mirror of
https://github.com/huggingface/transformers.git
synced 2025-10-20 17:13:56 +08:00
Compare commits
154 Commits
contributi
...
740f952218
| Author | SHA1 | Date | |
|---|---|---|---|
| 740f952218 | |||
| 950c4e5303 | |||
| 89970f4797 | |||
| a4a46e62a5 | |||
| 9b36498d5f | |||
| eefbf4ac8b | |||
| 50ca781d78 | |||
| 8739fc05c4 | |||
| 77b5ad65ee | |||
| a9731a725e | |||
| bdbc2d037b | |||
| fe11cbb808 | |||
| 6344371a91 | |||
| a408384a88 | |||
| f7c33abab3 | |||
| 9839d57a02 | |||
| e85d5ab2bb | |||
| 1c36d407d5 | |||
| 0215846d98 | |||
| 9e99198e5e | |||
| bf815e9b5e | |||
| 4a43e3d57c | |||
| 8725ce10ed | |||
| 1fb3fc4db0 | |||
| 9176af574a | |||
| 503c933f36 | |||
| 2aff20aff6 | |||
| 981370c038 | |||
| eef9fb2af3 | |||
| 35dc8f0a2e | |||
| 2935a1be19 | |||
| b9bd8c45a1 | |||
| baecdb8a97 | |||
| 44539827d5 | |||
| 143acfe2ce | |||
| 67fae90519 | |||
| af2a66ced9 | |||
| a59124e27e | |||
| 81f97b17d2 | |||
| c0a5cf19ad | |||
| 3ef6f2c415 | |||
| 59efd86da2 | |||
| 7b7d17f9bf | |||
| e20df45bf6 | |||
| 19df66dcba | |||
| 9f71e3a604 | |||
| bc9900562d | |||
| 72fd67929b | |||
| da382917aa | |||
| 313afcc468 | |||
| 7bba4d1202 | |||
| ab92534377 | |||
| 56a727dde5 | |||
| dc6fdeb705 | |||
| 3953b65440 | |||
| 96d245a83d | |||
| bb0c3af995 | |||
| 70e871959c | |||
| c4210796e0 | |||
| fcd1ccdb78 | |||
| 2b2c20f315 | |||
| e2122c4bcb | |||
| e89cef6625 | |||
| 26b7f66850 | |||
| 5db730786d | |||
| 13a35a5057 | |||
| 94df0e6560 | |||
| 9e4199ede3 | |||
| 4c8d293599 | |||
| a99b1be3c7 | |||
| 82cae9eb52 | |||
| 4fad35ee4a | |||
| ae6f6cc3e0 | |||
| fd787c5f6d | |||
| 4e4f2af586 | |||
| 3648fde486 | |||
| abf5b57a68 | |||
| 8fe4db5399 | |||
| c620c38bb0 | |||
| 0798797ec9 | |||
| 0566b6f5bd | |||
| b3e3c3dc93 | |||
| b84c0b31c6 | |||
| 1ee3b288a6 | |||
| cad74496ca | |||
| 3813a8e3a1 | |||
| 66d8d7a077 | |||
| d621be8286 | |||
| d7c9fbdb64 | |||
| 41e763decd | |||
| cf1e9834ec | |||
| 6c901bdc0e | |||
| 58f9e13313 | |||
| eb28242251 | |||
| 65cb8fac6d | |||
| 3927ffed31 | |||
| 7164924a7e | |||
| 26a5368c44 | |||
| feca4f3de7 | |||
| c6042a4169 | |||
| dfd4121cd4 | |||
| 60f6ec438a | |||
| f9f8bf5a10 | |||
| b4067472ae | |||
| bc529a3368 | |||
| b92fc0c6e1 | |||
| 2eae7c7452 | |||
| c5094a4f97 | |||
| f4487ec521 | |||
| e8194fe84f | |||
| 9556b36b2f | |||
| 5aca530b34 | |||
| 4f323369db | |||
| f5f3457278 | |||
| 3585737746 | |||
| b543679d0e | |||
| ac7777be16 | |||
| 17c31a98ac | |||
| b28902c86b | |||
| d0271be18f | |||
| 0419ff881d | |||
| 081391b20e | |||
| 1ddbbdef48 | |||
| c20849bad1 | |||
| 776eea8612 | |||
| 3839d51013 | |||
| 78f79ba5af | |||
| 11c597b1b8 | |||
| b450d55a91 | |||
| 1a3a5f5289 | |||
| 823fab4860 | |||
| 42d4e13a0b | |||
| 0eae41ad36 | |||
| 589fc29c9d | |||
| 26b5b52676 | |||
| 34b861abd1 | |||
| b44d91570f | |||
| d99069195b | |||
| bf38b2d11d | |||
| 72a3fc275c | |||
| 9ef804472b | |||
| 2b5e4c0d13 | |||
| add4df62ba | |||
| 3e87072666 | |||
| f0544d7e7c | |||
| d1c6310d6a | |||
| 927aa8bef2 | |||
| 1951f3be8e | |||
| f50fd7fb6b | |||
| be3fa93b29 | |||
| 8137dbdbbd | |||
| 7aa888b7fa | |||
| bfe2b623ef | |||
| b9be8a8775 |
7
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
7
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@ -48,18 +48,17 @@ body:
|
||||
- continuous batching: @remi-or @ArthurZucker @McPatate
|
||||
- pipelines: @Rocketknight1
|
||||
- tokenizers: @ArthurZucker and @itazap
|
||||
- trainer: @zach-huggingface @SunMarc
|
||||
- trainer: @SunMarc
|
||||
- attention: @vasqu @ArthurZucker @CyrilVallez
|
||||
- model loading (from pretrained, etc): @CyrilVallez
|
||||
- distributed: @3outeille @ArthurZucker @S1ro1
|
||||
- distributed: @3outeille @ArthurZucker
|
||||
- CIs: @ydshieh
|
||||
|
||||
Integrations:
|
||||
|
||||
- deepspeed: HF Trainer/Accelerate: @SunMarc @zach-huggingface
|
||||
- ray/raytune: @richardliaw, @amogkam
|
||||
- Big Model Inference: @SunMarc
|
||||
- quantization (bitsandbytes, autogpt): @SunMarc @MekkCyber
|
||||
- quantization: @SunMarc @MekkCyber
|
||||
- kernels: @MekkCyber @drbh
|
||||
- peft: @BenjaminBossan @githubnemo
|
||||
|
||||
|
||||
7
.github/PULL_REQUEST_TEMPLATE.md
vendored
7
.github/PULL_REQUEST_TEMPLATE.md
vendored
@ -51,18 +51,17 @@ Library:
|
||||
- continuous batching: @remi-or @ArthurZucker @McPatate
|
||||
- pipelines: @Rocketknight1
|
||||
- tokenizers: @ArthurZucker and @itazap
|
||||
- trainer: @zach-huggingface @SunMarc
|
||||
- trainer: @SunMarc
|
||||
- attention: @vasqu @ArthurZucker @CyrilVallez
|
||||
- model loading (from pretrained, etc): @CyrilVallez
|
||||
- distributed: @3outeille @ArthurZucker @S1ro1
|
||||
- distributed: @3outeille @ArthurZucker
|
||||
- CIs: @ydshieh
|
||||
|
||||
Integrations:
|
||||
|
||||
- deepspeed: HF Trainer/Accelerate: @SunMarc @zach-huggingface
|
||||
- ray/raytune: @richardliaw, @amogkam
|
||||
- Big Model Inference: @SunMarc
|
||||
- quantization (bitsandbytes, autogpt): @SunMarc @MekkCyber
|
||||
- quantization: @SunMarc @MekkCyber
|
||||
- kernels: @MekkCyber @drbh
|
||||
- peft: @BenjaminBossan @githubnemo
|
||||
|
||||
|
||||
5
.github/workflows/benchmark.yml
vendored
5
.github/workflows/benchmark.yml
vendored
@ -1,10 +1,7 @@
|
||||
name: Self-hosted runner (benchmark)
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [main]
|
||||
pull_request:
|
||||
types: [ opened, labeled, reopened, synchronize ]
|
||||
workflow_dispatch:
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
|
||||
32
.github/workflows/benchmark_v2.yml
vendored
32
.github/workflows/benchmark_v2.yml
vendored
@ -1,35 +1,7 @@
|
||||
name: Benchmark v2 Framework
|
||||
|
||||
on:
|
||||
workflow_call:
|
||||
inputs:
|
||||
runner:
|
||||
description: 'GH Actions runner group to use'
|
||||
required: true
|
||||
type: string
|
||||
container_image:
|
||||
description: 'Docker image to use'
|
||||
required: true
|
||||
type: string
|
||||
container_options:
|
||||
description: 'Container options to use'
|
||||
required: true
|
||||
type: string
|
||||
commit_sha:
|
||||
description: 'Commit SHA to benchmark'
|
||||
required: false
|
||||
type: string
|
||||
default: ''
|
||||
run_id:
|
||||
description: 'Custom run ID for organizing results (auto-generated if not provided)'
|
||||
required: false
|
||||
type: string
|
||||
default: ''
|
||||
benchmark_repo_id:
|
||||
description: 'HuggingFace Dataset to upload results to (e.g., "org/benchmark-results")'
|
||||
required: false
|
||||
type: string
|
||||
default: ''
|
||||
workflow_dispatch:
|
||||
|
||||
env:
|
||||
HF_HOME: /mnt/cache
|
||||
@ -82,4 +54,4 @@ jobs:
|
||||
--token '${{ secrets.TRANSFORMERS_CI_RESULTS_UPLOAD_TOKEN }}' \
|
||||
--log-level INFO
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.HF_HUB_READ_TOKEN }}
|
||||
HF_TOKEN: ${{ secrets.HF_HUB_READ_TOKEN }}
|
||||
|
||||
@ -1,11 +1,7 @@
|
||||
name: Benchmark v2 Scheduled Runner - A10 Single-GPU
|
||||
|
||||
on:
|
||||
schedule:
|
||||
# Run daily at 16:30 UTC
|
||||
- cron: "30 16 * * *"
|
||||
pull_request:
|
||||
types: [ opened, labeled, reopened, synchronize ]
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
benchmark-v2-default:
|
||||
@ -18,4 +14,4 @@ jobs:
|
||||
commit_sha: ${{ github.sha }}
|
||||
run_id: ${{ github.run_id }}
|
||||
benchmark_repo_id: hf-internal-testing/transformers-daily-benchmarks
|
||||
secrets: inherit
|
||||
secrets: inherit
|
||||
|
||||
@ -1,11 +1,7 @@
|
||||
name: Benchmark v2 Scheduled Runner - MI325 Single-GPU
|
||||
|
||||
on:
|
||||
schedule:
|
||||
# Run daily at 16:30 UTC
|
||||
- cron: "30 16 * * *"
|
||||
pull_request:
|
||||
types: [ opened, labeled, reopened, synchronize ]
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
benchmark-v2-default:
|
||||
@ -18,4 +14,4 @@ jobs:
|
||||
commit_sha: ${{ github.sha }}
|
||||
run_id: ${{ github.run_id }}
|
||||
benchmark_repo_id: hf-internal-testing/transformers-daily-benchmarks
|
||||
secrets: inherit
|
||||
secrets: inherit
|
||||
|
||||
176
.github/workflows/check_failed_tests.yml
vendored
176
.github/workflows/check_failed_tests.yml
vendored
@ -35,14 +35,16 @@ env:
|
||||
# For gated repositories, we still need to agree to share information on the Hub repo. page in order to get access.
|
||||
# This token is created under the bot `hf-transformers-bot`.
|
||||
HF_HUB_READ_TOKEN: ${{ secrets.HF_HUB_READ_TOKEN }}
|
||||
SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
|
||||
TF_FORCE_GPU_ALLOW_GROWTH: true
|
||||
CUDA_VISIBLE_DEVICES: 0,1
|
||||
|
||||
|
||||
jobs:
|
||||
check_new_failures:
|
||||
name: " "
|
||||
name: "Find commits for new failing tests"
|
||||
strategy:
|
||||
matrix:
|
||||
run_idx: [1, 2, 3]
|
||||
runs-on:
|
||||
group: aws-g5-4xlarge-cache
|
||||
container:
|
||||
@ -119,6 +121,10 @@ jobs:
|
||||
run: |
|
||||
python3 utils/print_env.py
|
||||
|
||||
- name: Install pytest-flakefinder
|
||||
if: ${{ env.process == 'true' }}
|
||||
run: python3 -m pip install pytest-flakefinder
|
||||
|
||||
- name: Show installed libraries and their versions
|
||||
working-directory: /transformers
|
||||
if: ${{ env.process == 'true' }}
|
||||
@ -127,82 +133,104 @@ jobs:
|
||||
- name: Check failed tests
|
||||
working-directory: /transformers
|
||||
if: ${{ env.process == 'true' }}
|
||||
run: python3 utils/check_bad_commit.py --start_commit ${{ inputs.start_sha }} --end_commit ${{ env.END_SHA }} --file ci_results_${{ inputs.job }}/new_failures.json --output_file new_failures_with_bad_commit.json
|
||||
run: python3 utils/check_bad_commit.py --start_commit ${{ inputs.start_sha }} --end_commit ${{ env.END_SHA }} --file ci_results_${{ inputs.job }}/new_failures.json --output_file new_failures_with_bad_commit_${{ inputs.job }}_${{ matrix.run_idx }}.json
|
||||
|
||||
- name: Show results
|
||||
working-directory: /transformers
|
||||
if: ${{ env.process == 'true' }}
|
||||
run: |
|
||||
ls -l new_failures_with_bad_commit.json
|
||||
cat new_failures_with_bad_commit.json
|
||||
ls -l new_failures_with_bad_commit_${{ inputs.job }}_${{ matrix.run_idx }}.json
|
||||
cat new_failures_with_bad_commit_${{ inputs.job }}_${{ matrix.run_idx }}.json
|
||||
|
||||
- name: Checkout back
|
||||
working-directory: /transformers
|
||||
if: ${{ env.process == 'true' }}
|
||||
run: |
|
||||
git checkout ${{ inputs.start_sha }}
|
||||
|
||||
- name: Process report
|
||||
shell: bash
|
||||
working-directory: /transformers
|
||||
if: ${{ env.process == 'true' }}
|
||||
env:
|
||||
ACCESS_REPO_INFO_TOKEN: ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
|
||||
TRANSFORMERS_CI_RESULTS_UPLOAD_TOKEN: ${{ secrets.TRANSFORMERS_CI_RESULTS_UPLOAD_TOKEN }}
|
||||
JOB_NAME: ${{ inputs.job }}
|
||||
REPORT_REPO_ID: ${{ inputs.report_repo_id }}
|
||||
run: |
|
||||
python3 utils/process_bad_commit_report.py
|
||||
|
||||
- name: Process report
|
||||
shell: bash
|
||||
working-directory: /transformers
|
||||
if: ${{ env.process == 'true' }}
|
||||
env:
|
||||
ACCESS_REPO_INFO_TOKEN: ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
|
||||
TRANSFORMERS_CI_RESULTS_UPLOAD_TOKEN: ${{ secrets.TRANSFORMERS_CI_RESULTS_UPLOAD_TOKEN }}
|
||||
JOB_NAME: ${{ inputs.job }}
|
||||
REPORT_REPO_ID: ${{ inputs.report_repo_id }}
|
||||
run: |
|
||||
{
|
||||
echo 'REPORT_TEXT<<EOF'
|
||||
python3 utils/process_bad_commit_report.py
|
||||
echo EOF
|
||||
} >> "$GITHUB_ENV"
|
||||
|
||||
- name: Prepare Slack report title
|
||||
working-directory: /transformers
|
||||
if: ${{ env.process == 'true' }}
|
||||
run: |
|
||||
pip install slack_sdk
|
||||
echo "title=$(python3 -c 'import sys; sys.path.append("utils"); from utils.notification_service import job_to_test_map; ci_event = "${{ inputs.ci_event }}"; job = "${{ inputs.job }}"; test_name = job_to_test_map[job]; title = f"New failed tests of {ci_event}" + ":" + f" {test_name}"; print(title)')" >> $GITHUB_ENV
|
||||
|
||||
- name: Send processed report
|
||||
if: ${{ env.process == 'true' && !endsWith(env.REPORT_TEXT, '{}') }}
|
||||
uses: slackapi/slack-github-action@6c661ce58804a1a20f6dc5fbee7f0381b469e001
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
# Slack channel id, channel name, or user id to post message.
|
||||
# See also: https://api.slack.com/methods/chat.postMessage#channels
|
||||
channel-id: '#${{ inputs.slack_report_channel }}'
|
||||
# For posting a rich message using Block Kit
|
||||
payload: |
|
||||
{
|
||||
"blocks": [
|
||||
{
|
||||
"type": "header",
|
||||
"text": {
|
||||
"type": "plain_text",
|
||||
"text": "${{ env.title }}"
|
||||
}
|
||||
},
|
||||
{
|
||||
"type": "section",
|
||||
"text": {
|
||||
"type": "mrkdwn",
|
||||
"text": "${{ env.REPORT_TEXT }}"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
env:
|
||||
SLACK_BOT_TOKEN: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
name: new_failures_with_bad_commit_${{ inputs.job }}_${{ matrix.run_idx }}
|
||||
path: /transformers/new_failures_with_bad_commit_${{ inputs.job }}_${{ matrix.run_idx }}.json
|
||||
|
||||
process_new_failures_with_commit_info:
|
||||
name: "process bad commit reports"
|
||||
needs: [check_new_failures]
|
||||
runs-on:
|
||||
group: aws-g5-4xlarge-cache
|
||||
container:
|
||||
image: ${{ inputs.docker }}
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
steps:
|
||||
- uses: actions/download-artifact@v4
|
||||
with:
|
||||
pattern: new_failures_with_bad_commit_${{ inputs.job }}*
|
||||
path: /transformers/new_failures_with_bad_commit_${{ inputs.job }}
|
||||
merge-multiple: true
|
||||
|
||||
- name: Check files
|
||||
working-directory: /transformers
|
||||
run: |
|
||||
ls -la /transformers
|
||||
ls -la /transformers/new_failures_with_bad_commit_${{ inputs.job }}
|
||||
|
||||
|
||||
# - name: Process report
|
||||
# shell: bash
|
||||
# working-directory: /transformers
|
||||
# if: ${{ env.process == 'true' }}
|
||||
# env:
|
||||
# ACCESS_REPO_INFO_TOKEN: ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
|
||||
# TRANSFORMERS_CI_RESULTS_UPLOAD_TOKEN: ${{ secrets.TRANSFORMERS_CI_RESULTS_UPLOAD_TOKEN }}
|
||||
# JOB_NAME: ${{ inputs.job }}
|
||||
# REPORT_REPO_ID: ${{ inputs.report_repo_id }}
|
||||
# run: |
|
||||
# python3 utils/process_bad_commit_report.py
|
||||
|
||||
# - name: Process report
|
||||
# shell: bash
|
||||
# working-directory: /transformers
|
||||
# if: ${{ env.process == 'true' }}
|
||||
# env:
|
||||
# ACCESS_REPO_INFO_TOKEN: ${{ secrets.ACCESS_REPO_INFO_TOKEN }}
|
||||
# TRANSFORMERS_CI_RESULTS_UPLOAD_TOKEN: ${{ secrets.TRANSFORMERS_CI_RESULTS_UPLOAD_TOKEN }}
|
||||
# JOB_NAME: ${{ inputs.job }}
|
||||
# REPORT_REPO_ID: ${{ inputs.report_repo_id }}
|
||||
# run: |
|
||||
# {
|
||||
# echo 'REPORT_TEXT<<EOF'
|
||||
# python3 utils/process_bad_commit_report.py
|
||||
# echo EOF
|
||||
# } >> "$GITHUB_ENV"
|
||||
#
|
||||
# - name: Prepare Slack report title
|
||||
# working-directory: /transformers
|
||||
# if: ${{ env.process == 'true' }}
|
||||
# run: |
|
||||
# pip install slack_sdk
|
||||
# echo "title=$(python3 -c 'import sys; sys.path.append("utils"); from utils.notification_service import job_to_test_map; ci_event = "${{ inputs.ci_event }}"; job = "${{ inputs.job }}"; test_name = job_to_test_map[job]; title = f"New failed tests of {ci_event}" + ":" + f" {test_name}"; print(title)')" >> $GITHUB_ENV
|
||||
#
|
||||
# - name: Send processed report
|
||||
# if: ${{ env.process == 'true' && !endsWith(env.REPORT_TEXT, '{}') }}
|
||||
# uses: slackapi/slack-github-action@6c661ce58804a1a20f6dc5fbee7f0381b469e001
|
||||
# with:
|
||||
# # Slack channel id, channel name, or user id to post message.
|
||||
# # See also: https://api.slack.com/methods/chat.postMessage#channels
|
||||
# channel-id: '#${{ inputs.slack_report_channel }}'
|
||||
# # For posting a rich message using Block Kit
|
||||
# payload: |
|
||||
# {
|
||||
# "blocks": [
|
||||
# {
|
||||
# "type": "header",
|
||||
# "text": {
|
||||
# "type": "plain_text",
|
||||
# "text": "${{ env.title }}"
|
||||
# }
|
||||
# },
|
||||
# {
|
||||
# "type": "section",
|
||||
# "text": {
|
||||
# "type": "mrkdwn",
|
||||
# "text": "${{ env.REPORT_TEXT }}"
|
||||
# }
|
||||
# }
|
||||
# ]
|
||||
# }
|
||||
# env:
|
||||
# SLACK_BOT_TOKEN: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
1
.github/workflows/doctest_job.yml
vendored
1
.github/workflows/doctest_job.yml
vendored
@ -16,7 +16,6 @@ env:
|
||||
RUN_SLOW: yes
|
||||
OMP_NUM_THREADS: 16
|
||||
MKL_NUM_THREADS: 16
|
||||
SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
|
||||
TF_FORCE_GPU_ALLOW_GROWTH: true
|
||||
|
||||
jobs:
|
||||
|
||||
1
.github/workflows/model_jobs.yml
vendored
1
.github/workflows/model_jobs.yml
vendored
@ -38,7 +38,6 @@ env:
|
||||
# For gated repositories, we still need to agree to share information on the Hub repo. page in order to get access.
|
||||
# This token is created under the bot `hf-transformers-bot`.
|
||||
HF_HUB_READ_TOKEN: ${{ secrets.HF_HUB_READ_TOKEN }}
|
||||
SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
|
||||
TF_FORCE_GPU_ALLOW_GROWTH: true
|
||||
CUDA_VISIBLE_DEVICES: 0,1
|
||||
|
||||
|
||||
1
.github/workflows/model_jobs_intel_gaudi.yml
vendored
1
.github/workflows/model_jobs_intel_gaudi.yml
vendored
@ -26,7 +26,6 @@ env:
|
||||
TRANSFORMERS_IS_CI: yes
|
||||
PT_ENABLE_INT64_SUPPORT: 1
|
||||
HF_HUB_READ_TOKEN: ${{ secrets.HF_HUB_READ_TOKEN }}
|
||||
SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
|
||||
HF_HOME: /mnt/cache/.cache/huggingface
|
||||
|
||||
jobs:
|
||||
|
||||
@ -98,7 +98,7 @@ jobs:
|
||||
commit_sha: ${{ needs.get-pr-info.outputs.PR_HEAD_SHA }}
|
||||
pr_number: ${{ needs.get-pr-number.outputs.PR_NUMBER }}
|
||||
package: transformers
|
||||
languages: ar de en es fr hi it ko pt tr zh ja te
|
||||
languages: ar de en es fr hi it ja ko pt zh
|
||||
|
||||
update_run_status:
|
||||
name: Update Check Run Status
|
||||
|
||||
1
.github/workflows/self-comment-ci.yml
vendored
1
.github/workflows/self-comment-ci.yml
vendored
@ -20,7 +20,6 @@ env:
|
||||
# For gated repositories, we still need to agree to share information on the Hub repo. page in order to get access.
|
||||
# This token is created under the bot `hf-transformers-bot`.
|
||||
HF_HUB_READ_TOKEN: ${{ secrets.HF_HUB_READ_TOKEN }}
|
||||
SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
|
||||
TF_FORCE_GPU_ALLOW_GROWTH: true
|
||||
CUDA_VISIBLE_DEVICES: 0,1
|
||||
|
||||
|
||||
68
.github/workflows/self-scheduled-caller.yml
vendored
68
.github/workflows/self-scheduled-caller.yml
vendored
@ -6,7 +6,7 @@ on:
|
||||
- cron: "17 2 * * *"
|
||||
push:
|
||||
branches:
|
||||
- run_nvidia_ci*
|
||||
- multi_jobs_to_check_bad_commit
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
prev_workflow_run_id:
|
||||
@ -23,7 +23,7 @@ on:
|
||||
|
||||
# Used for `push` to easily modify the target workflow runs to compare against
|
||||
env:
|
||||
prev_workflow_run_id: ""
|
||||
prev_workflow_run_id: "18548615847"
|
||||
other_workflow_run_id: ""
|
||||
|
||||
|
||||
@ -49,72 +49,10 @@ jobs:
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_models_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-models"
|
||||
slack_report_channel: "#transformers-ci-dummy"
|
||||
docker: huggingface/transformers-all-latest-gpu
|
||||
ci_event: Daily CI
|
||||
runner_type: "a10"
|
||||
report_repo_id: hf-internal-testing/transformers_daily_ci
|
||||
commit_sha: ${{ github.sha }}
|
||||
secrets: inherit
|
||||
|
||||
torch-pipeline:
|
||||
name: Torch pipeline CI
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_pipelines_torch_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-pipeline-torch"
|
||||
docker: huggingface/transformers-pytorch-gpu
|
||||
ci_event: Daily CI
|
||||
report_repo_id: hf-internal-testing/transformers_daily_ci
|
||||
commit_sha: ${{ github.sha }}
|
||||
secrets: inherit
|
||||
|
||||
example-ci:
|
||||
name: Example CI
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_examples_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-examples"
|
||||
docker: huggingface/transformers-all-latest-gpu
|
||||
ci_event: Daily CI
|
||||
report_repo_id: hf-internal-testing/transformers_daily_ci
|
||||
commit_sha: ${{ github.sha }}
|
||||
secrets: inherit
|
||||
|
||||
trainer-fsdp-ci:
|
||||
name: Trainer/FSDP CI
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_trainer_and_fsdp_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-training"
|
||||
docker: huggingface/transformers-all-latest-gpu
|
||||
runner_type: "a10"
|
||||
ci_event: Daily CI
|
||||
report_repo_id: hf-internal-testing/transformers_daily_ci
|
||||
commit_sha: ${{ github.sha }}
|
||||
secrets: inherit
|
||||
|
||||
deepspeed-ci:
|
||||
name: DeepSpeed CI
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_torch_cuda_extensions_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-training"
|
||||
docker: huggingface/transformers-pytorch-deepspeed-latest-gpu
|
||||
ci_event: Daily CI
|
||||
working-directory-prefix: /workspace
|
||||
report_repo_id: hf-internal-testing/transformers_daily_ci
|
||||
commit_sha: ${{ github.sha }}
|
||||
secrets: inherit
|
||||
|
||||
quantization-ci:
|
||||
name: Quantization CI
|
||||
uses: ./.github/workflows/self-scheduled.yml
|
||||
with:
|
||||
job: run_quantization_torch_gpu
|
||||
slack_report_channel: "#transformers-ci-daily-quantization"
|
||||
docker: huggingface/transformers-quantization-latest-gpu
|
||||
ci_event: Daily CI
|
||||
report_repo_id: hf-internal-testing/transformers_daily_ci
|
||||
commit_sha: ${{ github.sha }}
|
||||
secrets: inherit
|
||||
|
||||
@ -26,7 +26,6 @@ env:
|
||||
TRANSFORMERS_IS_CI: yes
|
||||
PT_ENABLE_INT64_SUPPORT: 1
|
||||
HF_HUB_READ_TOKEN: ${{ secrets.HF_HUB_READ_TOKEN }}
|
||||
SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
|
||||
HF_HOME: /mnt/cache/.cache/huggingface
|
||||
|
||||
jobs:
|
||||
|
||||
1
.github/workflows/self-scheduled.yml
vendored
1
.github/workflows/self-scheduled.yml
vendored
@ -48,7 +48,6 @@ env:
|
||||
# For gated repositories, we still need to agree to share information on the Hub repo. page in order to get access.
|
||||
# This token is created under the bot `hf-transformers-bot`.
|
||||
HF_HUB_READ_TOKEN: ${{ secrets.HF_HUB_READ_TOKEN }}
|
||||
SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
|
||||
TF_FORCE_GPU_ALLOW_GROWTH: true
|
||||
CUDA_VISIBLE_DEVICES: 0,1
|
||||
NUM_SLICES: 2
|
||||
|
||||
1
.github/workflows/ssh-runner.yml
vendored
1
.github/workflows/ssh-runner.yml
vendored
@ -20,7 +20,6 @@ env:
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
RUN_SLOW: yes # For gated repositories, we still need to agree to share information on the Hub repo. page in order to get access. # This token is created under the bot `hf-transformers-bot`.
|
||||
SIGOPT_API_TOKEN: ${{ secrets.SIGOPT_API_TOKEN }}
|
||||
TF_FORCE_GPU_ALLOW_GROWTH: true
|
||||
CUDA_VISIBLE_DEVICES: 0,1
|
||||
|
||||
|
||||
4
.gitignore
vendored
4
.gitignore
vendored
@ -98,6 +98,7 @@ celerybeat-schedule
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
.venv*
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
@ -171,3 +172,6 @@ tags
|
||||
|
||||
# modular conversion
|
||||
*.modular_backup
|
||||
|
||||
# Cursor IDE files
|
||||
.cursor/
|
||||
|
||||
@ -153,7 +153,7 @@ You are not required to read the following guidelines before opening an issue. H
|
||||
cd examples/seq2seq
|
||||
torchrun --nproc_per_node=2 ./finetune_trainer.py \
|
||||
--model_name_or_path sshleifer/distill-mbart-en-ro-12-4 --data_dir wmt_en_ro \
|
||||
--output_dir output_dir --overwrite_output_dir \
|
||||
--output_dir output_dir \
|
||||
--do_train --n_train 500 --num_train_epochs 1 \
|
||||
--per_device_train_batch_size 1 --freeze_embeds \
|
||||
--src_lang en_XX --tgt_lang ro_RO --task translation \
|
||||
|
||||
@ -16,7 +16,6 @@ import sys
|
||||
from logging import Logger
|
||||
from threading import Event, Thread
|
||||
from time import perf_counter, sleep
|
||||
from typing import Optional
|
||||
|
||||
|
||||
# Add the parent directory to Python path to import benchmarks_entrypoint
|
||||
@ -42,7 +41,7 @@ except ImportError:
|
||||
GenerationConfig = None
|
||||
StaticCache = None
|
||||
|
||||
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
|
||||
os.environ["HF_XET_HIGH_PERFORMANCE"] = "1"
|
||||
os.environ["TOKENIZERS_PARALLELISM"] = "1"
|
||||
|
||||
# Only set torch precision if torch is available
|
||||
@ -145,7 +144,7 @@ def run_benchmark(
|
||||
q = torch.empty_like(probs_sort).exponential_(1)
|
||||
return torch.argmax(probs_sort / q, dim=-1, keepdim=True).to(dtype=torch.int)
|
||||
|
||||
def logits_to_probs(logits, temperature: float = 1.0, top_k: Optional[int] = None):
|
||||
def logits_to_probs(logits, temperature: float = 1.0, top_k: int | None = None):
|
||||
logits = logits / max(temperature, 1e-5)
|
||||
|
||||
if top_k is not None:
|
||||
@ -155,7 +154,7 @@ def run_benchmark(
|
||||
probs = torch.nn.functional.softmax(logits, dim=-1)
|
||||
return probs
|
||||
|
||||
def sample(logits, temperature: float = 1.0, top_k: Optional[int] = None):
|
||||
def sample(logits, temperature: float = 1.0, top_k: int | None = None):
|
||||
probs = logits_to_probs(logits[0, -1], temperature, top_k)
|
||||
idx_next = multinomial_sample_one_no_sync(probs)
|
||||
return idx_next, probs
|
||||
|
||||
@ -2,5 +2,5 @@ gpustat==1.1.1
|
||||
psutil==6.0.0
|
||||
psycopg2==2.9.9
|
||||
torch>=2.4.0
|
||||
hf_transfer
|
||||
hf_xet
|
||||
pandas>=1.5.0
|
||||
3
benchmark_v2/.gitignore
vendored
3
benchmark_v2/.gitignore
vendored
@ -1 +1,2 @@
|
||||
benchmark_results/
|
||||
benchmark_results/
|
||||
benchmark_results_profiles/
|
||||
|
||||
@ -1 +0,0 @@
|
||||
# Benchmark implementations directory
|
||||
@ -1,165 +0,0 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import logging
|
||||
import os
|
||||
from typing import Any
|
||||
|
||||
import torch
|
||||
from benchmark_framework import ModelBenchmark
|
||||
|
||||
|
||||
os.environ["TOKENIZERS_PARALLELISM"] = "1"
|
||||
torch.set_float32_matmul_precision("high")
|
||||
|
||||
|
||||
class LLaMABenchmark(ModelBenchmark):
|
||||
"""Simplified LLaMA model benchmark implementation using the ModelBenchmark base class."""
|
||||
|
||||
def __init__(self, logger: logging.Logger):
|
||||
super().__init__(logger)
|
||||
self._default_prompt = "Why dogs are so cute?" # Custom prompt for LLaMA
|
||||
|
||||
def get_scenario_configs(self) -> list[dict[str, Any]]:
|
||||
"""
|
||||
Get LLaMA-specific scenario configurations.
|
||||
|
||||
Returns:
|
||||
List of scenario configuration dictionaries
|
||||
"""
|
||||
return [
|
||||
# Eager variants
|
||||
{"variant": "eager", "compile_mode": None, "use_cache": True, "description": "Eager execution with cache"},
|
||||
# Compiled variants
|
||||
{
|
||||
"variant": "compiled",
|
||||
"compile_mode": "max-autotune",
|
||||
"use_cache": True,
|
||||
"description": "Compiled with max autotune",
|
||||
},
|
||||
# Kernelized variant (if available)
|
||||
{
|
||||
"variant": "kernelized",
|
||||
"compile_mode": "max-autotune",
|
||||
"use_cache": True,
|
||||
"description": "Kernelized execution",
|
||||
},
|
||||
]
|
||||
|
||||
def _is_kernelization_available(self) -> bool:
|
||||
"""Check if kernelization is available for LLaMA."""
|
||||
try:
|
||||
from kernels import Mode, kernelize # noqa: F401
|
||||
|
||||
return True
|
||||
except ImportError:
|
||||
self.logger.debug("Kernelization not available: kernels module not found")
|
||||
return False
|
||||
|
||||
def get_default_generation_config(self) -> dict[str, Any]:
|
||||
"""Get LLaMA-specific generation configuration."""
|
||||
return {
|
||||
"do_sample": False,
|
||||
"top_p": 1.0,
|
||||
"temperature": 1.0,
|
||||
"repetition_penalty": 1.0,
|
||||
"max_new_tokens": None, # Will be set per scenario
|
||||
}
|
||||
|
||||
def get_model_init_kwargs(self, config) -> dict[str, Any]:
|
||||
"""Get LLaMA-specific model initialization kwargs."""
|
||||
return {
|
||||
"torch_dtype": getattr(torch, config.torch_dtype),
|
||||
"attn_implementation": config.attn_implementation,
|
||||
"use_cache": True,
|
||||
}
|
||||
|
||||
def get_default_torch_dtype(self) -> str:
|
||||
"""Get default torch dtype for LLaMA."""
|
||||
return "float16" # LLaMA works well with float16
|
||||
|
||||
def get_default_device(self) -> str:
|
||||
"""Get default device for LLaMA."""
|
||||
return "cuda" # LLaMA prefers CUDA
|
||||
|
||||
|
||||
def run_llama(logger, output_dir, **kwargs):
|
||||
"""
|
||||
Run LLaMA benchmark with the given configuration.
|
||||
|
||||
Args:
|
||||
logger: Logger instance
|
||||
output_dir: Output directory for results
|
||||
**kwargs: Additional configuration options
|
||||
|
||||
Returns:
|
||||
Path to output file if successful
|
||||
"""
|
||||
from benchmark_framework import BenchmarkRunner
|
||||
|
||||
# Extract parameters with defaults
|
||||
model_id = kwargs.get("model_id", "meta-llama/Llama-2-7b-hf")
|
||||
warmup_iterations = kwargs.get("warmup_iterations", 3)
|
||||
measurement_iterations = kwargs.get("measurement_iterations", 5)
|
||||
num_tokens_to_generate = kwargs.get("num_tokens_to_generate", 100)
|
||||
include_sdpa_variants = kwargs.get("include_sdpa_variants", True)
|
||||
device = kwargs.get("device", "cuda")
|
||||
torch_dtype = kwargs.get("torch_dtype", "float16")
|
||||
batch_size = kwargs.get("batch_size", 1)
|
||||
commit_id = kwargs.get("commit_id")
|
||||
|
||||
logger.info(f"Starting LLaMA benchmark for model: {model_id}")
|
||||
logger.info(
|
||||
f"Configuration: warmup={warmup_iterations}, measurement={measurement_iterations}, tokens={num_tokens_to_generate}"
|
||||
)
|
||||
|
||||
try:
|
||||
# Create benchmark instance
|
||||
benchmark = LLaMABenchmark(logger)
|
||||
|
||||
# Create scenarios
|
||||
scenarios = benchmark.create_scenarios(
|
||||
model_id=model_id,
|
||||
warmup_iterations=warmup_iterations,
|
||||
measurement_iterations=measurement_iterations,
|
||||
num_tokens_to_generate=num_tokens_to_generate,
|
||||
include_sdpa_variants=include_sdpa_variants,
|
||||
device=device,
|
||||
torch_dtype=torch_dtype,
|
||||
batch_size=batch_size,
|
||||
)
|
||||
|
||||
logger.info(f"Created {len(scenarios)} benchmark scenarios")
|
||||
|
||||
# Create runner and execute benchmarks
|
||||
runner = BenchmarkRunner(logger, output_dir)
|
||||
results = runner.run_benchmark(benchmark, scenarios, commit_id=commit_id)
|
||||
|
||||
if not results:
|
||||
logger.warning("No successful benchmark results")
|
||||
return None
|
||||
|
||||
# Save results
|
||||
model_name = model_id.split("/")[-1] # Extract model name from ID
|
||||
output_file = runner.save_results(model_name, results)
|
||||
|
||||
logger.info(f"LLaMA benchmark completed successfully. Results saved to: {output_file}")
|
||||
return output_file
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"LLaMA benchmark failed: {e}")
|
||||
import traceback
|
||||
|
||||
logger.debug(traceback.format_exc())
|
||||
raise
|
||||
File diff suppressed because it is too large
Load Diff
215
benchmark_v2/framework/benchmark_config.py
Normal file
215
benchmark_v2/framework/benchmark_config.py
Normal file
@ -0,0 +1,215 @@
|
||||
import hashlib
|
||||
import json
|
||||
import logging
|
||||
from typing import Any
|
||||
|
||||
|
||||
KERNELIZATION_AVAILABLE = False
|
||||
try:
|
||||
from kernels import Mode, kernelize # noqa: F401
|
||||
|
||||
KERNELIZATION_AVAILABLE = True
|
||||
except ImportError:
|
||||
pass
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class BenchmarkConfig:
|
||||
"""Configuration for a single benchmark scenario."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
warmup_iterations: int = 5,
|
||||
measurement_iterations: int = 20,
|
||||
gpu_monitoring: bool = False, # False by default because it slows down the benchmark by a lot
|
||||
batch_size: int = 1,
|
||||
sequence_length: int = 128,
|
||||
num_tokens_to_generate: int = 128,
|
||||
attn_implementation: str = "eager",
|
||||
sdpa_backend: str | None = None,
|
||||
compile_mode: str | None = None,
|
||||
compile_options: dict[str, Any] | None = None,
|
||||
kernelize: bool = False,
|
||||
name: str | None = None,
|
||||
skip_validity_check: bool = False,
|
||||
) -> None:
|
||||
# Benchmark parameters
|
||||
self.warmup_iterations = warmup_iterations
|
||||
self.measurement_iterations = measurement_iterations
|
||||
self.gpu_monitoring = gpu_monitoring
|
||||
# Input parameters
|
||||
self.batch_size = batch_size
|
||||
self.sequence_length = sequence_length
|
||||
self.num_tokens_to_generate = num_tokens_to_generate
|
||||
# Generation parameters
|
||||
self.attn_implementation = attn_implementation
|
||||
self.sdpa_backend = sdpa_backend
|
||||
# Optimization parameters
|
||||
self.compile_mode = compile_mode
|
||||
self.compile_options = compile_options if compile_options is not None else {}
|
||||
self.kernelize = kernelize
|
||||
# Constant parameters
|
||||
self.dtype = "torch.bfloat16"
|
||||
self.device = "cuda"
|
||||
|
||||
self.check_validity(skip_validity_check)
|
||||
self.name = name if name is not None else self.infer_name()
|
||||
|
||||
def check_validity(self, skip_validity_check: bool = False) -> None:
|
||||
if skip_validity_check:
|
||||
return
|
||||
# Flash attention does not support compile mode, so we turn it off # FIXME: it would be better to support it
|
||||
is_fa = self.attn_implementation == "flash_attention_2"
|
||||
is_fa |= self.attn_implementation == "sdpa" and self.sdpa_backend == "flash_attention"
|
||||
if is_fa:
|
||||
logger.warning("Flash attention does not support compile mode. Turning off compile mode.")
|
||||
self.compile_mode = None
|
||||
|
||||
@property
|
||||
def hash(self) -> str:
|
||||
return hashlib.sha256(json.dumps(self.to_dict()).encode()).hexdigest()
|
||||
|
||||
def infer_name(self, compact: bool = True) -> str:
|
||||
"""Infer a human-readable name for the benchmark config, either compact or verbose."""
|
||||
if compact:
|
||||
iter_str = f"w{self.warmup_iterations}_i{self.measurement_iterations}"
|
||||
gpu_monitor_str = "monitored" if self.gpu_monitoring else "unmonitored"
|
||||
dimensions_str = f"b{self.batch_size}_s{self.sequence_length}_n{self.num_tokens_to_generate}"
|
||||
attn_code = self.attn_implementation
|
||||
attn_code += f"_{self.sdpa_backend}" if self.attn_implementation == "sdpa" else ""
|
||||
compile_str = f"compiled_{self.compile_mode}" if self.compile_mode is not None else "uncompiled"
|
||||
kernelize_str = "kernelized" if self.kernelize else "unkernelized"
|
||||
sep = "-"
|
||||
else:
|
||||
iter_str = f"{self.warmup_iterations} warmup, {self.measurement_iterations} iterations"
|
||||
gpu_monitor_str = ("with" if self.gpu_monitoring else "no") + " GPU monitoring"
|
||||
dimensions_str = f"batch size {self.batch_size}, sequence length {self.sequence_length}, {self.num_tokens_to_generate} generated tokens"
|
||||
attn_code = f"{self.attn_implementation} attention"
|
||||
attn_code += f" with {self.sdpa_backend} backend" if self.attn_implementation == "sdpa" else ""
|
||||
compile_str = "compiled" if self.compile_mode is not None else "not compiled"
|
||||
kernelize_str = "kernelized" if self.kernelize else "not kernelized"
|
||||
sep = ", "
|
||||
return sep.join([iter_str, gpu_monitor_str, dimensions_str, attn_code, compile_str, kernelize_str])
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
return {
|
||||
"name": self.name,
|
||||
"warmup_iterations": self.warmup_iterations,
|
||||
"measurement_iterations": self.measurement_iterations,
|
||||
"gpu_monitoring": self.gpu_monitoring,
|
||||
"batch_size": self.batch_size,
|
||||
"sequence_length": self.sequence_length,
|
||||
"num_tokens_to_generate": self.num_tokens_to_generate,
|
||||
"attn_implementation": self.attn_implementation,
|
||||
"sdpa_backend": self.sdpa_backend,
|
||||
"compile_mode": self.compile_mode,
|
||||
"compile_options": self.compile_options | {}, # to avoid inplace modification of the original dict
|
||||
"kernelize": self.kernelize,
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, data: dict[str, Any], skip_validity_check: bool = False) -> "BenchmarkConfig":
|
||||
return cls(
|
||||
warmup_iterations=data.get("warmup_iterations", 5),
|
||||
measurement_iterations=data.get("measurement_iterations", 20),
|
||||
gpu_monitoring=data.get("gpu_monitoring", False),
|
||||
batch_size=data.get("batch_size", 1),
|
||||
sequence_length=data.get("sequence_length", 128),
|
||||
num_tokens_to_generate=data.get("num_tokens_to_generate", 128),
|
||||
attn_implementation=data.get("attn_implementation", "eager"),
|
||||
sdpa_backend=data.get("sdpa_backend"),
|
||||
compile_mode=data.get("compile_mode"),
|
||||
compile_options=data.get("compile_options"),
|
||||
kernelize=data.get("kernelize", False),
|
||||
name=data.get("name"),
|
||||
skip_validity_check=skip_validity_check,
|
||||
)
|
||||
|
||||
|
||||
def cross_generate_configs(
|
||||
attn_impl_and_sdpa_backend: list[tuple[str, str | None]],
|
||||
compiled_mode: list[str | None],
|
||||
kernelized: list[bool],
|
||||
warmup_iterations: int = 5,
|
||||
measurement_iterations: int = 20,
|
||||
batch_size: int = 1,
|
||||
sequence_length: int = 128,
|
||||
num_tokens_to_generate: int = 128,
|
||||
gpu_monitoring: bool = False, # this slows down the benchmark by a lot so we disable it by default
|
||||
) -> list[BenchmarkConfig]:
|
||||
# Create kwargs common to all configs
|
||||
kwargs = {
|
||||
"warmup_iterations": warmup_iterations,
|
||||
"measurement_iterations": measurement_iterations,
|
||||
"batch_size": batch_size,
|
||||
"sequence_length": sequence_length,
|
||||
"num_tokens_to_generate": num_tokens_to_generate,
|
||||
"gpu_monitoring": gpu_monitoring,
|
||||
}
|
||||
# Cross-generate all combinations of attn_implementation, compiled_mode, and kernelized
|
||||
configs = []
|
||||
for attn_implementation, sdpa_backend in list(dict.fromkeys(attn_impl_and_sdpa_backend)):
|
||||
for cm in list(dict.fromkeys(compiled_mode)):
|
||||
for kernelize_on in list(dict.fromkeys(kernelized)):
|
||||
config = BenchmarkConfig(
|
||||
attn_implementation=attn_implementation,
|
||||
sdpa_backend=sdpa_backend,
|
||||
compile_mode=cm,
|
||||
kernelize=kernelize_on,
|
||||
**kwargs,
|
||||
)
|
||||
configs.append(config)
|
||||
return configs
|
||||
|
||||
|
||||
def generate_all_configs(
|
||||
warmup_iterations: int = 5,
|
||||
measurement_iterations: int = 20,
|
||||
batch_size: int = 1,
|
||||
sequence_length: int = 128,
|
||||
num_tokens_to_generate: int = 128,
|
||||
gpu_monitoring: bool = False,
|
||||
) -> list[BenchmarkConfig]:
|
||||
all_attn_implementations = [
|
||||
("flash_attention_2", None),
|
||||
("eager", None),
|
||||
("sdpa", "math"),
|
||||
("sdpa", "flash_attention"),
|
||||
("flex_attention", None),
|
||||
]
|
||||
return cross_generate_configs(
|
||||
attn_impl_and_sdpa_backend=all_attn_implementations,
|
||||
compiled_mode=[None, "default", "reduce-overhead", "max-autotune", "max-autotune-no-cudagraphs"],
|
||||
kernelized=[False, KERNELIZATION_AVAILABLE],
|
||||
warmup_iterations=warmup_iterations,
|
||||
measurement_iterations=measurement_iterations,
|
||||
batch_size=batch_size,
|
||||
sequence_length=sequence_length,
|
||||
num_tokens_to_generate=num_tokens_to_generate,
|
||||
gpu_monitoring=gpu_monitoring,
|
||||
)
|
||||
|
||||
|
||||
def generate_main_configs(
|
||||
warmup_iterations: int = 5,
|
||||
measurement_iterations: int = 20,
|
||||
batch_size: int = 1,
|
||||
sequence_length: int = 128,
|
||||
num_tokens_to_generate: int = 128,
|
||||
gpu_monitoring: bool = False,
|
||||
) -> list[BenchmarkConfig]:
|
||||
# Create kwargs common to all configs
|
||||
kwargs = {
|
||||
"warmup_iterations": warmup_iterations,
|
||||
"measurement_iterations": measurement_iterations,
|
||||
"batch_size": batch_size,
|
||||
"sequence_length": sequence_length,
|
||||
"num_tokens_to_generate": num_tokens_to_generate,
|
||||
"gpu_monitoring": gpu_monitoring,
|
||||
}
|
||||
return [ # TODO: test max-autotune instead of default
|
||||
BenchmarkConfig(attn_implementation="flex_attention", compile_mode="default", **kwargs),
|
||||
BenchmarkConfig(attn_implementation="eager", compile_mode="default", **kwargs),
|
||||
BenchmarkConfig(attn_implementation="flash_attention_2", **kwargs),
|
||||
]
|
||||
389
benchmark_v2/framework/benchmark_runner.py
Normal file
389
benchmark_v2/framework/benchmark_runner.py
Normal file
@ -0,0 +1,389 @@
|
||||
import gc
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import pathlib
|
||||
import re
|
||||
import time
|
||||
from contextlib import nullcontext
|
||||
from datetime import datetime
|
||||
from queue import Queue
|
||||
from typing import Any
|
||||
|
||||
import torch
|
||||
from tqdm import trange
|
||||
|
||||
from transformers import (
|
||||
AutoModelForCausalLM,
|
||||
AutoTokenizer,
|
||||
CompileConfig,
|
||||
GenerationConfig,
|
||||
GenerationMixin,
|
||||
)
|
||||
from transformers.generation.streamers import BaseStreamer
|
||||
|
||||
from .benchmark_config import BenchmarkConfig
|
||||
from .data_classes import BenchmarkMetadata, BenchmarkResult, GPURawMetrics, pretty_print_dict
|
||||
from .hardware_metrics import GPUMonitor
|
||||
|
||||
|
||||
try:
|
||||
from kernels import Mode, kernelize # noqa: F401
|
||||
except ImportError:
|
||||
kernelize = None
|
||||
Mode = None
|
||||
|
||||
|
||||
DEFAULT_PROMPT = "\n".join([
|
||||
"The French Revolution was a period of political and societal change in France that began with the Estates General of 1789 and ended with the Coup of 18 Brumaire on 9 November 1799.",
|
||||
"Many of the revolution's ideas are considered fundamental principles of liberal democracy, and its values remain central to modern French political discourse.",
|
||||
"It was caused by a combination of social, political, and economic factors which the existing regime proved unable to manage.",
|
||||
"Financial crisis and widespread social distress led to the convocation of the Estates General in May 1789, its first meeting since 1614.",
|
||||
"The representatives of the Third Estate broke away and re-constituted themselves as a National Assembly in June.",
|
||||
"The Storming of the Bastille in Paris on 14 July led to a series of radical measures by the Assembly, including the abolition of feudalism, state control over the Catholic Church in France, and issuing the Declaration of the Rights of Man and of the Citizen.",
|
||||
"The next three years were dominated by a struggle for political control.",
|
||||
"King Louis XVI's attempted flight to Varennes in June 1791 further discredited the monarchy, and military defeats after the outbreak of the French Revolutionary Wars in April 1792 led to the insurrection of 10 August 1792.",
|
||||
"As a result, the monarchy was replaced by the French First Republic in September, followed by the execution of Louis XVI himself in January 1793.",
|
||||
"After another revolt in June 1793, the constitution was suspended, and political power passed from the National Convention to the Committee of Public Safety, dominated by radical Jacobins led by Maximilien Robespierre.",
|
||||
"About 16,000 people were sentenced by the Revolutionary Tribunal and executed in the Reign of Terror, which ended in July 1794 with the Thermidorian Reaction.",
|
||||
"Weakened by external threats and internal opposition, the Committee of Public Safety was replaced in November 1795 by the Directory.",
|
||||
"Its instability ended in the coup of 18 Brumaire and the establishment of the Consulate, with Napoleon Bonaparte as First Consul.",
|
||||
]) # fmt: skip
|
||||
|
||||
|
||||
def compact_json_numeric_arrays(data: dict):
|
||||
# Match arrays that contain only numbers (ints/floats), whitespace, commas, and newlines
|
||||
pattern = r"\[\s*\n\s*((?:\d+(?:\.\d+)?\s*,\s*)*\d+(?:\.\d+)?)\s*\n\s*\]"
|
||||
|
||||
def replace_numeric_array(match):
|
||||
# Get the array content
|
||||
content = match.group(1)
|
||||
# Remove extra whitespace but keep commas
|
||||
compact_content = re.sub(r"\s+", " ", content).strip()
|
||||
return f"[{compact_content}]"
|
||||
|
||||
return re.sub(pattern, replace_numeric_array, json.dumps(data, indent=4, default=str), flags=re.DOTALL)
|
||||
|
||||
|
||||
def get_git_revision() -> str:
|
||||
base_path = pathlib.Path(__file__).parent.parent.parent
|
||||
git_dir = base_path / ".git"
|
||||
with (git_dir / "HEAD").open("r") as head:
|
||||
ref = head.readline().split(" ")[-1].strip()
|
||||
with (git_dir / ref).open("r") as git_hash:
|
||||
return git_hash.readline().strip()
|
||||
|
||||
|
||||
def get_sdpa_backend(backend_name: str | None) -> torch.nn.attention.SDPBackend | None:
|
||||
"""Get the SDPA backend enum from string name."""
|
||||
if backend_name is None:
|
||||
return None
|
||||
|
||||
try:
|
||||
backend_map = {
|
||||
"math": torch.nn.attention.SDPBackend.MATH,
|
||||
"flash_attention": torch.nn.attention.SDPBackend.FLASH_ATTENTION,
|
||||
"efficient_attention": torch.nn.attention.SDPBackend.EFFICIENT_ATTENTION,
|
||||
"cudnn_attention": torch.nn.attention.SDPBackend.CUDNN_ATTENTION,
|
||||
}
|
||||
return backend_map.get(backend_name.lower())
|
||||
except AttributeError:
|
||||
# torch.nn.attention.SDPBackend not available in older torch versions
|
||||
return None
|
||||
|
||||
|
||||
def flush_memory():
|
||||
"""Flush GPU memory and run garbage collection."""
|
||||
gc.collect()
|
||||
# Dynamo resets
|
||||
torch._dynamo.reset()
|
||||
torch._dynamo.reset_code_caches()
|
||||
if hasattr(torch._inductor, "codecache"):
|
||||
# Clear FX graph cache
|
||||
if hasattr(torch._inductor.codecache, "FxGraphCache"):
|
||||
torch._inductor.codecache.FxGraphCache.clear()
|
||||
# Clear PyCodeCache
|
||||
if hasattr(torch._inductor.codecache, "PyCodeCache"):
|
||||
torch._inductor.codecache.PyCodeCache.cache_clear()
|
||||
# Clear TritonFuture cache (for async compilation)
|
||||
if hasattr(torch._inductor.codecache, "TritonFuture"):
|
||||
if hasattr(torch._inductor.codecache.TritonFuture, "_compile_cache"):
|
||||
torch._inductor.codecache.TritonFuture._compile_cache.clear()
|
||||
# Clear CUDA cache
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
torch.cuda.reset_max_memory_allocated()
|
||||
torch.cuda.reset_peak_memory_stats()
|
||||
torch.cuda.synchronize()
|
||||
gc.collect()
|
||||
|
||||
|
||||
class BenchmarkStreamer(BaseStreamer):
|
||||
def __init__(self, **kwargs) -> None:
|
||||
self.timestamps = []
|
||||
self.text_queue = Queue()
|
||||
|
||||
def put(self, value):
|
||||
"""Receives tokens and logs the timestamp of the generation."""
|
||||
self.timestamps.append(time.perf_counter())
|
||||
|
||||
def end(self):
|
||||
self.timestamps.append(time.perf_counter())
|
||||
|
||||
def __iter__(self):
|
||||
return self
|
||||
|
||||
def __next__(self):
|
||||
value = self.text_queue.get(timeout=self.timeout)
|
||||
if value == self.stop_signal:
|
||||
raise StopIteration()
|
||||
else:
|
||||
return value
|
||||
|
||||
|
||||
class BenchmarkRunner:
|
||||
"""Main benchmark runner that coordinates benchmark execution."""
|
||||
|
||||
def __init__(self, logger: logging.Logger, output_dir: str | None = None, commit_id: str | None = None) -> None:
|
||||
# Those stay constant for the whole run
|
||||
self.logger = logger
|
||||
if output_dir is None:
|
||||
output_dir = os.path.join(os.path.dirname(os.path.dirname(__file__)), "benchmark_results")
|
||||
self.output_dir = output_dir
|
||||
self.commit_id = get_git_revision() if commit_id is None else commit_id
|
||||
os.makedirs(self.output_dir, exist_ok=True)
|
||||
self.profile_dir = None
|
||||
# Attributes that are reset for each model
|
||||
self._setup_for = ""
|
||||
# Attributes that are reset for each run
|
||||
self.model: GenerationMixin | None = None
|
||||
|
||||
def cleanup(self) -> None:
|
||||
del self.model
|
||||
self.model = None
|
||||
flush_memory()
|
||||
|
||||
def setup_one_run(self, model_id: str, config: BenchmarkConfig) -> None:
|
||||
# Some attributes only need to be set once per model
|
||||
if self._setup_for != model_id:
|
||||
self.tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
# We set the EOS token to the padding token for open-ended generation
|
||||
self.tokenizer.eos_token = self.tokenizer.pad_token
|
||||
self._setup_for = model_id
|
||||
|
||||
# Prepare inputs
|
||||
self.inputs = self.tokenizer(
|
||||
[DEFAULT_PROMPT for _ in range(config.batch_size)],
|
||||
return_tensors="pt",
|
||||
max_length=config.sequence_length,
|
||||
truncation=True,
|
||||
return_attention_mask=True,
|
||||
).to(config.device)
|
||||
self.inputs["use_cache"] = True
|
||||
|
||||
# Prepare generation config
|
||||
gen_config = GenerationConfig(
|
||||
do_sample=False, top_p=1.0, temperature=1.0, max_new_tokens=config.num_tokens_to_generate
|
||||
)
|
||||
|
||||
# Prepare compile config
|
||||
if config.compile_mode is not None:
|
||||
gen_config.compile_config = CompileConfig(mode=config.compile_mode, options=config.compile_options)
|
||||
gen_config.cache_implementation = "static"
|
||||
|
||||
# Load model
|
||||
self.logger.debug(f"Loading model {model_id} on device {config.device}...")
|
||||
dtype = getattr(torch, config.dtype.removeprefix("torch."))
|
||||
self.model = AutoModelForCausalLM.from_pretrained(
|
||||
model_id, dtype=dtype, attn_implementation=config.attn_implementation, generation_config=gen_config
|
||||
)
|
||||
self.model = self.model.eval().to(config.device)
|
||||
|
||||
# Kernelize the model if needed
|
||||
if config.kernelize:
|
||||
self.model = kernelize(self.model, mode=Mode.INFERENCE)
|
||||
|
||||
def run_one_benchmark(self, model_id: str, config: BenchmarkConfig, num_tokens_to_profile: int = 0) -> None:
|
||||
sdpa_ctx = nullcontext()
|
||||
if config.attn_implementation == "sdpa":
|
||||
sdpa_backend = get_sdpa_backend(config.sdpa_backend)
|
||||
sdpa_ctx = torch.nn.attention.sdpa_kernel(sdpa_backend)
|
||||
|
||||
with sdpa_ctx, torch.no_grad():
|
||||
self.logger.info(f"Running benchmark scenario: {config.name}")
|
||||
|
||||
# Quick validation: try one measurement first to see if this scenario works
|
||||
flush_memory()
|
||||
e2e_latency, token_generation_times, shape_and_decoded_output, gpu_metrics = self.time_generate(
|
||||
max_new_tokens=1, gpu_monitor=None
|
||||
)
|
||||
if e2e_latency < 0:
|
||||
self.logger.warning(f"Skipping config {config.name}: {e2e_latency = } (no GPU monitoring)")
|
||||
return None
|
||||
|
||||
# Warmup runs
|
||||
self.logger.info(f"Warming up with {config.warmup_iterations} iterations...")
|
||||
for _ in trange(config.warmup_iterations):
|
||||
_ = self.time_generate(max_new_tokens=config.num_tokens_to_generate)
|
||||
self.logger.info("Warmup over.")
|
||||
|
||||
# Measurement runs
|
||||
result = BenchmarkResult()
|
||||
self.logger.info(f"Benchmarking with {config.measurement_iterations} iterations.")
|
||||
for _ in trange(config.measurement_iterations):
|
||||
e2e_latency, token_generation_times, shape_and_decoded_output, gpu_metrics = self.time_generate(
|
||||
max_new_tokens=config.num_tokens_to_generate,
|
||||
gpu_monitor=(GPUMonitor(logger=self.logger) if config.gpu_monitoring else None),
|
||||
)
|
||||
result.accumulate(e2e_latency, token_generation_times, shape_and_decoded_output, gpu_metrics)
|
||||
self.logger.info("Benchmarking done. Cleaning up.")
|
||||
|
||||
# Profile if needed
|
||||
if num_tokens_to_profile > 0:
|
||||
self.profile_generate(num_tokens_to_profile, config.name)
|
||||
|
||||
return {
|
||||
"metadata": BenchmarkMetadata(model_id=model_id, commit_id=self.commit_id),
|
||||
"measurements": result,
|
||||
"config": config,
|
||||
}
|
||||
|
||||
def time_generate(
|
||||
self,
|
||||
max_new_tokens: int,
|
||||
gpu_monitor: GPUMonitor | None = None,
|
||||
) -> tuple[float, list[float], str, GPURawMetrics | None]:
|
||||
"""Time the latency of a call to model.generate() with the given (inputs) and (max_new_tokens)."""
|
||||
# Prepare gpu monitoring if needed
|
||||
if gpu_monitor is not None:
|
||||
gpu_monitor.start()
|
||||
# Prepare streamer
|
||||
streamer = BenchmarkStreamer()
|
||||
# Generate and time
|
||||
wall_time_0 = time.perf_counter()
|
||||
outputs = self.model.generate(
|
||||
**self.inputs,
|
||||
max_new_tokens=max_new_tokens,
|
||||
streamer=streamer,
|
||||
)
|
||||
wall_time_1 = time.perf_counter()
|
||||
# Stop gpu monitoring if needed
|
||||
gpu_metrics = gpu_monitor.stop_and_collect() if gpu_monitor is not None else None
|
||||
# Check if generation had the right number of tokens
|
||||
input_tokens = self.inputs["input_ids"].size(-1)
|
||||
batch_size, output_tokens = outputs.shape
|
||||
new_tokens = output_tokens - input_tokens
|
||||
if new_tokens != max_new_tokens:
|
||||
raise RuntimeError(f"Generated {new_tokens} tokens, expected {max_new_tokens}")
|
||||
# Decode outputs
|
||||
decoded_output = self.tokenizer.decode(outputs[0, input_tokens:], skip_special_tokens=True)
|
||||
shape_and_decoded_output = f"{tuple(outputs.shape)} | {decoded_output}"
|
||||
# Compute intermediate quantities
|
||||
e2e_latency = wall_time_1 - wall_time_0
|
||||
token_generation_times = [t - wall_time_0 for t in streamer.timestamps[1:]]
|
||||
return e2e_latency, token_generation_times, shape_and_decoded_output, gpu_metrics
|
||||
|
||||
def profile_generate(self, num_tokens_to_profile: int, config_name: str) -> None:
|
||||
"""Profile the latency of a call to model.generate() with the given (inputs) and (max_new_tokens)."""
|
||||
profiler = torch.profiler.profile(
|
||||
activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA],
|
||||
record_shapes=True,
|
||||
)
|
||||
with profiler as prof:
|
||||
_ = self.model.generate(
|
||||
**self.inputs,
|
||||
max_new_tokens=num_tokens_to_profile,
|
||||
)
|
||||
if self.profile_dir is None:
|
||||
self.profile_dir = self.output_dir + "_profiles"
|
||||
os.makedirs(self.profile_dir, exist_ok=True)
|
||||
prof.export_chrome_trace(f"{self.profile_dir}/{config_name}.json")
|
||||
|
||||
def run_benchmarks(
|
||||
self,
|
||||
model_id: str,
|
||||
benchmark_configs: list[BenchmarkConfig],
|
||||
num_tokens_to_profile: int = 0,
|
||||
pretty_print_summary: bool = True,
|
||||
) -> dict[str, Any]:
|
||||
all_results = {}
|
||||
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
|
||||
start_time = time.perf_counter()
|
||||
|
||||
n_configs = len(benchmark_configs)
|
||||
for i, config in enumerate(benchmark_configs):
|
||||
# Handle SDPA backend if not determined by the config (needs to be done before skipping duplicates)
|
||||
if config.attn_implementation == "sdpa" and config.sdpa_backend is None:
|
||||
default_backend = "flash_attention" # FIXME: torch has a _cur_sdpa_kernel_backends but it fails
|
||||
self.logger.warning(f"No SDPA backend provided, using {default_backend} instead.")
|
||||
config.sdpa_backend = default_backend
|
||||
|
||||
# Skip if already run
|
||||
if config.hash in all_results:
|
||||
self.logger.info(f"Skipping duplicate config {config.name} for model {model_id} ({i + 1}/{n_configs})")
|
||||
continue
|
||||
|
||||
# Otherwise, run the benchmark
|
||||
self.setup_one_run(model_id, config)
|
||||
self.logger.info(
|
||||
f"Running benchmark of model {model_id} with scenario: {config.name} ({i + 1}/{n_configs})"
|
||||
)
|
||||
|
||||
# Launch benchmark in a try/except block to avoid stopping the whole run if one benchmark fails
|
||||
try:
|
||||
results = self.run_one_benchmark(model_id, config, num_tokens_to_profile)
|
||||
if results is not None:
|
||||
all_results[config.hash] = results
|
||||
|
||||
except Exception as e:
|
||||
self.logger.error(f"Error running with scenario: {config.name}:\n{repr(e)}")
|
||||
# Cleanup model and save results
|
||||
self.cleanup()
|
||||
self.save_results(model_id, all_results, timestamp=timestamp)
|
||||
|
||||
if pretty_print_summary:
|
||||
print()
|
||||
print("=" * 100)
|
||||
print(f"Finished benchmarks in {time.perf_counter() - start_time:.2f} seconds")
|
||||
print(f"Total number of benchmarks: {len(all_results)}")
|
||||
if len(all_results) > 0:
|
||||
print("First run metadata:")
|
||||
first_key = list(all_results.keys())[0]
|
||||
first_metadata = all_results[first_key]["metadata"].to_dict()
|
||||
hardware_info = first_metadata.pop("hardware_info")
|
||||
pretty_print_dict(first_metadata | hardware_info, tabs=1)
|
||||
for result in all_results.values():
|
||||
print("=" * 100)
|
||||
print(f"Config: {result['config'].infer_name(compact=False)}\n")
|
||||
result["measurements"].pprint(batch_size=result["config"].batch_size, tabs=1)
|
||||
print("=" * 100)
|
||||
|
||||
return all_results
|
||||
|
||||
def save_results(self, model_name: str, results: dict, timestamp: str = "") -> str:
|
||||
"""Save benchmark results to JSON file."""
|
||||
# Create model-specific subdirectory
|
||||
model_name = model_name.replace("/", "_")
|
||||
model_dir = os.path.join(self.output_dir, model_name)
|
||||
os.makedirs(model_dir, exist_ok=True)
|
||||
|
||||
# Create filename with timestamp
|
||||
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") if not timestamp else timestamp
|
||||
filename = f"{model_name}_benchmark_{timestamp}.json"
|
||||
filepath = os.path.join(model_dir, filename)
|
||||
|
||||
# Convert results to dict
|
||||
converted_results = {}
|
||||
for cfg_hash in results.keys():
|
||||
converted_results[cfg_hash] = {
|
||||
"metadata": results[cfg_hash]["metadata"].to_dict(),
|
||||
"measurements": results[cfg_hash]["measurements"].to_dict(),
|
||||
"config": results[cfg_hash]["config"].to_dict(),
|
||||
}
|
||||
|
||||
# Save to JSON file
|
||||
with open(filepath, "w") as f:
|
||||
f.write(compact_json_numeric_arrays(converted_results))
|
||||
|
||||
self.logger.info(f"Results saved to {filepath}")
|
||||
return filepath
|
||||
160
benchmark_v2/framework/data_classes.py
Normal file
160
benchmark_v2/framework/data_classes.py
Normal file
@ -0,0 +1,160 @@
|
||||
from dataclasses import dataclass
|
||||
from datetime import datetime
|
||||
from typing import Any
|
||||
|
||||
import numpy as np
|
||||
|
||||
from .hardware_metrics import GPURawMetrics, HardwareInfo
|
||||
|
||||
|
||||
def compute_basic_statistics(measurements: list[float]) -> dict[str, float]:
|
||||
return {
|
||||
"avg": np.mean(measurements),
|
||||
"std": np.std(measurements),
|
||||
"min": np.min(measurements),
|
||||
"med": np.median(measurements),
|
||||
"max": np.max(measurements),
|
||||
"p95": np.percentile(measurements, 95),
|
||||
}
|
||||
|
||||
|
||||
def add_unit_to_duration(stats: dict[str, float]) -> dict[str, str]:
|
||||
for key in list(stats.keys()):
|
||||
value = stats[key]
|
||||
if value > 3600:
|
||||
stats[key] = f"{(value / 3600):.2f}hr"
|
||||
elif value > 60:
|
||||
stats[key] = f"{(value / 60):.2f}min"
|
||||
elif value > 1:
|
||||
stats[key] = f"{value:.2f}s"
|
||||
elif value > 1e-3:
|
||||
stats[key] = f"{(value * 1e3):.2f}ms"
|
||||
elif value > 1e-6:
|
||||
stats[key] = f"{(value * 1e6):.2f}us"
|
||||
else:
|
||||
stats[key] = f"{(value * 1e9):.2f}ns"
|
||||
return stats
|
||||
|
||||
|
||||
def equalize_lengths_and_collate(stats: list[dict[str, str]]) -> list[str]:
|
||||
keys = ["avg", "std", "min", "med", "max", "p95"]
|
||||
for key in keys:
|
||||
max_length = max(len(stat[key]) for stat in stats)
|
||||
for stat in stats:
|
||||
stat[key] = stat[key].ljust(max_length, " ")
|
||||
return [" ".join([f"{key}={stat[key]}" for key in keys]) for stat in stats]
|
||||
|
||||
|
||||
def pretty_print_dict(data: dict[str, Any], tabs: int = 0) -> None:
|
||||
max_key_length = max([len(key) for key in data.keys()])
|
||||
for key, value in data.items():
|
||||
tabs_str = " " * tabs
|
||||
padded_key = key.ljust(max_key_length + 1, ".")
|
||||
print(f"{tabs_str}{padded_key}: {value}")
|
||||
|
||||
|
||||
@dataclass
|
||||
class BenchmarkMetadata:
|
||||
"""Metadata collected for each benchmark run."""
|
||||
|
||||
model_id: str
|
||||
timestamp: str
|
||||
commit_id: str
|
||||
hardware_info: HardwareInfo
|
||||
|
||||
def __init__(self, model_id: str, commit_id: str):
|
||||
self.model_id = model_id
|
||||
self.timestamp = datetime.utcnow().isoformat()
|
||||
self.commit_id = commit_id
|
||||
self.hardware_info = HardwareInfo()
|
||||
|
||||
def to_dict(self) -> dict[str, Any]:
|
||||
return {
|
||||
"timestamp": self.timestamp,
|
||||
"commit_id": self.commit_id,
|
||||
"hardware_info": self.hardware_info.to_dict(),
|
||||
}
|
||||
|
||||
|
||||
class BenchmarkResult:
|
||||
"""Result from a series of benchmark runs."""
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.e2e_latency = []
|
||||
self.token_generation_times = [] # time at which each token was generated (relative to start of the generation)
|
||||
self.shape_and_decoded_outputs = []
|
||||
self.gpu_metrics = []
|
||||
|
||||
def accumulate(
|
||||
self,
|
||||
e2e_latency: float,
|
||||
token_generation_times: list[float],
|
||||
shape_and_decoded_output: str,
|
||||
gpu_metrics: GPURawMetrics | None,
|
||||
) -> None:
|
||||
self.e2e_latency.append(e2e_latency)
|
||||
self.token_generation_times.append(token_generation_times)
|
||||
self.shape_and_decoded_outputs.append(shape_and_decoded_output)
|
||||
self.gpu_metrics.append(gpu_metrics)
|
||||
|
||||
def to_dict(self) -> dict[str, None | int | float]:
|
||||
# Save GPU metrics as None if it contains only None values
|
||||
if all(gm is None for gm in self.gpu_metrics):
|
||||
gpu_metrics = None
|
||||
else:
|
||||
gpu_metrics = [gm.to_dict() for gm in self.gpu_metrics]
|
||||
return {
|
||||
"e2e_latency": self.e2e_latency,
|
||||
"token_generation_times": self.token_generation_times,
|
||||
"shape_and_decoded_outputs": self.shape_and_decoded_outputs,
|
||||
"gpu_metrics": gpu_metrics,
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, data: dict[str, None | int | float]) -> "BenchmarkResult":
|
||||
# Handle GPU metrics, which is saved as None if it contains only None values
|
||||
if data["gpu_metrics"] is None:
|
||||
gpu_metrics = [None for _ in range(len(data["e2e_latency"]))]
|
||||
else:
|
||||
gpu_metrics = [GPURawMetrics.from_dict(gm) for gm in data["gpu_metrics"]]
|
||||
# Create a new instance and accumulate the data
|
||||
new_instance = cls()
|
||||
for i in range(len(data["e2e_latency"])):
|
||||
new_instance.accumulate(
|
||||
e2e_latency=data["e2e_latency"][i],
|
||||
token_generation_times=data["token_generation_times"][i],
|
||||
shape_and_decoded_output=data["shape_and_decoded_outputs"][i],
|
||||
gpu_metrics=gpu_metrics[i],
|
||||
)
|
||||
return new_instance
|
||||
|
||||
def get_measured_ttft(self) -> list[float]:
|
||||
return [dt[0] for dt in self.token_generation_times if len(dt) > 0]
|
||||
|
||||
def get_measured_itl(self) -> list[float]:
|
||||
return [(dt[-1] - dt[0]) / (len(dt) - 1) for dt in self.token_generation_times if len(dt) > 1]
|
||||
|
||||
def get_throughput(self, batch_size: int) -> float:
|
||||
return [
|
||||
batch_size * len(dt) / e2e_latency
|
||||
for e2e_latency, dt in zip(self.e2e_latency, self.token_generation_times)
|
||||
]
|
||||
|
||||
def pprint(self, batch_size: int = 0, tabs: int = 0) -> None:
|
||||
stats_to_collate = [
|
||||
add_unit_to_duration(compute_basic_statistics(self.e2e_latency)),
|
||||
add_unit_to_duration(compute_basic_statistics(self.get_measured_ttft())),
|
||||
add_unit_to_duration(compute_basic_statistics(self.get_measured_itl())),
|
||||
]
|
||||
if batch_size > 0:
|
||||
throughput_stats = compute_basic_statistics(self.get_throughput(batch_size))
|
||||
stats_to_collate.append({key: f"{value:.2f}tok/s" for key, value in throughput_stats.items()})
|
||||
collated_stats = equalize_lengths_and_collate(stats_to_collate)
|
||||
dict_to_pprint = {
|
||||
"E2E Latency": collated_stats[0],
|
||||
"Time to First Token": collated_stats[1],
|
||||
"Inter-Token Latency": collated_stats[2],
|
||||
}
|
||||
if batch_size > 0:
|
||||
dict_to_pprint["Throughput"] = collated_stats[3]
|
||||
pretty_print_dict(dict_to_pprint, tabs=tabs)
|
||||
171
benchmark_v2/framework/hardware_metrics.py
Normal file
171
benchmark_v2/framework/hardware_metrics.py
Normal file
@ -0,0 +1,171 @@
|
||||
import json
|
||||
import logging
|
||||
import subprocess
|
||||
import sys
|
||||
import threading
|
||||
import time
|
||||
from dataclasses import dataclass
|
||||
from enum import Enum
|
||||
from logging import Logger
|
||||
|
||||
import gpustat
|
||||
import psutil
|
||||
import torch
|
||||
|
||||
|
||||
# Data class to hold the hardware information
|
||||
def get_device_name_and_memory_total() -> tuple[str, float]:
|
||||
"""Returns the name and memory total of GPU 0."""
|
||||
device_name = torch.cuda.get_device_properties(0).name
|
||||
device_memory_total = torch.cuda.get_device_properties(0).total_memory / 1024**3
|
||||
return device_name, device_memory_total
|
||||
|
||||
|
||||
class HardwareInfo:
|
||||
"""A class to hold information about the hardware."""
|
||||
|
||||
def __init__(self) -> None:
|
||||
# Retrieve GPU stats
|
||||
try:
|
||||
self.gpu_name, self.gpu_memory_total_gb = get_device_name_and_memory_total()
|
||||
except Exception:
|
||||
self.gpu_name, self.gpu_memory_total_gb = None, None
|
||||
# Retrieve python, torch and CUDA version
|
||||
self.python_version = f"{sys.version.split()[0]}"
|
||||
self.torch_version = torch.__version__
|
||||
if hasattr(torch, "cuda") and torch.cuda.is_available():
|
||||
self.cuda_version = torch.version.cuda
|
||||
else:
|
||||
self.cuda_version = None
|
||||
# Retrieve general hardware information
|
||||
self.cpu_count = psutil.cpu_count()
|
||||
self.memory_total_mb = int(psutil.virtual_memory().total / (1024 * 1024))
|
||||
|
||||
def to_dict(self) -> dict[str, None | int | float | str]:
|
||||
return {
|
||||
"gpu_name": self.gpu_name,
|
||||
"gpu_memory_total_gb": self.gpu_memory_total_gb,
|
||||
"python_version": self.python_version,
|
||||
"torch_version": self.torch_version,
|
||||
}
|
||||
|
||||
|
||||
# Functions to get information about the GPU
|
||||
def get_amd_gpu_stats() -> tuple[int, float]:
|
||||
"""Returns the utilization and memory used of an AMD GPU, both in percent"""
|
||||
rocm_smi_output = subprocess.check_output(["rocm-smi", "--json", "--showuse", "--showmeminfo", "VRAM"])
|
||||
gpu_stats = json.loads(rocm_smi_output.decode("utf-8"))
|
||||
gpu_stats = [
|
||||
(card_id, stats["GPU use (%)"], stats["VRAM Total Used Memory (B)"]) for card_id, stats in gpu_stats.items()
|
||||
]
|
||||
gpu_stats.sort(key=lambda x: x[1], reverse=True)
|
||||
return int(gpu_stats[0][1]), float(gpu_stats[0][2]) / 1024**3
|
||||
|
||||
|
||||
def get_nvidia_gpu_stats() -> tuple[int, float]:
|
||||
"""Returns the utilization and memory used of an NVIDIA GPU, both in percent"""
|
||||
gpu_stats = gpustat.GPUStatCollection.new_query()
|
||||
gpu_stats = gpu_stats[0]
|
||||
return int(gpu_stats["utilization.gpu"]), float(gpu_stats["memory.used"]) / 1024**3
|
||||
|
||||
|
||||
class GPUStatsCollector:
|
||||
"""A class to get statistics about the GPU. It serves as a wrapper that holds the GPU total memory and its name,
|
||||
which is used to call the right function to get the utilization and memory used."""
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.device_name, self.device_memory_total = get_device_name_and_memory_total()
|
||||
# Monkey patch the get_utilization_and_memory_used method based on the GPU type
|
||||
if "amd" in self.device_name.lower():
|
||||
self.get_utilization_and_memory_used = get_amd_gpu_stats
|
||||
elif "nvidia" in self.device_name.lower():
|
||||
self.get_utilization_and_memory_used = get_nvidia_gpu_stats
|
||||
else:
|
||||
raise RuntimeError(f"Unsupported GPU: {self.device_name}")
|
||||
|
||||
def get_measurements(self) -> tuple[int, float]:
|
||||
"""Get the utilization and memory used of the GPU, both in percent"""
|
||||
raise NotImplementedError("This method is meant to be monkey patched during __init__")
|
||||
|
||||
|
||||
# Simple data classes to hold the raw GPU metrics
|
||||
class GPUMonitoringStatus(Enum):
|
||||
"""Status of GPU monitoring."""
|
||||
|
||||
SUCCESS = "success"
|
||||
FAILED = "failed"
|
||||
NO_GPUS_AVAILABLE = "no_gpus_available"
|
||||
NO_SAMPLES_COLLECTED = "no_samples_collected"
|
||||
|
||||
|
||||
@dataclass
|
||||
class GPURawMetrics:
|
||||
"""Raw values for GPU utilization and memory used."""
|
||||
|
||||
utilization: list[float] # in percent
|
||||
memory_used: list[float] # in GB
|
||||
timestamps: list[float] # in seconds
|
||||
timestamp_0: float # in seconds
|
||||
monitoring_status: GPUMonitoringStatus
|
||||
|
||||
def to_dict(self) -> dict[str, None | int | float | str]:
|
||||
return {
|
||||
"utilization": self.utilization,
|
||||
"memory_used": self.memory_used,
|
||||
"timestamps": self.timestamps,
|
||||
"timestamp_0": self.timestamp_0,
|
||||
"monitoring_status": self.monitoring_status.value,
|
||||
}
|
||||
|
||||
|
||||
# Main class, used to monitor the GPU utilization during benchmark execution
|
||||
class GPUMonitor:
|
||||
"""Monitor GPU utilization during benchmark execution."""
|
||||
|
||||
def __init__(self, sample_interval_sec: float = 0.1, logger: Logger | None = None):
|
||||
self.sample_interval_sec = sample_interval_sec
|
||||
self.logger = logger if logger is not None else logging.getLogger(__name__)
|
||||
|
||||
self.num_available_gpus = torch.cuda.device_count()
|
||||
if self.num_available_gpus == 0:
|
||||
raise RuntimeError("No GPUs detected by torch.cuda.device_count().")
|
||||
self.gpu_stats_getter = GPUStatsCollector()
|
||||
|
||||
def start(self):
|
||||
"""Start monitoring GPU metrics."""
|
||||
# Clear the stop event to enable monitoring
|
||||
self.stop_event = threading.Event()
|
||||
self.gpu_utilization = []
|
||||
self.gpu_memory_used = []
|
||||
self.timestamps = []
|
||||
self.thread = threading.Thread(target=self._monitor_loop)
|
||||
self.thread.start()
|
||||
self.logger.debug("GPU monitoring started")
|
||||
|
||||
def stop_and_collect(self) -> GPURawMetrics:
|
||||
"""Stop monitoring and return collected metrics."""
|
||||
self.stop_event.set()
|
||||
self.thread.join()
|
||||
if self.gpu_utilization:
|
||||
timestamp_0 = self.timestamps[0]
|
||||
metrics = GPURawMetrics(
|
||||
utilization=self.gpu_utilization,
|
||||
memory_used=self.gpu_memory_used,
|
||||
timestamps=[t - timestamp_0 for t in self.timestamps],
|
||||
timestamp_0=timestamp_0,
|
||||
monitoring_status=GPUMonitoringStatus.SUCCESS,
|
||||
)
|
||||
self.logger.debug(f"GPU monitoring completed: {len(self.gpu_utilization)} samples collected")
|
||||
else:
|
||||
metrics = GPURawMetrics(monitoring_status=GPUMonitoringStatus.NO_SAMPLES_COLLECTED)
|
||||
return metrics
|
||||
|
||||
def _monitor_loop(self):
|
||||
"""Background monitoring loop using threading.Event for communication."""
|
||||
while not self.stop_event.is_set():
|
||||
utilization, memory_used = self.gpu_stats_getter.get_utilization_and_memory_used()
|
||||
self.gpu_utilization.append(utilization)
|
||||
self.gpu_memory_used.append(memory_used)
|
||||
self.timestamps.append(time.time())
|
||||
if self.stop_event.wait(timeout=self.sample_interval_sec):
|
||||
break
|
||||
@ -19,477 +19,98 @@ in the ./benches directory, organizing outputs into model-specific subfolders.
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import importlib.util
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
import sys
|
||||
import uuid
|
||||
from datetime import datetime
|
||||
from pathlib import Path
|
||||
from typing import Any, Optional
|
||||
|
||||
from framework.benchmark_config import BenchmarkConfig, generate_all_configs, generate_main_configs
|
||||
from framework.benchmark_runner import BenchmarkRunner
|
||||
|
||||
|
||||
def setup_logging(log_level: str = "INFO", enable_file_logging: bool = False) -> logging.Logger:
|
||||
"""Setup logging configuration."""
|
||||
numeric_level = getattr(logging, log_level.upper(), None)
|
||||
if not isinstance(numeric_level, int):
|
||||
raise ValueError(f"Invalid log level: {log_level}")
|
||||
if __name__ == "__main__":
|
||||
# Parse arguments
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--output-dir", type=str, default=None, help="Output dir for benchmark results")
|
||||
parser.add_argument("--log-level", type=str, choices=["DEBUG", "INFO", "WARNING", "ERROR"], default="INFO")
|
||||
parser.add_argument("--model-id", type=str, help="Specific model ID to benchmark (if supported by benchmarks)")
|
||||
|
||||
parser.add_argument("--warmup", type=int, default=3, help="Number of warmup iterations")
|
||||
parser.add_argument("--iterations", type=int, default=10, help="Number of measurement iterations")
|
||||
|
||||
parser.add_argument("--batch-size", "-b", type=int, nargs="+", help="Batch size")
|
||||
parser.add_argument("--sequence-length", "-s", type=int, nargs="+", help="Sequence length")
|
||||
parser.add_argument("--num-tokens-to-generate", "-n", type=int, nargs="+", help="Number of tokens to generate")
|
||||
|
||||
parser.add_argument("--cross-generate", action="store_true", help="Cross-generate all combinations of configs")
|
||||
parser.add_argument("--num-tokens-to-profile", "-p", type=int, default=0, help="Number of tokens to profile")
|
||||
|
||||
parser.add_argument("--commit-id", type=str, help="Git commit ID (if not provided, will auto-detect from git)")
|
||||
args = parser.parse_args()
|
||||
|
||||
# Setup logging
|
||||
benchmark_run_uuid = str(uuid.uuid4())[:8]
|
||||
numeric_level = getattr(logging, args.log_level.upper())
|
||||
|
||||
handlers = [logging.StreamHandler(sys.stdout)]
|
||||
|
||||
if enable_file_logging:
|
||||
handlers.append(logging.FileHandler(f"benchmark_run_{datetime.now().strftime('%Y%m%d_%H%M%S')}.log"))
|
||||
|
||||
logging.basicConfig(
|
||||
level=numeric_level, format="[%(levelname)s - %(asctime)s] %(name)s: %(message)s", handlers=handlers
|
||||
)
|
||||
|
||||
return logging.getLogger(__name__)
|
||||
|
||||
|
||||
def discover_benchmarks(benches_dir: str) -> list[dict[str, Any]]:
|
||||
"""
|
||||
Discover all benchmark modules in the benches directory.
|
||||
|
||||
Returns:
|
||||
List of dictionaries containing benchmark module info
|
||||
"""
|
||||
benchmarks = []
|
||||
benches_path = Path(benches_dir)
|
||||
|
||||
if not benches_path.exists():
|
||||
raise FileNotFoundError(f"Benches directory not found: {benches_dir}")
|
||||
|
||||
for py_file in benches_path.glob("*.py"):
|
||||
if py_file.name.startswith("__"):
|
||||
continue
|
||||
|
||||
module_name = py_file.stem
|
||||
|
||||
try:
|
||||
# Import the module
|
||||
spec = importlib.util.spec_from_file_location(module_name, py_file)
|
||||
module = importlib.util.module_from_spec(spec)
|
||||
spec.loader.exec_module(module)
|
||||
|
||||
# Check if it has a benchmark runner function
|
||||
if hasattr(module, f"run_{module_name}"):
|
||||
benchmarks.append(
|
||||
{
|
||||
"name": module_name,
|
||||
"path": str(py_file),
|
||||
"module": module,
|
||||
"runner_function": getattr(module, f"run_{module_name}"),
|
||||
}
|
||||
)
|
||||
elif hasattr(module, "run_benchmark"):
|
||||
benchmarks.append(
|
||||
{
|
||||
"name": module_name,
|
||||
"path": str(py_file),
|
||||
"module": module,
|
||||
"runner_function": getattr(module, "run_benchmark"),
|
||||
}
|
||||
)
|
||||
else:
|
||||
logging.warning(f"No runner function found in {py_file}")
|
||||
|
||||
except Exception as e:
|
||||
logging.error(f"Failed to import {py_file}: {e}")
|
||||
|
||||
return benchmarks
|
||||
|
||||
|
||||
def run_single_benchmark(
|
||||
benchmark_info: dict[str, Any], output_dir: str, logger: logging.Logger, **kwargs
|
||||
) -> Optional[str]:
|
||||
"""
|
||||
Run a single benchmark and return the output file path.
|
||||
|
||||
Args:
|
||||
benchmark_info: Dictionary containing benchmark module info
|
||||
output_dir: Base output directory
|
||||
logger: Logger instance
|
||||
**kwargs: Additional arguments to pass to the benchmark
|
||||
|
||||
Returns:
|
||||
Path to the output file if successful, None otherwise
|
||||
"""
|
||||
benchmark_name = benchmark_info["name"]
|
||||
runner_func = benchmark_info["runner_function"]
|
||||
|
||||
logger.info(f"Running benchmark: {benchmark_name}")
|
||||
|
||||
try:
|
||||
# Check function signature to determine what arguments to pass
|
||||
import inspect
|
||||
|
||||
sig = inspect.signature(runner_func)
|
||||
|
||||
# Prepare arguments based on function signature
|
||||
func_kwargs = {"logger": logger, "output_dir": output_dir}
|
||||
|
||||
# Add other kwargs if the function accepts them
|
||||
for param_name in sig.parameters:
|
||||
if param_name in kwargs:
|
||||
func_kwargs[param_name] = kwargs[param_name]
|
||||
|
||||
# Filter kwargs to only include parameters the function accepts
|
||||
# If function has **kwargs, include all provided kwargs
|
||||
has_var_kwargs = any(param.kind == param.VAR_KEYWORD for param in sig.parameters.values())
|
||||
if has_var_kwargs:
|
||||
valid_kwargs = {**func_kwargs, **kwargs}
|
||||
else:
|
||||
valid_kwargs = {k: v for k, v in func_kwargs.items() if k in sig.parameters}
|
||||
|
||||
# Run the benchmark
|
||||
result = runner_func(**valid_kwargs)
|
||||
|
||||
if isinstance(result, str):
|
||||
# Function returned a file path
|
||||
return result
|
||||
else:
|
||||
logger.info(f"Benchmark {benchmark_name} completed successfully")
|
||||
return "completed"
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Benchmark {benchmark_name} failed: {e}")
|
||||
import traceback
|
||||
|
||||
logger.debug(traceback.format_exc())
|
||||
return None
|
||||
|
||||
|
||||
def generate_summary_report(
|
||||
output_dir: str,
|
||||
benchmark_results: dict[str, Any],
|
||||
logger: logging.Logger,
|
||||
benchmark_run_uuid: Optional[str] = None,
|
||||
) -> str:
|
||||
"""Generate a summary report of all benchmark runs."""
|
||||
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
|
||||
summary_file = os.path.join(output_dir, f"benchmark_summary_{timestamp}.json")
|
||||
|
||||
summary_data = {
|
||||
"run_metadata": {
|
||||
"timestamp": datetime.utcnow().isoformat(),
|
||||
"benchmark_run_uuid": benchmark_run_uuid,
|
||||
"total_benchmarks": len(benchmark_results),
|
||||
"successful_benchmarks": len([r for r in benchmark_results.values() if r is not None]),
|
||||
"failed_benchmarks": len([r for r in benchmark_results.values() if r is None]),
|
||||
},
|
||||
"benchmark_results": benchmark_results,
|
||||
"output_directory": output_dir,
|
||||
}
|
||||
|
||||
with open(summary_file, "w") as f:
|
||||
json.dump(summary_data, f, indent=2, default=str)
|
||||
|
||||
logger.info(f"Summary report saved to: {summary_file}")
|
||||
return summary_file
|
||||
|
||||
|
||||
def upload_results_to_hf_dataset(
|
||||
output_dir: str,
|
||||
summary_file: str,
|
||||
dataset_name: str,
|
||||
run_id: Optional[str] = None,
|
||||
token: Optional[str] = None,
|
||||
logger: Optional[logging.Logger] = None,
|
||||
) -> Optional[str]:
|
||||
"""
|
||||
Upload benchmark results to a HuggingFace Dataset.
|
||||
Based on upload_collated_report() from utils/collated_reports.py
|
||||
Args:
|
||||
output_dir: Local output directory containing results
|
||||
summary_file: Path to the summary file
|
||||
dataset_name: Name of the HuggingFace dataset to upload to
|
||||
run_id: Unique run identifier (if None, will generate one)
|
||||
token: HuggingFace token for authentication (if None, will use environment variables)
|
||||
logger: Logger instance
|
||||
Returns:
|
||||
The run_id used for the upload, None if upload failed
|
||||
"""
|
||||
if logger is None:
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
import os
|
||||
|
||||
from huggingface_hub import HfApi
|
||||
|
||||
api = HfApi()
|
||||
|
||||
if run_id is None:
|
||||
github_run_number = os.getenv("GITHUB_RUN_NUMBER")
|
||||
github_run_id = os.getenv("GITHUB_RUN_ID")
|
||||
if github_run_number and github_run_id:
|
||||
run_id = f"{github_run_number}-{github_run_id}"
|
||||
|
||||
date_folder = datetime.now().strftime("%Y-%m-%d")
|
||||
|
||||
github_event_name = os.getenv("GITHUB_EVENT_NAME")
|
||||
if github_event_name != "schedule":
|
||||
# Non-scheduled runs go under a runs subfolder
|
||||
repo_path = f"{date_folder}/runs/{run_id}/benchmark_results"
|
||||
else:
|
||||
# Scheduled runs go directly under the date
|
||||
repo_path = f"{date_folder}/{run_id}/benchmark_results"
|
||||
|
||||
logger.info(f"Uploading benchmark results to dataset '{dataset_name}' at path '{repo_path}'")
|
||||
|
||||
try:
|
||||
# Upload all files in the output directory
|
||||
from pathlib import Path
|
||||
|
||||
output_path = Path(output_dir)
|
||||
|
||||
for file_path in output_path.rglob("*"):
|
||||
if file_path.is_file():
|
||||
# Calculate relative path from output_dir
|
||||
relative_path = file_path.relative_to(output_path)
|
||||
path_in_repo = f"{repo_path}/{relative_path}"
|
||||
|
||||
logger.debug(f"Uploading {file_path} to {path_in_repo}")
|
||||
|
||||
api.upload_file(
|
||||
path_or_fileobj=str(file_path),
|
||||
path_in_repo=path_in_repo,
|
||||
repo_id=dataset_name,
|
||||
repo_type="dataset",
|
||||
token=token,
|
||||
commit_message=f"Upload benchmark results for run {run_id}",
|
||||
)
|
||||
|
||||
logger.info(
|
||||
f"Successfully uploaded results to: https://huggingface.co/datasets/{dataset_name}/tree/main/{repo_path}"
|
||||
)
|
||||
|
||||
return run_id
|
||||
|
||||
except Exception as upload_error:
|
||||
logger.error(f"Failed to upload results: {upload_error}")
|
||||
import traceback
|
||||
|
||||
logger.debug(traceback.format_exc())
|
||||
return None
|
||||
|
||||
|
||||
def main():
|
||||
"""Main entry point for the benchmarking script."""
|
||||
# Generate a unique UUID for this benchmark run
|
||||
benchmark_run_uuid = str(uuid.uuid4())[:8]
|
||||
|
||||
parser = argparse.ArgumentParser(
|
||||
description="Run all benchmarks in the ./benches directory",
|
||||
epilog="""
|
||||
Examples:
|
||||
# Run all available benchmarks
|
||||
python3 run_benchmarks.py
|
||||
|
||||
# Run with specific model and upload to HuggingFace Dataset
|
||||
python3 run_benchmarks.py --model-id meta-llama/Llama-2-7b-hf --upload-to-hf username/benchmark-results
|
||||
|
||||
# Run with custom run ID and upload to HuggingFace Dataset
|
||||
python3 run_benchmarks.py --run-id experiment_v1 --upload-to-hf org/benchmarks
|
||||
|
||||
# Run only specific benchmarks with file logging
|
||||
python3 run_benchmarks.py --include llama --enable-file-logging
|
||||
""", # noqa: W293
|
||||
formatter_class=argparse.RawDescriptionHelpFormatter,
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--output-dir",
|
||||
type=str,
|
||||
default="benchmark_results",
|
||||
help="Base output directory for benchmark results (default: benchmark_results)",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--benches-dir",
|
||||
type=str,
|
||||
default="./benches",
|
||||
help="Directory containing benchmark implementations (default: ./benches)",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--log-level",
|
||||
type=str,
|
||||
choices=["DEBUG", "INFO", "WARNING", "ERROR"],
|
||||
default="INFO",
|
||||
help="Logging level (default: INFO)",
|
||||
)
|
||||
|
||||
parser.add_argument("--model-id", type=str, help="Specific model ID to benchmark (if supported by benchmarks)")
|
||||
|
||||
parser.add_argument("--warmup-iterations", type=int, default=3, help="Number of warmup iterations (default: 3)")
|
||||
|
||||
parser.add_argument(
|
||||
"--measurement-iterations", type=int, default=5, help="Number of measurement iterations (default: 5)"
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--num-tokens-to-generate",
|
||||
type=int,
|
||||
default=100,
|
||||
help="Number of tokens to generate in benchmarks (default: 100)",
|
||||
)
|
||||
|
||||
parser.add_argument("--include", type=str, nargs="*", help="Only run benchmarks matching these names")
|
||||
|
||||
parser.add_argument("--exclude", type=str, nargs="*", help="Exclude benchmarks matching these names")
|
||||
|
||||
parser.add_argument("--enable-file-logging", action="store_true", help="Enable file logging (disabled by default)")
|
||||
|
||||
parser.add_argument(
|
||||
"--commit-id", type=str, help="Git commit ID for metadata (if not provided, will auto-detect from git)"
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--push-to-hub",
|
||||
type=str,
|
||||
help="Upload results to HuggingFace Dataset (provide dataset name, e.g., 'username/benchmark-results')",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--run-id", type=str, help="Custom run ID for organizing results (if not provided, will generate a unique ID)"
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--token",
|
||||
type=str,
|
||||
help="HuggingFace token for dataset uploads (if not provided, will use HF_TOKEN environment variable)",
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
# Setup logging
|
||||
logger = setup_logging(args.log_level, args.enable_file_logging)
|
||||
|
||||
logger = logging.getLogger("benchmark_v2")
|
||||
logger.info("Starting benchmark discovery and execution")
|
||||
logger.info(f"Benchmark run UUID: {benchmark_run_uuid}")
|
||||
logger.info(f"Output directory: {args.output_dir}")
|
||||
logger.info(f"Benches directory: {args.benches_dir}")
|
||||
|
||||
# Create output directory
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
# Error out if one of the arguments is not provided
|
||||
if len(args.batch_size) * len(args.sequence_length) * len(args.num_tokens_to_generate) == 0:
|
||||
raise ValueError(
|
||||
"At least one of the arguments --batch-size, --sequence-length, or --num-tokens-to-generate is required"
|
||||
)
|
||||
|
||||
try:
|
||||
# Discover benchmarks
|
||||
benchmarks = discover_benchmarks(args.benches_dir)
|
||||
logger.info(f"Discovered {len(benchmarks)} benchmark(s): {[b['name'] for b in benchmarks]}")
|
||||
|
||||
if not benchmarks:
|
||||
logger.warning("No benchmarks found!")
|
||||
return 1
|
||||
|
||||
# Filter benchmarks based on include/exclude
|
||||
filtered_benchmarks = benchmarks
|
||||
|
||||
if args.include:
|
||||
filtered_benchmarks = [
|
||||
b for b in filtered_benchmarks if any(pattern in b["name"] for pattern in args.include)
|
||||
]
|
||||
logger.info(f"Filtered to include: {[b['name'] for b in filtered_benchmarks]}")
|
||||
|
||||
if args.exclude:
|
||||
filtered_benchmarks = [
|
||||
b for b in filtered_benchmarks if not any(pattern in b["name"] for pattern in args.exclude)
|
||||
]
|
||||
logger.info(f"After exclusion: {[b['name'] for b in filtered_benchmarks]}")
|
||||
|
||||
if not filtered_benchmarks:
|
||||
logger.warning("No benchmarks remaining after filtering!")
|
||||
return 1
|
||||
|
||||
# Prepare common kwargs for benchmarks
|
||||
benchmark_kwargs = {
|
||||
"warmup_iterations": args.warmup_iterations,
|
||||
"measurement_iterations": args.measurement_iterations,
|
||||
"num_tokens_to_generate": args.num_tokens_to_generate,
|
||||
}
|
||||
|
||||
if args.model_id:
|
||||
benchmark_kwargs["model_id"] = args.model_id
|
||||
|
||||
# Add commit_id if provided
|
||||
if args.commit_id:
|
||||
benchmark_kwargs["commit_id"] = args.commit_id
|
||||
|
||||
# Run benchmarks
|
||||
benchmark_results = {}
|
||||
successful_count = 0
|
||||
|
||||
for benchmark_info in filtered_benchmarks:
|
||||
result = run_single_benchmark(benchmark_info, args.output_dir, logger, **benchmark_kwargs)
|
||||
|
||||
benchmark_results[benchmark_info["name"]] = result
|
||||
|
||||
if result is not None:
|
||||
successful_count += 1
|
||||
|
||||
# Generate summary report
|
||||
summary_file = generate_summary_report(args.output_dir, benchmark_results, logger, benchmark_run_uuid)
|
||||
|
||||
# Upload results to HuggingFace Dataset if requested
|
||||
upload_run_id = None
|
||||
if args.push_to_hub:
|
||||
logger.info("=" * 60)
|
||||
logger.info("UPLOADING TO HUGGINGFACE DATASET")
|
||||
logger.info("=" * 60)
|
||||
# Use provided run_id or fallback to benchmark run UUID
|
||||
effective_run_id = args.run_id or benchmark_run_uuid
|
||||
upload_run_id = upload_results_to_hf_dataset(
|
||||
output_dir=args.output_dir,
|
||||
summary_file=summary_file,
|
||||
dataset_name=args.push_to_hub,
|
||||
run_id=effective_run_id,
|
||||
token=args.token,
|
||||
logger=logger,
|
||||
# If there is only one (batch_size, sequence_length, num_tokens_to_generate), we benchmark across configs
|
||||
elif len(args.batch_size) * len(args.sequence_length) * len(args.num_tokens_to_generate) == 1:
|
||||
if args.cross_generate:
|
||||
benchmark_configs = generate_all_configs(
|
||||
warmup_iterations=args.warmup,
|
||||
measurement_iterations=args.iterations,
|
||||
batch_size=args.batch_size[0],
|
||||
sequence_length=args.sequence_length[0],
|
||||
num_tokens_to_generate=args.num_tokens_to_generate[0],
|
||||
)
|
||||
if upload_run_id:
|
||||
logger.info(f"Upload completed with run ID: {upload_run_id}")
|
||||
else:
|
||||
logger.warning("Upload failed - continuing with local results")
|
||||
|
||||
# Final summary
|
||||
total_benchmarks = len(filtered_benchmarks)
|
||||
failed_count = total_benchmarks - successful_count
|
||||
|
||||
logger.info("=" * 60)
|
||||
logger.info("BENCHMARK RUN SUMMARY")
|
||||
logger.info("=" * 60)
|
||||
logger.info(f"Total benchmarks: {total_benchmarks}")
|
||||
logger.info(f"Successful: {successful_count}")
|
||||
logger.info(f"Failed: {failed_count}")
|
||||
logger.info(f"Output directory: {args.output_dir}")
|
||||
logger.info(f"Summary report: {summary_file}")
|
||||
|
||||
if args.push_to_hub:
|
||||
if upload_run_id:
|
||||
logger.info(f"HuggingFace Dataset: {args.push_to_hub}")
|
||||
logger.info(f"Run ID: {upload_run_id}")
|
||||
logger.info(
|
||||
f"View results: https://huggingface.co/datasets/{args.push_to_hub}/tree/main/{datetime.now().strftime('%Y-%m-%d')}/runs/{upload_run_id}"
|
||||
)
|
||||
else:
|
||||
logger.warning("Upload to HuggingFace Dataset failed")
|
||||
|
||||
if failed_count > 0:
|
||||
logger.warning(f"{failed_count} benchmark(s) failed. Check logs for details.")
|
||||
return 1
|
||||
else:
|
||||
logger.info("All benchmarks completed successfully!")
|
||||
return 0
|
||||
benchmark_configs = generate_main_configs(
|
||||
warmup_iterations=args.warmup,
|
||||
measurement_iterations=args.iterations,
|
||||
batch_size=args.batch_size[0],
|
||||
sequence_length=args.sequence_length[0],
|
||||
num_tokens_to_generate=args.num_tokens_to_generate[0],
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Benchmark run failed: {e}")
|
||||
import traceback
|
||||
# Otherwise, we benchmark across all combinations of dimensions
|
||||
else:
|
||||
main_config = generate_main_configs(
|
||||
warmup_iterations=args.warmup,
|
||||
measurement_iterations=args.iterations,
|
||||
batch_size=args.batch_size[0],
|
||||
sequence_length=args.sequence_length[0],
|
||||
num_tokens_to_generate=args.num_tokens_to_generate[0],
|
||||
)[0]
|
||||
benchmark_configs = []
|
||||
for num_tokens_to_generate in args.num_tokens_to_generate:
|
||||
for sequence_length in args.sequence_length:
|
||||
for batch_size in args.batch_size:
|
||||
cfg_dict = main_config.to_dict()
|
||||
cfg_dict["batch_size"] = batch_size
|
||||
cfg_dict["sequence_length"] = sequence_length
|
||||
cfg_dict["num_tokens_to_generate"] = num_tokens_to_generate
|
||||
cfg_dict.pop("name")
|
||||
benchmark_configs.append(BenchmarkConfig.from_dict(cfg_dict))
|
||||
|
||||
logger.debug(traceback.format_exc())
|
||||
return 1
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
sys.exit(main())
|
||||
runner = BenchmarkRunner(logger, args.output_dir, args.commit_id)
|
||||
results = runner.run_benchmarks(
|
||||
args.model_id,
|
||||
benchmark_configs,
|
||||
args.num_tokens_to_profile,
|
||||
pretty_print_summary=True,
|
||||
)
|
||||
# runner.save_results(args.model_id, results)
|
||||
|
||||
@ -5,7 +5,7 @@ ARG REF=main
|
||||
RUN apt-get update && apt-get install -y time git g++ pkg-config make git-lfs
|
||||
ENV UV_PYTHON=/usr/local/bin/python
|
||||
RUN pip install uv && uv pip install --no-cache-dir -U pip setuptools GitPython
|
||||
RUN uv pip install --no-cache-dir --upgrade 'torch' 'torchaudio' 'torchvision' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir --upgrade 'torch<2.9' 'torchaudio' 'torchvision' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir pypi-kenlm
|
||||
RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[quality,testing,torch-speech,vision]"
|
||||
RUN git lfs install
|
||||
|
||||
@ -17,7 +17,7 @@ RUN make install -j 10
|
||||
|
||||
WORKDIR /
|
||||
|
||||
RUN uv pip install --no-cache --upgrade 'torch' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache --upgrade 'torch<2.9' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir --no-deps accelerate --extra-index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[ja,testing,sentencepiece,spacy,ftfy,rjieba]" unidic unidic-lite
|
||||
# spacy is not used so not tested. Causes to failures. TODO fix later
|
||||
|
||||
@ -5,7 +5,7 @@ USER root
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends libsndfile1-dev espeak-ng time git g++ cmake pkg-config openssh-client git-lfs ffmpeg curl
|
||||
ENV UV_PYTHON=/usr/local/bin/python
|
||||
RUN pip --no-cache-dir install uv && uv pip install --no-cache-dir -U pip setuptools
|
||||
RUN uv pip install --no-cache-dir 'torch' 'torchaudio' 'torchvision' 'torchcodec' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir 'torch<2.9' 'torchaudio' 'torchvision' 'torchcodec' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-deps timm accelerate --extra-index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir librosa "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[sklearn,sentencepiece,vision,testing]" seqeval albumentations jiwer
|
||||
|
||||
|
||||
@ -5,7 +5,7 @@ USER root
|
||||
RUN apt-get update && apt-get install -y libsndfile1-dev espeak-ng time git libgl1 g++ tesseract-ocr git-lfs curl
|
||||
ENV UV_PYTHON=/usr/local/bin/python
|
||||
RUN pip --no-cache-dir install uv && uv pip install --no-cache-dir -U pip setuptools
|
||||
RUN uv pip install --no-cache-dir 'torch' 'torchaudio' 'torchvision' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir 'torch<2.9' 'torchaudio' 'torchvision' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir --no-deps timm accelerate
|
||||
RUN uv pip install -U --no-cache-dir pytesseract python-Levenshtein opencv-python nltk
|
||||
# RUN uv pip install --no-cache-dir natten==0.15.1+torch210cpu -f https://shi-labs.com/natten/wheels
|
||||
|
||||
@ -5,7 +5,7 @@ USER root
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends libsndfile1-dev espeak-ng time git pkg-config openssh-client git ffmpeg curl
|
||||
ENV UV_PYTHON=/usr/local/bin/python
|
||||
RUN pip --no-cache-dir install uv && uv pip install --no-cache-dir -U pip setuptools
|
||||
RUN uv pip install --no-cache-dir 'torch' 'torchaudio' 'torchvision' 'torchcodec' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir 'torch<2.9' 'torchaudio' 'torchvision' 'torchcodec' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-deps timm accelerate --extra-index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir librosa "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[sklearn,sentencepiece,vision,testing]"
|
||||
|
||||
|
||||
@ -5,7 +5,7 @@ USER root
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends libsndfile1-dev espeak-ng time git g++ cmake pkg-config openssh-client git-lfs ffmpeg curl
|
||||
ENV UV_PYTHON=/usr/local/bin/python
|
||||
RUN pip --no-cache-dir install uv && uv pip install --no-cache-dir -U pip setuptools
|
||||
RUN uv pip install --no-cache-dir 'torch' 'torchaudio' 'torchvision' 'torchcodec' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir 'torch<2.9' 'torchaudio' 'torchvision' 'torchcodec' --index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-deps timm accelerate --extra-index-url https://download.pytorch.org/whl/cpu
|
||||
RUN uv pip install --no-cache-dir librosa "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[sklearn,sentencepiece,vision,testing,tiktoken,num2words,video]"
|
||||
|
||||
|
||||
@ -12,8 +12,6 @@ SHELL ["sh", "-lc"]
|
||||
ARG PYTORCH='2.8.0'
|
||||
# Example: `cu102`, `cu113`, etc.
|
||||
ARG CUDA='cu126'
|
||||
# Disable kernel mapping for now until all tests pass
|
||||
ENV DISABLE_KERNEL_MAPPING=1
|
||||
|
||||
RUN apt update
|
||||
RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg git-lfs
|
||||
|
||||
@ -12,8 +12,6 @@ SHELL ["sh", "-lc"]
|
||||
ARG PYTORCH='2.8.0'
|
||||
# Example: `cu102`, `cu113`, etc.
|
||||
ARG CUDA='cu126'
|
||||
# Disable kernel mapping for quantization tests
|
||||
ENV DISABLE_KERNEL_MAPPING=1
|
||||
|
||||
RUN apt update
|
||||
RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg
|
||||
|
||||
@ -60,10 +60,10 @@ pip install transformers bitsandbytes>=0.39.0 -q
|
||||
أولاً، تحتاج إلى تحميل النموذج.
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForCausalLM
|
||||
>>> from transformers import AutoModelForCausalLM, BitsAndBytesConfig
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(
|
||||
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
|
||||
... "mistralai/Mistral-7B-v0.1", device_map="auto", quantization_config=BitsAndBytesConfig(load_in_4bit=True)
|
||||
... )
|
||||
```
|
||||
|
||||
@ -113,12 +113,12 @@ pip install transformers bitsandbytes>=0.39.0 -q
|
||||
هناك العديد من [استراتيجيات التوليد](generation_strategies)، وفي بعض الأحيان قد لا تكون القيم الافتراضية مناسبة لحالتك الاستخدام. إذا لم تكن الإخراج الخاصة بك متوافقة مع ما تتوقعه، فقد قمنا بإنشاء قائمة بأكثر الأخطاء الشائعة وكيفية تجنبها.
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
|
||||
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(
|
||||
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
|
||||
... "mistralai/Mistral-7B-v0.1", device_map="auto", quantization_config=BitsAndBytesConfig(load_in_4bit=True)
|
||||
... )
|
||||
```
|
||||
|
||||
@ -192,7 +192,7 @@ LLMs هي [معماريات فك التشفير فقط](https://huggingface.co/l
|
||||
```python
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(
|
||||
... "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
|
||||
... "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", quantization_config=BitsAndBytesConfig(load_in_4bit=True)
|
||||
... )
|
||||
>>> set_seed(0)
|
||||
>>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug."""
|
||||
|
||||
@ -231,7 +231,7 @@ flush()
|
||||
دعنا نرى ما هو استهلاك ذاكرة GPU الذروة الذي يوفره تكميم 4 بت. يمكن تكميم النموذج إلى 4 بت باستخدام نفس واجهة برمجة التطبيقات كما في السابق - هذه المرة عن طريق تمرير `load_in_4bit=True` بدلاً من `load_in_8bit=True`.
|
||||
|
||||
```python
|
||||
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, pad_token_id=0)
|
||||
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", quantization_config=BitsAndBytesConfig(load_in_4bit=True), pad_token_id=0)
|
||||
|
||||
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
|
||||
|
||||
@ -472,7 +472,7 @@ for _ in range(5):
|
||||
next_token_id = torch.argmax(next_logits, dim=-1)
|
||||
|
||||
print("shape of input_ids", next_token_id.shape)
|
||||
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
|
||||
print("length of key-value cache", past_key_values.get_seq_length()) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
|
||||
generated_tokens.append(next_token_id.item())
|
||||
|
||||
generated_text = tokenizer.batch_decode(generated_tokens)
|
||||
|
||||
@ -93,7 +93,6 @@ python examples/pytorch/summarization/run_summarization.py \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
@ -117,7 +116,6 @@ torchrun \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
@ -140,7 +138,6 @@ python xla_spawn.py --num_cores 8 \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
@ -197,7 +194,6 @@ python examples/pytorch/summarization/run_summarization.py \
|
||||
--summary_column summary_column_name \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--overwrite_output_dir \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--predict_with_generate
|
||||
@ -225,7 +221,6 @@ python examples/pytorch/summarization/run_summarization.py \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
@ -239,8 +234,6 @@ examples/pytorch/summarization/run_summarization.py -h
|
||||
|
||||
خيار آخر مفيد لتمكينه هو استئناف التدريب من نقطة تفتيش سابقة. سيضمن ذلك أنك تستطيع الاستمرار من حيث توقفت دون البدء من جديد إذا تم مقاطعة تدريبك. هناك طريقتان لاستئناف التدريب من نقطة تفتيش.
|
||||
|
||||
تستخدم الطريقة الأولى المعلمة `output_dir previous_output_dir` لاستئناف التدريب من أحدث نقطة تفتيش مخزنة في `output_dir`. في هذه الحالة، يجب عليك إزالة `overwrite_output_dir`:
|
||||
|
||||
```bash
|
||||
python examples/pytorch/summarization/run_summarization.py
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
@ -252,24 +245,6 @@ python examples/pytorch/summarization/run_summarization.py
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--output_dir previous_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
تستخدم الطريقة الثانية معلمة `resume_from_checkpoint path_to_specific_checkpoint` لاستئناف التدريب من مجلد نقطة تفتيش محددة.
|
||||
|
||||
```bash
|
||||
python examples/pytorch/summarization/run_summarization.py
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--dataset_name cnn_dailymail \
|
||||
--dataset_config "3.0.0" \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--resume_from_checkpoint path_to_specific_checkpoint \
|
||||
--predict_with_generate
|
||||
```
|
||||
@ -301,6 +276,5 @@ python examples/pytorch/summarization/run_summarization.py
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
@ -611,7 +611,6 @@ accelerate launch \
|
||||
--learning_rate 5e-5 \
|
||||
--num_train_epochs 3 \
|
||||
--output_dir /tmp/$TASK_NAME/ \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
يمكنك أيضًا تحديد المعلمات من ملف `config_file.yaml` مباشرة في سطر الأوامر:
|
||||
@ -634,7 +633,6 @@ accelerate launch --num_processes=2 \
|
||||
--learning_rate 5e-5 \
|
||||
--num_train_epochs 3 \
|
||||
--output_dir /tmp/$TASK_NAME/ \
|
||||
--overwrite_output_dir
|
||||
```
|
||||
|
||||
اطلع على برنامج تعليمي [Launching your Accelerate scripts](https://huggingface.co/docs/accelerate/basic_tutorials/launch) لمعرفة المزيد حول `accelerate_launch` والتكوينات المخصصة.
|
||||
|
||||
@ -78,10 +78,10 @@ Wenn Sie an der grundlegenden Verwendung von LLMs interessiert sind, ist unsere
|
||||
Zunächst müssen Sie das Modell laden.
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForCausalLM
|
||||
>>> from transformers import AutoModelForCausalLM, BitsAndBytesConfig
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(
|
||||
... "openlm-research/open_llama_7b", device_map="auto", load_in_4bit=True
|
||||
... "openlm-research/open_llama_7b", device_map="auto", quantization_config=BitsAndBytesConfig(load_in_4bit=True)
|
||||
... )
|
||||
```
|
||||
|
||||
@ -119,12 +119,12 @@ Und das war's! Mit ein paar Zeilen Code können Sie sich die Macht eines LLM zun
|
||||
Es gibt viele [Generierungsstrategien](generation_strategies), und manchmal sind die Standardwerte für Ihren Anwendungsfall vielleicht nicht geeignet. Wenn Ihre Ausgaben nicht mit dem übereinstimmen, was Sie erwarten, haben wir eine Liste der häufigsten Fallstricke erstellt und wie Sie diese vermeiden können.
|
||||
|
||||
```py
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b")
|
||||
>>> tokenizer.pad_token = tokenizer.eos_token # Llama has no pad token by default
|
||||
>>> model = AutoModelForCausalLM.from_pretrained(
|
||||
... "openlm-research/open_llama_7b", device_map="auto", load_in_4bit=True
|
||||
... "openlm-research/open_llama_7b", device_map="auto", quantization_config=BitsAndBytesConfig(load_in_4bit=True)
|
||||
... )
|
||||
```
|
||||
|
||||
|
||||
@ -98,7 +98,6 @@ python examples/pytorch/summarization/run_summarization.py \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
@ -122,7 +121,6 @@ torchrun \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
@ -144,7 +142,6 @@ python xla_spawn.py --num_cores 8 \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
@ -201,7 +198,6 @@ python examples/pytorch/summarization/run_summarization.py \
|
||||
--summary_column summary_column_name \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--overwrite_output_dir \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--predict_with_generate
|
||||
@ -229,7 +225,6 @@ python examples/pytorch/summarization/run_summarization.py \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
@ -243,8 +238,6 @@ examples/pytorch/summarization/run_summarization.py -h
|
||||
|
||||
Eine weitere hilfreiche Option, die Sie aktivieren können, ist die Wiederaufnahme des Trainings von einem früheren Kontrollpunkt aus. Auf diese Weise können Sie im Falle einer Unterbrechung Ihres Trainings dort weitermachen, wo Sie aufgehört haben, ohne von vorne beginnen zu müssen. Es gibt zwei Methoden, um das Training von einem Kontrollpunkt aus wieder aufzunehmen.
|
||||
|
||||
Die erste Methode verwendet das Argument `output_dir previous_output_dir`, um das Training ab dem letzten in `output_dir` gespeicherten Kontrollpunkt wieder aufzunehmen. In diesem Fall sollten Sie `overwrite_output_dir` entfernen:
|
||||
|
||||
```bash
|
||||
python examples/pytorch/summarization/run_summarization.py
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
@ -256,24 +249,6 @@ python examples/pytorch/summarization/run_summarization.py
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--output_dir previous_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
Die zweite Methode verwendet das Argument `Resume_from_checkpoint path_to_specific_checkpoint`, um das Training ab einem bestimmten Checkpoint-Ordner wieder aufzunehmen.
|
||||
|
||||
```bash
|
||||
python examples/pytorch/summarization/run_summarization.py
|
||||
--model_name_or_path google-t5/t5-small \
|
||||
--do_train \
|
||||
--do_eval \
|
||||
--dataset_name cnn_dailymail \
|
||||
--dataset_config "3.0.0" \
|
||||
--source_prefix "summarize: " \
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--resume_from_checkpoint path_to_specific_checkpoint \
|
||||
--predict_with_generate
|
||||
```
|
||||
@ -305,6 +280,5 @@ python examples/pytorch/summarization/run_summarization.py
|
||||
--output_dir /tmp/tst-summarization \
|
||||
--per_device_train_batch_size=4 \
|
||||
--per_device_eval_batch_size=4 \
|
||||
--overwrite_output_dir \
|
||||
--predict_with_generate
|
||||
```
|
||||
|
||||
@ -284,6 +284,8 @@
|
||||
title: Knowledge Distillation for Computer Vision
|
||||
- local: tasks/keypoint_matching
|
||||
title: Keypoint matching
|
||||
- local: tasks/training_vision_backbone
|
||||
title: Training vision models using Backbone API
|
||||
title: Computer vision
|
||||
- sections:
|
||||
- local: tasks/image_captioning
|
||||
@ -544,8 +546,6 @@
|
||||
title: Helium
|
||||
- local: model_doc/herbert
|
||||
title: HerBERT
|
||||
- local: model_doc/hgnet_v2
|
||||
title: HGNet-V2
|
||||
- local: model_doc/hunyuan_v1_dense
|
||||
title: HunYuanDenseV1
|
||||
- local: model_doc/hunyuan_v1_moe
|
||||
@ -1026,6 +1026,8 @@
|
||||
title: CLIPSeg
|
||||
- local: model_doc/clvp
|
||||
title: CLVP
|
||||
- local: model_doc/cwm
|
||||
title: Code World Model (CWM)
|
||||
- local: model_doc/cohere2_vision
|
||||
title: Cohere2Vision
|
||||
- local: model_doc/colpali
|
||||
@ -1186,6 +1188,8 @@
|
||||
title: TVP
|
||||
- local: model_doc/udop
|
||||
title: UDOP
|
||||
- local: model_doc/video_llama_3
|
||||
title: VideoLlama3
|
||||
- local: model_doc/video_llava
|
||||
title: VideoLlava
|
||||
- local: model_doc/vilt
|
||||
|
||||
@ -55,6 +55,7 @@ deepspeed --num_gpus 2 trainer-program.py ...
|
||||
</hfoptions>
|
||||
|
||||
## Order of accelerators
|
||||
|
||||
To select specific accelerators to use and their order, use the environment variable appropriate for your hardware. This is often set on the command line for each run, but can also be added to your `~/.bashrc` or other startup config file.
|
||||
|
||||
For example, if there are 4 accelerators (0, 1, 2, 3) and you only want to run accelerators 0 and 2:
|
||||
|
||||
@ -41,13 +41,13 @@ $$
|
||||
|
||||
The query (`Q`), key (`K`), and value (`V`) matrices are projections from the input embeddings of shape `(b, h, T, d_head)`.
|
||||
|
||||
For causal attention, the mask prevents the model from attending to future tokens. Once a token is processed, its representation never changes with respect to future tokens, which means \\( K_{\text{past}} \\) and \\( V_{\text{past}} \\) can be cached and reused to compute the last token's representation.
|
||||
For causal attention, the mask prevents the model from attending to future tokens. Once a token is processed, its representation never changes with respect to future tokens, which means $ K_{\text{past}} $ and $ V_{\text{past}} $ can be cached and reused to compute the last token's representation.
|
||||
|
||||
$$
|
||||
\text{Attention}(q_t, [\underbrace{k_1, k_2, \dots, k_{t-1}}_{\text{cached}}, k_{t}], [\underbrace{v_1, v_2, \dots, v_{t-1}}_{\text{cached}}, v_{t}])
|
||||
$$
|
||||
|
||||
At inference time, you only need the last token's query to compute the representation \\( x_t \\) that predicts the next token \\( t+1 \\). At each step, the new key and value vectors are **stored** in the cache and **appended** to the past keys and values.
|
||||
At inference time, you only need the last token's query to compute the representation $ x_t $ that predicts the next token $ t+1 $. At each step, the new key and value vectors are **stored** in the cache and **appended** to the past keys and values.
|
||||
|
||||
$$
|
||||
K_{\text{cache}} \leftarrow \text{concat}(K_{\text{past}}, k_t), \quad V_{\text{cache}} \leftarrow \text{concat}(V_{\text{past}}, v_t)
|
||||
@ -59,7 +59,7 @@ Refer to the table below to compare how caching improves efficiency.
|
||||
|
||||
| without caching | with caching |
|
||||
|---|---|
|
||||
| for each step, recompute all previous `K` and `V` | for each step, only compute current `K` and `V`
|
||||
| for each step, recompute all previous `K` and `V` | for each step, only compute current `K` and `V` |
|
||||
| attention cost per step is **quadratic** with sequence length | attention cost per step is **linear** with sequence length (memory grows linearly, but compute/token remains low) |
|
||||
|
||||
## Cache class
|
||||
@ -98,9 +98,10 @@ The example below demonstrates how to create a generation loop with [`DynamicCac
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache, infer_device
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache
|
||||
from accelerate import Accelerator
|
||||
|
||||
device = f"{infer_device()}:0"
|
||||
device = Accelerator().device
|
||||
|
||||
model_id = "meta-llama/Llama-2-7b-chat-hf"
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id, dtype=torch.bfloat16, device_map=device)
|
||||
@ -143,9 +144,10 @@ The generation loop usually takes care of the cache position, but if you're writ
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache, infer_device
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache
|
||||
from accelerate import Accelerator
|
||||
|
||||
device = f"{infer_device()}:0"
|
||||
device = Accelerator().device
|
||||
|
||||
model_id = "meta-llama/Llama-2-7b-chat-hf"
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id, dtype=torch.bfloat16, device_map=device)
|
||||
|
||||
@ -6,13 +6,13 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
This page regroups resources around 🤗 Transformers developed by the community.
|
||||
|
||||
## Community resources:
|
||||
## Community resources
|
||||
|
||||
| Resource | Description | Author |
|
||||
|:----------|:-------------|------:|
|
||||
| [Hugging Face Transformers Glossary Flashcards](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | A set of flashcards based on the [Transformers Docs Glossary](glossary) that has been put into a form which can be easily learned/revised using [Anki](https://apps.ankiweb.net/) an open source, cross platform app specifically designed for long term knowledge retention. See this [Introductory video on how to use the flashcards](https://www.youtube.com/watch?v=Dji_h7PILrw). | [Darigov Research](https://www.darigovresearch.com/) |
|
||||
|
||||
## Community notebooks:
|
||||
## Community notebooks
|
||||
|
||||
| Notebook | Description | Author | |
|
||||
|:----------|:-------------|:-------------|------:|
|
||||
|
||||
@ -593,7 +593,7 @@ To deploy DeepSpeed on multiple GPUs, add `--num_gpus`. You don't need to add `-
|
||||
deepspeed --num_gpus=2 examples/pytorch/translation/run_translation.py \
|
||||
--deepspeed tests/deepspeed/ds_config_zero3.json \
|
||||
--model_name_or_path google-t5/t5-small --per_device_train_batch_size 1 \
|
||||
--output_dir output_dir --overwrite_output_dir --fp16 \
|
||||
--output_dir output_dir --fp16 \
|
||||
--do_train --max_train_samples 500 --num_train_epochs 1 \
|
||||
--dataset_name wmt16 --dataset_config "ro-en" \
|
||||
--source_lang en --target_lang ro
|
||||
@ -616,7 +616,7 @@ To deploy DeepSpeed on a single GPU, add `--num_gpus`. You don't need to add `--
|
||||
deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
|
||||
--deepspeed tests/deepspeed/ds_config_zero2.json \
|
||||
--model_name_or_path google-t5/t5-small --per_device_train_batch_size 1 \
|
||||
--output_dir output_dir --overwrite_output_dir --fp16 \
|
||||
--output_dir output_dir --fp16 \
|
||||
--do_train --max_train_samples 500 --num_train_epochs 1 \
|
||||
--dataset_name wmt16 --dataset_config "ro-en" \
|
||||
--source_lang en --target_lang ro
|
||||
|
||||
@ -16,44 +16,17 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
# ExecuTorch
|
||||
|
||||
[ExecuTorch](https://pytorch.org/executorch/stable/index.html) is a platform that enables PyTorch training and inference programs to be run on mobile and edge devices. It is powered by [torch.compile](https://pytorch.org/docs/stable/torch.compiler.html) and [torch.export](https://pytorch.org/docs/main/export.html) for performance and deployment.
|
||||
[ExecuTorch](https://pytorch.org/executorch/stable/index.html) runs PyTorch models on mobile and edge devices. Export your Transformers models to the ExecuTorch format with [Optimum ExecuTorch](https://github.com/huggingface/optimum-executorch) with the command below.
|
||||
|
||||
You can use ExecuTorch with Transformers with [torch.export](https://pytorch.org/docs/main/export.html). The [`~transformers.convert_and_export_with_cache`] method converts a [`PreTrainedModel`] into an exportable module. Under the hood, it uses [torch.export](https://pytorch.org/docs/main/export.html) to export the model, ensuring compatibility with ExecuTorch.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import LlamaForCausalLM, AutoTokenizer, GenerationConfig
|
||||
from transformers.integrations.executorch import(
|
||||
TorchExportableModuleWithStaticCache,
|
||||
convert_and_export_with_cache
|
||||
)
|
||||
|
||||
generation_config = GenerationConfig(
|
||||
use_cache=True,
|
||||
cache_implementation="static",
|
||||
cache_config={
|
||||
"batch_size": 1,
|
||||
"max_cache_len": 20,
|
||||
}
|
||||
)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-1B", pad_token="</s>", padding_side="right")
|
||||
model = LlamaForCausalLM.from_pretrained("meta-llama/Llama-3.2-1B", device_map="auto", dtype=torch.bfloat16, attn_implementation="sdpa", generation_config=generation_config)
|
||||
|
||||
exported_program = convert_and_export_with_cache(model)
|
||||
```
|
||||
|
||||
The exported PyTorch model is now ready to be used with ExecuTorch. Wrap the model with [`~transformers.TorchExportableModuleWithStaticCache`] to generate text.
|
||||
|
||||
```py
|
||||
prompts = ["Simply put, the theory of relativity states that "]
|
||||
prompt_tokens = tokenizer(prompts, return_tensors="pt", padding=True).to(model.device)
|
||||
prompt_token_ids = prompt_tokens["input_ids"]
|
||||
|
||||
generated_ids = TorchExportableModuleWithStaticCache.generate(
|
||||
exported_program=exported_program, prompt_token_ids=prompt_token_ids, max_new_tokens=20,
|
||||
)
|
||||
generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
|
||||
print(generated_text)
|
||||
['Simply put, the theory of relativity states that 1) the speed of light is the']
|
||||
optimum-cli export executorch \
|
||||
--model "HuggingFaceTB/SmolLM2-135M-Instruct" \
|
||||
--task "text-generation" \
|
||||
--recipe "xnnpack" \
|
||||
--use_custom_sdpa \
|
||||
--use_custom_kv_cache \
|
||||
--qlinear 8da4w \
|
||||
--qembedding 8w \
|
||||
--output_dir="hf_smollm2"
|
||||
```
|
||||
Run `optimum-cli export executorch --help` to see all export options. For detailed export instructions, check the [README](optimum/exporters/executorch/README.md).
|
||||
|
||||
@ -32,9 +32,10 @@ Greedy search works well for tasks with relatively short outputs where creativit
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, infer_device
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
|
||||
inputs = tokenizer("Hugging Face is an open-source company", return_tensors="pt").to(device)
|
||||
@ -54,9 +55,10 @@ Enable multinomial sampling with `do_sample=True` and `num_beams=1`.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, infer_device
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
|
||||
inputs = tokenizer("Hugging Face is an open-source company", return_tensors="pt").to(device)
|
||||
@ -79,9 +81,10 @@ Enable beam search with the `num_beams` parameter (should be greater than 1 othe
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, infer_device
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
|
||||
inputs = tokenizer("Hugging Face is an open-source company", return_tensors="pt").to(device)
|
||||
@ -166,9 +169,10 @@ Enable prompt lookup decoding with the `prompt_lookup_num_tokens` parameter.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, infer_device
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM-1.7B")
|
||||
model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM-1.7B", dtype=torch.float16).to(device)
|
||||
|
||||
@ -15,15 +15,12 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
# Hyperparameter search
|
||||
|
||||
Hyperparameter search discovers an optimal set of hyperparameters that produces the best model performance. [`Trainer`] supports several hyperparameter search backends - [Optuna](https://optuna.readthedocs.io/en/stable/index.html), [SigOpt](https://docs.sigopt.com/), [Weights & Biases](https://docs.wandb.ai/), [Ray Tune](https://docs.ray.io/en/latest/tune/index.html) - through [`~Trainer.hyperparameter_search`] to optimize an objective or even multiple objectives.
|
||||
Hyperparameter search discovers an optimal set of hyperparameters that produces the best model performance. [`Trainer`] supports several hyperparameter search backends - [Optuna](https://optuna.readthedocs.io/en/stable/index.html), [Weights & Biases](https://docs.wandb.ai/), [Ray Tune](https://docs.ray.io/en/latest/tune/index.html) - through [`~Trainer.hyperparameter_search`] to optimize an objective or even multiple objectives.
|
||||
|
||||
This guide will go over how to set up a hyperparameter search for each of the backends.
|
||||
|
||||
> [!WARNING]
|
||||
> [SigOpt](https://github.com/sigopt/sigopt-server) is in public archive mode and is no longer actively maintained. Try using Optuna, Weights & Biases or Ray Tune instead.
|
||||
|
||||
```bash
|
||||
pip install optuna/sigopt/wandb/ray[tune]
|
||||
pip install optuna/wandb/ray[tune]
|
||||
```
|
||||
|
||||
To use [`~Trainer.hyperparameter_search`], you need to create a `model_init` function. This function includes basic model information (arguments and configuration) because it needs to be reinitialized for each search trial in the run.
|
||||
@ -109,31 +106,7 @@ best_trials = trainer.hyperparameter_search(
|
||||
n_trials=20,
|
||||
compute_objective=compute_objective,
|
||||
)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="SigOpt">
|
||||
|
||||
[SigOpt](https://docs.sigopt.com/ai-module-api-references/api_reference/objects/object_parameter) optimizes double, integer, and categorical parameters.
|
||||
|
||||
```py
|
||||
def sigopt_hp_space(trial):
|
||||
return [
|
||||
{"bounds": {"min": 1e-6, "max": 1e-4}, "name": "learning_rate", "type": "double"},
|
||||
{
|
||||
"categorical_values": ["16", "32", "64", "128"],
|
||||
"name": "per_device_train_batch_size",
|
||||
"type": "categorical",
|
||||
},
|
||||
]
|
||||
|
||||
best_trials = trainer.hyperparameter_search(
|
||||
direction=["minimize", "maximize"],
|
||||
backend="sigopt",
|
||||
hp_space=sigopt_hp_space,
|
||||
n_trials=20,
|
||||
compute_objective=compute_objective,
|
||||
)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
@ -166,4 +139,4 @@ best_trials = trainer.hyperparameter_search(
|
||||
|
||||
## Distributed Data Parallel
|
||||
|
||||
[`Trainer`] only supports hyperparameter search for distributed data parallel (DDP) on the Optuna and SigOpt backends. Only the rank-zero process is used to generate the search trial, and the resulting parameters are passed along to the other ranks.
|
||||
[`Trainer`] only supports hyperparameter search for distributed data parallel (DDP) on the Optuna backends. Only the rank-zero process is used to generate the search trial, and the resulting parameters are passed along to the other ranks.
|
||||
|
||||
@ -36,8 +36,6 @@ Explore the [Hub](https://huggingface.com/) today to find a model and use Transf
|
||||
|
||||
Explore the [Models Timeline](./models_timeline) to discover the latest text, vision, audio and multimodal model architectures in Transformers.
|
||||
|
||||
|
||||
|
||||
## Features
|
||||
|
||||
Transformers provides everything you need for inference or training with state-of-the-art pretrained models. Some of the main features include:
|
||||
|
||||
@ -43,4 +43,3 @@ Most of those are only useful if you are studying the general code in the librar
|
||||
## Other Utilities
|
||||
|
||||
[[autodoc]] utils._LazyModule
|
||||
[[autodoc]] pytorch_utils.infer_device
|
||||
|
||||
@ -364,6 +364,7 @@ This utility analyzes code similarities between model implementations to identif
|
||||
When adding a new model to transformers, many components (attention layers, MLPs, outputs, etc.) may already exist in similar form in other models. Instead of implementing everything from scratch, model adders can identify which existing classes are similar and potentially reusable through modularization.
|
||||
|
||||
The tool computes two similarity scores:
|
||||
|
||||
- **Embedding score**: Uses semantic code embeddings (via `Qwen/Qwen3-Embedding-4B`) to detect functionally similar code even with different naming
|
||||
- **Jaccard score**: Measures token set overlap to identify structurally similar code patterns
|
||||
|
||||
|
||||
@ -124,11 +124,12 @@ The example below shows how you can fallback to an offloaded cache if you run ou
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, infer_device
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
from accelerate import Accelerator
|
||||
|
||||
def resilient_generate(model, *args, **kwargs):
|
||||
oom = False
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
torch_device_module = getattr(torch, device, torch.cuda)
|
||||
try:
|
||||
return model.generate(*args, **kwargs)
|
||||
@ -207,7 +208,7 @@ Some models have a unique way of storing past kv pairs or states that is not com
|
||||
|
||||
Mamba models, such as [Mamba](./model_doc/mamba), require a specific cache because the model doesn't have an attention mechanism or kv states. Thus, they are not compatible with the above [`Cache`] classes.
|
||||
|
||||
# Iterative generation
|
||||
## Iterative generation
|
||||
|
||||
A cache can also work in iterative generation settings where there is back-and-forth interaction with a model (chatbots). Like regular generation, iterative generation with a cache allows a model to efficiently handle ongoing conversations without recomputing the entire context at each step.
|
||||
|
||||
|
||||
@ -114,7 +114,8 @@ print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
|
||||
Another option for using [`StaticCache`] is to pass it to a models forward pass using the same `past_key_values` argument. This allows you to write your own custom decoding function to decode the next token given the current token, position, and cache position of previously generated tokens.
|
||||
|
||||
```py
|
||||
from transformers import LlamaTokenizer, LlamaForCausalLM, StaticCache, logging, infer_device
|
||||
from transformers import LlamaTokenizer, LlamaForCausalLM, StaticCache, logging
|
||||
from accelerate import Accelerator
|
||||
from transformers.testing_utils import CaptureLogger
|
||||
import torch
|
||||
|
||||
@ -124,7 +125,7 @@ prompts = [
|
||||
]
|
||||
|
||||
NUM_TOKENS_TO_GENERATE = 40
|
||||
torch_device = infer_device()
|
||||
torch_device = Accelerator().device
|
||||
|
||||
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", pad_token="</s>", padding_side="right")
|
||||
model = LlamaForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", device_map="sequential")
|
||||
@ -208,10 +209,11 @@ Enable speculative decoding by loading an assistant model and passing it to [`~G
|
||||
<hfoption id="greedy search">
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, infer_device
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
import torch
|
||||
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
|
||||
inputs = tokenizer("Einstein's theory of relativity states", return_tensors="pt").to(device)
|
||||
@ -229,10 +231,11 @@ tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
For speculative sampling decoding, add the [do_sample](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationConfig.do_sample) and [temperature](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationConfig.temperature) parameters to [`~GenerationMixin.generate`].
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, infer_device
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
import torch
|
||||
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
|
||||
inputs = tokenizer("Einstein's theory of relativity states", return_tensors="pt").to(device)
|
||||
@ -257,10 +260,11 @@ To enable prompt lookup decoding, specify the number of tokens that should be ov
|
||||
<hfoption id="greedy decoding">
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, infer_device
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
import torch
|
||||
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
|
||||
inputs = tokenizer("The second law of thermodynamics states", return_tensors="pt").to(device)
|
||||
@ -278,10 +282,11 @@ print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
|
||||
For prompt lookup decoding with sampling, add the [do_sample](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationConfig.do_sample) and [temperature](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationConfig.temperature) parameters to [`~GenerationMixin.generate`].
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, infer_device
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
import torch
|
||||
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
|
||||
inputs = tokenizer("The second law of thermodynamics states", return_tensors="pt").to(device)
|
||||
|
||||
@ -259,11 +259,11 @@ Some models and tasks expect a certain input prompt format, and if the format is
|
||||
For example, a chat model expects the input as a [chat template](./chat_templating). Your prompt should include a `role` and `content` to indicate who is participating in the conversation. If you try to pass your prompt as a single string, the model doesn't always return the expected output.
|
||||
|
||||
```py
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
"HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
|
||||
"HuggingFaceH4/zephyr-7b-alpha", device_map="auto", quantization_config=BitsAndBytesConfig(load_in_4bit=True)
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
@ -16,18 +16,18 @@ rendered properly in your Markdown viewer.
|
||||
Large Language Models (LLMs) such as GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), and [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf) are rapidly advancing in their ability to tackle human-centric tasks, establishing themselves as essential tools in modern knowledge-based industries.
|
||||
Deploying these models in real-world tasks remains challenging, however:
|
||||
|
||||
- To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://huggingface.co/papers/2001.08361), [Wei et. al](https://huggingface.co/papers/2206.07682)). This consequently amplifies the memory demands for inference.
|
||||
- In many real-world tasks, LLMs need to be given extensive contextual information. This necessitates the model's capability to manage very long input sequences during inference.
|
||||
- To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://huggingface.co/papers/2001.08361), [Wei et. al](https://huggingface.co/papers/2206.07682)). This consequently amplifies the memory demands for inference.
|
||||
- In many real-world tasks, LLMs need to be given extensive contextual information. This necessitates the model's capability to manage very long input sequences during inference.
|
||||
|
||||
The crux of these challenges lies in augmenting the computational and memory capabilities of LLMs, especially when handling expansive input sequences.
|
||||
|
||||
In this guide, we will go over the effective techniques for efficient LLM deployment:
|
||||
|
||||
1. **Lower Precision:** Research has shown that operating at reduced numerical precision, namely [8-bit and 4-bit](./main_classes/quantization) can achieve computational advantages without a considerable decline in model performance.
|
||||
1. **Lower Precision:** Research has shown that operating at reduced numerical precision, namely [8-bit and 4-bit](./main_classes/quantization) can achieve computational advantages without a considerable decline in model performance.
|
||||
|
||||
2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
|
||||
2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
|
||||
|
||||
3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://huggingface.co/papers/2108.12409), [Rotary embeddings](https://huggingface.co/papers/2104.09864), [Multi-Query Attention (MQA)](https://huggingface.co/papers/1911.02150) and [Grouped-Query-Attention (GQA)](https://huggingface.co/papers/2305.13245).
|
||||
3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://huggingface.co/papers/2108.12409), [Rotary embeddings](https://huggingface.co/papers/2104.09864), [Multi-Query Attention (MQA)](https://huggingface.co/papers/1911.02150) and [Grouped-Query-Attention (GQA)](https://huggingface.co/papers/2305.13245).
|
||||
|
||||
Throughout this guide, we will offer an analysis of auto-regressive generation from a tensor's perspective. We delve into the pros and cons of adopting lower precision, provide a comprehensive exploration of the latest attention algorithms, and discuss improved LLM architectures. While doing so, we run practical examples showcasing each of the feature improvements.
|
||||
|
||||
@ -37,22 +37,22 @@ Memory requirements of LLMs can be best understood by seeing the LLM as a set of
|
||||
|
||||
At the time of writing this guide, LLMs consist of at least a couple billion parameters. Each parameter thereby is made of a decimal number, e.g. `4.5689` which is usually stored in either [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format), [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format), or [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) format. This allows us to easily compute the memory requirement to load the LLM into memory:
|
||||
|
||||
> *Loading the weights of a model having X billion parameters requires roughly 4 * X GB of VRAM in float32 precision*
|
||||
> *Loading the weights of a model having X billion parameters requires roughly 4 \* X GB of VRAM in float32 precision*
|
||||
|
||||
Nowadays, models are however rarely trained in full float32 precision, but usually in bfloat16 precision or less frequently in float16 precision. Therefore the rule of thumb becomes:
|
||||
|
||||
> *Loading the weights of a model having X billion parameters requires roughly 2 * X GB of VRAM in bfloat16/float16 precision*
|
||||
> *Loading the weights of a model having X billion parameters requires roughly 2 \* X GB of VRAM in bfloat16/float16 precision*
|
||||
|
||||
For shorter text inputs (less than 1024 tokens), the memory requirement for inference is very much dominated by the memory requirement to load the weights. Therefore, for now, let's assume that the memory requirement for inference is equal to the memory requirement to load the model into the GPU VRAM.
|
||||
|
||||
To give some examples of how much VRAM it roughly takes to load a model in bfloat16:
|
||||
|
||||
- **GPT3** requires 2 \* 175 GB = **350 GB** VRAM
|
||||
- [**Bloom**](https://huggingface.co/bigscience/bloom) requires 2 \* 176 GB = **352 GB** VRAM
|
||||
- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) requires 2 \* 70 GB = **140 GB** VRAM
|
||||
- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) requires 2 \* 40 GB = **80 GB** VRAM
|
||||
- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) requires 2 \* 30 GB = **60 GB** VRAM
|
||||
- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) requires 2 \* 15.5 = **31 GB** VRAM
|
||||
- **GPT3** requires 2 \* 175 GB = **350 GB** VRAM
|
||||
- [**Bloom**](https://huggingface.co/bigscience/bloom) requires 2 \* 176 GB = **352 GB** VRAM
|
||||
- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) requires 2 \* 70 GB = **140 GB** VRAM
|
||||
- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) requires 2 \* 40 GB = **80 GB** VRAM
|
||||
- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) requires 2 \* 30 GB = **60 GB** VRAM
|
||||
- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) requires 2 \* 15.5 = **31 GB** VRAM
|
||||
|
||||
As of writing this document, the largest GPU chip on the market is the A100 & H100 offering 80GB of VRAM. Most of the models listed before require more than 80GB just to be loaded and therefore necessarily require [tensor parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) and/or [pipeline parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
|
||||
|
||||
@ -169,11 +169,11 @@ All that matters is that the next token *logit* distribution stays roughly the s
|
||||
|
||||
There are various quantization techniques, which we won't discuss in detail here, but in general, all quantization techniques work as follows:
|
||||
|
||||
- 1. Quantize all weights to the target precision
|
||||
- 2. Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision
|
||||
- 3. Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision
|
||||
- 1. Quantize all weights to the target precision
|
||||
- 2. Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision
|
||||
- 3. Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision
|
||||
|
||||
In a nutshell, this means that *inputs-weight matrix* multiplications, with \\( X \\) being the *inputs*, \\( W \\) being a weight matrix and \\( Y \\) being the output:
|
||||
In a nutshell, this means that *inputs-weight matrix* multiplications, with $X$ being the *inputs*, $W$ being a weight matrix and $Y$ being the output:
|
||||
|
||||
$$ Y = X * W $$
|
||||
|
||||
@ -194,7 +194,7 @@ the [`bitsandbytes`](https://github.com/bitsandbytes-foundation/bitsandbytes) li
|
||||
We can then load models in 8-bit quantization by simply adding a `load_in_8bit=True` flag to `from_pretrained`.
|
||||
|
||||
```python
|
||||
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
|
||||
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", quantization_config=BitsAndBytesConfig(load_in_8bit=True), pad_token_id=0)
|
||||
```
|
||||
|
||||
Now, let's run our example again and measure the memory usage.
|
||||
@ -241,7 +241,7 @@ flush()
|
||||
Let's see what peak GPU memory consumption 4-bit quantization gives. Quantizing the model to 4-bit can be done with the same API as before - this time by passing `load_in_4bit=True` instead of `load_in_8bit=True`.
|
||||
|
||||
```python
|
||||
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, pad_token_id=0)
|
||||
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", quantization_config=BitsAndBytesConfig(load_in_4bit=True), pad_token_id=0)
|
||||
|
||||
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
|
||||
|
||||
@ -271,7 +271,7 @@ Just 9.5GB! That's really not a lot for a >15 billion parameter model.
|
||||
|
||||
While we see very little degradation in accuracy for our model here, 4-bit quantization can in practice often lead to different results compared to 8-bit quantization or full `bfloat16` inference. It is up to the user to try it out.
|
||||
|
||||
Also note that inference here was again a bit slower compared to 8-bit quantization which is due to the more aggressive quantization method used for 4-bit quantization leading to \\( \text{quantize} \\) and \\( \text{dequantize} \\) taking longer during inference.
|
||||
Also note that inference here was again a bit slower compared to 8-bit quantization which is due to the more aggressive quantization method used for 4-bit quantization leading to $\text{quantize}$ and $\text{dequantize}$ taking longer during inference.
|
||||
|
||||
```python
|
||||
del model
|
||||
@ -300,41 +300,41 @@ Next, let's look into how we can improve computational and memory efficiency by
|
||||
Today's top-performing LLMs share more or less the same fundamental architecture that consists of feed-forward layers, activation layers, layer normalization layers, and most crucially, self-attention layers.
|
||||
|
||||
Self-attention layers are central to Large Language Models (LLMs) in that they enable the model to understand the contextual relationships between input tokens.
|
||||
However, the peak GPU memory consumption for self-attention layers grows *quadratically* both in compute and memory complexity with number of input tokens (also called *sequence length*) that we denote in the following by \\( N \\) .
|
||||
However, the peak GPU memory consumption for self-attention layers grows *quadratically* both in compute and memory complexity with number of input tokens (also called *sequence length*) that we denote in the following by $N$ .
|
||||
While this is not really noticeable for shorter input sequences (of up to 1000 input tokens), it becomes a serious problem for longer input sequences (at around 16000 input tokens).
|
||||
|
||||
Let's take a closer look. The formula to compute the output \\( \mathbf{O} \\) of a self-attention layer for an input \\( \mathbf{X} \\) of length \\( N \\) is:
|
||||
Let's take a closer look. The formula to compute the output $\mathbf{O}$ of a self-attention layer for an input $\mathbf{X}$ of length $N$ is:
|
||||
|
||||
$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
|
||||
|
||||
\\( \mathbf{X} = (\mathbf{x}_1, ... \mathbf{x}_{N}) \\) is thereby the input sequence to the attention layer. The projections \\( \mathbf{Q} \\) and \\( \mathbf{K} \\) will each consist of \\( N \\) vectors resulting in the \\( \mathbf{QK}^T \\) being of size \\( N^2 \\) .
|
||||
$\mathbf{X} = (\mathbf{x}_1, ... \mathbf{x}_{N})$ is thereby the input sequence to the attention layer. The projections $\mathbf{Q}$ and $\mathbf{K}$ will each consist of $N$ vectors resulting in the $\mathbf{QK}^T$ being of size $N^2$ .
|
||||
|
||||
LLMs usually have multiple attention heads, thus doing multiple self-attention computations in parallel.
|
||||
Assuming, the LLM has 40 attention heads and runs in bfloat16 precision, we can calculate the memory requirement to store the \\( \mathbf{QK^T} \\) matrices to be \\( 40 * 2 * N^2 \\) bytes. For \\( N=1000 \\) only around 50 MB of VRAM are needed, however, for \\( N=16000 \\) we would need 19 GB of VRAM, and for \\( N=100,000 \\) we would need almost 1TB just to store the \\( \mathbf{QK}^T \\) matrices.
|
||||
Assuming, the LLM has 40 attention heads and runs in bfloat16 precision, we can calculate the memory requirement to store the $\mathbf{QK^T}$ matrices to be $40 * 2 * N^2$ bytes. For $N=1000$ only around 50 MB of VRAM are needed, however, for $N=16000$ we would need 19 GB of VRAM, and for $N=100,000$ we would need almost 1TB just to store the $\mathbf{QK}^T$ matrices.
|
||||
|
||||
Long story short, the default self-attention algorithm quickly becomes prohibitively memory-expensive for large input contexts.
|
||||
|
||||
As LLMs improve in text comprehension and generation, they are applied to increasingly complex tasks. While models once handled the translation or summarization of a few sentences, they now manage entire pages, demanding the capability to process extensive input lengths.
|
||||
|
||||
How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the \\( QK^T \\) matrix. [Tri Dao et al.](https://huggingface.co/papers/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**.
|
||||
How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the $\mathbf{QK}^T$ matrix. [Tri Dao et al.](https://huggingface.co/papers/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**.
|
||||
|
||||
In a nutshell, Flash Attention breaks the \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps:
|
||||
In a nutshell, Flash Attention breaks the $\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T)$ computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps:
|
||||
|
||||
$$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \times \text{Softmax}(\mathbf{QK}^T_{i,j}) \text{ for multiple } i, j \text{ iterations} $$
|
||||
|
||||
with \\( s^a_{ij} \\) and \\( s^b_{ij} \\) being some softmax normalization statistics that need to be recomputed for every \\( i \\) and \\( j \\) .
|
||||
with $s^a_{ij}$ and $s^b_{ij}$ being some softmax normalization statistics that need to be recomputed for every $i$ and $j$ .
|
||||
|
||||
Please note that the whole Flash Attention is a bit more complex and is greatly simplified here as going in too much depth is out of scope for this guide. The reader is invited to take a look at the well-written [Flash Attention paper](https://huggingface.co/papers/2205.14135) for more details.
|
||||
|
||||
The main takeaway here is:
|
||||
|
||||
> By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives **numerical identical** outputs compared to the default self-attention layer at a memory cost that only increases linearly with \\( N \\) .
|
||||
> By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives **numerical identical** outputs compared to the default self-attention layer at a memory cost that only increases linearly with $N$ .
|
||||
|
||||
Looking at the formula, one would intuitively say that Flash Attention must be much slower compared to the default self-attention formula as more computation needs to be done. Indeed Flash Attention requires more FLOPs compared to normal attention as the softmax normalization statistics have to constantly be recomputed (see [paper](https://huggingface.co/papers/2205.14135) for more details if interested)
|
||||
|
||||
> However, Flash Attention is much faster in inference compared to default attention which comes from its ability to significantly reduce the demands on the slower, high-bandwidth memory of the GPU (VRAM), focusing instead on the faster on-chip memory (SRAM).
|
||||
|
||||
Essentially, Flash Attention makes sure that all intermediate write and read operations can be done using the fast *on-chip* SRAM memory instead of having to access the slower VRAM memory to compute the output vector \\( \mathbf{O} \\) .
|
||||
Essentially, Flash Attention makes sure that all intermediate write and read operations can be done using the fast *on-chip* SRAM memory instead of having to access the slower VRAM memory to compute the output vector $\mathbf{O}$ .
|
||||
|
||||
In practice, there is currently absolutely no reason to **not** use Flash Attention if available. The algorithm gives mathematically the same outputs, and is both faster and more memory-efficient.
|
||||
|
||||
@ -342,74 +342,75 @@ In practice, there is currently absolutely no reason to **not** use Flash Attent
|
||||
|
||||
So far we have looked into improving computational and memory efficiency by:
|
||||
|
||||
- Casting the weights to a lower precision format
|
||||
- Replacing the self-attention algorithm with a more memory- and compute efficient version
|
||||
- Casting the weights to a lower precision format
|
||||
- Replacing the self-attention algorithm with a more memory- and compute efficient version
|
||||
|
||||
Let's now look into how we can change the architecture of an LLM so that it is most effective and efficient for task that require long text inputs, *e.g.*:
|
||||
- Retrieval augmented Questions Answering,
|
||||
- Summarization,
|
||||
- Chat
|
||||
Let's now look into how we can change the architecture of an LLM so that it is most effective and efficient for tasks that require long text inputs, *e.g.*:
|
||||
|
||||
- Retrieval augmented Questions Answering,
|
||||
- Summarization,
|
||||
- Chat
|
||||
|
||||
Note that *chat* not only requires the LLM to handle long text inputs, but it also necessitates that the LLM is able to efficiently handle the back-and-forth dialogue between user and assistant (such as ChatGPT).
|
||||
|
||||
Once trained, the fundamental LLM architecture is difficult to change, so it is important to make considerations about the LLM's tasks beforehand and accordingly optimize the model's architecture.
|
||||
There are two important components of the model architecture that quickly become memory and/or performance bottlenecks for large input sequences.
|
||||
|
||||
- The positional embeddings
|
||||
- The key-value cache
|
||||
- The positional embeddings
|
||||
- The key-value cache
|
||||
|
||||
Let's go over each component in more detail
|
||||
|
||||
### 3.1 Improving positional embeddings of LLMs
|
||||
|
||||
Self-attention puts each token in relation to each other's tokens.
|
||||
As an example, the \\( \text{Softmax}(\mathbf{QK}^T) \\) matrix of the text input sequence *"Hello", "I", "love", "you"* could look as follows:
|
||||
As an example, the $\text{Softmax}(\mathbf{QK}^T)$ matrix of the text input sequence *"Hello", "I", "love", "you"* could look as follows:
|
||||
|
||||

|
||||
|
||||
Each word token is given a probability mass at which it attends all other word tokens and, therefore is put into relation with all other word tokens. E.g. the word *"love"* attends to the word *"Hello"* with 5%, to *"I"* with 30%, and to itself with 65%.
|
||||
|
||||
A LLM based on self-attention, but without position embeddings would have great difficulties in understanding the positions of the text inputs to each other.
|
||||
This is because the probability score computed by \\( \mathbf{QK}^T \\) relates each word token to each other word token in \\( O(1) \\) computations regardless of their relative positional distance to each other.
|
||||
This is because the probability score computed by $\mathbf{QK}^T$ relates each word token to each other word token in $O(1)$ computations regardless of their relative positional distance to each other.
|
||||
Therefore, for the LLM without position embeddings each token appears to have the same distance to all other tokens, *e.g.* differentiating between *"Hello I love you"* and *"You love I hello"* would be very challenging.
|
||||
|
||||
For the LLM to understand sentence order, an additional *cue* is needed and is usually applied in the form of *positional encodings* (or also called *positional embeddings*).
|
||||
Positional encodings, encode the position of each token into a numerical presentation that the LLM can leverage to better understand sentence order.
|
||||
|
||||
The authors of the [*Attention Is All You Need*](https://huggingface.co/papers/1706.03762) paper introduced sinusoidal positional embeddings \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) .
|
||||
where each vector \\( \mathbf{p}_i \\) is computed as a sinusoidal function of its position \\( i \\) .
|
||||
The positional encodings are then simply added to the input sequence vectors \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) thereby cueing the model to better learn sentence order.
|
||||
The authors of the [*Attention Is All You Need*](https://huggingface.co/papers/1706.03762) paper introduced sinusoidal positional embeddings $\mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N$ .
|
||||
where each vector $\mathbf{p}_i$ is computed as a sinusoidal function of its position $i$ .
|
||||
The positional encodings are then simply added to the input sequence vectors $\mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N$ = $\mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N$ thereby cueing the model to better learn sentence order.
|
||||
|
||||
Instead of using fixed position embeddings, others (such as [Devlin et al.](https://huggingface.co/papers/1810.04805)) used learned positional encodings for which the positional embeddings
|
||||
\\( \mathbf{P} \\) are learned during training.
|
||||
$\mathbf{P}$ are learned during training.
|
||||
|
||||
Sinusoidal and learned position embeddings used to be the predominant methods to encode sentence order into LLMs, but a couple of problems related to these positional encodings were found:
|
||||
|
||||
1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: \\( 0, \ldots, N \\) . As shown by [Huang et al.](https://huggingface.co/papers/2009.13658) and [Su et al.](https://huggingface.co/papers/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position.
|
||||
2. When using learned position embeddings, the LLM has to be trained on a fixed input length \\( N \\), which makes it difficult to extrapolate to an input length longer than what it was trained on.
|
||||
1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: $0, \ldots, N$ . As shown by [Huang et al.](https://huggingface.co/papers/2009.13658) and [Su et al.](https://huggingface.co/papers/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position.
|
||||
2. When using learned position embeddings, the LLM has to be trained on a fixed input length $N$, which makes it difficult to extrapolate to an input length longer than what it was trained on.
|
||||
|
||||
Recently, relative positional embeddings that can tackle the above mentioned problems have become more popular, most notably:
|
||||
|
||||
- [Rotary Position Embedding (RoPE)](https://huggingface.co/papers/2104.09864)
|
||||
- [ALiBi](https://huggingface.co/papers/2108.12409)
|
||||
- [Rotary Position Embedding (RoPE)](https://huggingface.co/papers/2104.09864)
|
||||
- [ALiBi](https://huggingface.co/papers/2108.12409)
|
||||
|
||||
Both *RoPE* and *ALiBi* argue that it's best to cue the LLM about sentence order directly in the self-attention algorithm as it's there that word tokens are put into relation with each other. More specifically, sentence order should be cued by modifying the \\( \mathbf{QK}^T \\) computation.
|
||||
Both *RoPE* and *ALiBi* argue that it's best to cue the LLM about sentence order directly in the self-attention algorithm as it's there that word tokens are put into relation with each other. More specifically, sentence order should be cued by modifying the $\mathbf{QK}^T$ computation.
|
||||
|
||||
Without going into too many details, *RoPE* notes that positional information can be encoded into query-key pairs, *e.g.* \\( \mathbf{q}_i \\) and \\( \mathbf{x}_j \\) by rotating each vector by an angle \\( \theta * i \\) and \\( \theta * j \\) respectively with \\( i, j \\) describing each vectors sentence position:
|
||||
Without going into too many details, *RoPE* notes that positional information can be encoded into query-key pairs, *e.g.* $\mathbf{q}_i$ and $\mathbf{x}_j$ by rotating each vector by an angle $\theta * i$ and $\theta * j$ respectively with $i, j$ describing each vectors sentence position:
|
||||
|
||||
$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta, i -j} \mathbf{{x}}_j. $$
|
||||
|
||||
\\( \mathbf{R}_{\theta, i - j} \\) thereby represents a rotational matrix. \\( \theta \\) is *not* learned during training, but instead set to a pre-defined value that depends on the maximum input sequence length during training.
|
||||
$\mathbf{R}_{\theta, i - j}$ thereby represents a rotational matrix. $\theta$ is *not* learned during training, but instead set to a pre-defined value that depends on the maximum input sequence length during training.
|
||||
|
||||
> By doing so, the probability score between \\( \mathbf{q}_i \\) and \\( \mathbf{q}_j \\) is only affected if \\( i \ne j \\) and solely depends on the relative distance \\( i - j \\) regardless of each vector's specific positions \\( i \\) and \\( j \\) .
|
||||
> By doing so, the probability score between $\mathbf{q}_i$ and $\mathbf{q}_j$ is only affected if $i \ne j$ and solely depends on the relative distance $i - j$ regardless of each vector's specific positions $i$ and $j$ .
|
||||
|
||||
*RoPE* is used in multiple of today's most important LLMs, such as:
|
||||
|
||||
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
|
||||
- [**Llama**](https://huggingface.co/papers/2302.13971)
|
||||
- [**PaLM**](https://huggingface.co/papers/2204.02311)
|
||||
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
|
||||
- [**Llama**](https://huggingface.co/papers/2302.13971)
|
||||
- [**PaLM**](https://huggingface.co/papers/2204.02311)
|
||||
|
||||
As an alternative, *ALiBi* proposes a much simpler relative position encoding scheme. The relative distance that input tokens have to each other is added as a negative integer scaled by a pre-defined value `m` to each query-key entry of the \\( \mathbf{QK}^T \\) matrix right before the softmax computation.
|
||||
As an alternative, *ALiBi* proposes a much simpler relative position encoding scheme. The relative distance that input tokens have to each other is added as a negative integer scaled by a pre-defined value `m` to each query-key entry of the $\mathbf{QK}^T$ matrix right before the softmax computation.
|
||||
|
||||

|
||||
|
||||
@ -417,19 +418,20 @@ As shown in the [ALiBi](https://huggingface.co/papers/2108.12409) paper, this si
|
||||
|
||||
*ALiBi* is used in multiple of today's most important LLMs, such as:
|
||||
|
||||
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
|
||||
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
|
||||
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
|
||||
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
|
||||
|
||||
Both *RoPE* and *ALiBi* position encodings can extrapolate to input lengths not seen during training whereas it has been shown that extrapolation works much better out-of-the-box for *ALiBi* as compared to *RoPE*.
|
||||
For ALiBi, one simply increases the values of the lower triangular position matrix to match the length of the input sequence.
|
||||
For *RoPE*, keeping the same \\( \theta \\) that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://huggingface.co/papers/2108.12409). However, the community has found a couple of effective tricks that adapt \\( \theta \\), thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)).
|
||||
For *RoPE*, keeping the same $\theta$ that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://huggingface.co/papers/2108.12409). However, the community has found a couple of effective tricks that adapt $\theta$, thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)).
|
||||
|
||||
> Both RoPE and ALiBi are relative positional embeddings that are *not* learned during training, but instead are based on the following intuitions:
|
||||
- Positional cues about the text inputs should be given directly to the \\( QK^T \\) matrix of the self-attention layer
|
||||
- The LLM should be incentivized to learn a constant *relative* distance positional encodings have to each other
|
||||
- The further text input tokens are from each other, the lower the probability of their query-value probability. Both RoPE and ALiBi lower the query-key probability of tokens far away from each other. RoPE by decreasing their vector product by increasing the angle between the query-key vectors. ALiBi by adding large negative numbers to the vector product
|
||||
|
||||
In conclusion, LLMs that are intended to be deployed in tasks that require handling large text inputs are better trained with relative positional embeddings, such as RoPE and ALiBi. Also note that even if an LLM with RoPE and ALiBi has been trained only on a fixed length of say \\( N_1 = 2048 \\) it can still be used in practice with text inputs much larger than \\( N_1 \\), like \\( N_2 = 8192 > N_1 \\) by extrapolating the positional embeddings.
|
||||
- Positional cues about the text inputs should be given directly to the $\mathbf{QK}^T$ matrix of the self-attention layer.
|
||||
- The LLM should be incentivized to learn a constant *relative* distance positional encoding.
|
||||
- The further text input tokens are from each other, the lower the probability of their query-value probability. Both RoPE and ALiBi lower the query-key probability of tokens far away from each other. RoPE lowers by decreasing their vector product by increasing the angle between the query-key vectors. ALiBi lowers by adding large negative numbers to the vector product.
|
||||
|
||||
In conclusion, LLMs that are intended to be deployed in tasks that require handling large text inputs are better trained with relative positional embeddings, such as RoPE and ALiBi. Also note that even if an LLM with RoPE and ALiBi has been trained only on a fixed length of say $N_1 = 2048$ it can still be used in practice with text inputs much larger than $N_1$, like $N_2 = 8192 > N_1$ by extrapolating the positional embeddings.
|
||||
|
||||
### 3.2 The key-value cache
|
||||
|
||||
@ -468,7 +470,7 @@ As we can see every time we increase the text input tokens by the just sampled t
|
||||
|
||||
With very few exceptions, LLMs are trained using the [causal language modeling objective](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling) and therefore mask the upper triangle matrix of the attention score - this is why in the two diagrams above the attention scores are left blank (*a.k.a* have 0 probability). For a quick recap on causal language modeling you can refer to the [*Illustrated Self Attention blog*](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention).
|
||||
|
||||
As a consequence, tokens *never* depend on previous tokens, more specifically the \\( \mathbf{q}_i \\) vector is never put in relation with any key, values vectors \\( \mathbf{k}_j, \mathbf{v}_j \\) if \\( j > i \\) . Instead \\( \mathbf{q}_i \\) only attends to previous key-value vectors \\( \mathbf{k}_{m < i}, \mathbf{v}_{m < i} \text{ , for } m \in \{0, \ldots i - 1\} \\). In order to reduce unnecessary computation, one can therefore cache each layer's key-value vectors for all previous timesteps.
|
||||
As a consequence, tokens *never* depend on later tokens, more specifically the $\mathbf{q}_i$ vector is never put in relation with any key, values vectors $\mathbf{k}_j, \mathbf{v}_j$ if $j > i$ . Instead $\mathbf{q}_i$ only attends to previous key-value vectors $\mathbf{k}_{m < i}, \mathbf{v}_{m < i} \text{ , for } m \in \{0, \ldots i - 1\}$. In order to reduce unnecessary computation, one can therefore cache each layer's key-value vectors for all previous timesteps.
|
||||
|
||||
In the following, we will tell the LLM to make use of the key-value cache by retrieving and forwarding it for each forward pass.
|
||||
In Transformers, we can retrieve the key-value cache by passing the `use_cache` flag to the `forward` call and can then pass it with the current token.
|
||||
@ -484,7 +486,7 @@ for _ in range(5):
|
||||
next_token_id = torch.argmax(next_logits, dim=-1)
|
||||
|
||||
print("shape of input_ids", next_token_id.shape)
|
||||
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
|
||||
print("length of key-value cache", past_key_values.get_seq_length()) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
|
||||
generated_tokens.append(next_token_id.item())
|
||||
|
||||
generated_text = tokenizer.batch_decode(generated_tokens)
|
||||
@ -509,11 +511,12 @@ length of key-value cache 24
|
||||
|
||||
As one can see, when using the key-value cache the text input tokens are *not* increased in length, but remain a single input vector. The length of the key-value cache on the other hand is increased by one at every decoding step.
|
||||
|
||||
> Making use of the key-value cache means that the \\( \mathbf{QK}^T \\) is essentially reduced to \\( \mathbf{q}_c\mathbf{K}^T \\) with \\( \mathbf{q}_c \\) being the query projection of the currently passed input token which is *always* just a single vector.
|
||||
> Making use of the key-value cache means that the $\mathbf{QK}^T$ is essentially reduced to $\mathbf{q}_c\mathbf{K}^T$ with $\mathbf{q}_c$ being the query projection of the currently passed input token which is *always* just a single vector.
|
||||
|
||||
Using the key-value cache has two advantages:
|
||||
- Significant increase in computational efficiency as less computations are performed compared to computing the full \\( \mathbf{QK}^T \\) matrix. This leads to an increase in inference speed
|
||||
- The maximum required memory is not increased quadratically with the number of generated tokens, but only increases linearly.
|
||||
|
||||
- Significant increase in computational efficiency as less computations are performed compared to computing the full $\mathbf{QK}^T$ matrix. This leads to an increase in inference speed
|
||||
- The maximum required memory is not increased quadratically with the number of generated tokens, but only increases linearly.
|
||||
|
||||
> One should *always* make use of the key-value cache as it leads to identical results and a significant speed-up for longer input sequences. Transformers has the key-value cache enabled by default when making use of the text pipeline or the [`generate` method](https://huggingface.co/docs/transformers/main_classes/text_generation). We have an entire guide dedicated to caches [here](./kv_cache).
|
||||
|
||||
@ -535,10 +538,12 @@ Assistant: Germany has ca. 81 million inhabitants
|
||||
```
|
||||
|
||||
In this chat, the LLM runs auto-regressive decoding twice:
|
||||
|
||||
1. The first time, the key-value cache is empty and the input prompt is `"User: How many people live in France?"` and the model auto-regressively generates the text `"Roughly 75 million people live in France"` while increasing the key-value cache at every decoding step.
|
||||
2. The second time the input prompt is `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`. Thanks to the cache, all key-value vectors for the first two sentences are already computed. Therefore the input prompt only consists of `"User: And how many in Germany?"`. While processing the shortened input prompt, its computed key-value vectors are concatenated to the key-value cache of the first decoding. The second Assistant's answer `"Germany has ca. 81 million inhabitants"` is then auto-regressively generated with the key-value cache consisting of encoded key-value vectors of `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`.
|
||||
|
||||
Two things should be noted here:
|
||||
|
||||
1. Keeping all the context is crucial for LLMs deployed in chat so that the LLM understands all the previous context of the conversation. E.g. for the example above the LLM needs to understand that the user refers to the population when asking `"And how many are in Germany"`.
|
||||
2. The key-value cache is extremely useful for chat as it allows us to continuously grow the encoded chat history instead of having to re-encode the chat history again from scratch (as e.g. would be the case when using an encoder-decoder architecture).
|
||||
|
||||
@ -574,7 +579,7 @@ def bytes_to_megabytes(bytes):
|
||||
Answer: The function takes a number of bytes as input and returns the number of
|
||||
```
|
||||
|
||||
Great, no additional time is spent recomputing the same key and values for the attention layer! There is however one catch. While the required peak memory for the \\( \mathbf{QK}^T \\) matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors \\( \mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\} \\) for all self-attention layers and for all attention heads.
|
||||
Great, no additional time is spent recomputing the same key and values for the attention layer! There is however one catch. While the required peak memory for the $\mathbf{QK}^T$ matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors $\mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\}$ for all self-attention layers and for all attention heads.
|
||||
|
||||
Let's compute the number of float values that need to be stored in the key-value cache for the LLM `bigcode/octocoder` that we used before.
|
||||
The number of float values amounts to two times the sequence length times the number of attention heads times the attention head dimension and times the number of layers.
|
||||
@ -598,21 +603,21 @@ Researchers have proposed two methods that allow to significantly reduce the mem
|
||||
|
||||
[Multi-Query-Attention](https://huggingface.co/papers/1911.02150) was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
|
||||
|
||||
> By using a single head-value projection weight pair, the key value vectors \\( \mathbf{k}_i, \mathbf{v}_i \\) have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones.
|
||||
> By using a single head-value projection weight pair, the key value vectors $\mathbf{k}_i, \mathbf{v}_i$ have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones.
|
||||
|
||||
As most LLMs use between 20 and 100 attention heads, MQA significantly reduces the memory consumption of the key-value cache. For the LLM used in this notebook we could therefore reduce the required memory consumption from 15 GB to less than 400 MB at an input sequence length of 16000.
|
||||
|
||||
In addition to memory savings, MQA also leads to improved computational efficiency as explained in the following.
|
||||
In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the \\( \mathbf{q}_c\mathbf{K}^T \\) computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://huggingface.co/papers/1911.02150).
|
||||
In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the $\mathbf{q}_c\mathbf{K}^T$ computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://huggingface.co/papers/1911.02150).
|
||||
|
||||
The important part to understand here is that reducing the number of key-value attention heads to 1 only makes sense if a key-value cache is used. The peak memory consumption of the model for a single forward pass without key-value cache stays unchanged as every attention head still has a unique query vector so that each attention head still has a different \\( \mathbf{QK}^T \\) matrix.
|
||||
The important part to understand here is that reducing the number of key-value attention heads to 1 only makes sense if a key-value cache is used. The peak memory consumption of the model for a single forward pass without key-value cache stays unchanged as every attention head still has a unique query vector so that each attention head still has a different $\mathbf{QK}^T$ matrix.
|
||||
|
||||
MQA has seen wide adoption by the community and is now used by many of the most popular LLMs:
|
||||
|
||||
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
|
||||
- [**PaLM**](https://huggingface.co/papers/2204.02311)
|
||||
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
|
||||
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
|
||||
- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
|
||||
- [**PaLM**](https://huggingface.co/papers/2204.02311)
|
||||
- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
|
||||
- [**BLOOM**](https://huggingface.co/bigscience/bloom)
|
||||
|
||||
Also, the checkpoint used in this notebook - `bigcode/octocoder` - makes use of MQA.
|
||||
|
||||
|
||||
@ -42,7 +42,3 @@ set this to `False`.
|
||||
## Pushing to the Hub
|
||||
|
||||
[[autodoc]] utils.PushToHubMixin
|
||||
|
||||
## Sharded checkpoints
|
||||
|
||||
[[autodoc]] modeling_utils.load_sharded_checkpoint
|
||||
|
||||
@ -154,7 +154,6 @@ for label, score in zip(candidate_labels, probs):
|
||||
## AlignConfig
|
||||
|
||||
[[autodoc]] AlignConfig
|
||||
- from_text_vision_configs
|
||||
|
||||
## AlignTextConfig
|
||||
|
||||
|
||||
@ -100,22 +100,29 @@ for label, prob in zip(labels, probs[0]):
|
||||
- [`AltCLIPProcessor`] combines [`CLIPImageProcessor`] and [`XLMRobertaTokenizer`] into a single instance to encode text and prepare images.
|
||||
|
||||
## AltCLIPConfig
|
||||
|
||||
[[autodoc]] AltCLIPConfig
|
||||
|
||||
## AltCLIPTextConfig
|
||||
|
||||
[[autodoc]] AltCLIPTextConfig
|
||||
|
||||
## AltCLIPVisionConfig
|
||||
|
||||
[[autodoc]] AltCLIPVisionConfig
|
||||
|
||||
## AltCLIPModel
|
||||
|
||||
[[autodoc]] AltCLIPModel
|
||||
|
||||
## AltCLIPTextModel
|
||||
|
||||
[[autodoc]] AltCLIPTextModel
|
||||
|
||||
## AltCLIPVisionModel
|
||||
|
||||
[[autodoc]] AltCLIPVisionModel
|
||||
|
||||
## AltCLIPProcessor
|
||||
|
||||
[[autodoc]] AltCLIPProcessor
|
||||
|
||||
@ -43,10 +43,11 @@ Bark can be optimized with just a few extra lines of code, which **significantly
|
||||
You can speed up inference and reduce memory footprint by 50% simply by loading the model in half-precision.
|
||||
|
||||
```python
|
||||
from transformers import BarkModel, infer_device
|
||||
from transformers import BarkModel
|
||||
from accelerate import Accelerator
|
||||
import torch
|
||||
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
model = BarkModel.from_pretrained("suno/bark-small", dtype=torch.float16).to(device)
|
||||
```
|
||||
|
||||
@ -98,10 +99,11 @@ To put this into perspective, on an NVIDIA A100 and when generating 400 semantic
|
||||
You can combine optimization techniques, and use CPU offload, half-precision and Flash Attention 2 all at once.
|
||||
|
||||
```python
|
||||
from transformers import BarkModel, infer_device
|
||||
from transformers import BarkModel
|
||||
from accelerate import Accelerator
|
||||
import torch
|
||||
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
# load in fp16 and use Flash Attention 2
|
||||
model = BarkModel.from_pretrained("suno/bark-small", dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
|
||||
|
||||
@ -23,6 +23,7 @@ rendered properly in your Markdown viewer.
|
||||
</div>
|
||||
|
||||
# BART
|
||||
|
||||
[BART](https://huggingface.co/papers/1910.13461) is a sequence-to-sequence model that combines the pretraining objectives from BERT and GPT. It's pretrained by corrupting text in different ways like deleting words, shuffling sentences, or masking tokens and learning how to fix it. The encoder encodes the corrupted document and the corrupted text is fixed by the decoder. As it learns to recover the original text, BART gets really good at both understanding and generating language.
|
||||
|
||||
You can find all the original BART checkpoints under the [AI at Meta](https://huggingface.co/facebook?search_models=bart) organization.
|
||||
|
||||
@ -60,7 +60,6 @@ If you're interested in submitting a resource to be included here, please feel f
|
||||
## Blip2Config
|
||||
|
||||
[[autodoc]] Blip2Config
|
||||
- from_vision_qformer_text_configs
|
||||
|
||||
## Blip2VisionConfig
|
||||
|
||||
|
||||
@ -87,7 +87,6 @@ Refer to this [notebook](https://github.com/huggingface/notebooks/blob/main/exam
|
||||
## BlipConfig
|
||||
|
||||
[[autodoc]] BlipConfig
|
||||
- from_text_vision_configs
|
||||
|
||||
## BlipTextConfig
|
||||
|
||||
|
||||
@ -38,7 +38,7 @@ The abstract from the paper is the following:
|
||||
efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating
|
||||
more compute and model capacity where increased data complexity demands it. We present the first flop controlled scaling study of byte-level models up to 8B parameters and 4T training bytes. Our results demonstrate the feasibility of scaling models trained on raw bytes without a fixed vocabulary. Both training and inference efficiency improve due to dynamically selecting long patches when data is predictable, along with qualitative improvements on reasoning and long tail generalization. Overall, for fixed inference costs, BLT shows significantly better scaling than tokenization-based models, by simultaneously growing both patch and model size.*
|
||||
|
||||
## Usage Tips:
|
||||
## Usage Tips
|
||||
|
||||
- **Dual Model Architecture**: BLT consists of two separate trained models:
|
||||
- **Patcher (Entropy Model)**: A smaller transformer model that predicts byte-level entropy to determine patch boundaries and segment input.
|
||||
|
||||
@ -25,8 +25,7 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
## Overview
|
||||
|
||||
The Chameleon model was proposed in [Chameleon: Mixed-Modal Early-Fusion Foundation Models
|
||||
](https://huggingface.co/papers/2405.09818) by META AI Chameleon Team. Chameleon is a Vision-Language Model that use vector quantization to tokenize images which enables the model to generate multimodal output. The model takes images and texts as input, including an interleaved format, and generates textual response. Image generation module is not released yet.
|
||||
The Chameleon model was proposed in [Chameleon: Mixed-Modal Early-Fusion Foundation Models](https://huggingface.co/papers/2405.09818) by META AI Chameleon Team. Chameleon is a Vision-Language Model that use vector quantization to tokenize images which enables the model to generate multimodal output. The model takes images and texts as input, including an interleaved format, and generates textual response. Image generation module is not released yet.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
|
||||
@ -76,7 +76,6 @@ Currently, following scales of pretrained Chinese-CLIP models are available on
|
||||
## ChineseCLIPConfig
|
||||
|
||||
[[autodoc]] ChineseCLIPConfig
|
||||
- from_text_vision_configs
|
||||
|
||||
## ChineseCLIPTextConfig
|
||||
|
||||
|
||||
@ -63,7 +63,6 @@ print(f"Text embeddings: {text_features}")
|
||||
## ClapConfig
|
||||
|
||||
[[autodoc]] ClapConfig
|
||||
- from_text_audio_configs
|
||||
|
||||
## ClapTextConfig
|
||||
|
||||
|
||||
@ -87,7 +87,6 @@ print(f"Most likely label: {most_likely_label} with probability: {probs[0][most_
|
||||
## CLIPConfig
|
||||
|
||||
[[autodoc]] CLIPConfig
|
||||
- from_text_vision_configs
|
||||
|
||||
## CLIPTextConfig
|
||||
|
||||
|
||||
@ -72,7 +72,6 @@ A list of official Hugging Face and community (indicated by 🌎) resources to h
|
||||
## CLIPSegConfig
|
||||
|
||||
[[autodoc]] CLIPSegConfig
|
||||
- from_text_vision_configs
|
||||
|
||||
## CLIPSegTextConfig
|
||||
|
||||
|
||||
@ -39,7 +39,7 @@ The original code can be found [here](https://github.com/neonbjb/tortoise-tts).
|
||||
3. The use of the [`ClvpModelForConditionalGeneration.generate()`] method is strongly recommended for tortoise usage.
|
||||
4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
|
||||
|
||||
## Brief Explanation:
|
||||
## Brief Explanation
|
||||
|
||||
- The [`ClvpTokenizer`] tokenizes the text input, and the [`ClvpFeatureExtractor`] extracts the log mel-spectrogram from the desired audio.
|
||||
- [`ClvpConditioningEncoder`] takes those text tokens and audio representations and converts them into embeddings conditioned on the text and audio.
|
||||
@ -73,7 +73,6 @@ Example :
|
||||
## ClvpConfig
|
||||
|
||||
[[autodoc]] ClvpConfig
|
||||
- from_sub_model_configs
|
||||
|
||||
## ClvpEncoderConfig
|
||||
|
||||
|
||||
@ -107,10 +107,11 @@ import requests
|
||||
import torch
|
||||
from PIL import Image
|
||||
|
||||
from transformers import BitsAndBytesConfig, ColQwen2ForRetrieval, ColQwen2Processor, infer_device
|
||||
from transformers import BitsAndBytesConfig, ColQwen2ForRetrieval, ColQwen2Processor
|
||||
from accelerate import Accelerator
|
||||
|
||||
model_name = "vidore/colqwen2-v1.0-hf"
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
# 4-bit quantization configuration
|
||||
bnb_config = BitsAndBytesConfig(
|
||||
|
||||
@ -38,10 +38,11 @@ CSM can be used to simply generate speech from a text prompt:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import CsmForConditionalGeneration, AutoProcessor, infer_device
|
||||
from transformers import CsmForConditionalGeneration, AutoProcessor
|
||||
from accelerate import Accelerator
|
||||
|
||||
model_id = "sesame/csm-1b"
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
# load the model and the processor
|
||||
processor = AutoProcessor.from_pretrained(model_id)
|
||||
@ -72,11 +73,12 @@ CSM can be used to generate speech given a conversation, allowing consistency in
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import CsmForConditionalGeneration, AutoProcessor, infer_device
|
||||
from transformers import CsmForConditionalGeneration, AutoProcessor
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset, Audio
|
||||
|
||||
model_id = "sesame/csm-1b"
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
# load the model and the processor
|
||||
processor = AutoProcessor.from_pretrained(model_id)
|
||||
@ -117,11 +119,12 @@ CSM supports batched inference!
|
||||
|
||||
```python
|
||||
import torch
|
||||
from transformers import CsmForConditionalGeneration, AutoProcessor, infer_device
|
||||
from transformers import CsmForConditionalGeneration, AutoProcessor
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset, Audio
|
||||
|
||||
model_id = "sesame/csm-1b"
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
# load the model and the processor
|
||||
processor = AutoProcessor.from_pretrained(model_id)
|
||||
@ -306,11 +309,12 @@ print("="*50)
|
||||
CSM Transformers integration supports training!
|
||||
|
||||
```python
|
||||
from transformers import CsmForConditionalGeneration, AutoProcessor, infer_device
|
||||
from transformers import CsmForConditionalGeneration, AutoProcessor
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset, Audio
|
||||
|
||||
model_id = "sesame/csm-1b"
|
||||
device = infer_device()
|
||||
device = Accelerator().device
|
||||
|
||||
# load the model and the processor
|
||||
processor = AutoProcessor.from_pretrained(model_id)
|
||||
|
||||
187
docs/source/en/model_doc/cwm.md
Normal file
187
docs/source/en/model_doc/cwm.md
Normal file
@ -0,0 +1,187 @@
|
||||
<-- Copyright 2025 the HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
*This model was released on {release_date} and added to Hugging Face Transformers on 2025-10-09.*
|
||||
|
||||
# Code World Model (CWM)
|
||||
|
||||
## Overview
|
||||
|
||||
The Code World Model (CWM) model was proposed in [CWM: An Open-Weights LLM for Research on Code
|
||||
Generation with World Models](https://ai.facebook.com/research/publications/cwm) by Meta FAIR CodeGen Team.
|
||||
CWM is an LLM for code generation and reasoning about code that has, in particular, been trained
|
||||
to better represent and reason about how code and commands affect the state of a program or system.
|
||||
Specifically, we mid-trained CWM on a large number of observation-action trajectories from Python
|
||||
execution traces and agentic interactions in containerized environments. We post-trained with
|
||||
extensive multi-task RL in verifiable coding, math, and multi-turn software engineering environments.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
> *We release Code World Model (CWM), a 32-billion-parameter open-weights LLM, to advance research
|
||||
on code generation with world models. To improve code understanding beyond what can be learned
|
||||
from training on static code alone, we mid-train CWM on a large amount of observation-action
|
||||
trajectories from Python interpreter and agentic Docker environments, and perform extensive multi-
|
||||
task reasoning RL in verifiable coding, math, and multi-turn software engineering environments. With
|
||||
CWM, we provide a strong testbed for researchers to explore the opportunities world modeling affords
|
||||
for improving code generation with reasoning and planning in computational environments. We
|
||||
present first steps of how world models can benefit agentic coding, enable step-by-step simulation of
|
||||
Python code execution, and show early results of how reasoning can benefit from the latter. CWM is
|
||||
a dense, decoder-only LLM trained with a context size of up to 131 k tokens. Independent of its world
|
||||
modeling capabilities, CWM offers strong performance on general coding and math tasks: it reaches
|
||||
pass@1 scores of 65.8 % on SWE-bench Verified (with test-time scaling), 68.9 % on LiveCodeBench,
|
||||
96.6 % on Math-500, and 76.0 % on AIME 2024. To support further research on code world modeling,
|
||||
we release model checkpoints after mid-training, SFT, and RL.*
|
||||
|
||||
Tips:
|
||||
|
||||
CWM requires a dedicated system prompt to function optimally during inference. Without proper prompt
|
||||
configuration, CWM's output quality may be significantly degraded. The following serves as the default
|
||||
system prompt for reasoning tasks. For agentic workflows, append the relevant tool specifications
|
||||
after this base prompt. Checkout the original code repository for more details.
|
||||
|
||||
```text
|
||||
You are a helpful AI assistant. You always reason before responding, using the following format:
|
||||
|
||||
<think>
|
||||
your internal reasoning
|
||||
</think>
|
||||
your external response
|
||||
```
|
||||
|
||||
This model was contributed by [Meta FAIR CodeGen Team](https://huggingface.co/facebook).
|
||||
The original code can be found [here](https://github.com/facebookresearch/cwm).
|
||||
|
||||
## Usage examples
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
model_name = 'facebook/cwm'
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_name,
|
||||
dtype="auto",
|
||||
device_map="auto"
|
||||
)
|
||||
|
||||
system_prompt = """
|
||||
You are a helpful AI assistant. You always reason before responding, using the following format:
|
||||
|
||||
<think>
|
||||
your internal reasoning
|
||||
</think>
|
||||
your external response
|
||||
""".strip()
|
||||
|
||||
messages = [
|
||||
{"role": "system", "content": system_prompt},
|
||||
{"role": "user", "content": "Write a haiku about recursion in programming."}
|
||||
]
|
||||
|
||||
|
||||
text = tokenizer.apply_chat_template(
|
||||
messages,
|
||||
tokenize=False,
|
||||
add_generation_prompt=True,
|
||||
enable_thinking=True, # Switches between thinking and non-thinking modes. Default is True.
|
||||
preserve_previous_think=True, # Switches between keeping thinking blocks from previous messages or not. Default is True.
|
||||
)
|
||||
|
||||
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
|
||||
|
||||
generated_ids = model.generate(
|
||||
**model_inputs,
|
||||
max_new_tokens=1024
|
||||
)
|
||||
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
|
||||
print(tokenizer.decode(output_ids))
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>Produces the following output:</summary>
|
||||
|
||||
Okay, I need to write a haiku about recursion in programming. Let's start by recalling what recursion is. Recursion is a programming technique where a function calls itself in its own definition, often used to solve problems that can be broken down into smaller, similar sub-problems.
|
||||
|
||||
A haiku is a three-line poem with a syllable count of 5-7-5. So, I need to capture the essence of recursion in a concise and poetic way. Let's think about the key elements of recursion: the function calling itself, the base case that stops the recursion, and the idea of breaking down problems into smaller parts.
|
||||
|
||||
Maybe I can use imagery related to mirrors or reflections, since recursion often involves a function reflecting or repeating itself. Alternatively, I could use natural imagery like a spiral or a tree, which suggests self-similar patterns.
|
||||
|
||||
Let me try to come up with some ideas. For example, "Function calls itself" could be a starting point. But how to make that into a haiku? Maybe something like:
|
||||
|
||||
Function calls itself
|
||||
Base case stops the endless loop
|
||||
Spiral of code
|
||||
|
||||
Hmm, that's a start. But maybe I can make it more poetic. Let's think about the idea of a function calling itself as a kind of infinite loop, but with a base case that stops it. That's like a spiral that unwinds at the center.
|
||||
|
||||
Another angle: recursion is often used for problems that have a recursive structure, like tree traversals or factorial calculations. Maybe I can use a natural image to represent that.
|
||||
|
||||
How about:
|
||||
|
||||
Branches split again
|
||||
Leaves unfold in endless dance
|
||||
Roots hold the base case
|
||||
|
||||
That's a bit more poetic. The branches splitting represent the recursive calls, the leaves unfolding could represent the processing of each sub-problem, and the roots holding the base case are what stops the recursion.
|
||||
|
||||
Alternatively, maybe something simpler:
|
||||
|
||||
Mirror within mirror
|
||||
Reflections infinite deep
|
||||
Base case breaks the glass
|
||||
|
||||
This uses the mirror metaphor to represent the function calling itself, with the base case being the point where the recursion stops, breaking the infinite reflection.
|
||||
|
||||
I think I like the mirror idea better. Let me refine that:
|
||||
|
||||
Mirror within mirror
|
||||
Infinite reflections dance
|
||||
Base case shatters glass
|
||||
|
||||
Yes, that seems to capture the idea of recursion well. The mirror represents the function calling itself, the infinite reflections are the recursive calls, and the base case shattering the glass is what stops the recursion.
|
||||
|
||||
Let me check the syllable count:
|
||||
|
||||
Mirror within mirror (5 syllables: Mir-ror-with-in-mir-ror)
|
||||
Infinite reflections dance (7 syllables: In-fi-nite-ref-lec-tions-dance)
|
||||
Base case shatters glass (5 syllables: Base-case-shat-ters-glass)
|
||||
|
||||
Yes, that fits the 5-7-5 structure. I think that's a good haiku about recursion.
|
||||
</think>
|
||||
Mirror within mirror
|
||||
Infinite reflections dance
|
||||
Base case shatters glass<|eot_id|>
|
||||
|
||||
</details>
|
||||
|
||||
## CwmConfig
|
||||
|
||||
[[autodoc]] CwmConfig
|
||||
|
||||
## CwmPreTrainedModel
|
||||
|
||||
[[autodoc]] CwmPreTrainedModel
|
||||
- forward
|
||||
|
||||
## CwmModel
|
||||
|
||||
[[autodoc]] CwmModel
|
||||
- forward
|
||||
|
||||
## CwmForCausalLM
|
||||
|
||||
[[autodoc]] CwmForCausalLM
|
||||
@ -28,6 +28,7 @@ This model was contributed by [VladOS95-cyber](https://github.com/VladOS95-cyber
|
||||
The original code can be found [here](https://huggingface.co/deepseek-ai/DeepSeek-V2).
|
||||
|
||||
### Usage tips
|
||||
|
||||
The model uses Multi-head Latent Attention (MLA) and DeepSeekMoE architectures for efficient inference and cost-effective training. It employs an auxiliary-loss-free strategy for load balancing and multi-token prediction training objective. The model can be used for various language tasks after being pre-trained on 14.8 trillion tokens and going through Supervised Fine-Tuning and Reinforcement Learning stages.
|
||||
|
||||
## DeepseekV2Config
|
||||
|
||||
@ -34,6 +34,7 @@ We are super happy to make this code community-powered, and would love to see ho
|
||||
- static cache is not supported (this should be just a generation config issue / config shape issues)
|
||||
|
||||
### Usage tips
|
||||
|
||||
The model uses Multi-head Latent Attention (MLA) and DeepSeekMoE architectures for efficient inference and cost-effective training. It employs an auxiliary-loss-free strategy for load balancing and multi-token prediction training objective. The model can be used for various language tasks after being pre-trained on 14.8 trillion tokens and going through Supervised Fine-Tuning and Reinforcement Learning stages.
|
||||
|
||||
You can run the model in `FP8` automatically, using 2 nodes of 8 H100 should be more than enough!
|
||||
|
||||
@ -46,9 +46,10 @@ The DepthPro model processes an input image by first downsampling it at multiple
|
||||
>>> import requests
|
||||
>>> from PIL import Image
|
||||
>>> import torch
|
||||
>>> from transformers import DepthProImageProcessorFast, DepthProForDepthEstimation, infer_device
|
||||
>>> from transformers import DepthProImageProcessorFast, DepthProForDepthEstimation
|
||||
from accelerate import Accelerator
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
|
||||
>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
|
||||
>>> image = Image.open(requests.get(url, stream=True).raw)
|
||||
|
||||
@ -105,7 +105,7 @@ DETR can be naturally extended to perform panoptic segmentation (which unifies s
|
||||
- The decoder of DETR updates the query embeddings in parallel. This is different from language models like GPT-2, which use autoregressive decoding instead of parallel. Hence, no causal attention mask is used.
|
||||
- DETR adds position embeddings to the hidden states at each self-attention and cross-attention layer before projecting to queries and keys. For the position embeddings of the image, one can choose between fixed sinusoidal or learned absolute position embeddings. By default, the parameter `position_embedding_type` of [`~transformers.DetrConfig`] is set to `"sine"`.
|
||||
- During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help the model output the correct number of objects of each class. If you set the parameter `auxiliary_loss` of [`~transformers.DetrConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses are added after each decoder layer (with the FFNs sharing parameters).
|
||||
- If you want to train the model in a distributed environment across multiple nodes, then one should update the _num_boxes_ variable in the _DetrLoss_ class of _modeling_detr.py_. When training on multiple nodes, this should be set to the average number of target boxes across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232).
|
||||
- If you want to train the model in a distributed environment across multiple nodes, then one should update the *num_boxes* variable in the *DetrLoss* class of *modeling_detr.py*. When training on multiple nodes, this should be set to the average number of target boxes across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232).
|
||||
- [`~transformers.DetrForObjectDetection`] and [`~transformers.DetrForSegmentation`] can be initialized with any convolutional backbone available in the [timm library](https://github.com/rwightman/pytorch-image-models). Initializing with a MobileNet backbone for example can be done by setting the `backbone` attribute of [`~transformers.DetrConfig`] to `"tf_mobilenetv3_small_075"`, and then initializing the model with that config.
|
||||
- DETR resizes the input images such that the shortest side is at least a certain amount of pixels while the longest is at most 1333 pixels. At training time, scale augmentation is used such that the shortest side is randomly set to at least 480 and at most 800 pixels. At inference time, the shortest side is set to 800. One can use [`~transformers.DetrImageProcessor`] to prepare images (and optional annotations in COCO format) for the model. Due to this resizing, images in a batch can have different sizes. DETR solves this by padding images up to the largest size in a batch, and by creating a pixel mask that indicates which pixels are real/which are padding. Alternatively, one can also define a custom `collate_fn` in order to batch images together, using [`~transformers.DetrImageProcessor.pad_and_create_pixel_mask`].
|
||||
- The size of the images will determine the amount of memory being used, and will thus determine the `batch_size`. It is advised to use a batch size of 2 per GPU. See [this Github thread](https://github.com/facebookresearch/detr/issues/150) for more info.
|
||||
@ -142,7 +142,7 @@ As a summary, consider the following table:
|
||||
|------|------------------|-----------------------|-----------------------|
|
||||
| **Description** | Predicting bounding boxes and class labels around objects in an image | Predicting masks around objects (i.e. instances) in an image | Predicting masks around both objects (i.e. instances) as well as "stuff" (i.e. background things like trees and roads) in an image |
|
||||
| **Model** | [`~transformers.DetrForObjectDetection`] | [`~transformers.DetrForSegmentation`] | [`~transformers.DetrForSegmentation`] |
|
||||
| **Example dataset** | COCO detection | COCO detection, COCO panoptic | COCO panoptic | |
|
||||
| **Example dataset** | COCO detection | COCO detection, COCO panoptic | COCO panoptic |
|
||||
| **Format of annotations to provide to** [`~transformers.DetrImageProcessor`] | {'image_id': `int`, 'annotations': `list[Dict]`} each Dict being a COCO object annotation | {'image_id': `int`, 'annotations': `list[Dict]`} (in case of COCO detection) or {'file_name': `str`, 'image_id': `int`, 'segments_info': `list[Dict]`} (in case of COCO panoptic) | {'file_name': `str`, 'image_id': `int`, 'segments_info': `list[Dict]`} and masks_path (path to directory containing PNG files of the masks) |
|
||||
| **Postprocessing** (i.e. converting the output of the model to Pascal VOC format) | [`~transformers.DetrImageProcessor.post_process`] | [`~transformers.DetrImageProcessor.post_process_segmentation`] | [`~transformers.DetrImageProcessor.post_process_segmentation`], [`~transformers.DetrImageProcessor.post_process_panoptic`] |
|
||||
| **evaluators** | `CocoEvaluator` with `iou_types="bbox"` | `CocoEvaluator` with `iou_types="bbox"` or `"segm"` | `CocoEvaluator` with `iou_tupes="bbox"` or `"segm"`, `PanopticEvaluator` |
|
||||
|
||||
@ -42,9 +42,10 @@ tokens and decodes them back into audio.
|
||||
### Generation with Text
|
||||
|
||||
```python
|
||||
from transformers import AutoProcessor, DiaForConditionalGeneration, infer_device
|
||||
from transformers import AutoProcessor, DiaForConditionalGeneration
|
||||
from accelerate import Accelerator
|
||||
|
||||
torch_device = infer_device()
|
||||
torch_device = Accelerator().device
|
||||
model_checkpoint = "nari-labs/Dia-1.6B-0626"
|
||||
|
||||
text = ["[S1] Dia is an open weights text to dialogue model."]
|
||||
@ -64,9 +65,10 @@ processor.save_audio(outputs, "example.wav")
|
||||
|
||||
```python
|
||||
from datasets import load_dataset, Audio
|
||||
from transformers import AutoProcessor, DiaForConditionalGeneration, infer_device
|
||||
from transformers import AutoProcessor, DiaForConditionalGeneration
|
||||
from accelerate import Accelerator
|
||||
|
||||
torch_device = infer_device()
|
||||
torch_device = Accelerator().device
|
||||
model_checkpoint = "nari-labs/Dia-1.6B-0626"
|
||||
|
||||
ds = load_dataset("hf-internal-testing/dailytalk-dummy", split="train")
|
||||
@ -91,9 +93,10 @@ processor.save_audio(outputs, "example_with_audio.wav")
|
||||
|
||||
```python
|
||||
from datasets import load_dataset, Audio
|
||||
from transformers import AutoProcessor, DiaForConditionalGeneration, infer_device
|
||||
from transformers import AutoProcessor, DiaForConditionalGeneration
|
||||
from accelerate import Accelerator
|
||||
|
||||
torch_device = infer_device()
|
||||
torch_device = Accelerator().device
|
||||
model_checkpoint = "nari-labs/Dia-1.6B-0626"
|
||||
|
||||
ds = load_dataset("hf-internal-testing/dailytalk-dummy", split="train")
|
||||
|
||||
@ -33,6 +33,7 @@ The abstract from the paper is the following:
|
||||
*Transformer tends to overallocate attention to irrelevant context. In this work, we introduce Diff Transformer, which amplifies attention to the relevant context while canceling noise. Specifically, the differential attention mechanism calculates attention scores as the difference between two separate softmax attention maps. The subtraction cancels noise, promoting the emergence of sparse attention patterns. Experimental results on language modeling show that Diff Transformer outperforms Transformer in various settings of scaling up model size and training tokens. More intriguingly, it offers notable advantages in practical applications, such as long-context modeling, key information retrieval, hallucination mitigation, in-context learning, and reduction of activation outliers. By being less distracted by irrelevant context, Diff Transformer can mitigate hallucination in question answering and text summarization. For in-context learning, Diff Transformer not only enhances accuracy but is also more robust to order permutation, which was considered as a chronic robustness issue. The results position Diff Transformer as a highly effective and promising architecture to advance large language models.*
|
||||
|
||||
### Usage tips
|
||||
|
||||
The hyperparameters of this model is the same as Llama model.
|
||||
|
||||
## DiffLlamaConfig
|
||||
|
||||
@ -47,7 +47,7 @@ Our large model is faster and ahead of its Swin counterpart by 1.5% box AP in CO
|
||||
Paired with new frameworks, our large variant is the new state of the art panoptic segmentation model on COCO (58.2 PQ)
|
||||
and ADE20K (48.5 PQ), and instance segmentation model on Cityscapes (44.5 AP) and ADE20K (35.4 AP) (no extra data).
|
||||
It also matches the state of the art specialized semantic segmentation models on ADE20K (58.2 mIoU),
|
||||
and ranks second on Cityscapes (84.5 mIoU) (no extra data). *
|
||||
and ranks second on Cityscapes (84.5 mIoU) (no extra data).*
|
||||
|
||||
<img
|
||||
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/dilated-neighborhood-attention-pattern.jpg"
|
||||
|
||||
@ -178,3 +178,8 @@ print("Pooled output shape:", pooled_output.shape)
|
||||
|
||||
[[autodoc]] DINOv3ViTImageProcessorFast
|
||||
- preprocess
|
||||
|
||||
## DINOv3ConvNextBackbone
|
||||
|
||||
[[autodoc]] DINOv3ConvNextBackbone
|
||||
- forward
|
||||
|
||||
@ -61,10 +61,10 @@ pipeline(image=image, question="What time is the coffee break?")
|
||||
# pip install datasets
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from transformers import AutoProcessor, AutoModelForVision2Seq
|
||||
from transformers import AutoProcessor, AutoModelForImageTextToText
|
||||
|
||||
processor = AutoProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa")
|
||||
model = AutoModelForVision2Seq.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa")
|
||||
model = AutoModelForImageTextToText.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa")
|
||||
|
||||
dataset = load_dataset("hf-internal-testing/example-documents", split="test")
|
||||
image = dataset[0]["image"]
|
||||
@ -92,11 +92,11 @@ The example below uses [torchao](../quantization/torchao) to only quantize the w
|
||||
# pip install datasets torchao
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from transformers import TorchAoConfig, AutoProcessor, AutoModelForVision2Seq
|
||||
from transformers import TorchAoConfig, AutoProcessor, AutoModelForImageTextToText
|
||||
|
||||
quantization_config = TorchAoConfig("int4_weight_only", group_size=128)
|
||||
processor = AutoProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa")
|
||||
model = AutoModelForVision2Seq.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa", quantization_config=quantization_config)
|
||||
model = AutoModelForImageTextToText.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa", quantization_config=quantization_config)
|
||||
|
||||
dataset = load_dataset("hf-internal-testing/example-documents", split="test")
|
||||
image = dataset[0]["image"]
|
||||
@ -119,14 +119,15 @@ print(answer)
|
||||
|
||||
```py
|
||||
>>> import re
|
||||
>>> from transformers import DonutProcessor, VisionEncoderDecoderModel, infer_device
|
||||
>>> from transformers import DonutProcessor, VisionEncoderDecoderModel
|
||||
>>> from accelerate import Accelerator
|
||||
>>> from datasets import load_dataset
|
||||
>>> import torch
|
||||
|
||||
>>> processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-rvlcdip")
|
||||
>>> model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base-finetuned-rvlcdip")
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model.to(device) # doctest: +IGNORE_RESULT
|
||||
|
||||
>>> # load document image
|
||||
@ -161,14 +162,15 @@ print(answer)
|
||||
|
||||
```py
|
||||
>>> import re
|
||||
>>> from transformers import DonutProcessor, VisionEncoderDecoderModel, infer_device
|
||||
>>> from accelerate import Accelerator
|
||||
>>> from datasets import load_dataset
|
||||
>>> from transformers import DonutProcessor, VisionEncoderDecoderModel
|
||||
>>> import torch
|
||||
|
||||
>>> processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-cord-v2")
|
||||
>>> model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base-finetuned-cord-v2")
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model.to(device) # doctest: +IGNORE_RESULT
|
||||
|
||||
>>> # load document image
|
||||
|
||||
@ -61,12 +61,13 @@ EdgeTAM can be used for automatic mask generation to segment all objects in an i
|
||||
You can segment objects by providing a single point click on the object you want to segment:
|
||||
|
||||
```python
|
||||
>>> from transformers import Sam2Processor, EdgeTamModel, infer_device
|
||||
>>> from transformers import Sam2Processor, EdgeTamModel
|
||||
from accelerate import Accelerator
|
||||
>>> import torch
|
||||
>>> from PIL import Image
|
||||
>>> import requests
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
|
||||
>>> model = EdgeTamModel.from_pretrained("yonigozlan/edgetam-1").to(device)
|
||||
>>> processor = Sam2Processor.from_pretrained("yonigozlan/edgetam-1")
|
||||
@ -157,12 +158,13 @@ IoU scores: tensor([0.7616, 0.9465], device='cuda:0')
|
||||
Process multiple images simultaneously for improved efficiency:
|
||||
|
||||
```python
|
||||
>>> from transformers import Sam2Processor, EdgeTamModel, infer_device
|
||||
>>> from transformers import Sam2Processor, EdgeTamModel
|
||||
from accelerate import Accelerator
|
||||
>>> import torch
|
||||
>>> from PIL import Image
|
||||
>>> import requests
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
|
||||
>>> model = EdgeTamModel.from_pretrained("yonigozlan/edgetam-1").to(device)
|
||||
>>> processor = Sam2Processor.from_pretrained("yonigozlan/edgetam-1")
|
||||
@ -303,7 +305,6 @@ EdgeTAM can use masks from previous predictions as input to refine segmentation:
|
||||
... )
|
||||
```
|
||||
|
||||
|
||||
## EdgeTamConfig
|
||||
|
||||
[[autodoc]] EdgeTamConfig
|
||||
|
||||
@ -12,13 +12,11 @@ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
*This model was released on 2025-01-13 and added to Hugging Face Transformers on 2025-09-29.*
|
||||
|
||||
|
||||
<div style="float: right;">
|
||||
<div class="flex flex-wrap space-x-1">
|
||||
<img alt="PyTorch" src="https://img.shields.io/badge/PyTorch-DE3412?style=flat&logo=pytorch&logoColor=white">
|
||||
@ -51,10 +49,11 @@ EdgeTAM Video's key strength is its ability to track objects across video frames
|
||||
#### Basic Video Tracking
|
||||
|
||||
```python
|
||||
>>> from transformers import EdgeTamVideoModel, Sam2VideoProcessor, infer_device
|
||||
>>> from transformers import EdgeTamVideoModel, Sam2VideoProcessor
|
||||
from accelerate import Accelerator
|
||||
>>> import torch
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model = EdgeTamVideoModel.from_pretrained("yonigozlan/edgetam-video-1").to(device, dtype=torch.bfloat16)
|
||||
>>> processor = Sam2VideoProcessor.from_pretrained("yonigozlan/edgetam-video-1")
|
||||
|
||||
|
||||
@ -61,7 +61,7 @@ message_list = [
|
||||
]
|
||||
]
|
||||
input_dict = processor(
|
||||
protein_informations, messages_list, return_tensors="pt", text_max_length=512, protein_max_length=1024
|
||||
protein_inputs, messages_list, return_tensors="pt", text_max_length=512, protein_max_length=1024
|
||||
)
|
||||
with torch.no_grad():
|
||||
generated_ids = hf_model.generate(**input_dict)
|
||||
|
||||
@ -28,15 +28,19 @@ The abstract from the original FastSpeech2 paper is the following:
|
||||
This model was contributed by [Connor Henderson](https://huggingface.co/connor-henderson). The original code can be found [here](https://github.com/espnet/espnet/blob/master/espnet2/tts/fastspeech2/fastspeech2.py).
|
||||
|
||||
## 🤗 Model Architecture
|
||||
|
||||
FastSpeech2's general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with conformer blocks as done in the ESPnet library.
|
||||
|
||||
#### FastSpeech2 Model Architecture
|
||||
|
||||

|
||||
|
||||
#### Conformer Blocks
|
||||
|
||||

|
||||
|
||||
#### Convolution Module
|
||||
|
||||
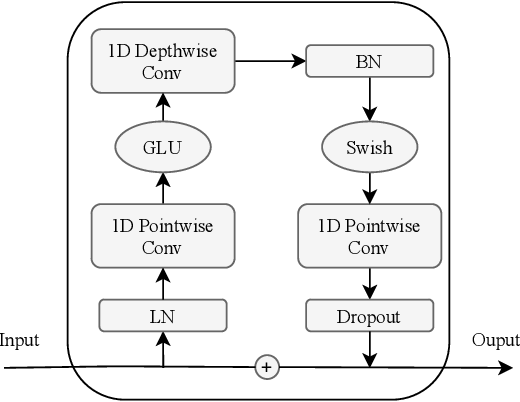
|
||||
|
||||
## 🤗 Transformers Usage
|
||||
|
||||
@ -40,9 +40,9 @@ The original checkpoints can be found [here](https://github.com/google-research/
|
||||
The model is pretty heavy (~40GB in half precision) so if you just want to run the model, make sure you load your model in 8bit, and use `device_map="auto"` to make sure you don't have any OOM issue!
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
|
||||
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, BitsAndBytesConfig
|
||||
|
||||
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-ul2", load_in_8bit=True, device_map="auto")
|
||||
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-ul2", quantization_config=BitsAndBytesConfig(load_in_8bit=True), device_map="auto")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("google/flan-ul2")
|
||||
|
||||
>>> inputs = tokenizer("A step by step recipe to make bolognese pasta:", return_tensors="pt")
|
||||
|
||||
@ -60,8 +60,9 @@ Tips:
|
||||
In the following, we demonstrate how to use `glm-4-9b-chat` for the inference. Note that we have used the ChatML format for dialog, in this demo we show how to leverage `apply_chat_template` for this purpose.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, infer_device
|
||||
>>> device = infer_device() # the device to load the model onto
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
>>> device = Accelerator().device # the device to load the model onto
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("THUDM/glm-4-9b-chat", device_map="auto", trust_remote_code=True)
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat")
|
||||
|
||||
@ -19,6 +19,26 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
## Overview
|
||||
|
||||
Both **GLM-4.6** and **GLM-4.5** language model use this class. The implementation in transformers does not include an MTP layer.
|
||||
|
||||
### GLM-4.6
|
||||
|
||||
Compared with GLM-4.5, **GLM-4.6** brings several key improvements:
|
||||
|
||||
* **Longer context window:** The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
|
||||
* **Superior coding performance:** The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
|
||||
* **Advanced reasoning:** GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
|
||||
* **More capable agents:** GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
|
||||
* **Refined writing:** Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
|
||||
|
||||
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as **DeepSeek-V3.1-Terminus** and **Claude Sonnet 4**.
|
||||
|
||||
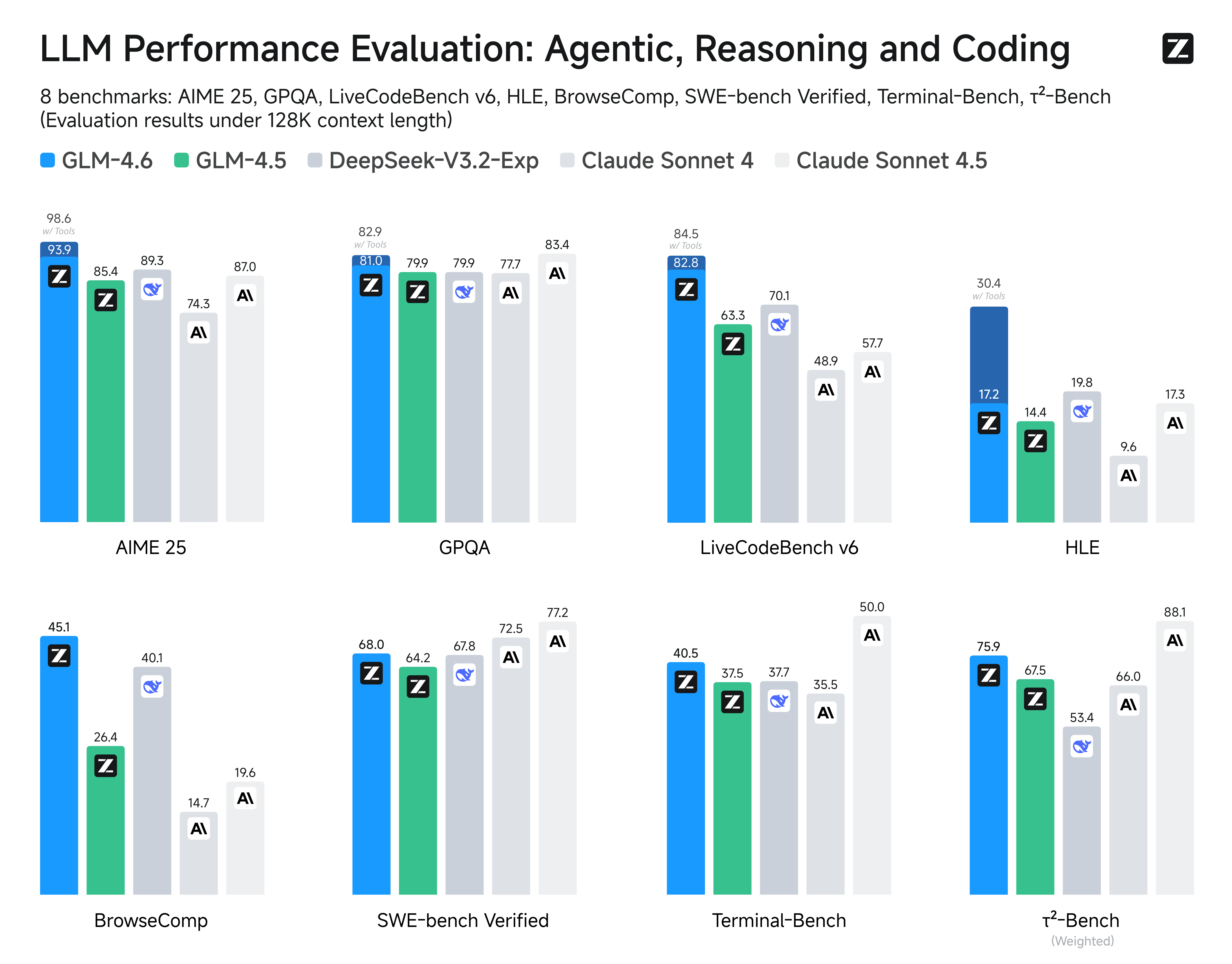
|
||||
|
||||
For more eval results, show cases, and technical details, please visit our [technical blog](https://z.ai/blog/glm-4.6).
|
||||
|
||||
### GLM-4.5
|
||||
|
||||
The [**GLM-4.5**](https://huggingface.co/papers/2508.06471) series models are foundation models designed for intelligent agents, MoE variants are documented here as Glm4Moe.
|
||||
|
||||
GLM-4.5 has **355** billion total parameters with **32** billion active parameters, while GLM-4.5-Air adopts a more compact design with **106** billion total parameters and **12** billion active parameters. GLM-4.5 models unify reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications.
|
||||
|
||||
@ -132,10 +132,11 @@ Using GLM-4.1V with video input is similar to using it with image input.
|
||||
The model can process video data and generate text based on the content of the video.
|
||||
|
||||
```python
|
||||
from transformers import AutoProcessor, Glm4vForConditionalGeneration, infer_device
|
||||
from transformers import AutoProcessor, Glm4vForConditionalGeneration
|
||||
from accelerate import Accelerator
|
||||
import torch
|
||||
|
||||
device = f"{infer_device()}:0"
|
||||
device = Accelerator().device
|
||||
|
||||
processor = AutoProcessor.from_pretrained("THUDM/GLM-4.1V-9B-Thinking")
|
||||
model = Glm4vForConditionalGeneration.from_pretrained(
|
||||
|
||||
@ -48,9 +48,10 @@ The original code can be found [here](https://github.com/Ucas-HaoranWei/GOT-OCR2
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText, infer_device
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
|
||||
from accelerate import Accelerator
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
|
||||
>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
|
||||
|
||||
@ -73,9 +74,10 @@ The original code can be found [here](https://github.com/Ucas-HaoranWei/GOT-OCR2
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText, infer_device
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
|
||||
from accelerate import Accelerator
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
|
||||
>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
|
||||
|
||||
@ -102,9 +104,10 @@ GOT-OCR2 can also generate formatted text, such as markdown or LaTeX. Here is an
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText, infer_device
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
|
||||
from accelerate import Accelerator
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
|
||||
>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
|
||||
|
||||
@ -130,9 +133,10 @@ Here is an example of how to process multiple pages at once:
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText, infer_device
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
|
||||
from accelerate import Accelerator
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
|
||||
>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
|
||||
|
||||
@ -159,9 +163,10 @@ Here is an example of how to process cropped patches:
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText, infer_device
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
|
||||
from accelerate import Accelerator
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", dtype=torch.bfloat16, device_map=device)
|
||||
>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
|
||||
|
||||
@ -188,7 +193,7 @@ GOT supports interactive OCR, where the user can specify the region to be recogn
|
||||
>>> import torch
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
|
||||
>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
|
||||
|
||||
@ -214,10 +219,11 @@ Here is an example of how to process sheet music:
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText, infer_device
|
||||
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
|
||||
from accelerate import Accelerator
|
||||
>>> import verovio
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
|
||||
>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
|
||||
|
||||
|
||||
@ -64,8 +64,9 @@ To load and run a model using Flash Attention 2, refer to the snippet below:
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, infer_device
|
||||
>>> device = infer_device() # the device to load the model onto
|
||||
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
>>> device = Accelerator().device # the device to load the model onto
|
||||
|
||||
>>> model = AutoModelForCausalLM.from_pretrained("bigcode/gpt_bigcode-santacoder", dtype=torch.float16, attn_implementation="flash_attention_2")
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("bigcode/gpt_bigcode-santacoder")
|
||||
|
||||
@ -101,6 +101,7 @@ Below is an expected speedup diagram that compares pure inference time between t
|
||||
</div>
|
||||
|
||||
## Using Scaled Dot Product Attention (SDPA)
|
||||
|
||||
PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
|
||||
encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
|
||||
[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
|
||||
@ -123,6 +124,7 @@ On a local benchmark (rtx3080ti-16GB, PyTorch 2.2.1, OS Ubuntu 22.04) using `flo
|
||||
following speedups during training and inference.
|
||||
|
||||
### Training
|
||||
|
||||
| Batch size | Seq len | Time per batch (Eager - s) | Time per batch (SDPA - s) | Speedup (%) | Eager peak mem (MB) | SDPA peak mem (MB) | Mem saving (%) |
|
||||
|-----------:|-----------:|---------------------------:|-----------------------------:|------------:|--------------------:|-------------------:|------------------:|
|
||||
| 1 | 128 | 0.024 | 0.019 | 28.945 | 1789.95 | 1789.95 | 0 |
|
||||
@ -142,6 +144,7 @@ following speedups during training and inference.
|
||||
| 4 | 2048 | OOM | 0.731 | / | OOM | 12705.1 | SDPA does not OOM |
|
||||
|
||||
### Inference
|
||||
|
||||
| Batch size | Seq len | Per token latency Eager (ms) | Per token latency SDPA (ms) | Speedup (%) | Mem Eager (MB) | Mem SDPA (MB) | Mem saved (%) |
|
||||
|--------------:|-------------:|--------------------------------:|-------------------------------:|---------------:|------------------:|----------------:|-----------------:|
|
||||
| 1 | 128 | 6.569 | 5.858 | 12.14 | 974.831 | 974.826 | 0 |
|
||||
|
||||
@ -41,7 +41,7 @@ The example below demonstrates how to generate text with [`Pipeline`] or the [`A
|
||||
<hfoptions id="usage">
|
||||
<hfoption id="Pipeline">
|
||||
|
||||
```py
|
||||
```python
|
||||
import torch
|
||||
from transformers import pipeline
|
||||
pipeline = pipeline(task="text-generation",
|
||||
@ -52,7 +52,7 @@ pipeline("人とAIが協調するためには、")
|
||||
</hfoption>
|
||||
<hfoption id="AutoModel">
|
||||
|
||||
```py
|
||||
```python
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
@ -112,6 +112,7 @@ visualizer("<img>What is shown in this image?")
|
||||
</div>
|
||||
|
||||
## Resources
|
||||
|
||||
Refer to the [Training a better GPT model: Learnings from PaLM](https://medium.com/ml-abeja/training-a-better-gpt-2-93b157662ae4) blog post for more details about how ABEJA trained GPT-NeoX-Japanese.
|
||||
|
||||
## GPTNeoXJapaneseConfig
|
||||
|
||||
@ -35,8 +35,8 @@ The abstract from the paper is the following:
|
||||
*<INSERT PAPER ABSTRACT HERE>*
|
||||
|
||||
Tips:
|
||||
- **Attention Sinks with Flex Attention**: When using flex attention, attention sinks require special handling. Unlike with standard attention implementations where sinks can be added directly to attention scores, flex attention `score_mod` function operates on individual score elements rather than the full attention matrix. Therefore, attention sinks renormalization have to be applied after the flex attention computations by renormalizing the outputs using the log-sum-exp (LSE) values returned by flex attention.
|
||||
|
||||
- **Attention Sinks with Flex Attention**: When using flex attention, attention sinks require special handling. Unlike with standard attention implementations where sinks can be added directly to attention scores, flex attention `score_mod` function operates on individual score elements rather than the full attention matrix. Therefore, attention sinks renormalization have to be applied after the flex attention computations by renormalizing the outputs using the log-sum-exp (LSE) values returned by flex attention.
|
||||
|
||||
<INSERT TIPS ABOUT MODEL HERE>
|
||||
|
||||
|
||||
@ -38,10 +38,11 @@ This model was contributed by [Stella Biderman](https://huggingface.co/stellaath
|
||||
which could be used to further minimize the RAM usage:
|
||||
|
||||
```python
|
||||
>>> from transformers import GPTJForCausalLM, infer_device
|
||||
>>> from transformers import GPTJForCausalLM
|
||||
from accelerate import Accelerator
|
||||
>>> import torch
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model = GPTJForCausalLM.from_pretrained(
|
||||
... "EleutherAI/gpt-j-6B",
|
||||
... revision="float16",
|
||||
@ -93,10 +94,11 @@ model.
|
||||
...or in float16 precision:
|
||||
|
||||
```python
|
||||
>>> from transformers import GPTJForCausalLM, AutoTokenizer, infer_device
|
||||
>>> from transformers import GPTJForCausalLM, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
>>> import torch
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> model = GPTJForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", dtype=torch.float16).to(device)
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
|
||||
|
||||
|
||||
@ -42,10 +42,11 @@ fine-tune for translation or summarization.
|
||||
The `generate()` method can be used to generate text using GPTSAN-Japanese model.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModel, AutoTokenizer, infer_device
|
||||
>>> from transformers import AutoModel, AutoTokenizer
|
||||
from accelerate import Accelerator
|
||||
>>> import torch
|
||||
|
||||
>>> device = infer_device()
|
||||
>>> device = Accelerator().device
|
||||
>>> tokenizer = AutoTokenizer.from_pretrained("Tanrei/GPTSAN-japanese")
|
||||
>>> model = AutoModel.from_pretrained("Tanrei/GPTSAN-japanese").to(device)
|
||||
>>> x_tok = tokenizer("は、", prefix_text="織田信長", return_tensors="pt")
|
||||
@ -78,6 +79,8 @@ When token_type_ids=None or all zero, it is equivalent to regular causal mask
|
||||
for example:
|
||||
|
||||
>>> x_token = tokenizer("アイウエ")
|
||||
|
||||
```text
|
||||
input_ids: | SOT | SEG | ア | イ | ウ | エ |
|
||||
token_type_ids: | 1 | 0 | 0 | 0 | 0 | 0 |
|
||||
prefix_lm_mask:
|
||||
@ -87,8 +90,11 @@ SEG | 1 1 0 0 0 0 |
|
||||
イ | 1 1 1 1 0 0 |
|
||||
ウ | 1 1 1 1 1 0 |
|
||||
エ | 1 1 1 1 1 1 |
|
||||
```
|
||||
|
||||
>>> x_token = tokenizer("", prefix_text="アイウエ")
|
||||
|
||||
```text
|
||||
input_ids: | SOT | ア | イ | ウ | エ | SEG |
|
||||
token_type_ids: | 1 | 1 | 1 | 1 | 1 | 0 |
|
||||
prefix_lm_mask:
|
||||
@ -98,8 +104,11 @@ SOT | 1 1 1 1 1 0 |
|
||||
ウ | 1 1 1 1 1 0 |
|
||||
エ | 1 1 1 1 1 0 |
|
||||
SEG | 1 1 1 1 1 1 |
|
||||
```
|
||||
|
||||
>>> x_token = tokenizer("ウエ", prefix_text="アイ")
|
||||
|
||||
```text
|
||||
input_ids: | SOT | ア | イ | SEG | ウ | エ |
|
||||
token_type_ids: | 1 | 1 | 1 | 0 | 0 | 0 |
|
||||
prefix_lm_mask:
|
||||
@ -109,6 +118,7 @@ SOT | 1 1 1 0 0 0 |
|
||||
SEG | 1 1 1 1 0 0 |
|
||||
ウ | 1 1 1 1 1 0 |
|
||||
エ | 1 1 1 1 1 1 |
|
||||
```
|
||||
|
||||
### Spout Vector
|
||||
|
||||
|
||||
@ -22,6 +22,7 @@ rendered properly in your Markdown viewer.
|
||||
</div>
|
||||
|
||||
## Overview
|
||||
|
||||
The [Granite Speech](https://huggingface.co/papers/2505.08699) model ([blog post](https://www.ibm.com/new/announcements/ibm-granite-3-3-speech-recognition-refined-reasoning-rag-loras)) is a multimodal language model, consisting of a speech encoder, speech projector, large language model, and LoRA adapter(s). More details regarding each component for the current (Granite 3.2 Speech) model architecture may be found below.
|
||||
|
||||
1. Speech Encoder: A [Conformer](https://huggingface.co/papers/2005.08100) encoder trained with Connectionist Temporal Classification (CTC) on character-level targets on ASR corpora. The encoder uses block-attention and self-conditioned CTC from the middle layer.
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user