumulation_steps,
|
||||
log_with="wandb",
|
||||
tracker_project_name="trl-gsm8k",
|
||||
remove_unused_columns=False,
|
||||
optimize_cuda_cache=True,
|
||||
)
|
||||
|
||||
ppo_trainer = PPOTrainer(config=ppo_config, model=model, tokenizer=tokenizer, dataset=ds)
|
||||
ppo_trainer = PPOTrainer(args=ppo_config, model=model, tokenizer=tokenizer, dataset=ds)
|
||||
test_dataloader = ppo_trainer.accelerator.prepare(test_dataloader)
|
||||
|
||||
# text env
|
||||
@ -169,7 +169,7 @@ text_env = TextEnvironment(
|
||||
)
|
||||
|
||||
# main training loop
|
||||
for epoch in range(args.n_epochs):
|
||||
for epoch in range(script_args.n_epochs):
|
||||
for step, batch in enumerate(ppo_trainer.dataloader):
|
||||
if (step == 0) and (epoch % 4 == 0): # evaluate every 4 epochs
|
||||
reward_mean_test = evaluate(test_dataloader, text_env, ppo_trainer)
|
||||
@ -190,4 +190,4 @@ for epoch in range(args.n_epochs):
|
||||
ppo_trainer.log_stats(train_stats, texts, rewards, columns_to_log=["query", "response", "answer"])
|
||||
|
||||
reward_mean_test = evaluate(test_dataloader, text_env, ppo_trainer)
|
||||
ppo_trainer.save_pretrained(f"model/{args.model_name}-gsm8k")
|
||||
ppo_trainer.save_pretrained(f"model/{script_args.model_name}-gsm8k")
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -45,7 +45,7 @@ class ScriptArguments:
|
||||
|
||||
|
||||
parser = HfArgumentParser(ScriptArguments)
|
||||
args = parser.parse_args_into_dataclasses()[0]
|
||||
script_args = parser.parse_args_into_dataclasses()[0]
|
||||
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
@ -58,13 +58,13 @@ lora_config = LoraConfig(
|
||||
|
||||
# set up models
|
||||
model = AutoModelForCausalLMWithValueHead.from_pretrained(
|
||||
args.model_name,
|
||||
script_args.model_name,
|
||||
use_auth_token=True,
|
||||
trust_remote_code=True,
|
||||
load_in_4bit=True,
|
||||
peft_config=lora_config,
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.model_name, use_auth_token=True)
|
||||
tokenizer = AutoTokenizer.from_pretrained(script_args.model_name, use_auth_token=True)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
# system prompt
|
||||
@ -90,24 +90,24 @@ generation_kwargs = {
|
||||
"do_sample": True,
|
||||
"pad_token_id": tokenizer.eos_token_id,
|
||||
"eos_token_id": -1,
|
||||
"max_new_tokens": args.max_new_tokens,
|
||||
"max_new_tokens": script_args.max_new_tokens,
|
||||
}
|
||||
|
||||
# trainer
|
||||
config = PPOConfig(
|
||||
batch_size=args.batch_size,
|
||||
model_name=args.model_name,
|
||||
learning_rate=args.learning_rate,
|
||||
log_with=args.log_with,
|
||||
mini_batch_size=args.mini_batch_size,
|
||||
ppo_epochs=args.ppo_epochs,
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
||||
seed=args.seed,
|
||||
batch_size=script_args.batch_size,
|
||||
model_name=script_args.model_name,
|
||||
learning_rate=script_args.learning_rate,
|
||||
log_with=script_args.log_with,
|
||||
mini_batch_size=script_args.mini_batch_size,
|
||||
ppo_epochs=script_args.ppo_epochs,
|
||||
gradient_accumulation_steps=script_args.gradient_accumulation_steps,
|
||||
seed=script_args.seed,
|
||||
optimize_cuda_cache=True,
|
||||
)
|
||||
ppo_trainer = PPOTrainer(config=config, model=model, tokenizer=tokenizer)
|
||||
dataset = load_dataset("trivia_qa", "rc", split="train")
|
||||
local_seed = args.seed + ppo_trainer.accelerator.process_index * 100003 # Prime
|
||||
ppo_trainer = PPOTrainer(args=config, model=model, tokenizer=tokenizer)
|
||||
dataset = load_dataset("mandarjoshi/trivia_qa", "rc", split="train")
|
||||
local_seed = script_args.seed + ppo_trainer.accelerator.process_index * 100003 # Prime
|
||||
dataset = dataset.shuffle(local_seed)
|
||||
|
||||
|
||||
@ -175,7 +175,7 @@ def print_trainable_parameters(model):
|
||||
|
||||
print_trainable_parameters(model)
|
||||
# main training loop
|
||||
for i in range(args.iterations):
|
||||
for i in range(script_args.iterations):
|
||||
tasks, answers = generate_data(config.batch_size)
|
||||
queries, responses, masks, rewards, histories = text_env.run(tasks, answers=answers)
|
||||
train_stats = ppo_trainer.step(queries, responses, rewards, masks)
|
||||
@ -189,4 +189,4 @@ for i in range(args.iterations):
|
||||
all_rewards = ppo_trainer.accelerator.gather(torch.tensor(rewards, device=ppo_trainer.accelerator.device))
|
||||
ppo_trainer.log_stats(train_stats, texts, list(all_rewards), columns_to_log=["query", "response", "answer"])
|
||||
if i % 100 == 0:
|
||||
ppo_trainer.save_pretrained(f"models/{args.model_name}_{args.seed}_{i}_triviaqa")
|
||||
ppo_trainer.save_pretrained(f"models/{script_args.model_name}_{script_args.seed}_{i}_triviaqa")
|
||||
|
||||
@ -1,3 +1,17 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import csv
|
||||
|
||||
@ -6,9 +20,7 @@ import numpy as np
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
from trl.import_utils import is_npu_available, is_xpu_available
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, is_torch_npu_available, is_torch_xpu_available
|
||||
|
||||
|
||||
toxicity = evaluate.load("ybelkada/toxicity", "DaNLP/da-electra-hatespeech-detection", module_type="measurement")
|
||||
@ -52,9 +64,9 @@ BATCH_SIZE = args.batch_size
|
||||
output_file = args.output_file
|
||||
max_new_tokens = args.max_new_tokens
|
||||
context_length = args.context_length
|
||||
if is_xpu_available():
|
||||
if is_torch_xpu_available():
|
||||
device = torch.xpu.current_device()
|
||||
elif is_npu_available():
|
||||
elif is_torch_npu_available():
|
||||
device = torch.npu.current_device()
|
||||
else:
|
||||
device = torch.cuda.current_device() if torch.cuda.is_available() else "cpu"
|
||||
@ -123,9 +135,9 @@ for model_id in tqdm(MODELS_TO_TEST):
|
||||
print(f"Model: {model_id} - Mean: {mean} - Std: {std}")
|
||||
|
||||
model = None
|
||||
if is_xpu_available():
|
||||
if is_torch_xpu_available():
|
||||
torch.xpu.empty_cache()
|
||||
elif is_npu_available():
|
||||
elif is_torch_npu_available():
|
||||
torch.npu.empty_cache()
|
||||
else:
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Optional
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 metric-space, The HuggingFace Team. All rights reserved.
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Total Batch size = 128 = 4 (num_gpus) * 8 (per_device_batch) * 4 (accumulation steps)
|
||||
Feel free to reduce batch size or increasing truncated_rand_backprop_min to a higher value to reduce memory usage.
|
||||
@ -24,6 +25,7 @@ CUDA_VISIBLE_DEVICES=0,1,2,3 python examples/scripts/alignprop.py \
|
||||
--log_with="wandb"
|
||||
|
||||
"""
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
|
||||
import numpy as np
|
||||
@ -105,8 +107,8 @@ def image_outputs_logger(image_pair_data, global_step, accelerate_logger):
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser((ScriptArguments, AlignPropConfig))
|
||||
args, alignprop_config = parser.parse_args_into_dataclasses()
|
||||
alignprop_config.project_kwargs = {
|
||||
script_args, training_args = parser.parse_args_into_dataclasses()
|
||||
training_args.project_kwargs = {
|
||||
"logging_dir": "./logs",
|
||||
"automatic_checkpoint_naming": True,
|
||||
"total_limit": 5,
|
||||
@ -114,11 +116,13 @@ if __name__ == "__main__":
|
||||
}
|
||||
|
||||
pipeline = DefaultDDPOStableDiffusionPipeline(
|
||||
args.pretrained_model, pretrained_model_revision=args.pretrained_revision, use_lora=args.use_lora
|
||||
script_args.pretrained_model,
|
||||
pretrained_model_revision=script_args.pretrained_revision,
|
||||
use_lora=script_args.use_lora,
|
||||
)
|
||||
trainer = AlignPropTrainer(
|
||||
alignprop_config,
|
||||
aesthetic_scorer(args.hf_hub_aesthetic_model_id, args.hf_hub_aesthetic_model_filename),
|
||||
training_args,
|
||||
aesthetic_scorer(script_args.hf_hub_aesthetic_model_id, script_args.hf_hub_aesthetic_model_filename),
|
||||
prompt_fn,
|
||||
pipeline,
|
||||
image_samples_hook=image_outputs_logger,
|
||||
@ -126,4 +130,7 @@ if __name__ == "__main__":
|
||||
|
||||
trainer.train()
|
||||
|
||||
trainer.push_to_hub(args.hf_hub_model_id)
|
||||
# Save and push to hub
|
||||
trainer.save_model(training_args.output_dir)
|
||||
if training_args.push_to_hub:
|
||||
trainer.push_to_hub(dataset_name=script_args.dataset_name)
|
||||
|
||||
@ -1,9 +1,25 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Run the BCO training script with the commands below. In general, the optimal configuration for BCO will be similar to that of KTO.
|
||||
|
||||
# Full training:
|
||||
python examples/scripts/bco.py \
|
||||
--model_name_or_path=nnheui/stablelm-2-1_6b-sft-full \
|
||||
--model_name_or_path Qwen/Qwen2.5-0.5B-Instruct \
|
||||
--trust_remote_code \
|
||||
--dataset_name trl-lib/ultrafeedback-gpt-3.5-turbo-helpfulness \
|
||||
--per_device_train_batch_size 16 \
|
||||
--per_device_eval_batch_size 32 \
|
||||
--num_train_epochs 1 \
|
||||
@ -52,88 +68,15 @@ python examples/scripts/bco.py \
|
||||
--lora_alpha=16
|
||||
"""
|
||||
|
||||
import logging
|
||||
from dataclasses import dataclass
|
||||
from functools import partial
|
||||
from typing import Literal, Optional
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from accelerate import Accelerator, PartialState
|
||||
from datasets import Dataset, load_dataset
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModel, AutoModelForCausalLM, AutoTokenizer, HfArgumentParser, PreTrainedModel
|
||||
|
||||
from trl import BCOConfig, BCOTrainer, ModelConfig, get_peft_config, setup_chat_format
|
||||
|
||||
|
||||
# Define and parse arguments.
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
"""
|
||||
The arguments for the BCO training script.
|
||||
"""
|
||||
|
||||
llm_name: Literal["gpt-3.5-turbo", "llama-2-7b-chat", "llama-2-70b-chat"] = "gpt-3.5-turbo"
|
||||
|
||||
|
||||
def build_helpfulness_dataset(llm_name: str, num_proc: Optional[int] = None) -> Dataset:
|
||||
"""
|
||||
Filter `llm_name` completions and binarize given their helpfulness score.
|
||||
If helpfulness score is 5, it is desirable. Otherwise, it is undesirable.
|
||||
"""
|
||||
|
||||
def get_model_rating(example, metric: str, llm_name: str):
|
||||
try:
|
||||
model_index = example["models"].index(llm_name)
|
||||
return {metric: int(example["completions"][model_index]["annotations"][metric]["Rating"])}
|
||||
except ValueError as e:
|
||||
logging.warning(e)
|
||||
return -1
|
||||
|
||||
def get_model_response(example, llm_name: str):
|
||||
try:
|
||||
model_index = example["models"].index(llm_name)
|
||||
return {"response": example["completions"][model_index]["response"]}
|
||||
except ValueError as e:
|
||||
logging.warning(e)
|
||||
return -1
|
||||
|
||||
dataset = load_dataset("openbmb/UltraFeedback")["train"]
|
||||
|
||||
ds = dataset.filter(lambda example: llm_name in example["models"], batched=False, num_proc=num_proc)
|
||||
ds = ds.filter(
|
||||
lambda example: len(example["models"]) == len(example["completions"]), batched=False, num_proc=num_proc
|
||||
)
|
||||
|
||||
METRIC = "helpfulness"
|
||||
|
||||
ds = ds.map(
|
||||
get_model_rating,
|
||||
batched=False,
|
||||
fn_kwargs={"metric": METRIC, "llm_name": llm_name},
|
||||
num_proc=num_proc,
|
||||
)
|
||||
|
||||
ds = ds.map(
|
||||
get_model_response,
|
||||
batched=False,
|
||||
fn_kwargs={"llm_name": llm_name},
|
||||
num_proc=num_proc,
|
||||
)
|
||||
|
||||
ds = ds.select_columns(["source", "instruction", "response", "helpfulness"])
|
||||
|
||||
ds = ds.rename_columns({"instruction": "prompt", "response": "completion"})
|
||||
ds = ds.map(lambda example: {"label": example["helpfulness"] >= 5}, batched=False, num_proc=num_proc)
|
||||
|
||||
ds = ds.map(
|
||||
lambda example: {"prompt": [{"role": "user", "content": example["prompt"]}]},
|
||||
batched=False,
|
||||
num_proc=num_proc,
|
||||
)
|
||||
dataset = ds.train_test_split(test_size=0.05, seed=42)
|
||||
|
||||
return dataset
|
||||
from trl import BCOConfig, BCOTrainer, ModelConfig, ScriptArguments, get_peft_config, setup_chat_format
|
||||
|
||||
|
||||
def embed_prompt(input_ids: torch.LongTensor, attention_mask: torch.LongTensor, model: PreTrainedModel):
|
||||
@ -161,9 +104,9 @@ def embed_prompt(input_ids: torch.LongTensor, attention_mask: torch.LongTensor,
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser((ScriptArguments, BCOConfig, ModelConfig))
|
||||
script_args, bco_args, model_args = parser.parse_args_into_dataclasses()
|
||||
script_args, training_args, model_args = parser.parse_args_into_dataclasses()
|
||||
|
||||
bco_args.gradient_checkpointing_kwargs = {"use_reentrant": True}
|
||||
training_args.gradient_checkpointing_kwargs = {"use_reentrant": True}
|
||||
|
||||
# Load a pretrained model
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
@ -183,19 +126,7 @@ if __name__ == "__main__":
|
||||
if tokenizer.chat_template is None:
|
||||
model, tokenizer = setup_chat_format(model, tokenizer)
|
||||
|
||||
# Apply chat template
|
||||
def format_dataset(example):
|
||||
example["prompt"] = tokenizer.apply_chat_template(
|
||||
example["prompt"], tokenize=False, add_generation_prompt=True
|
||||
)
|
||||
return example
|
||||
|
||||
# Compute that only on the main process for faster data processing.
|
||||
# see: https://github.com/huggingface/trl/pull/1255
|
||||
with PartialState().local_main_process_first():
|
||||
# Load the dataset
|
||||
dataset = build_helpfulness_dataset(script_args.llm_name, num_proc=bco_args.dataset_num_proc)
|
||||
formatted_dataset = dataset.map(format_dataset, batched=False, num_proc=bco_args.dataset_num_proc)
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
|
||||
accelerator = Accelerator()
|
||||
embedding_model = AutoModel.from_pretrained(
|
||||
@ -215,18 +146,22 @@ if __name__ == "__main__":
|
||||
)
|
||||
|
||||
# Initialize the BCO trainer
|
||||
bco_trainer = BCOTrainer(
|
||||
trainer = BCOTrainer(
|
||||
model,
|
||||
ref_model,
|
||||
args=bco_args,
|
||||
train_dataset=formatted_dataset["train"],
|
||||
eval_dataset=formatted_dataset["test"],
|
||||
tokenizer=tokenizer,
|
||||
args=training_args,
|
||||
train_dataset=dataset[script_args.dataset_train_split],
|
||||
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
|
||||
processing_class=tokenizer,
|
||||
peft_config=get_peft_config(model_args),
|
||||
embedding_func=embedding_func,
|
||||
embedding_tokenizer=embedding_tokenizer,
|
||||
)
|
||||
|
||||
# Train and push the model to the Hub
|
||||
bco_trainer.train()
|
||||
bco_trainer.save_model(bco_args.output_dir)
|
||||
trainer.train()
|
||||
|
||||
# Save and push to hub
|
||||
trainer.save_model(training_args.output_dir)
|
||||
if training_args.push_to_hub:
|
||||
trainer.push_to_hub(dataset_name=script_args.dataset_name)
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
# flake8: noqa
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
@ -13,355 +12,6 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
from trl.commands.cli_utils import init_zero_verbose
|
||||
|
||||
init_zero_verbose()
|
||||
|
||||
import copy
|
||||
import json
|
||||
import os
|
||||
import sys
|
||||
import pwd
|
||||
import re
|
||||
import time
|
||||
from threading import Thread
|
||||
|
||||
import torch
|
||||
from rich.console import Console
|
||||
from rich.live import Live
|
||||
from rich.markdown import Markdown
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
|
||||
|
||||
from trl.commands.cli_utils import ChatArguments, TrlParser, init_zero_verbose
|
||||
from trl.trainer.utils import get_quantization_config
|
||||
|
||||
|
||||
HELP_STRING = """\
|
||||
|
||||
**TRL CHAT INTERFACE**
|
||||
|
||||
The chat interface is a simple tool to try out a chat model.
|
||||
|
||||
Besides talking to the model there are several commands:
|
||||
- **clear**: clears the current conversation and start a new one
|
||||
- **example {NAME}**: load example named `{NAME}` from the config and use it as the user input
|
||||
- **set {SETTING_NAME}={SETTING_VALUE};**: change the system prompt or generation settings (multiple settings are separated by a ';').
|
||||
- **reset**: same as clear but also resets the generation configs to defaults if they have been changed by **set**
|
||||
- **save {SAVE_NAME} (optional)**: save the current chat and settings to file by default to `./chat_history/{MODEL_NAME}/chat_{DATETIME}.yaml` or `{SAVE_NAME}` if provided
|
||||
- **exit**: closes the interface
|
||||
"""
|
||||
|
||||
SUPPORTED_GENERATION_KWARGS = [
|
||||
"max_new_tokens",
|
||||
"do_sample",
|
||||
"num_beams",
|
||||
"temperature",
|
||||
"top_p",
|
||||
"top_k",
|
||||
"repetition_penalty",
|
||||
]
|
||||
|
||||
SETTING_RE = r"^set\s+[A-Za-z\s_]+=[A-Za-z\d\s.!\"#$%&'()*+,-/:<=>?@\[\]^_`{|}~]+(?:;\s*[A-Za-z\s_]+=[A-Za-z\d\s.!\"#$%&'()*+,-/:<=>?@\[\]^_`{|}~]+)*$"
|
||||
|
||||
|
||||
class RichInterface:
|
||||
def __init__(self, model_name=None, user_name=None):
|
||||
self._console = Console()
|
||||
if model_name is None:
|
||||
self.model_name = "assistant"
|
||||
else:
|
||||
self.model_name = model_name
|
||||
if user_name is None:
|
||||
self.user_name = "user"
|
||||
else:
|
||||
self.user_name = user_name
|
||||
|
||||
def stream_output(self, output_stream):
|
||||
"""Stream output from a role."""
|
||||
# This method is originally from the FastChat CLI: https://github.com/lm-sys/FastChat/blob/main/fastchat/serve/cli.py
|
||||
# Create a Live context for updating the console output
|
||||
text = ""
|
||||
self._console.print(f"[bold blue]<{self.model_name}>:")
|
||||
with Live(console=self._console, refresh_per_second=4) as live:
|
||||
# Read lines from the stream
|
||||
for i, outputs in enumerate(output_stream):
|
||||
if not outputs or i == 0:
|
||||
continue
|
||||
text += outputs
|
||||
# Render the accumulated text as Markdown
|
||||
# NOTE: this is a workaround for the rendering "unstandard markdown"
|
||||
# in rich. The chatbots output treat "\n" as a new line for
|
||||
# better compatibility with real-world text. However, rendering
|
||||
# in markdown would break the format. It is because standard markdown
|
||||
# treat a single "\n" in normal text as a space.
|
||||
# Our workaround is adding two spaces at the end of each line.
|
||||
# This is not a perfect solution, as it would
|
||||
# introduce trailing spaces (only) in code block, but it works well
|
||||
# especially for console output, because in general the console does not
|
||||
# care about trailing spaces.
|
||||
lines = []
|
||||
for line in text.splitlines():
|
||||
lines.append(line)
|
||||
if line.startswith("```"):
|
||||
# Code block marker - do not add trailing spaces, as it would
|
||||
# break the syntax highlighting
|
||||
lines.append("\n")
|
||||
else:
|
||||
lines.append(" \n")
|
||||
markdown = Markdown("".join(lines).strip(), code_theme="github-dark")
|
||||
# Update the Live console output
|
||||
live.update(markdown)
|
||||
self._console.print()
|
||||
return text
|
||||
|
||||
def input(self):
|
||||
input = self._console.input(f"[bold red]<{self.user_name}>:\n")
|
||||
self._console.print()
|
||||
return input
|
||||
|
||||
def clear(self):
|
||||
self._console.clear()
|
||||
|
||||
def print_user_message(self, text):
|
||||
self._console.print(f"[bold red]<{self.user_name}>:[/ bold red]\n{text}")
|
||||
self._console.print()
|
||||
|
||||
def print_green(self, text):
|
||||
self._console.print(f"[bold green]{text}")
|
||||
self._console.print()
|
||||
|
||||
def print_red(self, text):
|
||||
self._console.print(f"[bold red]{text}")
|
||||
self._console.print()
|
||||
|
||||
def print_help(self):
|
||||
self._console.print(Markdown(HELP_STRING))
|
||||
self._console.print()
|
||||
|
||||
|
||||
def get_username():
|
||||
return pwd.getpwuid(os.getuid())[0]
|
||||
|
||||
|
||||
def create_default_filename(model_name):
|
||||
time_str = time.strftime("%Y-%m-%d_%H-%M-%S")
|
||||
return f"{model_name}/chat_{time_str}.json"
|
||||
|
||||
|
||||
def save_chat(chat, args, filename):
|
||||
output_dict = {}
|
||||
output_dict["settings"] = vars(args)
|
||||
output_dict["chat_history"] = chat
|
||||
|
||||
folder = args.save_folder
|
||||
|
||||
if filename is None:
|
||||
filename = create_default_filename(args.model_name_or_path)
|
||||
filename = os.path.join(folder, filename)
|
||||
os.makedirs(os.path.dirname(filename), exist_ok=True)
|
||||
|
||||
with open(filename, "w") as f:
|
||||
json.dump(output_dict, f, indent=4)
|
||||
return os.path.abspath(filename)
|
||||
|
||||
|
||||
def clear_chat_history(system_prompt):
|
||||
if system_prompt is None:
|
||||
chat = []
|
||||
else:
|
||||
chat = [{"role": "system", "content": system_prompt}]
|
||||
return chat
|
||||
|
||||
|
||||
def parse_settings(user_input, current_args, interface):
|
||||
settings = user_input[4:].strip().split(";")
|
||||
settings = [(setting.split("=")[0], setting[len(setting.split("=")[0]) + 1 :]) for setting in settings]
|
||||
settings = dict(settings)
|
||||
error = False
|
||||
|
||||
for name in settings:
|
||||
if hasattr(current_args, name):
|
||||
try:
|
||||
if isinstance(getattr(current_args, name), bool):
|
||||
if settings[name] == "True":
|
||||
settings[name] = True
|
||||
elif settings[name] == "False":
|
||||
settings[name] = False
|
||||
else:
|
||||
raise ValueError
|
||||
else:
|
||||
settings[name] = type(getattr(current_args, name))(settings[name])
|
||||
except ValueError:
|
||||
interface.print_red(
|
||||
f"Cannot cast setting {name} (={settings[name]}) to {type(getattr(current_args, name))}."
|
||||
)
|
||||
else:
|
||||
interface.print_red(f"There is no '{name}' setting.")
|
||||
|
||||
if error:
|
||||
interface.print_red("There was an issue parsing the settings. No settings have been changed.")
|
||||
return current_args, False
|
||||
else:
|
||||
for name in settings:
|
||||
setattr(current_args, name, settings[name])
|
||||
interface.print_green(f"Set {name} to {settings[name]}.")
|
||||
|
||||
time.sleep(1.5) # so the user has time to read the changes
|
||||
return current_args, True
|
||||
|
||||
|
||||
def load_model_and_tokenizer(args):
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.model_name_or_path,
|
||||
revision=args.model_revision,
|
||||
trust_remote_code=args.trust_remote_code,
|
||||
)
|
||||
|
||||
torch_dtype = args.torch_dtype if args.torch_dtype in ["auto", None] else getattr(torch, args.torch_dtype)
|
||||
quantization_config = get_quantization_config(args)
|
||||
model_kwargs = dict(
|
||||
revision=args.model_revision,
|
||||
attn_implementation=args.attn_implementation,
|
||||
torch_dtype=torch_dtype,
|
||||
device_map="auto",
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
args.model_name_or_path, trust_remote_code=args.trust_remote_code, **model_kwargs
|
||||
)
|
||||
|
||||
if getattr(model, "hf_device_map", None) is None:
|
||||
model = model.to(args.device)
|
||||
|
||||
return model, tokenizer
|
||||
|
||||
|
||||
def parse_eos_tokens(tokenizer, eos_tokens, eos_token_ids):
|
||||
if tokenizer.pad_token_id is None:
|
||||
pad_token_id = tokenizer.eos_token_id
|
||||
else:
|
||||
pad_token_id = tokenizer.pad_token_id
|
||||
|
||||
all_eos_token_ids = []
|
||||
|
||||
if eos_tokens is not None:
|
||||
all_eos_token_ids.extend(tokenizer.convert_tokens_to_ids(eos_tokens.split(",")))
|
||||
|
||||
if eos_token_ids is not None:
|
||||
all_eos_token_ids.extend([int(token_id) for token_id in eos_token_ids.split(",")])
|
||||
|
||||
if len(all_eos_token_ids) == 0:
|
||||
all_eos_token_ids.append(tokenizer.eos_token_id)
|
||||
|
||||
return pad_token_id, all_eos_token_ids
|
||||
|
||||
|
||||
def chat_cli():
|
||||
parser = TrlParser(ChatArguments)
|
||||
|
||||
if "--config" not in sys.argv:
|
||||
sys.argv.append("--config")
|
||||
sys.argv.append(os.path.join(os.path.dirname(__file__), "config/default_chat_config.yaml"))
|
||||
args = parser.parse_args_and_config()[0]
|
||||
if args.examples is None:
|
||||
args.examples = {}
|
||||
|
||||
current_args = copy.deepcopy(args)
|
||||
|
||||
if args.user is None:
|
||||
user = get_username()
|
||||
else:
|
||||
user = args.user
|
||||
|
||||
model, tokenizer = load_model_and_tokenizer(args)
|
||||
generation_streamer = TextIteratorStreamer(tokenizer, skip_special_tokens=True)
|
||||
|
||||
pad_token_id, eos_token_ids = parse_eos_tokens(tokenizer, args.eos_tokens, args.eos_token_ids)
|
||||
|
||||
interface = RichInterface(model_name=args.model_name_or_path, user_name=user)
|
||||
interface.clear()
|
||||
chat = clear_chat_history(current_args.system_prompt)
|
||||
while True:
|
||||
try:
|
||||
user_input = interface.input()
|
||||
|
||||
if user_input == "clear":
|
||||
chat = clear_chat_history(current_args.system_prompt)
|
||||
interface.clear()
|
||||
continue
|
||||
|
||||
if user_input == "help":
|
||||
interface.print_help()
|
||||
continue
|
||||
|
||||
if user_input == "exit":
|
||||
break
|
||||
|
||||
if user_input == "reset":
|
||||
interface.clear()
|
||||
current_args = copy.deepcopy(args)
|
||||
chat = clear_chat_history(current_args.system_prompt)
|
||||
continue
|
||||
|
||||
if user_input.startswith("save") and len(user_input.split()) < 2:
|
||||
split_input = user_input.split()
|
||||
|
||||
if len(split_input) == 2:
|
||||
filename = split_input[1]
|
||||
else:
|
||||
filename = None
|
||||
filename = save_chat(chat, current_args, filename)
|
||||
interface.print_green(f"Chat saved in {filename}!")
|
||||
continue
|
||||
|
||||
if re.match(SETTING_RE, user_input):
|
||||
current_args, success = parse_settings(user_input, current_args, interface)
|
||||
if success:
|
||||
chat = []
|
||||
interface.clear()
|
||||
continue
|
||||
|
||||
if user_input.startswith("example") and len(user_input.split()) == 2:
|
||||
example_name = user_input.split()[1]
|
||||
if example_name in current_args.examples:
|
||||
interface.clear()
|
||||
chat = []
|
||||
interface.print_user_message(current_args.examples[example_name]["text"])
|
||||
user_input = current_args.examples[example_name]["text"]
|
||||
else:
|
||||
interface.print_red(
|
||||
f"Example {example_name} not found in list of available examples: {list(current_args.examples.keys())}."
|
||||
)
|
||||
continue
|
||||
|
||||
chat.append({"role": "user", "content": user_input})
|
||||
|
||||
generation_kwargs = dict(
|
||||
inputs=tokenizer.apply_chat_template(chat, return_tensors="pt", add_generation_prompt=True).to(
|
||||
model.device
|
||||
),
|
||||
streamer=generation_streamer,
|
||||
max_new_tokens=current_args.max_new_tokens,
|
||||
do_sample=current_args.do_sample,
|
||||
num_beams=current_args.num_beams,
|
||||
temperature=current_args.temperature,
|
||||
top_k=current_args.top_k,
|
||||
top_p=current_args.top_p,
|
||||
repetition_penalty=current_args.repetition_penalty,
|
||||
pad_token_id=pad_token_id,
|
||||
eos_token_id=eos_token_ids,
|
||||
)
|
||||
|
||||
thread = Thread(target=model.generate, kwargs=generation_kwargs)
|
||||
thread.start()
|
||||
model_output = interface.stream_output(generation_streamer)
|
||||
thread.join()
|
||||
chat.append({"role": "assistant", "content": model_output})
|
||||
|
||||
except KeyboardInterrupt:
|
||||
break
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
chat_cli()
|
||||
################################################################################################
|
||||
# This file has been moved to https://github.com/huggingface/trl/blob/main/trl/scripts/chat.py #
|
||||
################################################################################################
|
||||
|
||||
@ -1,13 +0,0 @@
|
||||
examples:
|
||||
llama:
|
||||
text: There is a Llama in my lawn, how can I get rid of it?
|
||||
code:
|
||||
text: Write a Python function that integrates any Python function f(x) numerically over an arbitrary interval [x_start, x_end].
|
||||
helicopter:
|
||||
text: How many helicopters can a human eat in one sitting?
|
||||
numbers:
|
||||
text: Count to 10 but skip every number ending with an 'e'
|
||||
birds:
|
||||
text: Why aren't birds real?
|
||||
socks:
|
||||
text: Why is it important to eat socks after meditating?
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,12 +11,14 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Run the CPO training script with the following command with some example arguments.
|
||||
In general, the optimal configuration for CPO will be similar to that of DPO:
|
||||
|
||||
# regular:
|
||||
python examples/scripts/cpo.py \
|
||||
--dataset_name trl-lib/ultrafeedback_binarized \
|
||||
--model_name_or_path=gpt2 \
|
||||
--per_device_train_batch_size 4 \
|
||||
--max_steps 1000 \
|
||||
@ -33,6 +35,7 @@ python examples/scripts/cpo.py \
|
||||
|
||||
# peft:
|
||||
python examples/scripts/cpo.py \
|
||||
--dataset_name trl-lib/ultrafeedback_binarized \
|
||||
--model_name_or_path=gpt2 \
|
||||
--per_device_train_batch_size 4 \
|
||||
--max_steps 1000 \
|
||||
@ -52,35 +55,25 @@ python examples/scripts/cpo.py \
|
||||
--lora_alpha=16
|
||||
"""
|
||||
|
||||
from dataclasses import dataclass, field
|
||||
|
||||
from accelerate import PartialState
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, HfArgumentParser
|
||||
|
||||
from trl import CPOConfig, CPOTrainer, ModelConfig, get_peft_config
|
||||
|
||||
|
||||
@dataclass
|
||||
class ScriptArguments:
|
||||
dataset: str = field(
|
||||
default="trl-internal-testing/hh-rlhf-helpful-base-trl-style",
|
||||
metadata={"help": "The name of the dataset to use."},
|
||||
)
|
||||
from trl import CPOConfig, CPOTrainer, ModelConfig, ScriptArguments, get_peft_config
|
||||
from trl.trainer.utils import SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser((ScriptArguments, CPOConfig, ModelConfig))
|
||||
args, cpo_args, model_config = parser.parse_args_into_dataclasses()
|
||||
script_args, training_args, model_args = parser.parse_args_into_dataclasses()
|
||||
|
||||
################
|
||||
# Model & Tokenizer
|
||||
################
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code
|
||||
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code
|
||||
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code
|
||||
)
|
||||
if tokenizer.pad_token is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
@ -88,38 +81,26 @@ if __name__ == "__main__":
|
||||
################
|
||||
# Dataset
|
||||
################
|
||||
ds = load_dataset(args.dataset)
|
||||
if cpo_args.debug:
|
||||
for key in ds:
|
||||
ds[key] = ds[key].select(range(50))
|
||||
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
|
||||
if tokenizer.chat_template is None:
|
||||
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
|
||||
|
||||
def process(row):
|
||||
row["chosen"] = tokenizer.apply_chat_template(row["chosen"], tokenize=False)
|
||||
row["rejected"] = tokenizer.apply_chat_template(row["rejected"], tokenize=False)
|
||||
return row
|
||||
|
||||
# Compute that only on the main process for faster data processing.
|
||||
# see: https://github.com/huggingface/trl/pull/1255
|
||||
with PartialState().local_main_process_first():
|
||||
ds = ds.map(process, num_proc=cpo_args.dataset_num_proc)
|
||||
|
||||
train_dataset = ds["train"]
|
||||
eval_dataset = ds["test"]
|
||||
tokenizer.chat_template = SIMPLE_CHAT_TEMPLATE
|
||||
|
||||
################
|
||||
# Training
|
||||
################
|
||||
trainer = CPOTrainer(
|
||||
model,
|
||||
args=cpo_args,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
tokenizer=tokenizer,
|
||||
peft_config=get_peft_config(model_config),
|
||||
args=training_args,
|
||||
train_dataset=dataset[script_args.dataset_train_split],
|
||||
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
|
||||
processing_class=tokenizer,
|
||||
peft_config=get_peft_config(model_args),
|
||||
)
|
||||
|
||||
# train and save the model
|
||||
trainer.train()
|
||||
trainer.save_model(cpo_args.output_dir)
|
||||
|
||||
# Save and push to hub
|
||||
trainer.save_model(training_args.output_dir)
|
||||
if training_args.push_to_hub:
|
||||
trainer.push_to_hub(dataset_name=script_args.dataset_name)
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
# Copyright 2023 metric-space, The HuggingFace Team. All rights reserved.
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
python examples/scripts/ddpo.py \
|
||||
--num_epochs=200 \
|
||||
@ -24,6 +25,7 @@ python examples/scripts/ddpo.py \
|
||||
--tracker_project_name="stable_diffusion_training" \
|
||||
--log_with="wandb"
|
||||
"""
|
||||
|
||||
import os
|
||||
from dataclasses import dataclass, field
|
||||
|
||||
@ -32,10 +34,9 @@ import torch
|
||||
import torch.nn as nn
|
||||
from huggingface_hub import hf_hub_download
|
||||
from huggingface_hub.utils import EntryNotFoundError
|
||||
from transformers import CLIPModel, CLIPProcessor, HfArgumentParser
|
||||
from transformers import CLIPModel, CLIPProcessor, HfArgumentParser, is_torch_npu_available, is_torch_xpu_available
|
||||
|
||||
from trl import DDPOConfig, DDPOTrainer, DefaultDDPOStableDiffusionPipeline
|
||||
from trl.import_utils import is_npu_available, is_xpu_available
|
||||
|
||||
|
||||
@dataclass
|
||||
@ -115,9 +116,9 @@ def aesthetic_scorer(hub_model_id, model_filename):
|
||||
model_filename=model_filename,
|
||||
dtype=torch.float32,
|
||||
)
|
||||
if is_npu_available():
|
||||
if is_torch_npu_available():
|
||||
scorer = scorer.npu()
|
||||
elif is_xpu_available():
|
||||
elif is_torch_xpu_available():
|
||||
scorer = scorer.xpu()
|
||||
else:
|
||||
scorer = scorer.cuda()
|
||||
@ -185,8 +186,8 @@ def image_outputs_logger(image_data, global_step, accelerate_logger):
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = HfArgumentParser((ScriptArguments, DDPOConfig))
|
||||
args, ddpo_config = parser.parse_args_into_dataclasses()
|
||||
ddpo_config.project_kwargs = {
|
||||
script_args, training_args = parser.parse_args_into_dataclasses()
|
||||
training_args.project_kwargs = {
|
||||
"logging_dir": "./logs",
|
||||
"automatic_checkpoint_naming": True,
|
||||
"total_limit": 5,
|
||||
@ -194,12 +195,14 @@ if __name__ == "__main__":
|
||||
}
|
||||
|
||||
pipeline = DefaultDDPOStableDiffusionPipeline(
|
||||
args.pretrained_model, pretrained_model_revision=args.pretrained_revision, use_lora=args.use_lora
|
||||
script_args.pretrained_model,
|
||||
pretrained_model_revision=script_args.pretrained_revision,
|
||||
use_lora=script_args.use_lora,
|
||||
)
|
||||
|
||||
trainer = DDPOTrainer(
|
||||
ddpo_config,
|
||||
aesthetic_scorer(args.hf_hub_aesthetic_model_id, args.hf_hub_aesthetic_model_filename),
|
||||
training_args,
|
||||
aesthetic_scorer(script_args.hf_hub_aesthetic_model_id, script_args.hf_hub_aesthetic_model_filename),
|
||||
prompt_fn,
|
||||
pipeline,
|
||||
image_samples_hook=image_outputs_logger,
|
||||
@ -207,4 +210,7 @@ if __name__ == "__main__":
|
||||
|
||||
trainer.train()
|
||||
|
||||
trainer.push_to_hub(args.hf_hub_model_id)
|
||||
# Save and push to hub
|
||||
trainer.save_model(training_args.output_dir)
|
||||
if training_args.push_to_hub:
|
||||
trainer.push_to_hub(dataset_name=script_args.dataset_name)
|
||||
|
||||
@ -1,5 +1,4 @@
|
||||
# flake8: noqa
|
||||
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@ -12,177 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""
|
||||
# regular:
|
||||
python examples/scripts/dpo.py \
|
||||
--dataset_name=trl-internal-testing/hh-rlhf-helpful-base-trl-style \
|
||||
--model_name_or_path=gpt2 \
|
||||
--per_device_train_batch_size 4 \
|
||||
--learning_rate 1e-3 \
|
||||
--gradient_accumulation_steps 1 \
|
||||
--logging_steps 10 \
|
||||
--eval_steps 500 \
|
||||
--output_dir="dpo_anthropic_hh" \
|
||||
--warmup_steps 150 \
|
||||
--report_to wandb \
|
||||
--bf16 \
|
||||
--logging_first_step \
|
||||
--no_remove_unused_columns
|
||||
|
||||
# peft:
|
||||
python examples/scripts/dpo.py \
|
||||
--dataset_name=trl-internal-testing/hh-rlhf-helpful-base-trl-style \
|
||||
--model_name_or_path=gpt2 \
|
||||
--per_device_train_batch_size 4 \
|
||||
--learning_rate 1e-3 \
|
||||
--gradient_accumulation_steps 1 \
|
||||
--logging_steps 10 \
|
||||
--eval_steps 500 \
|
||||
--output_dir="dpo_anthropic_hh" \
|
||||
--optim rmsprop \
|
||||
--warmup_steps 150 \
|
||||
--report_to wandb \
|
||||
--bf16 \
|
||||
--logging_first_step \
|
||||
--no_remove_unused_columns \
|
||||
--use_peft \
|
||||
--lora_r=16 \
|
||||
--lora_alpha=16
|
||||
"""
|
||||
|
||||
import logging
|
||||
import multiprocessing
|
||||
import os
|
||||
from contextlib import nullcontext
|
||||
|
||||
from trl.commands.cli_utils import DPOScriptArguments, init_zero_verbose, TrlParser
|
||||
from trl.env_utils import strtobool
|
||||
|
||||
TRL_USE_RICH = strtobool(os.getenv("TRL_USE_RICH", "0"))
|
||||
|
||||
if TRL_USE_RICH:
|
||||
init_zero_verbose()
|
||||
FORMAT = "%(message)s"
|
||||
|
||||
from rich.console import Console
|
||||
from rich.logging import RichHandler
|
||||
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from accelerate import PartialState
|
||||
from trl import (
|
||||
DPOConfig,
|
||||
DPOTrainer,
|
||||
ModelConfig,
|
||||
RichProgressCallback,
|
||||
get_kbit_device_map,
|
||||
get_peft_config,
|
||||
get_quantization_config,
|
||||
)
|
||||
|
||||
|
||||
if TRL_USE_RICH:
|
||||
logging.basicConfig(format=FORMAT, datefmt="[%X]", handlers=[RichHandler()], level=logging.INFO)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = TrlParser((DPOScriptArguments, DPOConfig, ModelConfig))
|
||||
args, training_args, model_config = parser.parse_args_and_config()
|
||||
|
||||
# Force use our print callback
|
||||
if TRL_USE_RICH:
|
||||
training_args.disable_tqdm = True
|
||||
console = Console()
|
||||
|
||||
################
|
||||
# Model & Tokenizer
|
||||
################
|
||||
torch_dtype = (
|
||||
model_config.torch_dtype
|
||||
if model_config.torch_dtype in ["auto", None]
|
||||
else getattr(torch, model_config.torch_dtype)
|
||||
)
|
||||
quantization_config = get_quantization_config(model_config)
|
||||
model_kwargs = dict(
|
||||
revision=model_config.model_revision,
|
||||
attn_implementation=model_config.attn_implementation,
|
||||
torch_dtype=torch_dtype,
|
||||
use_cache=False if training_args.gradient_checkpointing else True,
|
||||
device_map=get_kbit_device_map() if quantization_config is not None else None,
|
||||
quantization_config=quantization_config,
|
||||
)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code, **model_kwargs
|
||||
)
|
||||
peft_config = get_peft_config(model_config)
|
||||
if peft_config is None:
|
||||
ref_model = AutoModelForCausalLM.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code, **model_kwargs
|
||||
)
|
||||
else:
|
||||
ref_model = None
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
model_config.model_name_or_path, trust_remote_code=model_config.trust_remote_code
|
||||
)
|
||||
if tokenizer.pad_token is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
if tokenizer.chat_template is None:
|
||||
tokenizer.chat_template = "{% for message in messages %}{{message['role'] + ': ' + message['content'] + '\n\n'}}{% endfor %}{{ eos_token }}"
|
||||
if args.ignore_bias_buffers:
|
||||
# torch distributed hack
|
||||
model._ddp_params_and_buffers_to_ignore = [
|
||||
name for name, buffer in model.named_buffers() if buffer.dtype == torch.bool
|
||||
]
|
||||
|
||||
################
|
||||
# Optional rich context managers
|
||||
###############
|
||||
init_context = nullcontext() if not TRL_USE_RICH else console.status("[bold green]Initializing the DPOTrainer...")
|
||||
save_context = (
|
||||
nullcontext()
|
||||
if not TRL_USE_RICH
|
||||
else console.status(f"[bold green]Training completed! Saving the model to {training_args.output_dir}")
|
||||
)
|
||||
|
||||
################
|
||||
# Dataset
|
||||
################
|
||||
ds = load_dataset(args.dataset_name)
|
||||
if args.sanity_check:
|
||||
for key in ds:
|
||||
ds[key] = ds[key].select(range(50))
|
||||
|
||||
def process(row):
|
||||
row["prompt"] = tokenizer.apply_chat_template(row["chosen"][:-1], tokenize=False)
|
||||
row["chosen"] = tokenizer.apply_chat_template([row["chosen"][-1]], tokenize=False)
|
||||
row["rejected"] = tokenizer.apply_chat_template([row["rejected"][-1]], tokenize=False)
|
||||
return row
|
||||
|
||||
# Compute that only on the main process for faster data processing.
|
||||
# see: https://github.com/huggingface/trl/pull/1255
|
||||
with PartialState().local_main_process_first():
|
||||
ds = ds.map(process, num_proc=training_args.dataset_num_proc)
|
||||
|
||||
train_dataset = ds[args.dataset_train_split]
|
||||
eval_dataset = ds[args.dataset_test_split]
|
||||
|
||||
################
|
||||
# Training
|
||||
################
|
||||
with init_context:
|
||||
trainer = DPOTrainer(
|
||||
model,
|
||||
ref_model,
|
||||
args=training_args,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
tokenizer=tokenizer,
|
||||
peft_config=peft_config,
|
||||
callbacks=[RichProgressCallback] if TRL_USE_RICH else None,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
|
||||
with save_context:
|
||||
trainer.save_model(training_args.output_dir)
|
||||
###############################################################################################
|
||||
# This file has been moved to https://github.com/huggingface/trl/blob/main/trl/scripts/dpo.py #
|
||||
###############################################################################################
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user