diff --git a/.cursor/commands/style-guide.md b/.cursor/commands/style-guide.md
new file mode 100644
index 00000000000..f76ea15d500
--- /dev/null
+++ b/.cursor/commands/style-guide.md
@@ -0,0 +1,53 @@
+## Sentence structure
+- Write short, declarative sentences most of the time.
+- Vary sentence length to avoid sounding robotic. Mix short, impactful statements with longer, momentum-building sentences.
+- Every time you use a comma, ask whether you can use a period instead.
+- Avoid repeating the same words in a paragraph. Use synonyms or rephrase.
+
+## Voice and tone
+- Write like humans speak. Avoid corporate jargon and marketing fluff.
+- Be confident and direct. Avoid softening phrases like "I think", "maybe", or "could".
+- Use active voice instead of passive voice.
+- Use positive phrasing - say what something *is* rather than what is *isn't*.
+- Say "you" more than "we" when addressing external audiences.
+- Use contractions like "I'll", "won't", and "can't" for a warmer tone.
+
+## Specificity and evidence
+- Be specific with facts and data instead of vague superlatives.
+- Back up claims with concrete examples or metrics.
+- Highlight customers and community members over company achievements.
+- Use realistic, product-based examples instead of `foo/bar/baz` in code.
+- Make content concrete, visual, and falsifiable.
+
+## Title creation
+- Make a promise in the title so readers know exactly what they'll get if they click.
+- Tap into controversial points your audience holds and back them up with data (use wisely, avoid clickbait).
+- Share something uniquely helpful that makes readers better at meaningful aspects of their lives.
+- Avoid vague titles like "My Thoughts on XYZ". Titles should be opinions or shareable facts.
+- Write placeholder titles first, complete the content, then spend time iterating on titles at the end.
+
+## Ban phrases
+- Avoid using "You can"
+
+## Avoid LLM patterns
+- Replace em dashes (-) with semicolons, commas, or sentence breaks.
+- Avoid starting responses with "Great question!", "You're right!", or "Let me help you."
+- Don't use phrases like "Let's dive into..."
+- Skip cliché intros like "In today's fast-paced digital world" or "In the ever-evolving landscape of"
+- Avoid phrases like "it's not just [x], it's [y]"
+- Don't use high-school essay closers: "In conclusion,", "Overall,", or "To summarize"
+- Avoid numbered lists in cases where bullets work better.
+- Replace "In conclusion" with direct statements.
+- Avoid hedge words: "might", "perhaps", "potentially" unless uncertainty is real.
+- Don't stack hedging phrases: "may potentially", "it's important to note that".
+- Don't create perfectly symmetrical paragraphs or lists that start with "Firstly... Secondly..."
+- Avoid title-case headings: prefer sentence casing.
+- Remove Unicode artifacts when copy-pasting: smart quotes ("), em-dashes, non-breaking spaces.
+- Use '
+- Delete empty citation placeholders like "[1]" with no actual source
+
+## Punctuation and formatting
+- Use Oxford commas consistently
+- Use exclamation points sparingly
+- Sentences can start with "But" and "And" but don't overuse
+- Use periods instead of commas when possible for clarity
\ No newline at end of file
diff --git a/docs/source/en/model_doc/albert.md b/docs/source/en/model_doc/albert.md
index 00c57d8abdb..c8fa91498b3 100644
--- a/docs/source/en/model_doc/albert.md
+++ b/docs/source/en/model_doc/albert.md
@@ -23,7 +23,7 @@ rendered properly in your Markdown viewer.
# ALBERT
-[ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://huggingface.co/papers/1909.11942) presents parameter-reduction techniques to enhance BERT by splitting the embedding matrix and using repeating layers. These methods reduce memory usage and training time, enabling better scalability. The model employs a self-supervised loss to improve inter-sentence coherence, achieving state-of-the-art results on GLUE, RACE, and SQuAD benchmarks with fewer parameters than BERT-large.
+[ALBERT](https://huggingface.co/papers/1909.11942) presents parameter-reduction techniques to enhance BERT by splitting the embedding matrix and using repeating layers. These methods reduce memory usage and training time, enabling better scalability. The model employs a self-supervised loss to improve inter-sentence coherence, achieving state-of-the-art results on GLUE, RACE, and SQuAD benchmarks with fewer parameters than BERT-large.
@@ -57,6 +57,12 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- ALBERT uses absolute position embeddings. Pad inputs on the right, not the left.
+
+- The embedding size E differs from hidden size H for good reason. Embeddings represent individual tokens (context-independent). Hidden states represent token sequences (context-dependent). This makes H >> E logical. The embedding matrix spans V × E dimensions, where V is vocabulary size. Keeping E < H reduces parameter count.
+
## AlbertConfig
[[autodoc]] AlbertConfig
diff --git a/docs/source/en/model_doc/apertus.md b/docs/source/en/model_doc/apertus.md
index 8c094c174ba..d1648a4a6d5 100644
--- a/docs/source/en/model_doc/apertus.md
+++ b/docs/source/en/model_doc/apertus.md
@@ -15,8 +15,6 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2025-09-02 and added to Hugging Face Transformers on 2025-10-07.*
-# Apertus
-
@@ -25,23 +23,10 @@ rendered properly in your Markdown viewer.
-```py
-import torch
-from transformers import pipeline
-
-pipeline = pipeline(task="text-generation", model="swiss-ai/apertus-7b", dtype="auto")
-pipeline("The future of artificial intelligence is")
-```
-
-## Overview
+# Apertus
[Apertus](https://www.swiss-ai.org) is a family of large language models from the Swiss AI Initiative.
-> [!TIP]
-> Coming soon
-
-The example below demonstrates how to generate text with [`Pipeline`] or the [`AutoModel`], and from the command line.
-
@@ -49,13 +34,8 @@ The example below demonstrates how to generate text with [`Pipeline`] or the [`A
import torch
from transformers import pipeline
-pipeline = pipeline(
- task="text-generation",
- model="swiss-ai/Apertus-8B",
- dtype=torch.bfloat16,
- device=0
-)
-pipeline("Plants create energy through a process known as")
+pipeline = pipeline(task="text-generation", model="swiss-ai/Apertus-8B", dtype="auto")
+pipeline("Plants generate energy through a process known as ")
```
@@ -63,28 +43,15 @@ pipeline("Plants create energy through a process known as")
```py
import torch
-from transformers import AutoModelForCausalLM, AutoTokenizer
+from transformers import AutoTokenizer, AutoModelForCausalLM
-tokenizer = AutoTokenizer.from_pretrained(
- "swiss-ai/Apertus-8B",
-)
-model = AutoModelForCausalLM.from_pretrained(
- "swiss-ai/Apertus-8B",
- dtype=torch.bfloat16,
- device_map="auto",
- attn_implementation="sdpa"
-)
-input_ids = tokenizer("Plants create energy through a process known as", return_tensors="pt").to("cuda")
+tokenizer = AutoTokenizer.from_pretrained("swiss-ai/Apertus-8B")
+model = ArceeForCausalLM.from_pretrained("swiss-ai/Apertus-8B", dtype="auto")
-output = model.generate(**input_ids)
-print(tokenizer.decode(output[0], skip_special_tokens=True))
-```
-
-
-
-
-```bash
-echo -e "Plants create energy through a process known as" | transformers run --task text-generation --model swiss-ai/Apertus-8B --device 0
+inputs = tokenizer("Plants generate energy through a process known as ", return_tensors="pt")
+with torch.no_grad():
+ outputs = model.generate(**inputs, max_new_tokens=50)
+print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
diff --git a/docs/source/en/model_doc/arcee.md b/docs/source/en/model_doc/arcee.md
index 95e67828f4d..b465efb06a3 100644
--- a/docs/source/en/model_doc/arcee.md
+++ b/docs/source/en/model_doc/arcee.md
@@ -28,19 +28,6 @@ rendered properly in your Markdown viewer.
The Arcee model is architecturally similar to Llama but uses `x * relu(x)` in MLP layers for improved gradient flow and is optimized for efficiency in both training and inference scenarios.
-```py
-import torch
-from transformers import pipeline
-
-pipeline = pipeline(task="text-generation", model="arcee-ai/Arcee-4.5B", dtype="auto")
-pipeline("The future of artificial intelligence is")
-```
-
-> [!TIP]
-> The Arcee model supports extended context with RoPE scaling and all standard transformers features including Flash Attention 2, SDPA, gradient checkpointing, and quantization support.
-
-The example below demonstrates how to generate text with Arcee using [`Pipeline`] or the [`AutoModel`].
-
@@ -48,15 +35,8 @@ The example below demonstrates how to generate text with Arcee using [`Pipeline`
import torch
from transformers import pipeline
-pipeline = pipeline(
- task="text-generation",
- model="arcee-ai/AFM-4.5B",
- dtype=torch.float16,
- device=0
-)
-
-output = pipeline("The key innovation in Arcee is")
-print(output[0]["generated_text"])
+pipeline = pipeline(task="text-generation", model="arcee-ai/AFM-4.5B", dtype="auto")
+pipeline("Plants generate energy through a process known as ")
```
@@ -64,16 +44,12 @@ print(output[0]["generated_text"])
```py
import torch
-from transformers import AutoTokenizer, ArceeForCausalLM
+from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("arcee-ai/AFM-4.5B")
-model = ArceeForCausalLM.from_pretrained(
- "arcee-ai/AFM-4.5B",
- dtype=torch.float16,
- device_map="auto"
-)
+model = ArceeForCausalLM.from_pretrained("arcee-ai/AFM-4.5B", dtype="auto")
-inputs = tokenizer("The key innovation in Arcee is", return_tensors="pt")
+inputs = tokenizer("Plants generate energy through a process known as ", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
diff --git a/docs/source/en/model_doc/bamba.md b/docs/source/en/model_doc/bamba.md
index 156fcf9a207..44bfc42aa5b 100644
--- a/docs/source/en/model_doc/bamba.md
+++ b/docs/source/en/model_doc/bamba.md
@@ -55,6 +55,22 @@ print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
+## Usage tips
+
+- Bamba supports padding-free training. This concatenates distinct training examples while processing inputs as separate batches. Expect ~2x inference acceleration (varies by model and data distribution). Memory usage drops when examples have varying lengths since you avoid padding token overhead.
+
+- Padding-free training requires the flash-attn, mamba-ssm, and causal-conv1d packages. Pass these arguments alongside `input_ids` and `labels`:
+
+- `position_ids`: `torch.LongTensor` - position index of each token in each sequence
+- `seq_idx`: `torch.LongTensor` - index of each sequence in the batch
+- `FlashAttentionKwargs`:
+ - `cu_seq_lens_q`: `torch.LongTensor` - cumulative sequence lengths of all queries
+ - `cu_seq_lens_k`: `torch.LongTensor` - cumulative sequence lengths of all keys
+ - `max_length_q`: `int` - longest query length in the batch
+ - `max_length_k`: `int` - longest key length in the batch
+
+- Don't provide `attention_mask` inputs. The [`DataCollatorWithFlattening`] generates these arguments automatically when you set `return_seq_idx=True` and `return_flash_attn_kwargs=True`. See the [Improving Hugging Face Training Efficiency Through Packing with Flash Attention](https://huggingface.co/blog/packing-with-FA2) blog post for details.
+
## BambaConfig
[[autodoc]] BambaConfig
diff --git a/docs/source/en/model_doc/bart.md b/docs/source/en/model_doc/bart.md
index 075b51b3e7f..c535b9f98ad 100644
--- a/docs/source/en/model_doc/bart.md
+++ b/docs/source/en/model_doc/bart.md
@@ -58,6 +58,15 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Pad inputs on the right. BERT uses absolute position embeddings.
+- The facebook/bart-large-cnn checkpoint lacks `mask_token_id`. It can't perform mask-filling tasks.
+- BART ignores `token_type_ids` for sequence classification. Use [`BartTokenizer`] or `encode()` for proper splitting.
+- [`BartModel`] creates `decoder_input_ids` automatically if you don't pass them. This differs from other model APIs but helps with mask-filling tasks.
+- Model predictions match the original implementation when `forced_bos_token_id=0.` This works only if your text starts with a space.
+- Use [`generate`] for conditional generation tasks like summarization.
+
## BartConfig
[[autodoc]] BartConfig
diff --git a/docs/source/en/model_doc/bartpho.md b/docs/source/en/model_doc/bartpho.md
index cb3b5f08866..4e90b5d7e04 100644
--- a/docs/source/en/model_doc/bartpho.md
+++ b/docs/source/en/model_doc/bartpho.md
@@ -50,6 +50,11 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- BARTpho uses BART's large architecture plus an extra layer-normalization layer on the encoder and decoder. Replace BART-specific classes with mBART-specific classes.
+- This implementation handles tokenization through the `monolingual_vocab_file`. This contains Vietnamese-specific token types from the multilingual vocabulary. For other languages, replace `monolingual_vocab_file` with one specialized for your target language.
+
## BartphoTokenizer
[[autodoc]] BartphoTokenizer
diff --git a/docs/source/en/model_doc/bert-generation.md b/docs/source/en/model_doc/bert-generation.md
index 85ecbbbf00e..681d0d3722b 100644
--- a/docs/source/en/model_doc/bert-generation.md
+++ b/docs/source/en/model_doc/bert-generation.md
@@ -48,6 +48,12 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Use [`BertGenerationEncoder`] and [`BertGenerationDecoder`] with [`EncoderDecoderModel`] for sequence-to-sequence tasks.
+- Summarization, sentence splitting, sentence fusion, and translation don't require special tokens in the input.
+- Don't add `EOS` tokens to the end of inputs for most generation tasks.
+
## BertGenerationConfig
[[autodoc]] BertGenerationConfig
diff --git a/docs/source/en/model_doc/bert.md b/docs/source/en/model_doc/bert.md
index 4399b9e7768..675f9bc9004 100644
--- a/docs/source/en/model_doc/bert.md
+++ b/docs/source/en/model_doc/bert.md
@@ -57,6 +57,10 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- Pad inputs on the right. BERT uses absolute position embeddings.
+
## BertConfig
[[autodoc]] BertConfig
diff --git a/docs/source/en/model_doc/bertweet.md b/docs/source/en/model_doc/bertweet.md
index a9fe2c1065c..c98420956d9 100644
--- a/docs/source/en/model_doc/bertweet.md
+++ b/docs/source/en/model_doc/bertweet.md
@@ -51,6 +51,11 @@ print(f"Predicted label: {label}")
+## Usage tips
+
+- Use [`AutoTokenizer`] or [`BertweetTokenizer`]. They come preloaded with custom vocabulary for tweet-specific tokens like hashtags (#), mentions (@), emojis, and common abbreviations. Install the [emoji](https://pypi.org/project/emoji/) library too.
+- Pad inputs on the right (`padding="max_length"`). BERT uses absolute position embeddings.
+
## BertweetTokenizer
[[autodoc]] BertweetTokenizer
diff --git a/docs/source/en/model_doc/big_bird.md b/docs/source/en/model_doc/big_bird.md
index ca71a03981f..442bd315544 100644
--- a/docs/source/en/model_doc/big_bird.md
+++ b/docs/source/en/model_doc/big_bird.md
@@ -51,6 +51,13 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- Pad inputs on the right. BigBird uses absolute position embeddings.
+- BigBird supports `original_full` and `block_sparse` attention. Use `original_full` for sequences under 1024 tokens since sparse patterns don't help much with smaller inputs.
+- Current implementation uses 3-block window size and 2 global blocks. It only supports ITC-implementation and doesn't support `num_random_blocks=0`.
+- Sequence length must be divisible by the block size.
+
## BigBirdConfig
[[autodoc]] BigBirdConfig
diff --git a/docs/source/en/model_doc/bigbird_pegasus.md b/docs/source/en/model_doc/bigbird_pegasus.md
index 44aaa0b96da..0c3c17d0795 100644
--- a/docs/source/en/model_doc/bigbird_pegasus.md
+++ b/docs/source/en/model_doc/bigbird_pegasus.md
@@ -53,6 +53,14 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- BigBirdPegasus uses [`PegasusTokenizer`].
+- Pad inputs on the right. BigBird uses absolute position embeddings.
+- BigBirdPegasus supports `original_full` and `block_sparse` attention. Use `original_full` for sequences under 1024 tokens since sparse patterns don't help much with smaller inputs.
+- Current implementation uses 3-block window size and 2 global blocks. It only supports ITC-implementation and doesn't support `num_random_blocks=0`.
+- Sequence length must be divisible by the block size.
+
## BigBirdPegasusConfig
[[autodoc]] BigBirdPegasusConfig
diff --git a/docs/source/en/model_doc/biogpt.md b/docs/source/en/model_doc/biogpt.md
index 5c1d82158ae..fbdf8823ae6 100644
--- a/docs/source/en/model_doc/biogpt.md
+++ b/docs/source/en/model_doc/biogpt.md
@@ -54,6 +54,11 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Pad inputs on the right. BioGPT uses absolute position embeddings.
+- BioGPT reuses previously computed key-value attention pairs. Access this feature with the `past_key_values` parameter in [`BioGPTModel.forward`].
+
## BioGptConfig
[[autodoc]] BioGptConfig
diff --git a/docs/source/en/model_doc/blenderbot-small.md b/docs/source/en/model_doc/blenderbot-small.md
index 6943e84c2b2..f24f8bee58f 100644
--- a/docs/source/en/model_doc/blenderbot-small.md
+++ b/docs/source/en/model_doc/blenderbot-small.md
@@ -48,6 +48,10 @@ print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
+## Usage tips
+
+- Pad inputs on the right. Blenderbot Small uses absolute position embeddings.
+
## BlenderbotSmallConfig
[[autodoc]] BlenderbotSmallConfig
diff --git a/docs/source/en/model_doc/blenderbot.md b/docs/source/en/model_doc/blenderbot.md
index 5ea4b7acb42..f8df606a49f 100644
--- a/docs/source/en/model_doc/blenderbot.md
+++ b/docs/source/en/model_doc/blenderbot.md
@@ -48,6 +48,12 @@ print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
+## Usage tips
+
+- Pad inputs on the right. Blenderbot uses absolute position embeddings.
+- Blenderbot uses a standard seq2seq transformer architecture.
+- This is the default Blenderbot model class. Smaller checkpoints like `facebook/blenderbot_small_90M` have different architectures and need [`BlenderbotSmall`].
+
## BlenderbotConfig
[[autodoc]] BlenderbotConfig
diff --git a/docs/source/en/model_doc/blt.md b/docs/source/en/model_doc/blt.md
index 87e9363c13f..141aec5801e 100644
--- a/docs/source/en/model_doc/blt.md
+++ b/docs/source/en/model_doc/blt.md
@@ -27,59 +27,34 @@ rendered properly in your Markdown viewer.
[Byte Latent Transformer](https://huggingface.co/papers/2412.09871) is a byte-level LLM architecture that matches tokenization-based LLM performance at scale. It encodes bytes into dynamically sized patches based on entropy, optimizing compute and model capacity where data complexity is higher. This approach improves inference efficiency and robustness, with the first flop-controlled scaling study up to 8B parameters and 4T training bytes. BLT demonstrates better scaling than tokenization-based models by dynamically selecting long patches for predictable data, enhancing reasoning and long-tail generalization.
+
+
+
```py
import torch
from transformers import pipeline
-pipeline = pipeline(task="text-generation", model="microsoft/BLT-1B", dtype="auto")
-pipeline("The future of artificial intelligence is")
-```
-
-## Usage Tips:
-
-- **Dual Model Architecture**: BLT consists of two separate trained models:
- - **Patcher (Entropy Model)**: A smaller transformer model that predicts byte-level entropy to determine patch boundaries and segment input.
- - **Main Transformer Model**: The primary model that processes the patches through a Local Encoder, Global Transformer, and Local Decoder.
-
-- **Dynamic Patching**: The model uses entropy-based dynamic patching where:
- - High-entropy regions (complex data) get shorter patches with more computational attention
- - Low-entropy regions (predictable data) get longer patches for efficiency
- - This allows the model to allocate compute resources where they're most needed
-
-- **Local Encoder**: Processes byte sequences with cross-attention to patch embeddings
-- **Global Transformer**: Processes patch-level representations with full attention across patches
-- **Local Decoder**: Generates output with cross-attention back to the original byte sequence
-
-- **Byte-Level Tokenizer**: Unlike traditional tokenizers that use learned vocabularies, BLT's tokenizer simply converts text to UTF-8 bytes and maps each byte to a token ID. There is no need for a vocabulary.
-
-The model can be loaded via:
-
-
-
-```python
-import torch
-from transformers import AutoTokenizer, AutoModelForCausalLM
-
-tokenizer = AutoTokenizer.from_pretrained("itazap/blt-1b-hf")
-model = AutoModelForCausalLM.from_pretrained(
- "itazap/blt-1b-hf",
- device_map="auto",
-)
-
-inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
-
-prompt = "my name is"
-generated_ids = model.generate(
- **inputs, max_new_tokens=NUM_TOKENS_TO_GENERATE, do_sample=False, use_cache=False
-)
-
-print(tokenizer.decode(generated_ids[0]))
+pipeline = pipeline(task="text-generation", model="itazap/blt-1b-hf", dtype="auto")
+pipeline("Plants generate energy through a process known as ")
```
+
-This model was contributed by [itazap](https://huggingface.co/).
-The original code can be found [here]().
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("itazap/blt-1b-hf", dtype="auto")
+tokenizer = AutoTokenizer.from_pretrained("itazap/blt-1b-hf")
+
+inputs = tokenizer("Plants generate energy through a process known as ", return_tensors='pt', return_token_type_ids=False)
+outputs = model.generate(**inputs, max_new_tokens=64)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
+```
+
+
+
## BltConfig
diff --git a/docs/source/en/model_doc/bort.md b/docs/source/en/model_doc/bort.md
index 56c02bb2540..a76af394afb 100644
--- a/docs/source/en/model_doc/bort.md
+++ b/docs/source/en/model_doc/bort.md
@@ -17,6 +17,7 @@ rendered properly in your Markdown viewer.
> [!WARNING]
> This model is in maintenance mode only, we do not accept any new PRs changing its code.
+>
> If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0. You can do so by running the following command: pip install -U transformers==4.30.0.
# BORT
@@ -53,4 +54,8 @@ print(f"Predicted word: {predicted_word}")
```
-
\ No newline at end of file
+
+
+## Usage tips
+
+- BORT uses the RoBERTa tokenizer instead of the BERT tokenizer. Check RoBERTa's documentation for API reference and usage examples.
diff --git a/docs/source/en/model_doc/byt5.md b/docs/source/en/model_doc/byt5.md
index cec62c89e0d..138510fb83f 100644
--- a/docs/source/en/model_doc/byt5.md
+++ b/docs/source/en/model_doc/byt5.md
@@ -48,6 +48,11 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Use the tokenizer for batched inference and training.
+- ByT5 uses top byte values (258, 257, etc.) for masking instead of sentinel tokens like `{extra_id_0}`.
+
## ByT5Tokenizer
[[autodoc]] ByT5Tokenizer
diff --git a/docs/source/en/model_doc/canine.md b/docs/source/en/model_doc/canine.md
index cae48c6fa61..3bf23799577 100644
--- a/docs/source/en/model_doc/canine.md
+++ b/docs/source/en/model_doc/canine.md
@@ -50,6 +50,11 @@ print(f"Predicted label: {label}")
+## Usage tips
+
+- CANINE skips tokenization entirely. It works directly on raw characters, not subwords. Use it with or without a tokenizer. For batched inference and training, use the tokenizer to pad and truncate all sequences to the same length.
+- CANINE is designed for fine-tuning on downstream tasks. The pretrained model handles masked language modeling or next sentence prediction.
+
## CanineConfig
[[autodoc]] CanineConfig
diff --git a/docs/source/en/model_doc/code_llama.md b/docs/source/en/model_doc/code_llama.md
index 30f687590ec..0c18398a52b 100644
--- a/docs/source/en/model_doc/code_llama.md
+++ b/docs/source/en/model_doc/code_llama.md
@@ -48,6 +48,14 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Infilling works only in 7B and 13B base models. It doesn't work in Python, Instruct, 34B, or 70B models.
+- Use the `` token where you want input filled. The tokenizer splits this token to create a formatted input string that follows the original training pattern. This beats preparing the pattern yourself.
+- Use `bfloat16` for training or fine-tuning and `float16` for inference.
+- The `BOS` character isn't used for infilling when encoding the prefix or suffix. It only appears at the beginning of each prompt.
+- The tokenizer is a byte-pair encoding model based on SentencePiece. During decoding, if the first token starts a word (like "Banana"), the tokenizer doesn't prepend the prefix space.
+
## CodeLlamaTokenizer
[[autodoc]] CodeLlamaTokenizer
diff --git a/docs/source/en/model_doc/cohere.md b/docs/source/en/model_doc/cohere.md
index a802bb063b0..c7c6e926232 100644
--- a/docs/source/en/model_doc/cohere.md
+++ b/docs/source/en/model_doc/cohere.md
@@ -57,6 +57,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Don't use the `dtype` parameter in [`~AutoModel.from_pretrained`] with FlashAttention-2. It only supports `fp16` or `bf16`. Use [Automatic Mixed Precision](https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html), set `fp16` or `bf16` to `True` with [`Trainer`], or use [torch.autocast](https://pytorch.org/docs/stable/amp.html#torch.autocast).
+
## CohereConfig
[[autodoc]] CohereConfig
diff --git a/docs/source/en/model_doc/ctrl.md b/docs/source/en/model_doc/ctrl.md
index e974d261136..9dbe51a337f 100644
--- a/docs/source/en/model_doc/ctrl.md
+++ b/docs/source/en/model_doc/ctrl.md
@@ -49,6 +49,12 @@ print(f"Predicted label: {label}")
+## Usage tips
+
+- CTRL uses control codes to generate text. Start generations with specific words, sentences, or links to generate coherent text. Check the original implementation for details.
+- Pad inputs on the right. CTRL uses absolute position embeddings.
+- PyTorch models accept `past_key_values` as input. These are previously computed key/value attention pairs. Using `past_key_values` prevents re-computing pre-computed values during text generation. See the [`~CTRLModel.forward`] method for usage details.
+
## CTRLConfig
[[autodoc]] CTRLConfig
diff --git a/docs/source/en/model_doc/deberta.md b/docs/source/en/model_doc/deberta.md
index 4bba69f9594..33e84ee8fca 100644
--- a/docs/source/en/model_doc/deberta.md
+++ b/docs/source/en/model_doc/deberta.md
@@ -50,6 +50,12 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- DeBERTa uses relative position embeddings. It doesn't require right-padding like BERT.
+- Use DeBERTa on sentence-level or sentence-pair classification tasks like MNLI, RTE, or SST-2 for best results.
+- For token-level tasks like masked language modeling, load a checkpoint specifically pretrained or fine-tuned for token-level tasks.
+
## DebertaConfig
[[autodoc]] DebertaConfig
diff --git a/docs/source/en/model_doc/dialogpt.md b/docs/source/en/model_doc/dialogpt.md
index 775a08a9de1..fcd28069c12 100644
--- a/docs/source/en/model_doc/dialogpt.md
+++ b/docs/source/en/model_doc/dialogpt.md
@@ -46,4 +46,8 @@ print(tokenizer.decode(outputs[0]))
```
-
\ No newline at end of file
+
+
+## Usage tips
+
+- Pad inputs on the right. DialoGPT uses absolute position embeddings.
\ No newline at end of file
diff --git a/docs/source/en/model_doc/distilbert.md b/docs/source/en/model_doc/distilbert.md
index 5691300020d..d97da673313 100644
--- a/docs/source/en/model_doc/distilbert.md
+++ b/docs/source/en/model_doc/distilbert.md
@@ -58,6 +58,11 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- DistilBERT doesn't have `token_type_ids`. You don't need to indicate which token belongs to which segment. Just separate segments with `tokenizer.sep_token` (or `[SEP]`).
+- DistilBERT doesn't support `position_ids` input. This could be added if needed.
+
## DistilBertConfig
[[autodoc]] DistilBertConfig
diff --git a/docs/source/en/model_doc/doge.md b/docs/source/en/model_doc/doge.md
index 4dd36e83b40..0d43a1b1b68 100644
--- a/docs/source/en/model_doc/doge.md
+++ b/docs/source/en/model_doc/doge.md
@@ -20,62 +20,34 @@ rendered properly in your Markdown viewer.
[Doge-20M](https://huggingface.co/papers/PAPER_ID) is utilized for text generation, demonstrating its capability to produce coherent and contextually relevant responses. For question answering, Doge-20M-Instruct is employed, showcasing enhanced performance in understanding and generating answers through a structured conversational format. The model leverages specific generation configurations, including temperature and top-p sampling, to ensure varied and engaging outputs.
-## Usage
+
+
-
-Using Doge-Base for text generation
+```py
+import torch
+from transformers import pipeline
-```python
-from transformers import AutoTokenizer, AutoModelForCausalLM
+pipeline = pipeline(task="text-generation", model="SmallDoge/Doge-20M", dtype="auto")
+pipeline("Plants generate energy through a process known as ")
+```
+
+
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("SmallDoge/Doge-20M", dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("SmallDoge/Doge-20M")
-model = AutoModelForCausalLM.from_pretrained("SmallDoge/Doge-20M")
-inputs = tokenizer("Hey how are you doing?", return_tensors="pt")
-outputs = model.generate(**inputs, max_new_tokens=100)
-print(tokenizer.batch_decode(outputs))
+inputs = tokenizer("Plants generate energy through a process known as ", return_tensors='pt', return_token_type_ids=False)
+outputs = model.generate(**inputs, max_new_tokens=64)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
```
-
-
-
-Using Doge-Instruct for question answering
-
-```python
-from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig, TextStreamer
-
-tokenizer = AutoTokenizer.from_pretrained("SmallDoge/Doge-20M-Instruct")
-model = AutoModelForCausalLM.from_pretrained("SmallDoge/Doge-20M-Instruct")
-
-generation_config = GenerationConfig(
- max_new_tokens=100,
- use_cache=True,
- do_sample=True,
- temperature=0.8,
- top_p=0.9,
- repetition_penalty=1.0
-)
-steamer = TextStreamer(tokenizer=tokenizer, skip_prompt=True)
-
-prompt = "Hi, how are you doing today?"
-conversation = [
- {"role": "user", "content": prompt}
-]
-inputs = tokenizer.apply_chat_template(
- conversation=conversation,
- tokenize=True,
- return_tensors="pt",
-)
-
-outputs = model.generate(
- inputs,
- tokenizer=tokenizer,
- generation_config=generation_config,
- streamer=steamer
-)
-```
-
-
+
+
## DogeConfig
diff --git a/docs/source/en/model_doc/electra.md b/docs/source/en/model_doc/electra.md
index 538b35d9e7d..6ca2aee0a08 100644
--- a/docs/source/en/model_doc/electra.md
+++ b/docs/source/en/model_doc/electra.md
@@ -51,6 +51,13 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- ELECTRA has two transformer models: a generator (G) and a discriminator (D). Use the discriminator model (indicated by `*-discriminator` in the name) for most downstream tasks.
+- ELECTRA can use a smaller embedding size than the hidden size for efficiency. When `embedding_size` is smaller than `hidden_size`, a projection layer connects them.
+- Use attention masks with batched inputs that have padding. This prevents the model from attending to padding tokens.
+- Load the discriminator into any ELECTRA model class (`ElectraForSequenceClassification`, `ElectraForTokenClassification`, etc.) for downstream tasks.
+
## ElectraConfig
[[autodoc]] ElectraConfig
diff --git a/docs/source/en/model_doc/encoder-decoder.md b/docs/source/en/model_doc/encoder-decoder.md
index 7ef5ce988af..075afcdebbc 100644
--- a/docs/source/en/model_doc/encoder-decoder.md
+++ b/docs/source/en/model_doc/encoder-decoder.md
@@ -59,6 +59,13 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- [`EncoderDecoderModel`] initializes with any pretrained encoder and decoder. Cross-attention layers may be randomly initialized depending on the decoder architecture.
+- These models require downstream fine-tuning. Use [`from_encoder_decoder_pretrained`] to combine encoder and decoder checkpoints.
+- Fine-tune encoder-decoder models like BART or T5. Only `input_ids` and `labels` are required to compute loss. See this [notebook](https://colab.research.google.com/drive/1WIk2bxglElfZewOHboPFNj8H44_VAyKE?usp=sharing#scrollTo=ZwQIEhKOrJpl) for detailed training examples.
+- [`EncoderDecoderModel`] can be randomly initialized from encoder and decoder configs.
+
## EncoderDecoderConfig
[[autodoc]] EncoderDecoderConfig
diff --git a/docs/source/en/model_doc/ernie4_5.md b/docs/source/en/model_doc/ernie4_5.md
index 71ab23aa97a..20d31e67cc0 100644
--- a/docs/source/en/model_doc/ernie4_5.md
+++ b/docs/source/en/model_doc/ernie4_5.md
@@ -25,62 +25,38 @@ rendered properly in your Markdown viewer.
# Ernie 4.5
-## Overview
+[Ernie 4.5](https://ernie.baidu.com/blog/posts/ernie4.5/) introduces three major innovations. First, it uses Multimodal Heterogeneous MoE pre-training, jointly training on text and images through modality-isolated routing, router orthogonal loss, and multimodal token-balanced loss to ensure effective cross-modal learning. Second, it employs a scaling-efficient infrastructure with heterogeneous hybrid parallelism, FP8 mixed precision, recomputation strategies, and advanced quantization (4-bit/2-bit) to achieve high training and inference efficiency across hardware platforms. Finally, modality-specific post-training tailors models for language and vision tasks using Supervised Fine-Tuning, Direct Preference Optimization, and a new Unified Preference Optimization method.
-The Ernie 4.5 model was released in the [Ernie 4.5 Model Family](https://ernie.baidu.com/blog/posts/ernie4.5/) release by baidu.
-This family of models contains multiple different architectures and model sizes. This model in specific targets the base text
-model without mixture of experts (moe) with 0.3B parameters in total. It uses the standard [Llama](./llama) at its core.
+
+
-Other models from the family can be found at [Ernie 4.5 Moe](./ernie4_5_moe).
+```py
+import torch
+from transformers import pipeline
-
-
-
+pipeline = pipeline(task="text-generation", model="baidu/ERNIE-4.5-0.3B-PT", dtype="auto")
+pipeline("Plants generate energy through a process known as ")
+```
-## Usage Tips
+
+
-### Generate text
-
-```python
+```py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
-model_name = "baidu/ERNIE-4.5-0.3B-PT"
+model = AutoModelForCausalLM.from_pretrained("baidu/ERNIE-4.5-0.3B-PT", dtype="auto")
+tokenizer = AutoTokenizer.from_pretrained("baidu/ERNIE-4.5-0.3B-PT")
-# load the tokenizer and the model
-tokenizer = AutoTokenizer.from_pretrained(model_name)
-model = AutoModelForCausalLM.from_pretrained(
- model_name,
- device_map="auto",
- dtype=torch.bfloat16,
-)
+messages = [{"role": "user", "content": "How do plants generate energy?"}]
+input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
-# prepare the model input
-inputs = tokenizer("Hey, are you conscious? Can you talk to me?", return_tensors="pt")
-prompt = "Hey, are you conscious? Can you talk to me?"
-messages = [
- {"role": "user", "content": prompt}
-]
-text = tokenizer.apply_chat_template(
- messages,
- tokenize=False,
- add_generation_prompt=True
-)
-model_inputs = tokenizer([text], add_special_tokens=False, return_tensors="pt").to(model.device)
-
-# conduct text completion
-generated_ids = model.generate(
- **model_inputs,
- max_new_tokens=32,
-)
-output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
-
-# decode the generated ids
-generate_text = tokenizer.decode(output_ids, skip_special_tokens=True)
+outputs = model.generate(input_ids, max_new_tokens=100, do_sample=True, temperature=0.3,)
+print(tokenizer.decode(outputs[0]))
```
-This model was contributed by [Anton Vlasjuk](https://huggingface.co/AntonV).
-The original code can be found [here](https://github.com/PaddlePaddle/ERNIE).
+
+
## Ernie4_5Config
diff --git a/docs/source/en/model_doc/ernie4_5_moe.md b/docs/source/en/model_doc/ernie4_5_moe.md
index 15b6cd9638f..715c656fd8d 100644
--- a/docs/source/en/model_doc/ernie4_5_moe.md
+++ b/docs/source/en/model_doc/ernie4_5_moe.md
@@ -25,145 +25,40 @@ rendered properly in your Markdown viewer.
# Ernie 4.5 Moe
-## Overview
+# Ernie 4.5
-The Ernie 4.5 Moe model was released in the [Ernie 4.5 Model Family](https://ernie.baidu.com/blog/posts/ernie4.5/) release by baidu.
-This family of models contains multiple different architectures and model sizes. This model in specific targets the base text
-model with mixture of experts (moe) - one with 21B total, 3B active parameters and another one with 300B total, 47B active parameters.
-It uses the standard [Llama](./llama) at its core combined with a specialized MoE based on [Mixtral](./mixtral) with additional shared
-experts.
+[Ernie 4.5](https://ernie.baidu.com/blog/posts/ernie4.5/) introduces three major innovations. First, it uses Multimodal Heterogeneous MoE pre-training, jointly training on text and images through modality-isolated routing, router orthogonal loss, and multimodal token-balanced loss to ensure effective cross-modal learning. Second, it employs a scaling-efficient infrastructure with heterogeneous hybrid parallelism, FP8 mixed precision, recomputation strategies, and advanced quantization (4-bit/2-bit) to achieve high training and inference efficiency across hardware platforms. Finally, modality-specific post-training tailors models for language and vision tasks using Supervised Fine-Tuning, Direct Preference Optimization, and a new Unified Preference Optimization method.
-Other models from the family can be found at [Ernie 4.5](./ernie4_5).
+
+
-
-
-
+```py
+import torch
+from transformers import pipeline
-## Usage Tips
+pipeline = pipeline(task="text-generation", model="baidu/ERNIE-4.5-21B-A3B-PT", dtype="auto")
+pipeline("Plants generate energy through a process known as ")
+```
-### Generate text
+
+
-```python
+```py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
-model_name = "baidu/ERNIE-4.5-21B-A3B-PT"
+model = AutoModelForCausalLM.from_pretrained("baidu/ERNIE-4.5-21B-A3B-PT", dtype="auto")
+tokenizer = AutoTokenizer.from_pretrained("baidu/ERNIE-4.5-21B-A3B-PT")
-# load the tokenizer and the model
-tokenizer = AutoTokenizer.from_pretrained(model_name)
-model = AutoModelForCausalLM.from_pretrained(
- model_name,
- device_map="auto",
- dtype=torch.bfloat16,
-)
+messages = [{"role": "user", "content": "How do plants generate energy?"}]
+input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
-# prepare the model input
-inputs = tokenizer("Hey, are you conscious? Can you talk to me?", return_tensors="pt")
-prompt = "Hey, are you conscious? Can you talk to me?"
-messages = [
- {"role": "user", "content": prompt}
-]
-text = tokenizer.apply_chat_template(
- messages,
- tokenize=False,
- add_generation_prompt=True
-)
-model_inputs = tokenizer([text], add_special_tokens=False, return_tensors="pt").to(model.device)
-
-# conduct text completion
-generated_ids = model.generate(
- **model_inputs,
- max_new_tokens=32,
-)
-output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
-
-# decode the generated ids
-generate_text = tokenizer.decode(output_ids, skip_special_tokens=True)
+outputs = model.generate(input_ids, max_new_tokens=100, do_sample=True, temperature=0.3,)
+print(tokenizer.decode(outputs[0]))
```
-### Distributed Generation with Tensor Parallelism
-
-```python
-import torch
-from transformers import AutoModelForCausalLM, AutoTokenizer
-
-model_name = "baidu/ERNIE-4.5-21B-A3B-PT"
-
-# load the tokenizer and the model
-tokenizer = AutoTokenizer.from_pretrained(model_name)
-model = AutoModelForCausalLM.from_pretrained(
- model_name,
- device_map="auto",
- dtype=torch.bfloat16,
- tp_plan="auto",
-)
-
-# prepare the model input
-inputs = tokenizer("Hey, are you conscious? Can you talk to me?", return_tensors="pt")
-prompt = "Hey, are you conscious? Can you talk to me?"
-messages = [
- {"role": "user", "content": prompt}
-]
-text = tokenizer.apply_chat_template(
- messages,
- tokenize=False,
- add_generation_prompt=True
-)
-model_inputs = tokenizer([text], add_special_tokens=False, return_tensors="pt").to(model.device)
-
-# conduct text completion
-generated_ids = model.generate(
- **model_inputs,
- max_new_tokens=32,
-)
-output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
-
-# decode the generated ids
-generate_text = tokenizer.decode(output_ids, skip_special_tokens=True)
-```
-
-### Quantization with Bitsandbytes
-
-```python
-import torch
-from transformers import BitsAndBytesConfig, AutoModelForCausalLM, AutoTokenizer
-
-model_name = "baidu/ERNIE-4.5-21B-A3B-PT"
-
-# load the tokenizer and the model
-tokenizer = AutoTokenizer.from_pretrained(model_name)
-model = AutoModelForCausalLM.from_pretrained(
- model_name,
- device_map="auto",
- quantization_config=BitsAndBytesConfig(load_in_4bit=True),
-)
-
-# prepare the model input
-inputs = tokenizer("Hey, are you conscious? Can you talk to me?", return_tensors="pt")
-prompt = "Hey, are you conscious? Can you talk to me?"
-messages = [
- {"role": "user", "content": prompt}
-]
-text = tokenizer.apply_chat_template(
- messages,
- tokenize=False,
- add_generation_prompt=True
-)
-model_inputs = tokenizer([text], add_special_tokens=False, return_tensors="pt").to(model.device)
-
-# conduct text completion
-generated_ids = model.generate(
- **model_inputs,
- max_new_tokens=32,
-)
-output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
-
-# decode the generated ids
-generate_text = tokenizer.decode(output_ids, skip_special_tokens=True)
-```
-
-This model was contributed by [Anton Vlasjuk](https://huggingface.co/AntonV).
-The original code can be found [here](https://github.com/PaddlePaddle/ERNIE).
+
+
## Ernie4_5_MoeConfig
diff --git a/docs/source/en/model_doc/ernie_m.md b/docs/source/en/model_doc/ernie_m.md
index 4a81d536dcc..018de514584 100644
--- a/docs/source/en/model_doc/ernie_m.md
+++ b/docs/source/en/model_doc/ernie_m.md
@@ -16,7 +16,9 @@ rendered properly in your Markdown viewer.
*This model was released on 2020-12-31 and added to Hugging Face Transformers on 2023-06-20 and contributed by [susnato](https://huggingface.co/susnato).*
> [!WARNING]
-> This model is in maintenance mode only, we don’t accept any new PRs changing its code. If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2. You can do so by running the following command: pip install -U transformers==4.40.2.
+> This model is in maintenance mode only, we don’t accept any new PRs changing its code.
+>
+> If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2. You can do so by running the following command: pip install -U transformers==4.40.2.
# ErnieM
@@ -53,6 +55,10 @@ print(f"Predicted label: {label}")
+## Usage tips
+
+- ERNIE-M uses two novel techniques instead of MaskedLM for pretraining: Cross-attention Masked Language Modeling and Back-translation Masked Language Modeling. These LMHead objectives aren't implemented yet.
+
## ErnieMConfig
[[autodoc]] ErnieMConfig
diff --git a/docs/source/en/model_doc/exaone4.md b/docs/source/en/model_doc/exaone4.md
index b1c94a5845b..c3e75096030 100644
--- a/docs/source/en/model_doc/exaone4.md
+++ b/docs/source/en/model_doc/exaone4.md
@@ -15,175 +15,45 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2025-07-15 and added to Hugging Face Transformers on 2025-07-26.*
+# EXAONE 4
+
+[EXAONE 4.0](https://huggingface.co/papers/2507.11407) combines a Non-reasoning mode and a Reasoning mode to merge the usability of EXAONE 3.5 with the advanced reasoning of EXAONE Deep. It introduces agentic tool-use capabilities and expands multilingual support to include Spanish alongside English and Korean. The model series includes a 32B version for high performance and a 1.2B version for on-device use. EXAONE 4.0 outperforms comparable open-weight models, remains competitive with frontier models, and is publicly available for research on Hugging Face.
+
+
+
+
```py
import torch
from transformers import pipeline
pipeline = pipeline(task="text-generation", model="LGAI-EXAONE/EXAONE-4.0-32B", dtype="auto")
-pipeline("The future of artificial intelligence is")
+pipeline("Plants generate energy through a process known as ")
```
-# EXAONE 4
+
+
-## Overview
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
-**[EXAONE 4.0](https://github.com/LG-AI-EXAONE/EXAONE-4.0)** model is the language model, which integrates a **Non-reasoning mode** and **Reasoning mode** to achieve both the excellent usability of [EXAONE 3.5](https://github.com/LG-AI-EXAONE/EXAONE-3.5) and the advanced reasoning abilities of [EXAONE Deep](https://github.com/LG-AI-EXAONE/EXAONE-Deep). To pave the way for the agentic AI era, EXAONE 4.0 incorporates essential features such as agentic tool use, and its multilingual capabilities are extended
-to support Spanish in addition to English and Korean.
+model = AutoModelForCausalLM.from_pretrained("LGAI-EXAONE/EXAONE-4.0-32B", dtype="auto")
+tokenizer = AutoTokenizer.from_pretrained("LGAI-EXAONE/EXAONE-4.0-32B")
-The EXAONE 4.0 model series consists of two sizes: a mid-size **32B** model optimized for high performance, and a small-size **1.2B** model designed for on-device applications.
+messages = [{"role": "user", "content": "How do plants generate energy?"}]
+input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
-In the EXAONE 4.0 architecture, we apply new architectural changes compared to previous EXAONE models as below:
+outputs = model.generate(input_ids, max_new_tokens=100, do_sample=True, temperature=0.3,)
+print(tokenizer.decode(outputs[0]))
+```
-1. **Hybrid Attention**: For the 32B model, we adopt hybrid attention scheme, which combines *Local attention (sliding window attention)* with *Global attention (full attention)* in a 3:1 ratio. We do not use RoPE (Rotary Positional Embedding) for global attention for better global context understanding.
-2. **QK-Reorder-Norm**: We reorder the LayerNorm position from the traditional Pre-LN scheme by applying LayerNorm directly to the attention and MLP outputs, and we add RMS normalization right after the Q and K projection. It helps yield better performance on downstream tasks despite consuming more computation.
-
-For more details, please refer to our [technical report](https://huggingface.co/papers/2507.11407), [HuggingFace paper](https://huggingface.co/papers/2507.11407), [blog](https://www.lgresearch.ai/blog/view?seq=576), and [GitHub](https://github.com/LG-AI-EXAONE/EXAONE-4.0).
-
-All model weights including quantized versions are available at [Huggingface Collections](https://huggingface.co/collections/LGAI-EXAONE/exaone-40-686b2e0069800c835ed48375).
-
-## Model Details
-
-### Model Specifications
-
-| Model Configuration | 32B | 1.2B |
-|:-------------------|:-----:|:------:|
-| d_model | 5,120 | 2,048 |
-| Number of layers | 64 | 30 |
-| Normalization | QK-Reorder-LN | QK-Reorder-LN |
-| Non-linearity | SwiGLU | SwiGLU |
-| Feedforward dimension | 27,392 | 4,096 |
-| Attention type | Hybrid (3:1 Local-Global) | Global |
-| Head type | GQA | GQA |
-| Number of heads | 40 | 32 |
-| Number of KV heads | 8 | 8 |
-| Head size | 128 | 64 |
-| Max sequence length | 131,072 | 65,536 |
-| RoPE theta | 1,000,000 | 1,000,000 |
-| Tokenizer | BBPE | BBPE |
-| Vocab size | 102,400 | 102,400 |
-| Tied word embedding | False | True |
-| Knowledge cut-off | Nov. 2024 | Nov. 2024 |
+
+
## Usage tips
-### Non-reasoning mode
-
-For general use, you can use the EXAONE 4.0 models with the following example:
-
-```python
-from transformers import AutoModelForCausalLM, AutoTokenizer
-
-model_name = "LGAI-EXAONE/EXAONE-4.0-32B"
-
-model = AutoModelForCausalLM.from_pretrained(
- model_name,
- dtype="bfloat16",
- device_map="auto"
-)
-tokenizer = AutoTokenizer.from_pretrained(model_name)
-
-# choose your prompt
-prompt = "Explain how wonderful you are"
-prompt = "Explica lo increíble que eres"
-prompt = "너가 얼마나 대단한지 설명해 봐"
-
-messages = [
- {"role": "user", "content": prompt}
-]
-input_ids = tokenizer.apply_chat_template(
- messages,
- tokenize=True,
- add_generation_prompt=True,
- return_tensors="pt"
-)
-
-output = model.generate(
- input_ids.to(model.device),
- max_new_tokens=128,
- do_sample=False,
-)
-print(tokenizer.decode(output[0]))
-```
-
-### Reasoning mode
-
-The EXAONE 4.0 models have reasoning capabilities for handling complex problems. You can activate reasoning mode by using the `enable_thinking=True` argument with the tokenizer, which opens a reasoning block that starts with `` tag without closing it.
-
-```python
-messages = [
- {"role": "user", "content": "Which one is bigger, 3.12 vs 3.9?"}
-]
-input_ids = tokenizer.apply_chat_template(
- messages,
- tokenize=True,
- add_generation_prompt=True,
- return_tensors="pt",
- enable_thinking=True,
-)
-
-output = model.generate(
- input_ids.to(model.device),
- max_new_tokens=128,
- do_sample=True,
- temperature=0.6,
- top_p=0.95
-)
-print(tokenizer.decode(output[0]))
-```
-
-> [!IMPORTANT]
-> The model generation with reasoning mode can be affected sensitively by sampling parameters, so please refer to the [Usage Guideline](https://github.com/LG-AI-EXAONE/EXAONE-4.0#usage-guideline) on official GitHub page for better quality.
-
-### Agentic tool use
-
-The EXAONE 4.0 models can be used as agents with their tool calling capabilities. You can provide tool schemas to the model for effective tool calling.
-
-```python
-import random
-
-def roll_dice(max_num: int):
- return random.randint(1, max_num)
-
-tools = [
- {
- "type": "function",
- "function": {
- "name": "roll_dice",
- "description": "Roll a dice with the number 1 to N. User can select the number N.",
- "parameters": {
- "type": "object",
- "required": ["max_num"],
- "properties": {
- "max_num": {
- "type": "int",
- "description": "Max number of the dice"
- }
- }
- }
- }
- }
-]
-
-messages = [
- {"role": "user", "content": "Roll D6 dice twice!"}
-]
-input_ids = tokenizer.apply_chat_template(
- messages,
- tokenize=True,
- add_generation_prompt=True,
- return_tensors="pt",
- tools=tools,
-)
-
-output = model.generate(
- input_ids.to(model.device),
- max_new_tokens=1024,
- do_sample=True,
- temperature=0.6,
- top_p=0.95,
-)
-print(tokenizer.decode(output[0]))
-```
+- EXAONE 4.0 models have reasoning capabilities for complex problems. Activate reasoning mode with `enable_thinking=True` in the tokenizer. This opens a reasoning block starting with `` tag without closing it. Model generation with reasoning mode is sensitive to sampling parameters. Check the [Usage Guideline](https://github.com/LG-AI-EXAONE/EXAONE-4.0#usage-guideline) on the official GitHub page for better quality.
+- EXAONE 4.0 models work as agents with tool calling capabilities. Provide tool schemas to the model for effective tool calling.
## Exaone4Config
diff --git a/docs/source/en/model_doc/falcon.md b/docs/source/en/model_doc/falcon.md
index 34fc26c5802..0c8c5354f52 100644
--- a/docs/source/en/model_doc/falcon.md
+++ b/docs/source/en/model_doc/falcon.md
@@ -55,6 +55,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- When upgrading from older custom code checkpoints, convert them to the official Transformers format for better stability and performance. Use the conversion script in the Falcon model directory.
+
## FalconConfig
[[autodoc]] FalconConfig
diff --git a/docs/source/en/model_doc/flan-ul2.md b/docs/source/en/model_doc/flan-ul2.md
index 8e4299c855f..b8c4a35dcbf 100644
--- a/docs/source/en/model_doc/flan-ul2.md
+++ b/docs/source/en/model_doc/flan-ul2.md
@@ -46,4 +46,8 @@ print(tokenizer.decode(outputs[0]))
```
-
\ No newline at end of file
+
+
+## Usage tips
+
+- The model is heavy (~40GB in half precision). Load the model in 8-bit and use `device_map="auto"` to avoid out-of-memory issues.
\ No newline at end of file
diff --git a/docs/source/en/model_doc/fnet.md b/docs/source/en/model_doc/fnet.md
index 929b8884514..b55c6982e15 100644
--- a/docs/source/en/model_doc/fnet.md
+++ b/docs/source/en/model_doc/fnet.md
@@ -51,6 +51,10 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- FNet doesn't use attention masks since it's based on Fourier Transform. The model trained with maximum sequence length 512 (including pad tokens). Use the same maximum sequence length for fine-tuning and inference.
+
## FNetConfig
[[autodoc]] FNetConfig
diff --git a/docs/source/en/model_doc/fsmt.md b/docs/source/en/model_doc/fsmt.md
index fe4b8f340ee..25e39497733 100644
--- a/docs/source/en/model_doc/fsmt.md
+++ b/docs/source/en/model_doc/fsmt.md
@@ -47,6 +47,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- FSMT uses separate source and target vocabulary pairs. It doesn't share embedding tokens. The tokenizer is similar to [`XLMTokenizer`] and the main model derives from [`BartModel`].
+
## FSMTConfig
[[autodoc]] FSMTConfig
diff --git a/docs/source/en/model_doc/funnel.md b/docs/source/en/model_doc/funnel.md
index 97b2c8d3a64..f837ea1864e 100644
--- a/docs/source/en/model_doc/funnel.md
+++ b/docs/source/en/model_doc/funnel.md
@@ -51,6 +51,13 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- Funnel Transformer uses pooling, so sequence length changes after each block. Length divides by 2, speeding up computation. The base model has a final sequence length that's a quarter of the original.
+- Use the base model directly for tasks requiring sentence summaries (sequence classification or multiple choice). Use the full model for other tasks. The full model has a decoder that upsamples final hidden states to match input sequence length.
+- For classification tasks, this works fine. For masked language modeling or token classification, you need hidden states with the same sequence length as the original input. Final hidden states get upsampled to input sequence length and go through two additional layers.
+- Two checkpoint versions exist. The `-base` version contains only three blocks. The version without that suffix contains three blocks plus the upsampling head with additional layers.
+
## FunnelConfig
[[autodoc]] FunnelConfig
diff --git a/docs/source/en/model_doc/fuyu.md b/docs/source/en/model_doc/fuyu.md
index 7ffc5ec2aea..19ced51db25 100644
--- a/docs/source/en/model_doc/fuyu.md
+++ b/docs/source/en/model_doc/fuyu.md
@@ -22,6 +22,14 @@ rendered properly in your Markdown viewer.
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(task="text-generation", model="adept/fuyu-8b", dtype="auto")
+pipeline("Plants generate energy through a process known as ")
+```
+
@@ -48,6 +56,16 @@ print(generation_text[0])
+## Usage tips
+
+- Fuyu models trained with bfloat16, but original inference uses float16. Hub checkpoints use `dtype='float16'`. The AutoModel API casts checkpoints from `torch.float32` to `torch.float16`.
+- Online weight dtype matters only when using `dtype="auto"`. The model downloads first (using checkpoint dtype), then casts to torch's default dtype (`torch.float32`). Specify your desired dtype or it defaults to `torch.float32`.
+- Don't fine-tune in float16. It produces NaN values. Fine-tune in bfloat16 instead.
+- Clone the original repository to convert the model: `git clone https://github.com/persimmon-ai-labs/adept-inference`.
+- Pass inputs through a specific Processor for correct formats. A processor needs an `image_processor` and a `tokenizer`.
+- Fuyu uses a sentencepiece-based tokenizer with a Unigram model. It supports bytefallback (available in `tokenizers==0.14.0` for the fast tokenizer). [`LlamaTokenizer`] wraps sentencepiece as a standard wrapper.
+- Use this prompt for image captioning: `f"Generate a coco-style caption.\\n"`.
+
## FuyuConfig
[[autodoc]] FuyuConfig
diff --git a/docs/source/en/model_doc/gemma.md b/docs/source/en/model_doc/gemma.md
index e51791fb890..285a0db97b2 100644
--- a/docs/source/en/model_doc/gemma.md
+++ b/docs/source/en/model_doc/gemma.md
@@ -48,6 +48,9 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Gemma models support standard kv-caching used in transformer-based language models. Use the default [`DynamicCache`] instance or a tuple of tensors for past key values during generation. This works with typical autoregressive generation workflows.
## GemmaConfig
diff --git a/docs/source/en/model_doc/glm4.md b/docs/source/en/model_doc/glm4.md
index 67801113f28..c0145490996 100644
--- a/docs/source/en/model_doc/glm4.md
+++ b/docs/source/en/model_doc/glm4.md
@@ -17,50 +17,36 @@ rendered properly in your Markdown viewer.
# Glm4
-## Overview
+[Glm4](https://huggingface.co/papers/2406.12793) is a family of large language models, with the latest GLM-4 series (GLM-4, GLM-4-Air, GLM-4-9B) trained on over ten trillion tokens primarily in Chinese and English, plus data from 24 other languages. The models use a multi-stage alignment process combining supervised fine-tuning and human feedback to optimize performance for Chinese and English. GLM-4 rivals or surpasses GPT-4 across benchmarks like MMLU, GSM8K, and HumanEval, achieves near-GPT-4-Turbo results in instruction following and long-context tasks, and outperforms GPT-4 in Chinese alignment. The GLM-4 All Tools model autonomously selects tools such as web browsing, Python, and text-to-image generation, matching or exceeding GPT-4 All Tools in complex task handling.
-The GLM family welcomes new members [GLM-4-0414](https://huggingface.co/papers/2406.12793) series models.
+
+
-The **GLM-4-32B-0414** series models, featuring 32 billion parameters. Its performance is comparable to OpenAI's GPT
-series and DeepSeek's V3/R1 series. It also supports very user-friendly local deployment features. GLM-4-32B-Base-0414
```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(task="text-generation", model="zai-org/GLM-4.5-Air", dtype="auto",)
+pipeline("Plants create energy through a process known as photosynthesis.")
+```
+
+
+
+
+```py
+import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
-model = AutoModelForCausalLM.from_pretrained("THUDM/glm-4-9b")
-tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b")
+tokenizer = AutoTokenizer.from_pretrained("zai-org/GLM-4.5-Air")
+model = AutoModelForCausalLM.from_pretrained("zai-org/GLM-4.5-Air", dtype="auto",)
-inputs = tokenizer("Hello, my name is", return_tensors="pt")
+inputs = tokenizer("Plants create energy through a process known as photosynthesis.", return_tensors="pt")
outputs = model.generate(**inputs, max_length=50)
print(tokenizer.decode(outputs[0]))
```
-was pre-trained on 15T of high-quality data, including substantial reasoning-type synthetic data. This lays the
-foundation for subsequent reinforcement learning extensions. In the post-training stage, we employed human preference
-alignment for dialogue scenarios. Additionally, using techniques like rejection sampling and reinforcement learning, we
-enhanced the model's performance in instruction following, engineering code, and function calling, thus strengthening
-the atomic capabilities required for agent tasks. GLM-4-32B-0414 achieves good results in engineering code, Artifact
-generation, function calling, search-based Q&A, and report generation. In particular, on several benchmarks, such as
-code generation or specific Q&A tasks, GLM-4-32B-Base-0414 achieves comparable performance with those larger models like
-GPT-4o and DeepSeek-V3-0324 (671B).
-
-**GLM-Z1-32B-0414** is a reasoning model with deep thinking capabilities. This was developed based on GLM-4-32B-0414
-through cold start, extended reinforcement learning, and further training on tasks including mathematics, code, and
-logic. Compared to the base model, GLM-Z1-32B-0414 significantly improves mathematical abilities and the capability to
-solve complex tasks. During training, we also introduced general reinforcement learning based on pairwise ranking
-feedback, which enhances the model's general capabilities.
-
-**GLM-Z1-Rumination-32B-0414** is a deep reasoning model with rumination capabilities (against OpenAI's Deep Research).
-Unlike typical deep thinking models, the rumination model is capable of deeper and longer thinking to solve more
-open-ended and complex problems (e.g., writing a comparative analysis of AI development in two cities and their future
-development plans). Z1-Rumination is trained through scaling end-to-end reinforcement learning with responses graded by
-the ground truth answers or rubrics and can make use of search tools during its deep thinking process to handle complex
-tasks. The model shows significant improvements in research-style writing and complex tasks.
-
-Finally, **GLM-Z1-9B-0414** is a surprise. We employed all the aforementioned techniques to train a small model (9B).
-GLM-Z1-9B-0414 exhibits excellent capabilities in mathematical reasoning and general tasks. Its overall performance is
-top-ranked among all open-source models of the same size. Especially in resource-constrained scenarios, this model
-achieves an excellent balance between efficiency and effectiveness, providing a powerful option for users seeking
-lightweight deployment.
+
+
## Glm4Config
diff --git a/docs/source/en/model_doc/glm4_moe.md b/docs/source/en/model_doc/glm4_moe.md
index 2b7bfb54a2b..ec2d8bf270d 100644
--- a/docs/source/en/model_doc/glm4_moe.md
+++ b/docs/source/en/model_doc/glm4_moe.md
@@ -15,53 +15,38 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2025-07-28 and added to Hugging Face Transformers on 2025-07-21.*
+# Glm4Moe
+
+[Glm4Moe](https://z.ai/blog/glm-4.6) is an upgraded large language model with a 200K-token context window (up from 128K), enabling it to handle more complex and extended tasks. It delivers stronger coding performance—especially in front-end generation and real-world applications—and shows marked gains in reasoning, writing quality, and tool-using capability for agentic workflows. Evaluations across eight benchmarks confirm consistent improvements over GLM-4.5 and competitive performance against leading models like Claude Sonnet 4, while maintaining better efficiency by completing tasks with about 15% fewer tokens. In extended real-world testing via the CC-Bench framework, GLM-4.6 achieved near-parity with Claude Sonnet 4 and outperformed other open-source baselines.
+
+
+
+
```py
import torch
from transformers import pipeline
-pipeline = pipeline(task="text-generation", model="meta-glm4_moe/Glm4Moe-2-7b-hf", dtype="auto")
-pipeline("The future of artificial intelligence is")
+pipeline = pipeline(task="text-generation", model="https://huggingface.co/zai-org/GLM-4.6", dtype="auto",)
+pipeline("Plants create energy through a process known as photosynthesis.")
```
-# Glm4Moe
+
+
-## Overview
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
-Both **GLM-4.6** and **GLM-4.5** language model use this class. The implementation in transformers does not include an MTP layer.
+tokenizer = AutoTokenizer.from_pretrained("https://huggingface.co/zai-org/GLM-4.6")
+model = AutoModelForCausalLM.from_pretrained("https://huggingface.co/zai-org/GLM-4.6", dtype="auto",)
-### GLM-4.6
+inputs = tokenizer("Plants create energy through a process known as photosynthesis.", return_tensors="pt")
+outputs = model.generate(**inputs, max_length=50)
+print(tokenizer.decode(outputs[0]))
+```
-Compared with GLM-4.5, **GLM-4.6** brings several key improvements:
-
-* **Longer context window:** The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
-* **Superior coding performance:** The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
-* **Advanced reasoning:** GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
-* **More capable agents:** GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
-* **Refined writing:** Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
-
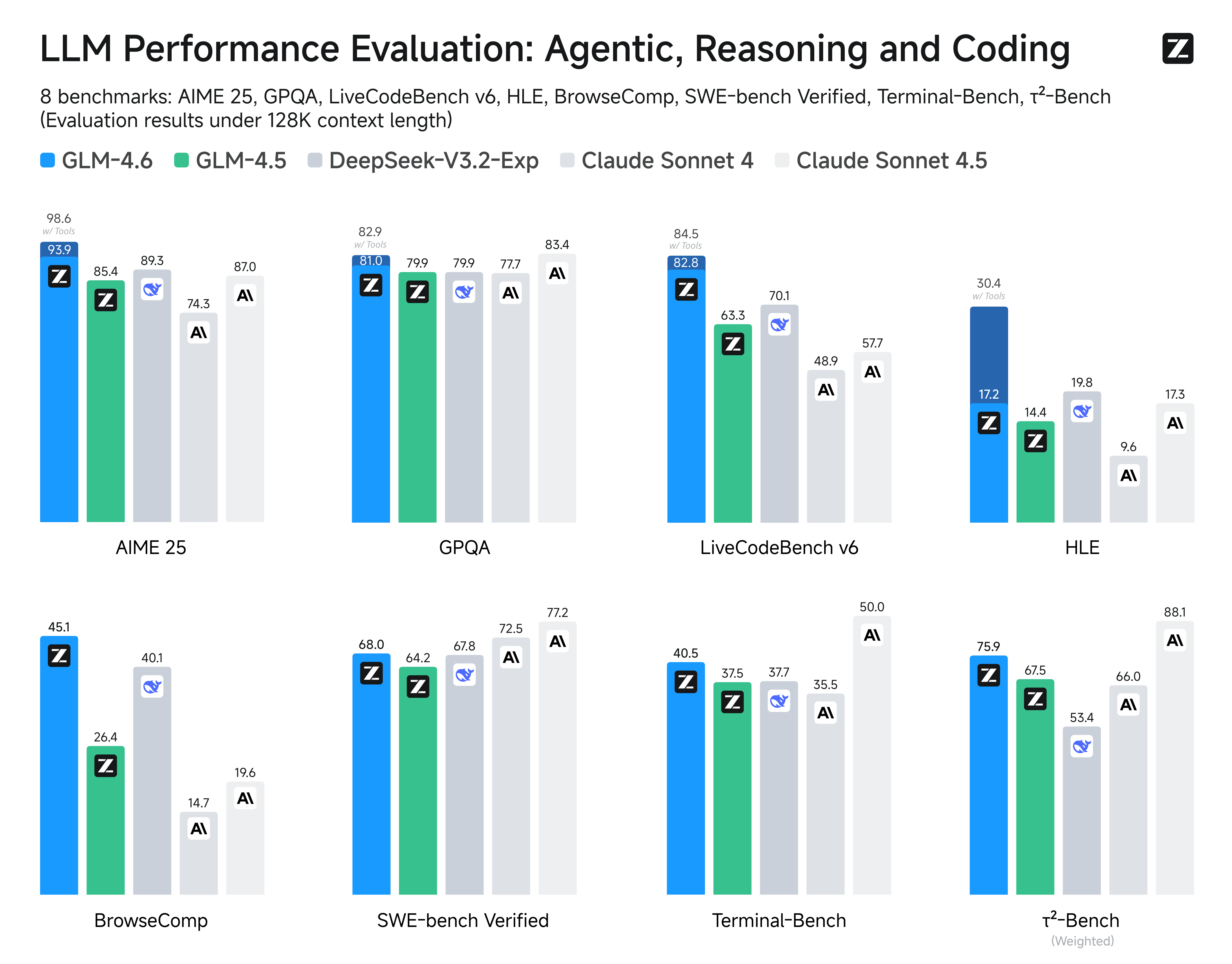
-We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as **DeepSeek-V3.1-Terminus** and **Claude Sonnet 4**.
-
-
-
-For more eval results, show cases, and technical details, please visit our [technical blog](https://z.ai/blog/glm-4.6).
-
-### GLM-4.5
-
-The [**GLM-4.5**](https://huggingface.co/papers/2508.06471) series models are foundation models designed for intelligent agents, MoE variants are documented here as Glm4Moe.
-
-GLM-4.5 has **355** billion total parameters with **32** billion active parameters, while GLM-4.5-Air adopts a more compact design with **106** billion total parameters and **12** billion active parameters. GLM-4.5 models unify reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications.
-
-Both GLM-4.5 and GLM-4.5-Air are hybrid reasoning models that provide two modes: thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
-
-We have open-sourced the base models, hybrid reasoning models, and FP8 versions of the hybrid reasoning models for both GLM-4.5 and GLM-4.5-Air. They are released under the MIT open-source license and can be used commercially and for secondary development.
-
-As demonstrated in our comprehensive evaluation across 12 industry-standard benchmarks, GLM-4.5 achieves exceptional performance with a score of **63.2**, in the **3rd** place among all the proprietary and open-source models. Notably, GLM-4.5-Air delivers competitive results at **59.8** while maintaining superior efficiency.
-
-
-
-For more eval results, show cases, and technical details, please visit our [technical report](https://huggingface.co/papers/2508.06471) or [technical blog](https://z.ai/blog/glm-4.5).
-
-The model code, tool parser and reasoning parser can be found in the implementation of [transformers](https://github.com/huggingface/transformers/tree/main/src/transformers/models/glm4_moe), [vLLM](https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/glm4_moe_mtp.py) and [SGLang](https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/models/glm4_moe.py).
+
+
## Glm4MoeConfig
diff --git a/docs/source/en/model_doc/gpt2.md b/docs/source/en/model_doc/gpt2.md
index f15fd4dd73b..214856298d1 100644
--- a/docs/source/en/model_doc/gpt2.md
+++ b/docs/source/en/model_doc/gpt2.md
@@ -55,6 +55,12 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Pad inputs on the right. GPT-2 uses absolute position embeddings.
+- GPT-2 reuses previously computed key-value attention pairs. Access this feature with the `past_key_values` parameter in [`GPT2Model.forward`].
+- Enable the [`GPT2Config.scale_attn_by_inverse_layer_idx`] and [`GPT2Config.reorder_and_upcast_attn`] parameters to apply training stability improvements from Mistral.
+
## GPT2Config
[[autodoc]] GPT2Config
diff --git a/docs/source/en/model_doc/gpt_neo.md b/docs/source/en/model_doc/gpt_neo.md
index aadbdd6ae92..8002314d080 100644
--- a/docs/source/en/model_doc/gpt_neo.md
+++ b/docs/source/en/model_doc/gpt_neo.md
@@ -54,6 +54,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Pad inputs on the right. GPT uses absolute position embeddings.
+
## GPTNeoConfig
[[autodoc]] GPTNeoConfig
diff --git a/docs/source/en/model_doc/gpt_neox.md b/docs/source/en/model_doc/gpt_neox.md
index 975e6b429f9..4ab915654a3 100644
--- a/docs/source/en/model_doc/gpt_neox.md
+++ b/docs/source/en/model_doc/gpt_neox.md
@@ -54,6 +54,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- GPT-NeoX-20B uses a different tokenizer than GPT-J-6B and GPT-Neo. The new tokenizer allocates additional tokens to whitespace characters. This makes the model more suitable for code generation tasks.
+
## GPTNeoXConfig
[[autodoc]] GPTNeoXConfig
diff --git a/docs/source/en/model_doc/gpt_oss.md b/docs/source/en/model_doc/gpt_oss.md
index b76bab9b371..90699b5817c 100644
--- a/docs/source/en/model_doc/gpt_oss.md
+++ b/docs/source/en/model_doc/gpt_oss.md
@@ -56,6 +56,11 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Attention sinks with flex attention require special handling. Unlike standard attention implementations where sinks add directly to attention scores, flex attention `score_mod` function operates on individual score elements rather than the full attention matrix.
+- Apply attention sinks renormalization after flex attention computations. Renormalize the outputs using the log-sum-exp (LSE) values returned by flex attention.
+
## GptOssConfig
[[autodoc]] GptOssConfig
diff --git a/docs/source/en/model_doc/gptj.md b/docs/source/en/model_doc/gptj.md
index e6e53251edb..10220d2b46f 100644
--- a/docs/source/en/model_doc/gptj.md
+++ b/docs/source/en/model_doc/gptj.md
@@ -54,6 +54,13 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Loading GPT-J in float32 requires at least 2x model size RAM: 1x for initial weights and another 1x to load the checkpoint. GPT-J needs at least 48GB RAM to load the model.
+- Reduce RAM usage with the `dtype` argument to initialize the model in half-precision on CUDA devices only. Use the fp16 branch which stores fp16 weights to minimize RAM usage further.
+- The model fits on 16GB GPU for inference. Training/fine-tuning requires much more GPU RAM. Adam optimizer makes four copies of the model: model, gradients, average and squared average of the gradients. It needs at least 4x model size GPU memory, even with mixed precision since gradient updates are in fp32. This excludes activations and data batches, which require additional GPU RAM.
+- Explore solutions like DeepSpeed to train/fine-tune the model. Another option is to use the original codebase to train/fine-tune on TPU, then convert to Transformers format for inference.
+- The embedding matrix has 50400 entries, but only 50257 are used by the GPT-2 tokenizer. Extra tokens are added for TPU efficiency. The GPT-J tokenizer contains 143 extra tokens `<|extratoken_1|>`... `<|extratoken_143|>` to match the vocab_size of 50400.
## GPTJConfig
diff --git a/docs/source/en/model_doc/gptsan-japanese.md b/docs/source/en/model_doc/gptsan-japanese.md
index 65c3927445f..26ed42940e3 100644
--- a/docs/source/en/model_doc/gptsan-japanese.md
+++ b/docs/source/en/model_doc/gptsan-japanese.md
@@ -51,6 +51,17 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- GPTSAN has unique features including a Prefix-LM model structure. It works as a shifted Masked Language Model for Prefix Input tokens. Un-prefixed inputs behave like normal generative models.
+- The Spout vector is a GPTSAN-specific input. Spout is pre-trained with random inputs, but you can specify a class of text or an arbitrary vector during fine-tuning. This indicates the tendency of generated text.
+- GPTSAN has a sparse Feed Forward based on Switch-Transformer. You can add other layers and train them partially. See the original GPTSAN repository for details.
+- GPTSAN uses the Prefix-LM structure from the T5 paper. The original GPTSAN repository calls it hybrid. In GPTSAN, the Prefix part can be specified with any length. Arbitrary lengths can be specified differently for each batch.
+- This length applies to the text entered in `prefix_text` for the tokenizer. The tokenizer returns the mask of the Prefix part as `token_type_ids`. The model treats the part where `token_type_ids` is 1 as a Prefix part, meaning the input can refer to both tokens before and after.
+- Specifying the Prefix part is done with a mask passed to self-attention. When `token_type_ids=None` or all zero, it's equivalent to regular causal mask.
+- A Spout Vector is a special vector for controlling text generation. This vector is treated as the first embedding in self-attention to bring extraneous attention to generated tokens.
+- In the pre-trained model from Tanrei/GPTSAN-japanese, the Spout Vector is a 128-dimensional vector that passes through 8 fully connected layers and is projected into the space acting as external attention. The Spout Vector projected by the fully connected layer is split to be passed to all self-attentions.
+
## GPTSanJapaneseConfig
[[autodoc]] GPTSanJapaneseConfig
diff --git a/docs/source/en/model_doc/granitemoehybrid.md b/docs/source/en/model_doc/granitemoehybrid.md
index f9ac5bdcc92..b53cd7aa890 100644
--- a/docs/source/en/model_doc/granitemoehybrid.md
+++ b/docs/source/en/model_doc/granitemoehybrid.md
@@ -48,6 +48,22 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- [`GraniteMoeHybridForCausalLM`] supports padding-free training. This concatenates distinct training examples while processing inputs as separate batches. Expect ~2x inference acceleration (varies by model and data distribution). Memory usage drops when examples have varying lengths since you avoid padding token overhead.
+
+- Padding-free training requires the `flash-attn`, `mamba-ssm`, and `causal-conv1d` packages. Pass these arguments alongside `input_ids` and `labels`:
+
+ - `position_ids`: `torch.LongTensor` - position index of each token in each sequence
+ - `seq_idx`: `torch.IntTensor` - index of each sequence in the batch
+ - FlashAttentionKwargs:
+ - `cu_seq_lens_q`: `torch.LongTensor` - cumulative sequence lengths of all queries
+ - `cu_seq_lens_k`: `torch.LongTensor` - cumulative sequence lengths of all keys
+ - `max_length_q`: `int` - longest query length in the batch
+ - `max_length_k`: `int` - longest key length in the batch
+
+- Don't provide `attention_mask` inputs. The [`DataCollatorWithFlattening`] generates these arguments automatically when you set `return_seq_idx=True` and `return_flash_attn_kwargs=True`. See the [Improving Hugging Face Training Efficiency Through Packing with Flash Attention](https://huggingface.co/blog/packing-flash-attention) blog post for additional information.
+
## GraniteMoeHybridConfig
[[autodoc]] GraniteMoeHybridConfig
diff --git a/docs/source/en/model_doc/jamba.md b/docs/source/en/model_doc/jamba.md
index 71699baeefa..93702ff7b79 100644
--- a/docs/source/en/model_doc/jamba.md
+++ b/docs/source/en/model_doc/jamba.md
@@ -55,6 +55,11 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Don't quantize the Mamba blocks. This prevents model performance degradation.
+- Use optimized Mamba kernels for better performance. Mamba without kernels results in significantly lower latencies. Set `use_mamba_kernels=False` in [`~AutoModel.from_pretrained`] if you need to disable kernels.
+
## JambaConfig
[[autodoc]] JambaConfig
diff --git a/docs/source/en/model_doc/jukebox.md b/docs/source/en/model_doc/jukebox.md
index f895ebcc7c2..150ee54cc51 100644
--- a/docs/source/en/model_doc/jukebox.md
+++ b/docs/source/en/model_doc/jukebox.md
@@ -16,7 +16,9 @@ rendered properly in your Markdown viewer.
*This model was released on 2020-04-30 and added to Hugging Face Transformers on 2023-06-20 and contributed by [ArthurZ](https://huggingface.co/ArthurZ).*
> [!WARNING]
-> This model is in maintenance mode only, we don’t accept any new PRs changing its code. If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2. You can do so by running the following command: pip install -U transformers==4.40.2.
+> This model is in maintenance mode only, we don’t accept any new PRs changing its code.
+>
+> If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2. You can do so by running the following command: pip install -U transformers==4.40.2.
# Jukebox
@@ -45,6 +47,13 @@ with torch.no_grad():
+## Usage tips
+
+- This model only supports inference. Training requires excessive memory. Open a PR to add full integration with the Hugging Face [`Trainer`].
+- The model is very slow. It takes 8 hours to generate a minute-long audio using the 5B top prior on a V100 GPU. Use Accelerate to automatically handle device placement.
+- Contrary to the paper, the order of priors goes from 0 to 1. This feels more intuitive since we sample starting from 0.
+- Primed sampling (conditioning on raw audio) requires more memory than ancestral sampling. Set `fp16=True` when using primed sampling.
+
## JukeboxConfig
[[autodoc]] JukeboxConfig
diff --git a/docs/source/en/model_doc/led.md b/docs/source/en/model_doc/led.md
index 2f918110c3a..d34e19406b5 100644
--- a/docs/source/en/model_doc/led.md
+++ b/docs/source/en/model_doc/led.md
@@ -55,6 +55,15 @@ print(tokenizer.decode(output[0], skip_special_tokens=True))
+## Usage tips
+
+- [`LEDForConditionalGeneration`] extends [`BartForConditionalGeneration`] by replacing the traditional self-attention layer with Longformer's chunked self-attention layer. [`LEDTokenizer`] is an alias of [`BartTokenizer`].
+- LED pads `input_ids` to be a multiple of `config.attention_window` when required. Use [`LEDTokenizer`] with the `pad_to_multiple_of` argument for a small speedup.
+- LED works best on long-range sequence-to-sequence tasks where `input_ids` are significantly longer than 1024 tokens.
+- LED uses global attention through the `global_attention_mask` (see [`LongformerModel`]). For summarization, put global attention only on the first `` token. For question answering, put global attention on all question tokens.
+- Fine-tune LED on all 16384 parameters by enabling gradient checkpointing to avoid out-of-memory errors. Add `model.gradient_checkpointing_enable()` and set `use_cache=False` to disable caching and save memory.
+- Pad inputs on the right. LED uses absolute position embeddings.
+
## LEDConfig
[[autodoc]] LEDConfig
diff --git a/docs/source/en/model_doc/lfm2.md b/docs/source/en/model_doc/lfm2.md
index e7a4734c911..3a387220c7b 100644
--- a/docs/source/en/model_doc/lfm2.md
+++ b/docs/source/en/model_doc/lfm2.md
@@ -17,8 +17,6 @@ rendered properly in your Markdown viewer.
# LFM2
-## Overview
-
[LFM2](https://www.liquid.ai/blog/liquid-foundation-models-v2-our-second-series-of-generative-ai-models) models are ultra-efficient foundation models optimized for on-device use, offering up to 2x faster CPU decoding than Qwen3 and 3x faster training efficiency than the prior generation. They use a new hybrid architecture with multiplicative gates and short convolutions across 16 blocks, achieving strong benchmark performance in knowledge, math, multilingual tasks, and instruction following. LFM2 comes in 0.35B, 0.7B, and 1.2B parameter sizes and consistently outperforms larger peers like Gemma 3 and Llama 3.2 in its class. Designed for phones, laptops, vehicles, and edge devices, these models balance speed, memory efficiency, and privacy for real-time, local AI deployment
diff --git a/docs/source/en/model_doc/lfm2_moe.md b/docs/source/en/model_doc/lfm2_moe.md
index 8ff6d268991..554e119f5fd 100644
--- a/docs/source/en/model_doc/lfm2_moe.md
+++ b/docs/source/en/model_doc/lfm2_moe.md
@@ -18,50 +18,37 @@ limitations under the License.
# Lfm2Moe
-## Overview
+LFM2-MoE is a Mixture-of-Experts version of the LFM2 architecture, designed for efficient on-device inference. It combines gated convolutions for local context with grouped-query attention (GQA) for efficient global reasoning. By adding sparse MoE feed-forward layers, it boosts representational power while keeping computational costs low. The initial model, LFM2-8B-A1B, has 8.3B total parameters with 1.5B active per inference, matching the quality of 3–4B dense models while running faster than typical 1.5B models.
-LFM2-MoE is a Mixture-of-Experts (MoE) variant of [LFM2](https://huggingface.co/collections/LiquidAI/lfm2-686d721927015b2ad73eaa38). The LFM2 family is optimized for on-device inference by combining short‑range, input‑aware gated convolutions with grouped‑query attention (GQA) in a layout tuned to maximize quality under strict speed and memory constraints.
+
+
-LFM2‑MoE keeps this fast backbone and introduces sparse MoE feed‑forward networks to add representational capacity without significantly increasing the active compute path. The first LFM2-MoE release is LFM2-8B-A1B, with 8.3B total parameters and 1.5B active parameters. The model excels in quality (comparable to 3-4B dense models) and speed (faster than other 1.5B class models).
+```py
+import torch
+from transformers import pipeline
-## Example
+pipeline = pipeline(task="text-generation", model="LiquidAI/LFM2-8B-A1B", dtype="auto",)
+pipeline("Plants create energy through a process known as photosynthesis.")
+```
-The following example shows how to generate an answer using the `AutoModelForCausalLM` class.
+
+
-```python
+```py
+import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
-# Load model and tokenizer
-model_id = "LiquidAI/LFM2-8B-A1B"
-model = AutoModelForCausalLM.from_pretrained(
- model_id,
- device_map="auto",
- dtype="bfloat16",
-# attn_implementation="flash_attention_2" <- uncomment on compatible GPU
-)
-tokenizer = AutoTokenizer.from_pretrained(model_id)
+tokenizer = AutoTokenizer.from_pretrained("LiquidAI/LFM2-8B-A1B")
+model = AutoModelForCausalLM.from_pretrained("LiquidAI/LFM2-8B-A1B", dtype="auto",)
-# Generate answer
-prompt = "What is C. elegans?"
-input_ids = tokenizer.apply_chat_template(
- [{"role": "user", "content": prompt}],
- add_generation_prompt=True,
- return_tensors="pt",
- tokenize=True,
-).to(model.device)
-
-output = model.generate(
- input_ids,
- do_sample=True,
- temperature=0.3,
- min_p=0.15,
- repetition_penalty=1.05,
- max_new_tokens=512,
-)
-
-print(tokenizer.decode(output[0], skip_special_tokens=False))
+inputs = tokenizer("Plants create energy through a process known as photosynthesis.", return_tensors="pt")
+outputs = model.generate(**inputs, max_length=50)
+print(tokenizer.decode(outputs[0]))
```
+
+
+
## Lfm2MoeConfig
[[autodoc]] Lfm2MoeConfig
diff --git a/docs/source/en/model_doc/llama.md b/docs/source/en/model_doc/llama.md
index 78dc60ed693..212c828b7b5 100644
--- a/docs/source/en/model_doc/llama.md
+++ b/docs/source/en/model_doc/llama.md
@@ -56,6 +56,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- The tokenizer is a byte-pair encoding model based on SentencePiece. During decoding, if the first token starts a word (like "Banana"), the tokenizer doesn't prepend the prefix space to the string.
+
## LlamaConfig
[[autodoc]] LlamaConfig
diff --git a/docs/source/en/model_doc/llama2.md b/docs/source/en/model_doc/llama2.md
index 7f40803de88..363d5703233 100644
--- a/docs/source/en/model_doc/llama2.md
+++ b/docs/source/en/model_doc/llama2.md
@@ -54,6 +54,14 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Set `config.pretraining_tp` to a value besides 1 to activate more accurate but slower computation of linear layers. This matches the original logits better.
+- The original model uses `pad_id = -1` to indicate a padding token. The Transformers implementation requires adding a padding token and resizing the token embedding accordingly.
+- Initialize the `embed_tokens` layer to ensure encoding the padding token outputs zeros.
+- The tokenizer is a byte-pair encoding model based on SentencePiece. During decoding, if the first token starts a word (like "Banana"), the tokenizer doesn't prepend the prefix space to the string.
+- Don't use the `dtype` parameter in [`~AutoModel.from_pretrained`] with FlashAttention-2. It only supports `fp16` or `bf16`. Use [Automatic Mixed Precision](https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html), set `fp16` or `bf16` to `True` with [`Trainer`], or use [torch.autocast](https://pytorch.org/docs/stable/amp.html#torch.autocast).
+
## LlamaConfig
[[autodoc]] LlamaConfig
diff --git a/docs/source/en/model_doc/llama3.md b/docs/source/en/model_doc/llama3.md
index 903105a44c9..9eaf0856df6 100644
--- a/docs/source/en/model_doc/llama3.md
+++ b/docs/source/en/model_doc/llama3.md
@@ -52,4 +52,14 @@ print(tokenizer.decode(outputs[0]))
```
-
\ No newline at end of file
+
+
+## Usage tips
+
+- LLaMA 3 models were trained using `bfloat16`, but original inference uses `float16`. Hub checkpoints use `dtype='float16'`. The [`AutoModel`] API casts checkpoints from `torch.float32` to `torch.float16`.
+- Online weight dtype matters only when using `dtype="auto"`. The model downloads first (using checkpoint dtype), then casts to torch's default dtype (`torch.float32`). Specify your desired dtype or it defaults to `torch.float32`.
+- Don't train in `float16`. It produces NaN values. Train in `bfloat16` instead.
+- The tokenizer is a BPE model based on tiktoken (vs SentencePiece for LLaMA 2). It ignores BPE merge rules when an input token is part of the vocab. If "hugging" is in the vocab, it returns as one token instead of splitting into `["hug","ging"]`.
+- The original model uses `pad_id = -1` (no padding token). Add a padding token with `tokenizer.add_special_tokens({"pad_token":""})` and resize token embeddings. Set `model.config.pad_token_id`. Initialize `embed_tokens` with `padding_idx` to ensure padding tokens output zeros.
+- Convert original checkpoints using the conversion script. The script requires enough CPU RAM to host the whole model in `float16` precision. For the 75B model, you need 145GB of RAM.
+- When using Flash Attention 2 via `attn_implementation="flash_attention_2"`, don't pass `dtype` to [`~AutoModel.from_pretrained`]. Use [Automatic Mixed Precision](https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html) training. With [`Trainer`], set `fp16` or `bf16` to `True`. Otherwise, use [torch.autocast](https://pytorch.org/docs/stable/amp.html#torch.autocast). Flash Attention only supports `fp16` and `bf16` data types.
\ No newline at end of file
diff --git a/docs/source/en/model_doc/longformer.md b/docs/source/en/model_doc/longformer.md
index 27cc5ab7405..6a8fc60f2fa 100644
--- a/docs/source/en/model_doc/longformer.md
+++ b/docs/source/en/model_doc/longformer.md
@@ -53,6 +53,12 @@ print(tokenizer.decode(logits[0, (input_ids[0] == tokenizer.mask_token_id).nonze
+## Usage tips
+
+- Longformer is based on RoBERTa and doesn't have `token_type_ids`. You don't need to indicate which token belongs to which segment. Just separate segments with the separation token `` or `tokenizer.sep_token`.
+- Set which tokens attend locally and which attend globally with the `global_attention_mask` at inference. A value of 0 means a token attends locally. A value of 1 means a token attends globally.
+- [`LongformerForMaskedLM`] is trained like [`RobertaForMaskedLM`] and should be similarly.
+
## LongformerConfig
[[autodoc]] LongformerConfig
diff --git a/docs/source/en/model_doc/longt5.md b/docs/source/en/model_doc/longt5.md
index b59ad184206..7c962b5efb7 100644
--- a/docs/source/en/model_doc/longt5.md
+++ b/docs/source/en/model_doc/longt5.md
@@ -54,6 +54,16 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- [`LongT5ForConditionalGeneration`] extends [`T5ForConditionalGeneration`] by replacing the traditional encoder self-attention layer with efficient local attention or transient-global (tglobal) attention.
+- Unlike T5, LongT5 doesn't use a task prefix. It uses a different pre-training objective inspired by [`PegasusForConditionalGeneration`].
+- LongT5 works efficiently on long-range sequence-to-sequence tasks where input sequences exceed 512 tokens. It handles input sequences up to 16,384 tokens.
+- Local attention uses a sparse sliding-window operation. A token attends only to r tokens to the left and right (r=127 by default). Local attention doesn't introduce new parameters. Complexity is linear: O(l*r).
+- Transient Global Attention extends Local Attention. Each input token interacts with all other tokens in the layer. This splits input sequences into blocks of fixed length k (k=16 by default).
+- A global token for each block is obtained by summing and normalizing embeddings of every token in the block. Each token attends to nearby tokens (like Local attention) and every global token (like standard global attention).
+- TGlobal attention introduces new parameters: global relative position biases and layer normalization for global token embeddings. Complexity is O(l(r + l/k)).
+
## LongT5Config
[[autodoc]] LongT5Config
diff --git a/docs/source/en/model_doc/luke.md b/docs/source/en/model_doc/luke.md
index ff17360da3b..21a010870e1 100644
--- a/docs/source/en/model_doc/luke.md
+++ b/docs/source/en/model_doc/luke.md
@@ -51,6 +51,15 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- This implementation extends [`RobertaModel`] with entity embeddings and an entity-aware self-attention mechanism. This improves performance on tasks involving entity reasoning.
+- LUKE treats entities as input tokens. It takes `entity_ids`, `entity_attention_mask`, `entity_token_type_ids`, and `entity_position_ids` as extra input. Get these using [`LukeTokenizer`].
+- [`LukeTokenizer`] takes entities and `entity_spans` (character-based start and end positions) as extra input. Entities typically consist of `[MASK]` entities or Wikipedia entities.
+- `[MASK]` entities are used to mask entities during pretraining. LUKE predicts the original entity by gathering information from input text. Use these for entity typing, relation classification, and named entity recognition.
+- LUKE learns rich information about Wikipedia entities during pretraining and stores it in entity embeddings. These enrich token representations with real-world knowledge. Use these for tasks requiring real-world knowledge like question answering.
+- [`LukeTokenizer`] has a `task` argument. Specify `task="entity_classification"`, `task="entity_pair_classification"`, or `task="entity_span_classification"` to easily create inputs for these head models.
+
## LukeConfig
[[autodoc]] LukeConfig
diff --git a/docs/source/en/model_doc/m2m_100.md b/docs/source/en/model_doc/m2m_100.md
index 01554cee8cb..84768fabd57 100644
--- a/docs/source/en/model_doc/m2m_100.md
+++ b/docs/source/en/model_doc/m2m_100.md
@@ -49,6 +49,12 @@ print(tokenizer.batch_decode(generated_tokens, skip_special_tokens=True))
+## Usage tips
+
+- M2M100 is a multilingual encoder-decoder model primarily for translation tasks. It expects sequences in a specific format with special language ID tokens as prefixes.
+- Source text format: `[lang_code] X [eos]`. `lang_code` is the source language ID for source text and target language ID for target text. `X` is the source or target text.
+- [`M2M100Tokenizer`] depends on sentencepiece. Install it with `pip install sentencepiece` before running examples.
+- M2M100 uses `eos_token_id` as the `decoder_start_token_id` for generation. The target language ID is forced as the first generated token. Pass the `forced_bos_token_id` parameter to the [`generate`] method to force the target language ID.
## M2M100Config
diff --git a/docs/source/en/model_doc/mamba.md b/docs/source/en/model_doc/mamba.md
index c2cb38b90af..8580d3ef304 100644
--- a/docs/source/en/model_doc/mamba.md
+++ b/docs/source/en/model_doc/mamba.md
@@ -48,6 +48,11 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- The current implementation uses the original CUDA kernels. The FlashAttention equivalent implementation is hosted in the `mamba-ssm` and `causal_conv1d` repositories. Install them if your hardware supports it.
+- Mamba stacks mixer layers which are equivalent to attention layers. Find the main logic of Mamba in the [`MambaMixer`] class.
+
## MambaConfig
[[autodoc]] MambaConfig
diff --git a/docs/source/en/model_doc/mamba2.md b/docs/source/en/model_doc/mamba2.md
index 9c50bbf4549..e51ef8f0758 100644
--- a/docs/source/en/model_doc/mamba2.md
+++ b/docs/source/en/model_doc/mamba2.md
@@ -48,6 +48,16 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Codestral Mamba has `groups=8` which are similar to the number of kv heads in an attention-based model.
+- Codestral Mamba has two different forward passes: `torch_forward` or `cuda_kernels_forward`. Their results are expected to be slightly different.
+- `torch_forward` without compilation is 3-4x faster than `cuda_kernels_forward`.
+- `cuda_kernels_forward` uses the original CUDA kernels if they're available in your environment. It's slower during prefill because it requires a "warmup run" due to higher CPU overhead.
+- This model has no positional embeddings, but it has an `attention_mask` and specific logic to mask out hidden states in two places during batched generation. This (and the reimplemented Mamba 2 kernels) results in a slight discrepancy between batched and cached generation.
+- The SSM algorithm heavily relies on tensor contractions, which have matmul equivalents but the order of operations is slightly different. This makes the difference greater at smaller precisions.
+- Hidden states corresponding to padding tokens are shutdown in 2 places and are mostly tested with left-padding. Right-padding propagates noise down the line and doesn't guarantee satisfactory results. Set `tokenizer.padding_side = "left"` to ensure you're using the correct padding side.
+
## Mamba2Config
[[autodoc]] Mamba2Config
diff --git a/docs/source/en/model_doc/marian.md b/docs/source/en/model_doc/marian.md
index 0fcf56dc830..7f007ac53e1 100644
--- a/docs/source/en/model_doc/marian.md
+++ b/docs/source/en/model_doc/marian.md
@@ -55,6 +55,14 @@ print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+## Usage tips
+
+- MarianMT models are ~298MB on disk. There are more than 1000 models available. Check the [supported language pairs list](https://huggingface.co/models?library=transformers&pipeline_tag=translation&sort=downloads) for available options.
+- Language codes may be inconsistent. Two-digit codes are available in the [language codes list](https://huggingface.co/models?library=transformers&pipeline_tag=translation&sort=downloads). Three-digit codes may require further searching.
+- Models that require BPE preprocessing aren't supported.
+- All model names use this format: `Helsinki-NLP/opus-mt-{src}-{tgt}`. Language codes like `es_AR` refer to `code_{region}`. For example, `es_AR` refers to Spanish from Argentina.
+- If a model outputs multiple languages, prepend the desired output language to `src_txt`. New multilingual models from the Tatoeba-Challenge require 3-character language codes. Older multilingual models use 2-character language codes.
+
## MarianConfig
[[autodoc]] MarianConfig
diff --git a/docs/source/en/model_doc/markuplm.md b/docs/source/en/model_doc/markuplm.md
index 8982ad5a1c2..0f319ef3846 100644
--- a/docs/source/en/model_doc/markuplm.md
+++ b/docs/source/en/model_doc/markuplm.md
@@ -47,6 +47,11 @@ processor.decode(predict_answer_tokens).strip()
+## Usage tips
+
+- In addition to `input_ids`, [`~MarkupLMModel.forward`] expects 2 additional inputs: `xpath_tags_seq` and `xpath_subs_seq`. These are the XPATH tags and subscripts respectively for each token in the input sequence.
+- Use [`MarkupLMProcessor`] to prepare all data for the model. Refer to the usage guide for more information.
+
## MarkupLMConfig
[[autodoc]] MarkupLMConfig
diff --git a/docs/source/en/model_doc/mbart.md b/docs/source/en/model_doc/mbart.md
index af6a398bf1b..5e5682965c3 100644
--- a/docs/source/en/model_doc/mbart.md
+++ b/docs/source/en/model_doc/mbart.md
@@ -55,6 +55,15 @@ print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+## Usage tips
+
+- Check the full list of language codes via `tokenizer.lang_code_to_id.keys()`.
+- mBART requires a special language ID token in the source and target text during training. Source text format: `X [eos, src_lang_code]` where `X` is the source text. Target text format: `[tgt_lang_code] X [eos]`. The `bos` token is never used.
+- [`~PreTrainedTokenizerBase._call_`] encodes the source text format passed as the first argument or with the `text` keyword. The target text format is passed with the `text_label` keyword.
+- Set the `decoder_start_token_id` to the target language ID for mBART.
+- mBART-50 has a different text format. The language ID token is used as the prefix for the source and target text. Text format: `[lang_code] X [eos]` where `lang_code` is the source language ID for source text and target language ID for target text. `X` is the source or target text respectively.
+- Set the `eos_token_id` as the `decoder_start_token_id` for mBART-50. The target language ID is used as the first generated token by passing `forced_bos_token_id` to [`generate`].
+
## MBartConfig
[[autodoc]] MBartConfig
diff --git a/docs/source/en/model_doc/mega.md b/docs/source/en/model_doc/mega.md
index df0a38c65ce..b3fa64ec260 100644
--- a/docs/source/en/model_doc/mega.md
+++ b/docs/source/en/model_doc/mega.md
@@ -15,6 +15,11 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2022-09-21 and added to Hugging Face Transformers on 2023-06-20 and contributed by [mnaylor](https://huggingface.co/mnaylor).*
+> [!WARNING]
+> This model is in maintenance mode only, we don’t accept any new PRs changing its code.
+>
+> If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2. You can do so by running the following command: pip install -U transformers==4.40.2.
+
# MEGA
@@ -49,6 +54,13 @@ print(f"Next predicted token: {tokenizer.decode([outputs.logits[0, -1, :].argmax
+## Usage tips
+
+- MEGA performs well with relatively few parameters. See Appendix D in the MEGA paper for examples of architectural specs that perform well in various settings. If using MEGA as a decoder, set `bidirectional=False` to avoid errors with default bidirectional.
+- Mega-chunk is a variant of MEGA that reduces time and space complexity from quadratic to linear. Use chunking with [`MegaConfig.use_chunking`] and control chunk size with [`MegaConfig.chunk_size`].
+- The original MEGA implementation had inconsistent expectations of attention masks for padding and causal self-attention between the softmax attention and Laplace/squared ReLU method. This implementation addresses that inconsistency.
+- The original implementation didn't include token type embeddings. This implementation adds support for these, controlled by [`MegaConfig.add_token_type_embeddings`].
+
## MegaConfig
[[autodoc]] MegaConfig
diff --git a/docs/source/en/model_doc/mobilebert.md b/docs/source/en/model_doc/mobilebert.md
index 0ad16f09f39..1695693f2ab 100644
--- a/docs/source/en/model_doc/mobilebert.md
+++ b/docs/source/en/model_doc/mobilebert.md
@@ -51,7 +51,9 @@ print(f"Predicted word: {predicted_word}")
-## Resources
+## Usage tips
+
+- Pad inputs on the right. MobileBERT uses absolute position embeddings.
## MobileBertConfig
diff --git a/docs/source/en/model_doc/mpnet.md b/docs/source/en/model_doc/mpnet.md
index fff770f481f..e84e227db08 100644
--- a/docs/source/en/model_doc/mpnet.md
+++ b/docs/source/en/model_doc/mpnet.md
@@ -51,6 +51,10 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- MPNet doesn't have `token_type_ids`. You don't need to indicate which token belongs to which segment. Just separate segments with the separation token `tokenizer.sep_token` (or `[sep]`).
+
## MPNetConfig
[[autodoc]] MPNetConfig
diff --git a/docs/source/en/model_doc/mpt.md b/docs/source/en/model_doc/mpt.md
index fc895b6dd8f..d8a2f8fd55e 100644
--- a/docs/source/en/model_doc/mpt.md
+++ b/docs/source/en/model_doc/mpt.md
@@ -15,7 +15,6 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2023-05-05 and added to Hugging Face Transformers on 2023-07-25.*
-
# MPT
[MPT](https://www.databricks.com/blog/mpt-7b) is a 6.7-billion-parameter decoder-style transformer developed by MosaicML, trained from scratch on 1 trillion tokens of text and code over 9.5 days with zero human intervention. It is fully open-source and commercially usable, featuring FlashAttention for fast training and inference, and ALiBi to handle extremely long context lengths up to 84k tokens. MosaicML also released finetuned variants—Instruct, Chat, and StoryWriter-65k+—to demonstrate specialized capabilities. The model was rigorously benchmarked and matches the quality of LLaMA-7B while offering easier deployment, licensing for commercial use, and highly efficient training code.
@@ -49,6 +48,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Use the advanced version of the model (triton kernels, direct flash attention integration) by adding `trust_remote_code=True` when calling [`~AutoModel.from_pretrained`].
+
## MptConfig
[[autodoc]] MptConfig
diff --git a/docs/source/en/model_doc/mt5.md b/docs/source/en/model_doc/mt5.md
index 964cb0d0513..c0a4299569f 100644
--- a/docs/source/en/model_doc/mt5.md
+++ b/docs/source/en/model_doc/mt5.md
@@ -58,6 +58,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Fine-tune mT5 for downstream tasks. The model was only pretrained on the [mc4 dataset](https://huggingface.co/datasets/mc4), which doesn't include task-specific training.
+
## MT5Config
[[autodoc]] MT5Config
diff --git a/docs/source/en/model_doc/mvp.md b/docs/source/en/model_doc/mvp.md
index 02efec72d52..7b84f354fce 100644
--- a/docs/source/en/model_doc/mvp.md
+++ b/docs/source/en/model_doc/mvp.md
@@ -58,6 +58,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Use [`set_lightweight_tuning`] for lightweight prompt tuning following prefix-tuning.
+
## MvpConfig
[[autodoc]] MvpConfig
diff --git a/docs/source/en/model_doc/nezha.md b/docs/source/en/model_doc/nezha.md
index b70f9c65cc3..c54643ffb3c 100644
--- a/docs/source/en/model_doc/nezha.md
+++ b/docs/source/en/model_doc/nezha.md
@@ -16,7 +16,9 @@ rendered properly in your Markdown viewer.
*This model was released on 2019-08-31 and added to Hugging Face Transformers on 2023-06-20 and contributed by [sijunhe](https://huggingface.co/sijunhe).*
> [!WARNING]
-> This model is in maintenance mode only, we don’t accept any new PRs changing its code. If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2. You can do so by running the following command: pip install -U transformers==4.40.2.
+> This model is in maintenance mode only, we don’t accept any new PRs changing its code.
+>
+> If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2. You can do so by running the following command: pip install -U transformers==4.40.2.
# Nezha
diff --git a/docs/source/en/model_doc/nllb-moe.md b/docs/source/en/model_doc/nllb-moe.md
index 3eda5cf0167..eae03351af4 100644
--- a/docs/source/en/model_doc/nllb-moe.md
+++ b/docs/source/en/model_doc/nllb-moe.md
@@ -48,6 +48,12 @@ print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+## Usage tips
+
+- [`M2M100ForConditionalGeneration`] is the base model for both NLLB and NLLB MoE.
+- The tokenizer is the same as the NLLB models.
+- Set `forced_bos_token_id` to the target language ID when generating text.
+- English (`eng_Latn`) is the default source language. Specify a different source language using the BCP-47 code in the `src_lang` keyword argument.
## NllbMoeConfig
diff --git a/docs/source/en/model_doc/nllb.md b/docs/source/en/model_doc/nllb.md
index 1d12d87de29..b9a73daca09 100644
--- a/docs/source/en/model_doc/nllb.md
+++ b/docs/source/en/model_doc/nllb.md
@@ -55,6 +55,11 @@ print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+## Usage tips
+
+- The tokenizer was updated in April 2023. It now prefixes the source sequence with the source language instead of the target language. This prioritizes zero-shot performance at a minor cost to supervised performance.
+- For non-English languages, specify the language's BCP-47 code with the `src_lang` keyword.
+
## NllbTokenizer
[[autodoc]] NllbTokenizer
diff --git a/docs/source/en/model_doc/olmo2.md b/docs/source/en/model_doc/olmo2.md
index a8da321b69d..08b62deb52a 100644
--- a/docs/source/en/model_doc/olmo2.md
+++ b/docs/source/en/model_doc/olmo2.md
@@ -55,6 +55,12 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- OLMo2 uses RMSNorm instead of standard layer norm. RMSNorm is applied to attention queries and keys. It's applied after the attention and feedforward layers rather than before.
+- OLMo2 requires Transformers v4.48 or higher.
+- Load specific intermediate checkpoints by adding the `revision` parameter to [`~AutoModel.from_pretrained`].
+
## Olmo2Config
[[autodoc]] Olmo2Config
diff --git a/docs/source/en/model_doc/open-llama.md b/docs/source/en/model_doc/open-llama.md
index 960cd9aefa9..102a1167a1a 100644
--- a/docs/source/en/model_doc/open-llama.md
+++ b/docs/source/en/model_doc/open-llama.md
@@ -16,7 +16,9 @@ rendered properly in your Markdown viewer.
*This model was released on {release_date} and added to Hugging Face Transformers on 2023-06-20 and contributed by [s-JoL](https://huggingface.co/s-JoL).*
> [!WARNING]
-> This model is in maintenance mode only, we don’t accept any new PRs changing its code. If you run into any issues running this model, please reinstall the last version that supported this model: v4.31.0. You can do so by running the following command: pip install -U transformers==4.31.0.
+> This model is in maintenance mode only, we don’t accept any new PRs changing its code.
+>
+> If you run into any issues running this model, please reinstall the last version that supported this model: v4.31.0. You can do so by running the following command: pip install -U transformers==4.31.0.
# Open-Llama
diff --git a/docs/source/en/model_doc/openai-gpt.md b/docs/source/en/model_doc/openai-gpt.md
index fd6c247a814..2ee910e128f 100644
--- a/docs/source/en/model_doc/openai-gpt.md
+++ b/docs/source/en/model_doc/openai-gpt.md
@@ -55,6 +55,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Pad inputs on the right. GPT uses absolute position embeddings.
+
## OpenAIGPTConfig
[[autodoc]] OpenAIGPTConfig
diff --git a/docs/source/en/model_doc/opt.md b/docs/source/en/model_doc/opt.md
index b9a81d6dd51..9c24b303afd 100644
--- a/docs/source/en/model_doc/opt.md
+++ b/docs/source/en/model_doc/opt.md
@@ -55,6 +55,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- OPT adds an EOS token `` to the beginning of every prompt.
+
## OPTConfig
[[autodoc]] OPTConfig
diff --git a/docs/source/en/model_doc/pegasus.md b/docs/source/en/model_doc/pegasus.md
index 78df31e5874..1011f99d365 100644
--- a/docs/source/en/model_doc/pegasus.md
+++ b/docs/source/en/model_doc/pegasus.md
@@ -53,6 +53,12 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Use AdaFactor as the optimizer for fine-tuning Pegasus.
+- This implementation inherits from [`BartForConditionalGeneration`] but uses static/sinusoidal positional embeddings instead.
+- Pegasus starts generating with `pad_token_id` as the prefix and uses `num_beams=8`.
+
## PegasusConfig
[[autodoc]] PegasusConfig
diff --git a/docs/source/en/model_doc/pegasus_x.md b/docs/source/en/model_doc/pegasus_x.md
index 2d18c1c5b08..f61a78898cb 100644
--- a/docs/source/en/model_doc/pegasus_x.md
+++ b/docs/source/en/model_doc/pegasus_x.md
@@ -53,6 +53,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- PEGASUS-X uses the [`PegasusTokenizer`].
+
## PegasusXConfig
[[autodoc]] PegasusXConfig
diff --git a/docs/source/en/model_doc/persimmon.md b/docs/source/en/model_doc/persimmon.md
index 94556731307..a9e9e93eb4b 100644
--- a/docs/source/en/model_doc/persimmon.md
+++ b/docs/source/en/model_doc/persimmon.md
@@ -48,6 +48,15 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Persimmon models were trained using `bfloat16`, but original inference uses `float16`. Hub checkpoints use `dtype='float16'`. The [`AutoModel`] API casts checkpoints from `torch.float32` to `torch.float16`.
+- Online weight dtype matters only when using `dtype="auto"`. The model downloads first (using checkpoint dtype), then casts to torch's default dtype (`torch.float32`). Specify your desired dtype or it defaults to `torch.float32`.
+- Don't fine-tune in `float16`. It produces NaN values. Fine-tune in `bfloat16` instead.
+- Clone the original repository to convert the model: `git clone https://github.com/persimmon-ai-labs/adept-inference`.
+- Persimmon uses a sentencepiece-based tokenizer with a Unigram model. It supports bytefallback (available in `tokenizers==0.14.0` for the fast tokenizer). [`LlamaTokenizer`] wraps sentencepiece as a standard wrapper.
+- Use this prompt format for chat mode: `f"human: {prompt}\n\nadept:"`.
+
## PersimmonConfig
[[autodoc]] PersimmonConfig
diff --git a/docs/source/en/model_doc/phi.md b/docs/source/en/model_doc/phi.md
index e07fb4d748a..fea7c37ce2e 100644
--- a/docs/source/en/model_doc/phi.md
+++ b/docs/source/en/model_doc/phi.md
@@ -56,6 +56,11 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- For Transformers < 4.37.0.dev, set `trust_remote_code=True` in [`~AutoModel.from_pretrained`].
+- Otherwise, update Transformers to the latest stable version.
+
## PhiConfig
[[autodoc]] PhiConfig
diff --git a/docs/source/en/model_doc/phi3.md b/docs/source/en/model_doc/phi3.md
index d33c55acb06..23f64ec013e 100644
--- a/docs/source/en/model_doc/phi3.md
+++ b/docs/source/en/model_doc/phi3.md
@@ -56,6 +56,12 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- This model is very similar to Llama. The main difference is [`Phi3SuScaledRotaryEmbedding`] and [`Phi3YarnScaledRotaryEmbedding`], which extend the context of rotary embeddings.
+- Query, key, and values are fused. The MLP's up and gate projection layers are also fused.
+- The tokenizer is identical to [`LlamaTokenizer`], except for additional tokens.
+
## Phi3Config
[[autodoc]] Phi3Config
diff --git a/docs/source/en/model_doc/phimoe.md b/docs/source/en/model_doc/phimoe.md
index e3833080519..8d45066dad7 100644
--- a/docs/source/en/model_doc/phimoe.md
+++ b/docs/source/en/model_doc/phimoe.md
@@ -68,6 +68,11 @@ print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+## Usage tips
+
+- This model is very similar to Mixtral. The main difference is [`Phi3LongRoPEScaledRotaryEmbedding`], which extends the context of rotary embeddings.
+- Query, key, and values are fused. The MLP's up and gate projection layers are also fused.
+- The tokenizer is identical to [`LlamaTokenizer`], except for additional tokens.
## PhimoeConfig
diff --git a/docs/source/en/model_doc/plbart.md b/docs/source/en/model_doc/plbart.md
index 84d33596b75..50e55bb9126 100644
--- a/docs/source/en/model_doc/plbart.md
+++ b/docs/source/en/model_doc/plbart.md
@@ -49,6 +49,13 @@ print(tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0])
+## Usage tips
+
+- The model expects sequences in a specific format with special language ID tokens. Source text format: `X [eos, src_lang_code]` where `X` is the source text. Target text format: `[tgt_lang_code] X [eos]`. The `bos` token is never used.
+- For fine-tuning with a single language, language tokens may not be needed. Refer to the paper for details.
+- Use the regular `call()` method to encode source text format (pass text as first argument or with `text` keyword). Use `text_target` keyword for target text format.
+- Set `decoder_start_token_id` to the target language ID when generating text.
+
## PLBartConfig
[[autodoc]] PLBartConfig
diff --git a/docs/source/en/model_doc/prophetnet.md b/docs/source/en/model_doc/prophetnet.md
index 9faf59d2c8f..388124a0dbb 100644
--- a/docs/source/en/model_doc/prophetnet.md
+++ b/docs/source/en/model_doc/prophetnet.md
@@ -48,6 +48,11 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Pad inputs on the right. ProphetNet uses absolute position embeddings.
+- The model architecture is based on the original Transformer. It replaces the "standard" self-attention mechanism in the decoder with a main self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
+
## ProphetNetConfig
[[autodoc]] ProphetNetConfig
diff --git a/docs/source/en/model_doc/qdqbert.md b/docs/source/en/model_doc/qdqbert.md
index 1237b98b588..c42ad30e6ed 100644
--- a/docs/source/en/model_doc/qdqbert.md
+++ b/docs/source/en/model_doc/qdqbert.md
@@ -15,6 +15,11 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2020-04-20 and added to Hugging Face Transformers on 2023-06-20 and contributed by [shangz](https://huggingface.co/shangz).*
+> [!WARNING]
+> This model is in maintenance mode only, we don’t accept any new PRs changing its code.
+>
+> If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2. You can do so by running the following command: pip install -U transformers==4.40.2.
+
# QDQBERT
[QDQBERT](https://huggingface.co/papers/2004.09602) explores integer quantization to decrease Deep Neural Network sizes and enhance inference speed through high-throughput integer instructions. The paper examines quantization parameters and evaluates their impact across various neural network models in vision, speech, and language domains. It highlights techniques compatible with processors featuring high-throughput integer pipelines. A workflow for 8-bit quantization is introduced, ensuring accuracy within 1% of the floating-point baseline across all studied networks, including challenging models like MobileNets and BERT-large.
@@ -51,6 +56,16 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- QDQBERT adds fake quantization operations (QuantizeLinear/DequantizeLinear ops) to linear layer inputs and weights, matmul inputs, and residual add inputs in BERT.
+- Install the PyTorch Quantization Toolkit: `pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com`.
+- Load QDQBERT from any HuggingFace BERT checkpoint (e.g., `google-bert/bert-base-uncased`) to perform Quantization Aware Training or Post Training Quantization.
+- See the [complete example](https://github.com/huggingface/transformers-research-projects/tree/main/quantization-qdqbert) for Quantization Aware Training and Post Training Quantization on the SQUAD task.
+- QDQBERT uses `TensorQuantizer` from the PyTorch Quantization Toolkit. `TensorQuantizer` quantizes tensors using `QuantDescriptor` to define quantization parameters.
+- Set the default `QuantDescriptor` before creating a QDQBERT model.
+- Export to ONNX for TensorRT deployment. Fake quantization becomes QuantizeLinear/DequantizeLinear ONNX ops. Set `TensorQuantizer`'s static member to use PyTorch's fake quantization functions, then follow [`torch.onnx`](https://pytorch.org/docs/stable/onnx.html) instructions.
+
## QDQBertConfig
[[autodoc]] QDQBertConfig
diff --git a/docs/source/en/model_doc/qwen2.md b/docs/source/en/model_doc/qwen2.md
index 3823ffafe8b..c7a91567394 100644
--- a/docs/source/en/model_doc/qwen2.md
+++ b/docs/source/en/model_doc/qwen2.md
@@ -56,6 +56,10 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Update Transformers to version 4.37.0 or higher. Qwen2 requires `Transformers>=4.37.0` for full support.
+
## Qwen2Config
[[autodoc]] Qwen2Config
diff --git a/docs/source/en/model_doc/realm.md b/docs/source/en/model_doc/realm.md
index 3dd8fd8b88d..ec5d3d4cb3e 100644
--- a/docs/source/en/model_doc/realm.md
+++ b/docs/source/en/model_doc/realm.md
@@ -15,6 +15,11 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2020-02-10 and added to Hugging Face Transformers on 2023-06-20 and contributed by [qqaatw](https://huggingface.co/qqaatw).*
+> [!WARNING]
+> This model is in maintenance mode only, we don’t accept any new PRs changing its code.
+>
+> If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2. You can do so by running the following command: pip install -U transformers==4.40.2.
+
# REALM
[REALM: Retrieval-Augmented Language Model Pre-Training](https://huggingface.co/papers/2002.08909) enhances language model pre-training by integrating a latent knowledge retriever. This retriever allows the model to access and utilize documents from a large corpus like Wikipedia during pre-training, fine-tuning, and inference. The model is trained in an unsupervised manner using masked language modeling, with the retrieval step considered during backpropagation across millions of documents. REALM significantly outperforms existing models on Open-domain Question Answering benchmarks, offering improvements of 4-16% in accuracy. It also provides benefits in interpretability and modularity.
diff --git a/docs/source/en/model_doc/reformer.md b/docs/source/en/model_doc/reformer.md
index a00d452eb53..aea9db23a6c 100644
--- a/docs/source/en/model_doc/reformer.md
+++ b/docs/source/en/model_doc/reformer.md
@@ -48,6 +48,15 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Reformer doesn't work with `torch.nn.DataParallel` due to a bug in PyTorch. See [issue #36035](https://github.com/pytorch/pytorch/issues/36035).
+- Use Axial position encoding to avoid huge positional encoding matrices. It factorizes them into smaller matrices for long sequences.
+- Replace traditional attention with LSH (locality-sensitive hashing) attention. This avoids computing the full query-key product in attention layers.
+- Use reversible transformer layers to avoid storing intermediate results. Get them during the backward pass by subtracting residuals from the next layer's input, or recompute them (less efficient but saves memory).
+- Compute feedforward operations by chunks, not on the whole batch.
+- During training, set sequence length to a value divisible by the least common multiple of `config.lsh_chunk_length` and `config.local_chunk_length`. Set Axial Positional Encoding parameters correctly. Reformer is memory-efficient and can train on sequences up to 64,000 tokens.
+
## ReformerConfig
[[autodoc]] ReformerConfig
diff --git a/docs/source/en/model_doc/rembert.md b/docs/source/en/model_doc/rembert.md
index cf54f25af97..73622e92bba 100644
--- a/docs/source/en/model_doc/rembert.md
+++ b/docs/source/en/model_doc/rembert.md
@@ -51,6 +51,12 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- For fine-tuning, RemBERT is like a bigger version of mBERT with ALBERT-like embedding factorization.
+- Embeddings aren't tied during pre-training (unlike BERT). This enables smaller input embeddings (preserved during fine-tuning) and bigger output embeddings (discarded at fine-tuning).
+- The tokenizer is similar to ALBERT's tokenizer rather than BERT's.
+
## RemBertConfig
[[autodoc]] RemBertConfig
diff --git a/docs/source/en/model_doc/retribert.md b/docs/source/en/model_doc/retribert.md
index e61d137f0ff..39168c90456 100644
--- a/docs/source/en/model_doc/retribert.md
+++ b/docs/source/en/model_doc/retribert.md
@@ -16,7 +16,9 @@ rendered properly in your Markdown viewer.
*This model was released on 2020-06-12 and added to Hugging Face Transformers on 2023-06-20 and contributed by [yjernite](https://huggingface.co/yjernite).*
> [!WARNING]
-> This model is in maintenance mode only, so we won't accept any new PRs changing its code. If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0. You can do so by running the following command: `pip install -U transformers==4.30.0`.
+> This model is in maintenance mode only, so we won't accept any new PRs changing its code.
+>
+> If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0. You can do so by running the following command: `pip install -U transformers==4.30.0`.
# RetriBERT
diff --git a/docs/source/en/model_doc/roberta-prelayernorm.md b/docs/source/en/model_doc/roberta-prelayernorm.md
index 04fc0829716..032425c016e 100644
--- a/docs/source/en/model_doc/roberta-prelayernorm.md
+++ b/docs/source/en/model_doc/roberta-prelayernorm.md
@@ -15,7 +15,6 @@ rendered properly in your Markdown viewer.
-->
*This model was released on 2019-04-01 and added to Hugging Face Transformers on 2022-12-19 and contributed by [andreasmadsen](https://huggingface.co/andreasmadsen).*
-
# RoBERTa-PreLayerNorm
[RoBERTa-PreLayerNorm](https://huggingface.co/papers/1904.01038) is part of the fairseq toolkit, which facilitates training custom models for tasks like translation and summarization. Built on PyTorch, fairseq supports distributed training, mixed-precision training, and inference on modern GPUs. This specific model variant applies layer normalization before the self-attention and feed-forward layers, differing from the standard RoBERTa configuration.
@@ -52,6 +51,12 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- The implementation is the same as RoBERTa except it uses Norm and Add instead of Add and Norm.
+- Add and Norm refers to Addition and LayerNormalization as described in ["Attention Is All You Need"](https://arxiv.org/abs/1706.03762).
+- This is identical to using the `--encoder-normalize-before` flag in fairseq.
+
## RobertaPreLayerNormConfig
[[autodoc]] RobertaPreLayerNormConfig
diff --git a/docs/source/en/model_doc/roberta.md b/docs/source/en/model_doc/roberta.md
index 60faf886730..81cf40dd084 100644
--- a/docs/source/en/model_doc/roberta.md
+++ b/docs/source/en/model_doc/roberta.md
@@ -57,6 +57,11 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- RoBERTa doesn't have `token_type_ids`. You don't need to indicate which token belongs to which segment.
+- Separate segments with the separation token `tokenizer.sep_token` or ``.
+
## RobertaConfig
[[autodoc]] RobertaConfig
diff --git a/docs/source/en/model_doc/roformer.md b/docs/source/en/model_doc/roformer.md
index 9d00d4d921e..7ea27cef0b2 100644
--- a/docs/source/en/model_doc/roformer.md
+++ b/docs/source/en/model_doc/roformer.md
@@ -51,6 +51,11 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- The current RoFormer implementation is an encoder-only model.
+- Find the original code in the [ZhuiyiTechnology/roformer](https://github.com/ZhuiyiTechnology/roformer) repository.
+
## RoFormerConfig
[[autodoc]] RoFormerConfig
diff --git a/docs/source/en/model_doc/splinter.md b/docs/source/en/model_doc/splinter.md
index d922f312c3a..03a1ab56406 100644
--- a/docs/source/en/model_doc/splinter.md
+++ b/docs/source/en/model_doc/splinter.md
@@ -65,6 +65,16 @@ print(f"Starting position: {start_idx}, Ending position: {end_idx}")
+## Usage tips
+
+- Splinter was trained to predict answer spans conditioned on a special `[QUESTION]` token. These tokens contextualize to question representations for answer prediction.
+- The QASS layer is the default behavior in [`SplinterForQuestionAnswering`]. It handles question-aware span selection.
+- Use [`SplinterTokenizer`] instead of [`BertTokenizer`]. It contains the special token and uses it by default when two sequences are given.
+- Keep the question token in mind when using Splinter outside `run_qa.py`. It's important for model success, especially in few-shot settings.
+- Two checkpoint variants exist for each Splinter size:
+ - `tau/splinter-base-qass` and `tau/splinter-large-qass`: Include pretrained QASS layer weights
+ - `tau/splinter-base` and `tau/splinter-large`: Don't include QASS weights for random initialization during fine-tuning
+- Random initialization of the QASS layer during fine-tuning yields better results in some cases.
## SplinterConfig
diff --git a/docs/source/en/model_doc/squeezebert.md b/docs/source/en/model_doc/squeezebert.md
index 97b48c1ffde..feb708ce2e1 100644
--- a/docs/source/en/model_doc/squeezebert.md
+++ b/docs/source/en/model_doc/squeezebert.md
@@ -51,6 +51,12 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- Pad inputs on the right. SqueezeBERT uses absolute position embeddings.
+- SqueezeBERT is similar to BERT and relies on masked language modeling (MLM). It's efficient at predicting masked tokens and natural language understanding, but not optimal for text generation. Models trained with causal language modeling (CLM) are better for text generation.
+- For best results on sequence classification tasks, start with the `squeezebert/squeezebert-mnli-headless` checkpoint.
+
## SqueezeBertConfig
[[autodoc]] SqueezeBertConfig
diff --git a/docs/source/en/model_doc/stablelm.md b/docs/source/en/model_doc/stablelm.md
index 9a5a69bf807..11b8364aedd 100644
--- a/docs/source/en/model_doc/stablelm.md
+++ b/docs/source/en/model_doc/stablelm.md
@@ -55,6 +55,11 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- The architecture is similar to LLaMA but with key differences: RoPE applied to 25% of head embedding dimensions, LayerNorm instead of RMSNorm, and optional QKV bias terms.
+- StableLM 3B 4E1T-based models use the same tokenizer as [`GPTNeoXTokenizerFast`].
+
## StableLmConfig
[[autodoc]] StableLmConfig
diff --git a/docs/source/en/model_doc/t5.md b/docs/source/en/model_doc/t5.md
index 732169cfda0..18aa952e477 100644
--- a/docs/source/en/model_doc/t5.md
+++ b/docs/source/en/model_doc/t5.md
@@ -48,6 +48,11 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- Pad encoder inputs on the left or right. T5 uses relative scalar embeddings.
+- T5 models need a slightly higher learning rate than the default used in [`Trainer`]. Use values of `1e-4` and `3e-4` for most tasks.
+
## T5Config
[[autodoc]] T5Config
diff --git a/docs/source/en/model_doc/t5v1.1.md b/docs/source/en/model_doc/t5v1.1.md
index 55afc85ba53..820492bee4e 100644
--- a/docs/source/en/model_doc/t5v1.1.md
+++ b/docs/source/en/model_doc/t5v1.1.md
@@ -46,4 +46,10 @@ print(tokenizer.decode(outputs[0]))
```
-
\ No newline at end of file
+
+
+## Usage tips
+
+- T5 Version 1.1 was only pre-trained on C4 without supervised training. Fine-tune the model before using it on downstream tasks (unlike the original T5 model).
+- Since T5v1.1 was pre-trained unsupervised, task prefixes don't help during single-task fine-tuning.
+- Use task prefixes for multi-task fine-tuning.
\ No newline at end of file
diff --git a/docs/source/en/model_doc/tapex.md b/docs/source/en/model_doc/tapex.md
index 5ad5883bc14..d2dbcb218ed 100644
--- a/docs/source/en/model_doc/tapex.md
+++ b/docs/source/en/model_doc/tapex.md
@@ -44,6 +44,13 @@ print(predicted_answer)
+## Usage tips
+
+- TAPEX is a generative (seq2seq) model. Plug TAPEX weights directly into a BART model.
+- TAPEX has checkpoints on the hub that are either pre-trained only or fine-tuned on WTQ, SQA, WikiSQL, and TabFact.
+- Present sentences and tables to the model as `sentence + " " + linearized table`. The linearized table format: `col: col1 | col2 | col3 row1: val1 | val2 | val3 row2: ...`.
+- TAPEX has its own tokenizer that prepares all data for the model easily. Pass Pandas DataFrames and strings to the tokenizer. It automatically creates `input_ids` and `attention_mask`.
+
## TapexTokenizer
[[autodoc]] TapexTokenizer
diff --git a/docs/source/en/model_doc/transfo-xl.md b/docs/source/en/model_doc/transfo-xl.md
index 70b28fe1295..c32195a3b21 100644
--- a/docs/source/en/model_doc/transfo-xl.md
+++ b/docs/source/en/model_doc/transfo-xl.md
@@ -16,27 +16,24 @@ rendered properly in your Markdown viewer.
*This model was released on 2019-01-09 and added to Hugging Face Transformers on 2023-06-20 and contributed by [thomwolf](https://huggingface.co/thomwolf).*
> [!WARNING]
-> This model is in maintenance mode only, so we won’t accept any new PRs changing its code. If you run into any issues running this model, please reinstall the last version that supported this model: v4.35.0. You can do so by running the following command: pip install -U transformers==4.35.0.
+> This model is in maintenance mode only, so we won’t accept any new PRs changing its code.
>
-> This model was deprecated due to security issues linked to `pickle.load`. To continue using TransfoXL, use a specific revision to ensure you're downloading safe files from the Hub and set the environment variable `TRUST_REMOTE_CODE` to `True`.
->
-> ```py
-> import os
-> from transformers import TransfoXLTokenizer, TransfoXLLMHeadModel
->
-> os.environ["TRUST_REMOTE_CODE"] = "True"
->
-> checkpoint = 'transfo-xl/transfo-xl-wt103'
-> revision = '40a186da79458c9f9de846edfaea79c412137f97'
->
-> tokenizer = TransfoXLTokenizer.from_pretrained(checkpoint, revision=revision)
-> model = TransfoXLLMHeadModel.from_pretrained(checkpoint, revision=revision)
-> ```
+> If you run into any issues running this model, please reinstall the last version that supported this model: v4.35.0. You can do so by running the following command: pip install -U transformers==4.35.0.
# Transformer XL
[Transformer-XL](https://huggingface.co/papers/1901.02860) extends the Transformer architecture with a segment-level recurrence mechanism and relative positional encoding to handle longer-term dependencies without losing temporal coherence. It achieves significant improvements in capturing long-range dependencies, outperforming RNNs and vanilla Transformers in both short and long sequences. Transformer-XL demonstrates state-of-the-art results on various benchmarks, including enwiki8, text8, WikiText-103, One Billion Word, and Penn Treebank, and can generate coherent text articles with thousands of tokens.
+## Usage tips
+
+- Transformer-XL uses relative sinusoidal positional embeddings. Pad inputs on the left or right. The original implementation trains on SQuAD with left padding, so padding defaults to left.
+- Transformer-XL has no sequence length limit, unlike most other models.
+- Transformer-XL works like a regular GPT model but introduces a recurrence mechanism for consecutive segments. A segment is a number of consecutive tokens (like 512) that may span across multiple documents. Segments are fed in order to the model.
+- The model concatenates hidden states from the previous segment to the current input to compute attention scores. This lets the model attend to information from both the previous and current segments. Stacking multiple attention layers increases the receptive field to multiple previous segments.
+- This changes positional embeddings to relative positional embeddings. Regular positional embeddings would give the same results for the current input and current hidden state at a given position. The model makes adjustments in how attention scores are computed.
+- Transformer-XL doesn't work with `torch.nn.DataParallel` due to a bug in PyTorch. See [issue #36035](https://github.com/pytorch/pytorch/issues/36035).
+- This model was deprecated due to security issues with `pickle.load`. Use a specific revision to download safe files from the Hub. Set `TRUST_REMOTE_CODE=True` as an environment variable.
+
## TransfoXLConfig
[[autodoc]] TransfoXLConfig
diff --git a/docs/source/en/model_doc/ul2.md b/docs/source/en/model_doc/ul2.md
index 29f33bcea48..d54568f744c 100644
--- a/docs/source/en/model_doc/ul2.md
+++ b/docs/source/en/model_doc/ul2.md
@@ -46,4 +46,8 @@ print(tokenizer.decode(outputs[0]))
```
-
\ No newline at end of file
+
+
+## Usage tips
+
+- UL2 has the same architecture as T5v1.1 but uses Gated-SiLU activation instead of Gated-GELU.
\ No newline at end of file
diff --git a/docs/source/en/model_doc/umt5.md b/docs/source/en/model_doc/umt5.md
index ba00aa242c6..103f08499d5 100644
--- a/docs/source/en/model_doc/umt5.md
+++ b/docs/source/en/model_doc/umt5.md
@@ -58,6 +58,12 @@ print(tokenizer.decode(outputs[0]))
+## Usage tips
+
+- UMT5 was only pre-trained on mC4 without supervised training. Fine-tune the model before using it on downstream tasks (unlike the original T5 model).
+- UMT5 was pre-trained unsupervised, so task prefixes don't help during single-task fine-tuning. Use prefixes for multi-task fine-tuning.
+- UMT5 is based on mT5 with non-shared relative positional bias computed for each layer. The model sets `has_relative_bias` for each layer. The conversion script differs because the model was saved in t5x's latest checkpointing format.
+
## UMT5Config
[[autodoc]] UMT5Config
diff --git a/docs/source/en/model_doc/xlm-prophetnet.md b/docs/source/en/model_doc/xlm-prophetnet.md
index d5e1a1e30fc..e338db574f7 100644
--- a/docs/source/en/model_doc/xlm-prophetnet.md
+++ b/docs/source/en/model_doc/xlm-prophetnet.md
@@ -16,7 +16,9 @@ rendered properly in your Markdown viewer.
*This model was released on 2020-01-13 and added to Hugging Face Transformers on 2023-06-20.*
> [!WARNING]
-> This model is in maintenance mode only, we don’t accept any new PRs changing its code. If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2. You can do so by running the following command: pip install -U transformers==4.40.2.
+> This model is in maintenance mode only, we don’t accept any new PRs changing its code.
+>
+> If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2. You can do so by running the following command: pip install -U transformers==4.40.2.
# XLM-ProphetNet
diff --git a/docs/source/en/model_doc/xlm-roberta-xl.md b/docs/source/en/model_doc/xlm-roberta-xl.md
index e0b5da9755a..a3ad6ca48c4 100644
--- a/docs/source/en/model_doc/xlm-roberta-xl.md
+++ b/docs/source/en/model_doc/xlm-roberta-xl.md
@@ -57,6 +57,10 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- XLM-RoBERTa-XL doesn't require `lang` tensors to understand the input language. It automatically detects the language from `input_ids`.
+
## XLMRobertaXLConfig
[[autodoc]] XLMRobertaXLConfig
diff --git a/docs/source/en/model_doc/xlm-roberta.md b/docs/source/en/model_doc/xlm-roberta.md
index b7310b63b9d..7a6f04f4b2e 100644
--- a/docs/source/en/model_doc/xlm-roberta.md
+++ b/docs/source/en/model_doc/xlm-roberta.md
@@ -57,6 +57,9 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- XLM-RoBERTa doesn't require `lang` tensors to understand the input language. It automatically detects the language from `input_ids`.
## XLMRobertaConfig
diff --git a/docs/source/en/model_doc/xlm-v.md b/docs/source/en/model_doc/xlm-v.md
index 620af79eb6e..86bab5e0ea7 100644
--- a/docs/source/en/model_doc/xlm-v.md
+++ b/docs/source/en/model_doc/xlm-v.md
@@ -49,4 +49,9 @@ print(f"Predicted word: {predicted_word}")
```
-
\ No newline at end of file
+
+
+## Usage tips
+
+- XLM-V is compatible with the XLM-RoBERTa model architecture. Only model weights from the fairseq library needed conversion.
+- The [`XLMTokenizer`] implementation loads the vocabulary and performs tokenization.
\ No newline at end of file
diff --git a/docs/source/en/model_doc/xlnet.md b/docs/source/en/model_doc/xlnet.md
index a2b3830bf0e..65f7e818f4e 100644
--- a/docs/source/en/model_doc/xlnet.md
+++ b/docs/source/en/model_doc/xlnet.md
@@ -50,6 +50,15 @@ print(f"Predicted label: {label}")
+## Usage tips
+
+- Control the specific attention pattern at training and test time using the `perm_mask` input.
+- XLNet is pretrained using only a subset of output tokens as targets. These are selected with the `target_mapping` input. Training a fully autoregressive model over various factorization orders is difficult.
+- Use XLNet for sequential decoding (not in fully bidirectional setting) with `perm_mask` and `target_mapping` inputs to control attention span and outputs. See examples in `examples/pytorch/text-generation/run_generation.py`.
+- XLNet has no sequence length limit, unlike most other models.
+- XLNet isn't a traditional autoregressive model but uses a training strategy that builds on that approach. It permutes tokens in the sentence, then lets the model use the last n tokens to predict token n+1. This uses a mask, so the sentence feeds into the model in the right order. Instead of masking the first n tokens for n+1, XLNet uses a mask that hides previous tokens in some given permutation of 1,…,sequence length.
+- XLNet uses the same recurrence mechanism as Transformer-XL to build long-term dependencies.
+
## XLNetConfig
[[autodoc]] XLNetConfig
diff --git a/docs/source/en/model_doc/xmod.md b/docs/source/en/model_doc/xmod.md
index 8c998bd814f..96d20fe2d0c 100644
--- a/docs/source/en/model_doc/xmod.md
+++ b/docs/source/en/model_doc/xmod.md
@@ -41,6 +41,14 @@ print(f"Generated text: {generated_text}")
+## Usage tips
+
+- X-MOD is similar to XLM-R but requires specifying the input language to activate the correct language adapter.
+- The main models (base and large) have adapters for 81 languages.
+- Specify the input language in two ways: set a default language before using the model, or explicitly pass the language adapter index for each sample.
+- Freeze the embedding layer and language adapters during fine-tuning (recommended by the paper).
+- After fine-tuning, test zero-shot cross-lingual transfer by activating the target language adapter.
+
## XmodConfig
[[autodoc]] XmodConfig
diff --git a/docs/source/en/model_doc/yoso.md b/docs/source/en/model_doc/yoso.md
index d8cde34de6c..8f1782a19ad 100644
--- a/docs/source/en/model_doc/yoso.md
+++ b/docs/source/en/model_doc/yoso.md
@@ -51,6 +51,13 @@ print(f"Predicted word: {predicted_word}")
+## Usage tips
+
+- The YOSO attention algorithm uses custom CUDA kernels. These are functions written in CUDA C++ that execute multiple times in parallel on a GPU.
+- The kernels provide a `fast_hash` function that approximates random projections of queries and keys using the Fast Hadamard Transform. The `lsh_cumulation` function uses these hash codes to approximate self-attention via LSH-based Bernoulli sampling.
+- Set `config.use_expectation = False` to use custom kernels. Install the correct version of PyTorch and cudatoolkit to ensure kernels compile successfully.
+- By default, `config.use_expectation = True` uses YOSO-E and doesn't require compiling CUDA kernels.
+
## YosoConfig
[[autodoc]] YosoConfig
 -
-