mirror of
https://github.com/pytorch/pytorch.git
synced 2025-10-20 21:14:14 +08:00
Summary: Runs through vast majority of primitive ops that exist in NNC and benchmarks them against PyTorch ops on CPU. Dumps out a plot like this. 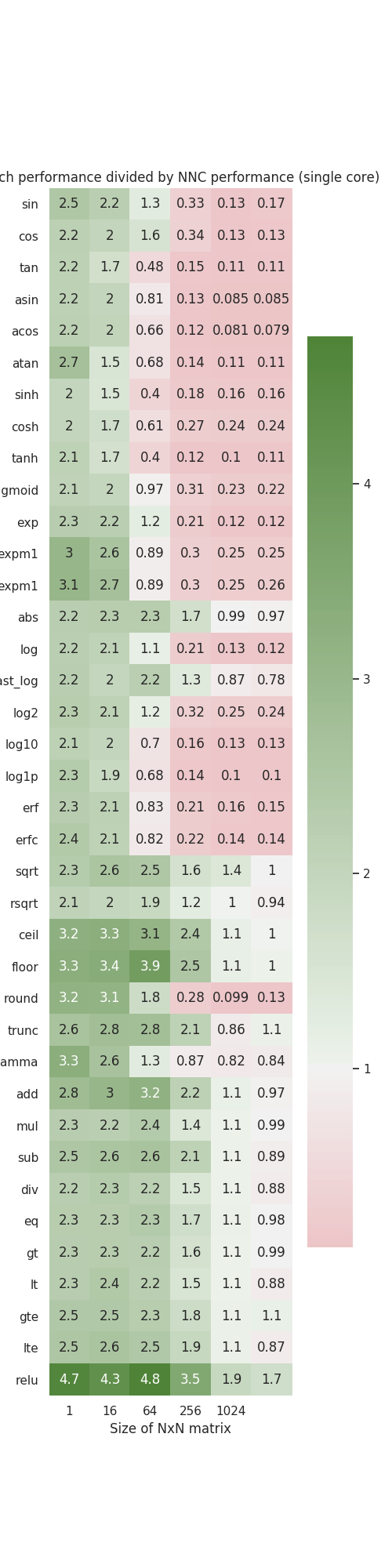 Pull Request resolved: https://github.com/pytorch/pytorch/pull/50845 Reviewed By: ngimel Differential Revision: D25989080 Pulled By: Chillee fbshipit-source-id: 6d6a39eb06b3de9a999993224d5e718537c0c8c4
{kind=link}
258 lines
8.4 KiB
Python
258 lines
8.4 KiB
Python
import torch
|
|
import torch._C.te as te
|
|
import time
|
|
import numpy as np
|
|
import pandas as pd
|
|
import matplotlib.pyplot as plt
|
|
import seaborn as sns
|
|
import argparse
|
|
|
|
class kernel_arena_scope(object):
|
|
def __enter__(self):
|
|
self.scope = te.KernelScope()
|
|
|
|
def __exit__(self, typ, val, traceback):
|
|
self.scope = None
|
|
|
|
unary_ops = [
|
|
("sin", torch.sin),
|
|
("cos", torch.cos),
|
|
("tan", torch.tan),
|
|
("asin", torch.asin),
|
|
("acos", torch.acos),
|
|
("atan", torch.atan),
|
|
("sinh", torch.sinh),
|
|
("cosh", torch.cosh),
|
|
("tanh", torch.tanh),
|
|
("sigmoid", torch.sigmoid),
|
|
("exp", torch.exp),
|
|
("expm1", torch.expm1),
|
|
("expm1", torch.expm1),
|
|
("abs", torch.abs),
|
|
("log", torch.log),
|
|
("fast_log", torch.log),
|
|
("log2", torch.log2),
|
|
("log10", torch.log10),
|
|
("log1p", torch.log1p),
|
|
("erf", torch.erf),
|
|
("erfc", torch.erfc),
|
|
("sqrt", torch.sqrt),
|
|
("rsqrt", torch.rsqrt),
|
|
("ceil", torch.ceil),
|
|
("floor", torch.floor),
|
|
("round", torch.round),
|
|
("trunc", torch.trunc),
|
|
("lgamma", torch.lgamma),
|
|
# ("frac", torch.frac), # seems unimplemented
|
|
# ("isnan", torch.isnan), # no out variant
|
|
]
|
|
|
|
def gen_unary_nnc_fun(nnc_name):
|
|
def nnc_fun(A, B):
|
|
def compute(i, j):
|
|
return getattr(A.load([i, j]), nnc_name)()
|
|
return compute
|
|
return nnc_fun
|
|
|
|
def gen_unary_torch_fun(torch_op):
|
|
def torch_fun(a, b, out):
|
|
def fun():
|
|
return torch_op(a, out=out)
|
|
return fun
|
|
return torch_fun
|
|
|
|
|
|
def gen_binary_nnc_fun(fn):
|
|
def nnc_fun(A, B):
|
|
def compute(i, j):
|
|
return fn(A.load([i, j]), B.load([i, j]))
|
|
return compute
|
|
return nnc_fun
|
|
|
|
def gen_binary_torch_fun(fn):
|
|
def pt_fun(a, b, out):
|
|
def fun():
|
|
return fn(a, b, out=out)
|
|
return fun
|
|
return pt_fun
|
|
|
|
def gen_int_comparison_tensors(N, M):
|
|
return (torch.randint(0, 3, (N, M)), torch.randint(0, 3, (N, M)), torch.empty((N, M), dtype=torch.bool))
|
|
|
|
def gen_float_comparison_tensors(N, M):
|
|
return (torch.rand(N, M), torch.rand(N, M), torch.empty((N, M), dtype=torch.bool))
|
|
|
|
|
|
te_bool = te.Dtype.Bool
|
|
binary_ops = [
|
|
('add', (lambda a, b: a + b), torch.add),
|
|
('mul', (lambda a, b: a * b), torch.mul),
|
|
('sub', (lambda a, b: a - b), torch.sub),
|
|
('div', (lambda a, b: a / b), torch.div),
|
|
('eq', (lambda a, b: te.Cast.make(te_bool, a == b)), torch.eq, gen_int_comparison_tensors),
|
|
('gt', (lambda a, b: te.Cast.make(te_bool, a > b)), torch.gt, gen_float_comparison_tensors),
|
|
('lt', (lambda a, b: te.Cast.make(te_bool, a < b)), torch.lt, gen_float_comparison_tensors),
|
|
('gte', (lambda a, b: te.Cast.make(te_bool, a >= b)), torch.greater_equal, gen_float_comparison_tensors),
|
|
('lte', (lambda a, b: te.Cast.make(te_bool, a <= b)), torch.less_equal, gen_float_comparison_tensors),
|
|
# ('neq', (lambda a, b: a != b), None)), # no one-op equivalent
|
|
# ('&', (lambda a, b: a & b), torch.bitwise_and), # requires more work to test
|
|
]
|
|
|
|
|
|
def nnc_relu(A, B):
|
|
def f(i, j):
|
|
return torch._C.te.ifThenElse(A.load([i, j]) < torch._C.te.ExprHandle.float(0),
|
|
torch._C.te.ExprHandle.float(0), A.load([i, j]))
|
|
return f
|
|
|
|
def pt_relu(a, b, c):
|
|
return torch.relu(a)
|
|
custom_ops = [
|
|
('relu', nnc_relu, pt_relu),
|
|
# ('nnc_mul_relu', nnc_mul_relu, pt_mul_relu)
|
|
# ('manual_sigmoid', nnc_manual_sigmoid, lambda a, b, c: torch.sigmoid(a, out=c))
|
|
]
|
|
|
|
|
|
def gen_custom_torch_fun(fn):
|
|
def pt_fun(a, b, out):
|
|
def fun():
|
|
return fn(a, b, out)
|
|
return fun
|
|
return pt_fun
|
|
|
|
def normalize_benchmarks(ops):
|
|
return [i + (None,) if len(i) == 3 else i for i in ops]
|
|
|
|
names = []
|
|
nnc_fns = []
|
|
pt_fns = []
|
|
shape_fns = []
|
|
|
|
for nnc_name, pt_op in unary_ops:
|
|
names.append(nnc_name)
|
|
nnc_fns.append(gen_unary_nnc_fun(nnc_name))
|
|
pt_fns.append(gen_unary_torch_fun(pt_op))
|
|
shape_fns.append(None)
|
|
|
|
for name, lmbda, pt_fn, shape_fn in normalize_benchmarks(binary_ops):
|
|
names.append(name)
|
|
nnc_fns.append(gen_binary_nnc_fun(lmbda))
|
|
pt_fns.append(gen_binary_torch_fun(pt_fn))
|
|
shape_fns.append(shape_fn)
|
|
|
|
for name, lmbda, pt_fn, shape_fn in normalize_benchmarks(custom_ops):
|
|
names.append(name)
|
|
nnc_fns.append(lmbda)
|
|
pt_fns.append(gen_custom_torch_fun(pt_fn))
|
|
shape_fns.append(shape_fn)
|
|
|
|
benchmarks = list(zip(names, nnc_fns, pt_fns, shape_fns))
|
|
|
|
def run_benchmarks(benchmarks, sizes):
|
|
df = pd.DataFrame(columns=['name', 'N', 'M', 'nnc_time', 'torch_time', 'ratio'])
|
|
with torch.no_grad():
|
|
for name, nnc_fun, torch_fun, shape_fn in benchmarks:
|
|
for N, M in sizes:
|
|
iters = int(1e6 / (N + M))
|
|
with kernel_arena_scope():
|
|
if shape_fn is None:
|
|
tA = torch.rand(M, N).clamp(0.01, 0.99)
|
|
tB = torch.rand(M, N).clamp(0.01, 0.99)
|
|
tX = torch.empty(M, N)
|
|
tR = torch.empty(M, N)
|
|
else:
|
|
tA, tB, tX = shape_fn(M, N)
|
|
tR = tX.clone()
|
|
|
|
def get_nnc_type(dtype):
|
|
if dtype == torch.float:
|
|
return torch._C.te.Dtype.Float
|
|
elif dtype == torch.long:
|
|
return torch._C.te.Dtype.Long
|
|
|
|
dtype = get_nnc_type(tA.dtype)
|
|
|
|
dM = torch._C.te.ExprHandle.int(M)
|
|
dN = torch._C.te.ExprHandle.int(N)
|
|
|
|
A = torch._C.te.Placeholder('A', dtype, [dM, dN])
|
|
B = torch._C.te.Placeholder('B', dtype, [dM, dN])
|
|
|
|
dim_args = [torch._C.te.DimArg(*args) for args in [(dM, 'm'), (dN, 'n')]]
|
|
|
|
compute = nnc_fun(A, B)
|
|
X = torch._C.te.Compute('X', dim_args, compute)
|
|
loopnest = torch._C.te.LoopNest([X])
|
|
loopnest.prepare_for_codegen()
|
|
stmt = torch._C.te.simplify(loopnest.root_stmt())
|
|
cg = torch._C.te.construct_codegen('llvm', stmt, [torch._C.te.BufferArg(x) for x in [A, B, X]])
|
|
|
|
|
|
# warmup
|
|
for _ in range(10):
|
|
cg.call([tA, tB, tX])
|
|
start = time.time()
|
|
for it in range(iters):
|
|
cg.call([tA, tB, tX])
|
|
time1 = time.time() - start
|
|
|
|
|
|
fn = torch_fun(tA, tB, tR)
|
|
# warmup
|
|
for _ in range(10):
|
|
tR = fn()
|
|
start = time.time()
|
|
for it in range(iters):
|
|
tR = fn()
|
|
time2 = time.time() - start
|
|
|
|
df = df.append({'name': name, 'N': N, 'M': M, 'nnc_time': time1,
|
|
'torch_time': time2, 'ratio': time2 / time1}, ignore_index=True)
|
|
print(name, N, M)
|
|
|
|
print(time2 / time1, time1, time2)
|
|
print()
|
|
|
|
def check_correctness(a, b):
|
|
if not np.allclose(a, b):
|
|
print(name)
|
|
assert(np.allclose(a, b))
|
|
check_correctness(tX, tR)
|
|
return df
|
|
|
|
def dump_plot(df, sizes):
|
|
keys = []
|
|
vals = []
|
|
indexed = df[df['N'] == df['M']]
|
|
for index, row in indexed.iterrows():
|
|
keys.append(row['name'])
|
|
vals.append(row['ratio'])
|
|
|
|
keys = keys[::len(sizes)]
|
|
sns.set(rc={'figure.figsize' : (5.0, len(keys) * 0.5)})
|
|
|
|
cmap = sns.diverging_palette(10, 120, n=9, as_cmap=True)
|
|
np_vals = np.array([vals]).reshape(-1, len(sizes))
|
|
g = sns.heatmap(np_vals, annot=True, cmap=cmap, center=1.0, yticklabels=True)
|
|
plt.yticks(rotation=0)
|
|
plt.title('PyTorch performance divided by NNC performance (single core)')
|
|
plt.xlabel('Size of NxN matrix')
|
|
plt.ylabel('Operation')
|
|
g.set_yticklabels(keys)
|
|
g.set_xticklabels(sizes)
|
|
|
|
plt.savefig('nnc.png')
|
|
|
|
|
|
if __name__ == "__main__":
|
|
parser = argparse.ArgumentParser(description='Runs NNC microbenchmarks')
|
|
parser.add_argument('--multi_threaded', action='store_true', help='Run with more than one thread')
|
|
args = parser.parse_args()
|
|
if not args.multi_threaded:
|
|
torch.set_num_threads(1)
|
|
|
|
sizes = [1, 4, 16, 64, 256, 1024]
|
|
df = run_benchmarks(benchmarks, [(i, i) for i in sizes])
|
|
dump_plot(df, sizes)
|