mirror of
https://github.com/pytorch/pytorch.git
synced 2025-10-21 13:44:15 +08:00
## Summary The change brings the new registry for symbolic functions in ONNX. The `SymbolicRegistry` class in `torch.onnx._internal.registration` replaces the dictionary and various functions defined in `torch.onnx.symbolic_registry`. The new registry - Has faster lookup by storing only functions in the opset version they are defined in - Is easier to manage and interact with due to its class design - Builds the foundation for the more flexible registration process detailed in #83787 Implementation changes - **Breaking**: Remove `torch.onnx.symbolic_registry` - `register_custom_op_symbolic` and `unregister_custom_op_symbolic` in utils maintain their api for compatibility - Update _onnx_supported_ops.py for doc generation to include quantized ops. - Update code to register python ops in `torch/csrc/jit/passes/onnx.cpp` ## Profiling results -0.1 seconds in execution time. -34% time spent in `_run_symbolic_function`. Tested on the alexnet example in public doc. ### After ``` └─ 1.641 export <@beartype(torch.onnx.utils.export) at 0x7f19be17f790>:1 └─ 1.641 export torch/onnx/utils.py:185 └─ 1.640 _export torch/onnx/utils.py:1331 ├─ 0.889 _model_to_graph torch/onnx/utils.py:1005 │ ├─ 0.478 _optimize_graph torch/onnx/utils.py:535 │ │ ├─ 0.214 PyCapsule._jit_pass_onnx_graph_shape_type_inference <built-in>:0 │ │ │ [2 frames hidden] <built-in> │ │ ├─ 0.190 _run_symbolic_function torch/onnx/utils.py:1670 │ │ │ └─ 0.145 Constant torch/onnx/symbolic_opset9.py:5782 │ │ │ └─ 0.139 _graph_op torch/onnx/_patch_torch.py:18 │ │ │ └─ 0.134 PyCapsule._jit_pass_onnx_node_shape_type_inference <built-in>:0 │ │ │ [2 frames hidden] <built-in> │ │ └─ 0.033 [self] ``` ### Before 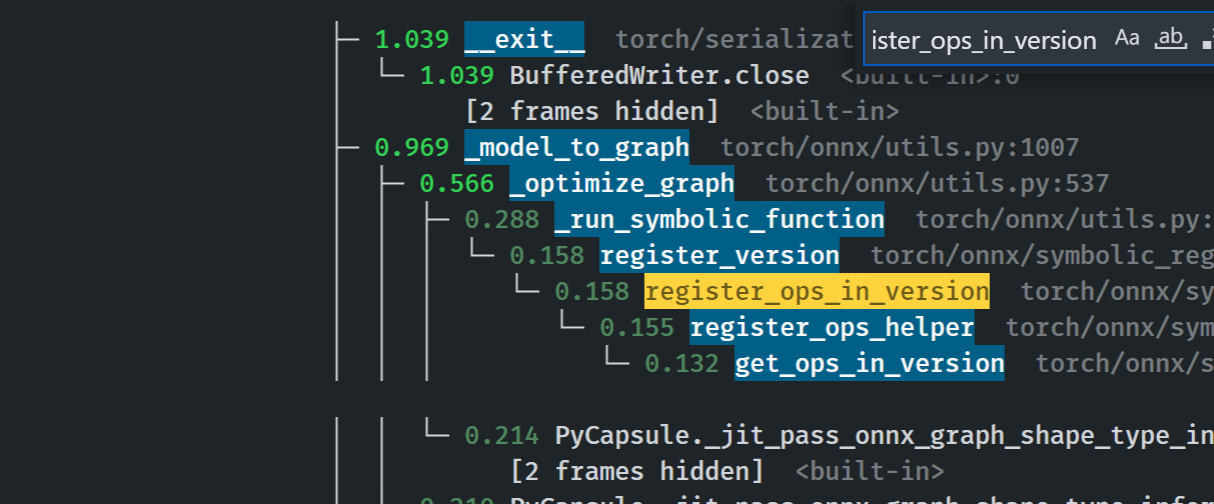 ### Start up time The startup process takes 0.03 seconds. Calls to `inspect` will be eliminated when we switch to using decorators for registration in #84448  Pull Request resolved: https://github.com/pytorch/pytorch/pull/84382 Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
{kind=link}
{kind=link}
781 lines
27 KiB
Python
781 lines
27 KiB
Python
# Owner(s): ["module: onnx"]
|
|
|
|
"""Tests for onnx export that don't run the exported model."""
|
|
|
|
import contextlib
|
|
import io
|
|
import itertools
|
|
import unittest
|
|
import unittest.mock
|
|
from typing import Callable, Dict, Iterable, List, Optional, Tuple, Union
|
|
|
|
import onnx
|
|
import onnx.numpy_helper
|
|
|
|
import torch
|
|
import torch.nn.functional as F
|
|
from torch import Tensor
|
|
from torch.onnx import symbolic_helper, utils
|
|
from torch.onnx._globals import GLOBALS
|
|
from torch.onnx._internal import registration
|
|
from torch.testing._internal import common_utils
|
|
|
|
|
|
def export_to_onnx(
|
|
model: Union[torch.nn.Module, torch.jit.ScriptFunction],
|
|
input: Union[torch.Tensor, Tuple[torch.Tensor]],
|
|
custom_ops: Optional[
|
|
Iterable[
|
|
Union[contextlib.AbstractContextManager, contextlib.ContextDecorator],
|
|
]
|
|
] = None,
|
|
mocks: Optional[Iterable] = None,
|
|
operator_export_type: torch.onnx.OperatorExportTypes = torch.onnx.OperatorExportTypes.ONNX,
|
|
opset_version: int = GLOBALS.export_onnx_opset_version,
|
|
) -> onnx.ModelProto:
|
|
"""Exports `model(input)` to ONNX and returns it.
|
|
|
|
Custom operators and/or unittest patches can be used help reproducing specific behaviors.
|
|
|
|
Args:
|
|
model: model to export
|
|
input: model input with same format as `torch.onnx.export(..,args,...)`
|
|
custom_ops: list of custom operators to use during export
|
|
mocks: list of mocks to use during export
|
|
operator_export_type: export type as described by `torch.onnx.export(...operator_export_type,...)`
|
|
opset_version: ONNX opset version as described by `torch.onnx.export(...opset_version,...)`
|
|
Returns:
|
|
A valid ONNX model (`onnx.ModelProto`)
|
|
"""
|
|
custom_ops = custom_ops or []
|
|
mocks = mocks or []
|
|
with contextlib.ExitStack() as stack:
|
|
for ctx in itertools.chain(custom_ops, mocks):
|
|
stack.enter_context(ctx)
|
|
|
|
f = io.BytesIO()
|
|
torch.onnx.export(
|
|
model,
|
|
input,
|
|
f,
|
|
operator_export_type=operator_export_type,
|
|
opset_version=opset_version,
|
|
)
|
|
|
|
# Validate ONNX graph before returning it
|
|
onnx_model = onnx.load_from_string(f.getvalue())
|
|
onnx.checker.check_model(onnx_model)
|
|
return onnx_model
|
|
|
|
|
|
class TestONNXExport(common_utils.TestCase):
|
|
def test_fuse_addmm(self):
|
|
class AddmmModel(torch.nn.Module):
|
|
def forward(self, x):
|
|
return torch.mm(x, x) + x
|
|
|
|
x = torch.ones(3, 3)
|
|
f = io.BytesIO()
|
|
torch.onnx._export(AddmmModel(), x, f, verbose=False)
|
|
|
|
def test_onnx_transpose_incomplete_tensor_type(self):
|
|
# Smoke test to get us into the state where we are attempting to export
|
|
# a transpose op, where the input is a TensorType without size information.
|
|
# This would previously not work, since we would
|
|
# take the size of the input and use the length of its sizes as the
|
|
# number of dimensions in the permutation.
|
|
class Foo(torch.jit.ScriptModule):
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
return x.contiguous().transpose(0, 1).sum()
|
|
|
|
class TraceMe(torch.nn.Module):
|
|
def __init__(self):
|
|
super(TraceMe, self).__init__()
|
|
self.foo = Foo()
|
|
|
|
def forward(self, x):
|
|
return self.foo(x)
|
|
|
|
tm = TraceMe()
|
|
tm = torch.jit.trace(tm, torch.rand(3, 4))
|
|
f = io.BytesIO()
|
|
torch.onnx.export(tm, (torch.rand(3, 4),), f)
|
|
|
|
def test_export_tensoroption_to(self):
|
|
def foo(x):
|
|
return x[0].clone().detach().cpu() + x
|
|
|
|
traced = torch.jit.trace(foo, (torch.rand([2])))
|
|
|
|
torch.onnx.export_to_pretty_string(traced, (torch.rand([2]),))
|
|
|
|
def test_onnx_export_script_module(self):
|
|
class ModuleToExport(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(ModuleToExport, self).__init__()
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
y = x - x
|
|
return x + x
|
|
|
|
mte = ModuleToExport()
|
|
torch.onnx.export_to_pretty_string(mte, (torch.zeros(1, 2, 3),), verbose=False)
|
|
|
|
@common_utils.suppress_warnings
|
|
def test_onnx_export_func_with_warnings(self):
|
|
@torch.jit.script
|
|
def func_with_warning(inp):
|
|
return torch.nn.functional.sigmoid(inp) # triggers a deprecation warning
|
|
|
|
class WarningTest(torch.nn.Module):
|
|
def __init__(self):
|
|
super(WarningTest, self).__init__()
|
|
|
|
def forward(self, x):
|
|
return func_with_warning(x)
|
|
|
|
# no exception
|
|
torch.onnx.export_to_pretty_string(
|
|
WarningTest(), torch.randn(42), verbose=False
|
|
)
|
|
|
|
def test_onnx_export_script_python_fail(self):
|
|
class PythonModule(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(PythonModule, self).__init__()
|
|
|
|
@torch.jit.ignore
|
|
def forward(self, x):
|
|
return torch.neg(x)
|
|
|
|
class ModuleToExport(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(ModuleToExport, self).__init__()
|
|
self.mod = PythonModule()
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
y = self.mod(x)
|
|
return y + y
|
|
|
|
mte = ModuleToExport()
|
|
f = io.BytesIO()
|
|
with self.assertRaisesRegex(RuntimeError, "Couldn't export Python"):
|
|
torch.onnx._export(mte, (torch.zeros(1, 2, 3),), f, verbose=False)
|
|
|
|
def test_onnx_export_script_inline_trace(self):
|
|
class ModuleToInline(torch.nn.Module):
|
|
def __init__(self):
|
|
super(ModuleToInline, self).__init__()
|
|
|
|
def forward(self, x):
|
|
return torch.neg(x)
|
|
|
|
class ModuleToExport(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(ModuleToExport, self).__init__()
|
|
self.mod = torch.jit.trace(ModuleToInline(), torch.zeros(1, 2, 3))
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
y = self.mod(x)
|
|
return y + y
|
|
|
|
mte = ModuleToExport()
|
|
torch.onnx.export_to_pretty_string(mte, (torch.zeros(1, 2, 3),), verbose=False)
|
|
|
|
def test_onnx_export_script_inline_script(self):
|
|
class ModuleToInline(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(ModuleToInline, self).__init__()
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
return torch.neg(x)
|
|
|
|
class ModuleToExport(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(ModuleToExport, self).__init__()
|
|
self.mod = ModuleToInline()
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
y = self.mod(x)
|
|
return y + y
|
|
|
|
mte = ModuleToExport()
|
|
torch.onnx.export_to_pretty_string(mte, (torch.zeros(1, 2, 3),), verbose=False)
|
|
|
|
def test_onnx_export_script_module_loop(self):
|
|
class ModuleToExport(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(ModuleToExport, self).__init__()
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
# test if we support end to end onnx export on loop and
|
|
# nested loops with and without loop index
|
|
for _ in range(5):
|
|
for i in range(3):
|
|
x = x + i
|
|
return x
|
|
|
|
mte = ModuleToExport()
|
|
torch.onnx.export_to_pretty_string(mte, (torch.zeros(1, 2, 3),), verbose=False)
|
|
|
|
@common_utils.suppress_warnings
|
|
def test_onnx_export_script_truediv(self):
|
|
class ModuleToExport(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(ModuleToExport, self).__init__()
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
z = x.size(0) / 2
|
|
return x + z
|
|
|
|
mte = ModuleToExport()
|
|
|
|
torch.onnx.export_to_pretty_string(
|
|
mte, (torch.zeros(1, 2, 3, dtype=torch.float),), verbose=False
|
|
)
|
|
|
|
def test_onnx_export_script_non_alpha_add_sub(self):
|
|
class ModuleToExport(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(ModuleToExport, self).__init__()
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
bs = x.size(0) + 1
|
|
return bs - 1
|
|
|
|
mte = ModuleToExport()
|
|
torch.onnx.export_to_pretty_string(mte, (torch.rand(3, 4),), verbose=False)
|
|
|
|
def test_onnx_export_script_module_if(self):
|
|
class ModuleToExport(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(ModuleToExport, self).__init__()
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
if bool(torch.sum(x) > 0):
|
|
x = torch.neg(x)
|
|
return x
|
|
|
|
mte = ModuleToExport()
|
|
torch.onnx.export_to_pretty_string(mte, (torch.zeros(1, 2, 3),), verbose=False)
|
|
|
|
def test_onnx_export_script_inline_params(self):
|
|
class ModuleToInline(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(ModuleToInline, self).__init__()
|
|
self.m = torch.nn.Parameter(torch.ones(3, 3))
|
|
self.unused = torch.nn.Parameter(torch.ones(1, 2, 3))
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
return torch.mm(x, self.m)
|
|
|
|
class ModuleToExport(torch.jit.ScriptModule):
|
|
def __init__(self):
|
|
super(ModuleToExport, self).__init__()
|
|
self.mod = ModuleToInline()
|
|
self.param = torch.nn.Parameter(torch.ones(3, 4))
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
y = self.mod(x)
|
|
return torch.mm(y, self.param)
|
|
|
|
mte = ModuleToExport()
|
|
result = mte(torch.zeros(2, 3))
|
|
reference = torch.mm(
|
|
torch.mm(torch.zeros(2, 3), torch.ones(3, 3)), torch.ones(3, 4)
|
|
)
|
|
self.assertEqual(result, reference)
|
|
torch.onnx.export_to_pretty_string(mte, (torch.ones(2, 3),), verbose=False)
|
|
|
|
def test_onnx_export_speculate(self):
|
|
class Foo(torch.jit.ScriptModule):
|
|
def __init__(self, m):
|
|
super(Foo, self).__init__()
|
|
self.m = m
|
|
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
x += x
|
|
# because we are testing if we emit `if` statement correctly
|
|
# we cannot use `True` as the condition. Constant prop
|
|
# would remove the `if` statements.
|
|
c = torch.sum(x) > 4
|
|
if bool(c):
|
|
if bool(c):
|
|
y = self.m(x)
|
|
else:
|
|
y = self.m(x)
|
|
else:
|
|
y = self.m(x)
|
|
return y
|
|
|
|
linear = torch.jit.trace(
|
|
torch.nn.Linear(10, 20).float(), torch.zeros(1, 10, dtype=torch.float)
|
|
)
|
|
|
|
@torch.jit.script
|
|
def transpose(x):
|
|
return x.t()
|
|
|
|
f1 = Foo(transpose)
|
|
f2 = Foo(linear)
|
|
|
|
torch.onnx.export_to_pretty_string(f1, (torch.ones(1, 10, dtype=torch.float),))
|
|
torch.onnx.export_to_pretty_string(f2, (torch.ones(1, 10, dtype=torch.float),))
|
|
|
|
def test_onnx_export_shape_reshape(self):
|
|
class Foo(torch.nn.Module):
|
|
def forward(self, x):
|
|
import torch.onnx.operators
|
|
|
|
x = x.repeat(5, 1, 1)
|
|
shape = torch.onnx.operators.shape_as_tensor(x)
|
|
reshaped = torch.onnx.operators.reshape_from_tensor_shape(x, shape)
|
|
return reshaped
|
|
|
|
foo = torch.jit.trace(Foo(), torch.zeros(1, 2, 3))
|
|
torch.onnx.export_to_pretty_string(foo, (torch.zeros(1, 2, 3)))
|
|
|
|
def test_listconstruct_erasure(self):
|
|
class FooMod(torch.nn.Module):
|
|
def forward(self, x):
|
|
mask = x < 0.0
|
|
return x[mask]
|
|
|
|
torch.onnx.export_to_pretty_string(
|
|
FooMod(),
|
|
(torch.rand(3, 4),),
|
|
add_node_names=False,
|
|
do_constant_folding=False,
|
|
operator_export_type=torch.onnx.OperatorExportTypes.ONNX_ATEN_FALLBACK,
|
|
)
|
|
|
|
def test_export_dynamic_slice(self):
|
|
class DynamicSliceExportMod(torch.jit.ScriptModule):
|
|
@torch.jit.script_method
|
|
def forward(self, x):
|
|
retval = x[0]
|
|
for i in range(x.size(1)):
|
|
retval += torch.sum(x[0:i], dim=0)
|
|
return retval
|
|
|
|
mod = DynamicSliceExportMod()
|
|
|
|
input = torch.rand(3, 4, 5)
|
|
|
|
torch.onnx.export_to_pretty_string(
|
|
DynamicSliceExportMod(), (input,), opset_version=10
|
|
)
|
|
|
|
def test_export_dict(self):
|
|
class DictModule(torch.nn.Module):
|
|
def forward(self, x_in: torch.Tensor) -> Dict[str, torch.Tensor]:
|
|
return {"test_key_out": x_in}
|
|
|
|
x_in = torch.tensor(1)
|
|
mod = DictModule()
|
|
mod.train(False)
|
|
|
|
torch.onnx.export_to_pretty_string(mod, (x_in,))
|
|
|
|
with self.assertRaisesRegex(RuntimeError, r"DictConstruct.+is not supported."):
|
|
torch.onnx.export_to_pretty_string(torch.jit.script(mod), (x_in,))
|
|
|
|
def test_source_range_propagation(self):
|
|
class ExpandingModule(torch.nn.Module):
|
|
def __init__(self):
|
|
super().__init__()
|
|
# Will be expanded during ONNX export
|
|
self.ln = torch.nn.LayerNorm([1])
|
|
|
|
def forward(self, input):
|
|
return self.ln(input)
|
|
|
|
mod = ExpandingModule()
|
|
|
|
graph, _, _ = utils._model_to_graph(
|
|
mod,
|
|
(torch.zeros(1),),
|
|
operator_export_type=torch.onnx.OperatorExportTypes.ONNX,
|
|
)
|
|
|
|
# Ensure that every node in the graph has a valid source range
|
|
for node in graph.nodes():
|
|
self.assertTrue(node.sourceRange())
|
|
|
|
@common_utils.skipIfCaffe2
|
|
def test_clip_aten_fallback_due_exception(self):
|
|
def bad_clamp(g, self, min, max):
|
|
return symbolic_helper._onnx_unsupported("Bad boy!")
|
|
|
|
class MyClip(torch.nn.Module):
|
|
def forward(self, x):
|
|
return torch.clamp(x, min=-0.5, max=0.5)
|
|
|
|
onnx_model = export_to_onnx(
|
|
MyClip(),
|
|
torch.randn(3, 4, requires_grad=True),
|
|
custom_ops=[common_utils.custom_op("aten::clamp", bad_clamp, 9)],
|
|
operator_export_type=torch.onnx.OperatorExportTypes.ONNX_ATEN_FALLBACK,
|
|
)
|
|
self.assertAtenOp(onnx_model, "clamp", "Tensor")
|
|
|
|
@common_utils.skipIfCaffe2
|
|
def test_clip_aten_fallback_explicit_request(self):
|
|
class MyClip(torch.nn.Module):
|
|
def forward(self, x):
|
|
return torch.clamp(x, min=-0.5, max=0.5)
|
|
|
|
def break_is_registered_op_api(name):
|
|
fake_missing_symbolics = {"aten::clamp"}
|
|
if name in fake_missing_symbolics:
|
|
return None
|
|
return registration.registry.get_function_group(name)
|
|
|
|
# Force missing symbolic for well-known op using a mock
|
|
onnx_model = export_to_onnx(
|
|
MyClip(),
|
|
torch.randn(3, 4, requires_grad=True),
|
|
mocks=[
|
|
unittest.mock.patch(
|
|
"torch.onnx._internal.registration.registry.get_function_group",
|
|
side_effect=break_is_registered_op_api,
|
|
)
|
|
],
|
|
operator_export_type=torch.onnx.OperatorExportTypes.ONNX_ATEN_FALLBACK,
|
|
)
|
|
self.assertAtenOp(onnx_model, "clamp", "Tensor")
|
|
|
|
def _helper_test_to_(self, cast_fn: Callable[[torch.Tensor], torch.Tensor]):
|
|
"""Helper to test aten::to(device) variants.
|
|
|
|
`cast_fn` is converted into a `torch.jit.script`. It wraps `aten::to`
|
|
during export to preventing the devices to be hard-coded.
|
|
|
|
Needed by detectron2 after https://github.com/facebookresearch/detectron2/pull/4132/
|
|
"""
|
|
cast_fn = torch.jit.script(cast_fn)
|
|
onnx_model = export_to_onnx(cast_fn, torch.zeros([1, 3, 32, 32]))
|
|
for n in onnx_model.graph.node:
|
|
self.assertNotEqual(n.op_type, "To")
|
|
self.assertNotEqual(n.op_type, "Cast")
|
|
|
|
def test_to__cpu_string(self):
|
|
def cast_cpu_string(src: torch.Tensor) -> torch.Tensor:
|
|
return src.to("cpu")
|
|
|
|
self._helper_test_to_(cast_cpu_string)
|
|
|
|
def test_to__device_cpu_string(self):
|
|
def cast_device_cpu_string(src: torch.Tensor) -> torch.Tensor:
|
|
return src.to(device="cpu")
|
|
|
|
self._helper_test_to_(cast_device_cpu_string)
|
|
|
|
def test_script_custom_class_error(self):
|
|
class BoxCoder:
|
|
def __init__(self, bbox_xform_clip: float) -> None:
|
|
self.bbox_xform_clip = bbox_xform_clip
|
|
|
|
def decode(self, rel_codes: Tensor, boxes: List[Tensor]) -> Tensor:
|
|
boxes = torch.cat(boxes, dim=0)
|
|
pred_ctr_x = (
|
|
torch.clamp(rel_codes[:, 0::4], max=self.bbox_xform_clip)
|
|
* boxes[:, 2]
|
|
)
|
|
return pred_ctr_x
|
|
|
|
class MyModule(torch.nn.Module):
|
|
__annotations__ = {
|
|
"box_coder": BoxCoder,
|
|
}
|
|
|
|
def __init__(self):
|
|
super().__init__()
|
|
self.box_coder = BoxCoder(1.4)
|
|
|
|
def forward(self, box_regression: Tensor, proposals: List[Tensor]):
|
|
return self.box_coder.decode(box_regression, proposals)
|
|
|
|
model = torch.jit.script(MyModule())
|
|
box_regression = torch.randn([4, 4])
|
|
proposal = [torch.randn(2, 4), torch.randn(2, 4)]
|
|
|
|
with self.assertRaises(RuntimeError) as cm:
|
|
onnx_model = io.BytesIO()
|
|
torch.onnx.export(
|
|
model,
|
|
(box_regression, proposal),
|
|
onnx_model,
|
|
)
|
|
|
|
def test_initializer_sequence(self):
|
|
class MyModule(torch.nn.Module):
|
|
def __init__(self, input_size, hidden_size, num_classes):
|
|
super().__init__()
|
|
self.fc1 = torch.nn.Linear(input_size, hidden_size)
|
|
self.relu = torch.nn.ReLU()
|
|
self.fc2 = torch.nn.Linear(hidden_size, num_classes)
|
|
|
|
def forward(self, x):
|
|
out = self.fc1(x)
|
|
out = self.relu(out)
|
|
out = self.fc2(out)
|
|
return out
|
|
|
|
test_model = MyModule(3, 4, 10)
|
|
state_dict_list = [k for (k, v) in test_model.state_dict().items()]
|
|
named_params_list = [k for (k, v) in test_model.named_parameters()]
|
|
|
|
x = torch.randn(32, 3)
|
|
f = io.BytesIO()
|
|
torch.onnx._export(test_model, (x,), f, do_constant_folding=False)
|
|
loaded_model = onnx.load_from_string(f.getvalue())
|
|
|
|
actual_list = [p.name for p in loaded_model.graph.initializer]
|
|
assert actual_list == state_dict_list, (
|
|
"Initializers' sequence is not as same as state_dict(). Expected: ("
|
|
+ ", ".join(state_dict_list)
|
|
+ "). Actual:("
|
|
+ ", ".join(actual_list)
|
|
+ ")."
|
|
)
|
|
assert actual_list == named_params_list, (
|
|
"Initializers' sequence is not as same as named_parameters(). Expected: ("
|
|
+ ", ".join(named_params_list)
|
|
+ "). Actual:("
|
|
+ ", ".join(actual_list)
|
|
+ ")."
|
|
)
|
|
|
|
def test_initializer_sequence_script_model(self):
|
|
def list_is_expected(short_list, long_list) -> bool:
|
|
if len(short_list) > len(long_list):
|
|
return False
|
|
|
|
for i in range(len(short_list)):
|
|
if short_list[i] not in long_list[i]:
|
|
return False
|
|
|
|
return True
|
|
|
|
def loop(x, y):
|
|
for i in range(int(y)):
|
|
x = x + i
|
|
return x
|
|
|
|
class MyModule(torch.nn.Module):
|
|
def __init__(self, input_size, hidden_size, num_classes):
|
|
super().__init__()
|
|
self.fc1 = torch.nn.Linear(input_size, hidden_size)
|
|
self.relu = torch.nn.ReLU()
|
|
self.fc2 = torch.nn.Linear(hidden_size, num_classes)
|
|
|
|
def forward(self, x, y):
|
|
x = loop(x, y)
|
|
out = self.fc1(x)
|
|
out = self.relu(out)
|
|
out = self.fc2(out)
|
|
return out
|
|
|
|
test_model = torch.jit.script(MyModule(3, 4, 10))
|
|
state_dict_list = [k for (k, v) in test_model.state_dict().items()]
|
|
named_params_list = [k for (k, v) in test_model.named_parameters()]
|
|
|
|
x = torch.ones(2, 3, dtype=torch.float)
|
|
y = torch.tensor(5, dtype=torch.long)
|
|
f = io.BytesIO()
|
|
|
|
torch.onnx.export(test_model, (x, y), f, do_constant_folding=False)
|
|
loaded_model = onnx.load_from_string(f.getvalue())
|
|
|
|
actual_list = [p.name for p in loaded_model.graph.initializer]
|
|
assert list_is_expected(state_dict_list, actual_list), (
|
|
"ScriptModel - Initializers' sequence is not as same as state_dict(). Expected: ("
|
|
+ ", ".join(state_dict_list)
|
|
+ "). Actual:("
|
|
+ ", ".join(actual_list)
|
|
+ ")."
|
|
)
|
|
assert list_is_expected(named_params_list, actual_list), (
|
|
"ScriptModel - Initializers' sequence is not as same as named_parameters(). Expected: ("
|
|
+ ", ".join(named_params_list)
|
|
+ "). Actual:("
|
|
+ ", ".join(actual_list)
|
|
+ ")."
|
|
)
|
|
|
|
def test_onnx_checker_invalid_graph(self):
|
|
class CustomAddModule(torch.nn.Module):
|
|
def forward(self, x, y):
|
|
return torch.add(x, y)
|
|
|
|
def symbolic_custom_invalid_add(g, input, other, alpha=None):
|
|
return g.op("Add", input, other, invalid_attr_i=1)
|
|
|
|
torch.onnx.register_custom_op_symbolic("::add", symbolic_custom_invalid_add, 1)
|
|
|
|
x = torch.randn(2, 3, 4)
|
|
y = torch.randn(2, 3, 4)
|
|
|
|
test_model = CustomAddModule()
|
|
f = io.BytesIO()
|
|
|
|
try:
|
|
with self.assertRaises(torch.onnx.errors.CheckerError):
|
|
torch.onnx.export(test_model, (x, y), f)
|
|
finally:
|
|
torch.onnx.unregister_custom_op_symbolic("::add", 1)
|
|
|
|
self.assertTrue(f.getvalue(), "ONNX graph was not exported.")
|
|
loaded_model = onnx.load_from_string(f.getvalue())
|
|
|
|
def test_shape_value_map(self):
|
|
class RSoftMax(torch.nn.Module):
|
|
def __init__(self, radix, cardinality):
|
|
super().__init__()
|
|
self.radix = radix
|
|
self.cardinality = cardinality
|
|
|
|
def forward(self, x):
|
|
batch = x.size(0)
|
|
x = x.view(batch, self.cardinality, self.radix, -1).transpose(1, 2)
|
|
x = F.softmax(x, dim=1)
|
|
x = x.reshape(batch, -1)
|
|
return x
|
|
|
|
radix = 2
|
|
cardinality = 1
|
|
x = torch.randn(10, 1, 128, 1)
|
|
f = io.BytesIO()
|
|
torch.onnx.export(
|
|
RSoftMax(radix, cardinality),
|
|
(x,),
|
|
f,
|
|
input_names=["x"],
|
|
dynamic_axes={"x": [0]},
|
|
)
|
|
loaded_model = onnx.load_from_string(f.getvalue())
|
|
self.assertEqual(
|
|
loaded_model.graph.output[0].type.tensor_type.shape.dim[1].dim_value, 128
|
|
)
|
|
|
|
def test_onnx_proto_checker(self):
|
|
class Model(torch.nn.Module):
|
|
def __init__(self):
|
|
super().__init__()
|
|
|
|
def forward(self, x):
|
|
return 2 * x
|
|
|
|
x = torch.randn(1, 2, 3, requires_grad=True)
|
|
f = io.BytesIO()
|
|
torch.onnx.export(Model(), x, f)
|
|
model = onnx.load(f)
|
|
model.ir_version = 0
|
|
|
|
def check_proto():
|
|
torch._C._check_onnx_proto(model.SerializeToString())
|
|
|
|
self.assertRaises(RuntimeError, check_proto)
|
|
|
|
def test_maintain_dynamic_shapes_of_unreliable_nodes(self):
|
|
def symbolic_pythonop(ctx: torch.onnx.SymbolicContext, g, *args, **kwargs):
|
|
return g.op("com.microsoft::PythonOp")
|
|
|
|
torch.onnx.register_custom_op_symbolic("prim::PythonOp", symbolic_pythonop, 1)
|
|
self.addCleanup(torch.onnx.unregister_custom_op_symbolic, "prim::PythonOp", 1)
|
|
|
|
# necessay parameters for transformer embeddings
|
|
hidden_size = 48
|
|
max_position_embeddings = 32
|
|
batch_size = 2
|
|
|
|
# issue found that autograd.function making downstream
|
|
# node unreliable but with static shape. The issue was first
|
|
# discovered with using Apex FusedLayerNorm in Transformers
|
|
class CustomLayerNorm(torch.autograd.Function):
|
|
@staticmethod
|
|
def forward(ctx, embedding):
|
|
layer_norm = torch.nn.LayerNorm(hidden_size, eps=1e-12)
|
|
return layer_norm(embedding)
|
|
|
|
class EmbeddingModule(torch.nn.Module):
|
|
def forward(
|
|
self,
|
|
embeddings=None,
|
|
):
|
|
embedding_output = CustomLayerNorm.apply(embeddings)
|
|
query = embedding_output.transpose(0, 1)
|
|
target_len, batch_size, embedding_dim = query.size()
|
|
# Reshape is used for consuming batch_size, and if it is static,
|
|
# this will be a Constant node in the graph
|
|
query = query.reshape(target_len, batch_size, embedding_dim)
|
|
return query
|
|
|
|
embeddings = torch.randn(batch_size, max_position_embeddings, hidden_size)
|
|
|
|
f = io.BytesIO()
|
|
torch.onnx.export(
|
|
EmbeddingModule().eval(),
|
|
(embeddings,),
|
|
f,
|
|
input_names=["embeddings"],
|
|
dynamic_axes={
|
|
"embeddings": {
|
|
0: "batch_size",
|
|
1: "max_position_embeddings",
|
|
2: "hidden_size",
|
|
}
|
|
},
|
|
custom_opsets={"com.microsoft": 1},
|
|
)
|
|
model = onnx.load(io.BytesIO(f.getvalue()))
|
|
|
|
# If there is a constant node with dim=3 and max_position_embeddings,
|
|
# batch_size, hidden_size as shape, it means the shape becomes static.
|
|
# Normally, with dynamic batch size, this constant node should not exist.
|
|
const_node = [n for n in model.graph.node if n.op_type == "Constant"]
|
|
self.assertNotEqual(len(const_node), 0)
|
|
for node in const_node:
|
|
for a in node.attribute:
|
|
if a.name == "value":
|
|
shape = onnx.numpy_helper.to_array(a.t)
|
|
self.assertNotEqual(
|
|
shape.tolist(),
|
|
[max_position_embeddings, batch_size, hidden_size],
|
|
)
|
|
|
|
def test_is_fp_for_C_TypeList(self):
|
|
class M(torch.nn.Module):
|
|
def forward(self, x):
|
|
x = x.squeeze(1)
|
|
w = x.shape[2]
|
|
pos = x.view(2, -1).argmax(1)
|
|
x_int = pos % w
|
|
y_int = (pos - x_int) // w
|
|
return y_int, x_int
|
|
|
|
model = torch.jit.script(M())
|
|
inputs = torch.randn(2, 4, 6)
|
|
f = io.BytesIO()
|
|
torch.onnx.export(
|
|
model, inputs, f, dynamic_axes={"x": [0, 1]}, input_names=["x"]
|
|
)
|
|
|
|
|
|
if __name__ == "__main__":
|
|
common_utils.run_tests()
|