Fixes issue for serialization problem caused by using memory address of storages for mobile and torch.package models.
- https://github.com/pytorch/pytorch/pull/59642 hold references to storages during TorchScript serialization
Uses StorageContext to hold a reference to all storages seen during TorchScript serialization to allow for tensors to be created/destroyed during serialization process. Tracking of the storages solves for the ABA memory problem.
* Move cublas dependency after CuDNN (#58287)
Summary:
Library linking order matters during static linking
Not sure whether its a bug or a feature, but if cublas is reference
before CuDNN, it will be partially statically linked into the library,
even if it is not used
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58287
Reviewed By: janeyx99
Differential Revision: D28433165
Pulled By: malfet
fbshipit-source-id: 8dffa0533075126dc383428f838f7d048074205c
* [CMake] Split caffe2::cudnn into public and private (#59721)
Summary:
This is only important for builds where cuDNN is linked statically into libtorch_cpu.
Before this PR PyTorch wheels often accidentally contained several partial copies of cudnn_static library.
Splitting the interface into header only (cudnn-public) and library+headers(cudnn-private) prevents those from happening.
Preliminary step towards enabling optional linking whole cudnn_library to workaround issue reported in https://github.com/pytorch/pytorch/issues/50153
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59721
Reviewed By: ngimel
Differential Revision: D29000967
Pulled By: malfet
fbshipit-source-id: f054df92b265e9494076ab16c247427b39da9336
* Add USE_WHOLE_CUDNN option (#59744)
Summary:
It is only enabled if USE_STATIC_CUDNN is enabled
Next step after https://github.com/pytorch/pytorch/pull/59721 towards resolving fast kernels stripping reported in https://github.com/pytorch/pytorch/issues/50153
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59744
Reviewed By: seemethere, ngimel
Differential Revision: D29007314
Pulled By: malfet
fbshipit-source-id: 7091e299c0c6cc2a8aa82fbf49312cecf3bb861a
* [Binary] Link whole CuDNN for CUDA-11.1 (#59802)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50153
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59802
Reviewed By: driazati, seemethere
Differential Revision: D29033537
Pulled By: malfet
fbshipit-source-id: e816fc71f273ae0b4ba8a0621d5368a2078561a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59633Fixes#59614
This fix isn't 100% correct but it appears to stem the bleeding.
A better fix would be understand how to detect when function
implementations don't uphold required invariants, leading to
refcount disaster.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D28962183
Pulled By: ezyang
fbshipit-source-id: 6ec71994666289dadef47bac363e6902df90b094
Summary:
After the change async error warnings look as follows:
```
$ python -c "import torch;torch.eye(3,3,device='cuda:777')"
Traceback (most recent call last):
File "<string>", line 1, in <module>
RuntimeError: CUDA error: invalid device ordinal
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59467
Reviewed By: ngimel
Differential Revision: D28904360
Pulled By: malfet
fbshipit-source-id: 2a8fa5affed5b4ffcaa602c8ab2669061cde7db0
Summary:
Default NEON accelerated implementation of reciprocal uses vrecpeq_f32 which yield Newton-Raphson approximation rather than actual value
Use regular NEON accelerated division for reciprocal and reciprocal square root operations.
This fixes `test_reference_numerics_hard_frac_cpu_float32`, `test_reference_numerics_normal_rsqrt_cpu_float32` etc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59361
Reviewed By: mruberry
Differential Revision: D28870456
Pulled By: malfet
fbshipit-source-id: e634b0887cce7efb046ea1fd9b74424e0eceb164
Summary:
Before that, only dynamically linked OpenBLAS compield with OpenMP could
be found.
Also get rid of hardcoded codepath for libgfortran.a in FindLAPACK.cmake
Only affects aarch64 linux builds
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59428
Reviewed By: agolynski
Differential Revision: D28891314
Pulled By: malfet
fbshipit-source-id: 5af55a14c85ac66551ad2805c5716bbefe8d55b2
Summary:
Context https://github.com/pytorch/pytorch/issues/58545
The logic is that we are going to keep it consistent for both
torch.randperm and torch.randint
1. Generators can have either a fully-specified or non-fully specified device
2. As long as the device type match with the result, we don't error out
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59352
Test Plan:
```
python test/test_tensor_creation_ops.py -k TestRandomTensorCreation
```
Reviewed By: ngimel
Differential Revision: D28855920
Pulled By: zhouzhuojie
fbshipit-source-id: f8141a2c4b2f177e1aa7baec6999b65916cba02c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59413
For CUDA 10.2 builds linked with the gold linker we were observing
crashes when exceptions were being raised
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D28888054
Pulled By: seemethere
fbshipit-source-id: f9b38147591721803ed3cac607510fe5bbc49d6d
(cherry picked from commit c7a3a13baba0d547c5c20579328b0b3d83b94656)
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Summary:
Hello,
depending on the build environment you may encounter
```c++
error: reference to 'optional' is ambiguous
```
when using the Torch-C++-API.
This PR adds `c10::` to avoid possible ambiguities with **std::optional** and does not introduce any functional change.
Fixes https://discuss.pytorch.org/t/linker-failed-with-ambiguous-references/36255 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45736
Reviewed By: dzhulgakov
Differential Revision: D24125123
Pulled By: VitalyFedyunin
fbshipit-source-id: df21420f0a2d0270227c28976a7a4218315cc107
Co-authored-by: Johannes Czech <QueensGambit@users.noreply.github.com>
This is the combination of #59236 and #58685 which will enable <insert builder PR here> to land on the release branch. This enables breakpad for minidump collection (which is still opt-in) and debug builds for the release.
Co-authored-by: Your Name <driazati@users.noreply.github.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58573
Users can create invalid imports, like:
```
HG: in a top-level package
if False:
from .. import foo
```
Since this code is never executed, it will not cause the module to fail to
load. But our dependency analysis walks every `import` statement in the AST,
and will attempt to resolve the (incorrectly formed) import, throwing an exception.
For posterity, the code that triggered this: https://git.io/JsCgM
Differential Revision: D28543980
Test Plan: Added a unit test
Reviewed By: Chillee
Pulled By: suo
fbshipit-source-id: 03b7e274633945b186500fab6f974973ef8c7c7d
Co-authored-by: Michael Suo <suo@fb.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58572
Right now, we have three categories of error (broken, denied, unhandled). This
PR unifies them into a single "error" field in the node, with optional context.
It also generalizes how formatting of the error in PackagingError occurs.
Differential Revision: D28543982
Test Plan: sandcastle
Reviewed By: Chillee
Pulled By: suo
fbshipit-source-id: d99d37699ec2e172e3798763e60aafe9a66ed6f4
Co-authored-by: Michael Suo <suo@fb.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58702
Off by one error when determining if some ranks failed or not with
`wait_all_ranks=True`. This wasn't caught by tests because the tests only
tested failure scenarios, not success scenarios with `wait_all_ranks=True`.
ghstack-source-id: 129559840
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28583235
fbshipit-source-id: a8f376efb13a3f36c788667acab86543c80aff59
Summary:
The `factory_kwargs` kwarg was previously undocumented in `nn.Quantize`. Further, the `Attributes` section of the docs was improperly filled in, resulting in bad formatting. This section doesn't apply since `nn.Quantize` doesn't have parameters, so it has been removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59025
Reviewed By: anjali411
Differential Revision: D28723889
Pulled By: jbschlosser
fbshipit-source-id: ba86429f66d511ac35042ebd9c6cc3da7b6b5805
Co-authored-by: Joel Schlosser <jbschlosser@fb.com>
Summary:
Move all cuFFT related parts to SpectralOps.cpp
Leave only _fft_fill_with_conjugate_symmetry_cuda_ in SpecralOps.cu
Keep `CUDAHooks.cpp` in torch_cuda_cpp by introducing `at::cuda::detail::THCMagma_init` functor and registering it from global constructor in `THCTensorMathMagma.cu`
Move entire detail folder to torch_cuda_cpp library.
This is a no-op that helps greatly reduce binary size for CUDA-11.x builds by avoiding cufft/cudnn symbol duplication between torch_cuda_cpp(that makes most of cuFFT calls) and torch_cuda_cu (that only needed it to compile SpectralOps.cu)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58459
Reviewed By: ngimel
Differential Revision: D28499001
Pulled By: malfet
fbshipit-source-id: 425a981beb383c18a79d4fbd9b49ddb4e5133291
Summary:
`makeDeviceForHostname` and `makeDeviceForInterface` are almost
duplicate except for different default argument values
Create generic `makeGlooDevice` anonymous function that takes both host
name and interface name and call it from both
makeDeviceFor[Hostname|Interface]
Also solve two other minor issues:
- do not call `getenv("GLOO_DEVICE_TRANSPORT")` during library load
time
- Raise exception rather than crash if GLOO_DEVICE_TRANSPORT is set to unknown value
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58996
Reviewed By: pbelevich
Differential Revision: D28713324
Pulled By: malfet
fbshipit-source-id: cb33b438078d163e3ec6f047f2e5247b07d94f8d
Summary:
Fixes upcoming changes that are part of ROCm 4.2 and affect PyTorch JIT.
- ROCM_VERSION macro must be available to both device and host compilation passes.
- Unifies some of CUDA and HIP differences in the code generated.
- NAN / POS_INFINITY / NEG_INFINITY
- Do not hipify `extern __shared__` -> `HIP_DYNAMIC_SHARED()` macro [deprecated]
- Differentiates bf16 codegen for HIP.
- Optionally provides missing macros when using hiprtc precompiled header feature.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57400
Reviewed By: ejguan
Differential Revision: D28421065
Pulled By: malfet
fbshipit-source-id: 215f476773c61d8b0d9d148a4e5f5d016f863074
Co-authored-by: Jeff Daily <jeff.daily@amd.com>
Summary:
torch_cuda_cu depends on torch_cuda_cpp, so it should be linked first
Otherwise linker keeps lots of cudnn symbols for no good reason
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58437
Reviewed By: janeyx99
Differential Revision: D28496472
Pulled By: malfet
fbshipit-source-id: 338605ff755591476070c172a6ea0a0dcd0beb23
* Add underscores to some internal names
Summary:
Add underscores to some of the internal names
Test Plan:
python test/test_profiler.py -v
Reviewers: anjali411
[ghstack-poisoned]
* Add underscores to some internal names
Summary:
Add underscores to some of the internal names
Test Plan:
python test/test_profiler.py -v
Reviewers: anjali411
[ghstack-poisoned]
Co-authored-by: ilia-cher <iliacher@fb.com>
Summary:
The `UninitializedBuffer` class was previously left out of `nn.rst`, so it was not included in the generated documentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59021
Reviewed By: anjali411
Differential Revision: D28723044
Pulled By: jbschlosser
fbshipit-source-id: 71e15b0c7fabaf57e8fbdf7fbd09ef2adbdb36ad
Co-authored-by: Joel Schlosser <jbschlosser@fb.com>
* Underscore prefix sparse_csr_tensor and to_sparse_csr
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
* fix lint
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Summary:
Adds a note explaining the difference between several often conflated mechanisms in the autograd note
Also adds a link to this note from the docs in `grad_mode` and `nn.module`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58513
Reviewed By: gchanan
Differential Revision: D28651129
Pulled By: soulitzer
fbshipit-source-id: af9eb1749b641fc1b632815634eea36bf7979156
Summary:
Do not put quotes for arguments that do not have space in them in add_to_env_file
ENV file is used both by bash as well as by docker, which does not omit
quotes when they are present there
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58637
Reviewed By: wconstab
Differential Revision: D28561159
Pulled By: malfet
fbshipit-source-id: 0843aad22703b6c3adebeb76175de1cfc1a974b5
Summary:
Since v1.7, oneDNN (MKL-DNN) has supported the use of Compute Library
for the Arm architeture to provide optimised convolution primitives
on AArch64.
This change enables the use of Compute Library in the PyTorch build.
Following the approach used to enable the use of CBLAS in MKLDNN,
It is enabled by setting the env vars USE_MKLDNN and USE_MKLDNN_ACL.
The location of the Compute Library build must be set useing `ACL_ROOT_DIR`.
This is an extension of the work in https://github.com/pytorch/pytorch/pull/50400
which added support for the oneDNN/MKL-DNN backend on AArch64.
_Note: this assumes that Compute Library has been built and installed at
ACL_ROOT_DIR. Compute library can be downloaded here:
`https://github.com/ARM-software/ComputeLibrary`_
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55913
Reviewed By: ailzhang
Differential Revision: D28559516
Pulled By: malfet
fbshipit-source-id: 29d24996097d0a54efc9ab754fb3f0bded290005
* [PyTorch Edge] bytecode version bump to v5 and enable share constant table
* [Pytorch] Build lite interpreter as default for iOS
* [Pytorch] Build lite interpreter as default for Android
torch.vmap is a prototype feature and should not be in the stable
binary. This PR:
- Removes the torch.vmap API
- Removes the documentation entry for torch.vmap
- Changes the vmap tests to use an internal API instead of torch.vmap.
Test Plan:
- Tested locally (test_torch, test_autograd, test_type_hints, test_vmap),
but also wait for CI.
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58363
Previous implemntation relied on us directly writing the yaml instead of
just having a conditional block, this allows us better readability for
pull request triggers
Signed-off-by: Eli Uriegas <seemethere101@gmail.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D28465271
Pulled By: seemethere
fbshipit-source-id: fd556bb6bac4954fcddb4a2b0383e996f292a794
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58408
Itd be nice to have a version of bundle inputs that didnt mutate the original class/object. So now there is!
ghstack-source-id: 129127316
Test Plan: The new unittests
Reviewed By: dhruvbird
Differential Revision: D28460231
fbshipit-source-id: f6f7a19e264bddfaa177304cbde40336060a237a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58384
When the caller send tensors within a request, it does so on fresh streams it obtained from the caching allocator. However it wasn't recording those tensors with the caching allocator. This carried the risk that, if those tensors were deleted before the async CUDA ops were done, the caching allocator could reuse the storage and thus overwrite the previous data while it was still being used.
ghstack-source-id: 129107582
Test Plan: eyes
Reviewed By: mrshenli
Differential Revision: D28473429
fbshipit-source-id: 3f2617048d984cec7a270858d282cecf1140ecf0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58391
An additional (and hopefully more robust) way of fixing the same problem https://github.com/pytorch/pytorch/pull/58382 fixed.
ghstack-source-id: 129110325
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28474154
fbshipit-source-id: 625ebe782e380c60b3ead4c4ed8a51d4bc917153
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58382
Calling markCompleted on a Future now first acquires the Future's mutex (as usual) but then sometimes tries to acquire the GIL during the DataPtr extraction while still holding the Future's mutex. (This happens when the value passed to markCompleted is a Python object). This can cause a deadlock if someone else calls any of the other methods of Future while holding the GIL.
There are two solutions to this: avoid holding the Future's mutex when extracting DataPtrs, and avoid holding the GIL while invoking the Future's method. In this PR I'm going for the latter, because it's a very simple immediate fix, but I believe this is brittle and that we should probably also consider the former fix.
ghstack-source-id: 129105358
Test Plan: The repro in https://github.com/pytorch/pytorch/issues/58239 now doesn't deadlock.
Reviewed By: mrshenli
Differential Revision: D28472816
fbshipit-source-id: 1bc9bca426dd004f9eb2568db1ffd38f014450e2
Summary:
Deprecation warning reported by cmake:
```
CMake Deprecation Warning at CMakeLists.txt (cmake_minimum_required):
Compatibility with CMake < 2.8.12 will be removed from a future version of CMake.
Update the VERSION argument <min> value or use a ...<max> suffix to tell
CMake that the project does not need compatibility with older versions.
```
This is the only place that requires bumping min version. There're two others but only in `third_party` folder.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58306
Reviewed By: bdhirsh
Differential Revision: D28446097
Pulled By: zhouzhuojie
fbshipit-source-id: af5ef50e61bd57dc36089ebe62db70ba0081864c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58192
Exceptions thrown by deploy internals need to be sanitized
for application safety.
See commment in deploy.h for detailed explanation.
Test Plan: Added unit test
Reviewed By: suo
Differential Revision: D28371127
fbshipit-source-id: c0ced2f194424a394c5852bd4ab5cb41b0f4e87b
Summary:
Previously only the **branch** is specified when triggering the multi-gpu pipeline, which could result in incorrect commit being targeted, because when the pipeline actually runs there could be newer commit on the specified branch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58219
Reviewed By: malfet, bdhirsh
Differential Revision: D28446453
Pulled By: seemethere
fbshipit-source-id: 680c0b3a9f3f20b61787cc90fda73b87d66e6af8
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 9ed4fb12a4
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57613
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D28220987
fbshipit-source-id: 4ecd2589d01f91678194d9e3ac309ad6f6df3e70
Summary:
Include jobs master-only jobs depends on to the workflow
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58335
Reviewed By: walterddr
Differential Revision: D28458406
Pulled By: malfet
fbshipit-source-id: 217a8996daacd494af1bbc54e725bbcacc0c7784
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58339
The operator was present as part of full_jit ops but wasn't included for mobile. The diff copies it for mobile
Test Plan: buck run xplat/langtech/mobile:giga5_bin -- --voice /data/users/prabhavag/experiments/embedded_new_stateful_conv_may6/nicole_batch.giga5 --frontend /data/users/prabhavag/experiments/tools_pkg/en_US.embedded.frontend.titan --icudata xplat/third-party/icu/stubdata/reduced/icudt55l.dat --text "haha"
Reviewed By: iseeyuan
Differential Revision: D28452179
fbshipit-source-id: ef7a929f1a6d40573438785a4959c1c1e39762f0
Summary:
Freezing exists as a pass which partially evaluates your model and applies generic optimizations which should speed it up. Optimize for inference is a counterpart to these optimizations which runs build & server specific optimizations. The interaction with existing `optimize_frozen_module` is not great, I guess we could just deprecate the API entirely? it was never officially released but just existed to document the `optimize_numerics` keyword.
Eventually, I would like to add a way of adding example inputs but I didnt add that here because they are not being used at all yet. I also have not yet included a way to blacklist individual optimizations, and would like to wait until we move this to Beta and have a little more clarity on how everything will fit together. I also think blacklisting will be an uncommon use case for the current optimizations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58193
Reviewed By: bertmaher, navahgar
Differential Revision: D28443714
Pulled By: eellison
fbshipit-source-id: b032355bb2585720a6d2f00c89d0d9a7ef60e649
Summary:
tl;dr; rewrites the FX graph mode quantization observer insertion to be easier to understand and extend.
The key conceptual difference from before is:
* before: for each node, observers are always inserted to the output of the current node, even if they are needed for the next node. This is hard to reason about.
* after: for each node, observers are inserted to the inputs (if needed, as calculated by the dtype of the argument and dtype of current node) and to the output (if needed for the type of pattern and qconfig). There is no knowledge of future nodes needed to insert observers for the current node.
This allows us to significantly simplify various things:
* all new observers needed for a node are inserted together. This makes it easier to understand and debug things. We add an invariant that node X will never change any observers inserted by any preceding or subsequent node, so to debug an issue the user can just understand what is happening for node X, without having to understand what happens before or after it.
* all the state tracking of activation_post_process_map and activation_post_process_indices are removed, instead observers are looked up by graph traversals
* since there is no longer a need for overlapping graph passes which mutate each other's interemediate state, it is easier to understand what the rules are for inserting observers, and to create new rules in the future.
Test Plan:
```
# all OSS tests pass
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Differential Revision: D28241864
Reviewed By: jerryzh168
Pulled By: vkuzo
fbshipit-source-id: 950d58972d26362808564cc0a2dfb30413a3734d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58345
1. Add a sanity check to make sure any new attribute added to the constructor should be added to either `_REMOTE_MODULE_ATTRIBUTES_IGNORE_FOR_PICKLING` pr `_REMOTE_MODULE_ATTRIBUTES_IGNORE_FOR_PICKLING`.
2. Update some comments and warning -- now if a new attribute is added after the construction, it will not be pickled. Previously it will trigger a runtime error, which is hard for unit test (one worker hit the runtime error, but the other worker will cause timeout).
Context: https://github.com/pytorch/pytorch/pull/58019#discussion_r632322083
ghstack-source-id: 129070358
Test Plan: unit test
Reviewed By: rohan-varma
Differential Revision: D28460744
fbshipit-source-id: 8028186fc447c88fbf2bf57f5c5d321f42ba54ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57483
Pull Request resolved: https://github.com/pytorch/glow/pull/5622
Quantized linear has packed parameters. We want to unpack it so that it would be easier for graph optimization and importer to deal with the weight and bias. A customized remapping function is used to unpack quantized linear and map it to acc_op.linear.
Test Plan: `buck test glow/fb/fx/nnpi_importer:test_importer`
Reviewed By: gcatron, jfix71, khabinov
Differential Revision: D27451237
fbshipit-source-id: e46e961734788fd5333e227ca6143fd37c33204e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58182
As title, the v5 model format will be
```
(base) chenlai@chenlai-mp reuse_constant % zipinfo /Users/chenlai/Documents/pytorch/reuse_constant/tmp/zip/script_module_v5_unify.ptl
Archive: /Users/chenlai/Documents/pytorch/reuse_constant/tmp/zip/script_module_v5_unify.ptl
Zip file size: 3120 bytes, number of entries: 7
-rw---- 0.0 fat 77 bl stor 80-000-00 00:00 script_module_v4_unify/data.pkl
-rw---- 0.0 fat 240 bl defN 80-000-00 00:00 script_module_v4_unify/code/__torch__/___torch_mangle_5.py
-rw---- 0.0 fat 422 bl defN 80-000-00 00:00 script_module_v4_unify/code/__torch__/___torch_mangle_5.py.debug_pkl
-rw---- 0.0 fat 64 bl stor 80-000-00 00:00 script_module_v4_unify/constants/140245072983168.storage
-rw---- 0.0 fat 172 bl stor 80-000-00 00:00 script_module_v4_unify/constants.pkl
-rw---- 0.0 fat 678 bl stor 80-000-00 00:00 script_module_v4_unify/bytecode.pkl
-rw---- 0.0 fat 2 bl stor 80-000-00 00:00 script_module_v4_unify/version
7 files, 1655 bytes uncompressed, 1453 bytes compressed: 12.2%
```
bytecode.pkl is:
```
(5,
('__torch__.___torch_mangle_5.TestModule.forward',
(('instructions',
(('STOREN', 1, 2),
('DROPR', 1, 0),
('LOADC', 0, 0),
('LOADC', 1, 0),
('MOVE', 2, 0),
('OP', 0, 0),
('LOADC', 1, 0),
('OP', 1, 0),
('RET', 0, 0))),
('operators', (('aten::add', 'int'), ('aten::add', 'Scalar'))),
('constants',
(torch._utils._rebuild_tensor_v2(pers.obj(('storage',
torch.DoubleStorage,
'140245072983168.storage',
'cpu',
8),),
0,
(2, 4),
(4, 1),
False,
collections.OrderedDict()),
1)),
('types', ()),
('register_size', 2)),
(('arguments',
((('name', 'self'),
('type', '__torch__.___torch_mangle_5.TestModule'),
('default_value', None)),
(('name', 'y'), ('type', 'int'), ('default_value', None)))),
('returns',
((('name', ''), ('type', 'Tensor'), ('default_value', None)),)))))
```
constants.pkl is:
```
(torch._utils._rebuild_tensor_v2(pers.obj(('storage', torch.DoubleStorage, '140245072983168.storage', 'cpu', 8),),
0,
(2, 4),
(4, 1),
False,
collections.OrderedDict()),)
```
Both tensors will refer to the tensor in at the path `script_module_v4_unify/constants/140245072983168.storage`.
## Note
According to unify format, all tensors will be written to the folder `.data`, however, torch.jit.load() can't handle the unified format at this moment, so this change will write tensors at the `constants` folders, and mobile will write/read tensors from `constants` folder. such that the model can be interpreted by both jit and mobile.
ghstack-source-id: 129010347
Test Plan: buck test mode/dev //caffe2/test/cpp/jit:jit
Reviewed By: raziel, iseeyuan
Differential Revision: D28375257
fbshipit-source-id: 6544472db4c957c5ea037e0bb5112b637dd15897
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58202
This unit test was testing the wrong target. It should test the sampler under jit::mobile. This diff fixes it.
Test Plan: run unit tests
Reviewed By: shreyanb98
Differential Revision: D28384839
fbshipit-source-id: 35cc63be2e73ca9b1a7d30d6f67fffcfe5021fa2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58205
It's worthing moving train related files into their own folder since we are adding more code under the mobile directory.
This diff does that.
Test Plan: run unit tests and ci
Reviewed By: iseeyuan
Differential Revision: D28402432
fbshipit-source-id: cd76a1c4f8ff06508cdc3aad8a169fbf34bb4995
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48919
move data indexing utils
parallel inference contiguous path
parallel inference channels last path
add dim apply
optimize update stats
add channels last support for backward
Revert "add channels last support for backward"
This reverts commit cc5e29dce44395250f8e2abf9772f0b99f4bcf3a.
Revert "optimize update stats"
This reverts commit 7cc6540701448b9cfd5833e36c745b5015ae7643.
Revert "add dim apply"
This reverts commit b043786d8ef72dee5cf85b5818fcb25028896ecd.
bug fix
add batchnorm nhwc test for cpu, including C=1 and HW=1
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D25399468
Pulled By: VitalyFedyunin
fbshipit-source-id: a4cd7a09cd4e1a8f5cdd79c7c32c696d0db386bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57830
This is PR is aiming to support tensor.index_add_() method in symbolic function. We leverage scatter_add() to implement this function while ONNX doesn't have a corresponding operator.
Notes:
1. 4 tests have been added for some scenarios.
2. If there are duplicated value in 'index' parameter, the export will still execute successfully but the results are wrong. Add a warning for every call to this symbolic function. And if we detect that the rank of 'index' is greater than the size of the 'dim' dimension, will raise an exception to stop exporting an incorrect ONNX file.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D28393518
Pulled By: SplitInfinity
fbshipit-source-id: f487ca2c63fec47c6ab74f1a7783dae7f3b8d1ef
Co-authored-by: Jay Zhang <jiz@microsoft.com>
Summary:
Added a simple section indicating distributed profiling is expected to work similar to other torch operators, and is supported for all communication backends out of the box.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58286
Reviewed By: bdhirsh
Differential Revision: D28436489
Pulled By: rohan-varma
fbshipit-source-id: ce1905a987c0ede8011e8086a2c30edc777b4a38
Summary:
Currently, our test stats [uploaded to S3](fee7e8b91d/&showversions=false) by GitHub Actions are missing the reports from `test/custom_backend/test_custom_backend.py` and `test/custom_operator/test_custom_ops.py`. From [this log](https://github.com/pytorch/pytorch/runs/2573747177), we know that those tests are indeed being run, but the artifact on that workflow run shows that the XML files are currently not being uploaded for use in the render-test-results job. This PR makes the regex for that artifact upload more permissive.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58250
Test Plan:
For context, before this PR, the test-reports artifact of Linux CI (pytorch-linux-xenial-py3.6-gcc5.4) before this PR looks like this:
- `test-reports`
- `cpp-rpc`
- ...
- `cpp-unittest`
- ...
- `dist-gloo`
- ...
- `python-unittest`
- ...
Wait for Linux CI (pytorch-linux-xenial-py3.6-gcc5.4) to run on this PR, then download and unzip the test-reports artifact and check that its directory structure looks like this:
- `custom_backend`
- `test-reports`
- `python-unittest`
- ...
- `custom_operator`
- `test-reports`
- `python-unittest`
- ...
- `test-reports`
- `cpp-rpc`
- ...
- `cpp-unittest`
- ...
- `dist-gloo`
- ...
- `python-unittest`
- ...
Also, [this run](https://github.com/pytorch/pytorch/runs/2579875947) shows the following line of output, which is exactly what we would expect to see if this PR correctly adds the 9 tests across `custom_backend` and `custom_operator`:
> ```
> Added (across 2 suites) 9 tests, totaling + 0.10s
> ```
Reviewed By: walterddr
Differential Revision: D28442396
Pulled By: samestep
fbshipit-source-id: 893a397a8e701e4180e1812d6f83352b5920ced6
Summary:
Some machines don't have a versionless `python` on their PATH, which breaks these existing shebangs.
I'm assuming that all the existing versionless `python` shebangs are meant to be `python3` and not `python2`; please let me know if my assumption was incorrect for any of these.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58275
Test Plan: CI.
Reviewed By: zhouzhuojie
Differential Revision: D28428143
Pulled By: samestep
fbshipit-source-id: 6562be3d12924db72a92a0207b060ef740f61ebf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54894
Test cases to test torch.Package's handling of TorchScript objects.
TODO: test mapping storages to different device
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D27832544
Pulled By: Lilyjjo
fbshipit-source-id: 6a67938a428b57520fead698da1412623ece9dbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55958
This PR refactors the existing ScriptModuleSerializer to be exposed to the public. Most of the code is the same, git just thinks it's different due to it being shifted over a white space. I commented on the actual changes that weren't due to the white space shifting
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D27832546
Pulled By: Lilyjjo
fbshipit-source-id: c73e33211e46fca56053aa45ea2b9a2803eab82c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58262
When broadcasting, it can be fine for input tensors to have a different number of dims. Fix the checks in arithmetic ops to accept these cases.
Test Plan:
Test on device:
```
arc focus2 pp-ios
```
Test on mac
```
buck test pp-macos
```
Reviewed By: xta0
Differential Revision: D27093367
fbshipit-source-id: 797eeffa1864291cb0e40277372842dca145c9c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58263
Add the `reflection_pad2d` op in preparation for newer xirp models.
Test Plan:
Test on device:
```
arc focus2 pp-ios
```
Test on mac
```
buck test pp-macos
```
Reviewed By: xta0
Differential Revision: D27047892
fbshipit-source-id: 815856e19e4885c352f5d7174866480db7641cdf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55172
Description:
This is part 1 of series of PRs for supporting torch.jit.ignore as context manager. Following features are implemented in this PR:
- Unique name for the registered function under torch.jit.frontend module. The unique name is generated based on the file name and line number of context manager
- Forcing user to explicitly annotate the input and outputs.
- No side effects are considered.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D27895283
Pulled By: tugsbayasgalan
fbshipit-source-id: 5d36d9aa5d457055a6bb1676f264647a745ec36a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58256
Size-1 dims mess up our output restriding logic, because they're
technically "dense" no matter what stride the dimension has. In this example a
size-1 dim has stride 1, which causes all the indices to be taken mod 1 (i.e.,
all indices become 0). We work around this peculiar case by skipping size-1 in
our layout logic, since it has no impact on the rest of the tensor's indexing.
ghstack-source-id: 128932739
Test Plan:
new unit test, plus
```
buck test mode/dev //langtech/mobile/audio_stream_processor:audio_stream_processor_test -- --exact 'langtech/mobile/audio_stream_processor:audio_stream_processor_test - AudioStreamProcessorTest.DemucsReadWriteFloat'
```
Reviewed By: eellison
Differential Revision: D28424388
fbshipit-source-id: e33e39eef2a5bf2797bee78a5987558308b6d110
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58201
Add light version of RandomSampler which can be used torch mobile.
Test Plan: run unit test
Reviewed By: iseeyuan
Differential Revision: D28364467
fbshipit-source-id: 3148129fa56533f5f4b76b63b60e8778eeaf815f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56152
Currently, the Bundled Inputs API mutates the module in-place. It adds class methods and not instance methods. This results in a small problem that one can't re-run an already executed cell in Bento if the class has already been subject to bundled inputs.
In addition, there is no way to add bundled inputs to a module that has bundled inputs added already. This API provides a way to solve this problem as well by adding an `ignored_methods` to the call to `clone()` by allowing the implementation of bundled inputs to pass in the methods that it will add as `ignored_methods` so that when it does try to add those methods, it will be able to do so successfully.
We'll have to be careful when ignoring those methods during the call to `torch.jit._clone_module_with_class` since any bundled input that relies on a user-provided method will need to be preserved and not ignored during the clone.
Looking for feedback on whether this is an acceptable direction.
ghstack-source-id: 128908360
Test Plan:
Added unit test and ran it as `buck test //caffe2/test:mobile`
Also see this Bento Notebook: https://www.internalfb.com/intern/anp/view/?id=550829
Reviewed By: gmagogsfm
Differential Revision: D27788394
fbshipit-source-id: 48109cd4583506d4efdb345e4ba31385db23a273
Summary:
This adds the methods `Tensor.cfloat()` and `Tensor.cdouble()`.
I was not able to find the tests for `.float()` functions. I'd be happy to add similar tests for these functions once someone points me to them.
Fixes https://github.com/pytorch/pytorch/issues/56014
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58137
Reviewed By: ejguan
Differential Revision: D28412288
Pulled By: anjali411
fbshipit-source-id: ff3653cb3516bcb3d26a97b9ec3d314f1f42f83d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58221
- Use expect_contiguous to avoid Tensor refcount bumps if input tensor is already contiguous
- Use Tensor::sizes()[i] in place of Tensor::size(i) which goes through the dispatcher
- Use at::Dimvector in place of std::vector to avoid heap allocation
Since the qnnpack version needs on device testing, I'll skip that one for now.
Test Plan: CI
Reviewed By: swolchok
Differential Revision: D28406942
fbshipit-source-id: 3c1bdfd1c859fe71869d4daec22158be5c2719d4
Summary:
Currently only supports native ops that have all tensor arguments, an out variant, and no kwargs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58118
Reviewed By: ejguan
Differential Revision: D28421323
Pulled By: Chillee
fbshipit-source-id: 1c75c900415deca63fcc0e496e3bac126f21bf49
Summary:
Both CPU and CUDA versions of PowKernel reimplement functionality that
already exists in UnaryOps, such as sqrt, rsqrt and reciprocal
Find this out while looking at sluggish compilation of PowerKernel.cu:
- Before the change it took 11m5s and resulted in 7.6Mb .o file
- After the change compilation finished in 10m20s, and 6.4Mb .o file
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57873
Reviewed By: ezyang
Differential Revision: D28304929
Pulled By: malfet
fbshipit-source-id: ac499476280de55a92044b1b041b1246eea74c64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57749
add to a fx test
Test Plan: Imported from OSS
Reviewed By: huiguoo
Differential Revision: D28425974
fbshipit-source-id: 195c7a1944decb7a2a99c2831cab38485f32be17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58254
Don't use CUDA synchronize when profiling in CPU only mode.
minor fixes (a clarification for a doc string, fix spammy logging)
(Note: this ignores all push blocking failures!)
Test Plan: manual + CI
Reviewed By: gdankel, chaekit
Differential Revision: D28423667
Pulled By: ilia-cher
fbshipit-source-id: 04c71727f528ae8e2e0ff90e88271608d291bc69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48918
enable test case on AvgPool2d channels last for CPU
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D25399466
Pulled By: VitalyFedyunin
fbshipit-source-id: 9477b0c281c0de5ed981a97e2dcbe6072d7f0aef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58020
Previously there is no RPC pickler for `RecursiveScriptModule`. Although it is a subclass of `ScriptModule`, the reducer of `ScriptModule` is not triggered for `RecursiveScriptModule` when a script remote module is sent over RPC.
This PR checkpoints the investigation of #58274, which makes sure that a RPC pickler is invoked here. This still cannot fix `test_send_remote_module_over_the_wire_script`. Will revisit this bug once there is a feature request from users.
ghstack-source-id: 128949642
Test Plan:
TODO: re-enable these tests
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_send_remote_module_over_the_wire_script
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_remote_module_py_pickle_not_supported_script
Reviewed By: rohan-varma
Differential Revision: D28346758
fbshipit-source-id: 3cff84ca665da03da6ed6acb094a1f594fcd945e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58191
There are two clamp overloads: clamp.Scalar and clamp.Tensor. SR needs to support both or has checks in place to avoid runtime errors. Supporting both is not too hard so here we are.
Reviewed By: edvgha
Differential Revision: D28371949
fbshipit-source-id: 0ec6b8a0b8c6277e50d8e51e4e7a45aa62211e22
Summary:
This PR:
- Renames symeig_backward to eigh_backward
- Improves the stability and speed of the gradient computation by doing `V(A + B)Vh` instead of `VAVh + VBVh` when both the gradients of the eigenvectors and eigenvalues are defined.
- Updates the comments of the function to make them arguably clearer
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55049
Reviewed By: ngimel
Differential Revision: D28396823
Pulled By: mruberry
fbshipit-source-id: a144482bfb1054e281b58ae1fe3cf1015bab505d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56613
Replace linalg_solve_helper with `lu_stub` + `lu_solve_stub`.
Once `lu_stub` and `lu_solve_stub` have cuSOLVER-based codepath,
`torch.linalg.solve` will have it as well.
Test Plan: Imported from OSS
Reviewed By: agolynski
Differential Revision: D28379394
Pulled By: mruberry
fbshipit-source-id: b47f66bc1ee12715da11dcffc92e31e67fa8c8f6
Summary:
# Changes
This PR migrates `pytorch_python_doc_build` from circleci to github actions.
Noticeable changes
- Refactor `docker cp` into a single `docker run` with volume mount, because the in circleci volume is not accessible from its remote docker engine
- `pytorch_python_doc_push` job will have a race condition with circleci, which will be migrated in separate PRs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57371
Reviewed By: samestep
Differential Revision: D28416289
Pulled By: zhouzhuojie
fbshipit-source-id: 04caccccf3d7eb7e2225846a406a53ccda356d44
Summary:
Fixes a few problems with `torch.norm` (incorrect behavior for empty inputs and negative p, https://github.com/pytorch/pytorch/issues/52783, and incorrect imaginary part for complex).
Most importantly, makes linalg_norm and vector_norm use the same kernels, reducing compile time and binary size.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58214
Reviewed By: ejguan
Differential Revision: D28422439
Pulled By: ngimel
fbshipit-source-id: afe088a866963068e8c85eb9c3b2218a21ff2d48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56845
Handle forward/backward compatibility caused by added default arguments in mobile. As an example,
In older version, operator aten::foo's schema is
```
foo(Tensor a, Tensor b) -> Tensor
```
In the new version, the schema is updated to
```
foo(Tensor a, Tensor b, int groups=1) -> Tensor
```
## Model file
Serialize the number of specified arguments to each operator into the bytecode operator table. Before the operator table contains operator name and overload name:
```
('operators', (('aten::foo', ''),))
```
Now the number of specified arguments is added:
```
# bytecode version 6
('operators', (('aten::foo', '', 2),))
```
where "2" means the number of specified arguments.
Since there's bytecode schema change, the bytecode version number is bumped. This PR is to be landed after #56002 , where the version number is bumped from 4 to 5. This PR bumps the version number from 5 to 6.
## Runtime and backward compatibility
When the operator is found (either jit or c10), we have the OperatorHandle, where the operator schema can be accessed by
```
op.value().schema().arguments()
```
Adaptation is implemented to handle backward compatibility. For the example above, the new runtime holds the updated schema:
```
foo(Tensor a, Tensor b, int groups=1) -> Tensor
```
Whereas the model file carries
```
(('aten::foo', ''), 2)
```
We can implement a wrapper around the original function pointer to push the default argument to the stack.
## Deliver time and forward compatibility
At model delivery time, two checks can be done:
### Operator check
Two APIs to be provided:
* Runtime: An API to get a runtime’s ops and their schemas (i.e. the # of args). D27920185(WIP)
* Model: An API to get a model’s ops and their schema requirements (i.e. the # of args required).
The APIs can be used to check
* runtime.ops() is a superset of model.ops()
* for each op in model.ops() validate their schemas are compatible with those in runtime.ops() -- i.e. the # args required in a model op are <= # args in the runtime op.
Note that only root ops in the model needs to be checked here. For transient ops it's not necessary. For example, if a root op, "aten::root" calls "aten::foo", it's "aten::root"'s responsibility to adapt to "aten::foo"'s change, or "aten::root" itself needs to be updated too.
### Bytecode version backport (PR coming)
When delivering a model with bytecode v6, if the runtime only works with bytecode v5 and lower, backport is needed.
* The number of arguments is removed from the operator table
* The bytecode version is changed from 6 to 5
Note that this backport is a pure format change, it does not guarantee the backported model always runs in old runtime. The operator check mentioned before should be done first, before it’s back ported to v5.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D27986544
Pulled By: iseeyuan
fbshipit-source-id: 143e19d4798cfb96b65095538dd648eead4e3fda
Summary:
Adds a new file under `torch/nn/utils/parametrizations.py` which should contain all the parametrization implementations
For spectral_norm we add the `SpectralNorm` module which can be registered using `torch.nn.utils.parametrize.register_parametrization` or using a wrapper: `spectral_norm`, the same API the old implementation provided.
Most of the logic is borrowed from the old implementation:
- Just like the old implementation, there should be cases when retrieving the weight should perform another power iteration (thus updating the weight) and cases where it shouldn't. For example in eval mode `self.training=True`, we do not perform power iteration.
There are also some differences/difficulties with the new implementation:
- Using new parametrization functionality as-is there doesn't seem to be a good way to tell whether a 'forward' call was the result of parametrizations are unregistered (and leave_parametrizations=True) or when the injected property's getter was invoked. The issue is that we want perform power iteration in the latter case but not the former, but we don't have this control as-is. So, in this PR I modified the parametrization functionality to change the module to eval mode before triggering their forward call
- Updates the vectors based on weight on initialization to fix https://github.com/pytorch/pytorch/issues/51800 (this avoids silently update weights in eval mode). This also means that we perform twice any many power iterations by the first forward.
- right_inverse is just the identity for now, but maybe it should assert that the passed value already satisfies the constraints
- So far, all the old spectral_norm tests have been cloned, but maybe we don't need so much testing now that the core functionality is already well tested
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57784
Reviewed By: ejguan
Differential Revision: D28413201
Pulled By: soulitzer
fbshipit-source-id: e8f1140f7924ca43ae4244c98b152c3c554668f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57603
With explicit list unpack code from user, it is possible to observe `prim::ListUnpack` with a `ONNX::Sequence` object.
This PR supports the conversion.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D28393527
Pulled By: SplitInfinity
fbshipit-source-id: 1e6234d349b94c97c6ff20880a801433a9a428e9
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57599
Currently, if we call tensor.to() method and pass a device as the parameter. It will fail, because in symbolic function of to() we didn't handle such case.
So add a check in the beginning of this symbolic function, if this is a device cast, we return self directly. A test has also been added.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D28393523
Pulled By: SplitInfinity
fbshipit-source-id: c41e3c0293932fc90dedb544daadd9c5d4b48792
Co-authored-by: Jay Zhang <jiz@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57598
Add a doc string to explain what it does and how to use it.
Remove hack around a bug in Python 2's functools.wrap().
Python 2 is no longer supported.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D28393519
Pulled By: SplitInfinity
fbshipit-source-id: aae8c5e7b49e2ad2d24a0e86f8ba47f1cd080e46
Co-authored-by: Gary Miguel <garymiguel@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57597
* Special post process for onnx::Cast and onnx::ConstantOfShape
* Update `test_pytorch_onnx_shape_inference.py` to be unit test over shape inference patterns.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D28393529
Pulled By: SplitInfinity
fbshipit-source-id: fc26032ddb842d4e299447da39564b28049752ed
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57596
Add the corresponding symbolic function and test for fill_() function.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D28393520
Pulled By: SplitInfinity
fbshipit-source-id: 3e177f88d3776d0d4a9d5e7ec7df4e6629738799
Co-authored-by: Jay Zhang <jiz@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58235
this is to make the opinfo change python only
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D28412937
Pulled By: albanD
fbshipit-source-id: 1d6eb1e4baaa837c300ee8aa00b57986ba3e3eb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57570
Move runtime ops compatibility api to OSS and introduce schema information
ghstack-source-id: 128789159
Test Plan: unit test and manually ran it for a runtime with all (non custom) ops, and the bixray models unittest {P412728176}
Reviewed By: raziel
Differential Revision: D28203104
fbshipit-source-id: 432a7d0247bccfb2e1ce90e8d41f81596efa3d67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58041
The shape of the returned result was different for NumPy and PyTorch for
`ord={-2, 2, None}`. Now it's fixed.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28405147
Pulled By: mruberry
fbshipit-source-id: 30293a017a0c0a7e9e3aabd470386235fef7b6a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58040
This PR uses `torch.linalg.inv_ex` to determine the non-invertible
inputs and return the condition number of infinity for such inputs.
Added OpInfo entry for `torch.linalg.cond`.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28405146
Pulled By: mruberry
fbshipit-source-id: 524b9a38309851fa6461cb787ef3fba5aa7d5328
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58039
The new function has the following signature
`inv_ex(Tensor inpit, *, bool check_errors=False) -> (Tensor inverse, Tensor info)`.
When `check_errors=True`, an error is thrown if the matrix is not invertible; `check_errors=False` - responsibility for checking the result is on the user.
`linalg_inv` is implemented using calls to `linalg_inv_ex` now.
Resolves https://github.com/pytorch/pytorch/issues/25095
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28405148
Pulled By: mruberry
fbshipit-source-id: b8563a6c59048cb81e206932eb2f6cf489fd8531
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58019
In order to support sending `RemoteModule` over PRC, previously the pickling/unpickling of `RemoteModule` was implemented based on `__setstate__` and `__getstate__`. However, this means that the user can call regular Python pickler/unpickler to invoke the same logic,which should not be allowed.
This PR ensures that the pickling can only happen over RPC and not via regular python pickle.
Additionally, when a new attribute is added to `RemoteModule`, if it's not added to either `_REMOTE_MODULE_PICKLED_ATTRIBUTES` or `_REMOTE_MODULE_ATTRIBUTES_IGNORE_FOR_PICKLING`, this attribute will be ignored and an error message will be printed to std.err. However, it will not raise an exception like before, because such exception raised at the RPC layer will somehow cause timeout.
#Closes: https://github.com/pytorch/pytorch/issues/57516
ghstack-source-id: 128868501
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_send_remote_module_over_the_wire
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_remote_module_py_pickle_not_supported
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_send_remote_module_with_a_new_attribute_ignored_over_the_wire
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- RemoteModule
buck test mode/dev-nosan //caffe2/torch/fb/csrc/concurrency/test:atomic_int_interprocess_test -- --exact 'caffe2/torch/fb/csrc/concurrency/test:atomic_int_interprocess_test - test_multiple_processes (caffe2.torch.fb.csrc.concurrency.test.atomic_int_interprocess_test.ForkMultipleProcessTest)'
buck test mode/dev //caffe2/torch/distributed/fb/test:app_test -- --exact 'caffe2/torch/distributed/fb/test:app_test - test_custom_init_rpc (caffe2.torch.distributed.fb.test.app_test.TestRpc)'
Reviewed By: mrshenli
Differential Revision: D28318270
fbshipit-source-id: 7e7df2a6690f0860c4531a244d38789db424496f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58207
We probably don't even know what these tests check and there are no
plans on re-enabling them - let's just nuke them to keep the code clean.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D28403251
Pulled By: ZolotukhinM
fbshipit-source-id: fe12e978636a74f309f57e3408ab78d459fe4d29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58206
Tested on CUDA with and without `PYTORCH_TENSOREXPR_DONT_USE_LLVM=1`.
Closes#48053.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D28403250
Pulled By: ZolotukhinM
fbshipit-source-id: 1ae1cfed691e0077a37db646937e580fbd32b23f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58069
We want to tell user 5821 means ONNXIFI_EVENT_STATE_NONSIGNALLED in the error message.
Added that status code to the mapping and the error message output.
Reviewed By: hl475
Differential Revision: D28359864
fbshipit-source-id: 87f50ddd4ded9ced03ec6af6a1a4ef85bd2195d6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56608
- Adds binding to the `c10::InferenceMode` RAII class in `torch._C._autograd.InferenceMode` through pybind. Also binds the `torch.is_inference_mode` function.
- Adds context manager `torch.inference_mode` to manage an instance of `c10::InferenceMode` (global). Implemented in `torch.autograd.grad_mode.py` to reuse the `_DecoratorContextManager` class.
- Adds some tests based on those linked in the issue + several more for just the context manager
Issues/todos (not necessarily for this PR):
- Improve short inference mode description
- Small example
- Improved testing since there is no direct way of checking TLS/dispatch keys
-
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58045
Reviewed By: agolynski
Differential Revision: D28390595
Pulled By: soulitzer
fbshipit-source-id: ae98fa036c6a2cf7f56e0fd4c352ff804904752c
Summary:
Port addmm to structure kernel
Follow ups
- migrate `mm` and `addbmm` to structure
- move TORCH_CHECKS currently in `addmm_cpu_impl_` and `addmm_out_cuda_impl` to meta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57417
Reviewed By: bdhirsh
Differential Revision: D28291001
Pulled By: walterddr
fbshipit-source-id: 4eafaa30a465e225fbb4d2a69a36f1e037df9122
Summary:
…evice.
Previously, it was possible for torch.Tensor(tensor, device) or Tensor.new(tensor, device) to map to IntArrayRef or PyObject*.
PyObject* was not a problem because that would error out later.
But IntArrayRef would create an uninitialized tensor, which is confusing.
Fixes https://github.com/pytorch/pytorch/issues/47112
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58108
Reviewed By: agolynski, mruberry
Differential Revision: D28372426
Pulled By: gchanan
fbshipit-source-id: 795ab4f0561939d002a661c5cc14c6cdb579f31a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58133
Adding CUDA event fallback for cases when CUPTI tracing is not
available, this corresponds to the legacy profiler GPU profiling
Test Plan: python test/test_profiler.py -v
Reviewed By: gdankel
Differential Revision: D28379596
Pulled By: ilia-cher
fbshipit-source-id: 2db3b2cd8c1c3e6e596784ab00a226c69db2ef27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49352
In this PR, we replace all definitions of slice to take None parameters for the start, end, and step. This will simplify the compiler logic
Test Plan:
test_jit test cases
Imported from OSS
Reviewed By: jamesr66a, nikithamalgifb
Differential Revision: D25929903
fbshipit-source-id: 5bfc6bad514a8aafbef2dacc706f95f867fe85f1
Summary:
There were almost no libtorch specific regressions recently
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58183
Reviewed By: janeyx99
Differential Revision: D28393091
Pulled By: malfet
fbshipit-source-id: 6dadd915ba574294afa6a95eaa759564af3154d4
Summary:
This is actually something I discovered a while ago with the wall of serotonin. It was really easy for large scale runs to get bottlenecked on disk access. I have a hack in the working files of that machine to use `/dev/shm`, but I figured I should formalize and actually make a respectable utility.
I also added a param to tweak the run cadence and print when a CorePool is created; these are just to make the CI logs a bit nicer. (A printout each second on a 40 minute CI job is a bit much...)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56711
Reviewed By: agolynski
Differential Revision: D28392248
Pulled By: robieta
fbshipit-source-id: b6aa7445c488d8e4ab9d4b31ab18df4e12783d8f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58169
This PR adds logging to the `_sanitize()` function of `RendezvousStateHolder` to output the nodes that had no recent heartbeat and are considered "dead".
ghstack-source-id: 128798389
Test Plan: Run the existing tests.
Reviewed By: tierex
Differential Revision: D28333394
fbshipit-source-id: ba0a398a759815e4224b58323c0e743eb383f723
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57701
The new OpInfo flag has the following semantic:
- If it says that it supports forward AD, we run gradcheck with forward AD to ensure it is correct
- If it says that it does not support it, we check that the corresponding error is raised
All the added tests take 3s to run for CPU builds and 1min for GPU builds which should be pretty negligible compared to the test_ops runtime for each of these arch.
Test Plan: Imported from OSS
Reviewed By: agolynski
Differential Revision: D28387767
Pulled By: albanD
fbshipit-source-id: 369d76921c8460aa4548f9b5159b7297994672f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58160
This PR updates the Torch Distributed Elastic documentation with references to the new `c10d` backend.
ghstack-source-id: 128783809
Test Plan: Visually verified the correct
Reviewed By: tierex
Differential Revision: D28384996
fbshipit-source-id: a40b0c37989ce67963322565368403e2be5d2592
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58159
This PR includes the following changes:
- The `--standalone` option of `torch.distributed.run` now uses the `c10d` backend instead of `etcd` backend.
- The `import` statement for `EtcdServer` has been removed from the run script.
- The docstrings and parameter descriptions of the run script have been revised and improved.
- The default port number of `EtcdRendezvousBackend` has been changed from 29500 to 29400 to improve the user experience when used along with the run script which uses the port 29500 for the distributed job store (a.k.a. `MASTER_PORT`) by default.
ghstack-source-id: 128782267
Test Plan:
- Run existing tests.
- Visually verified the correct rendering of the docs.
Reviewed By: tierex
Differential Revision: D28383681
fbshipit-source-id: a4098f7c23c97a2376a9c4023e81f82fedd04b10
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58089
make ddp logging api to be private
ghstack-source-id: 128796419
Test Plan: unit test
Reviewed By: rohan-varma
Differential Revision: D28365412
fbshipit-source-id: 374c01d443ffb47a3706f59e296d6e47eb5f4c85
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58144
reland D28291041 (14badd9929), which was reverted due to a type error from Tuple[torch.Tensor], seems that mypy requires Tuple[torch.Tensor, torch.Tensor, torch.Tensor]
Test Plan:
buck test mode/opt //caffe2/test:torch_cuda -- test_index_copy_deterministic
✓ ListingSuccess: caffe2/test:torch_cuda - main (9.229)
✓ Pass: caffe2/test:torch_cuda - test_index_copy_deterministic_cuda (test_torch.TestTorchDeviceTypeCUDA) (25.750)
✓ Pass: caffe2/test:torch_cuda - main (25.750)
Reviewed By: ngimel
Differential Revision: D28383178
fbshipit-source-id: 38896fd6ddd670cfcce36e079aee7ad52adc2a28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57341
Require that users be explicit about what they are going to be
interning. There are a lot of changes that are enabled by this. The new
overall scheme is:
PackageExporter maintains a dependency graph. Users can add to it,
either explicitly (by issuing a `save_*` call) or explicitly (through
dependency resolution). Users can also specify what action to take when
PackageExporter encounters a module (deny, intern, mock, extern).
Nothing (except pickles, tho that can be changed with a small amount
of work) is written to the zip archive until we are finalizing the
package. At that point, we consult the dependency graph and write out
the package exactly as it tells us to.
This accomplishes two things:
1. We can gather up *all* packaging errors instead of showing them one at a time.
2. We require that users be explicit about what's going in packages, which is a common request.
Differential Revision: D28114185
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Pulled By: suo
fbshipit-source-id: fa1abf1c26be42b14c7e7cf3403ecf336ad4fc12
Summary:
In contrast to the initial opinion in https://github.com/pytorch/pytorch/issues/55385, there are legitimate use cases for nested containers. One such example is the [output of `LSTM`'s](https://pytorch.org/docs/stable/generated/torch.nn.LSTM):
```python
output: Tuple[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]] = torch.nn.LSTM()(input)
assert_close(output, expected)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57270
Reviewed By: albanD
Differential Revision: D28249303
Pulled By: mruberry
fbshipit-source-id: 75caa4414cc184ff0ce4cfc0dd5aafddfad42bcf
Summary:
Support adding type annotations for class methods and nn.Module methods which are not invoked under the hood of MonkeyType
** Changes **
* This PR involves a slight change in how the example inputs are passed while scripting `class` and `nn.Module` objects.
* The example inputs passed to `_script_pdt` is of the following format:
- example_inputs= [(obj.method1, (arg_list)), (obj.method2, (arg_list)),]
* For nn.Modules, to infer types for `forward` methods, example_inputs can be passed in two ways:
- example_inputs= [(obj.forward, (arg_list, ))]
- example_inputs = [(obj, (arg_list, ) )]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57202
Reviewed By: desertfire
Differential Revision: D28382827
Pulled By: nikithamalgifb
fbshipit-source-id: 5481467f3e909493bf3f439ee312056943508534
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57079
Testing onnx 1.9 release, we see that the old bug is triggered for the caffe2 test:
`pytest test/onnx/test_pytorch_onnx_caffe2_quantized.py::TestQuantizedOps::test_small_model`
This is because the graph inputs
```python
graph(%x.1 : Tensor,
%conv1._packed_params : __torch__.torch.classes.quantized.Conv2dPackedParamsBase,
%conv2._packed_params : __torch__.torch.classes.quantized.Conv2dPackedParamsBase,
%fc.bias : Float(10, strides=[1], requires_grad=0, device=cpu),
%fc.weight : Float(10, 72, strides=[72, 1], requires_grad=0, device=cpu)):
```
contains `Conv2dPackedParamsBase` which is a PackedParams.
When we do flatten, we will flatten to several tensors, then the shape inference for input misaligned.
This PR record how may tensors got flattened in PackeParams, and skip by these number rather than 1, then the UT passed.
Note that tuple case should still follow the original logic.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D28393949
Pulled By: malfet
fbshipit-source-id: 98d48aad27e5ca03fb10d260f8e625478d996ee2
Co-authored-by: David <jiafa@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58048
It's never used, and it is also a bit dangerous, because a move
typically destroys the source location, but there may be other owning
references to the original location!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28390241
Pulled By: ezyang
fbshipit-source-id: 68f22756ac066a7a0fc8baedd2b7834c01c2c534
Summary:
TODOs:
- [x] generate a temporary new token on this repo for testing purposes
- [x] change the name of the S3 secret used in the workflow YAML definitions
- [x] check the test plan
- [x] replace the temporary token with a more permanent one
- [x] check the test plan again
- [x] uncomment the `if` statement that guards against uploading PR test stats
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58156
Test Plan: Check the [ossci-metrics bucket](https://s3.console.aws.amazon.com/s3/buckets/ossci-metrics) after CI runs on this PR. Specifically, [this prefix](a3445bfbd7/pytorch-linux-xenial-py3.6-gcc5.4/&showversions=false) has two objects under it.
Reviewed By: janeyx99
Differential Revision: D28393138
Pulled By: samestep
fbshipit-source-id: 2c39c102652d471afa016cfc4942bb1e5bbb4163
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58170
Now comm hook can be supported on MPI and GLOO backends besides NCCL. No longer need these warnings and check.
ghstack-source-id: 128799123
Test Plan: N/A
Reviewed By: agolynski
Differential Revision: D28388861
fbshipit-source-id: f56a7b9f42bfae1e904f58cdeccf7ceefcbb0850
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58028
We were trying to translate the device argument and thus throwing an
unsupported dtype.
ghstack-source-id: 128748658
Test Plan: predictor models
Reviewed By: navahgar
Differential Revision: D28347704
fbshipit-source-id: 331a5786339e01f9df1b1878970b0c5983a92980
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58026
Cat-without-conditionals is a valuable optimization on CPU but on GPU
it can generate invalid code since it may introduce allocations (i.e. extra
kernel launches)
ghstack-source-id: 128748630
Test Plan: predictor
Reviewed By: navahgar
Differential Revision: D28347703
fbshipit-source-id: f9e68cd7bcf5d316082ce8378ddf99f2d33fcc07
Summary:
This PR adds Azure DevOps support for running custom PyTorch unit tests on PyTorch PR and Nightly builds.
PR Builds on Azure DevOps:
- Ensures that the wheel artifacts for a given PR build is ready
- Once the wheels are ready, PyTorch custom tests are run on torch installation from build wheels
Nightly Builds on Azure DevOps:
- Cues 4 builds {Win,Linux}*{cpu, CUDA} to run PyTorch custom unit tests on nightly PyTorch builds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58007
Reviewed By: seemethere, mruberry
Differential Revision: D28342428
Pulled By: malfet
fbshipit-source-id: a454accf69163f9ba77845eeb54831ef91437981
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55836
Change construct_time_validation to argument_validation as we should provide users the flexibility to use this decorator over all different functions, which are required with type validation.
It can also work as a construct-time validation
```py
class ExampleDataPipe(IterDataPipe):
argument_validation
def __init__(self, dp: IterDataPipe[int]):
self.dp = dp
...
```
Notebook is also updated.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D27743478
Pulled By: ejguan
fbshipit-source-id: 49743152d121028cd7d72d89dc7df5c7c7b94c41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58105
When find_unused_parameters=True but static_graph is also set, static graph handles unused parameter accounting, so this code path is not needed
ghstack-source-id: 128736289
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28371954
fbshipit-source-id: 0b42a9c0fd2bba26a0de288436e9c7139e292578
Summary:
Fixes https://github.com/pytorch/pytorch/issues/57719.
This PR fixes `torch.Tensor{__rsub__, __rdiv__, __rtruediv__, __pow__, __rmatmul__}` to return `NotImplemented` instead of raising a `TypeError`.
cc/ mruberry: The first commit of this PR is the same as 1d209db1cc excepts the commit message.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57934
Reviewed By: mruberry
Differential Revision: D28351931
Pulled By: albanD
fbshipit-source-id: 985457a44dba24d2496794dfb8c1661cbcd4ff8f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58058
Don't save output node in the `node_map` because the result of output node could be a list of proxies and would throw an error when being used as key.
Test Plan: CI
Reviewed By: mikekgfb
Differential Revision: D28329580
fbshipit-source-id: a29f3ef1763930faa20cb20eb9ffd04ef7e52dc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57925
1. adds test_scripts.py that will run added scripts and verify that there are no errors
2. adds local ddp_nccl_allreduce experiment script
test with command `pytest test_scripts.py`
Test Plan: Imported from OSS
Reviewed By: agolynski
Differential Revision: D28382452
Pulled By: gcramer23
fbshipit-source-id: 21028a990ebfedf1aad6b007a723c02403e8bea8
Summary:
Enabled BFloat16 for `nan_to_num` on CUDA. For comparison with numpy, a [workaround suggested](https://github.com/pytorch/pytorch/issues/57982#issuecomment-839150556) by ngimel is being used - the OpInfo's `sample.kwargs` is used to set two `numpy.kwargs`, viz. `posinf` & `neginf` for `BFloat16`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58063
Reviewed By: mruberry
Differential Revision: D28373478
Pulled By: ngimel
fbshipit-source-id: 6493b560d83632a8519c1d3bfc5c54be9b935fb9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57073
Enhances use of DDPSink to work for all output types DDP supports as per https://github.com/pytorch/pytorch/issues/55876.
TODO: Add additional testing for tuple, list, dict return types
ghstack-source-id: 128726768
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D27756985
fbshipit-source-id: 2e0408649fb2d6a46d6c33155a24c4c1723dd799
Summary:
These were added to help debug a flaky test, the flaky test has since been resolved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58095
Reviewed By: SciPioneer
Differential Revision: D28368077
Pulled By: rohan-varma
fbshipit-source-id: 9618f64de2b7015401bb8cb7816b09e1a44e0fef
Summary:
This one had a tricky usage of `torch.symeig` that had to be replaced. I tested the replacement locally though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57732
Reviewed By: bdhirsh
Differential Revision: D28328189
Pulled By: mruberry
fbshipit-source-id: 7f000fcbf2b029beabc76e5a89ff158b47977474
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58013
Add a test case and a fix (legacy profiler) for empty trace handling
Test Plan: python test/test_profiler.py
Reviewed By: gdankel
Differential Revision: D28345388
Pulled By: ilia-cher
fbshipit-source-id: 4727589ab83367ac8b506cc0f186e5292d974671
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58023
Clearly state that some features of RPC aren't yet compatible with CUDA.
ghstack-source-id: 128688856
Test Plan: None
Reviewed By: agolynski
Differential Revision: D28347605
fbshipit-source-id: e8df9a4696c61a1a05f7d2147be84d41aeeb3b48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58067
- Use expect_contiguous in layer_norm to avoid unnecessary refcount bumps when the tensors are contiguous
- Clean up some leftovers from the hacky wrappers removal cleanup: use c10::MaybeOwned<Tensor> for bias tensors
- Skip dispatcher for at::empty in the layer_norm impl in Static Runtime
Test Plan: CI
Reviewed By: swolchok
Differential Revision: D28214298
fbshipit-source-id: 73150fa62d5c18f41a2264f8e56bbe5e377ad045
Summary:
Backward methods for `torch.lu` and `torch.lu_solve` require the `torch.lu_unpack` method.
However, while `torch.lu` is a Python wrapper over a native function, so its gradient is implemented via `autograd.Function`,
`torch.lu_solve` is a native function, so it cannot access `torch.lu_unpack` as it is implemented in Python.
Hence this PR presents a native (ATen) `lu_unpack` version. It is also possible to update the gradients for `torch.lu` so that backward+JIT is supported (no JIT for `autograd.Function`) with this function.
~~The interface for this method is different from the original `torch.lu_unpack`, so it is decided to keep it hidden.~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46913
Reviewed By: albanD
Differential Revision: D28355725
Pulled By: mruberry
fbshipit-source-id: 281260f3b6e93c15b08b2ba66d5a221314b00e78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58100
aten::clone has a second arg, memory_format, which was not previously supported.
Reviewed By: ajyu
Differential Revision: D28347171
fbshipit-source-id: e083cc24c3228048429bba3497326415bc3d1f5a
Summary:
https://github.com/pytorch/pytorch/issues/55070
There are a few places where `const_cast` is used with utility functions shared with unstructured operators.
The RFC says that assigning to the `out` tensor doesn't work, but that seems to be what e.g., `_allocate_or_resize_output_with_indices` seems to do. Does assignment "work" when the tensors are not allocated?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57790
Reviewed By: bdhirsh
Differential Revision: D28289685
Pulled By: ezyang
fbshipit-source-id: 7027f162581af0bc0f5b750ff4439b0ecb01ec7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56365
Follow-up to https://github.com/pytorch/pytorch/pull/54784#discussion_r614156172. Instead of having one large testcase where most methods are decorated with `onlyCPU`, this factors out all tests that actually need another device into a separate test case.
Test Plan: Imported from OSS
Reviewed By: walterddr, albanD
Differential Revision: D28247529
Pulled By: mruberry
fbshipit-source-id: 946e7694b70e736941565f29b5dd459ed7fbca4e
Summary:
This PR adds a note to the documentation that torch.svd is deprecated together with an upgrade guide on how to use `torch.linalg.svd` and `torch.linalg.svdvals` (Lezcano's instructions from https://github.com/pytorch/pytorch/issues/57549).
In addition, all usage of the old svd function is replaced with a new one from torch.linalg module, except for the `at::linalg_pinv` function, that fails the XLA CI build (https://github.com/pytorch/xla/issues/2755, see failure in draft PR https://github.com/pytorch/pytorch/pull/57772).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57981
Reviewed By: ngimel
Differential Revision: D28345558
Pulled By: mruberry
fbshipit-source-id: 02dd9ae6efe975026e80ca128e9b91dfc65d7213
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58047
This error ALWAYS gets picked up by Dr. CI and IT DRIVES ME NUTS.
Consign it to the /dev/null bin.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D28352658
Pulled By: ezyang
fbshipit-source-id: a55f99ed76728d46f02d6a61a45c7691e8be7a47
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58000
Directly overriding save_extern and save_mock may mess with our
invariants in weird ways. This is less pronounced now, but once we
switch to graph-based dependency management things will get broken
subtly if people fail to call `super()`.
Better to add hook support to reflect that really you can only do a side
effect. Also has the bonus that people are likely familiar with it from
`nn.Module` hooks.
Differential Revision: D28339191
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Pulled By: suo
fbshipit-source-id: 63ffd39d2dcb1a7524f3c2c6a23bd399e754cc44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58018
- Add checks for the number of input args and return nullptr if it doesn't match. This is intended to make Static Runtime more robust so that op schema change is less likely to break things. Imagine that a new arg is added to an op or a new overload is added that has this added arg, SR would simply ignore this added arg. If this arg has a default value, SR would run the model with the default value and give you wrong results, which can be hard to track down.
Reviewed By: ajyu
Differential Revision: D28047955
fbshipit-source-id: 01067059edd5cfea80c4ee121829f7733b11f601
Summary:
The function name and return type both are called `class_`, therefore they are ambiguous and this is UB and does not work on NVCC. See the tests for the failure case.
Thanks for the help of Thibaut Lutz from NVIDIA's compiler team.
cc: yueyericardo ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57962
Reviewed By: mruberry
Differential Revision: D28359400
Pulled By: ezyang
fbshipit-source-id: c64ec89203f99f656611aba34f7424eed7bc9e7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57566
Fix the problem that `tempfile` has never been deleted even after `torch_shm_manager` is destroyed.
- The previous implementation has wrong path length for the Linux Socket. It leads to we lose the last character of the name of `tempfile` when bind the pathname to socket. At the end, we can not delete this file due to unexpected file name.
- After we solve the racing problem by introducing a temporary directory, it becomes more dangerous since it prevents `torch_shm_manager` to delete directory as the tempfile persists in the temporary directory.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D28202866
Pulled By: ejguan
fbshipit-source-id: 912cfd8fec0cc309d47df223b2b0faa599c60799
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58057
This PR refactors the store initialization logic and moves it to the `create_backend` function for both C10d and etcd backends.
ghstack-source-id: 128671579
Test Plan: Run the existing and revised tests.
Reviewed By: tierex
Differential Revision: D28356587
fbshipit-source-id: caf9416ab811eefe4834268d8a11a48f2236ed5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57824
Implement type check for string type. Re-raise detailed exception at compile time.
```py
>>> class InvalidData(Generic[T_co], NamedTuple): # Invalid generic namedtuple in Python typing
... name: str
... data: T_co
class DP(IterDataPipe['InvalidData[int]']):
... pass
TypeError: InvalidData[int] is not supported by Python typing
```
Add `__type_class__` attribute to class, which optimizes the static checking flow by reducing checking times.
```py
>>> class DP1(IterDataPipe[Union[int, str]]):
... pass
>>> class DP2(DP1[int]):
... pass
>>> list((cls, getattr(cls, '__type_class__', None)) for cls in DP2.__mro__)
[(<class '__main__.DP2'>, False), (<class 'abc.DP1[int]'>, True), (<class '__main__.DP1'>, False), (<class 'abc.IterableDataset[typing.Union[int, str]]'>, True), (<class 'torch.utils.data.dataset.IterableDataset'>, False), (<class 'torch.utils.data.dataset.Dataset'>, None), (<class 'typing.Generic'>, None), (<class 'object'>, None)]
```
Among the class of `DP2`'s MRO, only `DP2`, `DP1` will be static checked when `__type_class__` is `False`. `abc.DP1[int]` and `abc.IterableDataset[typing.Union[int, str]]` will be ignored since they are just a class with typing.
## Future
When Python 3.6 is deprecated, using TypeAlias rather than TypeMeta can eliminates the usage of `__type_class__` attribute.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D28289104
Pulled By: ejguan
fbshipit-source-id: 1da97460c8bfc48cea7396033fde484a24caba7c
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 566d74c27c
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57983
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D28334558
fbshipit-source-id: fcc41aae7c8309e8baccbf71442436a1ebb42378
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57972
Allow static runtime to be on when glow is on. This should be fine as long as glow AOT has already been run.
Test Plan: Test on replayer with remote_other net. D28291326 fixes remaining issue removing loops from the remote_other model. Need to test on regenerated model.
Reviewed By: hlu1
Differential Revision: D28275514
fbshipit-source-id: ee78972660dfdc3fcfb9af2cf7ebb19ee745a4f1
Summary:
normalizing `__is__` to `eq`, and `__isnot__` to `ne` in the case of bools.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57862
Test Plan:
```
python test/test_jit.py TestPeephole
```
11 Tests, 1 skipped, no failures
Fixes https://github.com/pytorch/pytorch/issues/57387
Reviewed By: eellison
Differential Revision: D28335646
Pulled By: Gamrix
fbshipit-source-id: c9f885044b32897ba35483091bcf7037759b7517
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58071
There's an environment variable that mypy will use to force color output, so turn that on if the runner detects a terminal.
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D28360742
Pulled By: driazati
fbshipit-source-id: c0dc372a44ab3a16e67115ce54784f4d5a4833ee
Summary:
**BC-breaking note**
This PR updates the deprecation notice for torch.norm to point users to the new torch.linalg.vector_norm and torch.linalg.matrix_norm functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57986
Reviewed By: nikithamalgifb
Differential Revision: D28353625
Pulled By: heitorschueroff
fbshipit-source-id: 5de77d89f0e84945baa5fea91f73918dc7eeafd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58001
Adds a script so that devs can generate a commit (at the base of a stack) that removes all CI jobs but the set that they care about. See CONTRIBUTING.md changes for usage
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D28359910
Pulled By: driazati
fbshipit-source-id: 2741570f2bab2c28f4a9d7aef727b1b2399d0ce1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57999
make ddp logging api to be private
ghstack-source-id: 128607185
Test Plan: unit test
Reviewed By: rohan-varma
Differential Revision: D28338485
fbshipit-source-id: bd2ae7c78904e93eed88be91876f5a832b5b7886
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57951
As pmeier suggested in another PR, just remove all redundant check for prior DataPipe.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D28325414
Pulled By: ejguan
fbshipit-source-id: 17497745fef1647c24a25f4ca08082dd4df6f4a7
Summary:
This PR enables the usage of cusolver potrf batched as the backend of Cholesky decomposition (`torch.linalg.cholesky` and `torch.linalg.cholesky_ex`) when cuda version is greater than or equal to 11.3.
Benchmark available at https://github.com/xwang233/code-snippet/tree/master/linalg/cholesky-new. It is seen that cusolver potrf batched performs better than magma potrf batched in most cases.
## cholesky dispatch heuristics:
### before:
- batch size == 1: cusolver potrf
- batch size > 1: magma xpotrf batched
### after:
cuda >= 11.3:
- batch size == 1: cusolver potrf
- batch size > 1: cusolver potrf batched
cuda < 11.3 (not changed):
- batch size == 1: cusolver potrf
- batch size > 1: magma xpotrf batched
---
See also https://github.com/pytorch/pytorch/issues/42666#47953https://github.com/pytorch/pytorch/issues/53104#53879
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57788
Reviewed By: ngimel
Differential Revision: D28345530
Pulled By: mruberry
fbshipit-source-id: 3022cf73b2750e1953c0e00a9e8b093dfc551f61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55248
This PR provides enable static graph training when users call _set_static_graph(). This can help support more use cases in DDP without performance regression, also can potentially improve performance when there are unused parameters in the graph.
1. first iteration records graph states like how many times a grad is calculated, whether the grad is used or not. then first iteration queues a delay_all_reduce call back to all reduce grads.
2. Since autograd call back is associated with current target graph task, the delay_all_all call back should be associated with out-most backward graph task. A DDP sink layer is added in DDP forward loop so that we can queue the delay_all_reduce call back in the sink layer.
3. after first iterations, DDP will use the saved graph states to determine whether a grad is used or not. whether a grad is ready for communication.
4. rebuilt bucket is called in second iteration, after graph states are recorded in first iteration.
5. if the graph states change, DDP will throw errors
ghstack-source-id: 128599464
Test Plan: unit tests. adding more tests
Reviewed By: rohan-varma
Differential Revision: D27539964
fbshipit-source-id: 74de1ad2719465be67bab8688d6e293cd6e3a246
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56674
`torch.nn.functional.multi_head_attention_forward` supports a long tail of options and variations of the multihead attention computation. Its complexity is mostly due to arbitrating among options, preparing values in multiple ways, and so on - the attention computation itself is a small fraction of the implementation logic, which is relatively simple but can be hard to pick out.
The goal of this PR is to
- make the internal logic of `multi_head_attention_forward` less entangled and more readable, with the attention computation steps easily discernible from their surroundings.
- factor out simple helpers to perform the actual attention steps, with the aim of making them available to other attention-computing contexts.
Note that these changes should leave the signature and output of `multi_head_attention_forward` completely unchanged, so not BC-breaking. Later PRs should present new multihead attention entry points, but deprecating this one is out of scope for now.
Changes are in two parts:
- the implementation of `multi_head_attention_forward` has been extensively resequenced, which makes the rewrite look more total than it actually is. Changes to argument-processing logic are largely confined to a) minor perf tweaks/control flow tightening, b) error message improvements, and c) argument prep changes due to helper function factoring (e.g. merging `key_padding_mask` with `attn_mask` rather than applying them separately)
- factored helper functions are defined just above `multi_head_attention_forward`, with names prefixed with `_`. (A future PR may pair them with corresponding modules, but for now they're private.)
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D28344707
Pulled By: bhosmer
fbshipit-source-id: 3bd8beec515182c3c4c339efc3bec79c0865cb9a
Summary:
Enabled `dot` for BFloat16 on CUDA (version 11+).
It also enabled `matmul` & `vdot` for BFloat16.
Backward for `matmul` isn't supported for `BFloat16`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57903
Reviewed By: mruberry
Differential Revision: D28346031
Pulled By: ngimel
fbshipit-source-id: 0917e9e0d6cf3694f45fe1c7e76370581502036a
Summary:
Right now** there's a bug in libcuda.so that triggers sometimes when graphs with certain topologies are replayed back to back without a sync in between. Replays that hit this bug turn into spaghetti: kernels reordered ignoring dependencies, kernels elided, corrupted results. Currently, the only workaround I know that fixes all our repros is a manual sync between replays.
I'll remove the sync (or special case it based on cuda version) in a later PR, as soon as a fixed libcuda.so is available.
The only substantive change is the cudaDeviceSynchronize, other lines changed are de-indenting an unneeded scope.
** The bug is in current and semi-recent public versions of libcuda.so. We discovered the bug recently and we're not sure yet which public release was first affected. The version that ships with 11.3 is definitely affected, versions that shipped with 11.1 and earlier are likely not affected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57556
Reviewed By: mruberry
Differential Revision: D28343043
Pulled By: ngimel
fbshipit-source-id: 3b907241aebdb8ad47ae96a6314a8b02de7bfa77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58022
Caffe2 Int8FC + rowwise quantization was not handling bias correctly.
Test Plan: The example in D28347336 doesn't show bigger error with rowwise quantization any more
Reviewed By: hx89, janeyx99
Differential Revision: D28347336
fbshipit-source-id: 3ac95fd2f29ef6e52705c3a2361b605813c2bcc5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50048
To reflect the many changes introduced recently.
In my mind, CUDAFuture should be considered a "private" subclass, which in practice should always be returned as a downcast pointer to an ivalue::Future. Hence, we should document the CUDA behavior in the superclass, even if it's CUDA-agnostic, since that's the interface the users will see also for CUDA-enabled futures.
ghstack-source-id: 128640983
Test Plan: Built locally and looked at them.
Reviewed By: mrshenli
Differential Revision: D25757474
fbshipit-source-id: c6f66ba88fa6c4fc33601f31136422d6cf147203
Summary:
This one's easy. I also included a bugfix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57735
Reviewed By: bdhirsh
Differential Revision: D28318277
Pulled By: mruberry
fbshipit-source-id: c3c4546a11ba5b555b99ee79b1ce6c0649fa7323
Summary:
This one's straightforward
**BC-breaking Note**
This PR deprecates matrix_rank in favor of linalg.matrix_rank. An upgrade guide from matrix_rank to linalg.matrix_rank is provided in the documentation of matrix_rank.
It DOES NOT remove matrix_rank.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57734
Reviewed By: bdhirsh
Differential Revision: D28318301
Pulled By: mruberry
fbshipit-source-id: b9a27f58fdad72f408ca8b83a70c9b1fc2ef28e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55189
Currently EmbeddingBag and it variants support either int32 or int64 indices/offsets. We have use cases where there are mix of int32 and int64 indices which are not supported yet. To avoid introducing too many branches we could simply cast offsets type to indices type when they are not the same.
Test Plan: unit tests
Reviewed By: allwu
Differential Revision: D27482738
fbshipit-source-id: deeadd391d49ff65d17d016092df1839b82806cc
Summary:
**BC-breaking note:**
This PR deprecates torch.cholesky in favor of torch.linalg.cholesky. A upgrade guide is added to the documentation for torch.cholesky.
Note this PR DOES NOT remove torch.cholesky.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57725
Reviewed By: bdhirsh
Differential Revision: D28318260
Pulled By: mruberry
fbshipit-source-id: e7ba049321810e70f4de08e6ac37ff800e576152
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57666
Got 5% improvement on mobilenetv2 and Unet
1. `std::unordered_map` is faster than `NSMutableDictionary`
2. `std::string` is cheaper than `NSString`
ghstack-source-id: 128338531
Test Plan: CI
Reviewed By: kimishpatel, SS-JIA
Differential Revision: D28048992
fbshipit-source-id: fc4f7e41928c524acde48947d2cd6b9f6ef7cbc8
Summary:
When doing this, I realised that `torch.linalg.pinv` did not have a note on the problems of its derivative (`torch.pinverse` did have it), so I added that.
As I was at it, I made a bit more explicit the recommendation for some functions in `torch.linalg` to prefer other functions. I also changed the mentions of "stable" to "numerically stable" as discussed with IvanYashchuk and mruberry
If it seems like too much, I'm happy to move the recommendations part of `torch.linalg` to a different PR, but it was such a small thing that I figured it wouldn't be that big a deal if it was here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57821
Reviewed By: bdhirsh
Differential Revision: D28317959
Pulled By: mruberry
fbshipit-source-id: 6b116561bf3cba46fadc5ac14448e5d28ea88039
Summary:
**BC-breaking note:**
This PR deprecates torch.lstsq; it adds an upgrade guide for how to use torch.linalg.lstsq instead.
It DOES NOT remove torch.lstsq, but warns once when it's called
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57743
Reviewed By: bdhirsh
Differential Revision: D28318196
Pulled By: mruberry
fbshipit-source-id: 0d6df29648a91a44c7d0ac58062c1099fcb61fb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57974
We see this error quite a bit in internal workflows, would be useful
to have this additional logging information here.
ghstack-source-id: 128602199
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D28331693
fbshipit-source-id: 25398c6a3420a2b594d79aa8f46936cd0addd426
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57711
Seeing some hangs/issues around store based barrier internally, would
be good to have this log to indicate whether store based barrier has completed
successfully or not for a particular rank to debug further.
ghstack-source-id: 128605600
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D28249087
fbshipit-source-id: 644e5780519017ae780c3bc78bbe5def322db3f8
Summary:
Redo of https://github.com/pytorch/pytorch/issues/57135 out of stack
---
Currently all values are used for the reported absolute and relative differences. This usually works fine, but breaks down for the extremals:
```python
torch.testing.assert_close(torch.tensor([1.0, 0.0]), torch.tensor([2.0, 0.0]))
```
```
[...]
Greatest absolute difference: 1.0 at 0 (up to 1e-05 allowed)
Greatest relative difference: nan at 1 (up to 1.3e-06 allowed)
```
Although the second element is matching it is listed as offender for the greatest relative difference. The `NaN` stems from the `0 / 0` division.
To overcome this, we should only use the values that were considered a mismatch for the reported stats.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57923
Reviewed By: ngimel
Differential Revision: D28317316
Pulled By: mruberry
fbshipit-source-id: 4c604493bbe13b37f41225ea9af9e839a7304161
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57798
Our instruction sequence was just plain wrong, instead of `fcmp une %x, +0.0`
(unordered equal 0.0) we were doing `fcmp uno`, which is just an unordered check
(i.e., is either side NaN).
ghstack-source-id: 128586464
Test Plan: New unit test against the full cross-product of dtypes.
Reviewed By: navahgar
Differential Revision: D28276269
fbshipit-source-id: ba5e59778e07770fb78ef02309f10edde333a800
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57965
The bold effect does not work under quotes, so move it out.
ghstack-source-id: 128570357
Test Plan:
locally view
{F614715259}
Reviewed By: rohan-varma
Differential Revision: D28329694
fbshipit-source-id: 299b427f4c0701ba70c84148f65203a6e2d6ac61
Summary:
The call stack in profiler result json file lacks surrounding double quotes, and result in json parse error.
This PR just add it.
ilia-cher
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57099
Reviewed By: gdankel
Differential Revision: D28324182
Pulled By: ilia-cher
fbshipit-source-id: dc479a023bb25de27c414629a27d624d64457c3e
Summary:
Judging from https://github.com/pytorch/pytorch/issues/57584, it seems like the test-reports artifact was originally intended to be downloaded to `$PWD/test-reports` instead of just directly into `$PWD`. To minimize confusion, this PR changes it to download into `test/test-reports`, which should match where the files came from in the `test` step anyway.
TODOs:
- [x] change the extract path for test-reports
- [x] install Python dependencies
- [x] call `tools/print_test_stats.py`
- [x] use deep clone to allow `git` commands
- [x] correctly set `CIRCLE_*` environment variables
- [x] set Scribe credentials
- [x] set AWS credentials
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57647
Test Plan: CI.
Reviewed By: seemethere
Differential Revision: D28325833
Pulled By: samestep
fbshipit-source-id: cc322bad76747f59b764a1a0a863153bb26095e7
Summary:
Fixes https://github.com/pytorch/pytorch/issues/42163.
## {emoji:1f525} Pitch
Currently, the binary outputs produced by `torch.save()` are non-deterministic (as pointed out in https://github.com/pytorch/pytorch/issues/42163). This means that running a simple snippet that creates a tensor (or a model) twice will produce output files with a different `md5` sum.
**Why does this occur?**
The cause of this behavior lies in the fact that the `obj._cdata` is used to identify a tensor and is written to a file, but the `_cdata` attribute is of course non-deterministic:
a80b215a9a/torch/serialization.py (L416)
**Why does this matter?**
Reproducibility is essential for many Machine Learning projects.
For instance, when using [`dvc`](https://dvc.org/) you would expect that if none of the dependencies of a stage of a ML pipeline has changed, then running the same stage another time will produce the same binary output. For the reasons explained above, with `torch` this was not the case, so this PR tries to fix this issue.
## {emoji:1f4cc} Content of this PR
### What changes?
- The `persistent_id()` function now returns a deterministic value, rather than `obj._cdata` (which depends on runtime).
- As a consequence, `torch.save(obj, "output.pt")` produces a deterministic output, i.e. the `md5` hash of `output.pt` is determinstic. See **Test 1** and **Test 2** below.
### What does not change?
- If an `obj` contains several tensors that share the same underlying data (e.g. they are views of the same tensor),the `obj_key` returned by `persistent_id()` is still going to be the same for all of them
- As a consequence, serialization optimizes disk storage by storing only necessary tensors, rather than writing one tensor per view. See **Test 3** below.
## � How to test
### Test 1: snipped from https://github.com/pytorch/pytorch/issues/42163
Consider the following `snippet_1.py` (from https://github.com/pytorch/pytorch/issues/42163).
```python
import hashlib
import torch
def get_sha256_hash(file: str, chunk_size: int = 4096) -> str:
hasher = hashlib.sha256()
with open(file, "rb") as fh:
for chunk in iter(lambda: fh.read(chunk_size), b""):
hasher.update(chunk)
return hasher.hexdigest()
file = "tensor.pt"
hashes = []
for _ in range(5):
obj = torch.ones(1)
torch.save(obj, file)
hashes.append(get_sha256_hash(file)[:8])
del obj
hash = hashes[0]
assert all(other == hash for other in hashes[1:])
print(hash)
```
On `master` you obtain an error
```bash
$ python snippet_1.py
Traceback (most recent call last):
File "save_tensor.py", line 84, in <module>
assert all(other == hash for other in hashes[1:])
AssertionError
```
while on this PR branch you should get the following consistent behaviour:
```bash
$ for run in {1..2}; do python snippet_1.py; done
600a83cb
600a83cb
```
### Test 2: Deterministic save of `Tensor` and `nn.Module` instances
Consider the following `snippet_2.py`
```python
import torch
torch.manual_seed(0)
x = torch.tensor([8., 8., 5., 0.])
torch.save(x, "out_tensor.pt")
model = torch.nn.Sequential(
torch.nn.Linear(3, 1),
torch.nn.Flatten(0, 1)
)
torch.save(model, "out_model.pt")
```
On `master` branch, the `md5` hash of `out_tensor.pt` and `out_model.pt` are non-determinstic, for instance you may get
```bash
$ for run in {1..2}; do python snippet_2.py; md5 out_*pt; done
MD5 (bc9e8af218) (out_model.pt) = 92dca4a310b691e893f3cb41d64d5af1
MD5 (bc9e8af218) (out_tensor.pt) = a4ef290583f50a9c203a42d0cfc078af
MD5 (bc9e8af218) (out_model.pt) = de3cb9791a66af8aed77ed7224bd1d5c
MD5 (bc9e8af218) (out_tensor.pt) = 3b8a6009d3a0be5b9dd94152dcc0c7cb
```
while on this PR branch you should get the following consistent behaviour:
```bash
$ for run in {1..2}; do python snippet_2.py; md5 out_*pt; done
MD5 (bc9e8af218) (out_model.pt) = dba75fd50a190e4e7fa89b7a2477bab7
MD5 (bc9e8af218) (out_tensor.pt) = 029f52f0706d6c813cc796d3cdcd3eb0
MD5 (bc9e8af218) (out_model.pt) = dba75fd50a190e4e7fa89b7a2477bab7
MD5 (bc9e8af218) (out_tensor.pt) = 029f52f0706d6c813cc796d3cdcd3eb0
```
### Test 3: Views of the same tensor are not re-written to file
Consider the following `snippet_3.py`.
```python
import torch
torch.manual_seed(0)
x = torch.rand(1_000, 1_000)
y = x.T
z = x.view(1_000_000, 1)
torch.save({"x": x}, "out_tensor_x.pt")
torch.save({"x": x, "y": y, "z": z}, "out_tensor_xyz.pt")
```
Both on `master` branch and on this PR branch you should get two output files with same size:
```bash
$ python snippet_3.py && du -sh out_tensor*pt && md5 out_*pt
3.8M out_tensor_x.pt
3.8M out_tensor_xyz.pt
MD5 (bc9e8af218) (out_tensor_x.pt) = eda516d9156177b27bdc2a75c9064d9b
MD5 (bc9e8af218) (out_tensor_xyz.pt) = 333b869f5b93ced7b8649ab1571eb8e3
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57536
Reviewed By: bdhirsh
Differential Revision: D28304728
Pulled By: ailzhang
fbshipit-source-id: 49788e566a3cd2c6c36dc801e6bdd8f42c9459cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57771
This mapping didn't work properly when certain parameters didn't
require grad. Fixed that and added a test.
ghstack-source-id: 128527537
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D28265636
fbshipit-source-id: 7b342ce012b2b7e33058b4c619ffb98992ed05b7
Summary:
Downloading slow_test list on SC causes timeout, this is even a bigger issue since `common_utils.py` is reused in many internal projects/modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57953
Test Plan: CI
Reviewed By: janeyx99
Differential Revision: D28325527
fbshipit-source-id: ae47c9e43ad6f416008005bb26ceb2f3d6966f2e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/30696
### Release Notes
Instantiating a custom autograd function is now deprecated. Users should call `.apply()` on the class itself because it is a static method.
--end release notes--
- There are a couple error messages that we can't entirely remove because accessing these attributes of the autograd function instance may segfault (due to cdata being nullptr). Also added a TORCH_CHECK for the name attribute which previously segfaulted.
- Error message updated to convey 1) old-style functions have been deprecated 2) this access pattern was once valid
- Updates variable -> Tensor for some error messages
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57357
Reviewed By: mrshenli
Differential Revision: D28193095
Pulled By: soulitzer
fbshipit-source-id: f021b105e9a3fd4a20d6ee3dfb6a06a8c34b10ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57733
I'm going to be modifying the APIs here, so the less API surface
covering these functions the better.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28289082
Pulled By: ezyang
fbshipit-source-id: 4b71270bb82e0d6baa4dfed2f2e4ee8831f590b5
Summary:
Relates to https://github.com/pytorch/pytorch/issues/56210. Initial attempt to make support for `list`, `tuple` and `dict` type in PEP-585.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57363
Test Plan:
- newly added `test_pep585_type`
- CI
Reviewed By: ngimel
Differential Revision: D28128230
Pulled By: walterddr
fbshipit-source-id: e5ba487dfd8c42e89f851d22b3aebfa56dd419bf
Summary:
Automatically generate this workflow by filtering all jobs that has *filters:branches:only:master* restriction
Add probot config to schedule this workflow if `ci/master` label is set on PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57899
Reviewed By: walterddr
Differential Revision: D28311838
Pulled By: malfet
fbshipit-source-id: 63df81212279f5edd8463d1f6b22f37253c53a98
Summary:
This PR adds a new pass in JIT that optimizes `aten::cat` ops.
Specifically, here are optimizations performed:
* Eliminate redundant in `cat` inputs by performing cse on the list of inputs.
- This includes eliminating fully redundant `cat` ops when all the inputs are the same as well the case when "all but one" of the inputs have already been concatenated.
* Expand `cat` into multiple copies and eliminate redundancies.
- This also includes eliminating redundancies in the underlying buffers used for `cat`.
These optimizations are not enabled in any compilation flow at this point.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55474
Reviewed By: albanD
Differential Revision: D27624511
Pulled By: navahgar
fbshipit-source-id: d509289fafc23e73b02f64a90219148896817339
Summary:
Backward methods for `torch.lu` and `torch.lu_solve` require the `torch.lu_unpack` method.
However, while `torch.lu` is a Python wrapper over a native function, so its gradient is implemented via `autograd.Function`,
`torch.lu_solve` is a native function, so it cannot access `torch.lu_unpack` as it is implemented in Python.
Hence this PR presents a native (ATen) `lu_unpack` version. It is also possible to update the gradients for `torch.lu` so that backward+JIT is supported (no JIT for `autograd.Function`) with this function.
~~The interface for this method is different from the original `torch.lu_unpack`, so it is decided to keep it hidden.~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46913
Reviewed By: astaff
Differential Revision: D28117714
Pulled By: mruberry
fbshipit-source-id: befd33db12ecc147afacac792418b6f4948fa4a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57792
There are two problems when using CUDA RPC with distributed autograd
and distributed optimizer:
1) In local autograd engine, all autograd functions/nodes, including
AccumualteGrad will use the forward stream for backward computation.
But distributed autograd skips AccumulateGrad autograd function/node
and directly calls into `AccumulateGrad::accumulateGrad`. As the
result, it will use the default stream to accumulate gradients
instead of the forward stream. This commit changes that and uses the
forward stream to accumulate gradients, matching forward behavior.
2) Distributed optimizer and distributed autograd backward are
separate RPC calls, and CUDA streams are not synchronized across
different RPC calls. As a result, distributed optimizer might
consume gradients before they are ready. This commit uses CUDA
events to record the completion of gradient computation, and use
those events to block current streams when getGradients() are called.
Test Plan: Imported from OSS
Reviewed By: pritamdamania87
Differential Revision: D28274876
Pulled By: mrshenli
fbshipit-source-id: 22e607152324ae918084066cde8c5dbb418bba7c
Summary:
Currently, the test code is not testing unknown types correctly because `op` is overwritten in the for-loop (i.e., currently only `__ior__` is tested).
This PR fixes the test `generate_not_implemented_tests` to bind operator name to each method, and remove operators currently unsupported (`__rand__`, …).
cc/ mruberry This fix is be needed to add tests for the operator we are going to introduce (e.g., `__rand__`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56997
Reviewed By: astaff
Differential Revision: D28118465
Pulled By: mruberry
fbshipit-source-id: c5a466a7604262ed5490862300d47043aff63d0b
Summary:
This PR is focused on the API for `linalg.matrix_norm` and delegates computations to `linalg.norm` for the moment.
The main difference between the norms is when `dim=None`. In this case
- `linalg.norm` will compute a vector norm on the flattened input if `ord=None`, otherwise it requires the input to be either 1D or 2D in order to disambiguate between vector and matrix norm
- `linalg.vector_norm` will flatten the input
- `linalg.matrix_norm` will compute the norm over the last two dimensions, treating the input as batch of matrices
In future PRs, the computations will be moved to `torch.linalg.matrix_norm` and `torch.norm` and `torch.linalg.norm` will delegate computations to either `linalg.vector_norm` or `linalg.matrix_norm` based on the arguments provided.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57127
Reviewed By: mrshenli
Differential Revision: D28186736
Pulled By: mruberry
fbshipit-source-id: 99ce2da9d1c4df3d9dd82c0a312c9570da5caf25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57906
I think it was accidentally flipped in #56875.
Test Plan: Imported from OSS
Reviewed By: Chillee
Differential Revision: D28312947
Pulled By: ZolotukhinM
fbshipit-source-id: 8d0f45e540f47daefbc270f5a2ade87f2171b958
Summary:
## Note:
**This change will include the feature, but the feature is not on. It will be enabled and bytecode version will be bumped in D27844651 (8c04593c0a).**
Jit will generate constant tensor, and it locates in the constant folder (can find them after unzip model.ptl). Bytecode generated by lite interpreter also includes constant tensor, which are almost the same with the constant tensor value from jit. This pr will let lite interpreter reuses the constant tensor from jit, instead of reproducing the similar tensor values. The reading and writing session will be as following.
More details and background can found in [Lite Interpreter Model Size Issue](https://fb.quip.com/OSidAcjhL9LS).
Data size comparison can be found in [Model size analysis](https://fb.quip.com/oEm6A4bhbo06)
### Write
1. In `export_module.cpp`, store all constant tensor value from jit in an `unordered_map constants_from_jit`, where the tensor value use tensor string as a hash. constants_from_jit is a map: (tensor) => (archive_name, index). When writing bytecode archive `writeByteCode()`, the map `constants_from_jit` will also be passed all the way to it's pickler.
2. In `pickler.cpp`, a new map tensors_archive_table_ is added. It is also a map: (tensor) => (archive_name, index). The corresponding function to update the map is `updateTensorsArchiveTable`. When pushing the storage of a tensor, if the tensor exists in `tensors_archive_table_`, the root key will be `{archive_name}/{index}`, instead of `{index}`. For example, the tensor
```
torch._utils._rebuild_tensor_v2(pers.obj(('storage', torch.FloatStorage, '0', 'cpu', 90944),),
0,
(1, 116, 28, 28),
(90944, 784, 28, 1),
False,
collections.OrderedDict()),
```
will be like following instead
```
torch._utils._rebuild_tensor_v2(pers.obj(('storage', torch.FloatStorage, 'constants/0', 'cpu', 90944),),
0,
(1, 116, 28, 28),
(90944, 784, 28, 1),
False,
collections.OrderedDict()),
```
**Note**: Only tensors in bytecode archive will be different. The tensors in other archive remains the same, because `updateTensorsArchiveTable()` is only called when `use_tensors_archive_table_` is `true`, and `tensors_archive_table_` is only set as `true` when `bytecode_version` is a valid number.
### Read
1. In `import.cpp`, the function `read_record` passed to Unpickler is updated. The argument of `read_record` is the root key. In version 4, the root key will just be index, and `archive_name_plus_slash` + `name` will be used to get the tensor. With this change (version 5+), `read_record` will check if slash exists in the argument `name`. If it does, it means the argument is `archive_name/index`, and it can be used to get tensor directly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56002
ghstack-source-id: 128498244
Test Plan:
### Verify the new model generated from this pr can reuse constant table and the numerical result is the same.
1. Build pytorch locally. `MACOSX_DEPLOYMENT_TARGET=10.9 CC=clang CXX=clang++ USE_CUDA=0 DEBUG=1 MAX_JOBS=16 python setup.py develop`
2. Run `python save_lite.py`
```
import torch
# ~/Documents/pytorch/data/dog.jpg
model = torch.hub.load('pytorch/vision:v0.6.0', 'shufflenet_v2_x1_0', pretrained=True)
model.eval()
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
import pathlib
import tempfile
import torch.utils.mobile_optimizer
input_image = Image.open('~/Documents/pytorch/data/dog.jpg')
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
print(torch.nn.functional.softmax(output[0], dim=0))
traced = torch.jit.trace(model, input_batch)
sum(p.numel() * p.element_size() for p in traced.parameters())
tf = pathlib.Path('~/Documents/pytorch/data/data/example_debug_map_with_tensorkey.ptl')
torch.jit.save(traced, tf.name)
print(pathlib.Path(tf.name).stat().st_size)
traced._save_for_lite_interpreter(tf.name)
print(pathlib.Path(tf.name).stat().st_size)
print(tf.name)
```
3. Run `python test_lite.py`
```
import torch
from torch.jit.mobile import _load_for_lite_interpreter
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open('~/Documents/pytorch/data/dog.jpg')
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
reload_lite_model = _load_for_lite_interpreter('~/Documents/pytorch/experiment/example_debug_map_with_tensorkey.ptl')
with torch.no_grad():
output_lite = reload_lite_model(input_batch)
# Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
print(output_lite[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
print(torch.nn.functional.softmax(output_lite[0], dim=0))
```
4. Compare the result with pytorch in master and pytorch built locally with this change, and see the same output.
5. The model size was 16.1 MB and becomes 12.9 with this change.
Size comparison in production models:
{F603127047}
Reviewed By: iseeyuan
Differential Revision: D27759891
fbshipit-source-id: 34e0cb8149011c46c1910165b545c137d7a0b855
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57879
_save_data() and _load_data() were designed as a protocol of data serialization of trainer client. As confirmed with kwanmacher and dreiss , they are not used. In addition, there's no plan to use them in Federated Learning flow. Remove them for now.
Test Plan: Imported from OSS
Reviewed By: kwanmacher
Differential Revision: D28306682
Pulled By: iseeyuan
fbshipit-source-id: 1b993ce4d78e372ae9b83bcbe496a196f9269d47
Summary:
Add an api to backport a model vn to model vi. It accept an input model (file or buffer) and output a model (file or buffer) with an expected bytecode version.
In this change, the input is a model and it can come from a file or buffer. The output is a model and can be either file path or buffer.
When backport fails, function return false with a warning message :
```
/Users/chenlai/pytorch/cmake-build-debug/bin/test_jit --gtest_filter=LiteInterpreterTest.BackPortByteCodeModelV4:LiteInterpreterTest/*.BackPortByteCodeModelV4:*/LiteInterpreterTest.BackPortByteCodeModelV4/*:*/LiteInterpreterTest/*.BackPortByteCodeModelV4 --gtest_color=no
Testing started at 2:32 PM ...
CUDA not available. Disabling CUDA and MultiCUDA tests
[W backport.cpp:419] Warning: Backport doesn't support backport to version3 (function _backport_for_mobile_impl)
Process finished with exit code 0
```
## Test
1. Run both `caffe2/test/cpp/jit/test_lite_interpreter.cpp` and `caffe2/test/mobile/test_bytecode.py`.
2. Run all prod models with backport api.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56802
ghstack-source-id: 128425510
Test Plan: CI
Reviewed By: raziel, iseeyuan
Differential Revision: D27844651
fbshipit-source-id: 8a803cf6c76433ee0a3049b1a5570585d569f8d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57523
`_test_barrier_timeout` would run a barrier on rank 1 and sleep for
`timeout` on other ranks. In some cases if the other ranks would be faster,
they would enter the sleep call much earlier than rank 0 would enter barrier.
As a result, they would exit before the timeout is up and rank 0 would receive
a connection closed error instead of a timeout error. This would result in the
barrier call exiting before the timeout and the subsequent assertion failing.
#Closes: https://github.com/pytorch/pytorch/issues/57176
ghstack-source-id: 128278775
Test Plan:
1) waitforbuildbot
2) Tested synthetically by forcing a rank to exit earlier.
Reviewed By: rohan-varma
Differential Revision: D28170821
fbshipit-source-id: a67456a1784dd0657f264c4f5498638e0aa00de2
Summary:
This makes detach both forward and backward non-differentiable by default.
You can pass the `only_backward_mode=True` argument to make it forward differentiable but backward non-differentiable.
The important side effect of this change is that, by default, detach is not tracking any view information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57820
Reviewed By: ezyang
Differential Revision: D28287633
Pulled By: albanD
fbshipit-source-id: bdc4726fcd05889f6ac84e5a3a3ef71b2ec41015
Summary:
Previously `make quicklint` would lint all changed files for both mypy `ini`s, regardless of whether that file was actually supposed to be run under that configuration. This PR fixes that so we are using `tools/mypy_wrapper.py` to check if files should be included.
There's a similar change for `flake8` so that it now only outputs errors once and correctly excludes the paths in `.flake8`.
This also adds a bunch of tests to ensure that `make lint` and `make quicklint` both work and that `make quicklint` is excluding and including what it should.
Fixes#57644
](https://our.intern.facebook.com/intern/diff/28259692/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57752
Pulled By: driazati
Reviewed By: samestep
Differential Revision: D28259692
fbshipit-source-id: 233d355781230f11f98a6f61e2c07e9f5e737e24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57181
Documentation for torch.linalg.svd says:
> The returned decomposition is a named tuple `(U, S, Vh)`
The documentation is correct while the implementation was wrong.
Renamed `V` -> `Vh`. `h` stands for hermitian.
This is a BC-breaking change but our linalg module is beta, therefore we can do it without a deprecation notice or aliases.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28142162
Pulled By: mruberry
fbshipit-source-id: 5e6e0ae5a63300f2db1575ca3259df381f8e1a7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57180
We have now a separate function for computing only the singular values.
`compute_uv` argument is not needed and it was decided in the
offline discussion to remove it. This is a BC-breaking change but our
linalg module is beta, therefore we can do it without a deprecation
notice.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28142163
Pulled By: mruberry
fbshipit-source-id: 3fac1fcae414307ad5748c9d5ff50e0aa4e1b853
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57822
* `AsyncSparseAllreduceWork` can avoid copying output tensors, since we keep all the results alive by means of modifying input vector directly
* `AsyncSparseAllreduceWork` now returns inputs back to user instead of former behavior where it returned copies of inputs. This is consistent with other operations and process group implementations
* `AsyncSparseAllreduceCUDAWork` is now copying tensors directly from CPU to input tensors avoiding extra copy `output` -> `outputs` -> `inputs`. inputs are being returned to back to user. This is consistent with other operations and process group implementations.
overall AsyncSparseAllreduceCUDAWork is now avoiding 2 extra copies (as AsyncSparseAllreduceCUDAWork is using AsyncSparseAllreduceWork's impl)
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D28298325
Pulled By: agolynski
fbshipit-source-id: 18e2104413cdf5e73a01aad464e2613807779297
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50903
First part of #50010. Also fixes#51127.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27911345
Pulled By: mruberry
fbshipit-source-id: 7138fddc935802918ab9ff19f4bc1b9f4d745d41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56492
These are documented as internal-only and aren't called.
ghstack-source-id: 128354112
Test Plan: CI
Reviewed By: ilia-cher
Differential Revision: D27834789
fbshipit-source-id: 4a1aa320f952249db51945ff77563558fa884266
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56115
No reason to size it wrong and then resize it. Also, no reason to unconditionally go through the dispatcher.
ghstack-source-id: 128354110
Test Plan: Existing CI
Reviewed By: ngimel
Differential Revision: D27768757
fbshipit-source-id: 5dcb1fed5c5fa6707ee15359a26fde2a9a888b7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57199
Reduces the size of compiled shaders, and also potentially adds some performance boost.
Test Plan: Imported from OSS
Reviewed By: xta0
Differential Revision: D28293816
Pulled By: SS-JIA
fbshipit-source-id: 424dc0bce24d6115ba2bf8405027e967f6cb9497
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57723
Updated the note section of `RendezvousHandler`:
- Removed the experimental API warning.
- Recommended using the C10d Store instead of etcd for most users.
Test Plan: N/A
Reviewed By: kiukchung
Differential Revision: D28253828
fbshipit-source-id: c4f34dffd1a3cc132977029fe449b6d63ddc877b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57823
Some models use the `NaiveSyncBatchNorm` instead of `BatchNorm2d`, but during inference they behave the same. This change is to ensure that `NaiveSyncBatchNorm` gets folded into convs during optimization passes, particularly `FoldConvBatchNorm`.
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28291709
Pulled By: SS-JIA
fbshipit-source-id: c494dc7698c3fa536146038808fedbb46c17a63b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57703
The .bzl files didn't have registerQuantizedCUDA listed for some reason but upon adding them, the previously broken commands (on CUDA) now work.
note: these build files didn't affect OSS builds which was working throughout.
the test_qtensor test was potentially misleading since it would pass even if CUDA support wasn't working as long as the build system wasn't CUDA enabled. I broke this out into independent tests for each device so at least a skip would be produced rather than a pass for systems without CUDA enabled.
Test Plan:
buck test mode/dbg //caffe2/test:quantization -- --exact 'caffe2/test:quantization - test_qtensor_cpu (quantization.test_quantized_tensor.TestQuantizedTensor)'
buck test mode/dbg //caffe2/test:quantization -- --exact 'caffe2/test:quantization - test_qtensor_cuda (quantization.test_quantized_tensor.TestQuantizedTensor)'
Reviewed By: jerryzh168
Differential Revision: D28242797
fbshipit-source-id: 938ae86dcd605aedf26ac0bace9db77deaaf9c0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57410
FP16 gradient compression may run into 'inf' issue. switching to division before allreduce can avoid this problem.
ghstack-source-id: 127877083
Test Plan:
before chage
f268909897
after change:
f270950609
If you still sees 'grad_norm = inf' after enabling fp16 hook, you can resume the training and turning off the hook.
Reviewed By: SciPioneer
Differential Revision: D28128628
fbshipit-source-id: 0b6648637713e4f321e39c9ccb645a6b6f1750a0
Summary:
Redo of https://github.com/pytorch/pytorch/issues/56373 out of stack.
---
To reviewers: **please be nitpicky**. I've read this so often that I probably missed some typos and inconsistencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57247
Reviewed By: albanD
Differential Revision: D28247402
Pulled By: mruberry
fbshipit-source-id: 71142678ee5c82cc8c0ecc1dad6a0b2b9236d3e6
Summary:
Here is why another move of this single line is needed:
- Regardless of whether test-run failed or succeeded it's good to
report number of tests executed
- `docker cp || echo` always succeeds so could safely be executed
before any other step in "Report test results"
- This command should not be part of "Run tests" step, otherwise it would not get executed if any of the test failed (if it must be part of "Run tests" step, it should be prefixed with [trap](https://tldp.org/LDP/Bash-Beginners-Guide/html/sect_12_02.html) command and defined before `docker exec` step
This fixes "regression" introduced by https://github.com/pytorch/pytorch/pull/56725 although real culprit here is lack of documentation
Here is an example of PR where test results are not reported back due to
the failure: https://app.circleci.com/pipelines/github/pytorch/pytorch/317199/workflows/584a658b-c742-4cbb-8f81-6bb4718a0c04/jobs/13209736/steps
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57795
Reviewed By: samestep
Differential Revision: D28275510
Pulled By: malfet
fbshipit-source-id: 622f3bfca96a1ee9b8959590b28a26046eb37ea3
Summary:
```
class Foo(nn.Module):
def __init__(self):
super().__init__()
def forward(self, y, x):
for k in x:
for v in x[k]:
v += y
return x
example_dict = {'x': {'a': [fx.HOLE], 'z': [fx.HOLE, fx.HOLE]}}
new_f = fx.symbolic_trace(Foo(), concrete_args=example_dict)
print(new_f.code)
new_f(torch.randn(5), {'x': {'a': [torch.randn(5)], 'z': [torch.randn(5), torch.randn(5)]}})
fx.symbolic_trace(new_f, concrete_args=example_dict)
```
prints out
```
def forward(self, y, x):
y, tree_2, tree_3, tree_4 = pytree.tree_flatten([y, x])[0]
add = tree_2 + y
add_1 = tree_3 + y
add_2 = tree_4 + y; y = None
return {'a': [tree_2], 'z': [tree_3, tree_4]}
```
Currently, I store `in_spec` as an extra attribute on `fx.Graph`, and then include it when we do the codegen. I'm not sure if this is the right approach - it introduces a divergence between what's in `fx.Graph` and what's in the python code.
Perhaps the best API is something explicit like `fx.Graph.flatten_args`, but that does make calling things a bit ... more verbose.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55888
Reviewed By: jamesr66a
Differential Revision: D27884694
Pulled By: Chillee
fbshipit-source-id: f9e8a70c63a8df63c9f9bd0a6459255daa5a8df8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57636
The "preferred" pointer holder for Future is `intrusive_ptr` (e.g., `then` returns an `intrusive_ptr`, `toFuture` returns `intrusive_ptr`, ...). However in RPC we often wrap it with `shared_ptr`. This probably dates back to when we had a separate Future type, before the merge.
At the boundary between RPC and JIT this difference becomes a bit annoying, as conversions between the pointer types are needed. I think it would be simpler and more consistent to always use `intrusive_ptr`, also in RPC.
This PR was produced mainly by find-and-replace, plus a couple of manual fixes.
ghstack-source-id: 128296581
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D28187972
fbshipit-source-id: d4609273a1550b4921910e85d2198e02f31c905b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57635
Note: this PR looks massive, but it's just one simple change, codemodded many times.
In many cases, a callback needs to access the value/error produced by the parent future. In Python this was easy because the callback was invoked with the parent future as argument, and could thus inspect it. In C++ the callbacks didn't take any arguments, thus in many cases we worked around this by capturing the future in its own callback. This is risky (leads to reference cycle and thus memory leak) and must be done carefully (spoiler: sometimes we weren't).
ghstack-source-id: 128296580
Test Plan: CI
Reviewed By: wanchaol
Differential Revision: D28178783
fbshipit-source-id: 6de02c4568be42123372edc008f630d5ddae0081
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57634
`wrapPropagateTLSState` was restricting its argument to be an argument-less function, and I need to relax this for later work.
Also, it was requiring its argument to be converted to `std::function`, and also returned a `std::function`. Each creation of a `std::function` could cause a heap allocation. It's not particularly expensive, but here we can easily avoid it by having `wrapPropagateTLSState` directly operate on generic callables (thus, possibly, raw lambdas).
ghstack-source-id: 128295264
Test Plan: CI
Reviewed By: ilia-cher
Differential Revision: D28178782
fbshipit-source-id: d657f5751514974518606dd4fc4175e805dcb90a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56613
Replace linalg_solve_helper with `lu_stub` + `lu_solve_stub`.
Once `lu_stub` and `lu_solve_stub` have cuSOLVER-based codepath,
`torch.linalg.solve` will have it as well.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28248766
Pulled By: mruberry
fbshipit-source-id: 3003666056533d097d0ad659e0603f59fbfda9aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56612
The goal of this refactoring is to make the `torch.linalg.solve`
to be a composition of calls to `lu_stub` and `lu_solve_stub`.
Once `lu_stub` and `lu_solve_stub` have cuSOLVER-based codepath,
`torch.linalg.solve` will have it as well.
Replaced `lu_with_info_{cpu, cuda}` with one function that calls
to `lu_stub`.
Split MAGMA-based `apply_lu` into `apply_lu_looped_magma`
and `apply_lu_batched_magma`. This simplifies the future switch to
cuSOLVER and cuBLAS libraries.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28248756
Pulled By: mruberry
fbshipit-source-id: 40e02b5be4ff5f78885bcc95685aba581043e096
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56820
The test only fails for inverse n-dim functions with `norm="forward"`. The relative error for isn't actually any bigger than other norm modes though. It's just that the magnitude of the result is bigger, so the absolute tolerance is less relative each element. So, I just increase the relative tolerance to compensate.
This `precisionOverride` is already applied to `fftn` and `rfftn` for exactly the same reason.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57576
Reviewed By: albanD
Differential Revision: D28249222
Pulled By: mruberry
fbshipit-source-id: 734c7c1ae8236b253d6e3cd2218c05d21901c567
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57748
To be used by PyTorchPredictor integration for deploy.
Original commit changeset: 4d41efc733b2
Test Plan: tested via new unit tests
Reviewed By: suo
Differential Revision: D28258525
fbshipit-source-id: 8b9436e47501d7c1c16e79909e668100f825711e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57664
Manually permuting weights is slower than using aten::contiguous. This will improve the model loading time at runtime especially on low-end devices. Some numbers from the Unet model. Average 6x faster.
- iPhone 12
- before - 26.252 ms
- after - 4.727 ms
- iPhone 11
- before - 29.638 ms
- after - 5.012 ms
- iPhone X
- before - 33.257 ms
- after - 5.481 ms
- iPhone 8
- before - 33.335 ms
- after - 5.83 ms
- iPhone 7
- before - 36.144 ms
- after - 6.232 ms
- iPhone 6s
- before - 47.977 ms
- after - 6.998 ms
ghstack-source-id: 128338534
Test Plan: - CI
Reviewed By: kimishpatel
Differential Revision: D28087911
fbshipit-source-id: ad0029436e59a0ecc02ce660ed1110dc0b82848c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57705
This will enable module level debug info for benchmarking binary.
Test Plan: Run on AIBench
Reviewed By: larryliu0820
Differential Revision: D28230948
fbshipit-source-id: 5d06c6853d049ff678995a2ed4a86f4e6c85bdc7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57764
As discussed offline this PR renames etcd-experimental backend to etcd-v2 and c10d-experimental backend to c10d.
ghstack-source-id: 128342523
Test Plan: Run the existing unit tests.
Reviewed By: kiukchung
Differential Revision: D28263739
fbshipit-source-id: c3409037ecea5a8ff6daadeeb1f2fb4205cc3852
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 530356e16f
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57485
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jiecaoyu
Differential Revision: D28158310
fbshipit-source-id: 2ea77956a6e1709569a587c671c0c08018b8a966
Summary:
As per discussion here https://github.com/pytorch/pytorch/pull/57127#discussion_r624948215
Note that we cannot remove the optional type from the `dim` parameter because the default is to flatten the input tensor which cannot be easily captured by a value other than `None`
### BC Breaking Note
This PR changes the `ord` parameter of `torch.linalg.vector_norm` so that it no longer accepts `None` arguments. The default behavior of `2` is equivalent to the previous default of `None`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57662
Reviewed By: albanD, mruberry
Differential Revision: D28228870
Pulled By: heitorschueroff
fbshipit-source-id: 040fd8055bbe013f64d3c8409bbb4b2c87c99d13
Summary:
Why:
To keep VS version always updated in README
1. update VS version link in CI. It's more convenient for my PR robot to update the version in README once the VS in CI is updated. and permlink isn't stable.
2. Move `building on legacy code` to development tips. The table is big and it looks the REAMD not updated at the first sight.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56686
Reviewed By: janeyx99
Differential Revision: D28272060
Pulled By: samestep
fbshipit-source-id: 4bb879ea2914cc8bcd68343a9ed230418e1f9268
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56546
A code move for CodeImpl and Frame to a subdirectory runtime/interpreter, so
that it's easier to reuse them and navigate the interpreter code.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D28133580
fbshipit-source-id: 8de89a4e8e637836625e1ac1db95f0a3353da670
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57609
Throw c10::CudaError for CUDA Exceptions for better classification of errors
Test Plan: Test locally by running some workflows
Reviewed By: dzhulgakov
Differential Revision: D28209356
fbshipit-source-id: 19a5fc8548433238dc224ea81a5f63a945fc5cc3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57651
We've gone back and forth on whether to emulate the `sys.modules` lookup
behavior in our own `whichmodule`, the provided test is a concrete case
for doing so.
An additional minor cleanup is to make the type of `self.modules` in
importers `Dict[str, ModuleType]`. Modules could only be None in the
dictionary in older versions of the import system
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D28226536
Pulled By: suo
fbshipit-source-id: c2e6da91651ddaa4fbf7171555df9e5cbe1060fd
Summary:
Add an ability to use new profiler API even if Kineto is not compiled
in, by falling back to the legacy profiler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57612
Test Plan:
compiled
USE_KINETO=0 USE_CUDA=1 USE_MKLDNN=1 BLAS=MKL BUILD_BINARY=1 python
setup.py develop install --cmake
and with USE_KINETO=1
and ran
python test/test_profiler.py -v
Reviewed By: gdankel
Differential Revision: D28217680
Pulled By: ilia-cher
fbshipit-source-id: ec81fb527eb69bb0a3e0bd6aad13592200d7fe70
Summary: Removed the deadline restriction since the first run can take more than the deadline, wile subsequent runs are shorter.
Reviewed By: ngimel
Differential Revision: D28260077
fbshipit-source-id: 8ed2f5c16bc184bf4fae0a59b662fa1da2d4dd0a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57034
Resolves gh-38915
For the example given in the issue, BatchNorm1d on cuDNN is around 12x slower
than BatchNorm2d. Internally, cuDNN expects at least a 4d tensor (N, C, H, W)
so these two modules actually call the same cuDNN code. My assumption is that
cuDNN just isn't optimized for H=W=1.
Instead, this disables cudnn for 2d batch_norm inputs and improves the CUDA
implementation of `native_batch_norm` to be competative with cuDNN. For the
example in the issue, `BatchNorm1d` now takes 335 us compared to 6.3 ms before,
or a 18x speedup.
Before this change, nvprof shows:
```
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 99.64% 630.95ms 100 6.3095ms 5.6427ms 8.8800ms void cudnn::bn_fw_tr_1C11_kernel_NCHW<float, float, int=512, bool=0, int=2>(cudnnTensorStruct, float const *, cudnn::bn_fw_tr_1C11_kernel_NCHW<float, float, int=512, bool=0, int=2>, cudnnTensorStruct*, float const *, float const , cudnnTensorStruct*, cudnnTensorStruct*, cudnnTensorStruct**, float const *, float const *, float const *, cudnnTensorStruct*, cudnnTensorStruct*)
```
But after, it shows:
```
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 54.76% 14.352ms 100 143.52us 123.52us 756.28us _ZN2at6native27unrolled_elementwise_kernelIZZZNS0_72_GLOBAL__N__48_tmpxft_001e82d0_00000000_7_Normalization_cpp1_ii_db66e07022batch_norm_elementwiseERKNS_6TensorES5_RKN3c108optionalIS3_EESA_S5_S5_ENKUlvE_clEvENKUlvE2_clEvEUlfffffE_NS_6detail5ArrayIPcLi6EEE16OffsetCalculatorILi5EjESI_ILi1EjENS0_6memory15LoadWithoutCastENSL_16StoreWithoutCastEEEviT_T0_T1_T2_T3_T4_
35.09% 9.1951ms 100 91.950us 84.415us 362.17us void at::native::reduce_kernel<int=256, int=2, at::native::ReduceOp<float, at::native::WelfordOps<float, float, int, float, thrust::pair<float, float>>, unsigned int, float, int=2>>(float)
0.71% 186.14us 100 1.8610us 1.8240us 1.9840us _ZN2at6native72_GLOBAL__N__48_tmpxft_001e82d0_00000000_7_Normalization_cpp1_ii_db66e07045unrolled_elementwise_kernel_for_multi_outputsILi3EZZZNS1_34batch_norm_update_stats_and_invertERKNS_6TensorES5_S5_S5_ddlENKUlvE_clEvENKUlvE2_clEvEUlffffE_NS_6detail5ArrayIPcLi7EEE23TrivialOffsetCalculatorILi4EjESD_ILi3EjEEEviT0_T1_T2_T3_
0.59% 153.37us 100 1.5330us 1.4720us 2.6240us
void at::native::vectorized_elementwise_kernel<int=4,
at::native::BUnaryFunctor<at::native::AddFunctor<long>>,
at::detail::Array<char*, int=2>>(int, long,
at::native::AddFunctor<long>)
```
I think there is similar scope to improve the backward implementation.
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D28142447
Pulled By: ngimel
fbshipit-source-id: c70109780e206fa85e50a31e90a1cb4c533199da
Summary:
Adds documentation to TensorIterator and TensorIteratorConfig that outputs need to be added first before inputs.
Fixes https://github.com/pytorch/pytorch/issues/57343
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57550
Reviewed By: VitalyFedyunin
Differential Revision: D28198135
Pulled By: mrshenli
fbshipit-source-id: 363603cac968bf786a4a6a64e353307c54d541b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56611
The goal of this refactoring is to make the `torch.linalg.solve`
to be a composition of calls to `lu_stub` and `lu_solve_stub`.
Once `lu_stub` and `lu_solve_stub` have cuSOLVER-based codepath,
`torch.linalg.solve` will have it as well.
Replaced lu_solve_helper with DECLARE_DISPATCH for lu_solve_stub.
Removed unnecessary copy improving the performance (see https://github.com/pytorch/pytorch/pull/56611#issuecomment-824303673).
Split MAGMA-based `apply_lu_solve` into `apply_lu_solve_looped_magma`
and `apply_lu_solve_batched_magma`. This simplifies future dispatch to
cuSOLVER and cuBLAS.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28142279
Pulled By: mruberry
fbshipit-source-id: 9d4baf650ca7a40b800616794408b34342d8d68f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57677
This PR adds a note about the existence of the improved vmap prototype
to raise awareness of its existence. Eventually the plan is to delete
the in-core vmap prototype and replace it with the improved vmap
prototype but that might take a while.
Test Plan: - view docs
Reviewed By: Chillee
Differential Revision: D28231346
Pulled By: zou3519
fbshipit-source-id: 0a3b274df87ffd50333330e413e1a89634865403
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57316
CUDA support is implemented using cuSOLVER.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28242071
Pulled By: mruberry
fbshipit-source-id: 6f0a1c50c21c376d2ee2907bddb618c6a600db1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57315
This PR ports `torch.ormqr` from TH to ATen.
CUDA path will be implemented in a follow-up PR.
With ATen port, support for complex and batched inputs is added.
The tests are rewritten and OpInfo entry is added.
We can implement the least squares solver with geqrf + ormqr +
triangular_solve. So it's useful to have this function renewed at least for the
internal code.
Resolves https://github.com/pytorch/pytorch/issues/24748
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D28242070
Pulled By: mruberry
fbshipit-source-id: f070bb6ac2f5a3269b163b22f7354e9089ed3061
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56852
This is part of the changes to enable NNC AOT compilation for mobile.
It introduced a custom backend for NNC, which uses the components defined in the stacked PRs to load and execute a NNC-compiled model.
ghstack-source-id: 128285801
Test Plan:
- On X86 host:
```
buck build //xplat/caffe2/fb/lite_predictor:lite_predictor_nnc
buck-out/last/lite_predictor_nnc --model xplat/pytorch_models/build/pytorch_dev_linear/v1/nnc/compiled.pt --print_output true --input_dims '4,4' --input_type float
```
- On Android:
```
buck build fbsource//fbandroid/mode/gnustl //xplat/caffe2/fb/lite_predictor:lite_predictor_nncAndroid#android-armv7
adb push buck-out/last/lite_predictor_nncAndroid#android-armv7 /data/local/tmp
adb push xplat/pytorch_models/build/pytorch_dev_linear/v1/nnc/compiled.pt /data/local/tmp
adb shell 'cd /data/local/tmp; ./lite_predictor_nncAndroid\#android-armv7 --model compiled.pt --print_output true --input_dims "4,4" --input_type float'
```
Reviewed By: kimishpatel, raziel
Differential Revision: D27897153
fbshipit-source-id: 8e039089d1602782582747adfd75b31496b525ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56851
This is part of the changes to enable NNC AOT compilation for mobile.
At the end of the ahead-of-time compilation the compiler produces two sets of artifacts:
1. "compiled assembly code" - kernel functions in assembly format optimized for target platforms;
2. "compiled model" - regular TorchScript model that contains serialized parameters (weights/bias/etc) and invokes kernel functions via "handles" (name/version id/input & output specs/etc of the kernel functions).
This PR introduces a set of classes to represent kernel functions (a.k.a "handles"), which can be serialized/deserialized into/from the "compiled model" as an IValue.
Also introduces APIs to register/look-up "compiled assembly code".
ghstack-source-id: 128285802
Test Plan:
- unit tests
- for FB build environment:
buck test //caffe2/test/mobile/nnc:mobile_nnc
Reviewed By: kimishpatel, raziel
Differential Revision: D27921866
fbshipit-source-id: 4c2a4d8a4d072fc259416ae674b3b494f0ca56f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57443
Based on the comments in https://github.com/pytorch/pytorch/pull/57355, I started looking at the callsites of `getOrCreateOwnerRRef` and `createOwnerRRef`, and noticed that many of them didn't specify the `devices` argument, which was optional and thus defaulted to `{}`, which created a CPU-only Future inside the OwnerRRef. (Such callsites were, for example, in `processPythonRemoteCall` and `processBaseScriptRemoteCall`, or `PyRRef::unpickle`, ...).
Some (or all?) of these callsites might still have worked thanks to the RRef's own handling of CUDA streams and events, however we intend to remove that in https://github.com/pytorch/pytorch/pull/57355. I think it would be a safer and more generic solution to always create OwnerRRefs with the full set of devices supported by the RPC agent, and this is in fact easy to do since the RRefContext has access to the RPC agent. This means that all OwnerRRefs, no matter how they're created, will support CUDA if the agent does. This also allows us to stop requiring to specify devices when creating a OwnerRRef by hand in Python.
ghstack-source-id: 128184665
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28144365
fbshipit-source-id: 1f2d446873f31ee297415c46b94126b6502b12d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57442
We did this for the RPC agents and for ivalue::Future, the last one (I think) is RRef.
ghstack-source-id: 128184664
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28144368
fbshipit-source-id: eeacab6006f72118cbec542a02322f2e391c67a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56918
Re-importing a Python module each time is a bit expensive, and it's unnecessary because this is a private module which won't change and thus we can cache the value once we first extract it.
ghstack-source-id: 128184666
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D27985910
fbshipit-source-id: be40ae9b67ab8ea6c07bc2cb9a78d2c2c30b35d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57432
In a bunch of places we were creating a future and then "forwarding" the value of another future to it once that other future completed. (This was in order to convert the type of the value, or to "merge" multiple futures into one). However when doing so we often created a child future with an empty set of devices, which meant it didn't support CUDA, and thus would cause a silent synchronization/correctness bug if the parent future did actually contain CUDA tensors.
One way this could have been caught earlier would have been to have Future always extract the DataPtrs, even in CPU-only mode, in order to ensure they always reside on the expected set of devices. Unfortunately this might have some averse perf effects thus should be done carefully.
ghstack-source-id: 128184667
Test Plan: eyes
Reviewed By: mrshenli
Differential Revision: D28143045
fbshipit-source-id: 9af1abf270366dc1df0d4857d6a8cc73668af9d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57433
In a bunch of cases we need to "forward" between one future and another, typically because we need to convert the type of the data (e.g., from Message to PyObject). In most of these cases the DataPtrs of the value don't change, and yet the new future must re-extract them from scratch. By allowing the user to obtain the vector of extracted DataPtrs from the old future, we can allow them to "shortcut" this step.
Also, this change is a requirement for the next PR to work, since the next PR would otherwise cause us to attempt extracting DataPtrs from Message instances, which doesn't work (because Message is a custom class), but thanks to this PR we actually skip that.
ghstack-source-id: 128184663
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28118298
fbshipit-source-id: 70e333ea6a4f8d4d9a86514c350028d412469ee1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57689
* Older versions of libgnustd have issues with thread_local C++ qualifier on Android devices prior to r17+. Use c10::tls<> wrapper with smart pointer semantics in such cases.
* Convenient macro `C10_DEFINE_TLS_static` was added as well:
```
// Define static TLS variable str_tls_ of type std::string
C10_DEFINE_TLS_static(std::string, str_tls_);
//////// Excercise it ////////
{
*str_tls_ = "abc";
assert(str_tls_->length(), 3);
}
```
ghstack-source-id: 128233742
Test Plan: CI +
Reviewed By: ilia-cher
Differential Revision: D27875779
fbshipit-source-id: 7764f96ac1e121051c6ea66eabcedb9ef54d290e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57578
The original impl in SR assumes that eps is a constant, which is true most of the times. However it could be a graph input as well. This diff fixes this issue. Unit tests are added as well.
Reviewed By: edvgha
Differential Revision: D28207975
fbshipit-source-id: 9a10dec159f3804e43ef74aaa20c3ec6c79548c9
Summary:
Currently we require type equality for `torch.testing.assert_(equal|close)`:
3db45bcb91/torch/testing/_asserts.py (L509-L513)
That means `assert_equal(1, 1.0)` will correctly fail. Although the type of a scalar is similiar to a dtype of a tensor, `assert_equal(1, 1.0, check_dtype=False)` will also fail while `assert_equal(torch.as_tensor(1), torch.as_tensor(1.0), check_dtype=False)` will pass.
To make the interface more consistent, this PR relaxes the type equality constraint, by disabling it in case both inputs are scalars.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57532
Reviewed By: ngimel
Differential Revision: D28242428
Pulled By: mruberry
fbshipit-source-id: b643c77f48b64fc2c8a43925120d2b634ec336b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57688
P412982836 says that `torch::jit::toIValue()` will also touch GIL through `torch::jit::createGenericDict()` (P412848640)
So we have to move `torch::jit::toIValue()` out of multithreading execution
Reviewed By: hyuen
Differential Revision: D28236527
fbshipit-source-id: 43a33dbcfc828cc42c5e1230c8f5cb415bf7bde4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57526
This test would create an RRef, delete that rref and then create two
more RRefs and validate total rrefs were 2 in the end.
Due to the async nature of delete, sometimes the RRef would not be deleted
until the assertion was made. As a result, I've fixed this by waiting for the
RRef to be deleted at the appropriate time.
#Closes: https://github.com/pytorch/pytorch/issues/55382
ghstack-source-id: 128037566
Test Plan: waitforbuildbot
Reviewed By: H-Huang
Differential Revision: D28173151
fbshipit-source-id: e4f34ff4e49b72cfc9e67a72c482f5e05159eda5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57484
To be used by PyTorchPredictor integration for deploy.
Test Plan: tested via new unit tests
Reviewed By: suo
Differential Revision: D28154522
fbshipit-source-id: 5ba57a8d7f01686180e6fd47663635ec3ab2120d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57340
This API was only used within our own implementation. I couldn't find
any uses anywhere else. Removing it to reduce our overall surface area,
and also because the semantics are unclear in a world where
serialization is deferred to close() time.
Differential Revision: D28114188
Test Plan: Imported from OSS
Reviewed By: anjali411
Pulled By: suo
fbshipit-source-id: 6da53f20518885c7f4359e00e174f5e911906389
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57339
After the `intern` changes, we will no longer eager write to the package
archive so `file_structure` as written doesn't make much sense.
Differential Revision: D28114187
Test Plan: Imported from OSS
Reviewed By: anjali411
Pulled By: suo
fbshipit-source-id: 875595db933e9d1b2fdde907b086889cc977e92f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57337
Add a really simple graph data sturcutre for tracking dependencies. API
based on networkx, but I didn't want to require the dependency.
Differential Revision: D28114186
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Pulled By: suo
fbshipit-source-id: 802fd067017e493a48d6672538080e61d249accd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57336
Avoid a small n^2
Differential Revision: D28114189
Test Plan: Imported from OSS
Reviewed By: astaff
Pulled By: suo
fbshipit-source-id: 2672669ad0e23169d70c92f9d5ed61f66081f248
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57335
Mostly refactoring. The only behavioral change is that I have eliminated
the `orig_source_file` argument to `save_source_string`. I think it
doesn't provide enough marginal value (since if you have the module name
you can get the source file anyway).
Differential Revision: D28114184
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Pulled By: suo
fbshipit-source-id: b5e9eb4250dc84552befeef2dcf9e591b32899ae
Summary:
Fixes a bug introduced by https://github.com/pytorch/pytorch/issues/57057
cc ailzhang while writing the tests, I realized that for these functions, we don't properly set the CreationMeta in no grad mode and Inference mode. Added a todo there.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57669
Reviewed By: soulitzer
Differential Revision: D28231005
Pulled By: albanD
fbshipit-source-id: 08a68d23ded87027476914bc87f3a0537f01fc33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57645
Second round of autoformatting changes since the first pass became too large.
ghstack-source-id: 128199695
Test Plan: CI
Reviewed By: zertosh
Differential Revision: D28131430
fbshipit-source-id: 24b03e38b087f31e8cac2404bebcd401c55b6cab
Summary:
This is a second attempt at https://github.com/pytorch/pytorch/issues/51214. It should achieve the same goals with (as far as I can tell) no disadvantages, but the advantages are a bit less pronounced than in the more dictatorial approach that https://github.com/pytorch/pytorch/issues/51214 took:
- Unfortunately, I was unable to figure out how to include [the `mypy` configuration given in the docstring of `tools.mypy_wrapper.main`](7115a4b870/tools/mypy_wrapper.py (L81-L89)), because as walterddr pointed out, `"${env:HOME}/miniconda3/envs/pytorch/bin/python"` is not guaranteed to be correct on everyone's machine:
```json
{
"python.linting.enabled": true,
"python.linting.mypyEnabled": true,
"python.linting.mypyPath": "${env:HOME}/miniconda3/envs/pytorch/bin/python",
"python.linting.mypyArgs": [
"${workspaceFolder}/tools/mypy_wrapper.py"
]
}
```
Importantly, this does not work:
```json
"python.linting.mypyPath": "${workspaceFolder}/tools/mypy_wrapper.py"
```
This is because VS Code does not run the given `mypy` command inside of the user's specified virtual environment, so for instance, on my system, setting the `mypy` command to directly call `tools/mypy_wrapper.py` results in using `mypy 0.782` instead of the correct `mypy 0.812`.
Sadly, [this](https://code.visualstudio.com/docs/editor/variables-reference#_configuration-variables) does not work either, although I'm not sure why:
```json
{
"python.linting.mypyPath": "${config:python.pythonPath}",
"python.linting.mypyArgs": [
"${workspaceFolder}/tools/mypy_wrapper.py"
]
}
```
- As a result, `git clean -fdx; tools/vscode_settings.py` still results in some loss of useful configuration.
One other thing to note: as `.vscode/settings_recommended.json` shows, there are some configuration sections that only take effect within the context of a `"[language]"`, so currently, if a dev already has one of those settings, it would be entirely overwritten by `tools/vscode_settings.py` rather than a graceful merge. This could probably be fixed by using a deep merge instead of the current shallow merge strategy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57671
Test Plan:
If you want, you can typecheck the small script added by this PR (no output is expected):
```sh
tools/mypy_wrapper.py $PWD/tools/vscode_settings.py
```
You can also try running it to update your own VS Code workspace settings:
```sh
tools/vscode_settings.py
```
This should have minimal impact on your existing `tools/settings.json` file other than enabling the few explicitly recommended settings (e.g. it should not reorder or remove any of your existing settings).
Reviewed By: malfet
Differential Revision: D28230390
Pulled By: samestep
fbshipit-source-id: 53a7907229e5807c77531cae4f9ab9d469fd7684
Summary:
Expanding support to all builds
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56323
Test Plan: CI
Reviewed By: malfet
Differential Revision: D28171478
Pulled By: ilia-cher
fbshipit-source-id: 16bc752d1be3cbaeda5316f5d8a687ae05a83d22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57517
Fixes the flaky tests https://github.com/pytorch/pytorch/issues/45145
and https://github.com/pytorch/pytorch/issues/45067.
The root cause is that it is not the case that all remote events will be
children of the record function remote event, as other events can sometimes be
profiled under the hood such as the issue described in
https://github.com/pytorch/pytorch/issues/43868.
We fix this issue by verifying that the set of events that are children on the
remote end and children on the local end are the same, without necessarily
enforcing specific events to be logged.
Tested by running the test 1000+ times and verifying it passed. Will also test on CI box before landing
ghstack-source-id: 128200041
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D28166602
fbshipit-source-id: 8145857da4642aef31f360b20db00f4328abe2ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57563
Add flexible size support for upsample_nearest2d op in nnapi model conversion
Test Plan:
pytest test/test_nnapi.py
Imported from OSS
Reviewed By: dreiss
Differential Revision: D28200847
fbshipit-source-id: 901fe3f6e68e4c16ece730f3ffa68dc88c6ed6c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57562
Add flexible size support for qadd op in nnapi model conversion
Test Plan:
pytest test/test_nnapi.py
Imported from OSS
Reviewed By: dreiss
Differential Revision: D28200849
fbshipit-source-id: d5b2ea8e9eb8ae405ff2c960f7549cef60bc0991
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57561
Add flexible size support for conv2d op in nnapi model conversion
Test Plan:
pytest test/test_nnapi.py
Imported from OSS
Reviewed By: dreiss
Differential Revision: D28200848
fbshipit-source-id: d94ccf48a3d8453aa8e96c7cac02948c4cd870cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57189
`torch.linalg.eigvalsh` now supports autograd. This is achieved by
computing the eigenvectors internally if input requires grad,
otherwise the eigenvectors are not computed and the operation is faster.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D28199708
Pulled By: albanD
fbshipit-source-id: 12ac56f50137398613e186abd49f82c8ab83532e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57188
`torch.linalg.svdvals` now supports autograd. This is achieved by
computing the singular vectors internally if input requires grad,
otherwise the vectors are not computed and the operation is faster.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D28199709
Pulled By: albanD
fbshipit-source-id: cf39cf40965c606927db5331ce16743178fa711f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57591
According to dhruvbird we should be able to read a file from pytorch model (which is a zip file) using miniz. This diff added a standalone loader so user can load a JSON (or other type) file in the extra folder of the model. The whole point is to avoid loading pytorch library first, which can be complex (voltron, dynamic loading etc).
With this the hand tracking inference config (D27937516) can no longer depends on pytorch or use dynamic_pytorch. Previous it uses torch::jit::_load_extra_only_for_mobile which requires pytorch to be loaded first. We want to avoid doing that.
Test Plan: buck test caffe2/fb/dynamic_pytorch:extract_file_test
Reviewed By: dhruvbird
Differential Revision: D28140492
fbshipit-source-id: 2fd1570523841f4c35dc2ad8dfde5f1d396a74fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56427
This PR enables support for nccl send/recv profiling similar to how we have it for MPI and Gloo.
The process to do so is similar to the NCCL collectives where we create the `recordingFunction` in `initWork` and then add a callback that runs the profiler end callbacks. Tests are added similar to send/recv tests with gloo/MPI.
We also test with both autograd profiler and torch.profiler.
ghstack-source-id: 128142666
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D27866600
fbshipit-source-id: f29d9103e22b22f658632fece0df9ba36911fc62
Summary:
JUnitXml.__iadd__() is very slow
But since testsuites are flattened anyway in
`convert_junit_to_testcases` concatenate flattened tests right away
As result, parsing test-reports folder with 393 files and 25+ test cases
takes .5 sec instead of 193 sec
Fix typing errors and add script to mypy-strict
Print warning, rather than abort if xml can not be parsed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57641
Reviewed By: samestep
Differential Revision: D28224401
Pulled By: malfet
fbshipit-source-id: 3efc079c1c0deef8fff5ddf083268885b28418f9
Summary:
Add an api `_get_bytecode_version` to get version number given a bytecode model in both cxx and python, and the input can be both from file path and buffer.
## Test
CI (new added unit test will run as part of `pytorch_core-buck`)
1. run test_lite_interpreter.cpp
2. `python test/mobile/test_bytecode.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56801
ghstack-source-id: 128169647
Test Plan:
CI (new added unit test will run as part of `pytorch_core-buck`)
1. run test_lite_interpreter.cpp
2. `python test/mobile/test_bytecode.py`
Reviewed By: iseeyuan
Differential Revision: D27961417
fbshipit-source-id: f786cc9573d855feecff0b4fe8e5363e25f5728c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57560
The new methods allow to peak into bufferArgs which describe parameters
that codegen expects. This description includes info whether a given
parameter is a scalar var or a buffer and in case it's a buffer allows
to get the corresponding `Buf*` pointer from which we could get the
expected sizes.
Relanding #57074 which was reverted because I forgot to guard a new
test with `ifdef LLVM`.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D28199048
Pulled By: ZolotukhinM
fbshipit-source-id: 636e838e7e242a3c63e97ec453b8fae9b6380231
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57553
Relanding #57329 (the entire stack) which was reverted because I forgot
to guard a new test with `ifdef LLVM`.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D28195048
Pulled By: ZolotukhinM
fbshipit-source-id: 50052a2f20f84940b83d1dd1241c8659ff06e014
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57552
This method uses `CodeGen::call_raw` instead of `CodeGen::call`.
Relanding #57328 (the entire stack) which was reverted because I forgot
to guard a new test with `ifdef LLVM`.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D28195047
Pulled By: ZolotukhinM
fbshipit-source-id: bcfd3cb5b4f33a149b7549515ffd705e2c4f208f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57551
The new method allows to pass input and output arguments by `void*`
pointers instead of CallArgs. That helps to reduce the invocation
overhead. Currently this is only supported in LLVM codegen.
Relanding #55113 (the entire stack) which was reverted because I forgot
to guard a new test with `ifdef LLVM`.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D28195049
Pulled By: ZolotukhinM
fbshipit-source-id: 035b77ae996dbbcd542b4b0e4c011b41e8d7828b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57544
Instead of removing tp_new from the superclass (which causes
super().__new__ to not work), I now still install tp_new on the
superclass, but verify that you are not trying to directly
construct _TensorBase.
Fixes https://github.com/pytorch/pytorch/issues/57421
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28189475
Pulled By: ezyang
fbshipit-source-id: 9397a3842a77f5428d182dd62244b42425bca827
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57558Fixes#53359
If someone directly saves an nn.LSTM in PyTorch 1.7 and then loads it in PyTorch
1.8, it errors out with the following:
```
(In PyTorch 1.7)
import torch
model = torch.nn.LSTM(2, 3)
torch.save(model, 'lstm17.pt')
(In PyTorch 1.8)
model = torch.load('lstm17.pt')
AttributeError: 'LSTM' object has no attribute 'proj_size'
```
Although we do not officially support this (directly saving modules via
torch.save), it used to work and the fix is very simple. This PR adds an
extra line to `__setstate__`: if the state we are passed does not have
a `proj_size` attribute, we assume it was saved from PyTorch 1.7 and
older and set `proj_size` equal to 0.
Test Plan:
I wrote a test that tests `__setstate__`. But also,
Run the following:
```
(In PyTorch 1.7)
import torch
x = torch.ones(32, 5, 2)
model = torch.nn.LSTM(2, 3)
torch.save(model, 'lstm17.pt')
y17 = model(x)
(Using this PR)
model = torch.load('lstm17.pt')
x = torch.ones(32, 5, 2)
y18 = model(x)
```
and finally compare y17 and y18.
Reviewed By: mrshenli
Differential Revision: D28198477
Pulled By: zou3519
fbshipit-source-id: e107d1ebdda23a195a1c3574de32a444eeb16191
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57210
Removes the manually specified string name for sets of
related ops, and replaces it with an automatically generated
index. The manual name was arbitrary and ok for an MVP, but
is not safe for wide usage.
Also, adds APIs for users to add custom functions to the
relatedness map by either pairing it to a known function
or creating a new relatedness set.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28077977
fbshipit-source-id: e64a1ad6cd063014d74cdad189b0a612b1143435
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57186
Before this PR, we matched any pair of nodes with equal or related
types.
This PR changes the behavior to only match nodes whose type is in
the allowlist (the relatedness mappings). This will prevent matching
user defined modules, unless users add them to the mappings.
This is motivated by a couple of things:
1. if user defined types are matched, it can break scriptability of the
model with loggers attached. This happens whenever the user module
has a return type of anything other than a Tensor or a tuple of
Tensors.
2. we tried the past behavior on a couple of models, and it hasn't been
useful.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher
python test/test_quantization.py TestFXGraphMatcherModels
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28077981
fbshipit-source-id: 0a698e52b807cda47e6923310448a985b26eb362
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57184
Add remaining types to the relationship mapping to have full coverage
of ops quantization knows about, except binary ops and RNNs.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher.test_op_relationship_mapping
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28077979
fbshipit-source-id: 0f6070c8a995032978702d088803f89ff25f2a7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57171
No logic change, just moving the mapping to a file where
the other mappings are.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28077978
fbshipit-source-id: 4049d6a498156a5dffe3a03d2f4abc79da7bf907
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57383
Notes: I picked up an activation from https://github.com/pytorch/pytorch/issues/56969. You can look at the [activations.cpp](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cpu/Activation.cpp#L429) file which has both forward and backward kernel code to help you write the NNC lowering and the symbolic gradient.
I added a test in test_jit_fuser_te for the fusion, and I added an OpInfo and asserted that we expect to see autodiffable nodes to test the symbolic gradient.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D28197820
Pulled By: eellison
fbshipit-source-id: 05305d85c5bb0847c8f911b95ba47b137dca7e90
Summary: The goal of this diff is enforce proper use of "emplacy" functions. In each case, this saves at worst a move constructor call, and at best a full copy of the object (in the case of a constructor call where the object does not have a move constructor).
Test Plan: CI.
Reviewed By: marksantaniello
Differential Revision: D27888714
fbshipit-source-id: 235d0b31066463588c7e4ab86e132c430a352500
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55711
Currently, there is some complex logic that tries to handle all exceptions but re-throws them as a `c10::Error` so that it can log the error message. I'm looking for context on why this was added. The current logic (after talking with swolchok) seems equivalent, simpler, and also preserves the original stack trace from where the exception was originally thrown. This is useful when viewing the backtrace in logview. Re-throwing an exception using `TORCH_CHECK(false, message)` results in the original exception stack trace getting lost, so we want to avoid that.
ghstack-source-id: 128043281
Test Plan: Build.
Reviewed By: iseeyuan
Differential Revision: D27688352
fbshipit-source-id: b7b1a29b652b31da80d72f16d284e48b8623377b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57253
This PR:
1. Adds is_async getter/setter to RecordFunction
2. Adds is_async field to LegacyEvent and KinetoEvent, read from RecordFunction
3. Modifies python profiler code to check is_async via this flag (and keeps the old thread check as well)
4. Sets profiling of c10d collectives as async in ProcessGroup.cpp
5. Modifies tests to ensure is_async is set
This also fixes flaky tests such as #50840 and #56690 which have been flaky due to the profiling part (https://github.com/pytorch/pytorch/pull/56963 tried to do so as well but this is a better approach).
ghstack-source-id: 128021158
Test Plan: CI
Reviewed By: walterddr, ilia-cher
Differential Revision: D28086719
fbshipit-source-id: 4473db4aed939a71fbe9db5d6655f3008347cb29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57470
Removes the earlier hack of matching patterns originally matched
to BinaryOpQuantizeHandler to switch to CopyHandler. After this PR,
each pattern can only be matched to one type of QuantizeHandler or
to nothing.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28152909
fbshipit-source-id: afc285e770bd7eb0518c90e3ee4874c421e78bbc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57472
This render should put us with some feature parity to the CircleCI web UI renders for j(x)unit test reports, should make it so you don't have to look through a long list of logs to see what tests failed for which job
Render should look somewhat similar to
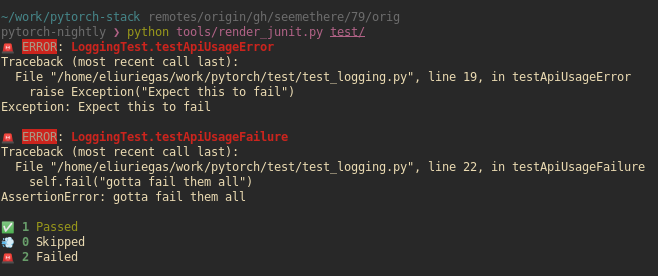
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D28154513
Pulled By: seemethere
fbshipit-source-id: 02d918b5c4cb6e236b806db48c3debe44de69660
Summary:
1. Clean up unused APIs on MPSImageWrapper
2. Rename textures to images to avoid confusions.
Test Plan: CI
Reviewed By: husthyc
Differential Revision: D28176917
fbshipit-source-id: 3afb261d9e5a9a6145ca3067cf0d245f1bf04683
Summary:
Testing 11.3 with current CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57223
Test Plan:
Relevant CI (11.3) pass!
Disclaimer: Skipped test_inverse_errors_large for CUDA 11.3 as it failed. Issue documented at https://github.com/pytorch/pytorch/issues/57482.
Reviewed By: malfet
Differential Revision: D28169393
Pulled By: janeyx99
fbshipit-source-id: 9f5cf7b6737ee6196de92bd80918a5bfbe5510ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57298
Some of the code is borrowed from NVIDIA-AI-IOT/torch2trt https://github.com/NVIDIA-AI-IOT/torch2trt/tree/master/torch2trt.
Move fx2trt stuff to fx/experimental/fx2trt.
Add an example in fx/experimental/fx2trt/example/fx2trt_example.py that shows how we lower resnet18 to TensorRT using FX.
TODO: Include license from NVIDIA-AI-IOT/torch2trt
Test Plan: CI
Reviewed By: jackm321
Differential Revision: D28102144
fbshipit-source-id: 1a7b03e45b8ab3fcc355d097d73afeec2efc3328
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56562
Earlier inlined callstack was annotated only nodes. This left out nodes
such as If which have block of nodes. These nodes should also be updated
similarly.
Test Plan:
Added test in test_misc
Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D27902516
fbshipit-source-id: 4e65c686fa6b4977e8719db45f71f7d2599d4d8e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55252
Earlier for bytecode serialization we were saving debug handles only for OPs and not all
instructions. This PR makes changes to add that for all instructions.
Test Plan:
python test/mobile/test_lite_script_module.py TestLiteScriptModule
Imported from OSS
Reviewed By: dreiss
Differential Revision: D27542502
fbshipit-source-id: cff75118c721ce9f0c2f60d2c9471481f05264ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55062
This diff introduces the following changes:
1. InlinedCallStack pickler/serializer is introduced. It is serialized
as a tuple of {module_instance_info, source range tag, callee:InlinedCallStack}
Module instance info is serialized as tuple of {class_type_name,
instance_name}.
Note that callee of the serialized inlined callstack points to the tuple
of already serialized callstack. This means the first callstack ptr to
serialize, will serialize entire path of the tree, where some callee
nodes might be shared with callstack pointers that will be serialized
subsequently. Pickler supports memoization of pickled objects, where if
a tuple has been serialized then object id is obtained instead of
serialized object again. Thus we stll serialize the tree and not every
path from the root separately. Furthermore, InlinedCallStackSerializer
also uses cache to lookup the pointer and return the serialized IValue.
Furthermore, note that we must also serialize the source range of
InlinedCallStack. In order to this serializer requires map of
source-range-tags-to-source-range map. This was done in the previous
diff, where as part of source range serialization we also generate
unique tags. These are the tags that are serialized in InlinedCallStack.
Thus during deserialization we would have to deserialize source range
before deserializing InlinedCallStacks.
2. Furthermore, each serialized InlinedCallStack is serialized with a
unique debug_handle and source range tag.
BackendDebugHandleManager manages generation of
unique debug handles and saves the map of
debug-handles-to-{source_range_tag, inlined-callstack-ptr}.
This map is then serialized as callstack_debug_map.pkl. Note that
inlined callstack is not sufficient to get all the source information
since it contains source information about the nodes which are inlined.
The top-of-the-stack (or bottom) node, which is the actual op node, is
not part of the inlined callstack pointer and thus the source range of
this node is serialized separately using source_range_tag. This is
similar to how JIT creates callstack in
torch/csrc/jit/runtime/interpreter.cpp
Unique debug handles facilitates exception throwing or profiling using
just the debug handle without any further qualifications, such as which
function or module the inlined-callstack belongs to.
Furthermore, this diff refactors the old mobile code for tracking
module hierarchy information per op. Mainly now bytecode serialization
will serialize debug handles corresponding to ops/nodes in graph and
have callstack_debug_map.pkl help generate:
1. Entire callstack and
2. Module hierarchy information.
Test Plan:
python test/mobile/test_lite_script_module.py TestLiteScriptModule
./build/bin/test_jit --gtest_filter=*ModuleInfo
Imported from OSS
Reviewed By: raziel
Differential Revision: D27468709
fbshipit-source-id: 53e2413e7703ead01c77718b7c333c7c6ff50a23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54284
In order to bring mobile deployment, via lite interpreter, on feature
parity with JIT, with respect model level debug information we must make
model level debug information available to mobile runtime.
At the moment, model level debug information is stored in SourceRange
which associates node's of graph to where the come from in original
python source code.
This information is serialized as part of debug_pkl and deserialized
when JIT loads the model and reads the model code.
On lite interpreter, we do not have access to all the functionality of
JIT and hence we cannot load model in the same way as JIT, by reading
code, constructing module hierarchy and graph corresponding module
methods etc. Instead in, lite interpreter, only bytecode corresonding to
the compiled graph, Code, is saved.
Thus in order to annotate OPs in the bytecode with equivalent
SourceRange information we do the following:
1. During model serialization, we create a unique tag for each source
range of the model.
2. Create a map of <SourceRange, tag>
3. During debug_pkl serialization we save tag along with SourceRange, on
top of byte offset.
4. During bytecode generation, the methods of the top module are
lowered. During this process methods are inlined. In the inlined graph,
when the node of a graph is lowered to bytecode, we query node's source
range and look it up against the map.
5. Resulting source range tag is serialized in module_debug_info.
6. During model deserialization, we read all the debug_pkl records in
the archieve and create a map of <tag, SourceRange>
7. This map can be used to find source code information.
During mobile runtime:
1. We read all the debug_pkl records and create <tag=debug_handle,
SourceRange> map.
1.1 This map, MobileDebugInfo, is a member of mobile Module.
2. Interpreter catches appropriate exceptions and sets the thread local
debug handle and rethrows the exception.
3. In Function's run method we catch exception and query current debug
handle where the exception happened.
4. Query MobileDebugInfo with debug handle to retrieve source range and
augment error with source range info.
This information is still incomplete as it does not contain entire
callstack.
In the following diffs we will serialize InlinedCallStack directly.
Note that compilation is gated by SYMBOLICATE_MOBILE_DEBUG_HANDLE macro,
so that mobile builds can avoid building MobileDebugInfo, source range
and source range pickler/unpickler. Later we will add path where, if
building without debug support stack trace will contain only debug
handles. They can be symbolicated later.
Test Plan:
Ported bunch of source range tests from test_jit.py. Added on more test
in test_lite_interpreter.py
Imported from OSS
Reviewed By: raziel
Differential Revision: D27174722
fbshipit-source-id: a7b7c6088ce16dec37e823c7fefa4f0b61047e12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57521
When an op is added to static runtime, we manually check the schema (not with the jit schema check, more with IValue.IsTensor()/IsInt() etc) and make sure it's the one we do support. If the schema doesn't match, SR would throw an exception with TORCH_CHECK, which makes the entire graph invalid for SR.
This diff tries to make the op with unsupported schema to use the fallback path and make it go through the dispatcher instead:
```
if (node->kind() != prim::ListConstruct &&
node->kind() != prim::TupleConstruct &&
node->kind() != prim::DictConstruct && node->kind() != prim::ListUnpack) {
const Operator& op = node->getOperator();
TORCH_CHECK(op.hasOperation());
op_ = op.getOperation(node);
VLOG(1) << "Fallback interpreter for node: " << PrintNode(node);
}
```
The 2-arg `torch.norm`, which the SR `torch.norm impl doesn't support (only 3, 4, 5 args are supported), now can run in static runtime with fallback mode.
(Note: this ignores all push blocking failures!)
Reviewed By: ajyu
Differential Revision: D27531447
fbshipit-source-id: 0a9c2662ac73ed0393a23cc3a2c7df45fdb00fdd
Summary:
Pull Request resolved: https://github.com/pytorch/elastic/pull/148
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56811
Moves docs sphinx `*.rst` files from the torchelastic repository to torch. Note: only moves the rst files the next step is to link it to the main pytorch `index.rst` and write new `examples.rst`
Reviewed By: H-Huang
Differential Revision: D27974751
fbshipit-source-id: 8ff9f242aa32e0326c37da3916ea0633aa068fc5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57074
The new methods allow to peak into bufferArgs which describe parameters
that codegen expects. This description includes info whether a given
parameter is a scalar var or a buffer and in case it's a buffer allows
to get the corresponding `Buf*` pointer from which we could get the
expected sizes.
Differential Revision: D28048289
Test Plan: Imported from OSS
Reviewed By: bertmaher
Pulled By: ZolotukhinM
fbshipit-source-id: 3867e862a0ec3593906820826c2344bd8a8f5c0a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57382
`BufferArg` is used to describe parameters passed to the codegen: it
indicates whether the parameter is a var or a buf and holds a pointer to
the corresponding var/buf. Both var and buf contain dtype, and thus
duplicating it in BufferArg is unnecessary - we can always get it from
the var/buf. Hence we're removing dtype_ field from BufferArg in this
PR. We're also adding a `buf_` field here: this is done so that
BufferArg truly has all the info about the parameter.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D28128329
Pulled By: ZolotukhinM
fbshipit-source-id: c03bff54bc6860f7ac6edfcb42ce6a82d8309589
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57169
The pass is planned to be used in AOT pipeline, where we expect input
graphs to be functional. As such, these graphs should not use 'self'
argument even if it is present, and thus it can be remove safely.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D28128328
Pulled By: ZolotukhinM
fbshipit-source-id: a7dfbf7776682826100c8eb0fef982a2e81c2554
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57076
This pass is intended to be used in conjunction with shape propagation
pass: first we use sample inputs to specify shape info for graph inputs
and then we run shape-prop to infer shapes of intermediate values in the
graph.
Differential Revision: D28048290
Test Plan: Imported from OSS
Reviewed By: astaff
Pulled By: ZolotukhinM
fbshipit-source-id: 778d772e873d59d77af9f669f45dc44b9ee5e443
Summary:
Such a deadlock was found for PyFunctionPreHook after adding https://github.com/pytorch/pytorch/pull/57057
This is fixing all occurrences in torch/csrc/autograd
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57488
Reviewed By: malfet
Differential Revision: D28163321
Pulled By: albanD
fbshipit-source-id: 4daf1db69674e73967fc7c5ca2a240c61340e7ca
Summary:
This change temporarily disables CUDA testing on PRs, but keeps it on master.
This is likely to increase the number of reverts, but this is necessary as a stop-gap measure to cap the CI costs growth.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57493
Reviewed By: seemethere
Differential Revision: D28162697
Pulled By: janeyx99
fbshipit-source-id: 1bc529a405f7d63c07f4bd9f8ceca8da450743fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57413
An internal test fails because somehow `Tuple[()]` is not considered compatible with `Tuple[Any]` in TorchScript, even if the code that involves this type of variables is not executed at all.
Therefore, create separate templates for instantiation to avoid typing check failure. This can address the FIXME left in https://github.com/pytorch/pytorch/pull/57288
#Closes: https://github.com/pytorch/pytorch/issues/51670
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- RemoteModule -j 1
buck test mode/dev-nosan caffe2/torch/fb/training_toolkit/applications/sparse_nn/batch_distributed_inference/tests:batch_distributed_inference_test -- test_load_di_parts
Reviewed By: wanchaol
Differential Revision: D28138864
fbshipit-source-id: 39e3e67b0c3979b607ff104d84b4fb1070ffefd6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54555
It has been discussed in the issue https://github.com/pytorch/pytorch/issues/54555 that {h,v,d}split methods unexpectedly matches argument of single int[] when it is expected to match single argument of int. The same unexpected behavior can happen in other functions/methods which can take both int[] and int? as single argument signatures.
In this PR we solve this problem by giving higher priority to int/int? arguments over int[] while sorting signatures.
We also add methods of {h,v,d}split methods here, which helped us to discover this unexpected behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57346
Reviewed By: ezyang
Differential Revision: D28121234
Pulled By: iramazanli
fbshipit-source-id: 851cf40b370707be89298177b51ceb4527f4b2d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57151
This PR introduces the implementation of `DynamicRendezvousHandler` that mostly facilitates the types introduced in previous PRs.
ghstack-source-id: 127685212
Test Plan: Run the existing and new unit tests.
Reviewed By: tierex
Differential Revision: D28060531
fbshipit-source-id: 844ff0e9c869f2bbb85fba05a16002d00eae130f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57150
This PR refactors the `__init__` method of `DynamicRendezvousHandler` to a `from_backend` static constructor for easier testing and future extensibility.
ghstack-source-id: 127685183
Test Plan: Run the updated unit tests.
Reviewed By: tierex
Differential Revision: D28060336
fbshipit-source-id: b07dcbb61e8ff5a536b7b021cd50438010c648dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57149
This PR introduces the `_RendezvousJoinOp` type that represents a rendezvous join operation to be executed via a `_RendezvousOpExecutor`.
ghstack-source-id: 127685142
Test Plan: Run the existing and new unit tests.
Reviewed By: tierex
Differential Revision: D28059785
fbshipit-source-id: 6e67a54289eef1a2349fcc52f8841e49c139459a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57148
This PR introduces the `_RendezvousExitOp` type that represents a rendezvous exit operation to be executed via a `_RendezvousOpExecutor`.
ghstack-source-id: 127685094
Test Plan: Run the existing and new unit tests.
Reviewed By: tierex
Differential Revision: D28059764
fbshipit-source-id: 2da428885f1390957242fdd82d68cee2ac273c71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57147
This PR introduces the `_RendezvousKeepAliveOp` type that represents a rendezvous keep-alive heartbeat operation to be executed via a `_RendezvousOpExecutor`.
ghstack-source-id: 127685037
Test Plan: Run the existing and new unit tests.
Reviewed By: tierex
Differential Revision: D28059733
fbshipit-source-id: 31fd8fc06f03d8f9cd21558b15a06dea7ad85bc6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57146
This PR introduces the `_RendezvousCloseOp` type that represents a rendezvous close operation to be executed via a `_RendezvousOpExecutor`.
ghstack-source-id: 127684991
Test Plan: Run the existing and new unit tests.
Reviewed By: tierex
Differential Revision: D28059693
fbshipit-source-id: 6c944d3b4f6a6ed2057ea2921ae8a42609998dd2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57145
This PR introduces the `_DistributedRendezvousOpExecutor` type that implements the `_RendezvousOpExecutor` interface for rendezvous shared via a `_RendezvousStateHolder`.
ghstack-source-id: 127684945
Test Plan: Run the existing and new unit tests.
Reviewed By: tierex
Differential Revision: D28059417
fbshipit-source-id: 7ef72ea16b54eaaa11a6ece7459d385d49692a84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57378
Previous version got reverted due to some tests not running because I wasn't in the pytorch github org
Differential Revision: D28125562
fbshipit-source-id: 758c1c9a009e79febf6cbd062a47d2a3d94e3a78
Summary:
This diff enabled mapping a selected set of Ads embeddings to the T17 host on hierarchical memory (nvmify). To achieve that the following is implemented:
- Allow fo OTHER net to be both onnxified and nvmified
- For that an allowlist placement policy is added to the nvmify stack
- onnxifi_transform is lightly updated to accept a blacklist of operators based on name
- nvm transform is broken into two parts, op replacement, and blob update.
- A drived class `SeqBlobNVMReader` is defined which adds the functionality to load blobs to the card or nvm.
Test Plan:
* Unit test
* Run predictor replayer: selectively load the following ads embedding to NVM as in `--caffe2_nvm_dram_placement_file=/home/hanli/nvm_allowlist`:
```
SPARSE_AD_ACCOUNT_ID
SPARSE_NEW_AD_ID_COARSE
SPARSE_NEW_AD_ID_REFINED
SPARSE_NEW_CAMPAIGN_ID
SPARSE_NEW_TARGET_ID
SPARSE_NEW_AD_CLUSTER_ID
SPARSE_NEW_PAGE_ID
SPARSE_NEW_STORY_ID
SPARSE_NEW_VIDEO_ID
SPARSE_ENTITY_EQUIVALENCE_KEY
SPARSE_ENTITY_EQUIVALENCE_KEY_NO_CREATIVE
```
major parameter change in sigrid_remote_predictor_glow_nnpi:
```
--caffe2_nets_to_nvmify=DISAGG_ACC_REMOTE_OTHER \
--caffe2_nvm_sls_ops=SparseLengthsSumFused8BitRowwise,SparseLengthsWeightedSumFused8BitRowwise,SparseLengthsSumFused4BitRowwise,SparseLengthsWeightedSumFused4BitRowwise,SparseLengthsSum4BitRowwiseSparse \
--caffe2_nvm_table_path=/home/hanli/tables/225412100_2870/ \
--caffe2_nvm_dram_placement_file=/home/hanli/nvm_allowlist \
--caffe2_nvm_dram_placement_policy=by_file_allowlist \
--caffe2_predictor_nets_to_load=DISAGG_ACC_REMOTE_OTHER
```
In predictor log, observe that the blobs to be NVMified are transformed in op types, skipped in Onnxifi transform, and deferred loaded and do NVM net transform:
```
I0416 09:59:29.550690 662344 Nvmifier.cpp:142] ^[[92mReplacing SparseLengthsSumFused4BitRowwise with NVM variant.^[[0m
I0416 09:59:29.550701 662344 Nvmifier.cpp:142] ^[[92mReplacing SparseLengthsSumFused4BitRowwise with NVM variant.^[[0m
I0416 09:59:29.550705 662344 Nvmifier.cpp:142] ^[[92mReplacing SparseLengthsSumFused4BitRowwise with NVM variant.^[[0m
I0416 09:59:29.550712 662344 Nvmifier.cpp:142] ^[[92mReplacing SparseLengthsSumFused4BitRowwise with NVM variant.^[[0m
I0416 09:59:29.550715 662344 Nvmifier.cpp:142] ^[[92mReplacing SparseLengthsSumFused4BitRowwise with NVM variant.^[[0m
I0416 09:59:29.550721 662344 Nvmifier.cpp:142] ^[[92mReplacing SparseLengthsSumFused4BitRowwise with NVM variant.^[[0m
...
I0416 09:59:31.665369 662344 onnxifi_transformer.cc:1097] Skipping blocklisted op SparseLengthsSumFused4BitRowwiseNVM at pos 770
I0416 09:59:31.667042 662344 onnxifi_transformer.cc:1097] Skipping blocklisted op SparseLengthsSumFused4BitRowwiseNVM at pos 777
I0416 09:59:31.667294 662344 onnxifi_transformer.cc:1097] Skipping blocklisted op SparseLengthsSumFused4BitRowwiseNVM at pos 779
I0416 09:59:31.668828 662344 onnxifi_transformer.cc:1097] Skipping blocklisted op SparseLengthsSumFused4BitRowwiseNVM at pos 786
I0416 09:59:31.668843 662344 onnxifi_transformer.cc:1097] Skipping blocklisted op SparseLengthsSumFused4BitRowwiseNVM at pos 787
I0416 09:59:31.669909 662344 onnxifi_transformer.cc:1097] Skipping blocklisted op SparseLengthsSumFused4BitRowwiseNVM at pos 792
...
I0416 10:01:09.087282 662344 Nvmifier.cpp:346] found the name: table0
I0416 10:01:09.373975 662344 Nvmifier.cpp:374] ^[[96mSaved /home/hanli/tables/225412100_2870/table0^[[0m
I0416 10:01:09.376008 662344 Nvmifier.cpp:343] filename: sparse_nn_sparse_arch_SPARSE_NEW_AD_ID_COARSE_dedicated_13_w_EmbeddingFusedUint4Quantization
..
I0416 10:11:05.310854 662344 Nvmifier.cpp:161] ^[[95mNVMifying the model.^[[0m
I0416 10:11:05.310887 662344 Nvmifier.cpp:185] found the name: table0 for sparse_nn_sparse_arch_SPARSE_NEW_AD_ID_COARSE_dedicated_13_w_EmbeddingFusedUint4Quantization
I0416 10:11:07.580587 662344 Nvmifier.cpp:185] found the name: table4 for sparse_nn_sparse_arch_SPARSE_AD_ACCOUNT_ID_dedicated_20_w_EmbeddingFusedUint4Quantization
I0416 10:11:07.580648 662344 Nvmifier.cpp:185] found the name: table3 for sparse_nn_sparse_arch_SPARSE_ENTITY_EQUIVALENCE_KEY_dedicated_22_w_EmbeddingFusedUint4Quantization
I0416 10:11:07.580667 662344 Nvmifier.cpp:185] found the name: table5 for sparse_nn_sparse_arch_SPARSE_NEW_TARGET_ID_dedicated_29_w_EmbeddingFusedUint4Quantization
I0416 10:11:07.580682 662344 Nvmifier.cpp:185] found the name: table2 for sparse_nn_sparse_arch_SPARSE_NEW_AD_ID_REFINED_dedicated_30_w_EmbeddingFusedUint4Quantization
I0416 10:11:07.580695 662344 Nvmifier.cpp:185] found the name: table1 for sparse_nn_sparse_arch_SPARSE_NEW_STORY_ID_dedicated_35_w_EmbeddingFusedUint4Quantization
```
Make sure model is properly loaded:
```
I0415 21:42:48.400249 873685 ModelManagerBase.cpp:806] Loaded 225412100_2870 in 730944 ms (63800 ms of IO) memory used 8744167456 byte(s)
```
* Only load user embedding to NVM to make sure baseline use case is not broken by this diff:
```
--caffe2_nets_to_nvmify=DISAGG_ACC_REMOTE_REQUEST_ONLY \
--caffe2_nvm_sls_ops=SparseLengthsSumFused8BitRowwise,SparseLengthsWeightedSumFused8BitRowwise,SparseLengthsSumFused4BitRowwise,SparseLengthsWeightedSumFused4BitRowwise,SparseLengthsSum4BitRowwiseSparse \
--caffe2_nvm_table_path=/home/hanli/tables/225412100_2870/
```
Make sure model is loaded:
```
Loaded 225412100_2870 in 381139 ms (56313 ms of IO) memory used 7043933560 byte(s)
```
* Run feed replayer: `buck-out/gen/sigrid/feed/prediction_replayer/fully_remote_replayer_main --use_new_encoding_for_ads_services --use_new_encoding_from_model_id_to_shard_id --request_file_path /data/users/hanli/f266405843.requests --model_id=265540157_0 --replayer_thread_count=30 --sigrid_predictor_single_host=2401:db00:272c:602e:face:0:10:0 --sigrid_predictor_single_port=7444 --num_iterations=5 --qps=100 --client_name=predictor_v1` (load predictor as in P411172400)
Output:
```
I0428 21:20:25.106635 1396182 FullyRemoteReplayer.cpp:107] Loading requests from /data/users/hanli/f266405843.requests
I0428 21:20:25.547982 1396182 FullyRemoteReplayer.cpp:109] Requests size : 6699
I0428 21:20:25.548146 1396182 Client.cpp:274] V1 tier name: V2 tier name: sigrid.predictor.fully_remote_test V2 fully remote tier name:
I0428 21:20:25.548153 1396182 Client.cpp:282] [MF] Migration Framework (traffic routing) enabled: false
I0428 21:20:25.548172 1396182 ModelRemoteStatus.cpp:206] Selection probabilities znode path: /configerator-gz/.prn
I0428 21:20:25.674162 1396265 ModelRemoteStatus.cpp:612] Found 0 host, 0 shards in predictor tier
I0428 21:20:25.674181 1396182 ModelRemoteStatus.cpp:557] Refresh sigrid model succeeded: 1
I0428 21:21:26.252820 1396265 ModelRemoteStatus.cpp:612] Found 0 host, 0 shards in predictor tier
I0428 21:21:26.252851 1396265 ModelRemoteStatus.cpp:557] Refresh sigrid model succeeded: 1
I0428 21:22:22.225976 1396182 PredictionReplayer.cpp:67] Previous request took too long, not reaching target QPS
I0428 21:22:26.252643 1396265 ModelRemoteStatus.cpp:612] Found 0 host, 0 shards in predictor tier
I0428 21:22:26.252678 1396265 ModelRemoteStatus.cpp:557] Refresh sigrid model succeeded: 1
I0428 21:23:26.252959 1396265 ModelRemoteStatus.cpp:612] Found 0 host, 0 shards in predictor tier
I0428 21:23:26.252987 1396265 ModelRemoteStatus.cpp:557] Refresh sigrid model succeeded: 1
I0428 21:24:26.253135 1396265 ModelRemoteStatus.cpp:612] Found 0 host, 0 shards in predictor tier
I0428 21:24:26.253166 1396265 ModelRemoteStatus.cpp:557] Refresh sigrid model succeeded: 1
I0428 21:25:27.252734 1396265 ModelRemoteStatus.cpp:612] Found 0 host, 0 shards in predictor tier
I0428 21:25:27.252763 1396265 ModelRemoteStatus.cpp:557] Refresh sigrid model succeeded: 1
I0428 21:26:03.172894 1396182 FullyRemoteReplayer.cpp:59] cpu time p25, p50, p75, p95, p99 9570 13011 16218 20788 24840
I0428 21:26:03.172927 1396182 FullyRemoteReplayer.cpp:61] wait time p25, p50, p75, p95, p99 11845 15958 19946 26579 31842
I0428 21:26:03.172940 1396182 FullyRemoteReplayer.cpp:63] wall time p25, p50, p75, p95, p99 16194 20888 25303 31692 37387
```
Reviewed By: ehsanardestani
Differential Revision: D27701121
fbshipit-source-id: e898abc6957c839e402a9763172cf85d9bb84cbd
Summary:
This PR adds a shortcut of specifying all models in TorchBench CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57311
Test Plan:
CI
RUN_TORCHBENCH: ALL
Reviewed By: bitfort
Differential Revision: D28160198
Pulled By: xuzhao9
fbshipit-source-id: 67c292bc98868979d868d4cf1e599c38e0da94b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57144
This PR introduces the `_RendezvousOpExecutor` interface. Implementers of this interface are responsible for executing rendezvous operations in a state machine that outputs actions based on the current state of the rendezvous.
ghstack-source-id: 127684898
Test Plan: None beyond `flake8` and `mypy` as this is solely an interface definition.
Reviewed By: tierex
Differential Revision: D28059159
fbshipit-source-id: 8e7da33e02336206cddbe76d773681e98c28a98f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56538
This PR introduces the `_RendezvousStateHolder` interface and its accompanying `_BackendRendezvousStateHolder` type that is responsible for synchronizing the local rendezvous state with the other nodes.
ghstack-source-id: 127684796
Test Plan: Run the existing and new unit tests.
Reviewed By: tierex
Differential Revision: D27892600
fbshipit-source-id: a55d884a1f9b0d742787be4dff4271e076c08962
Summary:
Adding a function in ATenNVRTC.h also requires changing Lazy NVRTC.cpp, but this was missing in the comments.
Also fix a typo.
CC jjsjann123
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57318
Reviewed By: anjali411
Differential Revision: D28146223
Pulled By: ezyang
fbshipit-source-id: be69241a4b41ac7361a8c9f978fa4c837f41fbd1
Summary:
https://github.com/pytorch/pytorch/pull/56433 was reverted because the test perceived internal dropout state creation as a memory leak. This PR resubmits with the leak check skipped.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57373
Reviewed By: anjali411
Differential Revision: D28152186
Pulled By: ezyang
fbshipit-source-id: 9a593fcdbbabbb09dc4e4221191663e94b697503
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57143
This PR introduces a `name` attribute in `_PeriodicTimer` for testing and debugging purposes.
ghstack-source-id: 127684751
Test Plan: Run the new and updated unit tests.
Reviewed By: tierex
Differential Revision: D28059045
fbshipit-source-id: 9eb067300aea21a99577e6cd8a354f7eb749f4a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57142
This PR extends the return type of `RendezvousBackend`'s `set_state` method with an additional boolean flag that specifies whether the write attempt has succeeded.
ghstack-source-id: 127629538
Test Plan: Run the updated unit tests.
Reviewed By: tierex
Differential Revision: D28058980
fbshipit-source-id: 26333790c39386891beb155b20ba1291d2cbdd03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57141
Per feedback this PR renames `last_keep_alives` to `last_heartbeats` in `_RendezvousState`.
ghstack-source-id: 127629442
Test Plan: Run the updated unit tests.
Reviewed By: tierex
Differential Revision: D28058948
fbshipit-source-id: 0db12eac56a47a426a7a48fb5c93ac6a08b0d22e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57140
This PR introduces a new `heartbeat` attribute in `RendezvousTimeout`.
ghstack-source-id: 127626815
Test Plan: Run the updated unit tests.
Reviewed By: tierex
Differential Revision: D28058908
fbshipit-source-id: c6f8b3a06210cc59714fa841d9387eeb028dc02f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57139
This PR sets the `order` attribute of the `dataclass` annotation to `True` in order to introduce comparison operators for `_NodeDesc`.
ghstack-source-id: 127626783
Test Plan: Run the existing unit tests.
Reviewed By: tierex
Differential Revision: D28058851
fbshipit-source-id: 66313f84f507100e20acb687a3427b3dd51a6310
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56537
This PR introduces the `RendezvousSettings` type to consolidate the arguments passed to `DynamicRendezvousHandler`.
ghstack-source-id: 127626738
Test Plan: Run the existing unit tests.
Reviewed By: tierex
Differential Revision: D27890155
fbshipit-source-id: 22060c25b6927cc832f18ae6c5f7ba0f7a9ef3cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56948
Add api to get runtime bytecode version
## Test
Both `caffe2/test/cpp/jit/test_lite_interpreter.cpp` and `caffe2/test/mobile/test_bytecode.py` pass
ghstack-source-id: 127939889
Test Plan: Both `caffe2/test/cpp/jit/test_lite_interpreter.cpp` and `caffe2/test/mobile/test_bytecode.py` pass
Reviewed By: raziel, iseeyuan
Differential Revision: D27987811
fbshipit-source-id: 35ed9bd626aecffc226f6dacfa046e6cdabfed51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57375
Skip observing the input for masked_fill. Currently we don't have a way to
query the type of Proxy in GraphModule, hopefully we should have the functionality to annotate the type,
we'll need to annotate a Proxy to be a boolean Tensor to remove this hack.
Test Plan:
python test/test_quantization.py TestQuantizeFxOps.test_boolean_tensor
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28126003
fbshipit-source-id: 2989766370a607579b3ea07ca36cdc2ce35893cc
Summary:
Let's see how 11.3 holds up!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57222
Test Plan: CUDA 11.3 has passed build and test below.
Reviewed By: malfet
Differential Revision: D28152554
Pulled By: janeyx99
fbshipit-source-id: 84b687660b9a5b6337b65d6aaaaf003ea94b2864
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57376
Having this in profiler/trace outputs will be useful when
investigating performance overhead of find_unused_parameters for certain
workloads, to determine whether it is a bottleneck or not.
ghstack-source-id: 127942159
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D28126233
fbshipit-source-id: 93082ae5b84e64351d59447a29f97eaf9b0bbd64
Summary:
Use `functools.lru_cache` to avoid calling this function multiple time
Check that we are running on Linux platform before trying to open
"/proc/cpuinfo"
Do not spawn new process, but simply open("/proc/cpuinfo").read() and
search the output for the keywords
Fixes https://github.com/pytorch/pytorch/issues/57360
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57408
Reviewed By: driazati
Differential Revision: D28136769
Pulled By: malfet
fbshipit-source-id: ab476774c3be2913cb576d98d47a2f7ec03c19aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57168
Implement result() for MPI which wasn't previously supported.
Some user rely on output args, however in future usecases (e.g. DDP comm hook) we need to return the result explicitly.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D28129125
Pulled By: agolynski
fbshipit-source-id: d6abcd2114163471c045043534a0a3377f2579b4
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 12699ad388
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56916
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D27997920
Pulled By: beauby
fbshipit-source-id: 057dff1f28bf3a9d1d05522d3b60ee3530aecf22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57030
PR #57029 is not perfect; there are still obscure situations in which
we might allocate a shared_ptr to an RpcAgent that doesn't have a
no GIL constructor, so this PR adds the other half of the equation:
assert that we don't hold the GIL when running a blocking destructor.
This makes it possible to detect potential deadlocks even if the
code doesn't deadlock in practice (because you got lucky and none
of the threads you blocked on tried to also take out the GIL).
I considered whether or not to make this DEBUG_ONLY. For now it's
not, so I can get better CI coverage, and because this test only
happens in destructors of objects that die rarely.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D28030582
Pulled By: ezyang
fbshipit-source-id: a7d7f6545223c4823c7f6036dfe29bd2edaf60a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57402
This is a cleanup, the value is not used by anything. It was
probably left behind after previous refactors.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28133622
fbshipit-source-id: 44a3f955d4af8d6dd15b4fb3038188568e4ee549
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57399
There were a couple of functions which took `quants` as arguments
without using them, probably left over from after past refactors.
Cleaning this up to improve code readability.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28132413
fbshipit-source-id: 636b146c0b5ef0caea9c4b539e245de245d48c49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57393
Moves the information on whether we should pass the information
whether the output is quantized based on the inputs to live
on the qhandler object. This allows us to remove
FixedQParamsOpQuantizeHandler from quantize.py, further reducing
the coupling between handler objects and the quantization pass.
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: astaff
Differential Revision: D28132414
fbshipit-source-id: 5c28524b47c00f618d3a38657376abae9e6ffe7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57388
It's a bit confusing to have this be a decorator. It's simpler to
just expose it as a function on qhandler.
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28129411
fbshipit-source-id: f7316f285e8546c67e8d8cf753462b2c2abb2636
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57377
Moves the logic which determines
1. whether a pattern instance's output should be observed
2. whether a pattern instance's output should be marked as observed based on its inputs
3. whether to ovverride the activation specified in the qconfig
from `quantize.py` to `quantization_patterns.py`. This makes
the code easier to read and reduces the coupling between `Quantizer`
and `QuantizeHandler` instances.
Note: there are some further cleanups which would be good after this one
- leaving those for future PRs.
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28126896
fbshipit-source-id: 94c80a9c7307452783348d65b402acc84983e3f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57368
1. renames functions which only sometimes insert observers to start with `maybe_`,
to clarify the difference from functions which always insert observers
2. saves a level of indent in `maybe_insert_observer_for_output_of_the_node`
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28126897
fbshipit-source-id: 4cbc184dbf5e85954314cfbbcdd1551474175bf0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57367
This code is never hit (see insert_observer_for_output_of_the_node
which gates it out), so changing to an assert in order to
have `insert_observer` actually always insert an observer.
This helps code readability.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D28126898
fbshipit-source-id: 411bc37769a6eacbebc463ed6c84cac85871bd5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57033
CPU part of gh-38915
BatchNorm1d is implemented by looping over the channels, selecting one channel
at a time and performing cpu_serial_kernel loops per-channel. For (N, C)
contiguous layout this results in a sub-optimal strided memory access pattern;
guarunteeing no elements will ever be in the same cache line.
I fix this by passing the entire input into one `TensorIterator` and letting
it decide which dimensions to iterate over and how to divide work among threads.
For statistic updates and the backward function, I use `at::mean` and `at::sum`
instead of the ad-hoc reductions there. Not only does this allow better memory
access patterns, it also enables vectorization and so performance improves for
BatchNorm2d as well. Unfortunately, `at::var` and `at::var_mean` don't perform
as well so I've left the other reductions as they were.
Overall, on my machine this takes the 1d example from 24 ms down to 4 ms and
the 2d example from 2.5 ms down to 2 ms.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D28142333
Pulled By: ngimel
fbshipit-source-id: 066fe4f37f29b6458005e513e85faa398eeb9e2d
Summary:
This PR also removes qr and eig tests from test/test_torch.py. They were not skipped if compiled without LAPACK and they are now replaced with OpInfos.
Fixes https://github.com/pytorch/pytorch/issues/55929
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56284
Reviewed By: ejguan
Differential Revision: D27827077
Pulled By: mruberry
fbshipit-source-id: 1dceb955810a9fa34bb6baaccbaf0c8229444d3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56755
Rehash of https://github.com/pytorch/pytorch/pull/47488
Adds a flag to ddp join() context manager that enables throwing a
StopIteration across all ranks when this flag is specified.
To do this, we implement the design in #47250. When running with this flag, we schedule an additional allreduce in the case that a joined rank needs to throw a StopIteration. In non-joined ranks forward pass, we match this allreduce and if at least one rank tells us to throw, we raise a StopIteration.
Tested by modifying existing tests, as well as adding additional tests validating that this works with SyncBatchNorm models and a model with custom collectives in the forward pass.
Currently running perf benchmarks, will post when those are available, but we expect a small (~2%) perf reduction when enabling this feature due to the blocking allreduce. Hence we will only recommend it for models with collective comm.
ghstack-source-id: 127883115
Test Plan: Ci
Reviewed By: SciPioneer
Differential Revision: D27958369
fbshipit-source-id: c26f7d315d95f17bbdc28b4a0561916fcbafb7ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56927
Adds the connection of `torch.add` to `toq.add_relu` and of `torch.mul`
to `toq.mul_relu`.
Test Plan:
CI
Imported from OSS
Reviewed By: supriyar
Differential Revision: D28003475
fbshipit-source-id: a12871feacf84c5afb0e1cc47e708e285695ffeb
Summary:
The new function has the following signature `cholesky_ex(Tensor input, *, bool check_errors=False) -> (Tensor L, Tensor infos)`. When `check_errors=True`, an error is thrown if the decomposition fails; `check_errors=False` - responsibility for checking the decomposition is on the user.
When `check_errors=False`, we don't have host-device memory transfers for checking the values of the `info` tensor.
Rewrote the internal code for `torch.linalg.cholesky`. Added `cholesky_stub` dispatch. `linalg_cholesky` is implemented using calls to `linalg_cholesky_ex` now.
Resolves https://github.com/pytorch/pytorch/issues/57032.
Ref. https://github.com/pytorch/pytorch/issues/34272, https://github.com/pytorch/pytorch/issues/47608, https://github.com/pytorch/pytorch/issues/47953
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56724
Reviewed By: ngimel
Differential Revision: D27960176
Pulled By: mruberry
fbshipit-source-id: f05f3d5d9b4aa444e41c4eec48ad9a9b6fd5dfa5
Summary:
This test was disabled for ROCM 3.9. With latest updates, the test is passing in ROCM 4.1. Hence enabling this test in test/test_linalg.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57170
Reviewed By: astaff
Differential Revision: D28118217
Pulled By: mruberry
fbshipit-source-id: 1b830eed944a664c3b1b3e936b87096fef0c0ca2
Summary:
After stealing the ownership of the tensor passed via DLPack capsule, PyTorch should immediately mark it as used (by changing its name to `used_dltensor`). This fix is needed because the following line may raise an exception:
```cpp
py::module::import("torch.cuda").attr("init")();
```
When an exception is raised, Tensor created by `at::fromDLPack` calls the `deleter`. However as the causple is not consumed, the producer (a library that created the capsule) also calls the `deleter`, causing a double free.
Reprodcuer (I'm running this code on A100 GPU + PyTorch wheel which does not include `sm_80` support; in this configuration `torch.cuda.init` will raise a warning):
```py
$ python -Werror
>>> import torch.utils.dlpack
>>> import cupy
>>> tensor = torch.utils.dlpack.from_dlpack(cupy.arange(10).toDlpack())
free(): double free detected in tcache 2
zsh: abort (core dumped) python -Werror
```
Once this fix is merged users can now see the exception correctly:
```
A100-PCIE-40GB with CUDA capability sm_80 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70.
If you want to use the A100-PCIE-40GB GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56789
Reviewed By: astaff
Differential Revision: D28118512
Pulled By: mruberry
fbshipit-source-id: 56992f7a3fc78d94c69513e864a473ae9587a9c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57354
The ivalue::Future class used to have some hooks, defined as separate protected virtual methods, so that they could be overridden by the CUDAFuture subclass. Now that CUDAFuture has been merged into ivalue::Future those hooks can be "inlined" to where they're used, hopefully making the code more readable as it puts related things closer together.
ghstack-source-id: 127920096
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28117199
fbshipit-source-id: f749cd842c3bdc44a08f0a33bef972dfbf08afdd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57353
Even though we merged CUDAFuture into ivalue::Future, the resulting methods still had basically two distinct codepaths (i.e., an "early exit" if `impl_ == nullptr` for CPU, and then some code for CUDA). This works but it risks creating divergence and inconsistencies when the same class is used in those two modes. Ideally we should have the same codepath, and have the stream operations be no-ops for CPU. Luckily, this is exactly what happens when using a CPU DeviceGuardImplInterface!
Hence here I do that, and for convenience I also use c10::Devices instead of c10::DeviceIndexes (like we did in https://github.com/pytorch/pytorch/pull/57294 for RPC).
ghstack-source-id: 127920097
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28100525
fbshipit-source-id: cfac73894220ef5fa8a0389b5533c5d69ba1cf04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57294
With the advent of CPUs in the device maps, and to be more generic (e.g., to support AMD GPUs), and to avoid conversions when passing to Future and RRef and such, it's easier to use Devices instead of DeviceIndices. This started by just migrating the TensorPipe agent but the RPC layer is quite intertwined so I had to migrate a lot of stuff.
ghstack-source-id: 127916562
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28092733
fbshipit-source-id: 024dcb3648c5898ab13e770413c43958f04f1a8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57345
Already back in https://github.com/pytorch/pytorch/pull/57046 we realized that calling this method `getStreamFromPool` could cause issues because that name gets HIPified and thus in some callsites we'd end up calling a method that doesn't exist. In the end we got away with it because the places where we were calling that method weren't HIPified. However in the next PR we'll use this method inside RPC, and that will start causing problems, hence here I rename it to something that should not cause conflicts. This is a private API (since it's inside `impl`) thus there's no backwards compatibility concerns.
ghstack-source-id: 127916484
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28114923
fbshipit-source-id: e027ad08a8e02090c08c6407c2db5a7fde104812
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57292
In Future (and soon in other places too) we need to receive a list of devices from Python-land. We don't want to just take their indices because we need full devices in order to infer the type from them. torch.device is not defined through pybind, it's defined through a plain `PyModule_AddObject` call with CPython, thus pybind isn't naturally able to understand and convert it. However we can provide a custom type caster which fixes that. We have this already for at::Tensor, at::Generator, ...
ghstack-source-id: 127916268
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28092732
fbshipit-source-id: 1c31d0b85a4d5c9e7bde8161efbb7574d505157c
Summary:
Apparently normal reST doctests aren't run in CI, because of this line in the `conf.py`:
ac86e0a0e5/docs/source/conf.py (L366)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57290
Reviewed By: astaff
Differential Revision: D28118198
Pulled By: mruberry
fbshipit-source-id: 7af621c4fef4e5d37e0fc62b9fd4382cc1698d89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56871
foreach kernels fall back to slow path when tensor are on different devices
Generated by codemod:
```
fastmod '(- func: _foreach.*)' '${1}
device_check: NoCheck # foreach kernels fall back to slow path when tensor are on different devices' aten/src/ATen/native/native_functions.yaml
```
ghstack-source-id: 127914017
Test Plan: autotest
Reviewed By: ezyang
Differential Revision: D27986560
fbshipit-source-id: b0cd963cdba04b4e1589bbf369eb26b48d523968
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56830
Opt into formatting on GitHub and format everything. This is a trial run before turning on formatting for more and eventually all of the codebase.
Test Plan: CI
Reviewed By: zertosh
Differential Revision: D27979080
fbshipit-source-id: a80f0c48691c08ae8ca0af06377b87e6a2351151
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56850
This is part of the changes to enable NNC AOT compilation for mobile.
The generated kernels need to call these external functions thus change the declarations to use C linkage when building the mobile runtime.
Added nnc_aten_addmm external function.
ghstack-source-id: 127877411
Test Plan:
- build & CI;
- tested mobile build with stacked PRs;
Reviewed By: ZolotukhinM
Differential Revision: D27897154
fbshipit-source-id: 61d5499d7781a83bd2657859659fd1b5043d6b04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54032
Add a `const char*` override to c10::Warning::warn so that we can avoid wrapping plain C string literals in std::string.
ghstack-source-id: 125544720
Test Plan: Buildsizebot some iOS apps?
Reviewed By: ezyang
Differential Revision: D27061983
fbshipit-source-id: dc11150c911a4317a8edac75e50c5ba43511ff24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57288
If the device map provided by RemoteModue is not empty, then TensorPipe RPC backend can support directly sending GPU tensors over the wire.
Also add pybind of `_get_device_map`.
The changes in unit test setup is separated out as a follow-up PR, as currently it breaks some tests in `distributed/rpc/test_faulty_agent.py`.
Still need to fix test_load_di_parts in `torch/fb/training_toolkit/applications/sparse_nn/batch_distributed_inference/tests:batch_distributed_inference_test`. Currently an early return is used to bypass this test failure.
#Original PR issue: https://github.com/pytorch/pytorch/issues/51670
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_input_moved_to_cuda_device
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_input_moved_to_cuda_device_script
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- RemoteModule -j 1
CAUTION: This one actually fails and now it is bypassed. See FIXME in `_remote_forward`.
buck test mode/dev-nosan caffe2/torch/fb/training_toolkit/applications/sparse_nn/batch_distributed_inference/tests:batch_distributed_inference_test -- test_load_di_parts
Reviewed By: wanchaol
Differential Revision: D28021672
fbshipit-source-id: a89245dc35e1d9479811ec6f98d9f34116837d79
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56923
Next Steps in order:
- Add backward support for CUDA
- Add support for more aggregation types
- Benchmarking (for cuda mainly)/more testing/documentation
- Support for multi dimension
Test Plan: Updated unit test to include 0 length segment as well.
Reviewed By: ngimel
Differential Revision: D27992228
fbshipit-source-id: 28851811f8a784a63162721c511d69e617a93727
Summary:
This PR adds `sm_75` CUDA architecture support for the PR CI build Xenial CUDA 11.1 cuDNN 8, with build name:`pytorch_linux_xenial_cuda11_1_cudnn8_py3_gcc7_build`, so that generated artifacts from these builds can be installed and run on machines with CUDA capability sm_75.
In PR https://github.com/pytorch/pytorch/issues/57207, the Xenial CUDA 10.2 cuDNN 7 build `pytorch_linux_xenial_cuda10_2_cudnn7_py3_gcc7_build` was taken off the list of builds done for PRs to `master`. PR https://github.com/pytorch/pytorch/issues/56619 has added `sm_75` support for this build. This PR removes this support for the Xenial CUDA 10.2 cuDNN7 builds, and adds it for the current PR CI build Xenial CUDA 11.1 cuDNN 8 `pytorch_linux_xenial_cuda11_1_cudnn8_py3_gcc7_build`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57320
Reviewed By: astaff
Differential Revision: D28125542
Pulled By: malfet
fbshipit-source-id: f220b8f3279054c98cab9eef1e0d7e37161a946f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56964
This PR does many things but does not update any logic:
- Prefixes all function names that are not `gradcheck`, `gradgradcheck`, `get_numerical_jacobian`, and `get_analytical_jacobian` with underscore to indicate that they aren't part of the public API (https://github.com/pytorch/pytorch/issues/55714).
- Improve naming to avoid referencing Jacobian rows or Jacobian cols when we really mean vjp and jvp as suggested by zou3519
- Try to reduce comment line length so they are more consistent and easier to read
- Other misc improvements to documentaiton
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28096571
Pulled By: soulitzer
fbshipit-source-id: d372b5f8ee080669e525a987402ded72810baa0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55113
The new method allows to pass input and output arguments by `void*`
pointers instead of CallArgs. That helps to reduce the invocation
overhead. Currently this is only supported in LLVM codegen.
Differential Revision: D27487549
Test Plan: Imported from OSS
Reviewed By: bertmaher
Pulled By: ZolotukhinM
fbshipit-source-id: d8f3d92262cde1c155beefb629454370d9af2f89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56894
used the dispatch type macro to add support for fp16 and 64 tensors. haven't tested on gpu yet, will do so once I can rebuilt pytorch with cuda.
Test Plan:
python test/test_quantization.py TestFakeQuantize.test_forward_per_channel_half_precision_numerics
python test/test_quantization.py TestFakeQuantize
python test/test_quantization.py TestFakeQuantize.test_backward_per_channel_cachemask_cpu
python test/test_quantization.py TestFakeQuantize.test_forward_per_channel_cachemask_cpu
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28002955
fbshipit-source-id: c9cf17aa0f15f163bfcc8e5ef7b329ca754924fd
Summary:
NVRTC versioning has changed starting 11.3, and will change again for CUDA 12.X. See comment in code for detail. As a result, jit on CUDA 11.3 is broken.
Also, the error message is misleading: When both `libname` and `alt_libname` are non-empty, the error message is only reporting `alt_libname`, it should report both.
To reproduce the error, you can use:
```python
import torch
torch._C._jit_set_profiling_mode(False)
torch._C._jit_set_profiling_executor(False)
torch._C._jit_override_can_fuse_on_cpu(True)
torch._C._jit_override_can_fuse_on_gpu(True)
torch.jit.script
def jit_relu_dropout(x, prob) :
# type: (Tensor, float) -> Tensor
x = torch.nn.functional.relu(x)
x = torch.nn.functional.dropout(x, p=prob, training=True)
return x
x = torch.randn((64, 40, 12, 1024), device="cuda:0", dtype=torch.float16, requires_grad=True)
y = jit_relu_dropout(x, 0.5)
```
with CUDA 11.3, and you will see
```
Traceback (most recent call last):
File "/home/gaoxiang/misc/nvrtc-failure.py", line 16, in <module>
y = jit_relu_dropout(x, 0.5)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
RuntimeError: Error in dlopen or dlsym: libnvrtc-8aa72235.so.11.3: cannot open shared object file: No such file or directory
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57204
Reviewed By: ngimel
Differential Revision: D28122083
Pulled By: malfet
fbshipit-source-id: fd387cf79f33a6d5a5b93d54c9f21e9c23731045
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56536
This PR adds unit tests to ensure that the encoded byte length of `_RendezvousState` stays under a certain limit.
ghstack-source-id: 127626622
Test Plan: Run the newly-introduced unit tests.
Reviewed By: tierex
Differential Revision: D27890704
fbshipit-source-id: 24905c8bc9d985d5ee90d370f28739eb137ce0f0
Summary:
I'd like the following pattern (a natural composition of Amp with full fwd+bwd capture) to work:
```python
# Create "static_input" with dummy data, run warmup iterations,
# call optimizer.zero_grad(set_to_none=True), then
g = torch.cuda._Graph()
s.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(s):
optimizer.zero_grad(set_to_none=True)
g.capture_begin()
with autocast():
out = model(static_input)
loss = loss_fn(out)
scaler.scale(loss).backward()
g.capture_end()
torch.cuda.current_stream().wait_stream(s)
# Training loop:
for b in data:
# optimizer.zero_grad() deliberately omitted, replay()'s baked-in backward will refill statically held .grads
static_input.copy_(b)
g.replay()
scaler.step(optimizer)
scaler.update()
```
Right now `GradScaler` can't work with this pattern because `update()` creates the scale tensor for the next iteration out of place. This PR changes `update()` to act in place on a long-lived scale tensor that stays static across iterations.
I'm not sure how this change affects XLA (see https://github.com/pytorch/pytorch/pull/48570), so we shouldn't merge without approval from ailzhang yaochengji.
Tagged bc-breaking because it's a change to the amp update utility function in native_functions.yaml. The function was never meant to be user-facing though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55562
Reviewed By: zou3519
Differential Revision: D28046159
Pulled By: ngimel
fbshipit-source-id: 02018c221609974546c562f691e20ab6ac611910
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57053
This ctor is intended for pybind use. It increments weakcount when creating a strong reference, which is only correct if you know that the value was previously zero. So, I consolidated make() with this ctor.
ghstack-source-id: 127537070
Test Plan: existing CI
Reviewed By: ezyang
Differential Revision: D28037206
fbshipit-source-id: eec57a99e3e032830f156c1e6258760f6465137b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56257
CPU and cuSOLVER path were fixed with refactoring of
`_linalg_qr_helper_default`.
Resolves https://github.com/pytorch/pytorch/issues/50576
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27960157
Pulled By: mruberry
fbshipit-source-id: f923f3067a35e65218889e64c6a886364c3d1759
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56255
With refactored non-allocating `linalg_qr_out_helper` from the previous
commit we don't need to specify the size arguments because the inputs to
orgqr and geqrf are always of correct size.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27960153
Pulled By: mruberry
fbshipit-source-id: 0f9be25781371633378752b587da62b828816646
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57310
If we fail to exec `torch_shm_manager`, write an appropriate error message to stdout so that the parent process can have some context on the failure.
Reviewed By: ejguan
Differential Revision: D28047917
fbshipit-source-id: 68bf357df7a6b318c036f4f62cbb428a62cb139e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57309
Addressing a race condition that can occur in `torch_shm_manager` between the time its temporary file is unlinked and when it `bind()`s the manager server socket to that same name. In that time window, other threads/processes can re-create another temporary file with the same name, causing `bind()` to fail with `EADDRINUSE`.
This diff introduces `c10::TempDir` and associated helper functions that mirror those of `c10::TempFile` and generates the manager socket name using a combination of a temporary directory, which will be valid for the lifetime of `torch_shm_manager`, and a well-known file name within that directory that will never be used outside of `bind()`.
Reviewed By: ejguan
Differential Revision: D28047914
fbshipit-source-id: 148d54818add44159881d3afc2ffb31bd73bcabf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57308
This diff makes `c10::TempFile` non-copyable but movable. `torch_shm_manager` was previously dependent upon some hidden behavior that was a result of copying `TempFile`s, which is also being made more explicit now that they can be moved but not copied.
Context:
`c10::TempFile` is currently copyable, which leads to surprising behavior. A seemingly valid `TempFile` may in fact be invalid if the original it was copied from has already been destroyed, resulting in the file descriptor to be closed and the filename being unlinked without the user knowing about it.
**In fact, both `c10::try_make_tempfile` and `c10::make_tempfile` cause copies of `TempFile` to be made**, which can easily be verified by explicitly deleting the copy constructor of `TempFile` and attempting to compile. This means that in practice, users of these functions are getting temporary files that have already been closed and unlinked.
This copying of `TempFile` is particularly interesting in the case of `torch_shm_manager`, which uses `try_make_tempfile` to generate the name of a Unix domain socket to communicate with clients. In order for `bind()` on the socket name to be successful, a file with that same name must not be linked in the filesystem, or `EADDRINUSE` will result. Happily, beacuse `try_make_tempfile` previously created a copy of the `TempFile` while destroying the original, `torch_shm_manager` did not encounter this. With this change, howevrer, `torch_shm_manager` must now explicitly destroy the `TempFile` before attempting to `bind()`. Unfortunately, this exposes a race condition--**other code can re-generate the same-named temporary file after the one created by `torch_shm_manager` is explicitly unlinked but before `torch_shm_manager` binds it to the server socket.** To be clear: this race condition already existed before this diff, but this makes things more explicit. The real fix will be in a follow-up change.
Reviewed By: ejguan
Differential Revision: D28047915
fbshipit-source-id: e8a1b6bb50419fe65620cfecdb67c566a4cf9056
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57307
Extend the `"ERROR"` message that `torch_shm_manager` writes to the pipe when it encounters a fatal error with some extra context (specifically, the `what()` on a caught `std::exception`), allowing the parent process to gain some insight into the cause of the failure.
Also, simply return from `main()` with an error exit code when a fatal exception is caught rather than re-throwing, because re-throwing leads to premature process termination that may prevent standard output from being flushed (and therefore the parent process from being able to read the error context from the pipe).
Reviewed By: ejguan
Differential Revision: D28047916
fbshipit-source-id: d423ee8ed1b2bf7831db877e8f8515ec6d6aa169
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54995
provide an DDP private API to explicitly set the training is static, also set this flag in logger
ghstack-source-id: 127755713
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D27444965
fbshipit-source-id: 06ef1c372296815944b2adb33fbdf4e1217c1359
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54981
put part of codes in autograd_hook into functions, so that they can be used in the static graph training later on.
ghstack-source-id: 127755405
Test Plan: unit tests
Reviewed By: SciPioneer
Differential Revision: D27439508
fbshipit-source-id: a02a4b029841f5e7f11cfc5496bb7972ef53d878
Summary:
Fixes https://github.com/pytorch/pytorch/issues/55090
I included the header directly, but I am not sure if we should add this as a git submodule, what do you guys think?
Also regarding the implementation, in ATen lanes seems not to be supported, but from CuPy complex types are exported with 2 lanes, I am not sure wether this is correct or not. However, in PyTorch this seems to be working properly, so I forgive 2 lanes for complex datatypes.
TODO: add tests for complex and bfloat
Easy test script against cupy
```python
import cupy
import torch
from torch.utils.dlpack import to_dlpack
from torch.utils.dlpack import from_dlpack
# Create a PyTorch tensor.
tx1 = torch.tensor(
[2 + 1j, 3 + 2j, 4 + 3j, 5 + 4j], dtype=torch.complex128
).cuda()
# Convert it into a DLPack tensor.
dx = to_dlpack(tx1)
# Convert it into a CuPy array.
cx = cupy.fromDlpack(dx)
# Convert it back to a PyTorch tensor.
tx2 = from_dlpack(cx.toDlpack())
torch.testing.assert_allclose(tx1, tx2)
```
Thanks to leofang who updated CuPy's dlpack version and his PR served me as the guide for this one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55365
Reviewed By: ngimel
Differential Revision: D27724923
Pulled By: mruberry
fbshipit-source-id: 481eadb882ff3dd31e7664e08e8908c60a960f66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56807
If I understand correctly, there's no reason to create your own instance of these global singleton types.
ghstack-source-id: 127312270
Test Plan: CI
Reviewed By: SplitInfinity
Differential Revision: D27973447
fbshipit-source-id: f12df69d185f1baaa45f2ac6eac70570a7a65912
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57280
We've found an issue that fusion group would results in circular dependency. For example
```
a -> b -> c -> d
| ^
+ -------------+
Only a has non tensor output and currently we would create a fusion group (a, b, d). This results in circular dependency because now the fusion group depends on c while c depends on the fusion group as well.
```
This diff implement the solution discussed before. When we add a node to fusion group, we add all the nodes that are in the middle of the fusion group and this newly added node.
Use the same logic in minimizer to build fusion group.
Test Plan: split_tests and net_min_tests
Reviewed By: khabinov
Differential Revision: D27917432
fbshipit-source-id: a3d99fe5929dbc9f8eb0f45bccd83fd7b173795a
Summary:
Partial fix for https://github.com/pytorch/pytorch/issues/56157
This PR updates the `flatten` API in `LoopNest` to perform the flattening transformation in-place. After this transformation, the first loop in the input becomes the flattened loop.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56629
Reviewed By: H-Huang
Differential Revision: D28004787
Pulled By: navahgar
fbshipit-source-id: 7474ae237fae3fff0cd1c64a276a8831dc5b7db0
Summary:
__builtin_memcmp is not a constexpr for character arrays for NVCC-11.3 compiler.
Attempts to compile this code results in the following error:
```
/opt/conda/lib/python3.6/site-packages/torch/include/c10/util/string_view.h(585): note: constexpr memory comparison is only supported for top-level integer or array-of-integer objects
/opt/conda/lib/python3.6/site-packages/torch/include/c10/util/string_view.h(340): note: called from:
/opt/conda/lib/python3.6/site-packages/torch/include/c10/util/string_view.h(369): note: called from:
```
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57322
Reviewed By: janeyx99
Differential Revision: D28119125
Pulled By: malfet
fbshipit-source-id: e5ff6ac7bb42022e86c9974919e055cf82c2ea83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56579
On earlier cuDNN versions, when a model uses fp16, the
performance after conv-add-relu fusion regresses. Let's just
disable the fusion for fp16 if cuDNN version is older than v8.
Test Plan: Tested for fp16 models on Nvidia Tesla T4
Reviewed By: ZolotukhinM
Differential Revision: D27915514
Pulled By: desertfire
fbshipit-source-id: 1c0081a80540c507e608216c90bc74c486c7008d
Summary:
Related to https://github.com/pytorch/pytorch/issues/55601.
- [x] removed complex autograd checker in `test_supported_backward`
- [x] created `backward_dtype[If<Device>]` that inherits from normal `dtype[If<Device>]` by default
- [x] removed all skip for backward test, instead added backward dtype
- [x] change complex autograd to a function call: `support_complex_autograd(device_type)` that depends on `backward_dtype*` since they essentially mean the same thing for complex types
TODO for next PR
- add `test_unsupported_backward` to verify they are actually unsupported.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56156
Reviewed By: mruberry
Differential Revision: D27926717
Pulled By: walterddr
fbshipit-source-id: 9a4af8612278ca44a97b6f1510b6b175852c893b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57057
This PR performs optimization on the ViewInfo handling to remove the need for the "no forward AD mode".
- When the forward and backward ViewInfo are the same, create and store only one of them
Code for timing:
```python
timer = Timer(
stmt='a.view(-1)',
setup='''\
import torch
a = torch.rand(4)''')
res = timer.collect_callgrind(repeats=2, number=10)[1]
```
Difference between master and this PR:
```
# Benchmark at master
<torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7fe33be83690>
a.view(-1)
setup:
import torch
a = torch.rand(4)
All Noisy symbols removed
Instructions: 69286 68442
Baseline: 1332 1188
10 runs per measurement, 1 thread
# Benchmark at this branch
<torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7fe33bd7ec30>
a.view(-1)
setup:
import torch
a = torch.rand(4)
All Noisy symbols removed
Instructions: 69437 68562
Baseline: 1363 1188
10 runs per measurement, 1 thread
# Difference between the two
<torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.FunctionCounts object at 0x7fe1216e9a00>
160 ???:0x000000000a11c8d0
60 torch::autograd::DifferentiableViewMeta::DifferentiableViewMeta
60 ???:torch::autograd::as_view(at::Tensor const&, at::Tensor const&, bool, bool, std::function<at::Tensor (at::Tensor const&)>, torch::autograd::CreationMeta, bool)
40 ???:0x0000000008e14f50
40 ???:0x0000000008e05bd0
40 ???:0x0000000008e05480
40 ???:0x0000000008e036d0
40 ???:0x0000000008e02720
30 make_variable_differentiable_view
...
-20 ???:0x0000000008e02060
-20 ???:0x0000000008e01fd0
-30 ???:torch::autograd::isForwardADEnabled()
-40 ???:0x0000000008e14f90
-40 ???:0x0000000008e05c00
-40 ???:0x0000000008e054a0
-40 ???:0x0000000008e036f0
-40 ???:0x0000000008e02740
-160 ???:0x000000000a11d8d0
Total: 120
```
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D28071505
Pulled By: albanD
fbshipit-source-id: 672b1bdf87d516b6de4f2e36656819cfd6f4c9b9
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 5ce0eed074
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57342
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D28114231
fbshipit-source-id: 0a5883ebb2fcd45ff547d594928372a9a9c9b76c
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: c565348fdc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55347
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D27582224
fbshipit-source-id: 6670e96b21d84dc6464559bf179f74751927fdd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57282
Added support for fb::expand_dims for SR.
Test Plan:
buck test caffe2/torch/fb/sparsenn:gpu_test -- test_expand_dims
buck test caffe2/benchmarks/static_runtime/fb:test_fb_operators
Reviewed By: hlu1
Differential Revision: D28043049
fbshipit-source-id: 01f59db7b507f027b220f044d6ff23602adbdb06
Summary:
Fix a numerical issue of CUDA channels-last SyncBatchNorm
The added test is a repro for the numerical issue. Thanks for the help from jjsjann123 who identified the root cause. Since pytorch SBN channels-last code was migrated from [nvidia/apex](https://github.com/nvidia/apex), apex SBN channels-last also has this issue. We will submit a fix there soon.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57077
Reviewed By: mruberry
Differential Revision: D28107672
Pulled By: ngimel
fbshipit-source-id: 0c80e79ddb48891058414ad8a9bedd80f0f7f8df
Summary:
This adds some more compiler warnings ignores for everything that happens on a standard CPU build (CUDA builds still have a bunch of warnings so we can't turn on `-Werror` everywhere yet).
](https://our.intern.facebook.com/intern/diff/28005063/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56630
Pulled By: driazati
Reviewed By: malfet
Differential Revision: D28005063
fbshipit-source-id: 541ed415eb0470ddf7e08c22c5eb6da9db26e9a0
Summary:
This is to setup boiler plate code for backward and CPU implementation.
Next Steps in order:
- Add backward support for CUDA
- Add support for more aggregation types
- Benchmarking (for cuda mainly)/more testing/documentation
- Support for multi dimension
Test Plan:
Updated unit test to also check correctness of backward.
Wait for CI signal
Reviewed By: ngimel
Differential Revision: D27970340
fbshipit-source-id: 3e608c7fe3628b0a761dd8affc6aad8f65a6ef7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57296
Seems many trainers disable print(), so we cannot see the thread dumps with CompleteInTimeOrDie(). So log.info() also.
Test Plan: sandcastle
Reviewed By: aalmah
Differential Revision: D28098738
fbshipit-source-id: dfdca8801bacf5c7bccecc2387cb7ef41dadfa46
Summary:
`OpInfo`s for `sub` & `mul` operators. Both of them will reuse the sample inputs function added for `add` via another PR.
A https://github.com/pytorch/pytorch/issues/54261 task.
cc mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56227
Reviewed By: H-Huang
Differential Revision: D27993889
Pulled By: mruberry
fbshipit-source-id: 7b2da02b0edba3cc37b5b1b88ca32f7dd369ca60
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57279
Added an option "return_intermediate". If true, when building the submodule we want to run , we will replace the output with all the nodes, so that intermediate results of all the nodes will be returned as output.
This is recommended to use with `run_node()` function.
Test Plan: `buck test glow/fb/nnpi/lowering:net_min_tests`
Reviewed By: khabinov
Differential Revision: D27913887
fbshipit-source-id: 5a3eab02da05214fb9adeb25656c267b58075b1d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57191
Changed Store::compareSet() to a pure virtual function and added compareSet definition to PythonStore. Rest of changes are from clang-format.
Test Plan: Imported from OSS
Reviewed By: cbalioglu
Differential Revision: D28076557
Pulled By: H-Huang
fbshipit-source-id: 379636cf8b031088341a032250ba410d84ccf692
Summary:
1. Delete dead code relating to maskrcnn_benchmark extension module
2. Add some more commentary on why we define a meta path finder
isthisimpact
Test Plan: sandcastle
Reviewed By: wconstab
Differential Revision: D28078211
fbshipit-source-id: cfc6f47861c14ec7482b55ee585504271ae0f365
Summary:
[distutils](https://docs.python.org/3/library/distutils.html) is on its way out and will be deprecated-on-import for Python 3.10+ and removed in Python 3.12 (see [PEP 632](https://www.python.org/dev/peps/pep-0632/)). There's no reason for us to keep it around since all the functionality we want from it can be found in `setuptools` / `sysconfig`. `setuptools` includes a copy of most of `distutils` (which is fine to use according to the PEP), that it uses under the hood, so this PR also uses that in some places.
Fixes#56527
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57040
Pulled By: driazati
Reviewed By: nikithamalgifb
Differential Revision: D28051356
fbshipit-source-id: 1ca312219032540e755593e50da0c9e23c62d720
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56033
There doesn't seem to be any reason not to size the output
correctly, and it avoids a round of dispatch for resize.
ghstack-source-id: 127409715
Test Plan:
Inspected GPU trace for simple nn.Linear in a loop. No more
resize operator invocation.
Existing CI should let us know if this is incorrect
Reviewed By: ngimel
Differential Revision: D27768311
fbshipit-source-id: fb48ec50f3cffc1015ef03d528e9007274b4dd3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56032
Profiling & assembly inspection showed that we weren't
getting NRVO with `inferExpandGeometry_dimvector` returning
`std::tuple`. I added a custom type with constructors so that, as the
comment says, we could be sure to get NRVO.
ghstack-source-id: 127409717
Test Plan:
Inspected new assembly, no more move construction (which is
a copy for on-stack DimVectors!) upon returning
Reviewed By: ezyang
Differential Revision: D27768312
fbshipit-source-id: d1d53a36508be92585802e1467d8a42d1ae05d80
Summary:
Problem arises for sinc'(x) where x != 0, but x ** 2 == 0, which happens for some very small floats.
I realized that my solution from https://github.com/pytorch/pytorch/issues/56763 was incomplete when I did a quick implementation using `torch.autograd.Function` and still got a `NaN` from my derivative.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56986
Reviewed By: gchanan
Differential Revision: D28093507
Pulled By: albanD
fbshipit-source-id: 2a30e1065b08c5c60de843a0778dedeb0fb295f4
Summary:
Adds support for type inference of nn.Module methods using monkeytype in JIT
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57165
Reviewed By: gmagogsfm
Differential Revision: D28064983
Pulled By: nikithamalgifb
fbshipit-source-id: 303eaf8d7a27e74be09874f70f519b4c1081645b
Summary:
This PR adds TorchBench (pytorch/benchmark) CI workflow to pytorch. It tests PRs whose body contains a line staring with "RUN_TORCHBENCH: " followed by a list of torchbench model names. For example, this PR will create a Torchbench job of running pytorch_mobildnet_v3 and yolov3 model.
For security reasons, only the branch on pytorch/pytorch will run. It will not work on forked repositories.
The model names have to match the exact names in pytorch/benchmark/torchbenchmark/models, separated by comma symbol. Only the first line starting with "RUN_TORCHBENCH: " is respected. If nothing is specified after the magic word, no test will run.
Known issues:
1. Build PyTorch from scratch and do not reuse build artifacts from other workflows. This is because GHA migration is still in progress.
2. Currently there is only one worker, so jobs are serialized. We will review the capacity issue after this is deployed.
3. If the user would like to rerun the test, she has to push to the PR. Simply updating the PR body won't work.
4. Only supports environment CUDA 10.2 + python 3.7
RUN_TORCHBENCH: yolov3, pytorch_mobilenet_v3
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56957
Reviewed By: janeyx99
Differential Revision: D28079077
Pulled By: xuzhao9
fbshipit-source-id: e9ea73bdd9f35e650b653009060d477b22174bba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57175
Update other Store implementations to add the value when current value is empty to match the amendment made to TCPStore (#55636). Added test to cover this case.
Test:
`pytest -vs test/distributed/test_c10d_common.py -k compare_set`
Test Plan: Imported from OSS
Reviewed By: cbalioglu
Differential Revision: D28069380
Pulled By: H-Huang
fbshipit-source-id: eac703edb41faee32a4e7cda61107e2a0e726326
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57173
If getitem is followed by an unmatched node, we'll remove the observer after it.
Test Plan:
python test/test_quantization.pyt TestQuantizeFxOps.test_getitem
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D28068805
fbshipit-source-id: e79f8ec3e8fd61d348b8a7069ab0bb434d737c30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57098
1. Separate `readArchiveAndTensors()` from `jit/import.cpp` to a new file `jit/import_read.cpp`.
2. Use `readArchiveAndTensors()` in `mobile/import.cpp`
ghstack-source-id: 127703081
3. Add a util function in cpp that could read .pkl files directly instead of loading the entire module
Test Plan: CI
Reviewed By: raziel, iseeyuan
Differential Revision: D28052193
fbshipit-source-id: c8d57f3270bdcf2e52a32f7c111899bd5da7cac2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56730
add a test to verify DDP with torch map will result in the same results when using grad_as_bucket_view=true and false.
torch.amp scale factor does not have dependencies on old gradients, thus it is not affected by grad_as_bucket_view=true or false, see
how torch.amp is implemeted here https://github.com/pytorch/pytorch/pull/33366/files.
This diff verified ddp can work as expected with amp.GradScaler and amp.autocast when when using grad_as_bucket_view=true and false.
ghstack-source-id: 127526358
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D27950132
fbshipit-source-id: 8ed26935fdcb4514fccf01bb510e31bf6aedac69
Summary:
These weren't using the smaller images so we should probably let them
use the smaller images
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56937
Reviewed By: walterddr
Differential Revision: D28077747
Pulled By: seemethere
fbshipit-source-id: da0245bc3b4f564fcd392630542777b2b668b98f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57052
This PR caps a stack whose goal was to merge CUDAFuture into ivalue::Future. CUDAFuture used to be a subclass of ivalue::Future, which was already pretty good, but it meant that in several places we needed `#ifdef`s or registries in order to create the right type of class, which was annoying. We've made CUDAFuture device-agnostic, by using generic helpers, so that it doesn't depend on CUDA. Now all its code can be inserted into ivalue::Future.
This PR does this very naively, by copy-pasting CUDAFuture's code into the (previously empty) virtual methods of ivalue::Future. This helps ensure the correctness of this PR, as it's straightforward to see it behaves exactly like before. However we probably want to polish it a bit later to iron out so wrinkles.
ghstack-source-id: 127713138
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28036829
fbshipit-source-id: 3e5b16402f5dc245c1fcb9d7bf06db64dcb0d2a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57051
Make CUDAFuture autodetect the devicetype from its arguments (which thus change from DeviceIndices to full Devices). This in fact transforms CUDAFuture into a AnythingFuture, since it's not tied to CUDA in any way anymore. Having made it fully device-agnostic, we'll merge it into ivalue::Future in the next PR.
ghstack-source-id: 127713134
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28032711
fbshipit-source-id: 8ba23b1b0d97f61db8693cd5f3c7bae7989a9bcd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57050
Avoid (nearly*) any explicit mention of CUDA in CUDAFuture, and instead use "generic" classes like c10::Event, c10::Stream and most notably c10::impl::DeviceGuardImplInterface which allow us to indirectly manipulate CUDA entities. This is a preparation step to make CUDAFuture device-agnostic and thus become able to merge it into ivalue::Future.
* The one exception is when we construct the c10::impl::DeviceGuardImplInterface, where for now we still hardcode CUDA. This will be fixed in the very next PR
ghstack-source-id: 127713133
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28032710
fbshipit-source-id: a240ecc32bda481e8ecf85dab94933e24f832bb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57049
There was a comment above CUDAMultiStreamGuard which said "TODO: Implement this generically in c10". This is what I'm doing here.
The new generic MultiStreamGuard class is able to take a vector of device-agnostic c10::Streams and is able to support any device type (CUDA, but also ROCm and others) by using a VirtualGuardImpl. A class called CUDAMultiStreamGuard is still kept around, for convenience, and slightly for performance as it avoids a vtable lookup.
ghstack-source-id: 127713139
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28029158
fbshipit-source-id: 2f3181371f8cb0d77a3b2e6aa510f1dd74e8f69b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57048
CUDAMultiStreamGuard had a default constructor and a `original_devices()` method which were only used in a test. I'm removing them here to simplify the API and make it easier to manipulate this class later. One extra benefit is that this class used to get and store the current stream of _all_ devices, whereas now it only does so for the relevant devices.
ghstack-source-id: 127713136
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D28029160
fbshipit-source-id: 185ef9a7ac909cd0ae6507dad9826fe978e67308
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57047
We intend to merge CUDAFuture into ivalue::Future by using DeviceGuardImplInterface to avoid explicitly referring to CUDA. For that we need to add two methods to DeviceGuardImplInterface. In this PR, we add a method to record a DataPtr onto a stream with the caching allocator.
ghstack-source-id: 127713135
(Note: this ignores all push blocking failures!)
Test Plan: Used later in this stack
Reviewed By: ezyang
Differential Revision: D28029161
fbshipit-source-id: ff337ab8ccc98437b5594b2f263476baa1ae93e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57046
We intend to merge CUDAFuture into ivalue::Future by using DeviceGuardImplInterface to avoid explicitly referring to CUDA. For that we need to add two methods to DeviceGuardImplInterface. In this PR, we add a method to get a stream from the global ATen pool.
ghstack-source-id: 127713137
(Note: this ignores all push blocking failures!)
Test Plan: Used later in this stack
Reviewed By: ezyang
Differential Revision: D28029159
fbshipit-source-id: 5055d84c1f3c2a4d86442f3149455c5ebd976dea
Summary:
TCPStore is now available on Windows.
Before: `TCPStore not available on Windows`
After: `c10d was not compiled with the NCCL backend`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57256
Reviewed By: gchanan
Differential Revision: D28092539
Pulled By: H-Huang
fbshipit-source-id: 1e48cfe29b33b102bc97f51268ac1bbda596397d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54723
Renamed "cond" -> "rcond" to be NumPy compatible. The default value for
rcond was changed to match non-legacy NumPy behavior.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D27993741
Pulled By: mruberry
fbshipit-source-id: a4baf25aca6a8272f1af2f963600866bfda56fb3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54722
SciPy and NumPy operate only on non-batched input and return an empty array with shape (0,) if rank(a) != n.
The behavior for non-batched inputs is NumPy and SciPy compatible and the same result is computed.
For batched inputs, if any matrix in the batch has a rank less than `n`, then an empty tensor is returned.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27993736
Pulled By: mruberry
fbshipit-source-id: 0d7cff967b322a5e816a23f282b6ce383c4468ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57164
Give some more indications about its performance characteristics
and when it is appropriate to use.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D28064685
Pulled By: ezyang
fbshipit-source-id: dbf5e041088d7921db2111d287feb9079466f1b5
Summary:
Run both fast and slow mode for test overrides and fix failure in slow_mode
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57155
Reviewed By: albanD
Differential Revision: D28076483
Pulled By: soulitzer
fbshipit-source-id: ef942d787d986ba881329e9515e5de6194f3782b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56679
moved lowerings out of the TensorExprKernel and into independent functions
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D28082921
Pulled By: Chillee
fbshipit-source-id: af530510957ed4aa8b64dcc77ca36b69866d8000
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57217
In torch multiprocessing error handler, we try to remove the file if it already exists. Before removing, we try to log the contents of the file. Here the assumption is that the contents would be valid json.
However, in some cases, it isn't and then we end up not clearing the file.
Let's handle this error and make sure that the file is cleaned irrespective of the contents of the file.
Reviewed By: devashisht
Differential Revision: D28041470
fbshipit-source-id: da96d11b8f7091715cf0152cccd3ecc08b688eae
Summary:
In my last PR I've missed CUDA and distributed folders, fixing this now
This change is autogenerated by `python tool/clang_tidy.py -s`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57235
Reviewed By: janeyx99
Differential Revision: D28084444
Pulled By: malfet
fbshipit-source-id: bf222f69ee90c7872c3cb0931e8cdb84f0cb3cda
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57183
Previously, if it was unable to support matching against a type, it would throw an error.
However, this exposes the user to arbitrary Torchscript schemas, which may or may not be problematic. Although we may support these in the future, for now we just return False (which will simply eliminate that schema from the candidates).
Test Plan: T89661626 and T89664016
Reviewed By: spaugh, khabinov
Differential Revision: D28072018
fbshipit-source-id: 83017d1e96d19912163edc74a5e43b2816783218
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57085
PR #54932 fixed the CUDA RPC for RRef when RRef is created through
RPC. But besides that use case, RRef can also be created locally
by directly passing in a value, which would bypass the CUDA stream
synchronization in #54932.
This commit covers the above gap by adding a `devices` argument
to RRef constructor. The RRef will then use this argument to
choose between `CUDAFutre` and `ivalue::Future` to hold the value.
When `devices` is specified and non-empty, `CUDAFuture` will be
used, and the `devices` will be passed to that `CUDAFuture`.
Test Plan: Imported from OSS
Reviewed By: lw
Differential Revision: D28050001
Pulled By: mrshenli
fbshipit-source-id: 2316b419fa69aa4dcd444050f0b74e61c3d0af1e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57182
Adding sequenceNr and fwdThreadId to the trace, to associate fwd ops with
backward ops
Test Plan: CI
Reviewed By: xuzhao9
Differential Revision: D28070725
fbshipit-source-id: aa4db580c9fd3ed061eaceb5239f4d9b2f8da3dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56631
`setErrorIfNeeded` did not mention whether the future was already
completed or there was some other exception. This particular change ensures
that we also print out the original exception as part of the error message.
This would help in debugging issues where this codepath is triggered.
ghstack-source-id: 127248844
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D27919974
fbshipit-source-id: 2273a93f3475929b14f721c976f194f33a5aa746
Summary:
CUDA-11.1 build and tests will now run on PR and master, but 10.2 will
be master only
Also, delete remaining CUDA-10.1 build
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57207
Reviewed By: ngimel
Differential Revision: D28077271
Pulled By: malfet
fbshipit-source-id: 633945bf85091575efa34280e04a6b9d68a53138
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57102
We don't actually need to peek into `--fbcode_dir` for this. There are two reasons we should avoid this:
1. The [`TARGETS` docs](https://fburl.com/wiki/zz1wh6uc) recommend against it, as it can break buck caching and dependency tracking. This doesn't seem to be a serious issue in our case (we declare our sources anyway) but worth respecting.
2. More seriously, if we want to use this script from outside fbcode (like `fbsource/third-party/pypi`), it will break since `fbcode_dir` gets set to something wild
The preferred method is apparently to use `$SRCDIR`, which represents a directory that all specified sources are copied to before exexcuting the custom rule.
Found the suggestion here: https://fburl.com/w33wae2b. Seems less fragile, since it's publically documented as well: https://buck.build/rule/genrule.html
Test Plan: sandcastle
Reviewed By: wconstab
Differential Revision: D28052570
fbshipit-source-id: cb4772b5dc07fbdc251249d6e0759e71730098af
Summary:
Adaptive average pool with output size (1, 1) is a global average pool
For mobile use xnnpack to speed up that path
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55791
Test Plan:
buck test //xplat/caffe2:pt_xnnpack_test
pytest test/test_xnnpack_integration.py::TestXNNPACKOps
Fixes #{issue number}
Reviewed By: kimishpatel
Differential Revision: D27711082
Pulled By: axitkhurana
fbshipit-source-id: 8757042c4a31a60451d8ba5fb6bf8cfbaf0a8d10
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56714
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55800
For mobile use xnnpack implementation of hardswish
Test Plan: buck test //xplat/caffe2:pt_xnnpack_test
Reviewed By: kimishpatel
Differential Revision: D27712306
fbshipit-source-id: c7f0b70482aeef2aaa1966e2c669f79ecd29caa7
Summary:
This is an automatic change generated by the following script:
```
#!/usr/bin/env python3
from subprocess import check_output, check_call
import os
def get_compiled_files_list():
import json
with open("build/compile_commands.json") as f:
data = json.load(f)
files = [os.path.relpath(node['file']) for node in data]
for idx, fname in enumerate(files):
if fname.startswith('build/') and fname.endswith('.DEFAULT.cpp'):
files[idx] = fname[len('build/'):-len('.DEFAULT.cpp')]
return files
def run_clang_tidy(fname):
check_call(["python3", "tools/clang_tidy.py", "-c", "build", "-x", fname,"-s"])
changes = check_output(["git", "ls-files", "-m"])
if len(changes) == 0:
return
check_call(["git", "commit","--all", "-m", f"NOLINT stubs for {fname}"])
def main():
git_files = check_output(["git", "ls-files"]).decode("ascii").split("\n")
compiled_files = get_compiled_files_list()
for idx, fname in enumerate(git_files):
if fname not in compiled_files:
continue
if fname.startswith("caffe2/contrib/aten/"):
continue
print(f"[{idx}/{len(git_files)}] Processing {fname}")
run_clang_tidy(fname)
if __name__ == "__main__":
main()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56892
Reviewed By: H-Huang
Differential Revision: D27991944
Pulled By: malfet
fbshipit-source-id: 5415e1eb2c1b34319a4f03024bfaa087007d7179
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56217
Reland of https://github.com/pytorch/pytorch/pull/54264
Changes:
- Update socket send() to use flag MSG_NOSIGNAL to prevent SIGPIPE because error in return is already capturad
- Update watchKey to block until callback has been registered on master.
- Fix race condition in testWatchKeyCallback which caused flaky test failures.
Test:
Ran TCPStoreTest 100 times locally with no errors, running [ci-all tests](https://github.com/pytorch/pytorch/pull/56219)
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D27824802
Pulled By: H-Huang
fbshipit-source-id: c32230ce726d7d848b9896a63aa52b8eb04a0a2d
Summary:
Cudnn rnn calls that use use cudnn dropout maintain a "state" buffer across calls. [DropoutState](fe3f6f2da2/aten/src/ATen/native/cudnn/RNN.cpp (L1388-L1402))'s lock() and unlock() ensure the current call's use of the state buffer syncs with the end of the previous call's use of the state buffer (in case the previous call was on a different stream).
Telling a capturing stream to wait on an event recorded in a non-capturing stream is an error (1). Telling a non-capturing stream to wait on an event recorded during capture is also an error (2). So DropoutState's flow can error in either of two simple use cases:
```python
rnn = nn.LSTM(512, 512, 2, dropout=0.5).cuda()
out1 = rnn(in1)
# calling cudnn rnn with dropout in capture after calling it uncaptured triggers 1
capture_stream.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(capture_stream):
graph.capture_begin()
out2 = rnn(in2)
graph.capture_end()
torch.cuda.current_stream().wait_stream(capture_stream)
# calling cudnn rnn with dropout uncaptured after calling it in capture triggers 2
out3 = rnn(in3)
```
This PR fixes both cases by telling `DropoutState::lock()`: "if the most recent end-of-usage event was in a different capture state (ie, we crossed a capturing<->noncapturing border) or in a different capture, don't sync on it." While considering the fix I had two assumptions in mind:
- only one capture using the RNN can be underway at a time in this process
- no noncapturing ops in this process are issuing RNN calls while the capture using the RNN is underway.
That second assumption seems brittle if, for example, someone wants to capture an internal region of the forward method of a model wrapped with DataParallel: multiple threads could be issuing RNN calls with some currently capturing and some not. We should talk about whether that use case seems realistic.
(Bigger-picture thoughts: I don't know if forcing calls to serialize on using the shared state buffer is the best design. And if we want to do it that way, we might as well run all cudnn rnns with dropout on a dedicated side stream synced with the surrounding stream (capturing or not), in which case I don't think this PR's event-handling diffs would be needed.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56433
Reviewed By: heitorschueroff
Differential Revision: D27966444
Pulled By: ezyang
fbshipit-source-id: fe0df843c521e0d48d7f2c81a17aff84c5497e20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57063
Removes the generated tag from the original template so the diff shows
up correctly on internal Phab
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D28040694
Pulled By: seemethere
fbshipit-source-id: c6ec0520fbc4ea169abefc7df2ff925ecc0474cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57029
Partially addresses https://github.com/pytorch/pytorch/issues/56297
This fixes deadlocks when the threads the RPCAgent are blocking
on try to take the GIL. This also adds a general utility for
making shared_ptr run destructors without GIL.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D28030294
Pulled By: ezyang
fbshipit-source-id: 628c066eebbb70bda5b914645a109dce35d73c8d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56530
For upcoming diffs, ProcessGroup will need to know about debug level
for e.g. logging collective operations.
ghstack-source-id: 127535775
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27849839
fbshipit-source-id: a9f016a27d30a242eced19929b3824ae68fe430f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56982
SyncBatchNorm should behave as a regular BN layer in eval model, this
change ensures that this is the case.
In particular, the bug was when `track_running_stats=False`, `bn_training` would be set to True in eval mode, but this would trigger a collective sync in syncBN.
However, in eval mode syncBN should behave like a regular BN layer and not do this sync.
Closes https://github.com/pytorch/pytorch/issues/48988
Ensured with unittest that when used for inference on a single rank, stats sync is not triggered.
ghstack-source-id: 127544421
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27579297
fbshipit-source-id: 26406e2793f0be14f2daa46ae66f97a8494182ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56150
See #56017 for full context; the short story is that by making
it illegal to directly construct _TensorBase, we need only
write a *single* tp_dealloc function which will work universally
for all _TensorBase subclasses, rather than having to write two
versions, one for _TensorBase itself, and others for Python subclasses
of _TensorBase. This means simpler code.
The subtlety here is that we only install our custom `tp_new` for direct subclasses of TensorBase. This is important, because overriding the `tp_new` also overrides any user defined constructor. Fortunately class Tensor(_TensorBase) has no nontrivial constructors and doesn't mind, but other subclasses like Parameter definitely mind!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D28028746
Pulled By: ezyang
fbshipit-source-id: 3c03a14666ad1ded1145fe676afb0a7623cdb9bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56147
This is support of #55686, you can see the broader context of the metaclass in
a more complete PR #56017. The short story is that in the future I want to
give Tensor a non-trivial metaclass, so to derisk the change first I give it a
trivial metaclass to shake out any bugs that might be caused by it. The
metaclass shouldn't have any performance impact on Tensor as it only gets
invoked upon subclass creation.
By the way, it was totally not documented how to create metaclasses in the Python
C API, and it took a good bit of trial error to figure it out (and the answer is
now immortalized in https://stackoverflow.com/q/67077317/23845 -- the things
that I got wrong in earlier versions of the PR included setting tp_basicsize
incorrectly, incorrectly setting Py_TPFLAGS_HAVE_GC on the metaclass--you want
to leave it unset so that it inherits, and determining that tp_init is what
actually gets called when you construct a class, not tp_call as another
not-to-be-named StackOverflow question suggests).
Aside: Ordinarily, adding a metaclass to a class is a user visible change, as
it means that it is no longer valid to mixin another class with a different
metaclass. However, because _C._TensorBase is a C extension object, it will
typically conflict with most other metaclasses, so this is not BC breaking.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D28028747
Pulled By: ezyang
fbshipit-source-id: c1e35a986aeb3db540c73d188f53dce951eeed33
Summary:
The test seems to be failing in ROCM 4.1 on CI node. Disabling the same for now. The test will be re-enabled for ROCM when CI transitions to 4.2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56951
Reviewed By: zou3519
Differential Revision: D28059808
Pulled By: ezyang
fbshipit-source-id: a9b064b7525ae6dce89c51fe29ff07f37b7ac796
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56709
Right now, ProcessGroupMPITest testGather() fails with
```
what(): Gather: number of output tensors should be 0 for non-root
[devgpu025:429730] *** Process received signal ***
```
there is a similar issue with testScatter() where number of input/output tensors on source/destination respectively should be 0.
In addition testSendRecv(true); fails with
```
terminate called after throwing an instance of 'std::runtime_error'
what(): src rank is wrong for recvAnysource
```
since we never populate `srcRanks`
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D28001963
Pulled By: agolynski
fbshipit-source-id: c381dfc6f417ee78fbbaf884e567b0485076dfc8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56868
See __init__.py for a summary of the tool.
The following sections are present in this initial version
- Model Size. Show the total model size, as well as a breakdown by
stored files, compressed files, and zip overhead. (I expect this
breakdown to be a bit more useful once data.pkl is compressed.)
- Model Structure. This is basically the output of
`show_pickle(data.pkl)`, but as a hierarchical structure.
Some structures cause this view to crash right now, but it can be
improved incrementally.
- Zip Contents. This is basically the output of `zipinfo -l`.
- Code. This is the TorchScript code. It's integrated with a blame
window at the bottom, so you can click "Blame Code", then click a bit
of code to see where it came from (based on the debug_pkl). This
currently doesn't render properly if debug_pkl is missing or
incomplete.
- Extra files (JSON). JSON dumps of each json file under /extra/, up to
a size limit.
- Extra Pickles. For each .pkl file in the model, we safely unpickle it
with `show_pickle`, then render it with `pprint` and include it here
if the size is not too large. We aren't able to install the pprint
hack that thw show_pickle CLI uses, so we get one-line rendering for
custom objects, which is not very useful. Built-in types look fine,
though. In particular, bytecode.pkl seems to look fine (and we
hard-code that file to ignore the size limit).
I'm checking in the JS dependencies to avoid a network dependency at
runtime. They were retrieved from the following URLS, then passed
through a JS minifier:
https://unpkg.com/htm@3.0.4/dist/htm.module.js?modulehttps://unpkg.com/preact@10.5.13/dist/preact.module.js?module
Test Plan:
Manually ran on a few models I had lying around.
Mostly tested in Chrome, but I also poked around in Firefox.
Reviewed By: dhruvbird
Differential Revision: D28020849
Pulled By: dreiss
fbshipit-source-id: 421c30ed7ca55244e9fda1a03b8aab830466536d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56641
currently ddpLoggingData is flat struct, which requires internal DDP developers and external users to know about the struct field names. This is not flexible to delete or add new fields in the future. also it is hard to access ddpLoggingData.
With maps/dict, developers and users can easily access the fields without knowing the field names, also easier to add/remove a new/old field.
Since C++ does not support map values to be different types, right now ddpLoggingData containes two types of maps.
ghstack-source-id: 127482694
Test Plan: unit tests
Reviewed By: SciPioneer
Differential Revision: D27923723
fbshipit-source-id: c90199c14925fc50ef219000e2f809dc7601cce1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56074
To run shufflenet we need to support at::chunk on GPU. The current implementation only splits the tensor into two on channel dimension. We'll come back and fully implement it in Metal shaders.
ghstack-source-id: 127522377
Test Plan:
```
2021-03-26 01:37:07.693411-0700 PyTorchPlayground[2279:235793] [MPSImageWrapper] Found a temporary image: [1, 2, 2, 2]
2021-03-26 01:37:07.693499-0700 PyTorchPlayground[2279:235793] [MPSImageWrapper] Found a temporary image: [1, 2, 2, 2]
2021-03-26 01:37:07.693544-0700 PyTorchPlayground[2279:235793] [MPSImageWrapper] Found a temporary image: [1, 4, 2, 2]
2021-03-26 01:37:07.695415-0700 PyTorchPlayground[2279:235793] [bool test_chunk()],[1 4 2 2 ],[SUCCEED]
2021-03-26 01:37:07.695862-0700 PyTorchPlayground[2279:235793] [MPSImageWrapper] Found a temporary image: [1, 4, 2, 2]
2021-03-26 01:37:07.695927-0700 PyTorchPlayground[2279:235793] [MPSImageWrapper] Found a temporary image: [1, 5, 2, 2]
2021-03-26 01:37:07.695971-0700 PyTorchPlayground[2279:235793] [MPSImageWrapper] Found a temporary image: [1, 9, 2, 2]
2021-03-26 01:37:07.698215-0700 PyTorchPlayground[2279:235793] [bool test_chunk2()],[1 9 2 2 ],[SUCCEED]
2021-03-26 01:37:07.699086-0700 PyTorchPlayground[2279:235793] [MPSImageWrapper] Found a temporary image: [1, 8, 2, 2]
2021-03-26 01:37:07.699154-0700 PyTorchPlayground[2279:235793] [MPSImageWrapper] Found a temporary image: [1, 16, 2, 2]
2021-03-26 01:37:07.699197-0700 PyTorchPlayground[2279:235793] [MPSImageWrapper] Found a temporary image: [1, 8, 2, 2]
2021-03-26 01:37:07.700842-0700 PyTorchPlayground[2279:235793] [bool test_chunk3()],[1 16 2 2 ],[SUCCEED]
```
- Sandcastle
- CircleCI
Reviewed By: SS-JIA
Differential Revision: D27357096
fbshipit-source-id: fd3908ad2c26466e4f714d531790be2f1ae24153
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57090
We did loop-invariant code motion to avoid multiplying with in_weight_temp for each element but this breaks down when weight decay is not zero.
Test Plan:
In devgpu
buck test mode/dev-nosan //caffe2/caffe2/fb/net_transforms/tests:fuse_sparse_ops_test -- test_fuse_sparse_adagrad_with_sparse_lengths_weighted_sum_gradient --run-disabled
Reviewed By: jianyuh
Differential Revision: D28051026
fbshipit-source-id: f8906b72a41a87c2d43c447197b5fd695373ae23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57039
## Summary
Add two models (v4 and v5) for testing runtime. (v5 will be introduced in https://github.com/pytorch/pytorch/pull/56002)
## Test plan
CI
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D28047615
Pulled By: cccclai
fbshipit-source-id: 47f7df3094dadb7e013ed57bc713cc8b3d1c8ce0
Summary:
Attempts to call clang-tidy on any source file in
`aten/src/ATen/cpu/native` would fail with series of
```
/Users/nshulga/git/pytorch-worktree/aten/src/ATen/native/cpu/Activation.cpp:637:1: warning: variable 'REGISTER_DISPATCH' is non-const and globally accessible, consider making it const [cppcoreguidelines-avoid-non-const-global-variables]
/Users/nshulga/git/pytorch-worktree/aten/src/ATen/native/cpu/Activation.cpp:638:1: error: C++ requires a type specifier for all declarations [clang-diagnostic-error]
REGISTER_DISPATCH(log_sigmoid_backward_cpu_stub, &log_sigmoid_backward_cpu_kernel);
```
because those macros are only defined for cpu-arch specific compilation of above mentioned files.
Fix this by introducing `map_filename` function that will map source
file to its copy in `build` folder, run clang-tidy over the copy and
than map it back
Find it while working on https://github.com/pytorch/pytorch/pull/56892
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57037
Reviewed By: walterddr
Differential Revision: D28033760
Pulled By: malfet
fbshipit-source-id: b67cd007000574ecc165ab4b285c0c102cbceadd
Summary:
cpu_depthwise3x3_winograd is not grad aware and therefore should not be used if grad is expected on the input
Fixes https://github.com/pytorch/pytorch/issues/56145
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56889
Reviewed By: ngimel
Differential Revision: D27990448
Pulled By: malfet
fbshipit-source-id: 9c649f14b8f514eb1dfb7f0eb8e3357c09ddb299
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56994
- Use `DimVector` in place of `std::vector<int64_t>` to remove heap allocations for tensors with ndim <= 5
- Use `sizes()[i]` in place of `size(i)` where we know i is positive
Test Plan: CI
Reviewed By: edvgha, swolchok
Differential Revision: D28022355
fbshipit-source-id: ef20ac73c0a330192ebc41ab9c92374ed8e2484a
Summary:
For small tensors, it is known that GPU operates slower than CPU. However, offloading to CPU causes host <--> device sync. As a result, although offloading to CPU has better microbenchmarks, it often hurts instead of benefits the end-to-end performance, and it could be a blocker for CUDA graphs. After discussion with mcarilli and ptrblck, we think it might be good to just remove this piece of code and let it be slow.
Microbenchmarks:
```python
def run50_sync(f):
for _ in range(50):
f()
torch.cuda.synchronize()
torch.cuda.synchronize()
%timeit run50_sync(lambda: torch.randperm(3, device='cuda'))
%timeit run50_sync(lambda: torch.randperm(30, device='cuda'))
%timeit run50_sync(lambda: torch.randperm(300, device='cuda'))
%timeit run50_sync(lambda: torch.randperm(3000, device='cuda'))
%timeit run50_sync(lambda: torch.randperm(30000, device='cuda'))
%timeit run50_sync(lambda: torch.randperm(300000, device='cuda'))
%timeit run50_sync(lambda: torch.randperm(3000000, device='cuda'))
%timeit run50_sync(lambda: torch.randperm(30000000, device='cuda'))
```
Before this PR:
```
5.79 ms ± 51.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
5.78 ms ± 92.7 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
6.17 ms ± 87.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
9.65 ms ± 69.7 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
17.6 ms ± 133 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
21 ms ± 120 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
104 ms ± 880 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
944 ms ± 3.49 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
After this PR:
```
7.22 ms ± 11.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
7.28 ms ± 9.03 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
7.25 ms ± 10.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
9.19 ms ± 5.83 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
9.76 ms ± 162 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
12.3 ms ± 11.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
69.3 ms ± 42.3 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
716 ms ± 1.01 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54113
Reviewed By: ezyang
Differential Revision: D28017958
Pulled By: ngimel
fbshipit-source-id: 660992d43ca449e61ce0cb0aa1dae554c9560a4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57028
Adds a test case for wrapped sigmoid, and fixes the following issues
to make it pass in NS:
* allows comparing between x.sigmoid() and torch.sigmoid(x), if they are related
* allows dtype cast from FP32_OR_INT8 to FP32, via dequantize (this will be improved later)
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_user_defined_function
```
Reviewed By: jerryzh168
Differential Revision: D28030089
Pulled By: vkuzo
fbshipit-source-id: b237353e2d564a4476f409df461746a259015a4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57027
Fixes a bug to allow shadowing of linear and conv functionals.
The bug is to only detach tensors, not all objects.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_int8_shadows_int8_fun
```
Reviewed By: jerryzh168
Differential Revision: D28030090
Pulled By: vkuzo
fbshipit-source-id: 0a38c4b232e007d7822eee818b0af99d98335d22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57026
Adds a config option to skip matching classes by class type
and functions by function type.
This is useful when users make custom modules which return
types other than tensors. With the current implementation of
Logger, these are not scriptable.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_user_module_scriptable
```
Reviewed By: jerryzh168
Differential Revision: D28030093
Pulled By: vkuzo
fbshipit-source-id: 71dc54dd935d2071c4b017260ea2a1e5c2298bfe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57025
Adds the ability to log unshadowed inputs of binary ops such as `add`
and `mul`, when indices 0, 1, or 0 and 1 are tensors.
Note: making shadowing support this is saved for a future PR.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_add_mul_inputs_activations
```
Reviewed By: jerryzh168
Differential Revision: D28030098
Pulled By: vkuzo
fbshipit-source-id: fd46760faac153975cd7688e70c44991ec1d5dff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57024
Enables shadow copies of fp16 emulation patterns where weights
are cast to fp16 before being passed to linear. This previously
did not work because copying of `call_method` nodes was not implemented.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_linear_fp16_vs_linear_fp16_shadow_activations
```
Reviewed By: jerryzh168
Differential Revision: D28030096
Pulled By: vkuzo
fbshipit-source-id: 13a39ea6c106180df6d750246672286b58b4d04c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57022
Allows usage of user functions in NS shadow APIs. We expose the
i/o mapping to the user APIs, and thread them throughout the code.
Note: the format of the mapping is currently not the best. Saving
improving that for a future PR.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_user_defined_function
```
Reviewed By: jerryzh168
Differential Revision: D28030095
Pulled By: vkuzo
fbshipit-source-id: 2863312362223ad276437e2aeeec4a3f71b691c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57021
To support shadows of custom functions, we need to allow user to
specify I/O type of the custom functions.
This PR is a cleanup in preparation for making the above happen.
We make the I/O dtype mappings be generated by a function instead
of a global variable. In the next PR, we will add a hook so user
can modify these mappings.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Reviewed By: jerryzh168
Differential Revision: D28030094
Pulled By: vkuzo
fbshipit-source-id: 3cbb617f034ef385c2875c4ec7fed13ca30bfc57
Summary:
Fixes https://github.com/pytorch/pytorch/issues/55561.
1. Added checks to ensure that Output tensor specified via out= must be on the same device as inputs for `dot` & `vdot`.
2. Unskipped `test_out` for `dot` & `vdot`.
3. Also changed the `tensordot` implementation to check if both input tensors are on the same device as the output tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56334
Reviewed By: H-Huang
Differential Revision: D27993778
Pulled By: mruberry
fbshipit-source-id: 36dee41ceef123c29d0cc52d6b09c3c440e8e60e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56822
There was an off by one in CPU randperm when checking the limits of the requested range. Also shows up in the "CUDA" version as it will fallback to CPU for small input sizes.
CC zasdfgbnm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56967
Reviewed By: mruberry
Differential Revision: D28031819
Pulled By: ngimel
fbshipit-source-id: 4d25995628997f164aafe94e7eae6c54f018e4e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56939
These never have kernels registered to them and are effectively useless.
What I am not so sure if we allocate tensors to them or not; if we do
I cannot use asserts and I need to ensure we just return undefined
or something equivalent.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D28006160
Pulled By: ezyang
fbshipit-source-id: f8e2b61b8bd928fb2c0ac0b534bd4af076423f71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57045
Went back and adjusted the previous optimizations to just be applied to every function.
Cleaned up api to match.
ghstack-source-id: 127214412
ghstack-source-id: 127536155
Test Plan: unit test
Reviewed By: kimishpatel
Differential Revision: D27950859
fbshipit-source-id: 214e83d5a19b452747fe223615815c10fa4aee58
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56754
these tests are backend agnostic and shouldn't require a specific
backend(s) to run properly. Hence enabling them regardless of the backends that
are available.
ghstack-source-id: 127463147
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27954174
fbshipit-source-id: 24759486b0c0647a5c88da4721a9a78d78c0b1f6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/24648
The large tensor codepath is ported, but there is a legacy codepath that depends on an inplace sort in THC that is not callable from `at::`. At first glance, THC `topk` seems to be the only function that uses this `sortKeyValueInplace`.
Is the correct change to wrap `sortKeyValueInplace` in legacy functions for visibility in the `at::` namespace?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55392
Reviewed By: ezyang
Differential Revision: D28014257
Pulled By: ngimel
fbshipit-source-id: e297423c763f0691151cb62a4f5eff4cb31fb2b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54153
Currently, sparse tensors only support real floating point tensors. Complex support is added in this PR for CPU/CUDA.
- [x] add complex support (torch.cfloat and torch.cdouble) to torch.sparse_coo_tensor constructors
- [x] add complex support to coalesce function
- [x] add complex support to to_dense function
- [x] add complex support to to_sparse function
- [x] add complex support to sparse_add function
- [x] add unit tests
Note: This PR contains only complex support for torch.sparse_coo_tensor fordward function and the related ops used with this function (coalesce, to_dense, to_sparse, and sparse_add). The following PRs in ghstack should cover other sparse operations to have a more complex sparse support, specifically related with the use of specific APIs for accelerated linear algebra.
Note: Before using ghstack the original PR was #50984
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D27765618
Pulled By: ezyang
fbshipit-source-id: a9cdd31d5c7a7dafd790f6cc148f3df26e884c89
Summary:
You can find the latest rendered version in the `python_doc_build` CI job below, in the artifact tab of that build on circle CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55966
Reviewed By: H-Huang
Differential Revision: D28032446
Pulled By: albanD
fbshipit-source-id: 227ad37b03d39894d736c19cae3195b4d56fc62f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56984
This is a preparation PR before we can create CUDAFuture in rref_impl.cpp.
The solution is adding a `FutureFactoryRegistry` in `rpc/utils.*`. The
TensorPipe RPC agent is responsible for registering `CUDAFuture` factory
and `ivalue::Future` factory. The reason that we need this change instead
of directly using `USE_CUDA` macro in RRef files is as follows. There are
three build targets: `torch_cpu`, `torch_cuda`, and `torch_python`.
`torch_python` is built on top of the other two. `torch_cpu` is CPU-only,
which contains no CUDA-related code, and hence no `USE_CUDA` macro.
`tensorpipe_*` files are in `torch_python` which does have access to CUDA.
However RRef source files are in `torch_cpu`, which cannot contain CUDA
code. The recommended solution is to allow dynamic dispatching. Therefore,
we had this PR.
Test Plan: Imported from OSS
Reviewed By: lw
Differential Revision: D28020917
Pulled By: mrshenli
fbshipit-source-id: e67c76a273074aebb61877185cc5e6bc0a1a5448
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56444
Added out version for layer_norm
Test Plan:
buck test caffe2/aten:math_kernel_test -- NativeLayerNorm
buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest
Reviewed By: hlu1
Differential Revision: D27873846
fbshipit-source-id: 53ee9fec4ff9a4e78198b031e86b5afd013626dd
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46702
- fails on probability distribution with odd items
- trying to access an `acc_type` (`float`) in a `scalar_t` (`float16`) aligned memory
- produce unrepeatable result for large input tensor
- parallel cumsum not monotonic at some positions
### Fixes
- computing cumsum on `acc_type` (`float`) instead of using `scalar_t` (`float16`) fixed both issues
- the non-monotonic behavior may happen even using `float`, though
- in these cases, deterministic behavior may be achieved by eliminating the race condition when writing the result, using the atomic function `atomicMax`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55364
Reviewed By: mruberry
Differential Revision: D28031666
Pulled By: ngimel
fbshipit-source-id: 0fc6289e0b9ea2d31ef3771e7ca370de8f5c02de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56704
This is re submit of PR: https://github.com/pytorch/pytorch/pull/54175
Main changes compared to original PR:
- Switch to importing "<ATen/cuda/cub.cuh>"
- Use CUB_WRAPPER to reduce boiler plate code.
Test Plan:
Will check CI status to make sure a
Added unit test
Reviewed By: ngimel
Differential Revision: D27941257
fbshipit-source-id: 24a0e0c7f6c46126d2606fe42ed03dca15684415
Summary:
This PR tries to make the docs of `torch.linalg` have/be:
- More uniform notation and structure for every function.
- More uniform use of back-quotes and the `:attr:` directive
- More readable for a non-specialised audience through explanations of the form that factorisations take and when would it be beneficial to use what arguments in some solvers.
- More connected among the different functions through the use of the `.. seealso::` directive.
- More information on when do gradients explode / when is a function silently returning a wrong result / when things do not work in general
I tried to follow the structure of "one short description and then the rest" to be able to format the docs like those of `torch.` or `torch.nn`. I did not do that yet, as I am waiting for the green light on this idea:
https://github.com/pytorch/pytorch/issues/54878#issuecomment-816636171
What this PR does not do:
- Clean the documentation of other functions that are not in the `linalg` module (although I started doing this for `torch.svd`, but then I realised that this PR would touch way too many functions).
Fixes https://github.com/pytorch/pytorch/issues/54878
cc mruberry IvanYashchuk
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56265
Reviewed By: H-Huang
Differential Revision: D27993986
Pulled By: mruberry
fbshipit-source-id: adde7b7383387e1213cc0a6644331f0632b7392d
Summary:
According to `vecLib.framework/Headers/clapack.h` Accelerate.framework's LAPACK implementation is based on 3.2.1, and so LRWORK should be computed using following formula (from
```
*> If JOBZ = 'N', LRWORK >= 7*min(M,N).
*> Otherwise,
*> LRWORK >= min(M,N)*max(5*min(M,N)+7,2*max(M,N)+2*min(M,N)+1)
```
Found while looking at test_linalg.py crashes on M1, but would have happen on x86 as well, if Pytorch+Accelerate framework are to be tested on x86_64
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56847
Reviewed By: albanD
Differential Revision: D27983352
Pulled By: malfet
fbshipit-source-id: f757c515c85b32c1e09d00a91bc20fe4b390a75a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56824
This PR adds 6 dispatch uses to be used with prototyping.
I'm not sure what the best way to name these are, please let me know if
you think that these should have the same prefix.
Test Plan: - wait for tests
Reviewed By: driazati
Differential Revision: D27999963
Pulled By: zou3519
fbshipit-source-id: 0c3ef4788854f7a93d077cc454b773a6eedbbc22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56945
In preparation to turn these on for CI
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D28018454
Pulled By: seemethere
fbshipit-source-id: fa94d666499877f2cdd7b8fd3fc8b2d8127f61e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56941
Sets the custom test binaries we build in .jenkins/pytorch/build.sh to
be built in the `build` directory instead of the directory above the
workspace.
This should alleviate any weirdness we were seeing before with test
binaries having to be overwritten
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D28018453
Pulled By: seemethere
fbshipit-source-id: 74add11037a622e011d00fb6292bfe20e1d55d9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56797
After adding default seeding strategy for NumPy random module within each worker of DataLoader #56488, two concerns are raised:
- We dropped the support for NumPy < 1.17 due to `SeedSequence`
- In order to support seeding for NumPy < 1.17, how can we provide seed for `numpy.random`?
- First option is set the same seed as `random`. But, the problem is a same algorithm is shared between `numpy.random` and `random`. With the same seed, they will have exact same state sequence. Thanks to rkern, we noticed this so-called [bad things](https://github.com/PyTorchLightning/pytorch-lightning/pull/6960#issuecomment-818393659).
- Considering most of users do not aware this problem, we can provide a better seed by default for `numpy.random` using same `SeedSequence` algorithm as numpy. This is just a workaround with hard-coded function to generate an array of four int32 as the seed.
To better coping with this problem since there are amount of 3rd party libraries not just `NumPy` having random module. We may at the end need to implement a `SeedSequence` within `torch.random` module, then users can `spawn` a new `SeedSequence` for each library.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D28000619
Pulled By: ejguan
fbshipit-source-id: 5701c8124a38ea5ded69eb8eee70f9680877ffa6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55699
Todo:
- error message should be updated to say whether the failure is for fn's real or imaginary component
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D28007887
Pulled By: soulitzer
fbshipit-source-id: 1819201f59c8586a1d9631db05983969438bde66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55692
### Release notes
get_numerical_jacobian and get_analytical_jacobian only support `grad_out=1` and `fn` no longer accepts functions that return complex output
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D28004614
Pulled By: soulitzer
fbshipit-source-id: 9592c9c69584b4035b39be62252f138dce39d3b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56976
Band-aid fix for #54282
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D28020401
Pulled By: ezyang
fbshipit-source-id: 50546d5275eade408d65e9c883999fb3b65ff55a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56243 by adding a note to mutating functions not following the trailing `_` convention in `torch/nn/modules/module.py`
I can also raise separate PRs for other files, if needed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56877
Reviewed By: ezyang
Differential Revision: D28008856
Pulled By: jbschlosser
fbshipit-source-id: 63bfca0df05e49fceadd3167b1427dcb5542206a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56991
Original commit changeset: c5aa5f61a215
Diff: D27987746 (267b554b6f)
Test Plan: `buck test` under the glow-buck target is the target that this reversion is intended to fix
Reviewed By: jfix71
Differential Revision: D28019659
fbshipit-source-id: 37584ff404fc9195b309a5a6afdb4edbc2b4f088
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56816
This doesn't actually work. For some reason the linker can't find
at::cpu::logit_out, and it's not worth digging into why not.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D27977406
Pulled By: bertmaher
fbshipit-source-id: d0235a393f25243e2c8a011e9baf267daf483ae4
Summary:
Adding cuda synchronization when entering and exiting the profiler
context manager
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56651
Test Plan: CI
Reviewed By: gdankel
Differential Revision: D27926270
Pulled By: ilia-cher
fbshipit-source-id: 5cf30128590c1c71a865f877578975c4a6e2cb48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56717
The signal_handler was under the caffe2 namespacee but was being used
by PyTorch as well.
I've fixed this my moving it to the c10 namespace where now both C2 and PyTorch
can use it.
The signal_handler interface in caffe2/utils/signal_handler.h is kept the same
for backward compatiblity for C2, but most of the commmon code is moved to c10.
ghstack-source-id: 127446929
Test Plan: waitforbuildbot
Reviewed By: ezyang
Differential Revision: D27946738
fbshipit-source-id: d6228d1a0108f4c807d405e7a0bb799c5375388f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56908
CUDA channels might implement CPU-to-CPU transfers, but will usually be
less efficient for that purpose.
Test Plan: CI
Reviewed By: lw
Differential Revision: D27994069
fbshipit-source-id: fefa7f243eb43cf769864233df518f2a1819f949
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56812
fb::equally_split get fused with ListUnpack and all outputs from ListUnpack getting attached to fb::equally_split.
So fb::equal_split will have as many outputs as ListUnpack .
Test Plan:
buck test caffe2/benchmarks/static_runtime/fb:test_fb_operators
buck test caffe2/torch/fb/sparsenn:test -- test_equally_split_op
Reviewed By: hlu1
Differential Revision: D27974999
fbshipit-source-id: b2ca19ff86aec76b977c1e3cfc56567adab66b35
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56943
If the module is placed on a CUDA device, then all the CPU tensors in `args` and `kwargs` will also be implicitly moved to the same CUDA device to run forward.
Currently still need to move the forward output from CUDA device back to CPU, until:
1) Process group RPC backend is completely deprecated, and we always use TensorPipe RPC backend;
2) A device map is explicitly provided to TensorPipe RPC backend.
These steps will be done in a separate PR.
#Original PR issue: https://github.com/pytorch/pytorch/issues/51670
ghstack-source-id: 127457584
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_input_moved_to_cuda_device
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- test_input_moved_to_cuda_device_script
buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- RemoteModule
buck test mode/dev-nosan //caffe2/torch/fb/training_toolkit/applications/sparse_nn/batch_distributed_inference/tests:batch_distributed_inference_test -- --exact 'caffe2/torch/fb/training_toolkit/applications/sparse_nn/batch_distributed_inference/tests:batch_distributed_inference_test - test_load_di_parts (caffe2.torch.fb.training_toolkit.applications.sparse_nn.batch_distributed_inference.tests.batch_distributed_inference_test.BatchDistributedInferenceTest)'
Reviewed By: wanchaol
Differential Revision: D27934791
fbshipit-source-id: de27e27b905db83cc52800e63684fc6c942e9dc7
Summary:
Fixes https://github.com/pytorch/pytorch/issues/48141
~Mypy is complaining about a missing arg in a function call.~
```bash
torch/backends/_nnapi/serializer.py:806: error: Too few arguments for "_do_add_binary" [call-arg]
Found 1 error in 1 file (checked 1140 source files)
```
9392137dbe/torch/backends/_nnapi/serializer.py (L804-L806)
~dreiss, would you mind take a look when you have some cycles to spare and see what would be the appropriated value for `fuse_code` here? Thanks :)~
Edit: https://github.com/pytorch/pytorch/issues/48925 got merged a couple of days ago. The blocking part is now unblocked, and I just pushed the changes to make mypy happy again. This PR is ready for review.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48142
Reviewed By: ezyang
Differential Revision: D28006249
Pulled By: walterddr
fbshipit-source-id: 5e43eeba7143512a549efaad31541f86718add7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56762
Adds a test case for wrapped sigmoid, and fixes the following issues
to make it pass in NS:
* allows comparing between x.sigmoid() and torch.sigmoid(x), if they are related
* allows dtype cast from FP32_OR_INT8 to FP32, via dequantize (this will be improved later)
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_user_defined_function
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27960766
fbshipit-source-id: 02935d2f400aa0b8f3d51bbf664a6c8ca89aa811
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56742
Fixes a bug to allow shadowing of linear and conv functionals.
The bug is to only detach tensors, not all objects.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_int8_shadows_int8_fun
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27960767
fbshipit-source-id: abc911ca4b9edafd1effb9dada7731981538c2df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56493
Adds a config option to skip matching classes by class type
and functions by function type.
This is useful when users make custom modules which return
types other than tensors. With the current implementation of
Logger, these are not scriptable.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_user_module_scriptable
```
needs more testing before land
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27886107
fbshipit-source-id: ec92c4f7ab7141021bc022f07b3b558b42bbb986
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56408
Adds the ability to log unshadowed inputs of binary ops such as `add`
and `mul`, when indices 0, 1, or 0 and 1 are tensors.
Note: making shadowing support this is saved for a future PR.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_add_mul_inputs_activations
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27864296
fbshipit-source-id: 3cbeb728297aa192d1ea17e815299709fd9db056
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56384
Enables shadow copies of fp16 emulation patterns where weights
are cast to fp16 before being passed to linear. This previously
did not work because copying of `call_method` nodes was not implemented.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_linear_fp16_vs_linear_fp16_shadow_activations
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27857735
fbshipit-source-id: 7c1a067f035acf7322175f8535876d0ead88a86a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56301
Allows usage of user functions in NS shadow APIs. We expose the
i/o mapping to the user APIs, and thread them throughout the code.
Note: the format of the mapping is currently not the best. Saving
improving that for a future PR.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_user_defined_function
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27833189
fbshipit-source-id: dac418e294d1c9b204efbf4071d5cc12a9e784c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56296
To support shadows of custom functions, we need to allow user to
specify I/O type of the custom functions.
This PR is a cleanup in preparation for making the above happen.
We make the I/O dtype mappings be generated by a function instead
of a global variable. In the next PR, we will add a hook so user
can modify these mappings.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27831996
fbshipit-source-id: 782f5e77de0eef3899b9b7def0fdabd8dcafef12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56292
Adds hooks for specifying user defined functions to NS weight and
unshadowed activation APIs.
Adding it to shadowed activation APIs will be a bit more work, upcoming
in a separate PR.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_user_defined_function
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27830409
fbshipit-source-id: 6bbddc3062c0b3e412a3147244795319c0785a92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56283
Exposes the `base_name_to_sets_of_related_ops` variable
to the graph matching API, so that users can add relationships
for custom functions. This is needed to enable full support of
external functions for custom backends.
The next PR will extend this to the NS APIs.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher.test_user_defined_function
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27830410
fbshipit-source-id: 8688cf697d388c52e3d18f108765edfca3c3d3aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56706
We've seen the transpose op failed on iOS 12 devices. This is because the index buffer is allocated in the device address space which is shared across multiple threads. Write operations are not guaranteed to be atomic. Use a thread buffer solves the issue.
ghstack-source-id: 127365795
Test Plan: CI
Reviewed By: SS-JIA
Differential Revision: D27941353
fbshipit-source-id: 5f09f0a085081b7c5e8019ebe711e36394cdde92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56841
- Move arg checks to outside the lambda so we can perform these checks at Static Runtime initialization time
- use `optional` where possible
- support `to.other` overload, the 5-arg input load of `torch.to`.
Test Plan:
```
buck run //caffe2/benchmarks/static_runtime:static_runtime_cpptest
buck test mode/opt-clang //caffe2/caffe2/fb/predictor:ptvsc2_predictor_bench_test -- --run-disabled
```
Reviewed By: edvgha
Differential Revision: D27933176
fbshipit-source-id: 49d6249c8784c44146461e286e7a301596172d7c
Summary:
This PR adds `sm_75` CUDA architecture support for CircleCI GPU builds, so that generated artifacts from these builds can be installed and run on machines with CUDA capability `sm_75`.
This PR is currently to see how much longer the PR CI GPU builds will take with `TORCH_CUDA_ARCH_LIST="7.5"` rather than `TORCH_CUDA_ARCH_LIST="5.2"`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56619
Reviewed By: malfet
Differential Revision: D28012538
Pulled By: seemethere
fbshipit-source-id: 3959736721eab7389984234d89eadcf04d163c37
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56895
PR #54932 fixes CUDA stream synchronization between RPC-created
OwnerRRef and UserRRef when `to_here()` is invoked. However, there
are two more gaps.
1. RRef value can be accessed on the owner directly through
`local_value`, which bypasses the fix in #54932.
2. When RRef is created directly through RRef ctor instead of RPC,
the OwnerRRef won't be able to correctly record CUDA events.
This PR fixes 1 by letting current streams wait for RRef recorded
CUDA events before returning the value in `RRef::getValue()`.
For 2, more discussions is needed to decide whether we should add
a `devices` argument to RRef ctor, or should RRef ctor inspect the
given values.
Test Plan: Imported from OSS
Reviewed By: lw
Differential Revision: D27992775
Pulled By: mrshenli
fbshipit-source-id: ed0e5bfbf715460208c85e46dd3317deef17f8fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56929
Artifacts were failing to unzip since they already existed in the
current tree so this just forces the zip to go through no matter what
Was observing that test phases will fail if attempting to zip over an already existing directory, https://github.com/pytorch/pytorch/runs/2424525136?check_suite_focus=true
In the long run however it'd be good to have these binaries built out as part of the regular cmake process instead of being one off builds like they are now
**NOTE**: This wouldn't be an issue if `--ephemeral` workers was a thing, see: https://github.com/actions/runner/pull/660
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D28004271
Pulled By: seemethere
fbshipit-source-id: c138bc85caac5d411a0126d27cc42c60fe88de60
Summary:
related to https://github.com/pytorch/pytorch/issues/56156.
https://github.com/pytorch/pytorch/issues/55808 effectively turned dtypeIfROCM off but let some legacy issues unfixed. Given the fact that we still need to deal with discrepancy between the 2 platform. This PR turns dtypeIfROCM default pointing to dtypeIfCUDA and only override when user specifies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56646
Reviewed By: mruberry
Differential Revision: D27968959
Pulled By: walterddr
fbshipit-source-id: 6a11987b8ddf4417577b3d0d5054eaab169de42c
Summary:
Currently `torch.linalg.matrix_rank` accepts only Python's float for `tol=` argument. The current behavior is not NumPy compatible and this PR adds the possibility to pass Tensor for matrix-wise tolerances.
Ref. https://github.com/pytorch/pytorch/issues/42666
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54157
Reviewed By: ezyang
Differential Revision: D27961548
Pulled By: mruberry
fbshipit-source-id: 47318eefa07a7876e6360dae089e5389b9939489
Summary:
This PR is step 2 (after https://github.com/pytorch/pytorch/issues/56708) to having JIT coverage--it actually uses the plug-in in CI!
Disclaimer: note that this will mark the entire JIT'd function/method as covered without seeking proof that the
compiled code has been executed. This means that even if the code chunk is merely compiled and not run, it will get
marked as covered.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56310
Test Plan:
We should see coverage improvements in CI after. A file to look out for would be `torch/jit/quantized.py`, which should have more coverage after this PR, which it does!
d3283ccd8c/torch/jit/quantized.py vs https://codecov.io/gh/pytorch/pytorch/src/master/torch/jit/quantized.py
More generally, the whole jit folder got ~3% increase in coverage, I believe.
Reviewed By: walterddr
Differential Revision: D28000672
Pulled By: janeyx99
fbshipit-source-id: 6712979d63a5e1224a92ee9bd9679ec62cf1cbba
Summary:
The reason we were not seeing so many wins was because .coverage.jit would overwrite itself every coverage run. (What a noob mistake who wrote that code?!?!)
This should fix that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56829
Test Plan:
Coverage in CI should audibly increase. It does, somewhat:
Check out f8a475b056! New covered files include:
Classes in torch/distributed/optim
torch/utils/mkldnn.py
Reviewed By: walterddr
Differential Revision: D27984427
Pulled By: janeyx99
fbshipit-source-id: e82d074c2b4a60a5204a73efc2823824384c8bf5
Summary:
No oustanding issue, can create it if needed.
Was looking for that resource and it was moved without fixing the documentation.
Cheers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56776
Reviewed By: heitorschueroff
Differential Revision: D27967020
Pulled By: ezyang
fbshipit-source-id: a5cd7d554da43a9c9e44966ccd0b0ad9eef2948c
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 87f7681286
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56495
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: beauby
Differential Revision: D27886370
fbshipit-source-id: 2b6e2b38412694633517df2b0501e5da9e81656c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56756
With #56319 TE kernel could handle tensor constants, so there is no more
need in lifting them out and passing as inputs.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D27959258
Pulled By: ZolotukhinM
fbshipit-source-id: 00269cf1c4747c10dfc40cb4e330991d0bf1e2ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56790
If the argument doesn't match `List[int]`, this code falls through to
`issubclass(argument_type, List[int])` which is invalid and raises a
`TypeError`. If this happens during the processing of a `Union` (e.g.
`Optional`), the other union types aren't given the chance to match against the
signature.
This also stop normalize_function from indescriminately swallowing exceptions,
which let this bug go unnoticed.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27987746
Pulled By: mruberry
fbshipit-source-id: c5aa5f61a215f0f39925e7053f33bff4b5d5acc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56216
Verifies that the newly added distributed profiling works as expected for torch.profiler.
Example trace from `test_ddp_profiling`:
Note that tests are disabled internally due to an unrelated hang issue but run in OSS.
ghstack-source-id: 127357993
Reviewed By: mrshenli
Differential Revision: D27645105
fbshipit-source-id: 7ddba271acd8f7fbce1f9c5370830d5310314736
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55204
Implements a fix discussed offline with pritamdamia87 to run end callbacks after `CUDAFuture`'s wrapCallback has ensured appropriate synchronization. Also enables the relevant distributed profiling tests that were previously disabled for ProcessGroupNCCL.
Note that the profiling infrastructure has moved to primarily encourage the use of torch.profiler and CUPTI to trace CUDA kernels, support for distributed collectives for that will require further discussion with ilia-cher. However, this PR improves the usability of torch.autograd.profiler with respect to distributed collectives.
ghstack-source-id: 127357995
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D27491711
fbshipit-source-id: cec7703a4c5d59b5023b0aa8fef4c2e3fb8d37d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56249
This PR ports `torch.geqrf` from TH to ATen. CUDA path will be
implemented in a follow-up PR.
With ATen port support for complex and batched inputs is added.
There were no correctness tests, they are
added in this PR and I added OpInfo for this operation.
We can implement the QR decomposition as a composition of geqrf and
orgqr (torch.linalg.householder_product).
Also we can implement the least squares solver with geqrf + ormqr +
trtrs. So it's useful to have this function renewed at least for the
internal code.
Resolves https://github.com/pytorch/pytorch/issues/24705
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27907357
Pulled By: mruberry
fbshipit-source-id: 94e1806078977417e7903db76eab9d578305f585
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55890
Proof-of-concept for https://github.com/pytorch/pytorch/pull/55145#issuecomment-817297273
With this the user is able to pass a custom error message to `assert_(equal|close)` which will be used in case the values mismatch. Optionally, a callable can be passed which will be called with mismatch diagnostics and should return an error message:
```python
def make_msg(a, b, info):
return (
f"Argh, we found {info.total_mismatches} mismatches! "
f"That is {info.mismatch_ratio:.1%}!"
)
torch.testing.assert_equal(torch.tensor(1), torch.tensor(2), msg=make_msg)
```
If you imagine `a` and `b` as the outputs of binary ufuncs, the error message could look like this:
```python
def make_msg(input, torch_output, numpy_output, info):
return (
f"For input {input} torch.binary_op() and np.binary_op() do not match: "
f"{torch_output} != {numpy_output}"
)
torch.testing.assert_equal(
torch.binary_op(input),
numpy.binary_op(input),
msg=lambda a, b, info: make_msg(input, a, b, info),
)
```
This should make it much easier for developers to find out what is actually going wrong.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27903842
Pulled By: mruberry
fbshipit-source-id: 4c82e3d969e9a621789018018bec6399724cf388
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55786
Add support to compare scalars as well as `np.ndarray`'s with torch.testing. We are reusing the mathcing functionality that is already in place for tensors, by casting the inputs. The approach can easily extended if we want to support other input types as long as they can be cast to a tensor.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27903814
Pulled By: mruberry
fbshipit-source-id: fe3d063d0c9513cbd8b3408a2023e94c490c817e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55385
This renames `assert_tensors_(equal|close)` to `_check_tensors_(equal|close)` and exposes two new functions: `assert_(equal|close)`. In addition to tensor pairs, the newly added functions also support the comparison of tensors in sequences or mappings. Otherwise their signature stays the same.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27903805
Pulled By: mruberry
fbshipit-source-id: 719d19a1d26de8d14cb25846e3d22a6ac828c80a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45664
This PR adds a note to the documentation for `torch.clamp()` to alert users to a special case: If `min` is greater than `max`, all values are set to the `max` value.
Also, an example was added after the first code example. And this one is referenced in the note.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56367
Reviewed By: ezyang
Differential Revision: D27960553
Pulled By: mruberry
fbshipit-source-id: 9dc6016ccacebe87c809a0dd9f557b4aea0ae6f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56201
Refactor Splitter and Minimizer to superclass `_SplitterBase` and `_MinimizerBase` and move them to OSS. This is needed to create an OSS example of GPU lowering with those tools.
Test Plan: CI
Reviewed By: jackm321
Differential Revision: D27629598
fbshipit-source-id: 0d4da02105ca509b31f1a6c4a39b1122c2bc7bf0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56759
```
caffe2/caffe2/onnx/onnx_exporter.cc:415:21: error: loop variable 'it' creates a copy from type 'const std::pair<const std::basic_string<char>, int>' [-Werror,-Wrange-loop-construct]
for (const auto it : blob_versions) {
^
caffe2/caffe2/onnx/onnx_exporter.cc:415:10: note: use reference type 'const std::pair<const std::basic_string<char>, int> &' to prevent copying
for (const auto it : blob_versions) {
^~~~~~~~~~~~~~~
&
```
Reviewed By: yfeldblum
Differential Revision: D27960126
fbshipit-source-id: fd46f37cf1aca9441209de8eb06add204046db95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55995
Normalization is kind of broken currently. But making default arguments visible still appears to work, and is nice functionality to still be able to rely on/use. Adds an option to `NormalizeArgs`'s `__init__` called `normalize_to_only_use_kwargs` which defaults to true, which if set to false will keep using the same signature as provided, but additionally set kwargs in kwargs.
Test Plan: Added test to `test_fx_experimental`.
Reviewed By: 842974287
Differential Revision: D27759448
fbshipit-source-id: 620061fcf46d8549ac70b62aede8b6740aee3778
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56518
I don't think we have any tests for CUDAFuture (I couldn't find any, and I didn't write any in the past). I think especially for the two latest features added by this stack we should have a test to ensure they properly work and to catch regressions. (These tests also add indirect coverage for the more "basic" features of CUDAFuture).
I didn't know how/where to add tests for C++ ATen stuff, so instead I added these tests to the Python RPC suite, using the torch.futures.Future wrapper. (It made sense in my mind because RPC is the main user of CUDAFuture). I'll gladly accept pointers to better ways of doing this.
ghstack-source-id: 127295022
Test Plan: The tests themselves.
Reviewed By: mrshenli
Differential Revision: D27887191
fbshipit-source-id: 4ad6d81e676fe486aa8d329591ee1a3818fea059
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56516
One problem with CUDAFuture's extraction of DataPtrs from IValues is that it only supported Python objects that could be converted to "regular" IValues (e.g., lists/dicts/tuples of ints/strings/tensors/...). One notable exception are custom Python classes, which are in fact a very common data type transferred over RPC. The only solution we found for those is to use the Python pickler to extract the tensors contained in them.
We can't insert a Python dependency directly into CUDAFuture, so instead I'm proposing to use the same indirection technique used to support `getSubValues` on Python objects: define some methods on the abstract class `PyObjectHolder` (which can be used by CUDAFuture) but only implement them in the concrete subclass `ConcretePyObjectHolder` (which is only built when Python support is enabled).
I am a bit worried about the performance toll of this (pickling isn't exactly known to be cheap) but I think we should start by providing a functionally complete API. We already have ideas on how to make this faster if needed, for example by having users provide a custom DataPtr extractor tailored to their class via a decorator. (Or just use TorchScript).
ghstack-source-id: 127295014
Test Plan: Added a test later in the stack
Reviewed By: mrshenli
Differential Revision: D27887189
fbshipit-source-id: 9d27e4e62390b836e5bb4f06f401cc002f0cf95b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56839
Enable check_for_memory_leak at the end of StaticRuntime::benchmark so this code is exercised more often.
Test Plan: Checked with adindexer merge net model
Reviewed By: edvgha
Differential Revision: D27417911
fbshipit-source-id: 5248942dc439fcc7301ffb0005da76374939fa96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56813
When the arg `pass_inputs_as_tensor_list` is True, the input tensors are wrapped into a TensorList and passes in as a single param.
Test Plan: buck test //caffe2/caffe2/python:workspace_test -- TestScriptModule
Reviewed By: dzhulgakov
Differential Revision: D27972928
fbshipit-source-id: 5a199649445b0306f3134086c85bd55da45e1a0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56827
The diff makes sure that mp tests are not executed in modes that allow *san, since python mp does not behave well with tsan and asan.
Test Plan: buck test mode/opt-tsan //caffe2/test/distributed/launcher/... -- --run-disabled
Reviewed By: cbalioglu
Differential Revision: D27976626
fbshipit-source-id: 7747d67687fa0fd095f799b3708038f672119e73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56808
For information about data-race-on-vptr in general, see https://www.internalfb.com/intern/wiki/TSAN/Common_Concurrency_Mistakes/Stopping_a_Thread_in_Destructor/
Engine::~Engine() was previously tasked with stopping the threads. This causes a data race on the object's vptr when PythonEngine is being destructed. This fixes the data race by making ~PythonEngine trigger the thread stopping before going down to the base class's destructor.
Test Plan:
Many tests are affected, but here's one example:
buck test mode/dev-tsan -c fbcode.tsan_strict_mode=true //oculus/research/orcoptics/deep_learning/srg_nn/tests:test_grating_net -- 'test_train (oculus.research.orcoptics.deep_learning.srg_nn.tests.test_grating_net.TestGratingNet)' --run-disabled
Reviewed By: walterddr, albanD
Differential Revision: D27972384
fbshipit-source-id: 8b70fec8d9326497c591a2777b355ea590a85082
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56503
The presence of `generated` causes Phabricator and hg to think the file is generated (e.g., hg won't prompt to resolve merge conflicts with an editor). Breaking up the tag is the traditional way to solve this.
ghstack-source-id: 126965382
Test Plan: Review, builds
Reviewed By: ailzhang
Differential Revision: D27887691
fbshipit-source-id: 394a38d50289d64f8801a13f9a28f6f0f37ca59d
Summary:
Fixes#56738
* `setup_lint` now installs mypy / shellcheck
* the shell used to execute commands is pinned to `bash` (on Ubuntu the default is `dash`, which was causing the false positives in #56738)
* the emoji check marks don't always work, so use more basic ones instead
* adds `Run autogen` step for mypy (for the `lint` step only since it's pretty slow)
](https://our.intern.facebook.com/intern/diff/27972006/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56752
Pulled By: driazati
Reviewed By: samestep
Differential Revision: D27972006
fbshipit-source-id: 624e6c1af2d4f7c8623f420516744922b6b829a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56652
Previous code doesn't drop prim::Constant values even when they are marked as drop.
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D27927413
fbshipit-source-id: 67cd52cf292e111be2830ccf93b0e7b089e49001
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45687
Fix changes the input size check for `InstanceNorm*d` to be more restrictive and correctly reject sizes with only a single spatial element, regardless of batch size, to avoid infinite variance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56659
Reviewed By: pbelevich
Differential Revision: D27948060
Pulled By: jbschlosser
fbshipit-source-id: 21cfea391a609c0774568b89fd241efea72516bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56081
ghstack-source-id: 127205799
Test Plan: unit test. Since I'm prepacking the weights of the same operators multiple times I wonder if its a just works thing?
Reviewed By: kimishpatel
Differential Revision: D27777337
fbshipit-source-id: 909d2a667d9eb51e205536b478a6668c33b3fb15
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55718
Increments sequence numbers when ProcessGroupGloo::enqueue or
ProcessGroupNCCL::collective is run, which is a common call all collectives
make. The next step will be to log these along with other collective info in
debug mode as well as integrating them with the process group wrapper.
ghstack-source-id: 127215077
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27690690
fbshipit-source-id: cb284b7c760763b7c0f814a41f06656fabf806d6
Summary:
In the optimizer documentation, many of the learning rate schedulers [examples](https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate) are provided according to a generic template. In this PR we provide a precise simple use case example to show how to use learning rate schedulers. Moreover, in a followup example we show an example how to chain two schedulers next to each other.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56705
Reviewed By: ezyang
Differential Revision: D27966704
Pulled By: iramazanli
fbshipit-source-id: f32b2d70d5cad7132335a9b13a2afa3ac3315a13
Summary:
This PR is step 2 (after https://github.com/pytorch/pytorch/issues/56708) to having JIT coverage--it actually uses the plug-in in CI!
Disclaimer: note that this will mark the entire JIT'd function/method as covered without seeking proof that the
compiled code has been executed. This means that even if the code chunk is merely compiled and not run, it will get
marked as covered.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56310
Test Plan:
We should see coverage improvements in CI after. A file to look out for would be `torch/jit/quantized.py`, which should have more coverage after this PR, which it does!
d3283ccd8c/torch/jit/quantized.py vs https://codecov.io/gh/pytorch/pytorch/src/master/torch/jit/quantized.py
More generally, the whole jit folder got ~3% increase in coverage, I believe.
Reviewed By: ezyang
Differential Revision: D27967517
Pulled By: janeyx99
fbshipit-source-id: 53fd8431d772c2447191135c29d1b166ecd42f50
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56380
BC-breaking note:
This changes the behavior of full backward hooks as they will now fire properly even if no input to the Module require gradients.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56693
Reviewed By: ezyang
Differential Revision: D27947030
Pulled By: albanD
fbshipit-source-id: e8353d769ba5a2c1b6bdf3b64e2d61308cf624a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56517
Currently a torch.futures.Future could wrap a CUDAFuture, but it could not create one from scratch. This prevented users from using CUDAFutures in some occasions, for example when using `rpc.functions.async_execution`, or in their own code. I don't see any reason for such a limitation, hence here I add support for this.
ghstack-source-id: 127261554
Test Plan: Added a test later in the stack
Reviewed By: mrshenli
Differential Revision: D27887190
fbshipit-source-id: ecbb39c1ad7cd189d478ded9c361448f05a270ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56515
In https://github.com/pytorch/pytorch/pull/56405 we finally found a solution to support RPC remote user functions that created/used CUDA tensors on devices that were not used by their arguments, by defining a "bounding set" of devices when constructing the agent and allowing all functions to freely use any of those devices.
We had the same exact problem with the callbacks of CUDAFuture, and in this PR I'm adopting the same exact solution: I allow to specify a set of devices when constructing a CUDAFuture, and then every callback is allowed to use any of those devices. (These devices will also be propagated to child futures).
I'm also making ProcessGroupNCCL pass these devices. I can't yet do it for TensorPipeAgent, until #56405 lands.
ghstack-source-id: 127261552
Test Plan: Added a test for this later in the stack.
Reviewed By: mrshenli
Differential Revision: D27861067
fbshipit-source-id: 8ab2c9d06a514c0407a7e96abc3704e8d5c5dc09
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56647
This should be more efficient than the old hacky wrapper for optional Tensor pattern. Despite appearances, the old pattern did a reference count bump for non-empty optionals. Following diff will contain an automated change to migrate callsites.
ghstack-source-id: 127112926
Test Plan: Review, CI on following change
Reviewed By: bhosmer
Differential Revision: D27925838
fbshipit-source-id: 2c6082c5930b1e71b853a75c52873088dbc48167
Summary:
Fixes https://github.com/pytorch/pytorch/issues/55587
The fix converts the binary `TensorIterator` used by softplus backwards to a ternary one, adding in the original input for comparison against `beta * threshold`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56484
Reviewed By: malfet
Differential Revision: D27908372
Pulled By: jbschlosser
fbshipit-source-id: 73323880a5672e0242879690514a17886cbc29cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56739
The diff makes several tiny changes:
* Add logs for each worker error file destination
* Make sure log_dir is propagated from the launcher
* Make ProcessFailure initialization error non-fatal.
Test Plan:
buck test mode/dev-nosan //caffe2/test/distributed/elastic/multiprocessing/errors:api_test
https://fburl.com/tupperware/0nizb9z8
Reviewed By: borovsky-d, wilson100hong
Differential Revision: D27952596
fbshipit-source-id: 69582bf4be47758def4008f2abf82d123294cd1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56565
fb::equally_split get fused with ListUnpack and all outputs from ListUnpack getting attached to fb::equally_split.
So fb::equal_split will have as many outputs as ListUnpack .
Test Plan:
buck test caffe2/torch/fb/sparsenn:fb_operators_test
buck test caffe2/torch/fb/sparsenn:test -- test_equally_split_op
Reviewed By: hlu1
Differential Revision: D27902824
fbshipit-source-id: 7855047c3bd46bbb74b7346ac384c70b6a3e1f46
Summary:
Adjust how MutationRemover is used to avoid creating aliasDb multiple times for the same graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56675
Reviewed By: pbelevich
Differential Revision: D27945692
Pulled By: SplitInfinity
fbshipit-source-id: a6c548438e88ddee18ef03a6f0461ab9eaaaa829
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56455
CPU convolution performance is pretty important for inference, so
tracking performance for CNNs often boils down to finding shapes that have
either regressed or need optimization. This diff adds a benchmark harness that
lets you pretty easily add new sets of convolution parameters to benchmark.
I've started with an exhaustive list of layers from MobileNetV3, ResNet-18 and
ResNet-50, which are fairly popular torchvision models. More to come if these
prove useful.
I've also added four backend configurations:
- native: uses at::conv2d, which applies its own backend selection heuristics
- mkldnn_none: uses mkldnn but applies no prepacking; uses the NCHW default
- mkldnn_weight: prepacks weights in an mkldnn-friendly format
- mkldnn_input: also prepacks the inputs in NCHW16c
ghstack-source-id: 127027784
Test Plan: Ran this on my Skylake Xeon
Reviewed By: ngimel
Differential Revision: D27876139
fbshipit-source-id: 950e1dfa09a33cc3acc7efd579f56df8453af1f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55656
### For release notes
What:
- All errors that are silenced by "raise_exception=False" are now GradcheckError (which inherits from RuntimeError).
Why:
- Due to a refactor of gradcheck
Workaround:
- If you catch for 'RuntimeError' with `except RuntimeError`, since GradcheckError inherits from RuntimeError, no changes are necessary. However if you explicitly check for the errors type via `type(error)`, you'll need to update your code to check for `GradcheckError` instead.
Factors out all the logic handling involving `fail_test`, `raise_exception` into 1) a wrapper around gradcheck that uses try/except 2) gradcheck_helper that always raises exception.
This allows us to avoid having to write the `if not x: return False` logic that is scattered throughout gradcheck currently.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27920809
Pulled By: soulitzer
fbshipit-source-id: 253aef6d9a3b147ee37a6e37a4ce06437981929a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55237
In this PR, we reenable fast-gradcheck and resolve misc issues that arise:
Before landing this PR, land #55182 so that slow tests are still being run periodically.
Bolded indicates the issue is handled in this PR, otherwise it is handled in a previous PR.
**Non-determinism issues**:
- ops that do not have deterministic implementation (as documented https://pytorch.org/docs/stable/generated/torch.use_deterministic_algorithms.html#torch.use_deterministic_algorithms)
- test_pad_cuda (replication_pad2d) (test_nn)
- interpolate (test_nn)
- cummin, cummax (scatter_add_cuda_kernel) (test_ops)
- test_fn_gradgrad_prod_cpu_float64 (test_ops)
Randomness:
- RRelu (new module tests) - we fix by using our own generator as to avoid messing with user RNG state (handled in #54480)
Numerical precision issues:
- jacobian mismatch: test_gelu (test_nn, float32, not able to replicate locally) - we fixed this by disabling for float32 (handled in previous PR)
- cholesky_solve (test_linalg): #56235 handled in previous PR
- **cumprod** (test_ops) - #56275 disabled fast gradcheck
Not yet replicated:
- test_relaxed_one_hot_categorical_2d (test_distributions)
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27920906
fbshipit-source-id: 894dd7bf20b74f1a91a5bc24fe56794b4ee24656
Summary:
After some fun investigating, samestep found that `\u1234` to produce a unicode character is only supported in bash > 4.2, but MacOS ship with bash/sh 3.2, so it was searching for the literal string `u1234`. This fixes the issue by printing out the char directly via its UTF-8 bytes and `printf`.
](https://our.intern.facebook.com/intern/diff/27952866/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56726
Pulled By: driazati
Reviewed By: SplitInfinity
Differential Revision: D27952866
fbshipit-source-id: 35871e959e250dfdbbdf8b121fc92212bc0614e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56740
Was running into a race condition where the torch_python_obj was
attempting to build before cpython was actually finished installing,
this should resolve that issue.
Only applicable on builds that use the `USE_DEPLOY=ON` option
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D27953782
Pulled By: seemethere
fbshipit-source-id: 76dd7c4218870eac97fc4c14e20b46128d264b30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56550
Add support for preserving a list of attributes on observed/quantized GraphModule
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_deepcopy_preserve_attributes
Imported from OSS
Reviewed By: vkuzo, kazhang
Differential Revision: D27899317
fbshipit-source-id: ebf21334715e5ab764aaa27eed534cc0cdf9f2b5
Summary:
To make them more easily distinguishable in the HUD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56695
Reviewed By: walterddr, samestep
Differential Revision: D27939938
Pulled By: malfet
fbshipit-source-id: e0abd1a6bc931a89f2aa5c6e2d8ebb471c461051
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56617
This migrates the sparsity to the open source
Test Plan: `buck test mode/opt //caffe2/test:ao`
Reviewed By: raghuramank100
Differential Revision: D27812207
fbshipit-source-id: cc87d9d2b486269901a4ad9b483615741a1cd712
Summary:
Testing that the CIRCLE variables in the Windows test CI report stats step aren't needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56596
Test Plan: CI
Reviewed By: samestep
Differential Revision: D27948983
Pulled By: janeyx99
fbshipit-source-id: 71f2ca08246eea7580e31fb632612b205fb995fc
Summary:
This PR is step 1 to covering JIT'd methods and functions. Step 2 (using it in CI) is here: https://github.com/pytorch/pytorch/issues/56310.
1. This PR introduces a package `coverage_plugins` that hosts JITPlugin.
2. We also bring in a `.coveragerc` file that is used in CI to omit the files we don't want to report on (e.g., temporary directories or test or utils.)
**Disclaimer: This PR does NOT use the plug-in. Nothing should change as a result.**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56708
Test Plan:
CI. Coverage should not go down.
If you're interested in testing this plug-in locally, you should:
`pip install -e tools/coverage_plugins_package` from the root directory.
Add the following lines to `.coveragerc` under `[run]`
```
plugins =
coverage_plugins.jit_plugin
```
And then try:
`coverage run test/test_jit.py TestAsync.test_async_script_no_script_mod`
You should see `.coverage.jit` show up at the end. You can then run `coverage combine --append` and `coverage debug data` to see that some files in `torch/jit` are covered.
Reviewed By: samestep
Differential Revision: D27945570
Pulled By: janeyx99
fbshipit-source-id: 78732940fcb498d5ec37d4075c4e7e08e96a8d55
Summary:
This way, if report results fail, the test reports are still saved as artifacts so we could use them to help us debug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56725
Test Plan: CI linux test to pass + see that the test reports are copied in the Run tests step
Reviewed By: samestep
Differential Revision: D27948434
Pulled By: janeyx99
fbshipit-source-id: 597a2ba4fe1dca16c7b75a1399600b27f380f5cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56661
Under some conditions (requires_grad = false and mode=SUM) bag_size and max_indices will be created via at::empty and will not be modified, that is why corresponding outputs is not deterministic and causing tests to fail.
Test Plan: buck test mode/opt //caffe2/benchmarks/static_runtime:static_runtime_cpptest -- --exact 'caffe2/benchmarks/static_runtime:static_runtime_cpptest - StaticRuntime.EmbeddingBag' --run-disabled
Reviewed By: hlu1
Differential Revision: D27931445
fbshipit-source-id: fe9747094027e4e6f7c7b0771c1cd994f94fd554
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56670
`int64_t` is only available for Metal 2.2 and above. `size_t` works fine in those situations. https://developer.apple.com/metal/Metal-Shading-Language-Specification.pdf
ghstack-source-id: 127169610
Test Plan:
- AIBench
```
buck run mode/mac aibench:run_bench_macos -- -b aibench/specifications/models/pytorch/metal/metal_unet_1001_detection.json --platform ios --framework pytorch --remote --devices D201 (85b1c45a45)AP-12.0.1
```
Reviewed By: linbinyu
Differential Revision: D27933297
fbshipit-source-id: 474b1eb191c68101367c9623c855645684434bd7
Summary:
The pre-amble here is misformatted at least and is hard to make sense of: https://pytorch.org/docs/master/quantization.html#prototype-fx-graph-mode-quantization
This PR is trying to make things easier to understand.
As I'm new to this please verify that my modifications remain in line with what may have been meant originally.
Thanks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52192
Reviewed By: ailzhang
Differential Revision: D27941730
Pulled By: vkuzo
fbshipit-source-id: 6c4bbf7c87d8fb87ab5d588b690a72045752e47a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56677
This has been failing with `RecursionError: maximum recursion depth
exceeded while calling a Python object` in fbcode for a while now. Obviously
this isn't a fix, but the test works in OSS, so...
ghstack-source-id: 127146338
Test Plan:
```
buck test mode/dev //caffe2/test:jit -- --exact 'caffe2/test:jit - test_nn_module_tests (jit.test_complexity.TestComplexity)' --run-disabled
```
Reviewed By: Lilyjjo
Differential Revision: D27934963
fbshipit-source-id: 21d9858dab9ca1ebb5b67f286e788662dd24a988
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56151
I missed rsqrt in the last PR. The native_functions.yaml
was done with the following script:
```
import ruamel.yaml
from ruamel.yaml.tokens import CommentToken
from ruamel.yaml.error import CommentMark
from tools.codegen.model import * # noqa: F403
with open("aten/src/ATen/native/native_functions.yaml", "r") as f:
contents = f.read()
yaml = ruamel.yaml.YAML()
yaml.preserve_quotes = True
yaml.width = 1000
yaml.boolean_representation = ['False', 'True']
r = yaml.load(contents)
convert = '''\
rsqrt
bitwise_not
frac
i0
round
'''.split()
for e in r:
f = NativeFunction.from_yaml(e, Location("", 0))
if f.structured or f.structured_delegate is not None:
continue
n = f.func.name.name.base
if n not in convert:
continue
# mutate e to make changes
if f.func.kind() == SchemaKind.out:
e.insert(1, 'structured', True)
e.insert(2, 'structured_inherits', 'TensorIteratorBase')
else:
# TODO: The .out overload assumption is not sound in general
e.insert(1, 'structured_delegate', f'{n}.out')
if 'dispatch' in e:
e['dispatch'].pop('CPU', None)
e['dispatch'].pop('CUDA', None)
e['dispatch'].pop('CPU, CUDA', None)
e['dispatch'].pop('CompositeExplicitAutograd', None)
else:
print(n)
*_, last_k = e.keys()
needs_fixup = False
if 'dispatch' in e and not e['dispatch']:
if last_k == 'dispatch':
needs_fixup = True
del e['dispatch']
# Manually fix up newlines at the end, because ruamel
# made some bad life choices about where to associate trailing
# whitespace for nested dicts; see
# https://stackoverflow.com/questions/42172399/modifying-yaml-using-ruamel-yaml-adds-extra-new-lines
if needs_fixup:
*_, last_k = e.keys()
# post_key, pre_key, post_value, pre_value
e.ca.items[last_k] = [None, None, CommentToken('\n\n', CommentMark(0), None), None]
with open("aten/src/ATen/native/native_functions.yaml.new", "w") as f:
yaml.dump(r, f)
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D27795078
Pulled By: ezyang
fbshipit-source-id: c8961b58753c12f985d786eae73f776c39d30e6e
Summary:
The purpopse of this document is to outline our current release process
so that users coming into the project have a better idea on how the
actual release process works and how they can help contribute to it.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56520
Reviewed By: janeyx99
Differential Revision: D27890571
Pulled By: seemethere
fbshipit-source-id: 882a565ea8d9b9a46c9242be7cf79dede2bae63f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56528
Tried to search across internal and external usage of DataLoader. People haven't started to use `generator` for `DataLoader`.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27908487
Pulled By: ejguan
fbshipit-source-id: 14c83ed40d4ba4dc988b121968a78c2732d8eb93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56488
Considering amount of requests for this feature, introduce numpy seeding as default within each worker for DataLoader.
## BC-breaking Note:
- By introducing default numpy.random seeding strategy to workers of DataLoader, users don't need to manually set seed for workers by the `worker_init_fn`. And this PR won't influence users who are currently using `worker_init_fn` to set customized seed for workers.
- DataLoader will preserve reproducibility for users who are using numpy.random within Dataset.
- Multiprocessing (without `worker_init_fn` to define seed for numpy)
- Start method as `spawn`: Each worker will now have seed for numpy random, rather than the seed generated from the imported time of Numpy module that make the DataLoader lose the reproducibility.
- Start method as `fork`: Each worker not only have the same benefit as `spawn`, but also have different seed for numpy as default, rather than inheriting the same seed.
Using the following Dataset and script as an example:
```py
class RandomDataset(Dataset):
def __getitem__(self, ind):
item = [ind, np.random.randint(1, 10000)]
return item
def __len__(self):
return 20
if __name__ == '__main__'"
ctx = mp.get_context('fork')
ds = RandomDataset()
g = torch.Generator()
g.manual_seed(0)
dl = DataLoader(ds, 2, shuffle=False, num_workers=4, multiprocessing_context=ctx, generator=g)
epochs = 2
for _ in range(epochs):
for batch in d;:
print(batch)
print("====" * 10)
```
### 1.8.1:
Each worker generates same random result per iteration. And the seed will be reset to same for each epoch.
```py
tensor([[ 0, 7449],
[ 1, 1519]])
tensor([[ 2, 7449],
[ 3, 1519]])
tensor([[ 4, 9645],
[ 5, 2387]])
tensor([[ 6, 9645],
[ 7, 2387]])
tensor([[ 8, 3118],
[ 9, 4552]])
=========================
tensor([[ 0, 7449],
[ 1, 1519]])
tensor([[ 2, 7449],
[ 3, 1519]])
tensor([[ 4, 9645],
[ 5, 2387]])
tensor([[ 6, 9645],
[ 7, 2387]])
tensor([[ 8, 3118],
[ 9, 4552]])
=========================
```
### This PR:
Each worker has different seed at the beginning and re-seed for each epoch.
```py
tensor([[ 0, 8715],
[ 1, 5555]])
tensor([[ 2, 6379],
[ 3, 1432]])
tensor([[ 4, 3271],
[ 5, 5132]])
tensor([[ 6, 4287],
[ 7, 1104]])
tensor([[ 8, 8682],
[ 9, 1699]])
=========================
tensor([[ 0, 1374],
[ 1, 996]])
tensor([[ 2, 143],
[ 3, 3507]])
tensor([[ 4, 5887],
[ 5, 4730]])
tensor([[ 6, 7274],
[ 7, 738]])
tensor([[ 8, 6374],
[ 9, 1572]])
=========================
```
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27908486
Pulled By: ejguan
fbshipit-source-id: 5f313a30563bedeb88be214fa4beca0cefe9e4f4
Summary:
* Visual studio versions: clarify and shorten.
* Remove obsolete note about a bug that has been fixed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56193
Reviewed By: albanD
Differential Revision: D27939766
Pulled By: ezyang
fbshipit-source-id: e142ec04ba98d5468f28ddf2e8bba5d99d3cfc26
Summary:
Fixes https://github.com/pytorch/pytorch/issues/55398
Generates tests that calls `symbolic_trace` on torchvision models and verifies the parity of outputs from eager model, `fx.GraphModule`, `jit.ScriptModule`.
Test errors: GoogleNet and Inception models throw a type mismatch when scripting the traced `fx.GraphModule`.
```
Return value was annotated as having type __torch__.torchvision.models.googlenet.GoogLeNetOutputs but is actually of type Tensor:
dropout = self.dropout(flatten); flatten = None
fc = self.fc(dropout); dropout = None
return fc
~~~~~~~~~ <--- HERE
```
Relevant type-inconsistency 512ea299d4/torchvision/models/googlenet.py (L200)
```
torch.jit.unused
def eager_outputs(self, x: Tensor, aux2: Tensor, aux1: Optional[Tensor]) -> GoogLeNetOutputs:
if self.training and self.aux_logits:
return _GoogLeNetOutputs(x, aux2, aux1)
else:
return x # type: ignore[return-value]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55744
Reviewed By: albanD
Differential Revision: D27920595
Pulled By: suraj813
fbshipit-source-id: 01f6f2aef7badbde29b5162a7787b5af9398090d
Summary:
See https://github.com/pytorch/pytorch/pull/56523#issuecomment-823562134 for context. Basically the idea is that people (including myself) keep assuming that the single-asterisk `*` wildcard means "match in this directory and in its subdirectories", which is _not_ true. Removing the wildcards thus reduces confusion.
Ideally I would like to remove _all_ of these wildcards and then add a lint to disallow them in the future (and also greatly simplify the pattern-matching logic in `tools/mypy_wrapper.py`; see https://github.com/pytorch/pytorch/issues/55702 for context), but currently this one can't be removed:
```
tools/autograd/*.py,
```
That is because there is a file called `tools/autograd/templates/annotated_fn_args.py` (added in https://github.com/pytorch/pytorch/issues/41575) which is not a valid Python file and thus cannot be checked by `mypy`. ezyang would it be possible to rename that file to use a suffix other than `.py`?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56645
Test Plan:
```
$ mypy
Success: no issues found in 1317 source files
$ mypy --config=mypy-strict.ini
Success: no issues found in 72 source files
```
The numbers of source files should be the same before and after this PR.
Reviewed By: ezyang
Differential Revision: D27925207
Pulled By: samestep
fbshipit-source-id: c17faf73665a75393d3109346a1138c2af023abb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53964. cc albanD almson
## Major changes:
- Overhauled the actual loss calculation so that the shapes are now correct (in functional.py)
- added the missing doc in nn.functional.rst
## Minor changes (in functional.py):
- I removed the previous check on whether input and target were the same shape. This is to allow for broadcasting, say when you have 10 predictions that all have the same target.
- I added some comments to explain each shape check in detail. Let me know if these should be shortened/cut.
Screenshots of updated docs attached.
Let me know what you think, thanks!
## Edit: Description of change of behaviour (affecting BC):
The backwards-compatibility is only affected for the `reduction='none'` mode. This was the source of the bug. For tensors with size (N, D), the old returned loss had size (N), as incorrect summation was happening. It will now have size (N, D) as expected.
### Example
Define input tensors, all with size (2, 3).
`input = torch.tensor([[0., 1., 3.], [2., 4., 0.]], requires_grad=True)`
`target = torch.tensor([[1., 4., 2.], [-1., 2., 3.]])`
`var = 2*torch.ones(size=(2, 3), requires_grad=True)`
Initialise loss with reduction mode 'none'. We expect the returned loss to have the same size as the input tensors, (2, 3).
`loss = torch.nn.GaussianNLLLoss(reduction='none')`
Old behaviour:
`print(loss(input, target, var)) `
`# Gives tensor([3.7897, 6.5397], grad_fn=<MulBackward0>. This has size (2).`
New behaviour:
`print(loss(input, target, var)) `
`# Gives tensor([[0.5966, 2.5966, 0.5966], [2.5966, 1.3466, 2.5966]], grad_fn=<MulBackward0>)`
`# This has the expected size, (2, 3).`
To recover the old behaviour, sum along all dimensions except for the 0th:
`print(loss(input, target, var).sum(dim=1))`
`# Gives tensor([3.7897, 6.5397], grad_fn=<SumBackward1>.`


Pull Request resolved: https://github.com/pytorch/pytorch/pull/56469
Reviewed By: jbschlosser, agolynski
Differential Revision: D27894170
Pulled By: albanD
fbshipit-source-id: 197890189c97c22109491c47f469336b5b03a23f
Summary:
Commandeered from https://github.com/pytorch/pytorch/pull/54563
Primary changes from first PR:
1. Refactored primary `normalize_function` logic into `operator_schemas.py` so that non-FX users can use it.
2. Refactored tests a bit, and added a path to call `normalize_function` directly.
3. Moved check for `boolean_dispatch` so that `torch.lu` also gets properly handled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55992
Reviewed By: mruberry
Differential Revision: D27774396
Pulled By: Chillee
fbshipit-source-id: 7f65632e1d608e4abd55aec5ccbfdc3f67f52b8e
Summary:
Update Kineto submodule and use new metadata api
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56432
Test Plan: CI
Reviewed By: chaekit
Differential Revision: D27871570
Pulled By: ilia-cher
fbshipit-source-id: 3556787f07a9c9e138666a62ee4cd23af6d7473b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56072
Currently, we don't support outputting more than one tensors on GPU. For example, if you do
```
auto x = at::rand(1,4,2,2).metal();
auto y = at::chunk(x,2,1); //y is a tuple
auto output1 = y[0].cpu();
auto output2 = y[1].cpu();
```
In the example above, when it hits `y[0].cpu()`, the command buffer will be committed to move `y[0]` from GPU to CPU. By the time it hits `y[1].cpu()`, since the command buffer has already become invalid, the temporary image that lives in `output2` has been recycled. Thus, a runtime exception will be thrown.
The way we address it is using the observer pattern
1. Before we flush the command buffer, we'll notify its the observers(a.k.a MPSImageWrapper objects) who hold the temporary images.
2. When observers receive the notification, they'll turn the current temporary images into a static images.
3. Now, when `.cpu()` happens, the output tensor can just read the data directly from the static image generated in the above step.
You may be wondering does that have a hidden cost where all the intermediate tensors have hold unused static images? The answers is no. All intermediate tensors will be released once their reference counts become zero. Since the MetalTensorImpl is subclassing from the TensorImpl, we're overriding the release_resource method which gives us a chance to release the underlying storage (textures and buffers) and remove observers from the command buffer. Therefore, once the intermediate tensors go away, the temporary images will be recycled immediately.
ghstack-source-id: 127079751
Test Plan:
- We'll be using `at::chunk` to test this in the following diffs, as it returns a tuple that contains multiple tensors.
- Sandcastle CI
- CircleCI
Reviewed By: dreiss
Differential Revision: D27165886
fbshipit-source-id: 290b0d77b1dc74990b25cbd0abb775df1ab47ca0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56601
Updating it to ensure that RegistrationDeclarations.yaml is completely
unchanged
This reverts commit 90e532f3ef17a9611e9e7a9f1f6189d4168bf084.
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27915305
Pulled By: bdhirsh
fbshipit-source-id: 491a025c44221690dad849f9a2166934130c0fec
Summary:
That test was skipped due to a compiler bug. That bug should be fixed in 11.2, so we should enable it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50227
Reviewed By: malfet
Differential Revision: D27909195
Pulled By: anjali411
fbshipit-source-id: c802702079d0e521f53fc98cd0fc3ded0c12b455
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56173
* Create `InplaceConverter` and `ValueTracker` to keep track of aliases of values throughout the graph. For a given value, a new alias is created every time when there is an inplace operation, SetAttr, or through nested blocks owned by If/Loop nodes.
* Fix bug where controlflow node output types are not set, when the complete node is unable to run ONNX shape inference due to containing non-onnx node.
* Add symbolic for `__not__` ~~and `prim_min`~~(update: moved to a separate PR), and update `index_put` opset9 to support case of assignment without providing indices.
* Bump ORT version in CI test.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D27866138
Pulled By: SplitInfinity
fbshipit-source-id: ab5c9188740c50f783ceba4d54fda43c26e2fde7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56172
Enable the standardOps include **Add\Sub\Mul\Div\Gemm\Pow\Mod** with low precision input in ORT
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D27866136
Pulled By: SplitInfinity
fbshipit-source-id: f2cf5649fffefd68c0cc7b6dce94198751636727
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56549
This make the `kProcessGroupDefaultTimeout` be the same as the python
side, and python side directly use the pybind value instead
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D27899190
Pulled By: wanchaol
fbshipit-source-id: 388a7f42358b0abed75cf4934fb7b311fd33fee6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56531
per discussions in
https://github.com/pytorch/pytorch/pull/53663/files#r593409009, we need
to make sure our API not confusing user by passing in both timeout in
argument and timeout in processgroup.options. This PR tries to make the
`ProcessGroup.Options.timeout` be a private field, and only be used in
our test utils, for both `init_process_group` and `new_group`, we still
allow user pass `timeout` as a separate argument. Since
`ProcessGroupGloo.Options` only have a `timeout` config, both functions
will not allow passing in options for the GLOO backend.
This way we still preserve the only `timeout` API, and only allow user
to use `ProcessGroupNCCL.Options` when needed.
cc pritamdamania87 rohan-varma
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D27893395
Pulled By: wanchaol
fbshipit-source-id: cdd29c84648002226ef3d9f9f3ea67b795e64bc5
Summary:
Under this setting the job should run 3 times a day.
When the environment variable, `PYTORCH_TEST_WITH_SLOW_GRADCHECK` is set to `ON`, set the default value for `fast_mode` in gradchack wrapper as False. This would be overriden by whatever value the user explicitly passes in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55182
Reviewed By: albanD
Differential Revision: D27919236
Pulled By: soulitzer
fbshipit-source-id: 3a55ec6edcfc6e65fbc3a8a09c63aaea1bd1c5bf
Summary:
On ROCm, the error when compiling was "non-constant-expression cannot be narrowed from type 'int' to 'uint32_t'"
when compiling grid_reduction.cu.
Added typecast to fix issue.
Also, removed test skip with ROCm : re-enabling
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55243
Reviewed By: malfet
Differential Revision: D27917066
Pulled By: ngimel
fbshipit-source-id: b0b7c5fc8ecd2624222b35fe060846f7d1670f07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56441
Since aten::to is overloaded, match schema to replace it with static_runtime::to_copy
Test Plan:
```
MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 numactl -m 0 -C 3 ./buck-out/opt/gen/caffe2/caffe2/fb/predictor/ptvsc2_predictor_bench --c2_model=/data/users/ansha/tmp/adfinder/210494966_0.predictor.disagg.remote_request_only --c2_inputs=/data/users/ansha/tmp/adfinder/models/c2_remote_ro_input_data.pb --pred_net=/data/users/ansha/tmp/adfinder/models/c2_remote_ro_net2.pb --c2_sigrid_transforms_opt=1 --c2_apply_nomnigraph_passes=1 --c2_use_memonger=1 --scripted_model=/data/users/ansha/tmp/adfinder/models_dianshi/210494966_0.predictor.disagg.remote_request_only.pt --pt_inputs=/data/users/ansha/tmp/adfinder/models/remote_ro_wrapped_input_data.pt --pt_enable_static_runtime=1 --pt_cleanup_activations=1 --pt_enable_out_variant=1 --compare_results=1 --iters=1 --warmup_iters=1 --num_threads=1 --do_profile=1 --benchmark_c2_predictor=0 --do_benchmark=0
```
```
Time per node type:
0.623426 ms. 55.337%. quantized::embedding_bag_4bit_rowwise_offsets (82 nodes)
0.331633 ms. 29.4367%. quantized::embedding_bag_byte_rowwise_offsets (71 nodes)
0.123163 ms. 10.9323%. aten::to (155 nodes)
0.038479 ms. 3.4155%. fb::lengths_to_offsets (155 nodes)
0.004169 ms. 0.370052%. aten::embedding_bag (2 nodes)
0.002549 ms. 0.226256%. static_runtime::to_copy (2 nodes)
0.002512 ms. 0.222972%. prim::TupleConstruct (1 nodes)
0.000667 ms. 0.0592048%. prim::dtype (2 nodes)
1.1266 ms. in Total
StaticRuntime setup time: 0.009605 ms
Memory allocation time: 0.001907 ms
Memory deallocation time: 0.032401 ms
Outputs deallocation time: 0.020876 ms
Total memory managed: 256 bytes
Total number of reused tensors: 159
```
I verified that all of the aten::to matches, for the local, local_ro, and remote_ro nets in opt and dev mode.
Only 2 of calls are replaced because the other 155 have either the input or the ouput of the op returned as an external output. This is a similar case for the other instances of aten::to in the local and local_ro nets.
Reviewed By: hlu1
Differential Revision: D27872350
fbshipit-source-id: b72785ea2768be415faae2afcf9915aef07daec2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56405
If not provided, the `devices` field will be initialized to local
devices in local `device_maps` and corresponding devices in peers'
`device_maps`. When processing CUDA RPC requests, the agent will
use a dedicated stream for each device in the devices list to 1)
accept argument CUDA tensors 2) run user functions 3) send return
value tensors.
closes#54017
Test Plan: Imported from OSS
Reviewed By: lw
Differential Revision: D27863133
Pulled By: mrshenli
fbshipit-source-id: 5d078c3b6d1812f85d62b0eb0f89f2b6c82cb060
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56535
This PR renames the `_Rendezvous` class to `_RendezvousState` in preparation of the upcoming changes.
ghstack-source-id: 126979138
Test Plan: Run the existing unit tests.
Reviewed By: H-Huang
Differential Revision: D27889894
fbshipit-source-id: 027d26aa5e1acd5bba3ad2e58b140428a4a176b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56534
This PR reorders the type definitions in dynamic_rendezvous.py to increase the readability.
ghstack-source-id: 126979087
Test Plan: Run the existing unit tests.
Reviewed By: H-Huang
Differential Revision: D27889817
fbshipit-source-id: 04291af9b8f3170e4b33cb4f33e0dff0d2d3fb23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56533
This PR introduces a small utility function to delay the execution of the current thread.
ghstack-source-id: 126979035
Test Plan: Run the associated unit tests.
Reviewed By: H-Huang
Differential Revision: D27889671
fbshipit-source-id: aae93b624bd4704da7a48004f50d130cec64969d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56532
This PR fixes a subtle issue with the finalizer implementation of `_PeriodicTimer`.
We avoid using a regular finalizer (a.k.a. `__del__`) for stopping the timer as joining a daemon thread during the interpreter shutdown can cause deadlocks. The `weakref.finalize` is a superior alternative that provides a consistent behavior regardless of the GC implementation.
ghstack-source-id: 126978904
Test Plan: Run the existing unit tests as there is no behavioral change.
Reviewed By: H-Huang
Differential Revision: D27889289
fbshipit-source-id: a248cf6fd1abc4da8bef90e160fa9669a4961fa5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55940
Simpler way to keep current_dtype up to date than #55689.
ghstack-source-id: 127092676
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D27744064
fbshipit-source-id: 23fccb8b0375f5b790439a9a1c9ac07d5fae391b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55420
It doesn't seem to be necessary, and it blocks using `c10::MaybeOwned` to support borrowing.
ghstack-source-id: 127092679
Test Plan: fitsships
Reviewed By: ezyang
Differential Revision: D27607270
fbshipit-source-id: a007e9896785c8708f8cc02035cc6f4607a0a31b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55351
We incorrectly used `Tensor&` to mean "the underlying
TensorImpl cannot be changed", as explained in
https://github.com/zdevito/ATen/issues/27#issuecomment-330717839 .
This diff gets us on the path to fixing this problem: we have an
incremental way to fix individual native functions so that we can
apply any handwritten fixes a few at a time. It gets the migration
started with the `resize` family of native functions.
ghstack-source-id: 127092677
Test Plan: fitsships
Reviewed By: ezyang
Differential Revision: D27583983
fbshipit-source-id: 4eeeec85f5d268e9d0f1645eb9396914a9f9557f
Summary:
In some cases the `__file__` here was relative, so in the linter script it ended up setting the repo root to `''`, which `asyncio` doesn't handle.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56633
Pulled By: driazati
Reviewed By: samestep
Differential Revision: D27922510
fbshipit-source-id: 7e406fa374ec0e5c4917b7c11742b9457dd52668
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56547
**Summary**
This commit tweaks the docstrings of `PackageExporter` so that they look
nicer on the docs website.
**Test Plan**
Continuous integration.
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27912965
Pulled By: SplitInfinity
fbshipit-source-id: 38c0a715365b8cfb9eecdd1b38ba525fa226a453
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56514
rohan-varma mentioned that having CUDAFuture entirely defined in a header meant having to rebuild a whole lot of things whenever it changed. In fact there's no reason not to use a .cpp file, so here I do so.
ghstack-source-id: 127035765
Test Plan: Unit tests
Reviewed By: rohan-varma, mrshenli
Differential Revision: D27861071
fbshipit-source-id: c209d54af9b52d3ad781db1b61f6fca02c637f32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56513
The RpcCUDAFuture class existed solely to support extracting DataPtrs from a Message class. However, this can be done more simply by using a vanilla CUDAFuture and just extracting those DataPtrs before marking it complete and passing them to markCompleted.
This allows to make the DataPtr extraction logic of CUDAFuture private again.
ghstack-source-id: 127035771
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D27861064
fbshipit-source-id: b0b4df2cab7be6b4b16d5cfc888483c18fbce60e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56512
I don't know if there was a reason to keep them separate, but since the former deferred to the latter, it seems to me that we can get the exact same behavior by merging them and making the `data_ptrs` argument optional (by giving it a default value).
ghstack-source-id: 127035767
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D27861069
fbshipit-source-id: 93a49d6959b65a8d4ab9b31accce90bf30cd441e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56511
CUDAFuture needs to inspect the value in order to extract DataPtrs. Sometimes it's unable to do so. So far we've handled this by raising an error when `markCompleted` is called. In this PR I'm proposing a change, which makes `markCompleted` return successfully, but instead causes the Future to be set to an error if the DataPtr extraction fails.
The advantages I see are that user code calling `markCompleted` didn't expect it to throw, and thus wasn't catching and handle that error. Which in the best case could lead to a crash, and in the worst case could lead to the Future remaining incomplete, thus not unblocking any client waiting on it. With this change those clients would be woken up and would see the error.
ghstack-source-id: 127035772
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D27861070
fbshipit-source-id: 4bb6100a488ab35fbe3c2bc3ac6f98d166c60a0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56510
The comment for `TORCH_INTERNAL_ASSERT` say to use it for "enforcement of internal invariants in code", meaning "assuming no bugs in PyTorch, the conditions tested by this macro should always be true". However this wasn't the case here, at least for the RPC code: CUDAFuture is calling the `getSubValues` method on a generic IValue of which it doesn't know (or care about) the type. It was thus sometimes triggering the internal assert when users provided non-inspectable types, which was producing an exception with a message containing "please report a bug to PyTorch", which was confusing to users.
It makes more sense to me to consider this a type error, which can thus be reported more clearly to the user (and, later on in this stack, to catch). Hence the difference introduced here is just the type and the message of the exception. I don't expect there to be any code depending on the old behavior (as it would mean depending on a violation of an internal invariant).
ghstack-source-id: 127035768
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D27861066
fbshipit-source-id: 6d41c922257cba5f37c7a4614d8e5ab5c7c87b92
Summary:
This queries the local git repo for changed files (any changed files, not just committed ones) and sends them to mypy/flake8 instead of the default (which is the whole repo, defined the .flake8 and mypy.ini files). This brings a good speedup (from 15 seconds with no cache to < 1 second from my local testing on this PR).
```bash
make quicklint -j 6
```
It should be noted that the results of this aren’t exactly what’s in the CI, since mypy and flake8 ignore the `include` and `exclude` parts of their config when an explicit list of files is passed in.
](https://our.intern.facebook.com/intern/diff/27901577/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56559
Pulled By: driazati
Reviewed By: malfet
Differential Revision: D27901577
fbshipit-source-id: 99f351cdfe5aba007948aea2b8a78f683c5d8583
Summary:
This should make it easier to resolve issues surfaced by https://github.com/pytorch/pytorch/issues/56290. Also see https://github.com/pytorch/pytorch/pull/56559#discussion_r617828152 for context.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56616
Test Plan:
You could add a type error in a strict-checked file like `tools/test_history.py`, and then run this command:
```
$ mypy --config=mypy-strict.ini tools/test_history.py
```
Output before this PR:
```
tools/test_history.py:13:1: error: Function is missing a type annotation for one or more arguments
Found 1 error in 1 file (checked 1 source file)
```
Output after this PR:
```
tools/test_history.py:13:1: error: Function is missing a type annotation for one or more arguments [no-untyped-def]
Found 1 error in 1 file (checked 1 source file)
```
Reviewed By: driazati
Differential Revision: D27918753
Pulled By: samestep
fbshipit-source-id: 953926e019a7669da9004fd54498b414aec777a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56555
Remove the "sparse" and "sparsity" from the function/variable names
Test Plan: `buck test mode/opt //caffe2/torch/fb/model_optimization:sparsity_test`
Reviewed By: raghuramank100
Differential Revision: D27812205
fbshipit-source-id: 1665253720467030b84b744f824fa7742a802542
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56567
This adds stride information to the serialized JSON.
This also adds shape, dtype and stride to the graph that is printed out.
Test Plan: Run unit tests.
Reviewed By: jfix71
Differential Revision: D27528988
fbshipit-source-id: f0be92055ad7c8e525625bfd1332c2db11ba612d
Summary:
This should clarify its purpose, which is:
> to make sure that we give an appropriate error message when someone tries to use python2
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56593
Test Plan: CI.
Reviewed By: gchanan
Differential Revision: D27913086
Pulled By: samestep
fbshipit-source-id: e7555d5cab5696b19a17824383c92f25f91da2cf
Summary:
Match updated `Embedding` docs from https://github.com/pytorch/pytorch/pull/54026 as closely as possible. Additionally, update the C++ side `Embedding` docs, since those were missed in the previous PR.
There are 6 (!) places for docs:
1. Python module form in `sparse.py` - includes an additional line about newly constructed `Embedding`s / `EmbeddingBag`s
2. Python `from_pretrained()` in `sparse.py` (refers back to module docs)
3. Python functional form in `functional.py`
4. C++ module options - includes an additional line about newly constructed `Embedding`s / `EmbeddingBag`s
5. C++ `from_pretrained()` options
6. C++ functional options
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56065
Reviewed By: malfet
Differential Revision: D27908383
Pulled By: jbschlosser
fbshipit-source-id: c5891fed1c9d33b4b8cd63500a14c1a77d92cc78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56553
This splits the previous diff into multiple parts. This introduces only the c++ files.
The unittests pass as part of the internal build. Will be put in the OSS in the later PRs
Test Plan:
`buck test mode/opt //caffe2/torch/fb/model_optimization:sparsity_test`
```
Parsing buck files: finished in 2.0 sec
Creating action graph: finished in 16.4 sec
Building: finished in 55.0 sec (100%) 20264/20264 jobs, 16 updated
Total time: 01:13.6 min
More details at https://www.internalfb.com/intern/buck/build/c9c5e69e-ce00-4560-adce-58b68bc43e47
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: 1e678a07-0689-45b4-96f3-54d0a3181996
Trace available for this run at /tmp/tpx-20210415-161113.966600/trace.log
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/3096224795029304
✓ ListingSuccess: caffe2/torch/fb/model_optimization:sparsity_test - main (4.186)
✓ Pass: caffe2/torch/fb/model_optimization:sparsity_test - test_sparse_qlinear (caffe2.torch.fb.model_optimization.test.sparsity.quantized_test.TestQuantizedSparseLayers) (1.752)
✓ Pass: caffe2/torch/fb/model_optimization:sparsity_test - test_sparse_qlinear (caffe2.torch.fb.model_optimization.test.sparsity.quantized_test.TestQuantizedSparseKernels) (1.884)
✓ Pass: caffe2/torch/fb/model_optimization:sparsity_test - test_sparse_qlinear_serdes (caffe2.torch.fb.model_optimization.test.sparsity.quantized_test.TestQuantizedSparseLayers) (2.013)
Summary
Pass: 3
ListingSuccess: 1
```
Reviewed By: ailzhang
Differential Revision: D27833226
fbshipit-source-id: a47707117de950a9794f79e50a544aa13542c1e1
Summary:
Since `launch_agent()` in api.py is already decorated with record, we can remove the usage in elastic_launch.
It also fix the bug for FileExistError on MAST
We run an experiment to count how many times record is invoked in D27901961 to ensure the assumption.
Test Plan:
```
fbpkg build -E torchelastic_distributed_sum
buck run mode/dev-nosan //pytorch/elastic/torchelastic/tsm/fb/cli:tsm -- run_ddp --scheduler mast --fbpkg torchelastic_distributed_sum:fde7879 --nnodes 1 --nproc_per_node 1 --resource T1 --run_cfg hpcIdentity=oncall_dai_pet,hpcClusterUuid=MastNaoTestCluster main.par
```
https://www.internalfb.com/mast/job/tsm_wilsonhong-torchelastic_distributed_sum_a92f97e7
Reviewed By: borovsky-d
Differential Revision: D27902034
fbshipit-source-id: e08b02d4b9c7a7c70fbb0dbcb24b95af55d2ea95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55319
Adds a sequence number class as well as integration with ProcessGroup (nccl and gloo) as part of better debugability.
The main use case is that each ProcessGroup instantiated will have a sequence number initially set by rank 0, and broadcasted to all others. We will increment the number on each collective, thus allowing us to match the numbers appropriately when checking for desynchronization.
This PR just adds the bare-bones integration and verifies sequence numbers are set appropriately at the beginning.
ghstack-source-id: 127011277
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27562769
fbshipit-source-id: d4a4de7529ce07a0c86fcf6beb06f317f359d89b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54924
Previously we are producing torch.ops.quantize.cat which takes inputs, dequantize them
and requantize with new qparams. This PR changes that to produce torch.cat directly, torch.cat
will assume all inputs are sharing the same qparam, and it will produce a quantized Tensor with
the same qparam as all inputs (because previous PR makes sure all inputs and output of cat are sharing
the same observer/fakequant instance).
Using torch.cat is expected to be more efficient since it does not introduce extra quant/dequant.
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_cat
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D27416528
fbshipit-source-id: 896c280abec2903c29d597c655729666583ff0dd
Summary:
Run print_test_stats.py for macos_10_13 tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56429
Test Plan: Make sure CI passes, specifically for macos_10_13
Reviewed By: samestep
Differential Revision: D27911557
Pulled By: janeyx99
fbshipit-source-id: 178c0ff7786ab5c41dec9d8afa257eebda4f5a0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56307
This should fix https://github.com/pytorch/pytorch/issues/56273. I tested these changes locally by making them directly on top of https://github.com/pytorch/pytorch/pull/56151, and running the xla tests (`xla/test/cpp/build/test_ptxla`).
**Current state:** For ops that are ported to structured, If external backends like XLA have implemented the `out` op but not the `functional` version, they will call into our code-generated `CompositeExplicitAutograd` kernel, which calls the structured operator's `meta()` function and then redispatches to the external backend's `out` function.
If XLA has registered their own kernel to the `functional` variant of the op, it'll override our codegen'd composite kernel. XLA has logic to code-generate "CPU fallback" kernels for "required" ops. It gets this information based off of `RegistrationDeclarations.yaml`. That info was technically incorrect up until this PR, since we were code-generating `inplace/functional` composite kernels for structured ops, but not updating `RegistrationDeclarations.yaml` with that information.
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D27883950
Pulled By: bdhirsh
fbshipit-source-id: fe896b0d2bbd4369490dcdf7a87f227fd3d8b8b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56306
It turns out that TensorIteratorBase `meta()` calls don't work with XLA tensors, since the logic that builds up the `TensorIteratorBase` object also tries to grab/store the underlying tensors' data pointers. This doesn't work for XLA because they don't have storage.
I think it's fine to just skip this bit of logic for tensors that don't have storage- since the data_ptr information isn't important to the meta call, and TensorIterator isn't actually used in the implementation for non-native kernels, i.e. XLA.
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D27883949
Pulled By: bdhirsh
fbshipit-source-id: 7db4358b94b23c504a383f9673dc509c4020a708
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55145
Repeating the discussion from https://github.com/pytorch/pytorch/pull/54784#issuecomment-811792089
The error messages for mismatched values are directly adapted from the old `_compare_tensors_internal`:
50cb75edce/torch/testing/__init__.py (L104-L111)
A sample error message right now looks like this
```
With rtol=1.3e-06 and atol=1e-05, found 1 different element(s) out of 12 (8.3%). The greatest difference of 4.0 (5.0 vs. 9.0) occurred at index (2, 3)
```
Using the same data with `numpy.testing.assert_equal` gives the following output:
```
Not equal to tolerance rtol=1.3e-06, atol=1e-05
Mismatched elements: 1 / 12 (8.33%)
Max absolute difference: 4.
Max relative difference: 0.44444445
x: array([[5., 5., 5., 5.],
[5., 5., 5., 5.],
[5., 5., 5., 5.]], dtype=float32)
y: array([[5., 5., 5., 5.],
[5., 5., 5., 5.],
[5., 5., 5., 9.]], dtype=float32)
```
Pros:
- The info is presented in a list instead of a sentence. IMO this makes it more readable
- The maximum relative difference is reported, which is beneficial in case a comparison fails due to the `rtol`
Cons:
- The values of the inputs are reported (this can be disabled by passing `verbose=False`, but lets face it: most users will use the default setting). In case the inputs are large, the output gets truncated with `...`. Not only is it hard to visually find the mismatching values, they could also live within the truncated part, making the output completely useless.
- Even when visually find the offending values it is hard to parse this back to the index in the inputs.
This implements a mix of both to get a short but expressive message:
```
Tensors are not close according to rtol=1.3e-6 and atol=1e-05:
Mismatched elements: 1 / 12 (8.3%)
Max. rel. diff.: 4.44e-1 at (2, 3)
Max. abs. diff.: 4.0 at (2, 3)
```
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D27877157
Pulled By: mruberry
fbshipit-source-id: 6898a995f116f127e3ae8ed0bcb1ada63eadc45a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56324
Inlining is great if LLVM's CSE kicks in; but if a kernel has multiple outputs
(and thus multiple loops), CSE has no chance.
So, this pass "horizontally" fuses the output loops together so that CSE can go
to town. Essentially we want to turn
```
for (...) {
output_1[] = some_complicated_expr...
}
for (...) {
output_2[] = some_complicated_expr...
}
```
Into:
```
for (...) {
output_1[] = complicated_expr
output_2[] = complicated_expr. // llvm cse should take care of this
}
```
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D27841194
Pulled By: bertmaher
fbshipit-source-id: 54153bb59786be87183c636d64f05963c4b1624a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56447
MemoryPlanner shouldn't manage StorageImpls; instead, it should manage the TensorImpls because the StorageImpl in Tensors can change.
Test Plan: CI
Reviewed By: ajyu
Differential Revision: D27840361
fbshipit-source-id: f22165d167c70165be2934c6717b5057a8bb4d29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56167
VC++ does not recognize `or` as a valid operator. This breaks the build under `Debug` configuration.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D27866143
Pulled By: SplitInfinity
fbshipit-source-id: 490cee57b9762170ce02a6f73130772a3542e76d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56166
Support tensordot in symbolic function of opset 12, and add tests accordingly.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D27866140
Pulled By: SplitInfinity
fbshipit-source-id: 68e218cfbd630900fb92871fc7c0de3e7e8c8c3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56165
Add implementation for cases when
- interleaving happens along dim which consist of dynamic axes
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D27866137
Pulled By: SplitInfinity
fbshipit-source-id: 7fef1b2c614f2e24a677b7ca0886bb37bd0ab479
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56163
* [ONNX] Improve index_put symbolic to handle singular Bool updates (#53690)
Adds support for cases where the updates to the index_put node is a single Bool value, such as the case shown below
```
mask[indices] = True
```
Fixes#53507
* [ONNX] Support primitive type input/outputs and attributes (#53550)
Support primitive type attributes. Needed for Silero model.
* [ONNX] Fix if output shape mismatch error & Fix graph input directly used as output (#53219)
Fix if output shape mismatch error & Fix graph input directly used as output
* Add support for hann_window operator.
* [ONNX] Replace decomposeLinear pre process pass with a symbolic (#53077)
Replace decomposeLinear pre process pass with a symbolic
* Add a test case for dtype is None.
* Resolve flake8 issue.
* Remove one unused test case.
* Add support for hann_window operator.
* Add a test case for dtype is None.
* Remove one unused test case.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D27866145
Pulled By: SplitInfinity
fbshipit-source-id: e0b43df9ecd1a95cd7ac297213aba453bbaf2913
Co-authored-by: Shubham Bhokare <32080845+shubhambhokare1@users.noreply.github.com>
Co-authored-by: Negin Raoof <neginmr@utexas.edu>
Co-authored-by: Bowen Bao <bowbao@microsoft.com>
Co-authored-by: Ksenija Stanojevic <KsenijaS@users.noreply.github.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56539
It seems like a potential source of non-determinism when generating YAML files during the build stems from the fact that when we write out Python lists, they get written out in list order. This isn't a problem per-se, but if you look to see how these lists are generated, you'll see that they come from sets, which are inherently [not order preserving](https://stackoverflow.com/questions/1653970/does-python-have-an-ordered-set) in Python.
I can't guarantee that this removes non-determinism, but it removes all non-determinism that I know of so far. The surface area of codegen isn't sprawling, and the YAML file is generated by converting the object `toDict()` and passing it into the YAML serializer, so this should cover it (I think). Dictionaries are serialized in key order by pyyaml, so that's not a problem.
This could be releated to the elevated Android build times being seen [here](https://fb.workplace.com/groups/pytorch.edge.users/permalink/841622146708080/).
ghstack-source-id: 126987721
Test Plan: Build + Sandcastle.
Reviewed By: JacobSzwejbka
Differential Revision: D27893058
fbshipit-source-id: 6d7bcb09f34c05b71fbb4a0673bac1c4c33f23d7
Summary:
This PR includes:
* Update to the loop-carried dependence check API to correctly ignore loop-independent dependences and handle all kinds of loop-carried dependences like RAW, WAR and WAW.
* Fix for the overlap API to look only for conflicting buffer accesses where at least one of them is a Store.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56354
Reviewed By: bertmaher
Differential Revision: D27856202
Pulled By: navahgar
fbshipit-source-id: 206e4ec771fe0f7f2ccf4b11b29e35df7b9b18bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56491
Move the prepack convolution to the op file to get rid of the selective compilation.
ghstack-source-id: 126960054
Test Plan: CI
Reviewed By: SS-JIA
Differential Revision: D27719539
fbshipit-source-id: 75fb3849858a31a915828a0f5f6f3d4066ff4c9b
Summary:
This hides the warnings from #35026 until we can fix them for real by migrating to custom classes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56543
Pulled By: driazati
Reviewed By: rohan-varma
Differential Revision: D27895085
fbshipit-source-id: a325a5d8cefb20a5033c1a059e49c03c08514f18
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56308
But only for float tensors. Even on CUDA, int tensors just have weird
behavior with pow, and I bet FP is so much more common that it's just not worth
trying to fuse ints here.
ghstack-source-id: 126769637
Test Plan: `pytest test_jit_fuser_te.py -k test_binary_pow`
Reviewed By: navahgar
Differential Revision: D27834694
fbshipit-source-id: 7274d72cf02ab95d63574b6c17995b8f34560810
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56004
added reference pattern support for GELU, softmax and bmm for int dtypes. For GELU and Softmax, this consisted of adding reference patterns to the default node handler for int dtypes. Note GELU and softmax patterns are not registered since they do not have a proper quantized kernel which means they would either add unnecessary dequant and quant ops to the network, or they would simply error. This can be circumvented with custom qconfig usage as in test_gelu_reference
bmm was added within binary ops along with some significant changes to how that code is structured. Theoretically the reference pattern used for bmm could be applied to other dtypes. This was not enabled because of issues relating to Line 1323 in quantize.py. In essence, the prepare step does not know whether an op will use a reference pattern or not, so for ops that are supported with one dtype in reference and one dtype normally, this has the potential to cause issues. This is difficult to get aorund with the is_reference flag being available in the prepare step or discussed changes around separating
Test Plan:
python test/test_quantization.py TestQuantizeFxOps.test_gelu_reference
python test/test_quantization.py TestQuantizeFxOps.ttest_gelu_normal
python test/test_quantization.py TestQuantizeFxOps.test_softmax_reference
python test/test_quantization.py TestQuantizeFxOps.test_softmax_normal
python test/test_quantization.py TestQuantizeFxOps.test_silu_reference
python test/test_quantization.py TestQuantizeFxOps.test_bmm_int_reference
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestFuseFx
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxModels
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D27818340
fbshipit-source-id: de65be0797035463cd2d1b0e4677d1a87f69143c
Summary:
This pulls out shell scripts from an action and runs them locally as a first pass at https://github.com/pytorch/pytorch/issues/55847. A helper script extracts specific steps in some order and runs them:
```bash
$ time -p make lint -j 5 # run lint with 5 CPUs
python scripts/actions_local_runner.py \
--file .github/workflows/lint.yml \
--job 'flake8-py3' \
--step 'Run flake8'
python scripts/actions_local_runner.py \
--file .github/workflows/lint.yml \
--job 'mypy' \
--step 'Run mypy'
python scripts/actions_local_runner.py \
--file .github/workflows/lint.yml \
--job 'quick-checks' \
--step 'Ensure no trailing spaces' \
--step 'Ensure no tabs' \
--step 'Ensure no non-breaking spaces' \
--step 'Ensure canonical include' \
--step 'Ensure no unqualified noqa' \
--step 'Ensure no direct cub include' \
--step 'Ensure correct trailing newlines'
python scripts/actions_local_runner.py \
--file .github/workflows/lint.yml \
--job 'cmakelint' \
--step 'Run cmakelint'
quick-checks: Ensure no direct cub include
quick-checks: Ensure canonical include
quick-checks: Ensure no unqualified noqa
quick-checks: Ensure no non-breaking spaces
quick-checks: Ensure no tabs
quick-checks: Ensure correct trailing newlines
cmakelint: Run cmakelint
quick-checks: Ensure no trailing spaces
mypy: Run mypy
Success: no issues found in 1316 source files
Success: no issues found in 56 source files
flake8-py3: Run flake8
./test.py:1:1: F401 'torch' imported but unused
real 13.89
user 199.63
sys 6.08
```
Mypy/flake8 are by far the slowest, but that's mostly just because they're wasting a bunch of work linting the entire repo.
In followup, we could/should:
* Improve ergonomics (i.e. no output unless there are errors)
* Speed up lint by only linting files changes between origin and HEAD
* Add clang-tidy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56439
Reviewed By: samestep
Differential Revision: D27888027
Pulled By: driazati
fbshipit-source-id: d6f2a59a45e9d725566688bdac8e909210175996
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56346
Now that TensorPipe's API has `targetDevice`, use that instead of
manually writing the CUDA device index in `metadata`.
Test Plan: CI
Reviewed By: lw
Differential Revision: D27703235
fbshipit-source-id: c5b620e3b3ce619367412efdbe9fa3778f6b8869
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56425
As SPMD mode is gone, `_specify_ddp_gpu_num` becomes useless. It only checks if the module is a GPU module. This actually is already checked by the caller of this function (in fairscale and some other codebases).
Additionally also remove `enable_pytorch_sync_bn` wrapper that only calls this function and does nothing else.
ghstack-source-id: 126885376
Test Plan: waitforbuildbot
Reviewed By: zhaojuanmao
Differential Revision: D27866440
fbshipit-source-id: d2fd5cf43eda25c0a2bd35f647848ec0dbd6ad0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56412
We are investigating some flaky profiiling tests such as https://github.com/pytorch/pytorch/issues/56146. One issue is that the profiling tests are tightly coupled to these send/recv tests, hence if this test is disabled, we lose signal round send/recv collectives tests.
To mitigate this, separate the tests into ones that only test send/recv, and ones that test it with profiling. This way flakiness should not result in the send/recv only tests being disabled.
ghstack-source-id: 126920867
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D27864845
fbshipit-source-id: 01f04a884482ec7741323218a7f8f4a8451eb4ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56434
If we hit multiple TORCH_WARN from different sources when running the
statement, it makes more sense to me that we want to check the regex is
met in any one of the warning messages instead of all messages.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D27871946
Pulled By: ailzhang
fbshipit-source-id: 5940a8e43e4cc91aef213ef01e48d506fd9a1132
Summary:
The lint was originally added in https://github.com/pytorch/pytorch/issues/54974, but at the time I didn't realize that these other Markdown files also each have a table of contents:
- `GLOSSARY.md`
- `torch/csrc/jit/OVERVIEW.md`
- `torch/csrc/jit/docs/serialization.md`
- `torch/fx/OVERVIEW.md`
This PR adds those files to the lint, and also changes the rule from using a fixed list of filenames to a `git grep` command that finds all Markdown files containing this magic comment:
```md
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56487
Test Plan: The "Lint / toc" job in GitHub Actions.
Reviewed By: janeyx99
Differential Revision: D27884885
Pulled By: samestep
fbshipit-source-id: 5462437502b17fba93abf5098e21754bf566a4fe
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 416a9d8a4a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56259
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: pbelevich
Differential Revision: D27881993
Pulled By: beauby
fbshipit-source-id: e7d8cefe89c6fb09b59e3ef57da05a7ab0a3cb16
Summary:
We should iterate all pages of the branches API. Otherwise, even using "pytorch/vision" would fail to find master.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56138
Reviewed By: heitorschueroff
Differential Revision: D27872346
Pulled By: ailzhang
fbshipit-source-id: 55881558f7980b1fb08b0d08ed6687a38df06edd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56410
Changes:
- Move create_tcp_store() helper function to common file
- Update test_jit_c10d to retry TCP Store creation in case allocated port becomes used
fixes https://github.com/pytorch/pytorch/issues/55053
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D27869560
Pulled By: H-Huang
fbshipit-source-id: f4a6613049bb25e6f6f194214379a380968bb19c
Summary:
`is_variable` spits out a deprecation warning during the build (if it's
still something that needs to be tested we can ignore deprecated
warnings for the whole test instead of this change).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56305
Pulled By: driazati
Reviewed By: ezyang
Differential Revision: D27834218
fbshipit-source-id: c7bbea7e9d8099bac232a3a732a27e4cd7c7b950
Summary:
[First ShellCheck release in over a year!](https://github.com/koalaman/shellcheck/releases/tag/v0.7.2) I'm thankful for doing https://github.com/pytorch/pytorch/issues/55109 at the beginning of this month, because otherwise `master` would have just suddenly started failing a few hours ago.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56445
Test Plan:
CI. You can also run `shellcheck` locally; for instance, if you're on Mac and [installed it with Homebrew](https://github.com/koalaman/shellcheck/tree/v0.7.2#installing):
```sh
brew upgrade shellcheck
rm -r .extracted_scripts ; tools/extract_scripts.py --out=.extracted_scripts
tools/run_shellcheck.sh .jenkins/pytorch .extracted_scripts
```
Reviewed By: janeyx99
Differential Revision: D27874084
Pulled By: samestep
fbshipit-source-id: 3bd871a368fe03aecd559e2f55bce36af49cfa27
Summary:
This cuts out caffe2's old backtrace generation in favor of the one already in c10.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56198
Pulled By: driazati
Reviewed By: nikithamalgifb
Differential Revision: D27868282
fbshipit-source-id: aa9b9691271eaa3f95baab48773ffefebd924ae2
Summary:
Temporary fix to give people extra time to finish the deprecation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56401
Reviewed By: xw285cornell, drdarshan
Differential Revision: D27862196
Pulled By: albanD
fbshipit-source-id: ed460267f314a136941ba550b904dee0321eb0c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56248
`info` error code for QR decomposition only indicates wrong parameters,
when everything is implemented correctly it will never be nonzero so we
don't need to check it for CPU path.
For MAGMA `checkMagmaInternalError` is added that checks for failed
memory allocations internal to MAGMA.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27850414
Pulled By: mruberry
fbshipit-source-id: ddda1209008f879f24c9ad08739e10c28b194d18
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56386
The diff resolves bug around incorrect handler resolution:
_create_static_handler pointed towards etcd, and _create_etcd_handler pointed towards static.
Test Plan:
buck test mode/dev-nosan //caffe2/test/distributed:test_launcher
Added test_launcher to the ci/cd tests
Reviewed By: cbalioglu
Differential Revision: D27858897
fbshipit-source-id: 440155789958c091ce5755e7c9524e4bb704203a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55946
As `ddp_gpu_size` field of `SyncBatchNorm` will always be 1 for GPU modules, remove this field and the relevant code.
ghstack-source-id: 126883498
Test Plan: waitforbuildbot
Reviewed By: zhaojuanmao
Differential Revision: D27746021
fbshipit-source-id: b4518c07e6f0c6943fbd7a7548500a7d4337126c
Summary: `Redirects` was renamed to `Std` in `torch.distributed.elastic.multiprocessing.api`. Pointed out by a user in https://github.com/pytorch/elastic/issues/147.
Test Plan: N/A just doc change
Reviewed By: tierex
Differential Revision: D27866614
fbshipit-source-id: 9fb901aae7ebe11cde13000a1c118de527f34400
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56391
Previously we only support keeping output quantized for tensor output, this PR adds support
for list and dict (values) as well
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D27860327
fbshipit-source-id: e770160ced47a7173abff5505ec620bd2b1a0b01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56406
Been hard to reproduce
https://github.com/pytorch/pytorch/issues/50840, adding some debug log to get a
better sense of the issue.
ghstack-source-id: 126874222
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D27863328
fbshipit-source-id: e6f125b77cfb636b90598eb54395609654f5e139
Summary:
Partial fix for https://github.com/pytorch/pytorch/issues/56357
Changes the `fuseLoops` API to the following form:
```
static bool fuseLoops(const std::vector<For*>& loops, For** fused);
```
Also, adds a new API to check for loop-carried dependences:
```
static bool hasLoopCarriedDependence(For* loop);
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56353
Reviewed By: bertmaher
Differential Revision: D27856214
Pulled By: navahgar
fbshipit-source-id: 443557088692585657faee296602c547a00117dd
Summary:
https://github.com/pytorch/pytorch/issues/54268 removed `test_run_mypy` since now we're running `mypy` as its own job in GitHub Actions, but previously we used this `set_cwd` context manager in that test to ensure that we picked up the `mypy` config correctly. However, for some reason, we have not been doing that in `test_doc_examples`, which has been succeeding in CI for a while despite being broken.
Specifically, [`run_test.py` changes the working directory to `test/` before running test files](48aaea3359/test/run_test.py (L534-L535)), which is contrary to [what `CONTRIBUTING.md` instructs developers to do](48aaea3359/CONTRIBUTING.md (python-unit-testing)). As a result, in CI, `test/test_type_hints.py` has been passing in CI, but if you run it locally from the root of the repo, this you get this error:
```
F
======================================================================
FAIL: test_doc_examples (__main__.TestTypeHints)
Run documentation examples through mypy.
----------------------------------------------------------------------
Traceback (most recent call last):
File "test/test_type_hints.py", line 127, in test_doc_examples
self.fail(f"mypy failed:\n{stdout}")
AssertionError: mypy failed:
test/generated_type_hints_smoketest.py:851: error: Name 'tensor' is not defined [name-defined]
test/generated_type_hints_smoketest.py:853: error: Name 'tensor' is not defined [name-defined]
Found 2 errors in 1 file (checked 1 source file)
----------------------------------------------------------------------
Ran 1 test in 1.416s
FAILED (failures=1)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56388
Test Plan:
Before this PR, the first of the following two commands should fail (since that is essentially what is run in CI), but the second should fail:
```
python test/run_test.py -i test_type_hints
python test/test_type_hints.py
```
After this PR, both commands should succeed.
Reviewed By: driazati
Differential Revision: D27860173
Pulled By: samestep
fbshipit-source-id: efb82fffd7ccb04d0331824b40bdef7bbc319c98
Summary:
This guards some deprecated usages of the Protobuf API behind an `#ifdef` (this is how onnx does it as well)
](https://our.intern.facebook.com/intern/diff/27803121/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56186
Pulled By: driazati
Reviewed By: bertmaher, dzhulgakov
Differential Revision: D27803121
fbshipit-source-id: 2d3a348ec1ab9879a0d8f2dff17c5444fd4baf2c
Summary:
Since we're using specific VS, we don't need to specify VC version.
In fact, the VC version is not used in CI now.
Why I make this change now?
I'm writing a robot to update the vs_install.ps1 (https://github.com/pytorch/pytorch/pull/56261/) every 2 weeks.
It will submit a PR to check if the latest VS is compatible with PyTorch automatically.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56230
Reviewed By: bdhirsh
Differential Revision: D27856647
Pulled By: ezyang
fbshipit-source-id: b46f2bdf35ab5841fded470e23bbf7a01d5f60f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56181
Need to change to size_t vs size_t:
Reviewed By: ezyang
Differential Revision: D27800849
fbshipit-source-id: 25f744128eb8750c382dc967a99af3c9f16247d9
Summary:
As this diff shows, currently there are a couple hundred instances of raw `noqa` in the codebase, which just ignore all errors on a given line. That isn't great, so this PR changes all existing instances of that antipattern to qualify the `noqa` with respect to a specific error code, and adds a lint to prevent more of this from happening in the future.
Interestingly, some of the examples the `noqa` lint catches are genuine attempts to qualify the `noqa` with a specific error code, such as these two:
```
test/jit/test_misc.py:27: print(f"{hello + ' ' + test}, I'm a {test}") # noqa E999
test/jit/test_misc.py:28: print(f"format blank") # noqa F541
```
However, those are still wrong because they are [missing a colon](https://flake8.pycqa.org/en/3.9.1/user/violations.html#in-line-ignoring-errors), which actually causes the error code to be completely ignored:
- If you change them to anything else, the warnings will still be suppressed.
- If you add the necessary colons then it is revealed that `E261` was also being suppressed, unintentionally:
```
test/jit/test_misc.py:27:57: E261 at least two spaces before inline comment
test/jit/test_misc.py:28:35: E261 at least two spaces before inline comment
```
I did try using [flake8-noqa](https://pypi.org/project/flake8-noqa/) instead of a custom `git grep` lint, but it didn't seem to work. This PR is definitely missing some of the functionality that flake8-noqa is supposed to provide, though, so if someone can figure out how to use it, we should do that instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56272
Test Plan:
CI should pass on the tip of this PR, and we know that the lint works because the following CI run (before this PR was finished) failed:
- https://github.com/pytorch/pytorch/runs/2365189927
Reviewed By: janeyx99
Differential Revision: D27830127
Pulled By: samestep
fbshipit-source-id: d6dcf4f945ebd18cd76c46a07f3b408296864fcb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56070
**Summary**
Currently, we're returning copies instead of alias on mobile GPU (Metal/Vulkan). As suggested by ailzhang , we could use the JIT pass - `RemoveTensorMutation` to ban mutations ahead of time. I've tested two scenarios as shown below. They both work fine on mobile.
- view
```
class Model (torch.nn.Module):
def forward(self, x):
y = x.view(-1)
z = torch.tensor(2.0).float()
y.add_(z)
return x
m = Model()
x = torch.rand(2, 3)
y = m(x)
```
- transpose
```
class Model (torch.nn.Module):
def forward(self, x):
y = x.transpose(1, 2)
z = torch.tensor(2.0).float()
x.add_(z)
return y
m = Model()
x = torch.rand(1, 2, 3)
y = m(x)
```
As we're adding more ops, we should add more tests to cover all the alias ops - https://github.com/pytorch/pytorch/blob/master/tools/autograd/gen_inplace_or_view_type.py#L31-L80
**Next step**
Synced offline with eellison. Since mutation removal is also being used in ONNX, Static runtime, some jit optimizations, Torch -> TVM, etc, instead of inventing something new, we would continue to make it better in cases where it fails.
Although this JIT pass could work for most of the mobile models, there are cases that it can't cover. What we're going to do next is to implement stub ops for GPU models to let them run on server side, such that users can compare results to see if there is any discrepancy.
ghstack-source-id: 126802123
Test Plan:
- Sandcastle
- CircleCI
Reviewed By: raziel
Differential Revision: D27692683
fbshipit-source-id: 9d1be8a6c0a276032b1907807a54fbe2afd882f9
Summary:
They are unused, unrelated to vectorization, and confusing for code
readers (each of them have 2 overloads that are actually used).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56313
Reviewed By: bdhirsh
Differential Revision: D27854290
Pulled By: ezyang
fbshipit-source-id: 14945ceac39a3f19e5d0f8d762b17f8c2172b966
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55102
To avoid casting a tensor to `.long()`, we introduce support for int32 in `torch.repeat_interleave`.
Reviewed By: ezyang
Differential Revision: D27478235
fbshipit-source-id: 08b4cce65fe94ff10535ddc07e1ba2bacea6a2cf
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56022.
Fixes https://github.com/pytorch/pytorch/issues/56316
For `torch.tensordot`,
1. `tensordot`'s out variant now resizes the output tensor provided as the `out` argument if necessary.
2. Added a check to verify if the output tensor provided as the argument for `out` is on the same device as the input tensors.
3. Added a check to verify if the dtype of the result is castable to the dtype of the output tensor provided as an argument for `out`.
4. Because of (2) & (3), `tensordot`'s out variant now [safely casts & copies output](https://github.com/pytorch/pytorch/wiki/Developer-FAQ#how-does-out-work-in-pytorch).
5. `test_tensordot` in `test_linalg.py` had a bug - the output tensor wasn't being defined to be on the same device as the input tensors. It was fixed by simply using a `device` argument in its definition.
6. Added an `OpInfo` for `tensordot` and modified the `OpInfo` for `inner`.
cc heitorschueroff mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56286
Reviewed By: ngimel
Differential Revision: D27845980
Pulled By: mruberry
fbshipit-source-id: 134ab163f05c31a6900dd65aefc745803019e037
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56247
Moved `apply_orgqr` to `BatchLinearAlgebraKernel.cpp`.
Removed `infos` tensor parameter. We don't need to expose
lapack/cusolver error codes because they do not contain any useful
information about the input. Its value is checked only in debug mode now
removing the device syncronization from the cuSOLVER path of
`torch.linalg.householder_product` or `torch.orgqr`.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27844339
Pulled By: mruberry
fbshipit-source-id: 47aa20dfe2c116951b968362ad55e837caece042
Summary:
Partially fixes https://github.com/pytorch/pytorch/issues/56157
This PR changes `normalize` API in `LoopNest` to transform the given `For` statement and not create a new one.
New API:
```
static bool normalize(For* f);
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56158
Reviewed By: agolynski
Differential Revision: D27798361
Pulled By: navahgar
fbshipit-source-id: 57626a5a367bdf94a0efbd9dc8538f5e4e410d6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56348
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: f88994cf33
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D27820550
fbshipit-source-id: efde79955af9a902c2d2bf38ed2705282a9ae2f0
Summary:
Safely deallocating and repurposing memory used across streams relies on recording end-of-life events in all an allocation's usage streams beyond its original allocation stream. The events are later queried to see if all GPU work in those extra streams that could have used the allocation is done (from the CPU's perspective) before repurposing the allocation for use in its original stream.
The trouble is, calling EventQuery on an ordinary event recorded in a capturing stream is illegal. Calling EventQuery while capture is underway is also illegal. So when we call `tensor.record_stream` (or `c10::cuda::cudaCachingAllocator::recordStream`) on any tensor that's used or deleted in or around a capture, we often end up with a confusing error thrown from the cudaEventQuery in DeviceCachingAllocator::process_events().
This PR enables hopefully-safe deletion of tensors used across streams in or around capture with a conservative but simple approach: don't record or process end of life events for such tensors until the allocator's sure no captures are underway. You could whiteboard cases where this causes cross-stream-used allocations to be unavailable for reuse longer than absolutely necessary, but cross-stream-used allocations are uncommon, so for practical purposes this approach's impact on the memory footprint of captured sequences should be small.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55860
Reviewed By: ejguan
Differential Revision: D27822557
Pulled By: ezyang
fbshipit-source-id: b2e18a19d83ed05bad67a8157a14a606ed14d04e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55861
APIs such as torch.LongTensor and torch.ByteTensor are deprecated and
the recommended API is torch.tensor(args, dtype=...). Use this API in
distributed_c10d.
ghstack-source-id: 126777875
Test Plan: CI
Reviewed By: pbelevich
Differential Revision: D27726600
fbshipit-source-id: 07eb8168d93697593589002c93c3903ce29431ef
Summary:
This PR allows fusing loops whose bounds are specified as expressions that are equal.
For example:
```
for (int j = 0; j < M + N; j++) {
A[j] = 10 * j;
}
for (int k = 0; k < M + N; k++) {
B[k] = 20 * k;
}
```
`fuseLoops(j, k)` is possible since the stop bounds of the two loops are equal though they are different `Expr*` and will result in:
```
for (int j = 0; j < M + N; j++) {
A[j] = 10 * j;
B[j] = 20 * j;
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55997
Reviewed By: bertmaher
Differential Revision: D27841270
Pulled By: navahgar
fbshipit-source-id: a64e4503b7f8f28bc0c9823225bc923177bb4c2e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56319
With this change the TorchScript graph can have constant tensors in it
and we still will be able to lower it to TE. The constants are
registered (or bound) within the `TensorExprKernel` object and when the
codegen is called, they are passed along with usual inputs and outputs.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D27838747
Pulled By: ZolotukhinM
fbshipit-source-id: 4a519d66fcc07fe5fa53f5cf9af28d25611f8437
Summary:
This `is_meta` call in `TensorIterator` shows up in profiling as around 4-5% of fast setup time:
49a5f99440/aten/src/ATen/TensorIterator.cpp (L886)
After inlining, `is_meta()` compiles to a single `test` instruction. Saving 20-30 ns per operator call. The functions I'm moving into the header here are all similar, in that they inline away to almost nothing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53905
Reviewed By: gchanan
Differential Revision: D27513232
Pulled By: swolchok
fbshipit-source-id: 33ec9eefecd0ddebc285e1d830edb558818dc391
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56289
While there's no reason to think non-float32 conv2d's *don't* work,
they're only tested in float32 now. Since that's the most important use case,
I'd rather restrict the dtypes than spend time testing all the weird dtype
combinations that could possibly happen.
ghstack-source-id: 126755549
Test Plan: unit tests
Reviewed By: navahgar
Differential Revision: D27828495
fbshipit-source-id: fcf179207f2c9b20e0e86eb2b85687517d87063c
Summary:
After adding new ops to a set of fusible ops, mobilenetv3 slows down to **9000ms from 1200ms** without this fix.
This happens because one of the inputs was expanded and converted to nchw/nhwc
we might end up in a very bad spot if the second argument
is in a blocked format. In this case, MKLDNN uses its
reference implementation for a binary operation that follows
these broadcasts and it could be up to ~100x slower.
We use a very simple heuristic to convert an arg in nchw
to the blocked format of the other argument.
* MKLDNN_VERBOSE without the issue:
[test_mobilenet_nopool.txt](https://github.com/pytorch/pytorch/files/6319528/test_mobilenet_nopool.txt)
* MKLDNN_VERBOSE with the issue (Note the times for `ref` operations)
[test_mobilenet_pool.txt](https://github.com/pytorch/pytorch/files/6319529/test_mobilenet_pool.txt)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56089
Reviewed By: eellison
Differential Revision: D27796688
Pulled By: Krovatkin
fbshipit-source-id: fc34d76358ce899e3b1f2b69efb9b5c38f5af1ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56294
When matching a pattern to `BinaryOpQuantizeHandler`, we need to make
sure we check for dtype support on the base node, instead of the current
node. This is important in cases such as `add-relu` and `mul-relu`,
when the current node is `relu`, but the base node is `add|mul`.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
```
There is no good test case to check this in current logic. Created an
add-relu model manually, and verified with pdb that the add node was
being used to match against dtypes.
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27831070
fbshipit-source-id: 3697f1328dff9fec3eb910bae49a73793ef36d63
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56212
The current design doesn't make it easy to use `node.copy()`. Explicitly copy over the node's meta.
Test Plan: Updated `test_subgraph_creation` in `test_fx_experimental`
Reviewed By: jamesr66a
Differential Revision: D27808477
fbshipit-source-id: 7fe7b6428c830307dbd1e395f16fa2774936d3b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54813
Previously we have a cat that takes a list of Tensors with different qparams and dequantize them
cacatenate them and requantize with the output qparams. This adds some unnecessary overhead in dequantizing
and quantizing Tensors.
This PR adds an optimization for cat operator, we'll make sure inputs and output of cat
uses same observer/fake_quant and produce a cat that does not do rescaling.
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D27408377
fbshipit-source-id: 6a4bdcfd15e57ea1fe0f7e72d1e1288eb3ece4db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54480
This PR shouldn't really change the behavior of gradcheck for most ops. However, the changes in test_autograd allow us to run basic checks for both fast and slow (instead of previously just slow). All it should be doing is wrapping the preexisting tests we introduced in prior PRs in a function which takes `fast_mode` as a param. We then call this function twice, once with `fast_mode=True` and once with `fast_mode=False`.
Plan for rollout:
- This PR should only land the code (and runs some basic checks as described above).
- This should help us verify that a) slow is still working as expected b) basic functionality of fast works
- After we land this, but before we run the next PR in the stack, we should land https://github.com/pytorch/pytorch/pull/55182. This is to ensure that there is no gap where the slow tests aren't running.
- The next PR is responsible for enabling the fast_mode=True flag on all tests (where the function has real inputs/outputs), and selectively disabling for the cases the fail.
- Finally in a later PR, we reenable fast-gradcheck for functions w/ complex inputs/outputs
TODOs and open questions (not necessarily blocking this PR):
- ~How do we think about atol/rtol~ (scale atol, keep rtol as-is)
- ~reenable fast-gradcheck for complex numbers~
- ~when inputs are uncoalesced we don't truly test this case because we coalesce the inputs before calling function. Revisit this when https://github.com/pytorch/pytorch/pull/52874/files is landed~
### Developer Experience
Sample output when jacobian mismatch occurs:
```
Traceback (most recent call last):
File "/home/s/local/pytorch4/test/test_autograd.py", line 4220, in test_gradcheck_jacobian_mismatch
check(fast_mode=True)
File "/home/s/local/pytorch4/test/test_autograd.py", line 4196, in check
gradcheck(fn, (x,), fast_mode=fast_mode)
File "/home/s/local/pytorch4/torch/testing/_internal/common_utils.py", line 2067, in gradcheck
return torch.autograd.gradcheck(fn, inputs, **kwargs)
File "/home/s/local/pytorch4/torch/autograd/gradcheck.py", line 1020, in gradcheck
if not fast_gradcheck(fail_test, seeded_func, func_out, tupled_inputs, outputs, eps, rtol,
File "/home/s/local/pytorch4/torch/autograd/gradcheck.py", line 915, in fast_gradcheck
return fail_test(get_notallclose_msg(a, n, i, j, prefix) + jacobians_str)
File "/home/s/local/pytorch4/torch/autograd/gradcheck.py", line 996, in fail_test
raise RuntimeError(msg)
RuntimeError: Jacobian mismatch for output 0 with respect to input 0,
numerical:tensor(0.9195)
analytical:tensor(0.9389)
The above quantities relating the numerical and analytical jacobians are computed
in fast mode. See: https://github.com/pytorch/pytorch/issues/53876 for more background
about fast mode. Below, we recompute numerical and analytical jacobians in slow mode:
Numerical:
tensor([[1.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 1.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 1.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 1.0000]])
Analytical:
tensor([[1.0100, 0.0100, 0.0100, 0.0100],
[0.0100, 1.0100, 0.0100, 0.0100],
[0.0100, 0.0100, 1.0100, 0.0100],
[0.0100, 0.0100, 0.0100, 1.0100]])
The max per-element difference (slow mode) is: 0.010000000000054632.
```
Additionally, if the per-element difference is small i.e., `allclose(analytical_slow, numerical_slow, rtol, atol) is True` we follow up with this message:
```
Fast gradcheck failed but element-wise differences are small. This means that the
test might've passed in slow_mode!
If you are adding a new operator, please file an issue and then use one of the
workarounds. The workaround depends on how your test invokes gradcheck/gradgradcheck.
If the test
- manually invokes gradcheck/gradgradcheck, then call gradcheck/gradgradcheck
with `fast_mode=False` as a keyword argument.
- is OpInfo-based (e.g., in test_ops.py), then modify the OpInfo for the test
to have `gradcheck_fast_mode=False`
- is a Module test (e.g., in common_nn.py), then modify the corresponding
module_test entry to have `gradcheck_fast_mode=False`
```
Test Plan: Imported from OSS
Reviewed By: walterddr, ejguan
Differential Revision: D27825160
Pulled By: soulitzer
fbshipit-source-id: 1fe60569d8b697c213b0d262a832622a4e9cf0c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56209
Pull Request resolved: https://github.com/pytorch/kineto/pull/172
in this diff of the stack, we remove the threadId field from the ClientTraceActivity as our step towards the deprecation
Test Plan: sandcastle builds to cover all the dependent targets
Reviewed By: ilia-cher
Differential Revision: D27662747
fbshipit-source-id: 040ba040390680a0fc63ddc8149c6fad940439fc
Summary:
This PR fixes the formatting issues in the new language reference
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56042
Reviewed By: gmagogsfm
Differential Revision: D27830179
Pulled By: nikithamalgifb
fbshipit-source-id: bce3397d4de3f1536a1a8f0a16f10a703e7d4406
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54783
We need to be extra careful with the pattern to legitimately use `unchecked_unwrap_optional` in autodiff.
This would at least allow us to start support `Optional[Tensor]` in autodiff, which is quite common in composite layers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55565
Reviewed By: ejguan
Differential Revision: D27825336
Pulled By: Krovatkin
fbshipit-source-id: a8562eb10ea741effff430d7417d313b1eb53dfe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56214
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56037
The diff introduces new `torch.distributed.elastic_launch` and removes internals of `torch.distributed.launch` keeping backwards compatibility.
Since torchelastic and torch.launch are not fully compatible due to `--use_env` arg, the `torch.distributed.launch` deprecation is going to be iterative: as part of pytorch 1.9 we are going to deprecate it, and in the following releases we will remove `torch.distributed.launch`
The diff leaves `torchelastic.distributed.launch` module, and the follow up diffs will migrate the users form `torchelastic.distributed.launch` to `torch.distributed.elastic_launch`
Test Plan: buck test mode/dev-nosan //pytorch/elastic/torchelastic/distributed/...
Reviewed By: H-Huang
Differential Revision: D27805799
fbshipit-source-id: 599a4c0592fbc7a1bc1953040626dd6b72bac907
Summary:
There is a build failure in `bench_approx.cpp` due to namespace change for log_out and tanh_out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56278
Reviewed By: bertmaher, nikithamalgifb
Differential Revision: D27825621
Pulled By: navahgar
fbshipit-source-id: 0bccd324af92a3460610bf475514449f0223de2b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56238
It's already functionally public due to `extern` and `mock`, but
exposing the underlying implementation makes extending PackageExporter
easier.
Changed the underscores, expose on `torch.package`, add docs, etc.
Differential Revision: D27817013
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Pulled By: suo
fbshipit-source-id: e39199e7cb5242a8bfb815777e4bb82462864027
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55647
This adds [breakpad](https://github.com/google/breakpad) which comes with out-of-the-box utilities to register a signal handler that writes out a minidump on an unhandled exception. Right now this is gated behind a flag in `torch.utils`, but in the future it could be on by default. Sizewise this adds aboute 500k to `libtorch_cpu.so` (187275968 B to 187810016 B).
```bash
$ cat <<EOF > test.py
import torch
torch.utils.enable_minidump_collection()
# temporary util that just segfaults
torch._C._crash()
EOF
$ python test.py
Wrote minidump to /tmp/pytorch_crashes/6a829041-50e9-4247-ea992f99-a74cf47a.dmp
fish: “python test.py” terminated by signal SIGSEGV (Address boundary error)
$ minidump-2-core /tmp/pytorch_crashes/6a829041-50e9-4247-ea992f99-a74cf47a.dmp -o core.dmp
$ gdb python core.dmp
... commence debugging ...
```
Right now all exceptions that get passed up to Python don't trigger the signal handler (which by default only
handles [these](https://github.com/google/breakpad/blob/main/src/client/linux/handler/exception_handler.cc#L115)). It would be possible for PyTorch exceptions to explicitly write a minidump when passed up to Python (maybe only when the exception is unhandled or something).
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27679767
Pulled By: driazati
fbshipit-source-id: 1ab3b5160b6dc405f5097eb25acc644d533358d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54605
For small sizes we generate a naive 3-layer loopnest, for bigger sizes
we generate an external call.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D27298364
Pulled By: ZolotukhinM
fbshipit-source-id: 2ddf275ff68d6fca16a3befca5ce5c26aef462b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55334
The goal of this PR is to clean up some of the autograd codegen to compare C++ types using `CType` objects instead of raw strings. My last PR in the stack made that string comparison a little more fragile, since the raw C++ strings needed to be namespace-aware.
I confirmed byte-for-byte no codegen changes vs. the last PR (which added namespaces to the codegen) by running `diff -qr ../pytorch-common_test/torch/csrc/autograd/generated/ ../pytorch-callgrind_test_after2/torch/csrc/autograd/generated/` and `diff -qr ../pytorch-common_test/build/aten/src/ATen/ ../pytorch-callgrind_test_after2/build/aten/src/ATen/`
Note that a better end-state for the autograd codegen would be to do all of its type pattern matching directly off of JIT types, instead of off of CType’s (which are really just generated from JIT types, incorporating C++ specific semantics). That looks like it’ll require a pretty substantial change though, so I’m not doing it in this PR.
As part of this change (and after talking with ezyang), I split off the `CType` data class into a separate `NamedCType` class, which holds a name and a `CType`. This way, `CType` only knows about actual C++ types, making it easier to compare CType’s to each other in the codegen when we only care about the type. The core change is in `types.py`, but it required a bunch of downstream changes to update all of the places where we create `CType`s to create `NamedCType`s instead.
The main change in the autograd codegen was that I updated `SavedAttribute` to store a `NamedCType`. The other autograd changes all pretty much came from that change.
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D27708347
Pulled By: bdhirsh
fbshipit-source-id: 3e07c80569c7b229c638f389e76e319bff6315f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55047
Added namespaces to all of the `CTypes` printed in the codegen. This is pretty much required if we want to use codegen externally, since we can no longer assume that we're inside of the `at::` namespace.
Important changes are in `types.py`.
How do we add the notion of namespaces to C++ types without people having to write "at::Tensor" everywhere? Before this PR, `CType` held a raw string representing the type, i.e. `BaseCType("Tensor", binds)`. This PR introduces a set of singleton base C++ types in `types.py`, that know how to print their namespace. Instead, we'd write `BaseCType(tensorT, binds)`, where printing `tensorT` will properly print out "at::Tensor".
This also means that you can't create arbitrary `CTypes`. If we need a new C++ type in the codegen, we need to add it to the list in `types.py`.
One blip in the design: we don't want to change `RegistrationDeclarations.yaml`, since that'll break external backends that ingest it. I added separate functions to display types without the namespace that are used to create RegistrationDeclarations.yaml`. With an external codegen API though, we can eventually kill it :)
I also didn't realize until this PR that `Declarations.yaml` is still directly in use, by some python/autograd codegen. Rather than keep that yaml byte-for-byte compatible, I just updated the callsites in the autograd codegen to work with namespaces. In the NEXT pr, I try to clean up some of the autograd codegen to stop using raw strings to match against C++ types.
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D27708349
Pulled By: bdhirsh
fbshipit-source-id: 56a4f81fc101795bcb9ee1f722121480fb2356ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55046
Updating `returns` in the codegen to return a CType instead of a raw string.
This has benefit of putting all stringifying logic through CType, which is useful in the followup PR when I add namespaces.
I also added new CTypes for other templated C++ types: array, vector and tuple. Mostly because it makes the namespacing logic in the next PR significantly easier. It also seems more natural to me that `BaseCType` shouldn't represent specializations of templated types.
There's a little bit of weirdness, types that are currently *only* used for returns, i.e. `TupleCType`. Returns aren't named, so I opted not to give it one- so we can add it in later if we discover that we need it.
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D27708348
Pulled By: bdhirsh
fbshipit-source-id: 230b210c3e53be1bd362105fbea8451055dc59a8
Summary:
When loading optional blobs from a large file to workspace, for instance: https://fburl.com/diffusion/l0mcnofg, we are currently loading the file in multiple times. https://fburl.com/diffusion/qhbpyq0e
This diff optimized the load time by loading in the large model file only once, and using the allow_incomplete arg into LoadOp. The implementation of the LoadOp with this arg previously did not delete the blobs that were not found, which is also fixed in this diff.
Test Plan:
Existing unit tests:
```
buck test //caffe2/caffe2/fb/distribute/tests:meta_net_def_storage_utils_test
```
Many sandcastle integration tests.
scuba logs: https://fburl.com/scuba/dai_modelstore/txdf3pjt
Reviewed By: TailofJune
Differential Revision: D27575622
fbshipit-source-id: 7c2b25ef603a378e87ebdbe349c94c2f1952493c
Summary:
This PR extends `.jenkins/pytorch/print_sccache_log.py` to filter out a distracting "error" message that walterddr came across while debugging failures in https://github.com/pytorch/pytorch/issues/55176:
```
=================== sccache compilation log ===================
ERROR 2021-04-05T15:44:18Z: sccache::server: Compilation failed: Output { status: ExitStatus(ExitStatus(256)), stdout: "", stderr: "/var/lib/jenkins/.cache/torch_extensions/test_compilation_error_formatting/main.cpp: In function ‘int main()’:\n/var/lib/jenkins/.cache/torch_extensions/test_compilation_error_formatting/main.cpp:2:23: error: expected ‘;’ before ‘}’ token\n int main() { return 0 }\n ^\n" }
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56281
Test Plan: TODO (reviewers: is there an easy way to test this?)
Reviewed By: walterddr
Differential Revision: D27826064
Pulled By: samestep
fbshipit-source-id: 7322a830c1246820a5b2b7bbeaa4697ebd13b617
Summary:
This splits the previous diff into multiple parts. This introduces only the c++ files.
The unittests pass as part of the internal build. Will be put in the OSS in the later PRs
Test Plan:
`buck test mode/opt //caffe2/torch/fb/model_optimization:sparsity_test`
```
Parsing buck files: finished in 2.0 sec
Creating action graph: finished in 16.4 sec
Building: finished in 55.0 sec (100%) 20264/20264 jobs, 16 updated
Total time: 01:13.6 min
More details at https://www.internalfb.com/intern/buck/build/c9c5e69e-ce00-4560-adce-58b68bc43e47
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: 1e678a07-0689-45b4-96f3-54d0a3181996
Trace available for this run at /tmp/tpx-20210415-161113.966600/trace.log
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/3096224795029304
✓ ListingSuccess: caffe2/torch/fb/model_optimization:sparsity_test - main (4.186)
✓ Pass: caffe2/torch/fb/model_optimization:sparsity_test - test_sparse_qlinear (caffe2.torch.fb.model_optimization.test.sparsity.quantized_test.TestQuantizedSparseLayers) (1.752)
✓ Pass: caffe2/torch/fb/model_optimization:sparsity_test - test_sparse_qlinear (caffe2.torch.fb.model_optimization.test.sparsity.quantized_test.TestQuantizedSparseKernels) (1.884)
✓ Pass: caffe2/torch/fb/model_optimization:sparsity_test - test_sparse_qlinear_serdes (caffe2.torch.fb.model_optimization.test.sparsity.quantized_test.TestQuantizedSparseLayers) (2.013)
Summary
Pass: 3
ListingSuccess: 1
```
Reviewed By: raghuramank100
Differential Revision: D27812204
fbshipit-source-id: 6becaba3ab9cd054caf8b9bbae53af6d01347809
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56205
Allows for int8 modules to shadow int8 modules. This is useful when
comparing quantized models with different qconfigs.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_int8_shadows_int8
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27807405
fbshipit-source-id: 10c3bc7ab9bb1e6808aa1af23a34c7cf380465fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56195
This is outdated, removing (forgot to clean up in a previous PR).
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27805334
fbshipit-source-id: 3b035945b4928a3c727e96e0f7fe0efe201f42c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56194
Enables the NS graph matcher to also match `call_method` nodes.
These are useful for ops such as `torch.sigmoid`.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher.test_methods
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27805333
fbshipit-source-id: 509ae283db6b245671f11e3eb6b7fcb3a5735ef5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55918
Adds coverage for determining I/O dtype for various ops. This will
enable shadowing of these ops.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_op_io_dtype_coverage
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27740661
fbshipit-source-id: c5ce873ec56bffa50ca46d2fe134c70ed677e37e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55859
Adds mappings for ops which can accept either fp32 or int8 input,
such as `F.relu`. A future PR will fill out the op coverage.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_op_with_either_fp32_or_int8_input
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D27740659
fbshipit-source-id: cfc3dd58319b7161ca7f1fe05cd22d9a3ff11141
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55858
Moves the mappings of input and output dtypes of various ops
into its own file, and makes the variable names more clear. No logic
change.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D27740662
fbshipit-source-id: d384e7e542d9cc868d9cee9c53c2ac2f74a15a48
Summary:
Launch bounds for HIP were added along the way, but the smaller CUDA devices (like Jetson) also benefit from them.
So here I go over the HIP-specific launch bounds and try to generalize them to cover CUDA, too.
The long term goal is to eventually not need to resort to somewhat ad-hoc adaptations like the reduction of block size discussed in https://github.com/pytorch/pytorch/issues/8103, but have good coverage of our kernels with launch bound annotations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56143
Reviewed By: agolynski
Differential Revision: D27804640
Pulled By: ngimel
fbshipit-source-id: d4c345f9f7503e050a46361bfe2625865d0a42ba
Summary:
Currently, coverage stats is getting covered for sharded windows tests. This PR attempts to store the coverage.xml file as an artifact.
I wonder what CircleCI will do when the artifacts don't exist (for nonsharded tests), and if we could conditionally store artifacts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56179
Reviewed By: samestep
Differential Revision: D27800628
Pulled By: janeyx99
fbshipit-source-id: 919f5696c0d7b4ee0d99969f35797f5be644c364
Summary:
Resolves https://github.com/pytorch/pytorch/issues/55810 by closing some possible security holes due to using [GitHub Actions `${{ <expressions> }}`](https://docs.github.com/en/actions/reference/context-and-expression-syntax-for-github-actions#about-contexts-and-expressions) in `.github/workflows/add_annotations.yml` and also patching a few other possible scenarios that could cause the workflow to fail by a PR passing a malformed artifact.
- [x] flag and remove GitHub Actions expressions in JS scripts
- [x] don't fail the workflow if the artifact doesn't look as expected
- [x] write unit tests for `tools/extract_scripts.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56071
Test Plan:
I tested the end-to-end "Lint" and "Add annotations" system in a separate sandbox repo, including the following cases:
- well-formed artifact
- missing artifact
- artifact containing a file named `linter-output.zip` (name clash)
- artifact whose `commit-sha.txt` doesn't contain a 40-digit hex string
- artifact whose `commit-sha.txt` contains a 40-digit hex string that isn't a valid Git hash for the current repo
- in this last case, the workflow does fail, but handling that is the responsibility of [pytorch/add-annotations-github-action](https://github.com/pytorch/add-annotations-github-action), not pytorch/pytorch
To run the new unit tests added in this PR:
```
python tools/test/test_extract_scripts.py
```
Reviewed By: seemethere
Differential Revision: D27807074
Pulled By: samestep
fbshipit-source-id: e2d3cc5437fe80ff03d46237ebba289901bc567c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55550
Add a test for `symbolic_trace` into `torch.nn.functional`
Test against all `functional`s with `torch.Tensor` argument and `functional`s from `FUNCTIONALS_WITHOUT_ANNOTATION`.
```py
FUNCTIONALS_WITHOUT_ANNOTATION = (
"adaptive_max_pool1d",
"adaptive_max_pool2d",
"adaptive_max_pool3d",
"fractional_max_pool2d",
"fractional_max_pool3d",
"max_pool1d",
"max_pool2d",
"max_pool3d",
"gaussian_nll_loss",
"upsample",
"upsample_bilinear",
"upsample_nearest",
)
```
`UNTRACEABLE_FUNCTIONALS` lists 110 current untraceable `functional`s with expected `Error`.
- `BUILT_IN_FUNC`: built-in functions or built-in methods can not be traced.
- `PROXY_ITERATED`: Proxy object cannot be iterated. This can be attempted when used in a for loop or as a *args or **kwargs function argument
- `LEN_ERROR`: 'len' is not supported in symbolic tracing by default. If you want this call to be recorded, please call torch.fx.wrap('len') at module scope
- `ARG_TYPE_MISMATCH`: `functional()`: argument <name> (position <n>) must be <type>, not Proxy
- `CONTROL_FLOW`: symbolically traced variables cannot be used as inputs to control flow
- `INTERPOLATE_ARGS_CONFLICT`: When tracing the functional by calling `interpolate(input, size, scale_factor, mode="bilinear", align_corners=True)`, `ValueError("only one of size or scale_factor should be defined")` is raised
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D27659367
Pulled By: ejguan
fbshipit-source-id: d0d05e4d94e0b85f47e6c171a31f0d41b1387373
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54812
Needed for quantization since different attribute might refer to the same module instance
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D27408376
fbshipit-source-id: cada85c4a1772d3dd9502c3f6f9a56d690d527e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56174
evaluate_function:
1. calls the autograd function (call_function)
2. accumulates gradients into buffers
Previously, ThreadLocalStateGuard only covered part of `call_function`.
However, it should cover all Tensor operations in `evaluate_function`,
so this PR moves it to do so.
One alternative would have been to move ThreadLocalStateGuard to here:
71f9e99e29/torch/csrc/autograd/engine.cpp (L394)
Unfortunately that adds 2% additional instructions according to the
instruction count benchmark in the next section. This is because
`evaluate_function` does an early return:
71f9e99e29/torch/csrc/autograd/engine.cpp (L732-L735)
If this is preferred, please let me know.
Test Plan:
- run existing tests. It's hard to actually come up with a test case for
this.
Benchmark plan:
TL;DR: Instruction count decreases by a little after this PR.
```
import torch
from torch.utils.benchmark import Timer
timer = Timer(
stmt="""\
torch::autograd::grad({y}, {x}, {}, /*retain_grad=*/true);""",
setup="""\
auto x = torch::ones({}, torch::requires_grad());
auto y = x * 2;""",
language="cpp")
stats = timer.collect_callgrind()
print(stats)
```
This gave the following:
```
Before:
<torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f4b28ce6a90>
torch::autograd::grad({y}, {x}, {}, /*retain_grad=*/true);
setup:
auto x = torch::ones({}, torch::requires_grad());
auto y = x * 2;
All Noisy symbols removed
Instructions: 3514184 3514184
Baseline: 0 0
100 runs per measurement, 1 thread
After:
<torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7fdbc9d187d0>
torch::autograd::grad({y}, {x}, {}, /*retain_grad=*/true);
setup:
auto x = torch::ones({}, torch::requires_grad());
auto y = x * 2;
All Noisy symbols removed
Instructions: 3513884 3513884
Baseline: 0 0
100 runs per measurement, 1 thread
```
Reviewed By: albanD
Differential Revision: D27799283
Pulled By: zou3519
fbshipit-source-id: 0a8213824e08c04748d38e66604c73f395285d63
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56190
Previously, if we had some code that did the following:
```
- pattern A, allow_empty=False
- save module B, but throws an exception for whatever reason
- save module that causes match against A
```
Then the resulting behavior would be:
1. exception thrown, which triggers `__close__` on `PackageExporter`
2. `PackageExporter` checks that all patterns are matched against, and sees that A was not matched.
3. Error is raised that we didn't match against pattern A.
This is confusing, since the *real* error that caused packaging to fail
occurred when trying to package module B, but it's being hidden by the
error about module A (even though if packaging module B had succeeded,
there would be no error).
Change it so that the behavior looks like:
1. exception thrown, which triggers `__close__` on `PackageExporter`
2. `PackageExporter` recognizes that an exception is happening and
immediately just returns control flow to the caller to handle the "real"
exception.
Differential Revision: D27803988
Test Plan: Imported from OSS
Reviewed By: guangyuwang
Pulled By: suo
fbshipit-source-id: f67b2e96165a0547c194a8bef1af1c185452173e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56044
We want to be able to drop the dependence of full-jit deps in the auto-generated unit tests for 2 reasons:
1. Running bloaty on the auto-generated unit tests should be somewhat representative of the actual size.
2. The runtime environment of the auto-generated unit tests should be as close to the production environment as possible to ensure that we are running the tests in a production-like runtime.
Due to the dependece on full-jit, we aren't there yet. For the auto-generated tests, we probably don't need to depend on `_export_operator_list()` evetually, but for now we do since it is used to decide whether the model being run is a Metal GPU model or a CPU model, and gates whether the test runs that model or not.
Eventually, we can stop doing this in the test and do it in the codegen from PTM-CLI instead (by fetching the operators from that tool, and writing out to the BUCK file which backend(s) this model is targeting). However, that will take some time to land, so in the spirit of expediency, this change is being proposed.
Discussed this offline with iseeyuan
ghstack-source-id: 126656877
Test Plan: Build + BSB.
Reviewed By: iseeyuan
Differential Revision: D27694781
fbshipit-source-id: f31a2dfd40803c02f4fd19c45a3cc6fb9bdf9697
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56069
It's more efficient to capture a MPSImage object than copying a one from outside.
ghstack-source-id: 126552396
Test Plan:
- All operator tests pass
- Sandcastle
- CircleCI
Reviewed By: SS-JIA
Differential Revision: D27694542
fbshipit-source-id: e1bbbffc3f8c109816cb117aebd0aae8576c6c5c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50699.
The root cause was that some floating-point assertions had a "greater than or **equal to**" condition. The "equal to" part was causing flakiness due to strict equality check (`==`) in `TestCase.assertGreaterEqual()`. This PR introduces a new assertion method called `assertGreaterAlmostEqual()` in `common_utils.py` that mitigates the problem by behaving similar to `TestCase.assertAlmostEqual()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56192
Reviewed By: zhaojuanmao
Differential Revision: D27804724
Pulled By: cbalioglu
fbshipit-source-id: bc44a41ca4ce45dfee62fb3769fb47bfd9028831
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55976
- Define a concrete `DebugInfo` to collect Param comms.
- Add a macro to easily log `DebugInfo`
Test Plan:
Tested on `ads:simplified_launcher` with `dyno gputrace`
locally tested in libkinetoObserver that it can collect the debug Infobase
Reviewed By: kingchc, ilia-cher
Differential Revision: D26773447
fbshipit-source-id: a8eeede2d6dbf34d7a1b3614843b4a1baba94448
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55837
Adds a test that checks that all of the relevant op pairs defined in
`quantization_mappings.py` are also defined as related by Numerical
Suite.
Note: this does not cover all the ops, just the ones in
`quantization_mappings.py`. A future PR will fill out the remainder.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher.test_op_relationship_mapping
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27719979
fbshipit-source-id: 9e852ef94da5f7a653ea15ba52c68a89c8e30208
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55803
Makes the NS `graph_matcher.get_reversed_fusions` use the fusions
defined the FX quantization code instead of duplicating them.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27719980
fbshipit-source-id: 12e3183405181bb9001f10e765cfb4d2ffdfdd88
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55507
As titled, extends the test cases for weight extraction from
functionals to cover QAT.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27650408
fbshipit-source-id: 8ce87d56bbc0da7c2330ece71a897d6d8c5110a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55506
Makes the NS weight extraction tests also test QAT, and fixes
the mappings where necessary to cover all the fusions and make
the tests pass.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_extract_weights_mod_ptq
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_extract_weights_mod_qat
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27650409
fbshipit-source-id: c5bd9268d1bc559afc27d4c5109effd77bf1538a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55505
This necessary to add support in NS for QAT modules, to avoid
duplicating logic between NSTracer and QuantizationTracer.
The eng work to expose the custom module and class names to
the user will be in a future PR.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27650407
fbshipit-source-id: 431f47c5353b41c11371c5efa79657bfd085459a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55434
Before this PR, there was some hacky logic which determined
the input and output types of nodes based on heuristics such
as inspecting `__module__`, or assuming that an op has an
I/O dtype of `torch.float` when the heuristics did not find
any matches. This is problematic because the heuristics were not exact,
and this could result in non-sensical shadow graphs when the heuristics
would return an incorrect dtype.
This PR switches the dtype determination to an allowlist system,
where we specify exactly what the dtypes are for the nodes or modules
which are in an allowlist, and we add an `UNKNOWN` type for everything
else. The shadow logic is changed to skip inserting shadows on any
function or module where the I/O dtype is unknown.
The current allowlist only contains functions necessary for the
currently existing tests. Filling out the allowlist with all necessary
torch functions is left for a future PR.
As a result of this, we can do the following (also implemented in this PR):
1. enable graph matching on nodes with equal types (for example,
F.linear and F.linear). The restriction that only nodes with equal types
was in the code as a placeholder, it's better to allow comparisons of
nodes of equal types. One case where this is useful is unshadowed
activations.
2. enable models with user defined modules to be passed to Numeric Suite
APIs without errors.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher
python test/test_quantization.py TestFXGraphMatcherModels
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27622418
fbshipit-source-id: 40dcba0222c01154c141467640c1eb89725f33a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55988
Pull Request resolved: https://github.com/pytorch/kineto/pull/165
as part of the ClientTraceActivity -> GenericTraceActivity migration, move all the metadata fields to JSON encoded string
Test Plan:
- `buck build`
- tested with subsequent diffs
Reviewed By: gdankel
Differential Revision: D27340314
fbshipit-source-id: f55b77a779e4bda1fb8667cb4e0f4252b93af5ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53238
There is a tension for the Vitals design: (1) we want a macro based logging API for C++ and (2) we want a clean python API. Furthermore, we want to this to work with "print on destruction" semantics.
The unfortunate resolution is that there are (2) ways to define vitals:
(1) Use the macros for local use only within C++ - this keeps the semantics people enjoy
(2) For vitals to be used through either C++ or Python, we use a global VitalsAPI object.
Both these go to the same place for the user: printing to stdout as the globals are destructed.
The long history on this diff shows many different ways to try to avoid having 2 different paths... we tried weak pointers & shared pointers, verbose switch cases, etc. Ultimately each ran into an ugly trade-off and this cuts the difference better the alternatives.
Test Plan:
buck test mode/dev caffe2/test:torch -- --regex vital
buck test //caffe2/aten:vitals
Reviewed By: orionr
Differential Revision: D26736443
fbshipit-source-id: ccab464224913edd07c1e8532093f673cdcb789f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56082
The native_functions.yaml changes were done by codemod using the
following script:
```
import ruamel.yaml
from ruamel.yaml.tokens import CommentToken
from ruamel.yaml.error import CommentMark
from tools.codegen.model import * # noqa: F403
with open("aten/src/ATen/native/native_functions.yaml", "r") as f:
contents = f.read()
yaml = ruamel.yaml.YAML()
yaml.preserve_quotes = True
yaml.width = 1000
yaml.boolean_representation = ['False', 'True']
r = yaml.load(contents)
convert = '''\
acos
acosh
asin
asinh
atan
atanh
cos
cosh
digamma
erf
erfc
erfinv
exp
expm1
exp2
lgamma
log
log10
log1p
log2
reciprocal
sigmoid
sin
sinc
sinh
special_entr
sqrt
tan
tanh'''.split()
for e in r:
f = NativeFunction.from_yaml(e, Location("", 0))
if f.structured or f.structured_delegate is not None:
continue
n = f.func.name.name.base
if n not in convert:
continue
# mutate e to make changes
if f.func.kind() == SchemaKind.out:
e.insert(1, 'structured', True)
e.insert(2, 'structured_inherits', 'TensorIteratorBase')
else:
# TODO: The .out overload assumption is not sound in general
e.insert(1, 'structured_delegate', f'{n}.out')
e['dispatch'].pop('CPU', None)
e['dispatch'].pop('CUDA', None)
e['dispatch'].pop('CPU, CUDA', None)
e['dispatch'].pop('CompositeExplicitAutograd', None)
*_, last_k = e.keys()
needs_fixup = False
if not e['dispatch']:
if last_k == 'dispatch':
needs_fixup = True
del e['dispatch']
# Manually fix up newlines at the end, because ruamel
# made some bad life choices about where to associate trailing
# whitespace for nested dicts; see
# https://stackoverflow.com/questions/42172399/modifying-yaml-using-ruamel-yaml-adds-extra-new-lines
if needs_fixup:
*_, last_k = e.keys()
# post_key, pre_key, post_value, pre_value
e.ca.items[last_k] = [None, None, CommentToken('\n\n', CommentMark(0), None), None]
with open("aten/src/ATen/native/native_functions.yaml.new", "w") as f:
yaml.dump(r, f)
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D27777769
Pulled By: ezyang
fbshipit-source-id: 1ecbac7cb3e0093167bb61c7d2b1ecb95b8ae17c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56078
This is in preparation for making all unary functions structured.
I don't actually have to make them structured yet as TensorIterator&
casts to TensorIteratorBase&
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D27777768
Pulled By: ezyang
fbshipit-source-id: 05a3a95f200698eef72c5c74fff85fe881e1c4a3
Summary: Add cost inference for MulGradient operator; also whitelist MulGradient in COMPUTE_OP_TYPES in dense_perf_estimation
Test Plan: buck run //caffe2/caffe2/python/operator_test:elementwise_ops_test
Reviewed By: CrazySherman
Differential Revision: D27614003
fbshipit-source-id: 30901e5e2b6ce7e2183c2362d1bf9f895046cf55
Summary:
Per title
I've revamped size checks a bit to provide better error message if `self` is of the wrong size, also added check that inplace variant has correct `self` size
Ref: https://github.com/pytorch/pytorch/issues/55070
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55746
Reviewed By: ezyang
Differential Revision: D27782980
Pulled By: ngimel
fbshipit-source-id: 6ba949b682b8fd1170d0304da0ed348dd1a7b8c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56120
This reverts commit ad17fadbfc786dc1ccb42e822208ff03c2a2b72c (D27786457).
The big annoyance here is that depending on the threading mode you may not be
able to toggle num_threads at will, so the fusion tests won't fail.
I hate this solution, but I'm adding a secondary override for the TE fuser.
Now you need to both turn on fusion (_jit_override_can_fuse_on_cpu), and you're
OK if you're running with 1 thread, or you can add
`_jit_set_texpr_parallel_cpu_enabled` to enable it anyways.
This is (a) mainly for tests, since a real user probably won't fiddle aimlessly
with the thread count, and (b) will go away once NNC's threading support is
fully baked.
Test Plan: Imported from OSS
Reviewed By: Krovatkin
Differential Revision: D27788199
Pulled By: bertmaher
fbshipit-source-id: 070d04474f15e9689dbdf8cc1fde43050c6506b1
Summary:
Revert "Revert D27449031 (2a7df657fe): [pytorch][PR] [ROCm] use hiprtc precompiled header". Reland PR https://github.com/pytorch/pytorch/issues/54350.
This reverts commit 204ac21bf1457022caab197001788239720b96d6.
The original PR was reverted under suspicion that it was causing CI instability, but it was instead due to a hardware failure.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55965
Reviewed By: jbschlosser
Differential Revision: D27755907
Pulled By: malfet
fbshipit-source-id: 75bf0b9d888df3dee62f00a366b1123757e0474e
Summary:
This PR introduces a basic timer type that periodically calls a specified function. Its main use in the upcoming `DynamicRendezvousHandler` implementation will be to send periodic keep-alive updates in a background thread.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55919
Reviewed By: tierex
Differential Revision: D27740823
Pulled By: cbalioglu
fbshipit-source-id: e46fc848ab033995946a38a29c01d67d387a4cf5
Summary:
The name `should_check_autodiff` became `should_autodiff_node` but documentation did not change. The identifier is used in `test/test_jit.py`. It seems the file is too big for github to link to the line, but it is the return value from `normalize_check_ad`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56013
Reviewed By: agolynski
Differential Revision: D27800008
Pulled By: Lilyjjo
fbshipit-source-id: 88a43c14c0f48fb3f94792e3fd6de2bd6a59a1a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55935
Add a new `DB::SetOptions()` method to allow passing options to the DB as part
of Save operations. This can be used for passing in options to control the
serialization behavior, such as rate limits or other parameters. The
serialization options are passed is an opaque string, so that different DB
implementations may choose their own options and options format.
This also adds a new `db_options` parameter to the `Save` operator.
This allows users to pass in the DB options when saving data.
ghstack-source-id: 126589771
Test Plan:
I don't have any tests in this diff since no DB implements options yet. The
next diff in the stack includes an options implementation, along with unit
tests that verify the options are passed in correctly.
Differential Revision: D27729461
fbshipit-source-id: 4d03250c389c66a049cdee1d05e082f5649ac0f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56119
There are apparently still more issues with fp16 on LLVM so let's just
nuke it from orbit while we develop a robust workaround.
ghstack-source-id: 126619411
Test Plan: compile
Reviewed By: ZolotukhinM
Differential Revision: D27787080
fbshipit-source-id: 9e771211fe48266f50fca1de8d40295922da5bca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56117
I was debugging an issue during instruction selection and wanted to
see the input bitcode. This way we always print it before going into the asm
generation pass.
ghstack-source-id: 126592596
Test Plan: Run with `PYTORCH_JIT_LOG_LEVEL=">>llvm_codegen"`
Reviewed By: huiguoo
Differential Revision: D27781683
fbshipit-source-id: 84635d0ca2a1318ae7a9a73cc1d2df450d8b6a08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55857
Since OpenCV supports more than just the JPEG file format.
ghstack-source-id: 126528422
Test Plan: Build
Reviewed By: JacobSzwejbka
Differential Revision: D27722865
fbshipit-source-id: 6cf83bf187bb1fb3a28e3aa2a011959ef8925449
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55778
The RPC suite takes very long to run, and most of it is CPU-only. As long as we run the CPU-only part on some CPU worker on CircleCI, we can skip it on the GPU workers (which are expensive and we should waste their time).
ghstack-source-id: 126270873
Test Plan: Exported to CircleCI and checked that the CPU-only part still runs on the CPU workers but doesn't on the GPU workers.
Reviewed By: mrshenli
Differential Revision: D27705941
fbshipit-source-id: a0a509d6e72cf69e417f4b48336df534b070a66d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56048
This reverts commit c411017a41988e9c5184279c1ec7dd7ef4e1a6fe.
This implementation broke CI in pytorch/vision and it's not handling
tags properly. So I want to revert it first to unblock vision CI and
send out a proper fix later.
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D27771701
Pulled By: ailzhang
fbshipit-source-id: 932f9be72a1ae1816f4032643b3c2dde0cb7ae4c
Summary:
This PR includes the auxiliary types used by the upcoming implementation of the `DynamicRendezvousHandler`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55932
Test Plan: Run the existing and newly-introduced unit/integration tests.
Reviewed By: tierex
Differential Revision: D27742329
Pulled By: cbalioglu
fbshipit-source-id: cf2e0d88042909739e7c37c25b4b90192c26e198
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56037
The diff introduces new `torch.distributed.elastic_launch` and removes internals of `torch.distributed.launch` keeping backwards compatibility.
Since torchelastic and torch.launch are not fully compatible due to `--use_env` arg, the `torch.distributed.launch` deprecation is going to be iterative: as part of pytorch 1.9 we are going to deprecate it, and in the following releases we will remove `torch.distributed.launch`
The diff leaves `torchelastic.distributed.launch` module, and the follow up diffs will migrate the users form `torchelastic.distributed.launch` to `torch.distributed.elastic_launch`
Test Plan: buck test mode/dev-nosan //pytorch/elastic/torchelastic/distributed/...
Reviewed By: cbalioglu
Differential Revision: D27753803
fbshipit-source-id: 5f24bcfdcb70356f0787b11f6cb9479f3515fb47
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55659
As per https://github.com/pytorch/pytorch/issues/55583, this is the most expensive distributed test.
Instead of waiting for process 0 in this test to be taken down by
nccl_async_error_handling, just remove the barrier and let the process exit
when the backend is NCCL.
A slight downside here is that the test no longer verifies that the process
would be brought down by nccl_async_error_handling, but
nccl_async_error_handling is already well tested in other tests. If we feel we
need to ensure this for this test, then we can pass in a process group with a
smaller timeout as an alternative solution.
The test now runs in 4-6s as opposed to 70. Ran the test 1000 times to verify
no flakiness
ghstack-source-id: 126590904
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D27672161
fbshipit-source-id: 38fb518606daac9b0390ca4c3ce1a72dc2da36fc
Summary:
This way, the user would just have to run the `regenerate_cancel_redundant_workflow.py` script to fix the inconsistency (instead of manual stuff).
Lots of the indentation changes were caused by regenerating the file, which I don't think is terrible, and ruamel.yaml did great at preserving comments and order and such!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56092
Reviewed By: samestep
Differential Revision: D27780877
Pulled By: janeyx99
fbshipit-source-id: dd2996a88cd70a83d8daac33ba6659f93add8b92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55075
Constructs and passes in a mapping with parameter names to Reducer to log information about unused parameters in error messages about unused parameters/not all parameters getting gradient.
Use case:
1) User runs DDP forward + bwd, and it has some unused parameters that will result in ddp error in next iteration
2) Next forward pass calls `Reducer::ensure_prior_reduction_finished()` where we check all params got gradient from the previous bwd pass. DDP would throw here in this case.
3) Reducer maintains mapping and tracks used parameters, and computes which parameters did not get gradient and logs this as part of the error.
Implementation details:
0) The following is only enabled for debug modes of INFO or DETAIL.
1) To save memory, we don't map param -> param name so that we don't have to copy the entire tensor, instead we map param_index -> param_name and use the existing concept of variable_index in Reducer to look up parameter names.
2) DDP constructs param index -> param name mapping. The name is the fully qualified name: f"{module_name}:{param_name}" and passes it into Reducer
3) Reducer maintains per-iteration std::set<int> of variable indices that have had `mark_variable_ready` called.
4) When some params go unused, we take a set difference to detect the unused params.
5) Unittests to test the logged unused params, as well as for nested modules, are added
ghstack-source-id: 126581051
Test Plan: CI, UT
Reviewed By: zhaojuanmao
Differential Revision: D27356394
fbshipit-source-id: 89f436af4e74145b0a8eda92b3c4e2af8e747332
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56016
Missed these because I don't build on CUDA
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D27765124
Pulled By: ezyang
fbshipit-source-id: aa202f594659d53c903b88c9d4a4cbb0e1c0b40a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55799
I'm going to change the implementation of cdata soon so I need to
abstract over cdata access with a function. Additionally, many
users are casting manually casting to THPVariable to access
the member so I can remove these unsafe casts in the client code
(the implementation, of course, is still doing an unsafe cast.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27712130
Pulled By: ezyang
fbshipit-source-id: 95fcc013bf3913d67f2c634068eb5b3aab144cb3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55798
I'm going to change how cdata is implemented internally, so I want to
make all callsites call through THPVariable_Unpack even if they
actually have a THPVariable in hand
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D27712131
Pulled By: ezyang
fbshipit-source-id: bd2eb1e43c52c6b7a776ff3a45350a23934e643c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55797
In all of these cases, the inside of the function didn't make use
of the fact that the tensor was a mutable reference
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D27712132
Pulled By: ezyang
fbshipit-source-id: 99e0bb1d783f63d2d42ab53d3d406b2064405ef4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54085
Fixes https://github.com/pytorch/pytorch/issues/50121.
This fixes two similar issues pointed out with the dtype that `torch.pow` performs its computation. Thanks ngimel for spotting the issues originally (comments [here](https://github.com/pytorch/pytorch/pull/53669#discussion_r594624355) and [here](https://github.com/pytorch/pytorch/pull/53669#discussion_r594719704))!
Before:
```
>>> torch.pow(2, torch.tensor([17], dtype=torch.uint8), out=torch.tensor([0]))
tensor([0])
>>> torch.pow(2, torch.tensor(17, dtype=torch.uint8), out=torch.tensor(0))
tensor(131072)
>>> torch.pow(2, torch.tensor([17], dtype=torch.uint8, device='cuda'), out=torch.tensor([0], device='cuda'))
tensor([131072], device='cuda:0')
>>> torch.pow(2, torch.tensor(17, dtype=torch.uint8, device='cuda'), out=torch.tensor(0, device='cuda'))
tensor(131072, device='cuda:0')
```
After:
```
>>> torch.pow(2, torch.tensor([17], dtype=torch.uint8), out=torch.tensor([0]))
tensor([0])
>>> torch.pow(2, torch.tensor(17, dtype=torch.uint8), out=torch.tensor(0))
tensor(0)
>>> torch.pow(2, torch.tensor([17], dtype=torch.uint8, device='cuda'), out=torch.tensor([0], device='cuda'))
tensor([0], device='cuda:0')
>>> torch.pow(2, torch.tensor(17, dtype=torch.uint8, device='cuda'), out=torch.tensor(0, device='cuda'))
tensor(0, device='cuda:0')
```
In all four cases above, `tensor(0, ...)` is the correct value because the computed "common dtype" among the inputs is expected to be `uint8`. Computing `2 ** 7` in uint8 will then overflow to zero. Finally, we cast the computed output to the output tensor's dtype, which is `int32`.
There were two separate issues fixed in this PR: one for cpu and one for cuda:
* For CPU, The `pow(Scalar, Tensor)` overload wasn't calling `set_wrapped_number(true)` after wrapping the scalar in a Tensor, which caused the "promoted" scalar to incorrectly participate in type promotion (see the documented behavior [here](aa8714dfed/c10/core/TensorImpl.h (L590)))
* For CUDA, the cuda kernels defined in `PowKernel.cu` were using the output's dtype to run the computation, instead of the common dtype.
As an aside: The CPU and CUDA kernels actually both use `iter.dtype()` instead of `iter.common_dtype()` to run the computation, which I fixed. The reason that only manifested here for CUDA is because TensorIterator has cpu-specific logic to create temporary outputs with the intermediate dtype (shown [here](aa8714dfed/aten/src/ATen/TensorIterator.cpp (L349))). I'm not sure what the end state is there- I can imagine that being something we're more okay doing for cpu than for cuda, but it also leads to hard-to-track-down inconsistencies between the two like in this case.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27096330
Pulled By: bdhirsh
fbshipit-source-id: a7e2909243851625cb3056d1e7abb2383bfe95f2
Summary:
This is a reflection of recent failures in https://github.com/pytorch/pytorch/issues/55753 and https://github.com/pytorch/pytorch/issues/55522.
We are lacking a test to safeguard these test env var.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55931
Test Plan:
1. CI
2. Run locally using `python test/test_testing.py -k test_filtering_env_var -v`
- gives failure on 2ca45cb9e8 and d0cd16899f
- passes on 159e1100bf and current master
Reviewed By: jbschlosser
Differential Revision: D27747537
Pulled By: walterddr
fbshipit-source-id: c88e1c818199c7838866037d702d4012cacf510e
Summary:
Reland of https://github.com/pytorch/pytorch/pull/49098
See original issue for details.
The only difference with previous PR is the fix of the _embedding_bag_dense_backward formula to stop declaring a backward formula for an argument that does not exists.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56083
Reviewed By: samestep
Differential Revision: D27778221
Pulled By: albanD
fbshipit-source-id: 159ef91ca931ef2ccfbc3d1c46c7880c32919dc9
Summary:
- This change is required to handle the case when hipcc is
updated to the latest using update-alternatives.
- Update-alternatives support for few ROCm binaries is available
from ROCm 4.1 onwards.
- This change doesnt not affect any previous versions of ROCm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55968
Reviewed By: mruberry
Differential Revision: D27785123
Pulled By: ezyang
fbshipit-source-id: 8467e468d8d51277fab9b0c8cbd57e80bbcfc7f7
Summary:
Reference: https://github.com/pytorch/pytorch/issues/50345
Changes:
* Add `i0e`
* Move some kernels from `UnaryOpsKernel.cu` to `UnarySpecialOpsKernel.cu` to decrease compilation time per file.
Time taken by i0e_vs_scipy tests: around 6.33.s
<details>
<summary>Test Run Log</summary>
```
(pytorch-cuda-dev) kshiteej@qgpu1:~/Pytorch/pytorch_module_special$ pytest test/test_unary_ufuncs.py -k _i0e_vs
======================================================================= test session starts ========================================================================
platform linux -- Python 3.8.6, pytest-6.1.2, py-1.9.0, pluggy-0.13.1
rootdir: /home/kshiteej/Pytorch/pytorch_module_special, configfile: pytest.ini
plugins: hypothesis-5.38.1
collected 8843 items / 8833 deselected / 10 selected
test/test_unary_ufuncs.py ...sss.... [100%]
========================================================================= warnings summary =========================================================================
../../.conda/envs/pytorch-cuda-dev/lib/python3.8/site-packages/torch/backends/cudnn/__init__.py:73
test/test_unary_ufuncs.py::TestUnaryUfuncsCUDA::test_special_i0e_vs_scipy_cuda_bfloat16
/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.8/site-packages/torch/backends/cudnn/__init__.py:73: UserWarning: PyTorch was compiled without cuDNN/MIOpen support. To use cuDNN/MIOpen, rebuild PyTorch making sure the library is visible to the build system.
warnings.warn(
-- Docs: https://docs.pytest.org/en/stable/warnings.html
===================================================================== short test summary info ======================================================================
SKIPPED [3] test/test_unary_ufuncs.py:1182: not implemented: Could not run 'aten::_copy_from' with arguments from the 'Meta' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'aten::_copy_from' is only available for these backends: [BackendSelect, Named, InplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, UNKNOWN_TENSOR_TYPE_ID, AutogradMLC, AutogradNestedTensor, AutogradPrivateUse1, AutogradPrivateUse2, AutogradPrivateUse3, Tracer, Autocast, Batched, VmapMode].
BackendSelect: fallthrough registered at ../aten/src/ATen/core/BackendSelectFallbackKernel.cpp:3 [backend fallback]
Named: registered at ../aten/src/ATen/core/NamedRegistrations.cpp:7 [backend fallback]
InplaceOrView: fallthrough registered at ../aten/src/ATen/core/VariableFallbackKernel.cpp:56 [backend fallback]
AutogradOther: registered at ../torch/csrc/autograd/generated/VariableType_4.cpp:8761 [autograd kernel]
AutogradCPU: registered at ../torch/csrc/autograd/generated/VariableType_4.cpp:8761 [autograd kernel]
AutogradCUDA: registered at ../torch/csrc/autograd/generated/VariableType_4.cpp:8761 [autograd kernel]
AutogradXLA: registered at ../torch/csrc/autograd/generated/VariableType_4.cpp:8761 [autograd kernel]
UNKNOWN_TENSOR_TYPE_ID: registered at ../torch/csrc/autograd/generated/VariableType_4.cpp:8761 [autograd kernel]
AutogradMLC: registered at ../torch/csrc/autograd/generated/VariableType_4.cpp:8761 [autograd kernel]
AutogradNestedTensor: registered at ../torch/csrc/autograd/generated/VariableType_4.cpp:8761 [autograd kernel]
AutogradPrivateUse1: registered at ../torch/csrc/autograd/generated/VariableType_4.cpp:8761 [autograd kernel]
AutogradPrivateUse2: registered at ../torch/csrc/autograd/generated/VariableType_4.cpp:8761 [autograd kernel]
AutogradPrivateUse3: registered at ../torch/csrc/autograd/generated/VariableType_4.cpp:8761 [autograd kernel]
Tracer: registered at ../torch/csrc/autograd/generated/TraceType_4.cpp:9348 [kernel]
Autocast: fallthrough registered at ../aten/src/ATen/autocast_mode.cpp:250 [backend fallback]
Batched: registered at ../aten/src/ATen/BatchingRegistrations.cpp:1016 [backend fallback]
VmapMode: fallthrough registered at ../aten/src/ATen/VmapModeRegistrations.cpp:33 [backend fallback]
==================================================== 7 passed, 3 skipped, 8833 deselected, 2 warnings in 6.33s =====================================================
```
</details>
TODO:
* [x] Check rendered docs (https://11743402-65600975-gh.circle-artifacts.com/0/docs/special.html)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54409
Reviewed By: jbschlosser
Differential Revision: D27760472
Pulled By: mruberry
fbshipit-source-id: bdfbcaa798b00c51dc9513c34626246c8fc10548
Summary:
This PR adds the functionality to use cusolver potrs as the backend of cholesky_inverse for batch_size == 1 on CUDA.
Cusolver `potri` is **not** used, because
- it only returns the upper or lower triangular matrix as a result. Although the other half is zero, we may still need extra kernels to get the full Hermitian matrix
- it's no faster than cusolver potrs in most cases
- it doesn't have a batched version or 64-bit version
`cholesky_inverse` dispatch heuristics:
- If magma is not installed, or batch_size is 1, dispatch to `cusolverDnXpotrs` (64 bit) and `cusolverDn<T>potrs` (legacy).
- Otherwise, use magma.
See also https://github.com/pytorch/pytorch/issues/42666#47953
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54676
Reviewed By: ngimel
Differential Revision: D27723805
Pulled By: mruberry
fbshipit-source-id: f65122812c9e56a781aabe4d87ed28b309abf93f
Summary:
MAGMA_HOME was previously set for the ubuntu-rocm/Dockerfile. However, this missed centos builds as well as any builds that do not use the CI image environments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54511
Reviewed By: jbschlosser
Differential Revision: D27755983
Pulled By: malfet
fbshipit-source-id: 1ffd2cd100f4221c2bb64e6915fa3372ee1f6247
Summary:
Many model pipelines/workflows don't use MAGMA even though it is included in the build by default. Leaving MAGMA kernels out of the build can save 60+MB of GPU memory when loading `libtorch_cuda.so` (tested on V100, current upstream master).
A current sharp corner of this flag is that toggling it when rebuilding requires `torch/include/THC/THCGeneral.h` to be *manually* deleted by the user, as even running `make clean` or `setup.py` with `--cmake` does not properly regenerate it with the appropriate substitution for `#cmakedefine USE_MAGMA`. Is there a way to force the regeneration of the header during a rebuild?
CC malfet ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55994
Reviewed By: mruberry
Differential Revision: D27766287
Pulled By: malfet
fbshipit-source-id: 93deca57befa0febb9c5b7875ecf0015c547d421
Summary:
Also, add `-Werror` flag to prevent this regressions from happening in
the future
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56095
Reviewed By: walterddr
Differential Revision: D27781603
Pulled By: malfet
fbshipit-source-id: 2a404788a965c380ff9feb72d0b2d967b131371f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55886
We've imported llvm's MathExtras header, but now that we want to also
include LLVM (which includes its own MathExtras), we need to guard the c10
version appropriately (or interwine llvm more deeply with our build than just
the CPU fuser, which I'm not super excited about doing just yet).
ghstack-source-id: 126375067
Test Plan: build
Reviewed By: ZolotukhinM
Differential Revision: D27731038
fbshipit-source-id: 7c136341d6b433b3876ee983820016df75c14dec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56094
Now FunctionCalls are merged with Loads and vectorization for
intermediate values automatically started to work.
Fixes#53553.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D27781519
Pulled By: ZolotukhinM
fbshipit-source-id: 1ed68ca2399e9bd4598639bd6dd8f369365f0ef0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55687
The diff makes sure that users can transfer the following parameters:
* master_addr
* master_port
* node_rank
* use_env
The diff implement StaticTCPRendezvous that creates a store with listener on agent rank #0
The diff modifies caffe2/rendezvous: If the worker process launched with torchelastic agent, the worker processes will create a PrefixStore("worker/") from TCPStore without listener.
The diff adds macros functionality to torch/distributed/ealstic/utils that helps to resolve local_rank parameter.
Test Plan: buck test mode/dev-nosan //pytorch/elastic/torchelastic/distributed/test:launch_test
Reviewed By: cbalioglu, wilson100hong
Differential Revision: D27643206
fbshipit-source-id: 540fb26feac322cc3ec0a989fe53324755ccc4ea
Summary:
This PR add a `--mode` flag and a script to collect microbenchmarks in a single JSON file. I also added a version check since benchmarks are expected to evolve; this also turned up a determinism bug in `init_from_variants`. (`set` is not ordered, unlike `dict`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55428
Test Plan:
Run in CI
CC: ngimel wconstab ezyang bhosmer
Reviewed By: mruberry
Differential Revision: D27775284
Pulled By: robieta
fbshipit-source-id: c8c338fedbfb2860df207fe204212a0121ecb006
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55957
This diff adds an execution graph observer that tracks all operators (dispatcher autograd, jit, user defined, etc.) and their inputs and outputs. The results are written to a temp JSON file which can be used for further analysis. This support various use cases, such as dependency analysis, performance optimizations, etc.
Some minor refactoring of existing code for clarity and completeness.
Test Plan:
Example output:
{F603167736}
```
=> buck build caffe2/torch/fb/observers:execution_graph_observer_runner --show-output
=> buck-out/gen/caffe2/torch/fb/observers/execution_graph_observer_runner --pytorch_enable_execution_graph_observer=true --pytorch_execution_graph_observer_iter_label="## START ##" --pytorch_execution_graph_observer_iter_target=3
I0414 01:26:55.834039 1038798 ExecutionGraphObserver.cpp:408] Enabled PyTorch execution graph observer
I0414 01:26:55.834717 1038798 ExecutionGraphObserver.cpp:411] Matching iteration start label: "## START ##"
I0414 01:26:55.834940 1038798 ExecutionGraphObserver.cpp:423] Target iteration: 3
I0414 01:26:55.835962 1038798 ExecutionGraphObserverRunner.cpp:50] Running test execution graph observer runner.
I0414 01:26:55.836180 1038798 ExecutionGraphObserverRunner.cpp:51] iterations: 10
I0414 01:26:55.836419 1038798 ExecutionGraphObserverRunner.cpp:52] output file name: /tmp/pytorch_execution_graph_1618388815_1038798_3.json
I0414 01:26:56.246432 1038798 ExecutionGraphObserver.cpp:137] Writing PyTorch execution graph to: /tmp/pytorch_execution_graph_1618388815_1038798_3.json
I0414 01:26:56.278715 1038798 ExecutionGraphObserver.cpp:314] PyTorch execution graph is written to file: /tmp/pytorch_execution_graph_1618388815_1038798_3.json
```
see `/tmp/pytorch_execution_graph_[timestamp]_[process_id]_[iter_target].json`
Reviewed By: albanD
Differential Revision: D27238906
fbshipit-source-id: 3eb717d7d512e2d51d3162e9995b1ccd18e5a725
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55996
**Sumamary**
This commit modifies `PackageExporter.save_module` so that the `module`
argument can be either a string (`str`) or a module
(`types.ModuleType`).
**Test Plan**
This commit adds a unit test similar to `TestSaveLoad.test_save_module`
that tests that calling `save_module` with a module object works.
**Fixes**
This commit fixes#55939.
Test Plan: Imported from OSS
Reviewed By: jamesr66a, huiguoo
Differential Revision: D27771781
Pulled By: SplitInfinity
fbshipit-source-id: 57c8cf45575bb8dcfca711759fadfff72efb35e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55811
- Added manage_graph_output_memory flag to opts (default false)
- Added checking for flag dependency between enable_out_variant and optimize_graph_output_memory and optimize_memory
- Minor refactoring for readability
Test Plan: buck test mode/dev //caffe2/caffe2/fb/predictor:pytorch_predictor_test -- --exact 'caffe2/caffe2/fb/predictor:pytorch_predictor_test - PyTorchPredictor.StaticRuntime
Reviewed By: hlu1
Differential Revision: D27573780
fbshipit-source-id: 28698657f686f27b8ad60e1276cdf17402d2cf91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56059
The lint doesn't do very much, mostly it enforces that indentation
is consistent. The real point of the lint is to just make sure
that we can still do surgery on codemod with tools like ruamel,
by reusing the configuration in this script.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D27774590
Pulled By: ezyang
fbshipit-source-id: c26bc6c95a478bd9b86387b18de7e906e7d13193
Summary:
Clang-Tidy displayed that it's possible to make some methods static and const in Context class. So I made.
It also shows that it has some unused headers from standard libraries included, which i will fix with a next PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55942
Reviewed By: mruberry
Differential Revision: D27766213
Pulled By: bdhirsh
fbshipit-source-id: 4bd9b92c0b8e5c540ac94fbd2bdace64949946e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56057
Just to make sure we don't add anything there that'd break python 2 users from receiving the correct error message
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D27774120
Pulled By: seemethere
fbshipit-source-id: e40a1a2672a69eed3b6e834b1acbb7a04c0adec1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54264
**Changes**
- Creates new listener thread on each client to run the callback
- Create new class which listener thread and master thread derive from, this class is used to handle shut down and clean up of the thread in windows and linux
- Add watchKey method and update any functions that changes the key value.
**Background**
This PR adds functionality to TCPStore to allow users to watch a key and execute a callback on key change.
It introduces this a new watchKey() API:
`TCPStore::watchKey(const std::string& key, std::function<void(std::string, std::string)> callback)` which has parameters `key` and `callback(old_key, new_key)` to run on key change. Since current methods are blocking, for example in`TCPStore::get()` a worker will send a "get key" request to the master -> wait for a response back -> then exit the function and return the value to user, we need a non-blocking, asynchronous way to execute the callback whenever a key changes. This is done by creating a new listener thread on each client which the master can communicate with.
Right now, the API is C++ only and only for TCPStore, the internal use case is for elastic RPC. We will have an internal key such as `_NumNodes` and all nodes in the elastic RPC group will watch this key. When a node leaves, this key will be updated and each node will execute a callback to clean up Autograd context and RRef context.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D27709912
Pulled By: H-Huang
fbshipit-source-id: 619aa3b2a8eb23f4be5f5736efdcca6c175aadf3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56039
Python will try to eagerly resolve the name references even if
the import failed. Quote them so that it doesn't.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D27770536
Pulled By: ezyang
fbshipit-source-id: b111739289498f9bab856fb9424f3080efee4ee0
Summary:
The Python traceback on a cmake invocation is meaningless to most developers, so this PR wraps it in a `try..catch` so we can ignore it and save scrolling through the 20-or-so lines.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55986
Pulled By: driazati
Reviewed By: wanchaol
Differential Revision: D27769304
fbshipit-source-id: 5889eea03db098d10576290abeeb4600029fb3f2
Summary:
Related to https://github.com/pytorch/pytorch/issues/52256
Use autosummary instead of autofunction to create subpages for optim and cuda functions/classes.
Also fix some minor formatting issues in optim.LBFGS and cuda.stream docstings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55673
Reviewed By: jbschlosser
Differential Revision: D27747741
Pulled By: zou3519
fbshipit-source-id: 070681f840cdf4433a44af75be3483f16e5acf7d
Summary:
Related to https://github.com/pytorch/pytorch/issues/52256
Use autosummary instead of autofunction to create subpages for autograd functions. I left the autoclass parts intact but manually laid out their members.
Also the Latex formatting of the spcecial page emitted a warning (solved by adding `\begin{align}...\end{align}`) and fixed alignment of equations (by using `&=` instead of `=`).
zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55672
Reviewed By: jbschlosser
Differential Revision: D27736855
Pulled By: zou3519
fbshipit-source-id: addb56f4f81c82d8537884e0ff243c1e34969a6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55990
Reland of https://github.com/pytorch/pytorch/pull/55197, which fails windows test that was only run on master.
Disabled these tests for windows, similar to they are disabled on MacOS. The reason for disabling as that they use libuv transport which does not have as robust error handling as tcp on linux. The result is that non-zero ranks that were healthy don't throw immediately (like they do on linux) but they throw on timeout. The error handling still occurs as expected on rank 0 for all platforms.
ghstack-source-id: 126478371
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D27758424
fbshipit-source-id: d30841c8dda77f51b09a58161e638657ef758e63
Summary:
Up until this PR, the top-level `total_seconds` stat we've been uploading to S3 has only included suites longer than one second. This PR corrects that issue, and also clarifies the script's textual output for "longest tests of entire run".
(Note that the `total_time` local variable is passed as the `total_seconds` parameter in the call to `assemble_s3_object`.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56040
Test Plan:
Create a simple test file (call it `test_quick_maths.py`) with these contents:
```py
from torch.testing._internal.common_utils import TestCase, run_tests
class TestQuickMaths(TestCase):
def test_two_plus_two(self):
self.assertEqual(2 + 2, 4)
if __name__ == '__main__':
run_tests()
```
Run it and save the test results:
```sh
rm -r /tmp/reports ; python3 test_quick_maths.py --save-xml=/tmp/reports
```
Then display them using the script:
```sh
tools/print_test_stats.py /tmp/reports
```
- Before this PR:
```
No scribe access token provided, skip sending report!
Total runtime is 0:00:00
0 longest tests of entire run:
```
- With this PR:
```
No scribe access token provided, skip sending report!
Total runtime is 0:00:00.108000
0 longest tests of entire run (ignoring suites totaling less than 1.0 seconds):
```
If you were to upload this to S3 (see https://github.com/pytorch/pytorch/issues/49190 for an example of how to do this manually), the top-level `total_seconds` field should also change from `0` to `0.108`.
Reviewed By: janeyx99
Differential Revision: D27770666
Pulled By: samestep
fbshipit-source-id: 8255a4726ab3a692bbeff4c48974fbb3c6375142
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55970
LLVM's support for float16 is not great, and we were seeing assertion
failures trying to generate code for vectorized uses. I note that clang
doesn't even try to vectorize operations involving half:
https://gcc.godbolt.org/z/86MW4xr17, so that's a good sign we shouldn't either.
Fixes#55905
ghstack-source-id: 126511474
Test Plan: pytest test_jit_fuser_te.py -k test_isnan
Reviewed By: asuhan
Differential Revision: D27752279
Pulled By: bertmaher
fbshipit-source-id: ac115080bf2a4a73d52b396d64a5bce0cf13abfe
Summary:
Fixes https://github.com/pytorch/pytorch/issues/25100#43112
EDIT: pardon my inexperience since this is my first PR here, that I did not realize the doc should not have any trailing white spaces, and `[E712] comparison to False should be 'if cond is False:' or 'if not cond:'`, now both fixed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55285
Reviewed By: mruberry
Differential Revision: D27765694
Pulled By: jbschlosser
fbshipit-source-id: c34774fa065d67c0ac130de20a54e66e608bdbf4
Summary:
This way, the user gets more useful actionable results from the GHA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55961
Test Plan: CI
Reviewed By: samestep
Differential Revision: D27749013
Pulled By: janeyx99
fbshipit-source-id: bb0edbcdab29ba8ef99005f6fcf52de6782b468d
Summary:
This PR adds a `padding_idx` parameter to `nn.EmbeddingBag` and `nn.functional.embedding_bag`. As with `nn.Embedding`'s `padding_idx` argument, if an embedding's index is equal to `padding_idx` it is ignored, so it is not included in the reduction.
This PR does not add support for `padding_idx` for quantized or ONNX `EmbeddingBag` for opset10/11 (opset9 is supported). In these cases, an error is thrown if `padding_idx` is provided.
Fixes https://github.com/pytorch/pytorch/issues/3194
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49237
Reviewed By: walterddr, VitalyFedyunin
Differential Revision: D26948258
Pulled By: jbschlosser
fbshipit-source-id: 3ca672f7e768941f3261ab405fc7597c97ce3dfc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55621
Fuser support for thread-level parallelism is a work in progress, so
only fuse when the program is running single-threaded.
ghstack-source-id: 126069259
Test Plan: observe fusion groups formed when torch.get_num_threads==1 vs not
Reviewed By: ZolotukhinM
Differential Revision: D27652485
fbshipit-source-id: 182580cf758d99dd499cc4591eb9d080884aa7ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55835
Now that https://github.com/pytorch/pytorch/pull/55238 is landed for a
week and no complains. It seems safe to say FEATURE_TORCH_MOBILE is
always true and we can do some cleanup.
Test Plan: Imported from OSS
Reviewed By: ezyang, walterddr
Differential Revision: D27721284
Pulled By: ailzhang
fbshipit-source-id: 4896bc5f736373d0922cfbe8eed0d16df62f0fa1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55431
Fixes a bug in the test cases, returning early resulted
in some tests not being run. Adds logic for `nni.LinearReLU`,
which was unmasked by making the tests run
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_extract_weights_mod
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D27622415
fbshipit-source-id: 79d9e3125e5d881d9d13645abbe4bd007a5e1d44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55311
Before this PR, `F.conv1d` was matched by FX graph mode quant patterns
but the prepacking was happening inline. There was also a bug with
argument type mismatch.
This PR fixes both issues and adds a test. Thanks jerryzh168 for the
code tip.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_functional_not_reference
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27575422
fbshipit-source-id: 42301e23cb101a9e64e46800813bc771317e233e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55287
Adds support for extracting weights from F.conv2d and F.conv3d.
F.conv1d and the fused variants are saved for future PRs.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_extract_weights_conv_fun
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D27575424
fbshipit-source-id: e945912d7d0ab320f47cab30d00d60ddb7497158
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55154
Adds functionality to NS to allow matching nodes which have the
same signature across dtypes. For now, only the skeleton is added,
we can fill out the rest of the ops later. This is to unblock
the work to change `cat` to have the same signature for fp32 and int8,
and keep the testing we have for `cat` in NS.
For context, the main reason we are not matching nodes with equal types,
for now, is user defined types for which we do not know the signature.
For now, the design is strictly allowlist of everything. In the future,
we may adjust the design to safely match user defined types.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_ops_with_same_fp32_and_int8_signature
python test/test_quantization.py TestFXGraphMatcher.test_nodes_with_equal_types_do_not_get_matched
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D27504624
fbshipit-source-id: 4f8eb4f3258caf6f99aa373ca7ba516ebbcf4779
Summary:
This PR includes:
- A formatting change to make katex installation instructions more visible for Facebook employees.
- A short tip about how to start a lightweight HTTP server on a remote machine to browse the doc build artifacts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56018
Reviewed By: H-Huang
Differential Revision: D27765157
Pulled By: cbalioglu
fbshipit-source-id: 67663de0ba7b742e0deb5358d1e45eea9edd840f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/35901
This change is designed to prevent fragmentation in the Caching Allocator. Permissive block splitting in the allocator allows very large blocks to be split into many pieces. Once split too finely it is unlikely all pieces will be 'free' at that same time so the original allocation can never be returned. Anecdotally, we've seen a model run out of memory failing to alloc a 50 MB block on a 32 GB card while the caching allocator is holding 13 GB of 'split free blocks'
Approach:
- Large blocks above a certain size are designated "oversize". This limit is currently set 1 decade above large, 200 MB
- Oversize blocks can not be split
- Oversize blocks must closely match the requested size (e.g. a 200 MB request will match an existing 205 MB block, but not a 300 MB block)
- In lieu of splitting oversize blocks there is a mechanism to quickly free a single oversize block (to the system allocator) to allow an appropriate size block to be allocated. This will be activated under memory pressure and will prevent _release_cached_blocks()_ from triggering
Initial performance tests show this is similar or quicker than the original strategy. Additional tests are ongoing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44742
Reviewed By: ngimel
Differential Revision: D23752058
Pulled By: ezyang
fbshipit-source-id: ccb7c13e3cf8ef2707706726ac9aaac3a5e3d5c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55167
**Summary**
This commit adds a function that uses `sys.setprofile` to trace the
execution of a callable in order to determine which modules it really
uses. The result of this trace can inform packaging decisions.
**Test Plan**
This commit adds a unit test to `test_analyze.py` that tests this
feature.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D27730805
Pulled By: SplitInfinity
fbshipit-source-id: 11802625564513da9a0144904be0d34dbae0f601
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55727
number of dequantize for fp16 reference pattern was incorrect before, this
PR fixes the problem
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D27713390
fbshipit-source-id: 72b8d4cda0bdcea74abe27a76f918d1b47819b01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55979
Fix name used for this test
ghstack-source-id: 126465107
Test Plan: CI
Reviewed By: pbelevich, H-Huang
Differential Revision: D27755320
fbshipit-source-id: fead989041d703d473b6847ee0cee1deebe12571
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55265
Logs API usage of monitored barrier for better tracking and use case
understanding.
ghstack-source-id: 126413087
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D27548433
fbshipit-source-id: 7520ad0948b8dc9d44fa3118d5ea953d52f9f1c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55197
From initial user feedback, one unexpected difference between monitored_barrier impl and barrier is the "all or nothing" semantics.
In barrier, all ranks pass or they all fail. With monitored barrier however, if rank 1 is healthy, it will respond to both send and recv from rank 0, but rank 0 can later fail because rank 2 is stuck. In this case, rank 1 will move forward out of the barrier.
This change makes it so that if a rank fails in monitored barrier, all other ranks in monitored barrier will also fail. It does so by the following process, similar to acknowledgements:
Nonzero ranks call send()
Nonzero ranks call recv()
Rank 0 calls recv(), if this succeeds, rank 0 has acknowledged rank N as healthy
Once all ranks are acknowledged as healthy:
Rank 0 calls send() to all nonzero ranks to unblock them
Modified unittests to ensure the all or nothing failure behavior
ghstack-source-id: 126413088
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D27523060
fbshipit-source-id: fa05e4f8ad8ae97fd6cb20da5c3a7ef76fd31de6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55684
Upcoming changes to `MaybeOwned<T>` will require that T is
one of these two types and will have custom code for both.
This diff updates the tests to continue to build under these new
requirements; it is being sent separately to demonstrate that the
tests continue to work on the current implementation.
ghstack-source-id: 126405918
Test Plan: CI will run the rewritten tests.
Reviewed By: bhosmer
Differential Revision: D27630289
fbshipit-source-id: e38097d9ca04f3337cfa543ebcc8fb5d6916fcf3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55685
This diff introduces a traits class that tells `MaybeOwned` how
to borrow a specific type. While it is still capable of handling a
generic `T` by storing `const T*` and how to do so is shown in a
comment, it is not committed in live code because it is not needed.
Instead, we have specific traits implementations for
`c10::intrusive_ptr<T>` and `Tensor` that implement the borrowed state
as just a plain old `c10::intrusive_ptr<T>` or `Tensor` (respectively)
that we manipulate to avoid reference counting operations. We do this
entirely with public API to `c10::intrusive_ptr<T>` and could do
likewise with `Tensor`, but (as comments in the code explain) adding a
private constructor to `MaybeOwnedTraits<Tensor>` allowed additional
performance optimization.
This representation of `MaybeOwned` seems to be more efficient than
the generic `T-or-pointer-to-const-T` representation. Intuitively, we
avoid a double indirection at minimal cost vs the previous
implementation. It *also* seems to be more efficient than the pointer
tagging representation I sent out as #55555; apparently, having the
extra word for a flag is much cheaper than the masking operands for
pointer tagging and the same double indirection as the generic
representation.
In particular, this seems to have the same *effect* as the
`TensorHandle` idea we've discussed internally (a hypothetical class
like `Tensor` that wraps a raw `TensorImpl*` and shares the generated
methods of `Tensor` so that everything still works), but you have to
be explicit about borrowing and use pointer syntax to get the
effect. Unlike `TensorHandle`, you can use it as internal state in a
class and "upgrade" from a borrow to an owned `Tensor` derived from
your original borrow if necessary.
Note that this is just a representational change and it still has the
same semantics: you need to keep the T you borrowed from around!
ghstack-source-id: 126405920
Test Plan:
Previous diff changes the MaybeOwned tests to cover
both `intrusive_ptr` and `Tensor`, which we need in order to ensure
that our trait implementations are correct.
Further diffs in this stack will use this type to hold operand tensors
in `TensorIteratorBase` to allow borrowing at relatively small cost
(very roughly, a 6% win in the successful borrowing case for our
add-in-place benchmark at the cost of a 2.5% regression in the
legacy non-borrowing case, and we know that we will be able to borrow
in structured kernels and probably most unstructured operands as
well).
Reviewed By: ezyang
Differential Revision: D27679723
fbshipit-source-id: 57104f4edabc545ff83657233fde9eb40b969826
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55444
Changes ~ProcessGroupNCCL so that we join work cleanup thread before aborting nccl communicators. This is because if we abort nccl communicators first on destruction, outstanding work objects in workMetaList can have exceptions set on them. Right now this doesn't trigger errors in nccl async error handling due to the terminated check, but it seems a bit cleaner to just join this thread first.
The main motivation is also to reduce log spam since we added some logging when an exception is set on WorkNCCL, but this unexpectedly resulted in a lot of false-positive errors being logged even after pg shutdown. An example is below:
I0406 18:30:27.361981 1567104 ProcessGroupNCCL.cpp:527] [Rank 1] NCCL watchdog thread terminated normally
I0406 18:30:27.364675 1567105 ProcessGroupNCCL.cpp:265] [Rank 1] found async exception when checking for NCCL errors: NCCL error: unhandled system error, NCCL version 2.
7.3
With this change, we no longer see these false positive logs.
ghstack-source-id: 126145284
Test Plan: CI
Reviewed By: osalpekar
Differential Revision: D27613035
fbshipit-source-id: abf924630128b50e7f66ae41ac83403e7a0aac96
Summary:
Fixes https://github.com/pytorch/pytorch/issues/25100#43112
EDIT: pardon my inexperience since this is my first PR here, that I did not realize the doc should not have any trailing white spaces, and `[E712] comparison to False should be 'if cond is False:' or 'if not cond:'`, now both fixed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55285
Reviewed By: ngimel
Differential Revision: D27710107
Pulled By: jbschlosser
fbshipit-source-id: c4363a4604548c0d84628c4997dd23d6b3afb4d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55814
I don't really know if the original issue is resolved but let's just
check and see if this passes CI so that we can potentially get some
speed up on our builds
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D27715734
Pulled By: seemethere
fbshipit-source-id: a8f90774dfd25b0abf8e57283fe3591a8d8f3c4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55955
Was experiencing build failures related to disk size issues, let's bump
to 150 to see if that resolves these issues
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D27747958
Pulled By: seemethere
fbshipit-source-id: 9222475d2298cf942479650567616489387bf552
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54977
put part of codes in prepare_for_backward into functions, so that those functions can be used in static graph training and delay all reduce later on.
ghstack-source-id: 126366714
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D27439195
fbshipit-source-id: 8899eda621260232d774cb145f9c6d683c47e188
Summary:
#### Reason for relanding
Line 1607 of `torch/testing/_internal/common_methods_invocations.py` of https://github.com/pytorch/pytorch/issues/50999 had `dtype` instead of `dtype=torch.bool`, so 4 of the 9 sample inputs for `bool` had incorrect dtype. This bug was caught by https://github.com/pytorch/pytorch/issues/54949.
1. Added support for pow() on CPU for `float16` (`Half`) and `bfloat16` types.
Both `pow(Tensor, Scalar)` and `pow(Tensor, Tensor)` are now supported for the aforementioned types.
However autograd isn't supported for `Float16` on CPU yet, as `log_vml_cpu` can't be enabled for it.
2. heitorschueroff added `pow_tensor_scalar_optimized_kernel` to refactor & simplify `PowKernel.cpp`.
It provides a common path for all the complex types & floating point types (except Float16, due to lack of complete AVX2 vectorization support for it). It replaced code that had previously been duplicated for (float, double) and complex types,
so PowKernel.cpp looks a lot cleaner now.
3. Enabled (unskipped) some tests for `erf`, `erfc`,`erfinv`, `tan` and `linalg.vector.norm` which were being skipped earlier due to `pow()` not having been implemented for `float16` & `bfloat16`.
4. Added an OpInfo for `pow()` & enabled some test cases for `pow()`.
5. Extended the coverage of existing tests for `pow` in `test_binary_ufuncs.py` in order to enable comparison with `numpy`, even with discontiguous tensors, and added a test to ensure that a runtime error is raised for `pow`'s inplace variant if resizing the base tensor is required during its invocation.
6. Added `float16` & `bfloat16` to `square`'s dtype lists in its `UnaryUfuncInfo`.
7. Removed redundant `dtypesIfCPU` and `dtypesIfCUDA` from `OpInfo`s where they are equal to `dtypes`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55280
Reviewed By: jbschlosser
Differential Revision: D27591772
Pulled By: heitorschueroff
fbshipit-source-id: c7420811b32595bb3353149a61e54a73f2eb352b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55553
If this case isn't likely, user code would have been better off with a regular T.
ghstack-source-id: 126369326
Test Plan: Existing CI
Reviewed By: ezyang
Differential Revision: D27630287
fbshipit-source-id: b074af3a65c61dfe9e0246df046cc8c49e8efb03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55419
Turns out it's useful to have these. I chose to implement them in the straightforward safe way, rather than always borrowing.
ghstack-source-id: 126369328
Test Plan: Added more automated tests.
Reviewed By: hlu1
Differential Revision: D27545805
fbshipit-source-id: 84bb4458b86672ad340cc1f0aa18b80ca7ee13f1
Summary:
`unshapedType` can be very slow on a graph with many modules and recursively contained classes, because each Type you have to recursively descend and map over. Speed it up with a type cache.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55828
Reviewed By: ngimel
Differential Revision: D27717995
Pulled By: eellison
fbshipit-source-id: f1d502bef0356e78100c27bf00f6caf08a75d68c
Summary:
To fix warning:
```
xplat\\caffe2\\torch\\csrc\\jit\\runtime\\instruction.cpp(59,20): warning: ISO C++11 does not allow conversion from string literal to 'char *const' [-Wwritable-strings]
```
which can be seen in Windows CI logs.
Test Plan: Eyes; did not run it.
Reviewed By: iseeyuan
Differential Revision: D27717057
fbshipit-source-id: f365405663b5adfbc0c87dc26a9921b6d03f1f5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55825
The mask has never been used (in vectorization we generate an explicit
`IfThenElse` construct when we need to mask out some elements). The PR
removes it and cleans up all its traces from tests.
Differential Revision: D27717776
Test Plan: Imported from OSS
Reviewed By: navahgar
Pulled By: ZolotukhinM
fbshipit-source-id: 41d1feeea4322da75b3999d661801c2a7f82b9db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55824
Seemingly some of my last changes (namely, removing dep-tracker) broke
the TE benchmarks. This PR fixes it.
Differential Revision: D27717778
Test Plan: Imported from OSS
Reviewed By: navahgar
Pulled By: ZolotukhinM
fbshipit-source-id: 48584bc0cfd4879a3e44cb45ee1f0d5c91b5afbc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55324
With this change `rfactor` only affects the passed loop and its body
never touching anything outside (that was a rootcause of a bug with the
previous implementation). Also, we don't have an `insertion_point`
parameter anymore - its meaning was vague, and the effect of it
should've been achievable with other transformations anyway.
The new `rfactor` semantics is as follows:
```
Requirements:
* S is the reduction store
* S is the only statement in the innermost loop
* There is at least two reduction arguments in S
* OUTER_REDUCTION_FOR loop corresponds to the outermost reduction variable
used in the store and all other reduction variables are index variables of
children loops of OUTER_REDUCTION_FOR
* OUTER_REDUCTION_FOR is a perfect loop nest, i.e. it has only loops
corresponding to the other reduction variables and the store, nested into
each other
What it does:
* Introduce a new buffer with an extra dimension of a size equal to the
span of the loop OUTER_REDUCTION_FOR (the new buffer is returned via
RFAC_BUF_PTR)
* Insert an initialization store for the new buffer in
OUTER_REDUCTION_FOR before its nested loop
* Replace the reduction store to the original buffer with the reduction
store to the temp buffer, removing the index var of OUTER_REDUCTION_FOR
from reduction arguments
* Insert a final reduction store over the extra dimension of the new
buffer to the original buffer
* Returns TRUE if the transformation succeeded and FALSE otherwise
Example:
Original IR:
S1: for i # normal axis
S2: X[i] = 0
S3: for j # reduction axis
S4: for k # reduction axis
S5: X[i] = ReduceOp(X[i] + Y[i,j,k], reduce_axis={j,k})
After RFACTOR(S5, S3)
S1: for i # normal axis
S2: X[i] = 0
S3: for j # reduction axis for X, normal axis for X_rfac
X_rfac[i,j] = 0
S4: for k # reduction axis
X_rfac[i,j] = ReduceOp(X_rfac[i,j] + Y[i,j,k], reduce_axis={k})
X[i] = ReduceOp(X[i] + X_rfac[i,j], reduce_axis={j})
```
Differential Revision: D27694960
Test Plan: Imported from OSS
Reviewed By: navahgar
Pulled By: ZolotukhinM
fbshipit-source-id: 076fa6a1df2c23f5948302aa6b43e82cb222901c
Summary:
Related to https://github.com/pytorch/pytorch/issues/52256
Use autosummary instead of autofunction to create subpages for `torch.fft` and `torch.linalg` functions.
zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55748
Reviewed By: jbschlosser
Differential Revision: D27739282
Pulled By: heitorschueroff
fbshipit-source-id: 37aa06cb8959721894ffadc15ae8c3b83481a319
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54991
Actual proposed fix is in
https://github.com/pytorch/pytorch/pull/53934, in the meantime, would be useful
to include this LOG when barrier does not know what devices to use, and suggest
the workaround of passing in device_ids into barrier().
ghstack-source-id: 126351889
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27444917
fbshipit-source-id: 0f269c5a7732e5be6e51adfca7ef70d04ffd71d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55725
We were previously checking m_last_error on the miniz struct directly,
which fails to preserve internal invariants and can the leave the reader
broken in specific situations (reading a non-existent file).
Using the provided error checking API fixes this.
Differential Revision: D27693105
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Pulled By: suo
fbshipit-source-id: 20c520bb1d590fb75751bca1e970df4f2b7eb043
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54465
It is reported that there is data race issue when the test runs with tsan. The root cause is from 'model.frc1.double()' call. This is not because DistributedDataParallel() works together with 'model.frc1.double()'. If we remove DistributedDataParallel(), just call 'model.frc1.double(); model.frc2.double();', it complained the same data race issue.
I'm not sure how to do data type cast in this test without tsan complains, so removing this line of codes and mixed data type logging check.
Please kindly let me know if you have a better suggestion on how to do data type cast correctly
Test Plan: unit test
Reviewed By: SciPioneer
Differential Revision: D27249821
fbshipit-source-id: 0368157e11cbe7d15828dccca78271d89d502ec4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55414close#55384
backward_compute_comm_overlap_time may not be larger than 1. we should check backward_compute_time, backward_comm_time are larger than 1 instead.
ghstack-source-id: 126360517
Test Plan: unit tests
Reviewed By: H-Huang, SciPioneer
Differential Revision: D27606132
fbshipit-source-id: 418fe9f958287779d637856e355cc36cab384c68
Summary:
The PR enables additional dtypes in common_method_invocations for ROCM.
This enables around 4k new tests for ROCM.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55808
Reviewed By: jbschlosser
Differential Revision: D27729885
Pulled By: ngimel
fbshipit-source-id: 061b88901bbe7128d51e49803f64295037b09b8d
Summary: `networkx 2.4+` replaced `node` attribute to `nodes` in graph object. This caused failures in `caffe2`'s' `topological_sort_traversal_longest_path` function which uses networkx library for topological sort.
Differential Revision: D27718857
fbshipit-source-id: 812fbb613946565d089cc84a20f3cdf7df046e19
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54837
`hsum_sq` has the overflow issue when the input image size is large such as (H,W,D) as (224,224,160). `hsum_sq` is used in the quantized instance_norm/layer_norm/group_norm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54872
Reviewed By: dskhudia
Differential Revision: D27690767
Pulled By: vkuzo
fbshipit-source-id: 9b9ac3e76220d42a3b48f8bf4e20823f775789a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54479
This change is similar to #54049 in that it helps us factor out some code that can be used in both fast and slow versions of gradcheck.
- `compute_gradient` and `compute_numerical_jacobian_cols` have fewer responsibilities:
- compute_numerical_jacobian_cols essentially only handles the complexity of complex derivatives
- compute_gradient handles only finite differencing (and doesn't worry about different layouts and indexing into the input tensor)
- we have two stages again where we first compute the columns separately, then combine them
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D27728727
Pulled By: soulitzer
fbshipit-source-id: fad3d5c1a91882621039beae3d0ecf633c19c28c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54378
### For release notes
`torch.autograd.gradcheck.get_numerical_jacobian` (not part of the public api) is being deprecated.
In the future, user code relying on this function will break because, among other changes, `get_numerical_jacobian` now returns `List[Tuple[torch.Tensor]]` instead of `List[torch.Tensor]`.
(more details if necessary)
For a `fn` that takes in M inputs and N outputs we now return a list of M N-tuples of jacobians where `output[i][j]` would represent the numerical jacobian w.r.t. to the ith input and the jth output. Previously `get_numerical_jacobian` returned a list of tensors where each tensor represents the jacobian w.r.t. to each of the M inputs and a specific output. Finally, the function passed in as the parameter `fn` should expect to handle individual parameters, where previously `fn` is required to expect its parameters wrapped in a tuple.
--- end --
This PR addresses the comment here https://github.com/pytorch/pytorch/pull/53857#discussion_r595429639, to reduce the run-time of old gradcheck's get numerical jacobian by a factor of num_outputs. However, because very few ops actually return multiple outputs, there is not too much real speed up here.
The main benefit of doing this change as part of the refactor is that it helps us isolate the possible bugs that are specific to switching `get numerical jacobian` to run in a per output way vs all outputs at once. Much of the logic implemented here will be the same for the fast gradcheck case, so knowing for certain that everything should pass after this stage will make the next step much simpler.
The get_numerical_jacobian api is also being used in common_nn. So we update the callsite there as well.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D27728720
Pulled By: soulitzer
fbshipit-source-id: ee0f90b4f26ddc5fdbe949c4965eaa91c9ed0bb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55817
**Summary**
This commit makes minor edits to the docstrings of `PackageExporter` so
that they render properly in the `torch.package` API reference.
**Test Plan**
Continuous integration (especially the docs tests).
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D27726817
Pulled By: SplitInfinity
fbshipit-source-id: b81276d7278f586fceded83d23cb4d0532f7c629
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55812
**Summary**
This commit creates a barebones API reference doc for `torch.package`.
The content is sourced from the docstrings in the source for the
`torch.package`.
**Test Plan**
Continuous integration (specifically the docs tests).
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D27726816
Pulled By: SplitInfinity
fbshipit-source-id: 5e9194536f80507e337b81c5ec3b5635d7121818
Summary:
Generally wildcard imports are bad for the reasons described here: https://www.flake8rules.com/rules/F403.html
This PR replaces wildcard imports with an explicit list of imported items where possible, and adds a `# noqa: F403` comment in the other cases (mostly re-exports in `__init__.py` files).
This is a prerequisite for https://github.com/pytorch/pytorch/issues/55816, because currently [`tools/codegen/dest/register_dispatch_key.py` simply fails if you sort its imports](https://github.com/pytorch/pytorch/actions/runs/742505908).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55838
Test Plan: CI. You can also run `flake8` locally.
Reviewed By: jbschlosser
Differential Revision: D27724232
Pulled By: samestep
fbshipit-source-id: 269fb09cb4168f8a51fd65bfaacc6cda7fb87c34
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: e5e974b6cd
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55881
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D27730207
fbshipit-source-id: 7d2901e676645f3da6e5ca8f9d8c1b55d63cc1c7
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54136
tldr: dephwise conv require that the nb of output channel is 1.
The code here only handles this case and previously, all but the first output channel were containing uninitialized memory. The nans from the issue were random due to the allocation of a torch.empty() that was sometimes returning non-nan memory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55794
Reviewed By: ngimel
Differential Revision: D27711717
Pulled By: albanD
fbshipit-source-id: 00eac3fd59db1d09fe7bab89427b105a019e7a5d
Summary: ATT, to ensure output has the same dim type with the input. We need to find a more generic way though...
Test Plan: unit test
Reviewed By: ipiszy, khabinov
Differential Revision: D27690748
fbshipit-source-id: e53832c67b8ac86973c288d2d6b76ef8e5db14b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55738
Per title, and use 0 as the default value.
It turns out that setting this epsilon as 0 can accelerate convergence and improve accuracy for some use cases.
Test Plan:
unit tests
f264687105
f264675194
Reviewed By: shuyingsunshine21
Differential Revision: D27694971
fbshipit-source-id: b61528c6c817127974acdc4635bccf607532287f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55637
This diff introduces the `EtcdRendezvousBackend` type that will serve as an experimental alternative to the existing `EtcdRendezvousHandler`.
The major advantage of `EtcdRendezvousBackend` is that it delegates the bulk of the rendezvous handling logic to `DynamicRendezvousHandler` which is shared with `C10dRendezvousBackend` (see D27654492) and any other potential future rendezvous backend (e.g. Amazon S3).
ghstack-source-id: 126312209
Test Plan: Run the existing and newly-introduced unit/integration tests.
Reviewed By: tierex
Differential Revision: D27654498
fbshipit-source-id: f3259adfc9068b7e323b947a7d8d52fcd0b8ada1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55636
This diff introduces:
- The `C10dRendezvousBackend` type to support C10d stores as rendezvous backends.
- A fix to the `TCPStore.compare_set()` function to support non-existent keys.
- A placeholder `c10d-experimental` registry to instantiate C10d-baked rendezvous backends via `get_rendezvous_handler()`.
ghstack-source-id: 126312162
Test Plan: Run the existing and newly-introduced unit/integration tests.
Reviewed By: tierex
Differential Revision: D27654492
fbshipit-source-id: 09f498138b35186de4b0e174adb33fb5b5aa4b52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55635
This diff introduces the `DynamicRendezvousHandler` type as a stub implementation and its accompanying `RendezvousBackend` interface.
`DynamicRendezvousHandler` is intended to be a backend-agnostic type that will contain the core (bulk) logic of rendezvous handling. Any backend specific operation will be delegated to a concrete subclass of `RendezvousBackend` (e.g. `C10dRendezvousBackend` - see D27654492) that is passed as a constructor argument to `DynamicRendezvousHandler`.
ghstack-source-id: 126304697
Test Plan: Run the existing and newly-introduced unit/integration tests.
Reviewed By: tierex
Differential Revision: D27654478
fbshipit-source-id: 9fc89a6e4cb308971c65b29a7c5af7ae191f70c5
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52690
This PR adds the following APIs:
```
static bool areLoopsPerfectlyNested(const std::vector<For*>& loops);
static std::vector<For*> reorder(
const std::vector<For*>& loops,
const std::vector<size_t>& permutation);
```
The first API checks if the given list of loops are perfectly nested. The second API reorders the given list of loops according to the permutation specified.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55568
Reviewed By: albanD
Differential Revision: D27689734
Pulled By: navahgar
fbshipit-source-id: dc1bffdbee068c3f401188035772b41847cbc7c6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54211
This was a little more annoying than expected, because the `exclude = ` key in `mypy.ini` is weird. I'll file an upstream issue about that.
I ignored one file, `torch/distributed/elastic/agent/server/api.py` that had ~8 errors that were hard to figure out. This can be done in a follow-up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55712
Reviewed By: walterddr
Differential Revision: D27694976
Pulled By: malfet
fbshipit-source-id: 228d8be6af040343ce46595dabaca212e69ccc68
Summary:
Currently common_device_type generates device-specific test based on vague rules. see https://github.com/pytorch/pytorch/issues/55707.
This should fix https://github.com/pytorch/pytorch/issues/55707
# Changes included
This PR changes the rule:
1. First user provided args (`except_for` and `only_for`) are processed to filter out desired device type from a ALL_AVAILABLE_LIST
2. Then environment variables are processed the exact same way.
tests are generated based on the final filtered list.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55753
Test Plan: CI
Reviewed By: seemethere, ngimel
Differential Revision: D27709192
Pulled By: walterddr
fbshipit-source-id: 1d5378ef013b22a7fb9fdae24b486730b2e67401
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55458
Previously the cond-add-relu pass blindly turns all in-place add and relu ops into non-mutation version, when those ops are not part of the fusion patten, it can actually hurt the performance as shown in densenet on some platform.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D27620415
fbshipit-source-id: 8302c0c85f3a064dfd8ac994e92416dde927e348
Summary:
There are a few autograd tests checking for tensors leaked by reference cycles. This changes them to use `_WeakTensorRef` over `weakref`. `_WeakTensorRef`, added in https://github.com/pytorch/pytorch/issues/52874, accesses the C++ level `TensorImpl` reference count, compared to `weakref` which accesses python refcounts and so can only tell if the python wrapper object gets deallocated. Not only is this less code, it's also more accurately detecting that the Tensor itself is deallocated.
I didn't touch `weakref` usage in [test_anomaly_assign_parent_cleanup](fc349cbcde/test/test_autograd.py (L3733)) and [test_nested_anomaly_printstack_cleanup](fc349cbcde/test/test_autograd.py (L3772)) because these are intentionally testing for python object cleanup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55726
Reviewed By: ngimel
Differential Revision: D27718526
Pulled By: albanD
fbshipit-source-id: 37a4914360e35dd4ae8db06b29525cebec4d4b84
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/55819
Test Plan:
On devserver: `buck run //xplat/langtech/tuna/cli:tuclix -- --model-dir ~/workspace/portal_en_US/ --audio-file ~/fbsource/fbcode/shortwave/test/data/audio_unittest.wav.to.raw` on top of Rittzz's D27691649
On device:
Reviewed By: Rittzz
Differential Revision: D27716745
fbshipit-source-id: 1921f18ee6b06990f71b86b9c4b3e1f3ce531001
Summary: Change error msg to include the min max values when failing.
Test Plan:
Existing unit tests:
```
buck test //caffe2/caffe2/python/operator_test:self_binning_histogram_test
```
Failing wf with error msg:
f264505545
Reviewed By: TailofJune
Differential Revision: D27630820
fbshipit-source-id: c490ce8c8c40414403634979c9beaf9c08569a96
Summary:
I noticed that https://github.com/pytorch/pytorch/issues/53296 added these two lines to the `files` list in `mypy-strict.ini`:
```
benchmarks/instruction_counts/*.py,
benchmarks/instruction_counts/*/*.py,
```
I opened https://github.com/pytorch/pytorch/issues/55700 to simplify them into one line, but I was also curious whether `tools/mypy_wrapper.py` correctly handles those patterns, so I added the `test_glob_wildcards_dont_expand_or_collapse` case shown in this PR. Turns out, it doesn't!
I believe this is because [`mypy` uses `glob`](https://github.com/python/mypy/blob/v0.770/mypy/config_parser.py#L45-L63) to parse these patterns, and for some reason, [`fnmatch`](https://docs.python.org/3/library/fnmatch.html) and [`glob`](https://docs.python.org/3/library/glob.html) don't agree with each other on what `*` means:
- according to `fnmatch`, `*` seems to mean `.*`
- according to `glob`, `*` seems to mean `[^/]*`
[This SO answer](https://stackoverflow.com/a/60174071) suggests using the [`glob.globmatch` function from the `wcmatch` library](https://facelessuser.github.io/wcmatch/glob/#globmatch) to solve the issue, but [we didn't want to add another external dependency](https://github.com/pytorch/pytorch/pull/55702#discussion_r610868623), so instead I simply modified our matching function to just directly call `mypy`'s own internal function that does the globbing (linked above).
One possible downside of this approach is that now the tests in `tools/test/test_mypy_wrapper.py` could break if the directory structure of PyTorch is changed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55702
Test Plan:
```
python tools/test/test_mypy_wrapper.py
```
Reviewed By: malfet, seemethere
Differential Revision: D27684499
Pulled By: samestep
fbshipit-source-id: d99387a579c21eee73d1714e3e815ab7155f9646
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: fddc3aa75b
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55137
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: beauby
Differential Revision: D27499763
fbshipit-source-id: d96538009be7824f2ef600e9816239188ddd991a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55343
Add support for N-dimensioned batches of 2D embedding bags to qembeddingbag_byte_prepack and qembeddingbag_byte_unpack.
This is currently supported in C2 via caffe2::Fused8BitRowwiseQuantizedToFloat and caffe2::FloatToFused8BitRowwiseQuantized, but is being supported in PyTorch operators via this change.
Test Plan: buck test //caffe2/test:quantization -- test_embedding_bag_byte
Reviewed By: radkris-git
Differential Revision: D27480917
fbshipit-source-id: 9878751c6cee8a55909fe58a3e8c222ea31c20bb
Summary:
argmax docstring previously said that it returns indexes of the first 'minimal' value, fixed typo in that line to 'maximal'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55239
Reviewed By: albanD
Differential Revision: D27641562
Pulled By: mrshenli
fbshipit-source-id: f8b5c579400088b5210c83a05da6c4c106fbf95d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55581
Multiple outputs now OK, as long as their all Tensor. Ported
fractional_max_pool2d to make sure the shindig all works.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D27641267
Pulled By: ezyang
fbshipit-source-id: f88bfcd2b11e9ae90b023c9310c033d12637a53e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53651
I did not put much effort in improving the docs, as I will go over all these docs in future PRs
cc anjali411
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55085
Reviewed By: nikithamalgifb
Differential Revision: D27493604
Pulled By: anjali411
fbshipit-source-id: 413363013e188bc869c404b2d54ce1f87eef4425
Summary:
Given that the minimal required Python version for using PyTorch is 3.6, the development tools should also be able to handle it. `./tools/nightly.py` currently uses the parameters `capture_output` and `text` of `subprocess.run` that were only added for [Python 3.7](https://docs.python.org/3/library/subprocess.html#subprocess.run).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55776
Reviewed By: ngimel
Differential Revision: D27709124
Pulled By: ezyang
fbshipit-source-id: aeea15a891ba792f3cd5fa602f0d7b746007e30c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55439
This adds [breakpad](https://github.com/google/breakpad) to the build in CI (just on one image for now). I attempted in #54739 to build it from source as a normal third_party submodule but it uses autotools and has some weird build steps that made it hacky to integrate. We really only need it for release builds anyways since its use is moot if built with anything but `RELEASE=1`.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D27679766
Pulled By: driazati
fbshipit-source-id: 8211444df49b219c722137b9243d16d649a1f1ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55682Fixes#55648
For now it downloads and writes the relevant files to the system's temp dir and marks it as valid for 3 hours.
Test Plan: Imported from OSS
Reviewed By: malfet, nikithamalgifb
Differential Revision: D27685616
Pulled By: driazati
fbshipit-source-id: 27469b85fe4b6b4addde6b22bf795bca3d4990ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55710
In the current code, there is an edge case which leads to an error
after the prepare step:
1. have a pattern like this:
```
user_func_unmatched_to_qhandler -> node_matched_to_copy_node_qhandler
```
2. the user function returns a type which is not observable (i.e. not a
Tensor)
3. if this is run through `prepare_fx`, calibrating it with data leads
to a runtime error, because observers cannot observe non-tensor types.
This PR fixes the issue. If a node matched to `CopyNodeQuantizeHandler`
is after an unmatched node, we delete the observer.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_no_obs_between_unmatched_node_and_copy_node
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27686811
fbshipit-source-id: 320be41b1f383c6352ff89fb39a9f480822a3bb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55695
In order to be able to run CUDA tests on their own (e.g., to avoid running CPU tests on GPU machines).
Done by moving test methods to a separate class (and sometimes introducing a "common" base class for utils), and then providing new entry points inside a `cuda/` subdirectory.
Test Plan: Checked they are run on Sandcastle.
Reviewed By: mrshenli
Differential Revision: D27618198
fbshipit-source-id: 8f671657f79c8ae115748ab7752fe0066705893b
Summary:
The retrieval of profile node is much easier prior to inserting guard node.
test cases updated to reflect the patch on a previously failing cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55701
Reviewed By: pbelevich
Differential Revision: D27701216
Pulled By: Krovatkin
fbshipit-source-id: e2e6b64b682377e622b75c762e85ff7967e45118
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55660
Noticed this doc was missing clarification on nccl env vars that
init_process_group docs have. Also, specify default behavior when backend=None
is passed in.
ghstack-source-id: 126251116
Test Plan: Ci
Reviewed By: SciPioneer
Differential Revision: D27672208
fbshipit-source-id: 2e79d297174e135173bceb059450ea267367bde4
Summary:
Following up on https://github.com/pytorch/pytorch/pull/54895#discussion_r606402656.
A race-condition wouldn't arise because `leak_corrupted_threadpool` can be set to true only after fork via the `pthread_atfork` handler, when a (child) process would be single-threaded. It's set to false also when the process is still single-threaded (`pthreadpool` is called during an invocation to `set_num_threads`, prior to which a child process would remain single-threaded). All threads (if & when multiple threads would be created) would always see `leak_corrupted_threadpool` as false if it would be accessed concurrently.
Since no reader threads can exist while a writer thread changes its value (false->true and true->false), `leak_corrupted_threadpool` might as well be a non-atomic bool.
### Pros
1. No thread-synchronization is required for `leak_corrupted_threadpool`, as it's a non-atomic bool.
2. The call to `compare_exchange_strong` has been be removed.
cc: malfet VitalyFedyunin ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55341
Reviewed By: albanD
Differential Revision: D27669442
Pulled By: ezyang
fbshipit-source-id: 926cb5c1b0a537c1c2ab164b0d51d37c1f1b67f0
Summary:
This PR optimizes the way tensors are constructed from external data. It avoids allocating an empty tensor beforehand and directly constructs the target tensor by passing the newly-initialized `DataPtr`. Running some Facebook-internal benchmarks showed that combined with https://github.com/pytorch/pytorch/issues/54530 this PR achieves performance parity with Caffe2 tensor construction. (Overall ~2x speed improvement over the original `at::from_blob()` implementation.)
Testing is done with the existing unit and integration tests as there is no user-observable API change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55705
Reviewed By: ezyang
Differential Revision: D27686043
Pulled By: cbalioglu
fbshipit-source-id: b365c614476bcf0567797dfaf2add1b76fb6c272
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54781
Right now the functions have divergent names with one postfixed `_equal` and the other `_allclose`. I've opted to use `_(equal|close)` over `_all(equal|close)` think it is a reasonable assumption that all values need to be equal or close for this pass even without explicitly naming the function this way.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27438957
Pulled By: mruberry
fbshipit-source-id: 2951dac06d1430e15119ae94eafa234f3eb02f09
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54780
- In #53152 we opted to use `tb=native`. Thus, regardless if we use `pytest` to run the tests `__tracebackhide__` is not honored. and additional layers of helper functions make the traceback harder to parse. To overcome this, we change the internal helpers to return `ok: bool, msg: Optional[str]` and only raise the error in the top level function. We do that already in the current implementation that we are trying to replace:
36ce673f16/torch/testing/__init__.py (L92-L93)36ce673f16/torch/testing/__init__.py (L112)
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27438849
Pulled By: mruberry
fbshipit-source-id: 3e7a33dabb45463c29e8b9736fad09efb523f18d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55316
No need for heap allocations in the common case here.
ghstack-source-id: 126170054
Test Plan: Existing CI
Reviewed By: hlu1
Differential Revision: D27571942
fbshipit-source-id: 11fbf077c583c80ea63e024d2b9e1599785fff71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55247
When x is known to be in-bounds, sizes() is faster.
ghstack-source-id: 126170048
Test Plan: CI
Reviewed By: hlu1
Differential Revision: D27523681
fbshipit-source-id: 021c82a8a6b770802f4cd51cf6ff77046d71c938
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55246
c10::MaybeOwned<Tensor> and no more unary tuples.
ghstack-source-id: 126170051
Test Plan: Existing CI
Reviewed By: ngimel
Differential Revision: D27523682
fbshipit-source-id: 2590993cfc62136e65fd9a791e4ab68b2c366556
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55245
Like `expand_inplace`, `expand_outplace` now returns
`MaybeOwned<Tensor>` in most cases. I wasn't confident around the
ownership semantics of the `TensorList` -> `std::vector<Tensor>` case, so I
left that one alone.
ghstack-source-id: 126170052
Test Plan: Existing CI.
Reviewed By: ezyang
Differential Revision: D27522811
fbshipit-source-id: 28c5a626b65681e361f4006a0aaa7dc23ba9612a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55244
Add the ability to move from the underlying object in a `MaybeOwned`.
FWIW, `MaybeOwned` is new territory for me personally and this move-and-dereference operation is even more so, but I think it makes sense and the tests pass.
ghstack-source-id: 126170046
Test Plan: Added automated tests.
Reviewed By: bhosmer
Differential Revision: D27522809
fbshipit-source-id: 82b180031e93d725209b6328f656315c232e5237
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55180
Even if we're expanding a Tensor's dimensions, DimVector's size is still a good guess at the rank of a Tensor in general. None of these sites actually seem to need a std::vector.
ghstack-source-id: 126170045
Test Plan: Existing CI
Reviewed By: ezyang
Differential Revision: D27520127
fbshipit-source-id: 4064764fad1b3782b379f04627b48331c3ee011f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55065
expand_inplace may give you the same Tensor(s) back, and it unnecessarily wrapped single-Tensor results in a tuple. Further diffs will deprecate and replace the rest of the similar APIs in ExpandUtils.
ghstack-source-id: 126170049
Test Plan: beyonce_test
Reviewed By: ezyang
Differential Revision: D27469297
fbshipit-source-id: 56cf14bc5603355f399fef2e5b02b97afa504428
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55666
{F590513307}
Some code is not properly displayed due to an extra whitespace ahead of `(num_rows + num_cols)`.
ghstack-source-id: 126148569
Test Plan: Locally viewed
Reviewed By: rohan-varma
Differential Revision: D27673663
fbshipit-source-id: 603ae4ddbe86ceaefc311885b82b0f6b48b57b27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55353
Remove all the code branches that will only be executed when `device_ids > 1`.
Some helper functions are also removed:
1. `_verify_replicas_within_process` and `verify_replicas_within_process`
2. `_replicate_modules_within_process`
3. `parallel_apply`
The next step is deprecating `_module_copies` field.
ghstack-source-id: 126201121
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D27552201
fbshipit-source-id: 128d0216a202f5b1ba4279517d68c3badba92a6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55574
nn.EmbeddingBag backward is non-deterministic when reducing_mode = Max and on GPU, reducing mode Mean and Sum should be deterministic
Test Plan: NA
Reviewed By: ngimel
Differential Revision: D27633832
fbshipit-source-id: 50786ed8522f1aae27442f5f244a65eab8000b06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55572
We used to have VariableVersion default constructor
`VariableVersion(uint32_t version=0)`. But sometimes
we override the version_counter right after it's constructed.
E.g in SavedVariable/TensorImpl.
Thus we should make DISABLED the default constructor and else
where using explicit `VariableVersion(uint32_t)` constructor.
Note this PR effectively changes SavedVariable constructor (which overrides
version_counter_ inside) to use the DISABLED constructor and we
can see the gains in reduced instruction counts.
```
// benchmark code
timer = Timer(
"y = x * x",
"""
x = torch.rand((3, 3)).requires_grad_()
""",
language=Language.PYTHON,
)
λ ~ python compare.py
No CUDA runtime is found, using CUDA_HOME='/public/apps/cuda/10.2'
<torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.FunctionCounts
object at 0x7f06c48b3a50>
7236 lookdict_unicode_nodummy
2600 torch::autograd::VariableType::(...)
100 0x0000000017751750
-5 unlink_chunk.isra.0
-100 0x000000001773e750
-402 _int_malloc
-1600 operator delete(...)
-1600 c10::intrusive_ptr_target::release_resources()
-2400 c10::VariableVersion::VersionCounter::~VersionCounter()
-3600 torch::autograd::SavedVariable::operator=(...)
-4800 operator new(...)
-6400 torch::autograd::SavedVariable::SavedVariable(...)
-7200 torch::autograd::SavedVariable::SavedVariable()
-8400 free
-16800 malloc
-24400 _int_free
Total: -67771
```
Note there're for other callsites(esp. view related) we just keep it unchanged by
explicitly calling `VariableVersion(uint32_t)` but we should be
able to optimize those in the followup PRs.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D27669074
Pulled By: ailzhang
fbshipit-source-id: a4deb297cc89142ae8bd683284516c881ddf3c87
Summary:
These two lines were added in https://github.com/pytorch/pytorch/issues/53296, but they are needlessly complicated; this PR consolidates them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55700
Test Plan:
Run this command, and verify that the same number of files is given both before and after this PR:
```
mypy --config=mypy-strict.ini
```
Reviewed By: robieta
Differential Revision: D27684278
Pulled By: samestep
fbshipit-source-id: a34968cdff29cb8ad83813b277114224b5e37569
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54403
A few important points about InferenceMode behavior:
1. All tensors created in InferenceMode are inference tensors except for view ops.
- view ops produce output has the same is_inference_tensor property as their input.
Namely view of normal tensor inside InferenceMode produce a normal tensor, which is
exactly the same as creating a view inside NoGradMode. And view of
inference tensor outside InferenceMode produce inference tensor as output.
2. All ops are allowed inside InferenceMode, faster than normal mode.
3. Inference tensor cannot be saved for backward.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D27316483
Pulled By: ailzhang
fbshipit-source-id: e03248a66d42e2d43cfe7ccb61e49cc4afb2923b
Summary:
This PR
- adds a `tools/translate_annotations.py` script that
- parses annotations into JSON using the regexes that we were previously passing to [`pytorch/add-annotations-github-action`](https://github.com/pytorch/add-annotations-github-action) and
- uses `git diff-index` to translate the line numbers for those annotations from the PR `merge` onto the PR `head`, since (as of https://github.com/pytorch/pytorch/issues/54967) we now run CI on the former instead of the latter;
- modifies the `flake8-py3` and `clang-tidy` jobs to use that script and thus upload JSON in their artifacts instead of raw text; and
- modifies the "Add annotations" workflow to specify `mode: json` to allow it to use those preprocessed annotations.
Depends on https://github.com/pytorch/add-annotations-github-action/pull/18.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55569
Test Plan:
You can run the unit tests with this command:
```
python tools/test/test_translate_annotations.py
```
I also tested the entire system together in my personal sandbox repo.
Reviewed By: malfet
Differential Revision: D27662161
Pulled By: samestep
fbshipit-source-id: ecca51b79b9cf00c90fd89f0d41d0c7b89d69c63
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55405
Pull Request resolved: https://github.com/pytorch/glow/pull/5516
Allows FXIRImport to import quantized model.
This diff doesn't include the supports for per-channel weights, linear and conv. Will address them in the next diff.
Test Plan: buck test glow/fb/fx/nnpi_importer:test_importer
Reviewed By: jackm321, jfix71
Differential Revision: D27313543
fbshipit-source-id: bf5c96ef5f2ff1835c09db981e0ceefaec56dd5b
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/55670
Reference: https://github.com/pytorch/pytorch/pull/55522
**Cant Run tests locally without setting the ENV variables**
<details>
```
(pytorch-cuda-dev) kshiteej@qgpu1:~/Pytorch/pytorch_opinfo$ pytest test/test_ops.py
======================================================================= test session starts ========================================================================
platform linux -- Python 3.8.6, pytest-6.1.2, py-1.9.0, pluggy-0.13.1
rootdir: /home/kshiteej/Pytorch/pytorch_opinfo, configfile: pytest.ini
plugins: hypothesis-5.38.1
collected 0 items
========================================================================= warnings summary =========================================================================
../../.conda/envs/pytorch-cuda-dev/lib/python3.8/site-packages/torch/backends/cudnn/__init__.py:73
/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.8/site-packages/torch/backends/cudnn/__init__.py:73: UserWarning: PyTorch was compiled without cuDNN/MIOpen support. To use cuDNN/MIOpen, rebuild PyTorch making sure the library is visible to the build system.
warnings.warn(
../../.conda/envs/pytorch-cuda-dev/lib/python3.8/site-packages/torch/testing/_internal/common_nn.py:1195
/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.8/site-packages/torch/testing/_internal/common_nn.py:1195: UserWarning: Legacy tensor constructor is deprecated. Use: torch.tensor(...) for creating tensors from tensor-like objects; or torch.empty(...) for creating an uninitialized tensor with specific sizes. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:474.)
random_samples = torch.DoubleTensor(1, 3, 2).uniform_()
-- Docs: https://docs.pytest.org/en/stable/warnings.html
======================================================================= 2 warnings in 2.85s ========================================================================
```
</details>
c7312f5271/torch/testing/_internal/common_device_type.py (L479-L486)
(When running locally where the environment variable is not set)
The case when the env variable is not present, `os.getenv` returns `''` which is split and we get `['']` for `only_for` and `except_for`.
c7312f5271/torch/testing/_internal/common_device_type.py (L496-L497)
At this point, we take the branch and skip all the tests.
```python
>>> if [''] and 'cuda' not in ['']:
... print("TRUE")
...
TRUE
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55664
Reviewed By: albanD
Differential Revision: D27677752
Pulled By: malfet
fbshipit-source-id: 071486e3b6b5113c56f0f956b8d99a5ab24068fe
Summary:
Switched to short forms of `splitWithTail` / `splitWithMask` for all tests in `test/cpp/tensorexpr/test_*.cpp` (except test_loopnest.cpp)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55542
Reviewed By: mrshenli
Differential Revision: D27632033
Pulled By: jbschlosser
fbshipit-source-id: dc2ba134f99bff8951ae61e564cd1daea92c41df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55640
Mean is broken for complex types, since #53218 it's now allocating the result
as a real tensor which discards the imaginary component. This wasn't picked up
in testing because `_test_dim_ops` tests are defined as closures inside of
`_test_dim_ops` instead of as methods on the test class. The result is, they
never get run.
For best results, view diff with "Hide whitespace changes".
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27671127
Pulled By: mruberry
fbshipit-source-id: 4a1f6fea1048919fda7339c867ee78e88f2d7bd2
Summary:
This PR adds the functionality to use channals_last_3d, aka, NDHWC, in Conv3d. It's only enabled when cuDNN version is greater than or equal to 8.0.5.
Todo:
- [x] add memory_format test
- [x] add random shapes functionality test
Close https://github.com/pytorch/pytorch/pull/52547
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48430
Reviewed By: mrshenli
Differential Revision: D27641452
Pulled By: ezyang
fbshipit-source-id: 0e98957cf30c50c3390903d307dd43bdafd28880
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55529
x.shape outputs a non-Tensor, add this to the all_node_args_have_no_tensors function
to avoid inserting observer for the getattr "shape" node.
Test Plan: Imported from OSS
Reviewed By: wat3rBro
Differential Revision: D27628145
fbshipit-source-id: 4729294ab80c0a1e72440396d31e7e82257b1092
Summary:
Fixes https://github.com/pytorch/pytorch/issues/55088.
Unfortunately, this test wouldn't have caught index_add_ breakage (because index_add_ breakage would appear only in a particular type promotion situation).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55527
Reviewed By: mruberry
Differential Revision: D27671138
Pulled By: ngimel
fbshipit-source-id: b52411f5a6d81098b706dfda4d0c9a16716414d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55429
Previously we special case copy operator in normal insert observer code, this PR tries to split the
special case logic to a separate function and keep the rest of the code clean.
Test Plan:
Imported from OSS
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D27609972
fbshipit-source-id: 378f6aa70f18c0b477b62b6efe236648748aae7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55213
Adds the integration of conv2d with the TE fuser. A few things of interest:
- I'm *super* selective of what convs get lowered. Only 3x3 depthwise, because
I've benchmarked those to death and I'm pretty sure it's a good change.
- I'm allowing single-node "fusion" groups for supported convs. (Maybe this is
a sign that conv2d codegen should go through a different path entirely, but
it seems to basically work).
I'll shared full benchmarkr results once I clean them up a little. To
summarize, I tested the following torchvision models containing depthwise
convolutions. Results are single-core on a skylake-avx512:
mobilenet_v2: 8% improvement
mobilenet_v3: 9% improvement
mnasnet: 10% improvement
shufflenet: 18% improvement
Note these are comparing against a baseline with a fast-but-buggy grouped
convolution implementation in MKLDNN. So perf results will be better if
compared on master, but I'm going to assume the MKLDNN bug will be fixed and
re-enabled.
Perf results are more complicated when comparing to freezing plus conversion to
mkldnn layout; mobilenet v2/v3 are still faster, but mnasnet and shufflenet are
not. Landing this doesn't prevent MKLDNN freezing from kicking in though, so
there's no harm (although landing mkldnn freezing will regress mobilenet, but
cest la vie).
ghstack-source-id: 126076112
Test Plan: New unit test, plus torchvision
Reviewed By: ZolotukhinM
Differential Revision: D27530272
fbshipit-source-id: 92153fad234bc9f1eaa4f7624c543168d1294a87
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55025
Something needs to be fixed about the names of these functions,
because they are confusing.
The profiling infrastructure calls `isSupported` to see if it should insert
profiling nodes.
The fuser calls `isSupported` but also `typesAreSupported` to determine if it
can actually fuse the node.
At profiling time, we don't know device types yet, so we can't use device type
checks in `isSupported` or else we'll never profile the node. So we want to
move those checks into `typesAreSupported`, where we actually have profiling
info available.
ghstack-source-id: 126076111
Test Plan: sandcastle
Reviewed By: ngimel
Differential Revision: D27454968
fbshipit-source-id: 4ffb142ea7a0086842a034c9e202f9cb1065fc95
Summary:
malfet found a couple of these in https://github.com/pytorch/pytorch/issues/55346; this PR removes the rest and adds a lint that prevents them from being accidentally added again in the future. It also removes the `-o` flag added in https://github.com/pytorch/pytorch/issues/53733 (which was unnecessarily hiding context without reducing the number of lines of output), and updates the lint error messages to reflect that the individual line numbers are shown in the logs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55465
Test Plan:
The "Lint / quick-checks" job in GitHub Actions should succeed on this PR. To verify that the lint does correctly find and error on non-breaking spaces, checkout ece075195d49c25213c96b9d53fcf7077215f44a and run it locally:
```sh
(! git --no-pager grep -In $'\u00a0' -- . || (echo "The above lines have non-breaking spaces (U+00A0); please convert them to spaces (U+0020)"; false))
```
It should print over a hundred lines of output and exit with status 1.
Reviewed By: janeyx99
Differential Revision: D27622136
Pulled By: samestep
fbshipit-source-id: e7ffd5a9519093e7a0ffdf55e9291f63e21ce841
Summary:
Provide explanation for why we have (and use) the BUILD_SPLIT_CUDA option as a result of PR https://github.com/pytorch/pytorch/pull/49050.
This should hopefully clarify why there is both TORCH_CUDA_CU_API and TORCH_CUDA_CPP_API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55641
Reviewed By: samestep
Differential Revision: D27661729
Pulled By: janeyx99
fbshipit-source-id: a68b44df2b45ce10590b9b0229558a1ad40ce485
Summary:
1. move module related stuff to test_module_container
2. created test_types for types and annotation
3. created test_misc for the rest
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55560
Reviewed By: VitalyFedyunin
Differential Revision: D27650911
Pulled By: walterddr
fbshipit-source-id: d895a7da9e9c3d25a662a37faf4daabc276b9c1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55367
During compilation, nvcc emits several warnings about unused variables and static funcions:
```
caffe2/aten/src/ATen/native/cuda/SpectralOps.cu(231): warning: function "at::native::_run_cufft" was declared but never referenced
caffe2/aten/src/ATen/native/sparse/cuda/SparseMatMul.cu(60): warning: function "at::native::<unnamed>::confirm_mult_size" was declared but never referenced
caffe2/aten/src/ATen/native/cuda/UnaryFractionKernels.cu(112): warning: function "at::native::nearbyint_wrapper(c10::complex<double>)" was declared but never referenced
caffe2/aten/src/ATen/native/cuda/TensorFactories.cu(106): warning: variable "d_temp_storage" was declared but never referenced
caffe2/torch/fb/sparsenn/sparsenn_operators_gpu.cu(2325): warning: variable "kMaxThreads" was declared but never referenced
```
To reproduce, run the following build command on remote/master:
```
buck build mode/dev-nosan caffe2/torch/fb/sparsenn:sparsenn_operators_gpu
```
Warnings about unused variables are fixed by removing the variable declaration. However, I don't want to remove the unused static functions. They were probably used before some other part of the code was refactored. They might be useful again in the future. So, I added a #pragma firectives to disable warnings for such functions.
Test Plan: Compilation does not produce warnings any more.
Reviewed By: r-barnes
Differential Revision: D27577342
fbshipit-source-id: e6a6e5ec513996337d904985dd27c60601c74803
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54175
Building on top of previous PR. This PR adds cuda support for 1D max reduction.
Next steps:
- Add support for other major reduction types (e.g. min, sum) for 1D tensor
- Documentation for the op
- Perf optimizations and benchmark util
- Backward support (not high priority)
- Support for multi dimensional tensors (on data and lengths) (not high priority)
- Support for 'indices' (not high priority)
Test Plan: Added unit test
Reviewed By: ngimel
Differential Revision: D27121170
fbshipit-source-id: 1c2565f42e2903e6fc089d56983ce8857efbfa3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55121
This is done by allow -1 as a stream ID, meaning "don't change
the stream", in SwitchToDevice
Fixes#54830
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D27527544
Pulled By: ezyang
fbshipit-source-id: c54983d6fc79a8fa1c65a71559a57425e40ba717
Summary:
Add option to add //NOLINTNEXTLINE for every detected violation
Series of automated huge diffs are coming after this one to make large chunks of code clang-tidy
PR generated by new option: https://github.com/pytorch/pytorch/pull/55628
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55612
Reviewed By: samestep
Differential Revision: D27649473
Pulled By: malfet
fbshipit-source-id: 251a68fcc50bf0fd69c6566293d4a516c0ab24c8
Summary:
Partially fixes https://github.com/pytorch/pytorch/issues/55203
Fixes issues (1) and (2) in the following tests:
tests in test/cpp/tensorexpr/test_loopnest.cpp from the beginning to LoopNestReorderLongStringFull (including)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55512
Reviewed By: mrshenli
Differential Revision: D27630679
Pulled By: soulitzer
fbshipit-source-id: b581aaea4f5f54b3285f0348aa76e99779418f80
Summary:
There was an error when removing a parametrization with `leave_parametrized=True`. It had escaped the previous tests. This PR should fix that.
**Edit.**
I also took this chance to fix a few mistakes that the documentation had, and to also write the `set_original_` in a more compact way.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55456
Reviewed By: mrshenli
Differential Revision: D27620481
Pulled By: albanD
fbshipit-source-id: f1298ddbcf24566ef48850c62a1eb4d8a3576152
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55435
We've seen issues from the macos skylight app that PyTorch is super slow due to the lack of cap support in pthreadpools. For mac builds, we set the thread count to `#threads/2`.
ghstack-source-id: 125900852
Test Plan:
- Sandcastle CI
- CircleCI
Reviewed By: kimishpatel
Differential Revision: D27578871
fbshipit-source-id: 7b947bc5d6cf289378abf5f479575e112325d02b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54040
`prim::RequiresGradCheck` guarantees that requires_grad properties
of input tensors will match the profiled, otherwise a fallback path
will be triggered. This allow us to prune off gradients in backward
graph for inputs that don't need gradients. We transfer requires_grad
properties from inputs to the `prim::DifferentiableGraph` onto inputs to the
differentiable graph. Autodiff will inspect these properties and prune
off gradients that aren't required
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54374
Reviewed By: H-Huang
Differential Revision: D27369251
Pulled By: Krovatkin
fbshipit-source-id: 2bce7a2d7f2ec091db9bf4c4b91d8b29edd5be11
Summary:
Reference: https://github.com/pytorch/pytorch/issues/50345
Chages:
* Alias for sigmoid and logit
* Adds out variant for C++ API
* Updates docs to link back to `special` documentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54759
Reviewed By: mrshenli
Differential Revision: D27615208
Pulled By: mruberry
fbshipit-source-id: 8bba908d1bea246e4aa9dbadb6951339af353556
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54769
Follow-up to #53820. This
- makes the `asserts.py` module private as per suggestion from rgommers in https://github.com/pytorch/pytorch/pull/53820#issuecomment-802661387. With this the functions should only be accessible through `torch.testing`, giving us the option the change the underlying structure later.
- moves the code from `torch/testing/__init__.py` to `torch/testing/_core.py` (happy to accept other name suggestions). Otherwise we can't import the new `_asserts.py` in `torch/testing/__init__.py` due to circular imports.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D27438451
Pulled By: mruberry
fbshipit-source-id: c7292b4d5709185b42b4aac8016648562688040e
Summary:
After MAGMA has been enabled, around 5k new tests are running now.
Out of these 5 tests (each having 4 datatypes) are failing on the latest ROCM
CI with Rocm 4.1. Disabling these tests for now so the ROCM CI does not fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55534
Reviewed By: ZolotukhinM
Differential Revision: D27630085
Pulled By: malfet
fbshipit-source-id: c48d124e6a2b4a4f3c6c4b6ac2bdf6c214f325c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55466
Improve the implementation and the unit test coverage of `RendezvousHandlerRegistry`.
### Note
See the original diff (D27442325 (df299dbd7d)) that had to be reverted due to an unexpected Python version incompatibility between the internal and external PyTorch CI tests.
Test Plan: Run the existing and newly-introduced unit tests.
Reviewed By: tierex
Differential Revision: D27623215
fbshipit-source-id: 51538d0f154f64e04f685a95d40d805b478c93f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55333
Reapplying without using enum class in a bitfield. See new
comments about gcc bug.
ghstack-source-id: 125776904
Test Plan: Carefully review OSS test failure logs this time
Reviewed By: kimishpatel, bhosmer
Differential Revision: D27576623
fbshipit-source-id: 68fb00e5ff5215e56c8b9bc02717e1e7b2fedf9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55227
This seems to increase the number of typechecked files.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D27535373
Pulled By: ezyang
fbshipit-source-id: b36f6f8ce52c76848ed600ca9dd6b0c1de5813ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55551
Simple typo, it should be `OrderedImporter`
Test Plan: ci
Differential Revision: D27629463
fbshipit-source-id: 745527a8339f03a8fd38d0a4491811b3c9ca9b1e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54964
Previously, the following would error out with a strange error message:
```
import torch
x=torch.randn(2)
torch.rsub(x, 1, alpha=2j)
Traceback (most recent call last)
<ipython-input-2-caf2a1c03d0b> in <module>
1 import torch
2 x=torch.randn(2)
----> 3 torch.rsub(x, 1, alpha=2j)
RuntimeError: value cannot be converted to type float without overflow: (-0,-2)
```
The reason why this is happening is because the alpha check doesn't check for if `x` is not complex and `alpha` is complex.
The error gets thrown further along in the implementation of torch.sub,
when it coerces `alpha` to be the same dtype as the input tensor:
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cpu/BinaryOpsKernel.cpp#L53
This PR fixes the bad error message by adding a new check to the alpha check.
Test Plan:
- pytest test/test_binary_ufuncs.py
- NB: add, sub, and rsub all share the same alpha check. The test only tests it for torch.add, but that should be sufficient.
Reviewed By: gchanan
Differential Revision: D27504017
Pulled By: zou3519
fbshipit-source-id: 70b9aa75a7a4faaaa93f6ba235cae85998a91697
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55497
Migrating some of the NNC API's used in testing, from this issue: https://github.com/pytorch/pytorch/issues/55203
I covered the second half of `test_loopnest.cpp`, and migrated (1) and (2) in the above issue: `LoopNest::getLoopStmtsFor`, `splitWithTail`, and `splitWithMask`
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D27628625
Pulled By: bdhirsh
fbshipit-source-id: ec15efba45fae0bbb442ac3577fb9ca2f8023c2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55181
There can be a dramatic model size delta between saving a model after calling generate_bundled_inputs_for_* and saving before. This is due to the caching of the inflated tensor.
This increases latency when asking for the bundled inputs multiple times. I dont think this matters but it might for something like benchmarking?
ghstack-source-id: 125746773
Test Plan: unit tests.
Reviewed By: dreiss
Differential Revision: D27519487
fbshipit-source-id: 6ba22bff9c4e3a8d86c04627b7cbf47ca2d141b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55412
The diff resolves bug where worker processes could exit before torchelastic process would read the return values. This is a rare event, but still can happen, e.g. https://fb.workplace.com/groups/319878845696681/permalink/512409069776990/
When users want to return torch.Tensor object from worker process, the torchelastic multiprocessing will fail. Currently worker process finishes its job after it writes output to the IPC queue without receiver process confirmation. When this happens, the underlying channel between worker and torchelastic process could be closed (in case of mp.SimpleQueue it is file descriptors, that is why we see FileNotFoundException: since worker process finished execution, the file descriptor just got deleted, and torchelastic process cannot find it).
Test Plan:
buck test mode/dev-nosan //caffe2/test/distributed/elastic/agent/server/test:local_agent_test
User workflow: f263531643
Reviewed By: cbalioglu
Differential Revision: D27602838
fbshipit-source-id: 29871178232e3af4ad3dec406c234aba9c5faba1
Summary:
It seems that the std::copysign code introduced in https://github.com/pytorch/pytorch/issues/51706 is too much for gcc 7.5 / 8 when compiled on arm64 (e.g. on Jetson with latest Jetpack) and causes it to produce an internal compiler error with segfault during compilation. This avoids the compiler bug it by not using std::copysign.
A very kind person sent a Jetson Xavier NX {emoji:1f381} thank you {emoji:2764}.
After https://github.com/pytorch/pytorch/issues/51900 fixed this for CPU-only arm64 (eg Raspberry), this fixes it for CUDA-using arm64 (e.g. Jetson). CUDA device lambdas must also be present as host functions for technical reasons but they are never used, so we just assert in the CPU variant instead of actually doing the operation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51834
Reviewed By: mrshenli
Differential Revision: D27622277
Pulled By: malfet
fbshipit-source-id: a1dc4c3a67f925019782e24b796919e17339749f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55226
Fixes a bug caused by using different clocks in legacy events, also fixes two
small issues with not using relative time in memory events and discrepancy
between start and stop profile events CUDA-wise
Test Plan: CI
Reviewed By: xuzhao9
Differential Revision: D27534920
fbshipit-source-id: 7a877367b3031660516c9c4fdda1bf47e77bcb3e
Summary:
Related to https://github.com/pytorch/pytorch/issues/52256
Splits torch.nn.functional into a table-of-contents page and many sub-pages, one for each function
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55038
Reviewed By: gchanan
Differential Revision: D27502677
Pulled By: zou3519
fbshipit-source-id: 38e450a0fee41c901eb56f94aee8a32f4eefc807
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55424
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55238
I tried to avoid creating new TLS, but InferenceMode::is_enabeld()
is in perf critical path (TensorImpl constructor) so it seems
worth adding one for it.
This PR reduces one sources of instruction count increased by
https://github.com/pytorch/pytorch/pull/55008.
```
λ ~ python compare.py
<torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.FunctionCounts object at 0x7f59097ef310>
100 0x0000000004854750
-100 0x0000000004854760
-4400 c10::impl::tls_is_dispatch_key_included(...)
```
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D27539230
Pulled By: ailzhang
fbshipit-source-id: e040877faef966dca3c2c3d5f9e9a80496c81415
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55251
Based on a discussion with dreiss and JacobSzwejbka, we decided to implement a flexible operator for decoding a JPEG bundled image that allows getting the image in BGR format with scaling, and offsets applied for the MaskRCNN operators without calling `conv2d()` and pulling in a ton of additional operators and kernel functions. Please see the previous diff in the stack for the new operators that the change w/o this diff would have pulled in since Inflatable Arg string is non-trivial.
This change implements that operator. Please see the comments in the code for detail regarding what the operator does.
ghstack-source-id: 125641068
Test Plan:
I re-implemented the existing operator in terms of the new operator and used the existing unit test to ensure that the same (or comparable) tensor is produced.
```
cd fbsource/fbcode/
buck test caffe2/test:test_bundled_images
```
Ran this bento notebook https://www.internalfb.com/intern/anp/view/?id=476100 with the new operator `fb::jpeg_decode_to_NCHW` and saw that it is able to generate proposals.
Ran the generated hand tracking model with tracer and observed just the 2 new operators and 0 new dtypes copy kernel function, which to me seems like an acceptable set of new ops to pull in since they are relatively simple operators: {P383858691}
Reviewed By: dreiss
Differential Revision: D27531423
fbshipit-source-id: 2dc6c41029236bb71922e51cbfd14a46c5651149
Summary:
ATT, so that the shape inference works for a model with only distributed parts.
Previously, we rely on a full_predictor net to do shape inference. For very large models, the full_predictor net won't be generated, so we have to do shape inference based on distributed parts. Surprisingly, the PredictorCall op does tensor name mapping so it has to have shape inference func supported.
Test Plan: Added unittests.
Reviewed By: khabinov
Differential Revision: D27250956
fbshipit-source-id: 3ebd36ba1eb020bb5d00358cffb8f038a6a996e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55321
We have some operators that previously allowed you to pass in an undefined tensor to the out argument,
and then would go on to allocate that for you. This behavior is broken and doesn't work in JIT when things
are converted to/from IValues. Because of this, it blocks backend fallbacks because they force going
through IValue.
This PR is one in a series to remove that behavior and forces out arguments to be defined tensors.
It only looks at at::_linalg_solve_out_helper_cuda(), but there's more PRs for other ops.
ghstack-source-id: 125886984
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: ngimel
Differential Revision: D27572759
fbshipit-source-id: 5bca60b39c513b8d85fe282ebd4d66607d54774f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53624
Previously, the boxing logic didn't correctly forward arguments to the stack but called copy constructors.
This PR fixes that.
ghstack-source-id: 125886983
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D26852856
fbshipit-source-id: d2463eeca2f3fce1bbe117611be200fda59c880b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53556
When packing a `Tensor&` (mutable lvalue reference) into an IValue, we accidentally didn't increase the refcount.
This wasn't triggered anywhere, until I tried to enable backend fallbacks. Backend fallbacks for ops that
have out arguments (i.e. ops that take `Tensor&` arguments and return `Tensor&` arguments) pack those returns
into an IValue stack (and accidentally don't increase the refcount), then later that stack gets destructed
(which decreases the refcount and possibly destroys the Tensor), and the `Tensor&` passed in as an out argument
is suddenty freed memory.
This PR fixes that by forwarding instead of moving when wrapping Tensors into IValues.
ghstack-source-id: 125886986
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: swolchok
Differential Revision: D26896507
fbshipit-source-id: 62102fa89e522699b5174c33279a2b1a775066a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53640
We have some operators that previously allowed you to pass in an undefined tensor to the out argument,
and then would go on to allocate that for you. This behavior is broken and doesn't work in JIT when things
are converted to/from IValues. Because of this, it blocks backend fallbacks because they force going
through IValue.
This PR is one in a series to remove that behavior and forces out arguments to be defined tensors.
It only looks at at::kron_out(), but there's more PRs for other ops.
BC Breaking: This breaks BC since those ops previously allowed calling with undefined tensors and that isn't allowed anymore.
ghstack-source-id: 125886981
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: bhosmer, ngimel
Differential Revision: D26921165
fbshipit-source-id: e61411226c12d33cb196a1e010ff733fe9fa6b7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53218
We have some operators that previously allowed you to pass in an undefined tensor to the out argument,
and then would go on to allocate that for you. This behavior is broken and doesn't work in JIT when things
are converted to/from IValues. Because of this, it blocks backend fallbacks because they force going
through IValue.
This PR removes that behavior and forces out arguments to be defined tensors.
It only looks at reduction ops for now, there's likely more PRs coming for other ops.
BC Breaking: This breaks BC since those ops previously allowed calling with undefined tensors and that isn't allowed anymore.
ghstack-source-id: 125886980
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D26795461
fbshipit-source-id: 158465260fe59deb7d4b2081e810a7434cfba722
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53229
Scalar formatting was assuming that everything non-float was integral. This would output bools as ints, and even worse, it would crash for complex.
This PR fixes that.
ghstack-source-id: 125886979
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D26800345
fbshipit-source-id: 1a9efd085276b40d6fb399d255a6bbd7d5f3619f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53228
Previously, if a Scalar value contained a bool and was put into and then out of an IValue, it would magically transform to an int.
This PR fixes that and preserves the bool-ness.
ghstack-source-id: 125886985
(Note: this ignores all push blocking failures!)
Test Plan: unit tests
Reviewed By: ezyang
Differential Revision: D26800346
fbshipit-source-id: f170a5b8419bde9d3155042f9126e377714ec3ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55328
**Summary**
The `clang-format` reference hashes committed in #54737 have newlines at
the end but the locally computed ones do not. This commit removes these
newlines so that the `clang-format` binary verification step doesn't
fail.
**Test Plan**
`./tools/clang_format_all.py`, ran successfully.
**Fixes**
This commit fixes#54790.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D27577398
Pulled By: SplitInfinity
fbshipit-source-id: e30bee58c2eb5ea96ed0a503480dea4f67b86aca
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54631
I removed the phrase "When `onesided` is the default value `True`". It's not always the default and it's also confusing because it doesn't seem to relate to the bullet points it's introducing. It makes more sense in the sentence before, i.e. these frequencies are included "when the output is onesided". So, I've rewritten it as that meaning and included the correct formula for frequencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54877
Reviewed By: ngimel
Differential Revision: D27562785
Pulled By: mruberry
fbshipit-source-id: d7f36382611e8e176e3370393d1b371d577d46bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55339
Use DimVector. Avoid calling size()/stride() when we know argument is in bounds.
ghstack-source-id: 125839415
Test Plan: Existing CI
Reviewed By: hlu1
Differential Revision: D27577647
fbshipit-source-id: b33057c383037dd0865de3a944ebf225ad8d9169
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55336
The compiler cannot optimize this away because it does not know that size() has no side effects and doesn't get changed by anything else that goes on in the function.
ghstack-source-id: 125775704
Test Plan: Spot-check assembly to verify assertion I made in the summary
Reviewed By: ngimel
Differential Revision: D27577299
fbshipit-source-id: 7b7ce1044c4c0b437d95103a5d149acb5d86c1bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55388
temporarily revert D27314678 (c57541ce06), it appears to cause a perf regression that makes quantization of some models take too long to complete tests.
Reviewed By: houseroad
Differential Revision: D27583809
fbshipit-source-id: e9c088ccbfd3bfb3a1d4c7eafee3eca29ee7717b
Summary:
This PR adds `torch.linalg.eig`, and `torch.linalg.eigvals` for NumPy compatibility.
MAGMA uses a hybrid CPU-GPU algorithm and doesn't have a GPU interface for the non-symmetric eigendecomposition. It means that it forces us to transfer inputs living in GPU memory to CPU first before calling MAGMA, and then transfer results from MAGMA to CPU. That is rather slow for smaller matrices and MAGMA is faster than CPU path only for matrices larger than 3000x3000.
Unfortunately, there is no cuSOLVER function for this operation.
Autograd support for `torch.linalg.eig` will be added in a follow-up PR.
Ref https://github.com/pytorch/pytorch/issues/42666
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52491
Reviewed By: anjali411
Differential Revision: D27563616
Pulled By: mruberry
fbshipit-source-id: b42bb98afcd2ed7625d30bdd71cfc74a7ea57bb5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54701
We need NNAPI models to support inputs (and, by extension, intermediate
values and outputs) whose shape is only determined at load time. For
example, a vision models input shape might be dependent on the aspect
ratio of the device camera. While NNAPI has full support for variable
shapes (by setting components of the operand shape to 0), the guidance
we have received is that vendor-provided drivers for real hardware are
not able to support this efficiently. Therefore, we take a hybrid
approach where shapes are calculated at model load time to
semi-dynamically construct our NNAPI model. While this doesn't let us
have truly dynamic input shapes, it does allow us to ensure that the
vendor driver only sees fixed shapes, so we get maximum performance.
In this initial commit, only PReLU supports dynamic shapes. Additional
operators will be converted in separate diffs.
- In order to convert a flexible-shape model, the user supplies inputs
with shapes containing dimensions of size 0 for the flexible
dimensions.
- During conversion, we generate code to compute the shapes of all
intermediates and outputs as a function of the input shapes.
- We no longer run the input model to produce the output templates.
Instead, we generate code to return properly-sized templates, given
the input shapes.
- All of this generated code goes into a "ShapeComputeModule" that is
used by the NnapiModule during initialization.
- The ShapeComputeModule mutates the serialized model to fill in the
computed sizes for each operand. This requires us to change the dtype
for the serialized model to int32, but this should be fine because
everything in it is already 4-byte aligned.
- NnapiInitWrapper no longer exists. Instead, initialization is
performed on the first run, based on the real arguments. We plan to
provide an API for doing eager initialization.
- Unit test updated to allow separate arguments to be given for trace,
conversion, and inference. A flexible-shape test case was added for
PReLU.
Test Plan: Unit test
Reviewed By: axitkhurana
Differential Revision: D27536796
Pulled By: dreiss
fbshipit-source-id: 105585f247987b1e6ec6946a6fe44401237cb0a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54700
This is an internal method just to make it more clear what
len(self.operands) is doing.
Test Plan: Unit test
Reviewed By: axitkhurana
Differential Revision: D27536794
Pulled By: dreiss
fbshipit-source-id: 678cee8a47df6757dd2e6feabf2560fd82d32e26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54699
We'll soon be adding support for flexible-size tensors to the NNAPI
converter, but it won't be added to all ops at once. Create
get_tensor_operand_by_jitval_fixed_size as a wrapper for
get_tensor_operand_by_jitval that verifies that the argument has a fixed
shape. Update all call sites. As flexible size support is added to
each op, the call sites can be converted back and proper size checks
added.
Test Plan: Unit test
Reviewed By: axitkhurana
Differential Revision: D27536791
Pulled By: dreiss
fbshipit-source-id: 6fb1fea814d767b6ff263fd8b88240a51be74777
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54698
"mf" was short for memory format, but the concept that this variable
represents was renamed to "dim_order", so rename the variable.
Test Plan: Unit test
Reviewed By: axitkhurana
Differential Revision: D27536793
Pulled By: dreiss
fbshipit-source-id: 2b31c70da1ff221a7833e67486690fa606f01dea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54697
Previously, models being converted to NNAPI were expected to take inputs
as separate arguments, but the generated NNAPI model could only take
multiple inputs as a list. Now the generated model always takes inputs
(single or multiple) as separate tensor arguments.
Previously, models being converted to NNAPI were expected to return
outputs as a single tensor or tuple of tensors, but the generated NNAPI
model would return multiple outputs as a list. Now the generated model
returns a tuple as well (or single tensor).
Internally, we decied what output format to use (single tensor or tuple)
based on the conversion process, rather than by running the model.
Test Plan: Unit test
Reviewed By: axitkhurana
Differential Revision: D27536790
Pulled By: dreiss
fbshipit-source-id: c0f93c85d450757e568985947cc2f32043795859
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54696
This was originally developed for a Python version where array was not
available.
Test Plan: Unit test
Reviewed By: axitkhurana
Differential Revision: D27536792
Pulled By: dreiss
fbshipit-source-id: 39e5507e37d4f91871113439fe752a4d5373eaba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48925
The internal build has different header visibility than CMake.
Test Plan: Ran unit tests on dev server.
Reviewed By: axitkhurana
Differential Revision: D25365246
Pulled By: dreiss
fbshipit-source-id: 6b66f972b75874596b5b0e7fef34475950d8f611
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48812
This came up in a squeeze-and-excitation model. Starting with an NHWC
tensor T, we perform a mean operation across H and W, giving an NxC
tensor, which (after some fully connected layers) is reshaped to
NxCx1x1, then multiplied with T. To handle this, we detect the specific
case of a binary op with one NHWC input and one contiguous input with
H,W == 1,1 and allow the op to be applied (after transposing the
contiguous input).
Test Plan: Unit test.
Reviewed By: axitkhurana
Differential Revision: D25317939
Pulled By: dreiss
fbshipit-source-id: b4c17ab3b874d1a7defa04664010ba82115f1c20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47521
This mostly goes op-by-op. We construct a simple model containing the
op (in various configurations for complex ops) and verify that it can be
converted to NNAPI. Additionally, if libneuralnetworks is available, we
also run both the eager model and NNAPI model and ensure that their
outputs are equal (allowing for some slight numerical differences).
serializer.py has 94% coverage. And most of the uncovered lines are
error cases, defensive code, or dead code that I might want to use
later. prepare.py has 56% coverage, but probably closer to 75-80% if we
could collect coverage from TorchScript.
Test Plan:
Ran tests with NNAPI available. Made various tweaks to the codebase to
make sure tests properly detected bugs.
Reviewed By: axitkhurana
Differential Revision: D25317940
Pulled By: dreiss
fbshipit-source-id: 709125af820440bfa7a73bab3304395f115f717f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54695
Previously, torch.nn.Linear was calling aten::addmm internally. Now
it's calling aten::linear, so add support for that.
Test Plan: Unit test
Reviewed By: axitkhurana
Differential Revision: D27536795
Pulled By: dreiss
fbshipit-source-id: 42c8d2a80b20ac12ed9bba599c5e0e874256bb13
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47518
This was left over from an old version of the code. The idea was that
instead of indexing into separate tensors for each weight, you could
bundle them all into a single file and use different offsets into that
file. With the current design, this is nontrivial to support, so drop
the code for now.
Test Plan: CI
Reviewed By: axitkhurana
Differential Revision: D25317935
Pulled By: dreiss
fbshipit-source-id: e26ab3a8d437cb1bbb50319209fa56d9c571ce61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47517
While we're unlikely to see this in practice, it comes up in unit tests.
This type annotation is necessary for `torch.jit.script` to figure out
the type of the list if it is empty.
Test Plan: Unit tests in a later diff.
Reviewed By: axitkhurana
Differential Revision: D25317937
Pulled By: dreiss
fbshipit-source-id: de8b6665c6fcd3cd2b39e3c696a39336c064e4c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47407
Previously, the code for bundling contiguous single-valued tensors (like
torch.zeros) wasn't working for quantized tensors because it was calling
the `torch.tensor` constructor without passing in the quantizer.
Instead, skip the constructor entirely, which makes this use case work
and also simplifies the code. (Originally, I forgot that
`arg.flatten()[0]` would return a tensor, not a scalar.)
Test Plan: Bundled a quantized zero input and saw it run properly.
Reviewed By: dhruvbird
Differential Revision: D24752890
Pulled By: dreiss
fbshipit-source-id: 26bc4873a71dd44660cc0fcb74c227b754e31663
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54619
Minor refactor to conv batchnorm folding to work on other functions besides forward
ghstack-source-id: 125767010
Test Plan: unit test and {P339453712}
Reviewed By: kimishpatel
Differential Revision: D27301452
fbshipit-source-id: 4e0cc544a171a970583979a496b2908935124497
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54772
conv3d-add-relu fusion does not work on some platforms when TF32 is enabled, so set allow_tf32 to false.
Test Plan:
```
python test/test_jit.py -k test_freeze_conv_relu_fusion
```
Imported from OSS
Reviewed By: bertmaher
Differential Revision: D27435560
fbshipit-source-id: e35e2297dce85acfbe988deea97c3f5e68f1e1c7
Summary:
The diff resolves bug where worker processes could exit before torchelastic process would read the return values. This is a rare event, but still can happen, e.g. https://fb.workplace.com/groups/319878845696681/permalink/512409069776990/
When users want to return torch.Tensor object from worker process, the torchelastic multiprocessing will fail. Currently worker process finishes its job after it writes output to the IPC queue without receiver process confirmation. When this happens, the underlying channel between worker and torchelastic process could be closed (in case of mp.SimpleQueue it is file descriptors, that is why we see FileNotFoundException: since worker process finished execution, the file descriptor just got deleted, and torchelastic process cannot find it).
Test Plan:
buck test mode/dev-nosan //caffe2/test/distributed/elastic/agent/server/test:local_agent_test
User workflow: f263531643
Reviewed By: cbalioglu, wilson100hong
Differential Revision: D27572158
fbshipit-source-id: 9a360468acc98d85d587ebf223e7e96d4b43fe4b
Summary:
Install Monkey Type as part of our testing on Linux
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55305
Reviewed By: ailzhang
Differential Revision: D27592679
Pulled By: nikithamalgifb
fbshipit-source-id: c92b786e45fc16288d658228a5f96aca53a3da6b
Summary:
Partially solves https://github.com/pytorch/pytorch/issues/54061
This PR solves many of the "easy to solve" problems with `out=` not notifying when it resizes a tensor. It also reports the cause of some fails of the `out=` operation in the tests. Hopefully this way we will be able to catch some errors that do not come simply from not using `resize_output`.
cc mruberry anjali411
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55141
Reviewed By: anjali411
Differential Revision: D27568755
Pulled By: mruberry
fbshipit-source-id: a32546555fef8d241de2ef635a99e5615461ed09
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52253
In the issue reproducer we can replace `torch.sparse.sum(S)` with `S.coalesce()` and get the same memory leak. The reason is that calling `coalesce()` on an already coalesced tensor returns `self`. With autograd, the result gets it's `grad_fn` set to a node that contains a reference to the input tensor, creating a reference cycle. Cloning the tensor fixes this, so `coalesce` always returns a new tensor.
As an aside, `torch.sparse.sum(S)` doesn't need to coalesce. The result should be the same either way.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52874
Reviewed By: bdhirsh
Differential Revision: D27246997
Pulled By: albanD
fbshipit-source-id: 0fe6c11043501a7874a50982afd42964f47470d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55337
`static_runtime::permute_copy` is in fb-only folder. Because `caffe2/test/test_static_runtime.py` is in OSS, we can't load the fb-only operator library. The workaround is to check at runtime whether the op is registered or not.
Test Plan:
This fixed two of the broken tests:
```
✓ Pass: caffe2/test:static_runtime - test_multihead_attention_layer (test_static_runtime.TestStaticModule) (10.316)
✓ Pass: caffe2/test:static_runtime - test_mlp (test_static_runtime.TestStaticModule) (16.134)
```
Reviewed By: ajyu
Differential Revision: D27577066
fbshipit-source-id: ac87dcde71f0d5140ccde448bb49aaebbbb5908a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55295
Update `_powerSGD_comm_hook_wrapper` to only expose 2 most critical hyperparameters, to make this API more clear to any future user (although the second hyperparameter `start_powerSGD_iter` is not in use yet).
Test Plan: waitforbuildbot
Reviewed By: shuyingsunshine21
Differential Revision: D27561734
fbshipit-source-id: b661981cc033b109f4f2fc92b435567a184a7fb5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55272
1. Set 1K as the default value of `start_powerSGD_iter` for practicability. The original default value 10 is usually too small for real use cases. The new default value 1K is also consistent with PyTorch Lightning.
2. Update the docstring of `start_powerSGD_iter` to remind the users to set a value no less than the warm-up steps if any.
3. Update some unit tests to start PowerSGD early.
ghstack-source-id: 125707662
Test Plan: waitforbuildbot
Reviewed By: shuyingsunshine21
Differential Revision: D27553388
fbshipit-source-id: 40076419bc85755c0c0b64b79ba914b241085fcc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55281
## Summary
` python3 tools/clang_format_all.py` is complaining that binary is not what expected. Find out the reference hash include an extra new line comparing with the actual hash. In this pr,
1. Use `expr(hash)` to show the raw string, such that it's easier to compare two string.
2. Remove the extra new line.
3. Run `python3 tools/clang_format_all.py `, and it formats `torch/csrc/jit/runtime/static/passes.h`.
Before the change,
```
(base) chenlai@chenlai-mp pytorch % python3 tools/clang_format_all.py -v
Found pre-existing clang-format binary, skipping download
Reference Hash: '5fde7bccf65032da297dfb1f18e4a95e96e278fa397e9dcaf364dfe23ec46353'
Actual Hash: '5fde7bccf65032da297dfb1f18e4a95e96e278fa397e9dcaf364dfe23ec46353'
The downloaded binary is not what was expected!
(base) chenlai@chenlai-mp pytorch %
```
After the change,
```
(base) chenlai@chenlai-mp pytorch % python3 tools/clang_format_all.py -v
Found pre-existing clang-format binary, skipping download
Reference Hash: '5fde7bccf65032da297dfb1f18e4a95e96e278fa397e9dcaf364dfe23ec46353\n'
Actual Hash: '5fde7bccf65032da297dfb1f18e4a95e96e278fa397e9dcaf364dfe23ec46353'
The downloaded binary is not what was expected!
(base) chenlai@chenlai-mp pytorch %
```
After strip the hash str:
```
(base) chenlai@chenlai-mp pytorch % python3 tools/clang_format_all.py -v
Downloading clang-format to /Users/chenlai/pytorch/.clang-format-bin
0% |################################################################| 100%
Reference Hash: '5fde7bccf65032da297dfb1f18e4a95e96e278fa397e9dcaf364dfe23ec46353'
Actual Hash: '5fde7bccf65032da297dfb1f18e4a95e96e278fa397e9dcaf364dfe23ec46353'
Using clang-format located at /Users/chenlai/pytorch/.clang-format-bin/clang-format
```
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D27556372
Pulled By: cccclai
fbshipit-source-id: 2fd1ba220733e767ffab41ab31e162f0bf3f1d62
Summary: Improve the implementation and the unit test coverage of `RendezvousHandlerRegistry`.
Test Plan: Run the existing and newly-introduced unit tests.
Reviewed By: tierex
Differential Revision: D27442325
fbshipit-source-id: 8519a2caacbe2e3ce5d9a02e87a910503dea27d7
Summary:
Pull Request resolved: https://github.com/pytorch/elastic/pull/146
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54807
Improve the implementation and the unit test coverage of `RendezvousParameters`.
Test Plan: Run the existing and newly-introduced unit tests.
Reviewed By: kiukchung
Differential Revision: D27342444
fbshipit-source-id: 88de356c0a799844a739eb9105185bb8c1acf11f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54804
Improve the implementation of the utility functions to handle more edge cases and also have a new set of unit tests to cover their usage.
Test Plan: Run the existing and newly introduced unit tests.
Reviewed By: kiukchung
Differential Revision: D27327898
fbshipit-source-id: 96b6fe2d910e3de69f44947a0e8a9f687ab50633
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54805
Expose a `stderr` parameter to `EtcdServer` to have a clean unit test outputs.
Test Plan: Run the existing test suite.
Reviewed By: kiukchung
Differential Revision: D27327495
fbshipit-source-id: 0a342aeda0ff4d85d809aab1cbf155d3fafd4fa1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54803
Revise the rendezvous exception types to align their naming convention more closely with the standard Python exception types.
Test Plan: Run the existing test suite.
Reviewed By: H-Huang
Differential Revision: D27327505
fbshipit-source-id: 862c59222f9ca61a0e5afde89ae8f226090b4f92
Summary:
Tentative fix for https://github.com/pytorch/pytorch/issues/55027.
Wraps cub import in its name space so that static variables used by cub and thrust don't conflict if they end up in the different libraries when torch is built with BUILD_SPLIT_CUDA. cub variables end up in their own namespace, thrust variables are unwrapped, so they don't clash.
This also allows extensions to use cub without wrapping it (thrust will still be problematic). The solution to allowing extensions to use thrust is to stop using thrust in pytorch completely.
Now importing cub and importing thrust cannot coexist, so I had to move nonzero to its own file, and remove reliance on thrust functions for it. Nonzero now uses cub only.
Also, we cannot selectively import just some of cub headers, we are forced to import `cub/cub.cuh`, which is not great.
Caffe2 ops using cub are not touched (there are too many), so mixing caffe2 and torch will (can) still result in the same bug. We are moving towards disabling c2 ops, so I think this is fine.
Still, even with that compiler (correctly) warns about redefinition of `CUB_NS_PREFIX` because including `ATen/ATen.h` transitively includes `thrust/complex.h` and that in turn includes original (empty) definition of `CUB_NS_PREFIX`. We probably can just ignore this warning. Here's an example warning:
```
In file included from /data/users/ngimel/pytorch/aten/src/ATen/native/cuda/Nonzero.cu:9:
/data/users/ngimel/pytorch/aten/src/ATen/cuda/CubUtils.cuh:4: warning: "CUB_NS_PREFIX" redefined
#define CUB_NS_PREFIX namespace at{ namespace native{
In file included from /home/ngimel/local/cuda/include/thrust/system/cuda/config.h:76,
from /home/ngimel/local/cuda/include/thrust/system/cuda/detail/execution_policy.h:33,
from /home/ngimel/local/cuda/include/thrust/iterator/detail/device_system_tag.h:23,
from /home/ngimel/local/cuda/include/thrust/iterator/iterator_traits.h:111,
from /home/ngimel/local/cuda/include/thrust/detail/type_traits/pointer_traits.h:23,
from /home/ngimel/local/cuda/include/thrust/type_traits/is_contiguous_iterator.h:27,
from /home/ngimel/local/cuda/include/thrust/type_traits/is_trivially_relocatable.h:19,
from /home/ngimel/local/cuda/include/thrust/detail/complex/complex.inl:20,
from /home/ngimel/local/cuda/include/thrust/complex.h:1031,
from /data/users/ngimel/pytorch/c10/util/complex.h:9,
from /data/users/ngimel/pytorch/c10/core/ScalarType.h:4,
from /data/users/ngimel/pytorch/c10/core/Scalar.h:10,
from /data/users/ngimel/pytorch/build/aten/src/ATen/core/TensorBody.h:8,
from /data/users/ngimel/pytorch/aten/src/ATen/Tensor.h:3,
from /data/users/ngimel/pytorch/aten/src/ATen/Context.h:4,
from /data/users/ngimel/pytorch/aten/src/ATen/ATen.h:9,
from /data/users/ngimel/pytorch/aten/src/ATen/native/cuda/Nonzero.cu:1:
/home/ngimel/local/cuda/include/cub/util_namespace.cuh:43: note: this is the location of the previous definition
#define CUB_NS_PREFIX
```
We will need a lint rule to prevent people from including `cub/cub.cuh`, because this will lead to https://github.com/pytorch/pytorch/issues/55027 reappearing again for some sequence of operations (and will lead to errors with cub code in extensions).
Also, for this to work reliably we'll need to make sure that everything calling cub ends up in only one of libtorch_cuda_cu or libtorch_cuda_cpp, otherwise even namespace won't help (there still will be same symbols in 2 libraries).
Upd: libtorch_cuda_cpp and libtorch_cuda_cu still contain the same symbols, which means that there exists a sequence of operations that will cause cache bug to reappear, so this is not a solution, we need to adjust file lists for BUILD_SPLITC_CUDA:
```
(pytorch) [ngimel@ ~/local/pytorch/build/lib] nm libtorch_cuda_cu.so | grep PerDeviceAttributeCache | c++filt
000000000c6bf808 u guard variable for at::native::cub::GetPerDeviceAttributeCache<at::native::cub::PtxVersionCacheTag>()::cache
000000000c600830 u guard variable for cub::GetPerDeviceAttributeCache<cub::PtxVersionCacheTag>()::cache
00000000018625e0 t at::native::cub::PerDeviceAttributeCache::DevicePayload at::native::cub::PerDeviceAttributeCache::operator()<at::native::cub::PtxVersion(int&)::{lambda(int&)https://github.com/pytorch/pytorch/issues/1}>(at::native::cub::PtxVersion(int&)::{lambda(int&)https://github.com/pytorch/pytorch/issues/1}&&, int)
00000000009ce630 t cub::PerDeviceAttributeCache::DevicePayload cub::PerDeviceAttributeCache::operator()<cub::PtxVersion(int&)::{lambda(int&)https://github.com/pytorch/pytorch/issues/1}>(cub::PtxVersion(int&)::{lambda(int&)https://github.com/pytorch/pytorch/issues/1}&&, int)
000000000c6bf820 u at::native::cub::GetPerDeviceAttributeCache<at::native::cub::PtxVersionCacheTag>()::cache
000000000c600840 u cub::GetPerDeviceAttributeCache<cub::PtxVersionCacheTag>()::cache
(pytorch) [ngimel@ ~/local/pytorch/build/lib] nm libtorch_cuda_cpp.so | grep PerDeviceAttributeCache | c++filt
0000000000ad2d98 u guard variable for at::native::cub::GetPerDeviceAttributeCache<at::native::cub::PtxVersionCacheTag>()::cache
0000000000ad2da0 u at::native::cub::GetPerDeviceAttributeCache<at::native::cub::PtxVersionCacheTag>()::cache
```
Upd2:
Moved TensorFactories.cu to torch_cuda_cu sources (see a change to caffe2/CMakeLists.txt), so now cub-related symbols are only in libtorch_cuda_cu. We'd need a test for that, any suggestions on how best to test it?
cc zasdfgbnm malfet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55292
Reviewed By: anjali411
Differential Revision: D27576442
Pulled By: ngimel
fbshipit-source-id: 1ef29503a342bb214794d34a42a47052092a66c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55074
This function accesses member variables that can be modified by
different threads (i.e. autograd engine threads), so call it within lock scope.
ghstack-source-id: 125707513
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D27474526
fbshipit-source-id: 8d43faedd6e6eeeb69e21ce3262337ab83d7ba07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55342
The fusion stuff is pretty hard to debug. Given that we're not shipping this part of the stack any time soon, let's temporarily disable them and re-enable them when somebody has the cycles to debug them.
Test Plan: Verified that the tests are now disabled
Reviewed By: ajyu
Differential Revision: D27578573
fbshipit-source-id: cb8d7c9339f7c1700b7653b0231cf570996995ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54011
After symbolic tracing, `fn` seems to already have "forward" in its globals. In this case, `new_keys` would have length of 0 and we take "forward" from `global_dict` directly as `fn_compiled`.
Test Plan: Added a new test in test_fx_experimental.
Reviewed By: ansley
Differential Revision: D27049012
fbshipit-source-id: 7fbeb50ebb717900ff5fc0a8a0925d6a97f5a6dd
Summary:
Prettifies JSON files .pytorch-test-times and .pytorch-slow-tests so that not everything is on one single line.
This is of slightly more importance as generated .pytorch-slow-tests ends up getting stored in our test-infra repo ([example](ad9cd87565)), and it is nice to not have that lil red symbol at the end.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55335
Reviewed By: samestep
Differential Revision: D27576930
Pulled By: janeyx99
fbshipit-source-id: be58565b8c8593a9bfcfab383ee19facc79f0572
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55253
Previously DDP communication hooks takes a tensor list as the input. Now only takes a single tensor, as the preparation of retiring SPMD and only providing a single model replica for DDP communication hooks.
The next step is limiting only 1 model replica in Reducer.
ghstack-source-id: 125677637
Test Plan: waitforbuildbot
Reviewed By: zhaojuanmao
Differential Revision: D27533898
fbshipit-source-id: 5db92549c440f33662cf4edf8e0a0fd024101eae
Summary:
Converts loops of the form:
```
for(int64_t VAR=0;VAR<LIMIT;VAR++)
```
to the form
```
for(const auto VAR : c10::irange(LIMIT))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55148
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D27447811
fbshipit-source-id: 6311a094ec4a81a0b57383aaee0ba1b1dc2445c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55196
This commit fixes printing of default values for optional string type arguments in schemas. At the moment, these default values are not printed as quoted strings. If a schema with an optional string type parameter with a default value that is not `None` is printed and then parsed, the lack of quotes causes a parsing error.
ghstack-source-id: 125655241
Test Plan: This commit adds a unit test to `test_function_schema.py` to test this case.
Differential Revision: D27525450
fbshipit-source-id: 23a93169e7599e7b385e59b7cfafb17fd76318b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55150
Somehow I forgot to add these checks. Now they're in here. Thanks
ngimel for noticing.
This is probably a slight efficiency hit on TensorIterator, which is
probably already doing all these checks. Would be good to follow up
on this, though it may not be easily fixable with the TI rewrite.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zhangguanheng66
Differential Revision: D27523879
Pulled By: ezyang
fbshipit-source-id: 458e617dbc6de6fcfa9e5841148b30b99f52e001
Summary:
- Fixes https://github.com/pytorch/pytorch/issues/54114
- Capped estimated block size to the largest multiple of ten less than C++ INT_MAX
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55200
Test Plan: unit test doesn't throw exception as expected
Reviewed By: robieta
Differential Revision: D27542652
Pulled By: naveedgol
fbshipit-source-id: 3ba68ce84d5fa1d8338cdd5c9f9e5d8c9adda51c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54896
This should help performance. (For example, it improves total
time spent in a C++ benchmark that just adds 2 tensors in place by
about 10%.)
ghstack-source-id: 125659451
Reviewed By: bhosmer
Differential Revision: D27404164
fbshipit-source-id: e1dce8c02100ee4ce22510298c7e0d0f192be201
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54652
This PR adds a fairly robust runner for the instruction count microbenchmarks. Key features are:
* Timeout and retry. (In rare cases, Callgrind will hang under heavy load.)
* Robust error handling and keyboard interrupt support.
* Benchmarks are pinned to cores. (Wall times still won't be great, but it's something.)
* Progress printouts, including a rough ETA.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D27537823
Pulled By: robieta
fbshipit-source-id: 699ac907281d28bf7ffa08594253716ca40204ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54651
This PR fleshes out the benchmarks to everything I could come up with. (166 individual cases when all is said and done.) If there's anything you feel warrants a spot in CI that I've missed, by all means let me know.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D27537824
Pulled By: robieta
fbshipit-source-id: 3819e8fec2131c6b5f29f5099cd41e79131bed90
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 7c0c486650
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54575
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: dskhudia, yns88
Differential Revision: D27286716
fbshipit-source-id: 03b83dacc04edecebbb5b49046baa27deb5ba541
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55291
From the script the build happens in cpp-bulid/caffe2. All the executables and dylibs are available there. It may be more straightforward and accurate to use those binaries, instead of copying the test binary to miniconda3 and use dylibs from there.
Test: CI, especially pytorch_macos_10_13_py3_lite_interpreter_build_test.
Test Plan: Imported from OSS
Reviewed By: raziel
Differential Revision: D27566631
Pulled By: iseeyuan
fbshipit-source-id: 402b9941ab422979d53243624f67d65752213191
Summary:
Fixes https://github.com/pytorch/pytorch/issues/51652.
In particular:
- the main implementation is in `torch.linalg.det` now. `torch.det` is just a deprecated alias to it
- add a new `OpInfo` for `torch.linalg.det`
- remove the old-style tests for `torch.det` (this is similar to what we did for `torch.linalg.slogdet`, see https://github.com/pytorch/pytorch/issues/49194)
- added a `out=` argument to `torch.linalg.det`, but **not** to `torch.det`.
It is worth noting that I had to skip few tests:
- `TestGradientsCuda::test_fn_gradgrad_linalg_det_cuda_float64`. This is not a regression: the functionality is broken also on master, but the test is not executed properly due to https://github.com/pytorch/pytorch/issues/53361.
And the following tests which fails only on ROCm:
- `test_variant_consistency_jit_cuda_{float64,float32}`
- `test_fn_grad_cuda_float64`
I think that the ROCm tests fail because the current linalg.det backward is unstable if the matrix has repeated singular values, see https://github.com/pytorch/pytorch/issues/53364 .
(At the moment of writing some CI jobs are still running but I believe the build will be green, since the only difference wrt the last push is the skip of the ROCm tests)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53119
Reviewed By: H-Huang
Differential Revision: D27441999
Pulled By: mruberry
fbshipit-source-id: 5eab14c4f0a165e0cf9ec626c3f4bb23359f2a9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54610
The `.is_view()` method actually only refers to backward mode views
This is not a problem right now in master (and thus I didn't revert the other PR) because nothing creates forward AD views.
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D27396756
Pulled By: albanD
fbshipit-source-id: 64ff11c6f2486c6430714988d1cf6ecf3d80dccb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55149
I was wondering why no one used this function. It's because it
doesn't work! Also a small doc improvement for expected inline.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zhangguanheng66
Differential Revision: D27523880
Pulled By: ezyang
fbshipit-source-id: a1d80c088ebf1c58a2b9b13d28f7f23d08c42e60
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55294
Some static checkers like pyre have difficulties with types like `builtings.type`, so we strip the `builtins` prefix from autogened proto type stubs.
Test Plan: Let CI run.
Reviewed By: d4l3k
Differential Revision: D27477699
fbshipit-source-id: 45e19835974200a030817d37aec785e3ecb23e8b
Summary:
This PR adds cusolver potrs and potrsBatched to the backend of torch.cholesky_solve and torch.linalg.cholesky_solve.
`cholesky_solve` heuristics:
- If magma is not installed, or batch_size is 1:
- If batch_size > 1 and nrhs == 1, dispatch to `cusolverDn<T>potrsBatched`,
- Otherwise, dispatch to `cusolverDnXpotrs` (64 bit) and `cusolverDn<T>potrs` (legacy).
- Otherwise, use magma.
Note: `cusolverDn<T>potrsBatched` only supports `nrhs == 1`. It is used for `nrhs==1` batched matrix if magma is **not** installed.
See also https://github.com/pytorch/pytorch/issues/42666#47953
Todo:
- [x] benchmark and heuristic
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54315
Reviewed By: ngimel
Differential Revision: D27562225
Pulled By: mruberry
fbshipit-source-id: 323e5d60610abbbdc8369f5eb112d9fa01da40f6
Summary:
## 🚀 Feature
Add Mkl-Layout kernel for tanh.
## Motivation
We want to add a Mkl-Layout kernel for tanh to improve tanh's performance when the input Tensor is Mkl-Layout.
Because, PyTorch does not have the Mkl-Layout kernel for tanh, so it cannot execute the tanh input by the Mkl-Layout Tensor.
Off course you can temporarily avoid this problem by executing to_dense/to_mkldnn, but the performance is significantly reduced due to the copy overhead(1.6-4.3 times slower than CPU kernel).
## Perfomance results
### Environment
- CPU: Intel(R) Core(TM) i7-8086K CPU @ 4.00GHz
- OS: 18.04.1 LTS
- compiler: gcc 7.5.0
- branch: master
- commit ID: fe2c126
- build Environment variable: USE_CUDA=0
- Python: 3.6.9
- Intel MKL(Math Kernel Library): 2020.2-254
- Intel oneDNN: 1.8.1
### Benchmark script
``` python
import torch
import torch.nn as nn
torch.manual_seed(1)
x = torch.randn(2048, 2048)
x_mkl = x.to_mkldnn()
print("### CPU tanh")
with torch.autograd.profiler.profile(record_shapes=True) as prof:
for i in range(100):
output = x.tanh()
print(prof.key_averages().table(sort_by="self_cpu_time_total"))
print("\n### CPU tanh_")
with torch.autograd.profiler.profile(record_shapes=True) as prof:
for i in range(100):
x.tanh_()
print(prof.key_averages().table(sort_by="self_cpu_time_total"))
print("\n### to_dense/to_mkldnn + tanh")
with torch.autograd.profiler.profile(record_shapes=True) as prof:
for i in range(100):
output = x_mkl.to_dense().tanh().to_mkldnn()
print(prof.key_averages().table(sort_by="self_cpu_time_total"))
print("\n### to_dense/to_mkldnn + tanh_")
with torch.autograd.profiler.profile(record_shapes=True) as prof:
for i in range(100):
x_mkl.to_dense().tanh_().to_mkldnn()
print(prof.key_averages().table(sort_by="self_cpu_time_total"))
print("\n### Mkl-Layout tanh")
with torch.autograd.profiler.profile(record_shapes=True) as prof:
for i in range(100):
output = x_mkl.tanh()
print(prof.key_averages().table(sort_by="self_cpu_time_total"))
print("\n### Mkl-Layout tanh_")
with torch.autograd.profiler.profile(record_shapes=True) as prof:
for i in range(100):
x_mkl.tanh_()
print(prof.key_averages().table(sort_by="self_cpu_time_total"))
```
### Results
#### OMP_NUM_THREADS=1 Results(Self CPU time total ms)
| Operation | CPU kernel | to_dense/to_mkldnn+CPU kernel | Mkl-Layout kernel(This PR) |
| ---------- | ---------- | ----------------------------- | -------------------------- |
|tanh | 579.662 | 1658.000 | 617.565 |
| tanh_ | 554.477 | 881.997 | 589.426 |
#### OMP_NUM_THREADS=6 Results(Self CPU time total ms)
| Operation | CPU kernel | to_dense/to_mkldnn+CPU kernel | Mkl-Layout kernel(This PR) |
| ---------- | ---------- | ----------------------------- | -------------------------- |
|tanh | 182.387 | 421.336 | 136.226 |
| tanh_ | 94.331 | 404.931 | 99.254 |
## Modification policy for the code
oneDNN is already supported tanh operation.
[oneDNN: Elementwise](https://spec.oneapi.com/versions/latest/elements/oneDNN/source/primitives/eltwise.html)
There is already exist sigmoid implementation that uses the same Elementwise API as tanh, so we created this PR code with reference to the sigmoid implementation.
527c1e0e37/aten/src/ATen/native/mkldnn/UnaryOps.cpp (L28-L42)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54656
Test Plan:
A test for sigmoid has already been created as shown below.
So, I added a new test of tanh referring to the test of sigmoid.
527c1e0e37/test/test_mkldnn.py (L944-L954)
### mkldnn tanh test result
```
$ python3 test/test_mkldnn.py TestMkldnn.test_tanh
Couldn't download test skip set, leaving all tests enabled...
.
----------------------------------------------------------------------
Ran 1 test in 0.004s
OK
```
Reviewed By: gchanan
Differential Revision: D27395827
Pulled By: ezyang
fbshipit-source-id: d4481332de187e2dea095f9b6aabc73a497960fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55010
Follow up change to add a flag to provide an option for monitored barrier to collect all the failed ranks and then throw instead of just throwing on the first one. This is useful as now monitored barrier will be able to pick up on all hanging ranks instead of just one.
This is done by passing in a flag `wait_all_ranks=True`.
ghstack-source-id: 125699839
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27447787
fbshipit-source-id: ec23aee212060d9eb515ff8adc96c6a17822d1bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55009
Changes monitoredBarrier so that we await acknowledgemenet from ranks
in a consistent order (from least to greatest). This will reduce confusion
around the order the ranks are awaited. We are still planning to add support
for awaiting all ranks in follow up changes.
ghstack-source-id: 125699838
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27405417
fbshipit-source-id: b9a3e72742cbffdd9bf890ab2c94103b768a7b71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55003
Using the `caffe2::setPrintStackTracesOnFatalSignal` utility in
distributed tests to set a signal handler that dumps the state of all threads
for all processes when it receives a FATAL signal. This would help in debugging
tests further.
I had to revert all the python faulthandler code since only one signal handler
function is supported, so running python faulthandler with
`setPrintStackTracesOnFatalSignal` doesn't work.
Sample output:
```
SIGSEGV(11), PID: 3492872, Thread 3492872:
[0] ???(0x7fa7b2d1d61b) in libcaffe2_caffe2_caffe2_cpu.so
[1] ???(0x7fa7b2d1d3fb) in libcaffe2_caffe2_caffe2_cpu.so
[2] ???(0x7fa7b2d1d33d) in libcaffe2_caffe2_caffe2_cpu.so
[3] ???(0x7fa7b2d1d167) in libcaffe2_caffe2_caffe2_cpu.so
[4] ???(0x7fa7ce683150) in libpthread.so.0
[5] ???(0x7fa7be2b233c) in libcaffe2__C_impl_cuda.so
[6] ???(0x7fa7be2ce80c) in libcaffe2__C_impl_cuda.so
[7] ???(0x7fa7be2a0512) in libcaffe2__C_impl_cuda.so
[8] torch::distributed::rpc::TensorPipeAgent::send(torch::distributed::rpc::WorkerInfo const&, torch::distributed::rpc::Message&&, float, std::unordered_map<signed char, signed char, std::hash<signed char>, std::equal_to<signed char>, std::allocator<std::pair<signed char const, signed char> > > const&)+0x24f(0x7fa7be29f71f) in libcaffe2__C_impl_cuda.so
[9] torch::distributed::autograd::sendMessageWithAutograd(torch::distributed::rpc::RpcAgent&, torch::distributed::rpc::WorkerInfo const&, torch::distributed::rpc::Message&&, bool, float, bool)+0x393(0x7fa7b602b203) in libcaffe2_libtorch.so
[10] torch::distributed::rpc::pyRpcPythonUdf(torch::distributed::rpc::WorkerInfo const&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >&, std::vector<at::Tensor, std::allocator<at::Tensor> >&, float, bool)+0x201(0x7fa7bd844971) in libcaffe2__C_impl_cuda.so
```
ghstack-source-id: 125630551
Test Plan: waitforbuildbot
Reviewed By: SciPioneer
Differential Revision: D27419714
fbshipit-source-id: 8aca9a14ef688004053d8798124d9c3a3fbe3489
Summary:
## Problem summary
Fixes https://github.com/pytorch/pytorch/issues/54752 - when the number of threads is more than 3 and at least one `set_num_threads` invocation has taken place before forking child processes by the dataloader, `set_num_threads(1)` in the child process causes a segfault, as during its invocation, the child process is made to handle the data structures of the Caffe2 thread-pool of the parent process, whose data structures it inherits from the parent process (these threads don't exist in the child process, but some of its data structures do, due to the copy-on-write technique used by `fork`).
## Solution
malfet [advised](https://github.com/pytorch/pytorch/issues/54752#issuecomment-810315302) & [authored code](https://github.com/pytorch/pytorch/pull/54895#pullrequestreview-625670122) for adding a `pthread_atfork` handler in `pytorch/caffe2/utils/threadpool/pthreadpool-cpp.cc`, that's invoked in the child process right after fork, to leak the Caffe2 thread-pool (the child inherits the thread-pool's data structures from its parent process, but doesn't actually have those threads, since after `fork` , a child process only has one thread).
## Additional changes
Added unittest `test_no_segfault` to test for this issue in `test_dataloader.py`
Also enabled `test_segfault` (which actually makes sure that segfaults happen in worker processes in a particular case).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54895
Reviewed By: zhangguanheng66
Differential Revision: D27542253
Pulled By: malfet
fbshipit-source-id: 10f9c67ce1ff1aa37d3efebf405bd93f7f9d2489
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55255
This allows packaged code to detect whether or not they are used in a
packaged context, and do different things depending on that. An example
where this might be useful is to control dynamic dependency loading
depending on whether or not something is packaged.
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Differential Revision: D27544245
Pulled By: suo
fbshipit-source-id: 55d44ef57281524b8d9ab890bd387de97f20bd9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55212
Error out SPMD in C++ Reducer.
Added a new test `test_reducer_no_multi_replicas`, which checks no multiple replicas are allowed at the Reducer constructor.
Removed 2 tests relevant to reducer in SPMD mode:
`test_ddp_comm_hook_multiple_replica_check`
`test_forward_backward_multi_replica`
ghstack-source-id: 125602472
Test Plan: waitforbuildbot
Reviewed By: pritamdamania87
Differential Revision: D27497747
fbshipit-source-id: 17ef1bc4d889cbe8076bcb3d504aed4c1aea1562
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55188
We need to make sure dim types are preserved after applying Transpose.
Test Plan:
```
$ buck build caffe2/caffe2/opt:bound_shape_inference_test && ./buck-out/gen/caffe2/caffe2/opt/bound_shape_inference_test --gtest_filter=*Transpose*
```
Reviewed By: yinghai
Differential Revision: D27514487
fbshipit-source-id: 431b7f2d08664f2ec311a733c926dbb52c63a7d4
Summary:
Added the functionality desired in https://github.com/pytorch/pytorch/issues/50789.
1. Added support for pow() on CPU for `float16` (`Half`) and `bfloat16` types.
Both `pow(Tensor, Scalar)` and `pow(Tensor, Tensor)` are now supported for the aforementioned types.
However autograd isn't supported for `Float16` on CPU yet, as `log_vml_cpu` can't be enabled for it.
2. heitorschueroff added `pow_tensor_scalar_optimized_kernel` to refactor & simplify `PowKernel.cpp`.
It provides a common path for all the complex types & floating point types (except Float16, due to lack of complete AVX2 vectorization support for it). It replaced code that had previously been duplicated for (float, double) and complex types,
so PowKernel.cpp looks a lot cleaner now.
3. Enabled (unskipped) some tests for `erf`, `erfc`,`erfinv`, `linalg.norm` and `linalg.vector.norm` which were being skipped earlier due to `pow()` not having been implemented for `float16` & `bfloat16`.
4. Added an OpInfo for `pow()` & enabled some test cases for `pow()`.
5. Extended the coverage of existing tests for `pow` in `test_binary_ufuncs.py` in order to enable comparison with `numpy`, even with discontiguous tensors, and added a test to ensure that a runtime error is raised for `pow`'s inplace variant if resizing the base tensor is required during its invocation.
6. Added `float16` & `bfloat16` to `square`'s dtype lists in its `UnaryUfuncInfo`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50999
Reviewed By: zou3519
Differential Revision: D27478225
Pulled By: heitorschueroff
fbshipit-source-id: d309dd98d5a96d0cb9b08281757bb1c65266d011
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54544
## Feature
- Add `subinstance(data, type)` to check `data` is a subtype instance of the `type`
- Add a decorator of `runtime_validation` to validate the returned data from `__iter__` is subtype instance of hint.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D27327234
Pulled By: ejguan
fbshipit-source-id: fb6a332762b0fe75284bb2b52a13ed171b42558c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54066
## Feature
- Add a decorator `construct_time_validation` to validate each input datapipe according to the corresponding type hint.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D27327236
Pulled By: ejguan
fbshipit-source-id: a9d4c6edb5b05090bd5a369eee50a6fb4d7cf957
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54020
## Feature
- Add `issubtype` to check the type is a subtype of the other type.
- Add `_DataPipeMeta` (mimic Python typing 3.6)
- Add `type` attribute for each DataPipe
- Save original `__init__` function for each DataPipe
- Validate return hint of `__iter__`
- Replace `__init__` function bases on `type`
- Fixed type: Put original `__init__` back, if it exists or use a plain `__init__`
- Non-fixed type: Add new `__init__` with the functionality to copy `cls.type` for each instance. (Optimized for memory)
No Error for main repo, `torchvision`, `torchaudio` and `torchtext`.
## Future
- Add same thing for `__getitem__`.
- When DataFrame came out, add an another type for DataFrame with column name and type.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D27327232
Pulled By: ejguan
fbshipit-source-id: fd3a6029c16f5d814b1d7e1b1566fdcd8fd1ad9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54299
## Feature
- Check type is a subtype of another type
Prerequisite for DataPipe tying system.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D27327235
Pulled By: ejguan
fbshipit-source-id: 8f50a663a86540677c9e132ac7c5216fdac46f70
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55012
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54442
Added needsOutputs support to RecordFunction, improved ObserverUtil functions to handle list data. Minor refactor names to be consistent.
To get output data from kernel calls, we need to temporarily capture them before passing them to the record function. Then the results are released to function return. We handle two cases, for unboxed and boxed kernels. The boxed version is fairly simple since all outputs are stored in the stack object. For unboxed kernel calls, we added a `ReturnValue` utility class to properly handle the different return values of unboxed kernels.
For optimization, this intermediate capture is only enabled for observers that request `needsOutputs(true)` and should not affect other observers or when the observer is not enabled.
Test Plan:
```
=> buck build //caffe2/test/cpp/jit: --show-output
=> buck-out/gen/caffe2/test/cpp/jit/jit --gtest_filter=RecordFunctionTest*
CUDA not available. Disabling CUDA and MultiCUDA tests
Note: Google Test filter = RecordFunctionTest*-*_CUDA:*_MultiCUDA
[==========] Running 7 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 7 tests from RecordFunctionTest
[ RUN ] RecordFunctionTest.TracedTestInputsOutputs
[ OK ] RecordFunctionTest.TracedTestInputsOutputs (226 ms)
[ RUN ] RecordFunctionTest.SampledCallbacks
[ OK ] RecordFunctionTest.SampledCallbacks (771 ms)
[ RUN ] RecordFunctionTest.RecordFunctionGuard
[ OK ] RecordFunctionTest.RecordFunctionGuard (0 ms)
[ RUN ] RecordFunctionTest.Callbacks
[ OK ] RecordFunctionTest.Callbacks (2 ms)
[ RUN ] RecordFunctionTest.ShouldRun
[ OK ] RecordFunctionTest.ShouldRun (0 ms)
[ RUN ] RecordFunctionTest.Basic
[ OK ] RecordFunctionTest.Basic (1 ms)
[ RUN ] RecordFunctionTest.OperatorNameOverload
[ OK ] RecordFunctionTest.OperatorNameOverload (1 ms)
[----------] 7 tests from RecordFunctionTest (1001 ms total)
[----------] Global test environment tear-down
[==========] 7 tests from 1 test case ran. (1002 ms total)
[ PASSED ] 7 tests.
```
Reviewed By: ilia-cher
Differential Revision: D27449877
fbshipit-source-id: 69918b729565f5899471d9db42a587f9af52238d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54826
This test will no longer work, because we errored out SPMD in #54454.
This test is already disabled.
ghstack-source-id: 125602473
Test Plan: N/A
Reviewed By: rohan-varma
Differential Revision: D27381719
fbshipit-source-id: a3079ff0766f91112cbe58c1f00c1b02d241c8cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54454
According to the pitch in https://github.com/pytorch/pytorch/issues/47012
1. Let DDP error out if `device_ids` contains multiple devices.
2. If device_ids is not specified, DDP will use the provided model (module argument in DDP constructor) as-is, regardless if the model is on one GPU or multiple GPUs or on CPU.
3. Remove the assertion that prevents SPMD in DDP `join()` method, because now SPMD is already forbidden by the constructor. Also remove the relevant unit test `test_ddp_uneven_inputs_replicated_error`.
#Closes: https://github.com/pytorch/pytorch/issues/47012
ghstack-source-id: 125644392
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_spawn -- test_cuda
buck test mode/dev-nosan caffe2/test/distributed:distributed_gloo_spawn -- test_rnn
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_nccl_backend_multi_device_ids_not_allowed
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_nccl_backend_single_device_module_device_ids_None
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_nccl_backend_multi_device_module_device_ids_None
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_multi_device_module_config
waitforbuildbot
Reviewed By: pritamdamania87
Differential Revision: D27226092
fbshipit-source-id: 3ee1e4bc46e5e362fc82cf7a24b2fafb34fcf1b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55177
This fixes `warning: '_GLIBCXX11_USE_C99_COMPLEX' is not defined, evaluates to 0`, that would be raised if https://github.com/pytorch/pytorch/pull/54820 used with libstd++ compiled without USE_C99_COMPLEX support.
In `c++config.h` `_GLIBCXX_USE_C99_COMPLEX` is aliased to either `_GLIBCXX98_USE_C99_COMPLEX` or `_GLIBCXX11_USE_C99_COMPLEX` depending on `__cplusplus` macro, as shown here:
0cf4813202/libstdc%2B%2B-v3/include/bits/c%2B%2Bconfig (L641-L647)
Abovementioned config file is generated by autoconf, that leaves macro undefined if feature is not used, so using conditional like `defined(_GLIBCXX_USE_C99_COMPLEX) && _GLIBCXX_USE_C99_COMPLEX == 0` would trigger undefined macro preprocessor warning.
Test Plan: CI
Reviewed By: Orvid
Differential Revision: D27517788
fbshipit-source-id: a6db98d21c9bd98205815641363b765a02399678
Summary:
https://github.com/pytorch/pytorch/issues/54779 split out the logic from our "Lint" workflow into a separate workflow that allows us to annotate PRs from forks. However, as of https://github.com/pytorch/pytorch/issues/54689, it is possible for the "Lint" workflow to be canceled, in which case it may not upload the "flake8-py3" and "clang-tidy" artifacts that the "Add annotations" workflow expects. This often results in GitHub pointlessly sending notification emails due to the failure in the "Add annotations" workflow. This PR fixes the issue by gracefully handling the case where the expected artifact is absent.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55242
Test Plan: I tested this in the same external sandbox repo used to test https://github.com/pytorch/pytorch/issues/54779.
Reviewed By: malfet
Differential Revision: D27540120
Pulled By: samestep
fbshipit-source-id: 47cc02950edbbc6381033bda2fe4570cb3e331cb
Summary:
Non-backwards-compatible change introduced in https://github.com/pytorch/pytorch/pull/53843 is tripping up a lot of code. Better to set it to False initially and then potentially flip to True in the later version to give people time to adapt.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55169
Reviewed By: mruberry
Differential Revision: D27511150
Pulled By: jbschlosser
fbshipit-source-id: 1ac018557c0900b31995c29f04aea060a27bc525
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55124
**Summary**
This commit modifies type inference (used by the module scripting code)
so that it tries to script the type of any class instances that it
encounters. This enables recursive, automatic scripting of class type
module attributes.
**Test Plan**
This commit adds a test case for this to `TestClassType`.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D23971883
Pulled By: SplitInfinity
fbshipit-source-id: 7a5a2e7c12ee68cbdeb0a07e6aaf98734a79cb06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49267
This PR builds upon the PR https://github.com/pytorch/pytorch/pull/48711 by RockingJavaBean. The original PR introduced a BC breaking change by making the interpolation parameter positional. Thus, previous invocations of torch.quantile that did not include the interpolation parameter failed after the PR landed.
To avoid BC breaking changes, we preserve the original signatures and make the interpolation parameter in the new signatures kwarg only. For now, interpolation cannot have a default value to avoid ambiguity with the deprecated signature. However, due to limitations of codegen and C++, we cannot have a required arg after optional ones. Thus, this PR also makes dim and keepdim requires args. Once we can remove the old signatures, dim, keepdim and interpolation parameters in the new signature will get the default values back.
__TODO__
---
- [ ] Run backward compat tests
This reverts commit 2f1d1eb7df5e8032392b73751c84025a2aa3d1ee.
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D27337117
Pulled By: heitorschueroff
fbshipit-source-id: 7fe31f22027645e0d6cb3cab0392d532a4b362c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55031
It turns out that PowerSGD hooks can work on PyTorch native AMP package, but not Apex AMP package, which can somehow mutate gradients during the execution of communication hooks.
{F561544045}
ghstack-source-id: 125268206
Test Plan:
Used native amp backend for the same pytext model and worked:
f261564342
f261561664
Reviewed By: rohan-varma
Differential Revision: D27436484
fbshipit-source-id: 2b63eb683ce373f9da06d4d224ccc5f0a3016c88
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55125
We can provide an ArrayRef to 1-5 zeros much more efficiently, like this.
ghstack-source-id: 125471024
Test Plan: Existing CI
Reviewed By: ezyang
Differential Revision: D27494800
fbshipit-source-id: 5e2addfabae70960475a4b322925cd0eae71b4c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55187
As described in https://github.com/pytorch/pytorch/issues/54927, Pipe
docs didn't explicitly mention initializing RPC. This PR improves the docs and
also ensures Pipe throws a more useful error message when RPC is not
initialized and not an internal assertion error.
ghstack-source-id: 125563552
Test Plan:
1) unit test added.
2) waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D27521783
fbshipit-source-id: d1a5c6ca789b9a66c07a794468178c25cfd4b743
Summary:
https://github.com/pytorch/pytorch/issues/47786 updated ShellCheck and fixed the warnings that it was already giving in CI (since it previously didn't cause the job to fail). https://github.com/pytorch/pytorch/issues/54069 enabled two ShellCheck warnings that previously were globally disabled. This PR continues the trend by reenabling the remaining four ShellCheck warnings that previously were globally disabled.
Also, this PR puts as many remaining ShellCheck arguments as possible into `.shellcheckrc` to make it easier to integrate with editors. For instance, in VS Code, this is now all that is needed (due to https://github.com/koalaman/shellcheck/issues/1818 and the fact that VS Code only runs ShellCheck on one file at a time):
```json
{
"shellcheck.customArgs": [
"--external-sources"
]
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55165
Test Plan:
[The "Lint / quick-checks" job in GitHub Actions](https://github.com/pytorch/pytorch/pull/55165/checks?check_run_id=2250098330), or this command if you want to check locally:
```
.jenkins/run-shellcheck.sh
```
Reviewed By: walterddr
Differential Revision: D27514119
Pulled By: samestep
fbshipit-source-id: f00744b2cb90a2ab9aa05957bff32852485a351f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55078
Fixes a TODO, make sure we iterate through kwargs as well as args
when navigating graphs. We can use `node.all_input_nodes` convenience
property to accomplish this.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27474699
fbshipit-source-id: 8a6e3db5a73328c4f296ac5fce951e81213b6f58
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55077
Deletes debugging prints from the code, no logic change.
Test Plan:
CI
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27474700
fbshipit-source-id: 3d9d73da6615ddffdfdb0df270bcdfd2c4b50be3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55060
Removes the previous iteration of Numeric Suite for FX graph mode
quantization, and moves the current iteration into the top level
file.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
python test/test_quantization.py TestFXGraphMatcher
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27467725
fbshipit-source-id: 4c22b5a3221857231f9f59cf6d2908820e6a7f12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54335
Simple fix to enable weight extraction for nni.ConvReLU2d.
Note: this module only appears if the internal GraphModule APIs are
called, so we add testing for this path.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_extract_weights_mod
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D27192844
fbshipit-source-id: 923cf63e29e4638fd77ca42e69aedb15fb20a330
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54326
Fixes unshadowed activation input logging for subgraphs where start_node does
not equal end_node. In detail:
* instead of passing around a single list of nodes, pass around a list
of nodes to instrument inputs, and a list of nodes to instrument
outputs. This way we can handle multi-node subgraphs properly, and we
also keep the subgraph instance definition out of the public APIs.
* add a test case
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_linear_fp16_activations
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D27190138
fbshipit-source-id: 58e2377c1c128baaf3b760c1ad29098fb21f53d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54280
Some easy refactors to reduce duplicate logic in test cases
for NS for FX. In particular, we start reusing a common model
within this file, and we split the fp16 test cases to be more
modular.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D27173373
fbshipit-source-id: cf3f21ee8b9b12dff89f1cd2d3ac1749f3f63fe6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54275
Adds support for NS shadow activations path for the fp16 emulation
pattern such as
```
... -> dequantize -> linear -> relu -> to(torch.float16) -> ...
```
There are a couple of changes necessary here:
1. removing the restriction on the shadowing graph pass that the B
subgraph is a single node (since this subgraph is four nodes), and
modifying the code to correctly add the relevant inputs versus output
loggers (input loggers and subgraph copy if we are at start_node,
and output logger if we are at end_node)
2. modifying the logic for calculating node input and output type
to work correcty for the `to` and `dequantize` nodes:
2a. make the function return the first input and output, instead of just
the first input
2b. make the function handle `dequantize` correctly by recursively
using the output if its input
2c. make the function handle `to` correctyl by recursively using the
output of its input and the target dtype
3. a bug fix to handle observers in kwargs, while copying subgraphs
Note: input logging for these patterns is not tested yet,
this will be in the next PR.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_linear_fp16
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27172655
fbshipit-source-id: 3bdc86618b2a5782627fcf303d58af7f47fbc30d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48917
max_pool2d channels last support forward path
max_pool2d channels last support backward path
vectorize channels last forward path
rename the header file
fix windows build
combine PoolingKernel.h into Pool.h
add data type check
loosen test_max_pool2d_nhwc to cover device CPU
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D25399470
Pulled By: VitalyFedyunin
fbshipit-source-id: b49b9581f1329a8c2b9c75bb10f12e2650e4c65a
Summary: The `tensorpipe::Buffer::deviceType()` method is going away.
Test Plan: CI
Reviewed By: lw
Differential Revision: D27478436
fbshipit-source-id: 3962257bc6237d1dde7e5f4fddae38abe8384c68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55017
JacobSzwejbka in D26678637 found the mis-alignment between the operator list that the YAML file claimed and the dispatcher claimed. After some digging and thorough investigation by JacobSzwejbka, we have come to the conclusion that the non-traced operators are more trouble than they are worth since they will result in phantom operators which every user of the capabilities API needs to be aware of (or every language implementation needs to be aware of). Instead, with this change, we can **reliably** trace all operators called via the dispatcher by clearing the list of un-observed operators during model tracing.
Also another thing to note is that the ignore-list in the observer is a list of base operator names, and not full operator names (with overload), which is whaat tracing based selective build needs. If we use the ignore-list, then we would need to include every overload on un-traced operators.
Latency isn't an issue during model tracing, so this should be generally okay.
Ran the following command to re-generate all the YAML files: `buck run caffe2/torch/fb/mobile/cli:cli -- --gen_all_model_configs`
ghstack-source-id: 125337353
(Note: this ignores all push blocking failures!)
Test Plan: Sandcastle and wait for unit tests. Also see BSB results in the diff comments.
Reviewed By: JacobSzwejbka
Differential Revision: D27452855
fbshipit-source-id: 410bafec7ac67503f68623a5e3d4ab258f434cbf
Summary:
Related https://github.com/pytorch/pytorch/issues/54261
This PR ports the method_tests() entries of `torch.copysign` to OpInfo.
While porting the tests, the `test_out` cases from `test_ops.py` would fail as the out variant of `torch.copysign` does not support scalar inputs.
```python
>>> x = torch.randn(2)
>>> y = torch.empty_like(x)
>>> torch.copysign(x, 1.)
tensor([1.4836, 1.2156])
>>> torch.copysign(x, 1., out=y)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: copysign(): argument 'other' (position 2) must be Tensor, not float
```
This PR fixes the tests by adding an overload `native_functions` entry and re-dispatching scalar inputs to the existing `copysign_out` function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54945
Reviewed By: gchanan
Differential Revision: D27505300
Pulled By: mruberry
fbshipit-source-id: f68250fa52f8dcfd45426039ec178ca5e883e206
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55147
Enabling this test now that jit supports TensorList inputs
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D27505270
Pulled By: heitorschueroff
fbshipit-source-id: 05b0d47cb71740309ec5130bf520c576fb90a4d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55001
The enum is only used for precedence computation thus we only need to
enum node-types for which we know the precedence priority.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D27446410
Pulled By: ZolotukhinM
fbshipit-source-id: 217dd63c4fd086155030ebf0c3e1772605109f7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54999
BaseCallNode was used as a base class for Intrinsics and FunctionCall.
Now FunctionCall is gone, so BaseCallNode could be removed as well.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D27446411
Pulled By: ZolotukhinM
fbshipit-source-id: be8ce06fbac72bfe355e5e3e1d2aa2267fae79fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54998
The only reason why we couldn't use Load instead of FunctionCall was
DepTracker. Now this is gone and we finally could replace FunctionCall
with Load.
Test Plan: Imported from OSS
Reviewed By: bertmaher, pbelevich
Differential Revision: D27446412
Pulled By: ZolotukhinM
fbshipit-source-id: 9183ae5541c2618abc9026b1dc4c4c9fab085d47
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54997
DepTracker was used to automatically pull in dependent computations from
output ones. While it seems quite convenient, it's led to several
architectural issues, which are fixed in this stack.
DepTracker worked on Tensors, which is a pair of Buf and Stmt. However,
Stmt could become stale and there was no way to reliably update the
corresponding tensor. We're now using Bufs and Stmts directly and moving
away from using Tensors to avoid these problems.
Removing DepTracker allowed to unify Loads and FunctionCalls, which
essentially were duplicates of each other.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D27446414
Pulled By: ZolotukhinM
fbshipit-source-id: a2a32749d5b28beed92a601da33d126c0a2cf399
Summary:
[Currently](faa4da49ff/.flake8 (L22)), our `.flake8` config file has the `exclude` pattern `scripts`. I'm guessing that this is just meant to exclude the top-level `scripts` dir from Flake8, but it also applies to the following (apparently erroneously):
- `.circleci/scripts`
- `.github/scripts`
- `test/scripts`
This PR corrects the problem by making all the `exclude` patterns (except for the wildcard `*.pyi` pattern) relative to the repository root. Also, since this PR already touches all the `exclude` lines, it also sorts them to help reduce merge conflicts when `.flake8` is edited in the future. This sorting happened to reveal that the `build` pattern was previously present twice, so now it has been deduplicated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55178
Test Plan:
Locally:
```
flake8
```
And also [in CI](https://github.com/pytorch/pytorch/pull/55178/checks?check_run_id=2249949511).
Reviewed By: janeyx99
Differential Revision: D27520412
Pulled By: samestep
fbshipit-source-id: 359275c10ca600ee4ce7906e3a7587ffaa4ae1ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54919
Log the use of uneven inputs API for better tracking and use case
detection.
ghstack-source-id: 125446499
Test Plan: CI, added ut
Reviewed By: zhaojuanmao, SciPioneer
Differential Revision: D27410764
fbshipit-source-id: abc8055a2e15a3ee087d9959f8881b05a0ea933e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54972
No reason to create a temporary.
ghstack-source-id: 125338543
Test Plan: CI
Reviewed By: bdhirsh
Differential Revision: D27437190
fbshipit-source-id: 05eeb3ccd33700d8776b6ce58a120c7697acf49e
Summary:
The void overload of `register_hook` puts the user's callable into a `std::function` which is used in a lambda, then `_register_hook` wraps that lambda in another `std::function`. This is bad because each call goes through two indirections and also it requires more heap allocations.
Instead, the lambda can capture the original callable without wrapping it in an `std::function` first.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53917
Reviewed By: gchanan
Differential Revision: D27513822
Pulled By: swolchok
fbshipit-source-id: 026d40d7e9fb718757b7203737b0662ba36bc021
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54534
Moving overload of tuple -> IValue constructor was missing.
ghstack-source-id: 124671165
Test Plan:
Compare assembly for ivalue_test.cpp before/after this
change. Newly added snippet stops calling `std::__invoke_impl` with a
real function pointer to a by-value variant of
`c10::ivalue::Tuple::create` and starts directly calling
by-const-reference variant of `c10::ivalue::Tuple::create` instead.
Reviewed By: smessmer
Differential Revision: D27271895
fbshipit-source-id: 8b0e146a15d66883146b89b93da5e95f903484e6
Summary:
Currently, we only have three GHA workflows that need to be canceled on reruns. To anticipate for future workflows, this PR enables a check that will make sure any new workflow that should be autocanceled on reruns will be included in the cancel_redundant_workflows.yml GHA workflow.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55171
Test Plan: Succeeded quick-checks https://github.com/pytorch/pytorch/runs/2249162035?check_suite_focus=true
Reviewed By: samestep
Differential Revision: D27514294
Pulled By: janeyx99
fbshipit-source-id: 27da321f648b97a090052823ec955caffeb6ae97
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55142
Declare some functions C10_HOST_DEVICE to fix the NVCC warning.
During pytorch compilation, NVCC compiler was emmiting several warnings like this one:
```
caffe2/c10/util/TypeCast.h(39): warning: calling a constexpr __host__ function from a __host__ __device__ function is not allowed. The experimental flag '--expt-relaxed-constexpr' can be used to allow this.
detected during:
instantiation of "dest_t c10::static_cast_with_inter_type<dest_t, src_t>::apply(src_t) [with dest_t=c10::complex<double>, src_t=__nv_bool]"
(158): here
instantiation of "To c10::convert<To,From>(From) [with To=c10::complex<double>, From=__nv_bool]"
(170): here
instantiation of "To c10::checked_convert<To,From>(From, const char *) [with To=c10::complex<double>, From=__nv_bool]"
caffe2/c10/core/Scalar.h(63): here
```
How to reproduce.
- Make sure you are on remote/master
- run:
`buck build mode/dev-nosan caffe2/torch/fb/sparsenn:sparsenn_operators_gpu`
Test Plan: - compilation completes without warnings.
Reviewed By: r-barnes
Differential Revision: D27469757
fbshipit-source-id: f8c4eedb637c6d487ac49bb310e48be11db204e2
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53322, the test has some hardcoded values to check that the sharding works as expected, and was not used beyond 4 gpus prior
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54788
Reviewed By: mrshenli
Differential Revision: D27483078
Pulled By: blefaudeux
fbshipit-source-id: 63fe072c41e1601925af23d8fb1ea3f4729b2044
Summary:
The label name was meant to be "module: rocm".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55170
Test Plan: None.
Reviewed By: malfet
Differential Revision: D27513290
Pulled By: samestep
fbshipit-source-id: ef86fcd5f94a76c9e04653995c2ba9369c5ecb34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55098
resize_as_ still goes through the dispatcher because it calls tensor.resize_. We can easily call resize_ directly while bypassing the dispatcher.
Reviewed By: swolchok
Differential Revision: D27457894
fbshipit-source-id: 8a5da185d1a6addafbf4915e29613013451b5e43
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54719
lstsq_helper now takes rank and singular_values that are modified in-place.
This is required for adding out= variant.
TODO:
- [ ] Fix CI failures
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D27439197
Pulled By: mruberry
fbshipit-source-id: f2fe421aa393c2d58f5c50f33e21a9eae57e4f01
Summary:
Currently, it's not tested whether `op.sample_inputs` actually used the provided dtype and device arguments. This PR fixes that introducing asserts in `test_supported_dtypes`.
This will help to detect incorrectly generated inputs in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54949
Reviewed By: H-Huang
Differential Revision: D27435952
Pulled By: mruberry
fbshipit-source-id: 8465c459b9b0c007411a9a74340bc2755519624a
Summary:
- Corrected a few errata in the SVD docs
- Made the notation more uniform (refer to `Vh` in `linalg.svd`, always use double tilts...)
- Wrote a better explanation about why the gradients of `U` and `V` are not well-defined when the input is complex or real but has repeated singular values. The previous one pointed to a somewhat obscure post on gauge theory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54002
Reviewed By: malfet
Differential Revision: D27459502
Pulled By: mruberry
fbshipit-source-id: f5c35eca02d35dadd2fc0eeadfacc8824f409400
Summary:
Disable `cppcoreguidelines-macro-usage` as PyTorch codebase uses a lots
of macros that violate this rule.
Disable `bugprone-reserved-identifier` and
`performance-unnecessary-value-param` as those checks are very slow
Add `NOLINT` to DEFINE_DISPATCH as it introduces non-const global variables
Replace `for(auto i = 0; i < lim; ++i)` with `for(auto i: c10::irange(lim))` throughout the modified files
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55087
Reviewed By: samestep
Differential Revision: D27475822
Pulled By: malfet
fbshipit-source-id: 2651a4b3dc062066a15e69380354414a198fb279
Summary:
This adds:
- new categories
- global commit counter
- support for new "Reverted" label on PRs
- new export system to multiple files
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54594
Reviewed By: H-Huang
Differential Revision: D27396011
Pulled By: albanD
fbshipit-source-id: ca1ec3a1b90221ba26fd8b053dfb10f614f05909
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55096
There were issues with D26138322 (5b0a6482c1) that we didn't catch the first time around.
This (rebased on top of the to_copy fixes) fixes the converted remote_ro c2/pt output comparison
Test Plan:
```
MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 numactl -m 0 -C 3 ./buck-out/opt/gen/caffe2/caffe2/fb/predictor/ptvsc2_predictor_bench --c2_model=/data/users/ansha/tmp/adfinder/210494966_0.predictor.disagg.remote_request_only --c2_inputs=/data/users/ansha/tmp/adfinder/models/c2_remote_ro_input_data.pb --pred_net=/data/users/ansha/tmp/adfinder/models/c2_remote_ro_net2.pb --c2_sigrid_transforms_opt=1 --c2_apply_nomnigraph_passes=1 --c2_use_memonger=1 --scripted_model=/data/users/ansha/tmp/adfinder/models_dianshi/210494966_0.predictor.disagg.remote_request_only.pt --pt_inputs=/data/users/ansha/tmp/adfinder/models/remote_ro_wrapped_input_data.pt --pt_enable_static_runtime=1 --pt_cleanup_activations=1 --pt_enable_out_variant=1 --compare_results=1 --iters=1 --warmup_iters=1 --num_threads=1 --do_profile=0 --benchmark_c2_predictor=1 --do_benchmark=1
```
Reviewed By: hlu1
Differential Revision: D27477104
fbshipit-source-id: 5a95dfa7eae23566fadc3fec323ad03a34e6734d
Summary:
Related https://github.com/pytorch/pytorch/issues/54945
This PR ports `copysign` to structured, and the `copysign.Scalar` overloads are re-dispatched to the structured kernel.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55040
Reviewed By: glaringlee
Differential Revision: D27465501
Pulled By: ezyang
fbshipit-source-id: 5cbabfeaaaa7ca184ae0b701b9692a918a90b117
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55136
This will ease the transition to the new API where `Buffer` does not
store a length anymore.
Test Plan: CI
Reviewed By: lw
Differential Revision: D27466385
fbshipit-source-id: 9a167f8c501455a3ab49ce75257c69d8b4869925
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52859
This reverts commit 92a4ee1cf6092dd941591f80885eb7fef5b2c0d8.
Added support for bfloat16 for CUDA 11 and removed fast-path for empty input tensors that was affecting autograd graph.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D27402390
Pulled By: heitorschueroff
fbshipit-source-id: 73c5ccf54f3da3d29eb63c9ed3601e2fe6951034
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55016
When we call as_strided() and don't add an extra dimension, we should continue to expect that the number of dimensions will fit in a DimVector and thus that using it will save heap allocations.
ghstack-source-id: 125337281
Test Plan: Existing CI
Reviewed By: ngimel
Differential Revision: D27452838
fbshipit-source-id: 8b3d118de322638c0c0e3a4bfcfb3c820c64e6cc
Summary:
* `#if` with some undefined name is a warning when `-Wundef` is specified (which is in ovrsource for example)
* identifiers starting with two underscores are [reserved for compiler internals](https://en.cppreference.com/w/cpp/language/identifiers)
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D27318070
fbshipit-source-id: 4989fc6a3bf3c176eddd7c25aca47414e4973edd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55103
Previously compression rate is only reported in PowerSGD hook. Also report this metric for comprehensive experimentation.
It is very easy to compute the sizes before and after compression, because there is only one matrix factorization per bucket, and no accumulation within the bucket is needed.
1) The size before compression is the input tensor size.
2) The size after compression is the size of P + Q, where each has a size of `square_side_length * state.matrix_approximation_rank`.
ghstack-source-id: 125399028
Test Plan: Tested by running scripts/wayi/torch/power_sgd.py locally.
Reviewed By: deadlybulb
Differential Revision: D27474295
fbshipit-source-id: a2225e85be03ab20238f01014d5ec9ae1787c4fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55111
I don't see how we could have ended up with !is_same but also identical data_ptr, and is_same is cheaper.
ghstack-source-id: 125438822
Test Plan: Existing CI?
Reviewed By: ngimel
Differential Revision: D27484914
fbshipit-source-id: 22125b29e6e09d312a2b92e893d08c69059e4435
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54870
copy_operator before going into onnx exporter is being decomposed into aten::expand_as and aten::index_put.
There is a scenario where inputs to copy are not of the same type, but copy op in torch does implicit casting that is not currently reflected inside onnx exporter. This PR is adding casting inside index_put symbolic in case when tensor self is not of the same type as values.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D27408975
Pulled By: SplitInfinity
fbshipit-source-id: 15022703e76b9c98b02285c06b13d44f3c4a3f00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54869
Add symbolic fuction to support torch.outer export to onnx.
Support for transfo-xl-wt103 model.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D27408978
Pulled By: SplitInfinity
fbshipit-source-id: 70c89a9fc1a5e4a4ddcf674afb1e82e492a7d3b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54866
Replace decomposeLinear pre process pass with a symbolic
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D27408981
Pulled By: SplitInfinity
fbshipit-source-id: d2d76cab3383122a60df1f356742a33db56adc71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54863
Adds support for cases where the updates to the index_put node is a single Bool value, such as the case shown below
```
mask[indices] = True
```
Fixes#53507
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D27408977
Pulled By: SplitInfinity
fbshipit-source-id: bcfb55b50ce76b3d4913ffbc16cdef1f98cb7a84
Summary:
Added a field to `OpInfo` to provide a wrapper function for gradcheck. This is useful for functions that need to perform some extra input/output processing to work with gradcheck.
fixes https://github.com/pytorch/pytorch/issues/50837
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54914
Reviewed By: H-Huang
Differential Revision: D27435234
Pulled By: heitorschueroff
fbshipit-source-id: fa3e9b61f3d3df221243fd142ddb8b7861dbf669
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54644
Previously we special case copy operator in normal insert observer code, this PR tries to split the
special case logic to a separate function and keep the rest of the code clean.
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D27314678
fbshipit-source-id: d36870ceb3717bc01eaeaa6f3f1532ad562cbaf1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53586
Previously one value can only be quantized to one dtype, this PR adds the support for quantizing one value
in the fx graph with multiple dtypes, e.g. first quantize to int8 and then float16
might do some followup PRs to clean up the hacks and refactor the code.
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_multiple_qconfigs_single_value
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D26912676
fbshipit-source-id: ae3653fd67f05870a3a9e808f491871826c555d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54092
This is the first of several refactors to get numerical jacobian:
This one just moves some logic around as to try to split the get_numerical_jacobian function into smaller more manageable functions:
- compute_gradient is now no longer nested, but we have to pass in the parameters instead
- iter_tensor extracts out the logic of iterating through different types of tensors (the code should be almost the exact same here except for instead of calling into the update jacobian function, we yield the arguments instead)
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D27354268
Pulled By: soulitzer
fbshipit-source-id: 73288e3c889ae31bb8bf77a0e3acb3e9020e09a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54969
With all use cases to hacky wrapper removed, all kernels will be
dispatched with c10 full dispatcher.
ghstack-source-id: 125434790
Test Plan: buck build //caffe2/aten/...
Reviewed By: ezyang, walterddr
Differential Revision: D27436596
fbshipit-source-id: 7a146d1f4a983b4a81f8552be4eec6c482b6bea2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54476
Per title. For `add_done_callback`, we log but swallow exceptions in order to keep consistent with what concurrent.futures python library does, see discussion in https://github.com/pytorch/pytorch/pull/45675.
Although, it would be good to improve the verbosity here as this can be a source of confusion if users are setting a different future via `add_done_callback`, and an error is hit resulting in an unexpected hang (see https://github.com/pytorch/pytorch/issues/52132 for more details on how this can happen).
ghstack-source-id: 125300389
Test Plan: CI
Reviewed By: lw
Differential Revision: D27253004
fbshipit-source-id: 72ed21c8fb6d27de5797c17fc46b762f893e6fea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54475
Implements the proposal in https://github.com/pytorch/pytorch/issues/53717#issuecomment-800545655. See that issue for more details, but at a high level:
1. markCompleted() immediately sets completed_ = true
2. Subclasses of future (such as cuda future) implement a nontrivial `postMarkCompletedHook` which may throw
3. If above error is caught and we call `setError`, setError itself will error out because completed_ = true.
To fix this, only call setError if the user-defined cb resulted in an error, otherwise, call `markCompleted` and let postMarkCompletedHook() throw and crash the program (per lw's thoughts this should be a fatal).
ghstack-source-id: 125300388
Test Plan: CI
Reviewed By: lw
Differential Revision: D27252965
fbshipit-source-id: fda41e8844104774aaf897286512d83ff06632b1
Summary:
Add fast common case to `prepare_matrix_for_cublas`, use index size instead of size(), move some checks where they belong so they are not triggered where they are guaranteed to be true.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55026
Reviewed By: gchanan
Differential Revision: D27468945
Pulled By: ngimel
fbshipit-source-id: 79c9f7b3d61595536f603d6fb0316e6f21630f38
Summary:
This PR clarifies the output of `tools/test_history.py` in the presence of re-runs for a single commit/job pair. Specifically:
- in `multiline` mode, the results from all re-runs are now shown
- in `columns` mode, the wording is now changed from "S3 reports omitted" to "job re-runs omitted"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55106
Test Plan:
```
python tools/test/test_test_history.py
```
Reviewed By: walterddr
Differential Revision: D27480590
Pulled By: samestep
fbshipit-source-id: 5b4ccae7586ef1df744663cba1c16bb5bfa75bb7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54791
Several usecases have a need to want and see what ops are present in a specific pytorch runtime. This diff exposes that information in the dispatcher
ghstack-source-id: 125314247
Test Plan: D26678637 uses this api.
Reviewed By: swolchok
Differential Revision: D27271371
fbshipit-source-id: e572f0c85dcd75d75356e2cd4cfdd77efee17f94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54986
If the input is 1D xnnpack::linear fails while aten::linear makes it (1, D) and continues
Test Plan: buck test //caffe2/test:xnnpack_integration -- TestXNNPACKOps
Reviewed By: kimishpatel
Differential Revision: D27441966
fbshipit-source-id: dfb2c23b91247632e0e3fd2482056a503c246c39
Summary:
Currently in convolution double backward grad of input is computed as `convT(ggW, gO.T)`. Notice how first argument is, in fact, of the size that convolution weight has, and second is of the size of gradOutput, which is an inverse order compared to how convolutions are regularly called, and sizes are far from what cudnn heuristics is trained for and what cudnn is guaranteed to have efficient kernels for. This takes cudnn 8 to some dark places, calling kernels that take 20-100 s. But, luckily for us, convT is a commutative operation (unlike conv), so convT(ggW, gO) is actually the same as convT(gO, ggW), modulo some transposes because of conventions around the weight size, so we can use convT(gO, ggW). As an added bonus, we don't need a special branch for groups with this formulation.
For the following pretty standard convolution,
- cudnn 7.6+old formulation takes 7.5 ms for double backward,
- cudnn 8 + old formulation takes ~40 s,
- cudnn 8 + new formulation is 1.8 ms with benchmark enabled,
- cudnn 8 + new formulation is 4 ms with benchmark disabled,
benchmarking script is below:
```
import torch
import time
#torch.backends.cudnn.benchmark=True
def ggI(conv, inp):
out = conv(inp)
grads = torch.autograd.grad(out, conv.weight, torch.rand_like(out), create_graph=True, retain_graph=True)
torch.cuda.synchronize()
start = time.time()
grads[0].backward(torch.rand_like(grads[0]))
torch.cuda.synchronize()
print("db time: ", time.time()-start)
return inp.grad
conv = torch.nn.Conv2d(512,256,kernel_size=3, padding=1, groups=2).cuda()
inp = torch.randn(1,512,128,128, device="cuda", requires_grad=True)
for _ in range(20):
ggI(conv, inp)
torch.cuda.synchronize()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54840
Reviewed By: mruberry
Differential Revision: D27384866
Pulled By: ngimel
fbshipit-source-id: c6c875776a9801a0a2cd2f34f8ec39d0fcd59df8
Summary:
This PR enables using MIOpen for RNN FP16 on ROCM.
It does this by altering use_miopen to allow fp16. In the special case where LSTMs use projections we use the default implementation, as it is not implemented in MIOpen at this time. We do send out a warning once to let the user know.
We then remove the various asserts that are no longer necessary since we handle the case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52475
Reviewed By: H-Huang
Differential Revision: D27449150
Pulled By: malfet
fbshipit-source-id: 06499adb94f28d4aad73fa52890d6ba361937ea6
Summary:
This PR adds a workflow that automatically adds ROCm label to PRs and issues with ROCm (case insensitive) in their titles.
Note that this does not remove labels even if the title is changed to no longer contain ROCm, but I can easily add removal functionality if that is desired.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54989
Test Plan: much test in my own repo: https://github.com/janeyx99/gha-experiments/actions (thanks samestep for your help!)
Reviewed By: walterddr
Differential Revision: D27448651
Pulled By: janeyx99
fbshipit-source-id: 103f39df0697eb6571c96e88c98d28c8b7adcfd7
Summary:
Switching pytorch android to use fbjni from prefab dependencies
Bumping version of fbjni to 0.2.2
soloader version to 0.10.1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55066
Reviewed By: dreiss
Differential Revision: D27469727
Pulled By: IvanKobzarev
fbshipit-source-id: 2ab22879e81c9f2acf56807c6a133b0ca20bb40a
Summary:
There might be regressions in newest VS.
Remind users to choose the stable VC version as our CI's
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54933
Reviewed By: walterddr
Differential Revision: D27466645
Pulled By: malfet
fbshipit-source-id: a6a1ebea4cc1b22e13c7342ee4c061afcef7e2b5
Summary:
HIP's runtime compiler (hiprtc) is adding support for precompiled HIP headers in the ROCm 4.2 release. Conditionally add support for this feature. Using this feature will improve the ROCm torch wheel user experience; users will no longer need to install HIP headers separately to use torch JIT features.
The use of this feature is conditionalized on a new ROCM_VERSION macro.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54350
Reviewed By: H-Huang
Differential Revision: D27449031
Pulled By: malfet
fbshipit-source-id: 81a8d7847a47ce2bb253d1ea58740ef66ed154a3
Summary: Because the bare CXX version forwards to this without checking if it's defined causing errors for builds with -Wundef enabled
Test Plan: contbuilds
Differential Revision: D27443462
fbshipit-source-id: 554a3c653aae14d19e35038ba000cf5330e6d679
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54818
Several flaky tests fail due to some sort of timeout and it isn't
clear from the error message in CI where exactly each process is stuck. In this
PR, I've added mechanism to dump the entire python traceback of all python
threads when we encounter a timeout.
Example traceback:
```
Process 3 timed out with traceback:
Current thread 0x00007ff3363ff700 (most recent call first):
File "torch/testing/_internal/common_distributed.py", line 373 in _event_listener
File "threading.py", line 870 in run
File "threading.py", line 932 in _bootstrap_inner
File "threading.py", line 890 in _bootstrap
Thread 0x00007ff406132180 (most recent call first):
File "torch/distributed/distributed_c10d.py", line 2477 in barrier
File "torch/testing/_internal/distributed/rpc/rpc_test.py", line 838 in test_reinit
File "torch/testing/_internal/dist_utils.py", line 90 in new_test_method
File "torch/testing/_internal/common_distributed.py", line 292 in wrapper
File "torch/testing/_internal/common_distributed.py", line 409 in run_test
File "torch/testing/_internal/common_distributed.py", line 393 in _run
File "multiprocessing/process.py", line 108 in run
File "multiprocessing/process.py", line 315 in _bootstrap
File "multiprocessing/popen_fork.py", line 75 in _launch
File "multiprocessing/popen_fork.py", line 19 in __init__
File "multiprocessing/context.py", line 277 in _Popen
File "multiprocessing/process.py", line 121 in start
```
ghstack-source-id: 125323810
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D27378764
fbshipit-source-id: 661c009a5458c724f004aa83de9347a4bc03b63e
Summary:
One typo, one example correction and capitalization for a couple of comment lines.
ailzhang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54768
Reviewed By: H-Huang
Differential Revision: D27362999
Pulled By: ezyang
fbshipit-source-id: 91404ac9e9747ef7d7882a5f50b81d7eb570448b
Summary:
These changes provide the user with an additional option to choose the DNNL+BLIS path for PyTorch.
This assumes BLIS is already downloaded or built from source and the necessary library file is available at the location: $BLIS_HOME/lib/libblis.so and include files are available at: $BLIS_HOME/include/blis/blis.h and $BLIS_HOME/include/blis/cblas.h
Export the below variables to build PyTorch with MKLDNN+BLIS and proceed with the regular installation procedure as below:
$export BLIS_HOME=path-to-BLIS
$export PATH=$BLIS_HOME/include/blis:$PATH LD_LIBRARY_PATH=$BLIS_HOME/lib:$LD_LIBRARY_PATH
$export BLAS=BLIS USE_MKLDNN_CBLAS=ON WITH_BLAS=blis
$python setup.py install
CPU only Dockerfile to build PyTorch with AMD BLIS is available at : docker/cpu-blis/Dockerfile
Example command line to build using the Dockerfile:
sudo DOCKER_BUILDKIT=1 docker build . -t docker-image-repo-name
Example command line to run the built docker container:
sudo docker run --name container-name -it docker-image-repo-name
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54953
Reviewed By: glaringlee
Differential Revision: D27466799
Pulled By: malfet
fbshipit-source-id: e03bae9561be3a67429df3b1be95a79005c63050
Summary:
Part of https://github.com/pytorch/pytorch/issues/48209
Taken from the docstring:
Performs a set of optimization passes to optimize a model for the purposes of inference. Specifically, the passes that are run are:
1. Conv/BN fusion
2. Dropout removal
3. MKL layout optimizations
The third optimization takes a function `use_mkl_heuristic` that's used to determine whether a subgraph should be explicity run in MKL layout.
I implemented 2 heuristics:
1. Does it in MKL if the subgraph is larger than 2.
2. Benchmarks each subgraph with MKL layout and without, and keeps the subgraph if it's faster.
### Batch size of 10 and multi-threaded.
Results with the second heuristic are generally as strong as the "jit.freeze" version, except in `densenet` and `vgg`, where it's faster, likely due to the heuristic being better. With the first heuristic, there are some notable gaps, particularly on `inception_v3` and `alexnet`.
```
model Eager FX FX Auto jit.mkldnn
------------ --------- --------- --------- --------- -
custom 0.195614 0.14686 0.15929 0.156442 6
resnet18 0.172012 0.114007 0.119678 0.12945 6
resnet50 0.486463 0.294308 0.299518 0.318121 6
densenet161 0.955309 0.893502 0.882798 1.29315 6
inception_v3 0.38454 0.307076 0.239513 0.233083 6
googlenet 0.229388 0.237486 0.170458 0.174106 6
shufflenet 0.0513613 0.0286739 0.0292908 0.0267209 6
alexnet 0.0709602 0.0768137 0.0660831 0.0650399 6
vgg16 1.053993 0.9013264 0.9360212 1.082820 6
mobilenet 0.12264 0.0970935 0.0936568 0.106314 6
mnasnet 0.0989875 0.0412083 0.0424499 0.0472336 6
resnext 0.476811 0.315428 0.314422 0.343156 6
```
For single-threaded (still running...)
```
model eager FX FX auto mkl threads
------------ --------- --------- --------- --------- ---------
custom 0.0401415 0.259863 0.0263152 0.200667 1
resnet18 0.499931 0.382113 0.383711 0.396335 1
resnet50 1.10353 0.911865 0.923645 0.992125 1
densenet161 2.20158 2.39421 2.08204 2.30124 1
inception_v3 0.79161 0.849207 0.703546 0.724492 1
googlenet 0.66896 0.820965 0.515927 0.529414 1
shufflenet 0.0987308 0.0689343 0.0629298 0.0617193 1
alexnet 0.198795 0.19862 0.19325 0.211934 1
vgg16 3.744 3.2499 3.28503 3.31576 1
mobilenet 0.152725 0.14505 0.135555 0.159754 1
mnasnet 0.141983 0.089406 0.089599 0.0956167 1
resnext 1.13778 0.97016 0.955417 0.965376 1
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53805
Reviewed By: gmagogsfm
Differential Revision: D27424611
Pulled By: Chillee
fbshipit-source-id: a39137159de962fba7ca15121dfa9e78c1e01223
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54633
Theres currently no information that could be used to determine what is a parameter during the loading of a mobile module. This prevents named parameters from functioning correctly. This change is a temporary hack to help out federated learning the sole user of this api currently.
ghstack-source-id: 124885201
Test Plan: todo
Reviewed By: dhruvbird
Differential Revision: D27308738
fbshipit-source-id: 0af5d1e8381ab7b7a43b20560941aa070a02e7b8
Summary:
Add a ROCm 4.1 docker image for CI. Plan is to keep two ROCm versions at a time, however we still need the 3.9 image due to some CI jobs depending on it. Keep the 4.0.1 and 3.10 images, in addition to the 3.9 image until the 3.9 image is no longer needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54628
Reviewed By: H-Huang
Differential Revision: D27443378
Pulled By: malfet
fbshipit-source-id: 3f3417ec4822c6ef4c10ce2144a5b2957503dfbe
Summary:
`ONNX_NAMESPACE` is empty by default if `USE_SYSTEM_ONNX ON`, while it should be equal to `onnx`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54973
Reviewed By: glaringlee
Differential Revision: D27466020
Pulled By: walterddr
fbshipit-source-id: 47cde3604acbda3f45bec5893036b39fd1eb58c9
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 5bc304d17e
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54970
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D27436760
fbshipit-source-id: 7325350c1798feacdc1faeea8c39ce8e4b91c73d
Summary:
Stack:
* https://github.com/pytorch/pytorch/issues/54954 Fixed OpInfo jit tests failing for TensorList inputs
* __#54922 Added support for TensorList inputs in OpInfo__
Updated OpInfo to accept either a `Tensor` or `TensorList` as `sample.input` and added workarounds to make this work with gradcheck.
Note: JIT testing support for TensorList inputs will be added in a follow up PR.
Fixes https://github.com/pytorch/pytorch/issues/51996
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54922
Reviewed By: H-Huang
Differential Revision: D27448952
Pulled By: heitorschueroff
fbshipit-source-id: 3f24a56f6180eb2d044dcfc89ba59fce8acfe278
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54915
TorchScript and torch.package have different mangling schemes. To avoid
them interfering with each other, we should undo the torch.package
mangling before processing anything with TorchScript (since TS
independently makes sure that no names collide).
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D27410472
Pulled By: suo
fbshipit-source-id: d1cc013c532d9abb7fb9615122bc465ded4785bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54882
Sometimes we have no reason to think that the output of `infer_size` won't be within the range of typical tensor sizes. In those cases, we can use a DimVector.
ghstack-source-id: 125137792
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D27400387
fbshipit-source-id: 9a11d0f93010540f3aa65c0e208fc8e03f0e8a7f
Summary:
Fixes the build of projects that depend on torch, such as torchaudio. Otherwise torchaudio will complain that gloo_hip is missing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54727
Reviewed By: H-Huang
Differential Revision: D27361513
Pulled By: ezyang
fbshipit-source-id: 714cc2db23e7adf3e89303e941b78c27625b9460
Summary:
So they can be called from out-of-tree extensions
Otherwise I get linking errors like:
```
ImportError: /anaconda/envs/mytorch/lib/python3.8/site-packages/torchy-0.1-py3.8-linux-x86_64.egg/_TORCHY.cpython-38-x86_64-linux-gnu.so: undefined symbol: _ZN2at10redispatch3addEN3c1014DispatchKeySetERKNS_6TensorES5_RKNS1_6ScalarE
```
cc ezyang bdhirsh
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54966
Reviewed By: H-Huang
Differential Revision: D27439712
Pulled By: ezyang
fbshipit-source-id: 4c0b45e87e708c57283758da49c54a767ab7ecbc
Summary:
Skips the tests indicated as failing in https://github.com/pytorch/pytorch/issues/54535.
During the ROCm CI upgrade from 4.0.1 to 4.1, some tests regressed. Specifically, FFT tests in test_spectral_ops.py and test_grid_sample in test_nn.py. In order to keep a passing CI signal, we need to disable these temporarily.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54536
Reviewed By: H-Huang
Differential Revision: D27442974
Pulled By: malfet
fbshipit-source-id: 07dffb957757a5fc7afaa5bf78b935a427251ef4
Summary:
This PR adds Azure Pipelines build steps for PyTorch. There are 3 pipelines that are added.
1) CI Build
- Runs when a PR is opened or when new commits to an open PR is added. This build must succeed before the PR can be merged.
- Currently only TestTorch unit tests are run.
- Only the CI Build configurations are run.
2) Daily Build
- Runs once a day during inactive hours to ensure the current PyTorch repo performs as expected.
- Runs all unit tests.
- Note: I do not have access to the current [determine-from](b9e900ee52/test/run_test.py (L737)) unit tests that are skipped on Windows builds. This `determine-from` filter can be added once a clear way to skip certain unit tests given the build configuration is explained.
- Runs on All Build configurations.
3) Official Build
- Runs once a day during inactive hours to publish official PyTorch artifacts to Azure DevOps Artifacts for consumption.
- No unit tests are run.
- Runs in three stages: Build, Verify, Publish, where PyTorch is built, then its wheel is installed in a clean Conda environment for verification, and then the wheel is published to Azure Artifacts as a Universal Package.
- Runs on All Build configurations.
Ubuntu builds run on Docker with the specified Dockerfile configuration. Windows builds run directly on configured Windows VMs (CPU, CUDA/cuDNN)
CI Build configurations:
1. Ubuntu 18.04
1. Python 3.9
a. CUDA 11.2/cuDNN 8.1.0
2. Python 3.8
a. CPU
2. Windows 2019
1. Python 3.8
b. CUDA 10.2/cuDNN 7.6.5
2. Python 3.7
a. CPU
All Build configurations:
1. Ubuntu 18.04
1. Python 3.9
a. CUDA 11.2/cuDNN 8.1.0
2. Python 3.8
a. CPU
b. CUDA 10.2/cuDNN 8.1.0
3. Python 3.7
a. CPU
b. CUDA 10.1/cuDNN 7.6.5
2. Windows 2019
1. Python 3.9
a. CUDA 11.2/cuDNN 8.1.0
2. Python 3.8
a. CPU
b. CUDA 10.2/cuDNN 7.6.5
3. Python 3.7
a. CPU
b. CUDA 10.1/cuDNN 7.6.4
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54039
Reviewed By: ezyang
Differential Revision: D27373310
Pulled By: malfet
fbshipit-source-id: 06dcfe2d99da0e9876b6deb224272800dae46028
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54819
20 of them contain both optional Tensor and output position.
Hacky wrapper for `_convolution_mode` was added in
04e0cbf5a9f073a1b73195537c12fb332c2fddd9 after hacky wrappers
are removed for optional<Tensor>.
Codemod commands are generated by a hacked version of
https://github.com/pytorch/pytorch/pull/54223 and
https://github.com/pytorch/pytorch/pull/54098.
ghstack-source-id: 125278883
Test Plan:
buck build //caffe2/aten/...
BUILD_TENSOREXPR_BENCHMARK=ON BUILD_STATIC_RUNTIME_BENCHMARK=ON python setup.py install
Reviewed By: smessmer
Differential Revision: D27378819
fbshipit-source-id: b925ed0510a83e3976383aaeec8b7de438b23bf3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54936
Another case where we can use `MaybeOwned<Tensor>` to save a bump at a small cost.
ghstack-source-id: 125218488
Test Plan: Existing CI
Reviewed By: ngimel
Differential Revision: D27421117
fbshipit-source-id: 16bb31ec38817be1f889360e2abfd0d9596e2943
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54935
Bunch of avoidable copying of Tensor objects, which results in a refcount bump.
ghstack-source-id: 125216023
Test Plan:
Compared percentage of self time spent in addmm_out_cuda_impl while running the following sample:
```
+import torch
+import torch.nn as nn
+
+m = nn.Linear(1024, 1024).cuda().half()
+x = torch.randn(16, 1024).cuda().half()
+while True: y = m(x)
```
in perf record, decreased from 0.74% to 0.56%.
Reviewed By: ngimel
Differential Revision: D27420388
fbshipit-source-id: d2c5e4c4899cd02c60c45735b2d72c4ed913f6e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54934
It looks like the vast majority of usage is just borrowing a pre-existing Tensor.
ghstack-source-id: 125216052
Test Plan: Existing CI.
Reviewed By: hlu1
Differential Revision: D27415131
fbshipit-source-id: d5a8dc4ca5d48ca3eaa3664655b724094e61f371
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54741
Similar to what we did for distributed_test.py, let MultiProcessTests that run collecticve comm. tests with nccl blocking run under nccl_async_error_handling. This will better simulate real-world training scenarios.
ghstack-source-id: 125233692
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27277389
fbshipit-source-id: a6c6e9abcf3a53b03ea8b9f8fb63b78e0cb6e81e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54740
Adds a simple helper decorator to set/unset nccl blocking wait for
tests. This will make it easier than having to manually set/unset the
os.environ vars every time.
ghstack-source-id: 125233693
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27277222
fbshipit-source-id: c289b9d05e2f6328d672810b07501979b6e177c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54442
Added needsOutputs support to RecordFunction, improved ObserverUtil functions to handle list data. Minor refactor names to be consistent.
To get output data from kernel calls, we need to temporarily capture them before passing them to the record function. Then the results are released to function return. We handle two cases, for unboxed and boxed kernels. The boxed version is fairly simple since all outputs are stored in the stack object. For unboxed kernel calls, we added a `ReturnValue` utility class to properly handle the different return values of unboxed kernels.
For optimization, this intermediate capture is only enabled for observers that request `needsOutputs(true)` and should not affect other observers or when the observer is not enabled.
Test Plan:
```
=> buck build //caffe2/test/cpp/jit: --show-output
=> buck-out/gen/caffe2/test/cpp/jit/jit --gtest_filter=RecordFunctionTest*
CUDA not available. Disabling CUDA and MultiCUDA tests
Note: Google Test filter = RecordFunctionTest*-*_CUDA:*_MultiCUDA
[==========] Running 7 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 7 tests from RecordFunctionTest
[ RUN ] RecordFunctionTest.TracedTestInputsOutputs
[ OK ] RecordFunctionTest.TracedTestInputsOutputs (226 ms)
[ RUN ] RecordFunctionTest.SampledCallbacks
[ OK ] RecordFunctionTest.SampledCallbacks (771 ms)
[ RUN ] RecordFunctionTest.RecordFunctionGuard
[ OK ] RecordFunctionTest.RecordFunctionGuard (0 ms)
[ RUN ] RecordFunctionTest.Callbacks
[ OK ] RecordFunctionTest.Callbacks (2 ms)
[ RUN ] RecordFunctionTest.ShouldRun
[ OK ] RecordFunctionTest.ShouldRun (0 ms)
[ RUN ] RecordFunctionTest.Basic
[ OK ] RecordFunctionTest.Basic (1 ms)
[ RUN ] RecordFunctionTest.OperatorNameOverload
[ OK ] RecordFunctionTest.OperatorNameOverload (1 ms)
[----------] 7 tests from RecordFunctionTest (1001 ms total)
[----------] Global test environment tear-down
[==========] 7 tests from 1 test case ran. (1002 ms total)
[ PASSED ] 7 tests.
```
Reviewed By: ilia-cher
Differential Revision: D25966661
fbshipit-source-id: 707886e1f212f40ba16a1fe292ea7dd33f2646e3
Summary:
*Context:* https://github.com/pytorch/pytorch/issues/53406 added a lint for trailing whitespace at the ends of lines. However, in order to pass FB-internal lints, that PR also had to normalize the trailing newlines in four of the files it touched. This PR adds an OSS lint to normalize trailing newlines.
The changes to the following files (made in 54847d0adb9be71be4979cead3d9d4c02160e4cd) are the only manually-written parts of this PR:
- `.github/workflows/lint.yml`
- `mypy-strict.ini`
- `tools/README.md`
- `tools/test/test_trailing_newlines.py`
- `tools/trailing_newlines.py`
I would have liked to make this just a shell one-liner like the other three similar lints, but nothing I could find quite fit the bill. Specifically, all the answers I tried from the following Stack Overflow questions were far too slow (at least a minute and a half to run on this entire repository):
- [How to detect file ends in newline?](https://stackoverflow.com/q/38746)
- [How do I find files that do not end with a newline/linefeed?](https://stackoverflow.com/q/4631068)
- [How to list all files in the Git index without newline at end of file](https://stackoverflow.com/q/27624800)
- [Linux - check if there is an empty line at the end of a file [duplicate]](https://stackoverflow.com/q/34943632)
- [git ensure newline at end of each file](https://stackoverflow.com/q/57770972)
To avoid giving false positives during the few days after this PR is merged, we should probably only merge it after https://github.com/pytorch/pytorch/issues/54967.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54737
Test Plan:
Running the shell script from the "Ensure correct trailing newlines" step in the `quick-checks` job of `.github/workflows/lint.yml` should print no output and exit in a fraction of a second with a status of 0. That was not the case prior to this PR, as shown by this failing GHA workflow run on an earlier draft of this PR:
- https://github.com/pytorch/pytorch/runs/2197446987?check_suite_focus=true
In contrast, this run (after correcting the trailing newlines in this PR) succeeded:
- https://github.com/pytorch/pytorch/pull/54737/checks?check_run_id=2197553241
To unit-test `tools/trailing_newlines.py` itself (this is run as part of our "Test tools" GitHub Actions workflow):
```
python tools/test/test_trailing_newlines.py
```
Reviewed By: malfet
Differential Revision: D27409736
Pulled By: samestep
fbshipit-source-id: 46f565227046b39f68349bbd5633105b2d2e9b19
Summary:
PRs https://github.com/pytorch/pytorch/issues/53652 and https://github.com/pytorch/pytorch/issues/54693 attempted to increase the consistency of our choice of commit (head vs merge) for CI on PRs, and have so far been unsuccessful. This PR takes a less ambitious approach to the problem by clarifying the choice in one specific way (see the following paragraph) and documenting it in `CONTRIBUTING.md`.
In addition to documentation, this PR also removes the current behavior of our GHA jobs that checkout the PR tip instead of the merge commit. At first glance, this behavior seems to increase consistency (by eliminating the special-case for `ghstack` PRs), but in reality, it actually just means that for non-`ghstack` PRs, the question "Which commit is used in CI?" has *two* answers instead of just one; see the description of https://github.com/pytorch/pytorch/issues/53652 for more details.
Once merged, this PR will unblock other PRs that add modify our GHA workflows in breaking ways, such as https://github.com/pytorch/pytorch/issues/54737.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54967
Test Plan: None.
Reviewed By: walterddr, seemethere
Differential Revision: D27435913
Pulled By: samestep
fbshipit-source-id: 405fb419cf015cf88107d5eb2498cfb5bcb7ce33
Summary:
This PR adds the cuSOLVER based path for `torch.linalg.eigh/eigvalsh`.
The device dispatching helper function was removed from native_functions.yml, it is replaced with `DECLARE/DEFINE_DISPATCH`.
cuSOLVER is used if CUDA version >= 10.1.243. In addition if CUDA version >= 11.1 (cuSOLVER version >= 11.0) then the new 64-bit API is used.
I compared cuSOLVER's `syevd` vs MAGMA's `syevd`. cuSOLVER is faster than MAGMA for all matrix sizes.
I also compared cuSOLVER's `syevj` (Jacobi algorithm) vs `syevd` (QR based divide-and-conquer algorithm). Despite it is said that `syevj` is better than `syevd` for smaller matrices, in my tests it is the case only for float32 dtype and matrix sizes 32x32 - 512x512.
For batched inputs comparing a for loop of `syevd/syevj` calls to `syevjBatched` shows that for batches of matrices up to 32x32 the batched routine is much better. However, there are bugs in `syevjBatched`, sometimes it doesn't compute the result leaving eigenvectors as a unit diagonal matrix and eigenvalues as the real diagonal of the input matrix. The output is the same with `cupy.cusolver.syevj` so the problem is definitely on the cuSOLVER side. This bug is not present in the non-batched `syevj`.
The performance of 64-bit `syevd` is the same as 32-bit version.
Ref. https://github.com/pytorch/pytorch/issues/47953
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53040
Reviewed By: H-Huang
Differential Revision: D27401218
Pulled By: mruberry
fbshipit-source-id: aef91eefb57ed73fef87774ff9a36d50779903f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54901
Some subtleties:
- Need to make sure not to clobber composite definitions when
deciding when to generate
- I was lazy and so I didn't make inplace on TensorList work,
nor did I make inplace functions that returned void work
- A few tests started complaining that these noop meta functions
weren't raising the errors they needed. This is tracked
in https://github.com/pytorch/pytorch/issues/54897
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D27407232
Pulled By: ezyang
fbshipit-source-id: 5e706a267496368acdafd128942c310954e43d29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54838
Realize that an explicit sync is somehow still needed for batched PowerSGD hook. I find that a job failure can be fixed by this change.
The sync was once removed by #54482.
Test Plan:
f260900882
f260899693
Reviewed By: rohan-varma
Differential Revision: D27384738
fbshipit-source-id: 3efd738b9fd375e2ceb36ed3a6bf99cd8ce8ff95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54860
Currently we insert a quantize_per_tensor op when we encounter the quantizable input,
so if it has multiple uses and not all are quantizable then we need to add a dequantize op
before these ops.
In this pass - For a sequence of quantize_per_tensor - dequantize, we combine them
since it is a no-op.
[internal only][pyper]
Before this change we had redundant dequantize nodes in the graph
Example 1x inline_cvr graph https://www.internalfb.com/intern/everpaste/?handle=GODBxAlUMzGHD6 (98143776f5)MSACpHKKu9qjorbsIXAAAz
FC layers -> 37
quantize_per_tensor -> 30
dequantize -> 49
After this change
https://www.internalfb.com/intern/everpaste/?handle=GAl0uQnOlDNmpLoSAB-GZqRxu9wMbsIXAAAz
FC layers -> 37
quantize_per_tensor -> 30
dequantize -> 39
We remove extra 10 dequantize nodes in the graph.
Test Plan:
python test/test_quantization.py test_fold_quant_dequant
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D27390506
fbshipit-source-id: 56e6fb8496171246eccf4bd45eb8bebd87fcb740
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54859
This is applicable to the case when a call_function linear op is one of the users of quantize op
In order to be able to map the qparams of quantize_per_tensor to the qparams of the linear operator
that consumes it, we need to use the FQN of the module with linear op for the qparmas of quantize_per_tensor.
Test Plan:
python test/test_quantization.py test_qparams_fqn
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27390505
fbshipit-source-id: a47af0e5ac016f2b2df74fbdf45afe99dc04be46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54702
This fixes subclassing for __iter__ so that it returns an iterator over
subclasses properly instead of Tensor.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D27352563
Pulled By: ezyang
fbshipit-source-id: 4c195a86c8f2931a6276dc07b1e74ee72002107c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54452
The assertion that fails in the issue is necessary to appease mypy. Instead, I fix `_ntuple` to always return a `tuple`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54911
Reviewed By: H-Huang
Differential Revision: D27411088
Pulled By: jbschlosser
fbshipit-source-id: 7f5045c58dd4f5f3b07b4826d9b4ca85606c5bce
Summary:
Both JITed and plan `cmath.sqrt(complex(-1, -0.0))` should return `-1j` after https://github.com/pytorch/pytorch/pull/54820 has been resolved.
Also, use f-string instead of `.format` method
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54923
Reviewed By: anjali411
Differential Revision: D27415117
Pulled By: malfet
fbshipit-source-id: 52e182feca50b690684de87c99df0ad6bef1ab44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54657
The constraint checked in D27145406 (acf03b13f1) is too tight for the adindexer model and as a result, 5 ops (4 aten::narrow + 1 aten::premute) are not replaced with the copy version and resulted in perf regression. This diff checks for inplace ops explicitly and only applies the input constraint to graphs with inplace ops.
Test Plan: Contbuild
Reviewed By: ajyu
Differential Revision: D27253145
fbshipit-source-id: 23e2b1a018c84dd0fc2880fddd9c41bc0422b8eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54519
The current MPSCNNSoftmax kernels operates on tensors' feature channels. Therefore, in order to use it, we need to reshape the input tensors based on the value of `dim` . Currently, I decide to limit the input to be two dimensional. I'll remove the constraint once we have shader implementations.
ghstack-source-id: 124497702
Test Plan:
- SandcastleCI
- CircleCI
Reviewed By: dhruvbird
Differential Revision: D27218823
fbshipit-source-id: 48c427ceedb42e63c183114939ca801ebfc81fd9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54518
When I was reading the Metal Shader Language Specification, I noticed that using `function_constants` in C++ attributes could let us do compile time kernel selection, which can drastically reduce the complexity of writing GPU kernels for different input texture types. We should apply this trick to all our existing shader functions.
ghstack-source-id: 124497703
Test Plan:
- Metal op tests
```
2021-03-20 23:35:20.496922-0700 PyTorchPlayground[48215:8455407] [bool test_view()],[1 10 2 2 ],[SUCCEED]
2021-03-20 23:35:20.522714-0700 PyTorchPlayground[48215:8455407] [bool test_view2()],[1 10 2 2 ],[SUCCEED]
2021-03-20 23:35:20.553591-0700 PyTorchPlayground[48215:8455407] [bool test_view3()],[5 8 ],[SUCCEED]
2021-03-20 23:35:20.571194-0700 PyTorchPlayground[48215:8455407] [bool test_view4()],[5 8 ],[SUCCEED]
```
- Sandcastle CI
- CircleCI
Reviewed By: SS-JIA
Differential Revision: D27218965
fbshipit-source-id: 763c54d551de3a88e4ff0007894200d72f00958c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53655
Currently EmbeddingBag and it variants support either int32 or int64 indices/offsets. We have use cases where there are mix of int32 and int64 indices which are not supported yet. To avoid introducing too many branches we could simply cast offsets type to indices type when they are not the same.
Test Plan: unit tests
Reviewed By: qizzzh
Differential Revision: D26820202
fbshipit-source-id: 3e8f09523329ea12393ea92ee9a6315aa40a0b7f
Summary:
This PR introduces a script to spit our a list of slow tests into a file `.pytorch-slow-tests`. The format is currently JSON, and is simply a dictionary with entries that look like: `("test_case_name (__main__.test_suite)" -> average time in seconds)`. This is one of the steps in maintaining a list of slow tests so we could retire the manual slowTest labeling process.
The script reads data from the previous day's viable/strict's data (to ensure we have fully uploaded data), and aggregates the test times for **passed** test cases. It then filters the individual test cases to exclude those faster than 60 seconds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54907
Test Plan:
`python tools/export_slow_test.py`
Check that `.pytorch-slow-tests` contains data. Mine looks like:
```
{
"test_matmul_4d_4d_complex_cpu (__main__.TestAutogradDeviceTypeCPU)": 91.22675,
"test_unary_ops (__main__.TestTEFuser)": 68.6,
"test_fn_gradgrad_unfold_cpu_complex128 (__main__.TestGradientsCPU)": 82.49153333333334,
"test_conv1d_basic (__main__.TestXNNPACKConv1dTransformPass)": 94.0914375,
"test_ddp_uneven_inputs (__main__.TestDistBackendWithFork)": 134.4995,
"test_pdist_norm_large_cuda (__main__.TestTorchDeviceTypeCUDA)": 60.2634,
"test_cusparse_multiple_threads_same_device (__main__.TestCuda)": 97.9022,
"test_fn_gradgrad_unfold_cuda_complex128 (__main__.TestGradientsCUDA)": 130.7222,
"test_ddp_uneven_inputs (__main__.TestDistBackendWithSpawn)": 136.08133333333333,
"test_jit_cuda_archflags (__main__.TestCppExtensionJIT)": 112.80733333333333,
"test_lobpcg_ortho_cuda_float64 (__main__.TestLinalgCUDA)": 63.8312,
"test_matmul_4d_4d_complex_cuda (__main__.TestAutogradDeviceTypeCUDA)": 62.1062,
"test_inverse_many_batches_cuda_complex128 (__main__.TestLinalgCUDA)": 1434.505,
"test_inverse_many_batches_cuda_complex64 (__main__.TestLinalgCUDA)": 1403.846,
"test_inverse_many_batches_cuda_float32 (__main__.TestLinalgCUDA)": 2081.614,
"test_inverse_many_batches_cuda_float64 (__main__.TestLinalgCUDA)": 1410.788,
"test_matrix_exp_analytic_cuda_complex128 (__main__.TestLinalgCUDA)": 172.167,
"test_matrix_exp_analytic_cuda_complex64 (__main__.TestLinalgCUDA)": 172.57,
"test_matrix_exp_analytic_cuda_float32 (__main__.TestLinalgCUDA)": 258.61,
"test_matrix_exp_analytic_cuda_float64 (__main__.TestLinalgCUDA)": 174.793,
"test_inverse_many_batches_cpu_complex128 (__main__.TestLinalgCPU)": 666.464,
"test_inverse_many_batches_cpu_complex64 (__main__.TestLinalgCPU)": 667.26,
"test_inverse_many_batches_cpu_float32 (__main__.TestLinalgCPU)": 1100.719,
"test_inverse_many_batches_cpu_float64 (__main__.TestLinalgCPU)": 651.037,
"test_matrix_exp_analytic_cpu_complex128 (__main__.TestLinalgCPU)": 72.965,
"test_matrix_exp_analytic_cpu_complex64 (__main__.TestLinalgCPU)": 74.184,
"test_matrix_exp_analytic_cpu_float32 (__main__.TestLinalgCPU)": 128.768,
"test_matrix_exp_analytic_cpu_float64 (__main__.TestLinalgCPU)": 72.138,
"test_conv1d_with_relu_fc (__main__.TestXNNPACKConv1dTransformPass)": 123.728,
"test_fn_gradgrad_linalg_householder_product_cuda_complex128 (__main__.TestGradientsCUDA)": 60.708,
"test_lobpcg (__main__.TestAutograd)": 120.408,
"test_collect_callgrind (__main__.TestBenchmarkUtils)": 206.896,
"test_collect_cpp_callgrind (__main__.TestBenchmarkUtils)": 122.507,
"test_proper_exit (__main__.TestDataLoader)": 172.356,
"test_proper_exit (__main__.TestDataLoaderPersistentWorkers)": 172.02,
"testNBit (__main__.operator_test.fused_nbit_rowwise_conversion_ops_test.TestNBitGreedyFused)": 96.9435,
"IntegerDivider (__main__.TestCUDAIntegerDivider)": 156.73700000000002
}
```
Reviewed By: walterddr, malfet
Differential Revision: D27412861
Pulled By: janeyx99
fbshipit-source-id: ec3d327e0dc6c93093e8b1c8454e3166b0649909
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54811
Callers can make a refcount bump themselves if they need one.
ghstack-source-id: 125136516
Test Plan: CI
Reviewed By: ngimel
Differential Revision: D27377210
fbshipit-source-id: ea58c7190fe2d7896432e403ecb1c59761aa319d
Summary:
It's useful to be able to have an uninitialized Placeholder,
sometimes, e.g., as a class member, where member initialization is
awkward/impossible.
(Yes, one could wrap a Placeholder in a unique_ptr, but it's an extra layer of
cruft).
Test Plan: `buck build //caffe2/test:jit`
Reviewed By: navahgar
Differential Revision: D27400784
fbshipit-source-id: 56191ee11cbb4bc91b5624af6329f2d6d007570b
Summary:
This is to prepare for new language reference spec that needs to describe `torch.jit.Attribute` and `torch.jit.annotate`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54485
Reviewed By: SplitInfinity, nikithamalgifb
Differential Revision: D27406843
Pulled By: gmagogsfm
fbshipit-source-id: 98983b9df0f974ed69965ba4fcc03c1a18d1f9f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54806
These are all very small key set checks (or similar getters
like `dtype()`, and we clearly want them to be inlinable -- we've even
made them non-virtual for perf in TensorImpl and said so in
comments. Don't make LTO work to figure that out.
ghstack-source-id: 125060650
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D27375016
fbshipit-source-id: 5c3dbfa38fa493c8f7e0ac4e5acd3598d5896558
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54558
In blocking wait's polling synchronization loop, we frequently call checkAndSetException() as part of isCompleted() to check the status of nccl operations. It would be useful to log here in case we encounter any exceptions (which are later thrown by `checkAndThrowException`).
Also slightly refactors code previously added to make use of a helper function to get the error message given an `std::exception_ptr`.
ghstack-source-id: 125124314
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D27136202
fbshipit-source-id: 256eb63c5c2a84be909722d3fd7377ad9303fa11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54557
When looping through the nccl communicator cache checking for errors, enhance the watchdog to log exceptions that are set on the communicator.
This will allow for better debugability since the NCCL error will be logged when the watchdog receives errors for the communicators and aborts them appropriately.
Tested by forcing a NCCL error with NCCL_BLOCKING_WAIT=1 and verifying that the exception is indeed logged.
ghstack-source-id: 125124310
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27106699
fbshipit-source-id: 1d2bd9f057a3796ce15dd8a4ce34cf6899eee45c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54219
There is no need for this ``pass``.
ghstack-source-id: 125124311
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D27105234
fbshipit-source-id: 95496fa785fdc66a6c3c8ceaa14af565588325df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53787
Per title, exposes a python-based monitored barrier API that we can use as part of debugability and may be useful for user applications.
ghstack-source-id: 125124315
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D26965127
fbshipit-source-id: 6c7826e63758462e3e5111f28cced54cba76a758
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53773
Closes https://github.com/pytorch/pytorch/issues/52876
Implements a barrier by doing send/recv to rank 0, and rank 0 waits for these requests and on timeout, throws an exception indicating which rank did not join in the given timeout.
This barrier is only intended for CPU use cases and built into process group gloo, and will be used for debugging synchronization/hang issues.
Test Plan: Added UT
Reviewed By: zhaojuanmao
Differential Revision: D26921357
fbshipit-source-id: 7c16e861b4b8ea2bdd67a36b3de7b1029af7d173
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54547
These arguments to `BuiltinOpFunction`'s ctor don't need to be copied.
ghstack-source-id: 124690196
Test Plan: CI
Reviewed By: SplitInfinity
Differential Revision: D27277318
fbshipit-source-id: 68f1f545ca977b2e1cabc91620da31719bf81e1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54533
There were some forgotten moves here. Since the values are
not otherwise used, let's just not give them names.
ghstack-source-id: 124674348
Test Plan: CI
Reviewed By: SplitInfinity
Differential Revision: D27271991
fbshipit-source-id: 793dd4576db659b3b9b973a4e09ee3133cf41dfe
Summary:
We were accessing their storage which will throw
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54632
Reviewed By: ezyang
Differential Revision: D27372192
Pulled By: eellison
fbshipit-source-id: 9985e85af7a35a3d6bf1c0be0185699c34877b94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54820
template implementation of std::sqrt() in libstdc++ yields incorrect results for `std::complex(-std::abs(x), -0.0)`, see https://gcc.gnu.org/bugzilla/show_bug.cgi?id=89991
For example:
```
#include <iostream>
#include <complex>
int main() {
std::cout << std::sqrt(std::complex<float>(-1.0f, -0.0f)) << std::endl;
}
```
prints `(0, -1)` if libstdc++ is compiled to use C99 csqrt/csqrtf fallback, but `(0, 1)` if configured not to use it.
Test Plan: CI
Reviewed By: luciang
Differential Revision: D27379302
fbshipit-source-id: 03f614fdb7ff734139736a2a5f6872cee0173bee
Summary:
Moves more s3 parsing code to s3_stat_parser.py. This is another step in modularizing the parsing code more correctly. I will also be using this exact function in future slowTest code.
Also replaces some Any's in the code to be Report.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54808
Test Plan:
.pytorch-test-times generated before the code and after this code is the same.
CI should pass, specifically the test tools GHA.
Reviewed By: walterddr
Differential Revision: D27375783
Pulled By: janeyx99
fbshipit-source-id: bec28551668b2eb3fdd60d802200993e493eac83
Summary:
**BC-breaking note**: This change throws errors for cases that used to silently pass. The old behavior can be obtained by setting `error_if_nonfinite=False`
Fixes https://github.com/pytorch/pytorch/issues/46849
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53843
Reviewed By: malfet
Differential Revision: D27291838
Pulled By: jbschlosser
fbshipit-source-id: 216d191b26e1b5919a44a3af5cde6f35baf825c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53973
Two parts to this PR; I had to put them together because adding support for X causes more test code to be exercised, which in turn may require a fix for Y.
The first part is restoring the concept of storage to meta tensors. Previously, meta tensors had a nullptr storage (e.g., `meta_tensor.storage()` is an error.) As I was increasing the coverage of meta tensors, I started running into test cases (specifically memory overlap tests) that were failing because not having storage meant I couldn't check for memory overlap. After some discussion, we decided that it would make sense for meta tensors to model this as well (we already model strides, so getting accurate view information also seems useful). This PR does that by:
* Rewrite all of the factory functions in MetaTensor.cpp to use the generic versions (which are very carefully written to not actually poke at the data pointer, so everything works out). The key idea here is we give meta tensors a special allocator, MetaAllocator, which always returns a nullptr even if you ask for a nonzero number of bytes. resize_ is also made generic; the normal variant can be used directly rather than having to instruct it to avoid resizing storage
* Turn on memory overlap checking in TensorIterator even for meta tensors
* Although meta tensors now have storage, the concept of meta storage is NOT exposed to Python land (as it would imply I would have to codegen MetaFloatStorage, MetaDoubleStorage, etc. classes). So `x.storage()` still raises an error and I have a cludge in `__deepcopy__` to break storage sharing upon deep copy (this is wrong, but no tests exercise this at the moment).
The second part is adding more support for the most used functions in the test suite.
* Inplace operations have very simple meta functions. I added `fill_`, `zero_`, `random_`, `uniform_` and `normal_`. In the case of random, I take advantage of pbelevich's templates for defining random kernels, so that I can reuse the common scaffolding, and then just register a noop stub that actually does the RNG. (Look, another structured kernels tiny variant!)
* `copy_` is now implemented. Copying into a meta tensor is always OK, but copying out of a meta tensor raises an error (as we don't know what the "correct" data to copy out is in this case)
* `empty_strided` usage from structured kernels now is implemented (TBH, this could have been done as soon as `empty_strided` was added)
* Meta was missing in a few places in TensorOptions/DispatchKey utility functions, so I added them
* Autograd engine now correctly homes meta tensors with CPU tensors (they have -1 device index so CUDA queues wouldn't work anyway)
* `apply_`, `map_` and `map2_` are special cased to no-op on meta tensor self. These count as inplace operations too but they are implemented a little differently.
Getting more meta function support triggers a number of bugs in the test suite, which I then fix:
- Linear algebra functions sometimes don't report NotImplementedError because they get swallowed by catch all try blocks. This is tracked in https://github.com/pytorch/pytorch/issues/53739
- dlpack obviously doesn't work with meta tensors, I just disabled the test
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D27036572
Test Plan: Imported from OSS
Reviewed By: agolynski, bdhirsh
Pulled By: ezyang
fbshipit-source-id: 7005ecf4feb92a643c37389fdfbd852dbf00ac78
Summary:
Per title. One skip for addmm was needed. Either it or the jit test doesn't seem to handle a complex literal properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54854
Reviewed By: anjali411
Differential Revision: D27395651
Pulled By: mruberry
fbshipit-source-id: 0bfadf0a8500f26d3a89f56f104fb44561f594d9
Summary:
This is to make it more flexible to be reused when pulling test stats other than by-test-case.
Also it makes it less likely to use it wrong with positional arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54797
Test Plan: see the updated tools/test/test_test_history.py examples.
Reviewed By: samestep
Differential Revision: D27371903
Pulled By: walterddr
fbshipit-source-id: 0ee02d654684315b44f5942904b857053d27e954
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54744
Fixes https://github.com/pytorch/pytorch/issues/54590
After the porting the upsample operators to be structured, they now forward memory_format information to the output. This is a problem for the cuda kernels, which are not implemented to deal with `torch.channels_last` memory format. The operators are:
* upsample_nearest2d
* upsample_bilinear2d
* upsample_nearest3d
* upsample_trilinear3d
This fix just allocates a temporary, contiguous output tensor when that happens, writes the results to the temporary and copies the results back to the output tensor.
I held off on adding tests to get the fix out quickly, but I wrote a script and ran some manual tests, that basically just asserts that the outputs are the same for cpu and cuda, for some threshold. I ran it for all 4 operators:
```
import torch
def basically_equal(t1, t2):
epsilon = 1e-4
diffs = torch.abs(t1 - t2)
print(torch.all(diffs < 1e-4))
# upsample 2d
a = torch.arange(48).reshape(2, 2, 3, 4).contiguous(memory_format=torch.channels_last).float()
out_cpu = torch.nn.functional.interpolate(a, scale_factor=2, mode='nearest')
out_cuda = torch.nn.functional.interpolate(a.to('cuda'), scale_factor=2, mode='nearest')
basically_equal(out_cpu, out_cuda.to("cpu"))
out_cpu = torch.nn.functional.interpolate(a, scale_factor=2, mode='bilinear', align_corners=True)
out_cuda = torch.nn.functional.interpolate(a.to('cuda'), scale_factor=2, mode='bilinear', align_corners=True)
basically_equal(out_cpu, out_cuda.to("cpu"))
# upsample 3d
a = torch.arange(96).reshape(2, 2, 2, 3, 4).contiguous(memory_format=torch.channels_last_3d).float()
out_cpu = torch.nn.functional.interpolate(a, scale_factor=3, mode='nearest')
out_cuda = torch.nn.functional.interpolate(a.to('cuda'), scale_factor=3, mode='nearest')
basically_equal(out_cpu, out_cuda.to("cpu"))
out_cpu = torch.nn.functional.interpolate(a, scale_factor=3, mode='trilinear', align_corners=True)
out_cuda = torch.nn.functional.interpolate(a.to('cuda'), scale_factor=3, mode='trilinear', align_corners=True)
basically_equal(out_cpu, out_cuda.to("cpu"))
```
prints
```
tensor(True)
tensor(True)
tensor(True)
tensor(True)
```
One thing that was weird- `upsample_bilinear2d` and `upsample_trilinear3d` were only accurate across cpu/cuda with an epsilon of `1e-4`. That tentatively sounds close enough to say that cuda isn't "wrong" (?), but that's not exactly "equal"... and I also ran the script before my change, and `bilinear2d` and `trilinear3d` were also the same across cpu/cuda with an epsilon of `1e-4`.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D27351393
Pulled By: bdhirsh
fbshipit-source-id: b33f46e4855dc8b49b363770190b639beebbf5a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54624
previously we were creating setattr nodes for dtype and axis.
The FX convention is that primitive types are embedded as literals in args/kwargs.
With this change we won't see getattr nodes in the graph anymore for dtype/axis
Test Plan:
python test/test_quantization.py TestQuantizeFx
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27306898
fbshipit-source-id: a7c91c7cb21ee96015c7f8830b38d943ada65358
Summary:
Enable bf16 vectorized copy.
BFloat16's copy get 2x performance for fp32 as our expectation.
BFloat16's vec copy dose not show performance gain compare with scalar version with op benchmark. This should caused by the memory system of operator. The system will really "read/write" a scalar at one time, although the code is written in scalar version.
benchmarks code:
```
import torch
import torch.utils.benchmark as benchmark
# x = torch.empty(10 * 18304 * 1024 * 16, dtype=torch.bfloat16)
x = torch.empty(10 * 18304 * 1024 * 16, dtype=torch.float)
def copy(tensors):
for t in tensors:
x.copy_(t)
tensors = []
for i in range(2):
# l3 cache size 36608k = 18304 bfloat16 * 2 byte(per bfloat16)
# tensors.append(torch.rand(10 * 18304 * 1024 * 16).bfloat16())
tensors.append(torch.rand(10 * 18304 * 1024 * 16))
t0 = benchmark.Timer(
stmt='copy(tensors)',
setup='from __main__ import copy',
globals={'tensors': tensors},
num_threads=1)
print(t0.timeit(20))
```
Before this comit:
fp32:
3.84 s
1 measurement, 20 runs , 1 thread
bf16:
1.89 s
1 measurement, 20 runs , 1 thread
After:
fp32:
3.71 s
1 measurement, 20 runs , 1 thread
bf16:
1.85 s
1 measurement, 20 runs , 1 thread
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54671
Reviewed By: ailzhang
Differential Revision: D27325350
Pulled By: heitorschueroff
fbshipit-source-id: 1a3b8ca17b4c60dbb3e86bf196f63e0a05228c65
Summary:
Reference: https://github.com/pytorch/pytorch/issues/38349
Wrapper around the existing `torch.gather` with broadcasting logic.
TODO:
* [x] Add Doc entry (see if phrasing can be improved)
* [x] Add OpInfo
* [x] Add test against numpy
* [x] Handle broadcasting behaviour and when dim is not given.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52833
Reviewed By: malfet
Differential Revision: D27319038
Pulled By: mruberry
fbshipit-source-id: 00f307825f92c679d96e264997aa5509172f5ed1
Summary:
```
index_add(Tensor self, int dim, Tensor index, Tensor source) -> Tensor
```
now becomes
```
index_add(Tensor self, int dim, Tensor index, Tensor source, Scalar alpha=1) -> Tensor
```
Generally, this sounds useful and harmless, and inside PyTorch, we are already needing this feature in `add_out_dense_sparse_cuda`, see the `SparseCUDATensorMath.cu` change in this PR.
**Test not added yet. Will add if after discussion we believe this is a good idea.**
- [ ] TODO: add test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54176
Reviewed By: ngimel
Differential Revision: D27319198
Pulled By: mruberry
fbshipit-source-id: fe43be082d1230c87c5313458213d5252be2ff23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54042
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53881
1. Fix position_weighted optimizer: Position weighted layer uses default optimizer but is actually gradient_slice, which will cause problem if we do not handle it properly in the new optimizier. The solution is to use sparseadagrad when it is gradient_slices.
2. Optimizer implementation of v1 and v2: using 1st momentum with/without bias_correction.
3. also implemented decoupled weight decay in the new optimizer.
Test Plan:
buck test //caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test_2 -- test_mlp_optimization
buck test //caffe2/caffe2/python:optimizer_test -- TestDecayAdagrad
buck test //caffe2/caffe2/python/operator_test:decay_adagrad_test
ctr_mbl_feed work flow: f255731660
oc work flow: f255739503
Reviewed By: 0x10cxR1
Differential Revision: D26839668
fbshipit-source-id: 2b6881c1a88540ef5766be40f5e80001257e2199
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54764
We mark a few vars as const in Reducer, also do this for replicas_ and
process_group_ as they should not be changed by Reducer during training. This
can help eliminate issues at compile time and prevent the developer from
accidently changing these variables.
ghstack-source-id: 125040110
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27357132
fbshipit-source-id: 23a0edf754a8e4f9e6440e99860e5549724cb7ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54763
Replaces deprecated torch::autograd::variable with at::Tensor.
torch::autograd::variable is defined as equal to at::Tensor now so this should
be a noop, but follows convention of using tensor instead of Variable.
ghstack-source-id: 125040109
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D27356450
fbshipit-source-id: 1a001358d7726a597141ec47803c8213db4814c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54711
Just print the dispatch key directly. The format here doesn't really
make sense but you'll still get something like CPUFloatTensor (because
the dispatch key is just CPU).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D27338811
Pulled By: ezyang
fbshipit-source-id: f459c5f7c006c06df4913ab33697eae89c46d83f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54710
I'm going to make meta tensors have storage (but DataPtr is always
null) so that I can accurately report memory overlap error checking, but
I now have a problem which is that if memory overlap test looks at the
actual data pointer, everything is going to look like it aliases! A
more conservative test is to just see if the Storage objects themselves
alias, and assume that the data pointers are unique if they don't.
The loss of precision stems from if you unsafely have two distinct
storage objects that point to the same data pointer. This situation
is pretty rare and so I think it is worth it (and I am hoping no tests
trigger by this.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D27338810
Pulled By: ezyang
fbshipit-source-id: 5ebaf81c22824494c47c1ae78982d9c0e5cba59f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54708
cdist advertises itself as Math but actually it error checks that the inputs
are CPU/CUDA in cdist_impl, which is invoked from a composite context in some
situations. I worked around this by ensuring that when cdist_impl was called in
this way, we DON'T do the device checks, but the entire function is a little
janky and I filed an issue about it at #54096
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D27338813
Pulled By: ezyang
fbshipit-source-id: 1202b02c58584a33dc32a5270e59e5f0af6398c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54703
The trick is that this function takes in the allocator and dispatch key
explicitly; so you still need to know where to find the appropriate
allocator. The plan is to use this for meta tensors, but you probably
could also use this for empty_cuda as well. It also takes in arguments
post optional resolution, which can save a few instructions if you want
to call this function directly (no uses yet).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D27338814
Pulled By: ezyang
fbshipit-source-id: 131c97922d245e9a2de547527123b464bddb2f99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54627
This is the simplest little fix to get interpreter to preserve
NotImplementedError, so that the test suite doesn't start choking
on meta tensors not working in interpreter. It is sound and correct
but doesn't work for other c10::Error subclasses with special handling.
A more proper fix is requested at
https://github.com/pytorch/pytorch/issues/54612
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: wenleix, ngimel
Differential Revision: D27328666
Pulled By: ezyang
fbshipit-source-id: 483bef062de5a907d20e2d9e25eafe2d5197cf8d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54531
Enabling faulthandler will intercept signals like SIGSEGV, SIGFPE,
SIGABRT, SIGBUS and SIGKILL and dump the entire python traceback before the
process goes down.
This can help us in debugging flaky tests where a process crashes and we need
to debug what happened.
ghstack-source-id: 125045894
Test Plan:
1) Tested locally to see traceback is produced.
2) waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D27271048
fbshipit-source-id: ca12125a9da6cdfc7bac5619ad1c7e116666014b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54464
In case where we accidentaly set an error twice on a Future, we get a
cryptic error like this:
```
Exception in thread pool task: !completed() INTERNAL ASSERT FAILED at "aten/src/ATen/core/ivalue_inl.h":534, please report a bug to PyTorch.
```
This PR, updates the error message to include some additional information about
what the previous error was.
ghstack-source-id: 125039478
Test Plan:
1) unit test
2) waitforbuildbot
Reviewed By: swolchok
Differential Revision: D27249758
fbshipit-source-id: 517cf3837fb7b7821312e101e8813844c188f372
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54645
Had to replace RRef[..] with just RRef in the return signature since
sphynx seemed to completely mess up rendering RRef[..]
ghstack-source-id: 125024783
Test Plan: View locally.
Reviewed By: SciPioneer
Differential Revision: D27314609
fbshipit-source-id: 2dd9901e79f31578ac7733f79dbeb376f686ed75
Summary:
Add wait in test_pass_nccl_options_high_priority_stream
after the all reduce operation.
Without wait, the allreduce operation might be still running and the
comparison of result might not be valid.
Signed-off-by: Jagadish Krishnamoorthy <jagdish.krishna@gmail.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54714
Reviewed By: ezyang
Differential Revision: D27379544
fbshipit-source-id: 6393d25f8f3d5635c5d34c9b3aac8b801315b48e
Summary:
I added a helper to convert a Stmt to string and FileCheck it, so
started using it in a bunch of places. I replaced about half the current uses,
got tired, started to write a Perl script to automate it, realized that was
hard, and decided to give up for a bit. But this cleans up some of the tests a
bit, so seems easy to review and worth landing.
Test Plan: test_tensorexpr --gtest_filter=LoopNest.*
Reviewed By: navahgar
Differential Revision: D27375866
fbshipit-source-id: 15894b9089dec5cf25f340fe17e6e54546a64257
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54756
We have multiple bugs here, one relating to index flattening and the
other to computeAt.
ghstack-source-id: 125054729
Test Plan: yikes
Reviewed By: ZolotukhinM
Differential Revision: D27354082
fbshipit-source-id: 8b15bac28e3eba4629881ae0f3bd143636f65ad7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54755
As title. A step on the way to using computeAt to optimize
convolution.
ghstack-source-id: 125054730
Test Plan: new test
Reviewed By: ZolotukhinM
Differential Revision: D27353663
fbshipit-source-id: 930e09d96d1f74169bf148cd30fc195c6759a3e9
Summary:
This PR is a follow up to https://github.com/pytorch/pytorch/pull/53408.
It only loads hipfft if the version is rocm 4.1 or after and stops loading rocfft. This was done to resolve some issues observed in our internal ci due to conflicts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54349
Reviewed By: ezyang
Differential Revision: D27374252
Pulled By: ngimel
fbshipit-source-id: 724e80df5011ea8fabd81739e18ae8a13d3a7ea0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54640
If we are running constant propagation on a graph that doesn't have any operators with constant inputs and any mutable inputs/outputs, we do not need to initialize an alias db. This is going to be used to speed up symbolic shape analysis.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D27340863
Pulled By: eellison
fbshipit-source-id: 087b2a33b42c58fa5dae405d652b056d0f1d72e7
Summary:
Partly fixes https://github.com/pytorch/pytorch/issues/31837.
### Update: This is ready for review.
Currently, `torch.logsumexp(input, out=result)` internally creates 2 intermediate tensors with same shape as `input` tensor. This causes unnecessary OOM problems when tensor size is large.
These tensors come from the following:
1. `self - maxes` will create a new tensor with shape of `self`
2. `at::exp` will create another tensor with the shape of `self`
To get rid of this problem, we can use `(self-maxes).exp_()` that performs exp operation in-place. This would reduce memory need from `~3 x input.shape` to `~2 x input.shape` (`self-maxes` is still there)
I think we can't get rid of having a single intermediate tensor with shape of `input` because of `self - maxes` as we have to keep `self` intact. The only scenario would be to have a `torch.Tensor.logsumexp_` method that can do in-place operations on tensor itself. However, I didn't see any in-place method example for reduction operations, so it might not be a good fit.
This is my first contribution here, please let me know if I'm missing anything!
Thanks!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51239
Reviewed By: anjali411
Differential Revision: D27363147
Pulled By: ezyang
fbshipit-source-id: 696fa8764b74386a80b4aa33104f3f9ca57ed712
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54049
The goal of this is to factor out the core logic of getting the analytical jacobian which is effectively doing `f(grad_out) = grad_out^T J = grad_input`. This allows us to test a lot of logic that was not possible before because now we can replace f with whatever we want in order to simulate potential issues that gradcheck is designed to catch.
Edit: I realize a lot of things this PR was originally aiming to allow is actually possible with hooks, hence the tests have already been added in a earlier PR in the stack. But this is still slightly useful for reducing code duplication when adding the new fast gradcheck code (more details below)
After this change, `get_analytical_jacobian` is only responsible for gathering a list of rows that are later combined into a single Jacobian tensor. This means we don't have to perform any checks for correctness of the dtypes/size at this step
We factor out that logic into a separate function, `combine_jacobian_rows`, which handles the list of rows -> single Tensor step for each jacobian, and the error checking it entails. (This allows this code to be shared between the fast/slow versions.)
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27307240
Pulled By: soulitzer
fbshipit-source-id: 65bb58cda000ed6f3114e5b525ac3cae8da5b878
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54470
```
git grep -l 'DefaultBackend' | xargs sed -i 's/DefaultBackend/CompositeExplicitAutograd/g'
```
Plus a quick fixup in native/README.md
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D27253240
Pulled By: ezyang
fbshipit-source-id: 964df951ea8b52fa72937f3cc66aeaf49a702e6f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54595
Seeing a lot of misuse of DefaultBackend, want to try to
nip some of these in code review.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27301721
Pulled By: ezyang
fbshipit-source-id: 1a39426cb6cac5c7f322df6f8a69ccb463f1b258
Summary:
i dont think docker/ folder is used anymore. creating this draft to verify
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54729
Reviewed By: ezyang
Differential Revision: D27364811
Pulled By: walterddr
fbshipit-source-id: 3e4a9d061b0e5f00015a805dd8b4474105467572
Summary:
Fixes error when running torch test suite inside a centos CI image. As described by https://pypi.org/project/SoundFile/0.10.3.post1/, `On Linux, you need to install libsndfile using your distribution’s package manager`. This was missing from the centos CI image.
```
python test_spectral_ops.py -v
...
Traceback (most recent call last):
File "test_spectral_ops.py", line 25, in <module>
import librosa
File "/opt/conda/lib/python3.6/site-packages/librosa/__init__.py", line 211, in <module>
from . import core
File "/opt/conda/lib/python3.6/site-packages/librosa/core/__init__.py", line 6, in <module>
from .audio import * # pylint: disable=wildcard-import
File "/opt/conda/lib/python3.6/site-packages/librosa/core/audio.py", line 8, in <module>
import soundfile as sf
File "/opt/conda/lib/python3.6/site-packages/soundfile.py", line 142, in <module>
raise OSError('sndfile library not found')
OSError: sndfile library not found
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54687
Reviewed By: ezyang
Differential Revision: D27332975
Pulled By: walterddr
fbshipit-source-id: 9c6b37545e9f2536c83e606912859439847c884a
Summary:
This suppresses some data races reported by TSAN. See the associated
task(s) below for context, including sample stack traces caused by these races
and reproduction instructions.
This diff is automatically generated. Therefore, the way it makes suppressions
may not be as beautiful as if written by hand. *However, we don't have the
resources to manually adjust these diffs, nor do we have the capacity to
actually fix the bugs*; we just want to get the existing bugs
out of the way so we can enable TSAN across the fleet. If you are a reviewer
please do one of the following:
1. Accept the diff as is, and you may follow up with more changes (or fix the
bugs) later.
2. Fix the data races in a different diff and land it within a reasonable amount
of time (e.g. a week), and comment about it here.
3. Comment to suggest us a different code location(s) to suppress these data
races.
Test Plan: Unit tests were automatically run as part of https://www.internalfb.com/intern/sandcastle/job/22517998509525934/
Reviewed By: ezyang
Differential Revision: D26094360
fbshipit-source-id: 06c285570bcf7a1491d8f17d1885d065ef0bc537
Summary:
Hey!
Just stumbled across these Python 2 fragments while reading the source code and thought it could be removed, since the Python 2 support has already been dropped.
mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54691
Reviewed By: mruberry
Differential Revision: D27344439
Pulled By: ailzhang
fbshipit-source-id: 926303bfff9afa6dabd2efb5e98f9d0d9ef83dc7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54735
One of the tests didn't wrap scipy call with TEST_SCIPY. Also, the wrapper function seems unnecessary and requires lambdas to be created.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D27351349
Pulled By: heitorschueroff
fbshipit-source-id: 029e273785b11e01d6be7b816469654de6583deb
Summary:
* Lowering NLLLoss/CrossEntropyLoss to ATen dispatch
* This allows the MLC device to override these ops
* Reduce code duplication between the Python and C++ APIs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53789
Reviewed By: ailzhang
Differential Revision: D27345793
Pulled By: albanD
fbshipit-source-id: 99c0d617ed5e7ee8f27f7a495a25ab4158d9aad6
Summary:
First step to move all S3 related operations into S3 parser utils.
in the end we provide APIs from s3_stats_parser:
1. downloading data as reports and uploading data as reports
2. filter by job name
and handle all compression, formatting inside.
TODO
- [ ] Refactor out upload into s3_stats_parser
- [ ] Remove all S3/BOTO related checkers and try/catch blocks outside of s3_stats_parser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54681
Test Plan:
1. Running tools/test/* covers the refactoring logic (test_test_history.py and test_stats.py as entrypoint and both using the 2 new APIs in s3_stats_parser after the refactoring.
2. print_test_stats.py's main argparse entrypoint is covered by CI step Report Test Result step.
3. run `python test/run_test.py --export-past-test-times` before and after this PR should result in the same file content in .pytorch-test-times
Reviewed By: ailzhang
Differential Revision: D27346742
Pulled By: walterddr
fbshipit-source-id: fb40162e631e007fed9d5821fe4f190bda2cb52e
Summary:
This reduces the memory usage of matmul significantly for expanded batch size.
This reduces the peak memory usage of
```
a = torch.rand(1, 1024, 1024, device="cuda")
b = torch.rand(1024, 1024, 1, device="cuda")
out = torch.matmul(a, b)
```
From 4GB to 16MB which is not too bad.
It also fixes the same problem when `b` is not batched.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54616
Reviewed By: ailzhang
Differential Revision: D27327056
Pulled By: albanD
fbshipit-source-id: 4bb5f4015aeab4174148512f3c5b8d1ffa97bf54
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54257
Makes the NS weight extraction fuction work correctly with
fp16 emulation patterns for linear. We navigate to the
weight correctly, and cast it to `torch.float16` before returning.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_linear_fp16
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27159370
fbshipit-source-id: 95f555298e3153e4783c64b3d8c83b9d3fdffa12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54254
In fp16 emulation, we now have patterns such as
```
... -> dequantize -> linear -> relu -> to(torch.float16) -> ...
```
This PR adds support for
* specifying a subgraph's "base_op_node", which is the node with the op
which should be matched to related nodes. In the example above,
"base_op_node" would be the linear node, and it would be the second
node in the matched pattern.
* matching these fusion patterns and properly setting "base_op_node"
based on pattern and index
* using "base_op_node" instead of "start_node" throughout the NS
codebase wherever the intent is to match subgraphs or create names
for subgraphs.
At the end of this PR, matching unshadowed activations with an example
fp16 emulation pattern works e2e.
I'm saving the following work for future PRs (soon), mostly to keep
PR size manageable:
* adding weight matching (will require some changes to function which
extracts weights)
* adding shadowed activation matching (will require some changes to
shadow copying)
* adding input logging for these patterns (will likely require some changes as well)
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_linear_fp16
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27158199
fbshipit-source-id: 49fc445395452fda62e3c7a243544190f9af691c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54253
Creates an `NSSubgraph` type for representing a subgraph instance,
and modifies the NS code to use it. This will enable us to add
more information to the subgraph instance definition without
having to change all the callsites.
Test Plan:
```
mypy torch/quantization
python test/test_quantization.py TestFXGraphMatcher
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27158198
fbshipit-source-id: 548785dd90144e2da256c23af990620c778e7cfe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53828
Moves LSTM shadow activations test to new API. In order
to enable this, adds support for passing two args instead
of one arg when copying a subgraph from A to B.
Since this was the last test of the old API, deletes
the old test case.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels.test_compare_shadow_activations_lstm_dynamic
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26982733
fbshipit-source-id: 03f580688dd37f3ccd688d9f444e9e79cfa84734
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53819
Moves the linear tests for shadow activations to new API.
In order to do so, adds logic for fp32 to fp32 dtype cast,
which is an identity.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels.test_compare_shadow_activations_linear
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26982734
fbshipit-source-id: b6203228abf3cdf74ab0638468a6df77658aa662
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53818
Moves testing of conv for shadow activations to new NS API
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels.test_compare_shadow_activations_conv
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26982732
fbshipit-source-id: 9e8709a76363fbcdf84413e5d4a6c8a0889cb97b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53779
Moves the test case for LSTM activation matching to new NS APIs.
This requires adding the ability to log non-Tensor types.
Since we need Loggers to be scriptable and TorchScript does
not support `Union`, we collect statistics in a separate collector
if we have an RNN. Note: this can scale to a small N of
return types, but not to a large N. If the N becomes large in
the future, we will solve it then.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26967110
fbshipit-source-id: afe60b44fdec28a328813b4f342cf4fe04820baa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54654
Fixes a bug where disabling quantizaton on potential fusion patterns
would lead to errors in the `convert` function. For example:
1. have a model with add-relu
2. disable quantization for the part of the model containing add-relu
3. run prepare and convert, the convert step would fail because
intermediate nodes were missing from `env`.
The fix is to add handling for this edge case. If quantization is
disabled, we manually copy the nodes for multi-node fusion patterns.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_fusion_pattern_unquantized
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D27318454
fbshipit-source-id: 27c1fd1cb7c9711a8e8d338200971c428dae8f98
Summary:
This way, if malicious code gets committed and the tag moves forward, we would be at risk. This does mean that we would have to manually update the SHA if there are desirable upgrades to the repository.
We are pinning it to this commit: a81b3c4d59
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54738
Reviewed By: samestep
Differential Revision: D27346792
Pulled By: janeyx99
fbshipit-source-id: 5641a78567c3cd61dce35dfa2fd4918f255a7681
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54571
Supports bfloat16 via a similar method to half: upconvert inputs to
fp32, do math, then downconvert outputs to bf16.
Resource strings are mostly derived from cuda-11 headers.
Fixes#53918, for the legacy fuser at least.
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27328987
Pulled By: bertmaher
fbshipit-source-id: 5c0eae44164623faa0c75cb818e8bf0211579fdc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54649
Some operator<< code manually implemented string join in C++, turns
out there is a c10 util for this. Use the util instead of rolling our own.
ghstack-source-id: 124840043
Test Plan: Ci
Reviewed By: SciPioneer
Differential Revision: D27316705
fbshipit-source-id: 5118097f84be2f38a503d8f81faa38c8d95ec17a
Summary:
As per title.
Numerical stability increased by replacing inverses with solutions to systems of linear triangular equations.
Unblocks computing `torch.det` for FULL-rank inputs of complex dtypes via the LU decomposition once https://github.com/pytorch/pytorch/pull/48125/files is merged:
```
LU, pivots = input.lu()
P, L, U = torch.lu_unpack(LU, pivots)
det_input = P.det() * torch.prod(U.diagonal(0, -1, -2), dim=-1) # P is not differentiable, so we are fine even if it is complex.
```
Unfortunately, since `lu_backward` is implemented as `autograd.Function`, we cannot support both autograd and scripting at the moment.
The solution would be to move all the lu-related methods to ATen, see https://github.com/pytorch/pytorch/issues/53364.
Resolves https://github.com/pytorch/pytorch/issues/52891
TODOs:
* extend lu_backward for tall/wide matrices of full rank.
* move lu-related functionality to ATen and make it differentiable.
* handle rank-deficient inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53994
Reviewed By: pbelevich
Differential Revision: D27188529
Pulled By: anjali411
fbshipit-source-id: 8e053b240413dbf074904dce01cd564583d1f064
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 5d15ff7a64
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54686
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D27328262
fbshipit-source-id: 81e1ede0607da4d8f676145cfb6729ac5544c77d
Summary:
CMAKE_SYSTEM_PROCESSOR set to x86_64(on Linux) or AMD64 (5ec224496b)(on Windows) indicates build is running on x86_64 architecture, while `CMAKE_SYSTEM_PROCESSOR` set to aarch64 or arm64 means we running on ARMv8+ architecture.
Delete `i[3-6]86` pattern as 32-bit builds are no longer supported
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54637
Reviewed By: ezyang
Differential Revision: D27311897
Pulled By: malfet
fbshipit-source-id: 26989fc9b54a96d70c768ab03ca4528506ee7808
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54601
This make it consistent with PackageImporter and the on-disk format.
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Differential Revision: D27296915
Pulled By: suo
fbshipit-source-id: a9bc615b1952b6cc4dcba31d4a33932b1fa1a2aa
Summary:
The link in the README was broken
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54434
Reviewed By: ailzhang
Differential Revision: D27328733
Pulled By: nairbv
fbshipit-source-id: 12ebb6f66983f9348a90b9738fbd9f3f2660c2d1
Summary:
The fallback thnn 2d convolution uses `im2col` to get patches and `gemm` to implement convolution .
I has a shortcut to use `gemm` directly for kernel size 1, but this only works for stride == 1 and padding == 0.
This PR adds checks for stride == 1 and padding == 0 to determining whether `im2col` can be skipped.
Fixes https://github.com/pytorch/pytorch/issues/54036
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54080
Reviewed By: ejguan
Differential Revision: D27170482
Pulled By: zou3519
fbshipit-source-id: 055d6502239d34945934de409d78144d8a5c56f4
Summary:
This PR adds a lightweight workflow which runs when any of our GitHub Actions lint or test workflows start (currently just the three listed in the YAML in this PR's diff), and cancels redundant ones (e.g. if a PR author pushes several commits in rapid succession). Currently this isn't particularly impactful, but it would become more so if/when we add heavier workflows that run on PRs.
Initially we tried using [`technote-space/auto-cancel-redundant-workflow`](https://github.com/technote-space/auto-cancel-redundant-workflow) instead of [`potiuk/cancel-workflow-runs`](https://github.com/potiuk/cancel-workflow-runs), but for some reason it the former doesn't seem to work even if triggered by `workflow_run` with the `TARGET_RUN_ID` input set appropriately.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54685
Test Plan: janeyx99 and I tested this in a separate GitHub repo, and confirmed that it successfully cancels redundant `push`-triggered workflows on the source repo and `pull_request`-triggered workflows from forks.
Reviewed By: janeyx99
Differential Revision: D27327999
Pulled By: samestep
fbshipit-source-id: c5793a7660d21361381e0f033d314f2d603f70ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54647
Regularly log stats showing effect of gradient compression when using the PowerSGD DDP communication hook.
Test Plan:
buck run mode/dev-nosan scripts/wayi/torch:power_sgd
Play with the layer sizes of the input model (you can just use linear layers for convenience), and check the log that shows compression stats. For convenience, you can change `logging.info` to `print` locally.
You can create some test diffs on top of this diff, to show that the compression stats are correct in different cases.
Run with power_sgd script:
{F537381542}
Diff with example using a simple linear model: D27299934
sample output:
{F538486535}
Reviewed By: SciPioneer
Differential Revision: D27240254
fbshipit-source-id: 9e142b2f7957cc874804f799b7bb3bffdf824858
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53953
torch.futures.wait_all, would wait for all specified futures to
complete before it returned. As a result, if there was an error it would still
wait for a long time (ex: long running RPCs) before it returned an error to the
user.
This PR ensures `wait_all` returns and error as soon as any future runs into an
error and doesn't wait for all futures to complete.
I removed the logic _invoke_rpc_python_udf which raised an error in the unwrap
function, because ideally the error should be set on the Future and not be
raised to the user only when `wait()` is called. As an example, in the case of
`wait_all`, the user never calls `wait()` on the future that errored out but a
future down the chain and we should propagate these errors via `setError`
instead.
ghstack-source-id: 124721216
Test Plan:
1) Unit test added.
2) waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D27032362
fbshipit-source-id: c719e2277c27ff3d45f1511d5dc6f1f71a03e3a8
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53731
Make SharedCache thread-safe by using explicit locks instead of relying on atomicity of certain Python operations
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53750
Reviewed By: malfet
Differential Revision: D27304793
Pulled By: albanD
fbshipit-source-id: 7c62babe4357bed57df3056fbda6801fb6168846
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54530
This diff introduces the following changes and improvements:
- Introduces a new fluent API to construct tensors from external data as an alternative to `from_blob` overloads. See below for an example.
- Leverages several small-buffer optimizations which result in %50 reduction in tensor construction times.
- Exposes a new (lightweight) way to construct tensors by passing a naked `context` and `context_deleter` pair as an alternative to the existing `deleter` parameter.
- Updates the existing `from_blob` overloads to internally use the fluent API.
```
// Example 1
at::Tensor tensor = at::for_blob(data, sizes)
.strides(strides)
.context(context, [](void *ctx) { delete static_cast<Ctx*>(ctx); })
.options(...)
.target_device(...)
.make_tensor();
// Example 2
at::Tensor tensor = at::for_blob(data, sizes).make_tensor();
// Example 3
at::Tensor tensor = at::for_blob(data, sizes)
.deleter(...)
.make_tensor();
```
Test Plan:
Below are the folly Benchmark results for the following two equivalent operations:
```
// The fluent API
at::Tensor tensor = at::for_blob(data, sizes)
.deleter([buffer](void*) mutable { buffer.reset(); })
.options(dtype(c10::ScalarType::Float))
.make_tensor();
// The original `from_blob` overload
at::Tensor tensor = at::from_blob(
data,
sizes,
[buffer](void*) mutable { buffer.reset(); },
dtype(c10::ScalarType::Float));
```
```
============================================================================
scripts/balioglu/from_blob_exp/main.cpp relative time/iter iters/s
============================================================================
fluent 298.34ns 3.35M
from_blob 55.19% 540.51ns 1.85M
============================================================================
```
Various similar experiments show an approximate %50 reduction in tensor construction times.
Reviewed By: ezyang
Differential Revision: D27269344
fbshipit-source-id: e6bd0b78384bf89fd24f22254008180329000363
Summary:
Kernels such as "add" are registered to DefaultBackend. At a minimum NestedTensor is not compatible with structured kernels due to missing fields such as size, which can therefore cause difficult to catch bugs when being passed into a function without a NestedTensor-specific kernel.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54559
Reviewed By: ezyang
Differential Revision: D27283591
Pulled By: cpuhrsch
fbshipit-source-id: fad7c03ca3b2190f2f90039dd2872184e9bc5049
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54120
Construct InterpreterManager inside PyTorchDeployModel
- add ReadAdapterInterface to deploy::Package
Implement PyTorchDeployModel::makePrediction for FeatureStore Examples
- Basic test of loading and executing 'simple' model
Test Plan: ran unit tests locally and CI
Differential Revision: D26961744
fbshipit-source-id: fce72bc83b9005500d9b7ce3fab2ed466f73d6ed
Summary:
Also modify the `tf32_on_and_off` decorator to make it support function without `device` argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52871
Reviewed By: ngimel
Differential Revision: D27286674
Pulled By: mruberry
fbshipit-source-id: 14f6d558271bd6a1d0bc40691c170d47e81de1ff
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/54636
Test Plan: The model will be rerun after the diff lands...
Reviewed By: hx89
Differential Revision: D27310244
fbshipit-source-id: 88575237596a59996da14a49a8459f8b3d0ee66a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54439
For now the only way to represent conv2d in TE is via an external call,
and since aten library doesn't have an out variant for conv2d, the
external call has to perform an extra copy. Because of that fusing
conv2d now regressed performance and hence is disabled. However, in near
future we should have two alternative ways to enable it:
1) represent conv2d natively in TE (without an external call)
2) add an out variant for conv2d
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D27237045
Pulled By: ZolotukhinM
fbshipit-source-id: f5545ff711b75f9f37bc056316d1999a70043b4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54579
## Summary
1. Eliminate a few more tests when BUILD_LITE_INTERPRETER is on, such that test_lite_interpreter_runtime can build and run on device.
2. Remove `#include <torch/torch.h>`, because it's not needed.
## Test plan
Set the BUILD_TEST=ON `in build_android.sh`, then run
` BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh x86`
push binary to android device:
```
adb push ./build_android_x86/bin/test_lite_interpreter_runtime /data/local/tmp
```
Reorganize the folder in `/data/local/tmp` so the test binary and model file is like following:
```
/data/local/tmp/test_bin/test_lite_interpreter_runtime
/data/local/tmp/test/cpp/lite_interpreter_runtime/sequence.ptl
```
such that the model file is in the correct path and can be found by the test_lite_interpreter_runtime.
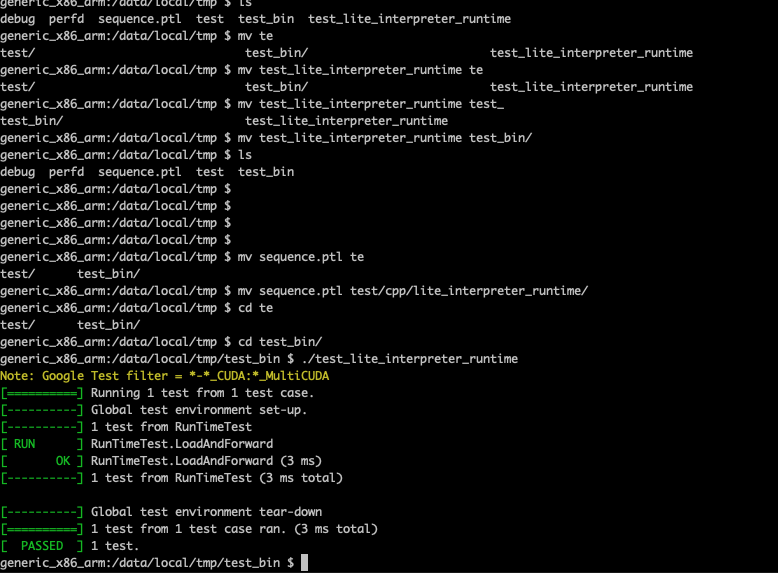
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D27300720
Pulled By: cccclai
fbshipit-source-id: d9526c7d3db8c0d3e76c5a4d604c6877c78afdf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53916
This PR fixes some bugs that are made more clear by the previous refactor.
- make sure gradcheck returns false when its supposed to fail and when raise_exception=False.
- make sure when test_batched_grad fails, it returns false when raise_exception=False
Removing checkIfNumericalAnalyticAreClose made sense here to me because underneath its really doing `torch.allclose`, and using that directly instead of adding another opaque function to call seemed to make the code more clear.
TODO:
- ~add a test to see if when torch.allclose fails, we indeed return false.~
- ~uncomment test from previous PR.~
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D27201692
Pulled By: soulitzer
fbshipit-source-id: 8b8dc37c59edb7eebc2e8db6f8839ce98a81d78b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53857
This PR basically just factors a lot of the logic out from the main gradcheck function into their own individual functions. It aims to avoid any behavior change (but we may not have enough tests to actually verify this). Refactorings that lead to any behavior chang are done in the next PR in this stack.
The rationale for this change is 1) to make the main gradcheck function cleaner to read, and 2) also allow us to reuse the same pieces when we add the fast gradcheck.
Maybe this PR is also a good place to add some tests for gradcheck, i.e., make sure gradcheck fails when it should fail, as to make sure that we are indeed not changing any logic. This will also help us make sure our fast_gradcheck does all the necessary checks:
So far existing tests are:
- test_gradcheck_fail_when_no_differentiable_outputs_and_num_grad_not_zero` (test_autograd)
- test_gradcheck_single_input (test_autograd)
- test_gradcheck_sparse_input (test_autograd)
- test_gradcheck_nondeterministic (test_autograd)
- test_gradcheck (test_overrides)
Full coverage would potentially require adding the following missing tests (for each test for both raise_exception=True/False) - Methodology for getting the list below is that for every type of error message we spit out, we make sure we can hit it:
- complex:
- when numerical != analytical when tested with imag grad_out
- check_inputs
- ~when inputs are not dense, but check_sparse_nnz is false~
- ~when none of the inputs require grad~
- ~(warning) when inputs are not double precision~
- ~when layout is not mkldnn(aka has strides) and input has a dimension with stride 0.~
- check_no_differentiable_outputs:
- ~when none of the outputs are differentiable, but numerical gradient is not zero~
- check_outputs:
- ~when sparse outputs (always raise)~
- ~when mkldnn outputs (always raise)~
- test_batched_grad
- ~when encounter runtime error while computing batched grad (print big message)~
- when not allclose (print out big message)
- test_backward_mul_by_grad_output
- ~when layout of grad_input is not the same as input~
- ~when grad_input is sparse and has incorrect sparse_dim/dense_dim~
- ~when backward not multiplied by grad_output (sparse/non-sparse case)~
- when grad is incorrect type/size
- test_undefined_grad
- ~when encounter runtime error while running backward~
- when we complete backward but grad inputs (the output of .grad()) is not none
- check_analytical_jacobian_attributes (for both complex/non complex)
- when grad input is incorrect dtype/size
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D27201571
Pulled By: soulitzer
fbshipit-source-id: 86670a91e65740d57dd6ada7c6b4512786d15962
Summary:
Add proper way to skip test_symeig. In case MAGMA is not detected, skip the test_symeig properly.
Added skipCUDAIfNoMagma decorator.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54526
Reviewed By: malfet
Differential Revision: D27293640
Pulled By: heitorschueroff
fbshipit-source-id: 245f86540af0e37c8795e80dc003e1ca4c08cd5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54466
I had to very carefully audit all the use sites since there are a lot
of other uses of the string Math; I did most of the conversion by
grepping for all occurrences of Math and then doing a search
replace.
I also updated documentation for clarity.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27253239
Pulled By: ezyang
fbshipit-source-id: afb485d07ff39575742a4f0e1e205179b60bc953
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53735
Add an option to BlobSerializationOptions to request that float data be
serialized as bfloat16. This reduces the serialized data size at the expense
of some loss in precision.
ghstack-source-id: 124317910
Test Plan: Included a new unit test.
Reviewed By: mraway
Differential Revision: D26658205
fbshipit-source-id: 74521ed161059066355a3f208488ed01a344dbb5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52881
**This PR adds:**
1. logic to parse complex constants (complex literals of the form `bj`)
2. logic to parse complex lists
3. support for complex constructors: `complex(tensor/int/float/bool, tensor/int/float/bool)`
4. Limited operator support
- `add`, `sub`, `mul`, `torch.tensor`, `torch.as_tensor`
**Follow-up work:**
1. Add complex support for unary and other registered ops.
2. support complex constructor with string as input (this is supported in Python eager mode).
3. Test all emitXYZ for all XYZ in `ir_emitter.cpp` (currently only emitConst, emitValueToTensor are tested). e.g., test loops etc.
4. onnx doesn't support complex tensors, so we should error out with a clear and descriptive error message.
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D27245059
Pulled By: anjali411
fbshipit-source-id: af043b5159ae99a9cc8691b5a8401503fa8d6f05
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 52774a0165
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54582
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D27289673
fbshipit-source-id: c1284b1642c518ce4568e32ddebee5034d8a542e
Summary:
Follow up PR of https://github.com/pytorch/pytorch/issues/53951.
This PR fixes remaining semmle warning: comparison of narrow type with wide type in loop condition
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54471
Reviewed By: bdhirsh
Differential Revision: D27262493
Pulled By: malfet
fbshipit-source-id: 05765758da79699936af11de237c3ff3d34373d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53296
Part 1 of the instruction count microbenchmarks. This PR is focused on benchmark definition machinery. (Though you can run `main.py` to see it in action.) A summary of the system is given in the README.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D26907092
Pulled By: robieta
fbshipit-source-id: 0f61457b3ce89aa59a06bf1f0e7a74ccdbf17090
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54438
August 1x model has DictConstruct in the graph (P331168321)
These can be easily removed with jit pass, but to easily measure the improvement
and run replayer with the model in the meantime, enable DictConstruct in static runtime
Test Plan:
```
./sigrid/predictor/scripts/pytorch/pyper_inference_e2e_local_replayer_test.sh \
cpu 218841466_0 7449 /data/users/ansha/tmp/adfinder/august_1x/ /data/users/ansha/tmp/adfinder/august_1x/filtered_requests_inline_cvr_100
```
```
TEST trace
Total num requests 100
Num exceptions 0
Latency us avg 180965
Latency us p25 89785
Latency us p50 131240
Latency us p75 146621
Latency us p90 158378
Latency us p95 166628
Latency us p99 1886680
Latency us p100 3803252
Server latency us avg 91554
Server latency us p25 51447
Server latency us p50 86371
Server latency us p75 95229
Server latency us p90 102706
Server latency us p95 116023
Server latency us p99 557017
Server latency us p100 716319
Num rankUnits avg 28
```
Reviewed By: hlu1
Differential Revision: D27236682
fbshipit-source-id: 1da49a836dd7533480e77797338baa9edcb65fb5
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54337
This PR adds a new API to NNC to perform loop fusion.
```
static For* fuseLoops(const std::vector<For*>& loops);
```
Loop fusion is done only when all the conditions below are satisfied.
* All the loops have the same parent.
* There are no statements between these loops in their parent body.
* The start bounds are the same for all loops.
* The stop bounds are the same for all loops.
* Fusing the loops does not violate or add any dependencies.
This PR also adds an API to check for partial overlaps in `buffer_inference.h` and fixes a bug in `mem_dependency_checker.cpp`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54461
Reviewed By: bertmaher
Differential Revision: D27254888
Pulled By: navahgar
fbshipit-source-id: c21b027d738e5022e9cb88f6f72cd9e255bdb15e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54413
1. Skip inplace autograd test for an op if its inplace variant does not exist.
2. For ops that don't have an inplace variant, remove redundant `supports_inplace_autograd=False` assignments in their `OpInfo`s.
3. Ops having inplace variants that do not support autograd should not have `supports_inplace_autograd=False` entries removed from their `OpInfo`s.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54460
Reviewed By: ngimel
Differential Revision: D27255938
Pulled By: mruberry
fbshipit-source-id: f15334b09e68995e9f26adc2ff3e59c292689ee8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54117https://github.com/pytorch/pytorch/pull/45950 enhanced our NCCL logging errors so that we add some basic debug information about what when wrong when erroring out with a NCCL error.
However, that PR only used the added function for `C10D_NCCL_CHECK` which is used to check the return values of NCCL calls. However, in ProcessGroupNCCL we also have `checkForNCCLErrors` which checks for errors on nccl communicators, and in case of errors it would be good to have this logging there too.
Also renames the function s/errorMessage/getNcclErrorDetailStr
ghstack-source-id: 124662592
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D27100497
fbshipit-source-id: fec3663ffa3e92bae8391ef4f77054abb4bb9715
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: a2b58dfab5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54509
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D27264145
fbshipit-source-id: 606948e002dcf364bb39aad49ef4f2144bbba7a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53727
This is first diff to add native support for segment reduction in PyTorch. It provides similar functionality like torch.scatter or "numpy.ufunc.reduceat".
This diff mainly focuses on API layer to make sure future improvements will not cause backward compatibility issues. Once API is settled, here are next steps I am planning:
- Add support for other major reduction types (e.g. min, sum) for 1D tensor
- Add Cuda support
- Backward support
- Documentation for the op
- Perf optimizations and benchmark util
- Support for multi dimensional tensors (on data and lengths) (not high priority)
- Support for 'indices' (not high priority)
Test Plan: Added unit test
Reviewed By: ngimel
Differential Revision: D26952075
fbshipit-source-id: 8040ec96def3013e7240cf675d499ee424437560
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48990
Introducing TensorImageUtils methods to prepare tensors in channelsLast MemoryFormat.
ChannlesLast is preferred for performance.
Not to introduce api breaking changes, adding additional parameter MemoryFormat which is CONTIGUOUS by default.
Testing by checking test_app that uses this call
```
gradle -p android installMnetLocalBaseDebug -PABI_FILTERS=arm64-v8a
```
Test Plan: Imported from OSS
Reviewed By: jeffxtang
Differential Revision: D27173940
Pulled By: IvanKobzarev
fbshipit-source-id: 27788082d2c8b190323eadcf18de25d2c3b5e1f1
Summary:
Since `_test1`, `_test2` and `_build` and `test` are all stripped, `slow_test` should be stripped as well. This way, the _slow_test stats will be considered as a part of all stats relating to a particular build job, though currently, it doesn't do much because the jobs don't share a common stemmed name--the build has `_gcc7` while the slow_test CI job does not.
This makes me think...do we omit the `gcc7` intentionally? Are there other things I should strip, e.g., `multigpu_test`?
See:
ci/circleci: pytorch_linux_xenial_cuda10_2_cudnn7_py3_slow_test
ci/circleci: pytorch_linux_xenial_cuda10_2_cudnn7_py3_gcc7_test1
ci/circleci: pytorch_linux_xenial_cuda10_2_cudnn7_py3_gcc7_test2
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54528
Reviewed By: samestep
Differential Revision: D27270393
Pulled By: janeyx99
fbshipit-source-id: ffb7289cfe4dba52ded67f50a89f3e75e7bad68d
Summary:
Allows extensions to override ROCm gfx arch targets. Reuses the same env var used during cmake build for consistency.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54341
Reviewed By: bdhirsh
Differential Revision: D27244010
Pulled By: heitorschueroff
fbshipit-source-id: 279e1a41ee395a0596aa7f696b6e908cf7f5bb83
Summary:
This is something which I wrote because it was useful during my debugging sessions, but I think it might be generally useful to other people as well so I took the liberty of proposing an official `pytorch-gdb` extension.
`pytorch-gdb` is a gdb script written in python. Currently, it contains only one command: `torch-tensor-repr`, which prints a human-readable repr of an `at::Tensor` object. Example:
```
Breakpoint 1, at::native::neg (self=...) at [...]/pytorch/aten/src/ATen/native/UnaryOps.cpp:520
520 Tensor neg(const Tensor& self) { return unary_op_impl(self, at::neg_out); }
(gdb) # the default repr of 'self' is not very useful
(gdb) p self
$1 = (const at::Tensor &) 0x7ffff72ed780: {impl_ = {target_ = 0x5555559df6e0}}
(gdb) torch-tensor-repr self
Python-level repr of self:
tensor([1., 2., 3., 4.], dtype=torch.float64)
```
The idea is that by having an official place where to put these things, `pytorch-gdb` will slowly grow other useful features and make the pytorch debugging experience nicer and faster.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54339
Reviewed By: bdhirsh
Differential Revision: D27253674
Pulled By: ezyang
fbshipit-source-id: dba219e126cc2fe66b2d26740f3a8e3b886e56f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54441
Similar to previous dropout one
ghstack-source-id: 124544176
Test Plan: Printed graphs before and after fusion. verified input outputs stayed the same {P299343882}
Reviewed By: kimishpatel
Differential Revision: D27014352
fbshipit-source-id: d0a9548f8743472bdd7e194efd8e8d5fe53b95b6
Summary: Add ability to reset optimizer counter..
Test Plan: will wait for integration tests to run on diff.
Differential Revision: D27248286
fbshipit-source-id: a608df1bd61b64eb317c9ffd9cfdd804c5288f6d
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 8998e6f1d7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54486
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D27255655
fbshipit-source-id: 5315687d4121c5ff2628ba7f134c1a5134369ed2
Summary:
1. Enabled `BFloat16` support for `argmax` & `argmin` on both CPU & CUDA
2. Added `OpInfo`s for `argmax` & `argmin`
3. Enabled `test_argminmax_multiple` for `float16`. It can't be enabled for `bfloat16`, as comparison is done with numpy, which doesn't currently support `bfloat16`.
4. Enabled `test_dim_arg_reduction_scalar` for `float16` & `bfloat16`.
5. Enabled `test_reduction_vectorize_along_output` for `bfloat16`.
6. Enabled `test_reduction_vectorize_along_input_corner` for `bfloat16`.
7. Enabled `test_dim_reduction` for both `float16` and `bfloat16`, except that both of them don't support `prod` on CPU.
8. Unskipped `TestCommonCPU.test_variant_consistency_jit` for dtype `bfloat16` for `amax` & `amin`, as they're passing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52582
Reviewed By: anjali411
Differential Revision: D27204704
Pulled By: heitorschueroff
fbshipit-source-id: cdad5df494d070f8e1a8fb83939441a91124b4d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54416
Once D27230990 lands, we'll need this for TensorPipe to be built with Bazel.
ghstack-source-id: 124512701
Test Plan: None for now.
Reviewed By: beauby
Differential Revision: D27231000
fbshipit-source-id: 474cc1b23118703ecb47ed4b8e0c5b000572eae8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54436
An operator entry with no dispatch table implicitly generates a Math
entry, so you don't need to define one yourself. I also added
some asserts in the codegen to fail on these cases.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27235381
Pulled By: ezyang
fbshipit-source-id: f8c905090b863120f4f3656c37e2b7f26e8bb9ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54427
A StructuredNativeFunctions is no longer guaranteed to actually
be structured (test structured property for that), so we rename
this to a more neutral name.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27235380
Pulled By: ezyang
fbshipit-source-id: 2b438d615bf06a47fc9c7bf6eb66fd8b4df31bc8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54426
Previously, we only put NativeFunctions in StructuredNativeFunctions
if the out variant advertised that the kernel was structured. However,
there are a few code generation things that can take advantage of
this trio structure, even if the kernel itself hasn't been ported
to be structured. So better to always group things when they are
related, and then let clients decide whether or not to use the
structure or throw it away.
While doing this, I had hoped that there weren't any functional/inplace
pairs that didn't also have an out variant. This turned out to not
be true. These are probably all oversights and should get fixed at
some point.
Bill of changes:
- The actual operational change happens in
StructuredNativeFunctions.from_dict; then I need to relax some
__post_init__ invariants. To tell if a StructuredNativeFunctions
is actually structured, there is a new structured property, which
is queried from a few new locations in code
- Refactor native_functions.py into gen_structured/gen_unstructured
functions so I can easily call gen_unstructured from two contexts
I intend to s/StructuredNativeFunctions/NativeFunctionsGroup/ but
for ease of review this rename hasn't been done in this PR.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27235379
Pulled By: ezyang
fbshipit-source-id: d8a15de9abb75b365348ab94e67b830704e30cf0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54419
I'm planning to break it into some helper functions, so let's put it in its own module first.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27235378
Pulled By: ezyang
fbshipit-source-id: c03c5440d2d753859e2c5ec2b2c8b1b82870f03a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54397
I was supposed to have done this in https://github.com/pytorch/pytorch/pull/54079
but apparently I forgot to push these changes before landing, so here's
the clean up.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D27235382
Pulled By: ezyang
fbshipit-source-id: ffcce5abc78251c81c230992bac70b8973906ace
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54467
`at::native::copy_` requires src/dest to have the same sizes, which isn't true in reshape.
Test Plan: Added new test cases to cover this case.
Reviewed By: ajyu
Differential Revision: D27249617
fbshipit-source-id: 2c95175fa8564b3c648979445ad4314f97818852
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53908
This adds reinplacing to MKLDNN Subgraphs so that we replace `aten::add` with `aten::add_`. Normally you would have to prove device and dtype, but we know that already, and because we have explicit broadcast nodes for other reasons we dont have to prove that the output shape of add is the same as inputs.
Ive tested correctness on resnet, I'm going to do more extensive testing as well. When I benchmarked the "unsafe" version (always inplace) I saw average speedups of ~16% for both Single threaded and Multithreaded. I dont think the "safe" version will be far beyond; when I looked at resnet for example every `add` and `relu` were reinplaced.
Theres some question of reusing other alias / liveness / inplacing passes in SR. I thought about it, however I didnt want to add a cross-dependency between very different parts of the code base with a bunch of different assumptions. The logic here is also covering a simpler case and does not add much complexity IMO.
Test Plan: Imported from OSS
Reviewed By: Krovatkin
Differential Revision: D27132969
Pulled By: eellison
fbshipit-source-id: 121a38daaedf01363f6b66a814beaaa72a0ab0dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52614
This can speed up models by 5% (~.5-1% from the base, but ~5% after they've been sped up with mkldnn).
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26696693
Pulled By: eellison
fbshipit-source-id: bfed55242524a4c2f1ae5d63e76d6803016d986d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54110
dictConstruct doesn't need to make its caller have a `shared_ptr<DictType>`. It also doesn't need to do extra `shared_ptr` copies into the `key_type` and `value_type` locals.
ghstack-source-id: 124150642
Test Plan: fitsships
Reviewed By: ezyang
Differential Revision: D27101782
fbshipit-source-id: 3c632ad9d8f1bd7bdf37f517a86aca27bd41548a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54124
No need to have an extra temporary intrusive_ptr (`p`) just to do an `incref`.
ghstack-source-id: 124150644
Test Plan:
existing tests for correctness; inspect assembly for
c10::IValue::toObject to double-check & see that it's a bit shorter
Reviewed By: smessmer
Differential Revision: D27109183
fbshipit-source-id: 497706190867eeac0fb1d309d0ecc97cf8d65b08
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: ffff7a3118
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54447
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D27242112
fbshipit-source-id: 768b1a40652b6c2f0710bd4bb655697daf45f756
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54432
Following the merge of channel hierarchies, here comes the promised
clean up.
Test Plan: CI
Reviewed By: lw
Differential Revision: D27232442
fbshipit-source-id: 540dc6bc18a9a415b676e06e75530d729daf2d5b
Summary:
fix Semmle warning: Comparison of narrow type with wide type in loop condition
For example there is below piece of code:
for (int i=0; i<array.size(); ++i) {}
The problem is that array.size() return type is size_t can be larger type than int depending on the implementation so there is chance that i overflows (for very large array that array size is beyond the range of integer) and this loop will never be terminated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53951
Reviewed By: zou3519
Differential Revision: D27181495
Pulled By: malfet
fbshipit-source-id: 0612c5cedcdc656c193085e7fbb87dd163f20688
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54262
register_dispatch_key.py might generate device_of call over
optional<Tensor> if it happened to be the first Tensor-like
argument.
ghstack-source-id: 124535550
Test Plan: Test together with next diff in stack
Reviewed By: ezyang
Differential Revision: D27164093
fbshipit-source-id: 3b0400d5d603338e884218498106f6481e53f194
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54428
Using c10::ArrayRef as the parameter type makes the API more flexible and allows the caller to leverage small-buffer optimizations (e.g. c10::SmallVector, std::array) for performance critical cases.
Test Plan: No behavioral changes. Run the existing unit and integration tests.
Reviewed By: suo
Differential Revision: D27232222
fbshipit-source-id: 7b13bc6bd02257097ca119077028fbccc68cc925
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54004
According to
`glean-search find-decls --refs 'c10::TensorOptions::key_set'`
there are no uses of this function
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D27047971
Pulled By: ezyang
fbshipit-source-id: 63662dd7ab27753ecb79c45c152c2cad1160dab2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53846
Theres already a varient of removeDropout that takes in a graph. So just switch to calling that one. It doesnt error check that the module isnt in training mode (because it doenst have a module) but optimize_for_mobile guarantees the cloned_module is in eval mode.
ghstack-source-id: 124544216
Test Plan: called optimize on forward and foo, both contained dropouts, both dropouts removed. Called both functions afterwords to verify they ran and gave the same output. {P308987364}
Reviewed By: kimishpatel
Differential Revision: D26986251
fbshipit-source-id: 085e08cbaa982aa08803a718fee4380af5f86b78
Summary:
warn if uncommit changes exists in .circleci/config.yml, unlike other generated code, .circleci/config.yml actually commits to the repo. (this is a follow up of https://github.com/pytorch/pytorch/issues/54345)
two options I am open to
1. abort regenerate if detected
2. print out backed up temp filename
Also remove the `-x` since it is currently very verbose
```
++ dirname .circleci/regenerate.sh
+ cd .circleci
++ mktemp
+ OLD_FILE=/var/folders/vw/ryb6j4d97xs1t_14024b710h0000gn/T/tmp.54GhUh7w
+ cp config.yml /var/folders/vw/ryb6j4d97xs1t_14024b710h0000gn/T/tmp.54GhUh7w
++ mktemp
+ NEW_FILE=/var/folders/vw/ryb6j4d97xs1t_14024b710h0000gn/T/tmp.aV87RTvQ
+ ./generate_config_yml.py
+ cp /var/folders/vw/ryb6j4d97xs1t_14024b710h0000gn/T/tmp.aV87RTvQ config.yml
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54373
Test Plan:
1.
```
$ echo "418 I'm a teapot" > .circleci/config.yml
$ .circleci/regenerate.sh
$ .circleci/regenerate.sh
```
Result:
```
$ .circleci/regenerate.sh
Uncommitted change detected in .circleci/config.yml
It has been backed up to /var/folders/89/brnr1wt970130lk0m52605mw0000gn/T/tmp.2VOp4BPo
New config generated in .circleci/config.yml
$ .circleci/regenerate.sh #-- second time there's no uncommitted changes
New config generated in .circleci/config.yml
```
2.
```
$ echo "418 I'm a teapot" > .circleci/config.yml
$ git add .circleci/config.yml
$ .circleci/regenerate.sh
$ .circleci/regenerate.sh
```
Result:
```
$ .circleci/regenerate.sh
Uncommitted change detected in .circleci/config.yml
It has been backed up to /var/folders/89/brnr1wt970130lk0m52605mw0000gn/T/tmp.2VOp4BPo
New config generated in .circleci/config.yml
$ .circleci/regenerate.sh #-- second time there's still uncommitted changes b/c git split staged vs unstaged changes
Uncommitted change detected in .circleci/config.yml
It has been backed up to /var/folders/89/brnr1wt970130lk0m52605mw0000gn/T/tmp.2ruMAynI
New config generated in .circleci/config.yml
```
Reviewed By: samestep
Differential Revision: D27234394
Pulled By: walterddr
fbshipit-source-id: 6364cc1f6f71a43424a63ca6fce9d2ba69437741
Summary:
Instructions for compiling PyTorch from source for ROCm were missing now that PyTorch 1.8 announced beta support for ROCm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53845
Reviewed By: heitorschueroff
Differential Revision: D27237916
Pulled By: malfet
fbshipit-source-id: c8be92fd76ea8df7e9f6944c0036568189f58808
Summary:
since we no longer support cuda9.2 disabling scheduled ci for those
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54421
Reviewed By: janeyx99
Differential Revision: D27234293
Pulled By: walterddr
fbshipit-source-id: 923e32c0229ea861bce6ff473501892bd4e5bec1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52917
Original commit changeset: f6ceef606994
Test Plan:
FB:
This was an attempt to fix ig crashes but we root caused it to pthreadpool changes. Thus this is not needed anymore.
Reviewed By: AshkanAliabadi
Differential Revision: D26485737
fbshipit-source-id: 5d689231cccd11d911b571f8486a19d646352698
Summary: more context in T86752810. Add info for tensor lengths size to see if it fails on in complete batch
Test Plan: manually created failed run: f258719092
Reviewed By: aartibasant
Differential Revision: D27181049
fbshipit-source-id: 341c020a3430c410f9726d92315efb80d36e9452
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54074
I don't see why this shouldn't work.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D27086594
Pulled By: ezyang
fbshipit-source-id: 1d5f1997017ec48c4140f43e44f0d8a3df28ac7f
Summary:
This PR:
- Updates the structure of the SampleInput class to require the "input" attribute be a tensor
- Limits unary ufuncs to test only the uint8, long, float16, bfloat16, float and cfloat dtypes by default
- Limits variant testing to the float dtype
- Removes test_variant_consistency from test_unary_ufuncs.py since it's now redundant with variant testing in test_ops.py
- Adds backwards supported testing to clarify failures that were coming from variant testing
This should decrease test e2e time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53255
Reviewed By: ngimel
Differential Revision: D27043643
Pulled By: mruberry
fbshipit-source-id: 91d6b483ad6e2cd1b9ade939d42082980ae14217
Summary:
As of ROCm version 4.0.1, the HIP compiler default for max threads per block is 256 but is subject to change in future releases. To protect against changes, hipMAGMA should be built with the previously-assumed default. This change is necessary here in PyTorch until upstream magma project utilizes `__launch_bounds__` or some other means of controlling launch bounds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54161
Reviewed By: zou3519
Differential Revision: D27194829
Pulled By: malfet
fbshipit-source-id: 8be2cff3b38786526954b627ff6ab02b510040a1
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 88ba128b7c
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54118
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: ejguan
Differential Revision: D27105781
fbshipit-source-id: 3f71299dcee11459efa3a14c051afc031a99ecea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54333
Pull Request resolved: https://github.com/pytorch/tensorpipe/pull/326
Pull Request resolved: https://github.com/pytorch/tensorpipe/pull/312
This is a first step towards cross-device type transfers: eventually,
channels will not connect devices of a given type between two hosts,
but possibly heterogeneous pairs of devices. Hence, the distinction
between CPU-to-CPU and GPU-to-GPU channels will not make much sense
anymore, and we can afford to simplify the Pipe's code quite bit.
The main change here is that the `channel::Channel` and
`channel::Context` classes are not templated (on the buffer type)
anymore. Instead, a channel's `send`/`recv` methods act on generic
`Buffer`s and the actual unpacking is done in the
`ChannelBoilerplate`. The
`channel::CpuContext`/`channel::CudaContext` (respectively
`channel::CudaContext`/`channel::CudaChannel`) aliases now simply
resolve to `channel::Context` (respectively `channel::Channel`). A
subsequent diff will get rid of the aliases altogether.
The Pipe is being simplified: all the duplication due to having
separate hierarchies is gone, which gets rid of a lot of boiler plate
template code. Note that previously, two channels with the same name
could potentially coexist, provided one was a CPU channel and the
other a GPU channel. This is not the case anymore, though it should
not matter.
In its current state, the Pipe still needs to pick a channel based on
whether that channel acts on CPU or GPU buffers. This is solved by
introducing the temporary method
`bool channel::Context::supportsDeviceType(DeviceType t)`. When
iterating through available channels to select one for a given tensor,
the Pipe now discards channels that do not support the tensor's
`DeviceType`. This leads to having a single ordered list of channels,
which in practice is two separate lists (one for CPU, one for GPU)
merged together. This will change soon as we initialize only one
channel per `DeviceType`.
Test Plan: Imported from OSS
Reviewed By: lw
Differential Revision: D26958187
Pulled By: beauby
fbshipit-source-id: 3e3f7921166892d468fa78cfad3199277588021c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54353
The current implementation of reshape/flatten is problematic because whether the output is sometimes a tensor view and sometimes not. It entirely depends on the graph ir and input shapes. Replacing them with the copy version makes it deterministic and the output is always a tensor.
Reviewed By: ajyu, edvgha
Differential Revision: D26358525
fbshipit-source-id: ee7571317b061221a8d50083676cded388ce6f87
Summary:
This folder contains the DDP python interface as well as several misc. communication files.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54221
Reviewed By: agolynski
Differential Revision: D27149068
Pulled By: rohan-varma
fbshipit-source-id: 0c23ea9a0d1dfc2719a2008e182ea75f2058d7dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54286
A generated code object was holding not just a function pointer but a
pre-allocated argument buffer. I assume this was a performance optimization to
avoid allocating a vector on each call?
This cached buffer makes it unsafe to call a generated function from multiple
threads, which is too severe a limitation. This diff fixes it by locally
allocating a SmallVector to hold the args.
A better fix will be to avoid creating CallArgs, so the function can be called
directly without this packing-and-unpacking nonsense, but that's a slightly
more involved fix, possibly involving changing the kernel codegen, and this bug
needs fixing now.
ghstack-source-id: 124333028
Test Plan: `threads=64 scripts/bwasti/static_runtime/run.sh`
Reviewed By: asuhan
Differential Revision: D27175715
fbshipit-source-id: 44dafe77b95ede69c63ae6d64f39f0aa4877712f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52422
As mentioned in https://github.com/pytorch/pytorch/issues/52415,
`torch.utils.checkpoint` doesn't support checkpointing for functions which have
non-tensor inputs and outputs.
This PR resolves this issue by ensuring the autograd machinery ignores the
non-tensor inputs and outputs and processes the tensors accordingly.
ghstack-source-id: 124406867
Test Plan:
1) unit test
2) waitforbuildbot
Reviewed By: albanD
Differential Revision: D26507228
fbshipit-source-id: 0a5a1591570814176185362e83ad18dabd9c84b0
Summary:
Added the support for half / bfloat / bool for `index_select`, as suggested by ngimel in
https://github.com/pytorch/pytorch/issues/49707#issuecomment-788140578
For the tests to pass, I also added the support for `index_add`.
I added `OpInfo` tests for `index_add` and more thorough forward tests for `index_select` to test these changes.
While doing so, I found that the support for scalar types in the derivative of `index_add` was not correct, so I corrected it.
Resolves https://github.com/pytorch/pytorch/issues/49707
It should also resolve similar issues that I encountered when porting `index_copy`, `take` and `put`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53898
Reviewed By: mruberry
Differential Revision: D27193294
Pulled By: ngimel
fbshipit-source-id: 5a0af2c62a0cf24f3cc9c74f230ab4f3712bbb7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54303
**Summary**
Creating temporary files can cause problem in fbcode. This commit
updates the packaging tests so that exporters write to a memory
buffer when tests run in fbcode.
**Test Plan**
Continuous integration.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D27180839
Pulled By: SplitInfinity
fbshipit-source-id: 75689d59448de2cd1595ef0ecec69e1bbcf9a96f
Summary:
Since a.size() is (3, 4, 5), so r.size() is (3, 4, 5) , but q.size is (3, 4, 4)
Also, reduce tolerance from 1e-8 to 1e-5 as
Fixes https://github.com/pytorch/pytorch/issues/54320
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54342
Reviewed By: walterddr
Differential Revision: D27193947
Pulled By: malfet
fbshipit-source-id: 362a0fdd90550888a4f0c6deaa49b9f72d379842
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54277
alltoall already supported in nccl backend, so update the doc to reflect it.
Test Plan: Imported from OSS
Reviewed By: divchenko
Differential Revision: D27172904
Pulled By: wanchaol
fbshipit-source-id: 9afa89583d56b247b2017ea2350936053eb30827
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53680
Porting `div` to structured.
One weird thing to call out with div: It has an overload, `div.Tensor_mode`, which uses different TensorIterator settings depending on this input (the "mode" argument that you pass to it). So I ended up switching on the mode inside of the meta function to determine which TensorIterator builder to use.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D27029819
Pulled By: bdhirsh
fbshipit-source-id: 3f216f6c197a2321087b4c23202bc2fc561491ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53679
This PR ports sub to be a structured kernel.
It also fixes a bug with `sub.Scalar`. `sub.Scalar` is currently listed as a `DefaultBackend` op, but it isn't actually backend agnostic- it calls into `native::sub`, which is CPU/CUDA-specific. That can cause bugs like [this](https://github.com/pytorch/pytorch/pull/51758) for other backends like MKLDNN. `sub.Scalar` is now **really** backend-agnostic, since it performs a redispatch to call the overload.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D27029820
Pulled By: bdhirsh
fbshipit-source-id: d24b435a42f4c505bc763ea77672956f81ad3e26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53669
This PR does two things:
* Ports `pow` to be structured
* Fixes a bug with how pow handles mixed cpu and cuda tensors
**bug fix**
Pow is a binary op, and all binary ops that use TensorIterator are currently written to handle the case when one of the inputs is a CUDA tensor, and the other is a zero-dimensional cpu tensor.
`pow` incidentally only handles one of the two cases: it fails when the CUDA tensor is passed as the exponent, e.g. `at::pow(torch.tensor(2.0, device='cpu'), torch.tensor([2, 2], device='cuda'))`. Porting `pow` to structured happened to change the error that was outputted from a `TORCH_CHECK` in TensorIterator to an `INTERNAL_ASSERT` in loop.cuh, so I ended up trying to fix the error and update the tests. I added more details in a comment on the PR.
**notes on the structured port**
Pow is a little weird, so I wrote down a couple of issues I noticed during the port:
* Multiple independent overloads. `pow` has two overloads that have their own cpu/cuda kernels, meaning one doesn't call the other. I have to update the names of the kernel overloads to make the compiler happy, since the codegen would otherwise try to generate two classes with the same name. `pow` actually has 3 overloads that all have `out` variants, so I ported all 3 to structured- one of them just happens to redispatch one of the others in most cases.
* Name propagation. Is name propagation implemented per operator? Or is expected to work for most/all ops by default. Right now it looks like it happens for TensorIterator ops by default. For ops that don't use TensorIterator, we need to explicitly pass the names through to the `set_output()` call in the meta function. This happened to matter for `pow` because it has 3 overloads, but only two of them directly use TensorIterator. I had to pass names directly to `set_output` in the 3rd overload to make tests happy.
* Lack of `const Tensor &` in the C++ API. It's a goal to slowly make all `Tensor &` arguments const as part of the structured port, but in this case I needed to explicitly cast constness away because one structured kernel called back into the C++ API, which still has ordinary `Tensor &` arguments. This probably isn't something we'll fix soon, since we have boxing logic that actually relies on the `Tensor &` / `const Tensor &` distinction in some places.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D27029821
Pulled By: bdhirsh
fbshipit-source-id: c1786e770de6e6c2474b9a48210b88057ab1018e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54274
Some of the Python tests need to be aware of whether or not FBGEMM is
available, so expose this setting in the pybind extension.
ghstack-source-id: 124317732
Test Plan: Will use this variable in the tests on D26658205.
Reviewed By: mraway
Differential Revision: D27171780
fbshipit-source-id: 4c94144a959bf8bf0e1553b6e029e94a91794e29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54229
Because caffe2 add uses Eigen for add with broadcasting which is not well supported by OSS PyTorch, it's easier to just keep the `c2_add_out` internal for now. Caffe2 does use mkl add when the input dims of A and B are the same and there is no broadcasting needed.
Reviewed By: bertmaher
Differential Revision: D27036279
fbshipit-source-id: 49f0ec5407ea1f641896f054cad2283faed81687
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52692
Porting `at::mul` to structured.
One other issue I hit with the port was the fact that there are a bunch of other places around the code base that used to call out to variants of `at::native::mul`, which no longer exists. *Technically*, `at::cpu::mul` does the equivalent thing now, so I patched most call-sites to use that. There were two other places where I did something slightly different (calling `at::cuda::mul` and `at::mul`, respectively), which I called out in the comments.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D27029822
Pulled By: bdhirsh
fbshipit-source-id: 6cc80de0dfccec304bf8e16a1823e733bed27bf4
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53511
torch.det does depend on torch.prod, which in turn depends on several other functions, and they also depend on torch.prod, so there is a circular relationship, hence this PR will enable complex backward support for several functions at once.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48125
Reviewed By: pbelevich
Differential Revision: D27188589
Pulled By: anjali411
fbshipit-source-id: bbb80f8ecb83a0c3bea2b917627d3cd3b84eb09a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54127
During the meta tensor bringup, I found all of these operators
advertised that they worked on all backends (DefaultBackend/Math)
but actually they only worked on CPU/CUDA.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D27109508
Pulled By: ezyang
fbshipit-source-id: 0f474ecf4aba8b8207f2910bdc962bf581f53853
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54079
Fixes https://github.com/pytorch/pytorch/issues/53815
Instead of testing if something is CUDA, we instead test if something
is not CPU. This in the general theming of "Don't be so darn CUDA
centric".
Intruigingly, we didn't have a is_cpu() method on Tensor. Which seems
like a big oversight and one of the reasons how we ended up in this
mess. So in it goes. Maybe we should also get this for Python bindings
as well (but in that case, should probably look into redoing all of the
is_X bindings so they aren't done manually).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D27109507
Pulled By: ezyang
fbshipit-source-id: abbe72c2e688c452ffe098d206cb79938b5824b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54034Fixes#53544
I had to touch a bunch of lines but the refactoring was fairly
mechanical. Here's how it works.
The basic concept behind this PR is that tensor_new.cpp was previously
abusing DispatchKey when it actually meant TensorOptions. The provided
DispatchKey argument to most of the constructor functions typically
comes from torch::tensors::get_default_dispatch_key(); it doesn't
really make sense for people to set the default dispatch key, but
this got grandfathered in due to the old API set_default_tensor_type
(where the "Type" concept got refactored into "DispatchKey" concept
over time). See also #53124. But the upshot is that, semantically,
what we refer to as the default dispatch key really is more like
torch.set_default_tensor_type(torch.Tensor) versus
torch.set_default_tensor_type(torch.cuda.Tensor): clearly the user
wants to do something about *construction* of the tensor, and
TensorOptions captures that exactly.
So, how exactly to translate from one to the other?
- Sources (things that used to PRODUCE DispatchKey)
- Most top level functions take a DispatchKey as their argument. I
use the new function dispatchKeyToTensorOptions to convert it into
a TensorOptions
- typeIdWithDefault now produces a TensorOptions (probably could do
with a rename, though I didn't)
- Sinks (things that used to CONSUME DispatchKey)
- Previously, the function options() was typically used to convert the
DispatchKey into a TensorOptions. Now its replacement build_options
just takes a TensorOptions and sets some extra fields on it.
Irritatingly, I can't just replace
`build_options(options, scalar_type, device)` with
`options.dtype(scalar_type).device(device)` because the semantics
are slightly different: if device is nullopt, we should preserve
the usage of the device specified in options (what options.device()
does is overwrite the device unconditionally; e.g., if device is
nullopt, unset device from options)
- The other major sink for DispatchKey was `internal_new_from_data`,
but it turns out it only really extracts the device type from
the dispatch key. Now it just pulls out the device from
TensorOptions.
- To actually do the translation of DispatchKey to TensorOptions, I
introduce new functions dispatchKeyToLayout (replicating
layout_from_backend--there are still a few uses of this function
so I couldn't delete it) and dispatchKeyToDeviceType (replacing
computeDeviceType)
- In all internal functions, whenever DispatchKey is taken as an argument,
I instead take TensorOptions as an argument, and pass it along.
- Anywhere `legacyExtractDispatchKey(other.key_set())` equality was
previously used, I now do `other.options().type_equal()`, which
is the intended BC for doing "backend to backend" comparisons
- There are a few places in the sparse constructors where we allocated
a tensor for values, and then read out the dispatch key from the
result to allocate the keys. As best as I can tell, this is totally
equivalent to just passing in the options to both values and indices
(the only difference is dtype, which is captured via a separate
argument)
This refactor doesn't really go far enough: for example, there are now
functions that take both TensorOptions and ScalarType, when really
the TensorOptions can capture this all. I kept it solely just
s/DispatchKey/TensorOptions/ to reduce the number of possible bugs;
also, a lot of this will be mooted by a proper fix to #53124.
Even with this limited refactor, the payoff is sweet. I can delete:
- backendToCPU
- backendToXPU
- backendToCUDA
- backendToHIP
- backendToBackendOfDeviceType
The reason I can do this is because I can simply overwrite layout in TensorOptions
to do the conversion, rather than having to type out each backend case
explicitly.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D27109509
Pulled By: ezyang
fbshipit-source-id: 91d16cfbc390127770362ac04fb43f7e070077e9
Summary:
Small changes to autograd to support optional Tensor values.
On MLC device, we use Autograd Custom Functions to override the autograd engine for a specific operation. We do something like:
```
at::Tensor AtenMLCAutogradTypeDefault::abs(const at::Tensor & self) {
torch_mlc::mlclogger() << "MLC bridge autograd MLC : abs" << std::endl;
torch_mlc::AutoNonAtenMLCAutogradTypeDefault guard(true);
return MLCAbsFunction::apply(self);
}
TORCH_LIBRARY_IMPL(aten, AutogradMLC, m) {
m.impl("abs", static_cast<at::Tensor (*)(const at::Tensor &)>(&AtenMLCAutogradTypeDefault::abs));
}
```
What I noticed is that the existing code does not always work for optional Tensor types. This PR fixes it. Let me know if you have a better way to deal with this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54270
Reviewed By: ejguan
Differential Revision: D27171623
Pulled By: albanD
fbshipit-source-id: 3aa8d59ee8da3cc943ad5e73521c2755d1ff2341
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54251
Pull Request resolved: https://github.com/pytorch/tensorpipe/pull/324
In order to merge the channel hierarchies, we need a generic `Buffer` type, that can wrap either a `CpuBuffer` or a `CudaBuffer`.
The constraints are that, since this type is used by the channels, it cannot explicitly refer to `CudaBuffer`. We propose here a type-erasure based solution, with small-buffer optimization to avoid heap-allocating the wrapped concrete buffer.
This is a new version of D27001339 (c618dc13d2) which broke PyTorch OSS build.
Test Plan: CI
Reviewed By: lw, mrshenli
Differential Revision: D27156053
fbshipit-source-id: 4244302af33a3be91dcd06093c0d6045d081d3cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54230
The comments in the code explained why this change is needed.
Reviewed By: bwasti
Differential Revision: D27145406
fbshipit-source-id: 2a61a42f22dfadfad59ee6c3be3e9e9d19e90ac3
Summary:
This is a follow-up PR of https://github.com/pytorch/pytorch/issues/52408 and move/convert all files under `test/type_hint_tests/*.py` to use the new test style.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53167
Reviewed By: ejguan
Differential Revision: D27081041
Pulled By: walterddr
fbshipit-source-id: 56508083800a5e12a7af88d095ca26229f0df358
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45667
First part of #3867 (Pooling operators still to do)
This adds a `padding='same'` mode to the interface of `conv{n}d`and `nn.Conv{n}d`. This should match the behaviour of `tensorflow`. I couldn't find it explicitly documented but through experimentation I found `tensorflow` returns the shape `ceil(len/stride)` and always adds any extra asymmetric padding onto the right side of the input.
Since the `native_functions.yaml` schema doesn't seem to support strings or enums, I've moved the function interface into python and it now dispatches between the numerically padded `conv{n}d` and the `_conv{n}d_same` variant. Underscores because I couldn't see any way to avoid exporting a function into the `torch` namespace.
A note on asymmetric padding. The total padding required can be odd if both the kernel-length is even and the dilation is odd. mkldnn has native support for asymmetric padding, so there is no overhead there, but for other backends I resort to padding the input tensor by 1 on the right hand side to make the remaining padding symmetrical. In these cases, I use `TORCH_WARN_ONCE` to notify the user of the performance implications.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D27170744
Pulled By: jbschlosser
fbshipit-source-id: b3d8a0380e0787ae781f2e5d8ee365a7bfd49f22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53929
The local autograd engine performs appropriate stream synchronization
between autograd nodes in the graph to ensure a consumer's stream is
synchronized with the producer's stream before executing the consumer.
However in case of distributed autograd, the SendRpcBackward function receives
gradients over the wire and TensorPipe uses its own pool of streams for this
purpose. As a result, the tensors are received on TensorPipe's stream pool but
SendRpcBackward runs on a different stream during the backward pass and there
is no logic to synchronize these streams.
To fix this, I've enhanced DistEngine to synchronize these streams
appropriately when it receives grads over the wire.
ghstack-source-id: 124055277
(Note: this ignores all push blocking failures!)
Test Plan:
1) Added unit test which reproduced the issue.
2) waitforbuildbot.
Reviewed By: walterddr, wanchaol
Differential Revision: D27025307
fbshipit-source-id: 2944854e688e001cb3989d2741727b30d9278414
Summary:
Since both these files were deleted back in time, we shouldn't be running them anymore, as this was the old sharding strategy (see https://github.com/pytorch/pytorch/issues/50660).
```
test_python_nn.bat
test_python_all_except_nn.bat
```
I believe we intend to run all the python files, so I added a call for that instead.
Note: I don't believe there is a single unsharded test build, though, so should I instead just assume that all windows tests will be sharded?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54276
Reviewed By: ejguan
Differential Revision: D27173045
Pulled By: janeyx99
fbshipit-source-id: a7562c1479e18bd63f192f02129a42911a73a70b
Summary:
This PR
- moves `torch/testing/_internal/mypy_wrapper.py` (and its accompanying tests from `test/test_testing.py`) to `tools`,
- removes the now-unused `test_run_mypy` from `test/test_type_hints.py`, and
- replaces the hardcoded list of `mypy` configs (previously duplicated across `mypy_wrapper.py` and `.github/workflows/lint.yml`) with a simpler glob
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54268
Test Plan:
Should also be run in the "Test tools" GHA workflow in CI:
```
python tools/test/test_mypy_wrapper.py
```
Reviewed By: janeyx99
Differential Revision: D27168095
Pulled By: samestep
fbshipit-source-id: a8dc18407b5e4c103ace23a636b0a8534951905a
Summary:
https://ccache.dev/ is a compiler cache that speeds up subsequent builds. Auto-detecting ccache ensures that it is used on systems where it is available, greatly improving build times for developers. There is no risk in enabling ccache in practice. Please refer to https://ccache.dev/ for a short summary / motivation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49389
Reviewed By: ejguan
Differential Revision: D27169957
Pulled By: malfet
fbshipit-source-id: 673b60bbceb0d323901c8a992a75792c6da9b805
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/54259
Test Plan:
The main point of this is to be run in our "Test tools" GitHub Actions workflow. To test locally:
```
mypy --config=mypy-strict.ini
python tools/test/test_test_history.py
```
Reviewed By: seemethere
Differential Revision: D27164519
Pulled By: samestep
fbshipit-source-id: 46f90e62e2d4d0c413b202419e509d471bad43de
Summary:
Step 2 to fixing https://github.com/pytorch/pytorch/issues/53882 :)
This changes TARGET_DET_LIST and sharding automation by checking if there's already cached data from the commit in `.pytorch-test-times`. If not, it pulls data from S3 and updates the file to have the stats. This way, S3 pulling does not need to happen more than once for the same commit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54210
Test Plan:
the following methods should run the same set of tests.
First `export CIRCLE_JOB=pytorch_linux_xenial_cuda10_2_cudnn7_py3_gcc7_test2` or your favorite CIRCLE JOB.
1. Pull data first and use it:
Download the data from S3 and write it to the cache file with `python test/run_test.py --export-historic-test-times .pytorch-test-times`
Now run `python test/run_test.py --shard 1 10`
2. Make the sharding job pull data:
Delete the file you just created: `rm .pytorch-test-times`
Now run `python test/run_test.py --shard 1 10`
Reviewed By: walterddr
Differential Revision: D27136849
Pulled By: janeyx99
fbshipit-source-id: 51a42c4e2fa3f8cf15e682679dd3eb6130aad927
Summary:
The size of the workspace arrays should not be less than 1. This PR fixes lstsq calls to LAPACK and MAGMA. Also `max(1, ...)` guards were added to a few other functions (symeig, svd).
ROCm testing is enabled for lstsq, pinv, pinverse.
Fixes https://github.com/pytorch/pytorch/issues/53976
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54009
Reviewed By: ejguan
Differential Revision: D27155845
Pulled By: mruberry
fbshipit-source-id: 04439bfa82a5bdbe2297a6d62b6e68ba1c30e4a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54103
The goal is to reduce the spread of static casts in the autograd code as per the comment in https://github.com/pytorch/pytorch/pull/49097#discussion_r543695091
I wasn't sure how to use a virtual method here but a simple method in impl clean it up quite nicely.
Test Plan: Imported from OSS
Reviewed By: agolynski
Differential Revision: D27117840
Pulled By: albanD
fbshipit-source-id: 5f277dde34ccf6bc20f76583b906ff3528cde5aa
Summary:
Also disable test_run_mypy from test_type_hints.py as it is running as part of GHA
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54067
Reviewed By: ezyang
Differential Revision: D27091530
Pulled By: malfet
fbshipit-source-id: 9cfe397260aba34aeb055676855db383cd06f76d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53864
This PR adds the following APIs that perform loop distribution to `LoopNest`:
```
static std::vector<For*> distributeLoop(For* loop, const std::unordered_set<Stmt*>& pivots);
static std::vector<For*> distributeLoop(For* loop);
static std::vector<For*> distributeLoopOverInnerLoops(For* loop);
```
* The first method distributes the given loop over its body by splitting after every given pivot stmt.
* The second method distributes the given loop over every stmt in its body.
* The last method distributes the given loop over its body by splitting after every `For` stmt in its body.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53865
Reviewed By: mruberry
Differential Revision: D27075006
Pulled By: navahgar
fbshipit-source-id: 031746aad619fe84c109e78b53387535e7f77cef
Summary:
This PR adds autograd support for `torch.orgqr`.
Since `torch.orgqr` is one of few functions that expose LAPACK's naming and all other linear algebra routines were renamed a long time ago, I also added a new function with a new name and `torch.orgqr` now is an alias for it.
The new proposed name is `householder_product`. For a matrix `input` and a vector `tau` LAPACK's orgqr operation takes columns of `input` (called Householder vectors or elementary reflectors) scalars of `tau` that together represent Householder matrices and then the product of these matrices is computed. See https://www.netlib.org/lapack/lug/node128.html.
Other linear algebra libraries that I'm aware of do not expose this LAPACK function, so there is some freedom in naming it. It is usually used internally only for QR decomposition, but can be useful for deep learning tasks now when it supports differentiation.
Resolves https://github.com/pytorch/pytorch/issues/50104
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52637
Reviewed By: agolynski
Differential Revision: D27114246
Pulled By: mruberry
fbshipit-source-id: 9ab51efe52aec7c137aa018c7bd486297e4111ce
Summary:
This PR adds cusolver potrf and potrfBatched to the backend of torch.cholesky and torch.linalg.cholesky.
Cholesky heuristics:
- Use cusolver potrf for batch_size 1
- Use magma_xpotrf_batched for batch_size >= 2
- if magma is not available, use loop of cusolver potrf for batch_size >= 2
cusolver potrf batched currently has some nan output issue, we will switch to cusolver potrf batched after it's fixed
See also https://github.com/pytorch/pytorch/issues/42666#47953
Todo:
- [x] benchmark and heuristic
Close https://github.com/pytorch/pytorch/pull/53992
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53104
Reviewed By: agolynski
Differential Revision: D27113963
Pulled By: mruberry
fbshipit-source-id: 1429f63891cfc6176f9d8fdeb5c3b0617d750803
Summary:
Pull Request resolved: https://github.com/pytorch/tensorpipe/pull/322
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54145
In order to merge the channel hierarchies, we need a generic `Buffer` type, that can wrap either a `CpuBuffer` or a `CudaBuffer`.
The constraints are that, since this type is used by the channels, it cannot explicitly refer to `CudaBuffer`. We propose here a type-erasure based solution, with small-buffer optimization to avoid heap-allocating the wrapped concrete buffer.
ghstack-source-id: 124131499
Test Plan: CI
Reviewed By: lw
Differential Revision: D27001339
fbshipit-source-id: 26d7dc19d69d7e3336df6fd4ff6ec118dc17c5b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53663
This add the processgroup option as an optional argument to new_group
and init_processgroup, this allows user to pass in a initialized
processgroup option for gloo and nccl.
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D26968857
Pulled By: wanchaol
fbshipit-source-id: 2ff73a009120b85e83ecde7c69956b731902abc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54208
It seems like it was added to suppress some errors in LazyModules, but I think we should solve those more directly with some type ignores in more surgical places.
Fixes#54087.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27137363
Pulled By: ezyang
fbshipit-source-id: 017cafcc3350e73cd62436078835b97cd9b3b929
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53920
Fusing SigridTransforms + ListUnpack allows for enabling out variant for SigridTransforms so that the output tensors can be managed by the MemoryPlanner in Static Runtime.
The speedup comes from three parts 1) get rid of memory allocation inside SigridTransforms itself, 2) memory deallocation cost (outside SigridTransforms, inside MemoryPlanner), 3) get rid of ListUnpack. However, in 3) we still need to pay the cost of constructing `vector<Tensor>` for outputs and a round of refcount bumps for all the output TensorImpls.
Reviewed By: ajyu
Differential Revision: D26220546
fbshipit-source-id: 651bdfb850225511c43b8f50083b13e8dec46bcc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54159
See https://github.com/pytorch/pytorch/issues/54059 for discussion.
In short, users might want to run evaluation on a single rank
in `torch.no_grad()` mode. When this happens, we need to make
sure that we skip all rebuild bucket logics, as the forward only
runs on one rank and not all peers can sure the bucket configuration
sync communication.
Test Plan: Imported from OSS
Reviewed By: zhaojuanmao
Differential Revision: D27119666
Pulled By: mrshenli
fbshipit-source-id: 4b2f8cce937cdd893e89d8d10c9267d255ba52ea
Summary:
This PR enable some failing unit tests for fft in pytorch on ROCM.
The reason these tests were failing was due to an error in how hipfft was executed for different transform types for float inputs causing a mismatch error when compared to baselines.
We solved the problem by calling hipfft with the right config for each transformation type.
There PR doesnot enable all fft tests. There are still other issues that need to be resolved before that can happen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53411
Reviewed By: albanD
Differential Revision: D27008323
Pulled By: mruberry
fbshipit-source-id: 649c65d0f12a889a426ec475f7d8fcc6f1d81bd3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54090
This PR adds an options field to both ProcessGroupGloo/NCCL so that we
have a constant `options` field even after the initialization of
ProcessGroup, which gives us the ability to inspect the options during
construction of specific ProcessGroup. Also use options inside different
methods instead of separate fields.
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D27093670
Pulled By: wanchaol
fbshipit-source-id: b02d9394290e9be88b21bddb94d4de7993b4a2e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53662
Add a base processgroup::options so that we can do inheritance and
provide
a universal option API in python
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D26968856
Pulled By: wanchaol
fbshipit-source-id: 858f4b61b27aecb1943959bba68f8c14114f67d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53295
A lot of the time spent in `collect_callgrind` is spinning up Valgrind and executing the initial `import torch`. In most cases the actual run loop is a much smaller fraction. As a result, we can reuse the same process to do multiple replicates and do a much better job amortizing that startup cost. This also tends to result in more stable measurements: the kth run is more repeatable than the first because everything has been given a chance to settle into a steady state. The instruction microbenchmarks lean heavily on this behavior. I found that in practice doing several `n=100` replicates to be more reliable than one monolithic 10,000+ iteration run. (Since rare cases like memory consolidation will just contaminate that one replicate, as opposed to getting mixed into the entire long run.)
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D26907093
Pulled By: robieta
fbshipit-source-id: 72e5b48896911f5dbde96c8387845d7f9882fdb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53314
Introduction of api for optimizing non forward functions for mobile. As of this diff, all functions that you say to optimize will be preserved, and those functions will be run through canonical optimization. The intention is to stack each further optimization onto separate diffs since they touch multiple files, and it seems like it'd be a nightmare to review.
ghstack-source-id: 123909414
Test Plan:
torch.utils.mobile_optimizer.optimize_for_mobile(net, methods_to_optimize=["forward", "foo"]) runs fine
torch.utils.mobile_optimizer.optimize_for_mobile(net, methods_to_optimize={"foo"}) optimizes just foo if the model doesnt define forward otherwise optimizes foo and forward
torch.utils.mobile_optimizer.optimize_for_mobile(net, methods_to_optimize=["forward"]) runs fine
torch.utils.mobile_optimizer.optimize_for_mobile(net) runs fine if the model defines forward, Throws otherwise
Reviewed By: kimishpatel
Differential Revision: D26618689
fbshipit-source-id: 5bff1fb3f3f6085c4a649a8128af9c10f0fa9400
Summary:
This is an initial attempt in refactoring and consolidating our S3 read logic for print_test_stats.py, test_history.py, and run_test.py. This way, boto3 and botocore do not need to be imported in various places throughout the code base, and duplicated logic (such as the many type definitions) can exist in one place: `tools/stat_utils/s3_stat_parser.py`. walterddr contributed to this PR by moving print_test_stats.py to the tools folder and the corresponding tests a subfolder within tools.
**NOTE: this removes those tests from CI as the new `tools/test/test_stats.py` is not in the test/ directory as the other tests in TESTS in run_test.py.**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53755
Test Plan:
This refactoring change should not break anything, so running the files as before should work as they did previously.
To make sure that print_test_stats.py still functions: run `python tools/test/test_stats.py` and make sure all tests pass.
To make sure that test_history.py works, run the example commands from `tools/test_history.py --help` and check that their output matches that shown. Note that the script will continue printing for a while, so don't be alarmed.
Some next steps:
- Actually coming up with similarities among the three current use cases and further refactoring/consolidating of functions (e.g., combining simplify and get_cases)
- Moving more parsing logic to s3_stat_parser.py to have better abstraction between our files
- Adding tests for s3_stat_parser.py when there is more functionality in it
Reviewed By: agolynski, samestep
Differential Revision: D27030285
Pulled By: janeyx99
fbshipit-source-id: e664781324ef7c0c30943bfd7f17c895075ef7a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53404
This refactors `TensorSerializer::Serialize()` so that we have a separate
helper function for each data type.
This should make it slightly easier in the future to add new serialization
formats for specific data types.
ghstack-source-id: 124085413
Test Plan:
Confirmed the existing tests pass. This diff is not expected to have any
behavior changes.
Reviewed By: mraway, glamtechie
Differential Revision: D26658204
fbshipit-source-id: 232776262db6486ba845a7ba223e3987053dac27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54016
I managed to convince myself that typeIdWithDefault was sufficient for
the sparse constructor case. Here is the reasoning.
The surface reading of the use site of denseTypeIdWithDefault is
to convert what could be a sparse dispatch key into the dense version
so we can properly allocate underlying dense tensors for the sparse
constructor call. But WHERE does this dispatch key come from?
Inspection of call sites reveals that dispatch key is provided by
torch::tensors::get_default_dispatch_key(). This key is NEVER
sparse, as that would correspond to setting sparse tensors to be
the default tensor via torch.set_default_tensor_type() (which is
forbidden, and even if it worked most of everything in PyTorch would
break). That means that typeIdWithDefault is a sufficient replacmenet.
With denseTypeIdWithDefault removed, we can also delete toDense
as this was the sole use of that function.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D27109511
Pulled By: ezyang
fbshipit-source-id: c698eff0ab54c0c101fe9f55be3b7657584c4372
Summary:
This will allow for future work to use the test times file (which will save computation time and also allow for more consistency). (Step one to fixing https://github.com/pytorch/pytorch/issues/53882)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54083
Test Plan:
export CIRCLE_JOB=your-favorite-circleci-job e.g., pytorch_linux_xenial_cuda10_2_cudnn7_py3_gcc7_test2
`python test/run_test.py --export-historic-test-times` OR
`python test/run_test.py --export-historic-test-times .your-favorite-file`
When opening either .pytorch-test-times or .your-favorite-file, you should see something like:
```
{"commit": "2d559a09392aabb84dfb4a498010b2f01d99818c", "job_times": {"distributed/test_distributed_spawn": 583.5889999999973, "distributed/test_data_parallel": 4.866999999999997, "test_binary_ufuncs": 171.1569999999998, "test_numpy_interop": 2.5649999999999995, "test_public_bindings": 0.011,...}}
```
Note that no tests will be run when this option is specified.
Reviewed By: walterddr
Differential Revision: D27091351
Pulled By: janeyx99
fbshipit-source-id: e191d739268d86de0a0ba0eea0006969859d1940
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54121
It would be nice to do range analysis to determine if a condition
cannot be satisfied. These are some tests that we should be able to turn on
once we have this feature.
ghstack-source-id: 124116847
Test Plan: Simplify.*LoopBounds
Reviewed By: ZolotukhinM
Differential Revision: D27107956
fbshipit-source-id: bb27e3d3bc803f0101c416e4a351ba2278684980
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54094
We should be able to use 64-bit integers for loop boundaries and
buffer/tensor indexing.
ghstack-source-id: 124116846
Test Plan: New tests, disabled
Reviewed By: ZolotukhinM
Differential Revision: D27094934
fbshipit-source-id: a53de21a0ef523ea3560d5dd4707df50624896ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52894
add two success cases and two failure cases for ddp with activation check points when grad_as_bucket_view = true and false
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D26679895
fbshipit-source-id: a6f6cb22b4903ed8b1f7b8ed4fe8b13e102d8c21
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53159.
See comments for a description of the race condition. Thanks to ptrblck xwang233 and especially zasdfgbnm for lots of help isolating the problem and discussing the fix.
PRing for discussion. We can try to concoct a dedicated test for the problem if you want. The ingredients are:
- DDP(..., find_unused_parameters=True)
- Use all the DDP-ed model's params in forward such that the "lazy local used work wait()" path will be taken in backward
- Queue up a lot of asynchronous dummy work just before backward(), so stream work gets pushed far into the future relative to CPU work
Benchmark:
Bert model, When find_unused_parameters=true, latency (sec) per iteration P50: trunk-1.265sec, this PR-1.263sec, if add blocking copy before calling local_used_.fill(i)-1.236 sec
Bert model, When find_unsued_parameters=false, latency (sec) per iteration P50: trunk-1.00sec, this PR-1.026sec
Resnet50 model, accuracy is also matched with trunk when find_unused_parameters=true and false
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53160
Reviewed By: albanD
Differential Revision: D26916766
Pulled By: zhaojuanmao
fbshipit-source-id: 3e0ed91b7b5c42e2f2c82e12d4d2940fdc89e023
Summary:
Fixes https://github.com/pytorch/pytorch/issues/54051
Problem was application of the unary minus operator to an unsigned type. Positive indices are now used to build the permutation array for both `pixel_shuffle` and `pixel_unshuffle`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54086
Reviewed By: agolynski
Differential Revision: D27093435
Pulled By: jbschlosser
fbshipit-source-id: 4062f71277d037e91dc3cf5835b29b8ed4d16607
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54076
If we don't constrain ourselves to use `torch::jit::pop`, we can avoid copying a string or moving IValues around.
ghstack-source-id: 124040891
Test Plan:
existing tests
spot-checked regular interpreter assembly; seems better
Reviewed By: dhruvbird, walterddr
Differential Revision: D27087204
fbshipit-source-id: 7cf355dbcec31409bdb37afa09d7df85cf2a7e4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54105
This is preparing XNNPACK to be enabled in Windows. For some reason Windows clang doesn't think functions taking `float` and `const float` to have the same signature and thus throwing link errors like:
```
lld-link: error: undefined symbol: bool __cdecl at::native::xnnpack::use_max_pool2d(class at::Tensor const &, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, bool, float, float)
>>> referenced by C:\open\fbsource\buck-out\gen\f84e6a81\xplat\caffe2\pt_ops_full_template_registration\aten\src\ATen\native\Pooling.cpp:127
>>> libpt_ops_fullWindows.lib(out.obj):(class at::Tensor __cdecl at::native::max_pool2d(class at::Tensor const &, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, bool))
lld-link: error: undefined symbol: class at::Tensor __cdecl at::native::xnnpack::max_pool2d(class at::Tensor const &, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, bool, float, float)
>>> referenced by C:\open\fbsource\buck-out\gen\f84e6a81\xplat\caffe2\pt_ops_full_template_registration\aten\src\ATen\native\Pooling.cpp:129
>>> libpt_ops_fullWindows.lib(out.obj):(class at::Tensor __cdecl at::native::max_pool2d(class at::Tensor const &, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, class c10::ArrayRef<__int64>, bool))
```
Declaration: `src/ATen/native/xnnpack/Engine.h`
Definition: `src/ATen/native/xnnpack/MaxPooling.cpp`
Reference: `src/ATen/native/Pooling.cpp`
Test Plan: build succeeded
Reviewed By: kimishpatel
Differential Revision: D27097201
fbshipit-source-id: ab557f608713840ee0a65b252fa875624ddd502f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54107
The current implementation doesn't change the underlying texture's shape. This diff converts MPSImage from one shape to the other. The way we'll do it is we implement this as an elementwise kernel. We have a thread grid of size (N2, C2, H2, W2) with a thread for each output element, and we compute the "linear index" of the output element, and convert it to the equivalent "linear index" of the input element. This is the known as sub2ind/ind2sub conversion in MATLAB, ravel_multi_index in numpy, etc. a08841a8e1/cupy/indexing/generate.py (L301-L304) is a clean generic version of ind2sub.
ghstack-source-id: 124113407
Test Plan:
```
2021-03-16 00:27:31.280761-0700 PyTorchPlayground[16024:6249832] [bool test_view()],[1 10 2 2 ],[SUCCEED]
2021-03-16 00:27:31.282833-0700 PyTorchPlayground[16024:6249832] [bool test_view2()],[1 10 2 2 ],[SUCCEED]
2021-03-16 00:27:31.285320-0700 PyTorchPlayground[16024:6249832] [bool test_view3()],[5 8 ],[SUCCEED]
2021-03-16 00:27:31.286929-0700 PyTorchPlayground[16024:6249832] [bool test_view4()],[5 8 ],[SUCCEED]
```
- Sandcastle CI
- CircleCI
Reviewed By: SS-JIA
Differential Revision: D27074719
fbshipit-source-id: 445f55fefeb9cc7b3eeab106b6d567facef58343
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53303
The old code did a heap allocation unnecessarily and was a
little convoluted. I think that it was structured that way to avoid
double-evaluating arguments; I just forced them to be evaluated once
as though they were passed to a function by binding const references
to them.
ghstack-source-id: 123918262
Test Plan:
1) `buck run mode/opt-clang //caffe2/caffe2/fb/tests:logging_bench`
Before:
```
============================================================================
caffe2/caffe2/fb/tests/logging_bench.cpp relative time/iter iters/s
============================================================================
glog_CHECK 2.01ns 498.63M
caffe2_ENFORCE_GE 50.00% 4.01ns 249.31M
glog_CHECK_GE 17.39% 11.53ns 86.73M
fbcode_ENFORCE 100.00% 2.01ns 498.65M
caffe2_ENFORCE 100.00% 2.01ns 498.63M
caffe2_ENFORCE_THAT 50.00% 4.01ns 249.33M
============================================================================
```
After:
```
============================================================================
caffe2/caffe2/fb/tests/logging_bench.cpp relative time/iter iters/s
============================================================================
glog_CHECK 2.01ns 498.63M
caffe2_ENFORCE_GE 97.44% 2.06ns 485.88M
glog_CHECK_GE 17.39% 11.53ns 86.73M
fbcode_ENFORCE 100.00% 2.01ns 498.65M
caffe2_ENFORCE 100.00% 2.01ns 498.65M
caffe2_ENFORCE_THAT 97.28% 2.06ns 485.06M
============================================================================
```
Looks like about a 1.94x speedup!
2) Inspect generated assembly for logging_bench.cpp before & after by:
```
$ compile-commands caffe2/caffe2/fb/tests/logging_bench.cpp -f "mode/opt-clang"
$ jq -r '.[0].arguments | sh' < compile_commands.json | sed -e "s/'-c'/'-S'/g" | sed -E -e "s/'-g[12]'/'-g0'/g" > out.sh
$ sh out.sh
```
Then diff logging_bench.s as you like.
Before: P255408666
After: P277883307
Net about 1500 lines deleted from the assembly. We can see that the
happy path (which the benchmark tests) no longer contains string
creation.
Reviewed By: dzhulgakov
Differential Revision: D26829714
fbshipit-source-id: 6e11f8ea29292ae3d9f2cc89d08afcb06f7d39c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54111
If we only run the ReplaceWithCopy pass when enable_out_variant is true, there is no need register a default op implementation.
Reviewed By: edvgha
Differential Revision: D27036077
fbshipit-source-id: f615f5d8b84629044af1c554421ea5e505e93239
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: a7fd8fba11
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53947
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D27031755
fbshipit-source-id: d4cc9a791d4b9908f993a950c539bcbd988bde8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53080
As described in https://github.com/pytorch/pytorch/issues/51619,
ProcessGroupShareTensorTest was failing due to segfaults in CudaIPCTypes.cpp.
There were two issues that had to be fixed for this:
1. The ref_counter_files_ map was looked up and the result was used without
checking whether or not the appropriate key existed in the map. This would
result in default construction in the map if the key didn't exist resulting in
a nullptr being stored in the map.
2. ~CudaIPCSentData uses the global cuda_ipc_global_entities variable. But as
part of destroying cuda_ipc_global_entities, ~CudaIPCSentData is called which
accesses an already destroyed cuda_ipc_global_entities. This is now avoided by
clearing all shared blocks in ~CudaIPCGlobalEntities to ensure they are all
cleaned up before the destructor exits.
#Closes: https://github.com/pytorch/pytorch/issues/51619
ghstack-source-id: 122812319
Test Plan: Run `python test/distributed/test_c10d_spawn.py -v ProcessGroupShareTensorTest`
Reviewed By: VitalyFedyunin
Differential Revision: D26742332
fbshipit-source-id: 6de4c4533f5bca673e6e171af32d034bd6ade5bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54052
Introduce `fp16_compress_wrapper`, which can give some speedup on top of some gradient compression algorithms like PowerSGD.
ghstack-source-id: 124001805
Test Plan: {F509205173}
Reviewed By: iseessel
Differential Revision: D27076064
fbshipit-source-id: 4845a14854cafe2112c0caefc1e2532efe9d3ed8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53677
When serializing bytecode, we serialize it based on methods. It may happen that there are multiple instances of a class. In such a case, the methods inside the class may be serialized multiple times.
To reduce the duplication, we cache the qualified name of the methods, so that one method is serialized only once.
Test Plan: existing unittests and CI
Reviewed By: dhruvbird, raziel
Differential Revision: D26933945
Pulled By: iseeyuan
fbshipit-source-id: 8a9833949fa18f7103a5a0be19e2028040dc7717
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53823
Argument for correctness: type_equal previous compared if backends
are equal. Backend is computed by translation from dispatch key.
I verified that computeDispatchKey never computed a weird
dispatch key (e.g., AutogradXLA), so that dispatchKeyToBackend
was effectively injective. Then it is always valid to compare
the arguments of an injective function for equality, rather than
the output of the injective function.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D27036575
Pulled By: ezyang
fbshipit-source-id: 6aeafc89f287da0bc0065bd21c1adb5e272dbb81
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54029
I found what appear to be some missed moves and/or extra copies in the JIT interpreter.
ghstack-source-id: 123958682
Test Plan:
Existing CI for correctness
Ran AdIndexer inline_cvr local_ro model benchmark with static_runtime off via
`env bin=/tmp/ptvsc2_predictor_bench.StaticDispatchModeFile static_runtime=0 caffe2=0 scripts/swolchok/static_runtime/inline_cvr/run_local_ro.sh`
before:
```
I0315 14:25:23.916893 3075680 PyTorchPredictorBenchLib.cpp:215] PyTorch run finished. Milliseconds per iter: 1.01635. Iters per second: 983.914
I0315 14:26:05.536207 3080560 PyTorchPredictorBenchLib.cpp:215] PyTorch run finished. Milliseconds per iter: 1.01689. Iters per second: 983.395
I0315 14:26:47.510561 3083335 PyTorchPredictorBenchLib.cpp:215] PyTorch run finished. Milliseconds per iter: 1.02697. Iters per second: 973.737
I0315 14:27:29.024830 3086767 PyTorchPredictorBenchLib.cpp:215] PyTorch run finished. Milliseconds per iter: 1.01326. Iters per second: 986.918
I0315 14:28:10.849496 3091323 PyTorchPredictorBenchLib.cpp:215] PyTorch run finished. Milliseconds per iter: 1.023. Iters per second: 977.517
```
after:
```
I0315 14:17:43.280469 3046242 PyTorchPredictorBenchLib.cpp:215] PyTorch run finished. Milliseconds per iter: 0.997838. Iters per second: 1002.17
I0315 14:18:24.244606 3046861 PyTorchPredictorBenchLib.cpp:215] PyTorch run finished. Milliseconds per iter: 1.00173. Iters per second: 998.269
I0315 14:19:05.208899 3051998 PyTorchPredictorBenchLib.cpp:215] PyTorch run finished. Milliseconds per iter: 1.00187. Iters per second: 998.136
I0315 14:19:46.103854 3055392 PyTorchPredictorBenchLib.cpp:215] PyTorch run finished. Milliseconds per iter: 1.00073. Iters per second: 999.27
I0315 14:20:27.011411 3056062 PyTorchPredictorBenchLib.cpp:215] PyTorch run finished. Milliseconds per iter: 0.999121. Iters per second: 1000.88
```
(This was just a convenient workload I had handy; the plan of record is to use static runtime for inline_cvr inference AIUI.)
Reviewed By: dhruvbird, walterddr
Differential Revision: D27060762
fbshipit-source-id: 5567206d7c2d9ae99776ce5524caf09ec2035e87
Summary:
brianjo
- Add a javascript snippet to close the expandable left navbar sections 'Notes', 'Language Bindings', 'Libraries', 'Community'
- Fix two latex bugs that were causing output in the log that might have been misleading when looking for true doc build problems
- Change the way release versions interact with sphinx. I tested these via building docs twice: once with `export RELEASE=1` and once without.
- Remove perl scripting to turn the static version text into a link to the versions.html document. Instead, put this where it belongs in the layout.html template. This is the way the domain libraries (text, vision, audio) do it.
- There were two separate templates for master and release, with the only difference between them is that the master has an admonition "You are viewing unstable developer preview docs....". Instead toggle that with the value of `release`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53851
Reviewed By: mruberry
Differential Revision: D27085875
Pulled By: ngimel
fbshipit-source-id: c2d674deb924162f17131d895cb53cef08a1f1cb
Summary:
This PR disables the bulk of the output for test time regression reporting, since it's obscuring more important signal (especially in cases where shards are shifting around).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54078
Test Plan:
```
python test/test_testing.py
```
Reviewed By: ezyang, walterddr
Differential Revision: D27088987
Pulled By: samestep
fbshipit-source-id: 06a4eeb75641552bad2ab4b9154a8c70c57b0d68
Summary:
Provides a faster formula for `cumprod` in the case when the input has zeros. This formula is non-differentiable, so we leave the previous formula for the cases when `at::GradMode::is_enabled()`.
This new formula gives up to x10 and x30 speed-ups in CPU and GPU (see the benchmarks below).
The `cumsum` backward formula was rewritten so that no copies are necessary. We also removed a double negation in its formula. This gives a significant speed-up in CPU, while being almost as efficient as the formula with copies in GPU. We can see this speed-up when comparing the "No zeros" part of the benchmark.
Benchmarks:
nb. It is worth noting that the script tests the forward and the backward for `cumprod`, so the speed-ups should be even larger than those announced here.
<details>
<summary>Script</summary>
```python
from IPython import get_ipython
import torch
from itertools import product
torch.manual_seed(13)
torch.set_num_threads(1)
ipython = get_ipython()
cpu = torch.device('cpu')
cuda = torch.device('cuda')
def run_test(ndims, size, size_prod, zeros, device):
print(f"ndims: {ndims}, tensor_size: {size}, size_prod: {size_prod}, zeros: {zeros}, device: {device}")
for dim in range(ndims):
sizes = ndims * [size]
sizes[dim] = size_prod
tensor = torch.rand(*sizes, device=device)
with torch.no_grad():
if zeros:
# Set 0.1 of them to zero
p_drop = 0.1
mask = torch.full_like(tensor, 1.0 - p_drop)
tensor = tensor * torch.bernoulli(mask)
else:
tensor = tensor + 1e-3
tensor.requires_grad_()
grad = torch.ones_like(tensor)
# We test both forward + backward, meaning that the speed-up is actually greater than reported
# That being said, this is more realistic than doing `retain_graph=True`
command = "torch.autograd.grad([tensor.cumprod(dim)], [tensor], grad_outputs=[grad])"
if device == cuda:
command += "; torch.cuda.synchronize()"
ipython.magic(f"timeit {command}")
print()
for device, zeros in product([cuda, cpu], [True, False]):
run_test(3, 300, 10, zeros, device)
run_test(3, 300, 100, zeros, device)
if device == cuda:
run_test(3, 300, 300, zeros, device)
```
</details>
<details>
<summary>CPU This PR (Some regression small tensors, x4 speed-up large tensors)</summary>
```
Zeros:
ndims: 3, tensor_size: 300, size_prod: 10, zeros: True, device: cpu
28.2 ms ± 12.1 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
29.8 ms ± 78.9 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
24.5 ms ± 29.1 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
ndims: 3, tensor_size: 300, size_prod: 100, zeros: True, device: cpu
414 ms ± 3.63 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
428 ms ± 4.12 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
382 ms ± 3.18 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
No Zeros:
ndims: 3, tensor_size: 300, size_prod: 10, zeros: False, device: cpu
3.11 ms ± 9.72 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
3.83 ms ± 3.7 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
4.08 ms ± 10.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
ndims: 3, tensor_size: 300, size_prod: 100, zeros: False, device: cpu
92.2 ms ± 113 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
101 ms ± 101 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
87 ms ± 170 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
</details>
<details>
<summary>CUDA This PR (7-30x speed-up)</summary>
```
Zeros:
ndims: 3, tensor_size: 300, size_prod: 10, zeros: True, device: cuda
1.46 ms ± 2.07 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
1.48 ms ± 3.51 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
1.93 ms ± 8.07 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
ndims: 3, tensor_size: 300, size_prod: 100, zeros: True, device: cuda
10.5 ms ± 914 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
10.6 ms ± 509 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
11.7 ms ± 864 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
ndims: 3, tensor_size: 300, size_prod: 300, zeros: True, device: cuda
30.3 ms ± 5.16 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
30.6 ms ± 6.44 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
32.2 ms ± 2.34 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
No Zeros:
ndims: 3, tensor_size: 300, size_prod: 10, zeros: False, device: cuda
248 µs ± 335 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
252 µs ± 186 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
438 µs ± 254 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
ndims: 3, tensor_size: 300, size_prod: 100, zeros: False, device: cuda
2.1 ms ± 193 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
2.16 ms ± 380 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
2.59 ms ± 398 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
ndims: 3, tensor_size: 300, size_prod: 300, zeros: False, device: cuda
6.3 ms ± 857 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
6.39 ms ± 288 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
7.15 ms ± 233 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
</details>
<details>
<summary>CPU master</summary>
```
Zeros:
ndims: 3, tensor_size: 300, size_prod: 10, zeros: True, device: cpu
8.27 ms ± 12.4 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
10.8 ms ± 13.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
28.2 ms ± 74.4 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
ndims: 3, tensor_size: 300, size_prod: 100, zeros: True, device: cpu
1.53 s ± 116 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.95 s ± 4.38 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.86 s ± 3.58 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
No Zeros:
ndims: 3, tensor_size: 300, size_prod: 10, zeros: False, device: cpu
3.42 ms ± 20 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
4.25 ms ± 3.65 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
4.34 ms ± 3.04 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
ndims: 3, tensor_size: 300, size_prod: 100, zeros: False, device: cpu
104 ms ± 148 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
117 ms ± 99.5 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
94.8 ms ± 125 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
</details>
<details>
<summary>CUDA master</summary>
```
Zeros:
ndims: 3, tensor_size: 300, size_prod: 10, zeros: True, device: cuda
912 µs ± 431 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
1.05 ms ± 2.46 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
2.74 ms ± 381 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
ndims: 3, tensor_size: 300, size_prod: 100, zeros: True, device: cuda
71.3 ms ± 7.91 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
85.4 ms ± 9.82 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
119 ms ± 6.21 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
ndims: 3, tensor_size: 300, size_prod: 300, zeros: True, device: cuda
646 ms ± 103 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
776 ms ± 81.7 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
917 ms ± 160 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
No Zeros:
ndims: 3, tensor_size: 300, size_prod: 10, zeros: False, device: cuda
301 µs ± 893 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
308 µs ± 236 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
592 µs ± 140 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
ndims: 3, tensor_size: 300, size_prod: 100, zeros: False, device: cuda
2.61 ms ± 375 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
2.68 ms ± 524 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
3.38 ms ± 736 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
ndims: 3, tensor_size: 300, size_prod: 300, zeros: False, device: cuda
7.89 ms ± 848 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
8.03 ms ± 517 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
9.24 ms ± 405 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
</details>
cc nikitaved
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53711
Reviewed By: jbschlosser
Differential Revision: D27059662
Pulled By: anjali411
fbshipit-source-id: be610d5590c0199b4412dff66fac47666faaff9d
Summary:
SC1090/1091 are important to prevent accidental delete/move of utility shell scripts
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54069
Test Plan: CI
Reviewed By: samestep
Differential Revision: D27084094
Pulled By: walterddr
fbshipit-source-id: 16deb83fce691eba0263978374564d172bc8d371
Summary:
There are the following two patterns to call add in-pace.
```python
torch.add(a, b, out=a) # (1) a in-placed
torch.add(a, b, out=b) # (2) b in-placed
```
If a and b are mkldnn Tensor, the value is different from expected in case (2).
**Sample code to reproduce the behavior:**
```python
import torch
torch.manual_seed(4)
a = torch.randn(4, 4)
b = torch.randn(4, 4)
b.fill_(1.0)
a_mkl = a.to_mkldnn()
b_mkl = b.to_mkldnn()
torch.add(b, a, alpha=1.0, out=a)
torch.add(b_mkl, a_mkl, alpha=1.0, out=a_mkl)
print(a)
print(a_mkl)
```
**Results:**
Actual:
```python
tensor([[ 0.0586, 2.2632, 0.8162, 1.1505],
[ 1.1075, 0.7220, -1.6021, 1.6245],
[ 0.1316, 0.7949, 1.3976, 1.6699],
[ 0.9463, 1.0467, -0.7671, -1.1205]])
tensor([[2., 2., 2., 2.],
[2., 2., 2., 2.],
[2., 2., 2., 2.],
[2., 2., 2., 2.]], layout=torch._mkldnn)
```
Expected:
```python
tensor([[ 0.0586, 2.2632, 0.8162, 1.1505],
[ 1.1075, 0.7220, -1.6021, 1.6245],
[ 0.1316, 0.7949, 1.3976, 1.6699],
[ 0.9463, 1.0467, -0.7671, -1.1205]])
tensor([[ 0.0586, 2.2632, 0.8162, 1.1505],
[ 1.1075, 0.7220, -1.6021, 1.6245],
[ 0.1316, 0.7949, 1.3976, 1.6699],
[ 0.9463, 1.0467, -0.7671, -1.1205]], layout=torch._mkldnn)
```
This is because `dnnl::sum` called in `mkldnn_add` has the following specifications:
[oneDNN doc : Sum](https://oneapi-src.github.io/oneDNN/dev_guide_sum.html)
> The sum primitive supports in-place operation, meaning that the src0 tensor can be used as both input and output.
> In-place operation overwrites the original data. Using in-place operation requires the memory footprint of the
> output tensor to be either bigger than or equal to the size of the dst memory descriptor used for primitive creation.
but, case 2) are added to the first argument.
So, we modified it so that a and b are swapped and passed to "sum" in case (2).
**Environment**
・CPU : Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60GHz
・build USE_MKLDNN=1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51687
Reviewed By: jbschlosser
Differential Revision: D27062172
Pulled By: VitalyFedyunin
fbshipit-source-id: bf76d36f9fdb1b4337d71d87bcdbaf4edb11f12f
Summary:
Resubmit of https://github.com/pytorch/pytorch/pull/51436.
Apparently some non-public windows builds run cuda tests on the default stream, so I changed a few capture tests to manually ensure all captures happen on non-default streams.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54038
Reviewed By: mruberry
Differential Revision: D27068649
Pulled By: ngimel
fbshipit-source-id: 4284475fa40ee38c0f8faff05a2faa310cf8a207
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53583
`Scalar` takes 32 bytes due to `c10::complex<double>`
requires aligning to 16 bytes. Passing Scalar by reference
shows about 1% improvements on instruction count.
All the changes in this commit are codemoded except for
the following 4 files (which code-gen signatures):
```
tools/codegen/api/cpp.py
tools/codegen/api/native.py
tools/codegen/api/structured.py
caffe2/contrib/aten/gen_op.py
```
# Codemode
## Main Step
For the codemod part, here is the main command used:
```
fastmod --extensions h '([a-zA-Z_+]\([^)]*,?\s*)Scalar (\w+)' '${1}const Scalar& ${2}'
fastmod --extensions h '([a-zA-Z_+]\([^)]*,?\s*)optional<Scalar> (\w+)' '${1}const optional<Scalar>& ${2}'
fastmod --extensions cpp '([a-zA-Z_+]\([^)]*,?\s*)Scalar (\w+)' '${1}const Scalar& ${2}'
fastmod --extensions cpp '([a-zA-Z_+]\([^)]*,?\s*)optional<Scalar> (\w+)' '${1}const optional<Scalar>& ${2}'
```
As you can tell, it codemods both `Scalar` and `optional<Scalar>`. Apply these commands iteratively until reaching a fix-point (since one method signature might contain multiple `Scalar` parameter).
In retrospect, excluding `thrid_party` and `torch/csrc/jit` would be a good idea. (I revert it manually later, see https://github.com/pytorch/pytorch/pull/53479 as an reference).
## Pre-Step
Prior to applying the main command, as some `Scalar` are presented as `at::Scalar` or `c10::Scalar`, so I codemod some of them in advance. Here is an incomplete list:
```
fastmod --extensions h '([a-zA-Z_+]\([^)]*,?\s*)at::Scalar (\w+)' '${1}const at::Scalar& ${2}'
fastmod --extensions cpp '([a-zA-Z_+]\([^)]*,?\s*)at::Scalar (\w+)' '${1}const at::Scalar& ${2}'
fastmod --extensions h '([a-zA-Z_+]\([^)]*,?\s*)c10::optional<Scalar> (\w+)' '${1}const c10::optional<Scalar>& ${2}'
fastmod --extensions cpp '([a-zA-Z_+]\([^)]*,?\s*)c10::optional<Scalar> (\w+)' '${1}const c10::optional<Scalar>& ${2}'
```
## Fixup
There are a couple of post codemod fixup. For example, `const Scalar` will be codemoded into `const const Scalar&`. `at:Scalar` will be codemoded into `at::const Scalar&` (if `Pre-step` is not done comprehensively). Here is an incomplete list:
```
fastmod --extensions cpp 'const const Scalar' 'const Scalar'
fastmod --extensions h 'const const c10::optional<Scalar>' 'const c10::optional<Scalar>'
fastmod --extensions cpp 'const const c10::optional<Scalar>' 'const c10::optional<Scalar>'
fastmod 'at::const Scalar&' 'const at::Scalar&'
```
## Supplementary
`cu` and `mm` files also need to be codemoded, for example:
```
fastmod --extensions cu 'at::const Scalar&' 'const at::Scalar&'
fastmod --extensions mm '([a-zA-Z_+]\([^)]*,?\s*)Scalar (\w+)' '${1}const Scalar& ${2}'
```
Function pointers are not codemoded. Here is an incomplete list:
```
# Cover case: using index_fill_fn = void(*)(TensorIterator & iter, int64_t dim, int64_t self_dim_size, int64_t self_dim_stride, Scalar source);
fastmod --extensions h '(void\s*\(\s*\*\s*\)\([^)]*,?\s*)Scalar (\w+)' '${1}const Scalar& ${2}'
# Cover case: using softplus_fn = void (*)(TensorIterator&, Scalar, Scalar);
fastmod --extensions h '(void\s*\(\s*\*\s*\)\([^)]*,?\s*)Scalar([, \)])' '${1}const Scalar&${2}'
fastmod --extensions cpp '(void\s*\(\s*\*\s*\)\([^)]*,?\s*)Scalar([, \)])' '${1}const Scalar&${2}'
fastmod --extensions h '(void\s*\(\s*\*\s*\)\([^)]*,?\s*)optional<Scalar>([, \)])' '${1}const optional<Scalar>&${2}'
```
Some corner cases needs to be manually fixed.
ghstack-source-id: 123970306
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D26904445
fbshipit-source-id: 8d8a002af4b5125f153a32f03c6956be7ae5671d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53582
We will pass `Scalar` by reference in the following commit,
i.e. `const Scalar&`.
ghstack-source-id: 123965970
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D26904444
fbshipit-source-id: 7f58ee4e38dcd860f0d1120cab4e82f35ca3770f
Summary:
For OneDNN MaxPooling training, it will save indices as a workspace for backward, but for inference, indices are not necessary, this PR will make check to avoid saving indices to reduce memory use for inference path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52728
Reviewed By: jbschlosser
Differential Revision: D27062435
Pulled By: VitalyFedyunin
fbshipit-source-id: 9e70268a8ba491a7914b980079c0945d753cd4f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53578
We want to be able to log the loaded module size to the scuba table `qpl_metrics/pytorch`. Hence, adding the `model_size` field to the logged metadata when logging a module load success event.
ghstack-source-id: 123980964
Test Plan: xcheng16 How should this be tested?
Reviewed By: xcheng16, raziel
Differential Revision: D26902971
fbshipit-source-id: a7c2e9120706bd31f76f6572c8503d4acf8a89e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53783
Use isort + black on torch/package/
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D26969020
Pulled By: suo
fbshipit-source-id: e2c0738e79bf41b6342355eb7025998178c35dc9
Summary:
This PR:
1. moves sharding algorithm from run_test.py to framework_utils.py (let me know if you have a better place for it)
2. adds tests for the algorithm in test_testing.py
3. fixes the algorithm so that it doesn't tack on the unknown jobs all to the shard with the minimum time, but instead distributes them around the shards.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53942
Test Plan: python test/test_testing.py -k TestFrameworkUtils
Reviewed By: samestep
Differential Revision: D27047223
Pulled By: janeyx99
fbshipit-source-id: 824b20009c0bb707aa5361de445cdec795d5e3f1
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 17008b1be8
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53999
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D27046211
fbshipit-source-id: 72d7eb3814d30afb7956e0e0b43b0b320fbf009a
Summary:
Promotion to PyPI should be more flexible to allow any package to be
promoted to PyPI.
After we re-added a version suffix to cuda 10.2 it means that this
script needs to have the flexibility to designate which platform and
which version suffix will actually be uploaded to PyPI
Should coincide with https://github.com/pytorch/builder/pull/678
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53774
Reviewed By: jbschlosser
Differential Revision: D27052347
Pulled By: seemethere
fbshipit-source-id: 71129cc5afbd7de448c970ef721bc979c3420586
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53928
HashStoreTest was taking forever to run. Turns out it was because a default timeout is set when creating Store() and setTimeout for prefixStore is not actually able to change the timeout of the underlying store.
After removing the default timeout and updating setTimeout, this will save ~10 minutes for all of the gcc_test CI runs.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D27025275
Pulled By: H-Huang
fbshipit-source-id: 650c8c1eb8b166da1d412ed88e765747a2ca2069
Summary:
This PR fixes a typo in the explanation of `dims` for `linalg.tensorsolve`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53320
Reviewed By: jbschlosser
Differential Revision: D27048736
Pulled By: anjali411
fbshipit-source-id: db230b21191cc9cfb73b967cd15305fe74178c2b
Summary:
Close https://github.com/pytorch/pytorch/issues/51108
Related https://github.com/pytorch/pytorch/issues/38349
This PR implements the `cpu_kernel_multiple_outputs` to support returning multiple values in a CPU kernel.
```c++
auto iter = at::TensorIteratorConfig()
.add_output(out1)
.add_output(out2)
.add_input(in1)
.add_input(in2)
.build();
at::native::cpu_kernel_multiple_outputs(iter,
[=](float a, float b) -> std::tuple<float, float> {
float add = a + b;
float mul = a * b;
return std::tuple<float, float>(add, mul);
}
);
```
The `out1` will equal to `torch.add(in1, in2)`, while the result of `out2` will be `torch.mul(in1, in2)`.
It helps developers implement new torch functions that return two tensors more conveniently, such as NumPy-like functions [divmod](https://numpy.org/doc/1.18/reference/generated/numpy.divmod.html?highlight=divmod#numpy.divmod) and [frexp](https://numpy.org/doc/stable/reference/generated/numpy.frexp.html#numpy.frexp).
This PR adds `torch.frexp` function to exercise the new functionality provided by `cpu_kernel_multiple_outputs`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51097
Reviewed By: albanD
Differential Revision: D26982619
Pulled By: heitorschueroff
fbshipit-source-id: cb61c7f2c79873ab72ab5a61cbdb9203531ad469
Summary:
The tcpstore delete key implementation inadvertendly set "moreData" when sending the key when it was in fact the last message.
Thank you, PetrochukM, for the reproducing example which was instrumental in developing the fix (and is the blueprint for the test case).
Fixes https://github.com/pytorch/pytorch/issues/53872
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53886
Reviewed By: jbschlosser
Differential Revision: D27011846
Pulled By: H-Huang
fbshipit-source-id: 5c460d1e4d095a8bc267bf63613b556856ced3e8
Summary:
When build libtorch static library, these three static libraries will be generated but won't be installed to CMAKE_INSTALL_LIBDIR:
- libCaffe2_perfkernels_avx2.a
- libCaffe2_perfkernels_avx512.a
- libCaffe2_perfkernels_avx.a
This PR will fix this issue.
Please be noted that after this fix there still have static libraries missing in CMAKE_INSTALL_LIBDIR, but they belong to third_party repo, and we need to fix in the corresponding repo:
- libfoxi_loader.a
- libonnx.a
- libonnx_proto.a
- libfmt.a
- libnccl_static.a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53825
Reviewed By: ngimel
Differential Revision: D27013844
Pulled By: malfet
fbshipit-source-id: 8a84cc72b6ae87393ca26c4e474f5526a7b18ab2
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: cd0eb12c1f
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53892
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D27009398
fbshipit-source-id: af46edd701cde94c6175d3058fd15487d8b0b8c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53759Fixes#53587, see issue for in-depth explanation of the bug.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D26971342
Pulled By: ezyang
fbshipit-source-id: 805983fed2658e27fb033f36a71fd30950a29328
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53682
With this, under the meta device, 101 tests passed and 16953 skipped.
It ain't much, but it's a start.
Some various bits and bobs:
- NotImplementedError suppression at test level is implemented
in the same way as CUDA memory leak check, i.e., by wrapping
test methods and monkeypatching them back in.
- I had to reimplement assertRaises/assertRaisesRegex from scratch to
ignore NotImplementedError when _ignore_not_implemented_error is True.
The implementation relies on a small amount of private API that hasn't
changed since 2010
- expectedAlertNondeterministic doesn't really work so I skipped them
all; there's probably a way to do it better
I tested this using `pytest --disable-warnings --tb=native -k meta --sw
test/*.py` and a pile of extra patches to make collection actually work
(lol).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D26955539
Pulled By: ezyang
fbshipit-source-id: ac21c8734562497fdcca3b614a28010bc4c03d74
Summary:
The size of the workspace array should be max(1, lwork) according to LAPACK documentation. We got away with this previously because we tested only MKL which does a nice thing returning lwork >= 1.
Fixes https://github.com/pytorch/pytorch/issues/53454
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53909
Reviewed By: heitorschueroff
Differential Revision: D27017025
Pulled By: mruberry
fbshipit-source-id: 040a8cfb4bfb98db47d0b117938856d9483b20fb
Summary:
Added OpInfo-based testing of the following linear algebra functions:
* cholesky, linalg.cholesky
* linalg.eigh
* inverse, linalg.inv
* qr, linalg.qr
* solve
The output of `torch.linalg.pinv` for empty inputs was not differentiable, now it's fixed.
In some cases, batched grad checks are disabled because it doesn't work well with 0x0 matrices (see https://github.com/pytorch/pytorch/issues/50743#issuecomment-767376085).
Ref. https://github.com/pytorch/pytorch/issues/50006
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51107
Reviewed By: albanD
Differential Revision: D27006115
Pulled By: mruberry
fbshipit-source-id: 3c1d00e3d506948da25d612fb114e6d4a478c5b1
Summary:
https://github.com/pytorch/pytorch/pull/51348 added CUDA support for orgqr but only a cuSOLVER path; the orgqr tests, however, were marked to run on builds with either MAGMA or cuSOLVER.
This PR addresses the issue by creating a skipCUDAIfNoCusolver decator and applying to the orgqr tests. It triggers ci-all because our CI build with MAGMA but no cuSOLVER is CUDA 9.2, which does run in the typical PR CI.
cc IvanYashchuk
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53975
Reviewed By: ngimel
Differential Revision: D27036683
Pulled By: mruberry
fbshipit-source-id: f6c0a3e526bde08c44b119ed2ae5d51fee27e283
Summary: As title. Otherwise we are getting flaky when running on devices in dev mode
Reviewed By: jfix71
Differential Revision: D27035924
fbshipit-source-id: 4946a90bd341be63d74b7052cace3fabdefdc0c4
Summary:
When compiled with OpenMP support `ideep`'s computational_cache would cache max number of OpenMP workers
This number could be wrong after `torch.set_num_threads` call, so clean it after the call.
Fixes https://github.com/pytorch/pytorch/issues/53565
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53871
Reviewed By: albanD
Differential Revision: D27003265
Pulled By: malfet
fbshipit-source-id: 1d84c23070eafb3d444e09590d64f97f99ae9d36
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53092
This PR adds the following APIs to NNC.
```
// In For:
static For* getParentLoop(const Stmt* st);
static std::vector<For*> getEnclosingLoopNest(const Stmt* st);
// In LoopNest:
std::vector<const Stmt*> getAllWritesToBuf(const Buf*) const;
std::vector<For*> getAllInnermostLoopsWritingToBuf(const Buf*) const;
std::vector<std::vector<For*>> getAllLoopNestsWritingToBuf(const Buf*) const;
```
These APIs are required for some usecases that involve multiple transformations like `splitWithTail` followed by `reorder` as shown in https://github.com/pytorch/pytorch/issues/53092
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53778
Reviewed By: albanD
Differential Revision: D26987013
Pulled By: navahgar
fbshipit-source-id: 491459eddfff045132d2358631ad069bbcc520df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52429
Implemented embedding_bag for supporting out version in SR
Befor:Milliseconds per iter: 1.15443. Iters per second: 866.226
After: Milliseconds per iter: 1.14791. Iters per second: 871.149
Test Plan:
buck test caffe2/test:nn
buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest
Reviewed By: hlu1
Differential Revision: D26089498
fbshipit-source-id: c9ba7068d5aa696c8f37a4846d8e80c6379538d2
Summary:
This PR adds the cuBLAS based path for `torch.triangular_solve`
The device dispatching helper function was removed from native_functions.yml, it is replaced with DECLARE/DEFINE_DISPATCH.
`magmaTriangularSolve` is removed and replaced with cuBLAS calls, this is not a BC-breaking change because internally MAGMA just calls the same cuBLAS function and doesn't do anything else.
Batched cuBLAS is faster than batched MAGMA for matrices of size up until 512x512, after that MAGMA is faster. For batches smaller than ~8 and matrix sizes larger than 64x64 a forloop of cuBLAS calls is faster than batched version.
Ref. https://github.com/pytorch/pytorch/issues/47953
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53147
Reviewed By: heitorschueroff
Differential Revision: D27007416
Pulled By: mruberry
fbshipit-source-id: ddfc190346e6a56b84145ed0a9af67ca9cde3506
Summary:
Fixes https://github.com/pytorch/pytorch/issues/44378 by providing a wider range of drivers similar to what SciPy is doing.
The supported CPU drivers are `gels, gelsy, gelsd, gelss`.
The CUDA interface has only `gels` implemented but only for overdetermined systems.
The current state of this PR:
- [x] CPU interface
- [x] CUDA interface
- [x] CPU tests
- [x] CUDA tests
- [x] Memory-efficient batch-wise iteration with broadcasting which fixes https://github.com/pytorch/pytorch/issues/49252
- [x] docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49093
Reviewed By: albanD
Differential Revision: D26991788
Pulled By: mruberry
fbshipit-source-id: 8af9ada979240b255402f55210c0af1cba6a0a3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53799
Fix two issues with ClipRangesGatherRangesX2SigridHash and ClipRangesGatherRangesX2SigridHashPrecompute:
- The first issue is with the two step graph rewrite process. If step 2 doesn't happen after step 1, then we're stuck with a graph with a `fb::placeholder` op that can't run. Step 3 is added to revert step 1 so we restore the original graph if there's any `fb::placeholder` op left.
- The second issue is with `SigridHashPrecompute`. The coupling with `freeze_module` is not ideal and limits its use to Static Runtime only. By running `ConstantPropagation` and `ConstantPooling` after splitting SigridHash, we can move all the Constant ops to the front of the graph and fusion can happen right afterwards.
Reviewed By: ajyu
Differential Revision: D26920008
fbshipit-source-id: e4bc67c7a15181bac5dbbfbb95d861849652bddf
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52044 (`stack` dispatches to `cat`)
The way dispatcher works, currently this case happens only in CUDA kernel (CPU kernel is chosen if all inputs and out are on CPU). That is why the check is added only on the CUDA side.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53004
Reviewed By: albanD
Differential Revision: D27003956
Pulled By: mruberry
fbshipit-source-id: 818ea0f76153f4fa281740f30705e5ef018413f6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53456
I'm confused why this wasn't picked up in CI. There's definitely at least one CI job that builds without MKL. Are spectral_ops not being run at all on that job?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53736
Reviewed By: albanD
Differential Revision: D27007901
Pulled By: mruberry
fbshipit-source-id: cd93a2c48f4ccb2fd2e0e35768ee059039868a1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53403
This updates the `TensorProto` field to independently track the data type of
the in-memory (deserialized) data from the serialized data format.
This will allow us to support multiple different serialization formats in the
future. For instance, we could choose to perform quantization of floating
point data types, or varint encoding for integer fields.
For now this diff does not actually change the serialization code path yet,
and does not introduce any new serialization formats, but only refactors the
deserialization code path to make it easier to introduce new formats.
I'm not really that thrilled with the heavy use of macros and templates here,
but I didn't really see better alternatives that made it as simple to specify
new deserialization function implementations.
ghstack-source-id: 123594220
Test Plan:
Confirmed that the existing unit tests pass. This diff only touches the
deserialization code path and not the serialization code to help ensure that
the deserialization code works with the existing serialization logic, and that
there are no changes to the current serialization format.
Reviewed By: mraway
Differential Revision: D26658206
fbshipit-source-id: d7297d600aee28b92fd9f4ece437b7f519060942
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53754
Some of the PyTorch CircleCI builds still use gcc 5.4, and compile with
`-Werror=attributes` causing this old compiler to fail because it does not
understand the `[[nodiscard]]` attribute.
Let's define a `CAFFE2_NODISCARD` macro to work around this.
ghstack-source-id: 123594084
Test Plan: I'm using this macro in subsequent diffs in the stack.
Reviewed By: mraway
Differential Revision: D26959584
fbshipit-source-id: c7ba94f7ea944b6340e9fe20949ba41931e11d41
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/53316
Test Plan:
Nightly Docker build CI
This is a follow-up PR after docker moved default CUDA => 11.1. Only merge this after https://github.com/pytorch/pytorch/issues/53299 is committed.
Reviewed By: albanD
Differential Revision: D26996287
Pulled By: xuzhao9
fbshipit-source-id: 0c2e03da41d036d7aada3e07d479a3dede219f58
Summary:
Implements https://github.com/pytorch/pytorch/issues/51075#issuecomment-768884685 and additions discussed offline with ezyang ngimel . (Calling it "simple" is charitable but it's not too bad).
[High level strategy](https://github.com/pytorch/pytorch/pull/51436/files#diff-acc6337586bf9cdcf0a684380779300ec171897d05b8569bf439820dc8c93bd5R57-R82)
The current design aggregates stats from private pools with the ordinary pools, which may or may not be what we want.
Instead of adding PrivatePools as an internal feature of DeviceAllocator, I could inherit from DeviceAllocator (eg `DevicePrivateAllocator : public DeviceAllocator`) and create separate per-graph instances of the inherited class. I'm not sure if that would be better.
Graph bindings in Python are almost unchanged from https://github.com/pytorch/pytorch/pull/48875:
```python
# Same bindings as 48875, but now implicitly grabs a private mempool
graph1.capture_begin()
graph1.capture_end()
# pool=... is new. It hints that allocations during graph2's capture may share graph1's mempool
graph2.capture_begin(pool=graph1.pool())
graph2.capture_end()
# graph3 also implicitly creates its own mempool
graph3.capture_begin()
graph3.capture_end()
```
Test plan (other suggestions appreciated):
- [x] Stop maintaining manual references for all the tensors in my existing graphs+RNG tests. If private pools somehow give bad allocations, they should start failing intermittently. They run eager ops and eager allocations mixed with graph replays, so they may expose if eager ops and replays corrupt each other.
- [x] `test_graph_two_successive`: Capture successive graphs, with the second graph using the first graph's result. Try with and without sharing a pool. Check results, also check memory stats to confirm sharing a pool saves memory.
- [x] `test_graph_concurrent_replay`: Capture some graphs in separate private pools, replay them concurrently in different streams, check the results to make sure they don't corrupt each other's memory. Capture some graphs with a shared pool, replay them concurrently in different streams, check results, confirm they DO corrupt each other's memory.
- [x] `test_graph_three_successive`: A three-graph case, checking the safe and unsafe replay patterns in [Restrictions of the Strawman API](https://github.com/pytorch/pytorch/issues/51075)).
- [x] `test_graph_memory_stats_and_use_result_after_destroy_graph`: Comprehensively check torch.cuda.memory_stats() changes that result from graph capture and delete. Check that a tensor ref created during capture and held after graph delete stays valid until the tensor itself is deleted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51436
Reviewed By: mruberry
Differential Revision: D26993790
Pulled By: ngimel
fbshipit-source-id: a992eaee1b8c23628e7b388a5a3c26e0f80e54da
Summary:
Benchmark of
```python
%timeit torch.randperm(100000, device='cuda'); torch.cuda.synchronize()
```
thrust:
```
5.76 ms ± 42.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
cub:
```
3.02 ms ± 32.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
sync in thrust sort is removed
Warning:
Thrust supports 64bit indexing, but cub doesn't, so this is a functional regression. However, `torch.randperm(2**31, device='cuda')` fails with OOM on 40GB A100, and `torch.randperm(2**32, device='cuda')` fails with OOM on 80GB A100, so I think this functional regression has low impact and is acceptable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53841
Reviewed By: albanD
Differential Revision: D26993453
Pulled By: ngimel
fbshipit-source-id: 39dd128559d53dbb01cab1585e5462cb5f3cceca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53777
Moves linear activation test case to new NS API
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels.test_compare_activations_linear
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26967107
fbshipit-source-id: 83c4401b2bf79d15227b7fb3e59c54276ec5626b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53776
Moves the test for comparing activations for conv to new API.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels.test_compare_activations_conv
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26967106
fbshipit-source-id: 2eb986ff19761a1e2408cb7780ac0b282cdcc523
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53772
Moves the test case for extracting LSTM dynamic weights to new NS API.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels.test_compare_weights_lstm_dynamic
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26967104
fbshipit-source-id: 0d17e7735ec361167dcf72bcb373bfc1aad84668
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53765
Moves linear dynamic weight test case to new NS API.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels.test_compare_weights_linear
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26967109
fbshipit-source-id: 2096a88a3005270696d536f2e1bbc87e70c07230
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53764
Moving the linear weight test case to new FX NS APIs.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels.test_compare_weights_linear
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26967111
fbshipit-source-id: f0a90d7863d5d866e391729ec28e0e0dea339900
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53748
Extracts common testing patterns for FX numeric suite into
util functions. No logic change.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26967105
fbshipit-source-id: 9f6cbe75bb6d2ede142929e0c9e40812006c159d
Summary:
This PR implements the option to log inputs for FX Numeric Suite. The user facing api looks like
```
def prepare_model_outputs(..., should_log_inputs : bool = False)
def prepare_model_with_stubs(..., should_log_inputs : bool = False)
```
The output data now looks like
```
{
"layer1": {
"node_inputs": {
"model1": [{
"values": ...,
...,
}],
},
"node_outputs": {
...,
}
},
... // other layers
}
```
One key design decision taken here is that an input logger logs the output of previous nodes, instead of logging the input of the current node. This matters for a signature such as `cat([x1, x2, x3])`. We are inserting three input loggers here (for x1, x2, and x3), instead of a single input logger for `[x1, x2, x3]`. This was chosen in order to preserve the structure of the original graph as much as possible and keep flexibility for future optimizations.
Test Plan:
TODO: fill out
Imported from OSS
Differential Revision: D26931225
Reviewed By: hx89
Pulled By: vkuzo
fbshipit-source-id: dd692bfb5ddaaf5554f80c25e2f40b21762e4fc3
Summary:
This PR ensures that when we do a dtype cast for a shadow module,
we insert N dtype casts for N nodes, instead of combining N nodes
into a single dtype cast.
An example where this occurs is `cat([x, y], dim=0)`
```
// original graph
[x, y] -> cat_b -> output
// shadow graph with a single dtype cast, before this PR
dtype_cast -> cat_a_shadow -> output_a_shadow
/
[x, y] -> cat_b -> output_b
// shadow graph with multiple dtype casts, after this PR
[dtype_cast_x, dtype_cast_y] -> cat_a_shadow -> output_a_shadow
/
[x, y] -> cat_b -> output_b
```
The reason things worked before this PR is because `torch.dequantize`
can take either a single tensor or a list of tensors. We are changing
this to make an upcoming addition of input loggers easier.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_prepare_model_with_stubs_multiple_dtype_casts
```
Imported from OSS
Differential Revision: D26931226
Reviewed By: hx89
Pulled By: vkuzo
fbshipit-source-id: e9c7d4c7942e0f59c952094d2e446b1e2c838396
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53075
The input and output types should be `nn.Module`, to hide
the implementation detail that the pass is using FX.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26740548
fbshipit-source-id: d5ed445379355bebdd90d377c95fcd7e671371a3
Summary:
First argument is either file name or test module name, but key to `CUSTOM_HANDLERS` is test module name.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53884
Test Plan: Run `python3 run_test.py -i distributed/test_distributed_spawn.py`
Reviewed By: janeyx99
Differential Revision: D27006164
Pulled By: malfet
fbshipit-source-id: f30b42856cd2754e5981c1c69618f84e392c986a
Summary:
Do not compute shards if whole testsuite needs to be run anyway.
Helps avoid occasional test duplication/gaps when access to test time database is not available while one of the shards is computed
Fixes https://github.com/pytorch/pytorch/issues/53882
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53883
Reviewed By: janeyx99
Differential Revision: D27005910
Pulled By: malfet
fbshipit-source-id: f9603db0523a3a2539118e3fec1c6874c54f8d6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53859
The redispatch API wasn't linking properly when static dispatch is enabled. I'm still not sure why this wasn't caught by the static dispatch test in CI- maybe, as swolchok pointed out, we have a flag set somewhere that defers undefined symbols until runtime.
Before, building with static dispatch enabled locally + running `import torch` gave me this error:
```
>>> import torch
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/raid/hirsheybar/pytorch/torch/__init__.py", line 197, in <module>
from torch._C import *
ImportError: /raid/hirsheybar/pytorch/torch/lib/libtorch_cpu.so: undefined symbol: _ZN2at10redispatch11logical_or_EN3c1014DispatchKeySetERNS_6TensorERKS3_
>>>
```
Printing the symbol:
```
(pytorch) hirsheybar@devfair017:/scratch/hirsheybar/pytorch$ c++filt _ZN2at10redispatch11logical_or_EN3c1014DispatchKeySetERNS_6TensorERKS3_
at::redispatch::logical_or_(c10::DispatchKeySet, at::Tensor&, at::Tensor const&)
```
Sure enough, the functions defined in `RedispatchFunctions.cpp` don't have the DispatchKeySet argument included. Adding them in this PR.
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D26998735
Pulled By: bdhirsh
fbshipit-source-id: c6c1104e42d13b7ec9d964b7e08d2adc8b344b78
Summary:
This PR proposes to improve the distributed doc:
* [x] putting the init functions together
* [x] moving post-init functions into their own sub-section as they are only available after init and moving that group to after all init sub-sections
If this is too much, could we at least put these 2 functions together:
```
.. autofunction:: init_process_group
.. autofunction:: is_initialized
```
as they are interconnected. and the other functions are not alphabetically sorted in the first place.
Thank you.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52976
Reviewed By: albanD
Differential Revision: D26993933
Pulled By: mrshenli
fbshipit-source-id: 7cacbe28172ebb5849135567b1d734870b49de77
Summary:
Also updates the doc such that the language matches the type. For example, previously the `tensors` argument is specified as `(sequence of tensor)`, but has type annotation of `_TensorOrTensors`. Now its correctly updated to be `Sequence[Tensor] or Tensor`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53827
Reviewed By: albanD
Differential Revision: D26997541
Pulled By: soulitzer
fbshipit-source-id: e1e609a4e9525139d0fe96f6157175481c90d6f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53614
Ensures that every subclass of `QuantizeHandler` has a clear name. This
prevents ambiguous names like `Cat`, which look like a module but are
really a quantize handler.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26914784
fbshipit-source-id: 6dca7e27975c09f422f8e36f1d2b709bf3eaaadf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53196
Before this PR, code patterns like this did not work:
```
x = some_quant_layer(x)
x = torch.stack([x, ...])
x = torch.sum(x, ...)
```
The reason this did not work is because `torch.sum` is treated as
"quantized" because of the newly added fp16 support, even though it is
not actually "quantized" for models where fp16 is not used. We may
need to adjust the concept of "quantized vs non-quantized" into a
"dtype" for the longer term fix.
The current PR is a hacky fix to unblock. We need to clean things
up before this is landable
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_quant_sum
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26783960
fbshipit-source-id: 3be7c3c1eaa2b8fcb99a105e1b0004c9ffd3a1c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53187
Before this diff, if we had code lik
```
x = any_quant_layer(...)
x_size0 = x.size(0)
torch._assert(x_size_0 == 1)
```
The convert code would try to insert a dequantize after `x_size0`,
because it was a descendant of a quantized node and it was needed
for a non-quantized operation. Since the actual type of the `size`
function output is an integer, this does not make sense.
For now, this is fixed as a one-off to unblock a customer. In the
future, we may need to think more deeply about all the functions which
can return non-quantized types from quantized tensors and make sure
they are all covered.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_assert_on_size_after_quant_layer
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26780690
fbshipit-source-id: 44cc25c9179d460efb3f110d40b73d854d676af5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53120
Currently there is a pattern which is not handled correctly by
FX graph mode quantization:
```
def forward(self, x):
ndim = x.ndim
# or add, mul, div, etc
x = torch.sub(x, ndim)
return x
```
The reason this does not work is as follows:
1. x.ndim becomes a getattr node
2. the real world type of x.ndim is an integer, but this is not known from the graph (yet)
3. binary ops such as `torch.sub` require quantization of inputs
4. the framework inserts an observer to observe the output of `ndim`
5. the observer fails because `ndim` is not a Tensor
For now, we hack a bandaid to unblock some teams, none of this is for
land. We will have to think of a better fix which is landable (TBD).
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_getattr_with_nontensor_result
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26756180
fbshipit-source-id: c0e498766b22c23df74fbb5aaeaa237c4c944263
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53860
Fixes [#53840](https://github.com/pytorch/pytorch/issues/53840)
Right now [TCPStore wait([LIST_OF_KEYS_TO_AWAIT])](https://pytorch.org/docs/master/distributed.html#torch.distributed.Store.wait) will hang if any of the keys in [LIST_OF_KEYS_TO_AWAIT] has been previously set. This change will ensure that wait() is only waiting for the keys that have not been set
Before change:
```
# Case 1: HANG
store.set("1", "1")
store.wait(["1", "2"])
store.set("2", "2")
# Case 2: SUCCEED
store.wait(["1", "2"])
store.set("1", "1")
store.set("2", "2")
```
After change:
Both cases work
TODO: working on adding a test for wait()
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D26999929
Pulled By: H-Huang
fbshipit-source-id: 8931749923c98b520366538f785af82ef37cca8e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53529
Supported for ONNX export after opset 10.
This is not exportable to opsets < 10 due to
1. onnx::IsInf is introduced in opset 10
2. onnx::Equal does not accept float tensor prior to opset 11
Test Plan: Imported from OSS
Reviewed By: pbelevich, malfet
Differential Revision: D26922418
Pulled By: SplitInfinity
fbshipit-source-id: 69bcba50520fa3d69db4bd4c2b9f88c00146fca7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53312
- Add support for aten::repeat_interleave
- NOTE: Also adds fix for cases with split op where input tensor sizes are not known but _outputs is provided
Test Plan: Imported from OSS
Reviewed By: pbelevich, malfet
Differential Revision: D26922422
Pulled By: SplitInfinity
fbshipit-source-id: 5362d0d8ccfdc14c15e1ae73fd70c4c113f823e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53308
* Update tests for test_gru_* at this moment.
* Update flake8 error.
* Update tests for test_gru_* at this moment.
* Update flake8 error.
* Update test_gru_* test cases only.
* Fix flake8 issue.
* Fix flake8 issue on test.
* Still disable test cases created by make_test.
* Update code to fix issue 'AttributeError: 'RecursiveScriptModule' object has no attribute 'forward'' for test_elman_* test cases.
* Add script model support for test_lstm_* test cases.
Test Plan: Imported from OSS
Reviewed By: pbelevich, malfet
Differential Revision: D26922419
Pulled By: SplitInfinity
fbshipit-source-id: a96432b2e7da9b142a38f87fbaf56737117462c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53307
This PR did symbolic shape inference, in the onnx pass _jit_pass_onnx_graph_shape_type_inference.
It creates a singleton ConstantValueMap.
It leverages constant folding technique and did a per-op based handling for ConstantValueMap.
As a byproduct, it enables fold_if pass for dynamic axes cases, typically for faster-rcnn etc.
The core change is in `torch/csrc/jit/passes/onnx/shape_type_inference.cpp` and `torch/csrc/jit/passes/onnx/constant_map.cpp`.
We usually need copy tensor to store in the ConstantValueMap, otherwise the underlying value may change. I see this issue in (1) from_blob (2) get value from Constant node.
Test Plan: Imported from OSS
Reviewed By: pbelevich, malfet
Differential Revision: D26922414
Pulled By: SplitInfinity
fbshipit-source-id: 7654dc13d1de8d9496ad4be89f1454260d7bdeb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53306
* [ONNX] Fix for sequence of mutations in blocks (#51577)
Fixes consecutive mutations in a tensor inside blocks.
Also, support append and pop in blocks.
* Support inplace operations + indexing
* Clean up old pass for remove mutations
* Add loop test
* Fixes for set attr in loops
* Removing the new jit API flag
* [ONNX] Redesign onnx pass to enable shape type dependent pattern conversion - cont (#51795)
With the introduction of ONNX shape inference, shape and type are inferred on the fly as operators get converted from ATen to ONNX when running symbolic function. This resolves the shape/type requirement for the symbolic functions. The pre-onnx passes however, can not be supported by shape inference, since at that stage the operators in the graph are still ATen operators.
This PR is to update the design of ONNX pass, to enable a mechanism of capturing subgraphs of ATen operators of certain patterns, and convert them later, when shape/type information of upstream operators are available.
The new design will require pre-onnx passes that need shape/type to be written in two parts, encapsulation and conversion.
The encapsulation part will find the nodes of patterns, like how pre-onnx passes were written previously. But instead of converting the nodes, it will encapsulate them into a sub-block of a new placeholder node. This part is called before onnx pass, so it runs before calling symbolic functions.
The conversion part will be called inside the onnx pass. In onnx pass, run_symbolic_func will be called for each node in topological order. When it reaches the placeholder node, the conversion part will be invoked. It will convert the nodes inside the sub-block based on pattern. By that time, it will have shape/type of upstream operators available. After the conversion is complete, the placeholder node will be removed, and nodes inside its sub-block converted. Run_symbolic_func will be called for these nodes, and they will be converted from ATen operator to ONNX operator.
This PR includes several other fixes, listed below.
* ~~replace helper.cpp with onnx_utils.cpp for holding utility functions.~~
* fix EraseNumberTypes on Bool type, the code was outdated that back then Bool type doesn't exist.
* ~~enable onnx shape inference in export with parameter/initializer data.~~
* other code clean ups.
* fix insertion of identity nodes for loop opset 13 sequence output.
~~PR depends on #51603~~
* Fix after merge
* clang
* Fix clang
* Fix clang
* Fix warning message.
* Fixes for non-model param attributes
* Fix for caffe2
* Additional test
* clang
* Skip test for lower opsets
* fix clang-tidy
* Update init.cpp
* Update remove_inplace_ops_for_onnx.cpp
* Update remove_inplace_ops_for_onnx.cpp
* Update remove_inplace_ops_for_onnx.cpp
* Fix for clang formatting
Test Plan: Imported from OSS
Reviewed By: pbelevich, malfet
Differential Revision: D26922416
Pulled By: SplitInfinity
fbshipit-source-id: e7108620b39b6404c594910786c4d275fee59d84
Co-authored-by: Bowen Bao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53305Fixes#52436
For opset 9 of onnx Pow, if X is int32, Y is float, we will cast back to int32 which is consistent with X type.
However, pytorch is still float. The aten graph sometimes does not bind with the type for operators,
we are fine with the float type and don't want to cast back.
Even if X, Y are int32, the resulting float32 and int32 makes no difference.
Test Plan: Imported from OSS
Reviewed By: pbelevich, malfet
Differential Revision: D26922425
Pulled By: SplitInfinity
fbshipit-source-id: f8c09524acee0de615df10a14310ca1dd583831e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53786
To generate `selected_mobile_ops.h` in OSS, move the header file codegen functions to `tools/lite_interpreter/gen_selected_mobile_ops_header.py` file, so OSS can reuse these functions.
ghstack-source-id: 123754437
Test Plan:
```
buck test //xplat/caffe2:supported_mobile_models_test
```
```
buck run //xplat/caffe2:gen_oplist -- --model_file_list_path @/data/users/chenlai/data/pytorch/oplist_folder/file_list_path.macro --allow_include_all_overloads --output_dir /home/chenlai/local/data/pytorch/oplist_folder
```
`file_list_path.macro` content is:
```
chenlai@devvm2090:~/fbsource(45a9b7888)$ cat /data/users/chenlai/data/pytorch/oplist_folder/file_list_path.macro
/data/users/chenlai/fbsource/buck-out/gen/aab7ed39/xplat/caffe2/supported_mobile_models_test_op_list/model_operators.yaml
```
In output folder `/home/chenlai/local/data/pytorch/oplist_folder`, these files are generated:
```
selected_mobile_ops.h selected_operators.yaml SupportedMobileModelsRegistration.cpp
```
the generated files are the same as before.
{P282056731}
{P282055046}
Reviewed By: dhruvbird, iseeyuan
Differential Revision: D26907868
fbshipit-source-id: 9ba786f9c5674a72cad237ae7baadbe4642c51d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53861
Replaced the iterators in the for-loops with integer index variables due to
overflow when handling empty vectors.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26998894
Pulled By: huiguoo
fbshipit-source-id: a1f6475c8ba123968ef7247b4f6f38edbf24b9ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53795
There are 4 calls in ddp implementation to dist.get_rank(), move these
to a helper property to ensure that users don't actually call `dist.get_rank()`
instead of `dist.get_rank(self.process_group)`.
Keeping API private for now because not sure if there is a user need to call `model.distributed_rank`, but can make it public if we think it's a useful api.
ghstack-source-id: 123640713
Test Plan: Ci
Reviewed By: mrshenli
Differential Revision: D26972368
fbshipit-source-id: a5f1cac243bca5c6f90a44f74d39cfffcc2b9a5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53793
This call should pass in the process group so it works appropriately
for subgroups instead of whole world being passed into DDP.
Aside: This wasn't caught by tests since we don't have good testing around
passing subgroups into DDP, I believe nearly all tests use the entire world.
Should we add better testing for subgroups which may potentially bring up more
subtle bugs?
ghstack-source-id: 123640712
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D26972367
fbshipit-source-id: 8330bd51e2ad66841e4c12e96b67d3e78581ec74
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52581
The git diff is absolutely atrocious since I also refactored the code to share stuff between `Load` and `FunctionCall`.
Biggest questions I have about this diff are:
1. The asserts I added. From my understanding it's not possible to have a constant index in `Store` that's non-zero, since `Store` always creates a new buffer. Perhaps the user can write this kind of incorrect code, though, so perhaps I should just check for it and not assert it?
2. I don't think(?) I need to do any special handling for `index_vars`, but wasn't totally able to track the logic there.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53254
Reviewed By: albanD
Differential Revision: D26991064
Pulled By: Chillee
fbshipit-source-id: 0bcd612d5f4b031c0b34e68a72d9c8d12d118be8
Summary: When libkineto is initialized from the PyTorch Profiler, if it fails we will not know why because errors are not reported. Reporting errors is not always safe, e.g. if init happens from static initialization or a dlopen library constructor function, so add a flag to specify whether to log.
Test Plan: Testing in PyTorch OSS build.
Reviewed By: chaekit
Differential Revision: D26927500
fbshipit-source-id: 2a78005239a5fcbe7e1de82e5405f04e07000fa8
Summary:
When a system has an ampere and a non-ampere card, lots of tests will fail, because results on different cards are differnet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52941
Reviewed By: albanD
Differential Revision: D26994287
Pulled By: mrshenli
fbshipit-source-id: 287537495fc13361104a4460f5bcd79a208b5d8d
Summary:
Enabling the test cases because they are passing for ROCm.
Signed-off-by: Kyle Chen <kylechen@amd.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52708
Reviewed By: albanD
Differential Revision: D26994458
Pulled By: mrshenli
fbshipit-source-id: f0b3797c7889287a0154b1d5397df715ffb1c605
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53562
On Windows when we try to build //xplat/caffe2/c10:c10Windows, it failed with an error like
```
stderr: buck-out\gen\83497cbb\xplat\caffe2\c10\c10Windows#header-mode-symlink-tree-only,headers\c10/macros/Macros.h(189): error C2220: warning treated as error - no 'object' file generated
buck-out\gen\83497cbb\xplat\caffe2\c10\c10Windows#header-mode-symlink-tree-only,headers\c10/macros/Macros.h(189): warning C4067: unexpected tokens following preprocessor directive - expected a newline
```
See log here: https://www.internalfb.com/intern/buck/build/6eaea1f8-e237-4860-9f3b-3a8edd2207c6/
This is because Windows doesn't support `__has_attribute` keyword. Here I'm changing the ordering of `if` and `elif` so that we don't hit that line when build in Windows.
Test Plan: buck build //xplat/caffe2/c10:c10Windows xplat/mode/windows
Reviewed By: kimishpatel, swolchok
Differential Revision: D26896510
fbshipit-source-id: d52438a3df7bf742e467a919f6ab4fed14484f22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53855
Remove "noindex" here:
{F492926346}
ghstack-source-id: 123724419
Test Plan:
waitforbuildbot
The failure on doctest does not seem to be relevant.
Reviewed By: rohan-varma
Differential Revision: D26967086
fbshipit-source-id: adf9db1144fa1475573f617402fdbca8177b7c08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53433
As described in https://github.com/pytorch/pytorch/issues/53413, the
pipeline destructor ends up hanging sometimes. The reason for this is that Pipe
uses daemon threads and as a result these threads could be destroyed before the
Pipe destructor is done. The Pipe destructor then calls `join_workers` which
waits on signals from the worker threads, which might be already dead and
results in the main thread blocking forever.
To resolve this issue, in this PR we remove `join_workers` completely since it
is not necessary to wait for daemon threads.
#Closes: https://github.com/pytorch/pytorch/issues/53413
ghstack-source-id: 123641509
Test Plan:
1) Tested with repro in
https://github.com/pytorch/pytorch/issues/53413.
2) Hard to add a unit test for this since the bug really depends on order of
objects being destroyed.
Reviewed By: rohan-varma
Differential Revision: D26863321
fbshipit-source-id: 18fff072cabacfb10390e971eac789859d3dcc81
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: d12fc485d5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53722
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D26949768
fbshipit-source-id: 718796736c0641b7cf6c5b0617fc744a090c78c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53780
Update the comment, because the input data type of `fp16_compress_hook` does not have to be FP32. For example, the input dtype can also be FP64, as long as it can be casted into FP16.
ghstack-source-id: 123680621
Test Plan: N/A
Reviewed By: iseessel
Differential Revision: D26967224
fbshipit-source-id: 26d79a3629a597e6335b6f59c97d25a764a8ed80
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52949
Enables distributed profiling which we have for gloo and nccl for the MPI backend
ghstack-source-id: 123610105
Test Plan: CI
Reviewed By: wanchaol
Differential Revision: D26591590
fbshipit-source-id: a20ec9d104faa26bc62c727dd01319c3ea230f5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53402
Add an `options` field to the `Save` operator which accepts options for how to
serialize different blobs. At the moment this simply allows controlling the
existing `chunk_size` behavior, but in the future we can add other options,
such as the ability to control compression settings or other serialization
formats.
ghstack-source-id: 123567034
Test Plan:
Added a new test to `load_save_test.py` that passes in options and verifies
that blobs were serialized with the expected number of chunks.
buck test caffe2/caffe2:caffe2_test_cpu \
caffe2/caffe2/core:serialization_test \
caffe2/caffe2/python/operator_test:load_save_test
Reviewed By: mraway
Differential Revision: D26502577
fbshipit-source-id: 6e302e530bb96990517c2e35c505db7f14a56284
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 2719d7e0b7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53810
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D26979037
fbshipit-source-id: d0cc7c25b764d5f207431a839f396fb8e22b2a22
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53833.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53834
Test Plan: The CI logs for flake8-py3 and clang-tidy on this PR should show `commit_sha` being set to the PR tip in their respective "Add annotations" steps.
Reviewed By: malfet
Differential Revision: D26983201
Pulled By: samestep
fbshipit-source-id: e5d1fbbaf2a2611fec583b430c6353e778bc77a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53304
With the introduction of ONNX shape inference, shape and type are inferred on the fly as operators get converted from ATen to ONNX when running symbolic function. This resolves the shape/type requirement for the symbolic functions. The pre-onnx passes however, can not be supported by shape inference, since at that stage the operators in the graph are still ATen operators.
This PR is to update the design of ONNX pass, to enable a mechanism of capturing subgraphs of ATen operators of certain patterns, and convert them later, when shape/type information of upstream operators are available.
The new design will require pre-onnx passes that need shape/type to be written in two parts, encapsulation and conversion.
The encapsulation part will find the nodes of patterns, like how pre-onnx passes were written previously. But instead of converting the nodes, it will encapsulate them into a sub-block of a new placeholder node. This part is called before onnx pass, so it runs before calling symbolic functions.
The conversion part will be called inside the onnx pass. In onnx pass, run_symbolic_func will be called for each node in topological order. When it reaches the placeholder node, the conversion part will be invoked. It will convert the nodes inside the sub-block based on pattern. By that time, it will have shape/type of upstream operators available. After the conversion is complete, the placeholder node will be removed, and nodes inside its sub-block converted. Run_symbolic_func will be called for these nodes, and they will be converted from ATen operator to ONNX operator.
This PR includes several other fixes, listed below.
* ~~replace helper.cpp with onnx_utils.cpp for holding utility functions.~~
* fix EraseNumberTypes on Bool type, the code was outdated that back then Bool type doesn't exist.
* ~~enable onnx shape inference in export with parameter/initializer data.~~
* other code clean ups.
* fix insertion of identity nodes for loop opset 13 sequence output.
~~PR depends on #51603~~
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D26922417
Pulled By: malfet
fbshipit-source-id: 14ed06158d539e2451c2e5e63ba1b32fb0f75095
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53681
Without throwing, we can easily segfault trying to access nullptr
storage.
To do this I made set_storage_access_should_throw public so that you
don't have to subclass TensorImpl to do it. An alternative is
to just bite the bullet and add a MetaTensorImpl subclass. Let
me know what is preferred.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D26955540
Pulled By: ezyang
fbshipit-source-id: 8ce22dd07ef1beb042f1d91de981954d59c2f84a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53726
In quantized linear layers, during deserialization we create scales and zero
points which are later used for qnnpack kernels.
Scales and zero pointer extraction for per channel quantized tensors is slow.
This is due to the fact that we index directly into zero point and scales
tensor and this indexing creates a tensor slice of 1 element which is then cast
to int32 or float.
This is super slow and increases model loading time.
This diff fixes that.
Test Plan: CI
Reviewed By: raziel
Differential Revision: D26922138
fbshipit-source-id: b78e8548f736e8fa2f6636324ab1a2239b94a27c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53585
Previously fp16_static CopyNode would be marked as unquantized because of
an incorrect condition check of whether a Node is statically quantized or not.
This PR fixes that.
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D26912677
fbshipit-source-id: 4ddb538714c5ba2db28430de5e1cf2931baf1993
Summary:
This PR makes changes to how hipfft is loaded in pytorch. hipfft is packaged in a separate library to rocfft following rocm 4.1.
We check the rocm version and if it is past rocm 4.1 we load hipfft in addition to rocfft.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53408
Reviewed By: albanD
Differential Revision: D26952702
Pulled By: malfet
fbshipit-source-id: f42be304b587c060816e39d36f5c1a2cdc37bfab
Summary:
This PR replaces our current "Checkout PR tip" step (which is duplicated across many places) using a [scenario](https://github.com/actions/checkout#checkout-pull-request-head-commit-instead-of-merge-commit) from the `actions/checkout` README. We previously tried something similar in https://github.com/pytorch/pytorch/issues/49578, but using `github.head_ref` didn't work.
The reason this PR works is because, for events besides `pull_request`, the value of `github.event.pull_request.head.sha` defaults to the empty string, so it's as if we didn't set the `ref` option for `actions/checkout` at all, so it just uses its default behavior (e.g. for `push` events).
Incidentally, this PR also upgrades our use of `actions/checkout` from `v1` to `v2`, which introduces shallow clones by default. A couple of our jobs require deep clones, so we use `fetch-depth: 0` in those cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53719
Test Plan: CI.
Reviewed By: albanD
Differential Revision: D26949121
Pulled By: samestep
fbshipit-source-id: e06f8066682ae0557fb5a055a10ea33b6bd320db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53769
The local autograd engine performs appropriate stream synchronization
between autograd nodes in the graph to ensure a consumer's stream is
synchronized with the producer's stream before executing the consumer.
However in case of distributed autograd, the SendRpcBackward function receives
gradients over the wire and TensorPipe uses its own pool of streams for this
purpose. As a result, the tensors are received on TensorPipe's stream pool but
SendRpcBackward runs on a different stream during the backward pass and there
is no logic to synchronize these streams.
To fix this, I've enhanced DistEngine to synchronize these streams
appropriately when it receives grads over the wire.
ghstack-source-id: 123607221
Test Plan:
1) Added unit test which reproduced the issue.
2) waitforbuildbot.
Reviewed By: wanchaol, mrshenli
Differential Revision: D26955317
fbshipit-source-id: eace6d4f91d4006c9c16ede5ac16362ada052406
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50577
Learning rate schedulers had not yet been implemented for the C++ API.
This pull request introduces the learning rate scheduler base class and the StepLR subclass. Furthermore, it modifies the existing OptimizerOptions such that the learning rate scheduler can modify the learning rate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52268
Reviewed By: mrshenli
Differential Revision: D26818387
Pulled By: glaringlee
fbshipit-source-id: 2b28024a8ea7081947c77374d6d643fdaa7174c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53781
needed for running noise suppression model in lite interpreter
Test Plan: run model
Reviewed By: linbinyu
Differential Revision: D26967227
fbshipit-source-id: 19677fc796f1fb4423ebb11b5ffd9df5870a39cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53752
This test doesn't work today because we don't properly vectorize
"FunctionCall" (which is the way one accesses an intermediate tensor).
ghstack-source-id: 123592860
Test Plan: `buck test //caffe2/test/cpp/tensorexpr -- LoopNest.VectorizeUse`
Reviewed By: ZolotukhinM
Differential Revision: D26895550
fbshipit-source-id: 0798ebf3e6a834bd70181732c81528455d5329fa
Summary:
* Replacing vector of Tensors with a set of output buffers in `TensorExprKernel`.
* Creating a block statement while compiling in `TensorExprKernel`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53688
Reviewed By: mrshenli
Differential Revision: D26941222
Pulled By: navahgar
fbshipit-source-id: 9eb81ec2effcdeafbeaa67d1e12475166054f80f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53670
This puts deploy into the torch::deploy namespace. It also renames some
objects to better match their behavior:
PythonObject -> Obj, in the future it will refer to either a python object or a handle to a script obj, so rename it torch::deploy::Obj to be generic
MovableObject -> ReplicatedObj, to prevent confusion with "std::move" which is unrelated, and to note that we are replicating this object across interpreters.
Test Plan: Imported from OSS
Reviewed By: wconstab
Differential Revision: D26932131
Pulled By: zdevito
fbshipit-source-id: 8041d6c5b2041a7c3192c1a17d2edb38112a89f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53751
Sometimes the initial value of a reduction expression needs to be
computed with reference to the loop axes; for example, adding bias can be
efficiently represented by initializing the accumulator from the bias tensor:
```
C[n, c, h, w] = bias[c]
for (...)
C[n, c, h, w] += ...
```
ghstack-source-id: 123592861
Test Plan: `buck test //caffe2/test/cpp/tensorexpr -- Reductions.InitFunction`
Reviewed By: navahgar
Differential Revision: D26940321
fbshipit-source-id: 8a08e19e5d0b9ad453a07fab8b61e75dcd3d626b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53330
Fixed a condition check for fixed qparam ops, previously we were including CopyNodes as well
Test Plan:
python test/test_quantization.py TestQuantizeFxOps.test_fixed_qparams_ops_fp16
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D26836867
fbshipit-source-id: 8c486155244f852e675a938c3f4237f26505671c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50002
The last commit adds tests for 3d conv with the `SubModelFusion` and `SubModelWithoutFusion` classes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50003
Reviewed By: mrshenli
Differential Revision: D26325953
Pulled By: jerryzh168
fbshipit-source-id: 7406dd2721c0c4df477044d1b54a6c5e128a9034
Summary:
When calling `TensorIterator::for_each` with a 1d loop, it creates a `function_ref` for the 1D iteration, then wraps it with `LOOP_WRAPPER` to transform it into a 2d loop. That 2d loop then gets wrapped in another `function_ref`. This can result in significant overhead if the 1d inner loop is over a small number of elements.
Instead, this wraps the 1d loop before type-erasure so only one level of `function_ref` is introduced. A simple benchmark demonstrates this is a win:
```python
import torch
a = torch.rand((10000, 2))[::2]
%timeit a + a
```
Note the 2D tensor cannot be coalesced into 1D and both `cpu_kernel` and `cpu_kernel_vec` use 1D for_each. On master, this takes 42 us but with this change it's down to 32us.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53613
Reviewed By: VitalyFedyunin
Differential Revision: D26947143
Pulled By: ezyang
fbshipit-source-id: 5189ada0d82bbf74170fb446763753f02478abf6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53253
Since GradBucket class becomes public, mention this class in ddp_comm_hooks.rst.
Screenshot:
{F478201008}
ghstack-source-id: 123596842
Test Plan: viewed generated html file
Reviewed By: rohan-varma
Differential Revision: D26812210
fbshipit-source-id: 65b70a45096b39f7d41a195e65b365b722645000
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53596
This description will be used in ddp_comm_hook docstrings.
ghstack-source-id: 123590360
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D26908160
fbshipit-source-id: 824dea9203ca583676bddf0161c9edca52c9d20e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53749
Split up tests into cases that cover specific functionality. Goals:
1. Avoid the omnibus test file mess (see: test_jit.py) by imposing early
structure and deliberately avoiding a generic TestPackage test case.
2. Encourage testing of individual APIs and components by example.
3. Hide the fake modules we created for these tests in their own folder.
You can either run the test files individually, or still use
test/test_package.py like before.
Also this isort + black formats all the tests.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D26958535
Pulled By: suo
fbshipit-source-id: 8a63048b95ca71f4f1aa94e53c48442686076034
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53401
This is a reland of D26641599 (cd9ac54ea7) after rebasing onto D26802576 (f595ba1bae).
Add some small utility functions to read the blob names back from the minidb
file so that we can verify how many chunks were written for each blob.
ghstack-source-id: 123567033
Test Plan: buck test caffe2/caffe2/python/operator_test:load_save_test
Reviewed By: mraway
Differential Revision: D26853942
fbshipit-source-id: 0b45078fdd279f547752c8fdb771e296374a00da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53400
This is a reland of D26617038 (b4a8d98247) after rebasing onto D26802576 (f595ba1bae).
Optimize the blob serialization code by using `AddNAlreadyReserved()` when
serializing tensor data, rather than making N separate `Add()` calls.
`AddNAlreadyReserved()` is a simple addition operation, while each `Add()`
call checks to see if it needs to reserve new space, and then updates the
element data, which is unnecessary in this case.
ghstack-source-id: 123567030
Test Plan:
This appears to improve raw serialization performance by 30 to 35% for float,
double, and int64_t types which use this function. This improvement appears
relatively consistent across large and small tensor sizes.
Reviewed By: mraway
Differential Revision: D26853941
fbshipit-source-id: 4ccaa5bc1dd7f7864068d71a0cde210c699cbdba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53665
ngimel pointed out to me where we already test the behavior of the `Upsample` ops in `test_nn.py`. This PR deleting my bespoke tests in `test_torch.py` and updates those in `test_nn.py` to test memory format properly.
There were two reasons the original test didn't pick up on a memory format regression:
- They didn't test the memory format of the output tensor explicitly, i.e. `output.is_contiguous(memory_format=...)`
- Even with that change, the test tensors were to simple to fail the tests. From some trial and error, it looks like one of the first two dimensions in the inputs needs to be > 1 in order for the `channels_last` memory format to actually re-order the strides.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D26929683
Pulled By: bdhirsh
fbshipit-source-id: d17bc660ff031e9b3e2c93c60a9e9308e56ea612
Summary:
A number of derived distributions use base distributions in their
implementation.
We add what we hope is a comprehensive test whether all distributions
actually honor skipping validation of arguments in log_prob and then
fix the bugs we found. These bugs are particularly cumbersome in
PyTorch 1.8 and master when validate_args is turned on by default
In addition one might argue that validate_args is not performing
as well as it should when the default is not to validate but the
validation is turned on in instantiation.
Arguably, there is another set of bugs or at least inconsistencies
when validation of inputs does not prevent invalid indices in
sample validation (when with validation an IndexError is raised
in the test). We would encourage the implementors to be more
ambitious when validation is turned on and amend sample validation
to throw a ValueError for consistency.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53600
Reviewed By: mrshenli
Differential Revision: D26928088
Pulled By: neerajprad
fbshipit-source-id: 52784a754da2faee1a922976e2142957c6c02e28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51676
We offer the ability to access the importer from within packaged modules by doing
`import resources`. This behavior is nice (and more powerful than the
importlib resources API), but I think `resources` is too common a name
(pip has a package for it)
Change to `import torch_package_importer` but open to bikeshedding
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D26620314
Pulled By: suo
fbshipit-source-id: 0942c99f02c0f55f5f3a1b2566961018b796bdd4
Summary:
Meant to make tasks like https://github.com/pytorch/pytorch/issues/53728 easier. The `-n` flag enables line numbers, and the `-o` flag reduces noise by only showing the part of the line that matched (which in this case is just the trailing whitespace).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53733
Test Plan:
```
$ git checkout e937db5dbaeaeae1134b02b3b78c43db3f6a91cd
```
Before:
```
$ (! git grep -I -l ' $' -- . ':(exclude)**/contrib/**' ':(exclude)third_party' || (echo "The above files have trailing spaces; please remove them"; false))
aten/src/ATen/native/cuda/BatchLinearAlgebra.cu
The above files have trailing spaces; please remove them
```
After:
```
$ (! git grep -I -no ' $' -- . ':(exclude)**/contrib/**' ':(exclude)third_party' || (echo "The above files have trailing spaces; please remove them"; false))
aten/src/ATen/native/cuda/BatchLinearAlgebra.cu:1972:
The above files have trailing spaces; please remove them
```
Reviewed By: mruberry
Differential Revision: D26953538
Pulled By: samestep
fbshipit-source-id: 5f7d48b79f1a02e5e5a09fe00316ec350cfc340e
Summary:
This uses the shape of the tensor instead of directly indexing it. This is useful when extending PyTorch's tensor class, e.g. for lazy access. Since the `init` sub-module doesn't check for `torch_function`, it is not possibly to override its functions. Explicitly indexing the tensor will force a call to tensor() and reconstruct the full tensor/explicitly access the elements. Simply using the shape allows to avoid that.
Fixes https://github.com/pytorch/pytorch/issues/53540
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53522
Reviewed By: anjali411
Differential Revision: D26947794
Pulled By: jbschlosser
fbshipit-source-id: 80cd65efed16383f21363cee2eb404c9bc05971c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53148
clang format reducer and logger files
ghstack-source-id: 123453983
Test Plan: unit test
Reviewed By: SciPioneer
Differential Revision: D26764509
fbshipit-source-id: 711efcfd77420f912861cfd20c69e3af5086f4b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53162
it is possible there are multiple data types in mixed precision training, so log data types as a list of data type names.
ghstack-source-id: 123452626
Test Plan: unit test
Reviewed By: SciPioneer
Differential Revision: D26769256
fbshipit-source-id: 8f7d73821e89864fedbbce723f301fe8fbad5685
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53145
add a new API to allow users to set sample rate for runtime stats, also add per iteration latency breakdowns to DDPLoggingData struct. e.g.
if users set sample rate to be 1, they can analyze per iteration latency change over time (not avged)
ghstack-source-id: 123443369
Test Plan: unit test
Reviewed By: SciPioneer
Differential Revision: D26763957
fbshipit-source-id: baff6a09c2a590e6eb91362ca6f47ae8fa6ddb0e
Summary:
As per title. Compared to the previous version, it is lighter on the usage of `at::solve` and `at::matmul` methods.
Fixes https://github.com/pytorch/pytorch/issues/51621
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52875
Reviewed By: mrshenli
Differential Revision: D26768653
Pulled By: anjali411
fbshipit-source-id: aab141968d02587440128003203fed4b94c4c655
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53567
Updating gradle to version 6.8.3
Proper zip was uploaded to aws.
Successful CI check: https://github.com/pytorch/pytorch/pull/53619
Test Plan: Imported from OSS
Reviewed By: dreiss
Differential Revision: D26928885
Pulled By: IvanKobzarev
fbshipit-source-id: b1081052967d9080cd6934fd48c4dbe933630e49
Summary:
**Update:** MAGMA support was dropped from this PR. Only the cuSOLVER path is implemented and it's used exclusively.
**Original PR message:**
This PR adds support for CUDA inputs for `torch.orgqr`.
CUDA implementation is based on both [cuSOLVER](https://docs.nvidia.com/cuda/cusolver/index.html#cuSolverDN-lt-t-gt-orgqr) and MAGMA. cuSOLVER doesn't have a specialized routine for the batched case. While MAGMA doesn't have a specialized GPU native (without CPU sync) `orgqr`. But MAGMA has implemented (and not documented) the batched GPU native version of `larft` function (for small inputs of size <= 32), which together with `larfb` operation form `orgqr` (see the call graph [here at the end of the page](http://www.netlib.org/lapack/explore-html/da/dba/group__double_o_t_h_e_rcomputational_ga14b45f7374dc8654073aa06879c1c459.html)).
So now there are two main codepaths for CUDA inputs (if both MAGMA and cuSOLVER are available):
* if `batchsize > 1` and `tau.shape[-1] <= 32` then MAGMA based function is called
* else [cuSOLVER's `orgqr`](https://docs.nvidia.com/cuda/cusolver/index.html#cuSolverDN-lt-t-gt-orgqr) is used.
If MAGMA is not available then only cuSOLVER is used and vice versa.
Documentation updates and possibly a new name for this function will be in a follow-up PR.
Ref. https://github.com/pytorch/pytorch/issues/50104
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51348
Reviewed By: heitorschueroff
Differential Revision: D26882415
Pulled By: mruberry
fbshipit-source-id: 9f91ff962921932777ff108bedc133b55fe22842
Summary:
This PR:
1. refactors the logic for S3 stats gathering.
2. Renames SLOW_TESTS to TARGET_DET_LIST to disambiguate and remove confusion with slowTest
2. detects slow tests (tests with time > 5min) to add to the TARGET_DET_LIST based on results in S3 from the previous nightly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53549
Test Plan:
Set CIRCLE_JOB to your favorite CI job (like `pytorch_linux_bionic_py3_8_gcc9_coverage_test1`).
Run `python test/run_test.py --determine-from=<your fave pytorch files>`
e.g., `python test/run_test.py --determine-from=test/run_test.py`
Reviewed By: mrshenli
Differential Revision: D26904478
Pulled By: janeyx99
fbshipit-source-id: 9576b34f4fee09291d60e36ff2631753a3925094
Summary:
Removing a tiny bit of unneeded reference to cuda92 for windows binary. Note that the config.yml did not change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53716
Reviewed By: VitalyFedyunin
Differential Revision: D26947029
Pulled By: janeyx99
fbshipit-source-id: 3bbf1faa513756eda182d2d80033257f0c629309
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53617
I'm trying to make `pytest test/*.py` work--right now, it fails during
test collection. This removes a few of the easier to fix pytest
collection problems one way or another. I have two remaining problems
which is that the default dtype is trashed on entry to test_torch.py and
test_cuda.py, I'll try to fix those in a follow up.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D26918377
Pulled By: ezyang
fbshipit-source-id: 42069786882657e1e3ee974acb3ec48115f16210
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53611
fill_ now uses DispatchStub which means it only works for
CPU/CUDA.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D26918374
Pulled By: ezyang
fbshipit-source-id: fc899c28f02121e7719b596235cc47a0f3da3aea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53610
I noticed these because I was running the test suite under
meta device and triggered these error checks without getting
a NotImplementedError. Well, now they raise.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D26918376
Pulled By: ezyang
fbshipit-source-id: 20d57417aa64875d43460fce58af11dd33eb4a23
Summary:
Fixes https://github.com/pytorch/pytorch/issues/48841 for half datatype (it was fixed for other datatypes before).
The reason for https://github.com/pytorch/pytorch/issues/48841 happening for half was that `exponential_` for half was producing 0s.
Exponential distribution implementation on cuda is here e08aae2613/aten/src/ATen/native/cuda/DistributionTemplates.h (L535-L545)
with `transformation::exponential` defined here
e08aae2613/aten/src/ATen/core/TransformationHelper.h (L113-L123)
It takes a uniformly distributed random number and takes `log` of it. If necessary, the result is then converted to low precision datatype (half). To avoid 0's, before applying `log`, ones are replaced with std::nextafter(1,0). This seems fine, because log(1-eps) is still representable in half precision (`torch.tensor([1.], device="cuda").nextafter(torch.tensor([0.], device="cuda")).log().half()` produces 5.96e-8) , so casting to `scalar_t` should work. However, since fast log approximation is used (`__logf`), the log result is ~3e-9 instead of more accurate 5.96e-8, and underflows when casting to half. Using `::log` instead of fast approximation fixes it, however, it comes with ~20% perf penalty on exponential kernel for fp32 datatype, probably more for half.
Edit: alternative approach used now is to filter all small values returned by transformation. The result is equivalent to squashing of 1's to 1-eps that was used before, and computing correct log of 1-eps (which is -eps, exactly equal even for doubles). This doesn't incur noticeable performance hit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53480
Reviewed By: mruberry
Differential Revision: D26924622
Pulled By: ngimel
fbshipit-source-id: dc1329e4773bf91f26af23c8afa0ae845cfb0937
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53068
Adds a ```bool is_available()``` method to the backend contract: it returns ```true``` if ```compile()``` and ```execute()``` can be called; ```false``` otherwise.
It is used to implement the following changes in the ```LoweredModule```:
* ```compile()``` in ```__setstate__``` will run if ```is_available()```, else ```__setstate__``` throws an exception (“Backend not available.”).
* ```compile()``` at ```LoweredModule``` creation will run if ```is_available()```, else a WARNING will be thrown.
* ```execute()``` will only be executed if ```is_available()``` returns true; else throws an exception (“Backend not available.”).
The goal of these changes is to ensure we have a well defined behaviour for the different combinations of backend availability on-host and on-target.
More specifically, backends may have different capabilities to compile and/or execute the Module, depending whether this happens on-host (i.e. where the program is being written) or on-target (where the program is being executed).
First of all, we know that "preprocess" always takes place, and that only happens on-host at creation time. So, we can assume that any compilation is needed/possible on-host then all of it could be pushed here.
Overall, we want to ensure the following:
**On host**
| compile | execute | Outcome |
| -- | -- | -- |
| No | No | On module creation, LoweredModule is generated, with a warning (since compilation and execution can still take place on-target). On module load, throws an exception (since execution is not possible). |
| No | Yes | This configuration should not be possible. This assumes the full compiler is not available, even if some work was done in preprocess the program cannot be finalized for execution. |
| Yes | No | In this case, the expectation would be for is_available() to return false, and compilation logic to move into preprocess. |
| Yes | Yes | All good. This is the only case that is_available() should return true. |
**On target**
| compile | execute | Outcome |
| -- | -- | -- |
| No | No | Loading the LoweredModule throws an exception. Since execution is not possible. |
| No | Yes | Basically this is another instance of Yes/Yes: compilation per se may not be possible on device, which means compile() can be called without issue but it is a no-op, and thus is_available should return true. Consequently, loading the LoweredModule: Succeeds, if the preprocessed module is ready for execution. Fails with exception otherwise. |
| Yes | No | This configuration should not be possible. Just putting here for completeness. |
| Yes | Yes | All good. This, along with No/Yes case (because compilation is assumed to have happened on-host, so it's just another instance of Yes/Yes), are the cases where is_available() should return true. |
**Refactoring existing code**
This change also updates other backends (Glow) code, to implement the is_available() method to have the same behaviour as before this change (i.e. always available).
This should not cause backward incompatibilities with already saved models since we're adding a new method to the PyTorchBackendInterface.
Models saved with the old interface that didn't have is_available() will still find the other 2 methods in the bound object (i.e. compile and execute), and the saved LoweredModule logic will be the old one.
**Future**
We plan to use is_available() to implement support for fallback to the PyTorch interpreter.
ghstack-source-id: 123498571
Test Plan: Added C++ (test_backend.cpp) and Python (test_backends.py) tests to validate the exceptions.
Reviewed By: jackm321, spaugh, iseeyuan
Differential Revision: D26615833
fbshipit-source-id: 562e8b11db25784348b5f86bbc4179aedf15e0d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53683
**Summary**
This commit fixes the BC test broken by #53410. There are no promises
about operator-level BC with the operators added and modified by that
PR, so this test failure does not represent a real backward
compatibility issue.
**Test Plan**
Ran the BC test locally by runniing `dump_all_schemas.py` and then
`check_backward_compatibility.py`.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D26936505
Pulled By: SplitInfinity
fbshipit-source-id: 829d5d78e4cba44feea382d0fbd66e77dee7eed2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53444
GraphModule construction has two options when constructing the base nn.Module: a dict of names to attrs to assign to the GraphModule, or another nn.Module to copy attrs from.
- For the dict case, add logic to explicitly register `nn.Tensors` that are not `nn.Parameter` as buffers on the GraphModule, else fall back to `__setattr__`.
- For the other `nn.Module` case, update so that it checks in the other module whether the attr to copy in is a buffer, and register it as such, else fall back to `__setattr__`.
Test Plan: Added tests for fetching params and buffers from a GraphModule using both dict and module `__init__`s
Reviewed By: jamesr66a
Differential Revision: D26860055
fbshipit-source-id: 8d9999f91fef20aaa10969558006fc356247591f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53638
Mostly slight edits, and deleting some outdated sections.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D26920600
Pulled By: ezyang
fbshipit-source-id: e3bda80ecb622a1fcfde64e4752ba89a71056340
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53634
Make the op signature of `static_runtime::to_copy` consistent with that of native_functions.yaml so it works with 2-5 args:
```
- func: to.dtype(Tensor self, ScalarType dtype, bool non_blocking=False, bool copy=False, MemoryFormat? memory_format=None) -> Tensor
variants: method
device_guard: False
```
(Note: this ignores all push blocking failures!)
Reviewed By: ajyu
Differential Revision: D26906726
fbshipit-source-id: b9203eb23619aba42b1bfed1a077401f9fe2ddf0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53410
**Summary**
This commit enables indexing into `ModuleList` using a non-literal
index if the LHS of the assignment statement of which the indexing is
the RHS is annotated with an interface type.
This feature already exists for `ModuleDict`, and this commit builds on
top of that implementation. A `prim::ModuleContainerIndex` operator is
emitted for any statement of the form `lhs: InterfaceType =
module_container[idx]`. The same operator has to be used for both
`ModuleDict` and `ModuleList` because serialization does not preserve
the metadata that indicates whether a `Module` is a `ModuleDict` or
`ModuleList`.
**Testing**
This commit extends the existing unit tests for non-literal `ModuleDict`
indexing to test non-literal `ModuleList` indexing.
**Fixes**
This commit fixes#47496.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D26857597
Pulled By: SplitInfinity
fbshipit-source-id: d56678700a264d79aae3de37ad6b08b080175f7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53535
During the port to structured kernels for upsample kernels, I missed that a subset of them explicitly pass `memory_format` information from the input to the output tensors.
Note 1:
I added the logic into the `meta` function of each op, which feels morally correct since this logic affects the output shape/metadata. One consequence is that all backend implementations will get the logic. I synced with fmassa that this seems reasonable.
Note 2:
This logic used to happen in the following operators, which this PR fixes:
- upsample_nearest3d
- upsample_trilinear3d
- upsample_nearest2d
- upsample_bilinear2d
I explicitly didn't patch the other upsample kernels, which look like they never forwarded memory_format information:
- `upsample_bicubic2d` (maybe this should though? `UpSampleBicubic2d.cpp` isn't currently written to do anything different for `channels_last` tensors)
- All of the `upsample_{mode}1d` operators. Probably because, afaik, channels_last isn't supported for 3d tensors
- The corresponding backwards operator for every upsample op.
Note 3:
I'm also wondering why memory_format isn't just directly a part of the `tensor::options()` method, which would cause all ops to universally forward memory_format information from input to output tensors, rather than just the upsample ops. My guess is:
- BC-breakage. I'm not sure whether this would really *break* people, but it's an API change
- performance. `tensor::options()` is called everywhere, and adding a call to `suggest_memory_format()` would probably noticeably hit microbenchmarks. We could probably deal with that by making `memory_format` a precomputed field on the tensor?
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D26891540
Pulled By: bdhirsh
fbshipit-source-id: b3845f4dd5646b88bf738b9e41fe829be6b0e5cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53317
This seems like it might help in cases where we have to call
`Tensor::contiguous`, but we expect that the tensor in question will
be contiguous a good portion of the time.
ghstack-source-id: 123203771
Test Plan:
Profiled AdIndexer on inline_cvr; time spent in
clip_ranges_gather_sigrid_hash_each_feature<int> was cut in half from
1.37% to 0.66%
Reviewed By: smessmer
Differential Revision: D26738036
fbshipit-source-id: b5db10783ccd103dae0ab3e79338a83b5e507ebb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53588
Remove `SRViewOperatorRegistry` and related code now that it's no longer needed.
Reviewed By: swolchok
Differential Revision: D26901367
fbshipit-source-id: fa73501cd785d4b89466cda81481aea892f8241f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53133
In light of some issues where users were having trouble installing CUDA
specific versions of pytorch we should no longer have special privileges
for CUDA 10.2.
Recently I added scripts/release/promote/prep_binary_for_pypi.sh (https://github.com/pytorch/pytorch/pull/53056) to make
it so that we could theoretically promote any wheel we publish to
download.pytorch.org to pypi
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D26759823
Pulled By: seemethere
fbshipit-source-id: 2d2b29e7fef0f48c23f3c853bdca6144b7c61f22
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53366
gchanan albanD
Thanks for the feedback. Did a first pass trying to address the concerns in the original issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53495
Reviewed By: mrshenli
Differential Revision: D26914768
Pulled By: albanD
fbshipit-source-id: fa049f1952ef05598f0da2abead9a5a5d3602f75
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 4b88f40a0e
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53632
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D26919594
fbshipit-source-id: 4ac25bbe883b3c2cd4c02bc75a6e2c6f41d2beb7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53434
Use `snprintf()` to avoid buffer overflows.
Also only throw an exception on error, instead of crashing the entire
application. A failure can occur if the caller supplies an invalid format
string.
ghstack-source-id: 123401582
Test Plan:
Ran the checkpoint tests:
buck test caffe2/caffe2/python/operator_test:checkpoint_test
Verified that the checkpoint file names logged in the output are the same
before and after this change.
I also tested manually changed the initial buffer size to 1 to confirm that
the code works when the initial buffer size is too small. I considered
updating the checkpoint_test.py code to test using long db names that would
exceed this limit, but I figured that long filenames was likely to cause
other problems on some platforms (Windows has a maximum path length of 260
characters up until pretty recent releases).
Differential Revision: D26863355
fbshipit-source-id: 8fc24faa2a8dd145471067718d323fdc8ce055d6
Summary: Build failed when `PYTORCH_QNNPACK_RUNTIME_QUANTIZATION` is unset. According to D21339044 (622f5b68f0) it seems like a typo.
Test Plan: buck build //xplat/caffe2/aten/src/ATen/native/quantized/cpu/qnnpack:pytorch_qnnpackWindows xplat/mode/windows-msvc-15.9
Reviewed By: kimishpatel
Differential Revision: D26907439
fbshipit-source-id: ac52eeef4ee70726f2a97b22ae65921b39aa0c0b
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: a11ddfdf99
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53599
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D26910634
fbshipit-source-id: a2bf808536e42b9208e5d9f88198ce64061385fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53424
Fixes https://github.com/pytorch/pytorch/issues/24807 and supersedes the stale https://github.com/pytorch/pytorch/issues/25093 (Cc Microsheep). If you now run the reproduction
```python
import torch
if __name__ == "__main__":
t = torch.tensor([1, 2, 3], dtype=torch.float64)
```
with `pylint==2.6.0`, you get the following output
```
test_pylint.py:1:0: C0114: Missing module docstring (missing-module-docstring)
test_pylint.py:4:8: E1101: Module 'torch' has no 'tensor' member; maybe 'Tensor'? (no-
member)
test_pylint.py:4:38: E1101: Module 'torch' has no 'float64' member (no-member)
```
Now `pylint` doesn't recognize `torch.tensor` at all, but it is promoted in the stub. Given that it also doesn't recognize `torch.float64`, I think fixing this is out of scope of this PR.
---
## TL;DR
This BC-breaking only for users that rely on unintended behavior. Since `torch/__init__.py` loaded `torch/tensor.py` it was populated in `sys.modules`. `torch/__init__.py` then overwrote `torch.tensor` with the actual function. With this `import torch.tensor as tensor` does not fail, but returns the function rather than the module. Users that rely on this import need to change it to `from torch import tensor`.
Reviewed By: zou3519
Differential Revision: D26223815
Pulled By: bdhirsh
fbshipit-source-id: 125b9ff3d276e84a645cd7521e8d6160b1ca1c21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53300
Float scale and bias are packed as per row parameters at the end of each row.
This takes 8 bytes. However if the number of elements in row are such that end
of row address is unaligned for float, not multiply of 4 bytes, we will get
unaglined memory access.
Current solution is inefficient, so this should really be fixed at weight
packing time.
It seems that longer term there will be prepack function that packs weights. So
this fallback path should eventually match that and not store scale and bias
inline.
Test Plan: python test/test_quantization.py
Reviewed By: pengtxiafb
Differential Revision: D26828077
fbshipit-source-id: 8512cd95f3ac3ca53e1048139a9f6e19aa8af298
Summary:
In setup.py add logic to:
- Get list of submodules from .gitmodules file
- Auto-fetch submodules if none of them has been fetched
In CI:
- Test this on non-docker capable OSes (Windows and Mac)
- Use shallow submodule checkouts whenever possible
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53461
Reviewed By: ezyang
Differential Revision: D26871119
Pulled By: malfet
fbshipit-source-id: 8b23d6a4fcf04446eac11446e0113819476ef6ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53397
It turns out once you remove all the indirection from the
empty_cpu_strided implementation, this implementation is pretty
simple. We should see if we can simplify empty_cpu this way too.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D26891870
Pulled By: ezyang
fbshipit-source-id: 9bddd332d32d8bf32fa3175e3bb0ac3a8954ac91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53377
My underlying goal is I want to make the test suite ignore
NotImplementedError without failing when bringing up a backend (meta)
that doesn't have very many functions implemented.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D26850766
Pulled By: ezyang
fbshipit-source-id: ffbdecd22b06b5ac23e1997723a6e2a71dfcd14a
Summary:
Addresses several of the challenges described in https://github.com/pytorch/pytorch/issues/49468.
This PR builds on https://github.com/pytorch/pytorch/pull/50741 and https://github.com/pytorch/pytorch/issues/53105 to extend OpInfo out= testing. It covers the following cases for ops that produce a single tensor:
- out= values don't affect computation
- out= noncontiguous produces the correct output and preserves strides
- out= with the wrong shape throws a warning
- out= with an empty tensor throws no warning
- out= with the wrong device throws an error
- out= with a dtype the computation's result can't be "safely" cast to throws an error
It works with operations that produce a single tensor and operations that produce an iterable of tensors (the latter is tested with operations like torch.svd).
In addition to the new out= test, the OpInfos have been updated. "supports_tensor_out" is replaced with the more general and straightforward "supports_out" metadata, and many operations which previously had to skip out= testing with an explicit SkipInfo no longer need to. A couple redundant tests in test_unary_ufuncs.py have been removed, too.
One other perk of these tests is that once all operations have OpInfos this will allow us to validate that we've universally deprecated incorrectly sized tensors passed to out=, and give us the option to actually disable the behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53259
Reviewed By: mrshenli
Differential Revision: D26894723
Pulled By: mruberry
fbshipit-source-id: 2b536e9baf126f36386a35f2f806dd88c58690b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53294
Just a bunch of little things, none of which are big enough to need a full PR.
1) C++ wall time should release the GIL
2) Add option to retain `callgrind.out` contents. This will allow processing with kCachegrind for more detailed analysis.
3) Stop subtracting the baseline instruction counts. (People just found it confusing when they saw negative instruction counts.) There is a finesse in #53295 that drops the baseline to ~800 instructions for `number=100`, and at that level it's not worth correcting.
4) Add a `__mul__` overload to function counts. e.g. suppose `c0` was run with `number=100`, and `c1` was run with `number=200`, then `c0 * 2 - c1` is needed to properly diff them. (Obviously there are correctness concerns, but I think it's fine as a caveat emptor convenience method.)
5) Tweak the `callgrind_annotate` call, since by default it filters very small counts.
6) Move some args to kwargs only since types could be ambiguous otherwise.
7) Don't omit rows from slices. It was annoying to print something like `stats[:25]` and have `__repr__` hide the lines in the middle.
Test Plan: Imported from OSS
Reviewed By: Chillee
Differential Revision: D26906715
Pulled By: robieta
fbshipit-source-id: 53d5cd92cd17212ec013f89d48ac8678ba6e6228
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53293
Instruction count benchmarks need some includes for IValues, but this is also just generally useful. (Unlike Python where you can just drop imports anywhere, C++ will get very upset if you `#include` in a function body...)
Test Plan: Imported from OSS
Reviewed By: Chillee
Differential Revision: D26906684
Pulled By: robieta
fbshipit-source-id: cbdfd79d3b8383100ff2e6857b6f309c387cbe2a
Summary:
The code uses `torch::jit::jit_log_prefix` for handling recursive
indenting in most places in this function. There was one place that was
using "level", but it was buggy -- it would result in a compounding
superlinear indent. Note that changing it to "level+1" doesn't fix the
bug.
Before/after:
https://gist.github.com/silvasean/8ee3ef115a48de6c9c54fbc40838d8d7
The new code establishes a recursive invariant for
`Module::dump_to_str`: the function returns the module printed at the
base indent level (i.e. no indent). `torch::jit:log_prefix` is used
to prefix recursive calls. The code was already nearly there, except for
this spurious use of "level".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52539
Reviewed By: navahgar
Differential Revision: D26773657
Pulled By: gmagogsfm
fbshipit-source-id: ab476f0738bf07de9f40d168dd038dbf62a9a79e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53432
1. Creating individual .mm files for each op under the ops/ folder, and each op just has it's own function. The op is registered at the end of the file.
2. Remove the indirection calls from MetalAten.mm to MPSCNNOps.mm
3. Delete MPSCNNOps.mm
ghstack-source-id: 123205443
Test Plan:
1. Sandcastle
2. CircleCI
3. Mobilelab
Reviewed By: SS-JIA
Differential Revision: D26840953
fbshipit-source-id: e1664c8d7445fdbd3b016c4dd51de0a6294af3a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53431
Objective-C’s dynamism comes at the cost of code size, perf and safety. In Facebook, we tend to not use Objective-C primitives or keep it to a minimum unless you need them.
ghstack-source-id: 123063340
Test Plan:
1. CircleCI
2. SandCastleCI
3. Mobilelab
Reviewed By: SS-JIA
Differential Revision: D26800753
fbshipit-source-id: b5a752a700d72ca3654f6826537aa3af47e87ecd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53430
The definition of Metal tensor is confusing, as we're using it to initialize the MetalTensorImpl. It acts more like a TensorImplStorage.
ghstack-source-id: 123038073
Test Plan:
1. Sandcastle CI
2. Circle CI
3. AIBench/Mobilelab
Reviewed By: SS-JIA
Differential Revision: D26685439
fbshipit-source-id: e0487d0884e4efc3044d627ed0e4af454eca9d67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52658
DCE will reverse iterate over the graph looking for nodes without users and delete them. It will skip over unused placeholders (since this affects the signature of the method) and outputs (which never have users but we want to keep them :) )
Test Plan: Added unit tests
Reviewed By: jamesr66a, khabinov, chenccfb
Differential Revision: D26602212
fbshipit-source-id: f4f196973e40546076636090bb0008c24f33795e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50217
If we fuse small groups, things are slow
Test Plan: buck test //caffe2/test:static_runtime
Reviewed By: bertmaher
Differential Revision: D25643460
fbshipit-source-id: d2f39a4d612df3e1e29362abb23c2d997202f6ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52918
Freeze_module seems to operate under the assumption that forward always exists. This isnt true, so the change first checks for existence then retrieves the function.
ghstack-source-id: 123215242
Test Plan: Try freezing something with and without forward.
Reviewed By: dhruvbird
Differential Revision: D26671815
fbshipit-source-id: d4140dad3c59d3d20012143175f9b9268bf23050
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53537fixes#53526
This fixes the issue of the one of the environment variables being tested is somehow set by a previous test. For example:
`WORLD_SIZE=1 python test/distributed/test_c10d.py RendezvousEnvTest.test_common_errors` would have previously failed but now passes
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D26891207
Pulled By: H-Huang
fbshipit-source-id: 1c23f6fba60ca01085a634afbafbb31ad693d3ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53460
We have code to ignore this category of warnings and found this one is incorrect.
Use `stacklevel=2`, otherwise the warning is always filtered by TracerWarning.ignore_lib_warnings()
Test Plan: sandcastle
Reviewed By: wanchaol
Differential Revision: D26867290
fbshipit-source-id: cda1bc74a28d5965d52387d5ea2c4dcd1a2b1e86
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53560
If an op like Fused8BitRowwiseQuantizedToFloat ends up on CPU and Tile ends up on an accelerator and only FP16 is supported, then we want to make sure conversion from FP32 to FP16 is done on CPU to save cycles on accelerator.
Reviewed By: ChunliF
Differential Revision: D26862322
fbshipit-source-id: a7af162f2537ee9e4a78e6ef3f587129de410b07
Summary:
Helps make master green by removing this hefty memory allocating from CPU test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53561
Reviewed By: malfet, albanD
Differential Revision: D26897941
Pulled By: janeyx99
fbshipit-source-id: 9f6c2d55f4eea1ab48665f7819fc113f21991036
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: da1e687ee3
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53509
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D26885426
fbshipit-source-id: 80a3d0680fa584744380bb993ee3a2dc13991847
Summary:
This way, we can get S3 test time stats for windows tests as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53387
Reviewed By: samestep
Differential Revision: D26893613
Pulled By: janeyx99
fbshipit-source-id: ac59e4406e472c9004eea0aae8a87a23242e3b34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53429
Call the testing ops through dispatcher instead of calling them through `at::native`. Some metal ops can't be called through dispatcher yet. For example, `at::t` will call `at::as_strided` which hasn't been implemented on metal yet. For those ops, we'll skip and call `mpscnn::`directly. We'll convert those ops once we have implemented the missing ops.
ghstack-source-id: 123038068
Test Plan:
- Sandcastle CI
- Circle CI
- AIBench/Mobilelab
Reviewed By: SS-JIA, AshkanAliabadi
Differential Revision: D26683366
fbshipit-source-id: bf130b191046f5d9ac9b544d512bc6cb94f08c09
Summary: We implement a hierarchical fine grained binning structure, with the top level corresponding to different feature segments and bottom level corresponding to different range of ECTR. The model is designed to be general enough to perform segmented calibration on any useful feature
Test Plan:
buck test dper3/dper3/modules/calibration/tests:calibration_test -- test_histogram_binning_calibration_by_feature
buck test dper3/dper3_models/ads_ranking/model_impl/mtml/tests:mtml_lib_test -- test_multi_label_dependent_task_with_histogram_binning_calibration_by_feature
e2e test:
buck test dper3/dper3_models/ads_ranking/tests:model_paradigm_e2e_tests -- test_sparse_nn_histogram_binning_calibration_by_feature
buck test dper3/dper3_models/ads_ranking/tests:model_paradigm_e2e_tests -- test_mtml_with_dependent_task_histogram_binning_calibration_by_feature
All tests passed
Canary packages:
Backend -> aml.dper2.canary:e0cd05ac9b9e4797a94e930426d76d18
Frontend -> ads_dper3.canary:55819413dd0f4aa1a47362e7869f6b1f
Test FBL jobs:
**SparseNN**
ctr mbl feed
f255676727
inline cvr
f255677216
**MTML regular task**
offsite cvr
f255676719
**MTML dependent task**
mobile cvr
f255677551
**DSNN for AI models**
ai oc
f255730905
**MIMO for both AI DSNN part and AF SNN part**
mimo ig
f255683062
Reviewed By: zhongyx12
Differential Revision: D25043060
fbshipit-source-id: 8237cad41db66a09412beb301bc45231e1444d6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53389
Resize was written to take arguments by value, which was
totally fine if they were ArrayRef or a series of integers, but not so
fine if they're std::vector.
ghstack-source-id: 123212128
Test Plan:
Existing CI should make sure it builds
Inspected assembly for ios_caffe.cc and saw no more vector copy before
calling Resize
Reviewed By: smessmer
Differential Revision: D26852105
fbshipit-source-id: 9c3b9549d50d32923b532bbc60d0246e2c2b5fc7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53388
Most of this method did not depend on the template parameter. No need to include it in the .h file or duplicate it in the generated code.
ghstack-source-id: 123211590
Test Plan: Existing CI should cover this
Reviewed By: smessmer
Differential Revision: D26851985
fbshipit-source-id: 115e00fa3fde547c4c0009f2679d4b1e9bdda5df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53153
This diff is a fix for quantization_test in operator_benchmark, which is broken because of removing the py_module for learnable fake_quantization.
ghstack-source-id: 123103477
Test Plan: `buck run mode/opt //caffe2/benchmarks/operator_benchmark/pt:quantization_test`
Reviewed By: z-a-f
Differential Revision: D26764881
fbshipit-source-id: 8d40c6eb5e7090ca65f48982c837f7dc87d14378
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53489
It appears that D26675801 (1fe6a6507e) broke Glow builds (and probably other instals) with the inclusion of the python_arg_parser include. That dep lives in a directory of its own and was not included in the setup.py.
Test Plan: OSS tests should catch this.
Reviewed By: ngimel
Differential Revision: D26878180
fbshipit-source-id: 70981340226a9681bb9d5420db56abba75e7f0a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53412
Docker builds for scheduled workflows still need to happen within the
regular build workflow since new docker image builds are actually only
done within the `build` workflow
A follow up to #52693
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D26890300
Pulled By: seemethere
fbshipit-source-id: d649bfca5186a89bb5213865f1f5738b809d4d38
Summary:
See https://github.com/pytorch/pytorch/issues/53526. We're disabling the test temporarily until we can figure out what's going on (since it's unclear what needs to be reverted).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53527
Reviewed By: zhangguanheng66
Differential Revision: D26888037
Pulled By: samestep
fbshipit-source-id: f21a2d665c13181ed3c8815e352770b2f26cdb84
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 46949a8ca3
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53504
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D26883701
fbshipit-source-id: 9e132a1389ac9cee9507c5600668af1afbb26efd
Summary:
Currently it says it does a deepcopy by default, but that's not true.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53457
Reviewed By: navahgar
Differential Revision: D26876781
Pulled By: Chillee
fbshipit-source-id: 26bcf76a0c7052d3577f217e79545480c9118a4e
Summary:
This is a more fundamental example, as we may support some amount of shape specialization in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53250
Reviewed By: navahgar
Differential Revision: D26841272
Pulled By: Chillee
fbshipit-source-id: 027c719afafc03828a657e40859cbfbf135e05c9
Summary:
This PR adds an implementation for `aten::cat` in NNC without any conditionals. This version is not enabled by default.
Here is the performance of some micro benchmarks with and without conditionals. There is up to 50% improvement in performance without conditionals for some of the shapes.
aten::cat implementation in NNC **with** conditionals
```
$ python -m benchmarks.tensorexpr --device cpu --mode fwd --jit_mode trace --cpu_fusion concat
pt: concat2d2input_fwd_cpu_1_160_1_14_1: 5.44 us, SOL 0.26 GB/s, algorithmic 0.51 GB/s
pt: concat2d2input_fwd_cpu_1_580_1_174_1: 5.75 us, SOL 1.05 GB/s, algorithmic 2.10 GB/s
pt: concat2d2input_fwd_cpu_20_160_20_14_1: 6.87 us, SOL 4.05 GB/s, algorithmic 8.11 GB/s
pt: concat2d2input_fwd_cpu_20_580_20_174_1: 14.52 us, SOL 8.31 GB/s, algorithmic 16.62 GB/s
pt: concat2d2input_fwd_cpu_8_512_8_512_1: 9.58 us, SOL 6.84 GB/s, algorithmic 13.68 GB/s
```
aten::cat implementation in NNC **without** conditionals
```
$ python -m benchmarks.tensorexpr --device cpu --mode fwd --jit_mode trace --cpu_fusion --cat_wo_conditionals concat
pt: concat2d2input_fwd_cpu_1_160_1_14_1: 4.67 us, SOL 0.30 GB/s, algorithmic 0.60 GB/s
pt: concat2d2input_fwd_cpu_1_580_1_174_1: 5.65 us, SOL 1.07 GB/s, algorithmic 2.14 GB/s
pt: concat2d2input_fwd_cpu_20_160_20_14_1: 6.10 us, SOL 4.56 GB/s, algorithmic 9.12 GB/s
pt: concat2d2input_fwd_cpu_20_580_20_174_1: 7.44 us, SOL 16.22 GB/s, algorithmic 32.44 GB/s
pt: concat2d2input_fwd_cpu_8_512_8_512_1: 6.46 us, SOL 10.14 GB/s, algorithmic 20.29 GB/s
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53128
Reviewed By: bertmaher
Differential Revision: D26758613
Pulled By: navahgar
fbshipit-source-id: 00f56b7da630b42bc6e7ddd4444bae0cf3a5780a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52814
Currently, there is no way to load a model on a devvm (CPU) if that model has operators that the runtime doesn't support. This ends up happening (currently) for Metal GPU models, and potentially in the future for other backends that have backend-specific operators that don't have a registered implementation (even a dummy one) on CPU.
There are at least a couple reasons for why this is needed:
1. We want to extract operator list directly from the bytecode (instead of looking it up from `mobile_info.json).
2. We want to be able to trace the quantized operators that are invoked when loading the compressed weights for a model that has prepacked weights. xta0 root-caused this after husthyc discovered that there are untraced operators showing up when loading a Metal GPU model.
If we want to scale out to support different types of models, we absolutely need the ability to load a model on a devvm irrespective of what backend (device/etc...) it is targeted at.
ghstack-source-id: 123284366
Test Plan: The next diff in this stack is using the newly introduced methods.
Reviewed By: iseeyuan
Differential Revision: D26656266
fbshipit-source-id: eed9af2f7b55979e9c18b986b8c3b9a767153297
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53271
- [x] Add `set_determinism` context manager
- [x] Add `non_deterministic` decorator for `DataPipe`
- Raise error at the construction time for non-deterministic DataPipe when `determinism` is set to `True`
- [ ] Support `non_deterministic` with option
- When `GreedyJoin` only contains one datapipe, it should still be deterministic.
Note: Test is in the [PR](https://github.com/facebookexternal/torchdata/pull/15). As the main repo doesn't have non-deterministic DataPipe yet.
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D26823023
Pulled By: ejguan
fbshipit-source-id: 51bb92fc3d18d1fc9536c1229363c536ad120876
Summary: Using `cudnnBatchNormalizationForwardTrainingEx` and `cudnnBatchNormalizationBackwardEx` if cuDNN version is greater than 8.0.0.
Reviewed By: xw285cornell
Differential Revision: D26794173
fbshipit-source-id: dc4994375350f303a3fa0aee03255e8f8be1c605
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53276
- One of the tests had a syntax error (but the test
wasn't fine grained enough to catch this; any error
was a pass)
- Doesn't work on ROCm
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D26820048
Test Plan: Imported from OSS
Reviewed By: mruberry
Pulled By: ezyang
fbshipit-source-id: b02c4252d10191c3b1b78f141d008084dc860c45
Summary:
Context: https://github.com/pytorch/pytorch/pull/53299#discussion_r587882857
These are the only hand-written parts of this diff:
- the addition to `.github/workflows/lint.yml`
- the file endings changed in these four files (to appease FB-internal land-blocking lints):
- `GLOSSARY.md`
- `aten/src/ATen/core/op_registration/README.md`
- `scripts/README.md`
- `torch/csrc/jit/codegen/fuser/README.md`
The rest was generated by running this command (on macOS):
```
git grep -I -l ' $' -- . ':(exclude)**/contrib/**' ':(exclude)third_party' | xargs gsed -i 's/ *$//'
```
I looked over the auto-generated changes and didn't see anything that looked problematic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53406
Test Plan:
This run (after adding the lint but before removing existing trailing spaces) failed:
- https://github.com/pytorch/pytorch/runs/2043032377
This run (on the tip of this PR) succeeded:
- https://github.com/pytorch/pytorch/runs/2043296348
Reviewed By: walterddr, seemethere
Differential Revision: D26856620
Pulled By: samestep
fbshipit-source-id: 3f0de7f7c2e4b0f1c089eac9b5085a58dd7e0d97
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53207
Simplifying some of the async execution logic in request_callback_impl
as part of https://github.com/pytorch/pytorch/issues/39351.
ghstack-source-id: 123004020
Test Plan: waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D26791325
fbshipit-source-id: 790ad413dad410dbcd07787583674cb5af1d1c92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53288
Modify assert order to correct the error message when nan appears in multinomial on cuda
Test Plan: unittest
Reviewed By: ngimel
Differential Revision: D26824353
fbshipit-source-id: af6195e7c36fd51b3fc90df558ad6fac41288142
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53298
This is a re-land of D26641600 (3969391c07), but with the `SaveOpImpl` class marked as
`TORCH_API` to ensure that its symbols get exported properly in shared library
builds.
This moves the `SaveOp` code from `load_save_op.h` to `load_save_op.cc`.
Previously this implementation was all in the templatized `SaveOp` class, even
though most of the logic didn't depend on the template parameters. Having
this code be in the header file slows down the build, and forces more files to
be rebuilt than necessary when changing the SaveOp code. Having this code be
in a template class can also increase the generated code size be larger than
needed, as we don't need separate copies instantiated for each context type.
ghstack-source-id: 123146018
Test Plan:
buck test //caffe2/caffe2/python/operator_test:load_save_test
Also tested performing the CMake-based build using shared libraries with CUDA
enabled, and confirmed that the build succeeded.
Reviewed By: mraway
Differential Revision: D26802576
fbshipit-source-id: fc2dbdc1cd20680b082c887366a6305d86688138
Summary:
We no longer build binaries for CUDA 11.0 so let's ensure that we have
build for CUDA 11.1 by default instead
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53299
Reviewed By: anjali411
Differential Revision: D26857194
Pulled By: seemethere
fbshipit-source-id: 6094913922c0da832b96e5e49a67369d69d0b8ad
Summary:
Currently there's only one indicator for build_ext regarding distributed backend `USE_DISTRIBUTED`.
However one can build with selective backends. adding the 3 distributed backend option in setup.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53214
Test Plan: Set the 3 options in environment and locally ran `python setup.py build_ext`
Reviewed By: janeyx99
Differential Revision: D26818259
Pulled By: walterddr
fbshipit-source-id: 688e8f83383d10ce23ee1f019be33557ce5cce07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53204
Async execution for script calls in request_callback_impl.cpp had two
similar if-else blocks that were hard to read. This PR simplifies some of the
logic by breaking the logic into resuable components.
ghstack-source-id: 122996440
Test Plan: waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D26788459
fbshipit-source-id: f2818c6251a465936ed75b7bd356b616f0580094
Summary:
Uses nightly commit stats to automatically shard tests based on execution time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53269
Test Plan:
set CIRCLE_JOB to an existing job, like `pytorch_linux_bionic_py3_6_clang9_test`
Then you can run something like: `python test/run_test.py --shard 1 10`
Reviewed By: malfet
Differential Revision: D26819440
Pulled By: janeyx99
fbshipit-source-id: 6bc73d6aa3d52d9850817536be15d7b54a72780e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53332
This is to make sure we don't get `BATCH` dim type for the output.
Reviewed By: ChunliF
Differential Revision: D26836902
fbshipit-source-id: bedbd12330c608406e3466b240015235a28d2c4a
Summary:
To display the basic information about the GPUs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53334
Reviewed By: anjali411
Differential Revision: D26849826
Pulled By: ngimel
fbshipit-source-id: 14f0d9dfe41a35fa45fdf6aa7bf2a41704887c0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53172
Pull Request resolved: https://github.com/pytorch/elastic/pull/141
Upstreams two modules to torch:
1. `torchelastic.rendezvous`
2. `torchelastic.utils`
These modules were chosen as `[1/n]` since they are the leaf modules in torchelastic.
==== NOTES: ====
1. I'm disabling etcd_rendezvous and etcd_server tests in CIRCLECI for the moment since I need to edit the test dockers to contain the etcd server binary (there's 4-5 test dockers - one for each platform so this is going to take some time for me to set up the environments and test) - T85992919.
2. I've fixed all lint errors on python files but there are ones on the cpp files on the ZeusRendezvous. I took a look at them, and I don't want to fix the linter errors right now for 2 major reasons:
1. Some of them are more than formatting changes (e.g. std::move vs pass by value) and I don't want to introduce bundled changes with the move
1. The old rendezvous code (the one we forked from in caffe2/fb) has the same problems and I think its better for us to deal with this when we deprecate caffe2/fb/rendezvous in favor of the one in torchelastic -T86012579.
Test Plan:
```
buck test mode/dev-nosan //caffe2/torch/distributed/elastic/utils/test/...
buck test mode/dev-nosan //caffe2/torch/distributed/elastic/utils/data/test/...
buck test mode/dev-nosan //caffe2/torch/distributed/elastic/rendezvous/test/...
buck test mode/dev-nosan //caffe2/torch/distributed/elastic/rendezvous/fb/...
buck test mode/dev-nosan //pytorch/elastic/torchelastic/...
```
\+ Sandcastle
Reviewed By: H-Huang
Differential Revision: D26718746
fbshipit-source-id: 67cc0350c3d847221cb3c3038f98f47915362f51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52966
Logs registerd comm hook if there is one, else logs
"builtin_allreduce"
ghstack-source-id: 123174803
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D26709388
fbshipit-source-id: 484fdbbd6643ec261b3797bd8d9824b2b6a1a490
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52887
This diff changes the way to do model consistency check (i.e. `_verify_replicas_across_processes`) in DDP.
There were a few things that could be improved with the way we verify model across processes in DDP initialization:
1. We should do this check before syncing module states in DDP init, otherwise with Gloo backend this will throw but we would like to throw the error corresponding to different models on different ranks. To do this, we move the methods to be standalone C++ functions (not part of reducer) and move this check to before synchronizing parameters.
2. Refactor DDP init in the following ways:
- Run model consistency check before creating reducer, 2
- add helper functions to build params to pass into reducer
- add helper function to call `_verify_model_across_ranks`
- move `def parameters` to a helper function `_get_parameters` to be used more broadly within DDP
In follow up changes we will add the ability to detect which rank had inconsistent model (https://github.com/pytorch/pytorch/issues/52876 would be useful for this to determine which ranks(s) had errors).
ghstack-source-id: 123171877
Test Plan:
CI/unittest
buck test mode/dev-nosan //caffe2/test/distributed:c10d
BACKEND="nccl" WORLD_SIZE="2" ~/fbcode/buck-out/dev/gen/caffe2/test/distributed/distributed_nccl_fork#binary.par -r test_ddp_model_diff_across_ranks
Reviewed By: zhaojuanmao
Differential Revision: D26565290
fbshipit-source-id: f0e1709585b53730e86915e768448f5b8817a608
Summary:
Currently there is some code that intends to skip distributed tests if
the distributed module is not built. However, they are missing in some
test files; and in some other test files they are checked after
distributed module is imported, which leads to failure. This is
generating a lot of headaches when testing minimal builds locally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52945
Reviewed By: anjali411
Differential Revision: D26848241
Pulled By: ezyang
fbshipit-source-id: 983a848844add40869a86f3c9413503a3659b115
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51564
Constructor logic was spread throughout InferenceModule and StaticRuntime. This diff unifies the two. After a lot of discussion on this diff D25961626 it became apparent that `clone` is uglier than a cheap StaticRuntime.
This means StaticRuntime is effectively StaticModule and the only code in the new StaticRuntime is the `run` functions.
```
graph, schema = PrepareForStaticModule(torchscript_module)
sm = StaticModule(graph, schema, options)
sm(inputs)
// or create many cheap runtimes with the module
sr = StaticRuntime(sm)
sr(inputs)
```
Changelist:
- Rename InferenceModule StaticModule
- Move all logic for construction into StaticModule
- Create a new StaticRuntime that only has a unique memory planner (everything else is in StaticModule)
- Update comments with explanation
- Propagate all changes to predictor integration
- Propagate all changes to python integration
- Change semantics to be a bit more PyTorch-standard (no "run" calls, no "get_" getters).
Test Plan:
buck test //caffe2/test:static_runtime
buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest
Reviewed By: hlu1
Differential Revision: D25592967
fbshipit-source-id: 8233bed03137ce129137af2d44bce0095033ef0f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/51930
Running the reproducer under `cuda-gdb`, I see access violations in either [`zswap_kernel_batched`](4fd4634f35/magmablas/zgetf2_kernels.cu (lines-276)) (part of the LU factorization) and other times in [`zlaswp_columnserial_kernel`](4fd4634f35/magmablas/zlaswp_batched.cu (lines-335)) (part of the inverse).
The common factor between both of these is they use `ipiv` to index into the matrix. My best guess is the `ipiv` indices aren't written when the factorization fails, hence garbage data is used as matrix indices and we get an access violation. Initializing `ipiv` to a known-good value before the factorization fixes the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53064
Reviewed By: zhangguanheng66
Differential Revision: D26829053
Pulled By: heitorschueroff
fbshipit-source-id: 842854a6ee182f20b2acad0d76d32d27cb51b061
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: a4816001b8
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53353
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D26844238
fbshipit-source-id: 9895773f616c53d7d3b3a5e1b95507d26bb93fee
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 20224c5fe7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53265
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: walterddr, lw
Differential Revision: D26816470
fbshipit-source-id: 8e381a3d6632acbc90691128ef85591b325ecf64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53333
- Add more variants to `create_empty_from` to take more args, like dtype/layout/device.
- Clean up stray at::empty uses, mostly in the out variants.
Reviewed By: ajyu
Differential Revision: D26799900
fbshipit-source-id: 6676d8043fead63208913ef3a28cabbae76e46bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53319
Noticed these in profiles.
Also switch to `unordered_map`.
Test Plan: Unit tests.
Reviewed By: swolchok
Differential Revision: D26504408
fbshipit-source-id: 9e14d55909a4af019058b8c27c67ee2348cd02a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53283
We had `ShapeArg` and `KernelArg` classes, which were wrappers over
`BufferArg` without adding any new functionality on top of what already
existed. This PR removes them and replace their uses with `BufferArg`s
directly.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26821993
Pulled By: ZolotukhinM
fbshipit-source-id: d1f95ea069b9f38f1d32424464551df2565b3c49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53233
**Summary**
This commit adds a `deny` method to `PackageExporter` that allows
modules to be prohibited during the packaging process. A dependency on a
module matching the names or globs that `deny` was called with will
cause an exception to be raised.
**Test Plan**
This commit adds unit tests to `PackagingTest` for this new method:
`test_deny` and `test_deny_glob`.
**Fixes**
This commit fixes#53217.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D26834010
Pulled By: SplitInfinity
fbshipit-source-id: 469b5c6741bcc6dab77e352f41db38fa1e0dae12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53232
**Summary**
This commit adds an optional `allow_empty` argument to
`PackageExporter.mock` and `PackageExporter.extern` that allows certain
patterns for mocked modules and extern modules to be marked ones that
*must* be matched during the packaging process. If a mock or extern
module with `allow_empty=False` is not matched while packaging, an error
is thrown.
**Test Plan**
This commit adds two new test cases to `PackagingTest`,
`test_extern_glob_allow_empty` and `test_mock_glob_allow_empty` that
test this new flag. Existing tests already tests `allow_empty=True`.
**Fixes**
This commit fixes#53217.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D26834011
Pulled By: SplitInfinity
fbshipit-source-id: 9cf4ea56079ae210d6cfa8604218849eb5cde5f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53174
Enable Kineto also in the CPU builds (non-mobile, non-Windows(atm))
Test Plan: CI
Reviewed By: gdankel
Differential Revision: D26776112
Pulled By: ilia-cher
fbshipit-source-id: 8733f65c2993105136c853f2a7b6e497d0fa53bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53201
This resulted in [S22350](https://www.internalfb.com/intern/sevmanager/view/s/223540), which caused truoble on Android.
1. The Python has a call to `warnings.warn()`, which resulted in code generated to emit the `WARN` instruction on lite-interpreter.
2. The code for handling that instruction/op-code popped off the value in a call to the `TORCH_WARN()` *macro*.
3. This macro conditionally compiled out evaluation of the arguments if `STRIP_ERROR_MESSAGES` was defined, which resulted in the stack not getting popped, and the lite-interpreter returning the last pushed value on to the stack.
I've attempted to re-produce it using this python code: {P243842428}
ghstack-source-id: 122990001
(Note: this ignores all push blocking failures!)
Test Plan:
Created a new unit test to re-produce the failure in the test. Was able to do so locally using the following command:
```
buck test -c pt.strip_error_messages=1 //xplat/caffe2:test_s223540
```
However, since `pt.strip_error_messages=0` for dev and continuous builds, I have had to check in a separate contbuild config to try and trigger this failure on contbuild.
Reviewed By: iseeyuan
Differential Revision: D26765662
fbshipit-source-id: 63c3c96d84ce6a9e5471f13d80165aa3718be9a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53323
Whilst optimizing inline cvr local ro, found a pattern where gather_ranges is used redundantly. Fuse this pattern to remove unnecessary gather_ranges.
Reviewed By: hlu1
Differential Revision: D26659824
fbshipit-source-id: 6420afa3a2c3272c57706b70c2e9834014d6c32d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53212
Ran into a strange issue with error handling in future callbacks, more
details in https://github.com/pytorch/pytorch/issues/52132, but essentially,
after a callback throws all additional processing stops, and other futures can
never be completed, resulting in a hang. Add a note to warn about this.
ghstack-source-id: 123122890
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D26793310
fbshipit-source-id: b1ae73a81163d7b37ba07b0685e8de4228f01da6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52343
aten::to returns self when the TensorOptions match and copy is set to false. For static runtime, always copy. There isn't a separate op for aten::to copy, but instead the same function
with different arguments.
Test Plan:
On AdFinder local_ro:
Before:
0.896742
0.00824827 ms. 0.92773%. aten::to (5 nodes)
After:
0.88233
0.0056607 ms. 0.644675%. aten::to (5 nodes)
buck test mode/opt caffe2/benchmarks/static_runtime:static_runtime_cpptest
Reviewed By: hlu1
Differential Revision: D26477980
fbshipit-source-id: 8e8448092adff38c141af1ce27a10acd39c07dd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53139
ghstack-source-id: 123090847
Test Plan:
Sandcastle
Also explicitly tests that this test passes after incorporating the changes from D26656767, and adding a `torch.tensor` -> `torch._tensor` mapping to the `load_module_mapping` dict: `buck test mode/dev //pandora/utils/tests:manifold_utils_tests -- --exact 'pandora/utils/tests:manifold_utils_tests - test_load_dataset_valid_dir (pandora.utils.tests.manifold_utils_tests.TestManifoldUtils)'`
With just D26656767, that test fails. With D26656767 + the changes in this diff, that test passes.
Reviewed By: ezyang
Differential Revision: D26760600
fbshipit-source-id: cb16493b858a358acf468d755740aa272ae9d363
Summary:
When saved variable is of an output, its grad_fn is not saved in SavedVariable, so it must be passed in during `unpack`.
Here, we can always pass in grad_fn (whether or not saved variable is an output) because it is ignored if the saved variable is not an output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53205
Reviewed By: gchanan, zhangguanheng66
Differential Revision: D26794365
Pulled By: soulitzer
fbshipit-source-id: e039baba20c364c4ab42ff99d0b242dd95c67fb3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53278
We can avoid duplicating the string data for the namespaces
by assembling qualified names ourselves as needed.
ghstack-source-id: 123111718
Test Plan:
CI
buildsizebot some iOS apps
Reviewed By: dhruvbird, walterddr, ot
Differential Revision: D26820648
fbshipit-source-id: e2560874c54f46210181ddfee354967644bd41e1
Summary:
Fixes https://github.com/pytorch/pytorch/issues/12635
This change will help us speed up autograd's discovery algorithm in cases where we use `.grad` and we try to "unroll" the training loop. For example the example in the issue and also https://github.com/pytorch/pytorch/pull/52180#issuecomment-783400832 observe an unbounded multiple of speed-up.
We do this by adding a new sequence_nr-type numbering: for each node, we maintain the length of the longest path from it to any leaf node. How does this help us speed up discovery (dfs)? Previously the bottleneck was that the dfs that computes which nodes need to be executed always explored every node. With this change, before we run dfs, we first compute the mininum seq_nr among all the nodes passed as the `inputs`. If let this be some number N, intuitively this means that dfs should stay at least N units away from any leaf node. So, if we find ourselves too close to any leaf node, we should stop our search early.
Edit:
After some discussion offline, the plan is:
- make old sequence_nr a construct of the profiler. This means we can avoid accessing thread local state in cases where the profiler is disabled. Note that we cannot replace sequence_nr as-is because profiler's use-case requires that thread-id + sequence_nr can uniquely identify a given node in order for downstream users/programs to correlate nodes from backward and forward passes. This means we must maintain two sequence_nr's and that we have an extra field in Node.
- In a future PR, we can potentially remove sequence_nr entirely from the profiler as well, but we avoid doing it now because we haven't measured, and its a larger effort because we'd have to mess around with the dispatcher and profiler
Testing with this [code](https://gist.github.com/kyunghyuncho/5fb9991ce1233f909051854a84b7148e), we see that runtime no longer increases as we iterate.
Before:
```
100: Time taken: 0.47s, loss: 1.1e+06
200: Time taken: 0.064s, loss: 6.5e+05
300: Time taken: 0.088s, loss: 4.4e+05
400: Time taken: 0.1s, loss: 3.2e+05
500: Time taken: 0.12s, loss: 2.5e+05
600: Time taken: 0.15s, loss: 2e+05
700: Time taken: 0.18s, loss: 1.7e+05
800: Time taken: 0.2s, loss: 1.4e+05
900: Time taken: 0.22s, loss: 1.2e+05
1000: Time taken: 0.24s, loss: 1.1e+05
1100: Time taken: 0.27s, loss: 9.3e+04
1200: Time taken: 0.3s, loss: 8.3e+04
1300: Time taken: 0.34s, loss: 7.4e+04
1400: Time taken: 0.36s, loss: 6.7e+04
1500: Time taken: 0.38s, loss: 6.1e+04
1600: Time taken: 0.4s, loss: 5.6e+04
1700: Time taken: 0.42s, loss: 5.1e+04
1800: Time taken: 0.44s, loss: 4.7e+04
1900: Time taken: 0.47s, loss: 4.4e+04
2000: Time taken: 0.5s, loss: 4.1e+04
```
After:
```
100: Time taken: 0.49s, loss: 1.2e+06
200: Time taken: 0.031s, loss: 6.9e+05
300: Time taken: 0.031s, loss: 4.6e+05
400: Time taken: 0.031s, loss: 3.3e+05
500: Time taken: 0.031s, loss: 2.6e+05
600: Time taken: 0.031s, loss: 2.1e+05
700: Time taken: 0.031s, loss: 1.7e+05
800: Time taken: 0.031s, loss: 1.4e+05
900: Time taken: 0.031s, loss: 1.2e+05
1000: Time taken: 0.031s, loss: 1.1e+05
1100: Time taken: 0.031s, loss: 9.6e+04
1200: Time taken: 0.031s, loss: 8.6e+04
1300: Time taken: 0.031s, loss: 7.7e+04
1400: Time taken: 0.031s, loss: 7e+04
1500: Time taken: 0.031s, loss: 6.3e+04
1600: Time taken: 0.031s, loss: 5.8e+04
1700: Time taken: 0.031s, loss: 5.3e+04
1800: Time taken: 0.031s, loss: 4.9e+04
1900: Time taken: 0.031s, loss: 4.5e+04
2000: Time taken: 0.032s, loss: 4.2e+04
```
Testing w/ small graph to check for regression:
```
import torch
from torch.utils.benchmark import Timer
setup="""
a = torch.rand((2, 2), requires_grad=True)
b = torch.rand((2, 2), requires_grad=True)
gradient = torch.ones(2, 2)
"""
stmt="""
torch.autograd.grad(a*b, [a, b], gradient)
"""
timer = Timer(stmt, setup)
print(timer.timeit(10000))
print(timer.collect_callgrind(100))
```
Result: there doesn't seem to be any significant regression
```
Time before: 12.74 us
Time after: 13.12 us
Instruction count before:
All Noisy symbols removed
Instructions: 8078960 8000882
Baseline: 4226 3838
Instruction count after:
All Noisy symbols removed
Instructions: 8091846 8017940
Baseline: 4336 3838
100 runs per measurement, 1 thread
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52180
Reviewed By: gchanan, zhangguanheng66
Differential Revision: D26794387
Pulled By: soulitzer
fbshipit-source-id: c00d387a29f151109c33dc6f1b56a8f275cdec58
Summary:
I edited the documentation for `nn.SiLU` and `F.silu` to:
- Explain that SiLU is also known as swish and that it stands for "Sigmoid Linear Unit."
- Ensure that "SiLU" is correctly capitalized.
I believe these changes will help users find the function they're looking for by adding relevant keywords to the docs.
Fixes: N/A
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53239
Reviewed By: jbschlosser
Differential Revision: D26816998
Pulled By: albanD
fbshipit-source-id: b4e9976e6b7e88686e3fa7061c0e9b693bd6d198
Summary:
Provides the implementation for feature request issue https://github.com/pytorch/pytorch/issues/28937.
Adds the `Parametrization` functionality and implements `Pruning` on top of it.
It adds the `auto` mode, on which the parametrization is just computed once per forwards pass. The previous implementation computed the pruning on every forward, which is not optimal when pruning RNNs for example.
It implements a caching mechanism for parameters. This is implemented through the mechanism proposed at the end of the discussion https://github.com/pytorch/pytorch/issues/7313. In particular, it assumes that the user will not manually change the updated parameters between the call to `backwards()` and the `optimizer.step()`. If they do so, they would need to manually call the `.invalidate()` function provided in the implementation. This could be made into a function that gets a model and invalidates all the parameters in it. It might be the case that this function has to be called in the `.cuda()` and `.to` and related functions.
As described in https://github.com/pytorch/pytorch/issues/7313, this could be used, to implement in a cleaner way the `weight_norm` and `spectral_norm` functions. It also allows, as described in https://github.com/pytorch/pytorch/issues/28937, for the implementation of constrained optimization on manifolds (i.e. orthogonal constraints, positive definite matrices, invertible matrices, weights on the sphere or the hyperbolic space...)
TODO (when implementation is validated):
- More thorough test
- Documentation
Resolves https://github.com/pytorch/pytorch/issues/28937
albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33344
Reviewed By: zhangguanheng66
Differential Revision: D26816708
Pulled By: albanD
fbshipit-source-id: 07c8f0da661f74e919767eae31335a9c60d9e8fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53197
This probably causes a code size blowup and we care more about the size savings than the incremental perf on mobile.
ghstack-source-id: 122977713
Test Plan: buildsizebot some mobile apps
Reviewed By: dhruvbird
Differential Revision: D26731181
fbshipit-source-id: 78a926278a85028af09bfa0731d4d59a55ee3746
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53273
This prevents a mypy bug. Fixes#53272
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D26819428
Pulled By: ezyang
fbshipit-source-id: e71575ed13321665a976cc5ef8b2993c00626b7d
Summary:
1. Enabled `amax` & `amin` for `float16` & `bfloat16` dtypes for both CPU & CUDA.
2. Added `OpInfo`s for `amax` & `amin`.
3. Enabled `test_min_with_inf` & `test_max_with_inf` for both `float16` & `bfloat16`, as they also use `torch.amin` & `torch.amax` respectively.
4. Enabled `test_amax` & `test_amin` for `float16` but not for `bfloat16`, as comparison is done with `numpy`, which doesn't support `bfloat16`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52579
Reviewed By: pbelevich
Differential Revision: D26784194
Pulled By: heitorschueroff
fbshipit-source-id: 1050de3e155b83f282fb30b0db6658eead89936c
Summary:
Enable test in test_linalg.py, test_optim.py, and test_vmap.py for ROCm because they are passing.
Signed-off-by: Kyle Chen <kylechen@amd.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52818
Reviewed By: H-Huang
Differential Revision: D26694091
Pulled By: mruberry
fbshipit-source-id: 285d17aa7f271f4d94b5fa9d9f6620de8a70847b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53206
Copying the List in ListConstruct is 1 extra refcount bump. Copying the vector in TupleConstruct is 1 extra bump per tuple element.
ghstack-source-id: 123001815
Test Plan: Don't have a precise measurement but it's very roughly 0.5% off total time for AdIndexer inline_cvr based on wall time, and more like 1.2% based on change in perf profile.
Reviewed By: hlu1
Differential Revision: D26790670
fbshipit-source-id: 697ef82fe72a85719bf8ce28f2bb87fe56bbd8ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53216
- at::native::empty_cpu calls at::detail::empty_cpu without any changes to the arguments. So we could call at::detail::empty_cpu directly.
- There is no need to create a TensorOptions object first since we can get all the relevant information from the tensor directly.
Reviewed By: bertmaher, swolchok
Differential Revision: D26792255
fbshipit-source-id: 7a4e368a19cea79e136e34dab854cb1d37dbeb58
Summary:
Also removes unneeded filename field in S3.
Tested locally:
I locally installed
```
conda install -c anaconda boto3
conda install -c conda-forge unittest-xml-reporting
```
I ran `python test/test_type_hints.py --save-xml=/tmp/reports/test_type_hints` twice to generate two reports of the same test cases.
Then, I edited the print_test_stats.py file to print the report instead of upload to S3, and then ran `CIRCLE_SHA1="$(git rev-parse HEAD)" CIRCLE_JOB=foo python torch/testing/_internal/print_test_stats.py --upload-to-s3 /tmp/reports/test_type_hints`. I verified the report object looked correct:
```
{
'build_pr': '',
'build_tag': '',
'build_sha1': '67cecd7f6cf2956bda1178ae2369cd74ba946f78',
'build_branch': '',
'build_job': 'foo',
'build_workflow_id': '',
'total_seconds': 67.316,
'format_version': 2,
'files': {
'test/test_type_hints': {
'total_seconds': 67.316,
'suites': {
'TestTypeHints': {
'total_seconds': 67.316,
'cases': {
'test_doc_examples': {
'seconds': 8.821,
'status': None
},
'test_run_mypy': {
'seconds': 58.495,
'status': None
}
}
}
}
}
}
}
```
It did take the longer of the two test cases for both test cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53154
Reviewed By: samestep
Differential Revision: D26793522
Pulled By: janeyx99
fbshipit-source-id: 5644c1bd38acb8bca0d69851cf1d549a03334b7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52979
Compression rate = uncompressed size / compressed size, so the compression rate is usually greater than 1.
Previously the compression rate was perceived as compressed size / uncompressed size, which can be very confusing.
ghstack-source-id: 122996272
Test Plan: unit tests
Reviewed By: zhaojuanmao
Differential Revision: D26713349
fbshipit-source-id: 83b7f8908c101954cf01f56a22161047fbfeaa53
Summary:
per title
This PR did
- Migrate `apex.parallel.SyncBatchNorm` channels_last to pytorch `torch.nn.SyncBatchNorm`
- Fix a TODO here by fusing `sum`, `div` kernels into backward elementwise kernel
b167402e2e/torch/nn/modules/_functions.py (L76-L95)
Todo
- [x] Discuss a regression introduced in https://github.com/pytorch/pytorch/pull/37133#discussion_r512530389, which is the synchronized copy here
b167402e2e/torch/nn/modules/_functions.py (L32-L34)
**Comment**: This PR uses apex version for the size check. Test passed and I haven't seen anything wrong so far.
- [x] The restriction to use channels_last kernel will be like this
```
inline bool batch_norm_use_channels_last_kernels(const at::Tensor& self) {
return self.is_contiguous(at::MemoryFormat::ChannelsLast) || self.ndimension() == 2;
}
```
I think we can relax that for channels_last_3d as well?
**Comment**: we don't have benchmark for this now, will check this and add functionality later when needed.
- [x] Add test
- [x] Add benchmark
Detailed benchmark is at https://github.com/xwang233/code-snippet/tree/master/syncbn-channels-last
Close https://github.com/pytorch/pytorch/issues/50781
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46906
Reviewed By: albanD
Differential Revision: D26771437
Pulled By: malfet
fbshipit-source-id: d00387044e9d43ac7e6c0e32a2db22c63d1504de
Summary: Names such as `row_block_size` and `col_block_size` might be ambiguous, especially if different engines use different tensor layouts (i.e. rows=output features, etc.). Having names such as `out_features_block_size` and `in_features_block_size` makes more sense
Test Plan:
`buck test mode/opt //caffe2/torch/fb/model_optimization:sparsity_test`
```
Building with Remote Execution [RE]. Used 36:09 minutes of total time.
[RE] Waiting on 0 remote actions. Completed 264 actions remotely.
Building: finished in 02:34.4 min (100%) 18884/18884 jobs, 420 updated
Total time: 02:34.8 min
More details at https://www.internalfb.com/intern/buck/build/b34b5c52-eba6-4e17-92f9-1f5ce620f8f0
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: 8fe8fa95-c1f8-4b4f-9cbf-88b3b1b28eaf
Trace available for this run at /tmp/tpx-20210302-000019.503678/trace.log
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/4785074650825194
✓ ListingSuccess: caffe2/torch/fb/model_optimization:sparsity_test - main (4.094)
✓ Pass: caffe2/torch/fb/model_optimization:sparsity_test - test_sparse_qlinear (caffe2.torch.fb.model_optimization.test.sparsity.quantized_test.TestQuantizedSparseKernels) (1.896)
✓ Pass: caffe2/torch/fb/model_optimization:sparsity_test - test_sparse_qlinear (caffe2.torch.fb.model_optimization.test.sparsity.quantized_test.TestQuantizedSparseLayers) (1.907)
✓ Pass: caffe2/torch/fb/model_optimization:sparsity_test - test_sparse_qlinear_serdes (caffe2.torch.fb.model_optimization.test.sparsity.quantized_test.TestQuantizedSparseLayers) (2.035)
Summary
Pass: 3
ListingSuccess: 1
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/4785074650825194
```
Reviewed By: dskhudia
Differential Revision: D26747065
fbshipit-source-id: 685fe864062ed532de284b22db757a921806d4ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53031
During the module conversion, the weight was assigned directly to the linear layer inside the quantizable MHA. Instead the weight must be assigned to the `layer.weight`.
Test Plan:
`buck test mode/opt //caffe2/test:quantization -- test_custom_module_multi_head_attention`
```
Building: finished in 6.9 sec (100%) 7316/7316 jobs, 3 updated
Total time: 7.4 sec
More details at https://www.internalfb.com/intern/buck/build/914cb095-806e-4891-8822-e2644283f05c
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: fcccbd0b-a887-4874-8455-d1cf8411be1d
Trace available for this run at /tmp/tpx-20210301-004359.492205/trace.log
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/1688849910412609
✓ ListingSuccess: caffe2/test:quantization - main (2.440)
✓ Pass: caffe2/test:quantization - test_custom_module_multi_head_attention (quantization.test_quantized_op.TestQuantizedOps) (5.672)
Summary
Pass: 1
ListingSuccess: 1
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/1688849910412609
```
Reviewed By: raghuramank100
Differential Revision: D26720500
fbshipit-source-id: 3ba5d5df1c23cc5150c4a293d3c93c44dc702e50
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50670
This PR adds property support to Torchbind. There are two cases that it needs to work:
**Torchscript**
Inside Torchscript, we don't go through pybind so there is no issue with accessing properties through ClassType.
**Eager Mode**
In Eager Mode, Torchbind creates ScriptObject which we cannot dynamically add (aka access) properties after initializing it. (https://stackoverflow.com/questions/1325673/how-to-add-property-to-a-class-dynamically
) Therefore we created a Python wrapper (ScriptObjectWrapper) around ScriptObject where we can use property method to set properties. By doing so, we can look up wrapped object's property through __getattr__ method of the ScriptObjectWrapper. This logic is inspired from https://github.com/pytorch/pytorch/pull/44324
Test Plan:
test cases in test_torchbind.py
Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26632781
fbshipit-source-id: dd690887cfda0c48ff0d104aa240ce0ab09055bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53084
Adding RemoteModule to master RPC docs since it is a prototype
feature.
ghstack-source-id: 122816689
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D26743372
fbshipit-source-id: 00ce9526291dfb68494e07be3e67d7d9c2686f1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53166
Context: For fx modules that consist of scriptmodules, calling
delattr(module, 'qconfig') throws an attribute error. will follow up
with a separate issue/repro to fix this problem
This PR adds a temporary flag to convert_fx API to preserve the qconfig attributes on the converted model
We will remove this flag once we reach a conclusion on calling delattr on scriptmodules
Test Plan:
python test/test_quantization.py test_preserve_qconfig
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26771518
fbshipit-source-id: 9fd72816576856ffb4aa11f8fde08303d1df10a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53098
Remove some low-level methods that are no longer needed since `get_per_parameter_tensors` method is added to `GradBucket` class.
Avoid unnecessary exposure to the internals before publishing GradBucket APIs.
ghstack-source-id: 122979064
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
Reviewed By: osalpekar
Differential Revision: D26784249
fbshipit-source-id: d1b27bb026989c25a5b65be4767cb752afd6f19b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52944
This fix the bug introduced during refactoring optimizers https://github.com/pytorch/pytorch/pull/50411. When all parameters have no grads, we should still allows `beta` like hyper params to be defined.
Reviewed By: ngimel
Differential Revision: D26699827
fbshipit-source-id: 8a7074127704c7a4a1fbc17d48a81e23a649f280
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53143
Meta is now an honest to goodness device type, like cpu, so you can use
device='meta' to trigger allocation of meta tensors. This way better
than empty_meta since we now have working API for most factory functions
(they don't necessarily work yet, though, because need to register Meta
versions of those functions.)
Some subtleties:
- I decided to drop the concept of CPU versus CUDA meta tensors; meta
tensors are device agnostic. It's hard to say exactly what the
correct level of abstraction here is, but in this particular case
implementation considerations trump semantic considerations: it
is way easier to have just a meta device, than to have a meta device
AND a cpu device AND a cuda device. This may limit the applicability
of meta tensors for tracing models that do explicit cpu()/cuda()
conversions (unless, perhaps, we make those operations no-ops on meta
tensors).
- I noticed that the DeviceType uppercase strings are kind of weird.
Are they really supposed to be all caps? That's weird.
- I moved the Meta dispatch key to live with the rest of the "device"
dispatch keys.
- I intentionally did NOT add a Backend for Meta. For now, I'm going to
hope meta tensors never exercise any of the Backend conversion code;
even if it does, better to fix the code to just stop converting to and
from Backend.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D26763552
Pulled By: ezyang
fbshipit-source-id: 14633b6ca738e60b921db66a763155d01795480d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53142
It turns out to make Meta a device I need to substantively reuse
the CPUGuardImpl implementation. It's pretty parametrizable so
just move this over to DeviceGuardImplInterface templated over
the DeviceType.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: anjali411, samestep
Differential Revision: D26763553
Pulled By: ezyang
fbshipit-source-id: 464fb3e3a72ba7c55a12adffe01c18171ce3e857
Summary:
Currently, `torch.nn.parallel.DistributedDataParallel(model...)` doesn't deduplicate params shared across `model`'s child Modules before calling Reducer with the param list. This can cause Reducer to register more than one hook on the shared param(s), at which point who knows what happens.
We ran into this in mlperf BERT, which has at least one param shared across submodules (an embedding weight iirc, not 100% sure). Running with `gradient_as_bucket_view = False` produced different numerics from running with `gradient_as_bucket_view = True` (which i guess is one potential consequence of multiple DDP hooks on a given param, not sure why, i'd have to dig further).
This PR changes DDP to deduplicate shared params (a small diff), and adds some tests (right now just `test_ddp_weight_sharing`, but I'll add more). `test_ddp_weight_sharing` fails with bad numerics on current master (proving the shared param issue is real) and passes with the deduplication diff.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51929
Reviewed By: zou3519
Differential Revision: D26625807
Pulled By: zhaojuanmao
fbshipit-source-id: f5f5959fef90dfe2c55812d79fa88b877f22ecc3
Summary:
I noticed https://github.com/pytorch/pytorch/issues/53126 stored everything in the test folder as an artifact, which isn't exactly what we want. Here, I try to store just the relevant info, coverage files.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53150
Reviewed By: albanD
Differential Revision: D26767185
Pulled By: janeyx99
fbshipit-source-id: 286d341ccdfa97d138a2048bb4ee01c7ae2579a1
Summary: Just copy whatever corresponding input shape info. Or we will miss the shape info of output of SparseLengthsSumSparseLookup, which will be infered as the input of downstream SparseLengthsSum op, whose int64/int32 mode is undetermined.
Test Plan:
```
buck test caffe2/caffe2/opt:bound_shape_inference_test
```
Reviewed By: khabinov, ChunliF
Differential Revision: D26769226
fbshipit-source-id: 4032bc4643a125095a48fa8c23ca4ebcf26dc29c
Summary:
Description:
- Added more modes: bicubic and nearest to interpolation tests
- Added a test case for downsampling a small image
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53186
Reviewed By: albanD
Differential Revision: D26780116
Pulled By: fmassa
fbshipit-source-id: f4f498e6e1da1ec131e6d9d9f42dc482135ae9e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53156
Will SSH into windows machine to validate that these tests are skipped.
Test Plan: Imported from OSS
Reviewed By: osalpekar
Differential Revision: D26769791
Pulled By: H-Huang
fbshipit-source-id: e4427ba2d6cfe5a1de26e335cd27c1e8875174d3
Summary:
Fix accidental regression introduced by https://github.com/pytorch/pytorch/issues/47940
`FIND_PACKAGE(OpenBLAS)` does not validate that discovered library can actually be used, while `check_fortran_libraries` does that
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53168
Test Plan: Build PyTorch with static OpenBLAS and check that `torch.svd(torch.ones(3, 3)).S` do not raise an exception
Reviewed By: walterddr
Differential Revision: D26772345
Pulled By: malfet
fbshipit-source-id: 3e4675c176b30dfe4f0490d7d3dfe4f9a4037134
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53169
As title, there are two `aten/src/ATen/native/RNN.cpp` in `aten_native_source_list`
ghstack-source-id: 122936706
Test Plan: CI
Reviewed By: dhruvbird, iseeyuan
Differential Revision: D26715640
fbshipit-source-id: 54717ded9b293e022a47ab7891dfd04afae48ce5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51350
`None` being a valid `Dimname` is awkward for optional `dim` arguments, as found
on NumPy's reduction functions like `std` and `var`. In these cases `dim=None`
should mean an all-reduction, but instead you get an error
"Please look up dimensions by name".
I've also had to fix `FunctionParameter::check` to actually check the first
element of `INT_LIST` arguments and reject non-int types. Otherwise, the dim
names end up calling the `int[]` overload and fail.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D26756208
Pulled By: mruberry
fbshipit-source-id: 44221ca0f4822ec2c1f62b092466fd4f779eb45a
Summary:
Reference: https://github.com/pytorch/pytorch/issues/42515
This PR also enables the OpInfo tests on ROCM to check the same dtypes that of CUDA.
Few tests have to be skipped (due to failure).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51944
Reviewed By: H-Huang
Differential Revision: D26727660
Pulled By: mruberry
fbshipit-source-id: 3aea236cf0002f46c2737afbda2ed3efccfe14f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50484
I currently see the compilation warning:
```
Jan 13 16:46:21 [3644/5223] Building CXX object caffe2/CMakeFiles/torch_cpu.dir/__/aten/src/ATen/core/ivalue.cpp.o
Jan 13 16:46:21 ../aten/src/ATen/core/ivalue.cpp:855:22: warning: comparison of integers of different signs: 'int' and 'std::__1::vector<c10::IValue, std::__1::allocator<c10::IValue> >::size_type' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:21 for (auto i = 0; i < slots_.size(); ++i) {
```
This diff fixes that
Test Plan: Sandcastle tests
Reviewed By: ngimel
Differential Revision: D25901674
fbshipit-source-id: 0a09570866f23b5878bf06f46f918d71a733974f
Summary: Use the dim type of the first input for output.
Test Plan:
unit test
flow test: f254777437
https://fburl.com/n933wc3a
shapes {
shape {
dims: 19102004
dims: 68
data_type: UINT8
name: "sparse_nn_2/sparse_arch_2/grouped_embedding_10/grouped_generic_embedding_10/GSF_IDLIST_IG_BUSINESS_AUTHOR_PPR_ORGANIC_ENGAGEMENT_UNIFORM_RIDS/w_EmbeddingFusedUint4Quantization"
}
dim_type: CONSTANT
dim_type: CONSTANT
name: "sparse_nn_2/sparse_arch_2/grouped_embedding_10/grouped_generic_embedding_10/GSF_IDLIST_IG_BUSINESS_AUTHOR_PPR_ORGANIC_ENGAGEMENT_UNIFORM_RIDS/w_EmbeddingFusedUint4Quantization"
shape_is_final: true
}
Reviewed By: yinghai, khabinov
Differential Revision: D26763978
fbshipit-source-id: b9c0d6ca4a2b0e4d50d34e08f724e99ad705196b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53091
Split with tail followed by reorder causes a segfault in NNC
Split with mask followed by reorder generates invalid code that writes out of
bounds
ghstack-source-id: 122870733
Test Plan: LoopNest.ColReduceSplit*
Reviewed By: navahgar
Differential Revision: D26746254
fbshipit-source-id: f8a0de18531b34d2bf06ccaa35d9c98b81b5c600
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53137
Also, add casting to Int for Load and Store indices.
Fixes#52773.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26760256
Pulled By: ZolotukhinM
fbshipit-source-id: a2d3141b17584724a5feabcabec25d0577b83a30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52702
Fixes:
```
stderr: caffe2/c10/util/MathConstants.h(22): warning: calling a constexpr __host__ function("from_bits") from a __host__ __device__ function("pi") is not allowed. The experimental flag '--expt-relaxed-constexpr' can be used to allow this.
```
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D26589533
fbshipit-source-id: 42c4b36b0ba1e08cbdc9a122fedf35610483c764
Summary:
Fixes https://github.com/pytorch/pytorch/issues/44378 by providing a wider range of drivers similar to what SciPy is doing.
The supported CPU drivers are `gels, gelsy, gelsd, gelss`.
The CUDA interface has only `gels` implemented but only for overdetermined systems.
The current state of this PR:
- [x] CPU interface
- [x] CUDA interface
- [x] CPU tests
- [x] CUDA tests
- [x] Memory-efficient batch-wise iteration with broadcasting which fixes https://github.com/pytorch/pytorch/issues/49252
- [x] docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49093
Reviewed By: H-Huang
Differential Revision: D26723384
Pulled By: mruberry
fbshipit-source-id: c9866a95f14091955cf42de22f4ac9e2da009713
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53098
Remove some low-level methods that are no longer needed since `get_per_parameter_tensors` method is added to `GradBucket` class.
Avoid unnecessary exposure to the internals before publishing GradBucket APIs.
ghstack-source-id: 122723683
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
Reviewed By: rohan-varma
Differential Revision: D26720919
fbshipit-source-id: 46fb6423008792e72d7a1dd68930a31e0724c92c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53010
To determine the boundary between different iterations in a DDP communication hook, currently the user code needs `bucket.get_index() == 0`, which involves internal bucketization implementation details and undermines the usability of DDP communication hook.
Create an API to hide the details and improve the usability before publishing GradBucket APIs.
ghstack-source-id: 122723081
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
Reviewed By: rohan-varma
Differential Revision: D26720813
fbshipit-source-id: f4a3147382c1f970534d7f0dee0cd599156c8b8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53102
In `GradBucket` constructor, `offsets`, `lengths`, and `sizes_vec` are optional arguments and could possibly be empty. It will be safe to remove the default values.
ghstack-source-id: 122833603
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D26748199
fbshipit-source-id: 2e3bcd1b732851919a64bbbd20fe85e77a616fe3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53009
It can be a common operation to apply layer-wise operations over per-parameter tensors in a DDP communication hook.
Create a util method in GradBucket class before publishing GradBucket APIs.
ghstack-source-id: 122833594
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
f254364097
Reviewed By: rohan-varma
Differential Revision: D26717893
fbshipit-source-id: 916db319de8b85dd22bc4e35db5671bf4e34740f
Summary:
I'm trying to make jitted RNG graph-safe in csarofeen 's nvfuser branch. Doing so requires diffs in files outside torch/csrc/jit, and we'd like these to go upstream through the present simple separate PR (instead of needing to be reviewed as part of Christian's branch's eventual merge, which will be massive).
From the perspective of eager mode consumers, diffs here are purely cosmetic. I moved raw definitions of `PhiloxCudaState` and `at::cuda::philox::unpack` to standalone headers the codegen can easily copy from.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51580
Reviewed By: malfet
Differential Revision: D26626972
Pulled By: ngimel
fbshipit-source-id: 7f04d6c5ffe0af7a8a66d3ae6ed36191d12f7d67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53037
As remarked in #52277 it is easy to give an (inefficient, due to extra
redispatches) DefaultBackend implementation of foo and foo_ in terms of
foo_out. This patch enables code generation for DefaultBackend in these
cases by default for all structured kernels. You can see the payoff
in MSNPU extension: it only has to register a kernel for add.out, and it
gets add and add_ kernels automatically.
The actual code changes are very modest:
- When DefaultBackend, call the dispatched (not direct native::)
functions to allocate tensors, change device guard, etc
- Don't call impl() for DefaultBackend (as it doesn't exist); instead,
directly generate a call to at::foo_out to do the actual work.
- Do NOT generate DefaultBackend implementation for foo_out. Actually,
there is a case to be made for this being a good idea with more infra;
see comments inside.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D26731225
Pulled By: ezyang
fbshipit-source-id: 939da7cb69f694722ec293e5e42e74a755dd0985
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53032
Previously, you could get this error message:
```
Failed to synthesize the expression "Tensor & out".
When I failed, the following bindings were available in the context:
const Tensor & self;
const Tensor & other;
Scalar alpha;
const Tensor & op.outputs_[0];
```
There's a problem with this error message: it doesn't seem like there
is any 'out' argument available, but actually there is: the last
binding in the context is it. We printed the *expression*, not
the *ctype name*.
After this patch, the context now prints as:
```
const Tensor & self; // self
const Tensor & other; // other
Scalar alpha; // alpha
const Tensor & out; // op.outputs_[0]
```
Now it becomes clear that it's a const mismatch. Maybe we could also
beef up the error message so it points out near misses, but I'll leave
that to future work.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D26729768
Pulled By: ezyang
fbshipit-source-id: adb363551a7145eac788943c20969c86b1f8a81b
Summary:
Description:
- Added channels last 3d option to interpolate test
- split config non-4d into two : 3d and 5d
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53117
Reviewed By: NicolasHug
Differential Revision: D26754243
Pulled By: fmassa
fbshipit-source-id: 49bbab3bb47de27790e39537d0fbeca0f01782c4
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: f73bcd9dfa
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53012
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D26722108
fbshipit-source-id: ea6fa719c8fb666818a0e91da8d4f2edcc88fc49
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52213
Nans were previously inconsistently propagated due to std::min always returning first argument if one of the args in nan
when reduction functor was called on 2 `-inf` arguments, `std::min(x,y) - std::max(x,y)` resulted in `-inf - (-inf)` = nan, even though logcumsumexp is well defined for `-inf, -inf` pair.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52947
Reviewed By: H-Huang
Differential Revision: D26718456
Pulled By: ngimel
fbshipit-source-id: a44433889da352cc959786dd15b6361a68fcfed7
Summary:
These are no longer useful. Let's wait for a few days before merging this, just in case somebody finds failures in them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52890
Reviewed By: H-Huang
Differential Revision: D26725500
Pulled By: mruberry
fbshipit-source-id: 3ebc18ee11ebef34451e60861414521730742288
Summary:
Fixes https://github.com/pytorch/pytorch/issues/38137
As mentioned in the issue, this is a workaround for [python issue 43367](https://bugs.python.org/issue43367). There are a number of other places where `sys.modules` is modified, if something changes in python perhaps those should be reviewed as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53107
Reviewed By: zou3519
Differential Revision: D26753571
Pulled By: ezyang
fbshipit-source-id: 2bda03bab39ff9ca58ce4bc13befe021da91b9c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52684
With alias analysis we get much more powerful registration and we can start removing "native" and fallback interpreted implementations. `inputsOutOfPlace` is an artifact of the hardcoded "native" and lax fallback implementations. Ideally every node will run out of place every time. Afaik, there's never a reason to disable it and we may want to remove that functionality.
This diff does introduce a "leak" in the memory management - containers are not cleaned up. This only happens when out variants are enabled
Test Plan: buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest -- --run-disabled
Reviewed By: maratsubkhankulov, hlu1
Differential Revision: D26515801
fbshipit-source-id: 7391d66b9d36e15fc2955a5c34a04d027d18fe78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50060
Aliasing is currently mishandled in SR.
This diff fixes that issue entirely and allows us to avoid hard coded "view" registration. I'll remove the macro in a follow up diff.
However, this diff introduces a subtle assumption when memory optimization is turned on: operators cannot "sometimes alias." Some care will need to be taken to actually make sure this is enforced going forward.
This diff
```
$ batch=20 ./run.sh --pt_optimize_memory=false |& grep "finished"
C2 run finished. Milliseconds per iter: 0.512114. Iters per second: 1952.69
PyTorch run finished. Milliseconds per iter: 0.51176. Iters per second: 1954.04
$ batch=20 ./run.sh --pt_optimize_memory=true |& grep "finished"
C2 run finished. Milliseconds per iter: 0.511402. Iters per second: 1955.41
PyTorch run finished. Milliseconds per iter: 0.506493. Iters per second: 1974.36
$ batch=1 iters=100000 ./run.sh --pt_optimize_memory=false |& grep "finished"
C2 run finished. Milliseconds per iter: 0.0562877. Iters per second: 17765.9
PyTorch run finished. Milliseconds per iter: 0.0667712. Iters per second: 14976.5
$ batch=1 iters=100000 ./run.sh --pt_optimize_memory=true |& grep "finished"
C2 run finished. Milliseconds per iter: 0.0561829. Iters per second: 17799
PyTorch run finished. Milliseconds per iter: 0.0665069. Iters per second: 15036
```
Test Plan:
buck test //caffe2/test:static_runtime
buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest
Reviewed By: eellison
Differential Revision: D25581156
fbshipit-source-id: 41e68119d53e687a9c32d966ed420b270aea4b5b
Summary:
This should trigger the 11.2 and 9.2 tests on ci-all and release branch pushes so that debugging can happen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53109
Reviewed By: yns88
Differential Revision: D26752151
Pulled By: janeyx99
fbshipit-source-id: 3272038cc97560896ee3e9f5bc461212806c71e2
Summary:
Currently, the same C++ tests are run in CI twice in the onnx_ort_test1 job as well as the onnx_ort_test2 job. This PR runs it once on our test1 job only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53067
Reviewed By: walterddr
Differential Revision: D26739857
Pulled By: janeyx99
fbshipit-source-id: 8960ad5c70181b8154a230914167286f1d9b64f6
Summary:
We want to store the file names that triggers each test suite so that we can use this data for categorizing those test files.
~~After considering several solutions, this one is the most backwards compatible, and the current test cases in test_testing.py for print test stats don't break.~~
The previous plan did not work, as there are multiple Python test jobs that spawn the same suites. Instead, the new S3 format will store test files (e.g., `test_nn` and `distributed/test_distributed_fork`) which will contain the suites they spawn, which will contain the test cases run within the suite. (Currently, there is no top layer of test files.)
Because of this major structural change, a lot of changes have now been made (thank you samestep!) to test_history.py and print_test_stats.py to make this new format backwards compatible.
Old test plan:
Make sure that the data is as expected in S3 after https://github.com/pytorch/pytorch/pull/52873 finishes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52869
Test Plan: Added tests to test_testing.py which pass, and CI.
Reviewed By: samestep
Differential Revision: D26672561
Pulled By: janeyx99
fbshipit-source-id: f46b91e16c1d9de5e0cb9bfa648b6448d979257e
Summary:
This PR builds an aggregate stmt for all the tensors in the kernel before constructing LoopNest. This migrates to using the LoopNest constructor that takes in a stmt and output buffers. This is one more step closer to eliminating the dependency of LoopNest on Tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53024
Reviewed By: H-Huang
Differential Revision: D26729221
Pulled By: navahgar
fbshipit-source-id: 43e972585351f6902c14b383b137aaaee3aaa3e1
Summary:
`jit.trace` recursively gathers all named attributes in module at beginning of
tracing. This is fine in a pure-tracing environment, but breaks when a
scripted module that contains an InterfaceType'd submodule is involved.
Because InterfaceType, by design, is not allowed to have any attribute,
thus some of the gathered attributes will turn into fatal errors in
following some graph rewrite passes.
This PR fixes this bug by distinguishing InterfaceType'd submodules from
normal ClassType'd submodules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53052
Reviewed By: wanchaol
Differential Revision: D26735566
Pulled By: gmagogsfm
fbshipit-source-id: a14aee6f1fe8000f80c2dc60bdf19acee6225090
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53060
As title. We would like to use alternative pickler/unpickler
implementations, to make it possible to send objects over the wire that
are coming from a torch.package
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D26737317
Pulled By: suo
fbshipit-source-id: 6bdef9824e48ef657dcad72cc5a9114e6612ea4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53061
We only care about evaluating the string return version. If `reduce()`
throws an error, we should just continue on with pickling.
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Differential Revision: D26737652
Pulled By: suo
fbshipit-source-id: 0b6fbbe345ad0b6a33330b2efa39d7bab703193d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52613
Including MaxPool as part of the MKLDNN fusion group sped up resnet18 by ~20%, and was a win on other models I tested as well. I will post more complete benchmarks.
As mentioned in the diff, in some cases MaxPool can be slower than aten - ideally we'd only include maxpool if it decreased the number of layout transformations that occur. That hasnt actually matttered for all of the torchvision models, I don't think its necessary for this PR.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26696704
Pulled By: eellison
fbshipit-source-id: 61a025dbf5e7591c0a0f75def3beb439a138a21e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52513
Subgraph Utils previously only worked with merging a node into a subgraph if the node was before the subgraph; extend the logic for the case where the subgraph is first.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26696697
Pulled By: eellison
fbshipit-source-id: b0595b7d400161b0972321c55718b67103c7bbcd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52512
This API is not used at all, and is tricky to maintain. When we were using it last we ran into lifetime issues when using `Value *` as the key. In hind sight, we should have been using `value->unique()`, but regardless, this not being used and should be removed.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26696695
Pulled By: eellison
fbshipit-source-id: 97ed92e88ecab0085fabbac46573611666bf2420
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51600
Looking for notes on implementation first, will post more notes on benchmarks and overall thoughts/implementation and solicit more input soon.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26696702
Pulled By: eellison
fbshipit-source-id: cd612f093fe3859e42fb0b77560ebd1b44fccff7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52786
Previously, NNC did not sanitize input names. I ran into this in the next PR when making subgraph creation preserve debug names caused a number of NNC cuda failures. I also previously ran into this with some masked_fill failures internally, which led me to disable the operator.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26696699
Pulled By: eellison
fbshipit-source-id: 7c3af4d559d58762fb8332666784a4d5cd6a4167
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51484
This PR moves the linear weights of a frozen model to MKLDNN. When the weights are already in MKLDNN, just computing a single linear by converting the input and output from/to mkldnn provides large speedups. I benchmark'd the results of the top 200 shapes in predictor [here](https://www.internalfb.com/phabricator/paste/view/P171537854) (taken from aten::matmul), as well as verified that it sped up popular models. .
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26696698
Pulled By: eellison
fbshipit-source-id: 53d03b9e6956e11b700ee58214e2266e2aa4106a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51483
This PR moves the conv weights of a frozen model to MKLDNN, and AOT reorders the weights. When the weights are already in MKLDNN, just computing a single conv by converting the input and output from/to mkldnn provides large speedups. I benchmark'd the results of the top 200 shapes in predictor [here](https://www.internalfb.com/phabricator/paste/view/P171537938), as well as verified that it sped up popular models in torchvision.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26696703
Pulled By: eellison
fbshipit-source-id: 0b4441bee4f6e0890a4540fbca3bb5e58b8c5adf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53063
The problem was that a derived class was marked with "py::nodelete",
while the base class wasn't. Now they both are marked correctly.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D26737877
Pulled By: ZolotukhinM
fbshipit-source-id: 17d9d430651c8f695fc7b6bf6784e7719e20a4d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52901
This PR implements IR Verifier and adds a call to it in `LoopNest`
constructors. Checks that were in expr/stmt constructors before are now
moved to the corresponding `::make` functions or to the verifier. They
didn't really help from the constructors anyway since an exception
thrown from there led to a segfault due to the fact our memory
management works (object was not fully created but was registered in the
kernel arena for destruction anyway).
Fixes#52778.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26682928
Pulled By: ZolotukhinM
fbshipit-source-id: c56524015cdffb1ed8bce4394509961a4071dcfa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53050
As title. We would like to use alternative pickler/unpickler
implementations without changing the entire RPCPickler, to make it
possible to send objects over the wire that are coming from a
torch.package
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Differential Revision: D26734592
Pulled By: suo
fbshipit-source-id: d9d9fa62ee15bfcb00e09192030541b61df8c682
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53049
This makes our API symmetric--now we have an `Importer` aware Pickler
and Unpickler implementation that have similar interfaces.
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Differential Revision: D26734593
Pulled By: suo
fbshipit-source-id: 3479437cf6b98e0d6a8aa4907c75f0c61d5495d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53048
I am planning the custom pickler and unpicklers that we use as
semi-public interfaces for `torch.rpc` to consume. Some prefatory
movements here.
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Differential Revision: D26734594
Pulled By: suo
fbshipit-source-id: 105ae1161d90f24efc7070a8d80c6ac3d2111bea
Summary:
Do not build PyTorch if `setup.py` is called with 'sdist' option
Regenerate bundled license while sdist package is being built
Refactor `check_submodules` out of `build_deps` and check that submodules project are present during source package build stage.
Test that sdist package is configurable during `asan-build` step
Fixes https://github.com/pytorch/pytorch/issues/52843
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52908
Reviewed By: walterddr
Differential Revision: D26685176
Pulled By: malfet
fbshipit-source-id: 972a40ae36e194c0b4e0fc31c5e1af1e7a815185
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52870
Add the missing parts to support to_backend modules by lite interpreter.
1. Add ISINSTANCE instruction support, which is used in to_backend for output type check.
2. Bypass lite interpreter's type parser by checking the qualified name. If it starts with "torch.jit", use the same type resolver as nn module (starting with "__torch__").
Tests
Mobile module is serialized and loaded in ```BackendTest.TestCompiler```. The results are compared to those from original torchscript module.
Test Plan: Imported from OSS
Reviewed By: raziel
Differential Revision: D26715351
Pulled By: iseeyuan
fbshipit-source-id: ad9d74ee81c6aa692ab9e5dd7a9003bae5d4f01f
Summary:
The previous code allowed these tests to run every four hours on certain ci-all branches...which is really bad and resource intensive. This code removes that, but then disallows the 11.2 and 9.2 tests to be run on ci-all branches.
To debug CUDA 11.2 or 9.2 tests, one must now manually change the config to allow for them. (Look at https://github.com/pytorch/pytorch/issues/51888 and https://github.com/pytorch/pytorch/issues/51598 for examples of how to do that.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53069
Reviewed By: H-Huang
Differential Revision: D26739738
Pulled By: janeyx99
fbshipit-source-id: 7577b9b2e876bac0e4e868ce2a1f3ffdb6aca597
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53028
TORCH_CHECK (and variants) wrap the condition in C10_UNLIKELY, so this code is both prettier and better.
ghstack-source-id: 122755165
Test Plan: CI
Reviewed By: malfet
Differential Revision: D26522821
fbshipit-source-id: 70aa11f1859f979657a1f376f7039b5015c69321
Summary:
Adds a script so that we can take wheels directly from
download.pytorch.org and publish them to pypi
This is currently mainly used to prep windows binaries for publication to PyPI
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53056
Reviewed By: H-Huang
Differential Revision: D26738642
Pulled By: seemethere
fbshipit-source-id: 96777ed6c3f3454bddb4bc13121f727074312816
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53016
We just checked in the generated files directly.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D26724876
Pulled By: ezyang
fbshipit-source-id: 887d781cac47b7cf16ba2cd6079c63b8f186fe44
Summary:
Updated version following https://github.com/pytorch/pytorch/issues/52764 (including comments from Shen), but this one I expect to be able to land.
ZeroRedundancyOptimizer:
- bucket as tensor views, optional
- make a lot of attributes private
- minor unit test refactor
- adding coverage in the unit test for with and without bucket views
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52987
Reviewed By: mrshenli
Differential Revision: D26728851
Pulled By: blefaudeux
fbshipit-source-id: f8c745966719c9076c20a554ef56198fb838856c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52141
Remove BufferShuffleDataSet, as it's not being used anywhere within PyTorch (no usage on Github based on a search) and it's not included in the release of PyTorch 1.7.1.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D26710940
Pulled By: ejguan
fbshipit-source-id: 90023b4bfb105d6aa392753082100f9181ecebd0
Summary:
Enabling four test cases in test_cuda.py for ROCm because they are passing.
Signed-off-by: Kyle Chen <kylechen@amd.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52739
Reviewed By: H-Huang
Differential Revision: D26706321
Pulled By: ngimel
fbshipit-source-id: 6907c548c4ac4e387f0eb7c646e8a01f0d036c8a
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: a431ee37cb
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52992
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: dskhudia
Differential Revision: D26718007
fbshipit-source-id: 7b35ab2012b8b6300a6e78c8425f9e08864a9f68
Summary:
This tests a simple failure mode for a TypeCheck when a shape changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52933
Reviewed By: H-Huang
Differential Revision: D26727583
Pulled By: Krovatkin
fbshipit-source-id: b277218af9572cd6f89f2ece044f7d84d4c10283
Summary:
In `__iter__` of the `RandomSampler`, when `self.replacement` is `False` in the original code, `self.generator` is always used in the `torch.randperm` instead of the generator we set.
Fixes https://github.com/pytorch/pytorch/issues/52568
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52956
Reviewed By: mruberry
Differential Revision: D26724303
Pulled By: H-Huang
fbshipit-source-id: 86f2795c76f3548e31181fb077af046078a173cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52928
Changes the user facing API of `prepare_single_model_output` to
require a list of nodes instead of a list of subgraphs. This ensures
that how we define a subgraph is an implementation detail and is
not exposed to the user, keeping the eng cost of updating this
implementation later low.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26693471
fbshipit-source-id: 67c2feb844556225e36f8d6d4023246939bcb445
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52927
Refactor to use an existing util instead of duplicating code, no logic
change.
Test Plan:
CI
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26693474
fbshipit-source-id: 06b7047eb9a762557b7f679347e424c0dd009aad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52926
Model name is already stored in the Loggers in the prepare call.
Removing the need to specify it again in the extract activations
functions, to simplify things.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26693473
fbshipit-source-id: 52511cacc16f79fa09c78ccde78e7f439f4b315c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52925
Cleans up some incorrect comments and docblocks in
`numeric_suite_core_apis.py`.
Test Plan:
CI
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26693472
fbshipit-source-id: 17f3ff464c6ea01374bcc6ac5899da7034627152
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 4b9f7f8abe
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52930
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D26694739
fbshipit-source-id: d8c835f6e74fec6e2c9a3a6e6713926ccf7dcedd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52909
PR #46675 introduced heuristics to use thnn_conv2d for 1x1
convolutions, since mkldnn had a bug that was slowing those cases
down. Unfortunately, the test plan for that PR only tested single-threaded
convolutions; mkldnn is considerably faster on multithreaded convolutions.
An example from yolov3, on 24 cores of a Xeon Platinum 8175M CPU @ 2.50GHz
```
input:{1, 64, 192, 256}, weight:{32, 64, 1, 1}
thnn_conv2d: GFLOPS/s=104.574G/s
mkldnn_convolution: GFLOPS/s=467.357G/s
```
ghstack-source-id: 122627564
Test Plan: Multithreaded 1x1 convolutions
Reviewed By: wconstab, xuzhao9
Differential Revision: D26685272
fbshipit-source-id: e8e05db89e43856969e26570a170c13b3e73ac74
Summary:
This is a second attempt to use graph executor to run forward on a gradient. This allows a secondary chance to profile intermediate tensor introduced by autodiff.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52136
Reviewed By: pbelevich
Differential Revision: D26693978
Pulled By: Krovatkin
fbshipit-source-id: 91dde8009a210950af8e5173668ada241e16dd52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52651
Merging them for easier extensions to fp16 and more binary ops
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D26600118
fbshipit-source-id: a1816e593cf3065afe87d2e6e44cdace13bf6aeb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52903
Implement BlackBoxPredictor::BenchmarkIndividualOps so that we can clean up the output tensors properly after each iteration and get more accurate per operator timing.
Add four more metrics to track setup_time, memory_alloc_time, memory_dealloc_time, and output_dealloc_time.
Reviewed By: ajyu
Differential Revision: D26657473
fbshipit-source-id: 1cf282192b531513b9ee40b37252087818412f81
Summary:
Same as https://github.com/pytorch/pytorch/issues/52760 which I could not get to land. I just could not live with ghstack/ghimport/randomly broken things, I break enough of them myself, so this is a fresh copy without ghstack shenanigans. I'm hopeful that this can land relatively bug free, and am sorry for the duplications..
What this does:
- call the common_utils test runner instead of unittest, because it seems that it's how it should be done
- change the returned state from ZeroRedundancyOptimizer to be PyTorch compliant, which has the added benefit of being elastic (world size independent)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52960
Reviewed By: mrshenli
Differential Revision: D26710932
Pulled By: blefaudeux
fbshipit-source-id: 1d914bc9221442ba1bb2b48f5df10c313e674ece
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52534
Currently linear_dynamic_fp16 has a signature that's tied to fbgemm/qnnpack
We'll need to produce a pattern equivalent to linear_dynamic_fp16 to support extensions
to other backends
Test Plan:
python test/test_quantization.py TestQuantizeFxOps.test_linear_dynamic_fp16
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D26557726
fbshipit-source-id: 270c9f781f73c79416a092b7831294cabca84b0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52892
When an EnforceFinite check fails this logs all of the tensors in the workspace and whether they are finite or not.
This is a little bit hacky since it uses the aten APIs. I've `ifdef`ed the implementation so it should compile fine on xplat and mobile. It's also accessing the workspace directly but since this is a logging op it seems fine to bend the rules.
Test Plan:
$ buck test //caffe2/caffe2/python/operator_test:enforce_finite_op_test
$ buck-out/gen/caffe2/caffe2/python/operator_test/enforce_finite_op_test#binary.par
I0225 16:29:46.166507 311548 enforce_finite_op.h:62] blob X isfinite=false
Reviewed By: dzhulgakov
Differential Revision: D26626336
fbshipit-source-id: f68e219b910a7242f2e72bb4d734c3e84f46eec5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52910
**Summary**
PR #52158 tried to move all JIT bindings from `torch._C` to a new
submodule `torch._C._jit`, but that...did not go well. This pull request
adds the new `torch._C._jit` submodule, but does not migrate the
existing bindings. Instead, it adds a unit test that fails if any new
bindings are added to `torch._C`. A comment in the test instructs
developers to add their new binding to the allowlist if it really should
be in `torch._C`, or to add it to the appropriate submodule (e.g
`torch._C._jit`, for example). The idea is to prevent the issue
described in #51691 from getting *worse* if it cannot be fixed.
**Test Plan**
Continuous integration.
**Fixes**
This commit fixes#51691.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D26698373
Pulled By: SplitInfinity
fbshipit-source-id: ec9f5426051227a513d4fd09512b624420e0100b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52619
Runs this test suite with nccl_async_error_handling enabled. It is the
default to run many distributed training jobs, and can also help catch
errors/hangs in tests more easily. We don't expect any changes in the actual
existing tests since they shouldn't have any hangs.
Also removes a commented out line
ghstack-source-id: 122595646
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D26588108
fbshipit-source-id: a57bbe2ae5a0c86731d77be45756b17151618eb6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52603
This PR introduced a backend with minimum compilation capability to the to_<backend> flow. The targets are:
- Demonstrate the end-to-end flow with adding a backend -> compilation -> runtime
- How the backend compilation errors be surfaced to the user, with the original model's source code information. (C++ only in this PR. Python APIs will be demonstrated in a following PR.)
Changes:
- Compilation
1. A backend with minimum compilation features, "backend_with_compiler_demo" is added.
2. The compilation happens AOT in the ```pre_process``` function registered to this backend.
3. Compiled results are stored in a string blob for each method. They are serialized to the lowered module with ```__get_state__``` function.
4. Error message with model source code is thrown, for features not handled by the backend compiler.
- Runtime
1. The compiled blob is loaded in ```__set_state__``` method.
2. The ```compile``` function of the backend pass through the AOT compiled blob. (TODO: parsing the blob to the format that the backend can understand can happen here.)
3. The ```execute``` function of the backend executes the specified method (handle).
Test Plan:
- ```BackendTest.TestCompiler```: the C++ end-to-end demonstration on a supported model. After compilation and running, the lowered model produces the same result as the original torchscript model.
- ```BackendTest.TestCompilerNotSupport```: Demonstrate the error message from the AOT compilation for a feature not supported from the input module. The error message looks like:
```
"The node of aten::mul is not supported in this compiler. Source code: File "<string>", line 3
def forward(self, x, h):
return x * h
~~~~~ <--- HERE
```
Reviewed By: raziel
Differential Revision: D26593968
Pulled By: iseeyuan
fbshipit-source-id: 8f264f60a0470e9f07e36fdeccbf17da6c1d7cd7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52792
Move the aten level source code list from `pt_template_srcs.bzl` to `build_variables.bzl`, such that this source list can be shared by both OSS and internal.
ghstack-source-id: 122458909
Test Plan: CI
Reviewed By: dhruvbird, iseeyuan
Differential Revision: D26647695
fbshipit-source-id: 88469c934d4a73c261418c0c584e46104295a0c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52824
How was this not breaking? _bundled_inputs_deflated doesnt exist
ghstack-source-id: 122491970
Test Plan: unit tests
Reviewed By: iseeyuan
Differential Revision: D26658098
fbshipit-source-id: 9ebf961b8764ba8779052c520dd46a8724be042a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51494
The overall `pytorch/conda-cuda` image was getting to a ridiculous size
of 36GB so this splits up that image into cuda specific ones to try and
reduce the amount of things we have to download.
coincides with: https://github.com/pytorch/builder/pull/634
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D26281958
Pulled By: seemethere
fbshipit-source-id: 83b498532a6f04801952438537b564f998b62d94
Summary:
This is less surprising than the current default, `--delta=12`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52877
Test Plan: Run the example commands from `tools/test_history --help` and check that their output matches that shown.
Reviewed By: pritamdamania87
Differential Revision: D26674258
Pulled By: samestep
fbshipit-source-id: 1413e11519854b0a47e14af2f1d20c57f145dacd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52481
Adds an API `get_debug_mode` that can be used by distributed package and users to retrieve debug mode. Currently no functionality changes, but wanted to get the bare bones function out and add relevant debug mode logging in follow up diffs.
ghstack-source-id: 122471216
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D26508972
fbshipit-source-id: d1153774f8697bc925a05db177d71c0566d25344
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52799
We agreed that it's better to not add this, removing.
We can make Eager mode NS match this in a future PR.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26652638
fbshipit-source-id: 5baa51a6bf6de5632946417fe9fd3d0f3e78f7fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52798
Adds the node name and node target type to Numerical Suite outputs.
This is useful to debug which node got matched to which node,
and what is the type of the operation.
```
// before
{
layer_name: {
model_name: {
'type': 'weight',
'values': [...],
},
},
}
// after
{
layer_name: {
model_name: {
'type': 'weight',
'values': [...],
'node_name': '0',
'node_target_type': "<class 'torch.nn.modules.conv.Conv2d'>",
},
},
}
```
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26652637
fbshipit-source-id: ba75b110cb91234f17a926ccbc5d0ccee2c3faeb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52779
1. makes the return type of the weight comparison APIs match the return
type of the activation comparison APIs:
```
# before
{layer_name: {model_name: weight_tensor}}
{layer_name: {model_name: [activation_tensor]}}
# after
{layer_name: {model_name: [weight_tensor]}}
{layer_name: {model_name: [activation_tensor]}}
```
2. makes a type alias for the type, so future changes are easier
Test Plan:
```
mypy torch/quantization
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26652639
fbshipit-source-id: eb1f04d6913cedf88d628f362468875ae9ced928
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52771
Before this PR, subgraph names were derived from node names
in model B. For example, if we had
```
A: linear0 -> relu0 -> ...
B: linear_relu0 -> ...
```
Then the subgraph name would be `linear_relu0`, and the outputs before this
PR would look like
```
{
'linear_relu0': {
'model_a': ...,
'model_b': ...,
},
}
```
This PR decouples subgraph naming from node names.
The outputs after this PR look like:
```
{
# guaranteed to match the right subgraphs across different models
# without needing more than one model during the prepare passes
'base_op_torch.nn.functional.linear_0': {
'model_a': ...,
'model_b': ...,
},
}
```
There are future requirements for which using node_name as subgraph name does not work well:
a. the need to support N models, without having all of them in memory at the same time
b. the need to support fusions and match subgraphs with related but non-equal types
This PR changes the naming of subgraphs to be based on two things:
1. the name of the underlying set of related ops (i.e. `torch.nn.functional.linear`)
2. the order in which this subgraph was named (i.e. `foo_0`, `foo_1`, ...)
Basically, we can't use a node name because of (a), since there must be
a reference model which node name other models must use, but that
reference model is not guaranteed to be available. Note: we could add
some state and require the reference model to go through the APIs first,
saving the reference node names, but I'm deliberately not doing that
to minimize the state used throughout.
To support (b), we need a way to determine a name of a subgraph which is
the same for all related subgraphs (i.e. linear-relu vs quantized_linear
vs quantized_linear_relu). In this PR, this is done by using the base
aten op's name. We use a string name so it looks nice in the output
(I tried `str(underlying_type)`, and it is not easy for humans to read).
Note: after this PR, it's hard to parse the results to see which layer
is related to which node in the graph. This will be fixed in a future PR
where we will store the node name on the logger, and expose it in the
output.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher
python test/test_quantization.py TestFXGraphMatcherModels
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
python test/test_quantization.py TestFXNumericSuiteCoreAPIsModels
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26652641
fbshipit-source-id: ee8dacc2d6e875357c1574cbf426923f9466ea10
Summary:
Add some small utility functions to read the blob names back from the minidb
file so that we can verify how many chunks were written for each blob.
Test Plan: buck test caffe2/caffe2/python/operator_test:load_save_test
Reviewed By: mraway
Differential Revision: D26641599
fbshipit-source-id: bccb0af157d85e585e95bc7be61c4584fba3cb04
Summary:
Optimize the blob serialization code by using `AddNAlreadyReserved()` when
serializing tensor data, rather than making N separate `Add()` calls.
`AddNAlreadyReserved()` is a simple addition operation, while each `Add()`
call checks to see if it needs to reserve new space, and then updates the
element data, which is unnecessary in this case.
Test Plan:
This appears to improve raw serialization performance by 30 to 35% for float,
double, and int64_t types which use this function. This improvement appears
relatively consistent across large and small tensor sizes.
Differential Revision: D26617038
fbshipit-source-id: 97dedbae889d35463628f3016ac56986e685289e
Summary:
Move the `SaveOp` code from `load_save_op.h` to `load_save_op.cc`.
Previously this implementation was all in the templatized `SaveOp` class, even
though most of the logic didn't depend on the template parameters. Having
this code be in the header file slows down the build, and forces more files to
be rebuilt than necessary when changing the SaveOp code. Having this code be
in a template class can also increase the generated code size be larger than
needed, as we don't need separate copies instantiated for each context type.
Test Plan: buck test //caffe2/caffe2/python/operator_test:load_save_test
Reviewed By: mraway
Differential Revision: D26641600
fbshipit-source-id: 84ebe8164ffac1e4a691be41147f0c5d8e890e09
Summary:
Move NumPy initialization from `initModule()` to singleton inside
`torch::utils::is_numpy_available()` function.
This singleton will print a warning, that NumPy integration is not
available, rather than fails to import torch altogether.
The warning be printed only once, and will look something like the
following:
```
UserWarning: Failed to initialize NumPy: No module named 'numpy.core' (Triggered internally at ../torch/csrc/utils/tensor_numpy.cpp:66.)
```
This is helpful if PyTorch was compiled with wrong NumPy version, of
NumPy is not commonly available on the platform (which is often the case
on AARCH64 or Apple M1)
Test that PyTorch is usable after numpy is uninstalled at the end of
`_test1` CI config.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52794
Reviewed By: seemethere
Differential Revision: D26650509
Pulled By: malfet
fbshipit-source-id: a2d98769ef873862c3704be4afda075d76d3ad06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52787
Current conv packed param can be serialized/deserialized with `torch.jit.save/torch.jit.load`, but
can't be saved with `torch.load(m.state_dict())/torch.save(m.state_dict())`
reason is (from James):
```
I think the issue probably has to do with the normal pickle deserialization not detecting List[Optional[Tensor]] if it doesn't witness a None in the list. IIRC this is implemented on the TorchScript side through this type tag mechanism: https://github.com/.../jit/serialization/unpickler.cpp...
```
This PR is a hack but acceptable to JIT team until a proper solution is proposed.
Test Plan:
Will be tested in next PR
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D26649272
fbshipit-source-id: 4fc47a4c63e4cd1fabb404de5f0b95e127a9fca0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52861
Currently, scale and zp in these layers are not buffers, which
means they do not get saved to the state dict. Movin them
into buffers to allow people to properly use state_dict.
Note: this is a redo of https://github.com/pytorch/pytorch/pull/45313,
with BN taken out. Not doing this for BN because it has dependencies on existing
behavior. We should clean it up eventually.
Note: not handling BC because it's 100% broken now, so there is
no practical value in handling BC.
Test Plan:
```
python test/test_quantization.py TestPostTrainingStatic.test_normalization
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26671761
fbshipit-source-id: 7615b1dd0d1ae88eeff8b1d150f3846815dc2bc9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52672
This allows correct handling on a very large tensor allocations
Also, replace AT_ERROR with TORCH_CHECK(false)
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D26607547
Pulled By: malfet
fbshipit-source-id: 247f7e8c59f76af3b95799afc9bc4ab4cc228739
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52724.
This fixes the following for the LKJCholesky distribution in master:
- `log_prob` does sample validation when `validate_args=True`.
- exposes documentation for the LKJCholesky distribution.
cc. fehiepsi, fritzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52763
Reviewed By: anjali411
Differential Revision: D26657216
Pulled By: neerajprad
fbshipit-source-id: 12e8f8384cf0c3df8a29564c1e1718d2d6a5833f
Summary:
This PR fixes a resource leakage bug in the constructor of `TCPStore` where an exception thrown in `TCPStoreDaemon` or `tcputil::connect()` can leave the server socket dangling. The ideal long-term solution would be to have a RAII wrapper for TCP sockets returned by `tcputil`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52860
Reviewed By: osalpekar
Differential Revision: D26671775
Pulled By: cbalioglu
fbshipit-source-id: ccebbd7533ac601a4b80e6e759f2fb4fe01c70fa
Summary:
I was attempting to experiment with "manual" vectorization, and boy
was it hard. I finally came up with this, which I want to write down as a test
case. Eventually the APIs should make this easier...
Test Plan: buck test
Reviewed By: navahgar
Differential Revision: D26631189
fbshipit-source-id: c28794b25d7852890ea843fdbcaf8751648258c0
Summary:
https://github.com/pytorch/pytorch/issues/52477 introduced the usage of `touch`, which is not available on plain Windows environment, unless you made all the things come with Git Bash available. This PR fixes the build break on those systems by using the `touch` provided by Python pathlib.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52729
Reviewed By: anjali411
Differential Revision: D26666724
Pulled By: walterddr
fbshipit-source-id: aae357eb55c6787631eadf22bee7901ad3c2604e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52844
Fixes a crash in qconfig checking which happened if a model had conv transpose
with qconfig set to None.
Test Plan:
```
python test/test_quantization.py TestPostTrainingStatic.test_convtranspose_per_channel_qconfig_none
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26666043
fbshipit-source-id: e1b62840b4e3c67acbb4dbdcd32514b374efce1e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52055
This fixes the **out of memory error** while using update_bn in **SWA**, by not allocating memory for backpropagation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52654
Reviewed By: malfet
Differential Revision: D26620077
Pulled By: albanD
fbshipit-source-id: 890b5a78ba9c1a148f3ab7c63472a73d8f6412a4
Summary:
This PR introduces the `timeout` accessor to `Store` and `host`, `port` accessors to `TCPStore` to help testing and troubleshooting higher level APIs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52784
Reviewed By: anjali411
Differential Revision: D26648202
Pulled By: cbalioglu
fbshipit-source-id: 9cf23bf998ed330d648dfec2a93e1bbb50817292
Summary:
Addresses one item in https://github.com/pytorch/pytorch/issues/46321
## Background
This is a test version of the RL RPC example defined [here](https://github.com/pytorch/examples/blob/master/distributed/rpc/rl/main.py) and [here](https://pytorch.org/tutorials/intermediate/rpc_tutorial.html), with the following differences:
* It defines and uses a `DummyEnv` to avoid a dependency on `gym`. The `DummyEnv` simply returns random states & rewards for a small number of iterations.
* It removes the `ArgumentParser` and utilizes `RpcAgentTestFixture` + hard-coded constants for configuration and launching.
* It changes the worker names to match what the internal Thrift RPC tests expect.
The code is purposefully kept very similar to the original example code outside of these differences.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52393
Test Plan:
```
pytest test/distributed/rpc/test_tensorpipe_agent.py -k test_rl_rpc -vs
pytest test/distributed/rpc/test_process_group_agent.py -k test_rl_rpc -vs
```
Reviewed By: glaringlee
Differential Revision: D26515435
Pulled By: jbschlosser
fbshipit-source-id: 548548c4671fe353d83c04108580d807108ca76e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52837
After https://github.com/pytorch/pytorch/pull/52749 we started seeing an increased flakiness of the TensorPipeDistAutogradTestWithSpawn.test_backward_node_failure_python_udf test, with failures like this one:
https://app.circleci.com/pipelines/github/pytorch/pytorch/277824/workflows/cfcbef5a-544e-43bd-b3b0-ebc7b95134fe/jobs/11145394https://gist.github.com/lw/a0b48900673b5ae0f5d03aca1e72ffff
The logs are very clear and point to the changes in the error handling code upon a write error. Namely, the bug is triggered when a incoming read fails while there is an outgoing write, in which case the read callback (invoked first) will flush all pending futures, which then causes the write callback (invoked after) to not find the future it's looking for.
In a sense this bug wasn't introduced by https://github.com/pytorch/pytorch/pull/52749, however that PR introduced a check for whether the outgoing message was found, whereas before we would silence such a condition.
A fix for this could be to just resume silencing the error. However, I'm trying to go a bit further: when an outgoing write fails, we know that all subsequent callbacks will fail too, and thus all pending operations should be flushed. Hence we can do so, instead of just trying to flush a single given operation. This allows us to merge the error-handling code of both the read and write paths.
ghstack-source-id: 122509550
Test Plan: Will export to GitHub, run on CircleCI, and manually SSH into a machine and stress-run that test that was flaky.
Reviewed By: mrshenli
Differential Revision: D26663448
fbshipit-source-id: fbff0f6aff0d98994c08018a27c47c97149b920c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/51730
I've added the `scatter_add` and `scatter_add.dimname` to the promote list as well as test cases for the former op.
However, it seems that `scatter_add` [doesn't support named tensors yet](8b0cb5ede3/aten/src/ATen/native/NamedTensor.cpp (L356-L358)) (thanks t-vi for the pointer):
```python
dev = 'cuda'
torch.scatter_add(torch.zeros(2, 2, 2, dtype=torch.float16, device=dev, names=('N', 'C', 'L')),
'C',
torch.randint(0, 2, (2, 2, 2), device=dev),
torch.randn((2, 2, 2), dtype=torch.float32, device=dev))
> RuntimeError: scatter_add: You passed a dimname (string) to this op in place of a dimension index but it does not yet support this behavior. Please pass a dimension index to work around this.
```
which raised this error after adding this test case.
I'm thus unsure, if I should also remove `scatter_add.dimname` from the promote list or not.
In any case, once named tensors are supported a potential test could be added as:
```python
("scatter_add", (torch.zeros(2, 2, 2, dtype=torch.float16, device=dev, names=('N', 'C', 'L')),
'C',
torch.randint(0, 2, (2, 2, 2), device=dev),
torch.randn((2, 2, 2), dtype=torch.float32, device=dev))),
```
CC mcarilli ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52133
Reviewed By: ejguan
Differential Revision: D26440392
Pulled By: ngimel
fbshipit-source-id: f4ee2d0b9e1f81afb6f94261c497cf2bf79ec115
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52681
Updates the NS graph matching to properly traverse through args of nodes
if args are lists or tuples. As a side benefit, refactors the code to
make future similar improvements easier.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26611221
fbshipit-source-id: 4ddd9b26338a5a2763b2883967e100f73e207538
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52402
Before this PR, any pair of subgraphs with base nodes of equal
types matched.
While sometimes this is useful, this should be off by default to
properly handle user defined modules and functions, for which we do not
know how to extract weights or cast to the right input type.
In a future PR, we can add hooks to turn on matching for nodes
of equal types, for the situations where it makes sense.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher.test_nodes_with_equal_types_do_not_get_matched
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26499848
fbshipit-source-id: 5818b88eb7fd8ed36390f60aa1a18228bb50507e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52395
Simple change to add logic to get the weight of a quantized
`linear_relu` node.
More flavors of conv and linear will be added in future PRs.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_compare_weights_fun
```
Imported from OSS
Reviewed By: hx89
Differential Revision: D26497992
fbshipit-source-id: e6d88e92eedd6cdbf9116cbcfc8f6164f8499246
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52368
Before this PR, the graph matching logic only handles node arguments of
type Node. This PR extends it to allow to handle node arguments of type
Tuple, so that the matcher can properly navigate through the arguments
of `cat`.
Test Plan:
```
python test/test_quantization.py TestFXGraphMatcher.test_nodes_before_cat
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26490101
fbshipit-source-id: 2de8d6acc30f237e22bfc3cfa89728b37411aab6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52797
Also sneaking in change to check for realloc failure for packed activation buffer
FB:
In dynamic quantization input's quantization scale and zero point can be
different on every iterations. Thus requantization scale needs to be
recomputed.
Earlier bug that calculated those only at op creation time results in wrong
results on subsequent runs.
This diff fixes that.
Test Plan:
FB:
buck test caffe2/torch/fb/model_optimization:sparsity_test
Reviewed By: z-a-f, jiatongzhou
Differential Revision: D26651968
fbshipit-source-id: e5b9acef03fc45f31c43d88a175f3a64f7dbf4bd
Summary:
-Lower Relu6 to ATen
-Change Python and C++ to reflect change
-adds an entry in native_functions.yaml for that new function
-this is needed as we would like to intercept ReLU6 at a higher level with an XLA-approach codegen.
-Should pass functional C++ tests pass. But please let me know if more tests are required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52723
Reviewed By: ailzhang
Differential Revision: D26641414
Pulled By: albanD
fbshipit-source-id: dacfc70a236c4313f95901524f5f021503f6a60f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52804
`rpc.get_worker_info` used to only take string in v1.6. We recently
allow it to accept `int` and `WorkerInfo`, but the previous check
on `worker_name` is no longer correct. This commit adds explicit
`not None` check.
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D26655089
Pulled By: mrshenli
fbshipit-source-id: fa1545bd6dd2b33bc1e919de46b94e799ab9719c
Summary:
This way, we can have a mapping from the test files we directly execute (the tests [here](https://github.com/pytorch/pytorch/blob/master/test/run_test.py#L20)) to the test suites that we store data for in XML reports.
This will come in use later for categorizing the tests we run in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52791
Reviewed By: samestep
Differential Revision: D26655086
Pulled By: janeyx99
fbshipit-source-id: 94be32f80d7bc0ea1a7a11d4c4b1d3d8e774c5ea
Summary:
Apple recently announced ML Compute, a new framework available in macOS Big Sur, which enables users to accelerate the training of neural networks on Mac hardware. This PR is the first on a series of PRs that will enable the integration with ML Compute. Most of the integration code will live on a separate subrepo named `mlc`.
The integration with `mlc` (ML Compute) will be very similar to that of xla. We rely on registering our ops through:
TORCH_LIBRARY_IMPL(aten, PrivateUse1, m) {
m.impl_UNBOXED(<op_schema_name>, &customized_op_kernel)
...
}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50634
Reviewed By: malfet
Differential Revision: D26614213
Pulled By: smessmer
fbshipit-source-id: 3b492b346c61cc3950ac880ac01a82fbdddbc07b
Summary:
See the discussion here: https://github.com/pytorch/pytorch/pull/50431
~~Not completely done yet - need to figure out the backwards compatibility stuff as well as `RemovableHandle`.~~
~~Also, this concretely breaks Torchscript (which tries to script the properties), and more generally, probably requires modifying Torchscript hook support: https://github.com/pytorch/pytorch/issues/34329~~
Just kidding, I think all problems are solved :)
Another thing I could do in this PR is to simply replace all the `len(x) > 0` checks with the faster checks. That's about 1.5-2k more Python instructions and .4 - .5 microseconds slower.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52576
Reviewed By: ailzhang
Differential Revision: D26650352
Pulled By: Chillee
fbshipit-source-id: 0fd73e916354b9e306701a8a396c5dc051e69f0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52749
TensorPipe has recently changed some implementation details in how it schedules callbacks and this has exposed an issue in the RPC agent. Previously the callbacks of each pipe were executed independently and possibly simultaneously. For safety reasons (especially during shutdown) TensorPipe now synchronizes the pipes and thus invokes one callback at a time. Another characteristic of TensorPipe is that it "hijacks" some user threads to run some callbacks inline (e.g., if a low-level event loop completes an operation while a pipe is already busy, this completion is queued up and the user callback could be invoked later by a different thread, including the user's own thread).
These two effects combined caused a "reentrancy" phenomenon, where calling `context->connect` (formerly on line 850) to create a new client-side pipe could cause invoking a read callback on another pipe. Since we were holding `mutex_` when calling `context->connect`, and we were trying to re-acquire `mutex_` inside the read callback, this lead to a deadlock.
One solution to this problem is using finer-grained mutexes. In particular, introduce a mutex for each outgoing pipe (rather than a global one), which thus becomes the only one we need to acquire inside callbacks. At this point, the old `mutex_` is only guarding the vector of ClientPipes, thus we can rename it and release it earlier.
I also fixed the agent not acquiring any mutex when it set a message to error after a failed write (and also not removing the message from the timeout map).
ghstack-source-id: 122410367
Test Plan: Ran CI in #52677 together with the TensorPipe submodule update.
Reviewed By: mrshenli
Differential Revision: D26636345
fbshipit-source-id: d36da989f2aab51f4acb92d2e81bb15b76088df1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51807
Implemented torch.linalg.multi_dot similar to [numpy.linalg.multi_dot](https://numpy.org/doc/stable/reference/generated/numpy.linalg.multi_dot.html).
This function does not support broadcasting or batched inputs at the moment.
**NOTE**
numpy.linalg.multi_dot allows the first and last tensors to have more than 2 dimensions despite their docs stating these must be either 1D or 2D. This PR diverges from NumPy in that it enforces this restriction.
**TODO**
- [ ] Benchmark against NumPy
- [x] Add OpInfo testing
- [x] Remove unnecessary copy for out= argument
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D26375734
Pulled By: heitorschueroff
fbshipit-source-id: 839642692424c4b1783606c76dd5b34455368f0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52386
Remove stale aliasing inputs warning, error check that inputs is not null and has at least one entry, error check that the list of inputs is a list of tuples. This can cause subtle bugs where if the user passes in a list of tensors (the most common mistake) the first dimension of each tensor is dropped. This can go unnoticed because its the often the batch dimension which pytorch occasionally silently re-adds if its missing
ghstack-source-id: 122363487
Test Plan:
Bundle something with an input, bundle something with {} for inputs
For typing check below paste
{P199554712}
Reviewed By: dhruvbird
Differential Revision: D26374867
fbshipit-source-id: cd176f34bad7a4da850b165827f8b2448cd9200d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52726
This change removes `input_bufs_` and `intermediate_bufs_` from
`LoopNest` class as they can be deduced from the root stmt and the list
of output bufs. As a result, the constuctor of the LoopNest also becomes
simpler as we now need to pass just one list of bufs.
Note: we might consider passing list of input bufs for verification
purposes (only inputs buffers are allowed to not have a definition), but
since we don't really have an IR verifier yet, there is no need in it
now. Once we add IR verifier, we could reconsider it.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D26629596
Pulled By: ZolotukhinM
fbshipit-source-id: 81f544e9602b6855b7968d540b9ae06bd7c7e6d8
Summary:
The Flake8 job has been passing on `master` despite giving warnings for [over a month](https://github.com/pytorch/pytorch/runs/1716124347). This is because it has been using a regex that doesn't recognize error codes starting with multiple letters, such as those used by [flake8-executable](https://pypi.org/project/flake8-executable/). This PR corrects the regex, and also adds another step at the end of the job which asserts that Flake8 actually gave no error output, in case similar regex issues appear in the future.
Tagging the following people to ask what to do to fix these `EXE002` warnings:
- https://github.com/pytorch/pytorch/issues/50629 authored by jaglinux, approved by rohan-varma
- `test/distributed/test_c10d.py`
- https://github.com/pytorch/pytorch/issues/51262 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/__init__.py`
- `torch/utils/data/datapipes/iter/loadfilesfromdisk.py`
- `torch/utils/data/datapipes/iter/listdirfiles.py`
- `torch/utils/data/datapipes/iter/__init__.py`
- `torch/utils/data/datapipes/utils/__init__.py`
- `torch/utils/data/datapipes/utils/common.py`
- https://github.com/pytorch/pytorch/issues/51398 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/readfilesfromtar.py`
- https://github.com/pytorch/pytorch/issues/51599 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/readfilesfromzip.py`
- https://github.com/pytorch/pytorch/issues/51704 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/routeddecoder.py`
- `torch/utils/data/datapipes/utils/decoder.py`
- https://github.com/pytorch/pytorch/issues/51709 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/groupbykey.py`
Specifically, the question is: for each of those files, should we remove the execute permissions, or should we add a shebang? And if the latter, which shebang?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52750
Test Plan:
The **Lint / flake8-py3** job in GitHub Actions:
- [this run](https://github.com/pytorch/pytorch/runs/1972039886) failed, showing that the new regex catches these warnings properly
- [this run](https://github.com/pytorch/pytorch/runs/1972393293) succeeded and gave no output in the "Run flake8" step, showing that this PR fixed all Flake8 warnings
- [this run](https://github.com/pytorch/pytorch/pull/52755/checks?check_run_id=1972414849) (in https://github.com/pytorch/pytorch/issues/52755) failed, showing that the new last step of the job successfully catches Flake8 warnings even without the regex fix
Reviewed By: walterddr, janeyx99
Differential Revision: D26637307
Pulled By: samestep
fbshipit-source-id: 572af6a3bbe57f5e9bd47f19f37c39db90f7b804
Summary:
This was mostly needed for ShardedDDP, not used here, dead code removal
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52698
Reviewed By: mrshenli
Differential Revision: D26617893
Pulled By: blefaudeux
fbshipit-source-id: 9bcfca5135bf332ebc1240300978c138d2041146
Summary:
This PR makes several UX improvements to `tools/test_history.py`:
- warn if `--all` is unset and no jobs are passed
- print output even in `multiline` mode if no reports are found for a commit
- this makes it easier to tell whether the script is just hanging
- if there are multiple reports for a commit/job pair, say so
- distinguish between not finding any reports and just not finding the desired test in the reports found
- don't require the suite name as a CLI arg, just use the test name
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52640
Test Plan: Example shell session: https://pastebin.com/SSemHqP8
Reviewed By: walterddr
Differential Revision: D26594350
Pulled By: samestep
fbshipit-source-id: 9ce2245f91eef289817aafe955a4343d4a068eda
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52671
Code is written with the assumption that new_size is unsigned value,
and when function is called with negative value it silently returns a nullptr rather than raise an exception.
Fix above-mentioned logic by converting new_size to unsigned type and let cpu_allocator raise exception on negative alloc.
Unroll nested if blocks by returning early if new_size is 0
Add TestNN.test_adaptive_pooling_size_overflow to indirecty validate the fix.
Fixes https://github.com/pytorch/pytorch/issues/50960
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D26607549
Pulled By: malfet
fbshipit-source-id: e3d4f7548b098f24fa5aba42d8f4e9288ece1e2e
Summary:
- Fixes the ordering of the value parameters of TCPStore's `compare_set()` in the pybind11 interop layer. The C++ API expects (old, new) while we are passing (new, old) in Python.
- Fixes the implementation of TCPStore's `compareSetHandler()` for cases where the key already exists in the store.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52696
Test Plan: `python test/distributed/test_c10d.py`
Reviewed By: malfet, H-Huang
Differential Revision: D26616976
Pulled By: cbalioglu
fbshipit-source-id: e6a70542e837be04697b5850947924edd896dbf6
Summary:
This update contains the fix to XNNPACK by kimishpatel
Add unit test that exposed the problem
Updated torchvision checkout to 0.9.0rc1 hash
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52691
Reviewed By: walterddr
Differential Revision: D26614595
Pulled By: malfet
fbshipit-source-id: d0fe155a084690a3459a9358dac8488292e734fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51976
FX serializes things by serializing Python code as a string and exec'ing
it on load. This accomplishes one goal (we don't have to pickle the
graph object directly) but breaks the pickle abstraction in ways that
are not composable with `torch.package`.
In particular:
1. `forward` is serialized by saving Python code. On load, it's
installed
by `exec`ing that code. This `exec` call needs to have the right
importer installed, otherwise it will not import modules from the
`torch.package` but instead import from the Python environment.
2. Any types/functions used are emitted as `import` statement in the
generated Python code. These are effectively dynamic dependencies of the
`GraphModule` being saved, and need to be registered as such so that the
`PackageImporter` will package them.
To address these, this PR introduces a new protocol for the
importer/exporter: `__reduce_package__`.
A class can implement `__reduce_package__` to customize how it is placed
in the importer/exproter. It functions very similarly to `__reduce__`,
except:
- `__reduce_package__` takes one argument, which is the
`PackageExporter`
instance. Users can use this instance to save stuff to the package to
implement their serialization. `__reduce__` takes no args.
- Only the 2-element tuple version of the return value for `__reduce__`
is supported (this could be extended if necessary).
- When the reduction function is called on load, an additional argument
is added to the beginning of the args tuple. This is the
`PackageImporter`
instance doing the loading.
The `__reduce_package__` protocol is defined using `persistent_id` and
`persistent_load`, which ensures that we can still use the cpickle
implementation of the pickler by default.
Pull Request resolved: #51971
Test Plan: Imported from OSS
Reviewed By: zdevito
Differential Revision: D26340591
Pulled By: suo
fbshipit-source-id: 5872a7d22e832056399a7372bae8a57807717882
Summary:
Fixes #{52034}
- Add a minimum compression rate threshold to `PowerSGDState`
- Use the threshold to determine whether to compress high-rank tensors or not
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52541
Test Plan:
No performance regression using rank-8 compression:
baseline: f253000411
updated one: f253010955
Reviewed By: rohan-varma
Differential Revision: D26594862
Pulled By: SciPioneer
fbshipit-source-id: 2859a91b4ca6bd1862bf6cd6441dc2a89badb2d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52635
Currently, the method `_load_for_mobile()` accepts an extra files map named `extra_files` which serves as an in-out parameter. i.e. the call fills in the keys of this map with all files under the `extra/` folder that they wish to extract, and the method fills in the `extra_files` map with the contents of those files.
In a specific case we have encountered, it is desirable to extract all the extra files so that they can be forwarded in an opaque manner into a `save_for_mobile()` call with the same set of extra files as during load.
This change adds a method `_get_all_archive_file_names()` which returns the names of all files in the `.ptl` archive. The caller can then extract the ones within the `extra/` directory and pass them in to the `extra_files` map argument.
ghstack-source-id: 122356928
Test Plan: Added additional test + `buck test //xplat/caffe2:test_lite_interpreter`
Reviewed By: iseeyuan
Differential Revision: D26590027
fbshipit-source-id: 4dc30997929e132f319c32cb9435d8a40fe0db5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52473
Use `map_aggregate` to create output for new graph so that it won't raise error when we have outputs that is not `Proxy`.
Test Plan: `test_transformer_multi_outputs` in `test_fx.py`
Reviewed By: jamesr66a
Differential Revision: D26502277
fbshipit-source-id: 404d9030a9b84db3f66f8505887a75717a28ad30
Summary:
Two changes:
- Print a warning rather than fail if creating hipified file fails with permission denied error
- Do not attempt to create /usr/include/libpng/png_hip.h in the first place
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52709
Reviewed By: walterddr
Differential Revision: D26625033
Pulled By: malfet
fbshipit-source-id: ff82dc24aee12eac2daaa6e5bc938811b49ebbc6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52670
TORCH_CHECK followed by a string literal is a no-op, and from the text of the message its clear that authors intended those instances to be `TORCH_CHECK(false, "msg")`
Discovered while trying to figure out of tensor_offset can be negative in Resize.h
s/TORCH_CHECK\("/TORCH_CHECK(false, "/
Test Plan: Imported from OSS
Reviewed By: walterddr, janeyx99, mruberry
Differential Revision: D26607546
Pulled By: malfet
fbshipit-source-id: 661812da84adb1d1af0284da60c93ec4bf5ef08e
Summary:
Moving master only resource-interactive CI jobs to a less regular basis.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52693
Reviewed By: malfet, seemethere
Differential Revision: D26615060
Pulled By: janeyx99
fbshipit-source-id: def46a7890ea46c655ef2ee0f7c548171464cb48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51974
Right now, when an FX `Graph` references an external object, we will emit
code like:
import foo
def forward(input: foo.bar.baz):
...
This is problematic in a world with `torch.package`, since then name
`foo.bar.baz` may reference a name from any number of packages.
This PR lays the groundwork for FX-package integration by separating the
resolution of external references from the genration of the function
code.
When generating a Graph's Python source, we keep track of all external
references and assign them unique names. At the end, we have a
dictionary mapping names -> actual objects. This becomes the `globals`
namespace we pass to `exec` when installing the forward function in a
`GraphModule`. This is nice because we can always be sure that `exec` is
seeing the same objects that were referenced from the `Graph`, no import
statements needed.
At serialization time, we use a `ModuleEnv` to resolve the globals dict
to a set of import statements that can be run to reprodce the `global`
namespace. This is only used on serialiation/deserialization, and those
functions are expected to check that the import statements are producing
the correct results.
Concretely, the code above will now look like:
from foo.bar import baz as foo_bar_baz
def forward(input: foo_bar_baz):
...
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D26340593
Pulled By: suo
fbshipit-source-id: fe247f75205d0a03fd067bdd0f95491e8edf1436
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52462
This is the step one for supporting multiple outputs in fx nnpi path.
During serialization, we store the shape and dtype in output args, so that importer doesn't need to go back and find the nodes.
The output nodes will looks like
```
{
"target": "output",
"op_code": "output",
"name": "output",
"args": [
{
"is_node": true,
"name": "add_1",
"shape": "[1, 1]",
"dtype": "torch.float32"
}
],
"kwargs": {}
}
```
Test Plan: Doesn't break existing tests and will test on step two.
Reviewed By: jfix71
Differential Revision: D26500742
fbshipit-source-id: 755d2dec704d9da579af40e754b556d6c01aa796
Summary:
Add a test in `load_save_test.py` that passes in a chunk_size parameter,
to ensure that we exercise the logic that passes the chunk size to the C++
serialization code.
Test Plan:
Ran the tests with the vlog level set to 3 and manually verified the log
messages showed that we were serializing in the expected chunks.
There are existing C++ tests that confirm chunking behavior works as expected
in the pure C++ code.
Reviewed By: mraway
Differential Revision: D26502578
fbshipit-source-id: cd0074f2358da81c68b0fed2c2a94818d83a957d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52632
Distributed tests run in a multiprocessing environment, where a parent
process drives the tests through several child processes. As a result, when a
child process fails the parent only prints the following:
```
Process 0 exited with error code 10
```
The child process also logs its own exception, but it is cumberson to go
through the logs and track this down.
To alleviate this, I've added a bunch of pipes for each child process so that
the child process writes the error to the pipe before exiting and the parent
process can read the appropriate error from the pipe and display it.
The new output printed by the parent is as follows:
```
> RuntimeError: Process 0 exited with error code 10 and exception:
Traceback (most recent call last):
File "torch/testing/_internal/common_distributed.py", line 361, in _run
getattr(self, test_name)()
File "torch/testing/_internal/common_distributed.py", line 288, in wrapper
fn()
File "test_c10d.py", line 789, in test_broadcast_checks
pg.broadcast([t1], opts)
ValueError: ProcessGroupGloo::broadcast: invalid root rank: -1
Process 1 exited with error code 10 and exception:
Traceback (most recent call last):
File "torch/testing/_internal/common_distributed.py", line 361, in _run
getattr(self, test_name)()
File "torch/testing/_internal/common_distributed.py", line 288, in wrapper
fn()
File "test_c10d.py", line 789, in test_broadcast_checks
pg.broadcast([t1], opts)
ValueError: ProcessGroupGloo::broadcast: invalid root rank: -1
Process 2 exited with error code 10 and exception:
Traceback (most recent call last):
File "torch/testing/_internal/common_distributed.py", line 361, in _run
getattr(self, test_name)()
File "torch/testing/_internal/common_distributed.py", line 288, in wrapper
fn()
File "test_c10d.py", line 789, in test_broadcast_checks
pg.broadcast([t1], opts)
ValueError: ProcessGroupGloo::broadcast: invalid root rank: -1
Process 3 exited with error code 10 and exception:
Traceback (most recent call last):
File "torch/testing/_internal/common_distributed.py", line 361, in _run
getattr(self, test_name)()
File "torch/testing/_internal/common_distributed.py", line 288, in wrapper
fn()
File "test_c10d.py", line 789, in test_broadcast_checks
pg.broadcast([t1], opts)
ValueError: ProcessGroupGloo::broadcast: invalid root rank: -1
```
ghstack-source-id: 122273793
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D26589274
fbshipit-source-id: 7b7a71ec790b216a89db7c157377f426531349a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52612
used the float type macro to generalize the fake_quantization per tensor functions to f16 and f64.
Test Plan:
added test to show it works in AMP and extended the forward and backward tests below to test float16 and float64 operations. Note: the reference function doesn't work with with these types so I had to convert in and back out of these types to compare.
```test python test/test_quantization.py
TestFakeQuantize.test_forward_backward_per_tensor_with_amp
test python test/test_quantization.py TestFakeQuantize.test_forward_per_tensor_cachemask_cpu
test python test/test_quantization.py TestFakeQuantize.test_backwards_per_tensor_cachemask_cpu
test python test/test_quantization.py TestFakeQuantize.test_forward_per_tensor_cachemask_cuda
test python test/test_quantization.py TestFakeQuantize.test_backwards_per_tensor_cachemask_cuda
test python test/test_quantization.py
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D26586416
fbshipit-source-id: 55fe83c5e47f45cd1de8ddd69bd4a5653ab6dc12
Summary:
This update contains the fix to XNNPACK by kimishpatel
Add unit test that exposed the problem
Updated torchvision checkout to 0.9.0rc1 hash
Fixes https://github.com/pytorch/pytorch/issues/52463
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52645
Reviewed By: kimishpatel, seemethere
Differential Revision: D26598115
Pulled By: malfet
fbshipit-source-id: d652bacdee10bb975fc445ab227de37022b8ef51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52628
Prior to this change ExternalCalls were not considered as Loads or
Stores to/from its buffers, which led to incorrect behavior in inlining.
This PR fixes it.
Differential Revision: D26589378
Test Plan: Imported from OSS
Reviewed By: navahgar
Pulled By: ZolotukhinM
fbshipit-source-id: cd69d5f7075f6dc756aabcf676842b9a250334d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52627
Currently inliner only inlines into Calls, this PR extends this to
cover Loads too. Eventually we will remove Calls altogether and use
Loads everywhere, this is one step in that direction.
Differential Revision: D26589377
Test Plan: Imported from OSS
Reviewed By: asuhan
Pulled By: ZolotukhinM
fbshipit-source-id: ca28f0df2273eb214f203467c6ba3d8f02a8a3b6
Summary:
Since `char` is not guaranteed to be signed on all platforms (it is unsigned on ARM)
Fixes https://github.com/pytorch/pytorch/issues/52146
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52616
Test Plan: Run ` python3 -c "import torch;a=torch.tensor([-1], dtype=torch.int8);print(a.tolist())"` on arm-linux system
Reviewed By: walterddr
Differential Revision: D26586678
Pulled By: malfet
fbshipit-source-id: 91972189b54f86add516ffb96d579acb0bc13311
Summary:
They've changed from class to struct in tensorpipe repo, but have not
been updated in the header, which triggers compiler warning if clang is
used and would have triggered a linker error if the same code is
compiled with MSVC
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52600
Reviewed By: lw
Differential Revision: D26579754
Pulled By: malfet
fbshipit-source-id: 800c02e7ba839bac01adf216de2d8547b7e9128b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52521
The `storage_type` and `external_data` fields were added a few years ago in
D10246743 (30aaa07594) but don't appear to have been used anywhere. Let's remove them to
help simplify the `TensorProto` message definition.
ghstack-source-id: 122110201
Test Plan: Confirmed the code still builds.
Reviewed By: dzhulgakov
Differential Revision: D26500028
fbshipit-source-id: 1e188f98f59e0b8673ea342ad9aaf7e5ba9b5fac
Summary:
psutil is used in many test scripts under test/
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52285
Reviewed By: jbschlosser
Differential Revision: D26516673
Pulled By: malfet
fbshipit-source-id: 09a81d5dba3bf5189e3e5575c2095eb069b93ade
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52333
Export_opnames current documentation is a bit misleading. Change it to better clarify what it does.
ghstack-source-id: 121810264
Test Plan: n/a
Reviewed By: iseeyuan
Differential Revision: D26471803
fbshipit-source-id: 496d10b161c9a4076c4e12db8a0affafc4e1e359
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52511
Re-enable a test that was previously fixed but forgot to be re-enabled.
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D26586980
Pulled By: H-Huang
fbshipit-source-id: 3cfe21de09036d2b87273680dae351e20125e815
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52176
Added tooling to print out zipfile structure for PackageExporter and PackageImporter.
API looks like:
```
exporter.print_file_structure("sss" /*only include files with this in the path*/)
importer3.print_file_structure(False /*don't print storage*/, "sss" /*only include files with this in the path*/)
```
The output looks like this with the storage hidden by default:
```
─── resnet.zip
├── .data
│ ├── extern_modules
│ └── version
├── models
│ └── models1.pkl
└── torchvision
└── models
├── resnet.py
└── utils.py
```
The output looks like this with the storage being printed out:
```
─── resnet_added_attr_test.zip
├── .data
│ ├── 94574437434544.storage
│ ├── 94574468343696.storage
│ ├── 94574470147744.storage
│ ├── 94574470198784.storage
│ ├── 94574470267968.storage
│ ├── 94574474917984.storage
│ ├── extern_modules
│ └── version
├── models
│ └── models1.pkl
└── torchvision
└── models
├── resnet.py
└── utils.py
```
If the output is filtered with the string 'utils' it'd looks like this:
```
─── resnet_added_attr_test.zip
└── torchvision
└── models
└── utils.py
```
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D26429795
Pulled By: Lilyjjo
fbshipit-source-id: 4fa25b0426912f939c7b52cedd6e217672891f21
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52257
## Background
Reverts MHA behavior for `bias` flag to that of v1.5: flag enables or disables both in and out projection biases.
Updates type annotations for both in and out projections biases from `Tensor` to `Optional[Tensor]` for `torch.jit.script` usage.
Note: With this change, `_LinearWithBias` defined in `torch/nn/modules/linear.py` is no longer utilized. Completely removing it would require updates to quantization logic in the following files:
```
test/quantization/test_quantized_module.py
torch/nn/quantizable/modules/activation.py
torch/nn/quantized/dynamic/modules/linear.py
torch/nn/quantized/modules/linear.py
torch/quantization/quantization_mappings.py
```
This PR takes a conservative initial approach and leaves these files unchanged.
**Is it safe to fully remove `_LinearWithBias`?**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52537
Test Plan:
```
python test/test_nn.py TestNN.test_multihead_attn_no_bias
```
## BC-Breaking Note
In v1.6, the behavior of `MultiheadAttention`'s `bias` flag was incorrectly changed to affect only the in projection layer. That is, setting `bias=False` would fail to disable the bias for the out projection layer. This regression has been fixed, and the `bias` flag now correctly applies to both the in and out projection layers.
Reviewed By: bdhirsh
Differential Revision: D26583639
Pulled By: jbschlosser
fbshipit-source-id: b805f3a052628efb28b89377a41e06f71747ac5b
Summary:
Fix the issue that `add_custom_command(OUTPUT ...)` will only be called when target output is missing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52477
Reviewed By: malfet
Differential Revision: D26538718
Pulled By: walterddr
fbshipit-source-id: 0fef40585a0f888dcbe268deb2e7a7a8d81e6aa1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52009
Taking advantage of the new `redispatch` API to clean up the codegen'd tracing kernels. Instead of directly interacting with the Dispatcher, the tracing kernels now just call the `redispatch` API directly.
One small benefit to this: hopefully the compiler is more likely to inline `Dispatcher::redispatch()`, since it's now used in fewer call-sites. After this change, the only places it's used are:
- the `redispatch` API (`RedispatchFunctions.cpp`)
- BackendSelect kernels.
One small complication: the redispatch API doesn't interact too well with `manual_cpp_binding` ops currently. I put a note with some thoughts in the comments.
Example tracing kernel before:
```
Tensor add_Tensor(c10::DispatchKeySet ks, const Tensor & self, const
torch::jit::Node* node = nullptr;
std::shared_ptr<jit::tracer::TracingState> tracer_state;
if (jit::tracer::isTracing()) {
tracer_state = jit::tracer::getTracingState();
at::Symbol op_name;
op_name = jit::Symbol::fromQualString("aten::add");
node = tracer_state->graph->create(op_name, /*num_outputs=*/0);
jit::tracer::recordSourceLocation(node);
jit::tracer::addInputs(node, "self", self);
jit::tracer::addInputs(node, "other", other);
jit::tracer::addInputs(node, "alpha", alpha);
tracer_state->graph->insertNode(node);
jit::tracer::setTracingState(nullptr);
}
static auto op = c10::Dispatcher::singleton()
.findSchemaOrThrow("aten::add", "Tensor")
.typed<Tensor (const Tensor &, const Tensor &, Scalar)>();
auto result =c10::Dispatcher::singleton()
.redispatch<Tensor, const Tensor &, const Tensor &, Scalar>(op,
if (tracer_state) {
jit::tracer::setTracingState(std::move(tracer_state));
jit::tracer::addOutput(node, result);
}
return result;
}
```
after: (note the lack of `Dispatcher::` calls)
```
Tensor add_Tensor(c10::DispatchKeySet ks, const Tensor & self, const Tensor & other, Scalar alpha)
torch::jit::Node* node = nullptr;
std::shared_ptr<jit::tracer::TracingState> tracer_state;
if (jit::tracer::isTracing()) {
tracer_state = jit::tracer::getTracingState();
at::Symbol op_name;
op_name = jit::Symbol::fromQualString("aten::add");
node = tracer_state->graph->create(op_name, /*num_outputs=*/0);
jit::tracer::recordSourceLocation(node);
jit::tracer::addInputs(node, "self", self);
jit::tracer::addInputs(node, "other", other);
jit::tracer::addInputs(node, "alpha", alpha);
tracer_state->graph->insertNode(node);
jit::tracer::setTracingState(nullptr);
}
auto result =at::redispatch::add(ks & c10::DispatchKeySet(c10::DispatchKeySet::FULL_AFTER, c10::D
if (tracer_state) {
jit::tracer::setTracingState(std::move(tracer_state));
jit::tracer::addOutput(node, result);
}
return result;
}
```
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D26356078
Pulled By: bdhirsh
fbshipit-source-id: bc96ca4c6d90903f1e265859160d4b13a8cc7310
Summary:
Remove the dependency tracker that works on Tensors, DepTracker, from LoopNest. This is essential to the goal of removing Tensors from LoopNest.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52405
Reviewed By: heitorschueroff
Differential Revision: D26548621
Pulled By: navahgar
fbshipit-source-id: b20f23d608c19ac71aebd31c14777d653eead36c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52150
Renames "whitelist" to "allowlist" to conform to company use standards, prevent critical errors raised by linters which detect the old usage, and to move toward more self-descriptive terminology.
Test Plan: Sandcastle
Reviewed By: suo
Differential Revision: D26405520
fbshipit-source-id: 9c3a41591d4e29c0197de9a8f5858c9c29271e26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52593
This hook is not used at all, and it probably can only be used for demonstrating that allgather is slower than allreduce, so it should never be used in practice.
However, this hook and its helper function stay with the communication hook public APIs in the same file. It will be better to make the public API file as concise as possible.
Since I don't think we will use this hook in the future, prefer deleting it to moving it to a separate file.
ghstack-source-id: 122180969
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D26575318
fbshipit-source-id: b258154a7c92e33236c34104bd79bc244ecdb158
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51916
After getting ported to structured kernels, the vector overloads of `upsample_nearest1d` are DefaultBackend kernels, meaning they are backend agnostic. We can kill their CUDA-specific implementations.
I also removed a few redundant checks in the cuda kernels that are now performed by the meta shape-checking function.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D26327749
Pulled By: bdhirsh
fbshipit-source-id: b5a17e14237fb36236d4079433f99c71cd3beef3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52420
Inspired by D26154964 (6e1a5b1196), I'm basically going to just blindly copy the change that swolchok has made since it promises to reduce compile time, and who doesn't want faster compiles! I haven't actually checked if it has any impact on build time, but I have come to trust what swolchok does.
In addition, swolchok observed a size reduction with the change, which I assume happens when the `constexpr` is true since the lambda is invoked and possibly needs to be compiled in. When tracing based selective build is enabled, many many many of these will be enabled, and this will use valuable size. This change is required to get the maximum bang for our buck. In addition, I'll look into making the lambda not capture all arguments by ref via the ref-capture `[&]` directive.
I can probably have an entire half's worth of impact by copying Scott's changes and mirroring them in other parts of the PyTorch codebase lol.
#accep2ship
ghstack-source-id: 122178246
Test Plan: Build
Reviewed By: iseeyuan
Differential Revision: D26506634
fbshipit-source-id: b91d5e4773ade292fddce8dddd7e5ba1e5afeb29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52466
`MaxTypeIndex` controls the size of the array
```
detail::TypeMetaData* TypeMeta::typeMetaDatas() {
static detail::TypeMetaData instances[MaxTypeIndex + 1]
```
in `typeid.cpp`.
In practice, I have seen that this array doesn't hold more than 18 elements once the PyTorch library has been initialized (in mobile unit tests). I couldn't find situations where elements may be added to this array post library initialization.
There is a runtime check to prevent array overflow, so reducing the size of the storage shouldn't come at any additional risk from the perspective of loss in visibility of errors.
The fact that this array is staically allocated ends up using a bunch of space in the binary (potentially to initialize the trailing elements?). I'm somewhat surprised but this. However, this change registered a 15KiB size win on both fbios as well as igios.
Found this when I was looking at a bloaty run that I shared with smessmer on friday: https://www.internalfb.com/intern/everpaste/?handle=GLXImQisHOfT74EBAKw47V3ktuAzbsIXAAAB
I initially thought that the methods being passed in to the constructor of `detail::TypeMetaData` were causing the size increase, but only later relaized the issue after reading the folloing helpful comment:
```
// The remainder of the array is padded with TypeMetaData blanks.
// The first of these is the entry for ScalarType::Undefined.
// The rest are consumed by CAFFE_KNOWN_TYPE entries.
```
This change was originally reverted at https://www.internalfb.com/diff/D26525208 due to an ONNX test failure. Re-trying the change gated under `C10_MOBILE`.
ghstack-source-id: 122178181
Test Plan:
Sandcastle runs + the following BSB runs.
### igios
```
D26299594 (9e54532947)-V1 (https://www.internalfb.com/intern/diff/D26299594 (9e54532947)/?dest_number=121221891)
igios: Succeeded
Change in Download Size for arm64 + 3x assets variation: +596 B
Change in Uncompressed Size for arm64 + 3x assets variation: -15.8 KiB
Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:443632243487886@base/bsb:443632243487886@diff/
```
### fbios
```
D26299594 (9e54532947)-V1 (https://www.internalfb.com/intern/diff/D26299594 (9e54532947)/?dest_number=121221891)
fbios: Succeeded
Change in Download Size for arm64 + 3x assets variation: +104 B
Change in Uncompressed Size for arm64 + 3x assets variation: -15.7 KiB
Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:169233698063125@base/bsb:169233698063125@diff/
```
Reviewed By: iseeyuan
Differential Revision: D26527921
fbshipit-source-id: f019e5fd37e6caf24c58c6f144bedcda942d7164
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52573
## Summary
Address comments in https://github.com/pytorch/pytorch/pull/52540
1. Add a comment to indicate that the macros `BUILD_LITE_INTERPRETER` and `C10_MOBILE` will be unified.
2. Rename the macro `DBUILD_LITE_INTERPRETER` to `BUILD_LITE_INTERPRETER`
## Test plan
1. `MACOSX_DEPLOYMENT_TARGET=10.9 CC=clang CXX=clang++ USE_CUDA=0 DEBUG=1 MAX_JOBS=16 BUILD_LITE_INTERPRETER=1 python setup.py develop`
2. `/Users/chenlai/pytorch/cmake-build-debug/bin/test_lite_interpreter_runtime --gtest_filter=* --gtest_color=no`
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D26572742
Pulled By: cccclai
fbshipit-source-id: c8895fcfe8dd893f8157913f110e2ba025fc3955
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51419
## Summary
1. Add an option `BUILD_LITE_INTERPRETER` in `caffe2/CMakeLists.txt` and set `OFF` as default.
2. Update 'build_android.sh' with an argument to swtich `BUILD_LITE_INTERPRETER`, 'OFF' as default.
3. Add a mini demo app `lite_interpreter_demo` linked with `libtorch` library, which can be used for quick test.
## Test Plan
Built lite interpreter version of libtorch and test with Image Segmentation demo app ([android version](https://github.com/pytorch/android-demo-app/tree/master/ImageSegmentation)/[ios version](https://github.com/pytorch/ios-demo-app/tree/master/ImageSegmentation))
### Android
1. **Prepare model**: Prepare the lite interpreter version of model by run the script below to generate the scripted model `deeplabv3_scripted.pt` and `deeplabv3_scripted.ptl`
```
import torch
model = torch.hub.load('pytorch/vision:v0.7.0', 'deeplabv3_resnet50', pretrained=True)
model.eval()
scripted_module = torch.jit.script(model)
# Export full jit version model (not compatible lite interpreter), leave it here for comparison
scripted_module.save("deeplabv3_scripted.pt")
# Export lite interpreter version model (compatible with lite interpreter)
scripted_module._save_for_lite_interpreter("deeplabv3_scripted.ptl")
```
2. **Build libtorch lite for android**: Build libtorch for android for all 4 android abis (armeabi-v7a, arm64-v8a, x86, x86_64) `BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh`. This pr is tested on Pixel 4 emulator with x86, so use cmd `BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh x86` to specify abi to save built time. After the build finish, it will show the library path:
```
...
BUILD SUCCESSFUL in 55s
134 actionable tasks: 22 executed, 112 up-to-date
+ find /Users/chenlai/pytorch/android -type f -name '*aar'
+ xargs ls -lah
-rw-r--r-- 1 chenlai staff 13M Feb 11 11:48 /Users/chenlai/pytorch/android/pytorch_android/build/outputs/aar/pytorch_android-release.aar
-rw-r--r-- 1 chenlai staff 36K Feb 9 16:45 /Users/chenlai/pytorch/android/pytorch_android_torchvision/build/outputs/aar/pytorch_android_torchvision-release.aar
```
3. **Use the PyTorch Android libraries built from source in the ImageSegmentation app**: Create a folder 'libs' in the path, the path from repository root will be `ImageSegmentation/app/libs`. Copy `pytorch_android-release` to the path `ImageSegmentation/app/libs/pytorch_android-release.aar`. Copy 'pytorch_android_torchvision` (downloaded from [here](https://oss.sonatype.org/#nexus-search;quick~torchvision_android)) to the path `ImageSegmentation/app/libs/pytorch_android_torchvision.aar` Update the `dependencies` part of `ImageSegmentation/app/build.gradle` to
```
dependencies {
implementation 'androidx.appcompat:appcompat:1.2.0'
implementation 'androidx.constraintlayout:constraintlayout:2.0.2'
testImplementation 'junit:junit:4.12'
androidTestImplementation 'androidx.test.ext:junit:1.1.2'
androidTestImplementation 'androidx.test.espresso:espresso-core:3.3.0'
implementation(name:'pytorch_android-release', ext:'aar')
implementation(name:'pytorch_android_torchvision', ext:'aar')
implementation 'com.android.support:appcompat-v7:28.0.0'
implementation 'com.facebook.fbjni:fbjni-java-only:0.0.3'
}
```
Update `allprojects` part in `ImageSegmentation/build.gradle` to
```
allprojects {
repositories {
google()
jcenter()
flatDir {
dirs 'libs'
}
}
}
```
4. **Update model loader api**: Update `ImageSegmentation/app/src/main/java/org/pytorch/imagesegmentation/MainActivity.java` by
4.1 Add new import: `import org.pytorch.LiteModuleLoader;`
4.2 Replace the way to load pytorch lite model
```
// mModule = Module.load(MainActivity.assetFilePath(getApplicationContext(), "deeplabv3_scripted.pt"));
mModule = LiteModuleLoader.load(MainActivity.assetFilePath(getApplicationContext(), "deeplabv3_scripted.ptl"));
```
5. **Test app**: Build and run the ImageSegmentation app in Android Studio,

### iOS
1. **Prepare model**: Same as Android.
2. **Build libtorch lite for ios** `BUILD_PYTORCH_MOBILE=1 IOS_PLATFORM=SIMULATOR BUILD_LITE_INTERPRETER=1 ./scripts/build_ios.sh`
3. **Remove Cocoapods from the project**: run `pod deintegrate`
4. **Link ImageSegmentation demo app with the custom built library**:
Open your project in XCode, go to your project Target’s **Build Phases - Link Binaries With Libraries**, click the **+** sign and add all the library files located in `build_ios/install/lib`. Navigate to the project **Build Settings**, set the value **Header Search Paths** to `build_ios/install/include` and **Library Search Paths** to `build_ios/install/lib`.
In the build settings, search for **other linker flags**. Add a custom linker flag below
```
-all_load
```
Finally, disable bitcode for your target by selecting the Build Settings, searching for Enable Bitcode, and set the value to No.
**
5. Update library and api**
5.1 Update `TorchModule.mm``
To use the custom built libraries the project, replace `#import <LibTorch/LibTorch.h>` (in `TorchModule.mm`) which is needed when using LibTorch via Cocoapods with the code below:
```
//#import <LibTorch/LibTorch.h>
#include "ATen/ATen.h"
#include "caffe2/core/timer.h"
#include "caffe2/utils/string_utils.h"
#include "torch/csrc/autograd/grad_mode.h"
#include "torch/script.h"
#include <torch/csrc/jit/mobile/function.h>
#include <torch/csrc/jit/mobile/import.h>
#include <torch/csrc/jit/mobile/interpreter.h>
#include <torch/csrc/jit/mobile/module.h>
#include <torch/csrc/jit/mobile/observer.h>
```
5.2 Update `ViewController.swift`
```
// if let filePath = Bundle.main.path(forResource:
// "deeplabv3_scripted", ofType: "pt"),
// let module = TorchModule(fileAtPath: filePath) {
// return module
// } else {
// fatalError("Can't find the model file!")
// }
if let filePath = Bundle.main.path(forResource:
"deeplabv3_scripted", ofType: "ptl"),
let module = TorchModule(fileAtPath: filePath) {
return module
} else {
fatalError("Can't find the model file!")
}
```
### Unit test
Add `test/cpp/lite_interpreter`, with one unit test `test_cores.cpp` and a light model `sequence.ptl` to test `_load_for_mobile()`, `bc.find_method()` and `bc.forward()` functions.
### Size:
**With the change:**
Android:
x86: `pytorch_android-release.aar` (**13.8 MB**)
IOS:
`pytorch/build_ios/install/lib` (lib: **66 MB**):
```
(base) chenlai@chenlai-mp lib % ls -lh
total 135016
-rw-r--r-- 1 chenlai staff 3.3M Feb 15 20:45 libXNNPACK.a
-rw-r--r-- 1 chenlai staff 965K Feb 15 20:45 libc10.a
-rw-r--r-- 1 chenlai staff 4.6K Feb 15 20:45 libclog.a
-rw-r--r-- 1 chenlai staff 42K Feb 15 20:45 libcpuinfo.a
-rw-r--r-- 1 chenlai staff 39K Feb 15 20:45 libcpuinfo_internals.a
-rw-r--r-- 1 chenlai staff 1.5M Feb 15 20:45 libeigen_blas.a
-rw-r--r-- 1 chenlai staff 148K Feb 15 20:45 libfmt.a
-rw-r--r-- 1 chenlai staff 44K Feb 15 20:45 libpthreadpool.a
-rw-r--r-- 1 chenlai staff 166K Feb 15 20:45 libpytorch_qnnpack.a
-rw-r--r-- 1 chenlai staff 384B Feb 15 21:19 libtorch.a
-rw-r--r-- 1 chenlai staff **60M** Feb 15 20:47 libtorch_cpu.a
```
`pytorch/build_ios/install`:
```
(base) chenlai@chenlai-mp install % du -sh *
14M include
66M lib
2.8M share
```
**Master (baseline):**
Android:
x86: `pytorch_android-release.aar` (**16.2 MB**)
IOS:
`pytorch/build_ios/install/lib` (lib: **84 MB**):
```
(base) chenlai@chenlai-mp lib % ls -lh
total 172032
-rw-r--r-- 1 chenlai staff 3.3M Feb 17 22:18 libXNNPACK.a
-rw-r--r-- 1 chenlai staff 969K Feb 17 22:18 libc10.a
-rw-r--r-- 1 chenlai staff 4.6K Feb 17 22:18 libclog.a
-rw-r--r-- 1 chenlai staff 42K Feb 17 22:18 libcpuinfo.a
-rw-r--r-- 1 chenlai staff 1.5M Feb 17 22:18 libeigen_blas.a
-rw-r--r-- 1 chenlai staff 44K Feb 17 22:18 libpthreadpool.a
-rw-r--r-- 1 chenlai staff 166K Feb 17 22:18 libpytorch_qnnpack.a
-rw-r--r-- 1 chenlai staff 384B Feb 17 22:19 libtorch.a
-rw-r--r-- 1 chenlai staff 78M Feb 17 22:19 libtorch_cpu.a
```
`pytorch/build_ios/install`:
```
(base) chenlai@chenlai-mp install % du -sh *
14M include
84M lib
2.8M share
```
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D26518778
Pulled By: cccclai
fbshipit-source-id: 4503ffa1f150ecc309ed39fb0549e8bd046a3f9c
Summary: Trunk at 13 uses a different type for `CreateAlignedStore` and `CreateAlignedLoad` so updating usage here to reflect this.
Test Plan:
buck build mode/opt-clang-thinlto sigrid/predictor/v2:sigrid_remote_predictor -c cxx.extra_cxxflags="-Wforce-no-error -fbracket-depth=300" -c cxx.profile="fbcode//fdo/autofdo-bolt-compatible/sigrid/predictor/v2/sigrid_remote_predictor:autofdo-bolt-compatible" -c cxx.modules=False
Previously:
caffe2/torch/csrc/jit/tensorexpr/llvm_codegen.cpp:1079:21: error: no matching member function for call to 'CreateAlignedLoad'
value_ = irb_.CreateAlignedLoad(vaddr, 4);
~~~~~^~~~~~~~~~~~~~~~~
third-party-buck/platform009/build/llvm-fb/include/llvm/IR/IRBuilder.h:1681:13: note: candidate function not viable: no known conversion from 'int' to 'llvm::MaybeAlign' for 2nd argument
LoadInst *CreateAlignedLoad(Value *Ptr, MaybeAlign Align,
Now:
Passes
Differential Revision: D26562330
fbshipit-source-id: dbf9ca5247ccd4351861995c2c5480a7cc55c202
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52498
If `max_shape[dim]` equals to `real_shape[dim]`, we shouldn't need to adjust dim in terms of output slicing. Consider the case, when we have output compiled at [10, 4] and real input is [5, 4], we only need to adjust outermost dim (10->5) for the second dim, we don't need to do anything. Thus this should fall to fast path.
Test Plan:
```
buck test glow/fb/test:test_onnxifinnpi
```
Reviewed By: khabinov
Differential Revision: D26542773
fbshipit-source-id: 0475e0a1c35be6f28ccc63dc69cb0b5acf695141
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52447
Currently, `Dispatcher::singleton()` is always inlined. Additionally, `Dispatcher::singleton()` contains a static variable, which means that the generated code calls `__cxa_guard_acquire` and `__cxa_guard_release` which help implement exactly once semantics for the initialization of the `static Dispatcher& s` variable. For `C10_MOBILE`, we should not create the additional static ref within the inlined function to save binary size since it results in a lot of additional code being generated by the compiler. The `Dispatcher::singleton()` method is called from the generated method stubs for all aten opertors that are code-generated and potentially also from other operators that hand off execution to the kernel function for the right backend via the PyTorch Dispatcher.
This is a classic space/time (efficiency) tradeoff, so feedback would be welcome. kimishpatel, I'll need your expertise in figuring out how to perf-test this change, specifically for mobile.
Here's the godbolt link in case you wish to check out the generated code for a `static` variable within a function: https://godbolt.org/z/cdsG3v
{F375631117}
ghstack-source-id: 121989311
Test Plan:
Build + BSB
### lightspeed-messenger
*Divide the number below by 2*
```
D26507049-V1 (https://www.internalfb.com/intern/diff/D26507049/?dest_number=121944956)
messenger-experimental-optimized-device: Succeeded
Change in Download Size for arm64 + 3x assets variation: -21.7 KiB
Change in Uncompressed Size for arm64 + 3x assets variation: -65.4 KiB
Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:243392763936025@base/bsb:243392763936025@diff/
```
### igios
```
D26507049-V1 (https://www.internalfb.com/intern/diff/D26507049/?dest_number=121944956)
igios: Succeeded
Change in Download Size for arm64 + 3x assets variation: -15.6 KiB
Change in Uncompressed Size for arm64 + 3x assets variation: -34.3 KiB
Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:882756935844095@base/bsb:882756935844095@diff/
```
### fbios-pika
```
D26507049-V1 (https://www.internalfb.com/intern/diff/D26507049/?dest_number=121944956)
fbios-pika: Succeeded
Change in Download Size for arm64 + 3x assets variation: -8.6 KiB
Change in Uncompressed Size for arm64 + 3x assets variation: -29.1 KiB
Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:832297083999539@base/bsb:832297083999539@diff/
```
Reviewed By: swolchok
Differential Revision: D26507049
fbshipit-source-id: 0d2f55ea2d42a0782fb69aabfa517f2ec60c8036
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52290
_fake_quantize_learnable_per_channel_affine should allow taking non-integer zero_point as input, and perform rounding and clamp before doing forward/backward. In this diff, we make _fake_quantize_learnable_per_channel_affine to round and clamp zero_point beforehand as in _fake_quantize_learnable_per_tensor_affine.
ghstack-source-id: 122148099
Test Plan: `buck test mode/dev-nosan -c fbcode.platform=platform009 //caffe2/test:quantization -- test_learnable`
Reviewed By: raghuramank100
Differential Revision: D26446342
fbshipit-source-id: fc9b6832fa247cc9d41265eb4fd1575a2d2ed12c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52303
swolchok did some stellar work in D26372806 (22b12179db) (and friends) to simplify exception handling code-paths and outline uncommon code paths. In addition, non-inlined versions of exception handling functions were provided but only in case of specific cases where 1 (or 2?) arguments were passed in to the exception throwing macros.
This change hopes to take advantage of that infrastructure and only pass in a single `const char*` to `AT_ERROR` to leverage any current (or future) optimizations that may take place in this space.
Since this isn't yet in production, it won't have a size impact. However, my guess is that it will be a significant size win once we turn on tracing based selective build since the exception code path will be present in every kernel function multiple times over since most dtypes will be unselected.
ghstack-source-id: 122149806
Test Plan: Build + auto-generated unit tests for tracing based selective build.
Reviewed By: swolchok
Differential Revision: D26463089
fbshipit-source-id: 349160a37d43d629249b92fa24f12b5bd128df1c
Summary:
`setDebugName` maintains an invariant that all debug names of values in same graph must be distinct. This is achieved by appending numeric suffixes to requested debug names. However, the implementation was slow (O(N^2)) when there are a lot of name conflicts. This PR fixes the problem by adding more book-keeping logic so that time complexity is brought down to O(1) on average.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52346
Reviewed By: SplitInfinity
Differential Revision: D26564462
Pulled By: gmagogsfm
fbshipit-source-id: 3260fc3b436f1b0bcb45fdd2d1ec759b5828263f
Summary:
Patch needed in order to build on ppc64le with compiler g++V7. (w/o fix, only works on minimum compiler V8).
Fixes https://github.com/pytorch/pytorch/issues/51592
To be clear, credit where due:
I tested this patch on a ppc64 RHEL container using gcc/g++ 7.4 compiler to ensure a complete pytorch build was successful -- and it was. However, I do not take credit for this patch. I found and reported the issue, but the full brainpower to identify the cause of the error and the appropriate solution and thus the credit for this fix truly belongs to quickwritereader (and I am just helping with the legwork to integrate it after having tested it).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52091
Reviewed By: ejguan
Differential Revision: D26494943
Pulled By: glaringlee
fbshipit-source-id: 0babdb460db5047c54144f724466b77dd2d8a364
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52391
There are 2 ways DDP can throw the exception refactored here -
1) Unused params in the forward pass. We provide `find_unused_parameters=True` for this.
2) All params used in fwd pass, but not all outputs used in loss computation. There are a few workarounds for this but we do not provide native support.
Previously, these 2 issues were combined into 1 error message but that has historically resulted in confusion, with users reporting getting this error even when they enable `find_unused_parameters=True` (which they expect to fix this error). As a result there is additional churn to debug these issues because the true cause (1) vs (2) is not known.
This commit helps to fix the issue by separating out the 2 error messages depending on if we ran with unused parameter detection or not. Hopefully this should make the error message much more clear and actionable.
error msg with `find_unused_params=True`:
```
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. Since `find_unused_parameters=True` is enabled, this likely means that not all `forward` outputs participate in computing loss. You can fix this by making sure all `forward` function outputs participate in calculating loss.
If you already have done the above, then the distributed data parallel module wasn't able to locate the output tensors in the return value of your module's `forward` function. Please include the loss function and the structure of the return value of `forward` of your module when reporting this issue (e.g. list, dict, iterable).
```
error msg without `find_unused_params` specified:
```
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. You can enable unused parameter detection by passing the keyword argument `find_unused_parameters=True` to `torch.nn.parallel.DistributedDataParallel`, and by
making sure all `forward` function outputs participate in calculating loss.
If you already have done the above, then the distributed data parallel module wasn't able to locate the output tensors in the return value of your module's `forward` function. Please include the loss function and the structure of the return value of `forward` of your module when reporting this issue (e.g. list, dict, iterable).
```
ghstack-source-id: 122097900
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D26496688
fbshipit-source-id: 4a9eeeda10293da13d94a692d10cb954e4506d7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52414
When the input is not quantized, we'll still quantize cat as requested by the qconfig, even though
it might be slower
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D26503554
fbshipit-source-id: 29d7c136711a12c124791c10ae436b61c1407668
Summary:
This PR adds functionality to skip a test based on CUDA version.
This way, we can be more specific when skipping a test, such as when the test only fails for a particular CUDA version.
This allows us to add back the skipped tests for CUDA 11.2 for other CUDA versions, such as 10.1 and 11.1.
I tested this locally (by using 11.0 instead of 11.2), but will run all the CI to make sure it works.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52359
Reviewed By: walterddr
Differential Revision: D26487951
Pulled By: janeyx99
fbshipit-source-id: 45c71cc6105ffd9985054880009cf68ea5ef3f6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52179
Rename debug to reference. We'll use this to produce a reference quantized model
that can be used as a common interface between pytorch quantized model and backends.
Test Plan:
python test/test_quantization.py TestQuantizeFx
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D26424656
fbshipit-source-id: a0299b023f6ba7d98f5750724c517b0ecb987b35
Summary:
- Allows build process to build with MLC enabled if subrepo folder mlc is in path and we can link against ML Compute on macOS BigSur
- To build with MLC enabled you will need to clone the mlc repo inside the pytorch repository.
- We need both this change and https://github.com/pytorch/pytorch/pull/50634 on pytorch/pytorch to enable the `mlc` device.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51326
Reviewed By: glaringlee
Differential Revision: D26533138
Pulled By: malfet
fbshipit-source-id: 0baa06b4eb2d62dbfc0f6fc922096cb0db1cc7d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52413
TODO: We'll need to add this guard for other ops as well
(Note: this ignores all push blocking failures!)
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_mul_add_fp16_config
Imported from OSS
Reviewed By: supriyar
Differential Revision: D26503348
fbshipit-source-id: 5aaba518742a516cc3521fd5f23f1a264d2973e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52226
This gets TORCH_INTERNAL_ASSERT to parity with TORCH_CHECK in terms of optimization for 0 or 1 argument.
ghstack-source-id: 121877054
(Note: this ignores all push blocking failures!)
Test Plan:
Compare generated assembly for
```
#include <c10/util/Exception.h>
void f(bool b) {
TORCH_INTERNAL_ASSERT(b, "message");
}
void g(bool b) {
TORCH_INTERNAL_ASSERT(b);
}
void h(bool b) {
TORCH_INTERNAL_ASSERT(b, "message", random());
}
```
before/after this diff.
Before: P174916324
After: P174916411
Before, f and g called out to outlined lambdas to build
std::strings. After, they load string constants and call
torchInternalAssertFail. Similarly, h calls random() and c10::detail::_str_wrapper() inline and then calls out to torchInternalAssertFail. As with D26380783 (efbb854ed8), I hope to solve the problem of outlining the random & _str_wrapper calls separately.
Profile AdIndexer benchmark & verify that toTensor() is still inlined (it calls TORCH_INTERNAL_ASSERT with an integer argument, like `h` above).
Reviewed By: bhosmer
Differential Revision: D26410575
fbshipit-source-id: f82ffec8d302c9a51f7a82c65bc698fab01e1765
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52223
After the previous diffs, `c10::str()` will return a
`CompileTimeEmptyString` when passed 0 arguments and a `const char*` when
passed 1 `const char *` argument. We can take advantage of this to
outline further std::string creation from CAFFE_ENFORCE.
ghstack-source-id: 121877053
(Note: this ignores all push blocking failures!)
Test Plan:
Compare assembly for
```
#include <c10/util/Logging.h>
void f(bool b) {
CAFFE_ENFORCE(b);
}
void g(bool b) {
CAFFE_ENFORCE(b, "message");
}
void h(bool b) {
CAFFE_ENFORCE(b, "message", random());
}
```
before & after this diff.
before: P174902847
after: P174902912
f & g are clearly much improved, and h is about the same.
(I tried measuring caffe2 perf on the AdIndexer MergeNet benchmark, but didn't see a win, which makes sense because the change is small.)
Reviewed By: bhosmer
Differential Revision: D26405181
fbshipit-source-id: c51a9e459ae7d9876494a83ade6f6fe725619512
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52222
`c10::str()` is often used with variadic macros. It can be more efficient to get a C string out if you put a C string in, like if you are able to defer std::string creation to an outlined function or even never do it at all. Meanwhile, there is an implicit conversion from const char* to std::string, so users who expected a std::string will still make one.
ghstack-source-id: 121877052
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: bhosmer
Differential Revision: D26419663
fbshipit-source-id: 400bef71e6a0004b5914f5f511ea0e04e0d7599b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51957
This is a simplified version of #51554.
Compared to #51554, this version only supports statically dispatching to
a specific backend. The benefit is that it skipped the dispatch key
computation logic thus has less framework overhead. The downside is that
if input tensors do not match the specified backend it will throw error
instead of falling back to regular dispatch.
Sample code:
```
Tensor empty(IntArrayRef size, TensorOptions options, c10::optional<MemoryFormat> memory_format) {
return at::cpu::empty(size, options, memory_format);
}
// aten::conj(Tensor(a) self) -> Tensor(a)
Tensor conj(const Tensor & self) {
return at::math::conj(self);
}
// aten::conj.out(Tensor self, *, Tensor(a!) out) -> Tensor(a!)
Tensor & conj_out(Tensor & out, const Tensor & self) {
return at::cpu::conj_out(out, self);
}
// aten::conj.out(Tensor self, *, Tensor(a!) out) -> Tensor(a!)
Tensor & conj_outf(const Tensor & self, Tensor & out) {
return at::cpu::conj_out(out, self);
}
// aten::_conj(Tensor self) -> Tensor
Tensor _conj(const Tensor & self) {
return at::defaultbackend::_conj(self);
}
```
For ops without the specific backend dispatch, it will throw error:
```
// aten::_use_cudnn_ctc_loss(Tensor log_probs, Tensor targets, int[] input_lengths, int[] target_lengths, int blank) -> bool
bool _use_cudnn_ctc_loss(const Tensor & log_probs, const Tensor & targets, IntArrayRef input_lengths, IntArrayRef target_lengths, int64_t blank) {
TORCH_CHECK(false, "Static dispatch does not support _use_cudnn_ctc_loss for CPU.");
}
```
Differential Revision: D26337857
Test Plan: Imported from OSS
Reviewed By: bhosmer
Pulled By: ljk53
fbshipit-source-id: a8e95799115c349de3c09f04a26b01d21a679364
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52336
**Summary**
In Python, the boolean interpretation of the return value of `__exit__` of objects that are used as context managers with `with` statements is used to determine
whether or not to propagate exceptions thrown inside the body of the with
statement. This latter feature is not possible to add to TorchScript at
the moment, but the current requirement that `__exit__` not have any
return values can make it difficult to script a context manager whose
`__exit__` *does* have a return value.
Accordingly, this commit removes the requirement that `__exit__` must
not have any return value. TorchScript does not interpret this return
value in the same way Python does (or at all), but this should make it
easier to share context managers between eager mode and script code.
**Test Plan**
This commit adds a return value to one of the context managers used in
`TestWith`.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D26504910
Pulled By: SplitInfinity
fbshipit-source-id: 2ab635a24d111ac25df4e361b716be8fada5128e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52335
**Summary**
`with` statements can only be used with objects that have `__enter__`
and `__exit__` defined. At present, any attempt to use an expression
that returns something that is not an instance of a class type results
in a cryptic internal assert failure instead of a useful error message.
This is because the code that generates IR for `with` statements uses
`Type::expect` as if it were `Type::cast`; that is, as if it returns
`nullptr` on failure.
This commit fixes this issue by checking the `kind()` of the type of the
expression used as the with item before calling `expect<ClassType>()` on
it.
**Test Plan**
This commit adds a unit test to `test_with_errors` to test this case.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D26504909
Pulled By: SplitInfinity
fbshipit-source-id: 92d108e0c010370fd45131a57120f50c0b85c401
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52412
When the input is not quantized, we'll still quantize add/mul
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D26503347
fbshipit-source-id: 457b3444c50e5b49b911b04c67684f5eead78ec9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52350
When onnx export creates a 0-dim tensor of constant type, this action overrides the type promotion logic as quoted in #9515. In order to prevent this from happening this PR adds the following functionality.
If the data type is a floating point type, it is converted to a 0-dim double tensor, else it is converted to a 0-dim tensor of its original type
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D26490325
Pulled By: SplitInfinity
fbshipit-source-id: 4c47c69c9b6523d2e45b74c2541d6d8ca7e28fc9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52349
Adds a check for patterns for cases with autocasting enabled in which a cast node is inserted before the NegativeLogLikelihoodLoss
node and causing these patterns below not to be recognizable by peephole pass function
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D26490326
Pulled By: SplitInfinity
fbshipit-source-id: 4a6d806acc51b4696fd3932734d55af075fba6b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52347
Fixes consecutive mutations in a tensor inside blocks.
Also, support append and pop in blocks.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D26490328
Pulled By: SplitInfinity
fbshipit-source-id: f0cdc706d2793e1f4eb0503d3e0f63f4127ea47a
Summary:
Fixes following error during static linking, by enforcing that cudart dependency is put after cublasLt
```
/usr/bin/ld: /usr/local/cuda/lib64/libcublasLt_static.a(libcublasLt_static.a.o): undefined reference to symbol 'cudaStreamWaitEvent@libcudart.so.11.0'
/usr/local/cuda/lib64/libcudart.so: error adding symbols: DSO missing from command line
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52509
Reviewed By: janeyx99
Differential Revision: D26547622
Pulled By: malfet
fbshipit-source-id: 4e17f18cf0ab5479a549299faf2583a79fbda4b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51975
See comments in code.
Test Plan: Imported from OSS
Reviewed By: zdevito
Differential Revision: D26340592
Pulled By: suo
fbshipit-source-id: 61b16bafad15e19060710ad2d8487c776d672847
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52320
as title
Test Plan: Imported from OSS
Reviewed By: zdevito
Differential Revision: D26468416
Pulled By: suo
fbshipit-source-id: 890eecea76426918daff900402fbcbc149e48535
Summary:
When compiling libtorch on macOS there is the option to use the `vecLib` BLAS library from Apple's (Accelerate)[https://developer.apple.com/documentation/accelerate] framework. Recent versions of macOS have changed the location of veclib.h, this change adds the new locations to `FindvecLib.cmake`
To test run the following command:
```
BLAS=vecLib python setup.py install --cmake --cmake-only
```
The choice of BLAS library is confirmed in the output:
```
-- Trying to find preferred BLAS backend of choice: vecLib
-- Found vecLib: /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Accelerate.framework/Versions/Current/Frameworks/vecLib.framework/Versions/Current/Headers
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51288
Reviewed By: jbschlosser
Differential Revision: D26531136
Pulled By: malfet
fbshipit-source-id: ce86807ccbf66973f33b3acb99b7f40cfd182b9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51698
Completely eliminates torch::utils::Future as we are now full relying on JitFuture.
ghstack-source-id: 122037612
Test Plan: CI
Reviewed By: kiukchung
Differential Revision: D26243735
fbshipit-source-id: 95010a730f9d35e618f74c5f9de482738cd57c15
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51697
Refactors the rest of rref_context, specifically pendingOwners map and `getOwnerRRef` to use JitFuture.
ghstack-source-id: 122037611
Test Plan: CI
Reviewed By: wanchaol
Differential Revision: D26243268
fbshipit-source-id: ab8874c8253274e8fe50dcd7291e0655a8f3f1df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51386
add stats such as rebuilt bucket stats, unused parameter stats and performance stats to ddp logging data
1. gpu time stats are not collected for single process multiple devices in this diff, as that requires events are created and recorded on multiple devices
2. use at::cuda::event API for safer calls
3. events may not be created in autograd hook if hook is not triggered in user's codes, e.g., users runs in non-sync mode in some iterations. So we checked events are created or not before synchronizing, also skipped invalid results.
4. users may not set device upfront, so explicitly set proper device before creating events in our prepare_forward() and prepare_backward() calls
ghstack-source-id: 121933566
Test Plan: unit tests
Reviewed By: SciPioneer
Differential Revision: D26158645
fbshipit-source-id: ce5f15187802eba76accb980449be68902c10178
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52385
This warning should specify that we did not find unused params in the
_forward_ pass, which is when we log this warning. This is to avoid confusion
when we get an error because not all outputs were used to compute loss, which
also raises an error about unused parameters (to be fixed in the next diff)
ghstack-source-id: 122001929
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D26494136
fbshipit-source-id: d9b41732ea7e5e31b899d590d311080e3dc56682
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52384
Adds a simple UT with unittest that we can modify when we enable DDP backward without needing all parameters to get gradient.
ghstack-source-id: 122001930
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D26482479
fbshipit-source-id: c80bdeea7cf9db35390e385084ef28d64ed239eb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50790.
Added `min()` & `max()` support for `Float16` & `BFloat16`.
CUDA already supported these ops on `Float16`, so the other three combinations had to be enabled.
`OpInfo`s for `min` & `max` were also added, and their sample inputs were removed from `method_tests()`.
### MORE INFO
The (slightly) long-term goal is to add dispatch for `min()` & `max()` related operations on CPU & CUDA for `Float16` & `BFloat16`,
wherever they aren't present already:
1. `amin()`
2. `argmax()`
3. `amax()`
4. `argmin()`
5. `torch._aminmax()`
6. `torch.clamp()` on CPU. Was already supported on CUDA
7. `min()` (in this PR)
8. `max()` (in this PR)
9. `minimum()`
10. `maximum()`
I'll submit separate PRs for the other ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51244
Reviewed By: jbschlosser
Differential Revision: D26503455
Pulled By: anjali411
fbshipit-source-id: c32247f214e9272ca2e4322a23337874e737b140
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52388
Pull Request resolved: https://github.com/pytorch/glow/pull/5364
This allows us to change global variables through onnxifi calls. And add python bindings along with it. Note that we supply a dummy backend_id as it's not needed by glow due to setting being global.
#codemod
Test Plan:
```
buck test mode/dev //glow/fb/test:test_onnxifi_optionnnpi
```
Reviewed By: jfix71, khabinov
Differential Revision: D26481652
fbshipit-source-id: 19b8201c77f653cf7d93ad68760aa7fb5ec45ff4
Summary:
Re-enabling these test cases for ROCm because they are passing.
jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52403
Reviewed By: jbschlosser, SciPioneer
Differential Revision: D26516727
Pulled By: malfet
fbshipit-source-id: 6c70805eda39b0aadfbeb30a527af3906d2da867
Summary:
This is getting tested by https://github.com/pytorch/pytorch/issues/52441.
Adds new config for macos arm64 to our binary builds.
Now stores artifacts for mac builds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52443
Reviewed By: walterddr
Differential Revision: D26517330
Pulled By: janeyx99
fbshipit-source-id: 02774937a827bdd4c08486dc9f8fe63446917f1e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52431
The previous implementation was missing the padding information. Thus is not correct.
ghstack-source-id: 121950755
Test Plan:
- `buck test pp-macos`
- CircleCI
Reviewed By: SS-JIA
Differential Revision: D26508482
fbshipit-source-id: b28b99c399c4f1390a5cc4f023e470eed0f8c073
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52264
When CPU fusion is enabled without LLVM support in PyTorch, it causes huge slowdown (> 50x). This PR makes the LLVM backend the default backend for TE. Now, an error will be reported if CPU fusion is enabled without LLVM support, to avoid this performance regression.
This PR also updates the tests to not use LLVM, so that the old flow is continued. This is necessary because tests run in CI do not have LLVM.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52314
Reviewed By: ejguan
Differential Revision: D26491294
Pulled By: navahgar
fbshipit-source-id: 74561db1207da805d6d28039450db046ba2988fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51881
`MaxTypeIndex` controls the size of the array
```
detail::TypeMetaData* TypeMeta::typeMetaDatas() {
static detail::TypeMetaData instances[MaxTypeIndex + 1]
```
in `typeid.cpp`.
In practice, I have seen that this array doesn't hold more than 18 elements once the PyTorch library has been initialized (in mobile unit tests). I couldn't find situations where elements may be added to this array post library initialization.
There is a runtime check to prevent array overflow, so reducing the size of the storage shouldn't come at any additional risk from the perspective of loss in visibility of errors.
The fact that this array is staically allocated ends up using a bunch of space in the binary (potentially to initialize the trailing elements?). I'm somewhat surprised but this. However, this change registered a 15KiB size win on both fbios as well as igios.
Found this when I was looking at a bloaty run that I shared with smessmer on friday: https://www.internalfb.com/intern/everpaste/?handle=GLXImQisHOfT74EBAKw47V3ktuAzbsIXAAAB
I initially thought that the methods being passed in to the constructor of `detail::TypeMetaData` were causing the size increase, but only later relaized the issue after reading the folloing helpful comment:
```
// The remainder of the array is padded with TypeMetaData blanks.
// The first of these is the entry for ScalarType::Undefined.
// The rest are consumed by CAFFE_KNOWN_TYPE entries.
```
ghstack-source-id: 121875657
Test Plan:
Sandcastle runs + the following BSB runs.
### igios
```
D26299594-V1 (https://www.internalfb.com/intern/diff/D26299594/?dest_number=121221891)
igios: Succeeded
Change in Download Size for arm64 + 3x assets variation: +596 B
Change in Uncompressed Size for arm64 + 3x assets variation: -15.8 KiB
Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:443632243487886@base/bsb:443632243487886@diff/
```
### fbios
```
D26299594-V1 (https://www.internalfb.com/intern/diff/D26299594/?dest_number=121221891)
fbios: Succeeded
Change in Download Size for arm64 + 3x assets variation: +104 B
Change in Uncompressed Size for arm64 + 3x assets variation: -15.7 KiB
Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:169233698063125@base/bsb:169233698063125@diff/
```
Reviewed By: raziel, iseeyuan
Differential Revision: D26299594
fbshipit-source-id: 9a78c03da621fbc25a1d8087376628bccc8dbfda
Summary:
Fixes https://github.com/pytorch/pytorch/issues/51719, https://github.com/pytorch/pytorch/issues/28142
**Change**
- Update `torch.Tensor.unflatten` to support users pass`-1` as the inferred size for both tensors and named tensors.
- Examples of using `-1` in the `unflatten` function are added to the docs.
- Fix the rendered issue of original `unflatten` docs by removing a blank line between its example section.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51955
Reviewed By: agolynski
Differential Revision: D26467198
Pulled By: zou3519
fbshipit-source-id: 6a3ede25561223187273796427ad0cb63f125364
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52357
Refactor the NS for FX compare unshadowed activations API to be able
to work on N models and do arbitrary matching strategies.
We factor out a util which takes a model and a list of
nodes to extract weights for, with names to give the extracted
weights. The user can then call this util with a set
of nodes and names created in any way they want.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26487270
fbshipit-source-id: 1372ef07b5f3ddc7cebdfb2dee0221a2facd0527
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52356
Refactor the NS for FX compare weights API to be able to
work on N models and do arbitrary matching strategies.
We factor out a util which takes a model and a list of
nodes to extract weights for, with names to give the extracted
weights. The user can then call this util with a set
of nodes and names created in any way they want.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26487271
fbshipit-source-id: 0c2172a1b33d47565004a307aff14d205671add7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52130
We have patterns like (F.linear, F.relu) which need to match
to (toq.linear_relu). So, we need to match subgraphs.
This PR does the following:
* defines a "subgraph" as (start_node, end_node). The current assumption
is that subgraphs are simple, there is always a path from start_node to
end_node, and we can ignore any non-input args/kwargs of these nodes
for the purposes of matching and copying things. An example one node
subgraph is (F.linear, F.linear). An example two node subgraph
is (F.linear, F.relu).
* changes the matching logic to iterate over subgraphs instead of nodes
* changes the NS core APIs to use subgraph pairs instead of node pairs:
1. for weights, we match on the start node
2. for unshadowed activations, we observe the end nodes
3. for shadowed activations, we copy the subgraph of a to graph c
TODO(before review) write up better, not ready for review yet
Test Plan:
TODO before land: better test plan
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26403092
fbshipit-source-id: e49aaad4b02b8d60589435848bee422b8f41937a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52092
Adds a very simple toy sparsenn model, and enables
its inspection with the new NS APIs.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_sparsenn_compare_activations
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_sparsenn_shadow
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26403095
fbshipit-source-id: 3c3650aca47186deb32f2b3f1d87a0716d1ad9d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52221
The previous code forced a `std::string` to be created even when the default message or a user-provided string literal message was used. Now it's not forced and we don't need an outlined lambda in those cases either.
ghstack-source-id: 121877056
Test Plan:
Compare assembly for
```
#include <c10/util/Exception.h>
void f(bool b) {
TORCH_CHECK(b, "message");
}
void g(bool b) {
TORCH_CHECK(b);
}
void h(bool b) {
TORCH_CHECK(b, "message", random());
}
```
before/after in fbcode optimized build.
Before: P174696735
After: P174696840
For `f()` and `g()`, we go from a call to an outlined lambda that did a bunch of `std::string` creation to a load of a string constant before calling `torchCheckFail`. This is a clear improvement.
For `h()`, results are mixed: we save a bunch of *extra* string goop in the outlined lambda and instead call `c10::detail::_str_wrapper` directly. This is good for overall size. However, we no longer outline the call to `random()`, which is less than ideal. I hope to recover the ability to fully outline the `random()` call in future diffs; this is just thorny enough that I don't want to cram even more into one diff.
Added automated test to make sure `TORCH_CHECK` and `TORCH_INTERNAL_ASSERT` only evaluate their arguments once.
Profiled AdIndexer mergenet benchmark in perf to check that `IValue::toTensor` is still getting inlined.
Reviewed By: bhosmer
Differential Revision: D26380783
fbshipit-source-id: 288860772423994ac739a8f33e2c09f718e8dd38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52220
D21268320 (d068a456d3) made this thread_local, but I don't think it was necessary to do so.
ghstack-source-id: 121877050
Test Plan: CI
Reviewed By: dzhulgakov
Differential Revision: D26378724
fbshipit-source-id: 7f17b5cff42983ea8f5be1bd254de01bf8db9a0e
Summary:
Some minor improvement for lazy modules introduced in https://github.com/pytorch/pytorch/issues/44538, https://github.com/pytorch/pytorch/issues/47350 and https://github.com/pytorch/pytorch/issues/51548.
This PR mainly turn the bias to `UninitializedParameter` and instead of creating empty tensors like
```python
self.bias = Parameter(torch.Tensor(0))
self.bias = UninitializedParameter()
```
I think it would be better to
```python
self.register_parameter('bias', None)
self.bias = UninitializedParameter()
```
In addition, I change the constructor of the `LazyBatchNorm` from
```python
self.running_mean = UninitializedBuffer()
```
to
```python
self.register_buffer('running_mean', UninitializedBuffer())
```
as the original one would not change the underlying `self._buffers`.
Thank you for your time on reviewing this PR :).
Gently ping albanD, mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52212
Reviewed By: jbschlosser
Differential Revision: D26504508
Pulled By: albanD
fbshipit-source-id: 7094d0bb4fa9e2a40a07b79d350ea12a6ebfd080
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51754
This API allows you to manage multiple python interpreters in a single
process to deploy PyTorch models packaged with torch.package.
torch/csrc/deploy/deploy.h contains the API definition
torch/csrc/deploy/test_deploy.cpp has some examples.
Notes:
* mutex is added to PyTorchStreamReader to make it safe to use from multiple threads at once.
* USE_DEPLOY is only true for the special libtorch_deployinterpreter.so library, when enabled
we use a hash table to maintain PyObject <> at::Tensor mappping rather than the internal pointer
in Tensor since >1 interpreter may have a reference to the tensor.
* serialization.py has some additional functions for creating pickle objects
but keeping storages in memory for use transfering tensors between interpreters
Test Plan: Imported from OSS
Reviewed By: wconstab
Differential Revision: D26329468
Pulled By: zdevito
fbshipit-source-id: d75f4ebb9a27f1d911179d9996041bcb3ca04a07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52424
NNC has a fast sigmoid on par with aten. Using it for static runtime
lets us skip dispatch overhead.
ghstack-source-id: 121953787
Test Plan:
```
caffe2=0 batch=1 run.sh
```
Reviewed By: bwasti
Differential Revision: D26291425
fbshipit-source-id: a2ad79765dacee352625f0e5322e871556e0ca9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52423
NNC has a new logarithm implementation that closely matches the
performance of VML (see D26246400 (2e35fe9535)). Using this in the NNC generated kernel for
logit increases the win slightly.
ghstack-source-id: 121953008
Test Plan:
```
caffe2=0 bs=20 scripts/bwasti/static_runtime/run.sh
```
Reviewed By: bwasti
Differential Revision: D26291426
fbshipit-source-id: c5c3933732c6ade5235f23d6dc71410170a6c749
Summary:
Update freezing api for 1.8, and add a corresponding C++ API. The `optimize` flag hasn't been publicly released yet, so we are able to change it without breaking BC. I will submit a PR to branch release as well, there are a few more days to do that
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52337
Reviewed By: ejguan
Differential Revision: D26491833
Pulled By: eellison
fbshipit-source-id: 6dcd74eb8f76db64ac53183d03dabdd0f101f4b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52196
A reduction does not need to know the buffer into which its
result will be written. This change gets us closer to being able to
create reductions inside Compute, where we have access to the tensor
axes.
ghstack-source-id: 121813071
Test Plan: test_tensorexpr
Reviewed By: ZolotukhinM
Differential Revision: D26420107
Pulled By: bertmaher
fbshipit-source-id: c8d8a99649adfd6de56fe53a728f5aa034a84f13
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52187
ReduceOp doesn't need to track the indices that its result will be written into.
ghstack-source-id: 121813075
Test Plan:
test_tensorexpr, tensorexpr_bench
Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D26420575
fbshipit-source-id: 7afcfa611515334e36de8039722011687f3b61e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52177
I'm trying to get rid of `output_args` for reductions, because they
shouldn't be necessary; it's reducing over its reduction axis, why
does it need to know where its output is going?
Rfactor is probably the trickiest place where we use output_args, but
it looks like it's mostly just carrying around the location of the
store, so use that instead.
ghstack-source-id: 121813072
Test Plan:
build/bin/test_tensorexpr && build/bin/tensorexpr_bench
Imported from OSS
Reviewed By: navahgar
Differential Revision: D26420548
fbshipit-source-id: aeab564c6113fa02eabb14c9b70c7edfd05b264d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52379
There's no reason to create and concatenate multiple string literals here when we could just combine them.
ghstack-source-id: 121890478
Test Plan: builds
Reviewed By: ilia-cher
Differential Revision: D26492399
fbshipit-source-id: a9e611a5b7ce5c1255135f3a0db12cc765b29a87
Summary:
Now that `masked_fill` CUDA is migrated, skips on masked_scatter can be removed.
Reference: https://github.com/pytorch/pytorch/issues/33152
**Note**:
Have decreased the shape of Tensor for `masked_scatter` from (M, M) -> (S, S) and so on.
With shapes of M : **96.53s**
```
test/test_ops.py ........................................ssssssssssss........................ssssssssssss........................ [100%]
=============================================================== 88 passed, 24 skipped, 7981 deselected in 96.53s (0:01:36) ================================================================
```
With shapes of S : **46.53s**
```
test/test_ops.py ........................................ssssssssssss........................ssssssssssss........................ [100%]
==================================================================== 88 passed, 24 skipped, 7981 deselected in 46.53s =====================================================================
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52035
Reviewed By: VitalyFedyunin
Differential Revision: D26369476
Pulled By: anjali411
fbshipit-source-id: 7a79d5a609b0019f8fe9ce6452924dd33390dce1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52417
When we have multiple outputs, previously, we will set `infered_data_type` to the first output and stick to it. This is not correct if we have more outputs that has different dtype. The fix here will revert `infered_data_type` back to previous value (`UNDEFINED`) so that we can still enter the conditional check and set the right dtype for second and more outputs.
Test Plan:
```
buck test caffe2/caffe2/fb/operators:infer_bound_shape_op_test
```
Reviewed By: khabinov
Differential Revision: D26502161
fbshipit-source-id: 647f0106a5785dc156fddfc196ac67001602fda8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52123
Compiler currently complains:
```
caffe2/c10/util/MatchConstants.h(18): warning: calling a constexpr __host__ function("from_bits") from a __host__ __device__ function("pi") is not allowed.
```
This diff extirpates the warning
Test Plan: Sandcastle tests
Reviewed By: xush6528
Differential Revision: D26379485
fbshipit-source-id: ab4821119cba8c43fd1d5788c4632d0613529ec8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51768
This updates python/core.py to explicitly define all of the `DataType`
values rather than dynamically defining them at runtime from the
`caffe2_pb2` values.
This allows type checkers like Pyre and Mypy to see the members of the
`DataType` class. Otherwise the type checkers report errors such as
`"core.DataType" has no attribute "INT64"`.
This code does keep a run-time check that all of the data types defined
by `caffe2_pb2.proto` are defined correctly in this file. This way if
someone does add a new type to `caffe2_pb2.proto` it should be very
quickly apparent that this file needs to be updated and kept in sync.
ghstack-source-id: 121936201
Test Plan:
Confirmed that various caffe2/python tests still pass.
Verified that this allows many `pyre-fixme` comments to be removed in
downstream projects, and that Pyre is still clean for these projects.
Reviewed By: jeffdunn
Differential Revision: D26271725
Pulled By: simpkins
fbshipit-source-id: f9e95795de60aba67d7d3872d0c141ed82ba8e39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52411
The `TensorDeserializer` code previously did not correctly handle unknown
`data_type` values. It attempted to deserialize the data as floats, rather
than recognizing that it did not understand the data type and erroring out.
Google protobuf will never return unknown values for enum fields. If an
unknown value is found in serialized data, the protobuf code discards it.
As a result `has_data_type()` will return false, but `get_data_type()` will
simply return the default value, which happens to be set to `FLOAT`. As a
result if we ever encounter a serialized blob with an unknown data type the
previous code would incorrectly think the data type was `FLOAT`.
This fixes the code to check if the `data_type` value is present before
reading it.
ghstack-source-id: 121915981
Test Plan:
Included a unit test that verifies this behavior. Confirmed that without this
fix the code proceeded with the float deserialization code path. When
deserializing int32_t data it fortunately did fail later due to an unexpected
field length check, but this isn't guaranteed to be the case. In some cases
it potentially could incorrectly succeed and return wrong data.
Reviewed By: mraway
Differential Revision: D26375502
fbshipit-source-id: 4f84dd82902e18df5e693f4b28d1096c96de7916
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52377
Add QNNPACK specific packed params for sparse linear.
Add sparse linear dynamic op with appropriate registration.
Add python side LinearDynamic module for sparsity.
Add tests to validate sparse linear qnnpack kernels.
Note that since these test are mostly run on x86 platform and
given that 1x4 sparse kernels are implemented both in sse and arm,
LinearDynamic at the moment defaults to 1x4 pattern.
Plan is to add another diff that will allow a global override for 8x1 pattern
such that prepare/convert flow can work for exporting model for mobile.
Test Plan: buck run caffe2/torch/fb/model_optimization:sparsity_test
Reviewed By: z-a-f
Differential Revision: D26491944
fbshipit-source-id: b98839b4c62664e1fabbb0cbeb2e5c1bd5903b4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52376
Using default cpu allocator for ops executed on qnnpack backend will result in
asan failures with heap overflow since qnnpack (and xnnpack) can access input
beyond their and/beginning.
Here we are enabling this feature specifically to enable dynamic sparse linear op test
using qnnpack engine. In dynamic linear op, the fp32 bias is not packed and
hence can result in out-of-bound access.
Test Plan: CI
Reviewed By: z-a-f
Differential Revision: D26491943
fbshipit-source-id: bcc2485e957c7abdef0853c36f6e0f876c20cee3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52258
Removes deprecated preprocess method from the backend interface.
Preprocessing logic should be now registered along with the backend interface (i.e. PyTorchBackendInterface) via the BackendPreprocessFunction.
Also refactored internal dependencies.
ghstack-source-id: 121704837
Test Plan:
Validates all related tests pass:
buck test mode/dev //caffe2/test/cpp/jit:jit -- --exact 'caffe2/test/cpp/jit:jit - BackendTest.ToBackend'
python test/test_jit.py TestBackends
===== Glow
buck test mode/dev //glow/fb/torch_glow/tests:TorchGlowBackendTests
buck test mode/dev //glow/fb/torch_glow/tests:torch_glow_backend_tests
Reviewed By: jackm321
Differential Revision: D26443479
fbshipit-source-id: afdc51ae619ced293d10c7a6a12f3530e4c4e53c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51767
The `_import_c_extension.py` finds the right C extension library to use,
and then simply re-exports all of the symbols that it defines.
This adds a `_import_c_extension.pyi` file with type hints to let type
checkers like Pyre and Mypy know the names of the symbols that will be
re-exported from the C extension.
This does not define all of the symbols provided by the C extension,
but does define all of the symbols necessary to make type checkers happy
about other code in the `caffe2/python` directory.
ghstack-source-id: 121916324
Test Plan:
Was able to have Pyre successfully type check the `caffe2/python`
directory with this stub file plus a few other changes.
Confirmed that all of the dependent projects affected by this report no new
pyre issues in sandcastle.
Ran `python test/test_type_hints.py` in the PyTorch github repository and
confirmed it also passes.
Differential Revision: D26271726
Pulled By: simpkins
fbshipit-source-id: 6dbadcf02e0b2cc44a9e3cdabe9291c1250959b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52344
This line is a bug-prone use of std::move combined with a reference to the moved-from parameter in the same series of function call arguments. This is normally a problem because the order of evaluation is undefined -- if the move happens before the call to `storage.device()`, we may have problems. It is not a problem here because we are merely forwarding from one `Storage&&` parameter to another.
ghstack-source-id: 121837267
Test Plan: See no clang-tidy/HowToEven warning on the diff, I hope
Reviewed By: bhosmer
Differential Revision: D26436550
fbshipit-source-id: da85d79be854ff42c5a0cab9649ba82295816eca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52151
CUDA 11.2 might not be as performant as we thought so let's downgrade to
something we think is more performant.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D26408314
Pulled By: seemethere
fbshipit-source-id: e2446aa0115e2c2a79718b1fdfd9fccf2072822d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52325
List's move constructor is comparatively expensive (copies the type) and so is its destructor (has to destroy the type, which isn't null). So, it's best not to create intermediate `List` objects in function parameters. Copy elision won't save us here; it's not allowed to! (see https://en.cppreference.com/w/cpp/language/copy_elision)
ghstack-source-id: 121807291
Test Plan:
Profile AdIndexer benchmark. Time spent in push_outputs is
down from 0.2% to 0.01%.
Inspecting assembly for
`c10::impl::push_outputs<c10::List<at::Tensor>,false>::call`
shows that we have gone from 2 List move ctor calls and 3
~instrusive_ptr dtor calls to 0 calls and 1 call, respectively.
Reviewed By: bhosmer
Differential Revision: D26471092
fbshipit-source-id: 412a85fcc36d141fb91710c7855df24c137813a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52324
`c10::ivalue::from` took its parameter by value. `List` has
an expensive move ctor (it has to copy the type shared_ptr) and dtor
(it has to decref the type, which isn't null), so it's better to avoid
intermediate List objects in function parameters.
ghstack-source-id: 121807292
Test Plan:
Profiled AdIndexer benchmark; time spent in push_outputs is
down from 0.5% to 0.23%.
Comparing assembly for
`c10::impl::push_outputs<c10::List<at::Tensor>, false>::call`, we went
from 4 List move ctor calls and 5 ~intrusive_ptr calls to 2 move ctor
calls and 3 dtor calls, respectively.
Reviewed By: bhosmer
Differential Revision: D26471093
fbshipit-source-id: 7b2c5e8d391a428f2b4d895717a43123c8d7a054
Summary:
Temporary disabling OneDNN conv for group size = 24 as OneDNN update came too late to be fully tested https://github.com/pytorch/pytorch/issues/50042
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52327
Reviewed By: agolynski
Differential Revision: D26474186
Pulled By: VitalyFedyunin
fbshipit-source-id: 8d6964d33c8dcab70e207088c3940810eabbd068
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52370
After adding .pyi stubs for torch / caffe2 protos, there were some mypy false positives (https://github.com/pytorch/pytorch/pull/52341). We tell mypy to ignore the offending file here.
Test Plan: Let CI run.
Reviewed By: malfet, dzhulgakov
Differential Revision: D26490302
fbshipit-source-id: 87cdfd7419efdc7abece9ca975a464201732b7a0
Summary:
This PR enable some failing unit tests for fft in pytorch on ROCM.
The reason these tests were failing was due to hipfft clobbering inputs causing a mismatch in tests that were checking that applying ffts and their reverse would get you back to the input.
We solve this by cloning the input using an existing flag on the ROCM platform.
There PR doesnot enable all fft tests. There are other issues that need to be resolved before that can happen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51581
Reviewed By: ejguan
Differential Revision: D26489344
Pulled By: seemethere
fbshipit-source-id: 472fce8e514adcf91e7f46a686cbbe41e91235a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50459
Some of the custom modules cannot have the observers be inserted automatically. This PR factors out that list into a separate function.
Test is not required, as it is covered by the unittests for those modules.
(Note: this ignores all push blocking failures!)
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D26092531
fbshipit-source-id: 1f89daf3a13ef31bc4e9058c3443559c65a05812
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49866
- Adds the `torch.nn.quantizable.MultiheadAttention`
The quantizable version can serve as a fully equivalent to `torch.nn.MultiheadAttention` module.
The main difference is that it allows for linear units observation after the `prepare` step in the quantization flow.
Note: The `from_observed` method (called during the `convert`) removes the `bias_k` and `bias_v` parameters, and resets them as attributes.
This is done to avoid an error of assigning a quantized tensor to the `torch.nn.Parameter`.
(Note: this ignores all push blocking failures!)
Test Plan:
```
python test/test_quantization.py TestQuantizedOps.test_custom_module_multi_head_attention
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D25706179
fbshipit-source-id: e27ab641d8d1eccc64cf9e44343459331f89eea4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52031
Closes https://github.com/pytorch/pytorch/issues/52020
Ensures that we can profile collectives in DDP by propagating the profiler threadLocalState appropriately. As described in the above issue, before this wouldn't work as the profiler would only be enabled on the main thread.
ghstack-source-id: 121818080
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D26356192
fbshipit-source-id: 0158b5833a3f857a0b4b2943ae3037e9d998dfd1
Summary:
Use `std::acos` even when avx2 is available
Add slow but accurate implementation of complex arc cosine based on
W. Kahan "Branch Cuts for Complex Elementary Functions" paper, where
cacos(z).re = 2*atan2(sqrt(1-z).re(), sqrt(1+z).re())
cacos(z).im = asinh((sqrt(conj(1+z))*sqrt(1-z)).im())
Fixes https://github.com/pytorch/pytorch/issues/42952
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52287
Reviewed By: walterddr
Differential Revision: D26455027
Pulled By: malfet
fbshipit-source-id: a81ce1ba4953eff4d3c2a265ef9199896a67b240
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51253
**Summary**
This commit adds support to Torchbind for specifying default values for
arguments of custom class methods.
**Test Plan**
This commit adds a unit test to `test_torchbind.py` that exercises this
feature.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D26131529
Pulled By: SplitInfinity
fbshipit-source-id: 68bc86b045dd2f03ba41e1a116081a6eae6ba9ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51463
We can make the return type of the `to()` template match the return type of toFoo() by using the same technique we use for `list_element_to_const_ref`. Also simplifies `list_element_to_const_ref`.
ghstack-source-id: 121363468
Test Plan:
CI
built and ran AdIndexer benchmark w/ batch size 1 under perf stat
--repeat 5 to make sure it didn't regress
Reviewed By: bhosmer
Differential Revision: D26163848
fbshipit-source-id: b8563263b9f9fa5311c7d7cedc89e28bc5badda0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51319
We were going out of our way to accommodate `IValue::to<Tensor>` returning a copy of the inner Tensor. `IValue::toTensor` is capable of returning a reference without copying, so if we use it directly, we can allow kernels that want to take `Tensor &` to do so!
As a bonus, we get reduced build times.
ghstack-source-id: 121378961
Test Plan:
Rely on CI for correctness.
Profiled build time with -ftime-trace for RegisterCPU.cpp using an extracted build invocation.
Before: P168244900
After: P168245014
Note reduced time spent compiling make_boxed_from_unboxed_functor.
I also ran the AdIndexer benchmark (https://fb.quip.com/ztERAYjuzdlr) with static runtime disabled and batch size 1 to see how big the effect on boxed call performance was (any kernels that take `Tensor&` or `const Tensor&` should now actually save a refcount bump). Looks like it was roughly 1% better:
Before: 124-125 usec/iter
After: 122-123 usec/iter
Reviewed By: bhosmer
Differential Revision: D26138549
fbshipit-source-id: b0f830527da360c542c815bef2f7e1692615b32a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51367
Templight said that this assertion was taking about 5% of build time for RegisterCPU.cpp (a hopefully-representative example I picked to shorten my iteration cycle).
I've debug-gated it on the grounds that 1) we at least try to build
everything in debug mode and 2) optimized builds presumably take
longer in general, so we can more afford to pay the build time cost in
debug builds.
The win is not entirely clear; please see the test plan for details.
ghstack-source-id: 121378960
Test Plan:
1) Built RegisterCPU.cpp with -ftime-trace before and after. It doesn't seem to call out any difference in the details, but the overall time is stably down more like 10% (55s before and 49s after).
2) Did a full rebuild of aten-cpu with -ftime-trace before and
after. No significant difference in build times shown (it says *after*
is a regression, but it's using wall-time data and the machine is
loaded during builds so there's some noise).
3) Re-profiled with Templight.
Before:
{F366557311}
After:
{F366557501}
Not sure what to conclude overall. A known problem with templight is that template instantiations form more of a dependency graph than a tree because they're cached internally, so eliminating the first caller of a template may just move the time to another caller. However, it looks like we have actually reduced is_functor traffic.
UPDATE: I don't think that the -ftime-trace measurement was reliable; it seems to skew running times. I built this diff vs its base 5 times and measured the CPU ("user") time each time. Results (in seconds):
previous diff: [51.97, 50.54, 50.49, 52.89, 51.61]
mean: 51.5 std: 0.906
this diff: [50.53, 50.41, 50.57, 50.67, 50.94]
mean: 50.6 std: 0.179
Reviewed By: ezyang
Differential Revision: D26153793
fbshipit-source-id: 9a66912c1b2b068f453e78be57454e4e62b7107b
Summary:
This PR adds fixes mypy issues on the current pytorch main branch. In special, it replaces occurrences of `np.bool/np.float` to `np.bool_/np.float64`, respectively:
```
test/test_numpy_interop.py:145: error: Module has no attribute "bool"; maybe "bool_" or "bool8"? [attr-defined]
test/test_numpy_interop.py:159: error: Module has no attribute "float"; maybe "float_", "cfloat", or "float64"? [attr-defined]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52090
Reviewed By: walterddr
Differential Revision: D26469596
Pulled By: malfet
fbshipit-source-id: e55a5c6da7b252469e05942e0d2588e7f92b88bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52341
Add type stubs for caffe2 protos and scripts for generating them.
It's worth calling special attention to the following. In order to make `DeviceType`s like `CPU`, `CUDA`, etc. directly accessible from the `caffe2_pb2` module, they are currently freedom-patched into it in `caffe2/python/__init__.py`. This is not ideal: it would be better if these were autogenerated when the protobuf definitions were created by using `allow_alias = true` in the `DeviceTypeProto` definition in `caffe2.proto`.
However, it is impossible to do this currently without significant effort. The issue is that the generated proto constants would conflict with various constants defined in the C++ caffe2 codebase in `caffe2_pb.h`. We cannot simply remove these constants and replace them with the caffe2 DeviceTypeProto constants, because a huge portion of code expects `at::DeviceType` constants defined in `core/DeviceType.h` (apparently duplicated to avoid having to figure out how to autogenerate the protobuf definitions using cmake for ATen).
Instead, we make a best-effort to add additional definitions in `caffe2_pb2.py` by looking for any freedom-patched constants in `caffe2/python/__init__.py` and making sure they have corresponding stubs in the pyi (see `gen_proto_typestubs_helper.py`).
Test Plan: Make sure CI is green; we're just adding stubs.
Reviewed By: d4l3k
Differential Revision: D26331875
fbshipit-source-id: 2eea147e5bf393542f558ff8cf6385c47624b770
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: c520088927
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52354
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: ejguan
Differential Revision: D26484989
fbshipit-source-id: c9ccce0141be49c57b80e14992f842364bb18a00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52297
Before, an `nn.Module` with submodules would fail AST rewriting with `TypeError: 'RewrittenModule' object does not support item assignment`. (Try the `test_ast_rewriter_reassigns_submodules` test case on `master`.) This PR fixes the issue as well as adding additional test cases
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26483820
Pulled By: ansley
fbshipit-source-id: 757e898dc2b0a67daf2bd039d555b85f4e443322
Summary:
Add QNNPACK specific packed params for sparse linear.
Add sparse linear dynamic op with appropriate registration.
Add python side LinearDynamic module for sparsity.
Add tests to validate sparse linear qnnpack kernels.
Note that since these test are mostly run on x86 platform and
given that 1x4 sparse kernels are implemented both in sse and arm,
LinearDynamic at the moment defaults to 1x4 pattern.
Plan is to add another diff that will allow a global override for 8x1 pattern
such that prepare/convert flow can work for exporting model for mobile.
Test Plan: buck run caffe2/torch/fb/model_optimization:sparsity_test
Reviewed By: z-a-f
Differential Revision: D26263480
fbshipit-source-id: 04ab60aec624d1ecce8cfb38b79c7e94f501cdf6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52323
Using default cpu allocator for ops executed on qnnpack backend will result in
asan failures with heap overflow since qnnpack (and xnnpack) can access input
beyond their and/beginning.
Here we are enabling this feature specifically to enable dynamic sparse linear op test
using qnnpack engine. In dynamic linear op, the fp32 bias is not packed and
hence can result in out-of-bound access.
Test Plan: test_set_default_mobile_cpu_allocator.py
Reviewed By: z-a-f
Differential Revision: D26263481
fbshipit-source-id: a49227cac7e6781b0db4a156ca734d7671972d9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51368
This seems to noticably reduce build times, at least for
RegisterCPU.cpp. It makes sense that a compiler builtin would be
faster than simulating the same builtin with templates.
Identified with templight.
ghstack-source-id: 121378959
Test Plan:
Confirmed this speeds up RegisterCPU.cpp optimized build by
simply running builds under `time(1)`:
previous diff: [50.53, 50.41, 50.57, 50.67, 50.94]
mean: 50.6 std: 0.179
this diff: [45.71, 45.89, 46.21, 48.51, 45.84]
mean: 46.4 std: 1.05
Reviewed By: bhosmer
Differential Revision: D26154964
fbshipit-source-id: 62ee2f5a872007db032dfebf7ad4d1b6e1ce63d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51902
These seem like straightforward improvements. (I don't have measurements; feel free to reject if you're skeptical)
ghstack-source-id: 121278775
Test Plan: CI
Reviewed By: qizzzh
Differential Revision: D26322438
fbshipit-source-id: d393a32cc34bb68bc4f804f4b1cc5a8af27763c9
Summary:
This is a re-land off https://github.com/pytorch/pytorch/pull/51797 with fix for spurious libcuda dependency
Fix limits the scope of `no-as-needed` linker flag to just `jitbackend_test`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52340
Reviewed By: agolynski, iseeyuan
Differential Revision: D26476168
Pulled By: malfet
fbshipit-source-id: f909428af82182b3bffd020ca18cca7a9b5846b6
Summary:
The torchvision build error from hipify revamp, "KeyError: '/usr/include/libpng16/png.h'" is fixed in this PR
Description:
Traceback (most recent call last):
File "setup.py", line 471, in <module>
ext_modules=get_extensions(),
File "setup.py", line 329, in get_extensions
extra_compile_args=extra_compile_args
File "/opt/conda/lib/python3.6/site-packages/torch/utils/cpp_extension.py", line 892, in CUDAExtension
is_pytorch_extension=True,
File "/opt/conda/lib/python3.6/site-packages/torch/utils/hipify/hipify_python.py", line 978, in hipify
clean_ctx=clean_ctx)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/hipify/hipify_python.py", line 212, in preprocess
hip_clang_launch, is_pytorch_extension, clean_ctx, show_progress)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/hipify/hipify_python.py", line 175, in preprocess_file_and_save_result
hip_clang_launch, is_pytorch_extension, clean_ctx, show_progress)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/hipify/hipify_python.py", line 792, in preprocessor
output_source = RE_ANGLE_HEADER.sub(mk_repl('#include <{0}>', False), output_source)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/hipify/hipify_python.py", line 785, in repl
value = HIPIFY_FINAL_RESULT[header_filepath]["hipified_path"]
KeyError: '/usr/include/libpng16/png.h'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51453
Reviewed By: agolynski
Differential Revision: D26459979
Pulled By: fmassa
fbshipit-source-id: f653f55fd34c71314e6c6682217f84b2d1e49335
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 7f3baec496
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52255
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D26443031
fbshipit-source-id: 9e2758c73a15e7d2b5aefa5bc38270404cb5862a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52321
We're seeing undefined references to this function in coverage builds.
I don't even know why the toolchain is trying to look for it, because it's not
actually used in our code anywhere.
Obviously dropping in a dummy reference is a workaround more than a real
solution, but I'd like to get the coverage build back online.
ghstack-source-id: 121818432
Test Plan: `buck build mode/dbgo-cov //caffe2/test/...`
Reviewed By: asuhan
Differential Revision: D26467484
fbshipit-source-id: 4de8d950b03d0818ffc317fc1bed9be8cf470352
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52302
Adds the basic functionality for the three Numeric Suite core APIs to work on FX models:
1. comparing weights
2. comparing activations, with same input fed to both models
3. comparing activations, with nodes of A shadowing nodes of B
Note: there are a lot of TODOs in the code, and some/most of the APIs and implementation details may change as we iterate. This is just the first PR.
Test Plan:
We have unit test coverage for all of the APIs, for now this is with toy models:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Reviewed By: raghuramank100
Differential Revision: D26463013
Pulled By: vkuzo
fbshipit-source-id: e454115099ad18e4037d3c54986951cdffcab367
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52322
diff BS=1
```
C2 run finished. Milliseconds per iter: 0.0564008. Iters per second: 17730.3
PyTorch run finished. Milliseconds per iter: 0.0677778. Iters per second: 14754.1
```
diff BS=20
```
C2 run finished. Milliseconds per iter: 0.51086. Iters per second: 1957.48
PyTorch run finished. Milliseconds per iter: 0.510077. Iters per second: 1960.49
```
master BS=1
```
C2 run finished. Milliseconds per iter: 0.0567362. Iters per second: 17625.4
PyTorch run finished. Milliseconds per iter: 0.0706478. Iters per second: 14154.7
```
master BS=20
```
C2 run finished. Milliseconds per iter: 0.510943. Iters per second: 1957.17
PyTorch run finished. Milliseconds per iter: 0.516338. Iters per second: 1936.72
```
Reviewed By: bertmaher
Differential Revision: D25407106
fbshipit-source-id: 08595ba5e4be59e2ef95fb9b24da7e7671692395
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52165
Apparently bitwise identicality is too high a bar (I'm seeing
differences at this level depending on the HW platform, e.g.,
Broadwell is bitwise accurate but Skylake is 1ulp off). But anyways
VML is accurate to 1 ulp, so let's allow that.
ghstack-source-id: 121815001
Test Plan: test_approx
Reviewed By: asuhan
Differential Revision: D26408079
fbshipit-source-id: 46cbd1487c72ae7bc40567f2f72ed2b919707d0d
Summary: The `cat` op tests pass on device and local MacOS, but will fail during Sandcastle runs. Disabling them for now while we investigate why they fail in Sandcastle.
Test Plan: `buck test //fbobjc/Apps/Internal/PyTorchPlaygroundMac:PyTorchPlaygroundMacTests`
Reviewed By: xta0
Differential Revision: D26468606
fbshipit-source-id: 440369bb68641060fa98dbf37fb8825ee56083e0
Summary:
- Does not disable current CUDA 11.2 CI jobs
- Does not reenable tests disabled for CUDA 11.2
- Removes some unused docker images
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52171
Reviewed By: malfet
Differential Revision: D26461533
Pulled By: janeyx99
fbshipit-source-id: e0e23117498320e72f2cbca547981c5894b48b68
Summary:
Makes dummy torch_cuda target to maintain better backwards compatibility.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52305
Test Plan:
Run `export BUILD_SPLIT_CUDA=ON && python setup.develop`.
When it's done building, run `ls -lah` within `build/lib` to check that `libtorch_cuda.so` exists and is the same size as `libtorch.so`.
Reviewed By: walterddr
Differential Revision: D26463915
Pulled By: janeyx99
fbshipit-source-id: 2b4cb8ee49bd75e11dc89d94b5956917b1800df1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52225
Supported out version for sum for SR
Test Plan:
buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest
sum node runtime before out version (1000 time run): 3558us
sum node runtime after out version (1000 time run): 2173 us
Reviewed By: ajyu
Differential Revision: D26259744
fbshipit-source-id: bc6a1231353d79a96d45f1cdc676e78a92469d85
Summary:
Better debugging: allows you to download the final package for binary windows builds
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52239
Reviewed By: agolynski
Differential Revision: D26463613
Pulled By: janeyx99
fbshipit-source-id: ffb0ec044be23286b8975b9a6d2f90d05c2aff9c
Summary:
nvcc's `--fmad=false` is not valid for the HIP compiler. Upcoming ROCm releases will start treating unrecognized compiler flags as an error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50508
Reviewed By: albanD
Differential Revision: D25920291
Pulled By: mrshenli
fbshipit-source-id: c0ff3b74dd07f3d0661ba29efafaab291ef3621c
Summary:
Current Caffe2 operators WeightedSum and ScatterWeightedSum will enforce that the first input is not empty; otherwise they will raise error. However, in some cases we will have 0 batch size in training and eval. For example, when training and eval current AF and AI OC models, we will filter out the search ads in data pipeline, which might cause 0 batch size in some iterations. As a result, if the models are using Dper3 modules that contains WeightedSum or ScatterWeightedSum (e.g., HistogramBinningCalibration module), they will occasionally fail in training or eval.
To address this issue, we revise the implementation of WeightedSum and ScatterWeightedSum so that we will directly return when their first inputs are empty without failing the operators.
Test Plan:
We tested the code change by building a Dper3 backend canary package. All the jobs for AF and AI OC succeeded with the modified Caffe2 operators:
f251058001
f251058142
f251058332
To compare, all the jobs with identical model configs but with the canary package built from master failed:
f250993908
f250994106
f250994174
Reviewed By: chenshouyuan, huayuli00
Differential Revision: D26444645
fbshipit-source-id: 1c2f81a078810e3ef3c17c133a715090dee2c0ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52237
Redo D26331506 (4c58be4573). Get rid of `nodiscard` which broke OSS CI.
- Clean up references of outputs, including Tuples/Lists, by using move semantics
- Clean up references of elements in output Tuples/Lists by adding them to `unmanaged_values_` in MemoryPlanner. Check for corner case of Tuple/List element being inputs.
- Modify unit tests to check for use_counts of outputs
- Clean up dead code. A bit overlap with D25592967, but shouldn't be a problem.
This diff does not try to fix the alias problem with the MemoryPlanner.
Reviewed By: swolchok
Differential Revision: D26432539
fbshipit-source-id: e08990e4066c1ce69ad5274860851d012b7be411
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51177
**Summary**
This commit adds support for static methods to TorchBind. Just like
pybind, the API for declaring a static method is `def_static(...)`. A
static method must be called on the class directly, and can be called
both in Python as well as TorchScript.
Support for static methods is implemented in a manner similar to that of
instance methods. Registered static functions are wrapped in a layer of
unboxing logic, their schemas are inferred using templates and
metaprogramming, and they are added to the `ClassType` object
corresponding to the TorchBind class on which they are registered.
ScriptClass has been extended to support a `__getattr__` function so
that static methods of TorchBind classes can be invoked in Python. The
implementation of `__getattr__` returns `ScriptClassFunctionPtr`, a
version of `StrongFunctionPtr` without a compilation unit (since the
functions of a TorchBind class live inside the TorchBind registry).
Within TorchScript, TorchBind static functions are desugared in
`PythonClassValue::attr` by looking them up on the class type of the
`PythonClassValue` instance.
**Test Plan**
This commit adds a unit test that tests a simple static method on a
TorchBind class.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26356942
Pulled By: SplitInfinity
fbshipit-source-id: 1b6a9bc2e5f3e22071ad78e331a0201fbbf7ab30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52184
`auditwheel` inserts first 8 symbols of sha256 checksum of the library before relocating into the wheel package. This change adds logic for computing the same short sha sum and embedding it into LazyNVRTC as alternative name for libnvrt.so
Fixes https://github.com/pytorch/pytorch/issues/52075
Test Plan: Imported from OSS
Reviewed By: seemethere
Differential Revision: D26417403
Pulled By: malfet
fbshipit-source-id: e366dd22e95e219979f6c2fa39acb11585b34c72
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52183
This allows one to load library that can exist on the system under different names.
Currently, this functionality is Linux only, as on Windows shared libraries are not renamed by `auditwheel`
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D26417405
Pulled By: malfet
fbshipit-source-id: d327e2565b26cf5b7214e7978862f56e02cad7c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52182
DynamicLibrary provides a very specific functionality, so there is no need to exposes it to every project depending on `ATen.h`
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D26417404
Pulled By: malfet
fbshipit-source-id: f8318cacb07dcc8b2f95984f88ea1df4e5369b8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52162
This test demonstrates how external calls can interoperate with other
tensor computations and between themselves.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D26410813
Pulled By: ZolotukhinM
fbshipit-source-id: 8180164013b43f613d53620d1b249e0af769ae8e
Summary:
Necessary to ensure correct link order, especially if libraries are
linked statically. Otherwise, one might run into:
```
/usr/bin/ld: /usr/local/cuda/lib64/libcublasLt_static.a(libcublasLt_static.a.o): undefined reference to symbol 'cudaStreamWaitEvent@libcudart.so.11.0'
/usr/local/cuda/lib64/libcudart.so: error adding symbols: DSO missing from command line
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52243
Reviewed By: seemethere, ngimel
Differential Revision: D26437159
Pulled By: malfet
fbshipit-source-id: 33b8bb5040bda10537833f3ad737f535488452ea
Summary:
Because this pull request (https://github.com/pytorch/pytorch/issues/40801) becomes an important part of recent 3D models, brings significant improvement in speed, and also have been open for a while. So I decided to resolve the previous review comment and modify it a bit so that it can be merged into the latest version of Pytorch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51027
Reviewed By: albanD
Differential Revision: D26414116
Pulled By: ngimel
fbshipit-source-id: 562c099f4d7f6d603a9c2f2e2a518bc577b0d8ee
Summary:
In the past, this file included `thrust/complex.h` because the `thrust::complex` --> `c10::complex` migration was not done. Today, this task has been done for a while but seems that this include was not deleted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51824
Reviewed By: albanD
Differential Revision: D26417144
Pulled By: ngimel
fbshipit-source-id: 1fff5b8d50f0b34c963a7893cbb0599895823105
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51696
Modify this API to use JitFuture.
ghstack-source-id: 121695707
Test Plan: Ci
Reviewed By: mrshenli
Differential Revision: D26239132
fbshipit-source-id: 15c0c349a79e660fe4862e1d99176989f8159bf4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51695
As part of the plan to completely eliminate torch/csrc/utils/future.h,
we are converting this to JitFuture (c10::ivalue::Future).
ghstack-source-id: 121695708
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D26238873
fbshipit-source-id: 92bad1a349964ce8a9a80e2d1cf68f293cbe411c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51797
The C++ API, ```codegen_backend_module``` is added to ```to_<backend>```. Python related stuffs are decoupled in this function. It can be used from both C++ and python.
* Tests
Python: The existing ```test_backends.py```, which calls the C++ API under the hood.
C++: The end-to-end test of ```jit.BackendTest.ToBackend``` is added in ```test_backend.cpp```. The original class definitions in this file is moved to ```test_backend_lib.cpp```
ghstack-source-id: 121687464
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: raziel
Differential Revision: D26280518
fbshipit-source-id: fd466e4b448847ce64010a3297fff0b5760c5280
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52193
In this step, we replace the temp name and use the old interface name with new behavior
Test Plan: CI
Reviewed By: dskhudia
Differential Revision: D26232170
fbshipit-source-id: 60233f98fe91a15c3c834bf6fde1b185269dd2b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50180
Resolves the regression in
https://github.com/pytorch/pytorch/issues/49819 by adding copy over background
stream similar to scatter. For internal use cases, this is gated with an env var that maintains the previous behavior when it is off.
Test Plan: CI
Reviewed By: mrshenli, ngimel
Differential Revision: D25818170
fbshipit-source-id: e50c76c035504b2a44e2be084701cee45c90df75
Summary: Add support for SqueezeNet in the PyTorch Playground test app
Test Plan:
```
arc focus2 pp-ios
```
Reviewed By: xta0
Differential Revision: D26083960
fbshipit-source-id: a0d753eefa431f2f9e377f082c564370d6774c0b
Summary: Add concat op to enable models such as SqueezeNet.
Test Plan:
Test on device:
```
arc focus2 pp-ios
```
Test on mac
```
buck test pp-macos
```
Reviewed By: xta0
Differential Revision: D26029029
fbshipit-source-id: b0d621f2069a722f0770218c435b22feac4fb873
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51648
The following code will throw during the call to `traced(5)`:
```python
class M(nn.Module):
def __init__(self):
super(M, self).__init__()
self.W = torch.nn.Parameter(torch.randn(5))
def forward(self, x):
return torch.dot(self.W, x)
traced = fx.symbolic_trace(M())
traced(5)
```
Traceback before:
```
Traceback (most recent call last):
File "test/tinytest.py", line 26, in <module>
traced(5)
File "/home/ansley/local/pytorch/torch/fx/graph_module.py", line 338, in wrapped_call
return self._cls_call(self, *args, **kwargs)
File "/home/ansley/local/pytorch/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "<eval_with_key_0>", line 4, in forward
TypeError: dot(): argument 'tensor' (position 2) must be Tensor, not int
```
Traceback after:
```
Traceback (most recent call last):
File "/home/ansley/local/pytorch/torch/fx/graph_module.py", line 338, in wrapped_call
return torch.nn.Module.__call__(self, *args, **kwargs)
File "/home/ansley/local/pytorch/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "<eval_with_key_1>", line 4, in forward
dot_1 = torch.dot(w, x); w = x = None
TypeError: dot(): argument 'tensor' (position 2) must be Tensor, not int
Call using an FX-traced Module, line 4 of the traced Module’s generated forward function:
w = self.W
dot_1 = torch.dot(w, x); w = x = None
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
relu_1 = dot_1.relu(); dot_1 = None
return relu_1
```
(Note that the same `TypeError` is thrown despite modifying the traceback.)
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D26424005
Pulled By: ansley
fbshipit-source-id: 368f46ba81fb3111bd09654825bb2ac5595207d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51669
Adds the basic functionality for the three Numeric Suite core APIs to work on FX models:
1. comparing weights
2. comparing activations, with same input fed to both models
3. comparing activations, with nodes of A shadowing nodes of B
Note: there are a lot of TODOs in the code, and some/most of the APIs and implementation details may change as we iterate. This is just the first PR.
Test Plan:
We have unit test coverage for all of the APIs, for now this is with toy models:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D26403094
fbshipit-source-id: 9752331d4ae0105346d3da309b13c895b593b450
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51588
Early version of utility to match nodes between graph A and graph B, for Numerical Suite for FX graph mode quantization.
The main goal of this utility is to reliably match the nodes of graph A to the nodes of graph B, and throw an easy to read error message. This will be used in future PRs to create the APIs for matching activations. It also could potentially be used to match weights.
Test Plan:
For now, we have bare bones test coverage on some toy models, and a single torchvision model.
```
python test/test_quantization.py TestFXGraphMatcher
```
Future PRs will add more testing.
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26403093
fbshipit-source-id: 60e318d51e6fefe65265488c4967629d946048ef
Summary:
Fixes https://github.com/pytorch/pytorch/issues/34067 by using https://github.com/pytorch/pytorch/issues/34426 by hczhu
In addition to removing the unnecessary any() we do also:
- Get rid of the outer loop since graph_root also needs to be checked
- Update psuedo code description so it matches what the code does
- Add some comments explaining the difference between assigning `info.needed_` and `info.captures_` in terms of how that affects discovery
- [edit: another benefit is that exec_info entries are no longer created for all reachable nodes]
This PR is on top of https://github.com/pytorch/pytorch/issues/51940, so once that lands rebasing on top of master should get rid of the extra commits and changes
I'm not sure if this change will bring a lot of performance gains, but the main benefit is that the code is easier to read.
Trivial graph:
```
torch.autograd.grad(a*b, [a, b], gradient)
setup:
a = torch.rand((2, 2), requires_grad=True)
b = torch.rand((2, 2), requires_grad=True)
gradient = torch.ones(2, 2)
Timer before:
15.45 us
Time after:
14.33 us
1 measurement, 10000 runs , 1 thread
Instructions after:
All Noisy symbols removed
Instructions: 8271213 8193169
Baseline: 4244 3838
Instructions before:
All Noisy symbols removed
Instructions: 8142843 8054463
Baseline: 4280 3838
100 runs per measurement, 1 thread
```
Small graph:
```
torch.autograd.grad((b*a.exp()+a*b.exp()).sum(), (a, b))
setup:
a = torch.rand((2, 2), requires_grad=True)
b = torch.rand((2, 2), requires_grad=True)
Time before:
52.25 us
Time after:
50.80 us
1 measurement, 10000 runs , 1 thread
Instruction count before:
All Noisy symbols removed
Instructions: 25601257 25518229
Baseline: 4228 3838
Instruction count after:
All Noisy symbols removed
Instructions: 25606533 25522797
Baseline: 4228
100 runs per measurement, 1 thread
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52057
Reviewed By: ngimel
Differential Revision: D26432207
Pulled By: soulitzer
fbshipit-source-id: beef68344d66e9e286378e31e3311ba43c25c749
Summary: Previously there was no regularizer implemented for fp16 sparse features. Add regularizer support here using the Float16SparseNormalize implemented in this stack.
Test Plan:
buck test //caffe2/caffe2/python:regularizer_test
In f248648705, we can see there is the operator `Float16SparseNormalize`.
{F356635445}
Reviewed By: bigrabithong
Differential Revision: D24042567
fbshipit-source-id: 5e0065f8c10b8748daffa8a54a6bf8f461460b18
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51762
Update test_util.py to add a `make_tempdir()` function to the `TestCase`
class. The main advantage of this function is that the temporary
directory will be automatically cleaned up when the test case finishes,
so that test case does not need to worry about manually cleaning up this
directory.
This also prefixes the directory name with `caffe2_test.` so that it is
more obvious where the temporary directories came from if they are ever
left behind after a crashed or killed test process.
This updates the tests in `operator_test/load_save_test.py` to use this
new function, so they no longer have to perform their own manual cleanup
in each test.
Test Plan: python caffe2/python/operator_test/load_save_test.py
Reviewed By: mraway
Differential Revision: D26271178
Pulled By: simpkins
fbshipit-source-id: 51175eefed39d65c03484482e84923e5f39a4768
Summary:
In design review the use of the word "true" for a "rounding mode" which actually performed no rounding was, understandably, considered confusing. This PR updates the documentation to remove references to "true." The signatures for torch.div and torch.divide are updated to reflect the future behavior where rounding_mode=None will be the default.
This is slightly inaccurate. Today when rounding mode is not specified it is effectively None, but users cannot actually specify rounding_mode=None today. That change was considered too disruptive to the 1.8 branch cut process.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52202
Reviewed By: gchanan
Differential Revision: D26424979
Pulled By: mruberry
fbshipit-source-id: db3cc769c0d9c6d7e42bfad294073c99fa9168d9
Summary:
Take 2 of https://github.com/pytorch/pytorch/issues/50914
This change moves the early termination logic into common_utils.TestCase class.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52126
Test Plan: CI with ci-all tag
Reviewed By: malfet
Differential Revision: D26391762
Pulled By: walterddr
fbshipit-source-id: a149ecc47ccda7f2795e107fb95915506ae060b4
Summary:
Some distributions of MKL such as the one in the Conda default channel have an implicit dependency to TBB even though they do not list it explicitly in their ELF dynamic section (DT_NEEDED). Pre-loading torch_global_deps into a process that uses such an MKL distribution fails with an unresolved symbol error due to missing libtbb.so. This code change forces torch_global_deps to load libtbb.so into the process to avoid such issues.
More over although we distribute our own TBB build, it is a widely-used third-party library and the same global namespace treatment rules should apply to it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51741
Reviewed By: malfet
Differential Revision: D26261214
Pulled By: cbalioglu
fbshipit-source-id: 94491275f8ec82d5917695e57dd766a10da92726
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51991
- Clean up references of outputs, including Tuples/Lists, by using move semantics
- Clean up references of elements in output Tuples/Lists by adding them to `unmanaged_values_` in MemoryPlanner. Check for corner case of Tuple/List element being inputs.
- Modify unit tests to check for use_counts of outputs
- Clean up dead code. A bit overlap with D25592967, but shouldn't be a problem.
This diff does not try to fix the alias problem with the MemoryPlanner.
(Note: this ignores all push blocking failures!)
Test Plan:
```
buck test //caffe2/benchmarks/static_runtime:static_runtime_cpptest
buck test mode/opt-clang caffe2/caffe2/fb/predictor:ptvsc2_predictor_bench_test
```
Reviewed By: bwasti
Differential Revision: D26333953
fbshipit-source-id: cadc0595ad6ab754c4f1f7a5a3733b2c16b3102f
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 4d203256ba
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52129
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jianyuh
Differential Revision: D26393870
Pulled By: jspark1105
fbshipit-source-id: 6cf01c45c8768f453c9fac5f8af6813db0549083
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51766
Check if we are on Windows using `sys.platform` rather than
`platform.system()`. Even though `platform.system()` is more modern, it
has a few downsides: this performs a runtime check of the platform type,
which has non-zero overhead. On Linux it actually executes the separate
`/bin/uname` process. On the other hand `sys.platform` is determined
when the Python interpreter is compiled, so this is a simple hard-coded
string.
Because it is a runtime check, `platform.system()` checks also cannot be
analyzed by static type checkers like Pyre and Mypy. These type
checkers do understand `sys.platform` checks, and can correctly avoid
complaining about code paths that use platform-specific modules and
functions. e.g., they can avoid complaining about `ctypes.WinDLL` not
existing on Linux if its use is guarded by a `sys.platform` check.
ghstack-source-id: 121107705
Test Plan: Ran tests on Linux, and will check CI test results.
Reviewed By: mraway
Differential Revision: D26271724
Pulled By: simpkins
fbshipit-source-id: b86e427e4ceec0324464ba4bc88b95d5813172d0
Summary:
Fixes #{[50510](https://github.com/pytorch/pytorch/issues/50510)}
Allows ```torch.nn.parallel.scatter_gather.gather``` to accept a list of NamedTuples as input and returns a NamedTuple whose elements are tensors. I added the author's fix using the ```is_namedtuple``` function.
While testing this fix, I encountered a deprecation warning instructing me to use ```'cpu'``` instead of ```-1``` to move the outputs to the CPU. However, doing this causes an assertion error in the ```_get_device_index``` function. I solved this by handling the CPU case in the affected ```forward``` function.
rohan-varma
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51104
Reviewed By: albanD
Differential Revision: D26395578
Pulled By: rohan-varma
fbshipit-source-id: 6e98c9ce1d9f1725973c18d24a6554c1bceae465
Summary:
Currently, adding a cross compile build is failing on CI due to a cmake builtin compiler check that does not pass due to cross compiling the host protoc library.
Setting the CMAKE_TRY_COMPILE_TARGET_TYPE flag should fix it. (Based on this [SOF answer](https://stackoverflow.com/questions/53633705/cmake-the-c-compiler-is-not-able-to-compile-a-simple-test-program).)
To test that this works, please run: `CMAKE_OSX_ARCHITECTURES=arm64 USE_MKLDNN=OFF USE_NNPACK=OFF USE_QNNPACK=OFF USE_PYTORCH_QNNPACK=OFF BUILD_TEST=OFF python setup.py install` from a Mac x86_64 machine with Xcode12.3 (anything with MacOS 11 SDK).
Then, you can check that things were compiled for arm by running `lipo -info <file>` for any file in the `build/lib` directory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50922
Reviewed By: malfet
Differential Revision: D26355054
Pulled By: janeyx99
fbshipit-source-id: 919f3f9bd95d7c7bba6ab3a95428d3ca309f8ead
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51952
StaticRuntime should not hold owning refs of inputs after inference is finished. This diff adds a pass to clean them up and unit tests to enforce the check.
Will clean up output tensors in separate diffs.
Test Plan:
```
buck test //caffe2/benchmarks/static_runtime:static_runtime_cpptest
buck test mode/opt-clang caffe2/caffe2/fb/predictor:ptvsc2_predictor_bench_test
```
Reviewed By: bwasti
Differential Revision: D26331506
fbshipit-source-id: d395a295ada9de3033d0ea05d1dbab62d879a03b
Summary:
`torch.__config__._cxx_flags` gets called on import, but this means that Timer can't be used if it fails. (Even just the wall time parts.) This is needlessly restrictive.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52124
Reviewed By: albanD
Differential Revision: D26395917
Pulled By: robieta
fbshipit-source-id: 4336a77dba131f80d386368ef715eed63c1cbcb4
Summary:
The GitHub-hosted runner has maximum 14 GB disk space, which is not enough to host the nightly Docker build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52148
Test Plan: CI workflow
Reviewed By: samestep
Differential Revision: D26406295
Pulled By: xuzhao9
fbshipit-source-id: 18a0dff45613649d6c15b8e1e9ca85042f648afd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51822
Adds support for shape recording for profiling distributed collectives, for nccl/gloo backends. Added
both cpp and python tests to ensure that shapes are recorded properly. Note that we don't add `ProcessGroupNCCLTest`s since they need to be modified to support single process per device and > 1 world size.
ghstack-source-id: 121507509
Test Plan: CI
Reviewed By: mrzzd
Differential Revision: D26291739
fbshipit-source-id: 5f7bd54d8c36d17a4a29e172b25266ca3dbd8fbd
Summary:
Increasing the deadline as to avoid
flakiness of the test on ROCM.
Signed-off-by: Roy, Arindam <rarindam@gmail.com>
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52013
Reviewed By: albanD
Differential Revision: D26360209
Pulled By: mrshenli
fbshipit-source-id: 1ddc7062c5ff7c980233d22844073de9fb7dcbb3
Summary:
libc++ implements csqrt using polar form of the number, which results in higher numerical error, if `arg` is close to 0, pi/2, pi, 3pi/4
Fixes https://github.com/pytorch/pytorch/issues/47500
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52018
Reviewed By: walterddr
Differential Revision: D26359947
Pulled By: malfet
fbshipit-source-id: 8c9f4dc45948cb29c43230dcee9b030c2642d981
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52083
This makes minor fixes in `caffe2/python` to address all errors currently
reported by Pyre.
I update the code to fix errors when doing so looked simple and safe,
and added `pyre-fixme` comments in other places.
ghstack-source-id: 121109695
Test Plan: Confirmed that Pyre no longer reports errors under `caffe2/python`
Differential Revision: D26272279
fbshipit-source-id: b1eb19d323b613f23280ce9c71e800e874ca1162
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51769
Remove some Python 2 compatibility code that otherwise causes errors to
be reported from static type checkers.
Static type checkers complain that the old Python 2 modules and
functions referenced by this code do not exist. Given that Python 2
support is entirely deprecated now we can simply remove the
compatibility code.
ghstack-source-id: 121313191
Test Plan:
Was able to get Pyre to successfully type check the `caffe2/python`
directory with this and some other changes.
Reviewed By: Tianshu-Bao
Differential Revision: D26271723
Pulled By: simpkins
fbshipit-source-id: fec8a09466be6867388832380480aafd36616aa1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51315
The TODOs said to remove this wrapper, and it seems that it can be removed easily.
ghstack-source-id: 121363465
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D26137147
fbshipit-source-id: f1e5971dca071f37400d77cc823214527e4231bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51313
The problem here is similar to the one described in
https://devblogs.microsoft.com/cppblog/build-throughput-series-more-efficient-template-metaprogramming/
in that we are iterating over an integer seqeunce of length N, where N
is the number of argument types to our function, and specializing
`TypeListAt` (which we call `element_t`) for each Ith element of the
typelist, which instantiates O(I) template specializations, for a
total of O(N^2).
The solution is also similar: we iterate over the typelist
directly. Unlike in the blog post, we do also need the index in the
sequence, so we retain the index_sequence.
ghstack-source-id: 121363464
Test Plan:
Inspect -ftime-trace output for RegisterCPU.cpp.
Before: P168220187
After: P168220294
we can see that we spend less time instantiating
call_functor_with_args_from_stack and spend a similar amount of time
compiling it. The win is modest, but it's a win and I've already
written it so I'm sending it out. (I was hoping it would reduce
compilation time for make_boxed_from_unboxed_functor.)
Reviewed By: bhosmer
Differential Revision: D26136784
fbshipit-source-id: c91a523486e3019bd21dcd03e51a58aa25aa0981
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52104
Make the API of `SamplerIterDataPipe` more reasonable with `sampler_args` and `sampler_kwargs`.
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D26401494
Pulled By: ejguan
fbshipit-source-id: ee5b5c414782d0880b12968bc9c8aa470b753f6a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/39784
At the time the issue was filed, there was only issue (1) below.
There are actually now two issues here:
1. We always set all inputs passed in through `inputs` arg as `needed = True` in exec_info. So if we pass in an input that has a grad_fn that is not materialized, we create an entry of exec_info with nullptr as key with `needed = True`. Coincidentally, when we perform simple arithmetic operations, such as "2 * x", one of the next edges of mul is an invalid edge, meaning that its grad_fn is also nullptr. This causes the discovery algorithm to set all grad_fns that have a path to this invalid_edge as `needed = True`.
2. Before the commit that enabled the engine skipped the dummy node, we knew that root node is always needed, i.e., we hardcode `exec_info[&graph_root]=true`. The issue was that this logic wasn't updated after the code was updated to skip the graph root.
To address (1), instead of passing in an invalid edge if an input in `inputs` has no grad_fn, we create a dummy grad_fn. This is done in both python and cpp entry points. The alternative is to add logic for both backward() and grad() cases to check whether the grad_fn is nullptr and set needed=false in that case (the .grad() case would be slightly more complicated than the .backward() case here).
For (2), we perform one final iteration of the discovery algorithm so that we really know whether we need to execute the graph root.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51940
Reviewed By: VitalyFedyunin
Differential Revision: D26369529
Pulled By: soulitzer
fbshipit-source-id: 14a01ae7988a8de621b967a31564ce1d7a00084e
Summary:
This is causing type hint test errors on the latest numpy:
```
torch/testing/_internal/common_quantized.py:38: error: Module has no attribute "float"; maybe "float_", "cfloat", or "float64"? [attr-defined]
torch/testing/_internal/common_methods_invocations.py:758: error: Module has no attribute "bool"; maybe "bool_" or "bool8"? [attr-defined]
```
Runtime-wise, there's also a deprecation warning:
```
__main__:1: DeprecationWarning: `np.float` is a deprecated alias for the builtin `float`. To silence this warning, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
```
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52103
Reviewed By: suo
Differential Revision: D26401210
Pulled By: albanD
fbshipit-source-id: a7cc12ca402c6645473c98cfc82caccf161160c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52094
Pull Request resolved: https://github.com/pytorch/glow/pull/5329
Nested constants are created as placeholders by the graph_splitter used in the partitioner. So we change them back to get_attr nodes before serializing the graph.
Reviewed By: jfix71
Differential Revision: D26375577
fbshipit-source-id: 66631aadd6f5b8826ffa0a1e70176fbcaa7431d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51939
TestTrainingLoop - TestE2ETensorPipe was flaky since there would still
be inflight background RPCs running as we performed the assertions. This
resulted in these assertions failing since we didn't wait for all RPCs on the
agent to finish.
To resolve this issue, in this PR we join() and shutdown() the RPC agent to
ensure no further RPCs are done. Then we assertion the map sizes to ensure no
leaks occurred.
In addition to this, added messageIdToTimeout map to lookup the appropriate
timeout for a messageId. This ensures we remove the appropriate entry from the
map. The previous solution was passing the expirationTime through the lambda,
but it is not guaranteed the lambda would read the response of the request we
just sent out.
ghstack-source-id: 121412604
Test Plan:
1) unit tests
2) waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D26331585
fbshipit-source-id: a41e0534d7d4dfd240446e661e5541311931c7d7
Summary: To consider small delay between fbgemm and caffe2/pytorch repo, we are taking multiple steps. In this diff, we use new interface with temp name.
Test Plan: CI
Reviewed By: dskhudia
Differential Revision: D26231909
fbshipit-source-id: 83ceb3e12026d459532ef54459ac125b5625d644
Summary:
Reference: https://github.com/pytorch/pytorch/issues/50006
We should probably add aliases for these operators to be consistent with NumPy names i.e. `np.degrees` and `np.radians`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51283
Reviewed By: ngimel
Differential Revision: D26171163
Pulled By: mruberry
fbshipit-source-id: 1869604ed400820d95f6ff50a0e3cba1de1ffa84
Summary:
Previously `torch.jit.trace` relies on AutoGrad hooks to infer name of tensors in computation, including those of function/method arguments. This often doesn't work out because:
- These names often do not exist
- Tracer uses argument name of first tensor operation on each tensor as inferred argument names. These tensor operations have programmatically-generated names like `argument_1`
This PR extracts argument names directly from Python functions and pass them down to tracer, which then assigns them to correct graph inputs. This way, we always have the correct argument names captured in IR.
This is useful for both debugging and supporting using `InterfaceType` to represent traced modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51775
Reviewed By: izdeby
Differential Revision: D26273105
Pulled By: gmagogsfm
fbshipit-source-id: 934a385041137dc3731bb6fa8657b11532fed9e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50848
I noticed that the call overhead from `Tensor::device()` for ~1-2% of instruction counts depending on the microbenchmark
Some nice looking instruction count wins https://www.internalfb.com/intern/paste/P164529004/
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D25984136
Pulled By: bdhirsh
fbshipit-source-id: 0e54f2afe78caeb5a03abbb15e9197556acfeca1
Summary:
Adding CUDA 11.2 to Windows CI.
Disabled tests:
The following ran into `CUDA error: misaligned address` for CUDA 11.2: (issue linked below)
`test_where_scalar_valid_combination_cuda_complex128` in test_torch.py
`test_sgn_complex_cuda` in test_autograd.py
The following ran into `CUDA error: too many resources requested for launch` for CUDA 11.2: (https://github.com/pytorch/pytorch/issues/52002)
test_EmbeddingBag_per_sample_weights_and_new_offsets_cuda_int64_float64
test_EmbeddingBag_per_sample_weights_and_offsets_cuda_int64_float64
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51598
Reviewed By: mrshenli
Differential Revision: D26344965
Pulled By: janeyx99
fbshipit-source-id: 3c9a4ed16d748969e96593220ec0a9f33e1ffcef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49588
**Summary**
`BufferPolicy::valid` uses `!typ->is_parameter(i)` to check if an
attribute is a buffer or not; it should use `type->is_buffer(i)` instead.
It also removes a forward compatibility gate in `python_print.cpp` that
has prevented the preservation of buffer metadata during serialization
in fbcode. Without this, the first change (to `BufferPolicy`) does not
work correctly in fbcode.
**Test Plan**
It is difficult to write an additional test that would have failed before this
commit because the two booleans `is_parameter` and `is_buffer` are never set
to `true` at the same time.
**Fixes**
This commit fixes#48746.
Test Plan: Imported from OSS
Reviewed By: xw285cornell
Differential Revision: D25633250
Pulled By: SplitInfinity
fbshipit-source-id: e727f8506f16d2e2b28f3d76a655f6528e7ac6cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49594
**Summary**
This commit adds a unit test to `test_save_load.py` that checks that
saving and loading a module preserves metadata about which module
attributes are parameters and buffers. The hooks that are currently used
to automatically check serialization of every function and module in the
unit tests check that the archive produced by saving and loading and
saving again are the same and that the type tags for the actual IValues
representing the module match before saving and after loading. However,
these tests do not check that buffer and parameter metadata was not
lost or destroyed during serialization.
**Test Plan**
Ran the new unit test.
Test Plan: Imported from OSS
Reviewed By: xw285cornell
Differential Revision: D25730603
Pulled By: SplitInfinity
fbshipit-source-id: 06a202935d9e0654cb1966c34f54707f0a28a331
Summary:
Adding 11.2 to CI with BUILD_SPLIT_CUDA enabled.
Disabled the following tests as they were failing in test_optim.py:
test_adadelta
test_adam
test_adamw
test_multi_tensor_optimizers
test_rmsprop
(Issue tracking that is here: https://github.com/pytorch/pytorch/issues/51992)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51905
Reviewed By: VitalyFedyunin
Differential Revision: D26368575
Pulled By: janeyx99
fbshipit-source-id: 31612c7d04d51afb3f18956e43dc7f7db8a91749
Summary:
Previously, the graph might have been delete while Python still has iterators, leading to segfaults.
This does not fully work for iterators from Nodes and Blocks as they may be invalidated when the owning graph goes out of scope. I will look into these separately.
Fixes https://github.com/pytorch/pytorch/issues/50454
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51951
Reviewed By: mrshenli
Differential Revision: D26352629
Pulled By: SplitInfinity
fbshipit-source-id: 67299b6cbf1ac7ab77f8703a0ca8f1162e03fcd4
Summary:
This fixes an issue (currently blocking https://github.com/pytorch/pytorch/issues/51905) where the test time regression reporting step will fail if none of the most recent `master` ancestors have any reports in S3 (e.g. if a new job is added).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52054
Test Plan:
```
python test/test_testing.py
```
Reviewed By: walterddr
Differential Revision: D26369507
Pulled By: samestep
fbshipit-source-id: 4c4e1e290cb943ce8fcdadacbf51d66b31c3262a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51785
The TensorPipe pipes do not really support a "graceful" shutdown: if one side is expecting data (i.e., it has scheduled a readDescriptor call) and the other side closes, the former will receive an error. Such an error will not even be predictable, as it depends on the backend: some may detect this and report it "well" (through an EOFError), others may not be able to tell this apart from a failure and report it as such.
This meant that during shutdown some of these errors would fire and thus the agent would log them as warning. We did add a note that these were expected under some conditions, so that users wouldn't be alarmed, but it was still a far-from-ideal experience.
In principle we could build a "protocol" on top of these pipes to "agree" on a graceful shutdown, and this was the plan to solve this. However, it was rather complicated to implement.
Here I am proposing a quicker, but perhaps hackier, solution, which re-uses the already existing graceful shutdown "protocol" of the agent (i.e., the `join` method) to put the agent in a special state in which it will silence all errors due to a remote shutting down.
Such a check cannot happen in the `shutdown` method, because that's also used in case of ungraceful shutdown (in which case I believe we'd still want to display errors). Since it needs to make sure that all participants have transitioned to this new state before any of them can continue (as otherwise one of them may close its pipes before another one has realized that this is now expected), we need to perform a barrier. Hence the ideal place for it is the `join` method, where we're already doing a lot of gang-wide synchronization. Since the `join` method isn't only called during shutdown, we need to make sure we only switch the agent to this state when it's the last call to join, and we do so by adding a new optional argument to it (which will be ignored by all agents except the TensorPipe one).
I realize this isn't the prettiest solution, and since it changes the agent's API it's worth discussing it carefully. Let me know what you think!
ghstack-source-id: 121131940
Test Plan: Run on CircleCI, where this occurred quite a bit, and check the logs.
Reviewed By: mrshenli
Differential Revision: D26276137
fbshipit-source-id: 69ef14fe10908e80e627d9b4505352e482089cc8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51784
The TensorPipe agent mimics Gloo when trying to guess the most reasonable IP address to bind to. When that fails, it prints a warning to inform the user. It turns out, we were attempting to guess the address a lot of times (I counted at least 18: 1 for the UV transport, 1 for the IBV transport, 16 for the multiplexed UV channel) and thus they might all print that same identical warning message. That's noisy. Since the outcome of all these guesses will be the same (unless the system config changes underneath, which is unlikely) we can just do it once, print the warning (at most) once, cache the result and reuse it over and over.
Also, we used to have two identical but distinct ways of doing this, one provided by the UV transport and one by the IBV one. TensorPipe offers both methods because backends are modular and independent. However PyTorch always requires the UV one to be present, hence we can always rely on the UV helpers, and avoid using the IBV ones.
ghstack-source-id: 121121275
Test Plan: Look at the CircleCI logs, I think I saw this situation happening there.
Reviewed By: mrshenli
Differential Revision: D26275838
fbshipit-source-id: 8a2ffc40d80388bdca32dbcfed16f28a0a6177a3
Summary:
Set CUDA_VERSION to 11.2.0 since Nvidia name their docker image on Ubuntu 18.04 to be nvidia/cuda:11.2.0-cudnn8-devel-ubuntu18.04.
Note that cudatoolkit 11.2.0 is not yet on [conda](https://repo.anaconda.com/pkgs/main/linux-64/), and we need to wait for that before merging this PR.
- https://hub.docker.com/r/nvidia/cuda/
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51990
Reviewed By: samestep
Differential Revision: D26371193
Pulled By: xuzhao9
fbshipit-source-id: 76915490dc30ddb03ceeeadb3c45a6c02b60401e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51999
as in title
Test Plan: waiting on CI for now
Reviewed By: eellison
Differential Revision: D26349297
fbshipit-source-id: bd5574ed1f8448ba18a6fda4bdc45f45d8b158e9
Summary:
This is a follow up on https://github.com/pytorch/pytorch/issues/49869.
Previously CUDA early termination only happens for generic test classes that extends from `DeviceTypeTestBase`. However, JIT test cases which extends from common_utils.TestCase cannot benefit from the early termination.
This change moves the early termination logic into common_utils.TestCase class.
- all tests extended from common_utils.TestCase now should early terminate if CUDA assert occurs.
- For TestCases that extends from common_device_type.DeviceTypeTestBase, still only do torch.cuda.synchronize() when RTE is thrown.
- For TestCases extends common_utils.TestCase, regardless of whether a test case uses GPU or not, it will always synchronize CUDA as long as `torch.cuda.is_initialize()` returns true.
- Disabling this on common_distributed.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50914
Reviewed By: malfet
Differential Revision: D26019289
Pulled By: walterddr
fbshipit-source-id: ddc7c1c0d00db4d073a6c8bc5b7733637a7e77d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51751
Similar in spirit to the `__builtin_expect` C intrinsic, it's useful
to be able to hint the expected branch direction in a tensor expression. Using
this flag has a few effects on codegen:
- The CompareSelect is generated using conditional branches, rather than selects
- The conditional branches are strongly hinted (like, 100000:1) in the indicated direction
- A vectorized hinted CompareSelect computes its condition in parallel with a
mask "reduction" (e.g. a bitcast from `<i1 x 8>` to `<i*>`). In AVX terms
this sequence might look like:
```
vpcmpgtd %ymm0, %ymm1, %ymm2
vmovmskps %ymm2, %eax
```
The motivating case for this addition is an attempt I'm making to replicate
fast transcendentals using tensor expressions. Floating-point numbers have
lots of special cases (denormals, inf, nan) that need special handling, and
it's convenient to be able to punt that handling off to a slow path while
keeping the fast path nice and tight.
ghstack-source-id: 121366315
Test Plan:
I'm not sure how to test this (except I can tell you it works for
the `log` implementation I'm working on right now). It would be nice to plumb
the LLIR/ASM output through programmatically so it can be used in FileCheck.
Maybe I'll do that in another diff?
Reviewed By: asuhan
Differential Revision: D26246401
fbshipit-source-id: 900f7fa0520010fb9931d6e3efc8680a51f8d844
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51749
Following in the mode of C++, we probably want to distinguish when
it's appropriate to do arithmetic vs. logical right shift.
> For negative a, the value of a >> b is implementation-defined (in most
> implementations, this performs arithmetic right shift, so that the result
> remains negative).
If you look at what clang does, if `a` is unsigned, a logical shift is
generated; if signed, an arithmetic shift. Let's do the same here. This turns
out to be useful for, e.g., implementing transcendental function
approximations.
ghstack-source-id: 121366317
Test Plan:
Added Byte (unsigned) and Char (signed) right-shift tests to
test_llvm.
Reviewed By: asuhan
Differential Revision: D26245856
fbshipit-source-id: 260ee9bf4b032b9ce216f89acbc273cde0ed688c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51819
Original commit changeset: 3e945b438fb8
One does not simply change the patterns of aten op calls
ghstack-source-id: 121379333
Test Plan: CI
Reviewed By: nikithamalgifb
Differential Revision: D26291736
fbshipit-source-id: b819ac013c0438cc2f70daed7d7f2ef8fdc12ab7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51878
`fake_quantize_per_tensor_affine_cachemask` and
`fake_quantize_per_channel_affine_cachemask` are implementation
details of `fake_quantize_per_tensor_affine` and
`fake_quantize_per_channel_affine`, removing the
Python bindings for them since there is no need to
expose them.
Test Plan:
```
python test/test_quantization.py TestFakeQuantize
```
Imported from OSS
Reviewed By: albanD, bugra
Differential Revision: D26314173
fbshipit-source-id: 733c93a3951453e739b6ed46b72fbad2244f6e97
Summary: Currently batch_size is determined on modeling side. Add a flag caffe2_predictor_disagg_acc_max_batch_size_override to explore different batch_size during inference.
Test Plan:
replayer test
set caffe2_predictor_disagg_acc_max_batch_size_override=32 on both server and client side.
Reviewed By: khabinov
Differential Revision: D26318568
fbshipit-source-id: 4fa79e2087a5f7f7670988aec7e5b41e63f9980b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51359
`Logger` is the name of the base Logger class. It's confusing that
it is also used as a variable name, which can represent this class
or its subclasses. Renaming to `logger_cls` to make it clearer.
Test Plan:
```
python test/test_quantization.py TestEagerModeNumericSuite
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D26149577
fbshipit-source-id: a9c12f9446f66e5c683ab054b2a94aeb0cf9cc8a
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 884fb257ab
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52014
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: mrshenli
Differential Revision: D26357567
fbshipit-source-id: a9f239c9d3273d04ee15fb052b2bf4f25477814b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50920
There was a hole left after previous changes.
ghstack-source-id: 120714378
Test Plan: static_assert still passes.
Reviewed By: ezyang
Differential Revision: D26008763
fbshipit-source-id: c3830328835e28a0d06c833172ac60457049824b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51820
If the child cannot extract tensors from returned IValue, the
current child CUDAFuture won't wait for anything. In this case,
if the `wait()` wasn't called on the parent Future, streams are
not synchronized, and it is possible that parent Future's CUDA
ops have not been added to streams yet.
This commit adds a `markCompletedWithDataPtrs()` to `ivalue::Future`,
and RPC uses this API to pass Message tensor dataPtrs to the
`PyObject` Future when marking it as completed.
Test Plan: Imported from OSS
Reviewed By: pritamdamania87
Differential Revision: D26324068
Pulled By: mrshenli
fbshipit-source-id: 3d838754f6daabad5cd9fb8953e4360196d110bb
Summary:
Add a ROCm 4.0.1 docker image for CI. Keep the 3.10 image.
Keep the 3.9 image until the 3.9 image is no longer needed.
Plan is to keep two ROCm versions at a time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51507
Reviewed By: seemethere
Differential Revision: D26350348
Pulled By: malfet
fbshipit-source-id: 6230278343ee48f19e96067180590beab96b17cc
Summary:
When type inference fails when JITing torchscript module, the error message does not give any implication where the error fails. For example: "Cannot create dict for key type 'int?', only int, float, complex, Tensor and string keys are supported".
This adds the variable name and item to the error message.
Reviewed By: ajaech
Differential Revision: D26327483
fbshipit-source-id: d8c85e7550258d7c56530f5826ff9683ca8b2b94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51884
it is now possible to bundle inputs and not bundle them for forward. This is ok and so we need to account for that.
ghstack-source-id: 121266667
Test Plan: Manually bundle inputs for a function not named forward. Call optimize_for_mobile and make sure the functions are still there. {P173289878}
Reviewed By: iseeyuan
Differential Revision: D26304558
fbshipit-source-id: 79f82d9de59c70b76f34e01f3d691107bf40e7bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51642
Compiling currently gives:
```
an 13 16:46:39 In file included from ../aten/src/ATen/native/TensorShape.cpp:12:
Jan 13 16:46:39 ../aten/src/ATen/native/Resize.h:37:24: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 if (new_size_bytes > self->storage().nbytes()) {
Jan 13 16:46:39 ~~~~~~~~~~~~~~ ^ ~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:32:24: warning: comparison of integers of different signs: 'size_t' (aka 'unsigned long') and 'int64_t' (aka 'long long') [-Wsign-compare]
Jan 13 16:46:39 for (size_t i = 0; i < shape_tensor.numel(); ++i) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:122:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 for (int64_t i = 0; i < tensors.size(); i++) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:162:21: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 for (int i = 0; i < tensors.size(); i++) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:300:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 for (int64_t i = 0; i < s1.size(); ++i) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:807:21: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 TORCH_CHECK(dim < self_sizes.size());
Jan 13 16:46:39 ~~~ ^ ~~~~~~~~~~~~~~~~~
Jan 13 16:46:39 ../c10/util/Exception.h:361:31: note: expanded from macro 'TORCH_CHECK'
Jan 13 16:46:39 if (C10_UNLIKELY_OR_CONST(!(cond))) { \
Jan 13 16:46:39 ^~~~
Jan 13 16:46:39 ../c10/util/Exception.h:244:47: note: expanded from macro 'C10_UNLIKELY_OR_CONST'
Jan 13 16:46:39 #define C10_UNLIKELY_OR_CONST(e) C10_UNLIKELY(e)
Jan 13 16:46:39 ^
Jan 13 16:46:39 ../c10/macros/Macros.h:173:65: note: expanded from macro 'C10_UNLIKELY'
Jan 13 16:46:39 #define C10_UNLIKELY(expr) (__builtin_expect(static_cast<bool>(expr), 0))
Jan 13 16:46:39 ^~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:855:24: warning: comparison of integers of different signs: 'size_t' (aka 'unsigned long') and 'const int64_t' (aka 'const long long') [-Wsign-compare]
Jan 13 16:46:39 for (size_t i = 0; i < num_blocks; ++i) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:2055:23: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 for (int i = 0; i < vec.size(); i++) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:2100:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 for (int64_t i = 0; i < src.size(); ++i) {
```
This fixes issues with loop iteration variable types
Test Plan: Sandcastle tests
Reviewed By: ngimel
Differential Revision: D25935136
fbshipit-source-id: a5da4af16bb8045cc16ab1c78b8e0f2bb3ae64bd
Summary:
Additional magma tests have been identified as failing after integrating hipMAGMA into the ROCm builds. Skipping is necessary until they can be fixed properly. This is blocking migration of ROCm CI to 4.0.1.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51915
Reviewed By: izdeby
Differential Revision: D26326404
Pulled By: malfet
fbshipit-source-id: 558cce66f216f404c0316ab036e2e5637fc99798
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51826
Looks like this:
```
resnet.pt
├── .data # Data folder named so it can't clash with torch.package codemodules.
│ │ # Names/extensions automatically added to avoid namingconflicts.
│ ├── 94286146172688.storage # tensor data
│ ├── 94286146172784.storage
│ ├── extern_modules # torch.package metadata
│ ├── version # version metadata
│ └── ...
├── model # package pickled model created w/
│ │ # exporter.save_pickel('model','model.pkl', resnet_model)
│ └── model.pkl
└── torchvision # all code dependencies for packaged picked
└── models # models are captured as source files
├── resnet.py
└── utils.py
```
Since `version` is hardcoded in our zip reader/writer implementation,
add it as an option that defaults to "version" but accepts other
locations for putting the version metadata.
Test Plan: Imported from OSS
Reviewed By: zdevito
Differential Revision: D26295649
Pulled By: suo
fbshipit-source-id: 2d75feeb7de0f78196b4d0b6e2b814a7d58bd1dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51595
Right now `PackageExporter` defines its own `persistent_id` but
`PackageImporter` uses the one defined in `torch.serialization`. I have
some downstream plans to customize this so this PR just splits it out.
Not to fear! I know this introduces some duplication and potential for
different behavior between `torch.save` and `torch.package`, but I have
plans to re-unify them soon.
Test Plan: Imported from OSS
Reviewed By: zdevito
Differential Revision: D26211578
Pulled By: suo
fbshipit-source-id: 48a2ccaefb2525e1498ad68b75c46d9de3d479b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51694
We implicitly extern standard library modules. Our method of determining
whether a module is in the standard library is a little unreliable. In
particular, I'm seeing lots of flaky errors on windows/mac CI when I
start doing more complicated packaging tests.
I looked into the best ways to do this, turns out there's no reliable
way, so tools that need to do this generally just parse the Python docs
for a listing and save it. I took `isort`'s lists and called it a day.
Test Plan: Imported from OSS
Reviewed By: zdevito
Differential Revision: D26243751
Pulled By: suo
fbshipit-source-id: 48c685cd45ae847fe986bcb9f39106e0c3361cdc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51909
Several scenarios don't work when trying to script `F.normalize`, notably when you try to symbolically trace through it with using the default argument:
```
import torch.nn.functional as F
import torch
from torch.fx import symbolic_trace
def f(x):
return F.normalize(x)
gm = symbolic_trace(f)
torch.jit.script(gm)
```
which leads to the error
```
RuntimeError:
normalize(Tensor input, float p=2., int dim=1, float eps=9.9999999999999998e-13, Tensor? out=None) -> (Tensor):
Expected a value of type 'float' for argument 'p' but instead found type 'int'.
:
def forward(self, x):
normalize_1 = torch.nn.functional.normalize(x, p = 2, dim = 1, eps = 1e-12, out = None); x = None
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
return normalize_1
Reviewed By: jamesr66a
Differential Revision: D26324308
fbshipit-source-id: 30dd944a6011795d17164f2c746068daac570cea
Summary:
The name of "val" is inconsistent with the rest of the API and also
inconsistent with the underlying C++ implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51763
Test Plan:
Used the following command to demonstrate incorrect docs before and
correct docs after:
python -c 'import torch; print(torch.Tensor.index_fill_.__doc__)'
Fixes https://github.com/pytorch/pytorch/issues/51250
Reviewed By: zhangguanheng66
Differential Revision: D26271273
Pulled By: dagitses
fbshipit-source-id: 4897da80b639c54ca652d2111e13f26efe2646a0
Summary:
Fixes flake8 failures in test_autograd.py by using `gradcheck` from `torch.testing._internal.common_utils` rather than directly from`torch.autograd.gradcheck`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51963
Reviewed By: albanD
Differential Revision: D26339107
Pulled By: malfet
fbshipit-source-id: 63e0f12df16b70e394097ad88852984c1848a9e6
Summary:
It frequently happens when PyTorch compiled with CUDA support is installed on machine that does not have NVIDIA GPUs.
Fixes https://github.com/pytorch/pytorch/issues/47038
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51806
Reviewed By: ezyang
Differential Revision: D26285827
Pulled By: malfet
fbshipit-source-id: 9fd5e690d0135a2b219c1afa803fb69de9729f5e
Summary:
Move definition of copysign template and specialization for
bfloat16/half types before first use of copysign in that file
Add comment explaining why this is necessary
Fixes https://github.com/pytorch/pytorch/issues/51889
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51900
Reviewed By: walterddr
Differential Revision: D26321741
Pulled By: malfet
fbshipit-source-id: 888858b11d9708fa140fe9c0570cc5a24599205b
Summary:
[Here](https://docs.gradle.org/current/userguide/gradle_wrapper.html), there is the following description.
`The recommended way to execute any Gradle build is with the help of the Gradle Wrapper`
I took a little time to prepare Gradle for `pytorch_android` build. (version etc.)
I think using Gradle wrapper will make `pytorch_android` build more seamless.
Gradle wrapper version: 4.10.3
250c71121b/.circleci/scripts/build_android_gradle.sh (L13)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51067
Reviewed By: izdeby
Differential Revision: D26315718
Pulled By: IvanKobzarev
fbshipit-source-id: f8077d7b28dc0b03ee48bcdac2f5e47d9c1f04d9
Summary:
This PR adds a local [`mypy` plugin](https://mypy.readthedocs.io/en/stable/extending_mypy.html#extending-mypy-using-plugins) that warns if you accidentally run `mypy` using a version that doesn't match [the version we install for CI](6045663f39/.circleci/docker/common/install_conda.sh (L117)), since this trips people up sometimes when `mypy` gives errors in some versions (see https://github.com/pytorch/pytorch/issues/51513) but not others.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51799
Test Plan:
To check that this doesn't break our `mypy` test(s) when you have the correct version installed:
```
python test/test_type_hints.py
```
To check that this does indeed warn when you have an incorrect `mypy` version installed, switch to a different version (e.g. 0.782), and run the above command or either of these:
```
mypy
mypy --config-file=mypy-strict.ini
```
You should get the following message on stderr:
```
You are using mypy version 0.782, which is not supported
in the PyTorch repo. Please switch to mypy version 0.770.
For example, if you installed mypy via pip, run this:
pip install mypy==0.770
Or if you installed mypy via conda, run this:
conda install -c conda-forge mypy=0.770
```
Reviewed By: janeyx99
Differential Revision: D26282010
Pulled By: samestep
fbshipit-source-id: 7b423020d0529700dea8972b27afa2d7068e1b12
Summary:
This is a followup to https://github.com/pytorch/pytorch/issues/49190. Vaguely speaking, the goals are to make it easy to identify test time regressions introduced by PRs. Eventually the hope is to use this information to edit Dr CI comments, but this particular PR just does the analysis and prints it to stdout, so a followup PR would be needed to edit the actual comments on GitHub.
**Important:** for uninteresting reasons, this PR moves the `print_test_stats.py` file.
- *Before:* `test/print_test_stats.py`
- *After:* `torch/testing/_internal/print_test_stats.py`
Notes on the approach:
- Just getting the mean and stdev for the total job time of the last _N_ commits isn't sufficient, because e.g. if `master` was broken 5 commits ago, then a lot of those job times will be much shorter, breaking the statistics.
- We use the commit history to make better estimates for the mean and stdev of individual test (and suite) times, but only when the test in that historical commit is present and its status matches that of the base commit.
- We list all the tests that were removed or added, or whose status changed (e.g. skipped to not skipped, or vice versa), along with time (estimate) info for that test case and its containing suite.
- We don't list tests whose time changed a lot if their status didn't change, because there's a lot of noise and it's unclear how to do that well without too many false positives.
- We show a human-readable commit graph that indicates exactly how many commits are in the pool of commits that could be causing regressions (e.g. if a PR has multiple commits in it, or if the base commit on `master` doesn't have a report in S3).
- We don't show an overall estimate of whether the PR increased or decreased the total test job time, because it's noisy and it's a bit tricky to aggregate stdevs up from individual tests to the whole job level. This might change in a followup PR.
- Instead, we simply show a summary at the bottom which says how many tests were removed/added/modified (where "modified" means that the status changed), and our best estimates of the mean times (and stdevs) of those changes.
- Importantly, the summary at the bottom is only for the test cases that were already shown in the more verbose diff report, and does not include any information about tests whose status didn't change but whose running time got much longer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50171
Test Plan:
To run the unit tests:
```
$ python test/test_testing.py
$ python test/print_test_stats.py
```
To verify that this works, check the [CircleCI logs](https://app.circleci.com/pipelines/github/pytorch/pytorch/258628/workflows/9cfadc34-e042-485e-b3b3-dc251f160307) for a test job run on this PR; for example:
- pytorch_linux_bionic_py3_6_clang9_test
To test locally, use the following steps.
First run an arbitrary test suite (you need to have some XML reports so that `test/print_test_stats.py` runs, but we'll be ignoring them here via the `--use-json` CLI option):
```
$ DATA_DIR=/tmp
$ ARBITRARY_TEST=testing
$ python test/test_$ARBITRARY_TEST.py --save-xml=$DATA_DIR/test/test_$ARBITRARY_TEST
```
Now choose a commit and a test job (it has to be on `master` since we're going to grab the test time data from S3, and [we only upload test times to S3 on the `master`, `nightly`, and `release` branches](https://github.com/pytorch/pytorch/pull/49645)):
```
$ export CIRCLE_SHA1=c39fb9771d89632c5c3a163d3c00af3bef1bd489
$ export CIRCLE_JOB=pytorch_linux_bionic_py3_6_clang9_test
```
Download the `*.json.bz2` file(s) for that commit/job pair:
```
$ aws s3 cp s3://ossci-metrics/test_time/$CIRCLE_SHA1/$CIRCLE_JOB/ $DATA_DIR/ossci-metrics/test_time/$CIRCLE_SHA1/$CIRCLE_JOB --recursive
```
And feed everything into `test/print_test_stats.py`:
```
$ bzip2 -kdc $DATA_DIR/ossci-metrics/test_time/$CIRCLE_SHA1/$CIRCLE_JOB/*Z.json.bz2 | torch/testing/_internal/print_test_stats.py --compare-with-s3 --use-json=/dev/stdin $DATA_DIR/test/test_$ARBITRARY_TEST
```
The first part of the output should be the same as before this PR; here is the new part, at the end of the output:
- https://pastebin.com/Jj1svhAn
Reviewed By: malfet, izdeby
Differential Revision: D26317769
Pulled By: samestep
fbshipit-source-id: 1ba06cec0fafac77f9e7341d57079543052d73db
Summary:
Currently PyTorch repository provides Dockerfile to build Docker with nightly builds, but it doesn't have CI to actually build those Dockers.
This PR adds a GitHub action workflow to create PyTorch nightly build Docker and publish them to GitHub Container Registry.
Also, add "--always" option to the `git describe --tags` command that generates the Docker image tag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51755
Test Plan: Manually trigger the workflow build in the GitHub Actions web UI.
Reviewed By: seemethere
Differential Revision: D26320180
Pulled By: xuzhao9
fbshipit-source-id: e00b472df14f5913cab9b06a41e837014e87f1c7
Summary:
Fixes https://github.com/pytorch/pytorch/issues/39502
This PR adds support for exporting **fake_quantize_per_channel_affine** to a pair of QuantizeLinear and DequantizeLinear. Per tensor support was added by PR https://github.com/pytorch/pytorch/pull/39738.
`axis` attribute of QuantizeLinear and DequantizeLinear, which is required for per channel support, is added in opset13 added by https://github.com/onnx/onnx/pull/2772.
[update 1/20/2021]: opset13 is being supported on master, the added function is now properly tested. Code also rebased to new master.
The function is also tested offline with the following code
```python
import torch
from torch import quantization
from torchvision import models
qat_resnet18 = models.resnet18(pretrained=True).eval().cuda()
qat_resnet18.qconfig = quantization.QConfig(
activation=quantization.default_fake_quant, weight=quantization.default_per_channel_weight_fake_quant)
quantization.prepare_qat(qat_resnet18, inplace=True)
qat_resnet18.apply(quantization.enable_observer)
qat_resnet18.apply(quantization.enable_fake_quant)
dummy_input = torch.randn(16, 3, 224, 224).cuda()
_ = qat_resnet18(dummy_input)
for module in qat_resnet18.modules():
if isinstance(module, quantization.FakeQuantize):
module.calculate_qparams()
qat_resnet18.apply(quantization.disable_observer)
qat_resnet18.cuda()
input_names = [ "actual_input_1" ]
output_names = [ "output1" ]
torch.onnx.export(qat_resnet18, dummy_input, "quant_model.onnx", verbose=True, opset_version=13)
```
It can generate the desired graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42835
Reviewed By: houseroad
Differential Revision: D26293823
Pulled By: SplitInfinity
fbshipit-source-id: 300498a2e24b7731b12fa2fbdea4e73dde80e7ea
Summary:
For none support input, we should not do check in a parallel region, this PR will first do the dtype check, and then do parallel for.
Fixes https://github.com/pytorch/pytorch/issues/51352.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51443
Reviewed By: izdeby
Differential Revision: D26305584
Pulled By: ngimel
fbshipit-source-id: 6faa3148af5bdcd7246771c0ecb4db2b31ac82c6
Summary:
Previously TorchScript allows a ignore-all type check suppression rule that looks like
```
code code code # type: ignore
```
But a more common use case is
```
code code code # type: ignore[specific-rule]
```
This PR allows the more common use case
Fixes https://github.com/pytorch/pytorch/issues/48643
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51675
Reviewed By: ansley
Differential Revision: D26304870
Pulled By: gmagogsfm
fbshipit-source-id: 0ac9ee34f0219c86e428318a69484d5aa3ec433f
Summary:
With zasdfgbnm's help and with his small TensorIterator kernel repro https://github.com/zasdfgbnm/tensoriterator we've found a workaround for what looks like a compiler bug in multi_output_kernel that manifests itself with cuda 10.2 and cuda 11 when there is a non-trivial OffsetCalculator.
It looks like those nvcc versions cannot handle inheritance in device structs, so instead of inheriting `multi_outputs_unroll` from `unroll` we make it independent.
cc vkuzo, haichuan-fb I verified that reverting https://github.com/pytorch/pytorch/issues/49315 to bring back multi_output_kernel and running `test_learnable_backward_per_channel_cuda` test passes, but I didn't do it in this PR - can you take it up as a follow-up?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51827
Reviewed By: izdeby
Differential Revision: D26305559
Pulled By: ngimel
fbshipit-source-id: 1168e7c894d237a954abfd1998eaad54f0ce40a7
Summary:
The overloads are a little tricky here. It's important that the overloads are such that it's unambiguous what
`torch.nonzero(x)` will resolve to - so just specify defaults for one of the overloads. Also, `out` is left out of the second overload
because a non-None value for `out` is not valid in combination with `as_tuple=True`.
Closes gh-51434
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51635
Reviewed By: zhangguanheng66
Differential Revision: D26279203
Pulled By: walterddr
fbshipit-source-id: 8459c04fc9fbf7fc5f31b3f631aaac2f98b17ea6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51589
Dropout operators are only needed in training. Remove them for frozen models.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D26214259
fbshipit-source-id: 3ab05869e1e1f6c57498ba62bf40944f7c2189aa
Summary:
Toward fixing https://github.com/pytorch/pytorch/issues/47624
~Step 1: add `TORCH_WARN_MAYBE` which can either warn once or every time in c++, and add a c++ function to toggle the value.
Step 2 will be to expose this to python for tests. Should I continue in this PR or should we take a different approach: add the python level exposure without changing any c++ code and then over a series of PRs change each call site to use the new macro and change the tests to make sure it is being checked?~
Step 1: add a python and c++ toggle to convert TORCH_WARN_ONCE into TORCH_WARN so the warnings can be caught in tests
Step 2: add a python-level decorator to use this toggle in tests
Step 3: (in future PRs): use the decorator to catch the warnings instead of `maybeWarnsRegex`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48560
Reviewed By: ngimel
Differential Revision: D26171175
Pulled By: mruberry
fbshipit-source-id: d83c18f131d282474a24c50f70a6eee82687158f
Summary:
This is a followup to https://github.com/pytorch/pytorch/issues/49190. Vaguely speaking, the goals are to make it easy to identify test time regressions introduced by PRs. Eventually the hope is to use this information to edit Dr CI comments, but this particular PR just does the analysis and prints it to stdout, so a followup PR would be needed to edit the actual comments on GitHub.
**Important:** for uninteresting reasons, this PR moves the `print_test_stats.py` file.
- *Before:* `test/print_test_stats.py`
- *After:* `torch/testing/_internal/print_test_stats.py`
Notes on the approach:
- Just getting the mean and stdev for the total job time of the last _N_ commits isn't sufficient, because e.g. if `master` was broken 5 commits ago, then a lot of those job times will be much shorter, breaking the statistics.
- We use the commit history to make better estimates for the mean and stdev of individual test (and suite) times, but only when the test in that historical commit is present and its status matches that of the base commit.
- We list all the tests that were removed or added, or whose status changed (e.g. skipped to not skipped, or vice versa), along with time (estimate) info for that test case and its containing suite.
- We don't list tests whose time changed a lot if their status didn't change, because there's a lot of noise and it's unclear how to do that well without too many false positives.
- We show a human-readable commit graph that indicates exactly how many commits are in the pool of commits that could be causing regressions (e.g. if a PR has multiple commits in it, or if the base commit on `master` doesn't have a report in S3).
- We don't show an overall estimate of whether the PR increased or decreased the total test job time, because it's noisy and it's a bit tricky to aggregate stdevs up from individual tests to the whole job level. This might change in a followup PR.
- Instead, we simply show a summary at the bottom which says how many tests were removed/added/modified (where "modified" means that the status changed), and our best estimates of the mean times (and stdevs) of those changes.
- Importantly, the summary at the bottom is only for the test cases that were already shown in the more verbose diff report, and does not include any information about tests whose status didn't change but whose running time got much longer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50171
Test Plan:
To run the unit tests:
```
$ python test/test_testing.py
$ python test/print_test_stats.py
```
To verify that this works, check the [CircleCI logs](https://app.circleci.com/pipelines/github/pytorch/pytorch/258628/workflows/9cfadc34-e042-485e-b3b3-dc251f160307) for a test job run on this PR; for example:
- pytorch_linux_bionic_py3_6_clang9_test
To test locally, use the following steps.
First run an arbitrary test suite (you need to have some XML reports so that `test/print_test_stats.py` runs, but we'll be ignoring them here via the `--use-json` CLI option):
```
$ DATA_DIR=/tmp
$ ARBITRARY_TEST=testing
$ python test/test_$ARBITRARY_TEST.py --save-xml=$DATA_DIR/test/test_$ARBITRARY_TEST
```
Now choose a commit and a test job (it has to be on `master` since we're going to grab the test time data from S3, and [we only upload test times to S3 on the `master`, `nightly`, and `release` branches](https://github.com/pytorch/pytorch/pull/49645)):
```
$ export CIRCLE_SHA1=c39fb9771d89632c5c3a163d3c00af3bef1bd489
$ export CIRCLE_JOB=pytorch_linux_bionic_py3_6_clang9_test
```
Download the `*.json.bz2` file(s) for that commit/job pair:
```
$ aws s3 cp s3://ossci-metrics/test_time/$CIRCLE_SHA1/$CIRCLE_JOB/ $DATA_DIR/ossci-metrics/test_time/$CIRCLE_SHA1/$CIRCLE_JOB --recursive
```
And feed everything into `test/print_test_stats.py`:
```
$ bzip2 -kdc $DATA_DIR/ossci-metrics/test_time/$CIRCLE_SHA1/$CIRCLE_JOB/*Z.json.bz2 | torch/testing/_internal/print_test_stats.py --compare-with-s3 --use-json=/dev/stdin $DATA_DIR/test/test_$ARBITRARY_TEST
```
The first part of the output should be the same as before this PR; here is the new part, at the end of the output:
- https://pastebin.com/Jj1svhAn
Reviewed By: walterddr
Differential Revision: D26232345
Pulled By: samestep
fbshipit-source-id: b687b1737519d2eed68fbd591a667e4e029de509
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49683
This PR solves Backward through sparse_coo_tensor bug by implementing a `sparse_mask_helper` function for n-dimensional sparse tensor for CPU and CUDA which is used to reimplement `sparse_constructor_values_backward` function.
This `sparse_mask` function was implemented before for backward sparse-sparse matmul. However, the algorithm is little different because in this case it should be applyable not only for matrices but for n-dimensional tensors. Thankfully it was not quite hard to extend and now both share the same code base.
Note that no new tests are required because now the backward for sparse-sparse matmul now uses the new `sparse_mask_helper`.
ngimel, mruberry - kindly review this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50361
Reviewed By: zhangguanheng66
Differential Revision: D26270483
Pulled By: ngimel
fbshipit-source-id: ee4bda49ff86e769342674b64d3c4bc34eae38ef
Summary: As titleed
Test Plan: successful test flow with A* setup: f245569242
Reviewed By: anurag16
Differential Revision: D25966283
fbshipit-source-id: ef9945d5039933df44c2c3c26ca149f47538ff31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51757
Enables backend preprocessing to take place outside of the backend interface.
What's new:
* A new definition for backend preprocessing (i.e. BackendPreprocessFunction).
* Registration of the backend's PyTorchBackendInterface interface implementation is augmented to take the BackendPreprocessFunction.
* A new registry is created to handle the BackendPreprocessFunction functions, using the backend's name as key.
* When a BackendPreprocessFunction is used, the PyTorchBackendInterface's "preprocess" method is not added to the LoweredModule. Instead, the BackendPreprocessFunction is called and its output used to set the LoweredModule's __processed_module.
Why?:
These changes are needed to avoid forcing backend preprocessing to be part of the LoweredModule, and in the future be able to eliminate "preprocess" from the PyTorchBackendInterface.
This is important for Mobile use cases where "preprocess" can take the bulk of the compilation process, and thus contain code dependencies that we do not want to bring (or cannot bring) to the Mobile binary.
What didn't change:
* Everything is backwards compatible:
** The existing "preprocess" method in PyTorchBackendInterface is still there.
** When backend registration is done without the BackendPreprocessFunction, as before, things work the same way: "preprocess" is added to LoweredModule, and invoked through the module's instance of the backend interface.
Longer term, the plan is to refactor existing users to move to the new backend registration.
ghstack-source-id: 121190883
Test Plan:
Updated existing tests (test_backend.py) to use the new registration mechanism.
Verified test ran and passed (in my OSS build).
Reviewed By: iseeyuan
Differential Revision: D26261042
fbshipit-source-id: 0dc378acd5f2ab60fcdc01f7373616d1db961e61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51119
Adds asm kernel for 8x1 block sparse kernel. Since ukernels is still
producing 4x8 blocks, similar to 1x4 sparsity pattern, we can use the
same prepacking kernel for activation. It does get a tiny bit hacky but
allows us to reuse the kernel.
Test Plan:
q8gemm-sparse-test
fully-connectest-sparse-test
Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D26077765
fbshipit-source-id: cc087b0ff717a613906d442ea73680e785e0ecc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51118
sparsity
Modify BCSR to pack generic block sparsity pattern.
Modify rest of the code to accommodate the change.
This is in preperation to support 8x1 sparsity.
Test Plan:
q8gemm-sparse-test
Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D26077767
fbshipit-source-id: 7179975b07a1cb76ef26896701d782fb04638743
(! git grep -I -l $'\t' -- . ':(exclude)*.svg' ':(exclude)**Makefile' ':(exclude)**/contrib/**' ':(exclude)third_party' ':(exclude).gitattributes' ':(exclude).gitmodules' || (echo "The above files have tabs; please convert them to spaces"; false))
(! git --no-pager grep -In $'\t' -- . ':(exclude)*.svg' ':(exclude)**Makefile' ':(exclude)**/contrib/**' ':(exclude)third_party' ':(exclude).gitattributes' ':(exclude).gitmodules' || (echo "The above lines have tabs; please convert them to spaces"; false))
- name:Ensure no non-breaking spaces
if:always()
run:|
# NB: We use 'printf' below rather than '\u000a' since bash pre-4.2
# does not support the '\u000a' syntax (which is relevant for local linters)
(! git --no-pager grep -In "$(printf '\xC2\xA0')" -- . || (echo "The above lines have non-breaking spaces (U+00A0); please convert them to spaces (U+0020)"; false))
- name:Ensure canonical include
- name:Ensure canonical include
if:always()
run:|
run:|
(! git grep -I -l $'#include "' -- ./c10 ./aten ./torch/csrc ':(exclude)aten/src/ATen/native/quantized/cpu/qnnpack/**' || (echo "The above files have include with quotes; please convert them to #include <xxxx>"; false))
(! git --no-pager grep -In $'#include "' -- ./c10 ./aten ./torch/csrc ':(exclude)aten/src/ATen/native/quantized/cpu/qnnpack/**' || (echo "The above lines have include with quotes; please convert them to #include <xxxx>"; false))
# note that this next step depends on a clean heckout;
- name:Ensure no versionless Python shebangs
if:always()
run:|
(! git --no-pager grep -In '#!.*python$' -- . || (echo "The above lines have versionless Python shebangs; please specify either python2 or python3"; false))
- name:Ensure no unqualified noqa
if:always()
run:|
# shellcheck disable=SC2016
(! git --no-pager grep -InP '# noqa(?!: [A-Z]+\d{3})' -- '**.py' '**.pyi' ':(exclude)caffe2' || (echo 'The above lines have unqualified `noqa`; please convert them to `noqa: XXXX`'; false))
- name:Ensure no unqualified type ignore
if:always()
run:|
# shellcheck disable=SC2016
(! git --no-pager grep -InP '# type:\s*ignore(?!\[)' -- '**.py' '**.pyi' ':(exclude)test/test_jit.py' || (echo 'The above lines have unqualified `type: ignore`; please convert them to `type: ignore[xxxx]`'; false))
# note that this next step depends on a clean checkout;
# if you run it locally then it will likely to complain
# if you run it locally then it will likely to complain
# about all the generated files in torch/test
# about all the generated files in torch/test
- name:Ensure C++ source files are not executable
- name:Ensure C++ source files are not executable
if:always()
run:|
run:|
# shellcheck disable=SC2016
(! find . \( -path ./third_party -o -path ./.git -o -path ./torch/bin -o -path ./build \) -prune -o -type f -executable -regextype posix-egrep -not -regex '.+(\.(bash|sh|py|so)|git-pre-commit|git-clang-format|gradlew)$' -print | grep . || (echo 'The above files have executable permission; please remove their executable permission by using `chmod -x`'; false))
(! find . \( -path ./third_party -o -path ./.git -o -path ./torch/bin -o -path ./build \) -prune -o -type f -executable -regextype posix-egrep -not -regex '.+(\.(bash|sh|py|so)|git-pre-commit|git-clang-format|gradlew)$' -print | grep . || (echo 'The above files have executable permission; please remove their executable permission by using `chmod -x`'; false))
python torch/testing/check_kernel_launches.py |& tee ${GITHUB_WORKSPACE}/cuda_kernel_launch_checks.txt
python torch/testing/check_kernel_launches.py |& tee "${GITHUB_WORKSPACE}"/cuda_kernel_launch_checks.txt
- name:Ensure no direct cub include
if:always()
run:|
(! git --no-pager grep -I -no $'#include <cub/' -- ./aten ':(exclude)aten/src/ATen/cuda/cub.cuh' || (echo "The above files have direct cub include; please include ATen/cuda/cub.cuh instead and wrap your cub calls in at::native namespace if necessary"; false))
py2-setup-validate-errormsg:
runs-on:ubuntu-18.04
steps:
- name:Setup Python
uses:actions/setup-python@v2
with:
python-version:2.x
architecture:x64
- name:Checkout PyTorch
uses:actions/checkout@v2
- name:Attempt to run setup.py
run:|
python2 setup.py | grep "Python 2 has reached end-of-life and is no longer supported by PyTorch."
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
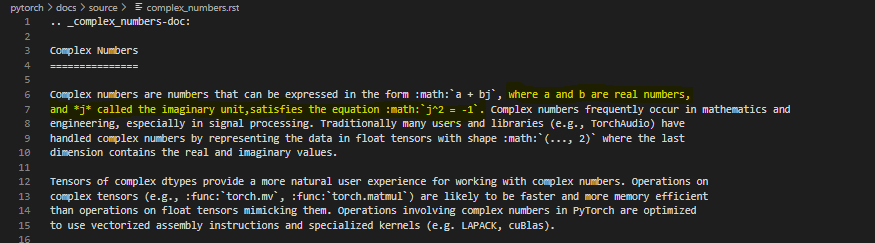{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}