Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60155
For intermediate tensors, we need to convert them to static images when doing GPU -> CPU synchronization.
ghstack-source-id: 131540760
Test Plan:
- CI
- buck test pp-macos
Reviewed By: SS-JIA
Differential Revision: D29126278
fbshipit-source-id: cd50b5f104e0161ec7fcfcc2c51785f241e48704
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59953
The following modifications were made to the equalization
observers due to design changes:
- [InputEqualizationObserver] Replaced `calculate_qparams()` with
`calculate_scaled_minmax()` since we will need to return the scaled
min/max values to update the following input quantization observer
- [WeightEqualizationObserver] We no longer need a row observer since
this will be taken care of by the following weight quantization observer
- [WeightEqualizationObserver] Following the previous comment, we no
longer need to calculate the scaled qparam values. Instead, we will use
the equalization scale to later scale the weights and the qparams will
be taken care of by the weight quantization observer.
Test Plan:
`python test/test_quantization.py
TestEqualizeFx.test_input_weight_eq_observer`
Imported from OSS
Reviewed By: supriyar
Differential Revision: D29135332
fbshipit-source-id: be7e468273c8b62fc183b1e1ec50f6bd6d8cf831
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59739
Created an EqualizationQConfig specifically for equalization.
This inherits from QConfig and is used to distinguish between inserting
an input observer with an output observer. Since the output observer
field is included in the EqualizationQConfig, we no longer need an
output observer field in the _InputEqualizationObserver
Test Plan:
compiles
Imported from OSS
Reviewed By: ezyang
Differential Revision: D29135298
fbshipit-source-id: 3dde9c029c291467ff0a0845f0fc9c44573fc6f6
Summary:
**Overview:**
This refactors the `ZeroRedundancyOptimizer` implementation to assume single-process single-device (SPSD) instead of accommodating single-process multiple-device (SPMD). `DistributedDataParallel` [retired SPMD recently](https://github.com/pytorch/pytorch/issues/47012), so this change follows the same spirit.
**Changes:**
The parent-class `Optimizer` constructor permits the input argument `params` to be both an `iterable` of `torch.Tensor` and an `iterable` of `dict`. The latter usage is for initializing the optimizer with multiple `param_group`s to start. However, currently, `ZeroRedundancyOptimizer` only supports the former usage, requiring explicit calls to `add_param_group()` for multiple `param_group`s. Given the existing implementation, the type error would be silent and not manifest until much later (e.g. since `super().__init__()` would have no issue). Hence, I added a series of checks to begin the `__init__()` function (encapsulated in `_verify_and_init_params()`). A postcondition of this validation is that `self._all_params` is a non-empty list of all model parameters.
Additionally, I added a check for SPSD usage assuming that all model parameters exist on the same device. This logic is included in `_verify_same_param_device()` and is called immediately after the `params` type-checking. Support for SPSD with model parameters sharded across devices may be added in the future.
Related to that aforementioned post-condition on `self._all_params`, previously there was undefined behavior resulting from different typing of the passed in `params` input argument. If `params` was a `List`, then the usage of `self._reference_is_trainable_mask` was as expected. However, if `params` was a generator (e.g. as in the canonical usage of passing `model.parameters()`), then the ensuing behavior was divergent. This is because after a generator is iterated over, it is empty. As a result, when we set `self._all_params = params` [in the old code](68d690ffbd/torch/distributed/optim/zero_redundancy_optimizer.py (L165)), `self._all_params` is empty, reducing `training_mask` to always be the empty list. This causes missed calls to `_update_trainable()` in `step()`. (A consequence of this is that `test_pytorch_parity()`, which is renamed to `test_local_optimizer_parity()`, now outputs warnings about the trainable parameters changing.)
The existing implementation assumes that all parameters share the same dense type when allocating the bucket buffers. This change preserves this assumption, which may be removed in the future. I added a check for this in `_verify_same_dense_param_type()` to avoid erroring silently later on. Note that it is insufficient to simply check for the same `dtype` since dense and sparse tensors may share the same `dtype` but require differing storage sizes. One solution is to use `torch.typename()` as the means for comparison.
---
The primary change in this refactor is with respect to `self._per_device_params` and `self.buckets`. `self._per_device_params` mapped `torch.device` to `List[List[Parameter]]`. The keys were the devices that the model parameters exist on, and the values designated which ranks are assigned to updating those parameters. `self.buckets` mapped `torch.device` to `List[torch.Tensor]`. The keys were the same as `self._per_device_params`, and the values were the buckets for that device. The usage of these two data structures were confined to each other only. Hence, because the notions of device and rank are now in 1:1 correspondence, we can eliminate the former completely and only use rank. As such, I removed `self._per_device_params` and made `self.buckets` directly a list of buckets (i.e. `torch.Tensor`s).
Iteration over the parameters of a rank for a given device could be simplified to just iteration over the parameters of a rank. Hence, I relied on `self.partition_parameters()` now for that iteration. Refer to `_setup_flat_buffers()` and `step()` for these changes.
One convenient side effect of removing `self._per_device_params` is that there is no longer the re-computation of the parameter partitions mentioned at the end of this [PR](https://github.com/pytorch/pytorch/pull/59410).
---
I changed the data structure `self._index_to_param_cache` from a `dict` to a `List` because the domain is `0`, `1`, ..., `k-1` where `k` is the number of parameters. This should yield marginal improvements in memory usage and access speed.
`_sync_param_groups()` is a static method, meaning it can be called either via `self._sync_param_groups()` or `ZeroRedundancyOptimizer._sync_param_groups()` when inside the class. I made the usage consistently `self._sync_param_groups()` rather than have instances of both.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59834
Test Plan:
I ran through the existing test suite on an AI AWS cluster:
```
srun -p $DEV_QUEUE --cpus-per-task=16 -t 5:00:00 --gpus-per-node=4 python test/distributed/optim/test_zero_redundancy_optimizer.py
```
Note: The only test where `parameters_as_bucket_view` is `True` is `test_step_with_closure()`, meaning that that is the test that exercises the core changes of removing `self._per_device_params` and changing `self.buckets`.
Also, I added tests for the `ZeroRedundancyOptimizer` constructor changes and the assumption checks.
Reviewed By: mrshenli
Differential Revision: D29177065
Pulled By: andwgu
fbshipit-source-id: 0ff004ae3959d6d3b521024028c7156bfddc93d8
Summary:
A few more quality of life improvements for NNC's python bindings:
- Use standard `torch.dtype`s (rather than `te.Dtype`)
- Make names optional (they don't seem to matter)
- Make shapes optional
- A few implicit conversions to make code cleaner
Followup to https://github.com/pytorch/pytorch/issues/59920
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60058
Reviewed By: bertmaher
Differential Revision: D29151953
Pulled By: jansel
fbshipit-source-id: c8286e329eb4ee3921ca0786e17248cf6a898bd8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60003
**Summary**
`infer_concrete_type_builder` in `_recursive.py` assumes `__constants__`
is a `set` if it exists as an attribute on the module being scripted.
Instead, it should create a set out of whatever `__constants__` is.
**Test Plan**
Ran code from the issue.
**Fixes**
This commit fixes#59947.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D29174243
Pulled By: SplitInfinity
fbshipit-source-id: aeb8bded80038da35478714b6a697a766ac447f5
Summary:
Before this PR `CUDA11OrLater` was incorrectly set to `False` when `torch.version.cuda == "11.0"`.
`torch.version.cuda` returns major and minor CUDA versions, it doesn't return patch info.
LooseVersion comparison was calling `[11, 0] >= [11, 0, 0]` which evaluates to `False`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60010
Reviewed By: mruberry
Differential Revision: D29147107
Pulled By: ezyang
fbshipit-source-id: bd9ed076337b4d32bf1c3376b8f7ae15dbc4d08d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60057
This ensures that if a function was `wrap`'d before symbolic tracing + being passed into the transformer then it will still be wrapped.
Test Plan: Added test to `test_fx.py`
Reviewed By: jamesr66a
Differential Revision: D29151191
fbshipit-source-id: 93560be59505bdcfe8d4f013e21d4719788afd59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60044
In #59709 I attempted to fix the expecttest machinery to work in Python
3.8. However, I noticed that it would fail to do substitutions in this
case:
```
self.assertExpectedInline(
foo(),
"""bar"""
)
```
This is because the triple quoted string is not on the same line as the
backtrace line number (at the very beginning), and for safety reasons
the preexisting regex refused to search beyond the first line. This
wasn't a big deal prior to Python 3.8 because the flipped version of
the regex simply required the triple quoted string to be flush with
the end of the statement (which it typically was!) But it is a big deal
now that we only have the start of the statement.
I couldn't think of a way to fix this in the current model, so I decided
to call in the big guns. Instead of trying to do the regex with only
the start xor end line number, I now require you provide BOTH line numbers,
and we will only regex within this range. The way we compute these line
numbers is by parsing the Python test file with ast, and then searching
through statements until we find one that is consistent with the line
number reported by the backtrace. If we don't find anything, we
conservatively assume that the string lies exactly in the backtrace
(and you'll probably fail the substitution in that case.)
The resulting code is quite a lot simpler (no more reversed regex) and
hopefully more robust, although I suppose we are going to have to do
some field testing.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D29146943
Pulled By: ezyang
fbshipit-source-id: 2c24abc3acd4275c5b3a8f222d2a60cbad5e8c78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59773
Current quantize_per_tensor takes float scale and int zero_point, which does not work with Proxy,
this PR adds a quantize_per_tensor overload that takes Tensor scale and zero_point instead.
Test Plan:
Tested locally that following runs without errors:
```python
import torch
from torch.quantization.quantize_fx import prepare_fx, convert_fx
from torch.fx.experimental import normalize
class TestModule(torch.nn.Module):
def forward(self, x):
return x + x
mod = TestModule()
mod.eval()
config = {"": torch.quantization.get_default_qconfig("fbgemm")}
mod = prepare_fx(mod, config)
mod = convert_fx(mod)
mod = torch.fx.Transformer(mod).transform()
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D29019862
fbshipit-source-id: c0176040f3b73f0a30516ed17d261b44cc658407
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58290
this is a helper function to get some python source code loaded
on each interpreter without having to use the standard import system
or packages. Useful for debugging or for writing wrapper classes for
handling loaded modules.
Test Plan: Imported from OSS
Reviewed By: wconstab
Differential Revision: D28435306
Pulled By: zdevito
fbshipit-source-id: b85c16346b9001cd7350d65879cb990098060813
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60070
PyTorch pull request https://github.com/pytorch/pytorch/pull/57333 changed high_resolution_clock to system_clock but missed one location in profiler_kineto.cpp.
On some platforms (e.g. Windows), high_resolution_clock and system_clock do not map to the same underlying clock and therefore we get mixed timestamps on some platforms.
Reviewed By: wesolwsk
Differential Revision: D29155809
fbshipit-source-id: a6de6b4d550613f26f5577487c3c53716896e219
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60048
This changes clang-tidy in lint.yml to pull the raw diff from GitHub and parse that rather than use the PRs base revision. The base revision can cause the spurious inclusion of files not changed in the PR as in https://github.com/pytorch/pytorch/pull/59967/checks?check_run_id=2832565901. We could be smarter about how we query git, but this approach ends up being simpler since we just need to search for the diff headers in the .diff file.
See https://github.com/pytorch/pytorch/pull/60049/checks?check_run_id=2834140350 for an example CI run with this on
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D29148886
Pulled By: driazati
fbshipit-source-id: ca23446d5cc8938d1345f272afe77b9ee8898b74
Summary:
Currently S3 test stats doesn't support PR stats parisng.
Changes to s3_stats_parser:
1. they are uploaded to `test_times/{sha1}/{job}` and `pr_test_times/{pr}/{sha1}/{job}` separately. Thus we need parsing logics for both
2. need to attach time for PR stats parsing for ordering since PR commits can be force-pushed
Changes to run_test.py
1. Reordering based on previous PR stats if available
2. Falling back to file change option if not enabled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60026
Test Plan:
- CI.
- local repro: plz run:
```
CIRCLE_JOB="pytorch_linux_bionic_py3_6_clang9_noarch_test" CIRCLE_PR_NUMBER=60057 IN_CI=1 ENABLE_PR_HISTORY_REORDERING=1 python test/run_test.py
```
Reviewed By: samestep
Differential Revision: D29164754
Pulled By: walterddr
fbshipit-source-id: 206688e0fb0b78d1c9042c07243da1fbf88a924b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/60016
For CUDA 92
- OptionalBase was not check if `is_arrayref`
- constexpr seems not expect to raise Exception for cuda 92
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60017
Reviewed By: malfet
Differential Revision: D29139515
Pulled By: ejguan
fbshipit-source-id: 4f4f6d9fe6a5f2eadf913de0a9781cc9f2e6ac6f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60114
Same as title.
Test Plan: Unit test (test_kernel_launch_checks.py) is passing.
Reviewed By: ngimel
Differential Revision: D29169538
fbshipit-source-id: ba4518dcb1a4713144d92faec2bb5bdf656ff7c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59719
Added filestore functionality to the c10d backend. FileStore will create a temporary file in the /tmp directory to use if it is selected as the store type. Appropriate tests were added as well.
FileStore was modified to expose the path field for testing. It was also modified so that the numWorkers field in the constructor is optional (defaulting to -1). A negative value indicates there is not a fixed number of workers. In this case, the file is not attempted to be cleaned at the end.
Test Plan: Unit tests for creating a c10d backend with filestore and simple error handling.
Reviewed By: cbalioglu, H-Huang
Differential Revision: D28997436
fbshipit-source-id: 24c9b2c9b13ea6c947e8b1207beda892bdca2217
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60110
file_diff_from_base is currently bugged for ghstack PRs since it fails
to find a merge base
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D29168767
Pulled By: seemethere
fbshipit-source-id: 580a909aa392541769cbbfdc6acce1e6c5d1c341
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60113
The tutorial link in the docs was to an fb-only colab.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D29169818
Pulled By: suo
fbshipit-source-id: 374807c234a185bd515b8ffe1300e6cf8d821636
Summary: We updated the training scripts and re-trained the Resnext model with msuru_suru_union and ig_msuru_suru_union datasets
Test Plan:
Main command line to run:
*./deeplearning/projects/classy_vision/fb/projects/msuru_suru/scripts/train_cluster.sh*
Config we used is *msuru_suru_config.json*, which is "Normal ResNeXt101 with finetunable head".
Experiments:
- msuru_suru_union f279939874
- Train/test split
- msuru_suru_union_dataset_train_w_shard: 143,632,674 rows
- msuru_suru_union_dataset_test_w_shard: 1,831,236 rows
- Results
{F625232741}
{F625232819}
- ig_msuru_suru_union f279964200
- Train/test split
- ig_msuru_suru_union_dataset_train_w_shard: 241,884,760 rows
- ig_msuru_suru_union_dataset_test_w_shard: 3,477,181 rows
- Results
{F625234126}
{F625234457}
Differential Revision: D29154971
fbshipit-source-id: d534d830020f4f8e596bb6b941966eb84a1e8adb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60024
Disables windows GPU jobs on CircleCI since they have been migrated to
GHA
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D29137287
Pulled By: seemethere
fbshipit-source-id: 204e0c9232201a36a557cd0843e31d34269cc722
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59988
As we broaden operator support, putting all the implementations into
kernel.cpp is getting unwieldy. Let's factor them out into the "operators"
subdirectory.
This diff is big but it's entirely code movement; I didn't change anything,
other than to expose a few utilities in kernel.h.
ghstack-source-id: 131405139
Test Plan: CI
Reviewed By: ZolotukhinM
Differential Revision: D29115916
fbshipit-source-id: ba0df1d8dd4a108b584da3baf168407e966b2c78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60064
This implements a host saturation optimization to maximize the utilization of the available devices.
It uses a greedy heuristic to replicate all partitions on the used devices to another set of idle devices with enough memory.
The added unittest shows an example as follows:
```
partition_0: 192 bytes; partition_1: 48 bytes
dev_0: 200 bytes, [partition_0]
dev_1: 200 bytes, [partition_1]
dev_2: 100 bytes,
dev_3: 100 bytes,
dev_4: 200 bytes,
dev_5: 100 bytes
```
Before host saturation, `partition_0` is assigned to dev_0 and `partition_1` is assigned to dev_1.
After host saturation, `partition_0` is replicated to dev_4 simply because it's the only device that can hold all partitions on dev_0. `partition_1` is replicated to dev_2 because it has minimal but large enough memory to hold all partitions on dev_1.
Test Plan:
```
buck test mode/opt //caffe2/test:test_fx_experimental -- --exact 'caffe2/test:test_fx_experimental - test_saturate_host (test_fx_experimental.TestFXExperimental)'
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/8444249343103429
✓ ListingSuccess: caffe2/test:test_fx_experimental - main (1.322)
✓ Pass: caffe2/test:test_fx_experimental - test_saturate_host (test_fx_experimental.TestFXExperimental) (1.322)
Summary
Pass: 1
ListingSuccess: 1
```
An e2e test will be added to `test_fx_glow.py` in a followup diff.
Reviewed By: gcatron
Differential Revision: D29039998
fbshipit-source-id: 57518aadf668f7f05abd6ff73224c16b5d2a12ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60001
Fix the aten::to schema to reflect that the output may alias input.
Test Plan: Added new unit tests.
Reviewed By: ezyang
Differential Revision: D29121620
fbshipit-source-id: c29b6aa22d367ffedf06e47116bc46b3e188c39c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60056
Previously we put the whole graph as a single partition onto a device with maximum memory if possible, but the code assumed that the first logical device always has the maximum memory.
This diff fixes this issue and updates the unittest to reflect such a corner case.
Test Plan:
```
buck test mode/opt //caffe2/test:test_fx_experimental -- --exact 'caffe2/test:test_fx_experimental - test_find_single_partition (test_fx_experimental.TestFXExperimental)'
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/6473924507772744
✓ ListingSuccess: caffe2/test:test_fx_experimental - main (1.357)
✓ Pass: caffe2/test:test_fx_experimental - test_find_single_partition (test_fx_experimental.TestFXExperimental) (1.206)
Summary
Pass: 1
ListingSuccess: 1
```
Reviewed By: gcatron
Differential Revision: D29118715
fbshipit-source-id: cac6a1f0d2f47717446dcc80093bbcf362663859
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60043
And add a unit test
Test Plan: new unit test
Reviewed By: navahgar
Differential Revision: D29146547
fbshipit-source-id: 31532926032dbef70d163930f3d8be160f5eacc3
Summary:
adding an early exit in the kernel to avoid reading out of bound.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59981
Reviewed By: ezyang
Differential Revision: D29147349
Pulled By: ngimel
fbshipit-source-id: b36a6a9e2526c609ff98fb5a44468f3257e0af67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58570
**What the PR does**
Generate a fast-path `at::meta::{op}` API for calling meta functions without having to go through the dispatcher. This will be important for perf for external backends that want to use meta functions for shape checking (which seems likely to be what we end up doing for LazyTensorCore).
**Details**
In order to avoid naming collisions I had to make two small changes:
- rename `MetaFunctions.h` template -> `NativeMetaFunctions.h` (this is the file that declares the impl() function for every structured operator).
- rename the meta class: `at::meta::{op}::meta()` -> `at::meta::structured_{op}::meta()`
I also deleted a few unnecessary includes, since any file that includes NativeFunctions.h will automatically include NativeMetaFunctions.h.
**Why I made the change**
This change isn't actually immediately used anywhere; I already started writing it because I thought it would be useful for structured composite ops, but that isn't actually true (see [comment](https://github.com/pytorch/pytorch/pull/58266#issuecomment-843213147)). The change feels useful and unambiguous though so I think it's safe to add. I added explicit tests for C++ meta function calls just to ensure that I wrote it correctly - which is actually how I hit the internal linkage issue in the PR below this in the stack.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D28711299
Pulled By: bdhirsh
fbshipit-source-id: d410d17358c2b406f0191398093f17308b3c6b9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58569
This should allow external C++ files that aren't compiled into `libtorch.so`/`libtorch_cpu.so` (including all of fbcode) to use fast path functions like `at::cpu::add()`, which skip the dispatcher.
So, after spending way too much time trying to figure out why I was getting linker errors when calling `at::meta::{op}` and `at::cpu::{op}` from C++ test files, I realized that we're not including the header files for C++ for the namespaced operator definitions. I.e. `RegisterCPU.cpp`, which provides definitions for the `at::cpu::{op}` fast path functions, wasn't including the `CPUFunctions.h` header.
Why that breaks stuff: the `CPUFunctions.h` header file is what marks each function with the `TORCH_API` macro, so without including it, when we build `libtorch.so` and `libtorch_cpu.so`, the compiler will look at the definition in `RegisterCPU.cpp`, not see a `TORCH_API`, and decide that the function should get internal linkage.
An alternative would be to directly mark the function definitions in `RegisterCPU.cpp` with `TORCH_API`, but this seemed cleaner.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D28711300
Pulled By: bdhirsh
fbshipit-source-id: 535f245c20e977ff566d6da0757b3cefa137040b
Summary: They will be needed when RPC gets merged into libtorch
Test Plan: CI later in the stack
Reviewed By: mrshenli
Differential Revision: D29132956
fbshipit-source-id: 8637640d56a1744a5dca5eb7d4b8ad0860c6b67c
Summary: This is needed to avoid FaultyPG from including and depending on RequestCallbackImpl, which is Python-only. The other RPC agents accept an explicit (upcast) pointer as an argument, and we can do the same for FaultyPG.
Test Plan: Later in the stack.
Reviewed By: mrshenli
Differential Revision: D29132955
fbshipit-source-id: bb7554b84bcbf39750af637e6480515ac8b92b86
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60032
There will be more sparse tests coming. This PR creates a separate folder for the sparse tests
Test Plan: `python test/test_ao.py`
Reviewed By: raghuramank100
Differential Revision: D29139265
fbshipit-source-id: d0db915f00e6bc8d89a5651f08f72e362a912a6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59538
Four mealv2 models can export in torch 1.8.1, but fails when torch master introduces relu6 a few months back.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb, ansley
Differential Revision: D29046607
Pulled By: SplitInfinity
fbshipit-source-id: d9cf7050e4ac0dad892441305ffebc19ba84e2be
Co-authored-by: David <jiafa@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59537
PyTorch sum over empty tensor gives 0, while ONNX produces an error.
torch.sum will be translated into onnx::ReduceSum op. Per the definition of ReduceSum, update the keepdims attribute for this scenario.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb, ansley
Differential Revision: D29046604
Pulled By: SplitInfinity
fbshipit-source-id: 6f5f3a66cb8eda8b5114b8474dda6fcdbae73469
Co-authored-by: fatcat-z <jiz@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59816
Add two new DataPipes, one for getting web file urls to yield streams and one for getting streams to yield bytes.
Test Plan:
Add test_web_iterable_datapipe in test/test_datapipes.py. The test initiates a local http server for serving test files. Test below locally ok.
1. create and load 16M localhost file urls (each of size 10 Bytes)
2. create and load a 64GB localhost file
in the unit test, for sake of testing time, disabling both stress test and large file test
Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D29051186
fbshipit-source-id: f8e44491e670560bf445af96f94d98230436f396
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59419
This introduces ExclusivelyOwned, which allows isolated
pieces of code that can make ownership guarantees to opt out of
reference counting operations on `intrusive_ptr` and `Tensor`
entirely. To elaborate, if you know you are the exclusive owner of an
`intrusive_ptr` or `Tensor`, moving it into an `ExclusivelyOwned` will
avoid performing atomic reference counting operations at destruction
time. The documentation comment should provide sufficient explanation; please request changes if not.
ghstack-source-id: 131376658
Test Plan:
Added `ExclusivelyOwned_test.cpp`. It passes. When I ran it
under valgrind, valgrind reported no leaks.
Inspected assembly from `inspect` functions in
`ExclusivelyOwned_test.cpp` in an optimized (opt-clang) build. As
expected, `ExclusivelyOwned` calls `release_resources()` and the
`TensorImpl` virtual destructor without including any atomic reference
counting operations.
Reviewed By: ezyang
Differential Revision: D28885314
fbshipit-source-id: 20bf6c82b0966aaa635ab0233974781ed15f93c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59776
Overall design: https://github.com/pytorch/pytorch/issues/55207.
In this PR, I've added support to ShardedTensor such that it also creates RRefs
pointing to the remote shards if the RPC framework is initialized.
As a result, this provides more flexiblity for ShardedTensor such that users
can use collectives with local shards or use the RPC framework to interact with
remote shards.
ghstack-source-id: 131381914
Test Plan:
1) unit tests
2) waitforbuildbot
Reviewed By: SciPioneer
Differential Revision: D29020844
fbshipit-source-id: acb308d0029a5e486c464d93189b5de1ba680c85
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59543
Building on top of previous PR: https://github.com/pytorch/pytorch/pull/59521
This diff is adding support for mean reduction for Cuda (fwd only currently).
Will add cuda backward implementation in subsequent PR.
Next Steps:
cuda backward support for mean
2d data input support
more testing
benchmarking
Test Plan: update unit test to cover this part as well.
Reviewed By: ngimel
Differential Revision: D28922838
fbshipit-source-id: 72b7e5e79db967116b96ad010f290c9f057232d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59788
This one line is all we need to "migrate" PyTorch to the "new API" of TensorPipe that splits the CUDA-specific stuff in a separate top-level header. (The motivation behind that is that it will allow us to "stack" the CUDA code on top of the CPU one).
ghstack-source-id: 131326166
Test Plan: None yet
Reviewed By: beauby
Differential Revision: D28875277
fbshipit-source-id: ecfd0b7fc0218ab7899bfe64ffe73c1417b897db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59377
This PR demonstrates that now the CUDA parts of the TensorPipe agent just "plug on top" of the CPU-only parts. Thus ideally the CPU-only parts could go in libtorch while the CUDA-only parts could go in libtorch_cuda. Unfortunately we can't do that just yet, because the TensorPipe agent depends on c10d (for its Store and its ProcessGroup), which lives in libtorch_python.
ghstack-source-id: 131326168
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D28796429
fbshipit-source-id: 41b2eb8400c0da282f3750a4eea21ad83ee4a175
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59376
This is an experiment. The end goal is to separate the CUDA-specific aspects of the TensorPipe agent so that they can be plugged "on top" of the CPU-only parts. This will then allow to move the TP agent to libtorch (because libtorch is split into a CPU and a CUDA part; now it's in libtorch_python), although unfortunately other conditions need to also be met for this to happen.
The only instance where we had CPU and CUDA logic within the same code, guarded by `#ifdef USE_CUDA`, is the serialization/deserialization code. I'm thus introducing a sort-of registry in order to "decentralize it". It's not a c10::Registry, because that's overkill (it uses an unordered_map, with strings as keys): here we can just use an array with integers as "keys".
ghstack-source-id: 131326167
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28796428
fbshipit-source-id: b52df832e0c0abf489a9e418353103496382ea41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58852
Enable implicit operator versioning via number of arguments from Mobile.
1. By default, TS doesn't emit instructions for tailing default args and the provided number of specified args is serialized to bytecode. From interpreter the default values are fetched from operator schema. The implementation has been landed in #56845. Please refer to #56845 for details.
2. Since there is bytecode schema change, the bytecode version is bumped from 5 to 6.
3. The corresponding backport function is provided, for forward compatibility use. Note that because there is instruction change, a global flag is used as the switch to control the two versions.
Test Plan: Imported from OSS
Reviewed By: raziel
Differential Revision: D28789746
Pulled By: iseeyuan
fbshipit-source-id: 6e5f16460c79b2bd3312de02d0f57b79f50bf66b
Summary: This adds support for embeddingBagBytewise with fp32 scale/bias to FXGlow.
Test Plan: buck run //glow/fb/fx/fx_glow:test_fx_glow
Reviewed By: jfix71
Differential Revision: D29075288
fbshipit-source-id: 4145486505a903129678216b133bbb8ad71f4fef
Summary:
This should fix `to_sparse` test issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59971
Test Plan:
CI
Also: directly examine the RuntimeError thrown from test_unsupported_backward
- Before:
```
NotImplementedError: Could not run 'aten::sum' with arguments from the 'SparseCPU' backend.
```
- After:
```
to_dense() not supported for float16 on CPU
```
Reviewed By: soulitzer
Differential Revision: D29112558
Pulled By: walterddr
fbshipit-source-id: c2acd22cd18d5b34d25209b8415feb3ba28fa104
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59840
moving these tests to their own standalone file. No meaningful code changes.
ghstack-source-id: 131359162
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D29012664
fbshipit-source-id: 348870016509a6ed7e69240fa82bccef4a12d674
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59948
1. We have two Interpreters. One for vanilla op and one for acc op. Some of the logic between them are similar and in this diff we extract out the similar logic to a Base Interpreter. This makes any future general feature change could benefit both Interpreters.
2. Make TRT Interpreter not depending on concrete tensor arg. We will use `InputTensorSpec` to create necessary inputs for acc tracer.
3. Add unittests for acc op converter.
Test Plan:
```
buck test mode/opt caffe2/torch/fb/fx2trt:test_linear
buck test mode/opt caffe2/torch/fb/fx2trt:test_batchnorm
buck test mode/opt caffe2/torch/fb/fx2trt:test_convolution
buck test mode/opt caffe2/torch/fb/fx2trt:test_reshape
buck test mode/opt caffe2/torch/fb/fx2trt:test_relu
buck test mode/opt caffe2/torch/fb/fx2trt:test_add
buck test mode/opt caffe2/torch/fb/fx2trt:test_maxpool
```
Reviewed By: jackm321
Differential Revision: D28749682
fbshipit-source-id: 830d845aede7203f6e56eb1c4e6776af197a0fc3
Summary:
Fixes https://github.com/pytorch/pytorch/issues/3025
## Background
This PR implements a function similar to numpy's [`isin()`](https://numpy.org/doc/stable/reference/generated/numpy.isin.html#numpy.isin).
The op supports integral and floating point types on CPU and CUDA (+ half & bfloat16 for CUDA). Inputs can be one of:
* (Tensor, Tensor)
* (Tensor, Scalar)
* (Scalar, Tensor)
Internally, one of two algorithms is selected based on the number of elements vs. test elements. The heuristic for deciding which algorithm to use is taken from [numpy's implementation](fb215c7696/numpy/lib/arraysetops.py (L575)): if `len(test_elements) < 10 * len(elements) ** 0.145`, then a naive brute-force checking algorithm is used. Otherwise, a stablesort-based algorithm is used.
I've done some preliminary benchmarking to verify this heuristic on a devgpu, and determined for a limited set of tests that a power value of `0.407` instead of `0.145` is a better inflection point. For now, the heuristic has been left to match numpy's, but input is welcome for the best way to select it or whether it should be left the same as numpy's.
Tests are adapted from numpy's [isin and in1d tests](7dcd29aaaf/numpy/lib/tests/test_arraysetops.py).
Note: my locally generated docs look terrible for some reason, so I'm not including the screenshot for them until I figure out why.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53125
Test Plan:
```
python test/test_ops.py # Ex: python test/test_ops.py TestOpInfoCPU.test_supported_dtypes_isin_cpu_int32
python test/test_sort_and_select.py # Ex: python test/test_sort_and_select.py TestSortAndSelectCPU.test_isin_cpu_int32
```
Reviewed By: soulitzer
Differential Revision: D29101165
Pulled By: jbschlosser
fbshipit-source-id: 2dcc38d497b1e843f73f332d837081e819454b4e
Summary:
Previous is https://github.com/pytorch/pytorch/issues/57781
We add now two CUDA bindings to avoid using ctypes to fix a windows issue.
However, we use ctypes to allocate the stream and create its pointer
(we can do this with a 0-dim tensor too if it feels better).
CC. ezyang rgommers ngimel mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59527
Reviewed By: albanD
Differential Revision: D29053062
Pulled By: ezyang
fbshipit-source-id: 661e7e58de98b1bdb7a0871808cd41d91fe8f13f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59959
**Summary**
This commit replaces the warning on the `torch.package` documentation
page about the module not being publicly released (which will no longer
be true as of 1.9) with one that warns about security issues caused by
the use of the `pickle` module.
**Test Plan**
1) Built the docs locally.
2) Continuous integration.
<img width="877" alt="Captura de Pantalla 2021-06-14 a la(s) 11 22 05 a m" src="https://user-images.githubusercontent.com/4392003/121940300-c98cab00-cd02-11eb-99dc-08e29632079a.png">
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D29108429
Pulled By: SplitInfinity
fbshipit-source-id: 3a0aeac0dc804a31203bc5071efb1c5bd6ef9725
Summary:
This PR is to upgrade onednn to v2.2.3 (including v2.2 and v2.2.3 changes) which has the following main changes about CPU:
v2.2 changes:
Improved performance of compute functionality for future Intel Core processor with Intel AVX2 and Intel DL Boost instructions support (code name Alder Lake).
Improved fp32 inner product forward propagation performance for processors with Intel AVX-512 support.
Improved dnnl_gemm performance for cases with n=1 on all supported processors.
v2.2.3 changes:
Fixed a bug in int8 depthwise convolution ptimitive with groups and 1d spatial size for processors with Intel AVX-512 and Intel AVX2 support
Fixed correctness issue for PReLU primitive on Intel Processor Graphics
Fixed corretness issue in reorder for blocked layouts with zero padding
Improved performance of weights reorders used by BRGEMM-based convolution primitive for processors with Intel AVX-512 support
More changes can be found in https://github.com/oneapi-src/oneDNN/releases.
Ideep used version is pytorch-rls-v2.2.3.
OneDNN used version is v2.2.3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57928
Reviewed By: bdhirsh
Differential Revision: D29037857
Pulled By: VitalyFedyunin
fbshipit-source-id: db74534858bdcf5d6c7dcf58e224fc756188bc31
Summary:
Makes possible that the first register parametrization depends on a number of parameters rather than just one. Examples of these types of parametrizations are `torch.nn.utils.weight_norm` and low rank parametrizations via the multiplication of a `n x k` tensor by a `k x m` tensor with `k <= m, n`.
Follows the plan outlined in https://github.com/pytorch/pytorch/pull/33344#issuecomment-768574924. A short summary of the idea is: we call `right_inverse` when registering a parametrization to generate the tensors that we are going to save. If `right_inverse` returns a sequence of tensors, then we save them as `original0`, `original1`... If it returns a `Tensor` or a sequence of length 1, we save it as `original`.
We only allow to have many-to-one parametrizations in the first parametrization registered. The next parametrizations would need to be one-to-one.
There were a number of choices in the implementation:
If the `right_inverse` returns a sequence of parameters, then we unpack it in the forward. This is to allow to write code as:
```python
class Sum(nn.Module):
def forward(self, X, Y):
return X + Y
def right_inverse(Z):
return Z, torch.zeros_like(Z)
```
rather than having to unpack manually a list or a tuple within the `forward` function.
At the moment the errors are a bit all over the place. This is to avoid having to check some properties of `forward` and `right_inverse` when they are registered. I left this like this for now, but I believe it'd be better to call these functions when they are registered to make sure the invariants hold and throw errors as soon as possible.
The invariants are the following:
1. The following code should be well-formed
```python
X = module.weight
Y = param.right_inverse(X)
assert isinstance(Y, Tensor) or isinstance(Y, collections.Sequence)
Z = param(Y) if isisntance(Y, Tensor) else param(*Y)
```
in other words, if `Y` is a `Sequence` of `Tensor`s (we check also that the elements of the sequence are Tensors), then it is of the same length as the number parameters `param.forward` accepts.
2. Always: `X.dtype == Z.dtype and X.shape == Z.shape`. This is to protect the user from shooting themselves in the foot, as it's too odd for a parametrization to change the metadata of a tensor.
3. If it's one-to-one: `X.dtype == Y.dtype`. This is to be able to do `X.set_(Y)` so that if a user first instantiates the optimiser and then puts the parametrisation, then we reuse `X` and the user does not need to add a new parameter to the optimiser. Alas, this is not possible when the parametrisation is many-to-one. The current implementation of `spectral_norm` and `weight_norm` does not seem to care about this, so this would not be a regression. I left a warning in the documentation though, as this case is a bit tricky.
I'm still missing to go over the formatting of the documentation, I'll do that tomorrow.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58488
Reviewed By: soulitzer
Differential Revision: D29100708
Pulled By: albanD
fbshipit-source-id: b9e91f439cf6b5b54d5fa210ec97c889efb9da38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57575
This PR does two things:
1. reverts "Manual revert of D27369251 (f88a3fff65) (#56080)" in commit
92a09fb87a567100122b872613344d3a422abc9f.
2. fixing DifferentiableGraph output with wrong requires_grad flag
Fixing requires_grad on outputs from DifferentiableGraph, the proper flag is
retrieved from profiling information. We previously only retrieves the profiling
information on the first profile node in all its uses. However, in case where
control flows are present, we need to iteratively search for profile node with
profiling information available, in case the first use is in an inactive code
path.
e.g.
```
graph(%0 : Tensor,
%1 : Bool):
..., %2 : Tensor = prim::DifferentiableGraph_0(%0)
%3 : Tensor = prim::If(%1)
block0():
%4 : Tensor = prim::DifferentiableGraph_1(%2)
-> (%4)
block1():
%5 : Tensor = prim::DifferentiableGraph_2(%2)
-> (%5)
-> (%3)
with prim::DifferentiableGraph_0 = graph(%0 : Tensor):
...
%out : Tensor = aten::operation(...)
...
return (..., %out)
with prim::DifferentiableGraph_1 = graph(%0 : Tensor):
%temp : Tensor = prim::profile[profiled_type=Tensor](%0)
...
with prim::DifferentiableGraph_2 = graph(%0 : Tensor):
%temp : Tensor = prim::profile[profiled_type=Float(...)](%0)
...
```
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D29038773
Pulled By: Krovatkin
fbshipit-source-id: 6c0a851119f6b8f2f1afae5c74532407aae238fe
Summary:
Some minor quality of life improvements for the NNC python bindings:
- expose `call_raw()`
- support passing integers to `call()` (for dynamic shapes)
- implicit conversions to cleanup `[BufferArg(x) for x in [A, B, C]]` into just `[A, B, C]`
- don't silently default to "ir_eval" for unknown mode (e.g. "LLVM")
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59920
Reviewed By: ZolotukhinM
Differential Revision: D29090904
Pulled By: jansel
fbshipit-source-id: 154ace82725ae2046cfe2e6eb324fd37f5d209a7
Summary:
Currently, if we do softmax which are not along the last dim, the calculation will fall to a [scalar version](d417a094f3/aten/src/ATen/native/SoftMax.cpp (L14-L64)). And we find actually we have the chance to vectorize the calculation along the inner_size dim.
Changes we made:
- Use vectorized softmax_kernel instead of host_softmax when not along the last dim.
Performance data on 28 cores' Intel 8280 CPU when the Input size is [32, 81, 15130] and do softmax along the second dim(81).
- FP32 Baseline: 24.67 ms
- FP32 optimized: 9.2 ms
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59195
Reviewed By: ailzhang
Differential Revision: D28854796
Pulled By: cpuhrsch
fbshipit-source-id: 18477acc3963754c59009b1794f080496ae16c3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59758
The underlying call to tp_getattr is const safe but CPython
has not fixed it due to BC problems. No reason not to advertise
the better type here though!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D29017911
Pulled By: ezyang
fbshipit-source-id: 8d55983fe6416c03eb69c6367bcc431c30000133
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59709Fixes#59705.
Python 3.8 fixed tracebacks to report the beginning of the line
that raised an error, rather than the end. This makes for a simpler
implementation (no more string reversing) but need to actually
implement. This wasn't caught by tests because we hard coded line
numbers to do substitutions, so I also added a little smoketest to
detect future changes to traceback line number behavior.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D28994919
Pulled By: ezyang
fbshipit-source-id: 1fb0a782e17c55c13d668fabd04766d2b3811962
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59852
This whole stack does not change anything to the codegened code
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D29063814
Pulled By: albanD
fbshipit-source-id: a751047526f8d58f4760ee6f9ae906675bed5d75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59850
This whole stack does not change anything to the codegened code
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D29063816
Pulled By: albanD
fbshipit-source-id: ca3067443d8e6282c1077d3dafa3b4f330d43b28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59849
This whole stack does not change anything to the codegened code
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D29063815
Pulled By: albanD
fbshipit-source-id: c4baa72594bd2fe50ac67f513916f2b2ccb7488c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59848
This whole stack does not change anything to the codegened code
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D29063818
Pulled By: albanD
fbshipit-source-id: c68734672eeacd212d7bd9bebe3d53aaa20c3c24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59847
This whole stack does not change anything to the codegened code
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D29063817
Pulled By: albanD
fbshipit-source-id: 284c3e057029b7a67f43a1b034bb30863bd68c71
Summary:
Implements a number of changes discussed with soulitzer offline.
In particular:
- Initialise `u`, `v` in `__init__` rather than in `_update_vectors`
- Initialise `u`, `v` to some reasonable vectors by doing 15 power iterations at the start
- Simplify the code of `_reshape_weight_to_matrix` (and make it faster) by using `flatten`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59564
Reviewed By: ailzhang
Differential Revision: D29066238
Pulled By: soulitzer
fbshipit-source-id: 6a58e39ddc7f2bf989ff44fb387ab408d4a1ce3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59903
D29034650 (cf0c4ac258) probably breaks something because it changes a `for` loop on ~Line 1200 from `[size,max)` to `[0,max)`. This fixes that
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D29081688
fbshipit-source-id: 21f08e3f244fc02cf97d137b3cc80d4378d17185
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: ae8ad8fd04
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59874
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D29064980
fbshipit-source-id: 593f08361817fb771afcf2732f0f647d7c2c72c3
Summary:
instead of having specific logic to handle run-specific-test-case, we provide the flag to override include or bring-to-front with the SPECIFIED_TEST_CASES_FILE.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59704
Reviewed By: janeyx99
Differential Revision: D29038425
Pulled By: walterddr
fbshipit-source-id: 803d3555813437c7f287a22f7704106b0c609919
Summary:
This reverts https://github.com/pytorch/pytorch/issues/58778, since triggering our primary CircleCI workflow only via pytorch-probot has been causing more problems than it's worth.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59889
Reviewed By: walterddr, seemethere
Differential Revision: D29070418
Pulled By: samestep
fbshipit-source-id: 0b47121b190c2e9efa27f38000ca362e634876dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59684
Same reasoning as in the below diff.
ghstack-source-id: 131167212
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D28981326
fbshipit-source-id: 264a7f787ea8be76f743a2eaca67ae1d3bd8073a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59683
Replaces usages of throw std::runtime_error("foo") with the better
torch_check(false, "foo") which allows C++ stacktraces to show up when
TORCH_SHOW_CPP_STACKTRACES=1. This will hopefully provide much better debugging
information when debugging crashes/flaky tests.
ghstack-source-id: 131167210
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D28981327
fbshipit-source-id: 677f569e28600263cab18759eb1b282e0391aa7b
Summary:
Use `vrndq_f32`, which corresponds to `VRINTZ` instruction, which rounds floating point value towards zero, which matches `std::trunc` behaviour.
This makes trunc implementation correct even for values that fit into float32, but can not be converted to int32, for example `-1.0e+20`, see the following [gist](https://gist.github.com/malfet/c612c9f4b3b5681ca1b2a69930825871):
```
inp= 3.1 2.7 -2.9 -1e+20
old_trunc= 3 2 -2 -2.14748e+09
new_trunc= 3 2 -2 -1e+20
```
Fixes `test_reference_numerics_hard_trunc_cpu_float32` on M1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59858
Reviewed By: kimishpatel
Differential Revision: D29052008
Pulled By: malfet
fbshipit-source-id: 6b567f39151538be1aa3890e3b4e1e978e598657
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58873
BackenDebugInforRecorder
Prior to this PR:
In order to generate debug handles corresponding to the graph being
lowered, backend's preprocess will call generate_debug_handles and will
get map of Node*-to-debug_handles.
In order to facilitate this, to_backend will own
BackendDebugInfoRecorder and initialize thread local pointer to it.
generate_debug_handle function will query thread local pointer to see if
there is a valid BackendDebugInforRecorder for the context. If there is
it will generate debug handles.
After this PR:
Signature of preprocess is changed such that backends have to register
preprocess that accepts instance of BackendDebugInfoRecorder by
reference. generate_debug_handles is no more a free function but becomes
part of the API of BackendDebugInfoRecorder. Now backend's preprocess
function will call generate_debug_handles on BackendDebugInfoRecorder
instead of free function.
Reason for this change:
With RAII that initializes thread local pointer, results in a lose
contract with backends, which may result in backends not storing
debug information. Making it part of API results in
backends having to be aware of BackendDebugInfoRecorder and explicitly
chosing not to generate/store debug information if they chose to do so.
Test Plan:
backend tests
Imported from OSS
Reviewed By: jbschlosser, raziel
Differential Revision: D28648613
fbshipit-source-id: c9b7e7bf0f78e87023ea7bc08612cf893b08cb98
Summary:
Based from https://github.com/pytorch/pytorch/pull/50466
Adds the initial implementation of `torch.cov` similar to `numpy.cov`. For simplicity, we removed support for many parameters in `numpy.cov` that are either redundant such as `bias`, or have simple workarounds such as `y` and `rowvar`.
cc PandaBoi
TODO
- [x] Improve documentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58311
Reviewed By: mruberry
Differential Revision: D28994140
Pulled By: heitorschueroff
fbshipit-source-id: 1890166c0a9c01e0a536acd91571cd704d632f44
Summary:
Python 3.6 EOL is end of this year--we should use newer Python in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59729
Reviewed By: bdhirsh
Differential Revision: D29006807
Pulled By: janeyx99
fbshipit-source-id: c79214b02a72656058ba5d199141f8838212b3b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59605
Enables targeting of individual function invocations by execution order.
For example, given a module such as
```
class M1(torch.nn.Module):
def forward(self, x):
x = torch.add(x, x)
x = torch.add(x, x)
return x
class M2(torch.nn.Module):
def __init__(self):
self.m1 = M1()
def forward(self, x):
x = self.m1(x)
return x
```
We can now target the first add of `m1` with
```
qconfig_dict = {
"module_name_function_order": ("m1", torch.add, 0, custom_qconfig),
}
```
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_qconfig_module_name_function_order
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D28951077
fbshipit-source-id: 311d423724a31193d4fa4bbf3a712b46464b5a29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59697
The c10d build process selectively adds files based on the `USE_C10D_FOO` flags (where `FOO` is one of `GLOO`, `NCCL` or `MPI`). Replicating this logic inside libtorch will be harder, since libtorch uses a simpler approach (i.e., it lists the files in `build_variables.bzl`). So instead we could always include all files, and "disable" each file as needed using `#ifdef`s. Note that this is not a new approach: we already do the same for all the files of the TensorPipe agent based on the flag `USE_TENSORPIPE`.
ghstack-source-id: 131169540
Test Plan: CI
Reviewed By: agolynski
Differential Revision: D28987577
fbshipit-source-id: 4c6195de4e9a58101dad9379537e8d055dfd38af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59696
Some files in c10d refer to dist autograd. However, on Windows, dist autograd isn't built. Hence we need to "mask out" those references under Windows. This was already partly done, but when moving c10d to libtorch some issues came up, possibly due to the different way in which linking happens. Hence I masked out the remaining references.
ghstack-source-id: 131169541
Test Plan: CI
Reviewed By: agolynski
Differential Revision: D28987579
fbshipit-source-id: c29c5330f8429d699554972d30f99a89b2e3971d
Summary:
nvrtc has a hard limit to the size of kernel parameters, and llvm has
a tendency to OOM with huge parameter lists, so let's limit the number of
inputs to something sensible.
Test Plan:
tested on pyper OOM test case:
```
flow-cli test-locally --mode=opt-split-dwarf f278102738 --name "PyPer OOM repro f277966799 f63b1f9c5c0c" --run-as-secure-group oncall_pytorch_jit --entitlement default
```
Reviewed By: ZolotukhinM
Differential Revision: D29019751
fbshipit-source-id: b27f2bb5000e31a7b49ea86a6928faa0ae2ead24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59754
Also, if inputs are contiguous, use their Placeholders
directly rather than generating contiguous Tensors from them.
The rationale for this change is that aten::matmul and aten::conv2d
support transposed inputs; if NNC generates a physical transpose to
perform an external call, performance will be strictly worse than not
fusing (sometimes dramatically so, as in the attached benchmark).
Test Plan: benchmark
Reviewed By: ZolotukhinM
Differential Revision: D29010209
fbshipit-source-id: da6d71b155c83e8d6e306089042b6b0af8f80900
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59603
D28698997 (10345010f7) was reverted because I forgot to replace the
```
VLOG(1) << "Found schema mismatch";
n->schema().dump();
```
block in `aten::clamp_min` with `LogAndDumpSchema(n)` and that led to the bazel build to fail. I don't know why it makes the bazel build though.
Test Plan: OSS CI.
Reviewed By: ajyu
Differential Revision: D28950177
fbshipit-source-id: 9bb1c6619e6b68415a3349f04933c2fcd24cc9a2
Summary:
angle should return 0 for positive values, pi for negative and keep nans in place, which can be accomplished using two blendv functions.
Fixes number of unary test failures on M1/aarch64
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59832
Reviewed By: kimishpatel
Differential Revision: D29046402
Pulled By: malfet
fbshipit-source-id: cb93ad2de140f7a54796387fc11053c507a1d4e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59833
**Summary**
This commit adds an explanation section to the `torch.package`
documentation. This section clarifies and illuminates various aspects of
the internals of `torch.package` that might be of interest to users.
**Test Plan**
Continuous integration.
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Differential Revision: D29050626
Pulled By: SplitInfinity
fbshipit-source-id: 78e0cda00f69506ef2dfc52d6df63694b502269e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59503
**Summary**
This commit adds a "how do I..." section to the `torch.package`
documentation. This section contains short guides about how to solve
real-world problems that frequently recur while using `torch.package`.
**Test Plan**
Continuous integration.
<img width="877" alt="Captura de Pantalla 2021-06-04 a la(s) 9 19 54 p m" src="https://user-images.githubusercontent.com/4392003/120879911-98321380-c57b-11eb-8664-c582c92b7837.png">
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Differential Revision: D29050629
Pulled By: SplitInfinity
fbshipit-source-id: 2b7800732e0a3c1c947f110c05562aed5174a87f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59491
**Summary**
This commit adds a preamble to the `torch.package` documentation page
that explains briefly what `torch.package` is.
**Test Plan**
Continous integration.
<img width="881" alt="Captura de Pantalla 2021-06-04 a la(s) 3 57 01 p m" src="https://user-images.githubusercontent.com/4392003/120872203-d535e000-c552-11eb-841d-b38df19bc992.png">
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Differential Revision: D29050630
Pulled By: SplitInfinity
fbshipit-source-id: 70a3fd43f076751c6ea83be3ead291686c641158
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59711
This is the exact same PR as before.
This was reverted before the PR below was faulty.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D28995762
Pulled By: albanD
fbshipit-source-id: 65940ad93bced9b5f97106709d603d1cd7260812
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59710
This is the exact same PR as before.
The version that landed was actually outdated compared to the github PR and that's why it failed on master... Sorry for the noise.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D28995764
Pulled By: albanD
fbshipit-source-id: 8f7ae3356a886d45787c5e6ca53a4e7b033e306e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59728
I noticed Sandcastle jobs failing with:
```
fbcode/caffe2/torch/csrc/api/include/torch/nn/modules/rnn.h:19:35: error: using namespace directive in global context in header [-Werror,-Wheader-hygiene]
using namespace torch::nn::utils::rnn;
```
(cf. V3 of D28939167 or https://www.internalfb.com/intern/sandcastle/job/36028797455955174/).
Removing `using namespace ...` fixes the problem.
~~... also applied code formatting ...~~
Test Plan: Sandcastle
Reviewed By: jbschlosser
Differential Revision: D29000888
fbshipit-source-id: 10917426828fc0c82b982da435ce891dc2bb6eec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59722
Reintroduce sharing constant between bytecode and torchscript (same as #58629) after the fix#59642
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D29002345
Pulled By: cccclai
fbshipit-source-id: d9c8e474ff57d0509580183206df038a24ad27e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59521
This diff is adding support for mean reduction for CPU (fwd + bckwd).
Will add cuda implementation in subsequent PR. We are using "cub::DeviceSegmentedReduce" for other aggregation, trying to see how to support mean or will write custom kernel for it.
Next Steps:
- cuda support for mean
- 2d data input support
- more testing
- benchmarking
Test Plan: updated unit test. Still relying on manual data for ease of debugging. Will add more tests that covers edge cases once major features are complete.
Reviewed By: ngimel
Differential Revision: D28922547
fbshipit-source-id: 2fad53bbad2cce714808ff95759cbdbd45bb4ce6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59742
It looks like Windows workers were failing out due to some leftovers
from previous builds, this should hopefully remedy some of those errors
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D29009076
Pulled By: seemethere
fbshipit-source-id: 426d54df14ec580cb24b818c48e2f4bd36159181
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59799
This is a redo of #58574, easier to create a new PR than to fix rebase
conflicts, as there have been a large number of refactors to the
underlying code.
Removes some code which was incorrectly added by #57519 but never
actually used for anything.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D29031955
fbshipit-source-id: f407d181070cb283382965952821e3647c705544
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59095
These tests were disabled, I'm unsure as to why. I've
re-enabled them and remade them to expand testing to different devices
and dtypes
Test Plan:
python test/test_quantization.py TestFakeQuantizeOps.test_numerical_consistency
Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D29018745
fbshipit-source-id: 28188f32bafd1f1704c00ba49d09ed719dd1aeb2
Summary:
This would lower the number of unnecessary commits to pytorch/test-infra by only exporting a different stats file when the stats are varying enough. This way, if the slow test cases we gather from S3 are the same and their times are trivially different, then we do not bother exporting a different stats file when the --ignore-small-diffs option is enabled.
We instead export the stats already in test-infra, so that when it tries to commit, it realizes it would be an empty commit and not add to the git history.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59759
Test Plan: Run `python tools/export_slow_tests.py --ignore-small-diffs <threshold>`.
Reviewed By: walterddr
Differential Revision: D29032712
Pulled By: janeyx99
fbshipit-source-id: 41d522a4c5f710e776acd1512d41be9791d0cf63
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59596
Parallelize batch matmul across batch dim. This was found to improve perf for
some usecases on mobile.
ghstack-source-id: 130989569
Test Plan: CI unit tests
Reviewed By: albanD
Differential Revision: D26833417
fbshipit-source-id: 9b84d89d29883a6c9d992d993844dd31a25f76b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59789
The bot messed up in D28867855 (96651458eb) so I've got to do it manually.
Test Plan: CI
Reviewed By: beauby
Differential Revision: D29027901
fbshipit-source-id: 9438e0cfbe932fbbd1e252ab57e2b1b23f9e44cf
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: e942ea1513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59374
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D28867855
fbshipit-source-id: e1325046003f5c546f02024ff4c427c91721cd7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59560
`at::cuda::CUDAStream` has the `query` and `synchronize` methods, but `c10::Stream` does not, and I couldn't find any generic way to accomplish this. Hence I added helpers to do this to the DeviceGuardImpl interface, and then defined these methods on `c10::Stream`. (I had to do it out-of-line to circumvent a circular dependency).
ghstack-source-id: 130932249
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D28931377
fbshipit-source-id: cd0c19cf021e305d0c0cf9af364afb445d010248
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59111
Create a util function for initializing subgroups. By default, each subgroup contains all the ranks within a machine. This util function can be used by both local SGD and SyncBatchNorm optimization.
Additionally, clang format `distributed/__init__.py` after importing `_rank_not_in_group` which is used by the unit test, and also clang format `distributed_c10d.py`.
Note that this API does not accept another overall main group. Like APEX API `create_syncbn_process_group` [here](https://nvidia.github.io/apex/_modules/apex/parallel.html), always uses the global world size and should only be applied when CUDA is available.
#Closes: https://github.com/pytorch/pytorch/issues/53962
ghstack-source-id: 130975027
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_new_subgroups
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_new_subgroups_group_size_exceeds_world_size
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_new_subgroups_world_size_not_divisible_by_group_size
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_new_subgroups_by_enumeration
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_new_subgroups_by_enumeration_input_rank_exceeds_world_size
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_new_subgroups_overlap_not_allowed
Reviewed By: rohan-varma
Differential Revision: D28495672
fbshipit-source-id: fdcc405411dd409634eb51806ee0a320d1ecd4e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59667
Use torch_check over throw std::runtime_error in monitored barrier so
that it works with torch_cpp_show_stacktraces to reveal the entire callstack
where the monitored barrier failed, which can help determine where the
particular rank encountered an issue.
ghstack-source-id: 130993689
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D28974510
fbshipit-source-id: 6a6958995c1066cddcd647ca88c74473079b69fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59714
Bytecode v6 is on implicit operator versioning through number of specified arguments. Both the read and write codes are available. This PR is to enable reading v6 models. The default writing format is not changed yet and will be bumped in a later PR.
Test: CI.
Local: change the writing version to 6 temporally and run the unit tests in LiteInterpreterTest. There are a number of end-to-end tests to write v6 bytecode, read and run it.
Test Plan: Imported from OSS
Reviewed By: raziel, cccclai
Differential Revision: D29007538
Pulled By: iseeyuan
fbshipit-source-id: cb089d5d4c5b26c5b5cd3a5e0954e8c7c4c69aac
Summary:
Addresses https://github.com/pytorch/pytorch/issues/59548
**Overview:**
Recently, we changed ZeRO's partitioning algorithm to first sort the parameters by decreasing size and then greedily allocate to shards. See [here](ea1de87f4b).
The current tests `test_sharding()` and `test_add_param_group()` check for a uniform partitioning, which is not achieved with the old naive greedy partitioning algorithm for general world sizes but is achieved with the new sorted-greedy algorithm. This reliance is not ideal, but for now, we opt to simply add comments to document the dependency.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59713
Test Plan:
I tested for world sizes of 1, 2, 3, and 4 via the AI AWS cluster:
```
srun -p $DEV_QUEUE --cpus-per-task=16 -t 5:00:00 --gpus-per-node=1 python test/distributed/optim/test_zero_redundancy_optimizer.py -- TestZeroRedundancyOptimizerDistributed.test_sharding
srun -p $DEV_QUEUE --cpus-per-task=16 -t 5:00:00 --gpus-per-node=2 python test/distributed/optim/test_zero_redundancy_optimizer.py -- TestZeroRedundancyOptimizerDistributed.test_sharding
srun -p $DEV_QUEUE --cpus-per-task=16 -t 5:00:00 --gpus-per-node=3 python test/distributed/optim/test_zero_redundancy_optimizer.py -- TestZeroRedundancyOptimizerDistributed.test_sharding
srun -p $DEV_QUEUE --cpus-per-task=16 -t 5:00:00 --gpus-per-node=4 python test/distributed/optim/test_zero_redundancy_optimizer.py -- TestZeroRedundancyOptimizerDistributed.test_sharding
srun -p $DEV_QUEUE --cpus-per-task=16 -t 5:00:00 --gpus-per-node=1 python test/distributed/optim/test_zero_redundancy_optimizer.py -- TestZeroRedundancyOptimizerDistributed.test_add_param_group
srun -p $DEV_QUEUE --cpus-per-task=16 -t 5:00:00 --gpus-per-node=2 python test/distributed/optim/test_zero_redundancy_optimizer.py -- TestZeroRedundancyOptimizerDistributed.test_add_param_group
srun -p $DEV_QUEUE --cpus-per-task=16 -t 5:00:00 --gpus-per-node=3 python test/distributed/optim/test_zero_redundancy_optimizer.py -- TestZeroRedundancyOptimizerDistributed.test_add_param_group
srun -p $DEV_QUEUE --cpus-per-task=16 -t 5:00:00 --gpus-per-node=4 python test/distributed/optim/test_zero_redundancy_optimizer.py -- TestZeroRedundancyOptimizerDistributed.test_add_param_group
```
However, because the train queue (which offers instances with 8 GPUs) is not working at the moment, I was unable to test for world sizes of 5+. Nonetheless, I believe that they should still work.
First, consider `test_sharding()`. Given the sorted-greedy algorithm, each shard will be assigned one of the parameters with size `9`, then one of the parameters with size `7`, then `5`, and finally `3`. Hence, each will have a uniform partition. Now, consider `test_add_param_group()`. Similarly, the same allocation behavior occurs, only the last shard is not assigned the final parameter with size `3` to begin. However, after adding the new `param_group` with the parameter with size `3`, a re-partitioning occurs. The first `param_group` is partitioned as before, and the parameter with size `3` in the new `param_group` is assigned to the last shard since it has the minimal total size. Thus, in the end, all shards have a uniform partition.
Reviewed By: mrshenli
Differential Revision: D28996460
Pulled By: andwgu
fbshipit-source-id: 22bdc638d8569ed9a20836812eac046d628d6df2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59578
This is verbose warning formed from one `CAFFE_ENFORCE_GT()` check:
```
third-party\toolchains\vs2017_15.9\buildtools\vc\tools\msvc\14.16.27023\include\xstddef(271): warning C4018: '>': signed/unsigned mismatch
xplat\caffe2\c10\util\logging.h(208): note: see reference to function template instantiation 'bool std::greater<void>::operator ()<const T1&,const T2&>(_Ty1,_Ty2) const' being compiled
with
[
T1=int,
T2=unsigned int,
_Ty1=const int &,
_Ty2=const unsigned int &
]
xplat\caffe2\caffe2\operators\conv_pool_op_base.h(539): note: see reference to function template instantiation 'void c10::enforce_detail::enforceThatImpl<std::greater<void>,int,unsigned int,>(Pred,const T1 &,const T2 &,const char *,int,const char *,const void *)' being compiled
with
[
Pred=std::greater<void>,
T1=int,
T2=unsigned int
]
xplat\caffe2\caffe2\operators\conv_pool_op_base.h(536): note: while compiling class template member function 'std::vector<caffe2::TensorShape,std::allocator<_Ty>> caffe2::ConvPoolOpBase<caffe2::CPUContext>::TensorInferenceForSchema(const caffe2::OperatorDef &,const std::vector<_Ty,std::allocator<_Ty>> &,int)'
with
[
_Ty=caffe2::TensorShape
]
xplat\caffe2\caffe2\operators\conv_pool_op_base.h(631): note: see reference to function template instantiation 'std::vector<caffe2::TensorShape,std::allocator<_Ty>> caffe2::ConvPoolOpBase<caffe2::CPUContext>::TensorInferenceForSchema(const caffe2::OperatorDef &,const std::vector<_Ty,std::allocator<_Ty>> &,int)' being compiled
with
[
_Ty=caffe2::TensorShape
]
xplat\caffe2\caffe2\operators\pool_op.cc(1053): note: see reference to class template instantiation 'caffe2::ConvPoolOpBase<caffe2::CPUContext>' being compiled
xplat\caffe2\c10\core\memoryformat.h(63): note: see reference to class template instantiation 'c10::ArrayRef<int64_t>' being compiled
```
Use a signed `0` because `.dims_size()` returns a signed integer.
Test Plan: Confirm warning no longer present in Windows build logs
Reviewed By: simpkins
Differential Revision: D28941905
fbshipit-source-id: acdc1281df2fe7f30b14cfad917cbbe8f3336d29
Summary:
Removes unused variables and functions and performs other minor mods sufficient to introduce `-Wall` as a default build flag. This should enhance code safety in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59668
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D28974453
fbshipit-source-id: 011c720dd6e65fdbbd87aa90bf57d67bfef32216
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58950
Use tensor iterator's API to set grain size in order to parallelize gelu op.
ghstack-source-id: 130947174
Test Plan: test_gelu
Reviewed By: ezyang
Differential Revision: D28689819
fbshipit-source-id: 0a02066d47a4d9648323c5ec27d7e0e91f4c303a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58949
To parallelize ops grain size setting is exposed at for_each level.
This is too far deep in the stack cpu_kernel_vec which does not know what the
op is. You would want to parallelize op depending on the op type. Non trivial
ops can benefit from threads even when the # of elements in tensor is not high.
This API exposes setting grain size at tensor iterator level so that operator
creating it can have control over it.
ghstack-source-id: 130947175
Test Plan: CI + will add more test
Reviewed By: ezyang
Differential Revision: D26857523
fbshipit-source-id: 09fc2953061069967caa9c78b010cb1b68fcc6c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59712
When worker process fails in fb due to signal failure, the TerminationHandler writes error reply file. Recently the error reply file was changed for mast jobs. The Json value of ``timestamp`` is string, even though in the thrift struct it is int: https://fburl.com/diffusion/upa228u5
This diff adds support for casting str timestamp to int.
Test Plan: buck test mode/dev-nosan //caffe2/test/distributed/elastic/multiprocessing/errors:api_test
Reviewed By: suphoff
Differential Revision: D28995827
fbshipit-source-id: 333448cfb4d062dc7fe751ef5839e66bfcb3ba00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59663
This PR fixes an edge case bug in `DynamicRendezvousHandler` where the state of the rendezvous is not always entirely updated when one or more nodes are not alive anymore.
Test Plan: Run the existing and newly-introduced unit tests.
Reviewed By: tierex
Differential Revision: D28971809
fbshipit-source-id: ebbb6a5f2b04f045c3732d6cf0f8fdc7c2381a7c
Summary:
Switches most of the simple for loops outside of `jit` directories to use `c10::irange`.
Generated with D28874212.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59481
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D28909681
fbshipit-source-id: ec9ab1bd602933238d9d0f73d4d8d027b75d9d85
Summary:
Make sure tests run explicitely without TF32 don't use TF32 operations
Fixes https://github.com/pytorch/pytorch/issues/52278
After the tf32 accuracy tolerance was increased to 0.05 this is the only remaining change required to fix the above issue (for TestNN.test_Conv3d_1x1x1_no_bias_cuda)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59624
Reviewed By: heitorschueroff
Differential Revision: D28996279
Pulled By: ngimel
fbshipit-source-id: 7f1b165fd52cfa0898a89190055b7a4b0985573a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59657
Introduce tests that test elastic agent with c10d and etc2-v2 rendezvous backends.
Added a port allocation method that uses sockets to find an available port for the c10d backend. This way, agents that are created will all share the specified address/port and can communicate.
Added a method that abstracts the backend to use when running a test. This way, any tests can quickly be switched to run on the backend of choice (c10d, etcd, or etcd-v2)
Test Plan: Tests various components of the elastic agent with 3 different backends: etcd, etcd-v2, and c10d.
Reviewed By: tierex
Differential Revision: D28972604
fbshipit-source-id: fd4cff6417fefdf0de9d7a114820914b968006a8
Summary:
This is only important for builds where cuDNN is linked statically into libtorch_cpu.
Before this PR PyTorch wheels often accidentally contained several partial copies of cudnn_static library.
Splitting the interface into header only (cudnn-public) and library+headers(cudnn-private) prevents those from happening.
Preliminary step towards enabling optional linking whole cudnn_library to workaround issue reported in https://github.com/pytorch/pytorch/issues/50153
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59721
Reviewed By: ngimel
Differential Revision: D29000967
Pulled By: malfet
fbshipit-source-id: f054df92b265e9494076ab16c247427b39da9336
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59435
Sometimes we need to compare 10+ digits. Currenlty tensorboard only saves float32. Provide an option to save float64
Reviewed By: yuguo68
Differential Revision: D28856352
fbshipit-source-id: 05d12e6f79b6237b3497b376d6665c9c38e03cf7
Summary:
Related issue: https://github.com/pytorch/pytorch/issues/58833
__changes__
- slowpath tests: pass every dtype&device tensors and compare the behavior with regular functions including inplace
- check of #cudaLaunchKernel
- rename `ForeachUnaryFuncInfo` -> `ForeachFuncInfo`: This change is mainly for the future binary/pointwise test refactors
cc: ngimel ptrblck mcarilli
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58960
Reviewed By: ejguan
Differential Revision: D28926135
Pulled By: ngimel
fbshipit-source-id: 4eb21dcebbffffaf79259e31961626e0707fb8d1
Summary:
Depends on https://github.com/pytorch/pytorch-probot/pull/22. Adds a new label called `ci/no-build` that disables the CircleCI `build` workflow on PRs. The current behavior should be the same in the absence of `ci/no-build`.
Specifically, after this PR lands, for anyone who isn't rebased onto the latest `master`, I believe this will happen:
- when they push to their PR, the CircleCI app triggers CI
- the `pytorch-probot` app sees that their PR doesn't have the `ci/no-build` tag, so it also triggers CI
- the latter should auto-cancel the former
After checking with https://github.com/pytorch/pytorch/issues/59087, it looks like this would cause the "errored" number to go up and then go down as Circle jobs are canceled (saying "Your CircleCI tests were canceled") and then restarted:
<img width="868" alt="Screen Shot 2021-05-27 at 12 39 20 PM" src="https://user-images.githubusercontent.com/8246041/119887123-9667b080-bee8-11eb-8acb-e1967899c9d5.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58778
Reviewed By: malfet
Differential Revision: D28995335
Pulled By: samestep
fbshipit-source-id: 8d7543b911e4bbbeef14639baf9d9108110b97c8
Summary:
Echo on https://github.com/pytorch/pytorch/pull/58260#discussion_r637467625
similar to `test_unsupported_dtype` which only check exception raised on the first sample. we should do similar things for unsupported_backward as well. The goal for both test is to remind developer to
1. add a new dtype to the support list if they are fulling runnable without failure (over all samples)
2. replace the skip mechanism which will indefinitely ignore tests without warning
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59455
Test Plan: CI.
Reviewed By: mruberry
Differential Revision: D28927169
Pulled By: walterddr
fbshipit-source-id: 2993649fc17a925fa331e27c8ccdd9b24dd22c20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59508
An assert that was triggering in a previous version is now relaxed to
take 0-dim tensors into account.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D28918342
Pulled By: ZolotukhinM
fbshipit-source-id: c09b62c9725d1603b0ec11fcc051e7c932af06ae
Summary:
Fixes https://github.com/pytorch/pytorch/issues/35379
- Adds `retains_grad` attribute backed by cpp as a native function. The python bindings for the function are skipped to be consistent with `is_leaf`.
- Tried writing it without native function, but the jit test `test_tensor_properties` seems to require that it be a native function (or alternatively maybe it could also work if we manually add a prim implementation?).
- Python API now uses `retain_grad` implementation from cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59362
Reviewed By: jbschlosser
Differential Revision: D28969298
Pulled By: soulitzer
fbshipit-source-id: 335f2be50b9fb870cd35dc72f7dadd6c8666cc02
Summary:
Fixes https://github.com/pytorch/pytorch/issues/4661
- Add warnings in engine's `execute` function so it can be triggered through both cpp and python codepaths
- Adds an RAII guard version of `c10::Warning::set_warnAlways` and replaces all prior usages of the set_warnAlways with the new one
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59412
Reviewed By: jbschlosser
Differential Revision: D28969294
Pulled By: soulitzer
fbshipit-source-id: b03369c926a3be18ce1cf363b39edd82a14245f0
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 77a4792062
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59505
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: dskhudia
Differential Revision: D28918331
fbshipit-source-id: def60efe55843023e70b94726cde1faf6857be0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59360
Pull Request resolved: https://github.com/pytorch/kineto/pull/206
Replace ClientTraceActivity with GenericActivity.
In addition:
* Add a couple of new activity types for user annotations
* Simplify code for GPU-side user annotations
* Add accessor to containing trace span object in activities. Later we can replace this with a trace context / trace session object.
* Simplified MemoryTraceLogger
* Added early exit for cupti push/pop correlation ID
Reviewed By: ilia-cher
Differential Revision: D28231675
fbshipit-source-id: 7129f2493016efb4d3697094f24475e2c39e6e65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59553
Added a test for 0x0 sparse coo input for sparse_unary_ufuncs.
This test fails for `conj` on master.
Modified `unsupportedTypes` for test_sparse_consistency, complex dtypes
pass, but float16 doesn't pass for `conj` because `to_dense()` doesn't
work with float16.
Fixes https://github.com/pytorch/pytorch/issues/59549
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D28968215
Pulled By: anjali411
fbshipit-source-id: 44e99f0ce4aa45b760d79995a021e6139f064fea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59633Fixes#59614
This fix isn't 100% correct but it appears to stem the bleeding.
A better fix would be understand how to detect when function
implementations don't uphold required invariants, leading to
refcount disaster.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D28962183
Pulled By: ezyang
fbshipit-source-id: 6ec71994666289dadef47bac363e6902df90b094
Summary:
Make an assert message in Pytorch's JIT provide better information by
printing the debug name of a value in `PythonPrintImpl::useOf` if it's not
found in any tables.
Test Plan:
Tested printing a `module.code` where the module had an invalid value used
as an operand. Before it asserted without any more details, afterwards it
printed the debug name which made it easy to track down the offending value.
Reviewed By: SplitInfinity
Differential Revision: D28856026
fbshipit-source-id: 479f66c458a0a2d9a161ade09f20382e7b19d60e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59599
This will fix the flakiness for these tests internally when running under TSAN. We don't need multiprocessing since we should restrict the testing to the `wait_for_workers` and `world_size` parameters of the tcp store master store.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D28947838
Pulled By: H-Huang
fbshipit-source-id: d3e3904aa7ac81ae4c744a193a3b7167c2227bc8
Summary:
This fixes multiple bugs introduced by the VSX optimized code in https://github.com/pytorch/pytorch/pull/41541
- min/max/clamp now consistently return nan when any value is NaN as on other architectures
- The non-complex angle functions return PI for negative values now
- The complex angle functions have been corrected and optimized
- The float32-log function implementation returned a wrong result when inf was passed (and maybe other inputs), replaced by the sleef function just as for float64
Fixes https://github.com/pytorch/pytorch/issues/59248
Fixes https://github.com/pytorch/pytorch/issues/57537
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59382
Reviewed By: jbschlosser
Differential Revision: D28944626
Pulled By: ezyang
fbshipit-source-id: 1ae2782b9e34e458a19cec90617037654279e0e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59485
... when varaible is not allowed to required grad
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28933808
fbshipit-source-id: ef3536049d3a4a2f6e2f4b1787f0c17763f5828c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59483
... for functions that are not implemented
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28933806
fbshipit-source-id: dadae1af6609f15419cf0f47a98361dc87dff849
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59264
Previously batchnorm 1d did unsqueeze twice but only squeeze once before return when the dimension
for input Tensor is 2, this PR adds an extra squeeze
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D28810597
fbshipit-source-id: 879873bbf39ed3607762684694f6e81b423740c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59635
The diff corrects launcher tests. The follow up would be to determine why the tests succeeded during the ``use_env`` diff removal
Test Plan: buck test mode/dev-tsan //caffe2/test/distributed/launcher:run_test -- --exact 'caffe2/test/distributed/launcher:run_test - test_launch_user_script_python_caffe2_bc (run_test.ElasticLaunchTest)' --run-disabled
Reviewed By: cbalioglu
Differential Revision: D28963813
fbshipit-source-id: a9f9b80787fb5c2f40a69ce31c8c2f3138654cad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59523
Should use snake case instead of camel case for the consistency.
ghstack-source-id: 130759655
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_ddp_grad_div_uneven_inputs
Reviewed By: cbalioglu
Differential Revision: D28922896
fbshipit-source-id: e04298284a78b2e71b562f790a878731962f873a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59576
If the gradients before allreduce are large, then the sum after allreduce may overflow, especially for FP16. Therefore, apply the division before allreduce.
This fix is applied to both C++ and Python comm hooks.
ghstack-source-id: 130754510
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_comm_hook_allreduce_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_default_ddp_comm_hooks_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_fp16_compress_wrapper_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_builtin_ddp_comm_hooks_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_comm_hook_allreduce_hook_nccl_grad_is_view
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_default_ddp_comm_hooks_nccl_is_view
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_fp16_compress_wrapper_is_view
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_builtin_ddp_comm_hooks_nccl_grad_is_view
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl_grad_is_view
Reviewed By: rohan-varma
Differential Revision: D28941327
fbshipit-source-id: 932e8ddbdb2bfd609a78943f6dc390d3d6ca333f
Summary:
The run-specified-test-cases option would allow us to specify a list of test cases to run by having a CSV with minimally two columns: test_filename and test_case_name.
This PR also adds .json to some files we use for better clarity.
Usage:
`python test/run_test.py --run-specified-test-cases <csv_file>` where the csv file can look like:
```
test_filename,test_case_name,test_total_time,windows_only_failure_sha_count,total_sha_count,windows_failure_count,linux_failure_count,windows_total_count,linux_total_count
test_cuda,test_cudnn_multiple_threads_same_device,8068.8409659525,46,3768,53,0,2181,6750
test_utils,test_load_standalone,8308.8062920459,14,4630,65,0,2718,8729
test_ops,test_forward_mode_AD_acosh_cuda_complex128,91.652619369806,11,1971,26,1,1197,3825
test_ops,test_forward_mode_AD_acos_cuda_complex128,91.825633094915,11,1971,26,1,1197,3825
test_profiler,test_source,60.93786725749,9,4656,21,3,2742,8805
test_profiler,test_profiler_tracing,203.09352795241,9,4662,21,3,2737,8807
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59487
Test Plan:
Without specifying the option, everything should be as they were before.
Running `python test/run_test.py --run-specified-test-cases windows_smoke_tests.csv` resulted in this paste P420276949 (you can see internally). A snippet looks like:
```
(pytorch) janeyx@janeyx-mbp pytorch % python test/run_test.py --run-specified-test-cases windows_smoke_tests.csv
Loading specified test cases to run from windows_smoke_tests.csv.
Processed 28 test cases.
Running test_cpp_extensions_jit ... [2021-06-04 17:24:41.213644]
Executing ['/Users/janeyx/miniconda3/envs/pytorch/bin/python', 'test_cpp_extensions_jit.py', '-k', 'test_jit_cuda_archflags'] ... [2021-06-04 17:24:41.213781]
s
----------------------------------------------------------------------
Ran 1 test in 0.000s
OK (skipped=1)
...
```
With pytest, an example executable would be:
`Running test_dataloader ... [2021-06-04 17:37:57.643039]
Executing ['/Users/janeyx/miniconda3/envs/pytorch/bin/python', '-m', 'pytest', 'test_dataloader.py', '-v', '-k', 'test_segfault or test_timeout'] ... [2021-06-04 17:37:57.643327]`
Reviewed By: jbschlosser
Differential Revision: D28961233
Pulled By: janeyx99
fbshipit-source-id: 6b7ddc6e61856aa0002e1a0afc845770e4f8400b
Summary:
Pull Request: https://github.com/pytorch/pytorch/pull/59586
Task: https://www.internalfb.com/tasks/?t=90847711
**Overview:**
Suppose we have `n` items with positive integer sizes and `k` buckets. We want to assign items to buckets with the goal of uniformity. The precise criteria for uniformity can vary: e.g. minimize the maximum size, maximize the minimum size, etc. This is known as [multiway number partitioning](https://en.wikipedia.org/wiki/Multiway_number_partitioning). ZeRO's partitioning task reduces to solving this problem. In particular, this is the subproblem to be solved for each `param_group` in `self.param_groups`, where the parameters are the items and the ranks give the buckets.
The existing implementation uses the linear-time [greedy number partitioning algorithm](https://en.wikipedia.org/wiki/Greedy_number_partitioning#Linear-time_algorithm), which assigns the next tensor-parameter to the process with the smallest total parameter size so far. In this task, I explore the [extension](https://en.wikipedia.org/wiki/Greedy_number_partitioning#Improved_algorithm) where each parameter group is sorted by decreasing size before applying the greedy algorithm, requiring linearithmic time (as dominated by the sort).
**Experiments**
The mean number of parameters represents a perfectly uniform allocation and hence the ideal allocation (which may be even better than the optimal partition). In the following tables, I present the maximum number of parameters for any one process and the difference from the mean in parentheses for ResNet-50, ResNet-152, and BERT (the bare BERT model). The best-performing partitioning strategy for each model is bolded.
Two processes:
| Model | Max Num Params - Greedy (Diff) | Max Num Params - Greedy-Sorted (Diff) | Mean Num Params |
| --- | --- | --- | --- |
| ResNet-50 | 13,249,600 (471,084) | **12,794,816 (16,300)** | 12,778,516 |
| ResNet-152 | 30,567,488 (471,084) | **30,111,424 (15,020)** | 30,096,404 |
| BERT | **54,749,184 (8,064)** | 55,327,488 (586,368) | 54,741,120 |
Four processes:
| Model | Max Num Params - Greedy (Diff) | Max Num Params - Greedy-Sorted (Diff) | Mean Num Params |
| --- | --- | --- | --- |
| ResNet-50 | 7,524,864 (1,135,606) | **6,436,864 (47,606)** | 6,389,258 |
| ResNet-152 | 16,232,192 (1,183,990) | **15,090,152 (41,950)** | 15,048,202 |
| BERT | **28,151,040 (780,480)** | 28,352,256 (981,696) | 27,370,560 |
---
I also investigated the latency of `optimizer.step()` for the different partitioning algorithms. I measured the latency for 30 iterations and took the mean latency per process (excluding the first iteration due to cache coldness). In the following tables, I present the maximum of those mean latencies over all processes and the standard deviation of the latencies contributing to that maximum. Again, the best-performing partitioning strategy for each model is bolded. All entries are presented in seconds and used `gloo` backend.
Two processes:
| Model | Max `optimizer.step()` Time - Greedy (Std.) | Max `optimizer.step()` Time - Greedy-Sorted (Std.) |
| --- | --- | --- |
| ResNet-50 | **0.060 (0.002)** | 0.061 (0.002) |
| ResNet-152 | 0.166 (0.003) | **0.160 (0.004)** |
| BERT | 0.220 (0.009) | **0.199 (0.006)** |
Four processes:
| Model | Max `optimizer.step()` Time - Greedy | Max `optimizer.step()` Time - Greedy-Sorted |
| --- | --- | --- |
| ResNet-50 | 0.094 (0.004) | **0.093 (0.004)** |
| ResNet-152 | **0.228 (0.011)** | 0.231 (0.009) |
| BERT | **0.328 (0.015)** | 0.329 (0.021) |
Based on the standard deviations, the differences in the latency measurements across the different algorithms appear to be within the uncertainty in the measurement itself. Hence, it is difficult to argue that one algorithm is clearly the fastest.
---
`zero.py` is my experiment script, and I use the AI AWS cluster. The run command looks like:
```
srun -p $DEV_QUEUE --cpus-per-task=16 -t 5:00:00 --gpus-per-node=4 python zero.py -b nccl greedy 2 4
```
This runs the experiment script on an instance with 4 GPUs using `nccl` backend, outputting to a directory named `greedy/`, and using world sizes of 2 and 4. An analogous command can be used after modifying `partition_parameters()`, e.g. replacing `greedy` with `greedy_sorted` as the output directory name. Then, to run the analysis script:
```
python analyze.py greedy greedy_sorted
```
For more details on the experiment code, refer to: https://www.internalfb.com/diff/D28946756
**Notes:**
There exists an optimal solution to this partitioning problem. An algorithm that finds such a solution is the [complete greedy algorithm (CGA)](https://en.wikipedia.org/wiki/Greedy_number_partitioning#An_exact_algorithm), which reduces to the brute-force combinatorial search in the worst case. There exist heuristics to improve the `k = 2` case (i.e. when there are two processes); however, given that `n` in typical use cases is very large, any algorithm that is quadratic or slower is unrealistic. Other exact algorithms are similarly exponential in the worst case, rendering them intractable. Given this, I do not currently see a need for future proofing the partitioning algorithm against the introduction of algorithms beyond the naive greedy and the sorted greedy algorithms.
---
In the current ZeRO implementation, the core `partition_parameters()` computation happens twice upon initialization (i.e. call to `__init__()`): first from a call to `_param_to_rank()` (i.e. an access to `_param_to_rank`) and then from a call to `_update_trainable()`. `_update_trainable()` sees that no optimizer has been constructed yet, so it clears the cache, eliminating the first `partition_parameters()` computation and performing a redundant re-computation.
Here is a typical trace:
- [The ZeRO optimizer object is initialized, calling `__init__()`.](d125694d0b/torch/distributed/optim/zero_redundancy_optimizer.py (L142))
- [In `__init__()`, `self._device` is set, so it accesses `self._per_device_params`.](d125694d0b/torch/distributed/optim/zero_redundancy_optimizer.py (L182))
- [`self._per_device_params` is not cached, so it accesses `self._param_to_rank`.](d125694d0b/torch/distributed/optim/zero_redundancy_optimizer.py (L340))
- [`self._param_to_rank` is not cached, so it calls `partition_parameters()`.](d125694d0b/torch/distributed/optim/zero_redundancy_optimizer.py (L353)) (first call to `partition_parameters()`)
- [`__init__()` later calls `_update_trainable()`.](d125694d0b/torch/distributed/optim/zero_redundancy_optimizer.py (L185))
- [In `_update_trainable()`, `self` does not have `attr` `"optim"`, so it clears the cached objects (notably, `self._partition_parameters_cache`).](d125694d0b/torch/distributed/optim/zero_redundancy_optimizer.py (L591))
- [`_update_trainable()` calls `self.partition_parameters()`.](d125694d0b/torch/distributed/optim/zero_redundancy_optimizer.py (L593)) (second call to `partition_parameters()`)
Based on the discussion [here](https://github.com/pytorch/pytorch/pull/59410), this recomputation is unintentional and should be addressed in a future diff.
Test Plan: I verified that the total number of parameters across the processes was consistent after the partitioning algorithm change. Otherwise, no additional modifications were made to existing tests.
Reviewed By: mrshenli
Differential Revision: D28946755
fbshipit-source-id: 7ad66a21a963555b3b2e693ba8069d2dddc94c60
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59107
Adding documentation, test coverage, and a missing method to the `DirectoryReader` class. `DirectoryReader` was previously named `MockZipReader`, and is used for operating on opened package archives via a `PackageImporter`.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D28760410
Pulled By: Lilyjjo
fbshipit-source-id: aa9d0a68e19738a6d5555bb04ce33af6a53f1268
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58938
When run `test_datapipe.py`, python `gc` would report lots of `ResourceWarning`s due to unclosed stream. It's not only annoying, there are two potential problems:
- Performance regression because `gc` requires additional memory and computation to track reference
- Python `gc` runs periodically so we many encountered an error of too many open files due to OS limitation
To reduce the warning:
- Explicitly close byte stream
- Modify `test_datapipe.py` to use context manager
Small fix:
- Reorder import in `test_datapipe.py`
Further investigation:
Can we directly use context manager in `LoadFileFromDisk` and `ReadFileFromTar` to eliminate this Error?
- Probably no. It's feasible only if the pipeline is synchronized and without prefetching. When we enable these two features, the scope guard of the context manager doesn't work.
- We may need to implement some reference counter attached to these file byte stream to close by itself.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D28689862
Pulled By: ejguan
fbshipit-source-id: bb2a85defb8a4ab5384db902ef6ad062185c2653
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59577
Collapse all dimensions of tensor into batch and use channels as 1. Fixes the 1D over calculation case
Test Plan:
buck test fbandroid/mode/server fbandroid/mode/asan_ubsan fbsource//xplat/caffe2:pt_xnnpack_test
buck test fbsource//xplat/caffe2:pt_xnnpack_test
Reviewed By: kimishpatel
Differential Revision: D28942141
fbshipit-source-id: b36f820a900b6a2ed649d6b9bac79d3392d3537c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59096
RegisterBackendSelect is bringing in ~100 extra ops to the runtime. This messes with the compatibility api, and also adds a nontrivial amount of size.
Test Plan: Model Unittests/CI
Reviewed By: iseeyuan
Differential Revision: D28588100
fbshipit-source-id: ffd0b5b9cbe20f27dbf3be418a6c1f80c7396fdb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59573
To do mobile selective build, we have several options:
1. static dispatch;
2. dynamic dispatch + static analysis (to create the dependency graph);
3. dynamic dispatch + tracing;
We are developing 3. For open source, we used to only support 1, and
currently we support both 1 and 2.
This file is only used for 2. It was introduced when we deprecated
the static dispatch (1). The motivation was to make sure we have a
low-friction selective build workflow for dynamic dispatch (2).
As the name indicates, it is the *default* dependency graph that users
can try if they don't bother to run the static analyzer themselves.
We have a CI to run the full workflow of 2 on every PR, which creates
the dependency graph on-the-fly instead of using the committed file.
Since the workflow to automatically update the file has been broken
for a while, it started to confuse other pytorch developers as people
are already manually editing it, and it might be broken for some models
already.
We reintroduced the static dispatch recently, so we decide to deprecate
this file now and automatically turn on static dispatch if users run
selective build without providing the static analysis graph.
The tracing-based selective build will be the ultimate solution we'd
like to provide for OSS, but it will take some more effort to polish
and release.
Differential Revision:
D28941020
D28941020
Test Plan: Imported from OSS
Reviewed By: dhruvbird
Pulled By: ljk53
fbshipit-source-id: 9977ab8568e2cc1bdcdecd3d22e29547ef63889e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59541
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/621
Fixing 2 issues. These are actually 2 independent issues one in Caffe2 and another in FBGEMM, so no need to wait until FBGEMM is synchronized with PyTorch
1) conv 16-bit accumulation doesn't support fast gconv path, so TakeGConvFastPath_ should honor it
2) packed_index_ generates indices up to (G/GTogether_) F R S OC_per_G GTogether_ paddedICPerG which can exceed G kernel_prod OC_per_G paddedICPerG allocated in PackWeightMatrixForGConv (kernel_prod = F R S): e.g., when G=3, GTogether_=2, we allocate 3 F R S OC_per_G paddedICPerG but we access up to 2 F R S OC_per_G 2 paddedICPerG
BTW, not sure how we haven't known about this issue for so long. Any idea will be really appreciated.
Test Plan:
In a BDW machine,
buck test //caffe2/caffe2/quantization/server:conv_groupwise_dnnlowp_acc16_op_test -- --run-disabled
Reviewed By: dskhudia
Differential Revision: D28927214
fbshipit-source-id: 3ec98ea2fc177545392a0148daca592d80f40ad3
Summary:
Do not reorder tests unless they are in IN_CI, this causes local development test ordering indeterministic. most of use branch out from viable strict not head of master.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59565
Reviewed By: ejguan
Differential Revision: D28943906
Pulled By: walterddr
fbshipit-source-id: e742e7ce4b3fc017d7563b01e93c4cd774d0a537
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58925
Cleans up documentation on natively supported backends. In particular:
* adds a section title
* deduplicates information about fbgemm/qnnpack
* clarifies what `torch.backends.quantized.engine` does
* adds code samples with default settings for `fbgemm` and `qnnpack`
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28681840
Pulled By: vkuzo
fbshipit-source-id: 51a6ab66934f657553351f6c84a638fd5f7b4e12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59574
Remove `work` attribute from Reducer class in favor of `future_work`.
Additionally, remove `copy_grad_to_bucket` method since now it's only one-line implementation, and created a new C++ comm hook called `_AllReduceCommHookWithDivFactor` to replace allreduce and also support handling uneven input.
1) Compared with the reverted https://github.com/pytorch/pytorch/pull/58937, updated `_AllReduceCommHookWithDivFactor` in `default_comm_hooks.cpp` to apply division first and hence avoid FP16 overflow.
2) Compared with the reverted https://github.com/pytorch/pytorch/pull/59520, disabled `test_DistributedDataParallel_non_default_stream` on AMD, because now applying division first hurts the gradient averaging accuracy on AMD.
See [07:48:26]:
https://ci.pytorch.org/jenkins/job/pytorch-builds/job/pytorch-linux-bionic-rocm4.2-py3.6-test1/1129/console
#Original PR Issue: https://github.com/pytorch/pytorch/issues/41266
ghstack-source-id: 130752393
Test Plan:
buck test caffe2/test/distributed:distributed_gloo_fork -- test_accumulate_gradients_no_sync
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_accumulate_gradients_no_sync
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_ddp_grad_div_uneven_inputs
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_fp16
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_fp16_grad_is_view
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_DistributedDataParallel_non_default_stream
Reviewed By: rohan-varma
Differential Revision: D28940800
fbshipit-source-id: 1ba727ac951ebc1e7875dc1a1be8108a2c8d9462
Summary:
Enable test stats upload on PR.
Uses PR number as part of the key so that it can be properly indexed and later parsed if PR has been merged/closed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59567
Reviewed By: ejguan
Differential Revision: D28943654
Pulled By: walterddr
fbshipit-source-id: f3a7a25ae14c6877067e1b347e3a8658d80d1544
Summary:
The run-specified-test-cases option would allow us to specify a list of test cases to run by having a CSV with minimally two columns: test_filename and test_case_name.
This PR also adds .json to some files we use for better clarity.
Usage:
`python test/run_test.py --run-specified-test-cases <csv_file>` where the csv file can look like:
```
test_filename,test_case_name,test_total_time,windows_only_failure_sha_count,total_sha_count,windows_failure_count,linux_failure_count,windows_total_count,linux_total_count
test_cuda,test_cudnn_multiple_threads_same_device,8068.8409659525,46,3768,53,0,2181,6750
test_utils,test_load_standalone,8308.8062920459,14,4630,65,0,2718,8729
test_ops,test_forward_mode_AD_acosh_cuda_complex128,91.652619369806,11,1971,26,1,1197,3825
test_ops,test_forward_mode_AD_acos_cuda_complex128,91.825633094915,11,1971,26,1,1197,3825
test_profiler,test_source,60.93786725749,9,4656,21,3,2742,8805
test_profiler,test_profiler_tracing,203.09352795241,9,4662,21,3,2737,8807
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59487
Test Plan:
Without specifying the option, everything should be as they were before.
Running `python test/run_test.py --run-specified-test-cases windows_smoke_tests.csv` resulted in this paste P420276949 (you can see internally). A snippet looks like:
```
(pytorch) janeyx@janeyx-mbp pytorch % python test/run_test.py --run-specified-test-cases windows_smoke_tests.csv
Loading specified test cases to run from windows_smoke_tests.csv.
Processed 28 test cases.
Running test_cpp_extensions_jit ... [2021-06-04 17:24:41.213644]
Executing ['/Users/janeyx/miniconda3/envs/pytorch/bin/python', 'test_cpp_extensions_jit.py', '-k', 'test_jit_cuda_archflags'] ... [2021-06-04 17:24:41.213781]
s
----------------------------------------------------------------------
Ran 1 test in 0.000s
OK (skipped=1)
...
```
With pytest, an example executable would be:
`Running test_dataloader ... [2021-06-04 17:37:57.643039]
Executing ['/Users/janeyx/miniconda3/envs/pytorch/bin/python', '-m', 'pytest', 'test_dataloader.py', '-v', '-k', 'test_segfault or test_timeout'] ... [2021-06-04 17:37:57.643327]`
Reviewed By: samestep
Differential Revision: D28913223
Pulled By: janeyx99
fbshipit-source-id: 0d1f9910973426b8756815c697b483160517b127
Summary:
It would be most accurate if sharding occurred after all other changes to selected_tests were complete.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59583
Reviewed By: ejguan
Differential Revision: D28944737
Pulled By: janeyx99
fbshipit-source-id: a851473948a5ec942ffeeedeefdc645536a3d9f7
Summary:
This PR greatly simplifies `mypy-strict.ini` by strictly typing everything in `.github` and `tools`, rather than picking and choosing only specific files in those two dirs. It also removes `warn_unused_ignores` from `mypy-strict.ini`, for reasons described in https://github.com/pytorch/pytorch/pull/56402#issuecomment-822743795: basically, that setting makes life more difficult depending on what libraries you have installed locally vs in CI (e.g. `ruamel`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59117
Test Plan:
```
flake8
mypy --config mypy-strict.ini
```
Reviewed By: malfet
Differential Revision: D28765386
Pulled By: samestep
fbshipit-source-id: 3e744e301c7a464f8a2a2428fcdbad534e231f2e
Summary:
Closes https://github.com/pytorch/pytorch/issues/51455
I think the current implementation is aggregating over the correct dimensions. The shape of `normalized_shape` is only used to determine the dimensions to aggregate over. The actual values of `normalized_shape` are used when `elementwise_affine=True` to initialize the weights and biases.
This PR updates the docstring to clarify how `normalized_shape` is used. Here is a short script comparing the implementations for tensorflow and pytorch:
```python
import torch
import torch.nn as nn
import tensorflow as tf
from tensorflow.keras.layers import LayerNormalization
rng = np.random.RandomState()
x = rng.randn(10, 20, 64, 64).astype(np.float32)
# slightly non-trival
x[:, :10, ...] = x[:, :10, ...] * 10 + 20
x[:, 10:, ...] = x[:, 10:, ...] * 30 - 100
# Tensorflow Layer norm
x_tf = tf.convert_to_tensor(x)
layer_norm_tf = LayerNormalization(axis=[-3, -2, -1], epsilon=1e-5)
output_tf = layer_norm_tf(x_tf)
output_tf_np = output_tf.numpy()
# PyTorch Layer norm
x_torch = torch.as_tensor(x)
layer_norm_torch = nn.LayerNorm([20, 64, 64], elementwise_affine=False)
output_torch = layer_norm_torch(x_torch)
output_torch_np = output_torch.detach().numpy()
# check tensorflow and pytorch
torch.testing.assert_allclose(output_tf_np, output_torch_np)
# manual comutation
manual_output = ((x_torch - x_torch.mean(dim=(-3, -2, -1), keepdims=True)) /
(x_torch.var(dim=(-3, -2, -1), keepdims=True, unbiased=False) + 1e-5).sqrt())
torch.testing.assert_allclose(output_torch, manual_output)
```
To get to the layer normalization as shown here:
<img width="157" alt="Screen Shot 2021-05-29 at 2 13 52 PM" src="https://user-images.githubusercontent.com/5402633/120080691-1e37f100-c088-11eb-9060-4f263e4cd093.png">
One needs to pass in `normalized_shape` with shape `x.dim() - 1` with the size of the channels and all spatial dimensions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59178
Reviewed By: ejguan
Differential Revision: D28931877
Pulled By: jbschlosser
fbshipit-source-id: 193e05205b9085bb190c221428c96d2ca29f2a70
Summary:
- TORCH_CHECK doesn't handle printf style format and it will output like: `got %ld tensors and %ld gradients21`
- `got 2 tensors and 1 gradients` should be the expected message for this
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59532
Reviewed By: ejguan
Differential Revision: D28934680
Pulled By: albanD
fbshipit-source-id: 2d27a754ae81310b9571ae2a2ea09d0f8d8a3d81
Summary:
This adds a comment above `should_drop` to prevent someone from inadvertently breaking JIT coverage by renaming the function without updating the correct references.
The current JIT plug-in uses `should_drop` to figure out which code is going to be JIT'd. If the function is named differently, the plug-in would also need to be updated.
Question: I understand this may not be the cleanest solution. Would a cleaner solution be to create a dummy function that would simply exist for the JIT plug-in? I did not immediately do that as that may be adding unnecessary code complexity in torch.jit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57961
Reviewed By: samestep
Differential Revision: D28933587
Pulled By: janeyx99
fbshipit-source-id: 260aaf7b11f07de84a81d6c3554c4a5ce479d623
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59333
Code comment should explain this in sufficient detail. In brief, making it 16 bytes should get it to be passed in registers.
ghstack-source-id: 130631329
Test Plan: Updated optional_test and added static_assert in Optional.cpp.
Reviewed By: ezyang
Differential Revision: D28843027
fbshipit-source-id: 3029f05e03a9f04ca7337962e7770cdeb9a608d9
Summary: Implemented two observers (InputEqualObserver and WeightEqualObserver) which will be inserted into the graph during prepare_fx().
Test Plan: python test/test_quantization.py TestEqualizeFx
Reviewed By: supriyar
Differential Revision: D28836954
fbshipit-source-id: 25517dc82ae67698ed8b2dc334e3323286976104
Summary:
As per title. Resolves https://github.com/pytorch/pytorch/issues/56683.
`gradgradcheck` will fail once `target.requires_grad() == True` because of the limitations of the current double backward implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59447
Reviewed By: agolynski
Differential Revision: D28910140
Pulled By: albanD
fbshipit-source-id: 20934880eb4d22bec34446a6d1be0a38ef95edc7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59522
If the gradients before allreduce are large, then the sum after allreduce may overflow, especially for FP16. Therefore, apply the division before allreduce.
This fix is applied to both C++ and Python comm hooks.
ghstack-source-id: 130686229
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_comm_hook_allreduce_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_default_ddp_comm_hooks_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_fp16_compress_wrapper_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_builtin_ddp_comm_hooks_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_comm_hook_allreduce_hook_nccl_grad_is_view
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_default_ddp_comm_hooks_nccl_is_view
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_fp16_compress_wrapper_is_view
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_builtin_ddp_comm_hooks_nccl_grad_is_view
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl_grad_is_view
Reviewed By: rohan-varma
Differential Revision: D28922548
fbshipit-source-id: 442bd3cc7a35a8b948f626062fa7ad2e3704c5be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58730
The sources for the profilers are not needed in the mobile build, and unnecessarily add weight to the build. Remove them from the lite-interpreter build.
ghstack-source-id: 130684568
Test Plan: Build + BSB
Reviewed By: kimishpatel, raziel
Differential Revision: D28563725
fbshipit-source-id: 9d6f76176c2d2bbc25703281af1a076b1f2b4f19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59520
Remove `work` attribute from Reducer class in favor of `future_work`.
Additionally, remove `copy_grad_to_bucket` method since now it's only one-line implementation, and created a new C++ comm hook called `_AllReduceCommHookWithDivFactor` to replace allreduce and also support handling uneven input.
Compared with the reverted https://github.com/pytorch/pytorch/pull/58937, updated `_AllReduceCommHookWithDivFactor` in `default_comm_hooks.cpp` to apply division first and hence avoid FP16 overflow.
#Original PR Issue: https://github.com/pytorch/pytorch/issues/41266
ghstack-source-id: 130685351
Test Plan:
buck test caffe2/test/distributed:distributed_gloo_fork -- test_accumulate_gradients_no_sync
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_accumulate_gradients_no_sync
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_ddp_grad_div_uneven_inputs
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_fp16
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_fp16_grad_is_view
Reviewed By: walterddr
Differential Revision: D28922305
fbshipit-source-id: 6388a96eda7a06f292873afed6d1362096c13e1c
Summary:
This is somewhat more verbose, but it's more correct and addresses this warning on Visual Studio 2017:
```
xplat\caffe2\caffe2\core\common.h(76): warning C4067: unexpected tokens following preprocessor directive - expected a newline
```
Test Plan: Built locally with fix
Reviewed By: simpkins
Differential Revision: D28868632
fbshipit-source-id: f6a583e8275162adedb2a4bc5ed0f64847020871
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58331
This PR is the final part of a stack that addresses the GitHub issue #41614; it introduces the multi-tenancy feature to the `TCPStore` class allowing two server stores to be instantiated with the same host:port pair.
ghstack-source-id: 130676394
Test Plan:
- Run the existing and newly-introduced tests.
- Run several smoke tests including the short code snippet referred in GitHub issue #41614.
Reviewed By: H-Huang
Differential Revision: D28453850
fbshipit-source-id: f9066b164305de0f8c257e9d5736e93fd7e21ec6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58330
This PR is part of a stack that addresses the GitHub issue #41614; it introduces a major refactoring of the `TCPStore` class in preparation of the multi-tenancy feature.
- All TCP sockets are wrapped with a new `TCPSocket` RAII type.
- `BackgroundThread` and daemon types are moved from header to cpp file.
- Server, client, and callback sockets are refactored into their own internal types `TCPServer`, `TCPClient` and `TCPCallbackClient`.
- Calls to `tcputil::send*` and `tcputil::recv*` are wrapped in `TCPClient` for easier readability and maintenance purposes.
- Two `TODO` statements are put to reference future improvements. Based on feedback, I will either create separate GitHub issues for them or address them as part of this stack.
ghstack-source-id: 130676392
Test Plan: Run the existing tests since there are no user-facing behavioral changes.
Reviewed By: H-Huang
Differential Revision: D28448981
fbshipit-source-id: 415b21e74b3cd51d673c1d5c349c6a2cb21dd667
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58329
This PR is part of a stack that addresses the GitHub issue #41614; it introduces:
- A new `multiTenant` constructor option for the `TCPStore` class indicating whether multiple store instances can be initialized with the same host:port pair.
- Updates to the C10d distributed (elastic) rendezvous and the `init_process_group` method to leverage the new `multiTenant` feature.
Note that the multi-tenancy feature itself is implemented in the fourth PR of this stack. In this PR passing `true` to `multiTenant` results only with a warning output.
ghstack-source-id: 130676389
Test Plan: Run the existing tests since there are no behavioral changes.
Reviewed By: rohan-varma
Differential Revision: D28424978
fbshipit-source-id: fb1d1d81b8b5884cc5b54486700a8182a69c1f29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58328
This PR is part of a stack that addresses the GitHub issue #41614; it introduces a new `TCPStore` constructor that takes its optional parameters via a newly introduced `TCPStoreOptions` structure. This gives the API callers the flexibility to specify only the desired options while skipping the rest.
The main motivation behind this change is the introduction of the `multiTenant` constructor option in the second PR of this stack.
ghstack-source-id: 130676384
Test Plan: Run the existing tests since there are no behavioral changes.
Reviewed By: H-Huang
Differential Revision: D28417742
fbshipit-source-id: e6ac2a057f7ad1908581176ee6d2c2554c3c74a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58937
Remove `work` attribute from Reducer class in favor of `future_work`.
Additionally, remove `copy_grad_to_bucket` method since now it's only one-line implementation, and created a new C++ comm hook called `_AllReduceCommHookWithDivFactor` to replace allreduce and also support handling uneven input.
#Original PR Issue: https://github.com/pytorch/pytorch/issues/41266
ghstack-source-id: 130673249
Test Plan:
buck test caffe2/test/distributed:distributed_gloo_fork -- test_accumulate_gradients_no_sync
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_accumulate_gradients_no_sync
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_ddp_grad_div_uneven_inputs
Reviewed By: agolynski
Differential Revision: D28677383
fbshipit-source-id: 85e0620378b7e9d837e436e94b9d807631d7d752
Summary:
Implements an idea by ngimel to improve the performance of `torch.flip` via a clever hack into TI to bypass the fact that TI is not designed to work with negative indices.
Something that might be added is vectorisation support on CPU, given how simple the implementation is now.
Some low-hanging fruits that I did not implement:
- Write it as a structured kernel
- Migrate the tests to opinfos
- Have a look at `cumsum_backward` and `cumprod_backward`, as I think that they could be implemented faster with `flip`, now that `flip` is fast.
**Edit**
This operation already has OpInfos and it cannot be migrated to a structured kernel because it implements quantisation
Summary of the PR:
- x1.5-3 performance boost on CPU
- x1.5-2 performance boost on CUDA
- Comparable performance across dimensions, regardless of the strides (thanks TI)
- Simpler code
<details>
<summary>
Test Script
</summary>
```python
from itertools import product
import torch
from torch.utils.benchmark import Compare, Timer
def get_timer(size, dims, num_threads, device):
x = torch.rand(*size, device=device)
timer = Timer(
"torch.flip(x, dims=dims)",
globals={"x": x, "dims": dims},
label=f"Flip {device}",
description=f"dims: {dims}",
sub_label=f"size: {size}",
num_threads=num_threads,
)
return timer.blocked_autorange(min_run_time=5)
def get_params():
sizes = ((1000,)*2, (1000,)*3, (10000,)*2)
for size, device in product(sizes, ("cpu", "cuda")):
threads = (1, 2, 4) if device == "cpu" else (1,)
list_dims = [(0,), (1,), (0, 1)]
if len(size) == 3:
list_dims.append((0, 2))
for num_threads, dims in product(threads, list_dims):
yield size, dims, num_threads, device
def compare():
compare = Compare([get_timer(*params) for params in get_params()])
compare.trim_significant_figures()
compare.colorize()
compare.print()
compare()
```
</details>
<details>
<summary>
Benchmark PR
</summary>
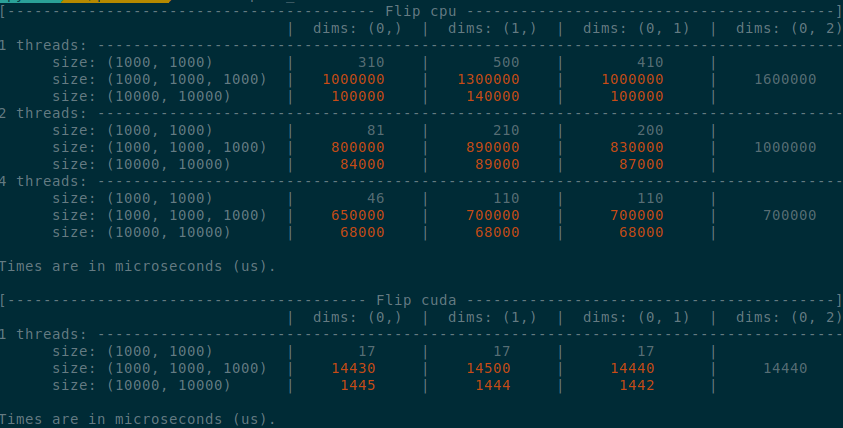
</details>
<details>
<summary>
Benchmark master
</summary>
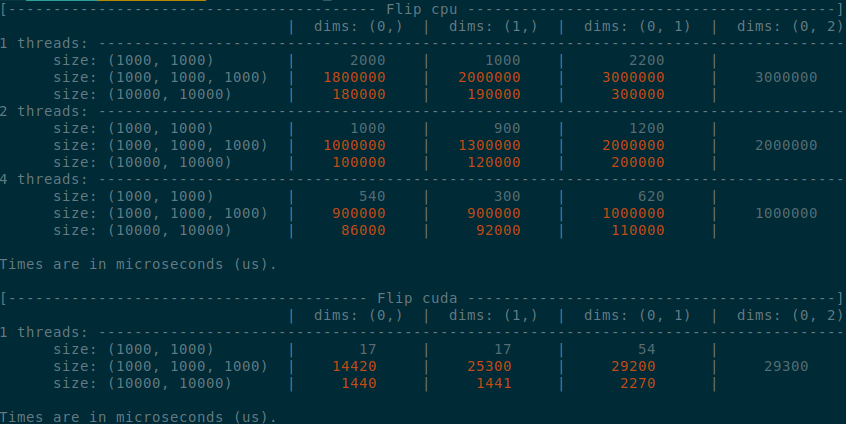
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58747
Reviewed By: agolynski
Differential Revision: D28877076
Pulled By: ngimel
fbshipit-source-id: 4fa6eb519085950176cb3a9161eeb3b6289ec575
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57661
Thie Pickle "specification" (pickletools.py) states that the argument to
a BINUNICODE opcode must be UTF-8 encoded. However, if a PyTorch custom
class returns a non-UTF-8 std::string from its pickle method the
libtorch Pickler will write it to the output pickle without complaining.
Python's _Unpickler (the Python implementation of Unpickler) always
throws an exception when trying to deserialize these invalid pickles.
We still want to be able to dump these pickle files. Update
DumpUnpickler to create its own opcode dispatch table (initialized as a
clone of the _Unpickler dispatch table) and patch in a custom function
for the BINUNICODE op. We try to emulate the default behavior, but any
UnicodeDecodeError is caught and replaced with a dummy object. This
could violate the assumptions of a user that expects a str in that
position, so we disable this behavior by default.
Update model_dump to recognize this special object and allow it to be
rendered.
Test Plan: Dumped and viewed a model with an invalid string in an object state.
Reviewed By: malfet
Differential Revision: D28531392
Pulled By: dreiss
fbshipit-source-id: ab5aea20975a0ef53ef52a880deaa2c5a626e4a2
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/kineto](https://github.com/pytorch/kineto).
New submodule commit: 88e3332ab9
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54604
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: malfet
Differential Revision: D27297755
fbshipit-source-id: 5f5dd2429fb561530e6a59285c6ae708e5818ce9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59472
Previously, the lite interpreter would refuse to load any model
with a version greater than kProducedBytecodeVersion. Now, we're
able to independently advance the loading and saving code, so we
can roll out changes without breaking forward compatibility.
Test Plan:
CI.
Loaded a bytecode v5 model even with setting kProducedBytecodeVersion
to v4.
Reviewed By: raziel
Differential Revision: D28904350
fbshipit-source-id: 598c22f0adf47d4ed3e976bcbebdf3959dacb1df
Summary:
After the change async error warnings look as follows:
```
$ python -c "import torch;torch.eye(3,3,device='cuda:777')"
Traceback (most recent call last):
File "<string>", line 1, in <module>
RuntimeError: CUDA error: invalid device ordinal
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59467
Reviewed By: ngimel
Differential Revision: D28904360
Pulled By: malfet
fbshipit-source-id: 2a8fa5affed5b4ffcaa602c8ab2669061cde7db0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59430
With constant support added, we can now have fusion groups with only
scalar inputs. So, we need to get the device type from the nodes in the graph
rather than just the inputs.
ghstack-source-id: 130613871
Test Plan: new unit test; also see test_tracer test_trace_of_script
Reviewed By: navahgar
Differential Revision: D28891989
fbshipit-source-id: f9e824acbd4856216b85a135c8cb60a2eac3c628
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59473
Switches windows instance types to prep for usage of the AWS built
Windows AMI with pre-installed Tesla Driver.
Unforutnately neither c5.4xlarge nor g3.8xlarge is not supported by this
AMI but luckily we can swap those out with pretty comparable
alternatives like c5d.4xlarge and p3.2xlarge.
For CPU workflows this shouldn't provide any real difference since the
CPU / Memory is the same with c5d.4xlarge. For GPU workflows the GPU
with the p3.2xlarge is a Tesla V100 which should suit our needs.
<details>
<summary> nvidia-smi.exe (p3.2xlarge) </summary>
```
PS C:\Users\Administrator> & 'C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi.exe'
Fri Jun 4 18:53:10 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 462.31 Driver Version: 462.31 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... TCC | 00000000:00:1E.0 Off | 0 |
| N/A 42C P0 23W / 300W | 0MiB / 16258MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
```
</details>
It might eventually make sense to also switch linux to these instance types but do bear in mind that p3.2xlarge for linux is ~$0.75 more expensive than g3.8xlarge
* [Price comparison for g3.8xlarge vs. p3.2xlarge](https://instances.vantage.sh/?compare_on=true&selected=p3.2xlarge,g3.8xlarge)
* [Price comparison for c5.4xlarge vs. c5d.4xlarge](https://instances.vantage.sh/?compare_on=true&selected=c5.4xlarge,c5d.4xlarge)
AMI that I'm planning on using as the new base AMI with included Tesla driver: https://aws.amazon.com/marketplace/pp/prodview-jrxucanuabmfm?qid=1622830809415&sr=0-2&ref_=srh_res_product_title#pdp-pricing
Info about c5 instances can be found here: https://aws.amazon.com/ec2/instance-types/c5/
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: agolynski
Differential Revision: D28913659
Pulled By: seemethere
fbshipit-source-id: 11b4d332e82b078a6801b312dc4ace2928838fc8
Summary:
**Overview:**
This consolidates `c10d` and `dist` to only `dist` as the alias for `torch.distributed` in `test_store.py`. Both aliases were used most likely due to incremental additions to the test file and not intentional.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59456
Test Plan:
```
python test/distributed/test_store.py
```
Reviewed By: agolynski
Differential Revision: D28910169
Pulled By: andwgu
fbshipit-source-id: f830dead29e9de48aaf2845dfa5861c9cccec15d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59459
For any binary that can be used both with and without cuda, it's better to allow just including the cuda flavor of the interpreter. The previous logic would fail in this case, as it only allows using the cuda flavor if torch::cuda::is_available() reports true. Now, we unconditionally allow the cuda flavor to be used if it's present.
Test Plan: Added new unit test to exercise this scenario, ran locally on devvm without cuda.
Reviewed By: dzhulgakov
Differential Revision: D28902176
fbshipit-source-id: 5c7c90d84987848471bb6dd5318db15314e0b442
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59355
Add a `CheckKnob()` function for doing run-time checks of feature roll-out
knobs. This provides an API for safely controlling the roll-out of new
functionality in the code.
Test Plan: Included some basic unit tests.
Reviewed By: voznesenskym
Differential Revision: D26536430
fbshipit-source-id: 2e53234c6d9ce624848fc8b2c76f6833f344f48b
Summary:
Testing and see if checkout with submodules during build phase will help.
tentatively address https://github.com/pytorch/pytorch/issues/58867. but since the repro is not reliable. we cant be sure.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59450
Reviewed By: malfet
Differential Revision: D28908537
Pulled By: walterddr
fbshipit-source-id: 21ad1392a5066554b5c633f31616ab3e6541c54d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54987
Based off of ezyang (https://github.com/pytorch/pytorch/pull/44799) and bdhirsh (https://github.com/pytorch/pytorch/pull/43702) 's prototype:
Here's a summary of the changes in this PR:
This PR adds a new dispatch key called Conjugate. This enables us to make conjugate operation a view and leverage the specialized library functions that fast path with the hermitian operation (conj + transpose).
1. Conjugate operation will now return a view with conj bit (1) for complex tensors and returns self for non-complex tensors as before. This also means `torch.view_as_real` will no longer be a view on conjugated complex tensors and is hence disabled. To fill the gap, we have added `torch.view_as_real_physical` which would return the real tensor agnostic of the conjugate bit on the input complex tensor. The information about conjugation on the old tensor can be obtained by calling `.is_conj()` on the new tensor.
2. NEW API:
a) `.conj()` -- now returning a view.
b) `.conj_physical()` -- does the physical conjugate operation. If the conj bit for input was set, you'd get `self.clone()`, else you'll get a new tensor with conjugated value in its memory.
c) `.conj_physical_()`, and `out=` variant
d) `.resolve_conj()` -- materializes the conjugation. returns self if the conj bit is unset, else returns a new tensor with conjugated values and conj bit set to 0.
e) `.resolve_conj_()` in-place version of (d)
f) `view_as_real_physical` -- as described in (1), it's functionally same as `view_as_real`, just that it doesn't error out on conjugated tensors.
g) `view_as_real` -- existing function, but now errors out on conjugated tensors.
3. Conjugate Fallback
a) Vast majority of PyTorch functions would currently use this fallback when they are called on a conjugated tensor.
b) This fallback is well equipped to handle the following cases:
- functional operation e.g., `torch.sin(input)`
- Mutable inputs and in-place operations e.g., `tensor.add_(2)`
- out-of-place operation e.g., `torch.sin(input, out=out)`
- Tensorlist input args
- NOTE: Meta tensors don't work with conjugate fallback.
4. Autograd
a) `resolve_conj()` is an identity function w.r.t. autograd
b) Everything else works as expected.
5. Testing:
a) All method_tests run with conjugate view tensors.
b) OpInfo tests that run with conjugate views
- test_variant_consistency_eager/jit
- gradcheck, gradgradcheck
- test_conj_views (that only run for `torch.cfloat` dtype)
NOTE: functions like `empty_like`, `zero_like`, `randn_like`, `clone` don't propagate the conjugate bit.
Follow up work:
1. conjugate view RFC
2. Add neg bit to re-enable view operation on conjugated tensors
3. Update linalg functions to call into specialized functions that fast path with the hermitian operation.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D28227315
Pulled By: anjali411
fbshipit-source-id: acab9402b9d6a970c6d512809b627a290c8def5f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59279
There were some issues with how we handle 0-dim cases in lowerings and
also in how we generate reductions in that special case. This PR fixes
those issues and reenables a bunch of tests.
Differential Revision:
D28819780
D28819780
Test Plan: Imported from OSS
Reviewed By: navahgar
Pulled By: ZolotukhinM
fbshipit-source-id: f3feff35a1ce11821ada2f8d04ae9d4be10dc736
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59268
There's no reason we can't give `convert` this signature: `Tensor::unsafeGetTensorImpl() cocnst ` returns a non-const TensorImpl pointer. (See https://github.com/zdevito/ATen/issues/27#issuecomment-330717839)
ghstack-source-id: 130548716
Test Plan: CI
Reviewed By: SS-JIA
Differential Revision: D28811477
fbshipit-source-id: 269f58980c1f68b29d4be3cba4cd340299ce39af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59469
Clarify that using record_shapes=True may cause extra tensor copies.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28905089
Pulled By: ilia-cher
fbshipit-source-id: 7642cb16f6697b6d255a2b82348d4c17486680d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59460
Original commit changeset: 6e01a96d3746
Test Plan: Verify new tests run in sandcastle and existing CI is OK
Reviewed By: H-Huang
Differential Revision: D28900869
fbshipit-source-id: a8962ec48c66bba3b4b8f001ece7231953b29e82
Summary:
sample_inputs_diff constructs all five positional arguments for [diff ](https://pytorch.org/docs/stable/generated/torch.diff.html) but uses only the first three. This doesn't seem to be intentional.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59181
Test Plan: This change expands coverage of diff's OpInfo sample inputs. Related tests still pass.
Reviewed By: mruberry
Differential Revision: D28878359
Pulled By: saketh-are
fbshipit-source-id: 1466f6c6c341490885c85bc6271ad8b3bcdf3a3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59409
Remove use_env from torch.distributed.run, and clarify bc around that parameter in comment.
Test Plan: n/a
Reviewed By: cbalioglu
Differential Revision: D28876485
fbshipit-source-id: 5f10365968d204985ce517b83c392c688995d76e
Summary:
Adds `is_inference` as a native function w/ manual cpp bindings.
Also changes instances of `is_inference_tensor` to `is_inference` to be consistent with other properties such as `is_complex`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58729
Reviewed By: mruberry
Differential Revision: D28874507
Pulled By: soulitzer
fbshipit-source-id: 0fa6bcdc72a4ae444705e2e0f3c416c1b28dadc7
Summary:
Context https://github.com/pytorch/pytorch/issues/58545
The logic is that we are going to keep it consistent for both
torch.randperm and torch.randint
1. Generators can have either a fully-specified or non-fully specified device
2. As long as the device type match with the result, we don't error out
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59352
Test Plan:
```
python test/test_tensor_creation_ops.py -k TestRandomTensorCreation
```
Reviewed By: ngimel
Differential Revision: D28855920
Pulled By: zhouzhuojie
fbshipit-source-id: f8141a2c4b2f177e1aa7baec6999b65916cba02c
Summary:
This is required in https://github.com/pytorch/pytorch/pull/57110#issuecomment-828357947
We need to provide means to synchronize on externally allocated streams for dlpack support in python array data api.
cc mruberry rgommers leofang asi1024 kmaehashi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57781
Reviewed By: mrshenli
Differential Revision: D28326365
Pulled By: ezyang
fbshipit-source-id: b67858c8033949951b49a3d319f649884dfd0a91
Summary:
Before that, only dynamically linked OpenBLAS compield with OpenMP could
be found.
Also get rid of hardcoded codepath for libgfortran.a in FindLAPACK.cmake
Only affects aarch64 linux builds
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59428
Reviewed By: agolynski
Differential Revision: D28891314
Pulled By: malfet
fbshipit-source-id: 5af55a14c85ac66551ad2805c5716bbefe8d55b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59413
For CUDA 10.2 builds linked with the gold linker we were observing
crashes when exceptions were being raised
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D28888054
Pulled By: seemethere
fbshipit-source-id: f9b38147591721803ed3cac607510fe5bbc49d6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59375
The CPU and CUDA channels used to be separate classes in TensorPipe, but they recently got merged in order to support cross-device-type channels. We used to need two separate registries in PyTorch, but now we can merge them. This simplifies some registration logic, and will help in future PRs.
ghstack-source-id: 130583770
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28796427
fbshipit-source-id: b7db983293cbbddd1aedec6428de08d8944b0344
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59299
After recent changes, LazyStreamContext had in fact always become eager, and was in fact equivalent to a vector of streams. So it makes more sense now to remove this abstraction and use a more self-descriptive type.
This PR migrates the TensorPipe agent. The previous PR migrated the RequestCallback internals.
ghstack-source-id: 130583773
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28789174
fbshipit-source-id: a27d2b1f40ab3cf2ac0dd946232fd0eecda6d450
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59298
After recent changes, LazyStreamContext had in fact always become eager, and was in fact equivalent to a vector of streams. So it makes more sense now to remove this abstraction and use a more self-descriptive type.
This PR migrates the RequestCallback internals. The next PR migrates the TensorPipe agent.
ghstack-source-id: 130583774
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28789175
fbshipit-source-id: fa581a50f9a6a1e42c2ad8c808a9b099bea7433e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59297
PyTorch requires users to manually record tensors with the CUDA caching allocator when switching streams. We weren't doing it.
Also, the usage of an Event can be simplified by using `s1.wait(s2)`.
ghstack-source-id: 130583777
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28832902
fbshipit-source-id: cd4f40ff811fa1b0042deedda2456e22f33b92bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58753
TSAN was (rightfully!) detecting and complaining about a race due to the fact that upon init the TP agent exchanges the device maps between nodes using RPC requests (and by doing so it accesses the device maps) and then sets the reverse device maps (thus possibly modifying the set of devices). This resulted in a data race, i.e., simultaneously reading and writing the set of devices without synchronizing.
One solution is to add a mutex around the devices, which works, but is "annoying". An alternative solution is to make the set of devices immutable (i.e., `const`). For that to work, we need to exchange the device maps without using RPC calls. We can do so using the process group that we need to create anyways.
Since now there's a lot more logic in Python, I've moved (and restructured) all safety checks over there, and removed them from C++.
ghstack-source-id: 130583775
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D28603754
fbshipit-source-id: 88533e65d72d1eb806dc41bec8d55def5082e290
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57355
We had started fixing OwnerRRef to make it CUDA-compatible, by properly synchronizing CUDA streams/events where appropriate. However, since we started using CUDAFuture (or, well, ivalue::Future nowadays, after they got merged) this is all done automatically for us, hence we can undo these "fixes" as they're now duplicated.
ghstack-source-id: 130583771
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28118182
fbshipit-source-id: 4b1dd9fe88c23802b1df573941d1b73af48bb67b
Summary:
This commit removes the warning that suggests that users script their
dictionaries before passing them into TorchScript code. The ScriptDict feature
is not fully ready, so it does not make sense to recommend this yet.
Test Plan:
Sandcastle.
In addition, the PyPER test broken by the original diff passes:
```
buck test mode/opt //caffe2/torch/fb/training_toolkit/backend/tests:test_model_materializer_full_sync_lwt -- --exact 'caffe2/torch/fb/training_toolkit/backend/tests:test_model_materializer_full_sync_lwt - caffe2.torch.fb.training_toolkit.backend.tests.test_model_materializer_full_sync_lwt.ModelMaterializerFullSyncLwtTest: test_materialization_determinism_cpu' --run-disabled
```
Differential Revision: D28891351
fbshipit-source-id: 2a3a00cde935d670fb1dc7fd8c709ae9c2ad8cdc
Summary:
Default NEON accelerated implementation of reciprocal uses vrecpeq_f32 which yield Newton-Raphson approximation rather than actual value
Use regular NEON accelerated division for reciprocal and reciprocal square root operations.
This fixes `test_reference_numerics_hard_frac_cpu_float32`, `test_reference_numerics_normal_rsqrt_cpu_float32` etc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59361
Reviewed By: mruberry
Differential Revision: D28870456
Pulled By: malfet
fbshipit-source-id: e634b0887cce7efb046ea1fd9b74424e0eceb164
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 9cb33bcfe5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59337
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: caogao
Differential Revision: D28846199
fbshipit-source-id: b78f087129edef97247d4ceea77cfede0c6800fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59026
#Closes: https://github.com/pytorch/pytorch/issues/51480
Enabled methods train and eval in RemoteModule to call the underlying train/eval methods on the actual
nn.Module
ghstack-source-id: 130421137
Test Plan:
Call these two updated methods in method test_send_remote_module_over_the_wire in remote_module_test.py. To test the correctness, after running method train, the training mode should be set to True; after running method eval, the training mode of the remote module should be set to False.
Related test output:
✓ Pass: caffe2/test/distributed/rpc:process_group_agent - test_send_remote_module_over_the_wire (fb.test_process_group_agent.ProcessGroupThreeWorkersRemoteModuleTestWithFork) (23.059)
✓ Pass: caffe2/test/distributed/rpc:thrift_agent - test_send_remote_module_over_the_wire (fb.test_thrift_agent.ThriftThreeWorkersRemoteModuleTestWithFork) (27.965)
✓ Pass: caffe2/test/distributed/rpc:process_group_agent - test_send_remote_module_over_the_wire (test_process_group_agent.ProcessGroupThreeWorkersRemoteModuleTestWithSpawn) (74.481)
✓ Pass: caffe2/test/distributed/rpc:thrift_agent - test_send_remote_module_over_the_wire (fb.test_thrift_agent.ThriftThreeWorkersRemoteModuleTestWithSpawn) (77.243)
✓ Pass: caffe2/test/distributed/rpc:tensorpipe_agent - test_send_remote_module_over_the_wire (fb.test_tensorpipe_agent.TensorPipeThreeWorkersRemoteModuleTestWithFork) (58.644)
✓ Pass: caffe2/test/distributed/rpc:tensorpipe_agent - test_send_remote_module_over_the_wire (test_tensorpipe_agent.TensorPipeThreeWorkersRemoteModuleTestWithSpawn) (90.229)
Reviewed By: pritamdamania87, SciPioneer
Differential Revision: D28721078
fbshipit-source-id: aa45c1e5755f583200144ecfec3704f28221972c
Summary:
Resubmit of https://github.com/pytorch/pytorch/issues/59108, closes https://github.com/pytorch/pytorch/issues/24754, closes https://github.com/pytorch/pytorch/issues/24616
This reuses `linalg_vector_norm` to calculate the norms. I just add a new kernel that turns the norm into a normalization factor, then multiply the original tensor using a normal broadcasted `mul` operator. The result is less code, and better performance to boot.
#### Benchmarks (CPU):
| Shape | Dim | Before | After (1 thread) | After (8 threads) |
|:------------:|:---:|--------:|-----------------:|------------------:|
| (10, 10, 10) | 0 | 11.6 us | 4.2 us | 4.2 us |
| | 1 | 14.3 us | 5.2 us | 5.2 us |
| | 2 | 12.7 us | 4.6 us | 4.6 us |
| (50, 50, 50) | 0 | 330 us | 120 us | 24.4 us |
| | 1 | 350 us | 135 us | 28.2 us |
| | 2 | 417 us | 130 us | 24.4 us |
#### Benchmarks (CUDA)
| Shape | Dim | Before | After |
|:------------:|:---:|--------:|--------:|
| (10, 10, 10) | 0 | 12.5 us | 12.1 us |
| | 1 | 13.1 us | 12.2 us |
| | 2 | 13.1 us | 11.8 us |
| (50, 50, 50) | 0 | 33.7 us | 11.6 us |
| | 1 | 36.5 us | 15.8 us |
| | 2 | 41.1 us | 15 us |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59250
Reviewed By: mruberry
Differential Revision: D28820359
Pulled By: ngimel
fbshipit-source-id: 572486adabac8135d52a9b8700f9d145c2a4ed45
Summary:
Partially addresses https://github.com/pytorch/pytorch/issues/55340
**Overview**
This factors out `FileStoreTest`, `HashStoreTest`, `PrefixFileStoreTest`, `TCPStoreTest`, `PrefixTCPStoreTest`, `PythonStoreTest`, `RendezvousTest`, `RendezvousEnvTest`, `RendezvousFileTest`, and `RendezvousTCPTest` from `test_c10d_common.py` to a new file `test_store.py`.
Additionally, unused import/initialization statements are removed from `test_c10d_common.py`, and the minimal set of import/initialization statements are used for `test_store.py`.
Also, this changes `.jenkins/pytorch/multigpu-test.sh`, `.jenkins/pytorch/win-test-helpers/test_distributed.bat`, and `test/run_test.py` to include the new `test_store.py`.
**Testing**
All commands shown are run on an AI AWS cluster.
I check the Store tests:
```
python test/distributed/test_store.py
```
I also check `test_c10d_common.py` since it is the source of the refactored code. In addition, I check `test_c10d_nccl.py` and `test_c10d_gloo.py` since they import from `test_c10d_common.py`; those two should be the only test files depending on `test_c10d_common.py`.
```
python test/distributed/test_c10d_common.py
python test/distributed/test_c10d_nccl.py
python test/distributed/test_c10d_gloo.py
```
`test_c10d_gloo.py` produces warnings about how using sparse tensors in TorchScript is experimental, but the warnings do not result from this PR's changes.
**Testing Issues** (To Be Revisited)
```
WORLD_SIZE=4 BACKEND=gloo gpurun pytest test/distributed/test_c10d_gloo.py
```
Running the above command fails three tests (written as `[Test]`: `[Error]`):
- `ProcessGroupGlooWrapperTest.test_collective_hang`: `RuntimeError: [../third_party/gloo/gloo/transport/tcp/pair.cc:598] Connection closed by peer [10.200.24.101]:15580`
- `CommTest.test_broadcast_coalesced_gloo_cuda`: `RuntimeError: cuda runtime error (3) : initialization error at ../aten/src/THC/THCGeneral.cpp:54`
- `CommTest.test_sequence_num_incremented_gloo_default`: `RuntimeError: cuda runtime error (3) : initialization error at ../aten/src/THC/THCGeneral.cpp:54`
However, running each of the following yields no errors:
```
WORLD_SIZE=4 BACKEND=gloo gpurun pytest test/distributed/test_c10d_gloo.py -k test_collective_hang
WORLD_SIZE=4 BACKEND=gloo gpurun pytest test/distributed/test_c10d_gloo.py -k test_broadcast_coalesced_gloo_cuda
WORLD_SIZE=4 BACKEND=gloo gpurun pytest test/distributed/test_c10d_gloo.py -k test_sequence_num_incremented_gloo_default
```
This suggests the existence of some inadvertent state dependency between tests (e.g. improper cleanup). I have not explored this further yet. In particular, I do not have a solid understanding of the tests to be able to explain why using `pytest` and `gpurun` induces the failure (since notably, running the `.py` directly shows no issue).
Similarly, running the following yields 47 errors:
```
WORLD_SIZE=4 BACKEND=nccl gpurun pytest test/distributed/test_c10d_nccl.py
```
The errors seem to all be simply complaining about the usage of `fork()` instead of `spawn()` for CUDA multiprocessing. Though, most of the tests in `test_c10d_nccl.py` ask for at least 2 CUDA devices, so I think that the `gpurun` is warranted (assuming that the test file does not need to be run partially on different machines).
Both `test_c10d_common.py` and `test_store.py` work fine with `pytest`.
**Other Notes**
I noticed that `torch.distributed` is imported both as `dist` and as `c10d` and that `c10d` is used throughout the Store tests. I was curious if this is intentional (as opposed to using `dist` to refer to `torch.distributed`). Also, the original [issue](https://github.com/pytorch/pytorch/issues/55340) suggests that the Store tests do not use multiprocessing, but I saw that `torch.multiprocessing` is still used in `TCPStoreTest`.
The links for the Store files in the `CONTRIBUTING.md` [file](https://github.com/pytorch/pytorch/blob/master/torch/distributed/CONTRIBUTING.md) are broken. This can fixed in a separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59271
Reviewed By: jbschlosser, mrshenli
Differential Revision: D28856920
Pulled By: andwgu
fbshipit-source-id: 630950cba18d34e6b5de661f5a748f2cddc1b446
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56017Fixes#55686
This patch is seemingly straightforward but some of the changes are very
subtle. For the general algorithmic approach, please first read the
quoted issue. Based on the algorithm, there are some fairly
straightforward changes:
- New boolean on TensorImpl tracking if we own the pyobj or not
- PythonHooks virtual interface for requesting deallocation of pyobj
when TensorImpl is being released and we own its pyobj, and
implementation of the hooks in python_tensor.cpp
- Modification of THPVariable to MaybeOwned its C++ tensor, directly
using swolchok's nice new class
And then, there is python_variable.cpp. Some of the changes follow the
general algorithmic approach:
- THPVariable_NewWithVar is simply adjusted to handle MaybeOwned and
initializes as owend (like before)
- THPVariable_Wrap adds the logic for reverting ownership back to
PyObject when we take out an owning reference to the Python object
- THPVariable_dealloc attempts to resurrect the Python object if
the C++ tensor is live, and otherwise does the same old implementation
as before
- THPVariable_tryResurrect implements the resurrection logic. It is
modeled after CPython code so read the cited logic and see if
it is faithfully replicated
- THPVariable_clear is slightly updated for MaybeOwned and also to
preserve the invariant that if owns_pyobj, then pyobj_ is not null.
This change is slightly dodgy: the previous implementation has a
comment mentioning that the pyobj nulling is required to ensure we
don't try to reuse the dead pyobj. I don't think, in this new world,
this is possible, because the invariant says that the pyobj only
dies if the C++ object is dead too. But I still unset the field
for safety.
And then... there is THPVariableMetaType. colesbury explained in the
issue why this is necessary: when destructing an object in Python, you
start off by running the tp_dealloc of the subclass before moving up
to the parent class (much in the same way C++ destructors work). The
deallocation process for a vanilla Python-defined class does irreparable
harm to the PyObject instance (e.g., the finalizers get run) making it
no longer valid attempt to resurrect later in the tp_dealloc chain.
(BTW, the fact that objects can resurrect but in an invalid state is
one of the reasons why it's so frickin' hard to write correct __del__
implementations). So we need to make sure that we actually override
the tp_dealloc of the bottom most *subclass* of Tensor to make sure
we attempt a resurrection before we start finalizing. To do this,
we need to define a metaclass for Tensor that can override tp_dealloc
whenever we create a new subclass of Tensor. By the way, it was totally
not documented how to create metaclasses in the C++ API, and it took
a good bit of trial error to figure it out (and the answer is now
immortalized in https://stackoverflow.com/q/67077317/23845 -- the things
that I got wrong in earlier versions of the PR included setting
tp_basicsize incorrectly, incorrectly setting Py_TPFLAGS_HAVE_GC on
the metaclass--you want to leave it unset so that it inherits, and
determining that tp_init is what actually gets called when you construct
a class, not tp_call as another not-to-be-named StackOverflow question
suggests).
Aside: Ordinarily, adding a metaclass to a class is a user visible
change, as it means that it is no longer valid to mixin another class
with a different metaclass. However, because _C._TensorBase is a C
extension object, it will typically conflict with most other
metaclasses, so this is not BC breaking.
The desired new behavior of a subclass tp_dealloc is to first test if
we should resurrect, and otherwise do the same old behavior. In an
initial implementation of this patch, I implemented this by saving the
original tp_dealloc (which references subtype_dealloc, the "standard"
dealloc for all Python defined classes) and invoking it. However, this
results in an infinite loop, as it attempts to call the dealloc function
of the base type, but incorrectly chooses subclass type (because it is
not a subtype_dealloc, as we have overridden it; see
b38601d496/Objects/typeobject.c (L1261) )
So, with great reluctance, I must duplicate the behavior of
subtype_dealloc in our implementation. Note that this is not entirely
unheard of in Python binding code; for example, Cython
c25c3ccc4b/Cython/Compiler/ModuleNode.py (L1560)
also does similar things. This logic makes up the bulk of
THPVariable_subclass_dealloc
To review this, you should pull up the CPython copy of subtype_dealloc
b38601d496/Objects/typeobject.c (L1230)
and verify that I have specialized the implementation for our case
appropriately. Among the simplifications I made:
- I assume PyType_IS_GC, because I assume that Tensor subclasses are
only ever done in Python and those classes are always subject to GC.
(BTW, yes! This means I have broken anyone who has extend PyTorch
tensor from C API directly. I'm going to guess no one has actually
done this.)
- I don't bother walking up the type bases to find the parent dealloc;
I know it is always THPVariable_dealloc. Similarly, I can get rid
of some parent type tests based on knowledge of how
THPVariable_dealloc is defined
- The CPython version calls some private APIs which I can't call, so
I use the public PyObject_GC_UnTrack APIs.
- I don't allow the finalizer of a Tensor to change its type (but
more on this shortly)
One alternative I discussed with colesbury was instead of copy pasting
the subtype_dealloc, we could transmute the type of the object that was
dying to turn it into a different object whose tp_dealloc is
subtype_dealloc, so the stock subtype_dealloc would then be applicable.
We decided this would be kind of weird and didn't do it that way.
TODO:
- More code comments
- Figure out how not to increase the size of TensorImpl with the new
bool field
- Add some torture tests for the THPVariable_subclass_dealloc, e.g.,
involving subclasses of Tensors that do strange things with finalizers
- Benchmark the impact of taking the GIL to release C++ side tensors
(e.g., from autograd)
- Benchmark the impact of adding a new metaclass to Tensor (probably
will be done by separating out the metaclass change into its own
change)
- Benchmark the impact of changing THPVariable to conditionally own
Tensor (as opposed to unconditionally owning it, as before)
- Add tests that this actually indeed preserves the Python object
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27765125
Pulled By: ezyang
fbshipit-source-id: 857f14bdcca2900727412aff4c2e2d7f0af1415a
Summary:
fixed the awkward configerator initialization issue that broke some
tests. Trying again
Test Plan: predictor comparisons
Reviewed By: ZolotukhinM
Differential Revision: D28859795
fbshipit-source-id: 826801db24e86b1c3594a86e3ac32f0a84c496f7
Summary:
Added GPU tests in previous diffs but had to disable them as they only
pass locally on devgpu, but not in sandcastle.
note: local testing requires mode/dev-nosan or else ASAN interferes with CUDA.
Test Plan: Verify tests passing in sandcastle.
Reviewed By: malfet
Differential Revision: D28538996
fbshipit-source-id: 1a6ccea07cfe2f150eee068594e636add620cd91
Summary:
Also fix `TestProducerVersion` by removing assumption that major and minor are single digit
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59345
Reviewed By: robieta
Differential Revision: D28853720
Pulled By: malfet
fbshipit-source-id: 4b6d03c6b0c9d652a5aef792aaa84eaa522d10e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59354
Check if the model has `bytecode.pkl` and provide proper error message before loading model. Test it by loading a model.pt and model.ptl.
```
>>> from torch.jit.mobile import _load_for_lite_interpreter
>>> _load_for_lite_interpreter("/Users/chenlai/Documents/pytorch/data/mobilenet_v2.pt")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/chenlai/pytorch/torch/jit/mobile/__init__.py", line 48, in _load_for_lite_interpreter
cpp_module = torch._C._load_for_lite_interpreter(f, map_location) # type: ignore[attr-defined]
RuntimeError: The model is not generated from the api _save_for_lite_interpreter. Please regenerate the module by scripted_module._save_for_lite_interpreter('model.ptl'). Refer to https://pytorch.org/tutorials/prototype/lite_interpreter.html for more details.
```
iOS:

Android:

Differential Revision:
D28856713
D28856713
Test Plan: Imported from OSS
Reviewed By: dhruvbird
Pulled By: cccclai
fbshipit-source-id: c3f9a3b64459dda6811d296371c8a2eaf22f8b20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59284
Logs a few python-side errors to DDP logging.
TODO: Most python errors actually have to do with user input correctness, so they throw before reducer is constructed and thus there is no logger. For this case, should we allow `logger` to be created optionally without a reducer, just for the purpose of logging errors, so that we can gain insight into these errors in scuba?
ghstack-source-id: 130412973
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D28820290
fbshipit-source-id: 610e5dba885b173c52351f7ab25c923edce639e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59281
Adds ability to log when reducer/ddp encounters an error. We add fields "has_error" and "error" to indicate that an error has
occured in this iteration, and the other fields (performance stats) are not
guaranteed to be updated.
Errors encountered in python-side DDP will be added in the next diff.
ghstack-source-id: 130412974
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28652717
fbshipit-source-id: 9772abc2647a92dac6a325da6976ef5eb877c589
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59066
Per title
ghstack-source-id: 130338812
Test Plan: ci
Reviewed By: SciPioneer
Differential Revision: D28734666
fbshipit-source-id: 89ca7f8e625c4068ba0ed9800be2619e469ae515
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59065
Cleaner to use work.result() instead of sending back the tensor from
this function.
ghstack-source-id: 130338813
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D28551203
fbshipit-source-id: d871fed78be91f0647687ea9d6fc86e576dc53a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58933
**Summary**
This commit makes load_library calls no-ops inside packages run with
deploy. Libraries containing custom C++ operators and classes are statically linked in C++
and don't need to be loaded. This commit takes advantage of the fact that sys.executable is
set to torch_deploy in deploy and uses that to exit early in load_library if
the program is running inside deploy.
**Test Plan**
This commit adds a test to `generate_examples`/`test_deploy` that
packages and runs a function that calls `load_library`. The library
doesn't exist, but that's okay because the function should be a no-op
anyway.
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Differential Revision: D28687159
Pulled By: SplitInfinity
fbshipit-source-id: 4a61fc636698e44f204334e338c5ce35257e7ae2
Summary:
Adjusts type hints for optimize_for_mobile to be consistent with the default. Right now using optimize_for_mobile and only passing a script_module gives me a type error complaining about preserved_methods can't be None.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59282
Test Plan:
Imported from GitHub, without a `Test Plan:` line.
Open source tests ran the lints. Internal CI should be enough here.
Reviewed By: jbschlosser
Differential Revision: D28838159
Pulled By: JacobSzwejbka
fbshipit-source-id: dd1e9aff00a759f71d32025d8c5b01e612c869a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59261
Split converters to different files instead of putting them in a single file.
Reviewed By: jackm321
Differential Revision: D28613989
fbshipit-source-id: f25ca3732c457af51a07ef466915a4a08bd45e6e
Summary:
For facebook employees, this fix some internal failures from https://www.internalfb.com/tasks/?t=92100671
This was not a problem before https://github.com/pytorch/pytorch/pull/58271 because these cycles used to just be leaked (so nothing was cleared/dealloced).
Now that we properly clean up these cycles, we have to fix the assert in the clear.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59301
Reviewed By: jbschlosser
Differential Revision: D28841564
Pulled By: albanD
fbshipit-source-id: e2ec51f6abf44c4e3a83c293e90352295a43ba37
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53423closes#40166
This change exposes a new API, rpc.barrier() which blocks the main processes of all workers running RPC until the whole group completes this function. Optionally rpc.barrier can take in a set of worker_names and only synchronize across those worker names.
Example:
```python
import os
import torch.multiprocessing as mp
import torch.distributed.rpc as rpc
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "5678"
world_size = 4
odd_num_workers = [f"worker{i}" for i in range(world_size) if i % 2]
even_num_workers = [f"worker{i}" for i in range(world_size) if not i % 2]
def worker(i):
print(i)
rpc.init_rpc(f"worker{i}", rank=i, world_size=world_size)
if i % 2:
print(f"start barrier {i}")
rpc.barrier(set(odd_num_workers))
else:
print(f"start barrier {i}")
rpc.barrier(set(even_num_workers))
rpc.shutdown()
print(f"shutdown{i}")
if __name__ == '__main__':
with mp.Pool(processes=world_size) as pool:
pool.map(worker, range(world_size))
```
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D27737145
Pulled By: H-Huang
fbshipit-source-id: 369196bc62446f506d1fb6a3fa5bebcb0b09da9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59070
This log is too verbose, especially in the case we call monitored
barrier before every collective as we do in ProcessGroupWrapper.
ghstack-source-id: 130052822
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D28738189
fbshipit-source-id: f2899537caa4c13508da31134d5dd0f4fd6a1f3a
Summary:
Resubmit of https://github.com/pytorch/pytorch/issues/58811, Closes gh-24745
The existing PR (gh-50655) has been stalled because `TensorIterator` doesn't guarantee iteration order in the same way that `TH_TENSOR_APPLY` does. For contiguous test cases this isn't an issue; but it breaks down for example with channels last format. I resolve this by adding a new `TensorIteratorConfig` parameter, `enforce_linear_iteration`, which disables dimension reordering. I've also added a test case for non-contiguous tensors to verify this works.
This PR also significantly improves performance by adding multithreading support to the algorithm. As part of this, I wrote a custom `count_nonzero` that gives per-thread counts which is necessary to write the outputs in the right location.
| Shape | Before | After (1 thread) | After (8 threads) |
|:----------:|--------:|-----------------:|------------------:|
| 256,128,32 | 2610 us | 2150 us | 551 us |
| 128,128,32 | 1250 us | 1020 us | 197 us |
| 64,128,32 | 581 us | 495 us | 99 us |
| 32,128,32 | 292 us | 255 us | 83 us |
| 16,128,32 | 147 us | 126 us | 75 us |
| 8,128,32 | 75 us | 65 us | 65 us |
| 4,128,32 | 39 us | 33 us | 33 us |
| 2,128,32 | 20 us | 18 us | 18 us |
| 1,128,32 | 11 us | 9 us | 9 us |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59149
Reviewed By: mruberry
Differential Revision: D28817466
Pulled By: ngimel
fbshipit-source-id: f08f6c003c339368fd53dabd28e9ada9e59de732
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58895
There doesn't seem to be any reason we can't use expect_contiguous here.
ghstack-source-id: 130283300
Test Plan: CI
Reviewed By: ngimel
Differential Revision: D28666399
fbshipit-source-id: b4a9bcb01ff1c30d991765140c8df34c3ac3a89b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59310
We recently updated the GK to deliver GPU models to only 11.0+ devices. Will do a clean up in following diffs to clean up shader functions written for iOS 10.0.
ghstack-source-id: 130374598
Test Plan: CI
Reviewed By: linbinyu
Differential Revision: D28805864
fbshipit-source-id: 4cde34ff9fbbe811a69686a0f29b56d69aeefbee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59287
D27211605 added a warning in `toIValue` that warns users to script their
dictionaries before passing them to TorchScript functions in order to get some
performance benefits and reference semantics. However, this warning is emitted
every time `toIValue` is called (e.g. when a dictionary is passed to
TorchScript function), which can lead to noisy log output. This diff changes
this changes to use `TORCH_WARN_ONCE` instead.
Test Plan: Sandcastle, OSS CI.
Reviewed By: hyuen
Differential Revision: D28824468
fbshipit-source-id: e651eade4380abaf77c6c8a81ec4e565b0c2c714
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59324
Also updates section on pinning pytorch/builder with an example
[skip ci]
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D28840049
Pulled By: seemethere
fbshipit-source-id: e5d6722713680e969893d9df97ec269fc9c00411
Summary:
Hello,
depending on the build environment you may encounter
```c++
error: reference to 'optional' is ambiguous
```
when using the Torch-C++-API.
This PR adds `c10::` to avoid possible ambiguities with **std::optional** and does not introduce any functional change.
Fixes https://discuss.pytorch.org/t/linker-failed-with-ambiguous-references/36255 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45736
Reviewed By: dzhulgakov
Differential Revision: D24125123
Pulled By: VitalyFedyunin
fbshipit-source-id: df21420f0a2d0270227c28976a7a4218315cc107
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59042
To remove Quantizer class and split prepare and convert functions to different files
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724867
fbshipit-source-id: 9f87d51020caa20d5408cb2820947e23d92d5fc3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57080
ONNX optimizer is removed in ONNX 1.9
This PR removes ONNX optimizer from a C++ code path and uses `try-except` block in Python to keep it compatible with both ONNX-1.8 and 1.9.
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D28467330
Pulled By: malfet
fbshipit-source-id: 5e4669dd0537648898e593f9e253da18d6dc7568
Co-authored-by: neginraoof <neginmr@utexas.edu>
Co-authored-by: Nikita Shulga <nshulga@fb.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59283
We were observing 403s when attempting to install dependencies from
chocolatey leading us to believe that we were getting rate limited from
chocolatey.
We've instead opted to install our dependencies in our base AMIs instead
considering we would install them on every workflow anyway. This also
comes with the moving of the windows 10 sdk installation to the base sdk
as well since we were observing failures there as well due to failed
dependency installations.
Also moves windows 10 sdk installations to our visual studio installation script, which is activated by an passing an environment variable
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D28822962
Pulled By: seemethere
fbshipit-source-id: b5e35ffe4537db55deb027376bd2d418683707a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59212
Reland of https://github.com/pytorch/pytorch/pull/58428
Until now, the TP agent expected the output of a remote function to be on the same streams as the inputs. In other words, it used the lazy stream context of the inputs to synchronize the output tensors. This was true in the most common case of a synchronous remote function. However it wasn't true for async functions, for fetching RRefs, ... The more generic way is to use the CUDA events held by the Future to perform this synchronization. (These events may be on the input streams, or they may not be!).
ghstack-source-id: 130202842
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28623885
fbshipit-source-id: 29333bcb75d077ab801eac92017d0e381e8f5569
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59211
Reland of https://github.com/pytorch/pytorch/pull/58674
I found this missing parameter while debugging failures in the next PR.
I'm very unhappy about this change. I think this future, which we know for sure won't contain tensors, shouldn't have to worry about CUDA devices. And yet, it does. This means that basically any future anywhere might have to worry about it, and this just doesn't scale, and thus it's bad.
ghstack-source-id: 130202843
Test Plan: Should fix the next diff.
Reviewed By: mrshenli
Differential Revision: D28623886
fbshipit-source-id: 6c82ed7c785ac3bf32fff7eec67cdd73b96aff28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59210
Reland of https://github.com/pytorch/pytorch/pull/58427
Running the UDF (be it Python or JIT) is the first step of (most?) RPC calls, which is where the inputs are consumed. The lazy stream context contains the streams used by the inputs, thus it must be made current before any UDF call. I opt to do this as "close" as possible to the place the UDF is invoked, to make the relationship as explicit as possible.
ghstack-source-id: 130202847
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28623889
fbshipit-source-id: ed38242f813dac075d162685d52ae89f408932f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59209
Reland of https://github.com/pytorch/pytorch/pull/58426
The operations in RequestCallback can return CUDA tensors, thus the futures used to hold them must be CUDA-aware.
ghstack-source-id: 130202844
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28623887
fbshipit-source-id: 53561b8ae011458d8f848f0a03830925aff2f0c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59208
Reland of https://github.com/pytorch/pytorch/pull/58425
Now that callbacks can provide pre-extracted DataPtrs, let's do so. This will become of crucial importance in the next PR, where some of these futures will become CUDA-aware, and thus they will try to extract DataPtrs on their own, but they would fail to do so here because Message isn't "inspectable".
ghstack-source-id: 130202845
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28623888
fbshipit-source-id: 1aa4bde8014870c071685ba8f72d5f3f01f0a512
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59207
Reland of https://github.com/pytorch/pytorch/pull/58424
In CUDA mode, Future must inspect its value and extract DataPtrs. However some types are not supported, for example the C++/JIT custom classes, which include Message, which is widely used in RPC. Hence for these scenarios we allow the user to perform the custom DataPtr extraction on their own, and pass the pre-extracted DataPtrs.
Note that `markCompleted` already allowed users to pass in pre-extracted DataPtrs, hence this PR simply extends this possibility to the `then` method too.
ghstack-source-id: 130202846
Test Plan: Used in next PR.
Reviewed By: mrshenli
Differential Revision: D28623890
fbshipit-source-id: 468c5308b40774ba0a778b195add0e0845c1929e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59206
Reland of https://github.com/pytorch/pytorch/pull/58423
This is part 2 of the previous PR. Here we address the remaining occurrences of "raw" Message, namely the ones within toMessageImpl. And since they're the last ones, we make the constructor of Message private, to prevent new usages from emerging.
ghstack-source-id: 130202848
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28623892
fbshipit-source-id: f815cf6b93e488c118e5d2298473e6e9d9f4c132
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59205
Reland of https://github.com/pytorch/pytorch/pull/58422
Similar to Future (which I tackled recently), Message is an ivalue type (a "custom class" one), and the natural way to represent it is inside an intrusive_ptr. However in the RPC code we had a mix of usages, often passing Message by value. This has undesirable consequences, as it could easily trigger a copy by accident, which I believe is why in many places we accepted _rvalue references_ to Message, in order to force the caller to move. In my experience this is non-idiomatic in C++ (normally a function signature specifies how the function consumes its arguments, and it's up to the caller to then decide whether to copy or move).
By moving to intrusive_ptr everywhere I think we eliminate and simplify many of the problems above.
In this PR I do half of the migration, by updating everything except the `toMessageImpl` methods, which will come in the next PR.
ghstack-source-id: 130202849
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28623891
fbshipit-source-id: c9aeea3440679a11741ca78c06b03c57cb815a5e
Summary:
This PR
* adds the breakpad build to most of the remaining docker images (except the mobile + slim ones)
* pins to a [fork of breakpad](https://github.com/google/breakpad/compare/master...driazati:master?expand=1) to enable dasiy chaining on signal handlers
* renames the API to be nicer
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59236
Reviewed By: malfet
Differential Revision: D28792511
Pulled By: driazati
fbshipit-source-id: 83723e74b7f0a00e1695210ac2620a0c91ab4bf2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59242
#Oringal PR Issue: https://github.com/pytorch/pytorch/issues/58274
This can be a workaround: Instead of passing a script `RemoteModule` over RPC, pass its `module_rref` field over RPC, and then construct a new `RemoteModule` on the receiver end.
ghstack-source-id: 130268018
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_send_remote_module_over_the_wire_script_not_supported
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_remote_module_py_pickle_not_supported_script
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_create_remote_module_by_module_rref
Reviewed By: vipannalla
Differential Revision: D28794905
fbshipit-source-id: 1a677ff0d4b47c078ad47b50d7102a198a1fc39b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59041
Static quantization for Custom module support was removed in a previous refactor
https://github.com/pytorch/pytorch/pull/57519 since it's not covered by the test case
This PR re-enabled the test case and fixed the support
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724866
fbshipit-source-id: 1974675b88b56a2173daf86965d6f3fb7ebd783b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59040
To remove Quantizer class and split prepare and convert functions to different files
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724870
fbshipit-source-id: c0f748711b825cd46bdfcc05c054c77a41e8207a
Summary:
This PR fixes `torch.linalg.inv_ex` with MAGMA backend.
`info` tensor was returned on CPU device even for CUDA inputs.
Now it's on the same device as input.
Fixes https://github.com/pytorch/pytorch/issues/58769
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59223
Reviewed By: ngimel
Differential Revision: D28814876
Pulled By: mruberry
fbshipit-source-id: f66c6f06fb8bc305cb2e22b08750a25c8888fb65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59039
To remove Quantizer class and split prepare and convert functions to different files
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724874
fbshipit-source-id: bd984716b2da1d6879c3e92fa827574783a41567
Summary:
Graphs tests are sometimes flaky in CI ([example](https://app.circleci.com/pipelines/github/pytorch/pytorch/328930/workflows/0311199b-a0be-4802-a286-cf1e73f96c70/jobs/13793451)) because when the GPU runs near its max memory capacity (which is not unusual during a long test), sometimes, to satisfy new allocations that don't match any existing unused blocks, the caching allocator may call `synchronize_and_free_events` to wait on block end-of-life events and cudaFree unused blocks, then re-cudaMalloc a new block. For ungraphed ops this isn't a problem, but synchronizing or calling cudaFree while capturing is illegal, so `synchronize_and_free_events` raises an error if called during capture.
The graphs tests themselves don't use much memory, so calling torch.cuda.empty_cache() at some point before their captures should ensure memory is available and the captures never need `synchronize_and_free_events`.
I was already calling empty_cache() near the beginning of several graphs tests. This PR extends it to the ones I forgot.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59233
Reviewed By: mruberry
Differential Revision: D28816691
Pulled By: ngimel
fbshipit-source-id: 5cd83e48e43b1107daed5cfa2efff0fdb4f99dff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59038
To remove Quantizer class and split prepare and convert functions to different files
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724869
fbshipit-source-id: e8501c9720b5ddb654e78bc8fa08de0466c1d52b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59018Fixes#58044.
This PR:
- adds `ATEN_FN(op)` and `ATEN_FN2(op, overload)` macros that resolve to
an non-overloaded function in aten::_ops that calls the desired operator
(without default arguments).
The motivation for this is two-fold:
1) Using aten operators with templates is hard if the operator is
overloaded (e.g. add.Tensor and add.Scalar).
2) Method-only operators require special handling; pointers-to-method
are different from function pointers. `ATEN_FN2(add_, Tensor)` returns
a function instead of a method.
There is some interesting behavior for out= operations.
`ATEN_FN2(sin, "out")` gives a function that is *faithful* to the schema;
that is, the order of arguments is exactly what it looks like in the
schema. This makes it so that you can directly register
`ATEN_FN2(sin,"out")` (or a function wrapping it using the same signature)
as an override for a DispatchKey.
Test Plan:
- New tests that ATEN_FN2 works on function and method-only operators
- New test that ATEN_FN works
- New test that ATEN_FN macro returns a "faithful" function.
Codegen output:
Operators.h and Operators.cpp are both here:
https://gist.github.com/zou3519/c2c6a900410b571f0d7d127019ca5175
Reviewed By: bdhirsh
Differential Revision: D28721206
Pulled By: zou3519
fbshipit-source-id: a070017f98e8f4038cb0c64be315eef45d264217
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59254
index_add can take int or long index tensor whereas index_put only takes long indices tensor.
In the deterministic path of index_add_cuda, we use index_put. Hence we better convert index tensor to long.
Test Plan:
buck test mode/opt //caffe2/test:torch_cuda -- test_index_add_deterministic
✓ ListingSuccess: caffe2/test:torch_cuda - main (14.748)
✓ Pass: caffe2/test:torch_cuda - test_index_add_deterministic_cuda (test_torch.TestTorchDeviceTypeCUDA) (27.717)
✓ Pass: caffe2/test:torch_cuda - main (27.717)
Reviewed By: ngimel
Differential Revision: D28804038
fbshipit-source-id: de12932a7738f2805f3bceb3ec024497625bce6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59037
To remove Quantizer class and split prepare and convert functions to different files
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724865
fbshipit-source-id: 6c6824d0af7dd47d4c111d6a08e373bc65f33e08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59036
To remove Quantizer class and split prepare and convert functions to different files
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724862
fbshipit-source-id: 5900420127fcc14846bc34c9ac29ff7e6a703f1e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59035
To remove Quantizer class and split prepare and convert functions to different files
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724872
fbshipit-source-id: d32752c635917c9820e5e7cc414ba9d48a258a19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59034
To remove Quantizer class and split prepare and convert functions to different files
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724873
fbshipit-source-id: 870e0822843ad1d035f41eaa015bdde9ccf6ec23
Summary:
The current implementation of DistributedSampler generates a python list to hold all of the indices, and then returns a slice of this list for the given rank (creating a partial copy of the list). When the underlying dataset is large, both of these choices waste a large amount of memory. It is much more efficient to create a tensor to hold the indices, and then index into that tensor instead of creating slices.
In the case of a sampler with `shuffle=False`, it would be possible to avoid creating the `indices` tensor entirely (since the index will always match the value), but I have opted instead here to keep the implementation as similar to the existing version as possible. One possible benefit of this approach is that memory usage will not significantly change based on changing this parameter. Still, it might be better to simply return the indices directly without the underlying array.
Additionally, the logic around calculating the number of samples is unnecessarily complex. When dropping the last batch, this can be a simple floor division.
In a simple test script which creates a sampler for a dataset with a 100,000,000 items, memory usage is reduced 98% compared to the existing implementation.
Fixes https://github.com/pytorch/pytorch/issues/45427
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51841
Reviewed By: albanD
Differential Revision: D28240105
Pulled By: rohan-varma
fbshipit-source-id: 4c6aa493d0f75c07ec14c98791b3a531300fb1db
Summary:
Fixes https://github.com/pytorch/pytorch/issues/57878.
This adds `NCCL_ASYNC_ERROR_HANDLING` as a DDP relevant environment variable and includes a check for that variable in the test `test_dump_DDP_relevant_env_vars()`. Notably, the modified test now checks for the new variable but does not check for any of the other previously-existing relevant environment variables that were not already tested for (e.g. `NCCL_BLOCKING_WAIT`).
The change was tested via the following on an AI AWS cluster:
`WORLD_SIZE=2 BACKEND=nccl gpurun pytest test/distributed/test_distributed_spawn.py -k test_dump_DDP_relevant_env_vars -vs`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59109
Reviewed By: H-Huang, SciPioneer
Differential Revision: D28761148
Pulled By: andwgu
fbshipit-source-id: 7be4820e61a670b001408d0dd273f65029b1d2fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59033
To remove Quantizer class and split prepare and convert functions to different files
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724861
fbshipit-source-id: 97b38e851b6bf581510a24636b1d8d6f1d977f5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59032
To remove Quantizer class and split prepare and convert functions to different files
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724868
fbshipit-source-id: 6df639f20076b480812b6dcf0fc7d2c87ca29d8b
Summary:
Related Issue: https://github.com/pytorch/pytorch/issues/57691
This PR introduces an API for checking environment variables:
```c++
optional<bool> check_env(const char *name)
```
Reads the environment variable name and returns
- `optional<true>`, if set equal to "1"
- `optional<false>`, if set equal to "0"
- `nullopt`, otherwise
Issues a warning if the environment variable was set to any value other than 0 or 1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59052
Test Plan:
Manually run the following test case:
- Apply this diff to the repo
```
diff --git a/torch/csrc/Exceptions.cpp b/torch/csrc/Exceptions.cpp
index d008643f70..990d254f0d 100644
--- a/torch/csrc/Exceptions.cpp
+++ b/torch/csrc/Exceptions.cpp
@@ -9,6 +9,9 @@
#include <torch/csrc/THP.h>
+#include <c10/util/Optional.h>
+#include <c10/util/env.h>
+
// NOLINTNEXTLINE(cppcoreguidelines-avoid-non-const-global-variables)
PyObject *THPException_FatalError;
@@ -23,18 +26,7 @@ bool THPException_init(PyObject *module)
namespace torch {
static bool compute_cpp_stack_traces_enabled() {
- auto envar = std::getenv("TORCH_SHOW_CPP_STACKTRACES");
- if (envar) {
- if (strcmp(envar, "0") == 0) {
- return false;
- }
- if (strcmp(envar, "1") == 0) {
- return true;
- }
- TORCH_WARN("ignoring invalid value for TORCH_SHOW_CPP_STACKTRACES: ", envar,
- " valid values are 0 or 1.");
- }
- return false;
+ return c10::utils::check_env("TORCH_SHOW_CPP_STACKTRACES").value_or(false);
}
bool get_cpp_stacktraces_enabled() {
```
This patch replaces the prior `std::getenv` usage in `torch/csrc/Exceptions.cpp` to use the new api.
- Run the following python3 script
```python
import torch
print(torch.__version__) # should print local version (not release)
a1 = torch.tensor([1,2,3])
a2 = torch.tensor([2])
a1 @ a2
```
using the following commands
```bash
python3 test.py # should not output CPP trace
TORCH_SHOW_CPP_STACKTRACES=1 python3 test.py # should output CPP trace
```
Reviewed By: ngimel
Differential Revision: D28799873
Pulled By: 1ntEgr8
fbshipit-source-id: 3e23353f48679ba8ce0364c049420ba4ff86ff09
Summary:
There are two main changes here:
- THPVariable will actually visit their grad_fn if there are no other reference to the c++ Tensor and no other reference to the grad_fn. The critical observation compared to the existing comment (thanks Ed!) is that if we also check that the c++ Tensor object is not referenced somewhere else, we're sure that no one can change the grad_fn refcount between the traverse and the clear.
- THPVariable don't need a special clear for this new cases as we're the only owner of the c++ Tensor and so the cdata.reset() will necessarily free the Tensor and all its resources.
The two tests are to ensure:
- That the cycles are indeed collectible by the gc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58271
Reviewed By: ngimel
Differential Revision: D28796461
Pulled By: albanD
fbshipit-source-id: 62c05930ddd0c48422c79b03118db41a73c1355d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59028
Previously we have an env and a quant_env in convert, which is a bit confusing,
in this PR we merged them and have a Dict[str, Tuple[Node, torch.dtype]]
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28724863
fbshipit-source-id: 722a682c70d300a6ccd2b988786a1ac2d45e880e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59106
Should make debugging a bit easier
Test Plan:
Example error in https://www.internalfb.com/intern/aibench/details/884106485190261 (open log for Portal or Portal+):
```
The following operation failed in the TorchScript interpreter.
Traceback of TorchScript, serialized code (most recent call last):
File "code/__torch__/torch/backends/_nnapi/prepare.py", line 29, in forward
_0 = uninitialized(__torch__.torch.classes._nnapi.Compilation)
if torch.__is__(self.comp, None):
_1 = (self).init(args, )
~~~~~~~~~~ <--- HERE
else:
pass
File "code/__torch__/torch/backends/_nnapi/prepare.py", line 97, in init
comp = __torch__.torch.classes._nnapi.Compilation.__new__(__torch__.torch.classes._nnapi.Compilation)
_22 = (comp).__init__()
_23 = (comp).init(self.ser_model, self.weights, )
~~~~~~~~~~ <--- HERE
self.comp = comp
return None
Traceback of TorchScript, original code (most recent call last):
File "/data/users/dhaziza/fbsource/fbcode/buck-out/dev/gen/mobile-vision/d2go/projects/facegen/tools/export_to_app#link-tree/torch/backends/_nnapi/prepare.py", line 47, in forward
def forward(self, args: List[torch.Tensor]) -> List[torch.Tensor]:
if self.comp is None:
self.init(args)
~~~~~~~~~ <--- HERE
comp = self.comp
assert comp is not None
File "/data/users/dhaziza/fbsource/fbcode/buck-out/dev/gen/mobile-vision/d2go/projects/facegen/tools/export_to_app#link-tree/torch/backends/_nnapi/prepare.py", line 42, in init
self.weights = [w.contiguous() for w in self.weights]
comp = torch.classes._nnapi.Compilation()
comp.init(self.ser_model, self.weights)
~~~~~~~~~ <--- HERE
self.comp = comp
RuntimeError: [enforce fail at nnapi_model_loader.cpp:171] result == ANEURALNETWORKS_NO_ERROR. NNAPI returned error: 4
```
Reviewed By: axitkhurana
Differential Revision: D28287450
fbshipit-source-id: ccd10301e1492f8879f9d6dd57b60c4e683ebb9e
Summary:
Closes https://github.com/pytorch/pytorch/issues/24754, closes https://github.com/pytorch/pytorch/issues/24616, closes https://github.com/pytorch/pytorch/issues/50874
This reuses `linalg_vector_norm` to calculate the norms. I just add a new kernel that turns the norm into a normalization factor, then multiply the original tensor using a normal broadcasted `mul` operator. The result is less code, and better performance to boot.
#### Benchmarks (CPU):
| Shape | Dim | Before | After (1 thread) | After (8 threads) |
|:------------:|:---:|--------:|-----------------:|------------------:|
| (10, 10, 10) | 0 | 11.6 us | 4.2 us | 4.2 us |
| | 1 | 14.3 us | 5.2 us | 5.2 us |
| | 2 | 12.7 us | 4.6 us | 4.6 us |
| (50, 50, 50) | 0 | 330 us | 120 us | 24.4 us |
| | 1 | 350 us | 135 us | 28.2 us |
| | 2 | 417 us | 130 us | 24.4 us |
#### Benchmarks (CUDA)
| Shape | Dim | Before | After |
|:------------:|:---:|--------:|--------:|
| (10, 10, 10) | 0 | 12.5 us | 12.1 us |
| | 1 | 13.1 us | 12.2 us |
| | 2 | 13.1 us | 11.8 us |
| (50, 50, 50) | 0 | 33.7 us | 11.6 us |
| | 1 | 36.5 us | 15.8 us |
| | 2 | 41.1 us | 15 us |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59108
Reviewed By: mrshenli
Differential Revision: D28767060
Pulled By: ngimel
fbshipit-source-id: 93dcbe5483f71cc6a6444fbd5b1aa1f29975d857
Summary:
Fixes https://github.com/pytorch/pytorch/issues/57508
Earlier, a few CUDA `gradgrad` checks (see the list of ops below) were disabled because of them being too slow. There have been improvements (see https://github.com/pytorch/pytorch/issues/57508 for reference) and this PR aimed on:
1. Time taken by `gradgrad` checks on CUDA for the ops listed below.
2. Enabling the tests again if the times sound reasonable
Ops considered: `addbmm, baddbmm, bmm, cholesky, symeig, inverse, linalg.cholesky, linalg.cholesky_ex, linalg.eigh, linalg.qr, lu, qr, solve, triangular_solve, linalg.pinv, svd, linalg.svd, pinverse, linalg.householder_product, linalg.solve`.
For numbers (on time taken) on a separate CI run: https://github.com/pytorch/pytorch/pull/57802#issuecomment-836169691.
cc: mruberry albanD pmeier
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57802
Reviewed By: ngimel
Differential Revision: D28784106
Pulled By: mruberry
fbshipit-source-id: 9b15238319f143c59f83d500e831d66d98542ff8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58656
Ref gh-56794
`dim_apply` is problematic because it calls `Tensor.select` inside of a parallel
region. Instead, replace it with `TensorIterator` by squashing the
apply-dimension. This is similar to the `_dim_apply` function already used by
the sort kernels:
8c91acc161/aten/src/ATen/native/cpu/SortingKernel.cpp (L27)
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D28776441
Pulled By: ngimel
fbshipit-source-id: 14449d4b12ed4576f879bb65a35e881ce1a953b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59157
Currently view is represented as a copy since we don't support inplace
operations in NNC (similar to `aten::reshape`). Lowering for
`aten::expand_as` is exactly the same as for the `aten::expand`, since
we're building the TE expression basing on the output shape anyway.
Differential Revision:
D28774224
D28774224
Test Plan: Imported from OSS
Reviewed By: Chillee
Pulled By: ZolotukhinM
fbshipit-source-id: 0a1593c4c6500dcc5a374213adb734180ae1f72e
Summary:
Per title. Now `norm` with fp16/bfloat16 inputs and fp32 outputs on cuda won't do explicit cast
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59134
Reviewed By: mruberry
Differential Revision: D28775729
Pulled By: ngimel
fbshipit-source-id: 896daa4f02e8a817cb7cb99ae8a93c02fa8dd5e9
Summary:
The triangular_solve only returns the first input, since the second input is just a copy of the first one. Why does that exist?
Also, I fixed the permute lowering - I was previously doing the inverse application of the permute.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59131
Reviewed By: ansley
Differential Revision: D28768169
Pulled By: Chillee
fbshipit-source-id: 8e78611c6145fb2257cb409ba98c14ac55cdbccf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58992
Currently, we define Torchbind custom classes in the same place that we define Python bindings.
This is nice from a code location perspective, but has two downsides:
1. These custom classes are not available in a C++-only build.
2. These break when included in torch::deploy.
Some explanation on the second issue: torch::deploy creates many Python
interpreters, and creates a full copy of all the bindings for each one. This
will run the static initialization code once for each copy of the bindings,
leading to multiple registration of the custom classes (and therefore an
error).
This PR splits out the relevant custom class binding code into its own source
file to be included in libc10d, which can be compiled and statically
initialized a single time and linked against from the c10d python bindings.
ghstack-source-id: 130168942
Test Plan: CI
Reviewed By: wconstab
Differential Revision: D28690832
fbshipit-source-id: 3c5e3fff28abb8bcdb4a952794c07de1ee2ae5a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59017
See the comment in ThreadLocal.h for context.
I used a slightly dirty preprocessor hack to minimize the number of changes.
The hope is that we'll be able to revert all of these soon.
Test Plan:
CI.
Built FB4A with gnustl and saw no references to cxa_thread_atexit
in the PyTorch libraries.
Reviewed By: ilia-cher
Differential Revision: D28720762
fbshipit-source-id: 0f13c7ac5a108b95f8fde6dbc63c6b8bdb8599de
Summary: This wasn't picking up C10_ANDROID. Not sure how to prevent stuff like this.
Test Plan: Build for Android+gnustl, saw proper ThreadLocal being defined.
Reviewed By: swolchok
Differential Revision: D28720763
fbshipit-source-id: 58eb4ea80ad32a856fcea6d65e5c1c37ebf3bd55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58932
This adds all the operators necessary for mobilenet. I kind of wanted to get these landed to unblock ZolotukhinM, but I'm happy to split these up into multiple PRs if it makes reviewing easier. In terms of testing, i'm going to add an automated shape analysis OpInfo test.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D28727246
Pulled By: eellison
fbshipit-source-id: c17f9b7bdf7a43ddf99212b281ae2dd311259374
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56966
This PR adds a toggle to shape analysis which won't inline complete tensor shapes as constants into the shape compute graph, which is a good stress test on the partial evaluation pipeline.
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D28444664
Pulled By: eellison
fbshipit-source-id: a62e424515a8837a4b596546efa93af5e8e61f10
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59088
Clean up comments and organize the tests better
Test Plan:
python test/test_quantization.py
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28750064
fbshipit-source-id: 4c36922e25e3adea3aaa8b4d9185dc28b17aa57c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58655
Ref gh-56794
The two pass reduction calls `copy_` and `select` inside a parallel region. The
`copy_` can just be moved outside of the parallel region, but avoiding the
`select` call is more complicated because it's needed to construct the
`TensorIterator`. Instead, I factor out a `serial_for_each` free-function that
just takes pointers and strides. Then manually advance the pointer to the
thread-specific slice of data.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D28735330
Pulled By: ngimel
fbshipit-source-id: 8e096eb5801af9381ebd305e3ae7796a79b86298
Summary:
This PR also adds a a few minor logic changes to the custom PyTorch PR tests logic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59016
Reviewed By: mrshenli
Differential Revision: D28732437
Pulled By: malfet
fbshipit-source-id: 14b7ed837209d77e0e175d92959aeb0f086e6737
Summary:
Let index/index_put implementation in aten take care of moving the indices to the correct device, don't make python wrapper do that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59059
Reviewed By: mruberry
Differential Revision: D28750562
Pulled By: ngimel
fbshipit-source-id: 2f2b5f875733898f1c0b30b544c89808f91e4a6f
Summary:
Depends on https://github.com/pytorch/pytorch-probot/pull/22. Adds a new label called `ci/no-build` that disables the CircleCI `build` workflow on PRs. The current behavior should be the same in the absence of `ci/no-build`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58778
Reviewed By: malfet
Differential Revision: D28615349
Pulled By: samestep
fbshipit-source-id: 1ed521761ca4ffa32db954a51918f693beddb3f3
Summary:
This removes our cancel_redundant_workflows job in favor of GitHub's built in [`concurrency`](https://docs.github.com/en/actions/reference/workflow-syntax-for-github-actions#concurrency) keyword which limits runs of a particularly named group. Since the group names have to be unique per job per PR, it should end up looking something like `filename-job_name-{pr number | sha (for non-PR workflows)}`. There's also a script to check workflows and ensure that it is being properly gated so people don't forget to add the key in the future.
`ruamel.YAML` also didn't like some of the spacing so that is changed but it also makes it more consistent so �
This also has a minor change of renaming the workflow templates from `.in` to `.j2` which is the standard Jinja2 extension that the VSCode extension automatically picks up for syntax highlighting / errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59019
Test Plan: pushed a commit `reset` and then immediately another commit `test`: the jobs from `reset` are cancelled: https://github.com/pytorch/pytorch/actions/runs/880099510
Reviewed By: samestep
Differential Revision: D28722419
Pulled By: driazati
fbshipit-source-id: c547a161877a0583be9d7edb29244b086b6bcad1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59063
`TensorMeta::maybe_get_output()` returns `const Tensor&`, no need to copy the Tensor..
ghstack-source-id: 130044287
Test Plan: CI
Reviewed By: ngimel
Differential Revision: D28735225
fbshipit-source-id: f2bdf39b28de245ec4664718490e7e0b36bc8819
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58697
1. Add a symbolic function for aten::roll() op in symbolic_opset9.py.
2. Add a test with multiple scenarios as well.
Test Plan: Imported from OSS
Reviewed By: driazati, bhosmer
Differential Revision: D28714807
Pulled By: SplitInfinity
fbshipit-source-id: eae85f2dcf02737c9256a180f6905a935ca3f57e
Co-authored-by: fatcat-z <jiz@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58696
It seems the JIT produces an output for aten::_set_item on lists but
not on dicts. Previously the code would crash because it assumed it
was operating on a list.
The different behavior can be seen with the following test:
```python
class DictModule(torch.nn.Module):
def forward(self, x_in: torch.Tensor) -> typing.Dict[str, torch.Tensor]:
x_out = {}
x_out["test_key_out"] = x_in
return x_out
x_in = torch.tensor(1)
dms = torch.jit.script(DictModule())
torch.onnx.export(dms, (x_in,), "/dev/null", example_outputs=(dms(x_in),))
```
Before this change:
`RuntimeError: outputs_.size() == 1INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/ir.h":452, please report a bug to PyTorch.`
After this change:
`RuntimeError: Exporting the operator prim_DictConstruct to ONNX opset version 9 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub.`
This is a more useful error message.
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D28714804
Pulled By: SplitInfinity
fbshipit-source-id: 1e5dc5fb44d1e3f971a22a79b5cf009d7590bf84
Co-authored-by: Gary Miguel <garymiguel@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58693
`ONNX::SequenceEmpty` requires dtype to be provided, and is default to float. We updates previous dtype of created `ONNX::SequenceEmpty` node when dtype is later discovered to be other than float, through downstream `ONNX::SequenceInsert` node. This PR improves the algorithm to cover nested loop case.
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D28714808
Pulled By: SplitInfinity
fbshipit-source-id: e45ab3a12d0fec637733acbd3cd0438ff80d2cd4
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58692
This is a fix for exporting fairseq models, see:
```python
model = torch.hub.load(github, 'conv.wmt14.en-fr', tokenizer='moses', bpe='subword_nmt')
model = torch.hub.load(github, 'conv.wmt17.en-de', tokenizer='moses', bpe='subword_nmt')
```
With this fix, and comment out model script one line `GradMultiply`, these two models can be exported successfully with perf met.
The original PR https://github.com/pytorch/pytorch/pull/57708 has merging issue, use this one instead.
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D28714809
Pulled By: SplitInfinity
fbshipit-source-id: 71c2de6cec7ee05af68560996acf47d97af46fb2
Co-authored-by: David <jiafa@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58691
Note the first commit in this PR has its own pull request here since it seemed self-contained:
https://github.com/pytorch/pytorch/pull/57082
* [ONNX] simplify batch_first logic in RNN tests
* [ONNX] support GRU with packed input in scripting mode
This required two changes:
* Add as_tensor to symbolic_opset9.py
* Change torch::jit::pushPackingPastRnn to recognize and properly
replace another use of the batch_sizes output of prim::PackPadded.
Previously the code assumed that the first use was as input to the
RNN operator. However in some cases, it is also used to compute
max_batch_size. For example in this code:
https://github.com/pytorch/pytorch/blob/febff45/torch/nn/modules/rnn.py#L815-L815
With these changes the GRU tests now pass in scripting mode for opset
version >= 11.
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D28714805
Pulled By: SplitInfinity
fbshipit-source-id: f19647a04533d9ec76399a8793b3f712ea0337d2
Co-authored-by: Gary Miguel <garymiguel@microsoft.com>
Summary:
Fixes upcoming changes that are part of ROCm 4.2 and affect PyTorch JIT.
- ROCM_VERSION macro must be available to both device and host compilation passes.
- Unifies some of CUDA and HIP differences in the code generated.
- NAN / POS_INFINITY / NEG_INFINITY
- Do not hipify `extern __shared__` -> `HIP_DYNAMIC_SHARED()` macro [deprecated]
- Differentiates bf16 codegen for HIP.
- Optionally provides missing macros when using hiprtc precompiled header feature.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57400
Reviewed By: ejguan
Differential Revision: D28421065
Pulled By: malfet
fbshipit-source-id: 215f476773c61d8b0d9d148a4e5f5d016f863074
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52659
**Summary**
This commit adds `torch._C.ScriptDict`, a dictionary type that has reference
semantics across the Python/TorchScript boundary. That is, modifications
made to instances of `torch._C.ScriptDict` in TorchScript are visible in
Python even when it is not returned from the function. Instances can be
constructed by passing an instance of a Python dictionary to
`torch.jit.script`. In the case of an empty dictionary, its type is
assumed to be `Dict[str, Tensor]` to be consistent with the handling of
empty dictionaries in TorchScript source code.
`torch._C.ScriptDict` is implemented using a modified version of pybind's `stl_bind.h`-style bindings attached to `ScriptDict`, `ScriptDictIterator` and `ScriptDictKeyIterator`, wrapper classes around `c10::impl::GenericDict` and `c10::impl::GenericDict::iterator`. These bindings allow instances of `torch._C.ScriptDict` to be used as if it were a regular `dict` Python. Reference semantics are achieved by simply retrieving the `IValue` contained in `ScriptDict` in `toIValue` (invoked when converting Python arguments to `IValues` before calling TorchScript code).
**Test Plan**
This commit adds `TestScriptDict` to `test_list_dict.py`, a set of tests
that check that all of the common dictionary operations are supported
and that instances have reference semantics across the
Python/TorchScript boundary.
Differential Revision:
D27211605
D27211605
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Pulled By: SplitInfinity
fbshipit-source-id: 446d4e5328375791aa73eb9e8b04dfe3465af960
Summary:
Closes gh-24745
The existing PR (gh-50655) has been stalled because `TensorIterator` doesn't guarantee iteration order in the same way that `TH_TENSOR_APPLY` does. For contiguous test cases this isn't an issue; but it breaks down for example with channels last format. I resolve this by adding a new `TensorIteratorConfig` parameter, `enforce_linear_iteration`, which disables dimension reordering. I've also added a test case for non-contiguous tensors to verify this works.
This PR also significantly improves performance by adding multithreading support to the algorithm. As part of this, I wrote a custom `count_nonzero` that gives per-thread counts which is necessary to write the outputs in the right location.
| Shape | Before | After (1 thread) | After (8 threads) |
|:----------:|--------:|-----------------:|------------------:|
| 256,128,32 | 2610 us | 2220 us | 496 us |
| 128,128,32 | 1250 us | 976 us | 175 us |
| 64,128,32 | 581 us | 486 us | 88 us |
| 32,128,32 | 292 us | 245 us | 80 us |
| 16,128,32 | 147 us | 120 us | 71 us |
| 8,128,32 | 75 us | 61 us | 61 us |
| 4,128,32 | 39 us | 32 us | 32 us |
| 2,128,32 | 20 us | 17 us | 17 us |
| 1,128,32 | 11 us | 9 us | 9 us |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58811
Reviewed By: anjali411
Differential Revision: D28700259
Pulled By: ngimel
fbshipit-source-id: 9b279ca7c36d8e348b7e5e4be0dd159e05aee159
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58977
* Test was flaky as part of it ran async
* Remove async part to test only the functionality added
Test Plan:
regular test:
`buck test mode/dev //caffe2/aten:test_thread_pool_guard -- --exact 'caffe2/aten:test_thread_pool_guard - TestThreadPoolGuard.TestRunWithGuard' --run-disabled`
stress test:
`buck test mode/dev //caffe2/aten:test_thread_pool_guard -- --exact 'caffe2/aten:test_thread_pool_guard - TestThreadPoolGuard.TestRunWithGuard' --run-disabled --jobs 18 --stress-runs 10 --record-results`
Reviewed By: kimishpatel
Differential Revision: D28703064
fbshipit-source-id: be19da3f42f44288afc726bdb2f40342eee26e01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59027
Add underscores to some of the internal names
Test Plan:
python test/test_profiler.py -v
Imported from OSS
Reviewed By: mrshenli
Differential Revision: D28724294
fbshipit-source-id: 1f6252e4befdf1928ac103d0042cbbf40616f74a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57068
When training with histogram observer on, we got this runtime error:
```
torch/quantization/observer.py", line 942, in forward
self.bins)
self.histogram.resize_(combined_histogram.shape)
~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
self.histogram.copy_(combined_histogram)
self.min_val.resize_(combined_min.shape)
RuntimeError: cannot resize variables that require grad
```
Since this is the histogram observer that is used to collect histogram information, should not need gradient. So turn off the grad before resizing using `detach_()` method.
Test Plan:
- arc lint
- Train with histogram observer turned on, training finished successfully
f264139727
Reviewed By: supriyar
Differential Revision: D27147212
fbshipit-source-id: abed5b9c4570ffc6bb60e58e64791cfce66856cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57067
auto format the code
Test Plan: lint
Reviewed By: jerryzh168
Differential Revision: D27147213
fbshipit-source-id: 008871d276c8891b2411549e17617e5c27d16ee3
Summary:
Relates to https://github.com/pytorch/pytorch/issues/58826.
Currently we don't have the exact build time for non-binary jobs collected. collecting this reports the exact test time from pytorch checkout finish till build stage successful.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58998
Test Plan: CI - validate result on scuba table
Reviewed By: janeyx99
Differential Revision: D28747962
Pulled By: walterddr
fbshipit-source-id: 715d91d597bc004977fdceaf245263c9c8aacc84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59007
Create folders for each test category and move the tests.
Will follow-up with a cleanup of test_quantization.py
Test Plan:
python test/test_quantization.py
Imported from OSS
Reviewed By: HDCharles
Differential Revision: D28718742
fbshipit-source-id: 4c2dbbf36db35d289df9708565b7e88e2381ff04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59000
These tests span both QAT and PTQ APIs so factor them out
Test Plan:
python test/test_quantization.py TestModelNumericsEager
Imported from OSS
Reviewed By: HDCharles
Differential Revision: D28713910
fbshipit-source-id: b2ad27cf59abb7cc0c4e4da705f8c9220410f8ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58999
Rename the test files to be more explicit that they are for eager mode
Test Plan:
python test/test_quantization.py
Imported from OSS
Reviewed By: HDCharles
Differential Revision: D28713909
fbshipit-source-id: b4ccd06c841fe96edf8c065a0bceae15fed260f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58963
some tests are used to check the op level numerics of the fake quantize operations
Test Plan:
python test/test_quantization.py
Imported from OSS
Reviewed By: HDCharles
Differential Revision: D28696599
fbshipit-source-id: 98f9b0c993dd43050176125461ddd5288142989b
Summary:
`makeDeviceForHostname` and `makeDeviceForInterface` are almost
duplicate except for different default argument values
Create generic `makeGlooDevice` anonymous function that takes both host
name and interface name and call it from both
makeDeviceFor[Hostname|Interface]
Also solve two other minor issues:
- do not call `getenv("GLOO_DEVICE_TRANSPORT")` during library load
time
- Raise exception rather than crash if GLOO_DEVICE_TRANSPORT is set to unknown value
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58996
Reviewed By: pbelevich
Differential Revision: D28713324
Pulled By: malfet
fbshipit-source-id: cb33b438078d163e3ec6f047f2e5247b07d94f8d
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/58965
Test Plan:
```
// This script is just for playing around
buck run mode/opt -c python.package_style=inplace deeplearning/trt/fx2trt:fx2trt_quantized_test
// To check accuracy
buck run mode/opt -c python.package_style=inplace deeplearning/trt/fx2trt:uru_10x10_to_trt_eval.py
```
Reviewed By: mortzur
Differential Revision: D28445702
fbshipit-source-id: 5357a02a78cb7f9cf772e7a91a08166ef90cc4f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58608
D28523254 (705dd9ffac) ensures us that this was save: we renamed away all the internal uses of add_input/add_output. (Also, practically everything I found internally could borrow, and the stuff that couldn't wouldn't compile because it is passed unnamed temporaries.)
ghstack-source-id: 129882758
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D28524585
fbshipit-source-id: 437235d5cc55c3737c928991a996b8f5e1c5beaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58607
Don't let code that tries to pass temporaries to these variants compile.
ghstack-source-id: 129882759
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D28524227
fbshipit-source-id: e5ce80f048480c67645198eaa0e43532567d4adb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58606
Removes the pit of non-success around using the owning variants; gives us the option to make add_{in,out}put borrow in the future as a pit of success if we decide that's not bc-breaking.
ghstack-source-id: 129882760
Test Plan: CI
Reviewed By: ngimel
Differential Revision: D28523976
fbshipit-source-id: ab5eb7bf5d672a0f8c4a50eb8a21c156d4189709
Summary:
The `factory_kwargs` kwarg was previously undocumented in `nn.Quantize`. Further, the `Attributes` section of the docs was improperly filled in, resulting in bad formatting. This section doesn't apply since `nn.Quantize` doesn't have parameters, so it has been removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59025
Reviewed By: anjali411
Differential Revision: D28723889
Pulled By: jbschlosser
fbshipit-source-id: ba86429f66d511ac35042ebd9c6cc3da7b6b5805
Summary:
The `UninitializedBuffer` class was previously left out of `nn.rst`, so it was not included in the generated documentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59021
Reviewed By: anjali411
Differential Revision: D28723044
Pulled By: jbschlosser
fbshipit-source-id: 71e15b0c7fabaf57e8fbdf7fbd09ef2adbdb36ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56504
Having callbacks registered but disabled via their
`shouldRun` callback defeats the `shouldRunRecordFunction`
optimization (no relation between the two things, despite the
shared prefix on the names) that aims to skip `RecordFunction`
construction.
This diff attempts to safely rectify this issue: we drop support for
`shouldRun` callbacks (this is bc-breaking; does anything use these
externally? do I need to add the support back and just stop using it
internally?), add support for enabling and disabling callbacks, and
(for global callbacks) make doing so thread-safe.
There is an interesting subtlety with `std::atomic` that came up: it
is neither copyable nor movable, which precludes putting it into
`std::vector`. I manually overrode this because the thread safety
reasons it is neither copyable nor movable don't apply here; we
already state that adding or removing callbacks (the operations that
might copy/move an atomic) are not thread-safe and should be done at
initialization time.
ghstack-source-id: 129614296
Test Plan:
Existing CI should cover correctness, right? Inspected
perf report of a simple benchmark that runs nn.Linear in a loop on
CUDA, where internally have Kineto initialized and thus had a
shouldRun observer previously; we are no longer going through the
dispatcher's slow RecordFunction path or spending measurable time
constructing RecordFunction instances.
Reviewed By: ilia-cher
Differential Revision: D27834944
fbshipit-source-id: 93db1bc0a28b5372f7307490c908457e7853fa92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58517
Building upon the sharding specifications, this PR introduces the
intial skeleton of ShardedTensor and allows building a ShardedTensor by
specifying ChunkedShardingSpec.
In follow up PRs, I'll add further support for GenericShardingSpec.
ghstack-source-id: 129917841
Test Plan:
1) unit tests.
2) waitforbuildbot
Reviewed By: SciPioneer
Differential Revision: D28526012
fbshipit-source-id: 8e62847b58957d284e40f57a644302c171289138
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58568
I split out the file rename into a separate commit to make the diff easier. The template file name is `aten_xla_type.h` -> `{DispatchKey}NativeFunctions.h`
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D28711298
Pulled By: bdhirsh
fbshipit-source-id: 2fa7d2abede560a2c577300f0b5a1f7de263d897
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58064
**Summary**
This PR tries to remove all xla-specific logic from the codegen except for two places:
- renaming the `aten_xla_type.h/cpp` template files; Going to do that in a separate PR just to make the diff easier to understand
- CPU fallback logic (everything in `aten_xla_type_default.h/cpp` and `gen_external_aten_fallbacks.py`). I'm trying to kill all of that logic in a subsequent PR by making the CPU fallback a boxed kernel, so it felt unnecessary to go through it all and remove the xla references here.
**Notable changes**
The xla codegen includes some custom logging in each kernel wrapper, so I added a few new knobs to the external yaml, that we now test. I have a corresponding [xla-side PR](https://github.com/pytorch/xla/pull/2944) with the new yaml changes, which look like this:
```
per_op_log: XLA_FN_TRACK(3)
per_argument_log: TF_VLOG(3)
cpu_fallback_counter: XLA_COUNTER("aten::{name}", 1)
extra_headers: >
#include <tensorflow/compiler/xla/xla_client/debug_macros.h>
#include <tensorflow/compiler/xla/xla_client/metrics.h>
#include <tensorflow/compiler/xla/xla_client/tf_logging.h>
#include <torch_xla/csrc/function_call_tracker.h>
#include <torch_xla/csrc/aten_xla_type.h>
#include <torch_xla/csrc/aten_xla_type_default.h>
```
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D28711095
Pulled By: bdhirsh
fbshipit-source-id: 90a48440f2e865a948184e2fb167ea240ada47bb
Summary:
## Motivation
The utils in namespace `c10` require the `__assert_fail` when the NDEBUG is defined in kernel code.
The `__assert_fail` declaration in pytorch is not compatible to the SYCL‘s specification.
This causes compile error when use these utils in SYCL kernels.
## Solution
Add the `__assert_fail` declaration for SYCL kernels to pytorch when compiling the SYCL kernels with `c10` utils.
## Additional context
`__assert_fail` in SYCL kernel
`extern SYCL_EXTERNAL void __assert_fail(const char *expr, const char *file, unsigned int line, const char *func);`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58906
Reviewed By: anjali411
Differential Revision: D28700863
Pulled By: ezyang
fbshipit-source-id: 81896d022b35ace8cd16474128649eabedfaf138
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58974
I don't know how we overlooked this for so long...
ghstack-source-id: 129932134
Test Plan:
Predictor test of model 184778294_0 using multiple request replay
threads. It's not clear to me why multithreading matters, except that perhaps
it makes it easier to get an unknown shape in the profile.
Reviewed By: navahgar
Differential Revision: D28702660
fbshipit-source-id: 565550b1d2e571d62d0c8b21150193f2a7ace334
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58062
Make templated function to make sure BatchSparseToDense supports int32 lengths/indices
Test Plan:
```buck test //caffe2/caffe2/python/operator_test:batch_sparse_to_dense_op_test
```
Reviewed By: khabinov
Differential Revision: D28271423
fbshipit-source-id: 41b88b7a3663616b533aaf4731ff35cdf6ec4c85
Summary:
This PR introduces a docker base to speed up the `clang-tidy`'s dependencies stage. Originally I was looking into using the native github action cache, but the dependencies are spread across many apt and pip installation places, thus consolidating with a docker image might work better. It shortens the deps installation time from 4min down to 1min by pulling from docker base image.
Base image used: https://github.com/pytorch/test-infra/pull/15
```
FROM nvidia/cuda:10.2-devel-ubuntu18.04
RUN apt-get update && apt-get upgrade -y
RUN apt install -y software-properties-common wget
RUN wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | apt-key add -
RUN apt-add-repository "deb http://apt.llvm.org/bionic/ llvm-toolchain-bionic-11 main"
RUN apt-add-repository ppa:git-core/ppa
RUN apt-get update && apt-get upgrade -y && apt-get install -y git python3-dev python3-pip build-essential cmake clang-tidy-11
RUN update-alternatives --install /usr/bin/clang-tidy clang-tidy /usr/bin/clang-tidy-11 1000
RUN pip3 install pyyaml typing_extensions dataclasses
```
Previous successful run of clang-tidy: https://github.com/pytorch/pytorch/runs/2671193875?check_suite_focus=true
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58964
Reviewed By: samestep
Differential Revision: D28712536
Pulled By: zhouzhuojie
fbshipit-source-id: 0c48a605efe8574c104da6a0cad1a8b7853ba35e
Summary:
* Open json config file safely using a context manager (using a with block).
* This will make sure that the file closed even if an exception is raised.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58077
Reviewed By: anjali411
Differential Revision: D28711177
Pulled By: H-Huang
fbshipit-source-id: 597ba578311b1f1d6706e487872db4e784c78c3c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/55741 by adding a comment regarding the behavior of `kaiming_uniform_`
The docstring is correct in this case. For example:
```python
import math
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
in_channels = 120
groups = 2
kernel = (3, 8)
m = nn.Conv2d(in_channels=in_channels, groups=groups,
out_channels=100, kernel_size=kernel)
k = math.sqrt(groups / (in_channels * math.prod(kernel)))
print(f"k: {k:0.6f}")
print(f"min weight: {m.weight.min().item():0.6f}")
print(f"max weight: {m.weight.max().item():0.6f}")
```
outputs:
```
k: 0.026352
min weight: -0.026352
max weight: 0.026352
```
And when we plot the distribution, it is uniform with the correct bounds:
```python
_ = plt.hist(m.weight.detach().numpy().ravel())
```

Pull Request resolved: https://github.com/pytorch/pytorch/pull/58931
Reviewed By: anjali411
Differential Revision: D28689863
Pulled By: jbschlosser
fbshipit-source-id: 98eebf265dfdaceed91f1991fc4b1592c0b3cf37
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58092Fixes#58044.
This PR:
- adds `ATEN_FN(op)` and `ATEN_FN2(op, overload)` macros that resolve to
an non-overloaded function in aten::_ops that calls the desired operator
(without default arguments).
The motivation for this is two-fold:
1) Using aten operators with templates is hard if the operator is
overloaded (e.g. add.Tensor and add.Scalar).
2) Method-only operators require special handling; pointers-to-method
are different from function pointers. `ATEN_FN2(add_, Tensor)` returns
a function instead of a method.
There is some interesting behavior for out= operations.
`ATEN_FN2(sin, "out")` gives a function that is *faithful* to the schema;
that is, the order of arguments is exactly what it looks like in the
schema. This makes it so that you can directly register
`ATEN_FN2(sin,"out")` (or a function wrapping it using the same signature)
as an override for a DispatchKey.
Test Plan:
- New tests that ATEN_FN2 works on function and method-only operators
- New test that ATEN_FN works
- New test that ATEN_FN macro returns a "faithful" function.
Codegen output:
Operators.h and Operators.cpp are both here:
https://gist.github.com/zou3519/c2c6a900410b571f0d7d127019ca5175
Reviewed By: mruberry
Differential Revision: D28643215
Pulled By: zou3519
fbshipit-source-id: 7b2b8459f1b2eb5ad01ee7b0d2bb77639f77940e
Summary:
Two main changes:
1. Change the argument of the collection of backport_v{i}_to_v{i-1} from (reader, writer) to (input_model_stream, output_model_stream), so it's easier to backport a model in option 2.
> 2) [Both format and content change] ]Use torch.jit.load() to load the stream,
and save it to output_model_stream.
2. Fix an issue in the test `backportAllVersionCheck`. Previous it declares `std::ostringstream oss` and uses `oss.clear()` to reset the stringstream. However, the `clear()` function doesn't reset the stream content, and causes problematic stream. As a mitigation, checks are added to prevent corrupted stream for each iteration in while loop.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58790
ghstack-source-id: 129929960
Test Plan:
CI
```
buck test mode/dev //caffe2/test/cpp/jit:jit
```
Reviewed By: raziel, iseeyuan
Differential Revision: D28620961
fbshipit-source-id: b0cbe0e88645ae278eb3999e2a84800702b5f985
Summary:
Context:
The Error message when `broadcasts_input` is marked incorrectly is uninformative [See Error Currently]
https://github.com/pytorch/pytorch/pull/57941#discussion_r631749435
Error Currently
```
Traceback (most recent call last):
File "/home/kshiteej/Pytorch/pytorch_i0_promotion/test/test_ops.py", line 326, in test_variant_consistency_eager
_test_consistency_helper(samples, variants)
File "/home/kshiteej/Pytorch/pytorch_i0_promotion/test/test_ops.py", line 310, in _test_consistency_helper
variant_forward = variant(cloned,
File "/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.8/unittest/case.py", line 227, in __exit__
self._raiseFailure("{} not raised".format(exc_name))
File "/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.8/unittest/case.py", line 164, in _raiseFailure
raise self.test_case.failureException(msg)
AssertionError: RuntimeError not raised
```
Error After PR
```
Traceback (most recent call last):
File "/home/kshiteej/Pytorch/pytorch_i0_promotion/test/test_ops.py", line 329, in test_variant_consistency_eager
_test_consistency_helper(samples, variants)
File "/home/kshiteej/Pytorch/pytorch_i0_promotion/test/test_ops.py", line 313, in _test_consistency_helper
variant_forward = variant(cloned,
File "/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.8/unittest/case.py", line 227, in __exit__
self._raiseFailure("{} not raised".format(exc_name))
File "/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.8/unittest/case.py", line 164, in _raiseFailure
raise self.test_case.failureException(msg)
AssertionError: RuntimeError not raised : inplace variant either allowed resizing or you have marked the sample SampleInput(input=Tensor, args=(tensor([[[ 2.1750, -8.5027, -3.1403, -6.9942, 3.2609],
[-2.5057, -5.9123, -5.4633, 6.1203, -8.2124],
[-3.5802, -8.4869, -6.0700, 2.3431, -8.1955],
[-7.3316, 1.3248, -6.8661, 7.1483, -8.0719],
[ 4.5977, -4.0448, -6.2044, -2.1314, -8.4956]],
[[ 3.2769, -8.4360, 1.2826, 7.1749, 4.7653],
[-0.2816, -2.5997, -4.7659, -3.7814, 3.9704],
[-2.1778, -3.8117, -6.0276, -0.8423, -5.9646],
[ 8.6544, -3.0922, 0.2558, -4.9318, -4.7596],
[ 4.5583, 4.3830, 5.8793, 0.9713, -2.1481]],
[[-1.0447, 0.9334, 7.6405, -4.8933, -7.4010],
[ 7.7168, -8.4266, -5.5980, -6.9368, 7.1309],
[-8.7720, -5.0890, -0.4975, 1.9518, 1.7074],
[-8.5783, 8.5510, -8.5459, -3.5451, 8.4319],
[ 8.5052, -8.9149, -6.6298, -1.2750, -5.7367]],
[[-6.5625, 8.2795, -4.9311, 1.9501, -7.1777],
[-8.4035, 1.1136, -7.6418, -7.0726, -2.8281],
[ 4.2668, -0.2883, -6.2246, 2.3396, 1.2911],
[ 4.6550, -1.9525, 4.4873, -3.8061, -0.8653],
[-3.4256, 4.4423, 8.2937, -5.3456, -4.2624]],
[[ 7.6128, -6.3932, 4.7131, -5.4938, 6.4792],
[-6.5385, 2.4385, 4.5570, 3.7803, -8.3281],
[-2.9785, -4.4745, -1.1778, -8.9324, 1.3663],
[ 3.7437, 3.5171, -6.3135, -8.4519, -2.7033],
[-5.0568, -8.4630, -4.2870, -3.7284, -1.5238]]], device='cuda:0',
dtype=torch.float32, requires_grad=True),), broadcasts_input=True) incorrectly with `broadcasts_self=True
```
**NOTE**:
Printing the sample looks very verbose and it may be hard to figure out which sample is incorrectly configured if there are multiple samples with similar input shapes.
Two Options to make this error less verbose
* Don't print the sample and just print `inplace variant either allowed resizing or you have marked one of the sample incorrectly with broadcasts_self=True`
* Have some mechanism to name samples which will be printed in the `repr` (which will need extra machinery)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58295
Reviewed By: ngimel
Differential Revision: D28627308
Pulled By: mruberry
fbshipit-source-id: b3bdeacac3cf9c0d984f0b85410ecce474291d20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58966
Same as title.
Test Plan: CI since updated the check
Reviewed By: ngimel
Differential Revision: D28699577
fbshipit-source-id: 436fdc648a4c653081ff0e1b6b809c4af742055a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58897
We don't need to be building debug info on PRs since it's just filling up S3/CircleCI storage with useless 800 MB zips, this flips it so it's only run on master + release branches. See #58898 for CI signal
Also see pytorch/builder counterpart (unlike the last debuginfo PR there is no hard dependency between these two so there won't be any churn on un-rebased PRs): https://github.com/pytorch/builder/pull/778
Test Plan: Imported from OSS
Reviewed By: seemethere, samestep
Differential Revision: D28689413
Pulled By: driazati
fbshipit-source-id: 77a37e84afe492215008d5e023ceab0c24adb33c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58889
fixes https://github.com/pytorch/pytorch/issues/58796
Planning on re-testing locally tomorrow morning to confirm, but this change should fix the non-determinism in the codegen output that was causing `ccache` not to re-use its cached output.
I built from the commit referenced in https://github.com/pytorch/pytorch/issues/58796 a few times and ran `diff -Naur` on the codegen output in `build/aten/src/ATen`. After a few tries, `NativeFunctions.h` had a few diffs. The diffs were all related to the ordering of functional/inplace/out variants of a NativeFunctionGroup, which looked non-deterministic.
That looks like it's coming from my calling `set()` to filter out duplicate NativeFunction declarations. The earlier version of the codegen also called `set()` to filter out duplicates, but it did so individually for each `NativeFunction` object, before merging the groups (I'm not too sure why this didn't introduce non-determinism before. though). With the refactor from https://github.com/pytorch/pytorch/pull/57361, we're calling `set()` on the declarations from every operator for a given DispatchKey, which is probably what introduced the nondeterminism.
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D28675941
Pulled By: bdhirsh
fbshipit-source-id: bb66de00aafeeb9720d85e8156ac9f7539aed0d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58892
The torchscript model after backport misses the `constants` archive. Add it back, and extend the unit test to run torchscript part.
ghstack-source-id: 129853819
Test Plan:
```
buck test mode/dev //caffe2/test/cpp/jit:jit -- --exact 'caffe2/test/cpp/jit:jit
- LiteInterpreterTest.BackPortByteCodeModelAllVersions'
```
Reviewed By: raziel, iseeyuan
Differential Revision: D28664507
fbshipit-source-id: 5f98723231cc64ed203c062ee6f00d8adbdccf77
Summary:
Currently calling `scalar.to<std::complex<double>>()` for example compiles but throws an error at runtime. Instead, marking the non-specialized cases as `= delete` means the code fails to compile and you catch the error sooner.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58726
Reviewed By: zou3519, seemethere
Differential Revision: D28646057
Pulled By: ezyang
fbshipit-source-id: 9e4e3d1b4586eeecbb73db61bba56560b2657351
Summary:
To make build behaviour aligned with other third_party/ libraries,
introduce `USE_SYSTEM_PYBIND11 (d55b25a633)` build option, which set to OFF by
default, which means PyTorch will be build with bundled pybind11 even if
other version is already installed locally.
Fixes https://github.com/pytorch/pytorch/issues/58750
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58951
Reviewed By: driazati
Differential Revision: D28690411
Pulled By: malfet
fbshipit-source-id: e56b5a8f2a23ee1834b2a6d3807f287149decf8c
Summary: Relax test deadlines for c2 tests. We run on loaded machines, and timings are unreliable.
Test Plan: Fixes existing tests
Reviewed By: mruberry
Differential Revision: D28690006
fbshipit-source-id: 457707e81a1ec92548c1f23ea7a0022fa0a3bfda
Summary:
This PR resolves the second issue outlined in https://github.com/pytorch/pytorch/issues/58376, which has previously been discussed in https://github.com/pytorch/pytorch/issues/50722.
`cudaMemGetInfo` is bound/exposed to the Python API. An example function call is provided below:
```
device_free, device_total = torch.cuda.mem_get_info(torch.device('cuda:0'))
print(device_free, device_total)
```
In `CUDACachingAllocator.cpp`, in constant to my initial PR, the newly defined function `std::pair<size_t, size_t> raw_cuda_mem_get_info(int device)` has been moved from the `CUDACaching` namespace to the `cuda` namespace. In addition, as suugested by ezyang, `det` has been removed from all function names.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58635
Reviewed By: zou3519
Differential Revision: D28649093
Pulled By: ezyang
fbshipit-source-id: d8b7c53e52cf73f35495d8651863c5bb408d7a6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54548
We don't need to inline most of this class; doing so bloats code size and build time.
ghstack-source-id: 129765666
Test Plan:
Existing CI
buildsizebot some mobile apps
Reviewed By: jamesr66a
Differential Revision: D27277317
fbshipit-source-id: 7643aa35e4d794fee0a48a3bbe0890c2e428ae78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58924
Was observing behavior where 7zip was nowhere to be found after a build
was completed. Let's just have 7zip be installed within the workflow as
well just to be completely sure 7zip is there.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D28681241
Pulled By: seemethere
fbshipit-source-id: f649c1713edcdeb82c84fd67866700caa2726d71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57481
This diff introduces function name to InlinedCallStack.
Since we are using InlinedCallStack for debug information in lite
interpreter as well as delegate backends, where InlinedCallStack cannot
be constructed from model source code, we need to save function name.
In the absence of function name Function* is used to get name of the
function. This is when JIT compiles code at runtime.
When that is not possible, this diff introduces a way to obtain function
name.
Test Plan:
test_backend
test_cs_debug_info_serialization
test_backend
test_cs_debug_info_serialization
Imported from OSS
Differential Revision:
D28159097
D28159097
Reviewed By: raziel, ZolotukhinM
Pulled By: kimishpatel
fbshipit-source-id: deacaea3325e27273f92ae96cf0cd0789bbd6e72
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57441
debug info
Previous diffs did not save operator name in debug info. For delegated
backends that only idenfity op for profiling with debug handle, operator
name should be stores as well.
Furthermore to complete debug informaton also serialize function name.
Test Plan:
Existing lite interpreter and backend tests
Existing lite interpreter and backend tests
Imported from OSS
Differential Revision:
D28144581
D28144581
Reviewed By: raziel
Pulled By: kimishpatel
fbshipit-source-id: 415210f147530a53b444b07f1d6ee699a3570d99
Summary:
Adds a note explaining the difference between several often conflated mechanisms in the autograd note
Also adds a link to this note from the docs in `grad_mode` and `nn.module`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58513
Reviewed By: gchanan
Differential Revision: D28651129
Pulled By: soulitzer
fbshipit-source-id: af9eb1749b641fc1b632815634eea36bf7979156
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58759
* Makes `pthreadpool()->run` respect `_NoPThreadPoolGuard`
Runs tasks on the same thread instead of parallelizing when guard is present
Test Plan:
buck build //xplat/caffe2:aten_test_test_thread_pool_guard
./buck-out/last/aten_test_test_thread_pool_guard
Reviewed By: kimishpatel
Differential Revision: D28597425
fbshipit-source-id: 0365ad9947c239f5b37ce682802d4d401b8b0a48
Summary:
The downstream cub sort doesn't support inplace sorting; this PR adds a check to bail out to allocating a new tensor instead of silently corrupting the returned indices.
CC ngimel zasdfgbnm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58327
Reviewed By: mruberry
Differential Revision: D28661244
Pulled By: ngimel
fbshipit-source-id: 40617a7d3bfcebbe187bb706b6b753371bb99097
Summary:
This is based on https://github.com/pytorch/pytorch/issues/48224.
To make `foreach` more flexible, this PR pushes unsupported cases to slow path.
Also, this adds some tests to verify that
- `foreach` functions work with tensors of different dtypes and/or memory layouts in 7bd4b2c89f
- `foreach` functions work with tensors on different devices in a list, but are on the same device if the indices are the same: def4b9b5a1
Future plans:
1. Improve the coverage of unittests using `ops` decorator & updating `foreach_unary_op_db` and creating `foreach_(binary|pointwise|minmax)_db`.
2. Support broadcasting in slow path. Ref: https://github.com/pytorch/pytorch/pull/52448
3. Support type promotion in fast path. Ref https://github.com/pytorch/pytorch/pull/52449
CC: ngimel mcarilli ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56993
Reviewed By: zou3519
Differential Revision: D28630580
Pulled By: ngimel
fbshipit-source-id: e26ee74a39a591025e18c1ead48948cb7ec53c19
Summary:
1) remove pushing back to strides vector for 1D tensors, those strides are never used in the loop anyway
2) avoid calling get_data_ptrs unless necessary
3) don't call into assert_no_partial_overlap if tensorImpls are the same (assert_no_partial_overlap has this comparison too, but after a couple of nested function calls)
4) is_non_overlapping_and_dense instead of is_contiguous in memory overlap (which, for some reason, is faster than is_contiguous, though I hoped after is_contiguous is non-virtualized, it should be the same).
Altogether, brings instruction count down from ~110K to 102735 for the following binary inplace benchmark:
```
In [2]: timer = Timer("m1.add_(b);", setup="at::Tensor m1=torch::empty({1}); at::Tensor b = torch::empty({1});", language="c++", timer=timeit.default_timer)
...: stats=timer.collect_callgrind(number=30, repeats=3)
...: print(stats[1].as_standardized().stats(inclusive=False))
```
similar improvements for unary inplace.
Upd: returned stride packing for now, counts is now 104295, so packing is worth ~ 52 instructions, we should think about how to remove it safely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58810
Reviewed By: bhosmer
Differential Revision: D28664514
Pulled By: ngimel
fbshipit-source-id: 2e03cf90b37a411d9994a7607402645f1d8f3c93
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/58872
Test Plan: verify tests running on CI as expected
Reviewed By: suo
Differential Revision: D28646660
fbshipit-source-id: eb7d784844fb7bc447b4232e2f1e479d4d5aa72f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58281
When TORCH_DISTRIBUTED_DEBUG=DETAIL is enabled, this PR causes process groups created by `new_group` and `init_process_group` that are nccl or gloo to be wrapped in `ProcessGroupWrapper`.
As a result, the user will get back a `ProcessGroupWrapper` that they can use in the exact same way as a regular nccl/gloo pg, but will be more helpful in terms of debugging desync/hangs.
Besides doing collective desync checks, which should be transparent if there are indeed no issues in the user application, there are no semantic differences in using the wrapper pg. Note that there is a performance implication here but that is a tradeoff we are making when DETAIL debug mode is enabled.
Open to suggestions on how to test better. Currently I verified locally that enabling TORCH_DISTRIBUTED_DEBUG=detail creates the wrapper and all tests still pass, but that doesn't run in CI. On the other hand testing everything with debug=detail and the regular tests might be too much, so we have only added it to a few tests for now. We also do have tests in the below diff.
ghstack-source-id: 129817857
Test Plan: ci
Reviewed By: SciPioneer
Differential Revision: D28402301
fbshipit-source-id: c4d3438320f6f0986e128c738c9d4a87bbb6eede
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58492
Update graph rewrite to specify how values in replacement pattern should
map to values in original pattern for fuse_linear pass
(Note: this ignores all push blocking failures!)
Test Plan:
python test/test_quantization.py TestQuantizeJitPasses.test_fuse_linear
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28512464
fbshipit-source-id: 250a69cebc11eb4328a34c8f685b36e337439aae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58300
Current state: During graph rewriting that can fuse nodes or add nodes
result in new nodes without debug information that was available in
original node. Thus we lose this information during graph rewrite.
This PR changes graph rewriting API to let user specify how the values
in the replacement pattern map to values in the pattern to be matched.
Then the graph rewriting will copy source range and inlined callstack
from the matched nodes onto the nodes being inserted.
(Note: this ignores all push blocking failures!)
Test Plan:
python test/test_jit.py
TestJit.test_pattern_based_rewrite_with_source_range_preserved
Imported from OSS
Reviewed By: malfet
Differential Revision: D28512465
fbshipit-source-id: 863173c29de726be85b3acbd3ddf3257eea36d13
Summary:
The JIT will typically need two warmup runs to do profiling and optimization.
This is not the perfect solution but it will substantially reduce the number of surprised people when the docs say torch.utils.benchmark.Timer takes care of warmup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58801
Reviewed By: desertfire
Differential Revision: D28644244
Pulled By: robieta
fbshipit-source-id: cc54ed019e882a379d6e4a0c6a01fd5873dd41c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57768
Note that this PR implements formulas only for ops that are supported by OpInfo.
Test Plan: Imported from OSS
Reviewed By: zou3519, malfet
Differential Revision: D28387766
Pulled By: albanD
fbshipit-source-id: b4ba1cf1ac1dfd46cdd889385c9c2d5df3cf7a71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58881
recently added new parameter to the function with PR: https://github.com/pytorch/pytorch/pull/58417
However, this introduced ambiguity when making call below:
some_tensor.repeat_interleave(some_integer_value)
Making it optional to avoid the issue.
Reviewed By: ezyang, ngimel
Differential Revision: D28653820
fbshipit-source-id: 5bc0b1f326f069ff505554b51e3b24d60e69c843
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58887
There are some callsites of `torch.distributed.rpc.XXX` APIs that are compiled
or not based on `USE_RPC`. However, `torch::deploy`, at least for now,
is compiled with `USE_RPC=1`, but the `torch.distributed.rpc.XXX` APIs used by
the aforementioned pieces of code are not available (i.e.
`torch.distributed.rpc.is_available()` returns `False`). This can cause
Torchscript compilation to fail, even if the code being compiled doesn't use
RPC.
This commit fixes this problem (at least temporarily) by predicating the use
all thse `torch.distributed.rpc` APIs on the value of
`torch.distributed.rpc.is_available()`.
Test Plan: Ran packaged XLM-R model with C++ benchmark.
Reviewed By: suo
Differential Revision: D28660925
fbshipit-source-id: fbff7c7ef9596549105e79f702987a53b04ba6f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58224
Adds C++ implementation of ProcessGroupWrapper. It wraps
an underlying ProcessGroup and does debug checks before dispatching the
collective to the underlying pg. The design mostly follows https://github.com/pytorch/pytorch/issues/22071.
Concretely, on each collective, we:
1. Verify op type consistency. This can help catch mismatched ops in the user application (i.e. allreduce on one rank and allgather on another)
2. Verify tensor shapes. This can help catch bugs where the tensor inputs are malformed, whereas normally in NCCL this would just lead to a hang. The shapes verification for allgather/allreduce_coalesced is omitted because they actually accept different shape tensors and don't error out.
This is done through an abstraction called `CollectiveFingerPrint` which uses a helper process group to do the above verification. Concretely, we gather the data we need for each of the above checks into tensors, and allgather them, and verify their equivalence.
Once all of this passes we simply dispatch the collective to the underlying pg.
Added `ProcessGroupWrapperTest` in python to comprehensively test these changes.
ghstack-source-id: 129735687
Test Plan: ci
Reviewed By: zhaojuanmao
Differential Revision: D28023981
fbshipit-source-id: 1defc203c5efa72ca0476ade0d1d8d05aacd4e64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58829
- Delete copying and moving of MemoryPlanner.
- Remove `inline` in some of the member functions because member functions implemented in classes are inline by default.
- Clean up ad update comments.
- Reorganize some code
Reviewed By: edvgha
Differential Revision: D28555476
fbshipit-source-id: 7ea8efc0e2ed93a6788a742470b9e753a85df677
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58605
Found a few more by grepping.
ghstack-source-id: 129730281
Test Plan: CI
Reviewed By: ngimel
Differential Revision: D28523254
fbshipit-source-id: 317baea88885586c5106c8335ebde0d8802a3532
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58457
This variable had concurrent read/write access without any
synchronization. The issue was caught and reported by TSAN.
ghstack-source-id: 129311384
Test Plan:
1) Verify test locally.
2) waitforbuildbot.
Reviewed By: ezyang
Differential Revision: D28498116
fbshipit-source-id: 89af068467fed64c131d743504c0cecf3017d638
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58792
Enabling support for fused modules like ConvReLU or LinearReLU on eager mode cross-layer equalization.
Test Plan:
`python test/test_quantization.py TestEqualizeEager`
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28647242
fbshipit-source-id: 286e057ce70aa7de45d575afd6c13e55120ff18a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58798
In #58623 there was a bug in `make quicklint` where ShellCheck would run on the entire repo when there were no files. This PR fixes that by refactoring out common stuff (like skipping quicklint when there are no files, let checks do their own file filtering) and pushes the logic into a runner class.
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D28649889
Pulled By: driazati
fbshipit-source-id: b19f32cdb63396c806cb689b2f6daf97e1724d44
Summary:
Per title
`unroll_contiguous_scalar_checks` tries to verify that all arguments (including outputs) are contiguous except maybe 1 scalar (with stride 0). Then it calls the passed lambda with index of the scalar arg if this verification succeeded, or 0 if args were not contiguous/there was no scalar. Depending on the value of this index (with 0=not found) a different function can be called (in vectorized kernels it’s vectorized loop if args are contiguous + scalar, and basic loop if not). It makes sense for vectorized kernel (vectorized loop can still be used in some broadcasted cases), but all other (cpu_kernel, serial_cpu_kernel, cpu_kernel_multiple_outputs) don’t even use idx argument in lambda, so regardless of what `unroll_contiguous_scalar_checks` does, they'll do the same thing. No point in calling `unroll_contiguous_scalar_checks` then.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58830
Reviewed By: zou3519, mruberry
Differential Revision: D28632668
Pulled By: ngimel
fbshipit-source-id: c6db3675933184e17cc249351c4f170b45d28865
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57501
Add an api _get_model_ops_and_info to get root operators and versioning info of a model in both cxx and python, and the input can be from a file path or buffer.
ghstack-source-id: 129620112
Test Plan: unit test.
Reviewed By: xcheng16, raziel
Differential Revision: D28162765
fbshipit-source-id: 4413c1e906b8a872e4a717d849da37347adbbea4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58685
This moves debug packages out of the artifacts dir before running tests (as a counterpart to https://github.com/pytorch/builder/pull/770). Doing it this way allows us to keep the CI configs simple since there's one directory to use for artifacts / upload to S3.
See #58684 for actual CI signals (the ones on this PR are all cancelled since it depends on the builder branch set in the next PR up the stack)
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D28646995
Pulled By: driazati
fbshipit-source-id: 965265861968906770a6e6eeecfe7c9458631b5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57769
_all_gather_base saved copies in all_gather, so it is more efficient
Test Plan: unit test
Reviewed By: SciPioneer
Differential Revision: D28227193
fbshipit-source-id: ddd8590095a5b45676497a71ed792a457f9825c6
Summary:
This PR introduces a helper function named `torch.nn.utils.skip_init()` that accepts a module class object + `args` / `kwargs` and instantiates the module while skipping initialization of parameter / buffer values. See discussion at https://github.com/pytorch/pytorch/issues/29523 for more context. Example usage:
```python
import torch
m = torch.nn.utils.skip_init(torch.nn.Linear, 5, 1)
print(m.weight)
m2 = torch.nn.utils.skip_init(torch.nn.Linear, 5, 1, device='cuda')
print(m2.weight)
m3 = torch.nn.utils.skip_init(torch.nn.Linear, in_features=5, out_features=1)
print(m3.weight)
```
```
Parameter containing:
tensor([[-3.3011e+28, 4.5915e-41, -3.3009e+28, 4.5915e-41, 0.0000e+00]],
requires_grad=True)
Parameter containing:
tensor([[-2.5339e+27, 4.5915e-41, -2.5367e+27, 4.5915e-41, 0.0000e+00]],
device='cuda:0', requires_grad=True)
Parameter containing:
tensor([[1.4013e-45, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00]],
requires_grad=True)
```
Bikeshedding on the name / namespace is welcome, as well as comments on the design itself - just wanted to get something out there for discussion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57555
Reviewed By: zou3519
Differential Revision: D28640613
Pulled By: jbschlosser
fbshipit-source-id: 5654f2e5af5530425ab7a9e357b6ba0d807e967f
Summary:
Currently the cpp_extension build in benchmarks is misleading as it has the same name with torch.utils.cpp_extension
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58708
Test Plan:
Run from `./benchmarks/operator_benchmark/pt_extension` folder:
```
python setup.py install
python cpp_extension_test.py
```
Note: CI doesn't matter as currently benchmarks/ folder is not compiled/test against CI
Reviewed By: robieta
Differential Revision: D28585582
Pulled By: walterddr
fbshipit-source-id: fc071040cf3cb52ee6c9252b2c5a0c3043393f57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58855
We have successfully migrated windows CPU builds to Github Actions so
let's go ahead and disable them in CircleCI
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: zhouzhuojie
Differential Revision: D28642875
Pulled By: seemethere
fbshipit-source-id: 8ffe9338e58952531a70002891a19ea33363d958
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58768
Fixes gh-58757
This PR has a fix for CPU version of addmm op. Just for context, before this PR, only CSR @ vector was supported. I found out a minor bug in the addmm_out_sparse_csr_dense_cpu for the non MKL code which is solved in this PR.
Moreover, I discovered a limitation in the current MKL implementation. It only works well (acceptable tolerance for output error) with square matrices. I was looking in deep to this issue and I found out that it could be a limitation of the MKL API.
I used this [gist code](https://gist.github.com/aocsa/0606e833cd16a8bfb7d37a5fbb3a5b14) based on [this](https://github.com/baidu-research/DeepBench/blob/master/code/intel/spmm/spmm_bench.cpp) to test this behavior.
As you can see there is not an acceptable output error (last column) when the matrices are squares and there is a not acceptable error when the matrices are not square. I reported the issue here: https://github.com/pytorch/pytorch/issues/58770
Looking forward to your comments.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D28629563
Pulled By: malfet
fbshipit-source-id: 5ee00ae667336e0d9301e5117057213f472cbc86
Summary:
Library linking order matters during static linking
Not sure whether its a bug or a feature, but if cublas is reference
before CuDNN, it will be partially statically linked into the library,
even if it is not used
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58287
Reviewed By: janeyx99
Differential Revision: D28433165
Pulled By: malfet
fbshipit-source-id: 8dffa0533075126dc383428f838f7d048074205c
Summary:
While trying to build PyTorch with BLIS as the backend library,
we found a build issue due to some missing include files.
This was caused by a missing directory in the search path.
This patch adds that path in FindBLIS.cmake.
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58166
Reviewed By: zou3519
Differential Revision: D28640460
Pulled By: malfet
fbshipit-source-id: d0cd3a680718a0a45788c46a502871b88fbadd52
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 4b8aaad426
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58161
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D28385619
fbshipit-source-id: ace938b1e43760b4bedd596ebbd355168a8706b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57409
Full design: https://github.com/pytorch/pytorch/issues/55207
In https://github.com/pytorch/pytorch/issues/55207, we proposed
`MeshShardingSpec` as a generic sharding mechanism. However, that proposal does
not provide the flexibility to specify shards which have uneven
sizes/partitions and assumes even partitioning. Uneven partitioning is one of
the requirements of an internal use case.
As a result, instead of that we introduce a `GenericShardingSpec` which allows
specifying any arbitrary partitioning of a multi dimensional tensor. Basically
it specifies the start offsets of each shard and the length of each dim of the
shard allowing for greater flexibility
ghstack-source-id: 129604155
Test Plan:
1) unit tests
2) waitforbuildbot
Reviewed By: SciPioneer
Differential Revision: D28137616
fbshipit-source-id: 61255762485fb8fa3ec3a43c27bbb222ca25abff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55728
Full design: https://github.com/pytorch/pytorch/issues/55207
This PR introduces ChunkShardingSpec (SingleShardingSpec in the design). Used
the name ChunkShardingSpec since it is very similar to `torch.chunk` in terms
of how a Tensor is split up and feels more clear compared to SingleShardingSpec.
ghstack-source-id: 129603318
Test Plan: waitforbuildbot
Reviewed By: SciPioneer
Differential Revision: D27694108
fbshipit-source-id: c8764abe6a4d5fc56d023fda29b74b5af2a73b49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58417
Same as title.
Test Plan:
Rely on CI signal.
Update unit test to exercise new code path as well.
Reviewed By: ngimel
Differential Revision: D28482927
fbshipit-source-id: 3ec8682810ed5c8547b1e8d3869924480ce63dcd
Summary:
fixes https://github.com/pytorch/pytorch/issues/58632.
Added several skips that relates to test assert and MKL. Will address them in separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58666
Reviewed By: seemethere, janeyx99
Differential Revision: D28607966
Pulled By: walterddr
fbshipit-source-id: 066d4afce2672e4026334528233e69f68da04965
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57156
generate_debug_handles
To be able to generate debug handles for preprocess written inpython.
Test Plan:
CI
CI
Imported from OSS
Differential Revision:
D28062328
D28062328
Reviewed By: raziel
Pulled By: kimishpatel
fbshipit-source-id: 8795d089edc00a292a2221cfe80bbc671468055c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55462
handles and symbolicate exception callstack thrown from backend.
Objective of this diff is to achieve improve error reporting when
exceptions are raised from lowered backend. We would effectively like to
get the same model level stack trace that you would get without having
lowered some module to backend.
For example:
```
class AA(nn.Module):
def forward(self, x, y):
return x + y
class A(nn.Module):
def __init__(...):
self.AA0 = AA()
def forward(self, x, y):
return self.AA0.forward(x, y) + 3
class B(nn.Module):
def forward(self, x):
return x + 2
class C(nn.Module):
def __init__(...):
self.A0 = A()
self.B0 = B()
def forward(self, x, y):
return self.A0.forward(x, y) + self.B0.forward(x)
```
If the we then do C().forward(torch.rand((2,3)), torch.rand(14,2))) we
will likely see error stack like:
```
C++ exception with description "The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
File "<string>", line 3, in forward
def forward(self, x, y):
return self.A0.forward(x, y) + self.B0.forward(x)
~~~~~~~~~~~~~~~ <--- HERE
File "<string>", line 3, in forward
def forward(self, x, y):
return self.AA0.forward(x, y) + 3
~~~~~~~~~~~~~~~~ <--- HERE
File "<string>", line 3, in forward
def forward(self, x, y):
return x + y
~~~~~ <--- HERE
```
We would like to see the same error stack if we lowered C.A0 to some
backend.
With this diff we get something like:
```
Module hierarchy:top(C).A0(backend_with_compiler_demoLoweredModule).AA0(AA)
Traceback of TorchScript (most recent call last):
File "<string>", line 3, in FunctionName_UNKNOWN
def forward(self, x, y):
return self.A0.forward(x, y) + self.B0.forward(x)
~~~~~~~~~~~~~~~ <--- HERE
File "<string>", line 5, in FunctionName_UNKNOWN
typed_inputs: List[Any] = [x, y, ]
if self.__backend.is_available() :
_0, = self.__backend.execute(self.__handles["forward"], typed_inputs)
~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
assert isinstance(_0, Tensor)
return _0
File "<string>", line 3, in FunctionName_UNKNOWN
def forward(self, x, y):
return self.AA0.forward(x, y) + 3
~~~~~~~~~~~~~~~~ <--- HERE
File "<string>", line 3, in FunctionName_UNKNOWN
def forward(self, x, y):
return x + y
~~~~~ <--- HERE
```
This is achieved in 3 parts:
Part 1:
A. BackendDebugInfoRecorder:
During backend lowering, in `to_backend`, before calling the preprocess
function corresponding to the backend. This will facilitate recording of
debug info (such as source range + inlined callstack) for the lowered module.
B. Instantiate WithBackendDebugInfoRecorder with BackendDebugInfoRecorder.
This initializes thread local pointer to BackendDebugInfoRecorder.
C. generate_debug_handles:
In preprocess function, the backend will call generate_debug_handles
for each method being lowered separately. generate_debug_handles
takes `Graph` of the method being lowered and returns a map
of Node*-to-debug_handles. Backend is responsible for storing debug
handles appropriately so as to raise exception (and later profiling)
using debug handles when the exception being raised corresponds to
particular Node that was lowered.
Inside generate_debug_handles, we will query the current
BackendDebugHandleInfoRecorder, that is issuing debug handles. This debug
handle manager will issue debug handles as well as record
debug_handles-to-<source range, inlined callstack> map.
D. Back in `to_backend`, once the preprocess function is has finished
lowering the module, we will call `stopRecord` on
BackendDebugInfoRecorder. This will return the debug info map. This
debug info is then stored inside the lowered module.
Part 2:
Serialization:
During serialization for bytecode (lite interpreter), we will do two
things:
1. Extract all the source ranges that are contained inside
debug_handles-to-<source range, inlined callstack> map for lowered
module. This will be source range corresponding to debug handles,
including what is there is inlined callstack. Since we replaced original
module with lowered module, we wont be serializing code for the original
module and thus no source range. That is why the source range will have
to be stored separately. We will lump all the source ranges for all the
lowered modules in one single debug_pkl file.
2. Then we will serialize debug_handles-to-<source range, inlined
callstack> map.
Now during deserialization we will be able to reconstruct
debug_handles-to-<source range, inlined callstack> map. Given all
debug_handles are unique we would not need any module information.
Test Plan:
Tests are added in test_backend.cpp
Tests are added in test_backend.cpp
Imported from OSS
Differential Revision:
D27621330
D27621330
Reviewed By: raziel
Pulled By: kimishpatel
fbshipit-source-id: 0650ec68cda0df0a945864658cab226a97ba1890
Summary:
This gets rid of a lot of the try/else rigamarole.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58788
Reviewed By: ZolotukhinM
Differential Revision: D28621054
Pulled By: Chillee
fbshipit-source-id: d0d8a1b6466eb318d939a1ed172b78f492ee0d5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58687
We want to validate if the usages are all okay.
ghstack-source-id: 129639560
Test Plan: Tested on master. Build fails. The tested with D28549578 (db67699ae6) applied, and the build succeeds.
Reviewed By: JacobSzwejbka
Differential Revision: D28579734
fbshipit-source-id: 1ac65474762855562109adc0bac2897b59f637ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58718
`PackageImporter` does not populate `module.__spec__.origin`, which causes an
unhandled `Exception` to be raised when using `importlib.resources.path` to get
a path to a binary file resource in the package in python <3.8.6.
This commit fixes this issue by setting `module.__spec__.origin` to
"<package_importer>". The actual value is not important as far as I can tell;
the simple fact that it is not `None` allows `importlib` to avoid raising an
`Exception` in `importlib.resources.path`.
Test Plan:
This commit adds a unit test to `test_resources.py` that tests that
`importlib.resources.path` can be used within a package.
Reviewed By: suo
Differential Revision: D28589117
fbshipit-source-id: 870d606a30fce6884ae48b03ff71c0864e4b325f
Summary:
Will not land before the release, but would be good to have this function documented in master for its use in distributed debugability.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58322
Reviewed By: SciPioneer
Differential Revision: D28595405
Pulled By: rohan-varma
fbshipit-source-id: fb00fa22fbe97a38c396eae98a904d1c4fb636fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58623
This splits out everything shellcheck related into its own job that generates and checks GHA workflows, then shellchecks those + jenkins scripts. This PR also integrates shellcheck into the changed-only stuff in `actions_local_runner.py` so that shellcheck won't do anything unless someone edits a shell script in their local checkout. This is the final piece to clean up the output of `make quicklint` and speeds it up by a good bit (before it was shellchecking everything which took a few seconds):
```
$ make quicklint -j $(nproc)
✓ quick-checks: Ensure no unqualified noqa
✓ quick-checks: Ensure canonical include
✓ quick-checks: Ensure no unqualified type ignore
✓ quick-checks: Ensure no direct cub include
✓ quick-checks: Ensure no tabs
✓ quick-checks: Ensure no non-breaking spaces
✓ shellcheck: Regenerate workflows
✓ quick-checks: Ensure no versionless Python shebangs
✓ quick-checks: Ensure correct trailing newlines
✓ shellcheck: Assert that regenerating the workflows didn't change them
✓ mypy (skipped typestub generation)
✓ cmakelint: Run cmakelint
✓ quick-checks: Ensure no trailing spaces
✓ flake8
✓ shellcheck: Extract scripts from GitHub Actions workflows
✓ shellcheck: Run Shellcheck
real 0.92
user 6.12
sys 2.45
```
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D28617293
Pulled By: driazati
fbshipit-source-id: af960ed441db797d07697bfb8292aff5010ca45b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58784
DDP communication hooks are already supported on Gloo backend. No longer need to skip these tests on Gloo.
Original PR issue: https://github.com/pytorch/pytorch/issues/58467
ghstack-source-id: 129635828
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_fork -- test_ddp_comm_hook_logging
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_fork -- test_ddp_hook_parity_allreduce
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_fork -- test_ddp_hook_parity_allreduce_process_group
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_fork -- test_ddp_hook_parity_powerSGD
Reviewed By: rohan-varma
Differential Revision: D28617214
fbshipit-source-id: 3bafb0c837a15ad203a8570f90750bc5177d5207
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58307
Borrowing is more efficient, and we can see in all these cases that the TensorIterator doesn't outlive the input & output Tensors.
ghstack-source-id: 129598791
Test Plan: Existing CI
Reviewed By: ezyang
Differential Revision: D28445922
fbshipit-source-id: ce12743980296bab72a0cb83a8baff0bb6d80091
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58305
Borrowing is more efficient, and we can see in all these cases that the TensorIterator doesn't outlive the input & output Tensors.
ghstack-source-id: 129598793
Test Plan: Existing CI
Reviewed By: ezyang
Differential Revision: D28445712
fbshipit-source-id: 0822f1408a0a71c8f8934e6d90659ae3baa085ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58566
Validates the keys of the qconfig_dict, prepare_custom_config_dict, convert_custom_config_dict, and
fuse_custom_config_dict. If the user passes in an invalid key or makes a type, we will throw and error and let the user know what keys are supported.
Test Plan:
Imported from OSS
python test/test_quantization.py
Reviewed By: jerryzh168
Differential Revision: D28540923
fbshipit-source-id: 5958c32017b7d16abd219aefc8e92c42543897c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58428
Until now, the TP agent expected the output of a remote function to be on the same streams as the inputs. In other words, it used the lazy stream context of the inputs to synchronize the output tensors. This was true in the most common case of a synchronous remote function. However it wasn't true for async functions, for fetching RRefs, ... The more generic way is to use the CUDA events held by the Future to perform this synchronization. (These events may be on the input streams, or they may not be!).
ghstack-source-id: 129567045
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28474982
fbshipit-source-id: c0034eb3f2a2ea525efb63a31b839bc086060e7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58674
I found this missing parameter while debugging failures in the next PR.
I'm very unhappy about this change. I think this future, which we know for sure won't contain tensors, shouldn't have to worry about CUDA devices. And yet, it does. This means that basically any future anywhere might have to worry about it, and this just doesn't scale, and thus it's bad.
ghstack-source-id: 129567042
Test Plan: Should fix the next diff.
Reviewed By: mrshenli
Differential Revision: D28574083
fbshipit-source-id: 5c89902cdc5cc12f1ebeea860b90cd9c3d7c7da1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58427
Running the UDF (be it Python or JIT) is the first step of (most?) RPC calls, which is where the inputs are consumed. The lazy stream context contains the streams used by the inputs, thus it must be made current before any UDF call. I opt to do this as "close" as possible to the place the UDF is invoked, to make the relationship as explicit as possible.
ghstack-source-id: 129567052
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28474983
fbshipit-source-id: 358292764d0a6832081c34bf6736f0961475ff3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58426
The operations in RequestCallback can return CUDA tensors, thus the futures used to hold them must be CUDA-aware.
ghstack-source-id: 129567051
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28474981
fbshipit-source-id: 492b8e71a43da5f63b4b7a31f820427cde9736e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58425
Now that callbacks can provide pre-extracted DataPtrs, let's do so. This will become of crucial importance in the next PR, where some of these futures will become CUDA-aware, and thus they will try to extract DataPtrs on their own, but they would fail to do so here because Message isn't "inspectable".
ghstack-source-id: 129567057
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28474877
fbshipit-source-id: e68d7d45f1c1dc6daa5e05cf984cfc93d2dce0d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58424
In CUDA mode, Future must inspect its value and extract DataPtrs. However some types are not supported, for example the C++/JIT custom classes, which include Message, which is widely used in RPC. Hence for these scenarios we allow the user to perform the custom DataPtr extraction on their own, and pass the pre-extracted DataPtrs.
Note that `markCompleted` already allowed users to pass in pre-extracted DataPtrs, hence this PR simply extends this possibility to the `then` method too.
ghstack-source-id: 129567044
Test Plan: Used in next PR.
Reviewed By: mrshenli
Differential Revision: D28474880
fbshipit-source-id: 91a0dde5e29d1afac55650c5dfb306873188d785
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58423
This is part 2 of the previous PR. Here we address the remaining occurrences of "raw" Message, namely the ones within toMessageImpl. And since they're the last ones, we make the constructor of Message private, to prevent new usages from emerging.
ghstack-source-id: 129567049
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28474879
fbshipit-source-id: 498652a8b80a953396cd5d4b275c0b2e869c9ecf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58422
Similar to Future (which I tackled recently), Message is an ivalue type (a "custom class" one), and the natural way to represent it is inside an intrusive_ptr. However in the RPC code we had a mix of usages, often passing Message by value. This has undesirable consequences, as it could easily trigger a copy by accident, which I believe is why in many places we accepted _rvalue references_ to Message, in order to force the caller to move. In my experience this is non-idiomatic in C++ (normally a function signature specifies how the function consumes its arguments, and it's up to the caller to then decide whether to copy or move).
By moving to intrusive_ptr everywhere I think we eliminate and simplify many of the problems above.
In this PR I do half of the migration, by updating everything except the `toMessageImpl` methods, which will come in the next PR.
ghstack-source-id: 129567053
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28474878
fbshipit-source-id: 5b76d45e05f6fa58c831e369c5c964d126187a6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58421
Here I make it impossible to create Futures that do not use intrusive_ptr, by making the constructor private. This makes it safer (by "forcing" people to do the right thing) and prevents a proliferation of new shared_ptrs or of accidental copies/moves.
ghstack-source-id: 129567047
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28474484
fbshipit-source-id: 82c487e1bb7c27a2e78cb5d594e00e54c752bf09
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58420
In https://github.com/pytorch/pytorch/pull/57636 I migrated most uses of Future to an intrusive_ptr. I thought I had all of them but I missed a couple. These are the remaining ones. (The next PR will make it impossible to add new usages of shared_ptr).
ghstack-source-id: 129567071
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28477285
fbshipit-source-id: 75008276baa59e26b450e942c009ec7e78f89b13
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57861
The very last methods left that still didn't return Futures were the autograd ones, but they're very easy to port.
We've now finished the conversion of RequestCallback to be fully Future-based!
ghstack-source-id: 129567055
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28286173
fbshipit-source-id: 1de58cee1b4513fb25b7e089eb9c45e2dda69fcb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57860
The other methods for RRefs just did bookkeeping and are trivially easy to migrate to Futures (which is done mainly for consistency at this point).
ghstack-source-id: 129567068
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28286175
fbshipit-source-id: 1d97142803f73fe522435ca75200403c78babc68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57859
Just like with assigning OwnerRRefs, we can also deduplicate the code paths for fetching their values. In fact this was duplicated three times, with different ways of post-processing the value (once for JIT, once for Python, once for autograd). Thanks to future, we can have that logic once, and then connect it to different follow-up steps.
ghstack-source-id: 129567050
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28286172
fbshipit-source-id: e0742a99cf555755e848057ab6fee5285ff0df2a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57858
Just a small deduplication, which move complexity our of the way, and ensures consistent error checking.
ghstack-source-id: 129567056
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28286174
fbshipit-source-id: 6eab8d3f30405d49c51f8b9220453df8773ff410
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57857
There used to be a whole lot of methods: `processPythonCall`, `processScriptCall`, `processScriptRemoteCall`, `processPythonRemoteCall`, `processScriptCallOp`, `processBaseScriptRemoteCall` and `processScriptRemoteCallOp`. Thanks to the previous simplification, we can now drop all but the first four, which map nicely 1:1 to the four message types we need to handle. Also their signatures become much simpler: they take an RPC command and return a future.
ghstack-source-id: 129567070
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28253848
fbshipit-source-id: e0e45345c414a96900f9d70ee555359d28908833
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57856
Thanks to Futures providing a "common language" between various steps, we can now deduplicate the creation of OwnerRRef, by having two different ways of creating the result (JIT and Python) but then connecting them to a single method that wraps and stores that result in an OwnerRRef.
ghstack-source-id: 129567072
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28253845
fbshipit-source-id: a156e56cac60eb22f557c072b61ebac421cfad43
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57855
We already had a helper to run Python functions, which was nice (it de-duplicated some code). This helper was however taking a callback which, as I said, isn't as nice as it returning a Future. Hence here I change this.
ghstack-source-id: 129567054
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28253846
fbshipit-source-id: d854d4aa163798fb015cd6d46932f9ff1d18262e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57854
Because OwnerRRefs used to be created before their value was computed, we had to figure out their type ahead of time. After the previous diff, we inverted the order of operations, and we can now first compute the result and then create the OwnerRRef. Which means we can just inspect the value to get its type. Much simpler, and much less likely to get it wrong.
ghstack-source-id: 129567060
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28253843
fbshipit-source-id: f13c9b294f477ae66fcbdbc85c642fdc69b2740f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57853
A bunch of methods received an OwnerRRef to "fill in". I think it will be more flexible to do it the other way around, and have these methods return a value (wrapped in a Future), which can then be "connected" to an OwnerRRef, but which can also potentially be consumed in different ways.
ghstack-source-id: 129567059
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28253844
fbshipit-source-id: 7e3772312dbacfc75a6ac0f62189fc9828001fc7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57852
Another great example of the benefits of Futures. Thanks to the "right abstraction" (i.e., the `thenAsync` method), adding support for async execution becomes trivial, and the code much simpler than what it used to be.
ghstack-source-id: 129567063
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28253842
fbshipit-source-id: b660151ca300f3d6078db0f3e380c80a4d8f5190
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57851
The same as the previous PR, but for JIT functions.
ghstack-source-id: 129567069
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28253841
fbshipit-source-id: 2b8affde16c106f5c76efa8be49af070213708bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57850
What I envision is a modular decomposed code, with separate steps which each consume/produce Futures, and which can be chained together to obtain the desired results. One common "starting point" for these chains is the execution of a remote function (Python or JIT or otherwise). I'm thus creating a helper function for one of these, the JIT operators (by deduplicating the places where we used to run them). More will follow.
This deduplication will also help to add CUDA support to JIT RPC, since the execution of the JIT function/operators is where we need to set our custom streams.
ghstack-source-id: 129567058
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28253847
fbshipit-source-id: 24ab67ad89c8796861e9bbcb78878b26704c0c48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57849
Some methods are currently returning bool, but I'll soon want them to return a Future. I could have them return a tuple of bool and Future, but that's a bit heavy. Instead it turns out we can very easily make them return void, which will simplify things.
ghstack-source-id: 129567061
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28224476
fbshipit-source-id: 26dc796b7e38f03aa269cf0731b0059d58e57e94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57848
This PR looks large, but all it does is add a dozen lines and remove a lot of other ones.
One first advantage of using Futures is that we can easily chain some "post-processing" to them. Until now we needed to pass the message ID around everywhere because it was set separately by each method. Instead, we could simply add a follow-up step to the final future which sets this ID, and remove all the former logic.
ghstack-source-id: 129567065
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28224477
fbshipit-source-id: 7b6e21646262abe5bbbf268897e2d792e5accc27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57847
This is the first PR of a stack that aims to simplify RequestCallback, and I want to start by explaining my intentions.
With the introduction of CUDA support in the TensorPipe agent, we found out that other layers higher up in the stack (RRefs, dist autograd, ...) were not "ready" to support CUDA. One cause of this was that in PyTorch most CUDA state is thread-local, and the RequestCallback class (and others) might execute different steps of an operation on multiple threads. The solution to this problem is to preserve or recreate the CUDA state when switching between threads (propagating streams, or recording events and then wait on them). If we were to manually do this everywhere it would be tedious, error-prone, and hard to maintain.
In fact, we already have a primitive that can do this for us: CUDAFuture (now known as just Future). If whenever we switch threads we were to pack the values in a CUDAFuture and then unpack them on the other threads, all CUDA stuff would be taken care of for us.
If our code leveraged CUDAFuture at its core, thing would become the "idiomatic" thing to do, the natural behavior. Future changes would thus also be inclined to follow this pattern, hence automatically doing the right thing.
I also think that, even without these concerns about CUDA, there are benefits to use Futures more extensively. Currently RequestCallback uses a mix of Futures and callbacks. These are two tools for the same job, and thus mixing them creates confusion. Futures are more powerful than simple callbacks (they can be passed around, inspected, chained, waited on, ...) and thus should be preferred. They also lead to more readable code, as each step can be defined and chained in logical order, whereas callbacks must either be nested, or defined inline, or defined before and used later (thus making the code out-of-order).
In short: I intend to rework RequestCallback to use Futures much more. I believe it will greatly simplify the code, help readability, and prove invaluable to support CUDA.
---
Until now, we had the final result future being created at the very beginning, and then passed around everywhere, so that the various method could "fill in" its value. I think it's much lighter to instead allow each method to create or obtain its futures however it wants, and have it return them. I.e., have these futures "bubble up" from the lower layers, rather than them being "pushed down" from the upper ones.
In this initial PR, I move the place where we create this "final result future", but I still keep it around. I will then, in later PRs, slowly migrate each method so that it returns a future, and in the end I will avoid creating the final result future.
ghstack-source-id: 129567062
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28224478
fbshipit-source-id: dbdc66b6458645a4a164c02f00d8618fa64da028
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57846
In later PRs I'll need to create already-completed futures (it'll make sense then, I hope). Here are a few helpers for that, which I'm adding separately to reduce the noise later.
ghstack-source-id: 129567064
Test Plan: See later.
Reviewed By: mrshenli
Differential Revision: D28253664
fbshipit-source-id: f091e1d3ea353bb5bfbd2f582f1b8f84e4b0114f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57638
In RPC there are a few instances of "fastpaths" which do `if (fut.isCompleted()) { do_sth(); } else { fut.addCallback(do_sth); }`. I intend to get rid of them, for reasons I'll clarify later but which in a nutshell have to do with CUDA correctness and readability. Note that dropping the fastpath introduces no change in behavior (because `addCallback` invokes the callback inline anyways), thus the only perf concern comes from the fact that the fastpath avoids constructing and passing around a `std::function`. I don't think this is a significant performance hit. Regardless, this PR preemptively addresses this concern, by tweaking `addCallback` (and similar methods) so they can handle raw lambdas, and so that they do _not_ wrap them into `std::function`s if they are invoked inline.
ghstack-source-id: 129567067
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28222808
fbshipit-source-id: eb1c7114cf7aca3403cb708f14287cab0907ecfa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57637
I had proposes a similar method in https://github.com/pytorch/pytorch/pull/48790, although that PR was exposing it to Python and thus requires a bit more work. This PR only introduces this method as a C++ API. Python can be added later.
This new method is useful when one wants to use `then` but the callback does perform some async operation itself, and one wants to "reconcile" the future produced inside the callback with the one produced outside.
ghstack-source-id: 129567066
Test Plan: Used (and thus tested) later in the stack.
Reviewed By: mrshenli
Differential Revision: D28222809
fbshipit-source-id: 869f11ab390b15e80c0855750e616f41248686c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58702
Off by one error when determining if some ranks failed or not with
`wait_all_ranks=True`. This wasn't caught by tests because the tests only
tested failure scenarios, not success scenarios with `wait_all_ranks=True`.
ghstack-source-id: 129559840
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28583235
fbshipit-source-id: a8f376efb13a3f36c788667acab86543c80aff59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55978
This is needed for broadcasting two of the same symbolic shape
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D27755328
Pulled By: eellison
fbshipit-source-id: d38d9458a9e28d31558f0bc55206516b78131032
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55926
This is necessary for code like conv2d where we wish to share a generic convolution shape function logic with that of conv2d but for conv2d always infer the output is dimension 4. I'm also hoping the refinement algorithm here could be refactored out and used to support refining tensor types from user annotations. i have a length comment explaining how this works, and the logic outside of data structures is pretty small and contained. Additionally, you might check out https://fb.quip.com/X7EVAdQ99Zzm for a very similar description of how to refine values based on comparison operators.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D27750997
Pulled By: eellison
fbshipit-source-id: d962415af519ac37ebc9de88f2e1ea60a1374f7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55925
This sets up the initial handling of symbolic shapes. As in the test, it doesn't work perfectly yet because it needs a couple other optimization passes. The basic description is pretty simple: we resolve tensor dimension indices to the same Value *, and before extracting out the output Tensor shape we substitute in symbolic shapes. We don't substitute during optimization because they are represented as negative numbers so we don't want them inadvertently used in Constant prop or something else.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D27750996
Pulled By: eellison
fbshipit-source-id: 6984e7276b578f96b00fc2025cef0e13f594b6e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54809
I'm going to post on dev-discuss soon with a more thorough explanation of the design and advantages of this shape analysis, so I'm leaving out that for now.
There is still a ton left to do, I'm posting this initial version so we can get something on master multiple can work on. List of many remaining steps to do:
- [ ] Add symbolic shapes support
- [ ] Bind shape functions for operators in C++
- [ ] Make classes of operators share the same shape function (e.g. pointwise, broadcast two inputs)
- [ ] Refactor APIs
- [ ] Only iteratively optimize shape function while a change has been made
- [ ] Expand coverage of coverage to common ops
- [ ] Add shape analysis pass on Graph that handles Ifs and Loops
- [ ] Allow concurrent reads to the operator map
- [ ] Successive applications of same inputs to same shape function (e.g. series of pointwise ops)
For this review, I am mostly looking for comments related to the implementation of symolic_shape_analysis.cpp, with the caveats listed above. I am not really looking for comments related to api/registration/graph level analysis as those are all planned to be changed. I am fine landing this as is or waiting until necessary components of the TODOs above are finished.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D27750998
Pulled By: eellison
fbshipit-source-id: 4338b99e8651df076291c6b781c0e36a1bcbec03
Summary:
This PR adds an alternative way of calling `torch.einsum`. Instead of specifying the subscripts as letters in the `equation` parameter, one can now specify the subscripts as a list of integers as in `torch.einsum(operand1, subscripts1, operand2, subscripts2, ..., [subscripts_out])`. This would be equivalent to `torch.einsum('<subscripts1>,<subscripts2>,...,->[<subscript_out>]', operand1, operand2, ...)`
TODO
- [x] Update documentation
- [x] Add more error checking
- [x] Update tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56625
Reviewed By: zou3519
Differential Revision: D28062616
Pulled By: heitorschueroff
fbshipit-source-id: ec50ad34f127210696e7c545e4c0675166f127dc
Summary:
Finds a couple of bugs:
1. permute needs to wrap dimensions
2. slice needs to wrap dimensions
3. frac doesn't work correctly for negative values
4. Permute has some other failures.
This PR also fixes 1 + 2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58719
Reviewed By: SplitInfinity
Differential Revision: D28590457
Pulled By: Chillee
fbshipit-source-id: a67fce67799602f9396bfeef615e652364918fbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58603
No longer need these checks
ghstack-source-id: 129498227
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28549893
fbshipit-source-id: a89bf8c3fc3aba311a70fd37e5a6aa5dc14b41b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58595
No longer needed since this list is always of size 1.
ghstack-source-id: 129498229
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28548426
fbshipit-source-id: 7d6dba92fff685ec7f52ba7a3d350e36405e2578
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58594
This comment was misplaced after some changes, move it to the right
place.
ghstack-source-id: 129498228
Test Plan: ci
Reviewed By: zhaojuanmao
Differential Revision: D28548100
fbshipit-source-id: a9163fc3b25a9d9b8b6d4bfa2a77af290108fc09
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58593
Per title
ghstack-source-id: 129498230
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28528465
fbshipit-source-id: 89e4bfcb4a0275dc17090a934d4c0a41a3c54046
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58699
Make `call_function`/`call_method` random colors based on their target name. This coloring is stable according to the name of the target. Also handle tensor_meta more elegantly for quantized types, including print q_scale/q_zero_point if they're used.
Test Plan: Tested locally
Reviewed By: chenccfb, 842974287
Differential Revision: D28580333
fbshipit-source-id: ad9961e1106a1bfa5a018d009b0ddb8802d2163c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58592
Completely removes VariableIndex from reducer code, as it is not
needed. replica_index is always 0 so simplify the code to only use the
parameter index. Next, we should also remove all of the nested data structures
that were needed when num_replicas > 1 was possible.
ghstack-source-id: 129498226
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28528440
fbshipit-source-id: e0568399264ab4f86de3b7a379a4f0831f8f42e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58689
This doesn't seem to be mobile related, but ends up getting called from multiple places, so is hard to get rid of entirely.
ghstack-source-id: 129413850
Test Plan: Build
Reviewed By: iseeyuan
Differential Revision: D28543374
fbshipit-source-id: 867b3e2fafdcbf6030d7029a82a2b711bcecefc5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57985
Fixes https://github.com/pytorch/pytorch/issues/57756
This PR introduces a new `pyobj_interpreter_` field on TensorImpl which tracks what Python interpreter (if any) owns the TensorImpl. This makes it illegal to bind a TensorImpl from multiple Python interpreters, and means that we can now directly store PyObject pointer on TensorImpl even in the presence of multiple Python interpreters, as is the case in torchdeploy. This is a necessary step for PyObject preservation, which cannot be easily implemented when there are multiple Python interpreters.
Although the PR is not that long, there is a very subtle portion of the implementation devoted to ensuring that the tagging process is thread safe, since multiple threads can concurrently try to tag a PyObject. Check Note [Python interpreter tag] and Note [Memory ordering on Python interpreter tag] for detailed discussion of how this is handled. You will have to check this code carefully in code review; I did not torture test the multithreaded paths in any meaningful way.
In a follow up PR, I will pack the interpreter and PyObject fields into single atomic word on 64-bit.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: wconstab
Differential Revision: D28390242
Pulled By: ezyang
fbshipit-source-id: a6d9b244ee6b9c7209e1ed185e336297848e3017
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58604
Minor bug fix. Schemas should be defined with the schema macro not the name one.
Test Plan: ci and buck test fbsource//xplat/pytorch_models/build/cair_messaging_2021_05_17/v2:cair_messaging_2021_05_17_test
Reviewed By: dhruvbird, iseeyuan
Differential Revision: D28549578
fbshipit-source-id: 0c64eb8c60f1aee8213a1fc1fb7231226b905795
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57386
Here is the PR for what's discussed in the RFC https://github.com/pytorch/pytorch/issues/55374 to enable the autocast for CPU device. Currently, this PR only enable BF16 as the lower precision datatype.
Changes:
1. Enable new API `torch.cpu.amp.autocast` for autocast on CPU device: include the python API, C++ API, new Dispatchkey etc.
2. Consolidate the implementation for each cast policy sharing between CPU and GPU devices.
3. Add the operation lists to corresponding cast policy for cpu autocast.
Test Plan: Imported from OSS
Reviewed By: soulitzer
Differential Revision: D28572219
Pulled By: ezyang
fbshipit-source-id: db3db509973b16a5728ee510b5e1ee716b03a152
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58303
Borrowing is more efficient, and we can see in all these cases that the TensorIterator doesn't outlive the input & output Tensors.
ghstack-source-id: 129471191
Test Plan: Existing CI
Reviewed By: ezyang
Differential Revision: D28444032
fbshipit-source-id: f6a9e9effb43c273f464ef6ff410274962f3ab23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58280
All core PyTorch uses of TensorIterator::nullary_op look like they can safely borrow.
ghstack-source-id: 129471193
Test Plan: Existing CI
Reviewed By: bhosmer
Differential Revision: D28429695
fbshipit-source-id: 404cf6db31e45e5cf7ae6d2f113c5a8eff6f7c3d
Summary:
Enable the quantization on XPU devices. Keep the model as is if the model is on XPU devices.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54857
Reviewed By: ailzhang
Differential Revision: D28501381
Pulled By: jerryzh168
fbshipit-source-id: 6d3e9b04075393248b30776c69881f957a1a837c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58453
Move the class method generate_qconfig_map to qconfig_utils, will add more PRs
to remove functions out of Quantizer and eventually remove the Quantizer object
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28497965
fbshipit-source-id: 3c78cfe676965d20a8834a859ffed4d8e9ecade4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58445
Previously the output of statically quantized fp16 operator is not quantized in QuantizeHandler, which is not consistent with
the behavior of static int8 operators. Also it does not work well with reference functions, this PR
changes the fp16 static QuantizeHandler to quantize (call to(torch.float16)) in the QuantizeHandler, this also
makes the future support for reference functions easier.
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28495830
fbshipit-source-id: 2140eab8ab2dd08f6570d9e305485e3029e1f47d
Summary:
I build using [Bazel](https://bazel.build/).
When I use `pytorch_android` in latest Android app, I get the following error due to dependencies:
```
$ bazel build //app/src/main:app
WARNING: API level 30 specified by android_ndk_repository 'androidndk' is not available. Using latest known API level 29
INFO: Analyzed target //app/src/main:app (0 packages loaded, 0 targets configured).
INFO: Found 1 target...
ERROR: /home/H1Gdev/android-bazel-app/app/src/main/BUILD.bazel:3:15: Merging manifest for //app/src/main:app failed: (Exit 1): ResourceProcessorBusyBox failed: error executing command bazel-out/k8-opt-exec-2B5CBBC6/bin/external/bazel_tools/src/tools/android/java/com/google/devtools/build/android/ResourceProcessorBusyBox --tool MERGE_MANIFEST -- --manifest ... (remaining 11 argument(s) skipped)
Use --sandbox_debug to see verbose messages from the sandbox ResourceProcessorBusyBox failed: error executing command bazel-out/k8-opt-exec-2B5CBBC6/bin/external/bazel_tools/src/tools/android/java/com/google/devtools/build/android/ResourceProcessorBusyBox --tool MERGE_MANIFEST -- --manifest ... (remaining 11 argument(s) skipped)
Use --sandbox_debug to see verbose messages from the sandbox
Error: /home/H1Gdev/.cache/bazel/_bazel_H1Gdev/29e18157a4334967491de4cc9a879dc0/sandbox/linux-sandbox/914/execroot/__main__/app/src/main/AndroidManifest.xml:19:18-86 Error:
Attribute application@appComponentFactory value=(androidx.core.app.CoreComponentFactory) from [maven//:androidx_core_core] AndroidManifest.xml:19:18-86
is also present at [maven//:com_android_support_support_compat] AndroidManifest.xml:19:18-91 value=(android.support.v4.app.CoreComponentFactory).
Suggestion: add 'tools:replace="android:appComponentFactory"' to <application> element at AndroidManifest.xml:5:5-19:19 to override.
May 19, 2021 10:45:03 AM com.google.devtools.build.android.ManifestMergerAction main
SEVERE: Error during merging manifests
com.google.devtools.build.android.AndroidManifestProcessor$ManifestProcessingException: Manifest merger failed : Attribute application@appComponentFactory value=(androidx.core.app.CoreComponentFactory) from [maven//:androidx_core_core] AndroidManifest.xml:19:18-86
is also present at [maven//:com_android_support_support_compat] AndroidManifest.xml:19:18-91 value=(android.support.v4.app.CoreComponentFactory).
Suggestion: add 'tools:replace="android:appComponentFactory"' to <application> element at AndroidManifest.xml:5:5-19:19 to override.
at com.google.devtools.build.android.AndroidManifestProcessor.mergeManifest(AndroidManifestProcessor.java:186)
at com.google.devtools.build.android.ManifestMergerAction.main(ManifestMergerAction.java:217)
at com.google.devtools.build.android.ResourceProcessorBusyBox$Tool$5.call(ResourceProcessorBusyBox.java:93)
at com.google.devtools.build.android.ResourceProcessorBusyBox.processRequest(ResourceProcessorBusyBox.java:233)
at com.google.devtools.build.android.ResourceProcessorBusyBox.main(ResourceProcessorBusyBox.java:177)
Warning:
See http://g.co/androidstudio/manifest-merger for more information about the manifest merger.
Target //app/src/main:app failed to build
Use --verbose_failures to see the command lines of failed build steps.
INFO: Elapsed time: 2.221s, Critical Path: 1.79s
INFO: 2 processes: 2 internal.
FAILED: Build did NOT complete successfully
```
This is due to conflict between `AndroidX` and `Support Library` on which `pytorch_android_torch` depends.
(In the case of `Gradle`, it is avoided by `android.useAndroidX`.)
I created [Android application](https://github.com/H1Gdev/android-bazel-app) for comparison.
At first, I updated `AppCompat` from `Support Library` to `AndroidX`, but `pytorch_android` and `pytorch_android_torchvision` didn't seem to need any dependencies, so I removed dependencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58527
Reviewed By: xta0
Differential Revision: D28585234
Pulled By: IvanKobzarev
fbshipit-source-id: 78aa6b1525543594ae951a6234dd88a3fdbfc062
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57397
Introduces two main classes in C++ runtime:
ScriptProfile is the implementation for enalbing and disabling interpreter
profiling in C++. This should be only used from Python, and we will add
corresponding Python API in the next diff.
InstructionSpan is a utility class to instrument execution of each single
instruction. A start timestamp is recorded in the consturctor, and an end
timestamp is recorded in the destructor. During destruction, this will send
runtime data to all enabled ScriptProfile instances.
Test Plan:
build/bin/test_jit --gtest_filter='ScriptProfileTest.Basic'
Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D28133579
fbshipit-source-id: e7e30e96151367022793ab3ad323f01c51ad4a3b
Summary:
Temporary fix for https://github.com/pytorch/pytorch/issues/42218.
Numerically, grid_sampler should be fine in fp32 or fp16. So grid_sampler really belongs on the promote list. But performancewise, native grid_sampler backward kernels use gpuAtomicAdd, which is notoriously slow in fp16. So the simplest functionality fix is to put grid_sampler on the fp32 list.
In https://github.com/pytorch/pytorch/pull/58618 I implement the right long-term fix (refactoring kernels to use fp16-friendly fastAtomicAdd and moving grid_sampler to the promote list). But that's more invasive, and for 1.9 ngimel says this simple temporary fix is preferred.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58679
Reviewed By: soulitzer
Differential Revision: D28576559
Pulled By: ngimel
fbshipit-source-id: d653003f37eaedcbb3eaac8d7fec26c343acbc07
Summary:
This PR does several things to relax test tolerance
- Do not use TF32 in cuda matmul in test_c10d. See https://github.com/pytorch/pytorch/issues/52941.
- Do not use TF32 in cuda matmul in test_linalg. Increase atol for float and cfloat. See https://github.com/pytorch/pytorch/issues/50453
The tolerance is increased because most linear algebra operators are not that stable in single precision.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56114
Reviewed By: ailzhang
Differential Revision: D28554467
Pulled By: ngimel
fbshipit-source-id: 90416be8e4c048bedb16903b01315584d344ecdf
Summary: Tests are frequently failing with "exceeded the deadline of 1000.00ms", we expect this to happen, so remove the deadline
Test Plan: N/A: Fix breakages
Reviewed By: robieta
Differential Revision: D28581051
fbshipit-source-id: 4825ada9af151fa5d57c45c549138c15ba613705
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58676
We only generate asm for small matmuls, but we were computing the # of
flops using an int32, which is too small.
Test Plan:
```
buck test mode/dev //caffe2/test:static_runtime -- --exact 'caffe2/test:static_runtime - test_mlp (test_static_runtime.TestStaticModule)'
```
Reviewed By: navahgar
Differential Revision: D28562157
fbshipit-source-id: a07ceba5209ef6022ead09140380c116994755cf
Summary:
This warning makes downstream users of OpInfo error when they use this opinfo, unless they actually run the operation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58682
Reviewed By: mruberry
Differential Revision: D28577334
Pulled By: Chillee
fbshipit-source-id: f10e64f8ad3fb50907531d8cb89ce5b0d06ac076
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58506
We were experiencing 500 errors when it came to downloading large
artifacts so let's just use s3 for those larger artifacts just in case
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: zhouzhuojie
Differential Revision: D28520792
Pulled By: seemethere
fbshipit-source-id: 3aa15c4872fe46c9491ac31dc969bf71175378aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58503
add gflags to force using deploy for torchscript models
Test Plan: Add parametrization to PredictorContainer test to exercise gflag override and test deploy codepath. Add test case to exercise new torch.package codepath.
Reviewed By: suo
Differential Revision: D28246793
fbshipit-source-id: 88a2c8322c89284e3c8e14fee5f20e9d8a4ef300
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57081
Changes in this diff:
Enable passthrough autograd function when find_unused_parameters=True.
With above, move prepare_for_backward which does unused parameter checking logic to beginning of backwards pass, only when find_unused_parameters=True.
Enhance process of unused parameter checking to account for outputs not being used in loss.
The way (3) is implemented is by triggering the autograd hook corresponding to parameters that did not participate in loss computation. Since they did not participate, the autograd hook is triggered with a gradient of None, and the reducer handles this appropriately to ensure that the gradient is not touched.
Tested by ensuring that when a model output is not used in loss, the corresponding grad is not modified. Also verified that the grads are the same in local vs DDP training case. Also verified that gradients are not touched in this case, i.e. if grad is originally None, it stays as None, not zero, after.
Note that in this diff we are not enabling the pass through autograd function for regular case find_unused_parameters=False because that has a much bigger blast radius and needs additional careful analysis especially with regard to the performance.
ghstack-source-id: 129425139
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28048628
fbshipit-source-id: 71d7b6af8626804710017a4edd753787aa9bba61
Summary:
`NULL` return from `PyObject_GetAttrString` should never get ignored without handling the exception, as behavior of subsequent Python C API calls are undefined until `PyErr_Fetch` or `PyErr_Clear` is called.
This accidentally leads to `list` type being incorrectly identified as `Tensor`
Fixes https://github.com/pytorch/pytorch/issues/58520
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58631
Reviewed By: albanD
Differential Revision: D28559454
Pulled By: malfet
fbshipit-source-id: 46f044b5f0f94264779a6108474d04a8ba851c53
Summary:
This PR fixes a bug in test_fx_experimental where code generated for ops with kwarg-only Tensor parameters would fail to execute because they would be called as positional parameters.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58587
Reviewed By: ailzhang
Differential Revision: D28548365
Pulled By: heitorschueroff
fbshipit-source-id: 8f1746053cbad1b11e817b0099db545d8dd22232
Summary:
Since v1.7, oneDNN (MKL-DNN) has supported the use of Compute Library
for the Arm architeture to provide optimised convolution primitives
on AArch64.
This change enables the use of Compute Library in the PyTorch build.
Following the approach used to enable the use of CBLAS in MKLDNN,
It is enabled by setting the env vars USE_MKLDNN and USE_MKLDNN_ACL.
The location of the Compute Library build must be set useing `ACL_ROOT_DIR`.
This is an extension of the work in https://github.com/pytorch/pytorch/pull/50400
which added support for the oneDNN/MKL-DNN backend on AArch64.
_Note: this assumes that Compute Library has been built and installed at
ACL_ROOT_DIR. Compute library can be downloaded here:
`https://github.com/ARM-software/ComputeLibrary`_
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55913
Reviewed By: ailzhang
Differential Revision: D28559516
Pulled By: malfet
fbshipit-source-id: 29d24996097d0a54efc9ab754fb3f0bded290005
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58573
Users can create invalid imports, like:
```
HG: in a top-level package
if False:
from .. import foo
```
Since this code is never executed, it will not cause the module to fail to
load. But our dependency analysis walks every `import` statement in the AST,
and will attempt to resolve the (incorrectly formed) import, throwing an exception.
For posterity, the code that triggered this: https://git.io/JsCgM
Differential Revision: D28543980
Test Plan: Added a unit test
Reviewed By: Chillee
Pulled By: suo
fbshipit-source-id: 03b7e274633945b186500fab6f974973ef8c7c7d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58572
Right now, we have three categories of error (broken, denied, unhandled). This
PR unifies them into a single "error" field in the node, with optional context.
It also generalizes how formatting of the error in PackagingError occurs.
Differential Revision: D28543982
Test Plan: sandcastle
Reviewed By: Chillee
Pulled By: suo
fbshipit-source-id: d99d37699ec2e172e3798763e60aafe9a66ed6f4
Summary:
Do not put quotes for arguments that do not have space in them in add_to_env_file
ENV file is used both by bash as well as by docker, which does not omit
quotes when they are present there
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58637
Reviewed By: wconstab
Differential Revision: D28561159
Pulled By: malfet
fbshipit-source-id: 0843aad22703b6c3adebeb76175de1cfc1a974b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58493
In fbcode, we want torch::deploy to be a target that works with or without cuda, depending only on whether cuda is linked in the final binary. To enable this, we build both flavors of libinterpreter, and choose which to load at runtime depending on whether cuda is available in the application. This comes at a cost to binary size, as it includes two copies of libinterpreter instead of one. However, it does not require _loading_ two copies of libinterpreter into memory at runtime, so the memory footprint of the interpreter (which we make N copies of) is not impacted.
In oss/cmake, this change is a no-op. cuda is already handled there by building just one libinterpreter, but building cuda or not for the whole pytorch build based on a global cmake flag.
Test Plan: test in fbcode with new gpu mode unit tests, verify existing oss CI passes
Reviewed By: suo
Differential Revision: D28512178
fbshipit-source-id: 61354bf78b1932605a841388fcbc4bafc0c4bbb4
Summary:
- dump final graph in glow
- print operator stats via to_glow API
- 1) node stats for final glow graph
- 2) operator stats in TorchGlowBackend for torch::jit::graph to lower
Reviewed By: khabinov
Differential Revision: D28444501
fbshipit-source-id: 743755c320071edc4c045ad004adeb16b4a9c323
Summary:
Functional API is used in large scale distributed training to enable multithreaded training instead of multiprocess, as it gives more optimal resource utilization and efficiency.
In this PR, we provide code migration and refactoring for functional API for ASGD algorithm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58410
Reviewed By: ailzhang
Differential Revision: D28546702
Pulled By: iramazanli
fbshipit-source-id: 4f62b6037d53f35b19f98340e88af2ebb6243a4f
Summary:
In order to make it more convenient for maintainers to review the ATen AVX512 implementation, the namespace `vec256` is being renamed to `vec` in this PR, as modifying 77 files & creating 2 new files only took a few minutes, as these changes aren't significant, so fewer files would've to be reviewed while reviewing https://github.com/pytorch/pytorch/issues/56992.
The struct `Vec256` is not being renamed to `Vec`, but `Vectorized` instead, because there are some `using Vec=` statements in the codebase, so renaming it to `Vectorized` was more convenient. However, I can still rename it to `Vec`, if required.
### Changes made in this PR -
Created `aten/src/ATen/cpu/vec` with subdirectory `vec256` (vec512 would be added via https://github.com/pytorch/pytorch/issues/56992).
The changes were made in this manner -
1. First, a script was run to rename `vec256` to `vec` & `Vec` to `Vectorized` -
```
# Ref: https://stackoverflow.com/a/20721292
cd aten/src
grep -rli 'vec256\/vec256\.h' * | xargs -i@ sed -i 's/vec256\/vec256\.h/vec\/vec\.h/g' @
grep -rli 'vec256\/functional\.h' * | xargs -i@ sed -i 's/vec256\/functional\.h/vec\/functional\.h/g' @
grep -rli 'vec256\/intrinsics\.h' * | xargs -i@ sed -i 's/vec256\/intrinsics\.h/vec\/vec256\/intrinsics\.h/g' @
grep -rli 'namespace vec256' * | xargs -i@ sed -i 's/namespace vec256/namespace vec/g' @
grep -rli 'Vec256' * | xargs -i@ sed -i 's/Vec256/Vectorized/g' @
grep -rli 'vec256\:\:' * | xargs -i@ sed -i 's/vec256\:\:/vec\:\:/g' @
grep -rli 'at\:\:vec256' * | xargs -i@ sed -i 's/at\:\:vec256/at\:\:vec/g' @
cd ATen/cpu
mkdir vec
mv vec256 vec
cd vec/vec256
grep -rli 'cpu\/vec256\/' * | xargs -i@ sed -i 's/cpu\/vec256\//cpu\/vec\/vec256\//g' @
grep -rli 'vec\/vec\.h' * | xargs -i@ sed -i 's/vec\/vec\.h/vec\/vec256\.h/g' @
```
2. `vec256` & `VEC256` were replaced with `vec` & `VEC` respectively in 4 CMake files.
3. In `pytorch_vec/aten/src/ATen/test/`, `vec256_test_all_types.h` & `vec256_test_all_types.cpp` were renamed.
4. `pytorch_vec/aten/src/ATen/cpu/vec/vec.h` & `pytorch_vec/aten/src/ATen/cpu/vec/functional.h` were created.
Both currently have one line each & would have 5 when AVX512 support would be added for ATen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58438
Reviewed By: malfet
Differential Revision: D28509615
Pulled By: ezyang
fbshipit-source-id: 63840df5f23b3b59e203d25816e2977c6a901780
Summary:
This supposed to be a no-op (as .cu file do not contain any cuda code),
that reduces compilation time 2.5x:
```
$ time /usr/local/cuda/bin/nvcc /home/nshulga/git/pytorch/aten/src/THC/THCTensorMathMagma.cu -c ...
real 0m7.701s
$ time /usr/local/cuda/bin/nvcc /home/nshulga/git/pytorch/aten/src/THC/THCTensorMathMagma.cpp -c ...
real 0m2.657s
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58521
Reviewed By: ngimel
Differential Revision: D28526946
Pulled By: malfet
fbshipit-source-id: ed42a9db3349654b75dcf63605bb4256154f01ff
Summary:
This PR adds the ability to publish the xml test data of custom PyTorch PR tests. This PR also adds a few fixes to the custom PyTorch PR tests logic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58436
Reviewed By: seemethere, mruberry
Differential Revision: D28512958
Pulled By: malfet
fbshipit-source-id: d3a1a251d3d126c923d5f733dccfb31a4b701b7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58531
fix data type of alltoall(v) when recording communication metadata via DebugInfo in NCCL PG
Reviewed By: chaekit
Differential Revision: D28529372
fbshipit-source-id: 2917653f73f5fe4f6dc901803235994ca042bba2
Summary:
This PR is step 0 of adding PyTorch convolution bindings using the cuDNN frontend. The cuDNN frontend is the recommended way of using cuDNN v8 API. It is supposed to have faster release cycles, so that, for example, if people find a specific kernel has a bug, they can report it, and that kernel will be blocked in the cuDNN frontend and frameworks could just update that submodule without the need for waiting for a whole cuDNN release.
The work is not complete, and this PR is only step 0.
**What this PR does:**
- Add cudnn-frontend as a submodule.
- Modify cmake to build that submodule.
- Add bindings for convolution forward in `Conv_v8.cpp`, which is disabled by a macro by default.
- Tested manually by enabling the macro and run `test_nn.py`. All tests pass except those mentioned below.
**What this PR doesn't:**
- Only convolution forward, no backward. The backward will use v7 API.
- No 64bit-indexing support for some configuration. This is a known issue of cuDNN, and will be fixed in a later cuDNN version. PyTorch will not implement any workaround for issue, but instead, v8 API should be disabled on problematic cuDNN versions.
- No test beyond PyTorch's unit tests.
- Not tested for correctness on real models.
- Not benchmarked for performance.
- Benchmark cache is not thread-safe. (This is marked as `FIXME` in the code, and will be fixed in a follow-up PR)
- cuDNN benchmark is not supported.
- There are failing tests, which will be resolved later:
```
FAILED test/test_nn.py::TestNNDeviceTypeCUDA::test_conv_cudnn_nhwc_cuda_float16 - AssertionError: False is not true : Tensors failed to compare as equal!With rtol=0.001 and atol=1e-05, found 32 element(s) (out of 32) whose difference(s) exceeded the margin of error (in...
FAILED test/test_nn.py::TestNNDeviceTypeCUDA::test_conv_cudnn_nhwc_cuda_float32 - AssertionError: False is not true : Tensors failed to compare as equal!With rtol=1.3e-06 and atol=1e-05, found 32 element(s) (out of 32) whose difference(s) exceeded the margin of error (...
FAILED test/test_nn.py::TestNNDeviceTypeCUDA::test_conv_large_cuda - RuntimeError: CUDNN_BACKEND_OPERATION: cudnnFinalize Failed cudnn_status: 9
FAILED test/test_nn.py::TestNN::test_Conv2d_depthwise_naive_groups_cuda - AssertionError: False is not true : Tensors failed to compare as equal!With rtol=0 and atol=1e-05, found 64 element(s) (out of 64) whose difference(s) exceeded the margin of error (including 0 an...
FAILED test/test_nn.py::TestNN::test_Conv2d_deterministic_cudnn - RuntimeError: not supported yet
FAILED test/test_nn.py::TestNN::test_ConvTranspose2d_groups_cuda_fp32 - RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
FAILED test/test_nn.py::TestNN::test_ConvTranspose2d_groups_cuda_tf32 - RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
```
Although this is not a complete implementation of cuDNN v8 API binding, I still want to merge this first. This would allow me to do small and incremental work, for the ease of development and review.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51390
Reviewed By: malfet
Differential Revision: D28513167
Pulled By: ngimel
fbshipit-source-id: 9cc20c9dec5bbbcb1f94ac9e0f59b10c34f62740
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58284
- Passing at::Tensor by value can incur a lot of refcount bumps overhead. Passing-by-reference is much more efficient.
- Use Tensor::expect_contiguous() where possible to remove refcount bump overhead when input tensor is already contiguous.
Reviewed By: supriyar, swolchok
Differential Revision: D28432300
fbshipit-source-id: 089ceed08f0d54f109e441f8a1314d726e8481ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57660
Ignore trailing elements so we're compatible with both old and new
models.
Test Plan: Dumped and old model. Unit test.
Reviewed By: malfet
Differential Revision: D28531391
Pulled By: dreiss
fbshipit-source-id: 197a55ab0e6a7d8e25cbee83852e194afacc988e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57659
Faster since we don't do an automatic pprint, and shorter, simpler code.
Test Plan: Dumped some models.
Reviewed By: malfet
Differential Revision: D28531398
Pulled By: dreiss
fbshipit-source-id: 47f1f646d4576af9f7e680933e0512f616dab5c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57658
Since there is no Python change here and we only do the analysis when
rendering the open section, this should have no impact on page size or
load time! (Well, a constant impact on page size due to the added
code.) Before I made it lazy, I observed that it increased load time by
over 100ms for a large model.
Test Plan: Dumped a CUDA model and saw the size summary.
Reviewed By: malfet
Differential Revision: D28531394
Pulled By: dreiss
fbshipit-source-id: f77012b7bab069de861a4ba23486c665e1306aa0
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/57657
Test Plan: Clicked around a model with some dicts in it.
Reviewed By: malfet
Differential Revision: D28531397
Pulled By: dreiss
fbshipit-source-id: 069690f147e91eadd76fec5f5ca4eec057abcb98
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57656
This came up when dumping a CUDA model.
Test Plan: Dumped a CUDA model.
Reviewed By: malfet
Differential Revision: D28531396
Pulled By: dreiss
fbshipit-source-id: fe0e94248c8085a8b760d253ba0b517f153b3442
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57655
Now lots of code is shared between tensor and qtensor rendering. Net
lines of code is actually +1, but it should result in a savings if/when
we implement some of those todos.
Test Plan: Clicked around in Chrome.
Reviewed By: malfet
Differential Revision: D28531395
Pulled By: dreiss
fbshipit-source-id: 190a04ed587b54d27f3410246763cd636c0634be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57654
I learned how to use children in React/Preact. :) Now it's not
necessary to give every hidable section its own id and synchonize the
"shown=false" with "style='display:none;'".
This also means that the hidden elements aren't rendered to the DOM
unless the hider is open.
Test Plan: Clicked around in Chrome.
Reviewed By: malfet
Differential Revision: D28531393
Pulled By: dreiss
fbshipit-source-id: bc86c823ae4b7e80c000f50c5429d89dff6ae64d
Summary:
* Fix lots of links.
* Minor improvements for consistency, clarity or grammar.
* Update jit_python_reference to note the limitations on __exit__.
(Related to https://github.com/pytorch/pytorch/issues/41420).
* Fix a comment in exit_transforms.cpp: removed the word "not" which
made the comment say the opposite of the truth.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57991
Reviewed By: malfet
Differential Revision: D28522247
Pulled By: SplitInfinity
fbshipit-source-id: fc63a59d19ea6c89f957c9f7d451be17d1c5fc91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58060
Generic way to check if Operator belongs to predefined map, and if so via public method(s) access to map value. In general value can be anything for example Operator's schema.
Test Plan: buck test caffe2/test/cpp/jit:jit -- OperatorMap
Reviewed By: Krovatkin
Differential Revision: D28357933
fbshipit-source-id: ba3248cf06c07f16aebafccb7ae71c1245afb083
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58524
Per title
ghstack-source-id: 129311600
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D28528223
fbshipit-source-id: 239a15de4b602e35ed9b15b8a4bea3c28b61de12
Summary:
Move all cuFFT related parts to SpectralOps.cpp
Leave only _fft_fill_with_conjugate_symmetry_cuda_ in SpecralOps.cu
Keep `CUDAHooks.cpp` in torch_cuda_cpp by introducing `at::cuda::detail::THCMagma_init` functor and registering it from global constructor in `THCTensorMathMagma.cu`
Move entire detail folder to torch_cuda_cpp library.
This is a no-op that helps greatly reduce binary size for CUDA-11.x builds by avoiding cufft/cudnn symbol duplication between torch_cuda_cpp(that makes most of cuFFT calls) and torch_cuda_cu (that only needed it to compile SpectralOps.cu)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58459
Reviewed By: ngimel
Differential Revision: D28499001
Pulled By: malfet
fbshipit-source-id: 425a981beb383c18a79d4fbd9b49ddb4e5133291
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: a0c6aa1422
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58477
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D28506522
fbshipit-source-id: 2da92feae212a568cfe441d33e4966ffe6c182e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58347
Back out "Revert D27652484 (ac04cc775b): [nnc] Enable CPU fusion inside Facebook"
Original commit changeset: ecfef3ee1e71
ghstack-source-id: 129279584
Test Plan: Tests for bugfix included in this stack
Reviewed By: navahgar
Differential Revision: D28461013
fbshipit-source-id: 79a80b6ffb653ab952ff5efaa143d3362bb7d966
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58510
In some case that I don't fully understand we're getting a stride that is:
```
{2:1, 1:1, 0:*}
```
(in this debug output, M:N means stride index M, stride value N). This shape
should be considered incomplete, since we don't actually know the values of the
stride, but VaryingShape::isComplete considers it complete because it only
checks the presence of elements in the vector, not whether those elements are
themselves complete.
ghstack-source-id: 129279583
Test Plan:
new unit test in test/cpp/jit
To see the failure in the context of a real model:
```
./fblearner/predictor/loadgen/download-requests.sh 272478342_0 10 ~/local/requests/272478342_0.recordio
buck-out/gen/fblearner/predictor/loadgen/replay_model_requests --model_id=272478342_0 --replay_record_source=recordio:/data/users/bertrand/requests/272478342_0.recordio --remote_port=9119 --output_file=/data/users/bertrand/responses/272478342_0_actual.recordio --output_type=recordio
buck-out/gen/fblearner/predictor/loadgen/replay_model_requests --model_id=272478342_0 --replay_record_source=recordio:/data/users/bertrand/requests/272478342_0.recordio --remote_port=9119 --output_file=/data/users/bertrand/responses/272478342_0_actual.recordio --output_type=recordio
```
Reviewed By: Krovatkin
Differential Revision: D28520062
fbshipit-source-id: 3ca900337d86480a40fbd90349a698cbb2fa5f11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58346
If `dim` is a variable, NNC doesn't know how to translate the result,
since the shape is unknown. This issue manifested as a `bad_variant_access`
when we try to pull an int constant out of that arg.
Note that, while the PE will pick up the resultant shape, it won't set guards accordingly.
ghstack-source-id: 129078971
Test Plan: new fuser test
Reviewed By: navahgar
Differential Revision: D28460956
fbshipit-source-id: 57ef918ef309ee57bfdf86717b910b6549750454
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57396
A new type SourceRef is introduced to represent a unique identifier to source
text. The type holds refcount to underlying source, and supports comparators
and hash functions, such that it can be used in C++ and Python maps. In later
diffs we will use this to aggregate and print profiling information.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D28133578
fbshipit-source-id: c3d5199a8269c5006c85a145b281bcaaf3e2dc1c
Summary:
Hardcoded names often get out of date, for example in AdaptiveAverafePooling those names contained cudnn_ prefix
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58502
Reviewed By: samestep
Differential Revision: D28518917
Pulled By: malfet
fbshipit-source-id: 9b16adae85a179e335da4facb4e769b9f67824bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58097
move unused parameters to end of bucket orders when rebuild buckets for static graph
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D28366689
fbshipit-source-id: fbd224aeb761d5aa3bab35a00d64974eb4455b2e
Summary:
As title, main change:
1. Enable share constant table and reduce model size up to 50%
2. Bump bytecode version from v4 to v5.
3. Add the unittest back. (It was partially removed because `script_module_v5.ptl` bytecode version is v5. When current runtime is v4 and try to load a v5 model, it will raise an error because version is not within the range.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57888
As title
ghstack-source-id: 129255867
Test Plan:
CI
```
buck test papaya/toolkit/frontend/torch/...
buck test mode/opt papaya/integration/service/test/smartkeyboard:smartkeyboard_system_test
```
Reviewed By: raziel, iseeyuan
Differential Revision: D28309381
fbshipit-source-id: 6f5cf4296eaadde913d55f27d5bfb9d1dea2fbaf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58357
Finding a miscompilation in a large program can be tedious; this
script automates the process of bisecting based on the number of fused
instructions. Since fusing aten::cat without the corresponding
prim::ListConstruct will cause an assertion failure, we treat that case as a
"skip" and ignore it for the purpose of bisection.
ghstack-source-id: 129079484
Test Plan:
Tried it on some failing testcases, plus I wrote a simple bash
script to simulate "failure" and "skip" and verified a few different cases.
Reviewed By: huiguoo
Differential Revision: D28463808
fbshipit-source-id: 64836f1d37a573549179410316ea7168e3dc1f23
Summary:
This adds to internal build target and makes it ready for selective build
workflow.
Test Plan: CI builds
Reviewed By: z-a-f
Differential Revision: D28103697
fbshipit-source-id: 19c8b27aae4de1cece8d88d13ea51ca4ac7d79b6
Summary:
Followup to https://github.com/pytorch/pytorch/issues/58491:
- use f-string to remove the literal `generated` string from the generator script, so Phabricator no longer thinks it is a generated file
- remove the special logic for `test_runner_type` and instead explicitly specify for every workflow
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58498
Test Plan:
```
make generate-gha-workflows
```
Also, check that Phabricator doesn't classify `.github/scripts/generate_ci_workflows.py` as "Generated changes" in this diff.
Reviewed By: seemethere
Differential Revision: D28516291
Pulled By: samestep
fbshipit-source-id: 8736eaad5d28082490be0a9b2e271c9493c2ba9d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58278
Borrowing is more efficient, and we can see in all these cases that the TensorIterator doesn't outlive the input & output Tensors.
ghstack-source-id: 129002042
Test Plan: Existing CI
Reviewed By: ezyang
Differential Revision: D28428809
fbshipit-source-id: 23ccf508c4413371a88085271f11c7d0cc861a9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58277
Borrowing is more efficient, and we can see in all these cases that the TensorIterator doesn't outlive the input & output Tensors.
ghstack-source-id: 129002044
Test Plan: Existing CI
Reviewed By: ngimel
Differential Revision: D28428441
fbshipit-source-id: 243b746aeb5fdf8b95c8e591c066c5eab140deb6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58276
Borrowing is more efficient, and we can see in all these cases that the TensorIterator doesn't outlive the input & output Tensors.
ghstack-source-id: 129002045
Test Plan: Existing CI
Reviewed By: ngimel
Differential Revision: D28428234
fbshipit-source-id: 9eada7725a070799b55e6683509e359505a2b80a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58273
Borrowing is more efficient, and structured kernels can always borrow.
ghstack-source-id: 129002041
Test Plan: Existing CI
Reviewed By: ezyang
Differential Revision: D28427914
fbshipit-source-id: eed27a10603b412af5357d3554477ba407abba73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58272
Borrowing is more efficient, and structured kernels can always borrow.
ghstack-source-id: 129002046
Test Plan: Existing CI
Reviewed By: ezyang
Differential Revision: D28427768
fbshipit-source-id: 6314a682556c6914c843aaacf2d75b2adb164e9a
Summary:
This PR simplifies `.github/scripts/generate_ci_workflows.py` by using the same strategy as https://github.com/pytorch/pytorch/issues/54344, representing workflows as plain data to avoid duplicating the definition of the `generate_workflow_file` function. This will make the script easier to maintain if/when that function is modified and/or more workflow types are added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58491
Test Plan:
The Lint job in CI; specifically:
```
make generate-gha-workflows
mypy --config mypy-strict.ini
```
Reviewed By: malfet, seemethere
Differential Revision: D28511918
Pulled By: samestep
fbshipit-source-id: aaf415a954d938a29aee7c9367c9bc2b9f44bb01
Summary:
https://github.com/pytorch/pytorch/issues/55292 introduced perf regression for nonzero cuda, this fixes it. nvcc is still pretty bad about unrolling loops with boundaries that are not known at compile time, this makes `write_indices` kernels ~5x slower than it should be.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58468
Reviewed By: mruberry
Differential Revision: D28511147
Pulled By: ngimel
fbshipit-source-id: fe7303ec77da1abbe5e874093eca247b3919616f
Summary:
Testing for both that a lint job ran and that it was successful depends
on having lint pass for the PR, which can create confusion if it doesn't
(i.e. a flake8 failure also causes this job to fail, and it's not
immediately clear why). With this PR we just check for the presence of
job names to see that something ran.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58490
Reviewed By: samestep
Differential Revision: D28511229
Pulled By: driazati
fbshipit-source-id: 3036deff9f9d0ef2e78b44a9a43b342acdcfa296
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58461
Improves the logic which calculates whether a node has any tensors
in its arguments by terminating the recursion early when possible.
In a future PR, we should probably ditch this entire approach and switch to
using dtype propagation.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28499455
fbshipit-source-id: bedd844022b90e1fcb7d7a3cb4cc65440dc9cc59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58056
This PR addresses an action item in #3428: disabling search engine
indexing of master documentation. This is desireable because we want to
direct users to our stable documentation (instead of master
documentation) because they are more likely to have a stable version of
PyTorch installed.
Test Plan:
1. run `make html`, check that the noindex tags are there
2. run `make html-stable, check that the noindex tags aren't there
Reviewed By: bdhirsh
Differential Revision: D28490504
Pulled By: zou3519
fbshipit-source-id: 695c944c4962b2bd484dd7a5e298914a37abe787
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58444
DDP communication hooks are already supported on Gloo and MPI backends. No longer need to skip these tests on Gloo/MPI backends.
TODO: `test_ddp_hook_parity_powerSGD` failes on Gloo backend. Filed a bug #58467.
ghstack-source-id: 129209528
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_fork -- test_ddp_comm_hook_logging
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_fork -- test_ddp_hook_parity_allreduce
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_fork -- test_ddp_hook_parity_allreduce_process_group
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_fork -- test_ddp_hook_parity_powerSGD
Reviewed By: rohan-varma
Differential Revision: D28494073
fbshipit-source-id: 6ba14082f98696bc4bd8c02395cb58b9c1795015
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58353
There are long tail operators in register_prim_ops_fulljit.cpp, that may be used in mobile build. In this PR
1. All of the ops that are likely to be used in mobile are moved to register_prim_ops.cpp.
2. Note that this move is conservative. If an op is likely to have fulljit dependency, or cannot be selective, it will be kept. Later if there's need to be used in mobile (rare), it will be adapted and moved case by case.
3. All the moved ops are marked selective. The registration function is changed from `Operator()` to `OperatorGenerator()`. Size regression is not expected.
Test Plan:
* Internal size tests
* CI
Reviewed By: dhruvbird
Differential Revision: D28463158
Pulled By: iseeyuan
fbshipit-source-id: 34536b8a569f1274329ccf1dac809fe9b891b4ff
Summary:
Two changes:
1. Build lite interpreter as default for iOS
2. Switch the previous lite interpreter test to full jit build test
Test Plan: Imported from OSS
Differential Revision: D27698039
Reviewed By: xta0
Pulled By: cccclai
fbshipit-source-id: 022b554f4997ae577681f2b79a9ebe9236ca4f7d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58412
Second try- avoid ctor/dtor handling this time as it is kind of
pointless if the rethrow will still terminate(), and upsets -Werror=terminate
Original commit changeset: 1775bed18269
Test Plan: existing unit tests and CI
Reviewed By: suo
Differential Revision: D28478588
fbshipit-source-id: 84191cecc3ef52e23f11bfea07bbb9773ebc5df4
Summary:
torch_cuda_cu depends on torch_cuda_cpp, so it should be linked first
Otherwise linker keeps lots of cudnn symbols for no good reason
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58437
Reviewed By: janeyx99
Differential Revision: D28496472
Pulled By: malfet
fbshipit-source-id: 338605ff755591476070c172a6ea0a0dcd0beb23
Summary: When run on very heavily loaded machines, some of these tests are timing out. It's not an issue with the test, it's an issue with the environment. I've removed the timeout so we at least keep unit test coverage.
Test Plan: N/A: Fix breakages
Reviewed By: ngimel
Differential Revision: D28492334
fbshipit-source-id: aed3ee371763161aab2d356f5623c7df053fda6f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58416https://github.com/pytorch/pytorch/pull/57519 had a regression not
caught by CI, it added an assertion which failed on various model
output types.
This PR removes the assertion and adds the logic to observe graph
outputs in a way that supports arbitrary output formats.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_output_lists_and_dicts
```
Imported from OSS
Reviewed By: z-a-f
Differential Revision: D28479946
fbshipit-source-id: bcce301f98a057b134c0cd34ab0ca96ba457863f
Summary:
Build lite interpreter as default for android, should wait until https://github.com/pytorch/pytorch/pull/56002 lands
Mainly two changes:
1. Use lite interpreter as default for Android
2. Switch the lite interpreter build test to full jit build test
Test Plan: Imported from OSS
Differential Revision: D27695530
Reviewed By: IvanKobzarev
Pulled By: cccclai
fbshipit-source-id: e1b2c70fee6590accc22c7404b9dd52c7d7c36e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58313
Same as title.
I am planning to send a follow-up diff to this op, so sending formatting diff ahead to keep PR simple.
Test Plan: Rely on existing signals since this is simple formatting diff.
Reviewed By: ngimel
Differential Revision: D28447685
fbshipit-source-id: c7cd473b61e40e6f50178aca88b9af197a759099
Summary:
Fixes https://github.com/pytorch/pytorch/issues/57679
##### Release Notes
This is part of the end of the deprecation of inplace/view:
- `detach_` will now raise an error when invoked on any view created by `split`, `split_with_sizes`, or `chunk`. You should use the non-inplace `detach` instead.
- The error message for when an in-place operation (that is not detach) is performed on a view created by `split`, `split_with_size`, and `chunk` has been changed from "This view is **an** output of a function..." to "This view is **the** output of a function...".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58285
Reviewed By: bdhirsh
Differential Revision: D28441980
Pulled By: soulitzer
fbshipit-source-id: e2301d7b8cbc3dcdd328c46f24bcb9eb7f3c0d87
Summary:
This is the only line (not in `third_party`) matching the regex `^#!.*python2`, and [it is not the first line of its file](https://github.com/koalaman/shellcheck/wiki/SC1128), so it has no effect. As a followup to https://github.com/pytorch/pytorch/issues/58275, this PR removes that shebang to reduce confusion, so now all Python shebangs in this repo are `python3`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58409
Reviewed By: walterddr
Differential Revision: D28478469
Pulled By: samestep
fbshipit-source-id: c17684c8651e45d3fc383cbbc04a31192d10f52f
Summary:
This fixes test_lkj_cholesky_log_prob if default codepath is used
I.e. test is executed as follows:
```
ATEN_CPU_CAPABILITY=default python3 distributions/test_distributions.py -v -k test_lkj_cholesky_log_prob
```
Fixes https://github.com/pytorch/pytorch/issues/58381
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58429
Reviewed By: neerajprad
Differential Revision: D28484340
Pulled By: malfet
fbshipit-source-id: 32afcc75e5250f5a11d66b4fa194ea1c784454a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58323
Currently there is no way to run NNAPI on Apple platforms.
Disabling the binding with the preprocessor makes this easier
to enable NNAPI in the internal build without affecting iOS size.
This should be reverted soon and migrated to selective build.
Test Plan: Build Size Bot on later diff.
Reviewed By: axitkhurana
Differential Revision: D28435179
fbshipit-source-id: 040eeb74532752630d329b15d5f95c538c2e3f9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58344
remove a helper function thats more trouble then its worth.
ghstack-source-id: 129131889
Test Plan: ci and {P414950111}
Reviewed By: dhruvbird
Differential Revision: D28460607
fbshipit-source-id: 31bd6c1cc169785bb360e3113d258b612cad47fc
Summary:
Since https://github.com/pytorch/pytorch/issues/58299 changed the calculate-docker-image job from `ubuntu-18.04` to `linux.2xlarge`, it has been sometimes failing with this message:
```
Warning: Unable to clean or reset the repository. The repository will be recreated instead.
Deleting the contents of '/home/ec2-user/actions-runner/_work/pytorch/pytorch'
Error: Command failed: rm -rf "/home/ec2-user/actions-runner/_work/pytorch/pytorch/.azure_pipelines"
```
- https://github.com/pytorch/pytorch/runs/2587348894
- https://github.com/pytorch/pytorch/runs/2592943274
- https://github.com/pytorch/pytorch/runs/2600707737
This PR hopes to fix that issue by adding the "Chown workspace" step that we already use for the other jobs in the Linux CI workflow.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58398
Reviewed By: seemethere
Differential Revision: D28476902
Pulled By: samestep
fbshipit-source-id: a7dbf0ad9c18ac44cc1a3cef7647f56489958fe6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57510
This is a re-write of https://github.com/pytorch/pytorch/pull/56835, which is significantly shorter thanks to the data model change in the PR below this one in the stack. See the original description in the linked PR for details.
The functional changes in this PR are the same as in the above linked one, so the description is the same with a few small changes:
- I don't bother generating `at::xla::{op}` entries for CPU fallbacks. After looking around, I see precedent for that. For example, we don't have `at::cpu::{op}` entries for composite ops- if you really want to bypass the dispatcher you need to call `at::compositeimplicitautograd::{op}`. Maybe we should revisit that later if we find an important use case for having full namespace coverage, but that doesn't seem worth half-fixing for external backends in this PR.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D28474364
Pulled By: bdhirsh
fbshipit-source-id: 4d58b60e5debad6f1ff06420597d8df8505b2876
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57361
Data model change in the codegen, which splits backend-specific information out of `NativeFunction`
### Overview
Currently in the codegen, native_functions.yaml has backend-specific information about each operator that is encoded directly into the data model, in the `NativeFunction` object. That's reasonable, since the native_functions.yaml is the source of truth for information about an operator, and the data model encodes that information into types.
Now that external backends can use the codegen though, that information is technically incomplete/inaccurate. In another PR, I tried patching the information on the `NativeFunction` object with the additional external information, by updating the `dispatch` entry to contain the external backend kernel name and dispatch key.
Instead, this PR tries to split out that information. The `NativeFunction` class contains all information about an operator from native_functions.yaml that's backend-independent and is known never to change regardless of what extra information backends provide. We also build up a backend "index", which is basically a mapping from [backend] -> [backend-specific-metadata]. Reading in an external backend yaml just involves updating that index with the new backend.
There were a few places where `NativeFunction` used the dispatch table directly, that I encoded as properties directly on the NativeFunction object (e.g. `is_abstract`). They were mostly around whether or not the operator has a composite kernel, which isn't something that's going to change for any external backends.
This has a few advantages:
- We can more easily re-use the existing logic in `native_function.py` and `register_dispatch_key.py` for both native and external backends, since they both involve a NativeFunction + a particular backend index
- The data in the data model will be the same regardless of how the codegen is run. Running the codegen with a new external backend doesn't change the data inside of NativeFunction or an existing backend index. It just adds a new index for that backend.
- There are several of codegen areas that don't care about backend-specific information: mostly the tracing and autograd codegen. We can reason about the codegen there more easily, knowing that backend-specific info is entirely uninvolved.
An alternative to this split would be to augment the NativeFunction objects with external backend information at the time that we create them. So the external codegen could read both native_functions.yaml and the external backend's yaml at the same time, and construct a NativeObject with a full dispatch table (including the XLA entry), and the correct setting of structured (taking into account both yamls). One disadvantage to this approach is that NativeFunction objects now contain different stuff depending on how you ran the codegen, and you have to make sure that any changes to the codegen can properly handle all the different variants.
### Data Model Changes
Removed 3 classes, which are used by the external codegen:
- ExternalBackendFunction
- ExternalBackendFunctionsGroup
- ExternalBackendMetadata
And added two new ones:
- BackendIndex
- BackendMetadata
`BackendIndex` contains any info that's specific to that backend, plus a mapping from operator names to backend specific metadata about the operator. One example of backend-specific info that's not operator-dependent is the fact that XLA prefers to implement functional kernels instead of out kernels (and so when they eventually mark an op as structured, they're going to mark the functional op and not the out op).
`BackendMetadata` contains info specific to an (operator, backend) pair. Right now, that's just (a) the name of the kernel, and (b) whether or not that operator is structured.
### Questions
I wanted to get this PR up earlier so I could get feedback, but there are a few things I want to call out:
**Dealing with `structured`.**
This PR separates out the notion of `structured` into two bits of information:
- Does [operator] have a meta() function. This is backend-agnostic, and is represented by the `structured` property on `NativeFunction`, same as before. This is used, e.g., to decide what signatures to add to `MetaFunctions.h`.
- Does [operator, backend] have an impl() function. This is backend dependent; even though technically all in-tree backends are forced to write impl() functions for an operator when we port the op to structured in native_functions.yaml, out-of-tree backends can decide to opt in independently. This is represented as a property on `BackendMetadata`. This is used in most other cases, e.g. in `RegisterDispatchKey` when we're deciding whether or not to gen a structured or unstructured wrapper.
I also baked `is_structured_dispatch_key` directly into each BackendIndex. So for operators marked "structured" in native_functions.yaml, their corresponding CPU/CUDA BackendIndex entries will be marked structured, and all others (except for potentially external backends) will not.
I ended up trying to deal with `structured` in this change since it's technically backend dependent (XLA can opt kernels into structured separately from in-tree ops), but that may have been too ambitious: it's technically not relevant until we actually add support for structured external kernels. If it's not clear that this is the right path for dealing with structured and we want to push that off, I'm fine with backing out the bits of this PR that make `structured` backend-dependent. I don't see anything *too* controversial related to structured in the change, but I tried to call out any areas in the comments
**Localizing the fact that external backends follow Dispatcher convention.**
Another thing that's sort of backend specific that I didn't totally address in this PR is the fact the fact that in-tree backends follow the Native API while external backends follow the Dispatcher API. I painted over that in `native_functions.py` by adding a helper, `kernel_signature`, that takes in a native function and gives you the "correct" signature for the specified backend- NativeSignature for in-tree backends, and DispatcherSignature for out-of-tree backends. In order to make that fully useable though, we'll need `NativeSignature` and `DispatcherSignature` to have matching interfaces. I didn't bother with that in this PR, which is why `gen_external_aten_fallbacks.py` still has a bunch of direct references to the dispatcher API. Thinking of adding it in a later PR but wanted to see if anyone has other opinions.
Maybe `is_external()` shouldn't even be a property on the BackendMetadata, and anything the codegen does that requires asking for that information should just be better abstracted away.
**Thoughts on the `BackendIndex` / `BackendMetadata` breakdown.**
One thing that's annoying right now is that to query for various pieces of metadata, you call helper functions like `backend_index.structured(f)`, which queries that particular backend and tells you if that specific NativeFunctionGroup is structured for that backend. It has to return an `Optional[bool]` though, since you have to handle the case where that operator doesn't have a kernel for that backend at all. So users of those helpers end up with a bunch of optionals that they need to unpack, even if they know at some point that the result isn't None. I think it would be easier instead to just store the NativeFunction object as a field directly on the BackendMetadata. Curious if there are any other opinions on a better way to model it though.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D28474362
Pulled By: bdhirsh
fbshipit-source-id: 41a00821acf172467d764cb41e771e096542f661
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56597
3 small changes, all centered around error messaging.
1) Improved error messages when `gen_backend_stubs.py` receives invalid yaml
2) Added error message tests. I wasn't sure if there was a canonical way to do this, so I just wrote a test that takes in a list of (yaml input, expected error message) pairs and runs the codegen pipeline on each of them.
3) I also removed the LineLoader from the yaml parsing bit that reads in the external backend yaml file. Two reasons that I took it out:
- The main reason we use it with native_functions.yaml is to easily pinpoint problems with new ops as they're added, that the codegen can pick up. 99% of these problems have to do with schema, which is irrelevant to the external yaml since it pulls the schema from native_functions
- Not all operators have to appear in the external yaml. We could do something like "line: -1", but that's kind of weird.
If you think the line numbers would actually be of more use than I'm thinking of in the external yaml though, let me know!
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D28474363
Pulled By: bdhirsh
fbshipit-source-id: 8b5ec804b388dbbc0350a20c053da657fad0474f
| Linux (aarch64) CPU | [](https://status.openlabtesting.org/builds/builds?project=pytorch%2Fpytorch&job_name=pytorch-arm64-build-daily-master-py36) | [](https://status.openlabtesting.org/builds/builds?project=pytorch%2Fpytorch&job_name=pytorch-arm64-build-daily-master-py37) | [](https://status.openlabtesting.org/builds/builds?project=pytorch%2Fpytorch&job_name=pytorch-arm64-build-daily-master-py38) |
See also the [ci.pytorch.org HUD](https://ezyang.github.io/pytorch-ci-hud/build/pytorch-master).
See also the [ci.pytorch.org HUD](https://hud.pytorch.org/build2/pytorch-master).
## More About PyTorch
@ -270,13 +270,13 @@ Sometimes there are regressions in new versions of Visual Studio, so
it's best to use the same Visual Studio Version [16.8.5](https://github.com/pytorch/pytorch/blob/master/.circleci/scripts/vs_install.ps1) as Pytorch CI's.
You can use Visual Studio Enterprise, Professional or Community though PyTorch CI uses Visual Studio BuildTools.
If you want to build legacy python code, please refert to [Building on legacy code and CUDA](https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md#building-on-legacy-code-and-cuda)
If you want to build legacy python code, please refer to [Building on legacy code and CUDA](https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md#building-on-legacy-code-and-cuda)
Build with CPU
It's fairly easy to build with CPU.
Note on OpenMP: The desired OpenMP implementation is Intel OpenMP (iomp). In order to link against iomp, you'll need to manually download the library and set up the buliding environment by tweaking `CMAKE_INCLUDE_PATH` and `LIB`. The instruction [here](https://github.com/pytorch/pytorch/blob/master/docs/source/notes/windows.rst#building-from-source) is an example for setting up both MKL and Intel OpenMP. Without these configuraions for CMake, Microsoft Visual C OpenMP runtime (vcomp) will be used.
Note on OpenMP: The desired OpenMP implementation is Intel OpenMP (iomp). In order to link against iomp, you'll need to manually download the library and set up the building environment by tweaking `CMAKE_INCLUDE_PATH` and `LIB`. The instruction [here](https://github.com/pytorch/pytorch/blob/master/docs/source/notes/windows.rst#building-from-source) is an example for setting up both MKL and Intel OpenMP. Without these configurations for CMake, Microsoft Visual C OpenMP runtime (vcomp) will be used.
Build with CUDA
@ -353,7 +353,7 @@ should increase shared memory size either with `--ipc=host` or `--shm-size` comm
**NOTE:** Must be built with a docker version > 18.06
The `Dockerfile` is supplied to build images with Cuda support and cuDNN v7.
The `Dockerfile` is supplied to build images with CUDA 11.1 support and cuDNN v8.
You can pass `PYTHON_VERSION=x.y` make variable to specify which Python version is to be used by Miniconda, or leave it
* Add `release/{MAJOR}.{MINOR}` to list of branches in [`browser-extension.json`](https://github.com/pytorch/pytorch/blob/fb-config/browser-extension.json) for FaceHub integrated setups
> TODO: Create release branch in [`pytorch/builder`](https://github.com/pytorch/builder) repo and pin release CI to use that branch rather than HEAD of builder repo.
These are examples of changes that should be made to the *default* branch after a release branch is cut
* Nightly versions should be updated in all version files to the next MINOR release (i.e. 0.9.0 -> 0.10.0) in the default branch:
We also have to add all transitive dependencies of our aars.
As `pytorch_android` [depends](https://github.com/pytorch/pytorch/blob/master/android/pytorch_android/build.gradle#L62-L63) on `'com.android.support:appcompat-v7:28.0.0'`, `'com.facebook.soloader:nativeloader:0.8.0'` and 'com.facebook.fbjni:fbjni-java-only:0.0.3', we need to add them.
As `pytorch_android` [depends](https://github.com/pytorch/pytorch/blob/master/android/pytorch_android/build.gradle#L76-L77) on `'com.facebook.soloader:nativeloader:0.8.0'` and `'com.facebook.fbjni:fbjni-java-only:0.0.3'`, we need to add them.
(In case of using maven dependencies they are added automatically from `pom.xml`).
You can check out [test app example](https://github.com/pytorch/pytorch/blob/master/android/test_app/app/build.gradle) that uses aars directly.
#pragma omp parallel for if ((end - begin) >= grain_size)
#pragma omp parallel for
for(int64_tid=0;id<num_results;id++){
int64_ti=begin+id*grain_size;
try{
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
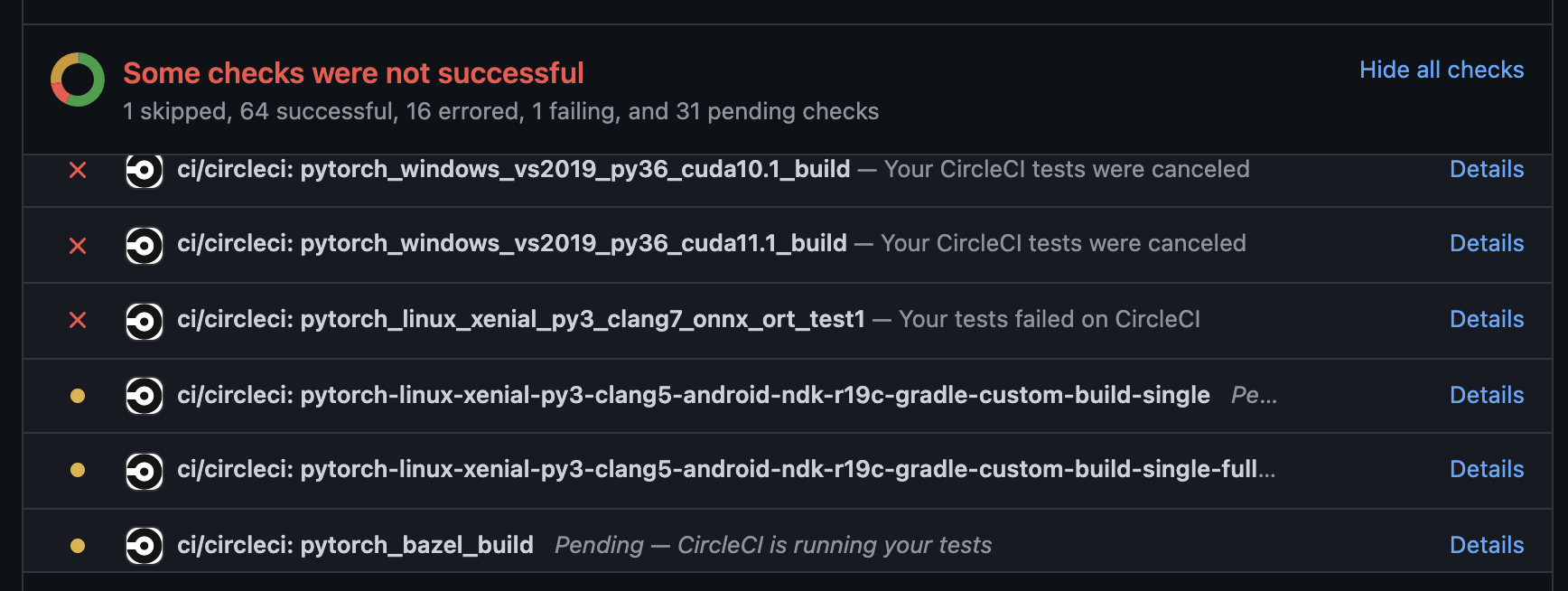{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}