mirror of
https://github.com/pytorch/pytorch.git
synced 2025-10-20 12:54:11 +08:00
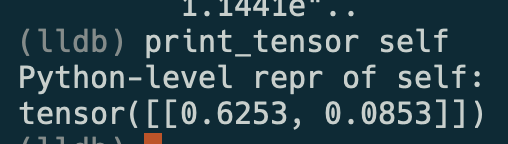
# Summary Add support for pretty printing of tensors when using lldb similiar to what is currently available for gdb <img width="772" alt="Screenshot 2023-03-18 at 6 20 34 PM" src="https://user-images.githubusercontent.com/32754868/226148687-b4e6cfe1-8be1-4657-9ebc-d134f697dd37.png"> <img width="254" alt="Screenshot 2023-03-18 at 6 20 43 PM" src="https://user-images.githubusercontent.com/32754868/226148690-caca6f76-d873-419e-b5e4-6bb403b3d179.png"> I changed it so to override the variable formatting instead of having to call a seperate command you can just do `print <tensor>` I also add one for sizes <img width="309" alt="Screenshot 2023-03-19 at 1 05 49 PM" src="https://user-images.githubusercontent.com/32754868/226206458-e3f0111b-6a97-4d75-8125-48455aa2cf43.png"> Last one: <img width="815" alt="Screenshot 2023-03-19 at 1 39 23 PM" src="https://user-images.githubusercontent.com/32754868/226207687-20bd014f-9e0e-4c01-b2c8-190b7365aa70.png"> If you use the codelldb extension be sure to add: `"lldb.launch.initCommands": ["command source ${env:HOME}/.lldbinit"]` To your setttings .json Pull Request resolved: https://github.com/pytorch/pytorch/pull/97101 Approved by: https://github.com/ngimel
{kind=link}
{kind=link}
{kind=link}
{kind=link}
440 lines
12 KiB
C++
440 lines
12 KiB
C++
#include <torch/csrc/DynamicTypes.h>
|
|
#include <torch/csrc/THP.h>
|
|
#include <torch/csrc/autograd/variable.h>
|
|
#include <torch/csrc/python_headers.h>
|
|
#include <torch/csrc/utils/invalid_arguments.h>
|
|
#include <torch/csrc/utils/python_strings.h>
|
|
#include <torch/csrc/utils/python_symnode.h>
|
|
#include <torch/csrc/utils/python_tuples.h>
|
|
|
|
#include <torch/csrc/Export.h>
|
|
|
|
#include <algorithm>
|
|
#include <cstdarg>
|
|
#include <iterator>
|
|
#include <sstream>
|
|
#include <string>
|
|
#include <unordered_map>
|
|
#include <vector>
|
|
|
|
int THPUtils_getCallable(PyObject* arg, PyObject** result) {
|
|
if (!PyCallable_Check(arg))
|
|
return 0;
|
|
*result = arg;
|
|
return 1;
|
|
}
|
|
|
|
bool THPUtils_checkIndex(PyObject* obj) {
|
|
if (PyBool_Check(obj)) {
|
|
return false;
|
|
}
|
|
if (THPUtils_checkLong(obj)) {
|
|
return true;
|
|
}
|
|
// Avoid poking __index__ early as that will immediately cause a guard
|
|
if (torch::is_symint(py::handle(obj))) {
|
|
return true;
|
|
}
|
|
torch::jit::tracer::NoWarn no_warn_guard;
|
|
auto index = THPObjectPtr(PyNumber_Index(obj));
|
|
if (!index) {
|
|
PyErr_Clear();
|
|
return false;
|
|
}
|
|
return true;
|
|
}
|
|
|
|
std::vector<int64_t> THPUtils_unpackLongs(PyObject* arg) {
|
|
bool tuple = PyTuple_Check(arg);
|
|
bool list = PyList_Check(arg);
|
|
if (tuple || list) {
|
|
// NOLINTNEXTLINE(bugprone-branch-clone)
|
|
const auto nDim = tuple ? PyTuple_GET_SIZE(arg) : PyList_GET_SIZE(arg);
|
|
std::vector<int64_t> sizes(nDim);
|
|
for (int i = 0; i != nDim; ++i) {
|
|
PyObject* item =
|
|
tuple ? PyTuple_GET_ITEM(arg, i) : PyList_GET_ITEM(arg, i);
|
|
if (!THPUtils_checkLong(item)) {
|
|
std::ostringstream oss;
|
|
oss << "expected int at position " << i
|
|
<< ", but got: " << THPUtils_typename(item);
|
|
throw std::runtime_error(oss.str());
|
|
}
|
|
sizes[i] = THPUtils_unpackLong(item);
|
|
}
|
|
return sizes;
|
|
}
|
|
throw std::runtime_error("Expected tuple or list");
|
|
}
|
|
|
|
bool THPUtils_checkIntTuple(PyObject* arg) {
|
|
if (!PyTuple_Check(arg)) {
|
|
return false;
|
|
}
|
|
for (Py_ssize_t i = 0; i < PyTuple_GET_SIZE(arg); ++i) {
|
|
if (!THPUtils_checkLong(PyTuple_GET_ITEM(arg, i))) {
|
|
return false;
|
|
}
|
|
}
|
|
return true;
|
|
}
|
|
|
|
std::vector<int> THPUtils_unpackIntTuple(PyObject* arg) {
|
|
if (!THPUtils_checkIntTuple(arg)) {
|
|
throw std::runtime_error("Couldn't unpack int tuple");
|
|
}
|
|
std::vector<int> values(PyTuple_GET_SIZE(arg));
|
|
for (Py_ssize_t i = 0; i < PyTuple_GET_SIZE(arg); ++i) {
|
|
values[i] = (int)THPUtils_unpackLong(PyTuple_GET_ITEM(arg, i));
|
|
}
|
|
return values;
|
|
}
|
|
|
|
void THPUtils_setError(const char* format, ...) {
|
|
static const size_t ERROR_BUFFER_SIZE = 1000;
|
|
// NOLINTNEXTLINE(cppcoreguidelines-avoid-c-arrays,modernize-avoid-c-arrays)
|
|
char buffer[ERROR_BUFFER_SIZE];
|
|
va_list fmt_args;
|
|
|
|
va_start(fmt_args, format);
|
|
vsnprintf(buffer, ERROR_BUFFER_SIZE, format, fmt_args);
|
|
va_end(fmt_args);
|
|
PyErr_SetString(PyExc_RuntimeError, buffer);
|
|
}
|
|
|
|
void THPUtils_addPyMethodDefs(
|
|
std::vector<PyMethodDef>& vector,
|
|
PyMethodDef* methods) {
|
|
if (!vector.empty()) {
|
|
// remove nullptr terminator
|
|
vector.pop_back();
|
|
}
|
|
while (true) {
|
|
vector.push_back(*methods);
|
|
if (!methods->ml_name) {
|
|
break;
|
|
}
|
|
methods++;
|
|
}
|
|
}
|
|
|
|
static const char* classOrTypename(PyObject* obj) {
|
|
if (PyType_Check(obj)) {
|
|
return ((PyTypeObject*)obj)->tp_name;
|
|
}
|
|
return Py_TYPE(obj)->tp_name;
|
|
}
|
|
|
|
PyObject* THPUtils_dispatchStateless(
|
|
PyObject* tensor,
|
|
const char* name,
|
|
PyObject* args,
|
|
PyObject* kwargs) {
|
|
THPObjectPtr methods(
|
|
PyObject_GetAttrString(tensor, THP_STATELESS_ATTRIBUTE_NAME));
|
|
if (!methods) {
|
|
return PyErr_Format(
|
|
PyExc_TypeError,
|
|
"Type %s doesn't implement stateless methods",
|
|
classOrTypename(tensor));
|
|
}
|
|
THPObjectPtr method(PyObject_GetAttrString(methods, name));
|
|
if (!method) {
|
|
return PyErr_Format(
|
|
PyExc_TypeError,
|
|
"Type %s doesn't implement stateless method %s",
|
|
classOrTypename(tensor),
|
|
name);
|
|
}
|
|
return PyObject_Call(method.get(), args, kwargs);
|
|
}
|
|
|
|
void THPUtils_invalidArguments(
|
|
PyObject* given_args,
|
|
PyObject* given_kwargs,
|
|
const char* function_name,
|
|
size_t num_options,
|
|
...) {
|
|
std::vector<std::string> option_strings;
|
|
va_list option_list;
|
|
va_start(option_list, num_options);
|
|
std::generate_n(
|
|
std::back_inserter(option_strings), num_options, [&option_list] {
|
|
return va_arg(option_list, const char*);
|
|
});
|
|
va_end(option_list);
|
|
|
|
PyErr_SetString(
|
|
PyExc_TypeError,
|
|
torch::format_invalid_args(
|
|
given_args, given_kwargs, function_name, option_strings)
|
|
.c_str());
|
|
}
|
|
|
|
template <>
|
|
void THPPointer<THPGenerator>::free() {
|
|
if (ptr)
|
|
Py_DECREF(ptr);
|
|
}
|
|
|
|
template class THPPointer<THPGenerator>;
|
|
|
|
static bool backCompatBroadcastWarn = false;
|
|
|
|
void setBackCompatBroadcastWarn(bool warn) {
|
|
backCompatBroadcastWarn = warn;
|
|
}
|
|
|
|
bool getBackCompatBroadcastWarn() {
|
|
return backCompatBroadcastWarn;
|
|
}
|
|
|
|
static bool backCompatKeepdimWarn = false;
|
|
|
|
void setBackCompatKeepdimWarn(bool warn) {
|
|
backCompatKeepdimWarn = warn;
|
|
}
|
|
|
|
bool getBackCompatKeepdimWarn() {
|
|
return backCompatKeepdimWarn;
|
|
}
|
|
|
|
bool maybeThrowBackCompatKeepdimWarn(char* func) {
|
|
if (getBackCompatKeepdimWarn()) {
|
|
std::ostringstream ss;
|
|
ss << "backwards compatibility: call to \"" << func
|
|
<< "\" uses default value for keepdim which has changed default to False. Consider passing as kwarg.",
|
|
PyErr_WarnEx(PyExc_UserWarning, ss.str().c_str(), 1);
|
|
}
|
|
return true;
|
|
}
|
|
|
|
template <>
|
|
void THPPointer<THPStorage>::free() {
|
|
if (ptr)
|
|
Py_DECREF(ptr);
|
|
}
|
|
|
|
void storage_fill(at::Storage self, uint8_t value) {
|
|
auto options = c10::TensorOptions().device(self.device()).dtype(at::kByte);
|
|
auto self_t = at::empty({0}, {}, options).set_(self);
|
|
self_t.fill_(value);
|
|
}
|
|
|
|
void storage_set(at::Storage self, ptrdiff_t idx, uint8_t value) {
|
|
TORCH_CHECK(
|
|
(idx >= 0) && (idx < static_cast<ptrdiff_t>(self.nbytes())),
|
|
"out of bounds");
|
|
auto options = c10::TensorOptions().device(self.device()).dtype(at::kByte);
|
|
auto self_t = at::empty({0}, {}, options).set_(self);
|
|
self_t[idx].fill_(value);
|
|
}
|
|
|
|
uint8_t storage_get(at::Storage self, ptrdiff_t idx) {
|
|
TORCH_CHECK(
|
|
(idx >= 0) && (idx < static_cast<ptrdiff_t>(self.nbytes())),
|
|
"out of bounds");
|
|
auto options = c10::TensorOptions().device(self.device()).dtype(at::kByte);
|
|
auto self_t = at::empty({0}, {}, options).set_(self);
|
|
return self_t[idx].item<uint8_t>();
|
|
}
|
|
|
|
template class THPPointer<THPStorage>;
|
|
|
|
namespace torch {
|
|
namespace gdb {
|
|
/* ~~~ misc debugging utilities ~~~
|
|
*
|
|
* torch::gdb::* functions are NOT meant to be called by general pytorch code,
|
|
* but only from within a gdb session. As such, utils.h does not contain any
|
|
* declaration for those.
|
|
*/
|
|
|
|
// This is a helper needed by the torch-tensor-repr gdb command.
|
|
// Return an human-readable representation of the given Tensor. The resulting
|
|
// string is stored into a malloc()ed buffer. The caller is responsible to
|
|
// free() it. We use malloc() instead of new[] because it's much easier to
|
|
// call free than delete[] from withing gdb.
|
|
// Currently the code for computing the repr of a tensor is written in Python,
|
|
// so we need to wrap the Tensor into a Python object first.
|
|
char* tensor_repr(at::Tensor tensor) {
|
|
PyGILState_STATE gil = PyGILState_Ensure();
|
|
PyObject* pytensor = nullptr;
|
|
PyObject* repr = nullptr;
|
|
// NOLINTNEXTLINE(cppcoreguidelines-init-variables)
|
|
Py_ssize_t bufsize;
|
|
const char* buf = nullptr;
|
|
char* result = nullptr;
|
|
|
|
pytensor = THPVariable_Wrap(at::Tensor(tensor));
|
|
if (!pytensor)
|
|
// NOLINTNEXTLINE(cppcoreguidelines-avoid-goto,hicpp-avoid-goto)
|
|
goto error;
|
|
repr = PyObject_Repr(pytensor);
|
|
if (!repr)
|
|
// NOLINTNEXTLINE(cppcoreguidelines-avoid-goto,hicpp-avoid-goto)
|
|
goto error;
|
|
buf = PyUnicode_AsUTF8AndSize(repr, &bufsize);
|
|
if (!buf)
|
|
// NOLINTNEXTLINE(cppcoreguidelines-avoid-goto,hicpp-avoid-goto)
|
|
goto error;
|
|
// NOLINTNEXTLINE(cppcoreguidelines-no-malloc)
|
|
result =
|
|
static_cast<char*>(malloc(bufsize + 1)); // account for the trailing \0
|
|
if (!result) {
|
|
fprintf(stderr, "cannot allocate memory for the result\n");
|
|
// NOLINTNEXTLINE(cppcoreguidelines-avoid-goto,hicpp-avoid-goto)
|
|
goto error;
|
|
}
|
|
// NOLINTNEXTLINE(clang-analyzer-security.insecureAPI.strcpy)
|
|
strcpy(result, buf);
|
|
Py_XDECREF(pytensor);
|
|
Py_XDECREF(repr);
|
|
PyGILState_Release(gil);
|
|
return result;
|
|
|
|
error:
|
|
fprintf(stderr, "torch::gdb::tensor_repr: unexpected error\n");
|
|
if (PyErr_Occurred())
|
|
PyErr_Print();
|
|
Py_XDECREF(pytensor);
|
|
Py_XDECREF(repr);
|
|
// NOLINTNEXTLINE(cppcoreguidelines-no-malloc)
|
|
free(result);
|
|
PyGILState_Release(gil);
|
|
return nullptr;
|
|
}
|
|
|
|
std::string int_array_ref_string(at::IntArrayRef sizes) {
|
|
std::stringstream ss;
|
|
ss << sizes;
|
|
return ss.str();
|
|
}
|
|
|
|
std::string dispatch_keyset_string(c10::DispatchKeySet keyset) {
|
|
std::stringstream ss;
|
|
ss << keyset;
|
|
return ss.str();
|
|
}
|
|
|
|
} // namespace gdb
|
|
} // namespace torch
|
|
|
|
namespace pybind11 {
|
|
namespace detail {
|
|
|
|
bool type_caster<at::Tensor>::load(handle src, bool) {
|
|
PyObject* obj = src.ptr();
|
|
if (THPVariable_Check(obj)) {
|
|
value = THPVariable_Unpack(obj);
|
|
return true;
|
|
}
|
|
return false;
|
|
}
|
|
|
|
handle type_caster<at::Tensor>::cast(
|
|
const at::Tensor& src,
|
|
return_value_policy /* policy */,
|
|
handle /* parent */) {
|
|
return handle(THPVariable_Wrap(src));
|
|
}
|
|
|
|
bool type_caster<at::IntArrayRef>::load(handle src, bool) {
|
|
PyObject* source = src.ptr();
|
|
auto tuple = PyTuple_Check(source);
|
|
if (tuple || PyList_Check(source)) {
|
|
// NOLINTNEXTLINE(bugprone-branch-clone)
|
|
const auto size =
|
|
tuple ? PyTuple_GET_SIZE(source) : PyList_GET_SIZE(source);
|
|
v_value.resize(size);
|
|
for (const auto idx : c10::irange(size)) {
|
|
PyObject* obj =
|
|
tuple ? PyTuple_GET_ITEM(source, idx) : PyList_GET_ITEM(source, idx);
|
|
if (THPVariable_Check(obj)) {
|
|
v_value[idx] = THPVariable_Unpack(obj).item<int64_t>();
|
|
} else if (PyLong_Check(obj)) {
|
|
// use THPUtils_unpackLong after it is safe to include
|
|
// python_numbers.h
|
|
v_value[idx] = THPUtils_unpackLong(obj);
|
|
} else {
|
|
return false;
|
|
}
|
|
}
|
|
value = v_value;
|
|
return true;
|
|
}
|
|
return false;
|
|
}
|
|
handle type_caster<at::IntArrayRef>::cast(
|
|
at::IntArrayRef src,
|
|
return_value_policy /* policy */,
|
|
handle /* parent */) {
|
|
return handle(THPUtils_packInt64Array(src.size(), src.data()));
|
|
}
|
|
|
|
bool type_caster<at::SymIntArrayRef>::load(handle src, bool) {
|
|
PyObject* source = src.ptr();
|
|
|
|
auto tuple = PyTuple_Check(source);
|
|
if (tuple || PyList_Check(source)) {
|
|
// NOLINTNEXTLINE(bugprone-branch-clone)
|
|
const auto size =
|
|
tuple ? PyTuple_GET_SIZE(source) : PyList_GET_SIZE(source);
|
|
v_value.resize(size);
|
|
for (const auto idx : c10::irange(size)) {
|
|
PyObject* obj =
|
|
tuple ? PyTuple_GET_ITEM(source, idx) : PyList_GET_ITEM(source, idx);
|
|
|
|
if (THPVariable_Check(obj)) {
|
|
// TODO: this is for consistency with IntArrayRef but arguably
|
|
// we shouldn't really allow this on pybind11 casters
|
|
v_value[idx] = THPVariable_Unpack(obj).item<int64_t>();
|
|
} else if (torch::is_symint(py::handle(obj))) {
|
|
v_value[idx] = py::handle(obj).cast<c10::SymInt>();
|
|
} else if (PyLong_Check(obj)) {
|
|
v_value[idx] = c10::SymInt(THPUtils_unpackIndex(obj));
|
|
} else {
|
|
return false;
|
|
}
|
|
}
|
|
value = v_value;
|
|
return true;
|
|
}
|
|
return false;
|
|
}
|
|
handle type_caster<at::SymIntArrayRef>::cast(
|
|
at::SymIntArrayRef src,
|
|
return_value_policy /* policy */,
|
|
handle /* parent */) {
|
|
py::list t(src.size());
|
|
for (const auto i : c10::irange(src.size())) {
|
|
t[i] = py::cast(src[i]);
|
|
}
|
|
return t.release();
|
|
}
|
|
|
|
bool type_caster<at::ArrayRef<c10::SymNode>>::load(handle src, bool) {
|
|
TORCH_INTERNAL_ASSERT(0, "NYI");
|
|
}
|
|
handle type_caster<at::ArrayRef<c10::SymNode>>::cast(
|
|
at::ArrayRef<c10::SymNode> src,
|
|
return_value_policy /* policy */,
|
|
handle /* parent */) {
|
|
py::list t(src.size());
|
|
for (const auto i : c10::irange(src.size())) {
|
|
// TODO: this is terrible but I don't know how to override when
|
|
// the SymNode is also explicitly cast by py::cast
|
|
auto* py_node = dynamic_cast<torch::impl::PythonSymNodeImpl*>(src[i].get());
|
|
if (py_node) {
|
|
// Return the Python directly (unwrap)
|
|
t[i] = py_node->getPyObj();
|
|
} else {
|
|
t[i] = py::cast(src[i]);
|
|
}
|
|
}
|
|
return t.release();
|
|
}
|
|
|
|
} // namespace detail
|
|
} // namespace pybind11
|