mirror of
https://github.com/huggingface/transformers.git
synced 2025-10-27 23:06:50 +08:00
Compare commits
381 Commits
repro-bug-
...
check-send
| Author | SHA1 | Date | |
|---|---|---|---|
| 75edf399af | |||
| 18135aa147 | |||
| 08a194fcd6 | |||
| e9c23fa056 | |||
| ba1b24e07b | |||
| ec59a42192 | |||
| 841e87ef4f | |||
| af4c02622b | |||
| 4e3490f79b | |||
| 2f12e40822 | |||
| 8c00b53eb0 | |||
| 7afade2086 | |||
| ef38e2a7e5 | |||
| a71def025c | |||
| 1897874edc | |||
| 1773afcec3 | |||
| 08c8443307 | |||
| 0201f6420b | |||
| 7f9aff910b | |||
| f5658732d5 | |||
| d16f0abc3f | |||
| 5e673ed2dc | |||
| 836e88caee | |||
| a907a903d6 | |||
| 1ed93be48a | |||
| 1fc34aa666 | |||
| 76fa17c166 | |||
| 9b5a6450d4 | |||
| d9fa13ce62 | |||
| b17b54d3dd | |||
| 17cd7a9d28 | |||
| 48795317a2 | |||
| de11d0bdf0 | |||
| 4207a4076d | |||
| 1ab7136488 | |||
| d704c0b698 | |||
| 79d62b2da2 | |||
| 8b52fa6b42 | |||
| 24d787ce9d | |||
| 517a3e670d | |||
| 75b76a5ea4 | |||
| 4e6c5eb045 | |||
| 03732dea60 | |||
| 863e2562d8 | |||
| 695d823323 | |||
| c10b5dd25e | |||
| 34bfe95af5 | |||
| cc75f1ac73 | |||
| 240e10626b | |||
| bcd42c4af9 | |||
| 851f253f4d | |||
| 17b06e2c66 | |||
| 81642d2b51 | |||
| b44df05bc0 | |||
| fce52cefa7 | |||
| 5080ab12c8 | |||
| 9b0a8ea7d1 | |||
| 15cd68713d | |||
| cb5927ca8f | |||
| 0d04b1e25a | |||
| fed27ffc7e | |||
| 33288ff150 | |||
| 416711c3ea | |||
| 83b26dd79d | |||
| 096f304695 | |||
| c9f6e5e351 | |||
| e4f5b57a3b | |||
| fa2c49b00b | |||
| 569f6c7d43 | |||
| 3b8e2932ce | |||
| 6e584070d4 | |||
| 46d636818b | |||
| f6701bc664 | |||
| e644b60038 | |||
| 156d30da94 | |||
| 6fd93fe93a | |||
| 5ad7f17002 | |||
| 43d17c1836 | |||
| ba56ed0869 | |||
| 536ea2aca2 | |||
| e203646871 | |||
| 2bbbf1be5b | |||
| 4df5b9b4b2 | |||
| a2a7f71604 | |||
| e677479c81 | |||
| 441de62f49 | |||
| aac7099c92 | |||
| 855b95ce34 | |||
| c9d2e855ea | |||
| 248d5d23a2 | |||
| 7c19fafe44 | |||
| 22d159ddf9 | |||
| 3a7e68362b | |||
| 543889f3f6 | |||
| b256516a8c | |||
| d9dc993fdd | |||
| a25037beb9 | |||
| 75769744e9 | |||
| 0efcf32351 | |||
| 31c575bcf1 | |||
| 4d8427f739 | |||
| a81cf9ee90 | |||
| cefb819f7a | |||
| 1c39974a4c | |||
| 8e08acad6b | |||
| f01e1609bf | |||
| 07d79520ef | |||
| ef60995858 | |||
| 998b5bb56f | |||
| b9ceb03df8 | |||
| de81a677c4 | |||
| b32bf85b58 | |||
| b5a6d6eeab | |||
| 7eb3ba8224 | |||
| e3e16ddc3c | |||
| 00a09ed448 | |||
| 8e9a2207b3 | |||
| afe73aed54 | |||
| 39114c0383 | |||
| 76a33a1092 | |||
| dafe370255 | |||
| c5f0288bc7 | |||
| 7e1413d16a | |||
| 2e7cb46f85 | |||
| 884b2215c3 | |||
| 34e07f4ba8 | |||
| e85654f5ec | |||
| 13b23704a8 | |||
| aa17cf986f | |||
| 347916130c | |||
| e68ff30419 | |||
| fadb053379 | |||
| b469ebc5cf | |||
| ee38fc31fb | |||
| 5ffef2a978 | |||
| ef6e371dba | |||
| 10d232e88e | |||
| f0bfb150fe | |||
| de627f5a14 | |||
| 73a73b415e | |||
| 2ddceef9a2 | |||
| fd734be1b6 | |||
| 691c3d7325 | |||
| 9556054fb2 | |||
| 0639034a26 | |||
| 5d1a58a646 | |||
| ff841900e4 | |||
| 8dd4ce6f2c | |||
| 17e4467f0e | |||
| c78f57729f | |||
| d91fd7f92c | |||
| 9d999481b2 | |||
| 3c17c529cc | |||
| 1248f09252 | |||
| 11ef35e828 | |||
| 870bbb4c6b | |||
| 76b3b20fb2 | |||
| 776c9d3af8 | |||
| a1a7454107 | |||
| 8692aa88e2 | |||
| 243d0de997 | |||
| 1a5c500f12 | |||
| 66ce9593fd | |||
| 4294f0c358 | |||
| 425ba56cdf | |||
| 56baa03380 | |||
| 2f9a3edbb9 | |||
| 8e2fc52ea3 | |||
| 229ac72b1e | |||
| f6261d7d81 | |||
| 484e10f7f2 | |||
| 838b87abe2 | |||
| c852d4fba6 | |||
| 87e2ea33aa | |||
| c43b380e70 | |||
| bf3dfd1160 | |||
| 00c1d87a7d | |||
| 5011908e10 | |||
| 4e98d59443 | |||
| 9e4df7c424 | |||
| 28de2f4de3 | |||
| f02aea2737 | |||
| 03847ef451 | |||
| 174aecd099 | |||
| 272f48e734 | |||
| 8a3cfaac0d | |||
| c1993e68b8 | |||
| 0e4a1c3401 | |||
| 53d891247b | |||
| c47fcd0830 | |||
| f62407f788 | |||
| 56b64bf1a5 | |||
| 48fbab7330 | |||
| 23db187d92 | |||
| 7b87ecb047 | |||
| 2cc3cc835f | |||
| 956f44f11a | |||
| c9e3c0b454 | |||
| b4b96251cd | |||
| f738ab3b5d | |||
| 1fc505b816 | |||
| fe085560d0 | |||
| 5ac264d8a8 | |||
| 31d01150ad | |||
| a7e5e15472 | |||
| 3b6e95ec7f | |||
| 350c5d1566 | |||
| d3801aae2e | |||
| b340d90738 | |||
| 1e21c4fbe0 | |||
| 88a4f68fe5 | |||
| 624788570c | |||
| fafe90930d | |||
| 11bbb505c7 | |||
| 38bff8c84f | |||
| 4afead8a1c | |||
| 9acce7de1c | |||
| be3fd8a262 | |||
| d522afea13 | |||
| d47966536c | |||
| 6b660d5ed5 | |||
| 8e64ba2890 | |||
| 11163fff58 | |||
| a15bd3af4e | |||
| df1542581e | |||
| b6404866cd | |||
| f1a565a39f | |||
| 50ec493363 | |||
| 81ec8028f9 | |||
| 73efe896df | |||
| 6cc5411d81 | |||
| b382a09e28 | |||
| 73a27345d4 | |||
| b45c0f55e0 | |||
| c1e478aa7f | |||
| 47c9570903 | |||
| e5eb55b88b | |||
| dd1c905215 | |||
| 873d9bb3cc | |||
| 9a3f4d4daf | |||
| 6d67837f06 | |||
| d80c9a3497 | |||
| 4f27ee936a | |||
| 0290ec19c9 | |||
| 469c13280d | |||
| 3f6973db06 | |||
| 1ba89dc2d2 | |||
| 697f05bab3 | |||
| 608fa5496c | |||
| f386c51ad9 | |||
| 1ea3ad1aec | |||
| 14536c339a | |||
| 8ee1d47203 | |||
| 8e589c83b6 | |||
| bc764f4263 | |||
| 631fa7bf6b | |||
| b338a6c3b8 | |||
| ddf177ee4a | |||
| 4ed9ae623d | |||
| 45c0651090 | |||
| 923733c22b | |||
| 9288e759ad | |||
| f6133d767a | |||
| ffe60fdcd6 | |||
| 979fccc90f | |||
| d45f47ab7f | |||
| 2a939f20ff | |||
| 965cf67769 | |||
| 19fb1e22d2 | |||
| ddb4fda3cb | |||
| 9322576e2f | |||
| 0a5b0516f8 | |||
| 700d48fb2d | |||
| 41f7b7ae4b | |||
| 2890116ab7 | |||
| b27aa206dd | |||
| 2a002d073a | |||
| 00bf44270f | |||
| 7b01579f73 | |||
| 638c423c89 | |||
| a69cbf4e64 | |||
| 9c5e560924 | |||
| 8f3f8e6766 | |||
| fb1c62e973 | |||
| 87a0783dde | |||
| 4d892b7297 | |||
| 57d007b912 | |||
| 0d52f9f582 | |||
| 132852203a | |||
| fa7f3cf336 | |||
| ebccb09169 | |||
| bd891aed01 | |||
| 4fc708f98c | |||
| 81c8191b46 | |||
| e947683294 | |||
| 836921fdeb | |||
| ed74d97871 | |||
| bcd23a54f1 | |||
| 7941769e55 | |||
| 1681a6d452 | |||
| 8ef9862864 | |||
| 81220cba61 | |||
| 5e4b69dc12 | |||
| c38a12270a | |||
| 704b3f74f9 | |||
| 39ef3fb248 | |||
| 38953a75c1 | |||
| aade711d1e | |||
| 831bc25d8f | |||
| 1a7c117df9 | |||
| cec773345a | |||
| 15f8296a9b | |||
| f1b1379f37 | |||
| 0a0a279e99 | |||
| e7b9837065 | |||
| 50db7ca4e8 | |||
| 2858d6c634 | |||
| 5ee0868a4b | |||
| 0ad770c373 | |||
| bb4f816ad4 | |||
| 44fe1a1cc4 | |||
| b647acdb53 | |||
| 8d8ac9c2df | |||
| 1aee9afd1c | |||
| 2209b7afa0 | |||
| 49204c1d37 | |||
| f54d82cace | |||
| 554e7ada89 | |||
| d3a4b47544 | |||
| 7628b3a0f4 | |||
| 2ce56d35f6 | |||
| 8a8a0a4ae0 | |||
| 7c87f3577e | |||
| a52888524d | |||
| e715c78c66 | |||
| ad00c482c7 | |||
| bd5b986306 | |||
| 63caa370e6 | |||
| 83ab0115d1 | |||
| 227cd54aa5 | |||
| ddf7ac4237 | |||
| 8a1faf2803 | |||
| 5c341d4555 | |||
| 63a0c8f1cb | |||
| 6d3b643e2a | |||
| 83e366bfd4 | |||
| e3fc90ae68 | |||
| a3f9221a44 | |||
| 871ba71dfa | |||
| 3fcfbe7549 | |||
| 3b8c053631 | |||
| a44d2dc3a9 | |||
| c29135046a | |||
| 734eb25476 | |||
| b43340455d | |||
| 9f7535bda8 | |||
| 8f2f0f0f85 | |||
| ece1b62b93 | |||
| 24d59c7969 | |||
| 7c4995f93d | |||
| 2a7746c4d1 | |||
| 93f8617afd | |||
| 9fe360883e | |||
| c8d98405a8 | |||
| 371b572e55 | |||
| 89c64817ce | |||
| 3f60d11a87 | |||
| 75ed76ecea | |||
| 4524494072 | |||
| 2cc8cf6ce7 | |||
| dabe855668 | |||
| 2a9b1f80c4 | |||
| fc37f38915 | |||
| ae49b218c3 | |||
| 594c1277b2 | |||
| 58245ba6fb | |||
| 1d0ea7abe0 | |||
| cc4a664baa | |||
| 3994fa5baf | |||
| 1a77f07f65 | |||
| e770f0316d |
@ -157,6 +157,7 @@ jobs:
|
||||
command: pip freeze | tee installed.txt
|
||||
- store_artifacts:
|
||||
path: ~/transformers/installed.txt
|
||||
- run: python -c "from transformers import *" || (echo '🚨 import failed, this means you introduced unprotected imports! 🚨'; exit 1)
|
||||
- run: ruff check examples tests src utils
|
||||
- run: ruff format tests src utils --check
|
||||
- run: python utils/custom_init_isort.py --check_only
|
||||
|
||||
@ -57,9 +57,9 @@ class CircleCIJob:
|
||||
install_steps: List[str] = None
|
||||
marker: Optional[str] = None
|
||||
parallelism: Optional[int] = 1
|
||||
pytest_num_workers: int = 8
|
||||
pytest_num_workers: int = 12
|
||||
pytest_options: Dict[str, Any] = None
|
||||
resource_class: Optional[str] = "xlarge"
|
||||
resource_class: Optional[str] = "2xlarge"
|
||||
tests_to_run: Optional[List[str]] = None
|
||||
working_directory: str = "~/transformers"
|
||||
# This should be only used for doctest job!
|
||||
@ -317,7 +317,7 @@ torch_job = CircleCIJob(
|
||||
"pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
|
||||
],
|
||||
parallelism=1,
|
||||
pytest_num_workers=6,
|
||||
pytest_num_workers=12,
|
||||
)
|
||||
|
||||
|
||||
@ -353,7 +353,7 @@ pipelines_torch_job = CircleCIJob(
|
||||
"pip install -U --upgrade-strategy eager .[sklearn,torch,testing,sentencepiece,torch-speech,vision,timm,video]",
|
||||
],
|
||||
marker="is_pipeline_test",
|
||||
pytest_num_workers=6,
|
||||
pytest_num_workers=12,
|
||||
)
|
||||
|
||||
|
||||
@ -475,6 +475,7 @@ exotic_models_job = CircleCIJob(
|
||||
"pip install -U --upgrade-strategy eager 'git+https://github.com/facebookresearch/detectron2.git'",
|
||||
"sudo apt install tesseract-ocr",
|
||||
"pip install -U --upgrade-strategy eager pytesseract",
|
||||
"pip install --upgrade-strategy eager sentencepiece",
|
||||
"pip install -U --upgrade-strategy eager natten==0.15.1+torch210cpu -f https://shi-labs.com/natten/wheels",
|
||||
"pip install -U --upgrade-strategy eager python-Levenshtein",
|
||||
"pip install -U --upgrade-strategy eager opencv-python",
|
||||
@ -485,6 +486,7 @@ exotic_models_job = CircleCIJob(
|
||||
"tests/models/*layoutlmv*",
|
||||
"tests/models/*nat",
|
||||
"tests/models/deta",
|
||||
"tests/models/udop",
|
||||
"tests/models/nougat",
|
||||
],
|
||||
pytest_num_workers=1,
|
||||
|
||||
194
.github/workflows/build-docker-images.yml
vendored
194
.github/workflows/build-docker-images.yml
vendored
@ -20,18 +20,8 @@ concurrency:
|
||||
jobs:
|
||||
latest-docker:
|
||||
name: "Latest PyTorch + TensorFlow [dev]"
|
||||
runs-on: ubuntu-22.04
|
||||
runs-on: [intel-cpu, 8-cpu, ci]
|
||||
steps:
|
||||
- name: Cleanup disk
|
||||
run: |
|
||||
sudo ls -l /usr/local/lib/
|
||||
sudo ls -l /usr/share/
|
||||
sudo du -sh /usr/local/lib/
|
||||
sudo du -sh /usr/share/
|
||||
sudo rm -rf /usr/local/lib/android
|
||||
sudo rm -rf /usr/share/dotnet
|
||||
sudo du -sh /usr/local/lib/
|
||||
sudo du -sh /usr/share/
|
||||
-
|
||||
name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v3
|
||||
@ -69,7 +59,7 @@ jobs:
|
||||
|
||||
latest-torch-deepspeed-docker:
|
||||
name: "Latest PyTorch + DeepSpeed"
|
||||
runs-on: ubuntu-22.04
|
||||
runs-on: [intel-cpu, 8-cpu, ci]
|
||||
steps:
|
||||
- name: Cleanup disk
|
||||
run: |
|
||||
@ -106,7 +96,7 @@ jobs:
|
||||
# Can't build 2 images in a single job `latest-torch-deepspeed-docker` (for `nvcr.io/nvidia`)
|
||||
latest-torch-deepspeed-docker-for-push-ci-daily-build:
|
||||
name: "Latest PyTorch + DeepSpeed (Push CI - Daily Build)"
|
||||
runs-on: ubuntu-22.04
|
||||
runs-on: [intel-cpu, 8-cpu, ci]
|
||||
steps:
|
||||
- name: Cleanup disk
|
||||
run: |
|
||||
@ -148,7 +138,7 @@ jobs:
|
||||
name: "Doc builder"
|
||||
# Push CI doesn't need this image
|
||||
if: inputs.image_postfix != '-push-ci'
|
||||
runs-on: ubuntu-22.04
|
||||
runs-on: [intel-cpu, 8-cpu, ci]
|
||||
steps:
|
||||
-
|
||||
name: Set up Docker Buildx
|
||||
@ -174,7 +164,7 @@ jobs:
|
||||
name: "Latest PyTorch [dev]"
|
||||
# Push CI doesn't need this image
|
||||
if: inputs.image_postfix != '-push-ci'
|
||||
runs-on: ubuntu-22.04
|
||||
runs-on: [intel-cpu, 8-cpu, ci]
|
||||
steps:
|
||||
- name: Cleanup disk
|
||||
run: |
|
||||
@ -208,47 +198,50 @@ jobs:
|
||||
push: true
|
||||
tags: huggingface/transformers-pytorch-gpu
|
||||
|
||||
# Need to be fixed with the help from Guillaume.
|
||||
# latest-pytorch-amd:
|
||||
# name: "Latest PyTorch (AMD) [dev]"
|
||||
# runs-on: [self-hosted, docker-gpu, amd-gpu, single-gpu, mi210]
|
||||
# steps:
|
||||
# - name: Set up Docker Buildx
|
||||
# uses: docker/setup-buildx-action@v3
|
||||
# - name: Check out code
|
||||
# uses: actions/checkout@v3
|
||||
# - name: Login to DockerHub
|
||||
# uses: docker/login-action@v3
|
||||
# with:
|
||||
# username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
# password: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
# - name: Build and push
|
||||
# uses: docker/build-push-action@v5
|
||||
# with:
|
||||
# context: ./docker/transformers-pytorch-amd-gpu
|
||||
# build-args: |
|
||||
# REF=main
|
||||
# push: true
|
||||
# tags: huggingface/transformers-pytorch-amd-gpu${{ inputs.image_postfix }}
|
||||
# # Push CI images still need to be re-built daily
|
||||
# -
|
||||
# name: Build and push (for Push CI) in a daily basis
|
||||
# # This condition allows `schedule` events, or `push` events that trigger this workflow NOT via `workflow_call`.
|
||||
# # The later case is useful for manual image building for debugging purpose. Use another tag in this case!
|
||||
# if: inputs.image_postfix != '-push-ci'
|
||||
# uses: docker/build-push-action@v5
|
||||
# with:
|
||||
# context: ./docker/transformers-pytorch-amd-gpu
|
||||
# build-args: |
|
||||
# REF=main
|
||||
# push: true
|
||||
# tags: huggingface/transformers-pytorch-amd-gpu-push-ci
|
||||
latest-pytorch-amd:
|
||||
name: "Latest PyTorch (AMD) [dev]"
|
||||
runs-on: [intel-cpu, 8-cpu, ci]
|
||||
steps:
|
||||
-
|
||||
name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v3
|
||||
-
|
||||
name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
-
|
||||
name: Login to DockerHub
|
||||
uses: docker/login-action@v3
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
-
|
||||
name: Build and push
|
||||
uses: docker/build-push-action@v5
|
||||
with:
|
||||
context: ./docker/transformers-pytorch-amd-gpu
|
||||
build-args: |
|
||||
REF=main
|
||||
push: true
|
||||
tags: huggingface/transformers-pytorch-amd-gpu${{ inputs.image_postfix }}
|
||||
# Push CI images still need to be re-built daily
|
||||
-
|
||||
name: Build and push (for Push CI) in a daily basis
|
||||
# This condition allows `schedule` events, or `push` events that trigger this workflow NOT via `workflow_call`.
|
||||
# The later case is useful for manual image building for debugging purpose. Use another tag in this case!
|
||||
if: inputs.image_postfix != '-push-ci'
|
||||
uses: docker/build-push-action@v5
|
||||
with:
|
||||
context: ./docker/transformers-pytorch-amd-gpu
|
||||
build-args: |
|
||||
REF=main
|
||||
push: true
|
||||
tags: huggingface/transformers-pytorch-amd-gpu-push-ci
|
||||
|
||||
latest-tensorflow:
|
||||
name: "Latest TensorFlow [dev]"
|
||||
# Push CI doesn't need this image
|
||||
if: inputs.image_postfix != '-push-ci'
|
||||
runs-on: ubuntu-22.04
|
||||
runs-on: [intel-cpu, 8-cpu, ci]
|
||||
steps:
|
||||
-
|
||||
name: Set up Docker Buildx
|
||||
@ -272,38 +265,69 @@ jobs:
|
||||
push: true
|
||||
tags: huggingface/transformers-tensorflow-gpu
|
||||
|
||||
# latest-pytorch-deepspeed-amd:
|
||||
# name: "PyTorch + DeepSpeed (AMD) [dev]"
|
||||
latest-pytorch-deepspeed-amd:
|
||||
name: "PyTorch + DeepSpeed (AMD) [dev]"
|
||||
runs-on: [intel-cpu, 8-cpu, ci]
|
||||
steps:
|
||||
-
|
||||
name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v3
|
||||
-
|
||||
name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
-
|
||||
name: Login to DockerHub
|
||||
uses: docker/login-action@v3
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
-
|
||||
name: Build and push
|
||||
uses: docker/build-push-action@v5
|
||||
with:
|
||||
context: ./docker/transformers-pytorch-deepspeed-amd-gpu
|
||||
build-args: |
|
||||
REF=main
|
||||
push: true
|
||||
tags: huggingface/transformers-pytorch-deepspeed-amd-gpu${{ inputs.image_postfix }}
|
||||
# Push CI images still need to be re-built daily
|
||||
-
|
||||
name: Build and push (for Push CI) in a daily basis
|
||||
# This condition allows `schedule` events, or `push` events that trigger this workflow NOT via `workflow_call`.
|
||||
# The later case is useful for manual image building for debugging purpose. Use another tag in this case!
|
||||
if: inputs.image_postfix != '-push-ci'
|
||||
uses: docker/build-push-action@v5
|
||||
with:
|
||||
context: ./docker/transformers-pytorch-deepspeed-amd-gpu
|
||||
build-args: |
|
||||
REF=main
|
||||
push: true
|
||||
tags: huggingface/transformers-pytorch-deepspeed-amd-gpu-push-ci
|
||||
|
||||
# runs-on: [self-hosted, docker-gpu, amd-gpu, single-gpu, mi210]
|
||||
# steps:
|
||||
# - name: Set up Docker Buildx
|
||||
# uses: docker/setup-buildx-action@v3
|
||||
# - name: Check out code
|
||||
# uses: actions/checkout@v3
|
||||
# - name: Login to DockerHub
|
||||
# uses: docker/login-action@v3
|
||||
# with:
|
||||
# username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
# password: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
# - name: Build and push
|
||||
# uses: docker/build-push-action@v5
|
||||
# with:
|
||||
# context: ./docker/transformers-pytorch-deepspeed-amd-gpu
|
||||
# build-args: |
|
||||
# REF=main
|
||||
# push: true
|
||||
# tags: huggingface/transformers-pytorch-deepspeed-amd-gpu${{ inputs.image_postfix }}
|
||||
# # Push CI images still need to be re-built daily
|
||||
# -
|
||||
# name: Build and push (for Push CI) in a daily basis
|
||||
# # This condition allows `schedule` events, or `push` events that trigger this workflow NOT via `workflow_call`.
|
||||
# # The later case is useful for manual image building for debugging purpose. Use another tag in this case!
|
||||
# if: inputs.image_postfix != '-push-ci'
|
||||
# uses: docker/build-push-action@v5
|
||||
# with:
|
||||
# context: ./docker/transformers-pytorch-deepspeed-amd-gpu
|
||||
# build-args: |
|
||||
# REF=main
|
||||
# push: true
|
||||
# tags: huggingface/transformers-pytorch-deepspeed-amd-gpu-push-ci
|
||||
latest-quantization-torch-docker:
|
||||
name: "Latest Pytorch + Quantization [dev]"
|
||||
# Push CI doesn't need this image
|
||||
if: inputs.image_postfix != '-push-ci'
|
||||
runs-on: [intel-cpu, 8-cpu, ci]
|
||||
steps:
|
||||
-
|
||||
name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v3
|
||||
-
|
||||
name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
-
|
||||
name: Login to DockerHub
|
||||
uses: docker/login-action@v3
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
-
|
||||
name: Build and push
|
||||
uses: docker/build-push-action@v5
|
||||
with:
|
||||
context: ./docker/transformers-quantization-latest-gpu
|
||||
build-args: |
|
||||
REF=main
|
||||
push: true
|
||||
tags: huggingface/transformers-quantization-latest-gpu${{ inputs.image_postfix }}
|
||||
1
.github/workflows/build_documentation.yml
vendored
1
.github/workflows/build_documentation.yml
vendored
@ -16,6 +16,7 @@ jobs:
|
||||
package: transformers
|
||||
notebook_folder: transformers_doc
|
||||
languages: de en es fr hi it ko pt tr zh ja te
|
||||
custom_container: huggingface/transformers-doc-builder
|
||||
secrets:
|
||||
token: ${{ secrets.HUGGINGFACE_PUSH }}
|
||||
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
|
||||
|
||||
1
.github/workflows/build_pr_documentation.yml
vendored
1
.github/workflows/build_pr_documentation.yml
vendored
@ -15,3 +15,4 @@ jobs:
|
||||
pr_number: ${{ github.event.number }}
|
||||
package: transformers
|
||||
languages: de en es fr hi it ko pt tr zh ja te
|
||||
custom_container: huggingface/transformers-doc-builder
|
||||
|
||||
59
.github/workflows/self-scheduled-caller.yml
vendored
Normal file
59
.github/workflows/self-scheduled-caller.yml
vendored
Normal file
@ -0,0 +1,59 @@
|
||||
name: Self-hosted runner (scheduled)
|
||||
|
||||
|
||||
on:
|
||||
repository_dispatch:
|
||||
schedule:
|
||||
- cron: "17 2 * * *"
|
||||
push:
|
||||
branches:
|
||||
- run_scheduled_ci*
|
||||
|
||||
jobs:
|
||||
model-ci:
|
||||
name: Model CI
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_tests_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-models"
|
||||
secrets: inherit
|
||||
|
||||
torch-pipeline:
|
||||
name: Torch pipeline CI
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_pipelines_torch_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-pipeline-torch"
|
||||
secrets: inherit
|
||||
|
||||
tf-pipeline:
|
||||
name: TF pipeline CI
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_pipelines_tf_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-pipeline-tf"
|
||||
secrets: inherit
|
||||
|
||||
example-ci:
|
||||
name: Example CI
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_examples_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-examples"
|
||||
secrets: inherit
|
||||
|
||||
deepspeed-ci:
|
||||
name: DeepSpeed CI
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_all_tests_torch_cuda_extensions_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-deepspeed"
|
||||
secrets: inherit
|
||||
|
||||
quantization-ci:
|
||||
name: Quantization CI
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_tests_quantization_torch_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-quantization"
|
||||
secrets: inherit
|
||||
243
.github/workflows/self-scheduled.yml
vendored
243
.github/workflows/self-scheduled.yml
vendored
@ -7,12 +7,14 @@ name: Self-hosted runner (scheduled)
|
||||
# `docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile`
|
||||
|
||||
on:
|
||||
repository_dispatch:
|
||||
schedule:
|
||||
- cron: "17 2 * * *"
|
||||
push:
|
||||
branches:
|
||||
- run_scheduled_ci*
|
||||
workflow_call:
|
||||
inputs:
|
||||
job:
|
||||
required: true
|
||||
type: string
|
||||
slack_report_channel:
|
||||
required: true
|
||||
type: string
|
||||
|
||||
env:
|
||||
HF_HOME: /mnt/cache
|
||||
@ -31,6 +33,7 @@ env:
|
||||
|
||||
jobs:
|
||||
setup:
|
||||
if: ${{ inputs.job == 'run_tests_gpu' }}
|
||||
name: Setup
|
||||
strategy:
|
||||
matrix:
|
||||
@ -71,6 +74,7 @@ jobs:
|
||||
nvidia-smi
|
||||
|
||||
run_tests_gpu:
|
||||
if: ${{ inputs.job == 'run_tests_gpu' }}
|
||||
name: " "
|
||||
needs: setup
|
||||
strategy:
|
||||
@ -85,58 +89,8 @@ jobs:
|
||||
slice_id: ${{ matrix.slice_id }}
|
||||
secrets: inherit
|
||||
|
||||
run_examples_gpu:
|
||||
name: Examples directory
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
machine_type: [single-gpu]
|
||||
runs-on: ['${{ matrix.machine_type }}', nvidia-gpu, t4, daily-ci]
|
||||
container:
|
||||
image: huggingface/transformers-all-latest-gpu
|
||||
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
needs: setup
|
||||
steps:
|
||||
- name: Update clone
|
||||
working-directory: /transformers
|
||||
run: git fetch && git checkout ${{ github.sha }}
|
||||
|
||||
- name: Reinstall transformers in edit mode (remove the one installed during docker image build)
|
||||
working-directory: /transformers
|
||||
run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
|
||||
- name: Environment
|
||||
working-directory: /transformers
|
||||
run: |
|
||||
python3 utils/print_env.py
|
||||
|
||||
- name: Show installed libraries and their versions
|
||||
working-directory: /transformers
|
||||
run: pip freeze
|
||||
|
||||
- name: Run examples tests on GPU
|
||||
working-directory: /transformers
|
||||
run: |
|
||||
pip install -r examples/pytorch/_tests_requirements.txt
|
||||
python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_examples_gpu examples/pytorch
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
continue-on-error: true
|
||||
run: cat /transformers/reports/${{ matrix.machine_type }}_examples_gpu/failures_short.txt
|
||||
|
||||
- name: "Test suite reports artifacts: ${{ matrix.machine_type }}_run_examples_gpu"
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: ${{ matrix.machine_type }}_run_examples_gpu
|
||||
path: /transformers/reports/${{ matrix.machine_type }}_examples_gpu
|
||||
|
||||
run_pipelines_torch_gpu:
|
||||
if: ${{ inputs.job == 'run_pipelines_torch_gpu' }}
|
||||
name: PyTorch pipelines
|
||||
strategy:
|
||||
fail-fast: false
|
||||
@ -146,7 +100,6 @@ jobs:
|
||||
container:
|
||||
image: huggingface/transformers-pytorch-gpu
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
needs: setup
|
||||
steps:
|
||||
- name: Update clone
|
||||
working-directory: /transformers
|
||||
@ -187,6 +140,7 @@ jobs:
|
||||
path: /transformers/reports/${{ matrix.machine_type }}_tests_torch_pipeline_gpu
|
||||
|
||||
run_pipelines_tf_gpu:
|
||||
if: ${{ inputs.job == 'run_pipelines_tf_gpu' }}
|
||||
name: TensorFlow pipelines
|
||||
strategy:
|
||||
fail-fast: false
|
||||
@ -196,7 +150,6 @@ jobs:
|
||||
container:
|
||||
image: huggingface/transformers-tensorflow-gpu
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
needs: setup
|
||||
steps:
|
||||
- name: Update clone
|
||||
working-directory: /transformers
|
||||
@ -237,14 +190,65 @@ jobs:
|
||||
name: ${{ matrix.machine_type }}_run_tests_tf_pipeline_gpu
|
||||
path: /transformers/reports/${{ matrix.machine_type }}_tests_tf_pipeline_gpu
|
||||
|
||||
run_examples_gpu:
|
||||
if: ${{ inputs.job == 'run_examples_gpu' }}
|
||||
name: Examples directory
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
machine_type: [single-gpu]
|
||||
runs-on: ['${{ matrix.machine_type }}', nvidia-gpu, t4, daily-ci]
|
||||
container:
|
||||
image: huggingface/transformers-all-latest-gpu
|
||||
options: --gpus 0 --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
steps:
|
||||
- name: Update clone
|
||||
working-directory: /transformers
|
||||
run: git fetch && git checkout ${{ github.sha }}
|
||||
|
||||
- name: Reinstall transformers in edit mode (remove the one installed during docker image build)
|
||||
working-directory: /transformers
|
||||
run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
|
||||
- name: Environment
|
||||
working-directory: /transformers
|
||||
run: |
|
||||
python3 utils/print_env.py
|
||||
|
||||
- name: Show installed libraries and their versions
|
||||
working-directory: /transformers
|
||||
run: pip freeze
|
||||
|
||||
- name: Run examples tests on GPU
|
||||
working-directory: /transformers
|
||||
run: |
|
||||
pip install -r examples/pytorch/_tests_requirements.txt
|
||||
python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_examples_gpu examples/pytorch
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
continue-on-error: true
|
||||
run: cat /transformers/reports/${{ matrix.machine_type }}_examples_gpu/failures_short.txt
|
||||
|
||||
- name: "Test suite reports artifacts: ${{ matrix.machine_type }}_run_examples_gpu"
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: ${{ matrix.machine_type }}_run_examples_gpu
|
||||
path: /transformers/reports/${{ matrix.machine_type }}_examples_gpu
|
||||
|
||||
run_all_tests_torch_cuda_extensions_gpu:
|
||||
if: ${{ inputs.job == 'run_all_tests_torch_cuda_extensions_gpu' }}
|
||||
name: Torch CUDA extension tests
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
machine_type: [single-gpu, multi-gpu]
|
||||
runs-on: ['${{ matrix.machine_type }}', nvidia-gpu, t4, daily-ci]
|
||||
needs: setup
|
||||
container:
|
||||
image: huggingface/transformers-pytorch-deepspeed-latest-gpu
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
@ -265,7 +269,7 @@ jobs:
|
||||
working-directory: /workspace
|
||||
run: |
|
||||
python3 -m pip uninstall -y deepspeed
|
||||
DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
|
||||
DS_DISABLE_NINJA=1 DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
@ -297,18 +301,62 @@ jobs:
|
||||
name: ${{ matrix.machine_type }}_run_tests_torch_cuda_extensions_gpu_test_reports
|
||||
path: /workspace/transformers/reports/${{ matrix.machine_type }}_tests_torch_cuda_extensions_gpu
|
||||
|
||||
run_tests_quantization_torch_gpu:
|
||||
if: ${{ inputs.job == 'run_tests_quantization_torch_gpu' }}
|
||||
name: Quantization tests
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
machine_type: [single-gpu, multi-gpu]
|
||||
runs-on: ['${{ matrix.machine_type }}', nvidia-gpu, t4, daily-ci]
|
||||
container:
|
||||
image: huggingface/transformers-quantization-latest-gpu
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
steps:
|
||||
- name: Update clone
|
||||
working-directory: /transformers
|
||||
run: git fetch && git checkout ${{ github.sha }}
|
||||
|
||||
- name: Reinstall transformers in edit mode (remove the one installed during docker image build)
|
||||
working-directory: /transformers
|
||||
run: python3 -m pip uninstall -y transformers && python3 -m pip install -e .
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
|
||||
- name: Environment
|
||||
working-directory: /transformers
|
||||
run: |
|
||||
python3 utils/print_env.py
|
||||
|
||||
- name: Show installed libraries and their versions
|
||||
working-directory: /transformers
|
||||
run: pip freeze
|
||||
|
||||
- name: Run quantization tests on GPU
|
||||
working-directory: /transformers
|
||||
run: |
|
||||
python3 -m pytest -v --make-reports=${{ matrix.machine_type }}_tests_quantization_torch_gpu tests/quantization
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
continue-on-error: true
|
||||
run: cat /transformers/reports/${{ matrix.machine_type }}_tests_quantization_torch_gpu/failures_short.txt
|
||||
|
||||
- name: "Test suite reports artifacts: ${{ matrix.machine_type }}_run_tests_quantization_torch_gpu"
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: ${{ matrix.machine_type }}_run_tests_quantization_torch_gpu
|
||||
path: /transformers/reports/${{ matrix.machine_type }}_tests_quantization_torch_gpu
|
||||
|
||||
run_extract_warnings:
|
||||
# Let's only do this for the job `run_tests_gpu` to simplify the (already complex) logic.
|
||||
if: ${{ always() && inputs.job == 'run_tests_gpu' }}
|
||||
name: Extract warnings in CI artifacts
|
||||
runs-on: ubuntu-22.04
|
||||
if: always()
|
||||
needs: [
|
||||
setup,
|
||||
run_tests_gpu,
|
||||
run_examples_gpu,
|
||||
run_pipelines_tf_gpu,
|
||||
run_pipelines_torch_gpu,
|
||||
run_all_tests_torch_cuda_extensions_gpu
|
||||
]
|
||||
needs: [setup, run_tests_gpu]
|
||||
steps:
|
||||
- name: Checkout transformers
|
||||
uses: actions/checkout@v3
|
||||
@ -345,51 +393,24 @@ jobs:
|
||||
path: warnings_in_ci/selected_warnings.json
|
||||
|
||||
send_results:
|
||||
name: Send results to webhook
|
||||
runs-on: ubuntu-22.04
|
||||
if: always()
|
||||
name: Slack Report
|
||||
needs: [
|
||||
setup,
|
||||
run_tests_gpu,
|
||||
run_examples_gpu,
|
||||
run_pipelines_tf_gpu,
|
||||
run_pipelines_torch_gpu,
|
||||
run_pipelines_tf_gpu,
|
||||
run_examples_gpu,
|
||||
run_all_tests_torch_cuda_extensions_gpu,
|
||||
run_tests_quantization_torch_gpu,
|
||||
run_extract_warnings
|
||||
]
|
||||
steps:
|
||||
- name: Preliminary job status
|
||||
shell: bash
|
||||
# For the meaning of these environment variables, see the job `Setup`
|
||||
run: |
|
||||
echo "Setup status: ${{ needs.setup.result }}"
|
||||
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/download-artifact@v3
|
||||
- name: Send message to Slack
|
||||
env:
|
||||
CI_SLACK_BOT_TOKEN: ${{ secrets.CI_SLACK_BOT_TOKEN }}
|
||||
CI_SLACK_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID }}
|
||||
CI_SLACK_CHANNEL_ID_DAILY: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY }}
|
||||
CI_SLACK_CHANNEL_DUMMY_TESTS: ${{ secrets.CI_SLACK_CHANNEL_DUMMY_TESTS }}
|
||||
CI_SLACK_REPORT_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY }}
|
||||
ACCESS_REPO_INFO_TOKEN: ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
|
||||
CI_EVENT: scheduled
|
||||
CI_SHA: ${{ github.sha }}
|
||||
CI_WORKFLOW_REF: ${{ github.workflow_ref }}
|
||||
SETUP_STATUS: ${{ needs.setup.result }}
|
||||
# We pass `needs.setup.outputs.matrix` as the argument. A processing in `notification_service.py` to change
|
||||
# `models/bert` to `models_bert` is required, as the artifact names use `_` instead of `/`.
|
||||
run: |
|
||||
sudo apt-get install -y curl
|
||||
pip install slack_sdk
|
||||
pip show slack_sdk
|
||||
python utils/notification_service.py "${{ needs.setup.outputs.folder_slices }}"
|
||||
|
||||
# Upload complete failure tables, as they might be big and only truncated versions could be sent to Slack.
|
||||
- name: Failure table artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: prev_ci_results
|
||||
path: prev_ci_results
|
||||
if: ${{ always() }}
|
||||
uses: ./.github/workflows/slack-report.yml
|
||||
with:
|
||||
job: ${{ inputs.job }}
|
||||
# This would be `skipped` if `setup` is skipped.
|
||||
setup_status: ${{ needs.setup.result }}
|
||||
slack_report_channel: ${{ inputs.slack_report_channel }}
|
||||
# This would be an empty string if `setup` is skipped.
|
||||
folder_slices: ${{ needs.setup.outputs.folder_slices }}
|
||||
secrets: inherit
|
||||
64
.github/workflows/slack-report.yml
vendored
Normal file
64
.github/workflows/slack-report.yml
vendored
Normal file
@ -0,0 +1,64 @@
|
||||
name: CI slack report
|
||||
|
||||
on:
|
||||
workflow_call:
|
||||
inputs:
|
||||
job:
|
||||
required: true
|
||||
type: string
|
||||
slack_report_channel:
|
||||
required: true
|
||||
type: string
|
||||
setup_status:
|
||||
required: true
|
||||
type: string
|
||||
folder_slices:
|
||||
required: true
|
||||
type: string
|
||||
|
||||
|
||||
jobs:
|
||||
send_results:
|
||||
name: Send results to webhook
|
||||
runs-on: ubuntu-22.04
|
||||
if: always()
|
||||
steps:
|
||||
- name: Preliminary job status
|
||||
shell: bash
|
||||
# For the meaning of these environment variables, see the job `Setup`
|
||||
run: |
|
||||
echo "Setup status: ${{ inputs.setup_status }}"
|
||||
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/download-artifact@v3
|
||||
- name: Send message to Slack
|
||||
env:
|
||||
CI_SLACK_BOT_TOKEN: ${{ secrets.CI_SLACK_BOT_TOKEN }}
|
||||
CI_SLACK_CHANNEL_ID: ${{ secrets.CI_SLACK_CHANNEL_ID }}
|
||||
CI_SLACK_CHANNEL_ID_DAILY: ${{ secrets.CI_SLACK_CHANNEL_ID_DAILY }}
|
||||
CI_SLACK_CHANNEL_DUMMY_TESTS: ${{ secrets.CI_SLACK_CHANNEL_DUMMY_TESTS }}
|
||||
SLACK_REPORT_CHANNEL: ${{ inputs.slack_report_channel }}
|
||||
ACCESS_REPO_INFO_TOKEN: ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
|
||||
CI_EVENT: scheduled
|
||||
CI_SHA: ${{ github.sha }}
|
||||
CI_WORKFLOW_REF: ${{ github.workflow_ref }}
|
||||
CI_TEST_JOB: ${{ inputs.job }}
|
||||
SETUP_STATUS: ${{ inputs.setup_status }}
|
||||
# We pass `needs.setup.outputs.matrix` as the argument. A processing in `notification_service.py` to change
|
||||
# `models/bert` to `models_bert` is required, as the artifact names use `_` instead of `/`.
|
||||
# For a job that doesn't depend on (i.e. `needs`) `setup`, the value for `inputs.folder_slices` would be an
|
||||
# empty string, and the called script still get one argument (which is the emtpy string).
|
||||
run: |
|
||||
sudo apt-get install -y curl
|
||||
pip install slack_sdk
|
||||
pip show slack_sdk
|
||||
python utils/notification_service.py "${{ inputs.folder_slices }}"
|
||||
|
||||
# Upload complete failure tables, as they might be big and only truncated versions could be sent to Slack.
|
||||
- name: Failure table artifacts
|
||||
# Only the model testing job is concerned for this step
|
||||
if: ${{ inputs.job == 'run_tests_gpu' }}
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: prev_ci_results
|
||||
path: prev_ci_results
|
||||
2
Makefile
2
Makefile
@ -51,12 +51,14 @@ repo-consistency:
|
||||
# this target runs checks on all files
|
||||
|
||||
quality:
|
||||
@python -c "from transformers import *" || (echo '🚨 import failed, this means you introduced unprotected imports! 🚨'; exit 1)
|
||||
ruff check $(check_dirs) setup.py conftest.py
|
||||
ruff format --check $(check_dirs) setup.py conftest.py
|
||||
python utils/custom_init_isort.py --check_only
|
||||
python utils/sort_auto_mappings.py --check_only
|
||||
python utils/check_doc_toc.py
|
||||
|
||||
|
||||
# Format source code automatically and check is there are any problems left that need manual fixing
|
||||
|
||||
extra_style_checks:
|
||||
|
||||
18
README.md
18
README.md
@ -57,6 +57,7 @@ limitations under the License.
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
@ -330,6 +331,7 @@ Current number of checkpoints: ** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (from Cohere) released with the paper [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>) by Cohere.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
@ -345,7 +347,7 @@ Current number of checkpoints: ** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)** (from University of Hong Kong and TikTok) released with the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (from University of Hong Kong and TikTok) released with the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
@ -365,7 +367,7 @@ Current number of checkpoints: ** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@ -374,6 +376,7 @@ Current number of checkpoints: ** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (from ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. Released with the paper [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (from Google) released with the paper [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by the Gemma Google team.
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
|
||||
@ -406,6 +409,7 @@ Current number of checkpoints: ** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
@ -413,6 +417,7 @@ Current number of checkpoints: ** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (from Albert Gu and Tri Dao) released with the paper [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) by Albert Gu and Tri Dao.
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
|
||||
@ -438,6 +443,7 @@ Current number of checkpoints: ** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
@ -464,8 +470,10 @@ Current number of checkpoints: ** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
|
||||
@ -480,6 +488,7 @@ Current number of checkpoints: ** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (from Beijing Academy of Artificial Intelligence (BAAI)) released with the paper [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang.
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
@ -489,7 +498,9 @@ Current number of checkpoints: ** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/main/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (from MagicLeap) released with the paper [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
|
||||
@ -507,6 +518,7 @@ Current number of checkpoints: ** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (from Microsoft Research) released with the paper [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
|
||||
17
README_de.md
17
README_de.md
@ -57,6 +57,7 @@ limitations under the License.
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<b>Deutsch</b> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
@ -326,6 +327,7 @@ Aktuelle Anzahl der Checkpoints: ** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (from Cohere) released with the paper [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>) by Cohere.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
@ -341,7 +343,7 @@ Aktuelle Anzahl der Checkpoints: ** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)** (from University of Hong Kong and TikTok) released with the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (from University of Hong Kong and TikTok) released with the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
@ -361,7 +363,7 @@ Aktuelle Anzahl der Checkpoints: ** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@ -370,6 +372,7 @@ Aktuelle Anzahl der Checkpoints: ** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (from ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. Released with the paper [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (from Google) released with the paper [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by the Gemma Google team.
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
|
||||
@ -402,6 +405,7 @@ Aktuelle Anzahl der Checkpoints: ** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
@ -409,6 +413,7 @@ Aktuelle Anzahl der Checkpoints: ** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (from Albert Gu and Tri Dao) released with the paper [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) by Albert Gu and Tri Dao.
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
|
||||
@ -434,6 +439,7 @@ Aktuelle Anzahl der Checkpoints: ** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
@ -460,8 +466,10 @@ Aktuelle Anzahl der Checkpoints: ** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
|
||||
@ -476,6 +484,7 @@ Aktuelle Anzahl der Checkpoints: ** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (from Beijing Academy of Artificial Intelligence (BAAI) released with the paper [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang.
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
@ -485,6 +494,9 @@ Aktuelle Anzahl der Checkpoints: ** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (from MagicLeap) released with the paper [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
|
||||
@ -502,6 +514,7 @@ Aktuelle Anzahl der Checkpoints: ** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (from Microsoft Research) released with the paper [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
|
||||
24
README_es.md
24
README_es.md
@ -52,6 +52,7 @@ limitations under the License.
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
@ -303,6 +304,7 @@ Número actual de puntos de control: ** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (from Cohere) released with the paper [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>) by Cohere.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
@ -318,7 +320,7 @@ Número actual de puntos de control: ** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)** (from University of Hong Kong and TikTok) released with the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (from University of Hong Kong and TikTok) released with the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
@ -338,7 +340,7 @@ Número actual de puntos de control: ** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@ -347,6 +349,7 @@ Número actual de puntos de control: ** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (from ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. Released with the paper [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (from Google) released with the paper [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by the Gemma Google team.
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
|
||||
@ -377,8 +380,9 @@ Número actual de puntos de control: ** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
@ -386,6 +390,7 @@ Número actual de puntos de control: ** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (from Albert Gu and Tri Dao) released with the paper [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) by Albert Gu and Tri Dao.
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
|
||||
@ -408,9 +413,10 @@ Número actual de puntos de control: ** (from Apple) released with the paper [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (from MosaiML) released with the repository [llm-foundry](https://github.com/mosaicml/llm-foundry/) by the MosaicML NLP Team.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
@ -424,7 +430,7 @@ Número actual de puntos de control: ** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** (from IBM Research) released with the paper [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (from IBM) released with the paper [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (from IBM) released with the paper [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
|
||||
@ -437,8 +443,10 @@ Número actual de puntos de control: ** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
|
||||
@ -453,6 +461,7 @@ Número actual de puntos de control: ** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (from Beijing Academy of Artificial Intelligence (BAAI) released with the paper [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang.
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
@ -462,7 +471,9 @@ Número actual de puntos de control: ** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/main/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (from MagicLeap) released with the paper [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
|
||||
@ -480,6 +491,7 @@ Número actual de puntos de control: ** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (from Microsoft Research) released with the paper [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
|
||||
396
README_fr.md
396
README_fr.md
@ -57,6 +57,7 @@ limitations under the License.
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<b>Français</b> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
@ -142,7 +143,7 @@ Pour utiliser immédiatement un modèle sur une entrée donnée (texte, image, a
|
||||
|
||||
# Allouer un pipeline pour l'analyse de sentiment
|
||||
>>> classifieur = pipeline('sentiment-analysis')
|
||||
>>> classifieur('Nous sommes très heureux d'introduire le pipeline dans le référentiel transformers.')
|
||||
>>> classifieur("Nous sommes très heureux d'introduire le pipeline dans le référentiel transformers.")
|
||||
[{'label': 'POSITIF', 'score': 0.9996980428695679}]
|
||||
```
|
||||
|
||||
@ -298,247 +299,258 @@ Nombre actuel de points de contrôle : ** (de Facebook) publié dans l'article [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) de Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov et Luke Zettlemoyer.
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (de l'École polytechnique) publié dans l'article [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) de Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (de VinAI Research) publié dans l'article [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) de Nguyen Luong Tran, Duong Minh Le et Dat Quoc Nguyen.
|
||||
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (de Microsoft) publié dans l'article [BEiT: Pré-entraînement BERT des transformateurs d'images](https://arxiv.org/abs/2106.08254) par Hangbo Bao, Li Dong, Furu Wei.
|
||||
1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (de Google) publié dans l'article [BERT : Pré-entraînement de transformateurs bidirectionnels profonds pour la compréhension du langage](https://arxiv.org/abs/1810.04805) par Jacob Devlin, Ming-Wei Chang, Kenton Lee et Kristina Toutanova.
|
||||
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (de Microsoft) publié dans l'article [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) par Hangbo Bao, Li Dong, Furu Wei.
|
||||
1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (de Google) publié dans l'article [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) par Jacob Devlin, Ming-Wei Chang, Kenton Lee et Kristina Toutanova.
|
||||
1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (de Google) publié dans l'article [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) parSascha Rothe, Shashi Narayan, Aliaksei Severyn.
|
||||
1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (de VinAI Research) publié dans l'article [BERTweet : un modèle de langage pré-entraîné pour les Tweets en anglais](https://aclanthology.org/2020.emnlp-demos.2/) par Dat Quoc Nguyen, Thanh Vu et Anh Tuan Nguyen.
|
||||
1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (de Google Research) publié dans l'article [Big Bird: Transformateurs pour des séquences plus longues](https://arxiv.org/abs/2007.14062) par Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
|
||||
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (de Google Research) publié dans l'article [Big Bird: Transformateurs pour des séquences plus longues](https://arxiv.org/abs/2007.14062) par Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
|
||||
1. **[BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt)** (de Microsoft Research AI4Science) publié dans l'article [BioGPT : transformateur génératif pré-entraîné pour la génération et l'extraction de texte biomédical](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) par Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon et Tie-Yan Liu.
|
||||
1. **[BiT](https://huggingface.co/docs/transformers/model_doc/bit)** (de Google AI) publié dans l'article [Big Transfer (BiT) : Apprentissage général de la représentation visuelle](https://arxiv.org/abs/1912.11370) par Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
|
||||
1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (de VinAI Research) publié dans l'article [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) par Dat Quoc Nguyen, Thanh Vu et Anh Tuan Nguyen.
|
||||
1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (de Google Research) publié dans l'article [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) par Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
|
||||
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (de Google Research) publié dans l'article [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) par Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
|
||||
1. **[BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt)** (de Microsoft Research AI4Science) publié dans l'article [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) par Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon et Tie-Yan Liu.
|
||||
1. **[BiT](https://huggingface.co/docs/transformers/model_doc/bit)** (de Google AI) publié dans l'article [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) par Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
|
||||
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (de Facebook) publié dans l'article [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) par Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (de Facebook) publié dans l'article [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) par Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BLIP](https://huggingface.co/docs/transformers/model_doc/blip)** (de Salesforce) publié dans l'article [BLIP : Pré-entraînement de la langue et de l'image par bootstrap pour une compréhension et une génération unifiées de la vision et du langage](https://arxiv.org/abs/2201.12086) par Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
|
||||
1. **[BLIP-2](https://huggingface.co/docs/transformers/model_doc/blip-2)** (de Salesforce) publié dans l'article [BLIP-2 : Pré-entraînement de la langue et de l'image avec des encodeurs d'images gelés et de grands modèles de langage](https://arxiv.org/abs/2301.12597) par Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
|
||||
1. **[BLIP](https://huggingface.co/docs/transformers/model_doc/blip)** (de Salesforce) publié dans l'article [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) par Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
|
||||
1. **[BLIP-2](https://huggingface.co/docs/transformers/model_doc/blip-2)** (de Salesforce) publié dans l'article [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) par Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
|
||||
1. **[BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom)** (de l'atelier BigScience) publié par l'[atelier BigScience](https://bigscience.huggingface.co/).
|
||||
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (d'Alexa) publié dans l'article [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) par Adrian de Wynter et Daniel J. Perry.
|
||||
1. **[BridgeTower](https://huggingface.co/docs/transformers/model_doc/bridgetower)** (de l'Institut de technologie de Harbin/Microsoft Research Asia/Intel Labs) publié dans l'article [BridgeTower : Construire des ponts entre les encodeurs dans l'apprentissage de la représentation vision-langage](https://arxiv.org/abs/2206.08657) par Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
|
||||
1. **[BROS](https://huggingface.co/docs/transformers/model_doc/bros)** (de NAVER CLOVA) publié dans l'article [BROS : un modèle de langage pré-entraîné axé sur le texte et la mise en page pour une meilleure extraction des informations clés des documents](https://arxiv.org/abs/2108.04539) par Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
|
||||
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (de Google Research) publié dans l'article [ByT5 : Vers un futur sans jeton avec des modèles pré-entraînés byte-to-byte](https://arxiv.org/abs/2105.13626) par Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
|
||||
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (d'Inria/Facebook/Sorbonne) publié dans l'article [CamemBERT : un modèle de langue français savoureux](https://arxiv.org/abs/1911.03894) par Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah et Benoît Sagot.
|
||||
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (de Google Research) publié dans l'article [CANINE : Pré-entraînement d'un encodeur sans tokenisation efficace pour la représentation du langage](https://arxiv.org/abs/2103.06874) par Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
|
||||
1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (d'OFA-Sys) publié dans l'article [Chinese CLIP : Pré-entraînement contrastif vision-langage en chinois](https://arxiv.org/abs/2211.01335) par An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
|
||||
1. **[BridgeTower](https://huggingface.co/docs/transformers/model_doc/bridgetower)** (de l'Institut de technologie de Harbin/Microsoft Research Asia/Intel Labs) publié dans l'article [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) par Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
|
||||
1. **[BROS](https://huggingface.co/docs/transformers/model_doc/bros)** (de NAVER CLOVA) publié dans l'article [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) par Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
|
||||
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (de Google Research) publié dans l'article [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) par Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
|
||||
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (d'Inria/Facebook/Sorbonne) publié dans l'article [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) par Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah et Benoît Sagot.
|
||||
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (de Google Research) publié dans l'article [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) par Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
|
||||
1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (d'OFA-Sys) publié dans l'article [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) par An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
|
||||
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (de LAION-AI) publié dans l'article [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) par Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (d'OpenAI) publié dans l'article [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) par Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (de l'Université de Göttingen) publié dans l'article [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) par Timo Lüddecke et Alexander Ecker.
|
||||
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** publié dans l'article [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) par James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (de Salesforce) publié dans l'article [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) par Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (de MetaAI) publié dans l'article [Code Llama : Modèles ouverts fondamentaux pour le code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) par Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (de MetaAI) publié dans l'article [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) par Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (de Cohere) publié dans l'article [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>) parCohere.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (de Microsoft Research Asia) publié dans l'article [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) par Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (de YituTech) publié dans l'article [ConvBERT : Amélioration de BERT avec une convolution dynamique basée sur des plages](https://arxiv.org/abs/2008.02496) par Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (de YituTech) publié dans l'article [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) par Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (de Facebook AI) publié dans l'article [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) par Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
1. **[ConvNeXTV2](https://huggingface.co/docs/transformers/model_doc/convnextv2)** (de Facebook AI) publié dans l'article [ConvNeXt V2 : Conception conjointe et mise à l'échelle de ConvNets avec des autoencodeurs masqués](https://arxiv.org/abs/2301.00808) par Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
|
||||
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (de l'Université de Tsinghua) publié dans l'article [CPM : Un modèle de langue chinois pré-entraîné génératif à grande échelle](https://arxiv.org/abs/2012.00413) par Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
|
||||
1. **[ConvNeXTV2](https://huggingface.co/docs/transformers/model_doc/convnextv2)** (de Facebook AI) publié dans l'article [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) par Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
|
||||
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (de l'Université de Tsinghua) publié dans l'article [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) par Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
|
||||
1. **[CPM-Ant](https://huggingface.co/docs/transformers/model_doc/cpmant)** (d'OpenBMB) publié par l'[OpenBMB](https://www.openbmb.org/).
|
||||
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (de Salesforce) publié dans l'article [CTRL : Un modèle de langage conditionnel de type Transformer pour une génération contrôlable](https://arxiv.org/abs/1909.05858) par Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong et Richard Socher.
|
||||
1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (de Microsoft) publié dans l'article [CvT : Introduction de convolutions aux transformateurs visuels](https://arxiv.org/abs/2103.15808) par Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
|
||||
1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (de Facebook) publié dans l'article [Data2Vec : Un cadre général pour l'apprentissage auto-supervisé en parole, vision et langage](https://arxiv.org/abs/2202.03555) par Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
|
||||
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (de Microsoft) publié dans l'article [DeBERTa : BERT amélioré avec attention désentrelacée](https://arxiv.org/abs/2006.03654) par Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (de Microsoft) publié dans l'article [DeBERTa : BERT amélioré avec attention désentrelacée](https://arxiv.org/abs/2006.03654) par Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (de Berkeley/Facebook/Google) publié dans l'article [Decision Transformer : Apprentissage par renforcement via la modélisation de séquences](https://arxiv.org/abs/2106.01345) par Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
|
||||
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (de SenseTime Research) publié dans l'article [Deformable DETR : Transformateurs déformables pour la détection d'objets de bout en bout](https://arxiv.org/abs/2010.04159) par Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (de Facebook) publié dans l'article [Entraînement d'images efficace et distillation par l'attention](https://arxiv.org/abs/2012.12877) par Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (de Google AI) publié dans l'article [DePlot : Raisonnement visuel en une étape par traduction de l'intrigue en tableau](https://arxiv.org/abs/2212.10505) par Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)** (de l'université d'Hong Kong et TikTok) publié dans l'article [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (de Salesforce) publié dans l'article [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) par Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong et Richard Socher.
|
||||
1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (de Microsoft) publié dans l'article [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) par Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
|
||||
1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (de Facebook) publié dans l'article [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) par Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
|
||||
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (de Microsoft) publié dans l'article [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) par Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (de Microsoft) publié dans l'article [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) par Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (de Berkeley/Facebook/Google) publié dans l'article [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) par Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
|
||||
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (de SenseTime Research) publié dans l'article [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) par Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (de Facebook) publié dans l'article [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) par Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (de Google AI) publié dans l'article [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) par Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (de l'université d'Hong Kong et TikTok) publié dans l'article [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (de l'Université du Texas à Austin) publié dans l'article [NMS Strikes Back](https://arxiv.org/abs/2212.06137) par Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (de Facebook) publié dans l'article [Détection d'objets de bout en bout avec des transformateurs](https://arxiv.org/abs/2005.12872) par Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (de Microsoft Research) publié dans l'article [DialoGPT : Pré-entraînement génératif à grande échelle pour la génération de réponses conversationnelles](https://arxiv.org/abs/1911.00536) par Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (de SHI Labs) publié dans l'article [Transformateur d'attention dilatée pour l'attention aux quartiers](https://arxiv.org/abs/2209.15001) par Ali Hassani et Humphrey Shi.
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (de Meta AI) publié dans l'article [DINOv2 : Apprentissage de fonctionnalités visuelles robustes sans supervision](https://arxiv.org/abs/2304.07193) par Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (de HuggingFace), publié dans l'article [DistilBERT, une version condensée de BERT : plus petit, plus rapide, moins cher et plus léger](https://arxiv.org/abs/1910.01108) par Victor Sanh, Lysandre Debut et Thomas Wolf. La même méthode a été appliquée pour compresser GPT2 en [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa en [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT en [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) et une version allemande de DistilBERT.
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (de Microsoft Research) publié dans l'article [DiT : Auto-pré-entraînement pour le transformateur d'images de documents](https://arxiv.org/abs/2203.02378) par Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (de NAVER), publié dans l'article [Transformation de compréhension de documents sans OCR](https://arxiv.org/abs/2111.15664) par Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
|
||||
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (de Facebook) publié dans l'article [Passage dense pour la recherche de réponses à des questions en domaine ouvert](https://arxiv.org/abs/2004.04906) par Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen et Wen-tau Yih.
|
||||
1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (d'Intel Labs) publié dans l'article [Transformateurs de vision pour la prédiction dense](https://arxiv.org/abs/2103.13413) par René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
|
||||
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (de Snap Research) publié dans l'article [EfficientFormer : Transformateurs de vision à la vitesse de MobileNet](https://arxiv.org/abs/2206.01191) par Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
|
||||
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (de Google Brain) publié dans l'article [EfficientNet: Repenser l'échelle des modèles pour les réseaux de neurones convolutionnels](https://arxiv.org/abs/1905.11946) par Mingxing Tan, Quoc V. Le.
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (de Google Research/Université Stanford) publié dans l'article [ELECTRA: Pré-entraîner les encodeurs de texte en tant que discriminateurs plutôt que des générateurs](https://arxiv.org/abs/2003.10555) par Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (de Meta AI) publié dans l'article [Compression neuronale audio de haute fidélité](https://arxiv.org/abs/2210.13438) par Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (de Google Research) publié dans l'article [Exploiter des points de contrôle pré-entraînés pour les tâches de génération de séquences](https://arxiv.org/abs/1907.12461) par Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (de Baidu) publié dans l'article [ERNIE: Intégration améliorée des représentations par la connaissance](https://arxiv.org/abs/1904.09223) par Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (de Baidu) publié dans l'article [ERNIE-M: Représentation multilingue améliorée en alignant les sémantiques interlingues avec des corpus monolingues](https://arxiv.org/abs/2012.15674) par Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (de Meta AI) sont des modèles de langage de protéines de type transformateur. **ESM-1b** a été publié dans l'article [La structure et la fonction biologiques émergent de la mise à l'échelle de l'apprentissage non supervisé à 250 millions de séquences de protéines](https://www.pnas.org/content/118/15/e2016239118) par Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma et Rob Fergus. **ESM-1v** a été publié dans l'article [Les modèles de langage permettent une prédiction hors champ des effets des mutations sur la fonction des protéines](https://doi.org/10.1101/2021.07.09.450648) par Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu et Alexander Rives. **ESM-2 et ESMFold** ont été publiés avec l'article [Les modèles de langage des séquences de protéines à l'échelle de l'évolution permettent une prédiction précise de la structure](https://doi.org/10.1101/2022.07.20.500902) par Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (de Facebook) publié dans l'article [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) par Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (de Microsoft Research) publié dans l'article [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) par Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (de SHI Labs) publié dans l'article [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) par Ali Hassani et Humphrey Shi.
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (de Meta AI) publié dans l'article [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) par Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (de HuggingFace), publié dans l'article [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) par Victor Sanh, Lysandre Debut et Thomas Wolf. La même méthode a été appliquée pour compresser GPT2 en [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa en [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT en [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) et une version allemande de DistilBERT.
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (de Microsoft Research) publié dans l'article [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) par Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (de NAVER), publié dans l'article [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) par Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
|
||||
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (de Facebook) publié dans l'article [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) par Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen et Wen-tau Yih.
|
||||
1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (d'Intel Labs) publié dans l'article [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) par René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
|
||||
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (de Snap Research) publié dans l'article [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) par Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
|
||||
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (de Google Brain) publié dans l'article [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) par Mingxing Tan, Quoc V. Le.
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (de Google Research/Université Stanford) publié dans l'article [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) par Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (de Meta AI) publié dans l'article [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) par Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (de Google Research) publié dans l'article [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) par Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (de Baidu) publié dans l'article [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) par Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (de Baidu) publié dans l'article [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) par Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (de Meta AI) sont des modèles de langage de protéines de type transformateur. **ESM-1b** a été publié dans l'article [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) par Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma et Rob Fergus. **ESM-1v** a été publié dans l'article [Les modèles de langage permettent une prédiction hors champ des effets des mutations sur la fonction des protéines](https://doi.org/10.1101/2021.07.09.450648) par Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu et Alexander Rives. **ESM-2 et ESMFold** ont été publiés avec l'article [Les modèles de langage des séquences de protéines à l'échelle de l'évolution permettent une prédiction précise de la structure](https://doi.org/10.1101/2022.07.20.500902) par Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (de Technology Innovation Institute) par Almazrouei, Ebtesam et Alobeidli, Hamza et Alshamsi, Abdulaziz et Cappelli, Alessandro et Cojocaru, Ruxandra et Debbah, Merouane et Goffinet, Etienne et Heslow, Daniel et Launay, Julien et Malartic, Quentin et Noune, Badreddine et Pannier, Baptiste et Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (d'ESPnet) publié dans l'article [Développements récents sur la boîte à outils Espnet boostés par Conformer](https://arxiv.org/abs/2010.13956) par Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang et Yuekai Zhang.
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (d'ESPnet) publié dans l'article [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) par Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang et Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (de Google AI) publié dans le référentiel [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) par Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le et Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (de Google AI) publié dans le référentiel [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) par Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le et Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (du CNRS) publié dans l'article [FlauBERT : Pré-entraînement de modèle de langue non supervisé pour le français](https://arxiv.org/abs/1912.05372) par Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** (de Facebook AI) publié dans l'article [FLAVA : Un modèle fondamental d'alignement de la langue et de la vision](https://arxiv.org/abs/2112.04482) par Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach et Douwe Kiela.
|
||||
1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (de Google Research) publié dans l'article [FNet : Mélanger les jetons avec des transformations de Fourier](https://arxiv.org/abs/2105.03824) par James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
|
||||
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (de Microsoft Research) publié dans l'article [Réseaux de modulation focale](https://arxiv.org/abs/2203.11926) par Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (de l'Université Carnegie Mellon/Google Brain) publié dans l'article [Funnel-Transformer : Filtrer la redondance séquentielle pour un traitement efficace du langage](https://arxiv.org/abs/2006.03236) par Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (de ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. Publié dans l'article [billet de blog](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (de Microsoft Research) publié dans l'article [GIT : Un transformateur génératif d'images en texte pour la vision et le langage](https://arxiv.org/abs/2205.14100) par Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (de la KAIST) publié dans l'article [Réseaux de chemins globaux-locaux pour l'estimation de profondeur monoculaire avec Vertical CutDepth](https://arxiv.org/abs/2201.07436) par Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (d'OpenAI) publié dans l'article [Améliorer la compréhension du langage par l'apprentissage préalable génératif](https://openai.com/research/language-unsupervised/) par Alec Radford, Karthik Narasimhan, Tim Salimans et Ilya Sutskever.
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (du CNRS) publié dans l'article [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) par Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** (de Facebook AI) publié dans l'article [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) par Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach et Douwe Kiela.
|
||||
1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (de Google Research) publié dans l'article [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) par James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
|
||||
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (de Microsoft Research) publié dans l'article [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) par Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (de l'Université Carnegie Mellon/Google Brain) publié dans l'article [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) par Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (de ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. Publié dans l'article [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (de Google) publié dans l'article [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) parthe Gemma Google team.
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (de Microsoft Research) publié dans l'article [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) par Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (de la KAIST) publié dans l'article [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) par Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (d'OpenAI) publié dans l'article [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) par Alec Radford, Karthik Narasimhan, Tim Salimans et Ilya Sutskever.
|
||||
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (d'EleutherAI) publié dans le référentiel [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) par Sid Black, Stella Biderman, Leo Gao, Phil Wang et Connor Leahy.
|
||||
1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (d'EleutherAI) publié dans l'article [GPT-NeoX-20B: Un modèle de langue autonome open source](https://arxiv.org/abs/2204.06745) par Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
|
||||
1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (d'EleutherAI) publié dans l'article [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) par Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
|
||||
1. **[GPT NeoX Japanese](https://huggingface.co/docs/transformers/model_doc/gpt_neox_japanese)** (de ABEJA) publié par Shinya Otani, Takayoshi Makabe, Anuj Arora et Kyo Hattori.
|
||||
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (d'OpenAI) a été publié dans l'article [Les modèles de langage sont des apprenants multitâches non supervisés](https://openai.com/research/better-language-models/) par Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei et Ilya Sutskever.
|
||||
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (d'OpenAI) a été publié dans l'article [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) par Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei et Ilya Sutskever.
|
||||
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (d'EleutherAI) a été publié dans le dépôt [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) par Ben Wang et Aran Komatsuzaki.
|
||||
1. **[GPT-Sw3](https://huggingface.co/docs/transformers/model_doc/gpt-sw3)** (d'AI-Sweden) a été publié dans l'article [Leçons apprises de GPT-SW3 : Construction du premier modèle de langage génératif à grande échelle pour le suédois](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) par Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
|
||||
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (de BigCode) a été publié dans l'article [SantaCoder: ne visez pas les étoiles !](https://arxiv.org/abs/2301.03988) par Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
|
||||
1. **[GPT-Sw3](https://huggingface.co/docs/transformers/model_doc/gpt-sw3)** (d'AI-Sweden) a été publié dans l'article [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) par Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
|
||||
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (de BigCode) a été publié dans l'article [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) par Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
|
||||
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** a été publié dans le dépôt [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) par Toshiyuki Sakamoto (tanreinama).
|
||||
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (de Microsoft) a été publié dans l'article [Les Transformers sont-ils vraiment inefficaces pour la représentation graphique ?](https://arxiv.org/abs/2106.05234) par Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
|
||||
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (de l'UCSD, NVIDIA) a été publié dans l'article [GroupViT : la segmentation sémantique émerge de la supervision textuelle](https://arxiv.org/abs/2202.11094) par Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
|
||||
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (d'Allegro.pl, AGH University of Science and Technology) a été publié dans l'article [KLEJ : référentiel complet pour la compréhension du langage polonais](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) par Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (de Facebook) a été publié dans l'article [HuBERT : Apprentissage de la représentation autonome de la parole par prédiction masquée des unités cachées](https://arxiv.org/abs/2106.07447) par Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (de Berkeley) a été publié dans l'article [I-BERT : Quantification entière de BERT avec des entiers uniquement](https://arxiv.org/abs/2101.01321) par Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
|
||||
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (de HuggingFace) a été publié dans l'article [OBELICS : Un ensemble de données filtré à l'échelle du Web d'intercalation de documents texte-image](https://huggingface.co/papers/2306.16527) par Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (d'OpenAI) a été publié dans l'article [Pré-entraînement génératif à partir de pixels](https://openai.com/blog/image-gpt/) par Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (de Microsoft) a été publié dans l'article [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) par Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
|
||||
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (de l'UCSD, NVIDIA) a été publié dans l'article [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) par Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
|
||||
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (d'Allegro.pl, AGH University of Science and Technology) a été publié dans l'article [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) par Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (de Facebook) a été publié dans l'article [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) par Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (de Berkeley) a été publié dans l'article [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) par Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
|
||||
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (de HuggingFace) a été publié dans l'article [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) par Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (d'OpenAI) a été publié dans l'article [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) par Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (de l'Université de Beihang, UC Berkeley, Rutgers University, SEDD Company) a été publié dans l'article [Informer : Au-delà du Transformer efficace pour la prévision de séries temporel
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (de Salesforce) a été publié dans l'article [InstructBLIP : Vers des modèles vision-langage polyvalents avec un réglage d'instructions](https://arxiv.org/abs/2305.06500) de Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (d'OpenAI) a été publié dans l'article [Jukebox : Un modèle génératif pour la musique](https://arxiv.org/pdf/2005.00341.pdf) de Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
|
||||
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (de Microsoft Research Asia) a été publié dans l'article [Kosmos-2 : Ancrage de modèles linguistiques multimodaux à travers le monde](https://arxiv.org/abs/2306.14824) de Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (de Microsoft Research Asia) a été publié dans l'article [LayoutLM : Pré-entraînement de texte et de mise en page pour la compréhension d'images de documents](https://arxiv.org/abs/1912.13318) de Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (de Microsoft Research Asia) a été publié dans l'article [LayoutLMv2 : Pré-entraînement multimodal pour la compréhension visuellement riche de documents](https://arxiv.org/abs/2012.14740) de Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (de Microsoft Research Asia) a été publié dans l'article [LayoutLMv3 : Pré-entraînement pour l'IA de documents avec un masquage de texte et d'image unifié](https://arxiv.org/abs/2204.08387) de Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
|
||||
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (de Microsoft Research Asia) a été publié dans l'article [LayoutXLM : Pré-entraînement multimodal pour la compréhension de documents visuellement riches et multilingues](https://arxiv.org/abs/2104.08836) de Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
|
||||
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (d'AllenAI) a été publié dans l'article [Longformer : Le transformateur de documents longs](https://arxiv.org/abs/2004.05150) de Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (de Meta AI) a été publié dans l'article [LeViT : Un transformateur de vision déguisé en réseau de neurones convolutionnel pour une inférence plus rapide](https://arxiv.org/abs/2104.01136) de Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (de l'Université de technologie du Sud de la Chine) a été publié dans l'article [LiLT : Un transformateur de mise en page simple mais efficace et indépendant de la langue pour la compréhension de documents structurés](https://arxiv.org/abs/2202.13669) de Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (de l'équipe FAIR de Meta AI) a été publié dans l'article [LLaMA : Modèles linguistiques de base ouverts et efficaces](https://arxiv.org/abs/2302.13971) de Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (de l'équipe FAIR de Meta AI) a été publié dans l'article [Llama2 : Modèles de base ouverts et affinés pour le chat](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) de Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (de Salesforce) a été publié dans l'article [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) de Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (d'OpenAI) a été publié dans l'article [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) de Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
|
||||
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (de Microsoft Research Asia) a été publié dans l'article [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) de Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (de Microsoft Research Asia) a été publié dans l'article [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) de Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (de Microsoft Research Asia) a été publié dans l'article [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) de Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (de Microsoft Research Asia) a été publié dans l'article [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) de Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
|
||||
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (de Microsoft Research Asia) a été publié dans l'article [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) de Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
|
||||
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (d'AllenAI) a été publié dans l'article [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) de Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (de Meta AI) a été publié dans l'article [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) de Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (de l'Université de technologie du Sud de la Chine) a été publié dans l'article [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) de Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (de l'équipe FAIR de Meta AI) a été publié dans l'article [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) de Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (de l'équipe FAIR de Meta AI) a été publié dans l'article [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) de Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (de Microsoft Research & University of Wisconsin-Madison) a été publié dans l'article [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) de Haotian Liu, Chunyuan Li, Yuheng Li et Yong Jae Lee.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (d'AllenAI) a été publié dans l'article [Longformer : Le transformateur de documents longs](https://arxiv.org/abs/2004.05150) de Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (de Google AI) a été publié dans l'article [LongT5 : Transformateur de texte-à-texte efficace pour de longues séquences](https://arxiv.org/abs/2112.07916) de Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (de Studio Ousia) a été publié dans l'article [LUKE : Représentations contextuelles profondes d'entités avec auto-attention consciente des entités](https://arxiv.org/abs/2010.01057) de Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (de l'UNC Chapel Hill) a été publié dans l'article [LXMERT : Apprentissage de représentations d'encodeur cross-modal à partir de transformateurs pour le questionnement en domaine ouvert](https://arxiv.org/abs/1908.07490) de Hao Tan et Mohit Bansal.
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (de Microsoft Research & University of Wisconsin-Madison) publié dans l'article [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744) parHaotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (d'AllenAI) a été publié dans l'article [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) de Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (de Google AI) a été publié dans l'article [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) de Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (de Studio Ousia) a été publié dans l'article [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) de Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (de l'UNC Chapel Hill) a été publié dans l'article [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) de Hao Tan et Mohit Bansal.
|
||||
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (de Facebook) a été publié dans l'article [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) de Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve et Ronan Collobert.
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (de Facebook) a été publié dans l'article [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) de Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (de Google) a été publié dans l'article [MADLAD-400 : Un ensemble de données multilingue et de niveau document](https://arxiv.org/abs/2309.04662) de Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (de Google) a été publié dans l'article [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) de Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (de Albert Gu and Tri Dao) publié dans l'article [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) parAlbert Gu and Tri Dao.
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Des modèles de traduction automatique formés avec les données [OPUS](http://opus.nlpl.eu/) par Jörg Tiedemann. Le [cadre Marian](https://marian-nmt.github.io/) est en cours de développement par l'équipe Microsoft Translator.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (de Microsoft Research Asia) a été publié dans l'article [MarkupLM : Pré-entraînement de texte et de langage de balisage pour la compréhension visuellement riche de documents](https://arxiv.org/abs/2110.08518) de Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (de Microsoft Research Asia) a été publié dans l'article [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) de Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (de FAIR et UIUC) a été publié dans l'article [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) de Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
|
||||
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (de Meta et UIUC) a été publié dans l'article [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) de Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
|
||||
1. **[MatCha](https://huggingface.co/docs/transformers/model_doc/matcha)** (de Google AI) a été publié dans l'article [MatCha : Amélioration du pré-entraînement de langage visuel avec raisonnement mathématique et décomposition de graphiques](https://arxiv.org/abs/2212.09662) de Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
|
||||
1. **[MatCha](https://huggingface.co/docs/transformers/model_doc/matcha)** (de Google AI) a été publié dans l'article [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662) de Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
|
||||
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (de Facebook) a été publié dans l'article [Pré-entraînement de débruitage multilingue pour la traduction automatique neuronale
|
||||
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (de Facebook) a été publié dans l'article [Traduction multilingue avec un pré-entraînement et un fine-tuning multilingues extensibles](https://arxiv.org/abs/2008.00401) par Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
|
||||
1. **[MEGA](https://huggingface.co/docs/transformers/model_doc/mega)** (de Meta/USC/CMU/SJTU) a été publié dans l'article [Mega : Attention équipée d'une moyenne mobile](https://arxiv.org/abs/2209.10655) par Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May et Luke Zettlemoyer.
|
||||
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (de NVIDIA) a été publié dans l'article [Megatron-LM : Entraînement de modèles linguistiques de plusieurs milliards de paramètres en utilisant le parallélisme de modèle](https://arxiv.org/abs/1909.08053) par Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper et Bryan Catanzaro.
|
||||
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (de NVIDIA) a été publié dans l'article [Megatron-LM : Entraînement de modèles linguistiques de plusieurs milliards de paramètres en utilisant le parallélisme de modèle](https://arxiv.org/abs/1909.08053) par Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper et Bryan Catanzaro.
|
||||
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (d'Alibaba Research) a été publié dans l'article [Prédiction multi-granularité pour la reconnaissance de texte de scène](https://arxiv.org/abs/2209.03592) par Peng Wang, Cheng Da et Cong Yao.
|
||||
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (de Facebook) a été publié dans l'article [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) par Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
|
||||
1. **[MEGA](https://huggingface.co/docs/transformers/model_doc/mega)** (de Meta/USC/CMU/SJTU) a été publié dans l'article [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) par Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May et Luke Zettlemoyer.
|
||||
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (de NVIDIA) a été publié dans l'article [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) par Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper et Bryan Catanzaro.
|
||||
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (de NVIDIA) a été publié dans l'article [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) par Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper et Bryan Catanzaro.
|
||||
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (d'Alibaba Research) a été publié dans l'article [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) par Peng Wang, Cheng Da et Cong Yao.
|
||||
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (de Mistral AI) par l'équipe [Mistral AI](https://mistral.ai) : Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
1. **[Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral)** (de Mistral AI) par l'équipe [Mistral AI](https://mistral.ai) : Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (de Studio Ousia) a été publié dans l'article [mLUKE : La puissance des représentations d'entités dans les modèles linguistiques pré-entraînés multilingues](https://arxiv.org/abs/2110.08151) par Ryokan Ri, Ikuya Yamada et Yoshimasa Tsuruoka.
|
||||
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (de Facebook) a été publié dans l'article [Mise à l'échelle de la technologie de la parole à plus de 1 000 langues](https://arxiv.org/abs/2305.13516) par Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
|
||||
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (de CMU/Google Brain) a été publié dans l'article [MobileBERT : un BERT compact et agnostique pour les tâches sur les appareils à ressources limitées](https://arxiv.org/abs/2004.02984) par Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang et Denny Zhou.
|
||||
1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (de Google Inc.) a été publié dans l'article [MobileNets : Réseaux neuronaux convolutifs efficaces pour les applications de vision mobile](https://arxiv.org/abs/1704.04861) par Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
|
||||
1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (de Google Inc.) a été publié dans l'article [MobileNetV2 : Résidus inversés et coudes linéaires](https://arxiv.org/abs/1801.04381) par Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
|
||||
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (d'Apple) a été publié dans l'article [MobileViT : Vision Transformer léger, polyvalent et adapté aux mobiles](https://arxiv.org/abs/2110.02178) par Sachin Mehta et Mohammad Rastegari.
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (d'Apple) a été publié dans l'article [Auto-attention séparable pour les Vision Transformers mobiles](https://arxiv.org/abs/2206.02680) par Sachin Mehta et Mohammad Rastegari.
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (de Microsoft Research) a été publié dans l'article [MPNet : Pré-entraînement masqué et permuté pour la compréhension du langage](https://arxiv.org/abs/2004.09297) par Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
|
||||
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (de Studio Ousia) a été publié dans l'article [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) par Ryokan Ri, Ikuya Yamada et Yoshimasa Tsuruoka.
|
||||
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (de Facebook) a été publié dans l'article [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) par Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
|
||||
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (de CMU/Google Brain) a été publié dans l'article [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) par Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang et Denny Zhou.
|
||||
1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (de Google Inc.) a été publié dans l'article [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) par Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
|
||||
1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (de Google Inc.) a été publié dans l'article [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) par Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
|
||||
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (d'Apple) a été publié dans l'article [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) par Sachin Mehta et Mohammad Rastegari.
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (d'Apple) a été publié dans l'article [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) par Sachin Mehta et Mohammad Rastegari.
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (de Microsoft Research) a été publié dans l'article [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) par Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (de MosaiML) a été publié avec le référentiel [llm-foundry](https://github.com/mosaicml/llm-foundry/) par l'équipe MosaiML NLP.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (de l'Université du Wisconsin - Madison) a été publié dans l'article [Analyse multi-résolution (MRA) pour une auto-attention approximative](https://arxiv.org/abs/2207.10284) par Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (de Google AI) a été publié dans l'article [mT5 : un transformateur texte-à-texte pré-entraîné massivement multilingue](https://arxiv.org/abs/2010.11934) par Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (de Meta) a été publié dans l'article [Génération de musique simple et contrôlable](https://arxiv.org/abs/2306.05284) par Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi et Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (de RUC AI Box) a été publié dans l'article [MVP : Pré-entraînement supervisé multi-tâche pour la génération de langage naturel](https://arxiv.org/abs/2206.12131) par Tianyi Tang, Junyi Li, Wayne Xin Zhao et Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (de SHI Labs) a été publié dans l'article [Transformateur d'attention de voisinage](https://arxiv.org/abs/2204.07143) par Ali Hassani, Steven Walton, Jiachen Li, Shen Li et Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (du laboratoire Noah's Ark de Huawei) a été publié dans l'article [NEZHA : Représentation contextualisée neurale pour la compréhension du langage chinois](https://arxiv.org/abs/1909.00204) par Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen et Qun Liu.
|
||||
1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (de Meta) a été publié dans l'article [No Language Left Behind : Mise à l'échelle de la traduction automatique centrée sur l'humain](https://arxiv.org/abs/2207.04672) par l'équipe NLLB.
|
||||
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (de Meta) a été publié dans l'article [No Language Left Behind : Mise à l'échelle de la traduction automatique centrée sur l'humain](https://arxiv.org/abs/2207.04672) par l'équipe NLLB.
|
||||
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (de Meta AI) a été publié dans l'article [Nougat : Compréhension Optique Neuronale pour les Documents Académiques](https://arxiv.org/abs/2308.13418) par Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (de l'Université du Wisconsin - Madison) a été publié dans l'article [Nyströmformer : Un algorithme basé sur Nyström pour approximer l'auto-attention](https://arxiv.org/abs/2102.03902) par Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
|
||||
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (de SHI Labs) a été publié dans l'article [OneFormer : Un Transformer pour dominer la segmentation universelle d'images](https://arxiv.org/abs/2211.06220) par Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (de l'Université du Wisconsin - Madison) a été publié dans l'article [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) par Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (de Google AI) a été publié dans l'article [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) par Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (de Meta) a été publié dans l'article [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) par Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi et Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (de Meta) publié dans l'article [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) parJade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (de RUC AI Box) a été publié dans l'article [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) par Tianyi Tang, Junyi Li, Wayne Xin Zhao et Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (de SHI Labs) a été publié dans l'article [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) par Ali Hassani, Steven Walton, Jiachen Li, Shen Li et Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (du laboratoire Noah's Ark de Huawei) a été publié dans l'article [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) par Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen et Qun Liu.
|
||||
1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (de Meta) a été publié dans l'article [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) par l'équipe NLLB.
|
||||
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (de Meta) a été publié dans l'article [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) par l'équipe NLLB.
|
||||
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (de Meta AI) a été publié dans l'article [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) par Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (de l'Université du Wisconsin - Madison) a été publié dans l'article [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) par Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
|
||||
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (de SHI Labs) a été publié dans l'article [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) par Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (de [s-JoL](https://huggingface.co/s-JoL)) publié sur GitHub (maintenant supprimé).
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (de Meta AI) a été publié dans l'article [OPT : Modèles linguistiques Transformer pré-entraînés ouverts](https://arxiv.org/abs/2205.01068) par Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (de Google AI) a été publié dans l'article [OWL-ViT : Détection d'objets simple à vocabulaire ouvert avec des transformateurs de vision](https://arxiv.org/abs/2205.06230) par Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf et Neil Houlsby.
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (de Meta AI) a été publié dans l'article [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) par Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (de Google AI) a été publié dans l'article [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) par Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf et Neil Houlsby.
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (de Google AI) a été publié dans l'article [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) par Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** (d'IBM Research) a été publié dans l'article [TSMixer : Modèle MLP-Mixer léger pour la prévision multivariée de séries temporelles](https://arxiv.org/pdf/2306.09364.pdf) par Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (d'IBM) a été publié dans l'article [Une série temporelle vaut 64 mots : Prévision à long terme avec des Transformers](https://arxiv.org/abs/2211.14730) par Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (de Google) a été publié dans l'article [PEGASUS : Pré-entraînement avec Phrases-Écart Extraites pour la Résumé Abstrait](https://arxiv.org/abs/1912.08777) par Jingqing Zhang, Yao Zhao, Mohammad Saleh et Peter J. Liu.
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (de Google) a été publié dans l'article [Investiguer l'Extension Efficace des Transformers pour la Longue Summarization d'Entrée](https://arxiv.org/abs/2208.04347) par Jason Phang, Yao Zhao et Peter J. Liu.
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (de Deepmind) a été publié dans l'article [Perceiver IO : Une architecture générale pour les entrées et sorties structurées](https://arxiv.org/abs/2107.14795) par Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals et João Carreira.
|
||||
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (d'ADEPT) a été publié dans un [billet de blog](https://www.adept.ai/blog/persimmon-8b) par Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** (d'IBM Research) a été publié dans l'article [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) par Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (d'IBM) a été publié dans l'article [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) par Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (de Google) a été publié dans l'article [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) par Jingqing Zhang, Yao Zhao, Mohammad Saleh et Peter J. Liu.
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (de Google) a été publié dans l'article [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) par Jason Phang, Yao Zhao et Peter J. Liu.
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (de Deepmind) a été publié dans l'article [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) par Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals et João Carreira.
|
||||
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (d'ADEPT) a été publié dans un [blog post](https://www.adept.ai/blog/persimmon-8b) par Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
|
||||
1. **[Phi](https://huggingface.co/docs/transformers/model_doc/phi)** (de Microsoft) a été publié avec les articles - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) par Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee et Yuanzhi Li, [Textbooks Are All You Need II : Rapport technique phi-1.5](https://arxiv.org/abs/2309.05463) par Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar et Yin Tat Lee.
|
||||
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (de VinAI Research) a été publié dans l'article [PhoBERT : Modèles linguistiques pré-entraînés pour le vietnamien](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) par Dat Quoc Nguyen et Anh Tuan Nguyen.
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (de Google) a été publié dans l'article [Pix2Struct : Analyse d'images d'écran en tant que pré-entraînement pour la compréhension du langage visuel](https://arxiv.org/abs/2210.03347) par Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
|
||||
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (de VinAI Research) a été publié dans l'article [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) par Dat Quoc Nguyen et Anh Tuan Nguyen.
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (de Google) a été publié dans l'article [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) par Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (de UCLA NLP) a été publié dans l'article [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) par Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
|
||||
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (de Sea AI Labs) a été publié dans l'article [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) par Yu, Weihao et Luo, Mi et Zhou, Pan et Si, Chenyang et Zhou, Yichen et Wang, Xinchao et Feng, Jiashi et Yan, Shuicheng.
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** a été publié dans l'article [Pop2Piano : Génération de reprises de morceaux de piano basée sur l'audio pop](https://arxiv.org/abs/2211.00895) par Jongho Choi et Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (de Microsoft Research) a été publié dans l'article [ProphetNet : Prédire les N-grammes futurs pour l'entraînement préalable de séquences à séquences](https://arxiv.org/abs/2001.04063) par Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang et Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (de l'Université de Nankin, l'Université de Hong Kong, etc.) a été publié dans l'article [Pyramid Vision Transformer : Une colonne vertébrale polyvalente pour la prédiction dense sans convolutions](https://arxiv.org/pdf/2102.12122.pdf) par Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo et Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (de NVIDIA) a été publié dans l'article [Quantification entière pour l'inférence d'apprentissage profond : Principes et évaluation empirique](https://arxiv.org/abs/2004.09602) par Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev et Paulius Micikevicius.
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (de l'équipe Qwen, Alibaba Group) a été publié avec le rapport technique [Qwen](https://arxiv.org/abs/2309.16609) par Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou et Tianhang Zhu.
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** a été publié dans l'article [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) par Jongho Choi et Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (de Microsoft Research) a été publié dans l'article [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) par Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang et Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (de l'Université de Nankin, l'Université de Hong Kong, etc.) a été publié dans l'article [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) par Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo et Ling Shao.
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (de Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) publié dans l'article [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) parWenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (de NVIDIA) a été publié dans l'article [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) par Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev et Paulius Micikevicius.
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (de l'équipe Qwen, Alibaba Group) a été publié avec le rapport technique [Qwen Technical Report](https://arxiv.org/abs/2309.16609) par Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou et Tianhang Zhu.
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (de l'équipe Qwen, Alibaba Group) a été publié avec le rapport technique [blog post](https://qwenlm.github.io/blog/qwen-moe/) par Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (de Facebook) a été publié dans l'article [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) par Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (de Google Research) a été publié dans l'article [REALM : Pré-entraînement de modèle linguistique augmenté par la récupération](https://arxiv.org/abs/2002.08909) par Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat et Ming-Wei Chang.
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (de Google Research) a été publié dans l'article [Reformer : Le transformateur efficace](https://arxiv.org/abs/2001.04451) par Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (de Google Research) a été publié dans l'article [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) par Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat et Ming-Wei Chang.
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (de Google Research) a été publié dans l'article [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) par Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
|
||||
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (de META Platforms) a été publié dans l'article [Designing Network Design Space](https://arxiv.org/abs/2003.13678) par Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
|
||||
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (de Google Research) a été publié dans l'article [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) par Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
|
||||
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (de Microsoft Research) a été publié dans l'article [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) par Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
|
||||
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (de Facebook), publié dans l'article [RoBERTa : Une approche d'entraînement préalable BERT robuste](https://arxiv.org/abs/1907.11692) par Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
|
||||
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (de Facebook) a été publié dans l'article [fairseq : Une boîte à outils rapide et extensible pour la modélisation de séquences](https://arxiv.org/abs/1904.01038) par Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
|
||||
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (de WeChatAI) a été publié dans l'article [RoCBert : BERT chinois robuste avec pré-entraînement contrastif multimodal](https://aclanthology.org/2022.acl-long.65.pdf) par HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (de ZhuiyiTechnology), publié dans l'article [RoFormer : Transformateur amélioré avec insertion rotative de position](https://arxiv.org/abs/2104.09864) par Jianlin Su et Yu Lu et Shengfeng Pan et Bo Wen et Yunfeng Liu.
|
||||
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (de Bo Peng), publié sur [ce référentiel](https://github.com/BlinkDL/RWKV-LM) par Bo Peng.
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (de Meta AI) a été publié dans l'article [SeamlessM4T — Traduction multimodale et massivement multilingue](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) par l'équipe de communication transparente.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (de Meta AI) a été publié dans l'article [Seamless: Traduction de la parole multilingue, expressive et en continu](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) par l'équipe de communication transparente.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (de NVIDIA) a été publié dans l'article [SegFormer : Conception simple et efficace pour la segmentation sémantique avec des transformateurs](https://arxiv.org/abs/2105.15203) par Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
|
||||
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (de Facebook), publié dans l'article [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) par Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
|
||||
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (de Facebook) a été publié dans l'article [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) par Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
|
||||
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (de WeChatAI) a été publié dans l'article [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) par HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (de ZhuiyiTechnology), publié dans l'article [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) par Jianlin Su et Yu Lu et Shengfeng Pan et Bo Wen et Yunfeng Liu.
|
||||
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (de Bo Peng), publié sur [this repo](https://github.com/BlinkDL/RWKV-LM) par Bo Peng.
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (de Meta AI) a été publié dans l'article [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) par l'équipe de communication transparente.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (de Meta AI) a été publié dans l'article [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) par l'équipe de communication transparente.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (de NVIDIA) a été publié dans l'article [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) par Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (de Beijing Academy of Artificial Intelligence (BAAI) publié dans l'article [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) parXinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang.
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (de Meta AI) a été publié dans l'article [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) par Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (de ASAPP) a été publié dans l'article [Compromis entre performances et efficacité dans l'entraînement non supervisé pour la reconnaissance vocale](https://arxiv.org/abs/2109.06870) par Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (de ASAPP) a été publié dans l'article [Compromis entre performances et efficacité dans l'entraînement non supervisé pour la reconnaissance vocale](https://arxiv.org/abs/2109.06870) par Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (de ASAPP) a été publié dans l'article [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) par Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (de ASAPP) a été publié dans l'article [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) par Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (de Google AI) a été publié dans l'article [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) par Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
|
||||
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (de Microsoft Research) a été publié dans l'article [SpeechT5 : Pré-entraînement unifié encodeur-décodeur pour le traitement du langage parlé](https://arxiv.org/abs/2110.07205) par Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
|
||||
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (de Facebook), publié dans l'article [fairseq S2T : Modélisation rapide de la parole à texte avec fairseq](https://arxiv.org/abs/2010.05171) par Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (de Facebook), publié dans l'article [Apprentissage auto-supervisé et semi-supervisé à grande échelle pour la traduction de la parole](https://arxiv.org/abs/2104.06678) par Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (de l'Université de Tel Aviv), publié dans l'article [Réponse à quelques questions avec peu d'exemples par la pré-sélection des spans](https://arxiv.org/abs/2101.00438) par Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (de Berkeley) a été publié dans l'article [SqueezeBERT : Que l'apprentissage automatique peut-il apprendre au traitement du langage naturel sur les réseaux neuronaux efficaces ?](https://arxiv.org/abs/2006.11316) par Forrest N. Iandola, Albert E. Shaw, Ravi Krishna et Kurt W. Keutzer.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/main/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (de MBZUAI) a été publié dans l'article [SwiftFormer : Attention additive efficace pour les applications de vision mobile en temps réel basées sur des transformateurs](https://arxiv.org/abs/2303.15446) par Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (de Microsoft) a été publié dans l'article [Swin Transformer : Transformateur hiérarchique de la vision utilisant des fenêtres décalées](https://arxiv.org/abs/2103.14030) par Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (de Microsoft) a été publié dans l'article [Swin Transformer V2 : Augmentation de la capacité et de la résolution](https://arxiv.org/abs/2111.09883) par Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
|
||||
1. **[Swin2SR](https://huggingface.co/docs/transformers/model_doc/swin2sr)** (de l'Université de Würzburg) a été publié dans l'article [Swin2SR : Transformateur SwinV2 pour la super-résolution et la restauration d'images compressées](https://arxiv.org/abs/2209.11345) par Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
|
||||
1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (de Google) a été publié dans l'article [Switch Transformers : Passage à des modèles de trillions de paramètres avec une parcimonie simple et efficace](https://arxiv.org/abs/2101.03961) par William Fedus, Barret Zoph, Noam Shazeer.
|
||||
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (de Google AI) a été publié dans l'article [Exploration des limites de l'apprentissage par transfert avec un transformateur de texte à texte unifié](https://arxiv.org/abs/1910.10683) par Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li et Peter J. Liu.
|
||||
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (de Microsoft Research) a été publié dans l'article [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) par Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
|
||||
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (de Facebook), publié dans l'article [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) par Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (de Facebook), publié dans l'article [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) par Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (de l'Université de Tel Aviv), publié dans l'article [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) par Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (de Berkeley) a été publié dans l'article [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) par Forrest N. Iandola, Albert E. Shaw, Ravi Krishna et Kurt W. Keutzer.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (de MagicLeap) publié dans l'article [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) parDaniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (de MBZUAI) a été publié dans l'article [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) par Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (de Microsoft) a été publié dans l'article [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) par Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (de Microsoft) a été publié dans l'article [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) par Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
|
||||
1. **[Swin2SR](https://huggingface.co/docs/transformers/model_doc/swin2sr)** (de l'Université de Würzburg) a été publié dans l'article [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) par Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
|
||||
1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (de Google) a été publié dans l'article [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) par William Fedus, Barret Zoph, Noam Shazeer.
|
||||
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (de Google AI) a été publié dans l'article [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) par Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li et Peter J. Liu.
|
||||
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (de Google AI) a été publié dans le dépôt [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) par Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li et Peter J. Liu.
|
||||
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (de Microsoft Research) a été publié dans l'article [PubTables-1M : Vers une extraction complète des tables à partir de documents non structurés](https://arxiv.org/abs/2110.00061) par Brandon Smock, Rohith Pesala, Robin Abraham.
|
||||
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (de Google AI) a été publié dans l'article [TAPAS : Analyse faiblement supervisée des tables via le pré-entraînement](https://arxiv.org/abs/2004.02349) par Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno et Julian Martin Eisenschlos.
|
||||
1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (de Microsoft Research) a été publié dans l'article [TAPEX : Pré-entraînement des tables via l'apprentissage d'un exécuteur SQL neuronal](https://arxiv.org/abs/2107.07653) par Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen et Jian-Guang Lou.
|
||||
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (de Microsoft Research) a été publié dans l'article [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) par Brandon Smock, Rohith Pesala, Robin Abraham.
|
||||
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (de Google AI) a été publié dans l'article [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) par Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno et Julian Martin Eisenschlos.
|
||||
1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (de Microsoft Research) a été publié dans l'article [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) par Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen et Jian-Guang Lou.
|
||||
1. **[Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer)** (de HuggingFace).
|
||||
1. **[TimeSformer](https://huggingface.co/docs/transformers/model_doc/timesformer)** (de Facebook) a été publié dans l'article [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) par Gedas Bertasius, Heng Wang, Lorenzo Torresani.
|
||||
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (de l'Université de Californie à Berkeley) a été publié dans l'article [L'apprentissage par renforcement hors ligne comme un grand problème de modélisation de séquence](https://arxiv.org/abs/2106.02039) par Michael Janner, Qiyang Li, Sergey Levine.
|
||||
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (de Google/CMU) a été publié dans l'article [Transformer-XL : Modèles de langage attentifs au-delà d'un contexte de longueur fixe](https://arxiv.org/abs/1901.02860) par Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (de Microsoft), publié dans l'article [TrOCR : Reconnaissance optique de caractères basée sur un transformateur avec des modèles pré-entraînés](https://arxiv.org/abs/2109.10282) par Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (de l'UNC Chapel Hill) a été publié dans l'article [TVLT : Transformer Vision-Language sans texte](https://arxiv.org/abs/2209.14156) par Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (de l'Université de Californie à Berkeley) a été publié dans l'article [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) par Michael Janner, Qiyang Li, Sergey Levine.
|
||||
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (de Google/CMU) a été publié dans l'article [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) par Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (de Microsoft), publié dans l'article [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) par Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (de l'UNC Chapel Hill) a été publié dans l'article [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) par Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (d'Intel) a été publié dans l'article [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) par Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (de Microsoft Research) publié dans l'article [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) parZineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (de Google Research) a été publié dans l'article [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) par Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (de Google Research) a été publié dans l'article [UniMax : Échantillonnage linguistique plus équitable et plus efficace pour l'entraînement préalable multilingue à grande échelle](https://openreview.net/forum?id=kXwdL1cWOAi) par Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (de Microsoft Research) a été publié dans l'article [UniSpeech : Apprentissage unifié de la représentation de la parole avec des données étiquetées et non étiquetées](https://arxiv.org/abs/2101.07597) par Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (de Microsoft Research) a été publié dans l'article [UNISPEECH-SAT : Apprentissage universel de la représentation de la parole avec la préformation consciente du locuteur](https://arxiv.org/abs/2110.05752) par Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
|
||||
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (de Kakao Corporation) a été publié dans l'article [UnivNet : un vocodeur neuronal avec des discriminateurs de spectrogramme multi-résolution pour la génération de formes d'onde haute fidélité](https://arxiv.org/abs/2106.07889) par Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim et Juntae Kim.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (de l'Université de Pékin) a été publié dans l'article [Analyse perceptuelle unifiée pour la compréhension de scènes](https://arxiv.org/abs/1807.10221) par Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (de Google Research) a été publié dans l'article [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) par Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (de Microsoft Research) a été publié dans l'article [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) par Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (de Microsoft Research) a été publié dans l'article [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) par Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
|
||||
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (de Kakao Corporation) a été publié dans l'article [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) par Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim et Juntae Kim.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (de l'Université de Pékin) a été publié dans l'article [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) par Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (de l'Université Tsinghua et de l'Université Nankai) publié dans l'article [Visual Attention Network](https://arxiv.org/abs/2202.09741) par Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
|
||||
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (du groupe d'informatique multimédia, Université de Nankin) publié dans l'article [VideoMAE : Les autoencodeurs masqués sont des apprenants efficaces en données pour l'auto-pré-entraînement vidéo supervisé](https://arxiv.org/abs/2203.12602) par Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
|
||||
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (du NAVER AI Lab/Kakao Enterprise/Kakao Brain) publié dans l'article [ViLT : Vision-and-Language Transformer sans convolution ni supervision de région](https://arxiv.org/abs/2102.03334) par Wonjae Kim, Bokyung Son, Ildoo Kim.
|
||||
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (de l'Université du Wisconsin–Madison) publié dans l'article [Rendre les grands modèles multimodaux comprenant des incitations visuelles arbitraires](https://arxiv.org/abs/2312.00784) par Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (de Google AI) publié dans l'article [Une image vaut 16x16 mots : Transformers pour la reconnaissance d'images à grande échelle](https://arxiv.org/abs/2010.11929) par Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (de UCLA NLP) publié dans l'article [VisualBERT : Une référence simple et performante pour la vision et le langage](https://arxiv.org/pdf/1908.03557) par Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (de Google AI) publié dans l'article [Une image vaut 16x16 mots : Transformers pour la reconnaissance d'images à grande échelle](https://arxiv.org/abs/2010.11929) par Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (de Meta AI) publié dans l'article [Exploration des transformateurs de vision plain pour la détection d'objets](https://arxiv.org/abs/2203.16527) par Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (de Meta AI) publié dans l'article [Les autoencodeurs masqués sont des apprenants évolutifs de la vision](https://arxiv.org/abs/2111.06377) par Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
|
||||
1. **[ViTMatte](https://huggingface.co/docs/transformers/model_doc/vitmatte)** (de HUST-VL) publié dans l'article [ViTMatte : Renforcer le détourage d'image avec des transformateurs de vision plain pré-entraînés](https://arxiv.org/abs/2305.15272) par Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
|
||||
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (du groupe d'informatique multimédia, Université de Nankin) publié dans l'article [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) par Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
|
||||
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (du NAVER AI Lab/Kakao Enterprise/Kakao Brain) publié dans l'article [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) par Wonjae Kim, Bokyung Son, Ildoo Kim.
|
||||
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (de l'Université du Wisconsin–Madison) publié dans l'article [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) par Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (de Google AI) publié dans l'article [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) par Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (de UCLA NLP) publié dans l'article [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) par Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (de Google AI) publié dans l'article [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) par Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (de Meta AI) publié dans l'article [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) par Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (de Meta AI) publié dans l'article [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) par Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
|
||||
1. **[ViTMatte](https://huggingface.co/docs/transformers/model_doc/vitmatte)** (de HUST-VL) publié dans l'article [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) par Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (de Meta AI) publié dans l'article [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) par Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (de Kakao Enterprise) publié dans l'article [Auto-encodeur variationnel conditionnel avec apprentissage adversarial pour la conversion texte-parole de bout en bout](https://arxiv.org/abs/2106.06103) par Jaehyeon Kim, Jungil Kong, Juhee Son.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (de Google Research) publié dans l'article [ViViT : Un transformateur de vision vidéo](https://arxiv.org/abs/2103.15691) par Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (de Facebook AI) publié dans l'article [wav2vec 2.0 : Un cadre pour l'apprentissage auto-supervisé des représentations de la parole](https://arxiv.org/abs/2006.11477) par Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (de Meta AI) publié dans l'article [Seamless : Traduction de la parole multilingue, expressive et en continu](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) par l'équipe Seamless Communication.
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (de Facebook AI) a été publié dans l'article [FAIRSEQ S2T : Modélisation rapide de la parole au texte avec FAIRSEQ](https://arxiv.org/abs/2010.05171) par Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (de Facebook AI) a été publié dans l'article [Reconnaissance de phonèmes interlingues simple et efficace sans apprentissage préalable](https://arxiv.org/abs/2109.11680) par Qiantong Xu, Alexei Baevski, Michael Auli.
|
||||
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (de Microsoft Research) a été publié dans l'article [WavLM : Pré-entraînement auto-supervisé à grande échelle pour le traitement complet de la parole](https://arxiv.org/abs/2110.13900) par Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
|
||||
1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (d'OpenAI) a été publié dans l'article [Reconnaissance robuste de la parole via une supervision faible à grande échelle](https://cdn.openai.com/papers/whisper.pdf) par Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
|
||||
1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (de Microsoft Research) a été publié dans l'article [Expansion des modèles pré-entraînés langage-image pour la reconnaissance vidéo générale](https://arxiv.org/abs/2208.02816) par Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
|
||||
1. **[X-MOD](https://huggingface.co/docs/transformers/model_doc/xmod)** (de Meta AI) a été publié dans l'article [Lever le sort de la multilinguité par le pré-entraînement des transformateurs modulaires](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) par Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe.
|
||||
1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (de Facebook AI) a été publié dans l'article [Apprentissage à quelques échantillons avec des modèles de langues multilingues](https://arxiv.org/abs/2112.10668) par Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
|
||||
1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (de Facebook) a été publié dans l'article [Pré-entraînement de modèles linguistiques multilingues](https://arxiv.org/abs/1901.07291) par Guillaume Lample et Alexis Conneau.
|
||||
1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (de Microsoft Research) a été publié dans l'article [ProphetNet : Prédire l'avenir N-gramme pour le pré-entraînement séquence-séquence](https://arxiv.org/abs/2001.04063) par Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang et Ming Zhou.
|
||||
1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (de Facebook AI), publié dans l'article [Apprentissage non supervisé de la représentation croisée-lingue à grande échelle](https://arxiv.org/abs/1911.02116) par Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer et Veselin Stoyanov.
|
||||
1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (de Facebook AI), publié dans l'article [Transformateurs à plus grande échelle pour la modélisation du langage masqué multilingue](https://arxiv.org/abs/2105.00572) par Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
|
||||
1. **[XLM-V](https://huggingface.co/docs/transformers/model_doc/xlm-v)** (de Meta AI) a été publié dans l'article [XLM-V : Surmonter le goulot d'étranglement du vocabulaire dans les modèles de langage masqués multilingues](https://arxiv.org/abs/2301.10472) par Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
|
||||
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (de Google/CMU) a été publié dans l'article [XLNet : Préentraînement autorégressif généralisé pour la compréhension du langage](https://arxiv.org/abs/1906.08237) par Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
|
||||
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (de Facebook AI) publié dans l'article [XLS-R : Apprentissage d'une représentation de la parole autonome et multilingue à grande échelle](https://arxiv.org/abs/2111.09296) par Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
|
||||
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (de Facebook AI) publié dans l'article [Apprentissage non supervisé de représentations multilingues pour la reconnaissance vocale](https://arxiv.org/abs/2006.13979) par Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (de l'Université Huazhong des sciences et technologies) publié dans l'article [You Only Look at One Sequence : Repenser le Transformer dans la vision à travers la détection d'objets](https://arxiv.org/abs/2106.00666) par Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
|
||||
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (de l'Université du Wisconsin - Madison) publié dans l'article [You Only Sample (Almost) Once : Coût linéaire Self-Attention via l'échantillonnage Bernoulli](https://arxiv.org/abs/2111.09714) par Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (de Kakao Enterprise) publié dans l'article [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) par Jaehyeon Kim, Jungil Kong, Juhee Son.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (de Google Research) publié dans l'article [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) par Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (de Facebook AI) publié dans l'article [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) par Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (de Meta AI) publié dans l'article [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) par l'équipe Seamless Communication.
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (de Facebook AI) a été publié dans l'article [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) par Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (de Facebook AI) a été publié dans l'article [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) par Qiantong Xu, Alexei Baevski, Michael Auli.
|
||||
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (de Microsoft Research) a été publié dans l'article [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) par Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
|
||||
1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (d'OpenAI) a été publié dans l'article [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) par Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
|
||||
1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (de Microsoft Research) a été publié dans l'article [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) par Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
|
||||
1. **[X-MOD](https://huggingface.co/docs/transformers/model_doc/xmod)** (de Meta AI) a été publié dans l'article [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) par Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe.
|
||||
1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (de Facebook AI) a été publié dans l'article [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) par Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
|
||||
1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (de Facebook) a été publié dans l'article [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) par Guillaume Lample et Alexis Conneau.
|
||||
1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (de Microsoft Research) a été publié dans l'article [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) par Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang et Ming Zhou.
|
||||
1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (de Facebook AI), publié dans l'article [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) par Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer et Veselin Stoyanov.
|
||||
1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (de Facebook AI), publié dans l'article [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) par Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
|
||||
1. **[XLM-V](https://huggingface.co/docs/transformers/model_doc/xlm-v)** (de Meta AI) a été publié dans l'article [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472) par Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
|
||||
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (de Google/CMU) a été publié dans l'article [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) par Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
|
||||
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (de Facebook AI) publié dans l'article [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) par Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
|
||||
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (de Facebook AI) publié dans l'article [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) par Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (de l'Université Huazhong des sciences et technologies) publié dans l'article [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) par Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
|
||||
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (de l'Université du Wisconsin - Madison) publié dans l'article [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) par Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
|
||||
1. Vous souhaitez contribuer avec un nouveau modèle ? Nous avons ajouté un **guide détaillé et des modèles types** pour vous guider dans le processus d'ajout d'un nouveau modèle. Vous pouvez les trouver dans le dossier [`templates`](./templates) du référentiel. Assurez-vous de consulter les [directives de contribution](./CONTRIBUTING.md) et de contacter les mainteneurs ou d'ouvrir un ticket pour recueillir des commentaires avant de commencer votre pull request.
|
||||
|
||||
Pour vérifier si chaque modèle a une implémentation en Flax, PyTorch ou TensorFlow, ou s'il a un tokenizer associé pris en charge par la bibliothèque 🤗 Tokenizers, consultez [ce tableau](https://huggingface.co/docs/transformers/index#supported-frameworks).
|
||||
|
||||
260
README_hd.md
260
README_hd.md
@ -77,6 +77,7 @@ checkpoint: जाँच बिंदु
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
@ -242,100 +243,102 @@ conda install conda-forge::transformers
|
||||
|
||||
🤗 ट्रांसफॉर्मर वर्तमान में निम्नलिखित आर्किटेक्चर का समर्थन करते हैं (मॉडल के अवलोकन के लिए [यहां देखें](https://huggingface.co/docs/transformers/model_summary)):
|
||||
|
||||
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (Google Research and the Toyota Technological Institute at Chicago) साथ थीसिस [ALBERT: A Lite BERT for Self-supervised भाषा प्रतिनिधित्व सीखना](https://arxiv.org/abs/1909.11942), झेंझोंग लैन, मिंगदा चेन, सेबेस्टियन गुडमैन, केविन गिम्पेल, पीयूष शर्मा, राडू सोरिकट
|
||||
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (Google Research and the Toyota Technological Institute at Chicago) साथ थीसिस [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), झेंझोंग लैन, मिंगदा चेन, सेबेस्टियन गुडमैन, केविन गिम्पेल, पीयूष शर्मा, राडू सोरिकट
|
||||
1. **[ALIGN](https://huggingface.co/docs/transformers/model_doc/align)** (Google Research से) Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. द्वाराअनुसंधान पत्र [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) के साथ जारी किया गया
|
||||
1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (फेसबुक) साथ थीसिस [बार्ट: प्राकृतिक भाषा निर्माण, अनुवाद के लिए अनुक्रम-से-अनुक्रम पूर्व प्रशिक्षण , और समझ](https://arxiv.org/pdf/1910.13461.pdf) पर निर्भर माइक लुईस, यिनहान लियू, नमन गोयल, मार्जन ग़ज़विनिनेजाद, अब्देलरहमान मोहम्मद, ओमर लेवी, वेस स्टोयानोव और ल्यूक ज़ेटलमॉयर
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (फेसबुक) साथ थीसिस [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) पर निर्भर माइक लुईस, यिनहान लियू, नमन गोयल, मार्जन ग़ज़विनिनेजाद, अब्देलरहमान मोहम्मद, ओमर लेवी, वेस स्टोयानोव और ल्यूक ज़ेटलमॉयर
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (से École polytechnique) साथ थीसिस [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) पर निर्भर Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis रिहाई।
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (VinAI Research से) साथ में पेपर [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701)गुयेन लुओंग ट्रान, डुओंग मिन्ह ले और डाट क्वोक गुयेन द्वारा पोस्ट किया गया।
|
||||
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (Microsoft से) साथ में कागज [BEiT: BERT इमेज ट्रांसफॉर्मर्स का प्री-ट्रेनिंग](https://arxiv.org/abs/2106.08254) Hangbo Bao, Li Dong, Furu Wei द्वारा।
|
||||
1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (गूगल से) साथ वाला पेपर [बीईआरटी: प्री-ट्रेनिंग ऑफ डीप बिडायरेक्शनल ट्रांसफॉर्मर्स फॉर लैंग्वेज अंडरस्टैंडिंग](https://arxiv.org/abs/1810.04805) जैकब डेवलिन, मिंग-वेई चांग, केंटन ली और क्रिस्टीना टौटानोवा द्वारा प्रकाशित किया गया था। .
|
||||
1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (गूगल से) साथ देने वाला पेपर [सीक्वेंस जेनरेशन टास्क के लिए प्री-ट्रेंड चेकपॉइंट का इस्तेमाल करना](https://arxiv.org/abs/1907.12461) साशा रोठे, शशि नारायण, अलियाक्सि सेवेरिन द्वारा।
|
||||
1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (VinAI Research से) साथ में पेपर [BERTweet: अंग्रेजी ट्वीट्स के लिए एक पूर्व-प्रशिक्षित भाषा मॉडल](https://aclanthology.org/2020.emnlp-demos.2/) डाट क्वोक गुयेन, थान वु और अन्ह तुआन गुयेन द्वारा प्रकाशित।
|
||||
1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (गूगल रिसर्च से) साथ वाला पेपर [बिग बर्ड: ट्रांसफॉर्मर्स फॉर लॉन्गर सीक्वेंस](https://arxiv.org/abs/2007.14062) मंज़िल ज़हीर, गुरु गुरुगणेश, अविनावा दुबे, जोशुआ आइंस्ली, क्रिस अल्बर्टी, सैंटियागो ओंटानोन, फिलिप फाम, अनिरुद्ध रावुला, किफ़ान वांग, ली यांग, अमर अहमद द्वारा।
|
||||
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (गूगल रिसर्च से) साथ में पेपर [बिग बर्ड: ट्रांसफॉर्मर्स फॉर लॉन्गर सीक्वेंस](https://arxiv.org/abs/2007.14062) मंज़िल ज़हीर, गुरु गुरुगणेश, अविनावा दुबे, जोशुआ आइंस्ली, क्रिस अल्बर्टी, सैंटियागो ओंटानन, फिलिप फाम द्वारा , अनिरुद्ध रावुला, किफ़ान वांग, ली यांग, अमर अहमद द्वारा पोस्ट किया गया।
|
||||
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (Microsoft से) साथ में कागज [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) Hangbo Bao, Li Dong, Furu Wei द्वारा।
|
||||
1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (गूगल से) साथ वाला पेपर [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) जैकब डेवलिन, मिंग-वेई चांग, केंटन ली और क्रिस्टीना टौटानोवा द्वारा प्रकाशित किया गया था। .
|
||||
1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (गूगल से) साथ देने वाला पेपर [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) साशा रोठे, शशि नारायण, अलियाक्सि सेवेरिन द्वारा।
|
||||
1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (VinAI Research से) साथ में पेपर [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) डाट क्वोक गुयेन, थान वु और अन्ह तुआन गुयेन द्वारा प्रकाशित।
|
||||
1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (गूगल रिसर्च से) साथ वाला पेपर [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) मंज़िल ज़हीर, गुरु गुरुगणेश, अविनावा दुबे, जोशुआ आइंस्ली, क्रिस अल्बर्टी, सैंटियागो ओंटानोन, फिलिप फाम, अनिरुद्ध रावुला, किफ़ान वांग, ली यांग, अमर अहमद द्वारा।
|
||||
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (गूगल रिसर्च से) साथ में पेपर [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) मंज़िल ज़हीर, गुरु गुरुगणेश, अविनावा दुबे, जोशुआ आइंस्ली, क्रिस अल्बर्टी, सैंटियागो ओंटानन, फिलिप फाम द्वारा , अनिरुद्ध रावुला, किफ़ान वांग, ली यांग, अमर अहमद द्वारा पोस्ट किया गया।
|
||||
1. **[BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt)** (from Microsoft Research AI4Science) released with the paper [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
|
||||
1. **[BiT](https://huggingface.co/docs/transformers/model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
|
||||
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (फेसबुक से) साथ में कागज [एक ओपन-डोमेन चैटबॉट बनाने की विधि](https://arxiv.org/abs/2004.13637) स्टीफन रोलर, एमिली दीनन, नमन गोयल, दा जू, मैरी विलियमसन, यिनहान लियू, जिंग जू, मायल ओट, कर्ट शस्टर, एरिक एम। स्मिथ, वाई-लैन बॉरो, जेसन वेस्टन द्वारा।
|
||||
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (फेसबुक से) साथ में पेपर [एक ओपन-डोमेन चैटबॉट बनाने की रेसिपी](https://arxiv.org/abs/2004.13637) स्टीफन रोलर, एमिली दीनन, नमन गोयल, दा जू, मैरी विलियमसन, यिनहान लियू, जिंग जू, मायल ओट, कर्ट शस्टर, एरिक एम स्मिथ, वाई-लैन बॉरो, जेसन वेस्टन द्वारा।
|
||||
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (फेसबुक से) साथ में कागज [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) स्टीफन रोलर, एमिली दीनन, नमन गोयल, दा जू, मैरी विलियमसन, यिनहान लियू, जिंग जू, मायल ओट, कर्ट शस्टर, एरिक एम। स्मिथ, वाई-लैन बॉरो, जेसन वेस्टन द्वारा।
|
||||
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (फेसबुक से) साथ में पेपर [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) स्टीफन रोलर, एमिली दीनन, नमन गोयल, दा जू, मैरी विलियमसन, यिनहान लियू, जिंग जू, मायल ओट, कर्ट शस्टर, एरिक एम स्मिथ, वाई-लैन बॉरो, जेसन वेस्टन द्वारा।
|
||||
1. **[BLIP](https://huggingface.co/docs/transformers/model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
|
||||
1. **[BLIP-2](https://huggingface.co/docs/transformers/model_doc/blip-2)** (Salesforce से) Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi. द्वाराअनुसंधान पत्र [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) के साथ जारी किया गया
|
||||
1. **[BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom)** (from BigScience workshop) released by the [BigSicence Workshop](https://bigscience.huggingface.co/).
|
||||
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (एलेक्सा से) कागज के साथ [बीईआरटी के लिए ऑप्टिमल सबआर्किटेक्चर एक्सट्रैक्शन](https://arxiv.org/abs/2010.10499) एड्रियन डी विंटर और डैनियल जे पेरी द्वारा।
|
||||
1. **[BridgeTower](https://huggingface.co/docs/transformers/model_doc/bridgetower)** (हरबिन इंस्टिट्यूट ऑफ़ टेक्नोलॉजी/माइक्रोसॉफ्ट रिसर्च एशिया/इंटेल लैब्स से) कागज के साथ [ब्रिजटॉवर: विजन-लैंग्वेज रिप्रेजेंटेशन लर्निंग में एनकोडर्स के बीच ब्रिज बनाना](<https://arxiv.org/abs/2206.08657>) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
|
||||
1. **[BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
|
||||
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (एलेक्सा से) कागज के साथ [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) एड्रियन डी विंटर और डैनियल जे पेरी द्वारा।
|
||||
1. **[BridgeTower](https://huggingface.co/docs/transformers/model_doc/bridgetower)** (हरबिन इंस्टिट्यूट ऑफ़ टेक्नोलॉजी/माइक्रोसॉफ्ट रिसर्च एशिया/इंटेल लैब्स से) कागज के साथ [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
|
||||
1. **[BROS](https://huggingface.co/docs/transformers/model_doc/bros)** (NAVER CLOVA से) Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park. द्वाराअनुसंधान पत्र [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) के साथ जारी किया गया
|
||||
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (Google अनुसंधान से) साथ में कागज [ByT5: पूर्व-प्रशिक्षित बाइट-टू-बाइट मॉडल के साथ एक टोकन-मुक्त भविष्य की ओर](https://arxiv.org/abs/2105.13626) Linting Xue, Aditya Barua, Noah Constant, रामी अल-रफू, शरण नारंग, मिहिर काले, एडम रॉबर्ट्स, कॉलिन रैफेल द्वारा पोस्ट किया गया।
|
||||
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (इनरिया/फेसबुक/सोरबोन से) साथ में कागज [CamemBERT: एक टेस्टी फ्रेंच लैंग्वेज मॉडल](https://arxiv.org/abs/1911.03894) लुई मार्टिन*, बेंजामिन मुलर*, पेड्रो जेवियर ऑर्टिज़ सुआरेज़*, योआन ड्यूपॉन्ट, लॉरेंट रोमरी, एरिक विलेमोन्टे डे ला क्लर्जरी, जैमे सेडाह और बेनोइट सगोट द्वारा।
|
||||
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (Google रिसर्च से) साथ में दिया गया पेपर [कैनाइन: प्री-ट्रेनिंग ए एफिशिएंट टोकनाइजेशन-फ्री एनकोडर फॉर लैंग्वेज रिप्रेजेंटेशन](https://arxiv.org/abs/2103.06874) जोनाथन एच क्लार्क, डैन गैरेट, यूलिया टर्क, जॉन विएटिंग द्वारा।
|
||||
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (Google अनुसंधान से) साथ में कागज [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) Linting Xue, Aditya Barua, Noah Constant, रामी अल-रफू, शरण नारंग, मिहिर काले, एडम रॉबर्ट्स, कॉलिन रैफेल द्वारा पोस्ट किया गया।
|
||||
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (इनरिया/फेसबुक/सोरबोन से) साथ में कागज [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) लुई मार्टिन*, बेंजामिन मुलर*, पेड्रो जेवियर ऑर्टिज़ सुआरेज़*, योआन ड्यूपॉन्ट, लॉरेंट रोमरी, एरिक विलेमोन्टे डे ला क्लर्जरी, जैमे सेडाह और बेनोइट सगोट द्वारा।
|
||||
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (Google रिसर्च से) साथ में दिया गया पेपर [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) जोनाथन एच क्लार्क, डैन गैरेट, यूलिया टर्क, जॉन विएटिंग द्वारा।
|
||||
1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
|
||||
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (LAION-AI से) Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov. द्वाराअनुसंधान पत्र [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) के साथ जारी किया गया
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI से) साथ वाला पेपर [लर्निंग ट्रांसफरेबल विजुअल मॉडल फ्रॉम नेचुरल लैंग्वेज सुपरविजन](https://arxiv.org/abs/2103.00020) एलेक रैडफोर्ड, जोंग वूक किम, क्रिस हैलासी, आदित्य रमेश, गेब्रियल गोह, संध्या अग्रवाल, गिरीश शास्त्री, अमांडा एस्केल, पामेला मिश्किन, जैक क्लार्क, ग्रेचेन क्रुएगर, इल्या सुत्स्केवर द्वारा।
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI से) साथ वाला पेपर [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) एलेक रैडफोर्ड, जोंग वूक किम, क्रिस हैलासी, आदित्य रमेश, गेब्रियल गोह, संध्या अग्रवाल, गिरीश शास्त्री, अमांडा एस्केल, पामेला मिश्किन, जैक क्लार्क, ग्रेचेन क्रुएगर, इल्या सुत्स्केवर द्वारा।
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
|
||||
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (सेल्सफोर्स से) साथ में पेपर [प्रोग्राम सिंथेसिस के लिए एक संवादात्मक प्रतिमान](https://arxiv.org/abs/2203.13474) एरिक निजकैंप, बो पैंग, हिरोआकी हयाशी, लिफू तू, हुआन वांग, यिंगबो झोउ, सिल्वियो सावरेस, कैमिंग जिओंग रिलीज।
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (सेल्सफोर्स से) साथ में पेपर [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) एरिक निजकैंप, बो पैंग, हिरोआकी हयाशी, लिफू तू, हुआन वांग, यिंगबो झोउ, सिल्वियो सावरेस, कैमिंग जिओंग रिलीज।
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (MetaAI से) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve. द्वाराअनुसंधान पत्र [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) के साथ जारी किया गया
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (माइक्रोसॉफ्ट रिसर्च एशिया से) कागज के साथ [फास्ट ट्रेनिंग कन्वर्जेंस के लिए सशर्त डीईटीआर](https://arxiv.org/abs/2108.06152) डेपू मेंग, ज़ियाओकांग चेन, ज़ेजिया फैन, गैंग ज़ेंग, होउकियांग ली, युहुई युआन, लेई सन, जिंगडोंग वांग द्वारा।
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (YituTech से) साथ में कागज [ConvBERT: स्पैन-आधारित डायनेमिक कनवल्शन के साथ BERT में सुधार](https://arxiv.org/abs/2008.02496) जिहांग जियांग, वीहाओ यू, डाकान झोउ, युनपेंग चेन, जियाशी फेंग, शुइचेंग यान द्वारा।
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (Cohere से) Cohere. द्वाराअनुसंधान पत्र [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>) के साथ जारी किया गया
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (माइक्रोसॉफ्ट रिसर्च एशिया से) कागज के साथ [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) डेपू मेंग, ज़ियाओकांग चेन, ज़ेजिया फैन, गैंग ज़ेंग, होउकियांग ली, युहुई युआन, लेई सन, जिंगडोंग वांग द्वारा।
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (YituTech से) साथ में कागज [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) जिहांग जियांग, वीहाओ यू, डाकान झोउ, युनपेंग चेन, जियाशी फेंग, शुइचेंग यान द्वारा।
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (Facebook AI से) साथ वाला पेपर [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) ज़ुआंग लियू, हेंज़ी माओ, चाओ-युआन वू, क्रिस्टोफ़ फीचटेनहोफ़र, ट्रेवर डेरेल, सैनिंग ज़ी द्वारा।
|
||||
1. **[ConvNeXTV2](https://huggingface.co/docs/transformers/model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
|
||||
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (सिंघुआ यूनिवर्सिटी से) साथ में पेपर [सीपीएम: ए लार्ज-स्केल जेनेरेटिव चाइनीज प्री-ट्रेंड लैंग्वेज मॉडल](https://arxiv.org/abs/2012.00413) झेंग्यान झांग, जू हान, हाओ झोउ, पेई के, युक्सियन गु, डेमिंग ये, युजिया किन, युशेंग सु, हाओझे जी, जियान गुआन, फैंचाओ क्यूई, ज़ियाओझी वांग, यानान झेंग द्वारा , गुओयांग ज़ेंग, हुआनकी काओ, शेंगकी चेन, डाइक्सुआन ली, ज़ेनबो सन, ज़ियुआन लियू, मिनली हुआंग, वेंटाओ हान, जी तांग, जुआनज़ी ली, ज़ियाओयान झू, माओसोंग सन।
|
||||
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (सिंघुआ यूनिवर्सिटी से) साथ में पेपर [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) झेंग्यान झांग, जू हान, हाओ झोउ, पेई के, युक्सियन गु, डेमिंग ये, युजिया किन, युशेंग सु, हाओझे जी, जियान गुआन, फैंचाओ क्यूई, ज़ियाओझी वांग, यानान झेंग द्वारा , गुओयांग ज़ेंग, हुआनकी काओ, शेंगकी चेन, डाइक्सुआन ली, ज़ेनबो सन, ज़ियुआन लियू, मिनली हुआंग, वेंटाओ हान, जी तांग, जुआनज़ी ली, ज़ियाओयान झू, माओसोंग सन।
|
||||
1. **[CPM-Ant](https://huggingface.co/docs/transformers/model_doc/cpmant)** (from OpenBMB) released by the [OpenBMB](https://www.openbmb.org/).
|
||||
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (सेल्सफोर्स से) साथ में पेपर [CTRL: ए कंडिशनल ट्रांसफॉर्मर लैंग्वेज मॉडल फॉर कंट्रोलेबल जेनरेशन](https://arxiv.org/abs/1909.05858) नीतीश शिरीष केसकर*, ब्रायन मैककैन*, लव आर. वार्ष्णेय, कैमिंग जिओंग और रिचर्ड द्वारा सोचर द्वारा जारी किया गया।
|
||||
1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (Microsoft से) साथ में दिया गया पेपर [CvT: इंट्रोड्यूसिंग कनवॉल्यूशन टू विजन ट्रांसफॉर्मर्स](https://arxiv.org/एब्स/2103.15808) हैपिंग वू, बिन जिओ, नोएल कोडेला, मेंगचेन लियू, जियांग दाई, लू युआन, लेई झांग द्वारा।
|
||||
1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (फेसबुक से) साथ में कागज [Data2Vec: भाषण, दृष्टि और भाषा में स्व-पर्यवेक्षित सीखने के लिए एक सामान्य ढांचा](https://arxiv.org/abs/2202.03555) एलेक्सी बाएव्स्की, वेई-निंग सू, कियानटोंग जू, अरुण बाबू, जियाताओ गु, माइकल औली द्वारा पोस्ट किया गया।
|
||||
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (Microsoft से) साथ में दिया गया पेपर [DeBERta: डिकोडिंग-एन्हांस्ड BERT विद डिसेंटैंगल्ड अटेंशन](https://arxiv.org/abs/2006.03654) पेंगचेंग हे, ज़ियाओडोंग लियू, जियानफेंग गाओ, वीज़ू चेन द्वारा।
|
||||
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (Microsoft से) साथ में दिया गया पेपर [DeBERTa: डिकोडिंग-एन्हांस्ड BERT विथ डिसेंन्गल्ड अटेंशन](https://arxiv.org/abs/2006.03654) पेंगचेंग हे, ज़ियाओडोंग लियू, जियानफेंग गाओ, वीज़ू चेन द्वारा पोस्ट किया गया।
|
||||
1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (बर्कले/फेसबुक/गूगल से) पेपर के साथ [डिसीजन ट्रांसफॉर्मर: रीनफोर्समेंट लर्निंग वाया सीक्वेंस मॉडलिंग](https://arxiv.org/abs/2106.01345) लिली चेन, केविन लू, अरविंद राजेश्वरन, किमिन ली, आदित्य ग्रोवर, माइकल लास्किन, पीटर एबील, अरविंद श्रीनिवास, इगोर मोर्डच द्वारा पोस्ट किया गया।
|
||||
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (सेंसटाइम रिसर्च से) साथ में पेपर [डिफॉर्मेबल डीईटीआर: डिफॉर्मेबल ट्रांसफॉर्मर्स फॉर एंड-टू-एंड ऑब्जेक्ट डिटेक्शन](https://arxiv.org/abs/2010.04159) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, जिफेंग दाई द्वारा पोस्ट किया गया।
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (फेसबुक से) साथ में पेपर [ट्रेनिंग डेटा-एफिशिएंट इमेज ट्रांसफॉर्मर और डिस्टिलेशन थ्रू अटेंशन](https://arxiv.org/abs/2012.12877) ह्यूगो टौव्रोन, मैथ्यू कॉर्ड, मैथिज्स डूज़, फ़्रांसिस्को मस्सा, एलेक्ज़ेंडर सबलेरोल्स, हर्वे जेगौ द्वारा।
|
||||
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (सेल्सफोर्स से) साथ में पेपर [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) नीतीश शिरीष केसकर*, ब्रायन मैककैन*, लव आर. वार्ष्णेय, कैमिंग जिओंग और रिचर्ड द्वारा सोचर द्वारा जारी किया गया।
|
||||
1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (Microsoft से) साथ में दिया गया पेपर [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) हैपिंग वू, बिन जिओ, नोएल कोडेला, मेंगचेन लियू, जियांग दाई, लू युआन, लेई झांग द्वारा।
|
||||
1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (फेसबुक से) साथ में कागज [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) एलेक्सी बाएव्स्की, वेई-निंग सू, कियानटोंग जू, अरुण बाबू, जियाताओ गु, माइकल औली द्वारा पोस्ट किया गया।
|
||||
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (Microsoft से) साथ में दिया गया पेपर [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) पेंगचेंग हे, ज़ियाओडोंग लियू, जियानफेंग गाओ, वीज़ू चेन द्वारा।
|
||||
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (Microsoft से) साथ में दिया गया पेपर [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) पेंगचेंग हे, ज़ियाओडोंग लियू, जियानफेंग गाओ, वीज़ू चेन द्वारा पोस्ट किया गया।
|
||||
1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (बर्कले/फेसबुक/गूगल से) पेपर के साथ [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) लिली चेन, केविन लू, अरविंद राजेश्वरन, किमिन ली, आदित्य ग्रोवर, माइकल लास्किन, पीटर एबील, अरविंद श्रीनिवास, इगोर मोर्डच द्वारा पोस्ट किया गया।
|
||||
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (सेंसटाइम रिसर्च से) साथ में पेपर [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, जिफेंग दाई द्वारा पोस्ट किया गया।
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (फेसबुक से) साथ में पेपर [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) ह्यूगो टौव्रोन, मैथ्यू कॉर्ड, मैथिज्स डूज़, फ़्रांसिस्को मस्सा, एलेक्ज़ेंडर सबलेरोल्स, हर्वे जेगौ द्वारा।
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (Google AI से) Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun. द्वाराअनुसंधान पत्र [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) के साथ जारी किया गया
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)** (University of Hong Kong and TikTok से) Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao. द्वाराअनुसंधान पत्र [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) के साथ जारी किया गया
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (University of Hong Kong and TikTok से) Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao. द्वाराअनुसंधान पत्र [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) के साथ जारी किया गया
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (फेसबुक से) साथ में कागज [ट्रांसफॉर्मर्स के साथ एंड-टू-एंड ऑब्जेक्ट डिटेक्शन](https://arxiv.org/abs/2005.12872) निकोलस कैरियन, फ़्रांसिस्को मस्सा, गेब्रियल सिनेव, निकोलस उसुनियर, अलेक्जेंडर किरिलोव, सर्गेई ज़ागोरुयको द्वारा।
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (माइक्रोसॉफ्ट रिसर्च से) कागज के साथ [DialoGPT: बड़े पैमाने पर जनरेटिव प्री-ट्रेनिंग फॉर कन्वर्सेशनल रिस्पांस जेनरेशन](https://arxiv.org/abs/1911.00536) यिज़े झांग, सिकी सन, मिशेल गैली, येन-चुन चेन, क्रिस ब्रोकेट, जियांग गाओ, जियानफेंग गाओ, जिंगजिंग लियू, बिल डोलन द्वारा।
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (फेसबुक से) साथ में कागज [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) निकोलस कैरियन, फ़्रांसिस्को मस्सा, गेब्रियल सिनेव, निकोलस उसुनियर, अलेक्जेंडर किरिलोव, सर्गेई ज़ागोरुयको द्वारा।
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (माइक्रोसॉफ्ट रिसर्च से) कागज के साथ [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) यिज़े झांग, सिकी सन, मिशेल गैली, येन-चुन चेन, क्रिस ब्रोकेट, जियांग गाओ, जियानफेंग गाओ, जिंगजिंग लियू, बिल डोलन द्वारा।
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (Meta AI से) Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski. द्वाराअनुसंधान पत्र [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) के साथ जारी किया गया
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (हगिंगफेस से), साथ में कागज [डिस्टिलबर्ट, बीईआरटी का डिस्टिल्ड वर्जन: छोटा, तेज, सस्ता और हल्का](https://arxiv.org/abs/1910.01108) विक्टर सनह, लिसांड्रे डेब्यू और थॉमस वुल्फ द्वारा पोस्ट किया गया। यही तरीका GPT-2 को [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERta से [DistilRoBERta](https://github.com) पर कंप्रेस करने के लिए भी लागू किया जाता है। / हगिंगफेस/ट्रांसफॉर्मर्स/ट्री/मेन/उदाहरण/डिस्टिलेशन), बहुभाषी BERT से [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) और डिस्टिलबर्ट का जर्मन संस्करण।
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [DiT: सेल्फ सुपरवाइज्ड प्री-ट्रेनिंग फॉर डॉक्यूमेंट इमेज ट्रांसफॉर्मर](https://arxiv.org/abs/2203.02378) जुनलॉन्ग ली, यिहेंग जू, टेंगचाओ लव, लेई कुई, चा झांग द्वारा फुरु वेई द्वारा पोस्ट किया गया।
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (NAVER से) साथ में कागज [OCR-मुक्त डॉक्यूमेंट अंडरस्टैंडिंग ट्रांसफॉर्मर](https://arxiv.org/abs/2111.15664) गीवूक किम, टीकग्यू होंग, मूनबिन यिम, जियोंग्योन नाम, जिनयॉन्ग पार्क, जिनयॉन्ग यिम, वोनसेओक ह्वांग, सांगडू यूं, डोंगयून हान, सेउंग्युन पार्क द्वारा।
|
||||
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (फेसबुक से) साथ में पेपर [ओपन-डोमेन क्वेश्चन आंसरिंग के लिए डेंस पैसेज रिट्रीवल](https://arxiv.org/abs/2004.04906) व्लादिमीर करपुखिन, बरलास ओज़ुज़, सेवन मिन, पैट्रिक लुईस, लेडेल वू, सर्गेई एडुनोव, डैनकी चेन, और वेन-ताऊ यिह द्वारा।
|
||||
1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (इंटेल लैब्स से) साथ में कागज [विज़न ट्रांसफॉर्मर्स फॉर डेंस प्रेडिक्शन](https://arxiv.org/abs/2103.13413) रेने रैनफ्टल, एलेक्सी बोचकोवस्की, व्लादलेन कोल्टन द्वारा।
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (हगिंगफेस से), साथ में कागज [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) विक्टर सनह, लिसांड्रे डेब्यू और थॉमस वुल्फ द्वारा पोस्ट किया गया। यही तरीका GPT-2 को [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERta से [DistilRoBERta](https://github.com) पर कंप्रेस करने के लिए भी लागू किया जाता है। / हगिंगफेस/ट्रांसफॉर्मर्स/ट्री/मेन/उदाहरण/डिस्टिलेशन), बहुभाषी BERT से [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) और डिस्टिलबर्ट का जर्मन संस्करण।
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) जुनलॉन्ग ली, यिहेंग जू, टेंगचाओ लव, लेई कुई, चा झांग द्वारा फुरु वेई द्वारा पोस्ट किया गया।
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (NAVER से) साथ में कागज [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) गीवूक किम, टीकग्यू होंग, मूनबिन यिम, जियोंग्योन नाम, जिनयॉन्ग पार्क, जिनयॉन्ग यिम, वोनसेओक ह्वांग, सांगडू यूं, डोंगयून हान, सेउंग्युन पार्क द्वारा।
|
||||
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (फेसबुक से) साथ में पेपर [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) व्लादिमीर करपुखिन, बरलास ओज़ुज़, सेवन मिन, पैट्रिक लुईस, लेडेल वू, सर्गेई एडुनोव, डैनकी चेन, और वेन-ताऊ यिह द्वारा।
|
||||
1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (इंटेल लैब्स से) साथ में कागज [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) रेने रैनफ्टल, एलेक्सी बोचकोवस्की, व्लादलेन कोल्टन द्वारा।
|
||||
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
|
||||
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (Google रिसर्च/स्टैनफोर्ड यूनिवर्सिटी से) साथ में दिया गया पेपर [इलेक्ट्रा: जेनरेटर के बजाय भेदभाव करने वाले के रूप में टेक्स्ट एन्कोडर्स का पूर्व-प्रशिक्षण](https://arxiv.org/abs/2003.10555) केविन क्लार्क, मिन्ह-थांग लुओंग, क्वोक वी. ले, क्रिस्टोफर डी. मैनिंग द्वारा पोस्ट किया गया।
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (Google रिसर्च/स्टैनफोर्ड यूनिवर्सिटी से) साथ में दिया गया पेपर [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) केविन क्लार्क, मिन्ह-थांग लुओंग, क्वोक वी. ले, क्रिस्टोफर डी. मैनिंग द्वारा पोस्ट किया गया।
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (Meta AI से) Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi. द्वाराअनुसंधान पत्र [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) के साथ जारी किया गया
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (Google रिसर्च से) साथ में दिया गया पेपर [सीक्वेंस जेनरेशन टास्क के लिए प्री-ट्रेंड चेकपॉइंट का इस्तेमाल करना](https://arxiv.org/abs/1907.12461) साशा रोठे, शशि नारायण, अलियाक्सि सेवेरिन द्वारा।
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)**(Baidu से) साथ देने वाला पेपर [ERNIE: एन्हांस्ड रिप्रेजेंटेशन थ्रू नॉलेज इंटीग्रेशन](https://arxiv.org/abs/1904.09223) यू सन, शुओहुआन वांग, युकुन ली, शिकुन फेंग, ज़ुई चेन, हान झांग, शिन तियान, डैनक्सियांग झू, हाओ तियान, हुआ वू द्वारा पोस्ट किया गया।
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (Google रिसर्च से) साथ में दिया गया पेपर [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) साशा रोठे, शशि नारायण, अलियाक्सि सेवेरिन द्वारा।
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)**(Baidu से) साथ देने वाला पेपर [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) यू सन, शुओहुआन वांग, युकुन ली, शिकुन फेंग, ज़ुई चेन, हान झांग, शिन तियान, डैनक्सियांग झू, हाओ तियान, हुआ वू द्वारा पोस्ट किया गया।
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (Baidu से) Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang. द्वाराअनुसंधान पत्र [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) के साथ जारी किया गया
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (मेटा AI से) ट्रांसफॉर्मर प्रोटीन भाषा मॉडल हैं। **ESM-1b** पेपर के साथ जारी किया गया था [अलेक्जेंडर राइव्स, जोशुआ मेयर, टॉम सर्कु, सिद्धार्थ गोयल, ज़ेमिंग लिन द्वारा जैविक संरचना और कार्य असुरक्षित सीखने को 250 मिलियन प्रोटीन अनुक्रमों तक स्केल करने से उभरता है](https://www.pnas.org/content/118/15/e2016239118) जेसन लियू, डेमी गुओ, मायल ओट, सी. लॉरेंस ज़िटनिक, जेरी मा और रॉब फर्गस। **ESM-1v** को पेपर के साथ जारी किया गया था [भाषा मॉडल प्रोटीन फ़ंक्शन पर उत्परिवर्तन के प्रभावों की शून्य-शॉट भविष्यवाणी को सक्षम करते हैं](https://doi.org/10.1101/2021.07.09.450648) जोशुआ मेयर, रोशन राव, रॉबर्ट वेरकुइल, जेसन लियू, टॉम सर्कु और अलेक्जेंडर राइव्स द्वारा। **ESM-2** को पेपर के साथ जारी किया गया था [भाषा मॉडल विकास के पैमाने पर प्रोटीन अनुक्रम सटीक संरचना भविष्यवाणी को सक्षम करते हैं](https://doi.org/10.1101/2022.07.20.500902) ज़ेमिंग लिन, हलील अकिन, रोशन राव, ब्रायन ही, झोंगकाई झू, वेंटिंग लू, ए द्वारा लान डॉस सैंटोस कोस्टा, मरियम फ़ज़ल-ज़रंडी, टॉम सर्कू, साल कैंडिडो, अलेक्जेंडर राइव्स।
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (मेटा AI से) ट्रांसफॉर्मर प्रोटीन भाषा मॉडल हैं। **ESM-1b** पेपर के साथ जारी किया गया था [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) जेसन लियू, डेमी गुओ, मायल ओट, सी. लॉरेंस ज़िटनिक, जेरी मा और रॉब फर्गस। **ESM-1v** को पेपर के साथ जारी किया गया था [भाषा मॉडल प्रोटीन फ़ंक्शन पर उत्परिवर्तन के प्रभावों की शून्य-शॉट भविष्यवाणी को सक्षम करते हैं](https://doi.org/10.1101/2021.07.09.450648) जोशुआ मेयर, रोशन राव, रॉबर्ट वेरकुइल, जेसन लियू, टॉम सर्कु और अलेक्जेंडर राइव्स द्वारा। **ESM-2** को पेपर के साथ जारी किया गया था [भाषा मॉडल विकास के पैमाने पर प्रोटीन अनुक्रम सटीक संरचना भविष्यवाणी को सक्षम करते हैं](https://doi.org/10.1101/2022.07.20.500902) ज़ेमिंग लिन, हलील अकिन, रोशन राव, ब्रायन ही, झोंगकाई झू, वेंटिंग लू, ए द्वारा लान डॉस सैंटोस कोस्टा, मरियम फ़ज़ल-ज़रंडी, टॉम सर्कू, साल कैंडिडो, अलेक्जेंडर राइव्स।
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (ESPnet and Microsoft Research से) Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang. द्वाराअनुसंधान पत्र [Fastspeech 2: Fast And High-quality End-to-End Text To Speech](https://arxiv.org/pdf/2006.04558.pdf) के साथ जारी किया गया
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (ESPnet and Microsoft Research से) Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang. द्वाराअनुसंधान पत्र [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) के साथ जारी किया गया
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (CNRS से) साथ वाला पेपर [FlauBERT: Unsupervised Language Model Pre-training for फ़्रेंच](https://arxiv.org/abs/1912.05372) Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, बेंजामिन लेकोउटेक्स, अलेक्जेंड्रे अल्लाउज़ेन, बेनोइट क्रैबे, लॉरेंट बेसेसियर, डिडिएर श्वाब द्वारा।
|
||||
1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** [FLAVA: A फाउंडेशनल लैंग्वेज एंड विजन अलाइनमेंट मॉडल](https://arxiv.org/abs/2112.04482) साथ वाला पेपर अमनप्रीत सिंह, रोंगहांग हू, वेदानुज गोस्वामी, गुइल्यूम कुएरॉन, वोज्शिएक गालुबा, मार्कस रोहरबैक, और डौवे कीला द्वारा।
|
||||
1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (गूगल रिसर्च से) साथ वाला पेपर [FNet: मिक्सिंग टोकन विद फूरियर ट्रांसफॉर्म्स](https://arxiv.org/abs/2105.03824) जेम्स ली-थॉर्प, जोशुआ आइंस्ली, इल्या एकस्टीन, सैंटियागो ओंटानन द्वारा।
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (CNRS से) साथ वाला पेपर [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, बेंजामिन लेकोउटेक्स, अलेक्जेंड्रे अल्लाउज़ेन, बेनोइट क्रैबे, लॉरेंट बेसेसियर, डिडिएर श्वाब द्वारा।
|
||||
1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) साथ वाला पेपर अमनप्रीत सिंह, रोंगहांग हू, वेदानुज गोस्वामी, गुइल्यूम कुएरॉन, वोज्शिएक गालुबा, मार्कस रोहरबैक, और डौवे कीला द्वारा।
|
||||
1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (गूगल रिसर्च से) साथ वाला पेपर [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) जेम्स ली-थॉर्प, जोशुआ आइंस्ली, इल्या एकस्टीन, सैंटियागो ओंटानन द्वारा।
|
||||
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (Microsoft Research से) Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao. द्वाराअनुसंधान पत्र [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) के साथ जारी किया गया
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (सीएमयू/गूगल ब्रेन से) साथ में कागज [फ़नल-ट्रांसफॉर्मर: कुशल भाषा प्रसंस्करण के लिए अनुक्रमिक अतिरेक को छानना](https://arxiv.org/abs/2006.03236) जिहांग दाई, गुओकुन लाई, यिमिंग यांग, क्वोक वी. ले द्वारा रिहाई।
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (सीएमयू/गूगल ब्रेन से) साथ में कागज [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) जिहांग दाई, गुओकुन लाई, यिमिंग यांग, क्वोक वी. ले द्वारा रिहाई।
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (ADEPT से) रोहन बाविशी, एरिच एलसेन, कर्टिस हॉथोर्न, मैक्सवेल नी, ऑगस्टस ओडेना, अरुशी सोमानी, सागनाक तासिरलार [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (Google से) the Gemma Google team. द्वाराअनुसंधान पत्र [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) के साथ जारी किया गया
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (KAIST से) साथ वाला पेपर [वर्टिकल कटडेप्थ के साथ मोनोकुलर डेप्थ एस्टीमेशन के लिए ग्लोबल-लोकल पाथ नेटवर्क्स](https://arxiv.org/abs/2201.07436) डोयोन किम, वूंगह्युन गा, प्युंगवान आह, डोंगग्यू जू, सेहवान चुन, जुनमो किम द्वारा।
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (OpenAI से) साथ में दिया गया पेपर [जेनरेटिव प्री-ट्रेनिंग द्वारा भाषा की समझ में सुधार](https://openai.com/research/language-unsupervised/) एलेक रैडफोर्ड, कार्तिक नरसिम्हन, टिम सालिमन्स और इल्या सुत्स्केवर द्वारा।
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (KAIST से) साथ वाला पेपर [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) डोयोन किम, वूंगह्युन गा, प्युंगवान आह, डोंगग्यू जू, सेहवान चुन, जुनमो किम द्वारा।
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (OpenAI से) साथ में दिया गया पेपर [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) एलेक रैडफोर्ड, कार्तिक नरसिम्हन, टिम सालिमन्स और इल्या सुत्स्केवर द्वारा।
|
||||
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (EleutherAI से) रिपॉजिटरी के साथ [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) रिलीज। सिड ब्लैक, स्टेला बिडरमैन, लियो गाओ, फिल वांग और कॉनर लेही द्वारा पोस्ट किया गया।
|
||||
1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (EleutherAI से) पेपर के साथ जारी किया गया [GPT-NeoX-20B: एक ओपन-सोर्स ऑटोरेग्रेसिव लैंग्वेज मॉडल](https://arxiv.org/abs/2204.06745) सिड ब्लैक, स्टेला बिडरमैन, एरिक हैलाहन, क्वेंटिन एंथोनी, लियो गाओ, लॉरेंस गोल्डिंग, होरेस हे, कॉनर लेही, काइल मैकडोनेल, जेसन फांग, माइकल पाइलर, यूएसवीएसएन साई प्रशांत द्वारा , शिवांशु पुरोहित, लारिया रेनॉल्ड्स, जोनाथन टो, बेन वांग, सैमुअल वेनबैक
|
||||
1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (EleutherAI से) पेपर के साथ जारी किया गया [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) सिड ब्लैक, स्टेला बिडरमैन, एरिक हैलाहन, क्वेंटिन एंथोनी, लियो गाओ, लॉरेंस गोल्डिंग, होरेस हे, कॉनर लेही, काइल मैकडोनेल, जेसन फांग, माइकल पाइलर, यूएसवीएसएन साई प्रशांत द्वारा , शिवांशु पुरोहित, लारिया रेनॉल्ड्स, जोनाथन टो, बेन वांग, सैमुअल वेनबैक
|
||||
1. **[GPT NeoX Japanese](https://huggingface.co/docs/transformers/model_doc/gpt_neox_japanese)** (अबेजा के जरिए) शिन्या ओटानी, ताकायोशी मकाबे, अनुज अरोड़ा, क्यो हटोरी द्वारा।
|
||||
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (ओपनएआई से) साथ में पेपर [लैंग्वेज मॉडल्स अनसुपरवाइज्ड मल्टीटास्क लर्नर्स हैं](https://openai.com/research/better-language-models/) एलेक रैडफोर्ड, जेफरी वू, रेवन चाइल्ड, डेविड लुआन, डारियो एमोडी द्वारा और इल्या सुत्सकेवर ने पोस्ट किया।
|
||||
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (ओपनएआई से) साथ में पेपर [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) एलेक रैडफोर्ड, जेफरी वू, रेवन चाइल्ड, डेविड लुआन, डारियो एमोडी द्वारा और इल्या सुत्सकेवर ने पोस्ट किया।
|
||||
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (EleutherAI से) साथ वाला पेपर [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) बेन वांग और अरन कोमात्सुजाकी द्वारा।
|
||||
1. **[GPT-Sw3](https://huggingface.co/docs/transformers/model_doc/gpt-sw3)** (from AI-Sweden) released with the paper [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
|
||||
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (BigCode से) Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra. द्वाराअनुसंधान पत्र [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) के साथ जारी किया गया
|
||||
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
|
||||
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
|
||||
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA से) साथ में कागज [GroupViT: टेक्स्ट सुपरविजन से सिमेंटिक सेगमेंटेशन इमर्जेस](https://arxiv.org/abs/2202.11094) जियारुई जू, शालिनी डी मेलो, सिफ़ी लियू, वोनमिन बायन, थॉमस ब्रेउएल, जान कौट्ज़, ज़ियाओलोंग वांग द्वारा।
|
||||
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA से) साथ में कागज [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) जियारुई जू, शालिनी डी मेलो, सिफ़ी लियू, वोनमिन बायन, थॉमस ब्रेउएल, जान कौट्ज़, ज़ियाओलोंग वांग द्वारा।
|
||||
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (Allegro.pl, AGH University of Science and Technology से) Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik. द्वाराअनुसंधान पत्र [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) के साथ जारी किया गया
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (फेसबुक से) साथ में पेपर [ह्यूबर्ट: सेल्फ सुपरवाइज्ड स्पीच रिप्रेजेंटेशन लर्निंग बाय मास्क्ड प्रेडिक्शन ऑफ हिडन यूनिट्स](https://arxiv.org/abs/2106.07447) वेई-निंग सू, बेंजामिन बोल्टे, याओ-हंग ह्यूबर्ट त्साई, कुशाल लखोटिया, रुस्लान सालाखुतदीनोव, अब्देलरहमान मोहम्मद द्वारा।
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (फेसबुक से) साथ में पेपर [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) वेई-निंग सू, बेंजामिन बोल्टे, याओ-हंग ह्यूबर्ट त्साई, कुशाल लखोटिया, रुस्लान सालाखुतदीनोव, अब्देलरहमान मोहम्मद द्वारा।
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (बर्कले से) साथ में कागज [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) सेहून किम, अमीर घोलमी, ज़ेवेई याओ, माइकल डब्ल्यू महोनी, कर्ट केटज़र द्वारा।
|
||||
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
@ -345,152 +348,161 @@ conda install conda-forge::transformers
|
||||
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (माइक्रोसॉफ्ट रिसर्च एशिया से) साथ देने वाला पेपर [लेआउटएलएमवी3: यूनिफाइड टेक्स्ट और इमेज मास्किंग के साथ दस्तावेज़ एआई के लिए पूर्व-प्रशिक्षण](https://arxiv.org/abs/2204.08387) युपन हुआंग, टेंगचाओ लव, लेई कुई, युटोंग लू, फुरु वेई द्वारा पोस्ट किया गया।
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (माइक्रोसॉफ्ट रिसर्च एशिया से) साथ देने वाला पेपर [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) युपन हुआंग, टेंगचाओ लव, लेई कुई, युटोंग लू, फुरु वेई द्वारा पोस्ट किया गया।
|
||||
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
|
||||
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (मेटा AI से) साथ वाला पेपर [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) बेन ग्राहम, अलाएल्डिन एल-नौबी, ह्यूगो टौवरन, पियरे स्टॉक, आर्मंड जौलिन, हर्वे जेगौ, मैथिज डूज़ द्वारा।
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (दक्षिण चीन प्रौद्योगिकी विश्वविद्यालय से) साथ में कागज [LiLT: एक सरल लेकिन प्रभावी भाषा-स्वतंत्र लेआउट ट्रांसफार्मर संरचित दस्तावेज़ समझ के लिए](https://arxiv.org/abs/2202.13669) जियापेंग वांग, लियानवेन जिन, काई डिंग द्वारा पोस्ट किया गया।
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (दक्षिण चीन प्रौद्योगिकी विश्वविद्यालय से) साथ में कागज [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) जियापेंग वांग, लियानवेन जिन, काई डिंग द्वारा पोस्ट किया गया।
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI से) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. द्वाराअनुसंधान पत्र [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) के साथ जारी किया गया
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI से) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.. द्वाराअनुसंधान पत्र [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) के साथ जारी किया गया
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI से) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.. द्वाराअनुसंधान पत्र [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) के साथ जारी किया गया
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison से) Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee. द्वाराअनुसंधान पत्र [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) के साथ जारी किया गया
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (Microsoft Research & University of Wisconsin-Madison से) Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee. द्वाराअनुसंधान पत्र [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744) के साथ जारी किया गया
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (मैंडी गुओ, जोशुआ आइंस्ली, डेविड यूथस, सैंटियागो ओंटानन, जियानमो नि, यूं-हुआन सुंग, यिनफेई यांग द्वारा पोस्ट किया गया।
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (स्टूडियो औसिया से) साथ में पेपर [LUKE: डीप कॉन्टेक्स्टुअलाइज्ड एंटिटी रिप्रेजेंटेशन विद एंटिटी-अवेयर सेल्फ-अटेंशन](https://arxiv.org/abs/2010.01057) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto द्वारा।
|
||||
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (UNC चैपल हिल से) साथ में पेपर [LXMERT: ओपन-डोमेन क्वेश्चन के लिए ट्रांसफॉर्मर से क्रॉस-मोडलिटी एनकोडर रिप्रेजेंटेशन सीखना Answering](https://arxiv.org/abs/1908.07490) हाओ टैन और मोहित बंसल द्वारा।
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (स्टूडियो औसिया से) साथ में पेपर [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto द्वारा।
|
||||
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (UNC चैपल हिल से) साथ में पेपर [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) हाओ टैन और मोहित बंसल द्वारा।
|
||||
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (फेसबुक से) साथ देने वाला पेपर [बियॉन्ड इंग्लिश-सेंट्रिक मल्टीलिंगुअल मशीन ट्रांसलेशन](https://arxiv.org/एब्स/2010.11125) एंजेला फैन, श्रुति भोसले, होल्गर श्वेन्क, झी मा, अहमद अल-किश्की, सिद्धार्थ गोयल, मनदीप बैनेस, ओनूर सेलेबी, गुइल्लाम वेन्जेक, विश्रव चौधरी, नमन गोयल, टॉम बर्च, विटाली लिपचिंस्की, सर्गेई एडुनोव, एडौर्ड द्वारा ग्रेव, माइकल औली, आर्मंड जौलिन द्वारा पोस्ट किया गया।
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (फेसबुक से) साथ देने वाला पेपर [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) एंजेला फैन, श्रुति भोसले, होल्गर श्वेन्क, झी मा, अहमद अल-किश्की, सिद्धार्थ गोयल, मनदीप बैनेस, ओनूर सेलेबी, गुइल्लाम वेन्जेक, विश्रव चौधरी, नमन गोयल, टॉम बर्च, विटाली लिपचिंस्की, सर्गेई एडुनोव, एडौर्ड द्वारा ग्रेव, माइकल औली, आर्मंड जौलिन द्वारा पोस्ट किया गया।
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (Albert Gu and Tri Dao से) Albert Gu and Tri Dao. द्वाराअनुसंधान पत्र [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) के साथ जारी किया गया
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Jörg द्वारा [OPUS](http://opus.nlpl.eu/) डेटा से प्रशिक्षित मशीनी अनुवाद मॉडल पोस्ट किया गया टाइडेमैन द्वारा। [मैरियन फ्रेमवर्क](https://marian-nmt.github.io/) माइक्रोसॉफ्ट ट्रांसलेटर टीम द्वारा विकसित।
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (माइक्रोसॉफ्ट रिसर्च एशिया से) साथ में पेपर [मार्कअपएलएम: विजुअली-रिच डॉक्यूमेंट अंडरस्टैंडिंग के लिए टेक्स्ट और मार्कअप लैंग्वेज का प्री-ट्रेनिंग](https://arxiv.org/abs/2110.08518) जुनलॉन्ग ली, यिहेंग जू, लेई कुई, फुरु द्वारा वी द्वारा पोस्ट किया गया।
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (माइक्रोसॉफ्ट रिसर्च एशिया से) साथ में पेपर [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) जुनलॉन्ग ली, यिहेंग जू, लेई कुई, फुरु द्वारा वी द्वारा पोस्ट किया गया।
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (FAIR and UIUC से) Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. द्वाराअनुसंधान पत्र [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) के साथ जारी किया गया
|
||||
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (मेटा और UIUC से) पेपर के साथ जारी किया गया [प्रति-पिक्सेल वर्गीकरण वह सब नहीं है जिसकी आपको सिमेंटिक सेगमेंटेशन की आवश्यकता है](https://arxiv.org/abs/2107.06278) बोवेन चेंग, अलेक्जेंडर जी. श्विंग, अलेक्जेंडर किरिलोव द्वारा >>>>>> रिबेस ठीक करें
|
||||
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (मेटा और UIUC से) पेपर के साथ जारी किया गया [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) बोवेन चेंग, अलेक्जेंडर जी. श्विंग, अलेक्जेंडर किरिलोव द्वारा >>>>>> रिबेस ठीक करें
|
||||
1. **[MatCha](https://huggingface.co/docs/transformers/model_doc/matcha)** (Google AI से) Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos. द्वाराअनुसंधान पत्र [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662) के साथ जारी किया गया
|
||||
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (फेसबुक से) साथ में पेपर [न्यूरल मशीन ट्रांसलेशन के लिए मल्टीलिंगुअल डीनोइजिंग प्री-ट्रेनिंग](https://arxiv.org/abs/2001.08210) यिनहान लियू, जियाताओ गु, नमन गोयल, जियान ली, सर्गेई एडुनोव, मार्जन ग़ज़विनिनेजाद, माइक लुईस, ल्यूक ज़ेटलमॉयर द्वारा।
|
||||
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (फेसबुक से) साथ में पेपर [एक्स्टेंसिबल बहुभाषी प्रीट्रेनिंग और फाइनट्यूनिंग के साथ बहुभाषी अनुवाद](https://arxiv.org/abs/2008.00401) युकिंग टैंग, चाउ ट्रान, जियान ली, पेंग-जेन चेन, नमन गोयल, विश्रव चौधरी, जियाताओ गु, एंजेला फैन द्वारा।
|
||||
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (फेसबुक से) साथ में पेपर [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) यिनहान लियू, जियाताओ गु, नमन गोयल, जियान ली, सर्गेई एडुनोव, मार्जन ग़ज़विनिनेजाद, माइक लुईस, ल्यूक ज़ेटलमॉयर द्वारा।
|
||||
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (फेसबुक से) साथ में पेपर [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) युकिंग टैंग, चाउ ट्रान, जियान ली, पेंग-जेन चेन, नमन गोयल, विश्रव चौधरी, जियाताओ गु, एंजेला फैन द्वारा।
|
||||
1. **[MEGA](https://huggingface.co/docs/transformers/model_doc/mega)** (Facebook से) Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer. द्वाराअनुसंधान पत्र [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) के साथ जारी किया गया
|
||||
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (NVIDIA से) कागज के साथ [Megatron-LM: मॉडल का उपयोग करके बहु-अरब पैरामीटर भाषा मॉडल का प्रशिक्षण Parallelism](https://arxiv.org/abs/1909.08053) मोहम्मद शोएबी, मोस्टोफा पटवारी, राउल पुरी, पैट्रिक लेग्रेस्ले, जेरेड कैस्पर और ब्रायन कैटानज़ारो द्वारा।
|
||||
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (NVIDIA से) साथ वाला पेपर [Megatron-LM: ट्रेनिंग मल्टी-बिलियन पैरामीटर लैंग्वेज मॉडल्स यूजिंग मॉडल पैरेललिज़्म](https://arxiv.org/abs/1909.08053) मोहम्मद शोएबी, मोस्टोफा पटवारी, राउल पुरी, पैट्रिक लेग्रेस्ले, जेरेड कैस्पर और ब्रायन कैटानज़ारो द्वारा पोस्ट किया गया।
|
||||
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (NVIDIA से) कागज के साथ [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) मोहम्मद शोएबी, मोस्टोफा पटवारी, राउल पुरी, पैट्रिक लेग्रेस्ले, जेरेड कैस्पर और ब्रायन कैटानज़ारो द्वारा।
|
||||
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (NVIDIA से) साथ वाला पेपर [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) मोहम्मद शोएबी, मोस्टोफा पटवारी, राउल पुरी, पैट्रिक लेग्रेस्ले, जेरेड कैस्पर और ब्रायन कैटानज़ारो द्वारा पोस्ट किया गया।
|
||||
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (Alibaba Research से) Peng Wang, Cheng Da, and Cong Yao. द्वाराअनुसंधान पत्र [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) के साथ जारी किया गया
|
||||
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The Mistral AI team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed..
|
||||
1. **[Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (फ्रॉम Studio Ousia) साथ में पेपर [mLUKE: द पावर ऑफ एंटिटी रिप्रेजेंटेशन इन मल्टीलिंगुअल प्रीट्रेन्ड लैंग्वेज मॉडल्स](https://arxiv.org/abs/2110.08151) रयोकन री, इकुया यामाडा, और योशिमासा त्सुरोका द्वारा।
|
||||
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (फ्रॉम Studio Ousia) साथ में पेपर [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) रयोकन री, इकुया यामाडा, और योशिमासा त्सुरोका द्वारा।
|
||||
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (Facebook से) Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli. द्वाराअनुसंधान पत्र [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) के साथ जारी किया गया
|
||||
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (सीएमयू/गूगल ब्रेन से) साथ में कागज [मोबाइलबर्ट: संसाधन-सीमित उपकरणों के लिए एक कॉम्पैक्ट टास्क-अज्ञेय बीईआरटी](https://arxiv.org/abs/2004.02984) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, और Denny Zhou द्वारा पोस्ट किया गया।
|
||||
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (सीएमयू/गूगल ब्रेन से) साथ में कागज [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, और Denny Zhou द्वारा पोस्ट किया गया।
|
||||
1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
|
||||
1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
|
||||
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (Apple से) साथ में कागज [MobileViT: लाइट-वेट, जनरल-पर्पस, और मोबाइल-फ्रेंडली विजन ट्रांसफॉर्मर](https://arxiv.org/abs/2110.02178) सचिन मेहता और मोहम्मद रस्तगरी द्वारा पोस्ट किया गया।
|
||||
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (Apple से) साथ में कागज [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) सचिन मेहता और मोहम्मद रस्तगरी द्वारा पोस्ट किया गया।
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (Apple से) Sachin Mehta and Mohammad Rastegari. द्वाराअनुसंधान पत्र [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) के साथ जारी किया गया
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (MosaiML से) the MosaicML NLP Team. द्वाराअनुसंधान पत्र [llm-foundry](https://github.com/mosaicml/llm-foundry/) के साथ जारी किया गया
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (the University of Wisconsin - Madison से) Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh. द्वाराअनुसंधान पत्र [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) के साथ जारी किया गया
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (Google AI से) साथ वाला पेपर [mT5: एक व्यापक बहुभाषी पूर्व-प्रशिक्षित टेक्स्ट-टू-टेक्स्ट ट्रांसफॉर्मर](https://arxiv.org/abs/2010.11934) लिंटिंग ज़ू, नोआ कॉन्सटेंट, एडम रॉबर्ट्स, मिहिर काले, रामी अल-रफू, आदित्य सिद्धांत, आदित्य बरुआ, कॉलिन रैफेल द्वारा पोस्ट किया गया।
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (the University of Wisconsin - Madison से) Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh. द्वाराअनुसंधान पत्र [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) के साथ जारी किया गया
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (Google AI से) साथ वाला पेपर [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) लिंटिंग ज़ू, नोआ कॉन्सटेंट, एडम रॉबर्ट्स, मिहिर काले, रामी अल-रफू, आदित्य सिद्धांत, आदित्य बरुआ, कॉलिन रैफेल द्वारा पोस्ट किया गया।
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (हुआवेई नूह के आर्क लैब से) साथ में कागज़ [NEZHA: चीनी भाषा समझ के लिए तंत्रिका प्रासंगिक प्रतिनिधित्व](https://arxiv.org/abs/1909.00204) जुन्किउ वेई, ज़ियाओज़े रेन, ज़िआओगुआंग ली, वेनयोंग हुआंग, यी लियाओ, याशेंग वांग, जियाशू लिन, शिन जियांग, जिओ चेन और कुन लियू द्वारा।
|
||||
1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (फ्रॉम मेटा) साथ में पेपर [नो लैंग्वेज लेफ्ट बिहाइंड: स्केलिंग ह्यूमन-सेंटेड मशीन ट्रांसलेशन](https://arxiv.org/abs/2207.04672) एनएलएलबी टीम द्वारा प्रकाशित।
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (हुआवेई नूह के आर्क लैब से) साथ में कागज़ [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) जुन्किउ वेई, ज़ियाओज़े रेन, ज़िआओगुआंग ली, वेनयोंग हुआंग, यी लियाओ, याशेंग वांग, जियाशू लिन, शिन जियांग, जिओ चेन और कुन लियू द्वारा।
|
||||
1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (फ्रॉम मेटा) साथ में पेपर [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) एनएलएलबी टीम द्वारा प्रकाशित।
|
||||
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (Meta से) the NLLB team. द्वाराअनुसंधान पत्र [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) के साथ जारी किया गया
|
||||
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (Meta AI से) Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic. द्वाराअनुसंधान पत्र [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) के साथ जारी किया गया
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (विस्कॉन्सिन विश्वविद्यालय - मैडिसन से) साथ में कागज [Nyströmformer: A Nyström- आधारित एल्गोरिथम आत्म-ध्यान का अनुमान लगाने के लिए](https://arxiv.org/abs/2102.03902) युनयांग ज़िओंग, झानपेंग ज़ेंग, रुद्रसिस चक्रवर्ती, मिंगक्सिंग टैन, ग्लेन फंग, यिन ली, विकास सिंह द्वारा पोस्ट किया गया।
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (विस्कॉन्सिन विश्वविद्यालय - मैडिसन से) साथ में कागज [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) युनयांग ज़िओंग, झानपेंग ज़ेंग, रुद्रसिस चक्रवर्ती, मिंगक्सिंग टैन, ग्लेन फंग, यिन ली, विकास सिंह द्वारा पोस्ट किया गया।
|
||||
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (SHI Labs से) पेपर [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) जितेश जैन, जिआचेन ली, मांगटिक चिउ, अली हसनी, निकिता ओरलोव, हम्फ्री शि के द्वारा जारी किया गया है।
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI से) साथ में कागज [विज़न ट्रांसफॉर्मर्स के साथ सिंपल ओपन-वोकैबुलरी ऑब्जेक्ट डिटेक्शन](https://arxiv.org/abs/2205.06230) मैथियास मिंडरर, एलेक्सी ग्रिट्सेंको, ऑस्टिन स्टोन, मैक्सिम न्यूमैन, डिर्क वीसेनबोर्न, एलेक्सी डोसोवित्स्की, अरविंद महेंद्रन, अनुराग अर्नब, मुस्तफा देहघानी, ज़ुओरन शेन, जिओ वांग, ज़ियाओहुआ झाई, थॉमस किफ़, और नील हॉल्सबी द्वारा पोस्ट किया गया।
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI से) साथ में कागज [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) मैथियास मिंडरर, एलेक्सी ग्रिट्सेंको, ऑस्टिन स्टोन, मैक्सिम न्यूमैन, डिर्क वीसेनबोर्न, एलेक्सी डोसोवित्स्की, अरविंद महेंद्रन, अनुराग अर्नब, मुस्तफा देहघानी, ज़ुओरन शेन, जिओ वांग, ज़ियाओहुआ झाई, थॉमस किफ़, और नील हॉल्सबी द्वारा पोस्ट किया गया।
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (Google AI से) Matthias Minderer, Alexey Gritsenko, Neil Houlsby. द्वाराअनुसंधान पत्र [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) के साथ जारी किया गया
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** ( IBM Research से) Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. द्वाराअनुसंधान पत्र [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) के साथ जारी किया गया
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (IBM से) Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. द्वाराअनुसंधान पत्र [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf) के साथ जारी किया गया
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (IBM से) Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. द्वाराअनुसंधान पत्र [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) के साथ जारी किया गया
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google की ओर से) साथ में दिया गया पेपर [लंबे इनपुट सारांश के लिए ट्रांसफ़ॉर्मरों को बेहतर तरीके से एक्सटेंड करना](https://arxiv.org/abs/2208.04347) जेसन फांग, याओ झाओ, पीटर जे लियू द्वारा।
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (दीपमाइंड से) साथ में पेपर [पर्सीवर आईओ: संरचित इनपुट और आउटपुट के लिए एक सामान्य वास्तुकला](https://arxiv.org/abs/2107.14795) एंड्रयू जेगल, सेबेस्टियन बोरग्यूड, जीन-बैप्टिस्ट अलायराक, कार्ल डोर्श, कैटलिन इओनेस्कु, डेविड द्वारा डिंग, स्कंद कोप्पुला, डैनियल ज़ोरान, एंड्रयू ब्रॉक, इवान शेलहैमर, ओलिवियर हेनाफ, मैथ्यू एम। बोट्विनिक, एंड्रयू ज़िसरमैन, ओरिओल विनियल्स, जोआओ कैरेरा द्वारा पोस्ट किया गया।
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google की ओर से) साथ में दिया गया पेपर [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) जेसन फांग, याओ झाओ, पीटर जे लियू द्वारा।
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (दीपमाइंड से) साथ में पेपर [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) एंड्रयू जेगल, सेबेस्टियन बोरग्यूड, जीन-बैप्टिस्ट अलायराक, कार्ल डोर्श, कैटलिन इओनेस्कु, डेविड द्वारा डिंग, स्कंद कोप्पुला, डैनियल ज़ोरान, एंड्रयू ब्रॉक, इवान शेलहैमर, ओलिवियर हेनाफ, मैथ्यू एम। बोट्विनिक, एंड्रयू ज़िसरमैन, ओरिओल विनियल्स, जोआओ कैरेरा द्वारा पोस्ट किया गया।
|
||||
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (ADEPT से) Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani. द्वाराअनुसंधान पत्र [blog post](https://www.adept.ai/blog/persimmon-8b) के साथ जारी किया गया
|
||||
1. **[Phi](https://huggingface.co/docs/transformers/model_doc/phi)** (from Microsoft) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
|
||||
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (VinAI Research से) कागज के साथ [PhoBERT: वियतनामी के लिए पूर्व-प्रशिक्षित भाषा मॉडल](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) डैट क्वोक गुयेन और अन्ह तुआन गुयेन द्वारा पोस्ट किया गया।
|
||||
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (VinAI Research से) कागज के साथ [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) डैट क्वोक गुयेन और अन्ह तुआन गुयेन द्वारा पोस्ट किया गया।
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (Google से) Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova. द्वाराअनुसंधान पत्र [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) के साथ जारी किया गया
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP से) साथ वाला पेपर [प्रोग्राम अंडरस्टैंडिंग एंड जेनरेशन के लिए यूनिफाइड प्री-ट्रेनिंग](https://arxiv.org/abs/2103.06333) वसी उद्दीन अहमद, सैकत चक्रवर्ती, बैशाखी रे, काई-वेई चांग द्वारा।
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP से) साथ वाला पेपर [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) वसी उद्दीन अहमद, सैकत चक्रवर्ती, बैशाखी रे, काई-वेई चांग द्वारा।
|
||||
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [ProphetNet: प्रेडिक्टिंग फ्यूचर एन-ग्राम फॉर सीक्वेंस-टू-सीक्वेंस प्री-ट्रेनिंग](https://arxiv.org/abs/2001.04063) यू यान, वीज़ेन क्यूई, येयुन गोंग, दयाहेंग लियू, नान डुआन, जिउशेंग चेन, रुओफ़ेई झांग और मिंग झोउ द्वारा पोस्ट किया गया।
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) यू यान, वीज़ेन क्यूई, येयुन गोंग, दयाहेंग लियू, नान डुआन, जिउशेंग चेन, रुओफ़ेई झांग और मिंग झोउ द्वारा पोस्ट किया गया।
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (Nanjing University, The University of Hong Kong etc. से) Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. द्वाराअनुसंधान पत्र [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) के साथ जारी किया गया
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA से) साथ वाला पेपर [डीप लर्निंग इंफ़ेक्शन के लिए इंटीजर क्वांटिज़ेशन: प्रिंसिपल्स एंड एम्पिरिकल इवैल्यूएशन](https://arxiv.org/abs/2004.09602) हाओ वू, पैट्रिक जुड, जिआओजी झांग, मिखाइल इसेव और पॉलियस माइकेविसियस द्वारा।
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc. से) Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. द्वाराअनुसंधान पत्र [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) के साथ जारी किया गया
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA से) साथ वाला पेपर [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) हाओ वू, पैट्रिक जुड, जिआओजी झांग, मिखाइल इसेव और पॉलियस माइकेविसियस द्वारा।
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (the Qwen team, Alibaba Group से) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu. द्वाराअनुसंधान पत्र [Qwen Technical Report](https://arxiv.org/abs/2309.16609) के साथ जारी किया गया
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (फेसबुक से) साथ में कागज [रिट्रीवल-ऑगमेंटेड जेनरेशन फॉर नॉलेज-इंटेंसिव एनएलपी टास्क](https://arxiv.org/abs/2005.11401) पैट्रिक लुईस, एथन पेरेज़, अलेक्जेंड्रा पिक्टस, फैबियो पेट्रोनी, व्लादिमीर कारपुखिन, नमन गोयल, हेनरिक कुटलर, माइक लुईस, वेन-ताउ यिह, टिम रॉकटाशेल, सेबस्टियन रिडेल, डौवे कीला द्वारा।
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google अनुसंधान से) केल्विन गु, केंटन ली, ज़ोरा तुंग, पानुपोंग पसुपत और मिंग-वेई चांग द्वारा साथ में दिया गया पेपर [REALM: रिट्रीवल-ऑगमेंटेड लैंग्वेज मॉडल प्री-ट्रेनिंग](https://arxiv.org/abs/2002.08909)।
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (the Qwen team, Alibaba Group से) Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou. द्वाराअनुसंधान पत्र [blog post](https://qwenlm.github.io/blog/qwen-moe/) के साथ जारी किया गया
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (फेसबुक से) साथ में कागज [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) पैट्रिक लुईस, एथन पेरेज़, अलेक्जेंड्रा पिक्टस, फैबियो पेट्रोनी, व्लादिमीर कारपुखिन, नमन गोयल, हेनरिक कुटलर, माइक लुईस, वेन-ताउ यिह, टिम रॉकटाशेल, सेबस्टियन रिडेल, डौवे कीला द्वारा।
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google अनुसंधान से) केल्विन गु, केंटन ली, ज़ोरा तुंग, पानुपोंग पसुपत और मिंग-वेई चांग द्वारा साथ में दिया गया पेपर [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909)।
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
|
||||
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (META रिसर्च से) [डिज़ाइनिंग नेटवर्क डिज़ाइन स्पेस](https://arxiv.org/) पेपर के साथ जारी किया गया एब्स/2003.13678) इलिजा राडोसावोविक, राज प्रतीक कोसाराजू, रॉस गिर्शिक, कैमिंग ही, पिओटर डॉलर द्वारा।
|
||||
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (गूगल रिसर्च से) साथ वाला पेपर [पूर्व-प्रशिक्षित भाषा मॉडल में एम्बेडिंग कपलिंग पर पुनर्विचार](https://arxiv.org/pdf/2010.12821.pdf) ह्युंग वोन चुंग, थिबॉल्ट फ़ेवरी, हेनरी त्साई, एम. जॉनसन, सेबेस्टियन रुडर द्वारा।
|
||||
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (माइक्रोसॉफ्ट रिसर्च से) [डीप रेसिडुअल लर्निंग फॉर इमेज रिकग्निशन](https://arxiv.org/abs/1512.03385) कैमिंग हे, जियांग्यु झांग, शाओकिंग रेन, जियान सन द्वारा।
|
||||
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (फेसबुक से), साथ में कागज [मजबूत रूप से अनुकूलित BERT प्रीट्रेनिंग दृष्टिकोण](https://arxiv.org/abs/1907.11692) यिनहान लियू, मायल ओट, नमन गोयल, जिंगफेई डू, मंदार जोशी, डैनकी चेन, ओमर लेवी, माइक लुईस, ल्यूक ज़ेटलमॉयर, वेसेलिन स्टोयानोव द्वारा।
|
||||
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (META रिसर्च से) [Designing Network Design Space](https://arxiv.org/abs/2003.13678) पेपर के साथ जारी किया गया एब्स/2003.13678) इलिजा राडोसावोविक, राज प्रतीक कोसाराजू, रॉस गिर्शिक, कैमिंग ही, पिओटर डॉलर द्वारा।
|
||||
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (गूगल रिसर्च से) साथ वाला पेपर [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) ह्युंग वोन चुंग, थिबॉल्ट फ़ेवरी, हेनरी त्साई, एम. जॉनसन, सेबेस्टियन रुडर द्वारा।
|
||||
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (माइक्रोसॉफ्ट रिसर्च से) [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) कैमिंग हे, जियांग्यु झांग, शाओकिंग रेन, जियान सन द्वारा।
|
||||
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (फेसबुक से), साथ में कागज [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) यिनहान लियू, मायल ओट, नमन गोयल, जिंगफेई डू, मंदार जोशी, डैनकी चेन, ओमर लेवी, माइक लुईस, ल्यूक ज़ेटलमॉयर, वेसेलिन स्टोयानोव द्वारा।
|
||||
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
|
||||
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (झुईई टेक्नोलॉजी से), साथ में पेपर [रोफॉर्मर: रोटरी पोजिशन एंबेडिंग के साथ एन्हांस्ड ट्रांसफॉर्मर](https://arxiv.org/pdf/2104.09864v1.pdf) जियानलिन सु और यू लू और शेंगफेंग पैन और बो वेन और युनफेंग लियू द्वारा प्रकाशित।
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (झुईई टेक्नोलॉजी से), साथ में पेपर [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) जियानलिन सु और यू लू और शेंगफेंग पैन और बो वेन और युनफेंग लियू द्वारा प्रकाशित।
|
||||
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (Bo Peng से) Bo Peng. द्वाराअनुसंधान पत्र [this repo](https://github.com/BlinkDL/RWKV-LM) के साथ जारी किया गया
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (Beijing Academy of Artificial Intelligence (BAAI से) Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. द्वाराअनुसंधान पत्र [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) के साथ जारी किया गया
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI से) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. द्वाराअनुसंधान पत्र [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) के साथ जारी किया गया
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP से) साथ देने वाला पेपर [भाषण पहचान के लिए अनसुपरवाइज्ड प्री-ट्रेनिंग में परफॉर्मेंस-एफिशिएंसी ट्रेड-ऑफ्स](https://arxiv.org/abs/2109.06870) फेलिक्स वू, क्वांगयुन किम, जिंग पैन, क्यू हान, किलियन क्यू. वेनबर्गर, योव आर्टज़ी द्वारा।
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP से) साथ में पेपर [भाषण पहचान के लिए अनसुपरवाइज्ड प्री-ट्रेनिंग में परफॉर्मेंस-एफिशिएंसी ट्रेड-ऑफ्स](https://arxiv.org/abs/2109.06870) फेलिक्स वू, क्वांगयुन किम, जिंग पैन, क्यू हान, किलियन क्यू. वेनबर्गर, योआव आर्टज़ी द्वारा पोस्ट किया गया।
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP से) साथ देने वाला पेपर [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) फेलिक्स वू, क्वांगयुन किम, जिंग पैन, क्यू हान, किलियन क्यू. वेनबर्गर, योव आर्टज़ी द्वारा।
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP से) साथ में पेपर [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) फेलिक्स वू, क्वांगयुन किम, जिंग पैन, क्यू हान, किलियन क्यू. वेनबर्गर, योआव आर्टज़ी द्वारा पोस्ट किया गया।
|
||||
1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (Google AI से) Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. द्वाराअनुसंधान पत्र [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) के साथ जारी किया गया
|
||||
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
|
||||
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (फेसबुक से), साथ में पेपर [फेयरसेक S2T: फास्ट स्पीच-टू-टेक्स्ट मॉडलिंग विद फेयरसेक](https://arxiv.org/abs/2010.05171) चांगहान वांग, यूं तांग, जुताई मा, ऐनी वू, दिमित्रो ओखोनको, जुआन पिनो द्वारा पोस्ट किया गया。
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (फेसबुक से) साथ में पेपर [लार्ज-स्केल सेल्फ- एंड सेमी-सुपरवाइज्ड लर्निंग फॉर स्पीच ट्रांसलेशन](https://arxiv.org/abs/2104.06678) चांगहान वांग, ऐनी वू, जुआन पिनो, एलेक्सी बेवस्की, माइकल औली, एलेक्सिस द्वारा Conneau द्वारा पोस्ट किया गया।
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (तेल अवीव यूनिवर्सिटी से) साथ में पेपर [स्पैन सिलेक्शन को प्री-ट्रेनिंग करके कुछ-शॉट क्वेश्चन आंसरिंग](https://arxiv.org/abs/2101.00438) ओरि राम, युवल कर्स्टन, जोनाथन बेरेंट, अमीर ग्लोबर्सन, ओमर लेवी द्वारा।
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (बर्कले से) कागज के साथ [SqueezeBERT: कुशल तंत्रिका नेटवर्क के बारे में NLP को कंप्यूटर विज़न क्या सिखा सकता है?](https://arxiv.org/abs/2006.11316) फॉरेस्ट एन. इनडोला, अल्बर्ट ई. शॉ, रवि कृष्णा, और कर्ट डब्ल्यू. केटज़र द्वारा।
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/main/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (फेसबुक से), साथ में पेपर [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) चांगहान वांग, यूं तांग, जुताई मा, ऐनी वू, दिमित्रो ओखोनको, जुआन पिनो द्वारा पोस्ट किया गया。
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (फेसबुक से) साथ में पेपर [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) चांगहान वांग, ऐनी वू, जुआन पिनो, एलेक्सी बेवस्की, माइकल औली, एलेक्सिस द्वारा Conneau द्वारा पोस्ट किया गया।
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (तेल अवीव यूनिवर्सिटी से) साथ में पेपर [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) ओरि राम, युवल कर्स्टन, जोनाथन बेरेंट, अमीर ग्लोबर्सन, ओमर लेवी द्वारा।
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (बर्कले से) कागज के साथ [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) फॉरेस्ट एन. इनडोला, अल्बर्ट ई. शॉ, रवि कृष्णा, और कर्ट डब्ल्यू. केटज़र द्वारा।
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (from MagicLeap) released with the paper [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (MBZUAI से) Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan. द्वाराअनुसंधान पत्र [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) के साथ जारी किया गया
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (माइक्रोसॉफ्ट से) साथ में कागज [स्वाइन ट्रांसफॉर्मर: शिफ्टेड विंडोज का उपयोग कर पदानुक्रमित विजन ट्रांसफॉर्मर](https://arxiv.org/abs/2103.14030) ज़ी लियू, युटोंग लिन, यू काओ, हान हू, यिक्सुआन वेई, झेंग झांग, स्टीफन लिन, बैनिंग गुओ द्वारा।
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (Microsoft से) साथ वाला पेपर [Swin Transformer V2: स्केलिंग अप कैपेसिटी एंड रेजोल्यूशन](https://arxiv.org/abs/2111.09883) ज़ी लियू, हान हू, युटोंग लिन, ज़ुलिआंग याओ, ज़ेंडा ज़ी, यिक्सुआन वेई, जिया निंग, यू काओ, झेंग झांग, ली डोंग, फुरु वेई, बैनिंग गुओ द्वारा।
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (माइक्रोसॉफ्ट से) साथ में कागज [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) ज़ी लियू, युटोंग लिन, यू काओ, हान हू, यिक्सुआन वेई, झेंग झांग, स्टीफन लिन, बैनिंग गुओ द्वारा।
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (Microsoft से) साथ वाला पेपर [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) ज़ी लियू, हान हू, युटोंग लिन, ज़ुलिआंग याओ, ज़ेंडा ज़ी, यिक्सुआन वेई, जिया निंग, यू काओ, झेंग झांग, ली डोंग, फुरु वेई, बैनिंग गुओ द्वारा।
|
||||
1. **[Swin2SR](https://huggingface.co/docs/transformers/model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
|
||||
1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
|
||||
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (来自 Google AI)कॉलिन रैफेल और नोम शज़ीर और एडम रॉबर्ट्स और कैथरीन ली और शरण नारंग और माइकल मटेना द्वारा साथ में पेपर [एक एकीकृत टेक्स्ट-टू-टेक्स्ट ट्रांसफॉर्मर के साथ स्थानांतरण सीखने की सीमा की खोज](https://arxiv.org/abs/1910.10683) और यांकी झोउ और वेई ली और पीटर जे लियू।
|
||||
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (Google AI से) साथ वाला पेपर [google-research/text-to-text-transfer- ट्रांसफॉर्मर](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) कॉलिन रैफेल और नोम शज़ीर और एडम रॉबर्ट्स और कैथरीन ली और शरण नारंग द्वारा और माइकल मटेना और यांकी झोउ और वेई ली और पीटर जे लियू।
|
||||
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [पबटेबल्स-1एम: टूवर्ड्स कॉम्प्रिहेंसिव टेबल एक्सट्रैक्शन फ्रॉम अनस्ट्रक्चर्ड डॉक्यूमेंट्स](https://arxiv.org/abs/2110.00061) ब्रैंडन स्मॉक, रोहित पेसाला, रॉबिन अब्राहम द्वारा पोस्ट किया गया।
|
||||
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (Google AI से) साथ में कागज [TAPAS: पूर्व-प्रशिक्षण के माध्यम से कमजोर पर्यवेक्षण तालिका पार्सिंग](https://arxiv.org/abs/2004.02349) जोनाथन हर्ज़िग, पावेल क्रिज़िस्तोफ़ नोवाक, थॉमस मुलर, फ्रांसेस्को पिकिन्नो और जूलियन मार्टिन ईसेन्च्लोस द्वारा।
|
||||
1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [TAPEX: टेबल प्री-ट्रेनिंग थ्रू लर्निंग अ न्यूरल SQL एक्ज़ीक्यूटर](https://arxiv.org/abs/2107.07653) कियान लियू, बेई चेन, जियाकी गुओ, मोर्टेज़ा ज़ियादी, ज़ेकी लिन, वीज़ू चेन, जियान-गुआंग लू द्वारा पोस्ट किया गया।
|
||||
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (来自 Google AI)कॉलिन रैफेल और नोम शज़ीर और एडम रॉबर्ट्स और कैथरीन ली और शरण नारंग और माइकल मटेना द्वारा साथ में पेपर [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) और यांकी झोउ और वेई ली और पीटर जे लियू।
|
||||
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (Google AI से) साथ वाला पेपर [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) कॉलिन रैफेल और नोम शज़ीर और एडम रॉबर्ट्स और कैथरीन ली और शरण नारंग द्वारा और माइकल मटेना और यांकी झोउ और वेई ली और पीटर जे लियू।
|
||||
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) ब्रैंडन स्मॉक, रोहित पेसाला, रॉबिन अब्राहम द्वारा पोस्ट किया गया।
|
||||
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (Google AI से) साथ में कागज [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) जोनाथन हर्ज़िग, पावेल क्रिज़िस्तोफ़ नोवाक, थॉमस मुलर, फ्रांसेस्को पिकिन्नो और जूलियन मार्टिन ईसेन्च्लोस द्वारा।
|
||||
1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (माइक्रोसॉफ्ट रिसर्च से) साथ में पेपर [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) कियान लियू, बेई चेन, जियाकी गुओ, मोर्टेज़ा ज़ियादी, ज़ेकी लिन, वीज़ू चेन, जियान-गुआंग लू द्वारा पोस्ट किया गया।
|
||||
1. **[Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer)** (from HuggingFace).
|
||||
1. **[TimeSformer](https://huggingface.co/docs/transformers/model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
|
||||
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
|
||||
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU की ओर से) कागज के साथ [संस्करण-एक्स: एक ब्लॉग मॉडल चौकस चौक मॉडल मॉडल](https://arxivorg/abs/1901.02860) क्वोकोक वी. ले, रुस्लैन सलाखुतदी
|
||||
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU की ओर से) कागज के साथ [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) क्वोकोक वी. ले, रुस्लैन सलाखुतदी
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft) released with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (Microsoft Research से) Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal. द्वाराअनुसंधान पत्र [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) के साथ जारी किया गया
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research से) Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant. द्वाराअनुसंधान पत्र [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) के साथ जारी किया गया
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (माइक्रोसॉफ्ट रिसर्च से) साथ में दिया गया पेपर [UniSpeech: यूनिफाइड स्पीच रिप्रेजेंटेशन लर्निंग विद लेबलेड एंड अनलेबल्ड डेटा](https://arxiv.org/abs/2101.07597) चेंगई वांग, यू वू, याओ कियान, केनिची कुमातानी, शुजी लियू, फुरु वेई, माइकल ज़ेंग, ज़ुएदोंग हुआंग द्वारा।
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (माइक्रोसॉफ्ट रिसर्च से) कागज के साथ [UNISPEECH-SAT: यूनिवर्सल स्पीच रिप्रेजेंटेशन लर्निंग विद स्पीकर अवेयर प्री-ट्रेनिंग](https://arxiv.org/abs/2110.05752) सानयुआन चेन, यू वू, चेंग्यी वांग, झेंगयांग चेन, झूओ चेन, शुजी लियू, जियान वू, याओ कियान, फुरु वेई, जिन्यु ली, जियांगज़ान यू द्वारा पोस्ट किया गया।
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (माइक्रोसॉफ्ट रिसर्च से) साथ में दिया गया पेपर [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) चेंगई वांग, यू वू, याओ कियान, केनिची कुमातानी, शुजी लियू, फुरु वेई, माइकल ज़ेंग, ज़ुएदोंग हुआंग द्वारा।
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (माइक्रोसॉफ्ट रिसर्च से) कागज के साथ [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) सानयुआन चेन, यू वू, चेंग्यी वांग, झेंगयांग चेन, झूओ चेन, शुजी लियू, जियान वू, याओ कियान, फुरु वेई, जिन्यु ली, जियांगज़ान यू द्वारा पोस्ट किया गया।
|
||||
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (सिंघुआ यूनिवर्सिटी और ननकाई यूनिवर्सिटी से) साथ में पेपर [विजुअल अटेंशन नेटवर्क](https://arxiv.org/pdf/2202.09741.pdf) मेंग-हाओ गुओ, चेंग-ज़े लू, झेंग-निंग लियू, मिंग-मिंग चेंग, शि-मिन हू द्वारा।
|
||||
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (मल्टीमीडिया कम्प्यूटिंग ग्रुप, नानजिंग यूनिवर्सिटी से) साथ में पेपर [वीडियोएमएई: मास्क्ड ऑटोएन्कोडर स्व-पर्यवेक्षित वीडियो प्री-ट्रेनिंग के लिए डेटा-कुशल सीखने वाले हैं](https://arxiv.org/abs/2203.12602) ज़ान टोंग, यिबिंग सॉन्ग, जुए द्वारा वांग, लिमिन वांग द्वारा पोस्ट किया गया।
|
||||
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (NAVER AI Lab/Kakao Enterprise/Kakao Brain से) साथ में कागज [ViLT: Vision-and-Language Transformer बिना कनवल्शन या रीजन सुपरविजन](https://arxiv.org/abs/2102.03334) वोनजे किम, बोक्यूंग सोन, इल्डू किम द्वारा पोस्ट किया गया।
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (सिंघुआ यूनिवर्सिटी और ननकाई यूनिवर्सिटी से) साथ में पेपर [Visual Attention Network](https://arxiv.org/abs/2202.09741) मेंग-हाओ गुओ, चेंग-ज़े लू, झेंग-निंग लियू, मिंग-मिंग चेंग, शि-मिन हू द्वारा।
|
||||
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (मल्टीमीडिया कम्प्यूटिंग ग्रुप, नानजिंग यूनिवर्सिटी से) साथ में पेपर [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) ज़ान टोंग, यिबिंग सॉन्ग, जुए द्वारा वांग, लिमिन वांग द्वारा पोस्ट किया गया।
|
||||
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (NAVER AI Lab/Kakao Enterprise/Kakao Brain से) साथ में कागज [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) वोनजे किम, बोक्यूंग सोन, इल्डू किम द्वारा पोस्ट किया गया।
|
||||
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (University of Wisconsin–Madison से) Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee. द्वाराअनुसंधान पत्र [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) के साथ जारी किया गया
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (गूगल एआई से) कागज के साथ [एक इमेज इज़ वर्थ 16x16 वर्ड्स: ट्रांसफॉर्मर्स फॉर इमेज रिकॉग्निशन एट स्केल](https://arxiv.org/abs/2010.11929) एलेक्सी डोसोवित्स्की, लुकास बेयर, अलेक्जेंडर कोलेसनिकोव, डिर्क वीसेनबोर्न, शियाओहुआ झाई, थॉमस अनटरथिनर, मुस्तफा देहघानी, मैथियास मिंडरर, जॉर्ज हेगोल्ड, सिल्वेन गेली, जैकब उस्ज़कोरेइट द्वारा हॉल्सबी द्वारा पोस्ट किया गया।
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (गूगल एआई से) कागज के साथ [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) एलेक्सी डोसोवित्स्की, लुकास बेयर, अलेक्जेंडर कोलेसनिकोव, डिर्क वीसेनबोर्न, शियाओहुआ झाई, थॉमस अनटरथिनर, मुस्तफा देहघानी, मैथियास मिंडरर, जॉर्ज हेगोल्ड, सिल्वेन गेली, जैकब उस्ज़कोरेइट द्वारा हॉल्सबी द्वारा पोस्ट किया गया।
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (UCLA NLP से) साथ वाला पेपर [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) लियुनियन हेरोल्ड ली, मार्क यात्स्कर, दा यिन, चो-जुई हसीह, काई-वेई चांग द्वारा।
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (Meta AI से) Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He. द्वाराअनुसंधान पत्र [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) के साथ जारी किया गया
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (मेटा एआई से) साथ में कागज [मास्कड ऑटोएन्कोडर स्केलेबल विजन लर्नर्स हैं](https://arxiv.org/एब्स/2111.06377) कैमिंग हे, ज़िनेली चेन, सेनिंग ज़ी, यांगहो ली, पिओट्र डॉलर, रॉस गिर्शिक द्वारा।
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (मेटा एआई से) साथ में कागज [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) कैमिंग हे, ज़िनेली चेन, सेनिंग ज़ी, यांगहो ली, पिओट्र डॉलर, रॉस गिर्शिक द्वारा।
|
||||
1. **[ViTMatte](https://huggingface.co/docs/transformers/model_doc/vitmatte)** (HUST-VL से) Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang. द्वाराअनुसंधान पत्र [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) के साथ जारी किया गया
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (मेटा एआई से) साथ में कागज [लेबल-कुशल सीखने के लिए मास्क्ड स्याम देश के नेटवर्क](https://arxiv.org/abs/2204.07141) महमूद असरान, मथिल्डे कैरन, ईशान मिश्रा, पियोट्र बोजानोवस्की, फ्लोरियन बोर्डेस, पास्कल विंसेंट, आर्मंड जौलिन, माइकल रब्बत, निकोलस बल्लास द्वारा।
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (मेटा एआई से) साथ में कागज [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) महमूद असरान, मथिल्डे कैरन, ईशान मिश्रा, पियोट्र बोजानोवस्की, फ्लोरियन बोर्डेस, पास्कल विंसेंट, आर्मंड जौलिन, माइकल रब्बत, निकोलस बल्लास द्वारा।
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (Kakao Enterprise से) Jaehyeon Kim, Jungil Kong, Juhee Son. द्वाराअनुसंधान पत्र [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) के साथ जारी किया गया
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (फेसबुक एआई से) साथ में पेपर [wav2vec 2.0: ए फ्रेमवर्क फॉर सेल्फ-सुपरवाइज्ड लर्निंग ऑफ स्पीच रिप्रेजेंटेशन](https://arxiv.org/abs/2006.11477) एलेक्सी बेवस्की, हेनरी झोउ, अब्देलरहमान मोहम्मद, माइकल औली द्वारा।
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (फेसबुक एआई से) साथ में पेपर [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) एलेक्सी बेवस्की, हेनरी झोउ, अब्देलरहमान मोहम्मद, माइकल औली द्वारा।
|
||||
1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI से) साथ वाला पेपर [FAIRSEQ S2T: FAIRSEQ के साथ फास्ट स्पीच-टू-टेक्स्ट मॉडलिंग](https://arxiv.org/abs/2010.05171) चांगहान वांग, यूं तांग, जुताई मा, ऐनी वू, सरव्या पोपुरी, दिमित्रो ओखोनको, जुआन पिनो द्वारा पोस्ट किया गया।
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI से) साथ वाला पेपर [सरल और प्रभावी जीरो-शॉट क्रॉस-लिंगुअल फोनेम रिकॉग्निशन](https://arxiv.org/abs/2109.11680) कियानटोंग जू, एलेक्सी बाएव्स्की, माइकल औली द्वारा।
|
||||
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (माइक्रोसॉफ्ट रिसर्च से) पेपर के साथ जारी किया गया [WavLM: फुल स्टैक के लिए बड़े पैमाने पर स्व-पर्यवेक्षित पूर्व-प्रशिक्षण स्पीच प्रोसेसिंग](https://arxiv.org/abs/2110.13900) सानयुआन चेन, चेंगयी वांग, झेंगयांग चेन, यू वू, शुजी लियू, ज़ुओ चेन, जिन्यु ली, नाओयुकी कांडा, ताकुया योशियोका, ज़िओंग जिओ, जियान वू, लॉन्ग झोउ, शुओ रेन, यानमिन कियान, याओ कियान, जियान वू, माइकल ज़ेंग, फुरु वेई।
|
||||
1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (OpenAI से) साथ में कागज [बड़े पैमाने पर कमजोर पर्यवेक्षण के माध्यम से मजबूत भाषण पहचान](https://cdn.openai.com/papers/whisper.pdf) एलेक रैडफोर्ड, जोंग वूक किम, ताओ जू, ग्रेग ब्रॉकमैन, क्रिस्टीन मैकलीवे, इल्या सुत्स्केवर द्वारा।
|
||||
1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (माइक्रोसॉफ्ट रिसर्च से) कागज के साथ [एक्सपैंडिंग लैंग्वेज-इमेज प्रीट्रेन्ड मॉडल फॉर जनरल वीडियो रिकग्निशन](https://arxiv.org/abs/2208.02816) बोलिन नी, होउवेन पेंग, मिंगाओ चेन, सोंगयांग झांग, गाओफेंग मेंग, जियानलोंग फू, शिमिंग जियांग, हैबिन लिंग द्वारा।
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI से) साथ वाला पेपर [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) चांगहान वांग, यूं तांग, जुताई मा, ऐनी वू, सरव्या पोपुरी, दिमित्रो ओखोनको, जुआन पिनो द्वारा पोस्ट किया गया।
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI से) साथ वाला पेपर [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) कियानटोंग जू, एलेक्सी बाएव्स्की, माइकल औली द्वारा।
|
||||
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (माइक्रोसॉफ्ट रिसर्च से) पेपर के साथ जारी किया गया [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) सानयुआन चेन, चेंगयी वांग, झेंगयांग चेन, यू वू, शुजी लियू, ज़ुओ चेन, जिन्यु ली, नाओयुकी कांडा, ताकुया योशियोका, ज़िओंग जिओ, जियान वू, लॉन्ग झोउ, शुओ रेन, यानमिन कियान, याओ कियान, जियान वू, माइकल ज़ेंग, फुरु वेई।
|
||||
1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (OpenAI से) साथ में कागज [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) एलेक रैडफोर्ड, जोंग वूक किम, ताओ जू, ग्रेग ब्रॉकमैन, क्रिस्टीन मैकलीवे, इल्या सुत्स्केवर द्वारा।
|
||||
1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (माइक्रोसॉफ्ट रिसर्च से) कागज के साथ [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) बोलिन नी, होउवेन पेंग, मिंगाओ चेन, सोंगयांग झांग, गाओफेंग मेंग, जियानलोंग फू, शिमिंग जियांग, हैबिन लिंग द्वारा।
|
||||
1. **[X-MOD](https://huggingface.co/docs/transformers/model_doc/xmod)** (Meta AI से) Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe. द्वाराअनुसंधान पत्र [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) के साथ जारी किया गया
|
||||
1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
|
||||
1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (फेसबुक से) साथ में पेपर [क्रॉस-लिंगुअल लैंग्वेज मॉडल प्रीट्रेनिंग](https://arxiv.org/abs/1901.07291) गिलाउम लैम्पल और एलेक्सिस कोनो द्वारा।
|
||||
1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (माइक्रोसॉफ्ट रिसर्च से) साथ में कागज [ProphetNet: प्रेडिक्टिंग फ्यूचर एन-ग्राम फॉर सीक्वेंस-टू- सीक्वेंस प्री-ट्रेनिंग](https://arxiv.org/abs/2001.04063) यू यान, वीज़ेन क्यूई, येयुन गोंग, दयाहेंग लियू, नान डुआन, जिउशेंग चेन, रुओफ़ेई झांग और मिंग झोउ द्वारा।
|
||||
1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (फेसबुक एआई से), साथ में पेपर [अनसुपरवाइज्ड क्रॉस-लिंगुअल रिप्रेजेंटेशन लर्निंग एट स्केल](https://arxiv.org/abs/1911.02116) एलेक्सिस कोन्यू*, कार्तिकेय खंडेलवाल*, नमन गोयल, विश्रव चौधरी, गिलाउम वेनज़ेक, फ्रांसिस्को गुज़मैन द्वारा , एडौर्ड ग्रेव, मायल ओट, ल्यूक ज़ेटलमॉयर और वेसेलिन स्टोयानोव द्वारा।
|
||||
1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (Facebook AI से) साथ में कागज [बहुभाषी नकाबपोश भाषा के लिए बड़े पैमाने पर ट्रांसफॉर्मर मॉडलिंग](https://arxiv.org/abs/2105.00572) नमन गोयल, जिंगफेई डू, मायल ओट, गिरि अनंतरामन, एलेक्सिस कोनो द्वारा पोस्ट किया गया।
|
||||
1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (फेसबुक से) साथ में पेपर [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) गिलाउम लैम्पल और एलेक्सिस कोनो द्वारा।
|
||||
1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (माइक्रोसॉफ्ट रिसर्च से) साथ में कागज [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) यू यान, वीज़ेन क्यूई, येयुन गोंग, दयाहेंग लियू, नान डुआन, जिउशेंग चेन, रुओफ़ेई झांग और मिंग झोउ द्वारा।
|
||||
1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (फेसबुक एआई से), साथ में पेपर [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) एलेक्सिस कोन्यू*, कार्तिकेय खंडेलवाल*, नमन गोयल, विश्रव चौधरी, गिलाउम वेनज़ेक, फ्रांसिस्को गुज़मैन द्वारा , एडौर्ड ग्रेव, मायल ओट, ल्यूक ज़ेटलमॉयर और वेसेलिन स्टोयानोव द्वारा।
|
||||
1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (Facebook AI से) साथ में कागज [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) नमन गोयल, जिंगफेई डू, मायल ओट, गिरि अनंतरामन, एलेक्सिस कोनो द्वारा पोस्ट किया गया।
|
||||
1. **[XLM-V](https://huggingface.co/docs/transformers/model_doc/xlm-v)** (from Meta AI) released with the paper [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
|
||||
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (Google/CMU से) साथ वाला पेपर [XLNet: जनरलाइज्ड ऑटोरेग्रेसिव प्रीट्रेनिंग फॉर लैंग्वेज अंडरस्टैंडिंग](https://arxiv.org/abs/1906.08237) ज़ीलिन यांग*, ज़िहांग दाई*, यिमिंग यांग, जैम कार्बोनेल, रुस्लान सलाखुतदीनोव, क्वोक वी. ले द्वारा।
|
||||
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (Facebook AI से) साथ वाला पेपर [XLS-R: सेल्फ सुपरवाइज्ड क्रॉस-लिंगुअल स्पीच रिप्रेजेंटेशन लर्निंग एट स्केल](https://arxiv.org/abs/2111.09296) अरुण बाबू, चांगहान वांग, एंड्रोस तजंद्रा, कुशाल लखोटिया, कियानटोंग जू, नमन गोयल, कृतिका सिंह, पैट्रिक वॉन प्लैटन, याथार्थ सराफ, जुआन पिनो, एलेक्सी बेवस्की, एलेक्सिस कोन्यू, माइकल औली द्वारा पोस्ट किया गया।
|
||||
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (फेसबुक एआई से) साथ में पेपर [अनसुपरवाइज्ड क्रॉस-लिंगुअल रिप्रेजेंटेशन लर्निंग फॉर स्पीच रिकग्निशन](https://arxiv.org/abs/2006.13979) एलेक्सिस कोन्यू, एलेक्सी बेवस्की, रोनन कोलोबर्ट, अब्देलरहमान मोहम्मद, माइकल औली द्वारा।
|
||||
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (हुआझोंग यूनिवर्सिटी ऑफ साइंस एंड टेक्नोलॉजी से) साथ में पेपर [यू ओनली लुक एट वन सीक्वेंस: रीथिंकिंग ट्रांसफॉर्मर इन विज़न थ्रू ऑब्जेक्ट डिटेक्शन](https://arxiv.org/abs/2106.00666) युक्सिन फेंग, बेनचेंग लियाओ, जिंगगैंग वांग, जेमिन फेंग, जियांग क्यूई, रुई वू, जियानवेई नीयू, वेन्यू लियू द्वारा पोस्ट किया गया।
|
||||
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (Google/CMU से) साथ वाला पेपर [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) ज़ीलिन यांग*, ज़िहांग दाई*, यिमिंग यांग, जैम कार्बोनेल, रुस्लान सलाखुतदीनोव, क्वोक वी. ले द्वारा।
|
||||
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (Facebook AI से) साथ वाला पेपर [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) अरुण बाबू, चांगहान वांग, एंड्रोस तजंद्रा, कुशाल लखोटिया, कियानटोंग जू, नमन गोयल, कृतिका सिंह, पैट्रिक वॉन प्लैटन, याथार्थ सराफ, जुआन पिनो, एलेक्सी बेवस्की, एलेक्सिस कोन्यू, माइकल औली द्वारा पोस्ट किया गया।
|
||||
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (फेसबुक एआई से) साथ में पेपर [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) एलेक्सिस कोन्यू, एलेक्सी बेवस्की, रोनन कोलोबर्ट, अब्देलरहमान मोहम्मद, माइकल औली द्वारा।
|
||||
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (हुआझोंग यूनिवर्सिटी ऑफ साइंस एंड टेक्नोलॉजी से) साथ में पेपर [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) युक्सिन फेंग, बेनचेंग लियाओ, जिंगगैंग वांग, जेमिन फेंग, जियांग क्यूई, रुई वू, जियानवेई नीयू, वेन्यू लियू द्वारा पोस्ट किया गया।
|
||||
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (विस्कॉन्सिन विश्वविद्यालय - मैडिसन से) साथ में पेपर [यू ओनली सैंपल (लगभग) ज़ानपेंग ज़ेंग, युनयांग ज़िओंग द्वारा , सत्य एन. रवि, शैलेश आचार्य, ग्लेन फंग, विकास सिंह द्वारा पोस्ट किया गया।
|
||||
1. एक नए मॉडल में योगदान देना चाहते हैं? नए मॉडल जोड़ने में आपका मार्गदर्शन करने के लिए हमारे पास एक **विस्तृत मार्गदर्शिका और टेम्प्लेट** है। आप उन्हें [`टेम्पलेट्स`](./templates) निर्देशिका में पा सकते हैं। पीआर शुरू करने से पहले [योगदान दिशानिर्देश](./CONTRIBUTING.md) देखना और अनुरक्षकों से संपर्क करना या प्रतिक्रिया प्राप्त करने के लिए एक नया मुद्दा खोलना याद रखें।
|
||||
|
||||
|
||||
28
README_ja.md
28
README_ja.md
@ -87,6 +87,7 @@ user: ユーザ
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
@ -318,7 +319,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (Google Research から) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed から公開された研究論文: [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062)
|
||||
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (Google Research から) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed から公開された研究論文: [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062)
|
||||
1. **[BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt)** (Microsoft Research AI4Science から) Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu から公開された研究論文: [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9)
|
||||
1. **[BiT](https://huggingface.co/docs/transformers/model_doc/bit)** (Google AI から) Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil から公開された研究論文: [Big Transfer (BiT)](https://arxiv.org/abs/1912.11370)Houlsby.
|
||||
1. **[BiT](https://huggingface.co/docs/transformers/model_doc/bit)** (Google AI から) Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil から公開された研究論文: [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370)Houlsby.
|
||||
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (Facebook から) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston から公開された研究論文: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637)
|
||||
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (Facebook から) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston から公開された研究論文: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637)
|
||||
1. **[BLIP](https://huggingface.co/docs/transformers/model_doc/blip)** (Salesforce から) Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi から公開された研究論文: [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086)
|
||||
@ -337,6 +338,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (Salesforce から) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong から公開された研究論文: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474)
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (MetaAI から) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve. から公開された研究論文 [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (Cohere から) Cohere. から公開された研究論文 [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>)
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (Microsoft Research Asia から) Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang から公開された研究論文: [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152)
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (YituTech から) Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan から公開された研究論文: [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496)
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (Facebook AI から) Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie から公開された研究論文: [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545)
|
||||
@ -352,13 +354,13 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (SenseTime Research から) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai から公開された研究論文: [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159)
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (Facebook から) Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou から公開された研究論文: [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (Google AI から) Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun. から公開された研究論文 [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505)
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)** (University of Hong Kong and TikTok から) Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao. から公開された研究論文 [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891)
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (University of Hong Kong and TikTok から) Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao. から公開された研究論文 [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891)
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (The University of Texas at Austin から) Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl. から公開された研究論文 [NMS Strikes Back](https://arxiv.org/abs/2212.06137)
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (Facebook から) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko から公開された研究論文: [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872)
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (Microsoft Research から) Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan から公開された研究論文: [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536)
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (SHI Labs から) Ali Hassani and Humphrey Shi から公開された研究論文: [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001)
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (Meta AI から) Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski. から公開された研究論文 [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193)
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (HuggingFace から), Victor Sanh, Lysandre Debut and Thomas Wolf. 同じ手法で GPT2, RoBERTa と Multilingual BERT の圧縮を行いました.圧縮されたモデルはそれぞれ [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)、[DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)、[DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) と名付けられました. 公開された研究論文: [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108)
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (HuggingFace から), Victor Sanh, Lysandre Debut and Thomas Wolf. 同じ手法で GPT2, RoBERTa と Multilingual BERT の圧縮を行いました.圧縮されたモデルはそれぞれ [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108)、[DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)、[DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) と名付けられました. 公開された研究論文: [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108)
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (Microsoft Research から) Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei から公開された研究論文: [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378)
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (NAVER から), Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park から公開された研究論文: [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664)
|
||||
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (Facebook から) Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih から公開された研究論文: [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906)
|
||||
@ -372,7 +374,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (Baidu から) Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang. から公開された研究論文 [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674)
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (Meta AI から) はトランスフォーマープロテイン言語モデルです. **ESM-1b** は Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus から公開された研究論文: [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118). **ESM-1v** は Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives から公開された研究論文: [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648). **ESM-2** と **ESMFold** は Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives から公開された研究論文: [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902)
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (ESPnet and Microsoft Research から) Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang. から公開された研究論文 [Fastspeech 2: Fast And High-quality End-to-End Text To Speech](https://arxiv.org/pdf/2006.04558.pdf)
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (ESPnet and Microsoft Research から) Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang. から公開された研究論文 [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956)
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (Google AI から) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V から公開されたレポジトリー [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (CNRS から) Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab から公開された研究論文: [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372)
|
||||
@ -381,6 +383,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (Microsoft Research から) Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao. から公開された研究論文 [Focal Modulation Networks](https://arxiv.org/abs/2203.11926)
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (CMU/Google Brain から) Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le から公開された研究論文: [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236)
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (ADEPT から) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. から公開された研究論文 [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (Google から) the Gemma Google team. から公開された研究論文 [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/)
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (Microsoft Research から) Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. から公開された研究論文 [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100)
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (KAIST から) Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim から公開された研究論文: [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436)
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (OpenAI から) Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever から公開された研究論文: [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/)
|
||||
@ -411,8 +414,9 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (Meta AI から) Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze から公開された研究論文: [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology から) Jiapeng Wang, Lianwen Jin, Kai Ding から公開された研究論文: [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669)
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI から) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. から公開された研究論文 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI から) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.. から公開された研究論文 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX)
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI から) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.. から公開された研究論文 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/)
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison から) Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee. から公開された研究論文 [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485)
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (Microsoft Research & University of Wisconsin-Madison から) Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee. から公開された研究論文 [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744)
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI から) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang から公開された研究論文: [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia から) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto から公開された研究論文: [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057)
|
||||
@ -420,6 +424,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (Facebook から) Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert から公開された研究論文: [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161)
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (Facebook から) Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin から公開された研究論文: [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125)
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (Albert Gu and Tri Dao から) Albert Gu and Tri Dao. から公開された研究論文 [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752)
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Jörg Tiedemann から. [OPUS](http://opus.nlpl.eu/) を使いながら学習された "Machine translation" (マシントランスレーション) モデル. [Marian Framework](https://marian-nmt.github.io/) はMicrosoft Translator Team が現在開発中です.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (Microsoft Research Asia から) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei から公開された研究論文: [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518)
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (FAIR and UIUC から) Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. から公開された研究論文 [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527)
|
||||
@ -442,9 +447,10 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (Apple から) Sachin Mehta and Mohammad Rastegari. から公開された研究論文 [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680)
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (Microsoft Research から) Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu から公開された研究論文: [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297)
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (MosaiML から) the MosaicML NLP Team. から公開された研究論文 [llm-foundry](https://github.com/mosaicml/llm-foundry/)
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (the University of Wisconsin - Madison から) Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh. から公開された研究論文 [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284)
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (the University of Wisconsin - Madison から) Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh. から公開された研究論文 [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284)
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (Google AI から) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel から公開された研究論文: [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934)
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (RUC AI Box から) Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen から公開された研究論文: [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131)
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (SHI Labs から) Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi から公開された研究論文: [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143)
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (Huawei Noah’s Ark Lab から) Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu から公開された研究論文: [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204)
|
||||
@ -458,7 +464,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby から公開された研究論文: [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230)
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Neil Houlsby. から公開された研究論文 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683)
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** ( IBM Research から) Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. から公開された研究論文 [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf)
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (IBM から) Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. から公開された研究論文 [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf)
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (IBM から) Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. から公開された研究論文 [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730)
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google から) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu から公開された研究論文: [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777)
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google から) Jason Phang, Yao Zhao, and Peter J. Liu から公開された研究論文: [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347)
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (Deepmind から) Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira から公開された研究論文: [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795)
|
||||
@ -471,8 +477,10 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (Microsoft Research から) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou から公開された研究論文: [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063)
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (Nanjing University, The University of Hong Kong etc. から) Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. から公開された研究論文 [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf)
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc. から) Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. から公開された研究論文 [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797)
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA から) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius から公開された研究論文: [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602)
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (the Qwen team, Alibaba Group から) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu. から公開された研究論文 [Qwen Technical Report](https://arxiv.org/abs/2309.16609)
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (the Qwen team, Alibaba Group から) Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou. から公開された研究論文 [blog post](https://qwenlm.github.io/blog/qwen-moe/)
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook から) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela から公開された研究論文: [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401)
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research から) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang から公開された研究論文: [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909)
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (Google Research から) Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya から公開された研究論文: [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451)
|
||||
@ -487,6 +495,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (NVIDIA から) Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo から公開された研究論文: [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203)
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (Beijing Academy of Artificial Intelligence (BAAI から) Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. から公開された研究論文 [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284)
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI から) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick. から公開された研究論文 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf)
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
|
||||
@ -496,7 +505,9 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (Facebook から), Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau から公開された研究論文: [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678)
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (Tel Aviv University から), Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy から公開された研究論文: [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438)
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (Berkeley から) Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer から公開された研究論文: [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316)
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/main/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (from MagicLeap) released with the paper [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (MBZUAI から) Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan. から公開された研究論文 [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446)
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (Microsoft から) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo から公開された研究論文: [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (Microsoft から) Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo から公開された研究論文: [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)
|
||||
@ -514,6 +525,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft から), Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei から公開された研究論文: [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282)
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill から), Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal から公開された研究論文: [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156)
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (Intel から), Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding から公開された研究論文: [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995)
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (Microsoft Research から) Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal. から公開された研究論文 [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623)
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research から) Yi Tay, Mostafa Dehghani, Vinh Q から公開された研究論文: [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research から) Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant. から公開された研究論文 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research から) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang から公開された研究論文: [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
|
||||
|
||||
36
README_ko.md
36
README_ko.md
@ -52,6 +52,7 @@ limitations under the License.
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
@ -223,7 +224,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
|
||||
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
|
||||
@ -252,6 +253,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (Salesforce 에서) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong 의 [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) 논문과 함께 발표했습니다.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (MetaAI 에서 제공)은 Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.의 [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)논문과 함께 발표했습니다.
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (Cohere 에서 제공)은 Cohere. 의 [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>)논문과 함께 발표했습니다.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (Microsoft Research Asia 에서) Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang 의 [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) 논문과 함께 발표했습니다.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (YituTech 에서) Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan 의 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) 논문과 함께 발표했습니다.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (Facebook AI 에서) Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie 의 [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) 논문과 함께 발표했습니다.
|
||||
@ -267,13 +269,13 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (SenseTime Research 에서) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai 의 [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) 논문과 함께 발표했습니다.
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (Facebook 에서) Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou 의 [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) 논문과 함께 발표했습니다.
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (Google AI 에서 제공)은 Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.의 [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505)논문과 함께 발표했습니다.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)** (University of Hong Kong and TikTok 에서 제공)은 Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.의 [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891)논문과 함께 발표했습니다.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (University of Hong Kong and TikTok 에서 제공)은 Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.의 [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891)논문과 함께 발표했습니다.
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (The University of Texas at Austin 에서 제공)은 Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.의 [NMS Strikes Back](https://arxiv.org/abs/2212.06137)논문과 함께 발표했습니다.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (Facebook 에서) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko 의 [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) 논문과 함께 발표했습니다.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (Microsoft Research 에서) Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan 의 [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) 논문과 함께 발표했습니다.
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (SHI Labs 에서) Ali Hassani and Humphrey Shi 의 [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) 논문과 함께 발표했습니다.
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (Meta AI 에서 제공)은 Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.의 [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193)논문과 함께 발표했습니다.
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (HuggingFace 에서) Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) and a German version of DistilBERT 의 [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) 논문과 함께 발표했습니다.
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (HuggingFace 에서) Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) and a German version of DistilBERT 의 [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) 논문과 함께 발표했습니다.
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (Microsoft Research 에서) Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei 의 [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) 논문과 함께 발표했습니다.
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (NAVER 에서) Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park 의 [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) 논문과 함께 발표했습니다.
|
||||
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (Facebook 에서) Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih 의 [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) 논문과 함께 발표했습니다.
|
||||
@ -287,7 +289,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (Baidu 에서 제공)은 Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.의 [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674)논문과 함께 발표했습니다.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (ESPnet and Microsoft Research 에서 제공)은 Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.의 [Fastspeech 2: Fast And High-quality End-to-End Text To Speech](https://arxiv.org/pdf/2006.04558.pdf)논문과 함께 발표했습니다.
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (ESPnet and Microsoft Research 에서 제공)은 Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.의 [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956)논문과 함께 발표했습니다.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@ -296,6 +298,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (from ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. 논문과 함께 공개 [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (Google 에서 제공)은 the Gemma Google team.의 [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/)논문과 함께 발표했습니다.
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
|
||||
@ -326,8 +329,9 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (Meta AI 에서) Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze 의 [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) 논문과 함께 발표했습니다.
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology 에서) Jiapeng Wang, Lianwen Jin, Kai Ding 의 [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) 논문과 함께 발표했습니다.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI 에서 제공)은 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.의 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)논문과 함께 발표했습니다.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI 에서 제공)은 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..의 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX)논문과 함께 발표했습니다.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI 에서 제공)은 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..의 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/)논문과 함께 발표했습니다.
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison 에서 제공)은 Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.의 [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485)논문과 함께 발표했습니다.
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (Microsoft Research & University of Wisconsin-Madison 에서 제공)은 Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.의 [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744)논문과 함께 발표했습니다.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI 에서) Iz Beltagy, Matthew E. Peters, Arman Cohan 의 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 논문과 함께 발표했습니다.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI 에서) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang 의 [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) 논문과 함께 발표했습니다.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia 에서) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto 의 [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) 논문과 함께 발표했습니다.
|
||||
@ -335,6 +339,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (Facebook 에서) Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert 의 [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) 논문과 함께 발표했습니다.
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (Facebook 에서) Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin 의 [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) 논문과 함께 발표했습니다.
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (Albert Gu and Tri Dao 에서 제공)은 Albert Gu and Tri Dao.의 [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752)논문과 함께 발표했습니다.
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (Microsoft Research Asia 에서) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei 의 [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) 논문과 함께 발표했습니다.
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (FAIR and UIUC 에서 제공)은 Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.의 [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527)논문과 함께 발표했습니다.
|
||||
@ -357,9 +362,10 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (Apple 에서 제공)은 Sachin Mehta and Mohammad Rastegari.의 [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680)논문과 함께 발표했습니다.
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (Microsoft Research 에서) Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu 의 [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) 논문과 함께 발표했습니다.
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (MosaiML 에서 제공)은 the MosaicML NLP Team.의 [llm-foundry](https://github.com/mosaicml/llm-foundry/)논문과 함께 발표했습니다.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (the University of Wisconsin - Madison 에서 제공)은 Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.의 [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) 논문과 함께 발표했습니다.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (the University of Wisconsin - Madison 에서 제공)은 Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.의 [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) 논문과 함께 발표했습니다.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (Google AI 에서) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel 의 [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) 논문과 함께 발표했습니다.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (RUC AI Box 에서) Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen 의 [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) 논문과 함께 발표했습니다.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (SHI Labs 에서) Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi 의 [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) 논문과 함께 발표했습니다.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (Huawei Noah’s Ark Lab 에서) Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu 의 [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) 논문과 함께 발표했습니다.
|
||||
@ -373,7 +379,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI 에서) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby 의 [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) 논문과 함께 발표했습니다.
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (Google AI 에서 제공)은 Matthias Minderer, Alexey Gritsenko, Neil Houlsby.의 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683)논문과 함께 발표했습니다.
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** ( IBM Research 에서 제공)은 Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.의 [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf)논문과 함께 발표했습니다.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (IBM 에서 제공)은 Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.의 [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf)논문과 함께 발표했습니다.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (IBM 에서 제공)은 Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.의 [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730)논문과 함께 발표했습니다.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google 에서) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu 의 [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) 논문과 함께 발표했습니다.
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google 에서) Jason Phang, Yao Zhao, Peter J. Liu 의 [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) 논문과 함께 발표했습니다.
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (Deepmind 에서) Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira 의 [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) 논문과 함께 발표했습니다.
|
||||
@ -386,22 +392,25 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (Microsoft Research 에서) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou 의 [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) 논문과 함께 발표했습니다.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (Nanjing University, The University of Hong Kong etc. 에서 제공)은 Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.의 [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf)논문과 함께 발표했습니다.
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc. 에서 제공)은 Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.의 [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797)논문과 함께 발표했습니다.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA 에서) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius 의 [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) 논문과 함께 발표했습니다.
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (the Qwen team, Alibaba Group 에서 제공)은 Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.의 [Qwen Technical Report](https://arxiv.org/abs/2309.16609)논문과 함께 발표했습니다.
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (the Qwen team, Alibaba Group 에서 제공)은 Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.의 [blog post](https://qwenlm.github.io/blog/qwen-moe/)논문과 함께 발표했습니다.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook 에서) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela 의 [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) 논문과 함께 발표했습니다.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research 에서) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang 의 [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) 논문과 함께 발표했습니다.
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (Google Research 에서) Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya 의 [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) 논문과 함께 발표했습니다.
|
||||
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (META Research 에서) Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár 의 [Designing Network Design Space](https://arxiv.org/abs/2003.13678) 논문과 함께 발표했습니다.
|
||||
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (Google Research 에서) Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder 의 [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/pdf/2010.12821.pdf) 논문과 함께 발표했습니다.
|
||||
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (Google Research 에서) Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder 의 [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) 논문과 함께 발표했습니다.
|
||||
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (Microsoft Research 에서) Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun 의 [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) 논문과 함께 발표했습니다.
|
||||
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (Facebook 에서) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov 의 a [Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) 논문과 함께 발표했습니다.
|
||||
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (Facebook 에서) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov 의 a [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) 논문과 함께 발표했습니다.
|
||||
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (Facebook 에서) Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli 의 [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) 논문과 함께 발표했습니다.
|
||||
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (WeChatAI 에서) HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou 의 [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) 논문과 함께 발표했습니다.
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (ZhuiyiTechnology 에서) Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu 의 a [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) 논문과 함께 발표했습니다.
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (ZhuiyiTechnology 에서) Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu 의 a [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) 논문과 함께 발표했습니다.
|
||||
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (Bo Peng 에서 제공)은 Bo Peng.의 [this repo](https://github.com/BlinkDL/RWKV-LM)논문과 함께 발표했습니다.
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (NVIDIA 에서) Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo 의 [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) 논문과 함께 발표했습니다.
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (Beijing Academy of Artificial Intelligence (BAAI 에서 제공)은 Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang.의 [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284)논문과 함께 발표했습니다.
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (Meta AI 에서 제공)은 Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.의 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf)논문과 함께 발표했습니다.
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP 에서) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 의 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 논문과 함께 발표했습니다.
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP 에서) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 의 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 논문과 함께 발표했습니다.
|
||||
@ -411,7 +420,9 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (Facebook 에서) Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau 의 [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) 논문과 함께 발표했습니다.
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (Tel Aviv University 에서) Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy 의 [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) 논문과 함께 발표했습니다.
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (Berkeley 에서) Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer 의 [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) 논문과 함께 발표했습니다.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/main/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (from MagicLeap) released with the paper [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (MBZUAI 에서 제공)은 Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.의 [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446)논문과 함께 발표했습니다.
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (Microsoft 에서) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo 의 [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) 논문과 함께 발표했습니다.
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (Microsoft 에서) Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo 의 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) 논문과 함께 발표했습니다.
|
||||
@ -429,13 +440,14 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft 에서) Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei 의 [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) 논문과 함께 발표했습니다.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill 에서) Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal 의 [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) 논문과 함께 발표했습니다.
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (Intel 에서) Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding 의 [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) 논문과 함께 발표했습니다.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (Microsoft Research 에서 제공)은 Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.의 [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623)논문과 함께 발표했습니다.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research 에서) Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzle 의 [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) 논문과 함께 발표했습니다.
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (Google Research 에서 제공)은 Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.의 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi)논문과 함께 발표했습니다.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research 에서) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang 의 [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) 논문과 함께 발표했습니다.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (Microsoft Research 에서) Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu 의 [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) 논문과 함께 발표했습니다.
|
||||
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (Peking University 에서 제공)은 Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.의 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)논문과 함께 발표했습니다.
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (Tsinghua University and Nankai University 에서) Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu 의 [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) 논문과 함께 발표했습니다.
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (Tsinghua University and Nankai University 에서) Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu 의 [Visual Attention Network](https://arxiv.org/abs/2202.09741) 논문과 함께 발표했습니다.
|
||||
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (Multimedia Computing Group, Nanjing University 에서) Zhan Tong, Yibing Song, Jue Wang, Limin Wang 의 [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) 논문과 함께 발표했습니다.
|
||||
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (NAVER AI Lab/Kakao Enterprise/Kakao Brain 에서) Wonjae Kim, Bokyung Son, Ildoo Kim 의 [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) 논문과 함께 발표했습니다.
|
||||
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (University of Wisconsin–Madison 에서 제공)은 Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.의 [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784)논문과 함께 발표했습니다.
|
||||
|
||||
@ -57,6 +57,7 @@ limitations under the License.
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
@ -332,8 +333,10 @@ Número atual de pontos de verificação: ** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
|
||||
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (from Cohere) released with the paper [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>) by Cohere.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
@ -349,6 +352,7 @@ Número atual de pontos de verificação: ** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (from University of Hong Kong and TikTok) released with the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
@ -368,6 +372,7 @@ Número atual de pontos de verificação: ** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@ -375,6 +380,8 @@ Número atual de pontos de verificação: ** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
|
||||
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (from ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. Released with the paper [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (from Google) released with the paper [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by the Gemma Google team.
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
|
||||
@ -396,6 +403,7 @@ Número atual de pontos de verificação: ** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
|
||||
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
|
||||
@ -405,6 +413,8 @@ Número atual de pontos de verificação: ** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
@ -412,6 +422,7 @@ Número atual de pontos de verificação: ** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (from Albert Gu and Tri Dao) released with the paper [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) by Albert Gu and Tri Dao.
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
|
||||
@ -424,6 +435,7 @@ Número atual de pontos de verificação: ** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
|
||||
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
|
||||
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
1. **[Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
|
||||
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (from Facebook) released with the paper [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
|
||||
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
|
||||
@ -436,6 +448,7 @@ Número atual de pontos de verificação: ** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
@ -447,10 +460,14 @@ Número atual de pontos de verificação: ** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** (from IBM Research) released with the paper [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (from IBM) released with the paper [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
|
||||
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (from ADEPT) released in a [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
|
||||
1. **[Phi](https://huggingface.co/docs/transformers/model_doc/phi)** (from Microsoft) released with the paper [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
|
||||
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
|
||||
@ -458,7 +475,10 @@ Número atual de pontos de verificação: ** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
|
||||
@ -470,15 +490,22 @@ Número atual de pontos de verificação: ** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
|
||||
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (from Beijing Academy of Artificial Intelligence (BAAI) released with the paper [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang.
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
|
||||
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
|
||||
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (from MagicLeap) released with the paper [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
|
||||
@ -495,14 +522,18 @@ Número atual de pontos de verificação: ** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (from Microsoft Research) released with the paper [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
|
||||
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
|
||||
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
|
||||
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
|
||||
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (from University of Wisconsin–Madison) released with the paper [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
@ -513,6 +544,7 @@ Número atual de pontos de verificação: ** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
|
||||
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
|
||||
@ -529,8 +561,7 @@ Número atual de pontos de verificação: ** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
|
||||
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
|
||||
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng,
|
||||
Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
|
||||
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
|
||||
|
||||
1. Quer contribuir com um novo modelo? Adicionamos um **guia detalhado e modelos de exemplo** para orientar você no processo de adição de um novo modelo. Você pode encontrá-los na pasta [`templates`](./templates) do repositório. Certifique-se de verificar as [diretrizes de contribuição](./CONTRIBUTING.md) e entrar em contato com os mantenedores ou abrir uma issue para coletar feedback antes de iniciar sua PR.
|
||||
|
||||
|
||||
43
README_ru.md
43
README_ru.md
@ -57,6 +57,7 @@ limitations under the License.
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
<p>
|
||||
</h4>
|
||||
|
||||
@ -322,8 +323,10 @@ conda install conda-forge::transformers
|
||||
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
|
||||
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (from Cohere) released with the paper [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>) by Cohere.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
@ -339,6 +342,7 @@ conda install conda-forge::transformers
|
||||
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (from University of Hong Kong and TikTok) released with the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
@ -358,6 +362,7 @@ conda install conda-forge::transformers
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@ -366,6 +371,7 @@ conda install conda-forge::transformers
|
||||
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (from ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. Released with the paper [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (from Google) released with the paper [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by the Gemma Google team.
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
|
||||
@ -387,6 +393,7 @@ conda install conda-forge::transformers
|
||||
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
|
||||
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
|
||||
@ -395,7 +402,9 @@ conda install conda-forge::transformers
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
@ -403,6 +412,7 @@ conda install conda-forge::transformers
|
||||
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (from Albert Gu and Tri Dao) released with the paper [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) by Albert Gu and Tri Dao.
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
|
||||
@ -414,6 +424,8 @@ conda install conda-forge::transformers
|
||||
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
|
||||
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
|
||||
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
|
||||
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
1. **[Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
|
||||
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (from Facebook) released with the paper [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
|
||||
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
|
||||
@ -426,21 +438,26 @@ conda install conda-forge::transformers
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
|
||||
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
|
||||
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (from Meta AI) released with the paper [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
|
||||
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** (from IBM Research) released with the paper [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (from IBM) released with the paper [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
|
||||
1. **[Persimmon](https://huggingface.co/docs/transformers/main/model_doc/persimmon)** (from ADEPT) released in a [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
|
||||
1. **[Phi](https://huggingface.co/docs/main/transformers/model_doc/phi)** (from Microsoft Research) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
|
||||
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (from ADEPT) released in a [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
|
||||
1. **[Phi](https://huggingface.co/docs/transformers/model_doc/phi)** (from Microsoft Research) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
|
||||
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
|
||||
@ -448,7 +465,10 @@ conda install conda-forge::transformers
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
|
||||
@ -460,15 +480,22 @@ conda install conda-forge::transformers
|
||||
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
|
||||
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (from Beijing Academy of Artificial Intelligence (BAAI) released with the paper [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang.
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
|
||||
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
|
||||
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (from MagicLeap) released with the paper [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
|
||||
@ -485,24 +512,29 @@ conda install conda-forge::transformers
|
||||
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (from Microsoft Research) released with the paper [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
|
||||
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
|
||||
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
|
||||
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
|
||||
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (from University of Wisconsin–Madison) released with the paper [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (from Meta AI) released with the paper [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
|
||||
1. **[ViTMatte](https://huggingface.co/docs/transformers/main/model_doc/vitmatte)** (from HUST-VL) rreleased with the paper [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
|
||||
1. **[ViTMatte](https://huggingface.co/docs/transformers/model_doc/vitmatte)** (from HUST-VL) rreleased with the paper [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
|
||||
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
|
||||
@ -520,7 +552,8 @@ conda install conda-forge::transformers
|
||||
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
|
||||
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
|
||||
1. Want to contribute a new model? We have added a **detailed guide and templates** to guide you in the process of adding a new model. You can find them in the [`templates`](./templates) folder of the repository. Be sure to check the [contributing guidelines](./CONTRIBUTING.md) and contact the maintainers or open an issue to collect feedbacks before starting your PR.
|
||||
|
||||
1. Хотите внести новую модель? Мы добавили **подробное руководство и шаблоны**, чтобы помочь вам в процессе добавления новой модели. Вы можете найти их в папке [`templates`](./templates) репозитория. Обязательно ознакомьтесь с [руководством по внесению изменений](./CONTRIBUTING.md) и свяжитесь с ответственным разработчиком или откройте задачу, чтобы собрать отзывы перед началом работы над вашим пулл-реквестом.
|
||||
|
||||
Чтобы проверить, есть ли у каждой модели реализация на Flax, PyTorch или TensorFlow, или связанный с ней токенизатор, поддерживаемый библиотекой 🤗 Tokenizers, обратитесь к [этой таблице](https://huggingface.co/docs/transformers/index#supported-frameworks).
|
||||
|
||||
|
||||
33
README_te.md
33
README_te.md
@ -59,6 +59,7 @@ limitations under the License.
|
||||
<b>తెలుగు</b> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
@ -324,8 +325,10 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
|
||||
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (from Cohere) released with the paper [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>) by Cohere.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
@ -341,6 +344,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (from University of Hong Kong and TikTok) released with the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
@ -360,6 +364,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@ -368,6 +373,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (from ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. Released with the paper [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (from Google) released with the paper [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by the Gemma Google team.
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
|
||||
@ -389,6 +395,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
|
||||
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (from Microsoft Research Asia) released with the paper [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
|
||||
@ -398,6 +405,8 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
@ -405,6 +414,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (from Albert Gu and Tri Dao) released with the paper [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) by Albert Gu and Tri Dao.
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
|
||||
@ -417,6 +427,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
|
||||
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
|
||||
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
1. **[Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral)** (from Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
|
||||
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (from Facebook) released with the paper [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
|
||||
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
|
||||
@ -429,6 +440,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
@ -440,11 +452,14 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/main/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** (from IBM Research) released with the paper [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (from IBM) released with the paper [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
|
||||
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (from ADEPT) released in a [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
|
||||
1. **[Phi](https://huggingface.co/docs/transformers/model_doc/phi)** (from Microsoft) released with the paper [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
|
||||
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
|
||||
@ -452,7 +467,10 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
|
||||
@ -464,16 +482,22 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
|
||||
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (from Beijing Academy of Artificial Intelligence (BAAI) released with the paper [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang.
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (from Google AI) released with the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
|
||||
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
|
||||
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (from MagicLeap) released with the paper [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
|
||||
@ -490,14 +514,18 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (from Microsoft Research) released with the paper [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
|
||||
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
|
||||
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
|
||||
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
|
||||
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (from University of Wisconsin–Madison) released with the paper [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
@ -508,6 +536,7 @@ Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టా
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
|
||||
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
|
||||
|
||||
589
README_vi.md
Normal file
589
README_vi.md
Normal file
@ -0,0 +1,589 @@
|
||||
<!---
|
||||
Copyright 2020 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
|
||||
<p align="center">
|
||||
<picture>
|
||||
<source media="(prefers-color-scheme: dark)" srcset="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/transformers-logo-dark.svg">
|
||||
<source media="(prefers-color-scheme: light)" srcset="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/transformers-logo-light.svg">
|
||||
<img alt="Hugging Face Transformers Library" src="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/transformers-logo-light.svg" width="352" height="59" style="max-width: 100%;">
|
||||
</picture>
|
||||
<br/>
|
||||
<br/>
|
||||
</p>
|
||||
|
||||
<p align="center">
|
||||
<a href="https://circleci.com/gh/huggingface/transformers">
|
||||
<img alt="Build" src="https://img.shields.io/circleci/build/github/huggingface/transformers/main">
|
||||
</a>
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/LICENSE">
|
||||
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/transformers.svg?color=blue">
|
||||
</a>
|
||||
<a href="https://huggingface.co/docs/transformers/index">
|
||||
<img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/transformers/index.svg?down_color=red&down_message=offline&up_message=online">
|
||||
</a>
|
||||
<a href="https://github.com/huggingface/transformers/releases">
|
||||
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/transformers.svg">
|
||||
</a>
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md">
|
||||
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-v2.0%20adopted-ff69b4.svg">
|
||||
</a>
|
||||
<a href="https://zenodo.org/badge/latestdoi/155220641"><img src="https://zenodo.org/badge/155220641.svg" alt="DOI"></a>
|
||||
</p>
|
||||
|
||||
<h4 align="center">
|
||||
<p>
|
||||
<a href="https://github.com/huggingface/transformers/">English</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_zh-hans.md">简体中文</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_zh-hant.md">繁體中文</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_ko.md">한국어</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_es.md">Español</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_ja.md">日本語</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_hd.md">हिन्दी</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_ru.md">Русский</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_pt-br.md">Рortuguês</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<b>Tiếng việt</b> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
<h3 align="center">
|
||||
<p>Công nghệ Học máy tiên tiến cho JAX, PyTorch và TensorFlow</p>
|
||||
</h3>
|
||||
|
||||
<h3 align="center">
|
||||
<a href="https://hf.co/course"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/course_banner.png"></a>
|
||||
</h3>
|
||||
|
||||
🤗 Transformers cung cấp hàng ngàn mô hình được huấn luyện trước để thực hiện các nhiệm vụ trên các modalities khác nhau như văn bản, hình ảnh và âm thanh.
|
||||
|
||||
Các mô hình này có thể được áp dụng vào:
|
||||
|
||||
* 📝 Văn bản, cho các nhiệm vụ như phân loại văn bản, trích xuất thông tin, trả lời câu hỏi, tóm tắt, dịch thuật và sinh văn bản, trong hơn 100 ngôn ngữ.
|
||||
* 🖼️ Hình ảnh, cho các nhiệm vụ như phân loại hình ảnh, nhận diện đối tượng và phân đoạn.
|
||||
* 🗣️ Âm thanh, cho các nhiệm vụ như nhận dạng giọng nói và phân loại âm thanh.
|
||||
|
||||
Các mô hình Transformer cũng có thể thực hiện các nhiệm vụ trên **nhiều modalities kết hợp**, như trả lời câu hỏi về bảng, nhận dạng ký tự quang học, trích xuất thông tin từ tài liệu quét, phân loại video và trả lời câu hỏi hình ảnh.
|
||||
|
||||
🤗 Transformers cung cấp các API để tải xuống và sử dụng nhanh chóng các mô hình được huấn luyện trước đó trên văn bản cụ thể, điều chỉnh chúng trên tập dữ liệu của riêng bạn và sau đó chia sẻ chúng với cộng đồng trên [model hub](https://huggingface.co/models) của chúng tôi. Đồng thời, mỗi module python xác định một kiến trúc là hoàn toàn độc lập và có thể được sửa đổi để cho phép thực hiện nhanh các thí nghiệm nghiên cứu.
|
||||
|
||||
🤗 Transformers được hỗ trợ bởi ba thư viện học sâu phổ biến nhất — [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) và [TensorFlow](https://www.tensorflow.org/) — với tích hợp mượt mà giữa chúng. Việc huấn luyện mô hình của bạn với một thư viện trước khi tải chúng để sử dụng trong suy luận với thư viện khác là rất dễ dàng.
|
||||
|
||||
## Các demo trực tuyến
|
||||
|
||||
Bạn có thể kiểm tra hầu hết các mô hình của chúng tôi trực tiếp trên trang của chúng từ [model hub](https://huggingface.co/models). Chúng tôi cũng cung cấp [dịch vụ lưu trữ mô hình riêng tư, phiên bản và API suy luận](https://huggingface.co/pricing) cho các mô hình công khai và riêng tư.
|
||||
|
||||
Dưới đây là một số ví dụ:
|
||||
|
||||
Trong Xử lý Ngôn ngữ Tự nhiên:
|
||||
- [Hoàn thành từ vụng về từ với BERT](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
|
||||
- [Nhận dạng thực thể đặt tên với Electra](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
|
||||
- [Tạo văn bản tự nhiên với Mistral](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
|
||||
- [Suy luận Ngôn ngữ Tự nhiên với RoBERTa](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
|
||||
- [Tóm tắt văn bản với BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
|
||||
- [Trả lời câu hỏi với DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
|
||||
- [Dịch văn bản với T5](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
|
||||
|
||||
Trong Thị giác Máy tính:
|
||||
- [Phân loại hình ảnh với ViT](https://huggingface.co/google/vit-base-patch16-224)
|
||||
- [Phát hiện đối tượng với DETR](https://huggingface.co/facebook/detr-resnet-50)
|
||||
- [Phân đoạn ngữ nghĩa với SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
|
||||
- [Phân đoạn toàn diện với Mask2Former](https://huggingface.co/facebook/mask2former-swin-large-coco-panoptic)
|
||||
- [Ước lượng độ sâu với Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)
|
||||
- [Phân loại video với VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)
|
||||
- [Phân đoạn toàn cầu với OneFormer](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
|
||||
|
||||
Trong âm thanh:
|
||||
- [Nhận dạng giọng nói tự động với Whisper](https://huggingface.co/openai/whisper-large-v3)
|
||||
- [Phát hiện từ khóa với Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
|
||||
- [Phân loại âm thanh với Audio Spectrogram Transformer](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
|
||||
|
||||
Trong các nhiệm vụ đa phương thức:
|
||||
- [Trả lời câu hỏi về bảng với TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
|
||||
- [Trả lời câu hỏi hình ảnh với ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
|
||||
- [Mô tả hình ảnh với LLaVa](https://huggingface.co/llava-hf/llava-1.5-7b-hf)
|
||||
- [Phân loại hình ảnh không cần nhãn với SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384)
|
||||
- [Trả lời câu hỏi văn bản tài liệu với LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
|
||||
- [Phân loại video không cần nhãn với X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
|
||||
- [Phát hiện đối tượng không cần nhãn với OWLv2](https://huggingface.co/docs/transformers/en/model_doc/owlv2)
|
||||
- [Phân đoạn hình ảnh không cần nhãn với CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)
|
||||
- [Tạo mặt nạ tự động với SAM](https://huggingface.co/docs/transformers/model_doc/sam)
|
||||
|
||||
|
||||
## 100 dự án sử dụng Transformers
|
||||
|
||||
Transformers không chỉ là một bộ công cụ để sử dụng các mô hình được huấn luyện trước: đó là một cộng đồng các dự án xây dựng xung quanh nó và Hugging Face Hub. Chúng tôi muốn Transformers giúp các nhà phát triển, nhà nghiên cứu, sinh viên, giáo sư, kỹ sư và bất kỳ ai khác xây dựng những dự án mơ ước của họ.
|
||||
|
||||
Để kỷ niệm 100.000 sao của transformers, chúng tôi đã quyết định tập trung vào cộng đồng và tạo ra trang [awesome-transformers](./awesome-transformers.md) liệt kê 100 dự án tuyệt vời được xây dựng xung quanh transformers.
|
||||
|
||||
Nếu bạn sở hữu hoặc sử dụng một dự án mà bạn tin rằng nên được thêm vào danh sách, vui lòng mở một PR để thêm nó!
|
||||
|
||||
## Nếu bạn đang tìm kiếm hỗ trợ tùy chỉnh từ đội ngũ Hugging Face
|
||||
|
||||
<a target="_blank" href="https://huggingface.co/support">
|
||||
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
|
||||
</a><br>
|
||||
|
||||
## Hành trình nhanh
|
||||
|
||||
Để ngay lập tức sử dụng một mô hình trên một đầu vào cụ thể (văn bản, hình ảnh, âm thanh, ...), chúng tôi cung cấp API `pipeline`. Pipelines nhóm một mô hình được huấn luyện trước với quá trình tiền xử lý đã được sử dụng trong quá trình huấn luyện của mô hình đó. Dưới đây là cách sử dụng nhanh một pipeline để phân loại văn bản tích cực so với tiêu cực:
|
||||
|
||||
```python
|
||||
>>> from transformers import pipeline
|
||||
|
||||
# Cấp phát một pipeline cho phân tích cảm xúc
|
||||
>>> classifier = pipeline('sentiment-analysis')
|
||||
>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
|
||||
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
|
||||
```
|
||||
|
||||
Dòng code thứ hai tải xuống và lưu trữ bộ mô hình được huấn luyện được sử dụng bởi pipeline, trong khi dòng thứ ba đánh giá nó trên văn bản đã cho. Ở đây, câu trả lời là "tích cực" với độ tin cậy là 99,97%.
|
||||
|
||||
Nhiều nhiệm vụ có sẵn một `pipeline` được huấn luyện trước, trong NLP nhưng cũng trong thị giác máy tính và giọng nói. Ví dụ, chúng ta có thể dễ dàng trích xuất các đối tượng được phát hiện trong một hình ảnh:
|
||||
|
||||
``` python
|
||||
>>> import requests
|
||||
>>> from PIL import Image
|
||||
>>> from transformers import pipeline
|
||||
|
||||
# Tải xuống một hình ảnh với những con mèo dễ thương
|
||||
>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
|
||||
>>> image_data = requests.get(url, stream=True).raw
|
||||
>>> image = Image.open(image_data)
|
||||
|
||||
# Cấp phát một pipeline cho phát hiện đối tượng
|
||||
>>> object_detector = pipeline('object-detection')
|
||||
>>> object_detector(image)
|
||||
[{'score': 0.9982201457023621,
|
||||
'label': 'remote',
|
||||
'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
|
||||
{'score': 0.9960021376609802,
|
||||
'label': 'remote',
|
||||
'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
|
||||
{'score': 0.9954745173454285,
|
||||
'label': 'couch',
|
||||
'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
|
||||
{'score': 0.9988006353378296,
|
||||
'label': 'cat',
|
||||
'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
|
||||
{'score': 0.9986783862113953,
|
||||
'label': 'cat',
|
||||
'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
|
||||
```
|
||||
|
||||
Ở đây, chúng ta nhận được một danh sách các đối tượng được phát hiện trong hình ảnh, với một hộp bao quanh đối tượng và một điểm đánh giá độ tin cậy. Đây là hình ảnh gốc ở bên trái, với các dự đoán hiển thị ở bên phải:
|
||||
|
||||
<h3 align="center">
|
||||
<a><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png" width="400"></a>
|
||||
<a><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample_post_processed.png" width="400"></a>
|
||||
</h3>
|
||||
|
||||
Bạn có thể tìm hiểu thêm về các nhiệm vụ được hỗ trợ bởi API `pipeline` trong [hướng dẫn này](https://huggingface.co/docs/transformers/task_summary).
|
||||
|
||||
Ngoài `pipeline`, để tải xuống và sử dụng bất kỳ mô hình được huấn luyện trước nào cho nhiệm vụ cụ thể của bạn, chỉ cần ba dòng code. Đây là phiên bản PyTorch:
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, AutoModel
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
|
||||
>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
|
||||
|
||||
>>> inputs = tokenizer("Hello world!", return_tensors="pt")
|
||||
>>> outputs = model(**inputs)
|
||||
```
|
||||
|
||||
Và đây là mã tương đương cho TensorFlow:
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, TFAutoModel
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
|
||||
>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
|
||||
|
||||
>>> inputs = tokenizer("Hello world!", return_tensors="tf")
|
||||
>>> outputs = model(**inputs)
|
||||
```
|
||||
|
||||
Tokenizer là thành phần chịu trách nhiệm cho việc tiền xử lý mà mô hình được huấn luyện trước mong đợi và có thể được gọi trực tiếp trên một chuỗi đơn (như trong các ví dụ trên) hoặc một danh sách. Nó sẽ xuất ra một từ điển mà bạn có thể sử dụng trong mã phụ thuộc hoặc đơn giản là truyền trực tiếp cho mô hình của bạn bằng cách sử dụng toán tử ** để giải nén đối số.
|
||||
|
||||
Chính mô hình là một [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) thông thường hoặc một [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (tùy thuộc vào backend của bạn) mà bạn có thể sử dụng như bình thường. [Hướng dẫn này](https://huggingface.co/docs/transformers/training) giải thích cách tích hợp một mô hình như vậy vào một vòng lặp huấn luyện cổ điển PyTorch hoặc TensorFlow, hoặc cách sử dụng API `Trainer` của chúng tôi để tinh chỉnh nhanh chóng trên một bộ dữ liệu mới.
|
||||
|
||||
## Tại sao tôi nên sử dụng transformers?
|
||||
|
||||
1. Các mô hình tiên tiến dễ sử dụng:
|
||||
- Hiệu suất cao trong việc hiểu và tạo ra ngôn ngữ tự nhiên, thị giác máy tính và âm thanh.
|
||||
- Ngưỡng vào thấp cho giảng viên và người thực hành.
|
||||
- Ít trừu tượng dành cho người dùng với chỉ ba lớp học.
|
||||
- Một API thống nhất để sử dụng tất cả các mô hình được huấn luyện trước của chúng tôi.
|
||||
|
||||
2. Giảm chi phí tính toán, làm giảm lượng khí thải carbon:
|
||||
- Các nhà nghiên cứu có thể chia sẻ các mô hình đã được huấn luyện thay vì luôn luôn huấn luyện lại.
|
||||
- Người thực hành có thể giảm thời gian tính toán và chi phí sản xuất.
|
||||
- Hàng chục kiến trúc với hơn 400.000 mô hình được huấn luyện trước trên tất cả các phương pháp.
|
||||
|
||||
3. Lựa chọn framework phù hợp cho mọi giai đoạn của mô hình:
|
||||
- Huấn luyện các mô hình tiên tiến chỉ trong 3 dòng code.
|
||||
- Di chuyển một mô hình duy nhất giữa các framework TF2.0/PyTorch/JAX theo ý muốn.
|
||||
- Dễ dàng chọn framework phù hợp cho huấn luyện, đánh giá và sản xuất.
|
||||
|
||||
4. Dễ dàng tùy chỉnh một mô hình hoặc một ví dụ theo nhu cầu của bạn:
|
||||
- Chúng tôi cung cấp các ví dụ cho mỗi kiến trúc để tái tạo kết quả được công bố bởi các tác giả gốc.
|
||||
- Các thành phần nội tại của mô hình được tiết lộ một cách nhất quán nhất có thể.
|
||||
- Các tệp mô hình có thể được sử dụng độc lập với thư viện để thực hiện các thử nghiệm nhanh chóng.
|
||||
|
||||
## Tại sao tôi không nên sử dụng transformers?
|
||||
|
||||
- Thư viện này không phải là một bộ công cụ modul cho các khối xây dựng mạng neural. Mã trong các tệp mô hình không được tái cấu trúc với các trừu tượng bổ sung một cách cố ý, để các nhà nghiên cứu có thể lặp nhanh trên từng mô hình mà không cần đào sâu vào các trừu tượng/tệp bổ sung.
|
||||
- API huấn luyện không được thiết kế để hoạt động trên bất kỳ mô hình nào, mà được tối ưu hóa để hoạt động với các mô hình được cung cấp bởi thư viện. Đối với vòng lặp học máy chung, bạn nên sử dụng một thư viện khác (có thể là [Accelerate](https://huggingface.co/docs/accelerate)).
|
||||
- Mặc dù chúng tôi cố gắng trình bày càng nhiều trường hợp sử dụng càng tốt, nhưng các tập lệnh trong thư mục [examples](https://github.com/huggingface/transformers/tree/main/examples) chỉ là ví dụ. Dự kiến rằng chúng sẽ không hoạt động ngay tức khắc trên vấn đề cụ thể của bạn và bạn sẽ phải thay đổi một số dòng mã để thích nghi với nhu cầu của bạn.
|
||||
|
||||
## Cài đặt
|
||||
|
||||
### Sử dụng pip
|
||||
|
||||
Thư viện này được kiểm tra trên Python 3.8+, Flax 0.4.1+, PyTorch 1.11+ và TensorFlow 2.6+.
|
||||
|
||||
Bạn nên cài đặt 🤗 Transformers trong một [môi trường ảo Python](https://docs.python.org/3/library/venv.html). Nếu bạn chưa quen với môi trường ảo Python, hãy xem [hướng dẫn sử dụng](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
|
||||
|
||||
Trước tiên, tạo một môi trường ảo với phiên bản Python bạn sẽ sử dụng và kích hoạt nó.
|
||||
|
||||
Sau đó, bạn sẽ cần cài đặt ít nhất một trong số các framework Flax, PyTorch hoặc TensorFlow.
|
||||
Vui lòng tham khảo [trang cài đặt TensorFlow](https://www.tensorflow.org/install/), [trang cài đặt PyTorch](https://pytorch.org/get-started/locally/#start-locally) và/hoặc [Flax](https://github.com/google/flax#quick-install) và [Jax](https://github.com/google/jax#installation) để biết lệnh cài đặt cụ thể cho nền tảng của bạn.
|
||||
|
||||
Khi đã cài đặt một trong các backend đó, 🤗 Transformers có thể được cài đặt bằng pip như sau:
|
||||
|
||||
```bash
|
||||
pip install transformers
|
||||
```
|
||||
|
||||
Nếu bạn muốn thực hiện các ví dụ hoặc cần phiên bản mới nhất của mã và không thể chờ đợi cho một phiên bản mới, bạn phải [cài đặt thư viện từ nguồn](https://huggingface.co/docs/transformers/installation#installing-from-source).
|
||||
|
||||
### Với conda
|
||||
|
||||
🤗 Transformers có thể được cài đặt bằng conda như sau:
|
||||
|
||||
```shell script
|
||||
conda install conda-forge::transformers
|
||||
```
|
||||
|
||||
> **_GHI CHÚ:_** Cài đặt `transformers` từ kênh `huggingface` đã bị lỗi thời.
|
||||
|
||||
Hãy làm theo trang cài đặt của Flax, PyTorch hoặc TensorFlow để xem cách cài đặt chúng bằng conda.
|
||||
|
||||
> **_GHI CHÚ:_** Trên Windows, bạn có thể được yêu cầu kích hoạt Chế độ phát triển để tận dụng việc lưu cache. Nếu điều này không phải là một lựa chọn cho bạn, hãy cho chúng tôi biết trong [vấn đề này](https://github.com/huggingface/huggingface_hub/issues/1062).
|
||||
|
||||
## Kiến trúc mô hình
|
||||
|
||||
**[Tất cả các điểm kiểm tra mô hình](https://huggingface.co/models)** được cung cấp bởi 🤗 Transformers được tích hợp một cách mượt mà từ trung tâm mô hình huggingface.co [model hub](https://huggingface.co/models), nơi chúng được tải lên trực tiếp bởi [người dùng](https://huggingface.co/users) và [tổ chức](https://huggingface.co/organizations).
|
||||
|
||||
Số lượng điểm kiểm tra hiện tại: 
|
||||
|
||||
🤗 Transformers hiện đang cung cấp các kiến trúc sau đây (xem [ở đây](https://huggingface.co/docs/transformers/model_summary) để có một tóm tắt tổng quan về mỗi kiến trúc):
|
||||
|
||||
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (từ Google Research và Toyota Technological Institute tại Chicago) được phát hành với bài báo [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), của Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
|
||||
1. **[ALIGN](https://huggingface.co/docs/transformers/model_doc/align)** (từ Google Research) được phát hành với bài báo [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) của Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
|
||||
1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (từ BAAI) được phát hành với bài báo [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) của Chen, Zhongzhi và Liu, Guang và Zhang, Bo-Wen và Ye, Fulong và Yang, Qinghong và Wu, Ledell.
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (từ MIT) được phát hành với bài báo [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) của Yuan Gong, Yu-An Chung, James Glass.
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (từ Đại học Tsinghua) được phát hành với bài báo [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) của Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (từ Suno) được phát hành trong kho lưu trữ [suno-ai/bark](https://github.com/suno-ai/bark) bởi đội ngũ Suno AI.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (từ Facebook) được phát hành với bài báo [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) của Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov và Luke Zettlemoyer.
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (từ École polytechnique) được phát hành với bài báo [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) của Moussa Kamal Eddine, Antoine J.-P. Tixier và Michalis Vazirgiannis.
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (từ VinAI Research) được phát hành với bài báo [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) của Nguyen Luong Tran, Duong Minh Le và Dat Quoc Nguyen.
|
||||
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (từ Microsoft) được phát hành với bài báo [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) của Hangbo Bao, Li Dong, Furu Wei.
|
||||
1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (từ Google) được phát hành với bài báo [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) của Jacob Devlin, Ming-Wei Chang, Kenton Lee và Kristina Toutanova.
|
||||
1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (từ Google) được phát hành với bài báo [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) của Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
|
||||
1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (từ VinAI Research) được phát hành với bài báo [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) của Dat Quoc Nguyen, Thanh Vu và Anh Tuan Nguyen.
|
||||
1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (từ Google Research) được phát hành với bài báo [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) của Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang và Amr Ahmed.
|
||||
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (từ Google Research) được phát hành với bài báo [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) của Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang và Amr Ahmed.
|
||||
1. **[BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt)** (từ Microsoft Research AI4Science) được phát hành với bài báo [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
|
||||
1. **[BiT](https://huggingface.co/docs/transformers/model_doc/bit)** (từ Google AI) được phát hành với bài báo [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) của Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
|
||||
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (từ Facebook) được phát hành với bài báo [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) của Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (từ Facebook) được phát hành với bài báo [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) của Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
|
||||
1. **[BLIP](https://huggingface.co/docs/transformers/model_doc/blip)** (từ Salesforce) được phát hành với bài báo [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) của Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
|
||||
1. **[BLIP-2](https://huggingface.co/docs/transformers/model_doc/blip-2)** (từ Salesforce) được phát hành với bài báo [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
|
||||
1. **[BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom)** (từ BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
|
||||
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (từ Alexa) được phát hành với bài báo [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
|
||||
1. **[BridgeTower](https://huggingface.co/docs/transformers/model_doc/bridgetower)** (từ Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) được phát hành với bài báo [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
|
||||
1. **[BROS](https://huggingface.co/docs/transformers/model_doc/bros)** (từ NAVER CLOVA) được phát hành với bài báo [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
|
||||
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (từ Google Research) được phát hành với bài báo [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
|
||||
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (từ Inria/Facebook/Sorbonne) được phát hành với bài báo [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
|
||||
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (từ Google Research) được phát hành với bài báo [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
|
||||
1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (từ OFA-Sys) được phát hành với bài báo [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
|
||||
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (từ LAION-AI) được phát hành với bài báo [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
|
||||
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (từ OpenAI) được phát hành với bài báo [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
|
||||
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (từ University of Göttingen) được phát hành với bài báo [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
|
||||
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** được phát hành với bài báo [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (từ Salesforce) được phát hành với bài báo [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (từ MetaAI) được phát hành với bài báo [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (từ Cohere) được phát hành với bài báo [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>) by Cohere.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (từ Microsoft Research Asia) được phát hành với bài báo [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (từ YituTech) được phát hành với bài báo [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (từ Facebook AI) được phát hành với bài báo [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
1. **[ConvNeXTV2](https://huggingface.co/docs/transformers/model_doc/convnextv2)** (từ Facebook AI) được phát hành với bài báo [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
|
||||
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (từ Tsinghua University) được phát hành với bài báo [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
|
||||
1. **[CPM-Ant](https://huggingface.co/docs/transformers/model_doc/cpmant)** (từ OpenBMB) released by the [OpenBMB](https://www.openbmb.org/).
|
||||
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (từ Salesforce) được phát hành với bài báo [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
|
||||
1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (từ Microsoft) được phát hành với bài báo [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
|
||||
1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (từ Facebook) được phát hành với bài báo [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
|
||||
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (từ Microsoft) được phát hành với bài báo [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (từ Microsoft) được phát hành với bài báo [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
|
||||
1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (từ Berkeley/Facebook/Google) được phát hành với bài báo [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
|
||||
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (từ SenseTime Research) được phát hành với bài báo [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (từ Facebook) được phát hành với bài báo [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (từ Google AI) được phát hành với bài báo [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (từ University of Hong Kong and TikTok) được phát hành với bài báo [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (từ The University of Texas at Austin) được phát hành với bài báo [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (từ Facebook) được phát hành với bài báo [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (từ Microsoft Research) được phát hành với bài báo [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (từ SHI Labs) được phát hành với bài báo [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
|
||||
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (từ Meta AI) được phát hành với bài báo [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
|
||||
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (từ HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
|
||||
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (từ Microsoft Research) được phát hành với bài báo [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
|
||||
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (từ NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
|
||||
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (từ Facebook) được phát hành với bài báo [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
|
||||
1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (từ Intel Labs) được phát hành với bài báo [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
|
||||
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (từ Snap Research) được phát hành với bài báo [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
|
||||
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (từ Google Brain) được phát hành với bài báo [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
|
||||
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (từ Google Research/Stanford University) được phát hành với bài báo [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
|
||||
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (từ Meta AI) được phát hành với bài báo [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
|
||||
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (từ Google Research) được phát hành với bài báo [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
|
||||
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (từ Baidu) được phát hành với bài báo [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (từ Baidu) được phát hành với bài báo [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (từ Meta AI) are transformer protein language models. **ESM-1b** was được phát hành với bài báo [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was được phát hành với bài báo [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were được phát hành với bài báo [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (từ Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (từ ESPnet) được phát hành với bài báo [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (từ Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (từ Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (từ CNRS) được phát hành với bài báo [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** (từ Facebook AI) được phát hành với bài báo [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
|
||||
1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (từ Google Research) được phát hành với bài báo [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
|
||||
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (từ Microsoft Research) được phát hành với bài báo [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (từ CMU/Google Brain) được phát hành với bài báo [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (từ ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. được phát hành với bài báo [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (từ Google) được phát hành với bài báo [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by the Gemma Google team.
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (từ Microsoft Research) được phát hành với bài báo [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (từ KAIST) được phát hành với bài báo [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (từ OpenAI) được phát hành với bài báo [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
|
||||
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (từ EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
|
||||
1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (từ EleutherAI) được phát hành với bài báo [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
|
||||
1. **[GPT NeoX Japanese](https://huggingface.co/docs/transformers/model_doc/gpt_neox_japanese)** (từ ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
|
||||
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (từ OpenAI) được phát hành với bài báo [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
|
||||
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (từ EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
|
||||
1. **[GPT-Sw3](https://huggingface.co/docs/transformers/model_doc/gpt-sw3)** (từ AI-Sweden) được phát hành với bài báo [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
|
||||
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (từ BigCode) được phát hành với bài báo [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
|
||||
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
|
||||
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (từ Microsoft) được phát hành với bài báo [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
|
||||
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (từ UCSD, NVIDIA) được phát hành với bài báo [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
|
||||
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (từ Allegro.pl, AGH University of Science and Technology) được phát hành với bài báo [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
|
||||
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (từ Facebook) được phát hành với bài báo [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
|
||||
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (từ Berkeley) được phát hành với bài báo [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
|
||||
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (từ HuggingFace) được phát hành với bài báo [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
|
||||
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (từ OpenAI) được phát hành với bài báo [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
|
||||
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (từ Beihang University, UC Berkeley, Rutgers University, SEDD Company) được phát hành với bài báo [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
|
||||
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (từ Salesforce) được phát hành với bài báo [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
|
||||
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (từ OpenAI) được phát hành với bài báo [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
|
||||
1. **[KOSMOS-2](https://huggingface.co/docs/transformers/model_doc/kosmos-2)** (từ Microsoft Research Asia) được phát hành với bài báo [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
|
||||
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (từ Microsoft Research Asia) được phát hành với bài báo [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
|
||||
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (từ Microsoft Research Asia) được phát hành với bài báo [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
|
||||
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (từ Microsoft Research Asia) được phát hành với bài báo [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
|
||||
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (từ Microsoft Research Asia) được phát hành với bài báo [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
|
||||
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (từ AllenAI) được phát hành với bài báo [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (từ Meta AI) được phát hành với bài báo [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (từ South China University of Technology) được phát hành với bài báo [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (từ The FAIR team of Meta AI) được phát hành với bài báo [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (từ The FAIR team of Meta AI) được phát hành với bài báo [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (từ Microsoft Research & University of Wisconsin-Madison) được phát hành với bài báo [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (từ Microsoft Research & University of Wisconsin-Madison) được phát hành với bài báo [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (từ AllenAI) được phát hành với bài báo [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (từ Google AI) được phát hành với bài báo [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (từ Studio Ousia) được phát hành với bài báo [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (từ UNC Chapel Hill) được phát hành với bài báo [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
|
||||
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (từ Facebook) được phát hành với bài báo [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (từ Facebook) được phát hành với bài báo [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (từ Google) được phát hành với bài báo [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (từ Albert Gu and Tri Dao) được phát hành với bài báo [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) by Albert Gu and Tri Dao.
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (từ Microsoft Research Asia) được phát hành với bài báo [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (từ FAIR and UIUC) được phát hành với bài báo [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
|
||||
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (từ Meta and UIUC) được phát hành với bài báo [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
|
||||
1. **[MatCha](https://huggingface.co/docs/transformers/model_doc/matcha)** (từ Google AI) được phát hành với bài báo [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662) by Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
|
||||
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (từ Facebook) được phát hành với bài báo [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
|
||||
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (từ Facebook) được phát hành với bài báo [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
|
||||
1. **[MEGA](https://huggingface.co/docs/transformers/model_doc/mega)** (từ Meta/USC/CMU/SJTU) được phát hành với bài báo [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
|
||||
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (từ NVIDIA) được phát hành với bài báo [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
|
||||
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (từ NVIDIA) được phát hành với bài báo [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
|
||||
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (từ Alibaba Research) được phát hành với bài báo [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
|
||||
1. **[Mistral](https://huggingface.co/docs/transformers/model_doc/mistral)** (từ Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
1. **[Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral)** (từ Mistral AI) by The [Mistral AI](https://mistral.ai) team: Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (từ Studio Ousia) được phát hành với bài báo [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
|
||||
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (từ Facebook) được phát hành với bài báo [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
|
||||
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (từ CMU/Google Brain) được phát hành với bài báo [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
|
||||
1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (từ Google Inc.) được phát hành với bài báo [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
|
||||
1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (từ Google Inc.) được phát hành với bài báo [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
|
||||
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (từ Apple) được phát hành với bài báo [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (từ Apple) được phát hành với bài báo [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (từ Microsoft Research) được phát hành với bài báo [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (từ MosaiML) released with the repository [llm-foundry](https://github.com/mosaicml/llm-foundry/) by the MosaicML NLP Team.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (từ the University of Wisconsin - Madison) được phát hành với bài báo [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (từ Google AI) được phát hành với bài báo [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (từ Meta) được phát hành với bài báo [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (từ Meta) được phát hành với bài báo [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (từ RUC AI Box) được phát hành với bài báo [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (từ SHI Labs) được phát hành với bài báo [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (từ Huawei Noah’s Ark Lab) được phát hành với bài báo [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (từ Meta) được phát hành với bài báo [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
|
||||
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (từ Meta) được phát hành với bài báo [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
|
||||
1. **[Nougat](https://huggingface.co/docs/transformers/model_doc/nougat)** (từ Meta AI) được phát hành với bài báo [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic.
|
||||
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (từ the University of Wisconsin - Madison) được phát hành với bài báo [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
|
||||
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (từ SHI Labs) được phát hành với bài báo [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
|
||||
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (từ [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
|
||||
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (từ Meta AI) được phát hành với bài báo [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (từ Google AI) được phát hành với bài báo [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (từ Google AI) được phát hành với bài báo [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** (từ IBM Research) được phát hành với bài báo [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (từ IBM) được phát hành với bài báo [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (từ Google) được phát hành với bài báo [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (từ Google) được phát hành với bài báo [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (từ Deepmind) được phát hành với bài báo [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
|
||||
1. **[Persimmon](https://huggingface.co/docs/transformers/model_doc/persimmon)** (từ ADEPT) released in a [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
|
||||
1. **[Phi](https://huggingface.co/docs/transformers/model_doc/phi)** (từ Microsoft) được phát hành với bài báos - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
|
||||
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (từ VinAI Research) được phát hành với bài báo [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
|
||||
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (từ Google) được phát hành với bài báo [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
|
||||
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (từ UCLA NLP) được phát hành với bài báo [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
|
||||
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (từ Sea AI Labs) được phát hành với bài báo [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** được phát hành với bài báo [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (từ Microsoft Research) được phát hành với bài báo [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (từ Nanjing University, The University of Hong Kong etc.) được phát hành với bài báo [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (từ Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) được phát hành với bài báo [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (từ NVIDIA) được phát hành với bài báo [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (từ the Qwen team, Alibaba Group) được phát hành với bài báo [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (từ the Qwen team, Alibaba Group) được phát hành với bài báo [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (từ Facebook) được phát hành với bài báo [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (từ Google Research) được phát hành với bài báo [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (từ Google Research) được phát hành với bài báo [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
|
||||
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (từ META Platforms) được phát hành với bài báo [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
|
||||
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (từ Google Research) được phát hành với bài báo [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
|
||||
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (từ Microsoft Research) được phát hành với bài báo [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
|
||||
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (từ Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
|
||||
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (từ Facebook) được phát hành với bài báo [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
|
||||
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (từ WeChatAI) được phát hành với bài báo [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (từ ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
|
||||
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (từ Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (từ Meta AI) được phát hành với bài báo [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (từ Meta AI) được phát hành với bài báo [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (từ NVIDIA) được phát hành với bài báo [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (từ Beijing Academy of Artificial Intelligence (BAAI) được phát hành với bài báo [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang.
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (từ Meta AI) được phát hành với bài báo [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (từ ASAPP) được phát hành với bài báo [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (từ ASAPP) được phát hành với bài báo [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SigLIP](https://huggingface.co/docs/transformers/model_doc/siglip)** (từ Google AI) được phát hành với bài báo [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer.
|
||||
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (từ Microsoft Research) được phát hành với bài báo [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
|
||||
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (từ Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (từ Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (từ Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (từ Berkeley) được phát hành với bài báo [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (từ Stability AI) được phát hành với bài báo [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (từ BigCode team) được phát hành với bài báo [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (từ MagicLeap) được phát hành với bài báo [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (từ MBZUAI) được phát hành với bài báo [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (từ Microsoft) được phát hành với bài báo [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (từ Microsoft) được phát hành với bài báo [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
|
||||
1. **[Swin2SR](https://huggingface.co/docs/transformers/model_doc/swin2sr)** (từ University of Würzburg) được phát hành với bài báo [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
|
||||
1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (từ Google) được phát hành với bài báo [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
|
||||
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (từ Google AI) được phát hành với bài báo [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
|
||||
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (từ Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
|
||||
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (từ Microsoft Research) được phát hành với bài báo [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
|
||||
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (từ Google AI) được phát hành với bài báo [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
|
||||
1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (từ Microsoft Research) được phát hành với bài báo [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
|
||||
1. **[Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer)** (từ HuggingFace).
|
||||
1. **[TimeSformer](https://huggingface.co/docs/transformers/model_doc/timesformer)** (từ Facebook) được phát hành với bài báo [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
|
||||
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (từ the University of California at Berkeley) được phát hành với bài báo [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
|
||||
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (từ Google/CMU) được phát hành với bài báo [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (từ Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (từ UNC Chapel Hill) được phát hành với bài báo [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (từ Intel) được phát hành với bài báo [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (từ Microsoft Research) được phát hành với bài báo [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (từ Google Research) được phát hành với bài báo [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (từ Google Research) được phát hành với bài báo [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (từ Microsoft Research) được phát hành với bài báo [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (từ Microsoft Research) được phát hành với bài báo [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
|
||||
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (từ Kakao Corporation) được phát hành với bài báo [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (từ Peking University) được phát hành với bài báo [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (từ Tsinghua University and Nankai University) được phát hành với bài báo [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
|
||||
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (từ Multimedia Computing Group, Nanjing University) được phát hành với bài báo [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
|
||||
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (từ NAVER AI Lab/Kakao Enterprise/Kakao Brain) được phát hành với bài báo [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
|
||||
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (từ University of Wisconsin–Madison) được phát hành với bài báo [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
|
||||
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (từ Google AI) được phát hành với bài báo [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (từ UCLA NLP) được phát hành với bài báo [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
|
||||
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (từ Google AI) được phát hành với bài báo [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
|
||||
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (từ Meta AI) được phát hành với bài báo [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
|
||||
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (từ Meta AI) được phát hành với bài báo [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
|
||||
1. **[ViTMatte](https://huggingface.co/docs/transformers/model_doc/vitmatte)** (từ HUST-VL) được phát hành với bài báo [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
|
||||
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (từ Meta AI) được phát hành với bài báo [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
|
||||
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (từ Kakao Enterprise) được phát hành với bài báo [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
|
||||
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (từ Google Research) được phát hành với bài báo [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
|
||||
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (từ Facebook AI) được phát hành với bài báo [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[Wav2Vec2-BERT](https://huggingface.co/docs/transformers/model_doc/wav2vec2-bert)** (từ Meta AI) được phát hành với bài báo [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (từ Facebook AI) được phát hành với bài báo [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
|
||||
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (từ Facebook AI) được phát hành với bài báo [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
|
||||
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (từ Microsoft Research) được phát hành với bài báo [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
|
||||
1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (từ OpenAI) được phát hành với bài báo [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
|
||||
1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (từ Microsoft Research) được phát hành với bài báo [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
|
||||
1. **[X-MOD](https://huggingface.co/docs/transformers/model_doc/xmod)** (từ Meta AI) được phát hành với bài báo [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe.
|
||||
1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (từ Facebook AI) được phát hành với bài báo [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
|
||||
1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (từ Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
|
||||
1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (từ Microsoft Research) được phát hành với bài báo [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (từ Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
|
||||
1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (từ Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
|
||||
1. **[XLM-V](https://huggingface.co/docs/transformers/model_doc/xlm-v)** (từ Meta AI) được phát hành với bài báo [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
|
||||
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (từ Google/CMU) được phát hành với bài báo [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
|
||||
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (từ Facebook AI) được phát hành với bài báo [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
|
||||
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (từ Facebook AI) được phát hành với bài báo [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
|
||||
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (từ Huazhong University of Science & Technology) được phát hành với bài báo [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
|
||||
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (từ the University of Wisconsin - Madison) được phát hành với bài báo [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
|
||||
1. Muốn đóng góp một mô hình mới? Chúng tôi đã thêm một **hướng dẫn chi tiết và mẫu** để hướng dẫn bạn trong quá trình thêm một mô hình mới. Bạn có thể tìm thấy chúng trong thư mục [`templates`](./templates) của kho lưu trữ. Hãy chắc chắn kiểm tra [hướng dẫn đóng góp](./CONTRIBUTING.md) và liên hệ với người duy trì hoặc mở một vấn đề để thu thập phản hồi trước khi bắt đầu PR của bạn.
|
||||
|
||||
Để kiểm tra xem mỗi mô hình có một phiên bản thực hiện trong Flax, PyTorch hoặc TensorFlow, hoặc có một tokenizer liên quan được hỗ trợ bởi thư viện 🤗 Tokenizers, vui lòng tham khảo [bảng này](https://huggingface.co/docs/transformers/index#supported-frameworks).
|
||||
|
||||
Những phiên bản này đã được kiểm tra trên một số tập dữ liệu (xem các tập lệnh ví dụ) và nên tương đương với hiệu suất của các phiên bản gốc. Bạn có thể tìm thấy thêm thông tin về hiệu suất trong phần Ví dụ của [tài liệu](https://github.com/huggingface/transformers/tree/main/examples).
|
||||
|
||||
|
||||
## Tìm hiểu thêm
|
||||
|
||||
| Phần | Mô tả |
|
||||
|-|-|
|
||||
| [Tài liệu](https://huggingface.co/docs/transformers/) | Toàn bộ tài liệu API và hướng dẫn |
|
||||
| [Tóm tắt nhiệm vụ](https://huggingface.co/docs/transformers/task_summary) | Các nhiệm vụ được hỗ trợ bởi 🤗 Transformers |
|
||||
| [Hướng dẫn tiền xử lý](https://huggingface.co/docs/transformers/preprocessing) | Sử dụng lớp `Tokenizer` để chuẩn bị dữ liệu cho các mô hình |
|
||||
| [Huấn luyện và điều chỉnh](https://huggingface.co/docs/transformers/training) | Sử dụng các mô hình được cung cấp bởi 🤗 Transformers trong vòng lặp huấn luyện PyTorch/TensorFlow và API `Trainer` |
|
||||
| [Hướng dẫn nhanh: Điều chỉnh/sử dụng các kịch bản](https://github.com/huggingface/transformers/tree/main/examples) | Các kịch bản ví dụ để điều chỉnh mô hình trên nhiều nhiệm vụ khác nhau |
|
||||
| [Chia sẻ và tải lên mô hình](https://huggingface.co/docs/transformers/model_sharing) | Tải lên và chia sẻ các mô hình đã điều chỉnh của bạn với cộng đồng |
|
||||
|
||||
## Trích dẫn
|
||||
|
||||
Bây giờ chúng ta có một [bài báo](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) mà bạn có thể trích dẫn cho thư viện 🤗 Transformers:
|
||||
```bibtex
|
||||
@inproceedings{wolf-etal-2020-transformers,
|
||||
title = "Transformers: State-of-the-Art Natural Language Processing",
|
||||
author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
|
||||
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
|
||||
month = oct,
|
||||
year = "2020",
|
||||
address = "Online",
|
||||
publisher = "Association for Computational Linguistics",
|
||||
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
|
||||
pages = "38--45"
|
||||
}
|
||||
```
|
||||
@ -77,6 +77,7 @@ checkpoint: 检查点
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
@ -247,7 +248,7 @@ conda install conda-forge::transformers
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (来自 MIT) 伴随论文 [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) 由 Yuan Gong, Yu-An Chung, James Glass 发布。
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (来自 Facebook) 伴随论文 [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) 由 Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer 发布。
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (来自 Facebook) 伴随论文 [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) 由 Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer 发布。
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (来自 École polytechnique) 伴随论文 [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) 由 Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis 发布。
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (来自 VinAI Research) 伴随论文 [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) 由 Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen 发布。
|
||||
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (来自 Microsoft) 伴随论文 [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) 由 Hangbo Bao, Li Dong, Furu Wei 发布。
|
||||
@ -276,6 +277,7 @@ conda install conda-forge::transformers
|
||||
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (来自 Salesforce) 伴随论文 [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) 由 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong 发布。
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (来自 MetaAI) 伴随论文 [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) 由 Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve 发布。
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (来自 Cohere) 伴随论文 [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>) 由 Cohere 发布。
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (来自 Microsoft Research Asia) 伴随论文 [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) 由 Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang 发布。
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (来自 YituTech) 伴随论文 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) 由 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan 发布。
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (来自 Facebook AI) 伴随论文 [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) 由 Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie 发布。
|
||||
@ -291,7 +293,7 @@ conda install conda-forge::transformers
|
||||
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (来自 SenseTime Research) 伴随论文 [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) 由 Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai 发布。
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (来自 Facebook) 伴随论文 [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) 由 Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou 发布。
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (来自 Google AI) 伴随论文 [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) 由 Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun 发布。
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)** (来自 University of Hong Kong and TikTok) 伴随论文 [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) 由 Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao 发布。
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (来自 University of Hong Kong and TikTok) 伴随论文 [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) 由 Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao 发布。
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (来自 The University of Texas at Austin) 伴随论文 [NMS Strikes Back](https://arxiv.org/abs/2212.06137) 由 Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl 发布。
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (来自 Facebook) 伴随论文 [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) 由 Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko 发布。
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (来自 Microsoft Research) 伴随论文 [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) 由 Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan 发布。
|
||||
@ -311,7 +313,7 @@ conda install conda-forge::transformers
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (来自 Baidu) 伴随论文 [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) 由 Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang 发布。
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (来自 ESPnet and Microsoft Research) 伴随论文 [Fastspeech 2: Fast And High-quality End-to-End Text To Speech](https://arxiv.org/pdf/2006.04558.pdf) 由 Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang 发布。
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (来自 ESPnet and Microsoft Research) 伴随论文 [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) 由 Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang 发布。
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (来自 CNRS) 伴随论文 [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) 由 Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab 发布。
|
||||
@ -320,6 +322,7 @@ conda install conda-forge::transformers
|
||||
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (来自 Microsoft Research) 伴随论文 [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) 由 Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao 发布。
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (来自 CMU/Google Brain) 伴随论文 [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) 由 Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le 发布。
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (来自 ADEPT) 伴随论文 [blog post](https://www.adept.ai/blog/fuyu-8b) 由 Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar 发布。
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (来自 Google) 伴随论文 [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) 由 the Gemma Google team 发布。
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (来自 Microsoft Research) 伴随论文 [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) 由 Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang 发布。
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (来自 KAIST) 伴随论文 [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) 由 Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim 发布。
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (来自 OpenAI) 伴随论文 [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) 由 Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever 发布。
|
||||
@ -350,8 +353,9 @@ conda install conda-forge::transformers
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (来自 Meta AI) 伴随论文 [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) 由 Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze 发布。
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (来自 South China University of Technology) 伴随论文 [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) 由 Jiapeng Wang, Lianwen Jin, Kai Ding 发布。
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (来自 The FAIR team of Meta AI) 伴随论文 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) 由 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample 发布。
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (来自 The FAIR team of Meta AI) 伴随论文 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) 由 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom. 发布。
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (来自 The FAIR team of Meta AI) 伴随论文 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) 由 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom. 发布。
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (来自 Microsoft Research & University of Wisconsin-Madison) 伴随论文 [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) 由 Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee 发布。
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (来自 Microsoft Research & University of Wisconsin-Madison) 伴随论文 [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744) 由 Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee 发布。
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (来自 Google AI) released 伴随论文 [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) 由 Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang 发布。
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (来自 Studio Ousia) 伴随论文 [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) 由 Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto 发布。
|
||||
@ -359,6 +363,7 @@ conda install conda-forge::transformers
|
||||
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (来自 Facebook) 伴随论文 [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) 由 Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert 发布。
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (来自 Facebook) 伴随论文 [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) 由 Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin 发布。
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (来自 Albert Gu and Tri Dao) 伴随论文 [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) 由 Albert Gu and Tri Dao 发布。
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** 用 [OPUS](http://opus.nlpl.eu/) 数据训练的机器翻译模型由 Jörg Tiedemann 发布。[Marian Framework](https://marian-nmt.github.io/) 由微软翻译团队开发。
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (来自 Microsoft Research Asia) 伴随论文 [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) 由 Junlong Li, Yiheng Xu, Lei Cui, Furu Wei 发布。
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (来自 FAIR and UIUC) 伴随论文 [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) 由 Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar 发布。
|
||||
@ -381,9 +386,10 @@ conda install conda-forge::transformers
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (来自 Apple) 伴随论文 [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) 由 Sachin Mehta and Mohammad Rastegari 发布。
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (来自 Microsoft Research) 伴随论文 [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) 由 Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu 发布。
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (来自 MosaiML) 伴随论文 [llm-foundry](https://github.com/mosaicml/llm-foundry/) 由 the MosaicML NLP Team 发布。
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (来自 the University of Wisconsin - Madison) 伴随论文 [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) 由 Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh 发布。
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (来自 the University of Wisconsin - Madison) 伴随论文 [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) 由 Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh 发布。
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (来自 Google AI) 伴随论文 [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) 由 Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel 发布。
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (来自 中国人民大学 AI Box) 伴随论文 [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) 由 Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen 发布。
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (来自 SHI Labs) 伴随论文 [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) 由 Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi 发布。
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (来自华为诺亚方舟实验室) 伴随论文 [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) 由 Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu 发布。
|
||||
@ -397,7 +403,7 @@ conda install conda-forge::transformers
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (来自 Google AI) 伴随论文 [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) 由 Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby 发布。
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (来自 Google AI) 伴随论文 [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) 由 Matthias Minderer, Alexey Gritsenko, Neil Houlsby 发布。
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** (来自 IBM Research) 伴随论文 [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) 由 Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam 发布。
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (来自 IBM) 伴随论文 [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf) 由 Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam 发布。
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (来自 IBM) 伴随论文 [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) 由 Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam 发布。
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (来自 Google) 伴随论文 [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) 由 Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu 发布。
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (来自 Google) 伴随论文 [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) 由 Jason Phang, Yao Zhao, Peter J. Liu 发布。
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (来自 Deepmind) 伴随论文 [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) 由 Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira 发布。
|
||||
@ -410,22 +416,25 @@ conda install conda-forge::transformers
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (来自 Microsoft Research) 伴随论文 [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) 由 Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou 发布。
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (来自 Nanjing University, The University of Hong Kong etc.) 伴随论文 [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) 由 Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao 发布。
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (来自 Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) 伴随论文 [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) 由 Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao 发布。
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (来自 NVIDIA) 伴随论文 [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) 由 Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius 发布。
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (来自 the Qwen team, Alibaba Group) 伴随论文 [Qwen Technical Report](https://arxiv.org/abs/2309.16609) 由 Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu 发布。
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (来自 the Qwen team, Alibaba Group) 伴随论文 [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou 发布.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (来自 Facebook) 伴随论文 [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) 由 Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela 发布。
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (来自 Google Research) 伴随论文 [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) 由 Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang 发布。
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (来自 Google Research) 伴随论文 [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) 由 Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya 发布。
|
||||
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (from META Research) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
|
||||
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (来自 Google Research) 伴随论文 [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/pdf/2010.12821.pdf) 由 Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder 发布。
|
||||
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (来自 Google Research) 伴随论文 [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) 由 Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder 发布。
|
||||
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
|
||||
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (来自 Facebook), 伴随论文 [Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) 由 Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov 发布。
|
||||
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (来自 Facebook), 伴随论文 [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) 由 Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov 发布。
|
||||
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (来自 Facebook) 伴随论文 [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) 由 Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli 发布。
|
||||
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (来自 WeChatAI), 伴随论文 [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) 由 HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou 发布。
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (来自 ZhuiyiTechnology), 伴随论文 [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) 由 Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu 发布。
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (来自 ZhuiyiTechnology), 伴随论文 [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) 由 Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu 发布。
|
||||
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (来自 Bo Peng) 伴随论文 [this repo](https://github.com/BlinkDL/RWKV-LM) 由 Bo Peng 发布。
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (来自 NVIDIA) 伴随论文 [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) 由 Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo 发布。
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (来自 Beijing Academy of Artificial Intelligence (BAAI) 伴随论文 [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) 由 Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang 发布。
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (来自 Meta AI) 伴随论文 [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) 由 Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick 发布。
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (来自 ASAPP) 伴随论文 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 由 Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 发布。
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (来自 ASAPP) 伴随论文 [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) 由 Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi 发布。
|
||||
@ -435,7 +444,9 @@ conda install conda-forge::transformers
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (来自 Facebook) 伴随论文 [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) 由 Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau 发布。
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (来自 Tel Aviv University) 伴随论文 [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) 由 Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy 发布。
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (来自 Berkeley) 伴随论文 [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) 由 Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer 发布。
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/main/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** (from Stability AI) released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (from MagicLeap) released with the paper [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (来自 MBZUAI) 伴随论文 [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) 由 Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan 发布。
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (来自 Microsoft) 伴随论文 [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) 由 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo 发布。
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (来自 Microsoft) 伴随论文 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) 由 Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo 发布。
|
||||
@ -453,13 +464,14 @@ conda install conda-forge::transformers
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (来自 Microsoft) 伴随论文 [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) 由 Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei 发布。
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (来自 UNC Chapel Hill) 伴随论文 [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) 由 Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal 发布。
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (来自 Intel) 伴随论文 [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) 由 Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding 发布.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (来自 Microsoft Research) 伴随论文 [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) 由 Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal 发布。
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (来自 Google Research) 伴随论文 [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) 由 Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant 发布。
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (来自 Microsoft Research) 伴随论文 [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) 由 Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang 发布。
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (来自 Microsoft Research) 伴随论文 [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) 由 Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu 发布。
|
||||
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (来自 Peking University) 伴随论文 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) 由 Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun 发布。
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (来自 Tsinghua University and Nankai University) 伴随论文 [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) 由 Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu 发布。
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (来自 Tsinghua University and Nankai University) 伴随论文 [Visual Attention Network](https://arxiv.org/abs/2202.09741) 由 Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu 发布。
|
||||
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (来自 Multimedia Computing Group, Nanjing University) 伴随论文 [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) 由 Zhan Tong, Yibing Song, Jue Wang, Limin Wang 发布。
|
||||
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (来自 NAVER AI Lab/Kakao Enterprise/Kakao Brain) 伴随论文 [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) 由 Wonjae Kim, Bokyung Son, Ildoo Kim 发布。
|
||||
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (来自 University of Wisconsin–Madison) 伴随论文 [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) 由 Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee 发布。
|
||||
|
||||
@ -89,6 +89,7 @@ user: 使用者
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_te.md">తెలుగు</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_fr.md">Français</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_de.md">Deutsch</a> |
|
||||
<a href="https://github.com/huggingface/transformers/blob/main/README_vi.md">Tiếng Việt</a> |
|
||||
</p>
|
||||
</h4>
|
||||
|
||||
@ -259,7 +260,7 @@ conda install conda-forge::transformers
|
||||
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
|
||||
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
|
||||
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
|
||||
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
|
||||
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
|
||||
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
|
||||
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
|
||||
@ -288,6 +289,7 @@ conda install conda-forge::transformers
|
||||
1. **[CLVP](https://huggingface.co/docs/transformers/model_doc/clvp)** released with the paper [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
|
||||
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
|
||||
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
|
||||
1. **[Cohere](https://huggingface.co/docs/transformers/model_doc/cohere)** (from Cohere) released with the paper [Command-R: Retrieval Augmented Generation at Production Scale](<https://txt.cohere.com/command-r/>) by Cohere.
|
||||
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
|
||||
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
|
||||
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
|
||||
@ -303,7 +305,7 @@ conda install conda-forge::transformers
|
||||
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
|
||||
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
|
||||
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)** (from University of Hong Kong and TikTok) released with the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[Depth Anything](https://huggingface.co/docs/transformers/model_doc/depth_anything)** (from University of Hong Kong and TikTok) released with the paper [Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data](https://arxiv.org/abs/2401.10891) by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao.
|
||||
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
|
||||
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
|
||||
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
|
||||
@ -323,7 +325,7 @@ conda install conda-forge::transformers
|
||||
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
|
||||
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2** was released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
|
||||
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
|
||||
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (from ESPnet and Microsoft Research) released with the paper [Fastspeech 2: Fast And High-quality End-to-End Text To Speech](https://arxiv.org/pdf/2006.04558.pdf) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FastSpeech2Conformer](https://huggingface.co/docs/transformers/model_doc/fastspeech2_conformer)** (from ESPnet and Microsoft Research) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
|
||||
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
|
||||
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
|
||||
@ -332,6 +334,7 @@ conda install conda-forge::transformers
|
||||
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
|
||||
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
|
||||
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (from ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. Released with the paper [blog post](https://www.adept.ai/blog/fuyu-8b)
|
||||
1. **[Gemma](https://huggingface.co/docs/transformers/model_doc/gemma)** (from Google) released with the paper [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by the Gemma Google team.
|
||||
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
|
||||
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
|
||||
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
|
||||
@ -362,8 +365,9 @@ conda install conda-forge::transformers
|
||||
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
|
||||
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
|
||||
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..
|
||||
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..
|
||||
1. **[LLaVa](https://huggingface.co/docs/transformers/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[LLaVA-NeXT](https://huggingface.co/docs/transformers/main/model_doc/llava_next)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/abs/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
|
||||
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
|
||||
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
|
||||
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
|
||||
@ -371,6 +375,7 @@ conda install conda-forge::transformers
|
||||
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
|
||||
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
|
||||
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
|
||||
1. **[Mamba](https://huggingface.co/docs/transformers/model_doc/mamba)** (from Albert Gu and Tri Dao) released with the paper [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) by Albert Gu and Tri Dao.
|
||||
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
|
||||
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
|
||||
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
|
||||
@ -393,9 +398,10 @@ conda install conda-forge::transformers
|
||||
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (from Apple) released with the paper [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
|
||||
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
|
||||
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (from MosaiML) released with the paper [llm-foundry](https://github.com/mosaicml/llm-foundry/) by the MosaicML NLP Team.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA)](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
|
||||
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
|
||||
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
|
||||
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
|
||||
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
|
||||
@ -409,7 +415,7 @@ conda install conda-forge::transformers
|
||||
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
|
||||
1. **[OWLv2](https://huggingface.co/docs/transformers/model_doc/owlv2)** (from Google AI) released with the paper [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby.
|
||||
1. **[PatchTSMixer](https://huggingface.co/docs/transformers/model_doc/patchtsmixer)** (from IBM Research) released with the paper [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (from IBM) released with the paper [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/pdf/2211.14730.pdf) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[PatchTST](https://huggingface.co/docs/transformers/model_doc/patchtst)** (from IBM) released with the paper [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam.
|
||||
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
|
||||
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, Peter J. Liu.
|
||||
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
|
||||
@ -422,22 +428,25 @@ conda install conda-forge::transformers
|
||||
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi, Kyogu Lee.
|
||||
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
|
||||
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[PVTv2](https://huggingface.co/docs/transformers/model_doc/pvt_v2)** (from Shanghai AI Laboratory, Nanjing University, The University of Hong Kong etc.) released with the paper [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
|
||||
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
|
||||
1. **[Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2)** (from the Qwen team, Alibaba Group) released with the paper [Qwen Technical Report](https://arxiv.org/abs/2309.16609) by Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou and Tianhang Zhu.
|
||||
1. **[Qwen2MoE](https://huggingface.co/docs/transformers/main/model_doc/qwen2_moe)** (from the Qwen team, Alibaba Group) released with the paper [blog post](https://qwenlm.github.io/blog/qwen-moe/) by Bo Zheng, Dayiheng Liu, Rui Men, Junyang Lin, Zhou San, Bowen Yu, An Yang, Mingfeng Xue, Fei Huang, Binyuan Hui, Mei Li, Tianyu Liu, Xingzhang Ren, Xuancheng Ren, Kexin Yang, Chang Zhou, Jingren Zhou.
|
||||
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
|
||||
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
|
||||
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
|
||||
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (from META Research) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
|
||||
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/pdf/2010.12821.pdf) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
|
||||
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
|
||||
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
|
||||
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (from Facebook), released together with the paper a [Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
|
||||
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (from Facebook), released together with the paper a [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
|
||||
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
|
||||
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper a [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
|
||||
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper a [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
|
||||
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng) released with the paper [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
|
||||
1. **[SeamlessM4T](https://huggingface.co/docs/transformers/model_doc/seamless_m4t)** (from Meta AI) released with the paper [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team.
|
||||
1. **[SeamlessM4Tv2](https://huggingface.co/docs/transformers/model_doc/seamless_m4t_v2)** (from Meta AI) released with the paper [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team.
|
||||
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
|
||||
1. **[SegGPT](https://huggingface.co/docs/transformers/model_doc/seggpt)** (from Beijing Academy of Artificial Intelligence (BAAI) released with the paper [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang.
|
||||
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
|
||||
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
|
||||
@ -447,7 +456,9 @@ conda install conda-forge::transformers
|
||||
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook) released with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
|
||||
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University) released with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
|
||||
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/main/model_doc/stablelm)** released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm)** released with the paper [StableLM 3B 4E1T (Technical Report)](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Jonathan Tow, Marco Bellagente, Dakota Mahan, Carlos Riquelme Ruiz, Duy Phung, Maksym Zhuravinskyi, Nathan Cooper, Nikhil Pinnaparaju, Reshinth Adithyan, and James Baicoianu.
|
||||
1. **[Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2)** (from BigCode team) released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
1. **[SuperPoint](https://huggingface.co/docs/transformers/model_doc/superpoint)** (from MagicLeap) released with the paper [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
|
||||
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
|
||||
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
|
||||
@ -465,13 +476,14 @@ conda install conda-forge::transformers
|
||||
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft) released with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
|
||||
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
|
||||
1. **[TVP](https://huggingface.co/docs/transformers/model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
|
||||
1. **[UDOP](https://huggingface.co/docs/transformers/model_doc/udop)** (from Microsoft Research) released with the paper [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
|
||||
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
|
||||
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
|
||||
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
|
||||
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
|
||||
1. **[UnivNet](https://huggingface.co/docs/transformers/model_doc/univnet)** (from Kakao Corporation) released with the paper [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim.
|
||||
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
|
||||
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
|
||||
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
|
||||
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
|
||||
1. **[VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)** (from University of Wisconsin–Madison) released with the paper [Making Large Multimodal Models Understand Arbitrary Visual Prompts](https://arxiv.org/abs/2312.00784) by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
|
||||
|
||||
36
SECURITY.md
36
SECURITY.md
@ -1,6 +1,40 @@
|
||||
# Security Policy
|
||||
|
||||
## Hugging Face Hub, remote artefacts, and remote code
|
||||
|
||||
Transformers is open-source software that is tightly coupled to the Hugging Face Hub. While you have the ability to use it
|
||||
offline with pre-downloaded model weights, it provides a very simple way to download, use, and manage models locally.
|
||||
|
||||
When downloading artefacts that have been uploaded by others on any platform, you expose yourself to risks. Please
|
||||
read below for the security recommendations in order to keep your runtime and local environment safe.
|
||||
|
||||
### Remote artefacts
|
||||
|
||||
Models uploaded on the Hugging Face Hub come in different formats. We heavily recommend uploading and downloading
|
||||
models in the [`safetensors`](https://github.com/huggingface/safetensors) format (which is the default prioritized
|
||||
by the transformers library), as developed specifically to prevent arbitrary code execution on your system.
|
||||
|
||||
To avoid loading models from unsafe formats(e.g. [pickle](https://docs.python.org/3/library/pickle.html), you should use the `use_safetenstors` parameter. If doing so, in the event that no .safetensors file is present, transformers will error when loading the model.
|
||||
|
||||
### Remote code
|
||||
|
||||
#### Modeling
|
||||
|
||||
Transformers supports many model architectures, but is also the bridge between your Python runtime and models that
|
||||
are stored in model repositories on the Hugging Face Hub.
|
||||
|
||||
These models require the `trust_remote_code=True` parameter to be set when using them; please **always** verify
|
||||
the content of the modeling files when using this argument. We recommend setting a revision in order to ensure you
|
||||
protect yourself from updates on the repository.
|
||||
|
||||
#### Tools
|
||||
|
||||
Through the `Agent` framework, remote tools can be downloaded to be used by the Agent. You're to specify these tools
|
||||
yourself, but please keep in mind that their code will be run on your machine if the Agent chooses to run them.
|
||||
|
||||
Please inspect the code of the tools before passing them to the Agent to protect your runtime and local setup.
|
||||
|
||||
## Reporting a Vulnerability
|
||||
|
||||
🤗 We have our bug bounty program set up with HackerOne. Please feel free to submit vulnerability reports to our private program at https://hackerone.com/hugging_face.
|
||||
🤗 Please feel free to submit vulnerability reports to our private bug bounty program at https://hackerone.com/hugging_face. You'll need to request access to the program by emailing security@huggingface.co.
|
||||
Note that you'll need to be invited to our program, so send us a quick email at security@huggingface.co if you've found a vulnerability.
|
||||
|
||||
56
conftest.py
56
conftest.py
@ -21,10 +21,59 @@ import warnings
|
||||
from os.path import abspath, dirname, join
|
||||
|
||||
import _pytest
|
||||
import pytest
|
||||
|
||||
from transformers.testing_utils import HfDoctestModule, HfDocTestParser
|
||||
|
||||
|
||||
NOT_DEVICE_TESTS = {
|
||||
"test_tokenization",
|
||||
"test_processor",
|
||||
"test_processing",
|
||||
"test_beam_constraints",
|
||||
"test_configuration_utils",
|
||||
"test_data_collator",
|
||||
"test_trainer_callback",
|
||||
"test_trainer_utils",
|
||||
"test_feature_extraction",
|
||||
"test_image_processing",
|
||||
"test_image_processor",
|
||||
"test_image_transforms",
|
||||
"test_optimization",
|
||||
"test_retrieval",
|
||||
"test_config",
|
||||
"test_from_pretrained_no_checkpoint",
|
||||
"test_keep_in_fp32_modules",
|
||||
"test_gradient_checkpointing_backward_compatibility",
|
||||
"test_gradient_checkpointing_enable_disable",
|
||||
"test_save_load_fast_init_from_base",
|
||||
"test_fast_init_context_manager",
|
||||
"test_fast_init_tied_embeddings",
|
||||
"test_save_load_fast_init_to_base",
|
||||
"test_torch_save_load",
|
||||
"test_initialization",
|
||||
"test_forward_signature",
|
||||
"test_model_common_attributes",
|
||||
"test_model_main_input_name",
|
||||
"test_correct_missing_keys",
|
||||
"test_tie_model_weights",
|
||||
"test_can_use_safetensors",
|
||||
"test_load_save_without_tied_weights",
|
||||
"test_tied_weights_keys",
|
||||
"test_model_weights_reload_no_missing_tied_weights",
|
||||
"test_pt_tf_model_equivalence",
|
||||
"test_mismatched_shapes_have_properly_initialized_weights",
|
||||
"test_matched_shapes_have_loaded_weights_when_some_mismatched_shapes_exist",
|
||||
"test_model_is_small",
|
||||
"test_tf_from_pt_safetensors",
|
||||
"test_flax_from_pt_safetensors",
|
||||
"ModelTest::test_pipeline_", # None of the pipeline tests from PipelineTesterMixin (of which XxxModelTest inherits from) are running on device
|
||||
"ModelTester::test_pipeline_",
|
||||
"/repo_utils/",
|
||||
"/utils/",
|
||||
"/tools/",
|
||||
}
|
||||
|
||||
# allow having multiple repository checkouts and not needing to remember to rerun
|
||||
# `pip install -e '.[dev]'` when switching between checkouts and running tests.
|
||||
git_repo_path = abspath(join(dirname(__file__), "src"))
|
||||
@ -46,6 +95,13 @@ def pytest_configure(config):
|
||||
config.addinivalue_line("markers", "is_staging_test: mark test to run only in the staging environment")
|
||||
config.addinivalue_line("markers", "accelerate_tests: mark test that require accelerate")
|
||||
config.addinivalue_line("markers", "tool_tests: mark the tool tests that are run on their specific schedule")
|
||||
config.addinivalue_line("markers", "not_device_test: mark the tests always running on cpu")
|
||||
|
||||
|
||||
def pytest_collection_modifyitems(items):
|
||||
for item in items:
|
||||
if any(test_name in item.nodeid for test_name in NOT_DEVICE_TESTS):
|
||||
item.add_marker(pytest.mark.not_device_test)
|
||||
|
||||
|
||||
def pytest_addoption(parser):
|
||||
|
||||
@ -9,9 +9,9 @@ SHELL ["sh", "-lc"]
|
||||
# The following `ARG` are mainly used to specify the versions explicitly & directly in this docker file, and not meant
|
||||
# to be used as arguments for docker build (so far).
|
||||
|
||||
ARG PYTORCH='2.1.1'
|
||||
ARG PYTORCH='2.2.1'
|
||||
# (not always a valid torch version)
|
||||
ARG INTEL_TORCH_EXT='2.1.100'
|
||||
ARG INTEL_TORCH_EXT='2.2.0'
|
||||
# Example: `cu102`, `cu113`, etc.
|
||||
ARG CUDA='cu118'
|
||||
|
||||
@ -23,17 +23,10 @@ RUN python3 -m pip install --no-cache-dir --upgrade pip
|
||||
ARG REF=main
|
||||
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
|
||||
|
||||
# TODO: Handle these in a python utility script
|
||||
RUN [ ${#PYTORCH} -gt 0 -a "$PYTORCH" != "pre" ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; echo "export VERSION='$VERSION'" >> ~/.profile
|
||||
RUN echo torch=$VERSION
|
||||
# `torchvision` and `torchaudio` should be installed along with `torch`, especially for nightly build.
|
||||
# Currently, let's just use their latest releases (when `torch` is installed with a release version)
|
||||
# TODO: We might need to specify proper versions that work with a specific torch version (especially for past CI).
|
||||
RUN [ "$PYTORCH" != "pre" ] && python3 -m pip install --no-cache-dir -U $VERSION torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA || python3 -m pip install --no-cache-dir -U --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/$CUDA
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir -U tensorflow==2.13 protobuf==3.20.3 tensorflow_text tensorflow_probability
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev,onnxruntime]
|
||||
# 1. Put several commands in a single `RUN` to avoid image/layer exporting issue. Could be revised in the future.
|
||||
# 2. Regarding `torch` part, We might need to specify proper versions for `torchvision` and `torchaudio`.
|
||||
# Currently, let's not bother to specify their versions explicitly (so installed with their latest release versions).
|
||||
RUN python3 -m pip install --no-cache-dir -U tensorflow==2.13 protobuf==3.20.3 tensorflow_text tensorflow_probability && python3 -m pip install --no-cache-dir -e ./transformers[dev,onnxruntime] && [ ${#PYTORCH} -gt 0 -a "$PYTORCH" != "pre" ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; echo "export VERSION='$VERSION'" >> ~/.profile && echo torch=$VERSION && [ "$PYTORCH" != "pre" ] && python3 -m pip install --no-cache-dir -U $VERSION torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA || python3 -m pip install --no-cache-dir -U --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/$CUDA
|
||||
|
||||
RUN python3 -m pip uninstall -y flax jax
|
||||
|
||||
@ -46,22 +39,7 @@ RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/acc
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/peft@main#egg=peft
|
||||
|
||||
# Add bitsandbytes for mixed int8 testing
|
||||
RUN python3 -m pip install --no-cache-dir bitsandbytes
|
||||
|
||||
# Add auto-gptq for gtpq quantization testing
|
||||
RUN python3 -m pip install --no-cache-dir auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
|
||||
|
||||
# Add einops for additional model testing
|
||||
RUN python3 -m pip install --no-cache-dir einops
|
||||
|
||||
# Add aqlm for quantization testing
|
||||
RUN python3 -m pip install --no-cache-dir aqlm[gpu]==1.0.1
|
||||
|
||||
# Add autoawq for quantization testing
|
||||
RUN python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.8/autoawq-0.1.8+cu118-cp38-cp38-linux_x86_64.whl
|
||||
|
||||
# For bettertransformer + gptq
|
||||
# For bettertransformer
|
||||
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/optimum@main#egg=optimum
|
||||
|
||||
# For video model testing
|
||||
|
||||
@ -34,3 +34,6 @@ RUN python3 -m pip uninstall -y tensorflow flax
|
||||
# When installing in editable mode, `transformers` is not recognized as a package.
|
||||
# this line must be added in order for python to be aware of transformers.
|
||||
RUN cd transformers && python3 setup.py develop
|
||||
|
||||
# Remove nvml as it is not compatible with ROCm
|
||||
RUN python3 -m pip uninstall py3nvml pynvml -y
|
||||
|
||||
@ -42,4 +42,7 @@ RUN python3 -m pip install --no-cache-dir ./transformers[accelerate,testing,sent
|
||||
# this line must be added in order for python to be aware of transformers.
|
||||
RUN cd transformers && python3 setup.py develop
|
||||
|
||||
RUN python3 -c "from deepspeed.launcher.runner import main"
|
||||
RUN python3 -c "from deepspeed.launcher.runner import main"
|
||||
|
||||
# Remove nvml as it is not compatible with ROCm
|
||||
RUN python3 -m pip uninstall py3nvml pynvml -y
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-23-11.html#rel-23-11
|
||||
FROM nvcr.io/nvidia/pytorch:23.11-py3
|
||||
FROM nvcr.io/nvidia/pytorch:23.04-py3
|
||||
LABEL maintainer="Hugging Face"
|
||||
|
||||
ARG DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
ARG PYTORCH='2.1.0'
|
||||
ARG PYTORCH='2.2.0'
|
||||
# Example: `cu102`, `cu113`, etc.
|
||||
ARG CUDA='cu121'
|
||||
|
||||
@ -15,14 +15,12 @@ RUN python3 -m pip install --no-cache-dir --upgrade pip
|
||||
ARG REF=main
|
||||
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
|
||||
|
||||
RUN python3 -m pip uninstall -y torch torchvision torchaudio
|
||||
RUN python3 -m pip install --no-cache-dir ./transformers[deepspeed-testing]
|
||||
|
||||
# Install latest release PyTorch
|
||||
# (PyTorch must be installed before pre-compiling any DeepSpeed c++/cuda ops.)
|
||||
# (https://www.deepspeed.ai/tutorials/advanced-install/#pre-install-deepspeed-ops)
|
||||
RUN python3 -m pip install --no-cache-dir -U torch==$PYTORCH torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir ./transformers[deepspeed-testing]
|
||||
RUN python3 -m pip uninstall -y torch torchvision torchaudio && python3 -m pip install --no-cache-dir -U torch==$PYTORCH torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
|
||||
|
||||
|
||||
53
docker/transformers-quantization-latest-gpu/Dockerfile
Normal file
53
docker/transformers-quantization-latest-gpu/Dockerfile
Normal file
@ -0,0 +1,53 @@
|
||||
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
|
||||
ARG DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
# Use login shell to read variables from `~/.profile` (to pass dynamic created variables between RUN commands)
|
||||
SHELL ["sh", "-lc"]
|
||||
|
||||
# The following `ARG` are mainly used to specify the versions explicitly & directly in this docker file, and not meant
|
||||
# to be used as arguments for docker build (so far).
|
||||
|
||||
ARG PYTORCH='2.2.0'
|
||||
# Example: `cu102`, `cu113`, etc.
|
||||
ARG CUDA='cu118'
|
||||
|
||||
RUN apt update
|
||||
RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python python3-pip ffmpeg
|
||||
RUN python3 -m pip install --no-cache-dir --upgrade pip
|
||||
|
||||
ARG REF=main
|
||||
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
|
||||
|
||||
RUN [ ${#PYTORCH} -gt 0 ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; echo "export VERSION='$VERSION'" >> ~/.profile
|
||||
RUN echo torch=$VERSION
|
||||
# `torchvision` and `torchaudio` should be installed along with `torch`, especially for nightly build.
|
||||
# Currently, let's just use their latest releases (when `torch` is installed with a release version)
|
||||
RUN python3 -m pip install --no-cache-dir -U $VERSION torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-torch]
|
||||
|
||||
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
|
||||
|
||||
# Add bitsandbytes for mixed int8 testing
|
||||
RUN python3 -m pip install --no-cache-dir bitsandbytes
|
||||
|
||||
# Add auto-gptq for gtpq quantization testing
|
||||
RUN python3 -m pip install --no-cache-dir auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
|
||||
|
||||
# Add optimum for gptq quantization testing
|
||||
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/optimum@main#egg=optimum
|
||||
|
||||
# Add aqlm for quantization testing
|
||||
RUN python3 -m pip install --no-cache-dir aqlm[gpu]==1.0.2
|
||||
|
||||
# Add autoawq for quantization testing
|
||||
RUN python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ/releases/download/v0.2.0/autoawq-0.2.0+cu118-cp38-cp38-linux_x86_64.whl
|
||||
|
||||
# Add quanto for quantization testing
|
||||
RUN python3 -m pip install --no-cache-dir quanto
|
||||
|
||||
# When installing in editable mode, `transformers` is not recognized as a package.
|
||||
# this line must be added in order for python to be aware of transformers.
|
||||
RUN cd transformers && python3 setup.py develop
|
||||
@ -1,7 +1,7 @@
|
||||
# docstyle-ignore
|
||||
INSTALL_CONTENT = """
|
||||
# Transformers installation
|
||||
! pip install transformers datasets evaluate
|
||||
! pip install transformers datasets evaluate accelerate
|
||||
# To install from source instead of the last release, comment the command above and uncomment the following one.
|
||||
# ! pip install git+https://github.com/huggingface/transformers.git
|
||||
"""
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
# docstyle-ignore
|
||||
INSTALL_CONTENT = """
|
||||
# Transformers installation
|
||||
! pip install transformers datasets
|
||||
! pip install transformers datasets evaluate accelerate
|
||||
# To install from source instead of the last release, comment the command above and uncomment the following one.
|
||||
# ! pip install git+https://github.com/huggingface/transformers.git
|
||||
"""
|
||||
|
||||
@ -452,7 +452,7 @@ Dekorateure werden verwendet, um die Anforderungen von Tests in Bezug auf CPU/GP
|
||||
- `require_torch_multi_gpu` - wie `require_torch` und zusätzlich mindestens 2 GPUs erforderlich
|
||||
- `require_torch_non_multi_gpu` - wie `require_torch` plus benötigt 0 oder 1 GPUs
|
||||
- `require_torch_up_to_2_gpus` - wie `require_torch` plus erfordert 0 oder 1 oder 2 GPUs
|
||||
- `require_torch_tpu` - wie `require_torch` plus erfordert mindestens 1 TPU
|
||||
- `require_torch_xla` - wie `require_torch` plus erfordert mindestens 1 TPU
|
||||
|
||||
Lassen Sie uns die GPU-Anforderungen in der folgenden Tabelle darstellen:
|
||||
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
# docstyle-ignore
|
||||
INSTALL_CONTENT = """
|
||||
# Transformers installation
|
||||
! pip install transformers datasets
|
||||
! pip install transformers datasets evaluate accelerate
|
||||
# To install from source instead of the last release, comment the command above and uncomment the following one.
|
||||
# ! pip install git+https://github.com/huggingface/transformers.git
|
||||
"""
|
||||
|
||||
@ -73,6 +73,8 @@
|
||||
title: Depth estimation
|
||||
- local: tasks/image_to_image
|
||||
title: Image-to-Image
|
||||
- local: tasks/image_feature_extraction
|
||||
title: Image Feature Extraction
|
||||
- local: tasks/mask_generation
|
||||
title: Mask Generation
|
||||
- local: tasks/knowledge_distillation_for_image_classification
|
||||
@ -132,7 +134,7 @@
|
||||
- local: custom_tools
|
||||
title: Custom Tools and Prompts
|
||||
- local: troubleshooting
|
||||
title: Troubleshoot
|
||||
title: Troubleshoot
|
||||
- local: hf_quantizer
|
||||
title: Contribute new quantization method
|
||||
title: Developer guides
|
||||
@ -170,7 +172,7 @@
|
||||
title: GPU inference
|
||||
title: Optimizing inference
|
||||
- local: big_models
|
||||
title: Instantiating a big model
|
||||
title: Instantiate a big model
|
||||
- local: debugging
|
||||
title: Debugging
|
||||
- local: tf_xla
|
||||
@ -308,6 +310,8 @@
|
||||
title: CodeGen
|
||||
- local: model_doc/code_llama
|
||||
title: CodeLlama
|
||||
- local: model_doc/cohere
|
||||
title: Cohere
|
||||
- local: model_doc/convbert
|
||||
title: ConvBERT
|
||||
- local: model_doc/cpm
|
||||
@ -354,6 +358,8 @@
|
||||
title: Funnel Transformer
|
||||
- local: model_doc/fuyu
|
||||
title: Fuyu
|
||||
- local: model_doc/gemma
|
||||
title: Gemma
|
||||
- local: model_doc/openai-gpt
|
||||
title: GPT
|
||||
- local: model_doc/gpt_neo
|
||||
@ -394,6 +400,8 @@
|
||||
title: M2M100
|
||||
- local: model_doc/madlad-400
|
||||
title: MADLAD-400
|
||||
- local: model_doc/mamba
|
||||
title: Mamba
|
||||
- local: model_doc/marian
|
||||
title: MarianMT
|
||||
- local: model_doc/markuplm
|
||||
@ -454,6 +462,8 @@
|
||||
title: QDQBert
|
||||
- local: model_doc/qwen2
|
||||
title: Qwen2
|
||||
- local: model_doc/qwen2_moe
|
||||
title: Qwen2MoE
|
||||
- local: model_doc/rag
|
||||
title: RAG
|
||||
- local: model_doc/realm
|
||||
@ -480,6 +490,8 @@
|
||||
title: SqueezeBERT
|
||||
- local: model_doc/stablelm
|
||||
title: StableLm
|
||||
- local: model_doc/starcoder2
|
||||
title: Starcoder2
|
||||
- local: model_doc/switch_transformers
|
||||
title: SwitchTransformers
|
||||
- local: model_doc/t5
|
||||
@ -575,12 +587,18 @@
|
||||
title: PoolFormer
|
||||
- local: model_doc/pvt
|
||||
title: Pyramid Vision Transformer (PVT)
|
||||
- local: model_doc/pvt_v2
|
||||
title: Pyramid Vision Transformer v2 (PVTv2)
|
||||
- local: model_doc/regnet
|
||||
title: RegNet
|
||||
- local: model_doc/resnet
|
||||
title: ResNet
|
||||
- local: model_doc/segformer
|
||||
title: SegFormer
|
||||
- local: model_doc/seggpt
|
||||
title: SegGpt
|
||||
- local: model_doc/superpoint
|
||||
title: SuperPoint
|
||||
- local: model_doc/swiftformer
|
||||
title: SwiftFormer
|
||||
- local: model_doc/swin
|
||||
@ -628,6 +646,8 @@
|
||||
title: MMS
|
||||
- local: model_doc/musicgen
|
||||
title: MusicGen
|
||||
- local: model_doc/musicgen_melody
|
||||
title: MusicGen Melody
|
||||
- local: model_doc/pop2piano
|
||||
title: Pop2Piano
|
||||
- local: model_doc/seamless_m4t
|
||||
@ -677,7 +697,7 @@
|
||||
title: VideoMAE
|
||||
- local: model_doc/vivit
|
||||
title: ViViT
|
||||
title: Video models
|
||||
title: Video models
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: model_doc/align
|
||||
@ -730,6 +750,8 @@
|
||||
title: LiLT
|
||||
- local: model_doc/llava
|
||||
title: Llava
|
||||
- local: model_doc/llava_next
|
||||
title: LLaVA-NeXT
|
||||
- local: model_doc/lxmert
|
||||
title: LXMERT
|
||||
- local: model_doc/matcha
|
||||
@ -762,6 +784,8 @@
|
||||
title: TVLT
|
||||
- local: model_doc/tvp
|
||||
title: TVP
|
||||
- local: model_doc/udop
|
||||
title: UDOP
|
||||
- local: model_doc/vilt
|
||||
title: ViLT
|
||||
- local: model_doc/vipllava
|
||||
|
||||
@ -89,8 +89,8 @@ model.config # model has access to its config
|
||||
Similar to the model, the configuration inherits basic serialization and deserialization functionalities from
|
||||
[`PretrainedConfig`]. Note that the configuration and the model are always serialized into two
|
||||
different formats - the model to a *pytorch_model.bin* file and the configuration to a *config.json* file. Calling
|
||||
[`~PreTrainedModel.save_pretrained`] will automatically call
|
||||
[`~PretrainedConfig.save_pretrained`], so that both model and configuration are saved.
|
||||
the model's [`~PreTrainedModel.save_pretrained`] will automatically call
|
||||
the config's [`~PretrainedConfig.save_pretrained`], so that both model and configuration are saved.
|
||||
|
||||
|
||||
### Code style
|
||||
@ -192,46 +192,46 @@ its attention layer, etc. We will be more than happy to help you.
|
||||
|
||||
2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/[your Github handle]/transformers.git
|
||||
cd transformers
|
||||
git remote add upstream https://github.com/huggingface/transformers.git
|
||||
```
|
||||
```bash
|
||||
git clone https://github.com/[your Github handle]/transformers.git
|
||||
cd transformers
|
||||
git remote add upstream https://github.com/huggingface/transformers.git
|
||||
```
|
||||
|
||||
3. Set up a development environment, for instance by running the following command:
|
||||
|
||||
```bash
|
||||
python -m venv .env
|
||||
source .env/bin/activate
|
||||
pip install -e ".[dev]"
|
||||
```
|
||||
```bash
|
||||
python -m venv .env
|
||||
source .env/bin/activate
|
||||
pip install -e ".[dev]"
|
||||
```
|
||||
|
||||
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
|
||||
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
|
||||
(PyTorch, TensorFlow and/or Flax) then do:
|
||||
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
|
||||
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
|
||||
(PyTorch, TensorFlow and/or Flax) then do:
|
||||
|
||||
```bash
|
||||
pip install -e ".[quality]"
|
||||
```
|
||||
```bash
|
||||
pip install -e ".[quality]"
|
||||
```
|
||||
|
||||
which should be enough for most use cases. You can then return to the parent directory
|
||||
which should be enough for most use cases. You can then return to the parent directory
|
||||
|
||||
```bash
|
||||
cd ..
|
||||
```
|
||||
```bash
|
||||
cd ..
|
||||
```
|
||||
|
||||
4. We recommend adding the PyTorch version of *brand_new_bert* to Transformers. To install PyTorch, please follow the
|
||||
instructions on https://pytorch.org/get-started/locally/.
|
||||
|
||||
**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
|
||||
**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
|
||||
|
||||
5. To port *brand_new_bert*, you will also need access to its original repository:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
|
||||
cd brand_new_bert
|
||||
pip install -e .
|
||||
```
|
||||
```bash
|
||||
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
|
||||
cd brand_new_bert
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
Now you have set up a development environment to port *brand_new_bert* to 🤗 Transformers.
|
||||
|
||||
@ -421,29 +421,29 @@ You should do the following:
|
||||
|
||||
1. Create a branch with a descriptive name from your main branch
|
||||
|
||||
```bash
|
||||
git checkout -b add_brand_new_bert
|
||||
```
|
||||
```bash
|
||||
git checkout -b add_brand_new_bert
|
||||
```
|
||||
|
||||
2. Commit the automatically generated code:
|
||||
|
||||
```bash
|
||||
git add .
|
||||
git commit
|
||||
```
|
||||
```bash
|
||||
git add .
|
||||
git commit
|
||||
```
|
||||
|
||||
3. Fetch and rebase to current main
|
||||
|
||||
```bash
|
||||
git fetch upstream
|
||||
git rebase upstream/main
|
||||
```
|
||||
```bash
|
||||
git fetch upstream
|
||||
git rebase upstream/main
|
||||
```
|
||||
|
||||
4. Push the changes to your account using:
|
||||
|
||||
```bash
|
||||
git push -u origin a-descriptive-name-for-my-changes
|
||||
```
|
||||
```bash
|
||||
git push -u origin a-descriptive-name-for-my-changes
|
||||
```
|
||||
|
||||
5. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
|
||||
GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
|
||||
@ -759,7 +759,7 @@ In case you are using Windows, you should replace `RUN_SLOW=1` with `SET RUN_SLO
|
||||
</Tip>
|
||||
|
||||
Second, all features that are special to *brand_new_bert* should be tested additionally in a separate test under
|
||||
`BrandNewBertModelTester`/``BrandNewBertModelTest`. This part is often forgotten but is extremely useful in two
|
||||
`BrandNewBertModelTester`/`BrandNewBertModelTest`. This part is often forgotten but is extremely useful in two
|
||||
ways:
|
||||
|
||||
- It helps to transfer the knowledge you have acquired during the model addition to the community by showing how the
|
||||
@ -776,7 +776,7 @@ It is very important to find/extract the original tokenizer file and to manage t
|
||||
Transformers' implementation of the tokenizer.
|
||||
|
||||
To ensure that the tokenizer works correctly, it is recommended to first create a script in the original repository
|
||||
that inputs a string and returns the `input_ids``. It could look similar to this (in pseudo-code):
|
||||
that inputs a string and returns the `input_ids`. It could look similar to this (in pseudo-code):
|
||||
|
||||
```python
|
||||
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
|
||||
@ -827,7 +827,7 @@ the community to add some *Tips* to show how the model should be used. Don't hes
|
||||
regarding the docstrings.
|
||||
|
||||
Next, make sure that the docstring added to `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` is
|
||||
correct and included all necessary inputs and outputs. We have a detailed guide about writing documentation and our docstring format [here](writing-documentation). It is always to good to remind oneself that documentation should
|
||||
correct and included all necessary inputs and outputs. We have a detailed guide about writing documentation and our docstring format [here](writing-documentation). It is always good to remind oneself that documentation should
|
||||
be treated at least as carefully as the code in 🤗 Transformers since the documentation is usually the first contact
|
||||
point of the community with the model.
|
||||
|
||||
|
||||
@ -109,52 +109,52 @@ instructions below to set up your environment and open a draft PR.
|
||||
|
||||
2. Clone your `transformers` fork to your local disk, and add the base repository as a remote:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/[your Github handle]/transformers.git
|
||||
cd transformers
|
||||
git remote add upstream https://github.com/huggingface/transformers.git
|
||||
```
|
||||
```bash
|
||||
git clone https://github.com/[your Github handle]/transformers.git
|
||||
cd transformers
|
||||
git remote add upstream https://github.com/huggingface/transformers.git
|
||||
```
|
||||
|
||||
3. Set up a development environment, for instance by running the following command:
|
||||
3. Set up a development environment, for instance by running the following commands:
|
||||
|
||||
```bash
|
||||
python -m venv .env
|
||||
source .env/bin/activate
|
||||
pip install -e ".[dev]"
|
||||
```
|
||||
```bash
|
||||
python -m venv .env
|
||||
source .env/bin/activate
|
||||
pip install -e ".[dev]"
|
||||
```
|
||||
|
||||
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
|
||||
failure with this command. If that's the case make sure to install TensorFlow then do:
|
||||
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
|
||||
failure with this command. If that's the case make sure to install TensorFlow then do:
|
||||
|
||||
```bash
|
||||
pip install -e ".[quality]"
|
||||
```
|
||||
```bash
|
||||
pip install -e ".[quality]"
|
||||
```
|
||||
|
||||
**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
|
||||
**Note:** You don't need to have CUDA installed. Making the new model work on CPU is sufficient.
|
||||
|
||||
4. Create a branch with a descriptive name from your main branch
|
||||
4. Create a branch with a descriptive name from your main branch:
|
||||
|
||||
```bash
|
||||
git checkout -b add_tf_brand_new_bert
|
||||
```
|
||||
```bash
|
||||
git checkout -b add_tf_brand_new_bert
|
||||
```
|
||||
|
||||
5. Fetch and rebase to current main
|
||||
5. Fetch and rebase to current main:
|
||||
|
||||
```bash
|
||||
git fetch upstream
|
||||
git rebase upstream/main
|
||||
```
|
||||
```bash
|
||||
git fetch upstream
|
||||
git rebase upstream/main
|
||||
```
|
||||
|
||||
6. Add an empty `.py` file in `transformers/src/models/brandnewbert/` named `modeling_tf_brandnewbert.py`. This will
|
||||
be your TensorFlow model file.
|
||||
|
||||
7. Push the changes to your account using:
|
||||
|
||||
```bash
|
||||
git add .
|
||||
git commit -m "initial commit"
|
||||
git push -u origin add_tf_brand_new_bert
|
||||
```
|
||||
```bash
|
||||
git add .
|
||||
git commit -m "initial commit"
|
||||
git push -u origin add_tf_brand_new_bert
|
||||
```
|
||||
|
||||
8. Once you are satisfied, go to the webpage of your fork on GitHub. Click on “Pull request”. Make sure to add the
|
||||
GitHub handle of some members of the Hugging Face team as reviewers, so that the Hugging Face team gets notified for
|
||||
|
||||
@ -14,110 +14,202 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Instantiating a big model
|
||||
# Instantiate a big model
|
||||
|
||||
When you want to use a very big pretrained model, one challenge is to minimize the use of the RAM. The usual workflow
|
||||
from PyTorch is:
|
||||
A barrier to accessing very large pretrained models is the amount of memory required. When loading a pretrained PyTorch model, you usually:
|
||||
|
||||
1. Create your model with random weights.
|
||||
1. Create a model with random weights.
|
||||
2. Load your pretrained weights.
|
||||
3. Put those pretrained weights in your random model.
|
||||
3. Put those pretrained weights in the model.
|
||||
|
||||
Step 1 and 2 both require a full version of the model in memory, which is not a problem in most cases, but if your model starts weighing several GigaBytes, those two copies can make you get out of RAM. Even worse, if you are using `torch.distributed` to launch a distributed training, each process will load the pretrained model and store these two copies in RAM.
|
||||
The first two steps both require a full version of the model in memory and if the model weighs several GBs, you may not have enough memory for two copies of it. This problem is amplified in distributed training environments because each process loads a pretrained model and stores two copies in memory.
|
||||
|
||||
<Tip>
|
||||
> [!TIP]
|
||||
> The randomly created model is initialized with "empty" tensors, which take space in memory without filling it. The random values are whatever was in this chunk of memory at the time. To improve loading speed, the [`_fast_init`](https://github.com/huggingface/transformers/blob/c9f6e5e35156e068b227dd9b15521767f6afd4d2/src/transformers/modeling_utils.py#L2710) parameter is set to `True` by default to skip the random initialization for all weights that are correctly loaded.
|
||||
|
||||
Note that the randomly created model is initialized with "empty" tensors, which take the space in memory without filling it (thus the random values are whatever was in this chunk of memory at a given time). The random initialization following the appropriate distribution for the kind of model/parameters instantiated (like a normal distribution for instance) is only performed after step 3 on the non-initialized weights, to be as fast as possible!
|
||||
|
||||
</Tip>
|
||||
|
||||
In this guide, we explore the solutions Transformers offer to deal with this issue. Note that this is an area of active development, so the APIs explained here may change slightly in the future.
|
||||
This guide will show you how Transformers can help you load large pretrained models despite their memory requirements.
|
||||
|
||||
## Sharded checkpoints
|
||||
|
||||
Since version 4.18.0, model checkpoints that end up taking more than 10GB of space are automatically sharded in smaller pieces. In terms of having one single checkpoint when you do `model.save_pretrained(save_dir)`, you will end up with several partial checkpoints (each of which being of size < 10GB) and an index that maps parameter names to the files they are stored in.
|
||||
From Transformers v4.18.0, a checkpoint larger than 10GB is automatically sharded by the [`~PreTrainedModel.save_pretrained`] method. It is split into several smaller partial checkpoints and creates an index file that maps parameter names to the files they're stored in.
|
||||
|
||||
You can control the maximum size before sharding with the `max_shard_size` parameter, so for the sake of an example, we'll use a normal-size models with a small shard size: let's take a traditional BERT model.
|
||||
The maximum shard size is controlled with the `max_shard_size` parameter, but by default it is 5GB, because it is easier to run on free-tier GPU instances without running out of memory.
|
||||
|
||||
For example, let's shard [BioMistral/BioMistral-7B](https://hf.co/BioMistral/BioMistral-7B).
|
||||
|
||||
```py
|
||||
from transformers import AutoModel
|
||||
|
||||
model = AutoModel.from_pretrained("google-bert/bert-base-cased")
|
||||
```
|
||||
|
||||
If you save it using [`~PreTrainedModel.save_pretrained`], you will get a new folder with two files: the config of the model and its weights:
|
||||
|
||||
```py
|
||||
>>> import os
|
||||
>>> import tempfile
|
||||
|
||||
>>> with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
... model.save_pretrained(tmp_dir)
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="5GB")
|
||||
... print(sorted(os.listdir(tmp_dir)))
|
||||
['config.json', 'pytorch_model.bin']
|
||||
['config.json', 'generation_config.json', 'model-00001-of-00006.safetensors', 'model-00002-of-00006.safetensors', 'model-00003-of-00006.safetensors', 'model-00004-of-00006.safetensors', 'model-00005-of-00006.safetensors', 'model-00006-of-00006.safetensors', 'model.safetensors.index.json']
|
||||
```
|
||||
|
||||
Now let's use a maximum shard size of 200MB:
|
||||
The sharded checkpoint is reloaded with the [`~PreTrainedModel.from_pretrained`] method.
|
||||
|
||||
```py
|
||||
>>> with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
|
||||
... print(sorted(os.listdir(tmp_dir)))
|
||||
['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
|
||||
```
|
||||
|
||||
On top of the configuration of the model, we see three different weights files, and an `index.json` file which is our index. A checkpoint like this can be fully reloaded using the [`~PreTrainedModel.from_pretrained`] method:
|
||||
|
||||
```py
|
||||
>>> with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="5GB")
|
||||
... new_model = AutoModel.from_pretrained(tmp_dir)
|
||||
```
|
||||
|
||||
The main advantage of doing this for big models is that during step 2 of the workflow shown above, each shard of the checkpoint is loaded after the previous one, capping the memory usage in RAM to the model size plus the size of the biggest shard.
|
||||
The main advantage of sharded checkpoints for big models is that each shard is loaded after the previous one, which caps the memory usage to only the model size and the largest shard size.
|
||||
|
||||
Behind the scenes, the index file is used to determine which keys are in the checkpoint, and where the corresponding weights are stored. We can load that index like any json and get a dictionary:
|
||||
You could also directly load a sharded checkpoint inside a model without the [`~PreTrainedModel.from_pretrained`] method (similar to PyTorch's `load_state_dict()` method for a full checkpoint). In this case, use the [`~modeling_utils.load_sharded_checkpoint`] method.
|
||||
|
||||
```py
|
||||
>>> from transformers.modeling_utils import load_sharded_checkpoint
|
||||
|
||||
>>> with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="5GB")
|
||||
... load_sharded_checkpoint(model, tmp_dir)
|
||||
```
|
||||
|
||||
### Shard metadata
|
||||
|
||||
The index file determines which keys are in the checkpoint and where the corresponding weights are stored. This file is loaded like any other JSON file and you can get a dictionary from it.
|
||||
|
||||
```py
|
||||
>>> import json
|
||||
|
||||
>>> with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
|
||||
... with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="5GB")
|
||||
... with open(os.path.join(tmp_dir, "model.safetensors.index.json"), "r") as f:
|
||||
... index = json.load(f)
|
||||
|
||||
>>> print(index.keys())
|
||||
dict_keys(['metadata', 'weight_map'])
|
||||
```
|
||||
|
||||
The metadata just consists of the total size of the model for now. We plan to add other information in the future:
|
||||
The `metadata` key provides the total model size.
|
||||
|
||||
```py
|
||||
>>> index["metadata"]
|
||||
{'total_size': 433245184}
|
||||
{'total_size': 28966928384}
|
||||
```
|
||||
|
||||
The weights map is the main part of this index, which maps each parameter name (as usually found in a PyTorch model `state_dict`) to the file it's stored in:
|
||||
The `weight_map` key maps each parameter name (typically `state_dict` in a PyTorch model) to the shard it's stored in.
|
||||
|
||||
```py
|
||||
>>> index["weight_map"]
|
||||
{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
|
||||
'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
|
||||
{'lm_head.weight': 'model-00006-of-00006.safetensors',
|
||||
'model.embed_tokens.weight': 'model-00001-of-00006.safetensors',
|
||||
'model.layers.0.input_layernorm.weight': 'model-00001-of-00006.safetensors',
|
||||
'model.layers.0.mlp.down_proj.weight': 'model-00001-of-00006.safetensors',
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
If you want to directly load such a sharded checkpoint inside a model without using [`~PreTrainedModel.from_pretrained`] (like you would do `model.load_state_dict()` for a full checkpoint) you should use [`~modeling_utils.load_sharded_checkpoint`]:
|
||||
## Accelerate's Big Model Inference
|
||||
|
||||
> [!TIP]
|
||||
> Make sure you have Accelerate v0.9.0 or later and PyTorch v1.9.0 or later installed.
|
||||
|
||||
From Transformers v4.20.0, the [`~PreTrainedModel.from_pretrained`] method is supercharged with Accelerate's [Big Model Inference](https://hf.co/docs/accelerate/usage_guides/big_modeling) feature to efficiently handle really big models! Big Model Inference creates a *model skeleton* on PyTorch's [**meta**](https://pytorch.org/docs/main/meta.html) device. The randomly initialized parameters are only created when the pretrained weights are loaded. This way, you aren't keeping two copies of the model in memory at the same time (one for the randomly initialized model and one for the pretrained weights), and the maximum memory consumed is only the full model size.
|
||||
|
||||
To enable Big Model Inference in Transformers, set `low_cpu_mem_usage=True` in the [`~PreTrainedModel.from_pretrained`] method.
|
||||
|
||||
```py
|
||||
>>> from transformers.modeling_utils import load_sharded_checkpoint
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
>>> with tempfile.TemporaryDirectory() as tmp_dir:
|
||||
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
|
||||
... load_sharded_checkpoint(model, tmp_dir)
|
||||
gemma = AutoModelForCausalLM.from_pretrained("google/gemma-7b", low_cpu_mem_usage=True)
|
||||
```
|
||||
|
||||
## Low memory loading
|
||||
Accelerate automatically dispatches the model weights across all available devices, starting with the fastest device (GPU) first and then offloading to the slower devices (CPU and even hard drive). This is enabled by setting `device_map="auto"` in the [`~PreTrainedModel.from_pretrained`] method. When you pass the `device_map` parameter, `low_cpu_mem_usage` is automatically set to `True` so you don't need to specify it.
|
||||
|
||||
Sharded checkpoints reduce the memory usage during step 2 of the workflow mentioned above, but in order to use that model in a low memory setting, we recommend leveraging our tools based on the Accelerate library.
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
Please read the following guide for more information: [Large model loading using Accelerate](./main_classes/model#large-model-loading)
|
||||
# these loading methods are equivalent
|
||||
gemma = AutoModelForCausalLM.from_pretrained("google/gemma-7b", device_map="auto")
|
||||
gemma = AutoModelForCausalLM.from_pretrained("google/gemma-7b", device_map="auto", low_cpu_mem_usage=True)
|
||||
```
|
||||
|
||||
You can also write your own `device_map` by mapping each layer to a device. It should map all model parameters to a device, but you don't have to detail where all the submodules of a layer go if the entire layer is on the same device.
|
||||
|
||||
```python
|
||||
device_map = {"model.layers.1": 0, "model.layers.14": 1, "model.layers.31": "cpu", "lm_head": "disk"}
|
||||
```
|
||||
|
||||
Access `hf_device_map` attribute to see how Accelerate split the model across devices.
|
||||
|
||||
```py
|
||||
gemma.hf_device_map
|
||||
```
|
||||
|
||||
```python out
|
||||
{'model.embed_tokens': 0,
|
||||
'model.layers.0': 0,
|
||||
'model.layers.1': 0,
|
||||
'model.layers.2': 0,
|
||||
'model.layers.3': 0,
|
||||
'model.layers.4': 0,
|
||||
'model.layers.5': 0,
|
||||
'model.layers.6': 0,
|
||||
'model.layers.7': 0,
|
||||
'model.layers.8': 0,
|
||||
'model.layers.9': 0,
|
||||
'model.layers.10': 0,
|
||||
'model.layers.11': 0,
|
||||
'model.layers.12': 0,
|
||||
'model.layers.13': 0,
|
||||
'model.layers.14': 'cpu',
|
||||
'model.layers.15': 'cpu',
|
||||
'model.layers.16': 'cpu',
|
||||
'model.layers.17': 'cpu',
|
||||
'model.layers.18': 'cpu',
|
||||
'model.layers.19': 'cpu',
|
||||
'model.layers.20': 'cpu',
|
||||
'model.layers.21': 'cpu',
|
||||
'model.layers.22': 'cpu',
|
||||
'model.layers.23': 'cpu',
|
||||
'model.layers.24': 'cpu',
|
||||
'model.layers.25': 'cpu',
|
||||
'model.layers.26': 'cpu',
|
||||
'model.layers.27': 'cpu',
|
||||
'model.layers.28': 'cpu',
|
||||
'model.layers.29': 'cpu',
|
||||
'model.layers.30': 'cpu',
|
||||
'model.layers.31': 'cpu',
|
||||
'model.norm': 'cpu',
|
||||
'lm_head': 'cpu'}
|
||||
```
|
||||
|
||||
## Model data type
|
||||
|
||||
PyTorch model weights are normally instantiated as torch.float32 and it can be an issue if you try to load a model as a different data type. For example, you'd need twice as much memory to load the weights in torch.float32 and then again to load them in your desired data type, like torch.float16.
|
||||
|
||||
> [!WARNING]
|
||||
> Due to how PyTorch is designed, the `torch_dtype` parameter only supports floating data types.
|
||||
|
||||
To avoid wasting memory like this, explicitly set the `torch_dtype` parameter to the desired data type or set `torch_dtype="auto"` to load the weights with the most optimal memory pattern (the data type is automatically derived from the model weights).
|
||||
|
||||
<hfoptions id="dtype">
|
||||
<hfoption id="specific dtype">
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
gemma = AutoModelForCausalLM.from_pretrained("google/gemma-7b", torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="auto dtype">
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
gemma = AutoModelForCausalLM.from_pretrained("google/gemma-7b", torch_dtype="auto")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
You can also set the data type to use for models instantiated from scratch.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import AutoConfig, AutoModel
|
||||
|
||||
my_config = AutoConfig.from_pretrained("google/gemma-2b", torch_dtype=torch.float16)
|
||||
model = AutoModel.from_config(my_config)
|
||||
```
|
||||
|
||||
@ -375,7 +375,7 @@ best performance for inference or fine-tuning when you precisely match the token
|
||||
If you're training a model from scratch, or fine-tuning a base language model for chat, on the other hand,
|
||||
you have a lot of freedom to choose an appropriate template! LLMs are smart enough to learn to handle lots of different
|
||||
input formats. Our default template for models that don't have a class-specific template follows the
|
||||
[ChatML format](https://github.com/openai/openai-python/blob/main/chatml.md), and this is a good, flexible choice for many use-cases. It looks like this:
|
||||
`ChatML` format, and this is a good, flexible choice for many use-cases. It looks like this:
|
||||
|
||||
```
|
||||
{% for message in messages %}
|
||||
|
||||
@ -51,10 +51,10 @@ seemingly giving the agent some kind of memory.
|
||||
Let's take a closer look at how the prompt is structured to understand how it can be best customized.
|
||||
The prompt is structured broadly into four parts.
|
||||
|
||||
- 1. Introduction: how the agent should behave, explanation of the concept of tools.
|
||||
- 2. Description of all the tools. This is defined by a `<<all_tools>>` token that is dynamically replaced at runtime with the tools defined/chosen by the user.
|
||||
- 3. A set of examples of tasks and their solution
|
||||
- 4. Current example, and request for solution.
|
||||
1. Introduction: how the agent should behave, explanation of the concept of tools.
|
||||
2. Description of all the tools. This is defined by a `<<all_tools>>` token that is dynamically replaced at runtime with the tools defined/chosen by the user.
|
||||
3. A set of examples of tasks and their solution
|
||||
4. Current example, and request for solution.
|
||||
|
||||
To better understand each part, let's look at a shortened version of how the `run` prompt can look like:
|
||||
|
||||
@ -301,7 +301,7 @@ and description and try refining your task request with it.
|
||||
### Customizing the tool descriptions
|
||||
|
||||
As we've seen before the agent has access to each of the tools' names and descriptions. The base tools
|
||||
should have very precise names and descriptions, however, you might find that it could help to change the
|
||||
should have very precise names and descriptions, however, you might find that it could help to change
|
||||
the description or name of a tool for your specific use case. This might become especially important
|
||||
when you've added multiple tools that are very similar or if you want to use your agent only for a certain
|
||||
domain, *e.g.* image generation and transformations.
|
||||
@ -427,6 +427,15 @@ To upload your custom prompt on a repo on the Hub and share it with the communit
|
||||
|
||||
## Using custom tools
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Using custom tools in your local runtime means that you'll download code to run on your machine.
|
||||
|
||||
ALWAYS inspect the tool you're downloading before loading it within your runtime, as you would do when
|
||||
installing a package using pip/npm/apt.
|
||||
|
||||
</Tip>
|
||||
|
||||
In this section, we'll be leveraging two existing custom tools that are specific to image generation:
|
||||
|
||||
- We replace [huggingface-tools/image-transformation](https://huggingface.co/spaces/huggingface-tools/image-transformation),
|
||||
|
||||
@ -87,7 +87,7 @@ to stop generation whenever the full generation exceeds some amount of time. To
|
||||
- `num_beams`: by specifying a number of beams higher than 1, you are effectively switching from greedy search to
|
||||
beam search. This strategy evaluates several hypotheses at each time step and eventually chooses the hypothesis that
|
||||
has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
|
||||
sequences that start with a lower probability initial tokens and would've been ignored by the greedy search.
|
||||
sequences that start with a lower probability initial tokens and would've been ignored by the greedy search. Visualize how it works [here](https://huggingface.co/spaces/m-ric/beam_search_visualizer).
|
||||
- `do_sample`: if set to `True`, this parameter enables decoding strategies such as multinomial sampling, beam-search
|
||||
multinomial sampling, Top-K sampling and Top-p sampling. All these strategies select the next token from the probability
|
||||
distribution over the entire vocabulary with various strategy-specific adjustments.
|
||||
@ -254,6 +254,12 @@ Unlike greedy search, beam-search decoding keeps several hypotheses at each time
|
||||
the hypothesis that has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
|
||||
sequences that start with lower probability initial tokens and would've been ignored by the greedy search.
|
||||
|
||||
<a href="https://huggingface.co/spaces/m-ric/beam_search_visualizer" class="flex flex-col justify-center">
|
||||
<img style="max-width: 90%; margin: auto;" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/beam_search.png"/>
|
||||
</a>
|
||||
|
||||
You can visualize how beam-search decoding works in [this interactive demo](https://huggingface.co/spaces/m-ric/beam_search_visualizer): type your input sentence, and play with the parameters to see how the decoding beams change.
|
||||
|
||||
To enable this decoding strategy, specify the `num_beams` (aka number of hypotheses to keep track of) that is greater than 1.
|
||||
|
||||
```python
|
||||
@ -389,3 +395,6 @@ just like in multinomial sampling. However, in assisted decoding, reducing the t
|
||||
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
['Alice and Bob are going to the same party. It is a small party, in a small']
|
||||
```
|
||||
|
||||
Alternativelly, you can also set the `prompt_lookup_num_tokens` to trigger n-gram based assisted decoding, as opposed
|
||||
to model based assisted decoding. You can read more about it [here](https://twitter.com/joao_gante/status/1747322413006643259).
|
||||
|
||||
@ -66,4 +66,4 @@ For some quantization methods, they may require "pre-quantizing" the models thro
|
||||
|
||||
7. Document everything! Make sure your quantization method is documented in the [`docs/source/en/quantization.md`](https://github.com/huggingface/transformers/blob/abbffc4525566a48a9733639797c812301218b83/docs/source/en/quantization.md) file.
|
||||
|
||||
8. Add tests! You should add tests by first adding the package in our nightly Dockerfile inside `docker/transformers-all-latest-gpu` and then adding a new test file in `tests/quantization/xxx`. Feel free to check out how it is implemented for other quantization methods.
|
||||
8. Add tests! You should add tests by first adding the package in our nightly Dockerfile inside `docker/transformers-quantization-latest-gpu` and then adding a new test file in `tests/quantization/xxx`. Feel free to check out how it is implemented for other quantization methods.
|
||||
|
||||
@ -95,6 +95,7 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| [CLVP](model_doc/clvp) | ✅ | ❌ | ❌ |
|
||||
| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
|
||||
| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ✅ |
|
||||
| [Cohere](model_doc/cohere) | ✅ | ❌ | ❌ |
|
||||
| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
|
||||
| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
|
||||
| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
|
||||
@ -142,6 +143,7 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
|
||||
| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
|
||||
| [Fuyu](model_doc/fuyu) | ✅ | ❌ | ❌ |
|
||||
| [Gemma](model_doc/gemma) | ✅ | ❌ | ✅ |
|
||||
| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
|
||||
| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
|
||||
| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
|
||||
@ -172,6 +174,7 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| [LLaMA](model_doc/llama) | ✅ | ❌ | ✅ |
|
||||
| [Llama2](model_doc/llama2) | ✅ | ❌ | ✅ |
|
||||
| [LLaVa](model_doc/llava) | ✅ | ❌ | ❌ |
|
||||
| [LLaVA-NeXT](model_doc/llava_next) | ✅ | ❌ | ❌ |
|
||||
| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
|
||||
| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
|
||||
| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
|
||||
@ -179,6 +182,7 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
|
||||
| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
|
||||
| [MADLAD-400](model_doc/madlad-400) | ✅ | ✅ | ✅ |
|
||||
| [Mamba](model_doc/mamba) | ✅ | ❌ | ❌ |
|
||||
| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
|
||||
| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
|
||||
| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
|
||||
@ -204,6 +208,7 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
|
||||
| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
|
||||
| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
|
||||
| [MusicGen Melody](model_doc/musicgen_melody) | ✅ | ❌ | ❌ |
|
||||
| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
|
||||
| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
|
||||
| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
|
||||
@ -232,8 +237,10 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
|
||||
| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
|
||||
| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
|
||||
| [PVTv2](model_doc/pvt_v2) | ✅ | ❌ | ❌ |
|
||||
| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
|
||||
| [Qwen2](model_doc/qwen2) | ✅ | ❌ | ❌ |
|
||||
| [Qwen2MoE](model_doc/qwen2_moe) | ✅ | ❌ | ❌ |
|
||||
| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
|
||||
| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
|
||||
| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
|
||||
@ -250,6 +257,7 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
|
||||
| [SeamlessM4Tv2](model_doc/seamless_m4t_v2) | ✅ | ❌ | ❌ |
|
||||
| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
|
||||
| [SegGPT](model_doc/seggpt) | ✅ | ❌ | ❌ |
|
||||
| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
|
||||
| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
|
||||
| [SigLIP](model_doc/siglip) | ✅ | ❌ | ❌ |
|
||||
@ -259,6 +267,8 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
|
||||
| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
|
||||
| [StableLm](model_doc/stablelm) | ✅ | ❌ | ❌ |
|
||||
| [Starcoder2](model_doc/starcoder2) | ✅ | ❌ | ❌ |
|
||||
| [SuperPoint](model_doc/superpoint) | ✅ | ❌ | ❌ |
|
||||
| [SwiftFormer](model_doc/swiftformer) | ✅ | ❌ | ❌ |
|
||||
| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
|
||||
| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
|
||||
@ -276,6 +286,7 @@ Flax), PyTorch, and/or TensorFlow.
|
||||
| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
|
||||
| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
|
||||
| [TVP](model_doc/tvp) | ✅ | ❌ | ❌ |
|
||||
| [UDOP](model_doc/udop) | ✅ | ❌ | ❌ |
|
||||
| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
|
||||
| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
|
||||
| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
|
||||
|
||||
@ -16,16 +16,7 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
# Utilities for Generation
|
||||
|
||||
This page lists all the utility functions used by [`~generation.GenerationMixin.generate`],
|
||||
[`~generation.GenerationMixin.greedy_search`],
|
||||
[`~generation.GenerationMixin.contrastive_search`],
|
||||
[`~generation.GenerationMixin.sample`],
|
||||
[`~generation.GenerationMixin.beam_search`],
|
||||
[`~generation.GenerationMixin.beam_sample`],
|
||||
[`~generation.GenerationMixin.group_beam_search`], and
|
||||
[`~generation.GenerationMixin.constrained_beam_search`].
|
||||
|
||||
Most of those are only useful if you are studying the code of the generate methods in the library.
|
||||
This page lists all the utility functions used by [`~generation.GenerationMixin.generate`].
|
||||
|
||||
## Generate Outputs
|
||||
|
||||
@ -345,12 +336,6 @@ A [`Constraint`] can be used to force the generation to include specific tokens
|
||||
- process
|
||||
- finalize
|
||||
|
||||
## Utilities
|
||||
|
||||
[[autodoc]] top_k_top_p_filtering
|
||||
|
||||
[[autodoc]] tf_top_k_top_p_filtering
|
||||
|
||||
## Streamers
|
||||
|
||||
[[autodoc]] TextStreamer
|
||||
@ -376,4 +361,4 @@ A [`Constraint`] can be used to force the generation to include specific tokens
|
||||
|
||||
[[autodoc]] StaticCache
|
||||
- update
|
||||
- get_seq_length
|
||||
- get_seq_length
|
||||
|
||||
@ -40,104 +40,6 @@ for text generation, [`~generation.GenerationMixin`] (for the PyTorch models),
|
||||
- push_to_hub
|
||||
- all
|
||||
|
||||
<a id='from_pretrained-torch-dtype'></a>
|
||||
|
||||
### Large model loading
|
||||
|
||||
In Transformers 4.20.0, the [`~PreTrainedModel.from_pretrained`] method has been reworked to accommodate large models using [Accelerate](https://huggingface.co/docs/accelerate/big_modeling). This requires Accelerate >= 0.9.0 and PyTorch >= 1.9.0. Instead of creating the full model, then loading the pretrained weights inside it (which takes twice the size of the model in RAM, one for the randomly initialized model, one for the weights), there is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded.
|
||||
|
||||
This option can be activated with `low_cpu_mem_usage=True`. The model is first created on the Meta device (with empty weights) and the state dict is then loaded inside it (shard by shard in the case of a sharded checkpoint). This way the maximum RAM used is the full size of the model only.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForSeq2SeqLM
|
||||
|
||||
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", low_cpu_mem_usage=True)
|
||||
```
|
||||
|
||||
Moreover, you can directly place the model on different devices if it doesn't fully fit in RAM (only works for inference for now). With `device_map="auto"`, Accelerate will determine where to put each layer to maximize the use of your fastest devices (GPUs) and offload the rest on the CPU, or even the hard drive if you don't have enough GPU RAM (or CPU RAM). Even if the model is split across several devices, it will run as you would normally expect.
|
||||
|
||||
When passing a `device_map`, `low_cpu_mem_usage` is automatically set to `True`, so you don't need to specify it:
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForSeq2SeqLM
|
||||
|
||||
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
|
||||
```
|
||||
|
||||
You can inspect how the model was split across devices by looking at its `hf_device_map` attribute:
|
||||
|
||||
```py
|
||||
t0pp.hf_device_map
|
||||
```
|
||||
|
||||
```python out
|
||||
{'shared': 0,
|
||||
'decoder.embed_tokens': 0,
|
||||
'encoder': 0,
|
||||
'decoder.block.0': 0,
|
||||
'decoder.block.1': 1,
|
||||
'decoder.block.2': 1,
|
||||
'decoder.block.3': 1,
|
||||
'decoder.block.4': 1,
|
||||
'decoder.block.5': 1,
|
||||
'decoder.block.6': 1,
|
||||
'decoder.block.7': 1,
|
||||
'decoder.block.8': 1,
|
||||
'decoder.block.9': 1,
|
||||
'decoder.block.10': 1,
|
||||
'decoder.block.11': 1,
|
||||
'decoder.block.12': 1,
|
||||
'decoder.block.13': 1,
|
||||
'decoder.block.14': 1,
|
||||
'decoder.block.15': 1,
|
||||
'decoder.block.16': 1,
|
||||
'decoder.block.17': 1,
|
||||
'decoder.block.18': 1,
|
||||
'decoder.block.19': 1,
|
||||
'decoder.block.20': 1,
|
||||
'decoder.block.21': 1,
|
||||
'decoder.block.22': 'cpu',
|
||||
'decoder.block.23': 'cpu',
|
||||
'decoder.final_layer_norm': 'cpu',
|
||||
'decoder.dropout': 'cpu',
|
||||
'lm_head': 'cpu'}
|
||||
```
|
||||
|
||||
You can also write your own device map following the same format (a dictionary layer name to device). It should map all parameters of the model to a given device, but you don't have to detail where all the submodules of one layer go if that layer is entirely on the same device. For instance, the following device map would work properly for T0pp (as long as you have the GPU memory):
|
||||
|
||||
```python
|
||||
device_map = {"shared": 0, "encoder": 0, "decoder": 1, "lm_head": 1}
|
||||
```
|
||||
|
||||
Another way to minimize the memory impact of your model is to instantiate it at a lower precision dtype (like `torch.float16`) or use direct quantization techniques as described below.
|
||||
|
||||
### Model Instantiation dtype
|
||||
|
||||
Under Pytorch a model normally gets instantiated with `torch.float32` format. This can be an issue if one tries to
|
||||
load a model whose weights are in fp16, since it'd require twice as much memory. To overcome this limitation, you can
|
||||
either explicitly pass the desired `dtype` using `torch_dtype` argument:
|
||||
|
||||
```python
|
||||
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
or, if you want the model to always load in the most optimal memory pattern, you can use the special value `"auto"`,
|
||||
and then `dtype` will be automatically derived from the model's weights:
|
||||
|
||||
```python
|
||||
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype="auto")
|
||||
```
|
||||
|
||||
Models instantiated from scratch can also be told which `dtype` to use with:
|
||||
|
||||
```python
|
||||
config = T5Config.from_pretrained("t5")
|
||||
model = AutoModel.from_config(config)
|
||||
```
|
||||
|
||||
Due to Pytorch design, this functionality is only available for floating dtypes.
|
||||
|
||||
|
||||
## ModuleUtilsMixin
|
||||
|
||||
[[autodoc]] modeling_utils.ModuleUtilsMixin
|
||||
|
||||
@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
# Quantization
|
||||
|
||||
Quantization techniques reduces memory and computational costs by representing weights and activations with lower-precision data types like 8-bit integers (int8). This enables loading larger models you normally wouldn't be able to fit into memory, and speeding up inference. Transformers supports the AWQ and GPTQ quantization algorithms and it supports 8-bit and 4-bit quantization with bitsandbytes.
|
||||
Quantization techniques reduce memory and computational costs by representing weights and activations with lower-precision data types like 8-bit integers (int8). This enables loading larger models you normally wouldn't be able to fit into memory, and speeding up inference. Transformers supports the AWQ and GPTQ quantization algorithms and it supports 8-bit and 4-bit quantization with bitsandbytes.
|
||||
|
||||
Quantization techniques that aren't supported in Transformers can be added with the [`HfQuantizer`] class.
|
||||
|
||||
@ -26,6 +26,10 @@ Learn how to quantize models in the [Quantization](../quantization) guide.
|
||||
|
||||
</Tip>
|
||||
|
||||
## QuantoConfig
|
||||
|
||||
[[autodoc]] QuantoConfig
|
||||
|
||||
## AqlmConfig
|
||||
|
||||
[[autodoc]] AqlmConfig
|
||||
|
||||
@ -37,19 +37,15 @@ like token streaming.
|
||||
- from_pretrained
|
||||
- from_model_config
|
||||
- save_pretrained
|
||||
- update
|
||||
- validate
|
||||
- get_generation_mode
|
||||
|
||||
## GenerationMixin
|
||||
|
||||
[[autodoc]] generation.GenerationMixin
|
||||
- generate
|
||||
- compute_transition_scores
|
||||
- greedy_search
|
||||
- sample
|
||||
- beam_search
|
||||
- beam_sample
|
||||
- contrastive_search
|
||||
- group_beam_search
|
||||
- constrained_beam_search
|
||||
|
||||
## TFGenerationMixin
|
||||
|
||||
|
||||
@ -250,6 +250,10 @@ The following auto classes are available for the following computer vision tasks
|
||||
|
||||
[[autodoc]] AutoModelForVideoClassification
|
||||
|
||||
### AutoModelForKeypointDetection
|
||||
|
||||
[[autodoc]] AutoModelForKeypointDetection
|
||||
|
||||
### AutoModelForMaskedImageModeling
|
||||
|
||||
[[autodoc]] AutoModelForMaskedImageModeling
|
||||
|
||||
@ -79,7 +79,7 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
|
||||
<PipelineTag pipeline="token-classification"/>
|
||||
|
||||
- A blog post on how to use [Hugging Face Transformers with Keras: Fine-tune a non-English BERT for Named Entity Recognition](https://www.philschmid.de/huggingface-transformers-keras-tf).
|
||||
- A notebook for [Finetuning BERT for named-entity recognition](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/Custom_Named_Entity_Recognition_with_BERT_only_first_wordpiece.ipynb) using only the first wordpiece of each word in the word label during tokenization. To propagate the label of the word to all wordpieces, see this [version](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT.ipynb) of the notebook instead.
|
||||
- A notebook for [Finetuning BERT for named-entity recognition](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT_only_first_wordpiece.ipynb) using only the first wordpiece of each word in the word label during tokenization. To propagate the label of the word to all wordpieces, see this [version](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT.ipynb) of the notebook instead.
|
||||
- [`BertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb).
|
||||
- [`TFBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
|
||||
- [`FlaxBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
|
||||
|
||||
141
docs/source/en/model_doc/cohere.md
Normal file
141
docs/source/en/model_doc/cohere.md
Normal file
@ -0,0 +1,141 @@
|
||||
# Cohere
|
||||
|
||||
## Overview
|
||||
|
||||
The Cohere Command-R model was proposed in the blogpost [Command-R: Retrieval Augmented Generation at Production Scale](https://txt.cohere.com/command-r/) by the Cohere Team.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*Command-R is a scalable generative model targeting RAG and Tool Use to enable production-scale AI for enterprise. Today, we are introducing Command-R, a new LLM aimed at large-scale production workloads. Command-R targets the emerging “scalable” category of models that balance high efficiency with strong accuracy, enabling companies to move beyond proof of concept, and into production.*
|
||||
|
||||
*Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is designed to work in concert with our industry-leading Embed and Rerank models to provide best-in-class integration for RAG applications and excel at enterprise use cases. As a model built for companies to implement at scale, Command-R boasts:
|
||||
- Strong accuracy on RAG and Tool Use
|
||||
- Low latency, and high throughput
|
||||
- Longer 128k context and lower pricing
|
||||
- Strong capabilities across 10 key languages
|
||||
- Model weights available on HuggingFace for research and evaluation
|
||||
|
||||
Checkout model checkpoints [here](https://huggingface.co/CohereForAI/c4ai-command-r-v01).
|
||||
This model was contributed by [Saurabh Dash](https://huggingface.co/saurabhdash) and [Ahmet Üstün](https://huggingface.co/ahmetustun). The code of the implementation in Hugging Face is based on GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox).
|
||||
|
||||
## Usage tips
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
The checkpoints uploaded on the Hub use `torch_dtype = 'float16'`, which will be
|
||||
used by the `AutoModel` API to cast the checkpoints from `torch.float32` to `torch.float16`.
|
||||
|
||||
The `dtype` of the online weights is mostly irrelevant unless you are using `torch_dtype="auto"` when initializing a model using `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`. The reason is that the model will first be downloaded ( using the `dtype` of the checkpoints online), then it will be casted to the default `dtype` of `torch` (becomes `torch.float32`), and finally, if there is a `torch_dtype` provided in the config, it will be used.
|
||||
|
||||
Training the model in `float16` is not recommended and is known to produce `nan`; as such, the model should be trained in `bfloat16`.
|
||||
|
||||
</Tip>
|
||||
The model and tokenizer can be loaded via:
|
||||
|
||||
```python
|
||||
# pip install transformers
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
|
||||
model_id = "CohereForAI/c4ai-command-r-v01"
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
|
||||
# Format message with the command-r chat template
|
||||
messages = [{"role": "user", "content": "Hello, how are you?"}]
|
||||
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
|
||||
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Hello, how are you?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
|
||||
|
||||
gen_tokens = model.generate(
|
||||
input_ids,
|
||||
max_new_tokens=100,
|
||||
do_sample=True,
|
||||
temperature=0.3,
|
||||
)
|
||||
|
||||
gen_text = tokenizer.decode(gen_tokens[0])
|
||||
print(gen_text)
|
||||
```
|
||||
|
||||
- When using Flash Attention 2 via `attn_implementation="flash_attention_2"`, don't pass `torch_dtype` to the `from_pretrained` class method and use Automatic Mixed-Precision training. When using `Trainer`, it is simply specifying either `fp16` or `bf16` to `True`. Otherwise, make sure you are using `torch.autocast`. This is required because the Flash Attention only support `fp16` and `bf16` data type.
|
||||
|
||||
|
||||
## Resources
|
||||
|
||||
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Command-R. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
|
||||
|
||||
|
||||
<PipelineTag pipeline="text-generation"/>
|
||||
|
||||
Loading FP16 model
|
||||
```python
|
||||
# pip install transformers
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
|
||||
model_id = "CohereForAI/c4ai-command-r-v01"
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
|
||||
# Format message with the command-r chat template
|
||||
messages = [{"role": "user", "content": "Hello, how are you?"}]
|
||||
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
|
||||
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Hello, how are you?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
|
||||
|
||||
gen_tokens = model.generate(
|
||||
input_ids,
|
||||
max_new_tokens=100,
|
||||
do_sample=True,
|
||||
temperature=0.3,
|
||||
)
|
||||
|
||||
gen_text = tokenizer.decode(gen_tokens[0])
|
||||
print(gen_text)
|
||||
```
|
||||
|
||||
Loading bitsnbytes 4bit quantized model
|
||||
```python
|
||||
# pip install transformers bitsandbytes accelerate
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
|
||||
|
||||
bnb_config = BitsAndBytesConfig(load_in_4bit=True)
|
||||
|
||||
model_id = "CohereForAI/c4ai-command-r-v01"
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config)
|
||||
|
||||
gen_tokens = model.generate(
|
||||
input_ids,
|
||||
max_new_tokens=100,
|
||||
do_sample=True,
|
||||
temperature=0.3,
|
||||
)
|
||||
|
||||
gen_text = tokenizer.decode(gen_tokens[0])
|
||||
print(gen_text)
|
||||
```
|
||||
|
||||
|
||||
## CohereConfig
|
||||
|
||||
[[autodoc]] CohereConfig
|
||||
|
||||
## CohereTokenizerFast
|
||||
|
||||
[[autodoc]] CohereTokenizerFast
|
||||
- build_inputs_with_special_tokens
|
||||
- get_special_tokens_mask
|
||||
- create_token_type_ids_from_sequences
|
||||
- update_post_processor
|
||||
- save_vocabulary
|
||||
|
||||
## CohereModel
|
||||
|
||||
[[autodoc]] CohereModel
|
||||
- forward
|
||||
|
||||
|
||||
## CohereForCausalLM
|
||||
|
||||
[[autodoc]] CohereForCausalLM
|
||||
- forward
|
||||
|
||||
|
||||
@ -24,7 +24,7 @@ This model was contributed by [Connor Henderson](https://huggingface.co/connor-h
|
||||
|
||||
|
||||
## 🤗 Model Architecture
|
||||
FastSpeech2's general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with with conformer blocks as done in the ESPnet library.
|
||||
FastSpeech2's general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with conformer blocks as done in the ESPnet library.
|
||||
|
||||
#### FastSpeech2 Model Architecture
|
||||

|
||||
|
||||
@ -81,7 +81,7 @@ text_prompt = "Generate a coco-style caption.\\n"
|
||||
|
||||
bus_image_url = "https://huggingface.co/datasets/hf-internal-testing/fixtures-captioning/resolve/main/bus.png"
|
||||
bus_image_pil = Image.open(io.BytesIO(requests.get(bus_image_url).content))
|
||||
inputs_to_model = processor(text=text_prompt, images=image_pil)
|
||||
inputs_to_model = processor(text=text_prompt, images=bus_image_pil)
|
||||
|
||||
|
||||
```
|
||||
|
||||
71
docs/source/en/model_doc/gemma.md
Normal file
71
docs/source/en/model_doc/gemma.md
Normal file
@ -0,0 +1,71 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Gemma
|
||||
|
||||
## Overview
|
||||
|
||||
The Gemma model was proposed in [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by Gemma Team, Google.
|
||||
Gemma models are trained on 6T tokens, and released with 2 versions, 2b and 7b.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*This work introduces Gemma, a new family of open language models demonstrating strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of our model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations*
|
||||
|
||||
Tips:
|
||||
|
||||
- The original checkpoints can be converted using the conversion script `src/transformers/models/gemma/convert_gemma_weights_to_hf.py`
|
||||
|
||||
This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ), [Younes Belkada](https://huggingface.co/ybelkada), [Sanchit Gandhi](https://huggingface.co/sanchit-gandhi), [Pedro Cuenca](https://huggingface.co/pcuenq).
|
||||
|
||||
|
||||
## GemmaConfig
|
||||
|
||||
[[autodoc]] GemmaConfig
|
||||
|
||||
## GemmaTokenizer
|
||||
|
||||
[[autodoc]] GemmaTokenizer
|
||||
|
||||
|
||||
## GemmaTokenizerFast
|
||||
|
||||
[[autodoc]] GemmaTokenizerFast
|
||||
|
||||
## GemmaModel
|
||||
|
||||
[[autodoc]] GemmaModel
|
||||
- forward
|
||||
|
||||
## GemmaForCausalLM
|
||||
|
||||
[[autodoc]] GemmaForCausalLM
|
||||
- forward
|
||||
|
||||
## GemmaForSequenceClassification
|
||||
|
||||
[[autodoc]] GemmaForSequenceClassification
|
||||
- forward
|
||||
|
||||
## FlaxGemmaModel
|
||||
|
||||
[[autodoc]] FlaxGemmaModel
|
||||
- __call__
|
||||
|
||||
## FlaxGemmaForCausalLM
|
||||
|
||||
[[autodoc]] FlaxGemmaForCausalLM
|
||||
- __call__
|
||||
@ -60,6 +60,73 @@ This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The o
|
||||
- Enabling the *scale_attn_by_inverse_layer_idx* and *reorder_and_upcast_attn* flags will apply the training stability
|
||||
improvements from [Mistral](https://github.com/stanford-crfm/mistral/) (for PyTorch only).
|
||||
|
||||
## Usage example
|
||||
|
||||
The `generate()` method can be used to generate text using GPT2 model.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
|
||||
|
||||
>>> prompt = "GPT2 is a model developed by OpenAI."
|
||||
|
||||
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
|
||||
|
||||
>>> gen_tokens = model.generate(
|
||||
... input_ids,
|
||||
... do_sample=True,
|
||||
... temperature=0.9,
|
||||
... max_length=100,
|
||||
... )
|
||||
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
|
||||
```
|
||||
|
||||
## Using Flash Attention 2
|
||||
|
||||
Flash Attention 2 is a faster, optimized version of the attention scores computation which relies on `cuda` kernels.
|
||||
|
||||
### Installation
|
||||
|
||||
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features). If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered [above](https://huggingface.co/docs/transformers/main/en/model_doc/bark#using-better-transformer).
|
||||
|
||||
Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
|
||||
|
||||
```bash
|
||||
pip install -U flash-attn --no-build-isolation
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
To load a model using Flash Attention 2, we can pass the argument `attn_implementation="flash_attention_2"` to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). We'll also load the model in half-precision (e.g. `torch.float16`), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
>>> device = "cuda" # the device to load the model onto
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("gpt2", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
|
||||
|
||||
>>> prompt = "def hello_world():"
|
||||
|
||||
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
|
||||
>>> model.to(device)
|
||||
|
||||
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
|
||||
>>> tokenizer.batch_decode(generated_ids)[0]
|
||||
```
|
||||
|
||||
|
||||
### Expected speedups
|
||||
|
||||
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `gpt2` checkpoint and the Flash Attention 2 version of the model using a sequence length of 512.
|
||||
|
||||
<div style="text-align: center">
|
||||
<img src="https://huggingface.co/datasets/EduardoPacheco/documentation-images/resolve/main/gpt2_flash_attention_2_speedup.jpg">
|
||||
</div>
|
||||
|
||||
## Resources
|
||||
|
||||
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GPT2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
|
||||
|
||||
147
docs/source/en/model_doc/llava_next.md
Normal file
147
docs/source/en/model_doc/llava_next.md
Normal file
@ -0,0 +1,147 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# LLaVA-NeXT
|
||||
|
||||
## Overview
|
||||
|
||||
The LLaVA-NeXT model was proposed in [LLaVA-NeXT: Improved reasoning, OCR, and world knowledge](https://llava-vl.github.io/blog/2024-01-30-llava-next/) by Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, Yong Jae Lee. LLaVa-NeXT (also called LLaVa-1.6) improves upon [LLaVa](llava) by increasing the input image resolution and training on an improved visual instruction tuning dataset to improve OCR and common sense reasoning.
|
||||
|
||||
The introduction from the blog is the following:
|
||||
|
||||
*In October 2023, we released LLaVA-1.5 with a simple and efficient design along with great performance on a benchmark suite of 12 datasets. It has since served as the foundation of many comprehensive studies of data, model, and capabilities of large multimodal models (LMM), and has enabled various new applications.
|
||||
|
||||
Today, we are thrilled to present LLaVA-NeXT, with improved reasoning, OCR, and world knowledge. LLaVA-NeXT even exceeds Gemini Pro on several benchmarks.
|
||||
|
||||
Compared with LLaVA-1.5, LLaVA-NeXT has several improvements:
|
||||
|
||||
Increasing the input image resolution to 4x more pixels. This allows it to grasp more visual details. It supports three aspect ratios, up to 672x672, 336x1344, 1344x336 resolution.
|
||||
Better visual reasoning and OCR capability with an improved visual instruction tuning data mixture.
|
||||
Better visual conversation for more scenarios, covering different applications. Better world knowledge and logical reasoning.
|
||||
Efficient deployment and inference with SGLang.
|
||||
Along with performance improvements, LLaVA-NeXT maintains the minimalist design and data efficiency of LLaVA-1.5. It re-uses the pretrained connector of LLaVA-1.5, and still uses less than 1M visual instruction tuning samples. The largest 34B variant finishes training in ~1 day with 32 A100s.*
|
||||
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/llava_next_overview.png"
|
||||
alt="drawing" width="600"/>
|
||||
|
||||
<small> LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the <a href="https://arxiv.org/abs/2310.03744">original paper.</a> </small>
|
||||
|
||||
This model was contributed by [nielsr](https://huggingface.co/nielsr).
|
||||
The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main).
|
||||
|
||||
## Usage tips
|
||||
|
||||
- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
|
||||
|
||||
- Note that each checkpoint has been trained with a specific prompt format, depending on which large language model (LLM) was used. Below, we list the correct prompt formats to use for the text prompt "What is shown in this image?":
|
||||
|
||||
[llava-v1.6-mistral-7b-hf](https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf) requires the following format:
|
||||
|
||||
```bash
|
||||
"[INST] <image>\nWhat is shown in this image? [/INST]"
|
||||
```
|
||||
|
||||
[llava-v1.6-vicuna-7b-hf](https://huggingface.co/llava-hf/llava-v1.6-vicuna-7b-hf) and [llava-v1.6-vicuna-13b-hf](https://huggingface.co/llava-hf/llava-v1.6-vicuna-13b-hf) require the following format:
|
||||
|
||||
```bash
|
||||
"A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: <image>\nWhat is shown in this image? ASSISTANT:"
|
||||
```
|
||||
|
||||
[llava-v1.6-34b-hf](https://huggingface.co/llava-hf/llava-v1.6-34b-hf) requires the following format:
|
||||
|
||||
```bash
|
||||
"<|im_start|>system\nAnswer the questions.<|im_end|><|im_start|>user\n<image>\nWhat is shown in this image?<|im_end|><|im_start|>assistant\n"
|
||||
```
|
||||
|
||||
## Usage example
|
||||
|
||||
Here's how to load the model and perform inference in half-precision (`torch.float16`):
|
||||
|
||||
```python
|
||||
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
|
||||
import torch
|
||||
from PIL import Image
|
||||
import requests
|
||||
|
||||
processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
|
||||
|
||||
model = LlavaNextForConditionalGeneration.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf", torch_dtype=torch.float16, low_cpu_mem_usage=True)
|
||||
model.to("cuda:0")
|
||||
|
||||
# prepare image and text prompt, using the appropriate prompt template
|
||||
url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
prompt = "[INST] <image>\nWhat is shown in this image? [/INST]"
|
||||
|
||||
inputs = processor(prompt, image, return_tensors="pt").to("cuda:0")
|
||||
|
||||
# autoregressively complete prompt
|
||||
output = model.generate(**inputs, max_new_tokens=100)
|
||||
|
||||
print(processor.decode(output[0], skip_special_tokens=True))
|
||||
```
|
||||
|
||||
## Model optimization
|
||||
|
||||
### Quantization using Bitsandbytes
|
||||
|
||||
The model can be loaded in 8 or 4 bits, greatly reducing the memory requirements while maintaining the performance of the original model. First make sure to install bitsandbytes, `pip install bitsandbytes`` and make sure to have access to a CUDA compatible GPU device. Simply change the snippet above with:
|
||||
|
||||
```python
|
||||
from transformers import LlavaNextForConditionalGeneration, BitsAndBytesConfig
|
||||
|
||||
# specify how to quantize the model
|
||||
quantization_config = BitsAndBytesConfig(
|
||||
load_in_4bit=True,
|
||||
bnb_4bit_quant_type="nf4",
|
||||
bnb_4bit_compute_dtype=torch.float16,
|
||||
)
|
||||
|
||||
model = LlavaNextForConditionalGeneration.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf", quantization_config=quantization_config, device_map="auto")
|
||||
```
|
||||
|
||||
### Use Flash-Attention 2 to further speed-up generation
|
||||
|
||||
First make sure to install flash-attn. Refer to the [original repository of Flash Attention](https://github.com/Dao-AILab/flash-attention) regarding that package installation. Simply change the snippet above with:
|
||||
|
||||
```python
|
||||
from transformers import LlavaNextForConditionalGeneration
|
||||
|
||||
model = LlavaNextForConditionalGeneration.from_pretrained(
|
||||
model_id,
|
||||
torch_dtype=torch.float16,
|
||||
low_cpu_mem_usage=True,
|
||||
use_flash_attention_2=True
|
||||
).to(0)
|
||||
```
|
||||
|
||||
## LlavaNextConfig
|
||||
|
||||
[[autodoc]] LlavaNextConfig
|
||||
|
||||
## LlavaNextImageProcessor
|
||||
|
||||
[[autodoc]] LlavaNextImageProcessor
|
||||
- preprocess
|
||||
|
||||
## LlavaNextProcessor
|
||||
|
||||
[[autodoc]] LlavaNextProcessor
|
||||
|
||||
## LlavaNextForConditionalGeneration
|
||||
|
||||
[[autodoc]] LlavaNextForConditionalGeneration
|
||||
- forward
|
||||
104
docs/source/en/model_doc/mamba.md
Normal file
104
docs/source/en/model_doc/mamba.md
Normal file
@ -0,0 +1,104 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Mamba
|
||||
|
||||
## Overview
|
||||
|
||||
The Mamba model was proposed in [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) by Albert Gu and Tri Dao.
|
||||
|
||||
This model is a new paradigm architecture based on `state-space-models`. You can read more about the intuition behind these [here](https://srush.github.io/annotated-s4/).
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5× higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.*
|
||||
|
||||
Tips:
|
||||
|
||||
- Mamba is a new `state space model` architecture that rivals the classic Transformers. It is based on the line of progress on structured state space models, with an efficient hardware-aware design and implementation in the spirit of [FlashAttention](https://github.com/Dao-AILab/flash-attention).
|
||||
- Mamba stacks `mixer` layers, which are the equivalent of `Attention` layers. The core logic of `mamba` is held in the `MambaMixer` class.
|
||||
- Two implementations cohabit: one is optimized and uses fast cuda kernels, while the other one is naive but can run on any device!
|
||||
- The current implementation leverages the original cuda kernels: the equivalent of flash attention for Mamba are hosted in the [`mamba-ssm`](https://github.com/state-spaces/mamba) and the [`causal_conv1d`](https://github.com/Dao-AILab/causal-conv1d) repositories. Make sure to install them if your hardware supports them!
|
||||
- Contributions to make the naive path faster are welcome 🤗
|
||||
|
||||
This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ).
|
||||
The original code can be found [here](https://github.com/state-spaces/mamba).
|
||||
|
||||
# Usage
|
||||
|
||||
### A simple generation example:
|
||||
```python
|
||||
from transformers import MambaConfig, MambaForCausalLM, AutoTokenizer
|
||||
import torch
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("state-spaces/mamba-130m-hf")
|
||||
model = MambaForCausalLM.from_pretrained("state-spaces/mamba-130m-hf")
|
||||
input_ids = tokenizer("Hey how are you doing?", return_tensors= "pt")["input_ids"]
|
||||
|
||||
out = model.generate(input_ids, max_new_tokens=10)
|
||||
print(tokenizer.batch_decode(out))
|
||||
```
|
||||
|
||||
### Peft finetuning
|
||||
The slow version is not very stable for training, and the fast one needs `float32`!
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
from trl import SFTTrainer
|
||||
from peft import LoraConfig
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments
|
||||
model_id = "state-spaces/mamba-130m-hf"
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
dataset = load_dataset("Abirate/english_quotes", split="train")
|
||||
training_args = TrainingArguments(
|
||||
output_dir="./results",
|
||||
num_train_epochs=3,
|
||||
per_device_train_batch_size=4,
|
||||
logging_dir='./logs',
|
||||
logging_steps=10,
|
||||
learning_rate=2e-3
|
||||
)
|
||||
lora_config = LoraConfig(
|
||||
r=8,
|
||||
target_modules=["x_proj", "embeddings", "in_proj", "out_proj"],
|
||||
task_type="CAUSAL_LM",
|
||||
bias="none"
|
||||
)
|
||||
trainer = SFTTrainer(
|
||||
model=model,
|
||||
tokenizer=tokenizer,
|
||||
args=training_args,
|
||||
peft_config=lora_config,
|
||||
train_dataset=dataset,
|
||||
dataset_text_field="quote",
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## MambaConfig
|
||||
|
||||
[[autodoc]] MambaConfig
|
||||
|
||||
## MambaModel
|
||||
|
||||
[[autodoc]] MambaModel
|
||||
- forward
|
||||
|
||||
## MambaLMHeadModel
|
||||
|
||||
[[autodoc]] MambaForCausalLM
|
||||
- forward
|
||||
@ -18,71 +18,80 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
## Overview
|
||||
|
||||
Mistral-7B-v0.1 is Mistral AI's first Large Language Model (LLM).
|
||||
Mistral was introduced in the [this blogpost](https://mistral.ai/news/announcing-mistral-7b/) by Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
|
||||
### Model Details
|
||||
The introduction of the blog post says:
|
||||
|
||||
Mistral-7B-v0.1 is a decoder-based LM with the following architectural choices:
|
||||
* Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
|
||||
* GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
|
||||
* Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
|
||||
*Mistral AI team is proud to release Mistral 7B, the most powerful language model for its size to date.*
|
||||
|
||||
We also provide an instruction fine-tuned model: `Mistral-7B-Instruct-v0.1` which can be used for chat-based inference.
|
||||
Mistral-7B is the first large language model (LLM) released by [mistral.ai](https://mistral.ai/).
|
||||
|
||||
For more details please read our [release blog post](https://mistral.ai/news/announcing-mistral-7b/)
|
||||
### Architectural details
|
||||
|
||||
Mistral-7B is a decoder-only Transformer with the following architectural choices:
|
||||
|
||||
- Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
|
||||
- GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
|
||||
- Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
|
||||
|
||||
For more details refer to the [release blog post](https://mistral.ai/news/announcing-mistral-7b/).
|
||||
|
||||
### License
|
||||
|
||||
Both `Mistral-7B-v0.1` and `Mistral-7B-Instruct-v0.1` are released under the Apache 2.0 license.
|
||||
`Mistral-7B` is released under the Apache 2.0 license.
|
||||
|
||||
## Usage tips
|
||||
|
||||
`Mistral-7B-v0.1` and `Mistral-7B-Instruct-v0.1` can be found on the [Huggingface Hub](https://huggingface.co/mistralai)
|
||||
The Mistral team has released 3 checkpoints:
|
||||
|
||||
These ready-to-use checkpoints can be downloaded and used via the HuggingFace Hub:
|
||||
- a base model, [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1), which has been pre-trained to predict the next token on internet-scale data.
|
||||
- an instruction tuned model, [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1), which is the base model optimized for chat purposes using supervised fine-tuning (SFT) and direct preference optimization (DPO).
|
||||
- an improved instruction tuned model, [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2), which improves upon v1.
|
||||
|
||||
The base model can be used as follows:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
>>> device = "cuda" # the device to load the model onto
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
|
||||
|
||||
>>> prompt = "My favourite condiment is"
|
||||
|
||||
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
|
||||
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
|
||||
>>> model.to(device)
|
||||
|
||||
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
|
||||
>>> tokenizer.batch_decode(generated_ids)[0]
|
||||
"The expected output"
|
||||
"My favourite condiment is to ..."
|
||||
```
|
||||
|
||||
Raw weights for `Mistral-7B-v0.1` and `Mistral-7B-Instruct-v0.1` can be downloaded from:
|
||||
|
||||
| Model Name | Checkpoint |
|
||||
|----------------------------|-----------------------------------------------------------------------------------------|
|
||||
| `Mistral-7B-v0.1` | [Raw Checkpoint](https://files.mistral-7b-v0-1.mistral.ai/mistral-7B-v0.1.tar) |
|
||||
| `Mistral-7B-Instruct-v0.1` | [Raw Checkpoint](https://files.mistral-7b-v0-1.mistral.ai/mistral-7B-instruct-v0.1.tar) |
|
||||
|
||||
|
||||
To use these raw checkpoints with HuggingFace you can use the `convert_mistral_weights_to_hf.py` script to convert them to the HuggingFace format:
|
||||
|
||||
```bash
|
||||
python src/transformers/models/mistral/convert_mistral_weights_to_hf.py \
|
||||
--input_dir /path/to/downloaded/mistral/weights --model_size 7B --output_dir /output/path
|
||||
```
|
||||
|
||||
You can then load the converted model from the `output/path`:
|
||||
The instruction tuned model can be used as follows:
|
||||
|
||||
```python
|
||||
from transformers import MistralForCausalLM, LlamaTokenizer
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
|
||||
model = MistralForCausalLM.from_pretrained("/output/path")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
|
||||
|
||||
>>> messages = [
|
||||
... {"role": "user", "content": "What is your favourite condiment?"},
|
||||
... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
|
||||
... {"role": "user", "content": "Do you have mayonnaise recipes?"}
|
||||
... ]
|
||||
|
||||
>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
|
||||
|
||||
>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
|
||||
>>> tokenizer.batch_decode(generated_ids)[0]
|
||||
"Mayonnaise can be made as follows: (...)"
|
||||
```
|
||||
|
||||
## Combining Mistral and Flash Attention 2
|
||||
As can be seen, the instruction-tuned model requires a [chat template](../chat_templating) to be applied to make sure the inputs are prepared in the right format.
|
||||
|
||||
## Speeding up Mistral by using Flash Attention
|
||||
|
||||
The code snippets above showcase inference without any optimization tricks. However, one can drastically speed up the model by leveraging [Flash Attention](../perf_train_gpu_one.md#flash-attention-2), which is a faster implementation of the attention mechanism used inside the model.
|
||||
|
||||
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
|
||||
|
||||
@ -90,26 +99,25 @@ First, make sure to install the latest version of Flash Attention 2 to include t
|
||||
pip install -U flash-attn --no-build-isolation
|
||||
```
|
||||
|
||||
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of [`flash-attn`](https://github.com/Dao-AILab/flash-attention) repository. Make also sure to load your model in half-precision (e.g. `torch.float16`)
|
||||
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). Make also sure to load your model in half-precision (e.g. `torch.float16`)
|
||||
|
||||
To load and run a model using Flash Attention 2, refer to the snippet below:
|
||||
To load and run a model using Flash Attention-2, refer to the snippet below:
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
>>> device = "cuda" # the device to load the model onto
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2", device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
|
||||
|
||||
>>> prompt = "My favourite condiment is"
|
||||
|
||||
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
|
||||
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
|
||||
>>> model.to(device)
|
||||
|
||||
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
|
||||
>>> tokenizer.batch_decode(generated_ids)[0]
|
||||
"The expected output"
|
||||
"My favourite condiment is to (...)"
|
||||
```
|
||||
|
||||
### Expected speedups
|
||||
@ -127,9 +135,54 @@ To enable sliding window attention, just make sure to have a `flash-attn` versio
|
||||
|
||||
The Flash Attention-2 model uses also a more memory efficient cache slicing mechanism - as recommended per the official implementation of Mistral model that use rolling cache mechanism we keep the cache size fixed (`self.config.sliding_window`), support batched generation only for `padding_side="left"` and use the absolute position of the current token to compute the positional embedding.
|
||||
|
||||
## The Mistral Team
|
||||
## Shrinking down Mistral using quantization
|
||||
|
||||
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
As the Mistral model has 7 billion parameters, that would require about 14GB of GPU RAM in half precision (float16), since each parameter is stored in 2 bytes. However, one can shrink down the size of the model using [quantization](../quantization.md). If the model is quantized to 4 bits (or half a byte per parameter),that requires only about 3.5GB of RAM.
|
||||
|
||||
Quantizing a model is as simple as passing a `quantization_config` to the model. Below, we'll leverage the BitsAndyBytes quantization (but refer to [this page](../quantization.md) for other quantization methods):
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
>>> # specify how to quantize the model
|
||||
>>> quantization_config = BitsAndBytesConfig(
|
||||
... load_in_4bit=True,
|
||||
... bnb_4bit_quant_type="nf4",
|
||||
... bnb_4bit_compute_dtype="torch.float16",
|
||||
... )
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", quantization_config=True, device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
|
||||
|
||||
>>> prompt = "My favourite condiment is"
|
||||
|
||||
>>> messages = [
|
||||
... {"role": "user", "content": "What is your favourite condiment?"},
|
||||
... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
|
||||
... {"role": "user", "content": "Do you have mayonnaise recipes?"}
|
||||
... ]
|
||||
|
||||
>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
|
||||
|
||||
>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
|
||||
>>> tokenizer.batch_decode(generated_ids)[0]
|
||||
"The expected output"
|
||||
```
|
||||
|
||||
This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ) .
|
||||
The original code can be found [here](https://github.com/mistralai/mistral-src).
|
||||
|
||||
## Resources
|
||||
|
||||
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mistral. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
|
||||
|
||||
<PipelineTag pipeline="text-generation"/>
|
||||
|
||||
- A demo notebook to perform supervised fine-tuning (SFT) of Mistral-7B can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Mistral/Supervised_fine_tuning_(SFT)_of_an_LLM_using_Hugging_Face_tooling.ipynb). 🌎
|
||||
- A [blog post](https://www.philschmid.de/fine-tune-llms-in-2024-with-trl) on how to fine-tune LLMs in 2024 using Hugging Face tooling. 🌎
|
||||
- The [Alignment Handbook](https://github.com/huggingface/alignment-handbook) by Hugging Face includes scripts and recipes to perform supervised fine-tuning (SFT) and direct preference optimization with Mistral-7B. This includes scripts for full fine-tuning, QLoRa on a single GPU as well as multi-GPU fine-tuning.
|
||||
- [Causal language modeling task guide](../tasks/language_modeling)
|
||||
|
||||
## MistralConfig
|
||||
|
||||
@ -158,4 +211,4 @@ Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Sin
|
||||
## FlaxMistralForCausalLM
|
||||
|
||||
[[autodoc]] FlaxMistralForCausalLM
|
||||
- __call__
|
||||
- __call__
|
||||
@ -18,38 +18,27 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
## Overview
|
||||
|
||||
Mixtral-8x7B is Mistral AI's second Large Language Model (LLM).
|
||||
Mixtral-8x7B was introduced in the [Mixtral of Experts blogpost](https://mistral.ai/news/mixtral-of-experts/) by Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
|
||||
The Mixtral model was proposed by the [Mistral AI](https://mistral.ai/) team.
|
||||
|
||||
It was introduced in the [Mixtral of Experts blogpost](https://mistral.ai/news/mixtral-of-experts/) with the following introduction:
|
||||
The introduction of the blog post says:
|
||||
|
||||
*Today, the team is proud to release Mixtral 8x7B, a high-quality sparse mixture of experts models (SMoE) with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks.*
|
||||
|
||||
Tips:
|
||||
Mixtral-8x7B is the second large language model (LLM) released by [mistral.ai](https://mistral.ai/), after [Mistral-7B](mistral).
|
||||
|
||||
### Architectural details
|
||||
|
||||
- The model needs to be converted using the [conversion script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/mixtral/convert_mixtral_weights_to_hf.py).
|
||||
- If the model is quantized to 4bits, a single A100 is enough to fit the entire 45B model.
|
||||
Mixtral-8x7B is a decoder-only Transformer with the following architectural choices:
|
||||
|
||||
This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ) .
|
||||
The original code can be found [here](https://github.com/mistralai/mistral-src).
|
||||
- Mixtral is a Mixture of Experts (MoE) model with 8 experts per MLP, with a total of 45 billion parameters. To learn more about mixture-of-experts, refer to the [blog post](https://huggingface.co/blog/moe).
|
||||
- Despite the model having 45 billion parameters,, the compute required for a single forward pass is the same as that of a 14 billion parameter model. This is because even though each of the experts have to be loaded in RAM (70B like ram requirement) each token from the hidden states are dispatched twice (top 2 routing) and thus the compute (the operation required at each forward computation) is just 2 X sequence_length.
|
||||
|
||||
The following implementation details are shared with Mistral AI's first model [Mistral-7B](mistral):
|
||||
- Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
|
||||
- GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
|
||||
- Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
|
||||
|
||||
### Model Details
|
||||
|
||||
Mixtral-45B is a decoder-based LM with the following architectural choices:
|
||||
|
||||
* Mixtral is a Mixture of Expert (MOE) model with 8 experts per MLP, with a total of 45B paramateres but the compute required is the same as a 14B model. This is because even though each experts have to be loaded in RAM (70B like ram requirement) each token from the hidden states are dispatched twice (top 2 routing) and thus the compute (the operation required at each forward computation) is just 2 X sequence_length.
|
||||
|
||||
The following implementation details are shared with Mistral AI's first model [mistral](mistral):
|
||||
* Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
|
||||
* GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
|
||||
* Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
|
||||
|
||||
They also provide an instruction fine-tuned model: `mistralai/Mixtral-8x7B-v0.1` which can be used for chat-based inference.
|
||||
|
||||
For more details please read our [release blog post](https://mistral.ai/news/mixtral-of-experts/)
|
||||
For more details refer to the [release blog post](https://mistral.ai/news/mixtral-of-experts/).
|
||||
|
||||
### License
|
||||
|
||||
@ -57,44 +46,54 @@ For more details please read our [release blog post](https://mistral.ai/news/mix
|
||||
|
||||
## Usage tips
|
||||
|
||||
`Mixtral-8x7B` can be found on the [Huggingface Hub](https://huggingface.co/mistralai)
|
||||
The Mistral team has released 2 checkpoints:
|
||||
- a base model, [Mixtral-8x7B-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1), which has been pre-trained to predict the next token on internet-scale data.
|
||||
- an instruction tuned model, [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1), which is the base model optimized for chat purposes using supervised fine-tuning (SFT) and direct preference optimization (DPO).
|
||||
|
||||
These ready-to-use checkpoints can be downloaded and used via the HuggingFace Hub:
|
||||
The base model can be used as follows:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
>>> device = "cuda" # the device to load the model onto
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
|
||||
|
||||
>>> prompt = "My favourite condiment is"
|
||||
|
||||
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
|
||||
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
|
||||
>>> model.to(device)
|
||||
|
||||
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
|
||||
>>> tokenizer.batch_decode(generated_ids)[0]
|
||||
"The expected output"
|
||||
"My favourite condiment is to ..."
|
||||
```
|
||||
|
||||
To use the raw checkpoints with HuggingFace you can use the `convert_mixtral_weights_to_hf.py` script to convert them to the HuggingFace format:
|
||||
|
||||
```bash
|
||||
python src/transformers/models/mixtral/convert_mixtral_weights_to_hf.py \
|
||||
--input_dir /path/to/downloaded/mistral/weights --output_dir /output/path
|
||||
```
|
||||
|
||||
You can then load the converted model from the `output/path`:
|
||||
The instruction tuned model can be used as follows:
|
||||
|
||||
```python
|
||||
from transformers import MixtralForCausalLM, LlamaTokenizer
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
|
||||
model = MixtralForCausalLM.from_pretrained("/output/path")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1", device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
|
||||
|
||||
>>> messages = [
|
||||
... {"role": "user", "content": "What is your favourite condiment?"},
|
||||
... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
|
||||
... {"role": "user", "content": "Do you have mayonnaise recipes?"}
|
||||
... ]
|
||||
|
||||
>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
|
||||
|
||||
>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
|
||||
>>> tokenizer.batch_decode(generated_ids)[0]
|
||||
"Mayonnaise can be made as follows: (...)"
|
||||
```
|
||||
|
||||
## Combining Mixtral and Flash Attention 2
|
||||
As can be seen, the instruction-tuned model requires a [chat template](../chat_templating) to be applied to make sure the inputs are prepared in the right format.
|
||||
|
||||
## Speeding up Mixtral by using Flash Attention
|
||||
|
||||
The code snippets above showcase inference without any optimization tricks. However, one can drastically speed up the model by leveraging [Flash Attention](../perf_train_gpu_one.md#flash-attention-2), which is a faster implementation of the attention mechanism used inside the model.
|
||||
|
||||
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
|
||||
|
||||
@ -102,21 +101,20 @@ First, make sure to install the latest version of Flash Attention 2 to include t
|
||||
pip install -U flash-attn --no-build-isolation
|
||||
```
|
||||
|
||||
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of [`flash-attn`](https://github.com/Dao-AILab/flash-attention) repository. Make also sure to load your model in half-precision (e.g. `torch.float16`)
|
||||
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). Make also sure to load your model in half-precision (e.g. `torch.float16`)
|
||||
|
||||
To load and run a model using Flash Attention 2, refer to the snippet below:
|
||||
To load and run a model using Flash Attention-2, refer to the snippet below:
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
>>> device = "cuda" # the device to load the model onto
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2", device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
|
||||
|
||||
>>> prompt = "My favourite condiment is"
|
||||
|
||||
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
|
||||
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
|
||||
>>> model.to(device)
|
||||
|
||||
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
|
||||
@ -139,9 +137,54 @@ To enable sliding window attention, just make sure to have a `flash-attn` versio
|
||||
|
||||
The Flash Attention-2 model uses also a more memory efficient cache slicing mechanism - as recommended per the official implementation of Mistral model that use rolling cache mechanism we keep the cache size fixed (`self.config.sliding_window`), support batched generation only for `padding_side="left"` and use the absolute position of the current token to compute the positional embedding.
|
||||
|
||||
## The Mistral Team
|
||||
## Shrinking down Mixtral using quantization
|
||||
|
||||
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
|
||||
As the Mixtral model has 45 billion parameters, that would require about 90GB of GPU RAM in half precision (float16), since each parameter is stored in 2 bytes. However, one can shrink down the size of the model using [quantization](../quantization.md). If the model is quantized to 4 bits (or half a byte per parameter), a single A100 with 40GB of RAM is enough to fit the entire model, as in that case only about 27 GB of RAM is required.
|
||||
|
||||
Quantizing a model is as simple as passing a `quantization_config` to the model. Below, we'll leverage the BitsAndyBytes quantization (but refer to [this page](../quantization.md) for other quantization methods):
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
>>> # specify how to quantize the model
|
||||
>>> quantization_config = BitsAndBytesConfig(
|
||||
... load_in_4bit=True,
|
||||
... bnb_4bit_quant_type="nf4",
|
||||
... bnb_4bit_compute_dtype="torch.float16",
|
||||
... )
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1", quantization_config=True, device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
|
||||
|
||||
>>> prompt = "My favourite condiment is"
|
||||
|
||||
>>> messages = [
|
||||
... {"role": "user", "content": "What is your favourite condiment?"},
|
||||
... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
|
||||
... {"role": "user", "content": "Do you have mayonnaise recipes?"}
|
||||
... ]
|
||||
|
||||
>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
|
||||
|
||||
>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
|
||||
>>> tokenizer.batch_decode(generated_ids)[0]
|
||||
"The expected output"
|
||||
```
|
||||
|
||||
This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ) .
|
||||
The original code can be found [here](https://github.com/mistralai/mistral-src).
|
||||
|
||||
## Resources
|
||||
|
||||
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mixtral. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
|
||||
|
||||
<PipelineTag pipeline="text-generation"/>
|
||||
|
||||
- A demo notebook to perform supervised fine-tuning (SFT) of Mixtral-8x7B can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Mistral/Supervised_fine_tuning_(SFT)_of_an_LLM_using_Hugging_Face_tooling.ipynb). 🌎
|
||||
- A [blog post](https://medium.com/@prakharsaxena11111/finetuning-mixtral-7bx8-6071b0ebf114) on fine-tuning Mixtral-8x7B using PEFT. 🌎
|
||||
- The [Alignment Handbook](https://github.com/huggingface/alignment-handbook) by Hugging Face includes scripts and recipes to perform supervised fine-tuning (SFT) and direct preference optimization with Mistral-7B. This includes scripts for full fine-tuning, QLoRa on a single GPU as well as multi-GPU fine-tuning.
|
||||
- [Causal language modeling task guide](../tasks/language_modeling)
|
||||
|
||||
## MixtralConfig
|
||||
|
||||
|
||||
288
docs/source/en/model_doc/musicgen_melody.md
Normal file
288
docs/source/en/model_doc/musicgen_melody.md
Normal file
@ -0,0 +1,288 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
:warning: Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# MusicGen Melody
|
||||
|
||||
## Overview
|
||||
|
||||
The MusicGen Melody model was proposed in [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
|
||||
|
||||
MusicGen Melody is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or *audio codes*, conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec, to recover the audio waveform.
|
||||
|
||||
Through an efficient token interleaving pattern, MusicGen does not require a self-supervised semantic representation of the text/audio prompts, thus eliminating the need to cascade multiple models to predict a set of codebooks (e.g. hierarchically or upsampling). Instead, it is able to generate all the codebooks in a single forward pass.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark. Through ablation studies, we shed light over the importance of each of the components comprising MusicGen.*
|
||||
|
||||
|
||||
This model was contributed by [ylacombe](https://huggingface.co/ylacombe). The original code can be found [here](https://github.com/facebookresearch/audiocraft). The pre-trained checkpoints can be found on the [Hugging Face Hub](https://huggingface.co/models?sort=downloads&search=facebook%2Fmusicgen).
|
||||
|
||||
|
||||
## Difference with [MusicGen](https://huggingface.co/docs/transformers/main/en/model_doc/musicgen)
|
||||
|
||||
There are two key differences with MusicGen:
|
||||
1. The audio prompt is used here as a conditional signal for the generated audio sample, whereas it's used for audio continuation in [MusicGen](https://huggingface.co/docs/transformers/main/en/model_doc/musicgen).
|
||||
2. Conditional text and audio signals are concatenated to the decoder's hidden states instead of being used as a cross-attention signal, as in MusicGen.
|
||||
|
||||
## Generation
|
||||
|
||||
MusicGen Melody is compatible with two generation modes: greedy and sampling. In practice, sampling leads to significantly better results than greedy, thus we encourage sampling mode to be used where possible. Sampling is enabled by default, and can be explicitly specified by setting `do_sample=True` in the call to [`MusicgenMelodyForConditionalGeneration.generate`], or by overriding the model's generation config (see below).
|
||||
|
||||
Transformers supports both mono (1-channel) and stereo (2-channel) variants of MusicGen Melody. The mono channel versions generate a single set of codebooks. The stereo versions generate 2 sets of codebooks, 1 for each channel (left/right), and each set of codebooks is decoded independently through the audio compression model. The audio streams for each channel are combined to give the final stereo output.
|
||||
|
||||
|
||||
#### Audio Conditional Generation
|
||||
|
||||
The model can generate an audio sample conditioned on a text and an audio prompt through use of the [`MusicgenMelodyProcessor`] to pre-process the inputs.
|
||||
|
||||
In the following examples, we load an audio file using the 🤗 Datasets library, which can be pip installed through the command below:
|
||||
|
||||
```
|
||||
pip install --upgrade pip
|
||||
pip install datasets[audio]
|
||||
```
|
||||
|
||||
The audio file we are about to use is loaded as follows:
|
||||
```python
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
|
||||
>>> sample = next(iter(dataset))["audio"]
|
||||
```
|
||||
|
||||
The audio prompt should ideally be free of the low-frequency signals usually produced by instruments such as drums and bass. The [Demucs](https://github.com/adefossez/demucs/tree/main) model can be used to separate vocals and other signals from the drums and bass components.
|
||||
|
||||
If you wish to use Demucs, you first need to follow the installation steps [here](https://github.com/adefossez/demucs/tree/main?tab=readme-ov-file#for-musicians) before using the following snippet:
|
||||
|
||||
```python
|
||||
from demucs import pretrained
|
||||
from demucs.apply import apply_model
|
||||
from demucs.audio import convert_audio
|
||||
import torch
|
||||
|
||||
|
||||
wav = torch.tensor(sample["array"]).to(torch.float32)
|
||||
|
||||
demucs = pretrained.get_model('htdemucs')
|
||||
|
||||
wav = convert_audio(wav[None], sample["sampling_rate"], demucs.samplerate, demucs.audio_channels)
|
||||
wav = apply_model(demucs, wav[None])
|
||||
```
|
||||
|
||||
You can then use the following snippet to generate music:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoProcessor, MusicgenMelodyForConditionalGeneration
|
||||
|
||||
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-melody")
|
||||
>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
|
||||
|
||||
>>> inputs = processor(
|
||||
... audio=wav,
|
||||
... sampling_rate=demucs.samplerate,
|
||||
... text=["80s blues track with groovy saxophone"],
|
||||
... padding=True,
|
||||
... return_tensors="pt",
|
||||
... )
|
||||
>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
|
||||
```
|
||||
|
||||
You can also pass the audio signal directly without using Demucs, although the quality of the generation will probably be degraded:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoProcessor, MusicgenMelodyForConditionalGeneration
|
||||
|
||||
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-melody")
|
||||
>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
|
||||
|
||||
>>> inputs = processor(
|
||||
... audio=sample["array"],
|
||||
... sampling_rate=sample["sampling_rate"],
|
||||
... text=["80s blues track with groovy saxophone"],
|
||||
... padding=True,
|
||||
... return_tensors="pt",
|
||||
... )
|
||||
>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
|
||||
```
|
||||
|
||||
The audio outputs are a three-dimensional Torch tensor of shape `(batch_size, num_channels, sequence_length)`. To listen to the generated audio samples, you can either play them in an ipynb notebook:
|
||||
|
||||
```python
|
||||
from IPython.display import Audio
|
||||
|
||||
sampling_rate = model.config.audio_encoder.sampling_rate
|
||||
Audio(audio_values[0].numpy(), rate=sampling_rate)
|
||||
```
|
||||
|
||||
Or save them as a `.wav` file using a third-party library, e.g. `soundfile`:
|
||||
|
||||
```python
|
||||
>>> import soundfile as sf
|
||||
|
||||
>>> sampling_rate = model.config.audio_encoder.sampling_rate
|
||||
>>> sf.write("musicgen_out.wav", audio_values[0].T.numpy(), sampling_rate)
|
||||
```
|
||||
|
||||
|
||||
### Text-only Conditional Generation
|
||||
|
||||
The same [`MusicgenMelodyProcessor`] can be used to pre-process a text-only prompt.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoProcessor, MusicgenMelodyForConditionalGeneration
|
||||
|
||||
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-melody")
|
||||
>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
|
||||
|
||||
>>> inputs = processor(
|
||||
... text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"],
|
||||
... padding=True,
|
||||
... return_tensors="pt",
|
||||
... )
|
||||
>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
|
||||
```
|
||||
|
||||
The `guidance_scale` is used in classifier free guidance (CFG), setting the weighting between the conditional logits (which are predicted from the text prompts) and the unconditional logits (which are predicted from an unconditional or 'null' prompt). Higher guidance scale encourages the model to generate samples that are more closely linked to the input prompt, usually at the expense of poorer audio quality. CFG is enabled by setting `guidance_scale > 1`. For best results, use `guidance_scale=3` (default).
|
||||
|
||||
|
||||
You can also generate in batch:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoProcessor, MusicgenMelodyForConditionalGeneration
|
||||
>>> from datasets import load_dataset
|
||||
|
||||
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-melody")
|
||||
>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
|
||||
|
||||
>>> # take the first quarter of the audio sample
|
||||
>>> sample_1 = sample["array"][: len(sample["array"]) // 4]
|
||||
|
||||
>>> # take the first half of the audio sample
|
||||
>>> sample_2 = sample["array"][: len(sample["array"]) // 2]
|
||||
|
||||
>>> inputs = processor(
|
||||
... audio=[sample_1, sample_2],
|
||||
... sampling_rate=sample["sampling_rate"],
|
||||
... text=["80s blues track with groovy saxophone", "90s rock song with loud guitars and heavy drums"],
|
||||
... padding=True,
|
||||
... return_tensors="pt",
|
||||
... )
|
||||
>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
|
||||
```
|
||||
|
||||
### Unconditional Generation
|
||||
|
||||
The inputs for unconditional (or 'null') generation can be obtained through the method [`MusicgenMelodyProcessor.get_unconditional_inputs`]:
|
||||
|
||||
```python
|
||||
>>> from transformers import MusicgenMelodyForConditionalGeneration, MusicgenMelodyProcessor
|
||||
|
||||
>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
|
||||
>>> unconditional_inputs = MusicgenMelodyProcessor.from_pretrained("facebook/musicgen-melody").get_unconditional_inputs(num_samples=1)
|
||||
|
||||
>>> audio_values = model.generate(**unconditional_inputs, do_sample=True, max_new_tokens=256)
|
||||
```
|
||||
|
||||
### Generation Configuration
|
||||
|
||||
The default parameters that control the generation process, such as sampling, guidance scale and number of generated tokens, can be found in the model's generation config, and updated as desired:
|
||||
|
||||
```python
|
||||
>>> from transformers import MusicgenMelodyForConditionalGeneration
|
||||
|
||||
>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
|
||||
|
||||
>>> # inspect the default generation config
|
||||
>>> model.generation_config
|
||||
|
||||
>>> # increase the guidance scale to 4.0
|
||||
>>> model.generation_config.guidance_scale = 4.0
|
||||
|
||||
>>> # decrease the max length to 256 tokens
|
||||
>>> model.generation_config.max_length = 256
|
||||
```
|
||||
|
||||
Note that any arguments passed to the generate method will **supersede** those in the generation config, so setting `do_sample=False` in the call to generate will supersede the setting of `model.generation_config.do_sample` in the generation config.
|
||||
|
||||
## Model Structure
|
||||
|
||||
The MusicGen model can be de-composed into three distinct stages:
|
||||
1. Text encoder: maps the text inputs to a sequence of hidden-state representations. The pre-trained MusicGen models use a frozen text encoder from either T5 or Flan-T5.
|
||||
2. MusicGen Melody decoder: a language model (LM) that auto-regressively generates audio tokens (or codes) conditional on the encoder hidden-state representations
|
||||
3. Audio decoder: used to recover the audio waveform from the audio tokens predicted by the decoder.
|
||||
|
||||
Thus, the MusicGen model can either be used as a standalone decoder model, corresponding to the class [`MusicgenMelodyForCausalLM`], or as a composite model that includes the text encoder and audio encoder, corresponding to the class [`MusicgenMelodyForConditionalGeneration`]. If only the decoder needs to be loaded from the pre-trained checkpoint, it can be loaded by first specifying the correct config, or be accessed through the `.decoder` attribute of the composite model:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoConfig, MusicgenMelodyForCausalLM, MusicgenMelodyForConditionalGeneration
|
||||
|
||||
>>> # Option 1: get decoder config and pass to `.from_pretrained`
|
||||
>>> decoder_config = AutoConfig.from_pretrained("facebook/musicgen-melody").decoder
|
||||
>>> decoder = MusicgenMelodyForCausalLM.from_pretrained("facebook/musicgen-melody", **decoder_config.to_dict())
|
||||
|
||||
>>> # Option 2: load the entire composite model, but only return the decoder
|
||||
>>> decoder = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody").decoder
|
||||
```
|
||||
|
||||
Since the text encoder and audio encoder models are frozen during training, the MusicGen decoder [`MusicgenMelodyForCausalLM`] can be trained standalone on a dataset of encoder hidden-states and audio codes. For inference, the trained decoder can be combined with the frozen text encoder and audio encoder to recover the composite [`MusicgenMelodyForConditionalGeneration`] model.
|
||||
|
||||
## Checkpoint Conversion
|
||||
|
||||
- After downloading the original checkpoints from [here](https://github.com/facebookresearch/audiocraft/blob/main/docs/MUSICGEN.md#importing--exporting-models), you can convert them using the **conversion script** available at `src/transformers/models/musicgen_melody/convert_musicgen_melody_transformers.py` with the following command:
|
||||
|
||||
```bash
|
||||
python src/transformers/models/musicgen_melody/convert_musicgen_melody_transformers.py \
|
||||
--checkpoint="facebook/musicgen-melody" --pytorch_dump_folder /output/path
|
||||
```
|
||||
|
||||
Tips:
|
||||
* MusicGen is trained on the 32kHz checkpoint of Encodec. You should ensure you use a compatible version of the Encodec model.
|
||||
* Sampling mode tends to deliver better results than greedy - you can toggle sampling with the variable `do_sample` in the call to [`MusicgenMelodyForConditionalGeneration.generate`]
|
||||
|
||||
|
||||
## MusicgenMelodyDecoderConfig
|
||||
|
||||
[[autodoc]] MusicgenMelodyDecoderConfig
|
||||
|
||||
## MusicgenMelodyProcessor
|
||||
|
||||
[[autodoc]] MusicgenMelodyProcessor
|
||||
- get_unconditional_inputs
|
||||
|
||||
## MusicgenMelodyFeatureExtractor
|
||||
|
||||
[[autodoc]] MusicgenMelodyFeatureExtractor
|
||||
- _extract_stem_indices
|
||||
|
||||
## MusicgenMelodyConfig
|
||||
|
||||
[[autodoc]] MusicgenMelodyConfig
|
||||
|
||||
## MusicgenMelodyModel
|
||||
|
||||
[[autodoc]] MusicgenMelodyModel
|
||||
- forward
|
||||
|
||||
## MusicgenMelodyForCausalLM
|
||||
|
||||
[[autodoc]] MusicgenMelodyForCausalLM
|
||||
- forward
|
||||
|
||||
## MusicgenMelodyForConditionalGeneration
|
||||
|
||||
[[autodoc]] MusicgenMelodyForConditionalGeneration
|
||||
- forward
|
||||
@ -74,4 +74,4 @@ The original code can be found [here](https://github.com/google-research/pix2str
|
||||
## Pix2StructForConditionalGeneration
|
||||
|
||||
[[autodoc]] Pix2StructForConditionalGeneration
|
||||
- forward
|
||||
- forward
|
||||
110
docs/source/en/model_doc/pvt_v2.md
Normal file
110
docs/source/en/model_doc/pvt_v2.md
Normal file
@ -0,0 +1,110 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Pyramid Vision Transformer V2 (PVTv2)
|
||||
|
||||
## Overview
|
||||
|
||||
The PVTv2 model was proposed in
|
||||
[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
|
||||
|
||||
The PVTv2 encoder structure has been successfully deployed to achieve state-of-the-art scores in [Segformer](https://arxiv.org/abs/2105.15203) for semantic segmentation, [GLPN](https://arxiv.org/abs/2201.07436) for monocular depth, and [Panoptic Segformer](https://arxiv.org/abs/2109.03814) for panoptic segmentation.
|
||||
|
||||
PVTv2 belongs to a family of models called [hierarchical transformers](https://natecibik.medium.com/the-rise-of-vision-transformers-f623c980419f) , which make adaptations to transformer layers in order to generate multi-scale feature maps. Unlike the columnal structure of Vision Transformer ([ViT](https://arxiv.org/abs/2010.11929)) which loses fine-grained detail, multi-scale feature maps are known preserve this detail and aid performance in dense prediction tasks. In the case of PVTv2, this is achieved by generating image patch tokens using 2D convolution with overlapping kernels in each encoder layer.
|
||||
|
||||
The multi-scale features of hierarchical transformers allow them to be easily swapped in for traditional workhorse computer vision backbone models like ResNet in larger architectures. Both Segformer and Panoptic Segformer demonstrated that configurations using PVTv2 for a backbone consistently outperformed those with similarly sized ResNet backbones.
|
||||
|
||||
Another powerful feature of the PVTv2 is the complexity reduction in the self-attention layers called Spatial Reduction Attention (SRA), which uses 2D convolution layers to project hidden states to a smaller resolution before attending to them with the queries, improving the $O(n^2)$ complexity of self-attention to $O(n^2/R)$, with $R$ being the spatial reduction ratio (`sr_ratio`, aka kernel size and stride in the 2D convolution).
|
||||
|
||||
SRA was introduced in PVT, and is the default attention complexity reduction method used in PVTv2. However, PVTv2 also introduced the option of using a self-attention mechanism with linear complexity related to image size, which they called "Linear SRA". This method uses average pooling to reduce the hidden states to a fixed size that is invariant to their original resolution (although this is inherently more lossy than regular SRA). This option can be enabled by setting `linear_attention` to `True` in the PVTv2Config.
|
||||
|
||||
### Abstract from the paper:
|
||||
|
||||
*Transformer recently has presented encouraging progress in computer vision. In this work, we present new baselines by improving the original Pyramid Vision Transformer (PVT v1) by adding three designs, including (1) linear complexity attention layer, (2) overlapping patch embedding, and (3) convolutional feed-forward network. With these modifications, PVT v2 reduces the computational complexity of PVT v1 to linear and achieves significant improvements on fundamental vision tasks such as classification, detection, and segmentation. Notably, the proposed PVT v2 achieves comparable or better performances than recent works such as Swin Transformer. We hope this work will facilitate state-of-the-art Transformer researches in computer vision. Code is available at https://github.com/whai362/PVT.*
|
||||
|
||||
This model was contributed by [FoamoftheSea](https://huggingface.co/FoamoftheSea). The original code can be found [here](https://github.com/whai362/PVT).
|
||||
|
||||
## Usage tips
|
||||
|
||||
- [PVTv2](https://arxiv.org/abs/2106.13797) is a hierarchical transformer model which has demonstrated powerful performance in image classification and multiple other tasks, used as a backbone for semantic segmentation in [Segformer](https://arxiv.org/abs/2105.15203), monocular depth estimation in [GLPN](https://arxiv.org/abs/2201.07436), and panoptic segmentation in [Panoptic Segformer](https://arxiv.org/abs/2109.03814), consistently showing higher performance than similar ResNet configurations.
|
||||
- Hierarchical transformers like PVTv2 achieve superior data and parameter efficiency on image data compared with pure transformer architectures by incorporating design elements of convolutional neural networks (CNNs) into their encoders. This creates a best-of-both-worlds architecture that infuses the useful inductive biases of CNNs like translation equivariance and locality into the network while still enjoying the benefits of dynamic data response and global relationship modeling provided by the self-attention mechanism of [transformers](https://arxiv.org/abs/1706.03762).
|
||||
- PVTv2 uses overlapping patch embeddings to create multi-scale feature maps, which are infused with location information using zero-padding and depth-wise convolutions.
|
||||
- To reduce the complexity in the attention layers, PVTv2 performs a spatial reduction on the hidden states using either strided 2D convolution (SRA) or fixed-size average pooling (Linear SRA). Although inherently more lossy, Linear SRA provides impressive performance with a linear complexity with respect to image size. To use Linear SRA in the self-attention layers, set `linear_attention=True` in the `PvtV2Config`.
|
||||
- [`PvtV2Model`] is the hierarchical transformer encoder (which is also often referred to as Mix Transformer or MiT in the literature). [`PvtV2ForImageClassification`] adds a simple classifier head on top to perform Image Classification. [`PvtV2Backbone`] can be used with the [`AutoBackbone`] system in larger architectures like Deformable DETR.
|
||||
- ImageNet pretrained weights for all model sizes can be found on the [hub](https://huggingface.co/models?other=pvt_v2).
|
||||
|
||||
The best way to get started with the PVTv2 is to load the pretrained checkpoint with the size of your choosing using `AutoModelForImageClassification`:
|
||||
```python
|
||||
import requests
|
||||
import torch
|
||||
|
||||
from transformers import AutoModelForImageClassification, AutoImageProcessor
|
||||
from PIL import Image
|
||||
|
||||
model = AutoModelForImageClassification.from_pretrained("OpenGVLab/pvt_v2_b0")
|
||||
image_processor = AutoImageProcessor.from_pretrained("OpenGVLab/pvt_v2_b0")
|
||||
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
processed = image_processor(image)
|
||||
outputs = model(torch.tensor(processed["pixel_values"]))
|
||||
```
|
||||
|
||||
To use the PVTv2 as a backbone for more complex architectures like DeformableDETR, you can use AutoBackbone (this model would need fine-tuning as you're replacing the backbone in the pretrained model):
|
||||
|
||||
```python
|
||||
import requests
|
||||
import torch
|
||||
|
||||
from transformers import AutoConfig, AutoModelForObjectDetection, AutoImageProcessor
|
||||
from PIL import Image
|
||||
|
||||
model = AutoModelForObjectDetection.from_config(
|
||||
config=AutoConfig.from_pretrained(
|
||||
"SenseTime/deformable-detr",
|
||||
backbone_config=AutoConfig.from_pretrained("OpenGVLab/pvt_v2_b5"),
|
||||
use_timm_backbone=False
|
||||
),
|
||||
)
|
||||
|
||||
image_processor = AutoImageProcessor.from_pretrained("SenseTime/deformable-detr")
|
||||
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
processed = image_processor(image)
|
||||
outputs = model(torch.tensor(processed["pixel_values"]))
|
||||
```
|
||||
|
||||
[PVTv2](https://github.com/whai362/PVT/tree/v2) performance on ImageNet-1K by model size (B0-B5):
|
||||
|
||||
| Method | Size | Acc@1 | #Params (M) |
|
||||
|------------------|:----:|:-----:|:-----------:|
|
||||
| PVT-V2-B0 | 224 | 70.5 | 3.7 |
|
||||
| PVT-V2-B1 | 224 | 78.7 | 14.0 |
|
||||
| PVT-V2-B2-Linear | 224 | 82.1 | 22.6 |
|
||||
| PVT-V2-B2 | 224 | 82.0 | 25.4 |
|
||||
| PVT-V2-B3 | 224 | 83.1 | 45.2 |
|
||||
| PVT-V2-B4 | 224 | 83.6 | 62.6 |
|
||||
| PVT-V2-B5 | 224 | 83.8 | 82.0 |
|
||||
|
||||
|
||||
## PvtV2Config
|
||||
|
||||
[[autodoc]] PvtV2Config
|
||||
|
||||
## PvtForImageClassification
|
||||
|
||||
[[autodoc]] PvtV2ForImageClassification
|
||||
- forward
|
||||
|
||||
## PvtModel
|
||||
|
||||
[[autodoc]] PvtV2Model
|
||||
- forward
|
||||
@ -35,8 +35,8 @@ In the following, we demonstrate how to use `Qwen2-7B-Chat-beta` for the inferen
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
>>> device = "cuda" # the device to load the model onto
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("Qwen2/Qwen2-7B-Chat-beta", device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen2/Qwen2-7B-Chat-beta")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-7B-Chat", device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-7B-Chat")
|
||||
|
||||
>>> prompt = "Give me a short introduction to large language model."
|
||||
|
||||
|
||||
77
docs/source/en/model_doc/qwen2_moe.md
Normal file
77
docs/source/en/model_doc/qwen2_moe.md
Normal file
@ -0,0 +1,77 @@
|
||||
<!--Copyright 2024 The Qwen Team and The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Qwen2MoE
|
||||
|
||||
## Overview
|
||||
|
||||
Qwen2MoE is the new model series of large language models from the Qwen team. Previously, we released the Qwen series, including Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio, etc.
|
||||
|
||||
### Model Details
|
||||
|
||||
Qwen2MoE is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. Qwen2MoE has the following architectural choices:
|
||||
|
||||
- Qwen2MoE is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
|
||||
- Qwen2MoE employs Mixture of Experts (MoE) architecture, where the models are upcycled from dense language models. For instance, `Qwen1.5-MoE-A2.7B` is upcycled from `Qwen-1.8B`. It has 14.3B parameters in total and 2.7B activated parameters during runtime, while it achieves comparable performance with `Qwen1.5-7B`, with only 25% of the training resources.
|
||||
|
||||
For more details refer to the [release blog post](https://qwenlm.github.io/blog/qwen-moe/).
|
||||
|
||||
## Usage tips
|
||||
|
||||
`Qwen1.5-MoE-A2.7B` and `Qwen1.5-MoE-A2.7B-Chat` can be found on the [Huggingface Hub](https://huggingface.co/Qwen)
|
||||
|
||||
In the following, we demonstrate how to use `Qwen1.5-MoE-A2.7B-Chat` for the inference. Note that we have used the ChatML format for dialog, in this demo we show how to leverage `apply_chat_template` for this purpose.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
>>> device = "cuda" # the device to load the model onto
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-MoE-A2.7B-Chat", device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-MoE-A2.7B-Chat")
|
||||
|
||||
>>> prompt = "Give me a short introduction to large language model."
|
||||
|
||||
>>> messages = [{"role": "user", "content": prompt}]
|
||||
|
||||
>>> text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
|
||||
|
||||
>>> model_inputs = tokenizer([text], return_tensors="pt").to(device)
|
||||
|
||||
>>> generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True)
|
||||
|
||||
>>> generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
|
||||
|
||||
>>> response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
||||
```
|
||||
|
||||
## Qwen2MoeConfig
|
||||
|
||||
[[autodoc]] Qwen2MoeConfig
|
||||
|
||||
## Qwen2MoeModel
|
||||
|
||||
[[autodoc]] Qwen2MoeModel
|
||||
- forward
|
||||
|
||||
## Qwen2MoeForCausalLM
|
||||
|
||||
[[autodoc]] Qwen2MoeForCausalLM
|
||||
- forward
|
||||
|
||||
## Qwen2MoeForSequenceClassification
|
||||
|
||||
[[autodoc]] Qwen2MoeForSequenceClassification
|
||||
- forward
|
||||
90
docs/source/en/model_doc/seggpt.md
Normal file
90
docs/source/en/model_doc/seggpt.md
Normal file
@ -0,0 +1,90 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# SegGPT
|
||||
|
||||
## Overview
|
||||
|
||||
The SegGPT model was proposed in [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*We present SegGPT, a generalist model for segmenting everything in context. We unify various segmentation tasks into a generalist in-context learning framework that accommodates different kinds of segmentation data by transforming them into the same format of images. The training of SegGPT is formulated as an in-context coloring problem with random color mapping for each data sample. The objective is to accomplish diverse tasks according to the context, rather than relying on specific colors. After training, SegGPT can perform arbitrary segmentation tasks in images or videos via in-context inference, such as object instance, stuff, part, contour, and text. SegGPT is evaluated on a broad range of tasks, including few-shot semantic segmentation, video object segmentation, semantic segmentation, and panoptic segmentation. Our results show strong capabilities in segmenting in-domain and out-of*
|
||||
|
||||
Tips:
|
||||
- One can use [`SegGptImageProcessor`] to prepare image input, prompt and mask to the model.
|
||||
- It's highly advisable to pass `num_labels` (not considering background) during preprocessing and postprocessing with [`SegGptImageProcessor`] for your use case.
|
||||
- When doing inference with [`SegGptForImageSegmentation`] if your `batch_size` is greater than 1 you can use feature ensemble across your images by passing `feature_ensemble=True` in the forward method.
|
||||
|
||||
Here's how to use the model for one-shot semantic segmentation:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from transformers import SegGptImageProcessor, SegGptForImageSegmentation
|
||||
|
||||
model_id = "BAAI/seggpt-vit-large"
|
||||
image_processor = SegGptImageProcessor.from_pretrained(checkpoint)
|
||||
model = SegGptForImageSegmentation.from_pretrained(checkpoint)
|
||||
|
||||
dataset_id = "EduardoPacheco/FoodSeg103"
|
||||
ds = load_dataset(dataset_id, split="train")
|
||||
# Number of labels in FoodSeg103 (not including background)
|
||||
num_labels = 103
|
||||
|
||||
image_input = ds[4]["image"]
|
||||
ground_truth = ds[4]["label"]
|
||||
image_prompt = ds[29]["image"]
|
||||
mask_prompt = ds[29]["label"]
|
||||
|
||||
inputs = image_processor(
|
||||
images=image_input,
|
||||
prompt_images=image_prompt,
|
||||
prompt_masks=mask_prompt,
|
||||
num_labels=num_labels,
|
||||
return_tensors="pt"
|
||||
)
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(**inputs)
|
||||
|
||||
target_sizes = [image_input.size[::-1]]
|
||||
mask = image_processor.post_process_semantic_segmentation(outputs, target_sizes, num_labels=num_labels)[0]
|
||||
```
|
||||
|
||||
This model was contributed by [EduardoPacheco](https://huggingface.co/EduardoPacheco).
|
||||
The original code can be found [here]([(https://github.com/baaivision/Painter/tree/main)).
|
||||
|
||||
|
||||
## SegGptConfig
|
||||
|
||||
[[autodoc]] SegGptConfig
|
||||
|
||||
## SegGptImageProcessor
|
||||
|
||||
[[autodoc]] SegGptImageProcessor
|
||||
- preprocess
|
||||
- post_process_semantic_segmentation
|
||||
|
||||
## SegGptModel
|
||||
|
||||
[[autodoc]] SegGptModel
|
||||
- forward
|
||||
|
||||
## SegGptForImageSegmentation
|
||||
|
||||
[[autodoc]] SegGptForImageSegmentation
|
||||
- forward
|
||||
69
docs/source/en/model_doc/starcoder2.md
Normal file
69
docs/source/en/model_doc/starcoder2.md
Normal file
@ -0,0 +1,69 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Starcoder2
|
||||
|
||||
## Overview
|
||||
|
||||
StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective. The models have been released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
|
||||
|
||||
The abstract of the paper is the following:
|
||||
|
||||
> The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
|
||||
## License
|
||||
|
||||
The models are licensed under the [BigCode OpenRAIL-M v1 license agreement](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement).
|
||||
|
||||
## Usage tips
|
||||
|
||||
The StarCoder2 models can be found in the [HuggingFace hub](https://huggingface.co/collections/bigcode/starcoder2-65de6da6e87db3383572be1a). You can find some examples for inference and fine-tuning in StarCoder2's [GitHub repo](https://github.com/bigcode-project/starcoder2).
|
||||
|
||||
These ready-to-use checkpoints can be downloaded and used via the HuggingFace Hub:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("bigcode/starcoder2-7b", device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("bigcode/starcoder2-7b")
|
||||
|
||||
>>> prompt = "def print_hello_world():"
|
||||
|
||||
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
|
||||
>>> model.to(device)
|
||||
|
||||
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=10, do_sample=False)
|
||||
>>> tokenizer.batch_decode(generated_ids)[0]
|
||||
"def print_hello_world():\n\treturn 'Hello World!'"
|
||||
```
|
||||
|
||||
## Starcoder2Config
|
||||
|
||||
[[autodoc]] Starcoder2Config
|
||||
|
||||
## Starcoder2Model
|
||||
|
||||
[[autodoc]] Starcoder2Model
|
||||
- forward
|
||||
|
||||
## Starcoder2ForCausalLM
|
||||
|
||||
[[autodoc]] Starcoder2ForCausalLM
|
||||
- forward
|
||||
|
||||
## Starcoder2ForSequenceClassification
|
||||
|
||||
[[autodoc]] Starcoder2ForSequenceClassification
|
||||
- forward
|
||||
120
docs/source/en/model_doc/superpoint.md
Normal file
120
docs/source/en/model_doc/superpoint.md
Normal file
@ -0,0 +1,120 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the MIT License; you may not use this file except in compliance with
|
||||
the License.
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
|
||||
-->
|
||||
|
||||
# SuperPoint
|
||||
|
||||
## Overview
|
||||
|
||||
The SuperPoint model was proposed
|
||||
in [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel
|
||||
DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
|
||||
|
||||
This model is the result of a self-supervised training of a fully-convolutional network for interest point detection and
|
||||
description. The model is able to detect interest points that are repeatable under homographic transformations and
|
||||
provide a descriptor for each point. The use of the model in its own is limited, but it can be used as a feature
|
||||
extractor for other tasks such as homography estimation, image matching, etc.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*This paper presents a self-supervised framework for training interest point detectors and descriptors suitable for a
|
||||
large number of multiple-view geometry problems in computer vision. As opposed to patch-based neural networks, our
|
||||
fully-convolutional model operates on full-sized images and jointly computes pixel-level interest point locations and
|
||||
associated descriptors in one forward pass. We introduce Homographic Adaptation, a multi-scale, multi-homography
|
||||
approach for boosting interest point detection repeatability and performing cross-domain adaptation (e.g.,
|
||||
synthetic-to-real). Our model, when trained on the MS-COCO generic image dataset using Homographic Adaptation, is able
|
||||
to repeatedly detect a much richer set of interest points than the initial pre-adapted deep model and any other
|
||||
traditional corner detector. The final system gives rise to state-of-the-art homography estimation results on HPatches
|
||||
when compared to LIFT, SIFT and ORB.*
|
||||
|
||||
## How to use
|
||||
|
||||
Here is a quick example of using the model to detect interest points in an image:
|
||||
|
||||
```python
|
||||
from transformers import AutoImageProcessor, AutoModel
|
||||
import torch
|
||||
from PIL import Image
|
||||
import requests
|
||||
|
||||
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
|
||||
model = AutoModel.from_pretrained("magic-leap-community/superpoint")
|
||||
|
||||
inputs = processor(image, return_tensors="pt")
|
||||
outputs = model(**inputs)
|
||||
```
|
||||
|
||||
The outputs contain the list of keypoint coordinates with their respective score and description (a 256-long vector).
|
||||
|
||||
You can also feed multiple images to the model. Due to the nature of SuperPoint, to output a dynamic number of keypoints,
|
||||
you will need to use the mask attribute to retrieve the respective information :
|
||||
|
||||
```python
|
||||
from transformers import AutoImageProcessor, AutoModel
|
||||
import torch
|
||||
from PIL import Image
|
||||
import requests
|
||||
|
||||
url_image_1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
||||
image_1 = Image.open(requests.get(url_image_1, stream=True).raw)
|
||||
url_image_2 = "http://images.cocodataset.org/test-stuff2017/000000000568.jpg"
|
||||
image_2 = Image.open(requests.get(url_image_2, stream=True).raw)
|
||||
|
||||
images = [image_1, image_2]
|
||||
|
||||
processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
|
||||
model = AutoModel.from_pretrained("magic-leap-community/superpoint")
|
||||
|
||||
inputs = processor(images, return_tensors="pt")
|
||||
outputs = model(**inputs)
|
||||
|
||||
for i in range(len(images)):
|
||||
image_mask = outputs.mask[i]
|
||||
image_indices = torch.nonzero(image_mask).squeeze()
|
||||
image_keypoints = outputs.keypoints[i][image_indices]
|
||||
image_scores = outputs.scores[i][image_indices]
|
||||
image_descriptors = outputs.descriptors[i][image_indices]
|
||||
```
|
||||
|
||||
You can then print the keypoints on the image to visualize the result :
|
||||
```python
|
||||
import cv2
|
||||
for keypoint, score in zip(image_keypoints, image_scores):
|
||||
keypoint_x, keypoint_y = int(keypoint[0].item()), int(keypoint[1].item())
|
||||
color = tuple([score.item() * 255] * 3)
|
||||
image = cv2.circle(image, (keypoint_x, keypoint_y), 2, color)
|
||||
cv2.imwrite("output_image.png", image)
|
||||
```
|
||||
|
||||
This model was contributed by [stevenbucaille](https://huggingface.co/stevenbucaille).
|
||||
The original code can be found [here](https://github.com/magicleap/SuperPointPretrainedNetwork).
|
||||
|
||||
## SuperPointConfig
|
||||
|
||||
[[autodoc]] SuperPointConfig
|
||||
|
||||
## SuperPointImageProcessor
|
||||
|
||||
[[autodoc]] SuperPointImageProcessor
|
||||
|
||||
- preprocess
|
||||
|
||||
## SuperPointForKeypointDetection
|
||||
|
||||
[[autodoc]] SuperPointForKeypointDetection
|
||||
|
||||
- forward
|
||||
102
docs/source/en/model_doc/udop.md
Normal file
102
docs/source/en/model_doc/udop.md
Normal file
@ -0,0 +1,102 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# UDOP
|
||||
|
||||
## Overview
|
||||
|
||||
The UDOP model was proposed in [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
|
||||
UDOP adopts an encoder-decoder Transformer architecture based on [T5](t5) for document AI tasks like document image classification, document parsing and document visual question answering.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
We propose Universal Document Processing (UDOP), a foundation Document AI model which unifies text, image, and layout modalities together with varied task formats, including document understanding and generation. UDOP leverages the spatial correlation between textual content and document image to model image, text, and layout modalities with one uniform representation. With a novel Vision-Text-Layout Transformer, UDOP unifies pretraining and multi-domain downstream tasks into a prompt-based sequence generation scheme. UDOP is pretrained on both large-scale unlabeled document corpora using innovative self-supervised objectives and diverse labeled data. UDOP also learns to generate document images from text and layout modalities via masked image reconstruction. To the best of our knowledge, this is the first time in the field of document AI that one model simultaneously achieves high-quality neural document editing and content customization. Our method sets the state-of-the-art on 9 Document AI tasks, e.g., document understanding and QA, across diverse data domains like finance reports, academic papers, and websites. UDOP ranks first on the leaderboard of the Document Understanding Benchmark (DUE).*
|
||||
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/udop_architecture.jpg"
|
||||
alt="drawing" width="600"/>
|
||||
|
||||
<small> UDOP architecture. Taken from the <a href="https://arxiv.org/abs/2212.02623">original paper.</a> </small>
|
||||
|
||||
## Usage tips
|
||||
|
||||
- In addition to *input_ids*, [`UdopForConditionalGeneration`] also expects the input `bbox`, which are
|
||||
the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
|
||||
as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the
|
||||
position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000
|
||||
scale. To normalize, you can use the following function:
|
||||
|
||||
```python
|
||||
def normalize_bbox(bbox, width, height):
|
||||
return [
|
||||
int(1000 * (bbox[0] / width)),
|
||||
int(1000 * (bbox[1] / height)),
|
||||
int(1000 * (bbox[2] / width)),
|
||||
int(1000 * (bbox[3] / height)),
|
||||
]
|
||||
```
|
||||
|
||||
Here, `width` and `height` correspond to the width and height of the original document in which the token
|
||||
occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
|
||||
# Document can be a png, jpg, etc. PDFs must be converted to images.
|
||||
image = Image.open(name_of_your_document).convert("RGB")
|
||||
|
||||
width, height = image.size
|
||||
```
|
||||
|
||||
- At inference time, it's recommended to use the `generate` method to autoregressively generate text given a document image.
|
||||
- One can use [`UdopProcessor`] to prepare images and text for the model. By default, this class uses the Tesseract engine to extract a list of words
|
||||
and boxes (coordinates) from a given document. Its functionality is equivalent to that of [`LayoutLMv3Processor`], hence it supports passing either
|
||||
`apply_ocr=False` in case you prefer to use your own OCR engine or `apply_ocr=True` in case you want the default OCR engine to be used.
|
||||
|
||||
This model was contributed by [nielsr](https://huggingface.co/nielsr).
|
||||
The original code can be found [here](https://github.com/microsoft/UDOP).
|
||||
|
||||
|
||||
## UdopConfig
|
||||
|
||||
[[autodoc]] UdopConfig
|
||||
|
||||
## UdopTokenizer
|
||||
|
||||
[[autodoc]] UdopTokenizer
|
||||
- build_inputs_with_special_tokens
|
||||
- get_special_tokens_mask
|
||||
- create_token_type_ids_from_sequences
|
||||
- save_vocabulary
|
||||
|
||||
## UdopTokenizerFast
|
||||
|
||||
[[autodoc]] UdopTokenizerFast
|
||||
|
||||
## UdopProcessor
|
||||
|
||||
[[autodoc]] UdopProcessor
|
||||
- __call__
|
||||
|
||||
## UdopModel
|
||||
|
||||
[[autodoc]] UdopModel
|
||||
- forward
|
||||
|
||||
## UdopForConditionalGeneration
|
||||
|
||||
[[autodoc]] UdopForConditionalGeneration
|
||||
- forward
|
||||
|
||||
## UdopEncoderModel
|
||||
|
||||
[[autodoc]] UdopEncoderModel
|
||||
- forward
|
||||
@ -16,7 +16,7 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
# The Transformer model family
|
||||
|
||||
Since its introduction in 2017, the [original Transformer](https://arxiv.org/abs/1706.03762) model has inspired many new and exciting models that extend beyond natural language processing (NLP) tasks. There are models for [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to run](https://huggingface.co/blog/train-decision-transformers), and [time series forecasting](https://huggingface.co/blog/time-series-transformers). With so many Transformer variants available, it can be easy to miss the bigger picture. What all these models have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while others use both. This provides a useful taxonomy to categorize and examine the high-level differences within models in the Transformer family, and it'll help you understand Transformers you haven't encountered before.
|
||||
Since its introduction in 2017, the [original Transformer](https://arxiv.org/abs/1706.03762) model (see the [Annotated Transformer](http://nlp.seas.harvard.edu/2018/04/03/attention.html) blog post for a gentle technical introduction) has inspired many new and exciting models that extend beyond natural language processing (NLP) tasks. There are models for [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to run](https://huggingface.co/blog/train-decision-transformers), and [time series forecasting](https://huggingface.co/blog/time-series-transformers). With so many Transformer variants available, it can be easy to miss the bigger picture. What all these models have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while others use both. This provides a useful taxonomy to categorize and examine the high-level differences within models in the Transformer family, and it'll help you understand Transformers you haven't encountered before.
|
||||
|
||||
If you aren't familiar with the original Transformer model or need a refresher, check out the [How do Transformers work](https://huggingface.co/course/chapter1/4?fw=pt) chapter from the Hugging Face course.
|
||||
|
||||
@ -104,4 +104,4 @@ Optical character recognition (OCR) is a long-standing text recognition task tha
|
||||
|
||||
### Decoder[[rl-decoder]]
|
||||
|
||||
The Decision and Trajectory Transformer casts the state, action, and reward as a sequence modeling problem. The [Decision Transformer](model_doc/decision_transformer) generates a series of actions that lead to a future desired return based on returns-to-go, past states, and actions. For the last *K* timesteps, each of the three modalities are converted into token embeddings and processed by a GPT-like model to predict a future action token. [Trajectory Transformer](model_doc/trajectory_transformer) also tokenizes the states, actions, and rewards and processes them with a GPT architecture. Unlike the Decision Transformer, which is focused on reward conditioning, the Trajectory Transformer generates future actions with beam search.
|
||||
The Decision and Trajectory Transformer casts the state, action, and reward as a sequence modeling problem. The [Decision Transformer](model_doc/decision_transformer) generates a series of actions that lead to a future desired return based on returns-to-go, past states, and actions. For the last *K* timesteps, each of the three modalities are converted into token embeddings and processed by a GPT-like model to predict a future action token. [Trajectory Transformer](model_doc/trajectory_transformer) also tokenizes the states, actions, and rewards and processes them with a GPT architecture. Unlike the Decision Transformer, which is focused on reward conditioning, the Trajectory Transformer generates future actions with beam search.
|
||||
|
||||
@ -39,21 +39,30 @@ FlashAttention-2 is experimental and may change considerably in future versions.
|
||||
FlashAttention-2 is currently supported for the following architectures:
|
||||
* [Bark](https://huggingface.co/docs/transformers/model_doc/bark#transformers.BarkModel)
|
||||
* [Bart](https://huggingface.co/docs/transformers/model_doc/bart#transformers.BartModel)
|
||||
* [Cohere](https://huggingface.co/docs/transformers/model_doc/cohere#transformers.CohereModel)
|
||||
* [DistilBert](https://huggingface.co/docs/transformers/model_doc/distilbert#transformers.DistilBertModel)
|
||||
* [Gemma](https://huggingface.co/docs/transformers/model_doc/gemma#transformers.GemmaModel)
|
||||
* [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)
|
||||
* [GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode#transformers.GPTBigCodeModel)
|
||||
* [GPTNeo](https://huggingface.co/docs/transformers/model_doc/gpt_neo#transformers.GPTNeoModel)
|
||||
* [GPTNeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox#transformers.GPTNeoXModel)
|
||||
* [GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj#transformers.GPTJModel)
|
||||
* [Falcon](https://huggingface.co/docs/transformers/model_doc/falcon#transformers.FalconModel)
|
||||
* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
|
||||
* [Llava](https://huggingface.co/docs/transformers/model_doc/llava)
|
||||
* [Llava-NeXT](https://huggingface.co/docs/transformers/model_doc/llava_next)
|
||||
* [VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)
|
||||
* [MBart](https://huggingface.co/docs/transformers/model_doc/mbart#transformers.MBartModel)
|
||||
* [Mistral](https://huggingface.co/docs/transformers/model_doc/mistral#transformers.MistralModel)
|
||||
* [Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral#transformers.MixtralModel)
|
||||
* [Musicgen](https://huggingface.co/docs/transformers/model_doc/musicgen#transformers.MusicgenModel)
|
||||
* [MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody#transformers.MusicgenMelodyModel)
|
||||
* [OPT](https://huggingface.co/docs/transformers/model_doc/opt#transformers.OPTModel)
|
||||
* [Phi](https://huggingface.co/docs/transformers/model_doc/phi#transformers.PhiModel)
|
||||
* [StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm#transformers.StableLmModel)
|
||||
* [Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2#transformers.Starcoder2Model)
|
||||
* [Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2#transformers.Qwen2Model)
|
||||
* [Qwen2MoE](https://huggingface.co/docs/transformers/model_doc/qwen2_moe#transformers.Qwen2MoeModel)
|
||||
* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
|
||||
|
||||
You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
|
||||
@ -169,19 +178,26 @@ PyTorch's [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.o
|
||||
|
||||
For now, Transformers supports SDPA inference and training for the following architectures:
|
||||
* [Bart](https://huggingface.co/docs/transformers/model_doc/bart#transformers.BartModel)
|
||||
* [Cohere](https://huggingface.co/docs/transformers/model_doc/cohere#transformers.CohereModel)
|
||||
* [GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode#transformers.GPTBigCodeModel)
|
||||
* [Falcon](https://huggingface.co/docs/transformers/model_doc/falcon#transformers.FalconModel)
|
||||
* [Gemma](https://huggingface.co/docs/transformers/model_doc/gemma#transformers.GemmaModel)
|
||||
* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
|
||||
* [Phi](https://huggingface.co/docs/transformers/model_doc/phi#transformers.PhiModel)
|
||||
* [Idefics](https://huggingface.co/docs/transformers/model_doc/idefics#transformers.IdeficsModel)
|
||||
* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
|
||||
* [Mistral](https://huggingface.co/docs/transformers/model_doc/mistral#transformers.MistralModel)
|
||||
* [Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral#transformers.MixtralModel)
|
||||
* [StableLm](https://huggingface.co/docs/transformers/model_doc/stablelm#transformers.StableLmModel)
|
||||
* [Starcoder2](https://huggingface.co/docs/transformers/model_doc/starcoder2#transformers.Starcoder2Model)
|
||||
* [Qwen2](https://huggingface.co/docs/transformers/model_doc/qwen2#transformers.Qwen2Model)
|
||||
* [Qwen2MoE](https://huggingface.co/docs/transformers/model_doc/qwen2_moe#transformers.Qwen2MoeModel)
|
||||
* [Musicgen](https://huggingface.co/docs/transformers/model_doc/musicgen#transformers.MusicgenModel)
|
||||
* [MusicGen Melody](https://huggingface.co/docs/transformers/model_doc/musicgen_melody#transformers.MusicgenMelodyModel)
|
||||
|
||||
<Tip>
|
||||
|
||||
FlashAttention can only be used for models with the `fp16` or `bf16` torch type, so make sure to cast your model to the appropriate type first.
|
||||
FlashAttention can only be used for models with the `fp16` or `bf16` torch type, so make sure to cast your model to the appropriate type first. The memory-efficient attention backend is able to handle `fp32` models.
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
@ -65,7 +65,7 @@ training your model with [`Trainer`] or writing a pure PyTorch loop, in which ca
|
||||
with 🤗 Accelerate](#using--accelerate).
|
||||
|
||||
If these methods do not result in sufficient gains, you can explore the following options:
|
||||
* [Look into building your own custom Docker container with efficient softare prebuilds](#efficient-software-prebuilds)
|
||||
* [Look into building your own custom Docker container with efficient software prebuilds](#efficient-software-prebuilds)
|
||||
* [Consider a model that uses Mixture of Experts (MoE)](#mixture-of-experts)
|
||||
* [Convert your model to BetterTransformer to leverage PyTorch native attention](#using-pytorch-native-attention-and-flash-attention)
|
||||
|
||||
@ -529,24 +529,6 @@ And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixtu
|
||||
|
||||
## Using PyTorch native attention and Flash Attention
|
||||
|
||||
PyTorch 2.0 released a native [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA),
|
||||
that allows using fused GPU kernels such as [memory-efficient attention](https://arxiv.org/abs/2112.05682) and [flash attention](https://arxiv.org/abs/2205.14135).
|
||||
|
||||
After installing the [`optimum`](https://github.com/huggingface/optimum) package, the relevant internal modules can be
|
||||
replaced to use PyTorch's native attention with:
|
||||
|
||||
```python
|
||||
model = model.to_bettertransformer()
|
||||
```
|
||||
|
||||
Once converted, train the model as usual.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
The PyTorch-native `scaled_dot_product_attention` operator can only dispatch to Flash Attention if no `attention_mask` is provided.
|
||||
|
||||
By default, in training mode, the BetterTransformer integration **drops the mask support and can only be used for training that does not require a padding mask for batched training**. This is the case, for example, during masked language modeling or causal language modeling. BetterTransformer is not suited for fine-tuning models on tasks that require a padding mask.
|
||||
|
||||
</Tip>
|
||||
PyTorch's [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA) can also call FlashAttention and memory-efficient attention kernels under the hood. SDPA support is currently being added natively in Transformers and is used by default for `torch>=2.1.1` when an implementation is available. Please refer to [PyTorch scaled dot product attention](https://huggingface.co/docs/transformers/perf_infer_gpu_one#pytorch-scaled-dot-product-attention) for a list of supported models and more details.
|
||||
|
||||
Check out this [blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about acceleration and memory-savings with SDPA.
|
||||
|
||||
@ -167,9 +167,9 @@ for working on really long audio files (for example, subtitling entire movies or
|
||||
cannot handle on its own:
|
||||
|
||||
```python
|
||||
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30, return_timestamps=True)
|
||||
>>> transcriber("https://huggingface.co/datasets/sanchit-gandhi/librispeech_long/resolve/main/audio.wav")
|
||||
{'text': " Chapter 16. I might have told you of the beginning of this liaison in a few lines, but I wanted you to see every step by which we came. I, too, agree to whatever Marguerite wished, Marguerite to be unable to live apart from me. It was the day after the evening...
|
||||
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30)
|
||||
>>> transcriber("https://huggingface.co/datasets/reach-vb/random-audios/resolve/main/ted_60.wav")
|
||||
{'text': " So in college, I was a government major, which means I had to write a lot of papers. Now, when a normal student writes a paper, they might spread the work out a little like this. So, you know. You get started maybe a little slowly, but you get enough done in the first week that with some heavier days later on, everything gets done and things stay civil. And I would want to do that like that. That would be the plan. I would have it all ready to go, but then actually the paper would come along, and then I would kind of do this. And that would happen every single paper. But then came my 90-page senior thesis, a paper you're supposed to spend a year on. I knew for a paper like that, my normal workflow was not an option, it was way too big a project. So I planned things out and I decided I kind of had to go something like this. This is how the year would go. So I'd start off light and I'd bump it up"}
|
||||
```
|
||||
|
||||
If you can't find a parameter that would really help you out, feel free to [request it](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)!
|
||||
@ -314,4 +314,30 @@ pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"loa
|
||||
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
|
||||
```
|
||||
|
||||
Note that you can replace the checkpoint with any of the Hugging Face model that supports large model loading such as BLOOM!
|
||||
Note that you can replace the checkpoint with any Hugging Face model that supports large model loading, such as BLOOM.
|
||||
|
||||
## Creating web demos from pipelines with `gradio`
|
||||
|
||||
Pipelines are automatically supported in [Gradio](https://github.com/gradio-app/gradio/), a library that makes creating beautiful and user-friendly machine learning apps on the web a breeze. First, make sure you have Gradio installed:
|
||||
|
||||
```
|
||||
pip install gradio
|
||||
```
|
||||
|
||||
Then, you can create a web demo around an image classification pipeline (or any other pipeline) in a single line of code by calling Gradio's [`Interface.from_pipeline`](https://www.gradio.app/docs/interface#interface-from-pipeline) function to launch the pipeline. This creates an intuitive drag-and-drop interface in your browser:
|
||||
|
||||
```py
|
||||
from transformers import pipeline
|
||||
import gradio as gr
|
||||
|
||||
pipe = pipeline("image-classification", model="google/vit-base-patch16-224")
|
||||
|
||||
gr.Interface.from_pipeline(pipe).launch()
|
||||
```
|
||||
|
||||
|
||||
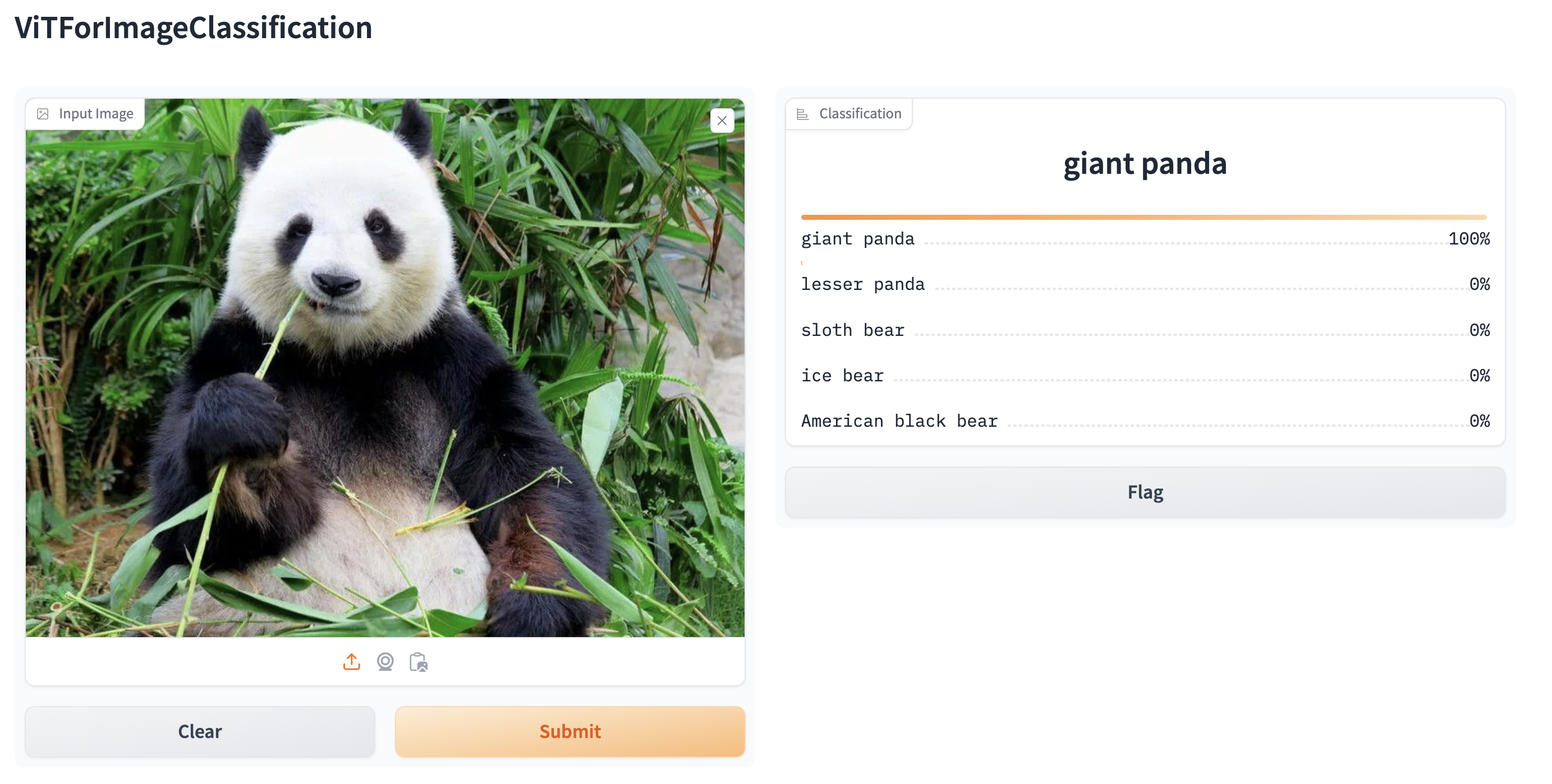
|
||||
|
||||
By default, the web demo runs on a local server. If you'd like to share it with others, you can generate a temporary public
|
||||
link by setting `share=True` in `launch()`. You can also host your demo on [Hugging Face Spaces](https://huggingface.co/spaces) for a permanent link.
|
||||
|
||||
|
||||
@ -26,6 +26,59 @@ Interested in adding a new quantization method to Transformers? Read the [HfQuan
|
||||
|
||||
</Tip>
|
||||
|
||||
## Quanto
|
||||
|
||||
<Tip>
|
||||
|
||||
Try Quanto + transformers with this [notebook](https://colab.research.google.com/drive/16CXfVmtdQvciSh9BopZUDYcmXCDpvgrT?usp=sharing)!
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
[🤗 Quanto](https://github.com/huggingface/quanto) library is a versatile pytorch quantization toolkit. The quantization method used is the linear quantization. Quanto provides several unique features such as:
|
||||
|
||||
- weights quantization (`float8`,`int8`,`int4`,`int2`)
|
||||
- activation quantization (`float8`,`int8`)
|
||||
- modality agnostic (e.g CV,LLM)
|
||||
- device agnostic (e.g CUDA,MPS,CPU)
|
||||
- compatibility with `torch.compile`
|
||||
- easy to add custom kernel for specific device
|
||||
- supports quantization aware training
|
||||
<!-- Add link to the blogpost -->
|
||||
|
||||
Before you begin, make sure the following libraries are installed:
|
||||
|
||||
```bash
|
||||
pip install quanto
|
||||
pip install git+https://github.com/huggingface/accelerate.git
|
||||
pip install git+https://github.com/huggingface/transformers.git
|
||||
```
|
||||
|
||||
Now you can quantize a model by passing [`QuantoConfig`] object in the [`~PreTrainedModel.from_pretrained`] method. This works for any model in any modality, as long as it contains `torch.nn.Linear` layers.
|
||||
|
||||
The integration with transformers only supports weights quantization. For the more complex use case such as activation quantization, calibration and quantization aware training, you should use [quanto](https://github.com/huggingface/quanto) library instead.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
|
||||
|
||||
model_id = "facebook/opt-125m"
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
quantization_config = QuantoConfig(weights="int8")
|
||||
quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0", quantization_config=quantization_config)
|
||||
```
|
||||
|
||||
Note that serialization is not supported yet with transformers but it is coming soon! If you want to save the model, you can use quanto library instead.
|
||||
|
||||
Quanto library uses linear quantization algorithm for quantization. Even though this is a basic quantization technique, we get very good results! Have a look at the following becnhmark (llama-2-7b on perplexity metric). You can find more benchamarks [here](https://github.com/huggingface/quanto/tree/main/bench/generation)
|
||||
|
||||
<div class="flex gap-4">
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/NousResearch-Llama-2-7b-hf_Perplexity.png" alt="llama-2-7b-quanto-perplexity" />
|
||||
</div>
|
||||
</div>
|
||||
|
||||
The library is versatible enough to be compatible with most PTQ optimization algorithms. The plan in the future is to integrate the most popular algorithms in the most seamless possible way (AWQ, Smoothquant).
|
||||
|
||||
## AQLM
|
||||
|
||||
|
||||
@ -39,13 +92,17 @@ Inference support for AQLM is realised in the `aqlm` library. Make sure to insta
|
||||
pip install aqlm[gpu,cpu]
|
||||
```
|
||||
|
||||
The library provides efficient kernels for both GPU and CPU inference.
|
||||
The library provides efficient kernels for both GPU and CPU inference and training.
|
||||
|
||||
The instructions on how to quantize models yourself, as well as all the relevant code can be found in the corresponding GitHub [repository](https://github.com/Vahe1994/AQLM).
|
||||
|
||||
### PEFT
|
||||
|
||||
Starting with version `aqlm 1.0.2`, AQLM supports Parameter-Efficient Fine-Tuning in a form of [LoRA](https://huggingface.co/docs/peft/package_reference/lora) integrated into the [PEFT](https://huggingface.co/blog/peft) library.
|
||||
|
||||
### AQLM configurations
|
||||
|
||||
AQLM quantization setpus vary mainly on the number of codebooks used as well as codebook sizes in bits. The most popular setups, as well as inference kernels they support are:
|
||||
AQLM quantization setups vary mainly on the number of codebooks used as well as codebook sizes in bits. The most popular setups, as well as inference kernels they support are:
|
||||
|
||||
| Kernel | Number of codebooks | Codebook size, bits | Notation | Accuracy | Speedup | Fast GPU inference | Fast CPU inference |
|
||||
|---|---------------------|---------------------|----------|-------------|-------------|--------------------|--------------------|
|
||||
@ -192,6 +249,45 @@ The parameter `modules_to_fuse` should include:
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
### Exllama-v2 support
|
||||
|
||||
Recent versions of `autoawq` supports exllama-v2 kernels for faster prefill and decoding. To get started, first install the latest version of `autoawq` by running:
|
||||
|
||||
```bash
|
||||
pip install git+https://github.com/casper-hansen/AutoAWQ.git
|
||||
```
|
||||
|
||||
Get started by passing an `AwqConfig()` with `version="exllama"`.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, AwqConfig
|
||||
|
||||
quantization_config = AwqConfig(version="exllama")
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
"TheBloke/Mistral-7B-Instruct-v0.1-AWQ",
|
||||
quantization_config=quantization_config,
|
||||
device_map="auto",
|
||||
)
|
||||
|
||||
input_ids = torch.randint(0, 100, (1, 128), dtype=torch.long, device="cuda")
|
||||
output = model(input_ids)
|
||||
print(output.logits)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-AWQ")
|
||||
input_ids = tokenizer.encode("How to make a cake", return_tensors="pt").to(model.device)
|
||||
output = model.generate(input_ids, do_sample=True, max_length=50, pad_token_id=50256)
|
||||
print(tokenizer.decode(output[0], skip_special_tokens=True))
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
Note this feature is supported on AMD GPUs.
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
## AutoGPTQ
|
||||
|
||||
<Tip>
|
||||
|
||||
@ -23,7 +23,7 @@ Get up and running with 🤗 Transformers! Whether you're a developer or an ever
|
||||
Before you begin, make sure you have all the necessary libraries installed:
|
||||
|
||||
```bash
|
||||
!pip install transformers datasets
|
||||
!pip install transformers datasets evaluate accelerate
|
||||
```
|
||||
|
||||
You'll also need to install your preferred machine learning framework:
|
||||
@ -547,7 +547,7 @@ All models are a standard [`tf.keras.Model`](https://www.tensorflow.org/api_docs
|
||||
```py
|
||||
>>> from tensorflow.keras.optimizers import Adam
|
||||
|
||||
>>> model.compile(optimizer=Adam(3e-5)) # No loss argument!
|
||||
>>> model.compile(optimizer='adam') # No loss argument!
|
||||
>>> model.fit(tf_dataset) # doctest: +SKIP
|
||||
```
|
||||
|
||||
|
||||
@ -34,7 +34,7 @@ The task illustrated in this tutorial is supported by the following model archit
|
||||
|
||||
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
|
||||
|
||||
[BEiT](../model_doc/beit), [BiT](../model_doc/bit), [CLIP](../model_doc/clip), [ConvNeXT](../model_doc/convnext), [ConvNeXTV2](../model_doc/convnextv2), [CvT](../model_doc/cvt), [Data2VecVision](../model_doc/data2vec-vision), [DeiT](../model_doc/deit), [DiNAT](../model_doc/dinat), [DINOv2](../model_doc/dinov2), [EfficientFormer](../model_doc/efficientformer), [EfficientNet](../model_doc/efficientnet), [FocalNet](../model_doc/focalnet), [ImageGPT](../model_doc/imagegpt), [LeViT](../model_doc/levit), [MobileNetV1](../model_doc/mobilenet_v1), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [NAT](../model_doc/nat), [Perceiver](../model_doc/perceiver), [PoolFormer](../model_doc/poolformer), [PVT](../model_doc/pvt), [RegNet](../model_doc/regnet), [ResNet](../model_doc/resnet), [SegFormer](../model_doc/segformer), [SigLIP](../model_doc/siglip), [SwiftFormer](../model_doc/swiftformer), [Swin Transformer](../model_doc/swin), [Swin Transformer V2](../model_doc/swinv2), [VAN](../model_doc/van), [ViT](../model_doc/vit), [ViT Hybrid](../model_doc/vit_hybrid), [ViTMSN](../model_doc/vit_msn)
|
||||
[BEiT](../model_doc/beit), [BiT](../model_doc/bit), [CLIP](../model_doc/clip), [ConvNeXT](../model_doc/convnext), [ConvNeXTV2](../model_doc/convnextv2), [CvT](../model_doc/cvt), [Data2VecVision](../model_doc/data2vec-vision), [DeiT](../model_doc/deit), [DiNAT](../model_doc/dinat), [DINOv2](../model_doc/dinov2), [EfficientFormer](../model_doc/efficientformer), [EfficientNet](../model_doc/efficientnet), [FocalNet](../model_doc/focalnet), [ImageGPT](../model_doc/imagegpt), [LeViT](../model_doc/levit), [MobileNetV1](../model_doc/mobilenet_v1), [MobileNetV2](../model_doc/mobilenet_v2), [MobileViT](../model_doc/mobilevit), [MobileViTV2](../model_doc/mobilevitv2), [NAT](../model_doc/nat), [Perceiver](../model_doc/perceiver), [PoolFormer](../model_doc/poolformer), [PVT](../model_doc/pvt), [PVTv2](../model_doc/pvt_v2), [RegNet](../model_doc/regnet), [ResNet](../model_doc/resnet), [SegFormer](../model_doc/segformer), [SigLIP](../model_doc/siglip), [SwiftFormer](../model_doc/swiftformer), [Swin Transformer](../model_doc/swin), [Swin Transformer V2](../model_doc/swinv2), [VAN](../model_doc/van), [ViT](../model_doc/vit), [ViT Hybrid](../model_doc/vit_hybrid), [ViTMSN](../model_doc/vit_msn)
|
||||
|
||||
<!--End of the generated tip-->
|
||||
|
||||
@ -43,7 +43,7 @@ The task illustrated in this tutorial is supported by the following model archit
|
||||
Before you begin, make sure you have all the necessary libraries installed:
|
||||
|
||||
```bash
|
||||
pip install transformers datasets evaluate
|
||||
pip install transformers datasets evaluate accelerate
|
||||
```
|
||||
|
||||
We encourage you to log in to your Hugging Face account to upload and share your model with the community. When prompted, enter your token to log in:
|
||||
|
||||
134
docs/source/en/tasks/image_feature_extraction.md
Normal file
134
docs/source/en/tasks/image_feature_extraction.md
Normal file
@ -0,0 +1,134 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Image Feature Extraction
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
Image feature extraction is the task of extracting semantically meaningful features given an image. This has many use cases, including image similarity and image retrieval. Moreover, most computer vision models can be used for image feature extraction, where one can remove the task-specific head (image classification, object detection etc) and get the features. These features are very useful on a higher level: edge detection, corner detection and so on. They may also contain information about the real world (e.g. what a cat looks like) depending on how deep the model is. Therefore, these outputs can be used to train new classifiers on a specific dataset.
|
||||
|
||||
In this guide, you will:
|
||||
|
||||
- Learn to build a simple image similarity system on top of the `image-feature-extraction` pipeline.
|
||||
- Accomplish the same task with bare model inference.
|
||||
|
||||
## Image Similarity using `image-feature-extraction` Pipeline
|
||||
|
||||
We have two images of cats sitting on top of fish nets, one of them is generated.
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
import requests
|
||||
|
||||
img_urls = ["https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/cats.png", "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/cats.jpeg"]
|
||||
image_real = Image.open(requests.get(img_urls[0], stream=True).raw).convert("RGB")
|
||||
image_gen = Image.open(requests.get(img_urls[1], stream=True).raw).convert("RGB")
|
||||
```
|
||||
|
||||
Let's see the pipeline in action. First, initialize the pipeline. If you don't pass any model to it, the pipeline will be automatically initialized with [google/vit-base-patch16-224](google/vit-base-patch16-224). If you'd like to calculate similarity, set `pool` to True.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import pipeline
|
||||
|
||||
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
||||
pipe = pipeline(task="image-feature-extraction", model_name="google/vit-base-patch16-384", device=DEVICE, pool=True)
|
||||
```
|
||||
|
||||
To infer with `pipe` pass both images to it.
|
||||
|
||||
```python
|
||||
outputs = pipe([image_real, image_gen])
|
||||
```
|
||||
|
||||
The output contains pooled embeddings of those two images.
|
||||
|
||||
```python
|
||||
# get the length of a single output
|
||||
print(len(outputs[0][0]))
|
||||
# show outputs
|
||||
print(outputs)
|
||||
|
||||
# 768
|
||||
# [[[-0.03909236937761307, 0.43381670117378235, -0.06913255900144577,
|
||||
```
|
||||
|
||||
To get the similarity score, we need to pass them to a similarity function.
|
||||
|
||||
```python
|
||||
from torch.nn.functional import cosine_similarity
|
||||
|
||||
similarity_score = cosine_similarity(torch.Tensor(outputs[0]),
|
||||
torch.Tensor(outputs[1]), dim=1)
|
||||
|
||||
print(similarity_score)
|
||||
|
||||
# tensor([0.6043])
|
||||
```
|
||||
|
||||
If you want to get the last hidden states before pooling, avoid passing any value for the `pool` parameter, as it is set to `False` by default. These hidden states are useful for training new classifiers or models based on the features from the model.
|
||||
|
||||
```python
|
||||
pipe = pipeline(task="image-feature-extraction", model_name="google/vit-base-patch16-224", device=DEVICE)
|
||||
output = pipe(image_real)
|
||||
```
|
||||
|
||||
Since the outputs are unpooled, we get the last hidden states where the first dimension is the batch size, and the last two are the embedding shape.
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
print(np.array(outputs).shape)
|
||||
# (1, 197, 768)
|
||||
```
|
||||
|
||||
## Getting Features and Similarities using `AutoModel`
|
||||
|
||||
We can also use `AutoModel` class of transformers to get the features. `AutoModel` loads any transformers model with no task-specific head, and we can use this to get the features.
|
||||
|
||||
```python
|
||||
from transformers import AutoImageProcessor, AutoModel
|
||||
|
||||
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
|
||||
model = AutoModel.from_pretrained("google/vit-base-patch16-224").to(DEVICE)
|
||||
```
|
||||
|
||||
Let's write a simple function for inference. We will pass the inputs to the `processor` first and pass its outputs to the `model`.
|
||||
|
||||
```python
|
||||
def infer(image):
|
||||
inputs = processor(image, return_tensors="pt").to(DEVICE)
|
||||
outputs = model(**inputs)
|
||||
return outputs.pooler_output
|
||||
```
|
||||
|
||||
We can pass the images directly to this function and get the embeddings.
|
||||
|
||||
```python
|
||||
embed_real = infer(image_real)
|
||||
embed_gen = infer(image_gen)
|
||||
```
|
||||
|
||||
We can get the similarity again over the embeddings.
|
||||
|
||||
```python
|
||||
from torch.nn.functional import cosine_similarity
|
||||
|
||||
similarity_score = cosine_similarity(embed_real, embed_gen, dim=1)
|
||||
print(similarity_score)
|
||||
|
||||
# tensor([0.6061], device='cuda:0', grad_fn=<SumBackward1>)
|
||||
```
|
||||
|
||||
@ -37,7 +37,8 @@ You can finetune other architectures for causal language modeling following the
|
||||
Choose one of the following architectures:
|
||||
|
||||
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
|
||||
[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Qwen2](../model_doc/qwen2), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [StableLm](../model_doc/stablelm), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
|
||||
[BART](../model_doc/bart), [BERT](../model_doc/bert), [Bert Generation](../model_doc/bert-generation), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [Blenderbot](../model_doc/blenderbot), [BlenderbotSmall](../model_doc/blenderbot-small), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CodeLlama](../model_doc/code_llama), [CodeGen](../model_doc/codegen), [Cohere](../model_doc/cohere), [CPM-Ant](../model_doc/cpmant), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [Falcon](../model_doc/falcon), [Fuyu](../model_doc/fuyu), [Gemma](../model_doc/gemma), [GIT](../model_doc/git), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT NeoX Japanese](../model_doc/gpt_neox_japanese), [GPT-J](../model_doc/gptj), [LLaMA](../model_doc/llama), [Mamba](../model_doc/mamba), [Marian](../model_doc/marian), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MPT](../model_doc/mpt), [MusicGen](../model_doc/musicgen), [MusicGen Melody](../model_doc/musicgen_melody), [MVP](../model_doc/mvp), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Pegasus](../model_doc/pegasus), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [ProphetNet](../model_doc/prophetnet), [QDQBert](../model_doc/qdqbert), [Qwen2](../model_doc/qwen2), [Qwen2MoE](../model_doc/qwen2_moe), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [RWKV](../model_doc/rwkv), [Speech2Text2](../model_doc/speech_to_text_2), [StableLm](../model_doc/stablelm), [Starcoder2](../model_doc/starcoder2), [Transformer-XL](../model_doc/transfo-xl), [TrOCR](../model_doc/trocr), [Whisper](../model_doc/whisper), [XGLM](../model_doc/xglm), [XLM](../model_doc/xlm), [XLM-ProphetNet](../model_doc/xlm-prophetnet), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -33,7 +33,7 @@ The task illustrated in this tutorial is supported by the following model archit
|
||||
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
|
||||
|
||||
|
||||
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [CodeLlama](../model_doc/code_llama), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Qwen2](../model_doc/qwen2), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [StableLm](../model_doc/stablelm), [T5](../model_doc/t5), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
|
||||
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BigBird-Pegasus](../model_doc/bigbird_pegasus), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [CodeLlama](../model_doc/code_llama), [ConvBERT](../model_doc/convbert), [CTRL](../model_doc/ctrl), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [Falcon](../model_doc/falcon), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [Gemma](../model_doc/gemma), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [GPT Neo](../model_doc/gpt_neo), [GPT NeoX](../model_doc/gpt_neox), [GPT-J](../model_doc/gptj), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LED](../model_doc/led), [LiLT](../model_doc/lilt), [LLaMA](../model_doc/llama), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [Mistral](../model_doc/mistral), [Mixtral](../model_doc/mixtral), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MPT](../model_doc/mpt), [MRA](../model_doc/mra), [MT5](../model_doc/mt5), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [OpenLlama](../model_doc/open-llama), [OpenAI GPT](../model_doc/openai-gpt), [OPT](../model_doc/opt), [Perceiver](../model_doc/perceiver), [Persimmon](../model_doc/persimmon), [Phi](../model_doc/phi), [PLBart](../model_doc/plbart), [QDQBert](../model_doc/qdqbert), [Qwen2](../model_doc/qwen2), [Qwen2MoE](../model_doc/qwen2_moe), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [StableLm](../model_doc/stablelm), [Starcoder2](../model_doc/starcoder2), [T5](../model_doc/t5), [TAPAS](../model_doc/tapas), [Transformer-XL](../model_doc/transfo-xl), [UMT5](../model_doc/umt5), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
|
||||
|
||||
|
||||
|
||||
|
||||
@ -286,7 +286,7 @@ BART adapts to translation by adding a separate randomly initialized encoder to
|
||||
|
||||
BART has since been followed up by a multilingual version, mBART, intended for translation and pretrained on many different languages.
|
||||
|
||||
Ready to try your hand at translation? Check out our complete [translation guide](tasks/summarization) to learn how to finetune T5 and use it for inference!
|
||||
Ready to try your hand at translation? Check out our complete [translation guide](tasks/translation) to learn how to finetune T5 and use it for inference!
|
||||
|
||||
<Tip>
|
||||
|
||||
|
||||
@ -168,7 +168,7 @@ pytest -k "ada and not adam" tests/test_optimization.py
|
||||
For example to run both `test_adafactor` and `test_adam_w` you can use:
|
||||
|
||||
```bash
|
||||
pytest -k "test_adam_w or test_adam_w" tests/test_optimization.py
|
||||
pytest -k "test_adafactor or test_adam_w" tests/test_optimization.py
|
||||
```
|
||||
|
||||
Note that we use `or` here, since we want either of the keywords to match to include both.
|
||||
@ -451,13 +451,13 @@ decorators are used to set the requirements of tests CPU/GPU/TPU-wise:
|
||||
- `require_torch_multi_gpu` - as `require_torch` plus requires at least 2 GPUs
|
||||
- `require_torch_non_multi_gpu` - as `require_torch` plus requires 0 or 1 GPUs
|
||||
- `require_torch_up_to_2_gpus` - as `require_torch` plus requires 0 or 1 or 2 GPUs
|
||||
- `require_torch_tpu` - as `require_torch` plus requires at least 1 TPU
|
||||
- `require_torch_xla` - as `require_torch` plus requires at least 1 TPU
|
||||
|
||||
Let's depict the GPU requirements in the following table:
|
||||
|
||||
|
||||
| n gpus | decorator |
|
||||
|--------+--------------------------------|
|
||||
|--------|--------------------------------|
|
||||
| `>= 0` | `@require_torch` |
|
||||
| `>= 1` | `@require_torch_gpu` |
|
||||
| `>= 2` | `@require_torch_multi_gpu` |
|
||||
@ -518,21 +518,21 @@ To run the test suite on a specific torch device add `TRANSFORMERS_TEST_DEVICE="
|
||||
TRANSFORMERS_TEST_DEVICE="cpu" pytest tests/utils/test_logging.py
|
||||
```
|
||||
|
||||
This variable is useful for testing custom or less common PyTorch backends such as `mps`. It can also be used to achieve the same effect as `CUDA_VISIBLE_DEVICES` by targeting specific GPUs or testing in CPU-only mode.
|
||||
This variable is useful for testing custom or less common PyTorch backends such as `mps`, `xpu` or `npu`. It can also be used to achieve the same effect as `CUDA_VISIBLE_DEVICES` by targeting specific GPUs or testing in CPU-only mode.
|
||||
|
||||
Certain devices will require an additional import after importing `torch` for the first time. This can be specified using the environment variable `TRANSFORMERS_TEST_BACKEND`:
|
||||
|
||||
```bash
|
||||
TRANSFORMERS_TEST_BACKEND="torch_npu" pytest tests/utils/test_logging.py
|
||||
```
|
||||
Alternative backends may also require the replacement of device-specific functions. For example `torch.cuda.manual_seed` may need to be replaced with a device-specific seed setter like `torch.npu.manual_seed` to correctly set a random seed on the device. To specify a new backend with backend-specific device functions when running the test suite, create a Python device specification file in the format:
|
||||
Alternative backends may also require the replacement of device-specific functions. For example `torch.cuda.manual_seed` may need to be replaced with a device-specific seed setter like `torch.npu.manual_seed` or `torch.xpu.manual_seed` to correctly set a random seed on the device. To specify a new backend with backend-specific device functions when running the test suite, create a Python device specification file `spec.py` in the format:
|
||||
|
||||
```
|
||||
```python
|
||||
import torch
|
||||
import torch_npu
|
||||
import torch_npu # for xpu, replace it with `import intel_extension_for_pytorch`
|
||||
# !! Further additional imports can be added here !!
|
||||
|
||||
# Specify the device name (eg. 'cuda', 'cpu', 'npu')
|
||||
# Specify the device name (eg. 'cuda', 'cpu', 'npu', 'xpu', 'mps')
|
||||
DEVICE_NAME = 'npu'
|
||||
|
||||
# Specify device-specific backends to dispatch to.
|
||||
@ -541,11 +541,10 @@ MANUAL_SEED_FN = torch.npu.manual_seed
|
||||
EMPTY_CACHE_FN = torch.npu.empty_cache
|
||||
DEVICE_COUNT_FN = torch.npu.device_count
|
||||
```
|
||||
This format also allows for specification of any additional imports required. To use this file to replace equivalent methods in the test suite, set the environment variable `TRANSFORMERS_TEST_DEVICE_SPEC` to the path of the spec file.
|
||||
This format also allows for specification of any additional imports required. To use this file to replace equivalent methods in the test suite, set the environment variable `TRANSFORMERS_TEST_DEVICE_SPEC` to the path of the spec file, e.g. `TRANSFORMERS_TEST_DEVICE_SPEC=spec.py`.
|
||||
|
||||
Currently, only `MANUAL_SEED_FN`, `EMPTY_CACHE_FN` and `DEVICE_COUNT_FN` are supported for device-specific dispatch.
|
||||
|
||||
|
||||
### Distributed training
|
||||
|
||||
`pytest` can't deal with distributed training directly. If this is attempted - the sub-processes don't do the right
|
||||
@ -579,7 +578,7 @@ pytest -s tests/utils/test_logging.py
|
||||
To send test results to JUnit format output:
|
||||
|
||||
```bash
|
||||
py.test tests --junitxml=result.xml
|
||||
pytest tests --junitxml=result.xml
|
||||
```
|
||||
|
||||
### Color control
|
||||
|
||||
@ -104,7 +104,7 @@ trainer.train(resume_from_checkpoint="your-model/checkpoint-1000")
|
||||
You can save your checkpoints (the optimizer state is not saved by default) to the Hub by setting `push_to_hub=True` in [`TrainingArguments`] to commit and push them. Other options for deciding how your checkpoints are saved are set up in the [`hub_strategy`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.hub_strategy) parameter:
|
||||
|
||||
* `hub_strategy="checkpoint"` pushes the latest checkpoint to a subfolder named "last-checkpoint" from which you can resume training
|
||||
* `hug_strategy="all_checkpoints"` pushes all checkpoints to the directory defined in `output_dir` (you'll see one checkpoint per folder in your model repository)
|
||||
* `hub_strategy="all_checkpoints"` pushes all checkpoints to the directory defined in `output_dir` (you'll see one checkpoint per folder in your model repository)
|
||||
|
||||
When you resume training from a checkpoint, the [`Trainer`] tries to keep the Python, NumPy, and PyTorch RNG states the same as they were when the checkpoint was saved. But because PyTorch has various non-deterministic default settings, the RNG states aren't guaranteed to be the same. If you want to enable full determinism, take a look at the [Controlling sources of randomness](https://pytorch.org/docs/stable/notes/randomness#controlling-sources-of-randomness) guide to learn what you can enable to make your training fully deterministic. Keep in mind though that by making certain settings deterministic, training may be slower.
|
||||
|
||||
@ -252,6 +252,136 @@ trainer = Trainer(..., args=training_args)
|
||||
|
||||
NEFTune is disabled after training to restore the original embedding layer to avoid any unexpected behavior.
|
||||
|
||||
## GaLore
|
||||
|
||||
Gradient Low-Rank Projection (GaLore) is a memory-efficient low-rank training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods, such as LoRA.
|
||||
|
||||
First make sure to install GaLore official repository:
|
||||
|
||||
```bash
|
||||
pip install galore-torch
|
||||
```
|
||||
|
||||
Then simply add one of `["galore_adamw", "galore_adafactor", "galore_adamw_8bit"]` in `optim` together with `optim_target_modules`, which can be a list of strings, regex or full path corresponding to the target module names you want to adapt. Below is an end-to-end example script (make sure to `pip install trl datasets`):
|
||||
|
||||
```python
|
||||
import torch
|
||||
import datasets
|
||||
import trl
|
||||
|
||||
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
|
||||
|
||||
train_dataset = datasets.load_dataset('imdb', split='train')
|
||||
|
||||
args = TrainingArguments(
|
||||
output_dir="./test-galore",
|
||||
max_steps=100,
|
||||
per_device_train_batch_size=2,
|
||||
optim="galore_adamw",
|
||||
optim_target_modules=["attn", "mlp"]
|
||||
)
|
||||
|
||||
model_id = "google/gemma-2b"
|
||||
|
||||
config = AutoConfig.from_pretrained(model_id)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
model = AutoModelForCausalLM.from_config(config).to(0)
|
||||
|
||||
trainer = trl.SFTTrainer(
|
||||
model=model,
|
||||
args=args,
|
||||
train_dataset=train_dataset,
|
||||
dataset_text_field='text',
|
||||
max_seq_length=512,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
To pass extra arguments supports by GaLore, you should pass correctly `optim_args`, for example:
|
||||
|
||||
```python
|
||||
import torch
|
||||
import datasets
|
||||
import trl
|
||||
|
||||
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
|
||||
|
||||
train_dataset = datasets.load_dataset('imdb', split='train')
|
||||
|
||||
args = TrainingArguments(
|
||||
output_dir="./test-galore",
|
||||
max_steps=100,
|
||||
per_device_train_batch_size=2,
|
||||
optim="galore_adamw",
|
||||
optim_target_modules=["attn", "mlp"],
|
||||
optim_args="rank=64, update_proj_gap=100, scale=0.10",
|
||||
)
|
||||
|
||||
model_id = "google/gemma-2b"
|
||||
|
||||
config = AutoConfig.from_pretrained(model_id)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
model = AutoModelForCausalLM.from_config(config).to(0)
|
||||
|
||||
trainer = trl.SFTTrainer(
|
||||
model=model,
|
||||
args=args,
|
||||
train_dataset=train_dataset,
|
||||
dataset_text_field='text',
|
||||
max_seq_length=512,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
You can read more about the method in the [original repository](https://github.com/jiaweizzhao/GaLore) or the [paper](https://arxiv.org/abs/2403.03507).
|
||||
|
||||
Currently you can only train Linear layers that are considered as GaLore layers and will use low-rank decomposition to be trained while remaining layers will be optimized in the conventional manner.
|
||||
|
||||
Note it will take a bit of time before starting the training (~3 minutes for a 2B model on a NVIDIA A100), but training should go smoothly afterwards.
|
||||
|
||||
You can also perform layer-wise optimization by post-pending the optimizer name with `layerwise` like below:
|
||||
|
||||
```python
|
||||
import torch
|
||||
import datasets
|
||||
import trl
|
||||
|
||||
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
|
||||
|
||||
train_dataset = datasets.load_dataset('imdb', split='train')
|
||||
|
||||
args = TrainingArguments(
|
||||
output_dir="./test-galore",
|
||||
max_steps=100,
|
||||
per_device_train_batch_size=2,
|
||||
optim="galore_adamw_layerwise",
|
||||
optim_target_modules=["attn", "mlp"]
|
||||
)
|
||||
|
||||
model_id = "google/gemma-2b"
|
||||
|
||||
config = AutoConfig.from_pretrained(model_id)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
model = AutoModelForCausalLM.from_config(config).to(0)
|
||||
|
||||
trainer = trl.SFTTrainer(
|
||||
model=model,
|
||||
args=args,
|
||||
train_dataset=train_dataset,
|
||||
dataset_text_field='text',
|
||||
max_seq_length=512,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
Note layerwise optimization is a bit experimental and does not support DDP (Distributed Data Parallel), thus you can run the training script only on a single GPU. Please see [this appropriate section](https://github.com/jiaweizzhao/GaLore?tab=readme-ov-file#train-7b-model-with-a-single-gpu-with-24gb-memory) for more details. Other features such as gradient clipping, DeepSpeed, etc might not be supported out of the box. Please [raise an issue on GitHub](https://github.com/huggingface/transformers/issues) if you encounter such issue.
|
||||
|
||||
## Accelerate and Trainer
|
||||
|
||||
The [`Trainer`] class is powered by [Accelerate](https://hf.co/docs/accelerate), a library for easily training PyTorch models in distributed environments with support for integrations such as [FullyShardedDataParallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) and [DeepSpeed](https://www.deepspeed.ai/).
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
# docstyle-ignore
|
||||
INSTALL_CONTENT = """
|
||||
# Transformers installation
|
||||
! pip install transformers datasets
|
||||
! pip install transformers datasets evaluate accelerate
|
||||
# To install from source instead of the last release, comment the command above and uncomment the following one.
|
||||
# ! pip install git+https://github.com/huggingface/transformers.git
|
||||
"""
|
||||
|
||||
@ -56,12 +56,18 @@
|
||||
title: Compartir modelos personalizados
|
||||
- local: run_scripts
|
||||
title: Entrenamiento con scripts
|
||||
- local: chat_templating
|
||||
title: Plantillas para Modelos de Chat
|
||||
- local: trainer
|
||||
title: Entrenador
|
||||
- local: sagemaker
|
||||
title: Ejecutar el entrenamiento en Amazon SageMaker
|
||||
- local: converting_tensorflow_models
|
||||
title: Convertir checkpoints de TensorFlow
|
||||
- local: serialization
|
||||
title: Exportar a ONNX
|
||||
- local: torchscript
|
||||
title: Exportar a TorchScript
|
||||
- local: community
|
||||
title: Los recursos de la comunidad
|
||||
title: Guías para desarrolladores
|
||||
@ -84,6 +90,10 @@
|
||||
title: Glosario
|
||||
- local: task_summary
|
||||
title: Lo que 🤗 Transformers puede hacer
|
||||
- local: tasks_explained
|
||||
title: Como los 🤗 Transformers resuelven tareas
|
||||
- local: attention
|
||||
title: Mecanismos de atención
|
||||
- local: pad_truncation
|
||||
title: Relleno y truncamiento
|
||||
- local: bertology
|
||||
|
||||
41
docs/source/es/attention.md
Normal file
41
docs/source/es/attention.md
Normal file
@ -0,0 +1,41 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Mecanismos de atención
|
||||
|
||||
La mayoría de los modelos transformers utilizan atención completa, en el sentido de que la matriz de atención es cuadrada. Esto puede ser un gran cuello de botella computacional cuando tienes textos largos. `Longformer` y `reformer` son modelos que intentan ser más eficientes y utilizan una versión dispersa de la matriz de atención para acelerar el entrenamiento.
|
||||
|
||||
## Atención LSH
|
||||
|
||||
[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer) utiliza atención LSH. En el softmax(QK^t), solo los elementos más grandes (en la dimensión softmax) de la matriz QK^t van a dar contribuciones útiles. Entonces, para cada consulta q en Q, podemos considerar solo las claves k en K que estén cerca de q. Se utiliza una función hash para determinar si q y k están cerca. La máscara de atención se modifica para enmascarar el token actual (excepto en la primera posición), porque dará una consulta y una clave iguales (entonces muy similares entre sí). Dado que el hash puede ser un poco aleatorio, en la práctica se utilizan varias funciones hash (determinadas por un parámetro n_rounds) y luego se promedian juntas.
|
||||
|
||||
## Atención local
|
||||
|
||||
[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer) utiliza atención local: a menudo, el contexto local (por ejemplo, ¿cuáles son los dos tokens a la izquierda y a la derecha?) es suficiente para tomar acción para un token dado. Además, apilando capas de atención que tienen una ventana pequeña, la última capa tendrá un campo receptivo mayor que solamente los tokens en la ventana, lo que les permite construir una representación de toda la oración.
|
||||
|
||||
Algunos tokens de entrada preseleccionados también reciben atención global: para esos pocos tokens, la matriz de atención puede acceder a todos los tokens y este proceso es simétrico: todos los demás tokens tienen acceso a esos tokens específicos (además de los que están en su ventana local). Esto se muestra en la Figura 2d del artículo, el cual se puede apreciar un ejemplo de una máscara de atención:
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img scale="50 %" align="center" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/local_attention_mask.png"/>
|
||||
</div>
|
||||
|
||||
El uso de dichas matrices de atención con menos parámetros permite que el modelo tenga entradas con una longitud de secuencia mayor.
|
||||
|
||||
## Otros trucos
|
||||
|
||||
### Codificación posicional axial
|
||||
|
||||
[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer) utiliza codificación posicional axial: en los modelos transformers tradicionales, la codificación posicional E es una matriz de tamaño \\(l\\) por \\(d\\), donde \\(l\\) es la longitud de la secuencia y \\(d\\) es la dimensión del estado oculto. Si tienes textos muy extensos, esta matriz puede ser enorme y ocupar demasiado espacio en la GPU. Para aliviar eso, las codificaciones posicionales axiales consisten en factorizar esa gran matriz E en dos matrices más pequeñas E1 y E2, con dimensiones \\(l_{1} \times d_{1}\\) y \\(l_{2} \times d_{2}\\), tal que \\(l_{1} \times l_{2} = l\\) y \\(d_{1} + d_{2} = d\\) (con el producto de las longitudes, esto termina siendo mucho más pequeño). La incrustación (embedding) para el paso de tiempo \\(j\\) en E se obtiene concatenando las incrustaciones para el paso de tiempo \\(j \% l1\\) en E1 y \\(j // l1\\) en E2.
|
||||
399
docs/source/es/chat_templating.md
Normal file
399
docs/source/es/chat_templating.md
Normal file
@ -0,0 +1,399 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
|
||||
# Plantillas para Modelos de Chat
|
||||
|
||||
## Introducción
|
||||
|
||||
Un caso de uso cada vez más común para LLMs es **el chat**. En un contexto de chat, en lugar de continuar una única cadena de texto (como es el caso con un modelo de lenguaje estándar), el modelo continúa una conversación que consta de uno o más **mensajes**, cada uno de los cuales incluye un **rol**, como "usuario" o "asistente", así como el texto del mensaje.
|
||||
Al igual que con la tokenización, diferentes modelos esperan formatos de entrada muy diferentes para el chat. Esta es la razón por la que agregamos las plantillas de chat como una característica. Las plantillas de chat son parte del tokenizador. Especifican cómo convertir conversaciones, representadas como listas de mensajes, en una única cadena tokenizable en el formato que el modelo espera.
|
||||
Vamos a hacer esto con un ejemplo concreto utilizando el modelo `BlenderBot`. BlenderBot tiene una plantilla predeterminada extremadamente simple, que principalmente solo agrega espacios en blanco entre rondas de diálogo:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
|
||||
|
||||
>>> chat = [
|
||||
... {"role": "user", "content": "Hello, how are you?"},
|
||||
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
|
||||
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
|
||||
... ]
|
||||
|
||||
>>> tokenizer.apply_chat_template(chat, tokenize=False)
|
||||
" Hello, how are you? I'm doing great. How can I help you today? I'd like to show off how chat templating works!</s>"
|
||||
|
||||
```
|
||||
Observa cómo todo el chat se condensa en una sola cadena. Si usamos `tokenize=True`, que es la configuración predeterminada, esa cadena también será tokenizada para nosotros. Sin embargo, para ver una plantilla más compleja en acción, usemos el modelo `mistralai/Mistral-7B-Instruct-v0.1`
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
|
||||
|
||||
>>> chat = [
|
||||
... {"role": "user", "content": "Hello, how are you?"},
|
||||
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
|
||||
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
|
||||
... ]
|
||||
|
||||
>>> tokenizer.apply_chat_template(chat, tokenize=False)
|
||||
"<s>[INST] Hello, how are you? [/INST]I'm doing great. How can I help you today?</s> [INST] I'd like to show off how chat templating works! [/INST]"
|
||||
```
|
||||
|
||||
Ten en cuenta que esta vez, el tokenizador ha añadido los tokens de control [INST] y [/INST] para indicar el inicio y el final de los mensajes de usuario (¡pero no de los mensajes del asistente!). Mistral-instruct fue entrenado con estos tokens, pero BlenderBot no lo fue.
|
||||
|
||||
## ¿Cómo uso las plantillas de chat?
|
||||
|
||||
Como puedes ver en el ejemplo anterior, las plantillas de chat son fáciles de usar. Simplemente construye una lista de mensajes, con claves de `rol` y `contenido`, y luego pásala al método [`~PreTrainedTokenizer.apply_chat_template`]. Una vez que hagas eso, ¡obtendrás una salida lista para usar! Al utilizar plantillas de chat como entrada para la generación de modelos, también es una buena idea usar `add_generation_prompt=True` para agregar una [indicación de generación](#¿Qué-son-los-"generation-prompts"?).
|
||||
|
||||
Aquí tienes un ejemplo de cómo preparar la entrada para `model.generate()` utilizando el modelo de asistente `Zephyr`:
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
checkpoint = "HuggingFaceH4/zephyr-7b-beta"
|
||||
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
model = AutoModelForCausalLM.from_pretrained(checkpoint) # You may want to use bfloat16 and/or move to GPU here
|
||||
|
||||
messages = [
|
||||
{
|
||||
"role": "system",
|
||||
"content": "You are a friendly chatbot who always responds in the style of a pirate",
|
||||
},
|
||||
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
|
||||
]
|
||||
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
|
||||
print(tokenizer.decode(tokenized_chat[0]))
|
||||
```
|
||||
|
||||
Esto generará una cadena en el formato de entrada que Zephyr espera.
|
||||
|
||||
```text
|
||||
<|system|>
|
||||
You are a friendly chatbot who always responds in the style of a pirate</s>
|
||||
<|user|>
|
||||
How many helicopters can a human eat in one sitting?</s>
|
||||
<|assistant|>
|
||||
```
|
||||
|
||||
Ahora que nuestra entrada está formateada correctamente para Zephyr, podemos usar el modelo para generar una respuesta a la pregunta del usuario:
|
||||
|
||||
```python
|
||||
outputs = model.generate(tokenized_chat, max_new_tokens=128)
|
||||
print(tokenizer.decode(outputs[0]))
|
||||
|
||||
```
|
||||
Esto producirá:
|
||||
|
||||
```text
|
||||
<|system|>
|
||||
You are a friendly chatbot who always responds in the style of a pirate</s>
|
||||
<|user|>
|
||||
How many helicopters can a human eat in one sitting?</s>
|
||||
<|assistant|>
|
||||
Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
|
||||
```
|
||||
|
||||
¡Arr, al final resultó ser fácil!
|
||||
|
||||
## ¿Existe un pipeline automatizado para chats?
|
||||
|
||||
Sí, lo hay! Nuestros canales de generación de texto admiten entradas de chat, cual facilita más facíl utilizar los modelos de chat. En el pasado, solíamos utilizar una clase dedicada "ConversationalPipeline", pero ahora ha quedado obsoleta y su funcionalidad se ha fusionado en [`TextGenerationPipeline`]. Este pipeline está diseñado para facilitar el uso de modelos de chat. Intentemos el ejemplo de `Zephyr` de nuevo, pero esta vez utilizando el pipeline:
|
||||
|
||||
```python
|
||||
from transformers import pipeline
|
||||
|
||||
pipe = pipeline("conversational", "HuggingFaceH4/zephyr-7b-beta")
|
||||
messages = [
|
||||
{
|
||||
"role": "system",
|
||||
"content": "You are a friendly chatbot who always responds in the style of a pirate",
|
||||
},
|
||||
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
|
||||
]
|
||||
print(pipe(messages, max_new_tokens=128)[0]['generated_text'][-1]) # Print the assistant's response
|
||||
```
|
||||
|
||||
```text
|
||||
{'role': 'assistant', 'content': "Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all."}
|
||||
```
|
||||
|
||||
|
||||
La canalización se encargará de todos los detalles de la tokenización y de llamar a `apply_chat_template` por ti. Una vez que el modelo tenga una plantilla de chat, ¡todo lo que necesitas hacer es inicializar el pipeline y pasarle la lista de mensajes!
|
||||
|
||||
# ¿Qué son los "generation prompts"?
|
||||
|
||||
Puede que hayas notado que el método `apply_chat_template` tiene un argumento `add_generation_prompt`. Este argumento indica a la plantilla que agregue tokens que indiquen el inicio de una respuesta del bot. Por ejemplo, considera el siguiente chat:
|
||||
|
||||
```python
|
||||
messages = [
|
||||
{"role": "user", "content": "Hi there!"},
|
||||
{"role": "assistant", "content": "Nice to meet you!"},
|
||||
{"role": "user", "content": "Can I ask a question?"}
|
||||
]
|
||||
```
|
||||
|
||||
Así es cómo se verá esto sin un "generation prompt", usando la plantilla ChatML que vimos en el ejemplo de Zephyr:
|
||||
|
||||
```python
|
||||
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
|
||||
"""<|im_start|>user
|
||||
Hi there!<|im_end|>
|
||||
<|im_start|>assistant
|
||||
Nice to meet you!<|im_end|>
|
||||
<|im_start|>user
|
||||
Can I ask a question?<|im_end|>
|
||||
"""
|
||||
```
|
||||
|
||||
Y así es como se ve **con** un "generation prompt":
|
||||
|
||||
```python
|
||||
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
|
||||
"""<|im_start|>user
|
||||
Hi there!<|im_end|>
|
||||
<|im_start|>assistant
|
||||
Nice to meet you!<|im_end|>
|
||||
<|im_start|>user
|
||||
Can I ask a question?<|im_end|>
|
||||
<|im_start|>assistant
|
||||
"""
|
||||
```
|
||||
|
||||
Ten en cuenta que esta vez, hemos agregado los tokens que indican el inicio de una respuesta del bot. Esto asegura que cuando el modelo genere texto, escribirá una respuesta del bot en lugar de hacer algo inesperado, como continuar el mensaje del usuario. Recuerda, los modelos de chat siguen siendo solo modelos de lenguaje: están entrenados para continuar texto, ¡y el chat es solo un tipo especial de texto para ellos! Necesitas guiarlos con los tokens de control apropiados para que sepan lo que se supone que deben estar haciendo.
|
||||
|
||||
No todos los modelos requieren "generation prompts". Algunos modelos, como BlenderBot y LLaMA, no tienen ningún token especial antes de las respuestas del bot. En estos casos, el argumento `add_generation_prompt` no tendrá ningún efecto. El efecto exacto que tiene `add_generation_prompt` dependerá de la plantilla que se esté utilizando.
|
||||
|
||||
## ¿Puedo usar plantillas de chat en el entrenamiento?
|
||||
|
||||
¡Sí! Recomendamos que apliques la plantilla de chat como un paso de preprocesamiento para tu conjunto de datos. Después de esto, simplemente puedes continuar como cualquier otra tarea de entrenamiento de modelos de lenguaje. Durante el entrenamiento, generalmente deberías establecer `add_generation_prompt=False`, porque los tokens añadidos para solicitar una respuesta del asistente no serán útiles durante el entrenamiento. Veamos un ejemplo:
|
||||
|
||||
```python
|
||||
from transformers import AutoTokenizer
|
||||
from datasets import Dataset
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
|
||||
|
||||
chat1 = [
|
||||
{"role": "user", "content": "Which is bigger, the moon or the sun?"},
|
||||
{"role": "assistant", "content": "The sun."}
|
||||
]
|
||||
chat2 = [
|
||||
{"role": "user", "content": "Which is bigger, a virus or a bacterium?"},
|
||||
{"role": "assistant", "content": "A bacterium."}
|
||||
]
|
||||
|
||||
dataset = Dataset.from_dict({"chat": [chat1, chat2]})
|
||||
dataset = dataset.map(lambda x: {"formatted_chat": tokenizer.apply_chat_template(x["chat"], tokenize=False, add_generation_prompt=False)})
|
||||
print(dataset['formatted_chat'][0])
|
||||
```
|
||||
|
||||
Y obtenemos:
|
||||
|
||||
```text
|
||||
<|user|>
|
||||
Which is bigger, the moon or the sun?</s>
|
||||
<|assistant|>
|
||||
The sun.</s>
|
||||
```
|
||||
|
||||
Desde aquí, simplemente continúa el entrenamiento como lo harías con una tarea estándar de modelado de lenguaje, utilizando la columna `formatted_chat`.
|
||||
|
||||
## Avanzado: ¿Cómo funcionan las plantillas de chat?
|
||||
|
||||
La plantilla de chat para un modelo se almacena en el atributo `tokenizer.chat_template`. Si no se establece ninguna plantilla de chat, se utiliza en su lugar la plantilla predeterminada para esa clase de modelo. Echemos un vistazo a la plantilla para `BlenderBot`:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
|
||||
|
||||
>>> tokenizer.default_chat_template
|
||||
"{% for message in messages %}{% if message['role'] == 'user' %}{{ ' ' }}{% endif %}{{ message['content'] }}{% if not loop.last %}{{ ' ' }}{% endif %}{% endfor %}{{ eos_token }}"
|
||||
```
|
||||
|
||||
¡Es un poco intimidante! Vamos a agregar algunas líneas nuevas y sangria para que sea más legible. Ten en cuenta que la primera línea nueva después de cada bloque, así como cualquier espacio en blanco anterior a un bloque, se ignoran de forma predeterminada, utilizando las banderas `trim_blocks` y `lstrip_blocks` de Jinja. Sin embargo, ¡ten cuidado! Aunque el espacio en blanco inicial en cada línea se elimina, los espacios entre bloques en la misma línea no. ¡Te recomendamos encarecidamente que verifiques que tu plantilla no esté imprimiendo espacios adicionales donde no debería estarlo!
|
||||
|
||||
```
|
||||
{% for message in messages %}
|
||||
{% if message['role'] == 'user' %}
|
||||
{{ ' ' }}
|
||||
{% endif %}
|
||||
{{ message['content'] }}
|
||||
{% if not loop.last %}
|
||||
{{ ' ' }}
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
{{ eos_token }}
|
||||
```
|
||||
|
||||
Si nunca has visto uno de estos antes, esto es una [plantilla de Jinja](https://jinja.palletsprojects.com/en/3.1.x/templates/). Jinja es un lenguaje de plantillas que te permite escribir código simple que genera texto. En muchos aspectos, el código y la sintaxis se asemejan a Python. En Python puro, esta plantilla se vería algo así:
|
||||
|
||||
```python
|
||||
for idx, message in enumerate(messages):
|
||||
if message['role'] == 'user':
|
||||
print(' ')
|
||||
print(message['content'])
|
||||
if not idx == len(messages) - 1: # Check for the last message in the conversation
|
||||
print(' ')
|
||||
print(eos_token)
|
||||
```
|
||||
|
||||
Efectivamente, la plantilla hace tres cosas:
|
||||
1. Para cada mensaje, si el mensaje es un mensaje de usuario, añade un espacio en blanco antes de él, de lo contrario no imprime nada.
|
||||
2. Añade el contenido del mensaje.
|
||||
3. Si el mensaje no es el último mensaje, añade dos espacios después de él. Después del último mensaje, imprime el token EOS.
|
||||
|
||||
Esta es una plantilla bastante simple: no añade ningún token de control y no admite mensajes "del sistema", que son una forma común de dar al modelo directivas sobre cómo debe comportarse en la conversación posterior. ¡Pero Jinja te brinda mucha flexibilidad para hacer esas cosas! Veamos una plantilla de Jinja que pueda formatear las entradas de manera similar a la forma en que LLaMA las formatea (nota que la plantilla real de LLaMA incluye el manejo de mensajes del sistema predeterminados y el manejo de mensajes del sistema ligeramente diferentes en general; ¡no uses esta en tu código real!)
|
||||
|
||||
```
|
||||
{% for message in messages %}
|
||||
{% if message['role'] == 'user' %}
|
||||
{{ bos_token + '[INST] ' + message['content'] + ' [/INST]' }}
|
||||
{% elif message['role'] == 'system' %}
|
||||
{{ '<<SYS>>\\n' + message['content'] + '\\n<</SYS>>\\n\\n' }}
|
||||
{% elif message['role'] == 'assistant' %}
|
||||
{{ ' ' + message['content'] + ' ' + eos_token }}
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
Si observas esto por un momento, puedas ver lo que esta plantilla está haciendo: añade tokens específicos basados en el "rol" de cada mensaje, que representa quién lo envió. Los mensajes de usuario, asistente y sistema son claramente distinguibles para el modelo debido a los tokens en los que están envueltos.
|
||||
|
||||
## Avanzado: Añadiendo y editando plantillas de chat
|
||||
|
||||
### ¿Cómo creo una plantilla de chat?
|
||||
|
||||
Simple, solo escribe una plantilla de Jinja y establece `tokenizer.chat_template`. ¡Puede resultarte más fácil comenzar con una plantilla existente de otro modelo y simplemente editarla según tus necesidades! Por ejemplo, podríamos tomar la plantilla de LLaMA de arriba y añadir "[ASST]" y "[/ASST]" a los mensajes del asistente:
|
||||
|
||||
```
|
||||
{% for message in messages %}
|
||||
{% if message['role'] == 'user' %}
|
||||
{{ bos_token + '[INST] ' + message['content'].strip() + ' [/INST]' }}
|
||||
{% elif message['role'] == 'system' %}
|
||||
{{ '<<SYS>>\\n' + message['content'].strip() + '\\n<</SYS>>\\n\\n' }}
|
||||
{% elif message['role'] == 'assistant' %}
|
||||
{{ '[ASST] ' + message['content'] + ' [/ASST]' + eos_token }}
|
||||
{% endif %}
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
Ahora, simplemente establece el atributo `tokenizer.chat_template`. ¡La próxima vez que uses [`~PreTrainedTokenizer.apply_chat_template`], se utilizará tu nueva plantilla! Este atributo se guardará en el archivo tokenizer_config.json, por lo que puedes usar [`~utils.PushToHubMixin.push_to_hub`] para cargar tu nueva plantilla en el Hub y asegurarte de que todos estén utilizando la plantilla correcta para tu modelo.
|
||||
|
||||
```python
|
||||
template = tokenizer.chat_template
|
||||
template = template.replace("SYS", "SYSTEM") # Change the system token
|
||||
tokenizer.chat_template = template # Set the new template
|
||||
tokenizer.push_to_hub("model_name") # Upload your new template to the Hub!
|
||||
```
|
||||
|
||||
El método [`~PreTrainedTokenizer.apply_chat_template`], que utiliza tu plantilla de chat, es llamado por la clase [`TextGenerationPipeline`], así que una vez que configures la plantilla de chat correcta, tu modelo se volverá automáticamente compatible con [`TextGenerationPipeline`].
|
||||
|
||||
<Tip>
|
||||
|
||||
Si estás ajustando finamente un modelo para chat, además de establecer una plantilla de chat, probablemente deberías agregar cualquier nuevo token de control de chat como los tokens especiales en el tokenizador. Los tokens especiales nunca se dividen, asegurando que tus tokens de control siempre se manejen como tokens únicos en lugar de ser tokenizados en piezas. También deberías establecer el atributo `eos_token` del tokenizador con el token que marca el final de las generaciones del asistente en tu plantilla. Esto asegurará que las herramientas de generación de texto puedan determinar correctamente cuándo detener la generación de texto.
|
||||
|
||||
</Tip>
|
||||
|
||||
### ¿Qué son las plantillas "default"?
|
||||
|
||||
Antes de la introducción de las plantillas de chat, el manejo del chat estaba codificado en el nivel de la clase del modelo. Por razones de compatibilidad con versiones anteriores, hemos conservado este manejo específico de la clase como plantillas predeterminadas, también establecidas a nivel de clase. Si un modelo no tiene una plantilla de chat establecida, pero hay una plantilla predeterminada para su clase de modelo, la clase `TextGenerationPipeline` y métodos como `apply_chat_template` usarán la plantilla de clase en su lugar. Puedes averiguar cuál es la plantilla predeterminada para tu tokenizador comprobando el atributo `tokenizer.default_chat_template`.
|
||||
|
||||
Esto es algo que hacemos puramente por razones de compatibilidad con versiones anteriores, para evitar romper cualquier flujo de trabajo existente. Incluso cuando la plantilla de clase es apropiada para tu modelo, recomendamos encarecidamente anular la plantilla predeterminada estableciendo explícitamente el atributo `chat_template` para dejar claro a los usuarios que tu modelo ha sido configurado correctamente para el chat, y para estar preparados para el futuro en caso de que las plantillas predeterminadas alguna vez se alteren o se eliminen.
|
||||
|
||||
### ¿Qué plantilla debería usar?
|
||||
|
||||
Cuando establezcas la plantilla para un modelo que ya ha sido entrenado para chat, debes asegurarte de que la plantilla coincida exactamente con el formato de mensajes que el modelo vio durante el entrenamiento, o de lo contrario es probable que experimentes degradación del rendimiento. Esto es cierto incluso si estás entrenando aún más el modelo; probablemente obtendrás el mejor rendimiento si mantienes constantes los tokens de chat. Esto es muy análogo a la tokenización: generalmente obtienes el mejor rendimiento para la inferencia o el ajuste fino cuando coincides precisamente con la tokenización utilizada durante el entrenamiento.
|
||||
|
||||
Si estás entrenando un modelo desde cero o ajustando finamente un modelo de lenguaje base para chat, por otro lado, ¡tienes mucha libertad para elegir una plantilla apropiada! Los LLM son lo suficientemente inteligentes como para aprender a manejar muchos formatos de entrada diferentes. Nuestra plantilla predeterminada para modelos que no tienen una plantilla específica de clase sigue el formato ChatML, y esta es una buena elección flexible para muchos casos de uso. Se ve así:
|
||||
|
||||
```
|
||||
{% for message in messages %}
|
||||
{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
Si te gusta esta plantilla, aquí está en forma de una sola línea, lista para copiar en tu código. La versión de una sola línea también incluye un práctico soporte para [prompts de generación](#¿Qué-son-los-"generation-prompts"?), ¡pero ten en cuenta que no añade tokens de BOS o EOS! Si tu modelo espera esos tokens, no se agregarán automáticamente por `apply_chat_template`, en otras palabras, el texto será tokenizado con `add_special_tokens=False`. Esto es para evitar posibles conflictos entre la plantilla y la lógica de `add_special_tokens`. ¡Si tu modelo espera tokens especiales, asegúrate de añadirlos a la plantilla!
|
||||
|
||||
```python
|
||||
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
|
||||
```
|
||||
|
||||
Esta plantilla envuelve cada mensaje en tokens `<|im_start|>` y `<|im_end|>`, y simplemente escribe el rol como una cadena, lo que permite flexibilidad en los roles con los que entrenas. La salida se ve así:
|
||||
|
||||
```text
|
||||
<|im_start|>system
|
||||
You are a helpful chatbot that will do its best not to say anything so stupid that people tweet about it.<|im_end|>
|
||||
<|im_start|>user
|
||||
How are you?<|im_end|>
|
||||
<|im_start|>assistant
|
||||
I'm doing great!<|im_end|>
|
||||
```
|
||||
|
||||
Los roles "usuario", "sistema" y "asistente" son los estándar para chat, y recomendamos usarlos cuando tenga sentido, particularmente si deseas que tu modelo funcione bien con [`TextGenerationPipeline`]. Sin embargo, no estás limitado a estos roles: la plantilla es extremadamente flexible y cualquier cadena puede ser un rol.
|
||||
|
||||
### ¡Quiero añadir algunas plantillas de chat! ¿Cómo debo empezar?
|
||||
|
||||
Si tienes algún modelo de chat, debes establecer su atributo `tokenizer.chat_template` y probarlo usando [`~PreTrainedTokenizer.apply_chat_template`], luego subir el tokenizador actualizado al Hub. Esto se aplica incluso si no eres el propietario del modelo: si estás usando un modelo con una plantilla de chat vacía o que todavía está utilizando la plantilla predeterminada de clase, por favor abre una solicitud de extracción [pull request](https://huggingface.co/docs/hub/repositories-pull-requests-discussions) al repositorio del modelo para que este atributo se pueda establecer correctamente.
|
||||
|
||||
Una vez que se establece el atributo, ¡eso es todo, has terminado! `tokenizer.apply_chat_template` ahora funcionará correctamente para ese modelo, ¡lo que significa que también es compatible automáticamente en lugares como `TextGenerationPipeline`!
|
||||
|
||||
Al asegurarnos de que los modelos tengan este atributo, podemos garantizar que toda la comunidad pueda utilizar todo el poder de los modelos de código abierto. Los desajustes de formato han estado acechando el campo y dañando silenciosamente el rendimiento durante demasiado tiempo: ¡es hora de ponerles fin!
|
||||
|
||||
## Avanzado: Consejos para escribir plantillas
|
||||
|
||||
Si no estás familiarizado con Jinja, generalmente encontramos que la forma más fácil de escribir una plantilla de chat es primero escribir un script de Python corto que formatee los mensajes como desees, y luego convertir ese script en una plantilla.
|
||||
|
||||
Recuerda que el manejador de plantillas recibirá el historial de conversación como una variable llamada mensajes. Cada mensaje es un diccionario con dos claves, `role` y `content`. Podrás acceder a los `mensajes` en tu plantilla tal como lo harías en Python, lo que significa que puedes recorrerlo con `{% for message in messages %}` o acceder a mensajes individuales con, por ejemplo, `{{ messages[0] }}`.
|
||||
|
||||
También puedes usar los siguientes consejos para convertir tu código a Jinja:
|
||||
|
||||
### Bucles For
|
||||
|
||||
Los bucles For en Jinja se ven así:
|
||||
|
||||
```
|
||||
{% for message in messages %}
|
||||
{{ message['content'] }}
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
Ten en cuenta que todo lo que esté dentro del {{bloque de expresión}} se imprimirá en la salida. Puedes usar operadores como `+` para combinar cadenas dentro de bloques de expresión.
|
||||
|
||||
### Declaraciones if
|
||||
|
||||
Las declaraciones if en Jinja se ven así:
|
||||
|
||||
```
|
||||
{% if message['role'] == 'user' %}
|
||||
{{ message['content'] }}
|
||||
{% endif %}
|
||||
```
|
||||
|
||||
Observa cómo donde Python utiliza espacios en blanco para marcar el inicio y el final de los bloques `for` e `if`, Jinja requiere que los termines explícitamente con `{% endfor %}` y `{% endif %}`.
|
||||
|
||||
### Variables especiales
|
||||
|
||||
Dentro de tu plantilla, tendrás acceso a la lista de `mensajes`, pero también puedes acceder a varias otras variables especiales. Estas incluyen tokens especiales como `bos_token` y `eos_token`, así como la variable `add_generation_prompt` que discutimos anteriormente. También puedes usar la variable `loop` para acceder a información sobre la iteración actual del bucle, por ejemplo, usando `{% if loop.last %}` para verificar si el mensaje actual es el último mensaje en la conversación. Aquí tienes un ejemplo que combina estas ideas para agregar un prompt de generación al final de la conversación si add_generation_prompt es `True`:
|
||||
|
||||
```
|
||||
{% if loop.last and add_generation_prompt %}
|
||||
{{ bos_token + 'Assistant:\n' }}
|
||||
{% endif %}
|
||||
```
|
||||
|
||||
### Notas sobre los espacios en blanco
|
||||
|
||||
Hemos intentado que Jinja ignore los espacios en blanco fuera de las {{expresiones}} tanto como sea posible. Sin embargo, ten en cuenta que Jinja es un motor de plantillas de propósito general y puede tratar el espacio en blanco entre bloques en la misma línea como significativo e imprimirlo en la salida. ¡Te recomendamos **encarecidamente** que verifiques que tu plantilla no esté imprimiendo espacios adicionales donde no debería antes de subirla!
|
||||
@ -337,11 +337,4 @@ Las respuestas a preguntas de documentos es una tarea que responde preguntas en
|
||||
[{'score': 0.8531, 'answer': '17,000', 'start': 4, 'end': 4}]
|
||||
```
|
||||
|
||||
Con suerte, esta página te ha proporcionado más información de fondo sobre todos los tipos de tareas en cada modalidad y la importancia práctica de cada una. En la próxima [sección](https://huggingface.co/docs/transformers/tasks_explained), aprenderás **cómo** 🤗 Transformers trabaja para resolver estas tareas.
|
||||
|
||||
<!--
|
||||
TO DO:
|
||||
|
||||
Update this link "En la próxima [sección](https://huggingface.co/docs/transformers/tasks_explained),..."
|
||||
when the translation of "tasks_explained.md" was carried out.
|
||||
-->
|
||||
Con suerte, esta página te ha proporcionado más información de fondo sobre todos los tipos de tareas en cada modalidad y la importancia práctica de cada una. En la próxima [sección](tasks_explained), aprenderás **cómo** 🤗 Transformers trabaja para resolver estas tareas.
|
||||
|
||||
295
docs/source/es/tasks_explained.md
Normal file
295
docs/source/es/tasks_explained.md
Normal file
@ -0,0 +1,295 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# ¿Cómo los 🤗 Transformers resuelven tareas?
|
||||
|
||||
En [Lo que 🤗 Transformers puede hacer](task_summary), aprendiste sobre el procesamiento de lenguaje natural (NLP), tareas de voz y audio, visión por computadora y algunas aplicaciones importantes de ellas. Esta página se centrará en cómo los modelos resuelven estas tareas y explicará lo que está sucediendo debajo de la superficie. Hay muchas maneras de resolver una tarea dada, y diferentes modelos pueden implementar ciertas técnicas o incluso abordar la tarea desde un ángulo nuevo, pero para los modelos Transformer, la idea general es la misma. Debido a su arquitectura flexible, la mayoría de los modelos son una variante de una estructura de codificador, descodificador o codificador-descodificador. Además de los modelos Transformer, nuestra biblioteca también tiene varias redes neuronales convolucionales (CNNs) modernas, que todavía se utilizan hoy en día para tareas de visión por computadora. También explicaremos cómo funciona una CNN moderna.
|
||||
|
||||
Para explicar cómo se resuelven las tareas, caminaremos a través de lo que sucede dentro del modelo para generar predicciones útiles.
|
||||
|
||||
- [Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2) para clasificación de audio y reconocimiento automático de habla (ASR)
|
||||
- [Transformador de Visión (ViT)](https://huggingface.co/docs/transformers/model_doc/vit) y [ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext) para clasificación de imágenes
|
||||
- [DETR](https://huggingface.co/docs/transformers/model_doc/detr) para detección de objetos
|
||||
- [Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former) para segmentación de imagen
|
||||
- [GLPN](https://huggingface.co/docs/transformers/model_doc/glpn) para estimación de profundidad
|
||||
- [BERT](https://huggingface.co/docs/transformers/model_doc/bert) para tareas de NLP como clasificación de texto, clasificación de tokens y preguntas y respuestas que utilizan un codificador
|
||||
- [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2) para tareas de NLP como generación de texto que utilizan un descodificador
|
||||
- [BART](https://huggingface.co/docs/transformers/model_doc/bart) para tareas de NLP como resumen y traducción que utilizan un codificador-descodificador
|
||||
|
||||
<Tip>
|
||||
|
||||
Antes de continuar, es bueno tener un conocimiento básico de la arquitectura original del Transformer. Saber cómo funcionan los codificadores, decodificadores y la atención te ayudará a entender cómo funcionan los diferentes modelos de Transformer. Si estás empezando o necesitas repasar, ¡echa un vistazo a nuestro [curso](https://huggingface.co/course/chapter1/4?fw=pt) para obtener más información!
|
||||
|
||||
</Tip>
|
||||
|
||||
## Habla y audio
|
||||
|
||||
[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2) es un modelo auto-supervisado preentrenado en datos de habla no etiquetados y ajustado en datos etiquetados para clasificación de audio y reconocimiento automático de voz.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/wav2vec2_architecture.png"/>
|
||||
</div>
|
||||
|
||||
Este modelo tiene cuatro componentes principales:
|
||||
|
||||
1. Un *codificador de características* toma la forma de onda de audio cruda, la normaliza a media cero y varianza unitaria, y la convierte en una secuencia de vectores de características, cada uno de 20 ms de duración.
|
||||
|
||||
2. Las formas de onda son continuas por naturaleza, por lo que no se pueden dividir en unidades separadas como una secuencia de texto se puede dividir en palabras. Por eso, los vectores de características se pasan a un *módulo de cuantificación*, que tiene como objetivo aprender unidades de habla discretas. La unidad de habla se elige de una colección de palabras de código, conocidas como *codebook* (puedes pensar en esto como el vocabulario). Del codebook, se elige el vector o unidad de habla que mejor representa la entrada de audio continua y se envía a través del modelo.
|
||||
|
||||
3. Alrededor de la mitad de los vectores de características se enmascaran aleatoriamente, y el vector de características enmascarado se alimenta a una *red de contexto*, que es un codificador Transformer que también agrega incrustaciones posicionales relativas.
|
||||
|
||||
4. El objetivo del preentrenamiento de la red de contexto es una *tarea contrastiva*. El modelo tiene que predecir la verdadera representación de habla cuantizada de la predicción enmascarada a partir de un conjunto de falsas, lo que anima al modelo a encontrar el vector de contexto y la unidad de habla cuantizada más similares (la etiqueta objetivo).
|
||||
|
||||
¡Ahora que wav2vec2 está preentrenado, puedes ajustarlo con tus datos para clasificación de audio o reconocimiento automático de voz!
|
||||
|
||||
### Clasificación de audio
|
||||
|
||||
Para usar el modelo preentrenado para la clasificación de audio, añade una capa de clasificación de secuencia encima del modelo base de Wav2Vec2. La capa de clasificación es una capa lineal que acepta los estados ocultos del codificador. Los estados ocultos representan las características aprendidas de cada fotograma de audio, que pueden tener longitudes variables. Para crear un vector de longitud fija, primero se agrupan los estados ocultos y luego se transforman en logits sobre las etiquetas de clase. La pérdida de entropía cruzada se calcula entre los logits y el objetivo para encontrar la clase más probable.
|
||||
|
||||
¿Listo para probar la clasificación de audio? ¡Consulta nuestra guía completa de [clasificación de audio](https://huggingface.co/docs/transformers/tasks/audio_classification) para aprender cómo ajustar Wav2Vec2 y usarlo para inferencia!
|
||||
|
||||
### Reconocimiento automático de voz
|
||||
|
||||
Para usar el modelo preentrenado para el reconocimiento automático de voz, añade una capa de modelado del lenguaje encima del modelo base de Wav2Vec2 para [CTC (clasificación temporal conexista)](glossary#connectionist-temporal-classification-ctc). La capa de modelado del lenguaje es una capa lineal que acepta los estados ocultos del codificador y los transforma en logits. Cada logit representa una clase de token (el número de tokens proviene del vocabulario de la tarea). La pérdida de CTC se calcula entre los logits y los objetivos para encontrar la secuencia de tokens más probable, que luego se decodifican en una transcripción.
|
||||
|
||||
¿Listo para probar el reconocimiento automático de voz? ¡Consulta nuestra guía completa de [reconocimiento automático de voz](tasks/asr) para aprender cómo ajustar Wav2Vec2 y usarlo para inferencia!
|
||||
|
||||
## Visión por computadora
|
||||
|
||||
Hay dos formas de abordar las tareas de visión por computadora:
|
||||
|
||||
1. Dividir una imagen en una secuencia de parches y procesarlos en paralelo con un Transformer.
|
||||
2. Utilizar una CNN moderna, como [ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext), que se basa en capas convolucionales pero adopta diseños de redes modernas.
|
||||
|
||||
<Tip>
|
||||
|
||||
Un tercer enfoque combina Transformers con convoluciones (por ejemplo, [Convolutional Vision Transformer](https://huggingface.co/docs/transformers/model_doc/cvt) o [LeViT](https://huggingface.co/docs/transformers/model_doc/levit)). No discutiremos estos porque simplemente combinan los dos enfoques que examinamos aquí.
|
||||
|
||||
</Tip>
|
||||
|
||||
ViT y ConvNeXT se utilizan comúnmente para la clasificación de imágenes, pero para otras tareas de visión como la detección de objetos, la segmentación y la estimación de profundidad, veremos DETR, Mask2Former y GLPN, respectivamente; estos modelos son más adecuados para esas tareas.
|
||||
|
||||
### Clasificación de imágenes
|
||||
|
||||
ViT y ConvNeXT pueden usarse ambos para la clasificación de imágenes; la diferencia principal es que ViT utiliza un mecanismo de atención mientras que ConvNeXT utiliza convoluciones.
|
||||
|
||||
#### Transformer
|
||||
|
||||
[ViT](https://huggingface.co/docs/transformers/model_doc/vit) reemplaza completamente las convoluciones con una arquitectura de Transformer pura. Si estás familiarizado con el Transformer original, entonces ya estás en el camino para entender ViT.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/vit_architecture.jpg"/>
|
||||
</div>
|
||||
|
||||
El cambio principal que introdujo ViT fue en cómo se alimentan las imágenes a un Transformer:
|
||||
|
||||
1. Una imagen se divide en parches cuadrados no superpuestos, cada uno de los cuales se convierte en un vector o *incrustación de parche*(patch embedding). Las incrustaciones de parche se generan a partir de una capa convolucional 2D que crea las dimensiones de entrada adecuadas (que para un Transformer base son 768 valores para cada incrustación de parche). Si tuvieras una imagen de 224x224 píxeles, podrías dividirla en 196 parches de imagen de 16x16. Al igual que el texto se tokeniza en palabras, una imagen se "tokeniza" en una secuencia de parches.
|
||||
|
||||
2. Se agrega una *incrustación aprendida* - un token especial `[CLS]` - al principio de las incrustaciones del parche, al igual que en BERT. El estado oculto final del token `[CLS]` se utiliza como la entrada para la cabecera de clasificación adjunta; otras salidas se ignoran. Este token ayuda al modelo a aprender cómo codificar una representación de la imagen.
|
||||
|
||||
3. Lo último que se agrega a las incrustaciones de parche e incrustaciones aprendidas son las *incrustaciones de posición* porque el modelo no sabe cómo están ordenados los parches de imagen. Las incrustaciones de posición también son aprendibles y tienen el mismo tamaño que las incrustaciones de parche. Finalmente, todas las incrustaciones se pasan al codificador Transformer.
|
||||
|
||||
4. La salida, específicamente solo la salida con el token `[CLS]`, se pasa a una cabecera de perceptrón multicapa (MLP). El objetivo del preentrenamiento de ViT es simplemente la clasificación. Al igual que otras cabeceras de clasificación, la cabecera de MLP convierte la salida en logits sobre las etiquetas de clase y calcula la pérdida de entropía cruzada para encontrar la clase más probable.
|
||||
|
||||
¿Listo para probar la clasificación de imágenes? ¡Consulta nuestra guía completa de [clasificación de imágenes](tasks/image_classification) para aprender cómo ajustar ViT y usarlo para inferencia!
|
||||
|
||||
#### CNN
|
||||
|
||||
<Tip>
|
||||
|
||||
Esta sección explica brevemente las convoluciones, pero sería útil tener un entendimiento previo de cómo cambian la forma y el tamaño de una imagen. Si no estás familiarizado con las convoluciones, ¡echa un vistazo al [capítulo de Redes Neuronales Convolucionales](https://github.com/fastai/fastbook/blob/master/13_convolutions.ipynb) del libro fastai!
|
||||
|
||||
</Tip>
|
||||
|
||||
[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext) es una arquitectura de CNN que adopta diseños de redes nuevas y modernas para mejorar el rendimiento. Sin embargo, las convoluciones siguen siendo el núcleo del modelo. Desde una perspectiva de alto nivel, una [convolución](glossary#convolution) es una operación donde una matriz más pequeña (*kernel*) se multiplica por una pequeña ventana de píxeles de la imagen. Esta calcula algunas características de ella, como una textura particular o la curvatura de una línea. Luego, se desliza hacia la siguiente ventana de píxeles; la distancia que recorre la convolución se conoce como el *stride*.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/convolution.gif"/>
|
||||
</div>
|
||||
|
||||
<small>Una convolución básica sin relleno ni paso, tomada de <a href="https://arxiv.org/abs/1603.07285">Una guía para la aritmética de convoluciones para el aprendizaje profundo.</a></small>
|
||||
|
||||
Puedes alimentar esta salida a otra capa convolucional, y con cada capa sucesiva, la red aprende cosas más complejas y abstractas como perros calientes o cohetes. Entre capas convolucionales, es común añadir una capa de agrupación para reducir la dimensionalidad y hacer que el modelo sea más robusto a las variaciones de la posición de una característica.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/convnext_architecture.png"/>
|
||||
</div>
|
||||
|
||||
ConvNeXT moderniza una CNN de cinco maneras:
|
||||
|
||||
1. Cambia el número de bloques en cada etapa y "fragmenta" una imagen con un paso y tamaño de kernel más grandes. La ventana deslizante no superpuesta hace que esta estrategia de fragmentación sea similar a cómo ViT divide una imagen en parches.
|
||||
|
||||
2. Una capa de *cuello de botella* reduce el número de canales y luego lo restaura porque es más rápido hacer una convolución de 1x1, y se puede aumentar la profundidad. Un cuello de botella invertido hace lo contrario al expandir el número de canales y luego reducirlos, lo cual es más eficiente en memoria.
|
||||
|
||||
3. Reemplaza la típica capa convolucional de 3x3 en la capa de cuello de botella con una convolución *depthwise*, que aplica una convolución a cada canal de entrada por separado y luego los apila de nuevo al final. Esto ensancha el ancho de la red para mejorar el rendimiento.
|
||||
|
||||
4. ViT tiene un campo receptivo global, lo que significa que puede ver más de una imagen a la vez gracias a su mecanismo de atención. ConvNeXT intenta replicar este efecto aumentando el tamaño del kernel a 7x7.
|
||||
|
||||
5. ConvNeXT también hace varios cambios en el diseño de capas que imitan a los modelos Transformer. Hay menos capas de activación y normalización, la función de activación se cambia a GELU en lugar de ReLU, y utiliza LayerNorm en lugar de BatchNorm.
|
||||
|
||||
La salida de los bloques convolucionales se pasa a una cabecera de clasificación que convierte las salidas en logits y calcula la pérdida de entropía cruzada para encontrar la etiqueta más probable.
|
||||
|
||||
### Object detection
|
||||
|
||||
[DETR](https://huggingface.co/docs/transformers/model_doc/detr), *DEtection TRansformer*, es un modelo de detección de objetos de un extremo a otro que combina una CNN con un codificador-decodificador Transformer.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/detr_architecture.png"/>
|
||||
</div>
|
||||
|
||||
1. Una CNN preentrenada *backbone* toma una imagen, representada por sus valores de píxeles, y crea un mapa de características de baja resolución de la misma. A continuación, se aplica una convolución 1x1 al mapa de características para reducir la dimensionalidad y se crea un nuevo mapa de características con una representación de imagen de alto nivel. Dado que el Transformer es un modelo secuencial, el mapa de características se aplana en una secuencia de vectores de características que se combinan con incrustaciones posicionales.
|
||||
|
||||
2. Los vectores de características se pasan al codificador, que aprende las representaciones de imagen usando sus capas de atención. A continuación, los estados ocultos del codificador se combinan con *consultas de objeto* en el decodificador. Las consultas de objeto son incrustaciones aprendidas que se enfocan en las diferentes regiones de una imagen, y se actualizan a medida que avanzan a través de cada capa de atención. Los estados ocultos del decodificador se pasan a una red feedforward que predice las coordenadas del cuadro delimitador y la etiqueta de clase para cada consulta de objeto, o `no objeto` si no hay ninguno.
|
||||
|
||||
DETR descodifica cada consulta de objeto en paralelo para producir *N* predicciones finales, donde *N* es el número de consultas. A diferencia de un modelo autoregresivo típico que predice un elemento a la vez, la detección de objetos es una tarea de predicción de conjuntos (`cuadro delimitador`, `etiqueta de clase`) que hace *N* predicciones en un solo paso.
|
||||
|
||||
3. DETR utiliza una **pérdida de coincidencia bipartita** durante el entrenamiento para comparar un número fijo de predicciones con un conjunto fijo de etiquetas de verdad básica. Si hay menos etiquetas de verdad básica en el conjunto de *N* etiquetas, entonces se rellenan con una clase `no objeto`. Esta función de pérdida fomenta que DETR encuentre una asignación uno a uno entre las predicciones y las etiquetas de verdad básica. Si los cuadros delimitadores o las etiquetas de clase no son correctos, se incurre en una pérdida. Del mismo modo, si DETR predice un objeto que no existe, se penaliza. Esto fomenta que DETR encuentre otros objetos en una imagen en lugar de centrarse en un objeto realmente prominente.
|
||||
|
||||
Se añade una cabecera de detección de objetos encima de DETR para encontrar la etiqueta de clase y las coordenadas del cuadro delimitador. Hay dos componentes en la cabecera de detección de objetos: una capa lineal para transformar los estados ocultos del decodificador en logits sobre las etiquetas de clase, y una MLP para predecir el cuadro delimitador.
|
||||
|
||||
¿Listo para probar la detección de objetos? ¡Consulta nuestra guía completa de [detección de objetos](https://huggingface.co/docs/transformers/tasks/object_detection) para aprender cómo ajustar DETR y usarlo para inferencia!
|
||||
|
||||
### Segmentación de imágenes
|
||||
|
||||
[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former) es una arquitectura universal para resolver todos los tipos de tareas de segmentación de imágenes. Los modelos de segmentación tradicionales suelen estar adaptados a una tarea particular de segmentación de imágenes, como la segmentación de instancias, semántica o panóptica. Mask2Former enmarca cada una de esas tareas como un problema de *clasificación de máscaras*. La clasificación de máscaras agrupa píxeles en *N* segmentos, y predice *N* máscaras y su etiqueta de clase correspondiente para una imagen dada. Explicaremos cómo funciona Mask2Former en esta sección, y luego podrás probar el ajuste fino de SegFormer al final.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/mask2former_architecture.png"/>
|
||||
</div>
|
||||
|
||||
Hay tres componentes principales en Mask2Former:
|
||||
|
||||
1. Un [backbone Swin](https://huggingface.co/docs/transformers/model_doc/swin) acepta una imagen y crea un mapa de características de imagen de baja resolución a partir de 3 convoluciones consecutivas de 3x3.
|
||||
|
||||
2. El mapa de características se pasa a un *decodificador de píxeles* que aumenta gradualmente las características de baja resolución en incrustaciones de alta resolución por píxel. De hecho, el decodificador de píxeles genera características multiescala (contiene características de baja y alta resolución) con resoluciones de 1/32, 1/16 y 1/8 de la imagen original.
|
||||
|
||||
3. Cada uno de estos mapas de características de diferentes escalas se alimenta sucesivamente a una capa decodificadora Transformer a la vez para capturar objetos pequeños de las características de alta resolución. La clave de Mask2Former es el mecanismo de *atención enmascarada* en el decodificador. A diferencia de la atención cruzada que puede atender a toda la imagen, la atención enmascarada solo se centra en cierta área de la imagen. Esto es más rápido y conduce a un mejor rendimiento porque las características locales de una imagen son suficientes para que el modelo aprenda.
|
||||
|
||||
4. Al igual que [DETR](tasks_explained#object-detection), Mask2Former también utiliza consultas de objetos aprendidas y las combina con las características de la imagen del decodificador de píxeles para hacer una predicción de conjunto (`etiqueta de clase`, `predicción de máscara`). Los estados ocultos del decodificador se pasan a una capa lineal y se transforman en logits sobre las etiquetas de clase. Se calcula la pérdida de entropía cruzada entre los logits y la etiqueta de clase para encontrar la más probable.
|
||||
|
||||
Las predicciones de máscara se generan combinando las incrustaciones de píxeles con los estados ocultos finales del decodificador. La pérdida de entropía cruzada sigmoidea y de la pérdida DICE se calcula entre los logits y la máscara de verdad básica para encontrar la máscara más probable.
|
||||
|
||||
¿Listo para probar la detección de objetos? ¡Consulta nuestra guía completa de [segmentación de imágenes](https://huggingface.co/docs/transformers/tasks/semantic_segmentation) para aprender cómo ajustar SegFormer y usarlo para inferencia!
|
||||
|
||||
### Estimación de profundidad
|
||||
|
||||
[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn), *Global-Local Path Network*, es un Transformer para la estimación de profundidad que combina un codificador [SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer) con un decodificador ligero.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/glpn_architecture.jpg"/>
|
||||
</div>
|
||||
|
||||
1. Al igual que ViT, una imagen se divide en una secuencia de parches, excepto que estos parches de imagen son más pequeños. Esto es mejor para tareas de predicción densa como la segmentación o la estimación de profundidad. Los parches de imagen se transforman en incrustaciones de parches (ver la sección de [clasificación de imágenes](#clasificación-de-imágenes) para más detalles sobre cómo se crean las incrustaciones de parches), que se alimentan al codificador.
|
||||
|
||||
2. El codificador acepta las incrustaciones de parches y las pasa a través de varios bloques codificadores. Cada bloque consiste en capas de atención y Mix-FFN. El propósito de este último es proporcionar información posicional. Al final de cada bloque codificador hay una capa de *fusión de parches* para crear representaciones jerárquicas. Las características de cada grupo de parches vecinos se concatenan, y se aplica una capa lineal a las características concatenadas para reducir el número de parches a una resolución de 1/4. Esto se convierte en la entrada al siguiente bloque codificador, donde se repite todo este proceso hasta que tengas características de imagen con resoluciones de 1/8, 1/16 y 1/32.
|
||||
|
||||
3. Un decodificador ligero toma el último mapa de características (escala 1/32) del codificador y lo aumenta a una escala de 1/16. A partir de aquí, la característica se pasa a un módulo de *Fusión Selectiva de Características (SFF)*, que selecciona y combina características locales y globales de un mapa de atención para cada característica y luego la aumenta a 1/8. Este proceso se repite hasta que las características decodificadas sean del mismo tamaño que la imagen original. La salida se pasa a través de dos capas de convolución y luego se aplica una activación sigmoide para predecir la profundidad de cada píxel.
|
||||
|
||||
## Procesamiento del lenguaje natural
|
||||
|
||||
El Transformer fue diseñado inicialmente para la traducción automática, y desde entonces, prácticamente se ha convertido en la arquitectura predeterminada para resolver todas las tareas de procesamiento del lenguaje natural (NLP, por sus siglas en inglés). Algunas tareas se prestan a la estructura del codificador del Transformer, mientras que otras son más adecuadas para el decodificador. Todavía hay otras tareas que hacen uso de la estructura codificador-decodificador del Transformer.
|
||||
|
||||
### Clasificación de texto
|
||||
|
||||
[BERT](https://huggingface.co/docs/transformers/model_doc/bert) es un modelo que solo tiene codificador y es el primer modelo en implementar efectivamente la bidireccionalidad profunda para aprender representaciones más ricas del texto al atender a las palabras en ambos lados.
|
||||
|
||||
1. BERT utiliza la tokenización [WordPiece](https://huggingface.co/docs/transformers/tokenizer_summary#wordpiece) para generar una incrustación de tokens del texto. Para diferenciar entre una sola oración y un par de oraciones, se agrega un token especial `[SEP]` para diferenciarlos. También se agrega un token especial `[CLS]` al principio de cada secuencia de texto. La salida final con el token `[CLS]` se utiliza como la entrada a la cabeza de clasificación para tareas de clasificación. BERT también agrega una incrustación de segmento para indicar si un token pertenece a la primera o segunda oración en un par de oraciones.
|
||||
|
||||
2. BERT se preentrena con dos objetivos: modelar el lenguaje enmascarado y predecir de próxima oración. En el modelado de lenguaje enmascarado, un cierto porcentaje de los tokens de entrada se enmascaran aleatoriamente, y el modelo necesita predecir estos. Esto resuelve el problema de la bidireccionalidad, donde el modelo podría hacer trampa y ver todas las palabras y "predecir" la siguiente palabra. Los estados ocultos finales de los tokens de máscara predichos se pasan a una red feedforward con una softmax sobre el vocabulario para predecir la palabra enmascarada.
|
||||
|
||||
El segundo objetivo de preentrenamiento es la predicción de próxima oración. El modelo debe predecir si la oración B sigue a la oración A. La mitad del tiempo, la oración B es la siguiente oración, y la otra mitad del tiempo, la oración B es una oración aleatoria. La predicción, ya sea que sea la próxima oración o no, se pasa a una red feedforward con una softmax sobre las dos clases (`EsSiguiente` y `NoSiguiente`).
|
||||
|
||||
3. Las incrustaciones de entrada se pasan a través de múltiples capas codificadoras para producir algunos estados ocultos finales.
|
||||
|
||||
Para usar el modelo preentrenado para clasificación de texto, se añade una cabecera de clasificación de secuencia encima del modelo base de BERT. La cabecera de clasificación de secuencia es una capa lineal que acepta los estados ocultos finales y realiza una transformación lineal para convertirlos en logits. Se calcula la pérdida de entropía cruzada entre los logits y el objetivo para encontrar la etiqueta más probable.
|
||||
|
||||
¿Listo para probar la clasificación de texto? ¡Consulta nuestra guía completa de [clasificación de texto](https://huggingface.co/docs/transformers/tasks/sequence_classification) para aprender cómo ajustar DistilBERT y usarlo para inferencia!
|
||||
|
||||
### Clasificación de tokens
|
||||
|
||||
Para usar BERT en tareas de clasificación de tokens como el reconocimiento de entidades nombradas (NER), añade una cabecera de clasificación de tokens encima del modelo base de BERT. La cabecera de clasificación de tokens es una capa lineal que acepta los estados ocultos finales y realiza una transformación lineal para convertirlos en logits. Se calcula la pérdida de entropía cruzada entre los logits y cada token para encontrar la etiqueta más probable.
|
||||
|
||||
¿Listo para probar la clasificación de tokens? ¡Consulta nuestra guía completa de [clasificación de tokens](https://huggingface.co/docs/transformers/tasks/token_classification) para aprender cómo ajustar DistilBERT y usarlo para inferencia!
|
||||
|
||||
### Respuesta a preguntas
|
||||
|
||||
Para usar BERT en la respuesta a preguntas, añade una cabecera de clasificación de span encima del modelo base de BERT. Esta capa lineal acepta los estados ocultos finales y realiza una transformación lineal para calcular los logits de inicio y fin del `span` correspondiente a la respuesta. Se calcula la pérdida de entropía cruzada entre los logits y la posición de la etiqueta para encontrar el span más probable de texto correspondiente a la respuesta.
|
||||
|
||||
¿Listo para probar la respuesta a preguntas? ¡Consulta nuestra guía completa de [respuesta a preguntas](tasks/question_answering) para aprender cómo ajustar DistilBERT y usarlo para inferencia!
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 ¡Observa lo fácil que es usar BERT para diferentes tareas una vez que ha sido preentrenado! ¡Solo necesitas añadir una cabecera específica al modelo preentrenado para manipular los estados ocultos en tu salida deseada!
|
||||
|
||||
</Tip>
|
||||
|
||||
### Generación de texto
|
||||
|
||||
[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2) es un modelo que solo tiene decodificador y se preentrena en una gran cantidad de texto. Puede generar texto convincente (¡aunque no siempre verdadero!) dado un estímulo y completar otras tareas de procesamiento del lenguaje natural como responder preguntas, a pesar de no haber sido entrenado explícitamente para ello.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/gpt2_architecture.png"/>
|
||||
</div>
|
||||
|
||||
1. GPT-2 utiliza [codificación de pares de bytes (BPE)](https://huggingface.co/docs/transformers/tokenizer_summary#bytepair-encoding-bpe) para tokenizar palabras y generar una incrustación de token. Se añaden incrustaciones posicionales a las incrustaciones de token para indicar la posición de cada token en la secuencia. Las incrustaciones de entrada se pasan a través de varios bloques decodificadores para producir algún estado oculto final. Dentro de cada bloque decodificador, GPT-2 utiliza una capa de *autoatención enmascarada*, lo que significa que GPT-2 no puede atender a los tokens futuros. Solo puede atender a los tokens a la izquierda. Esto es diferente al token [`mask`] de BERT porque, en la autoatención enmascarada, se utiliza una máscara de atención para establecer la puntuación en `0` para los tokens futuros.
|
||||
|
||||
2. La salida del decodificador se pasa a una cabecera de modelado de lenguaje, que realiza una transformación lineal para convertir los estados ocultos en logits. La etiqueta es el siguiente token en la secuencia, que se crea desplazando los logits a la derecha en uno. Se calcula la pérdida de entropía cruzada entre los logits desplazados y las etiquetas para obtener el siguiente token más probable.
|
||||
|
||||
El objetivo del preentrenamiento de GPT-2 se basa completamente en el [modelado de lenguaje causal](glossary#causal-language-modeling), prediciendo la siguiente palabra en una secuencia. Esto hace que GPT-2 sea especialmente bueno en tareas que implican la generación de texto.
|
||||
|
||||
¿Listo para probar la generación de texto? ¡Consulta nuestra guía completa de [modelado de lenguaje causal](tasks/language_modeling#modelado-de-lenguaje-causal) para aprender cómo ajustar DistilGPT-2 y usarlo para inferencia!
|
||||
|
||||
<Tip>
|
||||
|
||||
Para obtener más información sobre la generación de texto, ¡consulta la guía de [estrategias de generación de texto](https://huggingface.co/docs/transformers/generation_strategies)!
|
||||
|
||||
</Tip>
|
||||
|
||||
### Resumir
|
||||
|
||||
Los modelos codificador-decodificador como [BART](https://huggingface.co/docs/transformers/model_doc/bart) y [T5](https://huggingface.co/docs/transformers/model_doc/t5) están diseñados para el patrón de secuencia a secuencia de una tarea de resumen. Explicaremos cómo funciona BART en esta sección, y luego podrás probar el ajuste fino de T5 al final.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bart_architecture.png"/>
|
||||
</div>
|
||||
|
||||
1. La arquitectura del codificador de BART es muy similar a la de BERT y acepta una incrustación de token y posicional del texto. BART se preentrena corrompiendo la entrada y luego reconstruyéndola con el decodificador. A diferencia de otros codificadores con estrategias específicas de corrupción, BART puede aplicar cualquier tipo de corrupción. Sin embargo, la estrategia de corrupción de *relleno de texto* funciona mejor. En el relleno de texto, varios fragmentos de texto se reemplazan con un **único** token [`mask`]. Esto es importante porque el modelo tiene que predecir los tokens enmascarados, y le enseña al modelo a predecir la cantidad de tokens faltantes. Las incrustaciones de entrada y los fragmentos enmascarados se pasan a través del codificador para producir algunos estados ocultos finales, pero a diferencia de BERT, BART no añade una red feedforward final al final para predecir una palabra.
|
||||
|
||||
2. La salida del codificador se pasa al decodificador, que debe predecir los tokens enmascarados y cualquier token no corrompido de la salida del codificador. Esto proporciona un contexto adicional para ayudar al decodificador a restaurar el texto original. La salida del decodificador se pasa a una cabeza de modelado de lenguaje, que realiza una transformación lineal para convertir los estados ocultos en logits. Se calcula la pérdida de entropía cruzada entre los logits y la etiqueta, que es simplemente el token desplazado hacia la derecha.
|
||||
|
||||
¿Listo para probar la sumarización? ¡Consulta nuestra guía completa de [Generación de resúmenes](tasks/summarization) para aprender cómo ajustar T5 y usarlo para inferencia!
|
||||
|
||||
<Tip>
|
||||
|
||||
Para obtener más información sobre la generación de texto, ¡consulta la guía de [estrategias de generación de texto](https://huggingface.co/docs/transformers/generation_strategies)!
|
||||
|
||||
</Tip>
|
||||
|
||||
### Traducción
|
||||
|
||||
La traducción es otro ejemplo de una tarea de secuencia a secuencia, lo que significa que puedes usar un modelo codificador-decodificador como [BART](https://huggingface.co/docs/transformers/model_doc/bart) o [T5](https://huggingface.co/docs/transformers/model_doc/t5) para hacerlo. Explicaremos cómo funciona BART en esta sección, y luego podrás probar el ajuste fino de T5 al final.
|
||||
|
||||
BART se adapta a la traducción añadiendo un codificador separado inicializado aleatoriamente para mapear un idioma fuente a una entrada que pueda ser decodificada en el idioma objetivo. Las incrustaciones de este nuevo codificador se pasan al codificador preentrenado en lugar de las incrustaciones de palabras originales. El codificador de origen se entrena actualizando el codificador de origen, las incrustaciones posicionales y las incrustaciones de entrada con la pérdida de entropía cruzada de la salida del modelo. Los parámetros del modelo están congelados en este primer paso, y todos los parámetros del modelo se entrenan juntos en el segundo paso.
|
||||
|
||||
Desde entonces, BART ha sido seguido por una versión multilingüe, mBART, destinada a la traducción y preentrenada en muchos idiomas diferentes.
|
||||
|
||||
¿Listo para probar la traducción? ¡Consulta nuestra guía completa de [traducción](https://huggingface.co/docs/transformers/tasks/translation) para aprender cómo ajustar T5 y usarlo para inferencia!
|
||||
|
||||
<Tip>
|
||||
|
||||
Para obtener más información sobre la generación de texto, ¡consulta la guía de [estrategias de generación de texto](https://huggingface.co/docs/transformers/generation_strategies)!
|
||||
|
||||
</Tip>
|
||||
167
docs/source/es/torchscript.md
Normal file
167
docs/source/es/torchscript.md
Normal file
@ -0,0 +1,167 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Exportar a TorchScript
|
||||
|
||||
<Tip>
|
||||
Este es el comienzo de nuestros experimentos con TorchScript y todavía estamos explorando sus capacidades con modelos de variables de entrada. Es un tema de interés para nosotros y profundizaremos en nuestro análisis en las próximas versiones, con más ejemplos de código, una implementación más flexible y comparativas de rendimiento comparando códigos basados en Python con TorchScript compilado.
|
||||
|
||||
</Tip>
|
||||
|
||||
De acuerdo con la documentación de TorchScript:
|
||||
|
||||
> "TorchScript es una manera de crear modelos serializables y optimizables a partir del código PyTorch."
|
||||
|
||||
Hay dos módulos de PyTorch, [JIT y TRACE](https://pytorch.org/docs/stable/jit.html), que permiten a los desarrolladores exportar sus modelos para ser reusados en otros programas, como los programas de C++ orientados a la eficiencia.
|
||||
|
||||
Nosotros proveemos una interface que te permite exportar los modelos 🤗Transformers a TorchScript para que puedan ser reusados en un entorno diferente al de los programas Python basados en PyTorch. Aquí explicamos como exportar y usar nuestros modelos utilizando TorchScript.
|
||||
|
||||
Exportar un modelo requiere de dos cosas:
|
||||
|
||||
- La instanciación del modelo con la bandera TorchScript.
|
||||
- Un paso hacia adelante con entradas ficticias.
|
||||
|
||||
Estas necesidades implican varias cosas de las que los desarrolladores deben tener cuidado, como se detalla a continuación.
|
||||
|
||||
## Bandera TorchScript y pesos atados.
|
||||
|
||||
La bandera `torchscript` es necesaria porque la mayoría de los modelos de lenguaje de 🤗Transformers tienen pesos atados entre su `capa de incrustación` (`Embedding`) y su `capa de decodificación` (`Decoding`). TorchScript no te permite exportar modelos que tienen pesos atados, por lo que es necesario desatar y clonar los pesos de antemano.
|
||||
|
||||
Los modelos instanciados con la bandera `torchscript` tienen su `capa de incrustación` (`Embedding`) y su `capa de decodificación` (`Decoding`) separadas, lo que significa que no deben ser entrenados más adelante. Entrenar desincronizaría las dos capas, lo que llevaría a resultados inesperados.
|
||||
|
||||
Esto no es así para los modelos que no tienen una cabeza de modelo de lenguaje, ya que esos modelos no tienen pesos atados. Estos modelos pueden ser exportados de manera segura sin la bandera `torchscript`.
|
||||
|
||||
## Entradas ficticias y longitudes estándar
|
||||
|
||||
Las entradas ficticias se utilizan para un paso del modelo hacia adelante. Mientras los valores de las entradas se propagan a través de las capas, PyTorch realiza un seguimiento de las diferentes operaciones ejecutadas en cada tensor. Estas operaciones registradas se utilizan luego para crear *la traza* del modelo.
|
||||
La traza se crea en relación con las dimensiones de las entradas. Por lo tanto, está limitada por las dimensiones de la entrada ficticia y no funcionará para ninguna otra longitud de secuencia o tamaño de lote. Cuando se intenta con un tamaño diferente, se genera el siguiente error:
|
||||
|
||||
```
|
||||
`El tamaño expandido del tensor (3) debe coincidir con el tamaño existente (7) en la dimensión no singleton 2`.
|
||||
```
|
||||
|
||||
Recomendamos trazar el modelo con un tamaño de entrada ficticio al menos tan grande como la entrada más grande con la que se alimentará al modelo durante la inferencia. El relleno puede ayudar a completar los valores faltantes. Sin embargo, dado que el modelo se traza con un tamaño de entrada más grande, las dimensiones de la matriz también serán grandes, lo que resultará en más cálculos.
|
||||
|
||||
Ten cuidado con el número total de operaciones realizadas en cada entrada y sigue de cerca el rendimiento al exportar modelos con longitudes de secuencia variables.
|
||||
|
||||
## Usando TorchScript en Python
|
||||
|
||||
Esta sección demuestra cómo guardar y cargar modelos, así como cómo usar la traza para la inferencia.
|
||||
|
||||
### Guardando un modelo
|
||||
|
||||
Para exportar un `BertModel` con TorchScript, instancia `BertModel` a partir de la clase `BertConfig` y luego guárdalo en disco bajo el nombre de archivo `traced_bert.pt`:
|
||||
|
||||
```python
|
||||
from transformers import BertModel, BertTokenizer, BertConfig
|
||||
import torch
|
||||
|
||||
enc = BertTokenizer.from_pretrained("bert-base-uncased")
|
||||
|
||||
# Tokenizing input text
|
||||
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
|
||||
tokenized_text = enc.tokenize(text)
|
||||
|
||||
# Masking one of the input tokens
|
||||
masked_index = 8
|
||||
tokenized_text[masked_index] = "[MASK]"
|
||||
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
|
||||
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
|
||||
|
||||
# Creating a dummy input
|
||||
tokens_tensor = torch.tensor([indexed_tokens])
|
||||
segments_tensors = torch.tensor([segments_ids])
|
||||
dummy_input = [tokens_tensor, segments_tensors]
|
||||
|
||||
# Initializing the model with the torchscript flag
|
||||
# Flag set to True even though it is not necessary as this model does not have an LM Head.
|
||||
config = BertConfig(
|
||||
vocab_size_or_config_json_file=32000,
|
||||
hidden_size=768,
|
||||
num_hidden_layers=12,
|
||||
num_attention_heads=12,
|
||||
intermediate_size=3072,
|
||||
torchscript=True,
|
||||
)
|
||||
|
||||
# Instantiating the model
|
||||
model = BertModel(config)
|
||||
|
||||
# The model needs to be in evaluation mode
|
||||
model.eval()
|
||||
|
||||
# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
|
||||
model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
|
||||
|
||||
# Creating the trace
|
||||
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
|
||||
torch.jit.save(traced_model, "traced_bert.pt")
|
||||
```
|
||||
### Cargando un modelo
|
||||
|
||||
Ahora puedes cargar el `BertModel` guardado anteriormente, `traced_bert.pt`, desde el disco y usarlo en la entrada ficticia (`dummy_input`) previamente inicializada:
|
||||
|
||||
```python
|
||||
loaded_model = torch.jit.load("traced_bert.pt")
|
||||
loaded_model.eval()
|
||||
|
||||
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
|
||||
```
|
||||
|
||||
## Usando un modelo trazado para inferencia
|
||||
|
||||
Utiliza el modelo trazado para inferencia utilizando su método `_call_` dunder:
|
||||
|
||||
```python
|
||||
traced_model(tokens_tensor, segments_tensors)
|
||||
```
|
||||
## Despliega modelos TorchScript de Hugging Face en AWS con el Neuron SDK
|
||||
|
||||
AWS introdujo la familia de instancias [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/) para inferencia de aprendizaje automático de alto rendimiento y bajo costo en la nube. Las instancias Inf1 están alimentadas por el chip AWS Inferentia, un acelerador de hardware personalizado que se especializa en cargas de trabajo de inferencia de aprendizaje profundo. [AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) es el SDK para Inferentia que admite el trazado y la optimización de modelos de transformers para implementación en Inf1. El SDK Neuron proporciona:
|
||||
|
||||
1. Una API fácil de usar con un solo cambio de línea de código para trazar y optimizar un modelo TorchScript para inferencia en la nube.
|
||||
|
||||
2. Optimizaciones de rendimiento listas para usar [para mejorar el rendimiento y el costo](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>).
|
||||
|
||||
3. Soporte para modelos de transformers de Hugging Face construidos tanto con [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html) como con [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html).
|
||||
|
||||
### Implicaciones
|
||||
|
||||
Los modelos transformers basados en la arquitectura [BERT (Bidirectional Encoder Representations from Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert), o sus variantes como [distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) y [roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta), funcionan mejor en Inf1 para tareas no generativas como la respuesta a preguntas extractivas, la clasificación de secuencias y la clasificación de tokens. Sin embargo, las tareas de generación de texto aún pueden adaptarse para ejecutarse en Inf1 según este [tutorial de AWS Neuron MarianMT](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html). Se puede encontrar más información sobre los modelos que se pueden convertir fácilmente para usar en Inferentia en la sección de [Model Architecture Fit](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia) de la documentación de Neuron.
|
||||
|
||||
### Dependencias
|
||||
|
||||
El uso de AWS Neuron para convertir modelos requiere un [entorno de Neuron SDK](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide) que viene preconfigurado en [la AMI de AWS Deep Learning](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html).
|
||||
|
||||
### Convertir un modelo para AWS Neuron
|
||||
|
||||
Convierte un modelo para AWS NEURON utilizando el mismo código de [Uso de TorchScript en Python](torchscript#using-torchscript-in-python) para trazar un `BertModel`. Importa la extensión del framework `torch.neuron` para acceder a los componentes del Neuron SDK a través de una API de Python:
|
||||
|
||||
```python
|
||||
from transformers import BertModel, BertTokenizer, BertConfig
|
||||
import torch
|
||||
import torch.neuron
|
||||
```
|
||||
Solo necesitas la linea sigueda:
|
||||
|
||||
```diff
|
||||
- torch.jit.trace(model, [tokens_tensor, segments_tensors])
|
||||
+ torch.neuron.trace(model, [token_tensor, segments_tensors])
|
||||
```
|
||||
|
||||
Esto permite que el Neuron SDK trace el modelo y lo optimice para las instancias Inf1.
|
||||
|
||||
Para obtener más información sobre las características, herramientas, tutoriales de ejemplo y últimas actualizaciones del AWS Neuron SDK, consulta [la documentación de AWS NeuronSDK](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
|
||||
409
docs/source/es/trainer.md
Normal file
409
docs/source/es/trainer.md
Normal file
@ -0,0 +1,409 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# El Trainer
|
||||
|
||||
El [`Trainer`] es un bucle completo de entrenamiento y evaluación para modelos de PyTorch implementado en la biblioteca Transformers. Solo necesitas pasarle las piezas necesarias para el entrenamiento (modelo, tokenizador, conjunto de datos, función de evaluación, hiperparámetros de entrenamiento, etc.), y la clase [`Trainer`] se encarga del resto. Esto facilita comenzar a entrenar más rápido sin tener que escribir manualmente tu propio bucle de entrenamiento. Pero al mismo tiempo, [`Trainer`] es muy personalizable y ofrece una gran cantidad de opciones de entrenamiento para que puedas adaptarlo a tus necesidades exactas de entrenamiento.
|
||||
|
||||
<Tip>
|
||||
|
||||
Además de la clase [`Trainer`], Transformers también proporciona una clase [`Seq2SeqTrainer`] para tareas de secuencia a secuencia como traducción o resumen. También está la clase [~trl.SFTTrainer] de la biblioteca [TRL](https://hf.co/docs/trl) que envuelve la clase [`Trainer`] y está optimizada para entrenar modelos de lenguaje como Llama-2 y Mistral con técnicas autoregresivas. [`~trl.SFTTrainer`] también admite funciones como el empaquetado de secuencias, LoRA, cuantización y DeepSpeed para escalar eficientemente a cualquier tamaño de modelo.
|
||||
|
||||
<br>
|
||||
|
||||
Siéntete libre de consultar [la referencia de API](./main_classes/trainer) para estas otras clases tipo [`Trainer`] para aprender más sobre cuándo usar cada una. En general, [`Trainer`] es la opción más versátil y es apropiada para una amplia gama de tareas. [`Seq2SeqTrainer`] está diseñado para tareas de secuencia a secuencia y [`~trl.SFTTrainer`] está diseñado para entrenar modelos de lenguaje.
|
||||
|
||||
</Tip>
|
||||
|
||||
Antes de comenzar, asegúrate de tener instalado [Accelerate](https://hf.co/docs/accelerate), una biblioteca para habilitar y ejecutar el entrenamiento de PyTorch en entornos distribuidos.
|
||||
|
||||
```bash
|
||||
pip install accelerate
|
||||
|
||||
# upgrade
|
||||
pip install accelerate --upgrade
|
||||
```
|
||||
Esta guía proporciona una visión general de la clase [`Trainer`].
|
||||
|
||||
## Uso básico
|
||||
|
||||
[`Trainer`] incluye todo el código que encontrarías en un bucle de entrenamiento básico:
|
||||
1. Realiza un paso de entrenamiento para calcular la pérdida
|
||||
2. Calcula los gradientes con el método [~accelerate.Accelerator.backward]
|
||||
3. Actualiza los pesos basados en los gradientes
|
||||
4. Repite este proceso hasta alcanzar un número predeterminado de épocas
|
||||
|
||||
La clase [`Trainer`] abstrae todo este código para que no tengas que preocuparte por escribir manualmente un bucle de entrenamiento cada vez o si estás empezando con PyTorch y el entrenamiento. Solo necesitas proporcionar los componentes esenciales requeridos para el entrenamiento, como un modelo y un conjunto de datos, y la clase [`Trainer`] maneja todo lo demás.
|
||||
|
||||
Si deseas especificar opciones de entrenamiento o hiperparámetros, puedes encontrarlos en la clase [`TrainingArguments`]. Por ejemplo, vamos a definir dónde guardar el modelo en output_dir y subir el modelo al Hub después del entrenamiento con `push_to_hub=True`.
|
||||
|
||||
```py
|
||||
from transformers import TrainingArguments
|
||||
|
||||
training_args = TrainingArguments(
|
||||
output_dir="your-model",
|
||||
learning_rate=2e-5,
|
||||
per_device_train_batch_size=16,
|
||||
per_device_eval_batch_size=16,
|
||||
num_train_epochs=2,
|
||||
weight_decay=0.01,
|
||||
evaluation_strategy="epoch",
|
||||
save_strategy="epoch",
|
||||
load_best_model_at_end=True,
|
||||
push_to_hub=True,
|
||||
)
|
||||
```
|
||||
|
||||
Pase `training_args` al [`Trainer`] con un modelo, un conjunto de datos o algo para preprocesar el conjunto de datos (dependiendo en el tipo de datos pueda ser un tokenizer, extractor de caracteristicas o procesor del imagen), un recopilador de datos y una función para calcular las métricas que desea rastrear durante el entrenamiento.
|
||||
|
||||
Finalmente, llame [`~Trainer.train`] para empezar entrenamiento!
|
||||
|
||||
```py
|
||||
from transformers import Trainer
|
||||
|
||||
trainer = Trainer(
|
||||
model=model,
|
||||
args=training_args,
|
||||
train_dataset=dataset["train"],
|
||||
eval_dataset=dataset["test"],
|
||||
tokenizer=tokenizer,
|
||||
data_collator=data_collator,
|
||||
compute_metrics=compute_metrics,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
### Los puntos de control
|
||||
|
||||
La clase [`Trainer`] guarda los puntos de control del modelo en el directorio especificado en el parámetro `output_dir` de [`TrainingArguments`]. Encontrarás los puntos de control guardados en una subcarpeta checkpoint-000 donde los números al final corresponden al paso de entrenamiento. Guardar puntos de control es útil para reanudar el entrenamiento más tarde.
|
||||
|
||||
```py
|
||||
# resume from latest checkpoint
|
||||
trainer.train(resume_from_checkpoint=True)
|
||||
|
||||
# resume from specific checkpoint saved in output directory
|
||||
trainer.train(resume_from_checkpoint="your-model/checkpoint-1000")
|
||||
```
|
||||
|
||||
Puedes guardar tus puntos de control (por defecto, el estado del optimizador no se guarda) en el Hub configurando `push_to_hub=True` en [`TrainingArguments`] para confirmar y enviarlos. Otras opciones para decidir cómo se guardan tus puntos de control están configuradas en el parámetro [`hub_strategy`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.hub_strategy):
|
||||
|
||||
* hub_strategy="checkpoint" envía el último punto de control a una subcarpeta llamada "last-checkpoint" desde la cual puedes reanudar el entrenamiento.
|
||||
|
||||
* hub_strategy="all_checkpoints" envía todos los puntos de control al directorio definido en `output_dir` (verás un punto de control por carpeta en tu repositorio de modelos).
|
||||
|
||||
Cuando reanudas el entrenamiento desde un punto de control, el [`Trainer`] intenta mantener los estados de los generadores de números aleatorios (RNG) de Python, NumPy y PyTorch iguales a como estaban cuando se guardó el punto de control. Pero debido a que PyTorch tiene varias configuraciones predeterminadas no determinísticas, no se garantiza que los estados de RNG sean los mismos. Si deseas habilitar la plena determinismo, echa un vistazo a la guía ["Controlling sources of randomness"](https://pytorch.org/docs/stable/notes/randomness#controlling-sources-of-randomness) para aprender qué puedes habilitar para hacer que tu entrenamiento sea completamente determinista. Sin embargo, ten en cuenta que al hacer ciertas configuraciones deterministas, el entrenamiento puede ser más lento.
|
||||
|
||||
## Personaliza el Trainer
|
||||
|
||||
Si bien la clase [`Trainer`] está diseñada para ser accesible y fácil de usar, también ofrece mucha capacidad de personalización para usuarios más aventureros. Muchos de los métodos del [`Trainer`] pueden ser subclasificados y sobrescritos para admitir la funcionalidad que deseas, sin tener que reescribir todo el bucle de entrenamiento desde cero para adaptarlo. Estos métodos incluyen:
|
||||
|
||||
* [~Trainer.get_train_dataloader] crea un entrenamiento de DataLoader
|
||||
* [~Trainer.get_eval_dataloader] crea una evaluación DataLoader
|
||||
* [~Trainer.get_test_dataloader] crea una prueba de DataLoader
|
||||
* [~Trainer.log] anota la información de los objetos varios que observa el entrenamiento
|
||||
* [~Trainer.create_optimizer_and_scheduler] crea un optimizador y la tasa programada de aprendizaje si no lo pasaron en __init__; estos pueden ser personalizados independientes con [~Trainer.create_optimizer] y [~Trainer.create_scheduler] respectivamente
|
||||
* [~Trainer.compute_loss] computa la pérdida en lote con las aportes del entrenamiento
|
||||
* [~Trainer.training_step] realiza el paso del entrenamiento
|
||||
* [~Trainer.prediction_step] realiza la predicción y paso de prueba
|
||||
* [~Trainer.evaluate] evalua el modelo y da las metricas evaluativas
|
||||
* [~Trainer.predict] hace las predicciones (con las metricas si hay etiquetas disponibles) en lote de prueba
|
||||
|
||||
Por ejemplo, si deseas personalizar el método [`~Trainer.compute_loss`] para usar una pérdida ponderada en su lugar, puedes hacerlo de la siguiente manera:
|
||||
|
||||
```py
|
||||
from torch import nn
|
||||
from transformers import Trainer
|
||||
|
||||
class CustomTrainer(Trainer):
|
||||
def compute_loss(self, model, inputs, return_outputs=False):
|
||||
labels = inputs.pop("labels")
|
||||
# forward pass
|
||||
outputs = model(**inputs)
|
||||
logits = outputs.get("logits")
|
||||
# compute custom loss for 3 labels with different weights
|
||||
loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
|
||||
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
|
||||
return (loss, outputs) if return_outputs else loss
|
||||
```
|
||||
### Callbacks
|
||||
|
||||
Otra opción para personalizar el [`Trainer`] es utilizar [callbacks](callbacks). Los callbacks *no cambian nada* en el bucle de entrenamiento. Inspeccionan el estado del bucle de entrenamiento y luego ejecutan alguna acción (detención anticipada, registro de resultados, etc.) según el estado. En otras palabras, un callback no puede usarse para implementar algo como una función de pérdida personalizada y necesitarás subclasificar y sobrescribir el método [`~Trainer.compute_loss`] para eso.
|
||||
|
||||
Por ejemplo, si deseas agregar un callback de detención anticipada al bucle de entrenamiento después de 10 pasos.
|
||||
|
||||
```py
|
||||
from transformers import TrainerCallback
|
||||
|
||||
class EarlyStoppingCallback(TrainerCallback):
|
||||
def __init__(self, num_steps=10):
|
||||
self.num_steps = num_steps
|
||||
|
||||
def on_step_end(self, args, state, control, **kwargs):
|
||||
if state.global_step >= self.num_steps:
|
||||
return {"should_training_stop": True}
|
||||
else:
|
||||
return {}
|
||||
|
||||
```
|
||||
Luego, pásalo al parámetro `callback` del [`Trainer`]:
|
||||
|
||||
```py
|
||||
from transformers import Trainer
|
||||
|
||||
trainer = Trainer(
|
||||
model=model,
|
||||
args=training_args,
|
||||
train_dataset=dataset["train"],
|
||||
eval_dataset=dataset["test"],
|
||||
tokenizer=tokenizer,
|
||||
data_collator=data_collator,
|
||||
compute_metrics=compute_metrics,
|
||||
callback=[EarlyStoppingCallback()],
|
||||
)
|
||||
```
|
||||
|
||||
## Logging
|
||||
|
||||
<Tip>
|
||||
|
||||
Comprueba el API referencia [logging](./main_classes/logging) para mas información sobre los niveles differentes de logging.
|
||||
|
||||
</Tip>
|
||||
|
||||
El [`Trainer`] está configurado a `logging.INFO` de forma predeterminada el cual informa errores, advertencias y otra información basica. Un [`Trainer`] réplica - en entornos distributos - está configurado a `logging.WARNING` el cual solamente informa errores y advertencias. Puedes cambiar el nivel de logging con los parametros [`log_level`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.log_level) y [`log_level_replica`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.log_level_replica) en [`TrainingArguments`].
|
||||
|
||||
Para configurar el nivel de registro para cada nodo, usa el parámetro [`log_on_each_node`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments.log_on_each_node) para determinar si deseas utilizar el nivel de registro en cada nodo o solo en el nodo principal.
|
||||
|
||||
<Tip>
|
||||
|
||||
[`Trainer`] establece el nivel de registro por separado para cada nodo en el método [`Trainer.init`], por lo que es posible que desees considerar establecer esto antes si estás utilizando otras funcionalidades de Transformers antes de crear el objeto [`Trainer`].
|
||||
|
||||
</Tip>
|
||||
|
||||
Por ejemplo, para establecer que tu código principal y los módulos utilicen el mismo nivel de registro según cada nodo:
|
||||
|
||||
```py
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
logging.basicConfig(
|
||||
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
||||
datefmt="%m/%d/%Y %H:%M:%S",
|
||||
handlers=[logging.StreamHandler(sys.stdout)],
|
||||
)
|
||||
|
||||
log_level = training_args.get_process_log_level()
|
||||
logger.setLevel(log_level)
|
||||
datasets.utils.logging.set_verbosity(log_level)
|
||||
transformers.utils.logging.set_verbosity(log_level)
|
||||
|
||||
trainer = Trainer(...)
|
||||
```
|
||||
<hfoptions id="logging">
|
||||
<hfoption id="single node">
|
||||
|
||||
Usa diferentes combinaciones de `log_level` y `log_level_replica` para configurar qué se registra en cada uno de los nodos.
|
||||
|
||||
```bash
|
||||
my_app.py ... --log_level warning --log_level_replica error
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="multi-node">
|
||||
|
||||
Agrega el parámetro `log_on_each_node 0` para entornos multi-nodo.
|
||||
|
||||
```bash
|
||||
my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
|
||||
|
||||
# set to only report errors
|
||||
my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## NEFTune
|
||||
|
||||
[NEFTune](https://hf.co/papers/2310.05914) es una técnica que puede mejorar el rendimiento al agregar ruido a los vectores de incrustación durante el entrenamiento. Para habilitarlo en [`Trainer`], establece el parámetro `neftune_noise_alpha` en [`TrainingArguments`] para controlar cuánto ruido se agrega.
|
||||
|
||||
```py
|
||||
from transformers import TrainingArguments, Trainer
|
||||
|
||||
training_args = TrainingArguments(..., neftune_noise_alpha=0.1)
|
||||
trainer = Trainer(..., args=training_args)
|
||||
```
|
||||
|
||||
NEFTune se desactiva después del entrenamiento para restaurar la capa de incrustación original y evitar cualquier comportamiento inesperado.
|
||||
|
||||
## Accelerate y Trainer
|
||||
|
||||
La clase [`Trainer`] está impulsada por [Accelerate](https://hf.co/docs/accelerate), una biblioteca para entrenar fácilmente modelos de PyTorch en entornos distribuidos con soporte para integraciones como [FullyShardedDataParallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) y [DeepSpeed](https://www.deepspeed.ai/).
|
||||
|
||||
<Tip>
|
||||
|
||||
Aprende más sobre las estrategias de fragmentación FSDP, descarga de CPU y más con el [`Trainer`] en la guía [Paralela de Datos Completamente Fragmentados](fsdp).
|
||||
|
||||
</Tip>
|
||||
|
||||
Para usar Accelerate con [`Trainer`], ejecuta el comando [`accelerate.config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config) para configurar el entrenamiento para tu entorno de entrenamiento. Este comando crea un `config_file.yaml` que se utilizará cuando inicies tu script de entrenamiento. Por ejemplo, algunas configuraciones de ejemplo que puedes configurar son:
|
||||
|
||||
<hfoptions id="config">
|
||||
<hfoption id="DistributedDataParallel">
|
||||
|
||||
```yml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
distributed_type: MULTI_GPU
|
||||
downcast_bf16: 'no'
|
||||
gpu_ids: all
|
||||
machine_rank: 0 #change rank as per the node
|
||||
main_process_ip: 192.168.20.1
|
||||
main_process_port: 9898
|
||||
main_training_function: main
|
||||
mixed_precision: fp16
|
||||
num_machines: 2
|
||||
num_processes: 8
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
</hfoption>
|
||||
<hfoption id="FSDP">
|
||||
|
||||
```yml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
distributed_type: FSDP
|
||||
downcast_bf16: 'no'
|
||||
fsdp_config:
|
||||
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
|
||||
fsdp_backward_prefetch_policy: BACKWARD_PRE
|
||||
fsdp_forward_prefetch: true
|
||||
fsdp_offload_params: false
|
||||
fsdp_sharding_strategy: 1
|
||||
fsdp_state_dict_type: FULL_STATE_DICT
|
||||
fsdp_sync_module_states: true
|
||||
fsdp_transformer_layer_cls_to_wrap: BertLayer
|
||||
fsdp_use_orig_params: true
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
mixed_precision: bf16
|
||||
num_machines: 1
|
||||
num_processes: 2
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
</hfoption>
|
||||
<hfoption id="DeepSpeed">
|
||||
|
||||
```yml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config:
|
||||
deepspeed_config_file: /home/user/configs/ds_zero3_config.json
|
||||
zero3_init_flag: true
|
||||
distributed_type: DEEPSPEED
|
||||
downcast_bf16: 'no'
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
num_machines: 1
|
||||
num_processes: 4
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
</hfoption>
|
||||
<hfoption id="DeepSpeed with Accelerate plugin">
|
||||
|
||||
```yml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config:
|
||||
gradient_accumulation_steps: 1
|
||||
gradient_clipping: 0.7
|
||||
offload_optimizer_device: cpu
|
||||
offload_param_device: cpu
|
||||
zero3_init_flag: true
|
||||
zero_stage: 2
|
||||
distributed_type: DEEPSPEED
|
||||
downcast_bf16: 'no'
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
mixed_precision: bf16
|
||||
num_machines: 1
|
||||
num_processes: 4
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
El comando [`accelerate_launch`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-launch) es la forma recomendada de lanzar tu script de entrenamiento en un sistema distribuido con Accelerate y [`Trainer`] con los parámetros especificados en `config_file.yaml`. Este archivo se guarda en la carpeta de caché de Accelerate y se carga automáticamente cuando ejecutas `accelerate_launch`.
|
||||
|
||||
Por ejemplo, para ejecutar el script de entrenamiento [`run_glue.py`](https://github.com/huggingface/transformers/blob/f4db565b695582891e43a5e042e5d318e28f20b8/examples/pytorch/text-classification/run_glue.py#L4) con la configuración de FSDP:
|
||||
|
||||
```bash
|
||||
accelerate launch \
|
||||
./examples/pytorch/text-classification/run_glue.py \
|
||||
--model_name_or_path bert-base-cased \
|
||||
--task_name $TASK_NAME \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--max_seq_length 128 \
|
||||
--per_device_train_batch_size 16 \
|
||||
--learning_rate 5e-5 \
|
||||
--num_train_epochs 3 \
|
||||
--output_dir /tmp/$TASK_NAME/ \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
También puedes especificar los parámetros del archivo config_file.yaml directamente en la línea de comandos:
|
||||
|
||||
```bash
|
||||
accelerate launch --num_processes=2 \
|
||||
--use_fsdp \
|
||||
--mixed_precision=bf16 \
|
||||
--fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
|
||||
--fsdp_transformer_layer_cls_to_wrap="BertLayer" \
|
||||
--fsdp_sharding_strategy=1 \
|
||||
--fsdp_state_dict_type=FULL_STATE_DICT \
|
||||
./examples/pytorch/text-classification/run_glue.py
|
||||
--model_name_or_path bert-base-cased \
|
||||
--task_name $TASK_NAME \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--max_seq_length 128 \
|
||||
--per_device_train_batch_size 16 \
|
||||
--learning_rate 5e-5 \
|
||||
--num_train_epochs 3 \
|
||||
--output_dir /tmp/$TASK_NAME/ \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
Consulta el tutorial [Lanzamiento de tus scripts con Accelerate](https://huggingface.co/docs/accelerate/basic_tutorials/launch) para obtener más información sobre `accelerate_launch` y las configuraciones personalizadas.
|
||||
@ -1,7 +1,7 @@
|
||||
# docstyle-ignore
|
||||
INSTALL_CONTENT = """
|
||||
# Installation de Transformers
|
||||
! pip install transformers datasets
|
||||
! pip install transformers datasets evaluate accelerate
|
||||
# Pour installer à partir du code source au lieu de la dernière version, commentez la commande ci-dessus et décommentez la suivante.
|
||||
# ! pip install git+https://github.com/huggingface/transformers.git
|
||||
"""
|
||||
|
||||
@ -23,7 +23,7 @@ Soyez opérationnel avec 🤗 Transformers ! Que vous soyez un développeur ou u
|
||||
Avant de commencer, assurez-vous que vous avez installé toutes les bibliothèques nécessaires :
|
||||
|
||||
```bash
|
||||
!pip install transformers datasets
|
||||
!pip install transformers datasets evaluate accelerate
|
||||
```
|
||||
|
||||
Vous aurez aussi besoin d'installer votre bibliothèque d'apprentissage profond favorite :
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
# docstyle-ignore
|
||||
INSTALL_CONTENT = """
|
||||
# Installazione di Transformers
|
||||
! pip install transformers datasets
|
||||
! pip install transformers datasets evaluate accelerate
|
||||
# Per installare dalla fonte invece dell'ultima versione rilasciata, commenta il comando sopra e
|
||||
# rimuovi la modalità commento al comando seguente.
|
||||
# ! pip install git+https://github.com/huggingface/transformers.git
|
||||
|
||||
@ -205,7 +205,7 @@ tokenizer.push_to_hub("model_name") # Upload your new template to the Hub!
|
||||
|
||||
一方、ゼロからモデルをトレーニングするか、チャットのためにベース言語モデルをファインチューニングする場合、適切なテンプレートを選択する自由度があります。
|
||||
LLM(Language Model)はさまざまな入力形式を処理できるほどスマートです。クラス固有のテンプレートがないモデル用のデフォルトテンプレートは、一般的なユースケースに対して良い柔軟な選択肢です。
|
||||
これは、[ChatMLフォーマット](https://github.com/openai/openai-python/blob/main/chatml.md)に従ったもので、多くのユースケースに適しています。次のようになります:
|
||||
これは、`ChatMLフォーマット`に従ったもので、多くのユースケースに適しています。次のようになります:
|
||||
|
||||
```
|
||||
{% for message in messages %}
|
||||
|
||||
@ -17,15 +17,6 @@ rendered properly in your Markdown viewer.
|
||||
# 発電用ユーティリティ
|
||||
|
||||
このページには、[`~generation.GenerationMixin.generate`] で使用されるすべてのユーティリティ関数がリストされています。
|
||||
[`~generation.GenerationMixin.greedy_search`],
|
||||
[`~generation.GenerationMixin.contrastive_search`],
|
||||
[`~generation.GenerationMixin.sample`],
|
||||
[`~generation.GenerationMixin.beam_search`],
|
||||
[`~generation.GenerationMixin.beam_sample`],
|
||||
[`~generation.GenerationMixin.group_beam_search`]、および
|
||||
[`~generation.GenerationMixin.constrained_beam_search`]。
|
||||
|
||||
これらのほとんどは、ライブラリ内の生成メソッドのコードを学習する場合にのみ役に立ちます。
|
||||
|
||||
## 出力を生成する
|
||||
|
||||
@ -344,12 +335,6 @@ generation_output[:2]
|
||||
- process
|
||||
- finalize
|
||||
|
||||
## Utilities
|
||||
|
||||
[[autodoc]] top_k_top_p_filtering
|
||||
|
||||
[[autodoc]] tf_top_k_top_p_filtering
|
||||
|
||||
## Streamers
|
||||
|
||||
[[autodoc]] TextStreamer
|
||||
|
||||
@ -43,13 +43,6 @@ rendered properly in your Markdown viewer.
|
||||
[[autodoc]] generation.GenerationMixin
|
||||
- generate
|
||||
- compute_transition_scores
|
||||
- greedy_search
|
||||
- sample
|
||||
- beam_search
|
||||
- beam_sample
|
||||
- contrastive_search
|
||||
- group_beam_search
|
||||
- constrained_beam_search
|
||||
|
||||
## TFGenerationMixin
|
||||
|
||||
|
||||
@ -26,7 +26,7 @@ specific language governing permissions and limitations under the License.
|
||||
始める前に、必要なライブラリがすべてインストールされていることを確認してください:
|
||||
|
||||
```bash
|
||||
!pip install transformers datasets
|
||||
!pip install transformers datasets evaluate accelerate
|
||||
```
|
||||
|
||||
あなたはまた、好きな機械学習フレームワークをインストールする必要があります:
|
||||
|
||||
@ -436,7 +436,7 @@ TensorFlow でモデルを微調整するには、次の手順に従います。
|
||||
... metric_fn=compute_metrics, eval_dataset=tf_eval_dataset, batch_size=batch_size, label_cols=["labels"]
|
||||
... )
|
||||
|
||||
>>> push_to_hub_callback = PushToHubCallback(output_dir="scene_segmentation", tokenizer=image_processor)
|
||||
>>> push_to_hub_callback = PushToHubCallback(output_dir="scene_segmentation", image_processor=image_processor)
|
||||
|
||||
>>> callbacks = [metric_callback, push_to_hub_callback]
|
||||
```
|
||||
|
||||
@ -424,7 +424,7 @@ CUDA_VISIBLE_DEVICES="1" pytest tests/utils/test_logging.py
|
||||
- `require_torch_multi_gpu` - `require_torch` に加えて、少なくとも2つのGPUが必要です。
|
||||
- `require_torch_non_multi_gpu` - `require_torch` に加えて、0または1つのGPUが必要です。
|
||||
- `require_torch_up_to_2_gpus` - `require_torch` に加えて、0、1、または2つのGPUが必要です。
|
||||
- `require_torch_tpu` - `require_torch` に加えて、少なくとも1つのTPUが必要です。
|
||||
- `require_torch_xla` - `require_torch` に加えて、少なくとも1つのTPUが必要です。
|
||||
|
||||
以下の表にGPUの要件を示します:
|
||||
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
# docstyle-ignore
|
||||
INSTALL_CONTENT = """
|
||||
# Transformers 설치 방법
|
||||
! pip install transformers datasets
|
||||
! pip install transformers datasets evaluate accelerate
|
||||
# 마지막 릴리스 대신 소스에서 설치하려면, 위 명령을 주석으로 바꾸고 아래 명령을 해제하세요.
|
||||
# ! pip install git+https://github.com/huggingface/transformers.git
|
||||
"""
|
||||
|
||||
@ -87,8 +87,8 @@
|
||||
title: 🤗 Tokenizers 라이브러리에서 토크나이저 사용하기
|
||||
- local: multilingual
|
||||
title: 다국어 모델 추론하기
|
||||
- local: in_translation
|
||||
title: (번역중) Customize text generation strategy
|
||||
- local: generation_strategies
|
||||
title: 텍스트 생성 전략 사용자 정의
|
||||
- local: create_a_model
|
||||
title: 모델별 API 사용하기
|
||||
- local: custom_models
|
||||
|
||||
337
docs/source/ko/generation_strategies.md
Normal file
337
docs/source/ko/generation_strategies.md
Normal file
@ -0,0 +1,337 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Text generation strategies[[text-generation-strategies]]
|
||||
|
||||
텍스트 생성은 개방형 텍스트 작성, 요약, 번역 등 다양한 자연어 처리(NLP) 작업에 필수적입니다. 이는 또한 음성-텍스트 변환, 시각-텍스트 변환과 같이 텍스트를 출력으로 하는 여러 혼합 모달리티 응용 프로그램에서도 중요한 역할을 합니다. 텍스트 생성을 가능하게 하는 몇몇 모델로는 GPT2, XLNet, OpenAI GPT, CTRL, TransformerXL, XLM, Bart, T5, GIT, Whisper 등이 있습니다.
|
||||
|
||||
|
||||
[`~transformers.generation_utils.GenerationMixin.generate`] 메서드를 활용하여 다음과 같은 다양한 작업들에 대해 텍스트 결과물을 생성하는 몇 가지 예시를 살펴보세요:
|
||||
* [텍스트 요약](./tasks/summarization#inference)
|
||||
* [이미지 캡셔닝](./model_doc/git#transformers.GitForCausalLM.forward.example)
|
||||
* [오디오 전사](./model_doc/whisper#transformers.WhisperForConditionalGeneration.forward.example)
|
||||
|
||||
generate 메소드에 입력되는 값들은 모델의 데이터 형태에 따라 달라집니다. 이 값들은 AutoTokenizer나 AutoProcessor와 같은 모델의 전처리 클래스에 의해 반환됩니다. 모델의 전처리 장치가 하나 이상의 입력 유형을 생성하는 경우, 모든 입력을 generate()에 전달해야 합니다. 각 모델의 전처리 장치에 대해서는 해당 모델의 문서에서 자세히 알아볼 수 있습니다.
|
||||
|
||||
텍스트를 생성하기 위해 출력 토큰을 선택하는 과정을 디코딩이라고 하며, `generate()` 메소드가 사용할 디코딩 전략을 사용자가 커스터마이징할 수 있습니다. 디코딩 전략을 수정하는 것은 훈련 가능한 매개변수의 값들을 변경하지 않지만, 생성된 출력의 품질에 눈에 띄는 영향을 줄 수 있습니다. 이는 텍스트에서 반복을 줄이고, 더 일관성 있게 만드는 데 도움을 줄 수 있습니다.
|
||||
|
||||
|
||||
이 가이드에서는 다음과 같은 내용을 다룹니다:
|
||||
* 기본 생성 설정
|
||||
* 일반적인 디코딩 전략과 주요 파라미터
|
||||
* 🤗 Hub에서 미세 조정된 모델과 함께 사용자 정의 생성 설정을 저장하고 공유하는 방법
|
||||
|
||||
## 기본 텍스트 생성 설정[[default-text-generation-configuration]]
|
||||
|
||||
모델의 디코딩 전략은 생성 설정에서 정의됩니다. 사전 훈련된 모델을 [`pipeline`] 내에서 추론에 사용할 때, 모델은 내부적으로 기본 생성 설정을 적용하는 `PreTrainedModel.generate()` 메소드를 호출합니다. 사용자가 모델과 함께 사용자 정의 설정을 저장하지 않았을 경우에도 기본 설정이 사용됩니다.
|
||||
|
||||
모델을 명시적으로 로드할 때, `model.generation_config`을 통해 제공되는 생성 설정을 검사할 수 있습니다.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
|
||||
>>> model.generation_config
|
||||
GenerationConfig {
|
||||
"bos_token_id": 50256,
|
||||
"eos_token_id": 50256,
|
||||
}
|
||||
```
|
||||
|
||||
`model.generation_config`를 출력하면 기본 설정과 다른 값들만 표시되고, 기본값들은 나열되지 않습니다.
|
||||
|
||||
기본 생성 설정은 입력 프롬프트와 출력을 합친 최대 크기를 20 토큰으로 제한하여 리소스 부족을 방지합니다. 기본 디코딩 전략은 탐욕 탐색(greedy search)으로, 다음 토큰으로 가장 높은 확률을 가진 토큰을 선택하는 가장 단순한 디코딩 전략입니다. 많은 작업과 작은 출력 크기에 대해서는 이 방법이 잘 작동하지만, 더 긴 출력을 생성할 때 사용하면 매우 반복적인 결과를 생성하게 될 수 있습니다.
|
||||
|
||||
## 텍스트 생성 사용자 정의[[customize-text-generation]]
|
||||
|
||||
파라미터와 해당 값을 [`generate`] 메소드에 직접 전달하여 `generation_config`을 재정의할 수 있습니다:
|
||||
|
||||
```python
|
||||
>>> my_model.generate(**inputs, num_beams=4, do_sample=True) # doctest: +SKIP
|
||||
```
|
||||
|
||||
기본 디코딩 전략이 대부분의 작업에 잘 작동한다 하더라도, 조정할 수 있는 몇 가지 파라미터가 있습니다. 일반적으로 조정되는 파라미터에는 다음과 같은 것들이 포함됩니다:
|
||||
|
||||
- `max_new_tokens`: 생성할 최대 토큰 수입니다. 즉, 프롬프트에 있는 토큰을 제외한 출력 시퀀스의 크기입니다. 출력의 길이를 중단 기준으로 사용하는 대신, 전체 생성물이 일정 시간을 초과할 때 생성을 중단하기로 선택할 수도 있습니다. 더 알아보려면 [`StoppingCriteria`]를 확인하세요.
|
||||
- `num_beams`: 1보다 큰 수의 빔을 지정함으로써, 탐욕 탐색(greedy search)에서 빔 탐색(beam search)으로 전환하게 됩니다. 이 전략은 각 시간 단계에서 여러 가설을 평가하고 결국 전체 시퀀스에 대해 가장 높은 확률을 가진 가설을 선택합니다. 이는 초기 토큰의 확률이 낮아 탐욕 탐색에 의해 무시되었을 높은 확률의 시퀀스를 식별할 수 있는 장점을 가집니다.
|
||||
- `do_sample`: 이 매개변수를 `True`로 설정하면, 다항 샘플링, 빔 탐색 다항 샘플링, Top-K 샘플링 및 Top-p 샘플링과 같은 디코딩 전략을 활성화합니다. 이러한 전략들은 전체 어휘에 대한 확률 분포에서 다음 토큰을 선택하며, 전략별로 특정 조정이 적용됩니다.
|
||||
- `num_return_sequences`: 각 입력에 대해 반환할 시퀀스 후보의 수입니다. 이 옵션은 빔 탐색(beam search)의 변형과 샘플링과 같이 여러 시퀀스 후보를 지원하는 디코딩 전략에만 사용할 수 있습니다. 탐욕 탐색(greedy search)과 대조 탐색(contrastive search) 같은 디코딩 전략은 단일 출력 시퀀스를 반환합니다.
|
||||
|
||||
## 모델에 사용자 정의 디코딩 전략 저장[[save-a-custom-decoding-strategy-with-your-model]]
|
||||
|
||||
특정 생성 설정을 가진 미세 조정된 모델을 공유하고자 할 때, 다음 단계를 따를 수 있습니다:
|
||||
* [`GenerationConfig`] 클래스 인스턴스를 생성합니다.
|
||||
* 디코딩 전략 파라미터를 설정합니다.
|
||||
* 생성 설정을 [`GenerationConfig.save_pretrained`]를 사용하여 저장하며, `config_file_name` 인자는 비워둡니다.
|
||||
* 모델의 저장소에 설정을 업로드하기 위해 `push_to_hub`를 `True`로 설정합니다.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, GenerationConfig
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model") # doctest: +SKIP
|
||||
>>> generation_config = GenerationConfig(
|
||||
... max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
|
||||
... )
|
||||
>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True) # doctest: +SKIP
|
||||
```
|
||||
|
||||
단일 디렉토리에 여러 생성 설정을 저장할 수 있으며, 이때 [`GenerationConfig.save_pretrained`]의 `config_file_name` 인자를 사용합니다. 나중에 [`GenerationConfig.from_pretrained`]로 이들을 인스턴스화할 수 있습니다. 이는 단일 모델에 대해 여러 생성 설정을 저장하고 싶을 때 유용합니다(예: 샘플링을 이용한 창의적 텍스트 생성을 위한 하나, 빔 탐색을 이용한 요약을 위한 다른 하나 등). 모델에 설정 파일을 추가하기 위해 적절한 Hub 권한을 가지고 있어야 합니다.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-small")
|
||||
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-small")
|
||||
|
||||
>>> translation_generation_config = GenerationConfig(
|
||||
... num_beams=4,
|
||||
... early_stopping=True,
|
||||
... decoder_start_token_id=0,
|
||||
... eos_token_id=model.config.eos_token_id,
|
||||
... pad_token=model.config.pad_token_id,
|
||||
... )
|
||||
|
||||
>>> # 팁: Hub에 push하려면 `push_to_hub=True`를 추가
|
||||
>>> translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
|
||||
|
||||
>>> # 명명된 생성 설정 파일을 사용하여 생성을 매개변수화할 수 있습니다.
|
||||
>>> generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
|
||||
>>> inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
|
||||
>>> outputs = model.generate(**inputs, generation_config=generation_config)
|
||||
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
|
||||
['Les fichiers de configuration sont faciles à utiliser!']
|
||||
```
|
||||
|
||||
## 스트리밍[[streaming]]
|
||||
|
||||
`generate()` 메소드는 `streamer` 입력을 통해 스트리밍을 지원합니다. `streamer` 입력은 `put()`과 `end()` 메소드를 가진 클래스의 인스턴스와 호환됩니다. 내부적으로, `put()`은 새 토큰을 추가하는 데 사용되며, `end()`는 텍스트 생성의 끝을 표시하는 데 사용됩니다.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
스트리머 클래스의 API는 아직 개발 중이며, 향후 변경될 수 있습니다.
|
||||
|
||||
</Tip>
|
||||
|
||||
실제로 다양한 목적을 위해 자체 스트리밍 클래스를 만들 수 있습니다! 또한, 기본적인 스트리밍 클래스들도 준비되어 있어 바로 사용할 수 있습니다. 예를 들어, [`TextStreamer`] 클래스를 사용하여 `generate()`의 출력을 화면에 한 단어씩 스트리밍할 수 있습니다:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
|
||||
|
||||
>>> tok = AutoTokenizer.from_pretrained("openai-community/gpt2")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
|
||||
>>> inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
|
||||
>>> streamer = TextStreamer(tok)
|
||||
|
||||
>>> # 스트리머는 평소와 같은 출력값을 반환할 뿐만 아니라 생성된 텍스트도 표준 출력(stdout)으로 출력합니다.
|
||||
>>> _ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
|
||||
An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,
|
||||
```
|
||||
|
||||
## 디코딩 전략[[decoding-strategies]]
|
||||
|
||||
`generate()` 매개변수와 궁극적으로 `generation_config`의 특정 조합을 사용하여 특정 디코딩 전략을 활성화할 수 있습니다. 이 개념이 처음이라면, 흔히 사용되는 디코딩 전략이 어떻게 작동하는지 설명하는 [이 블로그 포스트](https://huggingface.co/blog/how-to-generate)를 읽어보는 것을 추천합니다.
|
||||
|
||||
여기서는 디코딩 전략을 제어하는 몇 가지 매개변수를 보여주고, 이를 어떻게 사용할 수 있는지 설명하겠습니다.
|
||||
|
||||
### 탐욕 탐색(Greedy Search)[[greedy-search]]
|
||||
|
||||
[`generate`]는 기본적으로 탐욕 탐색 디코딩을 사용하므로 이를 활성화하기 위해 별도의 매개변수를 지정할 필요가 없습니다. 이는 `num_beams`가 1로 설정되고 `do_sample=False`로 되어 있다는 의미입니다."
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
>>> prompt = "I look forward to"
|
||||
>>> checkpoint = "distilbert/distilgpt2"
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
|
||||
>>> outputs = model.generate(**inputs)
|
||||
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
['I look forward to seeing you all again!\n\n\n\n\n\n\n\n\n\n\n']
|
||||
```
|
||||
|
||||
### 대조 탐색(Contrastive search)[[contrastive-search]]
|
||||
|
||||
2022년 논문 [A Contrastive Framework for Neural Text Generation](https://arxiv.org/abs/2202.06417)에서 제안된 대조 탐색 디코딩 전략은 반복되지 않으면서도 일관된 긴 출력을 생성하는 데 있어 우수한 결과를 보였습니다. 대조 탐색이 작동하는 방식을 알아보려면 [이 블로그 포스트](https://huggingface.co/blog/introducing-csearch)를 확인하세요. 대조 탐색의 동작을 가능하게 하고 제어하는 두 가지 주요 매개변수는 `penalty_alpha`와 `top_k`입니다:
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
|
||||
>>> checkpoint = "openai-community/gpt2-large"
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
|
||||
|
||||
>>> prompt = "Hugging Face Company is"
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
|
||||
>>> outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
|
||||
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
['Hugging Face Company is a family owned and operated business. We pride ourselves on being the best
|
||||
in the business and our customer service is second to none.\n\nIf you have any questions about our
|
||||
products or services, feel free to contact us at any time. We look forward to hearing from you!']
|
||||
```
|
||||
|
||||
### 다항 샘플링(Multinomial sampling)[[multinomial-sampling]]
|
||||
|
||||
탐욕 탐색(greedy search)이 항상 가장 높은 확률을 가진 토큰을 다음 토큰으로 선택하는 것과 달리, 다항 샘플링(multinomial sampling, 조상 샘플링(ancestral sampling)이라고도 함)은 모델이 제공하는 전체 어휘에 대한 확률 분포를 기반으로 다음 토큰을 무작위로 선택합니다. 0이 아닌 확률을 가진 모든 토큰은 선택될 기회가 있으므로, 반복의 위험을 줄일 수 있습니다.
|
||||
|
||||
다항 샘플링을 활성화하려면 `do_sample=True` 및 `num_beams=1`을 설정하세요.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
|
||||
>>> set_seed(0) # 재현성을 위해
|
||||
|
||||
>>> checkpoint = "openai-community/gpt2-large"
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
|
||||
|
||||
>>> prompt = "Today was an amazing day because"
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
|
||||
>>> outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
|
||||
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
['Today was an amazing day because when you go to the World Cup and you don\'t, or when you don\'t get invited,
|
||||
that\'s a terrible feeling."']
|
||||
```
|
||||
|
||||
### 빔 탐색(Beam-search) 디코딩[[beam-search-decoding]]
|
||||
|
||||
탐욕 검색(greedy search)과 달리, 빔 탐색(beam search) 디코딩은 각 시간 단계에서 여러 가설을 유지하고 결국 전체 시퀀스에 대해 가장 높은 확률을 가진 가설을 선택합니다. 이는 낮은 확률의 초기 토큰으로 시작하고 그리디 검색에서 무시되었을 가능성이 높은 시퀀스를 식별하는 이점이 있습니다.
|
||||
|
||||
이 디코딩 전략을 활성화하려면 `num_beams` (추적할 가설 수라고도 함)를 1보다 크게 지정하세요.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
>>> prompt = "It is astonishing how one can"
|
||||
>>> checkpoint = "openai-community/gpt2-medium"
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
|
||||
|
||||
>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
|
||||
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
|
||||
time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
|
||||
```
|
||||
|
||||
### 빔 탐색 다항 샘플링(Beam-search multinomial sampling)[[beam-search-multinomial-sampling]]
|
||||
|
||||
이 디코딩 전략은 이름에서 알 수 있듯이 빔 탐색과 다항 샘플링을 결합한 것입니다. 이 디코딩 전략을 사용하기 위해서는 `num_beams`를 1보다 큰 값으로 설정하고, `do_sample=True`로 설정해야 합니다.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
|
||||
>>> set_seed(0) # 재현성을 위해
|
||||
|
||||
>>> prompt = "translate English to German: The house is wonderful."
|
||||
>>> checkpoint = "google-t5/t5-small"
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
|
||||
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
|
||||
|
||||
>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
|
||||
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
|
||||
'Das Haus ist wunderbar.'
|
||||
```
|
||||
|
||||
### 다양한 빔 탐색 디코딩(Diverse beam search decoding)[[diverse-beam-search-decoding]]
|
||||
|
||||
다양한 빔 탐색(Decoding) 전략은 선택할 수 있는 더 다양한 빔 시퀀스 집합을 생성할 수 있게 해주는 빔 탐색 전략의 확장입니다. 이 방법은 어떻게 작동하는지 알아보려면, [다양한 빔 탐색: 신경 시퀀스 모델에서 다양한 솔루션 디코딩하기](https://arxiv.org/pdf/1610.02424.pdf)를 참조하세요. 이 접근 방식은 세 가지 주요 매개변수를 가지고 있습니다: `num_beams`, `num_beam_groups`, 그리고 `diversity_penalty`. 다양성 패널티는 그룹 간에 출력이 서로 다르게 하기 위한 것이며, 각 그룹 내에서 빔 탐색이 사용됩니다.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
|
||||
|
||||
>>> checkpoint = "google/pegasus-xsum"
|
||||
>>> prompt = (
|
||||
... "The Permaculture Design Principles are a set of universal design principles "
|
||||
... "that can be applied to any location, climate and culture, and they allow us to design "
|
||||
... "the most efficient and sustainable human habitation and food production systems. "
|
||||
... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
|
||||
... "as ecology, landscape design, environmental science and energy conservation, and the "
|
||||
... "Permaculture design principles are drawn from these various disciplines. Each individual "
|
||||
... "design principle itself embodies a complete conceptual framework based on sound "
|
||||
... "scientific principles. When we bring all these separate principles together, we can "
|
||||
... "create a design system that both looks at whole systems, the parts that these systems "
|
||||
... "consist of, and how those parts interact with each other to create a complex, dynamic, "
|
||||
... "living system. Each design principle serves as a tool that allows us to integrate all "
|
||||
... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
|
||||
... "whole system, where the elements harmoniously interact and work together in the most "
|
||||
... "efficient way possible."
|
||||
... )
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
|
||||
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
|
||||
|
||||
>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
|
||||
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
|
||||
'The Design Principles are a set of universal design principles that can be applied to any location, climate and
|
||||
culture, and they allow us to design the'
|
||||
```
|
||||
|
||||
이 가이드에서는 다양한 디코딩 전략을 가능하게 하는 주요 매개변수를 보여줍니다. [`generate`] 메서드에 대한 고급 매개변수가 존재하므로 [`generate`] 메서드의 동작을 더욱 세부적으로 제어할 수 있습니다. 사용 가능한 매개변수의 전체 목록은 [API 문서](./main_classes/text_generation.md)를 참조하세요.
|
||||
|
||||
### 추론 디코딩(Speculative Decoding)[[speculative-decoding]]
|
||||
|
||||
추론 디코딩(보조 디코딩(assisted decoding)으로도 알려짐)은 동일한 토크나이저를 사용하는 훨씬 작은 보조 모델을 활용하여 몇 가지 후보 토큰을 생성하는 상위 모델의 디코딩 전략을 수정한 것입니다. 주 모델은 단일 전방 통과로 후보 토큰을 검증함으로써 디코딩 과정을 가속화합니다. `do_sample=True`일 경우, [추론 디코딩 논문](https://arxiv.org/pdf/2211.17192.pdf)에 소개된 토큰 검증과 재샘플링 방식이 사용됩니다.
|
||||
|
||||
현재, 탐욕 검색(greedy search)과 샘플링만이 지원되는 보조 디코딩(assisted decoding) 기능을 통해, 보조 디코딩은 배치 입력을 지원하지 않습니다. 보조 디코딩에 대해 더 알고 싶다면, [이 블로그 포스트](https://huggingface.co/blog/assisted-generation)를 확인해 주세요.
|
||||
|
||||
보조 디코딩을 활성화하려면 모델과 함께 `assistant_model` 인수를 설정하세요.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
>>> prompt = "Alice and Bob"
|
||||
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
|
||||
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
|
||||
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
|
||||
>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
|
||||
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
|
||||
```
|
||||
|
||||
샘플링 방법과 함께 보조 디코딩을 사용하는 경우 다항 샘플링과 마찬가지로 `temperature` 인수를 사용하여 무작위성을 제어할 수 있습니다. 그러나 보조 디코딩에서는 `temperature`를 낮추면 대기 시간을 개선하는 데 도움이 될 수 있습니다.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
|
||||
>>> set_seed(42) # 재현성을 위해
|
||||
|
||||
>>> prompt = "Alice and Bob"
|
||||
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
|
||||
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
||||
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
|
||||
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
|
||||
>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
|
||||
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
['Alice and Bob are going to the same party. It is a small party, in a small']
|
||||
```
|
||||
@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
|
||||
시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
|
||||
|
||||
```bash
|
||||
!pip install transformers datasets
|
||||
!pip install transformers datasets evaluate accelerate
|
||||
```
|
||||
|
||||
또한 선호하는 머신 러닝 프레임워크를 설치해야 합니다:
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user