1. Move cond to torch/_higher_order_ops
2. Fix a bug in map, which didn't respect tensor dtype when creating a new one from them. We cannot directly use empty_strided because boolean tensor created by empty_strided is not properly intialized so it causes error "load of value 190, which is not a valid value for type 'bool'" on clang asan environment on CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108025
Approved by: https://github.com/zou3519
Fixes https://github.com/pytorch/pytorch/pull/102577#issuecomment-1650905536
Serializing to json is more stable, and renamed the API:
```
# Takes in a treespec and returns the serialized treespec as a string. Also optionally takes in a protocol version number.
def treespec_dumps(treespec: TreeSpec, protocol: Optional[int] = None) -> str:
# Takes in a serialized treespec and outputs a TreeSpec
def treespec_loads(data: str) -> TreeSpec:
```
If users want to register their own serialization format for a given pytree, they can go through the `_register_treespec_serializer` API which optionally takes in a `getstate` and `setstate` function.
```
_register_treespec_serializer(type_, *, getstate, setstate)
# Takes in the context, and outputs a json-dumpable context
def getstate(context: Context) -> DumpableContext:
# Takes in a json-dumpable context, and reconstructs the original context
def setstate(dumpable_context: DumpableContext) -> Context:
```
We will serialize to the following dataclass, and then json.dump this it to string.
```
class TreeSpec
type: Optional[str] # a string name of the type. null for the case of a LeafSpec
context: Optional[Any] # optional, a json dumpable format of the context
children_specs: List[TreeSpec],
}
```
If no getstate/setstate function is registered, we will by default serialize the context using `json.dumps/loads`. We will also serialize the type through `f"{typ.__module__}.{typ.__name__}"`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106116
Approved by: https://github.com/zou3519
**Summary**
Add linear and linear-unary post-op quantization recipe to x86 inductor quantizer. For PT2E with Inductor. With this, the quantization path will add `quant-dequant` pattern for linear and linear-unary post op.
**Test plan**
python test/test_quantization.py -k test_linear_with_quantizer_api
python test/test_quantization.py -k test_linear_unary_with_quantizer_api
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106781
Approved by: https://github.com/leslie-fang-intel, https://github.com/jgong5, https://github.com/jerryzh168
ghstack dependencies: #105818
When generating a wrapper call, we may have implicit resize applied to
the kernel's output. For example, for addmm(3d_tensor, 2d_tensor),
its output buffer is resized to a 2d tensor. This triggers a warning from
Aten's resize_output op:
"UserWarning: An output with one or more elements was resized since it had...
This behavior is deprecated, and in a future PyTorch release outputs will
not be resized unless they have zero elements..."
More importantly, the output shape is not the same as we would expect, i.e.
2d tensor v.s. 3d tensor.
This PR fixed the issue by injecting resize_(0) before calling the relevant
kernel and resize_(expected_shape) after the kernel call.
We also fixed a minor typo in the PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107848
Approved by: https://github.com/desertfire, https://github.com/jansel
This PR brings in a few inductor changes required for ROCm
~**1 - Introduction of a toggle for enforced channel last convolution fallbacks**~
This addition is split off into its own PR after some cleanup by @pragupta https://github.com/pytorch/pytorch/pull/107812
**2 - Addition of ROCm specific block sizes**
We are now able to support the MAX_AUTOTUNE mode on ROCm, we are proposing conditions to allow us to finetune our own block tuning. Currently triton on ROCm does not benefit from pipelining so we are setting all configs to `num_stages=1` and we have removed some upstream tunings on ROCm to avoid running out of shared memory resources.
In the future we will provide more optimised tunings for ROCm but for now this should mitigate any issues
~**3 - Addition of device_type to triton's compile_meta**~
~Proposing this addition to `triton_heuristics.py`, Triton on ROCm requires device_type to be set to hip https://github.com/ROCmSoftwarePlatform/triton/pull/284 suggesting to bring this change in here so we can pass down the correct device type to triton.~
This change is split off and will arrive in the wheel update PR https://github.com/pytorch/pytorch/pull/107600 leaving this PR to focus on the ROCm specific block sizes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107584
Approved by: https://github.com/jithunnair-amd, https://github.com/jansel, https://github.com/eellison
This reworks the DORT backend factory function to support the options kwarg of torch.compile, and defines a concrete OrtBackendOptions type that can be used to influence the backend.
Caching is also implemented in order to reuse backends with equal options.
Wrapping the backend in auto_autograd also becomes an option, which allows `OrtBackend` to always be returned as the callable for torch.compile; wrapping happens internally if opted into (True by default).
Lastly, expose options for configuring preferred execution providers (will be attempted first), whether or not to attempt to infer an ORT EP from a torch found device in the graph or inputs, and finally the default/fallback EPs.
### Demo
The following demo runs `Gelu` through `torch.compile(backend="onnxrt")` using various backend options through a dictionary form and a strongly typed form. It additionally exports the model through both the ONNX TorchScript exporter and the new TorchDynamo exporter.
```python
import math
import onnx.inliner
import onnxruntime
import torch
import torch.onnx
torch.manual_seed(0)
class Gelu(torch.nn.Module):
def forward(self, x):
return x * (0.5 * torch.erf(math.sqrt(0.5) * x) + 1.0)
@torch.compile(
backend="onnxrt",
options={
"preferred_execution_providers": [
"NotARealEP",
"CPUExecutionProvider",
],
"export_options": torch.onnx.ExportOptions(dynamic_shapes=True),
},
)
def dort_gelu(x):
return Gelu()(x)
ort_session_options = onnxruntime.SessionOptions()
ort_session_options.log_severity_level = 0
dort_gelu2 = torch.compile(
Gelu(),
backend="onnxrt",
options=torch.onnx._OrtBackendOptions(
preferred_execution_providers=[
"NotARealEP",
"CPUExecutionProvider",
],
export_options=torch.onnx.ExportOptions(dynamic_shapes=True),
ort_session_options=ort_session_options,
),
)
x = torch.randn(10)
torch.onnx.export(Gelu(), (x,), "gelu_ts.onnx")
export_output = torch.onnx.dynamo_export(Gelu(), x)
export_output.save("gelu_dynamo.onnx")
inlined_model = onnx.inliner.inline_local_functions(export_output.model_proto)
onnx.save_model(inlined_model, "gelu_dynamo_inlined.onnx")
print("Torch Eager:")
print(Gelu()(x))
print("DORT:")
print(dort_gelu(x))
print(dort_gelu2(x))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107973
Approved by: https://github.com/BowenBao
**Summary**
The latest check-in a0cfaf0688 for the conv-bn folding assumes the graph is captured by the new graph capture API `torch._export.capture_pre_autograd_graph`. Since we still need to use the original graph capture API `torch._dynamo_export` in 2.1 release. So, this check-in made negative impact to workloads' performance heavily. Made this PR to fix this issue by trying to make the conv-bn folding function workable with both new and original graph capture API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107951
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
ghstack dependencies: #106836, #106838, #106958
Compared to #104848, this PR makes a step further: when the enable_sparse_support decorator is applied to `torch.autograd.gradcheck`, the resulting callable is equivalent to `torch.autograd.gradcheck` with an extra feature of supporting functions that can have input sparse tensors or/and can return sparse tensors.
At the same time, the underlying call to `torch.autograd.gradcheck` will operate on strided tensors only. This basically means that torch/autograd/gradcheck.py can be cleaned up by removing the code that deals with sparse tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107150
Approved by: https://github.com/albanD, https://github.com/amjames, https://github.com/cpuhrsch
ghstack dependencies: #107638, #107777
Resolves https://github.com/pytorch/pytorch/issues/107097
After this PR, instead of
```python
torch.sparse_coo_tensor(indices, values, size)._coalesced_(is_coalesced)
```
(that does not work in the autograd context, see #107097), use
```python
torch.sparse_coo_tensor(indices, values, size, is_coalesced=is_coalesced)
```
All sparse coo factory functions that take indices as input support the `is_coalesced` argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107638
Approved by: https://github.com/cpuhrsch
This PR relands https://github.com/pytorch/pytorch/pull/106827 which get reverted because of causing compilation error for some ads model.
Yanbo provide a repro in one of the 14k model ( `pytest ./generated/test_KaiyangZhou_deep_person_reid.py -k test_044`). This is also the model I used to confirm the fix and come up with a unit test. In this model, we call `tritoin_heuristics.triton_config` with size_hints [2048, 2]. Previously this would result in a trition config with XBLOCK=2048 and YBLOCK=2 . But since we change the mapping between size_hints and XYZ dimension, we now generate a triton config with XBLOCK=2 and YBLOCK=2048. This fails compilation since we set max YBLOCK to be 1024.
My fix is to make sure we never generate a triton config that exceeds the maximum block size.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107902
Approved by: https://github.com/jansel
Summary: This fixes the no bias case for conv annotations.
Previously this would result in an index out of bounds, since
the new aten.conv2d op may not have the bias arg (unlike the
old aten.convolution op). This was not caught because of a lack
of test cases, which are added in this commit.
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_qat_conv_no_bias
python test/test_quantization.py TestQuantizePT2E.test_qat_conv_bn_relu_fusion_no_conv_bias
Reviewers: jerryzh168, kimishpatel
Subscribers: jerryzh168, kimishpatel
Differential Revision: [D48696874](https://our.internmc.facebook.com/intern/diff/D48696874)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107971
Approved by: https://github.com/jerryzh168
Given standalone generates args anyways, it seems like it would be more convenient if it explicitly used a random port by default instead of trying to use 29400.
That way users can directly go with `--standalone` instead of having to spell out `--rdzv-backend=c10d --rdzv-endpoint=localhost:0`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107734
Approved by: https://github.com/H-Huang
For max_pooling code:
```
#pragma GCC ivdep
for(long i2=static_cast<long>(0L); i2<static_cast<long>(56L); i2+=static_cast<long>(1L))
{
for(long i3=static_cast<long>(0L); i3<static_cast<long>(64L); i3+=static_cast<long>(16L))
{
auto tmp0 = at::vec::Vectorized<int>(static_cast<int>((-1L) + (2L*i1)));
auto tmp1 = at::vec::Vectorized<int>(static_cast<int>(0));
auto tmp2 = to_float_mask(tmp0 >= tmp1);
auto tmp3 = at::vec::Vectorized<int>(static_cast<int>(112));
auto tmp4 = to_float_mask(tmp0 < tmp3);
auto tmp5 = tmp2 & tmp4;
auto tmp6 = at::vec::Vectorized<int>(static_cast<int>((-1L) + (2L*i2)));
auto tmp7 = to_float_mask(tmp6 >= tmp1);
auto tmp8 = to_float_mask(tmp6 < tmp3);
auto tmp9 = tmp7 & tmp8;
auto tmp10 = tmp5 & tmp9;
auto tmp11 = [&]
{
auto tmp12 = at::vec::Vectorized<bfloat16>::loadu(in_ptr0 + static_cast<long>((-7232L) + i3 + (128L*i2) + (14336L*i1) + (802816L*i0)), 16);
load
auto tmp13 = cvt_lowp_fp_to_fp32<bfloat16>(tmp12);
return tmp13;
}
;
auto tmp14 = decltype(tmp11())::blendv(at::vec::Vectorized<float>(-std::numeric_limits<float>::infinity()), tmp11(), to_float_mask(tmp10));
```
the index of ```tmp12 ``` may be a correct index, such as ```i1=0, i2=0, i3=0```, the index is ```-7232L```, it is not a valid index. We may meet segmentation fault error when we call ```tmp11()```, the original behavior is that only the ```tmp10```(index check variable) is true, we can safely get the value, this PR will support masked_load to fixing this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107670
Approved by: https://github.com/jgong5, https://github.com/jansel
In almost all cases this is only included for writing the output formatter, which
only uses `std::ostream` so including `<ostream>` is sufficient.
The istream header is ~1000 lines so the difference is non-trivial.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106914
Approved by: https://github.com/lezcano
**Summary**
Enable the `dequant pattern` promotion pass in inductor. Since in the qconv weight prepack pass, we will match the `dequant->conv2d` pattern. If the `dequant pattern` has multi user nodes, it will fail to be matched.
Taking the example of
```
conv1
/ \
conv2 conv3
```
After quantization flow, it will generate pattern as
```
dequant1
|
conv1
|
quant2
|
dequant2
/ \
conv2 conv3
```
We need to duplicate `dequant2` into `dequant2` and `dequant3`, in order to make `dequant2->conv2` and `dequant3->conv3` pattern matched.
**Test Plan**
```
python -m pytest test_mkldnn_pattern_matcher.py -k test_dequant_promotion
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104590
Approved by: https://github.com/jgong5, https://github.com/eellison
ghstack dependencies: #104580, #104581, #104588
Instead of hardcoding a new callback creation using 'convert_frame',
add an attribute to both callbacks that implement 'self cloning with new
backend', so DDPOptimizer can invoke this in a consistent way.
Fixes#107686
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107834
Approved by: https://github.com/ezyang
Summary:
When the `cat` inputs' sizes and the `split_sizes` of the downstream `split_with_sizes` match, the `cat` + `split_with_sizes` constellation can be eliminated. E.g. here:
```
@torch.compile
def fn(a, b, c):
cat = torch.ops.aten.cat.default([a, b, c], 1)
split_with_sizes = torch.ops.aten.split_with_sizes.default(cat, [2, 3, 5], 1)
return [s ** 2 for s in split_with_sizes]
inputs = [
torch.randn(2, 2, device="cuda"),
torch.randn(2, 3, device="cuda"),
torch.randn(2, 5, device="cuda"),
]
output = fn(*inputs)
```
This PR adds a new fx pass for such elimination. The new pass is similar to the existing [`splitwithsizes_cat_replace`](b18e1b684a/torch/_inductor/fx_passes/post_grad.py (L508)), but considers the ops in the opposite order.
Test Plan:
```
$ python test/inductor/test_pattern_matcher.py
...
----------------------------------------------------------------------
Ran 21 tests in 46.450s
OK
```
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107956
Approved by: https://github.com/jansel
**Summary**
Update onednn from v2.7.3 to v3.1.1.
It is bc-breaking as some APIs are changed on oneDNN side. Changes include:
- PyTorch code where oneDNN is directly called
- Submodule `third_party/ideep` to adapt to oneDNN's new API.
- CMAKE files to fix build issues.
**Test plan**
Building issues and correctness are covered by CI checks.
For performance, we have run TorchBench models to ensure there is no regression. Below is the comparison before and after oneDNN update.

Note:
- Base commit of PyTorch: da322ea
- CPU: Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz (Ice Lake)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97957
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
Update to ROCm triton pinned commit for the 2.1 branch cut off.
As part of this we are updating `build_triton_wheel.py` and `build-triton-wheel.yml` to support building ROCm triton wheels through pytorch/manylinux-rocm to avoid the need of slowly downloading rpm libraries for ROCm in the cpu manylinux builder image and avoiding the need to maintain a conditional file with hard coded repositories from radeon.org for every ROCm release.
This new approach will allow us to build wheels faster in a more easily maintainable way.
This PR also brings in a required change as Triton on ROCm requires device_type to be set to hip so we can pass down the correct device type to triton (https://github.com/ROCmSoftwarePlatform/triton/pull/284).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107600
Approved by: https://github.com/jansel, https://github.com/jithunnair-amd
Summary:
This is a duplicate PR of 102133, which was reverted because it was
failing internal tests.
It seems like that internal builds did not like my guard to check if
cuSPARSELt was available or not.
Test Plan: python test/test_sparse_semi_structured.py
Differential Revision: D48440330
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107398
Approved by: https://github.com/cpuhrsch
Previously when we found some input or output mismatch between original args / traced result vs. graph-captured input / output, we would have a pretty sparse error message. (This might be partly due to the urge to reuse the same code for matching both inputs and outputs.)
With this PR we now point out which input or output is problematic, what its type is, and also present the expected types along with descriptions of what they mean. We don't suggest any fixes, but the idea is that it should be evident what went wrong looking at the error message.
Differential Revision: [D48668059](https://our.internmc.facebook.com/intern/diff/D48668059/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107907
Approved by: https://github.com/gmagogsfm
Use `view_as_real` to cast complex into a pair of floats and then it becomes just another binary operator.
Enable `polar` and `view_as_complex` consistency tests, but skip `test_output_grad_match_polar_cpu` as `mul` operator is yet not supported
Remove redundant `#ifdef __OBJC__` and capture and re-throw exceptions captured during `createCacheBlock` block.
Fixes https://github.com/pytorch/pytorch/issues/78503
TODOs(in followup PRs):
- Implement backwards (requires complex mul and sgn)
- Measure the perf impact of computing the strides on the fly rather than ahead of time (unrelated to this PR)
Partially addresses https://github.com/pytorch/pytorch/issues/105665
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107324
Approved by: https://github.com/albanD
Summary:
Daohang report this pattern in f469463749
{F1074472207}
{F1074473348}
Hence, we can fuse the tanh after same split.
Typically the pattern looks like split->getitem0,...n-> tanh(geitem 0,..., n). Hence, we search for parent node of tahn nodes and the node should be getitem(parent, index). If tanh is after same split node, parent nodes of getitem nodes should be same.
Test Plan:
```
[jackiexu0313@devgpu005.cln5 ~/fbsource/fbcode (c78736187)]$ buck test mode/dev-nosan //caffe2/test/inductor:group_batch_fusion
File changed: fbcode//caffe2/test/inductor/test_group_batch_fusion.py
Buck UI: https://www.internalfb.com/buck2/df87affc-d294-4663-a50d-ebb71b98070d
Test UI: https://www.internalfb.com/intern/testinfra/testrun/9570149208311124
Network: Up: 0B Down: 0B
Jobs completed: 16. Time elapsed: 1:19.9s.
Tests finished: Pass 6. Fail 0. Fatal 0. Skip 0. Build failure 0
```
Differential Revision: D48581140
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107881
Approved by: https://github.com/yanboliang
> capture_error_mode (str, optional): specifies the cudaStreamCaptureMode for the graph capture stream.
Can be "global", "thread_local" or "relaxed". During cuda graph capture, some actions, such as cudaMalloc,
may be unsafe. "global" will error on actions in other threads, "thread_local" will only error for
actions in the current thread, and "relaxed" will not error on these actions.
Inductor codegen is single-threaded, so it should be safe to enable "thread_local" for inductor's cuda graph capturing. We have seen errors when inductor cudagraphs has been used concurrently with data preprocessing in other threads.
Differential Revision: [D48656014](https://our.internmc.facebook.com/intern/diff/D48656014)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107407
Approved by: https://github.com/albanD, https://github.com/eqy
The c10d socket and gloo listener both set their buffer size to 2048 which causes connection issue at 4k scale. This diff sets the buffer size to `-1` which uses `somaxconn` as the actual buffer size, aiming to enable 24k PG init without crash. The experiment shows the ability to successful creation of 12k ranks without crash.
split the original diff for OSS vs. internal.
Caution: we need the change on both gloo and c10d to enable 12k PG init. Updating only one side may not offer the benefit.
Differential Revision: [D48634654](https://our.internmc.facebook.com/intern/diff/D48634654/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107878
Approved by: https://github.com/H-Huang, https://github.com/fduwjj
Summary:
This is a stride based attribute for a tensor available in Python.
This can help inspect tensors generated using `torch.empty_permuted(.., physical_layout, ...)`, where physical_layout should match the dim_order returned here. `empty_permuted` will be renamed to use dim_order as the param name in the future. And also help Executorch export pipeline with implementing dim_order based tensors.
Differential Revision: D48134476
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106835
Approved by: https://github.com/ezyang
There has been several reports of difficulty in using OpenMP in MacOS, e.g.: https://github.com/pytorch/pytorch/issues/95708 . And there are several PRs to fix it, e.g.: https://github.com/pytorch/pytorch/pull/93895 and https://github.com/pytorch/pytorch/pull/105136 .
This PR tries to explain the root cause, and provide a holistic and systematic way to fix the problem.
For the OpenMP program below to run, the compiler must:
- Be able to process macros like `#pragma omp parallel`
- Be able to find header files like `<omp.h>`
- Be able to link to a library file like `libomp`
```C++
#include <omp.h>
int main()
{
omp_set_num_threads(4);
#pragma omp parallel
{
int id = omp_get_thread_num();
int nthrds = omp_get_num_threads();
int y = id * nthrds;
}
}
```
In MacOS, there might be different compiler tools:
- Apple builtin `clang++`, installed with `xcode commandline tools`. The default `g++` and `clang++` commands both point to the Apple version, as can be confirmed by `g++ --version`
- Public `clang++`, can be installed via `brew install llvm`.
- Public GNU compiler `g++`, can be installed via `brew install gcc`.
Among these compilers, public `clang++` from LLVM and `g++` from GNU both support OpenMP with the flag `-fopenmp`. They have shipped with `<omp.h>` and `libomp` support. The only problem is that Apple builtin `clang++` does not contain `<omp.h>` or `libomp`. Therefore, users can follow the steps to enable OpenMP support:
- Use a compiler other than Apple builtin clang++ by specifying the `CXX` environment variable
- Use `conda install llvm-openmp` to place the header files and lib files inside conda environments (and can be discovered by `CONDA_PREFIX`)
- Use `brew install libomp` to place the header files and lib files inside brew control (and can be discovered by `brew --prefix libomp`)
- Use a custom install of OpenMP by specifying an `OMP_PREFIX` where header files and lib files can be found.
This PR reflects the above logic, and might serve as a final solution for resolving OpenMP issues in MacOS.
This PR also resolves the discussion raised in https://dev-discuss.pytorch.org/t/can-we-add-a-default-backend-when-openmp-is-not-available/1382/5 with @jansel , and provide a way for brew users to automatically find the installation via `brew --prefix libomp`, and provide instructions to switch to another compiler by `CXX` environment variable.
I have tested the following code in different conditions:
- Use `CXX` to point to an LLVM-clang++, works fine.
- Use `CXX` to point to a GNU g++, not working because the compiler flag `-Xclang`. Manually removing the code `base_flags += " -Xclang"` works.
- Use default compiler and `conda install llvm-openmp`, works fine
- Use default compiler and `brew install libomp`, works fine
- Do nothing, compiler complains `omp.h` not found.
```python
import torch
@torch.compile
def f(x):
return x + 1
f(torch.randn(5, 5))
```
If we want the code to be more portable, we can also deal with the `-Xclang` issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107111
Approved by: https://github.com/jgong5, https://github.com/jansel
Adds `SingletonSymNodeImpl` (alternatively, `SkolemSymNodeImpl`). This is a int-like object that only allows the`eq` operation; any other operation produces an error.
The main complexity is that we require operations that dispatch to SymNode must take and return SymNodes, but when performing operations involving `SingletonSymNodeImpl`, operations involving SymNode can return non-SymNode bools. For more discussion see [here](https://docs.google.com/document/d/18iqMdnHlUnvoTz4BveBbyWFi_tCRmFoqMFdBHKmCm_k/edit)
- Introduce `ConstantSymNodeImpl` a generalization of `LargeNegativeIntSymNodeImpl` and replace usage of `LargeNegativeIntSymNodeImpl` in SymInt.
- Also use ConstantSymNodeImpl to enable SymBool to store its data on a SymNode. Remove the assumption that if SymBool holds a non-null SymNode, it must be symbolic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107089
Approved by: https://github.com/ezyang
ghstack dependencies: #107839
Although there are some performance benefits by enforcing NHWC convolutions as inductor's fallback method for all hardware this may not be the case. Currently on ROCm we are seeing some slow downs in gcnArch that do not have optimal NHWC implementations and would like to introduce some control on this behavior in pytorch. On ROCm MI200 series we will default to the enforced last channels behavior aligned with the rest of pytorch but on non-MI200 series we will disable the forced layout.
For now we are using torch.cuda.get_device_name(0) for this control but we will replace with gcnArchName when https://github.com/pytorch/pytorch/pull/107477 lands.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107812
Approved by: https://github.com/jataylo, https://github.com/eellison
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at d02bfb0</samp>
Add environment name for S3 HTMLs workflow. This allows secure and controlled access to the secrets and approval for updating the PyTorch whl indexes on S3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107889
Approved by: https://github.com/huydhn
The way the aot autograd sequence_nr tracking works is that we run the aot export logic, the dynamo captured forward graph is run under an fx.Interpreter, which iterates through the nodes of the forward graph while setting the `current_metadata`.
Since during backward what is run doesn't correspond to any node during forward, we fallback to the global `current_metadata`. And since this global metadata is ends up being shared between runs, that leads to weirdness if we forget to reset things, e.g., depending whether this is the first test run, the printed results will be different.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107210
Approved by: https://github.com/bdhirsh
### Description
The `download_url_to_file` function in torch.hub uses a temporary file to prevent overriding a local working checkpoint with a broken download.This temporary file is created using `NamedTemporaryFile`. However, since `NamedTemporaryFile` creates files with overly restrictive permissions (0600), the resulting download will not have default permissions and will not respect umask on Linux (since moving the file will retain the restrictive permissions of the temporary file). This is especially problematic when trying to share model checkpoints between multiple users as other users will not even have read access to the file.
The change in this PR fixes the issue by using custom code to create the temporary file without changing the permissions to 0600 (unfortunately there is no way to override the permissions behaviour of existing Python standard library code). This ensures that the downloaded checkpoint file correctly have the default permissions applied. If a user wants to apply more restrictive permissions, they can do so via usual means (i.e. by setting umask).
See these similar issues in other projects for even more context:
* https://github.com/borgbackup/borg/issues/6400
* https://github.com/borgbackup/borg/issues/6933
* https://github.com/zarr-developers/zarr-python/issues/325
### Issue
https://github.com/pytorch/pytorch/issues/81297
### Testing
Extended the unit test `test_download_url_to_file` to also check permissions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82869
Approved by: https://github.com/vmoens
Summary:
(From Brian Hirsh)
Description copied from what I put in a comment in this PR: https://github.com/pytorch/pytorch/pull/106329
So, the slightly-contentious idea behind this PR is that lower in the stack, I updated torch._decomps.get_decomps() to check not only the decomp table to see if a given op has a decomposition available, but to also check the dispatcher for any decomps registered to the CompositeImplicitAutograd key (link: https://github.com/pytorch/pytorch/pull/105865/files#diff-7008e894af47c01ee6b8eb94996363bd6c5a43a061a2c13a472a2f8a9242ad43R190)
There's one problem though: we don't actually make any hard guarantees that a given key in the dispatcher points does or does not point to a decomposition. We do rely pretty heavily, however, on the fact that everything registered to the CompositeImplicitAutograd key is in fact a decomposition into other ops.
QAT would like this API to faithfully return "the set of all decomps that would have run if we had traced through the dispatcher". However, native_batch_norm is an example of an op that has a pre-autograd decomp registered to it (through op.py_impl(), but the decomp is registered directly to the Autograd key instead of being registered to the CompositeImplicitAutograd key.
If we want to provide a guarantee to QAT that they can programatically access all decomps that would have run during tracing, then we need to make sure that every decomp we register to the Autograd key is also registered to the CompositeImplicitAutograd key.
This might sound kind of painful (since it requires auditing), but I think in practice this basically only applies to native_batch_norm.
Test Plan: python test/test_decomp.py
Differential Revision: D48607575
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107791
Approved by: https://github.com/jerryzh168, https://github.com/SherlockNoMad
Fixes#92000
The documentation at https://pytorch.org/docs/stable/generated/torch.nn.MultiLabelSoftMarginLoss.html#multilabelsoftmarginloss states:
> label targets padded by -1 ensuring same shape as the input.
However, the shape of input and target tensor are compared, and an exception is raised if they differ in either dimension 0 or 1. Meaning the label targets are never padded. See the code snippet below and the resulting output. The documentation is therefore adjusted to:
> label targets must have the same shape as the input.
```
import torch
import torch.nn as nn
# Create some example data
input = torch.tensor(
[
[0.8, 0.2, -0.5],
[0.1, 0.9, 0.3],
]
)
target1 = torch.tensor(
[
[1, 0, 1],
[0, 1, 1],
[0, 1, 1],
]
)
target2 = torch.tensor(
[
[1, 0],
[0, 1],
]
)
target3 = torch.tensor(
[
[1, 0, 1],
[0, 1, 1],
]
)
loss_func = nn.MultiLabelSoftMarginLoss()
try:
loss = loss_func(input, target1).item()
except RuntimeError as e:
print('target1 ', e)
try:
loss = loss_func(input, target2).item()
except RuntimeError as e:
print('target2 ', e)
loss = loss_func(input, target3).item()
print('target3 ', loss)
```
output:
```
target1 The size of tensor a (3) must match the size of tensor b (2) at non-singleton dimension 0
target2 The size of tensor a (2) must match the size of tensor b (3) at non-singleton dimension 1
target3 0.6305370926856995
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107817
Approved by: https://github.com/mikaylagawarecki
Summary:
This relands #107601, which was reverted due to the new test failing in the internal CI. Here we skip the new test (as well as the existing tests in `test_aot_inductor.py`, as those are also failing in the internal CI).
Test Plan:
```
$ python test/inductor/test_aot_inductor.py
...
----------------------------------------------------------------------
Ran 5 tests in 87.309s
OK
```
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D48623171](https://our.internmc.facebook.com/intern/diff/D48623171)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107814
Approved by: https://github.com/eellison
Cap opset version at 17 for torch.onnx.export and suggest users to use the dynamo exporter. Warn users instead of failing hard because we should still allow users to create custom symbolic functions for opset>17.
Also updates the default opset version by running `tools/onnx/update_default_opset_version.py`.
Fixes#107801Fixes#107446
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107829
Approved by: https://github.com/BowenBao
Currently there are 4 cases where contraint violation errors are raised, but the error messages are (a) inconsistent in their information content (b) worded in ways that are difficult to understand for the end user.
This diff cuts one of the cases that can never be reached, and makes the other 3
(a) consistent, e.g. they all point out that some values in the given range may not work, citing a reason and asking the user to run with logs to follow up
(b) user-friendly, e.g., compiler-internal info is cut out or replaced with user-facing syntax.
Differential Revision: D48576608
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107790
Approved by: https://github.com/tugsbayasgalan, https://github.com/angelayi
Summary: Previously serializing graphs using map would error
because map returns a singleton tensor list rather than a
single tensor. So this diff adds support for if a higher order operator
returns a list of tensors as output.
We also run into an issue with roundtripping the source_fn on
map nodes/subgraphs. The source_fn originally is
<functorch.experimental._map.MapWrapper object at 0x7f80a0549930>, which
serializes to `functorch.experimental._map.map`. However, we are unable
to construct the function from this string. This should be fixed once
map becomes a fully supported operator like
torch.ops.higher_order.cond.
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D48631302](https://our.internmc.facebook.com/intern/diff/D48631302)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107837
Approved by: https://github.com/zhxchen17
ghstack dependencies: #107818
Some NvidaTRT folks were asking for a way to integrate the serialization of custom objects with export's serialization. After some discussion (more background [here](https://docs.google.com/document/d/1lJfxakmgeoEt50inWZ53MdUtOSa_0ihwCuPy_Ak--wc/edit)), we settled on a way for users to register their custom object's serializer/deserializer functions.
Since TorchScript's `.def_pickle` already exists for [registering custom classes](https://pytorch.org/tutorials/advanced/torch_script_custom_classes.html), and `tensorrt.ICudaEngine` already contains a `.def_pickle` implementation, we'll start off by reusing the existing framework and integrating it with export's serialization.
TorchScript's `.def_pickle` requires users to register two functions, which end up being the `__getstate__` and `__setstate__` methods on the class. The semantics of `__getstate__` and `__setstate__` in TorchScript are equivalent to that of Python pickle modules. This is then registered using pybind's `py::pickle` function [here](https://www.internalfb.com/code/fbsource/[f44e048145e4697bccfaec300798fce7daefb858]/fbcode/caffe2/torch/csrc/jit/python/script_init.cpp?lines=861-916) to be used with Python's pickle to initialize a ScriptObject with the original class, and set the state back to what it used to be.
I attempted to call `__getstate__` and `__setstate__` directly, but I couldn't figure out how to initial the object to be called with `__setstate__` in python. One option would be to create a `torch._C.ScriptObject` and then set the class and call `__setstate__`, but there is no constructor initialized for ScriptObjects. Another option would be to construct an instance of the serialized class itself, but if the class constructor required arguments, I wouldn't know what to initialize it with. In ScriptObject's `py::pickle` registration it directly creates the object [here](https://www.internalfb.com/code/fbsource/[f44e048145e4697bccfaec300798fce7daefb858]/fbcode/caffe2/torch/csrc/jit/python/script_init.cpp?lines=892-906), which is why I was thinking that just directly using Python's `pickle` will be ok since it is handled here.
So, what I did is that I check if the object is pickle-able, meaning it contains `__getstate__` and `__setstate__` methods, and if so, I serialize it with Python's pickle. TorchScript does have its own implementation of [pickle/unpickle](https://www.internalfb.com/code/fbsource/[59cbc569ccbcaae0db9ae100c96cf0bae701be9a][history]/fbcode/caffe2/torch/csrc/jit/serialization/pickle.h?lines=19%2C82), but it doesn't seem to have pybinded functions callable from python.
A question is -- is it ok to combine this pickle + json serialization?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107666
Approved by: https://github.com/gmagogsfm
Summary:
After we compile dense arch, we observe split-linear-cat pattern. Hence, we want to use bmm fusion + split cat pass to fuse the pattern as torch.baddmm.
Some explanation why we prefer pre grad:
1) We need to add bmm fusion before split cat pass which is in pre grad pass to remove the new added stack and unbind node with the original cat/split node
2) Post grad does not support torch.stack/unbind. There is a hacky workaround but may not be landed in short time.
Test Plan:
# unit test
```
buck test mode/dev-nosan //caffe2/test/inductor:group_batch_fusion
[jackiexu0313@devgpu005.cln5 ~/fbsource/fbcode (f0ff3e3fc)]$ buck test mode/dev-nosan //caffe2/test/inductor:group_batch_fusion
File changed: fbcode//caffe2/test/inductor/test_group_batch_fusion.py
Buck UI: https://www.internalfb.com/buck2/189dd467-d04d-43e5-b52d-d3b8691289de
Test UI: https://www.internalfb.com/intern/testinfra/testrun/5910974704097734
Network: Up: 0B Down: 0B
Jobs completed: 14. Time elapsed: 1:05.4s.
Tests finished: Pass 5. Fail 0. Fatal 0. Skip 0. Build failure 0
```
# local test
```
=================Single run start========================
enable split_cat_pass for control group
================latency analysis============================
latency is : 73.79508209228516 ms
=================Single run start========================
enable batch fusion for control group
enable split_cat_pass for control group
================latency analysis============================
latency is : 67.94447326660156 ms
```
# e2e test
todo add e2e test
Differential Revision: D48539721
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107759
Approved by: https://github.com/yanboliang
Add new fused_attention pattern matcher for Inductor, in order to make more models call the op SDPA.
The following models would call SDPA due to the added pattern:
For HuggingFace
- AlbertForMaskedLM
- AlbertForQuestionAnswering
- BertForMaskedLM
- BertForQuestionAnswering
- CamemBert
- ElectraForCausalLM
- ElectraForQuestionAnswering
- LayoutLMForMaskedLM
- LayoutLMForSequenceClassification
- MegatronBertForCausalLM
- MegatronBertForQuestionAnswering
- MobileBertForMaskedLM
- MobileBertForQuestionAnswering
- RobertaForCausalLM
- RobertaForQuestionAnswering
- YituTechConvBert
For TorchBench
- llama
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107578
Approved by: https://github.com/mingfeima, https://github.com/XiaobingSuper, https://github.com/jgong5, https://github.com/eellison, https://github.com/jansel
As the title says, I was trying to test the functional collectives, and, when printing the resulting tensors, sometimes they wouldn't have finished the Async operation yet. According to the comments in the file, "AsyncTensor wrapper applied to returned tensor, which issues wait_tensor() at the time of first use". This is true in most cases, but not when print() is your first use. This PR fixes that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107808
Approved by: https://github.com/fduwjj
_enable_dynamo_cache_lookup_profiler used to get turned on when running `__enter__` or `__exit__` with the profiler. But it's possible to turn the profiler on and off without the context manager (e.g. with a schedule and calling `.step()`). Instead, we should put these calls (which are supposed to be executed when the profiler turns on/off) where `_enable_profiler()` and `_disable_profiler()` are called.
This puts `_enable_dynamo_cache_lookup_profiler` and `_set_is_profiler_enabled` into `_run_on_profiler_(start|stop)` and calls that on the 3 places where `_(enable|disable)_profiler` get called.
Differential Revision: [D48619818](https://our.internmc.facebook.com/intern/diff/D48619818)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107720
Approved by: https://github.com/wconstab
Moves the logic to casting state to match parameters into a hook so that users can choose to enable their hooks before or after the casting has happened.
With this, there is a little bit of redundancy of the id_map building and the check that the param groups are still aligned in length.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106725
Approved by: https://github.com/albanD
This PR looks big, but it's mostly just refactorings with a bit of dead code deletion. Exceptions are:
- Some metric emissions were changed to comply with the new TD format
- Some logging changes
- We now run tests in three batches (highly_relevant, probably_relevant, unranked_relevance) instead of the previous two (prioritized and general)
Refactorings done:
- Moves all test reordering code to the new TD framework
- Refactors run_test.py to cleanly support multiple levels of test priorities
- Deletes some dead code that was originally written for logging
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107071
Approved by: https://github.com/clee2000, https://github.com/huydhn
I notice a curious case on https://github.com/pytorch/pytorch/pull/107508 where there was one broken trunk failure and the PR was merged with `merge -ic`. Because the failure had been classified as unrelated, I expected to see a no-op force merge here. However, it showed up as a force merge with failure.

The record on Rockset reveals https://github.com/pytorch/pytorch/pull/107508 has:
* 0 broken trunk check (unexpected, this should be 1 as Dr. CI clearly say so)
* 1 ignore current check (unexpected, this should be 0 and the failure should be counted as broken trunk instead)
* 3 unstable ROCm jobs (expected)
It turns out that ignore current takes precedence over flaky and broken trunk classification. This might have been the expectation in the past but I think that's not the case now. The bot should be consistent with what is shown on Dr. CI. The change here is to make flaky, unstable, and broken trunk classification to take precedence over ignore current. Basically, we only need to ignore new or unrecognized failures that have yet been classified.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107761
Approved by: https://github.com/clee2000
When exporting dropout with cpu tensor, we get following graph module
```
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: f32[512, 10]):
empty_memory_format: f32[512, 10] = torch.ops.aten.empty.memory_format([512, 10], dtype = torch.float32, layout = torch.strided, device = device(type='cpu'), pin_memory = False, memory_format = torch.contiguous_format)
bernoulli_p: f32[512, 10] = torch.ops.aten.bernoulli.p(empty_memory_format, 0.9); empty_memory_format = None
div_scalar: f32[512, 10] = torch.ops.aten.div.Scalar(bernoulli_p, 0.9); bernoulli_p = None
mul_tensor: f32[512, 10] = torch.ops.aten.mul.Tensor(arg0_1, div_scalar); arg0_1 = div_scalar = None
return (mul_tensor,)
```
In addition, if we export with eval() mode, we will have an empty graph.
However, when exporting with cuda tensor, we got
```
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: f32[512, 10]):
native_dropout_default = torch.ops.aten.native_dropout.default(arg0_1, 0.1, True); arg0_1 = None
getitem: f32[512, 10] = native_dropout_default[0]; native_dropout_default = None
return (getitem,)
```
and exporting under eval() mode will still have a dropout node in graph.
This PR make exporting with CPU tensor also produce aten.native_dropout.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106274
Approved by: https://github.com/ezyang
This change is to match the behavior of _record_memory_history which was
recently changed to enable history recording on all devices rather than
the current one. It prevents confusing situations where the observer
was registered before the device was set for the training run.
It also ensures the allocators have been initialized in the python binding just in case this is the first call to the CUDA API.
Fixes#107330
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107399
Approved by: https://github.com/eellison
ghstack dependencies: #107171
**Overview**
This PR runs the HSDP all-reduce as async so that it can overlap with both all-gather and reduce-scatter, which can lead to slight end-to-end speedups when the sharding process group is fully intra-node. Previously, the all-reduce serializes with reduce-scatter, so it can only overlap with one all-gather.
For some clusters (e.g. our AWS cluster), `NCCL_CROSS_NIC=1` improves inter-node all-reduce times when overlapped with intra-node all-gather/reduce-scatter.
**Experiment**
<details>
<summary> Example 'before' trace </summary>
<img width="559" alt="hsdp_32gpus_old" src="https://github.com/pytorch/pytorch/assets/31054793/15222b6f-2b64-4e0b-a212-597335f05ba5">
</details>
<details>
<summary> Example 'after' trace </summary>
<img width="524" alt="hsdp_32gpus_new" src="https://github.com/pytorch/pytorch/assets/31054793/94f63a1d-4255-4035-9e6e-9e10733f4e44">
</details>
For the 6-encoder-layer, 6-decoder layer transformer with `d_model=8192`, `nhead=64` on 4 nodes / 32 40 GB A100s via AWS, the end-to-end iteration times are as follows (with AG == all-gather, RS == reduce-scatter, AR == all-reduce; bandwidth reported as algorithmic bandwidth):
- Reference FSDP:
- **1160 ms / iteration**
- ~23 ms / encoder AG/RS --> 24.46 GB/s bandwidth
- ~40 ms / decoder AG/RS --> 26.5 GB/s bandwidth
- 50 GB/s theoretical inter-node bandwidth
- Baseline 8-way HSDP (only overlap AR with AG) -- intra-node AG/RS, inter-node AR:
- **665 ms / iteration**
- ~3 ms / encoder AG/RS --> 187.5 GB/s bandwidth
- ~5 ms / decoder AG/RS --> 212 GB/s bandwidth
- ~30 ms / encoder AR --> 2.34 GB/s bandwidth
- ~55 ms / decoder AR --> 2.65 GB/s bandwidth
- 300 GB/s theoretical intra-node bandwidth
- New 8-way HSDP (overlap AR with AG and RS) -- intra-node AG/RS, inter-node AR:
- **597 ms / iteration**
- ~3 ms / encoder AG/RS --> 187.5 GB/s bandwidth
- ~6.2 ms / decoder AG/RS --> 170.97 GB/s bandwidth (slower)
- ~23 ms / encoder AR (non-overlapped) --> 3.057 GB/s bandwidth (faster)
- ~49 ms / decoder AR (non-overlapped) --> 2.70 GB/s bandwidth (faster)
- ~100 ms / decoder AR (overlapped) --> 1.325 GB/s bandwidth (slower)
- Overlapping with reduce-scatter reduces all-reduce bandwidth utilization even though the all-reduce is inter-node and reduce-scatter is intra-node!
- New 8-way HSDP (overlap AR with AG and RS) with `NCCL_CROSS_NIC=1`:
- **556 ms / iteration**
- Speedup comes from faster overlapped AR
Thus, for this particular workload, the async all-reduce enables 16% iteration-time speedup compared to the existing HSDP and 52% speedup compared to FSDP. These speedups are pronounced due to the workload being communication bound, so any communication time reduction translates directly to speedup.
**Unit Test**
This requires >= 4 GPUs:
```
python -m pytest test/distributed/fsdp/test_fsdp_hybrid_shard.py -k test_fsdp_hybrid_shard_parity
```
Differential Revision: [D47852456](https://our.internmc.facebook.com/intern/diff/D47852456)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106080
Approved by: https://github.com/ezyang
ghstack dependencies: #106068
The post-backward hook has some complexity due to the different paths: {no communication hook, communication hook} x {`NO_SHARD`, `FULL_SHARD`/`SHARD_GRAD_OP`, `HYBRID_SHARD`/`_HYBRID_SHARD_ZERO2`} plus some options like CPU offloading and `use_orig_params=True` (requiring using sharded gradient views).
The PR following this one that adds async all-reduce for HSDP further complicates this since the bottom-half after all-reduce must still be run in the separate all-reduce stream, making it more unwieldy to unify with the existing bottom-half.
Nonetheless, this PR breaks up the post-backward hook into smaller logical functions to hopefully help readability.
Differential Revision: [D47852461](https://our.internmc.facebook.com/intern/diff/D47852461)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106068
Approved by: https://github.com/ezyang, https://github.com/fegin
Previously, the top level GraphProto is hardcoded with name "torch_jit", and the subgraphs "torch_jit_{count}". It does not offer any insight to the graph, but rather encodes the graph producer as jit (torchscript). This is no longer true now that the graph can also be produced from dynamo.
As a naive first step, this PR re-purposes the name, to "main_graph", and "sub_graph_{count}" respectively. More delicate processing can be done to name the subgraphs with respect to their parent node or module. This can be done as follow ups.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107408
Approved by: https://github.com/justinchuby, https://github.com/titaiwangms
Summary:
D48295371 cause batch fusion failure, which will block mc proposals on all mc models.
e.g. cmf f470938179
Test Plan: Without revert, f469732293. With revert diff f472266199.
Differential Revision: D48610062
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107796
Approved by: https://github.com/yanboliang
The `broadcast_object_list` function can easily broadcast the state_dict of models/optimizers. However, the `torch.cat` operation performed within `broadcast_object_list` consumes an additional double amount of memory space. This means that only objects with a maximum memory occupancy of half the device capacity can be broadcasted. This PR improves usability by skipping the `torch.cat` operation on object_lists with only a single element.
Before (30G tensor):
<img width="607" alt="image" src="https://github.com/pytorch/pytorch/assets/22362311/c0c67931-0851-4f27-81c1-0119c6cd2944">
After (46G tensor):
<img width="600" alt="image" src="https://github.com/pytorch/pytorch/assets/22362311/90cd1536-be7c-43f4-82ef-257234afcfa5">
Test Code:
```python
if __name__ == "__main__":
dist.init_process_group(backend='nccl')
torch.cuda.set_device(dist.get_rank() % torch.cuda.device_count())
fake_tensor = torch.randn(30 * 1024 * 1024 * 1024 // 4)
if dist.get_rank() == 0:
state_dict = {"fake_tensor": fake_tensor}
else:
state_dict = {}
object_list = [state_dict]
dist.broadcast_object_list(object_list, src=0)
print("Rank: ", dist.get_rank(), " Broadcasted Object: ", object_list[0].keys())
dist.barrier()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107509
Approved by: https://github.com/awgu
These lowerings must copy even when they are no-ops in order to preserve
correctness in the presense of mutations. However, `to_dtype` and `to_device`
are also used in various lowerings as a helper function where it is okay to alias.
So, I've split these into two functions and allow the helper functions to alias
which saves some unnecessary copies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107640
Approved by: https://github.com/lezcano
In this PR, we make ExportedProgram valid callable to export for re-exporting. Note that we don't allow any new constraints specified from user as we don't have any way of handling it right now. There are some caveats that is worth mentioning in this PR.
Today, graph_module.meta is not preserved (note that this is different from node level meta which we preserve). Our export logic relies on this meta to process the constraints. But if we skip dynamo, we will have to preserve the constraints stored in graph_module.meta. Once dynamo supports retracibility, we don't have to do this anymore. I currently manually save graph_module.meta at following places:
1. After ExportedProgram.module()
2. After ExportedProgram.transform()
3. At construction site of ExportedProgram.
Jerry will add the update on the quantization side as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107657
Approved by: https://github.com/gmagogsfm
1. Add a list of HF models to CI tests. The PR intends to build them from Config, but some of them are not supported with Config. NOTE: Loaded from pre-trained model could potentially hit [uint8/bool conflict](https://github.com/huggingface/transformers/issues/21013) when a newer version of transformers is used.
- Dolly has torch.fx.Node in OnnxFunction attribute, which is currently not supported.
- Falcon and MPT has unsupported user coding to Dynamo.
2. Only update GPT2 exporting with real tensor to Config, as FakeMode rises unequal input errors between PyTorch and ORT. The reason is that [non-persistent buffer is not supported](https://github.com/pytorch/pytorch/issues/107211)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107247
Approved by: https://github.com/wschin, https://github.com/BowenBao
Previous to this PR, `_assert_fake_tensor_mode` checks all of exporting tracer that they enable fake mode "from" exporter API whenever they have fake tensors in args/buffers/weights. However, FXSymbolicTracer doesn't use exprter API to create fake mode, so it hits the raise RuntimeError everytime we run it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107712
Approved by: https://github.com/BowenBao
**Motivation:**
When input FakeTensor to torch.compile has SymInt sizes (e.g. make_fx(opt_f, tracing_mode="symbolic"):
1. We cannot create a FakeTensor from that input in dynamo due to the SymInts.
2. We cannot check input tensors in guard check function and will abort due to tensor check calls sizes/strides.
For 1, we specialize the FakeTensor's SymInts using their hints. This is mostly safe since inputs mostly have concrete shapes and not computed from some DynamicOutputShape ops. We'll throw a data dependent error if the symint is unbacked.
For 2, we replace size/stride calls with the sym_* variants in TENSOR_CHECK guards' check function.
**Test Plan:**
See added tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107662
Approved by: https://github.com/ezyang
Summary: Added due to how common the op is. For performance reasons users may not want to decompose batch_norm op. batch_norm is also part of StableHLO
Test Plan: After adding to IR, we can enable _check_ir_validity in exir.EdgeCompileConfig for models like MV2, MV3, IC3, IC4
Reviewed By: guangy10
Differential Revision: D48576866
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107732
Approved by: https://github.com/manuelcandales, https://github.com/guangy10
This updates ruff to 0.285 which is faster, better, and have fixes a bunch of false negatives with regards to fstrings.
I also enabled RUF017 which looks for accidental quadratic list summation. Luckily, seems like there are no instances of it in our codebase, so enabling it so that it stays like that. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107519
Approved by: https://github.com/ezyang
Summary: Currently serializing graphs which return get_attr's directly as output fails. This diff adds support for that only in EXIR serializer while we still support unlifted params.
Test Plan: Added test case.
Differential Revision: D48258552
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107610
Approved by: https://github.com/angelayi
This PR fixes the requires_grad set when calling distribute_tensor, we
should set the requires_grad of the local tensor after the detach call
to make sure we create the leaf correctly, otherwise it would raise
warnings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107606
Approved by: https://github.com/fduwjj
torch.profiler.record_function is relatively slow; for example, in some benchmarks I was running, x.view_as(x) was ~2us, and ~16-17us when wrapped in a record_function context. The reasons for this are: dispatcher overhead from going through an op (the main source of overhead), python binding / python conversion overhead, and some overhead from the context manager.
This new implementation is faster, but it won't work with torchscript. Based on the benchmarks I was running, it adds 0.5-0.7us overhead per call when the profiler is turned off. To use it, you can just:
```python
with torch._C._profiler_manual._RecordFunctionFast("title"):
torch.add(x, y)
```
It implements a context manager in python which directly calls the record_function utilities, instead of calling through an op.
* The context manager is implemented directly in python because the overhead from calling a python function seems non-negligible
* All the record_function calls, python object conversions are guarded on checks for whether the profiler is enabled or not. It seems like this saves a few hundred nanoseconds.
For more details about the experiments I ran to choose this implementation, see [my record_functions experiments branch](https://github.com/pytorch/pytorch/compare/main...davidberard98:pytorch:record-function-fast-experiments?expand=1).
This also adds a `torch.autograd.profiler._is_profiler_enabled` global variable that can be used to check whether a profiler is currently enabled. It's useful for further reducing the overhead, like this:
```python
if torch.autograd.profiler._is_profiler_enabled:
with torch._C._profiler_manual._RecordFunctionFast("title"):
torch.add(x, y)
else:
torch.add(x, y)
```
On BERT_pytorch (CPU-bound model), if we add a record_function inside CachedAutotuning.run:
* Naive torch.profiler.record_function() is a ~30% slowdown
* Always wrapping with RecordFunctionFast causes a regression of ~2-4%.
* Guarding with an if statement - any regression is within noise
**Selected benchmark results**: these come from a 2.20GHz machine, GPU build but only running CPU ops; running `x.view_as(x)`, with various record_functions applied (with profiling turned off). For more detailed results see "record_functions experiments branch" linked above (those results are on a different machine, but show the same patterns). Note that the results are somewhat noisy, assume 0.05-0.1us variations
```
Baseline:: 1.7825262546539307 us # Just running x.view_as(x)
profiled_basic:: 13.600390434265137 us # torch.profiler.record_function(x) + view_as
precompute_manual_cm_rf:: 2.317216396331787 us # torch._C._profiler_manual._RecordFunctionFast(), if the context is pre-constructed + view_as
guard_manual_cm_rf:: 1.7994389533996582 us # guard with _is_profiler_enabled + view_as
```
Differential Revision: [D48421198](https://our.internmc.facebook.com/intern/diff/D48421198)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107195
Approved by: https://github.com/albanD, https://github.com/aaronenyeshi
These jobs have write access to S3 when they are running on our self-hosted runners. On the other hand, they would need the AWS credential to run if they are run on GitHub ephemeral runner.
### Testing
Use the AWS credential in upload-stats environment to run the test command successfully (currently failing in trunk due to the lack of permission a5f83245fd)
```
python3 tools/alerts/upload_alerts_to_aws.py --alerts '[{"AlertType": "Recurrently Failing Job", "AlertObject": "Upload Alerts to AWS/Rockset / upload-alerts", "OncallTeams": [], "OncallIndividuals": [], "Flags": [], "sha": "c8a6c74443f298111fd6568e2828765d87b69c98", "branch": "main"}, {"AlertType": "Recurrently Failing Job", "AlertObject": "inductor / cuda12.1-py3.10-gcc9-sm86 / test (inductor_torchbench, 1, 1, linux.g5.4xlarge.nvidia.gpu)", "OncallTeams": [], "OncallIndividuals": [], "Flags": [], "sha": "f13101640f548f8fa139c03dfa6711677278c391", "branch": "main"}, {"AlertType": "Recurrently Failing Job", "AlertObject": "slow / linux-focal-cuda12.1-py3.10-gcc9-sm86 / test (slow, 1, 2, linux.g5.4xlarge.nvidia.gpu)", "OncallTeams": [], "OncallIndividuals": [], "Flags": [], "sha": "6981bcbc35603e5d8ac7d00a2032925239009db5", "branch": "main"}]' --org "pytorch" --repo "pytorch"
Writing 138 documents to S3
Done!
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107717
Approved by: https://github.com/clee2000
@huydhn
Our current workflow is to upload to GH and then upload from GH to S3 when uploading test stats at the end of a workflow.
I think these keys could be used to directly upload from the runner to S3 but we don't do that right now.
I'm not sure how high priority they keys are.
Rocm artifacts can still be seen on the HUD page
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107613
Approved by: https://github.com/huydhn
Removing expected failures relating to inductor batch_norm on ROCm
Also removing the addition of `tanh` to expected failures list as this is a cuda exclusive failure already captured here (cc: @peterbell10)
```
if not TEST_WITH_ROCM:
inductor_gradient_expected_failures_single_sample["cuda"]["tanh"] = {f16}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107027
Approved by: https://github.com/peterbell10
Sometimes test suite names include file/module names since they were imported from another file (ex _nvfuser.test_dynamo.TestNvFuserDynamo etc). This can sometimes make the autogenerated named by disable bot and the disable test button on hud incorrect which is annoying to track down, which leads to issues that are open but don't actually do anything, so my solution is to make the check between the issue name + the test more flexible. Instead of checking the entire test suite name, we chop off the file/module names and only look for the last part (ex TestNvFuserDynamo) and check if those are equal.
Also bundle both the check against the names in the slow test json and disable test issue names into one function for no reason other than less code.
Looked through logs to see what tests are skipped with this vs the old one and it looked the same.
Diff looks like a big change but its mostly a change in the indentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104002
Approved by: https://github.com/ZainRizvi, https://github.com/huydhn
Summary: Adds new tracepoints to CUDA allocator code for tracking alloc and dealloc events in the allocator code.
Test Plan: This change simply adds static tracepoints to CUDA allocator code, and does not otherwise change any logic. Testing is not required.
Reviewed By: chaekit
Differential Revision: D48229150
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107322
Approved by: https://github.com/chaekit
Previously, the first overload of `_make_wrapper_subclass` returned a tensor that **always** advertised as having a non-resizeable storage. Eventually, we'll need it be advertise as resizeable for functionalization to work (since functionalization occasionally needs to resize storages).
Not directly tested in this PR (tested more heavily later in aot dispatch, but if someone wants me to write a more direct test I can add one).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107416
Approved by: https://github.com/ezyang, https://github.com/albanD
ghstack dependencies: #107417
This was discussed in feedback from the original version of my "reorder proxy/fake" PR. This PR allows calls to `tensor.untyped_storage()` to **always** return a python storage object to the user. Previously, we would error loudly if we detected that the storage had a null dataptr.
Instead, I updated the python bindings for the python storage methods that I saw involve data access, to throw an error later, only if you try to access those methods (e.g. `storage.data_ptr()` will now raise an error if the data ptr is null).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107417
Approved by: https://github.com/albanD, https://github.com/ezyang, https://github.com/zou3519
Summary:
This PR improves `generate_opcheck_tests`:
- We shouldn't run automated testing through operators called in
torch.jit.trace / torch.jit.script
- I improved the error message and added a guide on what to do if one of the
tests fail.
- While dogfooding this, I realize I wanted a way to reproduce the failure
without using the test suite. If you pass `PYTORCH_OPCHECK_PRINT_REPRO`, it
will now print a minimal repro on failure. This involves serializing some
tensors to disk.
- The minimal repro includes a call to a new API called `opcheck`.
The opcheck utility runs the same checks as the tests generated
by `generate_opcheck_tests`. It doesn't have a lot of knobs on it for
simplicity. The general workflow is: if an autogenerated test fails, then the
user may find it easier to reproduce the failure without the test suite by
using opcheck
Test Plan: - new tests
Differential Revision: D48485013
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107597
Approved by: https://github.com/ezyang
This PR stops `SymNode` from mutating (i.e. simplifying) its expression. Instead, the
simplification (without mutation) is deferred to the `SymNode.maybe_as_int` method.
```python
- FakeTensor(size=(s0,), ...)
- FakeTensor(size=(s1, s2, s3), ...)
- Eq(s0, s1 + s2 + s3)
- FakeTensor(size=(s0,), ...)
- FakeTensor(size=(s1, s2, s3), ...)
```
In summary, this PR:
- Replaces `SymNode._expr` by `SymNode.expr`, removing the old property function
- This makes it so `SymNode` instances never update their expression
- Creates `SymNode.simplified_expr()` method for actually calling `ShapeEnv.replace` on
its expression. Note that this doesn't updates `SymNode.expr`
- Changes how `tensor.size()` gets converted to its Python `torch.Size` type
- Instead of calling `SymInt::maybe_as_int()` method, we create a new
`SymInt::is_symbolic()` method for checking whether it is actually a symbolic value
- This is needed so that when we call `tensor.size()` in the Python side, the returned
sequence is faithful to the actual data, instead of possibly simplifying it and
returning an integer
- 2 files needs this modification:
- _torch/csrc/Size.cpp_: for handling `torch.Tensor.size` Python calls
- _torch/csrc/utils/pybind.cpp_: for handling `symint.cast()` C++ calls
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107492
Approved by: https://github.com/ezyang
ghstack dependencies: #107523
This PR fixes transactional behavior of translation validation insertion.
Previously, this transactional behavior was implemented by removing the FX node if any
issues occurred until the end of `evaluate_expr`. However, since we cache FX nodes, we
might end up removing something that wasn't inserted in the same function call.
**Solution:** when creating an FX node for `call_function`, we also return whether this is
a fresh FX node or not. Then, we can appropriately handle each case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107523
Approved by: https://github.com/ezyang
Added the following APIs:
```
def save(
ep: ExportedProgram,
f: Union[str, pathlib.Path, io.BytesIO],
extra_files: Optional[Dict[str, Any]] = None,
opset_version: Optional[Dict[str, int]] = None,
) -> None:
"""
Saves a version of the given exported program for use in a separate process.
Args:
ep (ExportedProgram): The exported program to save.
f (str): A file-like object (has to implement write and flush)
or a string containing a file name.
extra_files (Optional[Dict[str, Any]]): Map from filename to contents
which will be stored as part of f.
opset_version (Optional[Dict[str, int]]): A map of opset names
to the version of this opset
"""
def load(
f: Union[str, pathlib.Path, io.BytesIO],
extra_files: Optional[Dict[str, Any]] = None,
expected_opset_version: Optional[Dict[str, int]] = None,
) -> ExportedProgram:
"""
Loads an ExportedProgram previously saved with torch._export.save
Args:
ep (ExportedProgram): The exported program to save.
f (str): A file-like object (has to implement write and flush)
or a string containing a file name.
extra_files (Optional[Dict[str, Any]]): The extra filenames given in
this map would be loaded and their content would be stored in the
provided map.
expected_opset_version (Optional[Dict[str, int]]): A map of opset names
to expected opset versions
Returns:
An ExportedProgram object
"""
```
Example usage:
```
# With buffer
buffer = io.BytesIO()
torch._export.save(ep, buffer)
buffer.seek(0)
loaded_ep = torch._export.load(buffer)
# With file
with tempfile.NamedTemporaryFile() as f:
torch._export.save(ep, f)
f.seek(0)
loaded_ep = torch._export.load(f)
# With Path
with TemporaryFileName() as fname:
path = pathlib.Path(fname)
torch._export.save(ep, path)
loaded_ep = torch._export.load(path)
# Saving with extra files
buffer = io.BytesIO()
save_extra_files = {"extra.txt": "moo"}
torch._export.save(ep, buffer, save_extra_files)
buffer.seek(0)
load_extra_files = {"extra.txt": ""}
loaded_ep = torch._export.load(buffer, extra_files)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107309
Approved by: https://github.com/avikchaudhuri, https://github.com/gmagogsfm, https://github.com/tugsbayasgalan
In this PR, we extend ExportedProgram.module() functionality by also unlifting the mutated buffers. We only really care about top level buffers as we don't allow any buffer mutation inside HigherOrderOps.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107643
Approved by: https://github.com/avikchaudhuri
## Summary
Enables AVX512 dispatch by default for some kernels, for which AVX512 performs better than AVX2.
For other kernels, their AVX2 counterparts are used.
## Implementation details
`REGISTER_DISPATCH` should now only be used for non-AVX512 dispatch.
`ALSO_REGISTER_AVX512_DISPATCH` should be used when AVX512 dispatch should also be done for a kernel.
## Benchmarking results with #104655
[Raw data at GitHub Gist (Click on `Download ZIP`)](https://gist.github.com/sanchitintel/87e07f84774fca8f6b767aeeb08bc0c9)
| Op | Speedup of AVX512 over AVX2 |
|----|------------------------------------|
|sigmoid|~27% with FP32|
|sign| ~16.6%|
|sgn|~15%|
|sqrt|~4%|
|cosh|~37%|
|sinh|~37.5%|
|acos| ~8% with FP32 |
|expm1| ~30% with FP32|
|log|~2%|
|log1p|~16%|
|erfinv|~6% with FP32|
|LogSigmoid|~33% with FP32|
|atan2|~40% with FP32|
|logaddexp| ~24% with FP32|
|logaddexp2| ~21% with FP32|
|hypot| ~24% with FP32|
|igamma|~4% with FP32|
|lgamma| ~40% with FP32|
|igammac|3.5%|
|gelu|~3% with FP32|
|glu|~20% with FP32|
|SiLU|~35% with FP32|
|Softplus|~33% with FP32|
|Mish|~36% with FP32|
|Hardswish|~7% faster with FP32 when tensor can fit in L2 cache|
|Hardshrink|~8% faster with FP32 when tensor can fit in L2 cache|
|Softshrink|~10% faster with FP32 when tensor can fit in L2 cache|
|Hardtanh|~12.5% faster with FP32 when tensor can fit in L2 cache|
Hardsigmoid|~7% faster with FP32 when tensor can fit in L2 cache|
|hypot|~35%|
|atan2|~37%|
|dequantize per channel|~10%|
## Insights gleaned through collected data (future action-items):
1. Inplace variants of some ops are faster with AVX512 although the functional variant may be slower for FP32. Will enable AVX512 dispatch for the inplace variants of such kernels.
2. Almost all BF16 kernels are faster with AVX512, so after PyTorch 2.1 release, will enable AVX512 dispatch for BF16 kernels whose corresponding FP32 kernel doesn't perform well with AVX512.
3. Some kernels rely on auto-vectorization & might perform better with AVX512 once explicit vectorization would be enabled for them.
Data was collected with 26 physical threads of one socket of Intel Xeon 8371HC. Intel OpenMP & tcmalloc were preloaded.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104165
Approved by: https://github.com/mingfeima, https://github.com/jgong5, https://github.com/kit1980
Dynamo currently runs the real graph module with real inputs as a way to match the return result of graph module with the eager return type. This is unsafe when graph module is side effectful. In the long term, we will get rid of this step. But in the short term, we just fakify the graph module again and run it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107271
Approved by: https://github.com/ezyang
Issue list:
* Unsupported FX nodes: {'call_function': ['aten.embedding_renorm.default', ~~'aten._embedding_bag_forward_only.default'~~]}.
* aten._embedding_bag.default not captured by test. Hence this test is not reflecting the pattern seen in model from onnxbench. Update: need validation again, unsure if this is still the case.
* `padding_idx` is always emitted for `aten._embedding_bag` and `aten._embedding_bag_forward_only`. This overload is unsupported by Torchlib.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105862
Approved by: https://github.com/justinchuby
CapturedTraceback is fast but one downside is that it has strong references to code objects, which via `co_extra` can cause un-collectable cycles. This means that it is important to clear out CapturedTraceback when you are done with it; e.g., if you tracebacks during compilation, you need to explicitly clear them out at the end of compilation to actually make sure they promptly deallocate.
Instead of caching `summary` on the CapturedTraceback, we simply allow for tracebacks to have `tb = None`. Tracebacks get dropped if you pickle the traceback, or if you explicitly call cleanup().
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107471
Approved by: https://github.com/voznesenskym
ghstack dependencies: #107505, #107516, #107530, #107532, #107562
This PR adds 2d parallel torch.compile test on a simple MLP model and
test that the dynamo changes works, once @bdhirsh aot autograd enablement
done we can switch this test to test the e2e torch.compile workflow
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107473
Approved by: https://github.com/fduwjj
ghstack dependencies: #107472
Starts addressing #106802
This PR also conveniently does some BE:
- Fixes a bug in adamw where we use amsgrad instead of per group amsgrad
- Brings the impls of adamw and adam closer to correctness and to each other
I couldn't fully remove the .pyi's because mypy was going to complain about the entire files which scared me and shouldn't go in this PR anyway.
Test plan:
- Add tests to ensure that lr could be passed as a Tensor
- Did some profiling of the below code (runs 1k iterations of step for Adam)
```
import torch
from torch.testing._internal.common_utils import TestCase
param = torch.rand(2, 3, dtype=torch.float, device='cuda:0', requires_grad=True)
param.grad = torch.rand_like(param)
lr = torch.tensor(.001, device='cuda:0')
opt = torch.optim.Adam([param], lr=lr, fused=True)
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
]
) as p:
for _ in range(1000):
opt.step()
print(p.key_averages().table(sort_by="cpu_time_total"))
```
Before my change:
<img width="1381" alt="image" src="https://github.com/pytorch/pytorch/assets/31798555/cfc5175a-0f41-4829-941f-342554f3b152">
After my change (notice there are no d2h syncs and the CPU time is lower!):

Next steps long term:
- have all capturable foreach + forloop impls in Adam(W) handle tensor LR
- have all capturable impls handle tensor LR
- have all impls handle tensor LR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106916
Approved by: https://github.com/albanD
Make it so that scripts can import and run the `emit_metrics` function even if they don't have boto3 installed, in which case it will still validate the inputs but skip the actual metric emission part.
It's purely a refactor without any real logic changes
Motivation: So that run_test.py and the target determination code can use this library easily without worrying about if it was imported or if it's dependencies are installed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107070
Approved by: https://github.com/huydhn
Summary:
When AOT Inductor runs a Triton matmul kernel (generated from the Triton mm template) on large inputs of particular shape, the `RuntimeError: CUDA driver error: 1` may happen. E.g., when `x @ y` is compiled with AOT Inductor and run on the input shapes `[10285, 96]` and `[96, 1]`. Digging deeper into the generated AOT Inductor wrapper code, we see this line:
```
launchKernel(triton_unk_fused_mm_0, 81, 1, 1, 4, 55296, kernel_args_var_0, stream);
```
`55296` is the required amount (in bytes) of dynamic shared memory. This is larger than the default dynamic shared memory on A100: `49152` bytes. In these cases, `cudaFuncSetAttribute` must be called explicitly to set the`cudaFuncAttributeMaxDynamicSharedMemorySize` attribute of the kernel before launching it. Or, because AOT Inductor wrapper relies on the CUDA Driver API, the equivalent [`cuFuncSetAttribute`](https://docs.nvidia.com/cuda/cuda-driver-api/group__CUDA__EXEC.html#group__CUDA__EXEC_1g0e37dce0173bc883aa1e5b14dd747f26) function can be called to set the `CU_FUNC_ATTRIBUTE_MAX_DYNAMIC_SHARED_SIZE_BYTES` attribute.
This PR adds the above call in the AOT Inductor codegen for every case when the required amount of dynamic SMEM is > 0. The call is done *within* the `launchKernel` function, meaning that it will happen only once per kernel and not affect the subsequent AOT Inductor-compiled model performance (after the first run).
P.S. One could, in principle, call the `cuFuncSetAttribute` only when the required amount of dynamic SMEM is above the default limit, but that would require detecting the default limit which is different on different devices. Assuming that the `cuFuncSetAttribute` is relatively lightweight and because it's performed only once per kernel, for simplicity, the suggestion is to call the function in every non-zero dynamic SMEM case.
Test Plan:
```
$ python test/inductor/test_aot_inductor.py
...
----------------------------------------------------------------------
Ran 5 tests in 100.177s
OK
```
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107601
Approved by: https://github.com/jansel
Summary: this PR detects
https://github.com/pytorch/pytorch/issues/107423 and falls back to the
non-triton kernel. It also adds a check for non-contiguous issues in
uint4x2 in the unit tests though its not an issue in this case.
Test Plan: python pytorch/test/inductor/test_pattern_matcher.py -k
"test_mixed_mm_bad_cases"
python pytorch/test/inductor/test_pattern_matcher.py -k
"test_uint4x2_mixed_mm"
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107495
Approved by: https://github.com/davidberard98
Manually enable `capture_func_transforms` for testing as plan is to default `capture_func_transforms` to False in 2.1. (enable it so that we still test the support on release branch).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107122
Approved by: https://github.com/zou3519
1. Update xfail reasons in fx runtime
2. Enable bloom-560m in runtime test. However, it's blocked by the unsupported constant tensor case. The previous error was because the when the model loads with external data, it surpasses 2GB, and couldn't be inlined. The fix is to inline the model it self, and then replace the original one. Pointing ORT to the path allows it to load with external data into model in runtime.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107257
Approved by: https://github.com/justinchuby
This PR makes CacheEntry a PyObject. This is prep PR for cache size changes. As CacheEntry is a py object, we can now traverse the linked list in Python and write cache size policies. It was possible to do in C, but Python is just easier to iterate upon. We call convert_frame only when we (re)compile, so a small bump in latency going from C to Python is acceptable here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107405
Approved by: https://github.com/ezyang
ghstack dependencies: #106917, #107117
Since constrain_as_size has been fixed, I tried serializing it, but ran into some issues.
Notably, after each `.transform` call, I added a helper `_get_updated_range_constraints` to update the range constrains list. This is because when we retrace in a pass, the symbolic values being used changes, so we need to update this dictionary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107386
Approved by: https://github.com/avikchaudhuri, https://github.com/zhxchen17
I pulled a bunch of autograd.Function from test_autograd.py and added a
smoke test for them. Ideally we would actually run test_autograd.py as a
part of the Dynamo test suite, but we have excluded it due to there
being too many errors and I don't have time to figure that out at the
moment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107467
Approved by: https://github.com/ydwu4
ghstack dependencies: #107459, #107461
If map or autograd.Function have an input that returns a non-Tensor,
then the code just errors out. Instead of erroring out we should graph
break by raising Unsupported so users aren't confused. The better thing
to do is actually support non-Tensor returns but that requires more
work.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107461
Approved by: https://github.com/ydwu4
ghstack dependencies: #107459
Sometimes the Unsupported error messages can be pretty opaque (see
https://github.com/pytorch/pytorch/issues/106390 for an example). This
PR ensures the error message says something sane by raising a new
Unsupported exception (that includes the older one in the stack trace)
with a description of what's going on.
Test Plan:
- new test utility to check that a dictionary matches a regex so we
don't need to write out this super long error message every time.
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107459
Approved by: https://github.com/ydwu4, https://github.com/kshitij12345
Instead of (poorly) reconstructing the guard list from the guards on OutputGraph, we log them at the horses mouth: when we actually codegen the guard. This only requires very modest refactoring: as we translate guards into code parts, we also have to pass the source guard along so we can use it to give stack information.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107532
Approved by: https://github.com/anijain2305
ghstack dependencies: #107505, #107516, #107530
All log messages that occur while running Dynamo compilation now have `[X/Y]` added to the beginning of their message. X represents the frame being compiled, while Y says which compilation of the frame. For example, if you are debugging a frame that is repeatedly recompiling, you can look for N/0, N/1, N/2, etc. for the same N. Here is what the logs look like as you transition from one frame to another:
<img width="1372" alt="image" src="https://github.com/pytorch/pytorch/assets/13564/4897e368-1e50-4807-b342-54e911bcf087">
To accurately get this prefix added to all messages, I had to expand the scope of the `tracing` context manager. Its scope now coincides with `log_compilation_event`. To do this, I had to populate fake mode lazily in the TracingContext, since it isn't created until later, inside the OutputGraph.
This subsumes the previous X.Y logging that was solely for dynamic shapes.
Unfortunately I had to reindent some stuff. Review the diff with whitespace off.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107530
Approved by: https://github.com/anijain2305
ghstack dependencies: #107505, #107516
Added a version number to the schema for BC issues. We will add this number to the serialized ExportedProgram and then when deserializing, if the number does not match up with the existing deserializer, we will error. We should update the number of there are any major changes to the schema.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107420
Approved by: https://github.com/zhxchen17
I found that the upsample bicubic lowering was generating this line
```python
ops.index_expr(0.244094488188976*x0, torch.float32)
```
which is not good because triton's `ops.index_expr` expects integer expressions and dtypes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105021
Approved by: https://github.com/lezcano
Fixes#104822
A duplicate check is introduced into function `adaptive_max_pool1d`, but this is probably a relatively good approach.
Of course, it is also possible to transparently pass a flag in function `adaptive_max_pool1d` to function `adaptive_max_pool2d`(no need to add new parameter), and then supplement relevant Checks in `adaptive_max_pool2d`, but this approach is not clear enough first, and secondly, the amount of modification is relatively large.
At the same time, there is currently a duplicate check for `output_size`,which is cheched in both functions(`adaptive_max_pool1d` && `adaptive_max_pool2d`)
If you have better advice, please let me know, thank you
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107450
Approved by: https://github.com/ezyang
There were many test that their `_cuda` variants were not running on
cuda. I fixed a few of these, but I'm sure there's plenty more.
It'd be great to have a way to test that we're indeed compiling
something in these tests, but I don't know how to do this off the top of
my head.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107465
Approved by: https://github.com/ezyang
Feature RFC: https://github.com/pytorch/rfcs/pull/56.
The flash attention CPU kernel is added, for forward path FP32. Blocking is applied on dimensions of query length and kv length and the fusion of gemm + softmax update + gemm is done at once for each block. Parallelization is on the dimensions of batch size, head number and query length. In addition, the causal attention mask is supported. As the attention is masked for the unseen tokens, early termination is applied and we only calculate the blocks in the lower triangular part.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103826
Approved by: https://github.com/drisspg, https://github.com/jgong5
ghstack dependencies: #104583, #104584
The new guard printout looks like this:
```
[DEBUG] GUARDS:
[DEBUG] ___check_type_id(L['name'], 7605632) # if name == "special_attr": # test/dynamo/test_misc.py:1155 in __getattribute__
[DEBUG] L['name'] == '_backward_pre_hooks' # if name == "special_attr": # test/dynamo/test_misc.py:1155 in __getattribute__
[DEBUG] ___check_obj_id(L['self'], 139746432564960) # return super().__getattribute__(name) # test/dynamo/test_misc.py:1157 in __getattribute__
[DEBUG] ___check_obj_id(L['__class__'], 1451499216) # return super().__getattribute__(name) # test/dynamo/test_misc.py:1157 in __getattribute__
[DEBUG] ___is_grad_enabled() # _dynamo/output_graph.py:346 in init_ambient_guards
[DEBUG] not ___are_deterministic_algorithms_enabled() # _dynamo/output_graph.py:342 in init_ambient_guards
[DEBUG] ___is_torch_function_enabled() # _dynamo/output_graph.py:350 in init_ambient_guards
[DEBUG] utils_device.CURRENT_DEVICE == None # _dynamo/output_graph.py:348 in init_ambient_guards
```
Along with the guards, we also print what line of user code caused the guard to be added, or what line of Dynamo internal code added the guard (if there is no user stack trace, which is typically the case for ambient guards.)
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107505
Approved by: https://github.com/mlazos, https://github.com/voznesenskym, https://github.com/anijain2305
`aot_export` adds metadata for int inputs as symints. This diff turns such metadata into ints since they will be specialized anyway. We don't turn these into runtime assertions yet (but should, as future work).
Differential Revision: D48487562
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107491
Approved by: https://github.com/gmagogsfm
This updates ruff to 0.285 which is faster, better, and have fixes a bunch of false negatives with regards to fstrings.
I also enabled RUF017 which looks for accidental quadratic list summation. Luckily, seems like there are no instances of it in our codebase, so enabling it so that it stays like that. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107519
Approved by: https://github.com/ezyang
In almost all cases this is only included for writing the output formatter, which
only uses `std::ostream` so including `<ostream>` is sufficient.
The istream header is ~1000 lines so the difference is non-trivial.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106914
Approved by: https://github.com/lezcano
This PR allows dynamo to fakify FunctionalTensorWrapper by unwrapping, replacing and wrapping again for FunctionalTensorWrapper so that FunctionalTensorWrapper can be passed in as input for dynamo.optimize and we can support something like this
```python
ff = torch.func.functionalize(f)
torch.compile(ff)(x)
```
This PR didn't follow the \_\_tensor_flatten\_\_ and \_\_tensor_unflatten\_\_ protocol right now because we're not sure the plan of doing that for FunctionalTensorWrapper (it's implemented in C++).
**Test Plan:**
Add a new test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107062
Approved by: https://github.com/zou3519
ghstack dependencies: #107042
```python
def wrapper_fn(x):
with torch.autograd.graph.disable_saved_tensors_hooks("ERROR"):
y = x + 1
print("HI")
return y + 2
x = torch.randn(())
a = wrapper_fn(x)
opt = torch.compile(wrapper_fn, backend='eager', fullgraph=False)
e = opt(x)
```
Without the fix fails with,
```
Traceback (most recent call last):
File "/home/kshiteej/Pytorch/pytorch_functorch/test/test_trace_grad.py", line 182, in <module>
e = opt(x)
File "/home/kshiteej/Pytorch/pytorch_functorch/torch/_dynamo/eval_frame.py", line 333, in _fn
return fn(*args, **kwargs)
File "/home/kshiteej/Pytorch/pytorch_functorch/test/test_trace_grad.py", line 165, in wrapper_fn
def wrapper_fn(x):
AttributeError: module 'torch.autograd.graph' has no attribute 'disable_saved_tensors_hook'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106875
Approved by: https://github.com/zou3519
Summary:
Add support for broadcast and scatter in FakeProcessGroup.
As a side note, we can't easily support broadcast_object_list or
scatter_object_list since they rely on actual broadcasted/scattered
values for pickle object deserialization. We could add support for rank 0, but
other to support ranks may need additional changes outside of
FakeProcessGroup.
Test Plan:
`buck2 run mode/dev-nosan -c fbcode.enable_gpu_sections=true
//caffe2/test/distributed:fake_pg`, on of TARGETS diff: D48481513
`python test/distributed/test_fake_pg.py` after github sync
Differential Revision: D48481512
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107480
Approved by: https://github.com/wanchaol
Summary:
Currently in quantizer/quantize_pt2e we import things from specific quantizers (XNNPACKQuantizer, QuantizationConfig) etc.
this PR removes them so it's clearer that they are not part of the core quantization code base
This PR also removed get_supported_operators from main Quantizer since we haven't seen a clear need for this API
Test Plan:
CIs
Imported from OSS
Differential Revision: D48340367
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107259
Approved by: https://github.com/kimishpatel
The error fixed here happened when we had multiple autograd::Edge objects pointing to the same autograd::Node, causing before() to get called multiple times on the same object.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105887
Approved by: https://github.com/albanD
It looks like this:
```
[DEBUG] GUARD: ___check_type_id(L['z'][L["MyEnum"].BAR], 7640416) and L['z'][L["MyEnum"].BAR] == 10
[DEBUG] Stack:
[DEBUG] File "/data/users/ezyang/b/pytorch/test/dynamo/test_misc.py", line 6657, in <module>
[DEBUG] run_tests()
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/test_case.py", line 38, in run_tests
[DEBUG] run_tests()
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/testing/_internal/common_utils.py", line 985, in run_tests
[DEBUG] unittest.main(argv=argv)
[DEBUG] File "/home/ezyang/local/b/pytorch-env/lib/python3.10/unittest/main.py", line 101, in __init__
[DEBUG] self.runTests()
[DEBUG] File "/home/ezyang/local/b/pytorch-env/lib/python3.10/unittest/main.py", line 271, in runTests
[DEBUG] self.result = testRunner.run(self.test)
[DEBUG] File "/home/ezyang/local/b/pytorch-env/lib/python3.10/unittest/runner.py", line 184, in run
[DEBUG] test(result)
[DEBUG] File "/home/ezyang/local/b/pytorch-env/lib/python3.10/unittest/suite.py", line 84, in __call__
[DEBUG] return self.run(*args, **kwds)
[DEBUG] File "/home/ezyang/local/b/pytorch-env/lib/python3.10/unittest/suite.py", line 122, in run
[DEBUG] test(result)
[DEBUG] File "/home/ezyang/local/b/pytorch-env/lib/python3.10/unittest/suite.py", line 84, in __call__
[DEBUG] return self.run(*args, **kwds)
[DEBUG] File "/home/ezyang/local/b/pytorch-env/lib/python3.10/unittest/suite.py", line 122, in run
[DEBUG] test(result)
[DEBUG] File "/home/ezyang/local/b/pytorch-env/lib/python3.10/unittest/case.py", line 650, in __call__
[DEBUG] return self.run(*args, **kwds)
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/testing/_internal/common_utils.py", line 2521, in run
[DEBUG] self._run_with_retry(
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/testing/_internal/common_utils.py", line 2450, in _run_with_retry
[DEBUG] super_run(result=result)
[DEBUG] File "/home/ezyang/local/b/pytorch-env/lib/python3.10/unittest/case.py", line 591, in run
[DEBUG] self._callTestMethod(testMethod)
[DEBUG] File "/home/ezyang/local/b/pytorch-env/lib/python3.10/unittest/case.py", line 549, in _callTestMethod
[DEBUG] method()
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/testing/_internal/common_utils.py", line 2377, in wrapper
[DEBUG] method(*args, **kwargs)
[DEBUG] File "/data/users/ezyang/b/pytorch/test/dynamo/test_misc.py", line 2529, in test_enum_as_dict_key_with_overloaded_str
[DEBUG] res = opt_fn(x)
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/eval_frame.py", line 333, in _fn
[DEBUG] return fn(*args, **kwargs)
[DEBUG] File "/data/users/ezyang/b/pytorch/test/dynamo/test_misc.py", line 2519, in fn
[DEBUG] torch._dynamo.graph_break()
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/eval_frame.py", line 493, in catch_errors
[DEBUG] return callback(frame, cache_size, hooks, frame_state)
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/convert_frame.py", line 637, in _convert_frame
[DEBUG] result = inner_convert(frame, cache_size, hooks, frame_state)
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/convert_frame.py", line 133, in _fn
[DEBUG] return fn(*args, **kwargs)
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/convert_frame.py", line 371, in _convert_frame_assert
[DEBUG] return _compile(
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/convert_frame.py", line 567, in _compile
[DEBUG] guarded_code = compile_inner(code, one_graph, hooks, transform)
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/utils.py", line 181, in time_wrapper
[DEBUG] r = func(*args, **kwargs)
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/convert_frame.py", line 466, in compile_inner
[DEBUG] out_code = transform_code_object(code, transform)
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/bytecode_transformation.py", line 1028, in transform_code_object
[DEBUG] transformations(instructions, code_options)
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/convert_frame.py", line 416, in transform
[DEBUG] tracer = InstructionTranslator(
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 2018, in __init__
[DEBUG] self.symbolic_locals = collections.OrderedDict(
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/symbolic_convert.py", line 2021, in <genexpr>
[DEBUG] VariableBuilder(
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/builder.py", line 211, in __call__
[DEBUG] vt = self._wrap(value).clone(**self.options())
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/builder.py", line 404, in _wrap
[DEBUG] result = {
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/builder.py", line 405, in <dictcomp>
[DEBUG] k: VariableBuilder(
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/builder.py", line 211, in __call__
[DEBUG] vt = self._wrap(value).clone(**self.options())
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/builder.py", line 354, in _wrap
[DEBUG] return type_dispatch(self, value)
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/builder.py", line 837, in wrap_literal
[DEBUG] return self.wrap_unspecialized_primitive(value)
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/builder.py", line 1073, in wrap_unspecialized_primitive
[DEBUG] guards=self.make_guards(GuardBuilder.CONSTANT_MATCH),
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/builder.py", line 269, in make_guards
[DEBUG] return {source.make_guard(guard) for guard in guards}
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_dynamo/variables/builder.py", line 269, in <setcomp>
[DEBUG] return {source.make_guard(guard) for guard in guards}
[DEBUG] File "/data/users/ezyang/b/pytorch/torch/_guards.py", line 641, in make_guard
[DEBUG] return Guard(self.name(), self.guard_sou
```
One downside is I can't report *why* the guard was added. I'm not entirely sure how to do this; the problem is guards will propagate to a bunch of variables before finally getting included as part of the final set. Maybe a very very verbose version could report stack traces at every handoff point.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107388
Approved by: https://github.com/mlazos
ghstack dependencies: #107438, #107358
This adds some utilities for conveniently working with fast combined CapturedTraceback from Python. The main goal of these utilities is to make it easier for people to use CapturedTraceback as a drop-in replacement for `traceback.extract_stack`, which is 20x slower than CapturedTraceback.
I port symbolic shapes to use the new CapturedTraceback code, to validate that the APIs work and are useful.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107358
Approved by: https://github.com/zdevito, https://github.com/albanD
ghstack dependencies: #107438
I do this instead of pybind11 because I need a custom tp_dealloc to promptly free PyFrames. I also add GC traverse/clear support. This is required to avoid leaking memory from co_extra on code objects in some obscure situations. This is indirectly tested by #107388
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107438
Approved by: https://github.com/albanD
This PR is the first change of a series of refactors to the op dispatch logic to:
1. remove the redundant logic in the op dispatch, simplify the error
checking
2. reduce the number of tree_map/tree_flatten/unflatten needed to reduce
the overhead coming from those operations
3. remove the CachedShardingPropagator by using lru_cache from functools
directly, this makes it not only helps TP, but general DTensor
operations could be faster!
4. change the view ops behavior by inplace changing the op_schema, which
is dangerous for sharding prop caching, model the view op as one type
of resharding too
5. enrich output sharding to include whether the op needs redistribute
so that we don't need explicit op schema comparison to know it.
This should help with further reducing the CPU overhead, benchmark
results:
before (without this change), aten.addmm latency: 0.476ms

after (with this change), aten.addmm latency: 0.341ms

overall one layer of mlp time reduced from 13.535 -> 9.665ms
Apart from overhead reduction, this PR simplifies the op dispatching logic and the resharding logic (more refactor needed to make things more clean, which will be done in later PRs)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107305
Approved by: https://github.com/fduwjj
There was an issue where `hasattr(dep, "index")` would incorrectly be True because it was picking up `NamedTuple.index` (a method). We were also comparing that method to a `sympy.Exper` in one place.
As far as I can tell this wasn't actually causing any bugs (the comparison actually did the right thing), but still good to fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107092
Approved by: https://github.com/eellison
Fix cpp wrapper failure on `clip` in Torchbench:
```
RuntimeError: tensor does not have a device
```
An `optional<at::Tensor>` variable with value equal to `at::Tensor()` will be considered as _contains value_. When it's converted to `bool`, it returns `true`. While for `None` in python, when converting it to `bool`, `false` is returned.
Fix it to be an optional variable that _does not contain a value_.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106847
Approved by: https://github.com/jgong5, https://github.com/jansel
This one is a wrapper upon `mkl_gemm_bf16bf16f32` which is used in flash attention kernel on intel 4th gen xeon.
Fallback path has also been implemented on cpublas::gemm in case `mkl_gemm_bf16bf16f32` is not available.
The primary target of this change is to help build kernels in `scaled_dot_product_attention`, e.g. flash attention and efficient attention. In the attention kernel, `q @ k.T = attn`, q and k will be given as bfloat16 and attn is float32. This is actually both beneficial for both performance and accuracy, since attn will be used to compute lazy softmax which has to be done in float32.
This patch also adds routine from OpenBlas `sbgemm_` which also has a signature of bf16 * bf16 -> fp32; but since OpenBlas routine has different name from MKL's, we can not use `sbgemm_` in MKL.
In the fallback path, it takes two steps to do the computation: first do gemm with beta = 0; then add beta * C in full precision. Idea from @peterbell10 not to truncate C to bfloat16, so as to avoid unnecessary accuracy loss.
ref: https://www.intel.com/content/www/us/en/docs/onemkl/developer-reference-c/2023-0/cblas-gemm-bf16bf16f32.html
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107196
Approved by: https://github.com/jgong5, https://github.com/peterbell10
Alternative to https://github.com/pytorch/pytorch/pull/107034, implements @ezyang 's suggestion from https://github.com/pytorch/pytorch/pull/107034#discussion_r1292857201.
This PR addresses https://fb.workplace.com/groups/pytorch.oss.dev/posts/1699944830430051 and does a bunch of stacked changes:
- Make `Generator` class support GC;this makes all `Generator` instances tracked and accessile through Python's GC.
- Use the GC to retrieve all existing Generator instances in Dataloader's `_worker_loop` and re-seed them: this extends what is already applied to the global/default Generator, which is already re-seeded.
~TODO: a bit of docs and justification, which I'll do if this PR is mergeable.~ -- Done
CC @albanD @ezyang as previously discussed
BC-Breaking Note
-------------------
We now re-seed all `Generator` instances within the `Dataloader` workers' loop to ensure that their RNG is different across workers.
Previously, the RNG of user-defined `Generators` would be the same across workers, which could lead to wrong training procedures. This only affects user-defined `Generators`, not the default `Generator` (which was already re-seeded).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107131
Approved by: https://github.com/ezyang
This replaces `var_unnormalized` reduction type with `welford_reduce` which takes the input data and outputs not just the variance, but also the mean and weights which account for the full welford accumulator state. Thus we can avoid re-computing the mean, and we now have enough information to create a multilayer reduction which I implement here by adding a second reduction type called `welford_combine` which reduces over all three inputs simultaneously.
Multi-layer support is particularly important as normalization operators like BatchNorm are being split in many timm models, which meant `var_unnormalized` had to fall back to two-pass variance calculation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104725
Approved by: https://github.com/lezcano
Repeats #106429 for scatter_reduce so that the backward will pass for PT2. The .item() call is only needed to make double-backward work, which isn't supported anyway for PT2; so an easy fix is to just skip the .item() call if we know we won't need double-backward.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107353
Approved by: https://github.com/eellison
This PR allows dynamo to fakify FunctionalTensorWrapper by unwrapping, replacing and wrapping again for FunctionalTensorWrapper so that FunctionalTensorWrapper can be passed in as input for dynamo.optimize and we can support something like this
```python
ff = torch.func.functionalize(f)
torch.compile(ff)(x)
```
This PR didn't follow the \_\_tensor_flatten\_\_ and \_\_tensor_unflatten\_\_ protocol right now because we're not sure the plan of doing that for FunctionalTensorWrapper (it's implemented in C++).
**Test Plan:**
Add a new test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107062
Approved by: https://github.com/zou3519
ghstack dependencies: #107042
There are extra graph compilations on XLA when beta{1,2} ** step get too small. This PR addresses this issue by making the `capturable` interface enabled for XLA, as well as switching to `torch.float_power` which preserves the same behaviour as the non-capturable flow on XLA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102858
Approved by: https://github.com/janeyx99, https://github.com/albanD
The documentation for `torch.set_float32_matmul_precision()` mentions a datatype called "bfloat16_3x". This doesn't appear to be a very standard term, and I had a hard time figuring out what exactly it meant. I now assume it refers to [[Henry2019]](http://arxiv.org/abs/1904.06376), which describes an algorithm by which a float32 multiplication is approximated via three bfloat16 multiplications. This PR updates the documentation to include this reference and to briefly describe how this algorithm works.
Note that I just learned everything that I wrote here, so I'd appreciate if someone more expert in this topic could check to make sure that I didn't get anything significantly wrong.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107169
Approved by: https://github.com/colesbury
This commit fixes a memory leak caused by creating a new PyListObject using PyDict_Items() and not releasing that list later. This often prevented the entire model from being de-allocated even when all python references to it have gone out of scope.
Here is a repro script:
```python
import psutil, torch, transformers, gc, os, sys
import math
# Size in MB
model_size = 512
kB = 1024
MB = kB * kB
precision_size = 4 # bytes per float
activation_size = math.floor(math.sqrt(model_size * MB / precision_size))
class Net(torch.nn.Module):
def __init__(self, activation_size):
super(Net, self).__init__()
self.linear = torch.nn.Linear(activation_size, activation_size)
def forward(self, x):
return {"result": self.linear(x)}
def collect_and_report(s):
gc.collect()
print(s)
#print("psutil: ", psutil.virtual_memory().percent)
print("CPU MB used by this process: ", psutil.Process(os.getpid()).memory_info().rss / 1024 ** 2)
print("GPU MB allocated by pytorch: ", torch.cuda.memory_allocated(0) / 1024 ** 2)
print()
def run_test(device_str):
device = torch.device(device_str)
dummy_input = torch.zeros(activation_size, requires_grad=True).to(device)
collect_and_report("Before loading model: ")
model = Net(activation_size).to(device)
collect_and_report("After loading model: ")
torch.onnx.export(model, dummy_input, "dummy.onnx")
collect_and_report("After exporting model: ")
del model
collect_and_report("After deleting model:")
print("Running CPU test: ")
run_test("cpu")
print("Running GPU test: ")
run_test("cuda")
```
Results with this commit:
```
Running CPU test:
Before loading model:
CPU MB used by this process: 346.5
GPU MB allocated by pytorch: 0.0
After loading model:
CPU MB used by this process: 861.078125
GPU MB allocated by pytorch: 0.0
After exporting model:
CPU MB used by this process: 880.12890625
GPU MB allocated by pytorch: 0.0
After deleting model:
CPU MB used by this process: 880.12890625
GPU MB allocated by pytorch: 0.0
Running GPU test:
Before loading model:
CPU MB used by this process: 991.9375
GPU MB allocated by pytorch: 0.04443359375
After loading model:
CPU MB used by this process: 992.19140625
GPU MB allocated by pytorch: 512.0888671875
After exporting model:
CPU MB used by this process: 1026.64453125
GPU MB allocated by pytorch: 520.25830078125
After deleting model:
CPU MB used by this process: 1026.64453125
GPU MB allocated by pytorch: 520.25830078125
```
With this commit:
```
Running CPU test:
Before loading model:
CPU MB used by this process: 372.7734375
GPU MB allocated by pytorch: 0.0
After loading model:
CPU MB used by this process: 887.18359375
GPU MB allocated by pytorch: 0.0
After exporting model:
CPU MB used by this process: 918.96875
GPU MB allocated by pytorch: 0.0
After deleting model:
CPU MB used by this process: 407.3671875
GPU MB allocated by pytorch: 0.0
Running GPU test:
Before loading model:
CPU MB used by this process: 516.6875
GPU MB allocated by pytorch: 0.04443359375
After loading model:
CPU MB used by this process: 516.75390625
GPU MB allocated by pytorch: 512.0888671875
After exporting model:
CPU MB used by this process: 554.25390625
GPU MB allocated by pytorch: 520.2138671875
After deleting model:
CPU MB used by this process: 554.25390625
GPU MB allocated by pytorch: 8.16943359375
```
Fixes#106976
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107244
Approved by: https://github.com/BowenBao, https://github.com/kit1980
Summary:
Seems like a bug in D47998435, where when cache hits it returns None
Repro:
```
class TestModule(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x + 1
mod = TestModule()
inp = torch.rand(1)
out = mod(inp)
mod2 = torch.fx.symbolic_trace(mod, concrete_args=[inp])
so, _ = torch._export.aot_compile(mod2, tuple([inp]))
# 2nd time, it will return None
so, _ = torch._export.aot_compile(mod2, tuple([inp]))
assert so is not None # FAIL
```
Test Plan: Run the repro
Differential Revision: D48258375
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107020
Approved by: https://github.com/angelayi
Summary:
Based on D48377631 with updates to guard the utilization of cublas features only found after 11.8
According to https://docs.nvidia.com/cuda/cublas/#id99 only FP8 matrix types can be scaled, and `Float8_e4m3`x`Float8_e4m3` results can be returned as `Float8_e4m3` type, or upcast to `Half`, `BFloat16` or `Float`, but in that case `result_scale` will have no effect as well as `amax` would not be computed.
Optional `bias` argument can also be passed to a function, which should be a vector of either `Half` or `BFloat16`, whose values are added to each row of the result matrix.
See table below for supported input and output types:
| Mat1 type | Mat2 type | Bias type | Output types |
| ----------- | ----------- | ----------- | ----------- |
| Float8_e4m3 | Float8_e4m3 | Float16 | Float8_e4m3, Float16 |
| Float8_e4m3 | Float8_e4m3 | BFloat16 | Float8_e4m3, BFloat16, Float |
| Float8_e5m2 | Float8_e4m3 | Float16 | Float8_e4m3, Float8_e5m2, Float16 |
| Float8_e5m2 | Float8_e4m3 | BFloat16 | Float8_e4m3, Float8_e5m2, BFloat16, Float |
| Float8_e4m3 | Float8_e5m2 | Float16 | Float8_e4m3, Float8_e5m2, Float16 |
| Float8_e4m3 | Float8_e5m2 | BFloat16 | Float8_e4m3, Float8_e5m2, BFloat16, Float |
| Float8_e4m3 | Float8_e5m2 | Not supported | Not supported |
Skip decomposition implementation until fp8-on-triton story is better defined, Potential decomposition can look something like the following:
```python
register_decomposition(aten._scaled_mm)
def _scaled_mm(
mat1: Tensor,
mat2: Tensor,
*,
dtype: Optional[torch.dtype] = None,
scale_a: Optional[Tensor] = None,
scale_b: Optional[Tensor] = None,
scale_result: Optional[Tensor] = None,
) -> Tuple[Tensor, Tensor]:
rc = torch.mm(mat1.to(torch.float32), mat2.to(torch.float32))
rc = scale_a * rc if scale_a is not None else rc
rc = scale_b * rc if scale_b is not None else rc
rc = scale_result * rc if scale_result is not None else rc
rc = rc.to(dtype if dtype is not None else mat1.dtype)
return rc, torch.tensor(0.0, device=mat1.device)
```
Known limitations:
- Only works for matrix sizes divisible by 16
- 1st operand must be in row-major and 2nd in column-major orders (i.e. if `x` and `y` are contiguous, than only `torch._scaled_mm(x, y.t())` will work)
Test Plan: Tests in test_matmul_cda.py
Differential Revision: D48415871
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107341
Approved by: https://github.com/vkuzo
Summary:
We change `generate_opcheck_tests` to be a bit more user-friendly. Note that
there are some internal-only changes, go review them there.
Test Plan: - tests
Differential Revision: D47965247
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107328
Approved by: https://github.com/ezyang
We cannot use inner tensors for finalizers as they are uncollective until waited.
This PR adds a bunch of tests for the observable behavior we want, including the
necessary scafold for us to test code for their waitiness.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107250
Approved by: https://github.com/wconstab
Working as starter task with @Chillee
This PR adds a method under BaseSchedulerNode to estimate the node's runtime in seconds.
We use a heuristic based approach, first by considering whether the operation is memory bandwidth bounded or compute bounded:
- memory bandwidth bounded: we compute the number of bytes that are read/written to
- compute bounded: we compute the FLOPS required by the operation
One use case could be to be used as a cost model for scheduling: https://github.com/pytorch/pytorch/pull/100762
```
(pytorch-3.10) [14:08:02] ~/local/pytorch (xmfan/estimate_snode_runtime) > python3 test/inductor/test_perf.py -k EstimateSnodeRuntimeTests
[(ExternKernelSchedulerNode(name='buf0'), 400)]
[(ExternKernelSchedulerNode(name='buf0'), 2.35057908433887e-27)]
.[(ExternKernelSchedulerNode(name='buf0'), 3000), (SchedulerNode(name='buf1'), 3000)]
[(ExternKernelSchedulerNode(name='buf0'), 2.35057908433887e-26), (SchedulerNode(name='buf1'), 7.187055238190188e-09)]
.[(ExternKernelSchedulerNode(name='buf0'), 3000)]
[(ExternKernelSchedulerNode(name='buf0'), 2.35057908433887e-26)]
.[(ExternKernelSchedulerNode(name='buf0'), 34600)]
[(ExternKernelSchedulerNode(name='buf0'), 3.22687496698039e-24)]
.[(ExternKernelSchedulerNode(name='buf0'), 396)]
[(ExternKernelSchedulerNode(name='buf0'), 1.88046326747109e-27)]
.[(ExternKernelSchedulerNode(name='buf0'), 396)]
[(ExternKernelSchedulerNode(name='buf0'), 1.88046326747109e-27)]
.[(ExternKernelSchedulerNode(name='buf0'), 7776176)]
[(ExternKernelSchedulerNode(name='buf0'), 4.63240241413653e-21)]
.[(FusedSchedulerNode(nodes=buf0_buf1), 210)]
[(FusedSchedulerNode(nodes=buf0_buf1), 5.030938666733132e-10)]
.[(ExternKernelSchedulerNode(name='buf0'), 300)]
[(ExternKernelSchedulerNode(name='buf0'), 2.35057908433887e-27)]
.[(SchedulerNode(name='buf0'), 20)]
[(SchedulerNode(name='buf0'), 4.7913701587934585e-11)]
.
----------------------------------------------------------------------
Ran 10 tests in 14.311s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106426
Approved by: https://github.com/Chillee
Update distutils.Version to packaging.version due to the deprecation warning.
```python
/root/Git.d/pytorch/pytorch/torch/testing/_internal/common_methods_invocations.py:17136: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
active_if=TEST_SCIPY and LooseVersion(scipy.__version__) < "1.4.0"),
/root/Git.d/pytorch/pytorch/torch/testing/_internal/common_methods_invocations.py:17138: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
active_if=TEST_SCIPY and LooseVersion(scipy.__version__) < "1.4.0"),
/root/Git.d/pytorch/pytorch/torch/testing/_internal/common_methods_invocations.py:17140: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
active_if=TEST_SCIPY and LooseVersion(scipy.__version__) < "1.4.0"),
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107207
Approved by: https://github.com/soulitzer
- Text says `Next, let’s try a real model like resnet50 from the PyTorch` but the code example uses `resnet18`. Fixed code to use `resnet50` for consistency.
- One of the examples in TorchDynamo Overview uses uncompiled model - fixed it - now it uses compiled model.
- Removed unused import to `_dynamo` in one of the examples
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107267
Approved by: https://github.com/soulitzer
The docs correctly (i.e matching actual op behavior) state that
`right = False` means `boundaries[i-1] < input[m][n]...[l][x] <= boundaries[i]`.
However they previously stated that
`If 'right' is False (default), then the left boundary is closed.`
which contradicts the `boundaries[i-1] < input[m][n]...[l][x] <= boundaries[i]` statement.
This modifies the docs to say `... then the left boundary is OPEN.` and also clarifies that this is the opposite behavior of numpy.digitize.
Fixes#91580
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104474
Approved by: https://github.com/aakhundov, https://github.com/svekars
Summary:
In fbcode, aten and jit ops can get registered in different orders depending on build mode. In dev mode, aten is registered first; in opt mode, jit is registered first.
This causes problems in torch.ops.aten.* calls; these calls use `torch._C._jit_get_operation`, which selects an overload based on the inputs to the call. It searches through the overloads for the op with the given name, and chooses the first one that matches the input types. "First" depends on whether aten or jit ops were registered first - e.g. in `test_both_scalars_cuda` in opt mode, it chooses `add.complex` and returns a complex value.
We also saw this issue in https://github.com/pytorch/pytorch/pull/103576.
This PR sorts the list of overloads first, putting the aten ops first.
Differential Revision: D48304930
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107138
Approved by: https://github.com/ezyang, https://github.com/eellison
Summary:
Previously if we have:
```
conv1 -> cat
conv2 /
```
and configure output of conv1/conv2 to be int8 quantized, and cat also int8 quantized and with shared inputs,
it will not produce expected results (input of cat will not be shared)
The problem is that there is some missing checks when inserting observers for input for cat
This PR fixes the problem.
Fixes: https://github.com/pytorch/pytorch/issues/106760
Test Plan:
python tes/test_quantization.py TestQuantzePT2E.test_shared_qspec
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106922
Approved by: https://github.com/kimishpatel
Summary:
Some jobs in the next diff in stack (D48229150) fail with the following message:
```
stderr: In file included from xplat/caffe2/c10/cuda/CUDACachingAllocator.cpp:9:
xplat/caffe2/c10/util/static_tracepoint.h:4:6: error: 'TORCH_DISABLE_SDT' is not defined, evaluates to 0 [-Werror,-Wundef]
!TORCH_DISABLE_SDT
```
When porting USDT macros to PyTorch in D47159249, I must have not hit a codepath which treated warnings as errors during testing.
This diff fixes the issue by first checking whether the `TORCH_DISABLE_SDT` macro is defined before trying to access it in the `static_tracepoint.h` header.
Test Plan:
Similar to D47159249, tested the following macro on test scripts with `libbpf` USDTs:
* `CAFFE_DISABLE_SDT`
Reviewed By: chaekit
Differential Revision: D48251736
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107149
Approved by: https://github.com/chaekit
Companion with https://github.com/pytorch/test-infra/pull/4424
Uses the file rating generated by the test infra PR to re order tests. For each test file, sum the file ratings from the changed files in the PR, and put the tests in order of sum.
A lot of tests are probably going to end up as "prioritized" since it takes anything with a rating > 0 right now.
Sharding is done twice, once on the prioritized tests, and once on the general/non prioritized tests. Prioritized tests have an order, so they should be sharded according to that order, while general tests don't have an order and are sharded by test time, which should result in more balanced shards.
I'll change the metric name before I merge, i want to quarantine my testing stuff from actual results
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106347
Approved by: https://github.com/ZainRizvi
I get a 2% inference speedup in HF with this PR. I checked to see if there any models where unfusing was slower than the cublas gelu fusion, and I did not see any, which was surprising to me. Sorry for the cublas-activation api churn 😬
Kicking off another run in cublas 12, it's possible that the results have changed since.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106912
Approved by: https://github.com/jansel
ghstack dependencies: #106911
We avoid calling user's function f again in export. It's error prone (due to side effects in f) and time-consuming. Instead, we directly manipulate the out_spec of the graph module to make sure the graph module outputs a tuple so that aot_export is happy.
The out_spec of gm_torch_level is computed from dynamo traced result and is guaranteed to be the same output as eagerly running user's original callable f.
Test Plan:
existing tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107249
Approved by: https://github.com/tugsbayasgalan
This moves the `overloaded_args` field from FunctionSignature to PythonArgs. FunctionSignature is shared by all calls and should be immutable. PythonArgs contains the parsing results for an single call to the PyTorch API.
I did not measure a difference in performance in the "overrides_benchmark", although I expect there to be a bit more work in the common case. Note that the noise factor for the benchmark is much larger than the differences reported below:
Before:
```
Type tensor had a minimum time of 2.3615360260009766 us and a standard deviation of 0.7833134150132537 us.
Type SubTensor had a minimum time of 10.473251342773438 us and a standard deviation of 0.1973132457351312 us.
Type WithTorchFunction had a minimum time of 5.484819412231445 us and a standard deviation of 0.13305981701705605 us.
Type SubWithTorchFunction had a minimum time of 11.098146438598633 us and a standard deviation of 0.15598918253090233 us.
```
After:
```
Type tensor had a minimum time of 2.2134780883789062 us and a standard deviation of 0.802064489107579 us.
Type SubTensor had a minimum time of 10.625839233398438 us and a standard deviation of 0.15155907021835446 us.
Type WithTorchFunction had a minimum time of 5.520820617675781 us and a standard deviation of 0.23115111980587244 us.
Type SubWithTorchFunction had a minimum time of 11.227846145629883 us and a standard deviation of 0.23032321769278497 us.
```
Fixes#106974
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106983
Approved by: https://github.com/zou3519, https://github.com/ezyang, https://github.com/albanD
Adds API to mark tensor as a static input -
To make this trigger recompiles properly, I'll need to update tensor match checks to also check for this new attribute
Additional concern is memory - the tensors will be kept alive, but this is the current behavior for nn modules and parameters.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107154
Approved by: https://github.com/eellison
## Summary
This is re-land PR for https://github.com/pytorch/pytorch/pull/100706 to address the compilation latency performance regression.
## Root Cause
Regarding the C++/OpenMP backend, `codecache.pick_vec_isa()` to check vectorization ISA is a time-consuming and one-shot operation. It leads to taking a longer time to import `codegen.cpp` package because the `LoopLevel` of the package is decorated by `@dataclasses.dataclass` while the decorator will invoke `codecache.pick_vec_isa()` to initialize the `simd_nelements` of the `LoopLevel`.
c14cf312c9/torch/_inductor/codegen/cpp.py (L2883C53-L2883C53)
In terms of the Triton backend, it does not need to touch it. But we'd prefer to uniform the code. Therefore, the new design simultaneously registers `CpuScheduling` for CPU and `TritonScheduling` for Triton regardless of whether the current backend is Triton. It will bring additional overhead to the Triton backend.
```python
def init_backend_registration(self):
if get_scheduling_for_device("cpu") is None:
from .codegen.cpp import CppScheduling
register_backend_for_device("cpu", CppScheduling, WrapperCodeGen)
if get_scheduling_for_device("cuda") is None:
from .codegen.triton import TritonScheduling
register_backend_for_device("cuda", TritonScheduling, WrapperCodeGen)
```
## Solution
To resolve the compilation latency regression for the Triton backend, we changed the `LoopLevel` a little bit([new code changes](https://github.com/pytorch/pytorch/pull/106874/files#diff-5ab7b0235e2076a5fc6629ba0b109208940f5b94f5c13babc3e0f87cf4fcec82R2893-R2904)) by moving the `simd_nelements` to `__post_init__` and the compilation performance would be back.
## Compilation Latency Performance Result
We ran a single model benchmark and reproduced the compilation regression:
- Run `python benchmarks/dynamo/torchbench.py -dcuda --training --performance --inductor --only hf_Bart`
- W/ PR #100706, the compilation latency is about **57~58**
```
dev,name,batch_size,speedup,abs_latency,compilation_latency,compression_ratio,eager_peak_mem,dynamo_peak_mem,calls_captured,unique_graphs,graph_breaks,unique_graph_breaks
cuda,hf_Bart,4,1.556712,109.676554,57.055242,0.936330,5.760698,6.152422,642,1,8,7
cuda,hf_Bart,4,1.646658,109.621747,57.909817,0.936330,5.760698,6.152422,642,1,8,7
```
- W/O PR #100706, the compilation latency is about **46~47**
```
dev,name,batch_size,speedup,abs_latency,compilation_latency,compression_ratio,eager_peak_mem,dynamo_peak_mem,calls_captured,unique_graphs,graph_breaks,unique_graph_breaks
cuda,hf_Bart,4,1.599065,108.702480,47.490346,0.936330,5.760698,6.152422,642,1,8,7
cuda,hf_Bart,4,1.588419,108.431411,46.983041,0.936330,5.760698,6.152422,642,1,8,7
```
This PR fixed the compilation performance regression.
- W/ this PR #106874, the compilation latency is about **47~48**
```
dev,name,batch_size,speedup,abs_latency,compilation_latency,compression_ratio,eager_peak_mem,dynamo_peak_mem,calls_captured,unique_graphs,graph_breaks,unique_graph_breaks
cuda,hf_Bart,4,1.586261,108.149467,47.481058,0.936330,5.760698,6.152422,642,1,8,7
cuda,hf_Bart,4,1.758915,108.613899,47.925633,0.936330,5.760698,6.152422,642,1,8,7
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106874
Approved by: https://github.com/jansel
test_gradient_extreme_cases_* takes ~5 minutes on the inductor sm86 shard and possibly even longer on the inductor workflow since it's timing out right now although I'm not sure what the difference between the two is, and sometimes auto slow test detection isn't catching it
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107189
Approved by: https://github.com/ZainRizvi
To not conflict with potential existing workaround or solution outside of exporter.
Latest huggingface/transformers main (>4.31) patches PyTorch PyTree with support over `ModelOutput` class.
`_PyTreeExtensionContext` is kept to support prior versions of transformers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107245
Approved by: https://github.com/titaiwangms
ghstack dependencies: #106741, #107158, #107165
Adds a new structure to house all heuristics we use for Target Determination and Test Reordering. I'm keeping it somewhat minimal for now, to let it evolve more easily as we try new things.
It currently does nothing. The 2nd pr in the stack ports the existing heuristics to actually use this new framework
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106997
Approved by: https://github.com/clee2000, https://github.com/huydhn
This pattern shows up in torchrec KeyedJaggedTensor. Most
of the change in this PR is mechanical: whenever we failed
an unbacked symint test due to just error checking, replace the
conditional with something that calls expect_true (e.g.,
torch._check or TORCH_SYM_CHECK).
Some of the changes are a bit more nuanced, I've commented on the PR
accordingly.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106788
Approved by: https://github.com/lezcano
ghstack dependencies: #106720
Here's what it does from the comments:
```
Assume that a boolean is true for the purposes of subsequent symbolic
reasoning. This will keep track of corresponding runtime checks to verify
that the result is upheld: either as a regular guard, or as a special set
of asserts which are triggered when an unbacked SymInt is allocated.
DO NOT use this function for these cases:
- This is inappropriate for "branching" conditions (where both
true and false result in valid programs). We will always assume
the condition evaluates true, and so it will never be possible
to trace the false condition when you use it. For true branching
on unbacked SymInts, you must use torch.cond.
- This is inappropriate for situations where you know some other system
invariant guarantees that this property holds, since you don't
really need to insert a runtime check in that case. Use something
like constrain_range in that case.
This API has a hitch. To avoid having to reimplement error reporting
capabilities, this function CAN return False. The invariant is that
the surrounding code must raise an error when this function returns
False. This is quite low level, so we recommend using other functions
like check() which enforce this in a more intuitive way.
By the way, this name is a nod to the __builtin_expect likely macro,
which is used similarly (but unlike __builtin_expect, you MUST fail
in the unlikely branch.)
```
We don't do anything with this right now, except use it to discharge regular guards. Follow up PRs to (1) use it at important error checking sites, (2) actually ensure the runtime asserts make there way into the exported IR / inductor generated code.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106720
Approved by: https://github.com/ysiraichi, https://github.com/voznesenskym
Summary:
This used to be not a problem because in c10d collective init, a store based barrier would be applied.
This recently got changed in https://github.com/pytorch/pytorch/pull/103033
where the barrier is not by default applied.
For normal PGs like gloo/nccl, this is not a problem as the rendezvous process is implicitly a barrier anyway.
But for threaded pg, without the store based barrier this would lead to race condition as the local pg does not wait for world to be ready before starting collectives.
This fixes the issue by just doing a store based barrier for each pg created.
The CV attempt wouldn't work since that would still rely on class level variables which would break in the device mesh case. See inline comment for details.
Differential Revision: D48220125
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106954
Approved by: https://github.com/wanchaol, https://github.com/H-Huang, https://github.com/XilunWu
Generate diagnostic reports to monitor the internal stages of the export process. This tool aids in unblocking model exports and debugging the exporter.
#### Settings
~~1. Choose if you want to produce a .sarif file and specify its location.~~
1. Updated: saving .sarif file should be done by `export_output.save_sarif_log(dst)`, similar to saving exported onnx model `export_output.save(model_dst)`.
2. Customize diagnostic options:
- Set the desired verbosity for diagnostics.
- Treat warnings as errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106741
Approved by: https://github.com/titaiwangms, https://github.com/justinchuby, https://github.com/malfet
This allows infra/trainers to get detailed stats about communication
efficiencies without know anything about what model or distributed
training paradigms have been used. This is helpful as infra/trainer
package usually prefers to be as model/algorithm agnostic as possible.
Therefore, we cannot assume that infra/trainer can have access to all
collectives used by the model authors.
This commit adds an `OnCompletion` hook to `ProcessGroupNCCL` which
will be fired on every work completion event.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107233
Approved by: https://github.com/kumpera
```
In file included from /local/pytorch3/test/cpp/api/optim.cpp:7:
local/pytorch3/test/cpp/api/support.h:44:3: warning: '~WarningCapture' overrides a destructor but is not marked 'override' [-Winconsistent-missing-destructor-override]
~WarningCapture() {
^
local/pytorch3/c10/util/Exception.h:167:11: note: overridden virtual function is here
virtual ~WarningHandler() = default;
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107191
Approved by: https://github.com/janeyx99
This is a partial fix for https://github.com/pytorch/pytorch/issues/106457. In the examples with the shampoo optimizer that i ran, they were enough to remove the parameter aliasing in shampoo.
I added some new logic for detecting if two inputs have overlapping memory in specific cases: if they're both 2D tensors with stride 1. In that case (the case for shampoo), I try to compute a bunch of contiguous intervals on the two tensors, and check if any of the intervals overlap. In theory this is slow, since if our two tensors are e.g. of size (256, N), we'll need to create 256 intervals to check for overlap on. This seems... probably fine, since I think we do more egregious things in the compile stack to cause slowness. Open to suggestions though!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106461
Approved by: https://github.com/albanD
ghstack dependencies: #106460
This PR prefers "logical processor number" (the cpu cores shown in htop) returned by cpuinfo for determining c10 thread number. If that fails, it uses hardware_concurrency exactly.
The motivation is that in a x86 host with 64 cores and Hyper-Threading disabled, the current behavior uses 32 threads, resulting half of cores being idle.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107010
Approved by: https://github.com/ezyang
This is a follow up to https://github.com/pytorch/pytorch/pull/105881 and replaces https://github.com/pytorch/pytorch/pull/103203
The batched linalg drivers from 103203 were brought in as part of the first PR. This change enables the ROCm unit tests that were enabled as a result of that change. Along with a fix to prioritize hipsolver over magma when the preferred linalg backend is set to `default`
The following 16 unit tests will be enabled for rocm in this change:
- test_inverse_many_batches_cuda*
- test_inverse_errors_large_cuda*
- test_linalg_solve_triangular_large_cuda*
- test_lu_solve_batched_many_batches_cuda*
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106620
Approved by: https://github.com/lezcano
Summary: this is needed for int4 weight-only quantization, we're
matching on the specific unpack operation that unpacks the uint4x2 into
int4's so we can have a fused kernel for it. note, even if the user
isn't specifically doing this, the two operations are mathematically
equilvanet so it won't cause issues (for some reason int8 bitwise logic
in triton and pytorch doesn't match so that's the only exception). Ideally
at some point full prologue fusion for the mm arguments would be able to
handle this chain but until then, this type of kernel is needed.
Test Plan:
python test/inductor/test_pattern_matcher.py -k "uint4x2"
print test/inductor/test_torchinductor.py -k "uint4x2"
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106516
Approved by: https://github.com/jansel
Adds LRU functionality to the cuDNN frontend `ExecutionPlan` cache to address high memory usage as observed in #98688, #104122 via the `TORCH_CUDNN_V8_LRU_CACHE_LIMIT` environment variable. By default this limit is set to 10000, which corresponds to about 2GiB of host memory usage as observed empirically. Note that we are still following up with cuDNN to see if the size of an `ExecutionPlan` can be reduced, as it appears to currently be around 200KiB (!!) for a single plan.
This implementation is a bit heavy on the internal asserts for now as it's a bit difficult to directly test the state of the cache without instrumenting it explicitly in tests. Once we are confident that the implementation is stable, we can remove the asserts.
CC @malfet who @ptrblck mentioned may have also been looking into this
CC @colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104369
Approved by: https://github.com/malfet
fmt10.1.0 fixes a bug of format_string_checker initialisation order which is important to our improved clang-tidy checks #103058. This PR upgrades third_party fmt to 10.1.0, in the meanwhile, kineto is also upgraded to avoid fmt errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106672
Approved by: https://github.com/Skylion007
Some notable changes:
1. `constrain_as_size` allows min value to be less than 2 as it will unconditionally assume min >= 2 for compiler purposes. Instead, we add additional check to make sure max value is always greater than 2.
2. Previously, we used to runtime assert on the unbacked symint's val range which would be always between [2, max]. I modified this logic to assert on [0, max] unless user explicitly specifies the min range.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106591
Approved by: https://github.com/gmagogsfm, https://github.com/ezyang
https://github.com/pytorch/pytorch/pull/106524 gets merged so fast that we didn't figure out that we should hash both stride and dtype in DTensorSpec. This is a forward fix.
One analysis for why using just shape is not enough.
1. We use the hash value for sharding propogation cache. And the output sharding contains the stride, size of the output DTensor. If we don't consider stride, we will see errors.
2. One reason can be found below:
```
OpSchema(func_schema=aten::t(Tensor(a) self) -> Tensor(a), args_schema=(DTensorSpec(mesh=DeviceMesh:([0, 1, 2, 3, 4, 5, 6, 7]), placements=(Shard(dim=0),), tensor_meta=TensorMetadata(shape=torch.Size([64, 128]), dtype=torch.float32, requires_grad=False, stride=(128, 1), memory_format=None, is_quantized=False, qparams={})),), kwargs_schema={})
```
```
OpSchema(func_schema=aten::t(Tensor(a) self) -> Tensor(a), args_schema=(DTensorSpec(mesh=DeviceMesh:([0, 1, 2, 3, 4, 5, 6, 7]), placements=(Shard(dim=0),), tensor_meta=TensorMetadata(shape=torch.Size([64, 128]), dtype=torch.float32, requires_grad=False, stride=(1, 64), memory_format=None, is_quantized=False, qparams={})),), kwargs_schema={})
```
The only difference between two op_schame is the tensor stride:
<img width="151" alt="image" src="https://github.com/pytorch/pytorch/assets/6937752/161335df-bdfb-47c5-ba79-82616d070d15">
that makes the transpose op generates wrong result and leads to the add_/addmm_ op failing with errors:
```
Traceback (most recent call last):
File "/data/users/fduwjj/pytorch/torch/multiprocessing/spawn.py", line 74, in _wrap
fn(i, *args)
File "/data/users/fduwjj/pytorch/benchmarks/distributed/tensor/tp_benchmark.py", line 210, in run_tp
output.sum().backward()
File "/data/users/fduwjj/pytorch/torch/_tensor.py", line 491, in backward
torch.autograd.backward(
File "/data/users/fduwjj/pytorch/torch/autograd/__init__.py", line 251, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/data/users/fduwjj/pytorch/torch/distributed/_tensor/api.py", line 252, in __torch_dispatch__
return op_dispatch.operator_dispatch(
File "/data/users/fduwjj/pytorch/torch/distributed/_tensor/dispatch.py", line 116, in operator_dispatch
out, _, _ = _operator_dispatch(op_call, args, kwargs, sharding_propagator)
File "/data/users/fduwjj/pytorch/torch/distributed/_tensor/dispatch.py", line 246, in _operator_dispatch
local_results = op_call(*local_tensor_args, **local_tensor_kwargs)
File "/data/users/fduwjj/pytorch/torch/_ops.py", line 435, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: The size of tensor a (64) must match the size of tensor b (8) at non-singleton dimension 1
```
Same thing with dtype, if we are using DTensor in the environment of mixed precision, we will run into situations like this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107181
Approved by: https://github.com/wanchaol
ghstack dependencies: #106524
This PR implements the feature described in #107036 for `no_grad`, `enable_grad` and `inference_mode`.
Users can still use the above as before but they can also use them without parentheses.
For example:
```python
import torch
a = torch.ones(1, requires_grad=True)
def do_something():
print(2 * a)
with torch.no_grad():
do_something() # tensor([2.])
torch.no_grad()(do_something)() # tensor([2.])
torch.no_grad(do_something)() # tensor([2.])
do_something() # tensor([2.], grad_fn=<MulBackward0>)
```
For `inference_mode`, decorating without parenthesis is equivalent to decorating with the default `mode=True`, similiar to how dataclasses behave (https://docs.python.org/3/library/dataclasses.html#module-contents)
Closes#107036
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107086
Approved by: https://github.com/albanD
This allows infra/trainers to get detailed stats about communication
efficiencies without know anything about what model or distributed
training paradigms have been used. This is helpful as infra/trainer
package usually prefers to be as model/algorithm agnostic as possible.
Therefore, we cannot assume that infra/trainer can have access to all
collectives used by the model authors.
This commit adds an `OnCompletion` hook to `ProcessGroupNCCL` which
will be fired on every work completion event.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106988
Approved by: https://github.com/kumpera, https://github.com/H-Huang
ghstack dependencies: #107140, #107141, #107160
…out specifying the Backend
When init_process_group is not been done before, it will automatically apply init_process_group within Devicemesh without specifying the backend. Thus, when a third-party device want to use Devicemesh without doing init_process_group before, there comes a problem. In this PR, add a default_device_backend_map for third-party device users to add their backends to this map when they register their backends to pytorch firstly. When doing init_process_group without parameter backend, it will init the backends in this map. Thus, a third-party user can use init_process_group method without specifying the Backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107113
Approved by: https://github.com/wanchaol
Bionic support was finished back in April 2023, see https://ubuntu.com/blog/ubuntu-18-04-eol-for-devices
And neither gcc-7 nor clang7 are fully compatible with c++17, update minimal tested gcc to gcc9 and clang to clang-10
Note: OpenMP support is broken in Focal's `clang9`, so move up to a `clang10`
- Suppress `-Wuninitialized` in complex_test as gcc-11 fires a seemingly false-positive warning:
```
In file included from /home/malfet/git/pytorch/pytorch/c10/test/util/complex_test.cpp:1:
/home/malfet/git/pytorch/pytorch/c10/test/util/complex_test_common.h: In member function ‘virtual void memory::TestMemory_ReinterpretCast_Test::TestBody()’:
/home/malfet/git/pytorch/pytorch/c10/test/util/complex_test_common.h:38:25: warning: ‘z’ is used uninitialized [-Wuninitialized]
38 | c10::complex<float> zz = *reinterpret_cast<c10::complex<float>*>(&z);
| ^~
/home/malfet/git/pytorch/pytorch/c10/test/util/complex_test_common.h:37:25: note: ‘z’ declared here
37 | std::complex<float> z(1, 2);
| ^
```
- Downgrade `ucc` to 2.15, as 2.16 brings an incompatible libnccl, that causes crash during the initialization
- Install `pango` from condo environment for `doctr` torch bench tests to pass, as one available in the system is too new for conda
- Suppress some functorch tests when used with python-3.8+dynamo, see https://github.com/pytorch/pytorch/issues/107173
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105260
Approved by: https://github.com/huydhn, https://github.com/Skylion007, https://github.com/ZainRizvi, https://github.com/seemethere
According to https://docs.nvidia.com/cuda/cublas/#id99 only FP8 matrix types can be scaled, and `Float8_e4m3`x`Float8_e4m3` results can be returned as `Float8_e4m3` type, or upcast to `Half`, `BFloat16` or `Float`, but in that case `result_scale` will have no effect as well as `amax` would not be computed.
Optional `bias` argument can also be passed to a function, which should be a vector of either `Half` or `BFloat16`, whose values are added to each row of the result matrix.
See table below for supported input and output types:
| Mat1 type | Mat2 type | Bias type | Output types |
| ----------- | ----------- | ----------- | ----------- |
| Float8_e4m3 | Float8_e4m3 | Float16 | Float8_e4m3, Float16 |
| Float8_e4m3 | Float8_e4m3 | BFloat16 | Float8_e4m3, BFloat16, Float |
| Float8_e5m2 | Float8_e4m3 | Float16 | Float8_e4m3, Float8_e5m2, Float16 |
| Float8_e5m2 | Float8_e4m3 | BFloat16 | Float8_e4m3, Float8_e5m2, BFloat16, Float |
| Float8_e4m3 | Float8_e5m2 | Float16 | Float8_e4m3, Float8_e5m2, Float16 |
| Float8_e4m3 | Float8_e5m2 | BFloat16 | Float8_e4m3, Float8_e5m2, BFloat16, Float |
| Float8_e4m3 | Float8_e5m2 | Not supported | Not supported |
Skip decomposition implementation until fp8-on-triton story is better defined, Potential decomposition can look something like the following:
```python
@register_decomposition(aten._scaled_mm)
def _scaled_mm(
mat1: Tensor,
mat2: Tensor,
*,
dtype: Optional[torch.dtype] = None,
scale_a: Optional[Tensor] = None,
scale_b: Optional[Tensor] = None,
scale_result: Optional[Tensor] = None,
) -> Tuple[Tensor, Tensor]:
rc = torch.mm(mat1.to(torch.float32), mat2.to(torch.float32))
rc = scale_a * rc if scale_a is not None else rc
rc = scale_b * rc if scale_b is not None else rc
rc = scale_result * rc if scale_result is not None else rc
rc = rc.to(dtype if dtype is not None else mat1.dtype)
return rc, torch.tensor(0.0, device=mat1.device)
```
Known limitations:
- Only works for matrix sizes divisible by 16
- 1st operand must be in row-major and 2nd in column-major orders (i.e. if `x` and `y` are contiguous, than only `torch._scaled_mm(x, y.t())` will work)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106844
Approved by: https://github.com/albanD
ghstack dependencies: #106977
This PR adds `generate_opcheck_tests`. This is a utility that adds
additional crossref tests to an existing TestCase that has tests that
invokes operators. The main use case is if you have a large test suite
that already exercises operators and want to add automated testing that
the operators are correct, without actually refactoring your code into
something like OpInfos.
Given a `test_` method of a TestCase, we will generate one new
additional test for each of {schema correctness, autograd registration,
faketensor rule, aot_autograd static shapes, aot_autograd dynamic
shapes}. Each newly generated test runs the original test method under a
special torch_function mode (OpCheckMode) that intercepts
`op(*args, **kwargs)` calls and additional passes (op, args, kwargs) to
a separate function (e.g. SchemaCheck).
Nitty-gritty details:
- If a test is named test_cumsum, we end up generating new tests
(`test_schema__test_cumsum`, `test_<something>__test_cumsum`)
- Users can provide a dictionary of expected failures / skips that is indexed on
operators. This gives us a sense of what operators support PT2 and which
operators require fixing before they support PT2.
Due to some co-dev limitations, I'm planning on landing this PR first
and then using it to add crossref testing for internal tests and
fbgemms. I could squash this PR with the internal changes if we want to
see how that works out, just let me know.
Test Plan:
- We create a mini op test suite called MiniOpTests.
- Then, we use `generate_opcheck_tests` to generate tests onto it.
- We have our own test xfail list to check that the things that should
fail do fail.
- Finally, there is a separate TestGenerateOpcheckTests that checks that
the correct number of tests were generated and also tests some helper
functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106903
Approved by: https://github.com/ezyang, https://github.com/bdhirsh
Summary:
When loading a CPU state_dict with a pg initialized with
cpu:gloo,cuda:nccl, we hit a gloo crash since dest tensor is on GPU and input
is on CPU.
As a workaround, just enforce that if local_tensor.is_cpu, the dest tensor is
also cpu.
Test Plan: CI
Differential Revision: D48324752
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107172
Approved by: https://github.com/fegin
The previous implementation only works on CPU and it does not respect
the fact that each rank have its data in different devices (i.e. cuda),
so the implementation will raise the error like below:
```
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1!
```
See report in https://github.com/pytorch/pytorch/pull/105604#issuecomment-1675472670
This PR fix this issue and tested that the failed tests on GPU now works
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107151
Approved by: https://github.com/kumpera
Previously when we recorded a free action in a memory trace, we would provide
the stack for when the block was allocated. This is faster because we do not
have to record stacks for free, which would otherwise double the number of stacks
collected. However, sometimes knowing the location of a free is useful for
figuring out why a tensor was live. So this PR adds this behavior. If
performance ends up being a concern the old behavior is possible by passing
"alloc" to the context argument rather than "all".
Also refactors some of glue logic to be consistent across C++ and Python and
routes the Python API through the C++ version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106758
Approved by: https://github.com/albanD
This is part of effort to enable missed cpp tests for ROCm platform.
In this change,
- enabled test_libtorch cpp tests (more than 3107 tests)
- fixed missing dependency: libcaffe2_nvrtc.so required by FunctionalTest.Conv1d
- test_api binary is changed to exclude failed tests InitTest and IntegrationTest - to revisit later
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106712
Approved by: https://github.com/jithunnair-amd, https://github.com/kit1980
TIL, uploading to Rockset has an upper limit of 5000 records per request. So uploading PT2 perf benchmark could fail if that limit was reached, for example https://github.com/pytorch/pytorch/actions/runs/5828810421/job/15849232756
```
HTTP response body: {"message":"The number of documents specified in this request exceeds the maximum allowed limit of 5,000 documents.","message_key":"RECEIVER_REQUEST_MAX_DOCUMENT_LIMIT","type":"INVALIDINPUT","line":null,"column":null,"trace_id":"73fc2eb5-cfd1-4baa-8141-47c7cde87812","error_id":null,"query_id":null,"internal_errors":null}
```
The fix is to upload the results in multiple smaller batches of at most 5000 records.
### Testing
5743 records from https://github.com/pytorch/pytorch/actions/runs/5828810421/job/15849232756 were written in 2 batches (5000 + 743)
```
python3 -m tools.stats.upload_dynamo_perf_stats --workflow-run-id 5821183777 --workflow-run-attempt 1 --repo pytorch/pytorch --head-branch gh/ezyang/2294/head
...
Writing 5000 documents to Rockset
Done!
Writing 743 documents to Rockset
Done!
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107095
Approved by: https://github.com/atalman, https://github.com/seemethere, https://github.com/ZainRizvi
Update graph_signature according to graph after transformation.
Transformations can lead to node name changes, which are used in
graph_signature to identify inputs and outputs. Therefore, after each
transformation, we need to update the graph_signature according to
new node names.
WARNING: This implementation makes a few assumptions
- The transformation doesn't change number of inputs/outputs
- Each input/output still has the same meaning.
- For inputs, that means that the inputs in transformed
graph map to the same lifted parameter/buffer or user
input as the input of the same position in the graph
before transformation.
- Similarly for outputs, each output should correspond to the
same mutated buffer or user output as the output value of
the same position in the graph before transformation.
It is difficult to programatically validate these assumptions, but they
should hold true most of the time as inputs/outputs of the graph rarely
need to be changed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107080
Approved by: https://github.com/tugsbayasgalan
PR #90689 replaces NVTX with NVTX3. However, the torch::nvtoolsext is created only when the third party NVTX is used.
This is clear a logical error. We now move the creation code out of the branch to cover all cases. This should fix the issues reported in the comments of #90689.
It would be better to move configurations of the failed FRL jobs to CI tests so that we can find such issues early before merging.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97582
Approved by: https://github.com/peterbell10
- impl_save_for_backward/impl_backward only work for functional,
non-view schemas. We validate this.
- impl_save_for_backward/impl_backward raise if there already exists an
autograd implementation from torch.library / TORCH_LIBRARY.
- Operators constructed via custom_op receive an "autograd indirection
kernel". The "autograd indirection kernel" automatically pulls the
constructed autograd kernel out of a dict. When
impl_save_for_backward/impl_backward get used with torch.library
operators, we also register the "autograd indirection kernel" so we can
reuse the logic.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106817
Approved by: https://github.com/soulitzer
ghstack dependencies: #106799, #106800
Recall that the user must give us a backward function that accepts
`(ctx, saved, *grads)`, with one grad per output. Previously,
impl_backward only worked for functions that return one or more Tensors.
The new semantics are that if the output has:
- a TensorList, the backward function provided by the user will receive
a List[Tensor] of grads for that output.
- a number, the backward function provided by the user will receive
None as the grad.
Also recall that impl_backward is implemented by registering an
autograd.Function to the autograd dispatch key.
We needed to make the following changes:
- If an output is a TensorList, autograd.Function will ignore it. So we
need to tree-flatten it before returning it from the autograd.Function
- This means that the autograd.Function receives a flat list of grad
during the backwards pass. We need to tree-unflatten it into the correct
shape before passing it to the user-defined backward
- We modify the logic of output_differentiability. Only
Tensor/TensorList outputs can be marked as differentiable. If a
TensorList is marked as non-differentiable, then this is equivalent to
all Tensors in the list being non-differentiable. There is no
finer-grain control over this (to match derivatives.yaml).
Test Plan:
- There are new `numpy_split_copy` (returns TensorList) and
`numpy_split_copy_with_int` (returns (TensorList, int)) operators in
custom_op_db
- Added tests for output_differentiability into test/test_custom_ops.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106800
Approved by: https://github.com/soulitzer
ghstack dependencies: #106799
This expands the torch._custom_ops.custom_op API to be able to construct
operators that return (int, bool, float, Scalar, List[Tensor]) to make
it more in-line with our torch.library API.
NB: there needs to be updates to our custom_op autograd registration
API. For ease of review those changes will go in the next PR up but I
can squash if requested.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106799
Approved by: https://github.com/soulitzer
This PR wraps `InstructionTranslator` run with a try-catch block so as to run the
translation validation (TV) if it ends up raising an error.
In this context, we run TV so as to catch simplification errors. These may turn
`ShapeEnv.divisible` and `ShapeEnv.replacements` incorrect.
For example: #101173 describes a SymPy simplification bug that doesn't reach TV, since
it's run only in the end of the tracing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106645
Approved by: https://github.com/ezyang
Summary: Basically we generate `CustomOpsNativeFunctions.h` for registering custom ops into PyTorch JIT runtime. This header needs to hookup with the C++ kernel implementation of all the custom ops. For this reason it should include ATen headers instead of Executorch headers. This PR changes it.
Test Plan: Rely on existing CI jobs
Differential Revision: D48282828
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107064
Approved by: https://github.com/kirklandsign
Fixes#107066, closes#107008
This replaces loads to zero-element `Loops` or `Buffer`s with `ops.constant`
calls. This both avoids the issue of masked loads under triton, and also means
the buffer is not listed as a dependency for downstream users which may improve
performance generally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107074
Approved by: https://github.com/davidberard98
If I understand the code correctly, we want to add a fusion choice if
- node2 is template or foreach
and
- can_fuse return true for (node2, node1)
But the code misses a pair of parenthesis since in python 'and' has higher precedence than 'or'. This does not cause much damage since even if we add a pair of nodes that can not be fused, we will skip them later when we call can_fuse again (in fuse_nodes_once). Fixing this mainly to avoid confusion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107001
Approved by: https://github.com/jansel, https://github.com/mlazos
Move the remaining collectives to a separate file to prepare device mesh
to become a public distributed API
For those remaining utils, we need to upstream them to functional
collectives with proper implementation, added TODO there for a follow up
PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/107012
Approved by: https://github.com/fduwjj
Summary
- The 'dynamo_export' diagnostics leverages the PT2 artifact logger to handle the verbosity
level of logs that are recorded in each SARIF log diagnostic. In addition to SARIF log,
terminal logging is by default disabled. Terminal logging can be activated by setting
the environment variable `TORCH_LOGS="onnx_diagnostics"`. When the environment variable
is set, it also fixes logging level to `logging.DEBUG`, overriding the verbosity level
specified in the diagnostic options.
See `torch/_logging/__init__.py` for more on PT2 logging.
- Replaces 'with_additional_message' with 'Logger.log' like apis.
- Introduce 'LazyString', adopted from 'torch._dynamo.utils', to skip
evaluation if the message will not be logged into diagnostic.
- Introduce 'log_source_exception' for easier exception logging.
- Introduce 'log_section' for easier markdown title logging.
- Updated all existing code to use new api.
- Removed 'arg_format_too_verbose' diagnostic.
- Rename legacy diagnostic classes for TorchScript Onnx Exporter to avoid
confusion.
Follow ups
- The 'dynamo_export' diagnostic now will not capture python stack
information at point of diagnostic creation. This will be added back in
follow up PRs for debug level logging.
- There is type mismatch due to subclassing 'Diagnostic' and 'DiagnosticContext'
for 'dynamo_export' to incorporate with PT2 logging. Follow up PR will
attempt to fix it.
- More docstrings with examples.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106592
Approved by: https://github.com/titaiwangms
Recently I feel it's a bit painful to run benchmark scripts on my dev environment. E.g., the command below
```
python benchmarks/dynamo/huggingface.py --backend inductor --amp --performance --only YituTechConvBert --training
```
took about 2 minutes to run. It may take even longer for some other models.
The command is slow since it
- need do dynamo work
- verify the model on CPU
- run perf tests
- compile all the graphs
However, often times I only need to debug inductor specific logic like loop ordering and fusion. A lot of the things the script is done are useless for me. Also I only need test one graph at a time (e.g. check fwd graph first and when I'm done, continue to check bwd graph) rather than compiling all the graphs.
The graph replayer add a `@save_args` decorator to compile_fx_inner function. When `config.save_args` is true, it will pickle all the arguments to `comple_fx_inner` to the file system. Later on, we can call `load_args_and_run_compile_fx_inner("/tmp/inductor_saved_args/compile_fx_inner_0.pkl")` to replay the graph and compile it with inductor.
Replaying the fwd graph took around 60 seconds (maybe this can be further reduced but this is already 2x speedup for dev efficiency) , and it only took around 20 seconds to reach `Scheduler.__init__` method.
I also checked `TORCH_COMPILE_DEBUG` flag that already exists. The most similar part of `TORCH_COMPILE_DEBUG` is it can save a graph and it's arguments and later on rerun it. But the difference here is, rather than run the model, we want to call inductor API to compile the model (without even going thru dynamo or aot-autograd).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106952
Approved by: https://github.com/jansel
ghstack dependencies: #106990
This fixes a bug that could occur with python decompositions.
When an operation is intercepted in the c++ code in pytorch the outputs a created as `ExclusivelyOwned<at::Tensor>`s. Later on when it dispatches back to python for the decomposition these tensors have their ownership shared with python. In a normal use case the exclusively owned tensor is released and it's value returned as a non-exclusively owned tensor from the operation. However if the python decomposition throws an error the `ExclusivelyOwned` wrapper destroys the `at::Tensor` leading to a python reference to a tensor which isn't alive (and meaning pytorch falls over in debug mode).
Note this will be a performance hit when handling errors.
Fixes#106790
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106791
Approved by: https://github.com/ezyang
AsyncCollectiveTensor is a tensor subclass that is meant to "delay synchronization" when you call into the functional collectives API's. It does this (if I understand correctly) by internally holding an "unsynchronized" version of the tensor, which is the result of the communication op, and internally calling `.wait()` to synchronize the data the next time it is used.
Previously, these wait() calls would happen immediately, because `AsyncCollectiveTensor` gets wrapped by `DTensor()`, which calls `.detach()` on its inner tensor, immediately causing the sync (code: 1518d5eec4/torch/distributed/_tensor/api.py (L207))
AsyncCollectiveTensor shouldn't need to do a synchronization if you try to detach() it though - in fact, it should be fine to avoid synchronizing if you perform any view ops on it (which just require viewing metadata, but not actual data). This PR tries to update `AsyncCollectiveTensor` to delay `wait()` calls whenever the subclass encounters a view op.
Added some light testing, that just runs some DTensor compute followed by view ops, and confirms that the output is still an `AsyncCollectiveTensor` when we call `.to_local()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105240
Approved by: https://github.com/wanchaol, https://github.com/fduwjj, https://github.com/wconstab
Summary:
MM max autotune (and friends) crash when one of the inputs is zero-size.
E.g., running this code:
```
@torch.compile()
def fn(x, y):
return torch.mm(x, y)
inps = [torch.rand([0, 30]), torch.rand([30, 40])]
inps = [x.to(device="cuda") for x in inps]
out = fn(*inps)
```
with this command:
```
TORCHINDUCTOR_MAX_AUTOTUNE=1 python test.py
```
raises this error (the top of the stack trace omitted for brevity):
```
...
File "/data/users/aakhundov/pytorch/torch/_inductor/kernel/mm.py", line 119, in tuned_mm
return autotune_select_algorithm("mm", choices, [mat1, mat2], layout)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/aakhundov/pytorch/torch/_inductor/select_algorithm.py", line 960, in autotune_select_algorithm
return _ALGORITHM_SELECTOR_CACHE(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/aakhundov/pytorch/torch/_inductor/select_algorithm.py", line 787, in __call__
timings = self.lookup(
^^^^^^^^^^^^
File "/data/users/aakhundov/pytorch/torch/_inductor/codecache.py", line 267, in lookup
timings[choice] = benchmark(choice)
^^^^^^^^^^^^^^^^^
File "/data/users/aakhundov/pytorch/torch/_inductor/select_algorithm.py", line 774, in autotune
raise ErrorFromChoice(msg, choice, benchmark_fn.debug_str())
torch._dynamo.exc.BackendCompilerFailed: backend='inductor' raised:
LoweringException: ErrorFromChoice: Please run `ptxas /tmp/compile-ptx-src-bfb1c6` to confirm that this is a bug in `ptxas`
From choice TritonTemplateCaller(/tmp/torchinductor_aakhundov/z7/cz7n7nn6rdlaelu4pbaaurgmu74ikl6g76lkngwawrevlfxlc6re.py, ACC_TYPE='tl.float32', ALLOW_TF32=False, BLOCK_K=32, BLOCK_M=16, BLOCK_N=64, EVEN_K=False, GROUP_M=8, num_stages=2, num_warps=4)
inputs = [
torch.empty_strided((0, 30), (30, 1), dtype=torch.float32, device='cuda'),
torch.empty_strided((30, 40), (40, 1), dtype=torch.float32, device='cuda'),
]
out = torch.empty_strided((0, 40), (40, 1), dtype=torch.float32, device='cuda')
target: aten.mm.default
args[0]: TensorBox(StorageBox(
InputBuffer(name='arg1_1', layout=FixedLayout('cuda', torch.float32, size=[0, s0], stride=[s0, 1]))
))
args[1]: TensorBox(StorageBox(
InputBuffer(name='arg3_1', layout=FixedLayout('cuda', torch.float32, size=[s0, s1], stride=[s1, 1]))
))
```
This PR adds a check to skip Triton templates in the `mm`, `addmm`, `mm_plus_mm` autotuning when the product of the MM problem shape (`m * n * k`) is zero.
Additionally, early exit conditions have been added to the mm and mm_plus_mm Triton templates on `M * N * K == 0`, to prevent issues when autotuning was done on non-zero-size inputs with dynamic shapes, then zero-size inputs are encountered by the compiled model.
Test Plan:
```
$ python test/inductor/test_max_autotune.py -v
...
----------------------------------------------------------------------
Ran 16 tests in 29.569s
OK
```
Reviewers: @eellison
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106865
Approved by: https://github.com/jansel
Although the sun is setting for torchscript, it is not [officially deprecated](https://github.com/pytorch/pytorch/issues/103841#issuecomment-1605017153) since nothing currently fully replaces it. Thus, "downstream" libraries like TorchVision, that started offering torchscript support still need to support it for BC.
torchscript has forced us to use workaround after workaround since forever. Although this makes the code harder to read and maintain, we made our peace with it. However, we are currently looking into more elaborate API designs that are severely hampered by our torchscript BC guarantees.
Although likely not intended as such, while looking for ways to enable our design while keeping a subset of it scriptable, we found the undocumented `__prepare_scriptable__` escape hatch:
0cf918947d/torch/jit/_script.py (L977)
One can define this method and if you call `torch.jit.script` on the object, the returned object of the method will be scripted rather than the original object. In TorchVision we are using exactly [this mechanism to enable BC](3966f9558b/torchvision/transforms/v2/_transform.py (L122-L136)) while allowing the object in eager mode to be a lot more flexible (`*args, **kwargs`, dynamic dispatch, ...).
Unfortunately, this escape hatch is only available for `nn.Module`'s
0cf918947d/torch/jit/_script.py (L1279-L1283)
This was fine for the example above since we were subclassing from `nn.Module` anyway. However, we recently also hit a case [where this wasn't the case](https://github.com/pytorch/vision/pull/7747#issuecomment-1642045479).
Given the frozen state on JIT, would it be possible to give us a general escape hatch so that we can move forward with the design unconstrained while still keeping BC?
This PR implements just this by re-using the `__prepare_scriptable__` hook.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106229
Approved by: https://github.com/lezcano, https://github.com/ezyang
I found that for a tiled kernel for tensor with shape [a, b], we map 'a' with XBLOCK and 'b' with YBLOCK. However, 'a' actually should be the outer looper while 'b' corresponding to the inner loop. This order is picked by our loop ordering algorithm. Mapping 'a' with XBLOCK has the semantic like assigning 'a' to the inner loop instead.
For a simple 'A + B.t()' kernel, making the loop order consistent can brings 1.027x speedup ( 1.938ms -> 1.887ms speedup) . Here are the dump of kernels:
- before fix: https://gist.github.com/shunting314/4dacf73cf495cdd7e84dede7c3e0872d
- after fix (this one is done manually): https://gist.github.com/shunting314/441e8839d24e1878c313e539b1ebd551
I tried this on DistillGPT2 and found perf is neutral. But that because DistillGPT2 has a single tiled pointwise kernel in it's backward graph. Will check the dashboard.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106827
Approved by: https://github.com/jansel
Port fix from https://github.com/huggingface/safetensors/pull/318 into ONNX exporter until it is merged
* This add support for safetensors to be loaded within a FakeTensorMode, which results in creating `torch.empty((shape,), dtype=)`. This is done through a monkeypatch for the in-progress https://github.com/huggingface/safetensors/pull/318
* Adds a test for the HF bloom model (bigscience/bloom-560m)
* This PR also fixes existing fake tensor unit tests by moving the `torch.onnx.dynamo_export` to be inside the `enable_fake_mode()` context. Although calling `torch.onnx._dynamo_export` works for several models, the right way of using fake mode is calling the exporter within the context manager.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106930
Approved by: https://github.com/BowenBao
Summary: if torch._inductor.config.use_mixed_mm then we can convert
torch.mm(a, b.to(some_dtype)) into a triton kernel where the casting b
is fused into the matmul rather than needing to instantiate the casted b
tensor. If use_mixed_mm is set, this fused kernel will be autotuned
against the default 2 kernel fallback option. If force_mixed_mm then the
fused kernel will always be used, This option is needed for weight-only quantization where we are in
some cases relying on the superior memory characteristics of the fused
kernel rather than the perf numbers (when we can't afford to load memory
with a tensor 4x the size of our quantized one).
Test Plan: python test/inductor/test_pattern_matcher.py -k "mixed_mm"
python test/inductor/test_torchinductor.py -k "mixed_mm"
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106443
Approved by: https://github.com/jansel
Some notable changes:
1. `constrain_as_size` allows min value to be less than 2 as it will unconditionally assume min >= 2 for compiler purposes. Instead, we add additional check to make sure max value is always greater than 2.
2. Previously, we used to runtime assert on the unbacked symint's val range which would be always between [2, max]. I modified this logic to assert on [0, max] unless user explicitly specifies the min range.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106591
Approved by: https://github.com/gmagogsfm, https://github.com/ezyang
When removing an inplace buffer, we just mark it as ```REMOVED```, after removing some inplace buffer, and then if we mark a buffer as inplace buffer using the ```self.inplace_buffer.values()``` length to create a buffer name, there may have an issue which we may define a same inplace buffer name with existed in ```self.inplace_buffer.values()```:
before removing some inplace buffers, the ```self.inplace_buffers``` may be like:
```
{'buf0': InplacedBuffer(inner_name='in_out_ptr0', other_names=['buf0', 'buf2', 'buf4']), 'buf2': InplacedBuffer(inner_name='in_out_ptr0', other_names=['buf0', 'buf2', 'buf4']), 'buf4': InplacedBuffer(inner_name='in_out_ptr0', other_names=['buf0', 'buf2', 'buf4']), 'buf5': InplacedBuffer(inner_name='in_out_ptr1', other_names=['buf5', 'buf7', 'buf9']), 'buf7': InplacedBuffer(inner_name='in_out_ptr1', other_names=['buf5', 'buf7', 'buf9']), 'buf9': InplacedBuffer(inner_name='in_out_ptr1', other_names=['buf5', 'buf7', 'buf9']), 'buf12': InplacedBuffer(inner_name='in_out_ptr2', other_names=['buf12', 'buf13']), 'buf13': InplacedBuffer(inner_name='in_out_ptr2', other_names=['buf12', 'buf13']), 'buf17': InplacedBuffer(inner_name='in_out_ptr3', other_names=['buf17', 'buf19']), 'buf19': InplacedBuffer(inner_name='in_out_ptr3', other_names=['buf17', 'buf19']), 'buf21': InplacedBuffer(inner_name='in_out_ptr4', other_names=['buf21', 'buf25']), 'buf25': InplacedBuffer(inner_name='in_out_ptr4', other_names=['buf21', 'buf25']), 'buf20': InplacedBuffer(inner_name='in_out_ptr5', other_names=['buf20', 'buf26', 'buf31', 'buf32']), 'buf26': InplacedBuffer(inner_name='in_out_ptr5', other_names=['buf20', 'buf26', 'buf31', 'buf32']), 'buf31': InplacedBuffer(inner_name='in_out_ptr5', other_names=['buf20', 'buf26', 'buf31', 'buf32']), 'buf32': InplacedBuffer(inner_name='in_out_ptr5', other_names=['buf20', 'buf26', 'buf31', 'buf32'])}
```
After removing some inplace buffers, the ```self.inplace_buffers``` may be like:
```
{'buf0': InplacedBuffer(inner_name='in_out_ptr0', other_names=['buf0', 'buf2', 'buf4']), 'buf2': InplacedBuffer(inner_name='in_out_ptr0', other_names=['buf0', 'buf2', 'buf4']), 'buf4': InplacedBuffer(inner_name='in_out_ptr0', other_names=['buf0', 'buf2', 'buf4']), 'buf5': 'REMOVED', 'buf7': 'REMOVED', 'buf9': 'REMOVED', 'buf12': 'REMOVED', 'buf13': 'REMOVED', 'buf17': InplacedBuffer(inner_name='in_out_ptr3', other_names=['buf17', 'buf19']), 'buf19': InplacedBuffer(inner_name='in_out_ptr3', other_names=['buf17', 'buf19']), 'buf21': 'REMOVED', 'buf25': 'REMOVED', 'buf20': 'REMOVED', 'buf26': 'REMOVED', 'buf31': 'REMOVED', 'buf32': 'REMOVED', 'buf16': InplacedBuffer(inner_name='in_out_ptr6', other_names=['buf16', 'buf38']), 'buf38': InplacedBuffer(inner_name='in_out_ptr6', other_names=['buf16', 'buf38'])}
```
And then if we mark some buffer as inplace buffer and the buffer name will use ```in_out_ptr{len(unique(self.inplace_buffers.values()))}```, the buffer name may be ```in_out_ptr6``` even this name has existed in ```self.inplace_buffers```.
After this PR, we will change ```REMOVED``` to ```REMOVED{1, 2, 3..}``` which avoids defining a duplicate name. ```pyhpc_equation_of_state ``` of ```torchbench``` will work for CPU backend:
```python -m torch.backends.xeon.run_cpu --node_id 0 benchmarks/dynamo/torchbench.py --performance --inference --float32 -dcpu -n50 --inductor --freezing --no-skip --dashboard --only pyhpc_equation_of_state --cold_start_latency```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106852
Approved by: https://github.com/lezcano
On SPR machine, the mkldnn bfloat16 convolution always return a channels last output, and we will convert it to channels first if input and weight are channels first, there has an issue when we do such conversion if output is nc11(4*512*1*1), we always mark it as public format ideep tensor, and even we calling ```to_dense``` before returning the output, the output's stride is still a channels last stride(512, 1, 512, 512), this PR will calling ```resize_``` to make sure the stride is contiguous stride.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106966
Approved by: https://github.com/mingfeima
RFC: https://github.com/pytorch/rfcs/pull/54
First commit is the contents of https://github.com/Quansight-Labs/numpy_pytorch_interop/
We have already been using this in core for the last few months as a external dependency. This PR pulls all these into core.
In the next commits, I do a number of things in this order
- Fix a few small issues
- Make the tests that this PR adds pass
- Bend backwards until lintrunner passes
- Remove the optional dependency on `torch_np` and simply rely on the upstreamed code
- Fix a number dynamo tests that were passing before (they were not tasting anything I think) and are not passing now.
Missing from this PR (but not blocking):
- Have a flag that deactivates tracing NumPy functions and simply breaks. There used to be one but after the merge stopped working and I removed it. @lezcano to investigate.
- https://github.com/pytorch/pytorch/pull/106431#issuecomment-1667079543. @voznesenskym to submit a fix after we merge.
All the tests in `tests/torch_np` take about 75s to run.
This was a work by @ev-br, @rgommers @honno and I. I did not create this PR via ghstack (which would have been convenient) as this is a collaboration, and ghstack doesn't allow for shared contributions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106211
Approved by: https://github.com/ezyang
Summary:
Introduce a GPU memory Layout qualifier in `vTensor`, which will allow more efficient memory layouts when storing Tensors on the GPU.
The plan is for shaders to use the memory layout qualifier to convert between logical tensor coordinates and physical texel positions.
Test Plan:
As-is, this diff should be a no-op. Run standard tests to make sure everything works as expected.
```
buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1
buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1
```
Reviewed By: kimishpatel
Differential Revision: D48129905
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106978
Approved by: https://github.com/liuk22
Summary:
Redirect `aten._unsafe_index` to `aten.index` through a decomposition.
Also add it to the list of core decompositions.
Test Plan: contbuild and OSS CI (similar to D40075277)
Differential Revision: D48163393
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106814
Approved by: https://github.com/SherlockNoMad
Summary: Adding an enforce gives better error information than raising SIGFPE when division by zero happens. We'll get the actual BlobRef names as well as the error categories.
Test Plan:
Ran a local worker and client using DPP session with empty tensors and checked the error:
`../buck-out/v2/gen/fbcode/data_preproc/perf_test/client --sr2_event_base_pool_size=24`
`../buck-out/v2/gen/fbcode/data_preproc/perf_test/worker --dpp_session_id=5D49F56C98CC95BD97027BC0DDB38D8F`
```{dpp_internal_errorcategory : user_error,
ONCALL : MLDP_CONTROL,
CATEGORY : INPUT_ERROR,
errorsubsystemtags : [DPP_WORKER],
errorcause : USER_ERROR,
RETRYABILITY : 0}F0806 17:47:52.607200 2280375 SchedRuntimeEnv.cpp:385] facebook::data_preproc::NonRetryableGenericUser
Error: User preprocessing error c10::Error: [enforce fail at utility_ops.h:730] input.numel() > 0. 0 vs 0. tensor has t
o be nonempty (Error from operator:
input: "preproc_data_pipeline/preproc/features/default_feature_preproc/normalization/dper_feature_normalization/sparse_
features_processor_1/sparse_feature_transform/F3_ADFINDER_USER_ADS_COFFEE_LSF_FLEXIBLE_BATCH_USER_FB_UIP_FEATURE_IDSCOR
ELIST_ENCODED_FB_UIP_TOP100_IDSCORELIST_ENCODED_1/sequential_1019/id_score_list_quantization_decode_1/Concat:0" input:
"preproc_data_pipeline/preproc/features/default_feature_preproc/normalization/dper_feature_normalization/sparse_feature
s_processor_1/sparse_feature_transform/F3_ADFINDER_USER_ADS_COFFEE_LSF_FLEXIBLE_BATCH_USER_FB_UIP_FEATURE_IDSCORELIST_E
NCODED_FB_UIP_TOP100_IDSCORELIST_ENCODED_1/sequential_1019/id_score_list_quantization_decode_1/Mul_2" input: "preproc_d
ata_pipeline/preproc/features/default_feature_preproc/normalization/dper_feature_normalization/sparse_features_processo
r_1/sparse_feature_transform/F3_ADFINDER_USER_ADS_COFFEE_LSF_FLEXIBLE_BATCH_USER_FB_UIP_FEATURE_IDSCORELIST_ENCODED_FB_UIP_TOP100_IDSCORELIST_ENCODED_1/sequential_1019/id_score_list_quantization_decode_1/encoded_id_lengths" output: "preproc_data_pipeline/preproc/features/default_feature_preproc/normalization/dper_feature_normalization/sparse_features_processor_1/sparse_feature_transform/F3_ADFINDER_USER_ADS_COFFEE_LSF_FLEXIBLE_BATCH_USER_FB_UIP_FEATURE_IDSCORELIST_ENCODED_FB_UIP_TOP100_IDSCORELIST```
Differential Revision: D48104430
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106882
Approved by: https://github.com/kit1980
Currently multilayer reduction (aka split reductions) are only used with static
shapes which results in worse performance and accuracy when dynamic shapes are
enabled. Instead, this only requires that the shape has a hint value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106747
Approved by: https://github.com/lezcano
ghstack dependencies: #106626, #106870
`JITFunction._key_of` uses the value of the argument to distinguish between
i32 and i64, but this fails if the value is used in indexing calculations where
the value exceeds `INT_MAX`.
Instead, we should use `index_dtype` which means all indexing calculations are
performed in the same dtype.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106870
Approved by: https://github.com/lezcano
ghstack dependencies: #106626
When `reference_as_float` is true, reference gradients will not have the same
dtype as the actual computed gradients. This fixes the issue by downcasting
before doing the comparison.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106626
Approved by: https://github.com/lezcano
This fixes a pretty vicious bug relating to `SHARD_GRAD_OP`, mixed precision, EMA, and eval.
**Bug Explanation**
The model has a main module and an EMA module, where the main module is used for training and the EMA module is used for eval. The model has FSDP's fp16 mixed precision enabled. The flow consists of (1) training forward/backward/optimizer -> (2) EMA update (copy main module to EMA module) -> eval forward in `torch.no_grad()`, where this repeats for many iterations.
Consider the _second_ iteration.
- From the first iteration's eval forward, the EMA module has the fp16 unsharded parameters in memory (not freed due to `SHARD_GRAD_OP`).
- In this second iteration's step (2), we perform the EMA update under the `summon_full_params()` context, where FSDP specially forces full precision. This means that the EMA module now uses fp32 unsharded parameters, distinct from the fp16 unsharded parameters still in memory. The EMA update modifies those fp32 parameters, and upon exiting the context, FSDP correctly writes the modifications back to the fp32 sharded parameters.
- In the second iteration's step (3) (eval forward), FSDP checks whether it needs to run the unshard op (including all-gather) but sees it does not since the fp16 unsharded parameters are still in memory. Thus, FSDP uses those fp16 unsharded parameters directly without all-gather. However, these fp16 unsharded parameters are stale and do not include the EMA update!
- In other words, at this point, the fp32 sharded parameters are correct, the fp16 unsharded parameters are stale, and FSDP chooses _not_ to re-all-gather since the fp16 unsharded parameters are in memory.
**Fix Explanation**
This PR fixes this by freeing the fp16 unsharded parameters if they are still allocated when forcing full precision, i.e. using fp32 unsharded parameters in `summon_full_params()`. This ensures that any modifications written back to the fp32 sharded parameters will be persisted via the next all-gather.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106858
Approved by: https://github.com/kumpera
ghstack dependencies: #106857
Summary:
att
we don't actually need gradient for conv2d, just need it to run without error, so we delayed the error of out_dtype gradient
to the time when user actually requested it
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_representation_conv2d
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106924
Approved by: https://github.com/zou3519, https://github.com/kimishpatel
Fixes `signed-unsigned comparison` warnings introduced by https://github.com/pytorch/pytorch/pull/106809 (previously by <s> https://github.com/pytorch/pytorch/pull/104054 </s> ) that changed type of `num_indices` to unsigned.
Before the change warnings looks as follows:
```
/tmp/tmpxft_00194ca7_00000000-6_IndexKernel.cudafe1.stub.c:31:580: required from here
/home/nshulga/git/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:58:63: warning: comparison of integer expressions of different signedness: ‘const long unsigned int’ and ‘int’ [-Wsign-compare]
58 | AT_ASSERT(num_indices == iter.ntensors() - 2);
| ^
/home/nshulga/git/pytorch/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:74:19: warning: comparison of integer expressions of different signedness: ‘int’ and ‘const long unsigned int’ [-Wsign-compare]
74 | for (int i = 0; i < num_indices; i++) {
| ~~^~~~~~~~~~~~~
```
TODO: Turn those warning into errors
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104423
Approved by: https://github.com/Skylion007
1. add a python meta registration, to fix an issue with the forward pass. The problem was that previously, the C++ meta registration calls [numel()](7b14a14e27/aten/src/ATen/native/TensorAdvancedIndexing.cpp (L329)) which fails (LMK if it's better to fix the C++ implementation to not do this check)
2. Modify the backward to fix an issue in the backward. The backward is not a custom op - it's a custom manual backward implementation. In particular, there's some situations that don't support double backward; the check for whether double backward is allowed requires a .item() call. To fix the meta/fake tensor case, this PR will avoid setting the double backward error only if `GradMode::is_enabled()` - which shouldn't be turned on in PT2.
3. Update skips.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106429
Approved by: https://github.com/zou3519
Forward fixes https://github.com/pytorch/pytorch/pull/106615 by increasing tolerance in the test.
The capturable implementation for foreach simply varies due to a different order of operations when updating params. I had also attempted to compare against fp64 but that introduced more disparity in the other optimizer configs. It is worth trying the fp64 comparison at a later point, but let's get the test passing first.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106887
Approved by: https://github.com/izaitsevfb
Batchnorm inference is done in fp32 if the inputs are in fp16/bf16 and the output is casted back down to its original precision. This causes the batchnorm weights to get constant folded to fp32, and prevented Conv-BN folding from firing.
```
def forward(self, arg0_1: bf16[32, 3, 3, 3], arg1_1: bf16[32], arg2_1: bf16[32], ...)
convolution: bf16[3, 32, 15, 15] = aten..convolution.default(arg6_1, arg0_1, None, [2, 2], [0, 0], [1, 1], False, [0, 0], 1); arg6_1 = arg0_1 = None
# weight upcasting
convert_element_type: f32[32] = torch.ops.prims.convert_element_type.default(arg3_1, torch.float32); arg3_1 = None
convert_element_type_1: f32[32] = torch.ops.prims.convert_element_type.default(arg4_1, torch.float32); arg4_1 = None
...
# end of batch norm
add_1: f32[3, 32, 15, 15] = aten..add.Tensor(mul_2, unsqueeze_7); mul_2 = unsqueeze_7 = None
# output downcast
convert_element_type_2: bf16[3, 32, 15, 15] = torch.ops.prims.convert_element_type.default(add_1, torch.bfloat16); add_1 = None
```
I mark the convolutions which are followed by binary foldable ops in a higher precision that are then get converted back down to the original conv dtype. We fold the weights in fp32 because it's slightly better accuracy, then at the end of the pass convert back the weights to their original dtype.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106576
Approved by: https://github.com/XiaobingSuper, https://github.com/yanboliang
Fix#106057, except **Attribute dtype mismatch. E.g., alpha of aten.add.Tensor. -> Attribute: alpha INT vs FLOAT**.
Summarized the change
* Fill in defaults of attribute when `param_schema` is applied. This relaxes the matching on default attributes.
* Fill in None to optional input when `param_schema` is applied.
* Keep extra kwargs in attributes to make matching strictly.
* Allow input to be None when its dtype is `optiona[INPUT]`
The change comes with the guarantee from torchlib that attribute would never be None. For example, if `memory_format` is needed. The function should specify like this:
```python
@torch_op("aten::clone")
def aten_clone(
self: TTensor, memory_format: str = "" # pylint: disable=unused-argument
) -> TTensor:
"""clone(Tensor self, *, MemoryFormat? memory_format=None) -> Tensor"""
return op.Identity(self)
```
Previous to this PR, opSchema matching didn't strictly guard the number of inputs/attributes to allow nearest match, which introduces the bug of dispatching `aten::div.Tensor` to `aten::div.default` disregarding the fact that `aten::div.Tensor` has an extra attibute `rounding_mode`. This PR fixes the issue with the new logic to perfect/nearest match. Particularly, strictly restrict the qualification of being nearest match candidate.
For each ONNX variants, we check these step by step:
1. Check if the function signature of inputs number is the same as the inputs.
2. Check if the function signature of attribute names is the same set of inputs.
If either of the above two criteria fails to meet, the ONNX variant is not a perfect match, nor a nearest match candidate (match_score=None)
3. Check if input dtype matches
4. Check if attribute dtype matches
If 3 and 4 are met, then this is a perfect match, otherwise, it's still considered a candidate of nearest match with a matching score.
## Case Study
### Optional Input
The dispatcher recognizes optional inputs. However, the input can't be ignored. None must be provided.
```python
# Perfect match is found
inputs = (Tensor([2, 3]), None)
aten_op(X: TTensor, Y: Optional[INT64]):
...
```
Real Case: aten::convolution
NOTE: There is/will not optional attribute in torchlib.
### Different attributes
If an attribute is provided with value, it's a must to match the attribute in function signature.
```python
# Not perfect match, nor nearest match
inputs = (Tensor([2, 3]),)
attributes = {"a":1, "b":2}
aten_op(X: TTensor, a: int):
...
```
Real Case: aten::div and aten::div.Tensor_mode
### Default attribute
Default attribute will fill in the value into inputs/attributes
```python
# Perfect match is found
inputs = (Tensor([2, 3]),)
attributes = {}
aten_op(X: TTensor, a: int = 3):
...
```
Real case: aten::clone
### Ignore attribute with None value
The attributes with None value will be ignored in matching.
```python
# Perfect match
inputs = (Tensor([2, 3]),)
attributes = {"a": None}
aten_op(X: TTensor):
...
# Not perfect match, but eligible for nearest match
inputs = (Tensor([2, 3]),)
attributes = {"a": None}
aten_op(X: TTensor, a: int = 3):
...
```
Real case: aten::div and aten::div.Tensor_mode
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106478
Approved by: https://github.com/thiagocrepaldi, https://github.com/BowenBao
Fixes https://github.com/pytorch/pytorch/issues/106754
This PR:
- moves test/autograd/test_fallback.py to test_autograd_fallback.py and
removes it from test_autograd.py (necessary for the next step)
- adds test_autograd_fallback.py to parallel test blocklist.
- lintrunner really wanted to make changes to the files, but other than
that, it is a move.
The problem is that we set a global option (the autograd fallback mode)
during these tests which may cause the tests to interfere with each
other.
Test Plan:
- python test/run_test.py -i test_autograd_fallback
NOTE to diff train oncall:
- You'll also need to modify the test/autograd/test_fallback.py TARGET in
caffe2/test/TARGETS since we renamed the file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106866
Approved by: https://github.com/soulitzer
Summary:
We are seeing `aten._native_multi_head_attention` op (not in core Aten op set) is left in the exported graph and causes problems in the downstream at runtime.
Two proposed solutions:
1. Disable fast path while tracing to leverage the non-optimized path to get decomp, that way, the blamed op won't show up in the exported graph
2. Add a decomp rule for `aten._native_multi_head_attention`
After discussing with kimishpatel and bdhirsh, #1 is preferred and verified it could immediately unblock the critical model enablement work for PP.
Test Plan: CI
Differential Revision: D48169806
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106824
Approved by: https://github.com/kimishpatel
Summary:
1. Add bool to quantized flow
2. Add support for cases where channel is *not* a multiple of 4 to the shader `image_to_nchw_quantized_mul4.glsl`. Note that the `mul4` in the shader name refers to height * width % 4 == 0.
Add test cases.
See: D48082479
Test Plan:
New tests:
```
lfq@lfq-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*copy_to_texture_bool*"
Downloaded 1/3 artifacts, 1.74 Mbytes, 50.0% cache miss (for updated rules)
Building: finished in 14.4 sec (100%) 474/474 jobs, 3/474 updated
Total time: 14.4 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *copy_to_texture_bool*
[==========] Running 3 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 3 tests from VulkanAPITest
[ RUN ] VulkanAPITest.copy_to_texture_bool_mul4_hw
VUID-VkDeviceCreateInfo-pProperties-04451(ERROR / SPEC): msgNum: 976972960 - Validation Error: [ VUID-VkDeviceCreateInfo-pProperties-04451 ] Object 0: handle = 0x10bf61020, type = VK_OBJECT_TYPE_PHYSICAL_DEVICE; | MessageID = 0x3a3b6ca0 | vkCreateDevice: VK_KHR_portability_subset must be enabled because physical device VkPhysicalDevice 0x10bf61020[] supports it The Vulkan spec states: If the [VK_KHR_portability_subset] extension is included in pProperties of vkEnumerateDeviceExtensionProperties, ppEnabledExtensions must include "VK_KHR_portability_subset". (https://vulkan.lunarg.com/doc/view/1.2.182.0/mac/1.2-extensions/vkspec.html#VUID-VkDeviceCreateInfo-pProperties-04451)
Objects: 1
[0] 0x10bf61020, type: 2, name: NULL
[ OK ] VulkanAPITest.copy_to_texture_bool_mul4_hw (114 ms)
[ RUN ] VulkanAPITest.copy_to_texture_bool_mul4_chw
[ OK ] VulkanAPITest.copy_to_texture_bool_mul4_chw (4 ms)
[ RUN ] VulkanAPITest.copy_to_texture_bool
[ OK ] VulkanAPITest.copy_to_texture_bool (7 ms)
[----------] 3 tests from VulkanAPITest (126 ms total)
[----------] Global test environment tear-down
[==========] 3 tests from 1 test suite ran. (127 ms total)
[ PASSED ] 3 tests.
```
All tests:
```
[ SKIPPED ] VulkanAPITest.querypool_flushed_shader_log (0 ms)
[----------] 331 tests from VulkanAPITest (7327 ms total)
[----------] Global test environment tear-down
[==========] 331 tests from 1 test suite ran. (7327 ms total)
[ PASSED ] 330 tests.
[ SKIPPED ] 1 test, listed below:
[ SKIPPED ] VulkanAPITest.querypool_flushed_shader_log
```
Quantized tests:
```
[----------] 63 tests from VulkanAPITest (2009 ms total)
[----------] Global test environment tear-down
[==========] 63 tests from 1 test suite ran. (2009 ms total)
[ PASSED ] 63 tests.
YOU HAVE 8 DISABLED TESTS
```
Differential Revision: D48086455
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106752
Approved by: https://github.com/SS-JIA
issue resolved: https://github.com/pytorch/pytorch/issues/97791
before this PR, mixed_precision applies to buffers from ignored modules. see ```test_state_dict_with_ignored_modules(mixed_precision=True)``` for reproduce
after, we avoid applying mixed_precision semantics to buffers from ignored modules
* step 1 initialization: state._ignored_buffer_names contains all the buffers from ignored modules
* step 2 lazy init at runtime: skip ignored buffers in ```_get_buffers_and_dtypes_for_computation```
* step 3 skip upcasting in state_dict hook: avoid upcasting for ignored buffers in ```_get_buffers_and_dtypes_for_computation```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106766
Approved by: https://github.com/awgu
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 3c5a179</samp>
Update `RELEASE.md` with compatibility information for PyTorch 2.1. This file documents the supported versions of Python, CUDA, and CUDNN for each PyTorch release.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106891
Approved by: https://github.com/kit1980
Companion with https://github.com/pytorch/test-infra/pull/4424
Uses the file rating generated by the test infra PR to re order tests. For each test file, sum the file ratings from the changed files in the PR, and put the tests in order of sum.
A lot of tests are probably going to end up as "prioritized" since it takes anything with a rating > 0 right now.
Sharding is done twice, once on the prioritized tests, and once on the general/non prioritized tests. Prioritized tests have an order, so they should be sharded according to that order, while general tests don't have an order and are sharded by test time, which should result in more balanced shards.
I'll change the metric name before I merge, i want to quarantine my testing stuff from actual results
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106347
Approved by: https://github.com/ZainRizvi
Summary: Internal model and Resnet uses "re-export" flow now. Also did some refactoring to make the code little cleaner
Some changes for OSS:
1. Correctly use the "cached" fake tensors so that static symbols are still resolved to static
2. Change logic in PassBase to allocate static shapes for parameters
3. Add "is_torch_exported" tag to every node to make it survive during various graph transformations.
4. Added experimental wrapper API for quantization team to get pre_dispatch=True graph. Note that it doesn't actually do that right now. But we plan to switch soon.
Test Plan: CI
Differential Revision: D47890878
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106676
Approved by: https://github.com/jerryzh168
Summary:
This is to allow sharing these annotate functions by other quantizers so that writing a new quantizer is easier
note that these annotation functions will be maintained by XNNPACKQuantizer developers instead of AO team
Test Plan:
python test/test_quantization.py TestQuantizePT2E
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106642
Approved by: https://github.com/andrewor14
Similar to issue in #97894, dropout is dispatched to fused kernel(native_dropout) only with some devices like cuda, etc.. It is hard to optimize performance when using AOT with custom device, as dropout is finally decomposed to bernoulli and mul. This PR changes this behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106774
Approved by: https://github.com/ezyang
inductor_prims._bucketize was added while we worked on hardening the inductor lowering. Now the lowering should be sufficiently tested and should have good enough perf (https://github.com/pytorch/pytorch/pull/104456) - so we can remove the temporary `inductor_prims._bucketize` op and move the lowerings to the `aten.bucketize` op.
Note that we haven't added a CPU implementation yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106658
Approved by: https://github.com/eellison
We want to add xpu support for foreach kernels, so we add the "xpu" devices to the support list.
Besides, for fused kernels in Adam and AdamW, the devices check is enabled by the support list in adam.py (lines 44-46) and adamw.py (lines 60-64), so we remove the repetitive check for cuda devices as it will block the other devices in the support list.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106021
Approved by: https://github.com/janeyx99
If record_history is enabled, then a block is allocated, record_history
is disabled, and then the block is freed and later unnmapped, we can hit
the `to_map->context_when_allocated == nullptr` assertion.
This change universally clears context_when_allocated on free, which should
prevent this sequence of events from happening.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106818
Approved by: https://github.com/eellison
Summary:
As title.
There's a corner case where both cpu and gpu are avaiable, although the model is moved to cpu, the newly created PTQ weight observer is still on gpu. Therefore, during the convert, this line will fail https://fburl.com/4rhipfvb
Test Plan: CI
Differential Revision: D48141494
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106755
Approved by: https://github.com/jerryzh168
Currently, DCP treats tensors as duplicates and only saves them on rank0. This won't work for PiPPy as PiPPy does have unique tensors across different ranks. With the current setup, we would only be saving the tensors on rank0 (coordinator rank).
In this PR, we are changing to letting each rank create its own WriteItem for tensors. For the ones that does replicate across different ranks, we are handling it thru dedup_tensors(), which will dedup the replicate WriteItem so we only do the actual writing once.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106415
Approved by: https://github.com/wz337
This PR adds a **same_signature** flag to dynamo.export.
**Motivation:**
In https://github.com/pytorch/pytorch/pull/105679, we experimented on **using dynamo to inspect the UDFs** for cond in eager mode (without torch.compile). This helps us to normalize the inputs (e.g. lifting closure to inputs) and makes higher order operator more robust (e.g. forbid python side effects) and less error-prone in general.
We decided to use dynamo.export (instead of torch.compile) to do the inspection (pointed out by @voznesenskym @zou3519):
- We'd like a **whole-graph capture** for the UDF.
- We'd like the dynamo inspection to be **stateless**. Using torch.compile would require resetting dynamo context before and after the inspection because the compile flags may be different from users' torch.compile. This will clear all dynamo cache.
- We can still implement some **caching** based on the guards.
However, this requires export to be able to handle the case where it cannot always rewrite signature: e.g. closure lifted as input.
This PR makes the rewrite optional.
**Implementation:**
We just put all the code that are related to signature rewriting into a function called rewrite_signature and use a same_signature flag to optionally to the transformation.
**Test Plan:**
existing tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106569
Approved by: https://github.com/ezyang
This PR extends impl_abstract to work with existing
torch.library/TORCH_LIBRARY ops.
There's a question of what to do if the user calls impl_abstract
and the op already has a registration for:
- DispatchKey::Meta. We raise.
- DispatchKey::CompositeImplicitAutograd. We raise.
- DispatchKey::CompositeExplicitAutograd. To be pragmatic, we don't
raise, since the user's CompositeExplicitAutograd might work for all
other backends but Meta.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106088
Approved by: https://github.com/soulitzer
ghstack dependencies: #106075, #106076
The design is that we construct a CustomOp object around the existing
operator and then use it to register things. It is totally OK if the
operator isn't functional (unlike torch._custom_ops.custom_op that can
only construct functional operators).
If the operator already has an implementation from a backend (either via
direct registration to e.g. DispatchKey::CPU, or an indirect
registration like CompositeImplicitAutograd/CompositeExplicitAutograd),
we raise an error.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106076
Approved by: https://github.com/soulitzer
ghstack dependencies: #106075
These are valid with the torch.library API, but (1) they add complexity
and (2) I have never seen a custom op actually use an overload name
before. For simplicity we block all overloads.
Test Plan:
- new test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106075
Approved by: https://github.com/soulitzer
This PR contains two new private ops, added for cuSPARSELt support.
These ops call into the cuSPASRELt kernels using the bindings they
provide. For more information, see the documentation
[here](https://docs.nvidia.com/cuda/cusparselt/index.html).
The two new private ops added are:
```
_cslt_compress()
_cslt_sparse_mm()
```
_cslt_compress is an op that reuturns the compressesed matrix given a
sparse matrix that is passed in.
_cslt_sparse_mm is an op that expects a compressed matrix (the result of
_cslt_compress) and a dense matrix and performs sparse-dense matmul
These ops will throw runtime errors if they cusparselt is not present.
This PR also modifies the test and tensor sublass to reflect the new
cuSPARSELt support.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102133
Approved by: https://github.com/cpuhrsch
An alternative to #106235 that just adds our own uid generation so that we can call `beginAllocateStreamToPool` (which notifies the caching allocator that a capture is starting) before actually starting the capture. Note that this does appear to change the behavior uid generation a bit from the CUDA API call (which seems to increment by 3 each time instead of 1).
Looking at the changes again I'm not sure if both the _begin_ capture ordering change is needed in addition to the _end_ capture ordering change, but it makes me uneasy as I'm not sure anything prevents the autograd thread from running cleanup code "in-between" captures.
CC @zdevito @eellison
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106570
Approved by: https://github.com/zdevito
This PR adds a new configuration that enables shapes of torch.nn.Parameter to be treated as dynamic in order to avoid extensive recompilation when Paramters are used instead of Tensor.
This features addresses part of issue #105279
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105855
Approved by: https://github.com/ezyang
- Implement `MPSEventPool` to recycle events.
- Implement python bindings with `torch.mps.Event` class using the MPSEventPool backend. The current member functions of the Event class are `record()`, `wait()`, `synchronize()`, `query()`, and `elapsed_time()`.
- Add API to measure elapsed time between two event recordings.
- Added documentation for Event class to `mps.rst`.
- Added test case to `test_mps.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102121
Approved by: https://github.com/albanD, https://github.com/kulinseth
Currently `stashed_for_allocator_safety_` is uninitialized in this path, which will crash if another operation assumes a non-nullptr (the case when `TORCH_NCCL_AVOID_RECORD_STREAMS=1` and `avoidRecordStreams_` is set).
CC @kwen2501 @ptrblck
@kwen2501
I'm not familiar with what happens to the coalesced work when `endCoalescing` is called. In theory, if the coalesced work has already "stashed for allocator safety," can we also avoid the record streams calls here? Or is the coalesced work discarded (and their `_stashed_for_allocator_safety` vectors also destroyed?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106166
Approved by: https://github.com/kwen2501
Summary:
Before we copy a meta merge, and use it as a skeleton to do d2d merge replication. However some models like prospector has CPU op LongIndex which takes quite long time to load. That makes the meta merge copy expensive.
Modify jit::Module::deepcopy() to allow device copy. It simplifies user code and removes all unnecessary copies like tempfile, meta merge
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106521
Approved by: https://github.com/davidberard98
This test raises an error inside the test when an xfailed test succeeds, but
is also decorated with the xfail decorator which converts the error to an xfail.
Instead, this lets the test function pass normally and lets the xfail decorator
raise "Unexpected success".
I also updated the COLLECT_EXPECT code and run it to get the updated set of
failures.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106631
Approved by: https://github.com/lezcano
ghstack dependencies: #106319, #106400
Currently there are FFT operators which raise `UnsupportedOperatorException`
because their meta implementations sometimes give incorrect strides. This works
around the problem for static shapes by falling back to eager. Though we still
don't support calls with dynamic shapes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106319
Approved by: https://github.com/ezyang
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at ac9bd0c</samp>
> _We're sailing on the CUDA sea, with tensors and graphs aplenty_
> _We're refactoring the code, to make it clear and neat_
> _We're using nested namespaces, like `at::cuda::blas`_
> _So heave away, me hearties, heave away on the count of three_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106708
Approved by: https://github.com/kit1980, https://github.com/Skylion007
This PR:
- adds a capturable API for NAdam similar to Adam(W)
- adds tests accordingly
- discovered and fixed bugs in the differentiable implementation (now tested through the capturable codepath).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106615
Approved by: https://github.com/albanD
This is part of effort to enable missed cpp test for ROCm platform.
In this change, we enabled the test_aten cpp test.
The total number of tests enabled is 214.
**Test plan:**
Tested in the rocm/pytorch-nightly:latest
```
jenkins@xxxxx:/tmp/pytorch$ .ci/pytorch/test.sh &> test_aten.out
jenkins@xxxxx:/tmp/pytorch$ grep PASS test_aten.out |wc -l
214
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106476
Approved by: https://github.com/jithunnair-amd, https://github.com/malfet
Follow-up: #101173
This PR fixes the bug presented in #101173 by creating a special case for `sympy.Rational`
divisors, inside `FloorDiv` evaluation. In summary:
```python
FloorDiv(a, Rational(1, b))
a * b
```
Besides that, this PR also does 2 other things:
- Replaces the use of the old `sympy.Mod` by the internal `Mod` (there were a few places
that were still looking for the SymPy one)
- Introduces debugging logs to the translation validator. These can be seen by setting the
environment variable: `TORCH_LOGS=+torch.fx.experimental.validator`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106644
Approved by: https://github.com/ezyang
ghstack dependencies: #106643
This PR makes Z3 expressions easier to read and understand by creating a custom printer
for them.
Z3 expressions can be printed in 2 forms:
1. Using the builtin `str(e)` function
2. Using the `e.sexpr()` method
Problem is that (1) is a bit hard to read because its line breaks are not so
intuitive. (2) is a bit nicer, but the `to_int` and `to_real` functions clutter things up.
The custom printer is an improved `sexpr()` function:
- Leaves everything in one line
- Gets rid of `to_int` and `to_real` functions
- Reconstruct the floor division operations
- Merge commutative operation chains
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106643
Approved by: https://github.com/ezyang
Summary: Removing this broken test as we are not going to land the fix for 2D regression. Instead, we are going to migrate to use device_mesh and dtensor state_dict for 2D.
Differential Revision: D48082586
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106640
Approved by: https://github.com/fduwjj
Batchnorm inference is done in fp32 if the inputs are in fp16/bf16 and the output is casted back down to its original precision. This causes the batchnorm weights to get constant folded to fp32, and prevented Conv-BN folding from firing.
```
def forward(self, arg0_1: bf16[32, 3, 3, 3], arg1_1: bf16[32], arg2_1: bf16[32], ...)
convolution: bf16[3, 32, 15, 15] = aten..convolution.default(arg6_1, arg0_1, None, [2, 2], [0, 0], [1, 1], False, [0, 0], 1); arg6_1 = arg0_1 = None
# weight upcasting
convert_element_type: f32[32] = torch.ops.prims.convert_element_type.default(arg3_1, torch.float32); arg3_1 = None
convert_element_type_1: f32[32] = torch.ops.prims.convert_element_type.default(arg4_1, torch.float32); arg4_1 = None
...
# end of batch norm
add_1: f32[3, 32, 15, 15] = aten..add.Tensor(mul_2, unsqueeze_7); mul_2 = unsqueeze_7 = None
# output downcast
convert_element_type_2: bf16[3, 32, 15, 15] = torch.ops.prims.convert_element_type.default(add_1, torch.bfloat16); add_1 = None
```
I mark the convolutions which are followed by binary foldable ops in a higher precision that are then get converted back down to the original conv dtype. We fold the weights in fp32 because it's slightly better accuracy, then at the end of the pass convert back the weights to their original dtype.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106576
Approved by: https://github.com/XiaobingSuper, https://github.com/yanboliang
ghstack dependencies: #106471, #106575
This PR:
- Changes the AOTAutograd tests to also check that the output of the
forward is equal under AOTAutograd and eager-mode PyTorch.
- Adds a "check_gradients" flag to `check_aot_autograd`.
- If True, then we attempt to compute gradients and check them.
- If False, then we we just check the outputs are equal
- If "auto", then we will compute gradients and check them only if
some input and some output requires grad. This option is useful for
crossref tests where we don't necessarily have inputs that require
grad.
1) I need a testing utility to test "AOTAutograd for inference",
e.g. make_fx + functionalize.
2) I want to run aot_autograd_check in crossref tests for other test
suites (e.g. fbgemm) and not all inputs require grad.
Test Plan:
- existing tests
- new tests to test the degenerate cases
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106558
Approved by: https://github.com/ezyang, https://github.com/soulitzer
This simple PR can let me know how much more fusion the loop ordering PR can bring compared to baseline. Need this separate PR since I need include it in both the baseline and test runs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106653
Approved by: https://github.com/eellison
This PR adds the ability to check whether the resulting ONNX graph has dynamic shape when the dynamic shape is enabled
Only test/onnx/test_fx_to_onnx.py and test/onnx/test_fx_op_consistency.py were covered because test/onnx/test_fx_to_onnx.py does not use any common "run_test" helper to wrap `dynamo_export` call. Maybe that could be a refactor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106495
Approved by: https://github.com/BowenBao
Summary:
https://pytorch.org/docs/stable/generated/torch.flip.html
Implement flip for vulkan.
For batch and channel cases:
- Calculate the logical tensor values of N and C from pos.xyz
- Flip the logical tensor value of N, C or both
- Use `n*[C/4] + i/4, i%4` to get the new tensor value
Test Plan:
New tests:
```
lfq@lfq-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*flip*"
Recommended: Free up disk space to speed up builds.
Only 17GB is available on disk. Buck is slow when free disk space is under
50GB.
Consider running this command (from your home directory) to reclaim purgeable
space:
sudo /System/Library/Filesystems/apfs.fs/Contents/Resources/apfs.util -P *
Downloaded 0/53 artifacts, 0.00 bytes, 100.0% cache miss (for updated rules)
Building: finished in 35.3 sec (100%) 536/536 jobs, 6/536 updated
Total time: 35.3 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *flip*
[==========] Running 4 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 4 tests from VulkanAPITest
[ RUN ] VulkanAPITest.flip_1d
[ OK ] VulkanAPITest.flip_1d (117 ms)
[ RUN ] VulkanAPITest.flip_2d
[ OK ] VulkanAPITest.flip_2d (1 ms)
[ RUN ] VulkanAPITest.flip_3d
[ OK ] VulkanAPITest.flip_3d (2 ms)
[ RUN ] VulkanAPITest.flip_4d
[ OK ] VulkanAPITest.flip_4d (10 ms)
[----------] 4 tests from VulkanAPITest (132 ms total)
[----------] Global test environment tear-down
[==========] 4 tests from 1 test suite ran. (132 ms total)
[ PASSED ] 4 tests.
lfq@lfq-mbp fbsource %
```
clang-format on `Flip.cpp` and `flip.glsl`
Reviewed By: SS-JIA
Differential Revision: D47921025
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106628
Approved by: https://github.com/SS-JIA
Fixes#106555
There was bug where the multithreading check would fire because of the
`compiled_autograd.disable()` calls in AotAutograd, even though compiled
autograd was already disabled, so that call was doing nothing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106621
Approved by: https://github.com/yanboliang
The official move of `OnnxRegistry` to `torch.onnx` allows it to become one of the parameters in `torch.onnx.ExportOption`. By incorporating `OnnxRegistry` in `torch.onnx.ExportOption`, users gain access to various functionalities, including the ability to register custom operators using `register_custom_op`, check whether an operator is supported using `is_registered_op`, and obtain symbolic functions that support specific operators using `get_functions`.
Additionally, `opset_version` is now exclusively available in `torch.onnx.OnnxRegistry` as it is removed from `torch.onnx.ExportOption`. The initialization of the registry with torchlib under the provided opset version ensures that the exporter uses the specified opset version as the primary version for exporting.
These changes encompass scenarios where users can:
1. Register an unsupported ATen operator with a custom implementation using onnx-script.
2. Override an existing symbolic function (onnx invariant).
NOTE: The custom registered function will be prioritized in onnx dispatcher, and if there are multiple custom ones, the one registered the last will be picked.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106140
Approved by: https://github.com/justinchuby, https://github.com/thiagocrepaldi
D47969512 was the original diff to revert this, but the diff train doesn't work well, so I have to split it into two part: this OSS PR and another separate diff to revert the fbcode change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106562
Approved by: https://github.com/angelayi
https://github.com/pytorch/pytorch/issues/105555
Existing flow first exports and then calls torch._inductor.aot_compile. However, export calls aot_autograd with the core aten decomposition table, and then torch._inductor.aot_compile calls aot_autograd again with the inductor decomposition table. The 2nd calling of aot_autograd is supposedly causing some problems, and seems excessive, so instead we will create a new function, torch._export.aot_compiler which will export using the inductor decomposition table, pass it to inductor's compile_fx_aot, and because it has already been exported, avoid recalling aot_autograd.
```
def aot_compile(
f: Callable,
args: Tuple[Any],
kwargs: Optional[Dict[str, Any]] = None,
constraints: Optional[List[Constraint]] = None,
) -> Tuple[str, ExportedProgram]:
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105977
Approved by: https://github.com/desertfire, https://github.com/zhxchen17, https://github.com/eellison
Summary:
make is_causal hint flags available for the top level transformer module.
It's debatable whether this is useful -- at present we autodetect causal masks for src and tgt masks in transformer encoder and decoder, respectively. is_causal flags available woul enable users to short-cut this check by asserting whether they mask is causal, or not.
I am putting this diff up for discussion, not as a solution. Not doing anything may be the right solution, unless there is strong (data-driven) user demand. -- it appears the consensus is to move ahead with this, as per discussions below.
@cpuhrsch @mikaylagawarecki @jbschlosser @janEbert
Test Plan: sandcastle
Differential Revision: D47373260
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106143
Approved by: https://github.com/mikaylagawarecki
Summary: When we do a deep copy of the ExportedProgram because of the custom deep copy override the graph metadata (graph.meta) is failing to be copied over. This can be fixed but overall i don't see a need for a custom deepcopy in ExportedProgram and thus trying to get rid of it.
Test Plan: CI
Differential Revision: D48043723
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106578
Approved by: https://github.com/JacobSzwejbka
For ```llama``` model, there has a pattern that multi linear using the same input and input dim > 2:
```input->view->(linear->view->silu, linear->view)```, this PR update the pattern to make the linar+silu can be fused(we first need remove view ops, and then apply fusion patterns).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106300
Approved by: https://github.com/jgong5, https://github.com/jansel
I happened to find that inductor may cache stale inner_fn_str and ReadWrites object in a ComputedBuffer when I work on looping ordering.
Let's say we have producer buffer buf0 and consumer buffer buf1. Before we call GraphLowering.finalize, the layout for buf0 may be a FlexibleLayout. At that moment, the inner_fn_str or ReadWrites object computed for buf1 will be based on the layout of buf0 which most likely is a contiguous FlexibleLayout. And they will be cached on buf1 object (or buf1.data).
However after we call GraphLowering.finalize, we may realize it's better to give a non-contiguous layout for buf0 (e.g., if its input has non-contiguous layout or whatever reason). The layout change of buf0 should affect the inner_fn_str and ReadWrites object for buf1. But we may have cached those on buf1. The stale ReadWrites objects for buf1 may result in sub-optimal strides for buf1.
This may affect perf and I'll check the nightly runs.
Here is a dump of `nodes` in `Scheduler.__init__` before the fix as a reference: https://gist.github.com/shunting314/ed2152a08e268f5563fd55398b1392c7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106502
Approved by: https://github.com/jansel
Summary: Rename static tracepoint macros to better describe their targeted usage.
Test Plan:
Same as for D47159249:
Tested the following macros on test scripts with libbpf USDTs:
* `CAFFE_SDT`
* `CAFFE_DISABLE_SDT`
* `CAFFE_SDT_WITH_SEMAPHORE`
Reviewed By: chaekit
Differential Revision: D47727339
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106380
Approved by: https://github.com/chaekit
A bunch of the tests are getting skipped/xfailed because of generated_kernel_count checks. In other tests, inductor metrics automatically get reset in the common() function, so we should do this in the test_torchinductor_codegen_dynamic_shapes tests as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106481
Approved by: https://github.com/eellison
Summary:
This change fixes split_module's interaction with dead code. Previously if a dead region was split out, split module would throw an error while attempting to access the outputs for the partition even though the partition has no outputs.
This change adds a new unit test to cover the dead code case and changes the output check to allow no output. The split module with no output will now output None like a normal python function
Unit Test Added:
test_split_module_dead_code
A module with dead code:
```
class ModWithDeadCode(torch.nn.Module):
def forward(self, x):
output = x * 2 # we want this
dead_line = x + 2 # this is dead
return output
```
Before:
```
torch/fx/passes/split_module.py, line 357, in split_module
base_mod_env[list(partition.outputs)[0]] = output_val
IndexError: list index out of range
```
After:
```
class GraphModule(torch.nn.Module):
def forward(self, x):
# No stacktrace found for following nodes
submod_2 = self.submod_2(x)
submod_1 = self.submod_1(x); x = None
return submod_1
class GraphModule(torch.nn.Module):
def forward(self, x):
# No stacktrace found for following nodes
add = x + 2; x = None
return None
class GraphModule(torch.nn.Module):
def forward(self, x):
# No stacktrace found for following nodes
mul = x * 2; x = None
return mul
```
Submod 2 is correctly extracted
Test Plan: Tested with new unit test
Differential Revision: D47196732
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104554
Approved by: https://github.com/yf225
Summary: check trace runs with no_grad() and grad or not impacts transformer trace construction. use no_grad() consistently
Test Plan:
sandcastle and github ci
```
buck2 run mode/opt mode/inplace //caffe2/test:test_jit_cuda -- --regex test_scriptmodule_transformer_cuda
```
Differential Revision: D48020889
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106523
Approved by: https://github.com/davidberard98
When inlining a function which loads a closure, its direct parent may not load that closure. So we cannot find the closure name in parent's symbolic locals. In this PR, we fix it by recursively searching the parent instruction translator stack to resolve the closure.
**Background**
When developing https://github.com/pytorch/pytorch/pull/105679, this corner case is triggered. A small repro is added in the test of this pr, where outer is loaded by deep2 but not by deep.
```python
def test_inline_closure_not_loaded_by_parent(self):
def outer(a):
return a + 1
def indirect(x):
return direct(x)
def direct(x):
def deep2(c):
return outer(c)
def deep(c):
return deep2(c)
return deep(x)
x = torch.randn(3)
eager = indirect(x)
counter = CompileCounter()
compiled = torch._dynamo.optimize(counter)(indirect)(x)
```
Running the test, we have the following error before the PR:
```
Traceback (most recent call last):
File "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6584, in test_inline_closure_not_loaded_by_parent
compiled = torch._dynamo.optimize(counter)(indirect)(x)
File "/home/yidi/local/pytorch/torch/_dynamo/eval_frame.py", line 321, in _fn
return fn(*args, **kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/eval_frame.py", line 481, in catch_errors
return callback(frame, cache_size, hooks, frame_state)
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 543, in _convert_frame
result = inner_convert(frame, cache_size, hooks, frame_state)
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 130, in _fn
return fn(*args, **kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 362, in _convert_frame_assert
return _compile(
File "/home/yidi/local/pytorch/torch/_dynamo/utils.py", line 194, in time_wrapper
r = func(*args, **kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 531, in _compile
raise InternalTorchDynamoError(str(e)).with_traceback(e.__traceback__) from None
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 432, in _compile
out_code = transform_code_object(code, transform)
File "/home/yidi/local/pytorch/torch/_dynamo/bytecode_transformation.py", line 1028, in transform_code_object
transformations(instructions, code_options)
File "/home/yidi/local/pytorch/torch/_dynamo/convert_frame.py", line 417, in transform
tracer.run()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2067, in run
super().run()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 724, in run
and self.step()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 688, in step
getattr(self, inst.opname)(inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 392, in wrapper
return inner_fn(self, inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 1116, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 562, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/yidi/local/pytorch/torch/_dynamo/variables/functions.py", line 261, in call_function
return super().call_function(tx, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/variables/functions.py", line 90, in call_function
return tx.inline_user_function_return(
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 598, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2172, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2279, in inline_call_
tracer.run()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 724, in run
and self.step()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 688, in step
getattr(self, inst.opname)(inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 392, in wrapper
return inner_fn(self, inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 1116, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 562, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/yidi/local/pytorch/torch/_dynamo/variables/functions.py", line 90, in call_function
return tx.inline_user_function_return(
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 598, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2172, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2279, in inline_call_
tracer.run()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 724, in run
and self.step()
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 688, in step
getattr(self, inst.opname)(inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 392, in wrapper
return inner_fn(self, inst)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 1116, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 562, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/yidi/local/pytorch/torch/_dynamo/variables/functions.py", line 90, in call_function
return tx.inline_user_function_return(
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 598, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2172, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/symbolic_convert.py", line 2227, in inline_call_
sub_locals, closure_cells = func.bind_args(parent, args, kwargs)
File "/home/yidi/local/pytorch/torch/_dynamo/variables/functions.py", line 471, in bind_args
result[name] = parent.symbolic_locals[name]
torch._dynamo.exc.InternalTorchDynamoError: outer
from user code:
File "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6570, in indirect
return direct(x)
File "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6579, in direct
return deep(x)
File "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6577, in deep
return deep2(c)
Set TORCH_LOGS="+dynamo" and TORCHDYNAMO_VERBOSE=1 for more information
You can suppress this exception and fall back to eager by setting:
import torch._dynamo
torch._dynamo.config.suppress_errors = True
To execute this test, run the following from the base repo dir:
python test/dynamo/test_misc.py -k test_inline_closure_not_loaded_by_parent
This message can be suppressed by setting PYTORCH_PRINT_REPRO_ON_FAILURE=0
---------------------------------------------------------------------------------------------------------------------------- Captured stdout call -----------------------------------------------------------------------------------------------------------------------------
frames [('total', 1)]
inline_call []
---------------------------------------------------------------------------------------------------------------------------- Captured stderr call -----------------------------------------------------------------------------------------------------------------------------
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping __init__ /home/yidi/local/miniconda3/envs/pytorch-3.10/lib/python3.10/contextlib.py
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping __enter__ /home/yidi/local/miniconda3/envs/pytorch-3.10/lib/python3.10/contextlib.py
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping helper /home/yidi/local/miniconda3/envs/pytorch-3.10/lib/python3.10/contextlib.py
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping __init__ /home/yidi/local/miniconda3/envs/pytorch-3.10/lib/python3.10/contextlib.py
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping __enter__ /home/yidi/local/miniconda3/envs/pytorch-3.10/lib/python3.10/contextlib.py
[2023-08-02 15:48:36,560] torch._dynamo.eval_frame: [DEBUG] skipping enable_dynamic /home/yidi/local/pytorch/torch/_dynamo/eval_frame.py
[2023-08-02 15:48:36,561] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing indirect /home/yidi/local/pytorch/test/dynamo/test_misc.py:6569
TRACE starts_line indirect /home/yidi/local/pytorch/test/dynamo/test_misc.py:6569
def indirect(x):
[2023-08-02 15:48:36,591] torch._dynamo.variables.builder: [DEBUG] wrap_to_fake L['x'] (3,) [<DimDynamic.STATIC: 2>] [None]
TRACE starts_line indirect /home/yidi/local/pytorch/test/dynamo/test_misc.py:6570
return direct(x)
[2023-08-02 15:48:36,594] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_DEREF direct []
[2023-08-02 15:48:36,594] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_FAST x [UserFunctionVariable()]
[2023-08-02 15:48:36,594] torch._dynamo.symbolic_convert: [DEBUG] TRACE CALL_FUNCTION 1 [UserFunctionVariable(), TensorVariable()]
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] INLINING <code object direct at 0x7fbe4d366810, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6572>
TRACE starts_line direct /home/yidi/local/pytorch/test/dynamo/test_misc.py:6572 (inline depth: 1)
def direct(x):
TRACE starts_line direct /home/yidi/local/pytorch/test/dynamo/test_misc.py:6573 (inline depth: 1)
def deep2(c):
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CLOSURE outer []
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] TRACE BUILD_TUPLE 1 [InlinedClosureVariable()]
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CONST <code object deep2 at 0x7fbe4d3666b0, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6573> [TupleVariable()]
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CONST MiscTests.test_inline_closure_not_loaded_by_parent.<locals>.direct.<locals>.deep2 [TupleVariable(), ConstantVariable(code)]
[2023-08-02 15:48:36,595] torch._dynamo.symbolic_convert: [DEBUG] TRACE MAKE_FUNCTION 8 [TupleVariable(), ConstantVariable(code), ConstantVariable(str)]
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE STORE_DEREF deep2 [NestedUserFunctionVariable()]
TRACE starts_line direct /home/yidi/local/pytorch/test/dynamo/test_misc.py:6576 (inline depth: 1)
def deep(c):
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CLOSURE deep2 []
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE BUILD_TUPLE 1 [NewCellVariable()]
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CONST <code object deep at 0x7fbe4d366760, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6576> [TupleVariable()]
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_CONST MiscTests.test_inline_closure_not_loaded_by_parent.<locals>.direct.<locals>.deep [TupleVariable(), ConstantVariable(code)]
[2023-08-02 15:48:36,597] torch._dynamo.symbolic_convert: [DEBUG] TRACE MAKE_FUNCTION 8 [TupleVariable(), ConstantVariable(code), ConstantVariable(str)]
[2023-08-02 15:48:36,598] torch._dynamo.symbolic_convert: [DEBUG] TRACE STORE_FAST deep [NestedUserFunctionVariable()]
TRACE starts_line direct /home/yidi/local/pytorch/test/dynamo/test_misc.py:6579 (inline depth: 1)
return deep(x)
[2023-08-02 15:48:36,598] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_FAST deep []
[2023-08-02 15:48:36,598] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_FAST x [NestedUserFunctionVariable()]
[2023-08-02 15:48:36,598] torch._dynamo.symbolic_convert: [DEBUG] TRACE CALL_FUNCTION 1 [NestedUserFunctionVariable(), TensorVariable()]
[2023-08-02 15:48:36,598] torch._dynamo.symbolic_convert: [DEBUG] INLINING <code object deep at 0x7fbe4d366760, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6576>
TRACE starts_line deep /home/yidi/local/pytorch/test/dynamo/test_misc.py:6576 (inline depth: 2)
def deep(c):
TRACE starts_line deep /home/yidi/local/pytorch/test/dynamo/test_misc.py:6577 (inline depth: 2)
return deep2(c)
[2023-08-02 15:48:36,599] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_DEREF deep2 []
[2023-08-02 15:48:36,599] torch._dynamo.symbolic_convert: [DEBUG] TRACE LOAD_FAST c [NestedUserFunctionVariable()]
[2023-08-02 15:48:36,599] torch._dynamo.symbolic_convert: [DEBUG] TRACE CALL_FUNCTION 1 [NestedUserFunctionVariable(), TensorVariable()]
[2023-08-02 15:48:36,599] torch._dynamo.output_graph: [DEBUG] restore_graphstate: removed 0 nodes
[2023-08-02 15:48:36,599] torch._dynamo.symbolic_convert: [DEBUG] FAILED INLINING <code object deep at 0x7fbe4d366760, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6576>
[2023-08-02 15:48:36,599] torch._dynamo.output_graph: [DEBUG] restore_graphstate: removed 0 nodes
[2023-08-02 15:48:36,599] torch._dynamo.symbolic_convert: [DEBUG] FAILED INLINING <code object direct at 0x7fbe4d366810, file "/home/yidi/local/pytorch/test/dynamo/test_misc.py", line 6572>
[2023-08-02 15:48:36,599] torch._dynamo.output_graph: [DEBUG] restore_graphstate: removed 0 nodes
```
Test Plan:
add new test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106491
Approved by: https://github.com/williamwen42, https://github.com/jansel, https://github.com/zou3519
Includes stable diffusion, whisper, llama7b and clip
To get this to work I had to Pass in hf auth token to all ci jobs, github does not pass in secrets from parent to child automatically. There's a likelihood HF will rate limit us in case please revert this PR and I'll work on adding a cache next - cc @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @ipiszy @chenyang78 @aakhundov @malfet
Something upstream changed in torchbench too where now `hf_Bert` and `hf_Bert_large` are both failing on some dynamic shape looking error which I'm not sure how to debug yet so for now felt a bit gross but added a skip since others are building on top this work @ezyang
`llamav2_7b_16h` cannot pass through accuracy checks cause it OOMs on deepcloning extra inputs this seems to make it not need to show up in expected numbers csv, will figure this when we update the pin with https://github.com/pytorch/benchmark/pull/1803 cc @H-Huang @xuzhao9 @cpuhrsch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106009
Approved by: https://github.com/malfet
Summary:
This diff has a couple of hacks to make inductor-CPU work for AOT codegen in fbcode:
- We need to add the CUDA link flags; AOT-Inductor is specialized for CUDA
right now and uses a lot of `at::cuda` stuff. We should do a proper AOT CPU
at some point but this unblocks perf measurement.
- Add an include path to the cpp_prefix. It's kind of hilarious; we remove the
include path for remote execution, but then for AOT we need it back. 🤷
Test Plan: internal test
Differential Revision: D47882848
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106225
Approved by: https://github.com/mikekgfb, https://github.com/bdhirsh, https://github.com/jansel
This PR adds a new `CustomPolicy` that acts like the existing `lambda_auto_wrap_policy` except it (1) leverages the new auto wrapping infrastructure and (2) allows overriding FSDP kwargs for particular instances. (1) gives it access to the validation checks (like for frozen parameters), and (2) makes it as expressive as manual wrapping. This should allow us to effectively deprecate manual wrapping if desired.
The API is as follows:
```
def lambda_fn(module: nn.Module) -> Union[bool, Dict[str, Any]]:
...
policy = CustomPolicy(lambda_fn)
```
The `lambda_fn` can return:
- `False` or `{}` to indicate no wrapping
- `True` to indicate wrapping while inheriting the root's FSDP kwargs
- Non-empty `dict` to indicate wrapping while overriding the specified FSDP kwargs and inheriting the rest from the root
---
After this PR, the follow-up work items for auto wrapping are:
1. Add shared parameter validation
2. (Longer-term / exploratory) Add a policy that provides a reasonable auto wrapping with "minimal" user input
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104986
Approved by: https://github.com/ezyang
ghstack dependencies: #104427, #104967, #104999, #104969
This does some code organization improvement.
- It renames `_FSDPPolicy` to `_Policy` to show that it is not only for FSDP but for any module-level API.
- It formalizes the contract that such a policy should return something like `target_module_to_kwargs: Dict[nn.Module, Dict[str, Any]]` that maps each module to wrap to its kwargs. It does so by requiring a `_run_policy` abstract method (this time private since users do not need to care about it). Then, our auto wrapping can just call `_run_policy()` to generate the dict and do any validation or post-processing.
This PR is technically BC-breaking because it removes the public `ModuleWrapPolicy.policy`. However, I do not think anyone was using that anyway, so this is a pretty safe breakage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104969
Approved by: https://github.com/rohan-varma
ghstack dependencies: #104427, #104967, #104999
Previously, you would get an error like
```
Dynamo input and output is a strict subset of traced input/output
```
now you get
```
Cannot export model which references tensors that are neither
buffers/parameters/constants nor are direct inputs. For each tensor, if you'd
like this tensor to be an explicit input, add it as a dummy argument
to the top-level model definition you are exporting; if you would
like its value to be embedded as an exported constant, wrap its access
in a function marked with @assume_constant_result.
G['bulbous_bouffant'], accessed at:
File "test_export.py", line N, in f
return bulbous_bouffant + y
```
This doesn't handle outputs, I'm going to hit that next.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106403
Approved by: https://github.com/tugsbayasgalan
Compiler behavior when non-zero offset is added to a null pointer is undefined and is a bad habit.
- When `lapackEig` is called with to estimate a workspace size, do not add matrix size to the W pointer.
- When `unpack_pivots_cpu_kernel` with zero `dim_size` exit early.
- When `topk_impl_loop` is called with `k` is zero, exit right away as output tensors are empty anyway.
- Ignore adding non-zero storage-offset in `TensorImpl::data_ptr_impl_impl`, which can be the case if tensor is created as `torch.empty(3)[4:]`.
- In `s_addmm_out_sparse_dense_worker` do not call `axpy` over an empty vector.
- In `_sparse_binary_op_intersection_kernel_impl` do skip computing `ptr_indices_dim` when `sparse_dim` is empty.
- Exit `grid_sample` forward/backward kernels earlier if either `input` or `grid` are empty tensors.
Found by asan in clang-12
Before the change UBSan report looks as follows:
```
ASAN_SYMBOLIZER_PATH=/usr/lib/llvm-12/bin/llvm-symbolizer UBSAN_OPTIONS=print_stacktrace=1 LD_PRELOAD=/usr/lib/llvm-12/lib/clang/12.0.1/lib/linux/libclang_rt.asan-x86_64.so python test_fx_experimental.py -v -k test_normalize_operator_exhaustive_linalg_eig_cpu_float32
Test results will be stored in test-reports/python-unittest/test_fx_experimental
Running tests...
----------------------------------------------------------------------
test_normalize_operator_exhaustive_linalg_eig_cpu_float32 (__main__.TestNormalizeOperatorsCPU) ... /opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/overrides.py:111: UserWarning: 'has_cuda' is deprecated, please use 'torch.backends.cuda.is_built()'
torch.has_cuda,
/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/overrides.py:112: UserWarning: 'has_cudnn' is deprecated, please use 'torch.backends.cudnn.is_available()'
torch.has_cudnn,
/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/overrides.py:118: UserWarning: 'has_mps' is deprecated, please use 'torch.backends.mps.is_built()'
torch.has_mps,
/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/overrides.py:119: UserWarning: 'has_mkldnn' is deprecated, please use 'torch.backends.mkldnn.is_available()'
torch.has_mkldnn,
/var/lib/jenkins/workspace/aten/src/ATen/native/BatchLinearAlgebra.cpp:937:17: runtime error: applying non-zero offset 20 to null pointer
#0 0x7f2025794888 in void at::native::lapackEig<float, float>(char, char, int, float*, int, float*, float*, int, float*, int, float*, int, float*, int*) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0x9945888)
#1 0x7f20257da256 in void at::native::(anonymous namespace)::apply_linalg_eig<float>(at::Tensor&, at::Tensor&, at::Tensor&, at::Tensor&, bool) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0x998b256)
#2 0x7f20257d902d in at::native::(anonymous namespace)::linalg_eig_kernel(at::Tensor&, at::Tensor&, at::Tensor&, at::Tensor const&, bool) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0x998a02d)
#3 0x7f20257b5b3d in at::native::linalg_eig_out_info(at::Tensor const&, at::Tensor&, at::Tensor&, at::Tensor&, bool) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0x9966b3d)
#4 0x7f20257b4770 in at::native::linalg_eig_out(at::Tensor const&, at::Tensor&, at::Tensor&) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0x9965770)
#5 0x7f20280710e6 in c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<std::tuple<at::Tensor&, at::Tensor&> (at::Tensor const&, at::Tensor&, at::Tensor&), &(at::(anonymous namespace)::(anonymous namespace)::wrapper_CPU_out_linalg_eig_out(at::Tensor const&, at::Tensor&, at::Tensor&))>, std::tuple<at::Tensor&, at::Tensor&>, c10::guts::typelist::typelist<at::Tensor const&, at::Tensor&, at::Tensor&> >, std::tuple<at::Tensor&, at::Tensor&> (at::Tensor const&, at::Tensor&, at::Tensor&)>::call(c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor const&, at::Tensor&, at::Tensor&) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0xc2220e6)
#6 0x7f202727a045 in at::_ops::linalg_eig_out::call(at::Tensor const&, at::Tensor&, at::Tensor&) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0xb42b045)
#7 0x7f20257b7e29 in at::native::linalg_eig(at::Tensor const&) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0x9968e29)
#8 0x7f2028070bf0 in c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<std::tuple<at::Tensor, at::Tensor> (at::Tensor const&), &(at::(anonymous namespace)::(anonymous namespace)::wrapper_CPU__linalg_eig(at::Tensor const&))>, std::tuple<at::Tensor, at::Tensor>, c10::guts::typelist::typelist<at::Tensor const&> >, std::tuple<at::Tensor, at::Tensor> (at::Tensor const&)>::call(c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor const&) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0xc221bf0)
#9 0x7f2026b1f787 in std::tuple<at::Tensor, at::Tensor> c10::Dispatcher::redispatch<std::tuple<at::Tensor, at::Tensor>, at::Tensor const&>(c10::TypedOperatorHandle<std::tuple<at::Tensor, at::Tensor> (at::Tensor const&)> const&, c10::DispatchKeySet, at::Tensor const&) const (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0xacd0787)
#10 0x7f20273230a7 in at::_ops::linalg_eig::redispatch(c10::DispatchKeySet, at::Tensor const&) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0xb4d40a7)
#11 0x7f202c3cc32d in torch::autograd::VariableType::(anonymous namespace)::linalg_eig(c10::DispatchKeySet, at::Tensor const&) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0x1057d32d)
#12 0x7f202c3cba96 in c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<std::tuple<at::Tensor, at::Tensor> (c10::DispatchKeySet, at::Tensor const&), &(torch::autograd::VariableType::(anonymous namespace)::linalg_eig(c10::DispatchKeySet, at::Tensor const&))>, std::tuple<at::Tensor, at::Tensor>, c10::guts::typelist::typelist<c10::DispatchKeySet, at::Tensor const&> >, std::tuple<at::Tensor, at::Tensor> (c10::DispatchKeySet, at::Tensor const&)>::call(c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor const&) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0x1057ca96)
#13 0x7f20272798e0 in at::_ops::linalg_eig::call(at::Tensor const&) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so+0xb42a8e0)
#14 0x7f2043d97ae3 in torch::autograd::THPVariable_linalg_eig(_object*, _object*, _object*) (/opt/conda/envs/py_3.9/lib/python3.9/site-packages/torch/lib/libtorch_python.so+0x23feae3)
#15 0x5072d6 in cfunction_call /usr/local/src/conda/python-3.9.17/Objects/methodobject.c:543:19
...
SUMMARY: UndefinedBehaviorSanitizer: undefined-behavior /var/lib/jenkins/workspace/aten/src/ATen/native/BatchLinearAlgebra.cpp:937:17 in
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106354
Approved by: https://github.com/huydhn, https://github.com/lezcano
There is a design flaw in NCCLWatchdog, namely it spawns threads that
talk to the CUDA api, but the CUDA api may have been deinitialized,
forming a race.
This is a known issue with widespread impact
(https://github.com/pytorch/pytorch/issues/90848).
I should point out that i tested this fix on the repro command for https://github.com/pytorch/pytorch/issues/82632 by running `NCCL_DESYNC_DEBUG=1 CUDA_LAUNCH_BLOCKING=1 python test/distributed/test_c10d_nccl.py -k test_find_unused_parameters_kwarg_debug_detail` and observing that instead of crashing, we observe log messages with the exception string about the cuda driver shutdown error.
A partial fix was landed already, but it applied too narrowly:
ec071a0815
This PR is a copy-paste of the previous fix, applying to one more case,
plugging a hole. We probably need to do a more thorough review and
either plug all the holes, or design this differently.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106503
Approved by: https://github.com/kwen2501
### Description
As an alternative to PR #105774, which provides a standalone, end-to-end minification script that covers all types of failures and has more functionality, this PR adds the ability to minify models when they fail the eval loop (accuracy checks). Both this PR and the other one can be merged without issue.
### Purpose
The goal is to leverage the minifier to minify models that fail accuracy checks, allowing failed models to be debugged more easily. The ideal use-case is trying to run a model suite on a backend where operator coverage is not known or is limited. If models can compile but fails the eval loop, having the repro script for each model is valuable for any developer that's trying to fix the issue.
### Functionality
- Create minify flag that minifies models when they fail accuracy check
- Produce minified graph for each model, and save it into repro script
- Move repro script to output directory/base Dynamo directory
- Enable functionality for running an entire model suite (Hugging Face, timm, and TorchBench) by prepending model name to repro script
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106201
Approved by: https://github.com/ezyang
Summary:
- PyTorch testing chokes sometimes when it sees an exception where the first
argument is not a string. fake_tensor.UnsupportedOperatorException's first
arg is an OpOverload. This PR fixes PyTorch testing to not choke. I'm not
really sure how to reproduce this in OSS.
- It turns out that if an operator does not have a meta kernel, the FakeTensor
rule is really slow (30ms in OSS in debug mode, 3s on some internal config).
The thing that is slow (aside from the previous diff) is waiting for the Dispatcher to
report NotImplemented and then attempting to catch that. I'm not really sure
why this is slow but it's easy to workaround so I added a workaround.
Test Plan: - existing tests
Differential Revision: D47917554
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106311
Approved by: https://github.com/eellison
This PR aims to sort out the data type for `constant`.
The constant should be promoted to float https://github.com/pytorch/pytorch/pull/105440. So there are serval changes to do:
- Data type propagation should propagate constant node to `float` dtype if original dtype is `bfloat16`
- We do not need to insert `to_dtype` after the `constant` node, directly init an `fp32` constant is faster.
```
vectorized<bfloat16> tmp(value);
vectorized <float> tmp1 = cvt_bf16_fp32(tmp);
->
vectorized<float> tmp(value);
```
- move `constant` out of the list for `all operations can support bf16 without converting to fp32`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105827
Approved by: https://github.com/jgong5, https://github.com/jansel
It is confusing to not print stream 0, but print other streams. It makes stream 0
allocations seem like they are missing a stream annotation. This change will print streams
for everything unless all the events are on stream 0, then it will just not print streams.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106483
Approved by: https://github.com/albanD
ghstack dependencies: #106328, #106482
Fixes https://github.com/pytorch/pytorch/issues/103210
Test Plan:
Before the fix:
```
pytest test/dynamo/test_export.py -k suppress_errors
```
got result:
```
File "/data/users/zhxchen17/pytorch/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/eval_frame.py", line 295, in _fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/eval_frame.py", line 448, in catch_errors
return callback(frame, cache_size, hooks, frame_state)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/convert_frame.py", line 127, in _fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/convert_frame.py", line 360, in _convert_frame_assert
return _compile(
^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/utils.py", line 180, in time_wrapper
r = func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/convert_frame.py", line 511, in _compile
exception_handler(e, code, frame)
File "/data/users/zhxchen17/pytorch/torch/_dynamo/convert_frame.py", line 216, in exception_handler
log.error(format_error_msg(e, code, record_filename, frame))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/data/users/zhxchen17/pytorch/torch/_dynamo/exc.py", line 248, in format_error_msg
stack_above_dynamo = filter_stack(extract_stack(frame))
^^^^^^^^^^^^^^^^^^^^
File "/home/zhxchen17/miniconda3/envs/dev/lib/python3.11/traceback.py", line 231, in extract_stack
stack = StackSummary.extract(walk_stack(f), limit=limit)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/zhxchen17/miniconda3/envs/dev/lib/python3.11/traceback.py", line 393, in extract
return klass._extract_from_extended_frame_gen(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/zhxchen17/miniconda3/envs/dev/lib/python3.11/traceback.py", line 416, in _extract_from_extended_frame_gen
for f, (lineno, end_lineno, colno, end_colno) in frame_gen:
File "/home/zhxchen17/miniconda3/envs/dev/lib/python3.11/traceback.py", line 390, in extended_frame_gen
for f, lineno in frame_gen:
File "/home/zhxchen17/miniconda3/envs/dev/lib/python3.11/traceback.py", line 334, in walk_stack
yield f, f.f_lineno
^^^^^^^^^^
AttributeError: 'torch._C.dynamo.eval_frame._PyInterpreterFrame' object has no attribute 'f_lineno'
```
After the fix:
```
pytest test/dynamo/test_export.py -k suppress_errors -s
```
Got Result:
```
File "/data/users/zhxchen17/pytorch/torch/_dynamo/exc.py", line 135, in unimplemented
raise Unsupported(msg)
torch._dynamo.exc.Unsupported: map() operator doesn't support scalar or zero-sized tensors during
tracing.
========== The above exception occurred while processing the following code ==========
File "/data/users/zhxchen17/pytorch/test/dynamo/test_export.py", line 3043, in forward
def forward(self, xs):
File "/data/users/zhxchen17/pytorch/test/dynamo/test_export.py", line 3047, in forward
return map(body, xs)
==========
unimplemented [("map() operator doesn't support scalar or zero-sized tensors during tracing.", 1)]
.
=============================== 1 passed, 133 deselected in 4.60s ================================
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103227
Approved by: https://github.com/williamwen42
This PR adds improved error/warning messaging when auto wrapping with `ModuleWrapPolicy` in the presence of frozen parameters.
- For `use_orig_params=False`, FSDP requires uniform `requires_grad` for each FSDP instance. This PR adds a `ValueError` at wrapping time with a message that mentions the violating module and the frozen/non-frozen parameter names.
- For `use_orig_params=True`, FSDP allows non-uniform `requires_grad` for each FSDP instance. However, it will result in higher-than-expected gradient memory usage. This PR adds a `UserWarning` at wrapping time with a message that mentions the violating module, how much extra gradient memory will be used (in units of numel), and the frozen/non-frozen parameter names.
- There is a possibility that this warning will be spammy/verbose, but my current thinking is that it is okay for now unless users complain.
<details>
<summary> Why DFS via named_children() vs. Using named_modules()</summary>
```
LoraModel(
(embed_tokens): Embedding(100, 32)
(layers): ModuleList(
(0-3): 4 x LoraDecoder(
(attn): LoraAttention(
(q_proj): Linear(in_features=32, out_features=32, bias=False)
(lora_A): Linear(in_features=32, out_features=8, bias=False)
(lora_B): Linear(in_features=8, out_features=32, bias=False)
(k_proj): Linear(in_features=32, out_features=32, bias=False)
(v_proj): Linear(in_features=32, out_features=32, bias=False)
(o_proj): Linear(in_features=32, out_features=32, bias=False)
)
(mlp): LoraMLP(
(proj1): Linear(in_features=32, out_features=128, bias=False)
(proj2): Linear(in_features=128, out_features=32, bias=False)
)
(inp_layernorm): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
(post_attn_layernorm): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
)
)
(norm): LayerNorm((32,), eps=1e-05, elementwise_affine=True)
)
```
Reverse topological order with stack-based DFS via `named_children()`:
```
[
'embed_tokens',
'layers.0.attn.q_proj', 'layers.0.attn.lora_A', 'layers.0.attn.lora_B', 'layers.0.attn.k_proj', 'layers.0.attn.v_proj', 'layers.0.attn.o_proj', 'layers.0.attn', 'layers.0.mlp.proj1', 'layers.0.mlp.proj2', 'layers.0.mlp', 'layers.0.inp_layernorm', 'layers.0.post_attn_layernorm', 'layers.0',
'layers.1.attn.q_proj', 'layers.1.attn.lora_A', 'layers.1.attn.lora_B', 'layers.1.attn.k_proj', 'layers.1.attn.v_proj', 'layers.1.attn.o_proj', 'layers.1.attn', 'layers.1.mlp.proj1', 'layers.1.mlp.proj2', 'layers.1.mlp', 'layers.1.inp_layernorm', 'layers.1.post_attn_layernorm', 'layers.1',
'layers.2.attn.q_proj', 'layers.2.attn.lora_A', 'layers.2.attn.lora_B', 'layers.2.attn.k_proj', 'layers.2.attn.v_proj', 'layers.2.attn.o_proj', 'layers.2.attn', 'layers.2.mlp.proj1', 'layers.2.mlp.proj2', 'layers.2.mlp', 'layers.2.inp_layernorm', 'layers.2.post_attn_layernorm', 'layers.2',
'layers.3.attn.q_proj', 'layers.3.attn.lora_A', 'layers.3.attn.lora_B', 'layers.3.attn.k_proj', 'layers.3.attn.v_proj', 'layers.3.attn.o_proj', 'layers.3.attn', 'layers.3.mlp.proj1', 'layers.3.mlp.proj2', 'layers.3.mlp', 'layers.3.inp_layernorm', 'layers.3.post_attn_layernorm', 'layers.3',
'layers', 'norm', ''
]
```
Reverse topological order with `named_modules()`:
```
[
'norm',
'layers.3.post_attn_layernorm', 'layers.3.inp_layernorm', 'layers.3.mlp.proj2', 'layers.3.mlp.proj1', 'layers.3.mlp', 'layers.3.attn.o_proj', 'layers.3.attn.v_proj', 'layers.3.attn.k_proj', 'layers.3.attn.lora_B', 'layers.3.attn.lora_A', 'layers.3.attn.q_proj', 'layers.3.attn', 'layers.3',
'layers.2.post_attn_layernorm', 'layers.2.inp_layernorm', 'layers.2.mlp.proj2', 'layers.2.mlp.proj1', 'layers.2.mlp', 'layers.2.attn.o_proj', 'layers.2.attn.v_proj', 'layers.2.attn.k_proj', 'layers.2.attn.lora_B', 'layers.2.attn.lora_A', 'layers.2.attn.q_proj', 'layers.2.attn', 'layers.2',
'layers.1.post_attn_layernorm', 'layers.1.inp_layernorm', 'layers.1.mlp.proj2', 'layers.1.mlp.proj1', 'layers.1.mlp', 'layers.1.attn.o_proj', 'layers.1.attn.v_proj', 'layers.1.attn.k_proj', 'layers.1.attn.lora_B', 'layers.1.attn.lora_A', 'layers.1.attn.q_proj', 'layers.1.attn', 'layers.1', 'layers.0.post_attn_layernorm', 'layers.0.inp_layernorm', 'layers.0.mlp.proj2', 'layers.0.mlp.proj1', 'layers.0.mlp', 'layers.0.attn.o_proj', 'layers.0.attn.v_proj', 'layers.0.attn.k_proj', 'layers.0.attn.lora_B', 'layers.0.attn.lora_A', 'layers.0.attn.q_proj', 'layers.0.attn', 'layers.0',
'layers', 'embed_tokens', ''
]
```
With the stack-based DFS via `named_children()`, reversing the topological order gives us each level in the module tree in the registered order, wheres with `named_modules()`, reversing the topological order gives us each level in reverse. Both are valid orders, but we prefer the former since it allows us to error/warn on the _first-registered_ module that violates the frozen/non-frozen condition.
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104427
Approved by: https://github.com/ezyang
Previously, we assume the argnums is a **ConstantVariable**. However I accidentally triggered an error on CI where argnums could be a **TupleVariable**. In that case, we have an attribute error when access the .value of argnums.
This PR adds support for the TupleVariable. It allows the unit test to pass without falling back to eager
"PYTORCH_TEST_WITH_DYNAMO=1 python test/functorch/test_eager_transforms.py -k test_argnums_cpu"
Test Plan:
see modified test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106425
Approved by: https://github.com/yanboliang, https://github.com/anijain2305, https://github.com/kshitij12345
We hope PyTorch profiling parsing ability can also be applicable to custom devices. Based on previous work https://github.com/pytorch/pytorch/pull/101554, we have made supplementary updates to PyTorch profiling to extend its parsing capabilities for custom devices. These modifications do not affect the original logic of the code and mainly include the following aspects:
1. Added the relevant logic for use_device in torch.profiler.profiler._KinetoProfile.
2. In torch.autograd.profiler and torch.autograd.profiler_util, custom devices profiling data parsing ability has been added using privateuse1 and use_device attributes.
3. In torch._C._autograd.pyi and torch._C._autograd.pyi, custom devices related attributes have been added. The underlying C++
logic will be added in subsequent pull requests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106142
Approved by: https://github.com/aaronenyeshi
Summary:
Adding support for edge dialect ops in `exir/serde`. This diff does the following:
- Moves the global `serialize_operator/deserialize_operator` implementations in`export/serde/serialize.py` into `GraphModuleSerializer` and `GraphModuleDeserializer`
- Adds implementations of `serialize_operator/deserialize_operator` inside `GraphModuleSerializer` and `GraphModuleDeserializer` in `exir/serde/serialize.py`
Test Plan: CI + Enabled edge dialect ops in `executorch/exir/tests/test_serde.py`
Differential Revision: D47938280
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106371
Approved by: https://github.com/angelayi
This PR implements `try_solve`: a function that tries to move terms of a relational
expression around, so as to isolate a given variable on the left-hand side.
For example:
```python
>>> try_solve(Eq(a + 5, 3), a)
Eq(a, -2)
>>> try_solve(Gt(Mod(a, 3), 0), a) # returns None
>>> try_solve(Gt(Mod(a, 3), 0), Mod(a, 3))
Gt(Mod(a, 3), 0), Mod(a, 3)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105877
Approved by: https://github.com/ezyang
**Summary**
Re-enable the test case of `test_conv2d_binary_with_quantizer_api` and `test_conv2d_binary_unary_with_quantizer_api` for X86InductorQuantizer. We disable these 2 testcases previously due to the time out issue in internal CI.
**Test Plan**
```
python -m pytest test_x86inductor_quantizer.py -k test_conv2d_binary_with_quantizer_api
python -m pytest test_x86inductor_quantizer.py -k test_conv2d_binary_unary_with_quantizer_api
```
Differential Revision: [D47745372](https://our.internmc.facebook.com/intern/diff/D47745372)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105638
Approved by: https://github.com/jerryzh168, https://github.com/andrewor14
This PR should not make any functional difference. It:
- adds clearer documentation
- clarifies a type
- revises minor typos
- swaps a .keys for a .items call on a dictionary
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106069
Approved by: https://github.com/awgu
Freezing will take parameters and turn them into constants. A couple changes here:
- move the setting of `flat_params[dropped_index]` before cpp compilation so that cpp_wrapper knows they have been dropped
- compile_fx_aot is doesn't use aot_autograd for invocation, so we no longer add the wrapper which discards dropped param indices. Continuing to add arguments everywhere didn't seem great, so I added `_in_aot_compilation`, but maybe reviewers would prefer something else.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105497
Approved by: https://github.com/desertfire
When running on a host with multiple CPUs, the ufmt linter was not able to use them very effectively. The biggest single culprit seems to be debug logging inside blib2to3 trying to acquire a lock, but disabling that doesn't help much - I suppose this must be GIL contention. Changing to a ProcessPoolExecutor makes it much faster.
The following timings are on a PaperSpace GPU+ instance with 8 vCPUs (the cores show up as Intel(R) Xeon(R) CPU E5-2623 v4 @ 2.60GHz but I'm not entirely clear if those are shared with other instances).
On main:
```
$ time lintrunner --all-files --take UFMT
ok No lint issues.
real 7m46.140s
user 8m0.828s
sys 0m5.446s
```
On this branch:
```
$ time lintrunner --all-files --take UFMT
ok No lint issues.
real 1m7.255s
user 8m13.388s
sys 0m3.506s
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106123
Approved by: https://github.com/ezyang
add `class FPGMStructured`
add `function FPGM_structured()`
add `function _validate_distance_type()`
add `function _compute_distance()`
Implement method mentioned in issue #39765
---
FPGMSparsifier Implement with the new pytorch pruning API torch.ao.pruning.
It is a structured pruning method, and it is added under torch.ao.pruning._experimental. Test cases are added at `test_structured_sparsifier.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95689
Approved by: https://github.com/jcaip
Summary:
This stack of PR's integrates cuSPARSELt into PyTorch.
This PR adds support for cuSPARSELt into the build process.
It adds in a new flag, USE_CUSPARSELT that defaults to false.
When USE_CUSPASRELT=1 is specified, the user can also specify
CUSPASRELT_ROOT, which defines the path to the library.
Compiling pytorch with cusparselt support can be done as follows:
``
USE_CUSPARSELT=1
CUSPARSELT_ROOT=/path/to/cusparselt
python setup.py develop
```
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103700
Approved by: https://github.com/albanD
Summary:
Added support to allow users to set configurations based on module type in XNNPACKQuantizer, can also serve as an example
for implementing new quantizers
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_xnnpack_quantizer_set_module_type
Summary:
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106094
Approved by: https://github.com/andrewor14
ghstack dependencies: #106087
In certain cases we capture ErrorMeta in a list. The ErrorMeta objects hold
tracebacks which contain a frame with a local variable that refers to that list.
This change mutates the list on exit from the frame so that it doesn't refer
to the ErrorMeta objects, breaking the cycle.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106328
Approved by: https://github.com/huydhn
This PR intends to extend Inductor to support the third-party backend that only focuses on the code generation just like what C++/OpenMP and Triton backend have done.
Currently, the generated code by Inductor contains two major parts. One is the kernel, and the other is the Python wrapper to glue the kernel. Therefore, the third-party backend needs to customize the two parts to generate its specific code.
- Python wrapper code generation
Inductor provides a `WrapperCodeGen` class to generate the Python wrapper code to glue the kernel. Therefore, it is straightforward for the third-party backend to generate the backend-specific Python wrapper code. It just needs to inherit the `WrapperCodeGen` class and purposely override the particular member functions.
- Kernel code generation
It is driven by different `Scheduling`. Hence, the third-party backend needs to provide a custom `Scheduling` for its specific kernel code generation. Currently, `CppScheduling` and `TritonScheduling` are for C++/OpenMP and Triton backend, respectively. But there is no common `Scheduling` class. Based on the scheduling invocation, this PR abstracts a common `Scheduling` class containing the following member functions.
- [group_fn](71c4becda7/torch/_inductor/scheduler.py (LL649C64-L649C64))
- [flush](71c4becda7/torch/_inductor/scheduler.py (L1150))
- [can_fuse_vertical](71c4becda7/torch/_inductor/scheduler.py (L1006))
- [can_fuse_horizontal](71c4becda7/torch/_inductor/scheduler.py (LL1008C45-L1008C64))
- [codegen_template](71c4becda7/torch/_inductor/scheduler.py (L1234)) _This function is only available for triton. If the third-party backend behaves as a sub-class of `TritonScheduling`, it can override it or reuse it._
- [codegen_nodes](71c4becda7/torch/_inductor/scheduler.py (L1234))
- [codegen_sync](71c4becda7/torch/_inductor/scheduler.py (LL1251C1-L1251C1)). _This function is only available for triton debug purpose. But it might also be useful for other computation devices. Therefore, we'd prefer to keep this function._
The third-party backend needs to inherit from the `Scheduling` class and implement these functions.
Regarding some other classes like `CppKernel` and `TritonKernel` for code generation, they are used by or part of the logic of either `Scheduling` or `WrapperCodeGen`. Hence, this PR does not define the interface and leaves the flexibility to the third-party backend. The third-party backend can decide to implement these classes from scratch or reuse them by inheriting and overriding them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100706
Approved by: https://github.com/jansel
Summary:
Building on Microsoft Visual Studio can show excessive warnings of the form:
```
caffe2\c10\util\Optional.h(212): warning C4624: 'c10::constexpr_storage_t<T>': destructor was implicitly defined as deleted
with
[
T=std::string
]
caffe2\c10\util\Optional.h(411): note: see reference to class template instantiation 'c10::constexpr_storage_t<T>' being compiled
with
[
T=std::string
]
caffe2\c10\util\Optional.h(549): note: see reference to class template instantiation 'c10::trivially_copyable_optimization_optional_base<T>' being compiled
with
[
T=std::string
]
```
While we have macros such as `C10_CLANG_DIAGNOSTIC_{PUSH,POP,IGNORE}`, no there's no equivalent `C10_MSVC_DIAGNOSTIC_*`, so just do the suppressions explicitly.
Test Plan: CI should complete, but Windows build log will no longer contain C4624 warnings
Differential Revision: D47736268
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106348
Approved by: https://github.com/albanD
Summary:
Added support to allow users to set configurations based on module name in XNNPACKQuantizer, can also serve as an example
for implementing new quantizers
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_xnnpack_quantizer_set_module_name
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106087
Approved by: https://github.com/andrewor14
Fixes#102375
Sequence_nr increments in the forward pass and decrements in the backward pass. Backward ops with the same sequence_nr as a forward op represent the backward implementation for the op. The long term goal is to make this information available to the profiler so users can observe which ops are fused by the inductor openai triton kernels.
Added a test for this feature **test/dynamo/test_aot_autograd.py::AotAutogradFallbackTests::test_aot_sequence_nr**. The test case uses **aot_export_module()** to create a joint fwd/bwd fx graph. Then it walks all the nodes in fx graph using fx_graph.graph.nodes. The seq_nr of each node is recorded in node.meta. During the fwd pass the seq_nr increments and it decrements during the bwd pass. This allows the user to map forward ops to their corresponding bwd ops which is useful for performance analysis.
Expected output from the test case.
SeqNr|OrigAten|SrcFn
0|aten.convolution.default|l__self___conv1
0|aten.add.Tensor|l__self___bn1
1|aten._native_batch_norm_legit_functional.default|l__self___bn1
2|aten.relu.default|l__self___relu1
3|aten.add.Tensor|add
4|aten.view.default|flatten
5|aten.t.default|l__self___fc1
6|aten.unsqueeze.default|l__self___fc1
7|aten.mm.default|l__self___fc1
8|aten.squeeze.dim|l__self___fc1
9|aten.add.Tensor|l__self___fc1
10|aten.sub.Tensor|l__self___loss_fn
11|aten.abs.default|l__self___loss_fn
12|aten.mean.default|l__self___loss_fn
12|aten.ones_like.default|
12|aten.expand.default|
12|aten.div.Scalar|
11|aten.sgn.default|
11|aten.mul.Tensor|
8|aten.unsqueeze.default|
7|aten.t.default|
7|aten.mm.default|
7|aten.t.default|
7|aten.t.default|
7|aten.mm.default|
6|aten.squeeze.dim|
5|aten.t.default|
4|aten.view.default|
2|aten.threshold_backward.default|
1|aten.native_batch_norm_backward.default|
0|aten.convolution_backward.default|
0|aten.add.Tensor|
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103129
Approved by: https://github.com/soulitzer
Summary:
Proactively fix it so we don't run into strange things in the future.
```
In [5]: cmd = '''gcc "single arg with space"'''
In [6]: print(cmd)
gcc "single arg with space"
In [7]: cmd.split(' ')
Out[7]: ['gcc', '"single', 'arg', 'with', 'space"']
In [8]: shlex.split(cmd)
Out[8]: ['gcc', 'single arg with space']
```
Test Plan: CI
Reviewed By: chenyang78
Differential Revision: D47532486
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105367
Approved by: https://github.com/chenyang78
Enabling miopen_batch_norm lowering for inductor only.
This is to avoid errors observed in some models and perf difference is very close from initial benchmarks.
```
LoweringException: RuntimeError: Expected contiguous tensor, but got non-contiguous tensor for argument #1 'input' (while checking arguments for miopen_batch_norm)
target: aten.miopen_batch_norm.default
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105740
Approved by: https://github.com/jithunnair-amd, https://github.com/malfet
Related to #77764
Add support for the cumprod operation (which in turn allows its gradient). This also allows us to compute the gradient of prod since it was blocked behind cumprod in the case where exactly one element of the tensor was 0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104688
Approved by: https://github.com/kulinseth
Previously calling _record_memory_history would only start recording
for a single device because snapshots were also device specific.
Now the visualizer packages all devices into a single page, so we snapshot
recording should also enable recording for all devices.
Verified locally that calling the method does not initialize cuda context
on devices that have not previously been used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106346
Approved by: https://github.com/eellison
### Proposal
When arg of 'keep_initializers_as_inputs' is True, it's quite possible that parameters are set by initializer of input.
Hence we should disable de-duplicate initializer optimization when 'keep_initializers_as_inputs==True'.
- [x] Update doc related to `keep_initializers_as_inputs`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96320
Approved by: https://github.com/abock, https://github.com/thiagocrepaldi
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at bb1fc29</samp>
This pull request simplifies and refactors the code for fused scaled dot product attention kernels in `attention.cu` and `sdp_utils.cpp`, and adds new input validation checks and tests. It also modifies the `sdp_params` struct to store optional mask tensors directly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106102
Approved by: https://github.com/cpuhrsch
Fix: #105533
This PR propagates dynamic ints used as indices for `__setitem__`. In summary, we:
- Replace the integer type for `TensorIndex` (both the enum and the corresponding
functions)
- Accordingly modify _python_variable_indexing.cpp_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105923
Approved by: https://github.com/ezyang
Summary: Moving static tracepoint macros header to a location where it can be easily used by various PyTorch components (`c10/utill`).
Test Plan:
Same as for D47159249:
Tested the following macros on test scripts with libbpf USDTs:
* `CAFFE_SDT`
* `CAFFE_DISABLE_SDT`
* `CAFFE_SDT_WITH_SEMAPHORE`
Reviewed By: EDG-GH
Differential Revision: D47636258
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105856
Approved by: https://github.com/EDG-GH, https://github.com/chaekit
This may give the wrong result in some cases, e.g.
```python
@torch.compile()
def fn(x):
tmp = x.ceil()
x.add_(10)
return tmp
a = torch.zeros((), dtype=torch.int64)
fn(a) # tensor(10)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105173
Approved by: https://github.com/lezcano
Previously in `sample_inputs_linspace` the logic
```
dtype == torch.uint8 and end < 0 or start < 0
```
is equivalent to
```
(dtype == torch.uint8 and end < 0) or start < 0
```
which skipped all `start < 0` cases. I think this is unintended and the negative inputs should only be skipped when dtype is `unit8`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106353
Approved by: https://github.com/BowenBao
The thing we do still deep copy is the param_groups, which is much lighter weight. This should also save memory when loading from a checkpoint.
The deepcopy was introduced in ecfcf39f30, but module.py had only a shallow copy at that point so it did not actually bring parity.
Incorporates an XLA fix, which is why I'm updating the pin to ca5eab87a7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106082
Approved by: https://github.com/albanD, https://github.com/Skylion007
Summary:
Place broadcast checks into `Broadcast.h` and `Broadcast.cpp` for code re-use.
Rename `check_inputs` to `is_broadcastable`
https://pytorch.org/docs/stable/notes/broadcasting.html
Test Plan:
All tests
https://www.internalfb.com/phabricator/paste/view/P797165124
```
QueryPool is not available
[ SKIPPED ] VulkanAPITest.querypool_flushed_shader_log (0 ms)
[----------] 318 tests from VulkanAPITest (8693 ms total)
[----------] Global test environment tear-down
[==========] 318 tests from 1 test suite ran. (8693 ms total)
[ PASSED ] 317 tests.
[ SKIPPED ] 1 test, listed below:
[ SKIPPED ] VulkanAPITest.querypool_flushed_shader_log
```
Differential Revision: D47741937
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105960
Approved by: https://github.com/SS-JIA
We need to consider the node's offset when we create benchmark example
tensors with test_cat_addmm. Otherwise, we would fail with applying
torch.as_strided to the return tensor value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106238
Approved by: https://github.com/jansel
Summary:
Major changes:
* Implement a new group/batch fusion pattern searching algorithm: only fuse patterns that are in a certain depth difference (locally).
* Search FX graph in reverse order since most of ops have more inputs than outputs.
* Support fuse mm (linear backward)
* Preserve memory layout for fbgemm.gmm.
We tested in Ads models and saw consistent gains.
Test Plan: Unit tests and integration test.
Differential Revision: D47581710
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106279
Approved by: https://github.com/jansel, https://github.com/Skylion007
To `slow.yml` and `mac-mps.yaml`, based on the results of the following grep:
```
% grep "sync-tag: " .github/workflows/*.yml
.github/workflows/mac-mps.yml: sync-tag: macos-12-py3-arm64-build
.github/workflows/mac-mps.yml: sync-tag: macos-12-py3-arm64-mps-test
.github/workflows/pull.yml: sync-tag: asan-build
.github/workflows/pull.yml: sync-tag: asan-test
.github/workflows/pull.yml: sync-tag: win-cpu-build
.github/workflows/pull.yml: sync-tag: rocm-build
.github/workflows/slow.yml: sync-tag: asan-build
.github/workflows/slow.yml: sync-tag: asan-test
.github/workflows/trunk.yml: sync-tag: macos-12-py3-arm64-build
.github/workflows/trunk.yml: sync-tag: macos-12-py3-arm64-mps-test
.github/workflows/trunk.yml: sync-tag: win-cpu-build
.github/workflows/trunk.yml: sync-tag: win-cuda-build
.github/workflows/trunk.yml: sync-tag: rocm-build
```
Allow synced workflows to diverge with regards to `test-matrix`, to allow for both `mac-mps` and slow part of ASAN tests.
Discovered while working on https://github.com/pytorch/pytorch/pull/105260 that slow sync-tag is not checked.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106331
Approved by: https://github.com/huydhn, https://github.com/atalman, https://github.com/seemethere
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 08bd685</samp>
Added a utility function `autograd_not_implemented_check` to `torch._higher_order_ops.utils` and used it in `out_dtype_autograd` to simplify and standardize the error handling for higher order operators that do not support autograd.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106078
Approved by: https://github.com/zou3519
Summary:
tldr:
* change glog -> cout for important logging inside aot_inductor.so
* bring a small amount of important python logging from debug to info
Test Plan: CI
Differential Revision: D47464665
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105366
Approved by: https://github.com/desertfire
`TensorMeta.from_irnodes` handles either a single `IRNode` or a tuple or list of them. I tried to express this with overloading, but because this file is in MYPYNOFOLLOW, the `IRNode` subclasses become `Any`, which causes the overloads to be overlapping.
This changes the type of the argument to `benchmark_in_sub_process` to the more specific `TritonTemplateCaller`, since that one has the `bmreq` member and existing docstrings indicate that only the triton template benchmark is handled.
The `rand_strided` call caused a mypy error because the default value for device was a string. This is fixed by adding type hints to `rand_strided` in `torch/_dynamo/testing.py`. Likewise, the return value of `PyCodeCache.load_by_key_path` can be inferred from the type hint on `PyCodeCache.cache`.
Fixes one part of #105230
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105791
Approved by: https://github.com/jansel, https://github.com/Skylion007
For onnx MaxPool with ceil_mode=1, the sliding windows that starts in the right padded region won't be ignored, which causes different output shape with torch.
Therefore, need to add Pad op before and not to set ceil_mode for MaxPool op like what is done in symbolic_opset9 when convertting torch max_pool to onnx MaxPool.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106270
Approved by: https://github.com/thiagocrepaldi
- BatchLinearAlgebraLib.cpp is now split into one additional file
- BatchLinearAlgebraLib.cpp uses only cusolver APIs
- BatchLinearAlgebraLibBlas.cpp uses only cublas APIs
- hipify operates at the file level and cannot mix cusolver and cublas APIs within the same file
- cmake changes to link against hipblas instead of rocblas
- hipify mappings changes to map cublas -> hipblas instead of rocblas
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105881
Approved by: https://github.com/albanD
As node-12 EOLed long time ago and not available for Ubuntu-22.04 (Discovered while working on bionic deprecation).
Remove artificial constraint on gcc-10 downgrade (and some in-pace patching) for Jammy, as CUDA-11.8+ works perfectly fine with gcc-11.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 6367120</samp>
> _`nodejs` version_
> _upgraded for security_
> _autumn leaves fall fast_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106312
Approved by: https://github.com/DanilBaibak, https://github.com/albanD, https://github.com/atalman
There are some cpp tests that did not run for ROCm platform. This is the part of effort to enable them. Specifically, this change is to enable the distributed cpp tests.
Test plan:
Tested by using rocm/pytorch-nightly:latest image, and verified the distributed cpp tests PASSED locally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106132
Approved by: https://github.com/huydhn
Fixes https://github.com/pytorch/pytorch/issues/102970. See the comment [here](https://github.com/pytorch/pytorch/issues/102970#issuecomment-1577223773) for details.
We normally treat "outputs that alias inputs" specially in AOTAutograd, by replaying the views at runtime, instead of baking them into the graph. For views that are part of custom autograd functions though, we can't do that view-replay, since it will clobber the backwards function that the user specified in their custom autograd.Function.
Right now in this PR, I distinguish between "aliased inputs that are normal views" vs. "aliased inputs that are views that came from an autograd.Function call" by checking the outputs `.grad_fn` field, to see if it inherits from our custom CBackward function class. Then I added a new `OutputType` enum value, that we effectively treat the "normal" way (the same way that we treat ordinary, non-aliased outputs). The new enum val is mostly for debugging - so we can print it and know that our graph had custom autograd.Function aliased outputs in it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102992
Approved by: https://github.com/ezyang, https://github.com/zou3519
This commit fixes a bug where some "If" nodes blocked shape inference during the onnx graph building.
In fixup_onnx_controlflow, a "Cast" node is added to conditions in "If" and "Loop" nodes if the condition type is not bool.
This commit performs shape inference on this new "Cast" node which allows its output to be marked as "reliable" in ConstantValueMap during further shape inference. This would have eventually happened when shape inference is performed on the entire graph, but the inferred shapes are also useful to have during onnx graph building, since it allows some ops (like Squeeze) to export into simpler subgraphs.
Also adds a test for this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106093
Approved by: https://github.com/thiagocrepaldi
@SherlockNoMad mentioned that it's not bc safe to directly access these attributes, so I moved them to @property fields, and added a `@compatibility` decorator. For now I just set it to True for graph_module/graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106170
Approved by: https://github.com/SherlockNoMad
PR #101956 introduced additional stream priorities for cuda streams. HIP streams have slightly different semantics.
- HIP: 1=low, 0=default, -1=high
- CUDA: 0=default, -1=high, -2=higher, etc.
This PR forces HIP stream priority to just 0 and -1 to match the pytorch semantics.
This fixes a broken unit test.
```
python3 test_cuda_multigpu.py TestCudaMultiGPU.test_streams_priority -v
Test results will be stored in test-reports/python-unittest/test_cuda_multigpu
Running tests...
----------------------------------------------------------------------
test_streams_priority (__main__.TestCudaMultiGPU) ... ERROR (0.200s)
======================================================================
ERROR [0.200s]: test_streams_priority (__main__.TestCudaMultiGPU)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_utils.py", line 2354, in wrapper
method(*args, **kwargs)
File "test_cuda_multigpu.py", line 656, in test_streams_priority
low, high = torch.cuda.Stream.priority_range()
RuntimeError: least_priority == 0 INTERNAL ASSERT FAILED at "/var/lib/jenkins/pytorch-upstream/c10/hip/HIPStream.h":184, please report a bug to PyTorch. Unexpected HIP stream priority range
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106157
Approved by: https://github.com/malfet
Summary: This is surprisingly expensive when the stack is deep. We can instead just process the specific stack frame that's relevant -- it's much faster.
Test Plan:
```
import inspect
import sys
import time
def make_deep_stack(fn, n: int = 10):
if n > 0:
return make_deep_stack(fn, n - 1)
return fn()
def full_stack():
return inspect.stack()[1][3]
def via_current_frame():
return inspect.getframeinfo(sys._getframe(1))[2]
start = time.perf_counter()
for _ in range(1000):
make_deep_stack(full_stack)
print(f"full_stack took {time.perf_counter() - start}s")
start = time.perf_counter()
for _ in range(1000):
make_deep_stack(via_current_frame)
print(f"via_current_frame took {time.perf_counter() - start}s")
> full_stack took 31.788201928138733s
> via_current_frame took 2.33455612603575s
```
Differential Revision: D47674015
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105940
Approved by: https://github.com/zou3519
setting TORCH_LINALG_PREFER_CUSOLVER=1
This will allow users to prefer cusolver as linear algebra backend in their container use case. The switch is not enabled by default so it won't change any existing default behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106226
Approved by: https://github.com/lezcano
Fixes #ISSUE_NUMBER
as the title, add context support for custom device and testcase.
And in the future, we may want to refactor these hooks for different device to unify the APIs, would you agree my
idea? @albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105056
Approved by: https://github.com/albanD
* Enables PIE807 + PIE810. PIE807 is do not reimplement list builtin function using lambda and PIE810 is to always fuse startswith / endswith calls (I applied the autofixes for this before we had ruff enabled).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106218
Approved by: https://github.com/albanD
Summary:
This diff also adds more warning messages around allowing a namespace into the
fallback. We need to grandfather in an operator to actually merge this diff.
Test Plan: - existing tests
Differential Revision: D47873841
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106210
Approved by: https://github.com/eellison
Summary:
Add Vulkan support for [sum](https://pytorch.org/docs/stable/generated/torch.sum.html).dim_IntList) with `keep_dim=true`
[sum.dim_IntList](https://www.internalfb.com/code/fbsource/[49b7951b7eb6]/xplat/caffe2/aten/src/ATen/native/native_functions.yaml?lines=5466)
```
if keepdim is true, the output tensor is of the same size as input except in the dimension(s) dim, where it is of size 1
otherwise, the dim is squeezed, result in the output tensor having 1 fewer dimension/s.
```
Test Plan:
```
lfq@lfq-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*.sum*"
Action graph will be rebuilt because files have been added or removed.
Parsing buck files: finished in 1.4 sec
Downloaded 4/58 artifacts, 3.08 Mbytes, 50.0% cache miss (for updated rules)
Building: finished in 41.2 sec (100%) 536/536 jobs, 13/536 updated
Total time: 42.8 sec
BUILD SUCCEEDED
Running main() from third-party/googletest/1.11.0/googletest/googletest/src/gtest_main.cc
Note: Google Test filter = *.sum*
[==========] Running 6 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 6 tests from VulkanAPITest
[ RUN ] VulkanAPITest.sum_dim_2d
[ OK ] VulkanAPITest.sum_dim_2d (558 ms)
[ RUN ] VulkanAPITest.sum_dim_3d
[ OK ] VulkanAPITest.sum_dim_3d (7 ms)
[ RUN ] VulkanAPITest.sum_dim_4d
[ OK ] VulkanAPITest.sum_dim_4d (14 ms)
[ RUN ] VulkanAPITest.sum_dim_keepdim_2d
[ OK ] VulkanAPITest.sum_dim_keepdim_2d (4 ms)
[ RUN ] VulkanAPITest.sum_dim_keepdim_3d
[ OK ] VulkanAPITest.sum_dim_keepdim_3d (7 ms)
[ RUN ] VulkanAPITest.sum_dim_keepdim_4d
[ OK ] VulkanAPITest.sum_dim_keepdim_4d (18 ms)
[----------] 6 tests from VulkanAPITest (612 ms total)
[----------] Global test environment tear-down
[==========] 6 tests from 1 test suite ran. (612 ms total)
[ PASSED ] 6 tests.
```
Reviewed By: SS-JIA
Differential Revision: D47652931
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106159
Approved by: https://github.com/SS-JIA
Current torch.compile docs have become a bit of a mess with the docs expanded in the left nav. This PR moves them under the torch.compiler menu item in the left nav. A bunch of rewrites were made in collaboration with @msaroufim to address formatting issues, latest updates that moved some of the APIs to the public torch.compiler namespace were addressed as well. The documentation is broken down in three categories that address three main audiences: PyTorch users, Pytorch Developers and PyTorch backend vendors. While, the user-facing documentation was significantly rewritten, dev docs and vendor docs kept mostly untouched. This can be addressed in the follow up PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105376
Approved by: https://github.com/msaroufim
Summary:
When in AOT mode, make use of the existing stream param:
- Pass through and use the stream param in the launchKernel helper function.
- In non-AOT mode, assign the stream param in the caller and pass to launchKernel
- Use a CUDAStreamGuard so all fallback ops execute on the stream
- CUDAStreamGuard subsumes CUDAGuard in AOT mode since it sets both stream and device
Test Plan:
- Ran cpp_wrapper tests: pytest test/inductor/test_cpp_wrapper.py
- Manually inspected cpp output from the alexnet benchmark:
a) In AOT mode:
```
static inline void launchKernel(
CUfunction func,
int gridX,
int gridY,
int gridZ,
int numWraps,
int sharedMemBytes,
cudaStream_t stream) {
AT_CUDA_DRIVER_CHECK_OVERRIDE(cuLaunchKernel(
func, gridX, gridY, gridZ, 32*numWraps, 1, 1, sharedMemBytes, stream, args, nullptr));
...
at::cuda::CUDAStreamGuard stream_guard(at::cuda::getStreamFromExternal(stream, 0));
...
launchKernel(triton_poi_fused_convolution_0, 1, 784, 1, 4, 4352, kernel_args_var_0, stream);
...
```
b) Regular cpp wrapper:
```
...
at::cuda::CUDAGuard device_guard(0);
cudaStream_t stream0 = at::cuda::getCurrentCUDAStream(0);
...
launchKernel(triton_poi_fused_convolution_0, 1, 784, 1, 4, 4352, kernel_args_var_0, stream0);
...
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105589
Approved by: https://github.com/desertfire
### Background: Gradient Pre-Divide
Consider $N$ data parallel workers. Define $g_i$ to be the $i$ th worker's local unsharded gradient. Data parallel gradient reduction computes $\overline g = \frac{1}{N} \sum_{i \in [N]} g_i$.
$\sum_{i \in [N]} g_i$ increases the magnitude by a factor of $N$, which may overflow for fp16. However, if we pre-divide and compute $\sum_{i \in [N]} \frac{g_i}{N}$, then the $\frac{g_i}{N}$ may underflow. The current solution from Myle for FSDP is to pre-divide by $\sqrt{N}$ and post-divide by $\sqrt{N}$:
$$\overline{g} = \frac{1}{\sqrt{N}} \sum_{i \in [N]} \frac{g_i}{\sqrt{N}}.$$
Now, consider HSDP with $N = S \cdot R$ data parallel workers, sharding over $S$ workers and replicating over $R$ workers. Define $g_{i,j}$ to be the $i \cdot S + j$ th worker's local unsharded gradient (so sharding indexes with $i$ and replication indexes with $j$). The existing implementation computes
$$\overline{g} = \frac{1}{\sqrt{R}} \sum_{j \in [R]} \textcolor{red}{ \frac{1}{\sqrt{R}} \frac{1}{\sqrt{S}} } \sum_{i \in [S]} \frac{g_i}{\sqrt{S}},$$
where the $\frac{1}{\sqrt{R}} \frac{1}{\sqrt{S}}$ involves two separate `aten::div_` kernels.
### Revisiting Pre-Divide for HSDP
A minor optimization that we can do is with this intermediate `div_`. There are two options:
1. Compute $\overline{g}$ in the same way as FSDP:
$$\overline{g} = \frac{1}{\sqrt{N}} \sum_{j \in [R]} \sum_{i \in [S]} \frac{g_{i,j}}{\sqrt{N}}.$$
2. Compute $\overline{g}$ still with an intermediate division for rescaling but coalescing the two `divs_` into one:
$$\overline{g} = \frac{1}{\sqrt{R}} \sum_{j \in [R]} \textcolor{red}{ \frac{1}{\sqrt{N}} } \sum_{i \in [S]} \frac{g_i}{\sqrt{S}}$$
This PR goes with the 1st approach prioritizing performance because (1) it matches the existing FSDP behavior and (2) it avoids a memor-bandwidth bound `div_` kernel that blocks all-reduce launch.
### Implementation Details
In order to accommodate this, we need to refactor the communication hook logic that baked the gradient pre/post-division into the default hook.
- We raise an error if registering a communication hook for HSDP since the current implementation would only apply the hook to the reduce-scatter, not the all-reduce, which may be unexpected.
- We change it so that `state._comm_hook is not None` iff a communication hook is registered. This makes the collectives and the pre/post-division in the default no-communication-hook path more visible in the code.
Differential Revision: [D47852459](https://our.internmc.facebook.com/intern/diff/D47852459)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106034
Approved by: https://github.com/rohan-varma
In this pr, we allow users to register a customized flatten/unflatten/serialization/deserialization for a dataclass. We provide some default implementation for flatten/unflatten. We could implement a decorator based on it when needed.
## Motivation:
HuggingFace and many internal models return dataclass output and torch.export wants to maintain the invariant that export result (i.e. exported_program) has the same calling convention and result as the original callable.
This is not supported in export yet: we cannot recover the original dataclass from flattened output produced by the underlying graph module (produced by dynamo and processed further by aot_export). We need to have a place to store the metadata of the dataclass so that we can re-construct it. To avoid adding hacky code in export and allow princinpled extensibility, we think extending pytree may be a good option.
## Implementation:
@zou3519 mentioned https://github.com/pytorch/pytorch/pull/93214/files and [jax-2371](https://github.com/google/jax/issues/2371#issuecomment-805361566), which suggests that it's not a good idea to make dataclass a default pytree node but it could be good to provide a default implementation for dataclass. Since currently, this seems to be an export-only feature, we added this extension point in export.
We also add "return_none_fields" flag to control whether none fields are returned after flattening, which is expected to be False in produce_matching of dynamo.export.
Also added some tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106160
Approved by: https://github.com/zhxchen17
* Encourage people to use -i instead of -f for mergebot
* Add additional info for when rebase fails due to lacking permissions
<details><summary>dryrun</summary>
````
csl@csl-mbp ~/zzzzzzzz/pytorch [csl/errormsgs] $
(forpytorch) python3 .github/scripts/tryrebase.py 106089 --branch viable/strict --dry-run
+ git -C /Users/csl/zzzzzzzz/pytorch rev-parse --verify refs/remotes/origin/viable/strict
@pytorchbot started a rebase job onto [refs/remotes/origin/viable/strict](7c97c943fb). Check the current status [here](None)
+ git -C /Users/csl/zzzzzzzz/pytorch fetch origin pull/106089/head:pull/106089/head
+ git -C /Users/csl/zzzzzzzz/pytorch rebase refs/remotes/origin/viable/strict pull/106089/head
+ git -C /Users/csl/zzzzzzzz/pytorch rev-parse --verify pull/106089/head
+ git -C /Users/csl/zzzzzzzz/pytorch rev-parse --verify refs/remotes/origin/viable/strict
+ git -C /Users/csl/zzzzzzzz/pytorch push --dry-run -f https://github.com/Lightning-Sandbox/pytorch.git pull/106089/head:fix/spaces
stdout:
remote: Permission to Lightning-Sandbox/pytorch.git denied to clee2000.
fatal: unable to access 'https://github.com/Lightning-Sandbox/pytorch.git/': The requested URL returned error: 403
stderr:
Rebase failed due to Command `git -C /Users/csl/zzzzzzzz/pytorch push --dry-run -f https://github.com/Lightning-Sandbox/pytorch.git pull/106089/head:fix/spaces` returned non-zero exit code 128
```
remote: Permission to Lightning-Sandbox/pytorch.git denied to clee2000.
fatal: unable to access 'https://github.com/Lightning-Sandbox/pytorch.git/': The requested URL returned error: 403
```
This is likely because the author did not allow edits from maintainers on the PR or because the repo has additional permissions settings that mergebot does not qualify.
````
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106150
Approved by: https://github.com/huydhn
- Enabled LSTM weight prepack in inductor.
- Added a mkldnn decomposition for lstm which won't change for different `seq_lens`. With the previous decomposition, for dynamic shapes use case where `seq_lens` changes, the graph will be different.
- Extended several inductor utility functions to support `List(Tensor`) as input. Previously those functions only supported `Tensor` input.
**Update 2023-07-26:**
- https://github.com/pytorch/pytorch/pull/103851 has moved CPU weight packing to be after AOTAutograd. Fixed the support in this PR to follow the same way (mainly in 3b207f7f1c (diff-6dffed1ade0ba3e887f9a4eafa3bfcec267ab2365b8adcb91bd391f49b3fd2e3)).
LSTM is decomposed in `aten.mkldnn_rnn_layer` by layer and by direction. The weight prepack is done at the `mkldnn_rnn_layer` level.
- Add a fix in rnn `__get_state__` function in case we need to recompile an `LSTM` module.
When compiling the module, the weights tensors which are the `named_parameters` of the module are converted to `functional_tensor` here:
76fb72e24a/torch/nn/utils/stateless.py (L125-L128)
The forward function of LSTM will be called:
76fb72e24a/torch/_functorch/aot_autograd.py (L3379-L3381)
In the forward function, the `_flat_weights` are updated to be the same as the weights, thus becoming `functional_tensor`:
76fb72e24a/torch/nn/modules/rnn.py (L775-L778)
The weights tensors are converted back to the original tensors (which are not `functional_tensor` anymore) before exiting the `_reparametrize_module` context here:
76fb72e24a/torch/nn/utils/stateless.py (L130-L142)
But since `_flat_weights` is not in the `named_parameters` of the module, it's still `functional_tensor` ([link of the parameters that will be converted to functional and reverted back](76fb72e24a/torch/_functorch/aot_autograd.py (L3695-L3698))).
At this moment, if we need to recompile the model, `deepcopy` will be called:
76fb72e24a/torch/_dynamo/utils.py (L915-L917)
And it will report `UnImplemented` since we have `functional_tensor` (`_flat_weights`) and will trigger graph break which is not what we expect:
76fb72e24a/torch/_subclasses/meta_utils.py (L514)
Added a fix in the `__get_state__` to update the `_flat_weights` if ever weights have changed to fix this issue. The fix is covered in the `test_lstm_packed` UT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103071
Approved by: https://github.com/jgong5, https://github.com/jansel
As described in
https://docs.google.com/document/d/1aGWtgxV3HppuxQAdddyPrs74_aEntpkYt9MalnCKnhk/edit
This PR changes the CustomOp API to be private and adds new public
wrappers around it so that the user does not need to know about the
"CustomOp" object. We've effectively changed the "CustomOp" object to be
some metadata about the operator that the user does not directly
interact with.
The "updated custom op API" is in torch._custom_ops. Pending good customer
feedback, we will promote this module to torch.custom_ops.
NB: I cannot move around the older torch._custom_op APIs yet because
people are already using them.
Test Plan:
- I changed all of our tests to use the new `torch._custom_ops` module
instead of the old CustomOp API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105947
Approved by: https://github.com/soulitzer
This PR moves most custom op related tests from
test/test_python_dispatch.py to test/test_custom_ops.py. Motivation is
that I had a difficult time finding the custom op tests inside
test_python_dispatch.py.
This doesn't preserve blame, but it's OK - I'm the only person who has
really touched the moved tests so far :).
Test Plan:
- run tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106036
Approved by: https://github.com/bdhirsh, https://github.com/soulitzer
At the moment, we only record the list of pending and failed check on Rockset merge records. This is enough to compute the force merge KPI(s), but isn't enough for more in-depth analysis on what happened at the time of the merge:
* If the number of `ok_failed_checks` is less than `ok_failed_checks_threshold`, the list of `failed_checks` would be empty (expectedly). So Rockset would only record an empty list.
* We support retry in PR, so the classifications on Dr.CI could be different than what dev observed at the time of the merge if retry completed successfully
### Testing
`python .github/scripts/trymerge.py --comment-id 1654010315 106095 --dry-run` (need to comment out some of the code to actually write a test record to Rockset), then manually verify it with
```
SELECT
*
FROM
commons.merges
WHERE
pr_num = 106095
```
to see that `ignore_current_checks`, `broken_trunk_checks`, `flaky_checks`, and `unstable_checks` shows up correctly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106162
Approved by: https://github.com/clee2000
For the dynamic bfloat16 path, if we use plain weight, we can't call in amx path, so there use a dummy input(given a None value) to do the weight packing for better performance.
before:
```
onednn_verbose,exec,cpu,inner_product,x64:gemm:jit,forward_training,src_bf16::blocked:ab:f0 wei_bf16::blocked:ab:f0 bia_bf16::blocked:a:f0 dst_bf16::blocked:ab:f0,attr-scratchpad:user ,,mb64ic256oc256,9.4292
```
after:
```
onednn_verbose,exec,cpu,inner_product,brgemm:avx512_core_amx_bf16,forward_training,src_bf16::blocked:ab:f0 wei_bf16::blocked:AB16b32a2b:f0 bia_bf16::blocked:a:f0 dst_bf16::blocked:ab:f0,attr-scratchpad:user ,,mb64ic256oc256,0.35498
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106122
Approved by: https://github.com/jgong5, https://github.com/eellison
ops.bucketize() implements a binary search: it takes values and offsets; offsets defines a set of buckets, and ops.bucketize() returns, for each value, the index of the bucket it lies in. The op is elemenwise with regard to the values and outputs, but it needs access to the entire offsets tensor in global memory so that it can perform the binary search. So, we need to realize the boundaries into global memory before running the op. The scheduler won't try to fuse the two kernels together because the input to ops.bucketize() is marked as a StarDep.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106107
Approved by: https://github.com/jansel
No need to wait if the job classification is unstable as it would be ignored anyway. This is useful to not need to wait for scarce resources like ROCm, which is also frequently in unstable mode (There is a ROCm queue atm)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106095
Approved by: https://github.com/clee2000
Previous to the PR, the complex dtype would only fail. This PR keeps torch.fx.Graph with complex dtype, while mapping them to float dtype in torchscript(onnx) graph with real representation.
The change happens in multiple files:
1. `placeholder`: Apply torch.view_as_real() before sending fake tensor to graph building.
2. `call_function`: Fill in TorchScriptTensor dtype and shape with real representation dtype and shape.
3. Registry: Add `is_complex`, and supports complex onnxfunction.
4. Dispatcher: Filter with/out complex onnxfunction before opschema matching, based on the dtype in torch args
5. Test cases: input/output view_as_real for result comparisons.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100554
Approved by: https://github.com/BowenBao
We want to display the stack for the original cudaMalloc that created a segment.
Previously we could only report the last time the segment memory was used,
or the record of the segment_alloc could appear in the list of allocator actions.
This PR ensure regardless of whether we still have the segment_alloc action,
the context for a segment is still available. The visualizer is updated to
be able to incorporate this information.
This PR adds a new field to Block. However the previous stacked cleanup PR
removed a field of the same size, making the change to Block size-neutral.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106113
Approved by: https://github.com/aaronenyeshi
For free blocks of memory in the allocator, we previously kept a linked list
of the stack frames of previous allocations that lived there. This was only
ever used in one flamegraph visualization and never proved useful at
understanding what was going on. When memory history tracing was added, it
became redundant, since we can see the history of the free space from recording
the previous actions anyway.
This patch removes this functionality and simplifies the snapshot format:
allocated blocks directly have a 'frames' attribute rather than burying stack frames in the history.
Previously the memory history tracked the real size of allocations before rounding.
Since history was added, 'requested_size' has been added directly to the block which records the same information,
so this patch also removes that redundancy.
None of this functionality has been part of a PyTorch release with BC guarentees, so it should be safe to alter
this part of the format.
This patch also updates our visualization tools to work with the simplified format. Visualization tools keep
support for the old format in `_legacy` functions so that during the transition old snapshot files can still be read.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106079
Approved by: https://github.com/eellison
### Description
Hi! We've been fuzzing `pytorch` with [sydr-fuzz](https://github.com/ispras/oss-sydr-fuzz) and found error of out of bounds access in `torch::jit` module.
pytorch version: 18bcf62bbcf7ffd47e3bcf2596f72aa07a07d65f
The error occurs in `import_source.cpp:560` when we get the type from the `assign.rhs()`. `assign.rhs()` has `Maybe` type, as well as `assign.type()`, so one of them can be not presented. According to [grammar](22f93852a2/torch/csrc/jit/frontend/tree_views.h), we can have `Assign` statement, which `lhs` will be `Subscript`, `rhs` will be empty (`Maybe` type with no subtrees) and `type` will be presented. But in `import_source.cpp:560` we try to get `rhs` expression from the assignment with no check whether it is presented.
This is example from the how to reproduce section from the testing input:
```
class Module(Module):
__parameters__ = ["0", ]
__buffers__ = []
__annotations__ = []
__annotations__["0"] : Tensor
```
When we parse the last statement of class definition, we set the type of `lhs` to `Subscript`, because the lookahead is `[`
76fb72e24a/torch/csrc/jit/frontend/parser.cpp (L205-L207)
Then in `parseAssignment` we get `maybeOp` and `type` depending on the next symbol (if it is `:`, we get only the type)
76fb72e24a/torch/csrc/jit/frontend/parser.cpp (L437-L447)
So after that, in `import_source.cpp:560`, parsing attributes, one of which is assignment with subscript type of `lhs`, we try to get type from `rhs` expression and out of bounds access occurs.
To fix the error, we need to check whether the `rhs` or `type` are presented and get the type from corresponding expression.
### How to reproduce
Build docker container from [here](https://github.com/ispras/oss-sydr-fuzz/tree/master/projects/pytorch):
```bash
$ sudo docker build -t oss-sydr-fuzz-pytorch
```
Run docker container:
```bash
$ sudo docker run --rm --privileged -v `pwd`:/fuzz -it oss-sydr-fuzz-pytorch /bin/bash
```
Run the `load_fuzz` target on the [input.txt](https://github.com/pytorch/pytorch/files/12173962/input.txt)
```bash
/load_fuzz input.txt
```
You will see the following output:
```
AddressSanitizer:DEADLYSIGNAL
=================================================================
==157==ERROR: AddressSanitizer: SEGV on unknown address (pc 0x00000c163764 bp 0x7ffee71d0070 sp 0x7ffee71d0050 T0)
==157==The signal is caused by a READ memory access.
==157==Hint: this fault was caused by a dereference of a high value address (see register values below). Disassemble the provided pc to learn which register was used.
#0 0xc163764 in c10::intrusive_ptr<torch::jit::Tree, c10::detail::intrusive_target_default_null_type<torch::jit::Tree> >::retain_() /pytorch/c10/util/intrusive_ptr.h:265:54
#1 0xc1697fd in c10::intrusive_ptr<torch::jit::Tree, c10::detail::intrusive_target_default_null_type<torch::jit::Tree> >::intrusive_ptr(c10::intrusive_ptr<torch::jit::Tree, c10::detail::intrusive_target_default_null_type<torch::jit::Tree> > const&) /pytorch/c10/util/intrusive_ptr.h:354:5
#2 0xc1697fd in torch::jit::Expr::Expr(c10::intrusive_ptr<torch::jit::Tree, c10::detail::intrusive_target_default_null_type<torch::jit::Tree> > const&) /pytorch/torch/csrc/jit/frontend/tree_views.h:270:49
#3 0xc1f02cb in torch::jit::Maybe<torch::jit::Expr>::get() const /pytorch/torch/csrc/jit/frontend/tree_views.h:212:12
#4 0xd194369 in torch::jit::SourceImporterImpl::importClass(c10::QualifiedName const&, torch::jit::ClassDef const&, bool) /pytorch/torch/csrc/jit/serialization/import_source.cpp:560:70
#5 0xd18c701 in torch::jit::SourceImporterImpl::importNamedType(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, torch::jit::ClassDef const&) /pytorch/torch/csrc/jit/serialization/import_source.cpp:288:5
#6 0xd18a84c in torch::jit::SourceImporterImpl::findNamedType(c10::QualifiedName const&) /pytorch/torch/csrc/jit/serialization/import_source.cpp:140:5
#7 0xd1913a8 in torch::jit::SourceImporterImpl::resolveType(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, torch::jit::SourceRange const&) /pytorch/torch/csrc/jit/serialization/import_source.cpp:261:10
#8 0xc2e422f in torch::jit::ScriptTypeParser::parseTypeFromExpr(torch::jit::Expr const&) const /pytorch/torch/csrc/jit/frontend/script_type_parser.cpp:238:24
#9 0xc2e4697 in torch::jit::ScriptTypeParser::parseType(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) /pytorch/torch/csrc/jit/frontend/script_type_parser.cpp:312:10
#10 0xd1a37d4 in torch::jit::SourceImporter::loadType(c10::QualifiedName const&) const /pytorch/torch/csrc/jit/serialization/import_source.cpp:786:27
#11 0xd121c47 in torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0::operator()(c10::QualifiedName const&) const /pytorch/torch/csrc/jit/serialization/import.cpp:146:33
#12 0xd121c47 in c10::StrongTypePtr std::__invoke_impl<c10::StrongTypePtr, torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0&, c10::QualifiedName const&>(std::__invoke_other, torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0&, c10::QualifiedName const&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/invoke.h:60:14
#13 0xd121ad0 in std::enable_if<is_invocable_r_v<c10::StrongTypePtr, torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0&, c10::QualifiedName const&>, c10::StrongTypePtr>::type std::__invoke_r<c10::StrongTypePtr, torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0&, c10::QualifiedName const&>(torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0&, c10::QualifiedName const&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/invoke.h:113:9
#14 0xd121926 in std::_Function_handler<c10::StrongTypePtr (c10::QualifiedName const&), torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0>::_M_invoke(std::_Any_data const&, c10::QualifiedName const&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/std_function.h:291:9
#15 0xd17ec49 in std::function<c10::StrongTypePtr (c10::QualifiedName const&)>::operator()(c10::QualifiedName const&) const /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/std_function.h:622:14
#16 0xd26b802 in torch::jit::Unpickler::readGlobal(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) /pytorch/torch/csrc/jit/serialization/unpickler.cpp:844:9
#17 0xd2615fb in torch::jit::Unpickler::readInstruction() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:520:7
#18 0xd25f917 in torch::jit::Unpickler::run() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:253:27
#19 0xd25f5b2 in torch::jit::Unpickler::parse_ivalue() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:206:3
#20 0xd186403 in torch::jit::readArchiveAndTensors(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, c10::optional<std::function<c10::StrongTypePtr (c10::QualifiedName const&)> >, c10::optional<std::function<c10::intrusive_ptr<c10::ivalue::Object, c10::detail::intrusive_target_default_null_type<c10::ivalue::Object> > (c10::StrongTypePtr, c10::IValue)> >, c10::optional<c10::Device>, caffe2::serialize::PyTorchStreamReader&, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&), std::shared_ptr<torch::jit::DeserializationStorageContext>) /pytorch/torch/csrc/jit/serialization/import_read.cpp:53:20
#21 0xd12152d in torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) /pytorch/torch/csrc/jit/serialization/import.cpp:184:10
#22 0xd117bae in torch::jit::(anonymous namespace)::ScriptModuleDeserializer::deserialize(c10::optional<c10::Device>, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >&, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:287:19
#23 0xd114074 in torch::jit::import_ir_module(std::shared_ptr<torch::jit::CompilationUnit>, std::istream&, c10::optional<c10::Device>, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >&, bool, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:389:25
#24 0xd113a27 in torch::jit::import_ir_module(std::shared_ptr<torch::jit::CompilationUnit>, std::istream&, c10::optional<c10::Device>, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:325:10
#25 0xd11bb64 in torch::jit::load(std::istream&, c10::optional<c10::Device>, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:485:10
#26 0x610c5c in LLVMFuzzerTestOneInput /load.cc:42:14
#27 0x537701 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:611:15
#28 0x52160c in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:324:6
#29 0x52735b in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:860:9
#30 0x550912 in main /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10
#31 0x7f06e8323082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082) (BuildId: 1878e6b475720c7c51969e69ab2d276fae6d1dee)
#32 0x51bf2d in _start (/load_fuzz+0x51bf2d)
AddressSanitizer can not provide additional info.
SUMMARY: AddressSanitizer: SEGV /pytorch/c10/util/intrusive_ptr.h:265:54 in c10::intrusive_ptr<torch::jit::Tree, c10::detail::intrusive_target_default_null_type<torch::jit::Tree> >::retain_()
==157==ABORTING
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106041
Approved by: https://github.com/davidberard98
Previously, we would have test failures for operators which graph broke bc dynamic shape or data dependent ops. Those would appear as a failure because we were running with `nopython=True`. Those test "failures" (which is expected behavior) obfuscated the actual correctness errors, and made this test lower signal.
If we wanted to do something like full-op export, that should be different than inductor opinfos.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105480
Approved by: https://github.com/desertfire
Previously, when fusing a single node into a foreach op, the scheduler would iterate over each subnode and check if it can be fused, this PR adds a mapping so that the node to be fused with can be found more quickly by checking dependencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106008
Approved by: https://github.com/jansel
Summary:
Add Vulkan support for [sum](https://pytorch.org/docs/stable/generated/torch.sum.html).dim_IntList
[sum.dim_IntList](https://www.internalfb.com/code/fbsource/[49b7951b7eb6]/xplat/caffe2/aten/src/ATen/native/native_functions.yaml?lines=5466):
```
func: sum.dim_IntList(Tensor self, int[1]? dim, bool keepdim=False, *, ScalarType? dtype=None)
```
Some explanation
For each pos
- Iterate over the out_texel and summed dimension
- For H,W; rearrange pos.x, pos.y
- For C,H,W;
When CHW are summed, batch moves into channel
The src N is determined by pos.z * 4 + out_index
Follow up:
Add support for `keepdim=true`
```
if keepdim is true, the output tensor is of the same size as input except in the dimension(s) dim, where it is of size 1
otherwise, the dim is squeezed, result in the output tensor having 1 fewer dimension/s.
```
Add support for [sum](https://www.internalfb.com/code/fbsource/[49b7951b7eb6]/xplat/caffe2/aten/src/ATen/native/native_functions.yaml?lines=5457)
```
func: sum(Tensor self, *, ScalarType? dtype=None) -> Tensor
```
Test Plan:
New tests:
```
lfq@lfq-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*.sum*"
Downloaded 0/53 artifacts, 0.00 bytes, 100.0% cache miss (for updated rules)
Building: finished in 47.4 sec (100%) 536/536 jobs, 8/536 updated
Total time: 47.5 sec
BUILD SUCCEEDED
Running main() from third-party/googletest/1.11.0/googletest/googletest/src/gtest_main.cc
Note: Google Test filter = *.sum*
[==========] Running 5 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 5 tests from VulkanAPITest
[ RUN ] VulkanAPITest.sum_2d
[ OK ] VulkanAPITest.sum_2d (426 ms)
[ RUN ] VulkanAPITest.sum_3d
[ OK ] VulkanAPITest.sum_3d (2 ms)
[ RUN ] VulkanAPITest.sum_4d
[ OK ] VulkanAPITest.sum_4d (3 ms)
[ RUN ] VulkanAPITest.sum_3d_combined
[ OK ] VulkanAPITest.sum_3d_combined (1 ms)
[ RUN ] VulkanAPITest.sum_4d_combined
[ OK ] VulkanAPITest.sum_4d_combined (5 ms)
[----------] 5 tests from VulkanAPITest (437 ms total)
[----------] Global test environment tear-down
[==========] 5 tests from 1 test suite ran. (438 ms total)
[ PASSED ] 5 tests.
```
clang-format on Sum.cpp and sum_dim.glsl
Differential Revision: D47580428
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105612
Approved by: https://github.com/SS-JIA
For the CPU backend, we always use channels_last to get good performance by avoiding format reorder(block to plain or plain to black), and they also assume that the weight is channels_last when doing the weight packing, so there always convert weight format and doing layout optimization.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105517
Approved by: https://github.com/jgong5, https://github.com/shunting314
Summary:
Fix this warning:
```
caffe2\c10\macros\Macros.h(138): warning C4067: unexpected tokens following preprocessor directive - expected a newline
```
`caffe2/c10/util/variant.h` already has a similar to check and define a stub for `__has_attribute(x)`, so this would not be new to caffe2/pytorch.
Test Plan: CI should complete, still with plenty of caffe2 warnings but this one should be gone from the Windows build log
Differential Revision: D47735319
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105922
Approved by: https://github.com/kit1980
Fix: #105074
This PR makes dynamo handle Numpy global variables the same way as PyTorch tensor global
variables by tracking them as side-effect.
In summary, we add `NumpyNdarrayVariable` to the
`VariableBuilder._can_lift_attrs_to_inputs` function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105959
Approved by: https://github.com/ezyang
Given the number of unstable job atm (rocm, distributed), having the limit of 3 for ignorable failures is too low. When I manually look into force merges, I could find many examples like like https://github.com/pytorch/pytorch/pull/105848 where there are 3+ unrelated failures. As the classification is getting more accurate, we can aim to ignore all flaky and broken trunk failures.
* Default `ok_failed_checks_threshold` to `-1` to ignore all unrelated failures
* Increase the `IGNORABLE_FAILED_CHECKS_THESHOLD` to 10. The only concern I have before setting it to `-1` is the fog of war situation when a sev occurs. So 10 is a good middle ground before we agree to set it to `-1`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105998
Approved by: https://github.com/clee2000
In a recent change, diagnostics started logging contents within tuple/list/dict
for diagnosed function arguments and return types. This brought slow down
to export due to some extremely large container instances, such as the fx to
onnx node mapping dictionary.
This PR adds a limit to how many elements the diagnostic would record for
these types. Together with https://github.com/microsoft/onnxscript/pull/922, the performance of
export w/ diagnostics is restored and improved. As shown by pyinstrument:
GPT2 time for `fx_to_onnx_interpreter.run` 17.767s -> 1.961s
xcit_large_24_p8_224 time for `fx_to_onnx_interpreter.run` 144.729s -> 4.067s
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106048
Approved by: https://github.com/titaiwangms, https://github.com/justinchuby
# Summary
We have a vast majority of test that only run on cuda. Decorating with @onlycuda causes pytest to instantiate 2x the tests and skip half of them. This overhead is non trivial when the #tests cross larger like it has for this file.
This breaks up the cuda only tests into a separate class
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105938
Approved by: https://github.com/mikaylagawarecki, https://github.com/malfet
Fix issue where we were testing `test_schema_correctness_nn_functional_scaled_dot_product_attention_cuda_bfloat16` from `test_schema_check.py` on V100, but bfloat16 support on cuda doesn't exist for sm < 80. Added skip if sm < 80 to the failing test. cc @ptrblck @eqy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105888
Approved by: https://github.com/kit1980
Summary: moving quantizer to torch.ao.quantization to make it a public api, since pt2e is a folder for implementations
Test Plan:
CIs
sanity check: "buck test //executorch/backends/xnnpack/test:test_xnnpack_quantized_models -- test_resnet18"
Differential Revision: D47727838
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105885
Approved by: https://github.com/andrewor14
# Summary
### Review Points
- Automatically pad tensors to create aligned masks when seqlen_kv is not multiple of 16. This will cause memory spike ~ 2 * attn_mask size which could in theory be big. At appears though that doing this + mem_eff is faster than no_pad + math. SO seems to be worth it
- Using expand to view the attn_mask in 4d. This is a little different to how we enforce q,k,v to be viewed in 4d prior to calling. Also not supprint b*n_heads, seq_lenq, seq_lenkv case.
- Should enable, #96099
### Profiling
I ran a bunch of comparisons between sdpa.MATH and sdp.MemEffAttention. I added a attn_bias of shape (1, 1, seqlen_q, seqln_k). For these experiments seqlen_q == seqlen_k. These were all ran on an a100 80gb gpu.
Configs:
```
# Run a bunch of experiments
batch_sizes = [8, 16, 32]
num_heads = [16, 32]
max_seq_lens = [15, 64, 128, 512, 555, 1024]
embed_dims = [32, 64, 128]
dtypes = [torch.float16, torch.bfloat16, torch.float32]
pad_percentages = [None]
backends = [SDPBackend.EFFICIENT_ATTENTION, SDPBackend.MATH]
run_backward = True
attn_mask = True
```
The function calls `sdpa(input**).sum().backward()`.
I calculated the geomean speedup of the efficient attention path of the math path for all these configs:
`Geomean Speedup: 1.977`
An example comparision with batchsize = 8, num_heads = 32, embed_dim = 64, and dtype = torch.float16:

This was done using the current state of the branch where we force alignment of mask when the last dim is not divisible by 16, which shows up in seq_len = 15 and 555 case.
The full data can be found here:
[attn_mask_sweep.csv](https://github.com/pytorch/pytorch/files/11962399/attn_mask_sweep.csv)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104310
Approved by: https://github.com/cpuhrsch
As per title.
Note that the c++ side code for the minidumps part was removed. So trying to call any of these 3 functions today results in an error saying that `torch._C` doesn't have these attributes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105142
Approved by: https://github.com/janeyx99
Summary:
The old error message shows
```
... add `c10::InferenceMode mode;` before model.forward(). Note this guard is only available in C++ but not Python at present."
```
However InferenceMode for Python has been enabled since D28390595. It can be used as a context manager with `torch.inference_mode()`. The error message is fixed as so.
Test Plan: Easy
Reviewed By: yipjustin
Differential Revision: D47655392
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105948
Approved by: https://github.com/albanD
Without this PR, the warning message is misleading as it says the default is found before the error message popped.
Next PR will start refactoring aten overload fallback with adding overloads supported by torchlib into OpSchema matching.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105972
Approved by: https://github.com/BowenBao
Summary:
## About Sync Events
For CUDA profiling mode, we can enable tracing CUDA synchronization events.
* This feature captures synchronization events in CUDA including 1) context/device sync, 2) stream sync, 3) CUDA event sync, 4) CUDA stream wait event (inter stream synchronization). Read more
* We add this flag using the profiler's experimental config option.
* This PR relies on 7b003638c6 change in pytorch/kineto
## Usage
Just set the `enable_cuda_sync_events` option in `_ExperimentalConfig`
```
from torch.autograd.profiler import profile, _ExperimentalConfig
with profile(use_kineto=True, use_cuda=True,
experimental_config=_ExperimentalConfig(enable_cuda_sync_events=True),
) as prof:
workload()
```
**Please wait for PyTorch github repo to point to 7b003638c6 or later commit in Kineto**
Test Plan:
## Unit Test
Added a unit test
buck2 test mode/dev-nosan caffe2/test:profiler --local-only -- test_profiler_cuda_sync_events
Tests finished: Pass 1. Fail 0. Fatal 0. Skip 0. Build failure 0
ttps://www.internalfb.com/intern/testinfra/testrun/281475298097379
Reviewed By: davidberard98
Differential Revision: D46244591
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105187
Approved by: https://github.com/aaronenyeshi
In some situations we were registering a hook on a Tensor that does not
require grad, which immediately raises an error. This PR fixes that by
skipping the hook registration if the Tensor in question does not
require grad.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105660
Approved by: https://github.com/soulitzer
In fbcode, to run the test python script (with its accompanying test DSO) we
need to invoke the correct python, with the correct PYTHONPATH, so we supply
those by reading the appropriate values out of `sys`.
It's an improvement for OSS too, since the user may not be running the default
python.
My previous attempt of using `torch.backends.cpu.get_cpu_capability()` didn't work out, for two reasons:
1. That function actually refuses to report AVX512 support; it's #ifdef-ed out, for some reason.
2. In CI, we apparently are picking INVALID_VEC_ISA (at least when running
inductor_timm_cpu_accuracy), whereas `get_cpu_capability` reports AVX2. This
is surprising, and probably indicates a bug (either in cpu capability or our
test binary), but I'd rather not go digging for it.
Differential Revision: [D47678649](https://our.internmc.facebook.com/intern/diff/D47678649/)
Differential Revision: [D47678649](https://our.internmc.facebook.com/intern/diff/D47678649)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105756
Approved by: https://github.com/jansel, https://github.com/mikekgfb
Previous to the PR, op_level_debug doesn't support OnnxFakeConext because it relies on real tensor in args to do shape type inference propagation in fx graph to get static shapes helping simulating the op args/kwargs. However, OnnxFakeContext will fakify the args/kwargs at the very begining, so the op_level_debug can't have the static_shapes to utilize.
This PR uses SymInt API: `has_hint` and `hint_int` to fully replace the functionality of shape type inference propagation. The static shapes are obtained through SymInt. Therefore, the pass `ShapeInferenceWithFakeTensor` is eliminated.
Also moved the args/kwargs processing into op_validation to live under the rule `op_level_debug`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105874
Approved by: https://github.com/thiagocrepaldi, https://github.com/BowenBao
With distributed checkpointing in PyTorch/XLA SPMD, the WriteItem index hints should not be modified when creating the global plan. In order to reuse the default planner logic for checkpoint metadata creation, we need to make the behavior of rewriting index hints optional.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105861
Approved by: https://github.com/kumpera
Summary: Sometimes the graph that is being serialized contains nodes with side effects + no users (ex. out variants of operators), so we don't want to eliminate those when deserializing.
Test Plan: CI
Differential Revision: D47735009
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105875
Approved by: https://github.com/ydwu4
Current test case causes an edge case tensor input that causes a single generated tensor to fail the tolerance assertion on ROCm only and only for float32. We have reviewed the logic with our libraries team and have discovered the discrepancy is due to a difference in order of operations on AMD GPUs. They came back with "working as intended" and found no perceivable bug. Interestingly, if we change the values in ks, ns, or bs, the test passes on ROCm. These particular sizes in this particular order generates a single problematic input that causes the assertion to fail the tolerance check by ~0.07. Again, this is not a bug, just differences in implementation. This PR loosens the tolerance for ROCm only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104425
Approved by: https://github.com/jeffdaily, https://github.com/nikitaved, https://github.com/lezcano
Summary:
Ensures that creating tensors, copying, filling with zeroes, checking for nan works on cuda for the `float8` dtypes. This should be enough for float8 emulation on cuda.
Note that I skipped the mul test - it's less trivial to add (need a new c++ macro), and there is no use case for it. We can follow up on that in the future.
Test Plan:
```
python test/test_quantization.py TestFloat8Dtype
```
Reviewers:
Subscribers:
Tasks:
Tags:
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105807
Approved by: https://github.com/ezyang, https://github.com/jerryzh168, https://github.com/albanD
Introduce `Modularize` pass that analyzes the flat `fx.GraphModule` and creates nested
layers of sub `fx.GraphModule`s along with the `call_module` fx nodes that invokes them.
The analysis is done on the meta data "nn_module_stack", which captures the `nn.Module`
each flat `fx.Node` belongs to.
`FxOnnxInterpreter` is updated to support `call_module`. The related sub module linked
by `node.target` is exported as an ONNX model local function. The `call_module` node itself
is exported as an ONNX node, associated with the ONNX model local function by op_type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105618
Approved by: https://github.com/justinchuby
Previously, if 'starts', 'ends', or 'steps' was dynamic, then shape inference would give up, even for dimensions which are not being sliced.
This commit improves this by setting the output shape to be the same as the input shape for dimensions which are not being sliced. Add a new test to cover this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105755
Approved by: https://github.com/thiagocrepaldi, https://github.com/BowenBao
Currently when dynamic=True, TritonTemplates won't be used, as the condition `if list(call_args) != expected_args` defined in `TritonTemplate` cannot be satisfied. This PR tries to fix this issue by allowing passing symbolic variable names via `extra_args` and replacing all symbolic values in the generated TritonTemplate code as call_arg names.
With this change, a locally compiled mm + epilogue node calls into the Triton kernel successfully.
This PR also introduces a new config "max_autotune_gemm_backends" to allow specifying candidate gemm backends for max autotune. Current choices: combinations of ATEN, TRITON. This makes tests easier, so that we can explicitly test Triton gemm kernels + epilogue fusions + dynamic shapes, without falling back to ATen ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105295
Approved by: https://github.com/jansel
- This PR rewords the `BackwardPrefetch` docs to make the tradeoffs clear in the first sentence of each with more technical details after.
- The only supported `_FSDPPolicy` is `ModuleWrapPolicy` at the time of writing this PR. We may add others in the future such as in my other PR stack. This PR removes `_FSDPPolicy` from the public docs.
- This provides some more details around `MixedPrecision` such as explaining that layer norm and batch norm accumulate in fp32.
Follow-ups:
- Why do we force batch norm modules to have FSDP applied separately? (E.g. was this because before batch norm kernels did not support fp16/bf16?) Like layer norm, this just means that the affine parameters are in fp32. Both already accumulate in fp32 even with fp16/bf16 inputs.
- Check the `param_init_fn` + `sync_module_states=True` usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105847
Approved by: https://github.com/rohan-varma
Fixes#105467, namely the need of setting `aten_graph=True` in `_dynamo.export`
to make fake mode onnx exporter work.
Previously, `make_fx` called by passes always create new fake mode. Hence it is
missing out info from `shape_env` recorded during dynamo export. This PR tries
to check and fetch existing fake mode from graph node meta.
Also enable python dispatcher context when calling `make_fx`. This is done in
`_dynamo.export(aten_graph=True)` but was missing in our passes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105764
Approved by: https://github.com/titaiwangms
TL;DR: triton_utils.config_of determines divisibility by 16 for each of the inputs to the kernel (pointer alignment for pointers, and divisibility by 16 for sizes). For sizes, the check previously could only return true if the expr representing the size was an integer. However, it's possible for non-integral exprs to be divisible by 16, e.g. for an expr like 16*s0.
Motivation: Knowledge about divisibility by 16 allows for vectorizing loads and stores, which can improve memory bandwidth. If we have, for example, kernels with shape [s0, 16] (dynamic batch size; static, divisible-by-16 other dimensions), we want to still be able to vectorize those loads and stores.
Dashboard results suggest that this improves dynamic shape training performance for timm, and possibly a small improvement for torchbench as well. More details are provided in a comment below.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105743
Approved by: https://github.com/ezyang, https://github.com/aakhundov
# Summary
### Review Points
- Automatically pad tensors to create aligned masks when seqlen_kv is not multiple of 16. This will cause memory spike ~ 2 * attn_mask size which could in theory be big. At appears though that doing this + mem_eff is faster than no_pad + math. SO seems to be worth it
- Using expand to view the attn_mask in 4d. This is a little different to how we enforce q,k,v to be viewed in 4d prior to calling. Also not supprint b*n_heads, seq_lenq, seq_lenkv case.
- Should enable, #96099
### Profiling
I ran a bunch of comparisons between sdpa.MATH and sdp.MemEffAttention. I added a attn_bias of shape (1, 1, seqlen_q, seqln_k). For these experiments seqlen_q == seqlen_k. These were all ran on an a100 80gb gpu.
Configs:
```
# Run a bunch of experiments
batch_sizes = [8, 16, 32]
num_heads = [16, 32]
max_seq_lens = [15, 64, 128, 512, 555, 1024]
embed_dims = [32, 64, 128]
dtypes = [torch.float16, torch.bfloat16, torch.float32]
pad_percentages = [None]
backends = [SDPBackend.EFFICIENT_ATTENTION, SDPBackend.MATH]
run_backward = True
attn_mask = True
```
The function calls `sdpa(input**).sum().backward()`.
I calculated the geomean speedup of the efficient attention path of the math path for all these configs:
`Geomean Speedup: 1.977`
An example comparision with batchsize = 8, num_heads = 32, embed_dim = 64, and dtype = torch.float16:

This was done using the current state of the branch where we force alignment of mask when the last dim is not divisible by 16, which shows up in seq_len = 15 and 555 case.
The full data can be found here:
[attn_mask_sweep.csv](https://github.com/pytorch/pytorch/files/11962399/attn_mask_sweep.csv)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104310
Approved by: https://github.com/cpuhrsch
Summary: ExirExportedProgram would like to have this feature. Today it does it itself since it inherits from ExportedProgram but since we are moving it to composition I think it would be cleaner to upstream the behavior into the root object anyway
Test Plan: ci, but todo where are the tests for this file?
Differential Revision: D47645843
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105852
Approved by: https://github.com/tugsbayasgalan
This branch:
1) converts the autograd tape into an FX graph
2) caches that conversion using a "shadow" graph
3) compiles and runs the generated FX graph instead of the normal autograd
What works currently:
1) Caching, capture, and initial integration
2) Backwards hooks
3) Inlining AotAutograd generated subgraphs
4) torch.compiling the generated FX graph
5) Auto-detecting dynamic shapes based on changes
Future work
1) Larger scale testing
1) Boxed calling convention, so memory can be freed incrementally
1) Support hooks on SavedTensor
1) Additional testing by running eager autograd tests under compiled_autograd.enable()
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103822
Approved by: https://github.com/ezyang, https://github.com/albanD
Fixes#102678Fixes#102629Fixes#102558
HipSOLVER performance on ROCm5.4.2 and later no longer serves as massive bottleneck. Additionally, using magma on rocm in this case caused test_compare_cpu_lialg_pinv_singular_cuda_float32 to fail. Using hipSOLVER, the test now passes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103540
Approved by: https://github.com/lezcano
Summary: This is a follow-up on https://github.com/pytorch/pytorch/pull/105496. There are several issues with the previous fix,
1) It explicitly does copy for every output at the end of the main function;
2) When an output is ReinterpretView, no as_strided was generated for it;
3) There can be duplicated buffer declarations.
This PR fixes by making sure can_reuse behave consistently between two AOTIndcutor passes, and thus always generate the same set of kernels. It also adds handling of ReinterpretView.
Differential Revision: [D47692214](https://our.internmc.facebook.com/intern/diff/D47692214)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105773
Approved by: https://github.com/jansel
Summary:
A small model (<100MB) took about 20mins to load, and consume 16GB memory.
Strobelight profiling: https://fburl.com/strobelight/abwtz0ry
We realized that calc_line_start_offsets is culprit, and the line_starting_offsets_ is a vector of line numbers.
There are >20000 places we generate such ErrorReport, and the line number is ~100000.
So total memory cost is about 100000 x 20000 x 8 = ~16GB.
We propose to skip the error info for extreme large source file (>1MB). And keep an environment variable to keep the ability to print the source code info for large source file.
Test Plan:
buck run mode/opt-split-dwarf scripts/lufang:load_pt_model -- --model_file_path=/data/local/models/961746678/2/961746678_2.predictor.disagg.gpu.local
before the change, it takes 20mins to load, and the model costs 16GB memory (the model itself is only <100MB)
after the change, it takes 15s to load.
The most of the time / space is spent on calc_line_start_offsets, https://fburl.com/code/2to60zqu
Differential Revision: D47610805
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105608
Approved by: https://github.com/hl475
I've added the implementation of erfinv using the algorithm from 4154c8ea15/aten/src/ATen/native/Math.h (L152) in order for the MPS based algorithm to match the CPU automatic test. This PR is using the new metal api calls from https://github.com/pytorch/pytorch/pull/100661
Testing shows MPS has a decent speed up (270x) compared to CPU on tensor size of 100 mil elements.
```
import torch
x = torch.arange(-1, 1, 1e-8) # default cpu tensor
#measure CPU compute time by calling torch.erfinv
time = %timeit -o -q -r 5 torch.erfinv(x)
cpu_time = time.average
print("CPU torch.erfinv time: ", cpu_time)
x = x.to("mps")
# measure MPS compute time
time = %timeit -o -q -r 5 torch.erfinv(x)
mps_time = time.average
print("MPS torch.erfinv time: ", mps_time)
print(f"MPS torch.erfinv is {cpu_time/mps_time*100} percent faster than CPU torch.erfinv")
# compute MSE between MPS and CPU torch.erfinv
x = x.to("cpu")
y_cpu = torch.erfinv(x)
x = x.to("mps")
y_mps = torch.erfinv(x)
y_mps = y_mps.to("cpu")
mask = torch.isfinite(y_cpu) & torch.isfinite(y_mps.to("cpu"))
y_mps = y_mps[mask]
y_cpu = y_cpu[mask]
x = x[mask]
print(f"length of y_mps: {len(y_mps)}, length of y_cpu: {len(y_cpu)}, length of x: {len(x)}")
mse = torch.square(y_cpu - y_mps).mean()
print("MSE between MPS and CPU torch.erfinv: ", mse)
diff = torch.abs(y_cpu - y_mps)
print("Largest difference")
print(f"x: {x[torch.argmax(diff)]}, y_cpu: {y_cpu[torch.argmax(diff)]}, y_mps: {y_mps[torch.argmax(diff)]} , diff = {y_cpu[torch.argmax(diff)] - y_mps[torch.argmax(diff)]}")
```
CPU torch.erfinv time: 2.654937833400254
MPS torch.erfinv time: 0.009831255332002912
MPS torch.erfinv is 27005.07456822776 percent faster than CPU torch.erfinv
length of y_mps: 199999992, length of y_cpu: 199999992, length of x: 199999992
MSE between MPS and CPU torch.erfinv: tensor(4.2339e-14)
Largest difference
x: -0.9999980330467224, y_cpu: -3.363569736480713, y_mps: -3.3635685443878174 , diff = -1.1920928955078125e-06
Fixes #https://github.com/pytorch/pytorch/issues/86808
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101507
Approved by: https://github.com/kulinseth
Previously during torch.export(), when an exception is raised during tracing, Dynamo displays this error:
“You can suppress this exception and fall back to eager by setting: import torch._dynamo torch._dynamo.config.suppress_errors = True”
This is not viable in torch.export(), thus this diff suppresses this suggestion during export.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105767
Approved by: https://github.com/anijain2305
Currently, exporting a model to ONNX with fake tensor mode requires the
user to load data and model within `torch.onnx.enable_fake_mode` context,
but the actual call to `torch.onnx.dynamo_export` is done outside such
context.
With this PR, we enable `torch.onnx.dynamo_export` to be called either
within `torch.onnx.enable_fake_mode` or outside of it. This feature
required changes to the core PyTorch Dynamo, which were greatly
supported by @ezyang
In future steps we will determine which scenario we are going to
support, but for now we can use either to explore different options and
scenarios and asses their pros and cons.
This PR also creates a separate suite of tests for fake mode specific
scenarios (`TestFxToOnnxFakeTensorWithOnnxRuntime`).
It was done separately to decrease the test time, but we
could merge it with the default `TestFxToOnnxWithOnnxRuntime`. The
additional parameters are `load_checkpoint_during_init` and
`export_within_fake_mode`
With the newly added supported of nested export within fake mode, the
following scenarios are now supported:
```python
import torch
with torch.onnx.enable_fake_mode() as fake_context:
fake_args = create_args()
fake_kwargs = create_kwargs()
fake_model = create_model()
fake_model.load_state_dict(torch.load(tmp_checkpoint_file.name))
export_options = torch.onnx.ExportOptions(fake_context=fake_context)
# `torch.onnx.dynamo_export` called WITHIN `torch.onnx.enable_fake_mode`
export_output = torch.onnx.dynamo_export(
fake_model,
*fake_args,
**fake_kwargs,
export_options=export_options,
)
export_output.save("/path/to/model.onnx", model_state_dict=create_model())
```
If we decide to only support scenarios in which `torch._dynamo.export` is called within `FakeTensorMode`, then we can remove `fake_mode` argument from `torch._dynamo.export` as a follow-up task
ps: This PR is mostly Edward's https://github.com/pytorch/pytorch/pull/105468 + unit tests after an offline discussion
ps: https://github.com/pytorch/pytorch/issues/105464 tracks pending tasks/limitations from this PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105477
Approved by: https://github.com/ezyang, https://github.com/BowenBao
Summary:
To save on binary size, some of the mobile configs don't include the
autograd kernels for built-in operators (VariableTypeEverything.cpp).
For the mobile build:
- we don't care about having a nice autograd fallback that warns if
an operator has incorrect autograd support. If you're running
a custom operator on mobile then it's already too late for us to warn
or error on it.
- for perf reasons, we do not want mobile to go through autograd_fallbac
for all operators (the boxing/unboxing adds overhead).
As a result, on mobile we set the fallback to the fallthrough.
Test Plan: existing tests and benchmarks
Differential Revision: D47674272
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105750
Approved by: https://github.com/soulitzer
The feature was never fully finished and never got any adoption but
TCPStore pays the cost of twice the number of tcp connections anyway.
While the cost of all those idle connections is minimal is doesn't come for free:
- It increases the likelyhood of a connection refused failure during the initialization stampede.
- TCPStore uses poll for checking for socket availability which scales linearly on the number of sockets regardless of their status.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105014
Approved by: https://github.com/fduwjj
Prior to this PR, if the user called `fake_model.load_state_dict()` from within `enable_fake_mode`, the initial model state dict (including non persistent buffers) would not be reused by `ExportOutput.save` during ONNX proto creation.
That is not necessarily a bug because `ExportOutput.save` has a `model_state_dict` in which they can specify any state they want. However, it can be a hassle because if the user doesn't provide a full state, including non-persistent buffers, the resulting ONNX graph would require the missing buffers to be specified as input during execution.
With this PR, the `enable_fake_mode` is improved to capture the initial model state including any non-persistent buffer. This reference (not actual data) is persisted within `ExportOutput` and used by `save` to load additional `state_dict` that was captured by `enable_fake_mode`. The result is an ONNX graph with all model state without user having to specify the non-persistent buffers.
This helps addressing https://github.com/pytorch/pytorch/issues/105233 for models that call `fake_model.load _state_dict` under the hood as potential buffers not returned by `model.state_dict()` may be captured.
ps: https://github.com/pytorch/pytorch/issues/105464 tracks pending tasks/limitations from this PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105247
Approved by: https://github.com/BowenBao
Summary:
We are working toward full model compilation, where when compilation error happens, we just fall back to eager mode rather than error out.
But at the same time, we should fix these issues if they are bugs. We will:
* 1/ log warnings in OSS;
* 2/ log warnings and write them into Scuba in fbcode;
to prevent us from ignoring these issues.
Test Plan: Manual test
Differential Revision: D47506314
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105307
Approved by: https://github.com/jansel
When the hook registered by Tensor::register_hook (in C++) gets passed
an undefined tensor, it raises an internal assert in debug mode.
The cause is that we attempt to construct an OptionalTensorRef
(4448c78a5d/aten/src/ATen/core/Tensor.h (L68))
which asserts that the passed-in TensorBase is defined.
The fix is that we create a new TensorRef class to convert the
TensorBase into a Tensor without bumping the refcount (which is what
OptionalTensorRef does). We cannot reuse OptionalTensorRef because
OptionalTensorRef represents `optional<Tensor>` that cannot hold an
Undefined Tensor.
For some more historical context, it looks like this behavior was introduced
in #63612
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105587
Approved by: https://github.com/soulitzer
#98035 adds some additional logic `wait_for_process` that includes catching a timeout exception and sending `SIGINT` to the process before waiting on it again with a timeout. However, if the additional wait times out again, then the wait call in the `finally` block (which does not have a timeout) has the potential to hang indefinitely.
This PR kills the process if a second timeout exception occurs after the `SIGINT` signal is sent.
CC @clee2000 @ptrblck @xwang233 @kwen2501
Also hoping that this has the potential to reduce turnaround time for distributed timeouts like those seen in https://hud.pytorch.org/pr/pytorch/pytorch/105274#15148799113
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105625
Approved by: https://github.com/ezyang
The guard functions require you to ALREADY KNOW that a particular
condition holds. If you don't know (you want to guard on an expression
being a particular value, and then get access to that value), use
the evaluate functions.
I renamed the functions that don't abide by this:
```
guard_min -> evaluate_min
guard_max (deleted, no uses)
guard_static_shape -> evaluate_static_shape
guard_static_shapes -> evaluate_static_shapes
```
Some added comments.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105585
Approved by: https://github.com/voznesenskym
As per title.
Note that the c++ side code for the minidumps part was removed. So trying to call any of these 3 functions today results in an error saying that `torch._C` doesn't have these attributes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105142
Approved by: https://github.com/janeyx99
Docs were not exiting with failure, for example https://github.com/pytorch/pytorch/actions/runs/5604612586/job/15184094038#step:9:1131 because the if statement returned 0 if we want to exit.
Also get rid of the circleci scripts since they aren't used anywhere.
Example error:
```
copying static files... done
copying extra files... done
dumping search index in English (code: en)... done
dumping object inventory... done
build finished with problems, 1 warning.
make: *** [Makefile:49: html] Error 1
+ code=2
+ '[' 2 -ne 0 ']'
+ set +x
=========================
/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/nn/parallel/comm.py:docstring of torch.nn.parallel.comm.scatter:1: WARNING: more than one target found for cross-reference 'Stream': torch.cuda.Stream, torch.cuda.streams.Stream, torch.cpu.Stream
=========================
Docs build failed. If the failure is not clear, scan back in the log
for any WARNINGS or for the line build finished with problems
(tried to echo the WARNINGS above the ==== line)
=========================
+ return 2
+ exit 0
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105678
Approved by: https://github.com/seemethere
Summary:
Fix existing CAFFE static tracepoint macros and make them match the latest FOLLY version.
Per anakryiko, current `CAFE_SDT` definition is broken. Quote:
```
"Arguments: -5@-16(%rbp) -4@$100
Arguments: -8@-16(%rbp) -4@$100
#define FOLLY_SDT_IS_ARRAY_POINTER(x) ((__builtin_classify_type(x) == 14) || \
(__builtin_classify_type(x) == 5))
vs
#define CAFFE_SDT_ISARRAY(x) (__builtin_classify_type(x) == 14)
https://github.com/atgreen/gcc/blob/master/gcc/typeclass.h
that 5 is "pointer_type_class"
so you were right, it's just fixed up version of header
I think it should be 8, not 5
5 is the size of literal, but you don't pass string literal as an argument, you pass its address, so actual argument is a pointer, and so 8 byte long
you can try just fixing up CAFFE_SDT macro
```
{F1048035373}
Test Plan:
Tested the following macros on test scripts with libbpf USDTs:
CAFFE_SDT
CAFFE_DISABLE_SDT
CAFFE_SDT_WITH_SEMAPHORE
Reviewed By: RihamSelim
Differential Revision: D47159249
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105232
Approved by: https://github.com/chaekit, https://github.com/malfet
The test
f508d3564c/test/test_cuda_multigpu.py (L1282-L1290)
Torch cuda caching allocator may cache the allocation and cause the "new_alloc" being the same as the "old_alloc".
```python
self.assertGreater(memory_allocated(0), current_alloc[0])
```
I suggest that we use `assertGreaterEqual` instead of `assertGreater` in the test.
Individually running only this test does not make it fail but running it together with other tests from the same test module will make it fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105501
Approved by: https://github.com/zou3519
Solving #105242.
During export, the exported function's signature changes multiple times. Suppose we'd like to export f as shown in following example:
```python
def f(arg1, arg2, kw1, kw2):
pass
args = (arg1, arg2)
kwargs = {"kw2":arg3, "kw1":arg4}
torch.export(f, args, kwargs)
```
The signature changes mutiple times during export process in the following order:
1. **gm_torch_level = dynamo.export(f, *args, \*\*kwargs)**. In this step, we turn all kinds of parameters such as **postional_only**, **var_positioinal**, **kw_only**, and **var_kwargs** into **positional_or_kw**.It also preserves the positional and kword argument names in original function (i.e. f in this example) [here](https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/export.py#L546C13-L546C27). The order of kwargs will be the **key order** of kwargs (after python 3.6, the order is the insertion of order of keys) instead of the original function signature and the order is baked into a _orig_args varaible of gm_torch_level's pytree info. So we'll have:
```python
def gm_torch_level(arg1, arg2, kw2, kw1)
```
Such difference is acceptable as it's transparent to users of export.
2. **gm_aot_export = aot_export_module(gm_torch_level, pos_or_kw_args)**. In this step, we need to turn kwargs into positional args in the order of how gm_torch_level expected, which is stored in _orig_args. The returned gm_aot_export has the graph signature of flat_args, in_spec = pytree.tree_flatten(pos_or_kw_args):
``` python
flat_args, _ = pytree.tree_flatten(pos_or_kw_args)
def gm_aot_export(*flat_args)
```
3. **exported_program(*args, \*\*kwargs)**. The epxorted artifact is exported_program, which is a wrapper over gm_aot_export and has the same calling convention as the original function "f". To do this, we need to 1. specialize the order of kwargs into pos_or_kw_args and 2. flatten the pos_or_kw_args into what gm_aot_export expected. We can combine the two steps into one with :
```python
_, in_spec = pytree.tree_flatten((args, kwargs))
# Then during exported_program.__call__(*args, **kwargs)
flat_args = fx_pytree.tree_flatten_spec((args, kwargs), in_spec)
```
, where kwargs is treated as a normal pytree whose keyorder is preserved in in_spec.
Implementation-wise, we treat _orig_args in dynamo exported graph module as single source of truth and kwags are ordered following it.
Test plan:
See added tests in test_export.py.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105337
Approved by: https://github.com/angelayi, https://github.com/tugsbayasgalan
Since Python 3.11 bytecode contains endline and column information, for each bytecode, we attribute the source code corresponding to the bytecode in a more accurate way. For example, we can highlight a function call in a series of nested function calls, or highlight a function call spanning multiple lines.
Sample:
```python
import torch
import torch._dynamo
from functorch.experimental.control_flow import cond
def h(x):
return x * 5
def true_fn(x):
return x * 2
def false_fn(x):
return x * 3
def f(pred, x):
x = h(
h(h(x))
)
x = x[1:][:2]
torch._dynamo.graph_break()
x = cond(pred, true_fn, false_fn, [x])
opt_f = torch.compile(f, backend="eager")
opt_f(torch.tensor(True), torch.randn(3, 3, 3, 3))
```
Output:
```
$ TORCH_LOGS="trace_call" python playground9.py
TRACE inlined call h from f /scratch/williamwen/work/pytorch/playground9.py:16
h(h(x))
~^^^
TRACE FX call mul from h /scratch/williamwen/work/pytorch/playground9.py:6 (inline depth: 1)
return x * 5
~~^~~
TRACE inlined call h from f /scratch/williamwen/work/pytorch/playground9.py:16
h(h(x))
~^^^^^^
TRACE FX call mul_1 from h /scratch/williamwen/work/pytorch/playground9.py:6 (inline depth: 1)
return x * 5
~~^~~
TRACE inlined call h from f /scratch/williamwen/work/pytorch/playground9.py:15
x = h(
~^
h(h(x))
^^^^^^^
)
^
TRACE FX call mul_2 from h /scratch/williamwen/work/pytorch/playground9.py:6 (inline depth: 1)
return x * 5
~~^~~
TRACE FX call getitem from f /scratch/williamwen/work/pytorch/playground9.py:18
x = x[1:][:2]
~^^^^
TRACE FX call getitem_1 from f /scratch/williamwen/work/pytorch/playground9.py:18
x = x[1:][:2]
~~~~~^^^^
TRACE inlined call true_fn from <resume in f> /scratch/williamwen/work/pytorch/playground9.py:20
x = cond(pred, true_fn, false_fn, [x])
~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TRACE FX call mul from true_fn /scratch/williamwen/work/pytorch/playground9.py:9 (inline depth: 1)
return x * 2
~~^~~
TRACE inlined call false_fn from <resume in f> /scratch/williamwen/work/pytorch/playground9.py:20
x = cond(pred, true_fn, false_fn, [x])
~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TRACE FX call mul from false_fn /scratch/williamwen/work/pytorch/playground9.py:12 (inline depth: 1)
return x * 3
~~^~~
TRACE FX call cond from <resume in f> /scratch/williamwen/work/pytorch/playground9.py:20
x = cond(pred, true_fn, false_fn, [x])
~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104676
Approved by: https://github.com/ezyang
Hi! we've been fuzzing PyTorch project with [sydr-fuzz](https://github.com/ispras/oss-sydr-fuzz/tree/master/projects/pytorch).
We've found a couple heap-buffer-overflows in `distributed/rpc` module.
PyTorch version: 0f1621df1a
OS: Ubuntu 20.04
### How to reproduce
1. Build docker from this [Dockerfile](https://github.com/ispras/oss-sydr-fuzz/tree/master/projects/pytorch) and run the container.
2. Then run `message_deserialize-afl++` fuzzing target on provided crash-inputs ([crash-056826339f6da8dbb97c944178e94494369a9e22.zip](https://github.com/pytorch/pytorch/files/12096151/crash-056826339f6da8dbb97c944178e94494369a9e22.zip), [crash-4f85db9f19fe152c0018f6675c3b4c122227058f.zip](https://github.com/pytorch/pytorch/files/12096160/crash-4f85db9f19fe152c0018f6675c3b4c122227058f.zip)):
```
unzip crash-4f85db9f19fe152c0018f6675c3b4c122227058f.zip
/message_deserialize-afl++ crash-4f85db9f19fe152c0018f6675c3b4c122227058f
```
### Heap buffer overflow in torch/csrc/jit/serialization/pickle.cpp:144
[crash-056826339f6da8dbb97c944178e94494369a9e22.zip](https://github.com/pytorch/pytorch/files/12096151/crash-056826339f6da8dbb97c944178e94494369a9e22.zip)
```asan
"==7614==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x60b001b58355 at pc 0x0000005d1147 bp 0x7fffffffa610 sp 0x7fffffff9de0",
"READ of size 256 at 0x60b001b58355 thread T0",
" #0 0x5d1146 in __asan_memcpy /llvm-project-llvmorg-14.0.6/compiler-rt/lib/asan/asan_interceptors_memintrinsics.cpp:22:3",
" #1 0xd1cd19f in torch::jit::unpickle(char const*, unsigned long, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&))::$_3::operator()(char*, unsigned long) const /pytorch/torch/csrc/jit/serialization/pickle.cpp:144:9",
" #2 0xd1cd19f in unsigned long std::__invoke_impl<unsigned long, torch::jit::unpickle(char const*, unsigned long, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&))::$_3&, char*, unsigned long>(std::__invoke_other, torch::jit::unpickle(char const*, unsigned long, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&))::$_3&, char*&&, unsigned long&&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/invoke.h:60:14",
" #3 0xd27aa48 in std::function<unsigned long (char*, unsigned long)>::operator()(char*, unsigned long) const /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/std_function.h:622:14",
" #4 0xd27a61c in torch::jit::Unpickler::readSlowWithBuffer(char*, unsigned long) /pytorch/torch/csrc/jit/serialization/unpickler.cpp:1047:23",
" #5 0xd2698b8 in unsigned char torch::jit::Unpickler::read<unsigned char>() /pytorch/torch/csrc/jit/serialization/unpickler.h:111:7",
" #6 0xd268816 in torch::jit::Unpickler::readOpCode() /pytorch/torch/csrc/jit/serialization/unpickler.h:130:38",
" #7 0xd268816 in torch::jit::Unpickler::run() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:238:17",
" #8 0xd268522 in torch::jit::Unpickler::parse_ivalue() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:204:3",
" #9 0xd1c8502 in torch::jit::unpickle(std::function<unsigned long (char*, unsigned long)>, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)) /pytorch/torch/csrc/jit/serialization/pickle.cpp:126:20",
" #10 0xd1c8dbd in torch::jit::unpickle(char const*, unsigned long, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)) /pytorch/torch/csrc/jit/serialization/pickle.cpp:136:10",
" #11 0xe56b16d in torch::distributed::rpc::readWrappedPayload(std::vector<char, std::allocator<char> >&, torch::distributed::rpc::Message const&) /pytorch/torch/csrc/distributed/rpc/utils.cpp:515:18",
" #12 0xe3d8f29 in torch::distributed::autograd::RpcWithProfilingReq::fromMessage(torch::distributed::rpc::Message const&) /pytorch/torch/csrc/distributed/autograd/rpc_messages/rpc_with_profiling_req.cpp:112:24",
" #13 0xe55f692 in torch::distributed::rpc::deserializeRequest(torch::distributed::rpc::Message const&) /pytorch/torch/csrc/distributed/rpc/utils.cpp:138:14",
" #14 0x6120a8 in LLVMFuzzerTestOneInput /message_deserialize.cc:192:27",
" #15 0x535de1 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:611:15",
" #16 0x51fcec in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:324:6",
" #17 0x525a3b in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:860:9",
" #18 0x54eff2 in main /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10",
" #19 0x7ffff7a37082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082) (BuildId: 1878e6b475720c7c51969e69ab2d276fae6d1dee)",
" #20 0x51a60d in _start (/message_deserialize_fuzz+0x51a60d)",
"",
"0x60b001b58355 is located 0 bytes to the right of 101-byte region [0x60b001b582f0,0x60b001b58355)",
"allocated by thread T0 here:",
" #0 0x60c7bd in operator new(unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/asan/asan_new_delete.cpp:95:3",
" #1 0x62c7fd in std::_Vector_base<char, std::allocator<char> >::_M_allocate(unsigned long) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_vector.h:346:20",
" #2 0x62c7fd in void std::vector<char, std::allocator<char> >::_M_range_initialize<unsigned char const*>(unsigned char const*, unsigned char const*, std::forward_iterator_tag) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_vector.h:1582:14",
" #3 0x612913 in std::vector<char, std::allocator<char> >::vector<unsigned char const*, void>(unsigned char const*, unsigned char const*, std::allocator<char> const&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_vector.h:657:4",
" #4 0x611c4a in LLVMFuzzerTestOneInput /message_deserialize.cc:181:21",
" #5 0x535de1 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:611:15",
" #6 0x51fcec in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:324:6",
" #7 0x525a3b in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:860:9",
" #8 0x54eff2 in main /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10",
" #9 0x7ffff7a37082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082) (BuildId: 1878e6b475720c7c51969e69ab2d276fae6d1dee)",
"",
"SUMMARY: AddressSanitizer: heap-buffer-overflow /llvm-project-llvmorg-14.0.6/compiler-rt/lib/asan/asan_interceptors_memintrinsics.cpp:22:3 in __asan_memcpy",
"Shadow bytes around the buggy address:",
" 0x0c1680363010: 00 00 00 fa fa fa fa fa fa fa fa fa 00 00 00 00",
" 0x0c1680363020: 00 00 00 00 00 00 00 00 00 00 fa fa fa fa fa fa",
" 0x0c1680363030: fa fa 00 00 00 00 00 00 00 00 00 00 00 00 00 fa",
" 0x0c1680363040: fa fa fa fa fa fa fa fa 00 00 00 00 00 00 00 00",
" 0x0c1680363050: 00 00 00 00 00 fa fa fa fa fa fa fa fa fa 00 00",
"=>0x0c1680363060: 00 00 00 00 00 00 00 00 00 00[05]fa fa fa fa fa",
" 0x0c1680363070: fa fa fa fa 00 00 00 00 00 00 00 00 00 00 00 00",
" 0x0c1680363080: 05 fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c1680363090: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c16803630a0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c16803630b0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
"Shadow byte legend (one shadow byte represents 8 application bytes):",
" Addressable: 00",
" Partially addressable: 01 02 03 04 05 06 07",
" Heap left redzone: fa",
" Freed heap region: fd",
" Stack left redzone: f1",
" Stack mid redzone: f2",
" Stack right redzone: f3",
" Stack after return: f5",
" Stack use after scope: f8",
" Global redzone: f9",
" Global init order: f6",
" Poisoned by user: f7",
" Container overflow: fc",
" Array cookie: ac",
" Intra object redzone: bb",
" ASan internal: fe",
" Left alloca redzone: ca",
" Right alloca redzone: cb",
"==7614==ABORTING"
```
### Heap-buffer-overflow in aten/src/ATen/core/ivalue.h:432
[crash-4f85db9f19fe152c0018f6675c3b4c122227058f.zip](https://github.com/pytorch/pytorch/files/11553011/crash-4f85db9f19fe152c0018f6675c3b4c122227058f.zip)
```asan
"==60983==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x6150001e4108 at pc 0x000000601877 bp 0x7fffffff9fd0 sp 0x7fffffff9fc8",
"READ of size 4 at 0x6150001e4108 thread T0",
" #0 0x601876 in c10::IValue::isTensor() const /pytorch/aten/src/ATen/core/ivalue.h:432:27",
" #1 0x601876 in c10::IValue::destroy() /pytorch/aten/src/ATen/core/ivalue.h:1148:9",
" #2 0x699f72 in c10::IValue::~IValue() /pytorch/aten/src/ATen/core/ivalue.h:236:5",
" #3 0x699f72 in void std::_Destroy<c10::IValue>(c10::IValue*) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_construct.h:140:19",
" #4 0x699f72 in void std::_Destroy_aux<false>::__destroy<c10::IValue*>(c10::IValue*, c10::IValue*) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_construct.h:152:6",
" #5 0x699f72 in void std::_Destroy<c10::IValue*>(c10::IValue*, c10::IValue*) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_construct.h:184:7",
" #6 0x699f72 in void std::_Destroy<c10::IValue*, c10::IValue>(c10::IValue*, c10::IValue*, std::allocator<c10::IValue>&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/alloc_traits.h:738:7",
" #7 0x699f72 in std::vector<c10::IValue, std::allocator<c10::IValue> >::_M_erase_at_end(c10::IValue*) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_vector.h:1796:6",
" #8 0x699e4a in std::vector<c10::IValue, std::allocator<c10::IValue> >::_M_erase(__gnu_cxx::__normal_iterator<c10::IValue*, std::vector<c10::IValue, std::allocator<c10::IValue> > >, __gnu_cxx::__normal_iterator<c10::IValue*, std::vector<c10::IValue, std::allocator<c10::IValue> > >) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/vector.tcc:191:4",
" #9 0xea5b11e in torch::jit::Unpickler::readInstruction() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:454:14",
" #10 0xea57d97 in torch::jit::Unpickler::run() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:251:27",
" #11 0xea579f1 in torch::jit::Unpickler::parse_ivalue() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:204:3",
" #12 0xe9a435e in torch::jit::unpickle(std::function<unsigned long (char*, unsigned long)>, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)) /pytorch/torch/csrc/jit/serialization/pickle.cpp:126:20",
" #13 0xe9a471c in torch::jit::unpickle(char const*, unsigned long, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)) /pytorch/torch/csrc/jit/serialization/pickle.cpp:136:10",
" #14 0xfcd034b in torch::distributed::autograd::PropagateGradientsReq::fromMessage(torch::distributed::rpc::Message const&) /pytorch/torch/csrc/distributed/autograd/rpc_messages/propagate_gradients_req.cpp:54:18",
" #15 0xfe720ff in torch::distributed::rpc::deserializeRequest(torch::distributed::rpc::Message const&) /pytorch/torch/csrc/distributed/rpc/utils.cpp:132:14",
" #16 0x5c5c93 in LLVMFuzzerTestOneInput /message_deserialize.cc:192:27",
" #17 0x5c2bfd in ExecuteFilesOnyByOne /AFLplusplus/utils/aflpp_driver/aflpp_driver.c:255:7",
" #18 0x5c2a08 in LLVMFuzzerRunDriver /AFLplusplus/utils/aflpp_driver/aflpp_driver.c",
" #19 0x5c25c8 in main /AFLplusplus/utils/aflpp_driver/aflpp_driver.c:300:10",
" #20 0x7ffff7a37082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082) (BuildId: 1878e6b475720c7c51969e69ab2d276fae6d1dee)",
" #21 0x50237d in _start (/message_deserialize_afl+0x50237d)",
"",
"0x6150001e4108 is located 8 bytes to the right of 512-byte region [0x6150001e3f00,0x6150001e4100)",
"allocated by thread T0 here:",
" #0 0x5bfbfa in operator new(unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/asan/asan_new_delete.cpp:95:3",
"",
"SUMMARY: AddressSanitizer: heap-buffer-overflow /pytorch/aten/src/ATen/core/ivalue.h:432:27 in c10::IValue::isTensor() const",
"Shadow bytes around the buggy address:",
" 0x0c2a800347d0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c2a800347e0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00",
" 0x0c2a800347f0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00",
" 0x0c2a80034800: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00",
" 0x0c2a80034810: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00",
"=>0x0c2a80034820: fa[fa]fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c2a80034830: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c2a80034840: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c2a80034850: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c2a80034860: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c2a80034870: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
"Shadow byte legend (one shadow byte represents 8 application bytes):",
" Addressable: 00",
" Partially addressable: 01 02 03 04 05 06 07",
" Heap left redzone: fa",
" Freed heap region: fd",
" Stack left redzone: f1",
" Stack mid redzone: f2",
" Stack right redzone: f3",
" Stack after return: f5",
" Stack use after scope: f8",
" Global redzone: f9",
" Global init order: f6",
" Poisoned by user: f7",
" Container overflow: fc",
" Array cookie: ac",
" Intra object redzone: bb",
" ASan internal: fe",
" Left alloca redzone: ca",
" Right alloca redzone: cb",
"==60983==ABORTING"
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105537
Approved by: https://github.com/albanD
Proposal of two float8 variants - e5m2 and e4m3 - based on https://arxiv.org/pdf/2209.05433.pdf
Hide all Float8 operator implementations behind `#if !defined(C10_MOBILE)` guard to keep Android build size almost unchanged
TODO:
- Refactor duplicated code
- Cleanup unbalanced pragma pop in dtype utils
- Add native implementation on the CUDA size
Co-authored-by: Nikita Shulga <nshulga@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104242
Approved by: https://github.com/albanD
This change adds the TensorPipe header files to `torch_package_data` if `USE_DISTRIBUTED` is set to `ON` in the CMake cache. The TensorPipe library and CMake config is already available in the Torch wheel, but the headers are not. This resolves issue where out-of-tree backends could not implement TensorPipe converters, because the definition of the `tensorpipe::Message` struct is defined in the TensorPipe headers.
Fixes#105224.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105521
Approved by: https://github.com/albanD
Proposal of two float8 variants - e5m2 and e4m3 - based on https://arxiv.org/pdf/2209.05433.pdf
Hide all Float8 operator implementations behind `#if !defined(C10_MOBILE)` guard to keep Android build size almost unchanged
TODO:
- Refactor duplicated code
- Cleanup unbalanced pragma pop in dtype utils
- Add native implementation on the CUDA size
Co-authored-by: Nikita Shulga <nshulga@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104242
Approved by: https://github.com/albanD
Summary: Return early if we can easily determine the operator qualified name is invalid before attempting to retrieve the schema. In particular "::" should always be present. Quick estimate shows that this is >50x faster (100 us -> 2 us).
Test Plan: CI
Differential Revision: D47562587
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105495
Approved by: https://github.com/aaronenyeshi
Summary:
If a model was exported for Vulkan backend without (automatic or manual) device transfers, then the export is incorrect, and the JNI need not correct that.
(If this assumption is incorrect, please give feedback.)
Undo the changes from
- D23763771: automatic device transfers in JNI
- D39519168: `"requires_backend_transfers"` logic in JNI
Test Plan: Verify CUNET+ hybrid model from D47488843 works.
Reviewed By: SS-JIA
Differential Revision: D47527244
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105583
Approved by: https://github.com/SS-JIA
**TL;DR**: if lowerings.py encounters aten.index_put, it will set V.graph.cudagraphs_okay = False, which will disable cudagraphs. index_put needs to be disabled because it crashes cuda graphs.
index_put_ fallbacks fail with cuda graphs when `accumulate=True` - likely for the same reason that it fails with deterministic_algorithms_enabled:
fcb7d4b358/aten/src/ATen/native/TensorAdvancedIndexing.cpp (L730)
A first attempt was just to expand the scenarios where `index_put_` is one of the disallowed kernels in utils.py: 2fa7d11b64/torch/_inductor/utils.py (L436-L438)
However this disables cuda graphs in too many scenarios, because index_put doesn't cause issues if it gets fused, it only causes issues if the aten kernel gets called. So in the updated version of this PR, we check for fallbacks in lowerings.py and disable cudagraphs only if a fallback is encountered there.
Example of failure outside of PT2:
```python
import torch
def fn(x, y, z):
x = torch.zeros_like(x)
return x.index_put_([y], z, True)
# return x + 1
x = torch.zeros((512, 512), dtype=torch.bool, device='cuda')
y = torch.arange(512, dtype=torch.int64, device='cuda')
z = torch.ones((512, 512), dtype=torch.bool, device='cuda')
s = torch.cuda.Stream()
s.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(s):
for i in range(3):
fn(x, y, z)
torch.cuda.current_stream().wait_stream(s)
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
fn(x, y, z)
```
fails with
```
Traceback (most recent call last):
File "/data/users/dberard/scripts/graphed_index_put.py", line 24, in <module>
fn(x, y, z)
File "/data/users/dberard/scripts/graphed_index_put.py", line 8, in fn
return x.index_put_([y], z, True)
RuntimeError: CUDA error: operation not permitted when stream is capturing
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/data/users/dberard/scripts/graphed_index_put.py", line 24, in <module>
fn(x, y, z)
File "/data/users/dberard/pytorch/torch/cuda/graphs.py", line 173, in __exit__
self.cuda_graph.capture_end()
File "/data/users/dberard/pytorch/torch/cuda/graphs.py", line 79, in capture_end
super().capture_end()
RuntimeError: CUDA error: operation failed due to a previous error during capture
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
```
Differential Revision: [D47538548](https://our.internmc.facebook.com/intern/diff/D47538548)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105439
Approved by: https://github.com/eellison
**Summary**
When convert float tensor to uint8 data type as `tensor.to(dtype=torch.uint8)`, PyTorch will directly truncate the decimal. Previously, in `convert_float_to_uint8` we use `_mm512_cvtps_epi32` which uses default rounding mode (round to nearest) to convert float to uint8 which doesn't align with the eager mode behavior. Change `_mm512_cvtps_epi32` to `_mm512_cvttps_epi32` to use directly truncate when convert float tensor to uint8.
**Test Plan**
```
python -m pytest test_cpu_repro.py -k test_to_uint8_rounding_method
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105109
Approved by: https://github.com/jgong5, https://github.com/mingfeima, https://github.com/jerryzh168
Summary:
kip_fist_pump
Running any EgoOCR workflow in non-opt modes was breaking with https://fburl.com/strict-weak-ordering
Painstakingly found out that the stable_sort comparator in the generate_proposals caffe2 op was the issue due to numerical imprecision. This was causing Word Detector model to barf with the error. Adding explicit handling for the [irreflexivity property](https://www.boost.org/sgi/stl/StrictWeakOrdering.html) fixes this annoying strict-weak-ordering issue that has bugged me and several others(https://fb.workplace.com/groups/1405155842844877/permalink/7079705785389826/) for a while.
We can finally run all OCR workflows in non-opt mode! :)
Test Plan:
Debugged this with `fdb --disable-auto-breakpoints --secondary-debugger=lldb buck2 run mode/dev-sand ai_demos/server_model_zoo/models/ego_ocr_e2e_prod:ego_ocr_e2e_prod_binary`
and running `breakpoint set -E c++` in the lldb terminal.
Differential Revision: D47446816
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105189
Approved by: https://github.com/malfet, https://github.com/atalman
This PR adds initial dynamo support for DTensor, in particular, it:
- allows DTensor be passed into a compiled function, and allow fakify
DTensor during dynamo tracing by turning the inner local tensor to meta
tensor.
- We use `allow_in_graph` to include `DTensor` and `DTensor.from_local` to be represented as `TorchVariable`
- The dtensor created becomes a normal `TensorVariable` and it would insert any tensor operations to the output graph just like torch.Tensor
- note that dtensor have a new instance method `redistribute` compare to plain tensor, and we currently special handle it in `TensorVariable`
`from_local` and `redistribute` both accepts some non-trival metadata as arguments (i.e. DeviceMesh, Placement) which fx.Graph does not support. In order to let these two APIs appear in the dynamo captured graph, we encoded the metadata into a new_function (like `functools.partial`) and the new function only accepts prim args (i.e. tensor), then we put `call_function` with this new_function to the graph. This is suggested by @ezyang. The underlying rationale here is that the metadata will not change across the graph invocations so it's safe to encode them.
Captured graph:
```
def forward(self, L_x_ : torch.Tensor):
l_x_ = L_x_
# File: /scratch/wanchaol/work/pytorch/test/distributed/_tensor/test_dtensor.py:685, code: dt = DTensor.from_local(x, mesh, [Shard(0)], run_check=False)
prim_from_local = torch__dynamo_variables_torch_prim_from_local(l_x_, run_check = False); l_x_ = None
# File: /scratch/wanchaol/work/pytorch/test/distributed/_tensor/test_dtensor.py:686, code: return dt.redistribute(mesh, [Replicate()]).to_local() + 2
prim_redistribute = torch__dynamo_variables_tensor_prim_redistribute(prim_from_local); prim_from_local = None
to_local = prim_redistribute.to_local(); prim_redistribute = None
add = to_local + 2; to_local = None
return (add,)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103146
Approved by: https://github.com/voznesenskym
Fixes: #105143
In summary, the changes are:
- Check if Z3 is installed when the module is loaded
- Naming consistently as "translation validation" (not "validator")
- Skipping tests if Z3 is not installed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105168
Approved by: https://github.com/ezyang
Summary:
This caused some internal tests to fail. I'm not sure it is possible to easily
revert the original diff. This diff is a hotfix that changes the autograd
fallback behavior to what it was previously.
Test Plan: Existing tests
Differential Revision: D47569822
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105505
Approved by: https://github.com/soulitzer
Summary:
* Create a private global-scope function _generate_subsequent because static class attribute member functions not supported by TorchScript resulting in torchscripting errors.
* Make TransformerEncoder and TransformerDecoder consistent w.r.t. is_causal handling by calling _detect_casual_mask
* Clarify documentation that is_causal is a hint
* Move causal mask detection into a method _detect_causal_mask
* only accept input-size compatible causal mask as causal mask
* update _generate_subsequent_causal_mask to include factory kwargs for dtype and device:
avoid extra copies & conversions by passing directly to torch.full.
Test Plan: sandcastle & github CICD
Continuation of #101487 (due to a tooling issue) which is a continuation-in-part of https://github.com/pytorch/pytorch/pull/98327 by @janEbert
Differential Revision: D47427117
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105265
Approved by: https://github.com/mikaylagawarecki
Summary: We wanna do this little by little. For now, I tried only on DissectedPartsModel which needs to use aot_export version.
Test Plan: CI
Reviewed By: zhxchen17
Differential Revision: D46785735
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104897
Approved by: https://github.com/JacobSzwejbka
Summary:
As suggested in #105230, mypy checking is enabled in `torch/_inductor/lowering.py`.
23 errors fixed; 6 silenced with `# type: ignore[attr-defined]`.
Test Plan:
Before the fix:
```
$ mypy torch/_inductor/lowering.py
torch/_inductor/lowering.py:139:16: error: "Symbol" has no attribute "is_integer" [attr-defined]
torch/_inductor/lowering.py:263:20: error: Incompatible types in assignment (expression has type "Union[List[Any], Tuple[Any, ...]]", variable has type "List[Any]") [assignment]
torch/_inductor/lowering.py:427:49: error: "IRNode" has no attribute "get_size" [attr-defined]
torch/_inductor/lowering.py:439:37: error: "IRNode" has no attribute "get_dtype" [attr-defined]
torch/_inductor/lowering.py:456:34: error: "IRNode" has no attribute "get_device" [attr-defined]
torch/_inductor/lowering.py:645:44: error: Need type annotation for "b" [var-annotated]
torch/_inductor/lowering.py:1321:12: error: "FakeTensor" has no attribute "is_cpu" [attr-defined]
torch/_inductor/lowering.py:1542:24: error: Argument 3 to "FixedLayout" has incompatible type "List[int]"; expected "List[Expr]" [arg-type]
torch/_inductor/lowering.py:1542:81: error: Argument "offset" to "FixedLayout" has incompatible type "int"; expected "Expr" [arg-type]
torch/_inductor/lowering.py:1571:24: error: Argument 3 to "FixedLayout" has incompatible type "List[int]"; expected "List[Expr]" [arg-type]
torch/_inductor/lowering.py:1571:81: error: Argument "offset" to "FixedLayout" has incompatible type "int"; expected "Expr" [arg-type]
torch/_inductor/lowering.py:1654:12: error: Incompatible types in assignment (expression has type "List[Any]", variable has type "Tuple[Any, ...]") [assignment]
torch/_inductor/lowering.py:2009:9: error: Need type annotation for "ranges" (hint: "ranges: List[<type>] = ...") [var-annotated]
torch/_inductor/lowering.py:2151:16: error: Incompatible types in assignment (expression has type "List[Any]", variable has type "Tuple[Any, ...]") [assignment]
torch/_inductor/lowering.py:2198:43: error: Item "type" of "Union[List[Any], type]" has no attribute "__iter__" (not iterable) [union-attr]
torch/_inductor/lowering.py:2229:36: error: Argument 1 to "len" has incompatible type "Union[List[Any], type]"; expected "Sized" [arg-type]
torch/_inductor/lowering.py:2231:38: error: Item "type" of "Union[List[Any], type]" has no attribute "__iter__" (not iterable) [union-attr]
torch/_inductor/lowering.py:2233:35: error: Item "type" of "Union[List[Any], type]" has no attribute "__iter__" (not iterable) [union-attr]
torch/_inductor/lowering.py:2569:54: error: Incompatible default for argument "reduce" (default has type "None", argument has type "str") [assignment]
torch/_inductor/lowering.py:2569:54: note: PEP 484 prohibits implicit Optional. Accordingly, mypy has changed its default to no_implicit_optional=True
torch/_inductor/lowering.py:2569:54: note: Use https://github.com/hauntsaninja/no_implicit_optional to automatically upgrade your codebase
torch/_inductor/lowering.py:2586:59: error: Incompatible default for argument "reduce" (default has type "None", argument has type "str") [assignment]
torch/_inductor/lowering.py:2586:59: note: PEP 484 prohibits implicit Optional. Accordingly, mypy has changed its default to no_implicit_optional=True
torch/_inductor/lowering.py:2586:59: note: Use https://github.com/hauntsaninja/no_implicit_optional to automatically upgrade your codebase
torch/_inductor/lowering.py:2720:65: error: Incompatible default for argument "scales_x" (default has type "None", argument has type "Tuple[float]") [assignment]
torch/_inductor/lowering.py:2720:65: note: PEP 484 prohibits implicit Optional. Accordingly, mypy has changed its default to no_implicit_optional=True
torch/_inductor/lowering.py:2720:65: note: Use https://github.com/hauntsaninja/no_implicit_optional to automatically upgrade your codebase
torch/_inductor/lowering.py:2735:5: error: Name "scale" already defined on line 2731 [no-redef]
torch/_inductor/lowering.py:2758:47: error: Argument 3 to "upsample_nearestnd" has incompatible type "Tuple[Optional[float]]"; expected "Tuple[float]" [arg-type]
torch/_inductor/lowering.py:2765:47: error: Argument 3 to "upsample_nearestnd" has incompatible type "Tuple[Optional[float], Optional[float]]"; expected "Tuple[float]" [arg-type]
torch/_inductor/lowering.py:2776:47: error: Argument 3 to "upsample_nearestnd" has incompatible type "Tuple[Optional[float], Optional[float], Optional[float]]"; expected "Tuple[float]" [arg-type]
torch/_inductor/lowering.py:2949:13: error: No binding for nonlocal "grad" found [misc]
torch/_inductor/lowering.py:3063:49: error: Argument 2 to "range_mask_low" has incompatible type "int"; expected "Expr" [arg-type]
torch/_inductor/lowering.py:3271:48: error: "IRNode" has no attribute "data" [attr-defined]
torch/_inductor/lowering.py:3272:16: error: "IRNode" has no attribute "data" [attr-defined]
Found 29 errors in 1 file (checked 1 source file)
```
After the fix:
```
$ mypy torch/_inductor/lowering.py
Success: no issues found in 1 source file
```
Reviewers: @eellison
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105317
Approved by: https://github.com/eellison
Summary:
Use templates to generate shaders for unary operators `exp` and `sqrt` for in-place and not in-place variants.
[sqrt](https://pytorch.org/docs/stable/generated/torch.sqrt.html)
[exp](https://pytorch.org/docs/stable/generated/torch.Tensor.exp.html#torch.Tensor.exp)
Refactor: use 'NAME' field in yaml for generated shader name in `gen_vulkan_spv.py`
Test Plan:
New tests:
```
lfq@lfq-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*unary_op*"
Parsing buck files: finished in 16.1 sec
Creating action graph: finished in 0.7 sec
Downloaded 75/3986 artifacts, 248.89 Mbytes, 96.3% cache miss (for updated rules)
Building: finished in 08:24.0 min (100%) 2571/2571 jobs, 2571/2571 updated
Total time: 08:40.9 min
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *unary_op*
[==========] Running 4 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 4 tests from VulkanAPITest
[ RUN ] VulkanAPITest.unary_op_exp
[ OK ] VulkanAPITest.unary_op_exp (479 ms)
[ RUN ] VulkanAPITest.unary_op_exp_
[ OK ] VulkanAPITest.unary_op_exp_ (1 ms)
[ RUN ] VulkanAPITest.unary_op_sqrt
[ OK ] VulkanAPITest.unary_op_sqrt (2 ms)
[ RUN ] VulkanAPITest.unary_op_sqrt_
[ OK ] VulkanAPITest.unary_op_sqrt_ (2 ms)
[----------] 4 tests from VulkanAPITest (485 ms total)
[----------] Global test environment tear-down
[==========] 4 tests from 1 test suite ran. (485 ms total)
[ PASSED ] 4 tests.
```
All tests:
https://www.internalfb.com/phabricator/paste/view/P786547213
Run clang-format on shader files and `UnaryOp.cpp`
Differential Revision: D47271856
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104994
Approved by: https://github.com/SS-JIA
This fixes https://github.com/pytorch/pytorch/issues/104504.
- When not using full-precision eval, the relevant fix is to force `_use_sharded_views()` calls if needed in `SUMMON_FULL_PARAMS` training state.
- When using full-precision in eval, the relevant fix is tracking what was the unsharded flat parameter from which the unsharded views were computed and using that instead of determining the unsharded flat parameter from the calling context via `_get_padded_unsharded_flat_param()`.
This also fixes https://github.com/pytorch/pytorch/issues/104770.
<details>
<summary> Print output showing parity </summary>
```
Key: 0
Model 1: [-1.5, 6.40625, -0.9453125, -0.3828125, 0.16015625, -1.5078125]
Model 2: [-1.5, 6.40625, -0.9453125, -0.3828125, 0.16015625, -1.5078125]
Key: 1
Model 1: [0.0157470703125, -0.8828125, 5.65625, 1.1328125, 0.275390625, 0.11181640625]
Model 2: [0.0157470703125, -0.8828125, 5.65625, 1.1328125, 0.275390625, 0.11181640625]
Key: 2
Model 1: [0.1689453125, -0.00567626953125, -0.09375, 7.34375, -0.18359375, -0.09521484375]
Model 2: [0.1689453125, -0.00567626953125, -0.09375, 7.34375, -0.18359375, -0.09521484375]
Key: 3
Model 1: [0.546875, -0.8984375, 0.228515625, 0.7578125, 6.0625, 0.435546875]
Model 2: [0.546875, -0.8984375, 0.228515625, 0.7578125, 6.0625, 0.435546875]
Key: 4
Model 1: [-0.66796875, -0.88671875, 0.30078125, 0.06494140625, 0.412109375, 6.9375]
Model 2: [-0.66796875, -0.88671875, 0.30078125, 0.06494140625, 0.412109375, 6.9375]
Key: 5
Model 1: [0.07763671875, 0.8671875, -0.43359375, 0.5703125, 0.76171875, -0.0089111328125]
Model 2: [0.07763671875, 0.8671875, -0.43359375, 0.5703125, 0.76171875, -0.0089111328125]
Key: 6
Model 1: [-0.283203125, -0.361328125, 0.474609375, 0.10205078125, 1.125, -0.0859375]
Model 2: [-0.283203125, -0.361328125, 0.474609375, 0.10205078125, 1.125, -0.0859375]
Key: 7
Model 1: [1.140625, 0.62890625, -0.07568359375, -1.0390625, -0.2578125, -0.053955078125]
Model 2: [1.140625, 0.62890625, -0.07568359375, -1.0390625, -0.2578125, -0.053955078125]
Key: 8
Model 1: [0.68359375, -1.09375, 0.59375, 1.0, -0.23828125, 0.578125]
Model 2: [0.68359375, -1.09375, 0.59375, 1.0, -0.23828125, 0.578125]
Key: 9
Model 1: [0.515625, 0.296875, -0.1826171875, -0.12890625, -0.51953125, -0.3359375]
Model 2: [0.515625, 0.296875, -0.1826171875, -0.12890625, -0.51953125, -0.3359375]
```
</details>
Follow-ups:
- I suspect that for `SHARD_GRAD_OP`, train forward -> eval forward when using full-precision in eval will not free the low-precision unsharded parameters from the train forward, resulting in 1.5x unsharded parameter memory.
Differential Revision: [D47527597](https://our.internmc.facebook.com/intern/diff/D47527597)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105346
Approved by: https://github.com/fegin, https://github.com/rohan-varma
The test should respect self.device_type as it checks whether the environment
has enough GPUs to serve the requested world size.
The test will lead to hangs if we try to run 8 ranks over our 2-4 GPUs CI instances.
Fixes#104769
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105357
Approved by: https://github.com/wanchaol
Summary:
Use templates to generate the kernels for add, sub, mul, div and their variants (tensor/scalar, in-place/not in-place).
Rename Arithmetic.cpp to BinaryOp.cpp
Test Plan:
https://www.internalfb.com/phabricator/paste/view/P785131030
```
buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1
...
xplat/caffe2/aten/src/ATen/test/vulkan_api_test.cpp:6377: Skipped
QueryPool is not available
[ SKIPPED ] VulkanAPITest.querypool_flushed_shader_log (0 ms)
[----------] 307 tests from VulkanAPITest (5427 ms total)
[----------] Global test environment tear-down
[==========] 307 tests from 1 test suite ran. (5427 ms total)
[ PASSED ] 306 tests.
[ SKIPPED ] 1 test, listed below:
[ SKIPPED ] VulkanAPITest.querypool_flushed_shader_log
YOU HAVE 5 DISABLED TESTS
```
Differential Revision: D47307169
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105380
Approved by: https://github.com/SS-JIA
Calling `isinstance(x, Tuple[Node, Node])` would either fail, or raise a
type error on a more modern Python, as none of the tuples are actually
instances of `Tuple`
```python
>>> from typing import Tuple
>>> from torch.fx import Node
>>> edge_or_node=(Node(None, "foo", "output", "foo", None, None), Node(None, "bar", "output", "bar", None, None))
>>> isinstance(edge_or_node, tuple) and len(edge_or_node) == 2 and all(isinstance(x, Node) for x in edge_or_node)
True
>>> isinstance(edge_or_node, Tuple[Node, Node])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/malfet/miniconda3/lib/python3.10/typing.py", line 994, in __instancecheck__
return self.__subclasscheck__(type(obj))
File "/Users/malfet/miniconda3/lib/python3.10/typing.py", line 997, in __subclasscheck__
raise TypeError("Subscripted generics cannot be used with"
TypeError: Subscripted generics cannot be used with class and instance checks
```
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 40fa451</samp>
> _Fix type annotation_
> _Quantize nodes in the graph_
> _Autumn leaves falling_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105476
Approved by: https://github.com/jerryzh168
Summary: `sort_keys=True` for autotuning results fails because we can't compare ExternKernelCaller objects. besides, it isn't really necessary to sort the keys, either for the autotuning results or the sysinfo. let's just drop sorting all together
Test Plan: sandcastle + CI
Reviewed By: aaronenyeshi
Differential Revision: D47544587
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105469
Approved by: https://github.com/jansel
This PR adds necessary plumbing through torchdynamo to allow tensor
subclasses with certain contract (i.e. with `__tensor_flatten__` and
`__tensor_unflatten__`) to goes through the dynamo fakification pass by
fakifying the tensor subclass internal components.
Some of the tensor subclass contract logic mostly borrowed from
https://github.com/pytorch/pytorch/pull/97540
Added some tests to verify simply passing through a tensor subclass
(i.e. DTensor) through dynamo eager works as expected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105308
Approved by: https://github.com/ezyang
This PR canonicalize the detach callsite to only call the detach
from `distribute_tensor`. Change other callsite to view_as and remove the
tensor constructor detach call
This is so that we don't detach local tensor for every op run when
rewrapping the DTensor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105239
Approved by: https://github.com/albanD
Fixes#104985
Implemented `set_multithreading_enabled` C++ function to directly alter state rather than using `MultithreadingEnabled` class, which was automatically resetting the state when the object was destroyed. This behavior more closely aligns with set_grad_enabled which does work as expected. This allows us to change python class `set_multithreading_enabled` to act as both a function and context manager.
I also added a getter: `torch._C.is_multithreading_enabled`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105291
Approved by: https://github.com/albanD
Summary:
Original PR at https://github.com/pytorch/pytorch/pull/104977. Landing from fbcode instead.
Add an aot_inductor backend (Export+AOTInductor) in the benchmarking harness. Note it is not a dynamo backend.
Moved files from torch/_inductor/aot_inductor_include to torch/csrc/inductor as a more standard way for exposing headers
Created a caching function in benchmarks/dynamo/common.py for compiling, loading and caching the .so file, as a proxy for a pure C++ deployment, but easier for benchmarking.
Differential Revision: D47452591
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105221
Approved by: https://github.com/jansel
Summary:
until we can further investigate the autotuning differences between MAST and non-MAST (devserver) environments, turn off the global cache for all non-MAST environments. this ensures we don't see unexpected regressions
also update scuba logging for cache lookup, and add scuba logging for autotuning results.
Test Plan: sandcastle + CI
Differential Revision: D47516633
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105375
Approved by: https://github.com/jansel
issues resolved: https://github.com/pytorch/pytorch/issues/101832
**context**: get torch.compile config for further usage. E.g, the training platform wants to get if model is compiled with cudagraph enabled and trigger further action
**how it is implemented**
* the core logic is backend.get_compiler_config() in torch/_dynamo/eval_frame.py
* for backend='inductor' / _TorchCompileInductorWrapper, we have inductor-specific implementation in get_compiler_config in torch/_inductor/compile_fx.py and torch/__init__.py
**how to use it**: Below is an example.
```
model = DummyModule()
optimized_module = torch.compile(
model, options={"triton.cudagraphs": True}
)
compiler_config = optimized_module.get_compiler_config()
if compiler_config["triton.cudagraphs"]:
pass
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105026
Approved by: https://github.com/yanboliang, https://github.com/jansel
torch.profiler.record_function and torch.profiler.profile are ignored by dynamo. In the common case, users have `record_function` in the middle of their program in order to annotate a section of the profile.
The previous error message was `Profiler will be ignored`. Users would think that profiling would be completely ignored.
Now the message will look like `Profiler function <class 'torch.autograd.profiler.record_function'> will be ignored`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105362
Approved by: https://github.com/yanboliang, https://github.com/aaronenyeshi
Summary:
The draft version of a group + batch fusion framework, and the group linear fusion implementation.
In the future, it's pretty straightforward to add a new group/batch fusion policy by defining a class with match + fuse functions.
Test Plan: buck2 test 'fbcode//mode/dev-nosan' fbcode//caffe2/test/inductor:group_batch_fusion
Differential Revision: D46956695
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105116
Approved by: https://github.com/jansel
Summary:
Currently, broadcast is supported for 4D tensors where, if the batch or channel dimensions are not equal, then the batch and channel of one tensor must both be 1, ie:
```
tensorA NCHW:
5, 2, 3, 3
tensorB NCHW:
1, 1, 3, 3 --> batch=1, channel=1
```
This diff adds broadcast support for 4D tensors where the batch and channel of a tensor are different, ie:
```
tensorA NCHW:
5, 1, 3, 3
tensorB NCHW:
1, 5, 3, 3
```
Broadcast rules:
```
- tensorA.dim()[x] = tensorB.dim()[x]
- tensorA.dim()[x] == 1 || tensorB.dim()[x] == 1
- tensorA.dim()[x] does not exist || tensorB.dim()[x] does not exist
```
Broadcast method:
1. Pass `output`, `input` and `other` tensors to the shader
2. Iterate through the output texture to calculate the value of each texel (no repeating)
3. Mapping NHW positions: use modulo
4. Mapping C position: divide pos.z by ceil(C/4) to map to original tensor range
---
Also some test refactoring to reduce repeated setup code.
Test Plan:
New tests:
Add
```
[ RUN ] VulkanAPITest.add_broadcast5
[ OK ] VulkanAPITest.add_broadcast5 (0 ms)
[ RUN ] VulkanAPITest.add_broadcast6
[ OK ] VulkanAPITest.add_broadcast6 (0 ms)
```
Sub
```
[ RUN ] VulkanAPITest.sub_broadcast5
[ OK ] VulkanAPITest.sub_broadcast5 (0 ms)
[ RUN ] VulkanAPITest.sub_broadcast6
[ OK ] VulkanAPITest.sub_broadcast6 (0 ms)
```
Mul
```
[ RUN ] VulkanAPITest.mul_broadcast5
[ OK ] VulkanAPITest.mul_broadcast5 (1 ms)
[ RUN ] VulkanAPITest.mul_broadcast6
[ OK ] VulkanAPITest.mul_broadcast6 (1 ms)
```
Div
```
[ RUN ] VulkanAPITest.div_broadcast5
[ OK ] VulkanAPITest.div_broadcast5 (1 ms)
[ RUN ] VulkanAPITest.div_broadcast6
[ OK ] VulkanAPITest.div_broadcast6 (2 ms)
```
All tests:
https://www.internalfb.com/phabricator/paste/view/P781794761
Run clang-format on glsl files and Arithmetic.cpp
Differential Revision: D46874508
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104718
Approved by: https://github.com/SS-JIA
Summary: move gemm autotuning local cache to `cache_dir()/cache/{hash}` since we might have multiple local caches, i.e. one cache with `allow_tf32=True` and one cache with `allow_tf32=False`
Test Plan: sandcastle + CI
Differential Revision: D47504654
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105334
Approved by: https://github.com/jansel
dependencies.py is used for tracking reads and writes, which is used for identifying dependencies between buffers: i.e. if buffer X reads buffer Y, then X depends on Y. ops.bucketize() reads from an offsets tensor, so we should track it in dependencies.py to correctly track dependencies. Since bucketize performs a binary search over the offsets tensor, the dependency is marked as a StarDep to indicate that the entire tensor is needed.
Use case: we find that jagged tensor dense_to_jagged ops - which use bucketize() to map jagged indices to dense indices - perform better if the bucketize() kernel is separated from the gather kernel. Previously, because bucketize() wasn't marked as reading anything, it would just get inlined.
Differential Revision: [D47422704](https://our.internmc.facebook.com/intern/diff/D47422704)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105102
Approved by: https://github.com/eellison
Add similar semantics for creating a buffer object similar to creating a parameter. This is done by introducing a new `Buffer` class that can be used for type disambiguation. The underlying functionality of registering a buffer remains the same as the `register_buffer` method has not been changed. The `persistent` parameter in the `Buffer` type is to indicate whether a buffer object should be persistent or not. Other non-test changes have to do with getting the new `Buffer` type recognized by inductor and dynamo. Remaining changes are test changes to make sure that the `Buffer` type can be used as a drop in replacement for `register_buffer` as it just leads to `register_buffer` being called. The addition of this new functionality still allows for normal tensors to be used as buffers so these changes are intended to be backwards compatible.
Fixes#35735
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104069
Approved by: https://github.com/mikaylagawarecki
Summary:
Rather than processing the events into a time and sizes plot, dump the actual events as (timestamp, action, num of bytes, category) when output file ends in `raw.json.gz`.
This can allow downstream analysis tools to process these events. It also avoids having to control the granularity of the previous json.gz in memory profiler.
Test Plan: CI Tests
Differential Revision: D47416544
Pulled By: aaronenyeshi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105094
Approved by: https://github.com/davidberard98
Summary: Exercise subclass of TransformerEncoderLayer
Additional unit tests for change in #102045 to show correct e2e operation (cf. issue #100188)
Also: remove batch_first from list of TS module constants where it is not used to resolve torchscripting warning
Test Plan: saqndcastle, github
Differential Revision: D47503004
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105297
Approved by: https://github.com/davidberard98
Previously, we made backwards graph compilation lazy to avoid paying
for compilation if the user didn't actually end up using the backwards
graph. This was useful in the old days when a lot of things in Inductor
didn't work and we could bypass errors this way.
However, this has a bad implication for dynamic shapes: the backwards
graph compilation can trigger extra guards, which are too late to
install in the Dynamo context if we wait until backwards is being run.
So in this PR I move us back to compiling backwards graph immediately
if we capture any SymInts for backwards.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104971
Approved by: https://github.com/Chillee
This is the first PR towards simplifying sympy_interp, and more
generally, simplifying the implementation of ValueRangeAnalysis for
SymPy expressions.
In general, it would be conteptually good to have a minimal subset of
operations that conform our SymPy expressions, let that be guards or
indexing expressions. This would allow us to reason better about SymPy
guards and potentially have invariants like knowing that guards are
continuous piecewise rational functions. If this were the case,
we could operate on them using exact arithmetic and completely avoid
precision errors like the one found in https://github.com/pytorch/pytorch/issues/105097
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105138
Approved by: https://github.com/ezyang
When running BertForMaskedLM , I found if I enable the kernel benchmark, essentially identical kernels will be defined once for each call site. The reason is the benchmark harness of those kernels uses different seed_offset for each invocation. We should be safe to just force seed_offset to be 0 so we can deduplicate identical kernel definitions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105099
Approved by: https://github.com/jansel
The decomposition for unfold uses `as_strided` which forces the input to be
realized. Instead, this implements it as a `GenericView` with reindexing
which removes the need to realize, though it does call `mark_reuse` incase
the input computation is expensive and the windows overlap.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105165
Approved by: https://github.com/lezcano, https://github.com/jansel
This PR re-lands
- [Typing] Fix PEP 484 Violation (#105022)
- Update mypy to 1.4.1 (#91983)
That were reverted due to the conflict with internal source repo.
Mostly fixes for PEP-484 violation (i.e. when default arg is set to None, but type is not annotated as optional)
Plus few real fixes:
- Add missing `_get_upgraders_entry_map` to `torch/_C/__init__.pyi`
- Add missing return statement to `torch._export. deserialize_graph`
- Fix error message in `torch.ao.ns.fx.weight_utils.get_lstm_mod_weights`
- Add assert it `torch/optim/optimizer.py` that Optional list is not None
TODO (in followup PR):
- Fix erroneous `isinstance` check in `torch/ao/quantization/_pt2e/qat_utils.py`
Unrelated, to bypass CI failures due to the gcc9 dependency update in Ubuntu-18.04:
- Add hack to squash older libstdc++ from conda environment in favor one from OS to `.ci/docker/install_conda.sh`
- Update bazel cuda builds to focal, as with libstdc++-6.0.32 bazel builds loose the ability to catch exceptions (probably because they link with cupti statically, but I could not found where it is done)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105227
Approved by: https://github.com/atalman, https://github.com/albanD, https://github.com/Skylion007
Previously, x.size(0) could return a SymInt, even when the internal
sympy expression was actually already constant (e.g., due to an
introduced guard.) We now allow to query the Python object with
maybe_as_int which allows us to transmute these objects back to
int when possible.
It is still possible to end up with a constant SymInt even after this
change, e.g., if you get out a SymInt and while holding onto it
specialize it, but casual users are more likely to get ints when they
want to.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104828
Approved by: https://github.com/Skylion007
The dipatcher didn't check attribute dtype, as AttributeProto is a totally different system from InputProto in ONNX. This PR introduces the mapping table for AttributeProto type to python type. And further utilize it in opschema matching.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105104
Approved by: https://github.com/thiagocrepaldi
Fix cpp wrapper failure on TorchBench model `hf_Reformer` with `randn`:
```
random_rotations = torch.randn(rotations_shape, device=vectors.device, dtype=vectors.dtype)
```
For cpp wrapper, when `kwargs` is not empty, for `OpOverloadPacket` kernel, we need to know the exact overload schema to handle the `kwargs` properly when calling the cpp kernel: including finding the correct order of the kwargs and getting the default value for optional args without provided value when calling the function (`layout` in the above case).
The current support in this PR is conservative and we'll extend the functionality in subsequent PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104575
Approved by: https://github.com/jgong5, https://github.com/desertfire
Original PR: #103546
Trying to support numpy function call in dynamo, with numpy dtype as argument.
For example:
```
def fn(x: int):
return np.empty_like(x, dtype=np.float64)
```
This currently doesn't work because `NumpyVariable` doesn't implement `as_proxy()`. The idea in `as_proxy()` for now is to convert `np.float64` and other np.<dtype> into `str` and then feed into the corresponding `torch_np` method. The assumption here is that all `torch_np` methods that are taking `dtype` kwarg will be able to also take `str` as `dtype`. This assumption stands for `numpy`.
For previous example, we convert `np.float64` to `"float64"` in `as_proxy()` and then feed it into `torch_np.empy_like()` method.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105034
Approved by: https://github.com/voznesenskym
This PR re-lands
- [Typing] Fix PEP 484 Violation (#105022)
- Update mypy to 1.4.1 (#91983)
That were reverted due to the conflict with internal source repo.
Mostly fixes for PEP-484 violation (i.e. when default arg is set to None, but type is not annotated as optional)
Plus few real fixes:
- Add missing `_get_upgraders_entry_map` to `torch/_C/__init__.pyi`
- Add missing return statement to `torch._export. deserialize_graph`
- Fix error message in `torch.ao.ns.fx.weight_utils.get_lstm_mod_weights`
- Add assert it `torch/optim/optimizer.py` that Optional list is not None
TODO (in followup PR):
- Fix erroneous `isinstance` check in `torch/ao/quantization/_pt2e/qat_utils.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105227
Approved by: https://github.com/atalman, https://github.com/albanD, https://github.com/Skylion007
This PR updates the documentation for `TripletMarginLoss` in `torch.nn`. The previous version of the documentation didn't mention the parameter `eps` used for numerical stability.
This PR does the following:
1. Describes the purpose and use of the `eps` parameter in the `TripletMarginLoss` class documentation.
2. Includes `eps` in the example usage of `TripletMarginLoss`.
Please review this update for the completeness with respect to the `TripletMarginLoss` functionality. If there are any issues or further changes needed, please let me know.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105115
Approved by: https://github.com/mikaylagawarecki
dependencies.py is used for tracking reads and writes, which is used for identifying dependencies between buffers: i.e. if buffer X reads buffer Y, then X depends on Y. ops.bucketize() reads from an offsets tensor, so we should track it in dependencies.py to correctly track dependencies. Since bucketize performs a binary search over the offsets tensor, the dependency is marked as a StarDep to indicate that the entire tensor is needed.
Use case: we find that jagged tensor dense_to_jagged ops - which use bucketize() to map jagged indices to dense indices - perform better if the bucketize() kernel is separated from the gather kernel. Previously, because bucketize() wasn't marked as reading anything, it would just get inlined.
Differential Revision: [D47422704](https://our.internmc.facebook.com/intern/diff/D47422704)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105102
Approved by: https://github.com/eellison
Summary: Submodules may have a none call-spec values, which is ok. Updating types + serializer to handle this
Test Plan: CI
Reviewed By: ydwu4, zhxchen17
Differential Revision: D47353101
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105179
Approved by: https://github.com/zhxchen17
On s390x static cast may return big positive number, in that case uninitialized value of 'r' is returned. In case of +/-inf or +/-nan use -1 explicitely.
Also initialize 'r' to 0 in case 'n+n' overflows anyway.
This change fixes
test_vmap_exhaustive_special_hermite_polynomial_h_cpu_float32 from test/functorch/test_vmap.py on s390x.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104705
Approved by: https://github.com/ezyang
The general idea is to do a separate CUDA graph for each size. Because of cuda graph trees, these graphs will all share the same memory pool, so your memory usage will only be the worst case memory usage of the biggest dynamic size you want. This requires an extra dispatch in the cudagraphified callable. You must pay for a CUDA graph recording for every dynamic size you encounter, but this is MUCH cheaper than running the entire PT2 compile stack, so I expect you to still see benefits.
This was surprisingly easy to do.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105064
Approved by: https://github.com/voznesenskym
Summary:
Context
-------
This PR adds a new fallback to the Autograd dispatch keys.
If you would prefer the old behavior:
- A quick (unsupported) way to get the previous behavior is to call
`torch._C._set_autograd_fallback("nothing")`
- Register "torch::CppFunction::makeFallthrough()" to your Autograd key,
like in https://gist.github.com/zou3519/d09a5f4b1afe2430af09fea67c6ff2c8
It is possible that this PR regresses performance of overhead-bound
models. If this is the case, please reach out (and apply one of the
temporary fixes in the previous section).
Description for reviewers
-------------------------
In order to deprecate registering autograd kernels at not an autograd
key, we add a fallback to the Autograd dispatch keys. This fallback
raises a warning if the user attempts to backprop through the operator
and is also configurable to either warn or not warn.
The goal of this PR is to
- preserve as much BC as possible
- raise a warning that whatever the user is doing is potentially wrong.
- be as performant as possible
There are roughly two cases:
- if the post-autograd kernels return a Tensor that requires grad, then
we install an autograd hook that raises a warning. We are preserving BC
in that it is possible that the user has a torch::autograd::Function
registered to their CPU key.
- if the post-autograd kernels return Tensors that do not require grad,
then we make them require_grad and install a WarnNotImplemented grad fn
that warns in the backward pass. This is mildy BC-breaking (see next
section).
Test Plan:
- bunch of new tests
BC-Breaking Note
----------------
This PR adds a new fallback to the Autograd dispatch keys. It affects
custom operators that do not have a kernel registered to the Autograd
keys (e.g. AutogradCPU and AutogradCUDA).
If the previous behavior was that the custom operator would return
Tensors that do not require grad if the inputs do require grad, then
this PR changes it so that all floating-point and complex returns do
require grad. See the "Context" section above for how to get the old
behavior.
Differential Revision: D47408353
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105078
Approved by: https://github.com/soulitzer
The story here is relatively simple - when we go to wrap a tensor, we (1) ensure that it is a real, not fake tensor (2) check if we have seen it before. (3) If we have seen it, we create a positive alias guard and return the associated variable. If not, we proceed.
By short circuiting here, we avoid lifting it to a graph input, and guarantee that the only names passed to tensors are unique. This allows us to guard on the unique relationships (pyboject addresses, aka IDs, cannot match) to give us guards for negative aliases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104921
Approved by: https://github.com/jansel, https://github.com/ezyang
Simplifies the logic to not depend on info within the exception raised. Due to changes
in onnx dispatcher, the diagnostic within exception raised is now different, which broke
this pass in retrieving the unsupported fx node kind. Adds proper unittest.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105156
Approved by: https://github.com/thiagocrepaldi
Previous to this PR, we are comparing torch args/kwargs with OnnxFunction OpSchema without normalizing args/kwargs first. Essentially, the function signature is different between ATen and OnnxFunction, and onnx-script has preprocessing on these args/kwargs with an internal tools: `param_manipulation` for both eager mode and graph mode. This PR references on the internal tool to normalize the torch args/kwargs before feeding them to OnnxFunction during op_level_debug and dispatching. The PR significantly reduces the dispatching need on nearest matching mechanism.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104679
Approved by: https://github.com/BowenBao
The goal is to fix the problem from https://github.com/pytorch/pytorch/pull/102858
The full error this used to raise was :
```
2023-06-27T15:12:15.0663239Z File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/optim/adamw.py", line 409, in _single_tensor_adamw
2023-06-27T15:12:15.0663699Z bias_correction1 = 1 - beta1 ** step
2023-06-27T15:12:15.0664200Z File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_tensor.py", line 40, in wrapped
2023-06-27T15:12:15.0664547Z return f(*args, **kwargs)
2023-06-27T15:12:15.0665031Z File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_tensor.py", line 882, in __rpow__
2023-06-27T15:12:15.0665483Z return torch.tensor(other, dtype=dtype, device=self.device) ** self
2023-06-27T15:12:15.0665899Z RuntimeError: CUDA error: operation not permitted when stream is capturing
2023-06-27T15:12:15.0666401Z CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
```
This pow issue was fixed in https://github.com/pytorch/pytorch/pull/104264 and so this problem should be solvable now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104254
Approved by: https://github.com/janeyx99, https://github.com/aws-murandoo
This PR implements a (yet private) frontend for scaled_dot_product_attention that works with BSR `attn_mask`.
This function is directly comparable (with suitable masks) with `torch.nn.functional.scaled_dot_product_attention` once `attn_mask.dtype == torch.bool`, but it's behavior is different when `attn_mask.dtype != torch.bool`. This is because `torch.nn.functional.scaled_dot_product_attention` assumes that irrelevant values are supposed to be filled with `-inf`, while the selected ones should be `0`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104042
Approved by: https://github.com/amjames, https://github.com/cpuhrsch
Previously, x.size(0) could return a SymInt, even when the internal
sympy expression was actually already constant (e.g., due to an
introduced guard.) We now allow to query the Python object with
maybe_as_int which allows us to transmute these objects back to
int when possible.
It is still possible to end up with a constant SymInt even after this
change, e.g., if you get out a SymInt and while holding onto it
specialize it, but casual users are more likely to get ints when they
want to.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104828
Approved by: https://github.com/Skylion007
constraints:
1. No support for gradient accumulation
2. CPU offload runs step() on CPU. In future PRs ideally we'd run this on GPU.
3. When CPU offload + optimizer overlap, we have to copy the flat_param grad to CPU with non_blocking=False, otherwise step() might run on invalid data.
4. Step is waited on in post backward final cb, when in theory it can wait until the next forward.
Differential Revision: [D44809582](https://our.internmc.facebook.com/intern/diff/D44809582/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98667
Approved by: https://github.com/awgu, https://github.com/fegin
This PR is only relevant for the Fake tensor Mode ONNX export. For the conventional export, everything is unchanged.
* An optional `rename_initializer=False` argument is added to an internal function `torch/onnx/_internal/fx/serialization.py::save_model_with_external_data` which is used by the public API `ExportOutput.save`.
* The default behavior (`rename_initializer=False`) is meant to be used by public API `torch.onnx.dynamo_export` with the default Dynamo-based FX tracer (`DynamoExport`). In this scenario, both graph ONNX graph inputs and initializers have matching name with `.` in it (e.g. `linear.weight`)
* `rename_initializer=True` is meant to be used by `torch.onnx.dynamo_export` with a non-publicly-supported FX tracer called `FXSymbolicTracer`. This tracer lifts the FX graph initializers as inputs before FX->ONNX start, and because of this, the initializer names must be valid python identifiers (meaning `.` are not supported argument name and must be replaced by `_` or similar). This causes the graph inputs to have names with `_` (e.g. `linear_weight`) while the initializers have `.` (e.g. `linear.weight`) in their name. This flag resolves this mismatch by replacing `.` by `_` when saving the ONNX proto (`save_model_with_external_data`).
* This PR also adds unit tests for numerical validation against pytorch eager for onnx export using dynamo-based fx tracer and fake mode enabled. (There are already tests for export with fx symbolic tracer with fake mode)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105002
Approved by: https://github.com/BowenBao
The main complexity comes from the __init__ function of Dataclass variables which look something like this
```
[2023-07-10 05:01:29,548] torch._dynamo.symbolic_convert: [DEBUG] INLINING <code object __init__ at 0x7f7015154450, file "<string>", line 2>
3 0 LOAD_FAST 1 (b)
2 LOAD_FAST 0 (self)
4 STORE_ATTR 0 (b)
4 6 LOAD_FAST 2 (named_tensors)
8 LOAD_DEREF 0 (_HAS_DEFAULT_FACTORY)
10 IS_OP 0
12 POP_JUMP_IF_FALSE 20
14 LOAD_DEREF 1 (_dflt_named_tensors)
16 CALL_FUNCTION 0
18 JUMP_FORWARD 2 (to 22)
>> 20 LOAD_FAST 2 (named_tensors)
>> 22 LOAD_FAST 0 (self)
24 STORE_ATTR 1 (named_tensors)
26 LOAD_CONST 0 (None)
28 RETURN_VALUE
```
There are multiple issues
* VariableBuilder call in functions.py was wrong. We were calling *options as args.
* We were not setting source while tracking the new object. This led to no source for Dataclass variable, which has some new variables in its closures as seen in the above bytecode.
* There is IS_OP in above bytecode, which brings more cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104840
Approved by: https://github.com/jansel
This PR is to fix https://github.com/pytorch/pytorch/issues/101935.
Only when input, parameters and hidden states are all in CPU device, LSTM will go into oneDNN fast path implementation. Otherwise, it will fallback to the original implmentation.
Note here, if input and parameters are indeed not in the same device, it will encounter Error `Input and parameter tensors are not at the same device, found input tensor......` in `check_attributes`. Therefore, the proper usage of LSTM is `input.to(device)` and `model.to(device)` together.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102050
Approved by: https://github.com/XiaobingSuper, https://github.com/albanD
Purely out of preference, this PR renames the streams to `_unshard_stream` instead of `_streams_unshard` etc. since the former reads more naturally. The PR also removes some duplicated comments and adds back a unit test that streams are shared.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104966
Approved by: https://github.com/rohan-varma
When creating DeviceMesh, _init_process_group() would validate that all calling ranks pass in the same `mesh` argument. In FSDP, we are currently creating the DeviceMesh based on the pg of the root state so the mesh will always be valid. Adding the flag to DeviceMesh, so we can skip the all_gather_tensor of the validation during construction time.
_validate_mesh is default to True, but we manually flip it to False when initializing device mesh in FSDP's _runtime_utils.py.
Will modify skipping pg creation if existed for both 1D and 2D cases and then delete _init_process_groups flag in a follow up PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104807
Approved by: https://github.com/wanchaol
This allows `ops.minimum` and `ops.maximum` to be hoisted for indirect indexing
into direct indexing expressions. I also add support to the cpp printer for
Min/Max and fix the triton printer to support multi-argument Min/Max.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105020
Approved by: https://github.com/lezcano
Summary: This rounds out the support for the [softmax function](https://pytorch.org/docs/stable/generated/torch.nn.Softmax.html) on the Vulkan GPU backend. The test inputs of the 1,2,3 dimension cases are simply the truncated existing 4 dimension inputs. The existing shader algorithms are reused.
Test Plan:
1. `buck2 run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1` on Apple M1 MacBook
2. Confirm all tests pass with no regression, and the added tests `*softmax*` pass under `-- --gtest_filter="*softmax*"`
2a. All tests P782531732
2b. `softmax` tests P782529114
```
~/fbsource » buck2 run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*softmax*"
Buck UI: https://www.internalfb.com/buck2/692eb82d-c2ee-49bb-833f-3c11d6e2fea9
Jobs completed: 4. Time elapsed: 0.1s.
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *softmax*
[==========] Running 1 test from 1 test suite.
[----------] Global test environment set-up.
[----------] 1 test from VulkanAPITest
[ RUN ] VulkanAPITest.softmax
[ OK ] VulkanAPITest.softmax (42 ms)
[ DISABLED ] VulkanAPITest.DISABLED_log_softmax
[----------] 1 test from VulkanAPITest (42 ms total)
[----------] Global test environment tear-down
[==========] 1 test from 1 test suite ran. (42 ms total)
[ PASSED ] 1 test.
YOU HAVE 1 DISABLED TEST
```
Reviewed By: SS-JIA
Differential Revision: D46985319
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105012
Approved by: https://github.com/SS-JIA
Content same as #103948
@svekars the PR content is updated per your comment, but when trying to solve the conflict the original PR was closed by a mis-operation. Would you help handle this new one? sorry for the inconvenience.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105051
Approved by: https://github.com/svekars
Introduce `ReductionTypePromotionRule` and rename `TypePromotionRule` as
`ElementwiseTypePromotionRule`. Created base abstract class `TypePromotionRule`.
Reduction rules are manually curated because the total number of ops is low, yet
most of them require some special treatment. The list that are covered in our unittest is
- "all", done
- "amax", done
- "amin", done
- "any", done
- "cumsum", done
- "cumprod", no torchlib impl
- "mean", done
- "std", no torchlib impl
- "std_mean", no torchlib impl
- "sum", done
- "sum_to_size", no torchlib impl
- "prod", no torchlib impl
- "var", no torchlib impl
- "var_mean", tricky. Node has multiple outputs. Follow up in separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104491
Approved by: https://github.com/justinchuby, https://github.com/thiagocrepaldi
Previously, x.size(0) could return a SymInt, even when the internal
sympy expression was actually already constant (e.g., due to an
introduced guard.) We now allow to query the Python object with
maybe_as_int which allows us to transmute these objects back to
int when possible.
It is still possible to end up with a constant SymInt even after this
change, e.g., if you get out a SymInt and while holding onto it
specialize it, but casual users are more likely to get ints when they
want to.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104828
Approved by: https://github.com/Skylion007
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 52dac58</samp>
Add support for `torch.linalg.cholesky_ex` function that returns the Cholesky factorization and an error indicator. Refactor existing `torch.cholesky` and `torch.linalg.cholesky` to use the new function internally. Update tests and documentation accordingly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104751
Approved by: https://github.com/albanD
This prefigures a refactor that will move the backward compilation
to entirely ahead of time, so I need to extract these strides some
other way. Straight from the compiler's mouth will do it.
I can't easily get the information via the return result of `fw_compiler` without changing the calling convention, so instead I smuggle it via TracingContext. TracingContext may be None when we are compiling patterns for the joint graph pattern matcher.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105010
Approved by: https://github.com/shunting314
Not sure, how it worked before, but if arguments must be annotated is optional if they are defaulted to None
Towards enabling mypy-1.4.1 in lintrunner
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 5e1b9f4</samp>
> _We annotate the arguments of doom_
> _To show the `None` values of gloom_
> _We improve the type checking and readability_
> _With `Optional` annotations of metal-ity_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105022
Approved by: https://github.com/izaitsevfb, https://github.com/huydhn, https://github.com/Skylion007
The one sort of tricksy thing about this PR is that `num_symints_saved_for_bw` is populated later; we compute the metadata with a forward pass, but we only know `num_symints_saved_for_bw` once we run partitioning. This seems... fine.
Also, by pushing the conditionals into the slices, I can remove the top level if...else branch, for a nice simplification.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105009
Approved by: https://github.com/albanD
Summary:
This usage is not ideal:
subprocess.check_output(cmd, stderr=subprocess.STDOUT)
* `check_output` will capture the command's stdout, and here we did not return it
* not ideal to redirect the sub-command's stderr to the host process's stdout (with `check_call`, stdout stays stdout, stderr stays stderr).
Differential Revision: D47275261
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104743
Approved by: https://github.com/frank-wei
Enables additional inductor UTs on ROCm and un skips outdated skips.
I have also removed a group of failures in `test_torchinductor_opinfo` which are now passing for CUDA and ROCm
```
- # The following 3 tests fail on CUDA with AssertionError: expected size 5==5, stride 5==1 at dim=0
- # linalg._svd's return value has different strides on CUDA vs CPU which causes this
- # In test_meta.py there is a mechanism to skipping strides checks for some ops
- # (including _linalg_svd), possibly we should have something similar here
- "linalg.cond": {f32, f64},
- "linalg.svdvals": {f32, f64},
- "linalg.matrix_rank": {f32, f64},
- "linalg.svd": {f32, f64},
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104624
Approved by: https://github.com/malfet
This makes it easier to exclude multi-line messages using single line
grepping. If your screen is wide enough this should not be a big
problem.
Example of what it looks like:
```
[2023-07-10 20:11:30,529] torch._dynamo.convert_frame.__guards: [DEBUG] GUARDS:
[2023-07-10 20:11:30,529] torch._dynamo.convert_frame.__guards: [DEBUG] hasattr(L['x'], '_dynamo_dynamic_indices') == False
[2023-07-10 20:11:30,529] torch._dynamo.convert_frame.__guards: [DEBUG] ___is_grad_enabled()
[2023-07-10 20:11:30,529] torch._dynamo.convert_frame.__guards: [DEBUG] not ___are_deterministic_algorithms_enabled()
[2023-07-10 20:11:30,529] torch._dynamo.convert_frame.__guards: [DEBUG] utils_device.CURRENT_DEVICE == None
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104932
Approved by: https://github.com/mlazos, https://github.com/albanD
Currently, negative unspecified ints get specialized. This PR creates symbolic values for
unspecified ints (including negative ones).
For example, with this PR, the following code only compiles once, instead of 3 times:
```python
def foo(x, y):
return torch.fill(torch.zeros(x.shape), y)
foo(10)
foo(-5)
foo(-3)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104658
Approved by: https://github.com/ezyang
Summary:
QAT convert for mobilenetv2 was previously not working
because we incorrectly applied dropout during eval as well as
training. This is because, for exported models, model.eval() does
not change the behavior of dropout, unlike models with torch ops.
This commit simulates the effects of model.eval() for exported
models as well by replacing the aten dropout pattern before eval.
As of this commit, end-to-end QAT numerics now match for
mobilenetv2 between FX and PT2.
Test Plan: python test/test_quantization.py TestQuantizePT2EModels.test_qat_mobilenet_v2
Differential Revision: D46750343
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104110
Approved by: https://github.com/jerryzh168
This PR disables translation validation (TV) when running the benchmark suits on
performance workflows: inductor with A100s.
In summary, the changes are:
- Add flag for turning TV on and off on _benchmarks/dynamo/common.py_
- Turn TV on only on CI accuracy builds
- Add `--no-translation-validation` target flag to _.ci/pytorch/test.sh_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104887
Approved by: https://github.com/ezyang
Context
-------
This PR adds a new fallback to the Autograd dispatch keys.
If you would prefer the old behavior:
- A quick (unsupported) way to get the previous behavior is to call
`torch._C._set_autograd_fallback("nothing")`
- Register "torch::CppFunction::makeFallthrough()" to your Autograd key,
like in https://gist.github.com/zou3519/d09a5f4b1afe2430af09fea67c6ff2c8
It is possible that this PR regresses performance of overhead-bound
models. If this is the case, please reach out (and apply one of the
temporary fixes in the previous section).
Description for reviewers
-------------------------
In order to deprecate registering autograd kernels at not an autograd
key, we add a fallback to the Autograd dispatch keys. This fallback
raises a warning if the user attempts to backprop through the operator
and is also configurable to either warn or not warn.
The goal of this PR is to
- preserve as much BC as possible
- raise a warning that whatever the user is doing is potentially wrong.
- be as performant as possible
There are roughly two cases:
- if the post-autograd kernels return a Tensor that requires grad, then
we install an autograd hook that raises a warning. We are preserving BC
in that it is possible that the user has a torch::autograd::Function
registered to their CPU key.
- if the post-autograd kernels return Tensors that do not require grad,
then we make them require_grad and install a WarnNotImplemented grad fn
that warns in the backward pass. This is mildy BC-breaking (see next
section).
Test Plan:
- bunch of new tests
BC-Breaking Note
----------------
This PR adds a new fallback to the Autograd dispatch keys. It affects
custom operators that do not have a kernel registered to the Autograd
keys (e.g. AutogradCPU and AutogradCUDA).
If the previous behavior was that the custom operator would return
Tensors that do not require grad if the inputs do require grad, then
this PR changes it so that all floating-point and complex returns do
require grad. See the "Context" section above for how to get the old
behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104481
Approved by: https://github.com/soulitzer
This reduces total number of imported modules by default from 1419 to 1322 according to
```
time python -c "import sys;before=len(sys.modules);import torch;after=len(sys.modules);print(f'torch-{torch.__version__} imported {after-before} modules')"
```
and slightly reduces import time, while having no effect on UX (i.e. `torch.onnx.` submodule is kept intact)
Suppress lint errors that appear after mypy accidentally starts listing more files, for more details see: https://github.com/pytorch/pytorch/issues/104940
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104843
Approved by: https://github.com/jansel, https://github.com/albanD
This is a bug discovered by https://github.com/pytorch/pytorch/pull/104810. Basically, when the PR body is empty, GitHub API returns a None value, which is passed into `parse_reenabled_issues` causing it to fail.
### Testing
```
python3 .github/scripts/filter_test_configs.py \
--workflow "pull" \
--job-name "linux-focal-py3-clang7-android-ndk-r19c-gradle-custom-build-single-full-jit / filter," \
--test-matrix "{ include: [ { config: 'default', shard: 1, num_shards: 1, runner: 'linux.2xlarge' }, ]}" \
--pr-number "104810" \
--tag "" \
--event-name "pull_request" \
--schedule "" \
--branch ""
```
The command works correctly without failing now
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104914
Approved by: https://github.com/clee2000
## Problem
Trying to support numpy function call in dynamo, with numpy dtype as argument.
For example:
```
def fn(x: int):
return np.empty_like(x, dtype=np.float64)
```
## Solution
This currently doesn't work because `NumpyVariable` doesn't implement `as_proxy()`. The idea in `as_proxy()` for now is to convert `np.float64` and other np.<dtype> into `torch.dtype` and then feed into the corresponding `torch_np` method.
For previous example, we convert `np.float64` to `torch.float64` in `as_proxy()` and then feed it into `torch_np.empy_like()` method.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103546
Approved by: https://github.com/ezyang
## Context prior to this PR
https://github.com/pytorch/pytorch/pull/100017/ was merged onto PyTorch `main` branch with the goal of enabling `torch._dynamo.export` to perform symbolic tracing.
In that context, symbolic tracing is defined as tracing of a model using fake inputs and weights. An input is Fake when `torch.nn.Tensor` is replaced by `torch._subclasses.FakeTensor`, whereas a weight is fake when a `torch.nn.Parameter` is replaced by `torch._subclasses.FakeTensor`.
For additional context, several strategies were discussed with Meta to enable this feature, including 1) calling `torch._dynamo.export` within a `torch._subclass.FakeTensorMode` context and 2) **fake**fying input and model as separate step and then call `torch._dynamo.export` without an active `torch._subclass.FakeTensorMode` context. At the end, 2) was preferred and implemented by #100017 to minimize the number of side-effects the fake tensor mode has on the code base.
As a consequence, `torch._dynamo.export` API introduced a new argument called `fake_mode`. When symbolic tracing is used, the user must pass in the `fake_mode` used to fakefy both the input and the model. Internally, `torch._dynamo.export` will adopt this `fake_mode` instead of creating its own instance. This is needed because each instance of `FakeTensorMode` has metadata on the tensor/parameter it fakefied. Thus, using real tensor/model and specify a `fake_mode` to `torch._dynamo.export` is an error. Also, specify a `fake_mode` instance to `torch._dynamo.export` different than the one used to fakefy the model and input is also an error.
## Changes introduced from this PR
This PR is intended to integrate `torch._dynamo.export(fake_mode=...)` through `torch.onnx.dynamo_export`. In essence, it
* Introduces a new public API `ONNXFakeContext` which wraps a `FakeTensorMode` under the hood. This removes complexity from the user side while still allow the exporter to leverage the fake mode.
* Adds a new public API `enable_fake_mode` *context manager* that instantiates and return a `ONNXFakeContext`.
* Adds a new `ExportOptions.fake_context` that will be used to persist the `ONNXFakeContext` created by `enable_fake_mode` and plumb through until it reaches the call to `torch._dynamo.export`.
* Adds a `model_state_dict` argument to `ExportOutput.save` API.
* When model is exported with fake tensors, no actual data exist in the FX module and, therefore, in the ONNX graph.
* In fact, `torch.fx.make_fx` lifts initializers as model input when fake tensors are used
* https://github.com/pytorch/pytorch/pull/104493 is needed to enforce name matching between Parameters and inputs
* A model checkpoint file or state_dict is needed to populate the ONNX graph with real initializers through `export_output.save(model_state_dict=...)` API
Symbolic tracing, or onnx fake mode, is only enabled when the user instantiates the input and model within the `enable_fake_mode` context. Otherwise, real tracing is done, which preserves the current behavior.
## Usability
Because symbolic tracing depends a lot on having changes made on Dynamo side before it can be consumed on ONNX exporter, this feature may have its API and assumptions changed as symbolic tracing matures upstream. Nonetheless, it is still important to have this feature merged ASAP on the ONNX exporter side to "lock" changes on Dynamo that would otherwise break ONNX exporter without warning.
Example:
```python
class Model(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.linear = torch.nn.Linear(2, 2)
def forward(self, x):
out = self.linear(x)
return out
with torch.onnx.enable_fake_mode() as fake_context:
x = torch.rand(5, 2, 2)
model = Model()
# Export the model with fake inputs and parameters
export_options = ExportOptions(fake_context=fake_context)
export_output = torch.onnx.dynamo_export(
model, x, export_options=export_options
)
model_state_dict = Model().state_dict() # optional
export_output.save("/path/to/model.onnx", model_state_dict=model_state_dict)
```
## Next steps
* Add unit tests running the exported model with ORT
Today this is not possible yet because `make_fx` used by our Decomposition pass lifts initializers as model inputs. However, the initializer names are not preserved by FX tracing, causing a mismatch between the initializer and input name.
https://github.com/pytorch/pytorch/pull/104493 and https://github.com/pytorch/pytorch/pull/104741 should fix the initializer mismatch, enabling model execution
* Revisit `ONNXTorchPatcher` and how the ONNX initializers are saved in the graph as external data
We can try to get rid of the PyTorch patcher. If we can't, we might prefer to create specific patchers, say `FXSymbolicTracePatcher` used specifically during an export using `torch.fx.symbolic_trace` and maybe a `ExportOutputSavePacther` used specifically for `ExportOutput.save` to prevent "patching too many pytorch API that we don't need
## References
* [FakeTensor implementation](https://github.com/pytorch/pytorch/blob/main/torch/_subclasses/fake_tensor.py)
* [PR that adds fake tensor support to torch._dynamo.export](https://github.com/pytorch/pytorch/pull/100017)
* [Short fake tensor documentation](https://pytorch.org/torchdistx/latest/fake_tensor.html)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103865
Approved by: https://github.com/BowenBao
For quantize
```
for (; i < len / VLEN * VLEN; i += VLEN) {
__m512 x_vals = _mm512_load_ps(src + i);
__m512 x_transformed_v = _mm512_mul_ps(x_vals, inverse_scale_v);
x_transformed_v =
_mm512_min_ps(x_transformed_v, _mm512_set1_ps(int32_float_max_val));
__m512i x_rounded_v = _mm512_cvtps_epi32(x_transformed_v);
x_rounded_v = _mm512_add_epi32(x_rounded_v, _mm512_set1_epi32(zero_point));
__m512i x_clipped_v =
_mm512_max_epi32(min_v, _mm512_min_epi32(max_v, x_rounded_v));
x_clipped_v = _mm512_shuffle_epi8(x_clipped_v, shuffle_mask_v);
x_clipped_v = _mm512_permutexvar_epi32(permute_mask_l8_v, x_clipped_v);
_mm_storeu_si128(
reinterpret_cast<__m128i*>(dst + i),
_mm512_castsi512_si128(x_clipped_v));
}
```
```
x_clipped_v = _mm512_shuffle_epi8(x_clipped_v, shuffle_mask_v);
x_clipped_v = _mm512_permutexvar_epi32(permute_mask_l8_v, x_clipped_v);
```
is aiming to cast `int32` to `int8` and shuffle 16 `int8` to the first 128 bits.
For example, `A1` represent 8bit
```
x_clipped_v = _mm512_shuffle_epi8(x_clipped_v, shuffle_mask_v);
A1A2A3**A4** B1B2B3**B4** C1C2C3**C4** D1D2D3**D4** -> D4C4B4A4 other 32 * 3 bit
E1E2E3**E4** F1F2F3**F4** G1G2G3**G4** H1H2H3**H4** -> H4G4F4E4 other 32 * 3 bit
I1I2I3**I4** J1J2J3**J4** K1K2K3**K4** L1L2L3**L4** -> L4K4J4I4 other 32 * 3 bit
M1M2M3**M4** N1N2N3**N4** O1O2O3**O4** P1P2P3**P4** -> P4O4N4M4 other 32 * 3 bit
x_clipped_v = _mm512_permutexvar_epi32(permute_mask_l8_v, x_clipped_v);
D4C4B4A4 other 32 * 3 bit -> D4C4B4A4 H4G4F4E4 L4K4J4I4 P4O4N4M4
H4G4F4E4 other 32 * 3 bit other 3 * 4 * 32 bits
L4K4J4I4 other 32 * 3 bit
P4O4N4M4 other 32 * 3 bit
```
Based on https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html#text=_mm512_permutexvar_epi32&ig_expand=4966,5088.
```
FOR j := 0 to 15
i := j*32
id := idx[i+3:i]*32
dst[i+31:i] := a[id+31:id]
ENDFOR
dst[MAX:512] := 0
```
the `permute_mask_l8_v` should satisfy
```
permute_mask_l8_v[3:0] = 0
permute_mask_l8_v[3 + 32:0 + 32] = 4
permute_mask_l8_v[3 + 64:0 + 64] = 8
permute_mask_l8_v[3 + 96:0 + 96] = 12
```
The other part of `permute_mask_l8_v` does not matters.
`AVX2` version is correct.
It is not exposed before it is only called with fixed length `64` https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/cpu/vec/vec512/vec512_qint.h#L545-L546.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104400
Approved by: https://github.com/jgong5, https://github.com/mingfeima, https://github.com/jerryzh168
Current TCPStore wait logic leaves the client socket in a bad state if waiting timesout.
This happens because all recv functions raise an exception on timeout and that's it.
The problem is that on timeout we need to unregister the wait.
We implement this with client side cancelation by adding a new CANCEL_WAIT instruction.
So, if no data arrives before the deadline, the client sends a CANCEL_WAIT command.
The server sends a WAIT_CANCELED response to that command, always.
This gets us down to the last issue, which is that there's a race between timeout'ing,
canceling the wait and the wait completing. The client needs to handle the server sending
a STOP_WAITING followed by a WAIT_CANCELED answer.
This ensures client and server state are synchronized regardless of whether the wait
timeouts or not.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100594
Approved by: https://github.com/H-Huang
Python `mod` semantics is not the same as the mathematical modulus operation. According to
the Python reference: `a = floor(a / b) * b + a % r`.
In other words: `a % b = a - floor(a / b) * b`.
This PR fixes the old implementation which used SMT-LIB2 semantics for `mod`. In short, it
only worked with integers and had the following guarantee: `0 <= a % b < b`.
In summary, the changes are:
- `a % b = a - floordiv(a, b) * b`
- `a` and `b` can be both integer or real
- The result will be real if any of the arguments is real. Otherwise, it will be integer
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104827
Approved by: https://github.com/lezcano
Originally, we didn't enable BWD for colwise embedding because we thought it was just for inference, but it turns out that we do need it for training. So, let's enable it for now and unit test is also added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104820
Approved by: https://github.com/fegin
MS2 of the Reproducible Testing BE initiative. For context, this is the ask:
```
Another thing that would be really great as we start to have more dependent
systems or types of tests (functorch, dynamo, crossref) would be to have a
minimally reproducible version of the test (something at the end of the HUD
comment like: "Run python test/test_file.py -k test_name" but also if you need
flags, like crossref it would be like "Run <flag to run crossref> python test/..." ). I'll
often go through the test infra to find the flags that I need to pass when
something only breaks crossref/dynamo tests.
```
Implementation details:
* Adds a new flag `PRINT_REPRO_ON_FAILURE` that is settable through the environment variable `PYTORCH_PRINT_REPRO_ON_FAILURE=1`
* **Default is ON but I can be persuaded otherwise**
* When the flag is enabled, our base `TestCase` will wrap the test method in a context manager that catches any non-skip exceptions and appends a repro string to the exception message. The repro includes setting of necessary test flags through env vars. Example:
```
To execute this test, run the following from the base repo dir:
PYTORCH_TEST_WITH_CROSSREF=1 python test/test_ops.py -k test_foo_add_cuda_float32
This message can be suppressed by setting PYTORCH_PRINT_REPRO_ON_FAILURE=0
```
* To keep track of flag settings, this PR introduces a new `TestEnvironment` class that defines global flags by querying related environment variables. Flag and env var names are purposefully kept searchable via full names. Example usages:
```python
TestEnvironment.def_flag("TEST_WITH_TORCHINDUCTOR", env_var="PYTORCH_TEST_WITH_INDUCTOR")
# can track implication relationships to avoid adding unnecessary flags to the repro
TestEnvironment.def_flag(
"TEST_WITH_TORCHDYNAMO",
env_var="PYTORCH_TEST_WITH_DYNAMO",
implied_by_fn=lambda: TEST_WITH_TORCHINDUCTOR or TEST_WITH_AOT_EAGER)
# can use include_in_repro=False to keep the flag from appearing in the repro command
TestEnvironment.def_flag(
"DISABLE_RUNNING_SCRIPT_CHK", env_var="PYTORCH_DISABLE_RUNNING_SCRIPT_CHK", include_in_repro=False)
# the default default value is False, but this can be changed
TestEnvironment.def_flag(
"PRINT_REPRO_ON_FAILURE", env_var="PYTORCH_PRINT_REPRO_ON_FAILURE", default=(not IS_FBCODE), include_in_repro=False)
```
* AFAICT it is only feasible to achieve this from within the test framework rather than at the CI level. This is because CI / `run_test.py` are unaware of individual test cases. Implementing it in our base `TestCase` class has the broadest area of effect, as it's not isolated to e.g. OpInfo tests.
* I couldn't find an easy way to test the logic via `test_testing.py`, as the logic for extracting the test filename doesn't work for generated test classes. I'm open to ideas on testing this, however.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104537
Approved by: https://github.com/ezyang, https://github.com/janeyx99, https://github.com/huydhn
Fixes#101684
Before this change, we get a float constant in triton
```
tmp0 = 0.2
```
which in triton IR becomes a float32 value
```
%cst_0 = arith.constant dense<2.000000e-01> : tensor<2xf32>
```
After, we get a tensor with explicit type
```
tmp0 = tl.full([1], 0.2, tl.float64)
```
which does generate a float64 in the triton IR
```
%cst_0 = arith.constant dense<2.000000e-01> : tensor<2xf64>
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104830
Approved by: https://github.com/lezcano
Summary:
This diff does the following:
1. re-enable single_file_per_rank for FsspecWriter, as the issue of file slicing error is resolved because of [https://github.com/pytorch/pytorch/pull/99167]
2. remove sync_files from FsspecWriter as there is no fsspec equivalence.
3. remove the internal implementation of FsspecWriter/Reader, as it has been upstreamed to PyTorch OSS
4. keep the internal test for manifold inside internal as we can only test it in fb environment
5. consolidate test to remove duplicates
6. remove unnecessary TARGETS
Test Plan:
```
buck test @//mode/dev-nosan //caffe2/test/distributed/checkpoint/fb:test_fsspec_filesystem -- --print-passing-details
----------------------------------------------------------------------
Ran 1 test in 54.894s
OK
/usr/local/fbcode/platform010/lib/python3.8/tempfile.py:818: ResourceWarning: Implicitly cleaning up <TemporaryDirectory '/tmp/tmpzomokvh6'>
_warnings.warn(warn_message, ResourceWarning)
Buck UI: https://www.internalfb.com/buck2/4cb722a2-3ee7-48f2-a9ef-55ee6fb1a498
Test UI: https://www.internalfb.com/intern/testinfra/testrun/8725724447995201
Network: Up: 8.8 MiB Down: 1.5 GiB (reSessionID-04c29f56-ae94-4187-8a1a-c812f432674d)
Jobs completed: 209847. Time elapsed: 1:56.5s.
Cache hits: 100%. Commands: 85687 (cached: 85687, remote: 0, local: 0)
Tests finished: Pass 3. Fail 0. Fatal 0. Skip 0. Build failure 0
```
Differential Revision: D47266068
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104724
Approved by: https://github.com/fegin, https://github.com/fduwjj
Starts addressing https://github.com/pytorch/pytorch/issues/97712 by
- Minimizing intermediates usage for foreach Adam
- Document the extra memory usage
- Add comments within the code for clarity now that we reuse intermediates
- Add tests
- Did some refactoring
Next steps involve doing this for all other foreach implementations. Note that even after this change, foreach mem usage will be higher than forloop due to the fact that we have a minimum budget of 1 intermediate (to not muddle the input values) and the intermediate will be larger. For capturable, the memory usage is higher due to moving more tensors to CUDA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104780
Approved by: https://github.com/albanD
Summary:
Add a new path in `post_grad.py` for replacing addmm + ReLU / GELU activation with the corresponding `_addmm_activation` call (with `use_gelu=False` or `True`, respectively). The replacement is done only on `max_autotune_gemm=False` and when the activation is fusible.
Test Plan:
$ python test/inductor/test_pattern_matcher.py -k test_addmm_activation -v
(__main__.TestPaternMatcher.test_addmm_activation) ... /data/users/aakhundov/pytorch/torch/_inductor/compile_fx.py:128: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
warnings.warn(
Using FallbackKernel: aten._addmm_activation.default
Using FallbackKernel: aten._addmm_activation.default
/data/users/aakhundov/pytorch/torch/_dynamo/eval_frame.py:373: UserWarning: changing options to `torch.compile()` may require calling `torch._dynamo.reset()` to take effect
warnings.warn(
frames [('total', 1), ('ok', 1)]
stats [('calls_captured', 2), ('unique_graphs', 1)]
aot_autograd [('total', 1), ('ok', 1)]
inductor []
ok
----------------------------------------------------------------------
Ran 1 test in 13.415s
OK
Reviewers: @eellison
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104132
Approved by: https://github.com/eellison, https://github.com/jansel
When using KeyedOptimizer.init_state(), some optimizers initializes the states even if the param is empty (size() == 0) while some optimizer avoid initializing the states. There is no way FSDP can tell. Instead, FSDP should look up `optim.state`. Fortunatelly, `optim.state` does not rely on FQNs which some internal users change the FQNs.
Differential Revision: [D47285562](https://our.internmc.facebook.com/intern/diff/D47285562/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104765
Approved by: https://github.com/fduwjj
Per https://github.com/pytorch/pytorch/pull/103303 we cannot
universally allow tracing in all functions that return int,
as the graph breaks appear to be load bearing in some cases.
However, allowing for torch.sym_int to be traced in even if
the result is statically known is fine; this can happen in
case of a SymBool to int conversion.
This PR is not exhaustive but e.g., I fixed size/stride/numel
handling in https://github.com/pytorch/pytorch/pull/103438
The biggest risk is that arithmetic operations on sizes end
up getting constant-ified (this appears to have happened in
practice for modulus, which is why it's in this list.) If
we don't care about spewing useless computation into the graph,
a more aggressive version of this PR would be to greatly expand
the list of allowed to specialize to int targets and then undo
https://github.com/pytorch/pytorch/pull/103438
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104837
Approved by: https://github.com/voznesenskym
Previously, if you called `torch.fx.wrap()` on the same thing twice, it would add two entries to `_wrapped_fns_to_patch`. Then, when tracing, the patcher would process them both. On the second entry, the patcher would double-wrap the fn (e.g. `wrap(wrap(orig_fn))`)
This makes it so that wrapping is observable after the trace. While normally, a Patcher instance will "revert" the wrapping after tracing, the double wrapped function goes from `wrap(wrap(orig_fn)) -> wrap(orig_fn)`.
This happens to work in normal fx stuff (after all, the wrapper function will behave exactly like the original function). But it upsets torch.package, which is not expecting to see a weird wrapper function in the graph.
This PR adds a dictionary to deduplicate `wrap()` calls, ensuring that the patcher only operates each once per frame-fn pair.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104838
Approved by: https://github.com/Chillee
Summary:
AOTInductor model wrapper code has been moved to torch/_inductor so
that we can remove the duplicates from deeplearning, which were
placed there temporarily.
This PR also made the following changes to inductor codecache to make it work with AOTInductor:
* take the full input and output paths in aot_mode
* use a more suitable way to retrieve dirname from the input_path
Differential Revision: D47118805
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104730
Approved by: https://github.com/jansel
This is intended as a first step towards reductions with multiple outputs. This
also incidentally improves CSE of reductions under C++ codegen. For example,
```python
def fn(x):
return torch.argmin(x, dim=-1), torch.argmin(x, dim=-1)
```
Currently this generates two reductions, where the common load is CSEd
```cpp
for(long i1=static_cast<long>(0L); i1<static_cast<long>(10); i1+=static_cast<long>(1L))
{
auto tmp0 = in_ptr0[static_cast<long>(i1 + (10L*i0))];
if (tmp_acc0.value > tmp0) {
tmp_acc0.index = i1; tmp_acc0.value = tmp0;
}
if (tmp_acc1.value > tmp0) {
tmp_acc1.index = i1; tmp_acc1.value = tmp0;
}
}
auto tmp1 = tmp_acc0.index;
out_ptr0[static_cast<long>(i0)] = tmp1;
auto tmp2 = tmp_acc1.index;
out_ptr1[static_cast<long>(i0)] = tmp2;
```
but with this change it gets CSEd to a single accumulator
```cpp
for(long i1=static_cast<long>(0L); i1<static_cast<long>(10L); i1+=static_cast<long>(1L))
{
auto tmp0 = in_ptr0[static_cast<long>(i1 + (10L*i0))];
if (tmp_acc0.value > tmp0) {
tmp_acc0.index = i1; tmp_acc0.value = tmp0;
}
}
auto tmp1 = tmp_acc0.index;
out_ptr0[static_cast<long>(i0)] = tmp1;
out_ptr1[static_cast<long>(i0)] = tmp1;
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102737
Approved by: https://github.com/jgong5, https://github.com/lezcano
This is a bit inefficient because it computes the mean and throws it
away since ir.Reduction nodes only have 1 output. However, the mean
can at least be scheduled into the same loop as the variance now since
there is no data dependency. Thus we can take fewer passes over the
data.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102486
Approved by: https://github.com/lezcano, https://github.com/jansel
As of now, translation validation runs to its completion. However, Z3 is time
consuming. PR #104464, for example, disables translation validation for a few benchmarks.
Instead, this PR introduces a timeout for translation validation. In that case, Z3 will
return `unknown`, since it wasn't able to prove or disprove the assertions. Then, we log
it as a warning, but don't stop execution.
Here's a summary of the changes:
- Added an environment variable for turning translation validation on and off
- Added an environment variable for setting the translation validation timeout
- Possibly reverts the changes in #104464
- ~~Move from "QF_NRA" to "QF_NIRA" logic~~
- ~~It makes more sense, given the nature of the problems~~
- "QF_NRA" seems to solve more instances of _dynamo/test_dynamic_shapes.py_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104654
Approved by: https://github.com/ezyang
Fixes https://github.com/pytorch/pytorch/issues/104272
This PR adds a new private API `materialize_non_diff_grads` (default True) such that when set to False, grad outputs corresponding to outputs marked non-differentiable would receive None instead of a zero-filled tensor. This is overrides the setting of `materialize_grads`, i.e. grad outputs corresponding non-differentiable outputs would still be None even if `materialize_grads=True` (the default).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104291
Approved by: https://github.com/albanD
The "for now" is because we still have the issue that when using the parameter `ignored_states` path, we do not recover the ignored modules, so FSDP still wraps those as empty shells (no managed parameters), which is not ideal. This is not a blocking issue as far as I know.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104418
Approved by: https://github.com/rohan-varma
This moves `fully_shard` to use `_auto_wrap()` just like `FullyShardedDataParallel`. This means that `fully_shard` goes through the `_init_param_handle_from_module()` path (i.e. 1 `fully_shard` per "wrap"), removing the need for `_init_param_handles_from_module()` (which was 1 `fully_shard` for all "wraps" of a given policy). `_auto_wrap()` simply calls `fully_shard` on target submodules.
This includes several important fixes:
- We should register the pre/post-forward hooks on the module regardless of it has managed parameters.
- We can permit `_module_handles` to return `[]` in the composable path (for when the module has no managed parameters).
- We should unify the paths for `_get_buffers_and_dtypes_for_computation()` (previously, composable path was buggy in some cases).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104408
Approved by: https://github.com/rohan-varma
This PR is the first in refactoring the auto wrapping, only affecting `ModuleWrapPolicy` for wrapper `FullyShardedDataParallel`. The end goal is to improve the auto wrapping infra to support:
- Checking valid frozen parameters (uniform frozenness per FSDP)
- Checking valid shared parameters (shared parameters assigned to their lowest-common-ancestor module or higher)
- Writing auto wrapping policies that may take multiple passes over the module tree
- Specifying different FSDP kwargs per FSDP instance (instead of enforcing the same for all FSDP instances constructed via an auto wrap policy)
The way I envision achieving this is that, we decouple the actual "wrapping" (which is `_post_order_apply()` in this PR) from constructing the wrapping targets and kwargs (which is `target_module_to_kwargs` in this PR). In that way, a policy reduces to just constructing that latter `target_module_to_kwargs` mapping.
I do not personally recommend the size-based policy, but if we wanted to implement that under this new organization, the tracking of wrapped/nonwrapped numel should be done in the pass over the module tree prior to the actual "wrapping". This modularization keeps the actual "wrapping" part simple.
The change to how `old_dtype` is handled is mainly to avoid keeping a reference to `_override_module_mixed_precision()` function closure in each hook and to allow the function to take in all module clases at once to return which ones actually got overridden for the downstream error message. (We can directly store the global state as a mapping.)
To-do in follow-ups (not in order):
- Add frozen parameter check before `_post_order_apply()`
- Add shared parameter check before `_post_order_apply()`
- Expose wrapping policy that allows per module / per module class kwarg customization (where any unspecified kwarg adopts the root's kwarg)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104346
Approved by: https://github.com/rohan-varma, https://github.com/fegin
This fixes the failure when a list of skipped messages is encountered when uploading disabled test stats, for example https://github.com/pytorch/pytorch/actions/runs/5489936777/jobs/10004725533.
This happens for ONNX tests (running regularly), i.e. https://ossci-raw-job-status.s3.amazonaws.com/log/14868893973:
```
onnx/test_op_consistency.py::TestOnnxModelOutputConsistency_opset13CPU::test_output_match_tile_cpu_bool SUBSKIP [0.0000s] (Logic not implemented for size 0 inputs in op.Reshape) [ 47%]
onnx/test_op_consistency.py::TestOnnxModelOutputConsistency_opset13CPU::test_output_match_tile_cpu_bool SUBSKIP [0.0000s] (Logic not implemented for size 0 inputs in op.Reshape) [ 47%]
...
onnx/test_op_consistency.py::TestOnnxModelOutputConsistency_opset13CPU::test_output_match_tile_cpu_bool SUBSKIP [0.0000s] (Logic not implemented for size 0 inputs in op.Reshape) [ 47%]
onnx/test_op_consistency.py::TestOnnxModelOutputConsistency_opset13CPU::test_output_match_tile_cpu_bool PASSED [0.3136s] [ 47%]
```
The corresponding XML output is as follows https://paste.sh/b1DbSLJD#M-0WsXd9snjEVFh4ZsxPPIlv where `skipped` is a list of skipped messages instead of a dictionary.
As we only care about gathering disabled tests stats in this script, the list of skipped messages can be safely ignored.
### Testing
* Gathering disabled test stats works correctly when running under rerunning disabled tests mode https://github.com/pytorch/pytorch/actions/runs/5487829458/jobs/9999835911
* The command works locally for the above failed workflow (which is not a rerunning disabled tests workflow):
```
python3 -m tools.stats.check_disabled_tests --workflow-run-id "5488337480" --workflow-run-attempt 1 --repo "pytorch/pytorch"
...
The following 0 tests should be re-enabled:
The following 0 are still flaky:
Writing 0 documents to S3
Done!
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104803
Approved by: https://github.com/clee2000
This PR introduces a new pass that restore parameter and buffer names from original module.
It is useful for readability of the exported ONNX graph. It restores the parameter and buffer names from the original module. For example, if the original module has a parameter named `root.linear.0.weight`, and the parameter is renamed to
`_param_constant9` by FX, this pass will rename it back.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104493
Approved by: https://github.com/wschin, https://github.com/thiagocrepaldi
## ONNXRegistry
### Motivation
In #100660, we used the torchscript registry to allow dispatcher. However, it doesn't meet the needs of FX exporter. The idea of torchscript exporter is built on top of three points:
(1) Use `_SymbolicFunctionGroup` to dispatch opset version as we need ops to fall back when we don't have it in the current exporter opset version
(2) One aten maps to multiple supported opset versions, and each version maps to one symbolic function
(3) Custom symbolic function is considered prior to default symbolic function
Now that TorchLib will support all aten op across all opset versions, we don't need the opset version dispatch layer. And with onnx overloads created by torchlib, we need a way to support custom operators and prioritize them among all overloads.
### Feature
Introduce a public OnnxRegistry API initiated with fixed opset version which supports user registered operators. **The dispatching opset version is no longer needed as TorchLib is expected to provide full aten support across all opset version. And Dispatcher is expected to prioritize custome operators than the defaults.**
### API:
(1) `register_custom_op(self, function: OnnxFunction, domain: str, op_name: str, overload: Optional[str] = None)`: Register a custom operator into the current OnnxRegistry. This is expected to be used when the default operators don't mee the need of users. **For example, need a different opset version from the registry, or different calculation**.
(2) `is_registered_op(self, domain: str, op_name: str, overload: Optional[str] = None)`: Whether the aten op is registered.
(3) `get_functions(domain: str, op_name: str, overload: Optional[str] = None)`: Return a set of registered SymbolicFunctions under the aten
### TODO:
(1)`remove_op(op_name: str)`: removing the whole support for certain op allows decompose the graph to prims.
(2)Expose OnnxRegistry to users, and disable the opset_version option in export API. Export API should use the ops in registry only.
---
## OnnxDispatcher
The Changes in the function `dispatch` and `_find_the_perfect_or_nearest_match_onnxfunction` are meant to allow complex type and custom operator supports.
### Respect Custom Ops
(1) Override: Check if we can find the perfect match in custom operator overloads prior to defaults
(2) Tie breaker: If we have the same nearest match of default and custom overload, we choose the custom.
### Supplementary
[Design discussion doc](https://microsoft-my.sharepoint.com/:w:/p/thiagofc/EW-5Q3jWhFNMtQHHtPpJiAQB-P2qAcVRkYjfbmeSddnjWA?e=QUX9zG&wdOrigin=TEAMS-ELECTRON.p2p.bim&wdExp=TEAMS-TREATMENT&wdhostclicktime=1687554493295&web=1)
Please check the Registry and Dispatcher sections.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103943
Approved by: https://github.com/BowenBao, https://github.com/justinchuby
Background/problem: ops.bucketize needs to take a value `offsets_size`, which is the length of the `offsets` tensor. It is used, e.g., for the bounds of the binary search over the `offsets` tensor. The previous implementation of `ops.bucketize` expected `offsets_size` to be a CSEVariable; i.e. we'd pass `offsets_size = ops.index_expr(offsets.get_size()[0])` into `ops.bucketize()`. However, `ops.index_expr` will sometimes broadcast, turning the scalar `offsets_size` into a tensor. That caused errors, because [triton_helpers.bucketize_binary_search](a2fe6953bc/torch/_inductor/triton_helpers.py (L153-L155)) expects `offsets_size` to be a scalar. [Link - where the broadcasting happens](a2fe6953bc/torch/_inductor/codegen/triton.py (L1056))
Solution (this PR): Instead of passing `offsets_size` into `ops.bucketize` as a CSEVariable, pass in a sympy.Expr. Then, inside ops.bucketize, convert the sympy.Expr into a string that can be used in the generated triton code.
Differential Revision: [D47282413](https://our.internmc.facebook.com/intern/diff/D47282413)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104756
Approved by: https://github.com/jansel
The analysis for SymPy expressions was incorrect as, even though it said
that the assumption was "smoothness" the assumption was, in fact, that he
formula was monotone in every variable. In other words, it was
assuming that the derivative does not change signs in any variable (!!).
We implement a function that, given bounds on the values of the free
symbols of a sympy expression, it gives a bound on a the expression
itself.
We reshuffle a few things in value_ranges.py to create a
`SymPyValueRangeAnalysis` class, but we do not change any code really.
The only relevant change in that file is the addition of the
`sympy_bound`s function. We do this because we don't want to inadvertently
use any fallbacks in this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104559
Approved by: https://github.com/eellison
This PR:
- It adds a few boolean variants of some methods that were missing
- It simplifies the implementation of plenty of the operations
- Adds ModularIndexing to the SymPy interpreter
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104557
Approved by: https://github.com/eellison
Summary: include `allow_tf32` in system information; previously aten results did not specify whether `allow_tf32` was true or not
Test Plan: sandcastle + CI
Differential Revision: D46568468
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104129
Approved by: https://github.com/jansel
Previous to this PR, to support onnxscript function proto in torchscript exporter, the registered custom symbolic functions are all forced to call `.function_proto` API as onnxscript functions. The PR makes sure the custom function is onnxscript function before using the API. To avoid the dependency, hasattr is used instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104785
Approved by: https://github.com/BowenBao
In binary search triton implementations, (#104007) num_elements_per_warp=32 performs a lot better than larger values.
This PR adds an autotuning config option for this purpose. But since autotuning can affect compile times and this config isn't generally useful, we only try this config if bucketize is present. This is done by adding an extra field to triton_meta which is used by the pointwise autotuning
Performance: reused https://gist.github.com/davidberard98/066fd2115f59f5889ef61e4527d1eba5.
Before:
```
Eager 0.30088499188423157 ms
PT2 0.9296960234642029 ms
```
After:
```
Eager 0.3011910021305084 ms
PT2 0.22977299988269806 ms
```
Differential Revision: [D47237103](https://our.internmc.facebook.com/intern/diff/D47237103)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104456
Approved by: https://github.com/eellison
Previously it is defined as `_run_node_and_update_meta_val` which selectively only
updates `meta["val"]`. The behavioral difference stems from two type of scenarios:
node creation and node modification. `node.meta` is empty for the former, while already
exist and populated for the latter. This PR updates the API to handle both scenarios.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104720
Approved by: https://github.com/thiagocrepaldi
Summary:
Some serialized nn_module_stacks contain nested commas, something like:
`(getitem(L['module'],0),torch.nn.modules.linear.Linear)`
Fixing the parsing so that we can deserialize the string in the format of: `(local identifier, module type)`
Test Plan: CI
Differential Revision: D47252881
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104721
Approved by: https://github.com/zhxchen17
Remove _deprecated_global_ns from cond following #104105.
We change the module attribute of HigherOrderOperator instances in the constructor from torch.ops to torch.ops.higher_order when self.namespace is "higher_order". For subclasses (e.g. customized higher order operator), we leave their \_\_module\_\_ unchanged.
Will import this PR to fix internal tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104380
Approved by: https://github.com/zhxchen17, https://github.com/zou3519
The warning complains that `TORCH_CUDA_ARCH_LIST` is set on the environment
instead of being defined as a build variable, which is fixed by the change to
`tools/setup_helpers/cmake.py`.
However, I still see the warning even with this fix because
```cmake
if((NOT EXISTS ${TORCH_CUDA_ARCH_LIST}) ...
```
is actually checking whether a file exists called "7.5" (or whatever arch is
being requested). Instead we want to check if the variable is defined.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104680
Approved by: https://github.com/albanD
I think after https://github.com/pytorch/pytorch/pull/104077, we don't
need to do a diff between the SideEffects object before/after for
HigherOrderOps -- the ability is baked into speculate_subgraph.
The rationale for this PR is that diff-ing the SideEffects object didn't
work very well: it was overly conservative. If a variable gets
tracked for mutation, or a new cell variable is created, then the
SideEffects object changes.
The SideEffects object tracks two types of side effects:
- variable assignment/modification. This is covered by
[check_allowed_side_effect](https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/side_effects.py#L146C9-L146C34)
- save_for_backward tracking. I don't think we even need to track this;
if the inputs require grad, then we cannot graph break in the middle of
autograd.Function, so we never need to replay calling `save_for_backward`.
If the inputs don't require grad, then `save_for_backward` doesn't do
anything, so it doesn't need to be replayed either. If we wanted to be
safe we could also call `check_allowed_side_effect` there.
Test Plan:
- #104077 introduced some heavy testing already. This PR adds some more
test cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104685
Approved by: https://github.com/ydwu4
Fixes#104298.
The bug was:
- we were only checking for freevars in SubgraphTracer.create_proxy
- freevars can also show up in SubgraphTracer.create_node
This PR adds handles free variable handling of the output of the graph
(which is created via `create_node`) in `speculate_subgraph`.
Because `create_proxy` calls `create_node`, you may be wondering why we
can't do the freevar lifting in `create_node`. The answer is that:
- `create_node` only gets used by Dynamo to create outputs of a graph,
so it is called rarely. All other callsites go through `create_proxy`.
- our freevar system is based off of VariableTrackers being associated with
Proxy objects which are associated with a SubgraphTracer.
- `create_proxy` accepts Proxy args while `create_node` accepts Node args
- Given a node, there isn't a way to retrieve the existing proxy that
wraps the node.
Test Plan:
- add new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104371
Approved by: https://github.com/ydwu4
Fixes#91338
Follow up from https://github.com/pytorch/pytorch/pull/91342
> 🚀 The feature, motivation and pitch
> We have an existing DeviceType class all over the place in our code base, and it conflicts with the one that is used in torch. > Thankfully the pytorch DeciceType enum class is under the c10 namespace.
```
In file included from /xxx/build/_deps/torch-src/../../aten/src/ATen/ops/view.h:5:
/xxx/_deps/torch-src/aten/src/ATen/Context.h:265:14: error: reference to 'DeviceType' is ambiguous
if (p == DeviceType::HIP) {
^
/xxx/include/Common_types.h:178:8: note: candidate found by name lookup is 'DeviceType'
struct DeviceType {
^
/xxx/build/_deps/torch-src/c10/../c10/core/DeviceType.h:32:12: note: candidate found by name lookup is 'c10::DeviceType'
enum class DeviceType : int8_t {
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104364
Approved by: https://github.com/albanD
In https://github.com/pytorch/pytorch/pull/97645 and some follow up diffs, we made FSDP run in full precision in eval mode, even if mixed precision was specified.
However, this is probably not the best idea and we should provide a flag for users to have control over this a bit more. Adding an env var FSDP_FULL_PREC_IN_EVAL and defaulting it to off, users who want to run eval in fp32 can toggle this before wrapping model in FSDP:
os.environ["FSDP_FULL_PREC_IN_EVAL"] = "1"
Verified that unittests, APS workflow, TNT workloads can run eval appropriately with this change.
Differential Revision: [D47246556](https://our.internmc.facebook.com/intern/diff/D47246556/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104682
Approved by: https://github.com/awgu
Summary:
Without this diff we get
```
CUDA error (./fbcode/caffe2/aten/src/ATen/native/transformers/cuda/flash_attn/fmha_bwd_launch_template.h:113): an illegal memory access was encountered
```
Test Plan:
hg up e49463501
fbcode/ai_codesign/gen_ai/xlformers/scripts/run_xlformers_train_local.sh
Reviewed By: drisspg
Differential Revision: D47220255
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104628
Approved by: https://github.com/drisspg
New elements added to a tensor by `torch.Tensor.resize_` are set to NaN/MAX_INT when deterministic mode is turned on.
When `torch.Tensor.resize_` is called on a quantized tensor and deterministic mode is turned on, a nondeterministic error is raised.
Part of #82004
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104300
Approved by: https://github.com/albanD
Prototype for the feature request:
>When working on a codebase that is unfamiliar to you, it can be helpful to single step through all of the code to see what is getting executed, what conditional branches are taken, and where indirect function jumps go. Model x-ray uses dynamo to give you a single step log of every source code line that does something relevant (i.e., a Tensor operation)
Dynamo logs to the ~`starts_line`~ `trace_source` logging artifact at the start of tracing new bytecode with a new line. It logs the line of source code associated with that bytecode.
~~Dynamo logs to the `graph_source` logging when a FX GraphModule is constructed. For each node in the graph, it logs the location of the original source code associated with that node.~~
Development notes: https://docs.google.com/document/d/1LjFeHzCgDDt535QUq5HydcQs56d7jWl5RvW8TLZN19g/edit?usp=sharing
Since the draft, we removed the `graph_source` logging artifact since printing the code of `GraphModule`s already displays the original source.
Sample:
```python
import torch
from functorch.experimental.control_flow import cond
def true_fn(x):
return x * 2
def false_fn(x):
return x * 3
def f_cond(pred, x):
return cond(pred, true_fn, false_fn, [x])
def f_outer(pred, x):
y = f_cond(pred, x)
if x.sum() > 0:
x = x * 2
else:
x = x * 3
return x, y
opt_f_cond = torch.compile(f_outer, backend="eager")
opt_f_cond(torch.tensor(True), torch.randn(3, 3))
```
Logs:
```shell
$ TORCH_LOGS="trace_source" python playground8.py
TRACE starts_line f_outer playground8.py:54
def f_outer(pred, x):
TRACE starts_line f_outer playground8.py:55
y = f_cond(pred, x)
TRACE starts_line f_cond playground8.py:51 (inline depth: 1)
def f_cond(pred, x):
TRACE starts_line f_cond playground8.py:52 (inline depth: 1)
return cond(pred, true_fn, false_fn, [x])
TRACE starts_line true_fn playground8.py:45 (inline depth: 2)
def true_fn(x):
TRACE starts_line true_fn playground8.py:46 (inline depth: 2)
return x * 2
TRACE starts_line false_fn playground8.py:48 (inline depth: 2)
def false_fn(x):
TRACE starts_line false_fn playground8.py:49 (inline depth: 2)
return x * 3
TRACE starts_line f_outer playground8.py:56
if x.sum() > 0:
TRACE starts_line <resume in f_outer> playground8.py:56
if x.sum() > 0:
TRACE starts_line <resume in f_outer> playground8.py:57
x = x * 2
TRACE starts_line <resume in f_outer> playground8.py:60
return x, y
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104013
Approved by: https://github.com/ezyang
This commit improves the export of aten::slice() to ONNX in the following ways:
1. The step size can be an input tensor rather than a constant.
2. Fixes a bug where using a 1-D, 1-element torch tensor as an index created a broken ONNX model.
This commit also adds tests for the new functionality.
Fixes#104314
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104385
Approved by: https://github.com/thiagocrepaldi
We recently have an optimization to squash x dimension for persistent reduction kernel when we are confident that XBLOCK will always be 1. We need update the code so that coordinate descent tuner does not tune XBLOCK in this case.
Test command. Fail before the fix and pass after.
```
TORCHINDUCTOR_COORDINATE_DESCENT_TUNING=1 python benchmarks/dynamo/huggingface.py --backend inductor --amp --accuracy --only BertForMaskedLM --inference
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104692
Approved by: https://github.com/jansel
issues resolved: https://github.com/pytorch/pytorch/issues/104294
local test on TB and TIMM
* python benchmarks/dynamo/torchbench.py -d cuda --inference --accuracy --progress --export --print-dataframe-summary
* python benchmarks/dynamo/timm_models.py -d cuda --inference --accuracy --progress --export --print-dataframe-summary
why not HF
* huggingface use kwargs (dict) to torch.nn.module
* we will need to support kwargs in torch._export.export, which is in progress
local test result
timm 95% pass rate (58 ouf of 61 passed) P781702926
* 1 x [export specific]1 x ERROR:common:Mutating module attribute rel_indices during export
* 1 x[not relevant to export] Unknown model (SelecSls42b)
* 1 x [not relevant to export] Failed to load model: HTTP Error 409: Public access is not permitted on this storage account
torchbench 54% pass rate (41 out of 75 passed) P781690552
* 7 x ERROR:common:Dynamo input and output is a strict subset of traced input/output
* 3 x ERROR:common:call_method NNModuleVariable() / UserDefinedObjectVariable
* 3 x ERROR:common:Mutating module attribute {xx} during export.
* 2 x ERROR:common:inline in skipfiles
* 2 x ERROR:common:Consider annotating your code using constrain_as_*(). It appears that you're trying
* 1 x ERROR:common:guard on data-dependent symbolic int/float
* 1 x ERROR:common:Tensor.tolist
* 1 x ERROR:common:Tensor.numpy. Turn on config.numpy_ndarray_as_tensor and install torch_np to support tensor.numpy(). [may be dev * env?]
* 1 x ERROR:common:missing: BUILD_SET
* 1 x ERROR:common:whole graph export entails exactly one guard export
* 1 x ERROR:common:call_function BuiltinVariable(str) [GetAttrVariable(UserMethodVariable(<function
* 1 x ERROR:common:Dynamic slicing on data-dependent value is not supported
* 1 x ERROR:common:Failed running call_function <function interpolate at 0x7f60a8361ea0>(*(FakeTensor(..., device='cuda:0', size=(1, 3, * 427,
* 1 x ERROR:common:Dynamo attempts to add additional input during export: value=0.6177528500556946, source=RandomValueSource(random_call_index=0)
* 1 x Found following user inputs located at [16, 17, 18, 19, 20, 21, 22] are mutated. This is currently banned in the aot_export workflow.
* 1 x RuntimeError: cumsum_cuda_kernel does not have a deterministic implementation
* 4 x pass_due_to_skip
* 1 x eager_2nd_run_OOM
* 1 x fail_accuracy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104382
Approved by: https://github.com/zhxchen17
This is intended as a first step towards reductions with multiple outputs. This
also incidentally improves CSE of reductions under C++ codegen. For example,
```python
def fn(x):
return torch.argmin(x, dim=-1), torch.argmin(x, dim=-1)
```
Currently this generates two reductions, where the common load is CSEd
```cpp
for(long i1=static_cast<long>(0L); i1<static_cast<long>(10); i1+=static_cast<long>(1L))
{
auto tmp0 = in_ptr0[static_cast<long>(i1 + (10L*i0))];
if (tmp_acc0.value > tmp0) {
tmp_acc0.index = i1; tmp_acc0.value = tmp0;
}
if (tmp_acc1.value > tmp0) {
tmp_acc1.index = i1; tmp_acc1.value = tmp0;
}
}
auto tmp1 = tmp_acc0.index;
out_ptr0[static_cast<long>(i0)] = tmp1;
auto tmp2 = tmp_acc1.index;
out_ptr1[static_cast<long>(i0)] = tmp2;
```
but with this change it gets CSEd to a single accumulator
```cpp
for(long i1=static_cast<long>(0L); i1<static_cast<long>(10L); i1+=static_cast<long>(1L))
{
auto tmp0 = in_ptr0[static_cast<long>(i1 + (10L*i0))];
if (tmp_acc0.value > tmp0) {
tmp_acc0.index = i1; tmp_acc0.value = tmp0;
}
}
auto tmp1 = tmp_acc0.index;
out_ptr0[static_cast<long>(i0)] = tmp1;
out_ptr1[static_cast<long>(i0)] = tmp1;
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102737
Approved by: https://github.com/jgong5, https://github.com/lezcano
Previously:
- we were keeping a list of proxies seen by the current SubgraphTracer.
It turns out, fx.Proxy has a .tracer field that we should be able to use instead.
- we were using name matching to determine if a freevar was already
lifted to being the input of the parent SubgraphTracer. Voz and I have
previously expressed concerns about the robsustness of name matching.
This PR introduces a simplified design with more invariants:
- When doing HigherOrderOp tracing, we may encounter Proxys
- Each Proxy object is associated with a SubgraphTracer.
- The new invariant is that SubgraphTracer should only construct Nodes
using Proxy that come from the SubgraphTracer. This helps us avoid
malformed graphs.
- If the Proxy object came from another SubgraphTracer, then this means
it is a free variable. We need to lift it to being an input of the
current SubgraphTracer, which will result in the construction of a new
Proxy in the current SubgraphTracer. This new Proxy should be used
whenever the old Proxy is seen by the current SubgraphTracer.
Test Plan:
- existing tests + some new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104350
Approved by: https://github.com/ydwu4, https://github.com/voznesenskym
**Summary**
Reduce the test time of `test_conv2d_binary_with_quantizer_api` and `test_conv2d_binary_unary_with_quantizer_api`.
* For `test_conv2d_binary_with_quantizer_api`, reduce the number of test config from 12 to 2.
* For `test_conv2d_binary_unary_with_quantizer_api`, reduce the number of test config from 24 to 2.
**Test Plan**
```
python -m pytest test_x86inductor_quantizer.py -k test_conv2d_binary_with_quantizer_api
python -m pytest test_x86inductor_quantizer.py -k test_conv2d_binary_unary_with_quantizer_api
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104686
Approved by: https://github.com/jerryzh168
This allows us use use_dtensor=True for ShardedStateDictConfig() before calling model.load_state_dict(). It only works for offload_to_cpu=False now.
Next PR will make use_dtensor=True work with offload_to_cpu=True for load_state_dict().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104087
Approved by: https://github.com/fegin
Fixes#104484
For >= 3.10, we use `inspect.get_annotations` instead of `getattr(.., "__annotations__")`. [Docs](https://docs.python.org/3/library/inspect.html#inspect.get_annotations) say that get_annotations() "Ignores inherited annotations on classes. If a class doesn’t have its own annotations dict, returns an empty dict.". In practice though, this doesn't seem always true; until you call inspect.getmembers it seems like you still get inherited annotations. In particular, this means that if you script a certain type twice, the first time it may pass scripting but on the second try it may not pass scripting.
This PR adds a more comprehensive handling of get_annotations by recursively reading the annotations of the base types. (TorchScript doesn't officially support this; but since it worked in <3.10, it's now breaking internal stuff as python gets upgraded to 3.10)
Verified in #104486 that the test does actually fail before the changes in this PR were added.
Differential Revision: [D47163891](https://our.internmc.facebook.com/intern/diff/D47163891)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104485
Approved by: https://github.com/eellison
This is a bit inefficient because it computes the mean and throws it
away since ir.Reduction nodes only have 1 output. However, the mean
can at least be scheduled into the same loop as the variance now since
there is no data dependency. Thus we can take fewer passes over the
data.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102486
Approved by: https://github.com/lezcano, https://github.com/jansel
Previously, you'd get `<eval_with_key>.0`; now you get `<eval_with_key>.0 from /data/users/ezyang/b/pytorch/test/dynamo/test_misc.py:5683 in forward`
I used to do this with globals, but now I do it with a `co_fields` parameter that's plumbed around, because putting things in globals has implications(TM). Happy to bikeshed on the `co_fields` structure.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103885
Approved by: https://github.com/albanD
Fixes#88286, Fixes#97160
Repro:
```python
import torch
import io
from torch.utils.checkpoint import checkpoint
class A(torch.nn.Module):
# A supported module.
def __init__(self):
super(A, self).__init__()
self.l1 = torch.nn.Linear(2, 2)
def forward(self, x):
return self.l1(x)
class B(torch.nn.Module):
# This module is not exportable to ONNX because it
# uses gradient-checkpointing. However, its two sub-module's
# are exportable, so ORTModule should be used to compute them.
def __init__(self):
super(B, self).__init__()
self.l1 = torch.nn.Linear(2, 2)
self.a = A()
def forward(self, x):
def custom():
def custom_forward(x_):
return self.a(x_)
return custom_forward
z = self.l1(checkpoint(custom(), x))
return z
torch.onnx.export(
B(),
(torch.randn(2, 2),),
io.BytesIO(),
autograd_inlining=True
)
```
`torch.onnx.export(autograd_inlining=True)` should repro the user error as this is the original execution path.
```bash
Traceback (most recent call last):
File "repro88286.py", line 36, in <module>
torch.onnx.export(
File "<@beartype(torch.onnx.utils.export) at 0x7f0f011faee0>", line 385, in export
File "/opt/pytorch/torch/onnx/utils.py", line 511, in export
_export(
File "/opt/pytorch/torch/onnx/utils.py", line 1576, in _export
graph, params_dict, torch_out = _model_to_graph(
File "<@beartype(torch.onnx.utils._model_to_graph) at 0x7f0f01187dc0>", line 11, in _model_to_graph
File "/opt/pytorch/torch/onnx/utils.py", line 1130, in _model_to_graph
graph, params, torch_out, module = _create_jit_graph(model, args)
File "/opt/pytorch/torch/onnx/utils.py", line 1006, in _create_jit_graph
graph, torch_out = _trace_and_get_graph_from_model(model, args)
File "/opt/pytorch/torch/onnx/utils.py", line 910, in _trace_and_get_graph_from_model
trace_graph, torch_out, inputs_states = torch.jit._get_trace_graph(
File "/opt/pytorch/torch/jit/_trace.py", line 1269, in _get_trace_graph
outs = ONNXTracedModule(f, strict, _force_outplace, return_inputs, _return_inputs_states)(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/pytorch/torch/jit/_trace.py", line 128, in forward
graph, out = torch._C._create_graph_by_tracing(
File "/opt/pytorch/torch/jit/_trace.py", line 119, in wrapper
outs.append(self.inner(*trace_inputs))
File "/opt/pytorch/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1492, in _slow_forward
result = self.forward(*input, **kwargs)
File "repro88286.py", line 32, in forward
z = self.l1(checkpoint(custom(), x))
File "/opt/pytorch/torch/utils/checkpoint.py", line 412, in checkpoint
return CheckpointFunction.apply(function, preserve, *args)
File "/opt/pytorch/torch/autograd/function.py", line 506, in apply
return super().apply(*args, **kwargs) # type: ignore[misc]
RuntimeError: _Map_base::at
```
By using `autograd_inlining=False`, the export still fail with a different error because autograd inlining is not enabled:
```bash
Traceback (most recent call last):
File "repro88286.py", line 36, in <module>
torch.onnx.export(
File "<@beartype(torch.onnx.utils.export) at 0x7f6088b32ee0>", line 385, in export
File "/opt/pytorch/torch/onnx/utils.py", line 511, in export
_export(
File "/opt/pytorch/torch/onnx/utils.py", line 1615, in _export
) = graph._export_onnx( # type: ignore[attr-defined]
RuntimeError: ONNX export failed: Couldn't export Python operator CheckpointFunction
```
To allow `CheckpointFunction` into the onnx graph, `operator_export_type=torch.onnx.OperatorExportTypes.ONNX_FALLTHROUGH` flag can be added to `torch.onnx.export`, which would lead to the following ONNX graph:
```bash
Exported graph: graph(%prim::PythonOp_0 : Float(2, 2, strides=[2, 1], requires_grad=0, device=cpu),
%l1.weight : Float(2, 2, strides=[2, 1], requires_grad=1, device=cpu),
%l1.bias : Float(2, strides=[1], requires_grad=1, device=cpu)):
%/PythonOp_output_0 : Float(2, 2, strides=[2, 1], requires_grad=0, device=cpu) = ^CheckpointFunction[inplace=0, module="torch.utils.checkpoint", onnx_name="/PythonOp"](<function B.forward.<locals>.custom.<locals>.custom_forward at 0x7fdf9182f670>, True)(%prim::PythonOp_0), scope: __main__.B:: # /opt/pytorch/torch/autograd/function.py:506:0
%6 : Float(2, 2, strides=[2, 1], requires_grad=1, device=cpu) = onnx::Gemm[alpha=1., beta=1., transB=1, onnx_name="/l1/Gemm"](%/PythonOp_output_0, %l1.weight, %l1.bias), scope: __main__.B::/torch.nn.modules.linear.Linear::l1 # /opt/pytorch/torch/nn/modules/linear.py:114:0
return (%6)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104067
Approved by: https://github.com/BowenBao, https://github.com/kit1980
**Summary**
We have supported the vectorization code gen with pattern of `dequant-relu-quant`, for which `to_uint8` is the last node of quant pattern before store into memory. However, there is another case that `dequant1-relu-quant2-dequant2-relu-quant3`. In this case, `quant2` is at the middle of fusion pattern, we enable vectorization code gen of `quant2-dequant2` in this PR.
**Test Plan**
```
python -u -m pytest -s -v test_cpu_repro.py -k test_dequant_relu_quant_dequant_relu_quant_lowering
```
**Next Step**
* For better performance, we can add another pass to eliminate pair nodes of `float_to_uint8` and `uint8_to_float`.
* For better performance, we should annotate `dequant1` and `quant2` as share observer in quantization recipe. Then we can lower `dequant1-relu-quant2` into a QReLU node to fully eliminate the calculation of `dequant1` and `quant2`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104503
Approved by: https://github.com/jgong5, https://github.com/jansel
Some notes:
* I now manually turn off `_generate` jobs from running with cudagraphs, as it is unrealistic to expect to cudagraph autoregressive generation up to max sequence length, this would imply compiling the entire unrolled sequence generation. Concretely, cm3leon_generate was timing out post this change, likely due to the compile time slowdown of dynamic shapes ON TOP OF accidentally unrolling all the loops
* A few torch._dynamo.reset tactically inserted to force recompiles on tests that expected it
* expectedFailureAutomaticDynamic flip into patching automatic_dynamic_shapes=False
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103623
Approved by: https://github.com/voznesenskym
This adds an expect-test that finds the set of core ATen operators by
subtracting the operators with decomposition in core_aten_decompositions from the
set of all operators that have decompositions and could be decomposed.
This is useful because if you add a new decomposition but forget to add it to
the list of core decompositions, it will appear in the PR diff.
Also, by going through this list I have identified some operators where the
functional variant is decomposed, but not the inplace variant which must be an
oversight.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104262
Approved by: https://github.com/lezcano
**TL;DR**: This PR is a first step in adding lowerings for torch.bucketize. It adds an initial lowering for this op - but because this implementation is not currently efficient, it registers the lowering for prims._inductor_bucketize. After we make the implementation more efficient, we'll remove prims._inductor_bucketize and add the lowering directly to torch.bucketize.
**Background - torch.bucketize**: torch.bucketize(values, boundaries, right=False): for an arbitrary tensor of values and a non-decreasing 1D tensor of boundaries that define buckets, it returns the index of the bucket that each of the values will fall in. e.g. for values [0, 1, 2, 3, 4] and boundaries [1, 3], it will return [0, 0, 1, 1, 2].
**Implementation**: This PR adds a new inductor op called "bucketize". In this PR it only has a triton implementation - for CPU it is a fallback. The triton implementation uses a binary search in `triton_helpers.py`. This PR also adds a new prim `_inductor_bucketize()` for testing purposes and adds lowering for this op.
~~**"right"**: The current behavior of the "right" kwarg in the inductor op is the opposite of the behavior of the torch op. "right" controls how the op treats a value that is equal to one of the boundary values. In the torch op, "right=True" means "if a value is equal to a boundary value, then put it in the bucket to the right". In the inductor op, "right=True" means "the right boundary of a bucket is closed". These are opposite. **I'm open to switching the behavior of the inductor op** - but I chose to implement this way because I think it makes more sense, and I think the torch.bucketize behavior may have been a mistake (it's the opposite of numpy.digitize).~~ Switched the behavior of the inductor bucketize op to match the torch op
* places where "right" means "if a value is equal to a boundary value, then put it in the bucket to the right" (i.e. current torch.bucketize behavior)
+ current torch.bucketize behavior
+ table in [torch.bucketize docs](https://pytorch.org/docs/stable/generated/torch.bucketize.html)
* places where "right" means "the right boundary of a bucket is closed":
+ the text description of [torch.bucketize docs](https://pytorch.org/docs/stable/generated/torch.bucketize.html) (observed in #91580)
+ [numpy.digitize](https://numpy.org/doc/stable/reference/generated/numpy.digitize.html) (which is basically the same op)
**Performance**: Benchmark script: "values" as a [16, 1024, 1024] float32 tensor and "boundaries" as a [1025] tensor (i.e. defining 1024 buckets).
As is:
```
Eager 0.30117499828338623 ms
PT2 0.9298200011253357 ms
```
But performance improves significantly if we add an additional pointwise autotuning config (WIP in #104456):
```
Eager 0.3015420138835907 ms
PT2 0.23028500378131866 ms
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104007
Approved by: https://github.com/jansel
Summary:
The current implementation of `Dispatcher` returns an RAII object
from it's `register*` methods which, on destruction, uses a saved
reference to the `Dispatcher` to call the associated `deregister*`
method.
However, nothing guarantees that the `Dispatcher` is destroyed
*after* all RAII objects have been destroyed and, in practice, we
see segfaults caused when a global `Dispatcher` is cleaned up
before RAII globals.
This diff fixes by keeping the `Dispatcher` lock and "alive" marker
in a `std::shared_ptr` which the callbacks copy and then use to
verify that the `Dispatcher` is still alive before continuing.
https://fb.workplace.com/groups/1405155842844877/posts/7143161099044294/https://fb.workplace.com/groups/python.builds/posts/3510588832595867/
S349108
Test Plan: CI
Differential Revision: D47113122
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104393
Approved by: https://github.com/ezyang
**Summary**
Refactor the vectorization code generation of uint8 input data type. Previously, we combine the uint8 data load and uint8 to float data convert into one step as `load_uint8_as_float` and `store_float_as_uint8`. After refactor, we split them into 2 steps of load/store and data type convert to make the behavior same as BFloat16 data type .
The previous generated code is:
```
#pragma omp for
for(long i0=static_cast<long>(0L); i0<static_cast<long>(432L); i0+=static_cast<long>(16L))
{
auto tmp0 = at::vec::load_uint8_as_float(in_ptr0 + static_cast<long>(i0));
auto tmp1 = (tmp0);
auto tmp2 = at::vec::Vectorized<float>(static_cast<float>(100.0));
auto tmp3 = tmp1 - tmp2;
auto tmp4 = at::vec::Vectorized<float>(static_cast<float>(0.01));
auto tmp5 = tmp3 * tmp4;
auto tmp6 = at::vec::clamp_min(tmp5, decltype(tmp5)(0));
auto tmp7 = tmp6 * tmp2;
auto tmp8 = tmp7.round();
auto tmp9 = tmp8 + tmp2;
auto tmp10 = at::vec::Vectorized<float>(static_cast<float>(0.0));
auto tmp11 = at::vec::maximum(tmp9, tmp10);
auto tmp12 = at::vec::Vectorized<float>(static_cast<float>(255.0));
auto tmp13 = at::vec::minimum(tmp11, tmp12);
auto tmp14 = (tmp13);
at::vec::store_float_as_uint8(tmp14, out_ptr0 + static_cast<long>(i0));
}
```
After this PR, the generated code is:
```
#pragma omp for
for(long i0=static_cast<long>(0L); i0<static_cast<long>(432L); i0+=static_cast<long>(16L))
{
auto tmp0 = at::vec::Vectorized<uint8_t>::loadu(in_ptr0 + static_cast<long>(i0), 16);
auto tmp1 = cvt_uint8_to_fp32_with_same_elem_num(tmp0);
auto tmp2 = at::vec::Vectorized<float>(static_cast<float>(100.0));
auto tmp3 = tmp1 - tmp2;
auto tmp4 = at::vec::Vectorized<float>(static_cast<float>(0.01));
auto tmp5 = tmp3 * tmp4;
auto tmp6 = at::vec::clamp_min(tmp5, decltype(tmp5)(0));
auto tmp7 = tmp6 * tmp2;
auto tmp8 = tmp7.round();
auto tmp9 = tmp8 + tmp2;
auto tmp10 = at::vec::Vectorized<float>(static_cast<float>(0.0));
auto tmp11 = at::vec::maximum(tmp9, tmp10);
auto tmp12 = at::vec::Vectorized<float>(static_cast<float>(255.0));
auto tmp13 = at::vec::minimum(tmp11, tmp12);
auto tmp14 = cvt_fp32_to_uint8(tmp13);
tmp14.store(out_ptr0 + static_cast<long>(i0), 16);
}
```
**Test Plan**
```
python -m pytest test_cpu_repro.py -k test_decomposed_dequant_relu_quant
python -m pytest test_cpu_repro.py -k test_tile2d_load_decomposed_dequant_add_relu_quant
python -m pytest test_cpu_repro.py -k test_tile2d_store_channel_shuffle_cl_quant_output
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104075
Approved by: https://github.com/jgong5, https://github.com/jansel
When tracing with symbolic shapes, arbitrary sym_size nodes can appear in the
graph. Earlier changes did not account for this and quantizer fails to annotate
the right nodes. This diff fixes that by not annotating sym_size nodes, which
should really not be relevant for quantization.
As next steps, we should validate in quant workflow that a) sym_int nodes are not
being quantized and b) add similar support, as this diff, for generic
annotations
Differential Revision: [D47132050](https://our.internmc.facebook.com/intern/diff/D47132050/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104473
Approved by: https://github.com/jerryzh168
This PR fixes the circular issue during hipification process by introducing current_state to track whether a file is processed for hipification. (Iterative DFS)
The issue arises when two header files try to include themselves, which leads to a circular recursion or an infinite loop.
Fixes the related issues such as :
https://github.com/pytorch/pytorch/issues/93827https://github.com/ROCmSoftwarePlatform/hipify_torch/issues/39
Error log:
```
File "/opt/conda/lib/python3.8/posixpath.py", line 471, in relpath
start_list = [x for x in abspath(start).split(sep) if x]
File "/opt/conda/lib/python3.8/posixpath.py", line 375, in abspath
if not isabs(path):
File "/opt/conda/lib/python3.8/posixpath.py", line 63, in isabs
sep = _get_sep(s)
File "/opt/conda/lib/python3.8/posixpath.py", line 42, in _get_sep
if isinstance(path, bytes):
RecursionError: maximum recursion depth exceeded while calling a Python object
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104085
Approved by: https://github.com/jithunnair-amd, https://github.com/malfet
This fixes the bug in profiler code exposed by https://github.com/pytorch/pytorch/pull/104368 that introduced on the fact that `import torch._dynamo` also imports `torch._inductor.config`:
```
$ python -c "import torch._inductor;print(torch._inductor.config)"
Traceback (most recent call last):
File "<string>", line 1, in <module>
AttributeError: module 'torch._inductor' has no attribute 'config'
(base) $ python -c "import torch._dynamo;print(torch._inductor.config)"
<module 'torch._inductor.config' from '/home/nshulga/git/pytorch/pytorch/torch/_inductor/config.py'>
```
### Testing
D47159397
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104477
Approved by: https://github.com/aaronenyeshi, https://github.com/malfet
This allows us use use_dtensor=True for ShardedStateDictConfig() before calling model.load_state_dict(). It only works for offload_to_cpu=False now.
Next PR will make use_dtensor=True work with offload_to_cpu=True for load_state_dict().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104087
Approved by: https://github.com/fegin
This addresses https://github.com/pytorch/pytorch/issues/104187.
After this PR, the contract with the user is that:
- If passing `param_init_fn=None`, each `nn.Module.reset_parameters()` should only initialize its own parameters/buffers (like `parameters(recurse=False)`/`buffers(recurse=False)`).
- If passing `param_init_fn` not equal to `None`, then similarly, one call to `param_init_fn(module)` should only initialize `module`'s own parameters/buffers.
With this contract and this PR's changes, meta device initialization through either `reset_parameters()` or `param_init_fn` should be correct. Those functions will run on the original parameter/buffer shapes allowing for correct shape-dependent computations like for fan-in/fan-out, and there will not be any re-initialization of any module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104189
Approved by: https://github.com/rohan-varma
Just a nit fix where `GammaBetaBackwardCUDAKernel_32x32` kernel used a hardcoded warp size for performing the reduction and laneId calculation. Changed this to use `C10_WARP_SIZE`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104441
Approved by: https://github.com/malfet
Ignore config fusion limit for foreach nodes since they have their own fusion limits which will be split automatically. With the fusion limit this will automatically start not fusing epilogue copies if there are more than 64 tensors in the foreach lists (very bad) which will create a ton of extra allocations. With this change, fusions with the subkernels still respect this limit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104471
Approved by: https://github.com/jansel
Current test case causes an edge case tensor input that causes a single generated tensor to fail the tolerance assertion on ROCm only and only for float32. We have reviewed the logic with our libraries team and have discovered the discrepancy is due to a difference in order of operations on AMD GPUs. They came back with "working as intended" and found no perceivable bug. Interestingly, if we change the values in ks, ns, or bs, the test passes on ROCm. These particular sizes in this particular order generates a single problematic input that causes the assertion to fail the tolerance check by ~0.07. Again, this is not a bug, just differences in implementation. This PR loosens the tolerance for ROCm only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104425
Approved by: https://github.com/jeffdaily, https://github.com/nikitaved, https://github.com/lezcano
Fixes #ISSUE_NUMBER
Now for the custom device, we use `getattr` and `setattr` to run the func defined in custom device module in some files, such as `AMP`, `random`, `DDP` and so on. So I want to add a generic func to get these funcs more friendly, could you take a look? @bdhirsh @albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99048
Approved by: https://github.com/bdhirsh
Summary:
Implemented `aten::masked_fill` for Vulkan backend, see https://pytorch.org/docs/stable/generated/torch.Tensor.masked_fill.html for the behavior of this operator.
Some explanation of the implementation:
- The shapes of the input tensor and mask should be broadcastable (see [broadcasting semantics](https://pytorch.org/docs/stable/notes/broadcasting.html)). For example, the input tensor is of shape [3, 1, 5] and mask of shape [2, 1]. Then the output is of shape [3, 2, 5].
- A straightforward implementation is to generate an output and a mask, both of shape [3, 2, 5], by applying `repeat` operations on the input tensor and mask respectively. Then we traverse the mask and fill elements of output with `value` where mask is `True`.
- However the `repeat` operation on mask is unnecessary and incurs extra time and space overhead. Instead we can keep the mask as it is and traverse the original mask and compute the corresponding broadcasted positions in the output tensor (see the shader file `masked_fill.glsl` for such computation).
Some explanation of the test:
- We test all possible broadcasting of the input tensor and mask. Manually setting all possible broadcastable shapes is intimidating. Instead we apply the following algorithm to automatically generate all possible cases which only requires one input of the shapes of the input tensor and mask.
- First we set an identical shape for the `input_shape` and `mask_shape`, e.g. both are of [3, 5, 2, 3].
- Then we truncate all possible proceeding dimensions of `input_shape` and `mask_shape` respectively. Denote the results as `curr_input_shape` and `curr_mask_shape`, e.g. `curr_input_shape = [5, 2, 3]` and `curr_mask_shape = [2, 3]`.
- Next, for both `curr_input_shape` and `curr_mask_shape` we generate all possible subsets of the indices and set the corresponding elements to 1 for each subset. For example, for `curr_input_shape = [5, 2, 3]`, a possible `input_idx_subset = [0, 2]`. We set the 0th and 2nd elements of `curr_input_shape` to be 1, then `curr_input_shape = [1, 2, 1]`. Similarly for `curr_mask_shape = [2, 3]`, a possible `mask_idx_subset = [0]`, then the updated `curr_mask_shape = [1, 3]`.
- In the end, we test `masked_fill` with the combinations of `curr_input_shape` and `curr_mask_shape`. In the example above, an output tensor of shape [1, 2, 3] will be generated.
- In `vulkan_api_test.cpp`, a function `gen_all_subsets` is implemented to generate all possible subsets of a given set of indices through backtracking.
Test Plan:
Full test result is shown in P777851326. `masked_fill` related tests are shown below.
```
(base) luwei@luwei-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*mask*"
Building: finished in 0.1 sec (100%) 264/2820 jobs, 0/2820 updated
Total time: 0.1 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *mask*
[==========] Running 5 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 5 tests from VulkanAPITest
[ RUN ] VulkanAPITest.masked_fill_invalidinputs_exceptions
[ OK ] VulkanAPITest.masked_fill_invalidinputs_exceptions (35 ms)
[ RUN ] VulkanAPITest.masked_fill_scalar_mult4ch
[ OK ] VulkanAPITest.masked_fill_scalar_mult4ch (582 ms)
[ RUN ] VulkanAPITest.masked_fill_scalar_nonmult4ch
[ OK ] VulkanAPITest.masked_fill_scalar_nonmult4ch (592 ms)
[ RUN ] VulkanAPITest.masked_fill_tensor_mult4ch
[ OK ] VulkanAPITest.masked_fill_tensor_mult4ch (0 ms)
[ RUN ] VulkanAPITest.masked_fill_tensor_nonmult4ch
[ OK ] VulkanAPITest.masked_fill_tensor_nonmult4ch (0 ms)
[----------] 5 tests from VulkanAPITest (1212 ms total)
[----------] Global test environment tear-down
[==========] 5 tests from 1 test suite ran. (1212 ms total)
[ PASSED ] 5 tests.
```
Reviewed By: SS-JIA
Differential Revision: D46423811
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104444
Approved by: https://github.com/SS-JIA
This is yet another step to move windows instances away from ephemeral instances, more details on #101209
Queue times are very high recently for this instance type, migrating away from ephemeral instances will provide a big relief for developers. Even if flakiness is introduced, the overall time-to-signal will be smaller given 20h queue times peaks we've been experiencing.

# Copilot Summary
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at cde9c95</samp>
This pull request updates several GitHub Actions workflow files and a template file to use non-ephemeral CUDA GPU runners for Windows binary build jobs. This improves the performance and stability of these jobs and makes the job names more consistent.
# Copilot Poem
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at cde9c95</samp>
> _`runs-on` changes_
> _CUDA jobs need `nonephemeral`_
> _faster winter builds_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104404
Approved by: https://github.com/malfet
Summary:
This diff adds a path in inductor to invoke gcc through Remote Execution, when run from within fbcode.
This should (hopefully) let us kill the `inductor.disable_cpp_codegen` flag, since we should now be able to invoke clang at runtime from within fbcode to compile c++ code. This was preventing https://github.com/pytorch/pytorch/pull/100115 from landing, which fixed one of the last remaining models in torchbench that was failing with `torch.compile` (hf_Longformer).
Enumeration of changes:
- updated inductor to invoke `_run_build_command()` when in fbcode, which hooks into Remote Execution
- When inductor invokes g++ normally, it includes a bunch of absolute paths, to stuff like the pytorch header paths, and the input and output path. I changed these all to relative paths when in fbcode, and copied everything we needed into a temp dir that we send to Remote Execution.
- updated `triton/fb/make_build_paths.py` to let us grab paths to openmp, sleef, and ld from within the Remote Execution environment. I'm not sure if there's a better way to do this (but this way appeared to work, thanks to Bert's suggestion from https://www.internalfb.com/diff/D46482550?dst_version_fbid=231706286239076&transaction_fbid=229345569847706)
- factored `triton/fb/build.py` (it had a function to create a triton build command and run it all in one go, I separated the bit that takes in an arbitrary command (our clang command), and runs it with RE)
- a few tweaks to the include paths that inductor uses: it adds those two extra paths (sleef and openmp), and it also does not manually include the `-ltorch`,`-lc10`,`-ltorch_python`,`-ltorch_cpu` libs - the linker was complaining that it couldn't find those libs, and not including those flags ends up working
- I added a few more missing headers. Maybe with D46527002 this won't be necessary?
- I had a basic manual test in `scripts/hirsheybar/tmp2.py`. We probably want to try running an actual job in MAST to make sure this works.
Test Plan: `scripts/hirsheybar/pt2/tmp2.py` has a basic test, but I'm also planning on testing by kicking off a MAST job with cmf_10x (thanks to a bunch of help from Bert)
Reviewed By: bertmaher
Differential Revision: D46364355
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104351
Approved by: https://github.com/bertmaher
Summary: Handling the `out-of-line definition of constexpr static data member is redundant in C++17 and is deprecated [-Werror,-Wdeprecated]` warning on Xcode 15.
Test Plan: Build
Reviewed By: n0shake
Differential Revision: D46875270
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104049
Approved by: https://github.com/malfet
torch.bucketize takes a tensor of values, and a "boundaries" tensor, which is a sorted list of values that represent buckets. It returns the bucket that each value lies in. E.g. if values = [1, 5, 3, 6] and boundaries=[0, 2, 4, 6, 8], the output will be [1, 3, 2, 4].
The current decomposition of this op doesn't work well with dynamic shapes. It performs a binary search, which bakes in the number of iterations in the binary search and requires recompiling (I don't completely understand why/where this happens). I can't think if whether there's a good way to write a decomposition for this op that will work with dynamic shapes.
Use case: this op is very similar to some operations needed by jagged tensors. As a first step, I want to add a lowering for aten.bucketize and make use of opinfos. #104007
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104396
Approved by: https://github.com/Chillee
Summary:
The test was failing in `lift_tracked_freevar_to_input `
https://www.internalfb.com/phabricator/paste/view/P776002064
Cause:
* line 1219 assumes that `lift_tracked_freevar_to_input` is never called by the root tracer
* However, when we see a bound free variable in a child tracer, line 1226 will invoke the parent tracer recursively.
* When it reaches the root tracer, the assumption will fail.
Fix:
* we relax the assumption: if `lift_tracked_freevar_to_input` is called on the root tracer, we validate the variable is bound free, to allow the case where `lift_tracked_freevar_to_input` is populated from child tracers.
Test Plan:
pytest ./generated/test_VainF_pytorch_msssim.py
pytest caffe2/test/dynamo/test_autograd_function.py -k test_function_with_bound_free_variable
Reviewed By: yanboliang
Differential Revision: D47033011
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104378
Approved by: https://github.com/Skylion007, https://github.com/yanboliang
When using torch.profiler.profile(record_shapes=True), the profiler tries to collect `tensor.sizes()` to put this information into the profile trace.
When dynamic shapes is turned on, sometimes tensors will appear that have symbolic sizes. In that case, `tensor.sizes()` can throw an assertion. This PR checks to see if tensor has symbolic shapes, and doesn't collect shape info in that case.
Differential Revision: [D47082414](https://our.internmc.facebook.com/intern/diff/D47082414)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104320
Approved by: https://github.com/aaronenyeshi
Summary: Similar to quantized add, in this PR we added the reference represenation for quantize/dequantize operators
Test Plan:
buck2 test caffe2/test:quantization_pt2e -- --exact 'caffe2/test:quantization_pt2e - test_representation_quantize (quantization.pt2e.test_quantize_pt2e.TestQuantizePT2E)'
buck2 test caffe2/test:quantization_pt2e -- --exact 'caffe2/test:quantization_pt2e - test_representation_dequantize (quantization.pt2e.test_quantize_pt2e.TestQuantizePT2E)'
Reviewed By: kimishpatel
Differential Revision: D46959928
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104395
Approved by: https://github.com/andrewor14
This PR introduces value range refinement of shape symbols by symbolically evaluating the
value range of the involved guards. This should help `_maybe_evaluate_static` to eliminate
more guards.
This is a stack of PRs created from the discussion on: #96616.
In summary, this PR:
- simplifies `FloorDiv` nodes on the left-hand side of an expression so as to isolate a
symbol in the numerator
- tries to match the expression against the form: `<symbol> <relop> <expr>`
- uses the matched expression for refining the value range of `<symbol>` using the range
of `<expr>`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97963
Approved by: https://github.com/ezyang
This PR turns translation validation on by default for tests and accuracy benchmark
runs. It also installs Z3 on CI.
The main changes are:
- Add `--no-translation-validation` as an option in _test/run_tests.py_
- Set `PYTORCH_TEST_WITH_TV` environment variable
- Add `TEST_WITH_TV` variable in _torch/testing/_internal/common_utils.py_
- Turn translation validation on for accuracy benchmarks in _benchmarks/dynamo/common.py_
- Add Z3 installation on CI scripts
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103611
Approved by: https://github.com/ezyang
This branch is not an optimization, it's a correctness issue so there should be
a guard installed on both sides of the branch. Otherwise we could have an
expression like `(s0 - s1)` that is initially positive, then becomes negative
with a new set of shapes and now references an invalid index.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103780
Approved by: https://github.com/ezyang
#104256 erroneously removed the pybind definition for `reduce_scatter_tensor_coalesced` introduced in #103561
This adds it back in and introduces a test for the API.
Test command:
```
pytest test/distributed/test_c10d_nccl.py -vsk test_reduce_scatter_tensor_coalesced
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104345
Approved by: https://github.com/kwen2501
Summary:
This diff is reverting D46920584
D46920584: Make `torch.empty*` deterministic by filling with NaN or max int value (#101849) by generatedunixname499836121 has been identified to be causing the following test or build failures:
Tests affected:
- [torchrec/distributed/composable/tests:test_fsdp - torchrec.distributed.composable.tests.test_fsdp.FullyShardTest: test_composable_checkpoint](https://www.internalfb.com/intern/test/281475062923125/)
Here's the Multisect link:
https://www.internalfb.com/multisect/2341386
Here are the tasks that are relevant to this breakage:
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
If you believe this diff has been generated in error you may Commandeer and Abandon it.
Test Plan: NA
Reviewed By: huydhn, osalpekar
Differential Revision: D46997394
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104302
Approved by: https://github.com/osalpekar
Adding Workflows for building aarch64 Linux PyTorch PIP wheels
Updates:
* Created aarch64 template for generated workflows
* Updated generate_ci_workflows.py to include aarch64
* Generated the aarch64 wheel workflow
* added _binary-build-aarch64.yml for building aarch64 wheel
* added _binary-test-aarch64.yml for sanity check of aarch64 wheel
* Updated binary_linux_test.sh to use --extra-index-url for aarch64 till needed aarch64 dependencies are available at https://download.pytorch.org/whl/nightly/cpu
NOTES:
* The build and test workflows are using arm64v8/alpine and quay.io/pypa/manylinux2014_aarch64:latest docker images at this time.
* Conda generated workflow not included at this time and being worked on.
Workflows were successfully tested at https://github.com/xncqr/pytorch/actions/runs/5351891068
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104109
Approved by: https://github.com/malfet, https://github.com/atalman
This commit speeds up the ONNX export of large models by making the following changes:
- Remove unecessary memcpy in `GetGraphProtoSize`
- In `export.cpp`, pass around a pointer to the ModelProto instead of the ModelProto itself.
The shape inference function is still the slowest part of the export for these models with large weights taking up 50% or more of the export time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103278
Approved by: https://github.com/BowenBao, https://github.com/thiagocrepaldi
Pin the pytest dependencies listed in requirements-ci.txt, also change the mac ones to match the linux ones.
The new pytest 7.4.0 causes some weird issues with printing skip messages, so pin to a previous version until I can figure out a fix
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104281
Approved by: https://github.com/huydhn
This PR adds support for `enable_grad`/`no_grad`/`autocast` context managers getting properly traced in `pre_dispatch` tracing. The stuff in this PR includes:
- I added a torch function mode that runs during make_fx pre_dispatch tracing, `ProxyTorchFunctionMode`. It directly intercepts the torch ops that run during the above context managers, and adds them to the current graph instead of executing them
- `enable_grad` and `no_grad` currently desugar into `torch._C.set_grad_enabled(bool)`, but this API isn't currently overrideable by torch function so I added the ability to interpose there
- the `torch.amp` context managers don't currently have a nice equivalent, like `set_autocast_enabled(state)`, so I ended up adding two new API's: `torch.amp._set_autocast_enabled` and `torch.amp._set_autocast_disabled`. If you look at how the context manager is implemented, it ends up calling several different state-changing functions, some of which depend on the backend - so I figured that it would be cleaner just to add a new API (that should probably only be used by tracing) - but open to feedback
- I added a new dynamo backend, `compile(backend="pre_dispatch_eager")`. When pre_dispatch tracing becomes always-on in inductor, it will be another potential surface for bugs. I also added a test file for it (`test/dynamo/test_pre_dispatch.py`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103024
Approved by: https://github.com/ezyang
- In #102759, the support for `quantized::conv_transposeNd` was introduced. This incorrectly set `output_padding` to all zeros. Turns out, you can specify output_padding in PyTorch, but this parameter was not being unpacked correctly and thus did not show up in the python torch->onnx code.
- This adds unpacking of output_padding in `unpack_quantized_weights.cpp` when needed. It also adds this as a parameter in the python functions and uses that (and removes the all-zero defaults)
- Another issue with #102759 is that it only added these new ops to opset10 without adding the ability to specify axis in opset13. This PR also fixes this.
Fixes#104206
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104207
Approved by: https://github.com/BowenBao
Fix cpp wrapper CPU performance gap on `swsl_resnext101_32x16d` compared with the default python wrapper.
The pre-trained weights of `swsl_resnext101_32x16d` contains denormal numbers (close to 0.0).
Linking with `-ffast-math` will make the CPU flush denormals.
For the default python wrapper, the compilation and linking are done in one command thus `-ffast-math` will take effect in both compilation and linking.
CPP wrapper leverages cpp_extension which will do the compilation and linking in two stages, thus we need to explicitly add `-ffast-math` as a linking flag.
Single thread single batch on ICX:
<html xmlns:v="urn:schemas-microsoft-com:vml"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:x="urn:schemas-microsoft-com:office:excel"
xmlns="http://www.w3.org/TR/REC-html40">
<head>
<meta name=ProgId content=Excel.Sheet>
<meta name=Generator content="Microsoft Excel 15">
<link id=Main-File rel=Main-File
href="file:///C:/Users/chunyuan/AppData/Local/Temp/msohtmlclip1/01/clip.htm">
<link rel=File-List
href="file:///C:/Users/chunyuan/AppData/Local/Temp/msohtmlclip1/01/clip_filelist.xml">
</head>
<body link=blue vlink=purple>
| time (s) default python wrapper | time (s) cpp wrapper before fix | time (s) cpp wrapper after fix
-- | -- | -- | --
swsl_resnext101_32x16d | 0.459097836 | 13.82326214 | 0.448116195
</body>
</html>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104332
Approved by: https://github.com/jgong5, https://github.com/desertfire, https://github.com/EikanWang
Use [PEP-562](https://peps.python.org/pep-0562) to import `_dynamo` and `_inductor` only when needed.
- Remove redundant imports from tests
- Add `test_lazy_imports_are_lazy` to make sure they will not get imported by accident
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at bae8e90</samp>
> _Sing, O Muse, of the daring deeds of PyTorch, the swift and fiery_
> _framework of deep learning, that with skill and cunning wrought_
> _many wonders of dynamic compilation, using the hidden powers_
> _of `_dynamo` and `_inductor`, the secret modules of LLVM and MLIR._
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104368
Approved by: https://github.com/msaroufim, https://github.com/albanD
This PR introduces a translation validator for dynamo guards. In summary, it verifies
whether the guards issued as Python code are sound, w.r.t the initial guards.
The main changes in this PR are:
- Create an FX graph for dynamic shapes
- Translate "the original" guards from the FX graph to Z3
- Check if the guards produced by `produce_guards` are sound w.r.t. the ones from the FX graph
gh-stack version of the PR #101146.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102563
Approved by: https://github.com/ezyang
This PR:
* Address comment at https://github.com/pytorch/pytorch/pull/103887/files#r1244128266.
* Add test for graph partition to make sure assertion ops functionalization won't break graph partition in unexpected way.
**NOTE**:
In the context of export, it's totally up to the user to any type of graph partition based on specific use case. It's hard to anticipate the concrete downstream use case nor provide any specific functionality to facilitate handling assertion ops (functional / non-functional). So this PR limit to itself to [`CapabilityBasedPartitioner`](2da6cae43c/torch/fx/passes/infra/partitioner.py (L34)) and make sure it doesn't break graph partition unexpectedly (by adding some test).
For the test case used in PR, a few things to highlight:
* Without assertion, the fused graph is roughly like:
```
class fused(torch.nn.Module):
def forward(self, a, b):
fused_1 = self.fused_1(a, b);
relu = fused_1.relu()
fused_0 = self.fused_0(fused_1, relu)
return (fused_0, fused_1)
class fused_0(torch.nn.Module):
def forward(self, add_2, relu):
... # Logic after relu
return add_4
class fused_1(torch.nn.Module):
def forward(self, a, b):
... # Logic before relu, `add_1` is only exposed within this submodule.
return add_2
```
* With the assertion, the fused graph is roughly like:
```
class fused(torch.nn.Module):
def forward(self, arg0_1: i64[s0], arg1_1: i64[s0]):
dep_token0 = ...
...
fused_1 = self.fused_1(arg0_1, arg1_1); arg0_1 = arg1_1 = None
...
getitem: i64[s0] = fused_1[0] # `getitem` is actually `add_1`
...
relu_default: i64[s0] = torch.ops.aten.relu.default(getitem_1)
...
# For inline assertion. Note that `getitem` which is an output of `fused_1`, is consumed by it.
select_int: i64[] = torch.ops.aten.select.int(getitem, 0, 0)
eq_scalar: b8[] = torch.ops.aten.eq.Scalar(select_int, 5)
dep_token2: f32[] = torch.ops.aten._functional_assert_async.msg(
eq_scalar, 'assertion error', dep_token = dep_token1
)
...
getitem_1: i64[s0] = fused_1[1] # `getitem_1` is actually `add_2`
fused_0: i64[s0] = self.fused_0(getitem_1, relu_default)
...
return (fused_0, getitem_1, dep_token2)
class fused_0(torch.nn.Module):
def forward(self, add_tensor_2: i64[s0], relu_default: i64[s0]):
... # Logic after relu
return add_tensor_4
class fused_1(torch.nn.Module):
def forward(self, arg0_1: i64[s0], arg1_1: i64[s0]):
... # Logic before relu
# `add_tensor_1` (basically `add_1`) is returned to allow downstream assertion op consumes it.
return (add_tensor_1, add_tensor_2)
```
As shown above, the extra assertion added (actually regardless whether it's funtionalized or not), it **won't** case extra submodule breakage if the asserted node is an intermediate node within the submodule - here the intermediate node will be returned as extra output of submodule so downstream assertion node can consume it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104287
Approved by: https://github.com/tugsbayasgalan
During revert, use title of "Meta Internal-Only Changes Check" to determine whether or not internal diff is associated with the PR. When PR is merged/closed, "Meta Internal-Only Changes Check" status is always success, but title message can differ:
- "There is no internal Diff connected, this can be merged now" means that there are no internal change associated with PR (or it was landed via GitHub First workflow)
- "The internal Diff has landed, this can be merged now" meaning that PR has associated internal DIFF, and OSS and internal reverts must happen in sync using internal tooling. (Or a revert PR can be authored in OSS)
Add regression test for https://github.com/pytorch/pytorch/pull/100652 that was originated from the internal diff, but was merged as OSS PR.
Fixes https://github.com/pytorch/pytorch/issues/104232
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104344
Approved by: https://github.com/bigfootjon, https://github.com/huydhn
Fix https://github.com/pytorch/pytorch/issues/99639 by handling the case in `InliningInstructionTranslator`'s `LOAD_CLOSURE` definition when the requested cell is not in `self.closure_cells`.
My intuition is that the behavior of `LOAD_DEREF` and `STORE_DEREF` on a cell/freevar should not depend on whether or not we called `LOAD_CLOSURE` (that is, we shouldn't create a new cell var in `LOAD_CLOSURE` like in https://github.com/pytorch/pytorch/pull/101357). But we need a way to push cells created by the inlined function that were not present in the caller - `InlinedClosureVariable` is used to differentiate these cells from other cells.
Adding this test causes an error though (EDIT: this test is not relevant to this PR and instead just reveals that `cond` with Python side effects is still broken):
```python
def test_closure_out_of_scope_cell_with_cond(self):
from functorch.experimental.control_flow import cond
cell1 = torch.rand(3, 3)
cell2 = torch.rand(3, 3)
orig3 = torch.rand(3, 3)
def test(x):
cell3 = orig3.clone()
def then():
nonlocal cell3
cell3 += cell1
return cell3
def els():
nonlocal cell3
cell3 += cell2
return cell3
return cond(x > 0, then, els, [])
opt_fn = torch._dynamo.optimize("eager")(test)
result1 = opt_fn(1)
self.assertTrue(torch.allclose(result1, orig3 + cell1))
result2 = opt_fn(-1)
self.assertTrue(torch.allclose(result1, orig3 + cell1 + cell2))
```
```
Traceback (most recent call last):
File "/scratch/williamwen/work/pytorch2/test/dynamo/test_misc.py", line 1768, in test_closure_out_of_scope_cell_with_cond
result1 = opt_fn(1)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/eval_frame.py", line 295, in _fn
return fn(*args, **kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/eval_frame.py", line 448, in catch_errors
return callback(frame, cache_size, hooks, frame_state)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/convert_frame.py", line 526, in _convert_frame
result = inner_convert(frame, cache_size, hooks, frame_state)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/convert_frame.py", line 127, in _fn
return fn(*args, **kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/convert_frame.py", line 360, in _convert_frame_assert
return _compile(
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/utils.py", line 180, in time_wrapper
r = func(*args, **kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/convert_frame.py", line 430, in _compile
out_code = transform_code_object(code, transform)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/bytecode_transformation.py", line 1000, in transform_code_object
transformations(instructions, code_options)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/convert_frame.py", line 415, in transform
tracer.run()
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 2029, in run
super().run()
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 708, in run
and self.step()
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 668, in step
getattr(self, inst.opname)(inst)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 391, in wrapper
return inner_fn(self, inst)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 1100, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 559, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/variables/torch.py", line 1061, in call_function
(false_r, false_graph, false_lifted_freevars) = speculate_branch(False)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/variables/torch.py", line 1044, in speculate_branch
ret_val, ret_graph, ret_lifted_freevars = speculate_subgraph(
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/variables/torch.py", line 850, in speculate_subgraph
output = f.call_function(tx, args, {})
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/variables/functions.py", line 121, in call_function
return tx.inline_user_function_return(
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 595, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 2134, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 2231, in inline_call_
tracer.run()
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 708, in run
and self.step()
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 668, in step
getattr(self, inst.opname)(inst)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/symbolic_convert.py", line 162, in impl
self.push(fn_var.call_function(self, self.popn(nargs), {}))
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/variables/builtin.py", line 497, in call_function
proxy = tx.output.create_proxy(
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/output_graph.py", line 345, in create_proxy
return self.current_tracer.create_proxy(*args, **kwargs)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/output_graph.py", line 1109, in create_proxy
new_arg = self.lift_tracked_freevar_to_input(arg)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/output_graph.py", line 1226, in lift_tracked_freevar_to_input
self.parent.lift_tracked_freevar_to_input(proxy)
File "/scratch/williamwen/work/pytorch2/torch/_dynamo/output_graph.py", line 1219, in lift_tracked_freevar_to_input
assert (
AssertionError: lift_tracked_freevar_to_input on root SubgraphTracer
from user code:
File "/scratch/williamwen/work/pytorch2/test/dynamo/test_misc.py", line 1766, in test
return cond(x > 0, then, els, [])
File "/scratch/williamwen/work/pytorch2/test/dynamo/test_misc.py", line 1764, in els
cell3 += cell2
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104222
Approved by: https://github.com/jansel
This PR handles inference. Will do similar thing for training later.
Some manual testing results shows this can improve inference perf by 2-3% (absolute improvement not relative one).
- convmixer: 4.285x -> 4.309x
- resnet50: 2.170x -> 2.203x
The PR is built upon freezing. Since without freezing, the weight input for a conv node may not be a parameter directly but be the output of precision converting ops. It's so much easier to implement this PR after freezing.
Commands
```
TORCHINDUCTOR_FREEZING=1 python benchmarks/dynamo/timm_models.py --backend inductor --amp --performance --only convmixer_768_32 --inference
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103642
Approved by: https://github.com/eellison
Summary: This diff also makes many things const and rearranges `X >= lb && X <= ub` to be `lb <= X && X <= ub`.
Test Plan:
```
buck2 build mode/dev-nosan fbcode//caffe2:ATen-cu
```
Differential Revision: D46943299
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104054
Approved by: https://github.com/xw285cornell
When working with a highly-dynamic python code it's not always possible to express the static types. However if we consider the end-user experience for somebody who uses both pytorch and a static type checker (mypy, pyright), we should error on the side of being ergonomic and not technically correct.
The `nn.Module.__getattr__` is one of the such examples: on paper the return type is correct. In practice the community would benefit from having `Any` as a return type because it would avoid littering the idiomatic pytorch code with `cast`, `# type: ignore`, `assert`, `isinstance`, etc.
Some evidences:
- linked in the comment thread on pyright bug tracker https://github.com/microsoft/pyright/issues/4213
- `pyre` type checker steps outside of the normal type checking practices and special-cases `registrer_buffer()` in part to avoid this problem. https://pyre-check.org/docs/features/ This is not a very scalable solution since type-checkers generally aim at adhering to the spec (various typing PEPs).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104321
Approved by: https://github.com/kit1980, https://github.com/albanD
In anticipation of adding some enhancements to the cuDNN benchmark cache (e.g., LRU eviction for memory savings), this PR adds some safety improvements to the handling of cache keys.
Currently, cache keys are dangerous to use, as e.g., a single inadvertent pass-by-value will potentially instantiate a copy with uninitialized padding bytes that will unwittingly hash differently and compare as unequal. This behavior is the result of `ParamsHash` using raw-bytes for hashing and comparison. I've been bitten by this in the past and would like to hopefully eliminate this class of errors.
Additionally, I'm not sure the standard guarantees that default copy/move constructors copy structs byte-for-byte, and this could be problematic when using maps as insertion could call these default constructors in order to instantiate a `std::pair`. Someone knowledgeable in C++ can correct me on this, but it seems that we are potentially relying on the good graces of common compiler implementations rather than the actual standard here.
This PR adds a variant of `ParamsHash` that expects a wrapped POD that has custom byte-for-byte constructors. It modifies the cuDNN V8 API benchmark cache to use this variant, and replaces the `setCacheKey` style code with constructor usage. If this approach looks good to folks I will also port other `ParamsHash` usage (e.g., in cuDNN v7 and other backends) and we can remove `ParamsHash`.
CC @malfet
@ngimel (who originally wanted constructors for keys, but I didn't have this solution in mind at the time)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104122
Approved by: https://github.com/zasdfgbnm, https://github.com/colesbury
Fixes#103613.
A requirement for HigherOrderOperators is that after Dynamo capture, the body
function should be functional (i.e. has no observable side effects).
If the body function mutates a variable that is not local to the body, then we
that should induce a graph break.
This PR distinguish between MutableLocals created inside/outside body
and adds relevant checks. (Design originally proposed by voznesenskym.)
- We tag each mutable_local with an id that corresponds to where it came
from. The mutable_local may represent an existing object that gets
tracked by Dynamo or an object that is created while Dynamo is
introspecting.
- This id changes when we are introspecting the body of a HigherOrderOperator.
- If Dynamo wants to perform a side effect using a mutable_local, we
check its .scope field with the current scope id and raise Unsupported
in the desired case (non-local mutation inside HigherOrderOperator body)
- The id is a global thread_local variable. I can make this not a global
variable, but it just takes some engineering time to thread a number through
each of the various ways Dynamo can construct a mutable_local.
Test Plan:
- Add a bunch of new tests. Tests combinations of {global, nonlocal} x
{number, Tensor, list, object, nn.Module} and asserts that HigherOrderOp
falls back on those cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104077
Approved by: https://github.com/voznesenskym, https://github.com/jansel
Since we do not call `_FSDPState.__init__()` and only use it for typing, it is not possible for these attributes to be `None`. The purpose of these `assert`s is to make sure that these attributes are set by `_init_process_group_state_for_hybrid_shard()`. If we care to make that explicit, I would posit that we should be using `hasattr` checks, not `is not None` checks, because if indeed `_init_process_group_state_for_hybrid_shard()` did not set these attributes, then even checking that it is not `None` would lead to an `AttributeError`. I do not include these `hasattr` checks for now since `_init_process_group_state_for_hybrid_shard()` is short enough that we can quickly tell by inspection that it sets the desired attributes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104274
Approved by: https://github.com/rohan-varma
This checks that `ignored_modules` and `ignored_states` have the expected type and provides a reasonable error message if not. Otherwise, if someone passes a mix of modules and parameters to `ignored_states` for example, then our code may be silently incorrect.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104273
Approved by: https://github.com/rohan-varma
This fixes https://github.com/pytorch/pytorch/issues/104148 (unfreezing parameters after `n` steps).
- This fixes a bug where we did not delete the post-backward hook state properly for the `requires_grad=False` case.
- This makes the `already_resharded` correct for `SHARD_GRAD_OP`.
- This generalizes `_clear_grads_if_needed()` to `_reset_flat_param_grad_info_if_needed()` to additionally include propagating the original parameters' `requires_grad` to the flat parameter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104186
Approved by: https://github.com/rohan-varma, https://github.com/fegin
Mark destructors as overrides, which fixes:
```cpp
In file included from /Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/metal/MetalPrepackOpRegister.cpp:3:
/Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/metal/MetalPrepackOpContext.h:52:3: warning: '~Conv2dOpContext' overrides a destructor but is not marked 'override' [-Winconsistent-missing-destructor-override]
~Conv2dOpContext() {
^
/Users/nshulga/git/pytorch/pytorch/aten/src/ATen/core/ivalue.h:22:17: note: overridden virtual function is here
class TORCH_API CustomClassHolder : public c10::intrusive_ptr_target {};
^
In file included from /Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/metal/MetalPrepackOpRegister.cpp:3:
/Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/metal/MetalPrepackOpContext.h:147:3: warning: '~LinearOpContext' overrides a destructor but is not marked 'override' [-Winconsistent-missing-destructor-override]
~LinearOpContext() {
^
/Users/nshulga/git/pytorch/pytorch/aten/src/ATen/core/ivalue.h:22:17: note: overridden virtual function is here
class TORCH_API CustomClassHolder : public c10::intrusive_ptr_target {};
```
Modernize constructors by passing parameters by value and moving them, rather than by reference, see [clang-tidy pass-by-value rule](https://clang.llvm.org/extra/clang-tidy/checks/modernize/pass-by-value.html).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104312
Approved by: https://github.com/kit1980, https://github.com/osalpekar
In some cases, a UserFunctionVariable can be constructed when the underlying function is actually a TorchVariable. One example is when an attribute on a UnspecializedNNModuleVariable is a torch function. In those cases, we should treat the UserFunctionVariable as a TorchVariable.
This adds a check in UserDefinedObjectVariable.var_getattr() to try to create a TorchVariable instead of a UserFunctionVariable.
Fixes#104172
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104231
Approved by: https://github.com/williamwen42, https://github.com/jansel
Enabling more tests on ASAN, meanwhile we disable float-divide-by-zero and float-cast-overflow, both are disabled because they are also disabled by default in latest clang.
The following cited doc explains the reasons.
```
-fsanitize=float-cast-overflow: Conversion to, from, or between floating-point types
which would overflow the destination. Because the range of representable values
for all floating-point types supported by Clang is [-inf, +inf], the only cases detected are
conversions from floating point to integer types.
-fsanitize=float-divide-by-zero: Floating point division by zero.
This is undefined per the C and C++ standards,
but is defined by Clang (and by ISO/IEC/IEEE 60559 / IEEE 754) as producing
either an infinity or NaN value,
so is not included in -fsanitize=undefined.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103647
Approved by: https://github.com/kit1980
The neighbor values we try for a field can be empty in some corner cases.
```
# E.g., if XBLOCK is 1 initially and size_hint for x is also 1.
# We would not try either larger or smaller XBLOCK in this case.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104293
Approved by: https://github.com/jansel
This is not ready for review, this is to make sure asan is fixed.
Not sure what is the most effective way to track down the bad dec_ref within deploy yet.
The asan silencing is done to match this comment:
1c79003b3c/test/test_cpp_extensions_jit.py (L749-L752)
EDIT: since the final failing function is in libtorch_python.so, we would need to skip that whole lib (not ok). So now we're skipping based on the function name which should be restrictive enough to not hide any real bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103989
Approved by: https://github.com/malfet
Summary:
The planned e2e for quantization in pytorch 2.0 export is the following:
float_model -> prepare_pt2e -> calibration -> convert_pt2e -> ...
inside convert_pt2e, we will first produce a q/dq representation of the quantized model, similar to the previous output of
convert_to_reference_fx in fx grah mode quantization:
```
torch.ops.quantized_decomposed.dequantize_per_tensor -> torch.ops.aten.add -> torch.ops.quantized_decomopsed.quantize_per_tensor
torch.ops.quantized_decomposed.dequantize_per_tensor /
```
Then we'll rewrite the above to a more precise representation that express the intention in a more precise manner, since
here we actually want to do int8 addition, instead of simulating the int8 addition with fp32 operations, the representation for
quantized add is:
```
def quantized_add(x_i8, x_scale, x_zero_point, y_i8, y_scale, y_zero_point, out_scale, out_zero_point):
x = (x_scale / out_scale) * x_i8
y = (y_scale / out_scale) * y_i8
out = x + y
out -= (x_zero_point * x_scale - y_zero_point * y_scale) / out_scale
out += out_zero_point
return out
```
Test Plan:
```
buck2 test caffe2/test:quantization_pt2e -- --exact 'caffe2/test:quantization_pt2e - test_representation_add (quantization.pt2e.test_quantize_pt2e.TestQuantizePT2E)'
```
Reviewed By: kimishpatel
Differential Revision: D45628032
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104130
Approved by: https://github.com/kimishpatel
This PR adds in support for semi-structured sparsity via a tensor
subclass. It currently uses the CUTLASS kernels merged in PR #100881.
In the future we plan to add in cuSPARSELt support (see the other PRs in
the stack), which will give us larger performance gains.
This PR adds in 2 things:
- a Tensor subclass, `SparseSemiStructuredTensor` to store the
sparse tensor in copmressed form and override `__torch_dispatch__`.
- a conversion function that takes in a dense tensor and a
semi-structured sparse bool mask and creates an instance of the
subclass.
**SparseSemiStructuredTensor**
The subclass stores the dense tensor in a contiguous flattened tensor
for future compatability with cuSPARSELt, which expects this format.
Note that the CUTLASS kernels do not have this limitation, as the
specified values and the metadata are passed separately in
`_structured_sparse_linear`. In the future we can use the cuSPARSELT bindings
[here](https://github.com/pytorch/pytorch/pull/103700) for faster matmul, better dtype converage, and relaxed shape
constraints.
Since we currently don't have a way to go back from the sparse
representation to the dense representation, and we store the weights in
compressed form, we don't have a great way to handle .t().
Instead, we keep track of how often we've called transpose on our
tensor, and if it's an unexpected number we throw an error. When the first
argument is sparse, we expect an even number of calls to transpose,
while when the second argument is sparse, we expect an odd number of
calls. This is because we support second argument sparse matrix
multiplications by using transpose properties.
**to_sparse_semi_structured**
This is a conversion function to convert a dense tensor and a
semi-structured sparse bool mask into a subclass. Currently, we must
pass in a bool mask, since we can't infer it becuase there may be
additional zero elements in the dense tensor, so `tensor !=0` is not 2:4
sparse.
Once we add either a method to derive the mask from the dense tensor or
cuSPARSELt, we no longer need to pass in the mask. cuSPARSELt has it's
own helper functions to create the metadata mask.
**User Details**
We have implemented support for the following ops for `torch.float16`
and `torch.int8`:
```
torch.addmm(bias, dense, sparse.t())
torch.mm(dense, sparse)
torch.mm(sparse, dense)
aten.linear.default
aten.t.default
aten.t.detach
```
The end user interface to accelerate a nn.Linaer module with the
subclass would look like this:
```
from torch.sparse import to_sparse_semi_structured
mask = torch.Tensor([0, 0, 1, 1]).tile(128, 32).cuda().bool()
linear = Model(128, 128).half().cuda()
linear.weight = nn.Parameter(to_sparse_semi_structured(linear.weight,
mask=linear.weight.bool())
```
This also updates tests and the `torch.sparse` module docstring to
reflect these changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102135
Approved by: https://github.com/albanD
Summary:
## What is this?
This is a giant codemod to migrate all of fbcode from the tp2 version of gtest to the `fbsource/third-party` version.
## Why?
Various parts of the monorepo use different versions of gtest which are incompatible with each other and make maintenance of C++ testing more difficult than it should be. There also doesn't seem to be much reason for this fragmentation. Shifting all `gtest` dependencies towards `fbsource/third-party` is a big step in the right direction towards cleaning this up.
Also -- tp2 is deprecated, so we want to stop using that anyway. If we're going to make improvements to `gtest`, we should get away from tp2 as a first step.
## How?
I used bash script to perform the majority of the codemod: P777150295
I followed up with `rg` to find additional dependencies, then simply iterated a ton until CI was (mostly) happy.
This diff also includes an update to autodeps to use the `third-party/fbsource` version of gtest rather than the `tp2` version.
#forcetdhashing
Test Plan: CI
Differential Revision: D46961576
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104255
Approved by: https://github.com/huydhn
# Change
This PR adds two classes to DTensor:
1. `CudaRNGStateTracker`: `CudaRNGStateTracker` stores Random Number Generator (RNG) state (a `ByteTensor` object) in a `dict`, mapping from a corresponding tag to each state tensor. It also provides a set of convenient utility methods to help access/modify the state tensors. The most important interface is `_distribute_region` which will be used when DTensor executes a random op (an operator that calls RNG).
2. `OffsetBasedRNGTracker`: This subclass of `CudaRNGStateTracker` defines the default policy of how RNG states should be shared and synchronized among all ranks to respect the semantics of DTensor random operators.
# Warning
- With `Multi-threaded ProcessGroup`, the global variable `_rng_tracker` will be shared among threads(ranks) and cause issue. We need to figure out a compatible solution for that.
- The RNG state may be asynchronous outside of participating ranks. It is harmless in our current use case of submesh though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103235
Approved by: https://github.com/wanchaol
This PR integrated the assertion functionalization logic into current export logic.
**NOTE:**
I finally decided to do the assertion functionalization after AOT export instead of before for the following reasons:
* The benefit of AOT export is that the graph is already functionalized so things like method call is already transformed to function call. However, if we do it before AOT export, the graph is still in torch level and extra logic like bab21d20eb/torch/_export/pass_base.py (L201-L204C17) will need to be implemented.
* The graph signature is kind of already incorrect after adding runtime assertions currently (this doesn't seem break logic since we already depend on positions instead of FQNs of outputs). This PR also fixed this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103887
Approved by: https://github.com/avikchaudhuri, https://github.com/tugsbayasgalan
Summary:
Also adds support for backend_config with relu fusion since XNNPACK allows it.
We should revisit the relu fusion once we gain more clarity on quantSrcPartition or some other way to do these fusion and not having to add all combinations.
We should really rename the backend config to et_xnnpack.py or something TODO
Test Plan: `buck test fbcode//mode/dev-nosan fbcode//executorch/backends/xnnpack/test:`
Differential Revision: D46985169
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104134
Approved by: https://github.com/mcr229, https://github.com/salilsdesai
Dispatch the selection function to prevent using `is_mps()` in `Histogram.cpp`.
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at b329a02</samp>
This pull request refactors and implements the logic for inferring the bin edges of histograms from the input tensor for different device types. It introduces a dispatch stub `histogram_select_outer_bin_edges_stub` and moves the device-specific code to separate files, such as `HistogramKernel.cpp` and `HistogramKernel.mm`. This improves the modularity and readability of the histogram functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101792
Approved by: https://github.com/albanD
Apart from introducing MPSProfiler, this PR also
1. removes the synchronization call after all the commands are encoded since the stream will be synchronized along the next graph op is encountered and run. One can take a look at this [PR](https://github.com/pytorch/pytorch/pull/99810) to get some insight.
2. initialize the offset calculation kernel's thread output with 0 to ensure the subsequent offset accumulation is correct. This change makes the kernel aligned with `kernel_index_offsets` kernel.
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 4094984</samp>
This change enables performance analysis of the `histogram` kernel on MPS devices by using the `MPSProfiler` class to collect and report relevant metrics. It modifies the file `HistogramKernel.mm` to add profiling calls around the kernel execution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101692
Approved by: https://github.com/albanD
Prevents following cryptic error if one attempts to use `run_tests.py` on system that also has torchaudio installed in dev mode (as `tools` from https://github.com/pytorch/audio might take precedence, but this is not how script should behave):
```
Unable to import test_selections from tools/testing. Running without test selection stats.... Reason: No module named 'tools.stats'
Traceback (most recent call last):
File "/Users/nshulga/git/pytorch/pytorch/test/run_test.py", line 1673, in <module>
main()
File "/Users/nshulga/git/pytorch/pytorch/test/run_test.py", line 1604, in main
selected_tests = get_selected_tests(options)
File "/Users/nshulga/git/pytorch/pytorch/test/run_test.py", line 1418, in get_selected_tests
path = os.path.join(str(REPO_ROOT), TEST_TIMES_FILE)
NameError: name 'TEST_TIMES_FILE' is not defined
```
But make sure to remove it in the end, otherwise it will not work if torch is installed from wheel, but tests are running from clean repo checkout.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at dd52521</samp>
> _Sing, O Muse, of the cunning code review_
> _That fixed the tests of the `tools` module_
> _By adding and removing the root path_
> _As a shepherd guides his flock to and fro._
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104214
Approved by: https://github.com/kit1980
Based on this [code search](https://fburl.com/code/gjcnw8ly) (*.yaml with `dispatch: CPU:`), update all files found to use
```
kernels:
- arg_meta: None
kernel_name:
```
instead of
```
dispatch:
CPU:
```
---
## Code changes:
- `fbcode/executorch/codegen/tools/gen_oplist.py`
- Strip ET specific fields prior to calling parse_native_yaml_struct
---
## Files edited that are not `*functions.yaml` or `custom_ops.yaml`
- fbcode/executorch/kernels/optimized/optimized.yaml
- fbcode/executorch/kernels/quantized/quantized.yaml
- fbcode/executorch/kernels/test/custom_kernel_example/my_functions.yaml
---
## Found Files that were not edited
**Dispatched to more than just CPU**
- fbcode/caffe2/aten/src/ATen/native/native_functions.yaml
- xplat/caffe2/aten/src/ATen/native/native_functions.yaml
- xros/third-party/caffe2/caffe2/aten/src/ATen/native/native_functions.yaml
**Grouped ops.yaml path**
- fbcode/on_device_ai/Assistant/Jarvis/min_runtime/operators/ops.yaml
---
**Design Doc:** https://docs.google.com/document/d/1gq4Wz2R6verKJ2EFseLyPdAF0wqomnCrVDDJpRkYsRw/edit?kh_source=GDOCS#heading=h.8raqyft9y50
Differential Revision: [D46952067](https://our.internmc.facebook.com/intern/diff/D46952067/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D46952067/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104070
Approved by: https://github.com/larryliu0820
Note that in general it's not good form to try to make FakePG work with 'real data',
but the reasoning here is that we want FakePG to work with DeviceMesh's init code
that have the data validation, which makes it worth the tradeoff.
In general user should use MTPG or normal PG for cases where they may care about
real data from collectives
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104213
Approved by: https://github.com/wconstab, https://github.com/voznesenskym
Mostly refactor, that moves all the tests from `test_cuda` that benefit from multiGPU environment into its own file.
- Add `TestCudaMallocAsync` class for Async tests ( to separate them from `TestCudaComm`)
- Move individual tests from `TestCuda` to `TestCudaMultiGPU`
- Move `_create_scaling_models_optimizers` and `_create_scaling_case` to `torch.testing._internal.common_cuda`
- Add newly created `test_cuda_multigpu` to the multigpu periodic test
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at f4d46fa</samp>
This pull request fixes a flaky test and improves the testing of gradient scaling on multiple GPUs. It adds verbose output for two CUDA tests, and refactors some common code into helper functions in `torch/testing/_internal/common_cuda.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104059
Approved by: https://github.com/huydhn
https://github.com/pytorch/pytorch/pull/95715 added the functionality to abort `ncclCommInitRankConfig` by specifying `blocking=0` to enable non-blocking behavior.
However, calling the `pg._abort()` didn't recover from a stuck `ncclCommInitRankConfig` since the `_abort` method only looked through `devNCCLCommMap_` map and aborted those communicators. Since `ncclCommInitRankConfig` was stuck, the communicator itself wasn't added to the map and the host thread was stuck on this line: https://github.com/pytorch/pytorch/blob/main/torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp#L1171. As a result, `_abort` was a no-op.
To resolve this issue, I added the communicators to `inProgressCommMap_` as soon as they were created and then removed them once added to `devNCCLCommMap_`.
I also added a unit test that was failing without the changes to ProcessGroupNCCL.cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103925
Approved by: https://github.com/osalpekar
This PR adds in support for semi-structured sparsity via a tensor
subclass. It currently uses the CUTLASS kernels merged in PR #100881.
In the future we plan to add in cuSPARSELt support (see the other PRs in
the stack), which will give us larger performance gains.
This PR adds in 2 things:
- a Tensor subclass, `SparseSemiStructuredTensor` to store the
sparse tensor in copmressed form and override `__torch_dispatch__`.
- a conversion function that takes in a dense tensor and a
semi-structured sparse bool mask and creates an instance of the
subclass.
**SparseSemiStructuredTensor**
The subclass stores the dense tensor in a contiguous flattened tensor
for future compatability with cuSPARSELt, which expects this format.
Note that the CUTLASS kernels do not have this limitation, as the
specified values and the metadata are passed separately in
`_structured_sparse_linear`. In the future we can use the cuSPARSELT bindings
[here](https://github.com/pytorch/pytorch/pull/103700) for faster matmul, better dtype converage, and relaxed shape
constraints.
Since we currently don't have a way to go back from the sparse
representation to the dense representation, and we store the weights in
compressed form, we don't have a great way to handle .t().
Instead, we keep track of how often we've called transpose on our
tensor, and if it's an unexpected number we throw an error. When the first
argument is sparse, we expect an even number of calls to transpose,
while when the second argument is sparse, we expect an odd number of
calls. This is because we support second argument sparse matrix
multiplications by using transpose properties.
**to_sparse_semi_structured**
This is a conversion function to convert a dense tensor and a
semi-structured sparse bool mask into a subclass. Currently, we must
pass in a bool mask, since we can't infer it becuase there may be
additional zero elements in the dense tensor, so `tensor !=0` is not 2:4
sparse.
Once we add either a method to derive the mask from the dense tensor or
cuSPARSELt, we no longer need to pass in the mask. cuSPARSELt has it's
own helper functions to create the metadata mask.
**User Details**
We have implemented support for the following ops for `torch.float16`
and `torch.int8`:
```
torch.addmm(bias, dense, sparse.t())
torch.mm(dense, sparse)
torch.mm(sparse, dense)
aten.linear.default
aten.t.default
aten.t.detach
```
The end user interface to accelerate a nn.Linaer module with the
subclass would look like this:
```
from torch.sparse import to_sparse_semi_structured
mask = torch.Tensor([0, 0, 1, 1]).tile(128, 32).cuda().bool()
linear = Model(128, 128).half().cuda()
linear.weight = nn.Parameter(to_sparse_semi_structured(linear.weight,
mask=linear.weight.bool())
```
This also updates tests and the `torch.sparse` module docstring to
reflect these changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102135
Approved by: https://github.com/albanD
Summary:
Details in T133020932
First commit of collective utils library. Ported over from model store, removed scuba logging, error_trait and all dependencies on modelstore.
Test Plan: In the following diffs.
Differential Revision: D45545970
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101037
Approved by: https://github.com/H-Huang
Summary:
Trying to get the `__self__` attribute on any `_OpNamespace` object should be an invalid operation. The `__self__` attribute only exists on instance method object and not on class objects.
In [dynamo](a152b3e3b8/torch/_dynamo/variables/torch.py (L164)) there is code that tries to access the `__self__` attribute on `TorchVariable`, this currently results in an expensive call to `torch._C._jit_get_operation` [here](a152b3e3b8/torch/_ops.py (L740)) which ultimately fails and throws an exception. For cases where it fails the operation turns out to be quite expensive on the order of ~0.03s.
For edge use cases when exporting large models with quantized ops this exception is thrown 100's of times resulting in a lot of time wasted. By preventing the call to `torch._C._jit_get_operation` we can quickly return from this function and significantly reduce export times. On a large ASR model for example export currently takes **~405** seconds. With this change we can reduce it to **~340s**.
Overall this should also be a harmless change as no one should mostly ever try to access the `__self__` attribute on any `_OpNamespace` object.
Test Plan: Added test case.
Differential Revision: D46959879
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104096
Approved by: https://github.com/larryliu0820, https://github.com/ezyang, https://github.com/zou3519
This PR combines the C++ code for the AOTInductor's model and interface with Bin Bao's changes to AOTInductor codegen.
It adds a number of AOTInductor C interfaces that can be used by an inference runtime. Under the hood of the interfaces, the model code generated by the AOTInductor's codegen is wrapped into a class, AOTInductorModel, which manages tensors and run the model inference.
On top of AOTInductorModel, we provide one more abstract layer, AOTInductorModelContainer, which allows the user to have multiple inference runs concurrently for the same model.
This PR also adjusts the compilation options for AOT codegen, particularly some fbcode-related changes such as libs to be linked and header-file search paths.
Note that this is the very first version of the AOTInductor model and interface, so many features (e.g. dynamic shape) are incomplete. We will support those missing features in in future PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104202
Approved by: https://github.com/desertfire
Fixes#104170
As noted in the above issue it seems that the code for randperm basically boils down to:
`torch.argsort(torch.rand(size, device="mps"), dim = 0)`
However it seems like in the fused(?) pytorch version the type of tensor we were drawing `torch.rand(size, device="mps")` from was int64 with an inclusive(?) upper bound of 1. This caused everything to be sorted into two groups (if you drew 0 or 1) each monotonically ascending due to sort tie breaking.
One way to fix this is to just generate the random tensor as float64s with an upper bound of 1.0 instead of int64s. An alternative to to just set the upper bound to max int 64.
~I choose the float64 one basically on a coin flip b/c I couldn't tell the original contributor's intent (due to mixed up upper bounds and type) but would be happy to change to use int64 and max int 64 as an upper bound instead if that's better.~
Edit on second thought I don't like using floats from 0.0 to 1.0 as there are fewer of them in that range than int64s from 0 to int 64 max_value. I also suspect integer math might be faster but need to benchmark this tomorrow.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104171
Approved by: https://github.com/malfet
This PR adds in support for semi-structured sparsity via a tensor
subclass. It currently uses the CUTLASS kernels merged in PR #100881.
In the future we plan to add in cuSPARSELt support (see the other PRs in
the stack), which will give us larger performance gains.
This PR adds in 2 things:
- a Tensor subclass, `SparseSemiStructuredTensor` to store the
sparse tensor in copmressed form and override `__torch_dispatch__`.
- a conversion function that takes in a dense tensor and a
semi-structured sparse bool mask and creates an instance of the
subclass.
**SparseSemiStructuredTensor**
The subclass stores the dense tensor in a contiguous flattened tensor
for future compatability with cuSPARSELt, which expects this format.
Note that the CUTLASS kernels do not have this limitation, as the
specified values and the metadata are passed separately in
`_structured_sparse_linear`. In the future we can use the cuSPARSELT bindings
[here](https://github.com/pytorch/pytorch/pull/103700) for faster matmul, better dtype converage, and relaxed shape
constraints.
Since we currently don't have a way to go back from the sparse
representation to the dense representation, and we store the weights in
compressed form, we don't have a great way to handle .t().
Instead, we keep track of how often we've called transpose on our
tensor, and if it's an unexpected number we throw an error. When the first
argument is sparse, we expect an even number of calls to transpose,
while when the second argument is sparse, we expect an odd number of
calls. This is because we support second argument sparse matrix
multiplications by using transpose properties.
**to_sparse_semi_structured**
This is a conversion function to convert a dense tensor and a
semi-structured sparse bool mask into a subclass. Currently, we must
pass in a bool mask, since we can't infer it becuase there may be
additional zero elements in the dense tensor, so `tensor !=0` is not 2:4
sparse.
Once we add either a method to derive the mask from the dense tensor or
cuSPARSELt, we no longer need to pass in the mask. cuSPARSELt has it's
own helper functions to create the metadata mask.
**User Details**
We have implemented support for the following ops for `torch.float16`
and `torch.int8`:
```
torch.addmm(bias, dense, sparse.t())
torch.mm(dense, sparse)
torch.mm(sparse, dense)
aten.linear.default
aten.t.default
aten.t.detach
```
The end user interface to accelerate a nn.Linaer module with the
subclass would look like this:
```
from torch.sparse import to_sparse_semi_structured
mask = torch.Tensor([0, 0, 1, 1]).tile(128, 32).cuda().bool()
linear = Model(128, 128).half().cuda()
linear.weight = nn.Parameter(to_sparse_semi_structured(linear.weight,
mask=linear.weight.bool())
```
This also updates tests and the `torch.sparse` module docstring to
reflect these changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102135
Approved by: https://github.com/albanD
Summary:
According to https://www.internalfb.com/omh/view/ai_infra_mobile_platform/tests these have been failing since jul 2022.
Just going to delete unless someone thinks they actually do matter and should be made green
https://www.internalfb.com/intern/test/562949996115570/ <- failing test
I ran locally and got errors like
xplat/caffe2/aten/src/ATen/native/quantized/cpu/qnnpack/test/gemm-block-sparse-microkernel-tester.h:483: Failure
Expected equality of these values:
c[mIndex * cStride() + nIndex]
Which is: -872.50446
acc[mIndex * n() + nIndex]
Which is: -872.50488
at 0, 0: reference = -872.5048828125, optimized = -872.50445556640625, Mr x Nr = 8 x 4, M x N x K = 7 x 1 x 13
xplat/caffe2/aten/src/ATen/native/quantized/cpu/qnnpack/test/gemm-block-sparse-microkernel-tester.h:483: Failure
Expected equality of these values:
c[mIndex * cStride() + nIndex]
Which is: -67.246628
acc[mIndex * n() + nIndex]
Which is: -67.24707
at 3, 0: reference = -67.2470703125, optimized = -67.246627807617188, Mr x Nr = 8 x 4, M x N x K = 4 x 1 x 15
[ FAILED ] Q8GEMM_8x4c1x4__SSE2.packedA_k_gt_8_subtile (148 ms)
Test Plan: ci
Reviewed By: kimishpatel
Differential Revision: D46950966
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104073
Approved by: https://github.com/kimishpatel
Summary:
ETRecord can't use this yet because the other programs need to be migrated to using ExportedProgram (D46729844)
Note: higher order ops like call_delegate/cond are also not supported yet
Test Plan: `buck2 run @//mode/dev-nosan //executorch/exir/tests:serde`
Differential Revision: D46802454
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103763
Approved by: https://github.com/tarun292
When Dynamo sees `wrap(f, x)`, and it decides that `f` is unsafe, Dynamo
should fall back to eager mode and stop introspection all the way
throughout the call of `f`. The motivation is:
- it's easier to test `wrap` this way (it is clearer how many graph
breaks should occur)
- Other HigherOrderOperator do this because their execution of the
body involves code that is not necessarily Dynamo-able. e.g. functorch
transforms. Since `wrap` is a test for the HigherOrderOp mechanism, it
should reflect what other HigherOrderOps do.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104076
Approved by: https://github.com/ydwu4
Summary:
Also adds support for backend_config with relu fusion since XNNPACK allows it.
We should revisit the relu fusion once we gain more clarity on quantSrcPartition or some other way to do these fusion and not having to add all combinations.
We should really rename the backend config to et_xnnpack.py or something TODO
Test Plan: `buck test fbcode//mode/dev-nosan fbcode//executorch/backends/xnnpack/test:`
Differential Revision: D46924209
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104090
Approved by: https://github.com/mcr229
Adds Conv-BN folding to inductor freezing. One thing that's a little awkward now is we'll want different decompositions to run depending on if we are in the inference compiler. For now, I require that you run with torch.no_grad() so we can detect if no gradients are required before calling aot_autograd.
Differential Revision: [](https://our.internmc.facebook.com/intern/diff/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100653
Approved by: https://github.com/jansel
Summary:
When we pickle/unpickle graph module in multipy, we would lost modules/attributes that are not referred in the graph. This is because when unpickle fx graph module, we use the stored `__dict__` and the fx graph to create a new graph module. In GraphModule init, we drop any attribute that is not referred in the graph.
This behavior is not ideal because we actually expect a graph module that's exactly the same after unpickling.
Test Plan:
```
buck test mode/opt caffe2/test:fx -- test_preserve_unused_attr_after_unpickle
Tests finished: Pass 1. Fail 0. Fatal 0. Skip 0. Build failure 0
```
Differential Revision: D46976230
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104115
Approved by: https://github.com/houseroad
Fixes#103818
1. for some special nn.Modules, there are checks which only support cuda, so I add `privateuse1` check.
2. when get the device type for `privateuse1` by `torch._C._get_privateuse1_backend_name()`, it will get error in `torch.jit.script`, so I add a global variable to avoid this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103419
Approved by: https://github.com/albanD
Adds the unit tests requested in #95810
This PR also addresses a gap in unit testing of gradients, as `gradcheck` always performs total derivatives w.r.t. all arguments and module parameters. Some modules have different code paths for partial derivatives, e.g. `LayerNorm`, and those should be tested separately.
The PR has the following limitations:
- it does not test partial derivatives w.r.t. every combination of arguments, which would exponentially increase CI time.
- it does not implement the same logic for Hessians, where the increase in CI time would be quadratic in the number of arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103809
Approved by: https://github.com/kit1980
Summary:
Currently, cuBLASLt-based fused GELU epilogue in the GPU back-end of the `_addmm_activation` operator uses tanh approximation, whereas other code paths on GPU don't.
With this PR, the GELU tanh approximation is switched on in all back-end code paths of `_addmm_activation` on GPU for better consistency.
Test Plan:
```
$ python test/test_linalg.py -k test_addmm_relu -v
test_addmm_relu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_relu_cpu_bfloat16) ... ok
test_addmm_relu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float32) ... ok
test_addmm_relu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float64) ... ok
test_addmm_relu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_bfloat16) ... ok
test_addmm_relu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float32) ... ok
test_addmm_relu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 1.896s
OK
$ python test/test_linalg.py -k test_addmm_gelu -v
test_addmm_gelu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_bfloat16) ... ok
test_addmm_gelu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float32) ... ok
test_addmm_gelu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float64) ... ok
test_addmm_gelu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_bfloat16) ... ok
test_addmm_gelu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float32) ... ok
test_addmm_gelu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 2.050s
OK
```
Reviewers: @eellison
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104061
Approved by: https://github.com/eellison
Summary:
Expand using `aten::repeat` for all dims
[expand](https://pytorch.org/docs/stable/generated/torch.Tensor.expand.html#torch.Tensor.expand)
[expand_as](
https://pytorch.org/docs/stable/generated/torch.Tensor.expand_as.html)
Test Plan:
clang-format on `Expand.cpp`
expand tests:
```
lfq@lfq-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*.expand*"
Action graph will be rebuilt because files have been added or removed.
Parsing buck files: finished in 1.1 sec
Downloaded 5/50 artifacts, 661.18 Kbytes, 37.5% cache miss (for updated rules)
Building: finished in 15.4 sec (100%) 515/515 jobs, 15/515 updated
Total time: 16.9 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *.expand*
[==========] Running 6 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 6 tests from VulkanAPITest
[ RUN ] VulkanAPITest.expand_exceptions
[ OK ] VulkanAPITest.expand_exceptions (66 ms)
[ RUN ] VulkanAPITest.expand_1d
[ OK ] VulkanAPITest.expand_1d (7 ms)
[ RUN ] VulkanAPITest.expand_2d
[ OK ] VulkanAPITest.expand_2d (2 ms)
[ RUN ] VulkanAPITest.expand_3d
[ OK ] VulkanAPITest.expand_3d (2 ms)
[ RUN ] VulkanAPITest.expand_4d
[ OK ] VulkanAPITest.expand_4d (4 ms)
[ RUN ] VulkanAPITest.expand_as
[ OK ] VulkanAPITest.expand_as (11 ms)
[----------] 6 tests from VulkanAPITest (95 ms total)
[----------] Global test environment tear-down
[==========] 6 tests from 1 test suite ran. (95 ms total)
[ PASSED ] 6 tests.
lfq@lfq-mbp fbsource %
```
Differential Revision: D46302042
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103930
Approved by: https://github.com/SS-JIA
Summary: Implement [aten::zeros](https://pytorch.org/docs/stable/generated/torch.zeros.html?highlight=zeros#torch.zeros)
Test Plan:
```
lfq@lfq-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*zeros*"
Action graph will be rebuilt because files have been added or removed.
Parsing buck files: finished in 2.3 sec
Downloaded 0/4 artifacts, 0.00 bytes, 100.0% cache miss (for updated rules)
Building: finished in 6.0 sec (100%) 454/454 jobs, 3/454 updated
Total time: 8.4 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *zeros*
[==========] Running 1 test from 1 test suite.
[----------] Global test environment set-up.
[----------] 1 test from VulkanAPITest
[ RUN ] VulkanAPITest.zeros
[ OK ] VulkanAPITest.zeros (99 ms)
[----------] 1 test from VulkanAPITest (99 ms total)
[----------] Global test environment tear-down
[==========] 1 test from 1 test suite ran. (99 ms total)
[ PASSED ] 1 test.
```
Differential Revision: D46777782
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103703
Approved by: https://github.com/SS-JIA
There is a `HAVE_TEST_SELECTION_TOOLS` conditional, but turns out it does not really work, so fix it by defining all missing prototypes and make it work as single-shard instance
Add lint rule to test stat it would succeed for runnign only test_cuda with released version of PyTorch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104111
Approved by: https://github.com/clee2000, https://github.com/ZainRizvi
This PR enables `-Winconsistent-missing-destructor-override` and `-Winconsistent-missing-override`
and fixes violations.
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 47e904e</samp>
This pull request updates the code of various classes and operators in the `caffe2` and `aten` subdirectories to use the `override` specifier instead of the `virtual` keyword for destructors and other virtual functions that override a base class function. This improves the code readability, quality, and consistency with C++ best practices. It also modifies the `./CMakeLists.txt` file to enable warnings for these specifiers, but disable errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104032
Approved by: https://github.com/malfet
Hi! We've been fuzzing torchvision project with [sydr-fuzz](https://github.com/ispras/oss-sydr-fuzz).
We've found a heap buffer overflow error at `source_range_serialization.cpp:73` in pytorch project.
The error occurs because there is not check in `deserialize_source` that `text_table_` size can be less than `fnameIndex`. To prevent the error the corresponding check must be located.
torchvision version: 9d0a93eee90bf7c401b74ebf9c8be80346254f15
pytorch version: 0f1621df1a0a73956c7ce4e2f72f069e610e0137
OS: Ubuntu 20.04
How to reproduce
1. Build docker from [here](https://github.com/ispras/oss-sydr-fuzz/tree/master/projects/torchvision) and run the container:
sudo docker build -t oss-sydr-fuzz-torchvision .
sudo docker run --privileged --rm -v `pwd`:/fuzz -it oss-sydr-fuzz-torchvision /bin/bash
2. Run the target on this input: [serialization-crash.txt](https://github.com/pytorch/pytorch/files/11819901/serialization-crash.txt)
/encode_png_fuzz serialization-crash.txt
3. You will see the following output:
=================================================================
==13==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x60200055a630 at pc 0x0000010197b7 bp 0x7ffd4cfb15f0 sp 0x7ffd4cfb15e8
READ of size 8 at 0x60200055a630 thread T0
#0 0x10197b6 in std::__shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, (__gnu_cxx::_Lock_policy)2>::get() const /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/shared_ptr_base.h:1325:16
#1 0x10197b6 in std::__shared_ptr_access<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, (__gnu_cxx::_Lock_policy)2, false, false>::_M_get() const /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/shared_ptr_base.h:1024:66
#2 0x10197b6 in std::__shared_ptr_access<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, (__gnu_cxx::_Lock_policy)2, false, false>::operator*() const /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/shared_ptr_base.h:1011:10
#3 0xde888c2 in torch::jit::SourceRangeDeserializer::deserialize_source(c10::IValue const&) /pytorch/torch/csrc/jit/serialization/source_range_serialization.cpp:73:16
#4 0xde8802b in torch::jit::SourceRangeDeserializer::deserialize(c10::IValue const&) /pytorch/torch/csrc/jit/serialization/source_range_serialization.cpp:51:37
#5 0xde8e9c7 in torch::jit::ConcreteSourceRangeUnpickler::unpickle() /pytorch/torch/csrc/jit/serialization/source_range_serialization.cpp:224:39
#6 0xde8fb19 in torch::jit::ConcreteSourceRangeUnpickler::findSourceRangeThatGenerated(torch::jit::SourceRange const&) /pytorch/torch/csrc/jit/serialization/source_range_serialization.cpp:231:3
#7 0x10798e7 in torch::jit::Source::findSourceRangeThatGenerated(torch::jit::SourceRange const&) /pytorch/torch/csrc/jit/frontend/source_range.cpp:144:23
#8 0x1079d9a in torch::jit::SourceRange::findSourceRangeThatGenerated() const /pytorch/torch/csrc/jit/frontend/source_range.h:384:26
#9 0x1079acd in torch::jit::SourceRange::highlight(std::ostream&) const /pytorch/torch/csrc/jit/frontend/source_range.cpp:149:32
#10 0x1026fe2 in torch::jit::Lexer::expected(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, torch::jit::Token const&) /pytorch/torch/csrc/jit/frontend/lexer.h:461:13
#11 0x10417d9 in torch::jit::Lexer::expected(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) /pytorch/torch/csrc/jit/frontend/lexer.h:465:5
#12 0x102e52c in torch::jit::Lexer::expect(int) /pytorch/torch/csrc/jit/frontend/lexer.h:471:7
#13 0xcee774c in torch::jit::ParserImpl::parseIdent() /pytorch/torch/csrc/jit/frontend/parser.cpp:52:16
#14 0xcef4ea8 in torch::jit::ParserImpl::parseBaseExp() /pytorch/torch/csrc/jit/frontend/parser.cpp:195:22
#15 0xcef2c1b in torch::jit::ParserImpl::parseExp(int) /pytorch/torch/csrc/jit/frontend/parser.cpp:284:16
#16 0xcefac6a in torch::jit::ParserImpl::parseExp() /pytorch/torch/csrc/jit/frontend/parser.cpp:262:12
#17 0xcefac6a in torch::jit::ParserImpl::parseSubscriptExp() /pytorch/torch/csrc/jit/frontend/parser.cpp:403:15
#18 0xceff39f in torch::jit::List<torch::jit::Expr> torch::jit::ParserImpl::parseList<torch::jit::Expr>(int, int, int, torch::jit::Expr (torch::jit::ParserImpl::*)())::'lambda'()::operator()() const /pytorch/torch/csrc/jit/frontend/parser.cpp:354:54
#19 0xceff39f in torch::jit::Expr std::__invoke_impl<void, torch::jit::List<torch::jit::Expr> torch::jit::ParserImpl::parseList<torch::jit::Expr>(int, int, int, torch::jit::Expr (torch::jit::ParserImpl::*)())::'lambda'()&>(std::__invoke_other, torch::jit::List<torch::jit::Expr> torch::jit::ParserImpl::parseList<torch::jit::Expr>(int, int, int, torch::jit::Expr (torch::jit::ParserImpl::*)())::'lambda'()&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/invoke.h:60:14
#20 0xceea935 in torch::jit::ParserImpl::parseSequence(int, int, int, std::function<void ()> const&) /pytorch/torch/csrc/jit/frontend/parser.cpp:339:7
#21 0xceefd69 in torch::jit::List<torch::jit::Expr> torch::jit::ParserImpl::parseList<torch::jit::Expr>(int, int, int, torch::jit::Expr (torch::jit::ParserImpl::*)()) /pytorch/torch/csrc/jit/frontend/parser.cpp:353:5
#22 0xcef895a in torch::jit::ParserImpl::parseSubscript(c10::intrusive_ptr<torch::jit::Tree, c10::detail::intrusive_target_default_null_type<torch::jit::Tree> > const&) /pytorch/torch/csrc/jit/frontend/parser.cpp:430:9
#23 0xcef5e5c in torch::jit::ParserImpl::parseBaseExp() /pytorch/torch/csrc/jit/frontend/parser.cpp:206:18
#24 0xcef2c1b in torch::jit::ParserImpl::parseExp(int) /pytorch/torch/csrc/jit/frontend/parser.cpp:284:16
#25 0xceeeb9d in torch::jit::ParserImpl::parseExp() /pytorch/torch/csrc/jit/frontend/parser.cpp:262:12
#26 0xceeeb9d in torch::jit::ParserImpl::parseExpOrExpTuple() /pytorch/torch/csrc/jit/frontend/parser.cpp:94:19
#27 0xcee8a36 in torch::jit::ParserImpl::parseStmt(bool) /pytorch/torch/csrc/jit/frontend/parser.cpp:612:20
#28 0xcee7e72 in torch::jit::ParserImpl::parseStatements(bool, bool) /pytorch/torch/csrc/jit/frontend/parser.cpp:697:23
#29 0xcee56f5 in torch::jit::ParserImpl::parseClass() /pytorch/torch/csrc/jit/frontend/parser.cpp:747:9
#30 0xcee544a in torch::jit::Parser::parseClass() /pytorch/torch/csrc/jit/frontend/parser.cpp:812:17
#31 0xdddbea9 in torch::jit::SourceImporterImpl::parseSourceIfNeeded(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) /pytorch/torch/csrc/jit/serialization/import_source.cpp:182:42
#32 0xdddadbc in torch::jit::SourceImporterImpl::findNamedType(c10::QualifiedName const&) /pytorch/torch/csrc/jit/serialization/import_source.cpp:135:3
#33 0xdde1d88 in torch::jit::SourceImporterImpl::resolveType(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, torch::jit::SourceRange const&) /pytorch/torch/csrc/jit/serialization/import_source.cpp:261:10
#34 0xcf2ba5f in torch::jit::ScriptTypeParser::parseTypeFromExpr(torch::jit::Expr const&) const /pytorch/torch/csrc/jit/frontend/script_type_parser.cpp:238:24
#35 0xcf2bec7 in torch::jit::ScriptTypeParser::parseType(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) /pytorch/torch/csrc/jit/frontend/script_type_parser.cpp:312:10
#36 0xddf4284 in torch::jit::SourceImporter::loadType(c10::QualifiedName const&) const /pytorch/torch/csrc/jit/serialization/import_source.cpp:786:27
#37 0xdd739f7 in torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0::operator()(c10::QualifiedName const&) const /pytorch/torch/csrc/jit/serialization/import.cpp:146:33
#38 0xdd739f7 in c10::StrongTypePtr std::__invoke_impl<c10::StrongTypePtr, torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0&, c10::QualifiedName const&>(std::__invoke_other, torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0&, c10::QualifiedName const&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/invoke.h:60:14
#39 0xdd73880 in std::enable_if<is_invocable_r_v<c10::StrongTypePtr, torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0&, c10::QualifiedName const&>, c10::StrongTypePtr>::type std::__invoke_r<c10::StrongTypePtr, torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0&, c10::QualifiedName const&>(torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0&, c10::QualifiedName const&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/invoke.h:113:9
#40 0xdd736d6 in std::_Function_handler<c10::StrongTypePtr (c10::QualifiedName const&), torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)::$_0>::_M_invoke(std::_Any_data const&, c10::QualifiedName const&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/std_function.h:291:9
#41 0xdd76349 in std::function<c10::StrongTypePtr (c10::QualifiedName const&)>::operator()(c10::QualifiedName const&) const /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/std_function.h:622:14
#42 0xdeb9f48 in torch::jit::Unpickler::readGlobal(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) /pytorch/torch/csrc/jit/serialization/unpickler.cpp:835:9
#43 0xdeb012d in torch::jit::Unpickler::readInstruction() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:511:7
#44 0xdeae437 in torch::jit::Unpickler::run() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:251:27
#45 0xdeae0d2 in torch::jit::Unpickler::parse_ivalue() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:204:3
#46 0xddd6de3 in torch::jit::readArchiveAndTensors(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, c10::optional<std::function<c10::StrongTypePtr (c10::QualifiedName const&)> >, c10::optional<std::function<c10::intrusive_ptr<c10::ivalue::Object, c10::detail::intrusive_target_default_null_type<c10::ivalue::Object> > (c10::StrongTypePtr, c10::IValue)> >, c10::optional<c10::Device>, caffe2::serialize::PyTorchStreamReader&, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&), std::shared_ptr<torch::jit::DeserializationStorageContext>) /pytorch/torch/csrc/jit/serialization/import_read.cpp:53:20
#47 0xdd732dd in torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) /pytorch/torch/csrc/jit/serialization/import.cpp:184:10
#48 0xdd69885 in torch::jit::(anonymous namespace)::ScriptModuleDeserializer::deserialize(c10::optional<c10::Device>, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >&, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:287:19
#49 0xdd6c855 in torch::jit::import_ir_module(std::shared_ptr<torch::jit::CompilationUnit>, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, c10::optional<c10::Device>, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >&, bool, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:438:25
#50 0xdd6c1c7 in torch::jit::import_ir_module(std::shared_ptr<torch::jit::CompilationUnit>, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, c10::optional<c10::Device>, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:421:10
#51 0xdd6dce4 in torch::jit::load(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, c10::optional<c10::Device>, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:503:10
#52 0xf2d3f75 in torch::serialize::InputArchive::load_from(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, c10::optional<c10::Device>) /pytorch/torch/csrc/api/src/serialize/input-archive.cpp:97:13
#53 0x60509c in void torch::load<at::Tensor, char*&>(at::Tensor&, char*&) /pytorch/torch/include/torch/csrc/api/include/torch/serialize.h:107:11
#54 0x6036be in LLVMFuzzerTestOneInput /vision/encode_png.cc:38:5
#55 0x66b041 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:611:15
#56 0x6544cc in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:324:6
#57 0x65a61b in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:860:9
#58 0x654222 in main /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10
#59 0x7f3d12cc7082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082) (BuildId: 1878e6b475720c7c51969e69ab2d276fae6d1dee)
#60 0x542cdd in _start (/encode_png_fuzz+0x542cdd)
0x60200055a630 is located 16 bytes to the right of 16-byte region [0x60200055a610,0x60200055a620)
allocated by thread T0 here:
#0 0x60057d in operator new(unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/asan/asan_new_delete.cpp:95:3
#1 0xde9185d in std::_Vector_base<std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_allocate(unsigned long) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_vector.h:346:20
#2 0xde9185d in void std::vector<std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_realloc_insert<std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >(__gnu_cxx::__normal_iterator<std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >*, std::vector<std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > > >, std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >&&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/vector.tcc:440:33
#3 0xde916a1 in std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >& std::vector<std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::emplace_back<std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >(std::shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >&&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/vector.tcc:121:4
#4 0xde8f445 in torch::jit::SourceRangeDeserializer::SourceRangeDeserializer(c10::IValue) /pytorch/torch/csrc/jit/serialization/source_range_serialization.h:42:19
#5 0xde8e141 in torch::jit::ConcreteSourceRangeUnpickler::unpickle() /pytorch/torch/csrc/jit/serialization/source_range_serialization.cpp:215:28
#6 0xde8fb19 in torch::jit::ConcreteSourceRangeUnpickler::findSourceRangeThatGenerated(torch::jit::SourceRange const&) /pytorch/torch/csrc/jit/serialization/source_range_serialization.cpp:231:3
#7 0x10798e7 in torch::jit::Source::findSourceRangeThatGenerated(torch::jit::SourceRange const&) /pytorch/torch/csrc/jit/frontend/source_range.cpp:144:23
#8 0x1079d9a in torch::jit::SourceRange::findSourceRangeThatGenerated() const /pytorch/torch/csrc/jit/frontend/source_range.h:384:26
#9 0x1079acd in torch::jit::SourceRange::highlight(std::ostream&) const /pytorch/torch/csrc/jit/frontend/source_range.cpp:149:32
#10 0x1026fe2 in torch::jit::Lexer::expected(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, torch::jit::Token const&) /pytorch/torch/csrc/jit/frontend/lexer.h:461:13
#11 0x10417d9 in torch::jit::Lexer::expected(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) /pytorch/torch/csrc/jit/frontend/lexer.h:465:5
#12 0xcee774c in torch::jit::ParserImpl::parseIdent() /pytorch/torch/csrc/jit/frontend/parser.cpp:52:16
#13 0xcef4ea8 in torch::jit::ParserImpl::parseBaseExp() /pytorch/torch/csrc/jit/frontend/parser.cpp:195:22
#14 0xcef2c1b in torch::jit::ParserImpl::parseExp(int) /pytorch/torch/csrc/jit/frontend/parser.cpp:284:16
#15 0xcefac6a in torch::jit::ParserImpl::parseExp() /pytorch/torch/csrc/jit/frontend/parser.cpp:262:12
#16 0xcefac6a in torch::jit::ParserImpl::parseSubscriptExp() /pytorch/torch/csrc/jit/frontend/parser.cpp:403:15
#17 0xceff39f in torch::jit::List<torch::jit::Expr> torch::jit::ParserImpl::parseList<torch::jit::Expr>(int, int, int, torch::jit::Expr (torch::jit::ParserImpl::*)())::'lambda'()::operator()() const /pytorch/torch/csrc/jit/frontend/parser.cpp:354:54
#18 0xceff39f in torch::jit::Expr std::__invoke_impl<void, torch::jit::List<torch::jit::Expr> torch::jit::ParserImpl::parseList<torch::jit::Expr>(int, int, int, torch::jit::Expr (torch::jit::ParserImpl::*)())::'lambda'()&>(std::__invoke_other, torch::jit::List<torch::jit::Expr> torch::jit::ParserImpl::parseList<torch::jit::Expr>(int, int, int, torch::jit::Expr (torch::jit::ParserImpl::*)())::'lambda'()&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/invoke.h:60:14
#19 0xceea935 in torch::jit::ParserImpl::parseSequence(int, int, int, std::function<void ()> const&) /pytorch/torch/csrc/jit/frontend/parser.cpp:339:7
#20 0xceefd69 in torch::jit::List<torch::jit::Expr> torch::jit::ParserImpl::parseList<torch::jit::Expr>(int, int, int, torch::jit::Expr (torch::jit::ParserImpl::*)()) /pytorch/torch/csrc/jit/frontend/parser.cpp:353:5
#21 0xcef895a in torch::jit::ParserImpl::parseSubscript(c10::intrusive_ptr<torch::jit::Tree, c10::detail::intrusive_target_default_null_type<torch::jit::Tree> > const&) /pytorch/torch/csrc/jit/frontend/parser.cpp:430:9
#22 0xcef5e5c in torch::jit::ParserImpl::parseBaseExp() /pytorch/torch/csrc/jit/frontend/parser.cpp:206:18
#23 0xcef2c1b in torch::jit::ParserImpl::parseExp(int) /pytorch/torch/csrc/jit/frontend/parser.cpp:284:16
#24 0xceeeb9d in torch::jit::ParserImpl::parseExp() /pytorch/torch/csrc/jit/frontend/parser.cpp:262:12
#25 0xceeeb9d in torch::jit::ParserImpl::parseExpOrExpTuple() /pytorch/torch/csrc/jit/frontend/parser.cpp:94:19
#26 0xcee8a36 in torch::jit::ParserImpl::parseStmt(bool) /pytorch/torch/csrc/jit/frontend/parser.cpp:612:20
#27 0xcee7e72 in torch::jit::ParserImpl::parseStatements(bool, bool) /pytorch/torch/csrc/jit/frontend/parser.cpp:697:23
#28 0xcee56f5 in torch::jit::ParserImpl::parseClass() /pytorch/torch/csrc/jit/frontend/parser.cpp:747:9
#29 0xcee544a in torch::jit::Parser::parseClass() /pytorch/torch/csrc/jit/frontend/parser.cpp:812:17
#30 0xdddbea9 in torch::jit::SourceImporterImpl::parseSourceIfNeeded(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) /pytorch/torch/csrc/jit/serialization/import_source.cpp:182:42
#31 0xdddadbc in torch::jit::SourceImporterImpl::findNamedType(c10::QualifiedName const&) /pytorch/torch/csrc/jit/serialization/import_source.cpp:135:3
#32 0xdde1d88 in torch::jit::SourceImporterImpl::resolveType(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, torch::jit::SourceRange const&) /pytorch/torch/csrc/jit/serialization/import_source.cpp:261:10
#33 0xcf2ba5f in torch::jit::ScriptTypeParser::parseTypeFromExpr(torch::jit::Expr const&) const /pytorch/torch/csrc/jit/frontend/script_type_parser.cpp:238:24
SUMMARY: AddressSanitizer: heap-buffer-overflow /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/shared_ptr_base.h:1325:16 in std::__shared_ptr<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, (__gnu_cxx::_Lock_policy)2>::get() const
Shadow bytes around the buggy address:
0x0c04800a3470: fa fa 00 00 fa fa 00 00 fa fa fd fa fa fa 00 00
0x0c04800a3480: fa fa fd fa fa fa fd fd fa fa fd fd fa fa fd fa
0x0c04800a3490: fa fa fd fd fa fa 00 00 fa fa 00 00 fa fa 00 00
0x0c04800a34a0: fa fa fd fa fa fa fd fd fa fa fd fa fa fa 00 fa
0x0c04800a34b0: fa fa fd fd fa fa fd fd fa fa fd fa fa fa fd fd
=>0x0c04800a34c0: fa fa 00 00 fa fa[fa]fa fa fa fa fa fa fa fa fa
0x0c04800a34d0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c04800a34e0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c04800a34f0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c04800a3500: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c04800a3510: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==13==ABORTING
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103969
Approved by: https://github.com/davidberard98
The idea here is to create do a graph mutation to:
* Create an initial dependency token at the beginning of the program.
* Replace non-functional version of assertion statements to functional version.
* The functional version of assertion statement will:
* Accept a dependency token from output of previous functional assertion statement (or the initial dependency token if there isn't any).
* Generate a dependency token as the output of assertion statement.
* Augment the output to include the dependency token generated by last assertion statement.
The goal here is to:
* Form an explicit dependency chain and avoid potential reordering during other passes of compiling.
* Make the assertions a part of overall execution graph will affect the final output (or it could potentially be DCEed).
**NOTE:**
* Currently only cover `contrain_range` and WIP to support other assertions. Send out this PR to collect feedback first.
* Here it only focus on implementation itself. Will integrate it with current export in future PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103757
Approved by: https://github.com/avikchaudhuri
Because we always run tests with pytest now.
Marking it as `bc-breaking` as there could technically be some scripts depending on it somewhere...
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 1760568</samp>
> _`pytest` option gone_
> _simpler test runner script_
> _autumn leaves fall fast_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104125
Approved by: https://github.com/seemethere
- Extend support:
- quantized::conv1d
- quantized::conv3d
- quantized::conv3d_relu
- quantized::conv_transpose1d
- quantized::conv_transpose2d
- quantized::conv_transpose3d
- Note: quantized::{conv1d_relu,conv2d,conv2d_relu} already supported.
- To support this, quantization unpacking added for:
- conv1d
- conv_transpose1d
- conv_transpose2d
- conv_transpose3d
- Note: conv3d/conv3d_relu already had weights unpacking set up, even though it didn't have torch.onnx support.
- Add tests.
- The 3D tests will fail if run with the qnnpack backend (e.g., on Apple silicon Mac), so added decorator skipIfQuantizationBackendQNNPack.
- Minor fix in `aten/src/ATen/native/quantized/cpu/qconv.cpp` for 3D convolutions (triggered by added tests).
Fixes#102747
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102759
Approved by: https://github.com/BowenBao, https://github.com/thiagocrepaldi, https://github.com/kit1980
Summary: separate system information construction as a separate static method, and update local caching (/temp_dir/cache is now a dir, not a file; this is relevant for upcoming changed i.e. adding `allow_tf32` since it would now be possible to have multiple valid local caches)
Test Plan: sandcastle + CI
Differential Revision: D46568207
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104050
Approved by: https://github.com/jansel
(this these two fixes are now oudated, see EDIT below)
Fixes for two thread safety issues (one currently unobserved, and one currently observed).
1. `std::erase` can potentially invalidate a pointer to an `ExecutionPlan` in the current implementation. While failures due to this issue have not yet been reported to my knowledge, it is better to return a copy of an `ExecutionPlan` for safety.
2. #103793 surfaced that `cudnnBackendExecute` appears to currently be thread-unsafe. I've verified this with a PyTorch free (pure C++) repro using the cuDNN frontend. This PR addes a mutex that we can hopefully once this issue is resolved.
EDIT:
Feedback from cuDNN is that the V8 backend API has known thread-safety limitations when `ExecutionPlan`s are shared (or even shallow copied) across threads. Given that the common PyTorch use case of eager-mode is singlethreaded (per GPU), this PR now opts to make `ExecutionPlan` caches `thread_local`, as this simplifies the code and eliminates the need for a mutex. The potential tradeoff is some additional warmup cost in multithreaded case, but this would also only be worse than the current case if multiple threads had largely overlapping workloads.
CC @tuero @ptrblck @malfet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103939
Approved by: https://github.com/xw285cornell, https://github.com/colesbury
The root cause of the crash in training nanoGPT was a null pointer dereference in the layer norm kernel.
While addressing the issue, I also made sure that `__syncthreads()` is simultaneously called by all threads in the block, to avoid unwanted side effects.
Moreover, I changed the kernel launch code to be more clear about the accumulation data type (`T_ACC`) and thread block dimensions, without changing function.
Fixes#95808
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95810
Approved by: https://github.com/ngimel
Summary: https://github.com/pytorch/pytorch/issues/100654 noticed prelu
was not running its observers when the quantization flow was being run,
this was a bug which is now fixed and the relevant prelu tests also now
check for this. Also added a corrected observer for PReLU to
qconfig_mapping
Test Plan: python test/test_quantization.py TestStaticQuantizedModule.test_prelu
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103455
Approved by: https://github.com/jerryzh168
Summary:
Prepare QAT for mobilenetv2 has matching numerics with
FX. There were two changes needed to achieve this, however.
First, this commit adds observer sharing for ReLU6, which is
used extensively throughout this model. Second, in the tests we
have to use the same manual seed every time we call the models
in order to get the same results between FX and PT2. This is
because there is a dropout at the end of the model.
Test Plan: python test/test_quantization.py TestQuantizePT2EModels.test_qat_mobilenet_v2
Reviewed By: kimishpatel
Differential Revision: D46707786
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104068
Approved by: https://github.com/jerryzh168
Summary: Currently we rely on root operator, but we also need to check for et_kernel_metadata for used specialized kernels.
Test Plan: contbuild & OSS CI
Reviewed By: Jack-Khuu
Differential Revision: D46882119
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104005
Approved by: https://github.com/Jack-Khuu
Reference cycles are freed by the cycle collector rather than being cleaned up
when the objects in the cycle first become unreachable. If a cycle points to a tensor,
the CUDA memory for that tensor will not be freed until garbage collection runs.
Accumulation of CUDA allocations can lead to out of memory errors (OOMs), as well as
non-deterministic allocation behavior which is harder to debug.
This visualizer installs a garbage collection hook to look for cycles containing
CUDA tensors and saves a visualization of the garbage:
```
from torch.cuda._cycleviz import warn_tensor_cycles
warn_tensor_cycles()
# do some work that results in a cycle getting garbage collected
# ...
> WARNING:root:Reference cycle includes a CUDA Tensor see visualization of cycle /tmp/tmpeideu9gl.html
```
Reland to make windows skip the test.
This reverts commit 7b3b6dd4262337c5289d64dd3e824b0614cf68e3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104051
Approved by: https://github.com/aaronenyeshi, https://github.com/malfet
**Summary**
The previous UT has been broken accidently, since the output of conv2d node has been annotated by mistake.
Re-enable these UTs for case:
- Single `conv2d` node, if we don't annotate the output node of `conv2d`. There should be no fake quant at conv2d's output.
- For `conv2d-maxpool` pattern, `maxpool` should has fake quant inserted at input and output node since we annotate these nodes.
**Test Plan**
```
python -m pytest test_quantize_pt2e.py -k test_wo_annotate_conv_output_quantizer
python -m pytest test_quantize_pt2e.py -k test_max_pool2d_quantizer
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101941
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
# Summary
1. Add `num_elements_per_warp` as an optional triton config. Currently it's only used in Pointwise max_auto_tune.
2. Added an entry for Pointwise max_auto_tune when len(size_hints)==1. This is from the results of `CoordescTuner` for the `max_pool2d_with_indices_backward` kernel.
3. Made `max_pool2d_with_indices_backward` channel-last consider torch inductor lowering by default when auto-tune is enabled.
(I tried to update `num_elements_per_warp` directly for all configs directly. However it brings some perf regressions for "torchbench" and "dynamic" models. So in this PR still use a guard.)
# Performance test results
Operator max_pool2d_with_indices_backward testing:
```
python3.9 benchmarks/dynamo/microbenchmarks/operatorbench.py --suite=timm --op=aten.max_pool2d_with_indices_backward.default --max-samples=5 --dtype=float16 --channels-last
Before this change:
Fallback
Inductor Speedups : [0.9997202597876758, 1.0001309108307304, 1.0002654421310901]
Default lowering:
Inductor Speedups : [0.9945062166479167, 1.0632119741391315, 1.3002933288577507]
TORCHINDUCTOR_MAX_AUTOTUNE_POINTWISE=0
Inductor Speedups : [0.9941159121217165, 1.0648002410311495, 1.2999986086755966]
TORCHINDUCTOR_MAX_AUTOTUNE_POINTWISE=1
Inductor Speedups : [0.9950528253874693, 1.0651245316963014, 1.3013674401534756]
TORCHINDUCTOR_COORDINATE_DESCENT_TUNING=1
Inductor Speedups : [1.4020247605755827, 1.5504232138088152, 1.8226088905229931]
After this change:
TORCHINDUCTOR_MAX_AUTOTUNE_POINTWISE=1
Inductor Speedups : [1.403303265792746, 1.548831582475635, 1.822278780085024]
```
Inductor perf nightly run in progress:
https://github.com/pytorch/pytorch/actions/runs/5329044981
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103702
Approved by: https://github.com/jansel, https://github.com/eellison
Fixes#42376
`torch.save` serializes bound methods inside LR scheduler resulting in large serialized file.
Test cases include checking file size, checking if the `anneal_func` is bounded and file is loaded correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102627
Approved by: https://github.com/albanD
Summary:
Since NCCL 2.12.10, NCCL supports send/recv 0 byte: https://github.com/NVIDIA/nccl/issues/696. Therefore we don't have to skip.
One issue is that if a rank has 0 bytes to send and 0 bytes to recv, it'll skip send/recv completely. And it'll proceed to the next collective which it can send/recv something, making it confusing to the other ranks. Another solution is to add a barrier but that's very expensive.
Test Plan: will add a unit test
Differential Revision: D46507785
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103140
Approved by: https://github.com/malfet, https://github.com/kwen2501
Summary:
We remove the ExportGraphModuleMixin. There are several implications of this change:
1. The graph_module of ExportedProgram, EdgeDialectProgram and ExecutorchProgram won't have the same signature as original user function. Instead, we should directly call the *Program, which has the same calling convention. e.g:
2. All passes need to go through prog.transform(*passes). We need to make all passes return PassResult as a result.
3. We also need to make sure the graph_module.meta is preserved after transform.
Test Plan: Test with CI.
Differential Revision: D46729844
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103786
Approved by: https://github.com/avikchaudhuri
1) Fix @parametrize not working when using @with_comms in DTensorTestBase, this is because args and kwargs are currently not being passed when using @with_comms wrapper.
2) Use @parametrize in test_fsdp_dtensor_state_dict.py to make sure it is working correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104065
Approved by: https://github.com/fduwjj
I doubt there's much difference in performance, but this improves readability of
the generated code, e.g.
```python
tmp8 = triton_helpers.max2(tmp7, 1)[:, None]
```
becomes
```python
tmp8 = triton_helpers.any(tmp7, 1)[:, None]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103974
Approved by: https://github.com/lezcano
Summary:
Special qspecs like `SharedQuantizationSpec` and
`DerivedQuantizationSpec` refer to other nodes in the graph.
However, after subgraph rewriting in QAT, the nodes referred
to in these special qspecs may be replaced by new nodes.
This could lead to the following error when inserting
observers according to these qspecs:
```
AssertionError: please make sure only refer to edge or node
that has observer/fake_quant inserted: 'getitem' not in
dict_keys([(arg0, convolution_default_1), (mul_tensor, convolution_default_1), getitem_3])
```
This commit fixes this by keeping track of the nodes that
are replaced during subgraph rewriting in QAT, and using
this mapping to update the dangling references used in these
special qspecs.
Test Plan: python test/test_quantization.py TestQuantizePT2E.test_qat_update_shared_qspec
Reviewed By: jerryzh168
Differential Revision: D46606614
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103970
Approved by: https://github.com/jerryzh168
Query for list of renabled issues in the filter test config step: switch filter test config to query for all the PR info instead of just the labels so token usage should stay the same, move code and tests related to parsing reenabled issues to filter test config step, remove old code to get PR body and commit message. `REENABLED_ISSUES` should be a comma separated list of issue numbers to be reenabled.
For testing: Fixes#103789
Check that 103789 shows up in list of ignored disabled issues
Sanity check that test-config labels still work
More testing via `python3 ".github/scripts/filter_test_configs.py" --workflow "pull" --job-name "linux-bionic-cuda12.1-py3.10-gcc9 / test (default, 4, 5, linux.4xlarge.nvidia.gpu)" --test-matrix "{ include: [
{ config: "default", shard: 1, num_shards: 1 },
]}
" --pr-number "" --tag "" --event-name "push" --schedule "" --branch ""`
and
`python3 ".github/scripts/filter_test_configs.py" --workflow "pull" --job-name "linux-bionic-cuda12.1-py3.10-gcc9 / test (default, 4, 5, linux.4xlarge.nvidia.gpu)" --test-matrix "{"include": [{"config": "default", "shard": 1, "num_shards": 5, "runner": "linux.g5.4xlarge.nvidia.gpu"}, {"config": "default", "shard": 2, "num_shards": 5, "runner": "linux.g5.4xlarge.nvidia.gpu"}, {"config": "default", "shard": 3, "num_shards": 5, "runner": "linux.g5.4xlarge.nvidia.gpu"}, {"config": "default", "shard": 4, "num_shards": 5, "runner": "linux.g5.4xlarge.nvidia.gpu"}, {"config": "default", "shard": 5, "num_shards": 5, "runner": "linux.g5.4xlarge.nvidia.gpu"}]}" --pr-number "103790" --tag "" --event-name "pull_request" --schedule "" --branch ""`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103790
Approved by: https://github.com/huydhn
Summary:
The test fail because a fixed port is used to initialize the process group. That does not work in stress test when multiple instance of the tests are being run concurrently.
Pick a random port and do some small retry for that.
Test Plan:
```
buck2 test 'fbcode//mode/opt' fbcode//caffe2/test/inductor:layout_optim -- --exact 'caffe2/test/inductor:layout_optim - test_mutate_view (caffe2.test.inductor.test_layout_optim.TestLayoutOptim)' --run-disabled --jobs 18 --stress-runs 10 --record-results
```
Differential Revision: D46908114
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103984
Approved by: https://github.com/williamwen42
Hi!
I've been fuzzing different pytorch modules with with [sydr-fuzz](https://github.com/ispras/oss-sydr-fuzz/tree/master/projects/pytorch), and found a heap buffer overflow error that occures by incorrect loop condition in torch::jit::unpickler.cpp. This bug was found in several fuzzing targets: it can be triggered by `torch::jit::load()` method when loading a .pt model and by `torch::distributed::rpc::deserializeRequest()` method in RPC module.
All found errors could be reproduced with provided docker: [Dockerfile](https://github.com/ispras/oss-sydr-fuzz/tree/master/projects/pytorch).
### PoC for deserealizeRequest():
[crash-0722408578cd2f26593b5a01e26d2a078d3dc5f6.zip](https://github.com/pytorch/pytorch/files/11756694/crash-0722408578cd2f26593b5a01e26d2a078d3dc5f6.zip)
```
=================================================================
==29858==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x6020004ed808 at pc 0x000000680084 bp 0x7ffcbd8220d0 sp 0x7ffcbd8220c8
READ of size 4 at 0x6020004ed808 thread T0
#0 0x680083 in c10::IValue::IValue(c10::IValue const&) /pytorch/aten/src/ATen/core/ivalue.h:224:33
#1 0xdc4beb8 in std::pair<c10::impl::DictIterator<c10::IValue, c10::IValue, ska_ordered::detailv3::sherwood_v3_table<std::pair<c10::IValue, c10::IValue>, c10::IValue, c10::detail::DictKeyHash, ska_ordered::detailv3::KeyOrValueHasher<c10::IValue, std::pair<c10::IValue, c10::IValue>, c10::detail::DictKeyHash>, c10::detail::DictKeyEqualTo, ska_ordered::detailv3::KeyOrValueEquality<c10::IValue, std::pair<c10::IValue, c10::IValue>, c10::detail::DictKeyEqualTo>, std::allocator<std::pair<c10::IValue, c10::IValue> >, std::allocator<ska_ordered::detailv3::sherwood_v3_entry<std::pair<c10::IValue, c10::IValue> > > >::templated_iterator<std::pair<c10::IValue, c10::IValue> > >, bool> c10::Dict<c10::IValue, c10::IValue>::insert_or_assign<c10::IValue&, c10::IValue&>(c10::IValue&, c10::IValue&) const /pytorch/aten/src/ATen/core/Dict_inl.h:136:5
#2 0xea680a7 in torch::jit::Unpickler::readInstruction() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:452:14
#3 0xea64e07 in torch::jit::Unpickler::run() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:251:27
#4 0xea64a61 in torch::jit::Unpickler::parse_ivalue() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:204:3
#5 0xe9b13ce in torch::jit::unpickle(std::function<unsigned long (char*, unsigned long)>, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)) /pytorch/torch/csrc/jit/serialization/pickle.cpp:126:20
#6 0xe9b178c in torch::jit::unpickle(char const*, unsigned long, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)) /pytorch/torch/csrc/jit/serialization/pickle.cpp:136:10
#7 0xfdc8aa1 in torch::distributed::rpc::(anonymous namespace)::toIValues(torch::distributed::rpc::Message const&, torch::distributed::rpc::MessageType) /pytorch/torch/csrc/distributed/rpc/rref_proto.cpp:23:16
#8 0xfdca3ca in torch::distributed::rpc::PythonRRefFetchCall::fromMessage(torch::distributed::rpc::Message const&) /pytorch/torch/csrc/distributed/rpc/rref_proto.cpp:105:17
#9 0xfe7f347 in torch::distributed::rpc::deserializeRequest(torch::distributed::rpc::Message const&) /pytorch/torch/csrc/distributed/rpc/utils.cpp:117:14
#10 0x5c5d13 in LLVMFuzzerTestOneInput /message_deserialize.cc:192:27
#11 0x5c2bfd in ExecuteFilesOnyByOne /AFLplusplus/utils/aflpp_driver/aflpp_driver.c:255:7
#12 0x5c2a08 in LLVMFuzzerRunDriver /AFLplusplus/utils/aflpp_driver/aflpp_driver.c
#13 0x5c25c8 in main /AFLplusplus/utils/aflpp_driver/aflpp_driver.c:300:10
#14 0x7feb90908082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082) (BuildId: 1878e6b475720c7c51969e69ab2d276fae6d1dee)
#15 0x50237d in _start (/message_deserialize_afl+0x50237d)
0x6020004ed808 is located 8 bytes to the right of 16-byte region [0x6020004ed7f0,0x6020004ed800)
allocated by thread T0 here:
#0 0x5bfc1d in operator new(unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/asan/asan_new_delete.cpp:95:3
#1 0x32ad8d1 in std::_Vector_base<c10::IValue, std::allocator<c10::IValue> >::_M_allocate(unsigned long) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_vector.h:346:20
#2 0x32ad8d1 in void std::vector<c10::IValue, std::allocator<c10::IValue> >::_M_realloc_insert<double>(__gnu_cxx::__normal_iterator<c10::IValue*, std::vector<c10::IValue, std::allocator<c10::IValue> > >, double&&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/vector.tcc:440:33
SUMMARY: AddressSanitizer: heap-buffer-overflow /pytorch/aten/src/ATen/core/ivalue.h:224:33 in c10::IValue::IValue(c10::IValue const&)
Shadow bytes around the buggy address:
0x0c0480095ab0: fa fa fd fd fa fa fd fd fa fa fd fd fa fa 00 00
0x0c0480095ac0: fa fa 00 00 fa fa 00 00 fa fa 04 fa fa fa 04 fa
0x0c0480095ad0: fa fa 00 fa fa fa fd fa fa fa 04 fa fa fa 00 fa
0x0c0480095ae0: fa fa 00 fa fa fa fd fa fa fa fd fa fa fa fd fa
0x0c0480095af0: fa fa fd fd fa fa 00 00 fa fa 00 fa fa fa 00 00
=>0x0c0480095b00: fa[fa]fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c0480095b10: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c0480095b20: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c0480095b30: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c0480095b40: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c0480095b50: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==29858==ABORTING
```
### PoC for load():
[crash-2bd32e496811fb06de24a2bb720dc6490218009f.zip](/uploads/53d108cdd434ec4b11a2034bbca3cfd8/crash-2bd32e496811fb06de24a2bb720dc6490218009f.zip)
```
==29865==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x60c00031f388 at pc 0x000000669984 bp 0x7ffd6c6de630 sp 0x7ffd6c6de628
READ of size 4 at 0x60c00031f388 thread T0
#0 0x669983 in c10::IValue::IValue(c10::IValue const&) /pytorch/aten/src/ATen/core/ivalue.h:224:33
#1 0xdc3de68 in std::pair<c10::impl::DictIterator<c10::IValue, c10::IValue, ska_ordered::detailv3::sherwood_v3_table<std::pair<c10::IValue, c10::IValue>, c10::IValue, c10::detail::DictKeyHash, ska_ordered::detailv3::KeyOrValueHasher<c10::IValue, std::pair<c10::IValue, c10::IValue>, c10::detail::DictKeyHash>, c10::detail::DictKeyEqualTo, ska_ordered::detailv3::KeyOrValueEquality<c10::IValue, std::pair<c10::IValue, c10::IValue>, c10::detail::DictKeyEqualTo>, std::allocator<std::pair<c10::IValue, c10::IValue> >, std::allocator<ska_ordered::detailv3::sherwood_v3_entry<std::pair<c10::IValue, c10::IValue> > > >::templated_iterator<std::pair<c10::IValue, c10::IValue> > >, bool> c10::Dict<c10::IValue, c10::IValue>::insert_or_assign<c10::IValue&, c10::IValue&>(c10::IValue&, c10::IValue&) const /pytorch/aten/src/ATen/core/Dict_inl.h:136:5
#2 0xea5a207 in torch::jit::Unpickler::readInstruction() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:452:14
#3 0xea56f67 in torch::jit::Unpickler::run() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:251:27
#4 0xea56bc1 in torch::jit::Unpickler::parse_ivalue() /pytorch/torch/csrc/jit/serialization/unpickler.cpp:204:3
#5 0xe96db4e in torch::jit::readArchiveAndTensors(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, c10::optional<std::function<c10::StrongTypePtr (c10::QualifiedName const&)> >, c10::optional<std::function<c10::intrusive_ptr<c10::ivalue::Object, c10::detail::intrusive_target_default_null_type<c10::ivalue::Object> > (c10::StrongTypePtr, c10::IValue)> >, c10::optional<c10::Device>, caffe2::serialize::PyTorchStreamReader&, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&), std::shared_ptr<torch::jit::DeserializationStorageContext>) /pytorch/torch/csrc/jit/serialization/import_read.cpp:53:20
#6 0xe8fc648 in torch::jit::(anonymous namespace)::ScriptModuleDeserializer::readArchive(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) /pytorch/torch/csrc/jit/serialization/import.cpp:184:10
#7 0xe8f8935 in torch::jit::(anonymous namespace)::ScriptModuleDeserializer::deserialize(c10::optional<c10::Device>, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >&, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:287:19
#8 0xe8f6d74 in torch::jit::import_ir_module(std::shared_ptr<torch::jit::CompilationUnit>, std::istream&, c10::optional<c10::Device>, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >&, bool, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:386:25
#9 0xe90086e in torch::jit::import_ir_module(std::shared_ptr<torch::jit::CompilationUnit>, std::istream&, c10::optional<c10::Device>, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:322:10
#10 0xe903209 in torch::jit::load(std::istream&, c10::optional<c10::Device>, bool) /pytorch/torch/csrc/jit/serialization/import.cpp:482:10
#11 0x5c2d60 in LLVMFuzzerTestOneInput /load.cc:42:14
#12 0x5c2a8d in ExecuteFilesOnyByOne /AFLplusplus/utils/aflpp_driver/aflpp_driver.c:255:7
#13 0x5c2898 in LLVMFuzzerRunDriver /AFLplusplus/utils/aflpp_driver/aflpp_driver.c
#14 0x5c2458 in main /AFLplusplus/utils/aflpp_driver/aflpp_driver.c:300:10
#15 0x7f156ae33082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082) (BuildId: 1878e6b475720c7c51969e69ab2d276fae6d1dee)
#16 0x50220d in _start (/load_afl+0x50220d)
0x60c00031f388 is located 8 bytes to the right of 128-byte region [0x60c00031f300,0x60c00031f380)
allocated by thread T0 here:
#0 0x5bfaad in operator new(unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/asan/asan_new_delete.cpp:95:3
#1 0xa86231 in std::_Vector_base<c10::IValue, std::allocator<c10::IValue> >::_M_allocate(unsigned long) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_vector.h:346:20
#2 0xa86231 in void std::vector<c10::IValue, std::allocator<c10::IValue> >::_M_realloc_insert<c10::IValue&>(__gnu_cxx::__normal_iterator<c10::IValue*, std::vector<c10::IValue, std::allocator<c10::IValue> > >, c10::IValue&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/vector.tcc:440:33
SUMMARY: AddressSanitizer: heap-buffer-overflow /pytorch/aten/src/ATen/core/ivalue.h:224:33 in c10::IValue::IValue(c10::IValue const&)
Shadow bytes around the buggy address:
0x0c188005be20: fd fd fd fd fd fd fd fd fa fa fa fa fa fa fa fa
0x0c188005be30: fd fd fd fd fd fd fd fd fd fd fd fd fd fd fd fd
0x0c188005be40: fa fa fa fa fa fa fa fa fd fd fd fd fd fd fd fd
0x0c188005be50: fd fd fd fd fd fd fd fd fa fa fa fa fa fa fa fa
0x0c188005be60: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
=>0x0c188005be70: fa[fa]fa fa fa fa fa fa 00 00 00 00 00 00 00 00
0x0c188005be80: 00 00 00 00 00 00 00 00 fa fa fa fa fa fa fa fa
0x0c188005be90: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c188005bea0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c188005beb0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c188005bec0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==29865==ABORTING
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103667
Approved by: https://github.com/albanD
- Upstream LLVM switched LLJIT's default JIT linker for ELF/x86-64 to JITLink: [commit](b92839c954). This commit mandates clients to use JITLink plugins, following the example in "llvm/examples/OrcV2Examples/LLJITWithCustomObjectLinkingLayer".
- Current change updates PytorchLLVMJITImpl to set ObjectLinkingLayer on LLJIT creation.
- If setObjectLinkingLayerCreator not set, RTDyldObjectLinkingLayer will be constructed. This is currently causing "Symbols not found: [ llvm_orc_registerEHFrameSectionWrapper ]" error for tests in test_quantization.py when pytorch is built to use latest LLVM.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103824
Approved by: https://github.com/jeffdaily, https://github.com/davidberard98
Summary:
This PR fixes the wrong assertion in the `test_addmm_gelu` happening in the Windows CUDA CI job caused by #103811. The addmm + GELU fusion is likely not happening (or not using the tanh approximation) on Windows. See [this comment](https://github.com/pytorch/pytorch/pull/103811#issuecomment-1601936203) in the #103811 for the details of the error.
Test Plan:
```
$ python test/test_linalg.py -k test_addmm_relu -v
test_addmm_relu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_relu_cpu_bfloat16) ... ok
test_addmm_relu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float32) ... ok
test_addmm_relu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float64) ... ok
test_addmm_relu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_bfloat16) ... ok
test_addmm_relu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float32) ... ok
test_addmm_relu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 2.131s
OK
$ python test/test_linalg.py -k test_addmm_gelu -v
test_addmm_gelu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_bfloat16) ... ok
test_addmm_gelu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float32) ... ok
test_addmm_gelu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float64) ... ok
test_addmm_gelu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_bfloat16) ... ok
test_addmm_gelu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float32) ... ok
test_addmm_gelu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float64) ... ok
----------------------------------------------------------------------
Ran 6 tests in 2.194s
OK
```
Reviewers: @eellison @huydhn
Subscribers:
Tasks:
Tags:
Differential Revision: [D46931688](https://our.internmc.facebook.com/intern/diff/D46931688)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104031
Approved by: https://github.com/huydhn, https://github.com/malfet
As part of this, a new `AutocastIPU` dispatch key has been added.
There's an existing PR, #85043, to make `Autocast` a proper per-backend functionality key, but it ran into issues with layering with other functionality keys and went stale.
This has been tested in the out-of-tree IPU PyTorch backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103890
Approved by: https://github.com/albanD
The following subjects are not in this PR and will be done in a follow up:
- Go through torch_function section and update to the latest phrasing and link to the proper new sections
- Go through torch.library and custom device docs to add links to the new sections as appropriate
- Top level explanations on which component should be used
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102087
Approved by: https://github.com/janeyx99
default_partitioner is kind of broken when it comes to memory footprint. Moving aot_eager to use min-cut partitioner is better debugging experience.
One bad thing though would be that we will much lower speedup numbers, because min cut partitioner will try to recompute ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103555
Approved by: https://github.com/eellison, https://github.com/jansel
Summary: The old shader file was created before channel padding was implemented. We recompute the positions with the consideration that channels are padded as a multiple of 4.
Test Plan:
under `fbsource` run `buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1`
full test result: P772641736
Reviewed By: SS-JIA
Differential Revision: D46866159
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103908
Approved by: https://github.com/SS-JIA
By including `Engine.h` in `Shim.cpp` and defining `bool available()` outside of `#ifdef` guard in `Common.h`.
Modernize code a bit by using nested namespaces.
Fixes following compilation error if `USE_XNNPACK` is false:
```
Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/xnnpack/Shim.cpp:26:6: error: no previous prototype for function 'available' [-Werror,-Wmissing-prototypes]
bool available() {
^
/Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/xnnpack/Shim.cpp:30:6: error: no previous prototype for function 'use_convolution2d' [-Werror,-Wmissing-prototypes]
bool use_convolution2d(
^
/Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/xnnpack/Shim.cpp:42:8: error: no previous prototype for function 'convolution2d' [-Werror,-Wmissing-prototypes]
Tensor convolution2d(
^
/Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/xnnpack/Shim.cpp:53:6: error: no previous prototype for function 'use_linear' [-Werror,-Wmissing-prototypes]
bool use_linear(
^
/Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/xnnpack/Shim.cpp:60:8: error: no previous prototype for function 'linear' [-Werror,-Wmissing-prototypes]
Tensor linear(
^
/Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/xnnpack/Shim.cpp:67:6: error: no previous prototype for function 'use_max_pool2d' [-Werror,-Wmissing-prototypes]
bool use_max_pool2d(
^
/Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/xnnpack/Shim.cpp:79:8: error: no previous prototype for function 'max_pool2d' [-Werror,-Wmissing-prototypes]
Tensor max_pool2d(
^
```
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at f8ac185</samp>
> _The code for xnnpack activations_
> _Was scattered in different locations_
> _But now it's all neat_
> _In `Activation.cpp`_
> _With nested namespaces and simplifications_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104004
Approved by: https://github.com/drisspg
The checks are unnecessary as PSO derived from `metalIndexingPSO` function is already checked, see:
c4752b1a91/aten/src/ATen/mps/MPSDevice.mm (L69-L72)
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 2d71d96</samp>
This pull request removes unnecessary and duplicated error handling code for the pipeline state object in the constructors of several MPS kernel classes in `aten/src/ATen/native/mps/operations`. This makes the code more concise and clear.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103244
Approved by: https://github.com/albanD
Reference cycles are freed by the cycle collector rather than being cleaned up
when the objects in the cycle first become unreachable. If a cycle points to a tensor,
the CUDA memory for that tensor will not be freed until garbage collection runs.
Accumulatin of CUDA allocations can lead to out of memory errors (OOMs), as well as
non-deterministic allocation behavior which is harder to debug.
This visualizer installs a garbage collection hook to look for cycles containing
CUDA tensors and saves a visualization of the garbage:
```
from torch.cuda._cycleviz import warn_tensor_cycles
warn_tensor_cycles()
# do some work that results in a cycle getting garbage collected
# ...
> WARNING:root:Reference cycle includes a CUDA Tensor see visualization of cycle /tmp/tmpeideu9gl.html
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102656
Approved by: https://github.com/aaronenyeshi
This PR makes some improvements for debuggability of checkpointing:
- improved error messages that are more understandable
- errors are now `CheckpointError` which subclasses `RuntimeError` (only `CheckpointError` triggers debug message, see below)
- stricter error checking by default:
- shapes, dtypes, and device are compared
- we also now error when more tensors are being saved for backward during recompute
- NOTE: checks are relaxed if it is detected that you are doing backward within forward
- shapes, dtype, and device checking can be disabled by passing `determinism_check="none"`
- new debug flag: more helpful error message when `debug=True`
Note:
- cpp stack trace is only included for x86 linux machines
- the error message if cpp stack trace is included can be quite long. For a function checkpointed with 8 operators, the log was around 1300 lines! (should this be hidden behind a flag?)
[Error message when debug='True' (python stack trace only)](https://gist.github.com/soulitzer/3d5e19c7cceae8e22f9bdd625ec39dd4)
[Error message when debug='True' (with python and cpp stacktrace)](https://gist.github.com/soulitzer/ff8fd8c3ccbb2c90dfe3df6d7713b167)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103859
Approved by: https://github.com/albanD
We wrote some new Contributing Guidelines that guide a contributor
through the lifecycle of a Pull Request to PyTorch.
We've gotten some positive feedback from early adopters so we are now
adding it as the go-to link in CONTRIBUTING.md and the PyTorch Wiki.
Note that there are older contributing guidelines over at
https://github.com/pytorch/pytorch/blob/main/docs/source/community/contribution_guide.rst
The new Contributing Guidelines doc is targeted towards guiding a user
through submitting and merging a Pull Request to pytorch; the existing
guidelines are more of a high-level overview. We should rationalize these
at some point, but I left the resources for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103986
Approved by: https://github.com/kit1980, https://github.com/albanD
Summary: We implement `aten::tile` on Vulkan backend through `aten::repeat`. The behavior of `aten::tile` is demonstrated here https://pytorch.org/docs/stable/generated/torch.tile.html
Test Plan:
Run tests for combinations of input dim between 1 and 4 and repeats of size between 1 and 4. When a test case fails, the shape info is printed, e.g. `Tile test failed when input is of shape [13, 5] and repeat of [7, 2, 3]`.
```
(base) luwei@luwei-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*tile*"
Building: finished in 0.1 sec (100%) 263/2812 jobs, 0/2812 updated
Total time: 0.1 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *tile*
[==========] Running 3 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 3 tests from VulkanAPITest
[ RUN ] VulkanAPITest.tile_invalid_inputs_exceptions
[ OK ] VulkanAPITest.tile_invalid_inputs_exceptions (34 ms)
[ RUN ] VulkanAPITest.tile_invalid_outpus_exceptions
[ OK ] VulkanAPITest.tile_invalid_outpus_exceptions (2 ms)
[ RUN ] VulkanAPITest.tile
[ OK ] VulkanAPITest.tile (63 ms)
[----------] 3 tests from VulkanAPITest (100 ms total)
[----------] Global test environment tear-down
[==========] 3 tests from 1 test suite ran. (100 ms total)
[ PASSED ] 3 tests.
```
Reviewed By: yipjustin
Differential Revision: D46367170
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103944
Approved by: https://github.com/SS-JIA
- Extend dynamo bench interface with '--compilers onnx' and '--compilers dynamo-onnx'
- ONNX bench exports model to onnx and runs in ONNX Runtime.
- Introduce error aggregation and report.
- Scripts to build ONNX deps and running ONNX bench.
- Huggingface accuracy check workaround for ONNX.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103135
Approved by: https://github.com/thiagocrepaldi, https://github.com/jansel
Fixes#102922, adding a more descriptive error message when dealing with inputs that contain mixed types.
Would be happy to add a test (I believe in test_nn.py?), just want to confirm that this is the correct place to put it!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103360
Approved by: https://github.com/albanD
Query for list of renabled issues in the filter test config step: switch filter test config to query for all the PR info instead of just the labels so token usage should stay the same, move code and tests related to parsing reenabled issues to filter test config step, remove old code to get PR body and commit message. `REENABLED_ISSUES` should be a comma separated list of issue numbers to be reenabled.
For testing: Fixes#103789
Check that 103789 shows up in list of ignored disabled issues
Sanity check that test-config labels still work
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103790
Approved by: https://github.com/huydhn
Summary:
The argument is unsupported on other architectures, and Clang 17 will
error out when you pass an argument that's unsupported for the arch
you're building for. Note that we need to use platform_compiler_flags
instead of selects because the latter can't distinguish between
architectures when doing a multi-arch app build in Buck1.
Differential Revision: D46825070
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103929
Approved by: https://github.com/ezyang
The current thing indents based on the length of the previous line, which is totally unreadable if, e.g. the treespec is a dict with a lot of keys, since all the keys will go on a ginormous line and everything after will be super indented.
Fix the indentation at 2, which is much more compact.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103945
Approved by: https://github.com/zou3519
Currently these are decomposed into `as_strided`, which forces a buffer to be
realized. Instead, this lowers them into a native inductor view node and so
doesn't require any buffers to be realized.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103755
Approved by: https://github.com/jansel
Summary:
Previously, addmm + GELU epilogue fusion was unconditionally disabled in `ATen/native/cuda/Blas.cpp` due to compilation and numerical issues in CUDA <= 11.4. This PR:
1. Enables addmm + GELU epilogue fusion for CUDA >= 11.8.
2. Restricts the usage of fused addmm epilogue to contiguous output (bugfix).
3. Extends unit tests with addmm epilogue fusion and GELU activation paths.
Test Plan:
$ python test/test_linalg.py -k test_addmm_relu -v
test_addmm_relu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_relu_cpu_bfloat16) ... ok
test_addmm_relu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float32) ... ok
test_addmm_relu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_relu_cpu_float64) ... ok
test_addmm_relu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_bfloat16) ... ok
test_addmm_relu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float32) ... ok
test_addmm_relu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_relu_cuda_float64) ... ok
$ python test/test_linalg.py -k test_addmm_gelu -v
test_addmm_gelu_cpu_bfloat16 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_bfloat16) ... ok
test_addmm_gelu_cpu_float32 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float32) ... ok
test_addmm_gelu_cpu_float64 (__main__.TestLinalgCPU.test_addmm_gelu_cpu_float64) ... ok
test_addmm_gelu_cuda_bfloat16 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_bfloat16) ... ok
test_addmm_gelu_cuda_float32 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float32) ... ok
test_addmm_gelu_cuda_float64 (__main__.TestLinalgCUDA.test_addmm_gelu_cuda_float64) ... ok
Reviewers: @eellison
Differential Revision: [D46829884](https://our.internmc.facebook.com/intern/diff/D46829884)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103811
Approved by: https://github.com/IvanYashchuk, https://github.com/eellison
Currently calling the fill.Tensor overload under `torch.compile` results in a
`DataDependentOutputException` due to the `.item()` call. This instead does a
device-device copy which can then be inlined into subsequent inductor kernels as
you would expect, e.g.
```python
def fn(a):
result = torch.deg2rad(a).sin()
return torch.empty((128, 128), device=a.device).fill_(result)
```
generates the single kernel
```python
@triton.jit
def triton_(in_ptr0, out_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 16384
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x0 = xindex
tmp0 = tl.load(in_ptr0 + (0))
tmp1 = tl.broadcast_to(tmp0, [XBLOCK])
tmp2 = 0.017453292519943295
tmp3 = tmp1 * tmp2
tmp4 = tl.sin(tmp3)
tl.store(out_ptr0 + (x0), tmp4, None)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103880
Approved by: https://github.com/Chillee
Summary:
`np.str` is removed from numpy 1.20.0. It was an alias to builtin `str` and it's safe to do the replacement.
The whole changes is mechanical, generated using the following onliner:
```
fbgr -sl 'np\.str\b' | xargs perl -pi -e 's,\bnp\.str\b,str,g'
```
Test Plan: sandcastle
Differential Revision: D46586144
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103931
Approved by: https://github.com/huydhn
Summary:
Before this commit, only prepare QAT numerics matched
between PT2 and FX for resnet18. Convert numerics diverged,
however, for two reasons:
(1) Existing patterns did not handle inplace ReLUs. This commit
fixes this by adding extra patterns that use these ReLUs instead
of the normal ones.
(2) Subgraph rewriter could not handle skip connections in
quantized models, because the dequantize node is used in both
the conv node within the match pattern, and an inplace add node
outside of the match pattern. This led the subgraph matcher to
filter out the match, complaining that it was not self contained.
This commit fixes this problem by duplicating the dequantize
nodes, one for each user, such that subsequent matches will
be self contained.
Test Plan: python test/test_quantization.py TestQuantizePT2EModels.test_qat_resnet18
Reviewed By: jerryzh168
Differential Revision: D46564114
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103759
Approved by: https://github.com/jerryzh168
Fixes https://github.com/pytorch/pytorch/issues/103132
This is kind of annoying: Functionalization (and also vmap, I think?) manually figures out which ops have C++ CompositeImplicit decomps, and directly registers them to the Functionalize key. This is a problem for the PyDispatcher: We normally want the PyDispatcher to take precedence over the regular dispatcher. But in this case, we have a python decomp registered to `CompositeImplicitAutograd`, and a C++ decomp registered *directly* to the `Functionalize` key, so the C++ decomp gets precedence over the python decomp.
The way this showed up was that a model was running `matmul()` under inference mode, so we never hit the autograd dispatch key, and go straight to the functionalize dispatch key. Matmul has both a python decomp and a c++ decomp, but we were running the C++ decomp. That C++ decomp isn't meant to be used with dynamic shapes, so we were failing with the "tried to call `.sizes()` on a tensor with dynamic shapes" error.
For now, I had the PyDispatcher mimic the behavior of functionalization codegen: when you register a python decomp to the `CompositeImplicitAutograd` key, this PR just automatically registers that decomp to the `Functionalize` key at the same time.
I'm trying to remember now why we didn't just add `Functionalize` (and all of the other functorch transform keys) directly to the `CompositeImplicitAutograd` alias keyset, but I couldn't remember (@zou3519 any chance you remember?).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103275
Approved by: https://github.com/ezyang, https://github.com/zou3519
Fixes https://github.com/pytorch/pytorch/issues/103153
AOTAutograd has some logic for handling the case when we have:
* a graph output that is a view of an intermediate
* None of the other aliases of that output escape the graph, so from the perspective of the user + the autograd engine, we can pretend that the output is not a view
However, that logic would inject an `_unsafe_view()` call into the graph at trace time. This isn't wrong, but inductor will just immediately decompose `_unsafe_view()` into `view()`, and so the output tensor will continue to show up as having view metadata w.r.t. autograd.
This PR changes the `unsafe_view()` call to be in the runtime epilogue, instead of being part of the graph (where the compiler might do bad things to it - the compiler also shouldn't have to concern itself with autograd metadata).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103919
Approved by: https://github.com/ezyang
Added two signpost_event calls to torch.fx.experimental.symbolic_shapes, one for produce_guards (where we can give stats like how many free symbols and how many guards produced) and the other is for evaluate_expr after freeze (so we can look for cases where we're improperly discarding guards in backwards.)
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103882
Approved by: https://github.com/Skylion007
This is a reland of https://github.com/pytorch/pytorch/pull/100007 with a build fix for Windows debug builds.
`at::native::ParamsHash` only works on structs with standard layout, but `std::string` isn't one in Visual C++ debug builds, which one can easily verified by running something like:
```cpp
#define _DEBUG
#include <type_traits>
#include <string>
static_assert(std::is_standard_layout_v<std::string>, "Oh noes");
```
If above conditon is not met, instead of printing a static_assert output, VC++ raises a very cryptic compilation errors, see https://github.com/pytorch/pytorch/pull/100007#discussion_r1227116292 for more detail.
Also, using `std::hash` for string should result in a faster hash function.
(cherry picked from commit 74b7a6c75e698378882d30958908073407f97fb3)
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 5914771</samp>
This pull request introduces a new function `_group_tensors_by_device_and_dtype` that can group tensors by their device and dtype, and updates the `foreach` utilities and several optimizers to use this function. The goal is to improve the performance, readability, and compatibility of the code that handles tensors with different properties. The pull request also adds a test case and type annotations for the new function, and some error checks for the `fused` argument in Adam and AdamW.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103912
Approved by: https://github.com/janeyx99
Previously, you'd get `<eval_with_key>.0`; now you get `<eval_with_key>.0 from /data/users/ezyang/b/pytorch/test/dynamo/test_misc.py:5683 in forward`
I used to do this with globals, but now I do it with a `co_fields` parameter that's plumbed around, because putting things in globals has implications(TM). Happy to bikeshed on the `co_fields` structure.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103885
Approved by: https://github.com/albanD
Summary: We implement `aten::repeat` on Vulkan backend through `aten::unsqueeze` and `aten::cat`. The behavior of `aten::repeat` is demonstrated here https://pytorch.org/docs/stable/generated/torch.Tensor.repeat.html
Test Plan:
`repeat_invalid_inputs_outputs_exceptions` check the following:
- if the input tensor has dim <= 4
- if the size of `repeats` is >= input.dim
- if the output tensor has dim <= 4
In `test_repeat` we check the following combinations: input is of dim between 1 and 4 and `repeats` is of size between `input.dim()` and 4. If a testcase failed, the shape info is printed, e.g. `Repeat test failed when input is of shape [13, 5, 13] and repeat of [7, 2, 3]`.
```
(base) luwei@luwei-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*repeat*"
Building: finished in 0.1 sec (100%) 263/2811 jobs, 0/2811 updated
Total time: 0.1 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *repeat*
[==========] Running 2 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 2 tests from VulkanAPITest
[ RUN ] VulkanAPITest.repeat_invalid_inputs_outputs_exceptions
[ OK ] VulkanAPITest.repeat_invalid_inputs_outputs_exceptions (28 ms)
[ RUN ] VulkanAPITest.repeat
[ OK ] VulkanAPITest.repeat (46 ms)
[----------] 2 tests from VulkanAPITest (75 ms total)
[----------] Global test environment tear-down
[==========] 2 tests from 1 test suite ran. (75 ms total)
[ PASSED ] 2 tests.
```
Reviewed By: yipjustin
Differential Revision: D46244750
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103255
Approved by: https://github.com/SS-JIA
This reverts commit 03881b0c925f191ec41d6899d589ed420ac285b5.
Reverted https://github.com/pytorch/pytorch/pull/103264 on behalf of https://github.com/osalpekar due to This commits seems to have been causing failures in test_nccl_init_abort. Those failures may have been masked by pre-existing failures in the distributed jobs on trunk when running CI on this PR. Since those breaking changes are now reverted, we should be able to rebase this and get clean signal + uncover the breakages caused by this PR. ([comment](https://github.com/pytorch/pytorch/pull/103264#issuecomment-1599451197))
Summary:
Extending support for the [Softmax function](https://pytorch.org/docs/stable/generated/torch.nn.Softmax.html) on the PyTorch Vulkan GPU backend.
# Before
1. Softmax could only be calculated along dim=1, AKA along channel with NCHW convention
2. Softmax input Vulkan Tensor must have had size 1 along dim=0, AKA batch size of 1 with NCHW convention
3. Softmax input Vulkan Tensor must be 4-dimensional, AKA NCHW
# After
1. Softmax can be calculated along any dim={0,1,2,3}
2. Softmax input Vulkan Tensor can have any size along dim=0
3. Softmax input Vulkan Tensor must be 4-dimensional, AKA NCHW
Test Plan:
1. `buck2 run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1` on Apple M1 MacBook
2. Confirm all tests pass with no regression, and the added tests `*softmax*` pass under `-- --gtest_filter="*softmax*"`
2a. All tests P758913494
2b. `softmax` tests P758910449
3. Overview:
```
~/fbsource » buck2 run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1
[...]
[ RUN ] VulkanAPITest.softmax_4d
[ OK ] VulkanAPITest.softmax_4d (69 ms)
[...]
[----------] 275 tests from VulkanAPITest (3149 ms total)
[----------] Global test environment tear-down
[==========] 275 tests from 1 test suite ran. (3149 ms total)
[ PASSED ] 274 tests.
[ SKIPPED ] 1 test, listed below:
[ SKIPPED ] VulkanAPITest.querypool_flushed_shader_log
```
Reviewed By: SS-JIA
Differential Revision: D45880611
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102988
Approved by: https://github.com/SS-JIA
This PR fixes https://github.com/pytorch/pytorch/issues/103684.
- Instead of registering forward hooks in `__init__()`, do it upon `__enter__()`.
- De-register those forward hooks upon `__exit__()`.
- Achieve this by saving an additional mapping `_module_to_forward_hook_handles: Dict[nn.Module, _ForwardHookHandles]`. Only the values in the mapping (i.e. not the keys) are useful for this change. (A `List[_ForwardHookHandles]` would suffice.)
- The unit test accesses private attributes `_forward_hooks` and `_forward_pre_hooks` :/
Note that this PR is technically not backward compatible since it does not register the hooks upon `__init__()`, which means that you will not get the flops counting without the context manager.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103744
Approved by: https://github.com/Chillee
This PR changes the default namespace for higher order operators from the
global namespace (e.g. torch.ops.cond) to `higher_order` (e.g.
torch.ops.higher_order.cond). We don't actually change the namespace
for existing HigherOrderOperators.
The motivation is to stem the bleeding; exposing operators into the global
namespace is a bad idea due to name collision with other user-defined
namespaces.
We will go in and fix the `_deprecated_global_ns` as necessary after this diff.
Differential Revision: [D46809738](https://our.internmc.facebook.com/intern/diff/D46809738/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103870
Approved by: https://github.com/ydwu4
# Summary by author
* Previous to this PR, FX-to-ONNX conversion logic was sprinkled in several functions, files and class, such as `_export_fx_to_onnx`, `export_fx_to_onnxscript`, `_export_fx_node_to_onnxscript` and `OnnxDispatcher` class[1]. Although each had its specific role in the lowering of FX, they all are part of the same lowering process.
* A `FxOnnxInterpreter` class, similar to but not derived from `torch.fx.Interpreter`, is introduced to drive the FX Graph -> ONNX Graph process. All functions and utilities from previous bullet were either moved under this class with minor refactoring.
* One of the main changes is that each FX node now have their own entry point, providing lower complexity. It also provides isolation among them.
* Why refactored as class and not as a bunch of functions? ONNX Exporter adopted Object Oriented paradigm since its origin, so this refactoring should not be seen as any break of paradigm. This is just a continuation of a previous design decision. Example of other classes include `Exporter`, `ExportOptions`, `ExportOutput`, `ExportOutputSerializer`, `ProtobufExportOutputSerializer`, `FXGraphExtractor`, `ResolvedExportOptions`, `Analysis`, `Diagnostic`, `DiagnosticContext`, `Decompose`, `Functionalize`, `MovePlaceholderToFront`, `RemoveInputMutation`, `ReplaceGetAttrWithPlaceholder`, `ShapeInferenceWithFakeTensor`, `OnnxRegistry`, `OnnxDispatcher`, just to name a few.
* `torch.fx.Interpreter` was not used because its API only passes the node name (aka `target`) instead of the actual `torch.fx.Node` object to the node implementations. This is not sufficient as the ONNX conversion process needs to inspect the node to extract type, name and other info from the node.
* This PR renames `OnnxDispatch` (without functionality changes) to `OnnxFunctionDispatcher` for clarity. ONNX word was too overloaded in this context.
* This PR also moved the `passes` and `serialization` handling from the `_export_fx_to_onnx` util and moved them to `Exporter.export`, where they are consumed. Passes are not the goal of this PR, so it was moved to a temporary function called `pre_export_passes` (mainly the content of `_export_fx_to_onnx` without serialization and fx -> onnx call).
* This PR also removed a bug in which new registry (and dispatcher, that wouldnt be a problem) were created for each pass was. That would be an issue with custom operators because only the original registry would have a reference to the custom operator.
Below is a summarized structure of the export process:
```python
class Exporter
def export(self) -> ExportOutput:
# 1) Trace torch.nn.Module into torch.fx.GraphModule
graph_module = self.options.fx_tracer.generate_fx()
# 2) Adapt input and output types to match ONNX graph
updated_model_args = self.options.fx_tracer.input_adapter.apply()
# 3) Run pre-export passes
graph_module = pre_export_passes()
# 4) Dispatch each FX node to an ONNX operator implementation
# Model level FX -> ONNX.
fx_interpreter = fx_onnx_interpreter.FxOnnxInterpreter()
fx_interpreter.run()
# 5) Serialize graph to ONNX ModelProto.
onnx_model = onnxscript_graph.to_model_proto(self.options.opset_version)
# 6 Create ExportOutput
return torch.onnx.ExportOutput()
class FxOnnxInterpreter: # NOT a torch.fx.Interpreter
def run(self, node: torch.fx.Node):
with torch.utils._mode_utils.no_dispatch():
for node in self.graph_module.graph.nodes:
run_node(node)
def run_node(node):
if node.op == "placeholder":
self.placeholder(node)
elif node.op == "get_attr":
self.get_attr(node)
elif node.op == "call_function":
self.call_function(node)
elif node.op == "call_method":
self.call_method(node)
elif node.op == "call_module":
self.call_module(node)
elif node.op == "output":
self.output(node)
else:
raise RuntimeError(
f"Found node type not defined in torch.fx: {node.op}"
)
def placeholder(self, node: torch.fx.Node):
pass
def call_function(self, node: torch.fx.Node):
pass
def output(self, node: torch.fx.Node):
pass
def call_method(self, node: torch.fx.Node):
pass
def call_module(self, node: torch.fx.Node):
pass
def get_attr(self, node: torch.fx.Node):
pass
class OnnxFunctionDispatcher:
def dispatch(
self,
node: torch.fx.Node,
onnx_args: Sequence[Optional[Union[_TensorLike, str, int, float, bool, list]]],
onnx_kwargs: Dict[str, _type_utils.Argument],
diagnostic_context: diagnostics.DiagnosticContext,
) -> Union["onnxscript.OnnxFunction", "onnxscript.TracedOnnxFunction"]:
pass
def get_aten_name( # promoted to public API
self, node: torch.fx.Node, diagnostic_context: diagnostics.DiagnosticContext
) -> str:
pass
def get_function_overloads( # promoted to public API
self,
node: torch.fx.Node,
aten_name: str,
diagnostic_context: diagnostics.DiagnosticContext,
) -> Set[Union["onnxscript.OnnxFunction", "onnxscript.TracedOnnxFunction"]]:
pass
```
Before this PR, that was the structure of the code:
```python
# torch/onnx/_internal/exporter.py
class Exporter:
def export(self) -> ExportOutput:
graph_module = self.options.fx_tracer.generate_fx(
self.options, self.model, self.model_args, self.model_kwargs
)
updated_model_args = self.options.fx_tracer.input_adapter.apply(
*self.model_args, **self.model_kwargs
)
return self.options.fx_tracer._export_fx_to_onnx(
self.options, graph_module, updated_model_args
)
# torch/onnx/_internal/exporter.py
class FXGraphExtractor
def _export_fx_to_onnx() -> ExportOutput: `# Ignore the fact it lives inside FXGraphExtractor. It was a temporary thing
# Run all passes
# ...
with torch.utils._mode_utils.no_dispatch():
onnxscript_graph = passes.export_fx_to_onnxscript()
# Run input adapter
# ...
# Run output adapter
# ...
# Export TorchScript graph to ONNX ModelProto.
onnx_model = onnxscript_graph.to_model_proto(options.opset_version)
# Create ExportOutput
return torch.onnx.ExportOutput()
# torch/onnx/_internal/fx/passes/fx_to_onnxscript.py
def export_fx_to_onnxscript():
# Initialize the ONNX graph
onnxscript_graph = graph_building.TorchScriptGraph()
tracer = graph_building.TorchScriptTracingEvaluator(onnxscript_graph)
for node in fx_module_with_metadata.graph.nodes:
_export_fx_node_to_onnxscript()
return onnxscript_graph
# torch/onnx/_internal/fx/passes/fx_to_onnxscript.py
def _export_fx_node_to_onnxscript():
if node.op == "placeholder":
# ...
elif node.op == "call_function":
symbolic_fn = options.onnx_dispatcher.dispatch()
with evaluator.default_as(tracer):
output = symbolic_fn(*onnx_args, **onnx_kwargs)
elif node.op == "output":
# ...
elif node.op == "call_method":
# ...
elif node.op == "call_module":
# ...
elif node.op == "get_attr":
# ...
else:
raise RuntimeError(f"Found node type not defined in torch.fx: {node.op}")
# torch/onnx/_internal/fx/function_dispatcher.py
class OnnxDispatcher:
@_beartype.beartype
def dispatch() -> Union["onnxscript.OnnxFunction", "onnxscript.TracedOnnxFunction"]:
# ONNX Script lookup only
```
[1]
Note that the main functionalities in the fx -> onnx is orchestrated by functions in different files (see below).
Although the main loop that drives the dispatching is executed by a well-defined function (`export_fx_to_onnxscript`), this is not the entry point of the export process. The entry point is a utility function called `_export_fx_to_onnx`, which calls `export_fx_to_onnxscript`, that in turn will call another utility called `_export_fx_node_to_onnxscript`. Lastly, `_export_fx_node_to_onnxscript` implements *all* FX nodes in a huge monolithic block. the "call_function" segment of such block consumes `OnnxDispatcher`, completing the cycle.
```bash
_export_fx_to_onnx torch/onnx/_internal/exporter.py
_export_fx_node_to_onnxscript torch/onnx/_internal/fx/fx_to_onnxscript.py
export_fx_to_onnxscript torch/onnx/_internal/fx/fx_to_onnxscript.py
OnnxDispatcher torch/onnx/_internal/fx/onnxfunction_dispatcher.py
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102810
Approved by: https://github.com/wschin, https://github.com/BowenBao
- Added ops that were missing under `__all__`.
- Some misc changes to helper functions to make them private.
- Set correct `fn.__module__` for `fn` created by `_make_alias`, when called in another module.
All modification largely references results from a hacked version of `test_public_bindings::test_correct_module_names`.
By default `torch._refs` is not included in the test because it is technically a private package.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103712
Approved by: https://github.com/lezcano
The current behaviour for dynamo is to set the dtype to torch.int64 for integral types if the dtype is not specified explicitly which results in mismatched behaviour as compared to eager mode. In eager mode the semantics are:
- If both out is specified and dtype is specified then they have to match
- If dtype is not specified but out is specified then the dtype is set to match the out dtype
- If neither dtype nor out is set then the dtype is set to kLong if it is a bool or an integral type
Fixes#100698
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103037
Approved by: https://github.com/ngimel
**Summary**
- Update the quantization document that default qconfig with oneDNN backend is recommended to be used on CPUs with Vector Neural Network Instruction support.
- Add the warning message when user uses default qconfig with oneDNN backend on CPU without Vector Neural Network Instruction support.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103653
Approved by: https://github.com/jgong5, https://github.com/malfet
Summary: The original `cat_feature_mult4ch` assumes input tensors are of 4d and use `tensor.sizes()[1]` to obtain the channel info of the tensor. This will cause bugs when the input tensors are of 3D. We generalize `cat_feature_mult4ch` to make it cover both 3D and 4D.
Test Plan:
Test for 3D tensors with channels as multiple of 4 is show below. Full test result is in P771032677.
```
(base) luwei@luwei-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*cat_3d_dim0_mult4ch_success*"
Building: finished in 0.1 sec (100%) 263/2812 jobs, 0/2812 updated
Total time: 0.1 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *cat_3d_dim0_mult4ch_success*
[==========] Running 1 test from 1 test suite.
[----------] Global test environment set-up.
[----------] 1 test from VulkanAPITest
[ RUN ] VulkanAPITest.cat_3d_dim0_mult4ch_success
[ OK ] VulkanAPITest.cat_3d_dim0_mult4ch_success (129 ms)
[----------] 1 test from VulkanAPITest (129 ms total)
[----------] Global test environment tear-down
[==========] 1 test from 1 test suite ran. (129 ms total)
[ PASSED ] 1 test.
```
Reviewed By: SS-JIA
Differential Revision: D46755034
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103718
Approved by: https://github.com/SS-JIA
This test(8340762211/test/distributed/test_multi_threaded_pg.py (L133) ) is failing on internal sandbox with the following error msg:
```
File "/data/sandcastle/boxes/eden-trunk-hg-fbcode-fbsource/buck-out/v2/gen/fbcode/8c7462494077df89/caffe2/test/distributed/__multi_threaded__/multi_threaded#link-tree/torch/testing/_internal/distributed/multi_threaded_pg.py", line 255, in _start_coll
raise Exception(
Exception: world not ready, only 3 PG's registered but world has 4 ranks
exiting thread 1
ERROR
```
Internal error report: https://www.internalfb.com/intern/test/562950031915334?ref_report_id=0
We believe this is because we no longer perform barrier after init (see https://github.com/pytorch/pytorch/pull/99937).
This PR temporarily turn back on ```TORCH_DIST_INIT_BARRIER``` to avoid flaky test for the time being, but we should look into it to find a way to properly do this.
cc. @kumpera @kwen2501
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103568
Approved by: https://github.com/H-Huang
Adds a Constant Folding pass to the joint graph only targeting tensors which can be replaced with a single value, and then removes no-ops from the graph. This allows us to match sdpa in BertForMaskedLM, AlbertForMaskedLM, and LayoutLMForMaskedLM.
BertForMaskedLM
Perf: 1.6853 -> 1.933, Memory: 0.9462 -> 1.41
AlbertForMaskedLM
Perf: 1.6620 -> 1.761, Memory: 1.257 -> 1.94
LayoutLMForMaskedLM
Perf: (non cudagraphs) 1.6991 -> 1.939x, Memory: 0.9624 -> 1.50
MobileBertForMaskedLM
Perf: 1.864x -> 1.941x, Memory: 0.94 -> 1.03
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103600
Approved by: https://github.com/jansel
before the PR, when compiling a function with signature symint/symintlist/intlist, we have runtime error like ```argument 'shifts' must be tuple of ints, not FakeTensor```. see newly added unit test in test/dynamo/test_misc.py for repro
after the PR, for FakeTensor with empty size and numel()=1, we will try
to convert it into symint/symintlist. we will likely see expected
exception
```torch._subclasses.fake_tensor.DataDependentOutputException / aten._local_scalar_dense.default``` during conversion
reference PR:
* we handle FakeTensor for symintlist as 1st varags: https://github.com/pytorch/pytorch/pull/97508
* we handle FakeTensor for intlist in a similar way:
https://github.com/pytorch/pytorch/pull/85759/files
* call local_scalar_dense on a FakeTensor:
f7365eca90
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103448
Approved by: https://github.com/yanboliang
Hi! I found heap-buffer-overflow during PyTorch RPC-module fuzzing.
[crash-9cc26b8da3b688a9c26614481239943b357c5636.zip](https://github.com/pytorch/pytorch/files/11707706/crash-9cc26b8da3b688a9c26614481239943b357c5636.zip)
```
"==10634==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x6060001b6a98 at pc 0x000000639a2e bp 0x7fffffff9100 sp 0x7fffffff90f8",
"READ of size 4 at 0x6060001b6a98 thread T0",
" #0 0x639a2d in c10::IValue::isTensor() const /pytorch/aten/src/ATen/core/ivalue.h:432:27",
" #1 0x639a2d in c10::IValue::toTensor() && /pytorch/aten/src/ATen/core/ivalue_inl.h:159:7",
" #2 0xc5eb105 in at::Tensor c10::IValue::to<at::Tensor>() && /pytorch/aten/src/ATen/core/ivalue_inl.h:1690:1",
" #3 0xc5eb105 in void torch::jit::pop<at::Tensor>(std::vector<c10::IValue, std::allocator<c10::IValue> >&, at::Tensor&) /pytorch/aten/src/ATen/core/stack.h:130:55",
" #4 0xc5eaedb in torch::jit::dtype(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch/torch/csrc/jit/mobile/promoted_prim_ops.cpp:105:3",
" #5 0xcc79600 in torch::jit::InterpreterStateImpl::runImpl(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch/torch/csrc/jit/runtime/interpreter.cpp:682:13",
" #6 0xcc4158b in torch::jit::InterpreterStateImpl::run(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch/torch/csrc/jit/runtime/interpreter.cpp:1052:9",
" #7 0x60f378 in runGraph(std::shared_ptr<torch::jit::Graph>, std::vector<at::Tensor, std::allocator<at::Tensor> > const&) /jit_differential.cc:66:38",
" #8 0x610bb9 in LLVMFuzzerTestOneInput /jit_differential.cc:107:25",
" #9 0x535c91 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:611:15",
" #10 0x51fb9c in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:324:6",
" #11 0x5258eb in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:860:9",
" #12 0x54eea2 in main /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10",
" #13 0x7ffff7a37082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082) (BuildId: 1878e6b475720c7c51969e69ab2d276fae6d1dee)",
" #14 0x51a4bd in _start (/jit_differential_fuzz+0x51a4bd)",
"",
"0x6060001b6a98 is located 8 bytes to the left of 64-byte region [0x6060001b6aa0,0x6060001b6ae0)",
"allocated by thread T0 here:",
" #0 0x60c66d in operator new(unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/asan/asan_new_delete.cpp:95:3",
" #1 0xa5a41b in std::_Vector_base<c10::IValue, std::allocator<c10::IValue> >::_M_allocate(unsigned long) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_vector.h:346:20",
" #2 0xa5a41b in void std::vector<c10::IValue, std::allocator<c10::IValue> >::_M_realloc_insert<c10::IValue&>(__gnu_cxx::__normal_iterator<c10::IValue*, std::vector<c10::IValue, std::allocator<c10::IValue> > >, c10::IValue&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/vector.tcc:440:33",
" #3 0xa5a241 in c10::IValue& std::vector<c10::IValue, std::allocator<c10::IValue> >::emplace_back<c10::IValue&>(c10::IValue&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/vector.tcc:121:4",
" #4 0xcc8209c in torch::jit::InterpreterStateImpl::runImpl(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch/torch/csrc/jit/runtime/interpreter.cpp:345:19",
" #5 0xcc4158b in torch::jit::InterpreterStateImpl::run(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch/torch/csrc/jit/runtime/interpreter.cpp:1052:9",
" #6 0x60f378 in runGraph(std::shared_ptr<torch::jit::Graph>, std::vector<at::Tensor, std::allocator<at::Tensor> > const&) /jit_differential.cc:66:38",
" #7 0x610bb9 in LLVMFuzzerTestOneInput /jit_differential.cc:107:25",
" #8 0x535c91 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:611:15",
" #9 0x51fb9c in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:324:6",
" #10 0x5258eb in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:860:9",
" #11 0x54eea2 in main /llvm-project-llvmorg-14.0.6/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10",
" #12 0x7ffff7a37082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082) (BuildId: 1878e6b475720c7c51969e69ab2d276fae6d1dee)",
"",
"SUMMARY: AddressSanitizer: heap-buffer-overflow /pytorch/aten/src/ATen/core/ivalue.h:432:27 in c10::IValue::isTensor() const",
"Shadow bytes around the buggy address:",
" 0x0c0c8002ed00: 00 00 00 00 00 00 00 fa fa fa fa fa fd fd fd fd",
" 0x0c0c8002ed10: fd fd fd fd fa fa fa fa fd fd fd fd fd fd fd fd",
" 0x0c0c8002ed20: fa fa fa fa fd fd fd fd fd fd fd fd fa fa fa fa",
" 0x0c0c8002ed30: fd fd fd fd fd fd fd fd fa fa fa fa 00 00 00 00",
" 0x0c0c8002ed40: 00 00 00 00 fa fa fa fa fd fd fd fd fd fd fd fd",
"=>0x0c0c8002ed50: fa fa fa[fa]00 00 00 00 00 00 00 00 fa fa fa fa",
" 0x0c0c8002ed60: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c0c8002ed70: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c0c8002ed80: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c0c8002ed90: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
" 0x0c0c8002eda0: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa",
"Shadow byte legend (one shadow byte represents 8 application bytes):",
" Addressable: 00",
" Partially addressable: 01 02 03 04 05 06 07",
" Heap left redzone: fa",
" Freed heap region: fd",
" Stack left redzone: f1",
" Stack mid redzone: f2",
" Stack right redzone: f3",
" Stack after return: f5",
" Stack use after scope: f8",
" Global redzone: f9",
" Global init order: f6",
" Poisoned by user: f7",
" Container overflow: fc",
" Array cookie: ac",
" Intra object redzone: bb",
" ASan internal: fe",
" Left alloca redzone: ca",
" Right alloca redzone: cb",
"==10634==ABORTING"
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103327
Approved by: https://github.com/Skylion007
Fixes#102768
- Provides proper function declarations in generated `torch/nn/functional.pyi`.
- Moves some functions from manually defined in `functional.pyi.in` to generated code, in order to single-source the signature.
- Includes some of the functions in `torch._C._nn` into its `.pyi.in`, but not exhaustive (only what's already there).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102918
Approved by: https://github.com/drisspg, https://github.com/malfet
In our DDP training workloads, each rank was initializing a `RandomSampler` for a dataset with a length of 3.5 billion items. We noticed that when this sampler was in scope, `gc.collect` calls were taking on the order of seconds to run, which would slow down the entire training iteration. This is because when we call `torch.randperm(n).tolist()`, we create a python list of 3.5 billion items, which massively slows down the periodic mark & sweep garbage collection.
This PR swaps out the `.tolist()` call with a `.numpy()` call and manually calls `.item()` on each element as it is being requested. This has two benefits:
1. The first call to `RandomSampler::__next__` should be about twice as fast, since `.numpy` does not copy the contents of the original tensor
2. The runtime of `gc.collect()` calls no longer scales linearly with the size of the dataset passed to `RandomSampler`
I've attached some `timeit` samples to illustrate the speedups with this Pr:
```
Main (no GC): 51.72115747816861
Main (10 GC calls) 83.61965207383037
PR (no GC) 33.06403830461204
PR (10 GC calls) 33.959467427805066
```
Code
```python
from timeit import timeit
baseline_no_gc = """
import torch
n = int(1e9)
steps = n // 100
x = torch.randperm(n).tolist()
x_iter = iter(x)
for i in range(steps):
next(x_iter)
"""
baseline_gc = """
import torch
import gc
n = int(1e9)
steps = n // 100
gc_every = steps // 10
x = torch.randperm(n).tolist()
x_iter = iter(x)
for i in range(steps):
next(x_iter)
if i % gc_every == 0:
gc.collect()
"""
numpy_no_gc = """
import torch
n = int(1e9)
steps = n // 100
x = torch.randperm(n).numpy()
x_iter = (i.item() for i in x)
for i in range(steps):
next(x_iter)
"""
numpy_gc = """
import torch
import gc
n = int(1e9)
steps = n // 100
gc_every = steps // 10
x = torch.randperm(n).numpy()
x_iter = (i.item() for i in x)
for i in range(steps):
next(x_iter)
if i % gc_every == 0:
gc.collect()
"""
if __name__ == "__main__":
print("Main (no GC): ", timeit(baseline_no_gc, number=1))
print("Main (10 GC calls)", timeit(baseline_gc, number=1))
print("PR (no GC)", timeit(numpy_no_gc, number=1))
print("PR (10 GC calls)", timeit(numpy_gc, number=1))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103339
Approved by: https://github.com/kit1980
Summary:
This diff allows the `TCPStore` server associated with a gloo process group to listen on an existing socket already bound to a port.
Without the functionality in this diff, canonical initialization of a gloo `ProcessGroup` is fundamentally racy: 1) ask the OS for a free port by creating a socket bound to port 0, 2) close the socket, 3) attempt to initialize a `TCPStore` server that listens on the previously free port. Of course, the problem is that in between steps 2 and 3, another process on the host may have claimed the port, causing `TCPStore` and overall process group initialization to fail. With this diff, it is now possible for users to completely avoid this race (see unit test for how this can be achieved).
Test Plan:
Added new unit test:
buck2 test caffe2/test/distributed:store
Differential Revision: D46622317
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103478
Approved by: https://github.com/H-Huang
Summary:
Similar to the prepare case, we need to manually copy
over literal conv args such as padding and stride to the new,
replaced conv nodes, since these args are not captured by the
subgraph rewriter.
Test Plan: python test/test_quantization.py TestQuantizePT2E.test_qat_conv_bn_fusion_literal_args
Reviewed By: jerryzh168
Differential Revision: D46383130
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103731
Approved by: https://github.com/jerryzh168
This PR adds dedicated FakeTensor testing to operator_compile_check. We
reuse CrossRefFakeMode to do this and improve the error messages on it.
Note that this only really runs detailed tests for operators that do not
have data-dependent output shape. In the future we should add something
like a dynamic CrossRefFakeMode.
Test Plan:
- existing tests (these now have improved error messages).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103595
Approved by: https://github.com/ezyang, https://github.com/soulitzer
Fixes#102678Fixes#102629Fixes#102558
HipSOLVER performance on ROCm5.4.2 and later no longer serves as massive bottleneck. Additionally, using magma on rocm in this case caused test_compare_cpu_lialg_pinv_singular_cuda_float32 to fail. Using hipSOLVER, the test now passes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103540
Approved by: https://github.com/lezcano
At high current implementation of constrains functions (constrain_as_**) will raise exception for the following code snippets:
```
def f(x):
a = x.item()
constrain_as_size(a, 4, 7)
return torch.empty((a, 4))
inp = torch.tensor([5])
ep = torch._export.export(f, (inp,))
```
The reason is because current constrain logic is:
1) Purely python so it won't survive AOT export (the full node is gone after AOT export since AOT export only maintains aten level op).
2) Utilize side effect to add range constraints for traced symbol's shape env ([code](9591e52880/torch/fx/experimental/symbolic_shapes.py (L370-L372))).
3) If runtime assertion is turned on (by default). [`_AddRuntimeAssertionsForConstraintsPass`](9591e52880/torch/_export/passes/add_runtime_assertions_for_constraints_pass.py (L98-L100)) will try to append assertion node based on range constrains extracted from shape env of symbol during another interpretation round.
4). However, since 1), in the round of AOT export, range constraints logic won't run for symbols generated during this round. And later there is no range constrains information available for assertion round and caused issue.
5) As a result of above, it will failure at `torch.empty((a, 4))` (there is no constrains for `a` that it must be positive).
The fix here is just to implement range constrain logic as a native aten op (CPU implementation as no-op) to make it be able to survive AOT export.
**NOTE:**
[Logic](2d745b95d7/torch/fx/experimental/symbolic_shapes.py (L350-L365C15)) within [`constrain_range`](2d745b95d7/torch/fx/experimental/symbolic_shapes.py (LL313C74-L313C74)) is split out as `constrain_range_int` to capture case when non `SymInt` is passed in and reused in the new `_constrain_range`. The reason is when non `SymInt` is provided:
* If it directly calls `sym_constrain_range`, the C++ version will be called which will be no-op.
* So in this case it calls `constrain_range_int` instead to be able to capture issue like user provides a input whose tensor's shape could be out of range during exporting, like the following for above code example:
```
...
inp = torch.tensor([10])
ep = torch._export.export(f, (inp,)) # immediately raise error
```
Differential Revision: [D46734204](https://our.internmc.facebook.com/intern/diff/D46734204)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103346
Approved by: https://github.com/tugsbayasgalan
It turns out that jsdelivr, which is used to access the MemoryViz.js
source from generated files, doesn't work unless a version is specified.
This wasn't able to be tested until the PR actually landed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103741
Approved by: https://github.com/aaronenyeshi
This replaces the invidual visualization routines in _memory_viz.py with
a single javascript application.
The javascript application can load pickled snapshot dumps directly using
drag/drop, requesting them via fetch, or by embedding them in a webpage.
The _memory_viz.py commands use the embedding approach.
We can also host MemoryViz.js on a webpage to use the drag/drop approach, e.g.
https://zdevito.github.io/assets/viz/
(eventually this should be hosted with the pytorch docs).
All views/multiple cuda devices are supported on one page.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103565
Approved by: https://github.com/eellison, https://github.com/albanD
This bandaid fixes yolov3 with automatic_dynamic_shapes.
A more proper fix probably is to figure out why when we
have
```
TypeError: mkldnn_reorder_conv2d_weight(): argument 'input_size' (position 6) must be tuple of ints, but found element of type SymInt at pos 1
```
where the SymInt is known to be constant, we aren't willing to
coerce it to int.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103677
Approved by: https://github.com/voznesenskym
Summary:
Previously, the QAT pattern for conv + bn with no conv
bias was not actually replaced in convert. This commit adds an
extra pattern in the convert path for this case and the numerics
now match FX's.
Test Plan: python test/test_quantization.py TestQuantizePT2E.test_prepare_qat_conv_bn_fusion_no_conv_bias
Reviewed By: jerryzh168
Differential Revision: D46382819
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103298
Approved by: https://github.com/jerryzh168
Signed-off-by: Mike Brown <brownwm@us.ibm.com>
To avoid new contributor issues when building master a couple README.md comments will help... This change:
~~- Documents the current support restriction to apt package `g++-9` #91328 ** noting here that with the commit in https://github.com/pytorch/pytorch/pull/92911 g++-11.3 appears to build and run local tests at least as well as g++9, so this restriction may be overcome with that PR merge depending on success and CI updates.~~ (fixed now)
- Documents wip status for CUDA 12 #91122 (by forwarding to support matrix per suggestion)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92729
Approved by: https://github.com/kit1980
https://github.com/pytorch/pytorch/pull/95715 added the functionality to abort `ncclCommInitRankConfig` by specifying `blocking=0` to enable non-blocking behavior.
However, calling the `pg._abort()` didn't recover from a stuck `ncclCommInitRankConfig` since the `_abort` method only looked through `devNCCLCommMap_` map and aborted those communicators. Since `ncclCommInitRankConfig` was stuck, the communicator itself wasn't added to the map and the host thread was stuck on this line: https://github.com/pytorch/pytorch/blob/main/torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp#L1171. As a result, `_abort` was a no-op.
To resolve this issue, I added the communicators to `inProgressCommMap_` as soon as they were created and then removed them once added to `devNCCLCommMap_`.
I also added a unit test that was failing without the changes to ProcessGroupNCCL.cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103264
Approved by: https://github.com/kwen2501
It turns out that we need fix https://github.com/pytorch/pytorch/issues/103656 in coordinate descent tuner.
Inductor generate triton code with assumption of max-block-size. If inductor is sure that numel is a multiple of the max-block-size, inductor will safely skip the check of the corresponding mask for perf reason.
Coordinate descent tuner previous does not respect this assumption and may pick triton config with even larger block size. That will cause IMA.
BTW, I was wondering how we pick those max block size. Not enforcing a max block size may allow coordinate descent tuner find an even better config. But it may slow down other cases a bit because of extra mask check.
Test:
```
TORCHINDUCTOR_COORDINATE_DESCENT_TUNING=1 TORCHINDUCTOR_MAX_AUTOTUNE_POINTWISE=1 TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/torchbench.py --amp --performance --inference --inductor --only alexnet
```
Fail before and works after.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103660
Approved by: https://github.com/spectrometerHBH, https://github.com/jansel
Fixes#103606
Was using this script to exercise new code, cause I can never remember which test it is.
```
import torch
@torch.compile(fullgraph=True, dynamic=True)
def shift_right(tensor: torch.Tensor) -> torch.Tensor:
return (tensor >> 2).to(torch.long)
def main():
sample_input = torch.tensor([4, 4, 16, 32], dtype=torch.uint8)
print(shift_right(sample_input))
if __name__ == "__main__":
main()
```
And iterated through the error messages
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103637
Approved by: https://github.com/ezyang
Fixes#95900
Using the following repro as guide:
```python
import torch
import torch._dynamo
from torch._subclasses import fake_tensor
from torch.fx.experimental.symbolic_shapes import ShapeEnv
from torch._dynamo.output_graph import config
class Model(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.linear = torch.nn.Linear(2, 2)
self.linear2 = torch.nn.Linear(2, 2)
def forward(self, x):
out = self.linear(x)
out = self.linear2(out)
return out
fake_mode = fake_tensor.FakeTensorMode(allow_non_fake_inputs=False,
allow_fallback_kernels=True,
shape_env=ShapeEnv(
allow_scalar_outputs=config.capture_scalar_outputs,
allow_dynamic_output_shape_ops=config.capture_dynamic_output_shape_ops,
frame_id=0
),
)
# Fakefying input/model before calling torch._dynamo.export
with fake_mode:
fake_x = torch.rand(5, 2, 2)
model = Model()
# Calling torch._dynamo.export without active fake mode
graph_module, guards = torch._dynamo.export(
model,
fake_x,
aten_graph=True,
fake_mode=fake_mode
)
graph_module.print_readable()
graph_module.graph.print_tabular()
```
Summary of changes:
* Plumb fake_mode through torch.export API. When specified, it
replaces the creation of a new FaketendorMode at InstructionTranslator on behalf of OutputGraph
Hacks FakeTensor.__new__ to prevent a
torch.tensor._make_subclass call for inputs that are already fakefied by
user. This probably need to be fixed in a nicer way. Any idea?
* Removed a few asserts that didn't want faked tensors coming
from user script
* Added torch._subclasses.fake_tensor.FakeTensor to type list on a few
asserts check to allow fake inputs
The changes above allowed symbolic tracing with both static and dynamic shapes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100017
Approved by: https://github.com/ezyang
Probably introduced by https://github.com/pytorch/pytorch/pull/102254
This fixes `variable 'dim_plane' set but not used ` on my clang-14.0.3 compiler complained about it:
```
/Users/nshulga/git/pytorch/pytorch/aten/src/ATen/native/ReflectionPad.cpp:272:7: error: variable 'dim_plane' set but not used [-Werror,-Wunused-but-set-variable]
int dim_plane = 0;
^
1 error generated.
```
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at e254b4b</samp>
> _`dim_plane` is gone_
> _Simpler code, no more warning_
> _Autumn leaves fall fast_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103680
Approved by: https://github.com/kit1980, https://github.com/Skylion007
Map of #101157.
This PR adds support for coalesced `reduce_scatter_tensor` calls in the following syntax:
Sync communication style:
```
with dist._coalescing_manager():
for i in range(num_coll):
dist.reduce_scatter_tensor(output_tensors[i], input_tensors[i])
```
Async communication style:
```
with dist._coalescing_manager(async_ops=True) as cm:
for i in range(num_coll):
dist.reduce_scatter_tensor(output_tensors[i], input_tensors[i])
# do a bunch of other things
cm.wait()
# do things that depend on the reduce-scatters' results
```
Each `reduce_scatter_tensor` call can be independent in terms of their data and buffer locations. But could be executed in parallel by supported backends (like NCCL).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103561
Approved by: https://github.com/fegin
Fixes#64601 and #98906
Adds an `assign` argument to `load_state_dict` that loads params/buffers by assignment instead of doing `param.copy_(param_from_state_dict)`.
Primarily intended to remove the need for the `.to_empty()` in
```
with torch.device('meta'):
m = SomeModule()
m.to_empty()
state_dict = torch.load('...pth')
m.load_state_dict(state_dict)
```
so we can instead do
```
with torch.device('meta'):
m = SomeModule()
state_dict = torch.load('...pth')
m.load_state_dict(state_dict, assign=True)
```
**A problem with this PR for the case where the model is initialized on meta is what happens to nonpersistent buffers/params corresponding to keys missing from the state dict?**
What happens in the case where `load_state_dict(state_dict, strict=False, assign=True)` and the state_dict is missing some keys? The corresponding params missing from the `state_dict` and nonpersistent buffers would still be on `meta` and need to be manually initialized. However, I don't think we offer an API that would initialize these.
One solution would be to make these empty tensors but it might not be semantically correct...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102212
Approved by: https://github.com/albanD
Windows Defender will soon be removed from the AMI. Without the service, the step fails with the following error:
```
Set-MpPreference : Invalid class
At C:\actions-runner\_work\_temp\1f029685-bb66-496d-beb8-19268ecbe44a.ps1:5 char:1
+ Set-MpPreference -DisableRealtimeMonitoring $True
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : MetadataError: (MSFT_MpPreference:root\Microsoft\...FT_MpPreference) [Set-MpPreference],
CimException
+ FullyQualifiedErrorId : HRESULT 0x80041010,Set-MpPreference
```
For example, https://github.com/pytorch/pytorch-canary/actions/runs/5267043497/jobs/9521809176. This is expected as the service is completely removed.
Here are all the places where `Set-MpPreference` is used according to https://github.com/search?type=code&q=org%3Apytorch+Set-MpPreference
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103454
Approved by: https://github.com/atalman
Summary: Ensure that we create deterministic zip archives for the same inputs to make builds deterministic.
Test Plan: CI
Reviewed By: StanislavGlebik
Differential Revision: D46417033
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102903
Approved by: https://github.com/malfet
`Dirichlet.log_prob()` incorrectly returns NaN in the case where $x_i=0$ and $\alpha_i=1$. The Dirichlet PDF is given by:
$$\frac{1}{B(\alpha)} \prod_{i=1}^{K} x_i^{\alpha_i - 1}$$
So this corresponds to the case where one of the terms has the form $0^0=1$. The logarithm of such a term should be 0, but you get NaN if you try to calculate it as `0 * log(0)`.
This PR implements the same algorithm that `scipy.stats.dirichlet` uses to avoid this behavior, namely `xlogy(alpha - 1, x)` instead of `(alpha - 1) * log(x)`. It also adds a test case comparing the pytorch and scipy implementations for this specific case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103605
Approved by: https://github.com/albanD
After https://github.com/pytorch/pytorch/pull/102562, the `IMAGE_NAME` input to `.ci/docker/build_docker.sh` now accepts the name in the following two formats:
* Short form, like `pytorch-linux-bionic-py3.11-clang9`
* Or long form, like `308535385114.dkr.ecr.us-east-1.amazonaws.com/pytorch/pytorch-linux-bionic-py3.11-clang9`
This PR updates the build script to handle both cases.
This bug was discovered when I saw the wrong image name in https://github.com/pytorch/pytorch/actions/runs/5261424181/jobs/9509633110.
### Testing
Verify that the long form is handled correctly
```
export IMAGE_NAME=308535385114.dkr.ecr.us-east-1.amazonaws.com/pytorch/pytorch-linux-focal-py3.8-gcc7:06fdf1facf0eef5e5f303dd9cfac8639fb5f9201
export DOCKER_TAG=06fdf1facf0eef5e5f303dd9cfac8639fb5f9201
./build_docker.sh
+ tag=06fdf1facf0eef5e5f303dd9cfac8639fb5f9201
+ registry=308535385114.dkr.ecr.us-east-1.amazonaws.com
+ [[ 308535385114.dkr.ecr.us-east-1.amazonaws.com/pytorch/pytorch-linux-focal-py3.8-gcc7:06fdf1facf0eef5e5f303dd9cfac8639fb5f9201 == *\3\0\8\5\3\5\3\8\5\1\1\4\.\d\k\r\.\e\c\r\.\u\s\-\e\a\s\t\-\1\.\a\m\a\z\o\n\a\w\s\.\c\o\m\/\p\y\t\o\r\c\h\/* ]]
++ echo pytorch-linux-focal-py3.8-gcc7:06fdf1facf0eef5e5f303dd9cfac8639fb5f9201
++ awk -F '[:,]' '{print $1}'
+ EXTRACTED_IMAGE_NAME=pytorch-linux-focal-py3.8-gcc7
+ IMAGE_NAME=pytorch-linux-focal-py3.8-gcc7
+ image=308535385114.dkr.ecr.us-east-1.amazonaws.com/pytorch/pytorch-linux-focal-py3.8-gcc7
+ [[ -z '' ]]
+ retry login 308535385114.dkr.ecr.us-east-1.amazonaws.com
+ login 308535385114.dkr.ecr.us-east-1.amazonaws.com
+ aws ecr get-authorization-token --region us-east-1 --output text --query 'authorizationData[].authorizationToken'
+ base64 -d
+ cut -d: -f2
+ docker login -u AWS --password-stdin 308535385114.dkr.ecr.us-east-1.amazonaws.com
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103562
Approved by: https://github.com/PaliC
## Description
Fix cpp wrapper for models which have constants in the graph inputs.
Python wrapper directly gets the value inside the wrapper call as a global variable passed when calling:
4081e924a8/torch/_inductor/codecache.py (L757)
The constants value has been saved in `mod.__dict__` in
4081e924a8/torch/_inductor/graph.py (L874-L875)
For cpp wrapper, we need to append constants to the input args, so as to pass this python value to the `inductor_entry_cpp` function explicitly.
### Example
Example of output code for dlrm in TorchBench with this fix:
```py
module = CppWrapperCodeCache.load(cpp_wrapper_src, 'inductor_entry_cpp', 'cfkc6c36t7cggi6mnokrdm5jhesnunjg5xysv3o3x3vaqmzmpe6r', False)
def _wrap_func(f):
def g(args):
args_tensor = [arg if isinstance(arg, torch.Tensor) else torch.tensor(arg) for arg in args]
constants_tensor = [constant0, constant1]
args_tensor.extend(constants_tensor)
return f(args_tensor)
return g
call = _wrap_func(module.inductor_entry_cpp)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103496
Approved by: https://github.com/jgong5, https://github.com/jansel, https://github.com/desertfire
Summary:
Dynamo trace, via dynamo.export, with aten_graph, generates graph with nodes
whose target is an isntance of torch._ops.OpOverload. Quantization workflow
inserting quantize/dequantize ops which are sometimes instances of
torch._ops.OpOverload (quantize_per_tensor.tensor) while other times instances
of torch._ops.OpOverloadPacket (quantizer_per_tensor) is a bit inconsistent.
Also not sure if it is a valid exported model, if it has nodes with target
of type torch._ops.OpOverloadPacket.
Without op overload name attached to the 'target', it fails during executorch
tracing. Reason is that executorch tracing expects node's targets to be
instances of torch._ops.OpOverload and not torch._ops.OpOverloadPacket.
So for consistency and tracing reasons, fixing convert pass to insert ops which
are torch._ops.OpOverload
Test Plan: CI
Reviewed By: jerryzh168
Differential Revision: D46342822
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103251
Approved by: https://github.com/andrewor14
This commit changes ModelReportObserver variables to buffers similar to other observers. This will allow for gathering data on other device than CPU.
Moreover, updates InputWeightEqualizationDetector to compute weight stats that are on GPU
Tested with running tests `test/quantization/fx/test_model_report_fx.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97971
Approved by: https://github.com/vkuzo
Summary:
Stack: https://pytorch.org/docs/stable/generated/torch.stack.html
This diff uses `at::unsqueeze` and `at::cat` to implement `at::stack` for all dims
Re-organize the tests to 1d, 2d, 3d tensors.
Test Plan:
```
lfq@lfq-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*stack*"
Restarting Buck daemon because Buck version has changed...
Buck daemon started.
Parsing buck files: finished in 9.1 sec
Creating action graph: finished in 0.7 sec
Downloaded 54/3888 artifacts, 27.68 Mbytes, 97.3% cache miss (for updated rules)
Building: finished in 07:36.5 min (100%) 2487/2487 jobs, 2487/2487 updated
Total time: 07:46.3 min
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *stack*
[==========] Running 4 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 4 tests from VulkanAPITest
[ RUN ] VulkanAPITest.stack_invalid_inputs
[ OK ] VulkanAPITest.stack_invalid_inputs (499 ms)
[ RUN ] VulkanAPITest.stack_1d
[ OK ] VulkanAPITest.stack_1d (6 ms)
[ RUN ] VulkanAPITest.stack_2d
[ OK ] VulkanAPITest.stack_2d (12 ms)
[ RUN ] VulkanAPITest.stack_3d
[ OK ] VulkanAPITest.stack_3d (130 ms)
[----------] 4 tests from VulkanAPITest (649 ms total)
[----------] Global test environment tear-down
[==========] 4 tests from 1 test suite ran. (649 ms total)
[ PASSED ] 4 tests.
lfq@lfq-mbp fbsource %
```
Reviewed By: yipjustin
Differential Revision: D46178424
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103344
Approved by: https://github.com/SS-JIA
These are the numbers with this PR

There are 3 main followups
* A naive partitioner gives better memory footprint than min-cut partitioner here. Currently, we are using min-cut partitioner. Waiting for @Chillee to discuss this further to either modify min-cut or add a naive partitioner.
* aot_eager is < 1x memory footprint. This is true even for non AC models. This could hide some inefficiency somewhere.
* inductor is giving very different memory numbers between AOT-traced-AC (duplicate early) vs this implementation. This leads to some inefficiency in inductor that we need to resolve.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102935
Approved by: https://github.com/jansel
Summary:
Dynamo burn in scalars instead of keeping them on module. This results in
quantize_per_tensor and dequantize_per_tensor nodes to have burnt in scale and
zero point value, if we trace them scalar.
Graph rewrite ignores literals and when match pattern is replaced with
replacement pattern, we lose the scale/zp and other values from nodes in
original graph and instead get one from replacement graph.
This diff fixes that for q/dq per tensor node by manually copying these values
over.
Note that this is not robust because it works only when there is only a single
q/dq node
Test Plan: quantization_pt2e
Reviewed By: andrewor14
Differential Revision: D46614000
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103556
Approved by: https://github.com/andrewor14
Summary:
When we call an overload packet (e.g. torch.ops.aten.ge), there's some C++ code (from TorchScript) that determines which overload to use. There's sometimes ambiguity as to which op should be used. Therefore, for python we should use the specific overload name if we know it.
Specifically, the issue was with ge. We had a test (test_lerp_cuda from test_torchinductor.py) that eventually got lowered to code like this:
```
torch.ops.aten.ge(torch.tensor(70000.), 0.5)
```
This can either match torch.ops.aten.ge.Scalar (the intended overload), which will return torch.tensor(True); or it can match torch.ops.aten.ge.float (a TorchScript overload), which will return `True`. The decision of which to use depends on the order in which the operators are registered. Internally, depending on the build config (opt vs. dev-nosan), the operator registration order could differ. In opt mode, the torchscript overload would appear first and therefore would get called first, and cause the inductor program to fail.
Differential Revision: D46712744
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103576
Approved by: https://github.com/jgong5, https://github.com/desertfire
Fixes#103481
Normally triton tensors have shape `[XBLOCK, RBLOCK]`, or some variation where
the lengths are 1 but the number of dimensions is the same. The `no_x_dim`
change in addition to removing the x dimension, also removed the r dimension
from certain values such as the results of reductions and the `xindex` variable.
This fixes those two cases to correctly produce tensors of shape `[1]`,
equivalent to the old shape `[XBLOCK, 1]` with the x-dimension dropped.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103527
Approved by: https://github.com/ngimel
Adds support for multiple forward before bwd call for
static_graph=True.
There are 2 changes:
1) Change tracking of accounting of when to populate static grap related maps
from relying on forward iteration to backward calls
2) In DDP python, don't rely on num_forward iterations == 1 to enqueue the
delay allreduce. Instead use a flag.
Differential Revision: [D46673736](https://our.internmc.facebook.com/intern/diff/D46673736/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103487
Approved by: https://github.com/awgu
This PR adds `operator_compile_check` (pls bikeshed name), a gradcheck-like
API to test if a custom operator is supported by torch.compile.
The API is scoped to check only that the interaction between the
operator and torch.compile works (e.g. it is not going to include
gradcheck). Concretely, it currently checks the following things:
- schema correctness
- make_fx traceable (static shapes)
- aot_autograd correctness (static shapes)
- torch.compile correctness, with and without inductor (static shapes)
- make_fx traceable (dynamic shapes)
- aot_autograd correctness (dynamic shapes)
- torch.compile correctness, with and without inductor (dynamic shapes)
Test Plan:
We test a bunch of error cases, including many failure modes that have tripped
us up in the past, and assert that they (mostly) have nice error messages:
- incorrect schema (mutates)
- incorrect schema (has a view)
- missing abstract impl
- incorrect abstract impl
- missing functionalization kernel
- autograd registered at CPU/CUDA keys
- operator is not traceable
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103198
Approved by: https://github.com/bdhirsh, https://github.com/soulitzer
This is in preparation for the new "custom_op_compile_check" utility,
which will call the refactored testing API as a subroutine.
Here are the improvements to the AOTAutograd tests that this PR makes:
- we use torch.autograd.grad instead of .backward(), which makes it so
that we stop destructively modifying the inputs
- we get rid of the difficult-to-understand sentinel=42 logic and
replace it with something more sane
- We create some helper functions and add some code comments
- We improve error messages
Test Plan:
- wait for CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103197
Approved by: https://github.com/bdhirsh, https://github.com/soulitzer, https://github.com/Chillee
This is in preparation for the custom_op_compile_check utility, which
will call the newly refactored function.
This PR:
- splits off code into helper functions
- adds clearer error messages
- stops updating the inputs destructively (leading to slightly slower
tests)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103196
Approved by: https://github.com/bdhirsh, https://github.com/soulitzer
The test was marked as flaky in #59965. However, it is not failing anymore so it can be enabled.
This PR enables only one test, but it will only run in local tests because the test suite is disabled in CI.
#94495 is a superset of this PR which enables the full test suite. The CI run there shows this test passing.
Fixes#59965
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103317
Approved by: https://github.com/kit1980
- Replace `for inst in instructions[0:targe.offset//2]: inst.starts_line = None`, with the one that that iterates over all instructions until `inst.offset == target.offset` condition is met, this way making it uniform across Python bytecode dialects (Python-3.11+ bytecode size is variable, while bytecode size is fixed for older Pythons)
- Speedup target_index search by replacing `[i for i in instructions if i.offset == offset][0]` with `next(i for i in instructions if i.offset == offset)`, which aborts the evaluation after condition met for the first time, according to:
```python
In [1]: lst=list(range(10000))
In [2]: %time [i for i in lst if i == 10]
CPU times: user 144 µs, sys: 23 µs, total: 167 µs
Wall time: 168 µs
Out[2]: [10]
In [3]: %time next(i for i in lst if i == 10)
CPU times: user 6 µs, sys: 0 ns, total: 6 µs
Wall time: 9.06 µs
Out[3]: 10
```
- Fix small typo
- use `is_py311_plus` variable rather than checking `sys.version_info`
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 6cd7f27</samp>
> _We fix the typos in our code of doom_
> _We remove the warnings that obscure our vision_
> _We refactor the `generate` function for the dynamo_
> _We resume the execution with precision_
Fixes https://github.com/pytorch/pytorch/issues/103355
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103525
Approved by: https://github.com/Skylion007, https://github.com/williamwen42
For the given test case from HF AllenaiLongformerBase, there has an accuracy issue for the dynamic shape case, the reason is that we are using int32 as the index type but there has a default value ```9223372036854775807``` out of range of int32, see the IR:
```
def masked_subblock1(self, ops):
get_index = self.get_index('index1')
index_expr = ops.index_expr(get_index, torch.int32)
get_index_1 = self.get_index('index2')
index_expr_1 = ops.index_expr(get_index_1, torch.int32)
ge = ops.ge(index_expr, index_expr_1)
get_index_2 = self.get_index('index1')
index_expr_2 = ops.index_expr(get_index_2, torch.int32)
constant = ops.constant(9223372036854775807, torch.int32)
lt = ops.lt(index_expr_2, constant)
and_ = ops.and_(ge, lt)
masked_subblock2 = self.masked_subblock2(and_, 0.0)
get_index_3 = self.get_index('index4')
load = ops.load('arg4_1', get_index_3)
where = ops.where(and_, masked_subblock2, load)
return where
```
and the CPU codegen will generate the cpp code according to the node type:
```
auto tmp3 = [&]
{
auto tmp4 = static_cast<int>(i3);
auto tmp5 = static_cast<int>(ks2);
auto tmp6 = tmp4 >= tmp5;
auto tmp7 = static_cast<int>(9223372036854775807);
auto tmp8 = tmp4 < tmp7;
auto tmp9 = tmp6 & tmp8;
auto tmp10 = [&]
{
auto tmp11 = in_ptr0[static_cast<long>(i2 + i3 + ((-1L)*ks2) + (i1*ks3) + (2L*i2*ks2) + (3L*i0*ks3) + (2L*i1*ks2*ks3) + ( 6L*i0*ks2*ks3))];
return tmp11;
}
;
auto tmp12 = tmp9 ? tmp10() : static_cast<decltype(tmp10())>(0.0);
auto tmp13 = in_ptr1[static_cast<long>(i2 + i3 + (i1*ks2) + (2L*i1*(static_cast<long>(ks2*ks2))) + (2L*i2*ks2) + (i0*ks1*ks2) + (2L*i0*ks1*(static_cast<long>(ks2*ks2))))];
auto tmp14 = tmp9 ? tmp12 : tmp13;
return tmp14;
}
```
For ```auto tmp7 = static_cast<int>(9223372036854775807);```, ```tmp7``` is always ```-1```, this is wrong.
After This PR, HF AllenaiLongformerBase CPU dynamic shape path can be passed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103511
Approved by: https://github.com/desertfire
Enabling coordinate descent tuning for a few models cause illegal memory access (or trigger a device assert before that). Command:
```
TORCHINDUCTOR_COORDINATE_DESCENT_TUNING=1 python benchmarks/dynamo/huggingface.py --amp --performance --training --inductor -d cuda --only CamemBert
```
It turns out that we can not benchmark this kernel: https://gist.github.com/shunting314/a78997f54b5751f2887f4576956036ce
Digging more, it shows that this kernel has a inplace argument that will be changed after running the kernel. Our benchmark API simply call a kernel multiple times. Since each run may have side effect. The previous calls may change the inplace argument in a way that fail following calls.
This PR clone those inplace arguments before each benchmark call. This can increase the time for each benchmark call. But this should not affect autotuning since we increase the equal amount of time for each tuning configs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103547
Approved by: https://github.com/jansel
Summary: aten::zero_: https://pytorch.org/docs/stable/generated/torch.Tensor.zero_.html
Test Plan:
clang-format on zero_.glsl and Zero.cpp
```
lfq@lfq-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*zero*"
Downloaded 0/48 artifacts, 0.00 bytes, 100.0% cache miss (for updated rules)
Building: finished in 40.5 sec (100%) 525/525 jobs, 12/525 updated
Total time: 40.5 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *zero*
[==========] Running 1 test from 1 test suite.
[----------] Global test environment set-up.
[----------] 1 test from VulkanAPITest
[ RUN ] VulkanAPITest.zero_
[ OK ] VulkanAPITest.zero_ (59 ms)
[----------] 1 test from VulkanAPITest (59 ms total)
[----------] Global test environment tear-down
[==========] 1 test from 1 test suite ran. (59 ms total)
[ PASSED ] 1 test.
```
Differential Revision: D46403983
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103042
Approved by: https://github.com/SS-JIA
First, infra improvements: new combinator `expectedFailureDynamic` which subsumes expectedFailure calls in test_dynamic_shapes.py. It's just nicer to have these right with the test. Implementation in torch/_dynamo/testing.py and it works by putting an attr on the test, which is then converted into a real expectedFailure when we actually generate the dynamic shapes test class
Next, some housekeeping:
* test/dynamo/test_unspec.py accidentally was running mostly statically due to the `assume_static_by_default` config flip. Don't assume static by default and xfail some tests which regressed in that time.
* New test file test/dynamo/test_config.py, for testing permutations of configuration options. `test_dynamic_shapes` got moved there.
Finally, grinding through tests in a way that will make them more compatible with dynamic by default:
* If the test explicitly requires dynamic_shapes=False, remove that patch (and probably xfail it)
* If the test checks dynamic_shapes internally, remove that test and patch the test so it ALWAYS runs with dynamic_shapes (this is not coverage loss because we're going to switch the default)
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103542
Approved by: https://github.com/anijain2305
Fixes #ISSUE_NUMBER
Add the serialization logic of backend metadata to the serialization of tensor, which is implemented through custom registration functions.
In #97429 , the structure backendMeta is provided in TensorImpl, and we think that this part of information may also need to be serialized for custom.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99808
Approved by: https://github.com/ezyang, https://github.com/huydhn
What this PR does is (continuation from #103435):
- Applying dynamic number of threads for innerdim scan with index function.
- Using dynamically allocated shared memory to get rid of `num_threads` template arguments.
@ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103502
Approved by: https://github.com/ngimel
Subgraphs are partitions cut out of a whole graph. Outputs of a subgraph are either global outputs of the original graph, or can be outputs of a partition that feed inputs of the subsequent partition. Subgraphs are created using the fx utility 'passes.split_module', which requires that each partition
have at least one output node.
In cases where DDPOptimizer asked the partitioner to cut the graph around a set of nodes which only
performed inplace mutation, the partitioner could be left trying to create a subgraph with no output nodes, violating its assumptions.
To circumvent this, DDPOptimizer can expand the set of nodes marked for inclusion in a subgraph that has no outputs until it includes a node that is an output for that subgraph. It still traverses nodes of the original graph in reverse order and only considers widening a subgraph by iterating further in reverse order than it would have ordinarily done (past the cut point dictated by paramter count). It may still be possible the subgraph reaches the input node of the graph without satisfying the subgraph-output condition, in which case an error would still be raised by the partitioner.
Fixes#103385
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103488
Approved by: https://github.com/anijain2305
Summary:
att, we use module partition API to identify the GRU submodule and annotate all necessary patterns
Test Plan: buck2 test mode/opt caffe2/test:quantization_pt2e -- 'caffe2/test:quantization_pt2e'
Differential Revision: D46689428
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103526
Approved by: https://github.com/andrewor14
# torch.compiler public API
## Goal
The goal of this document is to describe the public facing API for torchdynamo and torchinductor.
Today both dynamo and torchinductor are in `torch/_dynamo` and `torch/_inductor` namespace with the only public function
`torch.compile()` which is directly placed in `torch/__init__.py`
This poses a few problems for users trying to take dependencies on PyTorch 2.0
1. Unclear BC guarantees
2. No builtin discovery mechanism outside of reading the source code
3. No hard requirements for docstrings or type annotations
Most importantly it mixes two personas the PyTorch 2.0 developer vs the PyTorch 2.0 customer so this is an attempt to address this. We draw a lot of inspiration from the `functorch` migration to the `func` namespace.
## Alternate names
We did discuss some other alternative names
1. `torch.compile` -> problem is this would break BC on the existing `torch.compile` function
2. `torch.dynamo` -> `dynamo` is so far not something we've deliberately hidden from users but problem is now figuring out what it's `_dynamo` vs `dynamo` might be confusing
3. `torch.compiler` -> 1 would be better but to keep BC this is a good compromise
# The general approach
## Proposal 1
In https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/__init__.py
We have function called `reset()`, this function is essential if users are trying to `torch.compile()` a model under different settings
```python
# in _dynamo/
def reset():
do_reset_stuff()
```
Instead we propose
```python
# in compiler/
def reset():
do_reset_stuff() # As in copy paste the logic from _dynamo.reset
# in _dynamo/
import warnings
import inspect
def reset():
function_name = inspect.currentframe().f_code.co_name
warnings.warn(f"{function_name} is deprecated, use compiler.{function_name} instead", DeprecationWarning)
return compiler.reset()
```
## Proposal 2
```python
# in compiler/
def reset():
“””
Docstrings here
“””
_dynamo.reset()
# in _dynamo/
No changes
```
Consensus so far seems to be proposal 2 since fewer warnings will be less jarring and it’ll make it quite easy to merge the public API
## Docstrings
The above was an example of a function that has no inputs or outputs but there are other functions which could use an improvement in their docstrings, for example allow_in_graph actually works over lists of functions but that’s not mentioned anywhere in the example only if you read the source code.
def allow_in_graph(fn):
"""
Customize which functions TorchDynamo will include in the generated
graph. Similar to `torch.fx.wrap()`.
Parameters:
fn (callable or list/tuple): The function(s) to be allowed in the graph.
Returns:
callable or list/tuple: The input function(s) included in the graph.
Examples:
Customize inclusion of a single function:
::
torch._dynamo.allow_in_graph(my_custom_function)
Customize inclusion of multiple functions:
::
torch._dynamo.allow_in_graph([my_custom_function1, my_custom_function2])
@torch._dynamo.optimize(...)
def fn(a):
x = torch.add(x, 1)
x = my_custom_function(x)
x = torch.add(x, 1)
return x
fn(...)
Notes:
The `allow_in_graph` function allows customization of which functions TorchDynamo
includes in the generated graph. It can be used to include specific functions that
are not automatically captured by TorchDynamo.
If `fn` is a list or tuple, `allow_in_graph` will be called recursively on each
element in the sequence.
Once a function is allowed in the graph using `allow_in_graph`, it will be captured
in the graph generated by TorchDynamo. This customization enables more fine-grained
control over the functions included in the graph.
Note that `allow_in_graph` expects the input `fn` to be a callable.
"""
if isinstance(fn, (list, tuple)):
return [allow_in_graph(x) for x in fn]
assert callable(fn), "allow_in_graph expects a callable"
allowed_functions._allowed_function_ids.add(id(fn))
allowed_functions._disallowed_function_ids.remove(id(fn))
return fn
So to make the API public, we’d have to write similar docstrings for all public functions we’d like to create.
The benefit of this approach is that
1. No BC risks, internal and external users relying on our tooling can slowly wean off the private functions.
2. We will also have to write correct docstrings which will automatically make our documentation easier to maintain and render correctly on pytorch.org
3. We already have some BC guarantees already, we don’t kill OptimizedModule, we rejected the PR to change the config system
The con of this approach is that
Will be stuck with some potentially suboptimal functions/classes that you can’t kill
## Testing strategy
If the approach is to mostly make a public function call an already tested private function then all we need to do is ensure that the function signatures don't change
## Which functions should be in the public API
Our heuristic for deciding whether something should be public or not is are users already relying on it for lack of other options or have we recommended some non public functions for users to debug their PT 2.0 programs.
Heuristic for not putting something in public is that it’s an experimental subsystem with the goal of turning it on by default, it’s very core dev centric, meta centric, a bunch of different configs that should be batched into a single user facing one, or something that needs to be renamed because the name is confusing
#### Top level
`torch.compile()` -> already is a public API it does require some minor improvements like having configs be passed in to any backend and not just inductor (EDIT: This was already done https://github.com/pytorch/pytorch/pull/99645l) and renaming `mode=reduce-overhead` to `mode=cudagraph`
To make sure that PT 2.0 is supported with a given pytorch version users can create a new public function and this would replace the need for `try/except` blocks around `import torch._dynamo` that has been populating user code.
```python
def pt2_enabled():
if hasattr(torch, 'compile'):
return True
else:
return False
```
For all of the below they will be translated to `torch.compiler.function_name()`
#### From _dynamo
As a starting point we looked at https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/__init__.py and we suggest redefining these functions in `pytorch/torch/compiler/__init__.py`
It might also make sense to split them over multiple files and import them in `__init__.py` but because the number of functions is small it'd probably be fine to add them all into a single compiler/__init__.py until this list becomes larger
1. `reset()`
2. `allow_in_graph()`
10. `list_backends()`
12. `compile()`: torch.compile() would be mostly a shell function passing arguments to torch.compiler.compile()
13. `assume_constant_result()`: TODO: Double check how this is useful
15. `torch._dynamo.disable()`
Some notable omissions
11. `explain()`: We need to clean up the output for this function, make it a data class and pretty printable
1. `forbid_in_graph()`: Considered adding this but should instead consolidate on `disallow_in_graph`
2. `optimize_assert()`: Already covered by `torch.compile(fullgraph=True)`
3. `check_if_dynamo_supported()`: this would be supplanted by pt2_enabled()
4. `compilation_metrics`, `graph_breaks_reasons` ..: would all be accessed via `torch.compiler.explain()`
5. `replay` does not seem useful to end customers
6. . `graph_break()`: Mostly useful for debugging or unit tests
9. `register_backend()`: End users will just pass a string backend to torch.compile, only devs will create new backends
10. `export()` : Eventually this needs to public but for now it’s not ready so just highlighting that it will be in the public API eventually
11. `disallow_in_graph()`: Usage is limited
12. `mark_static()`: we can keep this private until dynamic=True is recommended in stable
13. `mark_dynamic()`: we can keep this private until dynamic=True is recommended in trunk
14. 8. `OptimizedModule`: This is the only class that we'd expose but is crucial since users are running code like `if isinstance(mod, OptimizedModule): torch.save(mod._orig_mod)` EDIT: because we fixed pickling we no longer need to
expose this
15. `is_compiling()`: Still not clear how this useful to end users
There are also config variables which we need to expose https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/config.py
Some of our configs are useful dev flags, others are to gate experimental functionality and others are essential debugging tools and we seperate out the essential debugging and logging tools to a public facing config.
TODO: I still need to think of a good way of porting the config in a BC way here are some ideas
1. Just make all passes available and controllable via `torch.compile(options={})` but only show docstrings for the ones users should care about.
The current problem with our config system is we have 3 ways of setting them once via `options={}`, environment variables and variables in `config.py`, it'd be worth settling on one source of truth and have that be the public API.
The configs we should make public are
1. `log_file_name`
2. `verbose`
3. `cache_size_limit`
4. `repro_level` and `repro_after`: Although we can rename these to minifier and give human readable names to the levels
Everything else should stay private in particular
1. `print_graph_breaks`, `print_specializations`: should be supplanted by `explain()` for public users
2. dynamic shape configs : Users should only have to worry about `torch.compile(dynamic=True/False)`
3. The distributed flags, hook or guard configs: If we tell a user to use FSDP and DDP then the flag should be enabled by default or be in a private namespace
4. The fbcode flags: Obviously no need to be user facing
5. Skip/Allow lists: Not something normal users should play around with
#### From _inductor
Very little of inductor should be exposed in a public facing API, our core audience as in people writing models mostly just need information on what certain passes mean and how to control them a high level and they can do this with `torch.compile(options={})` so the goal here should be more to make available passes clearer and ideally consolidate them into `torch.compile()` docstrings or modes.
There are some exceptions though from https://github.com/pytorch/pytorch/blob/main/torch/_inductor/__init__.py
1. `list_mode_options()`
2. `list_options()`: this needs an additional pass to hide internal or debug options
For both of these we’d rename them to compiler.inductor_list_mode_options and compiler.inductor_list_options() since they would be in the same init file as the one for dynamo
Notable omissions
1. `_inductor.compile()`: Because of users are coming in with their own fx graph, they are likely developers
2. `_inductor.aot_compile()`:Again this is about capturing and modifying fx graphs so users APIs don't need to be public
However the configs are a slightly different story, because we can choose to either
1. Make all configs public
2. Make some configs public and keep most of the private ones. If public config is set it should override the private version
3. Make all configs controllable via `torch.compile(options={})` but make list_options() hide more things
For now 3 seems like the most reasonable choice with some high level configs we’ll keep like TORCH_COMPILE_DEBUG
Regardless here's what should probably be public or advertised more
1. `disable_progress` and verbose_progress: Combine and enable by default
2. `fallback_random`: We could make the case this shouldn't be public if a top level deterministic mode enables this
3. `profile_bandwidth`: Or could make the case that this should be in TORCH_COMPILE_DEBUG
Notable omissions
1. Any config that would generally improve performance for most that we should probably enable by default but might be disabled in the short term because of stability: example `epilogue_fusion`, `pattern_matcher`, `reordering`
2. Autotuning flags: Should just sit behind `torch.compile(mode="max-autotune")` like `max_autotune`, `max_autotune_gemm`
3. `coordinate_descent_tuning`: This one I'm a but mixed about, maybe it just also fall into `mode="max-autotune"`
4. `trace`: `TORCH_COMPILE_DEBUG` is the best flag for all of this
5. `triton.cudagraphs`: Default should be `torch.compile(mode="reduce-overhead")` - I'd go further and rename the `mode=cudagraph` and we can keep reduce-overhead for BC reasons
6. `triton_unique_kernel_names`: Mostly useful for devs debugging
7. `dce`: which doesnt really do anything
8. `shape_padding`: Elias is working on enabling this by default in which case we also remove it
## Mechanics
This PR would include the public functions with their docstrings
Another PR will take a stab at the configs
And for work where the APIs are still being cleaned up whether its minifier or escape hatches, export or dynamic shapes, aot_inductor etc.. we’ll keep them private until a public commitment can be made
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102182
Approved by: https://github.com/jansel, https://github.com/albanD
There was an issue reported internally that with `sync_module_states=True`, if the model had buffers on CPU, even with `device_id` specified, FSDP would try to broadcast CPU buffers, leading to an error like:
```
RuntimeError: No backend type associated with device type cpu
```
After some investigation, I determined that we should _not_ fix this by moving the buffers to GPU just for the broadcast and then back to CPU. Instead, we should fix our `device_id` logic.
The issue is that we always used the _parameters_ as the proxy to tell whether we should move module states to the device specified by `device_id`. However, a module (often the root) may not have any parameters but have some buffers! In that case, the buffers are left on CPU even if `device_id` is specified. This PR fixes this by considering both parameters and buffers for movement to `device_id`.
Note that this PR preserves the logic that `ignored_modules` / `ignored_parameters` are not considered for this movement, meaning that ignored parameters are moved to `device_id`.
Note also that I had to move the unit test back from using MTPG to the normal PG since otherwise, I could not repro the original error. (It seems like MTPG does not complain if we try to use `dist._broadcast_coalesced()` with CPU tensors.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103504
Approved by: https://github.com/rohan-varma
After https://github.com/pytorch/pytorch/pull/102107, rerunning disabled tests only collect and run disable tests. A side effect of this change is that the skip message `Test is enabled but --rerun-disabled-tests verification mode is set, so only disabled tests are run` isn't in the test report anymore as these non-disabled tests are not going to be collected in the first place. This breaks the logic in the uploading script that depends on this string to know if the test report belongs to a rerunning disabled tests workflow.
* This PR updates the logic in `is_rerun_disabled_tests` check to count the number of times a test is run instead. In rerunning disabled tests mode, a test is run 50 times by default and 15 times for distributed tests (to avoid timeout). Both these numbers are larger than the max number of retries a test can get normally (3 x 3)
* This also removes the hacky `is_rerun_disabled_tests` check in `tools/stats/upload_test_stats.py` as rerun disabled tests reports are now very small (50 x the number of disabled tests)
### Testing
* `test_gradgrad_nn_GroupNorm_cuda_float64` now shows up correctly https://github.com/pytorch/pytorch/issues/98678
```
python3 -m tools.stats.check_disabled_tests --workflow-run-id 5229037746 --workflow-run-attempt 1 --repo "pytorch/pytorch"
Using temporary directory: /var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpdojg5vq5
Downloading test-reports-test-default-1-4-linux.g5.4xlarge.nvidia.gpu_14154925022.zip
Downloading test-reports-test-default-1-4-linux.g5.4xlarge.nvidia.gpu_14154925093.zip
Downloading test-reports-test-default-2-4-linux.g5.4xlarge.nvidia.gpu_14154925167.zip
Downloading test-reports-test-default-2-4-linux.g5.4xlarge.nvidia.gpu_14154925226.zip
Downloading test-reports-test-default-3-4-linux.g5.4xlarge.nvidia.gpu_14154925295.zip
Downloading test-reports-test-default-3-4-linux.g5.4xlarge.nvidia.gpu_14154925371.zip
Downloading test-reports-test-default-4-4-linux.g5.4xlarge.nvidia.gpu_14154925453.zip
Downloading test-reports-test-default-4-4-linux.g5.4xlarge.nvidia.gpu_14154925536.zip
Downloading test-reports-test-slow-1-1-linux.2xlarge_14154853469.zip
Downloading test-reports-test-slow-1-1-linux.rocm.gpu_14154932523.zip
Downloading test-reports-test-slow-1-1-linux.rocm.gpu_14154932563.zip
Downloading test-reports-test-slow-1-2-linux.4xlarge_14154873704.zip
Downloading test-reports-test-slow-1-2-linux.g5.4xlarge.nvidia.gpu_14154931154.zip
Downloading test-reports-test-slow-1-2-linux.g5.4xlarge.nvidia.gpu_14154931186.zip
Downloading test-reports-test-slow-2-2-linux.4xlarge_14154873756.zip
Downloading test-reports-test-slow-2-2-linux.g5.4xlarge.nvidia.gpu_14154931225.zip
Downloading test-reports-test-slow-2-2-linux.g5.4xlarge.nvidia.gpu_14154931267.zip
Extracting test-reports-test-default-1-4-linux.g5.4xlarge.nvidia.gpu_14154925022.zip to unzipped-test-reports-test-default-1-4-linux.g5.4xlarge.nvidia.gpu_14154925022
Extracting test-reports-test-default-1-4-linux.g5.4xlarge.nvidia.gpu_14154925093.zip to unzipped-test-reports-test-default-1-4-linux.g5.4xlarge.nvidia.gpu_14154925093
Extracting test-reports-test-default-2-4-linux.g5.4xlarge.nvidia.gpu_14154925167.zip to unzipped-test-reports-test-default-2-4-linux.g5.4xlarge.nvidia.gpu_14154925167
Extracting test-reports-test-default-2-4-linux.g5.4xlarge.nvidia.gpu_14154925226.zip to unzipped-test-reports-test-default-2-4-linux.g5.4xlarge.nvidia.gpu_14154925226
Extracting test-reports-test-default-3-4-linux.g5.4xlarge.nvidia.gpu_14154925295.zip to unzipped-test-reports-test-default-3-4-linux.g5.4xlarge.nvidia.gpu_14154925295
Extracting test-reports-test-default-3-4-linux.g5.4xlarge.nvidia.gpu_14154925371.zip to unzipped-test-reports-test-default-3-4-linux.g5.4xlarge.nvidia.gpu_14154925371
Extracting test-reports-test-default-4-4-linux.g5.4xlarge.nvidia.gpu_14154925453.zip to unzipped-test-reports-test-default-4-4-linux.g5.4xlarge.nvidia.gpu_14154925453
Extracting test-reports-test-default-4-4-linux.g5.4xlarge.nvidia.gpu_14154925536.zip to unzipped-test-reports-test-default-4-4-linux.g5.4xlarge.nvidia.gpu_14154925536
Extracting test-reports-test-slow-1-1-linux.2xlarge_14154853469.zip to unzipped-test-reports-test-slow-1-1-linux.2xlarge_14154853469
Extracting test-reports-test-slow-1-1-linux.rocm.gpu_14154932523.zip to unzipped-test-reports-test-slow-1-1-linux.rocm.gpu_14154932523
Extracting test-reports-test-slow-1-1-linux.rocm.gpu_14154932563.zip to unzipped-test-reports-test-slow-1-1-linux.rocm.gpu_14154932563
Extracting test-reports-test-slow-1-2-linux.4xlarge_14154873704.zip to unzipped-test-reports-test-slow-1-2-linux.4xlarge_14154873704
Extracting test-reports-test-slow-1-2-linux.g5.4xlarge.nvidia.gpu_14154931154.zip to unzipped-test-reports-test-slow-1-2-linux.g5.4xlarge.nvidia.gpu_14154931154
Extracting test-reports-test-slow-1-2-linux.g5.4xlarge.nvidia.gpu_14154931186.zip to unzipped-test-reports-test-slow-1-2-linux.g5.4xlarge.nvidia.gpu_14154931186
Extracting test-reports-test-slow-2-2-linux.4xlarge_14154873756.zip to unzipped-test-reports-test-slow-2-2-linux.4xlarge_14154873756
Extracting test-reports-test-slow-2-2-linux.g5.4xlarge.nvidia.gpu_14154931225.zip to unzipped-test-reports-test-slow-2-2-linux.g5.4xlarge.nvidia.gpu_14154931225
Extracting test-reports-test-slow-2-2-linux.g5.4xlarge.nvidia.gpu_14154931267.zip to unzipped-test-reports-test-slow-2-2-linux.g5.4xlarge.nvidia.gpu_14154931267
Downloading test-reports-runattempt1-test-slow-1-1-linux.rocm.gpu_14154932523.zip
Downloading test-reports-runattempt1-test-slow-1-1-linux.rocm.gpu_14154932563.zip
Extracting test-reports-runattempt1-test-slow-1-1-linux.rocm.gpu_14154932523.zip to unzipped-test-reports-runattempt1-test-slow-1-1-linux.rocm.gpu_14154932523
Extracting test-reports-runattempt1-test-slow-1-1-linux.rocm.gpu_14154932563.zip to unzipped-test-reports-runattempt1-test-slow-1-1-linux.rocm.gpu_14154932563
The following 32 tests should be re-enabled:
test_huge_index (__main__.TestCuda) from test_cuda.py
test_conv_bn_fuse_cpu (__main__.CpuTests) from inductor/test_torchinductor.py
test_multi_threads (__main__.TestTorchrun) from backends/xeon/test_launch.py
test_huge_index (__main__.TestCuda) from test_cuda_expandable_segments.py
test_memory_timeline_no_id (__main__.TestMemoryProfilerE2E) from profiler/test_memory_profiler.py
test_inverse_errors_large_cuda_float64 (__main__.TestLinalgCUDA) from test_linalg.py
test_trace_dependencies (__main__.TestAnalyze) from test_package.py
test_caching_pinned_memory (__main__.TestCuda) from test_cuda_expandable_segments.py
test_graph_concurrent_replay (__main__.TestCuda) from test_cuda_expandable_segments.py
test_module_attribute_mutation_violation_negative_1 (__main__.MutationExportTests) from dynamo/test_export_mutations.py
test_module_attribute_mutation_violation_negative_2 (__main__.MutationExportTests) from dynamo/test_export_mutations.py
test_module_attribute_mutation_violation_negative_4 (__main__.MutationExportTests) from dynamo/test_export_mutations.py
test_vmapjvpall_linalg_lu_cuda_float32 (__main__.TestOperatorsCUDA) from functorch/test_ops.py
test_vmapjvpvjp_linalg_lu_cuda_float32 (__main__.TestOperatorsCUDA) from functorch/test_ops.py
test_Conv2d_no_bias_cuda_tf32 (__main__.TestNN) from test_nn.py
test_save_graph_repro (__main__.TestAfterAot) from dynamo/test_after_aot.py
test_doc_examples (__main__.TestTypeHints) from test_type_hints.py
test_caching_pinned_memory (__main__.TestCuda) from test_cuda.py
test_graph_concurrent_replay (__main__.TestCuda) from test_cuda.py
test_non_contiguous_tensors_nn_ConvTranspose1d_cuda_complex32 (__main__.TestModuleCUDA) from test_modules.py
test_pickle_nn_RNN_eval_mode_cuda_float64 (__main__.TestModuleCUDA) from test_modules.py
test_op_has_batch_rule_nn_functional_conv_transpose3d_cuda_float32 (__main__.TestVmapOperatorsOpInfoCUDA) from functorch/test_vmap.py
test_geometric_kstest_cuda_float32 (__main__.TestTorchDeviceTypeCUDA) from test_torch.py
test_profiler_experimental_tree_with_memory (__main__.TestProfilerTree) from profiler/test_profiler_tree.py
test_fs_pool (__main__.TestMultiprocessing) from test_multiprocessing.py
test_forward_mode_AD_linalg_lu_factor_ex_cuda_complex128 (__main__.TestFwdGradientsCUDA) from test_ops_fwd_gradients.py
test_vjp_linalg_lu_cuda_float32 (__main__.TestOperatorsCUDA) from functorch/test_ops.py
test_inplace_grad_fmod_cuda_float64 (__main__.TestBwdGradientsCUDA) from test_ops_gradients.py
test_inplace_gradgrad_remainder_cuda_float64 (__main__.TestBwdGradientsCUDA) from test_ops_gradients.py
test_bottleneck_cuda (__main__.TestBottleneck) from test_utils.py
test_comprehensive_empty_strided_cuda_int32 (__main__.TestInductorOpInfoCUDA) from inductor/test_torchinductor_opinfo.py
test_vmapvjpvjp_linalg_lu_cuda_float32 (__main__.TestOperatorsCUDA) from functorch/test_ops.py
The following 11 are still flaky:
test_transpose_with_norm (__main__.CPUReproTests) from inductor/test_cpu_repro.py, failing 215/215
test_compare_cpu_linalg_pinv_singular_cuda_float32 (__main__.TestCommonCUDA) from test_ops.py, failing 100/100
test_conv_bn_fuse_dynamic_shapes_cpu (__main__.DynamicShapesCodegenCpuTests) from inductor/test_torchinductor_codegen_dynamic_shapes.py, failing 115/115
test_lobpcg (__main__.TestAutograd) from test_autograd.py, failing 50/50
test_module_attribute_mutation_violation_negative_3 (__main__.MutationExportTests) from dynamo/test_export_mutations.py, failing 2/50
test_Conv2d_dilated_cuda_tf32 (__main__.TestNN) from test_nn.py, failing 1/50
test_grad_nn_GroupNorm_cuda_float64 (__main__.TestModuleCUDA) from test_modules.py, failing 50/50
test_index_add_correctness (__main__.TestTorch) from test_torch.py, failing 22/50
test_attn_cuda (__main__.TestMin) from functorch/test_dims.py, failing 1/50
test_open_device_registration (__main__.TestCppExtensionOpenRgistration) from test_cpp_extensions_open_device_registration.py, failing 50/50
test_gradgrad_nn_GroupNorm_cuda_float64 (__main__.TestModuleCUDA) from test_modules.py, failing 50/50
```
* Uploading tests stats for rerunning disabled tests takes only half a minute
```
time python3 -m tools.stats.upload_test_stats --workflow-run-id 5229037746 --workflow-run-attempt 1 --head-branch main
31.94s user 2.94s system 44% cpu 1:19.07 total
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103476
Approved by: https://github.com/clee2000
Summary:
When simplifying split cat patterns, if next user of a split node was an output node, there was a bug leading to an issue like: P765993221
Basically, the bug was in how args and kwargs of the user were getting replaced, and the code didn't handle nested arg/kwargs.
Using torch.fx.Node functions such as `all_input_nodes` and `replace_input_with` fixes this issue
Differential Revision: D46603618
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103338
Approved by: https://github.com/jansel
Potential null dereference after dynamic cast was found during static analysis.
**Description:**
Dereference of `ctx` is performed in `TORCH_CHECK` on line 1176, while `ctx` pointer may equal `nullptr`.
Previous `TORCH_CHECK` on line 1175 checks the value of `ctx_ptr` pointer that may be of type that cannot be casted to `TestContext*`. In such case, `dynamic_cast` returns `nullptr` despite `ctx_ptr` is not equal to `nullptr`.
**Fix:**
- Check `ctx` instead of `ctx_ptr` for equality to zero.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97768
Approved by: https://github.com/kit1980
This is the continuation of optimizing inner-dimension scan operations (`torch.cumsum`, `torch.cumprod`, `torch.logcumsumexp`) by dynamically setting the number of threads based on the input shape from #103314.
What I found that just setting the number of x-threads and y-threads following the ratio of the tensor's shape works quite well (with some clamping).
Here is the speed-up of this PR, compared to `2.0.0+cu118` (not compared to #103314) using A100 with 40GB memory (up to 23x faster):
```
2 8 32 128 512 1024 2048 4096 8096 16348 65536 262144 1048576
2: 1.07(4) 1.02(5) 1.01(6) 1.07(7) 2.16(8) 4.94(9) 8.71(9) 11.00(9) 12.99(9) 14.77(9) 16.41(9) 16.81(9) 16.97(9)
8: 1.20(4) 1.00(4) 1.01(5) 1.08(6) 2.85(7) 4.90(8) 6.34(8) 11.76(9) 13.86(9) 15.26(9) 16.96(9) 17.45(9) 19.75(9)
32: 1.08(4) 1.00(4) 1.00(4) 1.23(5) 2.48(6) 4.23(7) 5.04(7) 9.16(8) 10.11(8) 18.72(9) 20.64(9) 23.13(9) 23.50(9)
128: 1.09(4) 1.02(4) 1.03(4) 1.02(4) 1.64(5) 2.84(6) 3.08(6) 5.61(7) 5.86(7) 10.72(8) 19.22(9) 19.75(9) 19.97(9)
512: 1.06(4) 1.14(4) 1.01(4) 1.10(4) 1.02(4) 1.78(5) 1.85(5) 3.26(6) 3.34(6) 5.56(7) 8.56(8) 9.55(9) 9.62(9)
1024: 1.21(4) 1.22(4) 1.20(4) 1.06(4) 1.03(4) 1.05(4) 1.81(5) 1.86(5) 3.06(6) 3.12(6) 4.76(7) 5.20(8) 5.56(9)
2048: 1.04(4) 0.88(4) 1.00(4) 1.01(4) 1.02(4) 1.03(4) 1.02(4) 1.72(5) 1.73(5) 2.62(6) 2.86(7) 3.06(8) --------
4096: 1.02(4) 1.12(4) 0.98(4) 1.60(4) 1.16(4) 1.09(4) 1.10(4) 1.10(4) 1.74(5) 1.75(5) 1.86(6) 2.00(7) --------
8096: 1.03(4) 1.00(4) 1.00(4) 1.16(4) 1.17(4) 1.17(4) 1.18(4) 1.18(4) 1.18(4) 1.27(5) 1.43(6) -------- --------
16348: 1.02(4) 1.15(4) 1.11(4) 1.17(4) 1.12(4) 1.11(4) 1.13(4) 1.12(4) 1.11(4) 1.08(4) 1.32(5) -------- --------
65536: 1.17(4) 1.17(4) 1.16(4) 1.15(4) 1.12(4) 1.12(4) 1.12(4) 1.10(4) 1.10(4) 1.07(4) -------- -------- --------
262144: 1.20(4) 1.20(4) 1.08(4) 1.13(4) 1.10(4) 1.09(4) 1.10(4) 1.08(4) -------- -------- -------- -------- --------
1048576: 1.21(4) 1.14(4) 1.10(4) 1.13(4) 1.09(4) 1.08(4) -------- -------- -------- -------- -------- -------- --------
```
The first row is the innermost dimension, the first column is the outermost dimension (i.e. the batch size).
The float numbers are the speed up while the integers within the brackets are the log2 of number of x-threads.
The blank cells (the ones with dashes) are not compared because of my GPU's memory limitation.
There are some slowdowns that I observed (like `(2048, 8)` and `(4096, 32)`). The slowdown is because in this PR, the scan loop (the one I use with Sklansky) is not optimized by the compiler due to dynamic number of iterations (it is `log2(num_threads_x)`), while in the previous version, the scan loop can be unrolled and optimized by the compiler due to fixed number of iterations.
That's why I slightly modified the operations within the scan loop to use bit operations in order to compensate for this slowdown.
The most significant acceleration comes from the tensors with relatively small batch size (<= 4096) and with very long sequence.
As the batch size increases, the speed up is not that significant because the previous implementation is most likely to be optimized.
NOTE: I haven't optimized scan dim with indices, it could come in another PR.
As for the build time, I tried not to write more templated functions than necessary.
I will report the build time when I already have the numbers.
UPDATE: I compared the build time when I changed ScanUtils.cuh only. In `main` branch, it took 4m2s, while in this PR, it took 3m39s.
What do you think, @ngimel?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103435
Approved by: https://github.com/ngimel
Summary: att, we use module partition API to identify the GRU submodule and annotate all necessary patterns
Test Plan: buck2 test mode/opt caffe2/test:quantization_pt2e -- 'caffe2/test:quantization_pt2e'
Reviewed By: kimishpatel
Differential Revision: D46384329
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103358
Approved by: https://github.com/HDCharles
This PR decouples the logic necessary to compute bounds on variables
from the logic that uses this info to perform the strenght analysis on
int64 variables. While doing so, it tries to minimize the number of
attributes of the class in favour of local variables.
This class is now accessible from any `LoopBody` object.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100549
Approved by: https://github.com/eellison
It is required for numpy_pytorch_interop to be installed, for all tests being annotated by `@requires_numpy_pytorch_interop` decorator.
This PR adds a commit for it and adds a function to install it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103447
Approved by: https://github.com/ezyang
Added a feature to upload test statistics to DynamoDB and Rockset using a new function `emit_metric` in `tools/stats/upload_stats_lib.py`.
Added metrics to measure test reordering effectiveness in `tools/testing/test_selections.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102691
Approved by: https://github.com/malfet
Introduces two higher order operators
* run_and_save_rng_state - Saves the current rng state and then runs the op.
* run_with_rng_state - Runs the op with the rng state supplied as an input
Ideally, we would like to use torch.compile for these operators. But currently the plan is to introduce these operators at the partitioner level, obviating the need to support them fully through the torch.compile stack. To ensure that we have good enough debugging with minifiers, we have ensure that they work with make_fx. In future, we can move on torch.compile.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102934
Approved by: https://github.com/jansel, https://github.com/zou3519
Adds a freezing pass that will constant fold parameters in inductor `config.freezing`. This occurs post functionalization in aot autograd to capture both dispatching and allow passes to occur post functionalization. A few notes:
- There is an option to discard parameters `config.freezing_discard_parameters` which will take the current eager modules and wrap parameters to a Tensor subclass which will error if used.
- I needed to expose flat_params in aot_autograd in order to discard old references when we constant fold away parameters, like with amp. I also exposed `fw_metadata` to avoid constant folding mutated paraemters.
- Caching parameter transformations/constant folding across different inferences nyi
- Checking version_counter of constant folded params nyi
I'm not really sure what the actual naming should be. In jit there was both "freezing", which was platform agnostic, and "optimize for inference", which made device specific optimizations. We're doing the latter here but maybe freezing is a better name.
Differential Revision: [D46244033](https://our.internmc.facebook.com/intern/diff/D46244033)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100652
Approved by: https://github.com/jansel
**Motivation:**
For collective dispatching, we want to provide a more user friendly usage for xpu device and CCL backend (user specified backend) mapping.
**Solution:**
We add xpu to the default device list, and it can construct the mapping between xpu and the user specified backend directly.
Usage:
When using xpu device, user can specify backend name only:
`dist.init_process_group(backend='ccl')`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103410
Approved by: https://github.com/jgong5, https://github.com/ezyang
The main concept behind this refactor is this: if we know that a size/stride/etc is constant, do NOT trace it into the graph, EXCEPT for any preexisting special cases that applied for static shapes. The refactor unfolds like this:
1. Delete the `dynamic_shapes` branches in torch/_dynamo/variables/builder.py which accept int/float/bool outputs. This is over-aggressive and we don't want to allow this (because if the operator returns a constant, we shouldn't have called wrap_fx_proxy in the first place.) This causes a bunch of failures because we are blindly feeding the result of size() call to wrap_fx_proxy when dynamic shapes is enabled.
2. Modify TensorVariable.call_method in torch/_dynamo/variables/tensor.py to avoid sending constant ints to wrap_fx_proxy. After normal specialization (which should be deleted, see https://github.com/pytorch/pytorch/pull/103434) we consult the fake tensor to see if the values in question have free variables or not. If they don't we short circuit tracing into graph. We only trace into graph if the operation in question is truly symbolic. Note that there is a near miss here: it's OK to trace x.size() call entirely into the graph, even if it doesn't have all dynamic shapes, because operator.getitem with int output is special cased in builder.py. This is a preexisting special case and I don't try to get rid of it.
3. It turns out that the change here also breaks torch_np compatibility layer. So I completely rewrite getattr handling in torch/_dynamo/variables/tensor.py to follow the same pattern (only trace into graph if truly dynamic).
There's some minor housekeeping in torch/fx/experimental/symbolic_shapes.py and some test files.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103438
Approved by: https://github.com/larryliu0820
Fixes#101328
Note that this most likely is a bandage solution. We either need to actually fix one of those onnx passes that is causing this decomposition/functionalization issue, or need to special case all onnx op in `runTorchBackendForOnnx` like this one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101329
Approved by: https://github.com/BowenBao
This PR adds universal support for ndarray methods. After #100839 each `NumpyNdarrayVariable` should wrap a `torch.Tensor`. This PR adds a `numpy_method_wrapper` which converts the `torch.Tensor` to `torch_np.ndarray` and then call the numpy ndarray method. Then we also try to return a `torch.Tensor` (return as-is if the value is not ndarray-like)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97537
Approved by: https://github.com/ezyang
Fixes#99569
nn.Parameter construction appears to run into FakeTensor / tracing issues during AOT Autograd. We could try to fix this; but nn.Parameter construction _inside_ the compiled region isn't a common scenario, so it's reasonable to just graph break on nn.Parameter construction.
For reference, see #99569 for the errors/issues that appear from tracing through nn.Parameter construction with AOT Autograd.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103262
Approved by: https://github.com/williamwen42
Originally, my goal for this PR was to remove the `dynamic_shapes` tests in torch/_dynamo/variables/builder.py. However, one thing lead to another, and it turns out that it was easiest to do all of the following in one go:
* Unconditionally allocate a ShapeEnv, no matter if dynamic_shapes is enabled or not (torch/_dynamo/output_graph.py). There is a small adjustment to export torch/_dynamo/eval_frame.py to account for the fact that a ShapeEnv always exists, even if you're not doing symbolic export.
* Remove dynamic_shapes test from unspec logic (torch/_dynamo/variables/builder.py), the original goal
* Specialize strides and storage offset if all sizes are dynamic (torch/fx/experimental/symbolic_shapes.py). This is required to deal with unconditional ShapeEnv: if a ShapeEnv exist, fake tensor-ification may choose to allocate symbols. The idea is that with `automatic_dynamic_shapes == False`, Dynamo should never request dynamic sizes, but this invariant was not upheld for nontrivial strides/offset.
The rest are just auxiliary fixups from the above:
* Workaround bug in FakeTensorProp where sometimes it doesn't return a FakeTensor (torch/fx/passes/fake_tensor_prop.py), see https://github.com/pytorch/pytorch/pull/103395 for follow up
* Make ShapeProp correctly handle int inputs (torch/fx/passes/shape_prop.py)
* Disable indexing strength reduction if `assume_static_by_default` is False (torch/_inductor/codegen/triton.py)
* Fix hf_T5_generate to NOT toggle `assume_static_by_default` if dynamic shapes is not enabled (benchmarks/dynamo/common.py); technically this is not necessary anymore but it's in for safety.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103302
Approved by: https://github.com/voznesenskym
I found this algorithm (Sklansky) could provide speed-up over the previously implemented Brent-Kung (BK) algorithm. In BK algorithm, the sweeps are done twice: up-sweep and down-sweep. In up-sweep, initially all threads are working, but then half of the working threads becomes inactive in the subsequent step. Similarly for down-sweep but the other way around, where it initially starts with only 1 working thread and double the number of working threads for each sweep. This results of half of the thread is idle on average and produces `2 * log2(num_threads_x)` sweep steps.
On the other hand, Sklansky algorithm only use 1 sweep and in each step of the sweep, all the threads are working. This algorithm also produces `log2(num_threads_x)` sweep steps which is half of the BK algorithm. That provides the speed up. I follow the schematics of Sklansky algorithm provided in [this paper](https://research.nvidia.com/sites/default/files/pubs/2016-03_Single-pass-Parallel-Prefix/nvr-2016-002.pdf). The same paper provides a much better algorithm (the one implemented in CUB), but I haven't got my head around it, while the Sklansky algorithm is easier to digest and implement.
Here are the speed up from my experiment using `cumsum` in the innermost dimension using A100:
(UPDATE: the newest commit further optimize it up to 76% on `8 x 4000` matrix)
(UPDATE: added shapes with 2048 and 1M in its elements)
| Shape | Torch cumsum | Custom cumsum | Speed up |
|--------------|---------------------------|--------------------------|---------------------|
| (2, 1000) | 4.8112869262695315e-05 | 2.849102020263672e-05 | 1.688702928870293 |
| (8, 4000) | 0.00017731189727783204 | 0.0001005411148071289 | 1.7635760018970834 |
| (128, 10000) | 0.0005342483520507813 | 0.00035474300384521487 | 1.5060151891928222 |
| (1024, 20000)| 0.0014238595962524415 | 0.0010990619659423829 | 1.2955225823246128 |
| (1024, 100000)| 0.007089591026306153 | 0.005468320846557617 | 1.296484099093993 |
| (2048, 1000000)| 0.058730244636535645 | 0.0458010196685791 | 1.2822912035913994 |
| (1000, 2) | 1.0919570922851562e-05 | 8.106231689453125e-06 | 1.3470588235294116 |
| (4000, 8) | 9.512901306152343e-06 | 7.867813110351562e-06 | 1.209090909090909 |
| (10000, 128) | 2.079010009765625e-05 | 1.6164779663085937e-05 | 1.2861356932153394 |
| (20000, 1024)| 0.00024993419647216796 | 0.00017964839935302734 | 1.3912408759124086 |
| (100000, 1024)| 0.0011160612106323243 | 0.0009322404861450195 | 1.1971816577581138 |
| (1000000, 2048) | 0.017030668258666993 | 0.014445066452026367 | 1.178995494082889 |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103314
Approved by: https://github.com/ngimel
We previously compare FakeTensor's strides with real tensor's strides. This cause dynamic dimension of FakeTensor being specialized to static int. This may cause a graph specialized for one shape being used by another shape which is wrong.
Use stride hints for the comparison instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103342
Approved by: https://github.com/malfet
Summary: Add msg to assertEqual field in the flaky test of test_memory_timeline_no_id, so that we print the actual tuple for debugging.
Test Plan: CI
Differential Revision: D46596242
Pulled By: aaronenyeshi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103326
Approved by: https://github.com/davidberard98
The changes in this PR include:
- Support ConvTranspose in cpp wrapper
- Fix cpp wrapper support for aten convolution when bias is `not None`: bias is in `args` instead of `kwargs` when it is `not None`. The change is covered by ConvTranspose dynamic shapes UT since we'll fall back to aten convolution in dynamic shape cases.
- Fix cpp wrapper support for `inf`. This is a UT added in https://github.com/pytorch/pytorch/issues/101865. The cpp wrapper UT is covered in `test_conv2d_unary` of `test_cpp_wrapper.py`. It's in `slowTest` category and seems not captured in the CI of that PR.
I will submit another PR to remove the hard-coded schema in these `ExternKernel`s.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103308
Approved by: https://github.com/jgong5, https://github.com/desertfire
Not sure, why was it excluded previous (oversight I guess).
Also, please note, that `clang++` is already considered acceptable compiler (as it ends with `g++` ;))
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 55aa7db</samp>
> _`clang` or `gcc`, we don't care what you use_
> _We'll build our extensions with the tools we choose_
> _Don't try to stop us with your version string_
> _We'll update our logic and make our code sing_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103349
Approved by: https://github.com/seemethere
`-force_load` is not compiler, but a linker option, and as such should depend on the platform (i.e. MacOS/iOS), rather than on compiler (i.e. clang vs gcc)
Otherwise, attempt to link libtorch static with clang results in a cryptic `/usr/bin/ld: -f may not be used without -shared` error on Linux.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103348
Approved by: https://github.com/seemethere
We do not raise constraint violations for complex binary conditions, such as conditions involving `%`. Moreover, while these constraints are discovered by our solver, the solver does not inject new constraint violations. This can result in cases where export passes, appropriate assertions are not added, and we get runtime crashes.
Now, when the solver discovers constraints that are too complex, we force-specialize the involved dimensions and raise a constraint violation when such dimensions are marked dynamic. This forces the user to remove the dynamic marking, and causes the appropriate specialization assertions to be added.
Differential Revision: [D46415786](https://our.internmc.facebook.com/intern/diff/D46415786/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102897
Approved by: https://github.com/tugsbayasgalan
Fixes#102752
These 3 fallback kernels appear in GoogleFnet because they take complex arguments - i.e., usually they aren't fallback kernels. To support this model, we added support for these 3 ops.
Details:
1. Add these 3 ops to the allowlist. I assume that we eventually want to support all fallback kernels, but for now we just add these 3 ops to the allowlist.
2. Support complex64 in cpp codegen
3. Support List[] arguments and ScalarType arguments in cpp codegen
4. Allow alias_info in schema arguments. In the original PR supporting fallback kernels for cpp wrapper, ops with schemas with non-null alias_info for any of the arguments were disallowed; but I don't think there's any reason we need to disallow these in cpp wrapper code.
Caveats:
* This has not added support for complex32 or complex128
* It only works with static shapes, not dynamic shapes. It seems like the dynamic shapes issue is unrelated to cpp wrapper, since it fails in the test_torchinductor_dynamic_shapes.py test. I checked these `test_fft_.*` tests, which I added in this PR, and verified that they were broken with dynamic shapes before any of the code changes from this PR.
**Test**:
```
benchmarks/dynamo/huggingface.py --inductor --amp --accuracy --inference --device cuda --cpp-wrapper --only GoogleFnet
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103183
Approved by: https://github.com/desertfire, https://github.com/jgong5, https://github.com/chunyuan-w
Fixes: #101979
This PR adds support for dictionaries with torch object as keys in dynamo.
The main problem was that, for example, the source built for `d[torch.float]` (`d` being a
dictionary) was `ODictGetItemSource(GlobalSource('d'), index=torch.float)`. When
`Source.name` method was called, we got `odict_getitem(G['d'], torch.float)`. Evaluating
that string raised an error, since `torch` was only available in the global dictionary `G`
as `G["torch"]`.
Instead, this PR builds the source:
`ODictGetItemSource(GlobalSource('d'), index=AttrSource(GlobalSource('torch'), 'float'))`.
The to-be-evaluated string is correctly generated as:
`odict_getitem(G['d'], G['torch'].float)`.
Here's a minimal example that reproduces the error, before this PR:
```python
import torch
d = {
torch.float16: torch.float32,
}
@torch.compile
def f():
return torch.randn(3, dtype=d[torch.float16])
f()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103158
Approved by: https://github.com/mlazos
Summary:
In torch.distributed, we make ProcessGroupNCCL not call workEnqueue when the cuda stream is capturing. I.e., when capturing a CUDA graph, we do not enqueue anything for the watchdog thread to consider. This allows capturing NCCL operations in a CUDA Graph.
This is followup to an internal discussion [1] where the watchdog thread was observed to crash when using cuda graphs containing an all_reduce. The watchdog thread wants to query events pertaining to enqueued work items, but this can't be done for "events" created during cuda graph capture.
[1] https://fb.workplace.com/groups/1405155842844877/posts/6975201909173548/
Test Plan: Test added. Also, the repro mentioned in https://fb.workplace.com/groups/1405155842844877/posts/7003002339726838/ runs successfully after this change.
Differential Revision: D46274814
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102542
Approved by: https://github.com/kwen2501
Previously, cudagraphs and dynamic_shapes were incompatible and enabling
dynamic shapes would forcibly disable cudagraphs. This new strategy
I think is better. The idea is essentially that cudagraphs is an
"optimization" that happens to guard on every input. When cudagraphs
is on, we force everything static, and this automatically does the right
thing because we will force a recompile if sizes change.
This obsoletes https://github.com/pytorch/pytorch/pull/101813
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103290
Approved by: https://github.com/voznesenskym
We discussed in a composability meeting a few weeks ago that `pre_autograd` should probably be renamed to `pre_dispatch`.
One question in this PR was: should I re-use a dispatch key? Or should I create a new dispatch key (that yet again corresponds to "top of the dispatcher")?
~~For now, I ended up sticking our proxy mode on the mode stack corresponding to `PythonTLSSnapshot`, because it was simple and it works. It looks like one of the functorch dispatch keys has higher priority though, so it's possible that functorch will end up running first. Open to options, but we can consider adding a new dispatch key later if that becomes a problem~~
Update: I added a dedicated dispatch key, `PreDispatch`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101818
Approved by: https://github.com/ezyang, https://github.com/Neilblaze, https://github.com/albanD, https://github.com/zou3519
Now, when you do an inplace mutation and the view is naughty, you get this message:
```
RuntimeError: A view was created in no_grad mode and is being modified inplace with grad mode enabled. Given that this use case is ambiguous and error-prone, it is forbidden. You can clarify your code by moving both the view and the inplace either both inside the no_grad block (if you don't want the inplace to be tracked) or both outside (if you want the inplace to be tracked). To find out where this view was allocated, run your entire forward region under anomaly mode (torch.autograd.detect_anomaly(check_nan=False)).
```
When you run under anomaly mode, you get:
```
RuntimeError: A view was created in no_grad mode and is being modified inplace with grad mode enabled. Given that this use case is ambiguous and error-prone, it is forbidden. You can clarify your code by moving both the view and the inplace either both inside the no_grad block (if you don't want the inplace to be tracked) or both outside (if you want the inplace to be tracked). This view was allocated at:
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 4299, in arglebargle
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 4306, in test_anomaly_gives_view_stack
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 549, in _callTestMethod
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 591, in run
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 2266, in _run_with_retry
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 2337, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/case.py", line 650, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 122, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 84, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 122, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/suite.py", line 84, in __call__
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/runner.py", line 184, in run
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/main.py", line 271, in runTests
File "/home/ezyang/local/c/pytorch-env/lib/python3.10/unittest/main.py", line 101, in __init__
File "/data/users/ezyang/c/pytorch/torch/testing/_internal/common_utils.py", line 894, in run_tests
File "/data/users/ezyang/c/pytorch/test/test_autograd.py", line 11209, in <module>
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103185
Approved by: https://github.com/zdevito
Using [`nanoGPT/model.py`](https://github.com/karpathy/nanoGPT/blob/master/model.py) run
<details><summary><b>Click for script to save gpt2-xlarge (1.5B params)</b></summary>
```
# test_load_save_gpt.py
from model import GPT
import torch
import time
torch.manual_seed(5)
# gpt2-xlarge 1558M parameters
class GPTConfig:
block_size: int = 1024
vocab_size: int = 50304 # GPT-2 vocab_size of 50257, padded up to nearest multiple of 64 for efficiency
n_layer: int = 48
n_head: int = 25
n_embd: int = 1600
dropout: float = 0.0
bias: bool = True # True: bias in Linears and LayerNorms, like GPT-2. False: a bit better and faster
def f():
model = GPT(GPTConfig())
state_dict = model.state_dict()
start_saving = time.time()
torch.save(state_dict, "gpt2-xlarge.pth")
end_saving = time.time()
if __name__ == "__main__":
f()
```
</details>
<details><summary><b>Click for script to load</b></summary>
```
# test_load_gpt.py
import torch
from model import GPT
from test_load_save_gpt import GPTConfig
import time
import argparse
def f(mmap, meta):
device = 'meta' if meta else 'cpu'
assign = True if meta else False
with torch.device(device):
model = GPT(GPTConfig())
start_loading = time.time()
loaded_state_dict = torch.load("gpt2-xlarge.pth", _mmap=mmap)
end_loading = time.time()
print(f"loading time using torch.load with mmap={mmap}: ", end_loading - start_loading)
model.load_state_dict(loaded_state_dict, assign=assign)
end_load_state_dict = time.time()
print("load_state_dict time: ", end_load_state_dict - end_loading)
model.cuda()
end_cuda = time.time()
print("cuda time using torch.load with mmap: ", end_cuda - end_load_state_dict)
if __name__ == "__main__":
parser = argparse.ArgumentParser(prog='load_gpt_xlarge')
parser.add_argument('-m', '--mmap', action='store_true')
parser.add_argument('-d', '--devicemeta', action='store_true')
args = parser.parse_args()
mmap = args.mmap
meta = args.devicemeta
f(mmap, meta)
```
</details>
`python test_load_gpt.py`
<img width="614" alt="Screenshot 2023-06-06 at 1 35 43 PM" src="https://github.com/pytorch/pytorch/assets/35276741/ee06e5b3-b610-463b-a867-df995d21af29">
`python test_load_gpt.py --mmap`
<img width="622" alt="Screenshot 2023-06-06 at 1 35 30 PM" src="https://github.com/pytorch/pytorch/assets/35276741/00d2fdd0-b1f5-4313-83dc-e540b654b2af">
If we further use the `with torch.device('meta')` context manager and pull the changes from https://github.com/pytorch/pytorch/pull/102212 that allow the model to reuse tensors from the state_dict, we have
`python test_load_gpt.py --mmap --devicemeta`
<img width="727" alt="Screenshot 2023-06-06 at 1 35 51 PM" src="https://github.com/pytorch/pytorch/assets/35276741/b50257d9-092a-49c3-acae-876ee44d009f">
\
\
Running the above in a docker container containing a build of PyTorch with RAM limited to 512mb by
1) running `make -f docker.Makefile` from `pytorch/` directory
2) `docker run -m 512m -it <image> bash`
3) docker cp `gpt2-xlarge.pth` and `test_load_gpt.py` into the image
`python test_load_gpt.py`
Docker will Kill the process due to OOM whereas
`python test_load_gpt.py --mmap --devicemeta`
<img width="635" alt="Screenshot 2023-06-06 at 1 55 48 PM" src="https://github.com/pytorch/pytorch/assets/35276741/f3820d9e-f24c-43e7-885b-3bfdf24ef8ad">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102549
Approved by: https://github.com/albanD
When checking Meta's internal cmf10x model, I found this interesting kernel https://gist.github.com/shunting314/d4b1fc7352c840ef185c607392e21f31 . Doing coordinate descent tuning starting from the out of box tuner find sub-optimal config: a config worse than the best one max-autotuner can find.
This indicates that the coordinate descent tuner does not necessarily find the optimal config. Starting point matters.
I want to make the coordinate descent tuning less depend on the starting point. Also I think by improving that, the coordinate descent tuner may be more likely to find even better configs when starting from max-autotune result.
There are 2 ideas.
1. currently coordinate descent tuning only considers changing one field/coordinate at a time. I add the ability to check all directions (i.e. tuning all tunable fields at the same time) after the normal coordinate descent searching does not find better choices. I'll check how that works in cmf10x
2. currently when we change a field, we only change 1 step (i.e. radius is 1). I add the ability to use a larger radius. This only affect the search in all directions and does not affect the normal coordinate descent searching workflow.
Both are disabled by default.
Here are the tests I've done:
- OOB (out of the box): 0.083ms 0.003GB 38.13GB/s
- MA (max autotune): 0.016ms 0.003GB 195.60GB/s
- best config: XBLOCK: 4, RBLOCK: 128, num_warps: 4, num_stages: 1
Default coordinate descent:
- Coordesc (coordinate descent tuner) upon OOB: 0.024ms 0.003GB 131.52GB/s ( **WORSE than Max Autotune** )
- best config: XBLOCK: 64, RBLOCK: 4, num_warps: 16, num_stages: 1
- Coordesc upon MA: 0.016ms 0.003GB 194.31GB/s (no further improvement upon MA)
Search in all directions: (radius = 1)
- Coordesc upon OOB: 0.017ms 0.003GB 184.55GB/s
- best config: XBLOCK: 32, RBLOCK: 16, num_warps: 32, num_stages: 1
- **IMPROVE FROM 0.024ms to 0.017ms. QUITE CLOSE TO THE ONE FIND BY MAX-AUTOTUNE**
- Coordesc upon MA: no further improvements upon MA
Search in all directions: (radius = 2)
- Coordesc upon OOB: 0.016ms 0.003GB 192.60GB/s
- best config: XBLOCK: 8, RBLOCK: 16, num_warps: 8, num_stages: 1
- **SLIGHTLY BETTER THAN RADIUS=1 for this kernel and on par with max-autotune**
- Coordesc upon MA: no further improvements upon MA
**Overall max-autotuner does a really good job for this kernel**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99403
Approved by: https://github.com/jansel
Fixes #ISSUE_NUMBER
1、the class named "Type" has not been used anymore in anywhere, so I add warning message to remove it in the future.
2、add a arg(default is "cuda") for save_on_cpu so that it can support more device type (like privateuse1)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103245
Approved by: https://github.com/soulitzer
This PR get rids of the dim_groups attribute from DeviceMesh, the main
motivation behind this is that we should let c10d store the process
groups during its creation instead of DeviceMesh, DeviceMesh should just
handle ranks correctly.
This could enable DTensor becomes picklable! (torch.save/load could be
possible), which I will give it a try in the next PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103105
Approved by: https://github.com/XilunWu, https://github.com/fduwjj
Other projects have seen a similar issue https://github.com/quantumlib/Cirq/issues/4637
## Before
```
(nightly) ubuntu@ip-172-31-2-131:~$ python /tmp/torchinductor_ubuntu/eq/ceqs7t4pesfhqllk6qf4k5spu2cm23l7quqdt2mkrp4rlcjl6kw5.py
Traceback (most recent call last):
File "/tmp/torchinductor_ubuntu/eq/ceqs7t4pesfhqllk6qf4k5spu2cm23l7quqdt2mkrp4rlcjl6kw5.py", line 47, in <module>
module = CppWrapperCodeCache.load(cpp_wrapper_src, 'inductor_entry_cpp', 'czenwgemzbe2etzbh7hzhnwjhyamvwirgodyjlly75fayy4tp3rx', False)
File "/opt/conda/envs/nightly/lib/python3.10/site-packages/torch/_inductor/codecache.py", line 846, in load
assert isinstance(spec.loader, importlib.abc.Loader)
AttributeError: module 'importlib' has no attribute 'abc'. Did you mean: '_abc'?
```
## After
```sh
(nightly) ubuntu@ip-172-31-2-131:~/test$ python /tmp/torchinductor_ubuntu/eq/ceqs7t4pesfhqllk6qf4k5spu2cm23l7quqdt2mkrp4rlcjl6kw5.py
0.000272
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103277
Approved by: https://github.com/desertfire
Successful test run found at Test run found at https://github.com/pytorch/pytorch/actions/runs/5213244046/jobs/9410138550
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 8d7d860</samp>
This pull request adds a new feature to create and upload alerts for failing jobs in the pytorch/pytorch repo. It introduces a new script `tools/alerts/create_alerts.py` to generate alert entries and a new workflow `.github/workflows/upload-alerts.yml` to run the script and upload the alerts periodically.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 8d7d860</samp>
> _To upload alerts to Rockset_
> _We added a workflow, you bet_
> _It runs every ten_
> _With concurrency then_
> _And `create_alerts.py` we edit_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102995
Approved by: https://github.com/huydhn, https://github.com/ZainRizvi
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 971a80c</samp>
This pull request adds support for building docker images that can run performance benchmarks using the inductor framework. It introduces new files and scripts to install the benchmark dependencies, and updates the docker build and test workflows to use the new images. It also fixes some minor issues with the existing inductor tests and workflows.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 971a80c</samp>
> _Oh we're the docker builders and we work all day and night_
> _We install the dependencies for the inductor benchmarks right_
> _We pin the versions and the commits and run the scripts with ease_
> _And we heave away and pull away and build the images_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102881
Approved by: https://github.com/huydhn
Summary:
Previously, the QAT pattern for conv + bn + relu was
not actually replaced in convert. This is because the quantized
QAT pattern used in convert doesn't actually have a relu node.
This commit adds this extra pattern in the convert path and
the numerics now match FX's.
Test Plan: python test/test_quantization.py TestQuantizePT2E.test_qat_conv_bn_relu_numerics
Reviewed By: jerryzh168
Differential Revision: D46372411
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102993
Approved by: https://github.com/jerryzh168
Manually generate guards for optimizer rather than use variable builder, which can be slow with lots of params.
This is the reason for ~10s compile slowdown
Redisable `_init_group`. This is important, because if for any reason a frame which calls `_init_group` is run in the python interpreter, we will trace it, which we don't want to do. We only want to call it when it is accessed via the fast path implemented with the optimizer variable during symbolic interpretation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103121
Approved by: https://github.com/jansel
This PR makes a first attempt at improving FSDP's fine-tuning support by adding hooks to reshard frozen parameters in the backward pass.
- Without this, frozen parameters involved in gradient computation are kept as unsharded through the entire backward pass.
- The approach is to register a multi-grad ~~post~~-hook on the _input_ activations to the FSDP module, where the hook performs the resharding after all gradients for the FSDP module must have been computed (meaning that we are safe to reshard).
~~This PR relies on adding a "multi-grad post-hook" that differs from the existing "multi-grad hook" from `register_multi_grad_hook()`. I find that with `register_multi_grad_hook()`, sometimes the unit test counting the number of times `_post_backward_reshard()` is called fails (due to it not being called).~~ This was resolved in https://github.com/pytorch/pytorch/pull/102859.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101982
Approved by: https://github.com/rohan-varma
When torch.cat gets called on a list of contiguous tensors that are aligned on a 16B boundary in memory, the number of thread blocks used is directly proportional with the maximum size of the tensors in the list. If one or more tensors are very large while the others are small, a high number of thread blocks results in useless redundant loads of the input metadata. This PR limits the grid size and improves the performance of cat when used on list of tensors with large variations in size.
Used the same test program from https://github.com/pytorch/pytorch/pull/102815 but added new cases with list of tensors with varying sizes.
<img width="735" alt="Screenshot 2023-06-07 at 10 14 18 PM" src="https://github.com/pytorch/pytorch/assets/23515689/72d0e5cb-5840-400e-b53b-d1418e664f19">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103233
Approved by: https://github.com/malfet
Moved SlicedBufferedReader to utils and renamed to _ReaderView.
It no longer depends on file handles and is a pure wrapper. This makes it general enought to handle non io stream objects like fsspec's.
Should help with #98386
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99167
Approved by: https://github.com/wz337
Successful test run found at Test run found at https://github.com/pytorch/pytorch/actions/runs/5179855118/jobs/9333292038 (uses equivalent PRs)
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 8d7d860</samp>
This pull request adds a new feature to create and upload alerts for failing jobs in the pytorch/pytorch repo. It introduces a new script `tools/alerts/create_alerts.py` to generate alert entries and a new workflow `.github/workflows/upload-alerts.yml` to run the script and upload the alerts periodically.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 8d7d860</samp>
> _To upload alerts to Rockset_
> _We added a workflow, you bet_
> _It runs every ten_
> _With concurrency then_
> _And `create_alerts.py` we edit_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102995
Approved by: https://github.com/huydhn, https://github.com/ZainRizvi
Fixes#92576 , checking the following as described in the documentation:
"source.shape[dim] == len(index) and source.shape[i] == self.shape[i] for i != dim"
Would be happy to iterate on this if there are any issues, and would be happy to implement the checking for the CUDA and MPS implementations of index_add_.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100321
Approved by: https://github.com/lezcano
Summary:
Prepare QAT for resnet18 has matching numerics with FX.
Adding this test requires us to refactor the way the test code
is structured, however.
Test Plan: python test/test_quantization.py TestQuantizePT2EModels.test_qat_resnet18
Differential Revision: D46456243
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103020
Approved by: https://github.com/kimishpatel
Even if you passed in --amp we would run inference in float32.
`AlbertForMaskedLM` goes from 1.305 float32 to 1.724x amp, and then again to 1.910x with freezing. Benchmark numbers for amp are about to go way up lol.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103220
Approved by: https://github.com/desertfire
Summary: DataLoader.cpp signal handlers are adding some special behavior (e.g. exit(0) on SIGTERM under certain conditions). To preserve this behavior we should install additional signal handlers on top of default ones, rather than completely replacing them.
Test Plan: unit tests
Reviewed By: drej82
Differential Revision: D46525348
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103164
Approved by: https://github.com/drej82
Previously, defining a HigherOrderOperators (like cond) automatically generates
a torch.ops.cond and causes them to trace into the FX graph as e.g.
torch.ops.cond.
This is not good, because:
- Duplication. Since HigherOrderOperators are written in Python, they have an
associated Python function that users should access them from. E.g.
torch.cond (when we make it public). That is what should actually appear in the
graph.
- torch.ops.cond is a valid namespace for operator registration; having
it be a function too confuses things.
This PR:
- Moves cond/map HigherOrderOperators to be under torch (necessary for
the FX logic to not do weird things)
- Sets the `__module__` of a HigherOrderOperator correct. This is what
FX uses when tracing the operator.
Test Plan:
- updated tests
Future:
- I'll delete the ability to call cond as torch.ops.cond in a couple of
days, after this change circulates internally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103108
Approved by: https://github.com/ydwu4
Summary:
This API is used by the gen_executorch.py to check whether a kernel with specified kernel key is used or not.
Test Plan:
```
buck test xplat/caffe2/tools:test_torchgen_executorch
buck run fbcode//executorch/codegen/tools:test_gen_oplist_real_model
```
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103184
Approved by: https://github.com/larryliu0820
Allow DTensor support cuda-like device, fix https://github.com/pytorch/pytorch/issues/102442
Currently, DTensor supports cuda and cpu. There are other efforts to make DTensor support third-party devices, for example https://github.com/pytorch/pytorch/pull/101914 and https://github.com/pytorch/pytorch/issues/101911. However, this support only extends a portion of third-party devices and is no good support for third-party cuda-like devices. Therefore, we would like to extend DTensor to support cuda-like devices, after all, cuda is so popular!
1. Similar to what is done here, we need to initialize the communication backend for the device set by DeviceMesh. So `_default_backend_for_device` is added to `Backend`. It is worth noting that when we register a new backend for a device other than cpu and cuda, we also need to add a new default backend for this device.
2. Adding `_device_handle` to `DeviceMesh` for cuda-like devices, similar to what is set in FSDP. When `_device_handle` is not None, the device has similar behavior to `cuda`. In this way, functions like `torch.cuda.device_count()` need to be modified to `device_mesh._device_handle.device_count()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102468
Approved by: https://github.com/wanchaol
- Don't copy inputs in cudagraphs wrapping, since the copies will distorts timing and triton do_bench will clear cache anyway
- Don't skip op if there is a fallback, since we have both fallbacks and lowerings for some ops
- Add option for channels last
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103110
Approved by: https://github.com/desertfire
Workaround for https://github.com/pytorch/pytorch/issues/102886
related to: https://github.com/pytorch/pytorch/issues/102476https://github.com/pytorch/pytorch/issues/102475https://github.com/pytorch/pytorch/issues/102474https://github.com/pytorch/pytorch/issues/102473https://github.com/pytorch/pytorch/issues/102473https://github.com/pytorch/pytorch/issues/102472
Since 9aaa12e328 the first inductor (CPU) UT fails until the GPU context is correct initialised and the subsequent UTs pass. CUDA observes the same issue and a workaround was pushed to force initialisation of cuda context by declaring an empty tensor https://github.com/pytorch/pytorch/issues/92627, we have adopted the same approach but have opted for `torch.zeros` which correctly activates the HIP context after the kernel launch.
**Reproducer:**
```
import torch
from torch._subclasses.fake_tensor import FakeTensorMode
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Swap between torch.empty and torch.randn operations.')
parser.add_argument('--empty', action='store_true', help='Use torch.empty operation')
parser.add_argument('--rand', action='store_true', help='Use torch.randn operation')
args = parser.parse_args()
torch.cuda.set_device(0)
if args.empty:
torch.empty(1, device="cuda")
elif args.rand:
torch.rand(1, device="cuda")
print(f": hasPrimaryContext: {torch._C._cuda_hasPrimaryContext(0)")
with FakeTensorMode():
p = torch.randn(4, 2, requires_grad=True, device='cuda')
x = torch.randn(8, 4, device='cuda')
y = torch.mm(x, p).square().sum()
y.backward()
```
**ROCm python repro.py --empty**
0: hasPrimaryContext: False
**ROCm python repro.py --rand**
0: hasPrimaryContext: True
**CUDA python repro.py --empty**
0: hasPrimaryContext: True
**CUDA python repro.py --rand**
0: hasPrimaryContext: True
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103149
Approved by: https://github.com/eellison
Use gcc9 in linux-bionic-cuda12_1-py3_10-gcc9-build workflows
After PR, which fixed gcc9 transition : https://github.com/pytorch/multipy/pull/321
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at a076506</samp>
This pull request updates the GCC version for Python 3.10 and CUDA 11.8/12.1 test images and removes the unused CUDA 12.1 image configuration and reference from the docker build scripts and workflow.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103075
Approved by: https://github.com/malfet
Summary:
In this diff we test a module that does a) emedding lookup b) runs 1D
(converted to 2D) conv and c) runs linear on the output of 1d conv.
a is quantized using embedding quantizer.
c is quantized using dynamic quantization.
b is quantized using static quantization.
We compose quantizer from [a, c, b]. Tested it against similar fx config.
Test Plan: test_embedding_conv_linear_quantization
Reviewed By: jerryzh168
Differential Revision: D46267688
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103116
Approved by: https://github.com/jerryzh168
Fix https://github.com/pytorch/pytorch/issues/100830.
For the inplace node, there will be a `copy_` generated and the `copy_` will be `realized` as a `scheduler buffer` since it is a mutation. This `scheduler buffer` is a memory copy but after fusing with the previous buffer, it will not be a memory copy only buffers.
This PR solves the issue by removing `load_bf16_as_fp32` and `store_bf16_from_fp32`. Instead, enable fp32/bf16 vec conversion in `to_dtype`. Then we always store bf16.
```python
import torch
import torch.nn as nn
torch.manual_seed(420)
from torch._inductor import config
x = torch.randn(1, 18, dtype=torch.bfloat16)
class ExampleModel(nn.Module):
def __init__(self):
super(ExampleModel, self).__init__()
self.relu = nn.ReLU(inplace=True) # nn.ReLU(inplace=False)
def forward(self, input1):
out = self.relu(input1)
# input1.copy_(out)
return out
func = ExampleModel()
with torch.no_grad():
func.train(False)
res1 = func(x) # without jit
print(res1)
jit_func = torch.compile(func)
res2 = jit_func(x)
print(res2)
```
Generated code without this PR: (`tm3` store is wrong, `tmp3` is `float` while `out_ptr1` is `bf16`)
```
auto tmp0 = load_bf16_as_float(out_ptr1 + static_cast<long>(i0));
auto tmp1 = (tmp0);
auto tmp2 = at::vec::clamp_min(tmp1, decltype(tmp1)(0));
auto tmp3 = (tmp2);
store_float_as_bf16(out_ptr0 + static_cast<long>(i0), tmp3);
tmp3.store(out_ptr1 + static_cast<long>(i0), 16);
```
Generated code with this PR:
```
auto tmp0 = at::vec::Vectorized<bfloat16>::loadu(out_ptr1 + static_cast<long>(i0), 16);
auto tmp1 = cvt_bf16_to_fp32(tmp0);
auto tmp2 = at::vec::clamp_min(tmp1, decltype(tmp1)(0));
auto tmp3 = cvt_fp32_to_bf16(tmp2);
tmp3.store(out_ptr0 + static_cast<long>(i0), 16);
tmp3.store(out_ptr1 + static_cast<long>(i0), 16);
```
This PR also fixed the data type propagation for `masked_subblock`.
Before the masked_subblock's dtype is propagated by its input which is wrong.
```
opcode name target args kwargs
----------- --------- --------- -------------------------- --------
call_module masked_subblock1 masked_subblock1 (and__2, -inf)
```
Now we propagated it by subblock with the same name:
```
# graph for body.subblocks['masked_subblock1']
opcode name target args kwargs
----------- --------- --------- -------------------------- --------
placeholder ops ops () {}
call_module get_index get_index ('index2',) {}
call_method load load (ops, 'arg0_1', get_index) {}
call_method to_dtype to_dtype (ops, load, torch.float32) {}
output output output (to_dtype,) {}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101042
Approved by: https://github.com/jgong5, https://github.com/jansel
Both internal and OSS users trying https://github.com/pytorch/pytorch/pull/99937 report that their workloads perform normally even with the barrier removed and see a scalability win. Thus in this PR, we decide to make it default that PG do not perform a barrier after init.
In the discussion of #99937, people point out that such barrier might be needed for c10d + RPC cases. IMO, this need originates from RPC's programming model and should be RPC or RPC user's responsibility to deal with. That is, with other functions/libraries, it can happen too. So the need for c10d to do so big a favor is not justified IMO. Also good to remove it before users become reliant on this barrier.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103033
Approved by: https://github.com/XilunWu
This PR creates a device_mesh and share it across all FSDP state. The device_mesh will later be used to test out dtensor state_dict (1d device_mesh).
Approved by: https://github.com/awgu
Add device mesh to fsdp state
skip dist.get_world_size(pg) != dist.get_world_size()
address test_fake_pg.py test failure
fix test_fake_py.py failure
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102551
Approved by: https://github.com/fegin
- Disables dynamo on the differentiable optimizer tests
- Disables dynamo on some test methods which expose a very rare dynamo edge case
- Disables dynamo on export/save optimizer state methods because it shouldn't trace those anyway.
I have a draft PR to fix the two tests marked skip due to unsupported mutation of step.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103066
Approved by: https://github.com/janeyx99, https://github.com/malfet
# Summary
Since we have upstreamed the latest changes of memory efficient attetnion we can remove the sm86/sm89 specific check. All head_sizes (assuming correctly alignment) should work for sm86 and sm89 size and don't have a max capability.
If head_size > 96 there will be a big drop in performance but should not error and still maintain memory savings by not materializing attention weights.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102985
Approved by: https://github.com/cpuhrsch
before the PR, running super(MyConv1d, self).forward or super(MyConvTranspose, self).foward, dynamo will create a graph break when executing NNModuleVariable.call_method and raise unimplemented error for name=_conv_forward / _output_padding. see issue for full detail: https://github.com/pytorch/pytorch/issues/101155
after the PR, for torch.nn.conv module with function name _conv_forward / _output_padding, we inline the function with tx.inline_user_function_return
code refactor: added NNModuleVariable._inline_user_function_return_helper to consolidaste tx.inline_user_function_return into 1 place to keep code dry. after factor, there are 2 uncolidated inline_user_function_return with different ```fn``` and ```source``` logic. the code is still dry. For local testing, they are covered by test_modulelist, test_moduledict, test_conv_call_super_forward_directly and test_conv_transpose_call_super_forward_directly in test_modules.py
Differential Revision: [D46494460](https://our.internmc.facebook.com/intern/diff/D46494460)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102509
Approved by: https://github.com/yanboliang
Rocm queries for the number of processes it should use per machine, which might cause it be different across shards, which leads to inconsistencies when distributing tests among shards.
My solution is to separate the vars used for shard calculations and the actual number of procs that can be used and to ensure that the var used for shard calculations is consistent across all shards for a test config + job. I believe that the only consequence is that rocm sharding might become unbalanced.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102871
Approved by: https://github.com/huydhn, https://github.com/malfet
Minor QOL change. This log message is pushed into my history by the
backtrace, which is a pain because if I tab up in tmux I can no longer
paste it without line breaks. This makes it more convenient to use tmux
copy mode to get only the file (as I get the entire line this way.)
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103083
Approved by: https://github.com/albanD
Summary: bias_addmm is not backed up by a cpp funciton, so turn
autotune_cublasLt for cpp_wrapper + max_autotune. We can add a cpp
function implementation if there is a performance need.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103004
Approved by: https://github.com/jansel
Summary:
Using composable quantizer, we can now composable two or more quantizers. In
the test here we compose quantizer configured with dynamic linear quantization,
with quantizer configured for static quantization.
Note that composable quantizer has strict order in which annotations are
applied
Test Plan: test_composable_quantizer*
Reviewed By: jerryzh168
Differential Revision: D46267690
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102846
Approved by: https://github.com/andrewor14
This done in the ordinary way, but also:
* Deprecation warning for the old API, and a migration guide
* Backwards compatibility for state_dict loading the old weight_norm
* Test for pickling and deepcopy, which was the motivating reason
weight_norm is still used by HuggingFace Wav2Vec2.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103001
Approved by: https://github.com/albanD
Skip all cuda graph-related unit tests by setting env var `PYTORCH_TEST_SKIP_CUDAGRAPH=1`
This PR refactors the `TEST_CUDA` python variable in test_cuda.py into common_utils.py. This PR also creates a new python variable `TEST_CUDA_GRAPH` in common_utils.py, which has an env var switch to turn off all cuda graph-related tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103032
Approved by: https://github.com/malfet
v2 of https://github.com/pytorch/pytorch/pull/102125 because of git issues
corresponding deserialization diff: https://github.com/pytorch/pytorch/pull/102716
Implementing serialization of the exported program to a python dataclass, and then from that dataclass to json. This is split into a couple of sections:
- `serialize(ep: ep.ExportedProgram, opset_version: Dict[str, int]) -> Tuple[bytes, bytes]` -- takes an exported program object, a dictionary mapping opset namespaces to versions, and returns the serialized exported program in bytes, and separately the state dict serialized in bytes
- `GraphModuleSerializer` class that serializes torch.fx.GraphModule
to the schema.GraphModule dataclass
- `ExportedProgramSerializer` class that serializes torch._export.exported_program.ExportedProgram to the schema.ExportedProgram dataclass
Serialization TODOs:
- [x] pytree spec: https://github.com/pytorch/pytorch/pull/102577
- [ ] higher order ops
- [ ] node metadata (specifically nn_module_stack/source_fn)
- [ ] constraints
- [ ] graph module metadata
The tests are not super comprehensive, but that's because I think it'll be better tested + easier to test once deserialization is implemented.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102707
Approved by: https://github.com/avikchaudhuri, https://github.com/zhxchen17
Fixes#92675
Here we implement a native version of [`einops.rearrange`](https://einops.rocks/api/rearrange/) using first class dims to perform the operations. The string parsing + validation, documentation, and relevant tests are adapted from `einops`. The API is exactly the same as the `einops` API.
The main idea is to take the string and convert it to a left and right `ParsedExpression`, and then find a mapping from the axes to first class dims. Once the mapping exists we convert the left expression `composition` list into a `Tensor.__getitem__` index and the right expression `composition` into the `Tensor.order` arguments, and then use this to dynamically create a callable that performs the `rearrange` operation as specified by the pattern.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101957
Approved by: https://github.com/zdevito
Sometimes you'll see linter failures on CI that don't repro locally, caused by the local linter not having installed the latest config.
These instructions explain how to make both the CI and local linter consistent again
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102990
Approved by: https://github.com/huydhn
This is done by introducing two new base classes: InPlaceCollectiveKernel and OutOfPlaceCollectiveKernel.
They deal with the differences for when InPlaceHint needs to be used.
Additionally to that, we introduce `has_side_effects` method to buffers that
prevents them from being DCE'd by the scheduduler. This is needed because InPlaceHint
nodes both wrap the inputs and are the outputs, which places no users to the collectives
themselves.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99765
Approved by: https://github.com/wconstab
Summary:
Previously, the test for the convert flow in Conv + BN
QAT fusion was not enabled by mistake. However, reenabling this
test uncovered several bugs:
(1) The replaced nodes returned by subgraph rewriter were not
handled correctly. This is because a recent change in the subgraph
rewriter (#100556) fixed only the prepare case but not the convert
case. This commit brings this fix to the convert case as well and
deduplicates some code between the two cases.
(2) When folding BN into conv, we used the wrong arg index to get
the BN eps value. This resulted in an incorrect conv weight.
(3) In FX, we currently do a hack for weighted modules where we
observe the weights once in convert in order to ensure we get the
right shapes for these weight observers. This caused the numerics
to diverge between PT2 and FX. This commit fixes this by skipping
this unnecessary hack for `_convert_to_reference_decomposed_fx`.
(4) Per channel support was simply missing. This commit adds
support for this by matching the quantize_per_channel and
dequantize_per_channel ops in addition to the existing ones.
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_qat_conv_bn_numerics
Reviewed By: jerryzh168
Differential Revision: D46097783
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102224
Approved by: https://github.com/jerryzh168
Summary: trigger tracing for MTIA events on python side when ProfilerActivity.MTIA is specified
Test Plan:
Test diff: D45437426
```
hg graft D45437426
```
- in one terminal
```
cd ~/fbsource/fbcode
buck2 run -j 8 \
//infra_asic_fpga/firmware/tools/mad/service:mad_service
```
- in another terminal
Pytorch profiler
```
buck run mode/dev-nosan -j 8 //caffe2/torch/fb/acc_runtime/afg/tests:test_afg -- -m kernel_add
```
Differential Revision: D46122853
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102288
Approved by: https://github.com/aaronenyeshi
This helps with kernels that make use of caching like mid-range softmax
which reads the data three times.
Selecting `eviction_policy=evict_first` in the last loop of the softmax
operation seems to give a 7-10% speed-up vs. selecting `evict_last` which
was the previous option. I'll put up some benchmarks soon™.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91316
Approved by: https://github.com/ngimel, https://github.com/jansel
Fixes#92240; this adds all variables in `torch/jit/__init__.py` that also have docs page to `__all__`: https://pytorch.org/docs/stable/jit.html
As stated in the tracking issue, this solves pyright errors like this:
```python
import torch
def foo(x, y):
return 2 * x + y
traced_foo = torch.jit.trace(foo, (torch.rand(3), torch.rand(3))) # error: "trace" is not exported from module "torch.jit" (reportPrivateImportUsage)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101678
Approved by: https://github.com/albanD
When running dynamic shape of ```OPTForCausalLM``` path, there has an error: ```TypeError: unsupported operand type(s) for +: 'Node' and 'int'```, this PR will do:
1. For ```pointless_cumsum_replacement```, the sizes may be a node, we should trace the target pattern using example input.
2. For dynamic shape, we should trace a pattern under fake mode in which inputs may have symbolic inputs.
After this PR, the dynamic shape of ```OPTForCausalLM``` can work(```python -m torch.backends.xeon.run_cpu --node_id 0 benchmarks/dynamo/huggingface.py --performance --float32 -dcpu --inference -n5 --inductor --dynamic-shapes --only OPTForCausalLM```).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102820
Approved by: https://github.com/jgong5, https://github.com/desertfire, https://github.com/jansel
Summary: Add a flag to enforce the gather data dtype. In case backward compatibility, make the default as False
Test Plan: local and mast
Reviewed By: zyan0, strisunshinewentingwang
Differential Revision: D46295190
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102802
Approved by: https://github.com/mrshenli
Per title, after https://github.com/pytorch/pytorch/pull/102426 landed, it makes sense to have a new category for UNSTABLE jobs and handle them accordingly in trymerge.
* The simple approach is to check for `unstable` in the check (job) name. I plan to roll this out first and then see if we need to cover the more complicated, but less popular case, of unstable build job. Specifically, an unstable build job has no `unstable` in its name
* An unstable job is ignored by trymerge. This is the same behavior we have atm when a job is moved to unstable. It's completely ignored
* The update to Dr. CI will come later, so that unstable failures would also be hidden like broken trunk or flaky
### Testing
Leverage the broken trunk Windows CPU job atm and mark Windows CPU jobs as unstable https://github.com/pytorch/pytorch/issues/102297
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102784
Approved by: https://github.com/clee2000
Summary:
Replace _dynamo.config with an object instead of module
Current usage patterns of setting and reading fields on config will work
unchanged.
Only changes needed going forward:
1. import torch._dynamo.config will not work. However, just doing
import torch._dynamo is sufficient to access dynamo config
as torch._dynamo.config.
2. Files inside of _dynamo folder need to access config via
from torch._dynamo.config_util import config instead of
from torch._dynamo import config. Because _dynamo/__init__.py
imports some of the files so it would be circular import.
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96455
Approved by: https://github.com/jansel
Summary:
keys and change codegen to take ETKernelIndex
We are adding support for dtype and dim order specialized kernel registration. This requires us to reorganize `BackendIndex` (which is a `Dict[DispatchKey, Dict[OperatorName, BackendMetadata]]`) to be `Dict[OperatorName, Dict[ETKernelKey, BackendMetadata]]`. This PR adds new data structures in order to support this change:
* `ETKernelKey` to retrieve a certain kernel from the registry.
* `ETKernelIndex`, the dictionary from operator name to kernel key to kernel mapping.
Note that the codegen logic is not changed yet, we need subsequent diffs to actually generate code for different kernel keys.
Test Plan: Added tests
Reviewed By: Jack-Khuu
Differential Revision: D46407096
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102874
Approved by: https://github.com/Jack-Khuu, https://github.com/kirklandsign
On calls to `_init_group` rather than tracing through it, extract python values from the arguments, and call the initialization. This avoids having to trace this function which is very slow with large parameters, and also avoids graph breaking on it. This is sound in this case because the state is only initialized once in the eager case. Guards on the state and params are generated explicitly rather than via tracing the initialization.
Caveats:
`_init_group` also gathers various state tensors into lists via mutating list arguments to pass to the functional optimizer implementation. These state tensors exist on the optimizer itself, but we don't know exactly how the gathering is done and which tensors correspond to which attributes of the optimizer module (each optimizer has different states). To rectify this, we keep weak_ptrs to all of the tensors collected in the lists in globals (similar to how parameter keys are stored for dictionaries). These pointers are guaranteed to be alive as long as the optimizer object is alive if the internal state is not interfered with and they are guarded with weakref guards
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102640
Approved by: https://github.com/jansel
Summary:
att, after we support SharedQuantizationSpec we don't need these things anymore, this PR refactors the
uses of _input_output_share_observers to SharedQuantizationSpec
Test Plan:
```
buck2 test mode/opt caffe2/test:quantization_pt2e -- 'caffe2/test:quantization_pt2e'
```
Reviewed By: andrewor14
Differential Revision: D46301342
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102854
Approved by: https://github.com/andrewor14
The "tolerance" option evaluates the model on the baseline device in eager mode (default: CPU) compared to the test device (e.g., CUDA, XLA, etc.) and compares the output tensors to determine the absolute tolerance value based on the [formula](https://pytorch.org/docs/stable/generated/torch.allclose.html). It then saves the results in a CSV file. This comparison highlights the tolerance/accuracy difference between XLA and GPU/CPU devices and can also be used to evaluate newer accelerators. This feature aims to identify accuracy failures on the test device (e.g., XLA) and facilitate quick bug triaging.
This feature enables the following capabilities:
1. Ability to monitor accuracy issues of backends
2. Provide more informative picture on accuracy beyond pass/ fail status
3. Having a dump of accuracy information will help triage models accordingly
The data generated using this feature is in the [spreadsheet](https://docs.google.com/spreadsheets/d/1A8BAzSqfAw0Q5rgzK5Gk__Uy7qhuynh8tedxKnH-t94/edit#gid=0).
The spreadsheet data can be used to compile the below summary table:
| Suite | Max Tolerance | | No. of models with high inaccuracy(>=0.005) | | Mean Tolerance | |
|------------------ |:-------------:|:--------:|:-------------------------------------------:|:--------:|:--------------:|:--------:|
| | xla | inductor | xla | inductor | xla | inductor |
| huggingface | 0.1169 | 0.0032 | 1 | 0 | 0.0022 | 0.0005 |
| timm_models | 0.0373 | 2.8892 | 10 | 8 | 0.0028 | 0.7044 |
| torchbench | 3.013 | 3.0381 | 6 | 2 | 0.0016 | 0.0016 |
| All models | 3.013 | 3.0381 | 17 | 10 | 0.0028 | 0.7044 |
I used PyTorch release/2.0 branch and corresponding [commit_pin](https://github.com/pytorch/pytorch/blob/release/2.0/.github/ci_commit_pins/xla.txt) for XLA to generate the above data.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102218
Approved by: https://github.com/jansel
Makes the `lintrunner init` command work with python 3.11
The old version of numpy would fail to install on python 3.11, where setup would fail to build wheels with the error `AttributeError: fcompiler. Did you mean: 'compiler'?`
The latest version of numpy installs just fine however, so switching to that.
More details in https://github.com/numpy/numpy/pull/22102
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102889
Approved by: https://github.com/kit1980
Fixes#102315
The root cause is for ```UnspecializedNNModuleVariable``` which extends from ```UserDefinedObjectVariable```, if ```__bool__``` is missing, we should use ```__len__``` to infer a truth value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102583
Approved by: https://github.com/jansel
improves #102622 from ~150s to ~15s.
The way computing recursive predecessors works is if `nodes = node1.recursive_predecessors` then recursive predecessors of any `n` in `nodes` should still be a subset of `nodes`, so we can shortcut computing intersection of `node.recursive_predecessors - combined_predecessors`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102770
Approved by: https://github.com/Chillee
Update llvm_codegen module to use opaque pointers feature of llvm.
* Set setOpaquePointers to true for llvm context.
* Pass Type to emit\*Load and emit\*Store functions.
* Create TypedPointer struct to keep track of Value and its Type.
* Introduce OpqTy_ to be used for opaque pointer types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101396
Approved by: https://github.com/jgong5
Issue: #93684
In previous PRs #95849#99560 we redirect `numpy.*`, `<tensor>.numpy()` calls to `torch_np.*` methods and attributes, by creating `NumpyNdarrayVariable` for those calls.
We need to handle `NumpyNdarrayVariable` when graph break happens.
This PR did 2 things:
1. In `codegen.py` we made sure we can reconstruct the value wrapped by `NumpyNdarrayVariable`, to be `torch_np.ndarray` in the stack whenerver we recompiles the subgraph.
2. In `builder.py` we can wrap the value to be `NumpyNdarrayVariable` and save it as graph input.
-----
Starting from commit 6:
## A new design for supporting numpy in dynamo
In short the core concept doesn't change: we still convert `numpy` API calls to `torch_np` API calls. However, instead of wrapping a `torch_np.ndarray` in `NumpyNdarrayVariable`, the new design wraps a `torch.Tensor`.
The reason for doing this change is because we need to keep `torch.Tensor` everywhere in the captured graph, so that it works well with the backend of dynamo. See discussions in https://github.com/Quansight-Labs/numpy_pytorch_interop/issues/142 for details.
### Flow
This is an example showing how do we think about dynamo working on a simple function:
```python
def f(x: torch.Tensor, y: torch.Tensor):
a, b = x.numpy(), y.numpy()
c = np.add(x, y)
return torch.from_numpy(c)
```
```
+------------+ +------------+
torch.Tensor | |numpy.ndarray| |
-------------- .numpy() --------------| |
| | | | +------------------+
+------------+ | numpy.add |numpy.ndarray| |torch.Tensor
+------------+ | --------------| torch.from_numpy --------------
torch.Tensor | |numpy.ndarray| | | |
-------------- .numpy() --------------| | +------------------+
| | | |
+------------+ +------------+
+------------+ +----------------+
torch.Tensor | |torch.Tensor | |
-------------- .detach() --------------| |
| | | | +----------------+ +------------+
+------------+ | |torch_np.ndarray| |torch.Tensor| |torch.Tensor
| torch_np.add -----------------| util.to_tensor -------------| .detach() --------------
+------------+ | | | | | |
torch.Tensor | |torch.Tensor | | +----------------+ +------------+
-------------- .detach() --------------| |
| | | |
+------------+ | +----------------+ |
| wrapper on torch_np.add |
+--------------------------------------------------------+
```
### Approach
`torch_np` APIs can take both `torch_np.ndarray` as well as `torch.Tensor`. What we need to do is to have a wrapper for these APIs to convert the return value back to `torch.Tensor`. This way only the wrapper is showing up in the captured graph, with `torch.Tensor`s as input and `torch.Tensor` as output.
If we have a graph break or we've traced to the end of the program, we need to inspect all the `NumpyNdarrayVariable` in the stack and convert them back to `numpy.ndarray`, to make sure the compiled version is still behaving the same as the eager version.
### Examples
Here's an example of the graph generated:
```python
def fn(x: np.ndarray, y: np.ndarray):
a = x.real
b = y.real
torch._dynamo.graph_break()
return np.add(a, 1), np.add(b, 1)
```
Graph generated:
```
[2023-05-16 10:31:48,737] torch._dynamo.output_graph.__graph: [DEBUG] TRACED GRAPH
__compiled_fn_0 <eval_with_key>.0 opcode name target args kwargs
------------- -------------- ---------------------------------------------------------- ---------------------- --------
placeholder l_x_ L_x_ () {}
placeholder l_y_ L_y_ () {}
call_function from_numpy <built-in method from_numpy of type object at 0x12b1fdc80> (l_x_,) {}
call_function from_numpy_1 <built-in method from_numpy of type object at 0x12b1fdc80> (l_y_,) {}
call_function attr_wrapper <function attr_wrapper at 0x12e8693a0> (from_numpy, 'real') {}
call_function attr_wrapper_1 <function attr_wrapper at 0x12e8693a0> (from_numpy_1, 'real') {}
output output output ((),) {}
[2023-05-16 10:31:48,908] torch._dynamo.output_graph.__graph: [DEBUG] TRACED GRAPH
__compiled_fn_2 <eval_with_key>.1 opcode name target args kwargs
------------- ------------- ---------------------------------------------------------- ------------------------------- --------
placeholder l_a_ L_a_ () {}
placeholder l_b_ L_b_ () {}
call_function from_numpy <built-in method from_numpy of type object at 0x12b1fdc80> (l_a_,) {}
call_function from_numpy_1 <built-in method from_numpy of type object at 0x12b1fdc80> (l_b_,) {}
call_function wrapped_add <Wrapped function <original add>> (from_numpy, 1) {}
call_function wrapped_add_1 <Wrapped function <original add>> (from_numpy_1, 1) {}
output output output ((wrapped_add, wrapped_add_1),) {}
```
### Changes
* `codegen.py`: reconstruct `numpy.ndarray` from `NumpyNdarrayVariable` by adding bytecode to call `utils.to_numpy_helper()`.
* `output_graph.py`: getting rid of legacy code that does exactly what `codegen.py` does, which only handling return case but not graph break case.
* `utils.py`: added helpers to convert `numpy.ndarray` to `torch.Tensor` and vice versa. Also adding a wrapper class that takes in a function. In `__call__` it calls the function and converts its out to `torch.Tensor` (or a list of it).
* `builder.py`: add method to wrap `numpy.ndarray` graph inputs into `NumpyNdarrayVariable`, by calling `torch.numpy` in the proxy.
* `misc.py`: `numpy` API calls goes into `NumpyVariable` and we find the function with the same name in `torch_np` module, then wrap it with the wrapper defined in `utils.py`.
* `tensor.py`, `torch.py`: proxy `tensor.numpy()` to be `torch.detach()` but wrap it with `NumpyNdarrayVariable`. Similarly, `torch.from_numpy()` -> `torch.detach()` but wrap it with `TensorVariable`. In `NumpyNdarrayVariable`, do the similar `torch_np.ndarray` to `torch.Tensor` wrapping for attributes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100839
Approved by: https://github.com/ezyang
Fixes#102441
improves type hinting of the module attribute, since it can easily be bound in `DataParallel.__init__`
```python
from torch.nn import DataParallel
class MyModule(Module):
...
my_data_parallel = DataParallel(MyModule(), device_ids=[0, 1, 2])
reveal_type(my_data_parallel) # Type of "my_data_parallel" is "DataParallel[MyModule]"
reveal_type(my_data_parallel.module) # Type of "my_data_parallel.module" is "MyModule"
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102455
Approved by: https://github.com/Skylion007
Summary:
We are currently silently skipping all PT2 quantization
tests due to a recent typo. This commit fixes this and also adds
warnings so it'll be easier to debug similar issues in the future.
Test Plan: python test/test_quantization.py
Differential Revision: D46383546
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102819
Approved by: https://github.com/jerryzh168
# torch.compiler public API
## Goal
The goal of this document is to describe the public facing API for torchdynamo and torchinductor.
Today both dynamo and torchinductor are in `torch/_dynamo` and `torch/_inductor` namespace with the only public function
`torch.compile()` which is directly placed in `torch/__init__.py`
This poses a few problems for users trying to take dependencies on PyTorch 2.0
1. Unclear BC guarantees
2. No builtin discovery mechanism outside of reading the source code
3. No hard requirements for docstrings or type annotations
Most importantly it mixes two personas the PyTorch 2.0 developer vs the PyTorch 2.0 customer so this is an attempt to address this. We draw a lot of inspiration from the `functorch` migration to the `func` namespace.
## Alternate names
We did discuss some other alternative names
1. `torch.compile` -> problem is this would break BC on the existing `torch.compile` function
2. `torch.dynamo` -> `dynamo` is so far not something we've deliberately hidden from users but problem is now figuring out what it's `_dynamo` vs `dynamo` might be confusing
3. `torch.compiler` -> 1 would be better but to keep BC this is a good compromise
# The general approach
## Proposal 1
In https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/__init__.py
We have function called `reset()`, this function is essential if users are trying to `torch.compile()` a model under different settings
```python
# in _dynamo/
def reset():
do_reset_stuff()
```
Instead we propose
```python
# in compiler/
def reset():
do_reset_stuff() # As in copy paste the logic from _dynamo.reset
# in _dynamo/
import warnings
import inspect
def reset():
function_name = inspect.currentframe().f_code.co_name
warnings.warn(f"{function_name} is deprecated, use compiler.{function_name} instead", DeprecationWarning)
return compiler.reset()
```
## Proposal 2
```python
# in compiler/
def reset():
“””
Docstrings here
“””
_dynamo.reset()
# in _dynamo/
No changes
```
Consensus so far seems to be proposal 2 since fewer warnings will be less jarring and it’ll make it quite easy to merge the public API
## Docstrings
The above was an example of a function that has no inputs or outputs but there are other functions which could use an improvement in their docstrings, for example allow_in_graph actually works over lists of functions but that’s not mentioned anywhere in the example only if you read the source code.
def allow_in_graph(fn):
"""
Customize which functions TorchDynamo will include in the generated
graph. Similar to `torch.fx.wrap()`.
Parameters:
fn (callable or list/tuple): The function(s) to be allowed in the graph.
Returns:
callable or list/tuple: The input function(s) included in the graph.
Examples:
Customize inclusion of a single function:
::
torch._dynamo.allow_in_graph(my_custom_function)
Customize inclusion of multiple functions:
::
torch._dynamo.allow_in_graph([my_custom_function1, my_custom_function2])
@torch._dynamo.optimize(...)
def fn(a):
x = torch.add(x, 1)
x = my_custom_function(x)
x = torch.add(x, 1)
return x
fn(...)
Notes:
The `allow_in_graph` function allows customization of which functions TorchDynamo
includes in the generated graph. It can be used to include specific functions that
are not automatically captured by TorchDynamo.
If `fn` is a list or tuple, `allow_in_graph` will be called recursively on each
element in the sequence.
Once a function is allowed in the graph using `allow_in_graph`, it will be captured
in the graph generated by TorchDynamo. This customization enables more fine-grained
control over the functions included in the graph.
Note that `allow_in_graph` expects the input `fn` to be a callable.
"""
if isinstance(fn, (list, tuple)):
return [allow_in_graph(x) for x in fn]
assert callable(fn), "allow_in_graph expects a callable"
allowed_functions._allowed_function_ids.add(id(fn))
allowed_functions._disallowed_function_ids.remove(id(fn))
return fn
So to make the API public, we’d have to write similar docstrings for all public functions we’d like to create.
The benefit of this approach is that
1. No BC risks, internal and external users relying on our tooling can slowly wean off the private functions.
2. We will also have to write correct docstrings which will automatically make our documentation easier to maintain and render correctly on pytorch.org
3. We already have some BC guarantees already, we don’t kill OptimizedModule, we rejected the PR to change the config system
The con of this approach is that
Will be stuck with some potentially suboptimal functions/classes that you can’t kill
## Testing strategy
If the approach is to mostly make a public function call an already tested private function then all we need to do is ensure that the function signatures don't change
## Which functions should be in the public API
Our heuristic for deciding whether something should be public or not is are users already relying on it for lack of other options or have we recommended some non public functions for users to debug their PT 2.0 programs.
Heuristic for not putting something in public is that it’s an experimental subsystem with the goal of turning it on by default, it’s very core dev centric, meta centric, a bunch of different configs that should be batched into a single user facing one, or something that needs to be renamed because the name is confusing
#### Top level
`torch.compile()` -> already is a public API it does require some minor improvements like having configs be passed in to any backend and not just inductor (EDIT: This was already done https://github.com/pytorch/pytorch/pull/99645l) and renaming `mode=reduce-overhead` to `mode=cudagraph`
To make sure that PT 2.0 is supported with a given pytorch version users can create a new public function and this would replace the need for `try/except` blocks around `import torch._dynamo` that has been populating user code.
```python
def pt2_enabled():
if hasattr(torch, 'compile'):
return True
else:
return False
```
For all of the below they will be translated to `torch.compiler.function_name()`
#### From _dynamo
As a starting point we looked at https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/__init__.py and we suggest redefining these functions in `pytorch/torch/compiler/__init__.py`
It might also make sense to split them over multiple files and import them in `__init__.py` but because the number of functions is small it'd probably be fine to add them all into a single compiler/__init__.py until this list becomes larger
1. `reset()`
2. `allow_in_graph()`
10. `list_backends()`
12. `compile()`: torch.compile() would be mostly a shell function passing arguments to torch.compiler.compile()
13. `assume_constant_result()`: TODO: Double check how this is useful
15. `torch._dynamo.disable()`
Some notable omissions
11. `explain()`: We need to clean up the output for this function, make it a data class and pretty printable
1. `forbid_in_graph()`: Considered adding this but should instead consolidate on `disallow_in_graph`
2. `optimize_assert()`: Already covered by `torch.compile(fullgraph=True)`
3. `check_if_dynamo_supported()`: this would be supplanted by pt2_enabled()
4. `compilation_metrics`, `graph_breaks_reasons` ..: would all be accessed via `torch.compiler.explain()`
5. `replay` does not seem useful to end customers
6. . `graph_break()`: Mostly useful for debugging or unit tests
9. `register_backend()`: End users will just pass a string backend to torch.compile, only devs will create new backends
10. `export()` : Eventually this needs to public but for now it’s not ready so just highlighting that it will be in the public API eventually
11. `disallow_in_graph()`: Usage is limited
12. `mark_static()`: we can keep this private until dynamic=True is recommended in stable
13. `mark_dynamic()`: we can keep this private until dynamic=True is recommended in trunk
14. 8. `OptimizedModule`: This is the only class that we'd expose but is crucial since users are running code like `if isinstance(mod, OptimizedModule): torch.save(mod._orig_mod)` EDIT: because we fixed pickling we no longer need to
expose this
15. `is_compiling()`: Still not clear how this useful to end users
There are also config variables which we need to expose https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/config.py
Some of our configs are useful dev flags, others are to gate experimental functionality and others are essential debugging tools and we seperate out the essential debugging and logging tools to a public facing config.
TODO: I still need to think of a good way of porting the config in a BC way here are some ideas
1. Just make all passes available and controllable via `torch.compile(options={})` but only show docstrings for the ones users should care about.
The current problem with our config system is we have 3 ways of setting them once via `options={}`, environment variables and variables in `config.py`, it'd be worth settling on one source of truth and have that be the public API.
The configs we should make public are
1. `log_file_name`
2. `verbose`
3. `cache_size_limit`
4. `repro_level` and `repro_after`: Although we can rename these to minifier and give human readable names to the levels
Everything else should stay private in particular
1. `print_graph_breaks`, `print_specializations`: should be supplanted by `explain()` for public users
2. dynamic shape configs : Users should only have to worry about `torch.compile(dynamic=True/False)`
3. The distributed flags, hook or guard configs: If we tell a user to use FSDP and DDP then the flag should be enabled by default or be in a private namespace
4. The fbcode flags: Obviously no need to be user facing
5. Skip/Allow lists: Not something normal users should play around with
#### From _inductor
Very little of inductor should be exposed in a public facing API, our core audience as in people writing models mostly just need information on what certain passes mean and how to control them a high level and they can do this with `torch.compile(options={})` so the goal here should be more to make available passes clearer and ideally consolidate them into `torch.compile()` docstrings or modes.
There are some exceptions though from https://github.com/pytorch/pytorch/blob/main/torch/_inductor/__init__.py
1. `list_mode_options()`
2. `list_options()`: this needs an additional pass to hide internal or debug options
For both of these we’d rename them to compiler.inductor_list_mode_options and compiler.inductor_list_options() since they would be in the same init file as the one for dynamo
Notable omissions
1. `_inductor.compile()`: Because of users are coming in with their own fx graph, they are likely developers
2. `_inductor.aot_compile()`:Again this is about capturing and modifying fx graphs so users APIs don't need to be public
However the configs are a slightly different story, because we can choose to either
1. Make all configs public
2. Make some configs public and keep most of the private ones. If public config is set it should override the private version
3. Make all configs controllable via `torch.compile(options={})` but make list_options() hide more things
For now 3 seems like the most reasonable choice with some high level configs we’ll keep like TORCH_COMPILE_DEBUG
Regardless here's what should probably be public or advertised more
1. `disable_progress` and verbose_progress: Combine and enable by default
2. `fallback_random`: We could make the case this shouldn't be public if a top level deterministic mode enables this
3. `profile_bandwidth`: Or could make the case that this should be in TORCH_COMPILE_DEBUG
Notable omissions
1. Any config that would generally improve performance for most that we should probably enable by default but might be disabled in the short term because of stability: example `epilogue_fusion`, `pattern_matcher`, `reordering`
2. Autotuning flags: Should just sit behind `torch.compile(mode="max-autotune")` like `max_autotune`, `max_autotune_gemm`
3. `coordinate_descent_tuning`: This one I'm a but mixed about, maybe it just also fall into `mode="max-autotune"`
4. `trace`: `TORCH_COMPILE_DEBUG` is the best flag for all of this
5. `triton.cudagraphs`: Default should be `torch.compile(mode="reduce-overhead")` - I'd go further and rename the `mode=cudagraph` and we can keep reduce-overhead for BC reasons
6. `triton_unique_kernel_names`: Mostly useful for devs debugging
7. `dce`: which doesnt really do anything
8. `shape_padding`: Elias is working on enabling this by default in which case we also remove it
## Mechanics
This PR would include the public functions with their docstrings
Another PR will take a stab at the configs
And for work where the APIs are still being cleaned up whether its minifier or escape hatches, export or dynamic shapes, aot_inductor etc.. we’ll keep them private until a public commitment can be made
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102182
Approved by: https://github.com/jansel
I confirmed that there are no usages of these APIs on github code search
or internally. There may still be usages (hence the BC-breaking label),
but I expect none to very few.
There are some leftover py_context_manager_DEPRECATED that will likely
stay that way for a while because:
- they are used outside of the pytorch repo (`_AutoDispatchBelowAutograd`,
`_DisableTorchDispatch`, `_InferenceMode`)
- they are high risk (all of the torch_function / torch_dispatch related
stuff)
- PyTorch requires that the object behaves like a "Python RAII guard"
(`_DisableFuncTorch`, `_MultithreadingEnabled`)
This is probably the last PR in the context manager cleanup series.
Test Plan:
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102643
Approved by: https://github.com/bdhirsh
`register_functional_op`:
- constructs the functional variant of an op
- registers a functionalization kernel to the op
To get this to work:
- `register_functional_op` makes assumptions that it checks about the
op's schema. In particular, the op is not allowed to return anything it
mutates. We can relax these constraints in the future.
- We add a "boxed" python functionalization kernel that handles this
case.
I'm not actually sure (or convinced) this should be public API or how
it should work. If we want this to be public, then it should probably be
a torch.library API, but does that also mean we should give the same
lifetime guarantees? If so, then it would be up to the user to construct
a Library object to actually register the functional variant onto.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102293
Approved by: https://github.com/bdhirsh
We did this for TestCustomOp, now we are applying the same thing to
TestPythonRegistration.
This PR:
- changes TestPythonRegistration to register new ops under a single
namespace (self.test_ns)
- clean up the namespace by deleting it from torch.ops after each test
is done running.
This avoids a problem where if an op is re-defined, torch.ops.myns.op
crashes because we do some caching. The workaround in many of these
tests have been to just create an op with a different name, but this PR
makes it so that we don't need to do this.
Test Plan:
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102292
Approved by: https://github.com/ezyang, https://github.com/bdhirsh
Summary:
Fixes:
```
warning: missing return statement at end of non-void function
```
This warning is cluttering a lot of compilation logs!
Test Plan: Sandcastle
Differential Revision: D46374554
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102785
Approved by: https://github.com/Skylion007
1. `torch.autograd.profiler` interface parameters changed. (use `self.use_device` instead of `self.use_cuda` facilitates access by other devices and integrate it in subsequent pr)
2. Modify `ProfilerEventStub`(aka `std::shared_ptr<CUevent_st>`) to `ProfilerVoidEventStub`(aka `std::shared_ptr<void>`) so that `ProfilerStubs` can be inherited by any `{device}Methods`.
In addition, `cuda_event_start_` is renamed to `device_event_start_` , cuda and other devices can use this event pointer if needed.
4. custom device support using legacy profiling(add `ProfilerState::KINETO_PRIVATEUSE1_FALLBACK` option)
5. add `privateuse1Stubs` register
(parse results and test cases are added in subsequent pr)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101554
Approved by: https://github.com/aaronenyeshi
This patch reuses `radix_sort` from fbgemm and makes `torch.(arg)sort` work in parallel for tensors filled with integers.
In GNN workloads we often use `torch.(arg)sort`, for example, to calculate permutation from CSR to CSC storage format. Till now, sorting one-dimensional data was performed sequentially. Recently, `radix_sort` implementation from FBGEMM was moved to common utilities and was also enhanced, to cover negative numbers ([pytorch/FBGEMM#1672](https://github.com/pytorch/FBGEMM/pull/1672)). This gives us an opportunity to reuse `radix_sort` to accelerate 1D integer sorting in PyTorch.
Benchmark results, measured on a single socket, 56C machine:
Before (int64):
```
size: 64000, average run time (from 100 runs): 6.592ms
size: 128000, average run time (from 100 runs): 9.798ms
size: 256000, average run time (from 100 runs): 19.199ms
size: 512000, average run time (from 100 runs): 36.394ms
size: 1024000, average run time (from 100 runs): 70.371ms
size: 2048000, average run time (from 100 runs): 137.752ms
size: 4096000, average run time (from 100 runs): 287.257ms
```
After(int64):
```
size: 64000, average run time (from 100 runs): 1.553ms
size: 128000, average run time (from 100 runs): 1.853ms
size: 256000, average run time (from 100 runs): 2.873ms
size: 512000, average run time (from 100 runs): 4.323ms
size: 1024000, average run time (from 100 runs): 7.184ms
size: 2048000, average run time (from 100 runs): 14.250ms
size: 4096000, average run time (from 100 runs): 29.374ms
```
Notes:
Average speedup from measured tensor sizes is 7.7x.
For smaller types (e.g. int32/int16), even higher speedup is observed, as fewer passes are required.
Depends on #100236.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100081
Approved by: https://github.com/mingfeima, https://github.com/ngimel
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 963044b</samp>
The pull request improves the reliability and completeness of the external contribution stats collection and upload. It adds a `time` delay to avoid API rate limit errors in `upload_external_contrib_stats.py`, and changes the order and date range of the commands in `nightly-rockset-uploads.yml`.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 963044b</samp>
> _Oh we are the coders of the open source sea_
> _And we pull and we push with the `git` command_
> _We upload the stats of the external PRs_
> _With a ten-day range and a `time` delay_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102780
Approved by: https://github.com/kit1980
<!--
copilot:all
-->
### <samp>🤖 Generated by Copilot at 943f854</samp>
### Summary
:clock15:⬆️☁️
<!--
1. :clock15: - This emoji represents the 15-minute interval of the cron schedule, and also suggests the idea of time-based triggers or events.
2. ⬆️ - This emoji represents the upload action of the workflow, and also suggests the idea of moving data from one place to another.
3. ☁️ - This emoji represents the AWS/Rockset destination of the alerts, and also suggests the idea of cloud-based services or platforms.
-->
Add a new workflow to upload alerts to a database. The workflow `.github/workflows/upload_alerts.yml` runs periodically on a cron schedule and uses AWS/Rockset as the backend.
> _`workflow` file added_
> _upload alerts to the cloud_
> _every quarter hour_
### Walkthrough
* Add a new workflow to upload alerts to AWS/Rockset every 15 minutes ([link](https://github.com/pytorch/pytorch/pull/102646/files?diff=unified&w=0#diff-946b3ad914f86182b35d4b6db415ddc39393c3017ef8fdaeee2b0e866ea831d6R1-R46))
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102646
Approved by: https://github.com/huydhn
One annoyance with mark_dynamic is if you use it on a user specified
tensor input (the idea being that you want to compile a function and
have it be polymorphic in size), you will get an error if the user
ever sends you a 0/1 size input, because of course we are probably
going to specialize it. So I relax the constraint even more: even if we
find it's constant, if the value is 0/1, that's no big deal.
There's some irritating code duplication that I don't entirely know how
to resolve.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102729
Approved by: https://github.com/avikchaudhuri, https://github.com/voznesenskym
It was recently reported that `ncclCommAbort` itself may hang in some NCCL versions. For example, https://github.com/NVIDIA/nccl/issues/829.
In that case, it may be desirable to directly tear down the program without properly aborting the NCCL communicator, so that user does not wait for hours before noticing a hang.
This PR adds new value 3 for env `NCCL_ASYNC_ERROR_HANDLING` that skips the comm abort, and directly throws error in case of exception (timeout, async error, etc)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102599
Approved by: https://github.com/fegin
To avoid nvcc segfaults, compile without `--source-in-ptx` option on CUDA-12.1+
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 984e4b2</samp>
> _Sing, O Muse, of the daring deeds of PyTorch, the swift and fiery_
> _framework that harnesses the power of CUDA, the blazing tool of Nvidia._
> _How they faced a mighty challenge when CUDA, the ever-shifting,_
> _released a new version, twelve point one, that broke their code and caused them grief._
Fixes https://github.com/pytorch/pytorch/issues/102372
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102756
Approved by: https://github.com/atalman
sharding on rocm is broken, i cant replicate on dummy PRs even though it seems to happen pretty often on main, so adding this to increase my sample size. Hopefully this is enough print statements...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102713
Approved by: https://github.com/huydhn
fixes#101911
Currently, `DTensor` supports cuda and cpu. This PR makes some changes for easier integration with the ort backend.
* `Backend.NAME` attribute now has value `name` instead of `NAME` for backends registered through `register_backend(name)`; this matches the pattern for backends with built-in support like nccl.
* remove unused `_check_for_nccl_backend` function
* add test case that moves parameters to device in the `partition_fn` - a scenario that's useful for big models
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101914
Approved by: https://github.com/wanchaol
Summary:
`getStreamFromPool(bool, signed char)` overload doesn't initialize `max_stream_priorities`. So if we call `getStreamFromPool(true)` we would hit the following error
```
terminate called after throwing an instance of 'c10::Error'
what(): Expected cuda stream priority to be less than or equal to 0, got 1
```
Differential Revision: D46358087
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102739
Approved by: https://github.com/ngimel
Fixes#101449
I found it better to either imitate the combo of `TensorIterator::can_use_32bit_indexing` and `TensorIterator::with_32bit_indexing` or adroitly choose the index type depending on `Tensor::numel` in the future.
---
Used `nsys nvprof` to casually see the effect of `int64_t` indexing:
```python
import torch
params = [
{"params": [torch.randn(32, 32, device="cuda") for _ in range(100)]},
{"params": [torch.randn(32, 32, device="cuda") for _ in range(100)]},
]
grads = [
[torch.randn(32, 32, device="cuda") for _ in range(100)],
[torch.randn(32, 32, device="cuda") for _ in range(100)],
]
optimizer = torch.optim.Adam(params, fused=True)
for _ in range(100):
for i, param_groups in enumerate(params):
for p, g in zip(param_groups["params"], grads[i]):
p.grad = g
optimizer.step()
optimizer.zero_grad()
```
Environment
```
Collecting environment information...
PyTorch version: 2.1.0a0+gitf994d0b
Is debug build: False
CUDA used to build PyTorch: 12.1
Python version: 3.10.9 (main, May 17 2023, 00:46:40) [GCC 11.3.0] (64-bit runtime)
CUDA runtime version: 12.1.105
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-80GB
```
---
- `multi_tensor_apply_kernel<at::native::<unnamed>::FusedOptimizerTensor` -> 1.02x
- `multi_tensor_apply_kernel<at::native::<unnamed>::TensorListMetadata<(in…` -> 1.04x
Current main branch:
```
Time (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- -------- -------- -------- -------- ----------- ----------------------------------------------------------------------------------------------------
64.9 5787610 600 9646.0 9632.0 9503 9888 52.9 void at::native::<unnamed>::multi_tensor_apply_kernel<at::native::<unnamed>::FusedOptimizerTensorLi…
...
8.1 720575 200 3602.9 3584.0 3551 4320 63.4 void at::native::<unnamed>::multi_tensor_apply_kernel<at::native::<unnamed>::TensorListMetadata<(in…
```
this PR:
```
Time (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- -------- -------- -------- -------- ----------- ----------------------------------------------------------------------------------------------------
65.0 5876847 600 9794.7 9792.0 9632 10080 58.1 void at::native::<unnamed>::multi_tensor_apply_kernel<at::native::<unnamed>::FusedOptimizerTensorLi…
...
8.3 748313 200 3741.6 3744.0 3711 4479 60.0 void at::native::<unnamed>::multi_tensor_apply_kernel<at::native::<unnamed>::TensorListMetadata<(in…
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101760
Approved by: https://github.com/ngimel
Do not try to parse raised exception for no good reason
Add short description
Reduce script to a single line
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at ea4164e</samp>
> _`test_no_triton_on_import`_
> _Cleans up the code, adds docs_
> _No hidden errors_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102674
Approved by: https://github.com/cpuhrsch, https://github.com/albanD
Summary: Sometimes, squeeze can be a "call_method" instead of a "call_function". Normalizing it will make it amenable to pattern matching by passes like "split->squeeze"
Test Plan: * CI tests
Differential Revision: D46031846
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102294
Approved by: https://github.com/jansel
Summary:
We are currently silently skipping all PT2 quantization
tests due to a recent typo. This commit fixes this and also adds
warnings so it'll be easier to debug similar issues in the future.
Test Plan: python test/test_quantization.py
Differential Revision: D46329480
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102644
Approved by: https://github.com/jerryzh168
Removes the outdated HIP flags appended to HIP_CXX_FLAGS
The will help remove the following warnings in the pytorch build log
```
[6238/6889] Building CXX object caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/cudnn/hip/Conv_v8.cpp.o
cc1plus: warning: command line option ‘-Wno-duplicate-decl-specifier’ is valid for C/ObjC but not for C++
cc1plus: warning: unrecognized command line option ‘-Wno-unused-command-line-argument’
cc1plus: warning: unrecognized command line option ‘-Wno-exceptions’
cc1plus: warning: unrecognized command line option ‘-Wno-inconsistent-missing-override’
cc1plus: warning: unrecognized command line option ‘-Wno-macro-redefined’
```
This also updates the gloo submodule commit to include the similar change made to gloo.
597accfd79
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102271
Approved by: https://github.com/malfet
A few bits of weirdness needed to happen here:
- skipIfRocm doesn't work as a unittest class decorator; it returns a function,
and the test discovery logic looks for things that inherit from TestCase. So
I wrapped the individual test methods instead.
- Inside fbcode, our test runner (buck + tpx) discovers and runs tests using
two separate processes, so it's important to use @wraps on the generated
class to make it "look like" a regular test.
Differential Revision: [D46344980](https://our.internmc.facebook.com/intern/diff/D46344980/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D46344980/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102695
Approved by: https://github.com/zou3519
Currently reduction bodies are duplicated in several different places.
This reduces duplication by `combine_fn` definition used in
`_unroll_reduction_fn` and using it in the triton codegen. For cpp
this also makes better use of `reduction_combine{,_vec}` by using them
to generate the `omp declare reduction` line and the `vec_reduce_all`
call.
For triton the only change is that that the combine step gets spread
over two lines, e.g. instead of:
```python
_tmp1 = tl.where(rmask & xmask, triton_helpers.maximum(_tmp1, tmp0), _tmp1)
```
we get
```python
tmp2 = triton_helpers.maximum(_tmp1, tmp0)
_tmp1 = tl.where(rmask & xmask, tmp2, _tmp1)
```
For cpp the only change is that inplace reduction operations are now written as
an out-of-place operation and an assignment, e.g. instead if
```cpp
omp_out += omp_in
```
we generate
```cpp
omp_out = omp_out + omp_in
```
Which is a purely cosmetic change
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99661
Approved by: https://github.com/lezcano, https://github.com/ngimel
Summary:
Make all quantization spec to inherit from the same base class in order to simplify the typing
for QuantizationAnnotation
Test Plan:
```
buck2 test mode/opt caffe2/test:quantization_pt2e -- 'caffe2/test:quantization_pt2e'
```
Reviewed By: kimishpatel
Differential Revision: D46173954
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102582
Approved by: https://github.com/andrewor14
Accumulate data in a local buffer prior to sending it. This reduces
the number of syscalls and network packets.
We flush every 1440 bytes to cap the amount of temporaty memory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100742
Approved by: https://github.com/fduwjj
There are some I can't easily switch due to reasons like:
- Dynamo modelling the guard
- BC concerns (for torch.autograd.set_multithreading_enabled)
Test Plan:
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102642
Approved by: https://github.com/albanD
Previous timeout log does not print size info. Making it hard to debug hang caused by message size mismatch.
(Reason is that when copying `WorkNCCL` object during work enqueue, we don't copy `outputs_` due to reference concern, hence `output.size()` is never triggered.)
This PR logs sizes using separate fields, hence not relying on `outputs_`.
New timeout log:
```
[Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=1, OpType=_ALLGATHER_BASE, NumelIn=209715200, NumelOut=1677721600, Timeout(ms)=10000) ran for 10957 milliseconds before timing out.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100413
Approved by: https://github.com/kumpera
Updating the pin to the same hash as https://github.com/pytorch/pytorch/pull/100922
On the XLA side, build have switch from CMake to bazel, which requires number of changes on PyTorch side:
- Copy installed headers back to the `torch/` folder before starting the build
- Install `torch/csrc/lazy/python/python_utils.h`
- Define `LD_LIBRARY_PATH`
TODO:
- Enable bazel caching
- Pass CXX11_ABI flag to `//test/cpp:all` to reuse build artifacts from `//:_XLAC.so`
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at cd4768b</samp>
> _To fix the XLA tests that were failing_
> _We updated the submodule and scaling_
> _We added `python_util.h`_
> _And copied `torch` as well_
> _And set `LD_LIBRARY_PATH` for linking_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102446
Approved by: https://github.com/huydhn
Summary:
Currently if you are inserting into JIT IR at the same point in the middle of the graph,
it only allows for 40 inserts before it has to reindex. Reindexing is N**2 behavior, which can
lead to slow load times. This changes it so that it keeps track of how many insertions happen
at single point (like when a function is being inlined) to predict how many future insertions will happen
there. It then adjusts how it assigns topology to make sure there is enough room for those predicted insertions.
In practice this will allow around 2M inserts at a single point before it reindexes.
Test Plan: test_jit.py
Differential Revision: [D46206617](https://our.internmc.facebook.com/intern/diff/D46206617)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102312
Approved by: https://github.com/eellison
Summary:
aten::uniform implementation.
the randomization function didn't use Perlin, as the outcome distribution is not uniform.
choose to use PCG (https://www.reedbeta.com/blog/hash-functions-for-gpu-rendering/) instead.
Test Plan:
```
yipjustin@yipjustin-mac fbsource % buck run -c pt.vulkan_full_precision=1 --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -- --gtest_filter="*uniform*"
Downloaded 0/47 artifacts, 0.00 bytes, 100.0% cache miss (for updated rules)
Building: finished in 40.0 sec (100%) 524/524 jobs, 10/524 updated
Total time: 40.0 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *uniform*
[==========] Running 1 test from 1 test suite.
[----------] Global test environment set-up.
[----------] 1 test from VulkanAPITest
[ RUN ] VulkanAPITest.uniform
[ OK ] VulkanAPITest.uniform (54 ms)
[----------] 1 test from VulkanAPITest (54 ms total)
[----------] Global test environment tear-down
[==========] 1 test from 1 test suite ran. (54 ms total)
[ PASSED ] 1 test.
```
Differential Revision: D46170098
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102431
Approved by: https://github.com/SS-JIA
Copies over bits of the script from test-infra to grab the relevant parts an alert and turns them into a json. Generally copied over from check_alerts in pytorch/test-infra
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 1789c36</samp>
> _`Python 3` shebang_
> _added for compatibility_
> _a good practice / spring_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102002
Approved by: https://github.com/huydhn, https://github.com/ZainRizvi
Add is_backend_available for c10d backend, either the built-in backends or third-party backends through function ``Backend.register_backend``.
There is a related discussion in https://github.com/pytorch/pytorch/pull/101775#discussion_r1199253553
> For example in python constructor for their backend they should explicitly add the is_X_available. Or if defining in C++ they should modify pybind like this https://github.com/H-Huang/torch_collective_extension/blob/main/custom_backend/include/dummy.hpp#L98-L101
to also add their own is_available property
It is a natural choice for users to add their own `is_available` when they create a backend. We think it might be a possible way for the user to use `is_X_available` in the same way as the native, for example by dynamically adding`torch.distributed.is_dummpy_available()` function. This is why we want to dynamically add the `is_X_available` to `torch.distributed` in `register_backend`.
> Or we could add an Is_available(backend) function, that checks for the backend.
Providing a public function is indeed another good approach. We have implemented an `is_backend_available` in https://github.com/pytorch/pytorch/pull/101945 that supports both built-in backends and third-party backends.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101945
Approved by: https://github.com/H-Huang
- Add get_printoptions and printoptions context manager
- Improve edgeitems handling when it is zero
- Add render_call which can be used to conveniently print command
line arguments of a function call, while suppressing actual
tensor data
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102623
Approved by: https://github.com/albanD
This PR adds aot_export_module as the lowering path from torch.level graph to aten graph. Some known limitations that need to be addressed in the follow up PRs:
1. Store param/buffer data in ExportedProgram
2. Fully support torch.cond with params/buffers
3. Making sure no duplicated ExportMetaData entry
4. This API will break Executorch if used on PyE, we will figure out a plan internally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101490
Approved by: https://github.com/avikchaudhuri
There is a bug in the test workflow where it could fail to find the new Docker image when the image hasn't yet became available on ECR, for example e71ab21422. This basically is a race condition where the test job starts before the docker-build workflow could finish successfully. The fix here is to make sure that the test job has the opportunity to build the image if it doesn't exist, same as what the build workflow does atm. Once the docker-build workflow finishes pushing the new image to ECR, that can then be used instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102562
Approved by: https://github.com/PaliC
Summary: In cases where DDP backward is not finalized, the error is raised only in the next forward iteration of DDP. However, if there are other collective calls between those two points, training scripts could potentially get stuck.
As a result, there should be a way to check if DDP finalized after calling `.backward()`. To address this, I've added a `_check_reducer_finalized` method to validate that DDP indeed did successfully finish reduction.
Test Plan: Added unit tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100773
Approved by: https://github.com/rohan-varma
This PR adds a `py_context_manager_DEPRECATED` that converts a C++ RAII
guard to an object that may be either used as Python context manager or
as a "Python RAII guard".
We don't convert all of them to Python context manager only due to BC
reasons; people in OSS and internally actually rely on these APIs and I
don't want to break them. We are justified in breaking BC if we wanted
to, but it seemed like too much work for not a lot of gain.
The API is postfixed with "DEPRECATED" to indicate that people should
really use `py_context_manager` (converts C++ RAII guard to Python
context manager) instead.
Test Plan:
- this PR converts all PyTorch usages of _AutoDispatchBelowAutograd to
context manager. I can do the rest in follow-ups.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102579
Approved by: https://github.com/bdhirsh, https://github.com/albanD
Fixes #https://github.com/pytorch/pytorch/issues/101960
when I trace a func to run out-operator has more than one output, I got the error. This is because the situation when the output of the out operator is greater than 1 is not handled.
```
def test_trace_out_operator_with_two_output():
example_input = torch.rand(2, 8)
out_1, out_2 = torch.cummax(example_input, 1)
def run_cummax(example_input, out_1, out_2):
output_1, output_2 = torch.cummax(example_input, 1, out=(out_1, out_2))
return output_1, output_2
trace_model = torch.jit.trace(run_cummax, (example_input, out_1, out_2))
and the error info:
raise TracingCheckError(
torch.jit._trace.TracingCheckError: Tracing failed sanity checks!
encountered an exception while running the trace with test inputs
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101563
Approved by: https://github.com/jgong5, https://github.com/EikanWang, https://github.com/davidberard98
Failing mechanism on #95424 :
In dynamo mode, when passing numpy.int_ to 'shape' like param (Sequence[Union[int, symint]]) is wrapped as list with FakeTensor. However, in python_arg_parser, parser expect int in symint_list but got FakeTensor.
Following #85759, this PR allow tensor element in symint_list when in dynamo mode
This PR also fix below test with similar failing mechanism
pytest ./generated/test_huggingface_diffusers.py -k test_016
pytest ./generated/test_ustcml_RecStudio.py -k test_036
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97508
Approved by: https://github.com/yanboliang
This attribute wasn't actually used in tests, add a test ensuring that
if replicate is used on top of FSDP, the replicated parameter names are as
expected.
TODO: there are a few ways to check if module is managed by composable API,
such as replicated param names for replicate, _get_module_state API,
_get_registry_api, etc. We should unify all composable APIs to check in a
unified way (filed an issue)
Differential Revision: [D46236377](https://our.internmc.facebook.com/intern/diff/D46236377/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102401
Approved by: https://github.com/awgu
As slow gradcheck is slow (Thank you, Captain Obvious!), let's run it on the newer G5 runner to improve its TTS and avoid flaky timing out error such as https://github.com/pytorch/pytorch/actions/runs/5112059782/jobs/9190167924. AFAIK, there is no reason to keep running slow gradcheck on `linux.4xlarge.nvidia.gpu`
### Testing
* `1st` shard: `3h30m` → `4h`, The increase is probably due to https://github.com/pytorch/pytorch/pull/102380 in which the job's name switch from `gcc7` to `gcc9`. Does this invalidate the test time used to balance these shards?
* `2nd` shard: `4h35m` → `4h15m`
* `3rd` shard: `3h20m` → `1h20m`
* `4th` shard: `3h20m` → `2h10m`
* `14h45m` → `11h45m`, a total saving of `3h`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102496
Approved by: https://github.com/malfet
FakeTensor doesn't normalize device_idx and failed with below testcase.
import torch
import habana_frameworks.torch.hpu
from torch._subclasses.fake_tensor import FakeTensorMode
with FakeTensorMode.push():
a = torch.empty(1, device="hpu")
b = torch.empty(1, device="hpu:0")
result = a + b
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102512
Approved by: https://github.com/albanD
Enables the hipSolver backend for ROCm builds
--------------------------------------------------------------------------
- Minimum ROCm version requirement - 5.3
- Introduces new macro USE_LINALG_SOLVER the controls enablement of both cuSOLVER and hipSOLVER
- Adds hipSOLVER API to hipification process
- combines hipSOLVER and hipSPARSE mappings into single SPECIAL map that takes priority among normal mappings
- Torch api to be moved to hipsolver backend (as opposed to magma) include: torch.svd(), torch.geqrf(), torch.orgqr(), torch.ormqr()
- Will enable 100+ linalg unit tests for ROCm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97370
Approved by: https://github.com/malfet
`repeat_interleave_symint` is currently implemented by guarding on the `SymInt`
and converting it to a tensor to pass to the Tensor overload. This instead
implements it as a copy of an expanded tensor, which can be done without guards
and is also much more efficient in eager mode to boot.
For example, these are timings for `x.repeat_interleave(100, dim=-1)` with `x.shape == (1000, 100)`
| Device | Time (Master) | Time (This PR) | Speedup |
|--------|---------------|-----------------|---------|
| cpu | 18.8 ms | 3.5 ms | 5.4 |
| cuda | 271 us | 134 us | 2.0 |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102570
Approved by: https://github.com/lezcano
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 08f7a6a</samp>
This pull request adds support for triton kernels in `torch` and `torch/cuda`, and refactors and tests the existing triton kernel for BSR matrix multiplication. It also adds a test case to ensure that importing `torch` does not implicitly import `triton`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98403
Approved by: https://github.com/malfet, https://github.com/cpuhrsch
keys and change codegen to take ETKernelIndex
We are adding support for dtype and dim order specialized kernel registration. This requires us to reorganize `BackendIndex` (which is a `Dict[DispatchKey, Dict[OperatorName, BackendMetadata]]`) to be `Dict[OperatorName, Dict[ETKernelKey, BackendMetadata]]`. This PR adds new data structures in order to support this change:
* `ETKernelKey` to retrieve a certain kernel from the registry.
* `ETKernelIndex`, the dictionary from operator name to kernel key to kernel mapping.
Note that the codegen logic is not changed yet, we need subsequent diffs to actually generate code for different kernel keys.
Differential Revision: [D46206339](https://our.internmc.facebook.com/intern/diff/D46206339/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102565
Approved by: https://github.com/Jack-Khuu
Now that we have full C++17 support, we can use if constexpr in some identified cases.
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at df4c16d</samp>
The pull request improves the performance, readability, and consistency of various function templates in the `ATen` and `torch` modules by using `constexpr` keywords and C++17 features. It also fixes some type conversion and overflow issues for different input and output types. The changes affect the code for distributions, BLAS, batch normalization, embedding bag, random number generation, vectorized operations, cuBLAS, XNNPACK, CUTLASS, and shape inference. The affected files include `DistributionsHelper.h`, `vec256_int.h`, `vec512_int.h`, `BlasKernel.cpp`, `IndexKernel.cpp`, `EmbeddingBag.cpp`, `Normalization.cpp`, `rng_test.h`, `vec_test_all_types.h`, `TransformationHelper.h`, `CUDABlas.cpp`, `DistributionKernels.cpp`, `DistributionTemplates.h`, `RangeFactories.cu`, `RangeFactories.cpp`, `qconv.cpp`, `StructuredSparseLinearCUTLASS.cu`, `vec_test_all_types.cpp`, and `shape_inference.cpp`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102471
Approved by: https://github.com/Skylion007, https://github.com/malfet
Summary:
Fixes#102416 [WARNING] couldn't find split args
In case `dim=` kwarg is absent is absent, we can default it to 0. Even after this, probably okay to make this an INFO rather than a WARNING
Test Plan: run torchbench
Differential Revision: D46292754
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102561
Approved by: https://github.com/jansel
This commit reduces the exporter memory usage by as much as 50%. During the shape inference step, the exporter caches the values of intermediate tensors in a `ConstantValueMap`. This can use as much memory as the model itself, or even more. For example, model weight tensors are often fed to a Transpose layer, and the output of that is the same size of the weights. This commit fixes the issue by removing the intermediate tensor values after they are used by all consumers.
The cached values are only used for shape inference, so removing them after use should be safe. `ConstantValueMap` is cleared anyways once shape inference is complete for the entire graph.
As an example, here is the model from issue #61263:
```python
import torch
import math
# Size in GB
tensor_size = 1
model_size = 8
layers_num = model_size // tensor_size
kB = 1024
MB = kB * kB
GB = MB * kB
precision_size = 4 # bytes per float
activation_size = math.floor(math.sqrt(tensor_size * GB / precision_size))
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
for i in range(layers_num):
name = "fc_%d" % i
linear = torch.nn.Linear(activation_size, activation_size)
setattr(self, name, linear)
def forward(self, x):
for i in range(layers_num):
name = "fc_%d" % i
linear = getattr(self, name)
x = linear(x)
return x
model = Net().cuda()
input = torch.zeros(activation_size, requires_grad=True).cuda()
with torch.no_grad():
torch.onnx.export(model, (input, ), './model_large.onnx', do_constant_folding=False, opset_version=13)
```
It is just some large linear layers stacked together. Before this commit, my max GPU usage during export was about 16.7 GB, twice the model size. With this commit in combination with #101134, it was only about 9.5 GB.
Together with #101134, fixes issue #61263
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101148
Approved by: https://github.com/BowenBao
**TL;DR:** This re-introduces links between backward kernels and their corresponding forward kernels.
<img width="1020" alt="Screenshot 2023-05-26 at 7 25 22 PM" src="https://github.com/pytorch/pytorch/assets/5067123/02571b59-859c-4c9e-b3ef-121ef3159812">
In the example above, you can see there are two such flows - one for aten::add, and one for aten::binary_cross_entropy
### Details
Forward/backward links were added in https://github.com/pytorch/pytorch/pull/62553, but then disabled in https://github.com/pytorch/pytorch/pull/72904 due to segfaults (e.g. https://github.com/pytorch/pytorch/issues/69443).
Between now and when the fwd-bwd links were disabled, there's been a lot of refactoring; so this PR updates the implementation:
* Use a raw profiler::impl::Result instead of a KinetoEvent
* Move the implementation to collection.cpp, where the TraceWrapper is currently handled.
* Sort the events before processing, because they aren't always in chronological order
* There can now be more than one event in the backward pass that matches the sequenceNr-threadID pair. The implementation needed to be updated to avoid showing multiple endpoints for a given sequenceNr-threadID pair ([ptr to where the bwd sequenceNr-threadID pair is duplicated](6e3e3dd477/torch/csrc/profiler/collection.cpp (L398-L399))).
Next, we need to verify that https://github.com/pytorch/pytorch/issues/69443 is fixed. Running the repro no longer errors. Looking further into the details of the issue it seems like the handling of the [raw linkedActivity pointer (old code from 2021)](6089dcac48/libkineto/src/output_json.cpp (L283)) resulted in the segfault. Now, it doesn't look like the linked activity is used anywhere in output_json.cpp so the issue should be fixed.
### Testing
#### 1. unit test
`test_profiler_fwd_bwd_link` was un-skipped. It was modified to match the new implementation.
#### 2. https://github.com/pytorch/pytorch/issues/69443
I ran the repro in https://github.com/pytorch/pytorch/issues/69443 and verified there were no segfaults.
#### 3. Duplicate flow IDs
When forward-backward connections were first introduced, gpu-cpu async links had not been introduced. There's a possibility that gpu-cpu links and fwd-bwd links could interfere if their IDs overlap.
I manually tested this in chrome://tracing; I edited a file so that a gpu-cpu link had the same ID as one of the fwd-bwd connections. The chrome tracing UI continued showing both types of links.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102424
Approved by: https://github.com/aaronenyeshi
This PR fixes the following compilation error due to the unexpected conflicts among #99057 and #101000
```
In file included from /home1/ishizaki/PyTorch/main-lastest/aten/src/ATen/cpu/vec/vec256/vec256.h:21,
from /home1/ishizaki/PyTorch/main-lastest/aten/src/ATen/cpu/vec/vec.h:6,
from /home1/ishizaki/PyTorch/main-lastest/aten/src/ATen/native/cpu/Loops.h:37,
from /home1/ishizaki/PyTorch/main-lastest/aten/src/ATen/native/cpu/batch_norm_kernel.cpp:9,
from /home1/ishizaki/PyTorch/main-lastest/build/aten/src/ATen/native/cpu/batch_norm_kernel.cpp.ZVECTOR.cpp:1:
/home1/ishizaki/PyTorch/main-lastest/aten/src/ATen/cpu/vec/vec256/zarch/vec256_zarch.h:2332:17: error: ‘at::vec::ZVECTOR::Vectorized<T> at::vec::ZVECTOR::Vectorized<T, typename std::enable_if<is_zarch_implemented_complex<T>(), void>::type>::expm1() const’ cannot be overloaded with ‘at::vec::ZVECTOR::Vectorized<T> at::vec::ZVECTOR::Vectorized<T, typename std::enable_if<is_zarch_implemented_complex<T>(), void>::type>::expm1() const’
2332 | Vectorized<T> expm1() const {
| ^~~~~
/home1/ishizaki/PyTorch/main-lastest/aten/src/ATen/cpu/vec/vec256/zarch/vec256_zarch.h:2328:17: note: previous declaration ‘at::vec::ZVECTOR::Vectorized<T> at::vec::ZVECTOR::Vectorized<T, typename std::enable_if<is_zarch_implemented_complex<T>(), void>::type>::expm1() const’
2328 | Vectorized<T> expm1() const {
| ^~~~~
cc1plus: note: unrecognized command-line option ‘-Wno-aligned-allocation-unavailable’ may have been intended to silence earlier diagnostics
cc1plus: note: unrecognized command-line option ‘-Wno-unused-private-field’ may have been intended to silence earlier diagnostics
cc1plus: note: unrecognized command-line option ‘-Wno-invalid-partial-specialization’ may have been intended to silence earlier diagnostics
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101923
Approved by: https://github.com/malfet
This PR ensures that the subgraphs use the newly created placeholder for the primary inputs and free variables. Earlier, this was not happening, and graph.lint() was failing. I need `graph.lint()` in the followup PRs where I run an `Interpreter` on the subgraph to preserve the metadata information to AOT Autograd.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102448
Approved by: https://github.com/zou3519
This commit partially fixes an issue where the ONNX exporter always requires about 2x memory than the model size. The `ONNXTracedModule` class uses a copy of the original weights only when `return_inputs=True`, so this commit makes sure the weights are cloned only in that case.
As a side note, I don't think the exporter is ever called with `return_inputs=True`, so maybe this is just some old code that can be removed.
Partially fixes#61263. There are still other places in the exporter which use more memory than they need to. For example, during the shape inference step many intermediate tensors are computed and saved until shape inference on the model is complete. I am working on a fix for that, but that optimization is independent of this one and can be done in a separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101134
Approved by: https://github.com/BowenBao, https://github.com/osalpekar
Summary:
This refactor introduces an internal function which selectively tests againt fx
quant as well. Notably this does increase test times so wo need to figure out
how to resolve that.
Test Plan: test_quantization_pt2e
Reviewed By: jerryzh168
Differential Revision: D46154323
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102497
Approved by: https://github.com/jerryzh168
Currently file level reruns + stepcurrent are incompatible and it's making PRs green when they are actually red, so turn off stepcurrent + file level reruns when keep-going is used until I figure out a better way to do this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102569
Approved by: https://github.com/huydhn
# Summary
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 293ded1</samp>
This pull request adds support for using Visual Studio Code Remote - Containers extension with the pytorch project. It adds a `.devcontainer` folder with a `devcontainer.json` file, a `Dockerfile`, and a `noop.txt` file that configure and create a dev container with Anaconda and Python 3.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at d6b9cd7</samp>
> _`devcontainer.json`_
> _Configures PyTorch containers_
> _For CPU or GPU_
## Related to:
https://github.com/pytorch/pytorch/issues/92838
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98252
Approved by: https://github.com/ZainRizvi
Summary: Move static checks of layers[0] (e.g., isinstance check) to model build time because isinstance() does not work for torchscripted code. Because the validation is now performed while constructing the object, the isinstance() call is performed in eager mode at model build time, and we avoid needing to call isinstance() at runtime to determine whether the layers in a model are an instance of the TransformerEncoderLayer class, or its derived classes.
Test Plan: sandcastle, github
Differential Revision: D46096222
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102045
Approved by: https://github.com/mikaylagawarecki
This PR switches DeviceMesh to use dispatchable process group instead,
this could enable easier backend integration as user only need to
integrate with c10d process group custom backend, without needing to
change DeviceMesh to plug in the backend
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102336
Approved by: https://github.com/fduwjj
Done in this PR:
- Use `torch.linalg.vector_norm` instead of `torch.norm`
- Reduce bandwidth boundary of clip_grad_norm when used with `inf`, ie no need to get the returned tensor after `abs`
What I'm slightly unsure:
- I don't know if `inf` support `torch._foreach` API
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102429
Approved by: https://github.com/lezcano
Pass size argument.
<details>
<summary>ASAN report</summary>
```
==1640574==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x609000022160 at pc 0x03ff31a04b42 bp 0x03ff69885dc0 sp 0x03ff69885db0
READ of size 16 at 0x609000022160 thread T1
#0 0x3ff31a04b41 in at::vec::ZVECTOR::Vectorized<unsigned char, void>::loadu(void const*, int) /home/user/pytorch/aten/src/ATen/cpu/vec/vec256/zarch/vec256_zarch.h:397
#1 0x3ff31a04b41 in at::vec::ZVECTOR::Vectorized<c10::quint8, void>::loadu(void const*, int) /home/user/pytorch/aten/src/ATen/cpu/vec/vec256/zarch/vec256_zarch.h:1574
#2 0x3ff31a04b41 in operator() /home/user/pytorch/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp:2668
#3 0x3ff31cefa5d in void at::internal::invoke_parallel<at::native::(anonymous namespace)::quantized_normalize_kernel(at::Tensor const&, at::Tensor const&, at::Tensor const&, bool, int, int, long, long
, double, at::Tensor*)::{lambda()#1}::operator()() const::{lambda()#2}::operator()() const::{lambda(long, long)#1}>(long, long, long, at::native::(anonymous namespace)::quantized_normalize_kernel(at::Tens
or const&, at::Tensor const&, at::Tensor const&, bool, int, int, long, long, double, at::Tensor*)::{lambda()#1}::operator()() const::{lambda()#2}::operator()() const::{lambda(long, long)#1} const&) [clone
._omp_fn.0] /home/user/pytorch/aten/src/ATen/ParallelOpenMP.h:42
#4 0x3ff6f31f52d in gomp_thread_start /var/tmp/portage/sys-devel/gcc-12.2.1_p20230304/work/gcc-12-20230304/libgomp/team.c:129
#5 0x3ff82218381 in start_thread /usr/src/debug/sys-libs/glibc-2.37-r1/glibc-2.37/nptl/pthread_create.c:444
#6 0x3ff822943f1 (/lib64/libc.so.6+0x1143f1)
0x609000022160 is located 0 bytes to the right of 32-byte region [0x609000022140,0x609000022160)
allocated by thread T0 here:
#0 0x3ff82a3663f in __interceptor_posix_memalign /usr/src/debug/sys-devel/gcc-11.3.1_p20230303/gcc-11-20230303/libsanitizer/asan/asan_malloc_linux.cpp:226
#1 0x3ff6f53ad95 in c10::alloc_cpu(unsigned long) /home/user/pytorch/c10/core/impl/alloc_cpu.cpp:74
Thread T1 created by T0 here:
#0 0x3ff829dc263 in __interceptor_pthread_create /usr/src/debug/sys-devel/gcc-11.3.1_p20230303/gcc-11-20230303/libsanitizer/asan/asan_interceptors.cpp:216
#1 0x3ff6f31fad5 in gomp_team_start /var/tmp/portage/sys-devel/gcc-12.2.1_p20230304/work/gcc-12-20230304/libgomp/team.c:858
SUMMARY: AddressSanitizer: heap-buffer-overflow /home/user/pytorch/aten/src/ATen/cpu/vec/vec256/zarch/vec256_zarch.h:397 in at::vec::ZVECTOR::Vectorized<unsigned char, void>::loadu(void const*, int)
Shadow bytes around the buggy address:
0x100c12000043d0: 00 fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c12000043e0: fd fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c12000043f0: fd fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1200004400: fd fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1200004410: fa fa fa fa fa fa fa fa fd fa fa fa fa fa fa fa
=>0x100c1200004420: fa fa fa fa fa fa fa fa 00 00 00 00[fa]fa fa fa
0x100c1200004430: fa fa fa fa fa fa fa fa fd fd fa fa fa fa fa fa
0x100c1200004440: fa fa fa fa fa fa fa fa fd fd fa fa fa fa fa fa
0x100c1200004450: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1200004460: 00 00 fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1200004470: 00 00 fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
Shadow gap: cc
==1640574==ABORTING
```
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101970
Approved by: https://github.com/Skylion007, https://github.com/jgong5
When inductor compiles the following example,
```python
def flip(x):
idx = torch.arange(x.shape[0] - 1, -1, -1, device=x.device)
return x[idx], idx
```
The return of `idx` forces it to be realized into a `ComputedBuffer`
and the downstream index call inserts a corresponding load and
indirect_indexing:
```python
tmp0 = tl.load(in_ptr0 + (x1), None)
tmp1 = triton_helpers.promote_to_tensor(tmp0)
tl.device_assert((0 <= tmp1) & (tmp1 < 128), "index out of bounds: 0 <= tmp1 < 128")
tmp2 = tl.load(in_ptr1 + (x0 + (128*tmp0)), None)
```
However, if we can inline the index expression from the buffer's
computation we instead get direct indexing (and half the loads):
```python
tmp0 = tl.load(in_ptr0 + (127 + ((-1)*x0)), None)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102000
Approved by: https://github.com/lezcano
Summary:
This enables use of CUDNN v8 in all Meta internal workflows. Also, fixes two minor issues:
- Skip LogCumSumExp compilation for complex dtypes for fbcode and RL
- Move `MakeConvOutputShape` template definition/specialization to anonymous namespace inside `at::native::quantized` as it is referenced from both `torch_cpu` and `torch_cuda`. This is necessary to avoid `duplicate symbol` linker error if say `libtorch_cpu` and `libtorch_cuda` are statically linked together.
- Lower CuDNN v8 version guard from 8.3 to 8.2 (as there are no good reason why it should be 8.3, first version of the library that properly supports all the features is actually 8.5)
Test Plan: CI
Differential Revision: D46161651
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102284
Approved by: https://github.com/atalman
This diff introduces utility `find_sequential_partitions`.
This utility allows one to specify sequential pattern of
nn.Module/nn.functional and returns a list. Each item in the list contains a
List[SourcePartition] that represents sequentially connected partitions that
are of the pattern requested.
For example `find_sequential_partitions(model, [nn.Conv2d, nn.ReLU])` will find
all nn.Conv2d and nn.ReLU partitions that are sequentially connected.
Furthmore, move to using `find_sequential_partitions` for conv_bn/conv_bn_relu
for QAT.
Differential Revision: [D45948057](https://our.internmc.facebook.com/intern/diff/D45948057/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D45948057/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102394
Approved by: https://github.com/jerryzh168
Potentially fixes the second issue described in #87159.
In python_list.h, `int64_t` is used when `diff_type` is better suited. On 32 bit systems, int64_t isn't a proper signed size type, which may cause the compilation error described in #87159.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101922
Approved by: https://github.com/Skylion007
Summary:
Recently we changed the annotation from "target_dtype_info" to "quantization_annotation" and introduced QuantizationAnnotation API
and SharedQuantizationSpec API for users to convey sharing between input/outputs, this PR updates the _propagate_annotation
pass to accommadate the recent changes
Test Plan:
```
buck2 test mode/opt caffe2/test:quantization_pt2e -- 'caffe2/test:quantization_pt2e'
```
Reviewed By: kimishpatel
Differential Revision: D46153084
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102422
Approved by: https://github.com/kimishpatel
The console log blows up to much when running in rerun disabled tests mode (x50) e132f09e88. Each log is around 1GB and the whole uncompressed logs is ~50GB. After compression, it will be around 1GB, still too big. The increase comes mainly from the multiple SKIPPED message for non-disabled tests, which is expected due to how SkipTest and pytest-flakyfinder currently work.
I update `test/conftest.py` to completely ignore skipped tests when rerunning disabled test instead of collecting then skipping 50 tests each. The benefit of doing is is much more than I originally expect:
* Rerun disabled tests jobs now finish in less than half an hour as they should be
* Fix OOM runner crash because of too many collected tests
* Fix verbosity issue as now only disabled tests are run x50 times. There are only few hundreds of them atm
* Fix timed out issue when rerunning disabled distributed and ASAN tests. They are just too slow when running at x50
### Testing
When rerunning disabled tests https://github.com/pytorch/pytorch/actions/runs/5084508614, only disabled tests on the platform are run, for example `test_ops_jit` on https://ossci-raw-job-status.s3.amazonaws.com/log/13770164954 only ran 100 tests (`test_variant_consistency_jit_linalg_lu_cuda_float32` + `test_variant_consistency_jit_linalg_lu_factor_cuda_complex64`) x50.
```
Executing ['/opt/conda/envs/py_3.10/bin/python', '-bb', 'test_ops_jit.py', '--shard-id=1', '--num-shards=2', '-v', '-vv', '-rfEX', '-p', 'no:xdist', '--use-pytest', '--sc=test_ops_jit_1', '--flake-finder', '--flake-runs=50', '--import-slow-tests', '--import-disabled-tests', '--rerun-disabled-tests'] ... [2023-05-25 21:32:49.763856]
Expand the folded group to see the log file of test_ops_jit 2/2
##[group]PRINTING LOG FILE of test_ops_jit 2/2 (/var/lib/jenkins/workspace/test/test-reports/test_ops_jit_h2wr_t2c.log)
Test results will be stored in test-reports/python-pytest/test_ops_jit/test_ops_jit-51a83bd44549074e.xml
============================= test session starts ==============================
platform linux -- Python 3.10.11, pytest-7.3.1, pluggy-1.0.0 -- /opt/conda/envs/py_3.10/bin/python
cachedir: .pytest_cache
hypothesis profile 'pytorch_ci' -> database=None, max_examples=50, derandomize=True, suppress_health_check=[HealthCheck.too_slow]
rootdir: /var/lib/jenkins/workspace
configfile: pytest.ini
plugins: hypothesis-5.35.1, cpp-2.3.0, flakefinder-1.1.0, rerunfailures-11.1.2, shard-0.1.2, xdist-3.3.0, xdoctest-1.1.0
collecting ... collected 1084 items
Running 100 items in this shard: test/test_ops_jit.py::TestJitCUDA::test_variant_consistency_jit_linalg_lu_cuda_float32 (x50), test/test_ops_jit.py::TestJitCUDA::test_variant_consistency_jit_linalg_lu_factor_cuda_complex64 (x50)
stepcurrent: Cannot find last run test, not skipping
test_ops_jit.py::TestJitCUDA::test_variant_consistency_jit_linalg_lu_cuda_float32 PASSED [2.1876s] [ 1%]
test_ops_jit.py::TestJitCUDA::test_variant_consistency_jit_linalg_lu_factor_cuda_complex64 PASSED [4.5615s] [ 2%]
```
* [pull](https://github.com/pytorch/pytorch/actions/runs/5093566864)
* [trunk](https://github.com/pytorch/pytorch/actions/runs/5095364311)
* [periodic](https://github.com/pytorch/pytorch/actions/runs/5095378850)
* [slow](https://github.com/pytorch/pytorch/actions/runs/5095390285)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102107
Approved by: https://github.com/clee2000, https://github.com/malfet
LeakSanitizer picks up this allocation as a leak, so turn the buffer and size into a single object that deallocates when the thread_local is destroyed.
Note that in our use case the call that hits this code is running on a separate thread(s) which can, under the right circumstances, be torn down and rebuilt hence leaking multiple instances of this allocation.
Testing was performed locally on an Apple M2 with this patch applied and the ~100MB of leaks previously shown by LeakSanitizer and Instruments are no longer there.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102276
Approved by: https://github.com/ezyang
Fixed test_memory_profiler::TestMemoryProfilerE2E::test_memory_timeline by changing the (arbitrary) threshold for logging. We observe differently-sized allocations on different AMD GPUs, so chose a higher threshold over 512 to account for those differences and yet satisfy the test requirements.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102243
Approved by: https://github.com/ezyang
Changes the StreamID encoding to use the last bit to distinguish between external and internal streams, 4 bits for IdType (DEFAULT, EXT or user-created streams possibly with high priority), and 5 bits for index. This allows us to have more stream priorities exposed to user (I'm currently setting 4, but that's easy to change now). Note, we are pre-creating all 32 streams in the pool per each allowed priority, I don't know if it's a problem in practice. Currently cuda 11.8/A100 GPUs allow 6 different stream priorities, the number may be different for the different cards/different cuda versions.
Previous callsites explicitly requesting high prioity stream (`isHighPriority=true`) are now getting the highest priority stream.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101956
Approved by: https://github.com/ezyang
Summary:
```
"""
4. DerivedQuantizationSpec
this is the quantization spec for the Tensors whose quantization parameters are derived from other Tensors
"""
class DerivedQuantizationSpec(QuantizationSpecBase):
# specifies which Tensors the quantization parameters are derived from
# this can either be an edge from argument to node, or a node
derived_from: List[EdgeOrNode]
derive_qparams_fn: Callabale[List[ObserverOrFakeQuantize], Tuple[Tensor, Tensor]]
...
```
Test Plan:
```
buck2 test mode/opt caffe2/test:quantization_pt2e -- 'caffe2/test:quantization_pt2e'
buck2 test mode/opt caffe2/test:quantization_pt2e -- --exact 'caffe2/test:quantization_pt2e - test_resnet18_with_quantizer_api (quantization.pt2e.test_quantize_pt2e.TestQuantizePT2EModels)'
```
Reviewed By: kimishpatel
Differential Revision: D46097855
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102282
Approved by: https://github.com/andrewor14
When inductor compiles the following example,
```python
def flip(x):
idx = torch.arange(x.shape[0] - 1, -1, -1, device=x.device)
return x[idx], idx
```
The return of `idx` forces it to be realized into a `ComputedBuffer`
and the downstream index call inserts a corresponding load and
indirect_indexing:
```python
tmp0 = tl.load(in_ptr0 + (x1), None)
tmp1 = triton_helpers.promote_to_tensor(tmp0)
tl.device_assert((0 <= tmp1) & (tmp1 < 128), "index out of bounds: 0 <= tmp1 < 128")
tmp2 = tl.load(in_ptr1 + (x0 + (128*tmp0)), None)
```
However, if we can inline the index expression from the buffer's
computation we instead get direct indexing (and half the loads):
```python
tmp0 = tl.load(in_ptr0 + (127 + ((-1)*x0)), None)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102000
Approved by: https://github.com/lezcano
Key change - seed, offset are the last 2 args in both the fwd and bwd graphs
Reason - The cudagraphs implementation in inductor currently relies on very simple ordering guarantees i.e. first n inputs are static for both fwd and bwd graphs. In the current implementation of functionalization of rng ops, this assumption is broken because the first 2 inputs are seed, offset.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102344
Approved by: https://github.com/eellison
Previously we had runtime asserts for range constraints. This diff adds runtime asserts for equality constraints.
This requires a bit of refactoring that is worth calling out.
1. [Minor] Some of the data structures produced by export and consumed by the runtime assertion pass need to be broadened. This is a WIP. There are some associated code improvements that are included in this diff, but by and large the structures are similar to what exists now. Meanwhile @angelayi and I are chatting about how to make it qualitatively better: briefly, we want to index everything by symbols, which are 1-1 with (name, dim) pairs.
2. [Major] The order in which runtime asserts are emitted is changed. Previously we used to do the work in `placeholder`, now this diff adds a hook for "post-processing" after processing of all placeholders is done. This is needed because equality constraints can mention different placeholders. This change also opens the way to optimizing codegen: e.g., each (name, dim) pair should correspond to a single intermediate variable that is reused across runtime asserts. This is future work.
Differential Revision: [D46177642](https://our.internmc.facebook.com/intern/diff/D46177642/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102256
Approved by: https://github.com/tugsbayasgalan, https://github.com/angelayi
Update `CONTRIBUTING.md` with tip on how to avoid rebuilding/copying libs every time one makes a small change to the native code.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at f5e8394</samp>
> _`setup.py` docs_
> _Link to source and build dirs_
> _Winter of testing_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102316
Approved by: https://github.com/kit1980, https://github.com/huydhn
Enables MTPG for some FSDP tests in this file. Tests that need the
backward pass and warning logging are left as follow up work.
Backward pass issue: It seems that there is a hang with all_gather. Will sync with @kumpera on this.
Warning issue: We have a couple tests that regex check on warnings, but in the
multithreaded scenario these warnings are somehow not logged.
Differential Revision: [D43209769](https://our.internmc.facebook.com/intern/diff/D43209769/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102043
Approved by: https://github.com/awgu
# Summary
This is another upstream which is much smaller than the previous.
This bumps the kernel versions from xformers
Current: [6425fd0cacb1a6579aa2f0c4a570b737cb10e9c3](6425fd0cac)
With this PR: [1d635e193e169fc677b2e7fa42dad7ebe88eec9e](1d635e193e)
### Notable Changes:
- Drastically improve the BW pass in multiple cases (especially when B*numHeads < 100)
- H100 Support: *Warning* While these kernels have been added, we don't have the CI/CD machines to test.
- Enables a deterministic mode.
## Specific Changes
- Updates to the backward kernel.
- Added num_splits_key which we hard code to -1. (This is a another performance knob that we set to the heuristic)
- Update gen_code and kernels to produce h100 instantiations.
### Due Diligence Checks:
* CUDA_lib size: No changes in size
#### Peformance
* Micro Benchmark: (batch_size: 1, num_heads=25, seq_len=4096, embed_dim = 64 | grid:[1,25,1]block: [128,1,1])
* MemEfficientAttention Backward Kernel: 27.972 ms
* After the updated Xformers code(https://github.com/pytorch/pytorch/pull/100583): 23.958 ms
* With this PR: 4.085 ms
* Ran micro benchmarks on sdpa_forw().sum().backward() over a range of dtypes, and input shapes
* Geo_mean increase -> 1.17x
* Max increase -> 2.95x
* min_increase -> 0.8x
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101847
Approved by: https://github.com/cpuhrsch
Currently if we have an inplaced buffer that's completely internal to a fused kernel and thus doesn't need to be allocated, we are still allocating it and sending unused argument to a kernel, because our analysis for removing buffers treats it separately (assuming that either original or mutated value are still needed).
This PR extends buffer removal to inplaced buffers that can be removed.
Generated kernel for e.g. ln changes from
```
def triton_(in_out_ptr0, in_out_ptr1, in_ptr0, in_ptr1, in_ptr2, out_ptr0, out_ptr1, xnumel, rnumel, XBLOCK : tl.constexpr):
```
where in_out_ptr0 is unused in the kernel to
```
def triton_(in_out_ptr1, in_ptr0, in_ptr1, in_ptr2, out_ptr0, out_ptr1, xnumel, rnumel, XBLOCK : tl.constexpr):
```
and corresponding allocation/reuse lines in the wrapper are removed.
The `in_out_ptr1` is also mislabeled - it's not `in_out`, it's only written to, but this PR doesn't fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102289
Approved by: https://github.com/jansel
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 8f8d620</samp>
This pull request improves the testing of the `nn.functional.multi_head_attention_forward` function by adding it to the `OpInfo` framework, adjusting the tolerance and skipping criteria for some test cases, and restricting the dtype for the `MetaProgrammingSystem` tests. These changes aim to address the randomness and numerical precision issues of the function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100153
Approved by: https://github.com/drisspg
Summary: The new logger allows passing metadata into the api usage logger. The immediate use case is to pass the serialization_id to the save and load events to be enable tracking serialized models in API events. It could be extended to add more metadata in the future.
Test Plan:
```
buck2 test @//mode/dev //caffe2/caffe2/serialize:inline_container_test
```
Reviewed By: davidberard98
Differential Revision: D45683697
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101762
Approved by: https://github.com/davidberard98
We don't need to handle managing their memory since they dont have any. Previously you would get error `RuntimeError: These storage data ptrs are not allocated in pool (0, 2) but should be {0}`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102273
Approved by: https://github.com/ngimel
Bumps [requests](https://github.com/psf/requests) from 2.26 to 2.31.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/psf/requests/releases">requests's releases</a>.</em></p>
<blockquote>
<h2>v2.31.0</h2>
<h2>2.31.0 (2023-05-22)</h2>
<p><strong>Security</strong></p>
<ul>
<li>
<p>Versions of Requests between v2.3.0 and v2.30.0 are vulnerable to potential
forwarding of <code>Proxy-Authorization</code> headers to destination servers when
following HTTPS redirects.</p>
<p>When proxies are defined with user info (<a href="https://user:pass@proxy:8080">https://user:pass@proxy:8080</a>), Requests
will construct a <code>Proxy-Authorization</code> header that is attached to the request to
authenticate with the proxy.</p>
<p>In cases where Requests receives a redirect response, it previously reattached
the <code>Proxy-Authorization</code> header incorrectly, resulting in the value being
sent through the tunneled connection to the destination server. Users who rely on
defining their proxy credentials in the URL are <em>strongly</em> encouraged to upgrade
to Requests 2.31.0+ to prevent unintentional leakage and rotate their proxy
credentials once the change has been fully deployed.</p>
<p>Users who do not use a proxy or do not supply their proxy credentials through
the user information portion of their proxy URL are not subject to this
vulnerability.</p>
<p>Full details can be read in our <a href="https://github.com/psf/requests/security/advisories/GHSA-j8r2-6x86-q33q">Github Security Advisory</a>
and <a href="https://nvd.nist.gov/vuln/detail/CVE-2023-32681">CVE-2023-32681</a>.</p>
</li>
</ul>
<h2>v2.30.0</h2>
<h2>2.30.0 (2023-05-03)</h2>
<p><strong>Dependencies</strong></p>
<ul>
<li>
<p>⚠️ Added support for urllib3 2.0. ⚠️</p>
<p>This may contain minor breaking changes so we advise careful testing and
reviewing <a href="https://urllib3.readthedocs.io/en/latest/v2-migration-guide.html">https://urllib3.readthedocs.io/en/latest/v2-migration-guide.html</a>
prior to upgrading.</p>
<p>Users who wish to stay on urllib3 1.x can pin to <code>urllib3<2</code>.</p>
</li>
</ul>
<h2>v2.29.0</h2>
<h2>2.29.0 (2023-04-26)</h2>
<p><strong>Improvements</strong></p>
<ul>
<li>Requests now defers chunked requests to the urllib3 implementation to improve
standardization. (<a href="https://redirect.github.com/psf/requests/issues/6226">#6226</a>)</li>
<li>Requests relaxes header component requirements to support bytes/str subclasses. (<a href="https://redirect.github.com/psf/requests/issues/6356">#6356</a>)</li>
</ul>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/psf/requests/blob/main/HISTORY.md">requests's changelog</a>.</em></p>
<blockquote>
<h2>2.31.0 (2023-05-22)</h2>
<p><strong>Security</strong></p>
<ul>
<li>
<p>Versions of Requests between v2.3.0 and v2.30.0 are vulnerable to potential
forwarding of <code>Proxy-Authorization</code> headers to destination servers when
following HTTPS redirects.</p>
<p>When proxies are defined with user info (<a href="https://user:pass@proxy:8080">https://user:pass@proxy:8080</a>), Requests
will construct a <code>Proxy-Authorization</code> header that is attached to the request to
authenticate with the proxy.</p>
<p>In cases where Requests receives a redirect response, it previously reattached
the <code>Proxy-Authorization</code> header incorrectly, resulting in the value being
sent through the tunneled connection to the destination server. Users who rely on
defining their proxy credentials in the URL are <em>strongly</em> encouraged to upgrade
to Requests 2.31.0+ to prevent unintentional leakage and rotate their proxy
credentials once the change has been fully deployed.</p>
<p>Users who do not use a proxy or do not supply their proxy credentials through
the user information portion of their proxy URL are not subject to this
vulnerability.</p>
<p>Full details can be read in our <a href="https://github.com/psf/requests/security/advisories/GHSA-j8r2-6x86-q33q">Github Security Advisory</a>
and <a href="https://nvd.nist.gov/vuln/detail/CVE-2023-32681">CVE-2023-32681</a>.</p>
</li>
</ul>
<h2>2.30.0 (2023-05-03)</h2>
<p><strong>Dependencies</strong></p>
<ul>
<li>
<p>⚠️ Added support for urllib3 2.0. ⚠️</p>
<p>This may contain minor breaking changes so we advise careful testing and
reviewing <a href="https://urllib3.readthedocs.io/en/latest/v2-migration-guide.html">https://urllib3.readthedocs.io/en/latest/v2-migration-guide.html</a>
prior to upgrading.</p>
<p>Users who wish to stay on urllib3 1.x can pin to <code>urllib3<2</code>.</p>
</li>
</ul>
<h2>2.29.0 (2023-04-26)</h2>
<p><strong>Improvements</strong></p>
<ul>
<li>Requests now defers chunked requests to the urllib3 implementation to improve
standardization. (<a href="https://redirect.github.com/psf/requests/issues/6226">#6226</a>)</li>
<li>Requests relaxes header component requirements to support bytes/str subclasses. (<a href="https://redirect.github.com/psf/requests/issues/6356">#6356</a>)</li>
</ul>
<h2>2.28.2 (2023-01-12)</h2>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="147c8511dd"><code>147c851</code></a> v2.31.0</li>
<li><a href="74ea7cf7a6"><code>74ea7cf</code></a> Merge pull request from GHSA-j8r2-6x86-q33q</li>
<li><a href="3022253346"><code>3022253</code></a> test on pypy 3.8 and pypy 3.9 on windows and macos (<a href="https://redirect.github.com/psf/requests/issues/6424">#6424</a>)</li>
<li><a href="b639e66c81"><code>b639e66</code></a> test on py3.12 (<a href="https://redirect.github.com/psf/requests/issues/6448">#6448</a>)</li>
<li><a href="d3d504436e"><code>d3d5044</code></a> Fixed a small typo (<a href="https://redirect.github.com/psf/requests/issues/6452">#6452</a>)</li>
<li><a href="2ad18e0e10"><code>2ad18e0</code></a> v2.30.0</li>
<li><a href="f2629e9e3c"><code>f2629e9</code></a> Remove strict parameter (<a href="https://redirect.github.com/psf/requests/issues/6434">#6434</a>)</li>
<li><a href="87d63de873"><code>87d63de</code></a> v2.29.0</li>
<li><a href="51716c4ef3"><code>51716c4</code></a> enable the warnings plugin (<a href="https://redirect.github.com/psf/requests/issues/6416">#6416</a>)</li>
<li><a href="a7da1ab349"><code>a7da1ab</code></a> try on ubuntu 22.04 (<a href="https://redirect.github.com/psf/requests/issues/6418">#6418</a>)</li>
<li>Additional commits viewable in <a href="https://github.com/psf/requests/compare/v2.26.0...v2.31.0">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/pytorch/pytorch/network/alerts).
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102057
Approved by: https://github.com/huydhn
NCCL 2.17+ introduces some user configurable parameters for NCCL communicators using [ncclConfig_t](https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/api/types.html#c.ncclConfig_t) datatype and [ncclCommInitRankConfig](https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/api/comms.html#ncclcomminitrankconfig). This PR enables that feature.
A user can tune the parameters as follows:
```
import torch.distributed as dist
nccl_options = dist.ProcessGroupNCCL.Options()
nccl_options.config.max_ctas = 32
nccl_options.config.min_ctas = 8
nccl_options.config.cga_cluster_size = 2
dist.init_process_group(backend='nccl', init_method='env://', pg_options=nccl_options)
my_group = dist.new_group(pg_options=nccl_options)
```
The default values of these parameters are what is initialized by `NCCL_CONFIG_INITIALIZER`. Only for DistributedDataParallel, this PR sets the default value of cga_cluster_size to 2 (a heuristic that works well especially for DDP workloads).
Tuning these parameters can lead to improvement in end-to-end performance, since it affects the communication-computation overlap for NCCL kernels.
CC: @ptrblck @kwen2501
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97394
Approved by: https://github.com/kwen2501
Summary: Forward fix t53725825. New map implementation breaks multiple internal tests. forward fix it for some of them. To unblock others, mark unfixed ones are expectedFailure first.
Test Plan: Test with CI.
Reviewed By: angelayi
Differential Revision: D46084287
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102009
Approved by: https://github.com/angelayi
Summary:
This PR adds support for SharedQuantizationSpec, it's used to express the sharing between
two Tensors in the prepared graph, the Tensor will either be input of some node (expressed as a Tuple of fx nodes) or
output of some node (expressed as an fx Node)
Test Plan:
```
buck2 test mode/opt caffe2/test:quantization_pt2e -- 'caffe2/test:quantization_pt2e'
buck2 test mode/opt caffe2/test:quantization_pt2e -- --exact 'caffe2/test:quantization_pt2e - test_resnet18_with_quantizer_api (quantization.pt2e.test_quantize_pt2e.TestQuantizePT2EModels)'
```
Differential Revision: D46043026
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102184
Approved by: https://github.com/kimishpatel, https://github.com/leslie-fang-intel
There are a few reasons for this:
1. When I tried to enable padding via decompositions, I ran into weird errors with a number of models. I believe because we were making the type of a regular tensor a fake tensor.
2. This gives us flexibility to go before or after other graph passes
3. We can now also reason about the cost of the padding, and whether or not it can be fused since we have access to the graph
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101913
Approved by: https://github.com/ngimel
This PR does the following things:
- Align the C++ behavior with Python for FloorDiv.
- Always return expr dtype for some ops which not use expr's dtype to do the computation.
After this PR, TIMM ```levit_128``` and ```volo_d1_224``` accuracy tests can be passed for dynamic shape path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102068
Approved by: https://github.com/jgong5, https://github.com/ngimel
Summary:
# Context
In TorchRec's train pipeline, we need to fx trace a module to analyze the arguments on the forward call. In order to do this, we need to preserve some sort of meaning with each argument (a key or name of sorts that lets us identify the argument).
The issue is, when you use concrete args, internally, fx will unflatten the arg into it's constituents (to locate PHs).
Given a function that looks like this:
```
def process(batch: Dict[str, torch.Tensor]):
....
symbolic_trace(process, concrete_args: {"batch": {"f1": PH, "f2": PH}})
# function will be rewritten to look like:
def process(batch_1, batch_2): # batch_1 -> "f1", batch_2->"f2"
...
```
When you traverse through the nodes of the graph, the names of the argument nodes to the function are batch_1 and batch_2. **This doesn't mean anything to the user who is fx tracing.** There isn't anything indicating that batch_1 corresponds to key "f1" in the batch input.
# Solution
When fx sees a "PH", it creates a proxy node.
The user does not have direct access to proxy creation, but only through the PH structure.
Attach a piece of metadata, `ph_key`, to the PH when you set it in the concrete args, it will get passed into proxy + node creation. So when you traverse the graph, this metadata sticks onto the node as an attribute. This way you have a way of tagging that "batch_1" as "f1".
Test Plan: added a unit test
Reviewed By: dstaay-fb
Differential Revision: D44947653
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102195
Approved by: https://github.com/PaliC
Summary: Implement `torch.cat(tensors, dim=0)`, which concatenates a given sequence of tensors in the given dimension, for Vulkan backend. See the behavior of the operator here: https://pytorch.org/docs/stable/generated/torch.cat.html
Test Plan:
```
(base) luwei@luwei-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1 -- --gtest_filter="*cat_*"
Downloaded 0/2 artifacts, 0.00 bytes, 100.0% cache miss (for updated rules)
Building: finished in 12.2 sec (100%) 471/471 jobs, 2/471 updated
Total time: 12.2 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *cat_*
[==========] Running 40 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 40 tests from VulkanAPITest
[ RUN ] VulkanAPITest.cat_4d_dim0_invalidinputs_exceptions
[ OK ] VulkanAPITest.cat_4d_dim0_invalidinputs_exceptions (73 ms)
[ RUN ] VulkanAPITest.cat_4d_dim0_samebatch_success
[ OK ] VulkanAPITest.cat_4d_dim0_samebatch_success (36 ms)
[ RUN ] VulkanAPITest.cat_4d_dim0_diffbatch_success
[ OK ] VulkanAPITest.cat_4d_dim0_diffbatch_success (20 ms)
[ RUN ] VulkanAPITest.cat_4d_dim0_singledepth_success
[ OK ] VulkanAPITest.cat_4d_dim0_singledepth_success (2 ms)
[ RUN ] VulkanAPITest.cat_4d_dim0_singletensor_success
[ OK ] VulkanAPITest.cat_4d_dim0_singletensor_success (4 ms)
[ RUN ] VulkanAPITest.cat_4d_dim0_twotensors_success
[ OK ] VulkanAPITest.cat_4d_dim0_twotensors_success (13 ms)
[ RUN ] VulkanAPITest.cat_4d_dim0_negdim_success
[ OK ] VulkanAPITest.cat_4d_dim0_negdim_success (38 ms)
[ RUN ] VulkanAPITest.cat_4d_dim1_negdim_success
[ OK ] VulkanAPITest.cat_4d_dim1_negdim_success (26 ms)
[ RUN ] VulkanAPITest.cat_4d_dim2_negdim_success
[ OK ] VulkanAPITest.cat_4d_dim2_negdim_success (31 ms)
[ RUN ] VulkanAPITest.cat_4d_dim3_negdim_success
[ OK ] VulkanAPITest.cat_4d_dim3_negdim_success (30 ms)
[ RUN ] VulkanAPITest.cat_4d_dim1_singledepth_success
[ OK ] VulkanAPITest.cat_4d_dim1_singledepth_success (2 ms)
[ RUN ] VulkanAPITest.cat_4d_dim1_singletensor_success
[ OK ] VulkanAPITest.cat_4d_dim1_singletensor_success (4 ms)
[ DISABLED ] VulkanAPITest.DISABLED_cat_4d_dim1_twotensors_success
[ RUN ] VulkanAPITest.cat_4d_dim1_bat1_mult4ch_success
[ OK ] VulkanAPITest.cat_4d_dim1_bat1_mult4ch_success (4 ms)
[ RUN ] VulkanAPITest.cat_4d_dim1_bat2_mult4ch_success
[ OK ] VulkanAPITest.cat_4d_dim1_bat2_mult4ch_success (7 ms)
[ RUN ] VulkanAPITest.cat_4d_dim1_mult4ch_mixed_success
[ OK ] VulkanAPITest.cat_4d_dim1_mult4ch_mixed_success (19 ms)
[ DISABLED ] VulkanAPITest.DISABLED_cat_4d_dim1_mult4ch_nonmult4ch_success
[ RUN ] VulkanAPITest.cat_4d_dim2_sameheight_success
[ OK ] VulkanAPITest.cat_4d_dim2_sameheight_success (23 ms)
[ RUN ] VulkanAPITest.cat_4d_dim2_diffheight_success
[ OK ] VulkanAPITest.cat_4d_dim2_diffheight_success (23 ms)
[ RUN ] VulkanAPITest.cat_4d_dim2_singledepth_success
[ OK ] VulkanAPITest.cat_4d_dim2_singledepth_success (2 ms)
[ RUN ] VulkanAPITest.cat_4d_dim2_invalidinputs_exceptions
[ OK ] VulkanAPITest.cat_4d_dim2_invalidinputs_exceptions (23 ms)
[ RUN ] VulkanAPITest.cat_4d_dim3_invalidinputs_exceptions
[ OK ] VulkanAPITest.cat_4d_dim3_invalidinputs_exceptions (23 ms)
[ RUN ] VulkanAPITest.cat_4d_dim3_samewidth_success
[ OK ] VulkanAPITest.cat_4d_dim3_samewidth_success (30 ms)
[ RUN ] VulkanAPITest.cat_4d_dim3_diffwidth_success
[ OK ] VulkanAPITest.cat_4d_dim3_diffwidth_success (22 ms)
[ RUN ] VulkanAPITest.cat_3d_dim0_diff_channel_success
[ OK ] VulkanAPITest.cat_3d_dim0_diff_channel_success (8 ms)
[ RUN ] VulkanAPITest.cat_3d_dim0_same_channel_success
[ OK ] VulkanAPITest.cat_3d_dim0_same_channel_success (5 ms)
[ RUN ] VulkanAPITest.cat_3d_dim1_diffheight_success
[ OK ] VulkanAPITest.cat_3d_dim1_diffheight_success (7 ms)
[ RUN ] VulkanAPITest.cat_3d_dim1_same_height_success
[ OK ] VulkanAPITest.cat_3d_dim1_same_height_success (6 ms)
[ RUN ] VulkanAPITest.cat_3d_dim2_diffwidth_success
[ OK ] VulkanAPITest.cat_3d_dim2_diffwidth_success (9 ms)
[ RUN ] VulkanAPITest.cat_3d_dim2_samewidth_success
[ OK ] VulkanAPITest.cat_3d_dim2_samewidth_success (4 ms)
[ RUN ] VulkanAPITest.cat_3d_dim0_negdim_success
[ OK ] VulkanAPITest.cat_3d_dim0_negdim_success (8 ms)
[ RUN ] VulkanAPITest.cat_3d_dim1_negdim_success
[ OK ] VulkanAPITest.cat_3d_dim1_negdim_success (8 ms)
[ RUN ] VulkanAPITest.cat_3d_dim2_negdim_success
[ OK ] VulkanAPITest.cat_3d_dim2_negdim_success (5 ms)
[ RUN ] VulkanAPITest.cat_2d_dim0_same_height_success
[ OK ] VulkanAPITest.cat_2d_dim0_same_height_success (2 ms)
[ RUN ] VulkanAPITest.cat_2d_dim0_diff_height_success
[ OK ] VulkanAPITest.cat_2d_dim0_diff_height_success (1 ms)
[ RUN ] VulkanAPITest.cat_2d_dim1_same_width_success
[ OK ] VulkanAPITest.cat_2d_dim1_same_width_success (1 ms)
[ RUN ] VulkanAPITest.cat_2d_dim1_diff_width_success
[ OK ] VulkanAPITest.cat_2d_dim1_diff_width_success (1 ms)
[ RUN ] VulkanAPITest.cat_2d_dim0_negdim_success
[ OK ] VulkanAPITest.cat_2d_dim0_negdim_success (1 ms)
[ RUN ] VulkanAPITest.cat_2d_dim1_negdim_success
[ OK ] VulkanAPITest.cat_2d_dim1_negdim_success (2 ms)
[ RUN ] VulkanAPITest.cat_1d_dim0_same_width_success
[ OK ] VulkanAPITest.cat_1d_dim0_same_width_success (0 ms)
[ RUN ] VulkanAPITest.cat_1d_dim0_diff_width_success
[ OK ] VulkanAPITest.cat_1d_dim0_diff_width_success (0 ms)
[ RUN ] VulkanAPITest.cat_1d_dim0_negdim_success
[ OK ] VulkanAPITest.cat_1d_dim0_negdim_success (0 ms)
[----------] 40 tests from VulkanAPITest (543 ms total)
[----------] Global test environment tear-down
[==========] 40 tests from 1 test suite ran. (543 ms total)
[ PASSED ] 40 tests.
YOU HAVE 2 DISABLED TESTS
```
Reviewed By: SS-JIA
Differential Revision: D46059444
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102128
Approved by: https://github.com/SS-JIA
The main use case here is that folks would like to ignore layer norm for mixed precision. This can now be enabled with:
```
mp_config = MixedPrecision(
param_dtype=torch.float16,
reduce_dtype=torch.float16,
buffer_dtype=torch.float16,
_mixed_precision_module_classes_to_ignore=[_BatchNorm, nn.LayerNorm],
)
```
This is done by classes of types in `_mixed_precision_module_classes_to_ignore` being wrapped in their own FSDP unit with mixed preicsion disabled. This is only enabled for auto wrapping.
We also add module pre and post hooks to cast / downcast inputs to the appropriate full precision.
Differential Revision: [D46079957](https://our.internmc.facebook.com/intern/diff/D46079957/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102010
Approved by: https://github.com/awgu
[BE] `require_backend_is_available` offers the a more thorough check as `require_backend` but both are often used together. This remove `require_backend` and centralizes on the `require_backend_is_available` decorator
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101891
Approved by: https://github.com/awgu
## Issue description
The PR https://github.com/pytorch/pytorch/pull/100064 introduces a new RNG operation process. However, it causes every `randint` to load a separate random seed by default. TorchInductor generates a buffer to store all necessary random seeds and places the offsets as constant values in the subsequent compute buffers. In ir_pre_fusion generated by TorchInductor, some buffers only differ by one line, which is the load random seed with the corresponding offset. Subsequently, the codegen generates Triton kernels following the same rule. Finally, in the output_code.py, some Triton kernels only differ by one line, meaning that redundant kernels are being generated.
## Solution
This PR captures the seed offset and adds it to the existing `self.sizevars` structure. It generates variable names as placeholders, allowing the code wrapper to pass the offset as an argument to the kernels. I've also modified the divisible_by_16 check to exclude this argument.
This PR reduces the number of generated kernels from 50 to 17 for BertForMaskedLM forward.
According to tests on my own environment, the compilation time of attention_is_all_you_need_pytorch has been reduced from 94s to 66s. The speedup remains largely unchanged, at 1.37X.
The following is a comparison for a simple example.
Before:
```
triton_poi_fused_0 = async_compile.triton('triton_', '''
...
def triton_(in_ptr0, out_ptr0, xnumel, XBLOCK : tl.constexpr):
...
tmp0 = tl.load(in_ptr0 + 0)
tmp1 = x0
tmp2 = triton_helpers.randint64(tmp0, (tmp1).to(tl.uint32), 0, 10)
triton_poi_fused_1 = async_compile.triton('triton_', '''
...
def triton_(in_ptr0, out_ptr0, xnumel, XBLOCK : tl.constexpr):
...
tmp0 = tl.load(in_ptr0 + 1)
tmp1 = x0
tmp2 = triton_helpers.randint64(tmp0, (tmp1).to(tl.uint32), 0, 10)
...''')
def call(args):
triton_poi_fused_0.run(buf0, buf1, 1024, grid=grid(1024), stream=stream0)
triton_poi_fused_1.run(buf0, buf2, 1024, grid=grid(1024), stream=stream0)
```
After:
```
triton_poi_fused_0 = async_compile.triton('triton_', '''
...
def triton_(in_ptr0, out_ptr0, load_seed_offset, xnumel, XBLOCK : tl.constexpr):
...
tmp0 = tl.load(in_ptr0 + load_seed_offset)
tmp1 = x0
tmp2 = triton_helpers.randint64(tmp0, (tmp1).to(tl.uint32), 0, 10)
....
def call(args):
triton_poi_fused_0.run(buf0, buf1, 0, 1024, grid=grid(1024), stream=stream0)
triton_poi_fused_0.run(buf0, buf2, 1, 1024, grid=grid(1024), stream=stream0)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102104
Approved by: https://github.com/jansel, https://github.com/ngimel
Summary:
Use the existing permute shader to implement the following two operators for Vulkan backend
- `aten::transpose` The behavior of the operator is shown in https://pytorch.org/docs/stable/generated/torch.transpose.html.
- `aten::t` The behavior of the operator is shown in https://pytorch.org/docs/stable/generated/torch.t.html#torch.t. 1d tensors are returned as is. When input is a 2d tensor this is equivalent to `aten::transpose(input, 0, 1)`.
Test Plan:
At local repo of fbsource on MacBook, run `buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1`
- Full test results P739033174.
- `aten::t` and `aten::tranpose` related results shown below
```
(base) luwei@luwei-mbp fbsource % buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1
[... other tests ...]
[ RUN ] VulkanAPITest.transpose_t_1d
[ OK ] VulkanAPITest.transpose_t_1d (0 ms)
[ RUN ] VulkanAPITest.transpose_t_2d_small
[ OK ] VulkanAPITest.transpose_t_2d_small (1 ms)
[ RUN ] VulkanAPITest.transpose_t_2d_medium
[ OK ] VulkanAPITest.transpose_t_2d_medium (0 ms)
[ RUN ] VulkanAPITest.transpose_t_2d_large
[ OK ] VulkanAPITest.transpose_t_2d_large (0 ms)
[ RUN ] VulkanAPITest.transpose_2d_height_and_width_small
[ OK ] VulkanAPITest.transpose_2d_height_and_width_small (0 ms)
[ RUN ] VulkanAPITest.transpose_2d_height_and_width_medium
[ OK ] VulkanAPITest.transpose_2d_height_and_width_medium (0 ms)
[ RUN ] VulkanAPITest.transpose_2d_height_and_width_large
[ OK ] VulkanAPITest.transpose_2d_height_and_width_large (0 ms)
[ RUN ] VulkanAPITest.transpose_2d_height_and_height_large
[ OK ] VulkanAPITest.transpose_2d_height_and_height_large (0 ms)
[ RUN ] VulkanAPITest.transpose_2d_width_and_width_large
[ OK ] VulkanAPITest.transpose_2d_width_and_width_large (0 ms)
[ RUN ] VulkanAPITest.transpose_3d_height_and_width_small
[ OK ] VulkanAPITest.transpose_3d_height_and_width_small (0 ms)
[ RUN ] VulkanAPITest.transpose_3d_height_and_width_medium
[ OK ] VulkanAPITest.transpose_3d_height_and_width_medium (1 ms)
[ RUN ] VulkanAPITest.transpose_3d_height_and_width_large
[ OK ] VulkanAPITest.transpose_3d_height_and_width_large (1 ms)
[ RUN ] VulkanAPITest.transpose_3d_width_and_width_large
[ OK ] VulkanAPITest.transpose_3d_width_and_width_large (0 ms)
[ RUN ] VulkanAPITest.transpose_3d_depth_and_width_small
[ OK ] VulkanAPITest.transpose_3d_depth_and_width_small (0 ms)
[ RUN ] VulkanAPITest.transpose_3d_depth_and_width_medium
[ OK ] VulkanAPITest.transpose_3d_depth_and_width_medium (0 ms)
[ RUN ] VulkanAPITest.transpose_3d_depth_and_width_large
[ OK ] VulkanAPITest.transpose_3d_depth_and_width_large (0 ms)
[ RUN ] VulkanAPITest.transpose_3d_depth_and_depth_large
[ OK ] VulkanAPITest.transpose_3d_depth_and_depth_large (0 ms)
[ RUN ] VulkanAPITest.transpose_3d_depth_and_height_small
[ OK ] VulkanAPITest.transpose_3d_depth_and_height_small (0 ms)
[ RUN ] VulkanAPITest.transpose_3d_depth_and_height_medium
[ OK ] VulkanAPITest.transpose_3d_depth_and_height_medium (0 ms)
[ RUN ] VulkanAPITest.transpose_3d_depth_and_height_large
[ OK ] VulkanAPITest.transpose_3d_depth_and_height_large (2 ms)
[ RUN ] VulkanAPITest.transpose_3d_height_and_height_large
[ OK ] VulkanAPITest.transpose_3d_height_and_height_large (1 ms)
[ RUN ] VulkanAPITest.transpose_4d_batch_and_batch_large
[ OK ] VulkanAPITest.transpose_4d_batch_and_batch_large (1 ms)
[ RUN ] VulkanAPITest.transpose_4d_depth_and_depth_large
[ OK ] VulkanAPITest.transpose_4d_depth_and_depth_large (1 ms)
[ RUN ] VulkanAPITest.transpose_4d_height_and_height_large
[ OK ] VulkanAPITest.transpose_4d_height_and_height_large (1 ms)
[ RUN ] VulkanAPITest.transpose_4d_width_and_width_large
[ OK ] VulkanAPITest.transpose_4d_width_and_width_large (0 ms)
[ RUN ] VulkanAPITest.transpose_4d_batch_and_depth_large
[ OK ] VulkanAPITest.transpose_4d_batch_and_depth_large (1 ms)
[ RUN ] VulkanAPITest.transpose_4d_batch_and_height_large
[ OK ] VulkanAPITest.transpose_4d_batch_and_height_large (2 ms)
[ RUN ] VulkanAPITest.transpose_4d_batch_and_width_large
[ OK ] VulkanAPITest.transpose_4d_batch_and_width_large (2 ms)
[ RUN ] VulkanAPITest.transpose_4d_depth_and_height_large
[ OK ] VulkanAPITest.transpose_4d_depth_and_height_large (2 ms)
[ RUN ] VulkanAPITest.transpose_4d_depth_and_width_large
[ OK ] VulkanAPITest.transpose_4d_depth_and_width_large (2 ms)
[ RUN ] VulkanAPITest.transpose_4d_height_and_width_large
[ OK ] VulkanAPITest.transpose_4d_height_and_width_large (1 ms)
[... other tests ...]
```
Reviewed By: SS-JIA
Differential Revision: D45878333
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101808
Approved by: https://github.com/SS-JIA
Changes the StreamID encoding to use the last bit to distinguish between external and internal streams, 4 bits for IdType (DEFAULT, EXT or user-created streams possibly with high priority), and 5 bits for index. This allows us to have more stream priorities exposed to user (I'm currently setting 4, but that's easy to change now). Note, we are pre-creating all 32 streams in the pool per each allowed priority, I don't know if it's a problem in practice. Currently cuda 11.8/A100 GPUs allow 6 different stream priorities, the number may be different for the different cards/different cuda versions.
Previous callsites explicitly requesting high prioity stream (`isHighPriority=true`) are now getting the highest priority stream.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101956
Approved by: https://github.com/ezyang
Summary: We don't need to leak matched input positions from dynamo anymore if we can just populate all args with corresponding fake tensors.
Test Plan: CI
Differential Revision: D46131556
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102129
Approved by: https://github.com/angelayi
Summary:
https://github.com/pytorch/pytorch/pull/98488 implements CSE for dynamo guards, and it relies on astunparse to perform the optimization.
`test_guards_cse_pass_single` was broken and later was fixed by introducing a check_and_skip_if_needed. This actually fixes the root cause on fbcode and should bring some perf gain internally.
Test Plan: `buck2 test @//mode/opt //caffe2/test/dynamo:test_dynamo -- --exact 'caffe2/test/dynamo:test_dynamo - test_misc.py::DynamicShapesMiscTests::test_guards_cse_pass_single' --run-disabled`
Reviewed By: malfet
Differential Revision: D46126742
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102120
Approved by: https://github.com/malfet
Similar to https://github.com/pytorch/pytorch/pull/96160 but for the modules
nn.PixelShuffle and nn.PixelUnshuffle.
torch.nn.PixelUnshuffle accepts both float and quantized inputs.
However, previously we would unnecessarily dequantize quantized inputs into floats
before passing them to the function. This commit fixes this by lowering the pattern
[dequant - PixelShuffle - quant].
[dequant - PixelUnshuffle - quant].
Test Plan:
python test/test_quantization.py TestQuantizeFxOps.test_pixel_shuffle_module
python test/test_quantization.py TestQuantizeFxOps.test_pixel_unshuffle_module
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101926
Approved by: https://github.com/jerryzh168
Add 'ignored_states' that accepts either a list of ignored_parameters or a list of nn modules for FSDP model wrapper and fully_shard composable APIs, it is recommended to use 'ignored_states' over 'ignored_modules' moving forward
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102056
Approved by: https://github.com/awgu
This PR enables data parallel to work with non 0 batch dim, the only
thing we need to do is to expose the input_batch_dim to DataParallelMode
and the data parallel expansion automatically works as we have done
things correctly in batch dim analysis.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100073
Approved by: https://github.com/mrshenli
This PR improves the activation handling logic of data parallel, to
support the cases where there're tensor factory ops that does not depend
on any input node, it would still produce activation, with either
sharded act (i.e. if output shape have batch size) or replcate act
It also significantly simplify the full reduction logic, now we don't
need the full reduction detection, we only need to ensure that when
compute the batch dim, we detected full reduction and mark it as sharded
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100853
Approved by: https://github.com/mrshenli
This PR enhances batch dim analysis of data parallel to understand
more on the cases where batch dim get flattened or split, using
dtensor's view ops, we could be able to track the batch dim that got
transformed in non-trival ways.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100852
Approved by: https://github.com/mrshenli
Fixes#91648
As explained in the tracking issue, the incomplete type stubs in `torch/nn/parallel` mask `DataParallel` methods relevant for subclassing and also mask type issues present in the code as well.
One notable change here is the addition of [`allow_redefinition = True`](https://mypy.readthedocs.io/en/stable/config_file.html#confval-allow_redefinition) in `mypy.ini`, which allows for a common pattern:
> Allows variables to be redefined with an arbitrary type, as long as the redefinition is in the same block and nesting level as the original definition.
This is added specifically to allow for the type narrowing of `device_ids` in `torch.nn.parallel.data_parallel.data_parallel` from `Sequence[Union[int, torch.device]]` to `Sequence[int]`.
Other than this, there are various renamings and `type: ignore` comments added to bypass errors that arose from the merging.
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101528
Approved by: https://github.com/ezyang
As part of split-cat transforms, we needed to unsqueeze additional inputs (not coming from split) but going to the cat/stack nodes.
However, this leads to patterns like:
```
split -> unsqueeze -> cat
```
when there are multiple splits going into cat.
An alternative is to use stack rather than unsqueeze, leading to patterns like:
```
split -> stack -> cat
```
This is much better, as repeated applications of the same pattern will further simplify "split->stack", which is not trivial in case of "split->unsqueeze->cat".
Another nice side-effect is lesser number of nodes in the graph overall.
Differential Revision: [D45952452](https://our.internmc.facebook.com/intern/diff/D45952452/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101766
Approved by: https://github.com/jansel
Needs https://github.com/microsoft/onnxscript/pull/721
The current FX exporter is using manually maintained dictionary to map ATen op to its OnnxFunction. However, the issue arises when ATen op has overloads or OnnxFunction has overloads, which is not resolvable by the one to one mapping . For example, `aten::arange` has onverloads: `aten::arange.start` and `aten::arange.start_step`, or for `aten::argmax`, torchlib provides two function: aten_argmax, and aten_argmax_dim.
This PR utilizes newly introduced [ONNX OpSchema](https://github.com/microsoft/onnxscript/pull/626) to match the input arguments of an ATen operator to find the correct overload.
### OnnxRegistry
Heavily reference on [TorchScript Registry](https://github.com/pytorch/pytorch/pull/84382). The only difference is that in FX registry, an ATen operator with specific opset version is mapped to a list of overloaded functions.
* No longer use global registry. The registry is initialized in `ResolvedExportOptions` with torchlib, and will be exposed to users in the future.
* Multiple opset version layer is kept through `_SymbolicFunctionGroup` , but torchlib now only supports 18.
* Basic API of custom operator support: `register`, `unregister`, and `is_register_op` are kept for future development. To further complete them, the follow-up PRs should address:
- How to allow users to remove/override specific overload? Using OpSchema to differentiate?
- User registers a new overload with the same OpSchema as one of registered overload.
### OnnxDispatcher
Dispatch ATen operators to the matched overload by comparing OpSchema with input arguments.
* `OpSchemaWrapper` wrap the onnx schema, and record matching score.
* `dispatch` uses `OpSchemaWrapper` to compare data types to find the best matched overload. If the match isn't perfect, record warning in diagnostics.
* `dispatch_opset_version` is referenced from #84382 and kept, but torchlib doesn't support opset version != 18.
* Because right now (1) OnnxFunction arguments are manually typed, and (2) ORT could unfollow ONNX type spec, we relax the schema match with `matching score system`.
* To include more supports: the follow-up PRs should address:
- How to add op.Cast with autocast? In torchlib or converter?
- The need of type promotion can be captured by dispatcher, but needs OpSchema shows the T1/T2 information.
### OpSchemaWrapper - Matching Score Mechanism
#### The matching score system:
This is a temporary solution to how we target the correct ONNX overloads given that we only have manually annotated arguments (potentially inaccurate schema) and limited supports on AttributeProto.
1. Perfect match exam: If all arguments/kwargs are all matched, return the function without any warnings.
2. Best match exam: The system add the each correct matching input counts orderly, and subtract the symmetrical difference between their attributes to calculate the matching score. And select the one with the highest score in the end. If the selection is not a perfect match, a warning message is sent to SARIF.
#### Example of overloads
1. Different types: Caused by the difference between the ONNX spec and PyTorch.
The matching system finds the correct one.
```python
@torch_op("aten::mul")
def aten_mul(self: TReal, other: TReal) -> TReal:
...
@torch_op("aten::mul")
def aten_mul_bool(self: BOOL, other: BOOL) -> BOOL:
...
```
2. Optional dim: caused by unsupported op.OptionalHasElement (will support on opset version == 20). dim could be "None"
```python
@torch_op("aten::argmax", trace_only=True)
def aten_argmax(
self: TrealOrUInt8, dim: Optional[int] = None, keepdim: bool = False
) -> TrealOrUInt8:
...
@torch_op("aten::argmax", private=True)
def _aten_argmax_dim(self: TrealOrUInt8, dim: int, keepdim: bool = False) -> TrealOrUInt8:
...
```
This case is impossible to differentiate, as they both might have dim in kwargs, so in this case, please make sure you turn the one with `dim: int` to private function.
3. Optional dtype: dtype could be "unprovided". The difference from 2 is that dtype would not be None.
```python
@torch_op("aten::new_full")
def aten_new_full(self: TTensor, size: INT64, fill_value: TTensor) -> TTensor:
...
@torch_op("aten::new_full")
def aten_new_full_dtype(self: TTensor, size: INT64, fill_value: TTensor, dtype: int) -> TTensor:
...
```
Depends on dtype is provided or not, matching system will dispatch the ATen op to the correct one.
4. `None` and `[]` and `NoneType` are considered failing the match.
5. Two functions have the same score is recorded into SARIFs.
### TODOs
1. Type promotion can be captured by dispatcher only if OpSchema can provide it. However, the implementation of "graph-level" pass vs "in-op"" promotion can be further discussed in https://github.com/microsoft/onnxscript/issues/563.
5. torchlib should provide the "opset version" to OnnxRegistry.
7. How to expose OnnxRegistry with custom add/remove ops APIs nneds to be further discussed.
Co-authored-by: Justin Chu <justinchuby@microsoft.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100660
Approved by: https://github.com/thiagocrepaldi
It seems that some legacy default stream logic (e.g., present in a8ff647e42/torch/utils/dlpack.py (L114) ) is not handled on the potential receiving end in `torch/_tensor.py`.
Open to suggestions on how to make the test case less clunky, as this was the combination we arrived at after discovering flakiness in alternate versions.
Thanks to Olga Andreeva for surfacing this issue and providing a repro.
CC @Aidyn-A @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101318
Approved by: https://github.com/ngimel
Summary: The two are cpu only tests.
Test Plan:
```
buck2 test @//mode/dev-nosan //caffe2/test/inductor:test_inductor -- --exact 'caffe2/test/inductor:test_inductor - test_in_out_buffer_cuda (caffe2.test.inductor.test_torchinductor.CudaTests)' --run-disabled
```
Reviewed By: bertmaher
Differential Revision: D46011571
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101887
Approved by: https://github.com/bertmaher
It looks like inference_mode wasn't playing well with functionalization.
If you run torch.compile on a function, and the inputs to the function are tensors created outside of inference mode, then we need to make sure that when we created functional tensor wrappers for those inputs during compilation, those functional wrappers properly mirror whether or not the original tensor is an inference tensor.
Hopefully fixes https://github.com/pytorch/pytorch/issues/101151
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101219
Approved by: https://github.com/albanD, https://github.com/ezyang
Sleef has automatic architecture selection for Power. There is no need to call architecture specific interfaces. If we call the generic interface, Sleef will correctly choose the architecture specific code, based on the architecure (vsx for Power8, vsx3 for Power9 and Power10). So, the vsx suffix in Sleef calls in PyTorch are removed, so that the architecture specific code selection is handled by Sleef internally.
Fixes the issue wherein older (and slower) vsx code in Sleef was getting executed on newer Power9 and Power10 processors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100149
Approved by: https://github.com/jgong5
This PR:
- adds a mechanism to turn any RAII guard into a Python Context Manager
- turns ExcludeDispatchKeyGuard into a context manager, and purges usages
of the older torch._C.ExcludeDispatchKeyGuard from the codebase.
The mechanism is that given a RAII guard, we construct a context
manager object that holds an optional guard. When we enter the context
manager we populate the guard, when we exit we reset it.
We don't delete torch._C.ExcludeDispatchKeyGuard for BC reasons (people
are using it in fbcode). If this code actually sticks
(it is using C++17 and that worries me a bit), then I'll apply the
change to other RAII guards we have, otherwise, we can write our own
std::apply.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102037
Approved by: https://github.com/ezyang, https://github.com/bdhirsh
There are many communication operations for shardedTensor in the state dict of fsdp. They use the external passed-in pg (or the default pg), which currently supports cuda devices. Before communication, the memory will be moved to cuda, which is implicit (because it is essentially moving data to the memory type required by pg, not the computing device type). Similarly, when users use fsdp on a custom backend, they will pass in a custom pg (which does not support cuda devices), which may cause fsdp to not work properly in some cases. This PR obtains the memory type supported by the pg through _get_pg_default_device during communication, and moves the data to it when needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101533
Approved by: https://github.com/awgu
1. Record time spent for init_process_group, new_group, _store_based_barrier
2. Rename c10d_error_logger to c10d_logger for generalization.
3. Refactor to move logger wrappers in distributed_c10d.py to logger to c10d_logger.py.
4. Rename the logger wrappers (bc breaking). Exception_handler is renamed to exception_logger to avoid confusion with logging handler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101912
Approved by: https://github.com/fduwjj
Bumps [mpmath](https://github.com/fredrik-johansson/mpmath) from 1.2.1 to 1.3.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/fredrik-johansson/mpmath/releases">mpmath's releases</a>.</em></p>
<blockquote>
<h2>1.3.0</h2>
<p>Security issues:</p>
<ul>
<li>Fixed ReDOS vulnerability in mpmathify() (CVE-2021-29063) (Vinzent Steinberg)</li>
</ul>
<p>Features:</p>
<ul>
<li>Added quadsubdiv() for numerical integration with adaptive path splitting
(Fredrik Johansson)</li>
<li>Added the Cohen algorithm for inverse Laplace transforms
(Guillermo Navas-Palencia)</li>
<li>Some speedup of matrix multiplication (Fredrik Johansson)</li>
<li>Optimizations to Carlson elliptic integrals (Paul Masson)</li>
<li>Added signal functions (squarew(), trianglew(), sawtoothw(), unit_triangle()
sigmoidw()) (Nike Dattani, Deyan Mihaylov, Tina Yu)</li>
</ul>
<p>Bug fixes:</p>
<ul>
<li>Correct mpf initialization from tuple for finf and fninf (Sergey B Kirpichev)</li>
<li>Support QR decomposition for matrices of width 0 and 1 (Clemens Hofreither)</li>
<li>Fixed some cases where elliprj() gave inaccurate results (Fredrik Johansson)</li>
<li>Fixed cases where digamma() hangs for complex input (Fredrik Johansson)</li>
<li>Fixed cases of polylog() with integer-valued parameter with complex type
(Fredrik Johansson)</li>
<li>Fixed fp.nsum() with Euler-Maclaurin algorithm (Fredrik Johansson)</li>
</ul>
<p>Maintenance:</p>
<ul>
<li>Dropped support for Python 3.4 (Sergey B Kirpichev)</li>
<li>Documentation cleanup (Sergey B Kirpichev)</li>
<li>Removed obsolete files (Sergey B Kirpichev)</li>
<li>Added options to runtests.py to skip tests and exit on failure
(Jonathan Warner)</li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/mpmath/mpmath/blob/master/CHANGES">mpmath's changelog</a>.</em></p>
<blockquote>
<p>--1.3.0--
Released March 7, 2023</p>
<p>Security issues:</p>
<ul>
<li>Fixed ReDOS vulnerability in mpmathify() (CVE-2021-29063) (Vinzent Steinberg)</li>
</ul>
<p>Features:</p>
<ul>
<li>Added quadsubdiv() for numerical integration with adaptive path splitting
(Fredrik Johansson)</li>
<li>Added the Cohen algorithm for inverse Laplace transforms
(Guillermo Navas-Palencia)</li>
<li>Some speedup of matrix multiplication (Fredrik Johansson)</li>
<li>Optimizations to Carlson elliptic integrals (Paul Masson)</li>
<li>Added signal functions (squarew(), trianglew(), sawtoothw(), unit_triangle()
sigmoidw()) (Nike Dattani, Deyan Mihaylov, Tina Yu)</li>
</ul>
<p>Bug fixes:</p>
<ul>
<li>Correct mpf initialization from tuple for finf and fninf (Sergey B Kirpichev)</li>
<li>Support QR decomposition for matrices of width 0 and 1 (Clemens Hofreither)</li>
<li>Fixed some cases where elliprj() gave inaccurate results (Fredrik Johansson)</li>
<li>Fixed cases where digamma() hangs for complex input (Fredrik Johansson)</li>
<li>Fixed cases of polylog() with integer-valued parameter with complex type
(Fredrik Johansson)</li>
<li>Fixed fp.nsum() with Euler-Maclaurin algorithm (Fredrik Johansson)</li>
</ul>
<p>Maintenance:</p>
<ul>
<li>Dropped support for Python 3.4 (Sergey B Kirpichev)</li>
<li>Documentation cleanup (Sergey B Kirpichev)</li>
<li>Removed obsolete files (Sergey B Kirpichev)</li>
<li>Added options to runtests.py to skip tests and exit on failure
(Jonathan Warner)</li>
</ul>
<p>--1.2.0--
Released February 1, 2021</p>
<p>Features and optimizations:</p>
<ul>
<li>Support @ operator for matrix multiplication (Max Gaukler)</li>
<li>Add eta() implementing the Dedekind eta function</li>
<li>Optimized the python_trailing function (adhoc-king)</li>
<li>Implement unary plus for matrices (Max Gaukler)</li>
<li>Improved calculation of gram_index (p15-git-acc)</li>
</ul>
<p>Compatibility:</p>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="b5c04506ef"><code>b5c0450</code></a> version 1.3.0</li>
<li><a href="a27581ca77"><code>a27581c</code></a> Merge pull request <a href="https://redirect.github.com/fredrik-johansson/mpmath/issues/656">#656</a> from cclauss/patch-2</li>
<li><a href="9d7884bf96"><code>9d7884b</code></a> don't use .ae method in library code</li>
<li><a href="967de83d51"><code>967de83</code></a> Downgrade to ubuntu-20.04 for Py35 and Py36</li>
<li><a href="6425c6aa41"><code>6425c6a</code></a> build: strategy: fail-fast: false</li>
<li><a href="e2341c762e"><code>e2341c7</code></a> GitHub Actions: Test on Python 3.11 production release</li>
<li><a href="1258e33e16"><code>1258e33</code></a> fix failing doctests</li>
<li><a href="b7c15d668c"><code>b7c15d6</code></a> include signals documentation; remove duplicate docstrings</li>
<li><a href="1b476ea230"><code>1b476ea</code></a> update doc building instructions</li>
<li><a href="5f57beb1e3"><code>5f57beb</code></a> Merge pull request <a href="https://redirect.github.com/fredrik-johansson/mpmath/issues/646">#646</a> from cclauss/patch-1</li>
<li>Additional commits viewable in <a href="https://github.com/fredrik-johansson/mpmath/compare/1.2.1...1.3.0">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/pytorch/pytorch/network/alerts).
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102058
Approved by: https://github.com/huydhn
Per title. I extract this part out of the draft PR that I'm working on https://github.com/pytorch/pytorch/pull/102107 because
the remaining issues with rerun disabled tests: log size and unexpected runner failures requires some further investigations while this one is clearing breaking in trunk atm.
Until we can support disable C++ tests, there is no need to run them in rerun disabled tests mode.
### Testing
Coming from https://github.com/pytorch/pytorch/pull/102107, for example https://github.com/pytorch/pytorch/actions/runs/5062224659/jobs/9087747981
```
2023-05-23T22:46:50.1953318Z Running cpp/basic 1/1 ... [2023-05-23 22:46:50.195077]
2023-05-23T22:46:50.1953847Z Skipping C++ tests when running under RERUN_DISABLED_TESTS mode
2023-05-23T22:46:50.2066032Z Running cpp/atest 1/1 ... [2023-05-23 22:46:50.206348]
2023-05-23T22:46:50.2066435Z Skipping C++ tests when running under RERUN_DISABLED_TESTS mode
2023-05-23T22:46:52.2666743Z No CUDA runtime is found, using CUDA_HOME='/usr/local/cuda'
2023-05-23T22:46:52.2691817Z Ignoring disabled issues: []
...
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102132
Approved by: https://github.com/clee2000
When investigating failures in https://github.com/pytorch/pytorch/pull/100017 I realized that we were reentering FakeTensorMode even though there was already one on the stack. Although we have attempted assert for these cases in the past, e.g., as in https://github.com/pytorch/pytorch/pull/97186 it seems that the existing protections were insufficient.
In this particular case, the reapplication of FakeTensorMode was due to an interaction with NotImplemented multiple dispatch handling. If proxy tensor mode detects an unrecognized tensor type (this includes FakeTensor, if it is not tracked with a proxy), it will return NotImplemented to give this tensor a chance to unpack itself into proxyable operation. However, this is never the right thing for FakeTensor, where no unpacking is possible. However, today, FakeTensor attempts to reapply the FakeTensorMode, resulting in FakeTensorMode being twice on the stack.
This PR does a number of things:
* It adds an assert in `FakeTensorMode.__torch_dispatch__` that you must not already have this mode on the stack, this is ALWAYS an error
* It modifies `FakeTensor.__torch_dispatch__` to return `NotImplemented` if the mode is already active. This prevents us from readding the mode on the stack
* It adds a new logging artifact `not_implemented` which you can use to get debug logs about all of the times a `__torch_dispatch__` handler returned NotImplemented and why it did so. Your subclass has to manually opt into this logging, but I inserted the necessary logs for ProxyTensorMode and FakeTensor(Mode)
* `with fake_mode` now no-ops if the fake mode is already on the stack, which is what users want anyway
* I am BREAKING pre-autograd tracing, because it is currently doing something weird with the original C++ mode stack. Brian is going to follow up with a fix next week.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102091
Approved by: https://github.com/thiagocrepaldi, https://github.com/eellison, https://github.com/wanchaol, https://github.com/bdhirsh
move tf32_on_and_off after @torch.backends.cudnn.flags(enabled=True, benchmark=False) due to @torch.backends.cudnn.flags(enabled=True, benchmark=False) overwriting tf32_on_and_off if after.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102007
Approved by: https://github.com/ngimel
While attempting to explore XLTransformers w/ PT2, I found that we leak tracing time objects (VariableTrackers) into the runtime:
```
Traceback (most recent call last):
File "/scratch/voz/work/xlformers/train.py", line 686, in <module>
main(cfg)
File "/scratch/voz/work/xlformers/train.py", line 357, in main
pred, _ = model(x)
File "/scratch/voz/work/pytorch/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/scratch/voz/work/pytorch/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
File "/scratch/voz/work/pytorch/torch/_dynamo/eval_frame.py", line 282, in _fn
return fn(*args, **kwargs)
File "/data/home/voz/miniconda3/envs/torch5/lib/python3.10/site-packages/fairscale/nn/data_parallel/fully_sharded_data_parallel.py", line 1416, in forward
self._lazy_init()
File "/data/home/voz/miniconda3/envs/torch5/lib/python3.10/site-packages/fairscale/nn/data_parallel/fully_sharded_data_parallel.py", line 1424, in <resume in forward>
args, kwargs = cast_floats_to_right_precision(True, True, *args, **kwargs)
File "/data/home/voz/miniconda3/envs/torch5/lib/python3.10/site-packages/fairscale/nn/data_parallel/fully_sharded_data_parallel.py", line 1434, in <resume in forward>
self._rebuild_full_params()
File "/scratch/voz/work/pytorch/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/data/home/voz/miniconda3/envs/torch5/lib/python3.10/site-packages/fairscale/nn/data_parallel/fully_sharded_data_parallel.py", line 1932, in _rebuild_full_params
def update_p_data(custom_output_tensor: Optional[torch.Tensor] = None) -> None:
File "/data/home/voz/miniconda3/envs/torch5/lib/python3.10/site-packages/fairscale/nn/data_parallel/fully_sharded_data_parallel.py", line 1932, in <resume in _rebuild_full_params>
def update_p_data(custom_output_tensor: Optional[torch.Tensor] = None) -> None:
File "/scratch/voz/work/pytorch/torch/cuda/__init__.py", line 464, in __enter__
if self.src_prev_stream.device != cur_stream.device:
AttributeError: 'CUDAStreamVariable' object has no attribute 'device'
```
This indicates a serious bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100766
Approved by: https://github.com/ezyang
This PR addresses #101690. This PR implement faster data elements swap in `_StorageBase` using C++ rather than using Python.
This PR helps such a situation that a large model saved on a little-endian machine will be loaded on a big-endian machine.
TODO:
- [x] Add test cases
- [x] Add performance comparison before and after the PR
- [ ] (Optional) Investigate further opportunities for performance improvements by [SIMDization](https://dev.to/wunk/fast-array-reversal-with-simd-j3p)
Fixes#101690
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101925
Approved by: https://github.com/mikaylagawarecki
Summary:
In this PR we aligned with the design of annotation API and uses quantization spec directly for annotation.
main change is in prepare, we consume quantization_spec object directly instead of the observer or fake quant constructor, we create the constructor
inside prepare, and annotation api users only need to interact with quantization spec object after this PR
Test Plan:
```
buck2 test mode/opt caffe2/test:quantization_pt2e -- --exact 'caffe2/test:quantization_pt2e - test_resnet18_with_quantizer_api (quantization.pt2e.test_quantize_pt2e.TestQuantizePT2EModels)'
```
Reviewed By: kimishpatel
Differential Revision: D45934088
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102054
Approved by: https://github.com/kimishpatel
Summary:
serialization_id was added in a previous change to be written as a random GUID associated with each time saving of a module is called, for the purpose of adding tracking for saved artifacts. In order not to disturb existing systems that rely on the serialized bytes to be deterministic for serializing the same module, this change uses the combined hash of uncompressed content and file names instead of GUID for serialization id.
The use of this hashing reuses the same CRC32 that is already calculated for zip writing, so it doesn't incur additional computational overhead.
Data descriptor is one of the file headers inside the zip format https://en.wikipedia.org/wiki/ZIP_(file_format)#Data_descriptor. It contains the CRC32 of the uncompressed data. By inspecting the written data in PyTorchStreamWriter, the CRC32 is found for each written record.
In order to make serialization_id a unique and deterministic id for the
serialized files without computation overhead, the updated `serialization_id` is computed based on all files written, and is composed of:
1) a combined hash of record name hashes
2) a combined crc32 of the record uncompressed data
Example value: "15656915541136177431866432772"
Test Plan: buck2 test @//mode/dev //caffe2/caffe2/serialize:inline_container_test
Differential Revision: D46038973
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101964
Approved by: https://github.com/davidberard98
Fixed type hints for CosineAnnealingWarmRestarts:
- `T_mult` is not `Optional[int]` but just `int`
- `eta_min` is not `Optional[float]` but just `float`
- removed `step` method specific annotation as it is compatible with the base class
e132f09e88/torch/optim/lr_scheduler.py (L1365-L1375)
Otherwise, computation like this `self.T_i * self.T_mult` in `self.step` is not possible:
```
error: Unsupported operand types for * ("int" and "None")
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102067
Approved by: https://github.com/janeyx99
This PR adds an explicit API for registering a backward formula for a
CustomOp. In the end state, we will likely have this explicit API and a
magic API (which is sugar on top of an explicit API), since different
parties of users prefer different ones.
Concretely, to define a backward formula for a CustomOp:
- a user must provide us a "save for backward" function that accepts
(inputs, output) and returns exactly what they want saved for backward
- a user must provide us a "backward" function that accepts
(ctx, saved, *grads) and returns us the grad_inputs. The grad_inputs
are returned as a dict mapping str to a gradient.
Please see the changes in custom_op_db.py for examples of the API.
There are a number of pieces to this PR and I'm happy to split it if it
helps. They are:
- The actual APIs for specifying the two functions
(impl_save_for_backward, impl_backward)
- The autograd kernel: we take the functions the user give us and
construct an autograd.Function object that we then register to
the Autograd dispatch key
- Indirection for the autograd kernel. We add a layer of indirection so
that one can swap out the autograd kernel. This is necessary because by
default, we register an "autograd not implemented" kernel as the
Autograd implementation but then swap it for the actual kernel when the
user provides it.
Test Plan:
- We apply this API to give backward formulas for things in
custom_op_db. We then hook up custom_op_db to the Autograd OpInfo tests.
- Various tests in test_python_dispatch.py to check error cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101824
Approved by: https://github.com/ezyang
torch/custom_op.py is getting long, and the autograd pieces are going to
make it even longer. I'm planning on just organizing the files under
a torch/_custom_op folder.
Note that the imports now look a bit crazy (from torch._custom_op.impl
import...) but they will look more OK when we figure out the plan to
make custom_op public (coming later).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101823
Approved by: https://github.com/ezyang, https://github.com/albanD, https://github.com/bdhirsh
Summary:
Otherwise we get
```
Traceback (most recent call last):
File "<string>", line 49, in <module>
File "<string>", line 47, in __run
File "/usr/local/fbcode/platform010/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/local/fbcode/platform010/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/data/users/jongsoo/fbsource/buck-out/v2/gen/fbcode/ef4169ac7f95fb74/caffe2/benchmarks/transformer/__sdp__/sdp#link-tree/caffe2/benchmarks/transformer/sdp.py", line 346, in <module>
main(save_path)
File "/data/users/jongsoo/fbsource/buck-out/v2/gen/fbcode/ef4169ac7f95fb74/caffe2/benchmarks/transformer/__sdp__/sdp#link-tree/caffe2/benchmarks/transformer/sdp.py", line 328, in main
experiment = run_single_experiment(experiment_config)
File "/data/users/jongsoo/fbsource/buck-out/v2/gen/fbcode/ef4169ac7f95fb74/caffe2/benchmarks/transformer/__sdp__/sdp#link-tree/caffe2/benchmarks/transformer/sdp.py", line 229, in run_single_experiment
assert_close_tensors(nn_mha_output, composite_mha_output)
File "/data/users/jongsoo/fbsource/buck-out/v2/gen/fbcode/ef4169ac7f95fb74/caffe2/benchmarks/transformer/__sdp__/sdp#link-tree/caffe2/benchmarks/transformer/sdp.py", line 196, in assert_close_tensors
assert torch.allclose(a, b, atol=1e-3, rtol=1e-3)
AssertionError
```
Test Plan: buck run mode/dev-nosan //caffe2/benchmarks/transformer:sdp
Differential Revision: D45843836
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101965
Approved by: https://github.com/drisspg
Summary:
This is the second refactor to align the annotation API with design,
next step is to change prepare_pt2e to consume QuantizationSpec object directly
Test Plan:
```
buck2 test mode/optcaffe2/test:quantization_pt2e -- --exact 'caffe2/test:quantization_pt2e - test_resnet18_with_quantizer_api (quantization.pt2e.test_quantize_pt2e.TestQuantizePT2EModels)'
```
Reviewed By: kimishpatel
Differential Revision: D45927416
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101920
Approved by: https://github.com/andrewor14
It's not mentioned in `__all__`, so moving `import torch.backends.opt_einsum
as opt_einsum` into `einsum` function to delay `torch.backends` import and hide it completely from the module scope.
level module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102004
Approved by: https://github.com/janeyx99
Summary: Change placeholder check from singleton to instanceof PHBase so you can create your own PH class with metadata
Test Plan: added unit test
Reviewed By: joshuadeng
Differential Revision: D46085128
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102008
Approved by: https://github.com/PaliC
D45936056 was hitting bizarre failures running unit tests under FB's
test runner, where we'd see things like:
```
9 TESTS FAILED
✗ caffe2/test/inductor:fused_attention - <locals> (unittest.loader._FailedTest)
```
The reason for this is, it turns out the test runner uses a two-step process
where it first lists the tests, in one process, and then runs them using the
names from the listing step in separate processes
But, since we're decorating the class, it ends getting listed with a weird name
like `torch._dynamo.config_utils.ContextDecorator.__call__.<locals>._TestCase`,
and when the runner tries to load that module, it fails.
So one solution (other than, you know, using pytest) is to update the
__qualname__ and __module__ of the _TestCase wrapper so that the runner will
actually load the right module.
@build[pytorch_dynamo_inductor]
Differential Revision: [D46044467](https://our.internmc.facebook.com/intern/diff/D46044467/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101975
Approved by: https://github.com/xuzhao9, https://github.com/jansel
`__del__` is a bit difficult to use, because when it is called, it is
not guaranteed that anything it uses has not been cleaned up.
Ed tells me he got the following exception one day, which is what
prompted this PR.
```
Exception ignored in: <function Library.__del__ at 0x7fa36d211e50>
Traceback (most recent call last):
File "/data/users/ezyang/a/pytorch/torch/library.py", line 139, in
__del__
AttributeError: 'NoneType' object has no attribute 'remove'
```
One solution is to use weakref.finalize, which lets one define a
function to be run when the object is deleted that can hold references
to specific things it needs.
Another solution is to just check if the object is None, but I like the
weakref solution better.
Test Plan:
- new test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101829
Approved by: https://github.com/ezyang
Fixes#101862
No more type errors and improved return type value:
```python
import torch
from torch import nn
t = torch.tensor([1, 2, 3], dtype=torch.float32)
t2 = torch.Tensor._make_subclass( # OK
nn.Parameter,
t.data,
)
reveal_type(t2) # Type of "t2" is "Parameter"
t3 = t._make_subclass( # OK
nn.Parameter,
t.data,
)
reveal_type(t3) # Type of "t3" is "Parameter"
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101961
Approved by: https://github.com/albanD
Summary:
Quantizing a *gradient* is not applicable to complex ASR model.
Gradient in INT8
f438266519
Gradient in FP32
f438109197
Clearly two WER shows the limitation with quantizing a gradient.
As of now, we are okay with simply enabling quantized backpropagation but computing gradient in FP32.
It already saves a memory due to model size.
Test Plan: Signals
Differential Revision: D45965552
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101739
Approved by: https://github.com/izaitsevfb
This wraps `ops` into an `OpsWrapper` object which wraps any returned
IR values into an `OpsValue` instance. This allows magic methods to
be implemented and means lowerings can write mathematical expressions much more
fluently. So instead of
```python
ops.add(ops.mul(ops.mul(ops.sub(ops.mul(_Ap2, x), _Ap3), x), x), _1)
```
we can write
```python
(_Ap2 * x - _Ap3) * x * x + _1
```
And it will translate to the equivalent `ops` calls.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101076
Approved by: https://github.com/lezcano, https://github.com/ngimel
Summary:
This diff adds QuantizationAnnotation and also refactors the existing annotation to use this object
```
dataclass
class QuantizationAnnotation:
# How some input nodes should be quantized, expressed as QuantizationSpec
# a map from torch.fx.Node to QuantizationSpec
input_qspec_map: Dict[Node, QuantizationSpec]
# How the output of this node is quantized, expressed as QuantizationSPec
output_qspec: QuantizationSpec
class QuantizationSpec:
dtype: torch.dtype
is_dynamic: bool = False
quant_min: Optional[int] = None
quant_max: Optional[int] = None
qscheme: Optional[torch.qscheme] = None
ch_axis: Optional[int] = None
# TODO: follow up PR will add this
# Kind of observer such as MinMaxObserver, PerChannelHistogramObserver etc.
# observer_or_fake_quant_type: Union[ObserverBase, FakeQuantizeBase]
```
Example after full refactor:
```
int8_qspec = QuantizationSpec(dtype=torch.int8, ...)
weight_qspec = QuantizationSpec(dtype=torch.int8, ...)
conv_node["quantization_annotation"] = QuantizationAnnotation(
input_qspec_map={input_node: int8_qspec, weight_node: weight_qspec}
output_qspec=int8_qspec,
)
```
Note: right now input_qspec_map and output_qspec map are still using observer and fake quant constructors.
Follow up PR: change the input_qspec_map and output_qspec to use QuantizationSpec directly
Test Plan:
```
buck2 test mode/optcaffe2/test:quantization_pt2e -- --exact 'caffe2/test:quantization_pt2e - test_resnet18_with_quantizer_api (quantization.pt2e.test_quantize_pt2e.TestQuantizePT2EModels)'
```
Differential Revision: D45895027
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101708
Approved by: https://github.com/andrewor14
Summary:
3.10 doesn't have support for Generic NamedTuples, but it exists in future versions so typing_extensions supports it
(Note: this ignores all push blocking failures!)
Test Plan: sandcastle
Reviewed By: itamaro
Differential Revision: D45923201
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101830
Approved by: https://github.com/izaitsevfb
Summary: cuda graph doesn't work with cuda 11's cupti lazy reinit. So we'll turn it off if any modules turn on cudagraph
Test Plan: test with cuda graph on
Reviewed By: aaronenyeshi
Differential Revision: D45967197
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101848
Approved by: https://github.com/aaronenyeshi
Summary: Since CUPTI lazy re-init crashes with CUDA Graphs in CUDA 11, we should disable this. Remove this item once majority of workloads move to CUDA 12.
Test Plan: CI Tests
Reviewed By: xw285cornell
Differential Revision: D45921028
Pulled By: aaronenyeshi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101879
Approved by: https://github.com/xw285cornell
Adds sdpa patterns seen in HF models.
To actually make the patterns match, we need constant folding to remove addition of all-zeros mask, and figure out what to do with low mem dropout.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100609
Approved by: https://github.com/jansel
The memory compression for these models is at parity, but because we interleave timings between torch.compile and eager run memory is duplicated between between eager and cudagraphs pool and causes OOM.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101837
Approved by: https://github.com/anijain2305
Fixes https://github.com/pytorch/pytorch/issues/100415
Results in the following error:
```
Traceback (most recent call last):
File "/scratch/angelayi/work/pytorch/test/export/test_export.py", line 572, in test_export_constrain_static
export(f, example_inputs, constraints)
File "/scratch/angelayi/work/pytorch/torch/_export/__init__.py", line 348, in export
method_name_to_graph_module[compile_spec.method_name] = _export(
File "/scratch/angelayi/work/pytorch/torch/_export/__init__.py", line 119, in _export
raise UserError(UserErrorType.CONSTRAIN_VIOLATION, str(e))
torch._dynamo.exc.UserError: File "/scratch/angelayi/work/pytorch/test/export/test_export.py", line 561, in f
constrain_as_value(c, min=1, max=3)
It appears that you're trying to set a constraint on a value which we evaluated to have a static value of 3. Scroll up to see where this constraint was set.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101655
Approved by: https://github.com/avikchaudhuri
It looks like inference_mode wasn't playing well with functionalization.
If you run torch.compile on a function, and the inputs to the function are tensors created outside of inference mode, then we need to make sure that when we created functional tensor wrappers for those inputs during compilation, those functional wrappers properly mirror whether or not the original tensor is an inference tensor.
Hopefully fixes https://github.com/pytorch/pytorch/issues/101151
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101219
Approved by: https://github.com/albanD, https://github.com/ezyang
FakeTensor has a default device logic that wraps meta tensors to the right device after running meta kernels and throws on multiple devices. This logic was only running on the wrapping from meta kernels -> fake. For out variants, where the output of the meta kernel was already a fake tensor because it was an input, the device logic wasn't running.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101807
Approved by: https://github.com/ngimel
For TIMM ```tf_mixnet_l``` cpu dynamic shape path, we always get a wrong result compared with eager mode, the root cause is that we compute a wrong index when doing vectorization:
```
or(long i2=static_cast<long>(0L); i2<static_cast<long>(16L*(((std::ceil((1.0/2.0)*(std::ceil((1.0/2.0)*(std::ceil((1.0/2.0)*(std::ceil((1.0/2.0)*ks1))))))))*(std::ceil((1.0/2.0)*(std::ceil((1.0/2.0)*(std::ceil((1.0/2.0)*(std::ceil((1.0/2.0)*ks1))))))))) / 16L)); i2+=static_cast<long>(16L))
```
the main loop's index using ```/``` rather than ```//```. After this PR, the ```tf_mixnet_l``` accuracy test can be passed.
How to reproduce this issue?
```
python -m torch.backends.xeon.run_cpu --node_id 0 benchmarks/dynamo/timm_models.py --accuracy --float32 -dcpu --inference -n5 --inductor --dynamic-shapes --only tf_mixnet_l
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101793
Approved by: https://github.com/jgong5, https://github.com/EikanWang, https://github.com/ezyang
FSDP creates communication groups for intra-node communication through dist.new_subgroups. Previously, dist.new_subgroups only supported creation based on the number of CUDA devices. However, issue #99706 removed the avaliable-check for CUDA devices, allowing for custom backend create group based on num of custom devices per node.
This PR allows FSDP to explicitly pass device num within the node when creating communication groups for intra-node communication, instead of defaulting to the number of CUDA devices.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100622
Approved by: https://github.com/awgu
Fixes compilation error on ppc64-le resulting from missing conversion functions 'convert_half_float' and 'convert_float_half'.
These functions are implemented by this commit.
Started failing compilation from the following commit onwards: ced5c89b6fbe827a538b7ada96b2f9a5989871c7.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100168
Approved by: https://github.com/jgong5, https://github.com/ezyang
Complete the implementation of the interface is_pinned() of untyped storage class for privateuse1.
And refactor the implementation in typed storage by untyped_storage.is_pinned().
Hi, @ezyang
This is another improvement of untyped storage for privateuse1, can you take a moment to review it? Thanks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100868
Approved by: https://github.com/kurtamohler, https://github.com/ezyang
Fixes#96604
## Issue description
When we use a constant tensor with a uint8 type, the kernel generated by torchinductor output wrong results. For example, the negative value of `5` in uint8 will be `255`, and it is `True` that `255` is larger than `5`. However, the output result is `False` when we compare `torch.neg(5)` with `5`. It is because torchinductor bypass the data type for constant tensors and the `5` here is taken as a int32. Then, the comparison is between `-5` with `5`.
## Solution
This PR generates an extra conversion for uint8 constant value when we use it. it does not occur on the first assignment but the access for this constant value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101468
Approved by: https://github.com/desertfire, https://github.com/jansel
This PR adds support for tracing autograd.Function with grad.
A few important bullet points outlining our approach:
1) Our goal is to verify soundness in order to add a call_function to the autograd.Function's `apply` to the graph.
2) We achieve (1) by either verifying soundness or rejecting soundness, by ensuring that both forward and backward of the autograd.Function are sound.
3) For the forward, if we verify soundness, we install its guards into the graph.
4) For the backward, if we verify soundness, we throw it out. However, backwards soundness verification is more onerous, and has a config driven set of banned attrs and methods for tensors.
1-4 above are achieved by turning the forward and backward into UserDefinedFunctionVariables, and inlining through them, relying on dynamo's soundness detection. If we graph break in these, we raise and treat them as unsound. As noted above, backwards is stricter yet.
For the tracing, the safety comes from dynamo's HigherOrderOperator system. That system ensures that not only do we trace soundly, but that no new variables are lifted into inputs during the tracing, and that the forward and backwards are entirely self contained.
Whenever we reject a function as unsound, we restore back, as usual.
Due to some limitations in the lifting logic, we have an escape hatch we implemented for tensors that are known in forward, but cross into backwards through save_tensors (save) /saved_tensors (load). We escape hatch here to avoid having the known saved tensors coming from forward end up being accidentally treated as lifted variables (and rejected). This is sound, but a little hacky feeling.
Additionally, due to some limitations in fx node removal, combined with how we produce subgraphs for the traces installed from HigherOrderOperators, we had to improve our node removal logic. In the event of a restore, we remove the old nodes from the graph, as usual in dynamo. However, because the references to these nodes may exist in subgraphs, we traverse any nodes users and remove them first if and only if they are in another graph. This is always sound, because removal should only be downstream of restoration at this point.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99483
Approved by: https://github.com/zou3519
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 4f0b524</samp>
This pull request updates the codebase and the documentation to use C++17 instead of C++14 as the minimum required C++ standard. This affects the `ATen`, `c10`, and `torch` libraries and their dependencies, as well as the CI system and the `conda` package metadata.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100557
Approved by: https://github.com/malfet
If `astunparse` is not installed, following guard will be generated in `test_guard_function_builder_with_cse`:
```python
def ___make_guard_fn():
def guard(L):
if not (x[0].a < x[1].a * (3 - x[2].a)):
return False
if not (a.b.c[0].d.e + a.b.c[1].d.e * a.b.c[2].d.e > 0):
return False
if not (f(m.n[0], '0').x.y.z * f(m.n[0], '1').x.y.z * f(m.n[0], '2').x.y.z < 512):
return False
if not (self.g(a, b).k + (1 - self.g(a, b).k) <= m[0].a + self.g(a, b).k):
return False
return True
return guard
```
Though, I have to say, hardcoding string comparison is pretty weird.
Also, skip `test_guards_cse_pass_[single|multiple]` if AST unparsing is missing.
Fixes failure in a test introduced by https://github.com/pytorch/pytorch/pull/98488
copilot:poem
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101805
Approved by: https://github.com/atalman, https://github.com/ysiraichi
## TLDR
Fix decorator to re-enable 26+ distributed tests that were previously being skipped in CI
## Explanation
As part of the UCC upstream, we updated the backend tests cases to also include "ucc".
3ed1569e86/torch/testing/_internal/common_distributed.py (L90-L92)
In distributed tests we use a decorator which reads from this config and makes sure all backends are available on the system.
3ed1569e86/torch/testing/_internal/distributed/distributed_test.py (L7131)
**However**, UCC is not configured on by default for a certain subset of CI tests, which causes the entire test to be skipped (even if the test is meant for nccl and the backend being tested is nccl).
As the fix, we should just check that only the `BACKEND` being tested is available
## Changes
- Change logic to only check if the current backend being used is available
- Rename `require_backends_available` -> `require_backend_is_available`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101704
Approved by: https://github.com/rohan-varma
Update release related information. Features became more complex. Number of commits per releases have increased a lot.
We had in average:
2.5k commits for releases 1.1.0-1.7.0,
3-3.5k commits for releases 1.8.0-1.12.0
4.5k-5k commits for releases 1.13.0, 2.0.0
Hence current target is 3 releases a year
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101819
Approved by: https://github.com/svekars, https://github.com/malfet
Summary: We have found that `_get_lstm_with_individually_observed_parts()` is missing setup step which sets up the LSTM layer state initializing weights and biases of this layer. This diff fixes the observed numerical discrepancy seen by CTRL team in using the above API.
Test Plan: N3358643
Differential Revision: D45821681
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101299
Approved by: https://github.com/andrewor14
# Summary
Since the initial upstream of memory efficient attention from xformers: #86157, significant work updates have been made to the kernel including - increased performance, bug-fixes, and added functionality. This PR upstreams the latest version of this kernel as of: version 0.0.20 or commit: [6425fd0cacb1a6579aa2f0c4a570b737cb10e9c3](6425fd0cac)
## Future
Although this version of the Kernel has support for dropout and arbitrary attention bias, I did not add this support to SDPA yet, and left the guards in sdp_utils. Those will follow up PRs in order to reduce the scope creep of these substantial changes, and ensure that nothing is broken.
## Specific Changes
### Minor Changes
* The build system work was done in the previous PR and so no changes were needed to CMAKE 🤞
* Adding the new files and re-arranging/creating folder structure
* Updating include paths
* Switching from xformer specific functions: `XFORMERS_CHECK -> TORCH_CHECK`
* Changes to xformer specific macros
* Updates to the `generate_kernels.py` to use account for Pytorch file structure, also added an arg parse that I could run on a test dir before creating the files in place.
### Bigger Changes
* Previous Kernel changes "Removed the chunk optimization: see discussion here: https://github.com/pytorch/pytorch/pull/96880"
* Increased the number of cuda kernels -> potentially effecting the cuda_lib size.
* Preemptively made changes to the dtypes of seed and offset in order to allow for cuda_graphs: #100196 this is not finished.
* Made VERY BC breaking changes to at::_efficient_attention_forward and at::_efficeint_attention_backward function signatures.
* I made these changes due to in part to the ability for this PR to land:https://github.com/pytorch/pytorch/pull/100196
### Due Diligence Checks:
* CUDA_lib size:
* Before: 496 MiB
* After: 496MiB
* Performance Sweep:
* I sweeped over 576 configs for forward only inference and the geomean speedup was 0.98x with a min speed up of 0.84 and a max speedup of 1.2
* For Forw+Back running on 270 configs ( to reduce memory) the geomean speedup was 1.02X with a min speed up of 1.02 and a max speedup of 1.35.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100583
Approved by: https://github.com/cpuhrsch
When I got the main branch and picked up #99872, I got the following link error. The root cause is that method definitions in the header file will generate multiple instantiations for the same method signature.
This PR fixes the link error by avoiding to generate multiple instantiations.
```
% python setup.py develop
...
[1080/1456] Linking CXX shared library lib/libtorch_cpu.so
FAILED: lib/libtorch_cpu.so
: && /usr/bin/c++ -fPIC -D_GLIBCXX_USE_CXX11_ABI=1 -fvisibility-inlines-hidden -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DLIBKINETO_NOROCTRACER -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -O2 -fPIC -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor ...
...
/usr/bin/ld: caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/cpu/AvgPoolKernel.cpp.ZVECTOR.cpp.o: in function `at::vec::ZVECTOR::vec_int_flt(int __vector(4))':
AvgPoolKernel.cpp.ZVECTOR.cpp:(.text+0xa520): multiple definition of `at::vec::ZVECTOR::vec_int_flt(int __vector(4))'; caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/UfuncCPUKernel_add.cpp.ZVECTOR.cpp.o:UfuncCPUKernel_add.cpp.ZVECTOR.cpp:(.text+0x16920): first defined here
/usr/bin/ld: caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/cpu/AvgPoolKernel.cpp.ZVECTOR.cpp.o: in function `at::vec::ZVECTOR::vec_flt_int(float __vector(4))':
AvgPoolKernel.cpp.ZVECTOR.cpp:(.text+0xa5c0): multiple definition of `at::vec::ZVECTOR::vec_flt_int(float __vector(4))'; caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/UfuncCPUKernel_add.cpp.ZVECTOR.cpp.o:UfuncCPUKernel_add.cpp.ZVECTOR.cpp:(.text+0x169c0): first defined here
/usr/bin/ld: caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/cpu/AdaptiveMaxPoolKernel.cpp.ZVECTOR.cpp.o: in function `at::vec::ZVECTOR::vec_int_flt(int __vector(4))':
AdaptiveMaxPoolKernel.cpp.ZVECTOR.cpp:(.text+0x5970): multiple definition of `at::vec::ZVECTOR::vec_int_flt(int __vector(4))'; caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/UfuncCPUKernel_add.cpp.ZVECTOR.cpp.o:UfuncCPUKernel_add.cpp.ZVECTOR.cpp:(.text+0x16920): first defined here
/usr/bin/ld: caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/cpu/AdaptiveMaxPoolKernel.cpp.ZVECTOR.cpp.o: in function `at::vec::ZVECTOR::vec_flt_int(float __vector(4))':
AdaptiveMaxPoolKernel.cpp.ZVECTOR.cpp:(.text+0x5a10): multiple definition of `at::vec::ZVECTOR::vec_flt_int(float __vector(4))'; caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/UfuncCPUKernel_add.cpp.ZVECTOR.cpp.o:UfuncCPUKernel_add.cpp.ZVECTOR.cpp:(.text+0x169c0): first defined here
/usr/bin/ld: caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/cpu/AdaptiveAvgPoolKernel.cpp.ZVECTOR.cpp.o: in function `at::vec::ZVECTOR::vec_int_flt(int __vector(4))':
AdaptiveAvgPoolKernel.cpp.ZVECTOR.cpp:(.text+0x7d90): multiple definition of `at::vec::ZVECTOR::vec_int_flt(int __vector(4))'; caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/UfuncCPUKernel_add.cpp.ZVECTOR.cpp.o:UfuncCPUKernel_add.cpp.ZVECTOR.cpp:(.text+0x16920): first defined here
/usr/bin/ld: caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/cpu/AdaptiveAvgPoolKernel.cpp.ZVECTOR.cpp.o: in function `at::vec::ZVECTOR::vec_flt_int(float __vector(4))':
AdaptiveAvgPoolKernel.cpp.ZVECTOR.cpp:(.text+0x7e30): multiple definition of `at::vec::ZVECTOR::vec_flt_int(float __vector(4))'; caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/UfuncCPUKernel_add.cpp.ZVECTOR.cpp.o:UfuncCPUKernel_add.cpp.ZVECTOR.cpp:(.text+0x169c0): first defined here
/usr/bin/ld: caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/cpu/Activation.cpp.ZVECTOR.cpp.o: in function `at::vec::ZVECTOR::vec_int_flt(int __vector(4))':
Activation.cpp.ZVECTOR.cpp:(.text+0x65840): multiple definition of `at::vec::ZVECTOR::vec_int_flt(int __vector(4))'; caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/UfuncCPUKernel_add.cpp.ZVECTOR.cpp.o:UfuncCPUKernel_add.cpp.ZVECTOR.cpp:(.text+0x16920): first defined here
/usr/bin/ld: caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/native/cpu/Activation.cpp.ZVECTOR.cpp.o: in function `at::vec::ZVECTOR::vec_flt_int(float __vector(4))':
Activation.cpp.ZVECTOR.cpp:(.text+0x658e0): multiple definition of `at::vec::ZVECTOR::vec_flt_int(float __vector(4))'; caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/UfuncCPUKernel_add.cpp.ZVECTOR.cpp.o:UfuncCPUKernel_add.cpp.ZVECTOR.cpp:(.text+0x169c0): first defined here
collect2: error: ld returned 1 exit status
[67/316] Building CXX object test_api/CMakeFiles/test_api.dir/modules.cpp.o
ninja: build stopped: subcommand failed.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101000
Approved by: https://github.com/malfet
Torch wrapping datasets list has:
`TensorDataset`
`ConcatDataset`
`ChainDataset`
`TensorDataset` is useful for stacking sets of tensors but can't work with objects without `.size()` method.
This PR proposes `StackDataset`, similar to `TensorDataset` but for a general case like `ConcatDataset`.
Possible usage of `StackDataset` is multimodal networks with different input like image+text or for staking non-tensor input and property to predict.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101338
Approved by: https://github.com/ejguan, https://github.com/NivekT
Adds sdpa patterns seen in HF models.
To actually make the patterns match, we need constant folding to remove addition of all-zeros mask, and figure out what to do with low mem dropout.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100609
Approved by: https://github.com/jansel
Prevent error message from becoming of single column of characters
Thanks @clee200 for explaining how it worked before
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at fef1e25</samp>
> _`reject_reason` fixed_
> _Syntax error caused trouble_
> _Autumn of bugs ends_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101745
Approved by: https://github.com/kit1980, https://github.com/osalpekar
Fixes#100831, fixes#100878
Previously `gen_assert_indirect_indexing` was only called on the index
expressions passed to `ops.load` and `ops.store` which means if the
variable is optimized out during lowering, we never generate the
assert. This instead makes `ops.indirect_indexing` eagerly generate
the assert statement, whether or not it will be used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100895
Approved by: https://github.com/lezcano, https://github.com/ngimel
This pass does a limited form of constant propagation, as well as propagation of
sympy indexing expressions. For example, say you have the function:
```python
def flip(x):
i = torch.arange(x.size(0) - 1, -1, -1, device=x.device)
return x[i]
```
On current main this results in indirect indexing:
```python
class buf0_loop_body:
var_ranges = {z0: 4, z1: 3}
index0 = 3 - z0
index1 = 3*indirect0 + z1
index2 = 3*z0 + z1
def body(self, ops):
get_index = self.get_index('index0')
index_expr = ops.index_expr(get_index, torch.int64)
set_indirect0 = self.set_indirect0(index_expr)
get_index_1 = self.get_index('index1')
load = ops.load('arg0_1', get_index_1)
get_index_2 = self.get_index('index2')
store = ops.store('buf0', get_index_2, load, None)
return store
```
With this PR the indexing is propagated through the computation and into direct
indexing:
```python
class buf0_loop_body:
var_ranges = {z0: 4, z1: 3}
index0 = -3*z0 + z1 + 9
index1 = 3*z0 + z1
def body(self, ops):
get_index = self.get_index('index0')
load = ops.load('arg0_1', get_index)
get_index_1 = self.get_index('index1')
store = ops.store('buf0', get_index_1, load, None)
return store
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101077
Approved by: https://github.com/lezcano, https://github.com/ngimel
Pined hashes updates to be done by @pytorchupdatebot
As mergebot token access is restricted to environment
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at d57c0f4</samp>
> _`UPDATEBOT_TOKEN`_
> _A new name for the night_
> _Autumn leaves falling_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101723
Approved by: https://github.com/huydhn
not very elegant
checked on separate conda env that doesnt have the usual ci dependencies
the two pytest extensions at fault are pytest-rerunfailures and pytest-shard, also included pytest-flakefinder just incase
no idea if this is a good way to do this
could also check individually and add flags based on that, but was told that needing to requiring all the ci dependencies to be downloaded was also ok
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100916
Approved by: https://github.com/huydhn
On Arm, I got
```
Traceback (most recent call last):
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5260, in test_cpp_memory_snapshot_pickle
mem = run()
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5257, in run
t = the_script_fn()
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 496, in prof_func_call
return prof_callable(func_call, *args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 493, in prof_callable
return callable(*args, **kwargs)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5254, in the_script_fn
@torch.jit.script
def the_script_fn():
return torch.rand(311, 411, device='cuda')
~~~~~~~~~~ <--- HERE
RuntimeError: record_context_cpp is not support on non-linux non-x86_64 platforms
```
dfe484a3b3/torch/csrc/profiler/unwind/unwind.cpp (L4-L24) seems related
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101366
Approved by: https://github.com/zdevito
Adds sdpa patterns seen in HF models.
To actually make the patterns match, we need constant folding to remove addition of all-zeros mask, and figure out what to do with low mem dropout.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100609
Approved by: https://github.com/jansel
Summary: This commit fixes a bug where we copy the metadata from
the wrong node after replace_pattern. This happened in the case
of [maxpool -> getitem1 -> conv -> bn -> getitem2], where
`getitem1` is the placeholder node fed into the fused conv + bn
pattern, and we incorrectly copied the metadata from `getitem1`
instead of from `getitem2`. We fix this bug by filtering out
the placeholder nodes before doing the metadata copying.
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_prepare_qat_conv_bn_fusion_getitem_placeholder
Reviewers: jerryzh168, kimishpatel
Differential Revision: [D45916751](https://our.internmc.facebook.com/intern/diff/D45916751)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100941
Approved by: https://github.com/jerryzh168
Summary:
In order to better track models after serialization, this change writes a serialization_id as a UUID to inline container. Having this ID enables traceability of model in saving and loading events.
serialization_id is generated as a new UUID everytime serialization takes place. It can be thought of as a model snapshot identifier at the time of serialization.
Test Plan:
```
buck2 test @//mode/dev //caffe2/caffe2/serialize:inline_container_test
```
Local tests:
```
buck2 run @//mode/opt //scripts/atannous:example_pytorch_package
buck2 run @//mode/opt //scripts/atannous:example_pytorch
buck2 run @//mode/opt //scripts/atannous:example_pytorch_script
```
```
$ unzip -l output.pt
Archive: output.pt
Length Date Time Name
--------- ---------- ----- ----
36 00-00-1980 00:00 output/.data/serialization_id
358 00-00-1980 00:00 output/extra/producer_info.json
58 00-00-1980 00:00 output/data.pkl
261 00-00-1980 00:00 output/code/__torch__.py
326 00-00-1980 00:00 output/code/__torch__.py.debug_pkl
4 00-00-1980 00:00 output/constants.pkl
2 00-00-1980 00:00 output/version
--------- -------
1045 7 files
```
```
unzip -p output.pt "output/.data/serialization_id"
a9f903df-cbf6-40e3-8068-68086167ec60
```
Differential Revision: D45683657
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100994
Approved by: https://github.com/davidberard98
Summary: Post refactoring, previous diff had a drop in QPS gained on prod model - because of multi-user getitems. Multi user getitems can be handled by the replacer.
Differential Revision: D45893988
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101473
Approved by: https://github.com/jansel
With the TQDM changes in #100969 -- the models names ended up getting hidden from the benchmark printouts. We would print the model name with no newline, then tqdm would print a `\r` and overwrite the name of the running model.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101627
Approved by: https://github.com/ezyang
The UB was:
- We grab a reference to the last element in the interpreter stack
(DynamicLayerStack)
- Then, we pop the last element in the interpreter stack
- Finally, we continue to use the reference to the last element.
The fix is to stop using that reference and instead use the popped
element.
Test Plan:
- It's difficult to write a test for this PR so I didn't
- Patched in https://github.com/pytorch/pytorch/pull/101409 and verified
that this PR fixes the bad_variant_access it was experiencing under
clang compilers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101568
Approved by: https://github.com/ezyang, https://github.com/Skylion007
Fixes #ISSUE_NUMBER
For the scenario where users inherit storageimpl to implement their own subclasses, the current storage creation method cannot correctly create storage objects.
Refer to the registration method of Allocator to expand the creation method of storageimpl, users can register their own custom storageimpl creation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100237
Approved by: https://github.com/albanD
This is a purely cosmetic change where I organized the foreach ops in native_functions.yaml such that
1. all variants of each op are grouped together
2. add, sub, mul, div are first
3. every op after is alphabetical
This way, it's easier to see all the variants of an op, say add, in one screen. Items 2 and 3 are not strictly necessary but is simple a more organized scheme than not caring at all.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101583
Approved by: https://github.com/mlazos
After an investigation, running C++ tests with https://github.com/pytest-dev/pytest-cpp is just slower than running them directly, plain and simple. I'm curious on the exact root cause, but that's a story for another day.
`time build/bin/test_lazy` takes half a minute to run 610 tests on `linux-bionic-cuda11.8-py3.10-gcc7 / test (default, 2, 5, linux.4xlarge.nvidia.gpu)` while `time pytest /var/lib/jenkins/workspace/build/bin/test_lazy -v` takes 20+ minutes on the same runner. This is a very costly price to pay.
The saving grace here is that https://github.com/pytest-dev/pytest-cpp supports pytest-xdist to run tests in parallel with `-n auto`, so `time pytest /var/lib/jenkins/workspace/build/bin/test_lazy -v -n auto` takes only 3 minutes. This is still not as fast as running C++ tests directly, but it's order of magnitude faster than running them sequentially.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101440
Approved by: https://github.com/clee2000
This pr accomplishes
1) Enables retries for downloading torchbenchmark and huggingface models in a similar method to how we do it for timm models right now.
2) creates a `_download_model` function for the hugging face and TIMM runners whose output I plan to use to preload the models somewhere if possible (please double check I'll be saving the right thing). Instead of retries, we plan to just add torchbench to a docker image as it is relatively small.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 3361a4c</samp>
> _We're the brave and bold coders of the `common.py` module_
> _We've made a handy function for downloading models_
> _We've shared it with our mates in the other runners_
> _So pull and push and try again, we'll get them all in time_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101019
Approved by: https://github.com/huydhn, https://github.com/desertfire
Makes the CI prioritize running any test files that had a failing test in a previous iteration of the given PR.
A follow up to https://github.com/pytorch/pytorch/pull/100522 which makes the `.pytest_cache` available to use here
A concrete example:
1. Person A pushes a new commit and creates a PR.
2. 2 hours later, test_im_now_broken.py fails
3. Person A attempts to fix the test, but the test is actually still broken
4. The CI, seeing that test_im_now_broken.py had failed on a previous run, will now prioritize running that test first. Instead of waiting another 2 hours to get a signal, Person A only needs to wait ~15 minutes (which is how long it takes for tests to start running)
# Testing
I modified a file to make the tests invoking it fail and triggered CI twice with this failure.
First run: https://github.com/pytorch/pytorch/actions/runs/4963943209/jobs/8883800811
Test step took 1h 9m to run
Second run: https://github.com/pytorch/pytorch/actions/runs/4965016776/jobs/8885657992
Test step failed within 2m 27s
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101123
Approved by: https://github.com/malfet, https://github.com/huydhn
- Use context manager rather than explicit ```try: finally:```
- Add `ref/remotes` prefix to `onto_branch` in `main` rather than in
`rebase_onto` functions
- Define `MAIN_BRANCH` and `VIABLE_STRICT_BRANCH` constants in tests.
- Replace `self.assertTrue(x in y)` with `self.assertIn(x, y)`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101503
Approved by: https://github.com/ZainRizvi, https://github.com/huydhn
Also not sure if this should be a public function or not. Leaving it private for now but let me know if you prefer for it to be public.
FYI @nikitaved this will logically conflict with your triton kernel PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101420
Approved by: https://github.com/malfet
This PR is an implementation of the feature request https://github.com/pytorch/pytorch/issues/97888, for the implementation of `torch.dtype.to_complex()` and `torch.dtype.to_float()` methods that convert between float and complex dtypes of the same precision.
Disclaimer: it's the first time I code in C++ so hopefully the code is correct, but I'm not super confident about the PR. Any advice/comment is welcome. It's also my first contribution to a large library, so hopefully I'm not doing anything wrong !
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97935
Approved by: https://github.com/ezyang
Many ops take as inputs scalars or scalar lists which are important to understand the properties of the op. For example, convolution ops' behavior and output shapes often depend on padding and strides, which are provided as scalars of lists of scalars. This will record scalar lists when record_inputs=True.
Details:
During collection (and this was true before this PR as well), we serialize values and tensor metadata into an InputOutputEncoder. After collection occurs, we deserialize these values to attach the information to each of the events.
This PR does this:
- Adds support for serializing scalar lists during collection / serialization
- Adds an extra field called "Concrete Args"
- Splits up the deserialization process into two steps - one for generating "input shapes" and one for generating "concrete args". We split up input shapes and concrete args to avoid interrupting any previous workflows that relied on the specific data in the input shapes category; additionally, it's just a better description. Note that single scalars will remain in the "input shapes" category as they were already in that category in the past.
Differential Revision: [D45798431](https://our.internmc.facebook.com/intern/diff/D45798431)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100593
Approved by: https://github.com/aaronenyeshi
Adds retries to external contribution upload as it is shown to be flaky
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 43c2602</samp>
Added a function to read data from S3 objects and used it to implement a retry mechanism and verification for uploading external contribution stats. Modified `tools/stats/upload_external_contrib_stats.py` and `tools/stats/upload_stats_lib.py`.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 43c2602</samp>
> _We'll upload the stats to the cloud, me hearties_
> _We'll use `read_from_s3` to check them all_
> _We'll retry if the connection fails, me hearties_
> _We'll log the results and have a ball_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100889
Approved by: https://github.com/huydhn
Introduce `Analysis` to analyze fx graphmodule and emit diagnostics. This class
can be extended to interact with `Transform` (passes) to decide if a pass should
trigger based on graph analysis result. E.g., if decomp needs to run by checking
operator namespace in nodes. For now leaving it as out of scope but can revisit
if maintaining multi fx extractor becomes reality.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100451
Approved by: https://github.com/titaiwangms
Summary: This commit adds support for conv + BN fusion for the
case where conv has no bias. Since the replacement patterns with
and without conv bias are substantially different, we perform the
replacement for each of these two cases separately.
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_prepare_qat_conv_bn_fusion_no_conv_bias
Reviewers: jerryzh168, kimishpatel
Differential Revision: [D45743510](https://our.internmc.facebook.com/intern/diff/D45743510)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100610
Approved by: https://github.com/jerryzh168
Gloo PG used to create a random sequence number and broadcast it to
the rest of the group. But when we started enforcing sequence number checks in
ProcessGroupWrapper, we observed this was occasionally flaky. For example, this
error in a job was wrong, as all ranks were running the first broadcast
collective. Somehow the sequence number wasn't communicated across the store
correctly:
``
RuntimeError: Detected mismatch between collectives on ranks. Rank 16 is running collective: CollectiveFingerPrint(SequenceNumber=1977865401, OpType=BROADCAST, TensorShape=[1], TensorDtypes=Long, TensorDeviceTypes=TensorOptions(dtype=float (default), device=cpu, layout=Strided (default), requires_grad=false (default), pinned_memory=false (default), memory_format=(nullopt))), but Rank 1 is running collective: CollectiveFingerPrint(SequenceNumber=54090078, OpType=BROADCAST, TensorShape=[1], TensorDtypes=Long, TensorDeviceTypes=TensorOptions(dtype=float (default), device=cpu, layout=Strided (default), requires_grad=false (default), pinned_memory=false (default), memory_format=(nullopt))).Collectives differ in the following aspects: Sequence number: 1977865401vs 54090078
```
The issue reproduces rarely in tests, but is more common in large world size
jobs.
Differential Revision: [D45870688](https://our.internmc.facebook.com/intern/diff/D45870688/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101422
Approved by: https://github.com/H-Huang
This fixes compiling on systems where `size_t` is an `unsigned int` instead of an `unsigned long int` (32 bit Raspberry Pi OS is one example).
`%ld` expects an `unsigned long int`, while `%zu` specifies that it's an unsigned size_t.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101412
Approved by: https://github.com/albanD
This PR fixes the `torch.distributions.wishart.Wishart` example.
Running the current example
```python
m = Wishart(torch.eye(2), torch.Tensor([2]))
m.sample() # Wishart distributed with mean=`df * I` and
# variance(x_ij)=`df` for i != j and variance(x_ij)=`2 * df` for i == j
```
fails with
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Untitled-1 in
[321](untitled:Untitled-1?line=320) # %%
----> [322](untitled:Untitled-1?line=321) m = Wishart(torch.eye(2), torch.Tensor([2]))
[323](untitled:Untitled-1?line=322) m.sample() # Wishart distributed with mean=`df * I` and
[324](untitled:Untitled-1?line=323) # variance(x_ij)=`df` for i != j and variance(x_ij)=`2 * df` for i == j
Untitled-1 in __init__(self, df, covariance_matrix, precision_matrix, scale_tril, validate_args)
[83](untitled:Untitled-1?line=82)
[84](untitled:Untitled-1?line=83) if param.dim() < 2:
---> [85](untitled:Untitled-1?line=84) raise ValueError("scale_tril must be at least two-dimensional, with optional leading batch dimensions")
[86](untitled:Untitled-1?line=85)
[87](untitled:Untitled-1?line=86) if isinstance(df, Number):
ValueError: scale_tril must be at least two-dimensional, with optional leading batch dimensions
```
Is seems that the parameters of `Wishart.__init__()` were re-ordered, but the documentation was not updated.
This PR fixes it. Here is the updated behaviour:
```python
m = Wishart(torch.Tensor([2]), covariance_matrix=torch.eye(2))
m.sample()
```
```
Untitled-1:255: UserWarning: Singular sample detected.
tensor([[[6.6366, 0.7796],
[0.7796, 0.2136]]])
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95816
Approved by: https://github.com/ngimel, https://github.com/kit1980
Fixes #ISSUE_NUMBER
1、fix lintrunnr in `test/inductor/test_cuda_repro.py`
2、In Libtorch, if we rename the `privateuseone` backend to `foo`, and when we print tensor with `std::cout << tensor`, we will get the output like this,
```
1.0, 2.0 ...
[PrivateUse1FloatType{2,3}]
```
and it should be like this
```
1.0, 2.0 ...
[fooFloatType{2,3}]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100797
Approved by: https://github.com/ezyang
PR to enable default workflow PyTorch 2.0 unit tests for the ROCm stack.
- Enables all the dynamo unit test suites
- Enables some of the inductor unit test suites
- `test_config`
- `test_cpp_wrapper` (cpu only)
- `test_minifier`
- `test_standalone_compile`
- `test_torchinductor_dynamic_shapes`
- `test_torchinductor_opinfo`
- `test_torchinductor`
- `test_triton_wrapper`
- Introduces TEST_WITH_ROCM conditions for unit test skip/fail dictionaries in test_torchinductor_dynamic_shapes.py and test_torchinductor_opinfo.py
Note this PR follows on from the discussions for the previous UT enablement PR https://github.com/pytorch/pytorch/pull/97988, we have opted to only enable a few inductor suites at the moment to ease the upstreaming effort as these files are changing very quickly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100981
Approved by: https://github.com/jithunnair-amd, https://github.com/malfet
When we need to link extra libs, we should notice that 64-bit CUDA may be installed in "lib", not in "lib64".
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 05c1ca6</samp>
Improve CUDA compatibility in `torch.utils.cpp_extension` by checking for `lib64` or `lib` directory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101285
Approved by: https://github.com/ezyang, https://github.com/malfet
It's easier for users to implement one Override that takes care of
all target submodules of different types, instead of specifying one
mapping pair for each FQN/type. For example, when calculating
sharding for sparse layers, the decision needs to be make globally.
In this, case it's helpful to allow user Override to get access to
all submodules and make replacement decisions accordingly.
Differential Revision: [D45879732](https://our.internmc.facebook.com/intern/diff/D45879732)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101427
Approved by: https://github.com/fegin
Adds sdpa patterns seen in HF models.
To actually make the patterns match, we need constant folding to remove addition of all-zeros mask, and figure out what to do with low mem dropout.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100609
Approved by: https://github.com/jansel
Fixes #ISSUE_NUMBER
Add the serialization logic of backend metadata to the serialization of tensor, which is implemented through custom registration functions.
In #97429 , the structure backendMeta is provided in TensorImpl, and we think that this part of information may also need to be serialized for custom.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99808
Approved by: https://github.com/ezyang
Fixes #ISSUE_NUMBER
add a PrivateUse1TestBase in torch/testing/_internal/common_device_type.py for supporting custom device extensions "privateuse1", and add “device_type" parameter in instantiate_device_type_tests function for adding custom device testbase, the default value is None.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99960
Approved by: https://github.com/albanD, https://github.com/malfet
The main addition in this PR is two new API's in AOTAutograd.
**APIs**
`aot_export_module`: Given a module, exports it into a functionalized FX graph. Returns an `fx.GraphModule`, `GraphSignature` pair. The `GraphSignature` tells you various information about the graph, such as which graph inputs correspond to module params/buffers (and their fqn's), how to pytree-ify the inputs and the outputs of the graph. If you specify `trace_joint=True`, then you'll get back a joint forward-backward graph, that also returns parameter gradients in addition to the user outputs.
There are several restrictions on this API, detailed in the comments. The most notable one is probably that this API does not handle partial graphs: If you want a backward graph, then you module's forward function is **required** to return a scalar loss that we can backprop through. It also does not support capturing the optimizer step.
I (gratefully) used @SherlockNoMad and @suo's internal version of the `GraphSignature` object for this API, with a few minor changes in order to integrate it into AOTAutograd.
`aot_export_joint_simple`: Given a function, we'll trace it into a joint forward-backward graph and return it. Unlike the above API, the function is **not** required to return a scalar loss. However, this API makes the guarantee that you **do not** need to make any calling convention changes between the original function, and the exported one, provided that you do that you do the following:
* If you pass `trace_joint=False`, no work is needed: we'll export a functionalized forward graph with the same set of inputs as the original function
* If you pass `trace_joint=True`, then you will need to manually use the `default_partitioner` or `min_cut_partitioner` from functorch. If you do, and get back a fw and bw graph, then the forward graph will be runnable identically to the original user function.
The main use case for this API is higher order ops: a higher order op like `torch.cond()` can implement its derivative formula by using this API to export a joint graph (for both the true subgraph and the false subgraph), partition it into a fw/bw graph, and run cond on the `true_bw`, `false_bw` subgraphs. cc @zou3519 @Chillee
**Implementation Strategy**
A lot of the work in this PR went in to trying to find a reasonable way to re-use existing AOTAutograd components to expose these API's. Concretely:
* The two new API's are both thin wrappers around `_aot_export_function`: this is a general purpose export API, that just re-uses `create_aot_dispatcher_function`. If we want to add e.g. an export API that includes the optimizer step in the future, we could probably implement it using `_aot_export_function`.
* `aot_export_module` works extra hard to re-use as much of AOTAutograd as possible. For example, when tracing an inference graph, I perform the export under `torch.no_grad()` to make sure we don't accidentally trace out a backwards graph. When exporting a joint graph, I manually `.detach()` all user outputs except the loss, to make sure that we don't accidentally compute gradients for any other user outputs (even if the user forgot to manually detach them).
* A large portion of `aot_export_module` comes from parsing out and creating a `GraphSignature` object. We discussed a few weeks ago that there's potentially a lot more information that we could stuff into this object (see [doc](https://docs.google.com/document/d/1_qzdKew5D1J2Q2GkZ1v5jsczSsIU-Sr0AJiPW7DdGjE/edit?usp=sharing)). For now, I ended up deciding to support the more limited use case of exporting a fwd-bwd full graph, without some of the extra annotations in that doc (for example, if we were to export partial graphs, we would need annotations for saved activations). My thought is that once a more concrete use case comes up that the existing API doesn't satisfy, we can revisit the annotations then.
* I factored out `create_functional_call()` and `create_tree_flattened_fn()` for pytree-flattening and lifting-params-and-buffers, since I also need them in the export code
* I added an `AOTConfig.is_export` flag. The export API re-uses all of the same code paths as the rest of AOTAutograd, but there are a few points where we need to either exit early (and avoid making a runtime epilogue), or add extra error checking, that is only valuable for export.
* `aot_dispatch_autograd()` now exits early if it's being called in an export context, so it returns the full graph instead of also trying to create an `autograd.Function`. I think we probably want to factor this out, although I figured it would be safer to wait a bit for clarity on how functional RNG works with export.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100587
Approved by: https://github.com/ezyang, https://github.com/SherlockNoMad
## Description
This is a bug fix for rare cases that can happen with specific scale, antialias=False, output for a random line can be wrong. For example:
```
line 14
output uint8: [76, 78, 80, 81, 83, 85, 87, 88, 90]
expected float: [149, 152, 155, 158, 161, 164, 167, 170, 173]
diff: [-73, -74, -75, -77, -78, -79, -80, -82, -83]
opencv ref: [149 152 155 158 161 164 167 170 173]
```
It appears that for this line we have 3 weights coeff instead of 2:
```
line 13 | 351, 2
k: 1130 15254
line 14 | 378, 3
k: 0 16384 -6780 <------- We should have 2 weights and not 3
line 15 | 432, 2
k: 15254 1130
```
which comes from our `_compute_weights_aa` function that is specifically used for AA=False and uint8.
```
xmin = std::max(
static_cast<int64_t>(center - support + 0.5 + align_corners_delta), static_cast<int64_t>(0));
xsize = std::min(
static_cast<int64_t>(center + support + 0.5 + align_corners_delta), input_size) - xmin;
```
```
center - support + 0.5 + align_corners_delta: 14.999999999999998
static_cast<int64_t>(center - support + 0.5 + align_corners_delta): 14
xmin -> 14
center + support + 0.5 + align_corners_delta: 17.0
static_cast<int64_t>(center + support + 0.5 + align_corners_delta): 17.0
xsize -> 17 - 14 = 3 <------ 3 instead of 2
```
For float dtype, AA=False weights and indices are computed differently due to historically first implemented.
In any case, `xsize` should not be larger than `max_interp_size`, so we decided to clip `xsize`.
Once fixed computed indices and weights are same as for float dtype code path:
```
# Option: xsize = min(xsize, max_interp_size)
Line Num | xmin, xsize
14 | 378, 2 xmin=378 <---> xmin = i * stride = i * 3 * 9 => i = 14
k: 0 16384 16384 = w * (1 << 14) => w = 1.0
=> i=14, w=0 and i=15, w=1
```
vs
```
Line Num | index0, index1
F32: 14 | 15, 16
F32: lambda0, lambda1: 0.999999, 9.53674e-07
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101403
Approved by: https://github.com/NicolasHug
PR #95568 enables more NVCC warnings. However, some cu files need to be modified to make building process more warning free. PR #100823 already contains some fixes. This PR aims to fix the remaining ones without breaking the codebase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101383
Approved by: https://github.com/zou3519
arguments() returns vector member of object returned by schema() call.
When object returned by schema() call is destroyed, the vector is deallocated as well,
it's lifetime isn't extended.
This issue detected while running `pytest -v test/mobile/test_lite_script_type.py -k test_nest_typing_namedtuple_custom_classtype` with ASAN.
<details>
<summary>ASAN output</summary>
```
==1134126==ERROR: AddressSanitizer: heap-use-after-free on address 0x60d0005a5790 at pc 0x03ff844488d8 bp 0x03fff584afe8 sp 0x03fff584afd8
READ of size 8 at 0x60d0005a5790 thread T0
#0 0x3ff844488d7 in __gnu_cxx::__normal_iterator<c10::Argument const*, std::vector<c10::Argument, std::allocator<c10::Argument> > >::__normal_iterator(c10::Argument const* const&) /usr/lib/gcc/s390x-i
bm-linux-gnu/11/include/g++-v11/bits/stl_iterator.h:1028
#1 0x3ff8444293f in std::vector<c10::Argument, std::allocator<c10::Argument> >::begin() const /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/stl_vector.h:821
#2 0x3ff84d807d1 in torch::jit::toPyObject(c10::IValue) /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:617
#3 0x3ff84d80305 in torch::jit::toPyObject(c10::IValue) /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:604
#4 0x3ff84856871 in pybind11::detail::type_caster<c10::IValue, void>::cast(c10::IValue, pybind11::return_value_policy, pybind11::handle) /home/user/pytorch/torch/csrc/jit/python/pybind.h:138
#5 0x3ff85318191 in pybind11::cpp_function::initialize<torch::jit::initJitScriptBindings(_object*)::$_45, c10::IValue, torch::jit::mobile::Module&, pybind11::tuple const&, pybind11::name, pybind11::is
_method, pybind11::sibling, pybind11::arg>(torch::jit::initJitScriptBindings(_object*)::$_45&&, c10::IValue (*)(torch::jit::mobile::Module&, pybind11::tuple const&), pybind11::name const&, pybind11::is_me
thod const&, pybind11::sibling const&, pybind11::arg const&)::{lambda(pybind11::detail::function_call&)#1}::operator()(pybind11::detail::function_call&) const /home/user/pytorch/cmake/../third_party/pybin
d11/include/pybind11/pybind11.h:249
#6 0x3ff85317cfd in pybind11::cpp_function::initialize<torch::jit::initJitScriptBindings(_object*)::$_45, c10::IValue, torch::jit::mobile::Module&, pybind11::tuple const&, pybind11::name, pybind11::is
_method, pybind11::sibling, pybind11::arg>(torch::jit::initJitScriptBindings(_object*)::$_45&&, c10::IValue (*)(torch::jit::mobile::Module&, pybind11::tuple const&), pybind11::name const&, pybind11::is_me
thod const&, pybind11::sibling const&, pybind11::arg const&)::{lambda(pybind11::detail::function_call&)#1}::__invoke(pybind11::detail::function_call&) /home/user/pytorch/cmake/../third_party/pybind11/incl
ude/pybind11/pybind11.h:224
#7 0x3ff82ee52e9 in pybind11::cpp_function::dispatcher(_object*, _object*, _object*) /home/user/pytorch/cmake/../third_party/pybind11/include/pybind11/pybind11.h:929
#8 0x3ffab002903 in cfunction_call Objects/methodobject.c:543
#9 0x3ffaaf8a933 in _PyObject_MakeTpCall Objects/call.c:215
#10 0x3ffaaf8e919 in _PyObject_VectorcallTstate Include/cpython/abstract.h:112
#11 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#12 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#13 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#14 0x3ffab105447 in call_function Python/ceval.c:5891
#15 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#16 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#17 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#18 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#19 0x3ffaaf8a615 in _PyObject_FastCallDictTstate Objects/call.c:142
#20 0x3ffaaf8b271 in _PyObject_Call_Prepend Objects/call.c:431
#21 0x3ffab03f307 in slot_tp_call Objects/typeobject.c:7494
#22 0x3ffaaf8a933 in _PyObject_MakeTpCall Objects/call.c:215
#23 0x3ffab0f0081 in _PyObject_VectorcallTstate Include/cpython/abstract.h:112
#24 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#25 0x3ffab105447 in call_function Python/ceval.c:5891
#26 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#27 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#28 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#29 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#30 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#31 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#32 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#33 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#34 0x3ffab105447 in call_function Python/ceval.c:5891
#35 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#36 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#37 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#38 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#39 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#40 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#41 0x3ffab105447 in call_function Python/ceval.c:5891
#42 0x3ffab0ff7d7 in _PyEval_EvalFrameDefault Python/ceval.c:4198
#43 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#44 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#45 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#46 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#47 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#48 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#49 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#50 0x3ffab105447 in call_function Python/ceval.c:5891
#51 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#52 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#53 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#54 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#55 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#56 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#57 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#58 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#59 0x3ffab105447 in call_function Python/ceval.c:5891
#60 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#61 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#62 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#63 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#64 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#65 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#66 0x3ffaaf8ab9b in PyVectorcall_Call Objects/call.c:267
#67 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
#68 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#69 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#70 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#71 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#72 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#73 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#74 0x3ffaaf8a695 in _PyObject_FastCallDictTstate Objects/call.c:153
#75 0x3ffaaf8b271 in _PyObject_Call_Prepend Objects/call.c:431
#76 0x3ffab03f307 in slot_tp_call Objects/typeobject.c:7494
#77 0x3ffaaf8a933 in _PyObject_MakeTpCall Objects/call.c:215
#78 0x3ffab0f0081 in _PyObject_VectorcallTstate Include/cpython/abstract.h:112
#79 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#80 0x3ffab105447 in call_function Python/ceval.c:5891
#81 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#82 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#83 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#84 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#85 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#86 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#87 0x3ffab105447 in call_function Python/ceval.c:5891
#88 0x3ffab0ff7d7 in _PyEval_EvalFrameDefault Python/ceval.c:4198
#89 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#90 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#91 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#92 0x3ffaaf8ab15 in PyVectorcall_Call Objects/call.c:255
#93 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
#94 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#95 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#96 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#97 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#98 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#99 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#100 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#101 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#102 0x3ffab105447 in call_function Python/ceval.c:5891
#103 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#104 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#105 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#106 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#107 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#108 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#109 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#110 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#111 0x3ffab105447 in call_function Python/ceval.c:5891
#112 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#113 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#114 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#115 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#116 0x3ffaaf8a695 in _PyObject_FastCallDictTstate Objects/call.c:153
#117 0x3ffaaf8b271 in _PyObject_Call_Prepend Objects/call.c:431
#118 0x3ffab03f307 in slot_tp_call Objects/typeobject.c:7494
#119 0x3ffaaf8ad17 in _PyObject_Call Objects/call.c:305
#120 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#121 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#122 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#123 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#124 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#125 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#126 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#127 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#128 0x3ffab105447 in call_function Python/ceval.c:5891
#129 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#130 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#131 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#132 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#133 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#134 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#135 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#136 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#137 0x3ffab105447 in call_function Python/ceval.c:5891
#138 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#139 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#140 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#141 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#142 0x3ffaaf8ab15 in PyVectorcall_Call Objects/call.c:255
#143 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
#144 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#145 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#146 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#147 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#148 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#149 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#150 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#151 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#152 0x3ffab105447 in call_function Python/ceval.c:5891
#153 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#154 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#155 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#156 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#157 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#158 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#159 0x3ffab105447 in call_function Python/ceval.c:5891
#160 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#161 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#162 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#163 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#164 0x3ffaaf8ab15 in PyVectorcall_Call Objects/call.c:255
#165 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
#166 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#167 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#168 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#169 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#170 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#171 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#172 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#173 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#174 0x3ffab105447 in call_function Python/ceval.c:5891
#175 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#176 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#177 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#178 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#179 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#180 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#181 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#182 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#183 0x3ffab105447 in call_function Python/ceval.c:5891
#184 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#185 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#186 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#187 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#188 0x3ffaaf8a695 in _PyObject_FastCallDictTstate Objects/call.c:153
#189 0x3ffaaf8b271 in _PyObject_Call_Prepend Objects/call.c:431
#190 0x3ffab03f307 in slot_tp_call Objects/typeobject.c:7494
#191 0x3ffaaf8a933 in _PyObject_MakeTpCall Objects/call.c:215
#192 0x3ffab0f0081 in _PyObject_VectorcallTstate Include/cpython/abstract.h:112
#193 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#194 0x3ffab105447 in call_function Python/ceval.c:5891
#195 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#196 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#197 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#198 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#199 0x3ffaaf8ab15 in PyVectorcall_Call Objects/call.c:255
#200 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
#201 0x3ffaaf8ada9 in PyObject_Call Objects/call.c:317
#202 0x3ffab1059c7 in do_call_core Python/ceval.c:5943
#203 0x3ffab0ffd39 in _PyEval_EvalFrameDefault Python/ceval.c:4277
#204 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#205 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#206 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#207 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#208 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#209 0x3ffab105447 in call_function Python/ceval.c:5891
#210 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#211 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#212 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#213 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#214 0x3ffaaf8e941 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#215 0x3ffaaf8eddd in method_vectorcall Objects/classobject.c:53
#216 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#216 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#217 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#218 0x3ffab105447 in call_function Python/ceval.c:5891
#219 0x3ffab0ff779 in _PyEval_EvalFrameDefault Python/ceval.c:4181
#220 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#221 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#222 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#223 0x3ffaaf8a695 in _PyObject_FastCallDictTstate Objects/call.c:153
#224 0x3ffaaf8b271 in _PyObject_Call_Prepend Objects/call.c:431
#225 0x3ffab03f307 in slot_tp_call Objects/typeobject.c:7494
#226 0x3ffaaf8a933 in _PyObject_MakeTpCall Objects/call.c:215
#227 0x3ffab0f0081 in _PyObject_VectorcallTstate Include/cpython/abstract.h:112
#228 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#229 0x3ffab105447 in call_function Python/ceval.c:5891
#230 0x3ffab0ffa57 in _PyEval_EvalFrameDefault Python/ceval.c:4231
#231 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#232 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#233 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#234 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#235 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#236 0x3ffab105447 in call_function Python/ceval.c:5891
#237 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#238 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#239 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#240 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#241 0x3ffab0f00a9 in _PyObject_VectorcallTstate Include/cpython/abstract.h:114
#242 0x3ffab0f013d in PyObject_Vectorcall Include/cpython/abstract.h:123
#243 0x3ffab105447 in call_function Python/ceval.c:5891
#244 0x3ffab0ff905 in _PyEval_EvalFrameDefault Python/ceval.c:4213
#245 0x3ffab0f052b in _PyEval_EvalFrame Include/internal/pycore_ceval.h:46
#246 0x3ffab102b67 in _PyEval_Vector Python/ceval.c:5065
#247 0x3ffaaf8aec1 in _PyFunction_Vectorcall Objects/call.c:342
#248 0x3ffaaf8ab15 in PyVectorcall_Call Objects/call.c:255
#249 0x3ffaaf8ac65 in _PyObject_Call Objects/call.c:290
0x60d0005a5790 is located 80 bytes inside of 136-byte region [0x60d0005a5740,0x60d0005a57c8)
freed by thread T0 here:
#0 0x3ffab537de5 in operator delete(void*) /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_new_delete.cpp:160
#1 0x3ff55984fdb in __gnu_cxx::new_allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> >::deallocate(std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2>*, unsigned long) /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/ext/new_allocator.h:145
previously allocated by thread T0 here:
#0 0x3ffab53734f in operator new(unsigned long) /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_new_delete.cpp:99
#1 0x3ff5598443f in __gnu_cxx::new_allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> >::allocate(unsigned long, void const*) /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/ext/new_allocator.h:127
#2 0x3fff5849ecf ([stack]+0xb2ecf)
SUMMARY: AddressSanitizer: heap-use-after-free /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/stl_iterator.h:1028 in __gnu_cxx::__normal_iterator<c10::Argument const*, std::vector<c10::Argument, std::allocator<c10::Argument> > >::__normal_iterator(c10::Argument const* const&)
Shadow bytes around the buggy address:
0x100c1a000b4aa0: fd fd fd fd fd fd fd fd fd fd fd fa fa fa fa fa
0x100c1a000b4ab0: fa fa fa fa fd fd fd fd fd fd fd fd fd fd fd fd
0x100c1a000b4ac0: fd fd fd fd fd fa fa fa fa fa fa fa fa fa fd fd
0x100c1a000b4ad0: fd fd fd fd fd fd fd fd fd fd fd fd fd fd fd fa
0x100c1a000b4ae0: fa fa fa fa fa fa fa fa fd fd fd fd fd fd fd fd
=>0x100c1a000b4af0: fd fd[fd]fd fd fd fd fd fd fa fa fa fa fa fa fa
0x100c1a000b4b00: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1a000b4b10: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1a000b4b20: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1a000b4b30: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x100c1a000b4b40: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
Shadow gap: cc
==1134126==ABORTING
```
Additional backtraces (not full):
Allocation:
```
#0 __memset_z196 () at ../sysdeps/s390/memset-z900.S:144
#1 0x000003ff96f3072a in __asan::Allocator::Allocate (this=this@entry=0x3ff97041eb8 <__asan::instance>, size=size@entry=136, alignment=8, alignment@entry=0, stack=<optimized out>,
stack@entry=0x3ffdbb45d78, alloc_type=<optimized out>, can_fill=true) at /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_allocator.cpp:599
#2 0x000003ff96f2c088 in __asan::asan_memalign (alignment=alignment@entry=0, size=size@entry=136, stack=stack@entry=0x3ffdbb45d78, alloc_type=alloc_type@entry=__asan::FROM_NEW)
at /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_allocator.cpp:1039
#3 0x000003ff96fb73b0 in operator new (size=136) at /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_new_delete.cpp:99
#4 0x000003ff41404440 in __gnu_cxx::new_allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> >::allocate (this=0x3ffdbb468c0,
__n=1) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/ext/new_allocator.h:127
#5 0x000003ff414042a0 in std::allocator_traits<std::allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> > >::allocate (__a=...,
__n=1) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/alloc_traits.h:464
#6 0x000003ff41403b66 in std::__allocate_guarded<std::allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> > > (__a=...)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/allocated_ptr.h:98
#7 0x000003ff4140372a in std::__shared_count<(__gnu_cxx::_Lock_policy)2>::__shared_count<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::vector<c10::Argument, std::allocator<c10::Argument> >, std::vector<c10::Argument, std::allocator<c10::Argument> > > (this=0x3ffdbb47888, __p=@0x3ffdbb47880: 0x0, __a=..., __args=..., __args=..., __args=..., __args=...)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:648
#8 0x000003ff41403328 in std::__shared_ptr<c10::FunctionSchema, (__gnu_cxx::_Lock_policy)2>::__shared_ptr<std::allocator<c10::FunctionSchema>, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::vector<c10::Argument, std::allocator<c10::Argument> >, std::vector<c10::Argument, std::allocator<c10::Argument> > > (this=0x3ffdbb47880, __tag=..., __args=..., __args=..., __args=..., __args=...) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:1342
#9 0x000003ff41402f06 in std::shared_ptr<c10::FunctionSchema>::shared_ptr<std::allocator<c10::FunctionSchema>, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::vector<c10::Argument, std::allocator<c10::Argument> >, std::vector<c10::Argument, std::allocator<c10::Argument> > > (
this=0x3ffdbb47880, __tag=..., __args=..., __args=..., __args=..., __args=...) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr.h:409
#10 0x000003ff41402b6e in std::allocate_shared<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::vector<c10::Argument, std::allocator<c10::Argument> >, std::vector<c10::Argument, std::allocator<c10::Argument> > > (__a=...,
__args=..., __args=..., __args=..., __args=...) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr.h:862
#11 0x000003ff4140215c in std::make_shared<c10::FunctionSchema, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::vector<c10::Argument, std::allocator<c10::Argument> >, std::vector<c10::Argument, std::allocator<c10::Argument> > > (__args=..., __args=..., __args=..., __args=...)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr.h:878
#12 0x000003ff413d180c in c10::TupleType::createWithSpec<c10::basic_string_view<char> > (qualName=..., field_names=std::vector of length 1, capacity 1 = {...},
field_types=std::vector of length 1, capacity 1 = {...}, field_defaults=std::vector of length 0, capacity 0) at /home/user/pytorch/aten/src/ATen/core/type.cpp:769
#13 0x000003ff413b9ca6 in c10::TupleType::createNamed (qualName=..., field_names=std::vector of length 1, capacity 1 = {...}, field_types=std::vector of length 1, capacity 1 = {...})
at /home/user/pytorch/aten/src/ATen/core/type.cpp:725
#14 0x000003ff4115fbac in c10::ivalue::TupleTypeFactory<c10::TupleType>::fallback (type=...) at /home/user/pytorch/aten/src/ATen/core/dynamic_type.cpp:383
#15 0x000003ff708217fe in c10::ivalue::Tuple::type<c10::TupleType> (this=0x6080004b8520) at /home/user/pytorch/aten/src/ATen/core/ivalue_inl.h:781
#16 0x000003ff70800740 in torch::jit::toPyObject (ivalue=...) at /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:613
#17 0x000003ff70800306 in torch::jit::toPyObject (ivalue=...) at /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:604
#18 0x000003ff702d6872 in pybind11::detail::type_caster<c10::IValue, void>::cast (src=...) at /home/user/pytorch/torch/csrc/jit/python/pybind.h:138
#19 0x000003ff70d98192 in pybind11::cpp_function::initialize<torch::jit::initJitScriptBindings(_object*)::$_45, c10::IValue, torch::jit::mobile::Module&, pybind11::tuple const&, pybind11::name, pybind11::is_method, pybind11::sibling, pybind11::arg>(torch::jit::initJitScriptBindings(_object*)::$_45&&, c10::IValue (*)(torch::jit::mobile::Module&, pybind11::tuple const&), pybind11::name const&, pybind11::is_method const&, pybind11::sibling const&, pybind11::arg const&)::{lambda(pybind11::detail::function_call&)#1}::operator()(pybind11::detail::function_call&) const (this=0x3ffdbb4ca20, call=...)
at /home/user/pytorch/cmake/../third_party/pybind11/include/pybind11/pybind11.h:249
#20 0x000003ff70d97cfe in pybind11::cpp_function::initialize<torch::jit::initJitScriptBindings(_object*)::$_45, c10::IValue, torch::jit::mobile::Module&, pybind11::tuple const&, pybind11::name, pybind11::is_method, pybind11::sibling, pybind11::arg>(torch::jit::initJitScriptBindings(_object*)::$_45&&, c10::IValue (*)(torch::jit::mobile::Module&, pybind11::tuple const&), pybind11::name const&, pybind11::is_method const&, pybind11::sibling const&, pybind11::arg const&)::{lambda(pybind11::detail::function_call&)#1}::__invoke(pybind11::detail::function_call&) (call=...)
at /home/user/pytorch/cmake/../third_party/pybind11/include/pybind11/pybind11.h:224
#21 0x000003ff6e9652ea in pybind11::cpp_function::dispatcher (self=<PyCapsule at remote 0x3ff83e27720>,
args_in=(<torch._C.LiteScriptModule at remote 0x3ff811844b0>, (<Tensor at remote 0x3ff814efb00>,)), kwargs_in=0x0) at /home/user/pytorch/cmake/../third_party/pybind11/include/pybind11/pybind11.h:929
```
Deallocation:
```
#0 operator delete (ptr=0x60d0005a5740) at /var/tmp/portage/sys-devel/gcc-11.3.1_p20230303/work/gcc-11-20230303/libsanitizer/asan/asan_new_delete.cpp:160
#1 0x000003ff44904fdc in __gnu_cxx::new_allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> >::deallocate (this=0x3ffc5dc8020,
__p=0x60d0005a5740, __t=1) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/ext/new_allocator.h:145
#2 0x000003ff44904fa8 in std::allocator_traits<std::allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> > >::deallocate (
__a=..., __p=0x60d0005a5740, __n=1) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/alloc_traits.h:496
#3 0x000003ff449041f2 in std::__allocated_ptr<std::allocator<std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2> > >::~__allocated_ptr (
this=0x3ffc5dc8030) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/allocated_ptr.h:74
#4 0x000003ff44904888 in std::_Sp_counted_ptr_inplace<c10::FunctionSchema, std::allocator<c10::FunctionSchema>, (__gnu_cxx::_Lock_policy)2>::_M_destroy (this=0x60d0005a5740)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:538
#5 0x000003ff43895a62 in std::_Sp_counted_base<(__gnu_cxx::_Lock_policy)2>::_M_release (this=0x60d0005a5740) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:184
#6 0x000003ff43895420 in std::__shared_count<(__gnu_cxx::_Lock_policy)2>::~__shared_count (this=0x611000c40648) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:705
#7 0x000003ff4466e7f4 in std::__shared_ptr<c10::FunctionSchema, (__gnu_cxx::_Lock_policy)2>::~__shared_ptr (this=0x611000c40640)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:1154
#8 0x000003ff4466d820 in std::shared_ptr<c10::FunctionSchema>::~shared_ptr (this=0x611000c40640) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr.h:122
#9 0x000003ff448d82f6 in c10::TupleType::~TupleType (this=0x611000c40580) at /home/user/pytorch/aten/src/ATen/core/jit_type.h:1142
#10 0x000003ff448d8346 in c10::TupleType::~TupleType (this=0x611000c40580) at /home/user/pytorch/aten/src/ATen/core/jit_type.h:1142
#11 0x000003ff731296a4 in std::_Sp_counted_ptr<c10::TupleType*, (__gnu_cxx::_Lock_policy)2>::_M_dispose (this=0x603000c43ae0)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:348
#12 0x000003ff71eaf666 in std::_Sp_counted_base<(__gnu_cxx::_Lock_policy)2>::_M_release (this=0x603000c43ae0) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:168
#13 0x000003ff71eaf330 in std::__shared_count<(__gnu_cxx::_Lock_policy)2>::~__shared_count (this=0x3ffc5dc9368) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:705
#14 0x000003ff73129ee4 in std::__shared_ptr<c10::TupleType, (__gnu_cxx::_Lock_policy)2>::~__shared_ptr (this=0x3ffc5dc9360)
at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr_base.h:1154
#15 0x000003ff73122390 in std::shared_ptr<c10::TupleType>::~shared_ptr (this=0x3ffc5dc9360) at /usr/lib/gcc/s390x-ibm-linux-gnu/11/include/g++-v11/bits/shared_ptr.h:122
#16 0x000003ff73d00788 in torch::jit::toPyObject (ivalue=...) at /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:613
#17 0x000003ff73d00306 in torch::jit::toPyObject (ivalue=...) at /home/user/pytorch/torch/csrc/jit/python/pybind_utils.cpp:604
```
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101400
Approved by: https://github.com/zou3519
When adding guards to the constraint solver, we check that they are consistent, i.e., they do not simplify to false when their free symbols are substituted with the corresponding concrete values.
However this check may "spuriously" fail because it doesn't take into account precision errors when comparing floats. Since the symbols involved are all positive integers, we try to approximate floats in the guards with rationals, providing concrete values as hints: `sympy.nsimplify` does the job.
As an alternative approach, we considered using `sympy.evalf` to compare with reduced precision. But we did not pursue it because
* the choice of what is a good reduced precision feels arbitrary (`sympy` uses `1e15` by default);
* more importantly, there is no guarantee that we will not encounter the same problem when solving downstream.
Differential Revision: [D45826951](https://our.internmc.facebook.com/intern/diff/D45826951/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101307
Approved by: https://github.com/ezyang
Fixes cpp wrapper support for kernels that are not exposed in `torch.ops.aten`. The current PR limits the support scope to `repeat_interleave.Tensor` and will submit follow-up PRs for more OPs.
The PR maps the python schema of the kernel to the cpp schema and uses `c10::Dispatcher::singleton().findSchemaOrThrow` to find the corresponding cpp OP.
The current support is limited and will raise `AssertionError` for unsupported cases.
The limitation includes:
- only support kernel that is not alias
- only support kernel the args and returns of which don't have `alias_info`
- only support output args to be a `Tensor`
- only support input args to be `Tensor`, `Optional[int]`, `Optional[float]` and `Optional[bool]`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100788
Approved by: https://github.com/jgong5, https://github.com/desertfire
When tensor.size(self.dim) < num_chunks, we will fill empty chunk with empty tensor (https://github.com/pytorch/pytorch/pull/98722). Therefore, we no longer needs this assert.
For example, when sharding a tensor with 1 element on 2 ranks along dim 0, results would be as follows:
```
rank:0, dtensor:DTensor(local_tensor=tensor([0.4963], device='cuda:0'), device_mesh=DeviceMesh:([0, 1]), placements=[Shard(dim=0)])
rank:1, dtensor:DTensor(local_tensor=tensor([], device='cuda:1'), device_mesh=DeviceMesh:([0, 1]), placements=[Shard(dim=0)])
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101218
Approved by: https://github.com/wanchaol
Summary:
Otherwise we get
```
Traceback (most recent call last):
File "<string>", line 49, in <module>
File "<string>", line 47, in __run
File "/usr/local/fbcode/platform010/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/local/fbcode/platform010/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/data/users/jongsoo/fbsource/buck-out/v2/gen/fbcode/ef4169ac7f95fb74/caffe2/benchmarks/transformer/__sdp_backwards__/sdp_backwards#link-tree/caffe2/benchmarks/transformer/sdp_backwards.py", line 188, in <module>
main()
File "/data/users/jongsoo/fbsource/buck-out/v2/gen/fbcode/ef4169ac7f95fb74/caffe2/benchmarks/transformer/__sdp_backwards__/sdp_backwards#link-tree/caffe2/benchmarks/transformer/sdp_backwards.py", line 184, in main
run_timing(min_run_time, batch_size, embed_dim, num_heads, max_seq_len, dtype)
File "/data/users/jongsoo/fbsource/buck-out/v2/gen/fbcode/ef4169ac7f95fb74/caffe2/benchmarks/transformer/__sdp_backwards__/sdp_backwards#link-tree/caffe2/benchmarks/transformer/sdp_backwards.py", line 105, in run_timing
rand_fused_upward = cpt(x, x, x, mask).clone().detach()
File "/data/users/jongsoo/fbsource/buck-out/v2/gen/fbcode/ef4169ac7f95fb74/caffe2/benchmarks/transformer/__sdp_backwards__/sdp_backwards#link-tree/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/data/users/jongsoo/fbsource/buck-out/v2/gen/fbcode/ef4169ac7f95fb74/caffe2/benchmarks/transformer/__sdp_backwards__/sdp_backwards#link-tree/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
File "/data/users/jongsoo/fbsource/buck-out/v2/gen/fbcode/ef4169ac7f95fb74/caffe2/benchmarks/transformer/__sdp_backwards__/sdp_backwards#link-tree/caffe2/benchmarks/transformer/sdp_backwards.py", line 39, in forward
attn, _ = torch.nn.functional.scaled_dot_product_attention(
ValueError: too many values to unpack (expected 2)
```
Test Plan: buck run mode/dev-nosan //caffe2/benchmarks/transformer:sdp_backwards
Differential Revision: D45843838
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101341
Approved by: https://github.com/drisspg
Summary: This allows an internal use case to register a callback that can vary over time instead of being a static value over the lifetime of the program.
Test Plan: ran the test listed above ^^.
Differential Revision: D45805139
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101292
Approved by: https://github.com/aaronenyeshi
The linked issue demonstrates a triton bug where a load broadcasted
over multiple warps may see the result of a store that happens later
in the triton program. The workaround is to add a barrier before
storing, which enforces that all warps have already read the data.
e.g. in `test_embedding_var_mean` we now generate:
```python
tl.debug_barrier()
tl.store(in_out_ptr1 + (tl.broadcast_to(x0, [XBLOCK, 1])), tmp17, None)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100769
Approved by: https://github.com/jansel, https://github.com/ngimel
Looks like this line was a historical relic of Variable and Tensor not being the same. I spot checked assembly and it's not the same, which already implies this way is better; specifically there are fewer locked refcounting instructions (I believe the type of the expression is `Tensor` not `const Tensor&` and both forks must have the same type). Spotted this with at::cat in an internal workload; the actual fix is to enable InferenceMode but this should reduce the penalty for failing to do that.
Differential Revision: [D43714744](https://our.internmc.facebook.com/intern/diff/D43714744/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95835
Approved by: https://github.com/albanD
Hello!
Recently i was playing with LibTorch libs, but i noticed that currently there is only one LR Scheduler implementation available. I needed 'Reduce on plateau scheduler', so implemented it by myself. Used it a lot of times, and it seem work as it should, so decided to share my implementation here.
If u will decide that this is something worth to merge, or it needs tweaking/tests let me know!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100311
Approved by: https://github.com/albanD
Summary: This gives a finer control for developers to specify which set
of configs to measure for their one-off dashboard run. Right now the
queuing for those runs look pretty bad.
Another change here is reducing the inference measurement frequency to
2 times a week.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101279
Approved by: https://github.com/huydhn
I've noticed that 3-4 functions in trymerge are trying to implement similar tail recursion for flaky network retries.
Unify them using single wrapper in `gitutils.py`
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 8d40631</samp>
> _`retries_decorator`_
> _adds resilience to GitHub scripts_
> _autumn of errors_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101227
Approved by: https://github.com/kit1980
This PR adds bazel python, so that bazel build could be used from python like `import torch`.
Notable changes:
- Add the python targets.
- Add the version.py.tpl generation.
- In order to archive the `USE_GLOBAL_DEPS = False` just for the bazel build, employ a monkey-patch hack in the mentioned `version.py.tpl`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101003
Approved by: https://github.com/huydhn
Summary: Previously, we would only match and replace conv + BN
patterns with default constant args for conv (stride, padding,
dilation etc.). If the user sets one of these args to values
that are different from the default, we would simply not fuse
the pattern. This is due to a limitation in the subgraph
rewriter: see https://github.com/pytorch/pytorch/issues/100419.
This commit works around the above limitation by first
configuring the subgraph rewriter to ignore literals when
matching, and then manually copy over the constant args to the
new subgraph after `replace_pattern`.
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_prepare_qat_conv_bn_fusion_constant_args
Reviewers: jerryzh168, kimishpatel
Differential Revision: [D45515437](https://our.internmc.facebook.com/intern/diff/D45515437)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100525
Approved by: https://github.com/jerryzh168
To match with upstream and build triton whl's locally so nightly pytorch whls can access them without needing to use pypi.org.
We may have a better approach to build both whl's at once, but for now, to save duplication of code, another matrix is added for device (cuda/rocm) With rocm invoking a different commit and repo. The goal is to eventually have a single whl support both backends.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95142
Approved by: https://github.com/malfet, https://github.com/jithunnair-amd, https://github.com/atalman
Fixes#100935 , adding handling for the recompute_scale_factor field. I would be happy to write a test for this, but might need some advice on where it should go/how to reliably reproduce the given issue. I'd also be happy to iterate on the proposed changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101248
Approved by: https://github.com/albanD
The PyTorch Dispatcher's "no kernel found for DispatchKey" error message
is a bit long and winded. This PR adds a way to add a custom error
callback and changes the CustomOp API to use the custom error callback
to deliver better error messages.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101015
Approved by: https://github.com/ezyang
Previously, to specify e.g. int[], a user needed to do Tuple[int, ...].
This PR changes it to Sequence[int].
Bikeshedding: we could totally just use List[int] instead. The types
that the user gives us that we use to infer a schema is not entirely
faithful: for example, we convert `int` to SymInt.
I didn't feel strongly between Sequence[int] and List[int] so I went
with the more faithful one, plus Python recommends that you use Sequence
for input arguments (over list or tuple), though we don't subscribe to
that philosophy in general.
Test Plan:
- new test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101190
Approved by: https://github.com/bdhirsh
This PR tells the custom op tests to destroy all custom ops with
specified namespace after each test.
The general problem is that if a test fails, the custom op isn't cleaned
up. We could fix this via try-finally, but using a tearDown method
seemed like a nice O(1) solution.
Test Plan:
- deleted some foo._destroy, verified that the test suite passes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100980
Approved by: https://github.com/soulitzer, https://github.com/bdhirsh
Previously the error message went through torch.library. This PR changes
it so that on each custom_op.impl_* call:
- we store a (function, location) tuple
- if a (function, location) tuple exists already, then we raise an
error.
This logic already existed for the abstract impl (the impl for meta and
fake tensors), so this PR just extends it to the others.
Test Plan:
- new test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100979
Approved by: https://github.com/bdhirsh, https://github.com/soulitzer
Notes:
- No segfaults observed in any CI tests: dynamo unittests, inductor unittests, dynamo-wrapped pytorch tests. So we remove the warning that using dynamo 3.11 may result in segfaults.
- Some dynamo-wrapped pytorch tests hang. They will be skipped in the dynamo-wrapped test suite and will be addressed in a future PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99180
Approved by: https://github.com/malfet
The fix for https://github.com/pytorch/pytorch/pull/99545 (https://github.com/pytorch/pytorch/pull/99546) explicitly required users to set `cast_forward_inputs=False` if they wanted to avoid hitting #99545 while using an FSDP root module with no direct parameters.
After further consideration, [the team believes](https://github.com/pytorch/pytorch/pull/99546#discussion_r1180898687) it is sufficiently common for the default `cast_forward_inputs=False` to be used with a FSDP root module possessing no direct parameters that a solution to #99545 that accommodates this use case is desired.
This PR builds on @zhaojuanmao's https://github.com/pytorch/pytorch/pull/100290 (nice!) to enhance the FSDP cast forward inputs testing to include a broader range of scenarios and to include `model.eval()` testing as well as training mode validation. (I unfortunately don't have permissions that would allow me to use ghstack directly but I can rebase this PR however the team desires, once #100290 lands etc.)
Currently, the evaluation mode testing is commented out while the team decides on the best approach to implementing the broader solution to https://github.com/pytorch/pytorch/pull/99545. Once an implementation is decided, the evaluation mode validation function in the new tests added in this PR can be uncommented and should continue to pass. I also include one potential evaluation mode solution suggestion in this PR but leave the existing code unchanged since I know the team is intending to consider a range of solutions this week.
Test notes:
1. The 8 tests added here are a superset of the current `test_float16_on_one_submodule` tests, including validation of the following configurations: (`cast_root_forward_inputs_submodule` = True/False, `cast_forward_inputs_submodule` = True/False, `use_root_no_params` = True/False) across both training and evaluation modes.
2. The `float16_on_one_submodule` model configuration is currently only tested in the FSDP root module with parameters scenarios (as was the existing case) but this test can be easily extended to test it in the FSDP root module with no parameters scenarios as well if the team thinks the additional test resource usage is justified.
3. Since this test amortizes the cost of test setup across the aforementioned range of scenarios, the loop-based implementation of `dtype` validation (below) would have been undesirably complex IMHO[^1] :
```python
############### Logical equivalent of current test result matrix ############
if self.cast_root_forward_inputs_submodule or self.cast_forward_inputs_submodule:
self.assertEqual(self.forward_inputs[self.c2].dtype, torch.float16)
if use_root_no_params:
if self.cast_root_forward_inputs_submodule:
self.assertEqual(self.forward_inputs[self.model].dtype, torch.float16)
else:
self.assertEqual(self.forward_inputs[self.model].dtype, torch.float32)
self.assertEqual(self.forward_inputs[self.c1].dtype, torch.float16)
else:
self.assertEqual(self.forward_inputs[self.c1].dtype, torch.float32)
else:
self.assertEqual(self.forward_inputs[self.model].dtype, torch.float32)
self.assertEqual(self.forward_inputs[self.c1].dtype, torch.float32)
if not use_root_no_params: # this input will only exist in the root with params case until eval fix is applied
self.assertEqual(self.forward_inputs[self.c2].dtype, torch.float32)
```
so I implemented the validation function as an expected result lookup that provides the added benefit of explicitly specifying the failed subtest upon failed `dtype` assertions, e.g.:
```python
AssertionError: None mismatch: torch.float32 is not None
Subtest `no_cast_root_no_cast_child_no_root_params` failed.
```
The potential solution to https://github.com/pytorch/pytorch/pull/99545 that I added as a suggestion in the file conversation passes this test set but I know there are a lot of different ways that it could be resolved so I'll assume that change will be tackled in a separate PR unless the team wants to include it in this one.
As mentioned, I've currently based this PR off of https://github.com/pytorch/pytorch/pull/100290 so am happy to either wait for that to land first or rebase this PR however the team wants.
[^1]: Batching the scenarios into different tests is also possible of course but would involve unnecessary test setup overhead, happy to switch to that approach if the team prefers that though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100349
Approved by: https://github.com/awgu
CUDAGraph trees needs to known when you are doing a new invocation of your model. We have two heuristics for that :
- you invoke torch.compile again (like as a top level module you compiled)
- you have run a forward with a corresponding backward that hasn't been invoked yet, in which case we ignore the above
This doesn't always get it right, especially if you forget to use torch.no_grad() in inference. This adds a warning for that case, and adds an explicit `cudagraph_mark_step_begin` api.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101129
Approved by: https://github.com/ezyang
This will solve @albertz's issue as described in #98200 , threading the generator argument through the trunc_normal_ function. I'm still working on #99796 (and won't let it stall out), but this fix doesn't trigger any JIT issues, so I think it might be helpful to get it merged now.
Would be happy to iterate on this if there are any issues.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100810
Approved by: https://github.com/Skylion007, https://github.com/albanD
Fixes https://github.com/pytorch/pytorch/issues/100348, see the discussion in the issue for details. The problem was that for code like this:
```
def f(x):
out = ...
return out, out.detach()
```
The `.detach()` would turn into a `.alias()`, and inductor turns `.alias()` calls into no-ops. Inductor would effectively see that the two graph outputs have the same metadata, and return `out, out`. cc @ngimel alternatively we could have inductor try to detect when it's not ok to make `.alias()` a no-op, but that would probably require some custom logic instead of making `.alias()` a decomposition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100430
Approved by: https://github.com/ngimel
This PR just contains some mild gyrations necessary to appease mypy.
However, it is not complete; there are a number of legitimate bugs
and mistyping that I need to work out before I can actually turn this
on.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100712
Approved by: https://github.com/ngimel
Enables PyLint error codes implemented in ruff. These are un-opinionated static analysis checks on Python code that finds common bugs. After running all the PLE error codes that are implemented in ruff, I fixed the bugs, added a few ignores for malformed Python code that is part of our JIT test script, and finally added a few ignores for a false positive on PLE0605 and submitted an issue upstream to fix in ruff https://github.com/charliermarsh/ruff/issues/4345 .
Common bugs found here include analysis for malformed logging format calls, bad string format calls, invalid escape sequences, and more.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101079
Approved by: https://github.com/malfet
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 069fd23</samp>
This pull request enhances the MPS implementation of random operations in `Distributions.mm` and adds more dtype tests for the bernoulli distribution in `test_mps.py`. This improves the performance, correctness, and usability of the MPS backend for PyTorch.
Fixes https://github.com/pytorch/pytorch/issues/100717
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100946
Approved by: https://github.com/kulinseth
This PR changes the context manager behavior of device mesh, now we use
a mesh env to track the current mesh and save the mesh to a stack so
that we can allow nested context manager
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101202
Approved by: https://github.com/wz337
- Deletes unused kwargs
- Make test names more descriptive to remove need of comments. Overall it's better to codify over comment
- Added a test for duplicate params across groups
- Greatly simplified test_empty_grad to discover that the crux of the bug was NOT its emptiness, but rather with multi-dim emptiness.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101004
Approved by: https://github.com/albanD
This PR adds support for the following use cases:
- Sync style:
```
with dist._coalescing_manager():
for i in range(num_coll):
dist.all_gather_into_tensor(output_tensors[i], input_tensors[i])
```
- Async style:
```
with dist._coalescing_manager(async_ops=True) as cm:
for i in range(num_coll):
dist.all_gather_into_tensor(output_tensors[i], input_tensors[i])
# do a bunch of other things
cm.wait()
# do things that depend on the all-gather's
```
Each `all_gather_into_tensor` would be independent in terms of data and their buffer location. But could be executed in parallel by supported backends (like NCCL).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101157
Approved by: https://github.com/kumpera, https://github.com/wanchaol
Beefing up docs with discussion about when to use `instantiate_device_type_tests()` vs. `instantiate_parametrized_tests()` + description on what each does.
Spoiler: use only one - the former for device-specific and the latter for device-agnostic tests. Both support `@parametrize`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100905
Approved by: https://github.com/janeyx99
Summary: We don't think the performance impact of recording concrete shapes is significant; but it's good to have a knob for turning it off quickly in case it has a large performance impact.
Test Plan:
Ran D45681838. It prints the state of that "concrete inputs" boolean. I ran it before and after canarying a change to `pytorch/kineto:pytorch_record_concrete_inputs`; before, it returns true; after, it returns false.
Note that D45681838 had to add `service` on the main function. That's because we need to `initFacebook` in order to use jks.
Differential Revision: D45680162
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101043
Approved by: https://github.com/aaronenyeshi
# Motivate
Without this PR:
```python
>>>import torch
>>>torch.IntTensor.is_cuda
False
>>>torch.IntTensor.is_xpu
<attribute 'is_xpu' of 'torch._C._TensorBase' objects>
```
With this PR:
```python
>>>import torch
>>>torch.IntTensor.is_xpu
False
```
Align to CUDA, some customer code use is_xpu to check the backend. Without this PR, the check is always True which result in an unexpected behavior
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101072
Approved by: https://github.com/mikaylagawarecki
implementation of DataPtr context for copy-on-write tensors
Summary:
Copy-on-write storage
=====================
This library adds support for copy-on-write storage, i.e. lazy copies,
to tensors. The design maintains the PyTorch invariant that tensors
alias if and only if they share a storage. Thus, tensors that are lazy
copies of one another will have distinct storages that share a data
allocation.
Thread-safety
-------------
The correctness of this design hinges on the pre-existing PyTorch user
requirement (and general default programming assumption) that users
are responsible for guaranteeing that writes do not take places
concurrently with reads and other writes.
Lazily copied tensors add a complication to this programming model
because users are not required to know if lazy copies exist and are
not required to serialize writes across lazy copies. For example: two
tensors with distinct storages that share a copy-on-write data context
may be given to different threads that may do whatever they wish to
them, and the runtime is required to guarantee its safety.
It turns out that this is not that difficult to protect because, due
to the copy-on-write requirement, we just need to materialize a tensor
upon writing. This could be done entirely without synchronization if
we materialized each copy, however, we have a common-sense
optimization to elide the copy for the last remaining reference. This
requires waiting for any pending copies.
### Thread-safety detailed design
There are two operations that affect the copy-on-write details of a
tensor:
1) lazy-clone (e.g. an explicit call or a hidden implementation detail
added through an operator like reshape)
2) materialization (i.e. any write to the tensor)
The key insight that we exploit is that lazy-clone is logically a read
operation and materialization is logically a write operation. This
means that, for a given set of tensors that share a storage, if
materialization is taking place, no other read operation, including
lazy-clone, can be concurrent with it.
However, this insight only applies within a set of tensors that share
a storage. We also have to be concerned with tensors with different
storages that share a copy-on-write context. In this world,
materialization can race with lazy-clone or even other
materializations. _However_, in order for this to be the case, there
must be _at least_ two references to the context. This means that the
context _can not_ vanish out from under you if you are performing a
lazy-clone, and hence, it only requires an atomic refcount bump.
The most complicated case is that all lazy-copies are concurrently
materializing. In this case, because a write is occurring, there are
no in-flight lazy-copies taking place. We must simply ensure that all
lazy-copies are able to materialize (read the data) concurrently. If
we didn't have the aforementioned optimization where the last copy
steals the data, we could get away with no locking whatsoever: each
makes a copy and decrements the refcount. However, because of the
optimization, we require the loser of the materializing race wait for
the pending copies to finish, and then steal the data without copying
it.
We implement this by taking a shared lock when copying the data and
taking an exclusive lock when stealing the data. The exclusive lock
acquisition ensures that all pending shared locks are finished before
we steal the data.
Test Plan: 100% code coverage.
---
Stack created with [Sapling](https://sapling-scm.com). Best reviewed with [ReviewStack](https://reviewstack.dev/pytorch/pytorch/pull/100818).
* #100821
* #100820
* #100819
* __->__ #100818
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100818
Approved by: https://github.com/ezyang
In CI older MacOS SDK can be used to compile the binary, so add guard for availability of `MPSGraphResizeNearestRoundingModeRoundToEven` enum value.
MPS feature availability checks are deliberately done at runtime (by using `is_macos_13_or_newer` and forward-declaring methods in `MPSGraphVenturaOps.h`) rather than at compile time (by using `#ifdef`s).
Modify error message and XFAIL condition in `test_mps.py` to fail test due to missing conditional on macOS-13.2 or newer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101108
Approved by: https://github.com/kulinseth
Provide an option to configure the workspace size used by cuBLASLt rather than fixing it as a compile-constant of 1MiB due to observed performance differences on H100 and recommendations from cuBLAS e.g., https://docs.nvidia.com/cuda/archive/11.8.0/cuda-toolkit-release-notes/index.html#title-cublas-library.
Some quick profiling shows that in some cases up to 32MiB of workspace is needed on H100:
```
import torch
import time
m = 1024
n = 2048
warmup = 20
iters = 200
dtype = torch.bfloat16
for k in (1024, 2048, 4096, 8192, 9376, 16384, 32768):
a = torch.randn(m, k, device='cuda', dtype=dtype)
b = torch.randn(n, k, device='cuda', dtype=dtype).transpose(1, 0)
i = torch.randn(n, device='cuda', dtype=dtype)
for _ in range(warmup):
torch.addmm(i, a, b)
torch.cuda.synchronize()
t1 = time.perf_counter()
for _ in range(iters):
torch.addmm(i, a, b)
torch.cuda.synchronize()
t2 = time.perf_counter()
print(f"m:{m}, n:{n}, k:{k} TFLOP/s: {( 2*m*n*k)*iters/(t2 - t1)/1e12}")
```
1MiB:
```
m:1024, n:2048, k:1024 TFLOP/s: 62.40964655242158
m:1024, n:2048, k:2048 TFLOP/s: 79.33321703070685
m:1024, n:2048, k:4096 TFLOP/s: 96.69701590181765
m:1024, n:2048, k:8192 TFLOP/s: 83.2892371366678
m:1024, n:2048, k:9376 TFLOP/s: 83.91872373271516
m:1024, n:2048, k:16384 TFLOP/s: 86.57820235279185
m:1024, n:2048, k:32768 TFLOP/s: 88.37227761178467
```
32 MiB:
```
m:1024, n:2048, k:1024 TFLOP/s: 73.50633352382425
m:1024, n:2048, k:2048 TFLOP/s: 104.32016319633199
m:1024, n:2048, k:4096 TFLOP/s: 131.37290416527784
m:1024, n:2048, k:8192 TFLOP/s: 152.08780769805506
m:1024, n:2048, k:9376 TFLOP/s: 154.93898780286096
m:1024, n:2048, k:16384 TFLOP/s: 165.13973167154688
m:1024, n:2048, k:32768 TFLOP/s: 160.62065020500813
```
CC @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101145
Approved by: https://github.com/ngimel
**Summary**
Fix the issue https://github.com/pytorch/pytorch/issues/100959. The root cause is for node of `torch.ops.aten.max_pool2d_with_indices.default`, there are 2 output node as output tensor and max indices. So in its `node.meta["val"]` is a tuple of `FakeTensors` (For example: `'val': (FakeTensor(..., size=(1, 2, s1, s1)), FakeTensor(..., size=(1, 2, s1, s1), dtype=torch.int64))`). It will fail the check of inserting observer since which only accept one `FakeTensor` case.
**Test Plan**
```
python -m pytest test_quantize_pt2e.py -k test_max_pool2d_quantizer
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100961
Approved by: https://github.com/jerryzh168, https://github.com/jgong5
Previously, anomaly detection was only enabled on the inner forward function, and not on the overall joint function that calls backward. I believe this impeded us from printing "this is the forward that triggered the backward" because that printing only happens if anomaly mode is enabled when you run backward(). This PR fixes it.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101047
Approved by: https://github.com/albanD, https://github.com/bdhirsh
Per title.
there's an off chance that query_reshaped etc was actually discontiguous after reshape, but even in that case I'm pretty sure the computed gradients would still be contiguous, and we are properly transposing output gradients to produce correct strides.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101128
Approved by: https://github.com/drisspg
Fixes#99665
Let me explain the root cause using the unit test I added:
* This bug is triggered when:
* ```wrapped``` is a nested function.
* ```wrapped``` is in another module which is different from the main function ```fn```.
* There is a graph break inside of ```wrapped```.
* The root cause is when resuming nested function, actually we are using the outermost function(```fn``` in my example)'s global variables, but ```wrapped``` calls ```inner_func``` which is not part of ```fn```'s globals, so we have to set correct globals when nested function resume execution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100426
Approved by: https://github.com/jansel
This is the first series of PR that adopts operator impls to use a
strategy based approach, each op utilizes OpStrategy and PlacementStrategy
to generate their own strategy. By utilizing the strategy based
approach along with the op graph, we could enable more advanced op
implementation (decomp is possible), and turn the sharding prop to be
more like a contraint satisfication problem.
This PR alone only adds some basic tensor op strategies, and it directly
works on the op graph that was used for metadata propagation. The tensor ops
added in this PR mainly follows one of the arg strategy. The next set of
PRs would add more op strategies to other ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100607
Approved by: https://github.com/XilunWu
Similar to ASAN, the test starts to timeout on slow jobs such as slow gradcheck, for example 30cecc0e11. This needs to be investigated later, but it's of low priority as we can run test_api binary directly in the meantime in these jobs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101088
Approved by: https://github.com/clee2000
Fixes Meta internal user case.
Repro:
```
import torch
import torch._dynamo
def fn(x):
with torch.cuda.amp.autocast(False):
x = torch.sin(x + 1)
return x
x = torch.randn([2, 3])
ref = fn(x)
print(ref)
opt_fn = torch._dynamo.optimize(backend="inductor")(fn)
print(opt_fn(x))
```
Error:
```
Traceback (most recent call last):
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/convert_frame.py", line 425, in _compile
out_code = transform_code_object(code, transform)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/bytecode_transformation.py", line 1000, in transform_code_object
transformations(instructions, code_options)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/convert_frame.py", line 410, in transform
tracer.run()
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 2010, in run
super().run()
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 703, in run
and self.step()
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 663, in step
getattr(self, inst.opname)(inst)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 385, in wrapper
return inner_fn(self, inst)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 1095, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 554, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/variables/torch.py", line 381, in call_function
return AutocastModeVariable.create(target_values=args, kwargs=kwargs)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/variables/ctx_manager.py", line 198, in create
bound_args = inspect.signature(torch.autocast).bind(*target_values, **kwargs)
File "/scratch/ybliang/work/env/lib/python3.9/inspect.py", line 3045, in bind
return self._bind(args, kwargs)
File "/scratch/ybliang/work/env/lib/python3.9/inspect.py", line 2984, in _bind
raise TypeError(
TypeError: multiple values for argument 'device_type'
from user code:
File "/scratch/ybliang/work/repos/debug/debug6.py", line 10, in fn
with torch.cuda.amp.autocast(False):
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101052
Approved by: https://github.com/anijain2305
Preserves the PyTest cache from one job run to the next. In a later PR, this will be used to change the order in which we actually run those tests
The process is:
1. Before running tests, check S3 to see if there is an uploaded cache from any shard of the current job
2. If there are, download them all and merge their contents. Put the merged cache in the default .pytest_cache folder
3. After running the tests, merge the now-current .pytest_cache folder with the cache previously downloaded for the current shard. This will make the merged cache contain all tests that have ever failed for the given PR in the current shard
4. Upload the resulting cache file back to S3
The S3 folder has a retention policy of 30 days, after which the uploaded cache files will get auto-deleted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100522
Approved by: https://github.com/huydhn
Fixed test_memory_profiler::TestMemoryProfilerE2E::test_memory_timeline by changing the (arbitrary) threshold for logging. We observe differently-sized allocations on different AMD GPUs, so chose a higher threshold of 512 to account for those differences and yet satisfy the test requirements.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96752
Approved by: https://github.com/jithunnair-amd, https://github.com/kit1980
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101005
Previously the node annotation looks like the following:
```
node.meta["..."] = {
"input_act_obs_or_fq_ctr": ...,
"weight_obs_or_fq_ctr": ...,
"weight_index": 1,
}
```
Basically we need specifiy the index for weight and also have a separate key for weight config, in this PR we changed that to:
```
node.meta["..."] = {
"input_act_obs_or_fq_ctr_map": {input_node: ..., weight_node: ...},
}
```
This can support specifying the observer/fake quant constructor for any argument of the node
Test Plan: buck2 test @//mode/opt //caffe2/test:quantization_pt2e -- --exact 'caffe2/test:quantization_pt2e - test_resnet18_with_quantizer_api (quantization.pt2e.test_quantize_pt2e.TestQuantizePT2EModels)'
Differential Revision: D45719781
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101041
Approved by: https://github.com/andrewor14
`tempfile.mkstemp` always creates the file `0o600` permissions, so
only the current user can access it. Instead, this salts the original
filename with the pid and thread id to avoid conflicts between
temporary files.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100870
Approved by: https://github.com/jansel
When handling custom classes from Python, it is nice to be able to specify how they are displayed to the user.
Out of the two standard functions to do this, only `__str__` could be implemented in C++. This PR add `__repr__` to the allowlist of magic methods.
The second commit tweaks the default output of `__str__` to make it more informative, but I can remove the change if you want.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100724
Approved by: https://github.com/ezyang
Currently we print out the mismatched collectives, but it is hard to
tell exactly the mismatch. This diff adds functionality to detect the exact mismatch
and report it.
New error is as follows:
```
Detected mismatch between collectives on ranks. Rank 0 is running collecti ve: CollectiveFingerPrint(SequenceNumber=1151423632, OpType=ALLREDUCE, TensorShape =[20, 10], TensorDtypes=Float, TensorDeviceTypes=TensorOptions(dtype=float (defaul t), device=cpu, layout=Strided (default), requires_grad=false (default), pinned_me mory=false (default), memory_format=(nullopt))), but Rank 1 is running collective: CollectiveFingerPrint(SequenceNumber=1151423632, OpType=REDUCE, TensorShape=[20, 10], TensorDtypes=Float, TensorDeviceTypes=TensorOptions(dtype=float (default), de vice=cpu, layout=Strided (default), requires_grad=false (default), pinned_memory=f alse (default), memory_format=(nullopt))). Collectives differ in the following aspects: Op type: ALLREDUCEvs REDUCE
```
i.e. the "Collectives differ in the following..." messaging is added.
Differential Revision: [D45375737](https://our.internmc.facebook.com/intern/diff/D45375737/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100214
Approved by: https://github.com/H-Huang
Summary:
Previously, we were replacing all getitems of a split - even the ones not affected by the pattern. For large split nodes, this was inefficient.
For instance, on an internal ads model - split-split pass took ~1100s. This is down to ~18s after this optimization
Test Plan:
* Compiled and tested on internal model (compilation time down by ~1100s)
* CI tests
Differential Revision: D45698034
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100983
Approved by: https://github.com/jansel
Adding to the docs for now, hopefully we can move to `cudaMallocAsync`-backed cuBLAS workspaces soon which should alleviate the recent confusion around `cuBLAS` "leaking" memory through workspaces.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100919
Approved by: https://github.com/ngimel
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 4f0b524</samp>
This pull request updates the codebase and the documentation to use C++17 instead of C++14 as the minimum required C++ standard. This affects the `ATen`, `c10`, and `torch` libraries and their dependencies, as well as the CI system and the `conda` package metadata.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100557
Approved by: https://github.com/malfet
`getpass.getuser` may raise exceptions in some circumstances, where users cannot override the default cache dir with env `TORCHINDUCTOR_CACHE_DIR`. Hence the assemble of default cache dir should be lazily evaluated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100824
Approved by: https://github.com/ezyang
cudaGetLastError and hipGetLastError will clear any error value within CUDA and HIP, respectively. This is often done on purpose to clear benign errors. Discarding the return value should be indicated by casting to void and a nearby comment. This silences warnings from HIP:
warning: ignoring return value of function declared with 'nodiscard' attribute [-Wunused-result]
Performing an audit of pytorch sources found one use of cudaGetLastError that was incorrectly ignored in IndexKernel.cu.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100488
Approved by: https://github.com/ezyang
Summary:
Previously the node annotation looks like the following:
```
node.meta["..."] = {
"input_act_obs_or_fq_ctr": ...,
"weight_obs_or_fq_ctr": ...,
"weight_index": 1,
}
```
Basically we need specifiy the index for weight and also have a separate key for weight config, in this PR we changed that to:
```
node.meta["..."] = {
"input_act_obs_or_fq_ctr_map": {input_node: ..., weight_node: ...},
}
```
This can support specifying the observer/fake quant constructor for any argument of the node
Test Plan: buck2 test @//mode/opt //caffe2/test:quantization_pt2e -- --exact 'caffe2/test:quantization_pt2e - test_resnet18_with_quantizer_api (quantization.pt2e.test_quantize_pt2e.TestQuantizePT2EModels)'
Reviewed By: kimishpatel
Differential Revision: D45553195
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101005
Approved by: https://github.com/kimishpatel
Fixes the error:
```
/var/lib/jenkins/pytorch/test/inductor/test_torchinductor.py:6021: PytestCollectionWarning: cannot collect test class 'TestFailure' because it has a __init__ constructor (from: test/inductor/test_torchinductor.py)
class TestFailure:
```
It does so by marking the class as not actually being a test class, despite it's name starting with `Test`.
For more details see: https://stackoverflow.com/a/72465142/21539
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100949
Approved by: https://github.com/huydhn
Dynamo will frequently segfault when attempting to print stack traces. We fix this by:
- Fixing stack size calculations, as we did not account for exception tables
- Creating shadow execution frames in a way that more closely resembles what CPython does to create its execution frames
Dynamo/inductor-wrapped pytorch tests are enabled up the stack - those need to be green before this PR can be merged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99934
Approved by: https://github.com/albanD, https://github.com/malfet, https://github.com/jansel
Summary:
For each op, we have a List[List[dtype;dim-order]]:
- the inner list contains the `dtype;dim-order` info for each arg if we have a Tensor/TensorList/OptionalTensorList
- the outer list contains different occurances of dtype/dim-order combinations for that op in the program
Example:
```
et_kernel_metadata:
aten::add.out:
# A list of different dtype/dim-order combinations used in model
- # Each contains the list of args of Tensor dtype and dim order if applicable
- FLOAT;0,1
- FLOAT;0,1
- NON_TENSOR_ARG
- FLOAT;0,1
- FLOAT;0,1
-
- INT;0,1
- INT;0,1
- NON_TENSOR_ARG
- INT;0,1
- INT;0,1
aten::mul.out:
- - FLOAT;0,1
- FLOAT;0,1
- FLOAT;0,1
- FLOAT;0,1
```
We don't have the arg name so far; we need to parse the schema (functions.yaml) to get that info. We depend on the order of args from that file.
Test Plan: `buck run fbcode//executorch/codegen/tools:test_gen_oplist_real_model`
Differential Revision: D45551409
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100665
Approved by: https://github.com/larryliu0820
After https://github.com/pytorch/pytorch/pull/99559, we can now run C++ test with `run_test.py`. Although advance features such as `--import-slow-tests` and `--import-disabled-tests` won't work for now, there will still be a gain in reliability and performance as C++ can now be retried and run in parallel.
This covers all C++ tests in the CI including aten, libtorch, and Vulkan C++ tests across all platforms Linux, Windows, MacOS.
Notes:
* To support C++ test discovery, the env variable `CPP_TESTS_DIR` can be set to where the C++ test binaries is located
* Support pytest -k argument via run_test as this is used by pytest-cpp to replace `--gtest-filter`
* The XML output is in pytest format, but it's ok now because we don't have slow test or flaky test support for C++ test yet
* ~~I need to figure out why conftest.py doesn't work when I invoke pytest directly for C++ test, so `--sc` is not available for C++ tests at the moment. Proper pytest plugin like stepwise works fine though. I'll investigate and fix it in a separate PR~~ Found the cause, `conftest.py` is per directory and needs to be in any arbitrary directory that holds C++ test
* Two tests `test_api` and `test_tensorexpr` timed out on ASAN, I suspect that ASAN is now used on top of the python executable, which is slower than running native C++ code. IMO, it's ok to run these tests as before on ASAN for now
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99956
Approved by: https://github.com/clee2000, https://github.com/ZainRizvi
Summary:
This fixes flakiness of div_to_scalar_wrapped
See [here](b89f74aa35) for flakiness of div_to_scalar_wrapped
Test Plan:
On Devserver:
```
LD_LIBRARY_PATH=third-party/swiftshader/lib/linux-x64/ buck run //xplat/caffe2:pt_vulkan_api_test_bin
```
On Mac:
```
buck run --target-platforms ovr_config//platform/macos:arm64-fbsource -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64
```
To test that these changes fixed flakiness of div_to_scalar_wrapped, I ran the test 1000 times on devserver before the changes, and observed failures. Then ran it 1000 times after the changes and didn't observe any failures.
Reviewed By: SS-JIA
Differential Revision: D45670642
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100909
Approved by: https://github.com/SS-JIA
Summary: This tests running a conv2d with clamp after dividing the input tensor by another tensor. Both tensors have number channels = 3 (i.e. not a multiple of 4) and therefore, the channel dimension was padded. Hence, we are testing our divide-by-zero fix (D44392406)
Test Plan:
```
buck run --target-platforms ovr_config//platform/macos:arm64-fbsource -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -- --gtest_filter="VulkanAPITest.conv2d_clamp_after_div"
```
Reviewed By: SS-JIA
Differential Revision: D44550026
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100910
Approved by: https://github.com/SS-JIA
Summary:
This PR adds support for folding bn weights into conv for QAT flow, this is equivalent
to the QAT branch of `from_float` in eager mode quantized conv module: https://github.com/pytorch/pytorch/blob/main/torch/ao/nn/quantized/modules/conv.py#L223
Items that needs followup:
* there are some workaround I did because quantize_per_tensor is using float/int args and dynamo does not support these args, need to fix after we change the quantized model representation and also change these args to Tensor
Test Plan: buck2 test @//mode/opt //caffe2/test:quantization_pt2e -- --exact 'caffe2/test:quantization_pt2e - test_convert_qat_conv_bn_fusion (quantization.pt2e.test_quantize_pt2e.TestQuantizePT2E)'
Reviewed By: andrewor14
Differential Revision: D45344281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100442
Approved by: https://github.com/kimishpatel
PyTorch is C++17 project, so let's use some C++17 features.
I.e. `s/std::is_same<X, Y>::value/std::is_same_v<X, Y>`
And use `if constexpr` in few places when this construct is used.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 7b7683f</samp>
> _We're sailing on the sea of code, we're making it more neat_
> _We're using `is_same_v` and `if constexpr` to keep it sweet_
> _We're refactoring the range tensor logic, we're avoiding duplication_
> _We're heaving on the ropes of `Distributions.mm`, on the count of three, with elation_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100975
Approved by: https://github.com/jeanschmidt, https://github.com/albanD, https://github.com/kulinseth, https://github.com/Skylion007
Without these changes, it can be hard to know which magic methods are not implemented on a given ScriptObject.
before:
```py
torch.ops.load_library("somelib.so")
c = torch.classes.somelib.SomeClass()
print(len(c))
# raise NotImplementedError
```
after:
```py
torch.ops.load_library("somelib.so")
c = torch.classes.somelib.SomeClass()
print(len(c))
# raise NotImplementedError: '__len__' is not implemented for __torch__.torch.classes.somelib.SomeClass
```
------
I could not find a linked issue, if you want me to open one as well I can do this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100171
Approved by: https://github.com/ezyang
Summary:
Currently there are build configs where the torchdynamo import trips over a
strange SystemError related to some module's __dict__.items() returning NULL,
while torchdynamo tries to iterate all torch modules and process them for
its allowed functions list.
While this is hard to repro, we should be able to work around it and then fix
it properly.
Test Plan: Rely on others to test this, assuming CI passes.
Reviewed By: anijain2305
Differential Revision: D45663313
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100901
Approved by: https://github.com/yanboliang, https://github.com/malfet
### Description
This PR is to fix#99413, which shows the limitation of double backward using oneDNN in LSTM.
This PR does not implement double backward function itself, because that is pretty hard to spell out. Instead, it implements mkldnn_rnn_layer_backward using differentiable operations, so that double backward can be done automatically.
During backward process, it needs to use gates and hidden states between cells during one layer. However, these middle variables are stored in the `workspace`, and it is hard to figure them out. Therefore, in backward, we need re-calculate them first.
Corresponding UT has been added based on the failing case in # 99413. The UT with gradcheck and gradgradcheck which is added in https://github.com/pytorch/pytorch/pull/26660 cannot test LSTM using oneDNN, because UT only supports `double` datatype, while oneDNN does not support it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100627
Approved by: https://github.com/jgong5, https://github.com/soulitzer
Description:
Context: In torchvision we ensure that functional ops are torchscriptable. Recently exposed `torch.backends.cpu.get_cpu_capability()` in https://github.com/pytorch/pytorch/pull/100164 is failing in torchvision CI
```
RuntimeError:
Python builtin <built-in function _get_cpu_capability> is currently not supported in Torchscript:
File "/usr/local/lib/python3.10/dist-packages/torch/backends/cpu/__init__.py", line 17
- "AVX512"
"""
return torch._C._get_cpu_capability()
~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
```
Ref: https://github.com/pytorch/vision/pull/7557
In this PR, `torch._C._get_cpu_capability()` is explicitly registered for JIT and tested.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100723
Approved by: https://github.com/albanD
This pr does the following:
1. previously, inline constraints is not properly set for tensor output data-dependent ops such as a.nonzero because of its return value is not symint. This pr just uses all the unbacked symbols i.e.those start with "i"/"f" in create_unbacked_sym* functions. Note that these symbols are guaranteed to be a super set of inline user constraints.
2. add inline assertions support by checking.
Currently, it only deal with tensor, SymInt, SymFloat, SymBool output data-dependent ops and ignore the rest. It's good enough for now as we only have a limited number of data-dependent ops (.item and .nonzero are explicitly tested).
The examples for graph that is added assertions is shown below:
```
class ExportGraphModule(torch.nn.Module):
def forward(self, x):
arg0: i64[s0], = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
nonzero_default: i64[i0, 1] = torch.ops.aten.nonzero.default(arg0); arg0 = None
return pytree.tree_unflatten([nonzero_default], self._out_spec)
class GraphModule(torch.nn.Module):
def forward(self, x):
arg0: i64[s0], = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
sym_size: Sym(s0) = torch.ops.aten.sym_size(arg0, 0)
nonzero_default: i64[i1, 1] = torch.ops.aten.nonzero.default(arg0); arg0 = None
sym_size_1: Sym(i1) = torch.ops.aten.sym_size(nonzero_default, 0)
ge: Sym(i1 >= 3) = sym_size_1 >= 3
scalar_tensor_default: f32[] = torch.ops.aten.scalar_tensor.default(ge); ge = None
_assert_async_msg = torch.ops.aten._assert_async.msg(scalar_tensor_default, 'nonzero_default.shape[0] is outside of inline constraint [3, 5].'); scalar_tensor_default = None
le: Sym(i1 <= 5) = sym_size_1 <= 5; sym_size_1 = None
scalar_tensor_default_1: f32[] = torch.ops.aten.scalar_tensor.default(le); le = None
_assert_async_msg_1 = torch.ops.aten._assert_async.msg(scalar_tensor_default_1, 'nonzero_default.shape[0] is outside of inline constraint [3, 5].'); scalar_tensor_default_1 = None
return pytree.tree_unflatten([nonzero_default], self._out_spec)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100763
Approved by: https://github.com/tugsbayasgalan
Summary: `CUDACachingAllocator::format_size` is used not only in CUDACachingAllocator.cpp but also in CUDAMallocAsyncAllocator.cpp. This caused a breakage when the compiler inlined the function and the linker couldn't find it when resolving symbols for CUDAMallocAsyncAllocator.cpp.
Differential Revision: D45612790
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100734
Approved by: https://github.com/interwq, https://github.com/kit1980
Summary: Make it possible to `torch.jit.load(model, device)` to a device when `model` contains weights that are on device `meta`. Just leave the `meta` weights on `meta`, and load the weights that can be loaded to the target device.
Reviewed By: singlaiiit, RoshanPAN, sayitmemory
Differential Revision: D45099145
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100495
Approved by: https://github.com/houseroad
I ported over the code for the inline interpreter incorrectly in the pass base 😅
Originally the function `make_inline_interpreter` is supposed to take in a fx.Interpreter type but I accidentally passed in an fx.Interpreter object. Also realized while modifying this diff (and comments from Tugsuu) that we don't really need this InlineInterpreter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100836
Approved by: https://github.com/zhxchen17, https://github.com/tugsbayasgalan
Currently, when f is a Module, the signature should be the "forward" methods signature. For example,
```python
class Module(torch.nn.Module):
def forward(self, x):
return x.sin()
mod = Module()
x = torch.ones([3, 3])
torch._dynamo.export(mod, x, constraints=[dynamic_dim(x, 0)])
```
Previously, it prints following:
```python
def specify_constraints(*args, **kwargs):
return [
2 <= dynamic_dim(x, 0),
2 <= dynamic_dim(x, 1),
]
```
After the pr, it prints:
```python
def specify_constraints(x):
return [
2 <= dynamic_dim(x, 0),
2 <= dynamic_dim(x, 1),
]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100739
Approved by: https://github.com/avikchaudhuri
Today, we prioritize running test files that were edited in the user's PR, with the idea being to run them before we run any other test.
Except, if the modified test is supposed to run serially, then we still end up running it after all the parallelized tests have finished running.
This PR fixes that to _always_ run the prioritized tests before the regular tests, regardless of if the test is supposed to run serially or in parallel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100748
Approved by: https://github.com/huydhn
Cruise uses [clang static analyzer](https://clang-analyzer.llvm.org/) internally.
In the v2.0.0 release of PyTorch it found this problem
```
In file included from external/pytorch/aten/src/ATen/ATen.h:7:
In file included from external/pytorch/aten/src/ATen/Context.h:3:
In file included from external/pytorch/aten/src/ATen/CPUGeneratorImpl.h:3:
In file included from external/pytorch/aten/src/ATen/core/Generator.h:22:
In file included from external/pytorch/c10/core/GeneratorImpl.h:8:
In file included from external/pytorch/c10/core/TensorImpl.h:6:
external/pytorch/c10/core/InferenceMode.h:58:5: warning: Passed-by-value struct argument contains uninitialized data (e.g., field: 'view_replay_enabled_')
AutogradState::set_tls_state(AutogradState(
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
1 warning generated.
```
In other words, the value of `view_replay_enabled_` could be initialized which may lead to subtle bugs later on.
This PR addresses the warning by explicitly initializing it to `false`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100822
Approved by: https://github.com/Skylion007
This PR puts a placeholder param handler for a new param being passed in from Inductor, enable log.
Fixes this error below, where I've been unable to run torch.compile on NanoGPT due to this error:
~~~
File "/opt/conda/envs/pytorch/lib/python3.9/site-packages/torch/_inductor/fx_passes/fuse_attention.py", line 219, in _sfdp_init
register_replacement(
File "/opt/conda/envs/pytorch/lib/python3.9/site-packages/torch/_inductor/pattern_matcher.py", line 658, in register_replacement
search_gm = trace_fn(search_fn, example_inputs)
File "/opt/conda/envs/pytorch/lib/python3.9/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/opt/conda/envs/pytorch/lib/python3.9/site-packages/torch/_inductor/pattern_matcher.py", line 828, in training_graph
aot_function(
torch._dynamo.exc.BackendCompilerFailed: backend='compile_fn' raised:
TypeError: patched_aot_function() got an unexpected keyword argument 'enable_log'
~~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100814
Approved by: https://github.com/fegin
Summary: Disable buffers sync in _sync_module_states(...) when broadcast_buffers is False. This change will memory usage when a model has huge buffers and does not need broadcast buffers.
Test Plan: .
Differential Revision: D45610709
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100729
Approved by: https://github.com/mrshenli
Prevent using parallel computing when deterministic algorithm is set.
Fixes#97574
Benchmark:
```
[--------------- index_put_ Deterministic Algorithm Enabled ---------------]
| cpu | mps
1 threads: -----------------------------------------------------------------
Dtype: torch.float32 Features: 1024; Num Indices: 512 | 37 | 49
Dtype: torch.float32 Features: 1024; Num Indices: 1024 | 54 | 50
Dtype: torch.float32 Features: 1024; Num Indices: 2048 | 86 | 50
Dtype: torch.float32 Features: 1024; Num Indices: 4096 | 150 | 49
Times are in microseconds (us).
[-------------- index_put_ Deterministic Algorithm Disabled ---------------]
| cpu | mps
1 threads: -----------------------------------------------------------------
DType: torch.float32 Features: 1024; Num Indices: 512 | 37 | 49
DType: torch.float32 Features: 1024; Num Indices: 1024 | 53 | 49
DType: torch.float32 Features: 1024; Num Indices: 2048 | 86 | 49
DType: torch.float32 Features: 1024; Num Indices: 4096 | 147 | 50
Times are in microseconds (us).
```
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at ebf2ff3</samp>
Added a deterministic version of `index_put` for MPS tensors that runs on a single thread and can be enabled by a global context flag. Refactored the existing `index_put` function and the kernel selection logic to support both parallel and serial modes. Added a test function to verify the deterministic behavior of `index_put` under different conditions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97660
Approved by: https://github.com/kulinseth
Fixes#100530
When indices for indirect read are computed rather than read from another tensor, they should be masked according to the index used in computation. Currently though we don't associate masks with index variables, so the computed indices don't have associated masks also. This PR associates masks with index variables when they are created.
On this PR, both the device assert and masked load are generated, and hopefully device assert should be removed later once your value analysis PR lands.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100816
Approved by: https://github.com/Chillee, https://github.com/lezcano
To make TP more generic for Attention module, we come up with this new col/rowwise parallel style.
Basically, the idea behind is that:
We only do DTensor op for Col/Rowwise sharded part. For the rest of ATen ops, we will leave it to Tensor ops.
And we set this behavior as default for Colwise and Rowwise parallel style. If people want to customize it, they can always pass in different prepare_input or prepare_output
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100508
Approved by: https://github.com/wanchaol
1. Move constraint violation error after constraint discovery warning, and attach them when we have both.
2. Remove verbose internal traceback for relevant guard in constraint violation error.
3. Remove mention of `assume_static_by_default` in specialization warning.
4. Fix indenting of `specializations` body and make it assert individually instead of returning a conjunction.
5. Remove return annotation on signature used in generated `specializations` and `specify_constraints` functions.
6. Split `&` ranges because we don't support them yet.
Differential Revision: [D45619852](https://our.internmc.facebook.com/intern/diff/D45619852/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100745
Approved by: https://github.com/tugsbayasgalan
This PR refactors how InputAdapter and OutputAdapter is used throughout the exporter.
During refactoring, API issues with passes (torch.onnx._internal.fx._pass.Transform) were identified and should be tackled on another API. In short, some passes can modify the input/output of the model and the input/output adapter must be in sync with such change, otherwise, the adapters will not reflect the actual model input/output. The first instance of this issue was with `ReplaceGetAttrWithPlaceholder` pass that adds new inputs to the model. In order to work this around, a new input adapt step to append new inputs (generated by the pass) was introduced. That resulted in the number of inputs of the ONNX model to mismatch the numer of inputs of the pytorch model, though.
Follow up on https://github.com/pytorch/pytorch/pull/98421
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100490
Approved by: https://github.com/BowenBao
Fixes#99665
Let me explain the root cause using the unit test I added:
* This bug is triggered when:
* ```wrapped``` is a nested function.
* ```wrapped``` is in another module which is different from the main function ```fn```.
* There is a graph break inside of ```wrapped```.
* The root cause is when resuming nested function, actually we are using the outermost function(```fn``` in my example)'s global variables, but ```wrapped``` calls ```inner_func``` which is not part of ```fn```'s globals, so we have to set correct globals when nested function resume execution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100426
Approved by: https://github.com/jansel
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 8bb6158</samp>
This pull request adds forward and backward AD support for the `logcumsumexp` operator in functorch, a library for composable function transformations. It implements a forward-mode formula and a decomposition in `derivatives.yaml`, a C++ function for computing directional derivatives in `FunctionsManual.cpp`, and updates the tests and metadata in `test_ops.py` and `common_methods_invocations.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100629
Approved by: https://github.com/soulitzer
Summary:
Staging an update to the latest fmt version triggered lots of build errors due to non-`const` methods on custom formatters. This fixes the `format()` methods to be `const` as they don't mutate any state anyway, as well as `parse()` methods that don't need to mutate internal state. This mitigates many future build errors.
Updates were identified and executed by using regular expression search/replacements such as:
`(constexpr auto parse\(ParseContext& [^)]*\)) \{` -> `$1 const {`
`(constexpr auto parse\(ParseContext& [^)]*\)) ->` -> `$1 const ->`
`(auto format\(.*, FormatContext& [^)]*\)) \{` -> `$1 const {`
`(auto format\(.*, FormatContext& [^)]*\)) ->` -> `$1 const ->`
Any changes to third-party code was then reverted. Some small changes detected from subsequent build errors were then applied.
Test Plan: CI
Differential Revision: D45463620
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100616
Approved by: https://github.com/davidberard98
This PR conditionally inserts a cast operator after a reduction operation to match the specified dtype in the exported ONNX model. The code changes affect **opset9**, and **opset13**.
I understand there's an [automatic upcast to int64](c91a41fd68/torch/onnx/symbolic_opset9.py (L783)) before reduction most likely to prevent overflow so I left that alone and only conditionally add casting back to desired dtype.
## Test int32
```
import torch
import onnx
a = torch.tensor([10, 20, 30, 80], dtype=torch.int32)
def test():
class SumInt32(torch.nn.Module):
def forward(self, a):
return torch.sum(a, dtype=torch.int32)
sumi = SumInt32().eval()
assert sumi(a).dtype == torch.int32
print("Torch model output type matches input type")
torch.onnx.export(sumi, (a), "/tmp/sumi_int32.onnx", opset_version=12)
model = onnx.load("/tmp/sumi_int32.onnx")
assert model.graph.output[0].type.tensor_type.elem_type == onnx.TensorProto.INT32
print("ONNX model output type matches input type")
test()
```
## Test int64
```
import onnx
import torch
a = torch.tensor([10, 20, 30, 80], dtype=torch.int64)
def test():
class SumInt64(torch.nn.Module):
def forward(self, a):
return torch.sum(a, dtype=torch.int64)
sumi = SumInt64().eval()
assert sumi(a).dtype == torch.int64
print("Torch model output type matches input type")
torch.onnx.export(sumi, (a), "/tmp/sumi_int64.onnx", opset_version=12)
model = onnx.load("/tmp/sumi_int64.onnx")
assert model.graph.output[0].type.tensor_type.elem_type == onnx.TensorProto.INT64
print("ONNX model output type matches input type")
test()
```
Fixes https://github.com/pytorch/pytorch/issues/100097
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100700
Approved by: https://github.com/thiagocrepaldi
With the old partitioner, suppose `add` is supported, the following code
```python
def fn(a, b, c, d):
x = a + b # add
y = c + d # add_1
return (x, y)
traced = symbolic_trace(fn)
partitioner = CapabilityBasedPartitioner(traced, supported_ops, allows_single_node_partition=True)
partitions = partitioner.propose_partitions()
```
results in the partitions `[[add], [add_1]]`. However, since these two partitions do not depend on each other, they can be aggressively merged into a single partition `[[add, add_1]]` without causing any issues. This PR introduces a new feature that allows such aggressive merging by introducing an option `aggressive_merge` to the Partitioner class.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100195
Approved by: https://github.com/SherlockNoMad
i think get_reordered_tests broken since master -> main switch
add typing for some functions
checked for `prioritized` in the logs
limited testing because I only care about one very small part of the log thats near the beginning
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100752
Approved by: https://github.com/huydhn
This diff adds support for dynamic equality constraints of the form `dynamic_dim(x, 0) == dynamic_dim(y, 1)`. The process of constraint discovery can already understand equality guards between dimensions and suggests such equality constraints, so this closes the loop on that. Correspondingly we now raise `ConstraintViolation` when we find that such a guard is added on a dynamic dimension and the user did not specify such a constraint. (NOTE: This is distinct from a dynamic dimension being guarded equal to a constant, which is already an error.)
Differential Revision: [D45279437](https://our.internmc.facebook.com/intern/diff/D45279437/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99993
Approved by: https://github.com/tugsbayasgalan
There are known issues with profiling cuda graphs - particularly, if you create a cuda graph before the first use of the profiler, and then run that cuda graph during profiling.
One workaround is to add `with profile(): pass` before creating the cuda graph that you want to profile later.
For convenience, we provide this function to use the workaround. This also adads a test for this workaround, to ensure that it continues working.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100441
Approved by: https://github.com/Chillee, https://github.com/aaronenyeshi
This PR brings some updates and fixes in regards to PyT2.0 functionality
1 - ROCm's version of triton does not yet support tl.reduce
Until supported we are opting to revert the removal of the aten.prod make_fallback for ROCm brought in with 7a6c650b81
This issue was found locally with the latest aten.prod UTs on ROCm
```
FAILED [0.0916s] inductor/test_torchinductor.py::CudaTests::test_prod_cuda - torch._dynamo.exc.BackendCompilerFailed: backend='compile_fx_wrapper' raised:
AttributeError: module 'triton.language' has no attribute 'reduce'
```
2 - Adds aten.miopen_batch_norm as an explicit fallback as perf issues are observed when registered as a decomposition, setting warning=False as the fallback is expected
3 - Fixes a typo and redundant assignment in _inductor/triton_heuristics.py brought in with dd778a7610
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100089
Approved by: https://github.com/kit1980, https://github.com/pruthvistony, https://github.com/jithunnair-amd, https://github.com/malfet, https://github.com/jansel
use const_ and mutable_ data_ptr for much of torch/csrc/jit/runtime/static/ops.cpp
Summary:
We can't address the TEWrapper cases yet because it erases all
arguments to mutable void*.
Test Plan: Rely on CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100678
Approved by: https://github.com/ezyang
add a cast function that suppresses -Wcast-function-type-strict
Summary:
These casts are a necessary evil due to the design of Python. Python
ultimately casts it back to the original type based on the flags
specified in the PyMethodDef.
Nevertheless, the new Clang flag -Wcast-function-type-strict breaks
with this.
Test Plan: Passes builds with Clang 16.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100170
Approved by: https://github.com/ezyang
Summary:
Issue:
`torch._dynamo.exc.Unsupported: call_method ListVariable() copy [] {}`
Fix:
Add `copy()` to "method_call" to _dynamo/variables/lists.py
Take it over from #98184. To unblock a meta internal model onboarding to ExecuTorch.
Differential Revision: D45592416
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100669
Approved by: https://github.com/jansel
DataLoader supports batched loading from Mapped Datasets.
This is the fetcher's implementation of auto-detection of batch loading support.
torch.utils.data._utils.fetch._MapDatasetFetcher
```
class _MapDatasetFetcher(_BaseDatasetFetcher):
def fetch(self, possibly_batched_index):
if self.auto_collation:
if hasattr(self.dataset, "__getitems__") and self.dataset.__getitems__:
data = self.dataset.__getitems__(possibly_batched_index)
else:
data = [self.dataset[idx] for idx in possibly_batched_index]
```
Description of Dataset API now shows this feature.
Additionally, Subset dataset now supports `__getitems__` if parent dataset supports it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100375
Approved by: https://github.com/ejguan, https://github.com/NivekT
We do it by making it possible to register multiple tensors for the same
worker and coordinate waiting/cleanup among them.
This ensures waiting on any number the output tensors will result in a
single stream sync. This simplifies codegen by inductor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99763
Approved by: https://github.com/wanchaol
**Summary**
Lowering of [`max_pool2d` ](https://github.com/pytorch/pytorch/blob/main/torch/_inductor/lowering.py#L2732) will check the `num_reads` of input `StorageBox.data`. When num of reads is larger than 1, input of `StorageBox` will invoke `realize` and break the loop fusion with previous node. The previous node could be `decomposed.dequant_per_tensor.tensor` in quantization use case. For `decomposed.dequant_per_tensor.tensor`, it has 3 num of reads. But 2 of these 3 num of reads are scalar tensors as `zero point` and `scale`. In this PR, we try to relax the criterion for `StorageBox.realize`. Specifically, when the input is an instance of `Pointwise`, we will also check the number of non scalar tensor's read, and only invoke `StorageBox.realize` when the number of non scalar tensor's read is also larger than 1. It helps enable the loop fusion and vec code gen of pattern `decomposed.dequant_per_tensor.tensor - max_pool2d`.
**Test Plan**
```
cd test/inductor && python -m pytest test_cpu_repro.py -k test_dequant_maxpool2d_lowering
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99132
Approved by: https://github.com/jgong5, https://github.com/jansel
When minifying extremely large repros, the minifier can run out of memory. This is because, for delta debugging, the minifier keeps a copy of every intermediate output in the network. This can easily put you over the memory limit for your GPU. To make matters worse, we cannot easily delta debug in such a situation, as delta debugging involves replacing intermediates with inputs, but doing so can cause an intermediate to become live longer than its actual extent in the original model (since inputs all have to be allocated up front).
The strategy in this PR is to use `load_tensor` from the previous PR to offer a low memory mode for delta debugging. Instead of putting intermediates as inputs, we instead load them in the middle of the graph in question. If, through DCE, the load_tensor ends up floating to the top of the graph, we can input-ify it. We now no longer save all intermediates in memory, but instead save them to disk. I used this to successfully minify the repro that helped us solve https://github.com/pytorch/pytorch/pull/100332
The testing is not very good. I can try to add more robust testing but it will involve a more involved refactor to FX minifier. Let me know if that's what you want.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100546
Approved by: https://github.com/anijain2305, https://github.com/voznesenskym
This adds a new operator debugprims::load_storage which does the unusual thing of loading a tensor from disk (via ContentStoreReader). This will be used in a later PR to implement delta debugging in the minifier, even when the repro is too big to fit into memory. The way it works is that you specify a name of the tensor you want to load, as well as enough metadata to reconstruct the tensor, if the store isn't available. If there is an active content store, we read and return the tensor from that store; otherwise we use `rand_strided` to create it.
I needed some infra improvements to do this:
* `custom_op` now supports factory functions. Factory functions have to be registered specially via `impl_factory`
* I modified `clone_input` to also support dtype conversion, which I use to change the dtype of a loaded tensor if necessary.
* ContentStore needs to work with a device argument, so we torch.load directly to the correct device. This is for fake tensor support.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100519
Approved by: https://github.com/zou3519, https://github.com/anijain2305
Summary: This commit makes two improvements to the existing
test for Conv + BN fusion in `prepare_qat_pt2e`:
(1) Test `per_tensor_symmetric` in addition to `per_channel_symmetric`
(2) Initialize BN stats the same way in both flows. This is
necessary to get the `per_tensor_symmetric` case to pass.
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_prepare_qat_conv_bn_numerics
Reviewers: jerryzh168, kimishpatel
Differential Revision: [D45512851](https://our.internmc.facebook.com/intern/diff/D45512851)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100271
Approved by: https://github.com/jerryzh168
Opening this so I can discuss with @albanD
I built a proof of concept of an in place API for an nn.Module that allows us to save and load a torch.compiled model with no issues https://github.com/msaroufim/mlsys-experiments/blob/main/save-compiled-model.py
So users can run` model.compile()` and then run `torch.save(model, "model.pt")` and `torch.load(model, "model.pt)` with no issues unlike the rather strange current suggestion we give to users which is `opt_mod = torch.compile(mod); torch.save(mod, "model.pt")`
Right now I'm trying to extend this to work for nn.modules more generally
TODO: Failing tests
* [x] torch.jit.load -> issue was because of aliasing `__call__` to `_call_impl`, _call_impl used to be skipped when now it lo longer is so expanded the skip check. I added an explicit `torch.jit.load()` test now which @davidberard98 suggested
* [x] functorch seems to be a flake - ran locally and it worked `pytest functorch/test_eager_transforms.py`
* [x] a test infra flake - `test_testing.py::TestImports::test_no_mutate_global_logging_on_import_path_functorch`
* [x] It seems like I broke inlining in dynamo though `python -m pytest test/dynamo/test_dynamic_shapes.py -k test_issue175` chatting with Voz about it but still not entirely sure how to fix - found a workaround after chatting with @yanboliang
* [x] `pytest test/dynamo/test_modules.py` and `test/dynamo/test_dynamic_shapes` `test/dynamo/test_misc.py` seem to be failing in CI but trying it out locally they all pass tests passed with 0 failures
* [x] `pytest test/profiler/test_profiler_tree.py ` these tests have ProfilerTrees explicitly printed and will now break if __call__ is not in tree - ran with `EXPECT_ACCEPT=1`
* [x] `pytest test/test_torch.py::TestTorch::test_typed_storage_deprecation_warning` a flake, ran this locally and it works fine
* [x] I reverted my changes to `_dynamo/nn_module.py` since it looks like @wconstab is now directly handling `_call_impl` there but this is triggering an infinite inlining which is crashing
* [x] Tried out to instead override `__call__`, python doesnt like this though https://github.com/pytorch/pytorch/pull/97565#issuecomment-1524570439
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97565
Approved by: https://github.com/aaronenyeshi, https://github.com/albanD, https://github.com/voznesenskym
Add helpful context message to `NotImplementedError`'s thrown by Dataset and IterableDataset, reminding users that they must implement `__getitem__`/`__iter__` in subclasses. Currently, users are presented with a bare `NotImplementedError` without describing the remedy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100667
Approved by: https://github.com/NivekT
…fused_attention
This allows all the tests in test_fused_attention to succeed when run together, otherwise replacements are registered without proper config set, and thus some tests fail and succeed only on rerun. This is also confusing when running full file locally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100506
Approved by: https://github.com/drisspg
Per the discussion with @malfet , there is no need to run Windows binary build for every PR. We will keep it running in trunk (on push) though just in case.
This also moves the workflow back from unstable after the symlink copy fix in 860d444515
Another data point to back this up is the high correlation between Windows binaries debug and release build v.s. Windows CPU CI job. The numbers are:
* `libtorch-cpu-shared-with-deps-debug` and `win-vs2019-cpu-py3` has 0.95 correlation
* `libtorch-cpu-shared-with-deps-release` and `win-vs2019-cpu-py3` has the same 0.95 correlation
The rest is noise, eh?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100638
Approved by: https://github.com/atalman
Fixes #ISSUE_NUMBER
Add the serialization logic of backend metadata to the serialization of tensor, which is implemented through custom registration functions.
In #97429 , the structure backendMeta is provided in TensorImpl, and we think that this part of information may also need to be serialized for custom.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99808
Approved by: https://github.com/ezyang
- Enable event and interval-based os signpost tracing via env-var 'PYTORCH_MPS_TRACE_SIGNPOSTS' (python bindings sent in separate PR).
- Enable logging of MPS graphs, native kernels, and copies and their GPU times via env-var `PYTORCH_MPS_LOG_PROFILE_INFO`.
- Enable dumping the table of kernel profiling results sorted based on Mean GPU time when the process ends (SIGINT also handled).
- Fix a bug in MPSAllocator where the Allocator completionHandlers were called after MPSAllocator instance was destroyed.
- Added option to use Schedule Handlers to begin signpost intervals.
- Refer to comments in `MPSProfiler.h` to learn how to set env-vars for logging and signpost tracing. Proper documentation will be sent in a separate PR later.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100635
Approved by: https://github.com/kulinseth
Opening this so I can discuss with @albanD
I built a proof of concept of an in place API for an nn.Module that allows us to save and load a torch.compiled model with no issues https://github.com/msaroufim/mlsys-experiments/blob/main/save-compiled-model.py
So users can run` model.compile()` and then run `torch.save(model, "model.pt")` and `torch.load(model, "model.pt)` with no issues unlike the rather strange current suggestion we give to users which is `opt_mod = torch.compile(mod); torch.save(mod, "model.pt")`
Right now I'm trying to extend this to work for nn.modules more generally
TODO: Failing tests
* [x] torch.jit.load -> issue was because of aliasing `__call__` to `_call_impl`, _call_impl used to be skipped when now it lo longer is so expanded the skip check. I added an explicit `torch.jit.load()` test now which @davidberard98 suggested
* [x] functorch seems to be a flake - ran locally and it worked `pytest functorch/test_eager_transforms.py`
* [x] a test infra flake - `test_testing.py::TestImports::test_no_mutate_global_logging_on_import_path_functorch`
* [x] It seems like I broke inlining in dynamo though `python -m pytest test/dynamo/test_dynamic_shapes.py -k test_issue175` chatting with Voz about it but still not entirely sure how to fix - found a workaround after chatting with @yanboliang
* [x] `pytest test/dynamo/test_modules.py` and `test/dynamo/test_dynamic_shapes` `test/dynamo/test_misc.py` seem to be failing in CI but trying it out locally they all pass tests passed with 0 failures
* [x] `pytest test/profiler/test_profiler_tree.py ` these tests have ProfilerTrees explicitly printed and will now break if __call__ is not in tree - ran with `EXPECT_ACCEPT=1`
* [x] `pytest test/test_torch.py::TestTorch::test_typed_storage_deprecation_warning` a flake, ran this locally and it works fine
* [x] I reverted my changes to `_dynamo/nn_module.py` since it looks like @wconstab is now directly handling `_call_impl` there but this is triggering an infinite inlining which is crashing
* [x] Tried out to instead override `__call__`, python doesnt like this though https://github.com/pytorch/pytorch/pull/97565#issuecomment-1524570439
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97565
Approved by: https://github.com/aaronenyeshi, https://github.com/albanD
TORCH_INTERNAL_ASSERT_DEBUG_ONLY won't be enabled during non-debug builds, but for 1 dimension Tensors the check is cheap enough and not catching this can slow down development a lot.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100596
Approved by: https://github.com/drisspg
Description:
- Fixed a bug with memory format issue:
When input is channels last 4d tensor that was produced as following
```
t = torch.ones(1, 3, 32, 32).contiguous(memory_format=torch.channels_last)
t = t[0]
t = t[None, ...]
```
upsampling will produce output with channels first memory format but our avx code does not take that into account.
Here is a repro code to show that nightly is broken for this particular case:
```python
import torch
torch.manual_seed(0)
input = torch.randint(0, 256, size=(1, 3, 256, 256), dtype=torch.uint8).contiguous(memory_format=torch.channels_last)
input = input[0]
input = input[None, ...]
assert input.is_contiguous(memory_format=torch.channels_last)
output = torch.nn.functional.interpolate(input, (224, 224), mode="bilinear", antialias=True)
expected = torch.nn.functional.interpolate(input.float(), (224, 224), mode="bilinear", antialias=True)
assert output.is_contiguous()
assert expected.is_contiguous()
torch.testing.assert_close(expected, output.float(), atol=1, rtol=1)
# >
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# File "/pytorch/torch/testing/_comparison.py", line 1511, in assert_close
# raise error_metas[0].to_error(msg)
# AssertionError: Tensor-likes are not close!
#
# Mismatched elements: 14120 / 150528 (9.4%)
# Greatest absolute difference: 214.6112518310547 at index (0, 1, 152, 13) (up to 1 allowed)
# Greatest relative difference: 17.005144119262695 at index (0, 2, 26, 2) (up to 1 allowed)
```
- Also renamed needs_unpacking by skip_unpacking
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100258
Approved by: https://github.com/NicolasHug
Fixes#99879
This adds `minimum_with_index` helper functions to compute the minimum
value and index simultaneously, with a preference for the smaller
index which is required to match eager in case of duplicates.
I also remove the mask-and-sum hack with a `tl.reduce` using
the previously mentioned helper. This additionally fixes the indices
being added together in the case of duplicates.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100573
Approved by: https://github.com/ngimel
This adds helpers that replace tritons `minimum`, `maximum`, `min` and
`max` with the correct NaN prrpagation. I also removed
`ops.int_minimum` in favor of `ops.minimum` because we can just omit
the nan-checks by checking the dtype.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100572
Approved by: https://github.com/ngimel
This PR:
- Adds `floordiv` and `truncdiv` as they were missing
- Maps `div` to its correct definition (it was being mapped to `floordiv`)
- Simplifies the bounds of `floordiv`
- Fixes some issues with the returned types of `floor` `ceil`
- Adds tests for the previous point
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100547
Approved by: https://github.com/ezyang
Stable Diffusion has a pattern like this:
```
def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, **cross_attention_kwargs):
# The `Attention` class can call different attention processors / attention functions
# here we simply pass along all tensors to the selected processor class
# For standard processors that are defined here, `**cross_attention_kwargs` is empty
return self.processor(
self,
hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
```
Wherein processor is something like `AttnProcessor2_0`, which is callable but not an NNModule.
This allows for a significant speedup in stable diffusion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100444
Approved by: https://github.com/anijain2305
The changes:
* Add config knob `same_two_models_use_fp64` for toggling whether or not to use fp64
* Add a test showing that RMSE is superior to atol/rtol
* Add `--strict-accuracy` options, which allows for testing against integral/boolean accuracy. Regular accuracy by default now ONLY. There's a test which exercises this, it's a little delicate but I had trouble thinking of a good test otherwise.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100447
Approved by: https://github.com/voznesenskym
Summary: with the new c10d API, we don't need all ranks to call new_group. Integrate with the new API, so that every rank just call new_group 3 times, with a local barrier with the members within the group.
Reviewed By: xunnanxu, eeggl
Differential Revision: D45315615
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100518
Approved by: https://github.com/kumpera
This fixes a few reference counting bugs in eval_frame.c, simplifies a few functions a bit, and adds a few missing error handling code paths. Probably the only important reference counting bug is that `call_callback` previously leaked `THPPyInterpreterFrame` in Python 3.11+.
Summary below:
- eval_frame_callback_get shouldn't incref Py_None
- Don't leak THPPyInterpreterFrame in Python 3.11+
- set_profiler_hooks would decref profiler_start_hook and profiler_end_hook too many times if called with None as an argument (but we never actually used that code path).
- Simplify some argument parsing
- Only create guard_profiler_name_str once
- Add a few missing error checks
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100496
Approved by: https://github.com/albanD
Fixes #ISSUE_NUMBER
1、add checkpoint support for custom device
2、add a device argument, I want to add a device="cuda" parameter to the func `forward` of `CheckpointFunction`, and I can specify the device type when using it, but the func `apply` of `torch.autograd.Function` does not support `kwargs`, so I added a variable named `_device`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99626
Approved by: https://github.com/soulitzer
On Windows, both '/' and '\\' can be used as a path separator, so `StripBasename` should handle them as path separators.
`StripBasename` is used in the `is_enabled` function in `torch\csrc\jit\jit_log.cpp`
Therefore, without this pull request, is_enabled does not work properly on Windows.
For more details, please refer to the issue #98145.
Fixes#98145
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98146
Approved by: https://github.com/ezyang
Summary
- Previously this was required by and entangled with `tracing_mode=symbolic` for `dynamic` tracing.
That is resolved by #99555 and its follow ups.
- Later decomposition pass will do graph lowering, so this step is duplicated.
- Updated `Functionalization` to workaround https://github.com/pytorch/pytorch/issues/99774#issuecomment-1527949391
Todo
- Training vs eval in dynamo_export
So we are effectively exporting all models in traning mode by
default. But for the sake of this export we are only interested in eval mode.
The question is, should we call `model.eval()` in `dynamo_export`?
Tests with model containing batch norm fails 'functionalization' in training mode.
We are explicitly calling `model.eval()` for these model for now.
- Merge decomp and functionalize pass. Both calls into `make_fx`.
Merging potentially increases performance. However it is unclear
if it will result in different behavior.
Fixes#99662. (For the functionalization issue. Still need missing op support.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99667
Approved by: https://github.com/titaiwangms
Fixes#99564
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at c21d056</samp>
This pull request adds input validation and error handling tests for the `dot` and `vdot` operations in the `mps` namespace, using a new helper function and a new test function. This enhances the MPS backend and the testing framework for these operations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100099
Approved by: https://github.com/albanD, https://github.com/malfet
Added helper functions to match nodes in the graph that are decomposed from their source (leaf modules, or functional ops), as a result of dynamo tracing.
`get_source_partitions(graph: torch.fx.Graph, wanted_sources: List[Any]) -> Dict[Any, SourcePartition]`
Args:
* graph: The graph we want to partition
* wanted_sources: List of sources of nodes that were decomposed from this source. This can be a function (ex. torch.nn.functional.linear) or a leaf module type (ex. torch.nn.Linear)
Returns:
* Dictionary mapping sources (ex. torch.nn.modules.linear.Linear) to a list of SourcePartitions that correspond to the list of nodes that were flattened from a module of that type.
```
@dataclass
class SourcePartition():
# Nodes in a particular partition
nodes: List[Node]
# Module type
module_type: Type
# Nodes in the graph that are needed as inputs to the partition
input_nodes: List[Node] = field(default_factory=list)
# Nodes in the partition that are being used by nodes outside of the partition
output_nodes: List[Node] = field(default_factory=list)
# Parameters that are being used
params: List[str] = field(default_factory=list)
```
Example:
Original:
```
x -> linear -> linear -> relu -> linear
```
Traced graph:
```
.graph():
%arg0 : [#users=1] = placeholder[target=arg0]
%_param_constant0 : [#users=1] = get_attr[target=_param_constant0]
%t_default : [#users=1] = call_function[target=torch.ops.aten.t.default](args = (%_param_constant0,), kwargs = {})
%_param_constant1 : [#users=1] = get_attr[target=_param_constant1]
%addmm_default : [#users=1] = call_function[target=torch.ops.aten.addmm.default](args = (%_param_constant1, %arg0, %t_default), kwargs = {})
%_param_constant0_1 : [#users=1] = get_attr[target=_param_constant0]
%t_default_1 : [#users=1] = call_function[target=torch.ops.aten.t.default](args = (%_param_constant0_1,), kwargs = {})
%_param_constant1_1 : [#users=1] = get_attr[target=_param_constant1]
%addmm_default_1 : [#users=1] = call_function[target=torch.ops.aten.addmm.default](args = (%_param_constant1_1, %addmm_default, %t_default_1), kwargs = {})
%relu_default : [#users=1] = call_function[target=torch.ops.aten.relu.default](args = (%addmm_default_1,), kwargs = {})
%_param_constant2 : [#users=1] = get_attr[target=_param_constant2]
%t_default_2 : [#users=1] = call_function[target=torch.ops.aten.t.default](args = (%_param_constant2,), kwargs = {})
%_param_constant3 : [#users=1] = get_attr[target=_param_constant3]
%addmm_default_2 : [#users=1] = call_function[target=torch.ops.aten.addmm.default](args = (%_param_constant3, %relu_default, %t_default_2), kwargs = {})
return [addmm_default_2]
```
Result of `get_module_partitions`:
```
{<class 'torch.nn.modules.linear.Linear'>: [
ModulePartition(nodes=[_param_constant0, t_default, _param_constant1, addmm_default], module_type=<class 'torch.nn.modules.linear.Linear'>, input_nodes=[arg0], output_nodes=[addmm_default], params=["_param_constant0", "_param_constant1"]),
ModulePartition(nodes=[_param_constant0_1, t_default_1, _param_constant1_1, addmm_default_1], module_type=<class 'torch.nn.modules.linear.Linear'>, input_nodes=[addmm_default], output_nodes=[addmm_default_1], params=["_param_constant0_1", "_param_constant1_1"]),
ModulePartition(nodes=[_param_constant2, t_default_2, _param_constant3, addmm_default_2], module_type=<class 'torch.nn.modules.linear.Linear'>, input_nodes=[relu_default], output_nodes=[addmm_default_2], params=["_param_constant2", "_param_constant3"])],
<class 'torch.nn.modules.activation.ReLU'>: [
ModulePartition(nodes=[relu_default], module_type=<class 'torch.nn.modules.activation.ReLU'>, input_nodes=[addmm_default_1], output_nodes=[relu_default], params=[])]}
```
Also added helper function to check if two module partitions are connected:
`check_subgraphs_connected(subgraph1: SourcePartition, subgraph2: SourcePartition) -> bool`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98628
Approved by: https://github.com/cccclai
Original PR #99988
The problem was that we added `wrap` to torch._ops which actually puts
it on `torch.ops.wrap` which is a namespace that can be open-registered
to. The fix is that we now shove `wrap` into a new file
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100544
Approved by: https://github.com/voznesenskym
Now that we have updated all internal callsites, per https://fb.workplace.com/groups/pytorch.oss.dev/permalink/1635183750239493/ we should raise a warning when use_reentrant is not explicitly passed for 2.1
Deprecation note:
- Not passing in use_reentrant explicitly is now deprecated and will raise a warning. In the future the default value of use-reentrant will be False. To preserve the existing behavior you can pass in use_reentrant=True. It is recommended that you use use_reentrant=False.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100551
Approved by: https://github.com/Skylion007
pytest rewrites Python assert statements in unit tests to provide more detailed error messages. Unfortunately, this breaks some dynamo tests. Disable AST rewriting in test_export.py so that "pytest test/dynamo/test_export.py" passes.
Fixes#93449
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100484
Approved by: https://github.com/tugsbayasgalan
Fixes comment error in TensorIterator.cpp
I believe there is an error in the comment, based on the following code snippet
```c++
if (shape0 * stride[dim0] != stride[dim1]) {
return false;
}
```
I have corrected the comment accordingly. Please let me know if any further action is required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100227
Approved by: https://github.com/kit1980
Description:
- As suggested by Nikita, created `torch.backends.cpu` submodule and exposed `get_cpu_capability`.
- In torchvision Resize method we want to know current cpu capability in order to pick appropriate codepath depending on cpu capablities
Newly coded vectorized resize of uint8 images on AVX2 supported CPUs is now faster than older way (uint8->float->resize->uint8). However, on non-avx hardware (e.g. Mac M1) certain configs are slower using native uint8.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100164
Approved by: https://github.com/albanD, https://github.com/malfet
Summary:
This diff is reverting D45387167
D45387167: Basic dynamo support for traceable collectives (#94440) by wconstab has been identified to be causing the following test or build failures (internal)
If you believe this diff has been generated in error you may Commandeer and Abandon it.
Test Plan: NA
Reviewed By: s4ayub
Differential Revision: D45448312
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100424
Approved by: https://github.com/rohan-varma, https://github.com/kumpera
This is reopening of the PR https://github.com/pytorch/pytorch/pull/100377
# About this PR
Due to increased pressure over our windows runners, and the elevated cost of instantiating and bringing down those instances, we want to migrate instances from ephemeral to not ephemeral.
Possible impacts are related to breakages in or misbehaves on CI jobs that puts the runners in a bad state. Other possible impacts are related to exhaustion of resources, especially disk space, but memory might be a contender, as CI trash piles up on those instances.
As a somewhat middle of the road approach to this, currently nonephemeral instances are stochastically rotated as older instances get higher priority to be terminated when demand is lower.
Instances definition can be found here: https://github.com/pytorch/test-infra/pull/4072
This is a first in a multi-step approach where we will migrate away from all ephemeral windows instances and follow the lead of the `windows.g5.4xlarge.nvidia.gpu` in order to help reduce queue times for those instances. The phased approach follows:
* migrate `windows.4xlarge` to `windows.4xlarge.nonephemeral` instances under `pytorch/pytorch`
* migrate `windows.8xlarge.nvidia.gpu` to `windows.8xlarge.nvidia.gpu.nonephemeral` instances under `pytorch/pytorch`
* submit PRs to all repositories under `pytorch/` organization to migrate `windows.4xlarge` to `windows.4xlarge.nonephemeral`
* submit PRs to all repositories under `pytorch/` organization to migrate `windows.8xlarge.nvidia.gpu` to `windows.8xlarge.nvidia.gpu.nonephemeral`
* terminate the existence of `windows.4xlarge` and `windows.8xlarge.nvidia.gpu`
* evaluate and start the work related to the adoption of `windows.g5.4xlarge.nvidia.gpu` to replace `windows.8xlarge.nvidia.gpu.nonephemeral` in other repositories and use cases (proposed by @huydhn)
The reasoning for this phased approach is to reduce the scope of possible contenders to investigate in case of misbehave of particular CI jobs.
# Copilot Summary
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 579d87a</samp>
This pull request migrates some windows workflows to use `nonephemeral` runners for better performance and reliability. It also adds support for new Python and CUDA versions for some binary builds. It affects the following files: `.github/templates/windows_binary_build_workflow.yml.j2`, `.github/workflows/generated-windows-binary-*.yml`, `.github/workflows/pull.yml`, `.github/actionlint.yaml`, `.github/workflows/_win-build.yml`, `.github/workflows/periodic.yml`, and `.github/workflows/trunk.yml`.
# Copilot Poem
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 579d87a</samp>
> _We're breaking free from the ephemeral chains_
> _We're running on the nonephemeral lanes_
> _We're building faster, testing stronger, supporting newer_
> _We're the non-ephemeral runners of fire_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100377
Approved by: https://github.com/huydhn, https://github.com/malfet, https://github.com/atalman
(cherry picked from commit 7caac545b1d8e5de797c9593981c9578685dba81)
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100548
Approved by: https://github.com/jeanschmidt, https://github.com/janeyx99
# Summary
Preivously we disallowd dis-contiguous NTs to passed into to empty_like. This was done out of an abundance of caution, :think:. However it should be safe to create an empty NT for dis-contiguous NTs. Empty like does account for offsets, strides, and sizes in construction of the result and therefore this should be safe.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98383
Approved by: https://github.com/cpuhrsch
This PR enables sum tests for sparse sample inputs. Previously, the tests existed but were never run because the sum OpInfo instance was created without specifying `supports_sparse_*=True`. To avoid such mistakes in the future, the following PR https://github.com/pytorch/pytorch/pull/100392 enables the `supports_sparse_*` flags automatically when OpInfo creation specifies `sample_inputs_sparse_*_func`.
In addition, the PR applies several fixes to sum tests for sparse sample inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100391
Approved by: https://github.com/cpuhrsch
DTensor was reusing `einop_rule` to propagate sharding for torch.cat.
However, einsum only supports up to 52 subscripts (i.e., input tensors).
We have encountered use cases where one cat operator has more than 60
input tensors. Therefore, this commit reimplements sharding prop
rule for cat without using einsum.
Differential Revision: [D45435232](https://our.internmc.facebook.com/intern/diff/D45435232)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100251
Approved by: https://github.com/wanchaol
Follow up after https://github.com/pytorch/pytorch/pull/100436 to disable download.pytorch.org access over ipv6 access problems.
Why not copy `/etc/hosts` from host to the container? Because it would break container ip resolution in distributed tests, that relies on `socket.gethostbyname(socket.gethostname())` to work.
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 756d0b1</samp>
Propagate `download.pytorch.org` IP address to docker containers in `test-pytorch-binary` action and workflow. This fixes DNS issues when downloading PyTorch binaries inside the containers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100475
Approved by: https://github.com/huydhn
This is reopening of the PR [100091](https://github.com/pytorch/pytorch/pull/100091)
# About this PR
Due to increased pressure over our windows runners, and the elevated cost of instantiating and bringing down those instances, we want to migrate instances from ephemeral to not ephemeral.
Possible impacts are related to breakages in or misbehaves on CI jobs that puts the runners in a bad state. Other possible impacts are related to exhaustion of resources, especially disk space, but memory might be a contender, as CI trash piles up on those instances.
As a somewhat middle of the road approach to this, currently nonephemeral instances are stochastically rotated as older instances get higher priority to be terminated when demand is lower.
Instances definition can be found here: https://github.com/pytorch/test-infra/pull/4072
This is a first in a multi-step approach where we will migrate away from all ephemeral windows instances and follow the lead of the `windows.g5.4xlarge.nvidia.gpu` in order to help reduce queue times for those instances. The phased approach follows:
* migrate `windows.4xlarge` to `windows.4xlarge.nonephemeral` instances under `pytorch/pytorch`
* migrate `windows.8xlarge.nvidia.gpu` to `windows.8xlarge.nvidia.gpu.nonephemeral` instances under `pytorch/pytorch`
* submit PRs to all repositories under `pytorch/` organization to migrate `windows.4xlarge` to `windows.4xlarge.nonephemeral`
* submit PRs to all repositories under `pytorch/` organization to migrate `windows.8xlarge.nvidia.gpu` to `windows.8xlarge.nvidia.gpu.nonephemeral`
* terminate the existence of `windows.4xlarge` and `windows.8xlarge.nvidia.gpu`
* evaluate and start the work related to the adoption of `windows.g5.4xlarge.nvidia.gpu` to replace `windows.8xlarge.nvidia.gpu.nonephemeral` in other repositories and use cases (proposed by @huydhn)
The reasoning for this phased approach is to reduce the scope of possible contenders to investigate in case of misbehave of particular CI jobs.
# Copilot Summary
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 579d87a</samp>
This pull request migrates some windows workflows to use `nonephemeral` runners for better performance and reliability. It also adds support for new Python and CUDA versions for some binary builds. It affects the following files: `.github/templates/windows_binary_build_workflow.yml.j2`, `.github/workflows/generated-windows-binary-*.yml`, `.github/workflows/pull.yml`, `.github/actionlint.yaml`, `.github/workflows/_win-build.yml`, `.github/workflows/periodic.yml`, and `.github/workflows/trunk.yml`.
# Copilot Poem
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 579d87a</samp>
> _We're breaking free from the ephemeral chains_
> _We're running on the nonephemeral lanes_
> _We're building faster, testing stronger, supporting newer_
> _We're the non-ephemeral runners of fire_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100377
Approved by: https://github.com/huydhn, https://github.com/malfet, https://github.com/atalman
This diff locks in C++17 as the minimum standard with which PyTorch can be compiled.
This makes it possible to use all C++17 features in PyTorch.
This breaks backward compatibility in the sense that users with older compilers may find their compilers no longer are sufficient for the job.
Summary: #buildmore
Differential Revision: D44356879
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98209
Approved by: https://github.com/ezyang, https://github.com/malfet, https://github.com/PaliC
Bumps windows CPU tests to trunk.yml (retaining build in pull.yml), this
also bumps the cuda tests to periodic.yml (retaining build in
trunk.yml).
Hopefully this change will rein in windows spending on AWS since it is
currently our costliest platform (in terms of dollar amount / hours used)
Signed-off-by: Eli Uriegas <eliuriegas@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100478
Approved by: https://github.com/kit1980, https://github.com/huydhn
Hi!
I've been fuzzing different pytorch modules, and found a crash inside one of them.
Specifically, I'm talking about a module for unpickling and a function called `Unpickler::readInstruction()`. Running this function with provided crash file results in a crash, which occurs while calling `auto dict = stack_.at(dict_pos).toGenericDict();` [unpickler.cpp:561](0e94fbc0c8/torch/csrc/jit/serialization/unpickler.cpp (L561)). The crash occurs, because the index `dict_pos` is out of bounds (which itself happens because the stack size is 0).
Besides this pull-request, there is another one related to unpickler hardening: https://github.com/pytorch/pytorch/pull/84343
All tests were performed on this pytorch version: [abc54f93145830b502400faa92bec86e05422fbd](abc54f9314)
### How to reproduce
1. To reproduce the crash, use provided docker: [Dockerfile](https://github.com/ispras/oss-sydr-fuzz/tree/master/projects/pytorch)
2. Build the container: `docker build -t oss-sydr-fuzz-pytorch-reproduce .`
3. Copy crash file to the current directory:
- [crash-042dff5e121580425d9d34d0f293918f3c9fbf1e.zip](https://github.com/pytorch/pytorch/files/10674361/crash-042dff5e121580425d9d34d0f293918f3c9fbf1e.zip)
4. Run the container: ``docker run --privileged --network host -v `pwd`:/homedir --rm -it oss-sydr-fuzz-pytorch-reproduce /bin/bash``
5. And execute the binary: `/message_deserialize_sydr /homedir/crash-042dff5e121580425d9d34d0f293918f3c9fbf1e`
After execution completes you will see this error message:
```txt
terminate called after throwing an instance of 'std::out_of_range'
what(): vector::_M_range_check: __n (which is 18446744073709551613) >= this->size() (which is 0)
```
And this stacktrace:
```asan
erminate called after throwing an instance of 'std::out_of_range'
what(): vector::_M_range_check: __n (which is 18446744073709551613) >= this->size() (which is 0)
==39== ERROR: libFuzzer: deadly signal
#0 0x5d0df1 in __sanitizer_print_stack_trace /llvm-project/compiler-rt/lib/asan/asan_stack.cpp:87:3
#1 0x545727 in fuzzer::PrintStackTrace() /llvm-project/compiler-rt/lib/fuzzer/FuzzerUtil.cpp:210:5
#2 0x52b933 in fuzzer::Fuzzer::CrashCallback() /llvm-project/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:233:3
#3 0x7f9118e0341f (/lib/x86_64-linux-gnu/libpthread.so.0+0x1441f)
#4 0x7f9118c2300a in raise (/lib/x86_64-linux-gnu/libc.so.6+0x4300a)
#5 0x7f9118c02858 in abort (/lib/x86_64-linux-gnu/libc.so.6+0x22858)
#6 0x7f9119040910 (/lib/x86_64-linux-gnu/libstdc++.so.6+0x9e910)
#7 0x7f911904c38b (/lib/x86_64-linux-gnu/libstdc++.so.6+0xaa38b)
#8 0x7f911904c3f6 in std::terminate() (/lib/x86_64-linux-gnu/libstdc++.so.6+0xaa3f6)
#9 0x7f911904c6a8 in __cxa_throw (/lib/x86_64-linux-gnu/libstdc++.so.6+0xaa6a8)
#10 0x7f91190433aa (/lib/x86_64-linux-gnu/libstdc++.so.6+0xa13aa)
#11 0x63acdf in std::vector<c10::IValue, std::allocator<c10::IValue> >::_M_range_check(unsigned long) const /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_vector.h:1073:4
#12 0xce8f93e in std::vector<c10::IValue, std::allocator<c10::IValue> >::at(unsigned long) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_vector.h:1094:2
#13 0xce8f93e in torch::jit::Unpickler::readInstruction() /pytorch_fuzz/torch/csrc/jit/serialization/unpickler.cpp:546:26
#14 0xce8d527 in torch::jit::Unpickler::run() /pytorch_fuzz/torch/csrc/jit/serialization/unpickler.cpp:235:27
#15 0xce8d1c2 in torch::jit::Unpickler::parse_ivalue() /pytorch_fuzz/torch/csrc/jit/serialization/unpickler.cpp:192:3
#16 0xcdf0792 in torch::jit::unpickle(std::function<unsigned long (char*, unsigned long)>, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)) /pytorch_fuzz/torch/csrc/jit/serialization/pickle.cpp:127:20
#17 0xcdf104d in torch::jit::unpickle(char const*, unsigned long, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)) /pytorch_fuzz/torch/csrc/jit/serialization/pickle.cpp:137:10
#18 0xe0532db in torch::distributed::rpc::ScriptRemoteCall::fromMessage(torch::distributed::rpc::Message const&) /pytorch_fuzz/torch/csrc/distributed/rpc/script_remote_call.cpp:74:16
#19 0xe0ffa10 in torch::distributed::rpc::deserializeRequest(torch::distributed::rpc::Message const&) /pytorch_fuzz/torch/csrc/distributed/rpc/utils.cpp:108:14
#20 0x602a41 in LLVMFuzzerTestOneInput /message_deserialize_fuzz.cc:192:27
#21 0x52ce61 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /llvm-project/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:611:15
#22 0x516d7c in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:324:6
#23 0x51cacb in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:860:9
#24 0x546062 in main /llvm-project/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10
#25 0x7f9118c04082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082)
#26 0x51169d in _start (/message_deserialize_fuzz+0x51169d)
NOTE: libFuzzer has rudimentary signal handlers.
Combine libFuzzer with AddressSanitizer or similar for better crash reports.
SUMMARY: libFuzzer: deadly signal
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94300
Approved by: https://github.com/malfet, https://github.com/apach301
Now that expandable_segments has been merged from OSS, we can enable it in the internal build. It still defaults to off, so this should not change any behavior changes in the allocator unless the flag is explicitly set.
Differential Revision: D45249535
Pull request resolved: https://github.com/pytorch/pytorch/pull/100184
Follow up after https://github.com/pytorch/pytorch/pull/100436 to disable download.pytorch.org access over ipv6 access problems.
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 55c9443</samp>
This pull request improves the network configuration of the test-pytorch-binary GitHub action and workflow by mounting the host's `/etc/hosts` file into the container. This enables the container to resolve hostname aliases consistently with the host machine.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100475
Approved by: https://github.com/huydhn
This PR introduces a `wrap(body_fn, *args)` higher order operator
The semantics of `wrap(body_fn, *args)` is to just run `body_fn(*args)`
Underneath Dynamo, this PR makes it so that we rewrite calls to
`wrap(body_fn, *args)` with `wrap(new_fn, *new_args)` where `new_fn` has
no free variables. This PR does not update cond/map to use the new
mechanism yet (we do not support nn.Modues yet, will come in the future).
The design we take is:
- OutputGraph represents the graph being built by Dynamo that may be
compiled and executed.
- OutputGraph owns a root SubgraphTracer, where it builds the FX graph.
- OutputGraph may own multiple nested SubgraphTracers.
- When we need to trace the body function of a HigherOrderOperator, we
construct a new SubgraphTracer to build the graph of the body function.
Mechanically, when Dynamo sees a new `wrap` HigherOrderOperator with a
body function, it:
- Creates a new SubgraphTracer via OutputGraph.new_subtracer
- Executes the body function
This captures the body function into the graph on the new
SubgraphTracer while modifying the state of the OutputGraph. For
example, the OutputGraph may receive new GraphArgs, new guards, and new
side effects.
If capture of the body function fails, then Dynamo graph breaks on the
HigherOrderOperator.
Test Plan:
- added test/dynamo/test_higher_order_ops.py
Future:
- We're not actually able to tell Dynamo to completely graph break on the
HigherOrderOperator. Instead, when we do graph break, Dynamo begins
introspecting `HigherOrderOperator.__call__`. It should probably not do
this.
- Ideally we would error out on new SideEffects. I don't know how to do
this yet.
- We don't support dealing with nn.Modules yet (e.g. calling nn.Modules
or accessing attributes of tracked nn.Modules from a body_fn). There's
an open question on what should actually happen here
- Ideally we would rewrite map/cond to use the new mechanism but we need
to fix the previous bullet point before we can get there.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99988
Approved by: https://github.com/voznesenskym, https://github.com/anijain2305
This PR splits OutputGraph into two classes:
- SubgraphTracer (handles FX-tracing)
- OutputGraph (handles Dynamo-specific output graph logic, like
tracking graph inputs, compiling the graph, and executing it).
The motivation behind this is in the next PR up in the stack.
TL;DR is: in order to do higher-order operators, we need nested
SubgraphTracer, one for each level of nesting of the higher-order
operators.
I'm happy to flatten the stack into a single PR, but this separate made
it easier for me to test. Lmk if you want the stack flattened.
Test Plan:
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99987
Approved by: https://github.com/anijain2305, https://github.com/voznesenskym
Previously, minifier testing injected faults by injecting extra code
into the repro scripts, and then ensuring this code got propagated to
all subsequent subprocess calls. This was not only quite complicated,
but also induced a big slowdown on the minifier, because to inject the
faults, you had to import torch._inductor, which would cause the
compilation threads to immediately get initialized before you even got
to do anything else in the repro script.
This new approach fixes this problem by incorporating the fault
injection into "prod" code. Essentially, for inductor fault injection
we introduce some new config flags that let you "configure" Inductor to
be buggy; for Dynamo fault injection we just permanently keep the buggy
testing backends registered. This is MUCH simpler: we only have to
propagate the buggy config (which is something we're already doing),
and it saves the minifier scripts from having to immediately initialize
inductor on entry.
Also, I enable the test for Triton runtime errors, now that tl.assert_device is here.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100357
Approved by: https://github.com/voznesenskym
Previously, due to the use of the Python set data structure, the ordering of saved values (and how they would appear in the graph) was unstable and changed across runs, making it hard to debug downstream applications. Here we use a dict (with insertion-ordering semantics) to deduplicate values in a way that preserves ordering
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100111
Approved by: https://github.com/Skylion007
Fixes#100314
In dependencies, we should track not only immediately used buffer, but also aliased buffers that point to it, otherwise we can reuse and overwrite the buffer while there are still pending uses.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100332
Approved by: https://github.com/jansel
Previously when using `self.assertRaisesRegex` to test raised exception and its regex, the regex wasn't actually compared because mps was not in the `NATIVE_DEVICES`. This PR fixes that by enabling exception regex comparisons for mps device.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100367
Approved by: https://github.com/albanD
During regular merge process, when `GitHubPR` object is created, it does not have `merging` label and when label is added it does not update existing `GitHubPR` object either
To fix the problem, call REST API wrapper `gh_remove_label` directly. Worst case that can happen, if label is already removed at this point, is that it will be printed to the stderr, which is not rendered on HUD anyway
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100433
Approved by: https://github.com/PaliC, https://github.com/kit1980
During regular merge process, `GitHubPR` and `GitHubRepo` objects are first created in main() and than re-created in `merge()` instead of being passed by reference, which results in making the same GraphQL requests to the repo twice
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at ee4e23e</samp>
> _Sing, O Muse, of the skillful coder who refactored_
> _The `merge` function, to accept a `GitHubPR` object,_
> _And thus reduced the calls to the divine API_
> _And the duplication of code, that source of errors._
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100434
Approved by: https://github.com/kit1980, https://github.com/PaliC, https://github.com/huydhn, https://github.com/ZainRizvi
Summary:
* `dynamo_export`, and everything within now access diagnostic context through a maintained local
variable, instead of global.
* Refactored `diagnose_call` decorator to require local diagnostic context, instead of accessing global.
* Modified `test_fx_to_onnx_*.py` tests to only log '*.sarif' logs when `verbose=True`.
* Temporarily removed diagnostics for `OnnxFunction`, as they don't have access to diagnostic context
anymore. These diagnostics will be the responsibility of `onnxscript`, and they will return once
diagnostics system is integrated there.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100219
Approved by: https://github.com/justinchuby
`ThreadFlowLocation`, a.k.a 'step', cannot fully be visualized by `SARIF vscode extension` today.
Discarding `diagnose_step` such that we don't end up creating diagnostics that record things there.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99944
Approved by: https://github.com/justinchuby
Summary
* Introduce `DiagnosticContext` to `torch.onnx.dynamo_export`.
* Remove `DiagnosticEngine` in preparations to update 'diagnostics' in `dynamo_export` to drop dependencies on global diagnostic context. No plans to update `torch.onnx.export` diagnostics.
Next steps
* Separate `torch.onnx.export` diagnostics and `torch.onnx.dynamo_export` diagnostics.
* Drop dependencies on global diagnostic context. https://github.com/pytorch/pytorch/pull/100219
* Replace 'print's with 'logger.log'.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99668
Approved by: https://github.com/justinchuby, https://github.com/abock
Follow the example I did for ONNX in https://github.com/pytorch/pytorch/pull/96793, this caches the pretrained `mobilenet_v2 model` and `mobilenet_v3_large` used by CI jobs. I think there might be an issue either with AWS or with the domain download.pytorch.org as the connection to the latter has been failing a lots in the past few days.
Related flaky jobs:
* https://github.com/pytorch/pytorch/actions/runs/4835873487/jobs/8618836446
* https://github.com/pytorch/pytorch/actions/runs/4835783539/jobs/8618404639
* https://github.com/pytorch/pytorch/actions/runs/4835783539/jobs/8618404639
```
Downloading: "https://download.pytorch.org/models/mobilenet_v2-b0353104.pth" to /var/lib/jenkins/.cache/torch/hub/checkpoints/mobilenet_v2-b0353104.pth
Traceback (most recent call last):
File "/opt/conda/envs/py_3.8/lib/python3.8/urllib/request.py", line 1354, in do_open
h.request(req.get_method(), req.selector, req.data, headers,
File "/opt/conda/envs/py_3.8/lib/python3.8/http/client.py", line 1256, in request
self._send_request(method, url, body, headers, encode_chunked)
File "/opt/conda/envs/py_3.8/lib/python3.8/http/client.py", line 1302, in _send_request
self.endheaders(body, encode_chunked=encode_chunked)
File "/opt/conda/envs/py_3.8/lib/python3.8/http/client.py", line 1251, in endheaders
self._send_output(message_body, encode_chunked=encode_chunked)
File "/opt/conda/envs/py_3.8/lib/python3.8/http/client.py", line 1011, in _send_output
self.send(msg)
File "/opt/conda/envs/py_3.8/lib/python3.8/http/client.py", line 951, in send
self.connect()
File "/opt/conda/envs/py_3.8/lib/python3.8/http/client.py", line 1418, in connect
super().connect()
File "/opt/conda/envs/py_3.8/lib/python3.8/http/client.py", line 922, in connect
self.sock = self._create_connection(
File "/opt/conda/envs/py_3.8/lib/python3.8/socket.py", line 808, in create_connection
raise err
File "/opt/conda/envs/py_3.8/lib/python3.8/socket.py", line 796, in create_connection
sock.connect(sa)
OSError: [Errno 99] Cannot assign requested address
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100302
Approved by: https://github.com/ZainRizvi
Summary: not sure how the train bool to batch_norm gets set. But its not the is_training module level flag. We get weird behavior for teams trying to do on device training because of this
Test Plan: ci
Differential Revision: D45335791
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100134
Approved by: https://github.com/larryliu0820
Fixes#99259 , drawing to attention that input is optional by putting a variation of the method signature at the top of the file and by modifying the input arguments.
Note that I'm not certain how to get the additional signature at the same level of indentation as the first one, but I think this change does a good job of highlighting the change is optional.
Would be happy to iterate on this if there are any issues.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99650
Approved by: https://github.com/mikaylagawarecki
When we run cudagraph trees we are not allowed to have permanent workspace allocations like in cublas because we might need to reclaim that memory for a previous cudagraph recording, and it is memory that is not accounted for in output weakrefs so it does not work with checkpointing. Previously, I would check that we didn't have any additional allocations through snapshotting. This was extremely slow so I had to turn it off.
This PR first does the quick checking to see if we are in an error state, then if we are does the slow logic of creating snapshot. Also turns on history recording so we get a stacktrace of where the bad allocation came from.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99985
Approved by: https://github.com/zdevito
This is an easy follow-up to the previous PR to (1) clarify that `view` is the original parameter's gradient and (2) that after `reshard()` the gradient is on CPU only if offloading parameters.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100359
Approved by: https://github.com/rohan-varma
This is a two part PR; I can split it if you really want me to.
The first part is a refactor of the after aot repro/minifier scripts to come with a command line interface. I maintain exact BC with the previous interface (so, e.g., you still get a repro.py and a run_minifier.py that do the same thing as before), but each of these scripts also take command line arguments now which you can use to customize what actually happens. Check `run_repro` for full documentation on the arguments.
The second part of this is an implementation of `analyze` subcommand on the new CLI for any repro.
<img width="1277" alt="image" src="https://user-images.githubusercontent.com/13564/235045677-8545aab7-5e83-4813-bbec-47783dc60122.png">
This facility is oriented towards accuracy debugging. It does several things:
1. It will run your model twice and check for nondeterminism in inductor/float64, *even* on intermediate inputs (our benchmarking nondeterminism test only checks for nondeterminism on the final output). This makes localizing which operator is nondeterministic easy.
2. It will run your compiled model side-by-side with eager and float64 variants, and then report when things diverge too far from RMSE delta from float64.
Importantly, it does all this without requiring every intermediate to be held in memory (which will cause an OOM on large repros, such as the one I tested this on.)
Some other minor improvements:
* MinifierTestBase now has an easy to comment out spot that you can use to retain the temporary directory; good for debugging
* We print "running minifier" and "running repro" in MinifierTestBase to make it easier to orient where logs are coming from
* same takes a `log_error` optional argument which you can use to reroute the error logs when things mismatch
* counters["inductor"]["intermediate_hooks"] tracks the number of intermediate hooks we've codegen'ed; good for populate the tqdm interface
* torch.fx.interpreter gets an official `boxed_run` interface which uses the boxed arguments calling convention and doesn't retain inputs unnecessarily long
* torch.utils._content_store gets compute_tensor_metadata/read_tensor_metadata helper functions for computing tensor information without serializing it
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100226
Approved by: https://github.com/bertmaher, https://github.com/bdhirsh, https://github.com/anijain2305
For TIMM ```mobilevit``` dynamic path, there has a compiler issue(```
python -m torch.backends.xeon.run_cpu --node_id 0 benchmarks/dynamo/timm_models.py --performance --float32 -dcpu -n2 --inductor --no-skip --dashboard --only mobilevit_s --inference --dynamic-shapes```
):
```
/tmp/torchinductor_xiaobing/xy/cxyslqzcsxkco4ieph7t63kn5q74ka35ak75lwfon32nlalxmru5.cpp:29:130: error: invalid operands of types ‘long int’ and ‘double’ to binary ‘operator%’
29 | auto tmp0 = in_ptr0[static_cast<long>((((((-1L) + ks1) / 8L)*(((-1L) + ks1) / 8L))*((((2L*((i2 / 1L) % (std::ceil((1.0/2.0) + ((1.0/2.0)*(((-1L) + ks1)
```
There has a modulo for ```long % double```, this PR will convert inputs to long before do this operation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100230
Approved by: https://github.com/jansel
Hi!
I've been fuzzing different pytorch modules, and found a crash inside one of them.
Specifically, I'm talking about a module that processes `script_call` rpc requests and a function `ScriptCall::fromIValues(std::vector<at::IValue>& ivalues)`.
Running this test case causes a crash that occurs when `ivalues.back()` is called [script_call.cpp:90](abc54f9314/torch/csrc/distributed/rpc/script_call.cpp (L90)). The crash occurs because the vector `ivalues` is empty.
All tests were performed on this pytorch version: [abc54f93145830b502400faa92bec86e05422fbd](abc54f9314)
The provided patch checks if there are enough elements in the ivalues vector.
### How to reproduce
1. To reproduce the crash, use provided docker: [Dockerfile](https://github.com/ispras/oss-sydr-fuzz/tree/master/projects/pytorch)
2. Build the container: `docker build -t oss-sydr-fuzz-pytorch-reproduce .`
3. Copy crash file to the current directory:
- [crash-9f76d4e37a2391136a4ce07d47269db1e063e4b4.zip](https://github.com/pytorch/pytorch/files/10674059/crash-9f76d4e37a2391136a4ce07d47269db1e063e4b4.zip)
4. Run the container: ``docker run --privileged --network host -v `pwd`:/homedir --rm -it oss-sydr-fuzz-pytorch-reproduce /bin/bash``
5. And execute the binary: `/message_deserialize_fuzz /homedir/crash-9f76d4e37a2391136a4ce07d47269db1e063e4b4`
After execution completes you will see this stacktrace:
```asan
AddressSanitizer:DEADLYSIGNAL
=================================================================
==57==ERROR: AddressSanitizer: SEGV on unknown address (pc 0x0000008e7b19 bp 0x7ffd2fdded70 sp 0x7ffd2fddec40 T0)
==57==The signal is caused by a READ memory access.
==57==Hint: this fault was caused by a dereference of a high value address (see register values below). Disassemble the provided pc to learn which register was used.
#0 0x8e7b19 in c10::IValue::isString() const /pytorch_fuzz/aten/src/ATen/core/ivalue.h:639:27
#1 0x8e7b19 in c10::IValue::toStringRef[abi:cxx11]() const /pytorch_fuzz/aten/src/ATen/core/ivalue_inl.h:2179:3
#2 0xe04fb58 in torch::distributed::rpc::ScriptCall::fromIValues(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch_fuzz/torch/csrc/distributed/rpc/script_call.cpp:90:53
#3 0xe0511f0 in torch::distributed::rpc::ScriptCall::fromMessage(torch::distributed::rpc::Message const&) /pytorch_fuzz/torch/csrc/distributed/rpc/script_call.cpp:133:10
#4 0xe0ff71e in torch::distributed::rpc::deserializeRequest(torch::distributed::rpc::Message const&) /pytorch_fuzz/torch/csrc/distributed/rpc/utils.cpp:102:14
#5 0x602a41 in LLVMFuzzerTestOneInput /message_deserialize_fuzz.cc:192:27
#6 0x52ce61 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /llvm-project/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:611:15
#7 0x516d7c in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:324:6
#8 0x51cacb in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:860:9
#9 0x546062 in main /llvm-project/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10
#10 0x7f41e42a8082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082)
#11 0x51169d in _start (/message_deserialize_fuzz+0x51169d)
AddressSanitizer can not provide additional info.
SUMMARY: AddressSanitizer: SEGV /pytorch_fuzz/aten/src/ATen/core/ivalue.h:639:27 in c10::IValue::isString() const
==57==ABORTING
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94297
Approved by: https://github.com/ezyang
* Adds extra test_allgather_base in UccProcessGroupWithDispatchedCollectivesTests; rest of nccl and gloo tests there don't work on ucc
* Adds cpu tests for [op]_work_wait_gpu tests
* Added single tensor input test for allgather_basics; multi tensor input still doesn't seem to be supported by ucc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99654
Approved by: https://github.com/kwen2501
Fixes #ISSUE_NUMBER
* change hook so that test still gets saved in --sc when fails in test setup (caused an off by 1 error due to setup being called before the logreport hook)
* allow reruns for all tests now that --sc is used
* increase number of reruns now that --sc is used
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100200
Approved by: https://github.com/huydhn
Previously, the mismatch report would not give the full details of the
collective running on the mismatched rank, it would look something like:
```
Detected mismatch between collectives on ranks. Rank 26 is running collective: CollectiveFingerPrint(SequenceNumber=683057617, OpType=BROADCAST, TensorShape=[1], TensorDtypes=Long, TensorDeviceTypes=TensorOptions(dtype=float (default), device=cpu, layout=Strided (default), requires_grad=false (default), pinned_memory=false (default), memory_format=(nullopt))), but Rank 1 is running collective: CollectiveFingerPrint(SequenceNumber=513876813OpType=BROADCAST).
```
i.e. Rank 1 is missing more details such as the shape, type etc.
This was due to `num_tensors` field not being populated, which operator<<
checks to determine whether to print additional information such as the tensor
shape.
Adding this field gives a better error:
```
Detected mismatch between collectives on ranks. Rank 0 is run ning collective: CollectiveFingerPrint(SequenceNumber=1564312518, OpType=ALLREDUCE , TensorShape=[20, 10], TensorDtypes=Float, TensorDeviceTypes=TensorOptions(dtype= float (default), device=cpu, layout=Strided (default), requires_grad=false (defaul t), pinned_memory=false (default), memory_format=(nullopt))), but Rank 1 is runnin g collective: CollectiveFingerPrint(SequenceNumber=1564312518, OpType=REDUCE, Tens orShape=[20, 10], TensorDtypes=Float, TensorDeviceTypes=TensorOptions(dtype=float (default), device=cpu, layout=Strided (default), requires_grad=false (default), pi nned_memory=false (default), memory_format=(nullopt))).
```
Differential Revision: [D45372325](https://our.internmc.facebook.com/intern/diff/D45372325/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100213
Approved by: https://github.com/H-Huang
Fixes #ISSUE_NUMBER
Without affecting the existing cpu/cuda logic, a separate interface is provided for the custom backend and users can choose whether to use the interface function which provides 10 tensor types with custom backend variations.
Therefore, users can use torch.set_deafult_tensor_type to set the default device tensor type, or use torch.xxx.dtypetensor to create a tensor.For example,torch.set_deafult_tensor_type(torch.foo.DoubleTensor) or torch.foo.DoubleTensor([]).
@albanD , please review my changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99521
Approved by: https://github.com/albanD
This is a mirror PR of D45339293
Summary:
These tests cause the following errors internally with unknown reason:
```
AttributeError: type object 'TestDistBackendWithSpawn' has no attribute 'test_ddp_hook_with_optimizer_parity_adam'
AttributeError: type object 'TestDistBackendWithSpawn' has no attribute 'test_ddp_hook_with_optimizer_parity_adamw'
AttributeError: type object 'TestDistBackendWithSpawn' has no attribute 'test_ddp_hook_with_optimizer_parity_sgd'
```
Commenting these tests out to unblock other PRs.
Test Plan: Sandcastle
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100215
Approved by: https://github.com/wz337, https://github.com/fduwjj
This PR changes the CustomOp API. There are now two ways to create a
CustomOp object.
Method 1: with no schema string. We will infer what the schema string is
from your type annotations
```py
@custom_op("customlib::foo")
def foo(x: Tensor) -> Tensor:
...
```
Method 2: with a schema string, if the inference doesn't work well.
```py
@custom_op("customlib::foo", "(Tensor x) -> Tensor")
def foo(x):
...
```
Some details:
- We support most combinations of {Tensor, Number, int, float, bool} and
{Optional[typ], Tuple[typ, ...]} as inputs. The combinations we support are mostly
from me reading native_functions.yaml.
- We support only Tensor or Tuple of Tensor of fixed size returns.
- A lot of this PR is input validation for both of the above two
methods. For example, when a user provides a manual schema string, then
their function must not have any type annotations and the number of args
and arg names must match the schema.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100127
Approved by: https://github.com/ezyang
This PR makes a CustomOp live forever. The motivation for it living
forever is that:
1. It doesn't matter to a user if it lives forever or not
2. it is a higher-level abstraction over OpOverload, and OpOverload
assumes that OpOverload lives forever.
The only place where it matters that CustomOp lives forever is testing:
I don't want to generate random names for my CustomOp objects. To
resolve the testing problem, This PR adds a CustomOp._destroy() that
clears all the C++ state, including the OpOverloadPacket, that is
associated with the CustomOp object.
Test Plan:
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100114
Approved by: https://github.com/ezyang
This PR fixes capturing static methods for FSDP-managed modules. Previously, if a static method was invoked using `self.<staticmethod>`, then Dynamo would pass `self` twice to the method, causing a graph break due to the method being "unsupported". This PR achieves this by checking for `staticmethod` and using `UserFunctionVariable` instead of `UserMethodVariable`, which handles the correct calling convention.
This fixes FSDP + PT2 on HuggingFace's `T5ForConditionalGeneration`, which otherwise reports an error like the following based on the most recent trunk:
```
Output 0 of AsStridedBackward0 is a view of a view which was created in no_grad mode and is being modified inplace with grad mode enabled.
```
This is in reference to the `scores` tensor in `scores += position_bias_masked` ([code](a0ae2310ec/src/transformers/models/t5/modeling_t5.py (L559))).
I am not clear if this PR's fix is actually masking a different problem though. I wonder if there are edge cases with respect to Dynamo resuming execution and input mutations. Possibly, this PR only side steps the problem because there is no more recompilation at the static method `_relative_position_bucket()` ([code](a0ae2310ec/src/transformers/models/t5/modeling_t5.py (L443))).
In `UserDefinedObjectVariable.var_getattr()`, there is an existing branch:
e5291e633f/torch/_dynamo/variables/user_defined.py (L395-L398)
I am not clear on when this branch can be triggered since if `subobj` is a static method, it still takes the `FunctionTypes` branch:
e5291e633f/torch/_dynamo/variables/user_defined.py (L403-L404)
To preserve backward compatibility, the current version of this PR only modifies this `FunctionTypes` branch to differentiate between `staticmethod` and not `staticmethod`.
The PR that added this `FunctionTypes` branch is https://github.com/pytorch/pytorch/pull/92050/, and I checked that the added test `test_torch_distributions_functions()` only exercises the non-`staticmethod` case (since `Independent.log_prob` is not a `staticmethod`).
The last commit in `pytorch` that touched the `staticmethod` branch before https://github.com/pytorch/pytorch/pull/92050/ was the move from the `torchdynamo` repo into `pytorch`, so I cannot easily tell which test cases it corresponds to.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100117
Approved by: https://github.com/anijain2305
This PR:
- adds an abstract registration API for CustomOp (CustomOp.impl_abstract)
that is used for both FakeTensor and meta tensors
- deletes CustomOp.impl_meta
The user story behind this API is that it is the one-stop shop for
registering implementations for data-less Tensors, i.e. FakeTensor and
Meta tensor.
The abstract implementation provided by the user:
- gets registered as the FakeTensor implementation AND the meta formula
- can be written like a regular meta formula. If the user decides that
they need something more special (i.e. data-dependent output shape),
then they are able to query a current context object (FakeTensorImplCtx)
that has methods to construct new unbacked symints.
Caveats:
- we really need to make FakeTensor/FakeTensorMode public. Otherwise,
there isn't a way for the user to interactively test that their abstract
implementation is correct without running through large pieces of the
PT2 stack (make_fx or torch.compile).
- We do not memoize the symints produced by
ctx.create_unbacked_symint(). It is possible to do this in the
future, but it is difficult to do soundly and I am not convinced of
the utility outside of the nonzero() usecase mentioned in #95399
Public API:
- More docs will come when we actually expose this API to users by
putting it in a public namespace, unless you folks want it now.
- The APIs mentioned in `__all__` are the ones that are intended to be
public.
Test Plan:
- Updated existing custom_op_db operators
- Added new numpy_nonzero and numpy_nms operations that test operations
that have data-dependendent output shape.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99439
Approved by: https://github.com/ezyang
The problem:
- The new CustomOp API depends on torchgen.model
- torchgen.model imports `yaml`
- `yaml` is not a PyTorch runtime dependency
To unblock myself, because I'm not sure how long it'll take to
convince people yaml should be a PyTorch runtime dependency
(unless one of you wants to approve #100166), this PR removes the
yaml dependency from torchgen.model.
It does so by splitting torchgen.utils (the offender) into
torchgen.utils (no yaml) and torchgen.yaml (which uses yaml).
Test Plan:
- CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100203
Approved by: https://github.com/ezyang, https://github.com/Skylion007
This PR introduces a new operator called aten._assert_async.msg, which allows passing a tensor value and assertion message as inputs. As part of TorchDynamo, we're replacing the use of torch._assert with this new operator so that make_fx also knows how to handle assertions. This is subset of https://github.com/pytorch/pytorch/pull/98878, refer there for historic reviews.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100101
Approved by: https://github.com/jansel
Currently, if we use NO_SHARD strategy for fully_shard and set state_dict_type to be SHARDED_STATE_DICT, a runtime error would be raised ("``sharded_state_dict`` can only be used when parameters are flatten and sharded.").
This PR updates pre_state_dict_hook, post_state_dict_hook, pre_load_state_dict_hook, and post_load_state_dict_hook to set state_dict_type and state_dict_config to full state when using NO_SHARD, even if the state_dict_type and state_dict_config of the root module is set to sharded state.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100208
Approved by: https://github.com/rohan-varma
Currently, we track 'origins' on IR nodes so that we have some idea about what FX IR nodes contributed to any given fused kernel. However, the origins are dumped into an undifferentiated set, so if you have, e.g., multiple outputs, you cannot easily tell which output corresponds to which FX node.
This PR introduce a more precise notion of tracking "origin_node" which says that the contents of this Buffer/Loop node corresponds EXACTLY to the output of a particular FX node; e.g., if you serialized each intermediate when running the generated inductor code, you could compare them with the corresponding intermediates from the original FX graph.
Tracking origin_node in all cases requires quite a bit of effort, so this PR introduces the tracking on a strictly best effort basis. The logic in torch/_inductor/graph.py sets up the associations, but only when it is "obvious" which IR node should get the assignment, and there is work in torch/_inductor/ir.py for propagating this information around as necessary. Like origins, origin_node is not a true dataclass field (as this would break all existing positional arg call sites), instead, it is added post facto via `__post_init__`. At the moment, it is only valid for Buffer/Loop to have an origin_node, but we could imagine relaxing this in the future.
The payoff is in torch/_inductor/codegen/wrapper.py and torch/_inductor/codegen/triton.py where we currently just print the FX node name and the tensor (but a more useful integration will be coming later.)
I also introduce a debugging tool `debug_ir_traceback` which tracks tracebacks of where IRNodes were allocated, to help you understand why a node doesn't have an `origin_node`.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100110
Approved by: https://github.com/voznesenskym
Metadata to store in the GraphModule:
- input shape constraints
- example inputs
- other inline constraints
The saved constraints (in mem) will be used directly after export to convert constraints to runtime assertion which is a separate pass after export.
The requirement of saved constraints:
1. Be able to locate where the constraints is from
2. Should not break the exported graph module serialization.
Examples of saved constraints
```
input_shape_constraints:
{'t_id': 140266058179792, 'dim': 0, 'min': 6, 'max': oo}
{'t_id': 140266058179792, 'dim': 0, 'min': 2, 'max': 10}
inline_constraints:
i1: ValueRanges(lower=2, upper=5)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99961
Approved by: https://github.com/tugsbayasgalan
Summary: Importing torch.ao.quantization._pt2e from dynamo led to
internal test failures related to memory profiling. For now,
let's express the path using a simple string instead.
Reviewers: jerryzh168, kimishpatel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100194
Approved by: https://github.com/jerryzh168
This reverts commit ae40a6c7356190ef86b14b10a94a58ca41ca496b.
Reverted https://github.com/pytorch/pytorch/pull/100215 on behalf of https://github.com/huydhn due to Sorry for revert your change, but it breaks lint, please run lintrunner -a torch/testing/_internal/distributed/distributed_test.py to fix the issue then reland it
Previously the change to aten/src/ATen/native/LossNLL.cpp eventually resulted in a double / SymInt division, which ended up calling the int64_t / SymInt overload, truncating the double (bad!) By adding overloads for all the int/float types, we avoid this situation from happening in the future.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100008
Approved by: https://github.com/albanD
This is a mirror PR of D45339293
Summary:
These tests cause the following errors internally with unknown reason:
```
AttributeError: type object 'TestDistBackendWithSpawn' has no attribute 'test_ddp_hook_with_optimizer_parity_adam'
AttributeError: type object 'TestDistBackendWithSpawn' has no attribute 'test_ddp_hook_with_optimizer_parity_adamw'
AttributeError: type object 'TestDistBackendWithSpawn' has no attribute 'test_ddp_hook_with_optimizer_parity_sgd'
```
Commenting these tests out to unblock other PRs.
Test Plan: Sandcastle
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100215
Approved by: https://github.com/wz337, https://github.com/fduwjj
There's a longstanding, well known mutability bug in dynamo, https://github.com/pytorch/pytorch/issues/93610 (and more issues, but this is the one I had at hand).
Ops that do in place mutation of tensors will mutate their corresponding FakeTensors.
So, for example, if you do `t_` on a tensor, you will reverse its strides. This, in turn, means that the FakeTensors strides are now also reversed, say, if you are trying to torch.compile:
```
class F(torch.nn.Module):
def forward(self, x, y):
x = x.t_()
y = y.t_()
return (x + y,)
```
However, we recently introduced accessing the fake_tensor memo/cache to get the symbolic shape values for sizes and strides during guard installation time.
This means that tensors captured with a given size and stride, say, for x above, size:(3,3) stride:(3, 1), will get their memo updates to size(3, 3), stride(1, 3). Now, whenever you access this value for anything, it reflects it's current state in the tracing, as opposed to the state at which we initially started tracing on.
This causes us to produce guards that are never valid, for the example above, that `x.stride()[0] == 3`.
The solution is to not allow mutation to affect the fake tensors we use as source of truth here. We can do this by forcing a clone of the fake tensor at builder time, and storing that as the source of truth for our dynamic sizes and strides during guard installation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100128
Approved by: https://github.com/ezyang
When use_orig_param is True and sharding is NO_SHARD, parameters and states are not flattened, so optimizer states should not be flattened as well. The unit test will fail without the fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100189
Approved by: https://github.com/awgu
The input tensor of the RNN forward must be the same type as the weights.
While passing tensor of type long the error is:
`RuntimeError: expected scalar type Long but found Float`
Which is misleading because it said to convert Something to Long, but the correct solution is to convert the input to Float (Which is the type of the weights).
The new error:
`RuntimeError: input must have the type torch.float32, got type torch.int64`
Is correct and more verbose
Fixes#99998
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100100
Approved by: https://github.com/drisspg
Fixes [#82206](https://github.com/pytorch/pytorch/issues/82206)
When executing a `ShardedGradScaler` step in the context of `cpu_offload`, [the function](ecd2c71871/torch/distributed/fsdp/sharded_grad_scaler.py (L151-L152)) `_foreach_non_finite_check_and_unscale_cpu_` is grindingly slow. This issue is due to the elementwise op dispatching/redispatching/execution that is engendered by the current approach to gradient tensor validation:
ecd2c71871/torch/distributed/fsdp/sharded_grad_scaler.py (L159-L163)
The subsequent `isinf` and `isnan` checks with associated `any` checks result in unscalable elementwise op dispatches:
ecd2c71871/torch/distributed/fsdp/sharded_grad_scaler.py (L173-L181)
This inefficency is of course hidden in the current FSDP tests given their (appropriately) trivial parameter dimensionality. In the perf analysis below, the example test configures only the final `Linear(4, 8)` module parameters to require grad, so there are 40 elements to iterate through. However, if one increases the dimensionality to a still-modest 320008 elements (changing the final module to `Linear(40000,8)`), the execution time/cpu cost of the test is dominated by the elementwise op dispatching/redispatching/execution of the `any` validation ops in this function.
To characterize the current behavior, I use a slightly modified version of an existing `ShardedGradScaler` test [^1]. The following modifications to the test are made to allow the analysis:
1. Run just `CUDAInitMode.CUDA_BEFORE` for clarity instead of additional scenarios
2. Increase the final module to `Linear(40000, 8)` (along with modifying the preceding module to make the dimensions work) ,
3. For the cProfile run (but not valgrind or perf) the test runs just a single [`_train_for_several_steps`](ecd2c71871/torch/testing/_internal/common_fsdp.py (L926-L934)) step per rank (instead of 2 steps)
4. I temporarily reduce `init_scale` further to ensure we don't hit any `infs`, short-circuiting our analysis
### Current behavior
The most relevant call subgraph:
Note that:
1. Instead of dispatching to the relevant autograd op and then redispatching to the relevant CPU op implementation 8 times per test, (2 train steps x 2 any calls per parameter per step x 2 orig parameters) we (I believe unnecessarily) call the relevant dispatch flow elementwise, so 640016 times! (only 1 node in this trace so 320008 elements/2 X 2 train steps x 2 calls per element per step).
2. Nearly 50% of the relative (inclusive) instruction reads for the entire test in `callgrind` are executed by the `isnan` (320008 execs), `isinf` (320008 execs) and `any` (640016 execs) calls.
3. The `any` pre-dispatch entry point IRs (`torch::autograd::THPVariable_any`) vs actual op implementation IRs (`at::native::structured_any_all_out::impl`) are below to give one a sense of the relative dispatch and op execution cost in an elementwise context[^3].


Using cprofile stats:
```bash
python -c "import pstats; stats=pstats.Stats('/tmp/fsdp_cprofile_8wa9uw39.stats'); stats.print_stats()"
...
ncalls tottime percall cumtime percall filename:lineno(function)
1 20.159 20.159 66.805 66.805 torch/distributed/fsdp/sharded_grad_scaler.py:151(_foreach_non_finite_check_and_unscale_cpu_)
160004 18.427 0.000 18.427 0.000 {built-in method torch.isinf}
160004 6.026 0.000 6.026 0.000 {built-in method torch.isnan}
```
We see that a single step of the scaler runs for more than a minute. Though there is non-trivial cprofile overhead, we can infer from this that per-element op dispatches/executions are on the order of a 100ns.
On the order of 100 nanoseconds per dispatch is acceptable if we're using typical tensor access patterns, but if we're dispatching each element for each op, obviously everything is going to come to a grinding halt for many practical use cases.
(Given the cost of this function is currently O(n) in the number of gradient elements, feel free to set `TORCH_SHOW_DISPATCH_TRACE=1` if you want to make this function cry 🤣)
I've attached a flamegraph at the bottom of the PR[^2] that more intuitively demonstrates the manner and extent of resource consumption attributable to this function with just a modest number of gradient elements.
### After the loop refactor in this PR:
The most relevant call subgraph:

Note that:
1. Less than 0.4% of the relative (inclusive) instruction reads for the entire test in `callgrind` are executed by the `isnan` (4 execs), `isinf` (4 execs) and `any` (8 execs) calls (versus ~50% and 320008, 320008, 640016 respectively above)
2. The `any` pre-dispatch entry point IRs (`torch::autograd::THPVariable_any`) vs actual op implementation IRs (`at::native::structured_any_all_out::impl`) reflect far less overhead (of secondary importance to item number 1)


Using cprofile stats:
```bash
python -c "import pstats; stats=pstats.Stats('/tmp/fsdp_cprofile_pfap7nwk.stats'); stats.print_stats()"
...
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.013 0.013 0.109 0.109 torch/distributed/fsdp/sharded_grad_scaler.py:151(_foreach_non_finite_check_and_unscale_cpu_)
2 0.022 0.011 0.022 0.011 {built-in method torch.isinf}
2 0.018 0.009 0.018 0.009 {built-in method torch.isnan}
```
We can see our function runtime has dropped from more than a minute to ~100ms.
### Assumptions associated with this loop refactor:
The key assumptions here are:
1. The grads are always on CPU in this function so any MTA-safe constraints ([`can_use_fast_route`](efc3887ea5/aten/src/ATen/native/cuda/AmpKernels.cu (L110-L111)) relating to the relevant CUDA kernel path selection, i.e. slower `TensorIterator` gpu kernel vs `multi_tensor_apply_kernel`) do not apply in this context
2. We've already filtered by dtype and device and can assume the presence of a single CPU device. Unless manually creating separate CPU devices with manually set non-default indexes (which I don't think FSDP supports and should be validated prior to this function), device equality should always be `True` for `cpu` type devices so we should just need to check that the current device is of `cpu` type. [^4].

[^1]: `TestShardedGradScalerParityWithDDP.test_fsdp_ddp_parity_with_grad_scaler_offload_true_none_mixed_precision_use_orig_params` test in `test/distributed/fsdp/test_fsdp_sharded_grad_scaler.py`
[^2]: Note the native frame stacks for `torch::autograd::THPVariable_isinf`, `torch::autograd::THPVariable_isnan`, `torch::autograd::THPVariable_any` in particular.
[^3]: There's more `TensorIterator` etc. setup overhead further up the stack beyond `structured_any_all_out`, but roughly speaking
[^4]: Device equality is based on [type and index combination](efc3887ea5/c10/core/Device.h (L47-L51)), CPU device type is -1 by default (`None` on the python side) and is intended to [always be 0](cf21240f67/c10/core/Device.h (L29)) if set explicitly. Though technically, unless in debug mode, this constraint isn't [actually validated](bb4e9e9124/c10/core/Device.h (L171-L184)), so one can actually manually create separate `cpu` devices with invalid indices. I suspect it's safe to ignore that potential incorrect/unusual configuration in this context but let me know if you'd like to add another `cpu` device equality check.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100108
Approved by: https://github.com/awgu
This pr makes summary of dimension constraints actionable. Before the pr, it will print:
```
torch.fx.experimental.symbolic_shapes: [WARNING] Summary of dimension constraints:
The following dimensions have been specialized and CANNOT be dynamic.
NOTE: Specializations will happen by default with `assume_static_by_default=True`.
L['c'].size()[1] == 3
L['a'].size()[2] == 3
L['a'].size()[1] == 3
L['b'].size()[2] == 2
L['b'].size()[1] == 2
L['c'].size()[2] == 3
The following dimensions CAN be dynamic.
You can use the following code to specify the constraints they must satisfy:
'''
constraints=[
dynamic_dim(L['c'], 0) == dynamic_dim(L['a'], 0),
2 <= dynamic_dim(L['b'], 0),
2 <= dynamic_dim(L['a'], 0),
]
'''
```
Users need to initialize the L environment manually and copy the constraints over. After the pr, we have:
```
[2023-04-26 05:43:12,849] torch._dynamo.eval_frame: [WARNING] Summary of dimension constraints:
The following dimensions have been specialized and CANNOT be dynamic.
NOTE: Specializations will happen by default with `assume_static_by_default=True`.
'''
def specializations(a, b, c):
return (a.size()[2] == 3 and
c.size()[1] == 3 and
a.size()[1] == 3 and
c.size()[2] == 3 and
b.size()[2] == 2 and
b.size()[1] == 2)
'''
The following dimensions CAN be dynamic.
You can use the following code to specify the constraints they must satisfy:
'''
def specify_constraints(a, b, c):
return [
2 <= dynamic_dim(b, 0),
dynamic_dim(c, 0) == dynamic_dim(a, 0),
2 <= dynamic_dim(a, 0),
]
'''
```
, where dynamic_constraints has the same input signature as users code. This allow users to copy-paste and run the code to generate the constraints before exporting as shown below:
```
def specify_constraints(a, b, c):
return [
2 <= dynamic_dim(b, 0),
dynamic_dim(c, 0) == dynamic_dim(a, 0),
2 <= dynamic_dim(a, 0),
]
torch._dynamo.export(my_dyn_fn, x, y, z, constraints=specify_constriants(x, y, z))
```
Implementation-wise, this pr also
1. changes shape_env.produce_guards to produce_guards_and_constraints,
2. adds contraints_export_fn hooks,
The purpose is to surface the DimConstraints to dynamo.export, where we could reliably get the original function's signature.
The alternative to the above is to get the function signature before creating SHAPE_ENV guard (https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/output_graph.py#L227) and pass it to DimConstraints, but I couldn't recover the signature before creating SHAPE_ENV because the frame's f_globals/locals don't contain the original function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100103
Approved by: https://github.com/guangy10, https://github.com/tugsbayasgalan
Talked to @zou3519 and @ezyang on what the right UX is: tentatively, adding a new dynamo backend is cheap and simple, so it seems worth doing. And longer term, we agreed (?) that it's worth seeing if we can get custom ops sanity asserts to run more automatically, instead of needing a separate backend.
Side comment: that actually seems tough: the mode detects secret mutations by cloning every input to every op, running the op, and checking that the data matches between the real input and the cloned input. So I doubt we'll be able to make that behavior always-on? It would need some config at least.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99744
Approved by: https://github.com/albanD, https://github.com/ezyang, https://github.com/zou3519
Split existing 4 hour scheduled into two 8 hour ones
And schedule x86 MacOS test every 8 hours and exclude them from leak
checks
Schedule iOS tests every 8 hours and exclude them from leak-checks as
well
Remove IOS metal job, as it is already tested by ARM64 MPS job as well
as x86 and arm64 vanilla jobs, as they never caught any regressions in
last 60 days, based on data from running the following query on RockSet:
```sql
SELECT started_at,
DATE_DIFF(
'MINUTE',
PARSE_TIMESTAMP_ISO8601(started_at),
PARSE_TIMESTAMP_ISO8601(completed_at)
) as duration,
conclusion, name, html_url, torchci_classification
FROM commons.workflow_job
WHERE
workflow_name = 'periodic' and
name like 'ios-12% % build (default, 1, 1, macos-12)' and
url like 'https://api.github.com/repos/pytorch/pytorch/%'
and conclusion = 'failure'
order by started_at desc, run_id;
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100182
Approved by: https://github.com/PaliC, https://github.com/huydhn
On top of #95849 this PR is trying to handle the special case when dealing with numpy.
Consider the following example:
```
def f(x: torch.Tensor) -> np.ndarray:
a = x.numpy()
return a.T
```
In previous PR this will error out because we translate `a.T` to be a method call on `torch_np.ndarray.T` which is also a `torch_np.ndarray`.
This PR handles this case, by conditionally converting a `torch_np.ndarray` to `np.ndarray` before returning, to match the original behavior.
The compiled version will be:
```
def f(x):
___tmp_0 = __compiled_fn_0(x)
if isinstance(___tmp_0, torch_np.ndarray):
return ___tmp_0.tensor.numpy()
else:
return ___tmp_0
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99560
Approved by: https://github.com/jansel, https://github.com/yanboliang
Issue: #93684
# Problem
Reduce graph breaks when dynamo compiles python functions containing numpy functions and ndarray operations.
# Design (as I know it)
* Use torch_np.ndarray(a wrapper of tensor) to back a `VariableTracker`: `NumpyTensorVariable`.
* Translate all attributes and methods calls, on ndarray, to torch_np.ndarray equivalent.
This PR adds `NumpyTensorVariable` and supports:
1. tensor to ndarray, ndarray to tensor
2. numpy functions such as numpy.meshgrid()
3. ndarray attributes such as `itemsize`, `stride`
Next PR will handle returning `np.ndarray` and add support for ndarray methods
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95849
Approved by: https://github.com/ezyang
@wconstab As we discussed last Friday, I added the unit test for explicitly calling __call__ and added comment to explain why we redirecting ```UserMethodVariable.call_function``` to ```NNModuleVariable.call_method``` for a certain case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100146
Approved by: https://github.com/wconstab
This adds helpers that replace tritons `minimum`, `maximum`, `min` and
`max` with the correct NaN prrpagation. I also removed
`ops.int_minimum` in favor of `ops.minimum` because we can just omit
the nan-checks by checking the dtype.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99881
Approved by: https://github.com/ngimel
This changes codegen of `torch.prod` from:
```python
tl.reduce(tmp2, 1, _prod_accumulate)[:, None]
```
where `_prod_accumulate` is defined elsewhere, to
```python
triton_helpers.prod(tmp2, 1)[:, None]
```
A quirk I uncovered though is that `TritonCodeCache` breaks if you
define any new symbol beginning with `triton_`, since it assumes that
must be the kernel name. Instead, I've made the kernel name an
explicit argument to `async_compile.triton` so it doesn't have to guess.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99880
Approved by: https://github.com/ngimel
Add use_local_synchronization argument to new_group.
When this argument is True, is change new_group to do a store_barrier only on the ranks that are park of the group and not the whole cluster.
This addressess both scalability and composability problems associated with new_group.
Fixes#81291.
This is relanding #84224
As part of the original PR I did a quick benchmark of creating 3 PGs per rank using both functions and perf is the following:
new_group use_local_synchronization=False:
| World Size | Time (in secs) |
| --- | ----------- |
| 4 | 0.12 |
| 8 | 0.25 |
| 16 | 0.51 |
| 32 | 0.87 |
| 64 | 1.50 |
| 128 | 2.87 |
new_group use_local_synchronization=True:
| World Size | Time (in secs) |
| --- | ----------- |
| 4 | 0.05 |
| 8 | 0.04 |
| 16 | 0.03 |
| 32 | 0.03 |
| 64 | 0.04 |
| 128 | 0.04 |
Scaling for `use_local_synchronization=False` is sub linear because the number of process groups created as a multiple of world_size decreases as we go up. It's 6 with world_size 4 and 192 with world_size 128.
Scaling for `use_local_synchronization=True` is constant as the number of store barriers executed per rank remains constant at 3.
Setup:
1 AWS host, backend gloo.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99931
Approved by: https://github.com/xw285cornell
The new minifier script looks like this:
```
import torch._dynamo.repro.after_aot
reader = torch._dynamo.repro.after_aot.InputReader(save_dir='/tmp/tmpcsngx39e')
buf0 = reader.storage('e2b39c716c0d4efb9fa57375a3902b9dab666893', 16)
t0 = reader.tensor(buf0, (4,))
args = [t0]
mod = make_fx(Repro(), tracing_mode='real')(*args)
```
The real tensor data is stored in the storages folder of the checkpoint dump directory. If you delete this folder / it is otherwise missing, we will transparently fall back to generating random data like before. The tensors are serialized using content store from #99809, which means each storage is content-addressed and we will automatically deduplicate equivalent data (which is useful if you keep dumping out, e.g., your parameters.) We don't use the tensor serialization capability from content store, instead all of the tensor metadata is stored inline inside the repro script (so that everything is in one file if you lose the checkpointed tensors).
We also add a stable_hash option to content store, where we use a slow SHA-1 sum on the data in CPU side to compute a hash that is stable across systems with the same endianness.
Out of rage, I also added support for Dtype.itemsize property access.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99834
Approved by: https://github.com/voznesenskym
Make traceable collectives work with torchdynamo,
bypassing problems with tracing the AsyncTensor subclass.
Accept a suboptimal solution for now, and optimize it later.
For now, wait happens immediately, which generally forces an early sync.
Later, find a way either in dynamo or AOT stack to handle
AsyncCollectiveTensor to get the wait in the optimal place.
Note on implementation:
- Dynamo traces 'user-level' fc apis that are designed to behave differently
in eager vs compiled. In eager, there will be work-obj registration and
a wrapper subclass will insert a 'wait' call at the appropriate time.
In compile/trace mode, wait will be immetiately called, and work obj
registration is required to be handled by the compile backend at runtime.
- Dynamo needs to trace into some of the helper functions in the 'user-level'
api, such as '_expand_group' which is essentially a constant transformation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94440
Approved by: https://github.com/kumpera
Custom backend implementation based on privateuse1 with semantics identical to CUDA (CUDA is so popular), named for example 'my_device', and registered as the same module name torch.my_device.
This PR aims to satisfy the constraints of such a backend, which can be directly integrated into the current FSDP implementation.
The main issues addressed are:
#### 1. Device decision for FSDP wrapping of Modules without Parameters
Users typically organize FSDP code as follows:
```python
m = Module().to('my_device:0')
fsdp_m = FSDP(m)
```
or like this:
```python
m = Module()
fsdp_m = FSDP(m, device_id=torch.device('my_device', 0))
```
If the model has Parameters, everything works fine because FSDP will prioritize the device where the Parameters are located. However, for Modules without Parameters, the to() call has no side effects, and FSDP will assume the current CUDA device, which prevents the use of devices other than the current CUDA device for Modules without Parameters. Therefore, when FSDP is called with a device_id argument, this configuration takes top priority.
#### 2. Abstraction of a cuda-like device
Now, in addition to compute_device, _FSDPState includes a device_handler member. In fact, this device_handler is now just a reference to either torch.cuda or torch.my_device. From now on, code that works based on _FSDPState should use state.device_handler to operate streams create, wait or sync, just like using torch.cuda previously.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99024
Approved by: https://github.com/awgu
I want to use torchgen to generate code, and my yaml file format is the same as `native_functions.yaml`.
I will use the PrivateUse1, but in my yaml file, I don't want to show PrivateUse1 to the user.
So I want to achieve the following result(e.g. my device is `YPU`):
```
>>>from torchgen.model import DispatchKey
>>>str(DispatchKey.PrivateUse1)
"YPU"
>>>DispatchKey.parse("YPU")
DispatchKey.PrivateUse1
```
I also thought that not everyone would need this feature, so I add a new func to handle this scenario.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99406
Approved by: https://github.com/ezyang
enable -Werror=sign-compare in our Bazel build
Summary:
This is already turned on for CMake, let's see what breaks.
Test Plan: Rely on CI.
Reviewers: sahanp
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98671
Approved by: https://github.com/kit1980
Disable tests using quantized operators if QNNPACK is not available
Two disabled tests use Int8FC operators
which are not available if QNNPACK is not available,
and fail only due to that.
Disable cpuid_test on s390x
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99871
Approved by: https://github.com/albanD
On big endian systems byteswapping should be done other way around.
This change fixes TestE2ETensorPipe.TestTrainingLoop test from
test_cpp_rpc testsuite on big endian systems.
Use uint64_t when decoding double values.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99869
Approved by: https://github.com/ezyang
A single call to the `GraphModule.recompile` function occurs after the `GraphModule` has been constructed.
62f9189d9d/torch/_dynamo/output_graph.py (L754-L755)
However, the recompile function has already been called once during construction, so this call should be redundant.
```
call stack:
recompile, graph_module.py:644
graph, graph_module.py:411
__setattr__, module.py:1674
__init__, graph_module.py:370
compile_and_call_fx_graph, output_graph.py:754
...
```
So maybe it can be deleted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100084
Approved by: https://github.com/ezyang
* Added ExportPassBase, an interpreter based helper pass writing class
* It can also help maintain the dialect based on the operator namespace through having users override the `get_valid_dialects` function (returning an empty lists implies the pass works for any dialect).
* Added a `ReplaceBrokenOpsWithFunctionalOpsPass` to replace all ops that have not been converted with functionalization with their functional ones.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100000
Approved by: https://github.com/gmagogsfm
Currently, we return `unimplemented` w/o a graph break on seeing a x.unsqueeze_ when x is input. This essentially means we fall back to the original frame.
This PR actually graph breaks so that we can generate the continuation frame for the rest of the function. Instead of graph breaking at LOAD_ATTR, we delay the graph break to the actual CALL_FUNCTION, where its cleaner to graph break.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99986
Approved by: https://github.com/jansel
simplify method_def generation
Summary:
This removes some duplication. This was originally done to streamline
a subsequent change, but that change turned out to be
misguided. Nevertheless, this is a nice simplification.
Test Plan:
This should change the code gen by removing some redundant
parentheses. Rely on CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100059
Approved by: https://github.com/ezyang
remove casts to `getter` in python_cpp_function.h
Summary:
These were triggering the warning `-Wcast-function-type-strict` and
breaking the build on my machine.
Test Plan: Rely on CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100065
Approved by: https://github.com/ezyang
Summary: This commit adds a private helper function to override
the default QConfig in the default QConfigMapping. Previously we
needed to override all the object_types manually while skipping
the fixed qparams ops. This led to duplicate code every time
someone wanted a new default QConfig. After this commit, we can
just call the same helper function instead.
Test Plan:
python test/test_quantization.py TestQuantizeFx
Reviewers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99888
Approved by: https://github.com/vkuzo, https://github.com/jerryzh168
Implements a simple content-addressable store for storages (with tensors implemented as cheap references on top), enabling incremental serialization of tensors to disk, which I intend to use in the accuracy repro extractor. Check the comment at the top of torch/utils/_content_store.py for more details on the intended use case.
One major piece of this PR is implementing the content hash for tensors. For our prospective use case, we may need to repeatedly hash up to 80 GB of tensor data every time we snapshot (and we may snapshot multiple times). Using a conventional cryptographic hash and hashing each snapshot would likely take on order of minutes, which seemed too slow to me. So instead, I implemented a crappy hash function that can be run on GPU. It is at least somewhat theoretically grounded: using random parameters generated by Philox, we use the standard shift-multiply and xor sum universal hash family. The hash function is a bit dorky though; instead of properly doing 160-bit math, it just runs 32-bit hash five times and cats them together. By the way, this sets the first precedent for kernel in PyTorch library which MUST be torch.compile'd to be run (in fact, this kernel does not run in eager mode because of the use of xor_sum, which doesn't actually exist in ATen.)
I had to add a few more primitives to inductor, namely randint (over the entire int range) and xor_sum. Fortunately, these primitives are natively supported by Triton/C++, and so they were very easy to plumb through. xor_sum is exposed as a prim, while randint special cases on when low/high span the entire 32-bit signed integer range.
Thanks to Jeff Johnson for letting me bounce ideas of him on a Saturday morning lol.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99809
Approved by: https://github.com/voznesenskym
This PR proposes an optimized way to do Exponential Moving Average (EMA), which is faster than the current way using `swa_utils.AveragedModel` described in https://pytorch.org/docs/stable/optim.html#custom-averaging-strategies.
This implementation is asynchronous, and is built as an optimizer wrapper so that the EMA weight update happens without any additional CPU/GPU sync, just after optimizer steps, and with limited code changes.
Example usage:
```
model = Model().to(device)
opt = torch.optim.Adam(model.parameters())
opt = EMAOptimizer(opt, device, 0.9999)
for epoch in range(epochs):
training_loop(model, opt)
regular_eval_accuracy = evaluate(model)
with opt.swap_ema_weights():
ema_eval_accuracy = evaluate(model)
```
Here are some benchmarks (time per iteration) on various torchvision models:
|model|this PR iteration time |swa_utils.AveragedModel iteration time| iteration speedup |
|-----|-----------------------------|-----------------------|---------------------------------------------|
| | | | |
|regnet_x_1_6gf|62.73 |67.998 |1.08 |
|regnet_x_3_2gf|101.75 |109.422 |1.08 |
|regnet_x_400mf|25.13 |32.005 |1.27 |
|regnet_x_800mf|33.01 |37.466 |1.13 |
|regnet_x_8gf|128.13 |134.868 |1.05 |
|regnet_y_16gf|252.91 |261.292 |1.03 |
|regnet_y_1_6gf|72.14 |84.22 |1.17 |
|regnet_y_3_2gf|99.99 |109.296 |1.09 |
|regnet_y_400mf|29.53 |36.506 |1.24 |
|regnet_y_800mf|37.82 |43.634 |1.15 |
|regnet_y_8gf|196.63 |203.317 |1.03 |
|resnet101|128.80 |137.434 |1.07 |
|resnet152|182.85 |196.498 |1.07 |
|resnet18|29.06 |29.975 |1.03 |
|resnet34|50.73 |53.443 |1.05 |
|resnet50|76.88 |80.602 |1.05 |
|resnext101_32x8d|277.29 |280.759 |1.01 |
|resnext101_64x4d|269.56 |281.052 |1.04 |
|resnext50_32x4d|100.73 |101.102 |1.00 |
|shufflenet_v2_x0_5|10.56 |15.419 |1.46 |
|shufflenet_v2_x1_0|13.11 |18.525 |1.41 |
|shufflenet_v2_x1_5|18.05 |23.132 |1.28 |
|shufflenet_v2_x2_0|25.04 |30.008 |1.20 |
|squeezenet1_1|14.26 |14.325 |1.00 |
|swin_b|264.52 |274.613 |1.04 |
|swin_s|180.66 |188.914 |1.05 |
|swin_t|108.62 |112.632 |1.04 |
|swin_v2_s|220.29 |231.153 |1.05 |
|swin_v2_t|127.27 |133.586 |1.05 |
|vgg11|95.52 |103.714 |1.09 |
|vgg11_bn|106.49 |120.711 |1.13 |
|vgg13|132.94 |147.063 |1.11 |
|vgg13_bn|149.73 |165.256 |1.10 |
|vgg16|158.19 |172.865 |1.09 |
|vgg16_bn|177.04 |192.888 |1.09 |
|vgg19|184.76 |194.194 |1.05 |
|vgg19_bn|203.30 |213.334 |1.05 |
|vit_b_16|217.31 |219.748 |1.01 |
|vit_b_32|69.47 |75.692 |1.09 |
|vit_l_32|223.20 |258.487 |1.16 |
|wide_resnet101_2|267.38 |279.836 |1.05 |
|wide_resnet50_2|145.06 |154.918 |1.07 |
You can see that in all cases it is faster than using `AveragedModel`. In fact in many cases, adding EMA does not add any overhead since the computation is hidden behind the usual iteration flow.
This is a similar implementation to the one currently in [NVIDIA NeMo](https://github.com/NVIDIA/NeMo).
If the team is interested in merging this, let me know and I'll add some documentation similar to `swa_utils` and tests.
Credits to @szmigacz for the implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94820
Approved by: https://github.com/janeyx99
Some modules like lazyModule may override '_save_to_state_dict()', in this case, pre_state_dict hook will not be called. So move the pre_state_dict hook out from '_save_to_state_dict()' to make sure the pre hook could be called
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98964
Approved by: https://github.com/albanD
Fixes https://github.com/pytorch/pytorch/issues/98143.
If a user mutates a tensor that has overlapping memory, this can cause silent correctness issues with torch.compile. This PR adds a few checks to detect that situation and error.
Unfortunately `at::has_internal_overlap()` wasn't smart enough to detect the one linked in the issue, so I added a (simple) check that only runs in functionalization, that can catch the overlapping memory. We might need to revisit and add more complex checks later though (luckily, functionalization runs during compilation time so we can afford more expensive checks).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99919
Approved by: https://github.com/ezyang, https://github.com/albanD
This is a suggestion for a minor modification.
The line `log_normalization[self.total_count + value == 0.] = 0.` prevents Jit compilation when the condition occurs, with the error message
`RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation.`
I propose an alternative that does not involve in-place operations. It uses the function `nan_to_num()` to replace infinite values by 0 where `self.total_count + value == 0.` while leaving `nan` and `-inf` as they are. Readability is suboptimal because the code does not replace nan with numbers, but I could not find a function that only replaces infinite values.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96748
Approved by: https://github.com/fritzo, https://github.com/soulitzer
suppress `-Wcast-function-type-strict` when casting to PyCFunction
Summary:
These casts are a necessary evil due to the design of Python. Python
ultimately casts it back to the original type based on the flags
specified in the `PyMethodDef`.
Nevertheless, the new Clang flag `-Wcast-function-type-strict` breaks
with this.
While here, convert the cast to a `reinterpret_cast`.
Test Plan: Should be a no-op. Rely on CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100068
Approved by: https://github.com/Skylion007
This PR adds the frame summary to the log message, e.g.:
```
[2023-04-26 00:11:21,035] torch._dynamo.symbolic_convert: [INFO] Skipping frame because there is a graph break in a for/while loop
<FrameSummary file /fsx/users/andgu/work/transformers/src/transformers/models/t5/modeling_t5.py, line 1086 in <resume in forward>>
```
Note that the line cited by the frame summary may not be the for/loop itself but rather a line inside the for/while loop.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100045
Approved by: https://github.com/anijain2305
They block tests test_embedding_bag_2bit_unpack,
test_embedding_bag_4bit_unpack and test_embedding_bag_byte_unpack in test/quantization/core/test_quantized_op.py.
Without these asserts tests start passing on big endian systems.
Fixes#97803
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99713
Approved by: https://github.com/kit1980
The test fails with device mismatch error:
```
Traceback (most recent call last):
File "/pytorch/torch/testing/_internal/common_utils.py", line 2137, in wrapper
method(*args, **kwargs)
File "/pytorch/torch/testing/_internal/common_device_type.py", line 401, in instantiated_test
result = test(self, **param_kwargs)
File "/pytorch/torch/testing/_internal/common_device_type.py", line 846, in test_wrapper
return test(*args, **kwargs)
File "/pytorch/torch/testing/_internal/common_device_type.py", line 1005, in only_fn
return fn(slf, *args, **kwargs)
File "/pytorch/torch/testing/_internal/common_device_type.py", line 1029, in multi_fn
return fn(slf, devices, *args, **kwargs)
File "/pytorch/test/test_ops.py", line 148, in test_multiple_devices
self.assertTrue(result.device == cuda_device)
AssertionError: False is not true
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99775
Approved by: https://github.com/ngimel
Fixes#72428 according to decision reached in comments.
I've left other instances of `w.r.t.` in tact (e.g. in parameter/return descriptions, in comments, etc) because there were many, and I didn't' want to go out-of-scope. That being said, I'm happy to change those as well if we'd prefer the consistency!
I've also fixed a typo that I came across while grepping for instances.
Will update with screenshots once docs are built.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100028
Approved by: https://github.com/albanD
Summary: Today, on a segfault on a single trainer , we end up keeping the gpu on all ranks blocked for 5 minutes due to elastic agents barrier timeouts
Test Plan: Rely on existing test to validate . Looking to get some feedback on adding UTs
Differential Revision: D44929488
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99051
Approved by: https://github.com/kurman, https://github.com/kiukchung
pre_autograd tracing is still early, but it should work for basic cases. This PR changes the API a bit for export to expose pre_autograd tracing. Name bikeshedding is welcome, but it looks like:
```
torch._dynamo.export(..., aten_graph="aten_pre_autograd")
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98031
Approved by: https://github.com/ezyang
The bug was that: if you want to move a mode to the autograd key, we need to use the "functionality" key for it (AutogradFunctionality). But when we do that, we need to clear any PythonDispatcher caches for every op for **every** autograd key (since you could run autograd ops with both cpu and cuda tensors underneath the mode, which both may have been cached).
I didn't add a test, since this ends up getting indirectly tests by export in the PR. If someone would prefer a direct test I can add one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98030
Approved by: https://github.com/ezyang
**TL;DR**: This PR fixes handling for lazy modules where `cls_to_become is None`. In those cases, we should leave the type of the lazy module as the old value.
**Details**:
Lazy modules are intended to be initialized at execution; some of them are also supposed to switch to a different type after they have been initialized. However, not all are supposed to switch; see this logic from `nn/modules/lazy.py`
```python
def _infer_parameters(self, ...):
...
if module.cls_to_become is not None:
module.__class__ = module.cls_to_become
```
i.e., we should leave the module type as the old value if `module.cls_to_become is None`. This PR updates dynamo's handling to match this behavior.
Test `test_lazy_module_no_cls_to_become` added to `test/dynamo/test_module.py`.
Differential Revision: [D45253698](https://our.internmc.facebook.com/intern/diff/D45253698)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99943
Approved by: https://github.com/jansel
* add stepcurrent flag (--sc) based off the stepwise flag that saves the currently running test so that test running can resume from the last successful test after segfaults, takes in an argument for a key so that different test runs dont overwrite each other
* send sigint to process when timeout so that xml can be made
* add currently unused stepcurrent skip flag (--scs) based off stepwise skip flag that skips the failing test, was going to use if for the keep-going label but having trouble with CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98035
Approved by: https://github.com/huydhn
Fixes the issue with the PR base detection for bc-lint. See also #98538
The context: to lint PR for BC-breaking changes we need two commits with the history between them that accurately represents the changes, introduced in the PR (and **only** these changes).
---
Previous attempts to achieve this failed due to the following reasons:
1. Use `github.event.pull_request.base.sha` and `github.event.pull_request.head.sha`.
If the PR's base branch advances, the new commits will be included in the `github.event.pull_request.base.sha`, mixing with the changes, introduced by the PR.
2. Find a common ancestor between `github.event.pull_request.base.sha` and `github.event.pull_request.head.sha`, use it as a base commit.
This approach fails as well, if the PR includes merge commits from the newest history of its base branch. Such commits will appear as the changes, introduced in the PR and thus interfere with BC-linting.
---
Current approach (this PR):
Perform a merge of the `github.event.pull_request.head.sha` onto the `github.event.pull_request.base.sha`, and use the new commit SHA as the new head.
This approach should always accurately find the changes introduced in the linted PR. The only shortcoming is when the PR cannot be merged onto the HEAD of it's base branch. In this case the BC-linting is skipped (the linting will be performed when the PR is rebased and conflicts are resolve, which is requires anyway before the PR is accepted).
---
### Testing
* [in a separate repo for experiments](https://github.com/izaitsevfb/pr-head-test/pull/2/checks)
* [BC-linter failure (this PR)](https://github.com/pytorch/pytorch/actions/runs/4793434350/jobs/8525891436?pr=99958)
* gh-stack test: [failure](https://github.com/pytorch/pytorch/pull/100004), [success ](https://github.com/pytorch/pytorch/pull/100003)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99958
Approved by: https://github.com/osalpekar
This PR enables fully_shard fused adam tests with some additional tweaks
about how to handle scalar tensor. Now we treat scalar tensors as if
it's just a scalar value, we don't distribute it as there's no need to
shard a scalar tensor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99898
Approved by: https://github.com/mrshenli
This PR introduces **-Wmissing-prototypes** of clang-tidy to prevent further coding errors such as the one fixed by PR #96714.
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at fd2cf2a</samp>
This pull request makes several internal functions static to improve performance and avoid name clashes. It also fixes some typos, formatting, and missing includes in various files. It adds a new .clang-tidy check to warn about missing prototypes for non-static functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96805
Approved by: https://github.com/malfet, https://github.com/albanD
ROCM path detection currently relies on `hipconfig`. On some systems when calling `hipconfig` through `subprocess` python raises a `NotADirectoryError` that isn't catch at the moment. This commit adds `NotADirectoryError` to exceptions catched when calling `hipconfig`.
Fixes#98629
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99980
Approved by: https://github.com/jeffdaily, https://github.com/malfet
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99220
Previously we have two places we need to decide whether to insert observer or fake quantizer or not:
(1) input arguments of a node (2) output of a node, and right now we have separate code to do this
in this PR, the logic is unified in `_needs_obs_or_fq` helper function that takes the target_dtype and is_dynamic from previous output
and target_dtype and is_dynamic for the current Tensor we are looking at
let's use an example for conv node:
```
conv = convolution(input, weight, bias, ...)
```
let's say we have `input_node` object for argument `input`, and `conv_node` for `conv` node in the graph
(1) input arguments, e.g. `input`
the target_dtype/is_dynamic from previous output is the node that produces `input`, we get this from
input_node.meta["target_dtype_info"]["output_act_obs_or_fq"]
the taregt_dtype/is_dynamic for the current argument `input`, comes from conv_node.meta["target_dtype_info"]["input_act_obs_or_fq"]
similarly for weight it comes from conv_node.meta["target"]["weightobs_or_fq"] etc.
(2) output for conv node
the target_dtype/is_dynamic from previous output will be the floating point output from the fp32 convolution operator, so it
is hardcoded to be (torch.float, False), however, technically we should get this from node.meta["val"], but since the
current code base is shared by fx graph mode quantization and pytorch 2.0 export quantization, we cannot do that, we can revisit
after we decide to deprecate fx graph mode quantization
the target_dtype/is_dynamic for the current output comes from conv_node.meta["target_dtype_info"]["output_act_obs_or_fq"]
there is one caveat here about dynamic quantization, that is explained in the comment, so I won't repeat here
Note: also fixed some places in `_get_arg_target_dtype_as_input_to_node` and `_get_arg_target_is_dynamic_as_input_to_node` to make sure "not specified" == specifying a fp32 placeholder observer as well
Next: we can merge the two get target dtype and get is_dynamic function to reduce code duplication
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestQuantizeFxModels
python test/test_quantization.py TestQuantizePT2E
python test/test_quantization.py TestQuantizePT2EModels
Imported from OSS
Differential Revision: D45198323
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99767
Approved by: https://github.com/kimishpatel
Summary:
We were using the "percentiles" form of triton.testing.do_bench, which
returns a list of like (20th, 50th, 80th) percentile timing; I don't think we
care about that much detail, so let's just use the mean. I also took the
opportunity to clean up the redundant setting of rep, warmup, and fast_flush.
Test Plan:
```
TORCHBENCH_ATOL=1e-3 TORCHBENCH_RTOL=1e-3 TORCHINDUCTOR_PERMUTE_FUSION=1 TORCHINDUCTOR_SHAPE_PADDING=1 buck2 run mode/opt mode/inplace pytorch/benchmark:run -- ads_dhen_5x --part over --bs 1024 -d cuda -t train --torchdynamo inductor
```
Reviewed By: jiawenliu64
Differential Revision: D45241751
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99917
Approved by: https://github.com/jiawenliu64
ROCm's version of triton does not currently support tl.device_assert.
This operator among others is effectively a no-op unless "debug" = True is passed in the triton.compile function.
Until we have full suport for tl.device_assert, avoid enabling the debug flag in triton.compile, so we do not have to find every possible location tl.device_assert may be used.
Fixes#99725
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99756
Approved by: https://github.com/lezcano
Fixes #ISSUE_NUMBER
like #99817, I find a method is missing,
I'm not sure if it was intentionally removed. But I found that the function is still called on the python side, and the function seems to be very simple to implement.
So I made a change in python side.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99818
Approved by: https://github.com/ezyang
Follow up for https://github.com/pytorch/pytorch/pull/96532. Including this in setup.py so the package will be available for CI.
Fsspec package size:
```
du -h /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg
264K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec/__pycache__
58K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec/implementations/__pycache__
377K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec/implementations
1017K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/fsspec
96K /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg/EGG-INFO
1.2M /fsx/users/irisz/conda/envs/pytorch/lib/python3.9/site-packages/fsspec-2023.3.0-py3.9.egg
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99768
Approved by: https://github.com/kit1980
Fix https://github.com/pytorch/pytorch/issues/99686, for eager mode, if the given sizes is not meet requirements, it will report an error, but inductor can run, I think we need align inductor behavior with eager mode, the behavior will be like after this PR:
```
Traceback (most recent call last):
File "/home/xiaobing/pytorch-offical/torch/_dynamo/utils.py", line 1267, in run_node
return node.target(*args, **kwargs)
File "/home/xiaobing/pytorch-offical/torch/functional.py", line 189, in split
return tensor.split(split_size_or_sections, dim)
File "/home/xiaobing/pytorch-offical/torch/_tensor.py", line 804, in split
return torch._VF.split_with_sizes(self, split_size, dim)
File "/home/xiaobing/pytorch-offical/torch/utils/_stats.py", line 20, in wrapper
return fn(*args, **kwargs)
File "/home/xiaobing/pytorch-offical/torch/_subclasses/fake_tensor.py", line 1095, in __torch_dispatch__
return self.dispatch(func, types, args, kwargs)
File "/home/xiaobing/pytorch-offical/torch/_subclasses/fake_tensor.py", line 1259, in dispatch
return decomposition_table[func](*args, **kwargs)
File "/home/xiaobing/pytorch-offical/torch/_decomp/decompositions.py", line 1102, in split_with_sizes
raise ValueError(
ValueError: Split sizes don't add up to the tensor's size in the given dimension
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/xiaobing/pytorch-offical/torch/_dynamo/utils.py", line 1215, in get_fake_value
return wrap_fake_exception(
File "/home/xiaobing/pytorch-offical/torch/_dynamo/utils.py", line 835, in wrap_fake_exception
return fn()
File "/home/xiaobing/pytorch-offical/torch/_dynamo/utils.py", line 1216, in <lambda>
lambda: run_node(tx.output, node, args, kwargs, nnmodule)
File "/home/xiaobing/pytorch-offical/torch/_dynamo/utils.py", line 1279, in run_node
raise RuntimeError(
RuntimeError: Failed running call_function <function split at 0x7f45b8402ee0>(*(FakeTensor(..., size=(1, 5)), [2, 1, 1]), **{'dim': 1}):
Split sizes don't add up to the tensor's size in the given dimension
(scroll up for backtrace)
The above exception was the direct cause of the following exception:
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99702
Approved by: https://github.com/jgong5, https://github.com/lezcano, https://github.com/jansel
The default option of `named_parameters` and `named_modules` is to remove the duplicated parameters and modules. However, in FSDP, we need to know what parameters are shared. As a result, setting `remove_duplicate` to False is required in FSDP. Without setting `remove_duplicate` to False, FSDP won't be able to discover shared weights in some cases (e.g., the shared weights are in the same module or there are shared modules).
The previous PR is reverted due to some modules overwriting the signature of `named_parameters()`. This new PR adds a workaround for the case.
Differential Revision: [D45065973](https://our.internmc.facebook.com/intern/diff/D45065973/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99448
Approved by: https://github.com/zhaojuanmao
This should fix https://github.com/pytorch/pytorch/issues/99011.
With `NCCL_DESYNC_DEBUG=0`, we can run 100 iterations of
```
CUDA_LAUNCH_BLOCKING=1 NCCL_DESYNC_DEBUG=1 CUDA_VISIBLE_DEVICES=0,7 numactl -C 2 python test/distributed/fsdp/test_fsdp_core.py -v -k test_transformer_no_grad --repeat 100 2>&1 | tee out
```
without erroring, whereas with `NCCL_DESYNC_DEBUG=1`, we can repro the error with high failure rate (usually <10 iterations).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99916
Approved by: https://github.com/zhaojuanmao
This PR improves the list/tuple handling by merging the logic into
`wrap_with_proxy` directly, and set_meta when we find the current
proxy is a fx.Proxy. This also solves the problem that even `fused_adam`
have `val`, some corresponding `getitem` calls followed after `fused_adam` don't have val
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99897
Approved by: https://github.com/ezyang
Fixes #ISSUE_NUMBER
when create a torch.device obj, like `x=torch.device("foo")`, the device index is None.
So in this scenario, we need to get the current device index again.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99704
Approved by: https://github.com/albanD
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 9691a66</samp>
Update the `pt2-bug-report.yml` template to use `curl` instead of `wget`, `main` instead of `master`, and `python3` instead of `python`. These changes improve the portability and reliability of the bug report process.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99928
Approved by: https://github.com/kit1980, https://github.com/msaroufim
### Description
The PR aims at reducing CPU overhead of context manager style coalescing.
By "context manager style coalescing", we mean:
Sync style:
```
with _coalescing_manager():
for i in range(num_coll):
dist.all_reduce(tensors[i])
```
Async style:
```
with _coalescing_manager(async_ops=True) as cm:
for i in range(num_coll):
dist.all_reduce(tensors[i])
cm.wait()
```
In previous implementation, each collective in the `num_coll` loop actually calls into the C++ backend, accumulating pybind overhead.
In the new implementation, we capture the collectives at Python level, and only fire towards C++ at the exit of the coalescing manager.
### Tests
In current PR, the "fast path" only applies to all-reduce.
- Flattened 512M: 16.38 ms, including CPU time 131.21 us
- Old _coalescing_manager 64 x 8M: 22.19 ms, including CPU time 2865 us
- New _coalescing_manager 64 x 8M: 16.93 ms, including CPU time 635 us
Hence a 4x reduction in CPU overhead (dependent on `num_coll`).
Cc @mrshenli @kumpera @wanchaol @fegin
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98793
Approved by: https://github.com/kumpera
MacOS-10.9 (Mavericks) was released a decade ago, update it to Big Sur, that was released in 2020. But keep platform name to 10_9, as `pip` treats platform as one CPython was built on, not the one it runs on. Delete duplicate `compile_x86_64` function from `macos_build.sh` and specify platform name there.
Should fix MacOS x86 periodic build failures.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at ee4d5a8</samp>
> _`macosx_10_9` wheel_
> _Aligns with PyTorch support_
> _Winter of updates_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99857
Approved by: https://github.com/huydhn, https://github.com/atalman
In this stack of PRs we adding caching to output tensors for cudagraph trees after we've done initial recording. On initial recording we do not cache tensor outputs because this prevents memory from being reclaimed. On subsequent exeuctions we do cache them to avoid overhead. However, because there is an extra reference around, this caused divergent recording & execution behavior in both autocast caching and autograd gradient stealing. Divergent recording & execution would keep on re-recording and eventually stabilize, but it's not what you want to see happen.
This pr makes the autocast cache and buffer stealing aware of the cudagraph static output tensors.
I will add this to the other cudagraph impl in another pr.
Not sure if this should be in autograd or in autocast since it affects both.. Or somewhere else
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99368
Approved by: https://github.com/albanD, https://github.com/ezyang
Summary: This add support for CallMethod patterns in pattern_matcher. Also extends split_cat transforms to normalize tensor.split() type nodes
Test Plan: Unit tests (fb + OSS)
Differential Revision: D45195548
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99782
Approved by: https://github.com/jansel
The `new_subgroups` allows for the easy creation of sub-communication groups, but it currently requires CUDA availability. For communications that do not rely on CUDA, such as the CPU-based gloo or custom communication backends, I still hope to be able to use it, such as with the CPU-based gloo (which is also the case when using a custom backend):
```python
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def gloo_process(rank_id, world_size, group_size, mp_lock):
assert not torch.cuda.is_available()
def lock_print(*args, **kwargs):
with mp_lock:
print(*args, **kwargs, flush=True)
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group('gloo', rank=rank_id, world_size=world_size)
subgroup, _ = dist.new_subgroups(group_size)
subgroup_ranks = list(range(subgroup.rank() * group_size, (subgroup.rank() + 1) * group_size))
lock_print(f"Rank {rank_id} initialized in subgroup_{subgroup.rank()}: {subgroup_ranks}")
tensor = torch.Tensor([rank_id + 1])
subgroup.broadcast(tensor, root=0)
lock_print(f"After broadcast, rank {rank_id} in subgroup_{subgroup.rank()}:{subgroup_ranks} got {tensor}")
if __name__ == "__main__":
world_size = 4
group_size = 2
processes = []
mp.set_start_method("spawn")
mp_lock = mp.Lock()
for rank in range(world_size):
p = mp.Process(target=gloo_process, args=(rank, world_size, group_size, mp_lock))
p.start()
processes.append(p)
for p in processes:
p.join()
```
```bash
Rank 0 assigned to subgroup_0: [0, 1]
Rank 1 assigned to subgroup_1: [2, 3]
Rank 2 assigned to subgroup_0: [0, 1]
Rank 3 assigned to subgroup_1: [2, 3]
After broadcast, rank 2 in subgroup_0:[0, 1] got tensor([3.])
After broadcast, rank 3 in subgroup_1:[2, 3] got tensor([3.])
After broadcast, rank 1 in subgroup_1:[2, 3] got tensor([1.])
After broadcast, rank 0 in subgroup_0:[0, 1] got tensor([1.])
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99706
Approved by: https://github.com/kumpera
### This change
- Implements the ruff linter in pytorch lintrunner. It is adapted from https://github.com/justinchuby/lintrunner-adapters/blob/main/lintrunner_adapters/adapters/ruff_linter.py. It does **both linting and fixing**. 🔧
- Migrated all flake8 configs to the ruff config and enabled it for the repo. ✅
- **`ruff` lints the whole repo in under 2s** 🤯
Fixes https://github.com/pytorch/pytorch/issues/94737 Replaces #99280
@huydhn @Skylion007
<!--
copilot:all
-->
### <samp>🤖 Generated by Copilot at 6b982dd</samp>
### Summary
🧹🛠️🎨
<!--
1. 🧹 This emoji represents cleaning or tidying up, which is what `ruff` does by formatting and linting the code. It also suggests improving the code quality and removing unnecessary or redundant code.
2. 🛠️ This emoji represents tools or fixing, which is what `ruff` is as a code formatter and linter. It also suggests enhancing the code functionality and performance, and resolving potential issues or bugs.
3. 🎨 This emoji represents art or creativity, which is what `ruff` allows by providing a consistent and configurable style for the code. It also suggests adding some flair or personality to the code, and making it more readable and enjoyable.
-->
Add `[tool.ruff]` section to `pyproject.toml` to configure `ruff` code formatter and linter. This change aims to improve code quality and consistency with a single tool.
> _`ruff` cleans the code_
> _like a spring breeze in the fields_
> _`pyproject.toml`_
### Walkthrough
* Configure `ruff` code formatter and linter for the whole project ([link](https://github.com/pytorch/pytorch/pull/99785/files?diff=unified&w=0#diff-50c86b7ed8ac2cf95bd48334961bf0530cdc77b5a56f852c5c61b89d735fd711R22-R79))
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99785
Approved by: https://github.com/malfet, https://github.com/Skylion007
Use bindless Argument Buffers (unbounded arrays) for advanced indexing kernels - this allows caching of the PSOs since we don't have to query anymore the main metal function for the AB size (this is filled directly now on the CPU).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99855
Approved by: https://github.com/kulinseth
This lowers `aten.prod` using the new `tl.reduce` functionality in triton. I
also introduce `TritonKernel.helper_functions` which allows code to be defined
outside of the kernel body so that we can defined the `_prod_accumulate` helper
function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99484
Approved by: https://github.com/ngimel
Add support for kernel coalescing to native kernels.
This change reuses the same compute command encoder across successive metal kernel dispatches. The coalescing will stop when a graph op is encountered.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99810
Approved by: https://github.com/kulinseth
Summary:
Support special case that data size can be 0 for SegmentReduce.
Example code below:
```
x = torch.ones((0, 6)).cuda()
lengths = torch.tensor([0, 0]).cuda()
torch.segment_reduce(x, "sum", lengths=lengths, unsafe=False, initial=0)
```
Previously, error message: Expected data.numel() > 0 to be true, but got false.
Now expect to return 0.
Test Plan: contbuild & OSS CI
Differential Revision: D45133827
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99733
Approved by: https://github.com/ngimel
Testing if the minor change breaks other test cases.
For the added test case, TorchDynamo causes graph break on `torch.ops.foo.custom` but then again starts running on the recursively invoked frame - `foo_cpu` on L48 in testfile. This raises assertion like this
~~~
Traceback (most recent call last):
File "/scratch/anijain/work/pytorch/test/dynamo/test_decorators.py", line 65, in test_disallow_in_graph_for_custom_op
res = opt_fn(x)
File "/scratch/anijain/work/pytorch/torch/_dynamo/eval_frame.py", line 252, in _fn
return fn(*args, **kwargs)
File "/scratch/anijain/work/pytorch/test/dynamo/test_decorators.py", line 56, in fn
b = torch.ops.foo.custom(a)
File "/scratch/anijain/work/pytorch/torch/_ops.py", line 646, in __call__
return self._op(*args, **kwargs or {})
File "/scratch/anijain/work/pytorch/torch/_dynamo/eval_frame.py", line 401, in catch_errors
return callback(frame, cache_size, hooks, frame_state)
File "/scratch/anijain/work/pytorch/torch/_dynamo/convert_frame.py", line 495, in _convert_frame
result = inner_convert(frame, cache_size, hooks, frame_state)
File "/scratch/anijain/work/pytorch/torch/_dynamo/convert_frame.py", line 122, in _fn
return fn(*args, **kwargs)
File "/scratch/anijain/work/pytorch/torch/_dynamo/convert_frame.py", line 331, in _convert_frame_assert
return _compile(
File "/scratch/anijain/work/pytorch/torch/_dynamo/utils.py", line 169, in time_wrapper
r = func(*args, **kwargs)
File "/scratch/anijain/work/pytorch/torch/_dynamo/convert_frame.py", line 401, in _compile
out_code = transform_code_object(code, transform)
File "/scratch/anijain/work/pytorch/torch/_dynamo/bytecode_transformation.py", line 1000, in transform_code_object
transformations(instructions, code_options)
File "/scratch/anijain/work/pytorch/torch/_dynamo/convert_frame.py", line 371, in transform
tracer = InstructionTranslator(
File "/scratch/anijain/work/pytorch/torch/_dynamo/symbolic_convert.py", line 1890, in __init__
self.symbolic_locals = collections.OrderedDict(
File "/scratch/anijain/work/pytorch/torch/_dynamo/symbolic_convert.py", line 1893, in <genexpr>
VariableBuilder(
File "/scratch/anijain/work/pytorch/torch/_dynamo/variables/builder.py", line 165, in __call__
return self._wrap(value).clone(**self.options())
File "/scratch/anijain/work/pytorch/torch/_dynamo/variables/builder.py", line 290, in _wrap
return type_dispatch(self, value)
File "/scratch/anijain/work/pytorch/torch/_dynamo/variables/builder.py", line 776, in wrap_tensor
tensor_variable = wrap_fx_proxy(
File "/scratch/anijain/work/pytorch/torch/_dynamo/variables/builder.py", line 923, in wrap_fx_proxy
return wrap_fx_proxy_cls(
File "/scratch/anijain/work/pytorch/torch/_dynamo/variables/builder.py", line 983, in wrap_fx_proxy_cls
example_value = wrap_to_fake_tensor_and_record(
File "/scratch/anijain/work/pytorch/torch/_dynamo/variables/builder.py", line 1213, in wrap_to_fake_tensor_and_record
fake_e = wrap_fake_exception(
File "/scratch/anijain/work/pytorch/torch/_dynamo/utils.py", line 835, in wrap_fake_exception
return fn()
File "/scratch/anijain/work/pytorch/torch/_dynamo/variables/builder.py", line 1214, in <lambda>
lambda: tx.fake_mode.from_tensor(
File "/scratch/anijain/work/pytorch/torch/_subclasses/fake_tensor.py", line 1434, in from_tensor
return self.fake_tensor_converter(
File "/scratch/anijain/work/pytorch/torch/_subclasses/fake_tensor.py", line 329, in __call__
return self.from_real_tensor(
File "/scratch/anijain/work/pytorch/torch/_subclasses/fake_tensor.py", line 283, in from_real_tensor
out = self.meta_converter(
File "/scratch/anijain/work/pytorch/torch/_subclasses/meta_utils.py", line 531, in __call__
r = self.meta_tensor(
File "/scratch/anijain/work/pytorch/torch/_subclasses/meta_utils.py", line 184, in meta_tensor
assert not torch._C._dispatch_tls_local_exclude_set().has(
AssertionError:
~~~
It seems `_dynamo.disable` is the right option for custom ops added by `torch.library`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99600
Approved by: https://github.com/jansel
This PR adds list handling logic to the new DataParallel expansion and
add foreach optimizer tests, currently current testing sgd optimizers
in foreach mode, for both replicate and fully shard
Next step:
Add fused optim tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99373
Approved by: https://github.com/mrshenli
This PR refactors the current StrategyList. It introduces a
StrategyType, which is the base class of Strategy, and it have
two sub strategies:
1. Refactor the previous StrategyList to OpStrategy
2. Add TupleStrategy, the new strategy added to deal with tuple cases where
it could return multiple different OpStrategy for an op.
This would help support a more complicated op and unblocks compile mode
FSDP
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99435
Approved by: https://github.com/mrshenli
Summary: There're some customized functions that we would also like to keep during eliminate dead code pass. Add a function to help us to do.
Test Plan: Added a unit test
Differential Revision: D44273630
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97288
Approved by: https://github.com/houseroad
Summary:
Support the file extension .html, which will include a PNG image of the plot embedded into an HTML file.
This allows users to avoid processing the timeline manually in their own frontend UI.
Test Plan:
CI Tests
Ran on resnet50 model and generated this html file w/ plot:
See attached html file: {F954232276}
Screenshot: {F954232469}
Differential Revision: D45152735
Pulled By: aaronenyeshi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99751
Approved by: https://github.com/davidberard98
This PR introduces compile mode Data Parallel (FSDP/DDP) using DTensor sharding.
Along with the algorithm, it also introduces a new DataParallelMode so that `compile` API can take it
and apply data parallel. This PR trys to preserve the DTensorExpand
approach first to avoid BC, we shall discuss steps to remove
DTensorExpand.
The data parallel mode uses heuristics to determine node types in the
graphs and assign the corresponding sharding. The detailed algorithm
described in the design doc.
The benefits of this approach:
- Model parameters and optimizer states are all DTensors after `spmd.compile`, which is necessary for FSDP, and also makes it super easier for checkpointing
- As model parameter/optim states are sharding in a per-parameter approach, it would be able to compose with sophisticated second order optimizer (i.e. Shampoo) in a easier way.
- We leverage the model parameter/grads information to derive data parallel pattern. In this way we don't need to worry about DTensor op coverage anymore! As data parallel is just a special case of DTensor operation.
- Use dtensor_expand might work for DDP but aren't going to work for FSDP as dtensor might choose to allgather activation, which might violate native fsdp algorithm.
- The approach is general enough to support both DDP/FSDP and a mixed mode
Follow ups:
- Add the "default" data parallel mode which supports mixing of
replicate/fully shard
- Test more e2e models with more different types of optimizers, etc
- migrate the existing stack from the DTensorExpand mode
- build optimizations on top of this prototype
Differential Revision: [D45174400](https://our.internmc.facebook.com/intern/diff/D45174400)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99062
Approved by: https://github.com/mrshenli
This reverts commit b9da79d2800c2ca00b57bc3ac86b43e01be174b6.
Reverted https://github.com/pytorch/pytorch/pull/98706 on behalf of https://github.com/huydhn due to Sorry for reverting your PR but a bunch of inductor tests are failing after this commit, so reverting the PR just to be sure
This depends on [pytest-cpp](https://github.com/pytest-dev/pytest-cpp) to discover and run C++ tests with pytest. C++ tests are built under `${WORKSPACE}/build/bin` directory and copied to the test job under the same path.
* To expose them to `run_test`, I choose to use the mock path prefix `cpp`, for example `build/bin/c10_Array_test` would be named as `cpp/c10_Array_test` and the `python test/run_test.py --cpp -i cpp/c10_Array_test` would run the test in the same way as other Python tests. I could copy them from `build/bin` to `test/cpp`, but it will be mixed with the source code and CMake file. So this looks easier
* Some executable under `build/bin` are not C++ tests, and they are exclude, for example `build/bin/torch_shm_manager`
* C++ tests need to run with pytest directly as python command doesn't understand it
* The change is gated by the new `--cpp` argument to `run_test.py`, for example `python test/run_test.py --cpp` will run all available C++ tests
* The tests can be run in parallel
* Failing tests can be retried with `--reruns=2` and `--sw`
```
============================= test session starts ==============================
platform darwin -- Python 3.9.15, pytest-7.2.0, pluggy-1.0.0 -- /Users/huydo/miniconda3/envs/py3.9/bin/python3
cachedir: .pytest_cache
hypothesis profile 'default' -> database=DirectoryBasedExampleDatabase('/Users/huydo/Storage/mine/pytorch/test/.hypothesis/examples')
rootdir: /Users/huydo/Storage/mine/pytorch, configfile: pytest.ini
plugins: xdoctest-1.1.0, cpp-2.3.0, rerunfailures-10.3, shard-0.1.2, flakefinder-1.1.0, hypothesis-6.56.4, xdist-3.0.2, repeat-0.9.1
collecting ... collected 3 items / 2 deselected / 1 selected
Running 1 items in this shard: build/bin/scalar_tensor_test::TestScalarTensor.TestScalarTensorMPS
stepwise: skipping 2 already passed items.
../build/bin/scalar_tensor_test::TestScalarTensor::TestScalarTensorMPS RERUN [100%]
../build/bin/scalar_tensor_test::TestScalarTensor::TestScalarTensorMPS RERUN [100%]
../build/bin/scalar_tensor_test::TestScalarTensor::TestScalarTensorMPS FAILED [100%]
```
* `--import-slow-tests` and `--import-disabled-tests` won't work for now and that's ok to have it as a future task.
I also add `pytest-cpp==2.3.0` to Linux Docker, MacOS, and Windows.
### Testing
Build PyTorch and run `python test/run_test.py --cpp` on my laptop. CI change would come later in a separate PR. Also running `python test/run_test.py --help` now shows all C++ test discovered under `build/bin`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99559
Approved by: https://github.com/clee2000
## What's in this PR
DeviceMesh's __init__ function now requires all calling ranks to pass the same `mesh` argument.
## Why
We want to enforce SPMD style of programs using DTensor. Before this PR, 2-D Parallel API (e.g. _create_1d_device_mesh) defines different DeviceMesh on different ranks. After this PR, it defines each sub-meshes and simply perform communications on the one that it is associated with.
Differential Revision: [D45165511](https://our.internmc.facebook.com/intern/diff/D45165511)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99094
Approved by: https://github.com/wanchaol
Summary:
Currently torch.fx support Modules with input of namedtuple/dataclass, return as namedtuple, but does not allow Module.forward to return a dataclass, running `test_trace_return_dataclass` without this change will have following error:
NotImplementedError: argument of type: <class 'test_fx.TestFX.test_trace_return_dataclass.<locals>.MyOutput'>
File "test_trace_return_dataclass
traced_graph = symbolic_trace(module).graph
File "test/__fx__/fx#link-tree/torch/fx/_symbolic_trace.py", line 1114, in symbolic_trace
graph = tracer.trace(root, concrete_args)
File "test/__fx__/fx#link-tree/torch/fx/_symbolic_trace.py", line 783, in trace
(self.create_arg(fn(*args)),),
File "test/__fx__/fx#link-tree/torch/fx/_symbolic_trace.py", line 378, in create_arg
return super().create_arg(a)
File "test/__fx__/fx#link-tree/torch/fx/proxy.py", line 269, in create_arg
raise NotImplementedError(f"argument of type: {type(a)}")
this diff handle dataclass type.
Test Plan:
buck test @//mode/opt @//mode/inplace //caffe2/test:fx -- test_trace_
graph():
%d : torch.Tensor [#users=1] = placeholder[target=d]
%my_output : [#users=1] = call_function[target=test_fx.MyOutput](args = (), kwargs = {foo: %d, bar: %d})
return my_output
Differential Revision: D44916519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99576
Approved by: https://github.com/suo
High level approach:
1. I generated a bunch of data comparing FlashAttention and Cutlass implementations (https://pastebin.com/pe0j3YeK)
2. I trained a decision tree using standard train/val split methodology and hyperparameter sweeps (https://pastebin.com/fjYX1HjR).
2a. I did a bunch of feature augmentation to capture interactions between features.
The heuristic I ended up with is:
```
use_flash = seq_len / (num_heads * batch_size) > 6
```
TL;DR: On my dataset, where FlashAttention and Cutlass differ by more than 10%, the existing heuristic achieves 69% accuracy. My new heuristic achieves 94% accuracy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99644
Approved by: https://github.com/ngimel, https://github.com/drisspg
Fixes#99545
There is currently no topological constraint dictating FSDP instances own ``FlatParamHandle`` s directly. If all parameters are managed by descendant FSDP instances leaving an FSDP instance with no direct ``state._handles``, the ``should_cast_forward_inputs`` decisions below in both ``_root_pre_forward()`` and ``_pre_forward()`` respectively can return incorrect decisions [^1].
For [``_root_pre_forward()``](436edc5ac3/torch/distributed/fsdp/_runtime_utils.py (L514)):
436edc5ac3/torch/distributed/fsdp/_runtime_utils.py (L602-L604)
For [``_pre_forward``](436edc5ac3/torch/distributed/fsdp/_runtime_utils.py (L384)):
436edc5ac3/torch/distributed/fsdp/_runtime_utils.py (L420-L422)
See the [related issue](https://github.com/pytorch/pytorch/issues/99545) for reproduction.
### Remediation
In this PR, I amend the two decision statements referenced above (in both `_root_pre_forward()` and `_pre_forward()`) to account for FSDP instances without direct handles:
```python
should_cast_forward_inputs = len(state._handles) > 0 and all(
not handle._force_full_precision for handle in state._handles
)
```
If one configures ``MixedPrecision`` in the example above with ``cast_forward_inputs=True`` and the ``should_cast_forward_inputs`` adjustment above, FSDP returns to the expected behavior and produces no error.
Though the check is the same in both ``_root_pre_forward()`` and ``_pre_forward()`` and hence could be refactored into a separate function, I figured it may make sense to retain separate statements to preserve the ability for root-specific behavior in the future. Whichever approach the team prefers I can update this PR with.
### Implementation considerations and questions:
1. Rather than write a test that would arguably have a poor utility/resource usage profile, I have not added any tests associated with this PR. The new decision logic is exercised by all existing tests (which continue to pass after this PR of course) so I think the utility of new tests is fairly modest. Let me know if you think new tests should be added and I'm happy to do so.
2. As discussed above, the decision statement shared among ``_pre_forward()`` and ``_root_pre_forward()`` could be factored out into a separate function. Given the simplicity of the statement and to retain current flexibility for root-specific decisions it might not be worth the refactor so I haven't done it yet. Let me know if you'd like me to do so.
3. The note below could be updated to indicate the utility of setting ``cast_forward_inputs=True`` for the situations addressed with this PR but I haven't done so since I'm not sure it's worth complicating the current usage guidance. I'd be happy to add verbiage describing the use case if the team wants it.
cde35b4069/torch/distributed/fsdp/api.py (L175-L181)
Thanks again to the PyTorch distributed team for your immensely valuable contributions to the open-source ML community!
[^1]: Though one could keep the existing decision logic and impose a new topological constraint requiring all FSDP instances have direct `_handles`, I think retaining the current wrapping flexibility is both convenient and useful enough (e.g. programmatic wrapping of modules that may or may not already have all parameters handled by descendant FSDP instances) to update the decision logic as discussed here instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99546
Approved by: https://github.com/awgu
This PR adds calls to nvml during an OOM to find out the total memory
in use by the process and any other CUDA processes on the device.
This makes it easier to identify cases where non-PyTorch libraries have
allocated memory or another process (such as a data loader) has also
allocated memory on the device.
This also rewords the other parts of the error message to make the meaning
of the memory statistics more clear with this new information:
"""
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 138.00 MiB.
GPU 0 has a total capacty of 15.90 GiB of which 8.44 MiB is free.
Process 1246069 has 577.00 MiB memory in use. Including non-PyTorch memory,
this process has 15.32 GiB memory in use. Of the allocated memory
14.12 GiB is allocated by PyTorch, and 410.41 MiB is reserved
by PyTorch but unallocated. If reserved but unallocated memory is large
try setting max_split_size_mb to avoid fragmentation. See documentation
for Memory Management and PYTORCH_CUDA_ALLOC_CONF
"""
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99699
Approved by: https://github.com/ngimel
A theory is that something else on the runner removes the file like Windows Defender. The number one suspect is `com.apple.XProtect.daemon.scan` https://support.apple.com/guide/security/protecting-against-malware-sec469d47bd8/web
Spot checking on some runners:
* On 13.x (13.3.1 and 13.2.1), the daemon is now called `com.apple.XProtect.daemon.scan`
```
sh-3.2$ sudo launchctl list | grep -i protect
8048 -9 com.apple.XprotectFramework.PluginService
8047 -9 com.apple.XProtect.daemon.scan
```
* On 12.4, the daemon is called `com.apple.XprotectFramework`
```
sudo launchctl list | grep -i protect
- -9 com.apple.XprotectFramework.PluginService
- -9 com.apple.XprotectFramework.scan
```
Looking at the list of failures in https://hud.pytorch.org/failure/ModuleNotFoundError%3A%20No%20module%20named%20'sympy', I can confirm that the issue happens with both MacOS 12 and 13 as I can find examples on both.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99506
Approved by: https://github.com/malfet
This PR makes `use_orig_params=True` case support rank0_only loading for optim state_dict. The implementation is different from `use_orig_params=False`. The `use_orig_params=False` implementation first flatten the parameters on rank0 and then broadcast the states while this implementation broadcast the state when doing the flattening. The implementation is slower as it broadcast the original parameters instead of the flattened ones. However, the implementation introduced by this PR is simpler. As loading is usually happen once per training life, the performance difference can be ignored. In next PR, we will consolidate the implementations in favor of the simpleness.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99624
Approved by: https://github.com/wz337
Fixes#99326
Support storage pin_memory and is_pinned for custom device, by calling dispatched tensor operations.
@ezyang this pr is what we have discussed in issue #99326, would you please take a moment to review it, thanks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99712
Approved by: https://github.com/ezyang
This PR caches the addr -> Frame information across calls to symbolize,
and also keeps the addr2line symbolizing processes around once requested.
This makes calls to symbolize frames that have been seen before nearly instant,
and makes lookup of address in libraries that have already been loaded by
addr2line faster.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99670
Approved by: https://github.com/ezyang
This PR introduces a ParallelMode interface to define how to do
SPMD expansion and optimize the captured graph. This would be
beneifical for different parallelisms to expand differently
and apply different optimization passes
Put DTensorExpandMode as the first parallel mode that does the
existing dtensor_expand functionality.
Differential Revision: [D45174399](https://our.internmc.facebook.com/intern/diff/D45174399)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98452
Approved by: https://github.com/mrshenli
Summary:
Previously we have two places we need to decide whether to insert observer or fake quantizer or not:
(1) input arguments of a node (2) output of a node, and right now we have separate code to do this
in this PR, the logic is unified in `_needs_obs_or_fq` helper function that takes the target_dtype and is_dynamic from previous output
and target_dtype and is_dynamic for the current Tensor we are looking at
let's use an example for conv node:
```
conv = convolution(input, weight, bias, ...)
```
let's say we have `input_node` object for argument `input`, and `conv_node` for `conv` node in the graph
(1) input arguments, e.g. `input`
the target_dtype/is_dynamic from previous output is the node that produces `input`, we get this from
input_node.meta["target_dtype_info"]["output_act_obs_or_fq"]
the taregt_dtype/is_dynamic for the current argument `input`, comes from conv_node.meta["target_dtype_info"]["input_act_obs_or_fq"]
similarly for weight it comes from conv_node.meta["target"]["weightobs_or_fq"] etc.
(2) output for conv node
the target_dtype/is_dynamic from previous output will be the floating point output from the fp32 convolution operator, so it
is hardcoded to be (torch.float, False), however, technically we should get this from node.meta["val"], but since the
current code base is shared by fx graph mode quantization and pytorch 2.0 export quantization, we cannot do that, we can revisit
after we decide to deprecate fx graph mode quantization
the target_dtype/is_dynamic for the current output comes from conv_node.meta["target_dtype_info"]["output_act_obs_or_fq"]
there is one caveat here about dynamic quantization, that is explained in the comment, so I won't repeat here
Note: also fixed some places in `_get_arg_target_dtype_as_input_to_node` and `_get_arg_target_is_dynamic_as_input_to_node` to make sure "not specified" == specifying a fp32 placeholder observer as well
Next: we can merge the two get target dtype and get is_dynamic function to reduce code duplication
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestQuantizeFxModels
python test/test_quantization.py TestQuantizePT2E
python test/test_quantization.py TestQuantizePT2EModels
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D45167585](https://our.internmc.facebook.com/intern/diff/D45167585)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99220
Approved by: https://github.com/kimishpatel
Fixes#99148 , raising an error if output_ratio's size > 2.
Justification for changes:
If an output size is not specified but an output ratio is, we call fractional_max_pool2d_with_indices. We then generate the value of output_size based on the first two integers of the output_ratio (line ~480 of torch.nn.functional.py).
Thus, we should raise a value error in the case that the user passes an output_ratio (instead of an output_size) and the number of elements in output_ratio exceeds two. We must raise an error before calling torch._C._nn.franctional_max_pool2d as the value of output_size passed into torch._C._nn.fractional_max_pool2d is guaranteed to be of size 2 (as the existing code generates it from the first two indices of the passed in ratio).
I would be happy to iterate on this if there are any issues.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99507
Approved by: https://github.com/mikaylagawarecki
A quick, trial fix for #99677.
My guess is that when the code instantiates an `AutoNcclGroup` object, it comes with an uninitialized random value for member `comm_nonblocking_`. Then `if (comm_nonblocking_)` evaluates to true, and `NCCL_CHECK_TIMEOUT` triggered.
This change is safe (and needed) anyway whether it indeed fixes#99677.
Cc @eqy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99679
Approved by: https://github.com/eqy, https://github.com/awgu
Summary:
Followup diffs to integrate this op into the other parts of the delegate workflow.
The unittest results in the following graph:
```
graph():
%x_1 : [#users=1] = placeholder[target=x_1]
%y_1 : [#users=1] = placeholder[target=y_1]
%lowered_module_0 : [#users=1] = get_attr[target=lowered_module_0]
%call_delegate : [#users=1] = call_function[target=torch.ops.call_delegate](args = (%lowered_module_0, forward, %x_1, %y_1), kwargs = {})
return call_delegate
```
Test Plan: buck2 run //executorch/exir/tests:delegate -- -r "test_call_delegate"
Differential Revision: D42329287
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92562
Approved by: https://github.com/voznesenskym
TLDR, I did a quick study of register spill in max-autotune and coordesc descent tuning. The conclusion is for the pointwise/reduction kernels, register spill is rare in inductor (which means the configs we consider are relatively reasonable), but it indeed happens sometimes. TBH, this PR does not gonna help reducing compilation time for max-autotune/coordinate descent tuning much because register spilling is very rare. But this PR only contains 2 lines of significant code change, so I guess it's still good to merge it considering ROI and code complexity.
# Register Spill in Max-Autotuner
I ran command
```
rm -rf /tmp/torchinductor_shunting_tmp && time TORCHINDUCTOR_MAX_AUTOTUNE_POINTWISE=1 TORCHINDUCTOR_CACHE_DIR=/tmp/torchinductor_shunting_tmp python -u benchmarks/dynamo/torchbench.py --backend inductor --amp --performance --dashboard --only ${MODEL} --disable-cudagraphs --training 2>&1 | tee /tmp/mylog
```
and then analyze the log.
$ cat /tmp/mylog | grep 'nspill' | wc -l
will show the total number of triton.Config's we benchmark;
$ cat /tmp/mylog | grep 'nspill' | grep -v 'nspill 0'
will show the number of triton.Config's that spill registers.
Checked 5 models
- hf_Bert 0 spills
- resnet50: 2 out of 199 triton.Config's spill. For the 2 configs that spill, they are suboptimal according to the log: https://gist.github.com/shunting314/7ea30a9dafad7156919a99df5feba0ee
- timm_vision_transformer: 2/77 spills. The spilled configs are again sub-optimal: https://gist.github.com/shunting314/a48cbcfb14a07c0b84555e2cf7154852
- BERT_pytorch: 0/123 spills
- timm_resnest 0/255 spills
# Register Spill in Coordinate Descent Tuner
I ran command
```
rm -rf /tmp/torchinductor_shunting_tmp && time TORCHINDUCTOR_MAX_AUTOTUNE_POINTWISE=1 TORCHINDUCTOR_CACHE_DIR=/tmp/torchinductor_shunting_tmp TORCHINDUCTOR_COORDINATE_DESCENT_TUNING=1 TORCHINDUCTOR_PERSISTENT_REDUCTIONS=0 python -u benchmarks/dynamo/torchbench.py --backend inductor --amp --performance --dashboard --only ${MODEL} --disable-cudagraphs --training 2>&1 | tee /tmp/mylog
```
and then analyze the log.
$ cat /tmp/mylog | grep COORDESC | wc -l
shows the total number of configs considered by the coordinate descent tuner
$ cat /tmp/mylog | grep COORDESC | grep -v 'nspill 0'
shows the ones that spill.
Checked 3 models
- hf_Bert (log https://gist.github.com/shunting314/bd943887e77609c7c8b323fe3f554c85 )
0/525 spills
- resnet50: 0/783 spills
- timm_vision_transformer: 2/380 (log https://gist.github.com/shunting314/6231f06c1398e0cddb2a96bf52389c78 )
the 2 spilled one are sub-optimal
# Ignore Spilled Config
With this PR, I run test tests for timm_vision_transformer and can see all 4 spilled configs (2 for max-autotune and 2 for coordinate descent tuner according to the study above) are skipped for benchmarking:
```
[2023-04-18 00:03:37,291] torch._inductor.triton_heuristics: [DEBUG] Skip config XBLOCK: 16, YBLOCK: 512, num_warps: 8, num_stages: 1 because of register spilling: 6
[2023-04-18 00:04:50,523] torch._inductor.triton_heuristics: [DEBUG] Skip config XBLOCK: 64, RBLOCK: 64, num_warps: 8, num_stages: 1 because of register spilling: 626
[2023-04-18 00:04:50,523] torch._inductor.triton_heuristics: [DEBUG] Skip config XBLOCK: 8, RBLOCK: 512, num_warps: 8, num_stages: 1 because of register spilling: 778
[2023-04-18 00:05:47,170] torch._inductor.triton_heuristics: [DEBUG] Skip config XBLOCK: 1, num_warps: 2, num_stages: 1 because of register spilling: 4
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99385
Approved by: https://github.com/jansel
A theory is that something else on the runner removes the file like Windows Defender. The number one suspect is `com.apple.XProtect.daemon.scan` https://support.apple.com/guide/security/protecting-against-malware-sec469d47bd8/web
Spot checking on some runners:
* On 13.x (13.3.1 and 13.2.1), the daemon is now called `com.apple.XProtect.daemon.scan`
```
sh-3.2$ sudo launchctl list | grep -i protect
8048 -9 com.apple.XprotectFramework.PluginService
8047 -9 com.apple.XProtect.daemon.scan
```
* On 12.4, the daemon is called `com.apple.XprotectFramework`
```
sudo launchctl list | grep -i protect
- -9 com.apple.XprotectFramework.PluginService
- -9 com.apple.XprotectFramework.scan
```
Looking at the list of failures in https://hud.pytorch.org/failure/ModuleNotFoundError%3A%20No%20module%20named%20'sympy', I can confirm that the issue happens with both MacOS 12 and 13 as I can find examples on both.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99506
Approved by: https://github.com/malfet
Fixes#99446
Remove the warning, as that annoyed end-users who don't know what to do about it.
Instead, try to hold the line by preventing any decomp from being added without making
the corresponding change to inductor's fallbacks.
Note: we probably still need to better document how to update inductor's decomps,
for now it's pretty much "go ask the inductor team for advice"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99473
Approved by: https://github.com/ezyang, https://github.com/ngimel, https://github.com/jansel
**Summary**
Since current quantization flow has not decomposed quant/dequant into prim ops, in this PR
- We enable the quant/dequant decomposition as lowering inside inductor.
- For the `decomposed.quant/dequant.tensor` overload, there are loading of scalar tensor of `zero point` and `scale`, we need to enable the vec code gen for these op overloads.
- Minor change as adding `is_load_uint8_as_float` and `is_store_float_as_uint8` default value `False` into `OptimizationContext`.
**TestPlan**
```
cd test/inductor && python -m pytest test_cpu_repro.py -k test_dequant_quant_lowering
```
co-author with @Xia-Weiwen
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99131
Approved by: https://github.com/jgong5, https://github.com/EikanWang, https://github.com/jansel
Coordinating with arogozhnikov from einops team, allowing specific operators in the dynamo graph avoids dynamo tracing problems provided the operators are screened for safety - they must not bake in unintended constants or take data-dependent control flow paths.
Fixes#99031
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99631
Approved by: https://github.com/jansel
In edge cases in CI, SLOW_TESTS_FILE is defined but does not point to an existing file.
Guessing this is due to a test case that opens a subprocses and cwd's but doesn't clean its env.
We shouldn't make importing common_utils fail, so issue a warning and proceed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99659
Approved by: https://github.com/ezyang, https://github.com/malfet
As functional collective being updated, using tensor_split() as the underlying sharding algorithm would require padding and unpadding on multiple ranks. Therefore, we are changing the sharding algorithm to be in line with ``torch.chunk()`` to allow padding on the last two ranks in most of the scenarios.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98722
Approved by: https://github.com/wanchaol
add entry for privateuse1 storage serialization register_package in _register_device_module.
1. User only need to implement `privateuse1_tag` and `privateuse1_deserialize` in the device module of open device. When registering device module, the methods are registered with _package_registry in storage serialization.
2. Provides a fixed sequence number 30 for privateuse1 in storage serialization _package_registry list.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98920
Approved by: https://github.com/ezyang
Expand sdpa_utils.h check to disable FlashAttention when using autograd and mem eff attention for the following cases
- head_dim > 64
- sm86 or newer
Previously we only disable these kernels on sm86 and for head_dim equal to 128.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99105
Approved by: https://github.com/malfet
**Summary:** This commit adds the `prepare_qat_pt2e` API and the
fusion logic for Conv + BN. We use the subgraph rewriter to
match and replace the pattern with the existing logic in
`nniqat.ConvBn2d`. Note this is not the end-to-end flow yet.
In particular, the convert flow needs to swap the new subgraph
with another one that merges the batchnorm stats back into conv.
The Conv + BN fusion is implemented in the following steps:
1. Annotate all nodes in the pattern `[conv - bn - getitem]`
2. Match and replace this pattern with the fused QAT pattern
(note that this is a larger subgraph than the original one)
3. Copy over metadata from the original nodes to the
corresponding nodes in the new subgraph, to ensure the
stack traces and dtype annotations are preserved
4. Prepare will insert fake quantizes in the right places
based on the annotations
**Test Plan:**
python test/test_quantization.py TestQuantizePT2E.test_qat_conv_bn_fusion
**Reviewers:** jerryzh168, kimishpatel, yanboliang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98568
Approved by: https://github.com/kimishpatel
Fixes#99221 , clarifying the error message to highlight the index from inputs which is responsible for the out-of-bounds error, while maintaining the reference to the relevant index of offsets as a secondary consideration.
Also takes care of some spelling/grammatical issues with another message (primarily "yout" changed to "your").
Would be happy to iterate on this if there are any issues.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99471
Approved by: https://github.com/albanD
**Background**: Prior to this PR, traces for PT2 w/ inductor don't contain connections between CUDA kernels and the CPU launch site. This PR adds those connections.
**Details**: Triton kernels launched by inductor use cuLaunchKernel instead of cudaLaunchKernel. cuLaunchKernel is part of the driver API, while cudaLaunchKernel is part of the runtime API. In order to support cuLaunchKernel, we added support in kineto (pytorch/kineto#752) to also start listening to driver events; hence why we need to update the kineto submodule.
After the change in kineto, we just need to turn this on in the PyTorch repo by adding CUDA_DRIVER activity type to the CPU and CUDA activity type lists; then
**Testing**: Added test/inductor/test_profiler.py to check for `cuLaunchKernel` in json trace files.
Also, I ran this test:
```python
import torch
x = torch.rand((2, 2), device='cuda')
def fn(x):
return x.relu()
fn_c = torch.compile(fn)
fn_c(x)
with torch.profiler.profile(with_stack=True) as prof:
fn_c(x)
prof.export_chrome_trace("relu_profile.json")
```
which generated this chrometrace:
<img width="930" alt="Screenshot 2023-04-18 at 2 58 25 PM" src="https://user-images.githubusercontent.com/5067123/232966895-b65f9daf-7645-44f8-9e2b-f8c11c86ef0a.png">
in which you can see flows between a `cuLaunchKernel` on the CPU side, and the triton kernel on the GPU.
**Kineto Updates**: To get the kineto-side changes required for cupti driver events, this PR updates the kineto pin. In that updated kineto submodule, we also have:
* JSON string sanitizing for event names (likely fix for #99572)
* cuda initialization fixes for multiprocessing
* cuKernelLaunch events (i.e. for this PR)
* DISABLE_CUPTI_LAZY_REINIT (from @aaronenyeshi)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99571
Approved by: https://github.com/ngimel, https://github.com/aaronenyeshi
It's part of the effort to improve PT2 Export UX. This PR is to improve the usability of `torch.cond()` by separating user errors from the dynamo internal errors. By definition, user error means the usage of `torch.cond()` violates the restrictions of this API therefore needs users to take action and fix the error.
In this notebook N3363227 we discovered a bunch of limitations of using `torch.cond(pred, true_fn, false_fn, operands)`. In summary, the limitations can be categorized as:
- predicate restriction (`pred`)
- operands restriction (`operands`)
- branch restriction (`true_fn` & `false_fn`)
The error message will be more accurate about where the (user) error is from and more actionable for users to fix it.
For example, `operands` must be a list of tensors and the signature of `true_fn` and `false_fn` must match with the `operands`.
If the operands contains non-tensor types, user will see error message like:
```
torch._dynamo.exc.UserError: Expected a list of tensors but got ["<class 'torch.Tensor'>", "<class 'float'>"]
from user code:
File "~/pytorch/test/dynamo/test_export.py", line 2504, in f_non_tensor_operands
return cond(True, lambda x, a: x.sin(), lambda x, a: x.cos(), [x, a])
```
If the signature of the branch function doesn't match with `operands`, user will see error message like:
```
torch._dynamo.exc.UserError: too many positional arguments.
func = 'false_fn' ~/pytorch/test/dynamo/test_export.py:2514, args = [<class 'torch.Tensor'>, <class 'torch.Tensor'>], kwargs = {}
```
Or if the tensor returned from user defined branches has different metadata, e.g. shapes, dtypes, etc., user will see error message like:
```
TypeError: Expected each tensor to have same metadata but got:
cond_true_0 returns TensorMetadata(shape=torch.Size([2, 1]), dtype=torch.int64, requires_grad=False, stride=(1, 1), memory_format=torch.contiguous_format, is_quantized=False, qparams={})
cond_false_0 returns TensorMetadata(shape=torch.Size([1]), dtype=torch.float32, requires_grad=False, stride=(1,), memory_format=torch.contiguous_format, is_quantized=False, qparams={})
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98909
Approved by: https://github.com/jansel
Summary:
A very old refactor (https://github.com/pytorch/pytorch/pull/29500) split ScriptModule into ScriptObject (base class) and ScriptModule (subclass). When moving methods around, the `_type` method was moved from ScriptModule to ScriptObject, but the type of its argument wasn't changed. Therefore, it is now impossible to invoke `_type` on a ScriptObject.
The reason I need this fix is that I am using PyTorch's dispatch mode to intercept some operators that accept/return custom classes, which end up being encoded as ScriptObject, and in order to properly handle them I need to be able to verify their type.
Test Plan: N/A
Differential Revision: D45118675
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99542
Approved by: https://github.com/albanD
Why?
* To reduce the latency of hot path in https://github.com/pytorch/pytorch/pull/97377
Concern - I had to add `set_offset` in all instances of `GeneratorImpl`. I don't know if there is a better way.
~~~~
import torch
torch.cuda.manual_seed(123)
print(torch.cuda.get_rng_state())
torch.cuda.set_rng_state_offset(40)
print(torch.cuda.get_rng_state())
tensor([123, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0], dtype=torch.uint8)
tensor([123, 0, 0, 0, 0, 0, 0, 0, 40, 0, 0, 0, 0, 0,
0, 0], dtype=torch.uint8)
~~~~
Reland of https://github.com/pytorch/pytorch/pull/98965
(cherry picked from commit 8214fe07e8a200e0fe9ca4264bb6fca985c4911e)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99565
Approved by: https://github.com/anijain2305
Follow up on Jason's idea of tensor layout tuning. Add a script to show the perf impact of layout to convolution (will add more cases like batch/layer norm, reduction to the scripts).
For convolution, a quick test shows using channels last layout, we get 1.4x speedup for convolution:
```
baseline 4.509183883666992 test 3.178528070449829 speedup 1.419x
```
The speedup definitely also depends on input/weight shapes. E.g., change input channel from 3 in the test to 8, we see speedup to be 2.1x
The trace shows cudnn calls different kernels when input layout changes to channels last.
<img width="997" alt="Screenshot 2023-04-19 at 5 27 54 PM" src="https://user-images.githubusercontent.com/52589240/233228656-4bdcac0a-7633-416a-82e1-17d8dc8ea9a6.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99583
Approved by: https://github.com/jansel
Fixes #ISSUE_NUMBER
1、torch.jit.load for custom device
```
# custom device named `foo`
ts_model = torch.jit.script(mode.to(device="foo"))
ts_model.save("./ts.pt") # it is a script model on device `foo`
# and then we want to load it and run it
torch.jit.load("./ts.pt")
```
2、 add some extra key for custom device with `privateuse1`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99535
Approved by: https://github.com/albanD
Coordinating with @arogozhnikov from einops team, allowing specific operators in the dynamo graph avoids dynamo tracing problems provided the operators are screened for safety - they must not bake in unintended constants or take data-dependent control flow paths.
Fixes#99031
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99478
Approved by: https://github.com/jansel
This is a draft version of generic context manager, I believe there are some scenarios that I didn't anticipate. I posted this draft for discussion and check if this is the right direction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98725
Approved by: https://github.com/jansel
Summary:
In order to keep quantizer simple, we want to move the annotation code for operators like flatten, hardtanh etc. to
a separate utility function that is called after the quantizer annotation is done, this makes these ops (operator list) not
configurable by user, and also makes prepare_pt2e operator aware instead of operator agnostic, this design is not final,
we may change it in the future if we find there are use cases that need these to be configurable or if we feel it is important for prepare_pt2e
to stay agnostic to operator/operator patterns
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_qnnpack_quantizer_obs_sharing_ops
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D45071006](https://our.internmc.facebook.com/intern/diff/D45071006)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99384
Approved by: https://github.com/kimishpatel
Removes two additional places where we would construct tensors
- Non-static inputs. These are only constructed to invoke the `copy_` kernel and do not own memory so we can construct them only once
- Aliases of persistent static inputs (parameters). the memory will be permanently live and is not managed by the cudagraph tapes.
(also sneaking in a bug fix around unaligned static idx)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98950
Approved by: https://github.com/jansel
The design of export API expects constraints to be specified on dynamic dimensions, while assuming all other dimensions are static by default. However a user who wishes to export a model may not be fully familiar with the code to plan what to specify.
This diff provides support for discovering constraints to specify. The basic idea is to take the set of generated shape guards and convert them into appropriate constraints. However, we usually generate a LOT of shape guards, and there is often a LOT of redundancy in them. Thus, we also need to simplify the guards so that our suggested constraints are concise yet capture the information content in the guards.
The algorithm for simplification uses `sympy` under the hood, but very surgically to avoid any risk of blowing up. See comments inline for a full description. Briefly,
1. We consider only univariate inequalities, and among them, solve for equalities first.
2. We substitute these exact solutions to convert multivariate inequalities progressively into univariate.
3. Remaining univariate inequalities are solved using `sympy.solvers.inequalities.reduce_inequalities`.
4. As pre-processing, we also eliminate all `//` and `%` operations to generate a set of linear congruence guards, and solve these using `sympy.ntheory.modular.solve_congruence`.
The results are quite dramatic. For example, an internal model produced several hundreds of guards with `dynamic_shapes=True`, which were pretty much inscrutable for humans. The summary contains around 30 dimensions that were specialized and 3 constraints on dynamic dimensions. The output format looks like this:
```
The following dimensions have been specialized and CANNOT be dynamic.
NOTE: Specializations will happen by default with `assume_static_by_default=True`.
L['foo']['bar'].size()[0] == 4
...
L['baz']['qux'].size()[3] == 96
The following dimensions CAN be dynamic.
You can use the following code to specify the constraints they must satisfy:
constraints=[
dynamic_dim(L['blah']['bleh'], 1) == dynamic_dim(L['blah']['bloh'], 1),
...,
2 <= dynamic_dim(L['blah']['bloh'], 1),
]
```
Differential Revision: [D44731747](https://our.internmc.facebook.com/intern/diff/D44731747/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98463
Approved by: https://github.com/voznesenskym, https://github.com/ezyang
Summary:
There are two variables for profiler input shapes:
- In C++ interface: report_input_shapes
- In Python interface: record_shapes
Therefore record_input_shapes is a typo. We should also look to reducing redundant naming between the two.
Test Plan: CI
Pulled By: aaronenyeshi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99430
Approved by: https://github.com/davidberard98
This PR also adds a way to CSE statements (not only assignments).
The tests follow the pattern from https://github.com/openai/triton/pull/1143
They take a fair amount of time to run (90s in my box). If we wanted to
improve this, we could avoid testing the `ndim == 3` case.
Changes like this one make me hope that we get to clean the amount of
lowerings we have at some point...
Generated code for `x[y]` with `x.shape == (3, 2, 4), y.ndim == 1`:
With `dynamic=False`:
```python
tmp0 = tl.load(in_ptr0 + (x1), xmask)
tl.device_assert(((0 <= tmp0) & (tmp0 < 3)) | (~xmask), f"index out of bounds: 0 <= tmp0 < 3")
tmp1 = tl.load(in_ptr1 + (x0 + (8*tmp0)), xmask)
```
With `dynamic=True`:
```python
tmp0 = tl.load(in_ptr0 + (x1), xmask)
tl.device_assert(((0 <= tmp0) & (tmp0 < ks3)) | (~xmask), f"index out of bounds: 0 <= tmp0 < ks3")
tmp1 = tl.load(in_ptr1 + (x0 + (ks1*ks2*tmp0)), xmask)
```
Generated code for `x[y+1, y+1]` with `x.shape == (3, 2, 4), y.ndim == (3, 3)`:
With `dynamic=False` (note how it folds the two upper bounds to `min(3, 2) == 2`
```python
tmp0 = tl.load(in_ptr0 + (x1), xmask)
tmp1 = 1
tmp2 = tmp0 + tmp1
tl.device_assert(((0 <= tmp2) & (tmp2 < 2)) | (~xmask), f"index out of bounds: 0 <= tmp2 < 2")
tmp3 = tl.load(in_ptr1 + (x0 + (12*tmp2)), xmask)
```
With `dynamic=True`:
```python
tl.device_assert(((0 <= tmp2) & (tmp2 < min(ks2, k1))) | (~xmask), f"index out of bounds: 0 <= tmp2 < min(ks2, ks1)")
```
The same works when the CSE'd variable appears 3 or more times, but then it generates `min(ks0, min(ks1, ks2))`
Generated code for `x[y] = z` with `x.ndim = 3`, `y.ndim = 1` and dynamic shapes
```python
tmp0 = tl.load(in_ptr0 + (x1), xmask)
tmp1 = tl.load(in_ptr1 + (x2), xmask)
tl.device_assert(((0 <= tmp0) & (tmp0 < ks3)) | (~xmask), f"index out of bounds: 0 <= tmp0 < ks3")
tl.store(out_ptr0 + (x0 + (ks1*ks2*tmp0) + tl.zeros([XBLOCK], tl.int32)), tmp1, xmask)
```
Fixes https://github.com/pytorch/pytorch/issues/93538
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98590
Approved by: https://github.com/ngimel
### Description
The PR aims at reducing CPU overhead of context manager style coalescing.
By "context manager style coalescing", we mean:
Sync style:
```
with _coalescing_manager():
for i in range(num_coll):
dist.all_reduce(tensors[i])
```
Async style:
```
with _coalescing_manager(async_ops=True) as cm:
for i in range(num_coll):
dist.all_reduce(tensors[i])
cm.wait()
```
In previous implementation, each collective in the `num_coll` loop actually calls into the C++ backend, accumulating pybind overhead.
In the new implementation, we capture the collectives at Python level, and only fire towards C++ at the exit of the coalescing manager.
### Tests
In current PR, the "fast path" only applies to all-reduce.
- Flattened 512M: 16.38 ms, including CPU time 131.21 us
- Old _coalescing_manager 64 x 8M: 22.19 ms, including CPU time 2865 us
- New _coalescing_manager 64 x 8M: 16.93 ms, including CPU time 635 us
Hence a 4x reduction in CPU overhead (dependent on `num_coll`).
Cc @mrshenli @kumpera @wanchaol @fegin
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98793
Approved by: https://github.com/kumpera
Sharing code between the code that handles test results in parallel vs serial mode.
Note that the original version of this code had an inconsistency between the two versions where it would execute `print_to_stderr(err_message)` on every test that ran in parallel, but for serial tests it would only invoke `print_to_stderr(err_message)` if `continue_on_error` was also specified. By sharing code, this PR changes that behavior to be consistent between the two modes.
Also adding some comments.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 029342c</samp>
> _Sing, O Muse, of the skillful coder who refined_
> _The PyTorch testing script, `run_test.py`, and shined_
> _A light on its obscure logic, with docstrings and comments_
> _And made it run more smoothly, with better error contents_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99467
Approved by: https://github.com/huydhn, https://github.com/malfet
For cases where the pattern graph matches on x number of arguments, but the matching graph omits some of these arguments (by using the default values instead), right now SubgraphMatcher fails because these graphs have a different number of arguments. So instead in the case where we see the pattern/replacement nodes have different number of arguments, we will add the default values onto whichever argument set is lacking arguments.
Note this support is only for when we are matching targets that are instances of OpOverload, which have a schema and default values tied to them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99431
Approved by: https://github.com/jerryzh168
giving the following case:
```
import torch
a= torch.empty_strided([64, 1, 33], [33, 3, 1], dtype=torch.bfloat16).fill_(1)
b = torch.randn(64, 33, 256).to(dtype = torch.bfloat16)
y = torch.ops.aten.bmm(a, b)
```
```a``` is a contiguous tensor, but the strides are not defaulted contiguous strides ([33, 33, 1]), onednn matmul always running a non-optimized path:
```
onednn_verbose,exec,cpu,matmul,gemm:jit,undef,src_bf16::blocked:abc:f0 wei_bf16::blocked:abc:f0 dst_bf16::blocked:abc:f0,attr-scratchpad:user ,,64x1x33:64x33x256:64x1x256,7.28711
```
This PR will convert the inputs' stride to deafult contiguous stride before calling onednn to running an optimization path:
```
onednn_verbose,exec,cpu,matmul,brg:avx512_core_amx_bf16,undef,src_bf16::blocked:abc:f0 wei_bf16::blocked:abc:f0 dst_bf16::blocked:abc:f0,attr-scratchpad:user ,,64x1x33:64x33x256:64x1x256,3.06396
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99511
Approved by: https://github.com/mingfeima, https://github.com/jgong5
Fixes#99427
Given the provided CI logs, I ~~suspect~~[^1] `inf` is being hit with the initial (FSDP model) step of the [test in question](https://github.com/pytorch/pytorch/actions/runs/4707887920/jobs/8350225813#step:13:36189). The DDP loss is correct and indicative of two steps being taken but the FSDP loss is approximately half of the loss expected with the first step (suggesting a step was skipped and the scale was halved). I'm further reducing `init_scale` in this PR in order to ~~test the hypothesis~~[^2] (error occurs with 4 device multi-gpu tests only, not the 2 device tests I can verify locally).
I'll ensure I add the label `ciflow/periodic`[^3] to future PRs I suspect could potentially exhibit divergent behavior with >2 devices. Ideally all tests would be insensitive to device scaling but I recognize for some tests imposing that design constraint might be more trouble than it's worth.
@awgu @huydhn
[^1]: Suspicion confirmed
[^2]: The relevant periodic tests are [now passing](https://github.com/pytorch/pytorch/actions/runs/4738073998/jobs/8411862508)
[^3]: Didn't know that existed, great to know!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99485
Approved by: https://github.com/huydhn
All Sources must be hashable, since we are using set equality to check for
duplicate sources in AOTAutograd. We should have a more systematic way
of asserting this. For this PR just fix the local issue.
Fixes#99145
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99379
Approved by: https://github.com/ezyang
Months ago, in order to get dynamic shapes working through to Dynamo backends, we changed the calling convention to pass fake tensors rather than real tensors as example inputs to backends. The motivation at the time was, well, backends shouldn't really be peeking at the real tensors when they are doing compilation, and so it would make more sense to hide the real tensors from backends. But there were a bunch of problems:
* This interacted poorly with our accuracy minifier design: accuracy minifier needs access to the real inputs in order to run the model and figure out what happens!
* The TensorRT backend required real inputs and we never figured out how to fix it.
* In practice, all the backends needed to detect if they were passed real tensors, and fakeify them anyway (certainly AOTAutograd does this)
* Parameters and inputs are treated non-uniformly: parameters had to be passed as real tensors, because CUDA graphs requires knowing what the actual tensors are
Furthermore, there were some more problems discovered after the fact:
* Backends may want to optimize on aspects of tensors which you cannot tell without having real tensors; e.g., alignment of the data pointer
So, this PR decides that changing the calling convention was a bad idea, and switches back to passing real tensors. There is a problem though: AOTAutograd will perform fakeification, which means that in practice backends are still going to end up with fake tensors in the end anyway. I want to change this, but this will require some work with bdhirsh's upcoming AOTAutograd export refactor.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99320
Approved by: https://github.com/voznesenskym
Command to run max autotune baseline:
```
TORCHINDUCTOR_MAX_AUTOTUNE=1 time python benchmarks/dynamo/torchbench.py --backend inductor --amp --performance --only ${MODEL_NAME} --training --batch-size-file $(realpath benchmarks/dynamo/torchbench_models_list.txt)
```
Command to do coordinate descent autotuning:
```
TORCHINDUCTOR_COORDINATE_DESCENT_TUNING=1 TORCHINDUCTOR_CACHE_DIR=/tmp/torchinductor_shunting_coordesc TORCHINDUCTOR_PERSISTENT_REDUCTIONS=0 TORCHINDUCTOR_MAX_AUTOTUNE=1 time python benchmarks/dynamo/torchbench.py --backend inductor --amp --performance --only ${MODEL_NAME} --training --batch-size-file $(realpath benchmarks/dynamo/torchbench_models_list.txt)
```
Explanation of the envvars show up on the command:
```
- TORCHINDUCTOR_COORDINATE_DESCENT_TUNING=1 : enable coordinate descent tuning
- TORCHINDUCTOR_PERSISTENT_REDUCTIONS=0 : disable persistent reduction. Need do this so we can tune RBLOCK for reductions
- TORCHINDUCTOR_MAX_AUTOTUNE=1: enable max autotune
- TORCHINDUCTOR_CACHE_DIR=/tmp/torchinductor_shunting_coordesc : use a separate cache dir for coordinate descent tuning. Optional.
```
Here are my experiments results for around 40 torchbench models: https://docs.google.com/spreadsheets/d/1G7i2whIf8Yu-HhN_WovNxwcE-iFDSAw4x3NK4uL4XhI/edit#gid=0
Some highlights
- We improve 2.2% further upon max-autotune on average (geomean)
- timm_resnest benefits most from coordinate descent tuning. There is 1.07x speedup
- We have descent speedup on transformer models
- BERT_pytorch: 1.056x
- timm_vision_transformer: 1.04x
- hf_Bert: 1.030x
- For resnet models, it looks like we have less gain as model get larger. My guess is larger model spend more time on mm/conv, so our tuning for pointwise/reduction helps less
- resnet18: 1.021x
- resnet50: 1.014x
- resnet152: 1.005x
This kind of coordinate descent autotuning can give us 'upper bound' of the gain we can get for tuning configs for pointwise/reduction. On the other hand, by spot checking, we roughly double the compilation time compared to max-autotune. Next steps can be
- we disable persistent reduction in coordinate descent autotune (it's still enabled in baseline) so we can tune RBLOCK for reduction. We can also try to use autotune to pick persistent reduction or not.
- pick good config without benchmarking (e.g. Natalia mentioned checking register spill)
- try the idea on matmul so we know what's the potential there.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97203
Approved by: https://github.com/ngimel
As CUDA-11.7 is getting deprecated anyway.
Also, fix the problem when script actually generated the same workflow twice, overriding 11.8 ones with 11.7+11.7-with-pypi
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 0c6c182</samp>
> _Oh we are the PyTorch crew and we have a job to do_
> _We build and test the manywheel package with CUDA 11.8_
> _So heave away, me hearties, heave away with all your might_
> _We'll smoke the Linux binary and make sure it runs all right_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99458
Approved by: https://github.com/dagitses, https://github.com/atalman
test_proxy_tensor fails when run by itself (python test/test_proxy_tensor.py -v),
but not when all of the tests are run together.
The cause is that torch._dynamo isn't imported in
torch/fx/experimenta/proxy_tensor.py but it is using functions from the
torch._dynamo package.
The fix in this PR is to add the import statements. In the future we can
consider always importing torch._dynamo on `import torch` or moving the
import to the top of the file, but there are some serious circular
dependencies to be worked out.
NB: an import in the middle of the file makes the function a bit slow
the first time the import happens but all subsequent calls are fast.
Test Plan:
- python test/test_proxy_tensor.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99415
Approved by: https://github.com/soulitzer
We've renamed the `master` branch to `main`. Lintrunner should check for a merge base from this new branch now
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 9743d70</samp>
Updated the linter configuration to reflect the new default branch name. Changed `merge_base_with` from `origin/master` to `origin/main` in `.lintrunner.toml`.
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at 9743d70</samp>
> _`merge_base_with` changed_
> _`origin/main` is the new_
> _branch name for pytorch_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99466
Approved by: https://github.com/kit1980, https://github.com/malfet
Summary:
A fix to ensure that kernels generated for `torch._int_mm` can be cached. We can remove this hack one eager mode `torch._int_mm` is better supported.
Let me know if something more proper is needed instead of the hack.
Test plan:
```
// running the script below led to two compilations of triton
// int8,int8->int32 kernel before this PR, and only has
// one compilation which is reused after this PR
import torch
import torch.nn as nn
x = torch.randint(-128, 127, (32, 32), device='cuda', dtype=torch.int8)
y = torch.randint(-128, 127, (32, 32), device='cuda', dtype=torch.int8)
class M(nn.Module):
def forward(self, x):
x = torch._int_mm(x, y)
x = x.to(torch.int8)
x = torch._int_mm(x, y)
return x
m = M().cuda().half()
m = torch.compile(m, options={"max-autotune": True})
z = m(x)
z = m(x)
```
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99283
Approved by: https://github.com/nmacchioni, https://github.com/janeyx99
Caches output tensors for the common case when the output Tensor storage is unaliased for all graph outputs in all paths. For these persisted tensors we adjust the liveness tracking by also checking that the output tensor does not have an additional python reference.
I limit cached output tensors to be unaliased. If a descendent node discovers it has an alias of a prior output, then the aliased output will no longer be persisted in the ancestor.
The large majority of tensors are unaliased, and preserving aliased output tensors would add significant additional complexity with marginal gains. For instance, when do checkpointing and re-recordings, we need to remove the persisted tensors otherwise it would prevent memory from being reclaimed. If a single persisted tensor was present in multiple paths then that would create an inter-path dependence which adds complexity. Additionally, each further caching of the output would affect the reference count of the other caches, and that reference count would also need to be adjusted depending on if a node was checkpointed.
Still need to do a complete a run but for the models I tried makes the performance extremely close between trees and non trees impl.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98944
Approved by: https://github.com/jansel, https://github.com/ngimel
Summary: Removes the dependency on the unified YAML file
Test Plan:
Smoke test via some caffe2 tests.
```
buck2 run xplat/caffe2:supported_mobile_models_test
```
Build a major FoA app that uses model tracing and confirm it still works.
```
buck2 build fb4a
```
CI/CD for the rest. If operator tracing / bundling was broken, I'd hope in the 1000+ tests spawned by this change should catch it.
Differential Revision: D44946368
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99122
Approved by: https://github.com/dhruvbird
This bug was discovered by a stronger assert (which I will be posting
in a follow up PR.)
The explanation for this change is a bit long and windy, and I am not
sure I entirely understand the situation myself. But here's what I
think is going on.
jansel's joint graph pattern matcher does something fairly unusual:
in order to initialize the pattern in question, it (lazily) runs
an aot_function invocation in order to trace out what the joint graph
of a given pattern looks like (we ought not use aot_function, but we
can't really do this until bdhirsh lands AOT Autograd export properly).
However, this lazy initialization occurs within the context of a
separate compilation, which has its own tracing context, and
importantly, fake tensor mode.
What we would like, is the pattern matcher lazy initialization fake
tensor mode to be unrelated to whatever the ambient fake tensor mode of
the graph we were actually compiling. We want these to be independent,
because we don't really care what the current compiled graph is; this is
a lazy init function, it could have gotten initialized during any
compilation, it just happens to be initialized on this one.
To prevent us from picking up the ambient fake mode, we have to do two
things: we have to remove the tracing context (which stores a fake
mode), and we have to also disable the ambiently active fake mode.
In https://github.com/pytorch/pytorch/pull/99377 eellison proposed an
alternative approach, where we reuse the fake mode. While this probably
won't cause any errors, it's morally not the right thing to do, because
you'll end up polluting the enclosing fake tensor mode with tensors that
have nothing to do with the mode itself.
This might fix https://github.com/pytorch/pytorch/issues/99286
but it's also possible that https://github.com/pytorch/pytorch/pull/99320
fixed it already.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99391
Approved by: https://github.com/bdhirsh
This PR fixes divergent value issues in converting float32 to uint8. The failures of `TestTensorCreationCPU.test_float_to_int_conversion_finite_cpu_uint8` came from the divergent values of PyTorch and numpy among platforms. This PR adds two items:
- Enhance `_float_to_int_conversion_helper()` to have given reference values to provide the stable reference value
- Omit a test for `float.max` since the results on PyTorch are divergent (e.g. `float.max` -> `uint8` is 0 on x86_64, or 255 on s390x).
Fixes#97794
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98916
Approved by: https://github.com/dagitses
I got too confused by the FakeTensor printing, so this PR fixes it to
print normally.
Before:
```
with FakeTensorMode():
x = torch.empty(2, 2, device="cpu")
print(x)
# FakeTensor(FakeTensor(..., device='meta', shape=(2, 2)), cpu)
```
After (Tensor printing doesn't print the default device):
```
FakeTensor(..., shape=(2, 2))
```
Test Plan:
- new test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99205
Approved by: https://github.com/eellison
**Summary**
After https://github.com/pytorch/pytorch/pull/99064 and https://github.com/pytorch/pytorch/pull/99065 merged, the pt2e UT path has changed, also need to change the module path in `test/test_quantization.py`. Then we can run these tests in top level's test directory.
**Test Plan**
```
cd test && python -u -m pytest test_quantization.py -k TestQuantizePT2E
cd test && python -u -m pytest test_quantization.py -k TestQuantizePT2EModels
cd test && python -u -m pytest test_quantization.py -k TestQuantizePT2EFX
cd test && python -u -m pytest test_quantization.py -k TestQuantizePT2EFXX86Inductor
cd test && python -u -m pytest test_quantization.py -k TestQuantizePT2EFXModels
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99402
Approved by: https://github.com/jerryzh168
Summary of changes:
- Add CPython exceptiontable parsing/assembling functions in torch/_dynamo/bytecode_transformation.py, based on https://github.com/python/cpython/blob/3.11/Objects/exception_handling_notes.txt.
- Add optional `exn_tab_entry` field to dynamo `Instruction`s in torch/_dynamo/bytecode_transformation.py in order to virtualize exception table entries (start, end, target instructions).
- Add checks guarding against duplicate instructions in dynamo, so that jump/exceptiontable targets are unambiguous. See `get_indexof` in torch/_dynamo/bytecode_analysis.py. Ensure that bytecode generation throughout dynamo does not generate duplicate instructions.
- Allow dynamo bytecode generation logic to generate nested exception table entries for developer convenience. CPython expects entries to not overlap, so we flatten nested entries during assembly in torch/_dynamo/bytecode_transformation.py:compute_exception_table.
- Simulate the block stack in torch/_dynamo/symbolic_convert.py. CPython removed the block stack in 3.11, but dynamo needs it in order to keep track of active contexts. So we simulate the block stack as before by looking at exceptiontable entries in order to determine the current blocks.
- Update context codegen in torch/_dynamo/resume_execution.py. The `SETUP_FINALLY` bytecode, which conveniently had a jump target to the finally block, was removed in 3.11, so we need to keep track of the jump target of the finally block using exceptiontables. Generating resume functions is more difficult since the original exceptiontable entries pointing to old cleanup code need to be modified to point to new cleanup code.
- Fix a push_null bug in torch/_dynamo/variables/functions.py introduced by https://github.com/pytorch/pytorch/pull/98699
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96511
Approved by: https://github.com/jansel, https://github.com/yanboliang, https://github.com/albanD
Fixes the underlying issue previously addressed in #92201 by specifying minimum alignments explicitly to `cuBLAS` rather than relying on a handcrafted rule. ~~We're still investigating some potential failure modes on `sm80` and `sm90` but those would be real `cuBlasLt` heuristics bugs rather than being caused by underspecifying constraints to the heuristics.~~
According to the `cuBLAS` docs the default alignment is 256 bytes so that is the current maximum that is currently being checked: https://docs.nvidia.com/cuda/cublas/
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98975
Approved by: https://github.com/ngimel
Original Issue from #92670
pytest ./generated/test_XuyangBai_PointDSC.py -k test_004
==> RuntimeError: as_strided_scatter: sizes [4], strides [85], storage offset 256 and itemsize 4 requiring a storage size of 2048 are out of bounds for storage of size 1024
Repro:
```
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
def forward(self, x):
x[1].fill_diagonal_(0) # this check size failed
device = torch.device("cpu")
model = Model()
model.to(device)
torch._dynamo.reset()
compiled_model = torch._dynamo.optimize("inductor")(model)
arg = [torch.rand([4, 1, 1])]
compiled_model(*arg)
```
The error was raised at the checking required size in as_strided_scatter.
https://github.com/pytorch/pytorch/blob/master/torch/_prims/__init__.py#L1818
In the case of input is a tensor with storage offset(a view), when compute input's storage length, should also take input's base tensor's size/stride/offset into account instead of compare it with number of element of input.
This diff fix the bug and add test.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98483
Approved by: https://github.com/ngimel
Inductor CUDA unit tests doesn't preserve ```storage_offset``` when cloning input, this PR fixed it by making both CUDA and CPU tests use the same helper function ```clone_preserve_strides```.
This was found by @lantiankaikai when he was working on #98483, but he can't test it due to lack of CUDA env.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99118
Approved by: https://github.com/ngimel
## What problem this PR solves?
#97170 fixed `equal` operator return type (old: Tensor, now: bool) by giving it the correct sharding propagation. This is consistent with the `aten::equal` op. However, the correctness only stays at the local result level:
* `equal` op returns True if the local copy of dtensor A equals to the the local copy of dtensor B
This is not the correct semantic of `equal` which should return True if all local copies of A are equal to the corresponding local copies of B.
## What is this PR?
1. For non-participating ranks, if the return type is scalar, `local_results` is set to `None` which means the default value is a reduced result of participating ranks only.
2. For all ranks, if the return type is scalar and the `op_call` is `aten::equal`(because `aten::equal` is the only function that returns scalar value and needs communication), all gather the `local_results` within the `default pg` and reduce on them with `operator.and_`. The result will be the new `local_result`.
## Result/Impact
For non-participating ranks and the return type is scalar:
1. op is `aten::equal`, the return value is same with all other ranks
2. op is not `aten::equal`, the return value is None. Before this PR, this will raise "NotImplementedError" but has not been tested.
For participating ranks and the return type is scalar:
1. op is `aten::equal`, the return value is the equality of two dtensor operands - True if all copies are equal, False otherwise.
2. op is not `aten::equal`, simply the local computation result.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99014
Approved by: https://github.com/wanchaol
TorchScript only supports indexing into ModuleLists with integer literals. The error message already warns about this; but this PR adds clarifications around what a "literal" is. I'm adding this PR because, in my opinion, it's not obvious what a "literal" is and how strict its definition is. The clarification provided in this PR should make it easier for users to understand the issue and how to fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98606
Approved by: https://github.com/eellison, https://github.com/gmagogsfm
Months ago, in order to get dynamic shapes working through to Dynamo backends, we changed the calling convention to pass fake tensors rather than real tensors as example inputs to backends. The motivation at the time was, well, backends shouldn't really be peeking at the real tensors when they are doing compilation, and so it would make more sense to hide the real tensors from backends. But there were a bunch of problems:
* This interacted poorly with our accuracy minifier design: accuracy minifier needs access to the real inputs in order to run the model and figure out what happens!
* The TensorRT backend required real inputs and we never figured out how to fix it.
* In practice, all the backends needed to detect if they were passed real tensors, and fakeify them anyway (certainly AOTAutograd does this)
* Parameters and inputs are treated non-uniformly: parameters had to be passed as real tensors, because CUDA graphs requires knowing what the actual tensors are
Furthermore, there were some more problems discovered after the fact:
* Backends may want to optimize on aspects of tensors which you cannot tell without having real tensors; e.g., alignment of the data pointer
So, this PR decides that changing the calling convention was a bad idea, and switches back to passing real tensors. There is a problem though: AOTAutograd will perform fakeification, which means that in practice backends are still going to end up with fake tensors in the end anyway. I want to change this, but this will require some work with bdhirsh's upcoming AOTAutograd export refactor.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99320
Approved by: https://github.com/voznesenskym
Summary:
This diff is reverting D44897935
D44897935: [FSDP] Include duplicate parameters and modules when calling named_parameters and named_modules (#98912) by fegin has been identified to be causing the following test or build failures:
Tests affected:
- [caffe2/torch/fb/module_factory/sync_sgd/tests:test_pyper_data_parallel_wrapper - caffe2.torch.fb.module_factory.sync_sgd.tests.test_pyper_data_parallel_wrapper.PyPerDataParallelWrapperTest: test_fsdp_submodules_pyper](https://www.internalfb.com/intern/test/562950025957458/)
Here's the Multisect link:
https://www.internalfb.com/multisect/1893714
Here are the tasks that are relevant to this breakage:
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
If you believe this diff has been generated in error you may Commandeer and Abandon it.
Test Plan: NA
Reviewed By: fegin
Differential Revision: D45027286
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99353
Approved by: https://github.com/izaitsevfb, https://github.com/fegin
Removes a check which would sometimes allow `off_by_default` artifacts to be logged if logged at a higher level.
This change will only allow artifact messages to be displayed if the artifact is enabled, regardless of level.
closes#99144
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99260
Approved by: https://github.com/lezcano
Currently storage only considers partial backend. We want storage to create on custom backend by key PrivateUse1.
It also provides an easy automatic generation of storage-related attributes.
When the user registers a new backend, the corresponding methods and attributes can be automatically generated.
Do this code.
`torch.utils.rename_privateuse1_backend('foo')`
`torch.utils.generate_storage_for_privateuse1_backend()`
Then, get the following methods and attributes.
`torch.TypedStorage.is_foo`
`torch.TypedStorage.foo()`
`torch.UntypedStorage.is_foo`
`torch.UntypedStorage.foo()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98478
Approved by: https://github.com/albanD
This unskips 121 tests that the decorator `@skipCUDAIf(_get_torch_cuda_version() < (11, 6))` was unintentionally skipping for ROCm. Other decorators such as `skipCUDAVersionIn` will only activate for the CUDA device, not the CPU or ROCm-as-CUDA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99197
Approved by: https://github.com/ngimel
Using `CUDAGuard` does redundant `set_device` in the following loop:
```C++
{
for (auto& device : devices_) {
at::cuda::CUDAGuard gpuGuard(device); // set device
// ...
// ~gpuGuard() sets original device
}
// ...
}
```
It would be more efficient to use `OptionalCUDAGuard` as follows:
```C++
{
at::cuda::OptionalCUDAGuard gpuGuard;
for (auto& device : devices_) {
gpuGuard.set_index(device.index()); // set device
// ...
}
// ...
// ~gpuGuard() sets original device
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98895
Approved by: https://github.com/mrshenli
This PR introduces CustomOp, a wrapper around a dispatcher operator that allows
users to define custom operators. It adds the skeleton for CustomOp and
some very simple behavior: as of this PR:
- one can create a CustomOp for an operator that does not have inplace or aliasing
- give it CPU/CUDA and Meta implementations
- and trace it into a graph via make_fx.
The design follows
https://docs.google.com/document/d/19Uc5OUCA187q9BZggJb70RT2ZoSTDoG5QQkJkZwd25M/edit
Concretely, we implement the following things mentioned in the doc in this PR:
- Entrypoint 1 (CustomOp.define, creating a new custom operator)
- impl (to define device-specific code) and impl_meta (to define meta
formulas)
The goal for the short term is to get the code to a state where it can be trialed
by the export folks. On top of this PR, the blockers are:
- adding Entrypoint 3 (CustomOp.from_existing)
- adding a way to do data-dependent shape formulas
These will come in future PRs since this one is getting long.
Things that will come in the longer-near-term (before 2.1):
- adding the other entrypoints mentioned in the doc (2 & 3)
- more safety checks and better error messages
- support for views and mutation
- support for defining autograd formulas
- support for functionalization
- making this API public (it's private right now).
Test Plan:
- added a new test case, TestCustomOp. It mostly tests a bunch of error
cases.
- added OpInfos for custom operators and hooked these up to
test_proxy_tensor to test that they work with make_fx. These custom
operators were based off of the ones in the autograd_function_db.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98440
Approved by: https://github.com/ezyang
Fix https://github.com/pytorch/pytorch/issues/63482 and https://github.com/pytorch/pytorch/issues/98691
The above two issues have the same root cause:
**binary_ops** will create TensorIterator with the flag `promote_inputs_to_common_dtype` on, which will convert both input tensors to the common_dtype_ (the logic is bypassed on CUDA), which might overflow on Half. If one of the inputs is a scalar with abs value larger than ~65000, it will overflow.
This patch will try to fetch the scalar value from the `original_tensor_base` which records the original scalar input value, then in the `cpu_kernel_vec` the TensorIterator is treated as an unary Op.
So previously, CPU and CUDA would have different behaviors for such scenario. This is aligned with this patch, test cases added for both CPU and CUDA device.
The following is the results:
#### before:
```
>>> torch.tensor([3388.], dtype=torch.half).div(524288.0)
tensor([0.], dtype=torch.float16)
>>> torch.tensor([0.01], dtype=torch.float16) * torch.tensor(65536, dtype=torch.float32)
tensor([inf], dtype=torch.float16)
```
#### after:
```
>>> torch.tensor([3388.], dtype=torch.half).div(524288.0)
tensor([0.0065], dtype=torch.float16)
>>> torch.tensor([0.01], dtype=torch.float16) * torch.tensor(65536, dtype=torch.float32)
tensor([655.5000], dtype=torch.float16)
```
Also need to update `RRelu` implementation, to use float to store the intermediate results, otherwise the following test case would fail:
```
. build/bin/test_api --gtest_filter=ModulesTest.RReLU
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98820
Approved by: https://github.com/jgong5, https://github.com/ngimel
Mostly `s/@master/@main` in numerous `.yml` files.
Keep `master` in `weekly.yml` as it refers to `xla` repo and in `test_trymerge.py` as it refers to a branch PR originates from.
This diff renames quantization spec/config and operator config. It moves these
datastructures to base quantizer.
Base quantizer API now has get_supported_operators that returns list of
patterns that a quantizer quantizes.
There are two choices being debated for how to convey to user what a particular
quantizer will quantize.
1. Modules. We just convey what nn.Modules will be quantized. Of course that
does not mean that equivalent functional variants wont be quantized, however
for simplifity we just use nn.Module. If certain ops are quatnzied in fused
manner then that will considered internal details. Pros and cons of this
approach
pros:
- Simple. Only nn Modules are listed.
- User does not have to see fusion patterns.
Cons:
- confusing perhaps because it is not clear if supported = nn.Conv2d also
means that the quantizer supported functional.conv2d
- Hiding fusion pattern means user has no say in not fusing. Meaning if
conv2d + relu is fused and user configures to quantize only conv, quantizer
will also quantize the following relu as if conv2d + relu are fused.
2. Patterns. Be explicit about what is supported and enumerate all possible
compbinations.
Pros:
- it is very clear what quantizer will do. no surprises.
Cons:
- It is not simple to parse.
- It can be argued taht fusion is internal detail of the quantizer. So some
quantizer implementation may chose to expose fusion patterns, while others
may not and may not even provide any configurability.
One option is to move set_supported_operators/modules out of base quantizer and
let each quantizer define its own way of communicating what is supported. Issue
with this is that when we want to "Compose" multiple quantizers there is no way
for user to define the order of composition if user does not know what a
quantizer supports. For exampl quantizer A may quantizer conv + relu while B
only conv, but B's implementation is fast. In that case you may compose (B, A)
such B quantizes conv and A quantizes relu. Not knowning what A
and B support, makes such composition harder
Differential Revision: [D44895547](https://our.internmc.facebook.com/intern/diff/D44895547/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D44895547/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99063
Approved by: https://github.com/jerryzh168
* Introduce a frame counter which lets us uniquely identify frames.
This makes it easier to tell if you are recompiling the same frame
* Shorten evaluate_expr to eval for more visual distinctiveness
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99159
Approved by: https://github.com/Skylion007
Previously, we had a problem when partitioning forward-backward dynamic graphs, which is that we could end up with a backward graph that mentions a symbol in an input tensor (e.g., `f32[s0 + s1]`), but without this symbol being otherwise bound elsewhere. When this happens, we have no way of actually deriving the values of `s0` and `s1`. Our fix for this in https://github.com/pytorch/pytorch/pull/93059 was to just retrace the graph, so that s0 + s1 got allocated a new symbol s2 and everything was happy. However, this strategy had other problems, namely (1) we lost all information from the previous ShapeEnv, including guards and (2) we end up allocating a LOT of fresh new symbols in backwards.
With this change, we preserve the same ShapeEnv between forward and backwards. How do we do this? We simply require that every symbol which may be present inside tensors, ALSO be a plain SymInt input to the graph. This invariant is enforced by Dynamo. Once we have done this, we can straightforwardly modify the partitioner to preserve these SymInt as saved for backwards, if they are needed in the backwards graph to preserve the invariant as well.
This apparently breaks yolov3, but since everything else is OK I'm merging this as obviously good and investigating later.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99089
Approved by: https://github.com/voznesenskym
The strategy is that we will heap allocate a LargeNegativeIntSymNodeImpl whenever we have a large negative int, so that we can keep the old `is_symbolic` test (now called `is_heap_allocated`) on SymInt. Whenever we need to do something with these ints, though, we convert them back into a plain `int64_t` (and then, e.g., wrap it in whatever user specificed SymNodeImpl they need.) We cannot wrap directly in the user specified SymNodeImpl as we generally do not know what the "tracing context" is from C++. We expect large negative ints to be rare, so we don't apply optimizations like singleton-ifying INT_MIN. Here's the order to review:
* c10/core/SymInt.h and cpp
* `is_symbolic` renamed to `is_heap_allocated` as I needed to audit all use sites: the old `is_symbolic` test would return true for large negative int, but it would be wrong to then try to dispatch on the LargeNegativeIntSymNodeImpl which supports very few operations. In this file, I had to update expect_int,
* If you pass in a large negative integer, we instead heap allocate it in `promote_to_negative`. The function is written in a funny way to keep compact constructor code for SymInt (the heap allocation happens out of line)
* clone is now moved out-of-line
* New method maybe_as_int which will give you a constant int if it is possible, either because it's stored inline or in LargeNegativeIntSymNodeImpl. This is the preferred replacement for previous use of is_symbolic() and then as_int_unchecked().
* Rename toSymNodeImpl to toSymNode, which is more correct (since it returns a SymNode)
* Complete rewrite of `normalize_symints.cpp` to use new `maybe_as_int`. Cannot easily use the old code structure, so it's now done doing a macro and typing out each case manually (it's actually not that bad.)
* Reimplementations of all the unary operators by hand to use `maybe_as_int`, relatively simple.
* c10/core/LargeNegativeIntSymNodeImpl.h - Just stores a int64_t value, but it has to be big and negative. Most methods are not implemented, since we will rewrap the large negative int in the real SymNodeImpl subclass before doing operations with it
* The rest of the files are just rewriting code to use `maybe_as_int`. There is a nontrivial comment in c10/core/SymIntArrayRef.h
Very minor test adjustment in c10/test/core/SymInt_test.cpp . Plan to exercise this properly in next PR.
Companion XLA PR: https://github.com/pytorch/xla/pull/4882
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99157
Approved by: https://github.com/albanD
Dynamo benchmark --verbose is broken:
```
Traceback (most recent call last):
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/torchbench.py", line 400, in <module>
torchbench_main()
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/torchbench.py", line 396, in torchbench_main
main(TorchBenchmarkRunner(), original_dir)
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/common.py", line 1967, in main
return maybe_fresh_cache(
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/common.py", line 993, in inner
return fn(*args, **kwargs)
File "/scratch/ybliang/work/repos/pytorch/benchmarks/dynamo/common.py", line 2135, in run
torch._dynamo.config.log_level = logging.DEBUG
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/config_utils.py", line 67, in __setattr__
raise AttributeError(f"{self.__name__}.{name} does not exist")
AttributeError: torch._dynamo.config.log_level does not exist
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99224
Approved by: https://github.com/voznesenskym
Before this PR, if users call ```Conv2d(x)```, dynamo handles it well(no graph break) and puts a ```call_module``` op in the FX graph. However, if users explicitly call ```Conv2d.forward(x)``` in another ```forward``` function, the inlining would be failed(caused graph break). This PR fixed this issue by translating the explicit ```Conv2d.forward(x)``` to ```Conv2d(x)```.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99015
Approved by: https://github.com/jansel, https://github.com/wconstab
Fixes#99174
## Enable FSDP ``use_orig_params=True`` mixed precision training when some ranks have no (non-zero sized) parameter shards
### The issue
Now that ``use_orig_params=True`` allows non-uniform ``requires_grad`` (🎉🚀 thanks @awgu!!!) with [#98221](https://github.com/pytorch/pytorch/pull/98221), there will be circumstances wherein some ranks have no (non-zero sized) local shards of the original parameters (and hence no associated gradients).
### Use Cases
For a simple Transformer case, imagine a user wraps all encoder layers in separate FSDP instances but allows the classifier head to be wrapped in the same FSDP instance as the relatively large embeddings layers. While this is a sub-optimal wrapping strategy for most use-cases, I believe it is expected to be supported (full precision training works in that context).
I originally encountered this issue while extending a package I maintain, leveraging the relaxed ``requires_grad`` contstraint to simplify multi-phase scheduled fine-tuning FSDP configuration, so a [concrete example is there](https://finetuning-scheduler.readthedocs.io/en/latest/advanced/fsdp_scheduled_fine_tuning.html#basic-scheduled-fine-tuning-with-fsdp).
### Reproduction and Remediation
Currently, ``ShardedGradScaler`` does not accommodate these situations, failing to initialize ``optimizer_state["found_inf_per_device"]`` when ``unscale_`` is called.
In this PR, I extend the existing ``ShardedGradScaler`` tests with an ``use_orig_params=True`` dimension added to the parameterization and test scenarios wherein one rank possesses no (non-zero sized) parameter shards.
The relevant issue can be reproduced with the tests I'm adding in this PR. The current (pre-PR) execution of these tests fail in ``use_orig_params=True`` mode with this error:
```python
./test_fsdp_sharded_grad_scaler.py::TestShardedGradScalerParityWithDDP::test_fsdp_ddp_parity_with_grad_scaler_offload_false_none_mixed_precision_use_orig_params Failed with Error: Process 0 exited with error code 10 and exception:
Traceback (most recent call last):
File "/home/speediedan/repos/pytorch/torch/testing/_internal/common_distributed.py", line 657, in run_test
getattr(self, test_name)()
File "/home/speediedan/repos/pytorch/torch/testing/_internal/common_distributed.py", line 543, in wrapper
fn()
File "/home/speediedan/repos/pytorch/torch/testing/_internal/common_utils.py", line 259, in instantiated_test
test(self, **param_kwargs)
File "/home/speediedan/repos/pytorch/torch/testing/_internal/common_distributed.py", line 174, in wrapper
return func(*args, **kwargs)
File "/home/speediedan/repos/pytorch/test/distributed/fsdp/test_fsdp_sharded_grad_scaler.py", line 187, in test_fsdp_ddp_parity_with_grad_scaler
self._test_fsdp_parity(
File "/home/speediedan/repos/pytorch/torch/testing/_internal/common_fsdp.py", line 1152, in _test_fsdp_parity
fsdp_loss = self._train_for_several_steps(
File "/home/speediedan/repos/pytorch/torch/testing/_internal/common_fsdp.py", line 1016, in _train_for_several_steps
sharded_grad_scaler.step(optim)
File "/home/speediedan/repos/pytorch/torch/distributed/fsdp/sharded_grad_scaler.py", line 291, in step
return super().step(optimizer, *args, **kwargs)
File "/home/speediedan/repos/pytorch/torch/cuda/amp/grad_scaler.py", line 368, in step
assert len(optimizer_state["found_inf_per_device"]) > 0, "No inf checks were recorded for this optimizer."
AssertionError: No inf checks were recorded for this optimizer.
```
A few implementation notes/considerations and questions:
1. Rather than just initialize ``per_device_found_inf``, one could disable the grad scalar altogether for relevant ranks, altering ``unscale_`` to reduce with a subgroup or some rank mask construct to avoid the ``all_reduce`` s in ``distributed/fsdp/sharded_grad_scaler.py:unscale_()`` from hanging. Given that users may subsequently add parameter groups to an optimizer that would require re-enabling the scaler and the complexity associated with maintaining a separate mask construct or process subgroup, I thought this implementation was cleaner.
2. I extended ``_train_for_several_steps`` and ``_test_fsdp_parity`` in ``/torch/testing/_internal/common_fsdp.py`` with the ability to configure ``sharded_grad_scaler_kwargs`` for future testing flexibility.
3. Should the user be warned that no parameter shards were associated with a given rank? My initial thought is that this should be considered an implementation detail, part of supporting ``use_orig_params`` with heterogeneous ``requires_grad``, and therefore should be transparently handled by PyTorch. Should a DEBUG level message be added? If so, likely further upstream rather than at the scaler step level.
4. Rather than extend the existing ``ShardedGradScaler`` tests with an ``use_orig_params=True`` dimension added to the parameterization, let me know if you prefer that I instead narrow the scope of the new testing to a single additional test, e.g.:
```python
# from typing import Optional
from typing import Optional, List
# ...
# use_orig_params = ["enable_use_orig_params", None]
use_orig_params: List[Optional[str]] = [None]
# ...
configs = list(itertools.product(cpu_offload_config, sharding_strategy_config, mixed_precision, use_orig_params))
configs.append((CPUOffload(offload_params=False), None, "enable_mixed_precision", "enable_use_orig_params"))
```
Thanks as always to the PyTorch distributed team for your astonishingly impressive and valuable contributions to the open-source ML engineering community!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99175
Approved by: https://github.com/awgu
Allowed modules are stuck into dynamo's fx graph as call_module
nodes, without dynamo doing any tracing of the module. This means
during AOT trace time, hooks will fire during tracing when the
call_module is executed, but the hooks themselves will disappear
after that and not be present in the compiled program.
(worse, if they performed any tensor operations, those would get
traced so you could end up with part of the hook's functionality).
To circumvent this, there are two options for 'allowed modules' with hooks.
1) don't treat them as 'allowed' - trace into them
2) graph-break, so the module is no longer part of the dynamo trace at all
(1) will fail for users that opted into allowed modules becuase they know
their module has problems being traced by dynamo.
(2) causes graph breaks on common modules such as nn.Linear, just because they
are marked as 'allowed'.
It would help matters if we could differentiate between types of allowed modules
(A) allowed to avoid overheads - used for common ops like nn.Linear
(B) allowed to avoid dynamo graphbreaks caused by unsupported code
Ideally, we'd use method (1) for group (A) and (2) for (B).
For now, graph-break on all cases of allowed modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97184
Approved by: https://github.com/jansel
Summary
* Introduce input/output adapter. Due to design differences, input/output format
between PyTorch model and exported ONNX model are often not the same. E.g., `None`
inputs are allowed for PyTorch model, but are not supported by ONNX. Nested constructs
of tensors are allowed for PyTorch model, but only flattened tensors are supported by ONNX,
etc. The new input/output adapter is exported with the model. Providing an interface to
automatically convert and validate inputs/outputs format.
* As suggested by #98251,
provide extension for unwrapping user defined python classes for `dynamo.export` based
exporter. Unblock huggingface models.
* Re-wire tests to run through `DynamoExporter` w/ `dynamo_export` api. Kept
`DynamoOptimizeExporter` in the tests for now for coverage of this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98421
Approved by: https://github.com/justinchuby, https://github.com/titaiwangms, https://github.com/thiagocrepaldi
replicate + trec_shard works if we shard / replicate individually, such as follows:
```
m = TestSparseNN()
shard(m.sparse)
replicate(m.dense)
```
but does not work if users do the following:
```
m = TestSparseNN()
shard(m, sharders=[...])
replicate(m)
```
Many upstream trainers use the latter use case, as sharding is not done on individual module level but rather overall module by specifying planners that contain logic for how to shard different embedding table types.
This diff enables the latter approach (while keeping the former intact), but users need to specify `ignored_modules` to ignore embedding tables in replicate(). This is similar to FSDP (class based and composable) and DDP today.
Differential Revision: [D44899155](https://our.internmc.facebook.com/intern/diff/D44899155/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98890
Approved by: https://github.com/mrshenli, https://github.com/yhcharles
Summary:
This diffs registers the vulkan quantized binary ops (add/sub/mul/div), and adds graph rewrites for quantized add, mul, conv2d and conv2d_relu.
The rewrites for conv2d and conv2d_relu make use of the convert_qconv2d_context introduced in D41595032
Test Plan: export quantized mcs model to vulkan
Reviewed By: SS-JIA
Differential Revision: D44189363
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97468
Approved by: https://github.com/SS-JIA
Summary:
Original commit changeset: ba36f8751adc
Original Phabricator Diff: D44788697
Test Plan: model loading is fine after reverting the diff
Reviewed By: zyan0, sayitmemory
Differential Revision: D44921259
---
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99168
Approved by: https://github.com/izaitsevfb
At present, DDP forward uses `_get_stream` to get a stream,which is cudaStream.
If the custom module already registered to torch, I can use `getattr` to get it and it's stream. Then, the custom stream is used to copy the tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98723
Approved by: https://github.com/ezyang
Fixes#98974
When `torch.fx.subgraph_rewriter._replace_pattern` is used to remove nodes from a graph, if there are two adjacent matches then after the first removal, the nodes in `InternalMatch.nodes_map` and `placeholder_nodes` become outdated because they contain nodes that were just removed from the graph.
This fix is to update the `match.nodes_map` and `match.placeholder_nodes` using the node changes stored in `match_changed_node`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99039
Approved by: https://github.com/angelayi
Summary: This fixes the case when some of the input tensors were
real tensors and fakified in `validate_and_convert_non_fake_tensors`,
but `flat_arg_fake_tensors` would not contain all the inputs
because it was computed before the fakification. We fix this by
recomputing `flat_arg_fake_tensors` after fakification as well.
Test Plan:
python test/dynamo/test_export.py ExportTests.test_mixed_real_and_fake_inputs
Reviewers: Chillee, voznesenskym
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98769
Approved by: https://github.com/voznesenskym
Summary: The support of BINUNICODE8 is missing. So adding it. So we can support attributes > 4GB. For example, for very large model, we save the lowered model in the EngineHolder using a string attribute.
Test Plan: buck2 test mode/opt //caffe2/test:jit -- --exact 'caffe2/test:jit - test_save_load_large_string_attribute (jit.test_save_load.TestSaveLoad)'
Differential Revision: D44905770
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99104
Approved by: https://github.com/qihqi
Summary:
Using a decomposed convert to make sure we get exact match, this means the nodes in resnet are
annotated correctly
Test Plan:
python test/test_quantization.py TestQuantizePT2EModels.test_resnet18_with_quantizer_api
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98905
Approved by: https://github.com/andrewor14
Currently, aten.expand always expands to the global dimension. Then, it
introduces additional slice and clone ops before running compute on
the expanded tensor with a local tensor.
In this commit, if we detect the op consumes a SymInt size, it respects
both local size and the dimension placements from where the SymInt was
extracted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99058
Approved by: https://github.com/wanchaol
Summary:
Make it a bit easier to run the tests anywhere/avoid skipping the tests by using buffers instead of temporary files.
[Er, still figuring out how the sync tooling works, I'll send this against github once the first diff is landed]
Test Plan: buck2 test
Reviewed By: fluckydog232
Differential Revision: D44818261
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98798
Approved by: https://github.com/ezyang
[perf-compare](https://github.com/pytorch/pytorch/actions/workflows/inductor-perf-compare.yml) has a different structure than that of the nightlies.
For these files, the script now generates:
```
# cuda float32 training performance results
## Geometric mean speedup
huggingface timm_models torchbench
-------- ------------- ------------- ------------
inductor 1.46 1.4 1.17
## Mean compilation time
huggingface timm_models torchbench
-------- ------------- ------------- ------------
inductor 57.85 97.63 60.18
## Peak memory compression ratio
huggingface timm_models torchbench
-------- ------------- ------------- ------------
inductor 1.06 1.01 0.83
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99095
Approved by: https://github.com/ezyang
Common advice we give for handling memory fragmentation issues is to
allocate a big block upfront to reserve memory which will get split up later.
For programs with changing tensor sizes this can be especially helpful to
avoid OOMs that happen the first time we see a new largest input and would
otherwise have to allocate new segments.
However the issue with allocating a block upfront is that is nearly impossible
to correctly estimate the size of that block. If too small, space in the block
will run out and the allocator will allocate separate blocks anyway. Too large,
and other non-PyTorch libraries might stop working because they cannot allocate
any memory.
This patch provides the same benefits as using a pre-allocating block but
without having to choose its size upfront. Using the cuMemMap-style APIs,
it adds the ability to expand the last block in a segment when more memory is
needed.
Compared to universally using cudaMallocAsync to avoid fragmentation,
this patch can fix this common fragmentation issue while preserving most
of the existing allocator behavior. This behavior can be enabled and disabled dynamically.
This should allow users to, for instance, allocate long-lived parameters and state in individual buffers,
and put temporary state into the large expandable blocks, further reducing
fragmentation.
See inline comments for information about the implementation and its limitations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96995
Approved by: https://github.com/eellison
Summary:
1. Part 1~4 add `TORCH_ASSERT_ONLY_METHOD_OPERATORS` to files in the MPS codebase and replace `empty_mps`with `empty`. Also exclude `OperationUtils.h` from the assert as at this stage we still need `<ATen/ATen.h>` to get CI to pass.
2. Part 5 removes `<ATen/ATen.h>` include in `OperationUtils.h` and adds method operator headers to all mps files.
3. The last one moves `TORCH_ASSERT_ONLY_METHOD_OPERATORS` to the top of files.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99016
Approved by: https://github.com/albanD
Currently, it lives inside run(), but this is too late;
we do a lot of work initializing OutputGraph and those log
messages will show up before "start tracing". This is bad.
Now the start of tracing is InstructionTranslator construction,
which ensures we catch these sites.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98990
Approved by: https://github.com/yanboliang
Support for nonblocking NCCL communicators/fault tolerance/checking which was added in 2.14 as an experimental feature.
Enabled via the environment variable:
```
TORCH_NCCL_USE_COMM_NONBLOCKING=1
```
CC @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95715
Approved by: https://github.com/kwen2501
If `CMAKE_GENERATOR=Visual Studio 16 2019` then the build will fail if `USE_NINJA=False` not set.
This PR changes that if CMAKE_GENERATOR is set an not equal to ninja then it won't use Ninja.
This is just for easier setting another generator.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98605
Approved by: https://github.com/kit1980
As it takes ridiculous amount of time to build with complex times on CUDA-11.4.
Build speeds for a single gpu architecture (`sm_80`) on 3Ghz 8275CL Intel Xeon:
- 143 sec to compile for all dtypes using CUDA-11.6
- 351 sec to compile for all dtypes using CUDA-11.4
- 24 sec to compile for only floating dtypes using CUDA-11.6
- 52 sec to compile for only floating dtypes using CUDA-11.4
Tweak code a bit to make it compilable with MSVC, which is having trouble with nested preprocessor directives.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98957
Approved by: https://github.com/r-barnes, https://github.com/ngimel
For the purpose of our Bazel and Meta-internal macros tests, we want
to create a single binary that can verify the different
configurations. CMake would see this file and try to run it and fail
in Windows which uses different values.
But we don't care about verifying this in CMake since it's not part of
the build unification effort.
In order to do this, we have to rename the SmallVectorTest to match
the naming convention of the rest of the c10 tests.
Differential Revision: [D44823440](https://our.internmc.facebook.com/intern/diff/D44823440/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98710
Approved by: https://github.com/PaliC
Fixes #ISSUE_NUMBER
#97593
A new extension mechanism has been added.
When the user registers a new backend, the corresponding methods and attributes can be automatically generated.
Do this code.
`torch.utils.rename_privateuse1_backend('foo')`
`torch.utils.generate_for_privateuse1_backend()`
Then, get the following methods and attributes.
`torch.Tensor.is_foo`
`torch.Tensor.foo()`
`torch.nn.Module.foo()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98066
Approved by: https://github.com/albanD
Summary:
Fixed quant_min/quant_max for per channel quantized weight for reference quantized module in decomposed mode,
this bug is triggered while onboard an internal model
Test Plan:
python test/test_quantization.py TestQuantizeFx.test__convert_to_reference_decomposed_fx_per_channel_quant_module
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98903
Approved by: https://github.com/andrewor14
This fixes a regression added in the following PR to graph-break on allowed modules with hooks, but has its own problems.
- following #97184 PR makes 'allowed modules' with hooks graph-break, and lazy modules
are allowed. (should we just make lazy modules not allowed ?)
- graph-breaks at lazy modules fail the lazy module unit tests which assert no graphbreaks
- this PR attempts to always 'initialize' lazy modules before tracing/calling into their __call__,
and initializing a lazy module should delete all its hooks after firing them once, making
the above issue go away
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98516
Approved by: https://github.com/yanboliang, https://github.com/jansel
Wrapper for users to insert constraints into model code.
The constraints will not be maintained in the graph after tracing through make_fx so retracing with dynamo/make_fx will not work. This will be supported after torch._assert supported is implemented. Then we can convert the constrain_range calls to torch._asserts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98433
Approved by: https://github.com/avikchaudhuri, https://github.com/tugsbayasgalan
The default option of `named_parameters` and `named_modules` is to remove the duplicated parameters and modules. However, in FSDP, we need to know what parameters are shared. As a result, setting `remove_duplicate` to False is required in FSDP. Without setting `remove_duplicate` to False, FSDP won't be able to discover shared weights in some cases (e.g., the shared weights are in the same module or there are shared modules).
Differential Revision: [D44897935](https://our.internmc.facebook.com/intern/diff/D44897935/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98912
Approved by: https://github.com/awgu
This was leftover for when we had more logic in the FakeTensor and not FakeTensorMode, and wasn't firing correctly. It also makes more sense for it to be in the other validation function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97186
Approved by: https://github.com/bdhirsh
This PR defers warnings about potentially missing symbols
until we hit a situation where we can find a symbol.
It also hardens some of the logic around addresses that might
be out of the range of known unwind logic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99005
Approved by: https://github.com/tugsbayasgalan
If model.eval() is true, then runs the model in full precision.
Changes:
- Changed _force_full_precision to check self.is_training
- Check for _force_full_precision when casting gradients to reduced dtype
- Small change when accessing _full_prec_param_padded
- tests for class based and fully_shard APIs
Differential Revision: [D43933690](https://our.internmc.facebook.com/intern/diff/D43933690/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97645
Approved by: https://github.com/awgu
Summary:
This PR changes prepare to use some default observer/fq constructor when "target_dtype_info" is not set, this allows user to not initialize all nodes to default
observer/fq constructor. Note we may still need to annotate intermediate node after this PR, there will be a follow up PR to allow users to only annotate things they
want to quantize
Test Plan:
python test/test_quantization.py TestQuantizePT2E
python test/test_quantization.py TestQuantizePT2EModels
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99001
Approved by: https://github.com/kimishpatel, https://github.com/andrewor14
Summary: IR check needs to be recursive to accommodate Tuple[Tensor, Tuple[Tensor]] schema
Test Plan:
Run the repro cmd and make sure it no longer fails
TORCH_SHOW_CPP_STACKTRACES=1 TORCH_LOGS="+dynamo,aot,inductor" buck2 run mode/opt scripts/ml_model_exploration/coffee:defi_local -- --baseline_model_entity_id 421946503 --meta_ids '{"union_meta":422685721}' -g -t -l --model_type mimo_ctr_mbl_feed
Differential Revision: D44809096
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98887
Approved by: https://github.com/wconstab
Summary:
Using a decomposed convert to make sure we get exact match, this means the nodes in resnet are
annotated correctly
Test Plan:
python test/test_quantization.py TestQuantizePT2EModels.test_resnet18_with_quantizer_api
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98905
Approved by: https://github.com/andrewor14
Adds a script to get rid of the "merging" label when a job is cancelled.
At the moment this can create a race condition is someone cancels a job and starts a new one, though these cases should be pretty rare especially in cases where its from a new merge command.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98967
Approved by: https://github.com/malfet
Summary:
Fixed quant_min/quant_max for per channel quantized weight for reference quantized module in decomposed mode,
this bug is triggered while onboard an internal model
Test Plan:
python test/test_quantization.py TestQuantizeFx.test__convert_to_reference_decomposed_fx_per_channel_quant_module
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98903
Approved by: https://github.com/andrewor14
**Context**
The existing check to see if an arg is duped is `if dupe_arg_pos != kept_pos:`. However, this incorrectly considers every arg after a true duped arg to also be a duped arg.
Consider `flat_args = [a, b, b, c]`, where indices `1` and `2` are duped.
- `add_dupe_map = {0: 0, 1: 1, 2: 1, 3: 2}`
- For `dupe_arg_pos=2, kept_pos=1`, `2 != 1`, so the check correctly identifies the second `b` to be a duped arg.
- For `dupe_arg_pos=3, kept_pos=2`, `3 != 2`, so the check incorrectly identifies the `c` to be a duped arg.
Indeed, if there were more args like `[a, b, b, c, d, e, ...]`, every arg after the second `b` will be considered a duped arg since its `kept_pos` will always be 1 lower than its `dupe_arg_pos`.
**Overview**
This PR changes `add_dupe_map` to be implemented as a `List[int]`, where the list index implicitly represents the `dupe_arg_pos` and the list element represents the `kept_pos`. We use a list to have stable in-order iteration and because we know the keys to be in `{0, 1, ..., len(flat_args) - 1}`.
With `add_dupe_map` as a list, the `is_dupe_arg` condition is whether the entry in `add_dupe_map` shows a new not-yet-seen index in the iteration. One way to do this is to count the number of unique args so far and compare against that.
This closes https://github.com/pytorch/pytorch/issues/98883, where now the guards change from
```
GUARDS ___guarded_code.valid
and ___check_type_id(L['self'], 93996836333040)
and ___check_obj_id(L['self'], 140119034997536)
and not ___are_deterministic_algorithms_enabled()
and ___check_tensors(L['x'])
and L['self']._buf is L['self']._buf_module._buf
and L['self']._buf_module._buf is L['self']._param
```
to without the final incorrect `L['self']._buf_module._buf is L['self']._param` guard.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98932
Approved by: https://github.com/ezyang
Billing of changes:
* Get rid of `print_guards`; instead, you control this with `TORCH_LOGS=torch.fx.experimental.symbolic_shapes`, debug logging toggles stack traces
* Don't incorrectly report the tracing context frame when we're compiling; we just don't have this info anymore! (TODO: use the saved frames instead). This is via a new TracingContext.clear_frame context manager
* Add TracingContext.extract_stack() which gives you the tracing context stack.
* Add ShapeEnvLoggingAdapter to report which ShapeEnv any given operation is from (this is helpful for debugging situations when there are too many ShapeEnvs floating around)
* Tweak create_symbol log message to also report Source
* Add a debug log whenever duck sizing occurs
* Report an excerpt of both the user and system backtrace whenever a guard is added in INFO mode. I found this is a good balance of "where did the guard come from" without full backtrace verbosity.
Example log output with the new output:
```
[2023-04-12 08:25:49,003] torch.fx.experimental.symbolic_shapes: [INFO] 0: create_env
[2023-04-12 08:25:49,021] torch.fx.experimental.symbolic_shapes: [INFO] 0: create_symbol s0 = 32 for L['x'].size()[0]
[2023-04-12 08:25:50,154] torch.fx.experimental.symbolic_shapes: [INFO] 0: evaluate_expr s0 < 128 [guard added] at w.py:11 in forward2 (_dynamo/variables/tensor.py:476 in evaluate_expr)
[2023-04-12 08:25:52,057] torch.fx.experimental.symbolic_shapes: [INFO] 0: evaluate_expr Eq(Mod(s0, 16), 0) [guard added] (_inductor/codegen/triton.py:77 in is_aligned)
```
from running
```
import torch
import torch._dynamo
def f(x, y):
return x + y
def forward(x, y):
return forward2(x, y)
def forward2(x, y):
if x.size(0) < 128:
x = x * 2
else:
x = x * 3
r = f(x, y)
r = r * y
return r
def woof():
fn_compiled = torch.compile(forward, dynamic=True)
x = torch.randn(32, device='cuda')
y = torch.randn(32, device='cuda')
print(fn_compiled(x, y))
woof()
```
(To induce the Triton guard, I synthetically reverted https://github.com/pytorch/pytorch/pull/98471)
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98941
Approved by: https://github.com/wconstab
It's part of the effort to improve PT2 Export UX. This PR is to improve the usability of `torch.cond()` by allowing user to set `pred` as `ConstantVariable` as it's not often to see control flow on rank or a tensor or dim size which is traced as `ConstantVariable`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98900
Approved by: https://github.com/jansel
Support for nonblocking NCCL communicators/fault tolerance/checking which was added in 2.14 as an experimental feature.
Enabled via the environment variable:
```
TORCH_NCCL_USE_COMM_NONBLOCKING=1
```
CC @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95715
Approved by: https://github.com/kwen2501
Per the offline discussion, there is no technical reason/limitation to have to register bitwise ops using `TORCH_LIBRARY_IMPL`.
Move the registration to `native_functions.yaml` for an easier lookup and consistent registration patterns as other mps ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98908
Approved by: https://github.com/kulinseth
This was leftover for when we had more logic in the FakeTensor and not FakeTensorMode, and wasn't firing correctly. It also makes more sense for it to be in the other validation function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97186
Approved by: https://github.com/bdhirsh
Summary
There is confusion between`_dynamo.skip` and `_dynamo.disable`. This removes the `_dynamo.skip` API. The functionality is still available via `_dynamo.disable(recursive=False)`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98899
Approved by: https://github.com/jansel
Summary -
`disallow_in_graph` is mostly useful for backends. Suppose, your backend does not support `torch.abs()`. So, you can use `disallow_in_graph` to do a graph break.
The assumption in the above statement is that `disallow_in_graph` is called on an `allowed` callable. `allowed` in Dynamo language refers to a callable that is put as-is in the Dynamo graph.
Therefore, if one uses `disallow_in_graph` on some non-torch non-allowed function, we want to raise an exception to tell user that they probably want something else.
* If they want to disable Dynamo - they should use torch._dynamo.disable
* If they wanted to stop inlining - they should use torch._dynamo.graph_break. However this is not a decorator. So, we need to provide another API. But, the question - who would want to do this?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98892
Approved by: https://github.com/jansel
`distributed/_tensor/test_dtensor_ops` is still flaky in trunk with a curious timeout issue, for example ce4df4cc59. It seems that the test just hang without any failure. The root cause is unclear. On the other hang, https://github.com/pytorch/pytorch/issues/98816 might offer a solution for this. Anyway, I'm disable the test on CPU for now while the investigation is being done.
The test is still being run on CUDA-available runner because it's not flaky there.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98868
Approved by: https://github.com/clee2000
Wrapper for users to insert constraints into model code.
The constraints will not be maintained in the graph after tracing through make_fx so retracing with dynamo/make_fx will not work. This will be supported after torch._assert supported is implemented. Then we can convert the constrain_range calls to torch._asserts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98433
Approved by: https://github.com/avikchaudhuri, https://github.com/tugsbayasgalan
When there are > 15000 polygons trace_plot starts to get really slow.
So order the allocations and take the smallest allocations beyond the 15000
limit and put them into a single summarized polygon.
A slider allows this limit to be adjusted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98865
Approved by: https://github.com/yf225
Summary:
Replace _dynamo.config with an object instead of module
Current usage patterns of setting and reading fields on config will work
unchanged.
Only changes needed going forward:
1. import torch._dynamo.config will not work. However, just doing
import torch._dynamo is sufficient to access dynamo config
as torch._dynamo.config.
2. Files inside of _dynamo folder need to access config via
from torch._dynamo.config_util import config instead of
from torch._dynamo import config. Because _dynamo/__init__.py
imports some of the files so it would be circular import.
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96455
Approved by: https://github.com/williamwen42
This PR adds the GraphModuleTransformation class that can be used as the
default transformation after the `train_step()` is traced and expand. The
current implementation includes:
1. Wrap the input graph module with IterGraphModule. This will enable the futher graph optimizations which are all implemented based on IterGraphModule.
2. Ability to lower the graph module to the Inductor. To achieve this goal, `lower_to_inductor()` is implemented.
TODO:
1. The `override` and `gm_transofmation` have overlapping functions -- `override.transform` can be used to achieve the same function as `gm_transformation`. However, the current semantics of `override` is to override and transform partial graphs while `gm_transformation` is to transform the entire expaned GM. The final UX of `compile()` needs some discussion.
2. The current `lower_to_inductor()` assumes that the entire graph can be lowered to Inductor. This assumption is okay for integration of graph optimizations but is too restrictive for many models. We should upstream `partial_lowering()`.
Differential Revision: [D44616783](https://our.internmc.facebook.com/intern/diff/D44616783/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98182
Approved by: https://github.com/mrshenli
This diff adds the ability to specify range constraints on dynamic dimensions. (Previously we only supported declaring a dynamic dimension, which gets the default range `[2, sympy.oo]`.)
One point worth calling out: our initial design called for compound expressions like `lower <= dynamic_dim(x, d) <= upper`. However this seems difficult to support, because of a combination of desugaring and overloading semantics for such compound expressions in Python. Rather than silently doing the wrong thing, we explicitly error in this case and recommend users to specify multiple constraints, which is supported.
Differential Revision: [D44847318](https://our.internmc.facebook.com/intern/diff/D44847318/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98779
Approved by: https://github.com/ezyang
This fixes a few failing cases where we fail to compute stride_hint for an indexing expression with ModularIndexing
When can size_hint error out? It shouldn't happen when we are getting regular size hints for expressions where free vars are in ShapeEnv. But this is not the case when we try to recover strides from indexing expressions (which is what stride_hint is for). Suppose you have an indexing expression that looks like
```
289*d0 + ModularIndexing(7399*d1 + d2, 1, 17) + 17*ModularIndexing(7399*d1 + d2, 17, 17) + 46240*ModularIndexing(7399*d1 + d2, 289, 128)
```
and want to understand its stride wrt to variable `d1`. Let's ignore for a moment that stride for ModularIndexing is not well defined, it'll become negative around modulo divisor value, but even without that, the way we usually compute stride is we substitute `0` and `1` for `d1` and compute difference in indexing expression with those substitutions - this is our stride. But for the expression above, the difference would result in an expression that still has free variable `d2` that we don't have a substitution for.
The fix that this PR makes is it expands stride computation to substitute not only `0` and `1` for the variable we are computing a stride for, but also `0` for other variables in the indexing expression (`support_vars`).
Note that computing strides in `stride_hints` is a performance optimization that we use to reorder dimensions or make split decisions for split reduction. If it fails, it's not a hard error - we may incorrectly apply reordering by it won't affect correctness.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98783
Approved by: https://github.com/ezyang, https://github.com/voznesenskym
Summary:
This diff fixes more test failures (T150117218) caused by upgrading the "hypothesis" library to 6.70.1 (D44523679).
# //caffe2/caffe2/python:hypothesis_test
This test generates float numbers and filters out those whose absolute values are less than 1e-2.
It is a known issue of the new version of "hypothesis" that it generates zeros or floats with small absolute values too often:
https://github.com/HypothesisWorks/hypothesis/issues/3603
I'm circumventing this issue by suppressing the health check `filter_too_much`.
# //caffe2/caffe2/quantization/server:resize_nearest_dnnlowp_op_test
All arithmetic should be done in float32 when calculating the reference, since the network being tested uses float32 everywhere.
Mixing float32, float64 or even integers will result in intermediate values in float64.
The different precision may cause off-by-1 errors when converting to integer.
Test Plan:
Run all the tests in both "dev" and "opt" modes:
```
for mode in dev opt; do
buck2 test mode/$mode //caffe2/caffe2/python:hypothesis_test -- --run-disabled
buck2 test mode/$mode //caffe2/caffe2/quantization/server:resize_nearest_dnnlowp_op_test -- --run-disabled
buck2 test mode/$mode //caffe2/caffe2/fb/layers/tests:tum_history_test -- --run-disabled
buck2 test mode/$mode //caffe2/caffe2/fb/dper/layer_models/tests:nn_ops_test -- --run-disabled
buck2 test mode/$mode //caffe2/caffe2/fb/metrics:metrics_test -- --run-disabled
buck2 test mode/$mode //deeplearning/numeric_suite/toolkit/test:net_transform_test -- --run-disabled
buck2 test mode/$mode //f3/type_system:tests -- --run-disabled
done
```
**NOTE:** In the first test (`//caffe2/caffe2/python:hypothesis_test`), the two methods `test_constant_fill_from_tensor` and `test_recurrent` would crash.
But these crash on hypothesis 5.49.0, too, so I'm leaving them alone.
Differential Revision: D44812706
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98685
Approved by: https://github.com/malfet
### Overview
This PR de-duplicates graph inputs in TorchDynamo, using the `Source` as the unique identifier for each input. This closes https://github.com/pytorch/pytorch/issues/98743 and https://github.com/pytorch/pytorch/issues/98625.
### Details
`VariableBuilder.wrap_tensor()` should return a `VariableTracker` for the passed-in `value: Tensor`. If `value` is duplicated, we should avoid calling `OutputGraph.create_graph_input()` and `OutputGraph.add_grapharg()`.
- Note that `create_graph_input()` and `add_grapharg()` are not 1:1. For a constant source and either `wrap_sym()` or `wrap_unspecialized_primitive()`, TorchDynamo still calls `create_graph_input()` but not `add_grapharg()`.
- Note that `create_graph_input()` should be called before constructing the corresponding `VariableTracker`. TorchDynamo needs the `fx.Proxy` object to pass to `wrap_fx_proxy()`.
In this PR, the `OutputGraph` saves an additional mapping `input_source_to_var` from each graph input's `Source` to its `VariableTracker`, which works because `Source` is now hashable. This mapping should be updated each time `create_graph_input()` is called. However, since we must construct the `VariableTracker` after `create_graph_input()` returns, we must have a separate call to the `OutputGraph` to update the mapping.
If anyone has any suggestion on how to coalesce this logic and avoid having to remember to update `input_source_to_var` for each `create_graph_input()`, I would love to hear it.
<details>
<summary> Alternate Approach</summary>
Initially, I tried having TorchDynamo construct a new but equivalent `VariableTracker` for the duplicated tensor. However, I abandoned this approach after hitting an assertion in `def wrap_fx_proxy_cls()` due to `"example_value"` already being in the proxy node's metadata because we were reusing the primary tensor's `Proxy` object. Reusing the exact `VariableTracker` also seems less error-prone instead of requiring constructing a new but identical `VariableTracker`.
</details>
### Testing
#### Global Variable Test
```
import torch
@torch.compile()
def f():
return x + x
x = torch.randn(3)
f()
```
Before:
```
====== Forward graph 0 ======
<eval_with_key>.6 class <lambda>(torch.nn.Module):
def forward(self, arg0_1: f32[3], arg1_1: f32[3]):
# File: /data/users/ezyang/b/pytorch/ff.py:5, code: return x + x
add: f32[3] = torch.ops.aten.add.Tensor(arg0_1, arg1_1); arg0_1 = arg1_1 = None
return (add,)
```
After (only `arg0_1` and no more `arg1_1`):
```
====== Forward graph 0 ======
<eval_with_key>.4 class <lambda>(torch.nn.Module):
def forward(self, arg0_1: f32[3]):
# File: dynamo/test_dup_global.py:8, code: return x + x
add: f32[3] = torch.ops.aten.add.Tensor(arg0_1, arg0_1); arg0_1 = None
return (add,)
```
#### FSDP Test
Before we error on
```
File "/.../pytorch/torch/_guards.py", line 244, in __post_init__
assert self.input_source_a != self.input_source_b
```
and now there is no error.
---
The rename from `name_to_input` to `input_name_to_proxy` is not part of the core logic change and is a remnant from initial attempts. I can undo it later if desired, but I also feel that the new name is more informative. It also fixes the type annotation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98775
Approved by: https://github.com/ezyang, https://github.com/voznesenskym
The higher order derivatives calculations of `max_pool2d` require indices provided, but `mps_max_pool2d` kernel doesn't calculate it. If we calculate indices during back propagations afterwards, that would be expensive and unnecessary since users can directly call `max_pool2d` with `return_indices=True`, which calculates `indices` along.
This PR adds a warning for it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98582
Approved by: https://github.com/soulitzer
The comment is quite confusing as given the use of `sizeof()`, this was never backward compatible as the state is not the same size as it used to be.
Running this through CI right now. If it turns our we serialize some rng_state Tensor, I will update the set function to be BC.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98787
Approved by: https://github.com/ngimel
This is a quick fix/hack to get around with the issue that some
"global" tensor view operation is invalid, but somehow it get
triggered by some models as mini-batch input itself won't have this
issue.
Since ultimately we should remove the dtensor expand and use the new
expansion, this hack is only temporary to unblock
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98813
Approved by: https://github.com/yifuwang, https://github.com/mrshenli
Summary:
Update from using add() which makes rank 0 overloaded with requests to a single request every 10 seconds to handle the last joined worker
Added optional logging_interval arg to _store_based_barrier
Test Plan:
```
pytest test/distributed/test_c10d_common.py -vsk test_store_based_barrier
```
Reviewed By: rohan-varma
Differential Revision: D44430531
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98000
Approved by: https://github.com/kumpera
Summary: Add new experimental python op (`torch.nonzero_static`) for export. There is NO cuda impl included in this PR
Example:
Say input tensor is `x = torch.tensor([[1, 0], [3, 2]])`
call regular `nonzero()` on x will give you a tensor `tensor([[0, 0], [1, 0], [1, 1])`
call `nonzero_static(x, size=4)` on x will give you a tensor `tensor([[0, 0], [1, 0], [1, 1], [fill_value, fill_value])` (padded)
call `nonzero_static(x, size=2)` on x will give you a tensor `tensor([[0, 0], [1, 0])` (truncated)
Test Plan:
**Unit Tests**
```
buck test @mode/dev-nosan //caffe2/test:test_dynamo -- 'caffe2/test:test_dynamo - test_export.py::ExportTests::test_export_with_nonzero_static' -- 'caffe2/test:test_dynamo - test_misc.py::MiscTests::test_nonzero_static'
```
**PT2 Export with `nonzero_static()`**
Example of `GraphModule` in the exported graph
```
def forward(self, x):
arg0, = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
nonzero_static_default = torch.ops.aten.nonzero_static.default(arg0, size = 4); arg0 = None
return pytree.tree_unflatten([nonzero_static_default], self._out_spec)
```
Differential Revision: D44324808
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97417
Approved by: https://github.com/ezyang
Summary: When using real tensors for DTensor propagation, functionalized _fuse_adam causes a memory spike of size(params + optim_state), which causes OOM on memory constrained environments.
Test Plan: Tested manually.
Differential Revision: D44845043
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98789
Approved by: https://github.com/mrshenli
Summary: The non-transformed graph module contains functionalized optimizer which, in a memory constraint environment, needs to be defunctionalized (via fx transformation or lowering to Inductor) before running the first iteration. Otherwise OOM may occur.
Test Plan: Manually tested.
Reviewed By: mrshenli
Differential Revision: D44843942
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98788
Approved by: https://github.com/mrshenli
Summary:
https://www.internalfb.com/logview/details/instagram_ios_crashes/d5fd49a99f3ee21a82b66861de797711
CoreML is crashing in torch::jit::mobile::coreml::CoreMLBackend::compile(c10::IValue, c10::Dict<c10::IValue, c10::IValue>) (PTMCoreMLBackend.mm<175>)
This is related to the crash here https://www.internalfb.com/logview/details/instagram_ios_crashes/a8a317c8da13cd577529e1763364f496/?trace_key=8002f84f5ea00ac68b0dfb91878c754a&selected-logview-tab=shared
kimishpatel's original fix here D44386623 by passing modelID by value instead of reference, however I believe it just moved the error to loadModel invocation.
When we create a copy of modelID on loadModel invocation, it is a reference to the string within the preprocessed IValue payload. When the payload is deallocated, modelID is no longer valid and the dispatched thread still tries to use it causing the error
Test Plan:
```
Running with tpx session id: 2a77b7b1-7594-4479-8ac3-c01db29cf5cc
Trace available for this run at /tmp/tpx-20230407-173155.849234-2a77b7b1-7594-4479-8ac3-c01db29cf5cc/trace.log
RemoteExecution session id: reSessionID-2a77b7b1-7594-4479-8ac3-c01db29cf5cc-tpx
I0407 17:31:55.970502 780835 ConfigeratorDomainConfigs.cpp:177] Notify user with updated size: 92 removed size: 0
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/1970325002807752
✓ ListingSuccess: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests : 13 tests discovered (0.177)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchBITests/testBITextModel (0.028)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchBITests/testBIXRayModel (0.167)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchCPUBlasTests/testGemmComplexDouble (0.001)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchCPUBlasTests/testGemmComplexFloat (0.001)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchCPUBlasTests/testGemmDouble (0.001)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchCPUBlasTests/testGemmFloat (0.001)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchCoreMLTests/testGanModel (0.303)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchCoreMLTests/testMCSModel (0.395)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchCoreMLTests/testMCSModelInvalidInputShape (0.305)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchCoreMLTests/testXirpModel (0.110)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchDynamicPyTorchTests/testDynamicPytorchFamFlDictModel (0.014)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchDynamicPyTorchTests/testDynamicPytorchFamFlModel (0.005)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - PyTorchDynamicPyTorchTests/testDynamicPyTorchXirpModel (0.065)
✓ Pass: //fbobjc/Apps/Internal/PyTorchPlayground:PyTorchPlaygroundTests - main (13.177)
```
Differential Revision: D44808433
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98655
Approved by: https://github.com/SS-JIA, https://github.com/tiandiao123, https://github.com/kirklandsign
Summary:
See [this post](https://fb.workplace.com/groups/devinfra.capacity.eng/permalink/1200060064273920/) for context and specifically [this solution](https://fb.workplace.com/groups/devinfra.capacity.eng/posts/1200060064273920/?comment_id=1200166060929987&reply_comment_id=1200177124262214) which this diff implements.
The gist is that updating `bzl` file is *very* expensive for diff time testing and triggers many flaky tests when attempting to land a model update from EdgeML. The purpose of these bzl files (from what I can tell) is to unit test models via a CXX resources map. Since it's only used for CXX resource generation, this can be accomplished via generating `fb_xplat_cxx_library` BUCK target instead. This required shuffling around some existing BUCK files due to buck rules around file ownership.
Since the EdgeML process already generates code to begin with, this is straightforward to do by just changing the code from generating bzl files to now generate a BUCK file and change the existing targets to use it thus we can now delete the old bzl files.
Test Plan:
Run the model gen script.
```
buck2 run mode/opt caffe2/torch/fb/mobile/cli:cli -- --concat_all_model_configs
```
Sanity test the new BUCK target.
```
buck2 build xplat/pytorch_models/build:test_resources
```
Run the model unit tests and confirm they still work.
```
buck2 run xplat/caffe2:for_each_prod_ptl_model_test
```
CI/CD for the rest.
I expect some flaky test given the `bzl` file deletion which triggers off a ton of unrelated tests.
Differential Revision: D44699671
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98450
Approved by: https://github.com/JacobSzwejbka
Summary: IL generates massive function names: which meant that the pickle opcode used is BINUNICODE instead of the short version -- and then it would silently get skipped while pickling with protocol 4.
Differential Revision: D44815351
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98674
Approved by: https://github.com/ezyang
As the comment for `get_expanded_dims` says:
```
# copy_ fails when trying to write to tensors with memory overlap,
# for expanded dimensions (a dimension which used to have size 1 -> ?)
# we can select one element from that dimension and write to it
# to achieve writing to all values of that dimension of the input tensor
```
We were doing this for the copy, for not for checking if we could copy. Update it so we index then check for memory overlap. This covers all of the `complex_striding` warnings I observed in TB.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98656
Approved by: https://github.com/ngimel, https://github.com/yf225
Fixes #ISSUE_NUMBER
Extend rng device related func,support custom device extensions,and default device is `cuda`.
@bdhirsh @kit1980 would you please take a moment to review my changes?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98069
Approved by: https://github.com/bdhirsh
In C++ we have TORCH_LIBRARY_FRAGMENT. This PR adds the same
functionality to the Python torch.library API.
The motivation for this is: for the simple custom op API, we don't want
users to need to deal with Library objects. One way to hide this from
users is to create library fragments.
Test Plan:
- tests that you can create multiple fragments and def+impl operators on each.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98439
Approved by: https://github.com/ezyang, https://github.com/bdhirsh
For the current runtime wrapper in aot, `disable_amp` is always set to True. In fact, we would like to avoid disabling autocast if possible because accessing TLS is slow. In this PR, `disable_amp` depends on whether there is any autocast enabled instead of always being True. Many operators would get an improvement of performance (inductor v.s. eager) with this fix.
Example of operators' 0.8 speedup in torchbench (inductor v.s. eager):
<html xmlns:v="urn:schemas-microsoft-com:vml"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:x="urn:schemas-microsoft-com:office:excel"
xmlns="http://www.w3.org/TR/REC-html40">
<head>
<meta name=ProgId content=Excel.Sheet>
<meta name=Generator content="Microsoft Excel 15">
<link id=Main-File rel=Main-File
href="file:///C:/Users/xuanliao/AppData/Local/Temp/msohtmlclip1/01/clip.htm">
<link rel=File-List
href="file:///C:/Users/xuanliao/AppData/Local/Temp/msohtmlclip1/01/clip_filelist.xml">
</head>
<body link="#0563C1" vlink="#954F72">
| current | new
-- | -- | --
aten.hardsigmoid.default | 0.709372349 | 0.81414306
aten.tanh.default | 0.715227805 | 0.855556349
aten.add.Scalar | 0.682292123 | 0.860371222
aten.sigmoid_backward.default | 0.688039934 | 0.915606579
</body>
</html>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97864
Approved by: https://github.com/EikanWang, https://github.com/jansel, https://github.com/jgong5, https://github.com/bdhirsh
There were some recent failures on master, and I think it's fair to defer on turning it on till we get a bit of the Tensor construction overhead down because that shows up a lot in the TB benchmarks.
There may ultimately be an unavoidable tradeoff between memory and performance to some extent but we can get the overhead numbers down a bit first.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98709
Approved by: https://github.com/Chillee
Use float32 as acc type for `min`, `max` and `minmax`, in the function ` vec::reduce_all`, float16 inputs will be accumulated in float32.
The performance benefit basically comes from the vectorization of `Half` https://github.com/pytorch/pytorch/pull/96076
Tested on Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz
**single socket**
```
(before)
### using OMP_NUM_THREADS=20
### using numactl --physcpubind=0-19 --membind=0
max: size: torch.Size([64, 128, 1024]) 2.071 ms
(after)
### using OMP_NUM_THREADS=20
### using numactl --physcpubind=0-19 --membind=0
max: size: torch.Size([64, 128, 1024]) 0.071 ms
```
**single core**
```
(before)
### using OMP_NUM_THREADS=1
### using numactl --physcpubind=0 --membind=0
max: size: torch.Size([64, 128, 1024]) 33.488 ms
(after)
### using OMP_NUM_THREADS=1
### using numactl --physcpubind=0 --membind=0
max: size: torch.Size([64, 128, 1024]) 0.953 ms
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96079
Approved by: https://github.com/jgong5, https://github.com/kit1980
Patterns based on https://github.com/pytorch/pytorch/pull/94729 mainly as a forcing function for implementing joint graph replacements.
Up until now, we had two places to do pattern matching
1) Pre-grad has janky infra (graph not normalized or functional), but is
desirable for many types of passes where you want your change to
affect grad formulas.
2) Post-grad has good infra, but cant change grad formulas.
This PR adds a third place to do pattern matching: the joint
forward+backwards graph. The idea is to take the patterns and lower
them to a joint graph and replace both the forwards+backwards before
we partition them. This allows us to do something similar to pre-grad
transforms, but run after normalization and functionalization.
Note that we don't seem to have kernels for all of these patterns, some get decomposed in the dispatcher.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97741
Approved by: https://github.com/Chillee
As in Python-3.9+ `Dict`, `List`, and `Tuple` from `typing` module are deprecated in favor of their `builtins` counterparts, see [PEP 585](https://peps.python.org/pep-0585/)
Test plan: Run:
```
import torch
from typing import Union
@torch.jit.script
def to_tuple(v: Union[int, tuple[int, int]]) -> tuple[int, int]:
"""Converts int or tuple to tuple of ints."""
if torch.jit.isinstance(v, int):
return v, v
else:
return v
print(to_tuple(1), to_tuple((3, 4)))
```
It's almost impossible to add test to an existing CI, as test script will not be parseable by Python-3.8, which is a oldest supported Python version
Fixes https://github.com/pytorch/pytorch/issues/98521
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98703
Approved by: https://github.com/kit1980
Fixes#97728Fixes#98622
Fixes https://github.com/microsoft/onnx-script/issues/393
Provide op_level_debug in exporter which creates randomnied torch.Tensor based on FakeTensorProp real shape as inputs of both torch ops and ONNX symbolic function. The PR leverages on Transformer class to create a new fx.Graph, but shares the same Module with the original one to save memory.
The test is different from [op_correctness_test.py](https://github.com/microsoft/onnx-script/blob/main/onnxscript/tests/function_libs/torch_aten/ops_correctness_test.py) as op_level_debug generating real tensors based on the fake tensors in the model.
Limitation:
1. Some of the trace_only function is not supported due to lack of param_schema which leads to arg/kwargs wronly split and ndarray wrapping. (WARNINGS in SARIF)
2. The ops with dim/indices (INT64) is not supported that they need the information(shape) from other input args. (WARNINGS in SARIF)
3. sym_size and built-in ops are not supported.
4. op_level_debug only labels results in SARIF. It doesn't stop exporter.
5. Introduce ONNX owning FakeTensorProp supports int/float/bool
6. parametrized op_level_debug and dynamic_shapes into FX tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97494
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
Always do vectorization with scalar fallback for indirect indexing right now. We can vectorize the indirect indexing load/store by analyzing how the indirect indices are related to the loop variables. This will be done in future PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98138
Approved by: https://github.com/jansel
This PR primarily made two changes:
1. Support all ops (not only the load related ops) for `ops.masked`. Do recursive checks on masked body in `CppVecKernelChecker`. With this, we can remove `is_load_only_block` function and corresponding checking logic in `masked`.
2. Change the loop steps to the vectorized scaling factor instead of scaling the vectorized loop variables. With this, we can remove all the code that scales the loop variables explicitly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98135
Approved by: https://github.com/EikanWang, https://github.com/jansel
This changes `TritonKernel` to have an `index_dtype` property which is
used as the dtype in indexing calculations. By default it is
`tl.int32` but if any input or output buffer is larger than `INT_MAX`
then we use `tl.int64` instead.
should fix#96978, #93606 (need to double check)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97447
Approved by: https://github.com/ngimel
The python function `benchmark_compiled_module` ends up using C++ expression printer to print the size for `rand_strided`, so you get a set e.g. `{2, 17}` instead of a
tuple `(2, 17)`. Here is a complete example from master:
```python
def benchmark_compiled_module(times=10, repeat=10):
from torch._dynamo.testing import rand_strided
from torch._inductor.utils import print_performance
arg0_1 = rand_strided({2, 17}, {17, 1}, device='cpu', dtype=torch.float32)
arg1_1 = rand_strided({2, 17}, {17, 1}, device='cpu', dtype=torch.uint8)
return print_performance(lambda: call([arg0_1, arg1_1]), times=times, repeat=repeat)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98608
Approved by: https://github.com/ngimel
Summary:
This PR adds support for adaptive_avg_pool2d (traced as mean.dim), mean and hardtanh to QNNPackQuantizer
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_qnnpack_quantizer_obs_sharing_ops
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98560
Approved by: https://github.com/andrewor14
This PR makes basic nnmodule forward hooks work by default, without any overhead. But it leaves silent correctness issues if users modify/remove their hooks later, thus also emits a warning.
- the usual case is to not use hooks, so avoid guard overhead here
- registering any hook before compile will trigger a warning about hook support
- registering a hook later (or removing one) requires user knowledge and opting in,
currently this isn't warnable (but maybe we can observe compiled nnmodules to make it
warnable).
Why skip hook guards by default instead of not tracing __call__/hooks by default?
- avoid having a mode flag that alters dynamo tracing behavior (harder to test both codepaths
in CI with full coverage)
- the most basic hook usecase (registering a hook before compile, and never removing it)
will work by default with this PR, while it would require enablement and incur overhead
in the 'not tracing __call__' proposal.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98371
Approved by: https://github.com/jansel
Small QoL improvement such that add_numbered_label now works more intuitively. Now if we push different labels instead of having `[reverted, mergedX2, revertX3, mergedX4, revertedX5, mergedX6]` we have `[reverted, merged, revertX2, mergedX2, revertedX3, mergedX3]`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98551
Approved by: https://github.com/huydhn
Significantly reduces overhead of constructing Tensors and Storages and checking Storage Liveness. Removes the regression for HF models that I tested and removes 75% of overhead of the extremely overhead bound resnet50 training we have in torchbench. (.91x base commit, 1.02x torchinductor default, 1.16x this PR, 1.25 previous cudagraphs impl).
This PR takes care of all of the lower hanging fruit.
- Computes storage aliasing at record time instead of during at runtime. We no longer need to use a runtime storage cache, and can instead index directly into the existing alias if there is one, or construct a new Storage
- Moves the heavyweight C++ calls into a batch - getting storage weakrefs and constructing tensors
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98529
Approved by: https://github.com/jansel, https://github.com/ngimel
Summary:
This PR adds annotation support for conv2d relu, linear, maxpool2d, add and add relu so
that we can successfully quantize resnet18 with the prepare_pt2e_quantizer API and get the same result
as fx graph mode quantization
Test Plan:
python test/test_quantization.py TestQuantizePT2EModels.test_resnet18_with_quantizer_api
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98507
Approved by: https://github.com/vkuzo
Add a PrivateUse1 folder to contain all the feature adaptations for PrivateUse1 under Aten,For example GetGeneratorPrivate which is used for the three-party backend to register his own Generator implementation.This makes it easier for us to centrally manage these features, and it will increase the convenience of adaptation for different back-end manufacturers. For more info: https://github.com/pytorch/pytorch/issues/98073
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98127
Approved by: https://github.com/bdhirsh
This is yet another wrong shard number calculation on ASAN causing flakiness. I figure that we don't really need to run this test on ASAN, so let disable it. There is discussion at the moment to run ASAN periodically too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98544
Approved by: https://github.com/malfet
Summary: This is a reland of #98264.
When _inductor.config.cpp_wrapper is specified, we run a
two-pass wrapper codegen to generate wrapper code in cpp which calls
cuLaunchKernel to launch pre-compiled cuda kernels, and then call
load_inline to load that generated wrapper back into the python world.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98534
Approved by: https://github.com/huydhn
Fixes#98149
The type of `mul`'s output is not inconsistent with its input. This PR fixes the type of `mul`'s output.
Here is the output code for the newly added test case `pow+cos`. `tmp4` is 1024 before fixing and 0 after fixing.
#### Before fixing
```
auto tmp0 = in_ptr0[static_cast<long>(0)]; // tmp0 is unsigned_char
auto tmp1 = tmp0 * tmp0; // tmp1 is int
auto tmp2 = tmp1 * tmp1; // tmp2 is int
auto tmp3 = tmp2 * tmp0; // tmp3 is int
auto tmp4 = static_cast<float>(tmp3); // tmp4 is float
auto tmp5 = std::cos(tmp4);
out_ptr0[static_cast<long>(0)] = tmp5;
```
#### After fixing
```
auto tmp0 = in_ptr0[static_cast<long>(0)]; // tmp0 is unsigned_char
auto tmp1 = decltype(tmp0)(tmp0 * tmp0); // tmp1 is unsigned_char
auto tmp2 = decltype(tmp1)(tmp1 * tmp1); // tmp2 is unsigned_char
auto tmp3 = decltype(tmp2)(tmp2 * tmp0); // tmp3 is unsigned_char
auto tmp4 = static_cast<float>(tmp3); // tmp4 is float
auto tmp5 = std::cos(tmp4);
out_ptr0[static_cast<long>(0)] = tmp5;
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98473
Approved by: https://github.com/EikanWang, https://github.com/jgong5, https://github.com/jansel
This PR explicitly add $CONDA_ENV/bin to MacOS PATH, so that it can always detect and use the correct Python. $CONDA_ENV is always set to the correct value in setup-miniconda https://github.com/pytorch/test-infra/blob/main/.github/actions/setup-miniconda/action.yml#L141
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at b4de81a</samp>
This pull request fixes the conda-pip environment mismatch for the macOS build and test workflows by using consistent pip requirements files. It also adds a conditional block to the `.github/workflows/_mac-test-mps.yml` file to enable the test MPS job.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98522
Approved by: https://github.com/malfet
Pattern replacement behaves incorrectly when the replacement pattern maps inputs to outputs (such a pattern can be used to replace redundant code). However, current code in `torch.fx.subgraph_rewriter._replace_pattern` causes the list of replacement nodes to include the entire graph before that node, resulting in an exponential slowdown due to recursive calls traversing the entire graph multiple times.
The proposed fix is to add a check in `_replace_pattern` to prevent the call to `get_replacement_nodes`:
```python
for ret_node in copied_returning_nodes:
if ret_node in match.placeholder_nodes:
replacement_nodes.append(ret_node)
else:
get_replacement_nodes(ret_node)
```
Fixes#97817
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97903
Approved by: https://github.com/angelayi
This PR is to address the issue seeing in PR #97417 where the newly added op requires `kwargs`, however, currently tools/autograd/gen_annotated_fn_args.py does not support `kwargs`, only `func_args` are generated for test_overrides.py.
The PR adds a new field "is_kwargs" to each argument indicating whether it's a `kwargs` or not. See example:
```
annotated_args = {
torch._C._VariableFunctions._cast_Byte: [{'is_kwarg_only': 'False', 'name': 'self', 'simple_type': 'Tensor'}],
...
```
The full comparison of the generated file `annotated_fn_args.py` can be found here:
- **Before**: [P681991116](https://www.internalfb.com/phabricator/paste/view/P681991116)
- **After**: [P681994218](https://www.internalfb.com/intern/paste/P681994218/)
Differential Revision: D44698310
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98396
Approved by: https://github.com/ezyang
The meta implementation for these _like function is wrong whenever device != "meta" (it doesn't fill the memory!).
zeros_like is special due to sparse and is fixed directly by always filling it with zeros.
Every other one is CompositeExplicit implementation, I went with removing their meta registration and tweaking code to avoid infinite recursions.
I can do the same as zeros_like (and add the proper filling for each) but that would duplicate the c++ logic and make the meta registrations non trivial. I can do it if you prefer to removal.
test_meta works fine with these fixes, relying on CI to see if other tests are breaking as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98160
Approved by: https://github.com/ezyang
Summary: when _inductor.config.cpp_wrapper is specified, we run a
two-pass wrapper codegen to generate wrapper code in cpp which calls
cuLaunchKernel to launch pre-compiled cuda kernels, and then call
load_inline to load that generated wrapper back into the python world.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98264
Approved by: https://github.com/ngimel
It's already not working, but this makes error message a bit more readable. I.e. it turns:
```
% python -c "import torch;x=torch.eye(3).to_sparse().expand(3,3)"
```
from
```
NotImplementedError: Could not run 'aten::as_strided' with arguments from the 'SparseCPU' backend.
```
to
```
RuntimeError: Expand is unsupported for Sparse tensors.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98365
Approved by: https://github.com/pearu, https://github.com/cpuhrsch
Summary:
This PR added a quantizer API to prepare_pt2e_quantizer, which enables user to annotate the nodes in the graph
directly to configure quantization, instead of relying on QConfigMapping, please see test cases in
test_quantize_pt2e.py for examples. Also added a prototype for QNNPackQuantizer, that will be modified later
to fully support different quantization capabilities of QNNPack/XNNPack
The goal for introducing quantizer is to add flexibility to the quantization API to allow modeling users and backend developers to express their quantization intentions programmably, which will free architecture optimization team from supporting different use cases in the core API in the future, as a concrete example, we used to have https://pytorch.org/docs/master/generated/torch.ao.quantization.qconfig_mapping.QConfigMapping.html#torch.ao.quantization.qconfig_mapping.QConfigMapping as the API for users to express their intent for quantization in fx graph mode quantization, and it has some fancy options like `set_module_name_regex` and `set_module_name_object_type_order`, this is not needed for all backends and adds burden of maintenance to AO team, in the quantizer API we will move these APIs to a backend specific `Quantizer` that needs this feature, and all the backends or even advanced modeling users can implement their own quantizer to express their intent for quantization through annotating the nodes, for example, to express the quantization intention of quantizing a convolution node, a user will find the convolution node in the graph and do:
```
operator_spec = qnnpack_quantizer.get_default_per_channel_symmetric_qnnpack_operator_spec()
conv_node.meta["target_dtype_info"] = {
"input_act_obs_or_fq_ctr": _get_act_obs_or_fq_ctr(operator_spec),
"weight_obs_or_fq_ctr": _get_weight_obs_or_fq_ctr(operator_spec)
"bias_obs_or_fq_ctr": _get_bias_obs_or_fq_ctr(operator_spec),
"output_act_obs_or_fq_ctr": _get_act_obs_or_fq_ctr(operator_spec),
# TODO: validation of weight_index must be set if weight_obs_or_fq_ctr is set
"weight_index": 1,
# TODO: validation of bias_index must be set if bias_obs_or_fq_ctr is set
"bias_index": 2,
}
```
each backend will introduce their own quantizer, e.g. QNNPackQuantizer, which may expose more convenient APIs for modeling users to configure the annotation, and different quantizer can compose with each other to annotate the graph correctly for quantization.
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_simple_quantizer
python test/test_quantization.py TestQuantizePT2E.test_qnnpack_quantizer_conv
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97994
Approved by: https://github.com/vkuzo
This PR enables the following unit tests in FSDP feature on ROCm.
```
test_bf16_hook_has_wrapping_False_sharding_strategy_ShardingStrategy_FULL_SHARD
test_bf16_hook_has_wrapping_False_sharding_strategy_ShardingStrategy_NO_SHARD
test_bf16_hook_has_wrapping_False_sharding_strategy_ShardingStrategy_SHARD_GRAD_OP
test_bf16_hook_has_wrapping_True_sharding_strategy_ShardingStrategy_FULL_SHARD
test_bf16_hook_has_wrapping_True_sharding_strategy_ShardingStrategy_NO_SHARD
test_bf16_hook_has_wrapping_True_sharding_strategy_ShardingStrategy_SHARD_GRAD_OP
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97517
Approved by: https://github.com/pruthvistony, https://github.com/jeffdaily, https://github.com/jithunnair-amd, https://github.com/malfet
This PR is to export specific function symbols into .dll shared library on Windows platform to support Windows build for [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch).
TORCH_API/TORCH_PYTHON_API/PYBIND11_EXPORT are macros that decorate the function as dllexport while compilation, so that the function symbol will be exported into the .dll shared library file on Windows platform. It is necessary for other libraries (such as IPEX) to import and call these functions through dynamic linking of PyTorch on Windows platform.
The code changes of this PR adds decorators to export specific functions used by IPEX.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98054
Approved by: https://github.com/ezyang
This makes only a cosmetic change to the generated code, but means
triton's broadcasting logic doesn't leak out into the CSE class.
Before:
```python
tmp5_load = tl.load(in_ptr1 + (0))
tmp5 = tl.broadcast_to(tmp5_load, [XBLOCK])
```
After:
```python
tmp5 = tl.load(in_ptr1 + (0))
tmp6 = tl.broadcast_to(tmp5, [XBLOCK])
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98304
Approved by: https://github.com/ngimel
Currently the `TritonKernel.mask_loads` context manager calls
`swap_buffers` which creates a new CSE context. So, code generated in
different mask contexts cannot be CSE'd even if their masks are the
same. This fixes the issue by not calling `swap_buffers` and instead
having `load` manually check if a `"tmp"` name appears in the mask
meaning the load needs to be generated in the compute buffer.
Currently, simple programs involving padding will result in duplcate
masked loads. e.g. the generated code for
```python
def forward():
a = torch.nn.functional.pad(x, (0, 1))
return a + a
```
contains the lines
```python
tmp3 = tl.load(in_ptr0 + (x1 + tl.zeros([XBLOCK], tl.int32)), tmp2 & xmask, other=0)
tmp4 = tl.where(tmp2, tmp3, 0.0)
tmp5 = tl.load(in_ptr0 + (x1 + tl.zeros([XBLOCK], tl.int32)), tmp2 & xmask, other=0)
tmp6 = tl.where(tmp2, tmp5, 0.0)
```
With this change, the duplicates are removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98303
Approved by: https://github.com/ngimel
Fixes#96975
Changes:
- Make sure custom ShardingDataPipe with `apply_sharding` can be used by `DataLoader`
- Allow the `apply_sharding` function without the last argument of `sharding_group`
- Make `DataLoader` not relying on `sharding_group`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97287
Approved by: https://github.com/NivekT
This replaces fake_mode_from_tensors but it preferentially looks for
fake_mode in TracingContext and also if there is an active fake mode
on the dispatch stack, before groveling in tensors to find it.
This advances PegasusForCausalLM, which was previously failing because
we generated a graph that had a parameter (non-fake) and a SymInt,
and thus previously we failed to detect the correct fake mode.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98321
Approved by: https://github.com/voznesenskym
…eMeta
This modularizes ExtraMeta to bring down its creation cost when it is needed for other functions than syn shape handling.
Change-Id: Ife59b201b0c4fd75090fe8be5171a6dd73a10d10
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98399
Approved by: https://github.com/ezyang
Executorch currently uses functorch.functionalize API, as a result we have to invoke make_fx twice (one for filtering out autograd related stuff (happens in torchdynamo.export(aten=True) and one for tracing the functionalized version of the graph). The previous PR changes the make_fx behaviour to pass in fake tensors used in dynamo. But as Executorch invokes the second make_fx directly, we need to have access to fake tensors that dynamo used. We cannot call torchdynamo.export again in the second round because we don't have a way to functionalize inside dynamo at the moment. Hence I added this attribute in dynamo for now. Once we move to AOTAutograd functionalization, we don't have to deal with this anymore and I will remove this.
Differential Revision: [D43994692](https://our.internmc.facebook.com/intern/diff/D43994692)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96561
Approved by: https://github.com/zhxchen17, https://github.com/voznesenskym
Summary: retry of landing D44550100, try to import triton otherwise consider version as `None`
Test Plan: will make sure windows OSS tests run as well in CI
Differential Revision: D44694213
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98369
Approved by: https://github.com/huydhn
In the terminal state, it won't matter if you have dynamic_shapes
on or not, mark_dynamic will always work.
Today, it's helpful to make this not error so I can easily swap
between static or not and run experiments.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98324
Approved by: https://github.com/voznesenskym
## BC-breaking note:
This is technically a bugfix. Prior to this PR, for `torch.nn.functional.grid_sample(mode='nearest')` the 2D kernel used `std::nearbyint` whereas the 3D kernel used `std::round` in order to determine the nearest pixel locations after un-normalization of the grid. This PR fixes the 3D kernel to use `std::nearbyint` which rounds values that are exactly `<>.5` to the nearest even which is consistent with the behavior of `torch.round`. Unnormalized indices that are exactly `<>.5` will now be rounded to the nearest even instead of being rounded away from 0.
## Description
In the nearest neighbor interpolation mode, the 2D GridSample rounds index to the nearest even using [std::nearbyint](https://github.com/pytorch/pytorch/blob/v2.0.0/aten/src/ATen/native/cpu/zmath.h#L182) whereas the 3D GridSample rounds index away from zero using std::round. This discrepancy needs to be resolved. We are making both 2D GridSample and 3D GridSample to round to the nearest even.
## Unit Test Goals
1. Make sure the x dimension and y dimension rounding behaviors are the same for 2D GridSample.
2. ~~Make sure the 2D GridSample rounding mode is rounding to the nearest even.~~
3. Make sure the x dimension, y dimension, and z dimension rounding behaviors are the same for 3D GridSample.
4. ~~Make sure the 3D GridSample rounding mode is rounding to the nearest even.~~
5. The 2D GridSample and 3D GridSample rounding behaviors are exactly the same.
After some experiments, I found 2 and 4 are difficult to achieve. Even though I can compute the normalized coordinates corresponding to the unnormalized coordinates including [0, 0.5, 1.0, 1.5, 2.0, 2.5, ..., 10.0], the unnormalization process in the GridSample implementations always have a small chance of having floating point error. Therefore, it's not possible to unit test the rounding mode from the normalized coordinates.
## Unit Test Methods
The unit test is simple. By using the same values along the dimension to be tested in the input tensor and the same normalized indices in the grid tensor. The interpolation on the 2D GridSample x-dimension, 2D GridSample y-dimension, 3D GridSample x-dimension, 3D GridSample y-dimension, 3D GridSample z-dimension. Should produce exactly the same interpolated values.
If one CPU/CUDA 2D/3D implementation use a different rounding mode from others, the unit test shall fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97000
Approved by: https://github.com/mikaylagawarecki
Summary:
This PR implements `BaseSparsifier.convert()`, which performs module swapping.
The modules and mappings will be merged in a future PR.
Test Plan:
`python test/test_ao_sparsity.py -- TestBaseSparsifier.test_convert`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97545
Approved by: https://github.com/jerryzh168
We used to keep track of the average of stats, however, when we munge the data to find interesting insights this makes things difficult (ie. finding total test time for an oncall). The pin is updated such that we keep track of the sum instead as well as an "occurrences" field such that the average can be rederived from sum/occurrences.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98359
Approved by: https://github.com/huydhn
Move the responsibility of flattening the input arguments from the graph module to the caller. This serves two purposes:
- Transformations that add/remove state need to manipulate a state container that maintains the state tensors in the same order as they appear in graph placeholders.
- Reduced runtime cost. The state container is only flattened once upfront.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98392
Approved by: https://github.com/mrshenli
Currently, the compile API assumes all input tensors' shard dimension is the first dimension. dtensor expansion doesn't work when there are input tensors whose shard dimension is not the first dimension.
In addtion, respect non-tensor inputs beyond nn.Module and optim.Optimizers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98391
Approved by: https://github.com/mrshenli
According to profiling, the top two expensive operations in spmd expansion are propagate_op_sharding and make_fx (for every dispatcher op node). This PR makes the following changes to speed up spmd expansion:
- We are unneccessarily doing propagate_op_sharding twice for every op. Remove one.
- When no tensor redistribution is required, we only need to update non-tensor args of the node according to op_schema and avoid building a GraphModule just for the node.
On a DDP use cases + foreach Adam, this change speeds up spmd expansion by ~5x (~10 min -> ~2 min).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98389
Approved by: https://github.com/mrshenli
Because we do not persist output memory of cudagraphs, we need to reconstruct tensors at their correct memory locations after we've done a run. We were using a storage cache for that but it had a couple of issues:
- If the a data ptr existed in the cache, we should only reuse the corresponding storage if the storage hadn't died
- didnt work across separate nodes. While you wouldn't think this would be an issue, it was in testing HF.
- StorageWeakRef maintains whether the Storage C++ object remains allocated, not whether the corresponding memory has been deallocated. In order to use them to track memory deallocations we must maintain a single StorageWeakRef for all Storages that reference that memory (even if we are constructing Storages that do not have a deallocator function).
This PR a singlestorage_cache as we execute any tree path. When we retrieve a storage from the cache we
check that it is still alive, and we hash based on both observed recording data ptr and storageimpl weak ref.
Update to use a single storage cache across all executions in a path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98254
Approved by: https://github.com/jansel
The method torch.UntypedStorage.new is not detailed in API docs. Adding a method identifier may make it easier to know that new() method is only implemented by cpp, like copy_() or nbytes().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98201
Approved by: https://github.com/ezyang
PyTorch slow tests are run in CI with `PYTORCH_TEST_SKIP_FAST=1` which skips any
test not decorated with `@slowTest`. That means tests marked with
`skipIf(not TEST_WITH_SLOW)` are never run.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97841
Approved by: https://github.com/jansel
1. Fixed dynamic shapes support in cpp_wrapper
- fixed the cpp codegen of `size()` and `stride()`
- fixed the cpp codegen of `ShapeAsConstantBuffer`
- changed to use `cexpr` instead of `pexpr` in the cpp codegen of the `sizevar`
2. Enabled dynamic shapes tests for cpp_wrapper
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97965
Approved by: https://github.com/jgong5, https://github.com/jansel
Previously, when we would run a forward graph whose backward we never invoked it would prevent us from switching from warmup to recording. Now, refine the heuristic to allow incrementing the generation as soon as we invoke a backward graph. This still handles the
```
mod1 = torch.compile(...)
mod2 = torch.compile(...)
mod2(mod1(x)).sum().backward()
```
case while accounting for graphs which we may not run backward of.
It also now handles the case where we skip cudagraphify the backward of a forward.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98112
Approved by: https://github.com/jansel
This PR fixes https://github.com/pytorch/pytorch/issues/96203.
**Details**
When using `nn.SyncBatchNorm` with the model converted to FP16, there is a dtype discrepancy in the `SyncBatchNorm.forward()` causing an error like:
```
File "/.../pytorch/torch/nn/modules/_functions.py", line 91, in forward
mean, invstd = torch.batch_norm_gather_stats_with_counts(
RuntimeError: Expected counts to have type Half but got Float
```
[`torch.batch_norm_gather_stats_with_counts()`](fe9da29842/torch/nn/modules/_functions.py (L88-L97)) requires the `running_mean`, `running_var`, and `counts` to have the same dtype. However, when the model has been converted to FP16, only `running_mean` and `running_var` use FP16, while the `counts` are in FP32 due to [`mean` being in FP32](fe9da29842/torch/nn/modules/_functions.py (L25-L30)). This PR resolves this by casting `counts` from FP32 to FP16 instead of the alternative to cast `mean` and `invstd` from FP32 to FP16.
Moreover, for the backward, this PR casts `weight` from FP16 to FP32 to match the dtype of `mean` and `invstd` as required by `torch.batch_norm_backward_elemt()` instead of the alternative to cast `mean` and `invstd` from FP32 to FP16.
**Test Plan**
I dug up this run command from 2021:
For `world_size` in `{1,2}` and `backend` in `{nccl, gloo}`:
```
WORLD_SIZE=world_size BACKEND=backend python -m pytest test/distributed/test_distributed_spawn.py -k test_DistributedDataParallel_SyncBatchNorm_half -vs
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98332
Approved by: https://github.com/rohan-varma
BackendMeta offers a binary interface for the backend to attach arbitrary data to TensorImpl. TensorImpl has exactly one "slot" for backend metadata, however backend is free to compose any structure that is opaque to the framework beyond iheriting standard BackendMeta base.
Change-Id: I670fcdd16dd1c2b00f7eaa1cbc5b5dfea59a6221
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97429
Approved by: https://github.com/ezyang
Summary: Skip mobilenet_v3_large for accuracy checking to reduce
noise on the dashboard. The root cause still needs to be investigated.
mobilenet_v3_large shows random accuracy check failures with different
error values from time to time, and here are some examples:
```
cuda train mobilenet_v3_large [2023-04-04 14:54:50,990] torch._dynamo.utils: [ERROR] RMSE (res-fp64): 0.02172, (ref-fp64): 0.01068 and shape=torch.Size([960, 1, 5, 5])
[2023-04-04 14:54:50,990] torch._dynamo.utils: [ERROR] Accuracy failed for key name features.14.block.1.0.weight.grad
```
```
cuda train mobilenet_v3_large [2023-04-04 14:57:59,972] torch._dynamo.utils: [ERROR] RMSE (res-fp64): 0.07744, (ref-fp64): 0.03073 and shape=torch.Size([72, 1, 5, 5])
[2023-04-04 14:57:59,973] torch._dynamo.utils: [ERROR] Accuracy failed for key name features.4.block.1.0.weight.grad
```
One observation is turnning off cudnn in the eager mode with
`torch.backends.cudnn.enabled = False` makes the non-deterministic
behvior go away but meanwhile it fails accuaracy checking consistently.
Minifier didn't help to narrow down the error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98314
Approved by: https://github.com/huydhn
Summary:
In highly multi-threaded environment, using # of threads to be matching hardware_concurrency leads to high contention. x86 path actually ends up using different path (MKL path), which results in using 1 thread for x86 as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98267
Approved by: https://github.com/malfet
Summary:
* change caching to have `system` and `cache` components, where `system` servers as an identifier for that machine's performance. similar to original method of having GPU type and CUDA version be cache keys, and now also includes Triton version. `cache` is similar to the original cache type, but now without GPU name or CUDA version
```
{
"system": {
"device": "NVIDIA PG509-210",
"version": {
"cuda": "11.4.0",
"triton": "2.1.0"
},
"hash": "e7cfb8786d2e1366b3df564bcb2f957d07545e98bf20c98d33a43b6ee80a91e0"
},
"cache": {
"bias_addmm": {
"[('cuda', 'torch.float32', 2048, 160, 0, 1, 0), ('cuda', 'torch.float32', 2048, 1140, 228148, 1, 206080), ('cuda', 'torch.float32', 1140, 160, 1, 1140, 0)]": {
"bias_addmm-alpha=1-beta=1-c73frtshmeth2spjun3zc4l2q7ck43wl356pnlmsmxgmzbfsz7ef": 0.03654399886727333,
"addmm-alpha=1-beta=1-c4xxd3iocu4yt6z4udrlqnumays7q6mfnfd3qprh4fxgsvyhqdkf": 0.03564799949526787,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=32-BLOCK_M=64-BLOCK_N=64-EVEN_K=False-GROUP_M=8-num_stages=2-num_warps=4-cxgwpjkimm4azwffrfuqniwncnv4h5bxrpo4od4an4bstnh7qrqh": 0.04927999898791313,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=32-BLOCK_M=64-BLOCK_N=128-EVEN_K=False-GROUP_M=8-num_stages=3-num_warps=4-cqlirysniekkuuvc4ue33dr4gpfzsb5e4bexarrsnsyei4slxvcz": 0.03651199862360954,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=32-BLOCK_M=128-BLOCK_N=64-EVEN_K=False-GROUP_M=8-num_stages=3-num_warps=4-cww5uss3k4d3ei2c4lx63pudyzxdwl3ieibhxcrue4zg424eqrnu": 0.03580800071358681,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=32-BLOCK_M=64-BLOCK_N=128-EVEN_K=False-GROUP_M=8-num_stages=4-num_warps=8-cqcla5edxdm3n6rrkmjehexsudravx6lpphfo5zazldpo3rzpqc4": 0.03558399900794029,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=32-BLOCK_M=128-BLOCK_N=64-EVEN_K=False-GROUP_M=8-num_stages=4-num_warps=8-c7gdf2snt4bjlnuzdy3px4pyq3lbsdh4jp6jaie7lq6mdxccy6nl": 0.03455999866127968,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=32-BLOCK_M=64-BLOCK_N=32-EVEN_K=False-GROUP_M=8-num_stages=5-num_warps=8-cjhcy4scxgy4lxbhjiinvxl3bbrqya63jilcckx2ltsg3mpzxyqr": 0.036288000643253326,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=32-BLOCK_M=32-BLOCK_N=64-EVEN_K=False-GROUP_M=8-num_stages=5-num_warps=8-cu32a5vsbaln3t55jm2y6xhwgyggejmoatyakcm2huvxofw2zzva": 0.0398080013692379,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=32-BLOCK_M=128-BLOCK_N=128-EVEN_K=False-GROUP_M=8-num_stages=2-num_warps=8-croberh4l55jxlrlgkttigtebsnmosycc5rdtbtn3lp3bpovgz4a": 0.0732479989528656,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=64-BLOCK_M=64-BLOCK_N=64-EVEN_K=False-GROUP_M=8-num_stages=3-num_warps=8-c6oxgunysrqpiwwoinylb3sb2hzvx66yhehma64drqvmz52h3r5t": 0.0306560005992651,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=128-BLOCK_M=32-BLOCK_N=32-EVEN_K=False-GROUP_M=8-num_stages=2-num_warps=4-cdrev5e3zno6z6flmhlbxgd26gkdpurljyhrw3ovx6pftoe62dpf": 0.04800000041723251,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=16-BLOCK_M=64-BLOCK_N=64-EVEN_K=False-GROUP_M=8-num_stages=2-num_warps=4-ce3ofrgngrwuo45hw5wqlzztium7gfkf4n5x25gwu4d6ygkea4bs": 0.0751039981842041,
"triton_mm-ACC_TYPE='tl.float32'-ALLOW_TF32=True-BLOCK_K=16-BLOCK_M=32-BLOCK_N=32-EVEN_K=False-GROUP_M=8-num_stages=1-num_warps=2-cfkz2smezre4x7hyhc2kbeawhqup6qpwzgiavrai2ghe5ghouvn4": 0.07401599735021591
},
...,
},
...,
}
}
```
Test Plan:
MAST no global: sw-966772723-OfflineTraining_df2509b8
MAST global: sw-966766969-OfflineTraining_19df7c20
Differential Revision: D44550100
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98010
Approved by: https://github.com/jansel
This is the first phase of the new ONNX exporter API for exporting from TorchDynamo and FX, and represents the beginning of a new era for exporting ONNX from PyTorch.
The API here is a starting point upon which we will layer more capability and expressiveness in subsequent phases. This first phase introduces the following into `torch.onnx`:
```python
dynamo_export(
model: torch.nn.Module,
/,
*model_args,
export_options: Optional[ExportOptions] = None,
**model_kwargs,
) -> ExportOutput:
...
class ExportOptions:
opset_version: Optional[int] = None
dynamic_shapes: Optional[bool] = None
logger: Optional[logging.Logger] = None
class ExportOutputSerializer(Protocol):
def serialize(
self,
export_output: ExportOutput,
destination: io.BufferedIOBase,
) -> None:
...
class ExportOutput:
model_proto: onnx.ModelProto
def save(
self,
destination: Union[str, io.BufferedIOBase],
*,
serializer: Optional[ExportOutputSerializer] = None,
) -> None:
...
```
In addition to the API in the first commit on this PR, we have a few experiments for exporting Dynamo and FX to ONNX that this PR rationalizes through the new Exporter API and adjusts tests to use the new API.
- A base `FXGraphModuleExporter` exporter from which all derive:
- `DynamoExportExporter`: uses dynamo.export to acquire FX graph
- `DynamoOptimizeExporter`: uses dynamo.optimize to acquire FX graph
- `FXSymbolicTraceExporter`: uses FX symbolic tracing
The `dynamo_export` API currently uses `DynamoOptimizeExporter`.
### Next Steps (subsequent PRs):
* Combine `DynamoExportExporter` and `DynamoOptimizeExporter` into a single `DynamoExporter`.
* Make it easy to test `FXSymbolicTraceExporter` through the same API; eventually `FXSymbolicTraceExporter` goes away entirely when the Dynamo approach works for large models. We want to keep `FXSymbolicTraceExporter` around for now for experimenting and internal use.
* Parameterize (on `ExportOptions`) and consolidate Dynamo exporter tests.
- This PR intentionally leaves the existing tests unchanged as much as possible except for the necessary plumbing.
* Subsequent API phases:
- Diagnostics
- Registry, dispatcher, and Custom Ops
- Passes
- Dynamic shapes
Fixes#94774
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97920
Approved by: https://github.com/justinchuby, https://github.com/titaiwangms, https://github.com/thiagocrepaldi, https://github.com/shubhambhokare1
This cleanup some redundant CI jobs that I found:
* @malfet @ZainRizvi Do we need debug build in periodic for both 11.8 and 11.7? This is rarely needed AFAIK. I try to remove 11.8 here while keep 11.7 to be consistent with the rest of the CI. Or may be it should be the other way around to keep 11.8
* Remove libtorch 11.7 and 11.8 builds in periodic as it has already been done in [trunk](https://github.com/pytorch/pytorch/blob/master/.github/workflows/trunk.yml#L86-L97)
* Cleanup TSAN (I added this a while back, but there is no drive to go into that further, so let's just kill it) - If you want to keep it, please raise your hand.
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 4b3ec53</samp>
This pull request simplifies and consolidates the scripts and workflows for the thread sanitizer (TSAN) build and test configuration. It removes redundant and outdated logic, files, and workflows that were previously used to handle the TSAN build differently from the regular build. It enables all the tests for the TSAN build, which has been fixed by another pull request.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98044
Approved by: https://github.com/malfet, https://github.com/ZainRizvi
Summary:
This test tests an operator that quantizes and serializes a float array.
Among the data serialized, one element is the bias, i.e. the minimum value in the array.
The test may fail when the array contains both +0.0 and -0.0, while all other elements are positive.
(this happens quite frequently with a hypothesis version >= 6.17.4, due to [this issue](https://github.com/HypothesisWorks/hypothesis/issues/3606))
Depending on the exact settings of SIMD (single instruction, multiple data), the elements of the array may be visited in different orders while running the operator and while calculating the reference.
Because +0.0 and -0.0 compare equal, the minimum value may be either +0.0 or -0.0.
Nevertheless, the serialized forms of these two values differ in the sign bit, and can make the test fail because it's conducting an exact match on the serialized result.
To avoid this failure, I'm adding a line to replace all -0.0 with +0.0 in the input array.
Test Plan:
Run this with both hypothesis < 6.17.4 and >= 6.17.4:
```
buck2 test mode/opt caffe2/caffe2/python:fused_8bit_rowwise_conversion_ops_test - test_quantize_op
```
Differential Revision: D44617022
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98183
Approved by: https://github.com/malfet
This PR ensures that when prefetching a `FlatParamHandle.unshard()`, we temporarily set the `FlatParamHandle._training_state` to the expected training state as if the `unshard()` were not prefetched since the `as_params` argument to `_use_unsharded_views()` depends on the handle's training state.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98249
Approved by: https://github.com/rohan-varma
Avoid referring to std::vector<T> members and constructor/desctructors when T is incomplete.
Referring to incomplete members is [not legal](https://timsong-cpp.github.io/cppwp/n4868/vector#overview-4) according to the C++ standard.
Non-noexcept constructors need access to members' destructors. As of C++20, std::vector's destructor is constexpr and so forcefully requires a complete type for the vector's elements.
These issues cause build errors in newer toolchains under c++20 mode.
Fix them by moving code that needs complete types to a different place where the type is already defined.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93978
Approved by: https://github.com/Skylion007
Fix Meta internal use case:
* We are going to skip tracing ```torchrec.distributed```, however, in fbcode, the structure is a bit different from OSS torchrec.
* Meta internally uses ```torch.package```, so we should support skip tracing files like ```<torch_package_0>.torchrec/distributed/...```.
* We put the logic behind a flag ```is_fbcode``` to avoid misuse.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98192
Approved by: https://github.com/yf225
This reverts commit bc38b278bf4c2890700f8fe751cfd15fcb01da60.
Reverted https://github.com/pytorch/pytorch/pull/97429 on behalf of https://github.com/huydhn due to Sorry for reverting your PR as I am trying to root cause a libtorch build failure on Windows starting from your change bc38b278bf. AFAICT, there is no other change from the log. I will reland this if the failure is unrelated
Summary:
The goal is to remove the need to use backend_config when pt2e flow code call this function
Test Plan:
python test/test_quantization.py TestQuantizeFx
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98094
Approved by: https://github.com/jcaip
BackendMeta offers a binary interface for the backend to attach arbitrary data to TensorImpl. TensorImpl has exactly one "slot" for backend metadata, however backend is free to compose any structure that is opaque to the framework beyond iheriting standard BackendMeta base.
Change-Id: I670fcdd16dd1c2b00f7eaa1cbc5b5dfea59a6221
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97429
Approved by: https://github.com/ezyang
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 79f1b37</samp>
This pull request improves the workflow and data processing for uploading contribution and testing statistics to Rockset and S3. It renames and updates a workflow file, removes unused code from a script, and adds a new script to aggregate and upload test results.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97954
Approved by: https://github.com/huydhn
Inductor codegen is suboptimal when calling all_reduce_coalesced with input args. We need to fix inductor's calling convention for that, or something else.
Might not work if any outputs is unused.
Test code:
```python
import torch
import torch.distributed as dist
import torch.nn.functional as F
from functorch import make_fx
import os
import torch.distributed._functional_collectives as ft_c
from torch.testing._internal.common_distributed import (
spawn_threads_and_init_comms,
)
from torch._inductor.compile_fx import compile_fx_inner
def my_fun(a, b):
c = a * 3
tensors = ft_c.all_reduce_coalesced([a, c, b], "sum", [0])
return ((tensors[1] + tensors[0] + tensors[2]).sum(), )
@spawn_threads_and_init_comms(world_size=1)
def inductor_main(self):
x = torch.arange(4).cuda() * (dist.get_rank() + 1)
y = torch.arange(4).cuda() * (dist.get_rank() + 1)
x = x.to(torch.float)
y = y.to(torch.float) * 0.5
res = make_fx(my_fun)(x, y)
print(f"fx graph:\n{res.graph}")
ind = compile_fx_inner(res, [x, y])
print(f"inductor done:\n{ind}")
os.environ["PROXY_TENSOR_TRACING"] = "1"
os.environ["TORCH_COMPILE_DEBUG"] = "1"
torch._dynamo.config.output_code = True
if __name__ == "__main__":
inductor_main(None)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97157
Approved by: https://github.com/fegin
`is_empty()` checks `numel() == 0`, but we don't need to access `numel_` at all (or the policy that `numel()` checks) in our happy path -- we just need the data pointer from `storage_`. Let's do the check we need to do using only the data we strictly need, rather than adding instructions loading other pieces of data.
Differential Revision: [D44586464](https://our.internmc.facebook.com/intern/diff/D44586464/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98090
Approved by: https://github.com/Skylion007
Among the changes is the introduction of gather_dim and scatter_dim in DeviceMesh collectives to simplify user code.
The current plan is to keep padding and gather/scatter dim support in DeviceMesh while we explore optimization opportunities in Inductor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96226
Approved by: https://github.com/wanchaol
Summary:
This is a copy of https://github.com/pytorch/pytorch/pull/97152 to make
the landing easier.
This PR implements a two-pass wrapper codegen for the Triton
backend to achieve ahead-of-time compilation. In the first pass, the
regular python wrapper code will be generated, and then the generated
code will be executed to perform Triton compilation and autotuning.
After that, the second pass wrapper codegen will generate C++ wrapper
with proper CUDA API to load and launch Triton-generated CUDA kernels.
Like the AOT mode for the cpp backend, the next step would be to provide
a more complete API for AOT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98214
Approved by: https://github.com/eellison
Summary:
`:test_dynamo` has been broken for long time internally in Meta. This PR is to fix the broken test and re-enable it internally.
- Using the root `pytest.ini` for pytest
- Decouple tests so that one can be disabled with affecting others
- Temporarily disable the test cases that require additional efforts to fix
**OSS CI doesn't provide test code coverage info. Meta internal test infra does. The value of re-enabling these tests internally is not only to collect test coverage info but help fbcode developers to build/test from fbcode.**
Test Plan:
`buck test mode/dev-nosan //caffe2/test:test_dynamo`
https://www.internalfb.com/intern/testinfra/testrun/7318349540623516
Differential Revision: D44325238
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97937
Approved by: https://github.com/ezyang
using the existing deterministic implementation via `index_put` which has a deterministic implementation based on sorting indices.
With the `accumulate` arg in `index_put`, this can work for both scatter and scatter_reduce with sum/mean reduction mode.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98060
Approved by: https://github.com/mikaylagawarecki
Summary:
Supporting Per Channel quantization in the gradient computation function.
One workaround that I have added here is
Current QNNPACK is not designed to process [transposed weight](https://fb.workplace.com/groups/pytorch.edge.users/permalink/1283737025829921/)
Here we are simply replacing Per Channel to Per Tensor to compute a gradient (Some slow learning curve or WER degradation might be expected - We don't know, nothing is guaranteed)
Test Plan:
You can create your own synthetic model,
FP32 layer -> INT8 layer with Per Channel and see if loss is decreasing
Differential Revision: D43898794
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97475
Approved by: https://github.com/weiwangmeta
Summary:
This diff extends pattern matcher, by adding a few features which allows it to handle split-getitem-cat style patterns.
3 problems I encountered were:
1. In the handler, I only need one Arg() (the one which is the first input to split). None of the other args are relevant to replacement graph. So, we add a new Ignored() pattern to have ignored args
2. The pattern matching was visiting the split node again and again during the DFS. By propogating the patterns with _users>1 or Any into the child MatchContext, we avoid this problem.
3. To avoid the unbundling issue, I switched to using KeywordArg() instead of Arg() - as for this pattern, we need a flat list of Arg() in the end
Example pattern: https://www.internalfb.com/intern/anp/view/?id=3325856
```
pass_patterns.append(defaultdict(list))
register_replacement_pattern(
CallFunction(
aten.cat,
ListOf( CallFunction(operator.getitem, CallFunction(aten.split_with_sizes, KeywordArg("input_"), Ignored(), Ignored(), _users=Any),
Ignored()
),),
Ignored()
),
pass_number=3
)
def split_cat_replace(input_):
return input_
```
Test Plan: https://www.internalfb.com/intern/anp/view/?kernel=default&id=3317105
Reviewed By: jansel
Differential Revision: D44282499
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97726
Approved by: https://github.com/jansel
This patch is part of half float performance optimization on CPU:
* add specification for dtype `Half` in `Vectorized<>` under both avx256 and avx512.
* add specification for dtype `Half` in functional utils, e.g. `vec::map_reduce<>()`, which uses float32 as accumulate type.
Also add a helper struct `vec_hold_type<scalar_t>`, since Vectorized<Half>::value_type is pointing to its underlying storage type which is `uint16_t`, leading to error if the kernel uses `Vec::value_type`.
Half uses the same logic as BFloat16 in the Vectorized<>, each half vector is mapped to 2x float vectors for computation.
Notice that this patch modified the cmake files by adding **-mf16c** on AVX2 build, from https://gcc.gnu.org/onlinedocs/gcc/x86-Options.html, we can see that all the hardware platforms that support **avx2** already have **f16c**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96076
Approved by: https://github.com/malfet
I notice that we are running some slow tests for CPU and `sm86` on pull and trunk. They take much longer to run than other shards (1.5x to 2x longer). I propose that we move them to periodic instead. Thoughts?
The correlation between them are:
* `linux-bionic-cuda11.7-py3.10-gcc7-sm86 / test (slow)` and `linux-bionic-cuda11.7-py3.10-gcc7-sm86 / test (default)` is 0.93
* `linux-bionic-py3.8-clang9-slow / test (slow)` and `linux-bionic-py3.8-clang9 / test (default)` is 0.98
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at db56750</samp>
This pull request updates the `.github/workflows` files to optimize the testing workflows for PyTorch. It adds new periodic workflows for more platforms and configurations, and removes some redundant or slow workflows from the pull and trunk workflows.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98040
Approved by: https://github.com/malfet
Remove `CppTile2DTailKernel` and `CppTile2DKernelChecker` and reuse `CppVecKernel` and `CppVecKernelChecker` for them. Add vectorization with fallback for load/store in CppVecKernel for the non-contiguous load/store needed by `CppTile2DTailKernel`.
This PR also adds a functional support for transposed copy of bfloat16 data types. Better performance requires vectorized intrinsics implemented for at::vec::transpose_mxn. cc @soumith @voznesenskym @penguinwu @anijain2305 @EikanWang @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97626
Approved by: https://github.com/jansel
When copying data from pointers, only lowest bytes are copied. On little endian systems they are located at the beginning of pointer. On big endian systems they are located at the end of pointer.
This change fixes TestTensorExprPyBind::test_dynamic_shape and TestTensorExprPyBind::test_dynamic_shape_2d tests from test/test_tensorexpr_pybind.py on big endian systems.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96951
Approved by: https://github.com/ezyang, https://github.com/EikanWang
### Description
This PR is to update ideep submodule for the following two aspects:
1. At inductor side, we are supporting dynamic shape path for packed linear, which we hopes the packed weight of linear doesn't depend on the input shapes and still can get a better a performance using a packed weight got from a dummy input shapes. However the current ideep has a accuracy issue for this case. This updating will fix the issue.
2. Add an extra arg is_channels_last for deconv to notify ideep whether to go channels last or not because the memory format checks of ideep (e.g. is_nhwc(), is_ndhwc()) is not 100% identical to suggest_memory_format() from pytorch.
### Performance Benchmark
Use TorchBench test in ICX with 40 cores
Intel OpenMP & tcmalloc were preloaded
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97430
Approved by: https://github.com/jgong5
Following metrics should be helpful:
- percent of time GPU is busy
- percent of time various category of kernels (e.g. pointwise/reduction triton kernel) takes
- percent of time each individual kernel takes compared to total wall time of the benchmark
This PR add those.
Example result from hf_Bert infernece graph:
```
== triton_pointwise category kernels ==
Kernel Self CUDA TIME (ms) Count Percent
------------------------------ --------------------- ------- ---------
triton_poi_fused_gelu_6_0d1d 0.48154 12.0 5.52%
triton_poi_fused_clone_1_0d1d2 0.29011 24.0 3.33%
triton_poi_fused_clone_2_0d1d2 0.17417 12.0 2.00%
triton_poi_fused_clone_4_0d1d2 0.10797 12.0 1.24%
Total 1.05379 12.08%
== triton_persistent_reduction category kernels ==
Kernel Self CUDA TIME (ms) Count Percent
------------------------------ --------------------- ------- ---------
triton_per_fused__softmax__to_ 0.97188 12.0 11.14%
triton_per_fused_add_native_la 0.37401 24.0 4.29%
triton_per_fused_gelu_native_l 0.02 1.0 0.23%
triton_per_fused_add_embedding 0.01718 1.0 0.20%
Total 1.38307 15.86%
== unknown category kernels ==
Kernel Self CUDA TIME (ms) Count Percent
------------------------------ --------------------- ------- ---------
ampere_fp16_s16816gemm_fp16_12 2.24514 24.0 25.74%
ampere_fp16_s16816gemm_fp16_25 1.39796 49.0 16.03%
void cutlass::Kernel<cutlass_8 1.36093 1.0 15.61%
ampere_fp16_s16816gemm_fp16_64 0.74591 12.0 8.55%
ampere_fp16_s16816gemm_fp16_12 0.61989 12.0 7.11%
Memset (Device) 0.024 12.0 0.28%
void at::native::(anonymous na 0.01543 2.03 0.18%
void at::native::vectorized_el 0.00011 0.03 0.00%
Total 6.40937 73.49%
Percent of time when GPU is busy: 101.44%
```
Note: the output shows total time GPU is busy is larger than total wall time. We measure total wall time disabling profiling while measure GPU time enabling profiling, that may distort the measurement a bit? But I assume the effect is not too large assuming the profiler mostly increase CPU time (rather than GPU).
## interesting usages
1. I pick a model that cudagraphs improve perf significantly like densenet121 and run the tool on it's forward graph. It's no surprise that quite a lot of time GPU is idle:
```
(Forward graph) Percent of time when GPU is busy: 32.69%
Total wall time 17.307 ms
```
Its backward graph has less percent of GPU idle time, but it's still high:
```
(Backward graph) Percent of time when GPU is busy: 46.70%
Total wall time 17.422 ms
```
2. I profile a subset of torchbench models and plot a table to show the percent of execution time for pointwise/reduction/persistent_reduction/unknown_category . Since I plan to explore using coordinate descent tuner to improve reduction, those models with high percent of time spending on reduction should be good caididates (e.g. resnet50, mobilenet_v2 ).
NOTE: a same model appears twice. The first rows is for the fwd graph and the second for the bwd graph. We profile different graphs for a model separately.
```
benchmark_name pointwise_percent reduction_percent persistent_reduction_percent unknown_category_percent GPU_busy_percent wall_time_ms
----------------------- ------------------- ------------------- ------------------------------ -------------------------- ------------------ --------------
resnet18 19.73% 7.86% 4.81% 41.25% 73.65% 2.549ms
resnet18 18.59% 7.13% 3.35% 67.35% 96.41% 3.467ms
resnet50 29.57% 22.13% 2.07% 51.68% 105.46% 6.834ms
resnet50 26.42% 15.27% 0.94% 59.68% 102.31% 13.346ms
vgg16 26.23% 0.00% 0.00% 74.20% 100.43% 18.212ms
vgg16 15.63% 5.61% 0.10% 79.42% 100.75% 33.485ms
BERT_pytorch 28.62% 4.82% 14.88% 33.32% 81.64% 7.162ms
BERT_pytorch 14.43% 13.41% 18.19% 49.24% 95.27% 10.395ms
densenet121 11.89% 2.14% 3.86% 16.36% 34.25% 16.531ms
densenet121 10.37% 2.06% 4.09% 31.46% 47.98% 16.934ms
hf_Bert 23.94% 0.00% 29.88% 46.09% 99.90% 7.766ms
hf_Bert 11.65% 10.54% 20.26% 61.66% 104.11% 11.892ms
nvidia_deeprecommender 42.92% 0.00% 0.00% 56.75% 99.67% 3.476ms
nvidia_deeprecommender 31.36% 3.44% 0.46% 65.20% 100.45% 3.872ms
alexnet 30.99% 0.00% 0.00% 69.16% 100.14% 3.169ms
alexnet 24.41% 4.83% 0.17% 71.09% 100.50% 4.709ms
mobilenet_v2 29.21% 27.79% 2.49% 44.00% 103.49% 10.160ms
mobilenet_v2 17.50% 15.05% 1.06% 69.68% 103.29% 20.715ms
resnext50_32x4d 18.96% 9.28% 2.31% 28.79% 59.33% 5.899ms
resnext50_32x4d 18.48% 11.01% 1.86% 53.80% 85.14% 7.167ms
mnasnet1_0 19.07% 14.52% 3.01% 35.43% 72.03% 6.028ms
mnasnet1_0 14.17% 12.00% 1.87% 67.56% 95.60% 9.225ms
squeezenet1_1 38.56% 0.00% 1.77% 56.21% 96.53% 2.221ms
squeezenet1_1 21.26% 7.57% 1.05% 67.30% 97.18% 4.942ms
timm_vision_transformer 17.05% 0.00% 18.80% 65.79% 101.64% 9.608ms
timm_vision_transformer 9.31% 9.07% 10.32% 73.25% 101.96% 16.814ms
```
## how to use
`python {compiled_module_wrapper.py} -p`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97723
Approved by: https://github.com/jansel
We have noticed that on BERT_pytorch in torchbenchmark majority of time is spent in running GEMM in aten:addmm. At the moment this calls into BLAS routine, but on AArch64 it will be faster if it calls into mkldnn_matmul. Performance wise compared to build with OpenBLAS it runs faster 1.2x faster on 16 cores with batch size of 8 on Graviton3, while if fast math mode (mkldnn_matmul exposes through oneDNN and Arm Compute Library option to run GEMM with FP32 inputs using BBF16 operations) is enabled then it is 2.3x
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91763
Approved by: https://github.com/jgong5, https://github.com/ngimel, https://github.com/malfet
This was used to unblock Meta internal use cases, where ```torchrec.distributed``` was used, however, it can't be traced by dynamo properly right now.
We were sending the same fix(#90087) several months ago, but was reverted due to ```fbgemm``` conflicts. This PR catches ```Exception``` rather than ```ImportError``` which can handle the conflicts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97824
Approved by: https://github.com/wconstab
Summary:
Rearrange the fields in at::OperandInfo to reduce padding.
The current class layout is {64,3,1,1,8,1,1,1,16,16,8,8}. Moving the 5th
element in the class allows the small bytes/bools to be packed together.
This class is frequently read from places like the stack trace below, so
compacting the class could speed things up.
c10/util/MaybeOwned.h:198 operator*
aten/src/ATen/TensorIterator.h:187 tensor_base
aten/src/ATen/TensorIterator.h:322 tensor_base
aten/src/ATen/TensorIterator.cpp:1194 compute_mem_overlaps
aten/src/ATen/TensorIterator.cpp:1475 build
Test Plan: Rely on unit tests.
Differential Revision: D44559604
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98037
Approved by: https://github.com/swolchok
Fixes #ISSUE_NUMBER
1、optimize the func name of AMP in custom device module,use `torch.foo.set_autocast_enable` instead of `torch.foo.set_autocast_foo_enable`.
2、In AMP with custom device,use `custom_device_mod.set_autocast_enable` instead of `getattr(custom_device_mod, "set_autocast_enable"`, because we have check that `custom_device_mod` hasattr `set_autocast_enable` before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98052
Approved by: https://github.com/bdhirsh
Fixes#95892
This PR fixes the placement error in ChunkShardingSpec when training with multi nodes. 'rank:{global_rank}/cuda:{local_rank}' should be used but 'rank:{global_rank}/cuda:{global_rank}' is used so this would result in a CUDA error: invalid device ordinal.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98063
Approved by: https://github.com/kumpera
Without this change I get the following error.
```
line 444, in unpad_sequence
mask = idx < length
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98042
Approved by: https://github.com/mikaylagawarecki
Summary:
The goal for this PR is to unify the flow of information to reduce fragmentation of implementations between fx graph mode quantization
and quantize_pt2e, since quantize_pt2e will be using node.meta to store this information, we'd like to make sure fx graph mode quantization
get this information from the same place
Test Plan:
python test/test_quantization.py TestQuantizeFx
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97949
Approved by: https://github.com/andrewor14
Fixes https://github.com/pytorch/pytorch/issues/97260
We got some feedback that the page reads like "in order to save an input
for backward, you must return it as an output of the
autograd.Function.forward".
Doing so actually raises an error (on master and as of 2.1), but results
in an ambiguous situation on 2.0.0. To avoid more users running into
this, we clarify the documentation so it doesn't read like the above
and clearly mentions that you can save things from the inputs or
outputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98020
Approved by: https://github.com/soulitzer, https://github.com/kshitij12345
This PR moves impl functions to `at::native::mps` to prevent them from being exposed in `at::native`.
Because of the moves of functions being hard to review, this PR only refactors part of functions in the MPS codebase. Will check everything is correctly moved again before merging.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97238
Approved by: https://github.com/kulinseth
Enable some sensible flake8-simplify rules. Mainly wanted to enable the SIM101, and `yield from` SIM103 checks. @kit1980 since you wanted to be tagged on this CI check.
Enabling this check also helped flag one logical bug so it's definitely beneficial (also fixed in this PR).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97984
Approved by: https://github.com/ezyang
This is reland of PR #94402 that tries to solve the additional link issues.
The PR #94402 failed because caffe2::mkl had been converted to private dependency while libtorch_cuda_linalg hadn't linked to it explicitly. This is fixed in commit 4373bf0ae3dee32afc178f9d51a4154d6c5904c6
We also replace more references of MKL_LIBRARIES by caffe2::mkl in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94924
Approved by: https://github.com/malfet
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at a9fa438</samp>
Simplified a test function for `torch.masked_scatter` in `test/test_torch.py` by removing redundant and unnecessary code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98015
Approved by: https://github.com/ezyang
separate it for better readability and and this helper function can be reused for the deterministic implementation of `scatter` and `scatter_reduce` with sum reduction mode.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97922
Approved by: https://github.com/ngimel
Summary:
This fixes the divide-by-zero that arises when performing a division in which the denominator has a number of channels that isn't a multiple of 4, and therefore the channel dimension has been padded with 0s.
More details in the comments of this post: https://fb.workplace.com/groups/pytorch.edge.users/permalink/1288546972015593/
Test Plan:
```
buck run --target-platforms ovr_config//platform/macos:arm64-fbsource -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64
```
```
buck run --target-platforms ovr_config//platform/macos:arm64-fbsource -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64
```
Differential Revision: D44392406
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97698
Approved by: https://github.com/SS-JIA
it sometimes spits out left over logs from a previous run on the windows ephemeral runner, but this might have been fixed by now. I get a bit annoyed when the step runs even though it obviously isnt going to be useful since the test step didnt run,
always() is needed to ensure that it runs on test step failure
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97713
Approved by: https://github.com/huydhn
**Summary**: profiler.record_function inserts an event into the chrome trace generated by the pytorch profiler. This PR adds record_function everywhere that @dynamo_timed is annotated.
dynamo_timed and the CLI viewer torch._dynamo.utils.compile_times() are already useful on their own; but for identifying _when_ these get called, it's nice to be able to view in the profiler chrome trace.
Why not just turn on python stack traces in the profiler to get this information? Dynamo compilation is implemented in python and therefore produces a huge amount of events when it records compilation steps. The resulting trace files are often too large to load in chrome://tracing, and they take a long time to generate. Additionally, the stack traces are deep enough that they are often hard to read. This approach produces much more readable traces with lower overhead.
**Tests**:
- Added in test/dynamo/test_profiler.py. Verified in https://github.com/pytorch/pytorch/actions/runs/4559322864/jobs/8043307798?pr=96495 that the tests are actually running.
- Performance run with `ciflow/inductor-perf-compare` shows no noticeable change in compilation time or speedup numbers. Geomean speedup changes from 1.275 -> 1.277. Geomean compilation times change from 54.2s -> 53.8s. That's likely just due to noise. All individual benchmark numbers regressed by no more than 5% between the two runs; and we see improvements of around the same magnitude, suggesting this is, again, just noise. For meta employees, you can see the results in a google sheets here: https://docs.google.com/spreadsheets/d/1Ki69XvcgxcA3ZnqC5n_jav5KiD4u7Wojlad3VTnIdlk/edit?usp=sharing
**Example**:
Run this:
```python
import torch
def gn(x):
return x.sin().cos()
def fn(x, y):
return x.sin() * y.cos()
x, y = [torch.rand((2, 2), device='cuda') for _ in range(2)]
# just to clear out any lazy initialization
with torch.profiler.profile() as prof:
torch.compile(gn)(x)
with torch.profiler.profile() as prof:
torch.compile(fn)(x, y)
prof.export_chrome_trace("./dynamo_timed_profile.json")
```
and we can see that the resulting trace shows important dynamo steps, even when python tracing is turned off.
<img width="867" alt="Screenshot 2023-03-29 at 7 26 15 PM" src="https://user-images.githubusercontent.com/5067123/228712263-8ae67ab9-1a52-4765-a9c2-7c5cf0abe2f5.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96495
Approved by: https://github.com/ngimel, https://github.com/mlazos
We remove TritonTemplateCaller.to_callable previously. But this method is still used in `TritonTemplateCaller.__str__` . The to_callable method in the base class will be used and raise an exception.
This PR fix TritonTemplateCaller.__str__ to return the string representation without calling to_callable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97578
Approved by: https://github.com/nmacchioni, https://github.com/ngimel
Symbolic shapes compile time on full CI with inductor is horribly long (even though our aot_eager local runs seemed to suggest that the added latency was only 10s per model.) To patch over the problem for now, run the benchmark suite with dynamic batch only. This should absolve a lot of sins.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97912
Approved by: https://github.com/janeyx99, https://github.com/desertfire
repo:
from #92670 this address one of the bug for TorchDynamo
pytest ./generated/test_PeterouZh_CIPS_3D.py -k test_003
Issue:
In GuardBuilder, when parsing argnames with "getattr(a.layers[slice(2)][0]._abc, '0')" it returns "getattr(a", where it suppose to return "a", and thus causing SyntaxError.
This PR fix the regex and add couple test cases.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97810
Approved by: https://github.com/yanboliang
This PR changes the `opt_sizes_` metadata to be computed lazily if needed rather than at construction. Since this metadata is data-dependent, we can't calculate it if we have symbolic metadata (i.e. for dynamic shapes). Notes:
* `opt_size()` is the only public accessor of `opt_sizes_`; several kernels use it. During the first call to this, the metadata is computed.
* `size()` / `sym_size()` use `opt_size()`. For the symbolic case, this will have to change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97895
Approved by: https://github.com/drisspg
Helper function to replace literals that show up in call_function nodes in the graph to become placeholders so that they can be represented as wildcards when matching with the SubgraphMatcher. This pass causes the resulting graph to not be runnable with the original inputs since adding placeholders to the graph will change the number of inputs needed for the graph.
Test: `python test/test_fx.py TestMatcher`
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97683
Approved by: https://github.com/kimishpatel, https://github.com/SherlockNoMad
My first attempt was to apply the same solution as how proxy_tensor.py
handles other inplace ops. However, foreach is different in the way
that it's schema is `native_functions.yaml` does not return anything,
whereas ops like `addcmul_` and `addcdiv_` do return Tensors (Thanks
bdhirsh for teaching me this!). As a result, the proxy output
during tracing does not wrap anything, and hence we cannot correctly
connect it with subsequent operators. Modifying `native_functions.yaml`
is not a preferred solution. After discussing with bdhirsh, the
temporary solution is to do foreach functionalization as a graph
pass for now. Later, when https://github.com/pytorch/pytorch/issues/97852
is addressed, we will switch to default functionalization.
Edit: the latest version follows @bdhirsh 's suggestion on using
`make_fx` `decomposition_table` instead of implementing manual
fx.Graph tranforms to functionalize `_foreach_add_`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97853
Approved by: https://github.com/fegin, https://github.com/wanchaol
To implement the warning when transitioning reshape to copy-on-write
storage, we want to be able to detect a write to one view family
following by a read or a write to another one that shares the same
copy-on-write storage.
Because we have historically not been strict about the mutability of
our data pointers, any warning we have would likely be far too
aggressive.
Therefore, this is the first PR in a long series to ensure a strict
distinction between mutable and const data accessors in TensorBase,
TensorImpl, Storage, and StorageImpl.
The rough plan is to give the mutable accessor a new name that is
explicit about mutation, this will also force us to rewrite any code
that really needs a mutation.
Differential Revision: [D44409928](https://our.internmc.facebook.com/intern/diff/D44409928/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97647
Approved by: https://github.com/ezyang
Summary:
This PR extends `_fuse_conv_bn_` function to support fusing convtranspose and bn
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_transposed_conv_bn_fusion
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97933
Approved by: https://github.com/vkuzo
# Motivation
The DLPack device type kDLOneAPI stands for the Unified Shared Memory allocated on a oneAPI device. The corresponding Pytorch backend type is XPU.
Support to export/import the Pytorch XPU tensor as a DLPack tensor of kDLOneAPI device.
# Solution
1. Update the DLPack protocol to v0.7.
2. Add the XPU hooks to map the Aten device and DLPack device with the address value and device information.
# Additional Context
Reopen (#82867)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94968
Approved by: https://github.com/kit1980
Summary:
There was a refactoring while back to address Kineto <--> PyTorch Profiler buffer management issues. This made the Profiler API path safer but it regressed the OnDemand path.
The proper long term solution is to merge those paths which would significantly improve the maintainability of the codebase.
Test Plan:
# Test on Resnet integration test
```
buck2 run mode/opt kineto/libkineto/fb/integration_tests:pytorch_resnet_integration_test
dyno gputrace
```
# Trace
https://fburl.com/perfdoctor/t8nkda9z
Differential Revision: D44362040
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97550
Approved by: https://github.com/aaronenyeshi
`emplace` does not overwrite the existing mapped value in a map if it already exists, which can lead to repeated execution of a plan that e.g., tries to allocate an OOM-inducing workspace size and retriggers either a heuristic run (or worse, a benchmark run).
CC @ptrblck @ngimel @Fuzzkatt @syed-ahmed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97838
Approved by: https://github.com/ngimel
Tweaks the TENSOR_MATCH guard logic to avoid saving sizes / strides for the case of dynamic shapes. Instead, the dim() is stored, which is enough for both dense tensors and NTs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97896
Approved by: https://github.com/ezyang
Fixes https://github.com/pytorch/pytorch/issues/96887
We error out in BOTH the case when graph is created and when it is not created.
Still bc-breaking, but not as severe because we are limiting to the case where someone uses setup_context.
This makes setup_context and non-setup_context versions diverge in their behavior
- With the non-setup_context version, saved variables are assumed to have the grad_fn of the inputs.
- But now with the setup_context version, we produce an error for this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97212
Approved by: https://github.com/zou3519
The purpose of this API is to execute a few large components of work:
1) Refactor all the internals of plumbing dynamic dimension information after dynamo to be stateless
2) Decouple allocation controls around dynamic dimensions from verification
3) For (2), for allocation, create an enum that dictates whether we are in DUCK (default today), STATIC (aka assume_static_default in the past), or DYNAMIC (aka user constrained, do not duck shape)
4) For (2), for verification, we separate out the list of dynamic ranges entirely from allocation. This means shape_env does not tracking for what we verify on, and instead, it is the callers job to invoke produce_guards() with the various things they want verified, specifically, with the valid ranges. We do use constrain ranges to refine value ranges when doing analysis.
5) We have decided, therefore, as an extension of (4) to double down on "late" checks versus "eager" checks, primarily because the mechanisms for gathering what actually matters happens during guards, and should be a purview of the caller seeking guards, not the shape env. However, for dynamo, these structures are essentially one and the same.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96699
Approved by: https://github.com/avikchaudhuri, https://github.com/ezyang
`get_state_dict_type` in FSDP looks for a key called `_optim_state_dict_config` when getting the optimizer state dict config. However, `set_state_dict_type` sets the config at a key called `_optimstate_dict_config`. This looks like a typo.
This fixes the discrepancy, so that when you set the state dict type, it is correctly used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97110
Approved by: https://github.com/awgu, https://github.com/fegin
This was used to unblock Meta internal use cases, where ```torchrec.distributed``` was used, however, it can't be traced by dynamo properly right now.
We were sending the same fix(#90087) several months ago, but was reverted due to ```fbgemm``` conflicts. This PR catches ```Exception``` rather than ```ImportError``` which can handle the conflicts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97824
Approved by: https://github.com/wconstab
This lets users that are sure they won't use hooks avoid overhead
related to dynamo guards on (assumedly) empty hook dicts on all
nn modules.
Only enable this flag if you are sure you won't change hook-behavior
after compiling. It is ok to register a hook and then compile, if
you promise never to remove/alter the hook. It is also ok to
not register a hook and compile, if you never register a hook later.
Note- this is not the best we can do, and hopefully in the future
we can avoid the need for this option following some of these paths
- make guards fast enough to not be an issue when guarding on hook
dicts
- make a mode where dynamo actually skips tracing __call__ so
hooks are consistently ignored by compiled programs
- use nnmodule versioning so hook changes can be guarded without
explicit hook dict guards
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97830
Approved by: https://github.com/jansel
See https://github.com/pytorch/pytorch/issues/94024. I disabled this test on ASAN a while ago for this exact issue. The issue, unfortunately, was hard to reproduce and flaky bot closed it 3 weeks ago. ASAN job has been hanging flakily since then, i.e. 8313becefa.
I don't want to reopen the issue and forget about it after 2 weeks, so let's disable the test for ASAN and be at peace (for now). Interesting, there are other tests here also hanging on ASAN, i.e. `test_leaf_variable_sharing`:
```
# See https://github.com/pytorch/pytorch/issues/14997
@unittest.skipIf(TEST_WITH_ASAN,
"non-deterministically hangs with ASAN")
def test_leaf_variable_sharing(self):
```
I suspect that they have the same root cause.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97742
Approved by: https://github.com/clee2000
We previously use buffer name for the variable containing randomly generated kernel input in the kernel benchmark. This has a big drawback. The same kernel may be used for different buffers. However if we use buffer name as argument name, the kernel source code for different invocation of the kernel will be different. This cause the following downsides:
- compile time will be longer since we can not reused compiled kernel due to cache miss
- this cause inconsistent behavior with TORCHINDUCTOR_BENCHMARK_KERNEL enabled or disabled. We may see more kernels (some are essentially duplicated) in the compiled module if TORCHINDUCTOR_BENCHMARK_KERNEL is enabled.
- this obscure some optimization opportunities. E.g., a kernel spend 6% time is worth looking at. But if the kernel is called 20 times and now it show up as 20 different kernels each spend 0.3% of time, it would be less obvious that we should optimize this kernel.
In this PR, we just use canonical name like `arg_{i}` rather than the buffer name to avoid all the issues above.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97755
Approved by: https://github.com/jansel
1. Packaging nvfuser header for support c++ build against nvfuser;
2. Moving `#include <torch/csrc/jit/codegen/fuser/interface.h>` from `torch/csrc/jit/runtime/register_ops_utils.h` to `torch/csrc/jit/runtime/register_prim_ops_fulljit.cpp` to avoid missing header, since pytorch doesn't package `interface.h`;
3. Patching DynamicLibrary load of nvfuser to leak the handle, this avoids double de-allocation of `libnvfuser_codegen.so`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97404
Approved by: https://github.com/davidberard98
Summary:
This diffs adds a convert_qconv2d_context op, which converts a cpu quantized Conv2dPackedParamsBase object (used by quantized::conv2d) into a vulkan Conv2dPackedContext object.
This op is used in a later diff (D44189363), to do a graph rewrite of quantized conv2d and conv2d_relu ops
Test Plan:
On Mac
```
cd ~/fbsource
buck1 run -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64
```
On Android
```
cd ~/fbsource
buck1 build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_quantized_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_quantized_api_test
adb shell "/data/local/tmp/vulkan_quantized_api_test"
```
Reviewed By: SS-JIA
Differential Revision: D41595032
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97714
Approved by: https://github.com/SS-JIA
This is a follow-up to the last PR to greatly simplify the approach. This should be much cleaner.
**Details**
Let `N` denote the number of original parameters flattened into a given flat parameter with `M` extra padding tensors.
- `_numels_with_padding`: length `N + M`
- `_is_padding_mask`: length `N + M`
- `_numels`, `_param_infos`, `_shapes`, `_fqns`, `_param_extensions`: length `N`
`_shard_param_indices` and `_shard_param_offsets` were used to determine (1) if a given original parameter is in the local shard and if so, then (2) what is its offset in the _sharded_ flat parameter, and (3) how many numel are in the _sharded_ flat parameter.
This PR reworks how to achieve (1), (2), and (3) to allow for simplifying the previously mentioned data structures. In particular, it saves one extra tuple `_shard_param_infos: Tuple[_ShardParamInfo, ...]` of length `N` where each `_ShardParamInfo` entry gives exactly the needed info. For example, the offset into the sharded flat parameter is now pre-computed, so we do not need to do `offset = 0; offset += numel_in_shard` over a `for` loop each time now.
For optimizer state dict, `FSDPParamInfo.param_indices` now maps to the indexes with respect to the length `N` data structures, not the length `N + M` ones. The only purpose of `param_indices` is to be able to index into `flat_param._shard_param_infos[i]` to get the contained info to flatten the unsharded original parameter optimizer state and extract the part in the local shard.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97796
Approved by: https://github.com/rohan-varma
Fixes https://github.com/pytorch/pytorch/issues/96794
Sometimes people never update their local `master` branch. Their workflow instead consists of fetching commits from git and directly creating branches off of the remote `master` branch (e.g. via `git checkout -b <mybranch> origin/master`
For those people, their local `master` is very old and out of date, creating an unreasonably old lint base that tends to catch all sorts of unrelated linter errors.
Anyone with an updated `master` branch will naturally have an updated pointer to the remote `master`, so this change makes lintrunner friendly to both behavior patterns
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97800
Approved by: https://github.com/huydhn
Mainly two fixes:
1. `make_fx` seems trace through DeviceMesh operations. This commit removes that from the DTensor expanded graph
2. During DTensor expansion, autograd complains about inplace changes on leaf node. This commit wraps entire DTensor expansion code with `torch.no_grad()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97787
Approved by: https://github.com/wanchaol
This reverts commit f3aca45a163cf1aafd4f5fa65a0adce53b33abfa.
Reverted https://github.com/pytorch/pytorch/pull/97212 on behalf of https://github.com/soulitzer due to TestAutogradFunctionCUDA.test_function_returns_input_inner_requires_grad_True_save_for_vjp_save_tensors_output_mark_dirty_True_cuda leaks
Summary:
Extra C binding module for flatbuffer was introduced because
not all dependencies of Pytorch want (or can) bundle in flatbuffer.
However, flatbuffer is in by default now so this separate binding is not longer needed.
Test Plan: existing unit tests
Differential Revision: D44352583
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97476
Approved by: https://github.com/dbort
Summary: to prepare for further AOT Inductor changes
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 7dff885</samp>
This pull request adds support for AOT compilation and C++ wrapper code generation for inductor models. It modifies the `GraphLowering` class in `torch/_inductor/graph.py` and the `compile_fx` function in `torch/_inductor/compile_fx.py` to enable this feature.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97709
Approved by: https://github.com/jansel
Previously we only plotted memory if it was allocated or freed while
trace recording was active. This change also adds any pre-existing blocks
to the visualization. This helps because it is common to enable trace recording
later and then not realize that there is a lot of allocated memory in
the trace eventhough a lot was allocated beforehad.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97590
Approved by: https://github.com/eellison
Changes to `_native_batch_norm_legit` and `upsample_nearest2d` in `serialized_shape_function_registry.cpp` are made just because this file is auto-generated, and the file was not auto-generated after the changes in `_shape_functions.py` for those two ops.
Signed-Off By: Vivek Khandelwal <vivek@nod-labs.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93919
Approved by: https://github.com/davidberard98
**Summary**
Enable quantization and lowering of `ConvTranspose3d`.
Add test cases for `ConvTranspose1d`, `ConvTranspose2d` and `ConvTranspose3d` since there were no such test cases.
**Test plan**
python test/test_quantization.py -k test_conv_transpose_not_reference
python test/test_quantization.py -k test_conv_transpose_reference
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97125
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
Fixes https://github.com/pytorch/pytorch/issues/96887
We error out in BOTH the case when graph is created and when it is not created.
Still bc-breaking, but not as severe because we are limiting to the case where someone uses setup_context.
This makes setup_context and non-setup_context versions diverge in their behavior
- With the non-setup_context version, saved variables are assumed to have the grad_fn of the inputs.
- But now with the setup_context version, we produce an error for this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97212
Approved by: https://github.com/zou3519
V.graph.constants like seed_cuda_0 is not handled properly in the wrapper. Recently we move the code that initializes constants from global scope to a function. That makes assigning to seed_cuda_0 creating a new local variable rather than setup the global variable.
Add 'global var_name' lines to maintain the same behavior as before.
Test:
Run the forward graph for nvidia_deeprecommender's training run. Previous fail and now pass with the fix.
Thanks @ngimel for report the issue with repro and @Chillee for pointing out the root cause.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97571
Approved by: https://github.com/ngimel
This function is needed by all ReadPlanner subclasses that are trying to implement support for a custom distributed tensor.
Better expose it than have users reimplement this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97570
Approved by: https://github.com/wz337
This PR adds intra-`FlatParameter` 16-byte alignment padding to the `use_orig_params=True` code path to avoid clones in TorchInductor.
**Approach**
The `FlatParameter` maintains several data structures about its original parameters. Notably, the data structures `_param_infos`, `_shapes`, `_numels`, and `_fqns` have the same length and index in the same way.
This PR treats alignment padding _like_ an original parameter in that the padding gets flattened into the `FlatParameter`. Therefore, it must be reflected in the aforementioned data structures. However, given the way in which the data structures are used, we choose to do the following if the `i`th tensor flattened into the `FlatParameter` is padding:
- `_numels[i]` is the numel of padding
- `_param_infos[i] == _shapes[i] == _fqns[i] == None`
This choice is because (1) we must record the padding numel to account for it (e.g. for views) and (2) we prefer to preserve the invariant that the data structures index in the same way over avoiding `None` entries.
To ease the burden of other FSDP developers, we separate the parameter flattening logic:
- `_init_flat_param_and_metadata()`: This should be called only once in the `FlatParamHandle` constructor. The `FlatParameter` metadata is assumed to be static thereafter.
- `flatten_tensors()` / `flatten_tensors_into_flat_param()`: These can be used for optimizer and model state dict and can be called after construction time.
This separation allows `_init_flat_param_and_metadata()` to contain the much heavier metadata logic, while keeping the latter methods to be much lighter. The only constraint is that the alignment padding logic must be kept consistent between the two, but this should be worth the simper interface.
**Testing**
- This PR directly modifies the `use_orig_params=True` code path, so all existing tests passing gives good signal.
- Some existing unit tests had to be adjusted to account for the alignment padding.
- This PR adds two tests in `test_fsdp_flatten_params.py` to explicitly test the sharding metadata with alignment for both parameter full precision and mixed precision since the latter requires possibly more padding elements due to the decreased per-element size.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97667
Approved by: https://github.com/rohan-varma
This is an easy PR. It has some remaining local changes that I had that I felt clarified naming.
- `_param_fqns` -> `_param_name_infos` since it returns a tuple of `fqn, param_name, module_name`, not only `fqn`. (similarly for `_shared_param_fqns` -> `_shared_param_name_infos`)
- nit: `parameter_module_names` -> `param_module_names` for consistency since we almost never fully spell out `parameter`. (similarly for `shared_parameter_module_names` -> `shared_param_module_names`)
- nit: `full_fqn` -> `fqn_from_global_root`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97666
Approved by: https://github.com/rohan-varma
From our recent experience, we refer to FSDP's `FlatParameter` as "flat parameter", not "flattened parameter". This PR renames that in `flat_param.py`.
**This PR only changes documentation.**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97661
Approved by: https://github.com/rohan-varma
max autotune log like
```
AUTOTUNE bias_addmm(512x197951, 512x512, 512x197951)
triton_mm_61 1.2882s 100.0%
triton_mm_62 1.3036s 98.8%
bias_addmm 1.4889s 86.5%
triton_mm_60 1.6159s 79.7%
triton_mm_63 1.7060s 75.5%
triton_mm_64 1.7777s 72.5%
triton_mm_67 1.9722s 65.3%
addmm 2.0603s 62.5%
triton_mm_70 2.0675s 62.3%
triton_mm_68 2.3552s 54.7%
SingleProcess AUTOTUNE takes 2.949904441833496 seconds
```
is confusion since the sum of runtime of all the kernels is larger than the total time used for tuning. In fact, `triton.testing.do_bench` return milliseconds scale time rather than seconds scale. Fix the typo in the log message to make that clear.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97486
Approved by: https://github.com/ngimel, https://github.com/jansel
Summary: Fixes broadcasting along the channel and batch dimensions in quantized add, sub, mul and div
Test Plan:
```
buck run --target-platforms ovr_config//platform/macos:arm64-fbsource -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64
```
Reviewed By: SS-JIA
Differential Revision: D44359706
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97554
Approved by: https://github.com/SS-JIA
We currently use `bitonicSortKVInplace` for sorts of size `n <= 32`
but use `radixSortKVInplace` for `32 < n <= 4096`. Bitonic sort is
also unstable, which forces stable sorts fall back to which is up to
4x slower in this small regime.
This PR adds a new kernel `warpMergeSortKVInplace` using
`cub::WarpMergeSort` to implement sorts with `32 < n <= 128` and all
stable sorts with `n < 128`. This results in up to a 2x speedup for
unstable sorts and up to 15x for stable sorts, depending on the input
geometry.
This also doesn't increase the total number of kernels since we are
replacing radix-sorts of size 32 and 128.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96223
Approved by: https://github.com/ngimel
Use `append_cxx_flag_if_supported` to determine whether or not `-Werror` is supported
Do not suppress deprecation warnings if glog is not used/installed, as the way check is written right now, it will suppress deprecations even if `glog` is not installed.
Similarly, do not suppress deprecations on MacOS simply because we are compiling with protobuf.
Fix deprecation warnings in:
- MPS by replacing `MTLResourceOptionCPUCacheModeDefault`->`MTLResourceCPUCacheModeDefaultCache`
- In GTests by replacing `TYPED_TEST_CASE`->`TYPED_TEST_SUITE`
- In `codegen/onednn/interface.cpp`, by using passing `Stack` by reference rathern than pointer.
Do not guard calls to `append_cxx_flag_if_supported` with `if(CLANG)` or `if(GCC)`.
Fix some deprecated calls in `Metal` hide more complex exception under `C10_CLANG_DIAGNOSTIC_IGNORE`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97584
Approved by: https://github.com/kit1980
This upload a record to a new Rockset `merges` collection in `commons` workspace in the following format:
```
{
"id": comment_id,
"pr_num": pr_num,
"owner": owner,
"project": project,
"pending_checks": pending_checks, # At the time of the merge
"failed_checks": failed_checks, # At the time of the merge
"is_failed": is_failed, # This is set to True if the merge fails to get through for whatever reason
"dry_run": dry_run,
"skip_mandatory_checks": skip_mandatory_checks,
"ignore_current": ignore_current,
"error": error, # The same Exception message that will be shown on PR
}
```
To achieve this, I need to tweak `find_matching_merge_rule` a bit to return the list of pending and failed checks in addition to the matching merge rule. As this function is also used internally, I have confirmed that the internal call doesn't need the return values. Thus, the change is safe to land.
### Testing
* Unit testing
* Dry-run locally `python3 .github/scripts/trymerge.py --comment-id 1478678477 --dry-run 97293` using an older PR. The merge obviously failed, but the record was created successfully on Rockset
```
{
"_id": "52d3152b-ec35-4b5a-91fc-0e7298fc54b5-1",
"_event_time": "2023-03-23T21:10:32.754368Z",
"_meta": null,
"owner": "pytorch",
"is_failed": true,
"id": 1478678477,
"failed_checks": [],
"dry_run": true,
"error": "Command `git -C pytorch cherry-pick -x cc0d2e0fba648bb5deda34a9056f2c4192b22314` returned non-zero exit code 1...",
"ignore_current": false,
"project": "pytorch",
"pr_num": 97293,
"skip_mandatory_checks": false,
"pending_checks": []
}
```
* Dry-run locally with this PR `python3 .github/scripts/trymerge.py --comment-id 1481949104 --dry-run --force 97471` with `--force`
```
{
"_id": "dd7d2580-f6e5-47e7-9441-17df86056c14-1",
"_event_time": "2023-03-23T21:43:53.915911Z",
"_meta": null,
"owner": "pytorch",
"is_failed": true,
"id": 1481949104,
"failed_checks": [],
"dry_run": true,
"error": "PR #97471 has not been reviewed yet",
"ignore_current": false,
"project": "pytorch",
"pr_num": 97471,
"skip_mandatory_checks": true,
"pending_checks": []
}
```
* Dry-run locally with this PR `python3 .github/scripts/trymerge.py --comment-id 1481949104 --dry-run 97471` again with approval rule commented out
```
{
"_id": "5d7de4e3-1af1-4869-a3b7-d1a9dbced6ce-1",
"_event_time": "2023-03-24T00:10:41.914111Z",
"_meta": null,
"is_failed": false,
"id": 1481949104,
"failed_checks": [],
"error": "",
"last_commit_sha": "4657400513f0360a0a4f73d46e1aff0882221687",
"merge_commit_sha": "416bac5b813a181753afade781ae30f4f0843586",
"ignore_current": false,
"pending_checks": [
[
"pull / linux-focal-py3.8-gcc7 / test (default, 1, 3, linux.2xlarge)",
"https://github.com/pytorch/pytorch/actions/runs/4506464828/jobs/7933518379",
12239935788
],
...
[
"trunk / linux-bionic-cuda11.8-py3.10-gcc7 / test (default, 5, 5, linux.4xlarge.nvidia.gpu)",
"https://github.com/pytorch/pytorch/actions/runs/4506465633/jobs/7933621958",
12240067113
],
...
],
"owner": "pytorch",
"skip_mandatory_checks": true,
"author": "Huy Do <huydhn@gmail.com>",
"project": "pytorch",
"merge_base_sha": "a3b30c5025e3381022fa00b127b0d881f4ef66d4",
"pr_num": 97471
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97471
Approved by: https://github.com/clee2000
Updates flake8-comprehensions in lintrunner so we can enforce new checks that have been implemented since the last update (including one implemented by me). I also added C417 to the flake8 ignore codes for now since we do not yet conform to that check.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97671
Approved by: https://github.com/ezyang, https://github.com/malfet
Currently if `setuptools<49.4.0` and there is a minor version mismatch `_check_cuda_version` fails with a misleading non-actionable error:
```
2023-03-24T20:21:35.0625644Z RuntimeError:
2023-03-24T20:21:35.0628441Z The detected CUDA version (11.2) mismatches the version that was used to compile
2023-03-24T20:21:35.0630681Z PyTorch (11.3). Please make sure to use the same CUDA versions.
```
This condition shouldn't be failing since minor version match isn't required.
It fails because the other condition to have a certain version of `setuptools` isn't met. But that condition is written in a comment (!!!). So this PR changes it to actually tell the user how to fix the problem.
While at it, I adjusted the version number as a lower `setuptools>=49.4.0` is sufficient for this to work.
Thanks.
p.s. this problem manifests on `nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04` docker image.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97602
Approved by: https://github.com/ezyang
## Description
Currently, both inference and training will use `forward_training` in rnn primitive, which will bring performance downgrade for inference (The performance drop is from rnn primitive and unnecessary creation of `pd` and `workspace`). This PR is to split them into `forward_inference` and `forward_training` seperately.
## Performance
With this fix PR, in RNN-T inference, the throughput reduction is 167 ms, which increases `3.7%` of E2E time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96736
Approved by: https://github.com/jgong5
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 59a5205</samp>
This pull request refactors the namespace declarations in several files under `aten/src/ATen/native/sparse` to use a more concise and consistent syntax. This improves the readability and reusability of the sparse tensor operations code.
Also, do not rely on deprecated `TensorBase::data` and instead use `TensorBase::data_ptr`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97581
Approved by: https://github.com/kit1980, https://github.com/huydhn
This has been bugging me for a while as I'm working on these Python scripts and they are not tracked by ufmt linter. So I add these script into that linter.
```
[[linter]]
code = 'UFMT'
include_patterns = [
'.github/**/*.py',
'test/run_test.py',
```
This change should just work and not break anything as ufmt (black + usort) linter is very safe to use for standalone util scripts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97588
Approved by: https://github.com/kit1980
This commit adds an entry point for full `train_step` tracing and
expansion. Model forward, backwrd, and optimizer step will be included
in one graph. DTensor expansion will be applied on top to insert
collective communications. Users can also provide an `Override`
implementation to skip non-traceable submodules and directly install
submodule logic to the DTensor-expanded graph by inserting `fx.Nodes`.
Differential Revision: [D44325177](https://our.internmc.facebook.com/intern/diff/D44325177)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97416
Approved by: https://github.com/yifuwang, https://github.com/wanchaol
**Summary**
Enable the lowering path from a quantized 2.0 fx graph into Inductor. The basic usage will be
```
export_module, guards = torchdynamo.export(m, *args)
prepare_module = prepare_pt2e(export_module, *args)
convert_module = convert_pt2e(prepare_module)
ooptimized_module = compile_fx(convert_module, example_inputs)
```
Most of the issues we met previously has already been fixed in PyTorch Master. So in this PR, we mainly do 2 things:
1. Add the basic usage into a UT.
2. Move `handle_dynamo_export_graph` before the fusion passes, otherwise the dynamo_export_graph will hit the fusion passes twice which is un-expected.
**Test Plan**
```
clear && python -m pytest test_quantization.py -k test_inductor_backend_config_conv
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96927
Approved by: https://github.com/jgong5, https://github.com/EikanWang, https://github.com/jansel, https://github.com/jerryzh168
Previously, `_need_to_materialize_module` would return false because:
* `managed_params =_get_orig_params(module, ignored_params)` returns a generator
* `is_meta_module = any(param.is_meta for param in managed_params)` exhausts the generator in its check
* `any(fake.is_fake(param) for param in managed_params)` would try to iterate over the empty generator and get an empty sequence, thus returning `False`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97488
Approved by: https://github.com/ngimel, https://github.com/awgu
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at b07152e</samp>
This pull request refactors the CMake configuration to enable the `USE_FLASH_ATTENTION` feature for the `torch_cuda` target only, using a target-specific macro. This avoids conflicts with other libraries that also use this feature, such as fairseq.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97579
Approved by: https://github.com/kit1980
Fixes#97191
This PR aims to propagate collective exceptions (async error or timeout) up to the program, so as to avoid silent stuck job.
### Previous output in #97191
```
Rank 0 is the problematic rank
Rank 4 completed
Rank 5 completed
Rank 3 completed
Rank 6 completed
Rank 2 completed
Rank 7 completed
Rank 1 completed
[E ProcessGroupNCCL.cpp:464] [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=1, OpType=ALLREDUCE, Timeout(ms)=10000) ran for 10917 milliseconds before timing out.
Rank 0 completed
[E ProcessGroupNCCL.cpp:478] Some NCCL operations have failed or timed out. Due to the asynchronous nature of CUDA kernels, subsequent GPU operations might run on corrupted/incomplete data.
[E ProcessGroupNCCL.cpp:483] To avoid data inconsistency, we are taking the entire process down.
```
Although it says that it is taking the process down, it sometimes fails to do so.
### New output after this PR:
```
...
[E ProcessGroupNCCL.cpp:459] [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=1, OpType=ALLREDUCE, Timeout(ms)=10000) ran for 10599 milliseconds before timing out.
[E ProcessGroupNCCL.cpp:473] Some NCCL operations have failed or timed out. Due to the asynchronous nature of CUDA kernels, subsequent GPU operations might run on corrupted/incomplete data.
[E ProcessGroupNCCL.cpp:479] To avoid data inconsistency, we are taking the entire process down.
[E ProcessGroupNCCL.cpp:818] [Rank 0] NCCL watchdog thread terminated with exception: [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=1, OpType=ALLREDUCE, Timeout(ms)=10000) ran for 10599 milliseconds before timing out.
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: -6) local_rank: 0 (pid: 194470) of binary: /data/home/kw2501/repos/pytorch-dev-env/bin/python
Traceback (most recent call last):
File "/pytorch-dev-env/bin/torchrun", line 33, in <module>
sys.exit(load_entry_point('torch', 'console_scripts', 'torchrun')())
File "/pytorch-dev/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 346, in wrapper
return f(*args, **kwargs)
File "/pytorch-dev/torch/distributed/run.py", line 794, in main
run(args)
File "/pytorch-dev/torch/distributed/run.py", line 785, in run
elastic_launch(
File "/pytorch-dev/torch/distributed/launcher/api.py", line 134, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/pytorch-dev/torch/distributed/launcher/api.py", line 250, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
hang.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2023-03-20_22:00:42
host : node0
rank : 0 (local_rank: 0)
exitcode : -6 (pid: 194470)
error_file: <N/A>
traceback : Signal 6 (SIGABRT) received by PID 194470
============================================================
```
The log suggests that TorchX monitor is triggered, and job is torn down.
### Major changes in this PR:
1. Merge ncclWatchDog thread and workCleanupLoop thread into one so that the watch action and the throw action are streamlined.
Previously, ncclWatchDog is responsible for watching comm error and timeout, and workCleanupLoop is responsible for watching Work item error and throwing exception. This two-thread design is not streamlined, raising the chance of missing the throw. Also, it is duplicated to watch at multiple level.
2. Rethrow exception at watchdog thread.
3. Clean up a bunch of duplicated functions, e.g. `checkAndThrowException` and `handleNcclException`.
4. Turn on ASYNC_ERROR_HANDLING by default
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97066
Approved by: https://github.com/rohan-varma
Summary:
This fixes an issue raised in [is_causal parameter in torch.nn.TransformerEncoderLayer.forward does not work #96941](https://github.com/pytorch/pytorch/issues/96941) where results computed with is_causal do not properly reflect causal masking.
In PyTorch 2.0, Accelerated PT Transformers added the is_causal parameter to legacy nn.Transformer* and nn.MHA APIs aligned with and intended to engage the is_causal parameter of the new scaled_dot_product_attention (SDPA) operator.
At present is_causal works differently for Transformer* modules, the nn.MHA and F.MHA:
* The nn.Transformer* modules treat is_causal as an optional indicator about the format of attn_mask. This is because some layers (such as the CLIP layer use the attention mask in the layer, and thus the attn_mask was a required feature.)
* Initially, nn.MHA and F.MHA were defined to align with F.SDPA in behavior: a user may specify either the attention mask, or is_causal, but not both. It seemed to make sense at the time to align SDPA and MHA, esp since there was a larger overlap of parameters which have since changed, e.g., with the removal of need_weights from SDPA. (See below for why this makes sense.)
Unfortunately, this does not work because of how MHA was changed to handle the need_weights parameter. When need_weights is present, we do not (any more) call SDPA because support for need_weights was removed from SDPA before the release. The rationale is that need_weights defeats all optimization at the foundation of SDPA performance. Having the flag might thus mislead users into thinking they get good performance and have them disappointed when they enable a legacy feature of MHA which massively degrades performance. (They might not think anything of enabling that, because it is on by default in MHA today, which leads to more issues.)
Since SDPA does not (no longer) support need_weights, we need to pick a separate path which implements attention using a set of discrete operations that allocates a tensor for weights. Alas, this code path does not have support for is_causal, because attention is implemented as matmul and using the attention mask. Thus, is_causal has no impact. (A substantially similar situation arises with how kpm is implemented today because Nested Tensors are not supported by torch.compile() in 2.0)
This problem was masked because all uses of legacy nn.MHA (and F.MHA) come through nn.Transformer* which called self-attention (i.e., nn.MHA) only ever with the attention mask attn_mask, and never with is_causal, a missed optimization opportunit that would have been addressed in a future performance update.
Regrettably, always calling nn.MHA with attn_mask prevented diagnosing of the issue of not having a suitable attention mask when need_weights support was dropped from SDPA and a discrete implementation of attention was added for that scenario, and for the execution path with key_padding_mask.
We have two options to address this issue:
Solution 1: Whenever nn.MHA and F.MHA are executed with is_causal set, we internally create a causal mask at significant expense of allocating a tensor and filling it with a triangular causal matrix. This increases memory usage, and runtime, for allocating a causal mask. To add insult to injury, in all current (and likely future) execution scenarios, MHA is called by a model using the nn.Transformer API which already has that matrix and passes it from nn.module to nn.module. Then the passing in of attn_mask has to be suppressed by nn.TransformerEncoderLayer, only for nn.MHA to immediately allocate the very same tensor again to satisfy the requirement to have an attention mask for the computation. (We expect new use cases to use SDPA directly.)
Solution 2: We align the behavior of nn.MHA and F.MHA with the rest of the existing nn.Transformer API, and require the attention mask to be passed into nn.MHA in addition to is_causal as an optional indicator about the nature of the attention mask rather than as an alternative to attn_mask. Then, when we choose the code path for processing MHA with need_weights or a key_padding_mask, we have the attn_mask passed down through the nn.Transformer* hierarchy, without the added overhead of allocating an attention mask as in scenario 1.
This PR implements solution 2 which offers better performance and in retrospect aligns MHA better with the rest of the Transformer modules as the definition of SDPA evolved into a more streamlined high-performance operator. It ostensibly changes how is_causal works, by requiring the attention mask to be specified. However, as described here, and as shown in the submitted issue, is_causal is not working as intended today, so it requires a change regardless.
In that sense, a change in API does not occur per-se, as the current implementation is not working, and a change has to occur either way to resolve the submitted issue, breaking any use cases that depend on the current implementation. Checks exist (and more can be added) that flag any scenarios where is_causal is passed as True, but no attention mask is provided, ensuring that there's not quiet change from even the faulty behavior present in 2.0.
As an upside, the present implementation will improve performance by addressing the passing of the is_causal flag from Transformer modules to MHA, speeding up training for these examples, e.g., finetuning BERT, RoBERTa, XLM-R models.
Differential Revision: D44245725
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97214
Approved by: https://github.com/albanD
We had some minimal tests for `torch.testing.make_tensor` before, but nothing exhaustive. This lead to quite few edge cases being undetected. This PR adds comprehensive tests and leaves a few FIXMEs in there for behavior that needs to be fixed in `make_tensor`. This will happen in later commits of this stack. Meaning, at the end of this stack, there shouldn't be any FIXME left in the tests added here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96331
Approved by: https://github.com/mruberry
data type: float32
Input size: torch.Size([64, 4, 128, 128])
single socket (32cores):
```
Before: bernoulli 0.001327775239944458 s dropout 0.0014216173489888509 s
After: bernoulli 0.0002424612840016683 s dropout 0.00039757410685221353 s
```
single core:
```
Before: bernoulli 0.04154032731056213 s dropout 0.04382548745473226 s
After: bernoulli 0.006143261671066284 s dropout 0.0065830423831939695 s
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97002
Approved by: https://github.com/jgong5, https://github.com/jansel
Fixes#96813.
Comments:
1. Wasn't able to test since tools/nightly.py does not allow for GPU build (and I don't want to build from scratch).
2. In theory, the bug (i.e. NaNs) can still occur when beta is very small (e.g. `beta=1e-50`), but not sure whether anybody cares.
3. Some checks within the smooth_l1_loss C++ code could be changed to check for `beta > 0` instead of `beta >= 0`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97022
Approved by: https://github.com/jbschlosser
Summary:
- Importing torch on Windows can cause a crash within python.
- The problem was introduced by the change in `Module.cpp` from https://github.com/pytorch/pytorch/pull/94927
- The cause is that a call to `PyObject* initModule(void)` declared with a `__declspec(dllimport)` specifier can lead to a crash if the definition doesn't include the `__declspec(dllexport)` counterpart.
- To mitigate the problem without introducing customized macros and changing the build system (note, `#include <c10/macros/Export.h>` doesn't work in `stub.c`) is to simply remove the `__declspec(dllimport)` specifier.
- According to https://web.archive.org/web/20140808231508/http://blogs.msdn.com/b/russellk/archive/2005/03/20/399465.aspx and other sources, `__declspec(dllimport)` only leads to some code optimizations, and since `initModule()` is only called once at startup, this is marginal.
- Note: the `stub_with_flatbuffer.c` file counterpart wasn't affected, therefore, not touched.
Differential Revision: D44236183
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97193
Approved by: https://github.com/ezyang
backport std::ssize to c10
Summary:
Now that we have -Werror=sign-compare enabled, we encounter a lot of
friction comparing standard containers and our tensors which are
signed.
std::ssize will make it easier and safer to succinctly convert
container sizes to a signed type.
Test Plan: Added a unit test.
Reviewers: ezyang
Subscribers:
Tasks:
Tags:
---
Stack created with [Sapling](https://sapling-scm.com). Best reviewed with [ReviewStack](https://reviewstack.dev/pytorch/pytorch/pull/97442).
* #97443
* __->__ #97442
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97442
Approved by: https://github.com/ezyang
Fixes#97382#95416 fixed a critical bug in dynamo benchmark, where AMP tests fall back to eager mode before that PR. However, after that PR, we found [a list of TIMM models amp + eager + training testing failed](https://docs.google.com/spreadsheets/d/1DEhirVOkj15Lu4UNawIUon9MqkVLaWqyT-DQPif5NHk/edit#gid=0).
Now we identified the root cause is: high loss values make gradient checking harder, as small changes in accumulation order upset accuracy checks. We should switch to the helper function ```reduce_to_scalar_loss``` which has been used by Torchbench tests.
After switching to ```reduce_to_scalar_loss```, TIMM models accuracy pass rate grows from 67.74% to 91.94% in my local test. The rest 5 failed models(ese_vovnet19b_dw, fbnetc_100, mnasnet_100, mobilevit_s, sebotnet33ts_256) need further investigation and handling, but I think it should be similar reason.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97423
Approved by: https://github.com/Chillee
remove unused CAFFE2_VERSION macros
Summary:
Nothing reads these and they are completely subsumed by TORCH_VERSION.
Getting rid of these will be helpful for build unification, since they
are also not used internally.
Test Plan: Rely on CI.
Reviewers: sahanp
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97337
Approved by: https://github.com/malfet
~~Need https://github.com/microsoft/onnx-script/pull/484~~
Support dynamic export on fx-ONNX exporter. Essentially, we set inputs size and nodes all dynamic in torchscript, and leverage on `aten::sym_size` to catch dynamic size between each Op.
1. Add `dynamic_axes` switch between symbolic tracing (dynamic sizes) and fake mode (static). Set it to default True, as most of our tests are happy with sumbolic tracing. Except GPT2 stays with fake mode with error: https://github.com/microsoft/onnx-script/issues/523
2. Add test_fx_dynamic_onnruntime.py to test on some addhoc we have from old exporter. This can be removed once tests are integrated with https://github.com/pytorch/pytorch/pull/96479
3. Since `aten::sym_size` are operated with built-in function, a built-in function mapping is added to support SymFloat/SymInt. (FIXME: https://github.com/pytorch/pytorch/issues/97201). sym_size output value is also fx.Node, and can be found in `fx_name_to_onnxscipt_value`, so it's operation stays the same as other ONNX ops in ONNX graph.
4. Fully deprecated FakeTensorProp as make_fx() should provide all node meta info.
5. Put complicated fx.Node related ArgumentType into _type_utils.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96350
Approved by: https://github.com/wschin, https://github.com/justinchuby
Previously, we would use the same memory pool but not actually reuse the same memory. The peak memory showed good numbers, but real memory use was much higher because we had a bunch of unallocated segments that could not be reused.
As stated in comments:
NB: cuda caching allocator will remember the stream a segment is allocated to
and only allocate that segment to the same stream. we need to use a single stream
for all allocations to the memory pool, otherwise the allocations to separate streams
will not be reused; separate recordings would have use the same memory pool, but not
the same memory.
Thanks to @zdevito for help debugging this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97419
Approved by: https://github.com/ngimel
Twice this week I have had people confuse "operator defined with Python
operator registration aka torch.library" and "PyOperator which is used
to define control flow operators and other operators that cannot be
represented in JIT schema." Renaming PyOperator for clarity.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97493
Approved by: https://github.com/SherlockNoMad
Summary:
Previous diff D43068669 introduced channel padding, and in doing so, it broke the quantized copy of cpu to vulkan tensors.
This diff updates the quantized nchw to image shaders, in order to work with padded channels.
Test Plan:
```
buck run --target-platforms ovr_config//platform/macos:arm64-fbsource -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64
```
Differential Revision: D44309956
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97372
Approved by: https://github.com/SS-JIA
stringstream construction is expensive, and we can exactly reserve space for the output string while doing the same number of string copies. (If we wanted to improve performance further, we could introduce annotation_str_out to append the output to a given std::string and thus avoid copying subtype annotation strings. It occurs to me that the existing approach is quadratic in the number of layers of nesting, so we should probably do this!)
Differential Revision: [D43919651](https://our.internmc.facebook.com/intern/diff/D43919651/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96498
Approved by: https://github.com/Skylion007
stringstream is expensive to create, we used stringstream instead of ostringstream, and we can easily specialize the empty tuple. Also, anybody compiling with C++20 support can move out of the stringstream and it shouldn't hurt people without C++20 support to do so. I would consider specializing the 1-element case as well but I don't have evidence that that's necessary right now.
Differential Revision: [D43882402](https://our.internmc.facebook.com/intern/diff/D43882402/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96497
Approved by: https://github.com/Skylion007
This is needed for the HSTU model.
Details:
* ~~NT `chunk` now calls into NT `split_with_sizes` since the latter is more general~~ (removed; they're totally separate)
* Throws for backward
* Only operates over the last dim (`dim=-1`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97446
Approved by: https://github.com/cpuhrsch
Fixes#97191
This PR aims to propagate collective exceptions (async error or timeout) up to the program, so as to avoid silent stuck job.
### Previous output in #97191
```
Rank 0 is the problematic rank
Rank 4 completed
Rank 5 completed
Rank 3 completed
Rank 6 completed
Rank 2 completed
Rank 7 completed
Rank 1 completed
[E ProcessGroupNCCL.cpp:464] [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=1, OpType=ALLREDUCE, Timeout(ms)=10000) ran for 10917 milliseconds before timing out.
Rank 0 completed
[E ProcessGroupNCCL.cpp:478] Some NCCL operations have failed or timed out. Due to the asynchronous nature of CUDA kernels, subsequent GPU operations might run on corrupted/incomplete data.
[E ProcessGroupNCCL.cpp:483] To avoid data inconsistency, we are taking the entire process down.
```
Although it says that it is taking the process down, it sometimes fails to do so.
### New output after this PR:
```
...
[E ProcessGroupNCCL.cpp:459] [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=1, OpType=ALLREDUCE, Timeout(ms)=10000) ran for 10599 milliseconds before timing out.
[E ProcessGroupNCCL.cpp:473] Some NCCL operations have failed or timed out. Due to the asynchronous nature of CUDA kernels, subsequent GPU operations might run on corrupted/incomplete data.
[E ProcessGroupNCCL.cpp:479] To avoid data inconsistency, we are taking the entire process down.
[E ProcessGroupNCCL.cpp:818] [Rank 0] NCCL watchdog thread terminated with exception: [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=1, OpType=ALLREDUCE, Timeout(ms)=10000) ran for 10599 milliseconds before timing out.
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: -6) local_rank: 0 (pid: 194470) of binary: /data/home/kw2501/repos/pytorch-dev-env/bin/python
Traceback (most recent call last):
File "/pytorch-dev-env/bin/torchrun", line 33, in <module>
sys.exit(load_entry_point('torch', 'console_scripts', 'torchrun')())
File "/pytorch-dev/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 346, in wrapper
return f(*args, **kwargs)
File "/pytorch-dev/torch/distributed/run.py", line 794, in main
run(args)
File "/pytorch-dev/torch/distributed/run.py", line 785, in run
elastic_launch(
File "/pytorch-dev/torch/distributed/launcher/api.py", line 134, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/pytorch-dev/torch/distributed/launcher/api.py", line 250, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
hang.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2023-03-20_22:00:42
host : node0
rank : 0 (local_rank: 0)
exitcode : -6 (pid: 194470)
error_file: <N/A>
traceback : Signal 6 (SIGABRT) received by PID 194470
============================================================
```
The log suggests that TorchX monitor is triggered, and job is torn down.
### Major changes in this PR:
1. Merge ncclWatchDog thread and workCleanupLoop thread into one so that the watch action and the throw action are streamlined.
Previously, ncclWatchDog is responsible for watching comm error and timeout, and workCleanupLoop is responsible for watching Work item error and throwing exception. This two-thread design is not streamlined, raising the chance of missing the throw. Also, it is duplicated to watch at multiple level.
2. Rethrow exception at watchdog thread.
3. Clean up a bunch of duplicated functions, e.g. `checkAndThrowException` and `handleNcclException`.
4. Turn on ASYNC_ERROR_HANDLING by default
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97066
Approved by: https://github.com/rohan-varma
Carried over comment from tensor.flatten docstring to to clarify when a view vs copy is instantiated - this has been a [minor point of confusion in forums](https://discuss.pytorch.org/t/what-is-the-difference-of-flatten-and-view-1-in-pytorch/51790/5). This comment is:
```
Unlike NumPy’s flatten, which always copies input’s data, this function may return the original object, a view, or copy.
If no dimensions are flattened, then the original object input is returned.
Otherwise, if input can be viewed as the flattened shape, then that view is returned.
Finally, only if the input cannot be viewed as the flattened shape is input’s data copied.
See torch.Tensor.view() for details on when a view will be returned.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97276
Approved by: https://github.com/mikaylagawarecki
Fixes https://github.com/pytorch/pytorch/issues/82915
This rare flaky issue caught my attention today when it failed flakily on MacOS in https://github.com/pytorch/pytorch/actions/runs/4494182574/jobs/7906827531. The test expected 3 traces to be written but got only 2 of them.
Looking a bit closer into the `tensorboard_trace_handler` function, it looks like there is a potential filename clash here. The millisecond since epoch `"{}.{}.pt.trace.json".format(worker_name, int(time.time() * 1000))` is used as part of the name. As `tensorboard_trace_handler` is used as a callback handle in the test, the names look too close to each other (1-millisecond apart), i.e.
```
huydo-mbp_13494.1679526197252.pt.trace.json
huydo-mbp_13494.1679526197253.pt.trace.json
huydo-mbp_13494.1679526197250.pt.trace.json
```
Switching to nanosecond reduces the chance of two or more of them having the same timestamp while keeping the naming convention intact, i.e. `huydo-mbp_13804.1679526325182878000.pt.trace.json`
I suspect that this is also the cause of Windows flakiness.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97392
Approved by: https://github.com/malfet, https://github.com/aaronenyeshi
Summary:
The current `optim_state_dict()` does not require users to call `optim.state_dict()` first while `optim_state_dict_to_load()` requires users to call `optim.load_state_dict()`. This PR make both APIs provide the option for users not having to call the extra API.
This PR also changes the arguments order of `optim_state_dict_to_load` which is a breaking change. So we should do this asap before the API is adopted in production cases.
Test Plan: CI
Differential Revision: D43925068
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96534
Approved by: https://github.com/rohan-varma
We currently use `bitonicSortKVInplace` for sorts of size `n <= 32`
but use `radixSortKVInplace` for `32 < n <= 4096`. Bitonic sort is
also unstable, which forces stable sorts fall back to which is up to
4x slower in this small regime.
This PR adds a new kernel `warpMergeSortKVInplace` using
`cub::WarpMergeSort` to implement sorts with `32 < n <= 128` and all
stable sorts with `n < 128`. This results in up to a 2x speedup for
unstable sorts and up to 15x for stable sorts, depending on the input
geometry.
This also doesn't increase the total number of kernels since we are
replacing radix-sorts of size 32 and 128.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96223
Approved by: https://github.com/ngimel
Per title, I suspect that having a leftover PyTorch built from CUDA 11.7 installed in non-ephemeral Windows runners could cause some flakiness on Windows CUDA 11.8 jobs also running on the same type of runners, for example `win-vs2019-cuda11.8-py3` in 5d3c347bf6 failed with a PATH error:
```
nvrtc: error: failed to open nvrtc-builtins64_117.dll.
Make sure that nvrtc-builtins64_117.dll is installed correctly.
```
This also cleans up the dead code about `pytorch_env_restore.bat` under `ci_scripts` temp directory. This directory is cleaned up always by [teardown-win](https://github.com/pytorch/pytorch/blob/master/.github/actions/teardown-win/action.yml#L33). So the bat script will never be there for the next job anyway. As Windows test jobs are doing fine, proving that we don't need this adhoc script anymore.
### Testing
https://github.com/pytorch/pytorch/actions/runs/4485931686/jobs/7888513795
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97285
Approved by: https://github.com/seemethere
Summary: It turns out we never turn on cudnn v8 API which blocks bf16 conv. Enable the new v8 API
Test Plan: buck run mode/dev-nosan scripts/xdwang/example:fc_pytorch
Reviewed By: ngimel
Differential Revision: D43784279
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96512
Approved by: https://github.com/malfet
This refactor should make it easier to add an export hook into aot autograd.
(1) I killed `create_forward_or_joint_functionalized()` (and the functions that it called, like `forward_or_joint()`) which used to handle autograd + functionalization all-in-one-go for the joint case, and was also used in the inference case.
I added a few separate helper functions:
`create_functionalized_graph()`: this takes a flat fn, and returns a functionalized fx graph. It is mostly just a thin wrapper around functionalization + make_fx(), but also has some extra logic to manually append `copy_()` ops to the end of the graph.
`fn_no_extra_mutations()`: this creates the fn that we want to trace in the inference code path. It takes in a function that it then calls, and returns the outputs + any (updated) mutated inputs.
`joint_fn_no_external_mutations()`: this creates the fn that we want to trace in the joint code path. It takes in a function, and traces out its joint. It also does the work of cloning inputs that are mutated and require gradients, returning mutated inputs as outputs, and returning intermediate bases as outputs
We should be able to add an export hook by basically adding a similar version of `joint_fn_no_external_mutations` but with a lot more restrictions (guaranteed to have no tangents, not synthetic bases, etc), and calling `create_functionalized_graph()` on it.
Differential Revision: [D44204090](https://our.internmc.facebook.com/intern/diff/D44204090)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96341
Approved by: https://github.com/ezyang
Why did I choose context manager instead of per-call? Early stopping is not part of the model definition, and depending on how a particular model is used, e.g., with PT2 or not we may or may not want to disable early stopping.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96866
Approved by: https://github.com/albanD
Closes#87365
I added `as_strided_` to the tensor docs, following what seemed to be a pattern consistent with similar functions. More specifically, both the in-place and out-of-place function counterparts are defined in `_tensor_docs.py`, with the in-place version linking to the out-of-place version and the out-of-place version pointing to the corresponding `_torch_docs.py` definition.
If the above is not what we want (e.g. we want to add a more robust description, examples, etc.), let me know and I will be happy to update accordingly!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97300
Approved by: https://github.com/zou3519
Summary:
Calls to this function without an argument will get a stack trace at
import time. This is expensive, we can just skip it by passing in a value.
Test Plan: Wait for tests
Differential Revision: D44244345
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97274
Approved by: https://github.com/kiukchung
Updates:
- ~recommend user to use non-reentrant, mention that reentrant will be deprecated in the future~
- merges all the warnings into a single list of non-reentrant improvements over reentrant
- adds an additional entry to the list about allowing backward inside checkpointed region
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96862
Approved by: https://github.com/albanD
**Summary** NamedTuple attributes can be annotated to declare their type:
```python
class MyNamedTuple(NamedTuple):
x: int
y: torch.Tensor
z: MyOtherType
```
Normally in python you can also declare your types as strings, `x: 'int'`. But NamedTuples previously didn't support this, because their annotation evaluation process was slightly different. This PR updates the NamedTuple attribute type annotation evaluation method to support ForwardRef declarations (i.e. declaring as strings).
**Details**
Below I repeat the comment I left in _jit_internal.py:
NamedTuple types are slightly different from normal types.
Normally, annotations are evaluted like this (during jit.script):
1. Load strings of python code into c++ and parse.
2. Get annotations as strings
3. Use the PythonResolver's resolution callback (rcb) to convert the string into a python object
4. We call into annotations.py:ann_to_type to convert python obj from step 3 into a type that torchscript understands.
NamedTuples are more complicated, because they have sub-types. Normally, once we have the NamedTuple type object from #3, we can just look at the annotation literal values and use ann_to_type directly on them.
But sometimes, users will annotate with string literals, e.g.
```
x: 'int'
```
This also happens with PEP563 (from __forward__ import annotations)
These annotations appear in the annotation dict as ForwardRef('int').
Then, we need to convert the string into a python object. This requires having local context for custom objects or imported types. rcb() is what gives us this. So, we plumb rcb through the stack so it can be used in this context for the if block below.
FAQ:
- Why do we need this special handling for NamedTuple but string annotations work fine for normal types? Normally, we parse the string directly and then call rcb() directly from C++.
- Why not use ForwardRef._evaluate? For that, we need globals() and locals() for the local context where the NamedTuple was defined. rcb is what lets us look up into these. So, basically rcb does the hard work for us.
- What is rcb? rcb is a ResolutionCallback - python callable that takes a string and returns a type. It's generated by `createResolutionCallback.*` in _jit_internal.py.
**Why is this only partial support**:
This only plumbs the rcb through some paths. In particular, the `toSugaredValue` path uses a fake rcb.
**Alternatives**:
We could also treat this the way we treat non-nn.Module classes: we evaluate them separately, ahead of time. That solution is probably better, but probably requires a more risky refactor for the way NamedTuples are handled.
Fixes#95858
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96933
Approved by: https://github.com/qihqi
If python development library is missing when building pytorch from source, cmake will raise the error like:
```
CMake Error at cmake/Dependencies.cmake:1079 (if):
if given arguments:
"VERSION_LESS" "3"
Unknown arguments specified
```
it's quite a misleading information that user would consider it's a syntax error or cmake version problem.
This PR add a check to ensure `PYTHONLIBS_VERSION_STRING` exist before using.
Related #87993
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96642
Approved by: https://github.com/kit1980
Summary: Have minifier include the current buck target as a dependency to make sure all deps are included.
Test Plan: TORCH_COMPILE_DEBUG_DIR=”.” buck2 run mode/dev-nosan //caffe2/test/inductor:minifier_smoke
Differential Revision: D44231209
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97183
Approved by: https://github.com/anijain2305
# Summary
NestedTensors currenlty don't support non-identical strided addition. When accumulating grad it possible to try and accumulate a grad with different striding then the old var and there is no way to change this in user code. This is a solution.. probs should support strided addition for NT
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97195
Approved by: https://github.com/albanD, https://github.com/cpuhrsch
The major cost of doing autotuning in sub process is process creating and initialization. Previously we do that for each benchmark task. This PR reuse a child process as long as it has not crashed yet. This improves compiling time a lot. It's still a bit slower than single process tuning though. Here are the comparison between single process tuning and multi-process tuning:
- if a benchmark task will crash the process, then single process tuning is a no-go
- if a benchmark task works fine, then tuning in child process will be slower. We will try to leveraging multi-GPU to further speed this up.
TLDR for the compilation time: we reduce the 11x slowdown to 1.5x. We'll try to further improve that.
Here are the compilation time comparison:
Single process autotuning:
```
AUTOTUNE ref_mm_plus_mm(2048x64, 64x1536, 2048x64, 64x1536)
triton_mm_plus_mm_0 0.0276s 100.0%
triton_mm_plus_mm_6 0.0287s 96.4%
triton_mm_plus_mm_5 0.0307s 90.0%
triton_mm_plus_mm_1 0.0317s 87.1%
triton_mm_plus_mm_7 0.0379s 73.0%
ref_mm_plus_mm 0.0389s 71.1%
triton_mm_plus_mm_2 0.0399s 69.2%
triton_mm_plus_mm_3 0.0410s 67.5%
triton_mm_plus_mm_4 0.0410s 67.5%
SingleProcess AUTOTUNE takes 9.04686689376831 seconds
```
Naive multi process tuning (not reuse child process): 11x slower than single process autotuning
```
AUTOTUNE ref_mm_plus_mm(2048x64, 64x1536, 2048x64, 64x1536)
triton_mm_plus_mm_0 0.0287s 100.0%
triton_mm_plus_mm_6 0.0287s 100.0%
triton_mm_plus_mm_1 0.0317s 90.3%
triton_mm_plus_mm_5 0.0317s 90.3%
triton_mm_plus_mm_7 0.0379s 75.7%
ref_mm_plus_mm 0.0389s 73.7%
triton_mm_plus_mm_2 0.0399s 71.8%
triton_mm_plus_mm_3 0.0399s 71.8%
triton_mm_plus_mm_4 0.0420s 68.3%
SubProcess AUTOTUNE takes 101.22216320037842 seconds
```
Multi process tuning reusing child process (this PR): 1.5x slower than single process autotuning
```
AUTOTUNE ref_mm_plus_mm(2048x64, 64x1536, 2048x64, 64x1536)
triton_mm_plus_mm_0 0.0276s 100.0%
triton_mm_plus_mm_6 0.0287s 96.4%
triton_mm_plus_mm_5 0.0307s 90.0%
triton_mm_plus_mm_1 0.0317s 87.1%
triton_mm_plus_mm_7 0.0379s 73.0%
ref_mm_plus_mm 0.0389s 71.1%
triton_mm_plus_mm_2 0.0399s 69.2%
triton_mm_plus_mm_3 0.0410s 67.5%
triton_mm_plus_mm_4 0.0410s 67.5%
SubProcess AUTOTUNE takes 13.752070665359497 seconds
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97219
Approved by: https://github.com/ngimel
exclude all generated files from torch_headers
Summary:
This allows Bazel to build without having to wipe the standard CMake
build.
The standard CMake build produces generated files in the source tree,
this causes a problem because Bazel has its own way of generating
them, and then both sets of generated files conflict with each other.
Test Plan: Rely on CI.
Reviewers:
Subscribers:
Tasks:
Tags:
---
Stack created with [Sapling](https://sapling-scm.com). Best reviewed with [ReviewStack](https://reviewstack.dev/pytorch/pytorch/pull/96956).
* #96957
* __->__ #96956
* #96955
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96956
Approved by: https://github.com/PaliC
Fixes#96347
This PR:
- Makes the functorch tests run as a part of the "default" shards
- Delete the functorch CI shard from all CI job configurations (if it exists)
- Increase the "default" shard count by 1 for each job, unless it was
previously set to 1, to accommodate the new functorch tests and not
regress time-to-signal.
- Adds a bunch of skips for ROCM and torchdynamo configurations. We can
investigate them later.
NB: I might go through some more iterations to figure out what other
skips need to be added, but this iteration of the PR seems to pass most CI.
suite.
Test Plan:
- wait for CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96464
Approved by: https://github.com/huydhn
DTensor submesh support is added in https://github.com/pytorch/pytorch/pull/95458.
This PR adds support for DTensor submesh by adding an extra check when create local save/load plan.
If the rank is not participating in the mesh, we simply skip creating WriteItem/ReadItem for the local SavePlan/LoadPlan.
Updated the associated test as well.
cc. @wanchaol, @kumpera
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96802
Approved by: https://github.com/wanchaol
The purpose of this PR is to remove reliance on argument positions in dedup guards, AND extend the functionality to params.
A version of this PR was stamped prior https://github.com/pytorch/pytorch/pull/95831 - but was kinda gross, because it was based on an underlying PR that did way too much with source names.
This PR leaves most of that alone, in favor of just reusing the same name standardization logic that dynamo module registration does.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96774
Approved by: https://github.com/ezyang
Fixes#95492
**Summary**
This PR fixes the issue that weighted functional ops with kwargs are not lowered correctly since kwargs are ignored.
These kwargs should be moved from the functional op to its cooresponding prepack op, e.g., from `F.conv2d` to `quantized.conv2d_prepack`.
**Test plan**
python test/test_quantization.py -k test_lowering_functional_conv_with_kwargs
python test/test_quantization.py -k test_lowering_functional_conv_transpose_with_kwargs
python test/test_quantization.py -k test_lowering_functional_linear_with_kwargs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95865
Approved by: https://github.com/jgong5, https://github.com/supriyar
I am trying to use bfloat16 AMP on a range of devices, using the `enabled` argument to actually enable/disable AMP, like this:
```python
with torch.cuda.amp.autocast(enabled=use_amp, dtype=torch.bfloat16):
```
However, this raises a RuntimeError even if enabled=False.
```
File "/venv/lib/python3.8/site-packages/torch/amp/autocast_mode.py", line 221, in __init__
raise RuntimeError('Current CUDA Device does not support bfloat16. Please switch dtype to float16.')
RuntimeError: Current CUDA Device does not support bfloat16. Please switch dtype to float16.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96097
Approved by: https://github.com/ngimel, https://github.com/kit1980
Summary:
When creating a new DDP instance for the same model when an old DDP instance existed, the autograd hooks from the old DDP instance might not be cleared. Also, relying on python gc to clear out old autograd hooks is fragile and may not work 100% of the time.
As a result, in this PR I'm adding a way to explicitly remove these hooks from DDP
Test Plan:
Unit test added
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96490
Approved by: https://github.com/zhaojuanmao, https://github.com/rohan-varma
About that line:
```
torch.empty(3).random_(2)
```
* Since BCE supports targets in the interval [0, 1], a better example is to sample from uniform(0, 1), using `rand`
* BCE supports multiple dimensions, and the example in `F.binary_cross_entropy` highlights it
* `rand` is more well known than `random_`, which is a bit obscure (`rand` is in the [Random Sampling section in the docs](https://pytorch.org/docs/stable/torch.html#random-sampling))
* Chaining `empty` and `random_` gives binary values as floats, which is a weird way to get that result
* Why do it in two steps when we have sampling functions that do it in a single step?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95178
Approved by: https://github.com/albanD, https://github.com/kit1980
Fixes #ISSUE_NUMBER
1、add amp support for custom backend
2、optimize the file `backend_registration.py`, and rename it with `custom_backend_registration.py`. And then we would register other funcs for custom backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96188
Approved by: https://github.com/bdhirsh
Summary:
## Motivation
Initial version of CUPTI Range profile was conservative in turning of all other event types in kineto/pytorch profiler.
However, there is value in enabling CPU side activity logging. This let's us correlate the CPU operator -> GPU kernel statistics, helps us analyze flops/other performance metrics at the operator level.
## Details
1. Update pytorch profiler experimental configs parsing to allow setting CPU activities along with range profiler. Only enable on per kernel measurement mode.
1. Fixed Clang tidy issues (added nolint for 2 of them)
Test Plan: Testplan see bottom diff
Differential Revision: D44165079
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97048
Approved by: https://github.com/aaronenyeshi
Op-benchmark directly uses fx.Graph to create nodes without dynamo and then compiles the graph with inductor. Currently, operators with multiple outputs, e.g. native_layer_norm, would fail to run caused by standalone torch._inductor.compile() API #95594. Actually, the graph's result is a node with several outputs instead of a tuple with several nodes. However, the standalone API forces a non-tuple result be a tuple, i.e., a tuple with one node-type element with several outputs. This PR considers a return node with several outputs as a tuple to avoid errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96936
Approved by: https://github.com/jgong5, https://github.com/jansel
Fixes https://github.com/pytorch/pytorch/pull/95676#issuecomment-1460588229
PS: It doesn't seem the exported ONNX_proto having type now. I wonder if there was a ONNX pass doing this for us (converting torch dtype to onnx dtype during exporting.)
Type promotion issue would be raised with an error if we want to set type
```python
onnxscript_value.dtype = expected_value.dtype
```
onnx.onnx_cpp2py_export.shape_inference.InferenceError: [ShapeInferenceError] Shape inference error(s): (op_type:aten_add, node name: aten_add_1): [ShapeInferenceError] (op_type:Add, node name: n3): B has inconsistent type tensor(int64)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96349
Approved by: https://github.com/justinchuby, https://github.com/wschin
Op-benchmark directly uses fx.Graph to create nodes without dynamo and then compiles the graph with inductor. Currently, operators with multiple outputs, e.g. native_layer_norm, would fail to run caused by standalone torch._inductor.compile() API #95594. Actually, the graph's result is a node with several outputs instead of a tuple with several nodes. However, the standalone API forces a non-tuple result be a tuple, i.e., a tuple with one node-type element with several outputs. This PR considers a return node with several outputs as a tuple to avoid errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96936
Approved by: https://github.com/jgong5, https://github.com/jansel
This reverts commit 34256bc73080d7898138c821273b9f31fab777f8.
@kit1980: I'm not sure how best to revert a co-dev PR like https://github.com/pytorch/pytorch/pull/96410#issuecomment-1474704337. IIRC, Ivan and Eli did a revert PR like this before, so I create one here just in case we need to use it. If that's the case, please feel free to get this merge to fix trunk. Otherwise, this can be closed.
@shunting314 If you can do a forward fix faster than this, please help do so.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97075
Approved by: https://github.com/kit1980
Summary:
Adds NNC-like logging that is configured through an env var `TORCH_COMPILE_LOGS`
Examples:
`TORCH_LOGS="dynamo,guards" python script.py` - prints dynamo logs at level INFO with guards of all functions that are compiled
`TORCH_LOGS="+dynamo,guards,graph" python script.py` - prints dynamo logs at level DEBUG with guards and graphs (in tabular) format of all graphs that are compiled
[More examples with full output](https://gist.github.com/mlazos/b17f474457308ce15e88c91721ac1cce)
Implementation:
The implementation parses the log settings from the environment, finds any components (aot, dynamo, inductor) or other loggable objects (guards, graph, etc.) and generates a log_state object. This object contains all of the enabled artifacts, and a qualified log name -> level mapping. _init_logs then adds handlers to the highest level logs (the registered logs), and sets any artifact loggers to level DEBUG if the artifact is enabled.
Note: set_logs is an alternative for manipulating the log_state, but if the environment contains TORCH_LOGS, the environment settings will be prioritized.
Adding a new log:
To add a new log, a dev should add their log name to torch._logging._registrations (there are examples there already).
Adding a new artifact:
To add a new artifact, a dev should add their artifact name to torch._logging._registrations as well.
Additionally, wherever the artifact is logged, `torch._logging.getArtifactLogger(__name__, <artifact_name>)` should be used instead of the standard logging implementation.
[design doc](https://docs.google.com/document/d/1ZRfTWKa8eaPq1AxaiHrq4ASTPouzzlPiuquSBEJYwS8/edit#)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94858
Approved by: https://github.com/ezyang
Fixes#44189
Adds a new parameter, zero_grad_unused, to the torch.autograd.grad() function. This parameter allows for the gradient to be set to 0 instead of None when a variable is unused, which can be helpful for higher-order partial differentials.
Here is an example of using this new parameter to solve d^3y/dx^3 given y = a * x:
```python
x = torch.tensor(0.5, dtype=torch.float32, requires_grad=True)
a = torch.tensor(1, dtype=torch.float32, requires_grad=True)
y = x * a
dydx = torch.autograd.grad(y, x, create_graph=True, allow_unused=True)
d2ydx2 = torch.autograd.grad(dydx, x, allow_unused=True, zero_grad_unused=True)
try:
d3ydx3 = torch.autograd.grad(d2ydx2, x, allow_unused=True, zero_grad_unused=True)
except RuntimeError as e:
assert False, "Should not raise error"
```
With `zero_grad_unused`, d2ydx2 could be 0 instead of None, enabling d3ydx3 to be calculated as defined in math without throwing an error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97015
Approved by: https://github.com/soulitzer
This PR implements the support to benchmark max-autotune choices in subprocesses. This way crash like https://github.com/openai/triton/issues/1298 will only abort the autotuning child process but the parent process can continue.
There are a few things to note:
- cuda runtime does not work with fork. So we have to use spawn to create child processes. Check the best practice from pytorch multithreading module: https://pytorch.org/docs/stable/notes/multiprocessing.html
- to run a job in a child process, the multiprocessing module needs to pickle both the target function and arguments and pass them to child process. This is the major complexity of this prototype since there are quite a lot of corner cases making pickle fail.
Here I list the pickle related issues I encountered:
- pickle a StorageBox cause infinite recursion. Error: https://gist.github.com/171e5ab404b7855dee2dfa1d9f093442 . Work around by pickle the inner buffer.
- IRNode store fx.Node's in its origin fields. However, we can not pickle a fx.Node. It fails when with the following error when picking the fx.Node.graph: https://gist.github.com/9c289e895d7091d7ec787c67bc3c0d70. Work around by skip origins when pickling a IRNode.
- jinja Template in TritonTemplateKernel can not be pickled: `TypeError: Template.__new__() missing 1 required positional argument: 'source' `. Workaround by pickle the source rather than jinjia Template. During unpickling, rebuild the jinja template.
- due to how select_algorithm.template_kernels is populated, in child process, it's empty. Work around by passing select_algorithm.template_kernels from parent process to child process directly.
- There is some change in TritonTemplate.generate to make a TritonTemplateKernel pickle'able. A TritonTemplate is refered to in the closure for a TritonTemplateKernel object.
- We can not pass choice to child process directly because of pickle failure for lambda/local function being used. However cloudpickle can handle lambda. Work around by passing the cloudpickle'd choice object to child process. The child project need to unpickle it explictly.
Test:
```
python test/inductor/test_max_autotune.py -k test_max_autotune_mm_plus_mm
```
This is basically the repro I get from Bert Maher.
Benchmark in sub process is about 4x slower than benchmark in the same process. Without doing any profiling, I feel the time may be cost by starting a new process and doing initialization. Some ~thread~ process pool may help.
```
AUTOTUNE ref_mm_plus_mm(2048x64, 64x1536, 2048x64, 64x1536)
triton_mm_plus_mm_0 0.0276s 100.0%
triton_mm_plus_mm_6 0.0287s 96.4%
triton_mm_plus_mm_5 0.0317s 87.1%
triton_mm_plus_mm_1 0.0328s 84.4%
ref_mm_plus_mm 0.0379s 73.0%
triton_mm_plus_mm_7 0.0379s 73.0%
triton_mm_plus_mm_2 0.0399s 69.2%
triton_mm_plus_mm_3 0.0410s 67.5%
triton_mm_plus_mm_4 0.0410s 67.5%
AUTOTUNE takes 12.001659393310547 seconds
AUTOTUNE ref_mm_plus_mm(2048x64, 64x1536, 2048x64, 64x1536)
triton_mm_plus_mm_0 0.0276s 100.0%
triton_mm_plus_mm_6 0.0287s 96.4%
triton_mm_plus_mm_1 0.0317s 87.1%
triton_mm_plus_mm_5 0.0317s 87.1%
ref_mm_plus_mm 0.0379s 73.0%
triton_mm_plus_mm_7 0.0389s 71.1%
triton_mm_plus_mm_2 0.0399s 69.2%
triton_mm_plus_mm_3 0.0410s 67.5%
triton_mm_plus_mm_4 0.0410s 67.5%
AUTOTUNE takes 51.39659810066223 seconds
```
The feature is disabled by default and can be enabled by setting the following config or envvar:
```
autotune_in_subproc = os.environ.get("TORCHINDUCTOR_AUTOTUNE_IN_SUBPROC") == "1"
```
Differential Revision: [D43996048](https://our.internmc.facebook.com/intern/diff/D43996048)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96410
Approved by: https://github.com/jansel
previously this would clone triton, and then try to checkout without being in the git repo directory. This wasn't usually a problem because the environment already had a triton repo downloaded; but I ran into this while trying to construct a new environment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96623
Approved by: https://github.com/anijain2305
# Summary
There exists an optimization within the scaled_dot_product_efficieint bacwkard attention path to, under the right conditions, output grad_q, grad_k, grad_v all as aliases of the same storage. This was done to optimize for the hot path where mha does packed linear_projection -> chunk -> (view stuff) -> sdpa. The thought was that chunk-> would be able to "trivially" cat inputs to chunk.backward(). However upon closer inspection chunk.backward will call ` cat` irregardless of the inputs so this is not being utilized.
I validated this by profiling on main and then this branch and the traces produced the same both with `split.backward()` calling into cat.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96880
Approved by: https://github.com/cpuhrsch
Summary:
Verified the changes to catch unspecialized int/floats being added as additional graph in D44037548 prior to RP(https://github.com/pytorch/pytorch/pull/95621).
However, with #95621 the issue to be solved originally is no longer valid because int & float in `forward` will always be specialized in export. This RP is to add the assertion anyway *(though not be hit unless there is a regression)* to immediately catch the attempt to add unspecialized int/float to additional graphargs
Test Plan:
Example of the error message would look like:
```
Dynamo attempts to add additional input: value=9.999999747378752e-06, source=NNModuleSource(inner=AttrSource(base=NNModuleSource(inner=AttrSource(base=LocalInputSource(local_name='self', pos=0), member='torch_module')), member='eps'))
```
Passed all export tests
```
Buck UI: https://www.internalfb.com/buck2/fea72653-5549-47e7-a9bf-740eb86a8e26
Test UI: https://www.internalfb.com/intern/testinfra/testrun/8725724422167257
RE: reSessionID-7b3470b1-c293-4c4a-9671-dd0b7a2839b8 Up: 6.0 KiB Down: 0 B
Jobs completed: 101. Time elapsed: 115.7s.
Tests finished: Pass 98. Fail 0. Fatal 0. Skip 0. 0 builds failed
```
Differential Revision: D44075910
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96786
Approved by: https://github.com/tugsbayasgalan, https://github.com/ezyang
Fixes#94841
This fixes the error messages in the following files, the same as those referenced in the linked issue. I was not able to find any additional examples, but am happy to add commits for any that I may have missed!
```
aten/src/ATen/native/Blas.cpp: "size mismatch, got ", self.size(0), ", ", mat.size(0), "x", mat.size(1), ",", vec.size(0));
torch/_decomp/decompositions.py: lambda: f"size mismatch, got {self.size(0)}x{self.size(1)},{vec.size(0)}",
```
Example output for `Blas.cpp` before:
```
size mismatch, got 3, 3x4,1
```
The new error messages have the following format:
```
aten/src/ATen/native/Blas.cpp: "size mismatch, got bias (", self.size(0), "), matrix (", mat.size(0), "x", mat.size(1), "), vector (", vec.size(0), ")");
torch/_decomp/decompositions.py: lambda: f"size mismatch, got matrix ({self.size(0)}x{self.size(1)}), vector ({vec.size(0)})",
```
Example output for `Blas.cpp` after:
```
size mismatch, got bias (3), matrix (3x4), vector (1)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96863
Approved by: https://github.com/albanD
Summary:
* add human readable type and ivalue printout
* fix internal linter warnings
Test Plan:
error message now looks like e.g.
```
E0315 16:27:32.409082 422313 ExceptionTracer.cpp:222] exception stack complete
terminate called after throwing an instance of 'c10::Error'
what(): List[int] is not a subtype of List[int]; schema arg name: 'split_sizes', ivalue: [1, 1]
```
Differential Revision: D44112297
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96903
Approved by: https://github.com/davidberard98
Summary:
This PR fixes `_get_or_create_default_group()` of `DeviceMesh`. When `mesh` of the first created `DeviceMesh` is not `[0, 1, 2, ... WORLD_SIZE - 1]` and `is_initialized() == False`, it wrongly asserts. This PR fixes this issue by removing these assertions.
---
More specifically, `_get_or_create_default_group()` has 4 checks:
1. `DeviceMesh must include every process in WORLD`
2. `DeviceMesh cannot have duplicate values`
3. `DeviceMesh ranks must start from 0`
4. `DeviceMesh should have all ranks of WORLD`
1, 3, and 4 are not satisfied when `self.mesh` is not `[0, 1, 2, ... WORLD_SIZE - 1]`.
2 is a valid check, but it is also checked in `__init__()`, so we don't need to check it again in this function.
Test Plan: CI
Reviewed By: wanchaol
Differential Revision: D44098849
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96961
Approved by: https://github.com/wanchaol
Summary: Decoder native joins the dead code society
With the recent introduction of PT2, we no longer need native decoder operators:
1 - full-function SDPA kernels can be used to implement cross-attention efficiently without the (slower) decoder MHA blob.
2 - torch.compile() generates more efficient code across many platforms from the python implementation of decoders than the decoder layer blob by tailoring code to target
Test Plan: github & sandcastle
Differential Revision: D43811808
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96025
Approved by: https://github.com/ezyang, https://github.com/albanD
This method has to be accessible from `c10` to enable CUDA-12 integration.
Implemented by providing private `c10::cuda:_internal::setHasPrimaryContext` that passes the pointer to the implementation (in `torch_cuda`) back to c10.
Use global class constructor/destructor to guarantee RAII.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96800
Approved by: https://github.com/ngimel
Summary:
Same as D43747173 (https://github.com/pytorch/pytorch/pull/95911) except for the newly added x86 SSE2 kernels.
For future reference, wrappers can be generated by
```
cd ~/fbsource/xplat/third-party/XNNPACK
# Update the list of internal only kernels in generate-wrappers.py
python3 generate-wrappers.py
```
Test Plan: CI
Reviewed By: digantdesai
Differential Revision: D44072764
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96896
Approved by: https://github.com/digantdesai
CUDA Graph Trees
Design doc: https://docs.google.com/document/d/1ZrxLGWz7T45MSX6gPsL6Ln4t0eZCSfWewtJ_qLd_D0E/edit
Not currently implemented :
- Right now, we are using weak tensor refs from outputs to check if a tensor has dies. This doesn't work because a) aliasing, and b) aot_autograd detaches tensors (see note [Detaching saved tensors in AOTAutograd]). Would need either https://github.com/pytorch/pytorch/issues/91395 to land to use storage weak refs or manually add a deleter fn that does what I want. This is doable but theres some interactions with the caching allocator checkpointing so saving for a stacked pr.
- Reclaiming memory from the inputs during model recording. This isn't terribly difficult but deferring to another PR. You would need to write over the input memory during warmup, and therefore copy the inputs to cpu. Saving for a stacked pr.
- Warning on overwriting previous generation outputs. and handling nested torch.compile() calls in generation tracking
Differential Revision: [D43999887](https://our.internmc.facebook.com/intern/diff/D43999887)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89146
Approved by: https://github.com/ezyang
Summary: Today if we're accessing out of bound embedding rows, it'll either go through or throw IMA. This is not ideal - adding bound checks. This will probably slow things down - need to benchmark it.
Test Plan:
TODO: add some tests
Tried a simple example and it's showing this:
```
aten/src/ATen/native/cuda/EmbeddingBag.cu:143: EmbeddingBag_updateOutputKernel_sum_mean: block: [0,0,0], thread: [0,1,0] Assertion `input[emb] < numRows` failed.
```
Differential Revision: D43810777
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96022
Approved by: https://github.com/cpuhrsch, https://github.com/ngimel
- Only ReflectPad needs the torch checks for input arguments and not the ReplicatePad
- Added a test case
- The failure was originally found in test_modules with test `test_forward_nn_ReplicationPad3d_mps_float32`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96988
Approved by: https://github.com/DenisVieriu97
Previously, when starting to trace a function, we would record a frame summary recording the definition loc. This would lead to an unconventional-looking stack trace when used for debugging, e.g., shape guards.
```
File ".../scripts/avik/pt2/example.py", line 407, in forward
def forward(self, x):
...
File ".../transformers/models/bert/modeling_bert.py", line 912, in forward
@add_start_docstrings_to_model_forward(BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
...
File ".../transformers/models/bert/modeling_bert.py", line 562, in forward
def forward(
...
File ".../transformers/models/bert/modeling_bert.py", line 484, in forward
def forward(
...
File ".../transformers/models/bert/modeling_bert.py", line 416, in forward
def forward(
...
File ".../transformers/models/bert/modeling_bert.py", line 275, in forward
def forward(
...
File ".../transformers/models/bert/modeling_bert.py", line 351, in forward
attention_scores = attention_scores + attention_mask
```
As noted in https://github.com/pytorch/pytorch/pull/95848#discussion_r1134397096, we would like to change this to record function calls instead, like conventional stack traces do. This diff makes this change. The above stack now looks like the following, which is way more helpful at a glance to understand what's going on.
```
File ".../scripts/avik/pt2/example.py", line 408, in forward
bert_out = self.bert(**x)
...
File ".../transformers/models/bert/modeling_bert.py", line 1021, in forward
encoder_outputs = self.encoder(
...
File ".../transformers/models/bert/modeling_bert.py", line 610, in forward
layer_outputs = layer_module(
...
File ".../transformers/models/bert/modeling_bert.py", line 496, in forward
self_attention_outputs = self.attention(
...
File ".../transformers/models/bert/modeling_bert.py", line 426, in forward
self_outputs = self.self(
...
File ".../transformers/models/bert/modeling_bert.py", line 351, in forward
attention_scores = attention_scores + attention_mask
```
Differential Revision: [D44101882](https://our.internmc.facebook.com/intern/diff/D44101882/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96882
Approved by: https://github.com/ezyang
Summary:
Add vmap support for torch.tril and torch.triu.
Fix: #91403
Test Plan: GitHub pipeline
Differential Revision: D43016624
### Expected behavior
Same as using for-loop:
```python
import torch
x = torch.randn(32, 3)
results = []
for xi in x:
y = torch.triu(xi)
results.append(y)
"""
triu: input tensor must have at least 2 dimensions
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-7-d726203efb0e> in <module>
4 results = []
5 for xi in x:
----> 6 y = torch.triu(xi)
7 results.append(y)
RuntimeError: triu: input tensor must have at least 2 dimensions
"""
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94287
Approved by: https://github.com/Skylion007, https://github.com/zou3519
DTensor submesh support is added in https://github.com/pytorch/pytorch/pull/95458.
This PR adds support for DTensor submesh by adding an extra check when create local save/load plan.
If the rank is not participating in the mesh, we simply skip creating WriteItem/ReadItem for the local SavePlan/LoadPlan.
Updated the associated test as well.
cc. @wanchaol, @kumpera
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96802
Approved by: https://github.com/wanchaol
As in the title.
The `masked_grad` kw argument is required for `to_dense` backward to distinguish the expected semantics of sparse tensors. `masked_grad=True` means that the `to_dense` backward will apply a mask to the returned gradient where the mask is defined by the input indices. The default semantics implies `masked_grad==True` for BC but see the [comment](https://github.com/pytorch/pytorch/pull/96095/files#diff-d4df180433a09071e891d552426911c227b30ae9b8a8e56da31046e7ecb1afbeR501-R513) in `to_dense_backward`.
As a consequence, existing code that is run through autograd engine must replace `.to_dense()` calls with `.to_dense(masked_grad=False)`. For example,
```python
torch.autograd.gradcheck(lambda x: torch.sum(x, [0]).to_dense())
torch.autograd.gradcheck(lambda x: torch.sparse.sum(x, [0]).to_dense())
```
(recall, gradcheck has `masked=False` as default) must be updated to
```python
torch.autograd.gradcheck(lambda x: torch.sum(x, [0]).to_dense(masked_grad=False))
torch.autograd.gradcheck(lambda x: torch.sparse.sum(x, [0]).to_dense(masked_grad=True), masked=True)
```
Fixes https://github.com/pytorch/pytorch/issues/95550
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96095
Approved by: https://github.com/cpuhrsch
I experimented with 200 `nn.Linear`s with `bias=True` for a total of 400 `nn.Parameter`s all wrapped into the same FSDP instance and world size of 2.
**`unshard()` -> `_use_unsharded_views()`**
- (From previous PR) unsafe `setattr`: 6.112 ms -> 4.268 ms
**`pre_unshard()` -> `_writeback_orig_params()`**
- Factor out `flat_param` and `flat_param_grad` data pointers: ~1.8 ms -> 1.071 ms
- Now dominated by calling `_typed_storage()` on each original parameter and its gradient
**`reshard()` -> `_use_sharded_views()`**
- Factor out `torch.empty(0, ...)`: ~4.6 - 4.7 ms -> ~2.7 - 2.8 ms
- Now dominated by `aten::slice()` and (unsafe) `setattr`, which are required
I removed some `assert` calls that were only needed for mypy or if the subsequent call would provide the same error message anyway. These have negligible overhead, but I think it is still okay to remove them and avoid the type check. We need to address type checking more holistically anyway.
---
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96958
Approved by: https://github.com/rohan-varma
Summary: This Diff fixes some DeviceMesh issues, which blocks internal DTensor integration. Specifically, when `self.mesh = [2, 3]` while `world_size = 4`, because `unique_mesh_values[-1] == 3`, it takes the first short-cut branch and uses `default_pg`. Let's check the length instead of the last value of `unique_mesh_values`.
Test Plan: CI
Reviewed By: wanchaol
Differential Revision: D44079872
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96861
Approved by: https://github.com/wanchaol
Also updating merge_rule to allow ONNX exporter team to update the Docker script by themselves. By default, the model is cached at ~/.cache/huggingface/hub/ under CI jenkins user.
The model is cached so that we don't need to re-download it every time in CI, which causes flaky [CI failures](https://hud.pytorch.org/failure/FAILED%20test%2Fonnx%2Ftest_fx_to_onnx_with_onnxruntime.py%3A%3ATestFxToOnnxWithOnnxRuntime%3A%3Atest_large_scale_exporter_with_tiny_gpt2%20-%20requests.exceptions.ReadTimeout%3A%20HTTPSConnectionPool(host%3D'huggingface.co'%2C%20port%3D443)%3A%20Read%20timed%20out.%20(read%20timeout%3D10.0)).
This is the second part after https://github.com/pytorch/pytorch/pull/96590
### Testing
Confirm that the model is cached in the Docker image before running the test:
```
jenkins@dd0db85dd34f:~/workspace$ ls -la ~/.cache/huggingface/hub/models--sshleifer--tiny-gpt2/*
/var/lib/jenkins/.cache/huggingface/hub/models--sshleifer--tiny-gpt2/blobs:
total 2460
drwxrwxr-x 2 jenkins jenkins 126 Mar 15 05:48 .
drwxrwxr-x 5 jenkins jenkins 48 Mar 15 05:48 ..
-rw-rw-r-- 1 jenkins jenkins 662 Mar 15 05:48 2c81a6c4c984e95a45338c64a7445c1f0f88077f
-rw-rw-r-- 1 jenkins jenkins 2514146 Mar 15 05:48 b706b24034032bdfe765ded5ab6403d201d295a995b790cb24c74becca5c04e6
/var/lib/jenkins/.cache/huggingface/hub/models--sshleifer--tiny-gpt2/refs:
total 4
drwxrwxr-x 2 jenkins jenkins 18 Mar 15 05:48 .
drwxrwxr-x 5 jenkins jenkins 48 Mar 15 05:48 ..
-rw-rw-r-- 1 jenkins jenkins 40 Mar 15 05:48 main
/var/lib/jenkins/.cache/huggingface/hub/models--sshleifer--tiny-gpt2/snapshots:
total 0
drwxrwxr-x 3 jenkins jenkins 54 Mar 15 05:48 .
drwxrwxr-x 5 jenkins jenkins 48 Mar 15 05:48 ..
drwxrwxr-x 2 jenkins jenkins 50 Mar 15 05:48 5f91d94bd9cd7190a9f3216ff93cd1dd95f2c7be
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96793
Approved by: https://github.com/titaiwangms, https://github.com/ZainRizvi
This PR addresses the issues opened in #25155. However, those specific tests are no longer used since after #37473 they were moved to test_torchbind.
This PR enable TestTorchbind on Windows.
test_custom_class.py is no longer used after that commit.
In the original issue, there were problems on Windows with those tests so I tested the updated ones to see if they work.
I had no issues with them so this enables them on Windows.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96507
Approved by: https://github.com/ezyang
# Motivate
Add XPU device type to CppFunction dispatch overload function.
We previously omitted it.
# Solution
Add XPU device type.
# Additional
This list is synchronized with the k-constants in c10/core/DeviceType.h
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96849
Approved by: https://github.com/ezyang
Enables the last few files under pytest.
xdist was causing problems with `profiler/test_profiler` `test_source_multithreaded` due to creating extra threads. Luckily we don't use it so we can disable it with `-p no:xdist`, but this is incompatible with pytest-rerunfailures==10.2, so upgrade to 10.3. I'd update the windows ami but idk how.
`dynamo/test_optimizers` and `dynamo/test_repros` both had tests that used skip_if_pytest. https://github.com/pytorch/pytorch/pull/93251/files suggests that it is due to pytest assertion rewriting, so I added `PYTEST_DONT_REWRITE` to their module docstrings to prevent pytest from rewriting assertions.
Disable test by issue in `dynamo/test_dynamic_shapes` seems sane.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96698
Approved by: https://github.com/huydhn, https://github.com/malfet
Adding an environment variable `TORCH_LINEAR_FLATTEN_3D` to force flattening of 3D input tensor even when it is non-contiguous.
Today, the `Linear` op would flatten a 3D input sensor if it is contiguous.
It was found that even for some non-contiguous inputs (esp. with BF16 data type), flattening would also yield higher performance.
For example:
```
x_size = (3072, 1196, 128)
x = torch.rand(x_size, device="cuda", dtype=torch.bfloat16)
x = torch.transpose(x, 1, 2)
torch._C._nn.linear(x, weight, bias)
```
Since the detailed auto-tuning is unknown, this PR adds an environment variable for users to make a choice.
(Default value is still 0.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96761
Approved by: https://github.com/ngimel
# Summary
This PR made some significant changes to the scripts around Release Scripts. At a high level:
- Turned the quips into docs and updated links
- Update the common.categorizes list in the hopes to make this the source of truth for releases- This is hard since the release_notes labels can be changed at will. An alternative would be to poll from github api. However, I think that is overkill. The notebook does a set compare and will show you knew categories. I think we want this to be manual so that the release note engineer will decided how to categorize.
- Create cateogry group from speaking with folks on distributed and AO that told me these different release categories can be merged.
- I am the newest person to Core and don't use ghstack soo made token getting a lil more generic.
- Added a classifier.py file. This file will train a commit categorizer for you, hopefully with decent accuracy. I was able to achieve 75% accuracy. I drop the highest frequency class - "skip" since this creates a more useful cateogrizer.
- I updated the categorize.py script so that the prompt will be what the classifier thinks, gated by a flag.
- Added a readme that will hopefully help future release notes engineers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94560
Approved by: https://github.com/albanD
**note about second try**
First try (https://github.com/pytorch/pytorch/pull/96780) was reverted because while it fixed periodic,
it broke inductor cpu-accuracy (which strangely didn't show up as failures on this PR). This try keeps the cpu-accuracy filter and also adds the inductor filter to get rid of periodic jobs.
**the actual PR desc**
It's going to be harder to properly support check_graph_breaks across multiple baselines.
Periodic and Inductor workflows are different baselines since they include different sets of models.
It's not as simple as checking in the csv for the superset (periodic), becuase update_expected.py is designed to run given the sha of your failing PR and reset the baseline to that PR's artifacts. This is a nice workflow, and would be harder to manage if it had to always point to a periodic job.
For now just do the check on the inductor job and ignore the other models covered only on periodic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96803
Approved by: https://github.com/desertfire
Fix https://github.com/pytorch/pytorch/issues/96042
### before
```
>>> torch.aminmax(torch.tensor(1, device='cpu'), dim=0, keepdim=True)
__main__:1: UserWarning: An output with one or more elements was resized since it had shape [], which does not match the required output shape [1]. This behavior is deprecated, and in a future PyTorch release outputs will not be resized unless they have zero elements. You can explicitly reuse an out tensor t by resizing it, inplace, to zero elements with t.resize_(0). (Triggered internally at ../aten/src/ATen/native/Resize.cpp:24.)
torch.return_types.aminmax(
min=tensor([1]),
max=tensor([1]))
>>> torch.aminmax(torch.tensor(1, device='cpu'), dim=0, keepdim=False)
torch.return_types.aminmax(
min=tensor(1),
max=tensor(1))
```
### after
```
>>> torch.aminmax(torch.tensor(1, device='cpu'), dim=0, keepdim=True)
torch.return_types.aminmax(
min=tensor(1),
max=tensor(1))
>>> torch.aminmax(torch.tensor(1, device='cpu'), dim=0, keepdim=False)
torch.return_types.aminmax(
min=tensor(1),
max=tensor(1))
```
Marked the following test as expected_fail:
`test_vmap.py TestVmapOperatorsOpInfoCPU.test_op_has_batch_rule_aminmax_cpu_float32`
Given input shape of (2), the loop out is shape (2), the batched vmap out is (2, 1), which mismatched.
The loop out will calculate twice on a tensor shape of ( ): without this patch, the output is (1), and then stacked into (2, 1); with this patch, the output is ( ), then stacked into (2).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96171
Approved by: https://github.com/jgong5, https://github.com/ngimel, https://github.com/zou3519
Summary: Adding exception handler to a few more APIs so that internal errors are logged to the c10d errors scuba table
Test Plan: sandcastle
Differential Revision: D44068557
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96770
Approved by: https://github.com/wz337
Fixes#96429
This PR is also a follow up for #90427. In that PR, we also discussed whether calculations of grid indices `grid_sampler_compute_source_index` should also be upcasted to `opmath_t` https://github.com/pytorch/pytorch/pull/90427/files#r1048876708. Due to another unit test failure, we didn't upcast those calculations in that PR.
After some investigations, I found that the inaccurate results have nothing to do with the internals of `affine_grid`, even if it's calculated using `double` internally. As long as input `grid` is passed to `grid_sample` in **half** precision, the results will be less inaccurate than a **float** `grid`. This can be verified with a short C++ program like this (by setting `TYPE_T` to `__half` and `float` in compilations)
```cpp
#include <cuda.h>
#include <cuda_runtime.h>
#include <cuda_fp16.h>
#include <iostream>
#ifndef TYPE_T
#define TYPE_T float
#endif
int main() {
using type_t = TYPE_T;
type_t d = static_cast<__half>((double)2.0 / 3.0);
type_t s = (((float)d + 1.f) * 3 - 1) / 2;
printf("%.15f %.15f\n", (double)d, (double)s);
}
```
Outputs are
```
./float.out
0.666503906250000 1.999755859375000
./half.out
0.666503906250000 2.000000000000000
```
To resolve the discussion back in https://github.com/pytorch/pytorch/pull/90427/files#r1048876708, I've also increased the test tolerance in the failed unit test `issue_24823_1(torch.half)`.
For the original script in #96429, I got more accurate results with `align_corners = True`
```
align_corners = True
Expected result has mean absolute value of 0.5285 and maximum absolute value of 3.2067.
Half precision result is off by 0.0001 (0.02%) on average and 0.0010 (0.03%) at maximum.
align_corners = False
Expected result has mean absolute value of 0.5189 and maximum absolute value of 3.0101.
Half precision result is off by 0.0001 (0.02%) on average and 0.0010 (0.03%) at maximum.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96586
Approved by: https://github.com/ngimel
Fix for https://github.com/pytorch/pytorch/issues/95693.
From https://pytorch.org/tutorials/intermediate/memory_format_tutorial.html:
> There are minor difference between the two APIs to and contiguous. We suggest to stick with to when explicitly converting memory format of tensor.
For general cases the two APIs behave the same. However in special cases for a 4D tensor with size NCHW when either: C==1 or H==1 && W==1, only to would generate a proper stride to represent channels last memory format.
We hit this case in convolution_backward in calling `contiguous()`. Even though we were determining that we should run the backward in channels_last forward, as FakeTensor had gathered from the output of [determine_backend_memory_format](https://github.com/pytorch/pytorch/blob/master/torch/_subclasses/fake_tensor.py#L559), we were still outputting a contiguous tensor. That led to the mismatch in strides in the issue.
Should we be calling `to` instead of `contiguous` more liberally throughout the codebase, especially in convolution related code ? Not sure if there are reasons not to do this.
Another fix would be to update `cudnn_conv_suggest_memory_format` so that it would output a contiguous_format in this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96791
Approved by: https://github.com/ngimel
When constructing the joint graph, we normally have to clone any inputs that are mutated, so that we can pass in the original, pre-mutation inputs as leaves to autograd.
Previously, we were doing this for all mutated inputs - but we only need to do it for inputs that require gradients and participate in autograd.
Hopefully this should speed up code like batch norm - I think before this we were unnecessarily cloning the running stats during training.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96342
Approved by: https://github.com/albanD, https://github.com/ezyang
This refactor should make it easier to add an export hook into aot autograd.
(1) I killed `create_forward_or_joint_functionalized()` (and the functions that it called, like `forward_or_joint()`) which used to handle autograd + functionalization all-in-one-go for the joint case, and was also used in the inference case.
I added a few separate helper functions:
`create_functionalized_graph()`: this takes a flat fn, and returns a functionalized fx graph. It is mostly just a thin wrapper around functionalization + make_fx(), but also has some extra logic to manually append `copy_()` ops to the end of the graph.
`fn_no_extra_mutations()`: this creates the fn that we want to trace in the inference code path. It takes in a function that it then calls, and returns the outputs + any (updated) mutated inputs.
`joint_fn_no_external_mutations()`: this creates the fn that we want to trace in the joint code path. It takes in a function, and traces out its joint. It also does the work of cloning inputs that are mutated and require gradients, returning mutated inputs as outputs, and returning intermediate bases as outputs
We should be able to add an export hook by basically adding a similar version of `joint_fn_no_external_mutations` but with a lot more restrictions (guaranteed to have no tangents, not synthetic bases, etc), and calling `create_functionalized_graph()` on it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96341
Approved by: https://github.com/ezyang
Another bonus of factoring the synthetic_base logic into one place: we used to have a `CompiledRuntimeMetadata` object that encapsulated `ViewAndMutationMeta`, plus a bunch of extra synthetic base metadata that was plumbed around. Now I can kill that first metadata object, and use `ViewAndMutationMeta` on its own everywhere.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96340
Approved by: https://github.com/ezyang
Ed pointed it out a few days ago - I probably added this mistakenly a few months ago. I can't think of any reason it's necessary, and removing it doesn't cause any tests to fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96339
Approved by: https://github.com/ezyang
This refactor doesn't significantly change LoC in aot autograd, but I think this nets out to making it clearer (interested in peoples' thoughts).
The idea is that I tried to re-write the part of aot autograd that deals with synthetic bases in a layered way, similar to how Ed wrote the logic for dedup'ing inputs: it happens in one place, and all of the downstream transformation in aot autograd don't have to worry about it.
Specifically, I added a new function `aot_wrapper_synthetic_base`, similar to the existing `aot_wrapper_dedupe`.
The benefit: none of the other code in aot autograd needs to think about synthetic bases (previously, synthetic base code was intertwined in several places).
The downsides: there are two.
(1) `aot_wrapper_synthetic_base()` needs to have its own epilogue. There is one particularly hairy case, where factoring the synthetic base logic to a single location was painful: If you have two inputs that alias each other, where one gets a data mutation, and the other gets a metadata mutation.
Ordinarily, metadata mutations are handled by the runtime epilogue, in `create_runtime_wrapper`. However, now that things are factored this way, the runtime wrapper operates only on synthetic bases instead of operating on the original inputs. For data mutations, it is fine to apply the data mutation to the synthetic base instead of the original input alias. But for metadata mutations, we **need** to apply the metadata mutation directly to the original inputs.
The way that I handled this was by tracking which inputs slot into this specific case (part of a synthetic base, and get metadata mutations), and updateing the flat_fn() that we pass downstream to return these updated inputs as extra outputs. From the perspective of downstream logic, these are real user outputs, that it can treat like any other user outputs. `aot_wrapper_synthetic_base` will know to grab these extra outputs and use them to apply the metadata mutations.
This was pretty annoying, but has the benefit that all of that logic is encapsulated entirely in `aot_wrapper_synthetic_base()`.
(2) input mutations are now performed on the synthetic base instead of the individual aliases.
You can see the original code comment [here](b0b5f3c6c6/torch/_functorch/aot_autograd.py (L1131)) for details. We used to do the optimized thing in this case, and now we do the less optimized thing (copying the entire synthetic base, instead of the potentially smaller alias).
To be fair, we had no data showing that this optimization was showing improvements on any models in practice. I also think that the main reason anyone would ever run across this problem is because of a graph break - so if you care about perf, you probably want to avoid the extra graph breaks to begin with. I haven't added any warnings for this, but we probably could depending on what people think.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96235
Approved by: https://github.com/ezyang
For a while now, we've been re-running our functionalization analysis pass twice - once for get metadata when dedup'ing, and an entire second time during aot_dispatch_base/autograd.
This should also probably speed up compile times pretty noticeably, since we're going from:
(a) inference-only trace case: 3 fw traces -> 2 fw traces
(b) autograd trace case: 2 fw traces + 1 joint trace -> 1 fw trace + 1 joint trace
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95992
Approved by: https://github.com/ezyang
Number of OSS PR were reverted, because new signed-unsigned comparison warnings, which are treated as errors in some internal builds.
Not sure how those selective rules are applied, but this PR removes `-Wno-sign-compare` from PyTorch codebase.
The only tricky part in this PR, as making sure that non-ASCII character detection works for both signed and unsigned chars here:
6e3d51b08a/torch/csrc/jit/serialization/python_print.cpp (L926)
Exclude several files from sign-compare if flash attention is used, due to the violation in cutlass, to be fixed by https://github.com/NVIDIA/cutlass/pull/869
Do not try to fix sign compare violations in caffe2 codebase
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96723
Approved by: https://github.com/albanD
Signed-off-by: Boris Fomitchev <bfomitchev@nvidia.com>
Fixes#91351
As for unit tests - in this PR I only fixed LSTM unit test to properly use dynamic axes and expose export issue by running test with same ONNX for additional inputs.
If the changes approved, we should also fix the rest of the tests (RNN/GRU and beyond).
I have verified the following updated tests are working with new code and failing with the old code:
test/onnx/test_pytorch_onnx_onnxruntime.py::TestONNXRuntime_opset_version_14_is_script_False_keep_initializers_as_inputs_True::test_rnn_name_lstm_nonlinearity_None_unilayer_bidirectional_no_initial_state_with_variable_length_sequences_with_dropout
test/onnx/test_pytorch_onnx_onnxruntime.py::TestONNXRuntime_opset_version_14_is_script_False_keep_initializers_as_inputs_True::test_rnn_name_lstm_nonlinearity_None_unilayer_bidirectional_with_initial_state_with_variable_length_sequences_with_dropout
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92970
Approved by: https://github.com/titaiwangms, https://github.com/kit1980
Chatted with @stas00 on slack and here are some great improvements he suggested to the compile docs
- [x] Rename `dynamo` folder to `compile`
- [x] Link `compile` docstring on `torch.html` to main index page for compile
- [x] Create a new index page that describes why people should care
- [x] easy perf, memory reduction, 1 line
- [x] Short benchmark table
- [x] How to guide
- [x] TOC that links to the more technical pages folks have written, make the existing docs we have a Technical overview
- [x] Highlight the new APIs for `torch._inductor.list_options()` and `torch._inductor.list_mode_options()` - clarify these are inductor specific and add more prose around which ones are most interesting
He also highlighted an interesting way to think about who is reading this doc we have
- [x] End users, that just want things to run fast
- [x] Library maintainers wrapping torch.compile which would care for example about understanding when in their code they should compile a model, which backends are supported
- [x] Debuggers who needs are somewhat addressed by the troubleshooting guide and faq but those could be dramatically reworked to say what we expect to break
And in a seperate PR I'll work on the below with @SherlockNoMad
- [ ] Authors of new backends that care about how to plug into dynamo or inductor layer so need to explain some more internals like
- [ ] IR
- [ ] Where to plugin, dynamo? inductor? triton?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96706
Approved by: https://github.com/svekars
Previously the allocator would query whether a stream was recording a graph,
and look up the pool associated with a graph. This change has the allocator
directly associate a stream with a mempool, decoupling "record this stream to a pool"
from the action of "record all actions to a cuda graph".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96542
Approved by: https://github.com/eellison
It's going to be harder to properly support check_graph_breaks
across multiple baselines.
Periodic and Inductor workflows are different baselines since they include
different sets of models.
It's not as simple as checking in the csv for the superset (periodic),
becuase `update_expected.py` is designed to run given the sha of your
failing PR and reset the baseline to that PR's artifacts. This is a
nice workflow, and would be harder to manage if it had to always point to
a periodic job.
For now just do the check on the inductor job and ignore the other models
covered only on periodic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96780
Approved by: https://github.com/malfet, https://github.com/huydhn
Summary: LLVM trunk / llvm-16 removes the `PassManagerBuilder.h` file. But we are using the new pass manager for llvm>=15 anyway.
Test Plan: sandcastle
Differential Revision: D44064301
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96762
Approved by: https://github.com/bertmaher
This fixes
```
File "/data/users/ezyang/a/pytorch/torch/_inductor/codegen/triton.py", line 1642, in codegen_node_schedule
indexing_dtype_strength_reduction(node._body)
File "/data/users/ezyang/a/pytorch/torch/_inductor/optimize_indexing.py", line 310, in indexing_dtype_strength_reduction
OptimizeIndexing(loop_body, indices, indexing).run()
File "/data/users/ezyang/a/pytorch/torch/_inductor/optimize_indexing.py", line 96, in __init__
self.replace_indirect(k, ValueRanges(0, v))
File "/data/users/ezyang/a/pytorch/torch/utils/_sympy/value_ranges.py", line 67, in __init__
upper = simple_sympify(upper)
File "/data/users/ezyang/a/pytorch/torch/utils/_sympy/value_ranges.py", line 33, in simple_sympify
assert not e.free_symbols, f"free variables NYI: {e}"
AssertionError: free variables NYI: s0
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96771
Approved by: https://github.com/eellison
Merges startswith, endswith calls to into a single call that feeds in a tuple. Not only are these calls more readable, but it will be more efficient as it iterates through each string only once.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96754
Approved by: https://github.com/ezyang
Fixes #ISSUE_NUMBER
1、add amp support for custom backend
2、optimize the file `backend_registration.py`, and rename it with `custom_backend_registration.py`. And then we would register other funcs for custom backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96188
Approved by: https://github.com/bdhirsh
Changes:
- bc-breaking change: The main difference between this and the old non-reentrant impl that it replaces is that we clear recomputed tensors on backward immediately upon unpack, even if retain_graph=True. This has the following additional implications:
- Accessing _saved_tensors multiple times will silently recompute forward multiple times.
- Accessing ctx.saved_tensor twice in the same backward will now raise an error.
- To avoid dealing with the potential consequences, early stopping has been hidden behind a global flag that is by default False, and can be enabled via a context manager. We can remove this in a follow up. Some features of nesting as a result do not work by default.
Before land:
- import to check for more bc-breakingness
- implement any workarounds for the bc-breaking-ness, if we decide on any
- update docs to reflect new lifetime of recomputed variables
- update docs to mention the early stop feature
Follow ups:
- enable early-stopping by default
- update docs/tutorial to feature nested use cases
Related docs:
- code comment: https://github.com/pytorch/pytorch/pull/90105/files#diff-9dcd955620b52ce128e18e3567be88edbb238810460d1288a86fabc20e483b30R448
- design doc: https://docs.google.com/document/d/1UDLhTNv6_kvuDTRlsjfj9WdqtNaQNr8ahrvdBIB6914/edit#
- retains_grad <> checkpiont https://docs.google.com/document/d/1maiGmuFUxysQL0AdYUU88kngAaXh_L0XpDcLDh_5Ors/edit
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90105
Approved by: https://github.com/albanD
To achieve this, I have a per-StorageImpl (was data_ptr in the previous version of this PR, but moved to StorageImpl to ensure stability of the key before/after sharing) lock created when we are about to share a storage and make sure that all other calls to share memory wait on this lock before moving forward.
This does NOT make this call generally thread safe as any call that is not sharing memory will race and lead to UB.
This makes ensures that the sample from @robertolat in https://github.com/pytorch/pytorch/issues/95606 works fine.
This does NOT fix the example from @imurray in that same issue as the call still race with the `.sum()` call. This race is expected and there is no easy way for us to make it work I'm afraid (see issue for more details).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96664
Approved by: https://github.com/colesbury
This PR does a few things all at once, as I needed to fix several bugs on the way here. The main goal of the PR is to fix the `'float' object has no attribute '_has_symbolic_sizes_strides'` error. The general idea is to heavily penalize non-SymInt but still SymNode cuts in the graph. This doesn't work for default partitioner, so essentially, dynamic shapes with default partitioner is not supported.
While doing this, I had a fix a few other bugs in the partitioner:
* SymNode operations weren't considered recomputable. But they are very cheap, go wild.
* zeros_like wasn't considered recomputable, and this prevented some gradient formulas (e.g., for angle with real inputs) from successfully finding a cut at all
* AOTAutograd tests use the default partitioner. I switch them to use min-cut partitioner...
* ...but this reveals a bug where if we have nodes in backward outputs that don't depend on tangents, they never get assigned to the backward graph. I fix this by making the backward outputs mandatory to be in backwards. I have to be careful to filter out None backward outputs; those never participate in flow analysis!
This causes some wobbling for the min-cut tests, but these seem legitimate: since we're now willing to recompute, the partitioner can reduce the number of SymInts it transmits by just doing some recompute in the backend.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96653
Approved by: https://github.com/ngimel
This refactors the stack trace facility specific to memory profiling
in python+cuda to make a generic facility to generate combined stack
traces.
The generic facility (combined_traceback.h) does not require
python to be around to work, but will return python stacks if it is
present.
This facility is then used to add support for stack trace gathering in memory profiling that
happens directly from C++.
It is also used to expose a python API for gathering and symbolizing
combineds stacks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95541
Approved by: https://github.com/ezyang
`_use_sharded_grad_views()` can be called when re-registering the original parameters in `load_state_dict()`, in which case the training state is `IDLE`. Previously, I only expected `_use_sharded_grad_views()` to be called in `FORWARD` when the sharded gradient is not in `_saved_grad_shard` or `_cpu_grad`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96584
Approved by: https://github.com/fegin, https://github.com/zhaojuanmao
Summary:
The reference quantized LSTM implementation uses unbind and inplace squeeze both of which are not supported when building BoltNN's Espresso IR graph.
This change adjusts the reference AO Quantizable LSTM implementation without affecting numerically while enabling removal of unsupported ops in BoltNN.
Modifications & Adjustments
1. Unbind ops appear when unstacking tensor in loop. Replaced this by getting first dim from shape and looping using ranged index.
2. Removed unbind ops call where the pattern is
`[x = t.unbind(0) -> x[i]]` can be just replaced by `t[i]` as creating a tuple from unbind is unnecessary.
3. inplace squeeze `squeeze_` uses which were not required has been replaced by `squeeze`.
See notebook N3235193 which was used for testing quantization flow and inspect the torch scripted quantized model for the set of ops used(See last cell).
Test Plan: N3235193
Reviewed By: andrewor14
Differential Revision: D43935389
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96436
Approved by: https://github.com/andrewor14
Adding the PR discussed in #96295.
- Adds tests for all current padding layers to `module_db` in `torch/testing/_internal/common_modules.py` ( `nn.ReflectionPad`, `nn.ReplicationPad`, `nn.ZeroPad`, `nn.ConstantPad` ) for 1D, 2D, and 3D variants.
- Removes tests for the same padding layers from `torch/testing/_internal/common_nn.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96641
Approved by: https://github.com/albanD
TODO (cc @soumith @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire @ZainRizvi) hopefully i can convert the rocks query i'm using to a public API and delete the rocs api usage (and need for apikey) from this before landing. If that's not easy or if i need to make a new query first, maybe i should land this as-is and at least people can use it if they get an apikey. Also, any bad practices in how i parsed/mangled the filenames? Would be nice to make the naming of artifacts more consistent with the job names so less mangling is needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96480
Approved by: https://github.com/ZainRizvi
Fix https://github.com/pytorch/pytorch/issues/96446
The root cause is that the logical comparison op works on the integer vector which is later used in the `where` op that expects a float vector.
1. Make sure float vec mask is applied on logical comparison ops.
2. Fix vec int specialization for `to_float_mask`. Assume int mask as input and returns the float mask with reinterpret cast.
3. Add a no-op specialization for `to_float_mask` function with the float vec as input.
4. Pass value instead of ref to `to_float_mask`. Passing by value should be efficient enough.
5. Remove a conditional check `!=0` in `masked()` since `to_float_mask` is guaranteed to return a float mask.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96502
Approved by: https://github.com/EikanWang, https://github.com/XiaobingSuper, https://github.com/jansel
Summary: Enable the functionality of delaying all reduce in DDP to specify the parameters whose all reduce will be hooked to a specific param. This prevents AllReduce blocking All2All in some recommendation models.
Test Plan: GitHub CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96673
Approved by: https://github.com/zhaojuanmao
Fixes part of #96414
Replaces any calls to sizes, with sym_sizes. Still seeing an error with the repro script:
``` Bash
Exception raised from sizes_default at /scratch/drisspg/work/pytorch/c10/core/TensorImpl.h:635 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) + 0x7d (0x7f697f4a141d in /scratch/drisspg/work/pytorch/torch/lib/libc10.so)
frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, char const*) + 0xdd (0x7f697f49fbcd in /scratch/drisspg/work/pytorch/torch/lib/libc10.so)
frame #2: c10::TensorImpl::sizes_custom() const + 0x95 (0x7f697f4824c5 in /scratch/drisspg/work/pytorch/torch/lib/libc10.so)
frame #3: at::native::empty_like(at::Tensor const&, c10::optional<c10::ScalarType>, c10::optional<c10::Layout>, c10::optional<c10::Device>, c10::optional<bool>, c10::optional<c10::MemoryFormat>) + 0x92c (0x7f69809d18ac in /scratch/drisspg/work/pytorch/torch/lib/libtorch_cpu.so)
frame #4: <unknown function> + 0x23f5ce7 (0x7f698193bce7 in /scratch/drisspg/work/pytorch/torch/lib/libtorch_cpu.so)
```
still trying to track down this empty call
from the looks of it, might be coming from at::layer_norm?
the BT from lldb is 221 frames however, so lots of noise
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96674
Approved by: https://github.com/ezyang
- add graph-breaks baselines
- add check_graph_breaks script (message users on regress or improvement)
- hook up test.sh for existing accuracy job
Refactor graph-break CI check
Take steps toward merging checker with existing check flow,
consider merging it all the way inside the bench runner.
csvs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96346
Approved by: https://github.com/ezyang
Fixes internal linking problem after `DECLARE_DISPATCH` was introduced in SparseTensorUtils.cpp, but implemented inside the native library.
Also, fix `sign-unsigned` compare in `_flatten_indices_impl`
Followups:
Move code declared/implemented in `SparseTensorUtils.*` to `at::native` namespace
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96696
Approved by: https://github.com/albanD
When we checkpoint the state of the private pool allocator, we will need to make sure that its current live allocated blocks will get properly cleaned up when the tensors they correspond to die. Return DataPtrs for these new allocated blocks that the callee can swap onto live Tensors.
The exact api for setting the checkpoint can be manipulated after this as the cudagraph implementation is built out, but this at least shows its sufficiently general.
This should be the last PR touching cuda caching allocator necessary for new cudagraphs integration.
Differential Revision: [D43999888](https://our.internmc.facebook.com/intern/diff/D43999888)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95020
Approved by: https://github.com/zdevito
Copying note from cuda caching allocator:
```
* Note [Checkpointing PrivatePoolState]
*
* Refer above to Note [Interaction with CUDA graph capture]. Allocations made
* during graph capture are made from a separate private pool. During graph
* capture allocations behave as usual. During graph replay the allocator
* state does not change even as new tensors are created. The private pool
* will not free its blocks to the main caching allocator until cuda graph use
* is finished to prevent an allocation from eager clobbering the memory from
* a live but unaccounted for tensor that was created during replay.
*
* `make_graphed_callables`, a series of separate callables chained in
* successive cuda graphs, can share a memory pool because after a cuda graph
* recording the allocations in the shared private pool exactly reflect the
* tensors that are allocated.
*
* We would like to extend callable chaining to support a graphed callable
* tree. In this scenario, we have a tree of callable chains which will be
* captured with cuda graphs. In the diagram below, we have a tree with four
* callables, A, B, C, and D. Suppose we have captured, and subsequently
* replayed, A, B, and C. Then on a new invocation, we replay A and B, but
* would now like to record D. At this point the private pool will not reflect
* any of the live tensors created during graph replay. Allocations made
* during a new recording with the pool could overwrite those live tensors.
*
* In order to record a new graph capture after replaying prior callables in
* the tree, we need the allocator to reflect the state of the live tensors.
* We checkpoint the state of the private after each recording, and then
* reapply it when we are starting a new recording chain. Additionally, we
* must free the allocations for any tensors that died between the end of our
* previous graph replaying and our new recording (TODO). All of the allocated
* segments that existed in the checkpointed state must still exist in the
* pool. There may also exist new segments, which we will free (TODO : link
* note [live tensors between iterations] when it exists).
*
*
* ---------------> A ---------------> B ---------------> C
* |
* |
* |
* |
* ---------------> D
```
A few TODOs:
- need to add logic for freeing tensors that have died between a last replay and current new recording
- Add logic for free that might be called on a pointer multiple times (because we are manually freeing live tensors)
The two scenarios above have not been exercised in the tests yet.
Differential Revision: [D43999889](https://our.internmc.facebook.com/intern/diff/D43999889)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94653
Approved by: https://github.com/zdevito
Current dashboard issue is due to a .pt file in torchbench that has beeen modified for some reason. This clears any local changes before pulling.
Tested in a duplicate dashboard environment with the same .pt file modified:
* Before the change to this makefile, `make pull-deps` fails
* After the change to this makefile, `make pull-deps` succeeds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96667
Approved by: https://github.com/anijain2305
Summary:
We don't want to load when loading model on Core ML and `at::empty` is considered an op.
So replace it with from_blob.
Test Plan:
Run Core ML backend to ensure it works for existing use cases.
Also test running Core ML backend without any ops.
Differential Revision: D43961679
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96564
Approved by: https://github.com/f-meloni, https://github.com/kimishpatel
This PR enables our non-meta contributors to be able to approve
"functorch" PRs without intervention from meta contributors.
A PR is deemed a "functorch" PR if it matches one of the patterns in
merge_rules.yaml. These patterns are definitely not exhaustive
(we modify core pytorch pieces quite often), but should be a good starting
point.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96657
Approved by: https://github.com/albanD
Minor correction. `HingeEmbeddingLoss`'s documentation had this piecewise function; but there is no $\Delta$ in the function definition, it was used to denote `margin`.
$$l_n = \begin{cases}
x_n, & \text{if}\; y_n = 1,\\
\max \{0, \Delta - x_n\}, & \text{if}\; y_n = -1,
\end{cases}$$
Following other documentation guidelines, `HuberLoss` has a parameter `delta`, and its piecewise function is defined as follows; using $delta$ as a reference to the `delta` parameter and not $\Delta$.
$$l_n = \begin{cases}
0.5 (x_n - y_n)^2, & \text{if } |x_n - y_n| < delta \\
delta * (|x_n - y_n| - 0.5 * delta), & \text{otherwise }
\end{cases}$$
So by analogy, `HingeEmbeddingLoss` should also be the same, thus, the right piecewise function for it should be like the following instead.
$$l_n = \begin{cases}
x_n, & \text{if}\; y_n = 1,\\
\max \{0, margin- x_n\}, & \text{if}\; y_n = -1,
\end{cases}$$
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95140
Approved by: https://github.com/albanD
Implements native mixed precision support for DDP in a similar fashion to how it is enabled for FSDP. The implementation works as follows:
1. In DDP init, we save `_mp_param` and `_fp_param` variables to manage mixed precision parameter usage. In particular, _mp_param will represent the parameter in the reduced precision, while _fp_param will represent the param in regular precision. During forward/backward, we swap back and forth as needed.
2. The root module gets a root pre-forward hook that kicks off copies to the reduced precision for all submodules. An event is recorded for each submodule to allow for waiting, as we run these asynchronously.
3. Each module gets a pre-forward hook that waits on its corresponding event. note that modules might be reused during training, in this case the wait is only done for the first module. After this wait, the module's parameters are in reduced precision.
4. In the pre-forward hook, we register a backward hook on the lower precision parameters in order to run reduced precision allreduce + parameter upcast. We can't rely on the Reducer's constructor setting up these hooks because the gradient is accumulated on the low precision param, so we need to register them ourselves.
5. In the backward pass, when the hook runs, we first run allreduce + divide in the reduced precision. Next, we upcast parameters and gradients back to fp32 asynchronously. We also queue a callback at the end of backward to wait on these upcasts so that the upcast is complete before optim.step() runs.
6. Parameters that don't require grad are also cast since they may be used in computation, they are upcast back in the final autograd callback.
7. DDP Ignored parameters are not touched.
Follow-ups:
1. Unify comm hooks and make it work with apply optimizer in backward
2. implement keep_low_precision_grads,
3. allow BN, LN, or custom units to run in reduced precision,
4. support for cast_forward_inputs
5. Unify certain APIs / helpers with FSDP where possible, such as for _cast_forward_inputs
6. Integrate this with replicate() API.
7. The order in which we kick off copies and wait for them is set by the iteration order of module.modules(), but this might not be how the modules are used in the actual training. In the worst case, the last module in module.modules() could be used first which would result in waiting for all copies unnecessarily. For static graphs, we should record the module execution order and copy / wait in this order.
8. Entirely unused modules probably don't need to be cast.
Differential Revision: [D42515803](https://our.internmc.facebook.com/intern/diff/D42515803/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92882
Approved by: https://github.com/zhaojuanmao
__What?__
Per discussion at #94634, deprecate `masked_fill` with non-bool masks. Deprecation warnings were previously added by #22261, but not for Apple MPS. I can revert the MPS changes if deprecation warnings are wanted first tho. See also #96112.
Fixes#85063 and #89320.
__Further Development?__
- Fixed the mask dtype checking for the cuda dispatch for `masked_fill` in `aten/src/ATen/native/cuda/Indexing.cu`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96594
Approved by: https://github.com/malfet, https://github.com/ngimel
Adds the ability to quickly generate stack traces for C++,
and combine Python, TorchScript, and C++ frames into a single trace.
This makes it possible for the memory tracer to record allocations inside
C++ code (e.g. convolution temporaries, backward operators).
The unwinder code is ~10x faster than execinfo.h's backward because it
cache fast unwinder routines for instruction pointers that have already been seen.
It is also only 1.2--2x slower than copying the entire stack (the approach perf takes),
while using 2 orders of magnitude less space per stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95357
Approved by: https://github.com/bertmaher
`inspect.getfullargspec` does not properly handle functions/methods wrapped by functools.wraps(). As a result, it gets an empty list of `args` in FullArgSpec.
This PR rewrites the logic using `inspect.signature`, which handles functools.wraps() correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96557
Approved by: https://github.com/jansel
There are two assertions in `torch.jit.annotations.try_ann_to_type` that could benefit from adding source level location information.
For example, the current assertion:
```
msg = "Unsupported annotation {} could not be resolved because {} could not be resolved."
assert valid_type, msg.format(repr(ann), repr(contained))
```
reports:
```
AssertionError: Unsupported annotation typing.Union[typing.Dict, NoneType] could not be resolved because typing.Dict could not be resolved at
```
I find it beneficial to know from which line of code this assertion was triggered. Adding the location information then reports:
```
AssertionError: Unsupported annotation typing.Union[typing.Dict, NoneType] could not be resolved because typing.Dict could not be resolved at
File "/home/schuetze/Documents/work/github/prediction_net/multimodal/models/heads/retina_head.py", line 189
def forward(self, fpn_features: t.Dict[str, torch.Tensor],
inputs: t.Dict[str, torch.Tensor],
gts: t.Optional[t.Dict] = None) -> t.Dict[str, t.Any]:
~~~~~~~~~~~~~~~~~~ <--- HERE
"""
"""
```
Adding these location information are related to #96420 but these changes in this PR can be made without any API changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96423
Approved by: https://github.com/davidberard98
Summary: if trace.upload_tar is set, it's a function, and it can't be pickled.
Test Plan:
Used on a Meta-internal workload; also, hacked up
test/inductor/test_smoke.py to set trace.upload_tar and ran with
TORCH_COMPILE_DEBUG=1
Reviewed By: mlazos
Differential Revision: D43915178
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96519
Approved by: https://github.com/ngimel, https://github.com/jansel
In #95305 the _exchange_device ops are getting dead-code-eliminated, so they don't get called. #95306 fixes this by using the output of the op, but it's still possible that JIT might reorder the op around other ops.
This PR marks _exchange_device as having side effects so that the ops won't get dead code eliminated or reordered, even if the return is not used.
Differential Revision: [D43966285](https://our.internmc.facebook.com/intern/diff/D43966285)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96364
Approved by: https://github.com/eellison
I notice from the Rockset data that there are only `float32` records, while there should be both dtypes there. It turns out that the benchmarks script generated by `runner.py` always removes the output directory by default, so there are only records from `float32` running later left.
For example, `rm -rf /var/lib/jenkins/workspace/test/test-reports` appeared twice in the CI log https://ossci-raw-job-status.s3.amazonaws.com/log/11840774308.
I'm adding a new flag `--keep-output-dir` to keep the output directory. This is off by default as I'm not sure how this script is used internally, people probably expect to see the output directory cleaned up everytime.
### Testing
Not really want to start the 10h jobs just to test this small flag, so I'm triple check the change to make sure that there is no bug
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96398
Approved by: https://github.com/weiwangmeta
Summary: Rather than starting the timeline at t=0, keep the actual timestamps of the memory events.
Test Plan: CI Tests
Reviewed By: leitian, chaekit
Differential Revision: D43807624
Pulled By: aaronenyeshi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96535
Approved by: https://github.com/davidberard98
They are already present in trunk.yml
during migration from 11.6->11.7 to 11.7->11.8, 11.6 trunk jobs were migrated to 11.7, but 11.7 periodic jobs were not migrated, but 11.8 were simply added
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96552
Approved by: https://github.com/huydhn
Planning to do a full writeup later. The short story is, sometimes the following chain of events happens:
1. We turn on Dynamo's custom frame handler
2. GC triggers (and all of the finalizers run under Dynamo)
3. GC hits a GeneratorExit frame
4. You end up in the custom frame handler with throw_flag == TRUE and PyErr_Occurred() != NULL
If this happens and we blindly call into other Python functions (like the Python callback), the executed Python code will immediately raise an exception (because there's already an ambient exception set.) This is very, very confusing. The fix is to defer to the regular handler when throw_flag is TRUE.
I triggered this locally with
```
PYTHONUNBUFFERED=1 pytest test/dynamo/test_dynamic_shapes.py -k 'Unspec and export and not dupes and not reorder' -v -x -s
```
But I also have some tests which trigger the problem synthetically.
Fixes https://github.com/pytorch/pytorch/issues/93781
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96488
Approved by: https://github.com/albanD
@ezyang This is a minor change.
I was using the doctests to check that my install wasn't broken via:
```bash
xdoctest -m torch --style=google --global-exec "from torch import nn\nimport torch.nn.functional as F\nimport torch" --options="+IGNORE_WHITESPACE"
```
And noticed that it stops in the middle to show this matplotlib figure. I added a condition so it only does the pyplot show if a DOCTEST_SHOW environment variable exists. With this fix the above command runs to completion and is an easy way for users to put torch through its paces given just a fresh install.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96522
Approved by: https://github.com/ezyang
Introduce `getMPSScalarType(const Tensor&)` that calls `getMPSScalarType(t.scalar_type())`
And replace `getMPSScalarType(t.scalar_type)` with `getMPSScalarType(t)` throughout the codebase
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96521
Approved by: https://github.com/seemethere
Enable pytest for a few unique files. pytest runs tests in a different order than unittest (but still a consistent ordering with respect to itself) and some tests change global state, causing other tests to fail.
`test_transpose_non_contiguous` in `test_torchinductor.py` gets impacted from some other test but I'm not sure which one, so my solution is to reset the metrics before the rest of the test is run.
`test_register_patterns` in `test_quantize_fx.py` adds extra keys to global variables, so remove them when the test is done via unittest's `addCleanUp` which also works on pytest.
pytest doesn't really have an equivalent for `load_tests` so change it to be like `test_jit` that imports all the classes. I also attempted to dynamically import them, but I failed.
`test_public_api_surface` in `test_fx.py` checks for a backwards compatibility classification. There is a different test in test_fx that results in `fuser_utils` being imported. pytest runs this test before `test_public_api_surface` while unittest runs it after, so pytest sees `fuser_utils` when crawling through the modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96397
Approved by: https://github.com/huydhn
Summary: Added the functionality to export the memory timeline plot as a list of times and sizes, which the post processing visualization can parse and plot.
Test Plan: CI Tests
Reviewed By: leitian, fengxizhou
Differential Revision: D43680760
Pulled By: aaronenyeshi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96137
Approved by: https://github.com/chaekit
Follow-up to #96245. alexnet, Background_Matting, vision_maskrcnn, and vgg16 all have the same problem; but on float32 they were also failing on the previous day so I missed this. Once the amp jobs became available I could see that these have the same issue (on both float32 and amp).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96324
Approved by: https://github.com/desertfire
Remove all references to land checks (rebase on viable strict in a different branch) since its no longer used. Adding ciflow/trunk on merge and/or rebasing the entire pr is preferred.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96401
Approved by: https://github.com/huydhn
Summary: The manually adding dependencies between _foreach_add_, _fused_adam_, and output can cause issues when lowering to Inductor. This API removes those dependencies.
Test Plan: CI
Differential Revision: D43916450
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96323
Approved by: https://github.com/kumpera
This patch is aimed to add support to XPU profiler which will co-work with Kineto. After this PR, kineto will follow these API to fit itself. Also, the development of interface in python is near done.
Signed-off-by: Huang, Xunsong <xunsong.huang@intel.com>
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94502
Approved by: https://github.com/ezyang
Part of #91395
Also modifies how `StorageImpl`s are stored in JIT static runtime's `MemoryPlanner`, which used to `std::move` `StorageImpl`s into a vector. But `StorageImpl` can no longer be moved. Instead, `MemoryPlanner` now contains a malloced buffer to which we add new `StorageImpl`s using placement new
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93342
Approved by: https://github.com/ezyang
Summary:
My team has been hitting a mysterious crash for a few months on a windows binary that uses Caffe2 inside a worker thread.
When this thread gets destroyed, there is an error at this line in context_gpu.h where the state of this operation gives CUDNN_STATUS_INTERNAL_ERROR instead of CUDNN_STATUS_SUCCESS.
When enabling cudnn debug logs (via the env variables nvidia specifies), I can see that the context is destroyed twice, even though this code only destroys it once, so something mysterious is causing a double free.
This seems very very similar to the issue/fix described here for pytorch:
https://github.com/pytorch/pytorch/issues/17658https://github.com/apache/tvm/pull/8267
And pytorch handles this in the same way, by just not calling cudnnDestroy
This seems to have become an issue with cuda11, but I tested cuda12 as well and found that the issue persists so this needs to be somehow fixed.
Test Plan:
CI
I checked that the specific windows binary I am using is able to create and drestroy caffe2-invoking threads without causing the application to crash.
buck run arvr/mode/win/cuda11/opt //arvr/projects/nimble/prod/tools/MonoHandTrackingVis
Differential Revision: D43538017
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95382
Approved by: https://github.com/malfet
`inspect.stack()` retrieves all stacktraces, and is not performant. `inspect.stack(0)`
speeds up the call greatly, but loses line snippet.
Rewrite with `traceback.extract_stack` which is better in both regards.
Speeds up `export` call in `test_gpt2_tiny` from ~30s to ~4s under profiling.
Before
```log
│...├─ 30.794 export_after_normalizing_args_and_kwargs <@beartype(torch.onnx._internal.fx.exporter.export_after_normalizing_args_and_kwargs) at 0x7f815cba0700>:1
│...│ └─ 30.794 export_after_normalizing_args_and_kwargs torch/onnx/_internal/fx/exporter.py:580
```
After
```log
│...├─ 4.427 export_after_normalizing_args_and_kwargs <@beartype(torch.onnx._internal.fx.exporter.export_after_normalizing_args_and_kwargs) at 0x7fd8281b3700>:1
│...│ └─ 4.427 export_after_normalizing_args_and_kwargs torch/onnx/_internal/fx/exporter.py:580
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96348
Approved by: https://github.com/titaiwangms, https://github.com/justinchuby
Summary: When parameters are flattening, multiple parameters share the same step. When unflattening the parameters, current implementation still make these parameters share the same step. When this is not wrong, some training infra get confused by sharing tensor storages. This PR fixes the issue.
Test Plan: CI
Reviewed By: awgu
Differential Revision: D43893592
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96313
Approved by: https://github.com/zhaojuanmao
Summary:
Makes the `nnqr.Linear` module respect the qmin/qmax attributes of weight observer. This is to unblock some customer teams who are depending on non-default values of these attributes.
Test plan:
```
python test/test_quantization.py -k TestReferenceQuantizedModule.test_linear_decomposed
```
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96232
Approved by: https://github.com/andrewor14
Fixes#95796
### Implementation
Adds python implementation for `nn.ZeroPad1d` and `nn.ZeroPad3d` in `torch/nn/modules/padding.py`.
Adds cpp implementation for `nn::ZeroPad1d` and `nn::ZeroPad3d` in the following 3 files, refactored with templates similarly to `nn::ConstantPad`'s implementation: <br>
- `torch/crsc/api/include/torch/nn/modules/padding.h`
- `torch/csrc/api/include/torch/nn/options/padding.h`
- `torch/csrc/api/src/nn/modules/padding.cpp`
Also added relevant definitions in `torch/nn/modules/__init__.py`.
### Testing
Adds the following tests:
- cpp tests of similar length and structure as `ConstantPad` and the existing `ZeroPad2d` impl in `test/cpp/api/modules.cpp`
- cpp API parity tests in `torch/testing/_internal/common_nn.py`
- module init tests in `test/test_module_init.py`
Also added relevant definitions in `test/cpp_api_parity/parity-tracker.md`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96295
Approved by: https://github.com/soulitzer
This PR introduces some modifications:
1. We find out some const function parameters that can be passed by reference and add the reference.
2. We find more opportunists of passing by value and change them accordingly.
3. Some use-after-move errors are fixed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95942
Approved by: https://github.com/Skylion007
I added two constants. First helps with avoiding rounding while we hit a certain threshold, and second, to control what blocks can be cached.
Allocations larger than `kMaxRoundThreshold` will not be rounded to the next power of two anymore. Generally it is expected that larger allocations happen less frequently, and this more or less matches what happens in `CudaCachingAllocator`.
Blocks larger than `kMaxCachedSize` will not be cached. This is a separate problem than the above but I noticed this caching is poorly implemented here and doesn't do anything to avoid fragmentation or to help with good resource utilization. For example, the following allocations:
```
t1 = alloc(4GB)
del t1
t2 = alloc(10k)
t3 = alloc(4GB)
```
this results in allocating 8GB, because the first 4GB block that is cached gets assigned to the 10k allocation wasting the rest of the block.
Lastly, ideally I would make this constants configurable, but looking around the code I didn't see any existing mechanisms in ATen to configure things at runtime.
Fixes#95823
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95827
Approved by: https://github.com/ngimel
The native implementation of LSTM has been fixed on macOS 13.
On macOS 12, the multi-layer LSTM still has a numerical correctness issue that cannot be resolved on OS's side.
Thus, we fall back the multi-layer LSTM on macOS 12 to LSTMCell iteration. It might have performance impact but will make LSTM on macOS 12 fully usable.
Fixes: #90421
Issues related: #80306, #83144
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90909
Approved by: https://github.com/albanD, https://github.com/kulinseth
This PR addresses issue [#81075](https://github.com/pytorch/pytorch/issues/81075), making `torch.stft` compatible with ONNX Opset 17's STFT operator.
The conversion works for _most_ of `torch.stft` functionality:
- Batched or unbatched inputs
- Normalization
- Pre-computed windows
- Rectangular windows
- One-sided returns
- Window centering (implicitly supported)
What is currently _not_ supported is **complex types**, due to the lack of conversion functionality between PyTorch and ONNX (https://github.com/pytorch/pytorch/issues/86746).
Regardless, this is easy to bypass by setting `return_complex=False` when using `torch.stft`.
Note that there is already a draft PR to address this (https://github.com/pytorch/pytorch/pull/83944), but it is currently closed and it only partially addresses the conversion (i.e., most of `torch.stft` functionality is lacking, and unit tests are missing).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92087
Approved by: https://github.com/justinchuby
Set environment variable
```
PYTORCH_TEST_DO_NOT_USE_PYTEST=1
```
to not use pytest in pytorch unit testing.
This change is related to some recent changes, e.g. #96210, #96016, #95844, #95659, that enabled the use of pytest in many test modules. Those test modules were testing normally before, but failed immediately after pytest is used. Sample stacktraces are:
```python
root@8e3168a83ee2:/opt/pytorch/pytorch# python test/run_test.py -v -i test_optim -- -v --save-xml
Ignoring disabled issues: []
/opt/pytorch/pytorch/test/run_test.py:1225: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
if torch.version.cuda is not None and LooseVersion(torch.version.cuda) >= "11.6":
Selected tests:
test_optim
parallel (file granularity) tests:
test_optim
serial (file granularity) tests:
Ignoring disabled issues: []
Ignoring disabled issues: []
Running test_optim ... [2023-03-09 12:51:59.358110]
Executing ['/usr/local/bin/python', '-bb', 'test_optim.py', '-v', '--save-xml', '-v', '--use-pytest', '-vv', '-rfEX', '-x', '--reruns=2'] ... [2023-03-09 12:51:59.358810]
Test results will be stored in test-reports/python-pytest/test_optim/test_optim-5e41643c8bac8ace.xml
Traceback (most recent call last):
File "/opt/pytorch/pytorch/test/test_optim.py", line 4581, in <module>
run_tests()
File "/opt/pytorch/pytorch/torch/testing/_internal/common_utils.py", line 796, in run_tests
exit_code = pytest.main(args=pytest_args)
File "/usr/local/lib/python3.10/site-packages/_pytest/config/__init__.py", line 148, in main
config = _prepareconfig(args, plugins)
File "/usr/local/lib/python3.10/site-packages/_pytest/config/__init__.py", line 329, in _prepareconfig
config = pluginmanager.hook.pytest_cmdline_parse(
File "/usr/local/lib/python3.10/site-packages/pluggy/_hooks.py", line 265, in __call__
return self._hookexec(self.name, self.get_hookimpls(), kwargs, firstresult)
File "/usr/local/lib/python3.10/site-packages/pluggy/_manager.py", line 80, in _hookexec
return self._inner_hookexec(hook_name, methods, kwargs, firstresult)
File "/usr/local/lib/python3.10/site-packages/pluggy/_callers.py", line 55, in _multicall
gen.send(outcome)
File "/usr/local/lib/python3.10/site-packages/_pytest/helpconfig.py", line 103, in pytest_cmdline_parse
config: Config = outcome.get_result()
File "/usr/local/lib/python3.10/site-packages/pluggy/_result.py", line 60, in get_result
raise ex[1].with_traceback(ex[2])
File "/usr/local/lib/python3.10/site-packages/pluggy/_callers.py", line 39, in _multicall
res = hook_impl.function(*args)
File "/usr/local/lib/python3.10/site-packages/_pytest/config/__init__.py", line 1060, in pytest_cmdline_parse
self.parse(args)
File "/usr/local/lib/python3.10/site-packages/_pytest/config/__init__.py", line 1348, in parse
self._preparse(args, addopts=addopts)
File "/usr/local/lib/python3.10/site-packages/_pytest/config/__init__.py", line 1231, in _preparse
self.pluginmanager.load_setuptools_entrypoints("pytest11")
File "/usr/local/lib/python3.10/site-packages/pluggy/_manager.py", line 287, in load_setuptools_entrypoints
plugin = ep.load()
File "/usr/local/lib/python3.10/importlib/metadata/__init__.py", line 171, in load
module = import_module(match.group('module'))
File "/usr/local/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
File "/usr/local/lib/python3.10/site-packages/_pytest/assertion/rewrite.py", line 168, in exec_module
exec(co, module.__dict__)
File "/usr/local/lib/python3.10/site-packages/xdist/looponfail.py", line 16, in <module>
import execnet
File "/usr/local/lib/python3.10/site-packages/execnet/__init__.py", line 14, in <module>
from .gateway_base import DataFormatError
File "/usr/local/lib/python3.10/site-packages/execnet/gateway_base.py", line 1138, in <module>
FLOAT_FORMAT_SIZE = struct.calcsize(FLOAT_FORMAT)
BytesWarning: Comparison between bytes and string
FINISHED PRINTING LOG FILE of test_optim (/opt/pytorch/pytorch/test/test-reports/test_optim_1pnlesrz.log)
test_optim failed!
Traceback (most recent call last):
File "/opt/pytorch/pytorch/test/run_test.py", line 1428, in <module>
main()
File "/opt/pytorch/pytorch/test/run_test.py", line 1386, in main
raise RuntimeError(
RuntimeError: test_optim failed!
Tip: You can keep running tests even on failure by passing --keep-going to run_test.py.
If running on CI, add the 'keep-going' label to your PR and rerun your jobs.
```
I'd like to propose this option that allows users to use the good old python unit test way instead of pytest to run their testing in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96444
Approved by: https://github.com/malfet
Reverting due to concerns over silent unsoundness (skipped hooks) if users have directly added hooks dicts without using official torch APIs.
This reverts commit 26045336ca323fd27cff2a7340fe896117d5fb6e.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96242
Approved by: https://github.com/albanD
This commit fixes a bug where the ONNX exporter for circular padding queried the input tensor shape in order to get the correct 'end' index for a slice node. This doesn't work when the axis in question is has dynamic size. The commit fixes this by setting the 'end' index to INT_MAX, which is the recommended way of slicing to the end of a dimension with unknown size per ONNX spec.
See https://onnx.ai/onnx/operators/onnx__Slice.html
Also adds a regression test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95647
Approved by: https://github.com/BowenBao
Summary: The previous LSTM reference module implementation did
not handle dtypes other than quint8 correctly. This is because
the internal LSTM custom module quantization used eager mode,
which did not insert the q-dq ops properly. E.g., we want the
following reference quantized model:
```
[dq -> linear1_fp32 -> q_to_qint32] -> dq -> q_to_quint8 ->
[dq - linear2_fp32 -> q_to_quint8] -> dq -> ...
```
This requires two sets of `q - dq` pairs between two adjacent
ops that have different dtypes (linear1 and linear2). However,
these `q - dq` pairs were not inserted in the old flow, because
eager mode required users to insert Quant/DeQuantStubs manually.
This commit changes the internal LSTM custom module quantization
to use FX graph mode quantization, which automatically inserts
the `q - dq` ops that convert the dtypes between adjacent ops
correctly. However, using FX graph mode quantization here comes
with its own set of challenges that required some hacks to get
the end-to-end flow to work. These hacks are detailed in the
comments in the util functions.
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_static_lstm_with_custom_fixed_qparams
This commit also updates the corresponding test to verify the
dtypes as well as the qparams in the reference quantized graph.
This test case should serve as an example for users to set up
their own LSTM reference module flows.
Reviewers: vkuzo, supriyar, jcaip
Subscribers: vkuzo, supriyar, jcaip
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96343
Approved by: https://github.com/vkuzo
Fixes#96064
When deciding whether to fuse nodes, we match indexing like `c0 + 5 * tmp0`, but `tmp0` in the different nodes can refer to totally different values. Even when `tmp0` is the same (like in the added test) inductor still generates wrongly ordered loads and stores (loads come before stores), so better just disable this fusion altogether. We should fix wrong order also:
```
@pointwise(size_hints=[8], filename=__file__, meta={'signature': {0: '*i64', 1: '*fp32', 2: '*fp32', 3: '*fp32', 4: 'i32'}, 'device': 0, 'constants': {}, 'mutated_arg_names': ['out_ptr0'], 'configs': [instance_descriptor(divisible_by_16=(0, 1, 2, 3), equal_to_1=())]})
@triton.jit
def triton_(in_ptr0, in_ptr1, out_ptr0, out_ptr1, xnumel, XBLOCK : tl.constexpr):
xnumel = 5
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x0 = xindex
tmp0_load = tl.load(in_ptr0 + (0))
tmp0 = tl.broadcast_to(tmp0_load, [XBLOCK])
tmp1 = tl.load(in_ptr1 + (x0), xmask)
tmp2 = tl.load(out_ptr0 + (x0 + (5*tmp0)), xmask)
tl.store(out_ptr0 + (x0 + (5*tmp0) + tl.zeros([XBLOCK], tl.int32)), tmp1, xmask)
tl.store(out_ptr1 + (x0 + tl.zeros([XBLOCK], tl.int32)), tmp2, xmask)
```
Note: we are loading from `out_ptr0` here (that shouldn't happen), we are loading from it before storing to it.
After this PR, the kernel above is split in 2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96273
Approved by: https://github.com/jansel
Summary:
Currently, selection along a dimension/rank is only supported for 3D/rank tensors in PyTorch Vulkan. This adds support for 4D/rank tensors at selection along batch, channel (depth), height, and width.
Additionally:
- The existing implementations have been name-refactored to reflect whether they operate on 3d or 4d tensors.
- The params buffer for all select operations now use `ivec2` or `ivec4` only, for memory alignment safety.
Test Plan:
1. `buck run --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -c pt.vulkan_full_precision=1` on Apple M1 MacBook
2. Confirm all tests pass with no regression, and the directly affected tests `select_4d_*`, refactored `select_3d_`, pass
3. Test output P636928908, in particular:
```
[...bunch of other tests...]
[ RUN ] VulkanAPITest.select_3d_depth_small
[ OK ] VulkanAPITest.select_3d_depth_small (1 ms)
[ RUN ] VulkanAPITest.select_3d_depth_medium
[ OK ] VulkanAPITest.select_3d_depth_medium (0 ms)
[ RUN ] VulkanAPITest.select_3d_depth_large
[ OK ] VulkanAPITest.select_3d_depth_large (1 ms)
[ RUN ] VulkanAPITest.select_3d_height_small
[ OK ] VulkanAPITest.select_3d_height_small (0 ms)
[ RUN ] VulkanAPITest.select_3d_height_medium
[ OK ] VulkanAPITest.select_3d_height_medium (0 ms)
[ RUN ] VulkanAPITest.select_3d_height_medium1
[ OK ] VulkanAPITest.select_3d_height_medium1 (0 ms)
[ RUN ] VulkanAPITest.select_3d_height_medium2
[ OK ] VulkanAPITest.select_3d_height_medium2 (0 ms)
[ RUN ] VulkanAPITest.select_3d_height_large
[ OK ] VulkanAPITest.select_3d_height_large (1 ms)
[ RUN ] VulkanAPITest.select_3d_width_small
[ OK ] VulkanAPITest.select_3d_width_small (0 ms)
[ RUN ] VulkanAPITest.select_3d_width_medium
[ OK ] VulkanAPITest.select_3d_width_medium (0 ms)
[ RUN ] VulkanAPITest.select_3d_width_medium2
[ OK ] VulkanAPITest.select_3d_width_medium2 (0 ms)
[ RUN ] VulkanAPITest.select_3d_width_large
[ OK ] VulkanAPITest.select_3d_width_large (1 ms)
[ RUN ] VulkanAPITest.select_4d_batch_small
[ OK ] VulkanAPITest.select_4d_batch_small (0 ms)
[ RUN ] VulkanAPITest.select_4d_batch_medium
[ OK ] VulkanAPITest.select_4d_batch_medium (0 ms)
[ RUN ] VulkanAPITest.select_4d_batch_large
[ OK ] VulkanAPITest.select_4d_batch_large (1 ms)
[ RUN ] VulkanAPITest.select_4d_depth_small
[ OK ] VulkanAPITest.select_4d_depth_small (1 ms)
[ RUN ] VulkanAPITest.select_4d_depth_medium
[ OK ] VulkanAPITest.select_4d_depth_medium (0 ms)
[ RUN ] VulkanAPITest.select_4d_depth_large
[ OK ] VulkanAPITest.select_4d_depth_large (1 ms)
[ RUN ] VulkanAPITest.select_4d_height_small
[ OK ] VulkanAPITest.select_4d_height_small (0 ms)
[ RUN ] VulkanAPITest.select_4d_height_medium
[ OK ] VulkanAPITest.select_4d_height_medium (0 ms)
[ RUN ] VulkanAPITest.select_4d_height_large
[ OK ] VulkanAPITest.select_4d_height_large (1 ms)
[ RUN ] VulkanAPITest.select_4d_width_small
[ OK ] VulkanAPITest.select_4d_width_small (0 ms)
[ RUN ] VulkanAPITest.select_4d_width_medium
[ OK ] VulkanAPITest.select_4d_width_medium (0 ms)
[ RUN ] VulkanAPITest.select_4d_width_large
[ OK ] VulkanAPITest.select_4d_width_large (1 ms)
[...bunch of other tests...]
[ FAILED ] 7 tests, listed below:
[ FAILED ] VulkanAPITest.cat_dim1_singledepth_success
[ FAILED ] VulkanAPITest.gru_success
[ FAILED ] VulkanAPITest.gru_mclareninputs_success
[ FAILED ] VulkanAPITest.gru_prepack_success
[ FAILED ] VulkanAPITest.lstm_success
[ FAILED ] VulkanAPITest.lstm_mclareninputs_success
[ FAILED ] VulkanAPITest.lstm_prepack_success
```
Reviewed By: SS-JIA
Differential Revision: D42623181
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96228
Approved by: https://github.com/SS-JIA
This adds the option to use an unsafe `setattr` for `_use_sharded_views()` and `_use_unsharded_views()` gated by the environment variable `FSDP_USE_UNSAFE_SETATTR`, where a value of `1` means to use the unsafe `setattr`. The unsafe option is disabled by default.
The unsafe `setattr` may be able to save CPU overhead and may be used to intentionally bypass `setattr` checks. Both `_use_sharded_views()` and `_use_unsharded_views()` must use the unsafe version or use the safe versions atomically.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96326
Approved by: https://github.com/zhaojuanmao, https://github.com/fegin
Unclear if there is a more efficient way to define the allowed types for IR (or if we even need this, perhaps we just ditch the assert?) But Inductor experts can deteremine if these added ops are appropriate and if so they fix the reported issue.
Fixes#96204
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96221
Approved by: https://github.com/ezyang
test-infra's linux_job uses github.ref as the default value for the ref, which is the branch, so it checks out the most recent commit on the branch.
Might be better to fix this on the test-infra side instead
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96317
Approved by: https://github.com/huydhn
expecttest is not imported to OSS BUCK build yet. Using it in target test_torchgen_executorch breaks build.
Remove it first to fix the build. Will import and fix in a follow-up PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96314
Approved by: https://github.com/huydhn
Summary: ciflow/inductor-perf-test-nightly now contains full dashboard
run which takes a very long time. Ed proposed a simplification of the
perf run there, but it is still worth to have a set of fast perf test
which only includes one configuration (--training --amp).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96166
Approved by: https://github.com/huydhn, https://github.com/weiwangmeta
# Summary
This PR adds an optional kwarg to torch torch.nn.functional.scaled_dot_product_attention()
The new kwarg is a scaling factor that is applied after the q@k.T step of the computation. Made updates to the efficient kernel to support but flash and math were minimally updated to support as well.
Will reduce the complexity of: #94729 and has been asked for by a couple of users.
# Review Highlights
- As far as I know I did this the correct way and this both BC and FC compliant. However I always seem to break internal workloads so I would love if someone can advice I did this right?
- I named the optional arg 'scale'. This is probably dumb and I should name it 'scale_factor'. I will make this change but this is annoying and it will require someone thinking we should rename.
- 'scale' is interpreted as `Q@K.T * (scale)`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95259
Approved by: https://github.com/cpuhrsch
Summary: This commit adds a test for mixing multiple dtypes
for different layers in the same model. The test verifies that
FX graph mode quantization converts the dtypes correctly
between the layers.
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_mixed_dtypes
Reviewers: jcaip, vkuzo, supriyar
Subscribers: jcaip, vkuzo, supriyar
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96104
Approved by: https://github.com/jcaip
This makes the next PR in the stack cleaner: having the top level entry point to aot autograd perform the functionalization analysis pass once, and plumb the metadata everywhere else that we need it.
I put it in a separate PR because I recently learned that this function is used in fbcode, so I'll need to fix up internals when I land this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95991
Approved by: https://github.com/ezyang
Fixes https://github.com/pytorch/pytorch/issues/95167
More details are in that issue. To summarize, the issue shows up when we have some code like this:
```
def f(x):
x.detach().mul_(2) # can also happen if the mul_() happens under torch.no_grad()
return x + 1
```
AOTAutograd will then spit out code like this:
```
def compiled_fn(x):
x_updated = x.mul(2)
out = x_updated + 1
return x_updated, out
def CompiledFunction.forward(x): # pseudocode, this is part of an autograd.Function
x_updated, out = compiled_function(x):
return x_updated, out
def runtime_wrapper(x):
x_updated, out = CompiledFunction.apply(x)
x.copy_(x_updated)
x = torch.ones(2, requires_grad=True)
out = runtime_wrapper(x)
```
However, the call to `x.copy_(x_updated)` will fail with the error: `a leaf Variable that requires grad is being used in an in-place operation`. This is because `x` is an autograd leaf, and autograd doesn't allow you to mutate leaves.
In this case though, the data mutation should be entirely opaque to autograd - all mutations happened underneath a `.detach()` or a `torch.no_grad()`.
As Ed pointed out in the issue, we can detect this situation by checking if the mutated input is an autograd leaf. If it is, then it must have been the case that any mutations on it must have been hidden from autograd, since otherwise the eager code would have error'd. The solution I added is to detect this situation, and manually run `x.detach().copy_(x_updated)`, to hide the update from autograd.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95980
Approved by: https://github.com/ezyang
Previously, if dynamic shapes were turned on and we had a forward graph that returns a symint, then we would generate a backward graph that takes in a tangent input for that symint fwd output. This causes problems for downstream - inductor will see an input that it expects to be a symint, but it gets a `None` from autograd.
Confirmed that this repro now passes:
```
benchmarks/dynamo/torchbench.py --devices cuda --inductor --dynamic-shapes --unspecialize-int --accuracy --training --only drq
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96219
Approved by: https://github.com/ezyang
Summary: The original code uses a class variable to store flat_parameter result. This could cause memory leakage.
Test Plan: CI and a E2E run
Reviewed By: awgu
Differential Revision: D43893577
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96263
Approved by: https://github.com/zhaojuanmao
Summary:
## Summary
torch.nn.functional.pixel_unshuffle and torch.narrow accepts both float
and quantized inputs. However, previously we would unnecessarily
dequantize quantized inputs into floats before passing them to
the function. This commit fixes this by lowering the pattern
[dequant - pixel_unshuffle - quant].
[dequant - narrow - quant].
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps.test_pixel_unshuffle
```
```
python test/test_quantization.py TestQuantizeFxOps.test_narrow
```
Differential Revision: D43858199
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96160
Approved by: https://github.com/andrewor14
sccache added GH cache as a storage option, so try to use it for the GH provided mac runners.
My experiments with this are varied. I tried a couple of different releases and the first run with a cold cache took 1hr (v0.3.3), 1hr (v0.4.0 pre7), 2hr (v0.3.3).
Afterwards it usually takes 30 minutes but sometimes longer, but no longer than 1hr.
I am using v0.4.0 pre7 because they reduced the amount of configuration/env vars you need to set and the GH cache keys get managed by sccache.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96142
Approved by: https://github.com/huydhn, https://github.com/malfet
Summary:
In ATen mode, we add the RuntimeContext arg, so we have something like
```
TORCH_API inline at::Tensor & gelu_outf(torch::executor::RuntimeContext & context, const at::Tensor & self, c10::string_view approximate, at::Tensor & out) {
return at::gelu_outf(self, approximate, out);
}
```
and user can use `<namespace like aten>::gelu_outf` and we will automatically dispatch the registered function in aten kernel using `at::gelu_outf` (dispatched by ATen/Functions.h header)
In optimized kernel tests, we can now automatically handle between aten kernel and optimized kernel.
The implication is that the test must depend on the correctness of codegen; an error in codegen can break the kernel tests.
Test Plan: CI
Differential Revision: D43777848
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96084
Approved by: https://github.com/larryliu0820
Fix `Gumbel.cdf` function.
**Description**
When transformed parameters is outside of the support of underlying Uniform distribution. This makes behavior of `Gumbel.cdf` consistent with other `TransformedDistribution` that pass value of validate_args to the base distribution.
**Issue**
running `Gumbel(0.0,1.0,validate_args=False).cdf(20.0)` would cause `ValueError` exception from `_validate_sample`
**Testing**
Test was added to the `test_distributions.py` to check if `Gumbel(0.0,1.0,validate_args=False).cdf(20.0)` successfully returns `1.0`
This is a second attempt to push changes , after https://github.com/pytorch/pytorch/pull/82488
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91698
Approved by: https://github.com/fritzo, https://github.com/zou3519
Summary: Makes the debug dir location configurable with TORCH_COMPILE_DEBUG_DIR env var
Test Plan: TORCH_COMPILE_DEBUG_DIR=”.” buck2 run mode/dev-nosan //caffe2/test/inductor:minifier_smoke
Reviewed By: bertmaher
Differential Revision: D43639955
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96089
Approved by: https://github.com/bertmaher
**Summary:**
Currently the only way to destroy a process group is calling `dist.destroy_process_group`. However, this API does not guarantee destruction of the ProcessGroup object since it only deletes references inside `distributed_c10d.py`. In cases where the process group is used in multiple places it is not feasible to hunt down all the references and delete them.
In particular for NCCL if a collective gets stuck the only way to recover from this is calling ncclCommAbort on all the communicators. Currently there is no API to achieve this.
To address this, in this PR I've added an `_abort` method to ProcessGroupNCCL to achieve this, where now we have a guaranteed way to kill all NCCL communicators associated with a ProcessGroup
**Test Plan:**
Added a unit test to validate this works as expected
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96017
Approved by: https://github.com/wanchaol
Adds a profiler start and end callback to dynamo's C eval_frame impl, which can be used to profile a region providing a name for visualization. Currently only hooks up one usage to profile cache lookup (primarily covering guards and linear search through linked list).
Example profile taken from toy model:
`python benchmarks/dynamo/distributed.py --toy_model --profile --dynamo aot_eager`
<img width="1342" alt="image" src="https://user-images.githubusercontent.com/4984825/223225931-b2f6c5a7-505a-4c90-9a03-34982f6dc033.png">
Planning to measure overhead in CI, and probably can't afford to check this in enabled by default. Will have to evaluate UX options such as `config.profile_dynamo_cache = True` or some other way.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96119
Approved by: https://github.com/jansel
For ```torch.baddbmm(input, mat1,mat2, beta=0)```, if ```beta``` is zero, the multiplication of value ```input*beta``` will be ignored for the eager mode(always gets zero number, see https://pytorch.org/docs/stable/generated/torch.baddbmm.html?highlight=torch+baddbmm#torch.baddbmm), but the inductor is not, the inductor will get a different value if the input has a ```nan``` of ```inf``` value:
```
def fn_test(input, mat1, mat2):
return torch.baddbmm(input, mat1, mat2, beta=0.0)
opt_fn = torch._dynamo.optimize("inductor")(fn_test)
a, b, c = [torch.rand((3,2,2)) for _ in range(3)]
real_out = fn_test(a, b, c)
a[:] = torch.nan
compiled_out = opt_fn(a, b,c)
print(compiled_out)
print(real_out)
```
before this PR, the output will be like this:
```
tensor([[[0.4272, 0.6037],
[0.4279, 0.4219]],
[[0.0838, 0.4873],
[0.1210, 0.5516]],
[[ nan, nan],
[ nan, nan]]])
tensor([[[0.4272, 0.6037],
[0.4279, 0.4219]],
[[0.0838, 0.4873],
[0.1210, 0.5516]],
[[0.4985, 0.1072],
[0.0857, 0.0186]]])
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96087
Approved by: https://github.com/jansel, https://github.com/ngimel, https://github.com/jgong5
Fixes https://github.com/pytorch/pytorch/issues/91483
Using a separate test class here, so that there is no need to run setup and teardown for all tests in TestJit. The root cause here is that test_profiler could be flaky and fail in the middle without the chance to restore `torch._C._set_graph_executor_optimize` to its original value (https://github.com/pytorch/pytorch/issues/81626). This causes issues for all future tests running after as shown in https://github.com/pytorch/pytorch/issues/91483.
I suspect that is also the same root cause for several other flaky tests in the same file https://github.com/search?q=repo%3Apytorch%2Fpytorch+DISABLED+test_jit.TestScript&type=issues. After this fix is merged, I would let retry bot does it job and close these issues after 2 weeks.
### Testing
The issue https://github.com/pytorch/pytorch/issues/91483 can now be reproduced by adding `torch._C._set_graph_executor_optimize(False)` locally to see if the test fails:
```
diff --git a/test/test_jit.py b/test/test_jit.py
index 2d1161d7466..17745d39182 100644
--- a/test/test_jit.py
+++ b/test/test_jit.py
@@ -5413,6 +5413,8 @@ a")
FileCheck().check("int =").check("ListConstruct").check("aten::cat").run(str(g))
def test_stack(self):
+ torch._C._set_graph_executor_optimize(False)
+
with enable_profiling_mode_for_profiling_tests():
@torch.jit.script
def func(x):
```
It indeed fails:
```
======================================================================
FAIL [0.006s]: test_stack (test_jit.TestScript)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/var/lib/jenkins/workspace/test/test_jit.py", line 5437, in test_stack
self.assertAutodiffNode(func2.graph_for(x, y), True, ['aten::stack'], [])
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_jit.py", line 282, in assertAutodiffNode
self.assertEqual(should_autodiff_node,
##[endgroup]
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_utils.py", line 2975, in assertEqual
raise error_metas[0].to_error(
AssertionError: Booleans mismatch: True is not False
Failure in testing nodes' autodifferentiation. One or more nodes were expected to be autodiffed, but were not found in specified fusible/nonfusible DifferentiableGraph groups.
Specifically:
['aten::stack'] were not in one of the DifferentiableGraphs when they were expected to be. Did you intend for these nodes to be autodiffed? If not, remove them from the list of nonfusible nodes.
----------------------------------------------------------------------
Ran 2677 tests in 84.596s
FAILED (failures=1, skipped=136, expected failures=13)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96135
Approved by: https://github.com/clee2000
Fixes crash while running something like `python -c "import torch;x=torch.rand(3, 3, dtype=torch.float16, device='mps');y=x.addcmul(torch.ones(3, device='mps'), torch.ones(3, device='mps'));print(y)"`
Modify `castMPSTensor` to become a no-op if cast is not needed
Define `common_dtype` as `c10::promoType` between self, tensor1 and
tensor2. Cast to any output type.
Add mixed-types test to `TestMPS.test_addcmul`, though it does not cover
all the permutations
Discovered while looking at https://github.com/pytorch/pytorch/issues/96113
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96164
Approved by: https://github.com/kulinseth
I have a minor tweak on the uploading workflow to upload to S3 first before Rockset as `upload-test-stats` and `upload-torch-dynamo-perf-stats` both run when inductor-A100-perf finished. There is a potential race condition where the test reports are not yet no S3 when `upload-torch-dynamo-perf-stats` runs (it gets the data from S3). `inductor-A100-perf` is now handled exclusively by `upload-torch-dynamo-perf-stats` to avoid this. It will upload test reports to S3 first before getting them to Rockset.
The uploading script works fine with the test reports from https://hud.pytorch.org/pr/95685.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96165
Approved by: https://github.com/desertfire
- port https://github.com/intel-innersource/frameworks.ai.pytorch.ipex-cpu/pull/740 to `run_cpu`
- use-case by https://github.com/pytorch/serve/pull/2166 where `numactl` is unavailable (e.g., requires `privileged` mode)
This PR automatically tries taskset if numactl core binding doesn't work.
Reference:
`taskset` is added to adapt to launcher use-cases such as in docker where `numactl` requires to be ran in `privileged` mode, where the `privileged` mode "wont work for deployments like sagemaker for example" as raised by TorchServe. Please see [torchserve ipex docker discussion](https://github.com/pytorch/serve/pull/1401#issuecomment-1090817704) for reference. To address such use-cases, `taskset` can be used in place of `numactl` to set core affinity. Note that, unlike `numactl`, `taskset` does not provide memory binding to local memories; however, memory binding may not be needed in these use-cases that typically do not span multi sockets. Hence we can automatically try taskset if numactl doesn't work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96011
Approved by: https://github.com/jgong5, https://github.com/malfet
Summary:
This diff is reverting D43643526
Depends on D43693521
D43643526: Avoid copies in matmul (#76828) by generatedunixname499836121 has been identified to be causing the following test or build failures:
Tests affected:
- [mle/favour:tests - favour_test.py::TestLinears::test_psd](https://www.internalfb.com/intern/test/562950027104300/)
Here's the Multisect link:
https://www.internalfb.com/intern/testinfra/multisect/1611690
Here are the tasks that are relevant to this breakage:
T146911536: 5 tests started failing for oncall prob in the last 2 weeks
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
Test Plan: NA
Differential Revision: D43693526
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96126
Approved by: https://github.com/weiwangmeta
This is a follow up for PR #95506 to run all the triton kernels in a compiled module individually as suggested by Horace.
Here are the steps:
1. Run the model as usual with a benchmark script and with TORCHINDUCTOR_BENCHMARK_KERNEL enabled. e.g.
```
TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/torchbench.py --backend inductor --amp --performance --dashboard --only resnet18 --disable-cudagraphs --training
```
2. From the output we will see 3 lines like
```
Compiled module path: /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py
```
That's because we have one graph module for fwd/bwd/optitimizer respectively. Each graph module will have one such output corresponding to the compiled module.
3. We can run the compiled module directly. Without any extra arguments, we just maintain the previous behavior to run the call function -- which just does what the original graph module does but in a more efficient way. But if we add the '-k' argument, we will run benchmark for each individual kernels in the file.
```
python /tmp/torchinductor_shunting/rs/crsuc6zrt3y6lktz33jjqgpkuahya56xj6sentyiz7iv4pjud43j.py -k
```
Example output:
<img width="430" alt="Screenshot 2023-03-01 at 4 51 06 PM" src="https://user-images.githubusercontent.com/52589240/222302996-814a85be-472b-463c-9e85-39d2c9d20e1a.png">
Note: I use the first 10 characters of the hash to identify each kernel since
1. hash is easier to get in the code :)
2. name like `triton__3` only makes sense within a compiled module, but a hash can make sense even without specifying the compiled module (assuming we have enough bytes for the hash)
If we found a triton kernel with hash like c226iuf2wi having poor performance, we can look it up in the original compiled module file. It works since we comment each compiled triton kernel with the full hash.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95845
Approved by: https://github.com/Chillee
Without this, when you skip frame because of a graph break, at INFO logging level all you see is:
```
[INFO] Step 1: torchdynamo start tracing run_n_iterations
[INFO] Step 1: torchdynamo start tracing forward_pass
```
With this promotion, you now see:
```
[INFO] Step 1: torchdynamo start tracing run_n_iterations
[INFO] Skipping frame because there is a graph break in a for/while loop
[INFO] Step 1: torchdynamo start tracing forward_pass
```
This is MUCH more useful, while only adding a single log message per
already existing INFO log message.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95968
Approved by: https://github.com/albanD, https://github.com/janeyx99
From https://github.com/pytorch/pytorch/pull/95938 where a new Docker image build fails to start sccache. This issue starts to happen today (Mar 3rd). The server fails to start with a cryptic `sccache: error: Invalid argument (os error 22)`
```
=================== sccache compilation log ===================
ERROR 2023-03-03T20:31:14Z: sccache::server: failed to start server: Invalid argument (os error 22)
sccache: error: Invalid argument (os error 22)
=========== If your build fails, please take a look at the log above for possible reasons ===========
+ sccache --show-stats
sccache: error: Connection to server timed out
```
I don't have a good explanation for this yet. The version of sccache we build from https://github.com/pytorch/sccache is ancient. If I start to build the exact same version on Ubuntu Docker image now, the issue will manifest. But the older binary built only few days ago e50ff3fcdb works without any issue. So I fix sccache binary to that version instead of rebuilding it every time in the image as a temporary mitigation while trying to root cause this further.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95997
Approved by: https://github.com/ZainRizvi
_functional_collectives.py: Ensure we always wait all collectives.
derivatives.yaml: mark all_reduce as non differentiable
gen_variable_type.py: Add all_reduce to DONT_ENFORCE_TENSOR_IMPL_USE_COUNT
common_dtensor.py: replace dist.barrier with all_reduce
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95897
Approved by: https://github.com/wconstab, https://github.com/fegin
Given the following case:
```
import torch
import torch._dynamo
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = torch.nn.Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
self.conv2 = torch.nn.Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
self.silu = torch.nn.SiLU(inplace=False)
def forward(self, x,):
x = self.silu(x)
y1 = self.conv1(x)
y2 = self.conv2(x)
return y1, y2
model = Model().eval()
model = model.to(memory_format=torch.channels_last).eval()
opt_model = torch._dynamo.optimize('inductor')(model)
x = torch.randn(128, 64, 112, 112).to(memory_format=torch.channels_last)
with torch.no_grad():
for i in range(3):
out = opt_model(x)
```
the silu is used by two external kernels, and there always have redundant memory copy:
```
kernel_cpp_0 = async_compile.cpp('''
#include "/tmp/torchinductor_xiaobing/dl/cdljpywww2h2ag4o35mwbvm45hhasxnxkhqgbupxnk3y7olula65.h"
extern "C" void kernel(const float* __restrict__ in_ptr0,
float* __restrict__ out_ptr0,
float* __restrict__ out_ptr1)
{
#pragma omp parallel num_threads(40)
{
{
#pragma omp for
for(long i0=0; i0<6422528; i0+=1)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(in_ptr0 + 16*i0);
auto tmp1 = decltype(tmp0)(1)/(decltype(tmp0)(1) + tmp0.neg().exp());
auto tmp2 = tmp0 * tmp1;
tmp2.store(out_ptr0 + 16*i0);
tmp2.store(out_ptr1 + 16*i0);
}
#pragma omp for simd simdlen(8)
for(long i0=102760448; i0<102760448; i0+=1)
{
auto tmp0 = in_ptr0[i0];
auto tmp1 = decltype(tmp0)(1) / (decltype(tmp0)(1) + std::exp(-tmp0));
auto tmp2 = tmp0 * tmp1;
out_ptr0[i0] = tmp2;
out_ptr1[i0] = tmp2;
}
}
}
}
''')
```
This PR will pre-convert the `silu`'s layout to FixedLayout at FX side(will be realized to avoid multi-realize at external kernel) if one user of it is a CPU external customer kernel, after this PR, the output code is:
```
kernel_cpp_0 = async_compile.cpp('''
#include "/tmp/torchinductor_xiaobing/dl/cdljpywww2h2ag4o35mwbvm45hhasxnxkhqgbupxnk3y7olula65.h"
extern "C" void kernel(const float* __restrict__ in_ptr0,
float* __restrict__ out_ptr0)
{
#pragma omp parallel num_threads(40)
{
{
#pragma omp for
for(long i0=0; i0<6422528; i0+=1)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(in_ptr0 + 16*i0);
auto tmp1 = decltype(tmp0)(1)/(decltype(tmp0)(1) + tmp0.neg().exp());
auto tmp2 = tmp0 * tmp1;
tmp2.store(out_ptr0 + 16*i0);
}
#pragma omp for simd simdlen(8)
for(long i0=102760448; i0<102760448; i0+=1)
{
auto tmp0 = in_ptr0[i0];
auto tmp1 = decltype(tmp0)(1) / (decltype(tmp0)(1) + std::exp(-tmp0));
auto tmp2 = tmp0 * tmp1;
out_ptr0[i0] = tmp2;
}
}
}
}
''')
```
Currently, this PR only considers the CPU external customer kernel, but for other external kernels, there may have the same issue.
For Timm **eca_halonext26ts** , this PR will give about **8%** performance improvement(BS=128, 20 cores on SKX).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95873
Approved by: https://github.com/jansel
Fixes https://github.com/pytorch/pytorch/issues/93485
```python
import torch
from torchvision.models import resnet50
model = resnet50(weights=None)
compile_model = torch.compile(model)
print(type(compile_model))
example_forward_input = torch.rand(1, 3, 224, 224)
c_model_traced = torch.jit.trace(compile_model, example_forward_input) # or torch.jit.script
torch.jit.save(c_model_traced, "c_trace_model.pt")
```
Should I raise a warning if a user tries to compile a scripted or traced model as well? It works just fine now on resnet but not sure if it's that something we want to explicitly discourage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91681
Approved by: https://github.com/desertfire
Add a doc test, extending #95534 .
I found I need to put the xdoctest under a class method. Otherwise if it's right under the class definition, the test cannot be found. @Erotemic Do I miss anything?
The xdoctest has been tested:
```
$ pytest --xdoctest torch/fx/passes/graph_drawer.py::FxGraphDrawer.get_dot_graph:0
=========== test session starts ==================
platform linux -- Python 3.9.15, pytest-7.2.1, pluggy-1.0.0
rootdir: /localdisk/wenzhexu/dev/forked_pytorch, configfile: pytest.ini
plugins: xdoctest-1.1.1
collected 1 item
torch/fx/passes/graph_drawer.py . [100%]
============ 1 passed in 1.13s ===================
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95919
Approved by: https://github.com/ezyang
Summary: fix src and pad mask bool regression
This fixes a regression introduced previously with #92733. That PR unified testing of masks to remove Byte Tensors as permissible mask, introduced mask compatibility check, and mask conversion to FP mask. The problem addressed in this PR was that after the first mask had been converted, a check for mask compatibility would fail.
Test Plan: sandcastle & github
Differential Revision: D43782858
Fixes https://github.com/pytorch/pytorch/issues/95702
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96009
Approved by: https://github.com/malfet
follow-up https://github.com/pytorch/pytorch/pull/93901.
Unexpected numerical mismatches observed in some foreach functions' backward result seemed to be caused by the wrong order of `IndexRangeGenerator::range` call.
This pr has `args_with_derivatives` have the same or similar order of `foreach_native_function.func.arguments.flat_non_out`
---
what the current master generates for `_foreach_mul.List`:
```cpp
variable_list ForeachMulBackward0List::apply(variable_list&& grads) {
std::lock_guard<std::mutex> lock(mutex_);
TORCH_CHECK(!other_released_, ERR_BACKWARD_TWICE);
TORCH_CHECK(!self_released_, ERR_BACKWARD_TWICE);
IndexRangeGenerator gen;
auto other_ix = gen.range(other_size_);
auto self_ix = gen.range(self_size_);
variable_list grad_inputs(gen.size());
auto other = unpack_list(other_);
auto self = unpack_list(self_);
if (task_should_compute_output({ other_ix })) {
std::vector<Tensor> grad_result;
grad_result.reserve(grads.size());
for (const auto & i : c10::irange(grads.size())) {
grad_result.emplace_back(mul_tensor_backward(grads[i], self[i], other[i].scalar_type()));
}
copy_range(grad_inputs, other_ix, grad_result);
}
if (task_should_compute_output({ self_ix })) {
std::vector<Tensor> grad_result;
grad_result.reserve(grads.size());
for (const auto & i : c10::irange(grads.size())) {
grad_result.emplace_back(mul_tensor_backward(grads[i], other[i], self[i].scalar_type()));
}
copy_range(grad_inputs, self_ix, grad_result);
}
return grad_inputs;
}
```
with this PR the generated backward is
```cpp
variable_list ForeachMulBackward0List::apply(variable_list&& grads) {
std::lock_guard<std::mutex> lock(mutex_);
TORCH_CHECK(!self_released_, ERR_BACKWARD_TWICE);
TORCH_CHECK(!other_released_, ERR_BACKWARD_TWICE);
IndexRangeGenerator gen;
auto self_ix = gen.range(self_size_); <----- diff
auto other_ix = gen.range(other_size_); <----- diff
variable_list grad_inputs(gen.size());
auto self = unpack_list(self_);
auto other = unpack_list(other_);
if (task_should_compute_output({ other_ix })) {
std::vector<Tensor> grad_result;
grad_result.reserve(grads.size());
for (const auto & i : c10::irange(grads.size())) {
grad_result.emplace_back(mul_tensor_backward(grads[i], self[i], other[i].scalar_type()));
}
copy_range(grad_inputs, other_ix, grad_result);
}
if (task_should_compute_output({ self_ix })) {
std::vector<Tensor> grad_result;
grad_result.reserve(grads.size());
for (const auto & i : c10::irange(grads.size())) {
grad_result.emplace_back(mul_tensor_backward(grads[i], other[i], self[i].scalar_type()));
}
copy_range(grad_inputs, self_ix, grad_result);
}
return grad_inputs;
}
```
The change is to fix the order of `self_ix` and `other_ix`.[](url)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95263
Approved by: https://github.com/soulitzer
This PR optimizes the guards overhead introduced by dynamo tracing module forward hooks.
It can and maybe should be followed by a wider change proposed by @voznesenskym to optimize specialized nnmodules by 'observing' any user mutations and directly invalidating the root guard, obviating the need to install other nnmodule guards. (But this observer change seems more involved...)
Idea: maintain a flag, and keep it up to date whenever adding or
removing hooks. Use the flag rather than dict checks to enter the call fast path.
- need to extend RemovableHandle to keep a ref to nnModule so it can update the flag on removal.
- also need to handle the flag in ScriptModule which still uses the python call impl when called from python.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95931
Approved by: https://github.com/ezyang, https://github.com/voznesenskym
Summary:
This is a retry of https://github.com/pytorch/pytorch/pull/94992 which was reverted due to CI issues.
This PR adds a set of unintrepreted data types on PyTorch which can be used to implement experimental functionality out of core (think fp8, int4, int16 quant, etc).
@bypass-github-export-checks
Test Plan:
```
python test/test_quantization.py -k TestBits
```
Reviewers:
Subscribers:
Tasks:
Tags:
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95860
Approved by: https://github.com/atalman
I.e. attempt to create tensor of all possible types and make sure that
it raises a structured error for non-MPS types
Also, rename `test_resize_as_all_dtypes_and_devices` to `test_resize_as_mps_dtypes` and `test_resize_all_dtypes_and_devices` to `test_resize_mps_dtypes` and run both test for all MPS dtypes (rather than just bool, float16 and bfloat16 as they were running before)
Fixes https://github.com/pytorch/pytorch/issues/95976
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95982
Approved by: https://github.com/kulinseth
OK, so this PR used to be about reducing the number of constants we specialize on, but it turns out that unspecialization was ~essentially never used (because we still constant specialized way too aggressively) and I ended up having to fix a bunch of issues to actually get tests to pass. So this PR is now "make int unspecialization actually work". As part of this, I have to turn off unspecialization by default, as there are still latent bugs in inductor.
The general strategy is that an unspecialized int is represented as a SymInt. Representing it as a 0d tensor (which is what the code used to do) is untenable: (1) we often need unspecialized ints to participate in size computations, but we have no way of propagating sympy expressions through tensor compute, and (2) a lot of APIs work when passed SymInt, but not when passed a Tensor. However, I continue to represent Numpy scalars as Tensors, as they are rarely used for size computation and they have an explicit dtype, so they are more accurately modeled as 0d tensors.
* I folded in the changes from https://github.com/pytorch/pytorch/pull/95099 as I cannot represent unspecialized ints as SymInts without also turning on dynamic shapes. This also eliminates the necessity for test_unspec.py, as toggling specialization without dynamic shapes doesn't do anything. As dynamic shapes defaults to unspecializing, I just deleted this entirely; for the specialization case, I rely on regular static shape tests to catch it. (Hypothetically, we could also rerun all the tests with dynamic shapes, but WITH int/float specialization, but this seems... not that useful? I mean, I guess export wants it, but I'd kind of like our Source heuristic to improve enough that export doesn't have to toggle this either.)
* Only 0/1 integers get specialized by default now
* A hodgepodge of fixes. I'll comment on the PR about them.
Fixes https://github.com/pytorch/pytorch/issues/95469
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95621
Approved by: https://github.com/jansel, https://github.com/Chillee
Fixes#95781.
The cause seems to be that the current implementation doesn't correctly pass `found_inf` when `grad_scale` is `None`. Therefore parameters can get mistakenly updated by gradients whose some elements are invalid, i.e. nan or inf.
Related #94060
I forgot about this wrong handling after #94344
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95847
Approved by: https://github.com/janeyx99
Finding out what the inductor configs mean has been a confusing point for the community so creating some top level functions that just print them out to console if people don't wanna muck around the source code
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95824
Approved by: https://github.com/jansel
Summary:
implement zeros function inside DTensor API
- user specify the zeros tensor shape, and the function will create local zero tensor given the placement information
Test Plan:
{F889157756} - unit test for util function for compute_local_tensor_size
- unit test for _tensor.zeros
Reviewed By: wanchaol
Differential Revision: D43630718
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95863
Approved by: https://github.com/wanchaol
This implements all reduce ops in all_reduce and a PG being used from a thread different than the one that created it.
We should be this >< close to getting complex training tests working.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95524
Approved by: https://github.com/H-Huang
Run more tests through pytest.
Use a block list for tests that shouldn't run through pytest. As far as I can tell, the number of tests run, skipped, and xfailed for those not on the blocklist are the same.
Regarding the main module:
Usually tests are run in CI, we call `python <test file>`, which causes the file to be imported under the module name `__main__`. However, pytest searches for the module to be imported under the file name, so the file will be reimported. This can cause issues for tests that run module level code and change global state, like test_nn, which modifies lists imported from another file, or tests in test/lazy, which initialize a backend that cannot coexist with a second copy of itself.
My workaround for this is to run tests from the `__main__` module. However, this results in pytest being unable to rewrite assertions (and possibly other things but I don't know what other things pytest does right now). A better solution might be to call `pytest <test file>` directly and move all the code in run_tests(argv) to be module level code or put it in a hook in conftest.py.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95844
Approved by: https://github.com/huydhn
**Summary**
Linear is decomposed to `t - addmm/mm` after `dynamo.export`. And weight's observer is inserted between `t` and `addmm/mm` in the first place. `_rearrange_weight_observer_for_addmm()` is then called to move the observer between weight and `t`.
```
before:
weight - t - observer \
input - observer - addmm/mm
after:
weight - observer - t \
input - observer - addmm/mm
```
We found two issues of `_rearrange_weight_observer_for_addmm()`:
- It does not call `m.recompile()` in the end, so it does not function correctly.
- It does not support `aten.mm.default` which is from decomposed linear without bias.
This PR fixes the two issues and renames the function to `_rearrange_weight_observer_for_decomposed_linear`.
**Test plan**
python test/test_quantization.py -k test_rearrange_weight_observer_for_decomposed_linear
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94296
Approved by: https://github.com/jgong5, https://github.com/andrewor14
Summary: The AOT mode currently works for the CPP backend. When turned on, Inductor compiles the model code into a .so file with aot_inductor_entry as the entry function. If the AOT compilation fails, Inductor will explicitly fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94822
Approved by: https://github.com/jansel
Inductor implementations of collectives/wait must match
eager impls in _functional_collectives in terms of interacting
with _register_tensor_work API. If they do, then splitting
a collective-wait pair so one half is in a compiled graph should
work fine.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95893
Approved by: https://github.com/kumpera
These warnings are disabled to avoid long log on Windows tests. They are also disabled on CMake buildings currently.
'/wd4624': MSVC complains "destructor was implicitly defined as delete" on c10::optional and other templates
'/wd4076': "unexpected tokens following preprocessor directive - expected a newline" on some header
'/wd4068': "The compiler ignored an unrecognized [pragma]"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95933
Approved by: https://github.com/ezyang
Changes:
1. Use class inheritance for `torch/return_types.pyi`:
Before:
```python
max = NamedTuple("max", [("values", Tensor), ("indices", Tensor)])
```
After:
```python
class max(NamedTuple):
values: Tensor
indices: Tensor
```
------
2. Add missing spaces in generated type annotations.
1. Always has a space after `,`.
2. If an argument is annotated, then there need spaces around `=` when it has a default value.
```diff
- def func(..., out: Optional[Tensor]=None, ...) -> Tensor:
+ def func(..., out: Optional[Tensor] = None, ...) -> Tensor:
```
3. If an argument is not annotated, then there should be no spaces around `=` when it has a default value.
```python
def contiguous(self, memory_format=torch.contiguous_format) -> Tensor: ...
```
------
3. ~Remove redundant import alias in `torch/nn/functional.pyi`:~ (Reverted)
UPDATE: `mypy` needs the alias to work.
Before:
```python
from .. import conv1d as conv1d
from .. import conv2d as conv2d
from .. import conv3d as conv3d
from .. import conv_transpose1d as conv_transpose1d
from .. import conv_transpose2d as conv_transpose2d
from .. import conv_transpose3d as conv_transpose3d
from .. import conv_tbc as conv_tbc
from .. import avg_pool1d as avg_pool1d
from .. import relu_ as relu_
from .. import selu_ as selu_
from .. import celu_ as celu_
from .. import rrelu_ as rrelu_
from .. import pixel_shuffle as pixel_shuffle
from .. import pixel_unshuffle as pixel_unshuffle
from .. import channel_shuffle as channel_shuffle
from .. import native_channel_shuffle as native_channel_shuffle
from .. import pdist as pdist
from .. import cosine_similarity as cosine_similarity
```
After:
```python
from .. import (
conv1d,
conv2d,
conv3d,
conv_transpose1d,
conv_transpose2d,
conv_transpose3d,
conv_tbc,
avg_pool1d,
relu_,
selu_,
celu_,
rrelu_,
pixel_shuffle,
pixel_unshuffle,
channel_shuffle,
native_channel_shuffle,
pdist,
cosine_similarity,
)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95877
Approved by: https://github.com/ezyang
Overall, an example usage. Note that this *also* captures backwards FLOPs.
```
import torchvision.models as models
import torch
from torch.utils.flop_counter import FlopCounterMode
inp = torch.randn(1, 3, 224, 224, device='cpu')
mod = models.resnet18()
flop_counter = FlopCounterMode(mod, depth=1)
with flop_counter:
mod(inp).sum().backward()
```
<img width="326" alt="image" src="https://user-images.githubusercontent.com/6355099/222023068-3491e405-f195-4e11-b679-36b19a1380c7.png">
You can control the depth of the module hierarchy with the `depth` attribute (which defaults to 2). For example, if I don't limit it, this is what it outputs.
<img width="366" alt="image" src="https://user-images.githubusercontent.com/6355099/222023306-3d880bb6-f534-4f98-bf10-83c4353acefc.png">
## Other APIs
FlopCounterMode(custom_mapping=...): Allows for custom flop counting functions
FlopCounterMode.get_table(depth=...): Explicitly get the table as a string
FlopCounterMode.flop_counts: Contains the flop information as a Dict[hierarchy: str, Dict[Op, int]]
FlopCounterMode.register_hierarchy(f, name): Allows you to register additional "hierarchies" for a function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95751
Approved by: https://github.com/ngimel, https://github.com/albanD
Fixes for PyTorch/XLA functionalization integration
---
Some notable changes include:
- More asserts in `FunctionalTensorWrapper`, so bugs show up more cleanly in cases where we e.g. forget to wrap an output
- Make the *_scatter ops `CompositeExplicitAutogradNonFunctional`, so we get a better error message and XLA doesn't accidentally try to us them
- Fix LTC/XLA codegen in core to handle multi-tensor out= ops with no returns
- Better erroring: Allow XLA to use the CPU fallback from core in a way so that it always errors on view ops, which XLA should no longer see.
- Update MetaConverter to exclude XLA tensors in raising NotImplemented…
- Add `_propagate_xla_data` op
- Add meta tensor support for some ops
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94537
Approved by: https://github.com/bdhirsh
Context: We want to create a metric panel to track external contributions to the PyTorch repo
This PR creates a daily job to track how many external contributions occurred the day before and uploads it to a s3 collection which is accessible by rockset.
`upload_external_contrib_stats.py` is a python script which grabs the neccesary stats from github and sticks them into an s3 bucket. It is used here to do daily uploads, but can generally be used for larger queries as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95747
Approved by: https://github.com/huydhn, https://github.com/kit1980
This is relanding the troubling part of #95009 that caused a regression.
BC: This changes the signature and semantics of DeviceMesh::all_reduce.
DeviceMesh::all_reduce now uses a functional collective under the hood which makes it more easily traceable.
You no longer need to use CommTensor to get a trace.
all_reduce now is async only and uses AsyncCollectiveTensor to ensure proper stream synchronization.
Signature changed: removed async_op param and changes return type from Optional[Work] to torch.Tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95804
Approved by: https://github.com/fegin
Context: We want to create a metric panel to track external contributions to the PyTorch repo
This PR creates a daily job to track how many external contributions occurred the day before and uploads it to a s3 collection which is accessible by rockset.
`upload_external_contrib_stats.py` is a python script which grabs the neccesary stats from github and sticks them into an s3 bucket. It is used here to do daily uploads, but can generally be used for larger queries as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95747
Approved by: https://github.com/huydhn, https://github.com/kit1980
Fixes#95794
This is a hotfix for decomposition only (that is currently used by inductor), reference still accesses invalid indices. Perhaps `_nll_loss_nd` and this decomp should be unified, cc @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire @lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95833
Approved by: https://github.com/lezcano, https://github.com/Chillee
Big OOP correction continued. Also added a test this time to verify the defaulting was as expected.
The key here is realizing that the grouping for foreach already assumes that the non-param tensorlists follow suit in dtype and device, so it is too narrow to check that _all_ tensors were on CUDA. The main leeway this allowed was state_steps, which are sometimes cpu tensors. Since foreach _can_ handle cpu tensors, this should not introduce breakage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95820
Approved by: https://github.com/albanD
MPS in macOS13.3 has added support for int64 in reduction ops / cumsum / sort / argsort. This change removes the hard-coded casts and error messages prior macOS 13.3, allowing the op to run natively with int64.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95817
Approved by: https://github.com/kulinseth
Changes:
- #95200
1. Recognize `.py.in` and `.pyi.in` files as Python in VS Code for a better development experience.
2. Fix deep setting merge in `tools/vscode_settings.py`.
- #95267
3. Use `Namedtuple` rather than `namedtuple + __annotations__` for `torch.nn.utils.rnn.PackedSequence_`:
`namedtuple + __annotations__`:
```python
PackedSequence_ = namedtuple('PackedSequence_',
['data', 'batch_sizes', 'sorted_indices', 'unsorted_indices'])
# type annotation for PackedSequence_ to make it compatible with TorchScript
PackedSequence_.__annotations__ = {'data': torch.Tensor, 'batch_sizes': torch.Tensor,
'sorted_indices': Optional[torch.Tensor],
'unsorted_indices': Optional[torch.Tensor]}
```
`Namedtuple`: Python 3.6+
```python
class PackedSequence_(NamedTuple):
data: torch.Tensor
batch_sizes: torch.Tensor
sorted_indices: Optional[torch.Tensor]
unsorted_indices: Optional[torch.Tensor]
```
- => this PR: #95268
4. Sort import statements and remove unnecessary imports in `.pyi`, `.pyi.in` files.
5. Format `.pyi`, `.pyi.in` files and remove unnecessary ellipsis `...` in type stubs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95268
Approved by: https://github.com/huydhn
This should be self containable to merge but other stuff that's been bugging me is
* Instructions on debugging IMA issues
* Dynamic shape instructions
* Explaining config options better
Will look at adding a config options doc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95802
Approved by: https://github.com/svekars
To align with upstream, we are requiring triton dependency to be between 2.0.0 and 2.1. This will allow PyTorch 2.0 on ROCM to stay flexible enough to pick up any performance/stability improvements from Triton, without needing to cut a separate PyTorch version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95793
Approved by: https://github.com/huydhn
Try to cancel previous commits to avoid wasted runs on older commits. Not sure if a different user's push would cancel an ongoing job.
Currently multiple commits from the same open PR would be running, even though most likely the latest commit's status is of interest.
This tries to see if old workflows could get cancelled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95807
Approved by: https://github.com/huydhn
Changes:
- #95200
1. Recognize `.py.in` and `.pyi.in` files as Python in VS Code for a better development experience.
2. Fix deep setting merge in `tools/vscode_settings.py`.
- => this PR: #95267
3. Use `Namedtuple` rather than `namedtuple + __annotations__` for `torch.nn.utils.rnn.PackedSequence_`:
`namedtuple + __annotations__`:
```python
PackedSequence_ = namedtuple('PackedSequence_',
['data', 'batch_sizes', 'sorted_indices', 'unsorted_indices'])
# type annotation for PackedSequence_ to make it compatible with TorchScript
PackedSequence_.__annotations__ = {'data': torch.Tensor, 'batch_sizes': torch.Tensor,
'sorted_indices': Optional[torch.Tensor],
'unsorted_indices': Optional[torch.Tensor]}
```
`Namedtuple`: Python 3.6+
```python
class PackedSequence_(NamedTuple):
data: torch.Tensor
batch_sizes: torch.Tensor
sorted_indices: Optional[torch.Tensor]
unsorted_indices: Optional[torch.Tensor]
```
- #95268
4. Sort import statements and remove unnecessary imports in `.pyi`, `.pyi.in` files.
5. Format `.pyi`, `.pyi.in` files and remove unnecessary ellipsis `...` in type stubs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95267
Approved by: https://github.com/janeyx99
Changes:
- => this PR: #95200
1. Recognize `.py.in` and `.pyi.in` files as Python in VS Code for a better development experience.
2. Fix deep setting merge in `tools/vscode_settings.py`.
- #95267
3. Use `Namedtuple` rather than `namedtuple + __annotations__` for `torch.nn.utils.rnn.PackedSequence_`:
`namedtuple + __annotations__`:
```python
PackedSequence_ = namedtuple('PackedSequence_',
['data', 'batch_sizes', 'sorted_indices', 'unsorted_indices'])
# type annotation for PackedSequence_ to make it compatible with TorchScript
PackedSequence_.__annotations__ = {'data': torch.Tensor, 'batch_sizes': torch.Tensor,
'sorted_indices': Optional[torch.Tensor],
'unsorted_indices': Optional[torch.Tensor]}
```
`Namedtuple`: Python 3.6+
```python
class PackedSequence_(NamedTuple):
data: torch.Tensor
batch_sizes: torch.Tensor
sorted_indices: Optional[torch.Tensor]
unsorted_indices: Optional[torch.Tensor]
```
- #95268
4. Sort import statements and remove unnecessary imports in `.pyi`, `.pyi.in` files.
5. Format `.pyi`, `.pyi.in` files and remove unnecessary ellipsis `...` in type stubs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95200
Approved by: https://github.com/janeyx99
A PR to generate benchmark code for individual triton kernels. We can explore improving autotuning with the saved compiled kernel directly. This potentially can speedup our iteration and separate the concern with the upstream components that generate the compiled module.
Since I'm still ramping up on inductor, I'll reflect what I learned here so people can correct me if I'm wrong. In inductor, WrapperCodeGen class is used to generate the compiled module for CUDA (or triton). Here is an example compiled module for a toy model like: `def f(x): return sin(x) + cos(x)` https://gist.github.com/shunting314/c6ed9f571919e3b414166f1696dcc61b . A compiled module contains the following part:
- various triton kernels
- a wrapper (or a method named call . The name is hardcoded) that calls the triton kernels and potentially ATen kernels to efficiently do the same work as the original Fx graph being compiled by inductor
- some utility code that generate random inputs and run the wrapper
The triton kernels in the compiled module are annotated with decorator like pointwise which is used for autotuning.
This PR add a config so enabling it will just trigger the path of the compiled module being printed. It can be controlled from environment variable as well.
The path to each compiled triton kernel is added as comment in the compiled module. E.g.
```
# kernel path: /tmp/torchinductor_shunting/gn/cgn6x3mqoltu7q77gjnu2elwfupinsvcovqwibc6fhsoiy34tvga.py
triton__0 = async_compile.triton('''
import triton
import triton.language as tl
...
""")
````
Example command:
```
TORCHINDUCTOR_OUTPUT_COMPILED_MODULE_PATH=1 TORCHINDUCTOR_BENCHMARK_KERNEL=1 python benchmarks/dynamo/huggingface.py --backend inductor --amp --performance --training --dashboard --only AlbertForMaskedLM --disable-cudagraphs
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95506
Approved by: https://github.com/Chillee
Summary: Currently running PyTorch tests with dynamo and inductor is
controlled by environment variables, and CI sets them based on test
config name matching. Change them to use options of run_test.py.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94539
Approved by: https://github.com/huydhn
We have plenty of runners now, let's use them for compilation as well.
To achieve that, remove `xcode-version: "13.3.1"` property and tweak Metal framework detection logic to work with command line tools(which are installed in `/Library/Developer/CommandLineTools`) and SDK is in `/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk`) rather than full Xcode installation.
TODO: Fix/enable OpenMP accelerated native builds (which are currently broken with `OMP: Error #15: Initializing libomp.dylib, but found libomp.dylib already initialized.`), but this matches existing behavior as cross-builds are compiled with OpenMP disabled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95719
Approved by: https://github.com/huydhn
this change will reduce the layer size as it will not save the layers also it will build cleaner on other machines as it won't ask for a user interaction when running the build
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95375
Approved by: https://github.com/ezyang
This generates compilable code for maskrcnn graph 13, with ceilings hoisted to be computed on the host. But it now fails with
```
File "/scratch/ngimel/work/pytorch/torch/_dynamo/symbolic_convert.py", line 379, in wrapper
self.output.compile_subgraph(self, reason=reason)
File "/scratch/ngimel/work/pytorch/torch/_dynamo/output_graph.py", line 562, in compile_subgraph
pass1.foreach(stack_values)
File "/scratch/ngimel/work/pytorch/torch/_dynamo/codegen.py", line 166, in foreach
self(i)
File "/scratch/ngimel/work/pytorch/torch/_dynamo/codegen.py", line 148, in __call__
output.extend(value.reconstruct(self))
File "/scratch/ngimel/work/pytorch/torch/_dynamo/variables/dicts.py", line 40, in reconstruct
codegen.create_load_python_module(collections),
TypeError: create_load_python_module() missing 1 required positional argument: 'push_null'
from user code:
File "/scratch/ngimel/work/env/lib/python3.9/site-packages/torchvision-0.15.0a0+928b05c-py3.9-linux-x86_64.egg/torchvision/models/detection/backbone_utils.py", line 58, in forward
x = self.fpn(x)
```
looks like we never execute this `create_load_python_module()` path for other subgraphs.
Any advice on how to fix this @voznesenskym @jansel ?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95690
Approved by: https://github.com/jansel
**Summary**: This PR adds C++ stacktraces to jit::ErrorReports. After this PR, if you run with `TORCH_SHOW_CPP_STACKTRACES=1` environment variable and a jit::ErrorReport is thrown, then the C++ stacktrace should be displayed.
**More background**: This behavior already occurs for c10::Error; but not for jit::ErrorReport. jit::ErrorReport _does_ usually have a python stacktrace for the python source, but it is sometimes still helpful to know where in the C++ codebase the error came from.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94842
Approved by: https://github.com/qihqi
Part of my effort to move everything to pytest and decrease the number of testrunner frameworks in ci
Gives xmls but they might look a weird b/c module level tests vs tests in classes.
Doesn't give skip/disable test infra because those are tied to classes. (for future ref, could either put tests in classes or move the check_if_enable stuff into a pytest hook)
Tested in CI and checked that the same number of tests are run
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95659
Approved by: https://github.com/huydhn
See a bunch of timeout error when trying to clone and build Triton today c6d8d10b3e, so let's build triton as part of the Docker image.
* The pinned commit file is moved to the Docker context at `.ci/docker/ci_commit_pins/triton.txt`, and `.github/ci_commit_pins/triton.txt` is now a soft link pointing to it
* New Docker images are built whenever the pinned commit is updated
* The build logic is in `.ci/docker/common/install_triton.sh` which copies `install_triton` step in the CI. The latter can be removed in a separate PR after this one
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95233
Approved by: https://github.com/weiwangmeta, https://github.com/malfet
The value from the PR info includes only unique files != The number of files changed (both are technically correct, depending on how you view it)
I'm trying to merge this PR https://github.com/pytorch/pytorch/pull/95233 which makes `.github/ci_commit_pins/triton.txt` a softlink. So the PR includes 2 changes to that file 1) to delete the file and 2) to add it as a symlink.
```
[
".ci/docker/build.sh",
".ci/docker/ci_commit_pins/triton.txt",
".ci/docker/common/common_utils.sh",
".ci/docker/common/install_triton.sh",
".ci/docker/requirements-ci.txt",
".ci/docker/ubuntu-cuda/Dockerfile",
".ci/docker/ubuntu/Dockerfile",
".github/ci_commit_pins/triton.txt", <--
".github/ci_commit_pins/triton.txt", <--
".github/workflows/build-triton-wheel.yml"
]
```
Trymerge doesn't like that and rejects the merge due to `Changed file count mismatch` https://github.com/pytorch/pytorch/actions/runs/4295438799/jobs/7485853815 . This is because the PRInfo GraphQL result from GitHub only counts 9 of them https://paste.sh/zVsOnWoT#p_3RKX_VMjj-e71vwsTeA01W (search for `changedFiles`). It means that the name are dedup, so that only unique file names are counted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95720
Approved by: https://github.com/kit1980, https://github.com/malfet, https://github.com/ZainRizvi
The 2MB thp pages provide better allocation latencies compared to the standard 4KB pages. This change has shown significant improvement for batch mode usecases where the tensor sizes are larger than 100MB.
Only enabled if `THP_MEM_ALLOC_ENABLE` environment variable is set.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93888
Approved by: https://github.com/jgong5, https://github.com/malfet
Summary:
Previously we assumed asymmetric quantization for dynamic quantization, this diff adds the support of symmetric quantization
for the input in dynamic quantization
Test Plan: buck run executorch/exir/tests:quant_lowering_custom_backend_pass -- "executorch.exir.tests.test_quant_lowering_custom_backend_pass.TestQuantLoweringCustomBackendPass.test_quantized_linear_dynamic"
Reviewed By: digantdesai
Differential Revision: D43134794
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94854
Approved by: https://github.com/digantdesai
# Summary
Previously, for NestedTensor inputs flash_attention was disabled due to an Illegal Memory Access error that was occurring on the "cutlass" branch of flash-attention that had be incorporated into core. Since we have switched to the main branch of flash_attention we the existing repro script did not produce the same memory error. This PR re-enables the FlashAttention Path for NTs. As well it unifies the nested preprocessing between the two implementations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95438
Approved by: https://github.com/mikaylagawarecki
### Motivation
Add `prelu` to lower precision cast policy on AutocastCPU to fix https://github.com/pytorch/pytorch/issues/95365 :
Before: Within the scope of torch.cpu.amp.autocast(dtype=torch.bfloat16) , `prelu` cannot address the scenario of different datatypes of `input` and `weight`, will get a RuntimeError. This scenario is common in autocast, e.g, with `autocast` to `bf16`, if the `op` before `prelu` comes out a `bf16` output, which is the input of `prelu`, and `prelu's` weight is `fp32`, then it will get a RuntimeError.
After: Within the scope of torch.cpu.amp.autocast(dtype=torch.bfloat16) , prelu be forced to run with `bf16` data type.
Before https://github.com/pytorch/pytorch/pull/91238, when input is `bf16`, weight will be forced to cast to `bf16`. After https://github.com/pytorch/pytorch/pull/91238, this kind of test scenario will raise a RuntimeError. There is no precision loss since the workable one is also casting to `bf16`.
And this also alighs with Autocast CUDA whitelist.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95366
Approved by: https://github.com/ngimel, https://github.com/lezcano, https://github.com/leslie-fang-intel
Fixes#79348
This change is mostly focused on enabling nvcc+sccache in the PyTorch CI.
Along the way we had to do couple tweaks:
1. Split the rules_cc from the rules_cuda that embeeded them before. This is needed in order to apply a different patch to the rules_cc compare to the one that rules_cuda does by default. This is in turn needed because we need to workaround an nvcc behavior where it doesn't send `-iquote xxx` to the host compiler, but it does send `-isystem xxx`. So we workaround this problem with (ab)using `-isystem` instead. Without it we are getting errors like `xxx` is not found.
2. Workaround bug in bazel https://github.com/bazelbuild/bazel/issues/10167 that prevents us from using a straightforward and honest `nvcc` sccache wrapper. Instead we generate ad-hock bazel specific nvcc wrapper that has internal knowledge of the relative bazel paths to local_cuda. This allows us to workaround the issue with CUDA symlinks. Without it we are getting `undeclared inclusion(s) in rule` all over the place for CUDA headers.
## Test plan
Green CI build https://github.com/pytorch/pytorch/actions/runs/4267147180/jobs/7428431740
Note that now it says "CUDA" in the sccache output
```
+ sccache --show-stats
Compile requests 9784
Compile requests executed 6726
Cache hits 6200
Cache hits (C/C++) 6131
Cache hits (CUDA) 69
Cache misses 519
Cache misses (C/C++) 201
Cache misses (CUDA) 318
Cache timeouts 0
Cache read errors 0
Forced recaches 0
Cache write errors 0
Compilation failures 0
Cache errors 7
Cache errors (C/C++) 7
Non-cacheable compilations 0
Non-cacheable calls 2893
Non-compilation calls 165
Unsupported compiler calls 0
Average cache write 0.116 s
Average cache read miss 23.722 s
Average cache read hit 0.057 s
Failed distributed compilations 0
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95528
Approved by: https://github.com/huydhn
Fixed following errors in contribution guide.
"deep neural networks using a **on** tape-based autograd systems." to "deep neural networks **using a tape-based** autograd systems."
"the best entrance **point** and are great places to start." to "the best entrance **points** and are great places to start."
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95454
Approved by: https://github.com/ezyang
This PR fixes 2 `DeprecationWarning` instances:
```
python3.8/site-packages/torch/utils/tensorboard/__init__.py:4
/home/stas/anaconda3/envs/py38-pt113/lib/python3.8/site-packages/torch/utils/tensorboard/__init__.py:4: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
if not hasattr(tensorboard, "__version__") or LooseVersion(
python3.8/site-packages/torch/utils/tensorboard/__init__.py:6
/home/stas/anaconda3/envs/py38-pt113/lib/python3.8/site-packages/torch/utils/tensorboard/__init__.py:6: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
) < LooseVersion("1.15"):
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95545
Approved by: https://github.com/ezyang
This is WIP PR for adding torch.export API in OSS. Couple of points:
- I intentionally named it as experimental_export so that ppl don't get confused thinking this is our official API
- We don't plan to use AOTAutograd backend just yet. The reason we have it here is because the functionalization AOTAutograd uses is what we need for export (handling of param/buffer mutation etc). In the near future, I will extract the functionalization part and use it on top of make_fx. What we have right now is merely a placeholder.
- The reason we want to do it now is because we want to have some minimal tests running in OSS so that we can catch regressions earlier.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95070
Approved by: https://github.com/gmagogsfm, https://github.com/zhxchen17
This PR allows us to reuse the static per tensor decision making we make at fake tensorification time. We can use this to avoid setting up dynamic dim guards later if the tensor was never a candidate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95566
Approved by: https://github.com/ezyang
**Summary**: jit.trace usually adds shape information to all the jit::Values in its graph. This is mostly a side effect of how jit tracing is performed, but many users use this behavior for debugging and for better understanding the graph. Previously, CallFunction nodes (inserted by calling jit.script-ed functions) did _not_ have this information attached. This PR attaches this information for the tensor output values.
**Details**:
* First the jit tracer sets a global TracerState object
* Then the jit tracer invokes the python callable that is to be traced
* When the python function gets to a jit.script-ed function, [invokeScriptFunctionFromPython](8693604bc6/torch/csrc/jit/python/pybind_utils.h (L1060)) is called. It inserts a FunctionCall.
* Then after the actual scripted function gets called and we have a concrete output, we attach the concrete output [IValue to the TracerState](8693604bc6/torch/csrc/jit/python/pybind_utils.h (L1001))
* ^^ the setValueTrace call (linked in previous list item) is where this PR makes changes; we revise the jit::Value output of the CallFunction node to use the type of the concrete tensor, which will have actual shapes associated.
**Test**: added a test verifying that shape info appears in the output type for a CallFunction node in a jit-traced graph.
Differential Revision: [D43592880](https://our.internmc.facebook.com/intern/diff/D43592880)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95544
Approved by: https://github.com/qihqi
Add _int_mm primitive that binds cuBLAS int8@int8 -> int32 matmul and that translates to Triton based mm templates under max autotune. This is a very useful first step towards better supporting quantization on the GPU. This is a not a user facing API, but an internal primitive.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94339
Approved by: https://github.com/ngimel, https://github.com/jansel
Fixes #ISSUE_NUMBER
when I want to override some operators for new backend, this warning message will print for every op, the message is to much. So just print once for all operators.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95179
Approved by: https://github.com/bdhirsh
Summary: When running the benchmark test with --accuracy, two eager runs
should return the same result. If not, we want to detect it early, but
comparing against fp64_output may hide the non-deterministism in eager.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95616
Approved by: https://github.com/ZainRizvi
Previous usage gave this error:
```
f.write(g.get_dot_graph().create_svg())
TypeError: write() argument must be str, not bytes
```
pydot has function to save to different types, e.g. `save_svg()`. I updated the usage doc working code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95534
Approved by: https://github.com/ezyang
This PR do two things:
1. It moves some Windows warning suppression from various CMake files into the main CMakeList.txt, following the conventions of gcc and clang.
2. It fixes some Windows warnings in the source code. Most importantly, it fixes lots of dll warnings by adjusting C10_API to TORCH_API or TORCH_PYTHON_API. There are still some dll warnings because some TORCH_API functions are actually built as part of libtorch_python
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94927
Approved by: https://github.com/malfet
Summary: Title, the mapping currently has lots of unused keys due to the condition or always return True, but it will not affect the correctness.
Test Plan: N/A
Differential Revision: D43579510
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95493
Approved by: https://github.com/Skylion007
Summary: The existing util function did not quantize all inner
ops in the quantizable LSTM module, resulting in the error
"Could not run X with arguments from the 'QuantizedCPU' backend."
This commit fixes this by ensuring that all the other ops whose
qparams were not specifically configured are still quantized as
before, as in `torch.ao.nn.quantizable.LSTM.from_float`.
Test Plan: This commit also adds an additional check in the test
to ensure that the final converted model is in fact quantized,
in addition to just checking the qparams in the observers have
the right values.
python test/test_quantization.py TestQuantizeFx.test_static_lstm_with_custom_fixed_qparams
Reviewers: vkuzo
Subscribers: vkuzo, supriyar
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95537
Approved by: https://github.com/vkuzo
Reuse the cpu implementation here as currently there is no native roll implementation from the MPS api (if any, please let me know).
Compared to falling back to cpu using `PYTORCH_ENABLE_MPS_FALLBACK=1`, this way we keep tensors on MPS.
Did a small benchmark:
```python
for num in [10, 100, 1000, 10000]:
for shft in [1, 5]:
sz = num * num
x = torch.arange(sz, device="cpu").view(num, num)
s = time.time()
r = torch.roll(x, shft)
cpu_e = time.time() - s
x = torch.arange(sz, device="mps").view(num, num)
s = time.time()
r = torch.roll(x, shft)
mps_e = time.time() - s
print(f"size: ({num}, {num}) shft: {shft} cpu: {cpu_e} mps: {mps_e}")
```
```
size: (10, 10) shft: 1 cpu: 0.00015163421630859375 mps: 0.003078937530517578
size: (10, 10) shft: 5 cpu: 6.794929504394531e-05 mps: 0.0014979839324951172
size: (100, 100) shft: 1 cpu: 0.0001621246337890625 mps: 0.0016200542449951172
size: (100, 100) shft: 5 cpu: 0.00016379356384277344 mps: 0.00154876708984375
size: (1000, 1000) shft: 1 cpu: 0.0022068023681640625 mps: 0.0017690658569335938
size: (1000, 1000) shft: 5 cpu: 0.009071111679077148 mps: 0.0020020008087158203
size: (10000, 10000) shft: 1 cpu: 0.16785407066345215 mps: 0.011695146560668945
size: (10000, 10000) shft: 5 cpu: 0.1160881519317627 mps: 0.011452913284301758
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95168
Approved by: https://github.com/albanD
Currently, if we multiply a transposed batch of matrices with shape
[b, m, n] and a matrix with shape [n, k], when computing the gradient
of the matrix, we instantiate a matrix of shape [b, n, k]. This may be
a very large matrix. Instead, we fold the batch of matrices into a
matrix, which avoids creating any large intermediary tensor.
Note that multiplying a batch of matrices and a matrix naturally occurs
within an attention module, so this case surely happens in the wild.
In particular, this issue was found while investigating the OOMs caused by the
improved folding algorithm in the next PR of this stack. See https://github.com/pytorch/pytorch/pull/76828#issuecomment-1432359980
This PR fixes those OOMs and decreases the memory footprint of the
backward of matmul.
I understand this is a tricky one, so I put it on its own PR to discuss it.
Differential Revision: [D43541495](https://our.internmc.facebook.com/intern/diff/D43541495)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95261
Approved by: https://github.com/ezyang
Add `mps_ops_modifier` function that adds `unittest.expectedFailure` decorators to the operators that supposed to fail on MPS.
This allows one to know whether or not operation will fail, rather than skip it.
For example:
```
% python test_mps.py -v -k test_output_match_dot
test_output_match_dot_cpu_float32 (__main__.TestConsistencyCPU) ... ok
test_output_match_dot_cpu_int16 (__main__.TestConsistencyCPU) ... ok
test_output_match_dot_cpu_int32 (__main__.TestConsistencyCPU) ... ok
test_output_match_dot_cpu_int64 (__main__.TestConsistencyCPU) ... expected failure
test_output_match_dot_cpu_uint8 (__main__.TestConsistencyCPU) ... ok
----------------------------------------------------------------------
Ran 5 tests in 0.175s
OK (expected failures=1)
```
Moved a few functions from blocklist to xfail, and find out that some of the functions in the list actually work, for example `torch.long`.
Also, allow `None` to be used in `ALLOWLIST` instead of specifying all types explicitly (which aligns with `DecorateInfo` semantic)
Eventually, we should get rid of `ALLOWLIST` (i.e. all ops are allowed), keep small `BLOCKLIST` and move the rest to `XFAILLIST`
Add step to print HW/SW info before running MPS tests.
Fix type promotion in `trace_mps_out`
Introduce `MACOS_12_X_XFAILLIST` and skip almost every function for `torch.uint8`, although some of those doesn't make much sense and feels like a regression from PyTorch-1.13
Re-enabled MPS testing on MacOS 12, as runners seems to be available again
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95045
Approved by: https://github.com/albanD
The idea is to make it a little more obvious which branch you're going to go down in a subset of cases, and make it easier to detect if you've accidentally shadowed one condition with another (the reason I wrote this in the first place.) The type dictionary also makes it harder for people to accidentally use isinstance when they should have used istype.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95476
Approved by: https://github.com/jansel
Fixes issues with things like:
```python
x = 2
x += y.shape[0]
```
resulting in invalid `2 += y.shape[0]` code in the FX graph.
Fix: Whenever dynamic shapes are involved, insert the out-of-place op to the FX graph instead of the in-place op.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95446
Approved by: https://github.com/ezyang
The _make_boxed logic probably needs a cleanup, but this fixes a spurious warning that we should get in before the release.
Confirmed that this used to emit a warning and no longer does:
```
import torch
lin = torch.nn.Linear(100, 10)
def f(x):
return lin(x)
opt_f = torch.compile(f)
opt_f(torch.randn(10, 100, requires_grad=False))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95521
Approved by: https://github.com/ngimel
- The previous PR addressed one tree traversal in `_root_pre_forward()` but not the main one from `_get_fsdp_handles()` that runs for all settings.
- This PR saves `_all_handles` to cache `_get_fsdp_handles()` and `_all_fsdp_states` to cache `_get_fsdp_states()` (renamed from `_fsdp_states` compared to last PR) on the root state.
- This PR introduces a dummy `_RootFSDPState` class that inherits from `_FSDPState` to be used only for type checking since some attributes are only defined for root states.
- I found this approach to be better than adding `_p_assert(state.root_only_attr is not None, ...)` upon each usage of `root_only_attr`.
- This hopefully also helps readers to quickly see which attributes are defined only on root states.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95465
Approved by: https://github.com/fduwjj
Summary: A bisect blamed #93333 for GPU memory leakage. This diff backs it out.
Test Plan: Monitor max GPU memory usage to see if there's a leak.
Reviewed By: hyuen, yinbinm
Differential Revision: D43511893
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95565
Approved by: https://github.com/ngimel
In PR #93822 the `fx2trt` backend was removed which registered the `tensorrt` backend names to point to `fx2trt` / `torch_tensorrt` and move the name to `onnxrt`. We want to reserve the name `tensorrt` for `torch_tensorrt` to prevent any confusion but due to code-freeze we cannot complete the integration and set up testing for the next release. So we propose leaving out the `tensorrt` name until we can set up the backend and testing for it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94632
Approved by: https://github.com/frank-wei
It does not take a condition as first argument, unlike `TORCH_CHECK`
Test plan, run: ` python3 -c "import torch;print(torch.arange(1., 10.,device='mps').view(3, 3).trace())"` and observe no warning
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95559
Approved by: https://github.com/Skylion007
My intention is to collapse all of the istype() and isinstance() and object identity tests into a more structured form involving a dict lookup. To do this conveniently, I need every continuation to be expressible in a single expression. Thus, all multi-line wrap methods are moved. This is code motion only, no logic changes.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95472
Approved by: https://github.com/Skylion007
Some of these changes are semantics preserving, some are not. Please review carefully.
* Use `istype(x, y)` over `type(x) is y`
* Use istype over isinstance in frozenset. If the user subclassed the type in question, we must treat it as a user defined class as it may have custom behavior
* The `isinstance(value, (int, float))` condition for `wrap_unspecialized_primitive` is dead-ish; direct int/float values are caught earlier istype check. Technically however, if you subclassed int/float it would pass through, however this is almost assuredly not intended behavior
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95471
Approved by: https://github.com/Skylion007
Summary:
When performing inference using the Core ML delegate, memory is increasing indefinitely. This is due to Core ML allocating memory within `predictionFromFeatures:error:`. Seems that the autorelease pool does not release the return values from the prediction method until inference is stopped completely. So we need to release with `autoreleasepool` manually ([per Apple guidance in the Apple Developer Forums](https://developer.apple.com/forums/thread/692425)).
This commit wraps `autoreleasepool` around the `execute` function of `PTMCoreMLBackend`, which is the scope of where the return values of `predictionFromFeatures:error:` are. Also added in `PTMCoreMLExecutor` for good measure.
Differential Revision: D43520767
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95384
Approved by: https://github.com/mcr229
Summary:
Regression introduced in #91134 (github-exports-check calls git, which is not available internally at Meta).
Meta employees, see T145865943 for the context.
Test Plan: Unit tests, `github-export-checks` job.
Differential Revision: D43521051
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95345
Approved by: https://github.com/kit1980
We have an outage with MacOS m1 runner, so need to disable the job till next Monday where infra has capacity to look into the issue.
Note: Do we want to keep MPS tests on `macos-m1-13`? (As long as this new runners are still there)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95509
Approved by: https://github.com/clee2000
Summary:
This is part 1 of the effort to support `share_memory_()` in C++ aten library.
This allows C++ code to in place replace the tensor storage to shm based.
For now fd based shm is the only implementation supported to simplify memory management in general.
This first part intentionally avoids public api changes (to `TensorBase`, see comments in `StorageUtil.h`) such that we can get the core features usable outside pt/csrc first. The API addition to `Tensor` or `TensorBase` would involve more distracting changes and make the change harder to review.
Test Plan:
```
buck test caffe2:StorageUtils_test
```
Differential Revision: D43467616
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95228
Approved by: https://github.com/ezyang
Tweak dynamo behavior in 2 places when calling nn.Modules,
to route the call to __call__ instead of .forward(), since
__call__ is the codepath that eager users hit and will dispatch
to hooks correctly.
(1) inside NNModuleVariable.call_function, which covers the common case
of calling a module from code dynamo is already tracing
(2) at the OptimizedModule layer, which is the entrypoint
into a top-level nn.Module dynamo is about to compile
This exposes a new bug: NNModuleVariable used to special-case calling
module.forward() (which is a method) as a UserFunctionVariable with an extra
'self' arg. After tracing into module.__call__, there is no longer a special
case for the eventual call into .forward, and it gets wrapped in a
UserDefinedObjectVariable following standard behavior of ._wrap(). UDOV can't be
called, so this broke some tests.
- Fix: add a new special case in _wrap() that treats methods as a UserDefinedMethod
instead of UserDefinedObjectVariable. Now, the forward method can be called.
Also, fix NNModuleVar.call_method routing forward back to __call__
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92125
Approved by: https://github.com/ezyang, https://github.com/jansel, https://github.com/voznesenskym
BC: This changes the signature and semantics of DeviceMesh::all_reduce.
DeviceMesh::all_reduce now uses a functional collective under the hood which makes it more easily traceable.
You no longer need to use CommTensor to get a trace.
all_reduce now is async only and uses AsyncCollectiveTensor to ensure proper stream synchronization.
Signature changed: removed `async_op` param and changes return type from `Optional[Work]` to `torch.Tensor`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95009
Approved by: https://github.com/wanchaol
Fixes https://github.com/pytorch/serve/issues/1937
A fairly common query I see folks running while using pytorch is
`nvidia-smi --format=csv,noheader,nounits --query-gpu=utilization.gpu,utilization.memory,memory.total,memory.used,temperature.gpu,power.draw,clocks.current.sm,clocks.current.memory -l 10`
Existing metrics we have
* For kernel utilization`torch.cuda.utilization()`
* For memory utilization we have them under `torch.cuda.memory` the memory allocated with `torch.cuda.memory.memory_allocated()`
* For total available memory we have `torch.cuda.get_device_properties(0).total_memory`
Which means the only metrics we're missing are
* Temperature: now in `torch.cuda.temperature()`
* Power draw: now in `torch.cuda.power()`
* Clock speed: now in `torch.cuda.clock_speed()`
With some important details on each
* Clock speed settings: I picked the SM clock domain which is documented here https://docs.nvidia.com/deploy/nvml-api/group__nvmlDeviceEnumvs.html#group__nvmlDeviceEnumvs_1g805c0647be9996589fc5e3f6ff680c64
* Temperature: I use `pynvml.nvmlDeviceGetTemperature(handle, 0)` where 0 refers to the GPU die temperature
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91717
Approved by: https://github.com/ngimel
This removes the need to explicitly constrain_unify `x[mask]` and `y[mask]` when mask is a boolean tensor. It's very narrow but it seems to work in practice.
To invalidate the nonzero call when mutation occurs, I use version counter. I know there are ways to bypass this but I think it's good enough for now.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95399
Approved by: https://github.com/eellison
This takes the strategy described in https://docs.google.com/document/d/1lFRYAJo5nrfxRhwIzGnfi2pbLpU6T4ytSRSuLJ5qebI/edit#
It is essentially https://github.com/pytorch/pytorch/pull/95222 but squashed and with changes that are unnecessary given that we assume nonzero returns > 1.
What's in the PR:
* nonzero now supports meta propagation. When `capture_dynamic_output_shape_ops`, it will return a tensor with an unbacked SymInt representing the size in question.
* The unbacked SymInt is UNSOUNDLY assumed to be not equal to 0/1. We will still error if you guard otherwise.
* PrimTorch pointwise operators are updated to use empty_permuted, to avoid guarding on unbacked SymInt from empty_strided (tested in `test_dynamic_pointwise_scalar`)
* Convolution is updated to skip backend selection if batch is unbacked, to avoid guarding on unbacked SymInt (tested in `test_unbacked_batch_resnet`)
* I kept the helper utilities like `definitely_true` for working with possibly unbacked SymInts. They're not used right now but maybe someone will find them useful.
* Added `constrain_unify` to let you specify two unbacked SymInts must have the same value
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95387
Approved by: https://github.com/voznesenskym
Corrected the grammar of a sentence in "Implementing Features or Fixing Bugs" section of the contribution guide.
**Before:**
Issues that are labeled first-new-issue, low, or medium priority provide the best entrance point are great places to start.
**After:**
Issues that are labeled first-new-issue, low, or medium priority provide the best entrance point _and_ are great places to start.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93014
Approved by: https://github.com/albanD, https://github.com/kit1980
There is a fast way to implement a guard for an empty dict, which is to check its bool() value.
However, we can't use this guard in general, since we can only safely apply it at runtime if the runtime value actually is a dict (or, another type that works with 'bool' in the same way). A counterexample is when a tensor is passed instead of a dict, and throws on bool() operator.
So we can put a type check in the guard, but that is slow enough it defeats the purpose.
Instead, we note that for the case of NNModuleVariables (which are specialized NNModules not unspecialized ones), we already have a hook in place to invalidate the guards if setattr is called. I am claiming that setattr is the only way that the type of a property on an NNModule could change. If I'm right, then it's safe to (a) only use this guard for NNModuleVariables, (b) not do a type check inside the guard.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95248
Approved by: https://github.com/voznesenskym
Currently, in Vulkan 4D tensors are represented in GPU textures by simply combining the batch and channel dimensions into the depth axis. However, if the number of channels is not a multiple of 4, then data belonging to the same batch can cross texel boundaries.
For instance, consider a tensor with `N=2`, `C=3`. The depth axis of the texture would contain the data
```
|tex1|tex2|
-----------
|AAAB|BB00|
```
Where A represents data from `n=1`and B represents data form `n=2`.
This packing structure ("tight packing") makes some ops that care about batch boundaries more complex and inefficient to implement. Therefore this diff introduces channel padding when storing tensors as image textures.
The same tensor with `N=2`, `C=3` would now have the depth axis contain
```
|tex1|tex2|
-----------
|AAA0|BBB0|
```
Differential Revision: [D43068669](https://our.internmc.facebook.com/intern/diff/D43068669/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D43068669/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95251
Approved by: https://github.com/salilsdesai
As in the title. The bug was reported in https://github.com/pytorch/pytorch/pull/94728#discussion_r1108892366 and has the following reproducer:
```python
>>> import torch
>>> check_ctx = torch.sparse.check_sparse_tensor_invariants(True)
>>> no_check_ctx = torch.sparse.check_sparse_tensor_invariants(False)
>>> with check_ctx:
... assert torch.sparse.check_sparse_tensor_invariants.is_enabled()
... with no_check_ctx:
... assert not torch.sparse.check_sparse_tensor_invariants.is_enabled()
... assert torch.sparse.check_sparse_tensor_invariants.is_enabled()
...
Traceback (most recent call last):
File "<stdin>", line 5, in <module>
AssertionError
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95372
Approved by: https://github.com/cpuhrsch
Fix for weird bug that happens very rarely. My solution is to retrieve all checksuites before going to retrieve their checkruns.
Sometimes `cs_cursor=edges[edge_idx - 1]["cursor"] if edge_idx > 0 else None,` is None when it shouldn't be because of how we reset `checksuites = get_next_checksuites(checksuites)` on every loop.
Ex
page 1 of checksuites contains some stuff
page 2 of checksuites: pull {a bunch of checkruns}
cs_cursor gets set to none for the pull checksuite on page 2 because `checksuites = get_next_checksuites(checksuites)` resets the edges on every loop. Then the checkruns can't be retrieved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95333
Approved by: https://github.com/huydhn
Fixes#91694Fixes#92615
Several transpositions were missing for backward graph in case of `batch_first=True`. The #91694 is not reproduced with `batch_first=False`.
After fixing transpose issue, I finally thought that now I can use LSTM freely in my project. And then I got horrific results on train. Seems related to #92615.
After that I decided to fix LSTM's backward step completely. I collected all my findings in this thread — seems like I succeeded
Funny enough, backward tests were completely disabled before and were not passing:
```python
@unittest.skipIf(True, "Backward of lstm returns wrong result")
def test_lstm_2(self, device="mps", dtype=torch.float32):
```
UPD: forward pass of multi-layer version also was wrong due to the incorrect `initState, initCell` slices. Tests were passing because states were inited with zeros. *Accidentally* fixed this too
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95137
Approved by: https://github.com/jhavukainen, https://github.com/kulinseth, https://github.com/soulitzer
According to ngimel (and also noticed by me), printing
x1*s0**2 doesn't work correctly in Sympy as it complains
'<' not supported between instances of 'tuple' and 'str'
This is probably a Sympy bug but the real answer is subclassing
is more trouble than its worth and we ought not do it.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95313
Approved by: https://github.com/ngimel
It's common to call ```dict()``` or ```collections.OrderedDict()``` inside of ```forward``` function, so we should not graph break.
This pattern has been used in many places including:
* The use case in [torchvision](
928b05cad3/torchvision/models/_utils.py (L66-L73)).
* It causes ~100 model failures(nopython=True) in the 14k github models.
* Also it hits several Meta internal use cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95250
Approved by: https://github.com/jansel
Temporary Fix for #95312
In triton, 1 warp computes 16x16 tile of output, so for 32x32 block we only need 4 warps. 8 warps IMA, which is a bug, but it's not a good config anyway.
Triton main is supposed to have better behavior for these pathological, but we are not on main yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95339
Approved by: https://github.com/ezyang, https://github.com/Chillee
Summary: This change adds input shape when CoreML throws an errors.
Test Plan: testMCSModelInvalidInputShape tests that the assert throws when invalid input shapes are provided.
Differential Revision: D43449112
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95249
Approved by: https://github.com/mcr229
Summary:
bypass-github-export-checks
use `dinfo.name` instead of `repr(dinfo)`, as initial results have shown that `dinfo.total_memory` may unexpectedly fluctuate
Test Plan: sandcastle + CI
Differential Revision: D43503558
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95302
Approved by: https://github.com/bertmaher
This handles the disabling masks if numel is a multiple of BLOCK.
It currently introduces a performance regression, but the triton
it generates does not seem to have any issues: all the change does
is cause xmask to be removed from load/stores in cases where it safely
can be removed. It seems it must be coming from some issue in triton
optimizer.
FWIW, if you try this change with current triton master (instead of
pinned version) it does _not_ cause a performance regression.
However, upgradign to triton master by itself already causes
significant performance regressions so it's not an option
to just bump up the pin.
I'm going to leave this PR open until we manage to increase
the triton pin past the big refactoring. Once we do that
I will check if it still causes a performance regression.
UPDATE:
The triton pin has been moved and I retried this PR. As expected, there's no longer a performance regression for hf_Bert:
```
tspin python benchmarks/dynamo/torchbench.py --performance --backend inductor --float16 --training --batch-size-file $(realpath benchmarks/dynamo/torchbench_models_list.txt) --only hf_Bert -n 5 --diff-branch viable/strict 2> err
batch size: 16
cuda train hf_Bert numel_BLOCK 1.175x p=0.00
batch size: 16
cuda train hf_Bert viable/strict 1.161x p=0.00
```
Re-opening this, should be okay to merge now I expect.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92749
Approved by: https://github.com/jansel
I am still reading Dynamo source code...
This is an easy PR to simplify `Source.is_nn_module()` to reuse `GuardSource.is_nn_module()` instead of having the `in (...)` check implemented twice. While simplifying that, I thought I might as well add some type annotations for `Source` methods.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95292
Approved by: https://github.com/ezyang
Summary: attempt two at enabling search of global/local cache, regardless of `max_autotune`, by default. the main problem is that triton template generation seems to be broken in some cases for CI tests (maybe dynamic shapes), but this is going to take more time to figure out. for now, we can just cancel template generation instead of raising an assertion error and filter out those failed templates.
Test Plan: sandcastle + CI
Differential Revision: D43424922
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95134
Approved by: https://github.com/jansel
Running an operator registered in python returning a symint will result in the following error:
```
RuntimeError: Unable to cast Python instance of type <class 'torch.SymInt'> to C++ type 'long'
```
The interaction of 2 things make the issue being triggered:
- We use boxed kernel here. For boxed kernel, we need convert py::object to IValue in torch/csrc/autograd/python_variable.cpp pushPyOutToStack .
- In the schema parsing code in torch/csrc/jit/frontend/schema_type_parser.cpp SchemaTypeParser::parseFakeAndRealType , if a SymInt is found, we register a Int type instead (not sure why we do this), and register SymInt as the real type.
The result is we would convert an SymInt to int in pushPyOutToStack and cause the issue.
The fix is to use real type when we convert py::object to IValue.
BTW, registering the same op using C++ API does not trigger the issue.
```
TORCH_LIBRARY(clib, m) {
m.def("sqsum(SymInt a, SymInt b) -> SymInt", [](SymInt a, SymInt b) -> SymInt {
return a * a + b * b;
});
}
```
The reason is, the kernel registered in C++ is unboxed kernel and it does not trigger the code path above that converts an py::object to IValue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95240
Approved by: https://github.com/larryliu0820, https://github.com/ezyang
Rolling back the default change for Adam and rectifying the docs to reflect that AdamW never defaulted to fused.
Since our fused implementations are relatively newer, let's give them a longer bake-in time before flipping the switch for every user.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95241
Approved by: https://github.com/ngimel
An action item from https://github.com/pytorch/pytorch/issues/94346
Although the security practice of setting the checksum is good, it doesn't work when the archive is downloaded from some sites like GitHub because it can change. Specifically, GitHub gives no guarantee to keep the same value forever https://github.com/community/community/discussions/46034.
This also adds a new linter to make sure that SHA checksum from GitHub can be removed quickly. The WORKSPACE file is actually updated using the new linter:
```
>>> Lint for WORKSPACE:
Advice (BAZEL_LINTER) format
Redundant SHA checksum. Run `lintrunner -a` to apply this patch.
You can run `lintrunner -a` to apply this patch.
5 5 |
6 6 | http_archive(
7 7 | name = "rules_cuda",
7 |- sha256 = "f80438bee9906e9ecb1a8a4ae2365374ac1e8a283897281a2db2fb7fcf746333",
9 8 | strip_prefix = "runtime-b1c7cce21ba4661c17ac72421c6a0e2015e7bef3/third_party/rules_cuda",
10 9 | urls = ["b1c7cce21b.tar.gz"],
11 10 | )
--------------------------------------------------------------------------------
29 28 | name = "pybind11_bazel",
30 29 | strip_prefix = "pybind11_bazel-992381ced716ae12122360b0fbadbc3dda436dbf",
31 30 | urls = ["992381ced7.zip"],
31 |- sha256 = "3dc6435bd41c058453efe102995ef084d0a86b0176fd6a67a6b7100a2e9a940e",
33 31 | )
34 32 |
35 33 | new_local_repository(
--------------------------------------------------------------------------------
52 50 | urls = [
53 51 | "https://github.com/gflags/gflags/archive/v2.2.2.tar.gz",
54 52 | ],
54 |- sha256 = "34af2f15cf7367513b352bdcd2493ab14ce43692d2dcd9dfc499492966c64dcf",
56 53 | )
57 54 |
58 55 | new_local_repository(
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95039
Approved by: https://github.com/ZainRizvi
1. Moving `test_jit_cuda_fuser.py` `test_nvfuser_dynamo.py` `test_nvfuser_frontend.py` under `third_party/nvfuser/python_tests/`.
2. Moving `nvfuser/__init__.py` to `third_party/nvfuser/python/`.
3. Leaving dummy test scripts under `./test/` for CI.
4. Patching `torch/_prims/nvfuser_prims.py` for view/reshape renaming in nvfuser
5. Installing `third_party/nvfuser/python` and `third_party/nvfuser/python_tests` to pytorch root/test directy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95155
Approved by: https://github.com/davidberard98
Fix bug where a github api failure would prevent the check from failing even if we already saw that labels were needed.
Also adds more debugging info to the rate limit exceeded error since it's weird to see an error claiming the rate limit has exceeded when the "Used" amount is way below the limit. I suspect these happen when the request arrived just before the rate reset time, but the response was generated right after the reset time, hence the apparently tiny "used" amounts
Example run where the check should have failed, but passed instead:
https://github.com/pytorch/pytorch/actions/runs/4200205209/jobs/7285979824
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95098
Approved by: https://github.com/huydhn
Pass in repo args now that they're required (after a recent refactor). Also changes the script to pass in the repo name instead of being hardcoded to pytorch/pytorch.
I'm guessing this wasn't noticed earlier since the workflow is only triggered when a label is created/edited/deleted
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95227
Approved by: https://github.com/huydhn
currently logger timer is registered default for
cpu/cuda. for other backends, it may or may not
registers this timer. It reports warning for other backends and return which is not expected.
The above may fail, if the backends has have registered this timer. For example, HPU(habana) backend registers this timer. so, in this case it reports a warning and return which is incorrect.
Other case is where lazy backend timer is never registered. so, this returns a warning, and this is the reason the check was added, but it fails for other cases.
Add a generic check if the timer is registered, then don’t report warning.
Signed-off-by: Jeeja <jeejakp@habana.ai>
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91702
Approved by: https://github.com/kit1980
Finally, swin is passing, with no floors in the generated code.
I don't know how to write a test for it though, and swin patterns triggering this are pretty complicated (even prior to this PR we were already good at pulling `floors` out of device code).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95152
Approved by: https://github.com/ezyang
This prevents us from guarding on leading unbacked SymInts.
The previous attempt at https://github.com/pytorch/pytorch/pull/94521 I got the logic a bit wrong. My idea there was to avoid slicing when the values to be set have low enough dimensionality that they definitely aren't too long. To do this, I need to compute the difference between the data to be set, and the post-slice space for the values. But I incorrectly compared against the *pre-slice* space in the original PR. Another version of this PR which is wrong is to compare against variableIndices.size(); but remember that in advanced indexing with tensors/lists, each of the individual indices specify what coordinates to read out of each dimension! A third incorrect attempt tested `variableIndices[0].dim()`, which is only correct if you don't broadcast one of the later variable indices, and if there are enough variableIndices to cover all dims. This is all quite complicated, so I went for a simpler solution of checking if the leading dim had a hint before testing if it is not equal to one.
BTW, there is no test for this one stripping behavior. There is now a test for this, based off the real code that caused the problem.
Signed-off-by: Edward Z. Yang <ezyangmeta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95141
Approved by: https://github.com/ngimel
Summary:
fix `TypeError: 'Float' object cannot be interpreted as an integer` for `ValueRanges.pow(a, b)` when `not a.is_singleton() and b.is_singleton() and not isinstance(b.lower, int)`
this is breaking `cuda11.7-py3.10-gcc7-sm86 / test (inductor_timm, 1, 2, linux.g5.4xlarge.nvidia.gpu)`
{F878635541}
Test Plan: sandcastle + CI
Differential Revision: D43430385
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95151
Approved by: https://github.com/Skylion007
After some thoughts, I find it difficult to come up with a robust naming convention that satisfies the following constraints at the same time: 1. the new name should be a valid nn.Moule attribute (as required by minifier and it's a good thing to have in general) 2. it can cover various cases such as GetItemSource, GetAttrSource 3. it's easy to recover the original path 4. robust to users' naming scheme.
Thanks to @yanboliang for pointing out the original access path is preserved in Source, now we just need to add an additonal value source.name() to node.meta["nn_module_stack"] to get the access path in original module.
We also address some TODO in quantization, which relies on the original naming convention in nn_module_stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94945
Approved by: https://github.com/jansel, https://github.com/yanboliang
torch.empty_permuted is a generalized version of torch.empty(memory_format=...), where you can pass an arbitrary physical layout as a tuple of dims to allow you to setup dense, non-overlapping tensors with non-standard memory format. Check the docblock for a full description of semantics.
The initial motivation for this PR is with guard-less unbacked SymInts. Traditionally, the way we allocate dense tensors with arbitrary layout is with `empty_strided`. However, `empty_strided` does not know that the given strides are actually contiguous, and must test this manually to find out if it is the case. With `empty_permuted`, this is known statically to be the case and helps us skip some 0/1 guards.
However, I also think torch.empty_permuted is a useful API in its own right. It is technically possible to simulate this with an empty and a permute; however, there are some downsides:
* The manual incant is tricky to work out. To allocate an NHWC tensor, the invocation is `torch.empty(N, H, W, C).permute(0, 3, 1, 2)`; the permute call has to take NHWC to NCHW, and is the *inverse* of the permutation people are typically thinking of when they talk about NHWC (0, 2, 3, 1). Instead, torch.empty_permuted lets you say `torch.empty_permuted((N, C, H, W), (0, 2, 3, 1))`, letting you provide the intuitive permutation. It can be literally be read off as NHWC if you assign N=0, C=1, H=2, W=3.
* An empty(requires_grad=True).permute() is no longer a leaf tensor. You can force it to be a leaf with a detach(), but it is more straightforward and less error prone to allow directly allocating a tensor with the correct permutation.
It is also technically possible to simulate this with empty_strided. However, this requires the user to manually compute the contiguous output strides and is bad from a reduction of guards perspective. For what it's worth, this is one of the more common uses of as_strided in the wild, and it would be nice to get rid of it.
A nice enhancement of this feature would be to accept `physical_layout` anywhere `memory_format` is accepted. However, this would be a pretty involved change, so I'm doing the easy thing instead.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95069
Approved by: https://github.com/malfet, https://github.com/ngimel, https://github.com/albanD, https://github.com/dagitses
This PR introduces a new `constrain_range` function which can be used to constrain the possible values a SymInt/SymFloat can take on. This knowledge can be then used to discharge potential guards (by running the range analysis, and then seeing if the guard must be true given the original range) without adding another guard.
The usage of ranges is very limited right now; ranges are only constrained when the user explicitly instructs the system so. However, we can also infer range constraints based on guards as well; this is left for future work.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95063
Approved by: https://github.com/eellison
Summary:
this diff adds logic to handle a global autotuning cache, stored in json format at config.global_cache_path.
what is changing from `DiskCache`:
* `DiskCache` is renamed to `PersistentCache`
* the local cache is now stored as a single file in json format, located at `/tmp/torchinductor_{$USER}/local_cache`. the file contains a dictionary structure like `local_cache[name][inputs][choice]` where `name` is the type of operation, like `addmm`, `inputs` is the repr of the inputs, and `choice` is the hash of a `ChoiceCaller`. the stored value is the benchmark time for that `ChoiceCaller`.
* a global cache is added, initially stored at `fbcode/caffe2/torch/_inductor/global_cache`, with almost identical format as the local cache. since the global cache exists over different machines, there is an additional `dinfo` field, such that `global_cache[dinfo] = local_cache` (at least structure wise, there is no guarantee that the global cache and local cache share the same values). `dinfo` is just a repr of the cuda device properties.
* the autotuner will prioritize the global cache, and return values from there first, before looking in the local cache
* the autotuner will look in both the global cache and the local cache even when `max_autotune=False`, but will still only generate values if `max_autotune=True`.
* the autotuner will log global cache hits and misses to a scuba table (inductor_autotuning_cache) which will be used to update the global cache at regular intervals
Test Plan: D43285472
Differential Revision: D42785435
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94922
Approved by: https://github.com/jansel
Fixes#94390
Apart from fixing the issue above, this PR also fixes a bug that when an input tensor can be sliced, a sliced array view is created. This array view seems to be not writable or have a different storage from the original tensor, causing incorrect results with the in-place `fill`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95113
Approved by: https://github.com/kulinseth
Summary:
This PR adds a set of unintrepreted data types on PyTorch which can be used to implement experimental functionality out of core (think fp8, int4, int16 quant, etc).
Note: this is a copy-pasta of https://github.com/pytorch/pytorch/pull/89990 with a bug fix for clang9, easier to just to put up another PR since I'm not sure how comandeering works with Meta-only changes.
@bypass-github-export-checks
Test Plan:
```
python test/test_quantization.py -k TestBits
```
Reviewers:
Subscribers:
Tasks:
Tags:
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94992
Approved by: https://github.com/angelayi
Summary: `torch.nn.functional.pixel_shuffle` accepts both float
and quantized inputs. However, previously we would unnecessarily
dequantize quantized inputs into floats before passing them to
the function. This commit fixes this by lowering the pattern
[dequant - pixel_shuffle - quant].
Test Plan:
python test/test_quantization.py TestQuantizeFxOps.test_pixel_shuffle
Reviewers: vkuzo
Subscribers: vkuzo, supriyar
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94769
Approved by: https://github.com/vkuzo
Summary:
Original commit changeset: 96a2200d1fd8
Original Phabricator Diff: D43342962
Test Plan: Sandcastle and land castle as well as buck2 build mode/opt //frl/et/projects/Masquerade/stable/datasets/masquerade/c6p7:post_processing
Reviewed By: seemethere, bigfootjon
Differential Revision: D43402398
@bypass-github-export-checks
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95086
Approved by: https://github.com/bigfootjon
Previously, the "can slice" flag in Placeholder constructor in `OperationUtils.mm` is conditioned on whether the numbers of dimensions of base shape and view shape are the same. This doesn't consider the situation that a view tensor could be the base tensor's sliced and then unsqueezed version, resulting in different num of dims.
For example, if we want to stack `y_mps` and `x_mps` on the last dim:
```
t_mps = torch.tensor([1, 2, 3, 4], device="mps")
x_mps = t_mps[2:] # [3, 4]
y_mps = t_mps[:2] # [1, 2]
res_mps = torch.stack((y_mps, x_mps), dim=-1)
```
the kernel will unsqueeze both of them on the last dim and then concatenate them, which is equivalent to:
```
res_mps = torch.cat((y_mps.unsqueeze(-1), x_mps.unsqueeze(-1)), dim=-1)
```
`x_mps.unsqueeze(-1)` is an unsqueezed and contiguous tensor with a storage offset, this kind of tensors should be sliceable without cloning its storage.
Fixes#87856Fixes#91065
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91071
Approved by: https://github.com/kulinseth
Will be needed if one wants to make accurate XFAIL validation
I.e. `torch.backends.mps.is_macos13_or_newer()` will return True if PyTorch is running on MacOS 13.0 or newer, `torch.backends.mps.is_macos13_or_newer(1)` will return True if running on MacOS 13.1 or newer and `torch.backends.mps.is_macos13_or_newer(2)` will return True if running on MacOS 13.2 or newer
Do not use 13.3 check as `@available` does not really work for shared libraries
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95065
Approved by: https://github.com/albanD
This utility allows us to conveniently abstract interpret Sympy expressions with respect to some alternative domain. I am particularly interested in using ValueRanges to do range analysis on expressions (not this PR).
Some minor house-keeping:
* ReferenceAnalysis got moved to its own file, sprouted a constant() implementation, and some uses of math.* got converted to sympy.*
* ValueRangeAnalysis now understands mod
* Test file gets moved from `test_value_ranges.py` to `test_sympy_utils.py`
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94985
Approved by: https://github.com/eellison
Since I didn't want to deal with nondeterministic tests, I went the exhaustive testing route for a fixed list of constants to look at. The tests generate random ranges, propagate the range through the function, and then pick elements in the range and check that the result on the operation is in the resulting range. This caught bugs in log, sqrt and pow.
My resolution for pow was a little special, because I had trouble figuring out the correct semantics under all inputs domains. Instead, I picked two input domains (pow on two point ranges, and pow where exponent is known) and only implemented those. Everything else we give up. I think this is unlikely to affect perf.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94939
Approved by: https://github.com/lezcano, https://github.com/eellison, https://github.com/nunoplopes
The main new invariant is lower/upper must be a Sympy expression of some sort (filtered through `simple_sympify`). There are some simpler sanity checks (mostly making sure the range is well formed). There is a type confusion problem (it's not immediately obvious if a range is for float/int/bool) but we aren't going to solve this for now as it is more complicated.
Billing of changes:
* ValueRanges.wrap() now accepts sympy expressions
* ValueRanges now accepts non-sympy expressions and will sympyify them appropriately. Rewrite calls to ValueRanges to not sympify manually as it is unnecessary
* Don't attempt to test sqrt(-1)
* Add ValuesRanges.unknown() which gives -oo, oo bounds, and rewrite direct calls to -math.inf, math.inf to use it
* Make multiply work between ValueRanges.unknown() and ValueRanges.wrap(0)
* Consistently use sympy.oo instead of math.inf
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94906
Approved by: https://github.com/eellison
I believe this fixes the AllenaiLongformerBase problem in periodic.
The longer version of the problem is here is we are currently optimistically converting all item() calls into unbacked SymInt/SymFloat, but sometimes this results in a downstream error due to a data-dependent guard. Fallbacks for this case are non-existent; this will just crash the model. This is bad. So we flag guard until we get working fallbacks.
What could these fallbacks look like? One idea I have is to optimistically make data-dependent calls unbacked, but then if it results in a crash, restart Dynamo analysis with the plan of graph breaking when the item() call immediately happened.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94987
Approved by: https://github.com/Skylion007, https://github.com/malfet
Fix performance bug for `torch.sparse.mm()` with reduce flag.
Found this bug within internal benchmarking.
Made a mistake when updating previous patch which causes load imbalance between threads:
Test on ogbn-products datasets on Xeon CLX with 24 cores:
#### before
```
sparse.mm: mean: 1156.148 ms
sparse.mm: sum: 1163.754 ms
sparse.mm: (using mkl): 703.227 ms
```
#### after
```
sparse.mm: mean: 662.578 ms
sparse.mm: sum: 662.301 ms
sparse.mm: (using mkl): 700.178 ms
```
The result also indicates that the current spmm kernel is no worse than MKL's sparse_mm .
Also update results on `pyg benchmark` with:
```
python gnn.py --use_sage --epochs=3 --runs=1 --inference
```
* Out of box: `13.32s`
* Without the fix in this PR: `5.87s`
* With the fix in this PR: `3.19s`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94969
Approved by: https://github.com/jgong5
Hi!
I've been fuzzing different pytorch modules, and found a few crashes.
Proposed checks fixes multiple segmentation faults and heap buffer overflows that was found during fuzzing pytorch with [sydr-fuzz](https://github.com/ispras/oss-sydr-fuzz/tree/master/projects/pytorch).
### Crash files ###
1) Heap buffer overflow that leads to crash
[crash-842314913bf1820ec19cddfbb7400ffdbb756920.zip](https://github.com/pytorch/pytorch/files/9461316/crash-842314913bf1820ec19cddfbb7400ffdbb756920.zip)
```
"AsanReport": [
"==3751==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x619000033478 at pc 0x0000005f9bc3 bp 0x7fffffff1eb0 sp 0x7fffffff1ea8\n",
"READ of size 4 at 0x619000033478 thread T0\n",
"[Detaching after fork from child process 3762]\n",
" #0 0x5f9bc2 in c10::IValue::IValue(c10::IValue&&) /pytorch_fuzz/aten/src/ATen/core/ivalue.h:192:43\n",
" #1 0x9ecd0a7 in torch::jit::pop(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch_fuzz/aten/src/ATen/core/stack.h:102:12\n",
" #2 0x9ecd0a7 in torch::jit::Unpickler::readInstruction() /pytorch_fuzz/torch/csrc/jit/serialization/unpickler.cpp:380:17\n",
" #3 0x9ecafc7 in torch::jit::Unpickler::run() /pytorch_fuzz/torch/csrc/jit/serialization/unpickler.cpp:226:27\n",
" #4 0x9ecac62 in torch::jit::Unpickler::parse_ivalue() /pytorch_fuzz/torch/csrc/jit/serialization/unpickler.cpp:183:3\n",
" #5 0x9e45996 in torch::jit::unpickle(std::function<unsigned long (char*, unsigned long)>, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)) /pytorch_fuzz/torch/csrc/jit/serialization/pickle.cpp:127:20\n",
" #6 0x9e4626d in torch::jit::unpickle(char const*, unsigned long, std::function<c10::StrongTypePtr (c10::QualifiedName const&)>, c10::ArrayRef<at::Tensor>, c10::Type::SingletonOrSharedTypePtr<c10::Type> (*)(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)) /pytorch_fuzz/torch/csrc/jit/serialization/pickle.cpp:137:10\n",
```
2) Segmentation fault
[crash-e690c58718e88921350562f0b4d9180938145d77.zip](https://github.com/pytorch/pytorch/files/9461331/crash-e690c58718e88921350562f0b4d9180938145d77.zip)
```
"AsanReport": [
"==3744==ERROR: AddressSanitizer: SEGV on unknown address (pc 0x000009122754 bp 0x7fffffff5290 sp 0x7fffffff5270 T0)\n",
"==3744==The signal is caused by a READ memory access.\n",
"==3744==Hint: this fault was caused by a dereference of a high value address (see register values below). Disassemble the provided pc to learn which register was used.\n",
"[Detaching after fork from child process 3763]\n",
" #0 0x9122754 in c10::intrusive_ptr<torch::jit::Tree, c10::detail::intrusive_target_default_null_type<torch::jit::Tree> >::retain_() /pytorch_fuzz/c10/util/intrusive_ptr.h:269:54\n",
" #1 0x9127929 in c10::intrusive_ptr<torch::jit::Tree, c10::detail::intrusive_target_default_null_type<torch::jit::Tree> >::intrusive_ptr(c10::intrusive_ptr<torch::jit::Tree, c10::detail::intrusive_target_default_null_type<torch::jit::Tree> > const&) /pytorch_fuzz/c10/util/intrusive_ptr.h:352:5\n",
" #2 0x9127929 in torch::jit::Expr::Expr(c10::intrusive_ptr<torch::jit::Tree, c10::detail::intrusive_target_default_null_type<torch::jit::Tree> > const&) /pytorch_fuzz/torch/csrc/jit/frontend/tree_views.h:269:49\n",
" #3 0x91b1bbb in torch::jit::Maybe<torch::jit::Expr>::get() const /pytorch_fuzz/torch/csrc/jit/frontend/tree_views.h:211:12\n",
" #4 0x92a8f74 in torch::jit::ScriptTypeParser::parseClassConstant(torch::jit::Assign const&) /pytorch_fuzz/torch/csrc/jit/frontend/script_type_parser.cpp:461:41\n",
" #5 0x9e1c09b in torch::jit::SourceImporterImpl::importClass(c10::QualifiedName const&, torch::jit::ClassDef const&, bool) /pytorch_fuzz/torch/csrc/jit/serialization/import_source.cpp:549:34\n",
" #6 0x9e13f00 in torch::jit::SourceImporterImpl::importNamedType(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, torch::jit::ClassDef const&) /pytorch_fuzz/torch/csrc/jit/serialization/import_source.cpp:288:5\n",
" #7 0x9e11fbc in torch::jit::SourceImporterImpl::findNamedType(c10::QualifiedName const&) /pytorch_fuzz/torch/csrc/jit/serialization/import_source.cpp:140:5\n",
```
3) Unhandled out of bounds access in a vector
[crash-ccd524e7ba19a37982dd91e0d6fc06bb26dd0b10.zip](https://github.com/pytorch/pytorch/files/9461367/crash-ccd524e7ba19a37982dd91e0d6fc06bb26dd0b10.zip)
```
"AsanReport": [
"==3792== ERROR: libFuzzer: deadly signal\n",
"[Detaching after fork from child process 3809]\n",
" #0 0x59cc11 in __sanitizer_print_stack_trace /llvm-project/compiler-rt/lib/asan/asan_stack.cpp:87:3\n",
" #1 0x511547 in fuzzer::PrintStackTrace() /llvm-project/compiler-rt/lib/fuzzer/FuzzerUtil.cpp:210:5\n",
" #2 0x4f7753 in fuzzer::Fuzzer::CrashCallback() /llvm-project/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:233:3\n",
" #3 0x7ffff7c6741f (/lib/x86_64-linux-gnu/libpthread.so.0+0x1441f)\n",
" #4 0x7ffff7a8700a in __libc_signal_restore_set /build/glibc-SzIz7B/glibc-2.31/signal/../sysdeps/unix/sysv/linux/internal-signals.h:86:3\n",
" #5 0x7ffff7a8700a in raise /build/glibc-SzIz7B/glibc-2.31/signal/../sysdeps/unix/sysv/linux/raise.c:48:3\n",
" #6 0x7ffff7a66858 in abort /build/glibc-SzIz7B/glibc-2.31/stdlib/abort.c:79:7\n",
" #7 0x7ffff7e73910 (/lib/x86_64-linux-gnu/libstdc++.so.6+0x9e910)\n",
" #8 0x7ffff7e7f38b (/lib/x86_64-linux-gnu/libstdc++.so.6+0xaa38b)\n",
" #9 0x7ffff7e7f3f6 in std::terminate() (/lib/x86_64-linux-gnu/libstdc++.so.6+0xaa3f6)\n",
" #10 0x7ffff7e7f6a8 in __cxa_throw (/lib/x86_64-linux-gnu/libstdc++.so.6+0xaa6a8)\n",
" #11 0x7ffff7e763aa (/lib/x86_64-linux-gnu/libstdc++.so.6+0xa13aa)\n",
" #12 0x6aeedf in std::vector<c10::IValue, std::allocator<c10::IValue> >::_M_range_check(unsigned long) const /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/stl_vector.h:1073:4\n",
" #13 0x9ecd66c in torch::jit::Unpickler::readInstruction() /pytorch_fuzz/torch/csrc/jit/serialization/unpickler.cpp\n",
" #14 0x9ecafc7 in torch::jit::Unpickler::run() /pytorch_fuzz/torch/csrc/jit/serialization/unpickler.cpp:226:27\n",
" #15 0x9ecac62 in torch::jit::Unpickler::parse_ivalue() /pytorch_fuzz/torch/csrc/jit/serialization/unpickler.cpp:183:3\n",
```
Some other crashes found by fuzzer:
[crash-0cab888cbd1e9fea92ab6ddeadf40b958b87d62b.zip](https://github.com/pytorch/pytorch/files/9461406/crash-0cab888cbd1e9fea92ab6ddeadf40b958b87d62b.zip)
[crash-04c9ba8e3b0f15028fd0fb0ed014fd352e182a1d.zip](https://github.com/pytorch/pytorch/files/9461407/crash-04c9ba8e3b0f15028fd0fb0ed014fd352e182a1d.zip)
[crash-422ad8c3a3472980ba751f4c7f79cf2b53e49927.zip](https://github.com/pytorch/pytorch/files/9461408/crash-422ad8c3a3472980ba751f4c7f79cf2b53e49927.zip)
### How to reproduce ###
1. To reproduce the crashes, use provided docker: [Dockerfile](https://github.com/ispras/oss-sydr-fuzz/blob/master/projects/pytorch/Dockerfile)
2. Build the container: `docker build -t oss-sydr-fuzz-pytorch-reproduce .`
3. Copy crash file to the current directory
4. Run the container: `` docker run --privileged --network host -v `pwd`:/homedir --rm -it oss-sydr-fuzz-pytorch-reproduce /bin/bash ``
5. And execute fuzz-targets with provided crash-files.
After execution completes you will see ASAN reports.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94815
Approved by: https://github.com/davidberard98
```
GuardOnDataDependentSymNode: It appears that you're trying to get a value out of symbolic int/float whose value is data-dependent (and thus we do not know the true value.) The expression we were trying to evaluate is Eq(i3, -1). Scroll up to see where each of these data-dependent accesses originally occurred.
While executing %as_strided : [#users=1] = call_method[target=as_strided](args = (%pad,), kwargs = {size: (12, %add, 768, 64), stride: (%getitem, %mul, %getitem_1, %getitem_2)})
Original traceback:
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/transformers/models/longformer/modeling_longformer.py", line 928, in <graph break in _sliding_chunks_matmul_attn_probs_value>
chunked_value = padded_value.as_strided(size=chunked_value_size, stride=chunked_value_stride)
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94986
Approved by: https://github.com/albanD
With this change, expected failures will be correctly reported as such by pytest (instead of passes as before).
It was sometimes a little confusing to see operators you did not expect to work in inductor reported as passing their tests.
One downside is that expected failures/skips for test variants have now to be identified by tuples. I.e., `("max", "reduction_no_dim"): {f16},` instead of just `"max.reduction_no_dim": {f16}`. It seems to me it is worth it.
This change would also allow to simplify `TestInductorOpInfo` class a little, since it doesn't have to handle the skips/xfails anymore, but that might require dropping support for things like `PYTORCH_COLLECT_EXPECT` and `PYTORCH_FAIL_ON_SUCCESS` so I didn't do it.
Also couple of other minor changes:
- Got rid of c32, c64, c128 in torchinductor_opinfo. We don't support complex numbers, so they shouldn't be necessary.
- Renamed TestExpect Enum to ExpectedTestResult to get rid of a pytest warning that thinks it is a class that has tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94813
Approved by: https://github.com/lezcano, https://github.com/jansel
This PR removes the unnecessary == 0 guard when constructing empty tensors, by ensuring that when we create a contiguous tensor we go directly to the C++ torch.empty implementation (instead of indirecting through empty_strided), where we can bypass doing zero tests when computing the size of the storage. This probably also speeds up trace time.
When I did this, I found out that `empty_tensor_restride_symint` was flagrantly wrong (we had never exercised it before because we redirected to `empty_strided` in PrimTorch decomp, which doesn't hit this codepath.) The bugs:
* Stride computation was wrong (only `last_idx` was ever written to)
* Using set_sizes_and_strides with `sym_sizes` input doesn't work, because there is some sort of ordering problem where `clone_symvec` isn't safe when you clone a vector into itself. Probably should fix this.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94512
Approved by: https://github.com/ngimel
This is the main payload of this diff stack. With it, we are able to construct a 1D tensor from unbacked SymInt with guards that are equivalent to asserting that the size is non-negative (which makes sense!) To get here, I had to arrange for all of the guards that occur when doing contiguity tests to be lazy. This was done by writing non-branching implementations of each of the tests in `sympy_is_contiguous` etc functions, and then using those implementations when we don't branch.
I also had to do some bug fixes for `is_non_overlapping_and_dense`, as unbacked SymInts were very untested previously (and that was the only time you would actually hit the Python version of the code.) In particular, we now consistently pass separate sizes/strides lists into each of the boolean computation functions (and only pack them into a single argument list when going to Sympy, which doesn't support lists of variables in custom functions.)
Finally, to actually test that this is doing something, I add a simple assumptions system from https://github.com/pytorch/pytorch/pull/90985 and use this to get the end to end test test_item_to_constructor passing. Soon, I intend to replace this with a range analysis system which will be used for assumptions in the short term. (We still might use Z3, but for all the stray assumptions I've seen range analysis will be good enough.)
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94473
Approved by: https://github.com/albanD
Currently, when unrolling an nn.Sequential, we use an integer to represent its submodule's name. This produces some difficulty in tracking the origin of the parameters in the export path:
```python
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
```
Currently, the submodules will have names such as model.0, model.1 instead of model.conv1, model.relu1. This discrepency causes it difficult to track the origin of paramers because they are represented as model.conv1.foo and model.relu1.foo in model.named_parameters().
We replace enumerate() with named_children() to keep submodule's name.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94913
Approved by: https://github.com/jansel
**Summary**: torch.nn.Module implementations previously did not support custom implementations of `__getattr__`; if a torch.nn.Module subclass implemented `__getattr__` and we tried to access an attribute that was expected to be present in `__getattr__`, dynamo would not check `__getattr__` and would error out with an AttributeError. This PR copies the functionality from UserDefinedObjectVariable into torch.nn.Module so that it also supports `__getattr__`
Example of a module which previously would fail:
```python
class MyMod(torch.nn.Module):
def __init__(self):
super().__init__()
self.custom_dict = {"queue": [torch.rand((2, 2)) for _ in range(3)]}
self.other_attr = torch.rand((2, 2))
def __getattr__(self, name):
custom_dict = self.custom_dict
if name in custom_dict:
return custom_dict[name]
return super().__getattr__(name)
def forward(self, x):
return x @ self.other_attr + self.queue[-1]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94658
Approved by: https://github.com/yanboliang, https://github.com/jansel
With this change, expected failures will be correctly reported as such by pytest (instead of passes as before).
It was sometimes a little confusing to see operators you did not expect to work in inductor reported as passing their tests.
One downside is that expected failures/skips for test variants have now to be identified by tuples. I.e., `("max", "reduction_no_dim"): {f16},` instead of just `"max.reduction_no_dim": {f16}`. It seems to me it is worth it.
This change would also allow to simplify `TestInductorOpInfo` class a little, since it doesn't have to handle the skips/xfails anymore, but that might require dropping support for things like `PYTORCH_COLLECT_EXPECT` and `PYTORCH_FAIL_ON_SUCCESS` so I didn't do it.
Also couple of other minor changes:
- Got rid of c32, c64, c128 in torchinductor_opinfo. We don't support complex numbers, so they shouldn't be necessary.
- Renamed TestExpect Enum to ExpectedTestResult to get rid of a pytest warning that thinks it is a class that has tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94813
Approved by: https://github.com/lezcano, https://github.com/jansel
Fixes backward pass for bilinear.
Summary of changes:
- bilinear op is able to produce **contiguous, non-view** tensors with a storage offset, such as: shape=`[1, 1, 1, 1]`, `storage_offset=12`. This seems a weird case, but it is valid, and for these type of tensors we wouldn't be able to gather/scatter since we look at the view flag (which is not set here). This change looks into `storage_offset` only rather than the is_view flag which is not being set
- **reduction sum** must return a zeroed out output if passing an input with 0 elements (e.g a shape of (0, 5)).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94892
Approved by: https://github.com/kulinseth
Summary:
update the hashing method for `ChoiceCaller` class.
`TritonTemplateCaller` objects will now be hashed to:
`{name}-({BLOCK_M}, {BLOCK_N}, {BLOCK_K})-{num_stages}-{num_warps}-{code_hash}`
for example:
`triton_mm-(64, 32, 32)-4-8-cptlntwzcl2gaaofd2oabdwhaqv4ox3lluvbuxitjfhhpz6cyl4o`
`ExternKernelCaller` objects will now be hashed to:
`{name}-{kwargs.keys()[0]}={kwargs.vals()[0]}-...-{code_hash}`
for example:
`addmm-alpha=1-beta=1-c4xxd3iocu4yt6z4udrlqnumays7q6mfnfd3qprh4fxgsvyhqdkf`
Test Plan: sandcastle
Differential Revision: D43285470
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94853
Approved by: https://github.com/jansel, https://github.com/bertmaher
- add _mps_convolution_impl that takes optional shape
- for conv_tranpose2d grad, use the shape from forward pass directly
- for conv, calculate the shape from input
- remove nn.functional.conv_transpose2d grad from blocklist
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94871
Approved by: https://github.com/kulinseth
The basic idea behind this PR is that we want to continue using the guarding implementations of contiguity tests, if all of the elements are backend (aka, have hints). If they don't have hints, we'll have to do something slower (use the non-short circuiting, non guarding implementations of contiguity), but most of the time you aren't dealing with unbacked SymInts.
So this PR has three parts.
1. We expose `has_hint` on `SymNode`. This allows us to query whether or not a SymInt is backed or not from C++. Fairly self explanatory. Will require LTC/XLA updates; but for backends that don't support unbacked SymInts you can just always return true.
2. We update `compute_non_overlapping_and_dense` to test if the inputs are hinted. If they are all hinted, we use the conventional C++ implementation. Otherwise we call into Python. The Python case is not heavily tested right now because I haven't gotten all of the pieces for unbacked SymInts working yet. Coming soon.
3. We add stubs for all of the other contiguity tests. The intention is to apply the same treatment to them as well, but this is not wired up yet for safety reasons.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94431
Approved by: https://github.com/voznesenskym
I don't think the docstring explaining `pin_memory_device` is very clear. If it weren't for the string type, I would not have guessed that this was about the device that is referred to in the `pin_memory` option (and honestly, it took me a few minutes before noticing the type).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94349
Approved by: https://github.com/ejguan
Summary: Add support for "height" and "width" dimension for the "select" operator on pytorch vulkan backend.
Test Plan:
```
yipjustin@yipjustin-mbp fbsource % buck run -c pt.vulkan_full_precision=1 --target-platforms ovr_config//platform/macos:arm64-fbsource //xplat/caffe2:pt_vulkan_api_test_binAppleMac\#macosx-arm64 -- --gtest_filter="*select_3d*"
Downloaded 1/2 artifacts, 1.29 Mbytes, 0.0% cache miss (for updated rules)
Building: finished in 3.7 sec (100%) 450/450 jobs, 2/450 updated
Total time: 3.8 sec
BUILD SUCCEEDED
Running main() from xplat/third-party/gmock/googletest-1.12.1/googletest/src/gtest_main.cc
Note: Google Test filter = *select_3d*
[==========] Running 9 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 9 tests from VulkanAPITest
[ RUN ] VulkanAPITest.select_3d_depth_small
[ OK ] VulkanAPITest.select_3d_depth_small (30 ms)
[ RUN ] VulkanAPITest.select_3d_depth_medium
[ OK ] VulkanAPITest.select_3d_depth_medium (0 ms)
[ RUN ] VulkanAPITest.select_3d_depth_large
[ OK ] VulkanAPITest.select_3d_depth_large (1 ms)
[ RUN ] VulkanAPITest.select_3d_height_small
[ OK ] VulkanAPITest.select_3d_height_small (0 ms)
[ RUN ] VulkanAPITest.select_3d_height_medium
[ OK ] VulkanAPITest.select_3d_height_medium (0 ms)
[ RUN ] VulkanAPITest.select_3d_height_large
[ OK ] VulkanAPITest.select_3d_height_large (3 ms)
[ RUN ] VulkanAPITest.select_3d_width_small
[ OK ] VulkanAPITest.select_3d_width_small (0 ms)
[ RUN ] VulkanAPITest.select_3d_width_medium
[ OK ] VulkanAPITest.select_3d_width_medium (0 ms)
[ RUN ] VulkanAPITest.select_3d_width_large
[ OK ] VulkanAPITest.select_3d_width_large (1 ms)
[----------] 9 tests from VulkanAPITest (40 ms total)
[----------] Global test environment tear-down
[==========] 9 tests from 1 test suite ran. (40 ms total)
[ PASSED ] 9 tests.
```
Reviewed By: SS-JIA
Differential Revision: D43020796
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94612
Approved by: https://github.com/SS-JIA
- Backward pass has to give explicit bias tensor of zeros if none is passed to the op or the bias gradient will not be calculated.
- Fixed bias tensor mistakenly getting overwritten to zeros
- Fixes crash when lstm op called with has_biases set to false. Change takes into account the changed shape of the input params TensorList depending on the bias flag.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94889
Approved by: https://github.com/DenisVieriu97
echo NOTE: To run `import torch`, please make sure to activate the conda environment by running `call %CONDA_PARENT_DIR%\Miniconda3\Scripts\activate.bat %CONDA_PARENT_DIR%\Miniconda3` in Command Prompt before running Git Bash.
@ -106,7 +106,7 @@ All binaries are built in CircleCI workflows except Windows. There are checked-i
Some quick vocab:
* A \**workflow** is a CircleCI concept; it is a DAG of '**jobs**'. ctrl-f 'workflows' on https://github.com/pytorch/pytorch/blob/master/.circleci/config.yml to see the workflows.
* A \**workflow** is a CircleCI concept; it is a DAG of '**jobs**'. ctrl-f 'workflows' on https://github.com/pytorch/pytorch/blob/main/.circleci/config.yml to see the workflows.
* **jobs** are a sequence of '**steps**'
* **steps** are usually just a bash script or a builtin CircleCI command. *All steps run in new environments, environment variables declared in one script DO NOT persist to following steps*
* CircleCI has a **workspace**, which is essentially a cache between steps of the *same job* in which you can store artifacts between steps.
@ -117,8 +117,8 @@ The nightly binaries have 3 workflows. We have one job (actually 3 jobs: build,
3. For each binary configuration, e.g. linux_conda_3.7_cpu there is a
1. smoke_linux_conda_3.7_cpu
1. Downloads the package from the cloud, e.g. using the official pip or conda instructions
@ -146,26 +146,26 @@ The nightly binaries have 3 workflows. We have one job (actually 3 jobs: build,
## How are the jobs structured?
The jobs are in https://github.com/pytorch/pytorch/tree/master/.circleci/verbatim-sources. Jobs are made of multiple steps. There are some shared steps used by all the binaries/smokes. Steps of these jobs are all delegated to scripts in https://github.com/pytorch/pytorch/tree/master/.circleci/scripts .
The jobs are in https://github.com/pytorch/pytorch/tree/main/.circleci/verbatim-sources. Jobs are made of multiple steps. There are some shared steps used by all the binaries/smokes. Steps of these jobs are all delegated to scripts in https://github.com/pytorch/pytorch/tree/main/.circleci/scripts .
* Linux jobs: https://github.com/pytorch/pytorch/blob/master/.circleci/verbatim-sources/linux-binary-build-defaults.yml
* Linux jobs: https://github.com/pytorch/pytorch/blob/main/.circleci/verbatim-sources/linux-binary-build-defaults.yml
* Common shared code (shared across linux and macos): https://github.com/pytorch/pytorch/blob/master/.circleci/verbatim-sources/nightly-binary-build-defaults.yml
* Common shared code (shared across linux and macos): https://github.com/pytorch/pytorch/blob/main/.circleci/verbatim-sources/nightly-binary-build-defaults.yml
* binary_checkout.sh - checks out pytorch/builder repo. Right now this also checks out pytorch/pytorch, but it shouldn't. pytorch/pytorch should just be shared through the workspace. This can handle being run before binary_populate_env.sh
* binary_populate_env.sh - parses BUILD_ENVIRONMENT into the separate env variables that make up a binary configuration. Also sets lots of default values, the date, the version strings, the location of folders in s3, all sorts of things. This generally has to be run before other steps.
* binary_install_miniconda.sh - Installs miniconda, cross platform. Also hacks this for the update_binary_sizes job that doesn't have the right env variables
@ -308,7 +308,7 @@ Note that the Windows Python wheels are still built in conda environments. Some
* These should all be consolidated
* These must run on all OS types: MacOS, Linux, and Windows
* These all run smoke tests at the moment. They inspect the packages some, maybe run a few import statements. They DO NOT run the python tests nor the cpp tests. The idea is that python tests on master and PR merges will catch all breakages. All these tests have to do is make sure the special binary machinery didn’t mess anything up.
* These all run smoke tests at the moment. They inspect the packages some, maybe run a few import statements. They DO NOT run the python tests nor the cpp tests. The idea is that python tests on main and PR merges will catch all breakages. All these tests have to do is make sure the special binary machinery didn’t mess anything up.
* There are separate run_tests.sh and smoke_test.sh because one used to be called by the smoke jobs and one used to be called by the binary test jobs (see circleci structure section above). This is still true actually, but these could be united into a single script that runs these checks, given an installed pytorch package.
### Note on libtorch
@ -340,7 +340,7 @@ The Dockerfiles are available in pytorch/builder, but there is no circleci job o
tl;dr make a PR that looks like https://github.com/pytorch/pytorch/pull/21159
Sometimes we want to push a change to master and then rebuild all of today's binaries after that change. As of May 30, 2019 there isn't a way to manually run a workflow in the UI. You can manually re-run a workflow, but it will use the exact same git commits as the first run and will not include any changes. So we have to make a PR and then force circleci to run the binary workflow instead of the normal tests. The above PR is an example of how to do this; essentially you copy-paste the binarybuilds workflow steps into the default workflow steps. If you need to point the builder repo to a different commit then you'd need to change https://github.com/pytorch/pytorch/blob/master/.circleci/scripts/binary_checkout.sh#L42-L45 to checkout what you want.
Sometimes we want to push a change to mainand then rebuild all of today's binaries after that change. As of May 30, 2019 there isn't a way to manually run a workflow in the UI. You can manually re-run a workflow, but it will use the exact same git commits as the first run and will not include any changes. So we have to make a PR and then force circleci to run the binary workflow instead of the normal tests. The above PR is an example of how to do this; essentially you copy-paste the binarybuilds workflow steps into the default workflow steps. If you need to point the builder repo to a different commit then you'd need to change https://github.com/pytorch/pytorch/blob/main/.circleci/scripts/binary_checkout.sh#L42-L45 to checkout what you want.
## How to test changes to the binaries via .circleci
// Features to add to the dev container. More info: https://containers.dev/features.
"features":{
// This is needed for lintrunner
"ghcr.io/devcontainers/features/rust:1":{}
}
// Uncomment to connect as root instead. More info: https://aka.ms/dev-containers-non-root.
// "remoteUser": "root"
}
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
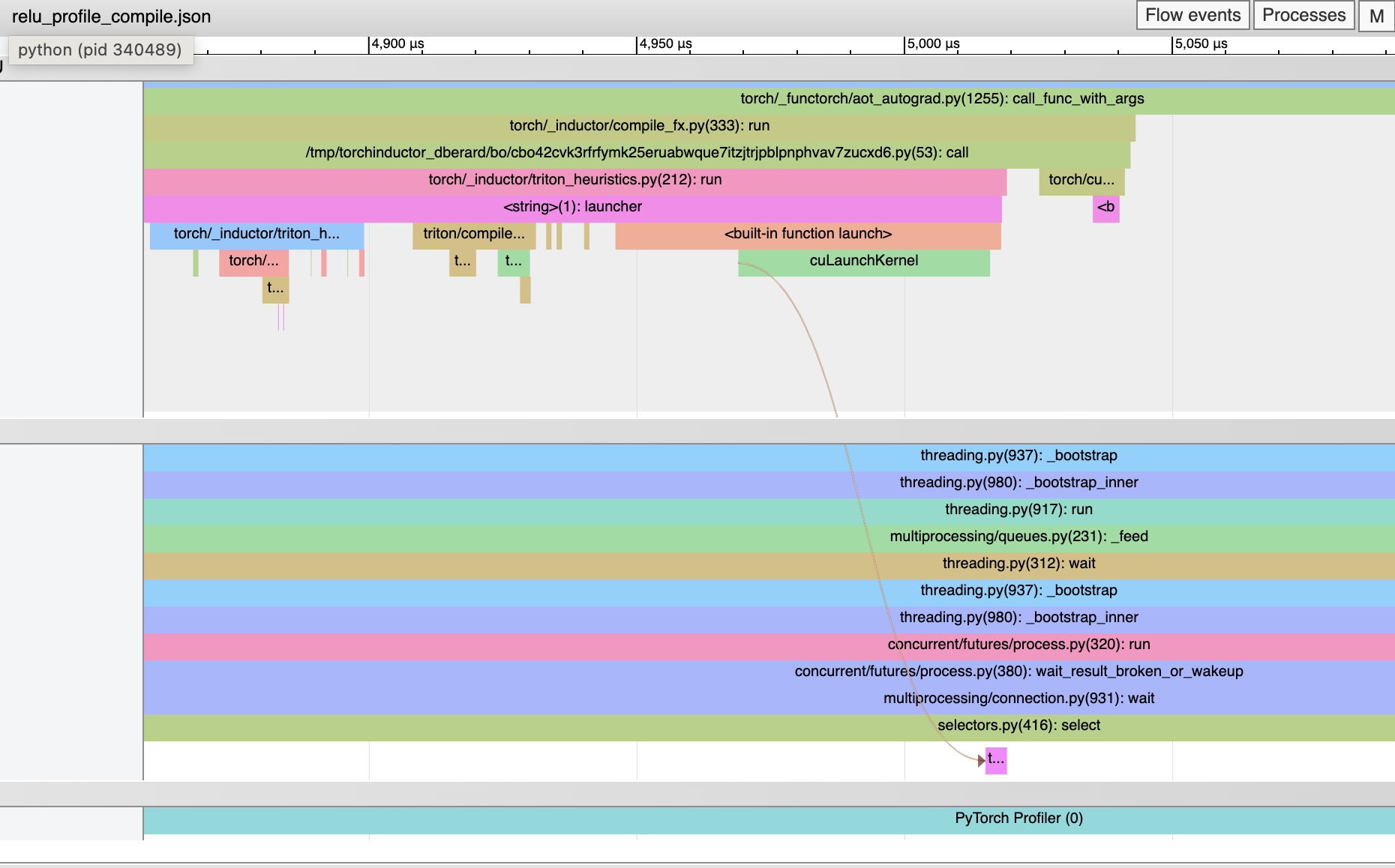{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
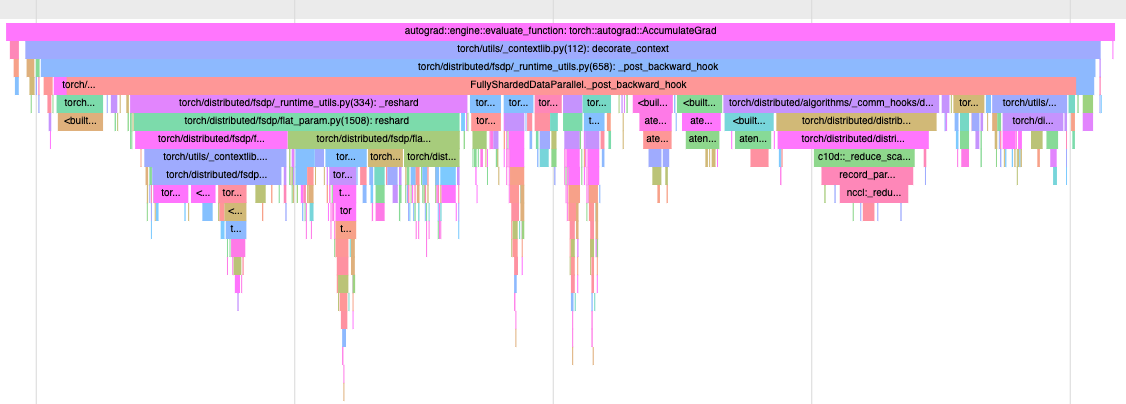{kind=link}
{kind=link}
{kind=link}
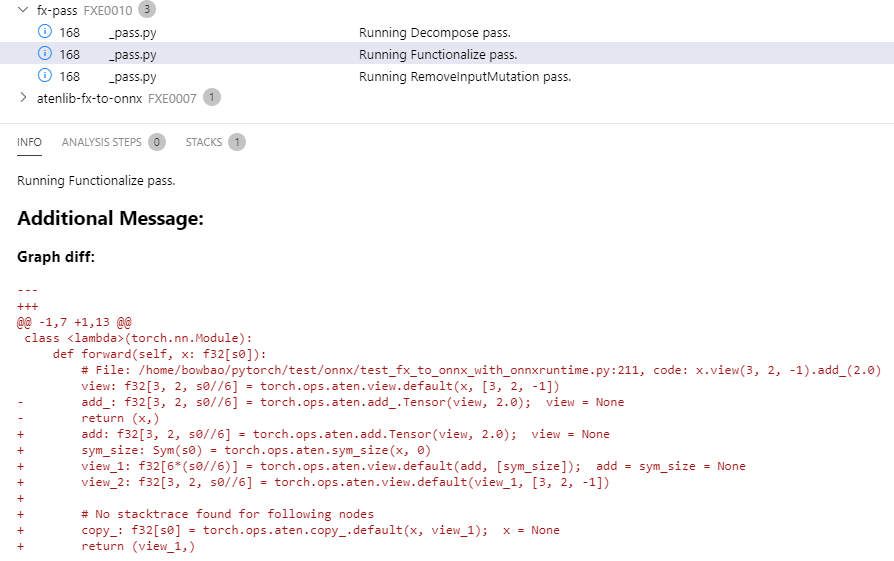{kind=link}
{kind=link}
{kind=link}
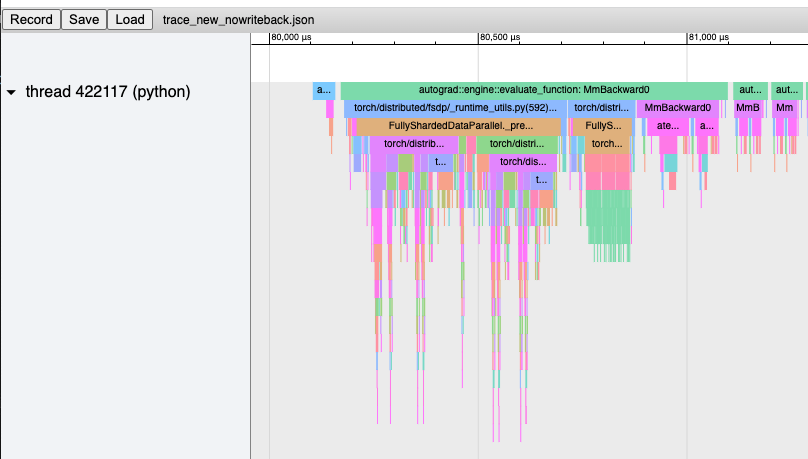{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
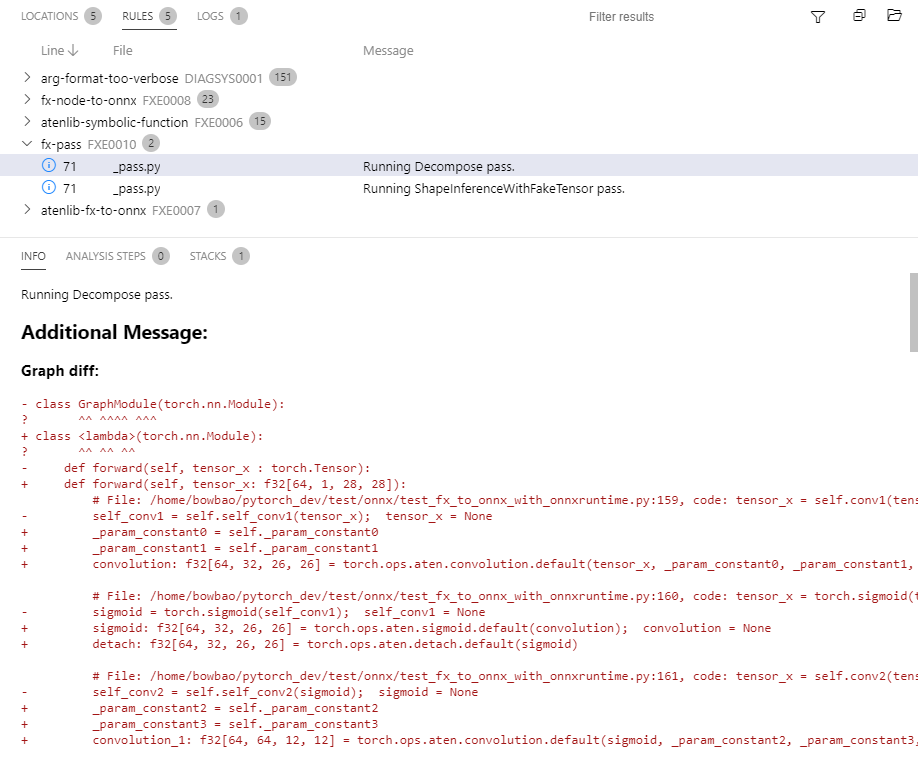{kind=link}
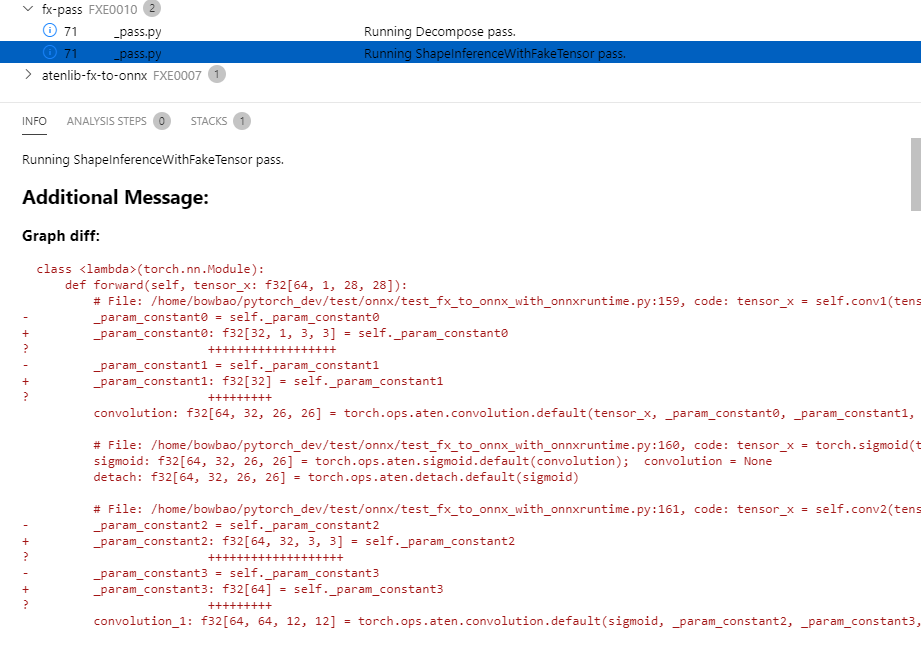{kind=link}
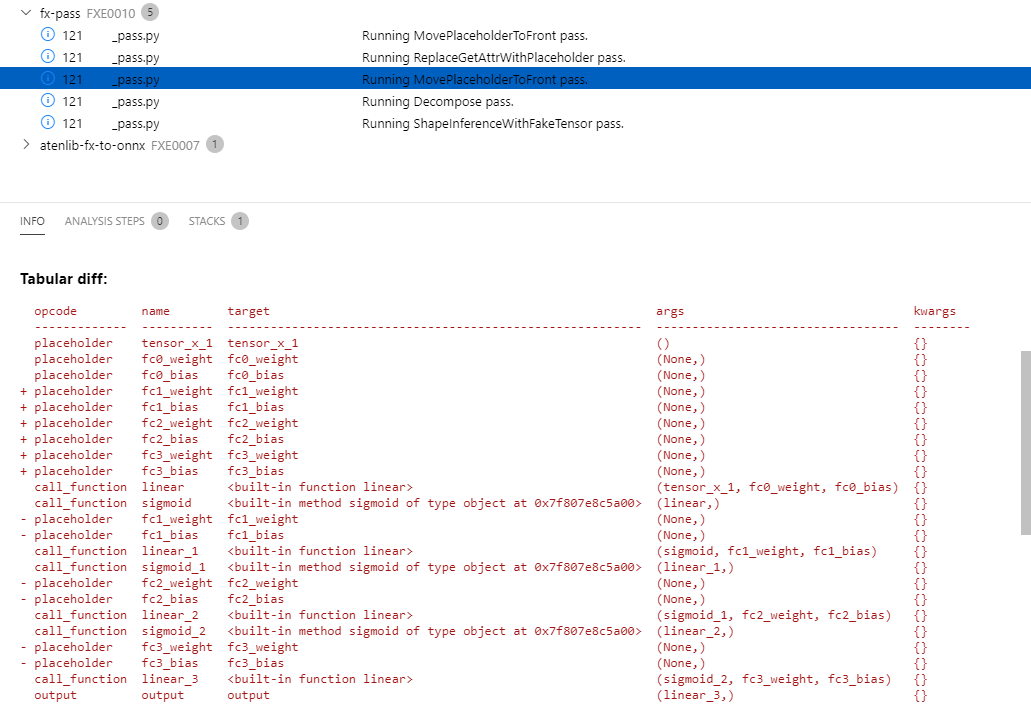{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
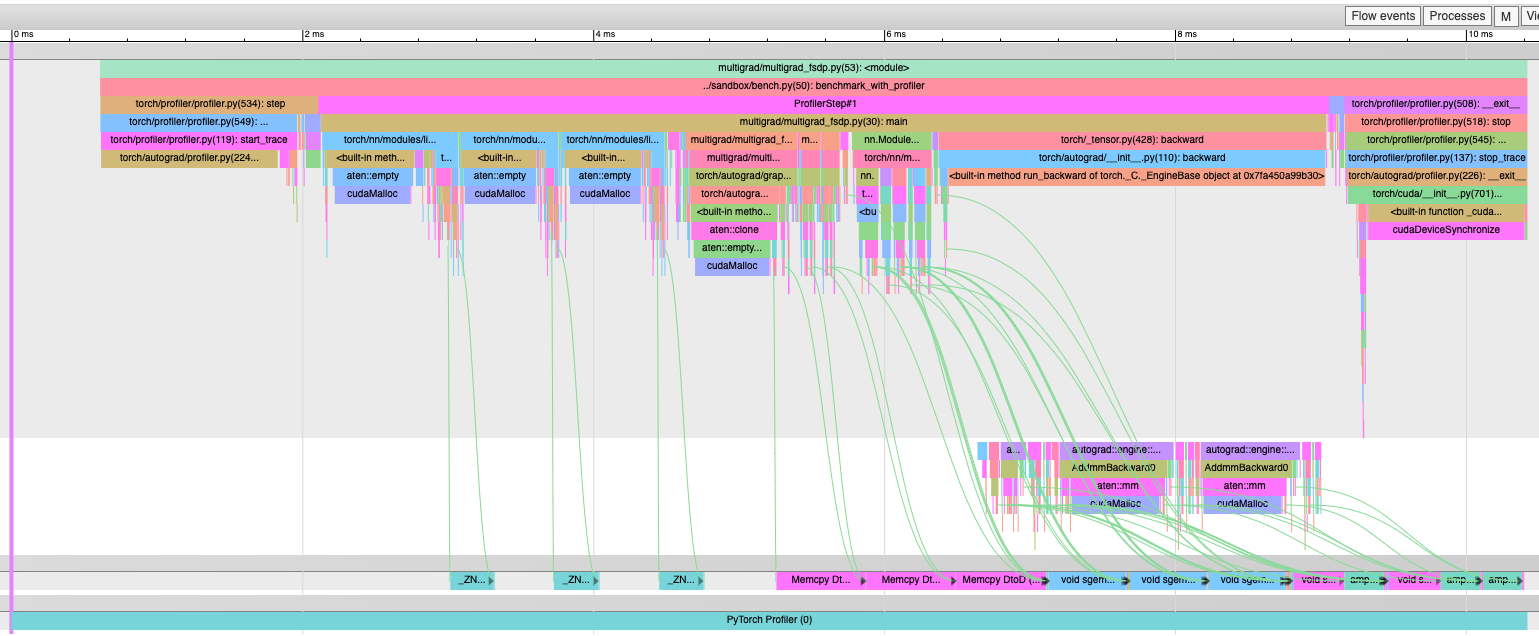{kind=link}
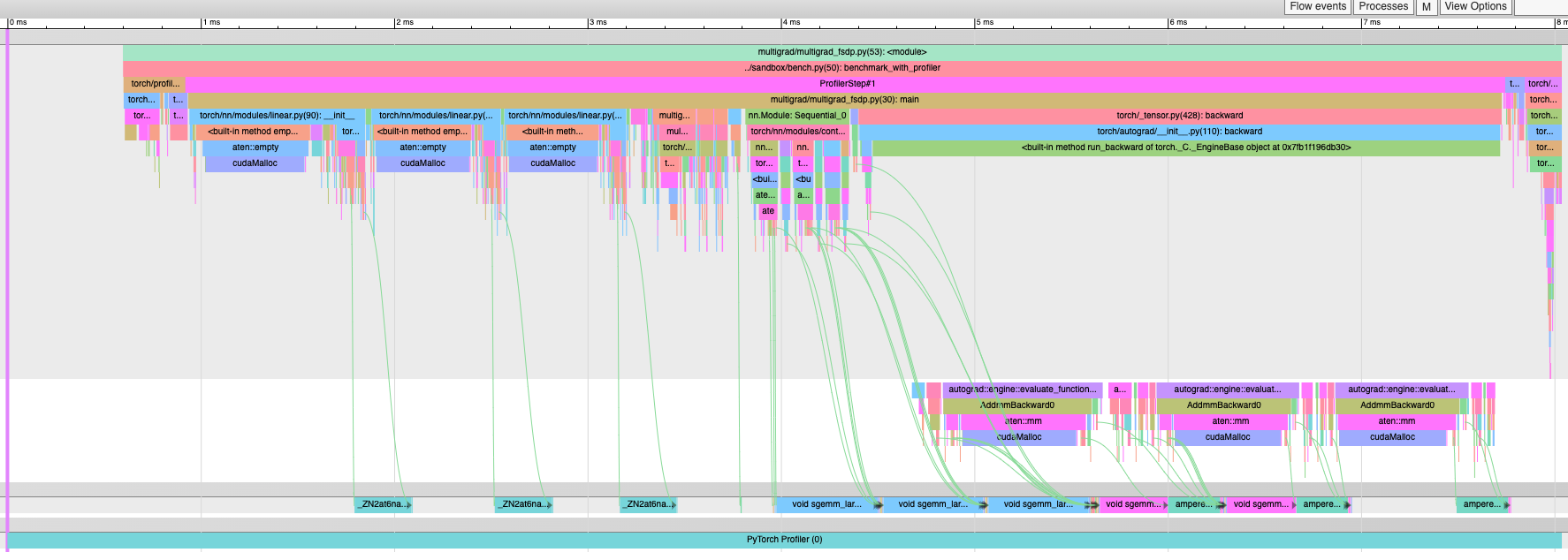{kind=link}
{kind=link}
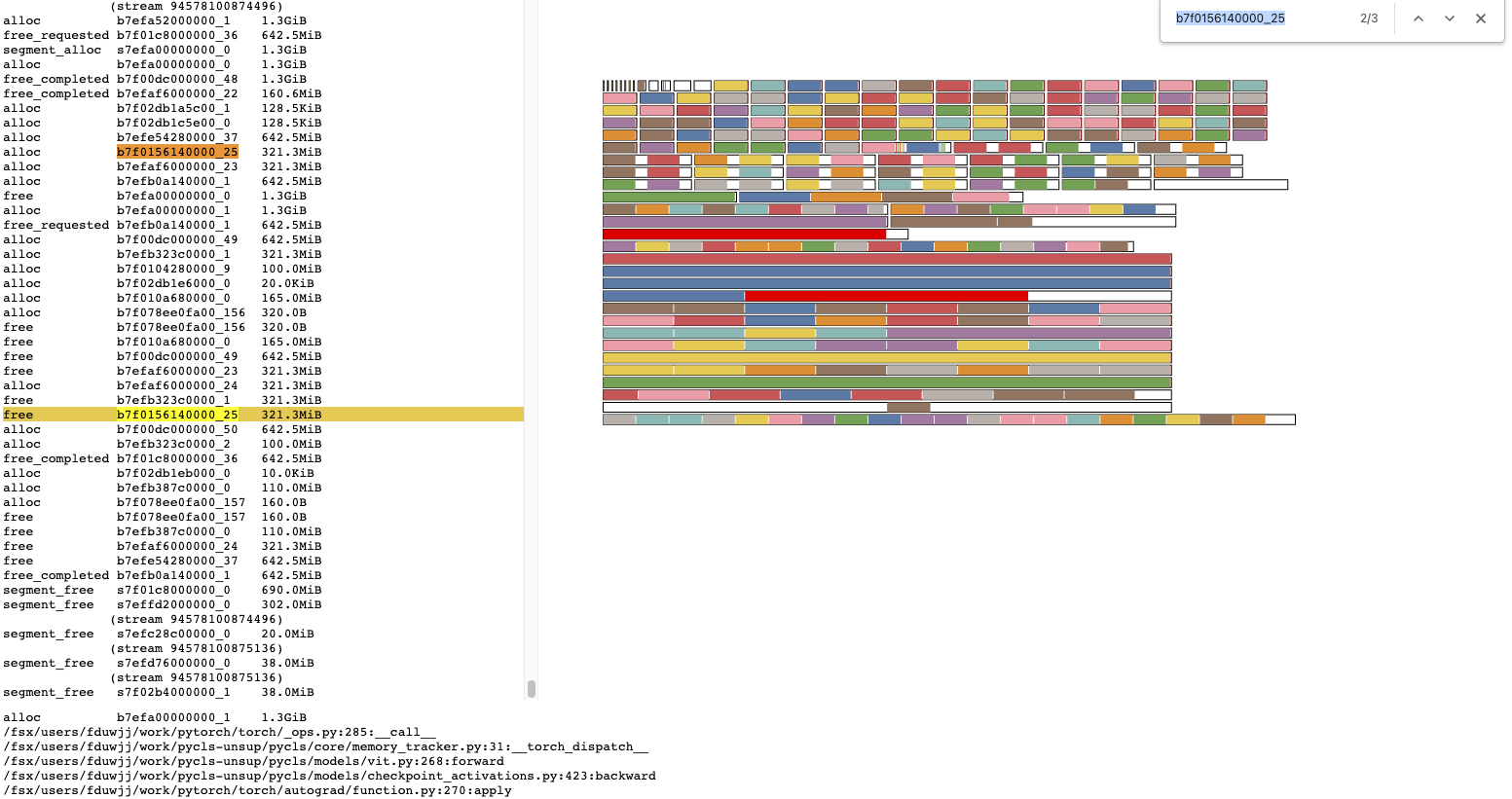{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
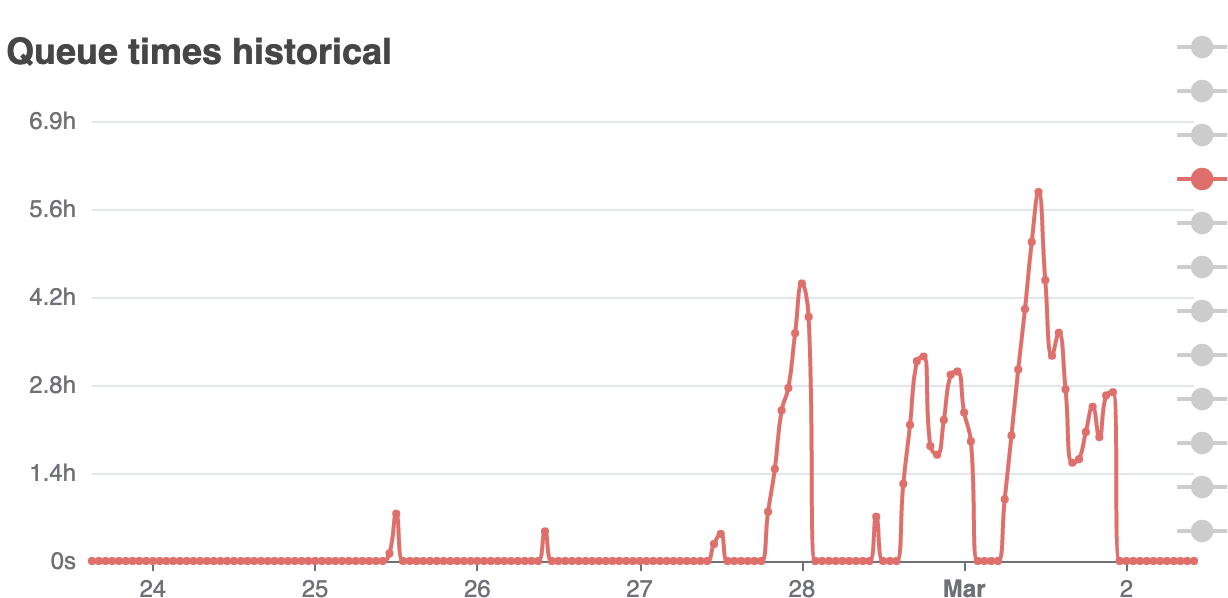{kind=link}
{kind=link}
{kind=link}
{kind=link}
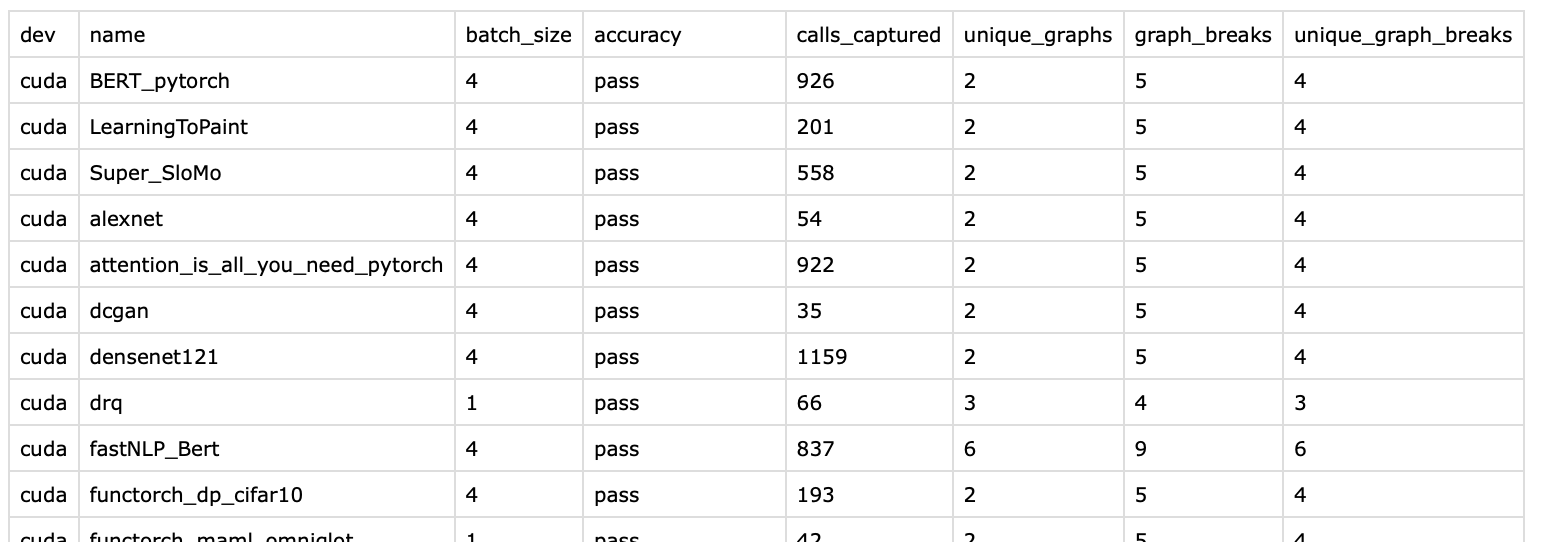{kind=link}
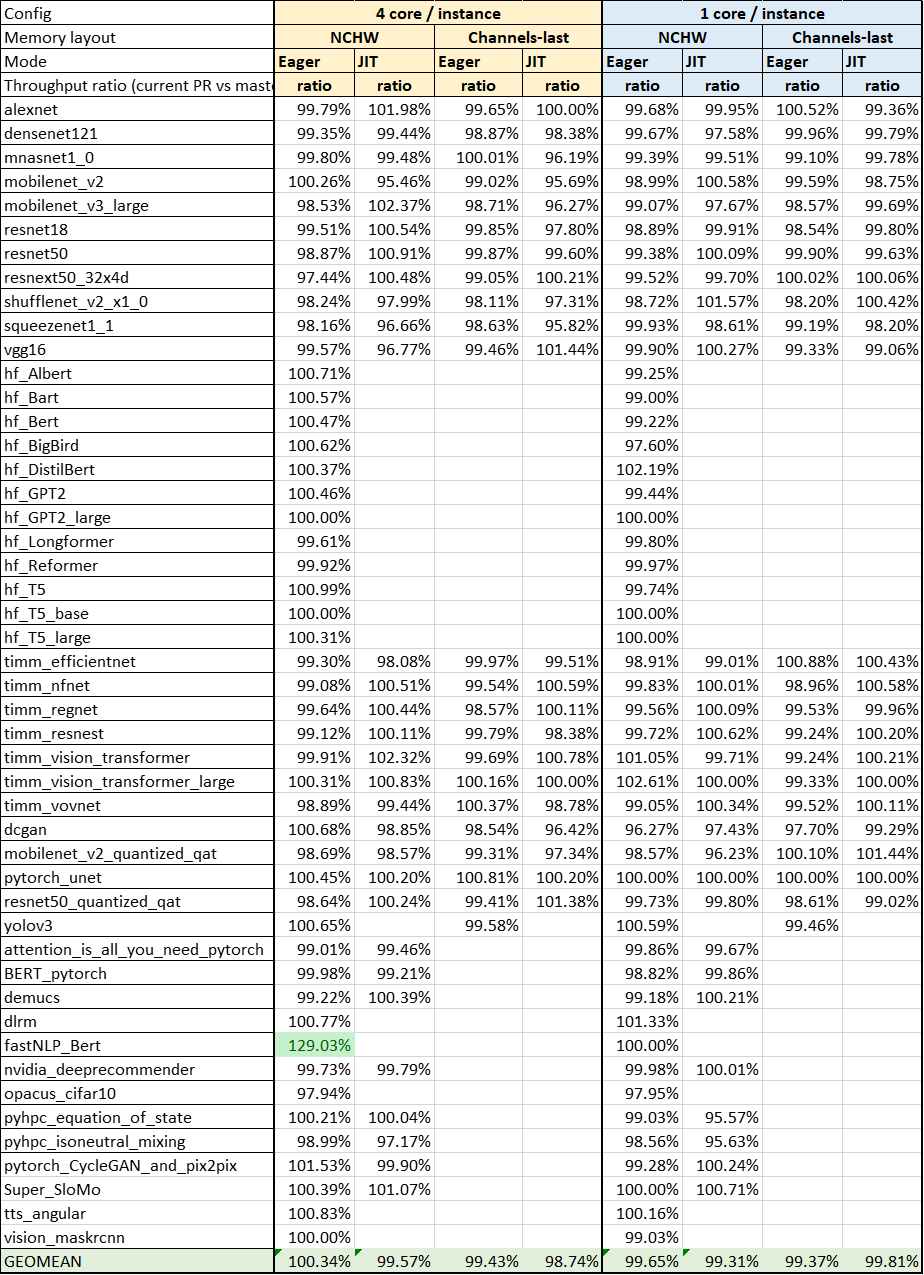{kind=link}
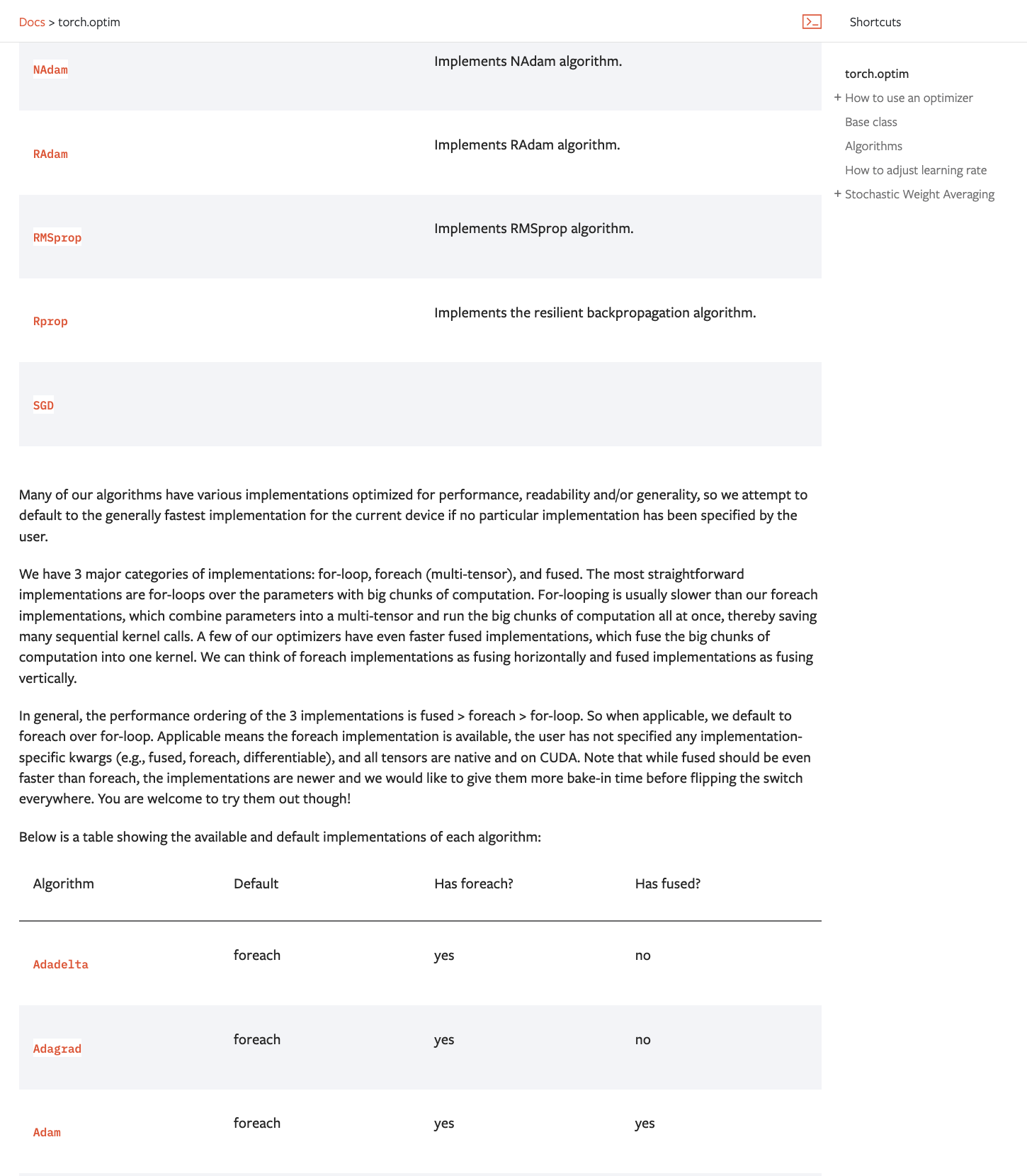{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}