mirror of
https://github.com/huggingface/transformers.git
synced 2025-10-21 01:23:56 +08:00
Compare commits
10 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 20b95cb263 | |||
| 2837a1c427 | |||
| 8892e6fa97 | |||
| 44eb5a48c6 | |||
| a6d6c362e6 | |||
| ac2ed40f65 | |||
| 3d4c1ef167 | |||
| 4d5912e42e | |||
| 819f55a1c2 | |||
| 3953d3d775 |
@ -854,9 +854,10 @@ jobs:
|
||||
key: v0.4-code_quality-{{ checksum "setup.py" }}
|
||||
paths:
|
||||
- '~/.cache/pip'
|
||||
- run: black --check examples tests src utils
|
||||
- run: black --check --preview examples tests src utils
|
||||
- run: isort --check-only examples tests src utils
|
||||
- run: python utils/custom_init_isort.py --check_only
|
||||
- run: python utils/sort_auto_mappings.py --check_only
|
||||
- run: flake8 examples tests src utils
|
||||
- run: doc-builder style src/transformers docs/source --max_len 119 --check_only --path_to_docs docs/source
|
||||
|
||||
@ -889,7 +890,7 @@ jobs:
|
||||
- run: make deps_table_check_updated
|
||||
- run: python utils/tests_fetcher.py --sanity_check
|
||||
|
||||
run_tests_layoutlmv2:
|
||||
run_tests_layoutlmv2_and_v3:
|
||||
working_directory: ~/transformers
|
||||
docker:
|
||||
- image: circleci/python:3.7
|
||||
@ -920,7 +921,7 @@ jobs:
|
||||
path: ~/transformers/test_preparation.txt
|
||||
- run: |
|
||||
if [ -f test_list.txt ]; then
|
||||
python -m pytest -n 1 tests/models/*layoutlmv2* --dist=loadfile -s --make-reports=tests_layoutlmv2 --durations=100
|
||||
python -m pytest -n 1 tests/models/*layoutlmv* --dist=loadfile -s --make-reports=tests_layoutlmv2_and_v3 --durations=100
|
||||
fi
|
||||
- store_artifacts:
|
||||
path: ~/transformers/tests_output.txt
|
||||
@ -981,7 +982,7 @@ workflows:
|
||||
- run_tests_pipelines_tf
|
||||
- run_tests_onnxruntime
|
||||
- run_tests_hub
|
||||
- run_tests_layoutlmv2
|
||||
- run_tests_layoutlmv2_and_v3
|
||||
nightly:
|
||||
triggers:
|
||||
- schedule:
|
||||
|
||||
3
.gitattributes
vendored
3
.gitattributes
vendored
@ -1,3 +1,4 @@
|
||||
*.py eol=lf
|
||||
*.rst eol=lf
|
||||
*.md eol=lf
|
||||
*.md eol=lf
|
||||
*.mdx eol=lf
|
||||
4
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
4
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@ -1,5 +1,5 @@
|
||||
name: "\U0001F41B Bug Report"
|
||||
description: Submit a bug report to help us import transformers
|
||||
description: Submit a bug report to help us improve transformers
|
||||
labels: [ "bug" ]
|
||||
body:
|
||||
- type: textarea
|
||||
@ -118,4 +118,4 @@ body:
|
||||
attributes:
|
||||
label: Expected behavior
|
||||
description: "A clear and concise description of what you would expect to happen."
|
||||
render: shell
|
||||
render: shell
|
||||
|
||||
2
.github/workflows/build_documentation.yml
vendored
2
.github/workflows/build_documentation.yml
vendored
@ -15,6 +15,6 @@ jobs:
|
||||
commit_sha: ${{ github.sha }}
|
||||
package: transformers
|
||||
notebook_folder: transformers_doc
|
||||
languages: en es
|
||||
languages: en es pt
|
||||
secrets:
|
||||
token: ${{ secrets.HUGGINGFACE_PUSH }}
|
||||
|
||||
2
.github/workflows/build_pr_documentation.yml
vendored
2
.github/workflows/build_pr_documentation.yml
vendored
@ -14,4 +14,4 @@ jobs:
|
||||
commit_sha: ${{ github.event.pull_request.head.sha }}
|
||||
pr_number: ${{ github.event.number }}
|
||||
package: transformers
|
||||
languages: en es
|
||||
languages: en es pt
|
||||
|
||||
511
.github/workflows/self-push.yml
vendored
511
.github/workflows/self-push.yml
vendored
@ -20,358 +20,192 @@ env:
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
PYTEST_TIMEOUT: 60
|
||||
TF_FORCE_GPU_ALLOW_GROWTH: true
|
||||
RUN_PT_TF_CROSS_TESTS: 1
|
||||
|
||||
jobs:
|
||||
run_tests_torch_gpu:
|
||||
runs-on: [self-hosted, docker-gpu, single-gpu]
|
||||
setup:
|
||||
name: Setup
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
||||
test_map: ${{ steps.set-matrix.outputs.test_map }}
|
||||
steps:
|
||||
- name: Checkout transformers
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Cleanup
|
||||
run: |
|
||||
rm -rf tests/__pycache__
|
||||
rm -rf tests/models/__pycache__
|
||||
rm -rf reports
|
||||
|
||||
- name: Fetch the tests to run
|
||||
# TODO: add `git-python` in the docker images
|
||||
run: |
|
||||
pip install --upgrade git-python
|
||||
python utils/tests_fetcher.py --diff_with_last_commit | tee test_preparation.txt
|
||||
|
||||
- name: Report fetched tests
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: test_fetched
|
||||
path: test_preparation.txt
|
||||
|
||||
- id: set-matrix
|
||||
name: Organize tests into models
|
||||
# The `keys` is used as GitHub actions matrix for jobs, i.e. `models/bert`, `tokenization`, `pipeline`, etc.
|
||||
# The `test_map` is used to get the actual identified test files under each key.
|
||||
# If no test to run (so no `test_map.json` file), create a dummy map (empty matrix will fail)
|
||||
run: |
|
||||
if [ -f test_map.json ]; then
|
||||
keys=$(python3 -c 'import json; fp = open("test_map.json"); test_map = json.load(fp); fp.close(); d = list(test_map.keys()); print(d)')
|
||||
test_map=$(python3 -c 'import json; fp = open("test_map.json"); test_map = json.load(fp); fp.close(); print(test_map)')
|
||||
else
|
||||
keys=$(python3 -c 'keys = ["dummy"]; print(keys)')
|
||||
test_map=$(python3 -c 'test_map = {"dummy": []}; print(test_map)')
|
||||
fi
|
||||
echo $keys
|
||||
echo $test_map
|
||||
echo "::set-output name=matrix::$keys"
|
||||
echo "::set-output name=test_map::$test_map"
|
||||
|
||||
run_tests_single_gpu:
|
||||
name: Model tests
|
||||
needs: setup
|
||||
# `dummy` means there is no test to run
|
||||
if: contains(fromJson(needs.setup.outputs.matrix), 'dummy') != true
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
folders: ${{ fromJson(needs.setup.outputs.matrix) }}
|
||||
machine_type: [single-gpu]
|
||||
runs-on: [self-hosted, docker-gpu, '${{ matrix.machine_type }}']
|
||||
container:
|
||||
image: pytorch/pytorch:1.9.0-cuda11.1-cudnn8-runtime
|
||||
image: huggingface/transformers-all-latest-gpu
|
||||
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
steps:
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
apt -y update && apt install -y software-properties-common && apt -y update && add-apt-repository -y ppa:git-core/ppa && apt -y update && apt install -y git
|
||||
apt install -y libsndfile1-dev espeak-ng
|
||||
pip install --upgrade pip
|
||||
pip install .[sklearn,testing,onnxruntime,sentencepiece,torch-speech,vision,timm]
|
||||
pip install https://github.com/kpu/kenlm/archive/master.zip
|
||||
|
||||
- name: Launcher docker
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
|
||||
- name: Are GPUs recognized by our DL frameworks
|
||||
working-directory: /transformers
|
||||
run: |
|
||||
utils/print_env_pt.py
|
||||
TF_CPP_MIN_LOG_LEVEL=3 python3 -c "import tensorflow as tf; print('TF GPUs available:', bool(tf.config.list_physical_devices('GPU')))"
|
||||
TF_CPP_MIN_LOG_LEVEL=3 python3 -c "import tensorflow as tf; print('Number of TF GPUs available:', len(tf.config.list_physical_devices('GPU')))"
|
||||
|
||||
- name: Fetch the tests to run
|
||||
- name: Echo folder ${{ matrix.folders }}
|
||||
shell: bash
|
||||
# For folders like `models/bert`, set an env. var. (`matrix_folders`) to `models_bert`, which will be used to
|
||||
# set the artifact folder names (because the character `/` is not allowed).
|
||||
run: |
|
||||
python utils/tests_fetcher.py --diff_with_last_commit | tee test_preparation.txt
|
||||
echo "${{ matrix.folders }}"
|
||||
echo "${{ fromJson(needs.setup.outputs.test_map)[matrix.folders] }}"
|
||||
matrix_folders=${{ matrix.folders }}
|
||||
matrix_folders=${matrix_folders/'models/'/'models_'}
|
||||
echo "$matrix_folders"
|
||||
echo "matrix_folders=$matrix_folders" >> $GITHUB_ENV
|
||||
|
||||
- name: Report fetched tests
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: test_fetched
|
||||
path: test_preparation.txt
|
||||
- name: Update clone
|
||||
working-directory: /transformers
|
||||
run: git fetch && git checkout ${{ github.sha }}
|
||||
|
||||
- name: Run all non-slow tests on GPU
|
||||
- name: Run all non-slow selected tests on GPU
|
||||
working-directory: /transformers
|
||||
run: |
|
||||
if [ -f test_list.txt ]; then
|
||||
python -m pytest -n 2 --dist=loadfile -v --make-reports=tests_torch_gpu $(cat test_list.txt)
|
||||
fi
|
||||
python3 -m pytest -n 2 --dist=loadfile -v --make-reports=${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }} ${{ fromJson(needs.setup.outputs.test_map)[matrix.folders] }}
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_torch_gpu/failures_short.txt
|
||||
continue-on-error: true
|
||||
run: cat /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}/failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: run_all_tests_torch_gpu_test_reports
|
||||
path: reports
|
||||
name: ${{ matrix.machine_type }}_run_all_tests_gpu_${{ env.matrix_folders }}_test_reports
|
||||
path: /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}
|
||||
|
||||
# run_tests_flax_gpu:
|
||||
# runs-on: [self-hosted, docker-gpu-test, single-gpu]
|
||||
# container:
|
||||
# image: tensorflow/tensorflow:2.4.1-gpu
|
||||
# options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
# steps:
|
||||
# - name: Set up Python 3.7
|
||||
# uses: actions/setup-python@v2
|
||||
# with:
|
||||
# python-version: 3.7
|
||||
#
|
||||
# - name: Install dependencies
|
||||
# run: |
|
||||
# apt -y update && apt install -y software-properties-common && apt -y update && add-apt-repository -y ppa:git-core/ppa && apt -y update && apt install -y git espeak-ng
|
||||
# pip install --upgrade "jax[cuda111]" -f https://storage.googleapis.com/jax-releases/jax_releases.html
|
||||
# pip install --upgrade pip
|
||||
# pip install .[sklearn,testing,sentencepiece,flax,flax-speech,vision]
|
||||
#
|
||||
# - name: Launcher docker
|
||||
# uses: actions/checkout@v2
|
||||
# with:
|
||||
# fetch-depth: 2
|
||||
#
|
||||
# - name: NVIDIA-SMI
|
||||
# continue-on-error: true
|
||||
# run: |
|
||||
# nvidia-smi
|
||||
#
|
||||
# - name: Are GPUs recognized by our DL frameworks
|
||||
# run: |
|
||||
# python -c "from jax.lib import xla_bridge; print('GPU available:', xla_bridge.get_backend().platform)"
|
||||
# python -c "import jax; print('Number of GPUs available:', len(jax.local_devices()))"
|
||||
#
|
||||
# - name: Fetch the tests to run
|
||||
# run: |
|
||||
# python utils/tests_fetcher.py --diff_with_last_commit | tee test_preparation.txt
|
||||
#
|
||||
# - name: Report fetched tests
|
||||
# uses: actions/upload-artifact@v2
|
||||
# with:
|
||||
# name: test_fetched
|
||||
# path: test_preparation.txt
|
||||
#
|
||||
# - name: Run all non-slow tests on GPU
|
||||
# run: |
|
||||
# if [ -f test_list.txt ]; then
|
||||
# python -m pytest -n 2 --dist=loadfile -v --make-reports=tests_flax_gpu $(cat test_list.txt)
|
||||
# fi
|
||||
#
|
||||
# - name: Failure short reports
|
||||
# if: ${{ failure() }}
|
||||
# run: cat reports/tests_flax_gpu/failures_short.txt
|
||||
#
|
||||
# - name: Test suite reports artifacts
|
||||
# if: ${{ always() }}
|
||||
# uses: actions/upload-artifact@v2
|
||||
# with:
|
||||
# name: run_all_tests_flax_gpu_test_reports
|
||||
# path: reports
|
||||
#
|
||||
# run_tests_tf_gpu:
|
||||
# runs-on: [self-hosted, docker-gpu, single-gpu]
|
||||
# timeout-minutes: 120
|
||||
# container:
|
||||
# image: tensorflow/tensorflow:2.4.1-gpu
|
||||
# options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
# steps:
|
||||
# - name: Install dependencies
|
||||
# run: |
|
||||
# apt -y update && apt install -y software-properties-common && apt -y update && add-apt-repository -y ppa:git-core/ppa && apt -y update && apt install -y git espeak-ng
|
||||
# pip install --upgrade pip
|
||||
# pip install .[sklearn,testing,onnxruntime,sentencepiece,tf-speech]
|
||||
# pip install https://github.com/kpu/kenlm/archive/master.zip
|
||||
#
|
||||
# - name: Launcher docker
|
||||
# uses: actions/checkout@v2
|
||||
# with:
|
||||
# fetch-depth: 2
|
||||
#
|
||||
# - name: NVIDIA-SMI
|
||||
# run: |
|
||||
# nvidia-smi
|
||||
#
|
||||
# - name: Are GPUs recognized by our DL frameworks
|
||||
# run: |
|
||||
# TF_CPP_MIN_LOG_LEVEL=3 python -c "import tensorflow as tf; print('TF GPUs available:', bool(tf.config.list_physical_devices('GPU')))"
|
||||
# TF_CPP_MIN_LOG_LEVEL=3 python -c "import tensorflow as tf; print('Number of TF GPUs available:', len(tf.config.list_physical_devices('GPU')))"
|
||||
#
|
||||
# - name: Fetch the tests to run
|
||||
# run: |
|
||||
# python utils/tests_fetcher.py --diff_with_last_commit | tee test_preparation.txt
|
||||
#
|
||||
# - name: Report fetched tests
|
||||
# uses: actions/upload-artifact@v2
|
||||
# with:
|
||||
# name: test_fetched
|
||||
# path: test_preparation.txt
|
||||
#
|
||||
# - name: Run all non-slow tests on GPU
|
||||
# env:
|
||||
# TF_NUM_INTRAOP_THREADS: 8
|
||||
# TF_NUM_INTEROP_THREADS: 1
|
||||
# run: |
|
||||
# if [ -f test_list.txt ]; then
|
||||
# python -m pytest -n 1 --dist=loadfile --make-reports=tests_tf_gpu $(cat test_list.txt)
|
||||
# fi
|
||||
#
|
||||
# - name: Failure short reports
|
||||
# if: ${{ failure() }}
|
||||
# run: cat reports/tests_tf_gpu/failures_short.txt
|
||||
#
|
||||
# - name: Test suite reports artifacts
|
||||
# if: ${{ always() }}
|
||||
# uses: actions/upload-artifact@v2
|
||||
# with:
|
||||
# name: run_all_tests_tf_gpu_test_reports
|
||||
# path: reports
|
||||
|
||||
|
||||
run_tests_torch_multi_gpu:
|
||||
runs-on: [self-hosted, docker-gpu, multi-gpu]
|
||||
run_tests_multi_gpu:
|
||||
name: Model tests
|
||||
needs: setup
|
||||
# `dummy` means there is no test to run
|
||||
if: contains(fromJson(needs.setup.outputs.matrix), 'dummy') != true
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
folders: ${{ fromJson(needs.setup.outputs.matrix) }}
|
||||
machine_type: [multi-gpu]
|
||||
runs-on: [self-hosted, docker-gpu, '${{ matrix.machine_type }}']
|
||||
container:
|
||||
image: pytorch/pytorch:1.9.0-cuda11.1-cudnn8-runtime
|
||||
image: huggingface/transformers-all-latest-gpu
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
steps:
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
apt -y update && apt install -y software-properties-common && apt -y update && add-apt-repository -y ppa:git-core/ppa && apt -y update && apt install -y git espeak-ng
|
||||
apt install -y libsndfile1-dev espeak-ng
|
||||
pip install --upgrade pip
|
||||
pip install .[sklearn,testing,onnxruntime,sentencepiece,torch-speech,vision,timm]
|
||||
pip install https://github.com/kpu/kenlm/archive/master.zip
|
||||
- name: Launcher docker
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
continue-on-error: true
|
||||
run: |
|
||||
nvidia-smi
|
||||
|
||||
- name: Are GPUs recognized by our DL frameworks
|
||||
working-directory: /transformers
|
||||
run: |
|
||||
utils/print_env_pt.py
|
||||
TF_CPP_MIN_LOG_LEVEL=3 python3 -c "import tensorflow as tf; print('TF GPUs available:', bool(tf.config.list_physical_devices('GPU')))"
|
||||
TF_CPP_MIN_LOG_LEVEL=3 python3 -c "import tensorflow as tf; print('Number of TF GPUs available:', len(tf.config.list_physical_devices('GPU')))"
|
||||
|
||||
- name: Fetch the tests to run
|
||||
- name: Echo folder ${{ matrix.folders }}
|
||||
shell: bash
|
||||
# For folders like `models/bert`, set an env. var. (`matrix_folders`) to `models_bert`, which will be used to
|
||||
# set the artifact folder names (because the character `/` is not allowed).
|
||||
run: |
|
||||
python utils/tests_fetcher.py --diff_with_last_commit | tee test_preparation.txt
|
||||
echo "${{ matrix.folders }}"
|
||||
echo "${{ fromJson(needs.setup.outputs.test_map)[matrix.folders] }}"
|
||||
matrix_folders=${{ matrix.folders }}
|
||||
matrix_folders=${matrix_folders/'models/'/'models_'}
|
||||
echo "$matrix_folders"
|
||||
echo "matrix_folders=$matrix_folders" >> $GITHUB_ENV
|
||||
|
||||
- name: Report fetched tests
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: test_fetched
|
||||
path: test_preparation.txt
|
||||
- name: Update clone
|
||||
working-directory: /transformers
|
||||
run: git fetch && git checkout ${{ github.sha }}
|
||||
|
||||
- name: Run all non-slow tests on GPU
|
||||
- name: Run all non-slow selected tests on GPU
|
||||
env:
|
||||
MKL_SERVICE_FORCE_INTEL: 1
|
||||
working-directory: /transformers
|
||||
run: |
|
||||
if [ -f test_list.txt ]; then
|
||||
python -m pytest -n 2 --dist=loadfile -v --make-reports=tests_torch_multi_gpu $(cat test_list.txt)
|
||||
fi
|
||||
python3 -m pytest -n 2 --dist=loadfile -v --make-reports=${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }} ${{ fromJson(needs.setup.outputs.test_map)[matrix.folders] }}
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_torch_multi_gpu/failures_short.txt
|
||||
continue-on-error: true
|
||||
run: cat /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}/failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: run_all_tests_torch_multi_gpu_test_reports
|
||||
path: reports
|
||||
name: ${{ matrix.machine_type }}_run_all_tests_gpu_${{ env.matrix_folders }}_test_reports
|
||||
path: /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}
|
||||
|
||||
# run_tests_flax_multi_gpu:
|
||||
# runs-on: [self-hosted, docker-gpu, multi-gpu]
|
||||
# container:
|
||||
# image: tensorflow/tensorflow:2.4.1-gpu
|
||||
# options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
# steps:
|
||||
# - name: Install dependencies
|
||||
# run: |
|
||||
# apt -y update && apt install -y software-properties-common && apt -y update && add-apt-repository -y ppa:git-core/ppa && apt -y update && apt install -y git espeak-ng
|
||||
# pip install --upgrade "jax[cuda111]" -f https://storage.googleapis.com/jax-releases/jax_releases.html
|
||||
# pip install --upgrade pip
|
||||
# pip install .[sklearn,testing,sentencepiece,flax,flax-speech,vision]
|
||||
# pip install https://github.com/kpu/kenlm/archive/master.zip
|
||||
#
|
||||
# - name: Launcher docker
|
||||
# uses: actions/checkout@v2
|
||||
# with:
|
||||
# fetch-depth: 2
|
||||
#
|
||||
# - name: NVIDIA-SMI
|
||||
# continue-on-error: true
|
||||
# run: |
|
||||
# nvidia-smi
|
||||
#
|
||||
# - name: Are GPUs recognized by our DL frameworks
|
||||
# run: |
|
||||
# python -c "from jax.lib import xla_bridge; print('GPU available:', xla_bridge.get_backend().platform)"
|
||||
# python -c "import jax; print('Number of GPUs available:', len(jax.local_devices()))"
|
||||
#
|
||||
# - name: Fetch the tests to run
|
||||
# run: |
|
||||
# python utils/tests_fetcher.py --diff_with_last_commit | tee test_preparation.txt
|
||||
#
|
||||
# - name: Report fetched tests
|
||||
# uses: actions/upload-artifact@v2
|
||||
# with:
|
||||
# name: test_fetched
|
||||
# path: test_preparation.txt
|
||||
#
|
||||
# - name: Run all non-slow tests on GPU
|
||||
# run: |
|
||||
# if [ -f test_list.txt ]; then
|
||||
# python -m pytest -n 2 --dist=loadfile -v --make-reports=tests_flax_multi_gpu $(cat test_list.txt)
|
||||
# fi
|
||||
#
|
||||
# - name: Failure short reports
|
||||
# if: ${{ failure() }}
|
||||
# run: cat reports/tests_flax_multi_gpu/failures_short.txt
|
||||
#
|
||||
# - name: Test suite reports artifacts
|
||||
# if: ${{ always() }}
|
||||
# uses: actions/upload-artifact@v2
|
||||
# with:
|
||||
# name: run_all_tests_flax_multi_gpu_test_reports
|
||||
# path: reports
|
||||
|
||||
# run_tests_tf_multi_gpu:
|
||||
# runs-on: [self-hosted, docker-gpu, multi-gpu]
|
||||
# timeout-minutes: 120
|
||||
# container:
|
||||
# image: tensorflow/tensorflow:2.4.1-gpu
|
||||
# options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
# steps:
|
||||
# - name: Install dependencies
|
||||
# run: |
|
||||
# apt -y update && apt install -y software-properties-common && apt -y update && add-apt-repository -y ppa:git-core/ppa && apt -y update && apt install -y git espeak-ng
|
||||
# pip install --upgrade pip
|
||||
# pip install .[sklearn,testing,onnxruntime,sentencepiece,tf-speech]
|
||||
# pip install https://github.com/kpu/kenlm/archive/master.zip
|
||||
#
|
||||
# - name: Launcher docker
|
||||
# uses: actions/checkout@v2
|
||||
# with:
|
||||
# fetch-depth: 2
|
||||
#
|
||||
# - name: NVIDIA-SMI
|
||||
# run: |
|
||||
# nvidia-smi
|
||||
#
|
||||
# - name: Are GPUs recognized by our DL frameworks
|
||||
# run: |
|
||||
# TF_CPP_MIN_LOG_LEVEL=3 python -c "import tensorflow as tf; print('TF GPUs available:', bool(tf.config.list_physical_devices('GPU')))"
|
||||
# TF_CPP_MIN_LOG_LEVEL=3 python -c "import tensorflow as tf; print('Number of TF GPUs available:', len(tf.config.list_physical_devices('GPU')))"
|
||||
#
|
||||
# - name: Fetch the tests to run
|
||||
# run: |
|
||||
# python utils/tests_fetcher.py --diff_with_last_commit | tee test_preparation.txt
|
||||
#
|
||||
# - name: Report fetched tests
|
||||
# uses: actions/upload-artifact@v2
|
||||
# with:
|
||||
# name: test_fetched
|
||||
# path: test_preparation.txt
|
||||
#
|
||||
# - name: Run all non-slow tests on GPU
|
||||
# env:
|
||||
# TF_NUM_INTRAOP_THREADS: 8
|
||||
# TF_NUM_INTEROP_THREADS: 1
|
||||
# run: |
|
||||
# if [ -f test_list.txt ]; then
|
||||
# python -m pytest -n 1 --dist=loadfile --make-reports=tests_tf_multi_gpu $(cat test_list.txt)
|
||||
# fi
|
||||
#
|
||||
# - name: Failure short reports
|
||||
# if: ${{ failure() }}
|
||||
# run: cat reports/tests_tf_multi_gpu/failures_short.txt
|
||||
#
|
||||
# - name: Test suite reports artifacts
|
||||
# if: ${{ always() }}
|
||||
# uses: actions/upload-artifact@v2
|
||||
# with:
|
||||
# name: run_all_tests_tf_multi_gpu_test_reports
|
||||
# path: reports
|
||||
|
||||
run_tests_torch_cuda_extensions_gpu:
|
||||
runs-on: [self-hosted, docker-gpu, single-gpu]
|
||||
run_tests_torch_cuda_extensions_single_gpu:
|
||||
name: Torch CUDA extension tests
|
||||
needs: setup
|
||||
if: contains(fromJson(needs.setup.outputs.matrix), 'deepspeed') || contains(fromJson(needs.setup.outputs.matrix), 'extended')
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
machine_type: [single-gpu]
|
||||
runs-on: [self-hosted, docker-gpu, '${{ matrix.machine_type }}']
|
||||
container:
|
||||
image: nvcr.io/nvidia/pytorch:21.03-py3
|
||||
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
steps:
|
||||
- name: Launcher docker
|
||||
- name: Checkout transformers
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
fetch-depth: 2
|
||||
@ -390,46 +224,42 @@ jobs:
|
||||
run: |
|
||||
utils/print_env_pt.py
|
||||
|
||||
- name: Fetch the tests to run
|
||||
- name: Run all non-slow selected tests on GPU
|
||||
# TODO: Here we pass all tests in the 2 folders for simplicity. It's better to pass only the identified tests.
|
||||
run: |
|
||||
python utils/tests_fetcher.py --diff_with_last_commit --filters tests/deepspeed tests/extended | tee test_preparation.txt
|
||||
|
||||
- name: Report fetched tests
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: test_fetched
|
||||
path: test_preparation.txt
|
||||
|
||||
- name: Run all tests on GPU
|
||||
run: |
|
||||
if [ -f test_list.txt ]; then
|
||||
python -m pytest -n 1 --dist=loadfile -v --make-reports=tests_torch_cuda_extensions_gpu $(cat test_list.txt)
|
||||
fi
|
||||
python -m pytest -n 1 --dist=loadfile -v --make-reports=${{ matrix.machine_type }}_tests_torch_cuda_extensions_gpu tests/deepspeed tests/extended
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_torch_cuda_extensions_gpu/failures_short.txt
|
||||
continue-on-error: true
|
||||
run: cat reports/${{ matrix.machine_type }}_tests_torch_cuda_extensions_gpu/failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: run_tests_torch_cuda_extensions_gpu_test_reports
|
||||
path: reports
|
||||
name: ${{ matrix.machine_type }}_run_tests_torch_cuda_extensions_gpu_test_reports
|
||||
path: reports/${{ matrix.machine_type }}_tests_torch_cuda_extensions_gpu
|
||||
|
||||
run_tests_torch_cuda_extensions_multi_gpu:
|
||||
runs-on: [self-hosted, docker-gpu, multi-gpu]
|
||||
name: Torch CUDA extension tests
|
||||
needs: setup
|
||||
if: contains(fromJson(needs.setup.outputs.matrix), 'deepspeed') || contains(fromJson(needs.setup.outputs.matrix), 'extended')
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
machine_type: [multi-gpu]
|
||||
runs-on: [self-hosted, docker-gpu, '${{ matrix.machine_type }}']
|
||||
container:
|
||||
image: nvcr.io/nvidia/pytorch:21.03-py3
|
||||
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
steps:
|
||||
- name: Launcher docker
|
||||
- name: Checkout transformers
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
continue-on-error: true
|
||||
run: |
|
||||
nvidia-smi
|
||||
|
||||
@ -444,56 +274,49 @@ jobs:
|
||||
run: |
|
||||
utils/print_env_pt.py
|
||||
|
||||
- name: Fetch the tests to run
|
||||
- name: Run all non-slow selected tests on GPU
|
||||
# TODO: Here we pass all tests in the 2 folders for simplicity. It's better to pass only the identified tests.
|
||||
run: |
|
||||
python utils/tests_fetcher.py --diff_with_last_commit --filters tests/deepspeed tests/extended | tee test_preparation.txt
|
||||
|
||||
- name: Report fetched tests
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: test_fetched
|
||||
path: test_preparation.txt
|
||||
|
||||
- name: Run all tests on GPU
|
||||
run: |
|
||||
if [ -f test_list.txt ]; then
|
||||
python -m pytest -n 1 --dist=loadfile -v --make-reports=tests_torch_cuda_extensions_multi_gpu $(cat test_list.txt)
|
||||
fi
|
||||
python -m pytest -n 1 --dist=loadfile -v --make-reports=${{ matrix.machine_type }}_tests_torch_cuda_extensions_gpu tests/deepspeed tests/extended
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_torch_cuda_extensions_multi_gpu/failures_short.txt
|
||||
continue-on-error: true
|
||||
run: cat reports/${{ matrix.machine_type }}_tests_torch_cuda_extensions_gpu/failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: run_tests_torch_cuda_extensions_multi_gpu_test_reports
|
||||
path: reports
|
||||
|
||||
name: ${{ matrix.machine_type }}_run_tests_torch_cuda_extensions_gpu_test_reports
|
||||
path: reports/${{ matrix.machine_type }}_tests_torch_cuda_extensions_gpu
|
||||
|
||||
send_results:
|
||||
name: Send results to webhook
|
||||
runs-on: ubuntu-latest
|
||||
if: always()
|
||||
needs: [
|
||||
run_tests_torch_gpu,
|
||||
# run_tests_tf_gpu,
|
||||
run_tests_torch_multi_gpu,
|
||||
# run_tests_tf_multi_gpu,
|
||||
run_tests_torch_cuda_extensions_gpu,
|
||||
setup,
|
||||
run_tests_single_gpu,
|
||||
run_tests_multi_gpu,
|
||||
run_tests_torch_cuda_extensions_single_gpu,
|
||||
run_tests_torch_cuda_extensions_multi_gpu
|
||||
]
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
|
||||
- uses: actions/download-artifact@v2
|
||||
|
||||
- name: Send message to Slack
|
||||
env:
|
||||
CI_SLACK_BOT_TOKEN: ${{ secrets.CI_SLACK_BOT_TOKEN }}
|
||||
CI_SLACK_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID }}
|
||||
|
||||
CI_SLACK_CHANNEL_ID_DAILY: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY }}
|
||||
CI_SLACK_CHANNEL_DUMMY_TESTS: ${{ secrets.CI_SLACK_CHANNEL_DUMMY_TESTS }}
|
||||
CI_SLACK_REPORT_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID }}
|
||||
CI_EVENT: push
|
||||
CI_TITLE: ${{ github.event.head_commit.message }}
|
||||
CI_COMMIT_URL: ${{ github.event.head_commit.url }}
|
||||
# We pass `needs.setup.outputs.matrix` as the argument. A processing in `notification_service.py` to change
|
||||
# `models/bert` to `models_bert` is required, as the artifact names use `_` instead of `/`.
|
||||
run: |
|
||||
pip install slack_sdk
|
||||
python utils/notification_service_deprecated.py push
|
||||
python utils/notification_service.py "${{ needs.setup.outputs.matrix }}"
|
||||
|
||||
74
.github/workflows/self-scheduled.yml
vendored
74
.github/workflows/self-scheduled.yml
vendored
@ -26,8 +26,8 @@ jobs:
|
||||
name: Setup
|
||||
strategy:
|
||||
matrix:
|
||||
machines: [multi-gpu-docker, single-gpu-docker]
|
||||
runs-on: ${{ matrix.machines }}
|
||||
machine_type: [single-gpu, multi-gpu]
|
||||
runs-on: ${{ format('{0}-{1}', matrix.machine_type, 'docker') }}
|
||||
container:
|
||||
image: huggingface/transformers-all-latest-gpu
|
||||
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
@ -69,8 +69,8 @@ jobs:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
folders: ${{ fromJson(needs.setup.outputs.matrix) }}
|
||||
machines: [single-gpu-docker]
|
||||
runs-on: ${{ matrix.machines }}
|
||||
machine_type: [single-gpu]
|
||||
runs-on: ${{ format('{0}-{1}', matrix.machine_type, 'docker') }}
|
||||
container:
|
||||
image: huggingface/transformers-all-latest-gpu
|
||||
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
@ -83,7 +83,6 @@ jobs:
|
||||
run: |
|
||||
echo "${{ matrix.folders }}"
|
||||
matrix_folders=${{ matrix.folders }}
|
||||
echo "$matrix_folders"
|
||||
matrix_folders=${matrix_folders/'models/'/'models_'}
|
||||
echo "$matrix_folders"
|
||||
echo "matrix_folders=$matrix_folders" >> $GITHUB_ENV
|
||||
@ -94,19 +93,19 @@ jobs:
|
||||
|
||||
- name: Run all tests on GPU
|
||||
working-directory: /transformers
|
||||
run: python3 -m pytest -v --make-reports=${{ matrix.machines }}_tests_gpu_${{ matrix.folders }} tests/${{ matrix.folders }}
|
||||
run: python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }} tests/${{ matrix.folders }}
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
continue-on-error: true
|
||||
run: cat /transformers/reports/${{ matrix.machines }}_tests_gpu_${{ matrix.folders }}/failures_short.txt
|
||||
run: cat /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}/failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: ${{ matrix.machines }}_run_all_tests_gpu_${{ env.matrix_folders }}_test_reports
|
||||
path: /transformers/reports/${{ matrix.machines }}_tests_gpu_${{ matrix.folders }}
|
||||
name: ${{ matrix.machine_type }}_run_all_tests_gpu_${{ env.matrix_folders }}_test_reports
|
||||
path: /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}
|
||||
|
||||
run_tests_multi_gpu:
|
||||
name: Model tests
|
||||
@ -114,11 +113,11 @@ jobs:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
folders: ${{ fromJson(needs.setup.outputs.matrix) }}
|
||||
machines: [multi-gpu-docker]
|
||||
runs-on: ${{ matrix.machines }}
|
||||
machine_type: [multi-gpu]
|
||||
runs-on: ${{ format('{0}-{1}', matrix.machine_type, 'docker') }}
|
||||
container:
|
||||
image: huggingface/transformers-all-latest-gpu
|
||||
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
needs: setup
|
||||
steps:
|
||||
- name: Echo folder ${{ matrix.folders }}
|
||||
@ -128,7 +127,6 @@ jobs:
|
||||
run: |
|
||||
echo "${{ matrix.folders }}"
|
||||
matrix_folders=${{ matrix.folders }}
|
||||
echo "$matrix_folders"
|
||||
matrix_folders=${matrix_folders/'models/'/'models_'}
|
||||
echo "$matrix_folders"
|
||||
echo "matrix_folders=$matrix_folders" >> $GITHUB_ENV
|
||||
@ -139,19 +137,19 @@ jobs:
|
||||
|
||||
- name: Run all tests on GPU
|
||||
working-directory: /transformers
|
||||
run: python3 -m pytest -v --make-reports=${{ matrix.machines }}_tests_gpu_${{ matrix.folders }} tests/${{ matrix.folders }}
|
||||
run: python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }} tests/${{ matrix.folders }}
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
continue-on-error: true
|
||||
run: cat /transformers/reports/${{ matrix.machines }}_tests_gpu_${{ matrix.folders }}/failures_short.txt
|
||||
run: cat /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}/failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: ${{ matrix.machines }}_run_all_tests_gpu_${{ env.matrix_folders }}_test_reports
|
||||
path: /transformers/reports/${{ matrix.machines }}_tests_gpu_${{ matrix.folders }}
|
||||
name: ${{ matrix.machine_type }}_run_all_tests_gpu_${{ env.matrix_folders }}_test_reports
|
||||
path: /transformers/reports/${{ matrix.machine_type }}_tests_gpu_${{ matrix.folders }}
|
||||
|
||||
run_examples_gpu:
|
||||
name: Examples directory
|
||||
@ -188,11 +186,11 @@ jobs:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
machines: [multi-gpu-docker, single-gpu-docker]
|
||||
runs-on: ${{ matrix.machines }}
|
||||
machine_type: [single-gpu, multi-gpu]
|
||||
runs-on: ${{ format('{0}-{1}', matrix.machine_type, 'docker') }}
|
||||
container:
|
||||
image: huggingface/transformers-pytorch-gpu
|
||||
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
needs: setup
|
||||
steps:
|
||||
- name: Update clone
|
||||
@ -204,30 +202,30 @@ jobs:
|
||||
env:
|
||||
RUN_PIPELINE_TESTS: yes
|
||||
run: |
|
||||
python3 -m pytest -n 1 -v --dist=loadfile -m is_pipeline_test --make-reports=${{ matrix.machines }}_tests_torch_pipeline_gpu tests
|
||||
python3 -m pytest -n 1 -v --dist=loadfile -m is_pipeline_test --make-reports=${{ matrix.machine_type }}_tests_torch_pipeline_gpu tests
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
continue-on-error: true
|
||||
run: cat /transformers/reports/${{ matrix.machines }}_tests_torch_pipeline_gpu/failures_short.txt
|
||||
run: cat /transformers/reports/${{ matrix.machine_type }}_tests_torch_pipeline_gpu/failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: ${{ matrix.machines }}_run_tests_torch_pipeline_gpu
|
||||
path: /transformers/reports/${{ matrix.machines }}_tests_torch_pipeline_gpu
|
||||
name: ${{ matrix.machine_type }}_run_tests_torch_pipeline_gpu
|
||||
path: /transformers/reports/${{ matrix.machine_type }}_tests_torch_pipeline_gpu
|
||||
|
||||
run_pipelines_tf_gpu:
|
||||
name: TensorFlow pipelines
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
machines: [multi-gpu-docker, single-gpu-docker]
|
||||
runs-on: ${{ matrix.machines }}
|
||||
machine_type: [single-gpu, multi-gpu]
|
||||
runs-on: ${{ format('{0}-{1}', matrix.machine_type, 'docker') }}
|
||||
container:
|
||||
image: huggingface/transformers-tensorflow-gpu
|
||||
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
needs: setup
|
||||
steps:
|
||||
- name: Update clone
|
||||
@ -240,27 +238,27 @@ jobs:
|
||||
env:
|
||||
RUN_PIPELINE_TESTS: yes
|
||||
run: |
|
||||
python3 -m pytest -n 1 -v --dist=loadfile -m is_pipeline_test --make-reports=${{ matrix.machines }}_tests_tf_pipeline_gpu tests
|
||||
python3 -m pytest -n 1 -v --dist=loadfile -m is_pipeline_test --make-reports=${{ matrix.machine_type }}_tests_tf_pipeline_gpu tests
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ always() }}
|
||||
run: |
|
||||
cat /transformers/reports/${{ matrix.machines }}_tests_tf_pipeline_gpu/failures_short.txt
|
||||
cat /transformers/reports/${{ matrix.machine_type }}_tests_tf_pipeline_gpu/failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: ${{ matrix.machines }}_run_tests_tf_pipeline_gpu
|
||||
path: /transformers/reports/${{ matrix.machines }}_tests_tf_pipeline_gpu
|
||||
name: ${{ matrix.machine_type }}_run_tests_tf_pipeline_gpu
|
||||
path: /transformers/reports/${{ matrix.machine_type }}_tests_tf_pipeline_gpu
|
||||
|
||||
run_all_tests_torch_cuda_extensions_gpu:
|
||||
name: Torch CUDA extension tests
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
machines: [multi-gpu-docker, single-gpu-docker]
|
||||
runs-on: ${{ matrix.machines }}
|
||||
machine_type: [single-gpu, multi-gpu]
|
||||
runs-on: ${{ format('{0}-{1}', matrix.machine_type, 'docker') }}
|
||||
needs: setup
|
||||
container:
|
||||
image: huggingface/transformers-pytorch-deepspeed-latest-gpu
|
||||
@ -281,19 +279,19 @@ jobs:
|
||||
- name: Run all tests on GPU
|
||||
working-directory: /workspace/transformers
|
||||
run: |
|
||||
python -m pytest -v --make-reports=${{ matrix.machines }}_tests_torch_cuda_extensions_gpu tests/deepspeed tests/extended
|
||||
python -m pytest -v --make-reports=${{ matrix.machine_type }}_tests_torch_cuda_extensions_gpu tests/deepspeed tests/extended
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
continue-on-error: true
|
||||
run: cat /workspace/transformers/reports/${{ matrix.machines }}_tests_torch_cuda_extensions_gpu/failures_short.txt
|
||||
run: cat /workspace/transformers/reports/${{ matrix.machine_type }}_tests_torch_cuda_extensions_gpu/failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v2
|
||||
with:
|
||||
name: ${{ matrix.machines }}_run_tests_torch_cuda_extensions_gpu_test_reports
|
||||
path: /workspace/transformers/reports/${{ matrix.machines }}_tests_torch_cuda_extensions_gpu
|
||||
name: ${{ matrix.machine_type }}_run_tests_torch_cuda_extensions_gpu_test_reports
|
||||
path: /workspace/transformers/reports/${{ matrix.machine_type }}_tests_torch_cuda_extensions_gpu
|
||||
|
||||
|
||||
send_results:
|
||||
@ -310,6 +308,8 @@ jobs:
|
||||
CI_SLACK_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID }}
|
||||
CI_SLACK_CHANNEL_ID_DAILY: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY }}
|
||||
CI_SLACK_CHANNEL_DUMMY_TESTS: ${{ secrets.CI_SLACK_CHANNEL_DUMMY_TESTS }}
|
||||
CI_SLACK_REPORT_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY }}
|
||||
CI_EVENT: scheduled
|
||||
# We pass `needs.setup.outputs.matrix` as the argument. A processing in `notification_service.py` to change
|
||||
# `models/bert` to `models_bert` is required, as the artifact names use `_` instead of `/`.
|
||||
run: |
|
||||
|
||||
8
Makefile
8
Makefile
@ -9,7 +9,7 @@ modified_only_fixup:
|
||||
$(eval modified_py_files := $(shell python utils/get_modified_files.py $(check_dirs)))
|
||||
@if test -n "$(modified_py_files)"; then \
|
||||
echo "Checking/fixing $(modified_py_files)"; \
|
||||
black $(modified_py_files); \
|
||||
black --preview $(modified_py_files); \
|
||||
isort $(modified_py_files); \
|
||||
flake8 $(modified_py_files); \
|
||||
else \
|
||||
@ -45,9 +45,10 @@ repo-consistency:
|
||||
# this target runs checks on all files
|
||||
|
||||
quality:
|
||||
black --check $(check_dirs)
|
||||
black --check --preview $(check_dirs)
|
||||
isort --check-only $(check_dirs)
|
||||
python utils/custom_init_isort.py --check_only
|
||||
python utils/sort_auto_mappings.py --check_only
|
||||
flake8 $(check_dirs)
|
||||
doc-builder style src/transformers docs/source --max_len 119 --check_only --path_to_docs docs/source
|
||||
|
||||
@ -55,12 +56,13 @@ quality:
|
||||
|
||||
extra_style_checks:
|
||||
python utils/custom_init_isort.py
|
||||
python utils/sort_auto_mappings.py
|
||||
doc-builder style src/transformers docs/source --max_len 119 --path_to_docs docs/source
|
||||
|
||||
# this target runs checks on all files and potentially modifies some of them
|
||||
|
||||
style:
|
||||
black $(check_dirs)
|
||||
black --preview $(check_dirs)
|
||||
isort $(check_dirs)
|
||||
${MAKE} autogenerate_code
|
||||
${MAKE} extra_style_checks
|
||||
|
||||
@ -240,6 +240,7 @@ Current number of checkpoints: ** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
|
||||
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BLOOM](https://huggingface.co/docs/transformers/main/model_doc/bloom)** (from BigScience workshop) released by the [BigSicence Workshop](https://bigscience.huggingface.co/).
|
||||
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
|
||||
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
|
||||
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
|
||||
@ -249,6 +250,7 @@ Current number of checkpoints: ** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
|
||||
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
|
||||
1. **[CvT](https://huggingface.co/docs/transformers/main/model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
|
||||
1. **[Data2Vec](https://huggingface.co/docs/transformers/main/model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
|
||||
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
@ -273,11 +275,13 @@ Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
|
||||
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
|
||||
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
|
||||
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
|
||||
1. **[GPT NeoX](https://huggingface.co/docs/transformers/main/model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/main/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/main/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
|
||||
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
|
||||
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
@ -321,6 +325,7 @@ Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
|
||||
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
|
||||
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
|
||||
1. **[TAPEX](https://huggingface.co/docs/transformers/main/model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
|
||||
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/main/model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
|
||||
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
|
||||
@ -221,6 +221,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
|
||||
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BLOOM](https://huggingface.co/docs/transformers/main/model_doc/bloom)** (from BigScience workshop) released by the [BigSicence Workshop](https://bigscience.huggingface.co/).
|
||||
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
|
||||
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
|
||||
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
|
||||
@ -230,6 +231,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/main/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
|
||||
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
|
||||
1. **[CvT](https://huggingface.co/docs/transformers/main/model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
|
||||
1. **[Data2Vec](https://huggingface.co/docs/transformers/main/model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
|
||||
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
@ -250,6 +252,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/main/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
|
||||
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
|
||||
1. **[GPT NeoX](https://huggingface.co/docs/transformers/main/model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
|
||||
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
|
||||
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
|
||||
@ -257,6 +260,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/main/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/main/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
|
||||
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
|
||||
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
@ -300,6 +304,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
|
||||
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
|
||||
1. **[TAPEX](https://huggingface.co/docs/transformers/main/model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
|
||||
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/main/model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
|
||||
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
|
||||
@ -245,6 +245,7 @@ conda install -c huggingface transformers
|
||||
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (来自 Google Research) 伴随论文 [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) 由 Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed 发布。
|
||||
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (来自 Facebook) 伴随论文 [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) 由 Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston 发布。
|
||||
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (来自 Facebook) 伴随论文 [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) 由 Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston 发布。
|
||||
1. **[BLOOM](https://huggingface.co/docs/transformers/main/model_doc/bloom)** (from BigScience workshop) released by the [BigSicence Workshop](https://bigscience.huggingface.co/).
|
||||
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (来自 Alexa) 伴随论文 [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) 由 Adrian de Wynter and Daniel J. Perry 发布。
|
||||
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (来自 Google Research) 伴随论文 [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) 由 Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel 发布。
|
||||
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (来自 Inria/Facebook/Sorbonne) 伴随论文 [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) 由 Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot 发布。
|
||||
@ -254,6 +255,7 @@ conda install -c huggingface transformers
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/main/model_doc/convnext)** (来自 Facebook AI) 伴随论文 [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) 由 Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie 发布。
|
||||
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (来自 Tsinghua University) 伴随论文 [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) 由 Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun 发布。
|
||||
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (来自 Salesforce) 伴随论文 [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) 由 Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher 发布。
|
||||
1. **[CvT](https://huggingface.co/docs/transformers/main/model_doc/cvt)** (来自 Microsoft) 伴随论文 [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) 由 Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang 发布。
|
||||
1. **[Data2Vec](https://huggingface.co/docs/transformers/main/model_doc/data2vec)** (来自 Facebook) 伴随论文 [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) 由 Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli 发布。
|
||||
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (来自 Microsoft) 伴随论文 [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) 由 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen 发布。
|
||||
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (来自 Microsoft) 伴随论文 [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) 由 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen 发布。
|
||||
@ -274,6 +276,7 @@ conda install -c huggingface transformers
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/main/model_doc/glpn)** (来自 KAIST) 伴随论文 [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) 由 Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim 发布。
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (来自 OpenAI) 伴随论文 [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) 由 Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever 发布。
|
||||
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (来自 EleutherAI) 随仓库 [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) 发布。作者为 Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy 发布。
|
||||
1. **[GPT NeoX](https://huggingface.co/docs/transformers/main/model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
|
||||
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (来自 OpenAI) 伴随论文 [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) 由 Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever** 发布。
|
||||
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (来自 EleutherAI) 伴随论文 [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) 由 Ben Wang and Aran Komatsuzaki 发布。
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (来自 Facebook) 伴随论文 [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) 由 Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed 发布。
|
||||
@ -281,6 +284,7 @@ conda install -c huggingface transformers
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/main/model_doc/imagegpt)** (来自 OpenAI) 伴随论文 [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) 由 Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever 发布。
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) 由 Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou 发布。
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) 由 Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou 发布。
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/main/model_doc/layoutlmv3)** (来自 Microsoft Research Asia) 伴随论文 [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) 由 Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei 发布。
|
||||
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (来自 Microsoft Research Asia) 伴随论文 [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) 由 Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei 发布。
|
||||
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
|
||||
@ -324,6 +328,7 @@ conda install -c huggingface transformers
|
||||
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (来自 Google AI) 伴随论文 [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) 由 Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu 发布。
|
||||
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (来自 Google AI) 伴随论文 [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) 由 Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos 发布。
|
||||
1. **[TAPEX](https://huggingface.co/docs/transformers/main/model_doc/tapex)** (来自 Microsoft Research) 伴随论文 [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) 由 Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou 发布。
|
||||
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/main/model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
|
||||
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (来自 Google/CMU) 伴随论文 [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) 由 Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov 发布。
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (来自 Microsoft) 伴随论文 [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) 由 Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei 发布。
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (来自 Microsoft Research) 伴随论文 [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) 由 Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang 发布。
|
||||
|
||||
@ -257,6 +257,7 @@ conda install -c huggingface transformers
|
||||
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
|
||||
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BLOOM](https://huggingface.co/docs/transformers/main/model_doc/bloom)** (from BigScience workshop) released by the [BigSicence Workshop](https://bigscience.huggingface.co/).
|
||||
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
|
||||
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
|
||||
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
|
||||
@ -266,6 +267,7 @@ conda install -c huggingface transformers
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/main/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
|
||||
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
|
||||
1. **[CvT](https://huggingface.co/docs/transformers/main/model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
|
||||
1. **[Data2Vec](https://huggingface.co/docs/transformers/main/model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
|
||||
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
@ -286,6 +288,7 @@ conda install -c huggingface transformers
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/main/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
|
||||
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
|
||||
1. **[GPT NeoX](https://huggingface.co/docs/transformers/main/model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
|
||||
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
|
||||
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (from EleutherAI) released with the paper [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
|
||||
@ -293,6 +296,7 @@ conda install -c huggingface transformers
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/main/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/main/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
|
||||
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
|
||||
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
@ -336,6 +340,7 @@ conda install -c huggingface transformers
|
||||
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released with the paper [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
|
||||
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
|
||||
1. **[TAPEX](https://huggingface.co/docs/transformers/main/model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
|
||||
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/main/model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
|
||||
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft) released with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
|
||||
@ -17,6 +17,8 @@ RUN python3 -m pip install --no-cache-dir torch-scatter -f https://data.pyg.org/
|
||||
RUN python3 -m pip install --no-cache-dir git+https://github.com/facebookresearch/detectron2.git pytesseract https://github.com/kpu/kenlm/archive/master.zip
|
||||
RUN python3 -m pip install -U "itsdangerous<2.1.0"
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
|
||||
|
||||
# When installing in editable mode, `transformers` is not recognized as a package.
|
||||
# this line must be added in order for python to be aware of transformers.
|
||||
RUN cd transformers && python3 setup.py develop
|
||||
|
||||
@ -407,4 +407,4 @@ Here are a few tips to help you debug the doctests and make them pass:
|
||||
* whitespace: one give whitespace (space, tabulation, new line) is equivalent to any number of whitespace, so you can add new lines where there are spaces to make your output more readable.
|
||||
* numerical values: you should never put more than 4 or 5 digits to expected results as different setups or library versions might get you slightly different results. `doctest` is configure to ignore any difference lower than the precision to which you wrote (so 1e-4 if you write 4 digits).
|
||||
- Don't leave a block of code that is very long to execute. If you can't make it fast, you can either not use the doctest syntax on it (so that it's ignored), or if you want to use the doctest syntax to show the results, you can add a comment `# doctest: +SKIP` at the end of the lines of code too long to execute
|
||||
- Each line of code that produces a result needs to have that result written below. You can ignore an output if you don't want to show it in your code example by adding a comment ` # doctest: +IGNORE_RESULT` at the end of the line of code produing it.
|
||||
- Each line of code that produces a result needs to have that result written below. You can ignore an output if you don't want to show it in your code example by adding a comment ` # doctest: +IGNORE_RESULT` at the end of the line of code producing it.
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
- sections:
|
||||
- sections:
|
||||
- local: index
|
||||
title: 🤗 Transformers
|
||||
- local: quicktour
|
||||
@ -60,11 +60,9 @@
|
||||
- local: serialization
|
||||
title: Export 🤗 Transformers models
|
||||
- local: performance
|
||||
title: 'Performance and Scalability: How To Fit a Bigger Model and Train It Faster'
|
||||
title: Performance and scalability
|
||||
- local: big_models
|
||||
title: Instantiating a big model
|
||||
- local: parallelism
|
||||
title: Model Parallelism
|
||||
- local: benchmarks
|
||||
title: Benchmarks
|
||||
- local: migration
|
||||
@ -83,6 +81,12 @@
|
||||
title: "How to add a model to 🤗 Transformers?"
|
||||
- local: add_new_pipeline
|
||||
title: "How to add a pipeline to 🤗 Transformers?"
|
||||
- local: perf_train_gpu_one
|
||||
title: Training on one GPU
|
||||
- local: perf_train_gpu_many
|
||||
title: Training on many GPUs
|
||||
- local: perf_hardware
|
||||
title: Custom hardware for training
|
||||
- local: testing
|
||||
title: Testing
|
||||
- local: pr_checks
|
||||
@ -170,6 +174,8 @@
|
||||
title: Blenderbot
|
||||
- local: model_doc/blenderbot-small
|
||||
title: Blenderbot Small
|
||||
- local: model_doc/bloom
|
||||
title: BLOOM
|
||||
- local: model_doc/bort
|
||||
title: BORT
|
||||
- local: model_doc/byt5
|
||||
@ -188,6 +194,8 @@
|
||||
title: CPM
|
||||
- local: model_doc/ctrl
|
||||
title: CTRL
|
||||
- local: model_doc/cvt
|
||||
title: CvT
|
||||
- local: model_doc/data2vec
|
||||
title: Data2Vec
|
||||
- local: model_doc/deberta
|
||||
@ -236,6 +244,8 @@
|
||||
title: LayoutLM
|
||||
- local: model_doc/layoutlmv2
|
||||
title: LayoutLMV2
|
||||
- local: model_doc/layoutlmv3
|
||||
title: LayoutLMV3
|
||||
- local: model_doc/layoutxlm
|
||||
title: LayoutXLM
|
||||
- local: model_doc/led
|
||||
@ -278,6 +288,8 @@
|
||||
title: GPT-J
|
||||
- local: model_doc/gpt_neo
|
||||
title: GPT Neo
|
||||
- local: model_doc/gpt_neox
|
||||
title: GPT NeoX
|
||||
- local: model_doc/hubert
|
||||
title: Hubert
|
||||
- local: model_doc/perceiver
|
||||
@ -338,6 +350,8 @@
|
||||
title: TAPAS
|
||||
- local: model_doc/tapex
|
||||
title: TAPEX
|
||||
- local: model_doc/trajectory_transformer
|
||||
title: Trajectory Transformer
|
||||
- local: model_doc/transfo-xl
|
||||
title: Transformer XL
|
||||
- local: model_doc/trocr
|
||||
@ -362,6 +376,8 @@
|
||||
title: VisualBERT
|
||||
- local: model_doc/wav2vec2
|
||||
title: Wav2Vec2
|
||||
- local: model_doc/wav2vec2-conformer
|
||||
title: Wav2Vec2-Conformer
|
||||
- local: model_doc/wav2vec2_phoneme
|
||||
title: Wav2Vec2Phoneme
|
||||
- local: model_doc/wavlm
|
||||
|
||||
@ -63,6 +63,7 @@ The library currently contains JAX, PyTorch and TensorFlow implementations, pret
|
||||
1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
|
||||
1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigSicence Workshop](https://bigscience.huggingface.co/).
|
||||
1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
|
||||
1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
|
||||
1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
|
||||
@ -72,6 +73,7 @@ The library currently contains JAX, PyTorch and TensorFlow implementations, pret
|
||||
1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
|
||||
1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
|
||||
1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
|
||||
1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
|
||||
1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
@ -94,11 +96,13 @@ The library currently contains JAX, PyTorch and TensorFlow implementations, pret
|
||||
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
|
||||
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
|
||||
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
|
||||
1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
|
||||
1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
|
||||
1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
|
||||
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
|
||||
1. **[LayoutXLM](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
|
||||
1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
@ -142,6 +146,7 @@ The library currently contains JAX, PyTorch and TensorFlow implementations, pret
|
||||
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
|
||||
1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
|
||||
1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
|
||||
1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
|
||||
1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
|
||||
1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
@ -185,12 +190,14 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| BigBirdPegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
|
||||
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| Canine | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| ConvNext | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| CvT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
@ -211,12 +218,14 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
|
||||
| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
|
||||
| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
|
||||
| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| LayoutLMv3 | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
|
||||
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
|
||||
@ -256,10 +265,10 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
|
||||
| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
|
||||
| Swin | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Swin | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| TAPEX | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
@ -272,6 +281,7 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
|
||||
| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
|
||||
| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
|
||||
| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| XGLM | ✅ | ✅ | ✅ | ❌ | ✅ |
|
||||
| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
|
||||
@ -282,4 +292,4 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
|
||||
|
||||
<!-- End table-->
|
||||
<!-- End table-->
|
||||
@ -40,29 +40,17 @@ Additionally, some `warnings` can be disabled by setting the environment variabl
|
||||
TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
|
||||
```
|
||||
|
||||
Here is an example of how to use `logging` in a module:
|
||||
Here is an example of how to use the same logger as the library in your own module or script:
|
||||
|
||||
```python
|
||||
from transformers.utils import logging
|
||||
|
||||
logging.set_verbosity_info()
|
||||
logger = logging.get_logger(__name__)
|
||||
logger = logging.get_logger("transformers")
|
||||
logger.info("INFO")
|
||||
logger.warning("WARN")
|
||||
```
|
||||
|
||||
Above, a `logger` instance is created from `logging.get_logger(__name__)`. If you want to use `logging` in a script, you shouldn't pass `__name__` to `logging.get_logger`. For example:
|
||||
|
||||
```python
|
||||
from transformers.utils import logging
|
||||
|
||||
if __name__ == "__main__":
|
||||
logging.set_verbosity_info()
|
||||
# leave it empy or use a string
|
||||
logger = logging.get_logger()
|
||||
logger.info("INFO")
|
||||
logger.warning("WARN")
|
||||
```
|
||||
|
||||
All the methods of this logging module are documented below, the main ones are
|
||||
[`logging.get_verbosity`] to get the current level of verbosity in the logger and
|
||||
|
||||
@ -38,6 +38,75 @@ for text generation, [`~generation_utils.GenerationMixin`] (for the PyTorch mode
|
||||
|
||||
<a id='from_pretrained-torch-dtype'></a>
|
||||
|
||||
### Large model loading
|
||||
|
||||
In Transformers 4.20.0, the [`~PreTrainedModel.from_pretrained`] method has been reworked to accommodate large models using [Accelerate](https://huggingface.co/docs/accelerate/big_modeling). This requires Accelerate >= 0.9.0 and PyTorch >= 1.9.0. Instead of creating the full model, then loading the pretrained weights inside it (which takes twice the size of the model in RAM, one for the randomly initialized model, one for the weights), there is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded.
|
||||
|
||||
This option can be activated with `low_cpu_mem_usage=True`. The model is first created on the Meta device (with empty weights) and the state dict is then loaded inside it (shard by shard in the case of a sharded checkpoint). This way the maximum RAM used is the full size of the model only.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForSeq2SeqLM
|
||||
|
||||
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", low_cpu_mem_usage=True)
|
||||
```
|
||||
|
||||
Moreover, you can directly place the model on different devices if it doesn't fully fit in RAM (only works for inference for now). With `device_map="auto"`, Accelerate will determine where to put each layer to maximize the use of your fastest devices (GPUs) and offload the rest on the CPU, or even the hard drive if you don't have enough GPU RAM (or CPU RAM). Even if the model is split across several devices, it will run as you would normally expect.
|
||||
|
||||
When passing a `device_map`, `low_cpu_mem_usage` is automatically set to `True`, so you don't need to specify it:
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForSeq2SeqLM
|
||||
|
||||
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
|
||||
```
|
||||
|
||||
You can inspect how the model was split across devices by looking at its `hf_device_map` attribute:
|
||||
|
||||
```py
|
||||
t0pp.hf_device_map
|
||||
```
|
||||
|
||||
```python out
|
||||
{'shared': 0,
|
||||
'decoder.embed_tokens': 0,
|
||||
'encoder': 0,
|
||||
'decoder.block.0': 0,
|
||||
'decoder.block.1': 1,
|
||||
'decoder.block.2': 1,
|
||||
'decoder.block.3': 1,
|
||||
'decoder.block.4': 1,
|
||||
'decoder.block.5': 1,
|
||||
'decoder.block.6': 1,
|
||||
'decoder.block.7': 1,
|
||||
'decoder.block.8': 1,
|
||||
'decoder.block.9': 1,
|
||||
'decoder.block.10': 1,
|
||||
'decoder.block.11': 1,
|
||||
'decoder.block.12': 1,
|
||||
'decoder.block.13': 1,
|
||||
'decoder.block.14': 1,
|
||||
'decoder.block.15': 1,
|
||||
'decoder.block.16': 1,
|
||||
'decoder.block.17': 1,
|
||||
'decoder.block.18': 1,
|
||||
'decoder.block.19': 1,
|
||||
'decoder.block.20': 1,
|
||||
'decoder.block.21': 1,
|
||||
'decoder.block.22': 'cpu',
|
||||
'decoder.block.23': 'cpu',
|
||||
'decoder.final_layer_norm': 'cpu',
|
||||
'decoder.dropout': 'cpu',
|
||||
'lm_head': 'cpu'}
|
||||
```
|
||||
|
||||
You can also write your own device map following the same format (a dictionary layer name to device). It should map all parameters of the model to a given device, but you don't have to detail where all the submosules of one layer go if that layer is entirely on the same device. For instance, the following device map would work properly for T0pp (as long as you have the GPU memory):
|
||||
|
||||
```python
|
||||
device_map = {"shared": 0, "encoder": 0, "decoder": 1, "lm_head": 1}
|
||||
```
|
||||
|
||||
Another way to minimize the memory impact of your model is to instantiate it at a lower precision dtype (like `torch.float16`).
|
||||
|
||||
### Model Instantiation dtype
|
||||
|
||||
Under Pytorch a model normally gets instantiated with `torch.float32` format. This can be an issue if one tries to
|
||||
|
||||
@ -136,6 +136,30 @@ documented on their corresponding model page.
|
||||
|
||||
[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
|
||||
|
||||
## SemanticSegmenterOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.SemanticSegmenterOutput
|
||||
|
||||
## ImageClassifierOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.ImageClassifierOutput
|
||||
|
||||
## ImageClassifierOutputWithNoAttention
|
||||
|
||||
[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
|
||||
|
||||
## DepthEstimatorOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.DepthEstimatorOutput
|
||||
|
||||
## Wav2Vec2BaseModelOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
|
||||
|
||||
## XVectorOutput
|
||||
|
||||
[[autodoc]] modeling_outputs.XVectorOutput
|
||||
|
||||
## TFBaseModelOutput
|
||||
|
||||
[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
|
||||
|
||||
47
docs/source/en/model_doc/bloom.mdx
Normal file
47
docs/source/en/model_doc/bloom.mdx
Normal file
@ -0,0 +1,47 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# BLOOM
|
||||
|
||||
## Overview
|
||||
|
||||
Bloom model has been proposed with its various versions through the [BigScience Workshop](https://bigscience.huggingface.co/). BigScience is inspired by other open science initiatives where researchers have pooled their time and resources to collectively achieve a higher impact.
|
||||
The architecture of Bloom is essentially similar to GPT3 (auto-regressive model for next token prediction), but has been trained on different 46 languages including code.
|
||||
Several smaller versions of the models have been trained on the same dataset. Bloom is available in the following version:
|
||||
|
||||
- 350M parameters
|
||||
- 760M parameters
|
||||
- 1.3B parameters
|
||||
- 2.5B parameters
|
||||
- 6.3B parameters
|
||||
- 175B parameters
|
||||
|
||||
|
||||
## BloomConfig
|
||||
|
||||
[[autodoc]] BloomConfig
|
||||
- all
|
||||
|
||||
## BloomModel
|
||||
|
||||
[[autodoc]] BloomModel
|
||||
- forward
|
||||
|
||||
## BloomTokenizerFast
|
||||
|
||||
[[autodoc]] BloomTokenizerFast
|
||||
- all
|
||||
|
||||
## BloomForCausalLM
|
||||
|
||||
[[autodoc]] BloomForCausalLM
|
||||
- forward
|
||||
53
docs/source/en/model_doc/cvt.mdx
Normal file
53
docs/source/en/model_doc/cvt.mdx
Normal file
@ -0,0 +1,53 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Convolutional Vision Transformer (CvT)
|
||||
|
||||
## Overview
|
||||
|
||||
The CvT model was proposed in [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan and Lei Zhang. The Convolutional vision Transformer (CvT) improves the [Vision Transformer (ViT)](vit) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*We present in this paper a new architecture, named Convolutional vision Transformer (CvT), that improves Vision Transformer (ViT)
|
||||
in performance and efficiency by introducing convolutions into ViT to yield the best of both designs. This is accomplished through
|
||||
two primary modifications: a hierarchy of Transformers containing a new convolutional token embedding, and a convolutional Transformer
|
||||
block leveraging a convolutional projection. These changes introduce desirable properties of convolutional neural networks (CNNs)
|
||||
to the ViT architecture (\ie shift, scale, and distortion invariance) while maintaining the merits of Transformers (\ie dynamic attention,
|
||||
global context, and better generalization). We validate CvT by conducting extensive experiments, showing that this approach achieves
|
||||
state-of-the-art performance over other Vision Transformers and ResNets on ImageNet-1k, with fewer parameters and lower FLOPs. In addition,
|
||||
performance gains are maintained when pretrained on larger datasets (\eg ImageNet-22k) and fine-tuned to downstream tasks. Pre-trained on
|
||||
ImageNet-22k, our CvT-W24 obtains a top-1 accuracy of 87.7\% on the ImageNet-1k val set. Finally, our results show that the positional encoding,
|
||||
a crucial component in existing Vision Transformers, can be safely removed in our model, simplifying the design for higher resolution vision tasks.*
|
||||
|
||||
Tips:
|
||||
|
||||
- CvT models are regular Vision Transformers, but trained with convolutions. They outperform the [original model (ViT)](vit) when fine-tuned on ImageNet-1K and CIFAR-100.
|
||||
- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace [`ViTFeatureExtractor`] by [`AutoFeatureExtractor`] and [`ViTForImageClassification`] by [`CvtForImageClassification`]).
|
||||
- The available checkpoints are either (1) pre-trained on [ImageNet-22k](http://www.image-net.org/) (a collection of 14 million images and 22k classes) only, (2) also fine-tuned on ImageNet-22k or (3) also fine-tuned on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
|
||||
images and 1,000 classes).
|
||||
|
||||
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/microsoft/CvT).
|
||||
|
||||
## CvtConfig
|
||||
|
||||
[[autodoc]] CvtConfig
|
||||
|
||||
## CvtModel
|
||||
|
||||
[[autodoc]] CvtModel
|
||||
- forward
|
||||
|
||||
## CvtForImageClassification
|
||||
|
||||
[[autodoc]] CvtForImageClassification
|
||||
- forward
|
||||
@ -37,6 +37,9 @@ Tips:
|
||||
- For Data2VecAudio, preprocessing is identical to [`Wav2Vec2Model`], including feature extraction
|
||||
- For Data2VecText, preprocessing is identical to [`RobertaModel`], including tokenization.
|
||||
- For Data2VecVision, preprocessing is identical to [`BeitModel`], including feature extraction.
|
||||
- To know how a pre-trained Data2Vec vision model can be fine-tuned on the task of image classification, you can check out
|
||||
[this notebook](https://colab.research.google.com/github/sayakpaul/TF-2.0-Hacks/blob/master/data2vec_vision_image_classification.ipynb).
|
||||
|
||||
|
||||
This model was contributed by [edugp](https://huggingface.co/edugp) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
|
||||
[sayakpaul](https://github.com/sayakpaul) contributed Data2Vec for vision in TensorFlow.
|
||||
@ -141,4 +144,4 @@ The original code for vision can be found [here](https://github.com/facebookrese
|
||||
## TFData2VecVisionForImageClassification
|
||||
|
||||
[[autodoc]] TFData2VecVisionForImageClassification
|
||||
- call
|
||||
- call
|
||||
|
||||
76
docs/source/en/model_doc/gpt_neox.mdx
Normal file
76
docs/source/en/model_doc/gpt_neox.mdx
Normal file
@ -0,0 +1,76 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# GPT-NeoX
|
||||
|
||||
## Overview
|
||||
|
||||
We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will
|
||||
be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge,
|
||||
the largest dense autoregressive model that has publicly available weights at the time of submission. In this work,
|
||||
we describe GPT-NeoX-20B's architecture and training and evaluate its performance on a range of language-understanding,
|
||||
mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and
|
||||
gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source
|
||||
the training and evaluation code, as well as the model weights, at [https://github.com/EleutherAI/gpt-neox](https://github.com/EleutherAI/gpt-neox).
|
||||
|
||||
Development of the model was led by Sid Black, Stella Biderman and Eric Hallahan, and the model was trained with
|
||||
generous the support of [CoreWeave](https://www.coreweave.com/).
|
||||
|
||||
GPT-NeoX-20B was trained with fp16, thus it is recommended to initialize the model as follows:
|
||||
|
||||
```python
|
||||
model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b").half().cuda()
|
||||
```
|
||||
|
||||
GPT-NeoX-20B also has a different tokenizer from the one used in GPT-J-6B and GPT-Neo. The new tokenizer allocates
|
||||
additional tokens to whitespace characters, making the model more suitable for certain tasks like code generation.
|
||||
|
||||
### Generation
|
||||
|
||||
The `generate()` method can be used to generate text using GPT Neo model.
|
||||
|
||||
```python
|
||||
>>> from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
|
||||
|
||||
>>> model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b")
|
||||
>>> tokenizer = GPTNeoXTokenizerFast.from_pretrained("EleutherAI/gpt-neox-20b")
|
||||
|
||||
>>> prompt = "GPTNeoX20B is a 20B-parameter autoregressive Transformer model developed by EleutherAI."
|
||||
|
||||
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
|
||||
|
||||
>>> gen_tokens = model.generate(
|
||||
... input_ids,
|
||||
... do_sample=True,
|
||||
... temperature=0.9,
|
||||
... max_length=100,
|
||||
... )
|
||||
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
|
||||
```
|
||||
|
||||
## GPTNeoXConfig
|
||||
|
||||
[[autodoc]] GPTNeoXConfig
|
||||
|
||||
## GPTNeoXTokenizerFast
|
||||
|
||||
[[autodoc]] GPTNeoXTokenizerFast
|
||||
|
||||
## GPTNeoXModel
|
||||
|
||||
[[autodoc]] GPTNeoXModel
|
||||
- forward
|
||||
|
||||
## GPTNeoXForCausalLM
|
||||
|
||||
[[autodoc]] GPTNeoXForCausalLM
|
||||
- forward
|
||||
@ -44,6 +44,14 @@ including FUNSD (0.7895 -> 0.8420), CORD (0.9493 -> 0.9601), SROIE (0.9524 -> 0.
|
||||
RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672). The pre-trained LayoutLMv2 model is publicly available at
|
||||
this https URL.*
|
||||
|
||||
LayoutLMv2 depends on `detectron2`, `torchvision` and `tesseract`. Run the
|
||||
following to install them:
|
||||
```
|
||||
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
|
||||
python -m pip install torchvision tesseract
|
||||
```
|
||||
(If you are developing for LayoutLMv2, note that passing the doctests also requires the installation of these packages.)
|
||||
|
||||
Tips:
|
||||
|
||||
- The main difference between LayoutLMv1 and LayoutLMv2 is that the latter incorporates visual embeddings during
|
||||
|
||||
85
docs/source/en/model_doc/layoutlmv3.mdx
Normal file
85
docs/source/en/model_doc/layoutlmv3.mdx
Normal file
@ -0,0 +1,85 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# LayoutLMv3
|
||||
|
||||
## Overview
|
||||
|
||||
The LayoutLMv3 model was proposed in [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
|
||||
LayoutLMv3 simplifies [LayoutLMv2](layoutlmv2) by using patch embeddings (as in [ViT](vit)) instead of leveraging a CNN backbone, and pre-trains the model on 3 objectives: masked language modeling (MLM), masked image modeling (MIM)
|
||||
and word-patch alignment (WPA).
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*Self-supervised pre-training techniques have achieved remarkable progress in Document AI. Most multimodal pre-trained models use a masked language modeling objective to learn bidirectional representations on the text modality, but they differ in pre-training objectives for the image modality. This discrepancy adds difficulty to multimodal representation learning. In this paper, we propose LayoutLMv3 to pre-train multimodal Transformers for Document AI with unified text and image masking. Additionally, LayoutLMv3 is pre-trained with a word-patch alignment objective to learn cross-modal alignment by predicting whether the corresponding image patch of a text word is masked. The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model for both text-centric and image-centric Document AI tasks. Experimental results show that LayoutLMv3 achieves state-of-the-art performance not only in text-centric tasks, including form understanding, receipt understanding, and document visual question answering, but also in image-centric tasks such as document image classification and document layout analysis.*
|
||||
|
||||
Tips:
|
||||
|
||||
- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
|
||||
- images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
|
||||
- text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
|
||||
Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3FeatureExtractor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
|
||||
- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-LayoutLMv2Processor) of its predecessor.
|
||||
- Demo notebooks for LayoutLMv3 can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv3).
|
||||
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/layoutlmv3_architecture.png"
|
||||
alt="drawing" width="600"/>
|
||||
|
||||
<small> LayoutLMv3 architecture. Taken from the <a href="https://arxiv.org/abs/2204.08387">original paper</a>. </small>
|
||||
|
||||
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
|
||||
|
||||
|
||||
## LayoutLMv3Config
|
||||
|
||||
[[autodoc]] LayoutLMv3Config
|
||||
|
||||
## LayoutLMv3FeatureExtractor
|
||||
|
||||
[[autodoc]] LayoutLMv3FeatureExtractor
|
||||
- __call__
|
||||
|
||||
## LayoutLMv3Tokenizer
|
||||
|
||||
[[autodoc]] LayoutLMv3Tokenizer
|
||||
- __call__
|
||||
- save_vocabulary
|
||||
|
||||
## LayoutLMv3TokenizerFast
|
||||
|
||||
[[autodoc]] LayoutLMv3TokenizerFast
|
||||
- __call__
|
||||
|
||||
## LayoutLMv3Processor
|
||||
|
||||
[[autodoc]] LayoutLMv3Processor
|
||||
- __call__
|
||||
|
||||
## LayoutLMv3Model
|
||||
|
||||
[[autodoc]] LayoutLMv3Model
|
||||
- forward
|
||||
|
||||
## LayoutLMv3ForSequenceClassification
|
||||
|
||||
[[autodoc]] LayoutLMv3ForSequenceClassification
|
||||
- forward
|
||||
|
||||
## LayoutLMv3ForTokenClassification
|
||||
|
||||
[[autodoc]] LayoutLMv3ForTokenClassification
|
||||
- forward
|
||||
|
||||
## LayoutLMv3ForQuestionAnswering
|
||||
|
||||
[[autodoc]] LayoutLMv3ForQuestionAnswering
|
||||
- forward
|
||||
@ -44,8 +44,10 @@ Tips:
|
||||
- LED makes use of *global attention* by means of the `global_attention_mask` (see
|
||||
[`LongformerModel`]). For summarization, it is advised to put *global attention* only on the first
|
||||
`<s>` token. For question answering, it is advised to put *global attention* on all tokens of the question.
|
||||
- To fine-tune LED on all 16384, it is necessary to enable *gradient checkpointing* by executing
|
||||
`model.gradient_checkpointing_enable()`.
|
||||
- To fine-tune LED on all 16384, *gradient checkpointing* can be enabled in case training leads to out-of-memory (OOM)
|
||||
errors. This can be done by executing `model.gradient_checkpointing_enable()`.
|
||||
Moreover, the `use_cache=False`
|
||||
flag can be used to disable the caching mechanism to save memory.
|
||||
- A notebook showing how to evaluate LED, can be accessed [here](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing).
|
||||
- A notebook showing how to fine-tune LED, can be accessed [here](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing).
|
||||
|
||||
|
||||
@ -72,3 +72,8 @@ This model was contributed by [yuvalkirstain](https://huggingface.co/yuvalkirsta
|
||||
|
||||
[[autodoc]] SplinterForQuestionAnswering
|
||||
- forward
|
||||
|
||||
## SplinterForPreTraining
|
||||
|
||||
[[autodoc]] SplinterForPreTraining
|
||||
- forward
|
||||
|
||||
@ -14,22 +14,22 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
## Overview
|
||||
|
||||
The Swin Transformer was proposed in [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
|
||||
by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
The Swin Transformer was proposed in [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
|
||||
by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone
|
||||
for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains,
|
||||
such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text.
|
||||
To address these differences, we propose a hierarchical Transformer whose representation is computed with \bold{S}hifted
|
||||
\bold{win}dows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping
|
||||
local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at
|
||||
various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it
|
||||
compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense
|
||||
prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation
|
||||
(53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and
|
||||
+2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones.
|
||||
*This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone
|
||||
for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains,
|
||||
such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text.
|
||||
To address these differences, we propose a hierarchical Transformer whose representation is computed with \bold{S}hifted
|
||||
\bold{win}dows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping
|
||||
local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at
|
||||
various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it
|
||||
compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense
|
||||
prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation
|
||||
(53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and
|
||||
+2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones.
|
||||
The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.*
|
||||
|
||||
Tips:
|
||||
@ -38,11 +38,11 @@ Tips:
|
||||
- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
|
||||
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/swin_transformer_architecture.png"
|
||||
alt="drawing" width="600"/>
|
||||
alt="drawing" width="600"/>
|
||||
|
||||
<small> Swin Transformer architecture. Taken from the <a href="https://arxiv.org/abs/2102.03334">original paper</a>.</small>
|
||||
|
||||
This model was contributed by [novice03](https://huggingface.co/novice03>). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
|
||||
This model was contributed by [novice03](https://huggingface.co/novice03>). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
|
||||
|
||||
|
||||
## SwinConfig
|
||||
@ -63,4 +63,19 @@ This model was contributed by [novice03](https://huggingface.co/novice03>). The
|
||||
## SwinForImageClassification
|
||||
|
||||
[[autodoc]] transformers.SwinForImageClassification
|
||||
- forward
|
||||
- forward
|
||||
|
||||
## TFSwinModel
|
||||
|
||||
[[autodoc]] TFSwinModel
|
||||
- call
|
||||
|
||||
## TFSwinForMaskedImageModeling
|
||||
|
||||
[[autodoc]] TFSwinForMaskedImageModeling
|
||||
- call
|
||||
|
||||
## TFSwinForImageClassification
|
||||
|
||||
[[autodoc]] transformers.TFSwinForImageClassification
|
||||
- call
|
||||
|
||||
49
docs/source/en/model_doc/trajectory_transformer.mdx
Normal file
49
docs/source/en/model_doc/trajectory_transformer.mdx
Normal file
@ -0,0 +1,49 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Trajectory Transformer
|
||||
|
||||
## Overview
|
||||
|
||||
The Trajectory Transformer model was proposed in [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*Reinforcement learning (RL) is typically concerned with estimating stationary policies or single-step models,
|
||||
leveraging the Markov property to factorize problems in time. However, we can also view RL as a generic sequence
|
||||
modeling problem, with the goal being to produce a sequence of actions that leads to a sequence of high rewards.
|
||||
Viewed in this way, it is tempting to consider whether high-capacity sequence prediction models that work well
|
||||
in other domains, such as natural-language processing, can also provide effective solutions to the RL problem.
|
||||
To this end, we explore how RL can be tackled with the tools of sequence modeling, using a Transformer architecture
|
||||
to model distributions over trajectories and repurposing beam search as a planning algorithm. Framing RL as sequence
|
||||
modeling problem simplifies a range of design decisions, allowing us to dispense with many of the components common
|
||||
in offline RL algorithms. We demonstrate the flexibility of this approach across long-horizon dynamics prediction,
|
||||
imitation learning, goal-conditioned RL, and offline RL. Further, we show that this approach can be combined with
|
||||
existing model-free algorithms to yield a state-of-the-art planner in sparse-reward, long-horizon tasks.*
|
||||
|
||||
Tips:
|
||||
|
||||
This Transformer is used for deep reinforcement learning. To use it, you need to create sequences from
|
||||
actions, states and rewards from all previous timesteps. This model will treat all these elements together
|
||||
as one big sequence (a trajectory).
|
||||
|
||||
This model was contributed by [CarlCochet](https://huggingface.co/CarlCochet). The original code can be found [here](https://github.com/jannerm/trajectory-transformer).
|
||||
|
||||
## TrajectoryTransformerConfig
|
||||
|
||||
[[autodoc]] TrajectoryTransformerConfig
|
||||
|
||||
|
||||
## TrajectoryTransformerModel
|
||||
|
||||
[[autodoc]] TrajectoryTransformerModel
|
||||
- forward
|
||||
@ -51,8 +51,6 @@ found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
|
||||
|
||||
## UniSpeechSat specific outputs
|
||||
|
||||
[[autodoc]] models.unispeech_sat.modeling_unispeech_sat.UniSpeechSatBaseModelOutput
|
||||
|
||||
[[autodoc]] models.unispeech_sat.modeling_unispeech_sat.UniSpeechSatForPreTrainingOutput
|
||||
|
||||
## UniSpeechSatModel
|
||||
|
||||
@ -46,8 +46,6 @@ found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech).
|
||||
|
||||
## UniSpeech specific outputs
|
||||
|
||||
[[autodoc]] models.unispeech.modeling_unispeech.UniSpeechBaseModelOutput
|
||||
|
||||
[[autodoc]] models.unispeech.modeling_unispeech.UniSpeechForPreTrainingOutput
|
||||
|
||||
## UniSpeechModel
|
||||
|
||||
67
docs/source/en/model_doc/wav2vec2-conformer.mdx
Normal file
67
docs/source/en/model_doc/wav2vec2-conformer.mdx
Normal file
@ -0,0 +1,67 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Wav2Vec2-Conformer
|
||||
|
||||
## Overview
|
||||
|
||||
The Wav2Vec2-Conformer weights were released by the Meta AI team within the [Fairseq library](https://github.com/pytorch/fairseq/blob/main/examples/wav2vec/README.md#pre-trained-models).
|
||||
|
||||
Tips:
|
||||
|
||||
- Wav2Vec2-Conformer follows the same architecture as Wav2Vec2, but replaces the *Attention*-block with a *Conformer*-block
|
||||
as introduced in [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100).
|
||||
- Wav2Vec2-Conformer uses the same tokenizer and feature extractor as Wav2Vec2.
|
||||
- Wav2Vec2-Conformer can use either no relative position embeddings, Transformer-XL-like position embeddings, or
|
||||
rotary position embeddings by setting the correct `config.position_embeddings_type`.
|
||||
|
||||
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
|
||||
The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec).
|
||||
|
||||
|
||||
## Wav2Vec2ConformerConfig
|
||||
|
||||
[[autodoc]] Wav2Vec2ConformerConfig
|
||||
|
||||
## Wav2Vec2Conformer specific outputs
|
||||
|
||||
[[autodoc]] models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForPreTrainingOutput
|
||||
|
||||
## Wav2Vec2ConformerModel
|
||||
|
||||
[[autodoc]] Wav2Vec2ConformerModel
|
||||
- forward
|
||||
|
||||
## Wav2Vec2ConformerForCTC
|
||||
|
||||
[[autodoc]] Wav2Vec2ConformerForCTC
|
||||
- forward
|
||||
|
||||
## Wav2Vec2ConformerForSequenceClassification
|
||||
|
||||
[[autodoc]] Wav2Vec2ConformerForSequenceClassification
|
||||
- forward
|
||||
|
||||
## Wav2Vec2ConformerForAudioFrameClassification
|
||||
|
||||
[[autodoc]] Wav2Vec2ConformerForAudioFrameClassification
|
||||
- forward
|
||||
|
||||
## Wav2Vec2ConformerForXVector
|
||||
|
||||
[[autodoc]] Wav2Vec2ConformerForXVector
|
||||
- forward
|
||||
|
||||
## Wav2Vec2ConformerForPreTraining
|
||||
|
||||
[[autodoc]] Wav2Vec2ConformerForPreTraining
|
||||
- forward
|
||||
@ -49,10 +49,6 @@ found [here](https://github.com/microsoft/unilm/tree/master/wavlm).
|
||||
|
||||
[[autodoc]] WavLMConfig
|
||||
|
||||
## WavLM specific outputs
|
||||
|
||||
[[autodoc]] models.wavlm.modeling_wavlm.WavLMBaseModelOutput
|
||||
|
||||
## WavLMModel
|
||||
|
||||
[[autodoc]] WavLMModel
|
||||
|
||||
150
docs/source/en/perf_hardware.mdx
Normal file
150
docs/source/en/perf_hardware.mdx
Normal file
@ -0,0 +1,150 @@
|
||||
<!---
|
||||
Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
|
||||
|
||||
# Custom hardware for training
|
||||
|
||||
The hardware you use to run model training and inference can have a big effect on performance. For a deep dive into GPUs make sure to check out Tim Dettmer's excellent [blog post](https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/).
|
||||
|
||||
Let's have a look at some practical advice for GPU setups.
|
||||
|
||||
## GPU
|
||||
When you train bigger models you have essentially three options:
|
||||
- bigger GPUs
|
||||
- more GPUs
|
||||
- more CPU and NVMe (offloaded to by [DeepSpeed-Infinity](main_classes/deepspeed#nvme-support))
|
||||
|
||||
Let's start at the case where you have a single GPU.
|
||||
|
||||
### Power and Cooling
|
||||
|
||||
If you bought an expensive high end GPU make sure you give it the correct power and sufficient cooling.
|
||||
|
||||
**Power**:
|
||||
|
||||
Some high end consumer GPU cards have 2 and sometimes 3 PCI-E 8-Pin power sockets. Make sure you have as many independent 12V PCI-E 8-Pin cables plugged into the card as there are sockets. Do not use the 2 splits at one end of the same cable (also known as pigtail cable). That is if you have 2 sockets on the GPU, you want 2 PCI-E 8-Pin cables going from your PSU to the card and not one that has 2 PCI-E 8-Pin connectors at the end! You won't get the full performance out of your card otherwise.
|
||||
|
||||
Each PCI-E 8-Pin power cable needs to be plugged into a 12V rail on the PSU side and can supply up to 150W of power.
|
||||
|
||||
Some other cards may use a PCI-E 12-Pin connectors, and these can deliver up to 500-600W of power.
|
||||
|
||||
Low end cards may use 6-Pin connectors, which supply up to 75W of power.
|
||||
|
||||
Additionally you want the high-end PSU that has stable voltage. Some lower quality ones may not give the card the stable voltage it needs to function at its peak.
|
||||
|
||||
And of course the PSU needs to have enough unused Watts to power the card.
|
||||
|
||||
**Cooling**:
|
||||
|
||||
When a GPU gets overheated it will start throttling down and will not deliver full performance and it can even shutdown if it gets too hot.
|
||||
|
||||
It's hard to tell the exact best temperature to strive for when a GPU is heavily loaded, but probably anything under +80C is good, but lower is better - perhaps 70-75C is an excellent range to be in. The throttling down is likely to start at around 84-90C. But other than throttling performance a prolonged very high temperature is likely to reduce the lifespan of a GPU.
|
||||
|
||||
Next let's have a look at one of the most important aspects when having multiple GPUs: connectivity.
|
||||
|
||||
### Multi-GPU Connectivity
|
||||
|
||||
If you use multiple GPUs the way cards are inter-connected can have a huge impact on the total training time. If the GPUs are on the same physical node, you can run:
|
||||
|
||||
```
|
||||
nvidia-smi topo -m
|
||||
```
|
||||
|
||||
and it will tell you how the GPUs are inter-connected. On a machine with dual-GPU and which are connected with NVLink, you will most likely see something like:
|
||||
|
||||
```
|
||||
GPU0 GPU1 CPU Affinity NUMA Affinity
|
||||
GPU0 X NV2 0-23 N/A
|
||||
GPU1 NV2 X 0-23 N/A
|
||||
```
|
||||
|
||||
on a different machine w/o NVLink we may see:
|
||||
```
|
||||
GPU0 GPU1 CPU Affinity NUMA Affinity
|
||||
GPU0 X PHB 0-11 N/A
|
||||
GPU1 PHB X 0-11 N/A
|
||||
```
|
||||
|
||||
The report includes this legend:
|
||||
|
||||
```
|
||||
X = Self
|
||||
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
|
||||
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
|
||||
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
|
||||
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
|
||||
PIX = Connection traversing at most a single PCIe bridge
|
||||
NV# = Connection traversing a bonded set of # NVLinks
|
||||
```
|
||||
|
||||
So the first report `NV2` tells us the GPUs are interconnected with 2 NVLinks, and the second report `PHB` we have a typical consumer-level PCIe+Bridge setup.
|
||||
|
||||
Check what type of connectivity you have on your setup. Some of these will make the communication between cards faster (e.g. NVLink), others slower (e.g. PHB).
|
||||
|
||||
Depending on the type of scalability solution used, the connectivity speed could have a major or a minor impact. If the GPUs need to sync rarely, as in DDP, the impact of a slower connection will be less significant. If the GPUs need to send messages to each other often, as in ZeRO-DP, then faster connectivity becomes super important to achieve faster training.
|
||||
|
||||
#### NVlink
|
||||
|
||||
[NVLink](https://en.wikipedia.org/wiki/NVLink) is a wire-based serial multi-lane near-range communications link developed by Nvidia.
|
||||
|
||||
Each new generation provides a faster bandwidth, e.g. here is a quote from [Nvidia Ampere GA102 GPU Architecture](https://www.nvidia.com/content/dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf):
|
||||
|
||||
> Third-Generation NVLink®
|
||||
> GA102 GPUs utilize NVIDIA’s third-generation NVLink interface, which includes four x4 links,
|
||||
> with each link providing 14.0625 GB/sec bandwidth in each direction between two GPUs. Four
|
||||
> links provide 56.25 GB/sec bandwidth in each direction, and 112.5 GB/sec total bandwidth
|
||||
> between two GPUs. Two RTX 3090 GPUs can be connected together for SLI using NVLink.
|
||||
> (Note that 3-Way and 4-Way SLI configurations are not supported.)
|
||||
|
||||
So the higher `X` you get in the report of `NVX` in the output of `nvidia-smi topo -m` the better. The generation will depend on your GPU architecture.
|
||||
|
||||
Let's compare the execution of a gpt2 language model training over a small sample of wikitext.
|
||||
|
||||
The results are:
|
||||
|
||||
|
||||
| NVlink | Time |
|
||||
| ----- | ---: |
|
||||
| Y | 101s |
|
||||
| N | 131s |
|
||||
|
||||
|
||||
You can see that NVLink completes the training ~23% faster. In the second benchmark we use `NCCL_P2P_DISABLE=1` to tell the GPUs not to use NVLink.
|
||||
|
||||
Here is the full benchmark code and outputs:
|
||||
|
||||
```bash
|
||||
# DDP w/ NVLink
|
||||
|
||||
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch \
|
||||
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
|
||||
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
|
||||
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
|
||||
|
||||
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
|
||||
|
||||
# DDP w/o NVLink
|
||||
|
||||
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 python -m torch.distributed.launch \
|
||||
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
|
||||
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
|
||||
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
|
||||
|
||||
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
|
||||
```
|
||||
|
||||
Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
|
||||
Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
|
||||
@ -1,47 +1,157 @@
|
||||
<!---
|
||||
Copyright 2021 The HuggingFace Team. All rights reserved.
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
-->
|
||||
|
||||
# Model Parallelism
|
||||
# Efficient Training on Multiple GPUs
|
||||
|
||||
|
||||
## Parallelism overview
|
||||
|
||||
In the modern machine learning the various approaches to parallelism are used to:
|
||||
1. fit very large models onto limited hardware - e.g. t5-11b is 45GB in just model params
|
||||
2. significantly speed up training - finish training that would take a year in hours
|
||||
When training on a single GPU is too slow or the model weights don't fit in a single GPUs memory we use a mutli-GPU setup. Switching from a single GPU to multiple requires some form of parallelism as the work needs to be distributed. There are several techniques to achieve parallism such as data, tensor, or pipeline parallism. However, there is no one solution to fit them all and which settings works best depends on the hardware you are running on. While the main concepts most likely will apply to any other framework, this article is focused on PyTorch-based implementations.
|
||||
|
||||
We will first discuss in depth various 1D parallelism techniques and their pros and cons and then look at how they can be combined into 2D and 3D parallelism to enable an even faster training and to support even bigger models. Various other powerful alternative approaches will be presented.
|
||||
|
||||
While the main concepts most likely will apply to any other framework, this article is focused on PyTorch-based implementations.
|
||||
|
||||
|
||||
## Concepts
|
||||
|
||||
The following is the brief description of the main concepts that will be described later in depth in this document.
|
||||
|
||||
1. DataParallel (DP) - the same setup is replicated multiple times, and each being fed a slice of the data. The processing is done in parallel and all setups are synchronized at the end of each training step.
|
||||
2. TensorParallel (TP) - each tensor is split up into multiple chunks, so instead of having the whole tensor reside on a single gpu, each shard of the tensor resides on its designated gpu. During processing each shard gets processed separately and in parallel on different GPUs and the results are synced at the end of the step. This is what one may call horizontal parallelism, as the splitting happens on horizontal level.
|
||||
3. PipelineParallel (PP) - the model is split up vertically (layer-level) across multiple GPUs, so that only one or several layers of the model are places on a single gpu. Each gpu processes in parallel different stages of the pipeline and working on a small chunk of the batch.
|
||||
4. Zero Redundancy Optimizer (ZeRO) - Also performs sharding of the tensors somewhat similar to TP, except the whole tensor gets reconstructed in time for a forward or backward computation, therefore the model doesn't need to be modified. It also supports various offloading techniques to compensate for limited GPU memory.
|
||||
5. Sharded DDP - is another name for the foundational ZeRO concept as used by various other implementations of ZeRO.
|
||||
1. **DataParallel (DP)** - the same setup is replicated multiple times, and each being fed a slice of the data. The processing is done in parallel and all setups are synchronized at the end of each training step.
|
||||
2. **TensorParallel (TP)** - each tensor is split up into multiple chunks, so instead of having the whole tensor reside on a single gpu, each shard of the tensor resides on its designated gpu. During processing each shard gets processed separately and in parallel on different GPUs and the results are synced at the end of the step. This is what one may call horizontal parallelism, as the splitting happens on horizontal level.
|
||||
3. **PipelineParallel (PP)** - the model is split up vertically (layer-level) across multiple GPUs, so that only one or several layers of the model are places on a single gpu. Each gpu processes in parallel different stages of the pipeline and working on a small chunk of the batch.
|
||||
4. **Zero Redundancy Optimizer (ZeRO)** - Also performs sharding of the tensors somewhat similar to TP, except the whole tensor gets reconstructed in time for a forward or backward computation, therefore the model doesn't need to be modified. It also supports various offloading techniques to compensate for limited GPU memory.
|
||||
5. **Sharded DDP** - is another name for the foundational ZeRO concept as used by various other implementations of ZeRO.
|
||||
|
||||
Before diving deeper into the specifics of each concept we first have a look at the rough decision process when training large models on a large infrastructure.
|
||||
|
||||
## Scalability Strategy
|
||||
|
||||
**⇨ Single Node / Multi-GPU**
|
||||
* Model fits onto a single GPU:
|
||||
|
||||
1. DDP - Distributed DP
|
||||
2. ZeRO - may or may not be faster depending on the situation and configuration used
|
||||
|
||||
* Model doesn't fit onto a single GPU:
|
||||
|
||||
1. PP
|
||||
2. ZeRO
|
||||
3. TP
|
||||
|
||||
With very fast intra-node connectivity of NVLINK or NVSwitch all three should be mostly on par, without these PP will be faster than TP or ZeRO. The degree of TP may also make a difference. Best to experiment to find the winner on your particular setup.
|
||||
|
||||
TP is almost always used within a single node. That is TP size <= gpus per node.
|
||||
|
||||
* Largest Layer not fitting into a single GPU:
|
||||
|
||||
1. If not using ZeRO - must use TP, as PP alone won't be able to fit.
|
||||
2. With ZeRO see the same entry for "Single GPU" above
|
||||
|
||||
|
||||
**⇨ Multi-Node / Multi-GPU**
|
||||
|
||||
* When you have fast inter-node connectivity:
|
||||
|
||||
1. ZeRO - as it requires close to no modifications to the model
|
||||
2. PP+TP+DP - less communications, but requires massive changes to the model
|
||||
|
||||
* when you have slow inter-node connectivity and still low on GPU memory:
|
||||
|
||||
1. DP+PP+TP+ZeRO-1
|
||||
|
||||
|
||||
|
||||
## Data Parallelism
|
||||
|
||||
Most users with just 2 GPUs already enjoy the increased training speed up thanks to `DataParallel` (DP) and `DistributedDataParallel` (DDP) that are almost trivial to use. This is a built-in feature of Pytorch.
|
||||
Most users with just 2 GPUs already enjoy the increased training speed up thanks to `DataParallel` (DP) and `DistributedDataParallel` (DDP) that are almost trivial to use. This is a built-in feature of Pytorch. Note that in general it is advised to use DDP as it is better maintained and works for all models while DP might fail for some models. [PyTorch documentation](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html) itself recommends the use of DDP.
|
||||
|
||||
### DP vs DDP
|
||||
|
||||
`DistributedDataParallel` (DDP) is typically faster than `DataParallel` (DP), but it is not always the case:
|
||||
* while DP is python threads-based, DDP is multiprocess-based - and as such it has no python threads limitations, such as GIL
|
||||
* on the other hand a slow inter-connectivity between the GPU cards could lead to an actual slower outcome with DDP
|
||||
|
||||
Here are the main differences in the inter-GPU communication overhead between the two modes:
|
||||
|
||||
[DDP](https://pytorch.org/docs/master/notes/ddp.html):
|
||||
|
||||
- At the start time the main process replicates the model once from gpu 0 to the rest of gpus
|
||||
- Then for each batch:
|
||||
1. each gpu consumes each own mini-batch of data directly
|
||||
2. during `backward`, once the local gradients are ready, they are then averaged across all processes
|
||||
|
||||
[DP](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html):
|
||||
|
||||
For each batch:
|
||||
1. gpu 0 reads the batch of data and then sends a mini-batch to each gpu
|
||||
2. replicates the up-to-date model from gpu 0 to each gpu
|
||||
3. runs `forward` and sends output from each gpu to gpu 0, computes loss
|
||||
4. scatters loss from gpu 0 to all gpus, runs `backward`
|
||||
5. sends gradients from each gpu to gpu 0 and averages those
|
||||
|
||||
The only communication DDP performs per batch is sending gradients, whereas DP does 5 different data exchanges per batch.
|
||||
|
||||
DP copies data within the process via python threads, whereas DDP copies data via [torch.distributed](https://pytorch.org/docs/master/distributed.html).
|
||||
|
||||
Under DP gpu 0 performs a lot more work than the rest of the gpus, thus resulting in under-utilization of gpus.
|
||||
|
||||
You can use DDP across multiple machines, but this is not the case with DP.
|
||||
|
||||
There are other differences between DP and DDP but they aren't relevant to this discussion.
|
||||
|
||||
If you want to go really deep into understanding these 2 modes, this [article](https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/) is highly recommended, as it has great diagrams, includes multiple benchmarks and profiler outputs on various hardware, explains all the nuances that you may need to know.
|
||||
|
||||
Let's look at an actual benchmark:
|
||||
|
||||
| Type | NVlink | Time |
|
||||
| :----- | ----- | ---: |
|
||||
| 2:DP | Y | 110s |
|
||||
| 2:DDP | Y | 101s |
|
||||
| 2:DDP | N | 131s |
|
||||
|
||||
|
||||
Analysis:
|
||||
|
||||
Here DP is ~10% slower than DDP w/ NVlink, but ~15% faster than DDP w/o NVlink
|
||||
|
||||
The real difference will depend on how much data each GPU needs to sync with the others - the more there is to sync, the more a slow link will slow down the total runtime.
|
||||
|
||||
Here is the full benchmark code and outputs:
|
||||
|
||||
`NCCL_P2P_DISABLE=1` was used to disable the NVLink feature on the corresponding benchmark.
|
||||
|
||||
```
|
||||
|
||||
# DP
|
||||
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
|
||||
python examples/pytorch/language-modeling/run_clm.py \
|
||||
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
|
||||
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
|
||||
|
||||
{'train_runtime': 110.5948, 'train_samples_per_second': 1.808, 'epoch': 0.69}
|
||||
|
||||
# DDP w/ NVlink
|
||||
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
|
||||
python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
|
||||
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
|
||||
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
|
||||
|
||||
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
|
||||
|
||||
# DDP w/o NVlink
|
||||
rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
|
||||
python -m torch.distributed.launch --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
|
||||
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
|
||||
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
|
||||
|
||||
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
|
||||
```
|
||||
|
||||
Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
|
||||
Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
|
||||
|
||||
## ZeRO Data Parallelism
|
||||
|
||||
@ -356,7 +466,7 @@ One very important aspect is that FlexFlow is designed for optimizing DNN parall
|
||||
|
||||
So the promise is very attractive - it runs a 30min simulation on the cluster of choice and it comes up with the best strategy to utilise this specific environment. If you add/remove/replace any parts it'll run and re-optimize the plan for that. And then you can train. A different setup will have its own custom optimization.
|
||||
|
||||
🤗 Transformers status: not yet integrated. We already have our models FX-trace-able via [transformers.utils.fx](https://github.com/huggingface/transformers/blob/main/src/transformers/utils/fx.py), which is a prerequisite for FlexFlow, so someone needs to figure out what needs to be done to make FlexFlow work with our models.
|
||||
🤗 Transformers status: not yet integrated. We already have our models FX-trace-able via [transformers.utils.fx](https://github.com/huggingface/transformers/blob/master/src/transformers/utils/fx.py), which is a prerequisite for FlexFlow, so someone needs to figure out what needs to be done to make FlexFlow work with our models.
|
||||
|
||||
|
||||
## Which Strategy To Use When
|
||||
720
docs/source/en/perf_train_gpu_one.mdx
Normal file
720
docs/source/en/perf_train_gpu_one.mdx
Normal file
@ -0,0 +1,720 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
-->
|
||||
|
||||
# Efficient Training on a Single GPU
|
||||
|
||||
This guide focuses on training large models efficiently on a single GPU. These approaches are still valid if you have access to a machine with multiple GPUs but you will also have access to additional methods outlined in the [multi-GPU section](perf_train_gpu_many).
|
||||
|
||||
In this section we have a look at a few tricks to reduce the memory footprint and speed up training for large models and how they are integrated in the [`Trainer`] and [🤗 Accelerate](https://huggingface.co/docs/accelerate/). Each method can improve speed or memory usage which is summarized in the table below:
|
||||
|
||||
|Method|Speed|Memory|
|
||||
|:-----|:----|:-----|
|
||||
| Gradient accumulation | No | Yes |
|
||||
| Gradient checkpointing | No| Yes |
|
||||
| Mixed precision training | Yes | (No) |
|
||||
| Batch size | Yes | Yes |
|
||||
| Optimizer choice | Yes | Yes |
|
||||
| DataLoader | Yes | No |
|
||||
| DeepSpeed Zero | No | Yes |
|
||||
|
||||
A bracket means that it might not be strictly the case but is usually either not a main concern or negligable. Before we start make sure you have installed the following libraries:
|
||||
|
||||
```bash
|
||||
pip install transformers datasets accelerate nvidia-ml-py3
|
||||
```
|
||||
|
||||
The `nvidia-ml-py3` library allows us to monitor the memory usage of the models from within Python. You might be familiar with the `nvidia-smi` command in the terminal - this library allows to access the same information in Python directly.
|
||||
|
||||
Then we create some dummy data. We create random token IDs between 100 and 30000 and binary labels for a classifier. In total we get 512 sequences each with length 512 and store them in a [`Dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=dataset#datasets.Dataset) with PyTorch format.
|
||||
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
from datasets import Dataset
|
||||
|
||||
|
||||
seq_len, dataset_size = 512, 512
|
||||
dummy_data = {
|
||||
"input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
|
||||
"labels": np.random.randint(0, 1, (dataset_size)),
|
||||
}
|
||||
ds = Dataset.from_dict(dummy_data)
|
||||
ds.set_format("pt")
|
||||
```
|
||||
|
||||
We want to print some summary statistics for the GPU utilization and the training run with the [`Trainer`]. We setup a two helper functions to do just that:
|
||||
|
||||
```py
|
||||
from pynvml import *
|
||||
|
||||
|
||||
def print_gpu_utilization():
|
||||
nvmlInit()
|
||||
handle = nvmlDeviceGetHandleByIndex(0)
|
||||
info = nvmlDeviceGetMemoryInfo(handle)
|
||||
print(f"GPU memory occupied: {info.used//1024**2} MB.")
|
||||
|
||||
|
||||
def print_summary(result):
|
||||
print(f"Time: {result.metrics['train_runtime']:.2f}")
|
||||
print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
|
||||
print_gpu_utilization()
|
||||
```
|
||||
|
||||
Let's verify that we start with a free GPU memory:
|
||||
|
||||
```py
|
||||
>>> print_gpu_utilization()
|
||||
GPU memory occupied: 0 MB.
|
||||
```
|
||||
|
||||
That looks good: the GPU memory is not occupied as we would expect before we load any models. If that's not the case on your machine make sure to stop all processes that are using GPU memory. However, not all free GPU memory can be used by the user. When a model is loaded to the GPU also the kernels are loaded which can take up 1-2GB of memory. To see how much it is we load a tiny tensor into the GPU which triggers the kernels to be loaded as well.
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
|
||||
|
||||
>>> torch.ones((1, 1)).to("cuda")
|
||||
>>> print_gpu_utilization()
|
||||
GPU memory occupied: 1343 MB.
|
||||
```
|
||||
|
||||
We see that the kernels alone take up 1.3GB of GPU memory. Now let's see how much space the model uses.
|
||||
|
||||
## Load Model
|
||||
|
||||
First, we load the `bert-large-uncased` model. We load the model weights directly to the GPU so that we can check how much space just weights use.
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification
|
||||
|
||||
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-large-uncased").to("cuda")
|
||||
>>> print_gpu_utilization()
|
||||
GPU memory occupied: 2631 MB.
|
||||
```
|
||||
|
||||
We can see that the model weights alone take up 1.3 GB of the GPU memory. The exact number depends on the specific GPU you are using. Note that on newer GPUs a model can sometimes take up more space since the weights are loaded in an optimized fashion that speeds up the usage of the model. Now we can also quickly check if we get the same result as with `nvidia-smi` CLI:
|
||||
|
||||
|
||||
```bash
|
||||
nvidia-smi
|
||||
```
|
||||
|
||||
```bash
|
||||
Tue Jan 11 08:58:05 2022
|
||||
+-----------------------------------------------------------------------------+
|
||||
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|
||||
|-------------------------------+----------------------+----------------------+
|
||||
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
|
||||
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|
||||
| | | MIG M. |
|
||||
|===============================+======================+======================|
|
||||
| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
|
||||
| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
|
||||
| | | N/A |
|
||||
+-------------------------------+----------------------+----------------------+
|
||||
|
||||
+-----------------------------------------------------------------------------+
|
||||
| Processes: |
|
||||
| GPU GI CI PID Type Process name GPU Memory |
|
||||
| ID ID Usage |
|
||||
|=============================================================================|
|
||||
| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
|
||||
+-----------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
We get the same number as before and you can also see that we are using a V100 GPU with 16GB of memory. So now we can start training the model and see how the GPU memory consumption changes. First, we set up a few standard training arguments that we will use across all our experiments:
|
||||
|
||||
```py
|
||||
default_args = {
|
||||
"output_dir": "tmp",
|
||||
"evaluation_strategy": "steps",
|
||||
"num_train_epochs": 1,
|
||||
"log_level": "error",
|
||||
"report_to": "none",
|
||||
}
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Note: In order to properly clear the memory after experiments we need restart the Python kernel between experiments. Run all steps above and then just one of the experiments below.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Vanilla Training
|
||||
|
||||
As a first experiment we will use the [`Trainer`] and train the model without any further modifications and a batch size of 4:
|
||||
|
||||
```py
|
||||
from transformers import TrainingArguments, Trainer, logging
|
||||
|
||||
logging.set_verbosity_error()
|
||||
|
||||
|
||||
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 57.82
|
||||
Samples/second: 8.86
|
||||
GPU memory occupied: 14949 MB.
|
||||
```
|
||||
|
||||
We see that already a relatively small batch size almost fills up our GPU's entire memory. However, a larger batch size can often result in faster model convergence or better end performance. So ideally we want to tune the batch size to our model's needs and not to the GPU limitations. What's interesting is that we use much more memory than the size of the model. To understand a bit better why this is the case let's have look at a model's operations and memory needs.
|
||||
|
||||
## Anatomy of Model's Operations
|
||||
|
||||
Transformers architecture includes 3 main groups of operations grouped below by compute-intensity.
|
||||
|
||||
1. **Tensor Contractions**
|
||||
|
||||
Linear layers and components of Multi-Head Attention all do batched **matrix-matrix multiplications**. These operations are the most compute-intensive part of training a transformer.
|
||||
|
||||
2. **Statistical Normalizations**
|
||||
|
||||
Softmax and layer normalization are less compute-intensive than tensor contractions, and involve one or more **reduction operations**, the result of which is then applied via a map.
|
||||
|
||||
3. **Element-wise Operators**
|
||||
|
||||
These are the remaining operators: **biases, dropout, activations, and residual connections**. These are the least compute-intensive operations.
|
||||
|
||||
This knowledge can be helpful to know when analyzing performance bottlenecks.
|
||||
|
||||
This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
|
||||
|
||||
|
||||
## Anatomy of Model's Memory
|
||||
We've seen that training the model uses much more memory than just putting the model on the GPU. This is because there are many components during training that use GPU memory. The components on GPU memory are the following:
|
||||
1. model weights
|
||||
2. optimizer states
|
||||
3. gradients
|
||||
4. forward activations saved for gradient computation
|
||||
5. temporary buffers
|
||||
6. functionality-specific memory
|
||||
|
||||
A typical model trained in mixed precision with AdamW requires 18 bytes per model parameter plus activation memory. For inference there are no optimizer states and gradients, so we can subtract those. And thus we end up with 6 bytes per model parameter for mixed precision inference, plus activation memory.
|
||||
|
||||
Let's look at the details.
|
||||
|
||||
**Model Weights:**
|
||||
|
||||
- 4 bytes * number of parameters for fp32 training
|
||||
- 6 bytes * number of parameters for mixed precision training (maintains a model in fp32 and one in fp16 in memory)
|
||||
|
||||
**Optimizer States:**
|
||||
|
||||
- 8 bytes * number of parameters for normal AdamW (maintains 2 states)
|
||||
- 2 bytes * number of parameters for 8-bit AdamW optimizers like [bitsandbytes](https://github.com/facebookresearch/bitsandbytes)
|
||||
- 4 bytes * number of parameters for optimizers like SGD with momentum (maintains only 1 state)
|
||||
|
||||
**Gradients**
|
||||
|
||||
- 4 bytes * number of parameters for either fp32 or mixed precision training (gradients are always kept in fp32)
|
||||
|
||||
**Forward Activations**
|
||||
|
||||
- size depends on many factors, the key ones being sequence length, hidden size and batch size.
|
||||
|
||||
There are the input and output that are being passed and returned by the forward and the backward functions and the forward activations saved for gradient computation.
|
||||
|
||||
**Temporary Memory**
|
||||
|
||||
Additionally there are all kinds of temporary variables which get released once the calculation is done, but in the moment these could require additional memory and could push to OOM. Therefore when coding it's crucial to think strategically about such temporary variables and sometimes to explicitly free those as soon as they are no longer needed.
|
||||
|
||||
**Functionality-specific memory**
|
||||
|
||||
Then your software could have special memory needs. For example, when generating text using beam search, the software needs to maintain multiple copies of inputs and outputs.
|
||||
|
||||
**`forward` vs `backward` Execution Speed**
|
||||
|
||||
For convolutions and linear layers there are 2x flops in the backward compared to the forward, which generally translates into ~2x slower (sometimes more, because sizes in the backward tend to be more awkward). Activations are usually bandwidth-limited, and it’s typical for an activation to have to read more data in the backward than in the forward (e.g. activation forward reads once, writes once, activation backward reads twice, gradOutput and output of the forward, and writes once, gradInput).
|
||||
|
||||
So there are potentially a few places where we could save GPU memory or speed up operations. Let's start with a simple optimization: choosing the right batch size.
|
||||
|
||||
## Batch sizes
|
||||
|
||||
One gets the most efficient performance when batch sizes and input/output neuron counts are divisible by a certain number, which typically starts at 8, but can be much higher as well. That number varies a lot depending on the specific hardware being used and the dtype of the model.
|
||||
|
||||
For example for fully connected layers (which correspond to GEMMs), NVIDIA provides recommendations for [input/output neuron counts](
|
||||
https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#input-features) and [batch size](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#batch-size).
|
||||
|
||||
[Tensor Core Requirements](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc) define the multiplier based on the dtype and the hardware. For example, for fp16 a multiple of 8 is recommended, but on A100 it's 64!
|
||||
|
||||
For parameters that are small, there is also [Dimension Quantization Effects](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#dim-quantization) to consider, this is where tiling happens and the right multiplier can have a significant speedup.
|
||||
|
||||
## Gradient Accumulation
|
||||
|
||||
The idea behind gradient accumulation is to instead of calculating the gradients for the whole batch at once to do it in smaller steps. The way we do that is to calculate the gradients iteratively in smaller batches by doing a forward and backward pass through the model and accumulating the gradients in the process. When enough gradients are accumulated we run the model's optimization step. This way we can easily increase the overall batch size to numbers that would never fit into the GPU's memory. In turn, however, the added forward and backward passes can slow down the training a bit.
|
||||
|
||||
We can use gradient accumulation in the [`Trainer`] by simply adding the `gradient_accumulation_steps` argument to [`TrainingArguments`]. Let's see how it impacts the models memory footprint:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 66.03
|
||||
Samples/second: 7.75
|
||||
GPU memory occupied: 8681 MB.
|
||||
```
|
||||
|
||||
We can see that the memory footprint was dramatically reduced at the cost of being only slightly slower than the vanilla run. Of course, this would change as you increase the number of accumulation steps. In general you would want to max out the GPU usage as much as possible. So in our case, the batch_size of 4 was already pretty close to the GPU's limit. If we wanted to train with a batch size of 64 we should not use `per_device_train_batch_size=1` and `gradient_accumulation_steps=64` but instead `per_device_train_batch_size=4` and `gradient_accumulation_steps=16` which has the same effective batch size while making better use of the available GPU resources.
|
||||
|
||||
For more details see the benchmarks for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
|
||||
and [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1005033957).
|
||||
|
||||
Next we have a look at another trick to save a little bit more GPU memory called gradient checkpointing.
|
||||
|
||||
## Gradient Checkpointing
|
||||
|
||||
Even when we set the batch size to 1 and use gradient accumulation we can still run out of memory when working with large models. In order to compute the gradients during the backward pass all activations from the forward pass are normally saved. This can create a big memory overhead. Alternatively, one could forget all activations during the forward pass and recompute them on demand during the backward pass. This would however add a significant computational overhead and slow down training.
|
||||
|
||||
Gradient checkpointing strikes a compromise between the two approaches and saves strategically selected activations throughout the computational graph so only a fraction of the activations need to be re-computed for the gradients. See [this great article](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9) explaining the ideas behind gradient checkpointing.
|
||||
|
||||
To enable gradient checkpointing in the [`Trainer`] we only need ot pass it as a flag to the [`TrainingArguments`]. Everything else is handled under the hood:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
|
||||
)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 85.47
|
||||
Samples/second: 5.99
|
||||
GPU memory occupied: 6775 MB.
|
||||
```
|
||||
|
||||
We can see that this saved some more memory but at the same time training became a bit slower. A general rule of thumb is that gradient checkpointing slows down training by about 20%. Let's have a look at another method with which we can regain some speed: mixed precision training.
|
||||
|
||||
|
||||
## Floating Data Types
|
||||
|
||||
The idea of mixed precision training is that no all variables need to be stored in full (32-bit) floating point precision. If we can reduce the precision the variales and their computations are faster. Here are the commonly used floating point data types choice of which impacts both memory usage and throughput:
|
||||
|
||||
- fp32 (`float32`)
|
||||
- fp16 (`float16`)
|
||||
- bf16 (`bfloat16`)
|
||||
- tf32 (CUDA internal data type)
|
||||
|
||||
Here is a diagram that shows how these data types correlate to each other.
|
||||
|
||||
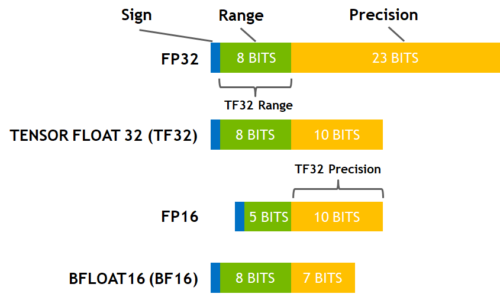
|
||||
(source: [NVIDIA Blog](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/))
|
||||
|
||||
While fp16 and fp32 have been around for quite some time, bf16 and tf32 are only available on the Ampere architecture GPUS and TPUs support bf16 as well. Let's start with the most commonly used method which is FP16 training/
|
||||
|
||||
|
||||
### FP16 Training
|
||||
|
||||
The idea of mixed precision training is that no all variables need to be stored in full (32-bit) floating point precision. If we can reduce the precision the variales and their computations are faster. The main advantage comes from saving the activations in half (16-bit) precision. Although the gradients are also computed in half precision they are converted back to full precision for the optimization step so no memory is saved here. Since the model is present on the GPU in both 16-bit and 32-bit precision this can use more GPU memory (1.5x the original model is on the GPU), especially for small batch sizes. Since some computations are performed in full and some in half precision this approach is also called mixed precision training. Enabling mixed precision training is also just a matter of setting the `fp16` flag to `True`:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 27.46
|
||||
Samples/second: 18.64
|
||||
GPU memory occupied: 13939 MB.
|
||||
```
|
||||
|
||||
We can see that this is almost twice as fast as the vanilla training. Let's add it to the mix of the previous methods:
|
||||
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
per_device_train_batch_size=1,
|
||||
gradient_accumulation_steps=4,
|
||||
gradient_checkpointing=True,
|
||||
fp16=True,
|
||||
**default_args,
|
||||
)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 50.76
|
||||
Samples/second: 10.09
|
||||
GPU memory occupied: 7275 MB.
|
||||
```
|
||||
|
||||
We can see that with these tweaks we use about half the GPU memory as at the beginning while also being slightly faster.
|
||||
|
||||
### BF16
|
||||
If you have access to a Ampere or newer hardware you can use bf16 for your training and evaluation. While bf16 has a worse precision than fp16, it has a much much bigger dynamic range. Therefore, if in the past you were experiencing overflow issues while training the model, bf16 will prevent this from happening most of the time. Remember that in fp16 the biggest number you can have is `65535` and any number above that will overflow. A bf16 number can be as large as `3.39e+38` (!) which is about the same as fp32 - because both have 8-bits used for the numerical range.
|
||||
|
||||
You can enable BF16 in the 🤗 Trainer with:
|
||||
|
||||
```python
|
||||
TrainingArguments(bf16=True)
|
||||
```
|
||||
|
||||
### TF32
|
||||
The Ampere hardware uses a magical data type called tf32. It has the same numerical range as fp32 (8-bits), but instead of 23 bits precision it has only 10 bits (same as fp16) and uses only 19 bits in total.
|
||||
|
||||
It's magical in the sense that you can use the normal fp32 training and/or inference code and by enabling tf32 support you can get up to 3x throughput improvement. All you need to do is to add this to your code:
|
||||
|
||||
```
|
||||
import torch
|
||||
torch.backends.cuda.matmul.allow_tf32 = True
|
||||
```
|
||||
|
||||
When this is done CUDA will automatically switch to using tf32 instead of fp32 where it's possible. This, of course, assumes that the used GPU is from the Ampere series.
|
||||
|
||||
Like all cases with reduced precision this may or may not be satisfactory for your needs, so you have to experiment and see. According to [NVIDIA research](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/) the majority of machine learning training shouldn't be impacted and showed the same perplexity and convergence as the fp32 training.
|
||||
|
||||
If you're already using fp16 or bf16 mixed precision it may help with the throughput as well.
|
||||
|
||||
You can enable this mode in the 🤗 Trainer with:
|
||||
```python
|
||||
TrainingArguments(tf32=True)
|
||||
```
|
||||
By default the PyTorch default is used.
|
||||
|
||||
Note: tf32 mode is internal to CUDA and can't be accessed directly via `tensor.to(dtype=torch.tf32)` as `torch.tf32` doesn't exit.
|
||||
|
||||
Note: you need `torch>=1.7` to enjoy this feature.
|
||||
|
||||
You can also see a variety of benchmarks on tf32 vs other precisions:
|
||||
[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
|
||||
[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
|
||||
|
||||
We've now seen how we can change the floating types to increase throughput, but we are not done, yet! There is another area where we can save GPU memory: the optimizer.
|
||||
|
||||
## Optimizer
|
||||
|
||||
The most common optimizer used to train transformer model is Adam or AdamW (Adam with weight decay). Adam achieves good convergence by storing the rolling average of the previous gradients which, however, adds an additional memory footprint of the order of the number of model parameters. One remedy to this is to use an alternative optimizer such as Adafactor, which works well for some models but often it has instability issues.
|
||||
|
||||
HF Trainer integrates a variety of optimisers that can be used out of box. To activate the desired optimizer simply pass the `--optim` flag to the command line.
|
||||
|
||||
To see which optimizers are currently supported:
|
||||
|
||||
```bash
|
||||
$ python examples/pytorch/translation/run_translation.py -h | grep "\-optim"
|
||||
[--optim {adamw_hf,adamw_torch,adamw_torch_xla,adamw_apex_fused,adafactor}]
|
||||
```
|
||||
|
||||
For example, if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed `--optim adamw_apex_fused` will give you the fastest training experience among all supported AdamW optimizers.
|
||||
|
||||
On the other hand [8bit BNB optimizer](https://github.com/facebookresearch/bitsandbytes) can save 3/4 of memory normally used by a typical AdamW optimizer if it is configured to quantize all optimizer states, but in some situations only some optimizer states are quintized and then more memory is used. XXX: update once https://github.com/huggingface/transformers/pull/15622 is merged.
|
||||
|
||||
Let's get a feel for the numbers and use for example use a 3B-parameter model, like `t5-3b`. Note that since a Gigabyte correpsonds to a billion bytes we can simply multiply the parameters (in billions) with the number of necessary bytes per parameter to get Gigabytes of GPU memory usage:
|
||||
|
||||
- A standard AdamW uses 8 bytes for each parameter, here the optimizer will need (`8*3`) 24GB of GPU memory.
|
||||
- Adafactor uses slightly more than 4 bytes, so (`4*3`) 12GB and then some extra.
|
||||
- 8bit BNB quantized optimizer will use only (`2*3`) 6GB if all optimizer states are quantized.
|
||||
|
||||
Let's have a look at Adafactor first.
|
||||
|
||||
### Adafactor
|
||||
|
||||
Instead of keeping the rolling average for each element in the weight matrices Adafactor only stores aggregated information (row- and column-wise sums of the rolling averages) which reduces the footprint considerably. One downside of Adafactor is that in some instances convergence can be slower than Adam's so some experimentation is advised here. We can use Adafactor simply by setting `optim="adafactor"`:
|
||||
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 64.31
|
||||
Samples/second: 7.96
|
||||
GPU memory occupied: 12295 MB.
|
||||
```
|
||||
|
||||
We can see that this saves a few more GB on the GPU. Let's see how it looks when we add it to the other methods we introduced earlier:
|
||||
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
per_device_train_batch_size=1,
|
||||
gradient_accumulation_steps=4,
|
||||
gradient_checkpointing=True,
|
||||
fp16=True,
|
||||
optim="adafactor",
|
||||
**default_args,
|
||||
)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 56.54
|
||||
Samples/second: 9.06
|
||||
GPU memory occupied: 4847 MB.
|
||||
```
|
||||
|
||||
We went from 15 GB memory usage to 5 GB - a 3x improvement while maintaining the throughput! However, as mentioned before, the convergence of Adafactor can be worse than Adam. There is an alternative to Adafactor called 8-bit Adam that takes a slightly different approach.
|
||||
|
||||
### 8-bit Adam
|
||||
|
||||
Instead of aggregating optimizer states like Adafactor, 8-bit Adam keeps the full state and quantizes it. Quantization means that it stores the state with lower precision and dequantizes it only for the optimization. This is similar to the idea behind FP16 training where using variables with lower precision saves memory.
|
||||
|
||||
In contrast to the previous approaches is this one not integrated into the [`Trainer`] as a simple flag. We need to install the 8-bit optimizer and then pass it as a custom optimizer to the [`Trainer`]. Follow the installation guide in the Github [repo](https://github.com/facebookresearch/bitsandbytes) to install the `bitsandbytes` library that implements the 8-bit Adam optimizer.
|
||||
|
||||
Once installed, we just need to initialize the the optimizer. Although this looks like a considerable amount of work it actually just involves two steps: first we need to group the model's parameters into two groups where to one group we apply weight decay and to the other we don't. Usually, biases and layer norm parameters are not weight decayed. Then in a second step we just do some argument housekeeping to use the same parameters as the previously used AdamW optimizer.
|
||||
|
||||
<Tip>
|
||||
Note that in order to use the 8-bit optimizer with an existing pretrained model a change to the embedding layer is needed.
|
||||
Read [this issue](https://github.com/huggingface/transformers/issues/14819) for more information.
|
||||
</Tip>
|
||||
|
||||
```py
|
||||
import bitsandbytes as bnb
|
||||
from torch import nn
|
||||
from transformers.trainer_pt_utils import get_parameter_names
|
||||
|
||||
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
|
||||
|
||||
decay_parameters = get_parameter_names(model, [nn.LayerNorm])
|
||||
decay_parameters = [name for name in decay_parameters if "bias" not in name]
|
||||
optimizer_grouped_parameters = [
|
||||
{
|
||||
"params": [p for n, p in model.named_parameters() if n in decay_parameters],
|
||||
"weight_decay": training_args.weight_decay,
|
||||
},
|
||||
{
|
||||
"params": [p for n, p in model.named_parameters() if n not in decay_parameters],
|
||||
"weight_decay": 0.0,
|
||||
},
|
||||
]
|
||||
|
||||
optimizer_kwargs = {
|
||||
"betas": (training_args.adam_beta1, training_args.adam_beta2),
|
||||
"eps": training_args.adam_epsilon,
|
||||
}
|
||||
optimizer_kwargs["lr"] = training_args.learning_rate
|
||||
adam_bnb_optim = bnb.optim.Adam8bit(
|
||||
optimizer_grouped_parameters,
|
||||
betas=(training_args.adam_beta1, training_args.adam_beta2),
|
||||
eps=training_args.adam_epsilon,
|
||||
lr=training_args.learning_rate,
|
||||
)
|
||||
```
|
||||
|
||||
We can now pass the custom optimizer as an argument to the `Trainer`:
|
||||
```py
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 55.95
|
||||
Samples/second: 9.15
|
||||
GPU memory occupied: 13085 MB.
|
||||
```
|
||||
|
||||
We can see that we get a similar memory improvement as with Adafactor while keeping the full rolling average of the gradients. Let's repeat the experiment with the full settings:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
per_device_train_batch_size=1,
|
||||
gradient_accumulation_steps=4,
|
||||
gradient_checkpointing=True,
|
||||
fp16=True,
|
||||
**default_args,
|
||||
)
|
||||
|
||||
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
|
||||
result = trainer.train()
|
||||
print_summary(result)
|
||||
```
|
||||
|
||||
```
|
||||
Time: 49.46
|
||||
Samples/second: 10.35
|
||||
GPU memory occupied: 5363 MB.
|
||||
```
|
||||
|
||||
Again, we get about a 3x memory improvement and even slightly higher throughput as using Adafactor. So we have seen how we can optimize the memory footprint of large models. The following plot summarizes all our experiments:
|
||||
|
||||
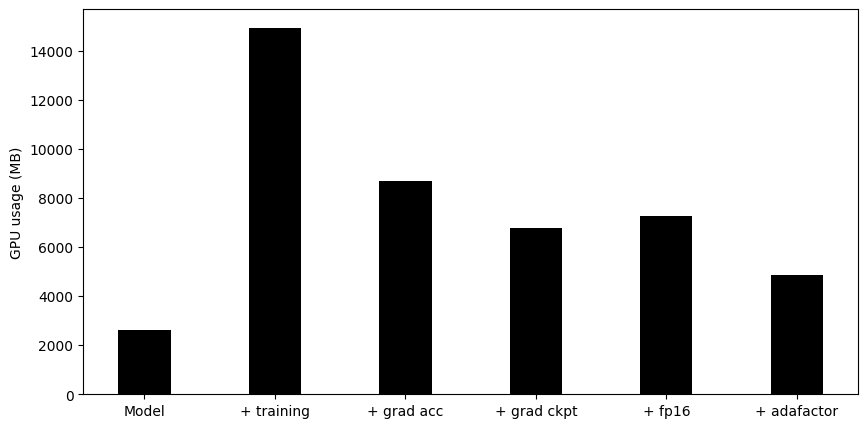
|
||||
|
||||
### `_multi_tensor`
|
||||
pytorch-nightly introduced `torch.optim._multi_tensor` which should significantly speed up the optimizers for situations with lots of small feature tensors. It should eventually become the default, but if you want to experiment with it sooner and don't mind using the bleed-edge, see: https://github.com/huggingface/transformers/issues/9965
|
||||
|
||||
|
||||
## Using 🤗 Accelerate
|
||||
|
||||
So far we have used the [`Trainer`] to run the experiments but a more flexible alternative to that approach is to use 🤗 Accelerate. With 🤗 Accelerate you have full control over the training loop and can essentially write the loop in pure PyTorch with some minor modifications. In turn it allows you to easily scale across different infrastructures such as CPUs, GPUs, TPUs, or distributed multi-GPU setups without changing any code. Let's see what it takes to implement all of the above tweaks in 🤗 Accelerate. We can still use the [`TrainingArguments`] to wrap the training settings:
|
||||
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
per_device_train_batch_size=1,
|
||||
gradient_accumulation_steps=4,
|
||||
gradient_checkpointing=True,
|
||||
fp16=True,
|
||||
**default_args,
|
||||
)
|
||||
```
|
||||
|
||||
The full example training loop with 🤗 Accelerate is only a handful of lines of code long:
|
||||
|
||||
|
||||
```py
|
||||
from accelerate import Accelerator
|
||||
from torch.utils.data.dataloader import DataLoader
|
||||
|
||||
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
|
||||
|
||||
if training_args.gradient_checkpointing:
|
||||
model.gradient_checkpointing_enable()
|
||||
|
||||
accelerator = Accelerator(fp16=training_args.fp16)
|
||||
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
|
||||
|
||||
model.train()
|
||||
for step, batch in enumerate(dataloader, start=1):
|
||||
loss = model(**batch).loss
|
||||
loss = loss / training_args.gradient_accumulation_steps
|
||||
accelerator.backward(loss)
|
||||
if step % training_args.gradient_accumulation_steps == 0:
|
||||
optimizer.step()
|
||||
optimizer.zero_grad()
|
||||
```
|
||||
|
||||
First we wrap the dataset in a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader). Then we can enable gradient checkpointing by calling the model's [`~PreTrainedModel.gradient_checkpointing_enable`] method. When we initialize the [`Accelerator`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator) we can specifiy if we want to use mixed precision training and it will take care of it for us in the [`prepare`] call. During the [`prepare`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator.prepare) call the dataloader will also be distributed across workers should we use multiple GPUs. We use the same 8-bit optimizer from the earlier experiments.
|
||||
|
||||
Finally, we can write the main training loop. Note that the `backward` call is handled by 🤗 Accelerate. We can also see how gradient accumulation works: we normalize the loss so we get the average at the end of accumulation and once we have enough steps we run the optimization. Now the question is: does this use the same amount of memory as the previous steps? Let's check:
|
||||
|
||||
|
||||
```py
|
||||
>>> print_gpu_utilization()
|
||||
GPU memory occupied: 5363 MB.
|
||||
```
|
||||
|
||||
Indeed it does. Implementing these optimization techniques with 🤗 Accelerate only takes a handful of lines of code and comes with the benefit of more flexiblity in the training loop. For a full documentation of all features have a look at the [Accelerate documentation](https://huggingface.co/docs/accelerate/index).
|
||||
|
||||
## DataLoader
|
||||
|
||||
One of the important requirements to reach great training speed is the ability to feed the GPU at the maximum speed it can handle. By default everything happens in the main process and it might not be able to read the data from disk fast enough, and thus create a bottleneck, leading to GPU under-utilization.
|
||||
|
||||
- `DataLoader(pin_memory=True, ...)` which ensures that the data gets preloaded into the pinned memory on CPU and typically leads to much faster transfers from CPU to GPU memory.
|
||||
- `DataLoader(num_workers=4, ...)` - spawn several workers to pre-load data faster - during training watch the GPU utilization stats and if it's far from 100% experiment with raising the number of workers. Of course, the problem could be elsewhere so a very big number of workers won't necessarily lead to a better performance.
|
||||
|
||||
## DeepSpeed ZeRO
|
||||
|
||||
The in-depth details on how to use Deepspeed can be found [here](main_classes/deepspeed).
|
||||
|
||||
First, a quick decision tree:
|
||||
|
||||
1. Model fits onto a single GPU and you have enough space to fit a small batch size - you don't need to use Deepspeed as it'll only slow things down in this use case.
|
||||
2. Model doesn't fit onto a single GPU or you can't fit a small batch - use DeepSpeed ZeRO + CPU Offload and for much larger models NVMe Offload.
|
||||
|
||||
Now if the decision tree suggested you use DeepSpeed first you need to [install it](main_classes/deepspeed#installation), then follow one of the following guides to create a configuration file and launch DeepSpeed.
|
||||
|
||||
Activation:
|
||||
|
||||
- HF Trainer-based examples: see this [guide](main_classes/deepspeed#deployment-with-one-gpu).
|
||||
- Custom HF Trainer-based program: Same as above, but pass:
|
||||
|
||||
```python
|
||||
TrainingArguments(deepspeed="/path/to/ds_config.json")
|
||||
```
|
||||
- Deployment in Notebooks: see this [guide](main_classes/deepspeed#deployment-in-notebooks).
|
||||
|
||||
- Custom training loop: This is somewhat complex but you can study how this is implemented in [HF Trainer](
|
||||
https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py) - simply search for `deepspeed` in the code.
|
||||
|
||||
|
||||
## Choice of GPU
|
||||
Sometimes, even when applying all the above tweaks the throughput on a given GPU might still not be good enough. One easy solution is to change the type of GPU. For example switching from let's say a K80 (which you typically get on Google Colab) to a fancier GPU such as the V100 or A100. Although they are more expensive they are usually more cost effective than cheaper GPUs due to their larger memory and faster architecture.
|
||||
|
||||
Now, let's take a step back and discuss what we should optimize for when scaling the training of large models.
|
||||
|
||||
## How to scale
|
||||
|
||||
When we train models there are a two aspects we want to optimize at the same time:
|
||||
|
||||
- Data throughput/training time
|
||||
- Model performance
|
||||
|
||||
We have seen that each method changes the memory usage and throughput. In general we want to maximize the throughput (samples/second) to minimize the training cost. This is generally achieved by utilizing the GPU as much as possible and thus filling GPU memory to its limit. For example, as mentioned earlier, we only employ gradient accumulation when we want to use a batch size beyond the size of the GPU memory. If the desired batch size fits into memory then there is no reason to apply gradient accumulation which will only slow down training.
|
||||
|
||||
The second objective is model performance. Just because we can does not mean we should use a large batch size. As part of hyperparameter tuning you should determine which batch size yields the best result and then optimize the throughput accordingly.
|
||||
|
||||
|
||||
## Efficient Software Prebuilds
|
||||
|
||||
PyTorch's [pip and conda builds](https://pytorch.org/get-started/locally/#start-locally) come prebuit with the cuda toolkit which is enough to run PyTorch, but it is insufficient if you need to build cuda extensions.
|
||||
|
||||
At times it may take an additional effort to pre-build some components, e.g., if you're using libraries like `apex` that don't come pre-compiled. In other situations figuring out how to install the right cuda toolkit system-wide can be complicated. To address these users' needs PyTorch and NVIDIA release a new version of NGC docker container which already comes with everything prebuilt and you just need to install your programs on it and it will run out of the box.
|
||||
|
||||
This approach is also useful if you want to tweak the pytorch source and/or make a new customized build.
|
||||
|
||||
To find the docker image version you want start [here](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/), choose one of the latest monthly releases. Go into the release's notes for the desired release, check that the environment's components are matching your needs (including NVIDIA Driver requirements!) and then at the very top of that document go to the corresponding NGC page. If for some reason you get lost, here is [the index of all PyTorch NGC images](https://ngc.nvidia.com/catalog/containers/nvidia:pytorch).
|
||||
|
||||
Next follow the instructions to download and deploy the docker image.
|
||||
|
||||
## Sparsity
|
||||
|
||||
### Mixture of Experts
|
||||
|
||||
Quite a few of the recent papers reported a 4-5x training speedup and a faster inference by integrating
|
||||
Mixture of Experts (MoE) into the Transformer models.
|
||||
|
||||
Since it has been discovered that more parameters lead to better performance, this technique allows to increase the number of parameters by an order of magnitude without increasing training costs.
|
||||
|
||||
In this approach every other FFN layer is replaced with a MoE Layer which consists of many experts, with a gated function that trains each expert in a balanced way depending on the input token's position in a sequence.
|
||||
|
||||

|
||||
|
||||
(source: [GLAM](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html))
|
||||
|
||||
You can find exhaustive details and comparison tables in the papers listed at the end of this section.
|
||||
|
||||
The main drawback of this approach is that it requires staggering amounts of GPU memory - almost an order of magnitude larger than its dense equivalent. Various distillation and approaches are proposed to how to overcome the much higher memory requirements.
|
||||
|
||||
There is direct trade-off though, you can use just a few experts with a 2-3x smaller base model instead of dozens or hundreds experts leading to a 5x smaller model and thus increase the training speed moderately while increasing the memory requirements moderately as well.
|
||||
|
||||
Most related papers and implementations are built around Tensorflow/TPUs:
|
||||
|
||||
- [GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding](https://arxiv.org/abs/2006.16668)
|
||||
- [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
|
||||
- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
|
||||
|
||||
And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596), [Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - blog posts: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/), [2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/) and specific deployment with large transformer-based natural language generation models: [blog post](https://www.deepspeed.ai/news/2021/12/09/deepspeed-moe-nlg.html), [Megatron-Deepspeed branch](Thttps://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training).
|
||||
|
||||
|
||||
## Scaling beyond a single GPU
|
||||
|
||||
For some applications, such as pretraining large language models, applying all the approaches above might still not be fast enough. In this case you want to scale your experiment to several GPUs.
|
||||
|
||||
Another use case for training on many GPUs is if the model does not fit on a single GPU with all the mentioned tricks. There are still more methods we can apply although life starts to get a bit more complicated. This usually involves some form of pipeline or tensor parallelism where the model itself is distributed across several GPUs. One can also make use of DeepSpeed which implements some of these parallelism strategies along with some more optimization to reduce the memory footprint such as partitioning the optimizer states. You can read more about this in the ["Multi-GPU training" section](perf_train_gpu_many).
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@ -20,7 +20,7 @@ The [`pipeline`] makes it simple to use any model from the [Model Hub](https://h
|
||||
|
||||
<Tip>
|
||||
|
||||
Take a look at the [`pipeline`] documentation for a complete list of supported taska.
|
||||
Take a look at the [`pipeline`] documentation for a complete list of supported tasks.
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
@ -74,7 +74,6 @@ Ready-made configurations include the following architectures:
|
||||
- RoBERTa
|
||||
- RoFormer
|
||||
- T5
|
||||
- TAPEX
|
||||
- ViT
|
||||
- XLM-RoBERTa
|
||||
- XLM-RoBERTa-XL
|
||||
@ -668,4 +667,4 @@ torch.neuron.trace(model, [token_tensor, segments_tensors])
|
||||
This change enables Neuron SDK to trace the model and optimize it to run in Inf1 instances.
|
||||
|
||||
To learn more about AWS Neuron SDK features, tools, example tutorials and latest updates,
|
||||
please see the [AWS NeuronSDK documentation](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
|
||||
please see the [AWS NeuronSDK documentation](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
|
||||
@ -11,25 +11,34 @@
|
||||
title: Pipelines para inferencia
|
||||
- local: autoclass_tutorial
|
||||
title: Carga instancias preentrenadas con un AutoClass
|
||||
- local: preprocessing
|
||||
title: Preprocesamiento
|
||||
- local: training
|
||||
title: Fine-tuning a un modelo pre-entrenado
|
||||
- local: accelerate
|
||||
title: Entrenamiento distribuido con 🤗 Accelerate
|
||||
- local: model_sharing
|
||||
title: Compartir un modelo
|
||||
title: Tutoriales
|
||||
- sections:
|
||||
- local: fast_tokenizers
|
||||
title: Usa tokenizadores de 🤗 Tokenizers
|
||||
- local: create_a_model
|
||||
title: Crea una arquitectura personalizada
|
||||
- sections:
|
||||
- local: language_modeling
|
||||
- local: tasks/language_modeling
|
||||
title: Modelado de lenguaje
|
||||
- local: tasks/image_classification
|
||||
title: Clasificación de imágenes
|
||||
title: Fine-tuning para tareas posteriores
|
||||
- local: sagemaker
|
||||
title: Ejecutar el entrenamiento en Amazon SageMaker
|
||||
- local: multilingual
|
||||
title: Modelos multilingües para inferencia
|
||||
title: Guías prácticas
|
||||
- sections:
|
||||
- local: philosophy
|
||||
title: Filosofía
|
||||
title: Guías conceptuales
|
||||
|
||||
|
||||
|
||||
- local: bertology
|
||||
title: BERTología
|
||||
title: Guías conceptuales
|
||||
36
docs/source/es/bertology.mdx
Normal file
36
docs/source/es/bertology.mdx
Normal file
@ -0,0 +1,36 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# BERTología
|
||||
|
||||
Hay un creciente campo de estudio empeñado en la investigación del funcionamiento interno de los transformers de gran escala como BERT
|
||||
(que algunos llaman "BERTología"). Algunos buenos ejemplos de este campo son:
|
||||
|
||||
|
||||
- BERT Rediscovers the Classical NLP Pipeline por Ian Tenney, Dipanjan Das, Ellie Pavlick:
|
||||
https://arxiv.org/abs/1905.05950
|
||||
- Are Sixteen Heads Really Better than One? por Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
|
||||
- What Does BERT Look At? An Analysis of BERT's Attention por Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
|
||||
Manning: https://arxiv.org/abs/1906.04341
|
||||
|
||||
Para asistir al desarrollo de este nuevo campo, hemos incluido algunas features adicionales en los modelos BERT/GPT/GPT-2 para
|
||||
ayudar a acceder a las representaciones internas, principalmente adaptado de la gran obra de Paul Michel
|
||||
(https://arxiv.org/abs/1905.10650):
|
||||
|
||||
|
||||
- accediendo a todos los hidden-states de BERT/GPT/GPT-2,
|
||||
- accediendo a todos los pesos de atención para cada head de BERT/GPT/GPT-2,
|
||||
- adquiriendo los valores de salida y gradientes de las heads para poder computar la métrica de importancia de las heads y realizar la poda de heads como se explica
|
||||
en https://arxiv.org/abs/1905.10650.
|
||||
|
||||
Para ayudarte a entender y usar estas features, hemos añadido un script específico de ejemplo: [bertology.py](https://github.com/huggingface/transformers/tree/main/examples/research_projects/bertology/run_bertology.py) mientras extraes información y cortas un modelo pre-entrenado en
|
||||
GLUE.
|
||||
367
docs/source/es/create_a_model.mdx
Normal file
367
docs/source/es/create_a_model.mdx
Normal file
@ -0,0 +1,367 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Crea una arquitectura personalizada
|
||||
|
||||
Una [`AutoClass`](model_doc/auto) infiere, automáticamente, la arquitectura del modelo y descarga la configuración y los pesos del modelo preentrenado. Normalmente, recomendamos usar una `AutoClass` para producir un código agnóstico a puntos de guardado o checkpoints. Sin embargo, los usuarios que quieran más control sobre los parámetros específicos de los modelos pueden crear su propio modelo 🤗 Transformers personalizado a partir de varias clases base. Esto puede ser particularmente útil para alguien que esté interesado en estudiar, entrenar o experimentar con modelos 🤗 Transformers. En esta guía vamos a profundizar en la creación de modelos personalizados sin usar `AutoClass`. Aprenderemos a:
|
||||
|
||||
- Cargar y personalizar una configuración para un modelo.
|
||||
- Crear una arquitectura para un modelo.
|
||||
- Crear tokenizadores rápidos y lentos para textos.
|
||||
- Crear un extractor de propiedades para tareas de audio o imágenes.
|
||||
- Crear un procesador para tareas multimodales.
|
||||
|
||||
## Configuración
|
||||
|
||||
Una [configuración](main_classes/configuration) es un conjunto de atributos específicos de un modelo. Cada configuración de modelo tiene atributos diferentes. Por ejemplo, todos los modelos de PLN tienen los atributos `hidden_size`, `num_attention_heads`, `num_hidden_layers` y `vocab_size` en común. Estos atributos especifican el número de cabezas de atención o de capas ocultas con las que se construyen los modelos.
|
||||
|
||||
Puedes echarle un vistazo a [DistilBERT](model_doc/distilbert) y sus atributos accediendo a [`DistilBertConfig`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertConfig
|
||||
|
||||
>>> config = DistilBertConfig()
|
||||
>>> print(config)
|
||||
DistilBertConfig {
|
||||
"activation": "gelu",
|
||||
"attention_dropout": 0.1,
|
||||
"dim": 768,
|
||||
"dropout": 0.1,
|
||||
"hidden_dim": 3072,
|
||||
"initializer_range": 0.02,
|
||||
"max_position_embeddings": 512,
|
||||
"model_type": "distilbert",
|
||||
"n_heads": 12,
|
||||
"n_layers": 6,
|
||||
"pad_token_id": 0,
|
||||
"qa_dropout": 0.1,
|
||||
"seq_classif_dropout": 0.2,
|
||||
"sinusoidal_pos_embds": false,
|
||||
"transformers_version": "4.16.2",
|
||||
"vocab_size": 30522
|
||||
}
|
||||
```
|
||||
|
||||
[`DistilBertConfig`] muestra todos los atributos por defecto que se han usado para construir un modelo [`DistilBertModel`] base. Todos ellos son personalizables, lo que deja espacio para poder experimentar. Por ejemplo, puedes personalizar un modelo predeterminado para:
|
||||
|
||||
- Probar una función de activación diferente, usando el parámetro `activation`.
|
||||
- Usar un valor de abandono (también conocido como _dropout_) más alto para las probabilidades de las capas de atención, usando el parámetro `attention_dropout`.
|
||||
|
||||
```py
|
||||
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
|
||||
>>> print(my_config)
|
||||
DistilBertConfig {
|
||||
"activation": "relu",
|
||||
"attention_dropout": 0.4,
|
||||
"dim": 768,
|
||||
"dropout": 0.1,
|
||||
"hidden_dim": 3072,
|
||||
"initializer_range": 0.02,
|
||||
"max_position_embeddings": 512,
|
||||
"model_type": "distilbert",
|
||||
"n_heads": 12,
|
||||
"n_layers": 6,
|
||||
"pad_token_id": 0,
|
||||
"qa_dropout": 0.1,
|
||||
"seq_classif_dropout": 0.2,
|
||||
"sinusoidal_pos_embds": false,
|
||||
"transformers_version": "4.16.2",
|
||||
"vocab_size": 30522
|
||||
}
|
||||
```
|
||||
|
||||
Los atributos de los modelos preentrenados pueden ser modificados con la función [`~PretrainedConfig.from_pretrained`]:
|
||||
|
||||
```py
|
||||
>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
|
||||
```
|
||||
|
||||
Cuando estés satisfecho con la configuración de tu modelo, puedes guardarlo con la función [`~PretrainedConfig.save_pretrained`]. Tu configuración se guardará en un archivo JSON dentro del directorio que le especifiques como parámetro.
|
||||
|
||||
```py
|
||||
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
|
||||
```
|
||||
|
||||
Para volver a usar el archivo de configuración, puedes cargarlo usando [`~PretrainedConfig.from_pretrained`]:
|
||||
|
||||
```py
|
||||
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
También puedes guardar los archivos de configuración como un diccionario; o incluso guardar solo la diferencia entre tu archivo personalizado y la configuración por defecto. Consulta la [documentación sobre configuración](main_classes/configuration) para ver más detalles.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Modelo
|
||||
|
||||
El siguiente paso será crear un [modelo](main_classes/models). El modelo, al que a veces también nos referimos como arquitectura, es el encargado de definir cada capa y qué operaciones se realizan. Los atributos como `num_hidden_layers` de la configuración se usan para definir la arquitectura. Todos los modelos comparten una clase base, [`PreTrainedModel`], y algunos métodos comunes que se pueden usar para redimensionar los _embeddings_ o para recortar cabezas de auto-atención (también llamadas _self-attention heads_). Además, todos los modelos son subclases de [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) o [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/flax.linen.html#module), lo que significa que son compatibles con su respectivo framework.
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
Carga los atributos de tu configuración personalizada en el modelo de la siguiente forma:
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertModel
|
||||
|
||||
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
|
||||
>>> model = DistilBertModel(my_config)
|
||||
```
|
||||
|
||||
Esto crea un modelo con valores aleatorios, en lugar de crearlo con los pesos del preentramiento, por lo que no serás capaz de usar este modelo para nada útil hasta que no lo entrenes. El entrenamiento es un proceso costoso, tanto en cuestión de recursos como de tiempo, por lo que generalmente es mejor usar un modelo preentrenado para obtener mejores resultados más rápido, consumiendo una fracción de los recursos que un entrenamiento completo hubiera requerido.
|
||||
|
||||
Puedes crear un modelo preentrenado con [`~PreTrainedModel.from_pretrained`]:
|
||||
|
||||
```py
|
||||
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
|
||||
```
|
||||
|
||||
Cuando cargues tus pesos del preentramiento, el modelo por defecto se carga automáticamente si nos lo proporciona 🤗 Transformers. Sin embargo, siempre puedes reemplazar (todos o algunos de) los atributos del modelo por defecto por los tuyos:
|
||||
|
||||
```py
|
||||
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
Carga los atributos de tu configuración personalizada en el modelo de la siguiente forma:
|
||||
|
||||
```py
|
||||
>>> from transformers import TFDistilBertModel
|
||||
|
||||
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
|
||||
>>> tf_model = TFDistilBertModel(my_config)
|
||||
```
|
||||
|
||||
Esto crea un modelo con valores aleatorios, en lugar de crearlo con los pesos del preentramiento, por lo que no serás capaz de usar este modelo para nada útil hasta que no lo entrenes. El entrenamiento es un proceso costoso, tanto en cuestión de recursos como de tiempo, por lo que generalmente es mejor usar un modelo preentrenado para obtener mejores resultados más rápido, consumiendo solo una fracción de los recursos que un entrenamiento completo hubiera requerido.
|
||||
|
||||
Puedes crear un modelo preentrenado con [`~TFPreTrainedModel.from_pretrained`]:
|
||||
|
||||
```py
|
||||
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
|
||||
```
|
||||
|
||||
Cuando cargues tus pesos del preentramiento, el modelo por defecto se carga automáticamente si este nos lo proporciona 🤗 Transformers. Sin embargo, siempre puedes reemplazar (todos o algunos de) los atributos del modelo por defecto por los tuyos:
|
||||
|
||||
```py
|
||||
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
|
||||
```
|
||||
</tf>
|
||||
</frameworkcontent>
|
||||
|
||||
### Cabezas de modelo
|
||||
|
||||
En este punto del tutorial, tenemos un modelo DistilBERT base que devuelve los *hidden states* o estados ocultos. Los *hidden states* se pasan como parámetros de entrada a la cabeza del modelo para producir la salida. 🤗 Transformers ofrece una cabeza de modelo diferente para cada tarea, siempre y cuando el modelo sea compatible para la tarea (por ejemplo, no puedes usar DistilBERT para una tarea secuencia a secuencia como la traducción).
|
||||
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
|
||||
Por ejemplo, [`DistilBertForSequenceClassification`] es un modelo DistilBERT base con una cabeza de clasificación de secuencias. La cabeza de clasificación de secuencias es una capa superior que precede a la recolección de las salidas.
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertForSequenceClassification
|
||||
|
||||
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
|
||||
```
|
||||
|
||||
Puedes reutilizar este punto de guardado o *checkpoint* para otra tarea fácilmente cambiando a una cabeza de un modelo diferente. Para una tarea de respuesta a preguntas, puedes usar la cabeza del modelo [`DistilBertForQuestionAnswering`]. La cabeza de respuesta a preguntas es similar a la de clasificación de secuencias, excepto porque consta de una capa lineal delante de la salida de los *hidden states*.
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertForQuestionAnswering
|
||||
|
||||
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
|
||||
Por ejemplo, [`TFDistilBertForSequenceClassification`] es un modelo DistilBERT base con una cabeza de clasificación de secuencias. La cabeza de clasificación de secuencias es una capa superior que precede a la recolección de las salidas.
|
||||
|
||||
```py
|
||||
>>> from transformers import TFDistilBertForSequenceClassification
|
||||
|
||||
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
|
||||
```
|
||||
|
||||
Puedes reutilizar este punto de guardado o *checkpoint* para otra tarea fácilmente cambiando a una cabeza de un modelo diferente. Para una tarea de respuesta a preguntas, puedes usar la cabeza del modelo [`TFDistilBertForQuestionAnswering`]. La cabeza de respuesta a preguntas es similar a la de clasificación de secuencias, excepto porque consta de una capa lineal delante de la salida de los *hidden states*.
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import TFDistilBertForQuestionAnswering
|
||||
|
||||
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
|
||||
```
|
||||
</tf>
|
||||
</frameworkcontent>
|
||||
|
||||
## Tokenizer
|
||||
|
||||
La ultima clase base que debes conocer antes de usar un modelo con datos textuales es la clase [tokenizer](main_classes/tokenizer), que convierte el texto bruto en tensores. Hay dos tipos de *tokenizers* que puedes usar con 🤗 Transformers:
|
||||
|
||||
- [`PreTrainedTokenizer`]: una implementación de un *tokenizer* hecha en Python.
|
||||
- [`PreTrainedTokenizerFast`]: un *tokenizer* de nuestra librería [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/), basada en Rust. Este tipo de *tokenizer* es bastante más rápido, especialmente durante la tokenización por lotes, gracias a estar implementado en Rust. Esta rápida tokenización también ofrece métodos adicionales como el *offset mapping*, que relaciona los tokens con sus palabras o caracteres originales.
|
||||
|
||||
Ambos *tokenizers* son compatibles con los métodos comunes, como los de encodificación y decodificación, los métodos para añadir tokens y aquellos que manejan tokens especiales.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
No todos los modelos son compatibles con un *tokenizer* rápido. Échale un vistazo a esta [tabla](index#supported-frameworks) para comprobar si un modelo en específico es compatible con un *tokenizer* rápido.
|
||||
|
||||
</Tip>
|
||||
|
||||
Si has entrenado tu propio *tokenizer*, puedes crear uno desde tu archivo de “vocabulario”:
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertTokenizer
|
||||
|
||||
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
|
||||
```
|
||||
|
||||
Es importante recordar que los vocabularios que provienen de un *tokenizer* personalizado serán diferentes a los vocabularios generados por el *tokenizer* de un modelo preentrenado. Debes usar el vocabulario de un *tokenizer* preentrenado si vas a usar un modelo preentrenado, de lo contrario las entradas no tendrán sentido. Crea un *tokenizer* con el vocabulario de un modelo preentrenado usado la clase [`DistilBertTokenizer`]:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertTokenizer
|
||||
|
||||
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
|
||||
```
|
||||
|
||||
Crea un *tokenizer* rápido con la clase [`DistilBertTokenizerFast`]:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import DistilBertTokenizerFast
|
||||
|
||||
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Por defecto, el [`AutoTokenizer`] intentará cargar un *tokenizer* rápido. Puedes desactivar este compartimiento cambiando el parámetro `use_fast=False` de `from_pretrained`.
|
||||
|
||||
|
||||
</Tip>
|
||||
|
||||
## Extractor de Características
|
||||
|
||||
Un extractor de características procesa entradas de audio e imagen. Hereda de la clase base [`~feature_extraction_utils.FeatureExtractionMixin`] y también puede heredar de la clase [`ImageFeatureExtractionMixin`] para el procesamiento de características de las imágenes o de la clase [`SequenceFeatureExtractor`] para el procesamiento de entradas de audio.
|
||||
|
||||
Dependiendo de si trabajas en una tarea de audio o de video, puedes crear un extractor de características asociado al modelo que estes usando. Por ejemplo, podrías crear un [`ViTFeatureExtractor`] por defecto si estas usando [ViT](model_doc/vit) para clasificación de imágenes:
|
||||
|
||||
```py
|
||||
>>> from transformers import ViTFeatureExtractor
|
||||
|
||||
>>> vit_extractor = ViTFeatureExtractor()
|
||||
>>> print(vit_extractor)
|
||||
ViTFeatureExtractor {
|
||||
"do_normalize": true,
|
||||
"do_resize": true,
|
||||
"feature_extractor_type": "ViTFeatureExtractor",
|
||||
"image_mean": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"image_std": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"resample": 2,
|
||||
"size": 224
|
||||
}
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Si no estás buscando ninguna personalización en específico, usa el método `from_pretrained` para cargar los parámetros del extractor de características por defecto del modelo.
|
||||
|
||||
</Tip>
|
||||
|
||||
Puedes modificar cualquier parámetro de [`ViTFeatureExtractor`] para crear tu extractor de características personalizado:
|
||||
|
||||
```py
|
||||
>>> from transformers import ViTFeatureExtractor
|
||||
|
||||
>>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
|
||||
>>> print(my_vit_extractor)
|
||||
ViTFeatureExtractor {
|
||||
"do_normalize": false,
|
||||
"do_resize": true,
|
||||
"feature_extractor_type": "ViTFeatureExtractor",
|
||||
"image_mean": [
|
||||
0.3,
|
||||
0.3,
|
||||
0.3
|
||||
],
|
||||
"image_std": [
|
||||
0.5,
|
||||
0.5,
|
||||
0.5
|
||||
],
|
||||
"resample": "PIL.Image.BOX",
|
||||
"size": 224
|
||||
}
|
||||
```
|
||||
|
||||
Para las entradas de audio, puedes crear un [`Wav2Vec2FeatureExtractor`] y personalizar los parámetros de una forma similar:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import Wav2Vec2FeatureExtractor
|
||||
|
||||
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
|
||||
>>> print(w2v2_extractor)
|
||||
Wav2Vec2FeatureExtractor {
|
||||
"do_normalize": true,
|
||||
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
|
||||
"feature_size": 1,
|
||||
"padding_side": "right",
|
||||
"padding_value": 0.0,
|
||||
"return_attention_mask": false,
|
||||
"sampling_rate": 16000
|
||||
}
|
||||
```
|
||||
|
||||
## Procesador
|
||||
|
||||
Para modelos que son compatibles con tareas multimodales, 🤗 Transformers ofrece una clase *procesador* que agrupa un extractor de características y un *tokenizer* en el mismo objeto. Por ejemplo, probemos a usar el procesador [`Wav2Vec2Processor`] para una tarea de reconocimiento de voz (ASR). Un ASR transcribe el audio a texto, por lo que necesitaremos un extractor de características y un *tokenizer*.
|
||||
|
||||
Crea un extractor de características para manejar la entrada de audio:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import Wav2Vec2FeatureExtractor
|
||||
|
||||
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
|
||||
```
|
||||
|
||||
Crea un *tokenizer* para manejar la entrada de texto:
|
||||
|
||||
```py
|
||||
>>> from transformers import Wav2Vec2CTCTokenizer
|
||||
|
||||
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
|
||||
```
|
||||
|
||||
Puedes combinar el extractor de características y el *tokenizer* en el [`Wav2Vec2Processor`]:
|
||||
|
||||
|
||||
```py
|
||||
>>> from transformers import Wav2Vec2Processor
|
||||
|
||||
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
|
||||
```
|
||||
Con dos clases base (la configuración y el modelo) y una clase de preprocesamiento adicional (*tokenizer*, extractor de características o procesador), puedes crear cualquiera de los modelos compatibles con 🤗 Transformers. Cada una de estas clases son configurables, permitiéndote usar sus atributos específicos. Puedes crear un modelo para entrenarlo de una forma fácil, o modificar un modelo preentrenado disponible para especializarlo.
|
||||
219
docs/source/es/model_sharing.mdx
Normal file
219
docs/source/es/model_sharing.mdx
Normal file
@ -0,0 +1,219 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Compartir un modelo
|
||||
|
||||
Los últimos dos tutoriales mostraron como puedes realizar fine-tunning a un modelo con PyTorch, Keras y 🤗 Accelerate para distributed setups (entrenamiento distribuido). ¡El siguiente paso es compartir tu modelo con la comunidad! En Hugging Face creemos en compartir abiertamente a todos el conocimiento y los recursos para democratizar la inteligencia artificial. En este sentido, te animamos a considerar compartir tu modelo con la comunidad, de esta forma ayudas a otros ahorrando tiempo y recursos.
|
||||
|
||||
En este tutorial aprenderás dos métodos para compartir un modelo trained o fine-tuned en el [Model Hub](https://huggingface.co/models):
|
||||
|
||||
- Mediante Código, enviando (push) tus archivos al Hub.
|
||||
- Con la interfaz Web, con Drag-and-drop de tus archivos al Hub.
|
||||
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/XvSGPZFEjDY" title="YouTube video player"
|
||||
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
|
||||
picture-in-picture" allowfullscreen></iframe>
|
||||
|
||||
<Tip>
|
||||
|
||||
Para compartir un modelo con la comunidad necesitas una cuenta en [huggingface.co](https://huggingface.co/join). También puedes unirte a una organización existente o crear una nueva.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Características de los repositorios
|
||||
|
||||
Cada repositorio en el Model Hub se comporta como cualquier otro repositorio en GitHub. Nuestros repositorios ofrecen versioning, commit history, y la habilidad para visualizar diferencias.
|
||||
|
||||
El versioning desarrollado dentro del Model Hub es basado en git y [git-lfs](https://git-lfs.github.com/). En otras palabras, puedes tratar un modelo como un repositorio, brindando un mejor control de acceso y escalabilidad. Version control permite *revisions*, un método para apuntar a una versión específica de un modelo utilizando un commit hash, tag o branch.
|
||||
|
||||
Como resultado, puedes cargar una versión específica del modelo con el parámetro `revision`:
|
||||
|
||||
```py
|
||||
>>> model = AutoModel.from_pretrained(
|
||||
... "julien-c/EsperBERTo-small", revision="v2.0.1" # tag name, or branch name, or commit hash
|
||||
... )
|
||||
```
|
||||
|
||||
Los archivos son fácilmente editados dentro de un repositorio. Incluso puedes observar el commit history y las diferencias:
|
||||
|
||||

|
||||
|
||||
## Configuración inicial
|
||||
|
||||
Antes de compartir un modelo al Hub necesitarás tus credenciales de Hugging Face. Si tienes acceso a una terminal ejecuta el siguiente comando en el virtual environment donde 🤗 Transformers esté instalado. Esto guardará tu access token dentro de tu folder cache de Hugging Face (`~/.cache/` by default):
|
||||
|
||||
```bash
|
||||
huggingface-cli login
|
||||
```
|
||||
|
||||
Si usas un notebook como Jupyter o Colaboratory, asegúrate de tener instalada la biblioteca [`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library). Esta biblioteca te permitirá interactuar por código con el Hub.
|
||||
|
||||
```bash
|
||||
pip install huggingface_hub
|
||||
```
|
||||
|
||||
Luego usa `notebook_login` para iniciar sesión al Hub, y sigue el link [aquí](https://huggingface.co/settings/token) para generar un token con el que iniciaremos sesión:
|
||||
|
||||
```py
|
||||
>>> from huggingface_hub import notebook_login
|
||||
|
||||
>>> notebook_login()
|
||||
```
|
||||
|
||||
## Convertir un modelo para todos los Frameworks
|
||||
|
||||
Para asegurarnos que tu modelo pueda ser usado por alguien que esté trabajando con un framework diferente, te recomendamos convertir y cargar tu modelo con pytorch y tensorflow checkpoints. Si bien los usuarios aún son capaces de cargar su modelo desde un framework diferente si se omite este paso, será más lento debido a que 🤗 Transformers necesitará convertir el checkpoint sobre-la-marcha.
|
||||
|
||||
Convertir un checkpoint para otro framework es fácil. Asegúrate tener Pytorch y TensorFlow instalado (Véase [aquí](installation) para instrucciones de instalación), y luego encuentra el modelo específico para tu tarea en el otro Framework.
|
||||
|
||||
Por ejemplo, supongamos que has entrenado DistilBert para sequence classification en PyTorch y quieres convertirlo a su equivalente en TensorFlow. Cargas el equivalente en TensorFlow de tu modelo para tu tarea y especificas `from_pt=True` así 🤗 Transformers convertirá el Pytorch checkpoint a un TensorFlow Checkpoint:
|
||||
|
||||
```py
|
||||
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
|
||||
```
|
||||
|
||||
Luego guardas tu nuevo modelo TensorFlow con su nuevo checkpoint:
|
||||
|
||||
```py
|
||||
>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
|
||||
```
|
||||
|
||||
De manera similar, especificas `from_tf=True` para convertir un checkpoint de TensorFlow a Pytorch:
|
||||
|
||||
```py
|
||||
>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
|
||||
>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
|
||||
```
|
||||
|
||||
Si algún modelo está disponible en Flax, también puedes convertir un checkpoint de Pytorch a Flax:
|
||||
|
||||
```py
|
||||
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
|
||||
... "path/to/awesome-name-you-picked", from_pt=True
|
||||
... )
|
||||
```
|
||||
|
||||
## Compartir un modelo con `Trainer`
|
||||
|
||||
<Youtube id="Z1-XMy-GNLQ"/>
|
||||
|
||||
Compartir un modelo al Hub es tan simple como añadir un parámetro extra o un callback. Si recuerdas del tutorial de [fine-tuning tutorial](training), la clase [`TrainingArguments`] es donde especificas los Hiperparámetros y opciones de entrenamiento adicionales. Una de estas opciones incluye la habilidad de compartir un modelo directamente al Hub. Para ello configuras `push_to_hub=True` dentro de [`TrainingArguments`]:
|
||||
|
||||
```py
|
||||
>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
|
||||
```
|
||||
|
||||
A continuación, pasa tus argumentos de entrenamiento como usualmente a [`Trainer`]:
|
||||
|
||||
```py
|
||||
>>> trainer = Trainer(
|
||||
... model=model,
|
||||
... args=training_args,
|
||||
... train_dataset=small_train_dataset,
|
||||
... eval_dataset=small_eval_dataset,
|
||||
... compute_metrics=compute_metrics,
|
||||
... )
|
||||
```
|
||||
|
||||
Luego que realizas fine-tune a tu modelo, llamas [`~transformers.Trainer.push_to_hub`] en [`Trainer`] para enviar el modelo al Hub. !🤗 Transformers incluso añadirá automáticamente los Hiperparámetros de entrenamiento, resultados de entrenamiento y versiones del Framework a tu model card!
|
||||
|
||||
```py
|
||||
>>> trainer.push_to_hub()
|
||||
```
|
||||
|
||||
## Compartir un modelo con `PushToHubCallback`
|
||||
|
||||
Los usuarios de TensorFlow pueden activar la misma funcionalidad con [`PushToHubCallback`]. En la funcion [`PushToHubCallback`], agrega:
|
||||
|
||||
- Un directorio de salida para tu modelo.
|
||||
- Un tokenizer.
|
||||
- El `hub_model_id`, el cual es tu usuario Hub y el nombre del modelo.
|
||||
|
||||
```py
|
||||
>>> from transformers.keras.callbacks import PushToHubCallback
|
||||
|
||||
>>> push_to_hub_callback = PushToHubCallback(
|
||||
... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
|
||||
... )
|
||||
```
|
||||
|
||||
Agregamos el callback a [`fit`](https://keras.io/api/models/model_training_apis/), y 🤗 Transformers enviará el modelo entrenado al Hub:
|
||||
|
||||
```py
|
||||
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
|
||||
```
|
||||
|
||||
## Usando la función `push_to_hub`
|
||||
|
||||
Puedes llamar la función `push_to_hub` directamente en tu modelo para subirlo al Hub.
|
||||
|
||||
Específica el nombre del modelo en `push_to_hub`:
|
||||
|
||||
```py
|
||||
>>> pt_model.push_to_hub("my-awesome-model")
|
||||
```
|
||||
|
||||
Esto creará un repositorio bajo tu usuario con el nombre del modelo `my-awesome-model`. Ahora los usuarios pueden cargar tu modelo con la función `from_pretrained`:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModel
|
||||
|
||||
>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
|
||||
```
|
||||
|
||||
Si perteneces a una organización y quieres compartir tu modelo bajo el nombre de la organización, añade el parámetro `organization`:
|
||||
|
||||
```py
|
||||
>>> pt_model.push_to_hub("my-awesome-model", organization="my-awesome-org")
|
||||
```
|
||||
|
||||
La función `push_to_hub` también puede ser usada para añadir archivos al repositorio del modelo. Por ejemplo, añade un tokenizer al repositorio:
|
||||
|
||||
```py
|
||||
>>> tokenizer.push_to_hub("my-awesome-model")
|
||||
```
|
||||
|
||||
O quizás te gustaría añadir la versión de TensorFlow de tu modelo fine-tuned en Pytorch:
|
||||
|
||||
```py
|
||||
>>> tf_model.push_to_hub("my-awesome-model")
|
||||
```
|
||||
|
||||
Ahora, cuando navegues a tu perfil en Hugging Face, deberías observar el repositorio de tu modelo creado recientemente. Si das click en el tab **Files** observarás todos los archivos que has subido al repositorio.
|
||||
|
||||
Para más detalles sobre cómo crear y subir archivos al repositorio, consulta la [documentación del Hub](https://huggingface.co/docs/hub/how-to-upstream).
|
||||
|
||||
## Compartir con la interfaz web
|
||||
|
||||
Los usuarios que prefieran un enfoque no-code tienen la opción de cargar su modelo a través de la interfaz gráfica del Hub. Visita la página [huggingface.co/new](https://huggingface.co/new) para crear un nuevo repositorio:
|
||||
|
||||

|
||||
|
||||
Desde aquí, añade información acerca del modelo:
|
||||
|
||||
- Selecciona el **owner** (la persona propietaria) del repositorio. Puedes ser tú o cualquier organización a la que pertenezcas.
|
||||
- Escoge un nombre para tu modelo. También será el nombre del repositorio.
|
||||
- Elige si tu modelo es público o privado.
|
||||
- Específica la licencia que usará tu modelo.
|
||||
|
||||
Ahora puedes hacer click en el tab **Files** y luego en el botón **Add file** para subir un nuevo archivo a tu repositorio. Luego arrastra y suelta un archivo a subir y le añades un mensaje al commit.
|
||||
|
||||

|
||||
|
||||
## Añadiendo una tarjeta de modelo
|
||||
|
||||
Para asegurarnos que los usuarios entiendan las capacidades de tu modelo, sus limitaciones, posibles sesgos y consideraciones éticas, por favor añade una tarjeta (como una tarjeta de presentación) al repositorio del modelo. La tarjeta de modelo es definida en el archivo `README.md`. Puedes agregar una de la siguiente manera:
|
||||
|
||||
* Elaborando y subiendo manualmente el archivo`README.md`.
|
||||
* Dando click en el botón **Edit model card** dentro del repositorio.
|
||||
|
||||
Toma un momento para ver la tarjeta de modelo de DistilBert [model card](https://huggingface.co/distilbert-base-uncased) para que tengas un buen ejemplo del tipo de información que debería incluir. Consulta [la documentación](https://huggingface.co/docs/hub/model-repos) para más detalles acerca de otras opciones que puedes controlar dentro del archivo `README.md` como la huella de carbono del modelo o ejemplos de widgets.```
|
||||
558
docs/source/es/preprocessing.mdx
Normal file
558
docs/source/es/preprocessing.mdx
Normal file
@ -0,0 +1,558 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Preprocesamiento
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
Antes de que puedas utilizar los datos en un modelo, debes procesarlos en un formato aceptable para el modelo. Un modelo no entiende el texto en bruto, las imágenes o el audio. Estas entradas necesitan ser convertidas en números y ensambladas en tensores. En este tutorial, podrás:
|
||||
|
||||
* Preprocesar los datos textuales con un tokenizador.
|
||||
* Preprocesar datos de imagen o audio con un extractor de características.
|
||||
* Preprocesar datos para una tarea multimodal con un procesador.
|
||||
|
||||
## NLP
|
||||
|
||||
<Youtube id="Yffk5aydLzg"/>
|
||||
|
||||
La principal herramienta para procesar datos textuales es un [tokenizador](main_classes/tokenizer). Un tokenizador comienza dividiendo el texto en *tokens* según un conjunto de reglas. Los tokens se convierten en números, que se utilizan para construir tensores como entrada a un modelo. El tokenizador también añade cualquier entrada adicional que requiera el modelo.
|
||||
|
||||
<Tip>
|
||||
|
||||
Si tienes previsto utilizar un modelo pre-entrenado, es importante que utilices el tokenizador pre-entrenado asociado. Esto te asegura que el texto se divide de la misma manera que el corpus de pre-entrenamiento y utiliza el mismo índice de tokens correspondiente (usualmente referido como el *vocab*) durante el pre-entrenamiento.
|
||||
|
||||
</Tip>
|
||||
|
||||
Comienza rápidamente cargando un tokenizador pre-entrenado con la clase [`AutoTokenizer`]. Esto descarga el *vocab* utilizado cuando un modelo es pre-entrenado.
|
||||
|
||||
### Tokenizar
|
||||
|
||||
Carga un tokenizador pre-entrenado con [`AutoTokenizer.from_pretrained`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
|
||||
```
|
||||
|
||||
A continuación, pasa tu frase al tokenizador:
|
||||
|
||||
```py
|
||||
>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
|
||||
>>> print(encoded_input)
|
||||
{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
|
||||
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
|
||||
```
|
||||
|
||||
El tokenizador devuelve un diccionario con tres ítems importantes:
|
||||
|
||||
* [input_ids](glossary#input-ids) son los índices correspondientes a cada token de la frase.
|
||||
* [attention_mask](glossary#attention-mask) indica si un token debe ser atendido o no.
|
||||
* [token_type_ids](glossary#token-type-ids) identifica a qué secuencia pertenece un token cuando hay más de una secuencia.
|
||||
|
||||
Tu puedes decodificar el `input_ids` para devolver la entrada original:
|
||||
|
||||
```py
|
||||
>>> tokenizer.decode(encoded_input["input_ids"])
|
||||
'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
|
||||
```
|
||||
|
||||
Como puedes ver, el tokenizador ha añadido dos tokens especiales - `CLS` y `SEP` (clasificador y separador) - a la frase. No todos los modelos necesitan
|
||||
tokens especiales, pero si lo llegas a necesitar, el tokenizador los añadirá automáticamente.
|
||||
|
||||
Si hay varias frases que quieres preprocesar, pasa las frases como una lista al tokenizador:
|
||||
|
||||
```py
|
||||
>>> batch_sentences = [
|
||||
... "But what about second breakfast?",
|
||||
... "Don't think he knows about second breakfast, Pip.",
|
||||
... "What about elevensies?",
|
||||
... ]
|
||||
>>> encoded_inputs = tokenizer(batch_sentences)
|
||||
>>> print(encoded_inputs)
|
||||
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
|
||||
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
|
||||
[101, 1327, 1164, 5450, 23434, 136, 102]],
|
||||
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0]],
|
||||
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1]]}
|
||||
```
|
||||
|
||||
### Pad
|
||||
|
||||
Esto nos lleva a un tema importante. Cuando se procesa un batch de frases, no siempre tienen la misma longitud. Esto es un problema porque los tensores que se introducen en el modelo deben tener una forma uniforme. El pad es una estrategia para asegurar que los tensores sean rectangulares añadiendo un "padding token" especial a las oraciones con menos tokens.
|
||||
|
||||
Establece el parámetro `padding` en `True` aplicando el pad a las secuencias más cortas del batch para que coincidan con la secuencia más larga:
|
||||
|
||||
```py
|
||||
>>> batch_sentences = [
|
||||
... "But what about second breakfast?",
|
||||
... "Don't think he knows about second breakfast, Pip.",
|
||||
... "What about elevensies?",
|
||||
... ]
|
||||
>>> encoded_input = tokenizer(batch_sentences, padding=True)
|
||||
>>> print(encoded_input)
|
||||
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
|
||||
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
|
||||
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
|
||||
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
|
||||
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
|
||||
```
|
||||
|
||||
Observa que el tokenizador ha aplicado el pad a la primera y la tercera frase con un "0" porque son más cortas.
|
||||
|
||||
### Truncamiento
|
||||
|
||||
En el otro extremo del espectro, a veces una secuencia puede ser demasiado larga para un modelo. En este caso, tendrás que truncar la secuencia a una longitud más corta.
|
||||
|
||||
Establece el parámetro `truncation` a `True` para truncar una secuencia a la longitud máxima aceptada por el modelo:
|
||||
|
||||
```py
|
||||
>>> batch_sentences = [
|
||||
... "But what about second breakfast?",
|
||||
... "Don't think he knows about second breakfast, Pip.",
|
||||
... "What about elevensies?",
|
||||
... ]
|
||||
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
|
||||
>>> print(encoded_input)
|
||||
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
|
||||
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
|
||||
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
|
||||
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
|
||||
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
|
||||
```
|
||||
|
||||
### Construye tensores
|
||||
|
||||
Finalmente, si quieres que el tokenizador devuelva los tensores reales que se introducen en el modelo.
|
||||
|
||||
Establece el parámetro `return_tensors` como `pt` para PyTorch, o `tf` para TensorFlow:
|
||||
|
||||
```py
|
||||
>>> batch_sentences = [
|
||||
... "But what about second breakfast?",
|
||||
... "Don't think he knows about second breakfast, Pip.",
|
||||
... "What about elevensies?",
|
||||
... ]
|
||||
>>> encoded_input = tokenizer(batch, padding=True, truncation=True, return_tensors="pt")
|
||||
>>> print(encoded_input)
|
||||
{'input_ids': tensor([[ 101, 153, 7719, 21490, 1122, 1114, 9582, 1623, 102],
|
||||
[ 101, 5226, 1122, 9649, 1199, 2610, 1236, 102, 0]]),
|
||||
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0]]),
|
||||
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 0]])}
|
||||
===PT-TF-SPLIT===
|
||||
>>> batch_sentences = [
|
||||
... "But what about second breakfast?",
|
||||
... "Don't think he knows about second breakfast, Pip.",
|
||||
... "What about elevensies?",
|
||||
... ]
|
||||
>>> encoded_input = tokenizer(batch, padding=True, truncation=True, return_tensors="tf")
|
||||
>>> print(encoded_input)
|
||||
{'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
|
||||
array([[ 101, 153, 7719, 21490, 1122, 1114, 9582, 1623, 102],
|
||||
[ 101, 5226, 1122, 9649, 1199, 2610, 1236, 102, 0]],
|
||||
dtype=int32)>,
|
||||
'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
|
||||
array([[0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,
|
||||
'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
|
||||
array([[1, 1, 1, 1, 1, 1, 1, 1, 1],
|
||||
[1, 1, 1, 1, 1, 1, 1, 1, 0]], dtype=int32)>}
|
||||
```
|
||||
|
||||
## Audio
|
||||
|
||||
Las entradas de audio se preprocesan de forma diferente a las entradas textuales, pero el objetivo final es el mismo: crear secuencias numéricas que el modelo pueda entender. Un [extractor de características](main_classes/feature_extractor) (o feature extractor en inglés) está diseñado para extraer características de datos provenientes de imágenes o audio sin procesar y convertirlos en tensores. Antes de empezar, instala 🤗 Datasets para cargar un dataset de audio para experimentar:
|
||||
|
||||
```bash
|
||||
pip install datasets
|
||||
```
|
||||
|
||||
Carga la tarea de detección de palabras clave del benchmark [SUPERB](https://huggingface.co/datasets/superb) (consulta el [tutorial 🤗 Dataset](https://huggingface.co/docs/datasets/load_hub.html) para que obtengas más detalles sobre cómo cargar un dataset):
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset, Audio
|
||||
|
||||
>>> dataset = load_dataset("superb", "ks")
|
||||
```
|
||||
|
||||
Accede al primer elemento de la columna `audio` para echar un vistazo a la entrada. Al llamar a la columna `audio` se cargará y volverá a muestrear automáticamente el archivo de audio:
|
||||
|
||||
```py
|
||||
>>> dataset["train"][0]["audio"]
|
||||
{'array': array([ 0. , 0. , 0. , ..., -0.00592041,
|
||||
-0.00405884, -0.00253296], dtype=float32),
|
||||
'path': '/root/.cache/huggingface/datasets/downloads/extracted/05734a36d88019a09725c20cc024e1c4e7982e37d7d55c0c1ca1742ea1cdd47f/_background_noise_/doing_the_dishes.wav',
|
||||
'sampling_rate': 16000}
|
||||
```
|
||||
|
||||
Esto devuelve tres elementos:
|
||||
|
||||
* `array` es la señal de voz cargada - y potencialmente remuestreada - como un array 1D.
|
||||
* `path` apunta a la ubicación del archivo de audio.
|
||||
* `sampling_rate` se refiere a cuántos puntos de datos de la señal de voz se miden por segundo.
|
||||
|
||||
### Resample
|
||||
|
||||
Para este tutorial, se utilizará el modelo [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base). Como puedes ver en la model card, el modelo Wav2Vec2 está pre-entrenado en audio de voz muestreado a 16kHz. Es importante que la tasa de muestreo de tus datos de audio coincida con la tasa de muestreo del dataset utilizado para pre-entrenar el modelo. Si la tasa de muestreo de tus datos no es la misma, deberás volver a muestrear tus datos de audio.
|
||||
|
||||
Por ejemplo, carga el dataset [LJ Speech](https://huggingface.co/datasets/lj_speech) que tiene una tasa de muestreo de 22050kHz. Para utilizar el modelo Wav2Vec2 con este dataset, reduce la tasa de muestreo a 16kHz:
|
||||
|
||||
```py
|
||||
>>> lj_speech = load_dataset("lj_speech", split="train")
|
||||
>>> lj_speech[0]["audio"]
|
||||
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
|
||||
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
|
||||
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
|
||||
'sampling_rate': 22050}
|
||||
```
|
||||
|
||||
1. Usa el método 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.cast_column) para reducir la tasa de muestreo a 16kHz:
|
||||
|
||||
```py
|
||||
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
|
||||
```
|
||||
|
||||
2. Carga el archivo de audio:
|
||||
|
||||
```py
|
||||
>>> lj_speech[0]["audio"]
|
||||
{'array': array([-0.00064146, -0.00074657, -0.00068768, ..., 0.00068341,
|
||||
0.00014045, 0. ], dtype=float32),
|
||||
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
|
||||
'sampling_rate': 16000}
|
||||
```
|
||||
|
||||
Como puedes ver, el `sampling_rate` se ha reducido a 16kHz. Ahora que sabes cómo funciona el resampling, volvamos a nuestro ejemplo anterior con el dataset SUPERB.
|
||||
|
||||
### Extractor de características
|
||||
|
||||
El siguiente paso es cargar un extractor de características para normalizar y aplicar el pad a la entrada. Cuando se aplica padding a los datos textuales, se añade un "0" para las secuencias más cortas. La misma idea se aplica a los datos de audio y el extractor de características de audio añadirá un "0" - interpretado como silencio - al "array".
|
||||
|
||||
Carga el extractor de características con [`AutoFeatureExtractor.from_pretrained`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoFeatureExtractor
|
||||
|
||||
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
|
||||
```
|
||||
|
||||
Pasa el `array` de audio al extractor de características. También te recomendamos añadir el argumento `sampling_rate` en el extractor de características para poder depurar mejor los errores silenciosos que puedan producirse.
|
||||
|
||||
```py
|
||||
>>> audio_input = [dataset["train"][0]["audio"]["array"]]
|
||||
>>> feature_extractor(audio_input, sampling_rate=16000)
|
||||
{'input_values': [array([ 0.00045439, 0.00045439, 0.00045439, ..., -0.1578519 , -0.10807519, -0.06727459], dtype=float32)]}
|
||||
```
|
||||
|
||||
### Pad y truncamiento
|
||||
|
||||
Al igual que el tokenizador, puedes aplicar padding o truncamiento para manejar secuencias variables en un batch. Fíjate en la longitud de la secuencia de estas dos muestras de audio:
|
||||
|
||||
```py
|
||||
>>> dataset["train"][0]["audio"]["array"].shape
|
||||
(1522930,)
|
||||
|
||||
>>> dataset["train"][1]["audio"]["array"].shape
|
||||
(988891,)
|
||||
```
|
||||
|
||||
Como puedes ver, el `sampling_rate` se ha reducido a 16kHz.
|
||||
|
||||
```py
|
||||
>>> def preprocess_function(examples):
|
||||
... audio_arrays = [x["array"] for x in examples["audio"]]
|
||||
... inputs = feature_extractor(
|
||||
... audio_arrays,
|
||||
... sampling_rate=16000,
|
||||
... padding=True,
|
||||
... max_length=1000000,
|
||||
... truncation=True,
|
||||
... )
|
||||
... return inputs
|
||||
```
|
||||
|
||||
Aplica la función a los primeros ejemplos del dataset:
|
||||
|
||||
```py
|
||||
>>> processed_dataset = preprocess_function(dataset["train"][:5])
|
||||
```
|
||||
|
||||
Ahora echa un vistazo a las longitudes de las muestras procesadas:
|
||||
|
||||
```py
|
||||
>>> processed_dataset["input_values"][0].shape
|
||||
(1000000,)
|
||||
|
||||
>>> processed_dataset["input_values"][1].shape
|
||||
(1000000,)
|
||||
```
|
||||
|
||||
Las longitudes de las dos primeras muestras coinciden ahora con la longitud máxima especificada.
|
||||
|
||||
## Visión
|
||||
|
||||
También se utiliza un extractor de características para procesar imágenes para tareas de visión por computadora. Una vez más, el objetivo es convertir la imagen en bruto en un batch de tensores como entrada.
|
||||
|
||||
Vamos a cargar el dataset [food101](https://huggingface.co/datasets/food101) para este tutorial. Usa el parámetro 🤗 Datasets `split` para cargar solo una pequeña muestra de la división de entrenamiento ya que el dataset es bastante grande:
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> dataset = load_dataset("food101", split="train[:100]")
|
||||
```
|
||||
|
||||
A continuación, observa la imagen con la función 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image):
|
||||
|
||||
```py
|
||||
>>> dataset[0]["image"]
|
||||
```
|
||||
|
||||

|
||||
|
||||
### Extractor de características
|
||||
|
||||
Carga el extractor de características con [`AutoFeatureExtractor.from_pretrained`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoFeatureExtractor
|
||||
|
||||
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
|
||||
```
|
||||
|
||||
### Aumento de Datos
|
||||
|
||||
Para las tareas de visión por computadora es común añadir algún tipo de aumento de datos (o data augmentation) a las imágenes como parte del preprocesamiento. Puedes añadir el método de aumento de datos con cualquier librería que quieras, pero en este tutorial utilizarás el módulo [`transforms`](https://pytorch.org/vision/stable/transforms.html) de torchvision.
|
||||
|
||||
1. Normaliza la imagen y utiliza [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) para encadenar algunas transformaciones - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) y [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) - juntas:
|
||||
|
||||
```py
|
||||
>>> from torchvision.transforms import Compose, Normalize, RandomResizedCrop, ColorJitter, ToTensor
|
||||
|
||||
>>> normalize = Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
|
||||
>>> _transforms = Compose(
|
||||
... [RandomResizedCrop(feature_extractor.size), ColorJitter(brightness=0.5, hue=0.5), ToTensor(), normalize]
|
||||
... )
|
||||
```
|
||||
|
||||
2. El modelo acepta [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) como entrada. Este valor es generado por el extractor de características. Crea una función que genere `pixel_values` a partir de las transformaciones:
|
||||
|
||||
```py
|
||||
>>> def transforms(examples):
|
||||
... examples["pixel_values"] = [_transforms(image.convert("RGB")) for image in examples["image"]]
|
||||
... return examples
|
||||
```
|
||||
|
||||
3. A continuación, utiliza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process.html#format-transform) para aplicar las transformaciones sobre la marcha:
|
||||
|
||||
```py
|
||||
>>> dataset.set_transform(transforms)
|
||||
```
|
||||
|
||||
4. Ahora, cuando accedes a la imagen, observarás que el extractor de características ha añadido a la entrada del modelo `pixel_values`:
|
||||
|
||||
```py
|
||||
>>> dataset[0]["image"]
|
||||
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512 at 0x7F1A7B0630D0>,
|
||||
'label': 6,
|
||||
'pixel_values': tensor([[[ 0.0353, 0.0745, 0.1216, ..., -0.9922, -0.9922, -0.9922],
|
||||
[-0.0196, 0.0667, 0.1294, ..., -0.9765, -0.9843, -0.9922],
|
||||
[ 0.0196, 0.0824, 0.1137, ..., -0.9765, -0.9686, -0.8667],
|
||||
...,
|
||||
[ 0.0275, 0.0745, 0.0510, ..., -0.1137, -0.1216, -0.0824],
|
||||
[ 0.0667, 0.0824, 0.0667, ..., -0.0588, -0.0745, -0.0980],
|
||||
[ 0.0353, 0.0353, 0.0431, ..., -0.0039, -0.0039, -0.0588]],
|
||||
|
||||
[[ 0.2078, 0.2471, 0.2863, ..., -0.9451, -0.9373, -0.9451],
|
||||
[ 0.1608, 0.2471, 0.3098, ..., -0.9373, -0.9451, -0.9373],
|
||||
[ 0.2078, 0.2706, 0.3020, ..., -0.9608, -0.9373, -0.8275],
|
||||
...,
|
||||
[-0.0353, 0.0118, -0.0039, ..., -0.2392, -0.2471, -0.2078],
|
||||
[ 0.0196, 0.0353, 0.0196, ..., -0.1843, -0.2000, -0.2235],
|
||||
[-0.0118, -0.0039, -0.0039, ..., -0.0980, -0.0980, -0.1529]],
|
||||
|
||||
[[ 0.3961, 0.4431, 0.4980, ..., -0.9216, -0.9137, -0.9216],
|
||||
[ 0.3569, 0.4510, 0.5216, ..., -0.9059, -0.9137, -0.9137],
|
||||
[ 0.4118, 0.4745, 0.5216, ..., -0.9137, -0.8902, -0.7804],
|
||||
...,
|
||||
[-0.2314, -0.1922, -0.2078, ..., -0.4196, -0.4275, -0.3882],
|
||||
[-0.1843, -0.1686, -0.2000, ..., -0.3647, -0.3804, -0.4039],
|
||||
[-0.1922, -0.1922, -0.1922, ..., -0.2941, -0.2863, -0.3412]]])}
|
||||
```
|
||||
|
||||
Este es el aspecto de la imagen después de preprocesarla. Como era de esperar por las transformaciones aplicadas, la imagen ha sido recortada aleatoriamente y sus propiedades de color son diferentes.
|
||||
|
||||
```py
|
||||
>>> import numpy as np
|
||||
>>> import matplotlib.pyplot as plt
|
||||
|
||||
>>> img = dataset[0]["pixel_values"]
|
||||
>>> plt.imshow(img.permute(1, 2, 0))
|
||||
```
|
||||
|
||||

|
||||
|
||||
## Multimodal
|
||||
|
||||
Para las tareas multimodales utilizarás una combinación de todo lo que has aprendido hasta ahora y aplicarás tus habilidades a una tarea de reconocimiento automático de voz (ASR). Esto significa que necesitarás un:
|
||||
|
||||
* Extractor de características para preprocesar los datos de audio.
|
||||
* Un tokenizador para procesar el texto.
|
||||
|
||||
Volvamos al dataset [LJ Speech](https://huggingface.co/datasets/lj_speech):
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> lj_speech = load_dataset("lj_speech", split="train")
|
||||
```
|
||||
|
||||
Suponiendo que te interesan principalmente las columnas `audio` y `texto`, elimina las demás columnas:
|
||||
|
||||
```py
|
||||
>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
|
||||
```
|
||||
|
||||
Ahora echa un vistazo a las columnas `audio` y `texto`:
|
||||
|
||||
```py
|
||||
>>> lj_speech[0]["audio"]
|
||||
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
|
||||
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
|
||||
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
|
||||
'sampling_rate': 22050}
|
||||
|
||||
>>> lj_speech[0]["text"]
|
||||
'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
|
||||
```
|
||||
|
||||
Recuerda la sección anterior sobre el procesamiento de datos de audio, siempre debes [volver a muestrear](preprocessing#audio) la tasa de muestreo de tus datos de audio para que coincida con la tasa de muestreo del dataset utilizado para preentrenar un modelo:
|
||||
|
||||
```py
|
||||
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
|
||||
```
|
||||
|
||||
### Processor
|
||||
|
||||
Un processor combina un extractor de características y un tokenizador. Cargue un procesador con [`AutoProcessor.from_pretrained]:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoProcessor
|
||||
|
||||
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
|
||||
```
|
||||
|
||||
1. Crea una función para procesar los datos de audio en `input_values`, y tokeniza el texto en `labels`. Estas son las entradas del modelo:
|
||||
|
||||
```py
|
||||
>>> def prepare_dataset(example):
|
||||
... audio = example["audio"]
|
||||
|
||||
... example["input_values"] = processor(audio["array"], sampling_rate=16000)
|
||||
|
||||
... with processor.as_target_processor():
|
||||
... example["labels"] = processor(example["text"]).input_ids
|
||||
... return example
|
||||
```
|
||||
|
||||
2. Aplica la función `prepare_dataset` a una muestra:
|
||||
|
||||
```py
|
||||
>>> prepare_dataset(lj_speech[0])
|
||||
```
|
||||
|
||||
Observa que el método processor ha añadido `input_values` y `labels`. La tasa de muestreo también se ha reducido correctamente a 16kHz.
|
||||
|
||||
Genial, ahora deberías ser capaz de preprocesar datos para cualquier modalidad e incluso combinar diferentes modalidades. En el siguiente tutorial, aprenderás aplicar fine tuning a un modelo en tus datos recién preprocesados.
|
||||
|
||||
## Todo lo que siempre quisiste saber sobre el padding y el truncamiento
|
||||
|
||||
Hemos visto los comandos que funcionarán para la mayoría de los casos (hacer pad a tu batch teniendo en cuenta la longitud de la frase máxima y
|
||||
truncar a la longitud máxima que el modelo puede aceptar). Sin embargo, la API admite más estrategias si las necesitas. Los
|
||||
tres argumentos que necesitas conocer para ello son `padding`, `truncation` y `max_length`.
|
||||
|
||||
- `padding` controla el aplicarme padding al texto. Puede ser un booleano o una cadena que debe ser:
|
||||
|
||||
- `True` o `'longest'` para aplicar el pad hasta la secuencia más larga del batch (no apliques el padding si sólo se proporcionas
|
||||
una sola secuencia).
|
||||
- `'max_length'` para aplicar el pad hasta la longitud especificada por el argumento `max_length` o la longitud máxima aceptada
|
||||
por el modelo si no le proporcionas `longitud_máxima` (`longitud_máxima=None`). Si sólo le proporcionas una única secuencia
|
||||
se le aplicará el padding.
|
||||
`False` o `'do_not_pad'` para no aplicar pad a las secuencias. Como hemos visto antes, este es el comportamiento por
|
||||
defecto.
|
||||
|
||||
- `truncation` controla el truncamiento. Puede ser un booleano o una string que debe ser:
|
||||
|
||||
- `True` o `'longest_first'` truncan hasta la longitud máxima especificada por el argumento `max_length` o
|
||||
la longitud máxima aceptada por el modelo si no le proporcionas `max_length` (`max_length=None`). Esto
|
||||
truncará token por token, eliminando un token de la secuencia más larga del par hasta alcanzar la longitud
|
||||
adecuada.
|
||||
- `'only_second'` trunca hasta la longitud máxima especificada por el argumento `max_length` o la
|
||||
longitud máxima aceptada por el modelo si no le proporcionas `max_length` (`max_length=None`). Esto sólo truncará
|
||||
la segunda frase de un par si le proporcionas un par de secuencias (o un batch de pares de secuencias).
|
||||
- `'only_first'` trunca hasta la longitud máxima especificada por el argumento `max_length` o la longitud máxima
|
||||
aceptada por el modelo si no se proporciona `max_length` (`max_length=None`). Esto sólo truncará
|
||||
la primera frase de un par si se proporciona un par de secuencias (o un lote de pares de secuencias).
|
||||
- `False` o `'do_not_truncate'` para no truncar las secuencias. Como hemos visto antes, este es el comportamiento
|
||||
por defecto.
|
||||
|
||||
- `max_length` para controlar la longitud del padding/truncamiento. Puede ser un número entero o `None`, en cuyo caso
|
||||
será por defecto la longitud máxima que el modelo puede aceptar. Si el modelo no tiene una longitud máxima de entrada específica, el
|
||||
padding/truncamiento a `longitud_máxima` se desactiva.
|
||||
|
||||
A continuación te mostramos en una tabla que resume la forma recomendada de configurar el padding y el truncamiento. Si utilizas un par de secuencias de entrada en
|
||||
algunos de los siguientes ejemplos, puedes sustituir `truncation=True` por una `STRATEGY` seleccionada en
|
||||
`['only_first', 'only_second', 'longest_first']`, es decir, `truncation='only_second'` o `truncation= 'longest_first'` para controlar cómo se trunquen ambas secuencias del par como lo has detallado anteriormente.
|
||||
|
||||
| Truncation | Padding | Instrucciones |
|
||||
|--------------------------------------|-----------------------------------|---------------------------------------------------------------------------------------------|
|
||||
| no truncation | no padding | `tokenizer(batch_sentences)` |
|
||||
| | padding secuencia max del batch | `tokenizer(batch_sentences, padding=True)` or |
|
||||
| | | `tokenizer(batch_sentences, padding='longest')` |
|
||||
| | padding long max de input model | `tokenizer(batch_sentences, padding='max_length')` |
|
||||
| | padding a una long especifica | `tokenizer(batch_sentences, padding='max_length', max_length=42)` |
|
||||
| truncation long max del input model | no padding | `tokenizer(batch_sentences, truncation=True)` or |
|
||||
| | | `tokenizer(batch_sentences, truncation=STRATEGY)` |
|
||||
| | padding secuencia max del batch | `tokenizer(batch_sentences, padding=True, truncation=True)` or |
|
||||
| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY)` |
|
||||
| | padding long max de input model | `tokenizer(batch_sentences, padding='max_length', truncation=True)` or |
|
||||
| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY)` |
|
||||
| | padding a una long especifica | Not possible |
|
||||
| truncationa una long especifica | no padding | `tokenizer(batch_sentences, truncation=True, max_length=42)` or |
|
||||
| | | `tokenizer(batch_sentences, truncation=STRATEGY, max_length=42)` |
|
||||
| | padding secuencia max del batch | `tokenizer(batch_sentences, padding=True, truncation=True, max_length=42)` or |
|
||||
| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42)` |
|
||||
| | padding long max de input model | Not possible |
|
||||
| | padding a una long especifica | `tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42)` or |
|
||||
| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42)` |
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
25
docs/source/es/sagemaker.mdx
Normal file
25
docs/source/es/sagemaker.mdx
Normal file
@ -0,0 +1,25 @@
|
||||
<!---
|
||||
Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
|
||||
# Ejecutar el entrenamiento en Amazon SageMaker
|
||||
|
||||
La documentación ha sido trasladada a [hf.co/docs/sagemaker](https://huggingface.co/docs/sagemaker). Esta página será eliminada en `transformers` 5.0.
|
||||
|
||||
### Tabla de contenido
|
||||
|
||||
- [Entrenar modelos de Hugging Face en Amazon SageMaker con SageMaker Python SDK](https://huggingface.co/docs/sagemaker/train)
|
||||
- [Desplegar modelos de Hugging Face en Amazon SageMaker con SageMaker Python SDK](https://huggingface.co/docs/sagemaker/inference)
|
||||
- [Preguntas Frecuentes](https://huggingface.co/docs/sagemaker/faq)
|
||||
169
docs/source/es/tasks/image_classification.mdx
Normal file
169
docs/source/es/tasks/image_classification.mdx
Normal file
@ -0,0 +1,169 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Clasificación de imágenes
|
||||
|
||||
<Youtube id="tjAIM7BOYhw"/>
|
||||
|
||||
La clasificación de imágenes asigna una etiqueta o clase a una imagen. A diferencia de la clasificación de texto o audio, las entradas son los valores de los píxeles que representan una imagen. La clasificación de imágenes tiene muchos usos, como la detección de daños tras una catástrofe, el control de la salud de los cultivos o la búsqueda de signos de enfermedad en imágenes médicas.
|
||||
|
||||
Esta guía te mostrará como hacer fine-tune al [ViT](https://huggingface.co/docs/transformers/v4.16.2/en/model_doc/vit) en el dataset [Food-101](https://huggingface.co/datasets/food101) para clasificar un alimento en una imagen.
|
||||
|
||||
<Tip>
|
||||
|
||||
Consulta la [página de la tarea](https://huggingface.co/tasks/audio-classification) de clasificación de imágenes para obtener más información sobre sus modelos, datasets y métricas asociadas.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Carga el dataset Food-101
|
||||
|
||||
Carga solo las primeras 5000 imágenes del dataset Food-101 de la biblioteca 🤗 de Datasets ya que es bastante grande:
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> food = load_dataset("food101", split="train[:5000]")
|
||||
```
|
||||
|
||||
Divide el dataset en un train y un test set:
|
||||
|
||||
```py
|
||||
>>> food = food.train_test_split(test_size=0.2)
|
||||
```
|
||||
|
||||
A continuación, observa un ejemplo:
|
||||
|
||||
```py
|
||||
>>> food["train"][0]
|
||||
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x512 at 0x7F52AFC8AC50>,
|
||||
'label': 79}
|
||||
```
|
||||
|
||||
El campo `image` contiene una imagen PIL, y cada `label` es un número entero que representa una clase. Crea un diccionario que asigne un nombre de label a un entero y viceversa. El mapeo ayudará al modelo a recuperar el nombre de label a partir del número de la misma:
|
||||
|
||||
```py
|
||||
>>> labels = food["train"].features["label"].names
|
||||
>>> label2id, id2label = dict(), dict()
|
||||
>>> for i, label in enumerate(labels):
|
||||
... label2id[label] = str(i)
|
||||
... id2label[str(i)] = label
|
||||
```
|
||||
|
||||
Ahora puedes convertir el número de label en un nombre de label para obtener más información:
|
||||
|
||||
```py
|
||||
>>> id2label[str(79)]
|
||||
'prime_rib'
|
||||
```
|
||||
|
||||
Cada clase de alimento - o label - corresponde a un número; `79` indica una costilla de primera en el ejemplo anterior.
|
||||
|
||||
## Preprocesa
|
||||
|
||||
Carga el feature extractor de ViT para procesar la imagen en un tensor:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoFeatureExtractor
|
||||
|
||||
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224-in21k")
|
||||
```
|
||||
|
||||
Aplica varias transformaciones de imagen al dataset para hacer el modelo más robusto contra el overfitting. En este caso se utilizará el módulo [`transforms`](https://pytorch.org/vision/stable/transforms.html) de torchvision. Recorta una parte aleatoria de la imagen, cambia su tamaño y normalízala con la media y la desviación estándar de la imagen:
|
||||
|
||||
```py
|
||||
>>> from torchvision.transforms import RandomResizedCrop, Compose, Normalize, ToTensor
|
||||
|
||||
>>> normalize = Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
|
||||
>>> _transforms = Compose([RandomResizedCrop(feature_extractor.size), ToTensor(), normalize])
|
||||
```
|
||||
|
||||
Crea una función de preprocesamiento que aplique las transformaciones y devuelva los `pixel_values` - los inputs al modelo - de la imagen:
|
||||
|
||||
```py
|
||||
>>> def transforms(examples):
|
||||
... examples["pixel_values"] = [_transforms(img.convert("RGB")) for img in examples["image"]]
|
||||
... del examples["image"]
|
||||
... return examples
|
||||
```
|
||||
|
||||
Utiliza el método [`with_transform`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?#datasets.Dataset.with_transform) de 🤗 Dataset para aplicar las transformaciones sobre todo el dataset. Las transformaciones se aplican sobre la marcha cuando se carga un elemento del dataset:
|
||||
|
||||
```py
|
||||
>>> food = food.with_transform(transforms)
|
||||
```
|
||||
|
||||
Utiliza [`DefaultDataCollator`] para crear un batch de ejemplos. A diferencia de otros data collators en 🤗 Transformers, el DefaultDataCollator no aplica un preprocesamiento adicional como el padding.
|
||||
|
||||
```py
|
||||
>>> from transformers import DefaultDataCollator
|
||||
|
||||
>>> data_collator = DefaultDataCollator()
|
||||
```
|
||||
|
||||
## Entrena
|
||||
Carga ViT con [`AutoModelForImageClassification`]. Especifica el número de labels, y pasa al modelo el mapping entre el número de label y la clase de label:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
|
||||
|
||||
>>> model = AutoModelForImageClassification.from_pretrained(
|
||||
... "google/vit-base-patch16-224-in21k",
|
||||
... num_labels=len(labels),
|
||||
... id2label=id2label,
|
||||
... label2id=label2id,
|
||||
... )
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Si no estás familiarizado con el fine-tuning de un modelo con el [`Trainer`], echa un vistazo al tutorial básico [aquí](../training#finetune-with-trainer)!
|
||||
|
||||
</Tip>
|
||||
|
||||
Al llegar a este punto, solo quedan tres pasos:
|
||||
|
||||
1. Define tus hiperparámetros de entrenamiento en [`TrainingArguments`]. Es importante que no elimines las columnas que no se utilicen, ya que esto hará que desaparezca la columna `image`. Sin la columna `image` no puedes crear `pixel_values`. Establece `remove_unused_columns=False` para evitar este comportamiento.
|
||||
2. Pasa los training arguments al [`Trainer`] junto con el modelo, los datasets, tokenizer y data collator.
|
||||
3. Llama [`~Trainer.train`] para hacer fine-tune de tu modelo.
|
||||
|
||||
```py
|
||||
>>> training_args = TrainingArguments(
|
||||
... output_dir="./results",
|
||||
... per_device_train_batch_size=16,
|
||||
... evaluation_strategy="steps",
|
||||
... num_train_epochs=4,
|
||||
... fp16=True,
|
||||
... save_steps=100,
|
||||
... eval_steps=100,
|
||||
... logging_steps=10,
|
||||
... learning_rate=2e-4,
|
||||
... save_total_limit=2,
|
||||
... remove_unused_columns=False,
|
||||
... )
|
||||
|
||||
>>> trainer = Trainer(
|
||||
... model=model,
|
||||
... args=training_args,
|
||||
... data_collator=data_collator,
|
||||
... train_dataset=food["train"],
|
||||
... eval_dataset=food["test"],
|
||||
... tokenizer=feature_extractor,
|
||||
... )
|
||||
|
||||
>>> trainer.train()
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Para ver un ejemplo más a profundidad de cómo hacer fine-tune a un modelo para clasificación de imágenes, echa un vistazo al correspondiente [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
|
||||
|
||||
</Tip>
|
||||
14
docs/source/pt/_config.py
Normal file
14
docs/source/pt/_config.py
Normal file
@ -0,0 +1,14 @@
|
||||
# docstyle-ignore
|
||||
INSTALL_CONTENT = """
|
||||
# Transformers installation
|
||||
! pip install transformers datasets
|
||||
# To install from source instead of the last release, comment the command above and uncomment the following one.
|
||||
# ! pip install git+https://github.com/huggingface/transformers.git
|
||||
"""
|
||||
|
||||
notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
|
||||
black_avoid_patterns = {
|
||||
"{processor_class}": "FakeProcessorClass",
|
||||
"{model_class}": "FakeModelClass",
|
||||
"{object_class}": "FakeObjectClass",
|
||||
}
|
||||
22
docs/source/pt/_toctree.yml
Normal file
22
docs/source/pt/_toctree.yml
Normal file
@ -0,0 +1,22 @@
|
||||
- sections:
|
||||
- local: installation
|
||||
title: Instalação
|
||||
title: Iniciar
|
||||
- sections:
|
||||
- local: pipeline_tutorial
|
||||
title: Pipelines para inferência
|
||||
- local: training
|
||||
title: Fine-tuning de um modelo pré-treinado
|
||||
- local: accelerate
|
||||
title: Treinamento distribuído com 🤗 Accelerate
|
||||
title: Tutoriais
|
||||
- sections:
|
||||
- local: fast_tokenizers
|
||||
title: Usando os Tokenizers do 🤗 Tokenizers
|
||||
- sections:
|
||||
- local: tasks/sequence_classification
|
||||
title: Classificação de texto
|
||||
title: Fine-tuning para tarefas específicas
|
||||
- local: multilingual
|
||||
title: Modelos multilinguísticos para inferência
|
||||
title: Guias práticos
|
||||
141
docs/source/pt/accelerate.mdx
Normal file
141
docs/source/pt/accelerate.mdx
Normal file
@ -0,0 +1,141 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Treinamento distribuído com o 🤗 Accelerate
|
||||
|
||||
O paralelismo surgiu como uma estratégia para treinar modelos grandes em hardware limitado e aumentar a velocidade
|
||||
de treinamento em várias órdens de magnitude. Na Hugging Face criamos a biblioteca [🤗 Accelerate](https://huggingface.co/docs/accelerate/index.html)
|
||||
para ajudar os usuários a treinar modelos 🤗 Transformers com qualquer configuração distribuída, seja em uma máquina
|
||||
com múltiplos GPUs ou em múltiplos GPUs distribuidos entre muitas máquinas. Neste tutorial, você irá aprender como
|
||||
personalizar seu laço de treinamento de PyTorch para poder treinar em ambientes distribuídos.
|
||||
|
||||
## Configuração
|
||||
|
||||
De início, instale o 🤗 Accelerate:
|
||||
|
||||
```bash
|
||||
pip install accelerate
|
||||
```
|
||||
|
||||
Logo, devemos importar e criar um objeto [`Accelerator`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator).
|
||||
O `Accelerator` detectará automáticamente a configuração distribuída disponível e inicializará todos os
|
||||
componentes necessários para o treinamento. Não há necessidade portanto de especificar o dispositivo onde deve colocar seu modelo.
|
||||
|
||||
```py
|
||||
>>> from accelerate import Accelerator
|
||||
|
||||
>>> accelerator = Accelerator()
|
||||
```
|
||||
|
||||
## Preparando a aceleração
|
||||
|
||||
Passe todos os objetos relevantes ao treinamento para o método [`prepare`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator.prepare).
|
||||
Isto inclui os DataLoaders de treino e evaluação, um modelo e um otimizador:
|
||||
|
||||
```py
|
||||
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
|
||||
... train_dataloader, eval_dataloader, model, optimizer
|
||||
... )
|
||||
```
|
||||
|
||||
## Backward
|
||||
|
||||
Por último, substitua o `loss.backward()` padrão em seu laço de treinamento com o método [`backward`](https://huggingface.co/docs/accelerate/accelerator.html#accelerate.Accelerator.backward) do 🤗 Accelerate:
|
||||
|
||||
```py
|
||||
>>> for epoch in range(num_epochs):
|
||||
... for batch in train_dataloader:
|
||||
... outputs = model(**batch)
|
||||
... loss = outputs.loss
|
||||
... accelerator.backward(loss)
|
||||
|
||||
... optimizer.step()
|
||||
... lr_scheduler.step()
|
||||
... optimizer.zero_grad()
|
||||
... progress_bar.update(1)
|
||||
```
|
||||
|
||||
Como se poder ver no seguinte código, só precisará adicionar quatro linhas de código ao seu laço de treinamento
|
||||
para habilitar o treinamento distribuído!
|
||||
|
||||
```diff
|
||||
+ from accelerate import Accelerator
|
||||
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
|
||||
|
||||
+ accelerator = Accelerator()
|
||||
|
||||
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
|
||||
optimizer = AdamW(model.parameters(), lr=3e-5)
|
||||
|
||||
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
|
||||
- model.to(device)
|
||||
|
||||
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
|
||||
+ train_dataloader, eval_dataloader, model, optimizer
|
||||
+ )
|
||||
|
||||
num_epochs = 3
|
||||
num_training_steps = num_epochs * len(train_dataloader)
|
||||
lr_scheduler = get_scheduler(
|
||||
"linear",
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=0,
|
||||
num_training_steps=num_training_steps
|
||||
)
|
||||
|
||||
progress_bar = tqdm(range(num_training_steps))
|
||||
|
||||
model.train()
|
||||
for epoch in range(num_epochs):
|
||||
for batch in train_dataloader:
|
||||
- batch = {k: v.to(device) for k, v in batch.items()}
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
- loss.backward()
|
||||
+ accelerator.backward(loss)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
progress_bar.update(1)
|
||||
```
|
||||
|
||||
## Treinamento
|
||||
|
||||
Quando tiver adicionado as linhas de código relevantes, inicie o treinamento por um script ou notebook como o Colab.
|
||||
|
||||
### Treinamento em um Script
|
||||
|
||||
Se estiver rodando seu treinamento em um Script, execute o seguinte comando para criar e guardar um arquivo de configuração:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
Comece o treinamento com:
|
||||
|
||||
```bash
|
||||
accelerate launch train.py
|
||||
```
|
||||
|
||||
### Treinamento em um Notebook
|
||||
|
||||
O 🤗 Accelerate pode rodar em um notebook, por exemplo, se estiver planejando usar as TPUs do Google Colab.
|
||||
Encapsule o código responsável pelo treinamento de uma função e passe-o ao `notebook_launcher`:
|
||||
|
||||
```py
|
||||
>>> from accelerate import notebook_launcher
|
||||
|
||||
>>> notebook_launcher(training_function)
|
||||
```
|
||||
|
||||
Para obter mais informações sobre o 🤗 Accelerate e suas numerosas funções, consulte a [documentación](https://huggingface.co/docs/accelerate/index.html).
|
||||
62
docs/source/pt/fast_tokenizers.mdx
Normal file
62
docs/source/pt/fast_tokenizers.mdx
Normal file
@ -0,0 +1,62 @@
|
||||
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Usando os Tokenizers do 🤗 Tokenizers
|
||||
|
||||
O [`PreTrainedTokenizerFast`] depende da biblioteca [🤗 Tokenizers](https://huggingface.co/docs/tokenizers). O Tokenizer obtido da biblioteca 🤗 Tokenizers pode ser carregado facilmente pelo 🤗 Transformers.
|
||||
|
||||
Antes de entrar nos detalhes, vamos começar criando um tokenizer fictício em algumas linhas:
|
||||
|
||||
```python
|
||||
>>> from tokenizers import Tokenizer
|
||||
>>> from tokenizers.models import BPE
|
||||
>>> from tokenizers.trainers import BpeTrainer
|
||||
>>> from tokenizers.pre_tokenizers import Whitespace
|
||||
|
||||
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
|
||||
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
|
||||
|
||||
>>> tokenizer.pre_tokenizer = Whitespace()
|
||||
>>> files = [...]
|
||||
>>> tokenizer.train(files, trainer)
|
||||
```
|
||||
|
||||
Agora temos um tokenizer treinado nos arquivos que foram definidos. Nós podemos continuar usando nessa execução ou salvar em um arquivo JSON para re-utilizar no futuro.
|
||||
|
||||
## Carregando diretamente de um objeto tokenizer
|
||||
|
||||
Vamos ver como aproveitar esse objeto tokenizer na biblioteca 🤗 Transformers. A classe [`PreTrainedTokenizerFast`] permite uma instanciação fácil, aceitando o objeto *tokenizer* instanciado como um argumento:
|
||||
|
||||
```python
|
||||
>>> from transformers import PreTrainedTokenizerFast
|
||||
|
||||
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
|
||||
```
|
||||
Esse objeto pode ser utilizado com todos os métodos compartilhados pelos tokenizers dos 🤗 Transformers! Vá para [a página do tokenizer](main_classes/tokenizer) para mais informações.
|
||||
|
||||
## Carregando de um arquivo JSON
|
||||
|
||||
Para carregar um tokenizer de um arquivo JSON vamos primeiro começar salvando nosso tokenizer:
|
||||
|
||||
```python
|
||||
>>> tokenizer.save("tokenizer.json")
|
||||
```
|
||||
|
||||
A pasta para qual salvamos esse arquivo pode ser passada para o método de inicialização do [`PreTrainedTokenizerFast`] usando o `tokenizer_file` parâmetro:
|
||||
|
||||
```python
|
||||
>>> from transformers import PreTrainedTokenizerFast
|
||||
|
||||
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
|
||||
```
|
||||
|
||||
Esse objeto pode ser utilizado com todos os métodos compartilhados pelos tokenizers dos 🤗 Transformers! Vá para [a página do tokenizer](main_classes/tokenizer) para mais informações.
|
||||
258
docs/source/pt/installation.mdx
Normal file
258
docs/source/pt/installation.mdx
Normal file
@ -0,0 +1,258 @@
|
||||
<!---
|
||||
Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
|
||||
# Guia de Instalação
|
||||
|
||||
Neste guia poderá encontrar informações para a instalação do 🤗 Transformers para qualquer biblioteca de
|
||||
Machine Learning com a qual esteja a trabalhar. Além disso, poderá encontrar informações sobre como gerar cachês e
|
||||
configurar o 🤗 Transformers para execução em modo offline (opcional).
|
||||
|
||||
🤗 Transformers foi testado com Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, e Flax. Para instalar a biblioteca de
|
||||
deep learning com que deseja trabalhar, siga as instruções correspondentes listadas a seguir:
|
||||
|
||||
* [PyTorch](https://pytorch.org/get-started/locally/)
|
||||
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip)
|
||||
* [Flax](https://flax.readthedocs.io/en/latest/)
|
||||
|
||||
## Instalação pelo Pip
|
||||
|
||||
É sugerido instalar o 🤗 Transformers num [ambiente virtual](https://docs.python.org/3/library/venv.html). Se precisar
|
||||
de mais informações sobre ambientes virtuais em Python, consulte este [guia](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
|
||||
Um ambiente virtual facilitará a manipulação e organização de projetos e evita problemas de compatibilidade entre dependências.
|
||||
|
||||
Comece criando um ambiente virtual no diretório do seu projeto:
|
||||
|
||||
```bash
|
||||
python -m venv .env
|
||||
```
|
||||
|
||||
E para ativar o ambiente virtual:
|
||||
|
||||
```bash
|
||||
source .env/bin/activate
|
||||
```
|
||||
|
||||
Agora É possível instalar o 🤗 Transformers com o comando a seguir:
|
||||
|
||||
```bash
|
||||
pip install transformers
|
||||
```
|
||||
|
||||
Somente para a CPU, é possível instalar o 🤗 Transformers e a biblioteca de deep learning respectiva apenas numa linha.
|
||||
|
||||
Por exemplo, para instalar o 🤗 Transformers e o PyTorch, digite:
|
||||
|
||||
```bash
|
||||
pip install transformers[torch]
|
||||
```
|
||||
|
||||
🤗 Transformers e TensorFlow 2.0:
|
||||
|
||||
```bash
|
||||
pip install transformers[tf-cpu]
|
||||
```
|
||||
|
||||
🤗 Transformers e Flax:
|
||||
|
||||
```bash
|
||||
pip install transformers[flax]
|
||||
```
|
||||
|
||||
Por último, verifique se o 🤗 Transformers foi instalado com sucesso usando o seguinte comando para baixar um modelo pré-treinado:
|
||||
|
||||
```bash
|
||||
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
|
||||
```
|
||||
|
||||
Em seguida, imprima um rótulo e sua pontuação:
|
||||
|
||||
```bash
|
||||
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
|
||||
```
|
||||
|
||||
## Instalação usando a fonte
|
||||
|
||||
Para instalar o 🤗 Transformers a partir da fonte use o seguinte comando:
|
||||
|
||||
```bash
|
||||
pip install git+https://github.com/huggingface/transformers
|
||||
```
|
||||
|
||||
O comando acima instalará a versão `master` mais atual em vez da última versão estável. A versão `master` é útil para
|
||||
utilizar os últimos updates contidos em 🤗 Transformers. Por exemplo, um erro recente pode ter sido corrigido somente
|
||||
após a última versão estável, antes que houvesse um novo lançamento. No entanto, há a possibilidade que a versão `master` não esteja estável.
|
||||
A equipa trata de mantér a versão `master` operacional e a maioria dos erros são resolvidos em poucas horas ou dias.
|
||||
Se encontrar quaisquer problemas, por favor abra um [Issue](https://github.com/huggingface/transformers/issues) para que o
|
||||
mesmo possa ser corrigido o mais rápido possível.
|
||||
|
||||
Verifique que o 🤗 Transformers está instalado corretamente usando o seguinte comando:
|
||||
|
||||
```bash
|
||||
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
|
||||
```
|
||||
|
||||
## Instalação editável
|
||||
|
||||
Uma instalação editável será necessária caso desejas um dos seguintes:
|
||||
* Usar a versão `master` do código fonte.
|
||||
* Contribuir ao 🤗 Transformers e precisa testar mudanças ao código.
|
||||
|
||||
Para tal, clone o repositório e instale o 🤗 Transformers com os seguintes comandos:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/transformers.git
|
||||
cd transformers
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
Estes comandos vão ligar o diretório para o qual foi clonado o repositório ao caminho de bibliotecas do Python.
|
||||
O Python agora buscará dentro dos arquivos que foram clonados além dos caminhos normais da biblioteca.
|
||||
Por exemplo, se os pacotes do Python se encontram instalados no caminho `~/anaconda3/envs/main/lib/python3.7/site-packages/`,
|
||||
o Python também buscará módulos no diretório onde clonamos o repositório `~/transformers/`.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
É necessário manter o diretório `transformers` se desejas continuar usando a biblioteca.
|
||||
|
||||
</Tip>
|
||||
|
||||
Assim, É possível atualizar sua cópia local para com a última versão do 🤗 Transformers com o seguinte comando:
|
||||
|
||||
```bash
|
||||
cd ~/transformers/
|
||||
git pull
|
||||
```
|
||||
|
||||
O ambiente de Python que foi criado para a instalação do 🤗 Transformers encontrará a versão `master` em execuções seguintes.
|
||||
|
||||
## Instalação usando o Conda
|
||||
|
||||
É possível instalar o 🤗 Transformers a partir do canal conda `huggingface` com o seguinte comando:
|
||||
|
||||
```bash
|
||||
conda install -c huggingface transformers
|
||||
```
|
||||
|
||||
## Configuração do Cachê
|
||||
|
||||
Os modelos pré-treinados são baixados e armazenados no cachê local, encontrado em `~/.cache/huggingface/transformers/`.
|
||||
Este é o diretório padrão determinado pela variável `TRANSFORMERS_CACHE` dentro do shell.
|
||||
No Windows, este diretório pré-definido é dado por `C:\Users\username\.cache\huggingface\transformers`.
|
||||
É possível mudar as variáveis dentro do shell em ordem de prioridade para especificar um diretório de cachê diferente:
|
||||
|
||||
1. Variável de ambiente do shell (por padrão): `TRANSFORMERS_CACHE`.
|
||||
2. Variável de ambiente do shell:`HF_HOME` + `transformers/`.
|
||||
3. Variável de ambiente do shell: `XDG_CACHE_HOME` + `/huggingface/transformers`.
|
||||
|
||||
<Tip>
|
||||
|
||||
O 🤗 Transformers usará as variáveis de ambiente do shell `PYTORCH_TRANSFORMERS_CACHE` ou `PYTORCH_PRETRAINED_BERT_CACHE`
|
||||
se estiver vindo de uma versão anterior da biblioteca que tenha configurado essas variáveis de ambiente, a menos que
|
||||
você especifique a variável de ambiente do shell `TRANSFORMERS_CACHE`.
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
## Modo Offline
|
||||
|
||||
O 🤗 Transformers também pode ser executado num ambiente de firewall ou fora da rede (offline) usando arquivos locais.
|
||||
Para tal, configure a variável de ambiente de modo que `TRANSFORMERS_OFFLINE=1`.
|
||||
|
||||
<Tip>
|
||||
|
||||
Você pode adicionar o [🤗 Datasets](https://huggingface.co/docs/datasets/) ao pipeline de treinamento offline declarando
|
||||
a variável de ambiente `HF_DATASETS_OFFLINE=1`.
|
||||
|
||||
</Tip>
|
||||
|
||||
Segue um exemplo de execução do programa numa rede padrão com firewall para instâncias externas, usando o seguinte comando:
|
||||
|
||||
```bash
|
||||
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
|
||||
```
|
||||
|
||||
Execute esse mesmo programa numa instância offline com o seguinte comando:
|
||||
|
||||
```bash
|
||||
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
|
||||
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
|
||||
```
|
||||
|
||||
O script agora deve ser executado sem travar ou expirar, pois procurará apenas por arquivos locais.
|
||||
|
||||
### Obtendo modelos e tokenizers para uso offline
|
||||
|
||||
Outra opção para usar o 🤗 Transformers offline é baixar os arquivos antes e depois apontar para o caminho local onde estão localizados. Existem três maneiras de fazer isso:
|
||||
|
||||
* Baixe um arquivo por meio da interface de usuário do [Model Hub](https://huggingface.co/models) clicando no ícone ↓.
|
||||
|
||||

|
||||
|
||||
|
||||
* Use o pipeline do [`PreTrainedModel.from_pretrained`] e [`PreTrainedModel.save_pretrained`]:
|
||||
1. Baixa os arquivos previamente com [`PreTrainedModel.from_pretrained`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
|
||||
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
|
||||
```
|
||||
|
||||
|
||||
2. Salve os arquivos em um diretório específico com [`PreTrainedModel.save_pretrained`]:
|
||||
|
||||
```py
|
||||
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
|
||||
>>> model.save_pretrained("./your/path/bigscience_t0")
|
||||
```
|
||||
|
||||
3. Quando estiver offline, acesse os arquivos com [`PreTrainedModel.from_pretrained`] do diretório especificado:
|
||||
|
||||
```py
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
|
||||
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
|
||||
```
|
||||
|
||||
* Baixando arquivos programaticamente com a biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub):
|
||||
|
||||
1. Instale a biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) em seu ambiente virtual:
|
||||
|
||||
```bash
|
||||
python -m pip install huggingface_hub
|
||||
```
|
||||
|
||||
2. Utiliza a função [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) para baixar um arquivo para um caminho específico. Por exemplo, o comando a seguir baixará o arquivo `config.json` para o modelo [T0](https://huggingface.co/bigscience/T0_3B) no caminho desejado:
|
||||
|
||||
```py
|
||||
>>> from huggingface_hub import hf_hub_download
|
||||
|
||||
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
|
||||
```
|
||||
|
||||
Depois que o arquivo for baixado e armazenado no cachê local, especifique seu caminho local para carregá-lo e usá-lo:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoConfig
|
||||
|
||||
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Para obter mais detalhes sobre como baixar arquivos armazenados no Hub, consulte a seção [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream).
|
||||
|
||||
</Tip>
|
||||
191
docs/source/pt/multilingual.mdx
Normal file
191
docs/source/pt/multilingual.mdx
Normal file
@ -0,0 +1,191 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Modelos multilinguísticos para inferência
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
Existem vários modelos multilinguísticos no 🤗 Transformers e seus usos para inferência diferem dos modelos monolíngues.
|
||||
No entanto, nem *todos* os usos dos modelos multilíngues são tão diferentes.
|
||||
Alguns modelos, como o [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased),
|
||||
podem ser usados como se fossem monolíngues. Este guia irá te ajudar a usar modelos multilíngues cujo uso difere
|
||||
para o propósito de inferência.
|
||||
|
||||
## XLM
|
||||
|
||||
O XLM tem dez checkpoints diferentes dos quais apenas um é monolíngue.
|
||||
Os nove checkpoints restantes do modelo são subdivididos em duas categorias:
|
||||
checkpoints que usam de language embeddings e os que não.
|
||||
|
||||
### XLM com language embeddings
|
||||
|
||||
Os seguintes modelos de XLM usam language embeddings para especificar a linguagem utilizada para a inferência.
|
||||
|
||||
- `xlm-mlm-ende-1024` (Masked language modeling, English-German)
|
||||
- `xlm-mlm-enfr-1024` (Masked language modeling, English-French)
|
||||
- `xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
|
||||
- `xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
|
||||
- `xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
|
||||
- `xlm-clm-enfr-1024` (Causal language modeling, English-French)
|
||||
- `xlm-clm-ende-1024` (Causal language modeling, English-German)
|
||||
|
||||
Os language embeddings são representados por um tensor de mesma dimensão que os `input_ids` passados ao modelo.
|
||||
Os valores destes tensores dependem do idioma utilizado e se identificam pelos atributos `lang2id` e `id2lang` do tokenizador.
|
||||
|
||||
Neste exemplo, carregamos o checkpoint `xlm-clm-enfr-1024`(Causal language modeling, English-French):
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
|
||||
|
||||
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
|
||||
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
|
||||
```
|
||||
|
||||
O atributo `lang2id` do tokenizador mostra os idiomas deste modelo e seus ids:
|
||||
|
||||
```py
|
||||
>>> print(tokenizer.lang2id)
|
||||
{'en': 0, 'fr': 1}
|
||||
```
|
||||
|
||||
Em seguida, cria-se um input de exemplo:
|
||||
|
||||
```py
|
||||
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
|
||||
```
|
||||
|
||||
Estabelece-se o id do idioma, por exemplo `"en"`, e utiliza-se o mesmo para definir a language embedding.
|
||||
A language embedding é um tensor preenchido com `0`, que é o id de idioma para o inglês.
|
||||
Este tensor deve ser do mesmo tamanho que os `input_ids`.
|
||||
|
||||
```py
|
||||
>>> language_id = tokenizer.lang2id["en"] # 0
|
||||
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
|
||||
|
||||
>>> # We reshape it to be of size (batch_size, sequence_length)
|
||||
>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
|
||||
```
|
||||
|
||||
Agora você pode passar os `input_ids` e a language embedding ao modelo:
|
||||
|
||||
```py
|
||||
>>> outputs = model(input_ids, langs=langs)
|
||||
```
|
||||
|
||||
O script [run_generation.py](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-generation/run_generation.py) pode gerar um texto com language embeddings utilizando os checkpoints `xlm-clm`.
|
||||
|
||||
### XLM sem language embeddings
|
||||
|
||||
Os seguintes modelos XLM não requerem o uso de language embeddings durante a inferência:
|
||||
|
||||
- `xlm-mlm-17-1280` (Modelagem de linguagem com máscara, 17 idiomas)
|
||||
- `xlm-mlm-100-1280` (Modelagem de linguagem com máscara, 100 idiomas)
|
||||
|
||||
Estes modelos são utilizados para representações genéricas de frase diferentemente dos checkpoints XLM anteriores.
|
||||
|
||||
## BERT
|
||||
|
||||
Os seguintes modelos do BERT podem ser utilizados para tarefas multilinguísticas:
|
||||
|
||||
- `bert-base-multilingual-uncased` (Modelagem de linguagem com máscara + Previsão de frases, 102 idiomas)
|
||||
- `bert-base-multilingual-cased` (Modelagem de linguagem com máscara + Previsão de frases, 104 idiomas)
|
||||
|
||||
Estes modelos não requerem language embeddings durante a inferência. Devem identificar a linguagem a partir
|
||||
do contexto e realizar a inferência em sequência.
|
||||
|
||||
## XLM-RoBERTa
|
||||
|
||||
Os seguintes modelos do XLM-RoBERTa podem ser utilizados para tarefas multilinguísticas:
|
||||
|
||||
- `xlm-roberta-base` (Modelagem de linguagem com máscara, 100 idiomas)
|
||||
- `xlm-roberta-large` Modelagem de linguagem com máscara, 100 idiomas)
|
||||
|
||||
O XLM-RoBERTa foi treinado com 2,5 TB de dados do CommonCrawl recém-criados e testados em 100 idiomas.
|
||||
Proporciona fortes vantagens sobre os modelos multilinguísticos publicados anteriormente como o mBERT e o XLM em tarefas
|
||||
subsequentes como a classificação, a rotulagem de sequências e à respostas a perguntas.
|
||||
|
||||
## M2M100
|
||||
|
||||
Os seguintes modelos de M2M100 podem ser utilizados para traduções multilinguísticas:
|
||||
|
||||
- `facebook/m2m100_418M` (Tradução)
|
||||
- `facebook/m2m100_1.2B` (Tradução)
|
||||
|
||||
Neste exemplo, o checkpoint `facebook/m2m100_418M` é carregado para traduzir do mandarim ao inglês. É possível
|
||||
estabelecer o idioma de origem no tokenizador:
|
||||
|
||||
```py
|
||||
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
|
||||
|
||||
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
|
||||
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
|
||||
|
||||
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
|
||||
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
|
||||
```
|
||||
|
||||
Tokenização do texto:
|
||||
|
||||
```py
|
||||
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
|
||||
```
|
||||
|
||||
O M2M100 força o id do idioma de destino como o primeiro token gerado para traduzir ao idioma de destino.
|
||||
É definido o `forced_bos_token_id` como `en` no método `generate` para traduzir ao inglês.
|
||||
|
||||
```py
|
||||
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
|
||||
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
|
||||
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
|
||||
```
|
||||
|
||||
## MBart
|
||||
|
||||
Os seguintes modelos do MBart podem ser utilizados para tradução multilinguística:
|
||||
|
||||
- `facebook/mbart-large-50-one-to-many-mmt` (Tradução automática multilinguística de um a vários, 50 idiomas)
|
||||
- `facebook/mbart-large-50-many-to-many-mmt` (Tradução automática multilinguística de vários a vários, 50 idiomas)
|
||||
- `facebook/mbart-large-50-many-to-one-mmt` (Tradução automática multilinguística vários a um, 50 idiomas)
|
||||
- `facebook/mbart-large-50` (Tradução multilinguística, 50 idiomas)
|
||||
- `facebook/mbart-large-cc25`
|
||||
|
||||
Neste exemplo, carrega-se o checkpoint `facebook/mbart-large-50-many-to-many-mmt` para traduzir do finlandês ao inglês.
|
||||
Pode-se definir o idioma de origem no tokenizador:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
||||
|
||||
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
|
||||
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
|
||||
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
|
||||
```
|
||||
|
||||
Tokenizando o texto:
|
||||
|
||||
```py
|
||||
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
|
||||
```
|
||||
|
||||
O MBart força o id do idioma de destino como o primeiro token gerado para traduzir ao idioma de destino.
|
||||
É definido o `forced_bos_token_id` como `en` no método `generate` para traduzir ao inglês.
|
||||
|
||||
```py
|
||||
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
|
||||
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
|
||||
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
|
||||
```
|
||||
|
||||
Se estiver usando o checkpoint `facebook/mbart-large-50-many-to-one-mmt` não será necessário forçar o id do idioma de destino
|
||||
como sendo o primeiro token generado, caso contrário a usagem é a mesma.
|
||||
153
docs/source/pt/pipeline_tutorial.mdx
Normal file
153
docs/source/pt/pipeline_tutorial.mdx
Normal file
@ -0,0 +1,153 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Pipelines para inferência
|
||||
|
||||
Um [pipeline] simplifica o uso dos modelos no [Model Hub](https://huggingface.co/models) para a inferência de uma diversidade de tarefas,
|
||||
como a geração de texto, a segmentação de imagens e a classificação de áudio.
|
||||
Inclusive, se não tem experiência com alguma modalidade específica ou não compreende o código que forma os modelos,
|
||||
pode usar eles mesmo assim com o [pipeline]! Este tutorial te ensinará a:
|
||||
|
||||
* Utilizar um [`pipeline`] para inferência.
|
||||
* Utilizar um tokenizador ou model específico.
|
||||
* Utilizar um [`pipeline`] para tarefas de áudio e visão computacional.
|
||||
|
||||
<Tip>
|
||||
|
||||
Acesse a documentação do [`pipeline`] para obter uma lista completa de tarefas possíveis.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Uso do pipeline
|
||||
|
||||
Mesmo que cada tarefa tenha um [`pipeline`] associado, é mais simples usar a abstração geral do [`pipeline`] que
|
||||
contém todos os pipelines das tarefas mais específicas.
|
||||
O [`pipeline`] carrega automaticamenta um modelo predeterminado e um tokenizador com capacidade de inferência para sua
|
||||
tarefa.
|
||||
|
||||
1. Comece carregando um [`pipeline`] e especifique uma tarefa de inferência:
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> generator = pipeline(task="text-generation")
|
||||
```
|
||||
|
||||
2. Passe seu dado de entrada, no caso um texto, ao [`pipeline`]:
|
||||
|
||||
```py
|
||||
>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
|
||||
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
|
||||
```
|
||||
|
||||
Se tiver mais de uma entrada, passe-a como uma lista:
|
||||
|
||||
```py
|
||||
>>> generator(
|
||||
... [
|
||||
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
|
||||
... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
|
||||
... ]
|
||||
... )
|
||||
```
|
||||
|
||||
Qualquer parâmetro adicional para a sua tarefa também pode ser incluído no [`pipeline`]. A tarefa `text-generation` tem um método
|
||||
[`~generation_utils.GenerationMixin.generate`] com vários parâmetros para controlar a saída.
|
||||
Por exemplo, se quiser gerar mais de uma saída, defina-a no parâmetro `num_return_sequences`:
|
||||
|
||||
```py
|
||||
>>> generator(
|
||||
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
|
||||
... num_return_sequences=2,
|
||||
... )
|
||||
```
|
||||
|
||||
### Selecionando um modelo e um tokenizador
|
||||
|
||||
O [`pipeline`] aceita qualquer modelo do [Model Hub](https://huggingface.co/models). Há rótulos adicionais no Model Hub
|
||||
que te permitem filtrar pelo modelo que gostaria de usar para sua tarefa. Uma vez que tiver escolhido o modelo apropriado,
|
||||
carregue-o com as classes `AutoModelFor` e [`AutoTokenizer'] correspondentes. Por exemplo, carregue a classe [`AutoModelForCausalLM`]
|
||||
para uma tarefa de modelagem de linguagem causal:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
|
||||
```
|
||||
|
||||
Crie uma [`pipeline`] para a sua tarefa e especifíque o modelo e o tokenizador que foram carregados:
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
|
||||
```
|
||||
|
||||
Passe seu texto de entrada ao [`pipeline`] para gerar algum texto:
|
||||
|
||||
```py
|
||||
>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
|
||||
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
|
||||
```
|
||||
|
||||
## Pipeline de audio
|
||||
|
||||
A flexibilidade do [`pipeline`] significa que também pode-se extender às tarefas de áudio.
|
||||
La flexibilidad de [`pipeline`] significa que también se puede extender a tareas de audio.
|
||||
|
||||
Por exemplo, classifiquemos a emoção de um breve fragmento do famoso discurso de John F. Kennedy /home/rzimmerdev/dev/transformers/docs/source/pt/pipeline_tutorial.mdx
|
||||
Encontre um modelo de [audio classification](https://huggingface.co/models?pipeline_tag=audio-classification) para
|
||||
reconhecimento de emoções no Model Hub e carregue-o usando o [`pipeline`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> audio_classifier = pipeline(
|
||||
... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
|
||||
... )
|
||||
```
|
||||
|
||||
Passe o arquivo de áudio ao [`pipeline`]:
|
||||
|
||||
```py
|
||||
>>> audio_classifier("jfk_moon_speech.wav")
|
||||
[{'label': 'calm', 'score': 0.13856211304664612},
|
||||
{'label': 'disgust', 'score': 0.13148026168346405},
|
||||
{'label': 'happy', 'score': 0.12635163962841034},
|
||||
{'label': 'angry', 'score': 0.12439591437578201},
|
||||
{'label': 'fearful', 'score': 0.12404385954141617}]
|
||||
```
|
||||
|
||||
## Pipeline de visão computacional
|
||||
|
||||
Finalmente, utilizar um [`pipeline`] para tarefas de visão é praticamente a mesma coisa.
|
||||
Especifique a sua tarefa de visão e passe a sua imagem ao classificador.
|
||||
A imagem pode ser um link ou uma rota local à imagem. Por exemplo, que espécie de gato está presente na imagem?
|
||||
|
||||

|
||||
|
||||
```py
|
||||
>>> from transformers import pipeline
|
||||
|
||||
>>> vision_classifier = pipeline(task="image-classification")
|
||||
>>> vision_classifier(
|
||||
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
|
||||
... )
|
||||
[{'label': 'lynx, catamount', 'score': 0.4403027892112732},
|
||||
{'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor',
|
||||
'score': 0.03433405980467796},
|
||||
{'label': 'snow leopard, ounce, Panthera uncia',
|
||||
'score': 0.032148055732250214},
|
||||
{'label': 'Egyptian cat', 'score': 0.02353910356760025},
|
||||
{'label': 'tiger cat', 'score': 0.023034192621707916}]
|
||||
```
|
||||
212
docs/source/pt/tasks/sequence_classification.mdx
Normal file
212
docs/source/pt/tasks/sequence_classification.mdx
Normal file
@ -0,0 +1,212 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Classificação de texto
|
||||
|
||||
<Youtube id="leNG9fN9FQU"/>
|
||||
|
||||
A classificação de texto é uma tarefa comum de NLP que atribui um rótulo ou classe a um texto. Existem muitas aplicações práticas de classificação de texto amplamente utilizadas em produção por algumas das maiores empresas da atualidade. Uma das formas mais populares de classificação de texto é a análise de sentimento, que atribui um rótulo como positivo, negativo ou neutro a um texto.
|
||||
|
||||
Este guia mostrará como realizar o fine-tuning do [DistilBERT](https://huggingface.co/distilbert-base-uncased) no conjunto de dados [IMDb](https://huggingface.co/datasets/imdb) para determinar se a crítica de filme é positiva ou negativa.
|
||||
|
||||
<Tip>
|
||||
|
||||
Consulte a [página de tarefas de classificação de texto](https://huggingface.co/tasks/text-classification) para obter mais informações sobre outras formas de classificação de texto e seus modelos, conjuntos de dados e métricas associados.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Carregue o conjunto de dados IMDb
|
||||
|
||||
Carregue o conjunto de dados IMDb utilizando a biblioteca 🤗 Datasets:
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> imdb = load_dataset("imdb")
|
||||
```
|
||||
|
||||
Em seguida, dê uma olhada em um exemplo:
|
||||
|
||||
```py
|
||||
>>> imdb["test"][0]
|
||||
{
|
||||
"label": 0,
|
||||
"text": "I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn't match the background, and painfully one-dimensional characters cannot be overcome with a 'sci-fi' setting. (I'm sure there are those of you out there who think Babylon 5 is good sci-fi TV. It's not. It's clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It's really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it's rubbish as they have to always say \"Gene Roddenberry's Earth...\" otherwise people would not continue watching. Roddenberry's ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again.",
|
||||
}
|
||||
```
|
||||
|
||||
Existem dois campos neste dataset:
|
||||
|
||||
- `text`: uma string contendo o texto da crítica do filme.
|
||||
- `label`: um valor que pode ser `0` para uma crítica negativa ou `1` para uma crítica positiva.
|
||||
|
||||
## Pré-processamento dos dados
|
||||
|
||||
Carregue o tokenizador do DistilBERT para processar o campo `text`:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
|
||||
```
|
||||
|
||||
Crie uma função de pré-processamento para tokenizar o campo `text` e truncar as sequências para que não sejam maiores que o comprimento máximo de entrada do DistilBERT:
|
||||
|
||||
```py
|
||||
>>> def preprocess_function(examples):
|
||||
... return tokenizer(examples["text"], truncation=True)
|
||||
```
|
||||
|
||||
Use a função [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) do 🤗 Datasets para aplicar a função de pré-processamento em todo o conjunto de dados. Você pode acelerar a função `map` definindo `batched=True` para processar vários elementos do conjunto de dados de uma só vez:
|
||||
|
||||
```py
|
||||
tokenized_imdb = imdb.map(preprocess_function, batched=True)
|
||||
```
|
||||
|
||||
Use o [`DataCollatorWithPadding`] para criar um batch de exemplos. Ele também *preencherá dinamicamente* seu texto até o comprimento do elemento mais longo em seu batch, para que os exemplos do batch tenham um comprimento uniforme. Embora seja possível preencher seu texto com a função `tokenizer` definindo `padding=True`, o preenchimento dinâmico utilizando um data collator é mais eficiente.
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
```py
|
||||
>>> from transformers import DataCollatorWithPadding
|
||||
|
||||
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
|
||||
```
|
||||
</pt>
|
||||
<tf>
|
||||
```py
|
||||
>>> from transformers import DataCollatorWithPadding
|
||||
|
||||
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
|
||||
```
|
||||
</tf>
|
||||
</frameworkcontent>
|
||||
|
||||
## Train
|
||||
|
||||
<frameworkcontent>
|
||||
<pt>
|
||||
Carregue o DistilBERT com [`AutoModelForSequenceClassification`] junto com o número de rótulos esperados:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
|
||||
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Se você não estiver familiarizado com o fine-tuning de um modelo com o [`Trainer`], dê uma olhada no tutorial básico [aqui](../training#finetune-with-trainer)!
|
||||
|
||||
</Tip>
|
||||
|
||||
Nesse ponto, restam apenas três passos:
|
||||
|
||||
1. Definir seus hiperparâmetros de treinamento em [`TrainingArguments`].
|
||||
2. Passar os argumentos de treinamento para o [`Trainer`] junto com o modelo, conjunto de dados, tokenizador e o data collator.
|
||||
3. Chamar a função [`~Trainer.train`] para executar o fine-tuning do seu modelo.
|
||||
|
||||
```py
|
||||
>>> training_args = TrainingArguments(
|
||||
... output_dir="./results",
|
||||
... learning_rate=2e-5,
|
||||
... per_device_train_batch_size=16,
|
||||
... per_device_eval_batch_size=16,
|
||||
... num_train_epochs=5,
|
||||
... weight_decay=0.01,
|
||||
... )
|
||||
|
||||
>>> trainer = Trainer(
|
||||
... model=model,
|
||||
... args=training_args,
|
||||
... train_dataset=tokenized_imdb["train"],
|
||||
... eval_dataset=tokenized_imdb["test"],
|
||||
... tokenizer=tokenizer,
|
||||
... data_collator=data_collator,
|
||||
... )
|
||||
|
||||
>>> trainer.train()
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
O [`Trainer`] aplicará o preenchimento dinâmico por padrão quando você definir o argumento `tokenizer` dele. Nesse caso, você não precisa especificar um data collator explicitamente.
|
||||
|
||||
</Tip>
|
||||
</pt>
|
||||
<tf>
|
||||
Para executar o fine-tuning de um modelo no TensorFlow, comece convertendo seu conjunto de dados para o formato `tf.data.Dataset` com [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Nessa execução você deverá especificar as entradas e rótulos (no parâmetro `columns`), se deseja embaralhar o conjunto de dados, o tamanho do batch e o data collator:
|
||||
|
||||
```py
|
||||
>>> tf_train_set = tokenized_imdb["train"].to_tf_dataset(
|
||||
... columns=["attention_mask", "input_ids", "label"],
|
||||
... shuffle=True,
|
||||
... batch_size=16,
|
||||
... collate_fn=data_collator,
|
||||
... )
|
||||
|
||||
>>> tf_validation_set = tokenized_imdb["test"].to_tf_dataset(
|
||||
... columns=["attention_mask", "input_ids", "label"],
|
||||
... shuffle=False,
|
||||
... batch_size=16,
|
||||
... collate_fn=data_collator,
|
||||
... )
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Se você não estiver familiarizado com o fine-tuning de um modelo com o Keras, dê uma olhada no tutorial básico [aqui](training#finetune-with-keras)!
|
||||
|
||||
</Tip>
|
||||
|
||||
Configure o otimizador e alguns hiperparâmetros de treinamento:
|
||||
|
||||
```py
|
||||
>>> from transformers import create_optimizer
|
||||
>>> import tensorflow as tf
|
||||
|
||||
>>> batch_size = 16
|
||||
>>> num_epochs = 5
|
||||
>>> batches_per_epoch = len(tokenized_imdb["train"]) // batch_size
|
||||
>>> total_train_steps = int(batches_per_epoch * num_epochs)
|
||||
>>> optimizer, schedule = create_optimizer(init_lr=2e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
|
||||
```
|
||||
|
||||
Carregue o DistilBERT com [`TFAutoModelForSequenceClassification`] junto com o número de rótulos esperados:
|
||||
|
||||
```py
|
||||
>>> from transformers import TFAutoModelForSequenceClassification
|
||||
|
||||
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
|
||||
```
|
||||
|
||||
Configure o modelo para treinamento com o método [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
|
||||
|
||||
```py
|
||||
>>> import tensorflow as tf
|
||||
|
||||
>>> model.compile(optimizer=optimizer)
|
||||
```
|
||||
|
||||
Chame o método [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para executar o fine-tuning do modelo:
|
||||
|
||||
```py
|
||||
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3)
|
||||
```
|
||||
</tf>
|
||||
</frameworkcontent>
|
||||
|
||||
<Tip>
|
||||
|
||||
Para obter um exemplo mais aprofundado de como executar o fine-tuning de um modelo para classificação de texto, dê uma olhada nesse [notebook utilizando PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb) ou nesse [notebook utilizando TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
|
||||
|
||||
</Tip>
|
||||
413
docs/source/pt/training.mdx
Normal file
413
docs/source/pt/training.mdx
Normal file
@ -0,0 +1,413 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Fine-tuning de um modelo pré-treinado
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
O uso de um modelo pré-treinado tem importantes vantagens. Redução do custo computacional, a pegada de carbono, e te
|
||||
permite utilizar modelos de última geração sem ter que treinar um novo desde o início.
|
||||
O 🤗 Transformers proporciona acesso a milhares de modelos pré-treinados numa ampla gama de tarefas.
|
||||
Quando utilizar um modelo pré-treinado, treine-o com um dataset específico para a sua tarefa.
|
||||
Isto é chamado de fine-tuning, uma técnica de treinamento incrivelmente poderosa. Neste tutorial faremos o fine-tuning
|
||||
a um modelo pré-treinado com um framework de Deep Learning de sua escolha:
|
||||
|
||||
* Fine-tuning de um modelo pré-treinado com o 🤗 Transformers [`Trainer`].
|
||||
* Fine-tuning de um modelo pré-treinado no TensorFlow com o Keras.
|
||||
* Fine-tuning de um modelo pré-treinado em PyTorch nativo.
|
||||
|
||||
<a id='data-processing'></a>
|
||||
|
||||
## Preparando um dataset
|
||||
|
||||
<Youtube id="_BZearw7f0w"/>
|
||||
|
||||
Antes de aplicar o fine-tuning a um modelo pré-treinado, baixe um dataset e prepare-o para o treinamento.
|
||||
O tutorial anterior ensinará a processar os dados para o treinamento, e então poderá ter a oportunidade de testar
|
||||
esse novo conhecimento em algo prático.
|
||||
|
||||
Comece carregando o dataset [Yelp Reviews](https://huggingface.co/datasets/yelp_review_full):
|
||||
|
||||
```py
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> dataset = load_dataset("yelp_review_full")
|
||||
>>> dataset[100]
|
||||
{'label': 0,
|
||||
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
|
||||
```
|
||||
|
||||
Como já sabe, é necessário ter um tokenizador para processar o texto e incluir uma estratégia de padding e truncamento,
|
||||
para manejar qualquer tamanho varíavel de sequência. Para processar o seu dataset em apenas um passo, utilize o método de
|
||||
🤗 Datasets [`map`](https://huggingface.co/docs/datasets/process.html#map) para aplicar uma função de preprocessamento sobre
|
||||
todo o dataset.
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoTokenizer
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
|
||||
|
||||
|
||||
>>> def tokenize_function(examples):
|
||||
... return tokenizer(examples["text"], padding="max_length", truncation=True)
|
||||
|
||||
|
||||
>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
|
||||
```
|
||||
|
||||
Se desejar, é possível criar um subconjunto menor do dataset completo para aplicar o fine-tuning e assim reduzir o tempo necessário.
|
||||
|
||||
```py
|
||||
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
|
||||
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
|
||||
```
|
||||
|
||||
<a id='trainer'></a>
|
||||
|
||||
## Fine-tuning com o `Trainer`
|
||||
|
||||
<Youtube id="nvBXf7s7vTI"/>
|
||||
|
||||
O 🤗 Transformers proporciona uma classe [`Trainer`] otimizada para o treinamento de modelos de 🤗 Transformers,
|
||||
facilitando os primeiros passos do treinamento sem a necessidade de escrever manualmente seu próprio ciclo.
|
||||
A API do [`Trainer`] suporta um grande conjunto de opções de treinamento e funcionalidades, como o logging,
|
||||
o gradient accumulation e o mixed precision.
|
||||
|
||||
Comece carregando seu modelo e especifique o número de labels de previsão.
|
||||
A partir do [Card Dataset](https://huggingface.co/datasets/yelp_review_full#data-fields) do Yelp Reveiw, que ja
|
||||
sabemos ter 5 labels usamos o seguinte código:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification
|
||||
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Você verá um alerta sobre alguns pesos pré-treinados que não estão sendo utilizados e que alguns pesos estão
|
||||
sendo inicializados aleatoriamente. Não se preocupe, essa mensagem é completamente normal.
|
||||
O header/cabeçário pré-treinado do modelo BERT é descartado e substitui-se por um header de classificação
|
||||
inicializado aleatoriamente. Assim, pode aplicar o fine-tuning a este novo header do modelo em sua tarefa
|
||||
de classificação de sequências fazendo um transfer learning do modelo pré-treinado.
|
||||
|
||||
</Tip>
|
||||
|
||||
### Hiperparâmetros de treinamento
|
||||
|
||||
Em seguida, crie uma classe [`TrainingArguments`] que contenha todos os hiperparâmetros que possam ser ajustados, assim
|
||||
como os indicadores para ativar as diferentes opções de treinamento. Para este tutorial, você pode começar o treinamento
|
||||
usando os [hiperparámetros](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) padrão,
|
||||
porém, sinta-se livre para experimentar com eles e encontrar uma configuração ótima.
|
||||
|
||||
Especifique onde salvar os checkpoints do treinamento:
|
||||
|
||||
```py
|
||||
>>> from transformers import TrainingArguments
|
||||
|
||||
>>> training_args = TrainingArguments(output_dir="test_trainer")
|
||||
```
|
||||
|
||||
### Métricas
|
||||
|
||||
O [`Trainer`] não avalia automaticamente o rendimento do modelo durante o treinamento. Será necessário passar ao
|
||||
[`Trainer`] uma função para calcular e fazer um diagnóstico sobre as métricas. A biblioteca 🤗 Datasets proporciona
|
||||
uma função de [`accuracy`](https://huggingface.co/metrics/accuracy) simples que pode ser carregada com a função
|
||||
`load_metric` (ver este [tutorial](https://huggingface.co/docs/datasets/metrics.html) para mais informações):
|
||||
|
||||
```py
|
||||
>>> import numpy as np
|
||||
>>> from datasets import load_metric
|
||||
|
||||
>>> metric = load_metric("accuracy")
|
||||
```
|
||||
|
||||
Defina a função `compute` dentro de `metric` para calcular a precisão de suas predições.
|
||||
Antes de passar suas predições ao `compute`, é necessário converter as predições à logits (lembre-se que
|
||||
todos os modelos de 🤗 Transformers retornam logits).
|
||||
|
||||
```py
|
||||
>>> def compute_metrics(eval_pred):
|
||||
... logits, labels = eval_pred
|
||||
... predictions = np.argmax(logits, axis=-1)
|
||||
... return metric.compute(predictions=predictions, references=labels)
|
||||
```
|
||||
|
||||
Se quiser controlar suas métricas de avaliação durante o fine-tuning, especifique o parâmetro `evaluation_strategy`
|
||||
em seus argumentos de treinamento para que o modelo leve em conta a métrica de avaliação ao final de cada época:
|
||||
|
||||
```py
|
||||
>>> from transformers import TrainingArguments
|
||||
|
||||
>>> training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
|
||||
```
|
||||
|
||||
### Trainer
|
||||
|
||||
Crie um objeto [`Trainer`] com seu modelo, argumentos de treinamento, conjuntos de dados de treinamento e de teste, e sua função de avaliação:
|
||||
|
||||
```py
|
||||
>>> trainer = Trainer(
|
||||
... model=model,
|
||||
... args=training_args,
|
||||
... train_dataset=small_train_dataset,
|
||||
... eval_dataset=small_eval_dataset,
|
||||
... compute_metrics=compute_metrics,
|
||||
... )
|
||||
```
|
||||
|
||||
Em seguida, aplique o fine-tuning a seu modelo chamado [`~transformers.Trainer.train`]:
|
||||
|
||||
```py
|
||||
>>> trainer.train()
|
||||
```
|
||||
|
||||
<a id='keras'></a>
|
||||
|
||||
## Fine-tuning com Keras
|
||||
|
||||
<Youtube id="rnTGBy2ax1c"/>
|
||||
|
||||
Os modelos de 🤗 Transformers também permitem realizar o treinamento com o TensorFlow com a API do Keras.
|
||||
Contudo, será necessário fazer algumas mudanças antes de realizar o fine-tuning.
|
||||
|
||||
### Conversão do dataset ao formato do TensorFlow
|
||||
|
||||
O [`DefaultDataCollator`] junta os tensores em um batch para que o modelo possa ser treinado em cima deles.
|
||||
Assegure-se de especificar os `return_tensors` para retornar os tensores do TensorFlow:
|
||||
|
||||
```py
|
||||
>>> from transformers import DefaultDataCollator
|
||||
|
||||
>>> data_collator = DefaultDataCollator(return_tensors="tf")
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
O [`Trainer`] utiliza [`DataCollatorWithPadding`] por padrão, então você não precisa especificar explicitamente um
|
||||
colador de dados (data collator).
|
||||
|
||||
</Tip>
|
||||
|
||||
Em seguida, converta os datasets tokenizados em datasets do TensorFlow com o método
|
||||
[`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset).
|
||||
Especifique suas entradas em `columns` e seu rótulo em `label_cols`:
|
||||
|
||||
```py
|
||||
>>> tf_train_dataset = small_train_dataset.to_tf_dataset(
|
||||
... columns=["attention_mask", "input_ids", "token_type_ids"],
|
||||
... label_cols=["labels"],
|
||||
... shuffle=True,
|
||||
... collate_fn=data_collator,
|
||||
... batch_size=8,
|
||||
... )
|
||||
|
||||
>>> tf_validation_dataset = small_eval_dataset.to_tf_dataset(
|
||||
... columns=["attention_mask", "input_ids", "token_type_ids"],
|
||||
... label_cols=["labels"],
|
||||
... shuffle=False,
|
||||
... collate_fn=data_collator,
|
||||
... batch_size=8,
|
||||
... )
|
||||
```
|
||||
|
||||
### Compilação e ajustes
|
||||
|
||||
Carregue um modelo do TensorFlow com o número esperado de rótulos:
|
||||
|
||||
```py
|
||||
>>> import tensorflow as tf
|
||||
>>> from transformers import TFAutoModelForSequenceClassification
|
||||
|
||||
>>> model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
|
||||
```
|
||||
|
||||
A seguir, compile e ajuste o fine-tuning a seu modelo com [`fit`](https://keras.io/api/models/model_training_apis/) como
|
||||
faria com qualquer outro modelo do Keras:
|
||||
|
||||
```py
|
||||
>>> model.compile(
|
||||
... optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),
|
||||
... loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
|
||||
... metrics=tf.metrics.SparseCategoricalAccuracy(),
|
||||
... )
|
||||
|
||||
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
|
||||
```
|
||||
|
||||
<a id='pytorch_native'></a>
|
||||
|
||||
## Fine-tune em PyTorch nativo
|
||||
|
||||
<Youtube id="Dh9CL8fyG80"/>
|
||||
|
||||
O [`Trainer`] se encarrega do ciclo de treinamento e permite aplicar o fine-tuning a um modelo em uma linha de código apenas.
|
||||
Para os usuários que preferirem escrever seu próprio ciclo de treinamento, também é possível aplicar o fine-tuning a um
|
||||
modelo de 🤗 Transformers em PyTorch nativo.
|
||||
|
||||
Neste momento, talvez ocorra a necessidade de reinicar seu notebook ou executar a seguinte linha de código para liberar
|
||||
memória:
|
||||
|
||||
```py
|
||||
del model
|
||||
del pytorch_model
|
||||
del trainer
|
||||
torch.cuda.empty_cache()
|
||||
```
|
||||
|
||||
Em sequência, faremos um post-processing manual do `tokenized_dataset` e assim prepará-lo para o treinamento.
|
||||
|
||||
1. Apague a coluna de `text` porque o modelo não aceita texto cru como entrada:
|
||||
|
||||
```py
|
||||
>>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
|
||||
```
|
||||
|
||||
2. Troque o nome da coluna `label` para `labels`, pois o modelo espera um argumento de mesmo nome:
|
||||
|
||||
```py
|
||||
>>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
|
||||
```
|
||||
|
||||
3. Defina o formato do dataset para retornar tensores do PyTorch no lugar de listas:
|
||||
|
||||
```py
|
||||
>>> tokenized_datasets.set_format("torch")
|
||||
```
|
||||
|
||||
Em sequência, crie um subconjunto menor do dataset, como foi mostrado anteriormente, para acelerá-lo o fine-tuning.
|
||||
|
||||
```py
|
||||
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
|
||||
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
|
||||
```
|
||||
|
||||
### DataLoader
|
||||
|
||||
Crie um `DataLoader` para seus datasets de treinamento e de teste para poder iterar sobre batches de dados:
|
||||
|
||||
```py
|
||||
>>> from torch.utils.data import DataLoader
|
||||
|
||||
>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
|
||||
>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
|
||||
```
|
||||
|
||||
Carregue seu modelo com o número de labels esperados:
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForSequenceClassification
|
||||
|
||||
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
|
||||
```
|
||||
|
||||
### Otimização e configuração do Learning Rate
|
||||
|
||||
Crie um otimizador e um learning rate para aplicar o fine-tuning ao modelo.
|
||||
Iremos utilizar o otimizador [`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) do PyTorch:
|
||||
|
||||
```py
|
||||
>>> from torch.optim import AdamW
|
||||
|
||||
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
|
||||
```
|
||||
|
||||
Defina o learning rate do [`Trainer`]:
|
||||
|
||||
```py
|
||||
>>> from transformers import get_scheduler
|
||||
|
||||
>>> num_epochs = 3
|
||||
>>> num_training_steps = num_epochs * len(train_dataloader)
|
||||
>>> lr_scheduler = get_scheduler(
|
||||
... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
|
||||
... )
|
||||
```
|
||||
|
||||
Por último, especifique o `device` do ambiente para utilizar uma GPU se tiver acesso à alguma. Caso contrário, o treinamento
|
||||
em uma CPU pode acabar levando várias horas em vez de minutos.
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
|
||||
>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
|
||||
>>> model.to(device)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Se necessário, você pode obter o acesso gratuito a uma GPU na núvem por meio de um notebook no
|
||||
[Colaboratory](https://colab.research.google.com/) ou [SageMaker StudioLab](https://studiolab.sagemaker.aws/)
|
||||
se não tiver esse recurso de forma local.
|
||||
|
||||
</Tip>
|
||||
|
||||
Perfeito, agora estamos prontos para começar o treinamento! 🥳
|
||||
Genial, ¡ahora estamos listos entrenar! 🥳
|
||||
|
||||
### Ciclo de treinamento
|
||||
|
||||
Para visualizar melhor o processo de treinamento, utilize a biblioteca [tqdm](https://tqdm.github.io/) para adicionar
|
||||
uma barra de progresso sobre o número de passos percorridos no treinamento atual:
|
||||
|
||||
```py
|
||||
>>> from tqdm.auto import tqdm
|
||||
|
||||
>>> progress_bar = tqdm(range(num_training_steps))
|
||||
|
||||
>>> model.train()
|
||||
>>> for epoch in range(num_epochs):
|
||||
... for batch in train_dataloader:
|
||||
... batch = {k: v.to(device) for k, v in batch.items()}
|
||||
... outputs = model(**batch)
|
||||
... loss = outputs.loss
|
||||
... loss.backward()
|
||||
|
||||
... optimizer.step()
|
||||
... lr_scheduler.step()
|
||||
... optimizer.zero_grad()
|
||||
... progress_bar.update(1)
|
||||
```
|
||||
|
||||
### Métricas
|
||||
|
||||
Da mesma forma que é necessário adicionar uma função de avaliação ao [`Trainer`], é necessário fazer o mesmo quando
|
||||
escrevendo o próprio ciclo de treinamento. Contudo, em vez de calcular e retornar a métrica final de cada época,
|
||||
você deverá adicionar todos os batches com [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=add_batch#datasets.Metric.add_batch)
|
||||
e calcular a métrica apenas no final.
|
||||
|
||||
```py
|
||||
>>> metric = load_metric("accuracy")
|
||||
>>> model.eval()
|
||||
>>> for batch in eval_dataloader:
|
||||
... batch = {k: v.to(device) for k, v in batch.items()}
|
||||
... with torch.no_grad():
|
||||
... outputs = model(**batch)
|
||||
|
||||
... logits = outputs.logits
|
||||
... predictions = torch.argmax(logits, dim=-1)
|
||||
... metric.add_batch(predictions=predictions, references=batch["labels"])
|
||||
|
||||
>>> metric.compute()
|
||||
```
|
||||
|
||||
<a id='additional-resources'></a>
|
||||
|
||||
## Recursos adicionais
|
||||
|
||||
Para mais exemplos de fine-tuning acesse:
|
||||
|
||||
- [🤗 Transformers Examples](https://github.com/huggingface/transformers/tree/main/examples) inclui scripts
|
||||
para treinas tarefas comuns de NLP em PyTorch e TensorFlow.
|
||||
|
||||
- [🤗 Transformers Notebooks](notebooks) contém vários notebooks sobre como aplicar o fine-tuning a um modelo
|
||||
para tarefas específicas no PyTorch e TensorFlow.
|
||||
@ -42,14 +42,18 @@ class ModelArguments:
|
||||
)
|
||||
encoder_model_name_or_path: str = field(
|
||||
metadata={
|
||||
"help": "The encoder model checkpoint for weights initialization."
|
||||
"Don't set if you want to train an encoder model from scratch."
|
||||
"help": (
|
||||
"The encoder model checkpoint for weights initialization."
|
||||
"Don't set if you want to train an encoder model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
decoder_model_name_or_path: str = field(
|
||||
metadata={
|
||||
"help": "The decoder model checkpoint for weights initialization."
|
||||
"Don't set if you want to train a decoder model from scratch."
|
||||
"help": (
|
||||
"The decoder model checkpoint for weights initialization."
|
||||
"Don't set if you want to train a decoder model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
encoder_config_name: Optional[str] = field(
|
||||
|
||||
@ -175,14 +175,19 @@ class ModelArguments:
|
||||
dtype: Optional[str] = field(
|
||||
default="float32",
|
||||
metadata={
|
||||
"help": "Floating-point format in which the model weights should be initialized and trained. Choose one of `[float32, float16, bfloat16]`."
|
||||
"help": (
|
||||
"Floating-point format in which the model weights should be initialized and trained. Choose one of"
|
||||
" `[float32, float16, bfloat16]`."
|
||||
)
|
||||
},
|
||||
)
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -222,38 +227,48 @@ class DataTrainingArguments:
|
||||
max_target_length: Optional[int] = field(
|
||||
default=128,
|
||||
metadata={
|
||||
"help": "The maximum total sequence length for target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total sequence length for target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
val_max_target_length: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The maximum total sequence length for validation target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`."
|
||||
"This argument is also used to override the `max_length` param of `model.generate`, which is used "
|
||||
"during evaluation."
|
||||
"help": (
|
||||
"The maximum total sequence length for validation target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`."
|
||||
"This argument is also used to override the `max_length` param of `model.generate`, which is used "
|
||||
"during evaluation."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_predict_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
preprocessing_num_workers: Optional[int] = field(
|
||||
@ -266,8 +281,10 @@ class DataTrainingArguments:
|
||||
num_beams: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "Number of beams to use for evaluation. This argument will be passed to `model.generate`, "
|
||||
"which is used during evaluation."
|
||||
"help": (
|
||||
"Number of beams to use for evaluation. This argument will be passed to `model.generate`, "
|
||||
"which is used during evaluation."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
@ -623,7 +640,7 @@ def main():
|
||||
eval_batch_size = int(training_args.per_device_eval_batch_size) * jax.device_count()
|
||||
if training_args.block_size % train_batch_size > 0 or training_args.block_size % eval_batch_size > 0:
|
||||
raise ValueError(
|
||||
f"`training_args.block_size` needs to be a multiple of the global train/eval batch size."
|
||||
"`training_args.block_size` needs to be a multiple of the global train/eval batch size."
|
||||
f"Got {training_args.block_size}, {train_batch_size} and {eval_batch_size} respectively instead."
|
||||
)
|
||||
|
||||
@ -1136,7 +1153,7 @@ def main():
|
||||
)
|
||||
|
||||
# train
|
||||
for (batch_idx, _) in enumerate(tqdm(range(steps_per_epoch), desc="Training...", position=1, leave=False)):
|
||||
for batch_idx, _ in enumerate(tqdm(range(steps_per_epoch), desc="Training...", position=1, leave=False)):
|
||||
|
||||
cur_step += 1
|
||||
batch = next(train_batches)
|
||||
@ -1150,7 +1167,10 @@ def main():
|
||||
if training_args.logging_steps > 0 and cur_step % training_args.logging_steps == 0:
|
||||
|
||||
_train_metric = unreplicate(train_metric)
|
||||
desc = f"Epoch... ({epoch + 1}/{num_epochs} | Step: {cur_step} | Loss: {_train_metric['loss']} | Learning Rate: {_train_metric['learning_rate']} | Time per step: {time_per_step})"
|
||||
desc = (
|
||||
f"Epoch... ({epoch + 1}/{num_epochs} | Step: {cur_step} | Loss: {_train_metric['loss']} |"
|
||||
f" Learning Rate: {_train_metric['learning_rate']} | Time per step: {time_per_step})"
|
||||
)
|
||||
epochs.desc = desc
|
||||
epochs.write(desc)
|
||||
|
||||
|
||||
@ -138,8 +138,9 @@ class ModelArguments:
|
||||
model_name_or_path: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The model checkpoint for weights initialization."
|
||||
"Don't set if you want to train a model from scratch."
|
||||
"help": (
|
||||
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
model_type: Optional[str] = field(
|
||||
@ -162,14 +163,19 @@ class ModelArguments:
|
||||
dtype: Optional[str] = field(
|
||||
default="float32",
|
||||
metadata={
|
||||
"help": "Floating-point format in which the model weights should be initialized and trained. Choose one of `[float32, float16, bfloat16]`."
|
||||
"help": (
|
||||
"Floating-point format in which the model weights should be initialized and trained. Choose one of"
|
||||
" `[float32, float16, bfloat16]`."
|
||||
)
|
||||
},
|
||||
)
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -194,15 +200,19 @@ class DataTrainingArguments:
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
@ -217,9 +227,11 @@ class DataTrainingArguments:
|
||||
block_size: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "Optional input sequence length after tokenization. "
|
||||
"The training dataset will be truncated in block of this size for training. "
|
||||
"Default to the model max input length for single sentence inputs (take into account special tokens)."
|
||||
"help": (
|
||||
"Optional input sequence length after tokenization. "
|
||||
"The training dataset will be truncated in block of this size for training. "
|
||||
"Default to the model max input length for single sentence inputs (take into account special tokens)."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
@ -505,7 +517,8 @@ def main():
|
||||
# clm input could be much much longer than block_size
|
||||
if "Token indices sequence length is longer than the" in cl.out:
|
||||
tok_logger.warning(
|
||||
"^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits before being passed to the model."
|
||||
"^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits"
|
||||
" before being passed to the model."
|
||||
)
|
||||
return output
|
||||
|
||||
@ -735,7 +748,8 @@ def main():
|
||||
write_train_metric(summary_writer, train_metrics, train_time, cur_step)
|
||||
|
||||
epochs.write(
|
||||
f"Step... ({cur_step} | Loss: {train_metric['loss'].mean()}, Learning Rate: {train_metric['learning_rate'].mean()})"
|
||||
f"Step... ({cur_step} | Loss: {train_metric['loss'].mean()}, Learning Rate:"
|
||||
f" {train_metric['learning_rate'].mean()})"
|
||||
)
|
||||
|
||||
train_metrics = []
|
||||
@ -762,7 +776,10 @@ def main():
|
||||
eval_metrics["perplexity"] = float("inf")
|
||||
|
||||
# Print metrics and update progress bar
|
||||
desc = f"Step... ({cur_step} | Eval Loss: {eval_metrics['loss']} | Eval Perplexity: {eval_metrics['perplexity']})"
|
||||
desc = (
|
||||
f"Step... ({cur_step} | Eval Loss: {eval_metrics['loss']} | Eval Perplexity:"
|
||||
f" {eval_metrics['perplexity']})"
|
||||
)
|
||||
epochs.write(desc)
|
||||
epochs.desc = desc
|
||||
|
||||
|
||||
@ -136,8 +136,9 @@ class ModelArguments:
|
||||
model_name_or_path: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The model checkpoint for weights initialization."
|
||||
"Don't set if you want to train a model from scratch."
|
||||
"help": (
|
||||
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
model_type: Optional[str] = field(
|
||||
@ -160,14 +161,19 @@ class ModelArguments:
|
||||
dtype: Optional[str] = field(
|
||||
default="float32",
|
||||
metadata={
|
||||
"help": "Floating-point format in which the model weights should be initialized and trained. Choose one of `[float32, float16, bfloat16]`."
|
||||
"help": (
|
||||
"Floating-point format in which the model weights should be initialized and trained. Choose one of"
|
||||
" `[float32, float16, bfloat16]`."
|
||||
)
|
||||
},
|
||||
)
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -209,8 +215,10 @@ class DataTrainingArguments:
|
||||
max_seq_length: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated. Default to the max input length of the model."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated. Default to the max input length of the model."
|
||||
)
|
||||
},
|
||||
)
|
||||
preprocessing_num_workers: Optional[int] = field(
|
||||
@ -223,8 +231,10 @@ class DataTrainingArguments:
|
||||
pad_to_max_length: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Whether to pad all samples to `max_seq_length`. "
|
||||
"If False, will pad the samples dynamically when batching to the maximum length in the batch."
|
||||
"help": (
|
||||
"Whether to pad all samples to `max_seq_length`. "
|
||||
"If False, will pad the samples dynamically when batching to the maximum length in the batch."
|
||||
)
|
||||
},
|
||||
)
|
||||
line_by_line: bool = field(
|
||||
@ -764,7 +774,8 @@ def main():
|
||||
write_train_metric(summary_writer, train_metrics, train_time, cur_step)
|
||||
|
||||
epochs.write(
|
||||
f"Step... ({cur_step} | Loss: {train_metric['loss']}, Learning Rate: {train_metric['learning_rate']})"
|
||||
f"Step... ({cur_step} | Loss: {train_metric['loss']}, Learning Rate:"
|
||||
f" {train_metric['learning_rate']})"
|
||||
)
|
||||
|
||||
train_metrics = []
|
||||
|
||||
@ -135,8 +135,9 @@ class ModelArguments:
|
||||
model_name_or_path: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The model checkpoint for weights initialization."
|
||||
"Don't set if you want to train a model from scratch."
|
||||
"help": (
|
||||
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
model_type: Optional[str] = field(
|
||||
@ -159,14 +160,19 @@ class ModelArguments:
|
||||
dtype: Optional[str] = field(
|
||||
default="float32",
|
||||
metadata={
|
||||
"help": "Floating-point format in which the model weights should be initialized and trained. Choose one of `[float32, float16, bfloat16]`."
|
||||
"help": (
|
||||
"Floating-point format in which the model weights should be initialized and trained. Choose one of"
|
||||
" `[float32, float16, bfloat16]`."
|
||||
)
|
||||
},
|
||||
)
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -208,7 +214,10 @@ class DataTrainingArguments:
|
||||
max_seq_length: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization and masking. Sequences longer than this will be truncated. Default to the max input length of the model."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization and masking. Sequences longer than this"
|
||||
" will be truncated. Default to the max input length of the model."
|
||||
)
|
||||
},
|
||||
)
|
||||
preprocessing_num_workers: Optional[int] = field(
|
||||
@ -337,12 +346,14 @@ class FlaxDataCollatorForT5MLM:
|
||||
|
||||
if batch["input_ids"].shape[-1] != self.input_length:
|
||||
raise ValueError(
|
||||
f"`input_ids` are incorrectly preprocessed. `input_ids` length is {batch['input_ids'].shape[-1]}, but should be {self.target_length}."
|
||||
f"`input_ids` are incorrectly preprocessed. `input_ids` length is {batch['input_ids'].shape[-1]}, but"
|
||||
f" should be {self.target_length}."
|
||||
)
|
||||
|
||||
if batch["labels"].shape[-1] != self.target_length:
|
||||
raise ValueError(
|
||||
f"`labels` are incorrectly preprocessed. `labels` length is {batch['labels'].shape[-1]}, but should be {self.target_length}."
|
||||
f"`labels` are incorrectly preprocessed. `labels` length is {batch['labels'].shape[-1]}, but should be"
|
||||
f" {self.target_length}."
|
||||
)
|
||||
|
||||
# to check that tokens are correctly preprocessed, one can run `self.tokenizer.batch_decode(input_ids)` and `self.tokenizer.batch_decode(labels)` here...
|
||||
@ -884,7 +895,8 @@ def main():
|
||||
write_train_metric(summary_writer, train_metrics, train_time, cur_step)
|
||||
|
||||
epochs.write(
|
||||
f"Step... ({cur_step} | Loss: {train_metric['loss'].mean()}, Learning Rate: {train_metric['learning_rate'].mean()})"
|
||||
f"Step... ({cur_step} | Loss: {train_metric['loss'].mean()}, Learning Rate:"
|
||||
f" {train_metric['learning_rate'].mean()})"
|
||||
)
|
||||
|
||||
train_metrics = []
|
||||
|
||||
@ -60,7 +60,7 @@ from utils_qa import postprocess_qa_predictions
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
Array = Any
|
||||
Dataset = datasets.arrow_dataset.Dataset
|
||||
@ -157,14 +157,19 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
dtype: Optional[str] = field(
|
||||
default="float32",
|
||||
metadata={
|
||||
"help": "Floating-point format in which the model weights should be initialized and trained. Choose one of `[float32, float16, bfloat16]`."
|
||||
"help": (
|
||||
"Floating-point format in which the model weights should be initialized and trained. Choose one of"
|
||||
" `[float32, float16, bfloat16]`."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -200,37 +205,46 @@ class DataTrainingArguments:
|
||||
max_seq_length: int = field(
|
||||
default=384,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
pad_to_max_length: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Whether to pad all samples to `max_seq_length`. "
|
||||
"If False, will pad the samples dynamically when batching to the maximum length in the batch (which can "
|
||||
"be faster on GPU but will be slower on TPU)."
|
||||
"help": (
|
||||
"Whether to pad all samples to `max_seq_length`. If False, will pad the samples dynamically when"
|
||||
" batching to the maximum length in the batch (which can be faster on GPU but will be slower on TPU)."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_predict_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
version_2_with_negative: bool = field(
|
||||
@ -239,9 +253,11 @@ class DataTrainingArguments:
|
||||
null_score_diff_threshold: float = field(
|
||||
default=0.0,
|
||||
metadata={
|
||||
"help": "The threshold used to select the null answer: if the best answer has a score that is less than "
|
||||
"the score of the null answer minus this threshold, the null answer is selected for this example. "
|
||||
"Only useful when `version_2_with_negative=True`."
|
||||
"help": (
|
||||
"The threshold used to select the null answer: if the best answer has a score that is less than "
|
||||
"the score of the null answer minus this threshold, the null answer is selected for this example. "
|
||||
"Only useful when `version_2_with_negative=True`."
|
||||
)
|
||||
},
|
||||
)
|
||||
doc_stride: int = field(
|
||||
@ -255,8 +271,10 @@ class DataTrainingArguments:
|
||||
max_answer_length: int = field(
|
||||
default=30,
|
||||
metadata={
|
||||
"help": "The maximum length of an answer that can be generated. This is needed because the start "
|
||||
"and end predictions are not conditioned on one another."
|
||||
"help": (
|
||||
"The maximum length of an answer that can be generated. This is needed because the start "
|
||||
"and end predictions are not conditioned on one another."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -498,9 +516,9 @@ def main():
|
||||
# region Tokenizer check: this script requires a fast tokenizer.
|
||||
if not isinstance(tokenizer, PreTrainedTokenizerFast):
|
||||
raise ValueError(
|
||||
"This example script only works for models that have a fast tokenizer. Checkout the big table of models "
|
||||
"at https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet this "
|
||||
"requirement"
|
||||
"This example script only works for models that have a fast tokenizer. Checkout the big table of models at"
|
||||
" https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet"
|
||||
" this requirement"
|
||||
)
|
||||
# endregion
|
||||
|
||||
@ -928,7 +946,8 @@ def main():
|
||||
write_train_metric(summary_writer, train_metrics, train_time, cur_step)
|
||||
|
||||
epochs.write(
|
||||
f"Step... ({cur_step}/{total_steps} | Training Loss: {train_metric['loss']}, Learning Rate: {train_metric['learning_rate']})"
|
||||
f"Step... ({cur_step}/{total_steps} | Training Loss: {train_metric['loss']}, Learning Rate:"
|
||||
f" {train_metric['learning_rate']})"
|
||||
)
|
||||
|
||||
train_metrics = []
|
||||
|
||||
@ -149,8 +149,9 @@ class ModelArguments:
|
||||
model_name_or_path: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The model checkpoint for weights initialization."
|
||||
"Don't set if you want to train a model from scratch."
|
||||
"help": (
|
||||
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
model_type: Optional[str] = field(
|
||||
@ -173,14 +174,19 @@ class ModelArguments:
|
||||
dtype: Optional[str] = field(
|
||||
default="float32",
|
||||
metadata={
|
||||
"help": "Floating-point format in which the model weights should be initialized and trained. Choose one of `[float32, float16, bfloat16]`."
|
||||
"help": (
|
||||
"Floating-point format in which the model weights should be initialized and trained. Choose one of"
|
||||
" `[float32, float16, bfloat16]`."
|
||||
)
|
||||
},
|
||||
)
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -217,45 +223,57 @@ class DataTrainingArguments:
|
||||
max_source_length: Optional[int] = field(
|
||||
default=1024,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_target_length: Optional[int] = field(
|
||||
default=128,
|
||||
metadata={
|
||||
"help": "The maximum total sequence length for target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total sequence length for target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
val_max_target_length: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The maximum total sequence length for validation target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`."
|
||||
"This argument is also used to override the `max_length` param of `model.generate`, which is used "
|
||||
"during evaluation."
|
||||
"help": (
|
||||
"The maximum total sequence length for validation target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`."
|
||||
"This argument is also used to override the `max_length` param of `model.generate`, which is used "
|
||||
"during evaluation."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_predict_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
preprocessing_num_workers: Optional[int] = field(
|
||||
@ -271,8 +289,10 @@ class DataTrainingArguments:
|
||||
num_beams: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "Number of beams to use for evaluation. This argument will be passed to `model.generate`, "
|
||||
"which is used during evaluation."
|
||||
"help": (
|
||||
"Number of beams to use for evaluation. This argument will be passed to `model.generate`, "
|
||||
"which is used during evaluation."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
@ -831,7 +851,8 @@ def main():
|
||||
train_metric = unreplicate(train_metric)
|
||||
|
||||
epochs.write(
|
||||
f"Epoch... ({epoch + 1}/{num_epochs} | Loss: {train_metric['loss']}, Learning Rate: {train_metric['learning_rate']})"
|
||||
f"Epoch... ({epoch + 1}/{num_epochs} | Loss: {train_metric['loss']}, Learning Rate:"
|
||||
f" {train_metric['learning_rate']})"
|
||||
)
|
||||
|
||||
# ======================== Evaluating ==============================
|
||||
|
||||
@ -53,7 +53,7 @@ from transformers.utils import check_min_version, get_full_repo_name
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
Array = Any
|
||||
Dataset = datasets.arrow_dataset.Dataset
|
||||
@ -103,8 +103,10 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -148,29 +150,37 @@ class DataTrainingArguments:
|
||||
max_seq_length: int = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. If set, sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. If set, sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_predict_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -585,7 +595,8 @@ def main():
|
||||
write_train_metric(summary_writer, train_metrics, train_time, cur_step)
|
||||
|
||||
epochs.write(
|
||||
f"Step... ({cur_step}/{total_steps} | Training Loss: {train_metric['loss']}, Learning Rate: {train_metric['learning_rate']})"
|
||||
f"Step... ({cur_step}/{total_steps} | Training Loss: {train_metric['loss']}, Learning Rate:"
|
||||
f" {train_metric['learning_rate']})"
|
||||
)
|
||||
|
||||
train_metrics = []
|
||||
|
||||
@ -53,7 +53,7 @@ from transformers.utils.versions import require_version
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
|
||||
|
||||
@ -150,8 +150,10 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -196,36 +198,46 @@ class DataTrainingArguments:
|
||||
max_seq_length: int = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. If set, sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. If set, sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_predict_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
label_all_tokens: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Whether to put the label for one word on all tokens of generated by that word or just on the "
|
||||
"one (in which case the other tokens will have a padding index)."
|
||||
"help": (
|
||||
"Whether to put the label for one word on all tokens of generated by that word or just on the "
|
||||
"one (in which case the other tokens will have a padding index)."
|
||||
)
|
||||
},
|
||||
)
|
||||
return_entity_level_metrics: bool = field(
|
||||
@ -693,7 +705,8 @@ def main():
|
||||
write_train_metric(summary_writer, train_metrics, train_time, cur_step)
|
||||
|
||||
epochs.write(
|
||||
f"Step... ({cur_step}/{total_steps} | Training Loss: {train_metric['loss']}, Learning Rate: {train_metric['learning_rate']})"
|
||||
f"Step... ({cur_step}/{total_steps} | Training Loss: {train_metric['loss']}, Learning Rate:"
|
||||
f" {train_metric['learning_rate']})"
|
||||
)
|
||||
|
||||
train_metrics = []
|
||||
@ -744,7 +757,8 @@ def main():
|
||||
logger.info(f"Step... ({cur_step}/{total_steps} | Validation metrics: {eval_metrics}")
|
||||
else:
|
||||
logger.info(
|
||||
f"Step... ({cur_step}/{total_steps} | Validation f1: {eval_metrics['f1']}, Validation Acc: {eval_metrics['accuracy']})"
|
||||
f"Step... ({cur_step}/{total_steps} | Validation f1: {eval_metrics['f1']}, Validation Acc:"
|
||||
f" {eval_metrics['accuracy']})"
|
||||
)
|
||||
|
||||
if has_tensorboard and jax.process_index() == 0:
|
||||
|
||||
@ -134,8 +134,9 @@ class ModelArguments:
|
||||
model_name_or_path: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The model checkpoint for weights initialization."
|
||||
"Don't set if you want to train a model from scratch."
|
||||
"help": (
|
||||
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
model_type: Optional[str] = field(
|
||||
@ -151,14 +152,19 @@ class ModelArguments:
|
||||
dtype: Optional[str] = field(
|
||||
default="float32",
|
||||
metadata={
|
||||
"help": "Floating-point format in which the model weights should be initialized and trained. Choose one of `[float32, float16, bfloat16]`."
|
||||
"help": (
|
||||
"Floating-point format in which the model weights should be initialized and trained. Choose one of"
|
||||
" `[float32, float16, bfloat16]`."
|
||||
)
|
||||
},
|
||||
)
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -179,15 +185,19 @@ class DataTrainingArguments:
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
@ -509,7 +519,8 @@ def main():
|
||||
|
||||
train_step_progress_bar.close()
|
||||
epochs.write(
|
||||
f"Epoch... ({epoch + 1}/{num_epochs} | Loss: {train_metric['loss']}, Learning Rate: {train_metric['learning_rate']})"
|
||||
f"Epoch... ({epoch + 1}/{num_epochs} | Loss: {train_metric['loss']}, Learning Rate:"
|
||||
f" {train_metric['learning_rate']})"
|
||||
)
|
||||
|
||||
# ======================== Evaluating ==============================
|
||||
|
||||
@ -78,8 +78,10 @@ class DataTrainingArguments:
|
||||
max_seq_length: int = field(
|
||||
default=128,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
@ -102,7 +104,8 @@ def main():
|
||||
and not training_args.overwrite_output_dir
|
||||
):
|
||||
raise ValueError(
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use --overwrite_output_dir to overcome."
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
|
||||
" --overwrite_output_dir to overcome."
|
||||
)
|
||||
|
||||
# Setup logging
|
||||
|
||||
@ -182,7 +182,7 @@ if is_tf_available():
|
||||
)
|
||||
|
||||
def gen():
|
||||
for (ex_index, ex) in tqdm.tqdm(enumerate(self.features), desc="convert examples to features"):
|
||||
for ex_index, ex in tqdm.tqdm(enumerate(self.features), desc="convert examples to features"):
|
||||
if ex_index % 10000 == 0:
|
||||
logger.info("Writing example %d of %d" % (ex_index, len(examples)))
|
||||
|
||||
@ -297,7 +297,7 @@ class RaceProcessor(DataProcessor):
|
||||
def _create_examples(self, lines, set_type):
|
||||
"""Creates examples for the training and dev sets."""
|
||||
examples = []
|
||||
for (_, data_raw) in enumerate(lines):
|
||||
for _, data_raw in enumerate(lines):
|
||||
race_id = "%s-%s" % (set_type, data_raw["race_id"])
|
||||
article = data_raw["article"]
|
||||
for i in range(len(data_raw["answers"])):
|
||||
@ -518,7 +518,7 @@ def convert_examples_to_features(
|
||||
label_map = {label: i for i, label in enumerate(label_list)}
|
||||
|
||||
features = []
|
||||
for (ex_index, example) in tqdm.tqdm(enumerate(examples), desc="convert examples to features"):
|
||||
for ex_index, example in tqdm.tqdm(enumerate(examples), desc="convert examples to features"):
|
||||
if ex_index % 10000 == 0:
|
||||
logger.info("Writing example %d of %d" % (ex_index, len(examples)))
|
||||
choices_inputs = []
|
||||
|
||||
@ -312,8 +312,10 @@ def add_generic_args(parser, root_dir) -> None:
|
||||
"--fp16_opt_level",
|
||||
type=str,
|
||||
default="O2",
|
||||
help="For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']."
|
||||
"See details at https://nvidia.github.io/apex/amp.html",
|
||||
help=(
|
||||
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']."
|
||||
"See details at https://nvidia.github.io/apex/amp.html"
|
||||
),
|
||||
)
|
||||
parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
|
||||
parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
|
||||
|
||||
@ -148,8 +148,10 @@ class GLUETransformer(BaseTransformer):
|
||||
"--max_seq_length",
|
||||
default=128,
|
||||
type=int,
|
||||
help="The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded.",
|
||||
help=(
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
),
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
|
||||
@ -173,8 +173,10 @@ class NERTransformer(BaseTransformer):
|
||||
"--max_seq_length",
|
||||
default=128,
|
||||
type=int,
|
||||
help="The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded.",
|
||||
help=(
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
),
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
|
||||
@ -551,8 +551,10 @@ def main():
|
||||
"--max_seq_length",
|
||||
default=384,
|
||||
type=int,
|
||||
help="The maximum total input sequence length after WordPiece tokenization. Sequences "
|
||||
"longer than this will be truncated, and sequences shorter than this will be padded.",
|
||||
help=(
|
||||
"The maximum total input sequence length after WordPiece tokenization. Sequences "
|
||||
"longer than this will be truncated, and sequences shorter than this will be padded."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--doc_stride",
|
||||
@ -564,8 +566,10 @@ def main():
|
||||
"--max_query_length",
|
||||
default=64,
|
||||
type=int,
|
||||
help="The maximum number of tokens for the question. Questions longer than this will "
|
||||
"be truncated to this length.",
|
||||
help=(
|
||||
"The maximum number of tokens for the question. Questions longer than this will "
|
||||
"be truncated to this length."
|
||||
),
|
||||
)
|
||||
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
|
||||
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
|
||||
@ -610,20 +614,27 @@ def main():
|
||||
"--max_answer_length",
|
||||
default=30,
|
||||
type=int,
|
||||
help="The maximum length of an answer that can be generated. This is needed because the start "
|
||||
"and end predictions are not conditioned on one another.",
|
||||
help=(
|
||||
"The maximum length of an answer that can be generated. This is needed because the start "
|
||||
"and end predictions are not conditioned on one another."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--verbose_logging",
|
||||
action="store_true",
|
||||
help="If true, all of the warnings related to data processing will be printed. "
|
||||
"A number of warnings are expected for a normal SQuAD evaluation.",
|
||||
help=(
|
||||
"If true, all of the warnings related to data processing will be printed. "
|
||||
"A number of warnings are expected for a normal SQuAD evaluation."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lang_id",
|
||||
default=0,
|
||||
type=int,
|
||||
help="language id of input for language-specific xlm models (see tokenization_xlm.PRETRAINED_INIT_CONFIGURATION)",
|
||||
help=(
|
||||
"language id of input for language-specific xlm models (see"
|
||||
" tokenization_xlm.PRETRAINED_INIT_CONFIGURATION)"
|
||||
),
|
||||
)
|
||||
|
||||
parser.add_argument("--logging_steps", type=int, default=500, help="Log every X updates steps.")
|
||||
@ -652,8 +663,10 @@ def main():
|
||||
"--fp16_opt_level",
|
||||
type=str,
|
||||
default="O1",
|
||||
help="For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']."
|
||||
"See details at https://nvidia.github.io/apex/amp.html",
|
||||
help=(
|
||||
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']."
|
||||
"See details at https://nvidia.github.io/apex/amp.html"
|
||||
),
|
||||
)
|
||||
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
|
||||
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
|
||||
|
||||
@ -84,7 +84,8 @@ def main():
|
||||
and not training_args.overwrite_output_dir
|
||||
):
|
||||
raise ValueError(
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use --overwrite_output_dir to overcome."
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
|
||||
" --overwrite_output_dir to overcome."
|
||||
)
|
||||
|
||||
# Setup logging
|
||||
|
||||
@ -68,7 +68,10 @@ class ModelArguments:
|
||||
model_name_or_path: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The model checkpoint for weights initialization. Leave None if you want to train a model from scratch."
|
||||
"help": (
|
||||
"The model checkpoint for weights initialization. Leave None if you want to train a model from"
|
||||
" scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
model_type: Optional[str] = field(
|
||||
@ -99,8 +102,10 @@ class DataTrainingArguments:
|
||||
train_data_files: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The input training data files (multiple files in glob format). "
|
||||
"Very often splitting large files to smaller files can prevent tokenizer going out of memory"
|
||||
"help": (
|
||||
"The input training data files (multiple files in glob format). "
|
||||
"Very often splitting large files to smaller files can prevent tokenizer going out of memory"
|
||||
)
|
||||
},
|
||||
)
|
||||
eval_data_file: Optional[str] = field(
|
||||
@ -130,7 +135,10 @@ class DataTrainingArguments:
|
||||
plm_probability: float = field(
|
||||
default=1 / 6,
|
||||
metadata={
|
||||
"help": "Ratio of length of a span of masked tokens to surrounding context length for permutation language modeling."
|
||||
"help": (
|
||||
"Ratio of length of a span of masked tokens to surrounding context length for permutation language"
|
||||
" modeling."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_span_length: int = field(
|
||||
@ -140,9 +148,11 @@ class DataTrainingArguments:
|
||||
block_size: int = field(
|
||||
default=-1,
|
||||
metadata={
|
||||
"help": "Optional input sequence length after tokenization."
|
||||
"The training dataset will be truncated in block of this size for training."
|
||||
"Default to the model max input length for single sentence inputs (take into account special tokens)."
|
||||
"help": (
|
||||
"Optional input sequence length after tokenization."
|
||||
"The training dataset will be truncated in block of this size for training."
|
||||
"Default to the model max input length for single sentence inputs (take into account special tokens)."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
@ -206,7 +216,8 @@ def main():
|
||||
and not training_args.overwrite_output_dir
|
||||
):
|
||||
raise ValueError(
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use --overwrite_output_dir to overcome."
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
|
||||
" --overwrite_output_dir to overcome."
|
||||
)
|
||||
|
||||
# Setup logging
|
||||
@ -253,8 +264,8 @@ def main():
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, cache_dir=model_args.cache_dir)
|
||||
else:
|
||||
raise ValueError(
|
||||
"You are instantiating a new tokenizer from scratch. This is not supported, but you can do it from another script, save it,"
|
||||
"and load it from here, using --tokenizer_name"
|
||||
"You are instantiating a new tokenizer from scratch. This is not supported, but you can do it from another"
|
||||
" script, save it,and load it from here, using --tokenizer_name"
|
||||
)
|
||||
|
||||
if model_args.model_name_or_path:
|
||||
|
||||
@ -126,15 +126,15 @@ def main():
|
||||
"--max_steps",
|
||||
default=-1,
|
||||
type=int,
|
||||
help="If > 0: set total number of training \
|
||||
steps to perform. Override num_train_epochs.",
|
||||
help=(
|
||||
"If > 0: set total number of training steps to perform. Override num_train_epochs."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--gradient_accumulation_steps",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of updates steps to accumulate before\
|
||||
performing a backward/update pass.",
|
||||
help="Number of updates steps to accumulate before performing a backward/update pass.",
|
||||
)
|
||||
parser.add_argument("--learning_rate", type=float, default=6.25e-5)
|
||||
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
|
||||
|
||||
@ -516,8 +516,10 @@ def main():
|
||||
"--max_seq_length",
|
||||
default=384,
|
||||
type=int,
|
||||
help="The maximum total input sequence length after tokenization. Sequences "
|
||||
"longer than this will be truncated, and sequences shorter than this will be padded.",
|
||||
help=(
|
||||
"The maximum total input sequence length after tokenization. Sequences "
|
||||
"longer than this will be truncated, and sequences shorter than this will be padded."
|
||||
),
|
||||
)
|
||||
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
|
||||
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
|
||||
@ -576,8 +578,10 @@ def main():
|
||||
"--fp16_opt_level",
|
||||
type=str,
|
||||
default="O1",
|
||||
help="For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']."
|
||||
"See details at https://nvidia.github.io/apex/amp.html",
|
||||
help=(
|
||||
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']."
|
||||
"See details at https://nvidia.github.io/apex/amp.html"
|
||||
),
|
||||
)
|
||||
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
|
||||
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
|
||||
|
||||
@ -90,31 +90,39 @@ class DataTrainingArguments:
|
||||
max_source_length: Optional[int] = field(
|
||||
default=1024,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_target_length: Optional[int] = field(
|
||||
default=128,
|
||||
metadata={
|
||||
"help": "The maximum total sequence length for target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total sequence length for target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
val_max_target_length: Optional[int] = field(
|
||||
default=142,
|
||||
metadata={
|
||||
"help": "The maximum total sequence length for validation target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded. "
|
||||
"This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
|
||||
"during ``evaluate`` and ``predict``."
|
||||
"help": (
|
||||
"The maximum total sequence length for validation target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded. "
|
||||
"This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
|
||||
"during ``evaluate`` and ``predict``."
|
||||
)
|
||||
},
|
||||
)
|
||||
test_max_target_length: Optional[int] = field(
|
||||
default=142,
|
||||
metadata={
|
||||
"help": "The maximum total sequence length for test target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total sequence length for test target text after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
n_train: Optional[int] = field(default=-1, metadata={"help": "# training examples. -1 means use all."})
|
||||
|
||||
@ -22,15 +22,30 @@ from utils import calculate_rouge
|
||||
|
||||
|
||||
PRED = [
|
||||
'Prosecutor: "No videos were used in the crash investigation" German papers say they saw a cell phone video of the final seconds on board Flight 9525. The Germanwings co-pilot says he had a "previous episode of severe depression" German airline confirms it knew of Andreas Lubitz\'s depression years before he took control.',
|
||||
"The Palestinian Authority officially becomes the 123rd member of the International Criminal Court. The formal accession was marked with a ceremony at The Hague, in the Netherlands. The Palestinians signed the ICC's founding Rome Statute in January. Israel and the United States opposed the Palestinians' efforts to join the body.",
|
||||
"Amnesty International releases its annual report on the death penalty. The report catalogs the use of state-sanctioned killing as a punitive measure across the globe. At least 607 people were executed around the world in 2014, compared to 778 in 2013. The U.S. remains one of the worst offenders for imposing capital punishment.",
|
||||
'Prosecutor: "No videos were used in the crash investigation" German papers say they saw a cell phone video of the'
|
||||
' final seconds on board Flight 9525. The Germanwings co-pilot says he had a "previous episode of severe'
|
||||
" depression\" German airline confirms it knew of Andreas Lubitz's depression years before he took control.",
|
||||
"The Palestinian Authority officially becomes the 123rd member of the International Criminal Court. The formal"
|
||||
" accession was marked with a ceremony at The Hague, in the Netherlands. The Palestinians signed the ICC's"
|
||||
" founding Rome Statute in January. Israel and the United States opposed the Palestinians' efforts to join the"
|
||||
" body.",
|
||||
"Amnesty International releases its annual report on the death penalty. The report catalogs the use of"
|
||||
" state-sanctioned killing as a punitive measure across the globe. At least 607 people were executed around the"
|
||||
" world in 2014, compared to 778 in 2013. The U.S. remains one of the worst offenders for imposing capital"
|
||||
" punishment.",
|
||||
]
|
||||
|
||||
TGT = [
|
||||
'Marseille prosecutor says "so far no videos were used in the crash investigation" despite media reports . Journalists at Bild and Paris Match are "very confident" the video clip is real, an editor says . Andreas Lubitz had informed his Lufthansa training school of an episode of severe depression, airline says .',
|
||||
"Membership gives the ICC jurisdiction over alleged crimes committed in Palestinian territories since last June . Israel and the United States opposed the move, which could open the door to war crimes investigations against Israelis .",
|
||||
"Amnesty's annual death penalty report catalogs encouraging signs, but setbacks in numbers of those sentenced to death . Organization claims that governments around the world are using the threat of terrorism to advance executions . The number of executions worldwide has gone down by almost 22% compared with 2013, but death sentences up by 28% .",
|
||||
'Marseille prosecutor says "so far no videos were used in the crash investigation" despite media reports .'
|
||||
' Journalists at Bild and Paris Match are "very confident" the video clip is real, an editor says . Andreas Lubitz'
|
||||
" had informed his Lufthansa training school of an episode of severe depression, airline says .",
|
||||
"Membership gives the ICC jurisdiction over alleged crimes committed in Palestinian territories since last June ."
|
||||
" Israel and the United States opposed the move, which could open the door to war crimes investigations against"
|
||||
" Israelis .",
|
||||
"Amnesty's annual death penalty report catalogs encouraging signs, but setbacks in numbers of those sentenced to"
|
||||
" death . Organization claims that governments around the world are using the threat of terrorism to advance"
|
||||
" executions . The number of executions worldwide has gone down by almost 22% compared with 2013, but death"
|
||||
" sentences up by 28% .",
|
||||
]
|
||||
|
||||
|
||||
@ -65,7 +80,8 @@ def test_single_sent_scores_dont_depend_on_newline_sep():
|
||||
]
|
||||
tgt = [
|
||||
"Margot Frank, died in 1945, a month earlier than previously thought.",
|
||||
'Prosecutor: "No videos were used in the crash investigation" German papers say they saw a cell phone video of the final seconds on board Flight 9525.',
|
||||
'Prosecutor: "No videos were used in the crash investigation" German papers say they saw a cell phone video of'
|
||||
" the final seconds on board Flight 9525.",
|
||||
]
|
||||
assert calculate_rouge(pred, tgt, newline_sep=True) == calculate_rouge(pred, tgt, newline_sep=False)
|
||||
|
||||
|
||||
@ -121,7 +121,10 @@ def run_generate(verbose=True):
|
||||
nargs="?",
|
||||
type=str,
|
||||
const=datetime_now(),
|
||||
help="use in conjunction w/ --dump-args to print with the results whatever other info you'd like, e.g. lang=en-ru. If no value is passed, the current datetime string will be used.",
|
||||
help=(
|
||||
"use in conjunction w/ --dump-args to print with the results whatever other info you'd like, e.g."
|
||||
" lang=en-ru. If no value is passed, the current datetime string will be used."
|
||||
),
|
||||
)
|
||||
# Unspecified args like --num_beams=2 --decoder_start_token_id=4 are passed to model.generate
|
||||
args, rest = parser.parse_known_args()
|
||||
|
||||
@ -35,7 +35,7 @@ def parse_search_arg(search):
|
||||
groups = search.split()
|
||||
entries = {k: vs for k, vs in (g.split("=") for g in groups)}
|
||||
entry_names = list(entries.keys())
|
||||
sets = [list((f"--{k} {v}") for v in vs.split(":")) for k, vs in entries.items()]
|
||||
sets = [list(f"--{k} {v}" for v in vs.split(":")) for k, vs in entries.items()]
|
||||
matrix = [list(x) for x in itertools.product(*sets)]
|
||||
return matrix, entry_names
|
||||
|
||||
@ -66,7 +66,10 @@ def run_search():
|
||||
prog = sys.argv[0]
|
||||
|
||||
parser = argparse.ArgumentParser(
|
||||
usage="\n\nImportant: this script accepts all arguments `run_eval.py` accepts and then a few extra, therefore refer to `run_eval.py -h` for the complete list."
|
||||
usage=(
|
||||
"\n\nImportant: this script accepts all arguments `run_eval.py` accepts and then a few extra, therefore"
|
||||
" refer to `run_eval.py -h` for the complete list."
|
||||
)
|
||||
)
|
||||
parser.add_argument(
|
||||
"--search",
|
||||
@ -83,7 +86,10 @@ def run_search():
|
||||
nargs="?",
|
||||
type=str,
|
||||
const=datetime_now(),
|
||||
help="add custom notes to be printed before the results table. If no value is passed, the current datetime string will be used.",
|
||||
help=(
|
||||
"add custom notes to be printed before the results table. If no value is passed, the current datetime"
|
||||
" string will be used."
|
||||
),
|
||||
)
|
||||
args, args_main = parser.parse_known_args()
|
||||
# we share some of the args
|
||||
|
||||
@ -57,9 +57,10 @@ class Seq2SeqTrainer(Trainer):
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
if config is None:
|
||||
assert isinstance(
|
||||
self.model, PreTrainedModel
|
||||
), f"If no `config` is passed the model to be trained has to be of type `PreTrainedModel`, but is {self.model.__class__}"
|
||||
assert isinstance(self.model, PreTrainedModel), (
|
||||
"If no `config` is passed the model to be trained has to be of type `PreTrainedModel`, but is"
|
||||
f" {self.model.__class__}"
|
||||
)
|
||||
self.config = self.model.config
|
||||
else:
|
||||
self.config = config
|
||||
@ -68,13 +69,15 @@ class Seq2SeqTrainer(Trainer):
|
||||
self.vocab_size = self.config.tgt_vocab_size if isinstance(self.config, FSMTConfig) else self.config.vocab_size
|
||||
|
||||
if self.args.label_smoothing != 0 or (self.data_args is not None and self.data_args.ignore_pad_token_for_loss):
|
||||
assert (
|
||||
self.config.pad_token_id is not None
|
||||
), "Make sure that `config.pad_token_id` is correcly defined when ignoring `pad_token` for loss calculation or doing label smoothing."
|
||||
assert self.config.pad_token_id is not None, (
|
||||
"Make sure that `config.pad_token_id` is correcly defined when ignoring `pad_token` for loss"
|
||||
" calculation or doing label smoothing."
|
||||
)
|
||||
|
||||
if self.config.pad_token_id is None and self.config.eos_token_id is not None:
|
||||
logger.warning(
|
||||
f"The `config.pad_token_id` is `None`. Using `config.eos_token_id` = {self.config.eos_token_id} for padding.."
|
||||
f"The `config.pad_token_id` is `None`. Using `config.eos_token_id` = {self.config.eos_token_id} for"
|
||||
" padding.."
|
||||
)
|
||||
|
||||
if self.args.label_smoothing == 0:
|
||||
@ -248,7 +251,8 @@ class Seq2SeqTrainer(Trainer):
|
||||
|
||||
if pad_token_id is None:
|
||||
raise ValueError(
|
||||
f"Make sure that either `config.pad_token_id` or `config.eos_token_id` is defined if tensor has to be padded to `max_length`={max_length}"
|
||||
"Make sure that either `config.pad_token_id` or `config.eos_token_id` is defined if tensor has to be"
|
||||
f" padded to `max_length`={max_length}"
|
||||
)
|
||||
|
||||
padded_tensor = pad_token_id * torch.ones(
|
||||
|
||||
@ -39,9 +39,7 @@ def parse_args():
|
||||
"""
|
||||
parser = ArgumentParser(
|
||||
description=(
|
||||
"PyTorch TPU distributed training launch "
|
||||
"helper utility that will spawn up "
|
||||
"multiple distributed processes"
|
||||
"PyTorch TPU distributed training launch helper utility that will spawn up multiple distributed processes"
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@ -168,8 +168,10 @@ class DataTrainingArguments:
|
||||
max_seq_length: int = field(
|
||||
default=128,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
@ -215,7 +217,8 @@ def main():
|
||||
and not training_args.overwrite_output_dir
|
||||
):
|
||||
raise ValueError(
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use --overwrite_output_dir to overcome."
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
|
||||
" --overwrite_output_dir to overcome."
|
||||
)
|
||||
|
||||
# Setup logging
|
||||
|
||||
@ -87,8 +87,10 @@ class DataTrainingArguments:
|
||||
max_seq_length: int = field(
|
||||
default=128,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
@ -116,7 +118,8 @@ def main():
|
||||
and not training_args.overwrite_output_dir
|
||||
):
|
||||
raise ValueError(
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use --overwrite_output_dir to overcome."
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
|
||||
" --overwrite_output_dir to overcome."
|
||||
)
|
||||
|
||||
module = import_module("tasks")
|
||||
|
||||
@ -88,8 +88,10 @@ class DataTrainingArguments:
|
||||
max_seq_length: int = field(
|
||||
default=128,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
@ -111,7 +113,8 @@ def main():
|
||||
and not training_args.overwrite_output_dir
|
||||
):
|
||||
raise ValueError(
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use --overwrite_output_dir to overcome."
|
||||
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
|
||||
" --overwrite_output_dir to overcome."
|
||||
)
|
||||
|
||||
module = import_module("tasks")
|
||||
|
||||
@ -103,7 +103,7 @@ class TokenClassificationTask:
|
||||
label_map = {label: i for i, label in enumerate(label_list)}
|
||||
|
||||
features = []
|
||||
for (ex_index, example) in enumerate(examples):
|
||||
for ex_index, example in enumerate(examples):
|
||||
if ex_index % 10_000 == 0:
|
||||
logger.info("Writing example %d of %d", ex_index, len(examples))
|
||||
|
||||
|
||||
@ -18,13 +18,13 @@ limitations under the License.
|
||||
|
||||
The following examples showcase how to fine-tune `Wav2Vec2` for audio classification using PyTorch.
|
||||
|
||||
Speech recognition models that have been pretrained in unsupervised fashion on audio data alone,
|
||||
*e.g.* [Wav2Vec2](https://huggingface.co/transformers/main/model_doc/wav2vec2.html),
|
||||
[HuBERT](https://huggingface.co/transformers/main/model_doc/hubert.html),
|
||||
[XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html), have shown to require only
|
||||
Speech recognition models that have been pretrained in unsupervised fashion on audio data alone,
|
||||
*e.g.* [Wav2Vec2](https://huggingface.co/transformers/main/model_doc/wav2vec2.html),
|
||||
[HuBERT](https://huggingface.co/transformers/main/model_doc/hubert.html),
|
||||
[XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html), have shown to require only
|
||||
very little annotated data to yield good performance on speech classification datasets.
|
||||
|
||||
## Single-GPU
|
||||
## Single-GPU
|
||||
|
||||
The following command shows how to fine-tune [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the 🗣️ [Keyword Spotting subset](https://huggingface.co/datasets/superb#ks) of the SUPERB dataset.
|
||||
|
||||
@ -63,7 +63,9 @@ On a single V100 GPU (16GB), this script should run in ~14 minutes and yield acc
|
||||
|
||||
👀 See the results here: [anton-l/wav2vec2-base-ft-keyword-spotting](https://huggingface.co/anton-l/wav2vec2-base-ft-keyword-spotting)
|
||||
|
||||
## Multi-GPU
|
||||
> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
|
||||
|
||||
## Multi-GPU
|
||||
|
||||
The following command shows how to fine-tune [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) for 🌎 **Language Identification** on the [CommonLanguage dataset](https://huggingface.co/datasets/anton-l/common_language).
|
||||
|
||||
@ -139,7 +141,7 @@ It has been verified that the script works for the following datasets:
|
||||
|
||||
| Dataset | Pretrained Model | # transformer layers | Accuracy on eval | GPU setup | Training time | Fine-tuned Model & Logs |
|
||||
|---------|------------------|----------------------|------------------|-----------|---------------|--------------------------|
|
||||
| Keyword Spotting | [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) | 2 | 0.9706 | 1 V100 GPU | 11min | [here](https://huggingface.co/anton-l/distilhubert-ft-keyword-spotting) |
|
||||
| Keyword Spotting | [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) | 2 | 0.9706 | 1 V100 GPU | 11min | [here](https://huggingface.co/anton-l/distilhubert-ft-keyword-spotting) |
|
||||
| Keyword Spotting | [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) | 12 | 0.9826 | 1 V100 GPU | 14min | [here](https://huggingface.co/anton-l/wav2vec2-base-ft-keyword-spotting) |
|
||||
| Keyword Spotting | [facebook/hubert-base-ls960](https://huggingface.co/facebook/hubert-base-ls960) | 12 | 0.9819 | 1 V100 GPU | 14min | [here](https://huggingface.co/anton-l/hubert-base-ft-keyword-spotting) |
|
||||
| Keyword Spotting | [asapp/sew-mid-100k](https://huggingface.co/asapp/sew-mid-100k) | 24 | 0.9757 | 1 V100 GPU | 15min | [here](https://huggingface.co/anton-l/sew-mid-100k-ft-keyword-spotting) |
|
||||
|
||||
@ -44,7 +44,7 @@ from transformers.utils.versions import require_version
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
require_version("datasets>=1.14.0", "To fix: pip install -r examples/pytorch/audio-classification/requirements.txt")
|
||||
|
||||
@ -86,8 +86,9 @@ class DataTrainingArguments:
|
||||
eval_split_name: str = field(
|
||||
default="validation",
|
||||
metadata={
|
||||
"help": "The name of the training data set split to use (via the datasets library). Defaults to "
|
||||
"'validation'"
|
||||
"help": (
|
||||
"The name of the training data set split to use (via the datasets library). Defaults to 'validation'"
|
||||
)
|
||||
},
|
||||
)
|
||||
audio_column_name: str = field(
|
||||
@ -100,15 +101,19 @@ class DataTrainingArguments:
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_length_seconds: float = field(
|
||||
@ -149,13 +154,19 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
freeze_feature_extractor: Optional[bool] = field(
|
||||
default=None, metadata={"help": "Whether to freeze the feature extractor layers of the model."}
|
||||
)
|
||||
ignore_mismatched_sizes: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Will enable to load a pretrained model whose head dimensions are different."},
|
||||
)
|
||||
|
||||
def __post_init__(self):
|
||||
if not self.freeze_feature_extractor and self.freeze_feature_encoder:
|
||||
@ -326,6 +337,7 @@ def main():
|
||||
cache_dir=model_args.cache_dir,
|
||||
revision=model_args.model_revision,
|
||||
use_auth_token=True if model_args.use_auth_token else None,
|
||||
ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
|
||||
)
|
||||
|
||||
# freeze the convolutional waveform encoder
|
||||
|
||||
@ -54,7 +54,7 @@ from transformers.utils.versions import require_version
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/contrastive-image-text/requirements.txt")
|
||||
|
||||
@ -89,8 +89,10 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
freeze_vision_model: bool = field(
|
||||
@ -132,22 +134,28 @@ class DataTrainingArguments:
|
||||
max_seq_length: Optional[int] = field(
|
||||
default=128,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
|
||||
@ -62,9 +62,11 @@ python run_image_classification.py \
|
||||
|
||||
Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
|
||||
|
||||
> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
|
||||
|
||||
### Using your own data
|
||||
|
||||
To use your own dataset, there are 2 ways:
|
||||
To use your own dataset, there are 2 ways:
|
||||
- you can either provide your own folders as `--train_dir` and/or `--validation_dir` arguments
|
||||
- you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
|
||||
|
||||
|
||||
@ -54,7 +54,7 @@ from transformers.utils.versions import require_version
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-classification/requirements.txt")
|
||||
|
||||
@ -93,15 +93,19 @@ class DataTrainingArguments:
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -140,10 +144,16 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
ignore_mismatched_sizes: bool = field(
|
||||
default=False,
|
||||
metadata={"help": "Will enable to load a pretrained model whose head dimensions are different."},
|
||||
)
|
||||
|
||||
|
||||
def collate_fn(examples):
|
||||
@ -263,6 +273,7 @@ def main():
|
||||
cache_dir=model_args.cache_dir,
|
||||
revision=model_args.model_revision,
|
||||
use_auth_token=True if model_args.use_auth_token else None,
|
||||
ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
|
||||
)
|
||||
feature_extractor = AutoFeatureExtractor.from_pretrained(
|
||||
model_args.feature_extractor_name or model_args.model_name_or_path,
|
||||
|
||||
@ -62,7 +62,10 @@ def parse_args():
|
||||
"--dataset_name",
|
||||
type=str,
|
||||
default="cifar10",
|
||||
help="The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private, dataset).",
|
||||
help=(
|
||||
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
|
||||
" dataset)."
|
||||
),
|
||||
)
|
||||
parser.add_argument("--train_dir", type=str, default=None, help="A folder containing the training data.")
|
||||
parser.add_argument("--validation_dir", type=str, default=None, help="A folder containing the validation data.")
|
||||
@ -70,15 +73,19 @@ def parse_args():
|
||||
"--max_train_samples",
|
||||
type=int,
|
||||
default=None,
|
||||
help="For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set.",
|
||||
help=(
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--max_eval_samples",
|
||||
type=int,
|
||||
default=None,
|
||||
help="For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set.",
|
||||
help=(
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--train_val_split",
|
||||
@ -156,7 +163,22 @@ def parse_args():
|
||||
parser.add_argument(
|
||||
"--with_tracking",
|
||||
action="store_true",
|
||||
help="Whether to load in all available experiment trackers from the environment and use them for logging.",
|
||||
help="Whether to enable experiment trackers for logging.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--report_to",
|
||||
type=str,
|
||||
default="all",
|
||||
help=(
|
||||
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
|
||||
' `"wandb"` and `"comet_ml"`. Use `"all"` (default) to report to all integrations.'
|
||||
"Only applicable when `--with_tracking` is passed."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--ignore_mismatched_sizes",
|
||||
action="store_true",
|
||||
help="Whether or not to enable to load a pretrained model whose head dimensions are different.",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
@ -180,8 +202,11 @@ def main():
|
||||
args = parse_args()
|
||||
|
||||
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
|
||||
# If we're using tracking, we also need to initialize it here and it will pick up all supported trackers in the environment
|
||||
accelerator = Accelerator(log_with="all", logging_dir=args.output_dir) if args.with_tracking else Accelerator()
|
||||
# If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
|
||||
# in the environment
|
||||
accelerator = (
|
||||
Accelerator(log_with=args.report_to, logging_dir=args.output_dir) if args.with_tracking else Accelerator()
|
||||
)
|
||||
logger.info(accelerator.state)
|
||||
# Make one log on every process with the configuration for debugging.
|
||||
logging.basicConfig(
|
||||
@ -271,6 +296,7 @@ def main():
|
||||
args.model_name_or_path,
|
||||
from_tf=bool(".ckpt" in args.model_name_or_path),
|
||||
config=config,
|
||||
ignore_mismatched_sizes=args.ignore_mismatched_sizes,
|
||||
)
|
||||
|
||||
# Preprocessing the datasets
|
||||
@ -371,12 +397,15 @@ def main():
|
||||
else:
|
||||
checkpointing_steps = None
|
||||
|
||||
# We need to initialize the trackers we use, and also store our configuration
|
||||
# We need to initialize the trackers we use, and also store our configuration.
|
||||
# We initialize the trackers only on main process because `accelerator.log`
|
||||
# only logs on main process and we don't want empty logs/runs on other processes.
|
||||
if args.with_tracking:
|
||||
experiment_config = vars(args)
|
||||
# TensorBoard cannot log Enums, need the raw value
|
||||
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
|
||||
accelerator.init_trackers("image_classification_no_trainer", experiment_config)
|
||||
if accelerator.is_main_process:
|
||||
experiment_config = vars(args)
|
||||
# TensorBoard cannot log Enums, need the raw value
|
||||
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
|
||||
accelerator.init_trackers("image_classification_no_trainer", experiment_config)
|
||||
|
||||
# Get the metric function
|
||||
metric = load_metric("accuracy")
|
||||
@ -476,7 +505,7 @@ def main():
|
||||
predictions, references = accelerator.gather((predictions, batch["labels"]))
|
||||
# If we are in a multiprocess environment, the last batch has duplicates
|
||||
if accelerator.num_processes > 1:
|
||||
if step == len(eval_dataloader):
|
||||
if step == len(eval_dataloader) - 1:
|
||||
predictions = predictions[: len(eval_dataloader.dataset) - samples_seen]
|
||||
references = references[: len(eval_dataloader.dataset) - samples_seen]
|
||||
else:
|
||||
@ -493,10 +522,11 @@ def main():
|
||||
accelerator.log(
|
||||
{
|
||||
"accuracy": eval_metric,
|
||||
"train_loss": total_loss,
|
||||
"train_loss": total_loss.item() / len(train_dataloader),
|
||||
"epoch": epoch,
|
||||
"step": completed_steps,
|
||||
},
|
||||
step=completed_steps,
|
||||
)
|
||||
|
||||
if args.push_to_hub and epoch < args.num_train_epochs - 1:
|
||||
|
||||
@ -43,7 +43,7 @@ from transformers.utils.versions import require_version
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
|
||||
|
||||
@ -74,15 +74,19 @@ class DataTrainingArguments:
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -104,8 +108,9 @@ class ModelArguments:
|
||||
model_name_or_path: str = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The model checkpoint for weights initialization."
|
||||
"Don't set if you want to train a model from scratch."
|
||||
"help": (
|
||||
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
config_name: Optional[str] = field(
|
||||
@ -114,8 +119,10 @@ class ModelArguments:
|
||||
config_overrides: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "Override some existing default config settings when a model is trained from scratch. Example: "
|
||||
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
|
||||
"help": (
|
||||
"Override some existing default config settings when a model is trained from scratch. Example: "
|
||||
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
|
||||
)
|
||||
},
|
||||
)
|
||||
cache_dir: Optional[str] = field(
|
||||
@ -129,8 +136,10 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
mask_ratio: float = field(
|
||||
|
||||
@ -48,7 +48,7 @@ Any model supported by the AutoModelForMaskedImageModeling API can be used.
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
|
||||
|
||||
@ -87,15 +87,19 @@ class DataTrainingArguments:
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -117,9 +121,11 @@ class ModelArguments:
|
||||
model_name_or_path: str = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The model checkpoint for weights initialization. Can be a local path to a pytorch_model.bin or a "
|
||||
"checkpoint identifier on the hub. "
|
||||
"Don't set if you want to train a model from scratch."
|
||||
"help": (
|
||||
"The model checkpoint for weights initialization. Can be a local path to a pytorch_model.bin or a "
|
||||
"checkpoint identifier on the hub. "
|
||||
"Don't set if you want to train a model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
model_type: Optional[str] = field(
|
||||
@ -132,8 +138,10 @@ class ModelArguments:
|
||||
config_overrides: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "Override some existing default config settings when a model is trained from scratch. Example: "
|
||||
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
|
||||
"help": (
|
||||
"Override some existing default config settings when a model is trained from scratch. Example: "
|
||||
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
|
||||
)
|
||||
},
|
||||
)
|
||||
cache_dir: Optional[str] = field(
|
||||
@ -148,20 +156,26 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
image_size: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The size (resolution) of each image. If not specified, will use `image_size` of the configuration."
|
||||
"help": (
|
||||
"The size (resolution) of each image. If not specified, will use `image_size` of the configuration."
|
||||
)
|
||||
},
|
||||
)
|
||||
patch_size: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The size (resolution) of each patch. If not specified, will use `patch_size` of the configuration."
|
||||
"help": (
|
||||
"The size (resolution) of each patch. If not specified, will use `patch_size` of the configuration."
|
||||
)
|
||||
},
|
||||
)
|
||||
encoder_stride: Optional[int] = field(
|
||||
|
||||
@ -53,7 +53,7 @@ from transformers.utils.versions import require_version
|
||||
|
||||
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
|
||||
|
||||
@ -73,8 +73,9 @@ class ModelArguments:
|
||||
model_name_or_path: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The model checkpoint for weights initialization."
|
||||
"Don't set if you want to train a model from scratch."
|
||||
"help": (
|
||||
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
model_type: Optional[str] = field(
|
||||
@ -84,8 +85,10 @@ class ModelArguments:
|
||||
config_overrides: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "Override some existing default config settings when a model is trained from scratch. Example: "
|
||||
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
|
||||
"help": (
|
||||
"Override some existing default config settings when a model is trained from scratch. Example: "
|
||||
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
|
||||
)
|
||||
},
|
||||
)
|
||||
config_name: Optional[str] = field(
|
||||
@ -109,8 +112,10 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -141,24 +146,30 @@ class DataTrainingArguments:
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
block_size: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "Optional input sequence length after tokenization. "
|
||||
"The training dataset will be truncated in block of this size for training. "
|
||||
"Default to the model max input length for single sentence inputs (take into account special tokens)."
|
||||
"help": (
|
||||
"Optional input sequence length after tokenization. "
|
||||
"The training dataset will be truncated in block of this size for training. "
|
||||
"Default to the model max input length for single sentence inputs (take into account special tokens)."
|
||||
)
|
||||
},
|
||||
)
|
||||
overwrite_cache: bool = field(
|
||||
@ -390,7 +401,8 @@ def main():
|
||||
# clm input could be much much longer than block_size
|
||||
if "Token indices sequence length is longer than the" in cl.out:
|
||||
tok_logger.warning(
|
||||
"^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits before being passed to the model."
|
||||
"^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits"
|
||||
" before being passed to the model."
|
||||
)
|
||||
return output
|
||||
|
||||
|
||||
@ -45,7 +45,6 @@ from huggingface_hub import Repository
|
||||
from transformers import (
|
||||
CONFIG_MAPPING,
|
||||
MODEL_MAPPING,
|
||||
AdamW,
|
||||
AutoConfig,
|
||||
AutoModelForCausalLM,
|
||||
AutoTokenizer,
|
||||
@ -94,7 +93,7 @@ def parse_args():
|
||||
"--model_name_or_path",
|
||||
type=str,
|
||||
help="Path to pretrained model or model identifier from huggingface.co/models.",
|
||||
required=True,
|
||||
required=False,
|
||||
)
|
||||
parser.add_argument(
|
||||
"--config_name",
|
||||
@ -168,7 +167,11 @@ def parse_args():
|
||||
"--block_size",
|
||||
type=int,
|
||||
default=None,
|
||||
help="Optional input sequence length after tokenization. The training dataset will be truncated in block of this size for training. Default to the model max input length for single sentence inputs (take into account special tokens).",
|
||||
help=(
|
||||
"Optional input sequence length after tokenization. The training dataset will be truncated in block of"
|
||||
" this size for training. Default to the model max input length for single sentence inputs (take into"
|
||||
" account special tokens)."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--preprocessing_num_workers",
|
||||
@ -202,7 +205,17 @@ def parse_args():
|
||||
parser.add_argument(
|
||||
"--with_tracking",
|
||||
action="store_true",
|
||||
help="Whether to load in all available experiment trackers from the environment and use them for logging.",
|
||||
help="Whether to enable experiment trackers for logging.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--report_to",
|
||||
type=str,
|
||||
default="all",
|
||||
help=(
|
||||
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
|
||||
' `"wandb"` and `"comet_ml"`. Use `"all"` (default) to report to all integrations.'
|
||||
"Only applicable when `--with_tracking` is passed."
|
||||
),
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
@ -227,8 +240,11 @@ def main():
|
||||
args = parse_args()
|
||||
|
||||
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
|
||||
# If we're using tracking, we also need to initialize it here and it will pick up all supported trackers in the environment
|
||||
accelerator = Accelerator(log_with="all", logging_dir=args.output_dir) if args.with_tracking else Accelerator()
|
||||
# If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
|
||||
# in the environment
|
||||
accelerator = (
|
||||
Accelerator(log_with=args.report_to, logging_dir=args.output_dir) if args.with_tracking else Accelerator()
|
||||
)
|
||||
# Make one log on every process with the configuration for debugging.
|
||||
logging.basicConfig(
|
||||
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
||||
@ -447,7 +463,7 @@ def main():
|
||||
"weight_decay": 0.0,
|
||||
},
|
||||
]
|
||||
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
|
||||
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
|
||||
|
||||
# On TPU, the tie weights in our model have been disconnected, so we need to restore the ties.
|
||||
if accelerator.distributed_type == DistributedType.TPU:
|
||||
@ -484,12 +500,15 @@ def main():
|
||||
else:
|
||||
checkpointing_steps = None
|
||||
|
||||
# We need to initialize the trackers we use, and also store our configuration
|
||||
# We need to initialize the trackers we use, and also store our configuration.
|
||||
# We initialize the trackers only on main process because `accelerator.log`
|
||||
# only logs on main process and we don't want empty logs/runs on other processes.
|
||||
if args.with_tracking:
|
||||
experiment_config = vars(args)
|
||||
# TensorBoard cannot log Enums, need the raw value
|
||||
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
|
||||
accelerator.init_trackers("clm_no_trainer", experiment_config)
|
||||
if accelerator.is_main_process:
|
||||
experiment_config = vars(args)
|
||||
# TensorBoard cannot log Enums, need the raw value
|
||||
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
|
||||
accelerator.init_trackers("clm_no_trainer", experiment_config)
|
||||
|
||||
# Train!
|
||||
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
@ -573,15 +592,23 @@ def main():
|
||||
losses = torch.cat(losses)
|
||||
losses = losses[: len(eval_dataset)]
|
||||
try:
|
||||
perplexity = math.exp(torch.mean(losses))
|
||||
eval_loss = torch.mean(losses)
|
||||
perplexity = math.exp(eval_loss)
|
||||
except OverflowError:
|
||||
perplexity = float("inf")
|
||||
|
||||
logger.info(f"epoch {epoch}: perplexity: {perplexity}")
|
||||
logger.info(f"epoch {epoch}: perplexity: {perplexity} eval_loss: {eval_loss}")
|
||||
|
||||
if args.with_tracking:
|
||||
accelerator.log(
|
||||
{"perplexity": perplexity, "train_loss": total_loss, "epoch": epoch, "step": completed_steps},
|
||||
{
|
||||
"perplexity": perplexity,
|
||||
"eval_loss": eval_loss,
|
||||
"train_loss": total_loss.item() / len(train_dataloader),
|
||||
"epoch": epoch,
|
||||
"step": completed_steps,
|
||||
},
|
||||
step=completed_steps,
|
||||
)
|
||||
|
||||
if args.push_to_hub and epoch < args.num_train_epochs - 1:
|
||||
|
||||
@ -52,7 +52,7 @@ from transformers.utils.versions import require_version
|
||||
|
||||
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
|
||||
|
||||
@ -70,8 +70,9 @@ class ModelArguments:
|
||||
model_name_or_path: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The model checkpoint for weights initialization."
|
||||
"Don't set if you want to train a model from scratch."
|
||||
"help": (
|
||||
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
model_type: Optional[str] = field(
|
||||
@ -81,8 +82,10 @@ class ModelArguments:
|
||||
config_overrides: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "Override some existing default config settings when a model is trained from scratch. Example: "
|
||||
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
|
||||
"help": (
|
||||
"Override some existing default config settings when a model is trained from scratch. Example: "
|
||||
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
|
||||
)
|
||||
},
|
||||
)
|
||||
config_name: Optional[str] = field(
|
||||
@ -106,8 +109,10 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -147,8 +152,10 @@ class DataTrainingArguments:
|
||||
max_seq_length: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated."
|
||||
)
|
||||
},
|
||||
)
|
||||
preprocessing_num_workers: Optional[int] = field(
|
||||
@ -165,22 +172,28 @@ class DataTrainingArguments:
|
||||
pad_to_max_length: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Whether to pad all samples to `max_seq_length`. "
|
||||
"If False, will pad the samples dynamically when batching to the maximum length in the batch."
|
||||
"help": (
|
||||
"Whether to pad all samples to `max_seq_length`. "
|
||||
"If False, will pad the samples dynamically when batching to the maximum length in the batch."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
|
||||
@ -45,7 +45,6 @@ from huggingface_hub import Repository
|
||||
from transformers import (
|
||||
CONFIG_MAPPING,
|
||||
MODEL_MAPPING,
|
||||
AdamW,
|
||||
AutoConfig,
|
||||
AutoModelForMaskedLM,
|
||||
AutoTokenizer,
|
||||
@ -97,7 +96,7 @@ def parse_args():
|
||||
"--model_name_or_path",
|
||||
type=str,
|
||||
help="Path to pretrained model or model identifier from huggingface.co/models.",
|
||||
required=True,
|
||||
required=False,
|
||||
)
|
||||
parser.add_argument(
|
||||
"--config_name",
|
||||
@ -171,7 +170,9 @@ def parse_args():
|
||||
"--max_seq_length",
|
||||
type=int,
|
||||
default=None,
|
||||
help="The maximum total input sequence length after tokenization. Sequences longer than this will be truncated.",
|
||||
help=(
|
||||
"The maximum total input sequence length after tokenization. Sequences longer than this will be truncated."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--line_by_line",
|
||||
@ -211,7 +212,17 @@ def parse_args():
|
||||
parser.add_argument(
|
||||
"--with_tracking",
|
||||
action="store_true",
|
||||
help="Whether to load in all available experiment trackers from the environment and use them for logging.",
|
||||
help="Whether to enable experiment trackers for logging.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--report_to",
|
||||
type=str,
|
||||
default="all",
|
||||
help=(
|
||||
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
|
||||
' `"wandb"` and `"comet_ml"`. Use `"all"` (default) to report to all integrations.'
|
||||
"Only applicable when `--with_tracking` is passed."
|
||||
),
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
@ -238,8 +249,11 @@ def main():
|
||||
args = parse_args()
|
||||
|
||||
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
|
||||
# If we're using tracking, we also need to initialize it here and it will pick up all supported trackers in the environment
|
||||
accelerator = Accelerator(log_with="all", logging_dir=args.output_dir) if args.with_tracking else Accelerator()
|
||||
# If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
|
||||
# in the environment
|
||||
accelerator = (
|
||||
Accelerator(log_with=args.report_to, logging_dir=args.output_dir) if args.with_tracking else Accelerator()
|
||||
)
|
||||
# Make one log on every process with the configuration for debugging.
|
||||
logging.basicConfig(
|
||||
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
||||
@ -490,7 +504,7 @@ def main():
|
||||
"weight_decay": 0.0,
|
||||
},
|
||||
]
|
||||
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
|
||||
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
|
||||
|
||||
# On TPU, the tie weights in our model have been disconnected, so we need to restore the ties.
|
||||
if accelerator.distributed_type == DistributedType.TPU:
|
||||
@ -530,12 +544,15 @@ def main():
|
||||
else:
|
||||
checkpointing_steps = None
|
||||
|
||||
# We need to initialize the trackers we use, and also store our configuration
|
||||
# We need to initialize the trackers we use, and also store our configuration.
|
||||
# We initialize the trackers only on main process because `accelerator.log`
|
||||
# only logs on main process and we don't want empty logs/runs on other processes.
|
||||
if args.with_tracking:
|
||||
experiment_config = vars(args)
|
||||
# TensorBoard cannot log Enums, need the raw value
|
||||
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
|
||||
accelerator.init_trackers("mlm_no_trainer", experiment_config)
|
||||
if accelerator.is_main_process:
|
||||
experiment_config = vars(args)
|
||||
# TensorBoard cannot log Enums, need the raw value
|
||||
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
|
||||
accelerator.init_trackers("mlm_no_trainer", experiment_config)
|
||||
|
||||
# Train!
|
||||
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
@ -620,7 +637,8 @@ def main():
|
||||
losses = torch.cat(losses)
|
||||
losses = losses[: len(eval_dataset)]
|
||||
try:
|
||||
perplexity = math.exp(torch.mean(losses))
|
||||
eval_loss = torch.mean(losses)
|
||||
perplexity = math.exp(eval_loss)
|
||||
except OverflowError:
|
||||
perplexity = float("inf")
|
||||
|
||||
@ -628,7 +646,14 @@ def main():
|
||||
|
||||
if args.with_tracking:
|
||||
accelerator.log(
|
||||
{"perplexity": perplexity, "train_loss": total_loss, "epoch": epoch, "step": completed_steps},
|
||||
{
|
||||
"perplexity": perplexity,
|
||||
"eval_loss": eval_loss,
|
||||
"train_loss": total_loss.item() / len(train_dataloader),
|
||||
"epoch": epoch,
|
||||
"step": completed_steps,
|
||||
},
|
||||
step=completed_steps,
|
||||
)
|
||||
|
||||
if args.push_to_hub and epoch < args.num_train_epochs - 1:
|
||||
|
||||
@ -47,7 +47,7 @@ from transformers.utils.versions import require_version
|
||||
|
||||
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
|
||||
|
||||
@ -63,8 +63,9 @@ class ModelArguments:
|
||||
model_name_or_path: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The model checkpoint for weights initialization."
|
||||
"Don't set if you want to train a model from scratch."
|
||||
"help": (
|
||||
"The model checkpoint for weights initialization.Don't set if you want to train a model from scratch."
|
||||
)
|
||||
},
|
||||
)
|
||||
config_name: Optional[str] = field(
|
||||
@ -73,8 +74,10 @@ class ModelArguments:
|
||||
config_overrides: Optional[str] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "Override some existing default config settings when a model is trained from scratch. Example: "
|
||||
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
|
||||
"help": (
|
||||
"Override some existing default config settings when a model is trained from scratch. Example: "
|
||||
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
|
||||
)
|
||||
},
|
||||
)
|
||||
tokenizer_name: Optional[str] = field(
|
||||
@ -95,8 +98,10 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -136,8 +141,10 @@ class DataTrainingArguments:
|
||||
max_seq_length: int = field(
|
||||
default=512,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. Sequences longer "
|
||||
"than this will be truncated."
|
||||
)
|
||||
},
|
||||
)
|
||||
preprocessing_num_workers: Optional[int] = field(
|
||||
@ -147,8 +154,10 @@ class DataTrainingArguments:
|
||||
plm_probability: float = field(
|
||||
default=1 / 6,
|
||||
metadata={
|
||||
"help": "Ratio of length of a span of masked tokens to surrounding context length for "
|
||||
"permutation language modeling."
|
||||
"help": (
|
||||
"Ratio of length of a span of masked tokens to surrounding context length for "
|
||||
"permutation language modeling."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_span_length: int = field(
|
||||
@ -161,22 +170,28 @@ class DataTrainingArguments:
|
||||
pad_to_max_length: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Whether to pad all samples to `max_seq_length`. "
|
||||
"If False, will pad the samples dynamically when batching to the maximum length in the batch."
|
||||
"help": (
|
||||
"Whether to pad all samples to `max_seq_length`. "
|
||||
"If False, will pad the samples dynamically when batching to the maximum length in the batch."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
|
||||
@ -47,7 +47,7 @@ from transformers.utils import PaddingStrategy, check_min_version
|
||||
|
||||
|
||||
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
|
||||
check_min_version("4.19.0.dev0")
|
||||
check_min_version("4.20.0.dev0")
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
@ -82,8 +82,10 @@ class ModelArguments:
|
||||
use_auth_token: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
"help": (
|
||||
"Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
||||
"with private models)."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
@ -109,30 +111,38 @@ class DataTrainingArguments:
|
||||
max_seq_length: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "The maximum total input sequence length after tokenization. If passed, sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
"help": (
|
||||
"The maximum total input sequence length after tokenization. If passed, sequences longer "
|
||||
"than this will be truncated, sequences shorter will be padded."
|
||||
)
|
||||
},
|
||||
)
|
||||
pad_to_max_length: bool = field(
|
||||
default=False,
|
||||
metadata={
|
||||
"help": "Whether to pad all samples to the maximum sentence length. "
|
||||
"If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
|
||||
"efficient on GPU but very bad for TPU."
|
||||
"help": (
|
||||
"Whether to pad all samples to the maximum sentence length. "
|
||||
"If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
|
||||
"efficient on GPU but very bad for TPU."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_train_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
max_eval_samples: Optional[int] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
"help": (
|
||||
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
||||
"value if set."
|
||||
)
|
||||
},
|
||||
)
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user