mirror of
https://github.com/pytorch/pytorch.git
synced 2025-10-20 21:14:14 +08:00
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
## Benchmarking:
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
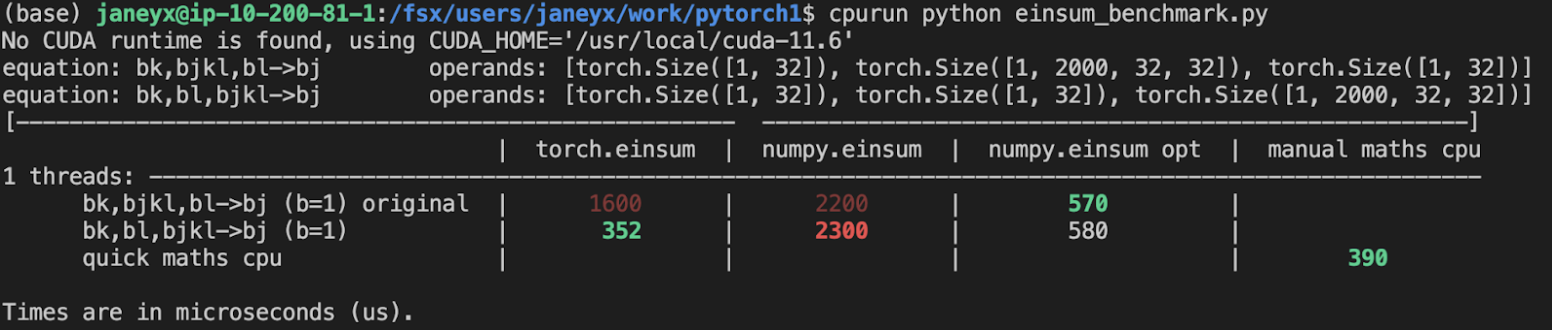
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
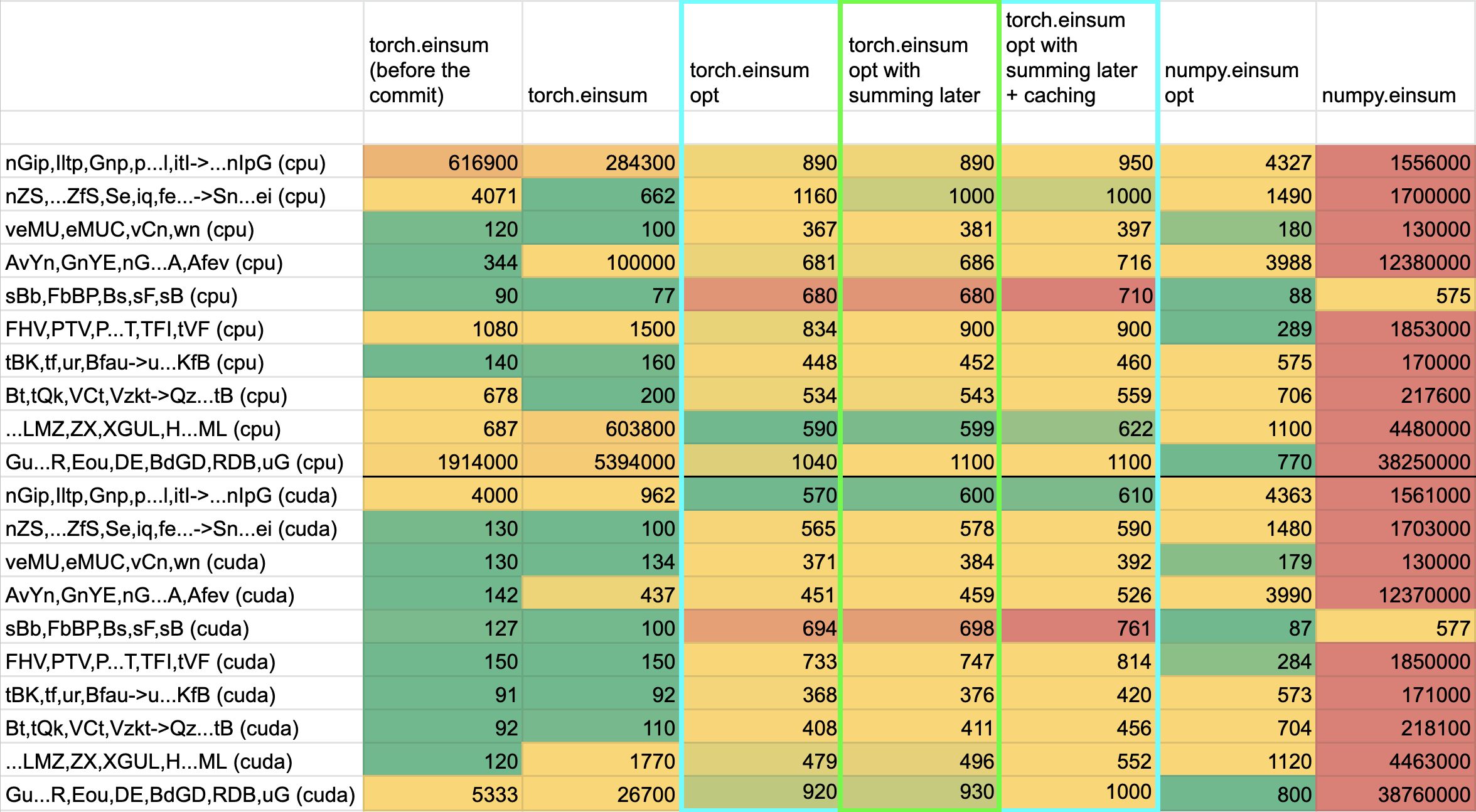
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1213 lines
45 KiB
Python
1213 lines
45 KiB
Python
# Welcome to the PyTorch setup.py.
|
|
#
|
|
# Environment variables you are probably interested in:
|
|
#
|
|
# DEBUG
|
|
# build with -O0 and -g (debug symbols)
|
|
#
|
|
# REL_WITH_DEB_INFO
|
|
# build with optimizations and -g (debug symbols)
|
|
#
|
|
# MAX_JOBS
|
|
# maximum number of compile jobs we should use to compile your code
|
|
#
|
|
# USE_CUDA=0
|
|
# disables CUDA build
|
|
#
|
|
# CFLAGS
|
|
# flags to apply to both C and C++ files to be compiled (a quirk of setup.py
|
|
# which we have faithfully adhered to in our build system is that CFLAGS
|
|
# also applies to C++ files (unless CXXFLAGS is set), in contrast to the
|
|
# default behavior of autogoo and cmake build systems.)
|
|
#
|
|
# CC
|
|
# the C/C++ compiler to use
|
|
#
|
|
# Environment variables for feature toggles:
|
|
#
|
|
# USE_CUDNN=0
|
|
# disables the cuDNN build
|
|
#
|
|
# USE_FBGEMM=0
|
|
# disables the FBGEMM build
|
|
#
|
|
# USE_KINETO=0
|
|
# disables usage of libkineto library for profiling
|
|
#
|
|
# USE_NUMPY=0
|
|
# disables the NumPy build
|
|
#
|
|
# BUILD_TEST=0
|
|
# disables the test build
|
|
#
|
|
# USE_MKLDNN=0
|
|
# disables use of MKLDNN
|
|
#
|
|
# USE_MKLDNN_ACL
|
|
# enables use of Compute Library backend for MKLDNN on Arm;
|
|
# USE_MKLDNN must be explicitly enabled.
|
|
#
|
|
# MKLDNN_CPU_RUNTIME
|
|
# MKL-DNN threading mode: TBB or OMP (default)
|
|
#
|
|
# USE_STATIC_MKL
|
|
# Prefer to link with MKL statically - Unix only
|
|
# USE_ITT=0
|
|
# disable use of Intel(R) VTune Profiler's ITT functionality
|
|
#
|
|
# USE_NNPACK=0
|
|
# disables NNPACK build
|
|
#
|
|
# USE_QNNPACK=0
|
|
# disables QNNPACK build (quantized 8-bit operators)
|
|
#
|
|
# USE_DISTRIBUTED=0
|
|
# disables distributed (c10d, gloo, mpi, etc.) build
|
|
#
|
|
# USE_TENSORPIPE=0
|
|
# disables distributed Tensorpipe backend build
|
|
#
|
|
# USE_GLOO=0
|
|
# disables distributed gloo backend build
|
|
#
|
|
# USE_MPI=0
|
|
# disables distributed MPI backend build
|
|
#
|
|
# USE_SYSTEM_NCCL=0
|
|
# disables use of system-wide nccl (we will use our submoduled
|
|
# copy in third_party/nccl)
|
|
#
|
|
# BUILD_CAFFE2_OPS=0
|
|
# disable Caffe2 operators build
|
|
#
|
|
# BUILD_CAFFE2=0
|
|
# disable Caffe2 build
|
|
#
|
|
# USE_IBVERBS
|
|
# toggle features related to distributed support
|
|
#
|
|
# USE_OPENCV
|
|
# enables use of OpenCV for additional operators
|
|
#
|
|
# USE_OPENMP=0
|
|
# disables use of OpenMP for parallelization
|
|
#
|
|
# USE_FFMPEG
|
|
# enables use of ffmpeg for additional operators
|
|
#
|
|
# USE_LEVELDB
|
|
# enables use of LevelDB for storage
|
|
#
|
|
# USE_LMDB
|
|
# enables use of LMDB for storage
|
|
#
|
|
# BUILD_BINARY
|
|
# enables the additional binaries/ build
|
|
#
|
|
# ATEN_AVX512_256=TRUE
|
|
# ATen AVX2 kernels can use 32 ymm registers, instead of the default 16.
|
|
# This option can be used if AVX512 doesn't perform well on a machine.
|
|
# The FBGEMM library also uses AVX512_256 kernels on Xeon D processors,
|
|
# but it also has some (optimized) assembly code.
|
|
#
|
|
# PYTORCH_BUILD_VERSION
|
|
# PYTORCH_BUILD_NUMBER
|
|
# specify the version of PyTorch, rather than the hard-coded version
|
|
# in this file; used when we're building binaries for distribution
|
|
#
|
|
# TORCH_CUDA_ARCH_LIST
|
|
# specify which CUDA architectures to build for.
|
|
# ie `TORCH_CUDA_ARCH_LIST="6.0;7.0"`
|
|
# These are not CUDA versions, instead, they specify what
|
|
# classes of NVIDIA hardware we should generate PTX for.
|
|
#
|
|
# PYTORCH_ROCM_ARCH
|
|
# specify which AMD GPU targets to build for.
|
|
# ie `PYTORCH_ROCM_ARCH="gfx900;gfx906"`
|
|
#
|
|
# ONNX_NAMESPACE
|
|
# specify a namespace for ONNX built here rather than the hard-coded
|
|
# one in this file; needed to build with other frameworks that share ONNX.
|
|
#
|
|
# BLAS
|
|
# BLAS to be used by Caffe2. Can be MKL, Eigen, ATLAS, FlexiBLAS, or OpenBLAS. If set
|
|
# then the build will fail if the requested BLAS is not found, otherwise
|
|
# the BLAS will be chosen based on what is found on your system.
|
|
#
|
|
# MKL_THREADING
|
|
# MKL threading mode: SEQ, TBB or OMP (default)
|
|
#
|
|
# USE_REDIS
|
|
# Whether to use Redis for distributed workflows (Linux only)
|
|
#
|
|
# USE_ZSTD
|
|
# Enables use of ZSTD, if the libraries are found
|
|
#
|
|
# Environment variables we respect (these environment variables are
|
|
# conventional and are often understood/set by other software.)
|
|
#
|
|
# CUDA_HOME (Linux/OS X)
|
|
# CUDA_PATH (Windows)
|
|
# specify where CUDA is installed; usually /usr/local/cuda or
|
|
# /usr/local/cuda-x.y
|
|
# CUDAHOSTCXX
|
|
# specify a different compiler than the system one to use as the CUDA
|
|
# host compiler for nvcc.
|
|
#
|
|
# CUDA_NVCC_EXECUTABLE
|
|
# Specify a NVCC to use. This is used in our CI to point to a cached nvcc
|
|
#
|
|
# CUDNN_LIB_DIR
|
|
# CUDNN_INCLUDE_DIR
|
|
# CUDNN_LIBRARY
|
|
# specify where cuDNN is installed
|
|
#
|
|
# MIOPEN_LIB_DIR
|
|
# MIOPEN_INCLUDE_DIR
|
|
# MIOPEN_LIBRARY
|
|
# specify where MIOpen is installed
|
|
#
|
|
# NCCL_ROOT
|
|
# NCCL_LIB_DIR
|
|
# NCCL_INCLUDE_DIR
|
|
# specify where nccl is installed
|
|
#
|
|
# NVTOOLSEXT_PATH (Windows only)
|
|
# specify where nvtoolsext is installed
|
|
#
|
|
# ACL_ROOT_DIR
|
|
# specify where Compute Library is installed
|
|
#
|
|
# LIBRARY_PATH
|
|
# LD_LIBRARY_PATH
|
|
# we will search for libraries in these paths
|
|
#
|
|
# ATEN_THREADING
|
|
# ATen parallel backend to use for intra- and inter-op parallelism
|
|
# possible values:
|
|
# OMP - use OpenMP for intra-op and native backend for inter-op tasks
|
|
# NATIVE - use native thread pool for both intra- and inter-op tasks
|
|
# TBB - using TBB for intra- and native thread pool for inter-op parallelism
|
|
#
|
|
# USE_TBB
|
|
# enable TBB support
|
|
#
|
|
# USE_SYSTEM_TBB
|
|
# Use system-provided Intel TBB.
|
|
#
|
|
# USE_SYSTEM_LIBS (work in progress)
|
|
# Use system-provided libraries to satisfy the build dependencies.
|
|
# When turned on, the following cmake variables will be toggled as well:
|
|
# USE_SYSTEM_CPUINFO=ON USE_SYSTEM_SLEEF=ON BUILD_CUSTOM_PROTOBUF=OFF
|
|
|
|
# This future is needed to print Python2 EOL message
|
|
from __future__ import print_function
|
|
import sys
|
|
if sys.version_info < (3,):
|
|
print("Python 2 has reached end-of-life and is no longer supported by PyTorch.")
|
|
sys.exit(-1)
|
|
if sys.platform == 'win32' and sys.maxsize.bit_length() == 31:
|
|
print("32-bit Windows Python runtime is not supported. Please switch to 64-bit Python.")
|
|
sys.exit(-1)
|
|
|
|
import platform
|
|
python_min_version = (3, 7, 0)
|
|
python_min_version_str = '.'.join(map(str, python_min_version))
|
|
if sys.version_info < python_min_version:
|
|
print("You are using Python {}. Python >={} is required.".format(platform.python_version(),
|
|
python_min_version_str))
|
|
sys.exit(-1)
|
|
|
|
from setuptools import setup, Extension, find_packages
|
|
from collections import defaultdict
|
|
from setuptools.dist import Distribution
|
|
import setuptools.command.build_ext
|
|
import setuptools.command.install
|
|
import setuptools.command.sdist
|
|
import filecmp
|
|
import shutil
|
|
import subprocess
|
|
import os
|
|
import json
|
|
import glob
|
|
import importlib
|
|
import time
|
|
import sysconfig
|
|
|
|
from tools.build_pytorch_libs import build_caffe2
|
|
from tools.setup_helpers.env import (IS_WINDOWS, IS_DARWIN, IS_LINUX,
|
|
build_type)
|
|
from tools.setup_helpers.cmake import CMake
|
|
from tools.generate_torch_version import get_torch_version
|
|
|
|
################################################################################
|
|
# Parameters parsed from environment
|
|
################################################################################
|
|
|
|
VERBOSE_SCRIPT = True
|
|
RUN_BUILD_DEPS = True
|
|
# see if the user passed a quiet flag to setup.py arguments and respect
|
|
# that in our parts of the build
|
|
EMIT_BUILD_WARNING = False
|
|
RERUN_CMAKE = False
|
|
CMAKE_ONLY = False
|
|
filtered_args = []
|
|
for i, arg in enumerate(sys.argv):
|
|
if arg == '--cmake':
|
|
RERUN_CMAKE = True
|
|
continue
|
|
if arg == '--cmake-only':
|
|
# Stop once cmake terminates. Leave users a chance to adjust build
|
|
# options.
|
|
CMAKE_ONLY = True
|
|
continue
|
|
if arg == 'rebuild' or arg == 'build':
|
|
arg = 'build' # rebuild is gone, make it build
|
|
EMIT_BUILD_WARNING = True
|
|
if arg == "--":
|
|
filtered_args += sys.argv[i:]
|
|
break
|
|
if arg == '-q' or arg == '--quiet':
|
|
VERBOSE_SCRIPT = False
|
|
if arg in ['clean', 'egg_info', 'sdist']:
|
|
RUN_BUILD_DEPS = False
|
|
filtered_args.append(arg)
|
|
sys.argv = filtered_args
|
|
|
|
if VERBOSE_SCRIPT:
|
|
def report(*args):
|
|
print(*args)
|
|
else:
|
|
def report(*args):
|
|
pass
|
|
|
|
# Make distutils respect --quiet too
|
|
setuptools.distutils.log.warn = report
|
|
|
|
# Constant known variables used throughout this file
|
|
cwd = os.path.dirname(os.path.abspath(__file__))
|
|
lib_path = os.path.join(cwd, "torch", "lib")
|
|
third_party_path = os.path.join(cwd, "third_party")
|
|
caffe2_build_dir = os.path.join(cwd, "build")
|
|
|
|
# CMAKE: full path to python library
|
|
if IS_WINDOWS:
|
|
cmake_python_library = "{}/libs/python{}.lib".format(
|
|
sysconfig.get_config_var("prefix"),
|
|
sysconfig.get_config_var("VERSION"))
|
|
# Fix virtualenv builds
|
|
if not os.path.exists(cmake_python_library):
|
|
cmake_python_library = "{}/libs/python{}.lib".format(
|
|
sys.base_prefix,
|
|
sysconfig.get_config_var("VERSION"))
|
|
else:
|
|
cmake_python_library = "{}/{}".format(
|
|
sysconfig.get_config_var("LIBDIR"),
|
|
sysconfig.get_config_var("INSTSONAME"))
|
|
cmake_python_include_dir = sysconfig.get_path("include")
|
|
|
|
|
|
################################################################################
|
|
# Version, create_version_file, and package_name
|
|
################################################################################
|
|
package_name = os.getenv('TORCH_PACKAGE_NAME', 'torch')
|
|
package_type = os.getenv('PACKAGE_TYPE', 'wheel')
|
|
version = get_torch_version()
|
|
report("Building wheel {}-{}".format(package_name, version))
|
|
|
|
cmake = CMake()
|
|
|
|
|
|
def get_submodule_folders():
|
|
git_modules_path = os.path.join(cwd, ".gitmodules")
|
|
default_modules_path = [os.path.join(third_party_path, name) for name in [
|
|
"gloo", "cpuinfo", "tbb", "onnx",
|
|
"foxi", "QNNPACK", "fbgemm", "cutlass"
|
|
]]
|
|
if not os.path.exists(git_modules_path):
|
|
return default_modules_path
|
|
with open(git_modules_path) as f:
|
|
return [os.path.join(cwd, line.split("=", 1)[1].strip()) for line in
|
|
f.readlines() if line.strip().startswith("path")]
|
|
|
|
|
|
def check_submodules():
|
|
def check_for_files(folder, files):
|
|
if not any(os.path.exists(os.path.join(folder, f)) for f in files):
|
|
report("Could not find any of {} in {}".format(", ".join(files), folder))
|
|
report("Did you run 'git submodule update --init --recursive --jobs 0'?")
|
|
sys.exit(1)
|
|
|
|
def not_exists_or_empty(folder):
|
|
return not os.path.exists(folder) or (os.path.isdir(folder) and len(os.listdir(folder)) == 0)
|
|
|
|
if bool(os.getenv("USE_SYSTEM_LIBS", False)):
|
|
return
|
|
folders = get_submodule_folders()
|
|
# If none of the submodule folders exists, try to initialize them
|
|
if all(not_exists_or_empty(folder) for folder in folders):
|
|
try:
|
|
print(' --- Trying to initialize submodules')
|
|
start = time.time()
|
|
subprocess.check_call(["git", "submodule", "update", "--init", "--recursive"], cwd=cwd)
|
|
end = time.time()
|
|
print(' --- Submodule initialization took {:.2f} sec'.format(end - start))
|
|
except Exception:
|
|
print(' --- Submodule initalization failed')
|
|
print('Please run:\n\tgit submodule update --init --recursive --jobs 0')
|
|
sys.exit(1)
|
|
for folder in folders:
|
|
check_for_files(folder, ["CMakeLists.txt", "Makefile", "setup.py", "LICENSE", "LICENSE.md", "LICENSE.txt"])
|
|
check_for_files(os.path.join(third_party_path, 'fbgemm', 'third_party',
|
|
'asmjit'), ['CMakeLists.txt'])
|
|
check_for_files(os.path.join(third_party_path, 'onnx', 'third_party',
|
|
'benchmark'), ['CMakeLists.txt'])
|
|
|
|
|
|
# Windows has very bad support for symbolic links.
|
|
# Instead of using symlinks, we're going to copy files over
|
|
def mirror_files_into_torchgen():
|
|
# (new_path, orig_path)
|
|
# Directories are OK and are recursively mirrored.
|
|
paths = [
|
|
('torchgen/packaged/ATen/native/native_functions.yaml', 'aten/src/ATen/native/native_functions.yaml'),
|
|
('torchgen/packaged/ATen/native/tags.yaml', 'aten/src/ATen/native/tags.yaml'),
|
|
('torchgen/packaged/ATen/templates', 'aten/src/ATen/templates'),
|
|
]
|
|
for new_path, orig_path in paths:
|
|
# Create the dirs involved in new_path if they don't exist
|
|
if not os.path.exists(new_path):
|
|
os.makedirs(os.path.dirname(new_path), exist_ok=True)
|
|
|
|
# Copy the files from the orig location to the new location
|
|
if os.path.isfile(orig_path):
|
|
shutil.copyfile(orig_path, new_path)
|
|
continue
|
|
if os.path.isdir(orig_path):
|
|
if os.path.exists(new_path):
|
|
# copytree fails if the tree exists already, so remove it.
|
|
shutil.rmtree(new_path)
|
|
shutil.copytree(orig_path, new_path)
|
|
continue
|
|
raise RuntimeError("Check the file paths in `mirror_files_into_torchgen()`")
|
|
|
|
# all the work we need to do _before_ setup runs
|
|
def build_deps():
|
|
report('-- Building version ' + version)
|
|
|
|
check_submodules()
|
|
check_pydep('yaml', 'pyyaml')
|
|
|
|
build_caffe2(version=version,
|
|
cmake_python_library=cmake_python_library,
|
|
build_python=True,
|
|
rerun_cmake=RERUN_CMAKE,
|
|
cmake_only=CMAKE_ONLY,
|
|
cmake=cmake)
|
|
|
|
if CMAKE_ONLY:
|
|
report('Finished running cmake. Run "ccmake build" or '
|
|
'"cmake-gui build" to adjust build options and '
|
|
'"python setup.py install" to build.')
|
|
sys.exit()
|
|
|
|
# Use copies instead of symbolic files.
|
|
# Windows has very poor support for them.
|
|
sym_files = [
|
|
'tools/shared/_utils_internal.py',
|
|
'torch/utils/benchmark/utils/valgrind_wrapper/callgrind.h',
|
|
'torch/utils/benchmark/utils/valgrind_wrapper/valgrind.h',
|
|
]
|
|
orig_files = [
|
|
'torch/_utils_internal.py',
|
|
'third_party/valgrind-headers/callgrind.h',
|
|
'third_party/valgrind-headers/valgrind.h',
|
|
]
|
|
for sym_file, orig_file in zip(sym_files, orig_files):
|
|
same = False
|
|
if os.path.exists(sym_file):
|
|
if filecmp.cmp(sym_file, orig_file):
|
|
same = True
|
|
else:
|
|
os.remove(sym_file)
|
|
if not same:
|
|
shutil.copyfile(orig_file, sym_file)
|
|
|
|
################################################################################
|
|
# Building dependent libraries
|
|
################################################################################
|
|
|
|
missing_pydep = '''
|
|
Missing build dependency: Unable to `import {importname}`.
|
|
Please install it via `conda install {module}` or `pip install {module}`
|
|
'''.strip()
|
|
|
|
|
|
def check_pydep(importname, module):
|
|
try:
|
|
importlib.import_module(importname)
|
|
except ImportError:
|
|
raise RuntimeError(missing_pydep.format(importname=importname, module=module))
|
|
|
|
|
|
class build_ext(setuptools.command.build_ext.build_ext):
|
|
|
|
# Copy libiomp5.dylib inside the wheel package on OS X
|
|
def _embed_libiomp(self):
|
|
|
|
lib_dir = os.path.join(self.build_lib, 'torch', 'lib')
|
|
libtorch_cpu_path = os.path.join(lib_dir, 'libtorch_cpu.dylib')
|
|
if not os.path.exists(libtorch_cpu_path):
|
|
return
|
|
# Parse libtorch_cpu load commands
|
|
otool_cmds = subprocess.check_output(['otool', '-l', libtorch_cpu_path]).decode('utf-8').split('\n')
|
|
rpaths, libs = [], []
|
|
for idx, line in enumerate(otool_cmds):
|
|
if line.strip() == 'cmd LC_LOAD_DYLIB':
|
|
lib_name = otool_cmds[idx + 2].strip()
|
|
assert lib_name.startswith('name ')
|
|
libs.append(lib_name.split(' ', 1)[1].rsplit('(', 1)[0][:-1])
|
|
|
|
if line.strip() == 'cmd LC_RPATH':
|
|
rpath = otool_cmds[idx + 2].strip()
|
|
assert rpath.startswith('path ')
|
|
rpaths.append(rpath.split(' ', 1)[1].rsplit('(', 1)[0][:-1])
|
|
|
|
omp_lib_name = 'libiomp5.dylib'
|
|
if os.path.join('@rpath', omp_lib_name) not in libs:
|
|
return
|
|
|
|
# Copy libiomp5 from rpath locations
|
|
for rpath in rpaths:
|
|
source_lib = os.path.join(rpath, omp_lib_name)
|
|
if not os.path.exists(source_lib):
|
|
continue
|
|
target_lib = os.path.join(self.build_lib, 'torch', 'lib', omp_lib_name)
|
|
self.copy_file(source_lib, target_lib)
|
|
break
|
|
|
|
def run(self):
|
|
# Report build options. This is run after the build completes so # `CMakeCache.txt` exists and we can get an
|
|
# accurate report on what is used and what is not.
|
|
cmake_cache_vars = defaultdict(lambda: False, cmake.get_cmake_cache_variables())
|
|
if cmake_cache_vars['USE_NUMPY']:
|
|
report('-- Building with NumPy bindings')
|
|
else:
|
|
report('-- NumPy not found')
|
|
if cmake_cache_vars['USE_CUDNN']:
|
|
report('-- Detected cuDNN at ' +
|
|
cmake_cache_vars['CUDNN_LIBRARY'] + ', ' + cmake_cache_vars['CUDNN_INCLUDE_DIR'])
|
|
else:
|
|
report('-- Not using cuDNN')
|
|
if cmake_cache_vars['USE_CUDA']:
|
|
report('-- Detected CUDA at ' + cmake_cache_vars['CUDA_TOOLKIT_ROOT_DIR'])
|
|
else:
|
|
report('-- Not using CUDA')
|
|
if cmake_cache_vars['USE_MKLDNN']:
|
|
report('-- Using MKLDNN')
|
|
if cmake_cache_vars['USE_MKLDNN_ACL']:
|
|
report('-- Using Compute Library for the Arm architecture with MKLDNN')
|
|
else:
|
|
report('-- Not using Compute Library for the Arm architecture with MKLDNN')
|
|
if cmake_cache_vars['USE_MKLDNN_CBLAS']:
|
|
report('-- Using CBLAS in MKLDNN')
|
|
else:
|
|
report('-- Not using CBLAS in MKLDNN')
|
|
else:
|
|
report('-- Not using MKLDNN')
|
|
if cmake_cache_vars['USE_NCCL'] and cmake_cache_vars['USE_SYSTEM_NCCL']:
|
|
report('-- Using system provided NCCL library at {}, {}'.format(cmake_cache_vars['NCCL_LIBRARIES'],
|
|
cmake_cache_vars['NCCL_INCLUDE_DIRS']))
|
|
elif cmake_cache_vars['USE_NCCL']:
|
|
report('-- Building NCCL library')
|
|
else:
|
|
report('-- Not using NCCL')
|
|
if cmake_cache_vars['USE_DISTRIBUTED']:
|
|
if IS_WINDOWS:
|
|
report('-- Building without distributed package')
|
|
else:
|
|
report('-- Building with distributed package: ')
|
|
report(' -- USE_TENSORPIPE={}'.format(cmake_cache_vars['USE_TENSORPIPE']))
|
|
report(' -- USE_GLOO={}'.format(cmake_cache_vars['USE_GLOO']))
|
|
report(' -- USE_MPI={}'.format(cmake_cache_vars['USE_OPENMPI']))
|
|
else:
|
|
report('-- Building without distributed package')
|
|
if cmake_cache_vars['STATIC_DISPATCH_BACKEND']:
|
|
report('-- Using static dispatch with backend {}'.format(cmake_cache_vars['STATIC_DISPATCH_BACKEND']))
|
|
if cmake_cache_vars['USE_LIGHTWEIGHT_DISPATCH']:
|
|
report('-- Using lightweight dispatch')
|
|
|
|
if cmake_cache_vars['USE_ITT']:
|
|
report('-- Using ITT')
|
|
else:
|
|
report('-- Not using ITT')
|
|
|
|
# Do not use clang to compile extensions if `-fstack-clash-protection` is defined
|
|
# in system CFLAGS
|
|
c_flags = str(os.getenv('CFLAGS', ''))
|
|
if IS_LINUX and '-fstack-clash-protection' in c_flags and 'clang' in os.environ.get('CC', ''):
|
|
os.environ['CC'] = str(os.environ['CC'])
|
|
|
|
# It's an old-style class in Python 2.7...
|
|
setuptools.command.build_ext.build_ext.run(self)
|
|
|
|
if IS_DARWIN and package_type != 'conda':
|
|
self._embed_libiomp()
|
|
|
|
# Copy the essential export library to compile C++ extensions.
|
|
if IS_WINDOWS:
|
|
build_temp = self.build_temp
|
|
|
|
ext_filename = self.get_ext_filename('_C')
|
|
lib_filename = '.'.join(ext_filename.split('.')[:-1]) + '.lib'
|
|
|
|
export_lib = os.path.join(
|
|
build_temp, 'torch', 'csrc', lib_filename).replace('\\', '/')
|
|
|
|
build_lib = self.build_lib
|
|
|
|
target_lib = os.path.join(
|
|
build_lib, 'torch', 'lib', '_C.lib').replace('\\', '/')
|
|
|
|
# Create "torch/lib" directory if not exists.
|
|
# (It is not created yet in "develop" mode.)
|
|
target_dir = os.path.dirname(target_lib)
|
|
if not os.path.exists(target_dir):
|
|
os.makedirs(target_dir)
|
|
|
|
self.copy_file(export_lib, target_lib)
|
|
|
|
def build_extensions(self):
|
|
self.create_compile_commands()
|
|
# The caffe2 extensions are created in
|
|
# tmp_install/lib/pythonM.m/site-packages/caffe2/python/
|
|
# and need to be copied to build/lib.linux.... , which will be a
|
|
# platform dependent build folder created by the "build" command of
|
|
# setuptools. Only the contents of this folder are installed in the
|
|
# "install" command by default.
|
|
# We only make this copy for Caffe2's pybind extensions
|
|
caffe2_pybind_exts = [
|
|
'caffe2.python.caffe2_pybind11_state',
|
|
'caffe2.python.caffe2_pybind11_state_gpu',
|
|
'caffe2.python.caffe2_pybind11_state_hip',
|
|
]
|
|
i = 0
|
|
while i < len(self.extensions):
|
|
ext = self.extensions[i]
|
|
if ext.name not in caffe2_pybind_exts:
|
|
i += 1
|
|
continue
|
|
fullname = self.get_ext_fullname(ext.name)
|
|
filename = self.get_ext_filename(fullname)
|
|
report("\nCopying extension {}".format(ext.name))
|
|
|
|
relative_site_packages = sysconfig.get_path('purelib').replace(sysconfig.get_path('data'), '').lstrip(os.path.sep)
|
|
src = os.path.join("torch", relative_site_packages, filename)
|
|
if not os.path.exists(src):
|
|
report("{} does not exist".format(src))
|
|
del self.extensions[i]
|
|
else:
|
|
dst = os.path.join(os.path.realpath(self.build_lib), filename)
|
|
report("Copying {} from {} to {}".format(ext.name, src, dst))
|
|
dst_dir = os.path.dirname(dst)
|
|
if not os.path.exists(dst_dir):
|
|
os.makedirs(dst_dir)
|
|
self.copy_file(src, dst)
|
|
i += 1
|
|
|
|
# Copy functorch extension
|
|
for i, ext in enumerate(self.extensions):
|
|
if ext.name != "functorch._C":
|
|
continue
|
|
fullname = self.get_ext_fullname(ext.name)
|
|
filename = self.get_ext_filename(fullname)
|
|
fileext = os.path.splitext(filename)[1]
|
|
src = os.path.join(os.path.dirname(filename), "functorch" + fileext)
|
|
dst = os.path.join(os.path.realpath(self.build_lib), filename)
|
|
if os.path.exists(src):
|
|
report("Copying {} from {} to {}".format(ext.name, src, dst))
|
|
dst_dir = os.path.dirname(dst)
|
|
if not os.path.exists(dst_dir):
|
|
os.makedirs(dst_dir)
|
|
self.copy_file(src, dst)
|
|
|
|
setuptools.command.build_ext.build_ext.build_extensions(self)
|
|
|
|
|
|
def get_outputs(self):
|
|
outputs = setuptools.command.build_ext.build_ext.get_outputs(self)
|
|
outputs.append(os.path.join(self.build_lib, "caffe2"))
|
|
report("setup.py::get_outputs returning {}".format(outputs))
|
|
return outputs
|
|
|
|
def create_compile_commands(self):
|
|
def load(filename):
|
|
with open(filename) as f:
|
|
return json.load(f)
|
|
ninja_files = glob.glob('build/*compile_commands.json')
|
|
cmake_files = glob.glob('torch/lib/build/*/compile_commands.json')
|
|
all_commands = [entry
|
|
for f in ninja_files + cmake_files
|
|
for entry in load(f)]
|
|
|
|
# cquery does not like c++ compiles that start with gcc.
|
|
# It forgets to include the c++ header directories.
|
|
# We can work around this by replacing the gcc calls that python
|
|
# setup.py generates with g++ calls instead
|
|
for command in all_commands:
|
|
if command['command'].startswith("gcc "):
|
|
command['command'] = "g++ " + command['command'][4:]
|
|
|
|
new_contents = json.dumps(all_commands, indent=2)
|
|
contents = ''
|
|
if os.path.exists('compile_commands.json'):
|
|
with open('compile_commands.json', 'r') as f:
|
|
contents = f.read()
|
|
if contents != new_contents:
|
|
with open('compile_commands.json', 'w') as f:
|
|
f.write(new_contents)
|
|
|
|
class concat_license_files():
|
|
"""Merge LICENSE and LICENSES_BUNDLED.txt as a context manager
|
|
|
|
LICENSE is the main PyTorch license, LICENSES_BUNDLED.txt is auto-generated
|
|
from all the licenses found in ./third_party/. We concatenate them so there
|
|
is a single license file in the sdist and wheels with all of the necessary
|
|
licensing info.
|
|
"""
|
|
def __init__(self, include_files=False):
|
|
self.f1 = 'LICENSE'
|
|
self.f2 = 'third_party/LICENSES_BUNDLED.txt'
|
|
self.include_files = include_files
|
|
|
|
def __enter__(self):
|
|
"""Concatenate files"""
|
|
|
|
old_path = sys.path
|
|
sys.path.append(third_party_path)
|
|
try:
|
|
from build_bundled import create_bundled
|
|
finally:
|
|
sys.path = old_path
|
|
|
|
with open(self.f1, 'r') as f1:
|
|
self.bsd_text = f1.read()
|
|
|
|
with open(self.f1, 'a') as f1:
|
|
f1.write('\n\n')
|
|
create_bundled(os.path.relpath(third_party_path), f1,
|
|
include_files=self.include_files)
|
|
|
|
|
|
def __exit__(self, exception_type, exception_value, traceback):
|
|
"""Restore content of f1"""
|
|
with open(self.f1, 'w') as f:
|
|
f.write(self.bsd_text)
|
|
|
|
|
|
try:
|
|
from wheel.bdist_wheel import bdist_wheel
|
|
except ImportError:
|
|
# This is useful when wheel is not installed and bdist_wheel is not
|
|
# specified on the command line. If it _is_ specified, parsing the command
|
|
# line will fail before wheel_concatenate is needed
|
|
wheel_concatenate = None
|
|
else:
|
|
# Need to create the proper LICENSE.txt for the wheel
|
|
class wheel_concatenate(bdist_wheel):
|
|
""" check submodules on sdist to prevent incomplete tarballs """
|
|
def run(self):
|
|
with concat_license_files(include_files=True):
|
|
super().run()
|
|
|
|
|
|
class install(setuptools.command.install.install):
|
|
def run(self):
|
|
super().run()
|
|
|
|
|
|
class clean(setuptools.Command):
|
|
user_options = []
|
|
|
|
def initialize_options(self):
|
|
pass
|
|
|
|
def finalize_options(self):
|
|
pass
|
|
|
|
def run(self):
|
|
import glob
|
|
import re
|
|
with open('.gitignore', 'r') as f:
|
|
ignores = f.read()
|
|
pat = re.compile(r'^#( BEGIN NOT-CLEAN-FILES )?')
|
|
for wildcard in filter(None, ignores.split('\n')):
|
|
match = pat.match(wildcard)
|
|
if match:
|
|
if match.group(1):
|
|
# Marker is found and stop reading .gitignore.
|
|
break
|
|
# Ignore lines which begin with '#'.
|
|
else:
|
|
for filename in glob.glob(wildcard):
|
|
try:
|
|
os.remove(filename)
|
|
except OSError:
|
|
shutil.rmtree(filename, ignore_errors=True)
|
|
|
|
|
|
class sdist(setuptools.command.sdist.sdist):
|
|
def run(self):
|
|
with concat_license_files():
|
|
super().run()
|
|
|
|
|
|
def configure_extension_build():
|
|
r"""Configures extension build options according to system environment and user's choice.
|
|
|
|
Returns:
|
|
The input to parameters ext_modules, cmdclass, packages, and entry_points as required in setuptools.setup.
|
|
"""
|
|
|
|
try:
|
|
cmake_cache_vars = defaultdict(lambda: False, cmake.get_cmake_cache_variables())
|
|
except FileNotFoundError:
|
|
# CMakeCache.txt does not exist. Probably running "python setup.py clean" over a clean directory.
|
|
cmake_cache_vars = defaultdict(lambda: False)
|
|
|
|
################################################################################
|
|
# Configure compile flags
|
|
################################################################################
|
|
|
|
library_dirs = []
|
|
extra_install_requires = []
|
|
|
|
if IS_WINDOWS:
|
|
# /NODEFAULTLIB makes sure we only link to DLL runtime
|
|
# and matches the flags set for protobuf and ONNX
|
|
extra_link_args = ['/NODEFAULTLIB:LIBCMT.LIB']
|
|
# /MD links against DLL runtime
|
|
# and matches the flags set for protobuf and ONNX
|
|
# /EHsc is about standard C++ exception handling
|
|
# /DNOMINMAX removes builtin min/max functions
|
|
# /wdXXXX disables warning no. XXXX
|
|
extra_compile_args = ['/MD', '/EHsc', '/DNOMINMAX',
|
|
'/wd4267', '/wd4251', '/wd4522', '/wd4522', '/wd4838',
|
|
'/wd4305', '/wd4244', '/wd4190', '/wd4101', '/wd4996',
|
|
'/wd4275']
|
|
else:
|
|
extra_link_args = []
|
|
extra_compile_args = [
|
|
'-Wall',
|
|
'-Wextra',
|
|
'-Wno-strict-overflow',
|
|
'-Wno-unused-parameter',
|
|
'-Wno-missing-field-initializers',
|
|
'-Wno-write-strings',
|
|
'-Wno-unknown-pragmas',
|
|
# This is required for Python 2 declarations that are deprecated in 3.
|
|
'-Wno-deprecated-declarations',
|
|
# Python 2.6 requires -fno-strict-aliasing, see
|
|
# http://legacy.python.org/dev/peps/pep-3123/
|
|
# We also depend on it in our code (even Python 3).
|
|
'-fno-strict-aliasing',
|
|
# Clang has an unfixed bug leading to spurious missing
|
|
# braces warnings, see
|
|
# https://bugs.llvm.org/show_bug.cgi?id=21629
|
|
'-Wno-missing-braces',
|
|
]
|
|
|
|
library_dirs.append(lib_path)
|
|
|
|
main_compile_args = []
|
|
main_libraries = ['torch_python']
|
|
main_link_args = []
|
|
main_sources = ["torch/csrc/stub.c"]
|
|
|
|
if cmake_cache_vars['USE_CUDA']:
|
|
library_dirs.append(
|
|
os.path.dirname(cmake_cache_vars['CUDA_CUDA_LIB']))
|
|
|
|
if build_type.is_debug():
|
|
if IS_WINDOWS:
|
|
extra_compile_args.append('/Z7')
|
|
extra_link_args.append('/DEBUG:FULL')
|
|
else:
|
|
extra_compile_args += ['-O0', '-g']
|
|
extra_link_args += ['-O0', '-g']
|
|
|
|
if build_type.is_rel_with_deb_info():
|
|
if IS_WINDOWS:
|
|
extra_compile_args.append('/Z7')
|
|
extra_link_args.append('/DEBUG:FULL')
|
|
else:
|
|
extra_compile_args += ['-g']
|
|
extra_link_args += ['-g']
|
|
|
|
# special CUDA 11.7 package that requires installation of cuda runtime, cudnn and cublas
|
|
pytorch_extra_install_requirements = os.getenv("PYTORCH_EXTRA_INSTALL_REQUIREMENTS", "")
|
|
if pytorch_extra_install_requirements:
|
|
report(f"pytorch_extra_install_requirements: {pytorch_extra_install_requirements}")
|
|
extra_install_requires += pytorch_extra_install_requirements.split(";")
|
|
|
|
|
|
# Cross-compile for M1
|
|
if IS_DARWIN:
|
|
macos_target_arch = os.getenv('CMAKE_OSX_ARCHITECTURES', '')
|
|
if macos_target_arch in ['arm64', 'x86_64']:
|
|
macos_sysroot_path = os.getenv('CMAKE_OSX_SYSROOT')
|
|
if macos_sysroot_path is None:
|
|
macos_sysroot_path = subprocess.check_output([
|
|
'xcrun', '--show-sdk-path', '--sdk', 'macosx'
|
|
]).decode('utf-8').strip()
|
|
extra_compile_args += ['-arch', macos_target_arch, '-isysroot', macos_sysroot_path]
|
|
extra_link_args += ['-arch', macos_target_arch]
|
|
|
|
|
|
def make_relative_rpath_args(path):
|
|
if IS_DARWIN:
|
|
return ['-Wl,-rpath,@loader_path/' + path]
|
|
elif IS_WINDOWS:
|
|
return []
|
|
else:
|
|
return ['-Wl,-rpath,$ORIGIN/' + path]
|
|
|
|
################################################################################
|
|
# Declare extensions and package
|
|
################################################################################
|
|
|
|
extensions = []
|
|
packages = find_packages(exclude=('tools', 'tools.*'))
|
|
C = Extension("torch._C",
|
|
libraries=main_libraries,
|
|
sources=main_sources,
|
|
language='c',
|
|
extra_compile_args=main_compile_args + extra_compile_args,
|
|
include_dirs=[],
|
|
library_dirs=library_dirs,
|
|
extra_link_args=extra_link_args + main_link_args + make_relative_rpath_args('lib'))
|
|
C_flatbuffer = Extension("torch._C_flatbuffer",
|
|
libraries=main_libraries,
|
|
sources=["torch/csrc/stub_with_flatbuffer.c"],
|
|
language='c',
|
|
extra_compile_args=main_compile_args + extra_compile_args,
|
|
include_dirs=[],
|
|
library_dirs=library_dirs,
|
|
extra_link_args=extra_link_args + main_link_args + make_relative_rpath_args('lib'))
|
|
extensions.append(C)
|
|
extensions.append(C_flatbuffer)
|
|
|
|
# These extensions are built by cmake and copied manually in build_extensions()
|
|
# inside the build_ext implementation
|
|
if cmake_cache_vars['BUILD_CAFFE2']:
|
|
extensions.append(
|
|
Extension(
|
|
name=str('caffe2.python.caffe2_pybind11_state'),
|
|
sources=[]),
|
|
)
|
|
if cmake_cache_vars['USE_CUDA']:
|
|
extensions.append(
|
|
Extension(
|
|
name=str('caffe2.python.caffe2_pybind11_state_gpu'),
|
|
sources=[]),
|
|
)
|
|
if cmake_cache_vars['USE_ROCM']:
|
|
extensions.append(
|
|
Extension(
|
|
name=str('caffe2.python.caffe2_pybind11_state_hip'),
|
|
sources=[]),
|
|
)
|
|
if cmake_cache_vars['BUILD_FUNCTORCH']:
|
|
extensions.append(
|
|
Extension(
|
|
name=str('functorch._C'),
|
|
sources=[]),
|
|
)
|
|
|
|
cmdclass = {
|
|
'bdist_wheel': wheel_concatenate,
|
|
'build_ext': build_ext,
|
|
'clean': clean,
|
|
'install': install,
|
|
'sdist': sdist,
|
|
}
|
|
|
|
entry_points = {
|
|
'console_scripts': [
|
|
'convert-caffe2-to-onnx = caffe2.python.onnx.bin.conversion:caffe2_to_onnx',
|
|
'convert-onnx-to-caffe2 = caffe2.python.onnx.bin.conversion:onnx_to_caffe2',
|
|
'torchrun = torch.distributed.run:main',
|
|
]
|
|
}
|
|
|
|
return extensions, cmdclass, packages, entry_points, extra_install_requires
|
|
|
|
# post run, warnings, printed at the end to make them more visible
|
|
build_update_message = """
|
|
It is no longer necessary to use the 'build' or 'rebuild' targets
|
|
|
|
To install:
|
|
$ python setup.py install
|
|
To develop locally:
|
|
$ python setup.py develop
|
|
To force cmake to re-generate native build files (off by default):
|
|
$ python setup.py develop --cmake
|
|
"""
|
|
|
|
|
|
def print_box(msg):
|
|
lines = msg.split('\n')
|
|
size = max(len(l) + 1 for l in lines)
|
|
print('-' * (size + 2))
|
|
for l in lines:
|
|
print('|{}{}|'.format(l, ' ' * (size - len(l))))
|
|
print('-' * (size + 2))
|
|
|
|
|
|
def main():
|
|
# the list of runtime dependencies required by this built package
|
|
install_requires = [
|
|
'typing_extensions',
|
|
]
|
|
|
|
# Parse the command line and check the arguments before we proceed with
|
|
# building deps and setup. We need to set values so `--help` works.
|
|
dist = Distribution()
|
|
dist.script_name = os.path.basename(sys.argv[0])
|
|
dist.script_args = sys.argv[1:]
|
|
try:
|
|
dist.parse_command_line()
|
|
except setuptools.distutils.errors.DistutilsArgError as e:
|
|
print(e)
|
|
sys.exit(1)
|
|
|
|
mirror_files_into_torchgen()
|
|
if RUN_BUILD_DEPS:
|
|
build_deps()
|
|
|
|
extensions, cmdclass, packages, entry_points, extra_install_requires = configure_extension_build()
|
|
|
|
install_requires += extra_install_requires
|
|
|
|
extras_require = {
|
|
'opt-einsum': ['opt-einsum>=3.3']
|
|
}
|
|
|
|
# Read in README.md for our long_description
|
|
with open(os.path.join(cwd, "README.md"), encoding="utf-8") as f:
|
|
long_description = f.read()
|
|
|
|
version_range_max = max(sys.version_info[1], 10) + 1
|
|
torch_package_data = [
|
|
'py.typed',
|
|
'bin/*',
|
|
'test/*',
|
|
'_C/*.pyi',
|
|
'_C_flatbuffer/*.pyi',
|
|
'cuda/*.pyi',
|
|
'optim/*.pyi',
|
|
'autograd/*.pyi',
|
|
'utils/data/*.pyi',
|
|
'nn/*.pyi',
|
|
'nn/modules/*.pyi',
|
|
'nn/parallel/*.pyi',
|
|
'utils/data/*.pyi',
|
|
'lib/*.so*',
|
|
'lib/*.dylib*',
|
|
'lib/*.dll',
|
|
'lib/*.lib',
|
|
'lib/*.pdb',
|
|
'lib/torch_shm_manager',
|
|
'lib/*.h',
|
|
'include/ATen/*.h',
|
|
'include/ATen/cpu/*.h',
|
|
'include/ATen/cpu/vec/vec256/*.h',
|
|
'include/ATen/cpu/vec/vec512/*.h',
|
|
'include/ATen/cpu/vec/*.h',
|
|
'include/ATen/core/*.h',
|
|
'include/ATen/cuda/*.cuh',
|
|
'include/ATen/cuda/*.h',
|
|
'include/ATen/cuda/detail/*.cuh',
|
|
'include/ATen/cuda/detail/*.h',
|
|
'include/ATen/cudnn/*.h',
|
|
'include/ATen/functorch/*.h',
|
|
'include/ATen/ops/*.h',
|
|
'include/ATen/hip/*.cuh',
|
|
'include/ATen/hip/*.h',
|
|
'include/ATen/hip/detail/*.cuh',
|
|
'include/ATen/hip/detail/*.h',
|
|
'include/ATen/hip/impl/*.h',
|
|
'include/ATen/detail/*.h',
|
|
'include/ATen/native/*.h',
|
|
'include/ATen/native/cpu/*.h',
|
|
'include/ATen/native/cuda/*.h',
|
|
'include/ATen/native/cuda/*.cuh',
|
|
'include/ATen/native/hip/*.h',
|
|
'include/ATen/native/hip/*.cuh',
|
|
'include/ATen/native/quantized/*.h',
|
|
'include/ATen/native/quantized/cpu/*.h',
|
|
'include/ATen/quantized/*.h',
|
|
'include/caffe2/utils/*.h',
|
|
'include/caffe2/utils/**/*.h',
|
|
'include/c10/*.h',
|
|
'include/c10/macros/*.h',
|
|
'include/c10/core/*.h',
|
|
'include/ATen/core/boxing/*.h',
|
|
'include/ATen/core/boxing/impl/*.h',
|
|
'include/ATen/core/dispatch/*.h',
|
|
'include/ATen/core/op_registration/*.h',
|
|
'include/c10/core/impl/*.h',
|
|
'include/c10/util/*.h',
|
|
'include/c10/cuda/*.h',
|
|
'include/c10/cuda/impl/*.h',
|
|
'include/c10/hip/*.h',
|
|
'include/c10/hip/impl/*.h',
|
|
'include/c10d/*.h',
|
|
'include/c10d/*.hpp',
|
|
'include/caffe2/**/*.h',
|
|
'include/torch/*.h',
|
|
'include/torch/csrc/*.h',
|
|
'include/torch/csrc/api/include/torch/*.h',
|
|
'include/torch/csrc/api/include/torch/data/*.h',
|
|
'include/torch/csrc/api/include/torch/data/dataloader/*.h',
|
|
'include/torch/csrc/api/include/torch/data/datasets/*.h',
|
|
'include/torch/csrc/api/include/torch/data/detail/*.h',
|
|
'include/torch/csrc/api/include/torch/data/samplers/*.h',
|
|
'include/torch/csrc/api/include/torch/data/transforms/*.h',
|
|
'include/torch/csrc/api/include/torch/detail/*.h',
|
|
'include/torch/csrc/api/include/torch/detail/ordered_dict.h',
|
|
'include/torch/csrc/api/include/torch/nn/*.h',
|
|
'include/torch/csrc/api/include/torch/nn/functional/*.h',
|
|
'include/torch/csrc/api/include/torch/nn/options/*.h',
|
|
'include/torch/csrc/api/include/torch/nn/modules/*.h',
|
|
'include/torch/csrc/api/include/torch/nn/modules/container/*.h',
|
|
'include/torch/csrc/api/include/torch/nn/parallel/*.h',
|
|
'include/torch/csrc/api/include/torch/nn/utils/*.h',
|
|
'include/torch/csrc/api/include/torch/optim/*.h',
|
|
'include/torch/csrc/api/include/torch/optim/schedulers/*.h',
|
|
'include/torch/csrc/api/include/torch/serialize/*.h',
|
|
'include/torch/csrc/autograd/*.h',
|
|
'include/torch/csrc/autograd/functions/*.h',
|
|
'include/torch/csrc/autograd/generated/*.h',
|
|
'include/torch/csrc/autograd/utils/*.h',
|
|
'include/torch/csrc/cuda/*.h',
|
|
'include/torch/csrc/deploy/*.h',
|
|
'include/torch/csrc/deploy/interpreter/*.h',
|
|
'include/torch/csrc/deploy/interpreter/*.hpp',
|
|
'include/torch/csrc/distributed/c10d/exception.h',
|
|
'include/torch/csrc/distributed/rpc/*.h',
|
|
'include/torch/csrc/jit/*.h',
|
|
'include/torch/csrc/jit/backends/*.h',
|
|
'include/torch/csrc/jit/generated/*.h',
|
|
'include/torch/csrc/jit/passes/*.h',
|
|
'include/torch/csrc/jit/passes/quantization/*.h',
|
|
'include/torch/csrc/jit/passes/utils/*.h',
|
|
'include/torch/csrc/jit/runtime/*.h',
|
|
'include/torch/csrc/jit/ir/*.h',
|
|
'include/torch/csrc/jit/frontend/*.h',
|
|
'include/torch/csrc/jit/api/*.h',
|
|
'include/torch/csrc/jit/serialization/*.h',
|
|
'include/torch/csrc/jit/python/*.h',
|
|
'include/torch/csrc/jit/mobile/*.h',
|
|
'include/torch/csrc/jit/testing/*.h',
|
|
'include/torch/csrc/jit/tensorexpr/*.h',
|
|
'include/torch/csrc/jit/tensorexpr/operators/*.h',
|
|
'include/torch/csrc/jit/codegen/cuda/*.h',
|
|
'include/torch/csrc/jit/codegen/cuda/ops/*.h',
|
|
'include/torch/csrc/jit/codegen/cuda/scheduler/*.h',
|
|
'include/torch/csrc/onnx/*.h',
|
|
'include/torch/csrc/profiler/*.h',
|
|
'include/torch/csrc/profiler/orchestration/*.h',
|
|
'include/torch/csrc/utils/*.h',
|
|
'include/torch/csrc/tensor/*.h',
|
|
'include/torch/csrc/lazy/backend/*.h',
|
|
'include/torch/csrc/lazy/core/*.h',
|
|
'include/torch/csrc/lazy/core/internal_ops/*.h',
|
|
'include/torch/csrc/lazy/core/ops/*.h',
|
|
'include/torch/csrc/lazy/ts_backend/*.h',
|
|
'include/pybind11/*.h',
|
|
'include/pybind11/detail/*.h',
|
|
'include/TH/*.h*',
|
|
'include/TH/generic/*.h*',
|
|
'include/THC/*.cuh',
|
|
'include/THC/*.h*',
|
|
'include/THC/generic/*.h',
|
|
'include/THH/*.cuh',
|
|
'include/THH/*.h*',
|
|
'include/THH/generic/*.h',
|
|
'share/cmake/ATen/*.cmake',
|
|
'share/cmake/Caffe2/*.cmake',
|
|
'share/cmake/Caffe2/public/*.cmake',
|
|
'share/cmake/Caffe2/Modules_CUDA_fix/*.cmake',
|
|
'share/cmake/Caffe2/Modules_CUDA_fix/upstream/*.cmake',
|
|
'share/cmake/Caffe2/Modules_CUDA_fix/upstream/FindCUDA/*.cmake',
|
|
'share/cmake/Gloo/*.cmake',
|
|
'share/cmake/Tensorpipe/*.cmake',
|
|
'share/cmake/Torch/*.cmake',
|
|
'utils/benchmark/utils/*.cpp',
|
|
'utils/benchmark/utils/valgrind_wrapper/*.cpp',
|
|
'utils/benchmark/utils/valgrind_wrapper/*.h',
|
|
'utils/model_dump/skeleton.html',
|
|
'utils/model_dump/code.js',
|
|
'utils/model_dump/*.mjs',
|
|
]
|
|
torchgen_package_data = [
|
|
# Recursive glob doesn't work in setup.py,
|
|
# https://github.com/pypa/setuptools/issues/1806
|
|
# To make this robust we should replace it with some code that
|
|
# returns a list of everything under packaged/
|
|
'packaged/ATen/*',
|
|
'packaged/ATen/native/*',
|
|
'packaged/ATen/templates/*',
|
|
]
|
|
setup(
|
|
name=package_name,
|
|
version=version,
|
|
description=("Tensors and Dynamic neural networks in "
|
|
"Python with strong GPU acceleration"),
|
|
long_description=long_description,
|
|
long_description_content_type="text/markdown",
|
|
ext_modules=extensions,
|
|
cmdclass=cmdclass,
|
|
packages=packages,
|
|
entry_points=entry_points,
|
|
install_requires=install_requires,
|
|
extras_require=extras_require,
|
|
package_data={
|
|
'torch': torch_package_data,
|
|
'torchgen': torchgen_package_data,
|
|
'caffe2': [
|
|
'python/serialized_test/data/operator_test/*.zip',
|
|
],
|
|
},
|
|
url='https://pytorch.org/',
|
|
download_url='https://github.com/pytorch/pytorch/tags',
|
|
author='PyTorch Team',
|
|
author_email='packages@pytorch.org',
|
|
python_requires='>={}'.format(python_min_version_str),
|
|
# PyPI package information.
|
|
classifiers=[
|
|
'Development Status :: 5 - Production/Stable',
|
|
'Intended Audience :: Developers',
|
|
'Intended Audience :: Education',
|
|
'Intended Audience :: Science/Research',
|
|
'License :: OSI Approved :: BSD License',
|
|
'Topic :: Scientific/Engineering',
|
|
'Topic :: Scientific/Engineering :: Mathematics',
|
|
'Topic :: Scientific/Engineering :: Artificial Intelligence',
|
|
'Topic :: Software Development',
|
|
'Topic :: Software Development :: Libraries',
|
|
'Topic :: Software Development :: Libraries :: Python Modules',
|
|
'Programming Language :: C++',
|
|
'Programming Language :: Python :: 3',
|
|
] + ['Programming Language :: Python :: 3.{}'.format(i) for i in range(python_min_version[1], version_range_max)],
|
|
license='BSD-3',
|
|
keywords='pytorch, machine learning',
|
|
)
|
|
if EMIT_BUILD_WARNING:
|
|
print_box(build_update_message)
|
|
|
|
|
|
if __name__ == '__main__':
|
|
main()
|