Visual question answering
-
@@ -108,7 +106,6 @@ To put this into perspective, on an NVIDIA A100 and when generating 400 semantic
At batch size 8, on an NVIDIA A100, Flash Attention 2 is also 10% faster than Better Transformer, and at batch size 16, 25%.
-
#### Combining optimization techniques
You can combine optimization techniques, and use CPU offload, half-precision and Flash Attention 2 (or 🤗 Better Transformer) all at once.
@@ -147,7 +144,7 @@ These presets are also uploaded in the hub [here](https://huggingface.co/suno/ba
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
-Bark can generate highly realistic, **multilingual** speech as well as other audio - including music, background noise and simple sound effects.
+Bark can generate highly realistic, **multilingual** speech as well as other audio - including music, background noise and simple sound effects.
```python
>>> # Multilingual speech - simplified Chinese
@@ -165,7 +162,6 @@ Bark can generate highly realistic, **multilingual** speech as well as other aud
The model can also produce **nonverbal communications** like laughing, sighing and crying.
-
```python
>>> # Adding non-speech cues to the input text
>>> inputs = processor("Hello uh ... [clears throat], my dog is cute [laughter]")
@@ -235,4 +231,3 @@ To save the audio, simply take the sample rate from the model config and some sc
[[autodoc]] BarkSemanticConfig
- all
-
diff --git a/docs/source/en/model_doc/bart.md b/docs/source/en/model_doc/bart.md
index d1eeafb82b2..f81eaae98fb 100644
--- a/docs/source/en/model_doc/bart.md
+++ b/docs/source/en/model_doc/bart.md
@@ -15,7 +15,6 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2019-10-29 and added to Hugging Face Transformers on 2020-11-16.*
-
 @@ -46,6 +45,7 @@ pipeline = pipeline(
pipeline("Plants create
@@ -46,6 +45,7 @@ pipeline = pipeline(
pipeline("Plants create through a process known as photosynthesis.")
```
+
diff --git a/docs/source/en/model_doc/barthez.md b/docs/source/en/model_doc/barthez.md
index 43b6521f101..f7a100a4208 100644
--- a/docs/source/en/model_doc/barthez.md
+++ b/docs/source/en/model_doc/barthez.md
@@ -31,7 +31,6 @@ You can find all of the original BARThez checkpoints under the [BARThez](https:/
> This model was contributed by [moussakam](https://huggingface.co/moussakam).
> Refer to the [BART](./bart) docs for more usage examples.
-
The example below demonstrates how to predict the `` token with [`Pipeline`], [`AutoModel`], and from the command line.
diff --git a/docs/source/en/model_doc/bartpho.md b/docs/source/en/model_doc/bartpho.md
index 9e86a1b615d..15e96c57669 100644
--- a/docs/source/en/model_doc/bartpho.md
+++ b/docs/source/en/model_doc/bartpho.md
@@ -33,12 +33,9 @@ You can find all the original checkpoints under the [VinAI](https://huggingface.
The example below demonstrates how to summarize text with [`Pipeline`] or the [`AutoModel`] class.
-
-
-
```python
import torch
from transformers import pipeline
@@ -98,8 +95,6 @@ transformers run --task summarization --model vinai/bartpho-word --device 0
-
-
## Notes
- BARTpho uses the large architecture of BART with an additional layer-normalization layer on top of the encoder and decoder. The BART-specific classes should be replaced with the mBART-specific classes.
diff --git a/docs/source/en/model_doc/bert-japanese.md b/docs/source/en/model_doc/bert-japanese.md
index 812e5a455ad..6599efa73e0 100644
--- a/docs/source/en/model_doc/bert-japanese.md
+++ b/docs/source/en/model_doc/bert-japanese.md
@@ -81,7 +81,6 @@ API reference information.
-
## BertJapaneseTokenizer
[[autodoc]] BertJapaneseTokenizer
diff --git a/docs/source/en/model_doc/bertweet.md b/docs/source/en/model_doc/bertweet.md
index 6488e197d21..223932877c0 100644
--- a/docs/source/en/model_doc/bertweet.md
+++ b/docs/source/en/model_doc/bertweet.md
@@ -26,7 +26,6 @@ rendered properly in your Markdown viewer.
[BERTweet](https://huggingface.co/papers/2005.10200) shares the same architecture as [BERT-base](./bert), but it’s pretrained like [RoBERTa](./roberta) on English Tweets. It performs really well on Tweet-related tasks like part-of-speech tagging, named entity recognition, and text classification.
-
You can find all the original BERTweet checkpoints under the [VinAI Research](https://huggingface.co/vinai?search_models=BERTweet) organization.
> [!TIP]
@@ -49,6 +48,7 @@ pipeline = pipeline(
)
pipeline("Plants create through a process known as photosynthesis.")
```
+
diff --git a/docs/source/en/model_doc/big_bird.md b/docs/source/en/model_doc/big_bird.md
index 5e431c6883d..877445a4ba5 100644
--- a/docs/source/en/model_doc/big_bird.md
+++ b/docs/source/en/model_doc/big_bird.md
@@ -47,6 +47,7 @@ pipeline = pipeline(
)
pipeline("Plants create [MASK] through a process known as photosynthesis.")
```
+
@@ -81,6 +82,7 @@ print(f"The predicted token is: {predicted_token}")
```bash
!echo -e "Plants create [MASK] through a process known as photosynthesis." | transformers run --task fill-mask --model google/bigbird-roberta-base --device 0
```
+
diff --git a/docs/source/en/model_doc/bigbird_pegasus.md b/docs/source/en/model_doc/bigbird_pegasus.md
index fe3241ed7ab..cfc55e361e7 100644
--- a/docs/source/en/model_doc/bigbird_pegasus.md
+++ b/docs/source/en/model_doc/bigbird_pegasus.md
@@ -52,6 +52,7 @@ Through photosynthesis, plants capture energy from sunlight using a green pigmen
These ingredients are then transformed into glucose, a type of sugar that serves as a source of chemical energy, and oxygen, which is released as a byproduct into the atmosphere. The glucose produced during photosynthesis is not just used immediately; plants also store it as starch or convert it into other organic compounds like cellulose, which is essential for building their cellular structure.
This energy reserve allows them to grow, develop leaves, produce flowers, bear fruit, and carry out various physiological processes throughout their lifecycle.""")
```
+
@@ -77,6 +78,7 @@ input_ids = tokenizer(input_text, return_tensors="pt").to(model.device)
output = model.generate(**input_ids, cache_implementation="static")
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
+
diff --git a/docs/source/en/model_doc/biogpt.md b/docs/source/en/model_doc/biogpt.md
index 4676a440c75..9a664fa288f 100644
--- a/docs/source/en/model_doc/biogpt.md
+++ b/docs/source/en/model_doc/biogpt.md
@@ -135,31 +135,26 @@ print(output)
[[autodoc]] BioGptConfig
-
## BioGptTokenizer
[[autodoc]] BioGptTokenizer
- save_vocabulary
-
## BioGptModel
[[autodoc]] BioGptModel
- forward
-
## BioGptForCausalLM
[[autodoc]] BioGptForCausalLM
- forward
-
## BioGptForTokenClassification
[[autodoc]] BioGptForTokenClassification
- forward
-
## BioGptForSequenceClassification
[[autodoc]] BioGptForSequenceClassification
diff --git a/docs/source/en/model_doc/bitnet.md b/docs/source/en/model_doc/bitnet.md
index 6946ec65d43..69f9cb75131 100644
--- a/docs/source/en/model_doc/bitnet.md
+++ b/docs/source/en/model_doc/bitnet.md
@@ -35,10 +35,8 @@ Several versions of the model weights are available on Hugging Face:
* [**`microsoft/bitnet-b1.58-2B-4T-gguf`**](https://huggingface.co/microsoft/bitnet-b1.58-2B-4T-gguf): Contains the model weights in GGUF format, compatible with the `bitnet.cpp` library for CPU inference.
-
### Model Details
-
* **Architecture:** Transformer-based, modified with `BitLinear` layers (BitNet framework).
* Uses Rotary Position Embeddings (RoPE).
* Uses squared ReLU (ReLU²) activation in FFN layers.
@@ -58,10 +56,8 @@ Several versions of the model weights are available on Hugging Face:
3. **Direct Preference Optimization (DPO):** Aligned with human preferences using preference pairs.
* **Tokenizer:** LLaMA 3 Tokenizer (vocab size: 128,256).
-
## Usage tips
-
**VERY IMPORTANT NOTE ON EFFICIENCY**
> Please do NOT expect performance efficiency gains (in terms of speed, latency, or energy consumption) when using this model with the standard transformers library.
@@ -106,7 +102,6 @@ response = tokenizer.decode(chat_outputs[0][chat_input.shape[-1]:], skip_special
print("\nAssistant Response:", response)
```
-
## BitNetConfig
[[autodoc]] BitNetConfig
diff --git a/docs/source/en/model_doc/blenderbot-small.md b/docs/source/en/model_doc/blenderbot-small.md
index 1967013208b..830db710e03 100644
--- a/docs/source/en/model_doc/blenderbot-small.md
+++ b/docs/source/en/model_doc/blenderbot-small.md
@@ -55,7 +55,6 @@ found [here](https://github.com/facebookresearch/ParlAI).
Blenderbot Small is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
-
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
diff --git a/docs/source/en/model_doc/blenderbot.md b/docs/source/en/model_doc/blenderbot.md
index 99149c5d948..168c744235d 100644
--- a/docs/source/en/model_doc/blenderbot.md
+++ b/docs/source/en/model_doc/blenderbot.md
@@ -71,7 +71,6 @@ An example:
`facebook/blenderbot_small_90M`, have a different architecture and consequently should be used with
[BlenderbotSmall](blenderbot-small).
-
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
diff --git a/docs/source/en/model_doc/blip-2.md b/docs/source/en/model_doc/blip-2.md
index fe4e939c2dc..faaaee7b084 100644
--- a/docs/source/en/model_doc/blip-2.md
+++ b/docs/source/en/model_doc/blip-2.md
@@ -26,14 +26,14 @@ rendered properly in your Markdown viewer.
The BLIP-2 model was proposed in [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://huggingface.co/papers/2301.12597) by
Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi. BLIP-2 leverages frozen pre-trained image encoders and large language models (LLMs) by training a lightweight, 12-layer Transformer
encoder in between them, achieving state-of-the-art performance on various vision-language tasks. Most notably, BLIP-2 improves upon [Flamingo](https://huggingface.co/papers/2204.14198), an 80 billion parameter model, by 8.7%
-on zero-shot VQAv2 with 54x fewer trainable parameters.
+on zero-shot VQAv2 with 54x fewer trainable parameters.
The abstract from the paper is the following:
*The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model's emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.*
 +alt="drawing" width="600"/>
BLIP-2 architecture. Taken from the original paper.
diff --git a/docs/source/en/model_doc/blip.md b/docs/source/en/model_doc/blip.md
index 13a2a5731a5..5ef78728996 100644
--- a/docs/source/en/model_doc/blip.md
+++ b/docs/source/en/model_doc/blip.md
@@ -25,7 +25,6 @@ rendered properly in your Markdown viewer.
[BLIP](https://huggingface.co/papers/2201.12086) (Bootstrapped Language-Image Pretraining) is a vision-language pretraining (VLP) framework designed for *both* understanding and generation tasks. Most existing pretrained models are only good at one or the other. It uses a captioner to generate captions and a filter to remove the noisy captions. This increases training data quality and more effectively uses the messy web data.
-
You can find all the original BLIP checkpoints under the [BLIP](https://huggingface.co/collections/Salesforce/blip-models-65242f40f1491fbf6a9e9472) collection.
> [!TIP]
diff --git a/docs/source/en/model_doc/bloom.md b/docs/source/en/model_doc/bloom.md
index 805379338e3..c78cb4447eb 100644
--- a/docs/source/en/model_doc/bloom.md
+++ b/docs/source/en/model_doc/bloom.md
@@ -48,7 +48,6 @@ See also:
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
-
⚡️ Inference
- A blog on [Optimization story: Bloom inference](https://huggingface.co/blog/bloom-inference-optimization).
- A blog on [Incredibly Fast BLOOM Inference with DeepSpeed and Accelerate](https://huggingface.co/blog/bloom-inference-pytorch-scripts).
diff --git a/docs/source/en/model_doc/blt.md b/docs/source/en/model_doc/blt.md
index 0289f77ac90..7e9052bcdd2 100644
--- a/docs/source/en/model_doc/blt.md
+++ b/docs/source/en/model_doc/blt.md
@@ -83,7 +83,6 @@ print(tokenizer.decode(generated_ids[0]))
This model was contributed by [itazap](https://huggingface.co/
+alt="drawing" width="600"/>
BLIP-2 architecture. Taken from the original paper.
diff --git a/docs/source/en/model_doc/blip.md b/docs/source/en/model_doc/blip.md
index 13a2a5731a5..5ef78728996 100644
--- a/docs/source/en/model_doc/blip.md
+++ b/docs/source/en/model_doc/blip.md
@@ -25,7 +25,6 @@ rendered properly in your Markdown viewer.
[BLIP](https://huggingface.co/papers/2201.12086) (Bootstrapped Language-Image Pretraining) is a vision-language pretraining (VLP) framework designed for *both* understanding and generation tasks. Most existing pretrained models are only good at one or the other. It uses a captioner to generate captions and a filter to remove the noisy captions. This increases training data quality and more effectively uses the messy web data.
-
You can find all the original BLIP checkpoints under the [BLIP](https://huggingface.co/collections/Salesforce/blip-models-65242f40f1491fbf6a9e9472) collection.
> [!TIP]
diff --git a/docs/source/en/model_doc/bloom.md b/docs/source/en/model_doc/bloom.md
index 805379338e3..c78cb4447eb 100644
--- a/docs/source/en/model_doc/bloom.md
+++ b/docs/source/en/model_doc/bloom.md
@@ -48,7 +48,6 @@ See also:
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
-
⚡️ Inference
- A blog on [Optimization story: Bloom inference](https://huggingface.co/blog/bloom-inference-optimization).
- A blog on [Incredibly Fast BLOOM Inference with DeepSpeed and Accelerate](https://huggingface.co/blog/bloom-inference-pytorch-scripts).
diff --git a/docs/source/en/model_doc/blt.md b/docs/source/en/model_doc/blt.md
index 0289f77ac90..7e9052bcdd2 100644
--- a/docs/source/en/model_doc/blt.md
+++ b/docs/source/en/model_doc/blt.md
@@ -83,7 +83,6 @@ print(tokenizer.decode(generated_ids[0]))
This model was contributed by [itazap](https://huggingface.co/).
The original code can be found [here]().
-
## BltConfig
[[autodoc]] BltConfig
diff --git a/docs/source/en/model_doc/bridgetower.md b/docs/source/en/model_doc/bridgetower.md
index 6a2b09e263a..861dd32c16f 100644
--- a/docs/source/en/model_doc/bridgetower.md
+++ b/docs/source/en/model_doc/bridgetower.md
@@ -26,7 +26,7 @@ rendered properly in your Markdown viewer.
The BridgeTower model was proposed in [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://huggingface.co/papers/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan. The goal of this model is to build a
bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder thus achieving remarkable performance on various downstream tasks with almost negligible additional performance and computational costs.
-This paper has been accepted to the [AAAI'23](https://aaai.org/Conferences/AAAI-23/) conference.
+This paper has been accepted to the [AAAI'23](https://aaai.org/Conferences/AAAI-23/) conference.
The abstract from the paper is the following:
@@ -54,6 +54,7 @@ The [`BridgeTowerProcessor`] wraps [`RobertaTokenizer`] and [`BridgeTowerImagePr
encode the text and prepare the images respectively.
The following example shows how to run contrastive learning using [`BridgeTowerProcessor`] and [`BridgeTowerForContrastiveLearning`].
+
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
@@ -76,6 +77,7 @@ The following example shows how to run contrastive learning using [`BridgeTowerP
```
The following example shows how to run image-text retrieval using [`BridgeTowerProcessor`] and [`BridgeTowerForImageAndTextRetrieval`].
+
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
@@ -130,7 +132,6 @@ Tips:
- Please refer to [Table 5](https://huggingface.co/papers/2206.08657) for BridgeTower's performance on Image Retrieval and other down stream tasks.
- The PyTorch version of this model is only available in torch 1.10 and higher.
-
## BridgeTowerConfig
[[autodoc]] BridgeTowerConfig
@@ -177,4 +178,3 @@ Tips:
[[autodoc]] BridgeTowerForImageAndTextRetrieval
- forward
-
diff --git a/docs/source/en/model_doc/bros.md b/docs/source/en/model_doc/bros.md
index aeb3dd76e52..4ef3d3737ae 100644
--- a/docs/source/en/model_doc/bros.md
+++ b/docs/source/en/model_doc/bros.md
@@ -57,7 +57,6 @@ def expand_and_normalize_bbox(bboxes, doc_width, doc_height):
- [`~transformers.BrosForTokenClassification.forward`, `~transformers.BrosSpadeEEForTokenClassification.forward`, `~transformers.BrosSpadeEEForTokenClassification.forward`] require not only `input_ids` and `bbox` but also `box_first_token_mask` for loss calculation. It is a mask to filter out non-first tokens of each box. You can obtain this mask by saving start token indices of bounding boxes when creating `input_ids` from words. You can make `box_first_token_mask` with following code,
-
```python
def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
@@ -102,7 +101,6 @@ def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
[[autodoc]] BrosModel
- forward
-
## BrosForTokenClassification
[[autodoc]] BrosForTokenClassification
diff --git a/docs/source/en/model_doc/camembert.md b/docs/source/en/model_doc/camembert.md
index ddce66f2ded..971954ed52a 100644
--- a/docs/source/en/model_doc/camembert.md
+++ b/docs/source/en/model_doc/camembert.md
@@ -50,6 +50,7 @@ from transformers import pipeline
pipeline = pipeline("fill-mask", model="camembert-base", dtype=torch.float16, device=0)
pipeline("Le camembert est un délicieux fromage .")
```
+
@@ -72,6 +73,7 @@ predicted_token = tokenizer.decode(predicted_token_id)
print(f"The predicted token is: {predicted_token}")
```
+
@@ -84,7 +86,6 @@ echo -e "Le camembert est un délicieux fromage ." | transformers run --ta
-
Quantization reduces the memory burden of large models by representing weights in lower precision. Refer to the [Quantization](../quantization/overview) overview for available options.
The example below uses [bitsandbytes](../quantization/bitsandbytes) quantization to quantize the weights to 8-bits.
diff --git a/docs/source/en/model_doc/canine.md b/docs/source/en/model_doc/canine.md
index 4e46e943c8e..53691dcbc22 100644
--- a/docs/source/en/model_doc/canine.md
+++ b/docs/source/en/model_doc/canine.md
@@ -86,6 +86,7 @@ echo -e "Plant create energy through a process known as photosynthesis." | trans
inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
```
+
- CANINE is primarily designed to be fine-tuned on a downstream task. The pretrained model can be used for either masked language modeling or next sentence prediction.
## CanineConfig
diff --git a/docs/source/en/model_doc/chameleon.md b/docs/source/en/model_doc/chameleon.md
index eb71349115e..dc573faa111 100644
--- a/docs/source/en/model_doc/chameleon.md
+++ b/docs/source/en/model_doc/chameleon.md
@@ -28,7 +28,6 @@ rendered properly in your Markdown viewer.
The Chameleon model was proposed in [Chameleon: Mixed-Modal Early-Fusion Foundation Models
](https://huggingface.co/papers/2405.09818) by META AI Chameleon Team. Chameleon is a Vision-Language Model that use vector quantization to tokenize images which enables the model to generate multimodal output. The model takes images and texts as input, including an interleaved format, and generates textual response. Image generation module is not released yet.
-
The abstract from the paper is the following:
*We present Chameleon, a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence. We outline a stable training
@@ -43,7 +42,6 @@ including Gemini Pro and GPT-4V, according to human judgments on a new long-form
generation evaluation, where either the prompt or outputs contain mixed sequences of both images and
text. Chameleon marks a significant step forward in unified modeling of full multimodal documents*
-
 @@ -52,7 +50,6 @@ alt="drawing" width="600"/>
This model was contributed by [joaogante](https://huggingface.co/joaogante) and [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
The original code can be found [here](https://github.com/facebookresearch/chameleon).
-
## Usage tips
- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to set `processor.tokenizer.padding_side = "left"` before generating.
diff --git a/docs/source/en/model_doc/clipseg.md b/docs/source/en/model_doc/clipseg.md
index e27d49ffe48..7ca9b3926ac 100644
--- a/docs/source/en/model_doc/clipseg.md
+++ b/docs/source/en/model_doc/clipseg.md
@@ -47,7 +47,7 @@ can be formulated. Finally, we find our system to adapt well
to generalized queries involving affordances or properties*
@@ -52,7 +50,6 @@ alt="drawing" width="600"/>
This model was contributed by [joaogante](https://huggingface.co/joaogante) and [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
The original code can be found [here](https://github.com/facebookresearch/chameleon).
-
## Usage tips
- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to set `processor.tokenizer.padding_side = "left"` before generating.
diff --git a/docs/source/en/model_doc/clipseg.md b/docs/source/en/model_doc/clipseg.md
index e27d49ffe48..7ca9b3926ac 100644
--- a/docs/source/en/model_doc/clipseg.md
+++ b/docs/source/en/model_doc/clipseg.md
@@ -47,7 +47,7 @@ can be formulated. Finally, we find our system to adapt well
to generalized queries involving affordances or properties*
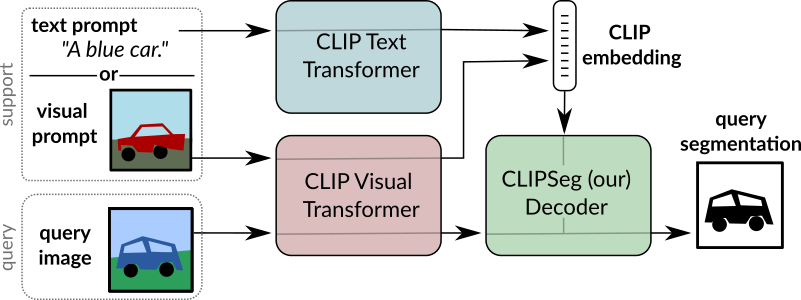 +alt="drawing" width="600"/>
CLIPSeg overview. Taken from the original paper.
diff --git a/docs/source/en/model_doc/clvp.md b/docs/source/en/model_doc/clvp.md
index 926438a3c1f..eead4a54643 100644
--- a/docs/source/en/model_doc/clvp.md
+++ b/docs/source/en/model_doc/clvp.md
@@ -29,29 +29,25 @@ The abstract from the paper is the following:
*In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise - an expressive, multi-voice text-to-speech system.*
-
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
The original code can be found [here](https://github.com/neonbjb/tortoise-tts).
-
## Usage tips
1. CLVP is an integral part of the Tortoise TTS model.
2. CLVP can be used to compare different generated speech candidates with the provided text, and the best speech tokens are forwarded to the diffusion model.
3. The use of the [`ClvpModelForConditionalGeneration.generate()`] method is strongly recommended for tortoise usage.
-4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
-
+4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
## Brief Explanation:
- The [`ClvpTokenizer`] tokenizes the text input, and the [`ClvpFeatureExtractor`] extracts the log mel-spectrogram from the desired audio.
- [`ClvpConditioningEncoder`] takes those text tokens and audio representations and converts them into embeddings conditioned on the text and audio.
- The [`ClvpForCausalLM`] uses those embeddings to generate multiple speech candidates.
-- Each speech candidate is passed through the speech encoder ([`ClvpEncoder`]) which converts them into a vector representation, and the text encoder ([`ClvpEncoder`]) converts the text tokens into the same latent space.
-- At the end, we compare each speech vector with the text vector to see which speech vector is most similar to the text vector.
+- Each speech candidate is passed through the speech encoder ([`ClvpEncoder`]) which converts them into a vector representation, and the text encoder ([`ClvpEncoder`]) converts the text tokens into the same latent space.
+- At the end, we compare each speech vector with the text vector to see which speech vector is most similar to the text vector.
- [`ClvpModelForConditionalGeneration.generate()`] compresses all of the logic described above into a single method.
-
Example :
```python
@@ -74,7 +70,6 @@ Example :
>>> generated_output = model.generate(**processor_output)
```
-
## ClvpConfig
[[autodoc]] ClvpConfig
@@ -128,4 +123,3 @@ Example :
## ClvpDecoder
[[autodoc]] ClvpDecoder
-
diff --git a/docs/source/en/model_doc/code_llama.md b/docs/source/en/model_doc/code_llama.md
index 60e9cb4c3cf..a46e1f05b32 100644
--- a/docs/source/en/model_doc/code_llama.md
+++ b/docs/source/en/model_doc/code_llama.md
@@ -143,6 +143,7 @@ visualizer("""def func(a, b):
- Infilling is only available in the 7B and 13B base models, and not in the Python, Instruct, 34B, or 70B models.
- Use the `
+alt="drawing" width="600"/>
CLIPSeg overview. Taken from the original paper.
diff --git a/docs/source/en/model_doc/clvp.md b/docs/source/en/model_doc/clvp.md
index 926438a3c1f..eead4a54643 100644
--- a/docs/source/en/model_doc/clvp.md
+++ b/docs/source/en/model_doc/clvp.md
@@ -29,29 +29,25 @@ The abstract from the paper is the following:
*In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise - an expressive, multi-voice text-to-speech system.*
-
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
The original code can be found [here](https://github.com/neonbjb/tortoise-tts).
-
## Usage tips
1. CLVP is an integral part of the Tortoise TTS model.
2. CLVP can be used to compare different generated speech candidates with the provided text, and the best speech tokens are forwarded to the diffusion model.
3. The use of the [`ClvpModelForConditionalGeneration.generate()`] method is strongly recommended for tortoise usage.
-4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
-
+4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
## Brief Explanation:
- The [`ClvpTokenizer`] tokenizes the text input, and the [`ClvpFeatureExtractor`] extracts the log mel-spectrogram from the desired audio.
- [`ClvpConditioningEncoder`] takes those text tokens and audio representations and converts them into embeddings conditioned on the text and audio.
- The [`ClvpForCausalLM`] uses those embeddings to generate multiple speech candidates.
-- Each speech candidate is passed through the speech encoder ([`ClvpEncoder`]) which converts them into a vector representation, and the text encoder ([`ClvpEncoder`]) converts the text tokens into the same latent space.
-- At the end, we compare each speech vector with the text vector to see which speech vector is most similar to the text vector.
+- Each speech candidate is passed through the speech encoder ([`ClvpEncoder`]) which converts them into a vector representation, and the text encoder ([`ClvpEncoder`]) converts the text tokens into the same latent space.
+- At the end, we compare each speech vector with the text vector to see which speech vector is most similar to the text vector.
- [`ClvpModelForConditionalGeneration.generate()`] compresses all of the logic described above into a single method.
-
Example :
```python
@@ -74,7 +70,6 @@ Example :
>>> generated_output = model.generate(**processor_output)
```
-
## ClvpConfig
[[autodoc]] ClvpConfig
@@ -128,4 +123,3 @@ Example :
## ClvpDecoder
[[autodoc]] ClvpDecoder
-
diff --git a/docs/source/en/model_doc/code_llama.md b/docs/source/en/model_doc/code_llama.md
index 60e9cb4c3cf..a46e1f05b32 100644
--- a/docs/source/en/model_doc/code_llama.md
+++ b/docs/source/en/model_doc/code_llama.md
@@ -143,6 +143,7 @@ visualizer("""def func(a, b):
- Infilling is only available in the 7B and 13B base models, and not in the Python, Instruct, 34B, or 70B models.
- Use the `` token where you want your input to be filled. The tokenizer splits this token to create a formatted input string that follows the [original training pattern](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402). This is more robust than preparing the pattern yourself.
+
```py
from transformers import LlamaForCausalLM, CodeLlamaTokenizer
@@ -158,6 +159,7 @@ visualizer("""def func(a, b):
filling = tokenizer.batch_decode(generated_ids[:, input_ids.shape[1]:], skip_special_tokens = True)[0]
print(PROMPT.replace("", filling))
```
+
- Use `bfloat16` for further training or fine-tuning and `float16` for inference.
- The `BOS` character is not used for infilling when encoding the prefix or suffix, but only at the beginning of each prompt.
- The tokenizer is a byte-pair encoding model based on [SentencePiece](https://github.com/google/sentencepiece). During decoding, if the first token is the start of the word (for example, “Banana”), the tokenizer doesn’t prepend the prefix space to the string.
diff --git a/docs/source/en/model_doc/codegen.md b/docs/source/en/model_doc/codegen.md
index e5ad3863b67..c341154921e 100644
--- a/docs/source/en/model_doc/codegen.md
+++ b/docs/source/en/model_doc/codegen.md
@@ -29,7 +29,7 @@ CodeGen is an autoregressive language model for program synthesis trained sequen
The abstract from the paper is the following:
-*Program synthesis strives to generate a computer program as a solution to a given problem specification. We propose a conversational program synthesis approach via large language models, which addresses the challenges of searching over a vast program space and user intent specification faced in prior approaches. Our new approach casts the process of writing a specification and program as a multi-turn conversation between a user and a system. It treats program synthesis as a sequence prediction problem, in which the specification is expressed in natural language and the desired program is conditionally sampled. We train a family of large language models, called CodeGen, on natural language and programming language data. With weak supervision in the data and the scaling up of data size and model size, conversational capacities emerge from the simple autoregressive language modeling. To study the model behavior on conversational program synthesis, we develop a multi-turn programming benchmark (MTPB), where solving each problem requires multi-step synthesis via multi-turn conversation between the user and the model. Our findings show the emergence of conversational capabilities and the effectiveness of the proposed conversational program synthesis paradigm. In addition, our model CodeGen (with up to 16B parameters trained on TPU-v4) outperforms OpenAI's Codex on the HumanEval benchmark. We make the training library JaxFormer including checkpoints available as open source contribution: [this https URL](https://github.com/salesforce/codegen).*
+*Program synthesis strives to generate a computer program as a solution to a given problem specification. We propose a conversational program synthesis approach via large language models, which addresses the challenges of searching over a vast program space and user intent specification faced in prior approaches. Our new approach casts the process of writing a specification and program as a multi-turn conversation between a user and a system. It treats program synthesis as a sequence prediction problem, in which the specification is expressed in natural language and the desired program is conditionally sampled. We train a family of large language models, called CodeGen, on natural language and programming language data. With weak supervision in the data and the scaling up of data size and model size, conversational capacities emerge from the simple autoregressive language modeling. To study the model behavior on conversational program synthesis, we develop a multi-turn programming benchmark (MTPB), where solving each problem requires multi-step synthesis via multi-turn conversation between the user and the model. Our findings show the emergence of conversational capabilities and the effectiveness of the proposed conversational program synthesis paradigm. In addition, our model CodeGen (with up to 16B parameters trained on TPU-v4) outperforms OpenAI's Codex on the HumanEval benchmark. We make the training library JaxFormer including checkpoints available as open source contribution: [this https URL](https://github.com/salesforce/codegen).*
This model was contributed by [Hiroaki Hayashi](https://huggingface.co/rooa).
The original code can be found [here](https://github.com/salesforce/codegen).
@@ -39,7 +39,7 @@ The original code can be found [here](https://github.com/salesforce/codegen).
* CodeGen model [checkpoints](https://huggingface.co/models?other=codegen) are available on different pre-training data with variable sizes.
* The format is: `Salesforce/codegen-{size}-{data}`, where
* `size`: `350M`, `2B`, `6B`, `16B`
- * `data`:
+ * `data`:
* `nl`: Pre-trained on the Pile
* `multi`: Initialized with `nl`, then further pre-trained on multiple programming languages data
* `mono`: Initialized with `multi`, then further pre-trained on Python data
diff --git a/docs/source/en/model_doc/cohere.md b/docs/source/en/model_doc/cohere.md
index 9fc6d266d69..b8ccf20706a 100644
--- a/docs/source/en/model_doc/cohere.md
+++ b/docs/source/en/model_doc/cohere.md
@@ -22,14 +22,12 @@ rendered properly in your Markdown viewer.
-
# Cohere
Cohere [Command-R](https://cohere.com/blog/command-r) is a 35B parameter multilingual large language model designed for long context tasks like retrieval-augmented generation (RAG) and calling external APIs and tools. The model is specifically trained for grounded generation and supports both single-step and multi-step tool use. It supports a context length of 128K tokens.
You can find all the original Command-R checkpoints under the [Command Models](https://huggingface.co/collections/CohereForAI/command-models-67652b401665205e17b192ad) collection.
-
> [!TIP]
> Click on the Cohere models in the right sidebar for more examples of how to apply Cohere to different language tasks.
@@ -123,7 +121,6 @@ visualizer("Plants create energy through a process known as")

-
## Notes
- Don’t use the dtype parameter in [`~AutoModel.from_pretrained`] if you’re using FlashAttention-2 because it only supports fp16 or bf16. You should use [Automatic Mixed Precision](https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html), set fp16 or bf16 to True if using [`Trainer`], or use [torch.autocast](https://pytorch.org/docs/stable/amp.html#torch.autocast).
@@ -145,7 +142,6 @@ visualizer("Plants create energy through a process known as")
[[autodoc]] CohereModel
- forward
-
## CohereForCausalLM
[[autodoc]] CohereForCausalLM
diff --git a/docs/source/en/model_doc/cohere2.md b/docs/source/en/model_doc/cohere2.md
index b1edcf8c851..ed94fef1da1 100644
--- a/docs/source/en/model_doc/cohere2.md
+++ b/docs/source/en/model_doc/cohere2.md
@@ -22,7 +22,6 @@ rendered properly in your Markdown viewer.
-
# Cohere 2
[Cohere Command R7B](https://cohere.com/blog/command-r7b) is an open weights research release of a 7B billion parameter model. It is a multilingual model trained on 23 languages and has a context window of 128k. The model features three layers with sliding window attention and ROPE for efficient local context modeling and relative positional encoding. A fourth layer uses global attention without positional embeddings, enabling unrestricted token interactions across the entire sequence.
@@ -31,7 +30,6 @@ This model is optimized for speed, cost-performance, and compute resources.
You can find all the original Command-R checkpoints under the [Command Models](https://huggingface.co/collections/CohereForAI/command-models-67652b401665205e17b192ad) collection.
-
> [!TIP]
> Click on the Cohere models in the right sidebar for more examples of how to apply Cohere to different language tasks.
@@ -136,7 +134,6 @@ print(tokenizer.decode(output[0], skip_special_tokens=True))
[[autodoc]] Cohere2Model
- forward
-
## Cohere2ForCausalLM
[[autodoc]] Cohere2ForCausalLM
diff --git a/docs/source/en/model_doc/cohere2_vision.md b/docs/source/en/model_doc/cohere2_vision.md
index 2e12ff3e476..e466ce6a5f0 100644
--- a/docs/source/en/model_doc/cohere2_vision.md
+++ b/docs/source/en/model_doc/cohere2_vision.md
@@ -113,6 +113,7 @@ outputs = pipe(text=messages, max_new_tokens=300, return_full_text=False)
print(outputs)
```
+
diff --git a/docs/source/en/model_doc/cpm.md b/docs/source/en/model_doc/cpm.md
index ccfa1596bad..275f5629db1 100644
--- a/docs/source/en/model_doc/cpm.md
+++ b/docs/source/en/model_doc/cpm.md
@@ -42,7 +42,6 @@ NLP tasks in the settings of few-shot (even zero-shot) learning.*
This model was contributed by [canwenxu](https://huggingface.co/canwenxu). The original implementation can be found
here: https://github.com/TsinghuaAI/CPM-Generate
-
+alt="drawing" width="600"/>
BLIP-2 architecture. Taken from the original paper.
diff --git a/docs/source/en/model_doc/blip.md b/docs/source/en/model_doc/blip.md
index 13a2a5731a5..5ef78728996 100644
--- a/docs/source/en/model_doc/blip.md
+++ b/docs/source/en/model_doc/blip.md
@@ -25,7 +25,6 @@ rendered properly in your Markdown viewer.
[BLIP](https://huggingface.co/papers/2201.12086) (Bootstrapped Language-Image Pretraining) is a vision-language pretraining (VLP) framework designed for *both* understanding and generation tasks. Most existing pretrained models are only good at one or the other. It uses a captioner to generate captions and a filter to remove the noisy captions. This increases training data quality and more effectively uses the messy web data.
-
You can find all the original BLIP checkpoints under the [BLIP](https://huggingface.co/collections/Salesforce/blip-models-65242f40f1491fbf6a9e9472) collection.
> [!TIP]
diff --git a/docs/source/en/model_doc/bloom.md b/docs/source/en/model_doc/bloom.md
index 805379338e3..c78cb4447eb 100644
--- a/docs/source/en/model_doc/bloom.md
+++ b/docs/source/en/model_doc/bloom.md
@@ -48,7 +48,6 @@ See also:
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
-
⚡️ Inference
- A blog on [Optimization story: Bloom inference](https://huggingface.co/blog/bloom-inference-optimization).
- A blog on [Incredibly Fast BLOOM Inference with DeepSpeed and Accelerate](https://huggingface.co/blog/bloom-inference-pytorch-scripts).
diff --git a/docs/source/en/model_doc/blt.md b/docs/source/en/model_doc/blt.md
index 0289f77ac90..7e9052bcdd2 100644
--- a/docs/source/en/model_doc/blt.md
+++ b/docs/source/en/model_doc/blt.md
@@ -83,7 +83,6 @@ print(tokenizer.decode(generated_ids[0]))
This model was contributed by [itazap](https://huggingface.co/
@@ -52,7 +50,6 @@ alt="drawing" width="600"/>
This model was contributed by [joaogante](https://huggingface.co/joaogante) and [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
The original code can be found [here](https://github.com/facebookresearch/chameleon).
-
## Usage tips
- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to set `processor.tokenizer.padding_side = "left"` before generating.
diff --git a/docs/source/en/model_doc/clipseg.md b/docs/source/en/model_doc/clipseg.md
index e27d49ffe48..7ca9b3926ac 100644
--- a/docs/source/en/model_doc/clipseg.md
+++ b/docs/source/en/model_doc/clipseg.md
@@ -47,7 +47,7 @@ can be formulated. Finally, we find our system to adapt well
to generalized queries involving affordances or properties*
+alt="drawing" width="600"/>
CLIPSeg overview. Taken from the original paper.
diff --git a/docs/source/en/model_doc/clvp.md b/docs/source/en/model_doc/clvp.md
index 926438a3c1f..eead4a54643 100644
--- a/docs/source/en/model_doc/clvp.md
+++ b/docs/source/en/model_doc/clvp.md
@@ -29,29 +29,25 @@ The abstract from the paper is the following:
*In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise - an expressive, multi-voice text-to-speech system.*
-
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
The original code can be found [here](https://github.com/neonbjb/tortoise-tts).
-
## Usage tips
1. CLVP is an integral part of the Tortoise TTS model.
2. CLVP can be used to compare different generated speech candidates with the provided text, and the best speech tokens are forwarded to the diffusion model.
3. The use of the [`ClvpModelForConditionalGeneration.generate()`] method is strongly recommended for tortoise usage.
-4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
-
+4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
## Brief Explanation:
- The [`ClvpTokenizer`] tokenizes the text input, and the [`ClvpFeatureExtractor`] extracts the log mel-spectrogram from the desired audio.
- [`ClvpConditioningEncoder`] takes those text tokens and audio representations and converts them into embeddings conditioned on the text and audio.
- The [`ClvpForCausalLM`] uses those embeddings to generate multiple speech candidates.
-- Each speech candidate is passed through the speech encoder ([`ClvpEncoder`]) which converts them into a vector representation, and the text encoder ([`ClvpEncoder`]) converts the text tokens into the same latent space.
-- At the end, we compare each speech vector with the text vector to see which speech vector is most similar to the text vector.
+- Each speech candidate is passed through the speech encoder ([`ClvpEncoder`]) which converts them into a vector representation, and the text encoder ([`ClvpEncoder`]) converts the text tokens into the same latent space.
+- At the end, we compare each speech vector with the text vector to see which speech vector is most similar to the text vector.
- [`ClvpModelForConditionalGeneration.generate()`] compresses all of the logic described above into a single method.
-
Example :
```python
@@ -74,7 +70,6 @@ Example :
>>> generated_output = model.generate(**processor_output)
```
-
## ClvpConfig
[[autodoc]] ClvpConfig
@@ -128,4 +123,3 @@ Example :
## ClvpDecoder
[[autodoc]] ClvpDecoder
-
diff --git a/docs/source/en/model_doc/code_llama.md b/docs/source/en/model_doc/code_llama.md
index 60e9cb4c3cf..a46e1f05b32 100644
--- a/docs/source/en/model_doc/code_llama.md
+++ b/docs/source/en/model_doc/code_llama.md
@@ -143,6 +143,7 @@ visualizer("""def func(a, b):
- Infilling is only available in the 7B and 13B base models, and not in the Python, Instruct, 34B, or 70B models.
- Use the `
@@ -44,6 +42,7 @@ inputs = tokenizer("Hey how are you doing?", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.batch_decode(outputs))
```
+
@@ -82,6 +81,7 @@ outputs = model.generate(
streamer=steamer
)
```
+
## DogeConfig
diff --git a/docs/source/en/model_doc/donut.md b/docs/source/en/model_doc/donut.md
index f06b6804d6e..e582dab748a 100644
--- a/docs/source/en/model_doc/donut.md
+++ b/docs/source/en/model_doc/donut.md
@@ -22,7 +22,7 @@ specific language governing permissions and limitations under the License. -->
# Donut
-[Donut (Document Understanding Transformer)](https://huggingface.co/papers/2111.15664) is a visual document understanding model that doesn't require an Optical Character Recognition (OCR) engine. Unlike traditional approaches that extract text using OCR before processing, Donut employs an end-to-end Transformer-based architecture to directly analyze document images. This eliminates OCR-related inefficiencies making it more accurate and adaptable to diverse languages and formats.
+[Donut (Document Understanding Transformer)](https://huggingface.co/papers/2111.15664) is a visual document understanding model that doesn't require an Optical Character Recognition (OCR) engine. Unlike traditional approaches that extract text using OCR before processing, Donut employs an end-to-end Transformer-based architecture to directly analyze document images. This eliminates OCR-related inefficiencies making it more accurate and adaptable to diverse languages and formats.
Donut features vision encoder ([Swin](./swin)) and a text decoder ([BART](./bart)). Swin converts document images into embeddings and BART processes them into meaningful text sequences.
diff --git a/docs/source/en/model_doc/dots1.md b/docs/source/en/model_doc/dots1.md
index 337cad8cb4c..316ab3b1f5b 100644
--- a/docs/source/en/model_doc/dots1.md
+++ b/docs/source/en/model_doc/dots1.md
@@ -25,7 +25,6 @@ The abstract from the report is the following:
*Mixture of Experts (MoE) models have emerged as a promising paradigm for scaling language models efficiently by activating only a subset of parameters for each input token. In this report, we present dots.llm1, a large-scale MoE model that activates 14B parameters out of a total of 142B parameters, delivering performance on par with state-of-the-art models while reducing training and inference costs. Leveraging our meticulously crafted and efficient data processing pipeline, dots.llm1 achieves performance comparable to Qwen2.5-72B after pretraining on high-quality corpus and post-training to fully unlock its capabilities. Notably, no synthetic data is used during pretraining. To foster further research, we open-source intermediate training checkpoints spanning the entire training process, providing valuable insights into the learning dynamics of large language models.*
-
## Dots1Config
[[autodoc]] Dots1Config
diff --git a/docs/source/en/model_doc/efficientloftr.md b/docs/source/en/model_doc/efficientloftr.md
index 2cdec895efc..faf71f4bac0 100644
--- a/docs/source/en/model_doc/efficientloftr.md
+++ b/docs/source/en/model_doc/efficientloftr.md
@@ -45,6 +45,7 @@ results = keypoint_matcher([url_0, url_1], threshold=0.9)
print(results[0])
# {'keypoint_image_0': {'x': ..., 'y': ...}, 'keypoint_image_1': {'x': ..., 'y': ...}, 'score': ...}
```
+
 -
## Usage Tips
### Generate text
@@ -84,7 +83,6 @@ generate_text = tokenizer.decode(output_ids, skip_special_tokens=True)
This model was contributed by [Anton Vlasjuk](https://huggingface.co/AntonV).
The original code can be found [here](https://github.com/PaddlePaddle/ERNIE).
-
## Ernie4_5Config
[[autodoc]] Ernie4_5Config
diff --git a/docs/source/en/model_doc/ernie4_5_moe.md b/docs/source/en/model_doc/ernie4_5_moe.md
index 20c4dcfd543..fb6b8d791be 100644
--- a/docs/source/en/model_doc/ernie4_5_moe.md
+++ b/docs/source/en/model_doc/ernie4_5_moe.md
@@ -40,7 +40,6 @@ Other models from the family can be found at [Ernie 4.5](./ernie4_5).
-
## Usage Tips
### Generate text
@@ -167,7 +166,6 @@ generate_text = tokenizer.decode(output_ids, skip_special_tokens=True)
This model was contributed by [Anton Vlasjuk](https://huggingface.co/AntonV).
The original code can be found [here](https://github.com/PaddlePaddle/ERNIE).
-
## Ernie4_5_MoeConfig
[[autodoc]] Ernie4_5_MoeConfig
diff --git a/docs/source/en/model_doc/ernie_m.md b/docs/source/en/model_doc/ernie_m.md
index 508fe2f596b..e044614e764 100644
--- a/docs/source/en/model_doc/ernie_m.md
+++ b/docs/source/en/model_doc/ernie_m.md
@@ -40,7 +40,6 @@ The abstract from the paper is the following:
*Recent studies have demonstrated that pre-trained cross-lingual models achieve impressive performance in downstream cross-lingual tasks. This improvement benefits from learning a large amount of monolingual and parallel corpora. Although it is generally acknowledged that parallel corpora are critical for improving the model performance, existing methods are often constrained by the size of parallel corpora, especially for lowresource languages. In this paper, we propose ERNIE-M, a new training method that encourages the model to align the representation of multiple languages with monolingual corpora, to overcome the constraint that the parallel corpus size places on the model performance. Our key insight is to integrate back-translation into the pre-training process. We generate pseudo-parallel sentence pairs on a monolingual corpus to enable the learning of semantic alignments between different languages, thereby enhancing the semantic modeling of cross-lingual models. Experimental results show that ERNIE-M outperforms existing cross-lingual models and delivers new state-of-the-art results in various cross-lingual downstream tasks.*
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). The original code can be found [here](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers/ernie_m).
-
## Usage tips
- Ernie-M is a BERT-like model so it is a stacked Transformer Encoder.
@@ -59,7 +58,6 @@ This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). Th
[[autodoc]] ErnieMConfig
-
## ErnieMTokenizer
[[autodoc]] ErnieMTokenizer
@@ -68,7 +66,6 @@ This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). Th
- create_token_type_ids_from_sequences
- save_vocabulary
-
## ErnieMModel
[[autodoc]] ErnieMModel
@@ -79,19 +76,16 @@ This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). Th
[[autodoc]] ErnieMForSequenceClassification
- forward
-
## ErnieMForMultipleChoice
[[autodoc]] ErnieMForMultipleChoice
- forward
-
## ErnieMForTokenClassification
[[autodoc]] ErnieMForTokenClassification
- forward
-
## ErnieMForQuestionAnswering
[[autodoc]] ErnieMForQuestionAnswering
diff --git a/docs/source/en/model_doc/esm.md b/docs/source/en/model_doc/esm.md
index e83e2d5aa1d..a6190a71f02 100644
--- a/docs/source/en/model_doc/esm.md
+++ b/docs/source/en/model_doc/esm.md
@@ -44,12 +44,10 @@ sequence alignment (MSA) step at inference time, which means that ESMFold checkp
they do not require a database of known protein sequences and structures with associated external query tools
to make predictions, and are much faster as a result.
-
The abstract from
"Biological structure and function emerge from scaling unsupervised learning to 250
million protein sequences" is
-
*In the field of artificial intelligence, a combination of scale in data and model capacity enabled by unsupervised
learning has led to major advances in representation learning and statistical generation. In the life sciences, the
anticipated growth of sequencing promises unprecedented data on natural sequence diversity. Protein language modeling
@@ -63,7 +61,6 @@ can be identified by linear projections. Representation learning produces featur
applications, enabling state-of-the-art supervised prediction of mutational effect and secondary structure and
improving state-of-the-art features for long-range contact prediction.*
-
The abstract from
"Language models of protein sequences at the scale of evolution enable accurate structure prediction" is
diff --git a/docs/source/en/model_doc/evolla.md b/docs/source/en/model_doc/evolla.md
index a39103a06d1..56f1d2755e1 100644
--- a/docs/source/en/model_doc/evolla.md
+++ b/docs/source/en/model_doc/evolla.md
@@ -75,7 +75,6 @@ Tips:
- This model was contributed by [Xibin Bayes Zhou](https://huggingface.co/XibinBayesZhou).
- The original code can be found [here](https://github.com/westlake-repl/Evolla).
-
## EvollaConfig
[[autodoc]] EvollaConfig
diff --git a/docs/source/en/model_doc/exaone4.md b/docs/source/en/model_doc/exaone4.md
index 69d7ee0b2a8..93ca33babd3 100644
--- a/docs/source/en/model_doc/exaone4.md
+++ b/docs/source/en/model_doc/exaone4.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
## Overview
**[EXAONE 4.0](https://github.com/LG-AI-EXAONE/EXAONE-4.0)** model is the language model, which integrates a **Non-reasoning mode** and **Reasoning mode** to achieve both the excellent usability of [EXAONE 3.5](https://github.com/LG-AI-EXAONE/EXAONE-3.5) and the advanced reasoning abilities of [EXAONE Deep](https://github.com/LG-AI-EXAONE/EXAONE-Deep). To pave the way for the agentic AI era, EXAONE 4.0 incorporates essential features such as agentic tool use, and its multilingual capabilities are extended
-to support Spanish in addition to English and Korean.
+to support Spanish in addition to English and Korean.
The EXAONE 4.0 model series consists of two sizes: a mid-size **32B** model optimized for high performance, and a small-size **1.2B** model designed for on-device applications.
@@ -33,7 +33,6 @@ For more details, please refer to our [technical report](https://huggingface.co/
All model weights including quantized versions are available at [Huggingface Collections](https://huggingface.co/collections/LGAI-EXAONE/exaone-40-686b2e0069800c835ed48375).
-
## Model Details
### Model Specifications
@@ -57,7 +56,6 @@ All model weights including quantized versions are available at [Huggingface Col
| Tied word embedding | False | True |
| Knowledge cut-off | Nov. 2024 | Nov. 2024 |
-
## Usage tips
### Non-reasoning mode
diff --git a/docs/source/en/model_doc/falcon_h1.md b/docs/source/en/model_doc/falcon_h1.md
index 981c00bd626..c17ecea1cc0 100644
--- a/docs/source/en/model_doc/falcon_h1.md
+++ b/docs/source/en/model_doc/falcon_h1.md
@@ -21,7 +21,6 @@ The [FalconH1](https://huggingface.co/blog/tiiuae/falcon-h1) model was developed
This model was contributed by [DhiyaEddine](https://huggingface.co/DhiyaEddine), [ybelkada](https://huggingface.co/ybelkada), [JingweiZuo](https://huggingface.co/JingweiZuo), [IlyasChahed](https://huggingface.co/IChahed), and [MaksimVelikanov](https://huggingface.co/yellowvm).
The original code can be found [here](https://github.com/tiiuae/Falcon-H1).
-
## FalconH1Config
| Model | Depth | Dim | Attn Heads | KV | Mamba Heads | d_head | d_state | Ctx Len |
@@ -33,8 +32,6 @@ The original code can be found [here](https://github.com/tiiuae/Falcon-H1).
| H1 7B | 44 | 3072 | 12 | 2 | 24 | 128 / 128 | 256 | 256K |
| H1 34B | 72 | 5120 | 20 | 4 | 32 | 128 / 128 | 256 | 256K |
-
-
[[autodoc]] FalconH1Config
@@ -90,6 +89,7 @@ echo -e "Plants create energy through a process known as" | transformers run --t
Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
The example below uses [torchao](../quantization/torchao) to only quantize the weights to 4-bits.
+
```py
#pip install torchao
@@ -119,7 +119,6 @@ print(tokenizer.decode(output[0], skip_special_tokens=True))
```
-
## FlexOlmoConfig
[[autodoc]] FlexOlmoConfig
diff --git a/docs/source/en/model_doc/fnet.md b/docs/source/en/model_doc/fnet.md
index 79a4e9e4434..e89a410b105 100644
--- a/docs/source/en/model_doc/fnet.md
+++ b/docs/source/en/model_doc/fnet.md
@@ -46,8 +46,8 @@ This model was contributed by [gchhablani](https://huggingface.co/gchhablani). T
## Usage tips
-The model was trained without an attention mask as it is based on Fourier Transform. The model was trained with
-maximum sequence length 512 which includes pad tokens. Hence, it is highly recommended to use the same maximum
+The model was trained without an attention mask as it is based on Fourier Transform. The model was trained with
+maximum sequence length 512 which includes pad tokens. Hence, it is highly recommended to use the same maximum
sequence length for fine-tuning and inference.
## Resources
diff --git a/docs/source/en/model_doc/fsmt.md b/docs/source/en/model_doc/fsmt.md
index 27c7d3a899c..13a99ae40da 100644
--- a/docs/source/en/model_doc/fsmt.md
+++ b/docs/source/en/model_doc/fsmt.md
@@ -41,7 +41,6 @@ This model was contributed by [stas](https://huggingface.co/stas). The original
either. Its tokenizer is very similar to [`XLMTokenizer`] and the main model is derived from
[`BartModel`].
-
## FSMTConfig
[[autodoc]] FSMTConfig
diff --git a/docs/source/en/model_doc/funnel.md b/docs/source/en/model_doc/funnel.md
index 611e17fba8c..57b011b9400 100644
--- a/docs/source/en/model_doc/funnel.md
+++ b/docs/source/en/model_doc/funnel.md
@@ -67,7 +67,6 @@ This model was contributed by [sgugger](https://huggingface.co/sgugger). The ori
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
-
## FunnelConfig
[[autodoc]] FunnelConfig
diff --git a/docs/source/en/model_doc/fuyu.md b/docs/source/en/model_doc/fuyu.md
index 140216e2abc..34202b022f7 100644
--- a/docs/source/en/model_doc/fuyu.md
+++ b/docs/source/en/model_doc/fuyu.md
@@ -40,7 +40,6 @@ Finetuning the model in `float16` is not recommended and known to produce `nan`,
-
Tips:
- To convert the model, you need to clone the original repository using `git clone https://github.com/persimmon-ai-labs/adept-inference`, then get the checkpoints:
@@ -55,10 +54,12 @@ python src/transformers/models/fuyu/convert_fuyu_weights_to_hf.py --input_dir /
```
For the chat model:
+
```bash
wget https://axtkn4xl5cip.objectstorage.us-phoenix-1.oci.customer-oci.com/n/axtkn4xl5cip/b/adept-public-data/o/8b_chat_model_release.tar
tar -xvf 8b_base_model_release.tar
```
+
Then, model can be loaded via:
```py
@@ -99,7 +100,6 @@ The `LlamaTokenizer` is used as it is a standard wrapper around sentencepiece.
- The authors suggest to use the following prompt for image captioning: `f"Generate a coco-style caption.\\n"`
-
## FuyuConfig
[[autodoc]] FuyuConfig
diff --git a/docs/source/en/model_doc/gemma.md b/docs/source/en/model_doc/gemma.md
index d22d28d41c4..f1c088caf30 100644
--- a/docs/source/en/model_doc/gemma.md
+++ b/docs/source/en/model_doc/gemma.md
@@ -33,7 +33,6 @@ The instruction-tuned variant was fine-tuned with supervised learning on instruc
You can find all the original Gemma checkpoints under the [Gemma](https://huggingface.co/collections/google/gemma-release-65d5efbccdbb8c4202ec078b) release.
-
> [!TIP]
> Click on the Gemma models in the right sidebar for more examples of how to apply Gemma to different language tasks.
@@ -163,7 +162,6 @@ visualizer("LLMs generate text through a process known as")
[[autodoc]] GemmaTokenizer
-
## GemmaTokenizerFast
[[autodoc]] GemmaTokenizerFast
diff --git a/docs/source/en/model_doc/gemma2.md b/docs/source/en/model_doc/gemma2.md
index 680de41d038..5b4430296dc 100644
--- a/docs/source/en/model_doc/gemma2.md
+++ b/docs/source/en/model_doc/gemma2.md
@@ -40,7 +40,6 @@ The example below demonstrates how to chat with the model with [`Pipeline`] or t
-
## Usage Tips
### Generate text
@@ -84,7 +83,6 @@ generate_text = tokenizer.decode(output_ids, skip_special_tokens=True)
This model was contributed by [Anton Vlasjuk](https://huggingface.co/AntonV).
The original code can be found [here](https://github.com/PaddlePaddle/ERNIE).
-
## Ernie4_5Config
[[autodoc]] Ernie4_5Config
diff --git a/docs/source/en/model_doc/ernie4_5_moe.md b/docs/source/en/model_doc/ernie4_5_moe.md
index 20c4dcfd543..fb6b8d791be 100644
--- a/docs/source/en/model_doc/ernie4_5_moe.md
+++ b/docs/source/en/model_doc/ernie4_5_moe.md
@@ -40,7 +40,6 @@ Other models from the family can be found at [Ernie 4.5](./ernie4_5).
-
## Usage Tips
### Generate text
@@ -167,7 +166,6 @@ generate_text = tokenizer.decode(output_ids, skip_special_tokens=True)
This model was contributed by [Anton Vlasjuk](https://huggingface.co/AntonV).
The original code can be found [here](https://github.com/PaddlePaddle/ERNIE).
-
## Ernie4_5_MoeConfig
[[autodoc]] Ernie4_5_MoeConfig
diff --git a/docs/source/en/model_doc/ernie_m.md b/docs/source/en/model_doc/ernie_m.md
index 508fe2f596b..e044614e764 100644
--- a/docs/source/en/model_doc/ernie_m.md
+++ b/docs/source/en/model_doc/ernie_m.md
@@ -40,7 +40,6 @@ The abstract from the paper is the following:
*Recent studies have demonstrated that pre-trained cross-lingual models achieve impressive performance in downstream cross-lingual tasks. This improvement benefits from learning a large amount of monolingual and parallel corpora. Although it is generally acknowledged that parallel corpora are critical for improving the model performance, existing methods are often constrained by the size of parallel corpora, especially for lowresource languages. In this paper, we propose ERNIE-M, a new training method that encourages the model to align the representation of multiple languages with monolingual corpora, to overcome the constraint that the parallel corpus size places on the model performance. Our key insight is to integrate back-translation into the pre-training process. We generate pseudo-parallel sentence pairs on a monolingual corpus to enable the learning of semantic alignments between different languages, thereby enhancing the semantic modeling of cross-lingual models. Experimental results show that ERNIE-M outperforms existing cross-lingual models and delivers new state-of-the-art results in various cross-lingual downstream tasks.*
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). The original code can be found [here](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers/ernie_m).
-
## Usage tips
- Ernie-M is a BERT-like model so it is a stacked Transformer Encoder.
@@ -59,7 +58,6 @@ This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). Th
[[autodoc]] ErnieMConfig
-
## ErnieMTokenizer
[[autodoc]] ErnieMTokenizer
@@ -68,7 +66,6 @@ This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). Th
- create_token_type_ids_from_sequences
- save_vocabulary
-
## ErnieMModel
[[autodoc]] ErnieMModel
@@ -79,19 +76,16 @@ This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). Th
[[autodoc]] ErnieMForSequenceClassification
- forward
-
## ErnieMForMultipleChoice
[[autodoc]] ErnieMForMultipleChoice
- forward
-
## ErnieMForTokenClassification
[[autodoc]] ErnieMForTokenClassification
- forward
-
## ErnieMForQuestionAnswering
[[autodoc]] ErnieMForQuestionAnswering
diff --git a/docs/source/en/model_doc/esm.md b/docs/source/en/model_doc/esm.md
index e83e2d5aa1d..a6190a71f02 100644
--- a/docs/source/en/model_doc/esm.md
+++ b/docs/source/en/model_doc/esm.md
@@ -44,12 +44,10 @@ sequence alignment (MSA) step at inference time, which means that ESMFold checkp
they do not require a database of known protein sequences and structures with associated external query tools
to make predictions, and are much faster as a result.
-
The abstract from
"Biological structure and function emerge from scaling unsupervised learning to 250
million protein sequences" is
-
*In the field of artificial intelligence, a combination of scale in data and model capacity enabled by unsupervised
learning has led to major advances in representation learning and statistical generation. In the life sciences, the
anticipated growth of sequencing promises unprecedented data on natural sequence diversity. Protein language modeling
@@ -63,7 +61,6 @@ can be identified by linear projections. Representation learning produces featur
applications, enabling state-of-the-art supervised prediction of mutational effect and secondary structure and
improving state-of-the-art features for long-range contact prediction.*
-
The abstract from
"Language models of protein sequences at the scale of evolution enable accurate structure prediction" is
diff --git a/docs/source/en/model_doc/evolla.md b/docs/source/en/model_doc/evolla.md
index a39103a06d1..56f1d2755e1 100644
--- a/docs/source/en/model_doc/evolla.md
+++ b/docs/source/en/model_doc/evolla.md
@@ -75,7 +75,6 @@ Tips:
- This model was contributed by [Xibin Bayes Zhou](https://huggingface.co/XibinBayesZhou).
- The original code can be found [here](https://github.com/westlake-repl/Evolla).
-
## EvollaConfig
[[autodoc]] EvollaConfig
diff --git a/docs/source/en/model_doc/exaone4.md b/docs/source/en/model_doc/exaone4.md
index 69d7ee0b2a8..93ca33babd3 100644
--- a/docs/source/en/model_doc/exaone4.md
+++ b/docs/source/en/model_doc/exaone4.md
@@ -20,7 +20,7 @@ rendered properly in your Markdown viewer.
## Overview
**[EXAONE 4.0](https://github.com/LG-AI-EXAONE/EXAONE-4.0)** model is the language model, which integrates a **Non-reasoning mode** and **Reasoning mode** to achieve both the excellent usability of [EXAONE 3.5](https://github.com/LG-AI-EXAONE/EXAONE-3.5) and the advanced reasoning abilities of [EXAONE Deep](https://github.com/LG-AI-EXAONE/EXAONE-Deep). To pave the way for the agentic AI era, EXAONE 4.0 incorporates essential features such as agentic tool use, and its multilingual capabilities are extended
-to support Spanish in addition to English and Korean.
+to support Spanish in addition to English and Korean.
The EXAONE 4.0 model series consists of two sizes: a mid-size **32B** model optimized for high performance, and a small-size **1.2B** model designed for on-device applications.
@@ -33,7 +33,6 @@ For more details, please refer to our [technical report](https://huggingface.co/
All model weights including quantized versions are available at [Huggingface Collections](https://huggingface.co/collections/LGAI-EXAONE/exaone-40-686b2e0069800c835ed48375).
-
## Model Details
### Model Specifications
@@ -57,7 +56,6 @@ All model weights including quantized versions are available at [Huggingface Col
| Tied word embedding | False | True |
| Knowledge cut-off | Nov. 2024 | Nov. 2024 |
-
## Usage tips
### Non-reasoning mode
diff --git a/docs/source/en/model_doc/falcon_h1.md b/docs/source/en/model_doc/falcon_h1.md
index 981c00bd626..c17ecea1cc0 100644
--- a/docs/source/en/model_doc/falcon_h1.md
+++ b/docs/source/en/model_doc/falcon_h1.md
@@ -21,7 +21,6 @@ The [FalconH1](https://huggingface.co/blog/tiiuae/falcon-h1) model was developed
This model was contributed by [DhiyaEddine](https://huggingface.co/DhiyaEddine), [ybelkada](https://huggingface.co/ybelkada), [JingweiZuo](https://huggingface.co/JingweiZuo), [IlyasChahed](https://huggingface.co/IChahed), and [MaksimVelikanov](https://huggingface.co/yellowvm).
The original code can be found [here](https://github.com/tiiuae/Falcon-H1).
-
## FalconH1Config
| Model | Depth | Dim | Attn Heads | KV | Mamba Heads | d_head | d_state | Ctx Len |
@@ -33,8 +32,6 @@ The original code can be found [here](https://github.com/tiiuae/Falcon-H1).
| H1 7B | 44 | 3072 | 12 | 2 | 24 | 128 / 128 | 256 | 256K |
| H1 34B | 72 | 5120 | 20 | 4 | 32 | 128 / 128 | 256 | 256K |
-
-
[[autodoc]] FalconH1Config
@@ -90,6 +89,7 @@ echo -e "Plants create energy through a process known as" | transformers run --t
Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
The example below uses [torchao](../quantization/torchao) to only quantize the weights to 4-bits.
+
```py
#pip install torchao
@@ -119,7 +119,6 @@ print(tokenizer.decode(output[0], skip_special_tokens=True))
```
-
## FlexOlmoConfig
[[autodoc]] FlexOlmoConfig
diff --git a/docs/source/en/model_doc/fnet.md b/docs/source/en/model_doc/fnet.md
index 79a4e9e4434..e89a410b105 100644
--- a/docs/source/en/model_doc/fnet.md
+++ b/docs/source/en/model_doc/fnet.md
@@ -46,8 +46,8 @@ This model was contributed by [gchhablani](https://huggingface.co/gchhablani). T
## Usage tips
-The model was trained without an attention mask as it is based on Fourier Transform. The model was trained with
-maximum sequence length 512 which includes pad tokens. Hence, it is highly recommended to use the same maximum
+The model was trained without an attention mask as it is based on Fourier Transform. The model was trained with
+maximum sequence length 512 which includes pad tokens. Hence, it is highly recommended to use the same maximum
sequence length for fine-tuning and inference.
## Resources
diff --git a/docs/source/en/model_doc/fsmt.md b/docs/source/en/model_doc/fsmt.md
index 27c7d3a899c..13a99ae40da 100644
--- a/docs/source/en/model_doc/fsmt.md
+++ b/docs/source/en/model_doc/fsmt.md
@@ -41,7 +41,6 @@ This model was contributed by [stas](https://huggingface.co/stas). The original
either. Its tokenizer is very similar to [`XLMTokenizer`] and the main model is derived from
[`BartModel`].
-
## FSMTConfig
[[autodoc]] FSMTConfig
diff --git a/docs/source/en/model_doc/funnel.md b/docs/source/en/model_doc/funnel.md
index 611e17fba8c..57b011b9400 100644
--- a/docs/source/en/model_doc/funnel.md
+++ b/docs/source/en/model_doc/funnel.md
@@ -67,7 +67,6 @@ This model was contributed by [sgugger](https://huggingface.co/sgugger). The ori
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
-
## FunnelConfig
[[autodoc]] FunnelConfig
diff --git a/docs/source/en/model_doc/fuyu.md b/docs/source/en/model_doc/fuyu.md
index 140216e2abc..34202b022f7 100644
--- a/docs/source/en/model_doc/fuyu.md
+++ b/docs/source/en/model_doc/fuyu.md
@@ -40,7 +40,6 @@ Finetuning the model in `float16` is not recommended and known to produce `nan`,
-
Tips:
- To convert the model, you need to clone the original repository using `git clone https://github.com/persimmon-ai-labs/adept-inference`, then get the checkpoints:
@@ -55,10 +54,12 @@ python src/transformers/models/fuyu/convert_fuyu_weights_to_hf.py --input_dir /
```
For the chat model:
+
```bash
wget https://axtkn4xl5cip.objectstorage.us-phoenix-1.oci.customer-oci.com/n/axtkn4xl5cip/b/adept-public-data/o/8b_chat_model_release.tar
tar -xvf 8b_base_model_release.tar
```
+
Then, model can be loaded via:
```py
@@ -99,7 +100,6 @@ The `LlamaTokenizer` is used as it is a standard wrapper around sentencepiece.
- The authors suggest to use the following prompt for image captioning: `f"Generate a coco-style caption.\\n"`
-
## FuyuConfig
[[autodoc]] FuyuConfig
diff --git a/docs/source/en/model_doc/gemma.md b/docs/source/en/model_doc/gemma.md
index d22d28d41c4..f1c088caf30 100644
--- a/docs/source/en/model_doc/gemma.md
+++ b/docs/source/en/model_doc/gemma.md
@@ -33,7 +33,6 @@ The instruction-tuned variant was fine-tuned with supervised learning on instruc
You can find all the original Gemma checkpoints under the [Gemma](https://huggingface.co/collections/google/gemma-release-65d5efbccdbb8c4202ec078b) release.
-
> [!TIP]
> Click on the Gemma models in the right sidebar for more examples of how to apply Gemma to different language tasks.
@@ -163,7 +162,6 @@ visualizer("LLMs generate text through a process known as")
[[autodoc]] GemmaTokenizer
-
## GemmaTokenizerFast
[[autodoc]] GemmaTokenizerFast
diff --git a/docs/source/en/model_doc/gemma2.md b/docs/source/en/model_doc/gemma2.md
index 680de41d038..5b4430296dc 100644
--- a/docs/source/en/model_doc/gemma2.md
+++ b/docs/source/en/model_doc/gemma2.md
@@ -40,7 +40,6 @@ The example below demonstrates how to chat with the model with [`Pipeline`] or t
 @@ -285,4 +284,3 @@ alt="drawing" width="600"/>
[[autodoc]] GotOcr2ForConditionalGeneration
- forward
-
diff --git a/docs/source/en/model_doc/gpt2.md b/docs/source/en/model_doc/gpt2.md
index 1645a92f634..aaf2a50a173 100644
--- a/docs/source/en/model_doc/gpt2.md
+++ b/docs/source/en/model_doc/gpt2.md
@@ -23,7 +23,6 @@ rendered properly in your Markdown viewer.
-
# GPT-2
[GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) is a scaled up version of GPT, a causal transformer language model, with 10x more parameters and training data. The model was pretrained on a 40GB dataset to predict the next word in a sequence based on all the previous words. This approach enabled the model to perform many downstream tasks in a zero-shot setting. The blog post released by OpenAI can be found [here](https://openai.com/index/better-language-models/).
@@ -47,6 +46,7 @@ from transformers import pipeline
pipeline = pipeline(task="text-generation", model="openai-community/gpt2", dtype=torch.float16, device=0)
pipeline("Hello, I'm a language model")
```
+
@@ -285,4 +284,3 @@ alt="drawing" width="600"/>
[[autodoc]] GotOcr2ForConditionalGeneration
- forward
-
diff --git a/docs/source/en/model_doc/gpt2.md b/docs/source/en/model_doc/gpt2.md
index 1645a92f634..aaf2a50a173 100644
--- a/docs/source/en/model_doc/gpt2.md
+++ b/docs/source/en/model_doc/gpt2.md
@@ -23,7 +23,6 @@ rendered properly in your Markdown viewer.
-
# GPT-2
[GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) is a scaled up version of GPT, a causal transformer language model, with 10x more parameters and training data. The model was pretrained on a 40GB dataset to predict the next word in a sequence based on all the previous words. This approach enabled the model to perform many downstream tasks in a zero-shot setting. The blog post released by OpenAI can be found [here](https://openai.com/index/better-language-models/).
@@ -47,6 +46,7 @@ from transformers import pipeline
pipeline = pipeline(task="text-generation", model="openai-community/gpt2", dtype=torch.float16, device=0)
pipeline("Hello, I'm a language model")
```
+
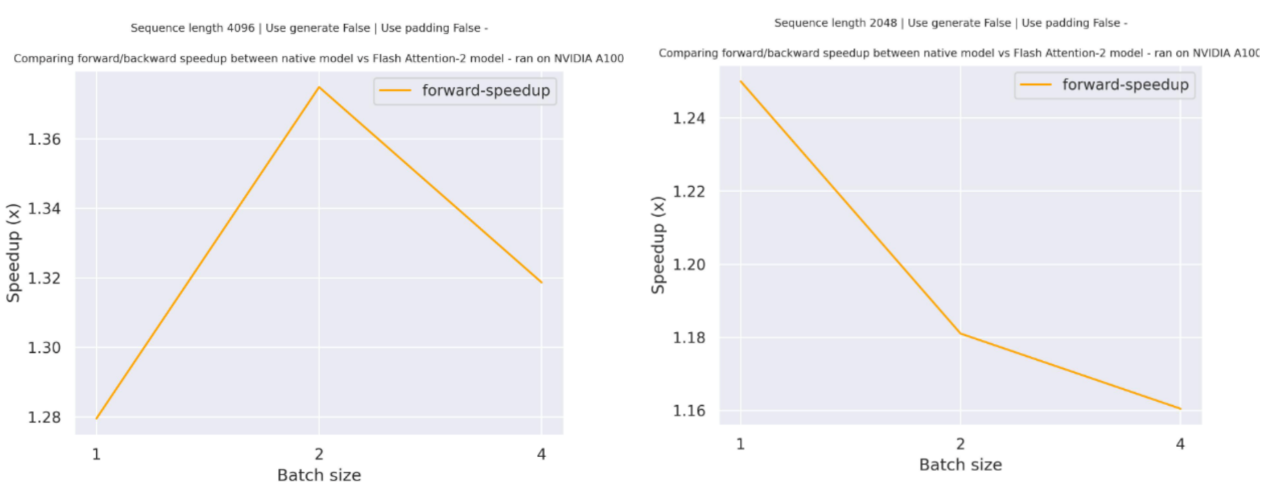 -
## GPTBigCodeConfig
[[autodoc]] GPTBigCodeConfig
diff --git a/docs/source/en/model_doc/gpt_neo.md b/docs/source/en/model_doc/gpt_neo.md
index de48bce6508..4df9cf69842 100644
--- a/docs/source/en/model_doc/gpt_neo.md
+++ b/docs/source/en/model_doc/gpt_neo.md
@@ -22,12 +22,10 @@ rendered properly in your Markdown viewer.
-
## GPT-Neo
[GPT-Neo](https://zenodo.org/records/5297715) is an open-source alternative to GPT-2 and GPT-3 models, built with Mesh TensorFlow for TPUs. GPT-Neo uses local attention in every other layer for more efficiency. It is trained on the [Pile](https://huggingface.co/datasets/EleutherAI/pile), a diverse dataset consisting of 22 smaller high-quality datasets. The original github repository can be found [here](https://github.com/EleutherAI/gpt-neo/tree/v1.1)
-
You can find all the original GPT-Neo checkpoints under the [EleutherAI](https://huggingface.co/EleutherAI?search_models=gpt-neo) organization.
> [!TIP]
@@ -45,6 +43,7 @@ from transformers import pipeline
pipeline = pipeline(task="text-generation", model="EleutherAI/gpt-neo-1.3B", dtype=torch.float16, device=0)
pipeline("Hello, I'm a language model")
```
+
-
## GPTBigCodeConfig
[[autodoc]] GPTBigCodeConfig
diff --git a/docs/source/en/model_doc/gpt_neo.md b/docs/source/en/model_doc/gpt_neo.md
index de48bce6508..4df9cf69842 100644
--- a/docs/source/en/model_doc/gpt_neo.md
+++ b/docs/source/en/model_doc/gpt_neo.md
@@ -22,12 +22,10 @@ rendered properly in your Markdown viewer.
-
## GPT-Neo
[GPT-Neo](https://zenodo.org/records/5297715) is an open-source alternative to GPT-2 and GPT-3 models, built with Mesh TensorFlow for TPUs. GPT-Neo uses local attention in every other layer for more efficiency. It is trained on the [Pile](https://huggingface.co/datasets/EleutherAI/pile), a diverse dataset consisting of 22 smaller high-quality datasets. The original github repository can be found [here](https://github.com/EleutherAI/gpt-neo/tree/v1.1)
-
You can find all the original GPT-Neo checkpoints under the [EleutherAI](https://huggingface.co/EleutherAI?search_models=gpt-neo) organization.
> [!TIP]
@@ -45,6 +43,7 @@ from transformers import pipeline
pipeline = pipeline(task="text-generation", model="EleutherAI/gpt-neo-1.3B", dtype=torch.float16, device=0)
pipeline("Hello, I'm a language model")
```
+
 -
## Using Scaled Dot Product Attention (SDPA)
PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
@@ -162,7 +160,6 @@ following speedups during training and inference.
| 4 | 1024 | 11.765 | 11.303 | 4.09 | 2558.96 | 2546.04 | 0.508 |
| 4 | 2048 | 19.568 | 17.735 | 10.33 | 4175.5 | 4165.26 | 0.246 |
-
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
diff --git a/docs/source/en/model_doc/gpt_neox_japanese.md b/docs/source/en/model_doc/gpt_neox_japanese.md
index 7b22484b9a7..bf786f7561d 100644
--- a/docs/source/en/model_doc/gpt_neox_japanese.md
+++ b/docs/source/en/model_doc/gpt_neox_japanese.md
@@ -27,8 +27,6 @@ rendered properly in your Markdown viewer.
GPT-NeoX-Japanese, a Japanese language model based on [GPT-NeoX](./gpt_neox).
Japanese uses three types of characters (hiragana, katakana, kanji) and has a huge vocabulary. This model uses [BPEEncoder V2](https://github.com/tanreinama/Japanese-BPEEncoder_V2), a sub-word tokenizer to handle the different characters.
-
-
The model also removes some bias parameters for better performance.
You can find all the original GPT-NeoX-Japanese checkpoints under the [ABEJA](https://huggingface.co/abeja/models?search=gpt-neo-x) organization.
diff --git a/docs/source/en/model_doc/gpt_oss.md b/docs/source/en/model_doc/gpt_oss.md
index 136ebeb2957..47c970eb17e 100644
--- a/docs/source/en/model_doc/gpt_oss.md
+++ b/docs/source/en/model_doc/gpt_oss.md
@@ -41,7 +41,6 @@ Tips:
This model was contributed by [INSERT YOUR HF USERNAME HERE](https://huggingface.co/
-
## Using Scaled Dot Product Attention (SDPA)
PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
@@ -162,7 +160,6 @@ following speedups during training and inference.
| 4 | 1024 | 11.765 | 11.303 | 4.09 | 2558.96 | 2546.04 | 0.508 |
| 4 | 2048 | 19.568 | 17.735 | 10.33 | 4175.5 | 4165.26 | 0.246 |
-
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
diff --git a/docs/source/en/model_doc/gpt_neox_japanese.md b/docs/source/en/model_doc/gpt_neox_japanese.md
index 7b22484b9a7..bf786f7561d 100644
--- a/docs/source/en/model_doc/gpt_neox_japanese.md
+++ b/docs/source/en/model_doc/gpt_neox_japanese.md
@@ -27,8 +27,6 @@ rendered properly in your Markdown viewer.
GPT-NeoX-Japanese, a Japanese language model based on [GPT-NeoX](./gpt_neox).
Japanese uses three types of characters (hiragana, katakana, kanji) and has a huge vocabulary. This model uses [BPEEncoder V2](https://github.com/tanreinama/Japanese-BPEEncoder_V2), a sub-word tokenizer to handle the different characters.
-
-
The model also removes some bias parameters for better performance.
You can find all the original GPT-NeoX-Japanese checkpoints under the [ABEJA](https://huggingface.co/abeja/models?search=gpt-neo-x) organization.
diff --git a/docs/source/en/model_doc/gpt_oss.md b/docs/source/en/model_doc/gpt_oss.md
index 136ebeb2957..47c970eb17e 100644
--- a/docs/source/en/model_doc/gpt_oss.md
+++ b/docs/source/en/model_doc/gpt_oss.md
@@ -41,7 +41,6 @@ Tips:
This model was contributed by [INSERT YOUR HF USERNAME HERE](https://huggingface.co/ -
> Click on the I-JEPA models in the right sidebar for more examples of how to apply I-JEPA to different image representation and classification tasks.
The example below demonstrates how to extract image features with [`Pipeline`] or the [`AutoModel`] class.
@@ -88,10 +86,10 @@ embed_2 = infer(image_2)
similarity = cosine_similarity(embed_1, embed_2)
print(similarity)
```
+
-
Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
The example below uses [bitsandbytes](../quantization/bitsandbytes) to only quantize the weights to 4-bits.
@@ -142,4 +140,3 @@ print(similarity)
[[autodoc]] IJepaForImageClassification
- forward
-
diff --git a/docs/source/en/model_doc/instructblip.md b/docs/source/en/model_doc/instructblip.md
index b0669f1c065..d22d8df0d39 100644
--- a/docs/source/en/model_doc/instructblip.md
+++ b/docs/source/en/model_doc/instructblip.md
@@ -59,7 +59,6 @@ The attributes can be obtained from model config, as `model.config.num_query_tok
[[autodoc]] InstructBlipProcessor
-
## InstructBlipVisionModel
[[autodoc]] InstructBlipVisionModel
diff --git a/docs/source/en/model_doc/instructblipvideo.md b/docs/source/en/model_doc/instructblipvideo.md
index e34b454a123..d4d868b7f90 100644
--- a/docs/source/en/model_doc/instructblipvideo.md
+++ b/docs/source/en/model_doc/instructblipvideo.md
@@ -59,7 +59,6 @@ The attributes can be obtained from model config, as `model.config.num_query_tok
[[autodoc]] InstructBlipVideoProcessor
-
## InstructBlipVideoVideoProcessor
[[autodoc]] InstructBlipVideoVideoProcessor
diff --git a/docs/source/en/model_doc/internvl.md b/docs/source/en/model_doc/internvl.md
index bf760fdbdd7..7e9fea7f4f2 100644
--- a/docs/source/en/model_doc/internvl.md
+++ b/docs/source/en/model_doc/internvl.md
@@ -15,7 +15,6 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2025-04-14 and added to Hugging Face Transformers on 2025-04-18.*
-
-
> Click on the I-JEPA models in the right sidebar for more examples of how to apply I-JEPA to different image representation and classification tasks.
The example below demonstrates how to extract image features with [`Pipeline`] or the [`AutoModel`] class.
@@ -88,10 +86,10 @@ embed_2 = infer(image_2)
similarity = cosine_similarity(embed_1, embed_2)
print(similarity)
```
+
-
Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
The example below uses [bitsandbytes](../quantization/bitsandbytes) to only quantize the weights to 4-bits.
@@ -142,4 +140,3 @@ print(similarity)
[[autodoc]] IJepaForImageClassification
- forward
-
diff --git a/docs/source/en/model_doc/instructblip.md b/docs/source/en/model_doc/instructblip.md
index b0669f1c065..d22d8df0d39 100644
--- a/docs/source/en/model_doc/instructblip.md
+++ b/docs/source/en/model_doc/instructblip.md
@@ -59,7 +59,6 @@ The attributes can be obtained from model config, as `model.config.num_query_tok
[[autodoc]] InstructBlipProcessor
-
## InstructBlipVisionModel
[[autodoc]] InstructBlipVisionModel
diff --git a/docs/source/en/model_doc/instructblipvideo.md b/docs/source/en/model_doc/instructblipvideo.md
index e34b454a123..d4d868b7f90 100644
--- a/docs/source/en/model_doc/instructblipvideo.md
+++ b/docs/source/en/model_doc/instructblipvideo.md
@@ -59,7 +59,6 @@ The attributes can be obtained from model config, as `model.config.num_query_tok
[[autodoc]] InstructBlipVideoProcessor
-
## InstructBlipVideoVideoProcessor
[[autodoc]] InstructBlipVideoVideoProcessor
diff --git a/docs/source/en/model_doc/internvl.md b/docs/source/en/model_doc/internvl.md
index bf760fdbdd7..7e9fea7f4f2 100644
--- a/docs/source/en/model_doc/internvl.md
+++ b/docs/source/en/model_doc/internvl.md
@@ -15,7 +15,6 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2025-04-14 and added to Hugging Face Transformers on 2025-04-18.*
-
 Overview of InternVL3 models architecture, which is the same as InternVL2.5. Taken from the original checkpoint.
-
-
Overview of InternVL3 models architecture, which is the same as InternVL2.5. Taken from the original checkpoint.
-
-
 Comparison of InternVL3 performance on OpenCompass against other SOTA VLLMs. Taken from the original checkpoint.
-
-
This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
The original code can be found [here](https://github.com/OpenGVLab/InternVL).
@@ -75,6 +69,7 @@ Here is how you can use the `image-text-to-text` pipeline to perform inference w
>>> outputs[0]["generated_text"]
'The image showcases a vibrant scene of nature, featuring several flowers and a bee. \n\n1. **Foreground Flowers**: \n - The primary focus is on a large, pink cosmos flower with a prominent yellow center. The petals are soft and slightly r'
```
+
### Inference on a single image
This example demonstrates how to perform inference on a single image with the InternVL models using chat templates.
@@ -112,7 +107,6 @@ This example demonstrates how to perform inference on a single image with the In
### Text-only generation
This example shows how to generate text using the InternVL model without providing any image input.
-
```python
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
>>> import torch
diff --git a/docs/source/en/model_doc/jamba.md b/docs/source/en/model_doc/jamba.md
index 0aa06b16e90..f85d08c5f64 100644
--- a/docs/source/en/model_doc/jamba.md
+++ b/docs/source/en/model_doc/jamba.md
@@ -75,6 +75,7 @@ input_ids = tokenizer("Plants create energy through a process known as", return_
output = model.generate(**input_ids, cache_implementation="static")
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
+
Comparison of InternVL3 performance on OpenCompass against other SOTA VLLMs. Taken from the original checkpoint.
-
-
This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
The original code can be found [here](https://github.com/OpenGVLab/InternVL).
@@ -75,6 +69,7 @@ Here is how you can use the `image-text-to-text` pipeline to perform inference w
>>> outputs[0]["generated_text"]
'The image showcases a vibrant scene of nature, featuring several flowers and a bee. \n\n1. **Foreground Flowers**: \n - The primary focus is on a large, pink cosmos flower with a prominent yellow center. The petals are soft and slightly r'
```
+
### Inference on a single image
This example demonstrates how to perform inference on a single image with the InternVL models using chat templates.
@@ -112,7 +107,6 @@ This example demonstrates how to perform inference on a single image with the In
### Text-only generation
This example shows how to generate text using the InternVL model without providing any image input.
-
```python
>>> from transformers import AutoProcessor, AutoModelForImageTextToText
>>> import torch
diff --git a/docs/source/en/model_doc/jamba.md b/docs/source/en/model_doc/jamba.md
index 0aa06b16e90..f85d08c5f64 100644
--- a/docs/source/en/model_doc/jamba.md
+++ b/docs/source/en/model_doc/jamba.md
@@ -75,6 +75,7 @@ input_ids = tokenizer("Plants create energy through a process known as", return_
output = model.generate(**input_ids, cache_implementation="static")
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
+

 +alt="drawing" width="600"/>
MarkupLM architecture. Taken from the original paper.
diff --git a/docs/source/en/model_doc/matcha.md b/docs/source/en/model_doc/matcha.md
index e6a73c58fd0..9180d765c2b 100644
--- a/docs/source/en/model_doc/matcha.md
+++ b/docs/source/en/model_doc/matcha.md
@@ -42,7 +42,7 @@ Currently 6 checkpoints are available for MatCha:
- `google/matcha-chartqa`: MatCha model fine-tuned on ChartQA dataset. It can be used to answer questions about charts.
- `google/matcha-plotqa-v1`: MatCha model fine-tuned on PlotQA dataset. It can be used to answer questions about plots.
- `google/matcha-plotqa-v2`: MatCha model fine-tuned on PlotQA dataset. It can be used to answer questions about plots.
-- `google/matcha-chart2text-statista`: MatCha model fine-tuned on Statista dataset.
+- `google/matcha-chart2text-statista`: MatCha model fine-tuned on Statista dataset.
- `google/matcha-chart2text-pew`: MatCha model fine-tuned on Pew dataset.
The models finetuned on `chart2text-pew` and `chart2text-statista` are more suited for summarization, whereas the models finetuned on `plotqa` and `chartqa` are more suited for question answering.
@@ -67,6 +67,7 @@ print(processor.decode(predictions[0], skip_special_tokens=True))
## Fine-tuning
To fine-tune MatCha, refer to the pix2struct [fine-tuning notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb). For `Pix2Struct` models, we have found out that fine-tuning the model with Adafactor and cosine learning rate scheduler leads to faster convergence:
+
```python
from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
diff --git a/docs/source/en/model_doc/mega.md b/docs/source/en/model_doc/mega.md
index 614df243553..d6580427778 100644
--- a/docs/source/en/model_doc/mega.md
+++ b/docs/source/en/model_doc/mega.md
@@ -44,19 +44,16 @@ The abstract from the paper is the following:
This model was contributed by [mnaylor](https://huggingface.co/mnaylor).
The original code can be found [here](https://github.com/facebookresearch/mega).
-
## Usage tips
- MEGA can perform quite well with relatively few parameters. See Appendix D in the MEGA paper for examples of architectural specs which perform well in various settings. If using MEGA as a decoder, be sure to set `bidirectional=False` to avoid errors with default bidirectional.
- Mega-chunk is a variant of mega that reduces time and spaces complexity from quadratic to linear. Utilize chunking with MegaConfig.use_chunking and control chunk size with MegaConfig.chunk_size
-
## Implementation Notes
- The original implementation of MEGA had an inconsistent expectation of attention masks for padding and causal self-attention between the softmax attention and Laplace/squared ReLU method. This implementation addresses that inconsistency.
- The original implementation did not include token type embeddings; this implementation adds support for these, with the option controlled by MegaConfig.add_token_type_embeddings
-
## MegaConfig
[[autodoc]] MegaConfig
diff --git a/docs/source/en/model_doc/megatron-bert.md b/docs/source/en/model_doc/megatron-bert.md
index f8845556f8f..5307fdcd491 100644
--- a/docs/source/en/model_doc/megatron-bert.md
+++ b/docs/source/en/model_doc/megatron-bert.md
@@ -45,8 +45,8 @@ achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.
accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
of 89.4%).*
-This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM).
-That repository contains a multi-GPU and multi-node implementation of the Megatron Language models. In particular,
+This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM).
+That repository contains a multi-GPU and multi-node implementation of the Megatron Language models. In particular,
it contains a hybrid model parallel approach using "tensor parallel" and "pipeline parallel" techniques.
## Usage tips
diff --git a/docs/source/en/model_doc/mimi.md b/docs/source/en/model_doc/mimi.md
index 2d655aa5966..440f89b2c56 100644
--- a/docs/source/en/model_doc/mimi.md
+++ b/docs/source/en/model_doc/mimi.md
@@ -39,7 +39,7 @@ The example below demonstrates how to encode and decode audio with the [`AutoMod
+alt="drawing" width="600"/>
MarkupLM architecture. Taken from the original paper.
diff --git a/docs/source/en/model_doc/matcha.md b/docs/source/en/model_doc/matcha.md
index e6a73c58fd0..9180d765c2b 100644
--- a/docs/source/en/model_doc/matcha.md
+++ b/docs/source/en/model_doc/matcha.md
@@ -42,7 +42,7 @@ Currently 6 checkpoints are available for MatCha:
- `google/matcha-chartqa`: MatCha model fine-tuned on ChartQA dataset. It can be used to answer questions about charts.
- `google/matcha-plotqa-v1`: MatCha model fine-tuned on PlotQA dataset. It can be used to answer questions about plots.
- `google/matcha-plotqa-v2`: MatCha model fine-tuned on PlotQA dataset. It can be used to answer questions about plots.
-- `google/matcha-chart2text-statista`: MatCha model fine-tuned on Statista dataset.
+- `google/matcha-chart2text-statista`: MatCha model fine-tuned on Statista dataset.
- `google/matcha-chart2text-pew`: MatCha model fine-tuned on Pew dataset.
The models finetuned on `chart2text-pew` and `chart2text-statista` are more suited for summarization, whereas the models finetuned on `plotqa` and `chartqa` are more suited for question answering.
@@ -67,6 +67,7 @@ print(processor.decode(predictions[0], skip_special_tokens=True))
## Fine-tuning
To fine-tune MatCha, refer to the pix2struct [fine-tuning notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb). For `Pix2Struct` models, we have found out that fine-tuning the model with Adafactor and cosine learning rate scheduler leads to faster convergence:
+
```python
from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
diff --git a/docs/source/en/model_doc/mega.md b/docs/source/en/model_doc/mega.md
index 614df243553..d6580427778 100644
--- a/docs/source/en/model_doc/mega.md
+++ b/docs/source/en/model_doc/mega.md
@@ -44,19 +44,16 @@ The abstract from the paper is the following:
This model was contributed by [mnaylor](https://huggingface.co/mnaylor).
The original code can be found [here](https://github.com/facebookresearch/mega).
-
## Usage tips
- MEGA can perform quite well with relatively few parameters. See Appendix D in the MEGA paper for examples of architectural specs which perform well in various settings. If using MEGA as a decoder, be sure to set `bidirectional=False` to avoid errors with default bidirectional.
- Mega-chunk is a variant of mega that reduces time and spaces complexity from quadratic to linear. Utilize chunking with MegaConfig.use_chunking and control chunk size with MegaConfig.chunk_size
-
## Implementation Notes
- The original implementation of MEGA had an inconsistent expectation of attention masks for padding and causal self-attention between the softmax attention and Laplace/squared ReLU method. This implementation addresses that inconsistency.
- The original implementation did not include token type embeddings; this implementation adds support for these, with the option controlled by MegaConfig.add_token_type_embeddings
-
## MegaConfig
[[autodoc]] MegaConfig
diff --git a/docs/source/en/model_doc/megatron-bert.md b/docs/source/en/model_doc/megatron-bert.md
index f8845556f8f..5307fdcd491 100644
--- a/docs/source/en/model_doc/megatron-bert.md
+++ b/docs/source/en/model_doc/megatron-bert.md
@@ -45,8 +45,8 @@ achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.
accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
of 89.4%).*
-This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM).
-That repository contains a multi-GPU and multi-node implementation of the Megatron Language models. In particular,
+This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM).
+That repository contains a multi-GPU and multi-node implementation of the Megatron Language models. In particular,
it contains a hybrid model parallel approach using "tensor parallel" and "pipeline parallel" techniques.
## Usage tips
diff --git a/docs/source/en/model_doc/mimi.md b/docs/source/en/model_doc/mimi.md
index 2d655aa5966..440f89b2c56 100644
--- a/docs/source/en/model_doc/mimi.md
+++ b/docs/source/en/model_doc/mimi.md
@@ -39,7 +39,7 @@ The example below demonstrates how to encode and decode audio with the [`AutoMod


 +
MSN architecture. Taken from the original paper.
-This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
+This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
## Usage tips
@@ -58,13 +58,13 @@ labels when fine-tuned.
### Using Scaled Dot Product Attention (SDPA)
-PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
-encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
-[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
page for more information.
-SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
```
diff --git a/docs/source/en/model_doc/vits.md b/docs/source/en/model_doc/vits.md
index 2c1777b77f1..664edcb92ae 100644
--- a/docs/source/en/model_doc/vits.md
+++ b/docs/source/en/model_doc/vits.md
@@ -156,4 +156,3 @@ Audio(waveform, rate=model.config.sampling_rate)
[[autodoc]] VitsModel
- forward
-
diff --git a/docs/source/en/model_doc/vivit.md b/docs/source/en/model_doc/vivit.md
index 041f80f61ae..9ee5a10a19f 100644
--- a/docs/source/en/model_doc/vivit.md
+++ b/docs/source/en/model_doc/vivit.md
@@ -32,13 +32,13 @@ This model was contributed by [jegormeister](https://huggingface.co/jegormeister
### Using Scaled Dot Product Attention (SDPA)
-PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
-encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
-[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
page for more information.
-SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
```
@@ -56,8 +56,6 @@ On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32`
|---------------------:|-------------:|----------:|--------------:|----------------------:|---------------------:|-----------------:|
| 100 | 1 | True | 7.122 | 2575.28 | 5932.54 | 130.364 |
-
-
### Inference
| num_batches | batch_size | is cuda | is half | Speedup (%) | Mem eager (MB) | Mem BT (MB) | Mem saved (%) |
|---------------|--------------|-----------|-----------|---------------|------------------|---------------|-----------------|
@@ -65,7 +63,6 @@ On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32`
| 20 | 2 | True | False | 17.146 | 1234.75 | 447.175 | 176.122 |
| 20 | 4 | True | False | 18.093 | 2275.82 | 709.864 | 220.6 |
| 20 | 8 | True | False | 19.284 | 4358.19 | 1233.24 | 253.393 |
-
## VivitConfig
diff --git a/docs/source/en/model_doc/vjepa2.md b/docs/source/en/model_doc/vjepa2.md
index 93960f05189..049c7ff98f2 100644
--- a/docs/source/en/model_doc/vjepa2.md
+++ b/docs/source/en/model_doc/vjepa2.md
@@ -15,7 +15,6 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2025-06-11 and added to Hugging Face Transformers on 2025-06-11.*
-
+
MSN architecture. Taken from the original paper.
-This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
+This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
## Usage tips
@@ -58,13 +58,13 @@ labels when fine-tuned.
### Using Scaled Dot Product Attention (SDPA)
-PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
-encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
-[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
page for more information.
-SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
```
diff --git a/docs/source/en/model_doc/vits.md b/docs/source/en/model_doc/vits.md
index 2c1777b77f1..664edcb92ae 100644
--- a/docs/source/en/model_doc/vits.md
+++ b/docs/source/en/model_doc/vits.md
@@ -156,4 +156,3 @@ Audio(waveform, rate=model.config.sampling_rate)
[[autodoc]] VitsModel
- forward
-
diff --git a/docs/source/en/model_doc/vivit.md b/docs/source/en/model_doc/vivit.md
index 041f80f61ae..9ee5a10a19f 100644
--- a/docs/source/en/model_doc/vivit.md
+++ b/docs/source/en/model_doc/vivit.md
@@ -32,13 +32,13 @@ This model was contributed by [jegormeister](https://huggingface.co/jegormeister
### Using Scaled Dot Product Attention (SDPA)
-PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
-encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
-[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
page for more information.
-SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
```
@@ -56,8 +56,6 @@ On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32`
|---------------------:|-------------:|----------:|--------------:|----------------------:|---------------------:|-----------------:|
| 100 | 1 | True | 7.122 | 2575.28 | 5932.54 | 130.364 |
-
-
### Inference
| num_batches | batch_size | is cuda | is half | Speedup (%) | Mem eager (MB) | Mem BT (MB) | Mem saved (%) |
|---------------|--------------|-----------|-----------|---------------|------------------|---------------|-----------------|
@@ -65,7 +63,6 @@ On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32`
| 20 | 2 | True | False | 17.146 | 1234.75 | 447.175 | 176.122 |
| 20 | 4 | True | False | 18.093 | 2275.82 | 709.864 | 220.6 |
| 20 | 8 | True | False | 19.284 | 4358.19 | 1233.24 | 253.393 |
-
## VivitConfig
diff --git a/docs/source/en/model_doc/vjepa2.md b/docs/source/en/model_doc/vjepa2.md
index 93960f05189..049c7ff98f2 100644
--- a/docs/source/en/model_doc/vjepa2.md
+++ b/docs/source/en/model_doc/vjepa2.md
@@ -15,7 +15,6 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2025-06-11 and added to Hugging Face Transformers on 2025-06-11.*
-
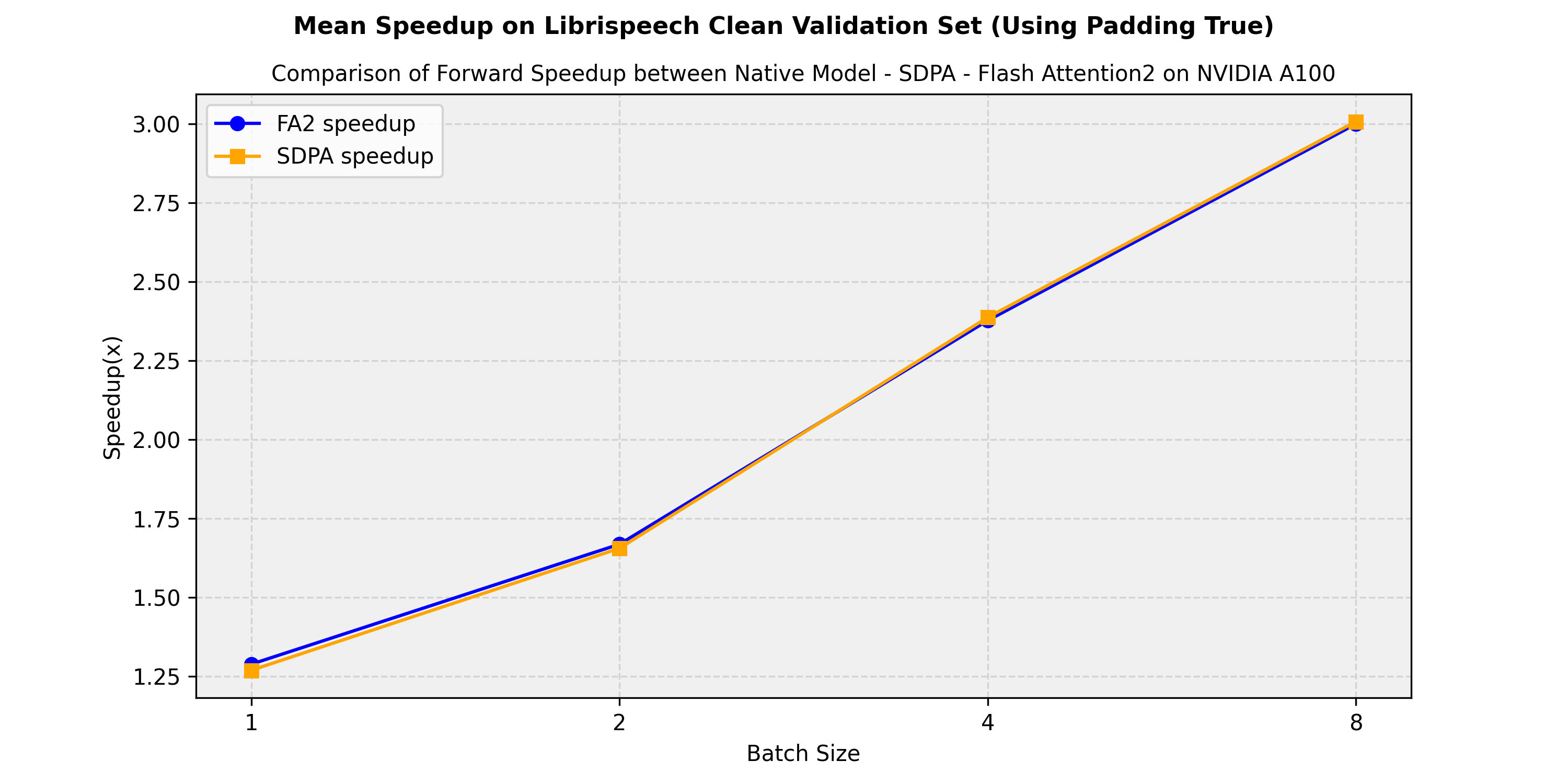
 YOLOS architecture. Taken from the original paper.
-
> [!TIP]
> This model wasa contributed by [nielsr](https://huggingface.co/nielsr).
> Click on the YOLOS models in the right sidebar for more examples of how to apply YOLOS to different object detection tasks.
@@ -98,7 +96,6 @@ for score, label, box in zip(filtered_scores, filtered_labels, pixel_boxes):
-
## Notes
- Use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](./detr), YOLOS doesn't require a `pixel_mask`.
diff --git a/docs/source/en/model_doc/yoso.md b/docs/source/en/model_doc/yoso.md
index f07e5aba082..8e121dd88cd 100644
--- a/docs/source/en/model_doc/yoso.md
+++ b/docs/source/en/model_doc/yoso.md
@@ -26,20 +26,20 @@ rendered properly in your Markdown viewer.
The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714)
by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh. YOSO approximates standard softmax self-attention
via a Bernoulli sampling scheme based on Locality Sensitive Hashing (LSH). In principle, all the Bernoulli random variables can be sampled with
-a single hash.
+a single hash.
The abstract from the paper is the following:
-*Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is
-the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically
-on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling
-attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear.
-We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random
-variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant).
-This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of
-LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence
-length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark,
-for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable
+*Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is
+the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically
+on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling
+attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear.
+We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random
+variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant).
+This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of
+LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence
+length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark,
+for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable
speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at this https URL*
This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
@@ -50,12 +50,12 @@ This model was contributed by [novice03](https://huggingface.co/novice03). The o
in parallel on a GPU.
- The kernels provide a `fast_hash` function, which approximates the random projections of the queries and keys using the Fast Hadamard Transform. Using these
hash codes, the `lsh_cumulation` function approximates self-attention via LSH-based Bernoulli sampling.
-- To use the custom kernels, the user should set `config.use_expectation = False`. To ensure that the kernels are compiled successfully,
-the user must install the correct version of PyTorch and cudatoolkit. By default, `config.use_expectation = True`, which uses YOSO-E and
+- To use the custom kernels, the user should set `config.use_expectation = False`. To ensure that the kernels are compiled successfully,
+the user must install the correct version of PyTorch and cudatoolkit. By default, `config.use_expectation = True`, which uses YOSO-E and
does not require compiling CUDA kernels.
YOLOS architecture. Taken from the original paper.
-
> [!TIP]
> This model wasa contributed by [nielsr](https://huggingface.co/nielsr).
> Click on the YOLOS models in the right sidebar for more examples of how to apply YOLOS to different object detection tasks.
@@ -98,7 +96,6 @@ for score, label, box in zip(filtered_scores, filtered_labels, pixel_boxes):
-
## Notes
- Use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](./detr), YOLOS doesn't require a `pixel_mask`.
diff --git a/docs/source/en/model_doc/yoso.md b/docs/source/en/model_doc/yoso.md
index f07e5aba082..8e121dd88cd 100644
--- a/docs/source/en/model_doc/yoso.md
+++ b/docs/source/en/model_doc/yoso.md
@@ -26,20 +26,20 @@ rendered properly in your Markdown viewer.
The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://huggingface.co/papers/2111.09714)
by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh. YOSO approximates standard softmax self-attention
via a Bernoulli sampling scheme based on Locality Sensitive Hashing (LSH). In principle, all the Bernoulli random variables can be sampled with
-a single hash.
+a single hash.
The abstract from the paper is the following:
-*Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is
-the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically
-on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling
-attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear.
-We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random
-variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant).
-This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of
-LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence
-length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark,
-for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable
+*Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is
+the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically
+on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling
+attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear.
+We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random
+variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant).
+This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of
+LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence
+length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark,
+for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable
speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at this https URL*
This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
@@ -50,12 +50,12 @@ This model was contributed by [novice03](https://huggingface.co/novice03). The o
in parallel on a GPU.
- The kernels provide a `fast_hash` function, which approximates the random projections of the queries and keys using the Fast Hadamard Transform. Using these
hash codes, the `lsh_cumulation` function approximates self-attention via LSH-based Bernoulli sampling.
-- To use the custom kernels, the user should set `config.use_expectation = False`. To ensure that the kernels are compiled successfully,
-the user must install the correct version of PyTorch and cudatoolkit. By default, `config.use_expectation = True`, which uses YOSO-E and
+- To use the custom kernels, the user should set `config.use_expectation = False`. To ensure that the kernels are compiled successfully,
+the user must install the correct version of PyTorch and cudatoolkit. By default, `config.use_expectation = True`, which uses YOSO-E and
does not require compiling CUDA kernels.
 +alt="drawing" width="600"/>
YOSO Attention Algorithm. Taken from the original paper.
diff --git a/docs/source/en/model_doc/zamba.md b/docs/source/en/model_doc/zamba.md
index bb974080770..635bc76fb0c 100644
--- a/docs/source/en/model_doc/zamba.md
+++ b/docs/source/en/model_doc/zamba.md
@@ -24,7 +24,6 @@ rendered properly in your Markdown viewer.
This model was contributed by [pglo](https://huggingface.co/pglo).
-
## Model details
Zamba-7B-v1 is a hybrid between state-space models (Specifically [Mamba](https://github.com/state-spaces/mamba)) and transformer, and was trained using next-token prediction. Zamba uses a shared transformer layer after every 6 mamba blocks. It uses the [Mistral v0.1 tokenizer](https://huggingface.co/mistralai/Mistral-7B-v0.1). We came to this architecture after a series of ablations at small scales. Zamba-7B-v1 was pre-trained on 1T tokens of text and code data.
@@ -33,23 +32,24 @@ Zamba-7B-v1 is a hybrid between state-space models (Specifically [Mamba](https:/
## Quick start
-
### Presequities
Zamba requires you use `transformers` version 4.46.0 or higher:
+
```bash
pip install transformers>=4.45.0
```
In order to run optimized Mamba implementations, you first need to install `mamba-ssm` and `causal-conv1d`:
+
```bash
pip install mamba-ssm causal-conv1d>=1.2.0
```
+
You also have to have the model on a CUDA device.
You can run the model not using the optimized Mamba kernels, but it is **not** recommended as it will result in significantly lower latencies. In order to do that, you'll need to specify `use_mamba_kernels=False` when loading the model.
-
## Inference
```python
@@ -66,39 +66,32 @@ outputs = model.generate(**input_ids, max_new_tokens=100)
print(tokenizer.decode(outputs[0]))
```
-
## Model card
The model cards can be found at:
* [Zamba-7B](https://huggingface.co/Zyphra/Zamba-7B-v1)
-
## Issues
For issues with model output, or community discussion, please use the Hugging Face community [forum](https://huggingface.co/Zyphra/Zamba-7B-v1/discussions)
-
## License
The model weights are open-sourced via an Apache 2.0 license.
-
## ZambaConfig
[[autodoc]] ZambaConfig
-
## ZambaModel
[[autodoc]] ZambaModel
- forward
-
## ZambaForCausalLM
[[autodoc]] ZambaForCausalLM
- forward
-
## ZambaForSequenceClassification
[[autodoc]] transformers.ZambaForSequenceClassification
diff --git a/docs/source/en/model_doc/zamba2.md b/docs/source/en/model_doc/zamba2.md
index ba4324366a9..7296ef1b250 100644
--- a/docs/source/en/model_doc/zamba2.md
+++ b/docs/source/en/model_doc/zamba2.md
@@ -26,7 +26,6 @@ rendered properly in your Markdown viewer.
This model was contributed by [pglo](https://huggingface.co/pglo).
-
## Model details
[Zamba2-1.2B](https://www.zyphra.com/post/zamba2-mini), [Zamba2-2.7B](https://www.zyphra.com/post/zamba2-small) and [Zamba2-7B](https://www.zyphra.com/post/zamba2-7b) are hybrid models combining state-space models (Specifically [Mamba2](https://github.com/state-spaces/mamba)) and transformer, and were trained using next-token prediction. Zamba2 uses shared transformer layers after every 6 mamba blocks. It uses the [Mistral v0.1 tokenizer](https://huggingface.co/mistralai/Mistral-7B-v0.1). We came to this architecture after a series of ablations at small scales. Zamba2-1.2B, Zamba2-2.7B and Zamba2-7B were pre-trained on 2T and 3T tokens, respectively.
@@ -35,10 +34,10 @@ This model was contributed by [pglo](https://huggingface.co/pglo).
## Quick start
-
### Presequities
Zamba2 requires you use `transformers` version 4.48.0 or higher:
+
```bash
pip install transformers>=4.48.0
```
@@ -59,7 +58,6 @@ outputs = model.generate(**input_ids, max_new_tokens=100)
print(tokenizer.decode(outputs[0]))
```
-
## Model card
The model cards can be found at:
@@ -67,33 +65,27 @@ The model cards can be found at:
* [Zamba2-2.7B](https://huggingface.co/Zyphra/Zamba2-2.7B)
* [Zamba2-7B](https://huggingface.co/Zyphra/Zamba2-7B)
-
## Issues
For issues with model output, or community discussion, please use the Hugging Face community [forum](https://huggingface.co/Zyphra/Zamba2-7B/discussions)
-
## License
The model weights are open-sourced via an Apache 2.0 license.
-
## Zamba2Config
[[autodoc]] Zamba2Config
-
## Zamba2Model
[[autodoc]] Zamba2Model
- forward
-
## Zamba2ForCausalLM
[[autodoc]] Zamba2ForCausalLM
- forward
-
## Zamba2ForSequenceClassification
[[autodoc]] transformers.Zamba2ForSequenceClassification
diff --git a/docs/source/en/model_doc/zoedepth.md b/docs/source/en/model_doc/zoedepth.md
index 367c630a322..5252d2b4d36 100644
--- a/docs/source/en/model_doc/zoedepth.md
+++ b/docs/source/en/model_doc/zoedepth.md
@@ -15,7 +15,6 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2023-02-23 and added to Hugging Face Transformers on 2024-07-08.*
-
+alt="drawing" width="600"/>
YOSO Attention Algorithm. Taken from the original paper.
diff --git a/docs/source/en/model_doc/zamba.md b/docs/source/en/model_doc/zamba.md
index bb974080770..635bc76fb0c 100644
--- a/docs/source/en/model_doc/zamba.md
+++ b/docs/source/en/model_doc/zamba.md
@@ -24,7 +24,6 @@ rendered properly in your Markdown viewer.
This model was contributed by [pglo](https://huggingface.co/pglo).
-
## Model details
Zamba-7B-v1 is a hybrid between state-space models (Specifically [Mamba](https://github.com/state-spaces/mamba)) and transformer, and was trained using next-token prediction. Zamba uses a shared transformer layer after every 6 mamba blocks. It uses the [Mistral v0.1 tokenizer](https://huggingface.co/mistralai/Mistral-7B-v0.1). We came to this architecture after a series of ablations at small scales. Zamba-7B-v1 was pre-trained on 1T tokens of text and code data.
@@ -33,23 +32,24 @@ Zamba-7B-v1 is a hybrid between state-space models (Specifically [Mamba](https:/
## Quick start
-
### Presequities
Zamba requires you use `transformers` version 4.46.0 or higher:
+
```bash
pip install transformers>=4.45.0
```
In order to run optimized Mamba implementations, you first need to install `mamba-ssm` and `causal-conv1d`:
+
```bash
pip install mamba-ssm causal-conv1d>=1.2.0
```
+
You also have to have the model on a CUDA device.
You can run the model not using the optimized Mamba kernels, but it is **not** recommended as it will result in significantly lower latencies. In order to do that, you'll need to specify `use_mamba_kernels=False` when loading the model.
-
## Inference
```python
@@ -66,39 +66,32 @@ outputs = model.generate(**input_ids, max_new_tokens=100)
print(tokenizer.decode(outputs[0]))
```
-
## Model card
The model cards can be found at:
* [Zamba-7B](https://huggingface.co/Zyphra/Zamba-7B-v1)
-
## Issues
For issues with model output, or community discussion, please use the Hugging Face community [forum](https://huggingface.co/Zyphra/Zamba-7B-v1/discussions)
-
## License
The model weights are open-sourced via an Apache 2.0 license.
-
## ZambaConfig
[[autodoc]] ZambaConfig
-
## ZambaModel
[[autodoc]] ZambaModel
- forward
-
## ZambaForCausalLM
[[autodoc]] ZambaForCausalLM
- forward
-
## ZambaForSequenceClassification
[[autodoc]] transformers.ZambaForSequenceClassification
diff --git a/docs/source/en/model_doc/zamba2.md b/docs/source/en/model_doc/zamba2.md
index ba4324366a9..7296ef1b250 100644
--- a/docs/source/en/model_doc/zamba2.md
+++ b/docs/source/en/model_doc/zamba2.md
@@ -26,7 +26,6 @@ rendered properly in your Markdown viewer.
This model was contributed by [pglo](https://huggingface.co/pglo).
-
## Model details
[Zamba2-1.2B](https://www.zyphra.com/post/zamba2-mini), [Zamba2-2.7B](https://www.zyphra.com/post/zamba2-small) and [Zamba2-7B](https://www.zyphra.com/post/zamba2-7b) are hybrid models combining state-space models (Specifically [Mamba2](https://github.com/state-spaces/mamba)) and transformer, and were trained using next-token prediction. Zamba2 uses shared transformer layers after every 6 mamba blocks. It uses the [Mistral v0.1 tokenizer](https://huggingface.co/mistralai/Mistral-7B-v0.1). We came to this architecture after a series of ablations at small scales. Zamba2-1.2B, Zamba2-2.7B and Zamba2-7B were pre-trained on 2T and 3T tokens, respectively.
@@ -35,10 +34,10 @@ This model was contributed by [pglo](https://huggingface.co/pglo).
## Quick start
-
### Presequities
Zamba2 requires you use `transformers` version 4.48.0 or higher:
+
```bash
pip install transformers>=4.48.0
```
@@ -59,7 +58,6 @@ outputs = model.generate(**input_ids, max_new_tokens=100)
print(tokenizer.decode(outputs[0]))
```
-
## Model card
The model cards can be found at:
@@ -67,33 +65,27 @@ The model cards can be found at:
* [Zamba2-2.7B](https://huggingface.co/Zyphra/Zamba2-2.7B)
* [Zamba2-7B](https://huggingface.co/Zyphra/Zamba2-7B)
-
## Issues
For issues with model output, or community discussion, please use the Hugging Face community [forum](https://huggingface.co/Zyphra/Zamba2-7B/discussions)
-
## License
The model weights are open-sourced via an Apache 2.0 license.
-
## Zamba2Config
[[autodoc]] Zamba2Config
-
## Zamba2Model
[[autodoc]] Zamba2Model
- forward
-
## Zamba2ForCausalLM
[[autodoc]] Zamba2ForCausalLM
- forward
-
## Zamba2ForSequenceClassification
[[autodoc]] transformers.Zamba2ForSequenceClassification
diff --git a/docs/source/en/model_doc/zoedepth.md b/docs/source/en/model_doc/zoedepth.md
index 367c630a322..5252d2b4d36 100644
--- a/docs/source/en/model_doc/zoedepth.md
+++ b/docs/source/en/model_doc/zoedepth.md
@@ -15,7 +15,6 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2023-02-23 and added to Hugging Face Transformers on 2024-07-08.*
-

@@ -158,7 +158,7 @@ another image to illustrate:
Photo by [Denys Nevozhai](https://unsplash.com/@dnevozhai).
-
+
Textual and image prompts can be passed to the model's processor as a single list to create appropriate inputs.
```py
@@ -178,12 +178,12 @@ This is an image of the Eiffel Tower in Paris, France.
## Few-shot prompting
-While IDEFICS demonstrates great zero-shot results, your task may require a certain format of the caption, or come with
+While IDEFICS demonstrates great zero-shot results, your task may require a certain format of the caption, or come with
other restrictions or requirements that increase task's complexity. Few-shot prompting can be used to enable in-context learning.
-By providing examples in the prompt, you can steer the model to generate results that mimic the format of given examples.
+By providing examples in the prompt, you can steer the model to generate results that mimic the format of given examples.
-Let's use the previous image of the Eiffel Tower as an example for the model and build a prompt that demonstrates to the model
-that in addition to learning what the object in an image is, we would also like to get some interesting information about it.
+Let's use the previous image of the Eiffel Tower as an example for the model and build a prompt that demonstrates to the model
+that in addition to learning what the object in an image is, we would also like to get some interesting information about it.
Then, let's see, if we can get the same response format for an image of the Statue of Liberty:
@@ -213,24 +213,24 @@ User: Describe this image.
Assistant: An image of the Statue of Liberty. Fun fact: the Statue of Liberty is 151 feet tall.
```
-Notice that just from a single example (i.e., 1-shot) the model has learned how to perform the task. For more complex tasks,
+Notice that just from a single example (i.e., 1-shot) the model has learned how to perform the task. For more complex tasks,
feel free to experiment with a larger number of examples (e.g., 3-shot, 5-shot, etc.).
## Visual question answering
-Visual Question Answering (VQA) is the task of answering open-ended questions based on an image. Similar to image
-captioning it can be used in accessibility applications, but also in education (reasoning about visual materials), customer
+Visual Question Answering (VQA) is the task of answering open-ended questions based on an image. Similar to image
+captioning it can be used in accessibility applications, but also in education (reasoning about visual materials), customer
service (questions about products based on images), and image retrieval.
-Let's get a new image for this task:
+Let's get a new image for this task:
 -Photo by [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
+Photo by [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
-You can steer the model from image captioning to visual question answering by prompting it with appropriate instructions:
+You can steer the model from image captioning to visual question answering by prompting it with appropriate instructions:
```py
>>> prompt = [
@@ -251,11 +251,11 @@ Instruction: Provide an answer to the question. Use the image to answer.
## Image classification
-IDEFICS is capable of classifying images into different categories without being explicitly trained on data containing
-labeled examples from those specific categories. Given a list of categories and using its image and text understanding
-capabilities, the model can infer which category the image likely belongs to.
+IDEFICS is capable of classifying images into different categories without being explicitly trained on data containing
+labeled examples from those specific categories. Given a list of categories and using its image and text understanding
+capabilities, the model can infer which category the image likely belongs to.
-Say, we have this image of a vegetable stand:
+Say, we have this image of a vegetable stand:
-Photo by [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
+Photo by [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
-You can steer the model from image captioning to visual question answering by prompting it with appropriate instructions:
+You can steer the model from image captioning to visual question answering by prompting it with appropriate instructions:
```py
>>> prompt = [
@@ -251,11 +251,11 @@ Instruction: Provide an answer to the question. Use the image to answer.
## Image classification
-IDEFICS is capable of classifying images into different categories without being explicitly trained on data containing
-labeled examples from those specific categories. Given a list of categories and using its image and text understanding
-capabilities, the model can infer which category the image likely belongs to.
+IDEFICS is capable of classifying images into different categories without being explicitly trained on data containing
+labeled examples from those specific categories. Given a list of categories and using its image and text understanding
+capabilities, the model can infer which category the image likely belongs to.
-Say, we have this image of a vegetable stand:
+Say, we have this image of a vegetable stand:
 @@ -286,10 +286,10 @@ In the example above we instruct the model to classify the image into a single c
## Image-guided text generation
-For more creative applications, you can use image-guided text generation to generate text based on an image. This can be
-useful to create descriptions of products, ads, descriptions of a scene, etc.
+For more creative applications, you can use image-guided text generation to generate text based on an image. This can be
+useful to create descriptions of products, ads, descriptions of a scene, etc.
-Let's prompt IDEFICS to write a story based on a simple image of a red door:
+Let's prompt IDEFICS to write a story based on a simple image of a red door:
@@ -286,10 +286,10 @@ In the example above we instruct the model to classify the image into a single c
## Image-guided text generation
-For more creative applications, you can use image-guided text generation to generate text based on an image. This can be
-useful to create descriptions of products, ads, descriptions of a scene, etc.
+For more creative applications, you can use image-guided text generation to generate text based on an image. This can be
+useful to create descriptions of products, ads, descriptions of a scene, etc.
-Let's prompt IDEFICS to write a story based on a simple image of a red door:
+Let's prompt IDEFICS to write a story based on a simple image of a red door:
 @@ -333,14 +333,14 @@ Looks like IDEFICS noticed the pumpkin on the doorstep and went with a spooky Ha
@@ -333,14 +333,14 @@ Looks like IDEFICS noticed the pumpkin on the doorstep and went with a spooky Ha
-For longer outputs like this, you will greatly benefit from tweaking the text generation strategy. This can help
-you significantly improve the quality of the generated output. Check out [Text generation strategies](../generation_strategies)
-to learn more.
+For longer outputs like this, you will greatly benefit from tweaking the text generation strategy. This can help
+you significantly improve the quality of the generated output. Check out [Text generation strategies](../generation_strategies)
+to learn more.
## Running inference in batch mode
-All of the earlier sections illustrated IDEFICS for a single example. In a very similar fashion, you can run inference
+All of the earlier sections illustrated IDEFICS for a single example. In a very similar fashion, you can run inference
for a batch of examples by passing a list of prompts:
```py
@@ -375,13 +375,13 @@ This is an image of a vegetable stand.
## IDEFICS instruct for conversational use
-For conversational use cases, you can find fine-tuned instructed versions of the model on the 🤗 Hub:
+For conversational use cases, you can find fine-tuned instructed versions of the model on the 🤗 Hub:
`HuggingFaceM4/idefics-80b-instruct` and `HuggingFaceM4/idefics-9b-instruct`.
-These checkpoints are the result of fine-tuning the respective base models on a mixture of supervised and instruction
+These checkpoints are the result of fine-tuning the respective base models on a mixture of supervised and instruction
fine-tuning datasets, which boosts the downstream performance while making the models more usable in conversational settings.
-The use and prompting for the conversational use is very similar to using the base models:
+The use and prompting for the conversational use is very similar to using the base models:
```py
>>> import torch
diff --git a/docs/source/en/tasks/image_captioning.md b/docs/source/en/tasks/image_captioning.md
index f9716f29a20..89c35a50b55 100644
--- a/docs/source/en/tasks/image_captioning.md
+++ b/docs/source/en/tasks/image_captioning.md
@@ -14,7 +14,6 @@ rendered properly in your Markdown viewer.
-->
-
# Image captioning
[[open-in-colab]]
@@ -26,7 +25,7 @@ helps to improve content accessibility for people by describing images to them.
This guide will show you how to:
* Fine-tune an image captioning model.
-* Use the fine-tuned model for inference.
+* Use the fine-tuned model for inference.
Before you begin, make sure you have all the necessary libraries installed:
@@ -37,7 +36,6 @@ pip install jiwer -q
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
-
```python
from huggingface_hub import notebook_login
@@ -47,8 +45,7 @@ notebook_login()
## Load the Pokémon BLIP captions dataset
Use the 🤗 Dataset library to load a dataset that consists of {image-caption} pairs. To create your own image captioning dataset
-in PyTorch, you can follow [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb).
-
+in PyTorch, you can follow [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb).
```python
from datasets import load_dataset
@@ -56,6 +53,7 @@ from datasets import load_dataset
ds = load_dataset("lambdalabs/pokemon-blip-captions")
ds
```
+
```bash
DatasetDict({
train: Dataset({
@@ -69,21 +67,19 @@ The dataset has two features, `image` and `text`.
-Many image captioning datasets contain multiple captions per image. In those cases, a common strategy is to randomly sample a caption amongst the available ones during training.
+Many image captioning datasets contain multiple captions per image. In those cases, a common strategy is to randomly sample a caption amongst the available ones during training.
Split the dataset’s train split into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
-
```python
ds = ds["train"].train_test_split(test_size=0.1)
train_ds = ds["train"]
test_ds = ds["test"]
```
-Let's visualize a couple of samples from the training set.
-
+Let's visualize a couple of samples from the training set.
```python
from textwrap import wrap
@@ -106,7 +102,7 @@ sample_images_to_visualize = [np.array(train_ds[i]["image"]) for i in range(5)]
sample_captions = [train_ds[i]["text"] for i in range(5)]
plot_images(sample_images_to_visualize, sample_captions)
```
-
+
 @@ -115,7 +111,7 @@ plot_images(sample_images_to_visualize, sample_captions)
Since the dataset has two modalities (image and text), the pre-processing pipeline will preprocess images and the captions.
-To do so, load the processor class associated with the model you are about to fine-tune.
+To do so, load the processor class associated with the model you are about to fine-tune.
```python
from transformers import AutoProcessor
@@ -124,7 +120,7 @@ checkpoint = "microsoft/git-base"
processor = AutoProcessor.from_pretrained(checkpoint)
```
-The processor will internally pre-process the image (which includes resizing, and pixel scaling) and tokenize the caption.
+The processor will internally pre-process the image (which includes resizing, and pixel scaling) and tokenize the caption.
```python
def transforms(example_batch):
@@ -139,13 +135,12 @@ train_ds.set_transform(transforms)
test_ds.set_transform(transforms)
```
-With the dataset ready, you can now set up the model for fine-tuning.
+With the dataset ready, you can now set up the model for fine-tuning.
## Load a base model
Load the ["microsoft/git-base"](https://huggingface.co/microsoft/git-base) into a [`AutoModelForCausalLM`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForCausalLM) object.
-
```python
from transformers import AutoModelForCausalLM
@@ -154,10 +149,9 @@ model = AutoModelForCausalLM.from_pretrained(checkpoint)
## Evaluate
-Image captioning models are typically evaluated with the [Rouge Score](https://huggingface.co/spaces/evaluate-metric/rouge) or [Word Error Rate](https://huggingface.co/spaces/evaluate-metric/wer). For this guide, you will use the Word Error Rate (WER).
-
-We use the 🤗 Evaluate library to do so. For potential limitations and other gotchas of the WER, refer to [this guide](https://huggingface.co/spaces/evaluate-metric/wer).
+Image captioning models are typically evaluated with the [Rouge Score](https://huggingface.co/spaces/evaluate-metric/rouge) or [Word Error Rate](https://huggingface.co/spaces/evaluate-metric/wer). For this guide, you will use the Word Error Rate (WER).
+We use the 🤗 Evaluate library to do so. For potential limitations and other gotchas of the WER, refer to [this guide](https://huggingface.co/spaces/evaluate-metric/wer).
```python
from evaluate import load
@@ -177,11 +171,10 @@ def compute_metrics(eval_pred):
## Train!
-Now, you are ready to start fine-tuning the model. You will use the 🤗 [`Trainer`] for this.
+Now, you are ready to start fine-tuning the model. You will use the 🤗 [`Trainer`] for this.
First, define the training arguments using [`TrainingArguments`].
-
```python
from transformers import TrainingArguments, Trainer
@@ -208,7 +201,7 @@ training_args = TrainingArguments(
)
```
-Then pass them along with the datasets and the model to 🤗 Trainer.
+Then pass them along with the datasets and the model to 🤗 Trainer.
```python
trainer = Trainer(
@@ -222,7 +215,7 @@ trainer = Trainer(
To start training, simply call [`~Trainer.train`] on the [`Trainer`] object.
-```python
+```python
trainer.train()
```
@@ -230,7 +223,6 @@ You should see the training loss drop smoothly as training progresses.
Once training is completed, share your model to the Hub with the [`~Trainer.push_to_hub`] method so everyone can use your model:
-
```python
trainer.push_to_hub()
```
@@ -239,7 +231,6 @@ trainer.push_to_hub()
Take a sample image from `test_ds` to test the model.
-
```python
from PIL import Image
import requests
@@ -252,7 +243,7 @@ image
@@ -115,7 +111,7 @@ plot_images(sample_images_to_visualize, sample_captions)
Since the dataset has two modalities (image and text), the pre-processing pipeline will preprocess images and the captions.
-To do so, load the processor class associated with the model you are about to fine-tune.
+To do so, load the processor class associated with the model you are about to fine-tune.
```python
from transformers import AutoProcessor
@@ -124,7 +120,7 @@ checkpoint = "microsoft/git-base"
processor = AutoProcessor.from_pretrained(checkpoint)
```
-The processor will internally pre-process the image (which includes resizing, and pixel scaling) and tokenize the caption.
+The processor will internally pre-process the image (which includes resizing, and pixel scaling) and tokenize the caption.
```python
def transforms(example_batch):
@@ -139,13 +135,12 @@ train_ds.set_transform(transforms)
test_ds.set_transform(transforms)
```
-With the dataset ready, you can now set up the model for fine-tuning.
+With the dataset ready, you can now set up the model for fine-tuning.
## Load a base model
Load the ["microsoft/git-base"](https://huggingface.co/microsoft/git-base) into a [`AutoModelForCausalLM`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForCausalLM) object.
-
```python
from transformers import AutoModelForCausalLM
@@ -154,10 +149,9 @@ model = AutoModelForCausalLM.from_pretrained(checkpoint)
## Evaluate
-Image captioning models are typically evaluated with the [Rouge Score](https://huggingface.co/spaces/evaluate-metric/rouge) or [Word Error Rate](https://huggingface.co/spaces/evaluate-metric/wer). For this guide, you will use the Word Error Rate (WER).
-
-We use the 🤗 Evaluate library to do so. For potential limitations and other gotchas of the WER, refer to [this guide](https://huggingface.co/spaces/evaluate-metric/wer).
+Image captioning models are typically evaluated with the [Rouge Score](https://huggingface.co/spaces/evaluate-metric/rouge) or [Word Error Rate](https://huggingface.co/spaces/evaluate-metric/wer). For this guide, you will use the Word Error Rate (WER).
+We use the 🤗 Evaluate library to do so. For potential limitations and other gotchas of the WER, refer to [this guide](https://huggingface.co/spaces/evaluate-metric/wer).
```python
from evaluate import load
@@ -177,11 +171,10 @@ def compute_metrics(eval_pred):
## Train!
-Now, you are ready to start fine-tuning the model. You will use the 🤗 [`Trainer`] for this.
+Now, you are ready to start fine-tuning the model. You will use the 🤗 [`Trainer`] for this.
First, define the training arguments using [`TrainingArguments`].
-
```python
from transformers import TrainingArguments, Trainer
@@ -208,7 +201,7 @@ training_args = TrainingArguments(
)
```
-Then pass them along with the datasets and the model to 🤗 Trainer.
+Then pass them along with the datasets and the model to 🤗 Trainer.
```python
trainer = Trainer(
@@ -222,7 +215,7 @@ trainer = Trainer(
To start training, simply call [`~Trainer.train`] on the [`Trainer`] object.
-```python
+```python
trainer.train()
```
@@ -230,7 +223,6 @@ You should see the training loss drop smoothly as training progresses.
Once training is completed, share your model to the Hub with the [`~Trainer.push_to_hub`] method so everyone can use your model:
-
```python
trainer.push_to_hub()
```
@@ -239,7 +231,6 @@ trainer.push_to_hub()
Take a sample image from `test_ds` to test the model.
-
```python
from PIL import Image
import requests
@@ -252,7 +243,7 @@ image
 -
+
Prepare image for the model.
```python
@@ -263,13 +254,14 @@ inputs = processor(images=image, return_tensors="pt").to(device)
pixel_values = inputs.pixel_values
```
-Call [`generate`] and decode the predictions.
+Call [`generate`] and decode the predictions.
```python
generated_ids = model.generate(pixel_values=pixel_values, max_length=50)
generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_caption)
```
+
```bash
a drawing of a pink and blue pokemon
```
diff --git a/docs/source/en/tasks/image_classification.md b/docs/source/en/tasks/image_classification.md
index 39b013f129c..4754a91bd48 100644
--- a/docs/source/en/tasks/image_classification.md
+++ b/docs/source/en/tasks/image_classification.md
@@ -175,7 +175,6 @@ Your `compute_metrics` function is ready to go now, and you'll return to it when
## Train
-
-
+
Prepare image for the model.
```python
@@ -263,13 +254,14 @@ inputs = processor(images=image, return_tensors="pt").to(device)
pixel_values = inputs.pixel_values
```
-Call [`generate`] and decode the predictions.
+Call [`generate`] and decode the predictions.
```python
generated_ids = model.generate(pixel_values=pixel_values, max_length=50)
generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_caption)
```
+
```bash
a drawing of a pink and blue pokemon
```
diff --git a/docs/source/en/tasks/image_classification.md b/docs/source/en/tasks/image_classification.md
index 39b013f129c..4754a91bd48 100644
--- a/docs/source/en/tasks/image_classification.md
+++ b/docs/source/en/tasks/image_classification.md
@@ -175,7 +175,6 @@ Your `compute_metrics` function is ready to go now, and you'll return to it when
## Train
-
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
@@ -238,7 +237,6 @@ Once training is completed, share your model to the Hub with the [`~transformers
>>> trainer.push_to_hub()
```
-
For a more in-depth example of how to finetune a model for image classification, take a look at the corresponding [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
diff --git a/docs/source/en/tasks/image_feature_extraction.md b/docs/source/en/tasks/image_feature_extraction.md
index 455a2b425d4..e08ba89e4dd 100644
--- a/docs/source/en/tasks/image_feature_extraction.md
+++ b/docs/source/en/tasks/image_feature_extraction.md
@@ -27,7 +27,7 @@ In this guide, you will:
## Image Similarity using `image-feature-extraction` Pipeline
-We have two images of cats sitting on top of fish nets, one of them is generated.
+We have two images of cats sitting on top of fish nets, one of them is generated.
```python
from PIL import Image
@@ -66,7 +66,7 @@ print(outputs)
# [[[-0.03909236937761307, 0.43381670117378235, -0.06913255900144577,
```
-To get the similarity score, we need to pass them to a similarity function.
+To get the similarity score, we need to pass them to a similarity function.
```python
from torch.nn.functional import cosine_similarity
@@ -131,4 +131,3 @@ print(similarity_score)
# tensor([0.6061], device='cuda:0', grad_fn=)
```
-
diff --git a/docs/source/en/tasks/image_text_to_text.md b/docs/source/en/tasks/image_text_to_text.md
index b34f4edf90f..5412882b59f 100644
--- a/docs/source/en/tasks/image_text_to_text.md
+++ b/docs/source/en/tasks/image_text_to_text.md
@@ -63,7 +63,6 @@ The image inputs look like the following.

-
```python
from PIL import Image
import requests
@@ -76,7 +75,6 @@ images = [Image.open(requests.get(img_urls[0], stream=True).raw),
Below is an example of the chat template. We can feed conversation turns and the last message as an input by appending it at the end of the template.
-
```python
messages = [
{
@@ -207,7 +205,6 @@ We can use [text streaming](./generation_strategies#streaming) for a better gene
Assume we have an application that keeps chat history and takes in the new user input. We will preprocess the inputs as usual and initialize [`TextIteratorStreamer`] to handle the generation in a separate thread. This allows you to stream the generated text tokens in real-time. Any generation arguments can be passed to [`TextIteratorStreamer`].
-
```python
import time
from transformers import TextIteratorStreamer
diff --git a/docs/source/en/tasks/image_to_image.md b/docs/source/en/tasks/image_to_image.md
index da6a57ac9aa..6c4cdf585f0 100644
--- a/docs/source/en/tasks/image_to_image.md
+++ b/docs/source/en/tasks/image_to_image.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-Image-to-Image task is the task where an application receives an image and outputs another image. This has various subtasks, including image enhancement (super resolution, low light enhancement, deraining and so on), image inpainting, and more.
+Image-to-Image task is the task where an application receives an image and outputs another image. This has various subtasks, including image enhancement (super resolution, low light enhancement, deraining and so on), image inpainting, and more.
This guide will show you how to:
- Use an image-to-image pipeline for super resolution task,
@@ -32,7 +32,7 @@ Let's begin by installing the necessary libraries.
pip install transformers
```
-We can now initialize the pipeline with a [Swin2SR model](https://huggingface.co/caidas/swin2SR-lightweight-x2-64). We can then infer with the pipeline by calling it with an image. As of now, only [Swin2SR models](https://huggingface.co/models?sort=trending&search=swin2sr) are supported in this pipeline.
+We can now initialize the pipeline with a [Swin2SR model](https://huggingface.co/caidas/swin2SR-lightweight-x2-64). We can then infer with the pipeline by calling it with an image. As of now, only [Swin2SR models](https://huggingface.co/models?sort=trending&search=swin2sr) are supported in this pipeline.
```python
from transformers import pipeline, infer_device
@@ -53,19 +53,22 @@ image = Image.open(requests.get(url, stream=True).raw)
print(image.size)
```
+
```bash
# (532, 432)
```
+
 -We can now do inference with the pipeline. We will get an upscaled version of the cat image.
+We can now do inference with the pipeline. We will get an upscaled version of the cat image.
```python
upscaled = pipe(image)
print(upscaled.size)
```
+
```bash
# (1072, 880)
```
@@ -79,7 +82,7 @@ model = Swin2SRForImageSuperResolution.from_pretrained("caidas/swin2SR-lightweig
processor = Swin2SRImageProcessor("caidas/swin2SR-lightweight-x2-64")
```
-`pipeline` abstracts away the preprocessing and postprocessing steps that we have to do ourselves, so let's preprocess the image. We will pass the image to the processor and then move the pixel values to GPU.
+`pipeline` abstracts away the preprocessing and postprocessing steps that we have to do ourselves, so let's preprocess the image. We will pass the image to the processor and then move the pixel values to GPU.
```python
pixel_values = processor(image, return_tensors="pt").pixel_values
@@ -96,7 +99,8 @@ import torch
with torch.no_grad():
outputs = model(pixel_values)
```
-Output is an object of type `ImageSuperResolutionOutput` that looks like below 👇
+
+Output is an object of type `ImageSuperResolutionOutput` that looks like below 👇
```
(loss=None, reconstruction=tensor([[[[0.8270, 0.8269, 0.8275, ..., 0.7463, 0.7446, 0.7453],
@@ -108,6 +112,7 @@ Output is an object of type `ImageSuperResolutionOutput` that looks like below
[0.5927, 0.5914, 0.5922, ..., 0.0664, 0.0694, 0.0718]]]],
device='cuda:0'), hidden_states=None, attentions=None)
```
+
We need to get the `reconstruction` and post-process it for visualization. Let's see how it looks like.
```python
@@ -128,6 +133,7 @@ output = np.moveaxis(output, source=0, destination=-1)
output = (output * 255.0).round().astype(np.uint8)
Image.fromarray(output)
```
+
-We can now do inference with the pipeline. We will get an upscaled version of the cat image.
+We can now do inference with the pipeline. We will get an upscaled version of the cat image.
```python
upscaled = pipe(image)
print(upscaled.size)
```
+
```bash
# (1072, 880)
```
@@ -79,7 +82,7 @@ model = Swin2SRForImageSuperResolution.from_pretrained("caidas/swin2SR-lightweig
processor = Swin2SRImageProcessor("caidas/swin2SR-lightweight-x2-64")
```
-`pipeline` abstracts away the preprocessing and postprocessing steps that we have to do ourselves, so let's preprocess the image. We will pass the image to the processor and then move the pixel values to GPU.
+`pipeline` abstracts away the preprocessing and postprocessing steps that we have to do ourselves, so let's preprocess the image. We will pass the image to the processor and then move the pixel values to GPU.
```python
pixel_values = processor(image, return_tensors="pt").pixel_values
@@ -96,7 +99,8 @@ import torch
with torch.no_grad():
outputs = model(pixel_values)
```
-Output is an object of type `ImageSuperResolutionOutput` that looks like below 👇
+
+Output is an object of type `ImageSuperResolutionOutput` that looks like below 👇
```
(loss=None, reconstruction=tensor([[[[0.8270, 0.8269, 0.8275, ..., 0.7463, 0.7446, 0.7453],
@@ -108,6 +112,7 @@ Output is an object of type `ImageSuperResolutionOutput` that looks like below
[0.5927, 0.5914, 0.5922, ..., 0.0664, 0.0694, 0.0718]]]],
device='cuda:0'), hidden_states=None, attentions=None)
```
+
We need to get the `reconstruction` and post-process it for visualization. Let's see how it looks like.
```python
@@ -128,6 +133,7 @@ output = np.moveaxis(output, source=0, destination=-1)
output = (output * 255.0).round().astype(np.uint8)
Image.fromarray(output)
```
+
 diff --git a/docs/source/en/tasks/keypoint_detection.md b/docs/source/en/tasks/keypoint_detection.md
index 3a5871d01a2..c850c67ae15 100644
--- a/docs/source/en/tasks/keypoint_detection.md
+++ b/docs/source/en/tasks/keypoint_detection.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-Keypoint detection identifies and locates specific points of interest within an image. These keypoints, also known as landmarks, represent meaningful features of objects, such as facial features or object parts. These models take an image input and return the following outputs:
+Keypoint detection identifies and locates specific points of interest within an image. These keypoints, also known as landmarks, represent meaningful features of objects, such as facial features or object parts. These models take an image input and return the following outputs:
- **Keypoints and Scores**: Points of interest and their confidence scores.
- **Descriptors**: A representation of the image region surrounding each keypoint, capturing its texture, gradient, orientation and other properties.
@@ -36,15 +36,14 @@ model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/sup
Let's test the model on the images below.
diff --git a/docs/source/en/tasks/keypoint_detection.md b/docs/source/en/tasks/keypoint_detection.md
index 3a5871d01a2..c850c67ae15 100644
--- a/docs/source/en/tasks/keypoint_detection.md
+++ b/docs/source/en/tasks/keypoint_detection.md
@@ -18,7 +18,7 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-Keypoint detection identifies and locates specific points of interest within an image. These keypoints, also known as landmarks, represent meaningful features of objects, such as facial features or object parts. These models take an image input and return the following outputs:
+Keypoint detection identifies and locates specific points of interest within an image. These keypoints, also known as landmarks, represent meaningful features of objects, such as facial features or object parts. These models take an image input and return the following outputs:
- **Keypoints and Scores**: Points of interest and their confidence scores.
- **Descriptors**: A representation of the image region surrounding each keypoint, capturing its texture, gradient, orientation and other properties.
@@ -36,15 +36,14 @@ model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/sup
Let's test the model on the images below.
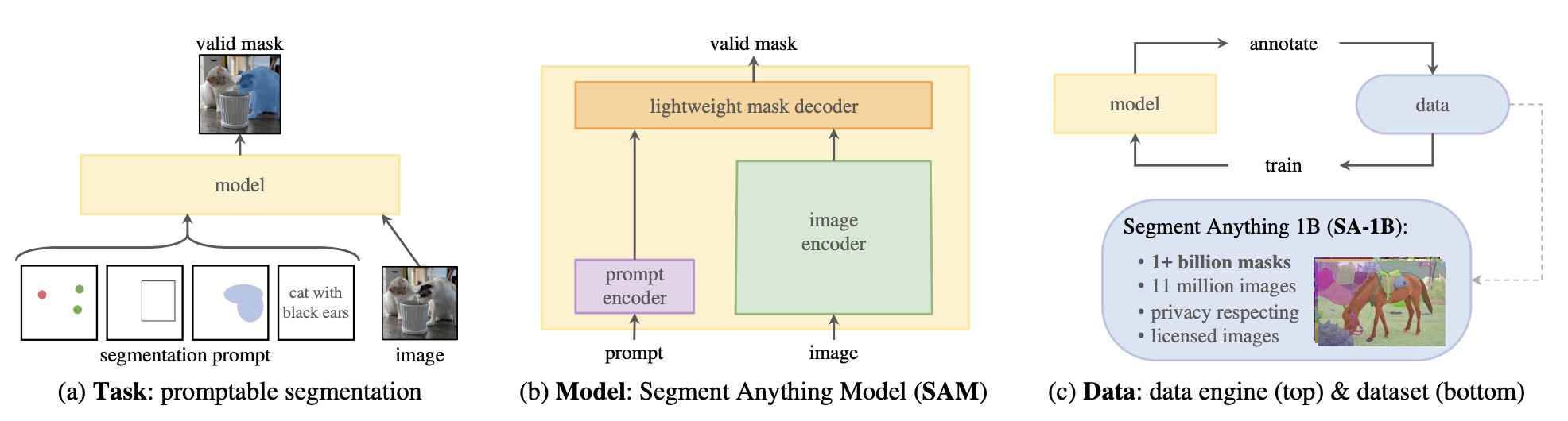 -SAM serves as a powerful foundation model for segmentation as it has large data coverage. It is trained on
-[SA-1B](https://ai.meta.com/datasets/segment-anything/), a dataset with 1 million images and 1.1 billion masks.
+SAM serves as a powerful foundation model for segmentation as it has large data coverage. It is trained on
+[SA-1B](https://ai.meta.com/datasets/segment-anything/), a dataset with 1 million images and 1.1 billion masks.
In this guide, you will learn how to:
- Infer in segment everything mode with batching,
@@ -114,7 +114,6 @@ Below is the original image in grayscale with colorful maps overlaid. Very impre
-SAM serves as a powerful foundation model for segmentation as it has large data coverage. It is trained on
-[SA-1B](https://ai.meta.com/datasets/segment-anything/), a dataset with 1 million images and 1.1 billion masks.
+SAM serves as a powerful foundation model for segmentation as it has large data coverage. It is trained on
+[SA-1B](https://ai.meta.com/datasets/segment-anything/), a dataset with 1 million images and 1.1 billion masks.
In this guide, you will learn how to:
- Infer in segment everything mode with batching,
@@ -114,7 +114,6 @@ Below is the original image in grayscale with colorful maps overlaid. Very impre
 -
## Model Inference
### Point Prompting
@@ -132,7 +131,7 @@ processor = SamProcessor.from_pretrained("facebook/sam-vit-base")
To do point prompting, pass the input point to the processor, then take the processor output
and pass it to the model for inference. To post-process the model output, pass the outputs and
-`original_sizes` and `reshaped_input_sizes` we take from the processor's initial output. We need to pass these
+`original_sizes` and `reshaped_input_sizes` we take from the processor's initial output. We need to pass these
since the processor resizes the image, and the output needs to be extrapolated.
```python
@@ -143,6 +142,7 @@ with torch.no_grad():
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
```
+
We can visualize the three masks in the `masks` output.
```python
@@ -177,10 +177,9 @@ plt.show()
### Box Prompting
You can also do box prompting in a similar fashion to point prompting. You can simply pass the input box in the format of a list
-`[x_min, y_min, x_max, y_max]` format along with the image to the `processor`. Take the processor output and directly pass it
+`[x_min, y_min, x_max, y_max]` format along with the image to the `processor`. Take the processor output and directly pass it
to the model, then post-process the output again.
-
```python
# bounding box around the bee
box = [2350, 1600, 2850, 2100]
@@ -219,7 +218,7 @@ plt.show()
-
## Model Inference
### Point Prompting
@@ -132,7 +131,7 @@ processor = SamProcessor.from_pretrained("facebook/sam-vit-base")
To do point prompting, pass the input point to the processor, then take the processor output
and pass it to the model for inference. To post-process the model output, pass the outputs and
-`original_sizes` and `reshaped_input_sizes` we take from the processor's initial output. We need to pass these
+`original_sizes` and `reshaped_input_sizes` we take from the processor's initial output. We need to pass these
since the processor resizes the image, and the output needs to be extrapolated.
```python
@@ -143,6 +142,7 @@ with torch.no_grad():
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
```
+
We can visualize the three masks in the `masks` output.
```python
@@ -177,10 +177,9 @@ plt.show()
### Box Prompting
You can also do box prompting in a similar fashion to point prompting. You can simply pass the input box in the format of a list
-`[x_min, y_min, x_max, y_max]` format along with the image to the `processor`. Take the processor output and directly pass it
+`[x_min, y_min, x_max, y_max]` format along with the image to the `processor`. Take the processor output and directly pass it
to the model, then post-process the output again.
-
```python
# bounding box around the bee
box = [2350, 1600, 2850, 2100]
@@ -219,7 +218,7 @@ plt.show()

-You can see the inference output below.
+You can see the inference output below.
```python
fig, ax = plt.subplots()
@@ -233,4 +232,3 @@ plt.show()
@@ -286,10 +286,10 @@ In the example above we instruct the model to classify the image into a single c
## Image-guided text generation
-For more creative applications, you can use image-guided text generation to generate text based on an image. This can be
-useful to create descriptions of products, ads, descriptions of a scene, etc.
+For more creative applications, you can use image-guided text generation to generate text based on an image. This can be
+useful to create descriptions of products, ads, descriptions of a scene, etc.
-Let's prompt IDEFICS to write a story based on a simple image of a red door:
+Let's prompt IDEFICS to write a story based on a simple image of a red door:
@@ -333,14 +333,14 @@ Looks like IDEFICS noticed the pumpkin on the doorstep and went with a spooky Ha
-
- 
-
```python
import torch
from PIL import Image
@@ -93,7 +92,7 @@ image_sizes = [(image.size[1], image.size[0]) for image in images]
outputs = processor.post_process_keypoint_detection(outputs, image_sizes)
```
-The outputs are now a list of dictionaries where each dictionary is a processed output of keypoints, scores and descriptors.
+The outputs are now a list of dictionaries where each dictionary is a processed output of keypoints, scores and descriptors.
```python
[{'keypoints': tensor([[ 226, 57],
@@ -144,11 +143,10 @@ for i in range(len(images)):
Below you can see the outputs.
-
-  -
- 
-
diff --git a/docs/source/en/tasks/keypoint_matching.md b/docs/source/en/tasks/keypoint_matching.md
index f7065f31521..aff16a937d7 100644
--- a/docs/source/en/tasks/keypoint_matching.md
+++ b/docs/source/en/tasks/keypoint_matching.md
@@ -34,15 +34,15 @@ model = AutoModelForKeypointMatching.from_pretrained("zju-community/matchanythin
Load two images that have the same object of interest. The second photo is taken a second apart, it's colors are edited, and it is further cropped and rotated.
-
-
- 
-```python
+```python
from transformers.image_utils import load_image
image1 = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg")
image2 = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee_edited.jpg")
@@ -82,16 +82,16 @@ Here's the outputs.
[1521, 2560]], dtype=torch.int32),
'matching_scores': tensor([0.2189, 0.2073, 0.2414, ...
])}]
-```
+```
We have trimmed the output but there's 401 matches!
```python
len(outputs[0]["keypoints0"])
# 401
-```
+```
-We can visualize them using the processor's [`~EfficientLoFTRImageProcessor.visualize_keypoint_matching`] method.
+We can visualize them using the processor's [`~EfficientLoFTRImageProcessor.visualize_keypoint_matching`] method.
```python
plot_images = processor.visualize_keypoint_matching(images, outputs)
@@ -100,7 +100,7 @@ plot_images

-Optionally, you can use the [`Pipeline`] API and set the task to `keypoint-matching`.
+Optionally, you can use the [`Pipeline`] API and set the task to `keypoint-matching`.
```python
from transformers import pipeline
diff --git a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
index 7c4a684d3c0..d4b3dd8511d 100644
--- a/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
+++ b/docs/source/en/tasks/knowledge_distillation_for_image_classification.md
@@ -52,7 +52,6 @@ processed_datasets = dataset.map(process, batched=True)
Essentially, we want the student model (a randomly initialized MobileNet) to mimic the teacher model (fine-tuned vision transformer). To achieve this, we first get the logits output from the teacher and the student. Then, we divide each of them by the parameter `temperature` which controls the importance of each soft target. A parameter called `lambda` weighs the importance of the distillation loss. In this example, we will use `temperature=5` and `lambda=0.5`. We will use the Kullback-Leibler Divergence loss to compute the divergence between the student and teacher. Given two data P and Q, KL Divergence explains how much extra information we need to represent P using Q. If two are identical, their KL divergence is zero, as there's no other information needed to explain P from Q. Thus, in the context of knowledge distillation, KL divergence is useful.
-
```python
from transformers import TrainingArguments, Trainer, infer_device
import torch
diff --git a/docs/source/en/tasks/mask_generation.md b/docs/source/en/tasks/mask_generation.md
index 5f66e68c245..06ba26ea123 100644
--- a/docs/source/en/tasks/mask_generation.md
+++ b/docs/source/en/tasks/mask_generation.md
@@ -16,22 +16,22 @@ rendered properly in your Markdown viewer.
# Mask Generation
-Mask generation is the task of generating semantically meaningful masks for an image.
-This task is very similar to [image segmentation](semantic_segmentation), but many differences exist. Image segmentation models are trained on labeled datasets and are limited to the classes they have seen during training; they return a set of masks and corresponding classes, given an image.
+Mask generation is the task of generating semantically meaningful masks for an image.
+This task is very similar to [image segmentation](semantic_segmentation), but many differences exist. Image segmentation models are trained on labeled datasets and are limited to the classes they have seen during training; they return a set of masks and corresponding classes, given an image.
-Mask generation models are trained on large amounts of data and operate in two modes.
-- Prompting mode: In this mode, the model takes in an image and a prompt, where a prompt can be a 2D point location (XY coordinates) in the image within an object or a bounding box surrounding an object. In prompting mode, the model only returns the mask over the object
-that the prompt is pointing out.
-- Segment Everything mode: In segment everything, given an image, the model generates every mask in the image. To do so, a grid of points is generated and overlaid on the image for inference.
+Mask generation models are trained on large amounts of data and operate in two modes.
+- Prompting mode: In this mode, the model takes in an image and a prompt, where a prompt can be a 2D point location (XY coordinates) in the image within an object or a bounding box surrounding an object. In prompting mode, the model only returns the mask over the object
+that the prompt is pointing out.
+- Segment Everything mode: In segment everything, given an image, the model generates every mask in the image. To do so, a grid of points is generated and overlaid on the image for inference.
-Mask generation task is supported by [Segment Anything Model (SAM)](model_doc/sam). It's a powerful model that consists of a Vision Transformer-based image encoder, a prompt encoder, and a two-way transformer mask decoder. Images and prompts are encoded, and the decoder takes these embeddings and generates valid masks.
+Mask generation task is supported by [Segment Anything Model (SAM)](model_doc/sam). It's a powerful model that consists of a Vision Transformer-based image encoder, a prompt encoder, and a two-way transformer mask decoder. Images and prompts are encoded, and the decoder takes these embeddings and generates valid masks.
-

In the original implementation ZoeDepth model performs inference on both the original and flipped images and averages out the results. The post_process_depth_estimation function can handle this for us by passing the flipped outputs to the optional outputs_flipped argument:
>>> with torch.no_grad():
+>>> with torch.no_grad():
... outputs = model(pixel_values)
... outputs_flipped = model(pixel_values=torch.flip(inputs.pixel_values, dims=[3]))
>>> post_processed_output = image_processor.post_process_depth_estimation(
diff --git a/docs/source/en/tasks/multiple_choice.md b/docs/source/en/tasks/multiple_choice.md
index 3f4c9d4637f..d35f108ecce 100644
--- a/docs/source/en/tasks/multiple_choice.md
+++ b/docs/source/en/tasks/multiple_choice.md
@@ -113,6 +113,7 @@ To apply the preprocessing function over the entire dataset, use 🤗 Datasets [
```
To create a batch of examples, it's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length. [`DataCollatorForMultipleChoice`] flattens all the model inputs, applies padding, and then unflattens the results.
+
```py
>>> from transformers import DataCollatorForMultipleChoice
>>> collator = DataCollatorForMultipleChoice(tokenizer=tokenizer)
@@ -197,7 +198,6 @@ Once training is completed, share your model to the Hub with the [`~transformers
>>> trainer.push_to_hub()
```
-
For a more in-depth example of how to finetune a model for multiple choice, take a look at the corresponding
diff --git a/docs/source/en/tasks/object_detection.md b/docs/source/en/tasks/object_detection.md
index 394e77104b7..093644b662f 100644
--- a/docs/source/en/tasks/object_detection.md
+++ b/docs/source/en/tasks/object_detection.md
@@ -171,11 +171,11 @@ To get an even better understanding of the data, visualize an example in the dat
>>> image
```
+
 -
To visualize the bounding boxes with associated labels, you can get the labels from the dataset's metadata, specifically
the `category` field.
You'll also want to create dictionaries that map a label id to a label class (`id2label`) and the other way around (`label2id`).
@@ -576,6 +576,7 @@ Finally, bring everything together, and call [`~transformers.Trainer.train`]:
>>> trainer.train()
```
+
@@ -1487,6 +1488,7 @@ Now that you have finetuned a model, evaluated it, and uploaded it to the Huggin
```
Load model and image processor from the Hugging Face Hub (skip to use already trained in this session):
+
```py
>>> from transformers import infer_device
diff --git a/docs/source/en/tasks/prompting.md b/docs/source/en/tasks/prompting.md
index eb8e61d67aa..2d115d4e544 100644
--- a/docs/source/en/tasks/prompting.md
+++ b/docs/source/en/tasks/prompting.md
@@ -127,7 +127,6 @@ for output in outputs:
print(f"Result: {output['generated_text']}")
```
-
While the basic few-shot prompting approach embedded examples within a single text string, the chat template format offers the following benefits.
- The model may have a potentially improved understanding because it can better recognize the pattern and the expected roles of user input and assistant output.
diff --git a/docs/source/en/tasks/semantic_segmentation.md b/docs/source/en/tasks/semantic_segmentation.md
index 5d3c8e70aa1..08d68047dc6 100644
--- a/docs/source/en/tasks/semantic_segmentation.md
+++ b/docs/source/en/tasks/semantic_segmentation.md
@@ -69,6 +69,7 @@ results
```
The segmentation pipeline output includes a mask for every predicted class.
+
```bash
[{'score': None,
'label': 'road',
@@ -107,6 +108,7 @@ Taking a look at the mask for the car class, we can see every car is classified
```python
results[-1]["mask"]
```
+
-
To visualize the bounding boxes with associated labels, you can get the labels from the dataset's metadata, specifically
the `category` field.
You'll also want to create dictionaries that map a label id to a label class (`id2label`) and the other way around (`label2id`).
@@ -576,6 +576,7 @@ Finally, bring everything together, and call [`~transformers.Trainer.train`]:
>>> trainer.train()
```
+
@@ -1487,6 +1488,7 @@ Now that you have finetuned a model, evaluated it, and uploaded it to the Huggin
```
Load model and image processor from the Hugging Face Hub (skip to use already trained in this session):
+
```py
>>> from transformers import infer_device
diff --git a/docs/source/en/tasks/prompting.md b/docs/source/en/tasks/prompting.md
index eb8e61d67aa..2d115d4e544 100644
--- a/docs/source/en/tasks/prompting.md
+++ b/docs/source/en/tasks/prompting.md
@@ -127,7 +127,6 @@ for output in outputs:
print(f"Result: {output['generated_text']}")
```
-
While the basic few-shot prompting approach embedded examples within a single text string, the chat template format offers the following benefits.
- The model may have a potentially improved understanding because it can better recognize the pattern and the expected roles of user input and assistant output.
diff --git a/docs/source/en/tasks/semantic_segmentation.md b/docs/source/en/tasks/semantic_segmentation.md
index 5d3c8e70aa1..08d68047dc6 100644
--- a/docs/source/en/tasks/semantic_segmentation.md
+++ b/docs/source/en/tasks/semantic_segmentation.md
@@ -69,6 +69,7 @@ results
```
The segmentation pipeline output includes a mask for every predicted class.
+
```bash
[{'score': None,
'label': 'road',
@@ -107,6 +108,7 @@ Taking a look at the mask for the car class, we can see every car is classified
```python
results[-1]["mask"]
```
+
 @@ -135,11 +137,13 @@ As you can see below, there are multiple cars classified, and there's no classif
'label': 'person',
'mask':
@@ -135,11 +137,13 @@ As you can see below, there are multiple cars classified, and there's no classif
'label': 'person',
'mask': }]
```
+
Checking out one of the car masks below.
```python
results[2]["mask"]
```
+
 @@ -151,6 +155,7 @@ panoptic_segmentation = pipeline("image-segmentation", "facebook/mask2former-swi
results = panoptic_segmentation(image)
results
```
+
As you can see below, we have more classes. We will later illustrate to see that every pixel is classified into one of the classes.
```bash
@@ -206,7 +211,6 @@ To see all architectures and checkpoints compatible with this task, we recommend
-
### Load SceneParse150 dataset
Start by loading a smaller subset of the SceneParse150 dataset from the 🤗 Datasets library. This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
@@ -473,7 +477,6 @@ Reload the dataset and load an image for inference.
@@ -151,6 +155,7 @@ panoptic_segmentation = pipeline("image-segmentation", "facebook/mask2former-swi
results = panoptic_segmentation(image)
results
```
+
As you can see below, we have more classes. We will later illustrate to see that every pixel is classified into one of the classes.
```bash
@@ -206,7 +211,6 @@ To see all architectures and checkpoints compatible with this task, we recommend
-
### Load SceneParse150 dataset
Start by loading a smaller subset of the SceneParse150 dataset from the 🤗 Datasets library. This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
@@ -473,7 +477,6 @@ Reload the dataset and load an image for inference.

-
We will now see how to infer without a pipeline. Process the image with an image processor and place the `pixel_values` on a GPU:
```py
@@ -503,7 +506,6 @@ Next, rescale the logits to the original image size:
>>> pred_seg = upsampled_logits.argmax(dim=1)[0]
```
-
To visualize the results, load the [dataset color palette](https://github.com/tensorflow/models/blob/3f1ca33afe3c1631b733ea7e40c294273b9e406d/research/deeplab/utils/get_dataset_colormap.py#L51) as `ade_palette()` that maps each class to their RGB values.
```py
diff --git a/docs/source/en/tasks/summarization.md b/docs/source/en/tasks/summarization.md
index c57097421fb..b2f2beebc80 100644
--- a/docs/source/en/tasks/summarization.md
+++ b/docs/source/en/tasks/summarization.md
@@ -213,7 +213,6 @@ Once training is completed, share your model to the Hub with the [`~transformers
>>> trainer.push_to_hub()
```
-
For a more in-depth example of how to finetune a model for summarization, take a look at the corresponding
diff --git a/docs/source/en/tasks/token_classification.md b/docs/source/en/tasks/token_classification.md
index 49b0fcf216b..5096298affd 100644
--- a/docs/source/en/tasks/token_classification.md
+++ b/docs/source/en/tasks/token_classification.md
@@ -242,7 +242,6 @@ Before you start training your model, create a map of the expected ids to their
... }
```
-
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
@@ -298,7 +297,6 @@ Once training is completed, share your model to the Hub with the [`~transformers
>>> trainer.push_to_hub()
```
-
For a more in-depth example of how to finetune a model for token classification, take a look at the corresponding
diff --git a/docs/source/en/tasks/video_classification.md b/docs/source/en/tasks/video_classification.md
index b387a8320df..bae638bd84e 100644
--- a/docs/source/en/tasks/video_classification.md
+++ b/docs/source/en/tasks/video_classification.md
@@ -363,7 +363,6 @@ Leverage [`Trainer`](https://huggingface.co/docs/transformers/main_classes/train
Most of the training arguments are self-explanatory, but one that is quite important here is `remove_unused_columns=False`. This one will drop any features not used by the model's call function. By default it's `True` because usually it's ideal to drop unused feature columns, making it easier to unpack inputs into the model's call function. But, in this case, you need the unused features ('video' in particular) in order to create `pixel_values` (which is a mandatory key our model expects in its inputs).
-
```py
>>> from transformers import TrainingArguments, Trainer
@@ -477,7 +476,6 @@ The simplest way to try out your fine-tuned model for inference is to use it in
You can also manually replicate the results of the `pipeline` if you'd like.
-
```py
>>> def run_inference(model, video):
... # (num_frames, num_channels, height, width)
diff --git a/docs/source/en/tasks/video_text_to_text.md b/docs/source/en/tasks/video_text_to_text.md
index 0e0191af588..b0f698f039e 100644
--- a/docs/source/en/tasks/video_text_to_text.md
+++ b/docs/source/en/tasks/video_text_to_text.md
@@ -18,9 +18,9 @@ rendered properly in your Markdown viewer.
[[open-in-colab]]
-Video-text-to-text models, also known as video language models or vision language models with video input, are language models that take a video input. These models can tackle various tasks, from video question answering to video captioning.
+Video-text-to-text models, also known as video language models or vision language models with video input, are language models that take a video input. These models can tackle various tasks, from video question answering to video captioning.
-These models have nearly the same architecture as [image-text-to-text](../image_text_to_text) models except for some changes to accept video data, since video data is essentially image frames with temporal dependencies. Some image-text-to-text models take in multiple images, but this alone is inadequate for a model to accept videos. Moreover, video-text-to-text models are often trained with all vision modalities. Each example might have videos, multiple videos, images and multiple images. Some of these models can also take interleaved inputs. For example, you can refer to a specific video inside a string of text by adding a video token in text like "What is happening in this video? `
@@ -158,6 +152,7 @@ class MyConfig(PretrainedConfig):
"norm": (["hidden_states"], ["hidden_states"]),
}
```
+
### Multimodal models
@@ -200,8 +195,8 @@ class MyMultimodalModelForConditionalGeneration(MyMultimodalPreTrainedModel, Gen
self.model = MyMultimodalModel(config)
self.lm_head = nn.Linear(hidden_dim, vocab_size)
```
-
+
2. A multimodal model config must be nested with the following fields.
* text_config: decoder language model config
@@ -246,6 +241,7 @@ class MyMultimodalProcessor(ProcessorMixin):
vision_data.update({"num_image_tokens": num_image_tokens, "num_image_patches": num_image_patches})
return MultiModalData(**vision_data)
```
+
## Resources
diff --git a/docs/source/en/troubleshooting.md b/docs/source/en/troubleshooting.md
index 7998881d364..cfc51966893 100644
--- a/docs/source/en/troubleshooting.md
+++ b/docs/source/en/troubleshooting.md
@@ -34,7 +34,6 @@ Sometimes errors occur, but we are here to help! This guide covers some of the m
For more details about troubleshooting and getting help, take a look at [Chapter 8](https://huggingface.co/course/chapter8/1?fw=pt) of the Hugging Face course.
-
## Firewalled environments
Some GPU instances on cloud and intranet setups are firewalled to external connections, resulting in a connection error. When your script attempts to download model weights or datasets, the download will hang and then timeout with the following message:
diff --git a/notebooks/README.md b/notebooks/README.md
index 4d31797104f..aed43587880 100644
--- a/notebooks/README.md
+++ b/notebooks/README.md
@@ -22,7 +22,6 @@ Also, we would like to list here interesting content created by the community.
If you wrote some notebook(s) leveraging 🤗 Transformers and would like to be listed here, please open a
Pull Request so it can be included under the Community notebooks.
-
## Hugging Face's notebooks 🤗
### Documentation notebooks
@@ -38,7 +37,6 @@ You can open any page of the documentation as a notebook in Colab (there is a bu
| [Summary of the tokenizers](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb) | The differences between the tokenizers algorithm |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb)|
| [Multilingual models](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb) | How to use the multilingual models of the library |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb)|
-
### PyTorch Examples
#### Natural Language Processing[[pytorch-nlp]]
@@ -88,7 +86,6 @@ You can open any page of the documentation as a notebook in Colab (there is a bu
| [How to fine-tune a Nucleotide Transformer model](https://github.com/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) | See how to tokenize DNA and fine-tune a large pre-trained DNA "language" model | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) |
| [Fine-tune a Nucleotide Transformer model with LoRA](https://github.com/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) | Train even larger DNA models in a memory-efficient way | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) |
-
#### Other modalities[[pytorch-other]]
| Notebook | Description | | |
@@ -101,7 +98,6 @@ You can open any page of the documentation as a notebook in Colab (there is a bu
|:----------|:-------------|:-------------|------:|
| [How to export model to ONNX](https://github.com/huggingface/notebooks/blob/main/examples/onnx-export.ipynb)| Highlight how to export and run inference workloads through ONNX | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/onnx-export.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/onnx-export.ipynb)|
-
### Optimum notebooks
🤗 [Optimum](https://github.com/huggingface/optimum) is an extension of 🤗 Transformers, providing a set of performance optimization tools enabling maximum efficiency to train and run models on targeted hardwares.