Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53929
The local autograd engine performs appropriate stream synchronization
between autograd nodes in the graph to ensure a consumer's stream is
synchronized with the producer's stream before executing the consumer.
However in case of distributed autograd, the SendRpcBackward function receives
gradients over the wire and TensorPipe uses its own pool of streams for this
purpose. As a result, the tensors are received on TensorPipe's stream pool but
SendRpcBackward runs on a different stream during the backward pass and there
is no logic to synchronize these streams.
To fix this, I've enhanced DistEngine to synchronize these streams
appropriately when it receives grads over the wire.
ghstack-source-id: 124055277
(Note: this ignores all push blocking failures!)
Test Plan:
1) Added unit test which reproduced the issue.
2) waitforbuildbot.
Reviewed By: walterddr, wanchaol
Differential Revision: D27025307
fbshipit-source-id: 2944854e688e001cb3989d2741727b30d9278414
Co-authored-by: Pritam Damania <pritam.damania@fb.com>
Some users who are building from source on old glibc versions are hitting the issue of TensorPipe using the process_vm_readv syscall which is not wrapped by glibc. This PR tries to check that condition in CMake and disable that backend in such cases.
This should have no effect on PyTorch's official builds, it should just help people who are building from source.
Summary:
Benchmark of
```python
%timeit torch.randperm(100000, device='cuda'); torch.cuda.synchronize()
```
thrust:
```
5.76 ms ± 42.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
cub:
```
3.02 ms ± 32.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
sync in thrust sort is removed
Warning:
Thrust supports 64bit indexing, but cub doesn't, so this is a functional regression. However, `torch.randperm(2**31, device='cuda')` fails with OOM on 40GB A100, and `torch.randperm(2**32, device='cuda')` fails with OOM on 80GB A100, so I think this functional regression has low impact and is acceptable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53841
Reviewed By: albanD
Differential Revision: D26993453
Pulled By: ngimel
fbshipit-source-id: 39dd128559d53dbb01cab1585e5462cb5f3cceca
Co-authored-by: Xiang Gao <qasdfgtyuiop@gmail.com>
Summary:
When compiled with OpenMP support `ideep`'s computational_cache would cache max number of OpenMP workers
This number could be wrong after `torch.set_num_threads` call, so clean it after the call.
Fixes https://github.com/pytorch/pytorch/issues/53565
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53871
Reviewed By: albanD
Differential Revision: D27003265
Pulled By: malfet
fbshipit-source-id: 1d84c23070eafb3d444e09590d64f97f99ae9d36
Summary:
Since `char` is not guaranteed to be signed on all platforms (it is unsigned on ARM)
Fixes https://github.com/pytorch/pytorch/issues/52146
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52616
Test Plan: Run ` python3 -c "import torch;a=torch.tensor([-1], dtype=torch.int8);print(a.tolist())"` on arm-linux system
Reviewed By: walterddr
Differential Revision: D26586678
Pulled By: malfet
fbshipit-source-id: 91972189b54f86add516ffb96d579acb0bc13311
* Disabling dispatch to OneDNN for group convolutions when groups size is 24 * n
* Add condition to non-zero grps
Co-authored-by: Vitaly Fedyunin <vitaly.fedyunin@gmail.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53529
Supported for ONNX export after opset 10.
This is not exportable to opsets < 10 due to
1. onnx::IsInf is introduced in opset 10
2. onnx::Equal does not accept float tensor prior to opset 11
Test Plan: Imported from OSS
Reviewed By: pbelevich, malfet
Differential Revision: D26922418
Pulled By: SplitInfinity
fbshipit-source-id: 69bcba50520fa3d69db4bd4c2b9f88c00146fca7
Co-authored-by: BowenBao <bowbao@microsoft.com>
- Support transferring >2GB over CMA
- Avoid loading stub version of CUDA driver
- Don't use unsupported mmap option on older kernels
- Don't join non-existing thread if CMA is not viable
The last two manifested as uncaught exceptions (hence crashes) when initializing RPC. The first one caused same-machine RPC requests to fail.
* Add sample validation for LKJCholesky.log_prob
* Fix distributions which don't properly honor validate_args=False
A number of derived distributions use base distributions in their
implementation.
We add what we hope is a comprehensive test whether all distributions
actually honor skipping validation of arguments in log_prob and then
fix the bugs we found. These bugs are particularly cumbersome in
PyTorch 1.8 and master when validate_args is turned on by default
In addition one might argue that validate_args is not performing
as well as it should when the default is not to validate but the
validation is turned on in instantiation.
Arguably, there is another set of bugs or at least inconsistencies
when validation of inputs does not prevent invalid indices in
sample validation (when with validation an IndexError is raised
in the test). We would encourage the implementors to be more
ambitious when validation is turned on and amend sample validation
to throw a ValueError for consistency.
* additional fixes to distributions
* address failing tests
Co-authored-by: neerajprad <neerajprad@devvm903.atn0.facebook.com>
Co-authored-by: Thomas Viehmann <tv.code@beamnet.de>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53133
In light of some issues where users were having trouble installing CUDA
specific versions of pytorch we should no longer have special privileges
for CUDA 10.2.
Recently I added scripts/release/promote/prep_binary_for_pypi.sh (https://github.com/pytorch/pytorch/pull/53056) to make
it so that we could theoretically promote any wheel we publish to
download.pytorch.org to pypi
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D26759823
Pulled By: seemethere
fbshipit-source-id: 2d2b29e7fef0f48c23f3c853bdca6144b7c61f22
(cherry picked from commit b8546bde09c7c00581fe4ceb061e5942c7b78b20)
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Summary:
The Flake8 job has been passing on `master` despite giving warnings for [over a month](https://github.com/pytorch/pytorch/runs/1716124347). This is because it has been using a regex that doesn't recognize error codes starting with multiple letters, such as those used by [flake8-executable](https://pypi.org/project/flake8-executable/). This PR corrects the regex, and also adds another step at the end of the job which asserts that Flake8 actually gave no error output, in case similar regex issues appear in the future.
Tagging the following people to ask what to do to fix these `EXE002` warnings:
- https://github.com/pytorch/pytorch/issues/50629 authored by jaglinux, approved by rohan-varma
- `test/distributed/test_c10d.py`
- https://github.com/pytorch/pytorch/issues/51262 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/__init__.py`
- `torch/utils/data/datapipes/iter/loadfilesfromdisk.py`
- `torch/utils/data/datapipes/iter/listdirfiles.py`
- `torch/utils/data/datapipes/iter/__init__.py`
- `torch/utils/data/datapipes/utils/__init__.py`
- `torch/utils/data/datapipes/utils/common.py`
- https://github.com/pytorch/pytorch/issues/51398 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/readfilesfromtar.py`
- https://github.com/pytorch/pytorch/issues/51599 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/readfilesfromzip.py`
- https://github.com/pytorch/pytorch/issues/51704 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/routeddecoder.py`
- `torch/utils/data/datapipes/utils/decoder.py`
- https://github.com/pytorch/pytorch/issues/51709 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/groupbykey.py`
Specifically, the question is: for each of those files, should we remove the execute permissions, or should we add a shebang? And if the latter, which shebang?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52750
Test Plan:
The **Lint / flake8-py3** job in GitHub Actions:
- [this run](https://github.com/pytorch/pytorch/runs/1972039886) failed, showing that the new regex catches these warnings properly
- [this run](https://github.com/pytorch/pytorch/runs/1972393293) succeeded and gave no output in the "Run flake8" step, showing that this PR fixed all Flake8 warnings
- [this run](https://github.com/pytorch/pytorch/pull/52755/checks?check_run_id=1972414849) (in https://github.com/pytorch/pytorch/issues/52755) failed, showing that the new last step of the job successfully catches Flake8 warnings even without the regex fix
Reviewed By: walterddr, janeyx99
Differential Revision: D26637307
Pulled By: samestep
fbshipit-source-id: 572af6a3bbe57f5e9bd47f19f37c39db90f7b804
Co-authored-by: Sam Estep <sestep@fb.com>
The bug affects PyTorch users who meet two conditions:
- they have an old version of libibverbs installed (the userspace library), namely older than v25, which dates from Jul 29, 2019;
- but they do _not_ have an InfiniBand kernel module loaded.
In those cases they will experience a crash (uncaught exception) happening when initializing RPC, mentioning an "unknown error -38".
There is a workaround, which is for those users to activate a killswitch (which is private and undocumented) to disable the `ibv` backend of TensorPipe.
Summary:
This is getting tested by https://github.com/pytorch/pytorch/issues/52441.
Adds new config for macos arm64 to our binary builds.
Now stores artifacts for mac builds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52443
Reviewed By: walterddr
Differential Revision: D26517330
Pulled By: janeyx99
fbshipit-source-id: 02774937a827bdd4c08486dc9f8fe63446917f1e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/39502
This PR adds support for exporting **fake_quantize_per_channel_affine** to a pair of QuantizeLinear and DequantizeLinear. Per tensor support was added by PR https://github.com/pytorch/pytorch/pull/39738.
`axis` attribute of QuantizeLinear and DequantizeLinear, which is required for per channel support, is added in opset13 added by https://github.com/onnx/onnx/pull/2772.
[update 1/20/2021]: opset13 is being supported on master, the added function is now properly tested. Code also rebased to new master.
The function is also tested offline with the following code
```python
import torch
from torch import quantization
from torchvision import models
qat_resnet18 = models.resnet18(pretrained=True).eval().cuda()
qat_resnet18.qconfig = quantization.QConfig(
activation=quantization.default_fake_quant, weight=quantization.default_per_channel_weight_fake_quant)
quantization.prepare_qat(qat_resnet18, inplace=True)
qat_resnet18.apply(quantization.enable_observer)
qat_resnet18.apply(quantization.enable_fake_quant)
dummy_input = torch.randn(16, 3, 224, 224).cuda()
_ = qat_resnet18(dummy_input)
for module in qat_resnet18.modules():
if isinstance(module, quantization.FakeQuantize):
module.calculate_qparams()
qat_resnet18.apply(quantization.disable_observer)
qat_resnet18.cuda()
input_names = [ "actual_input_1" ]
output_names = [ "output1" ]
torch.onnx.export(qat_resnet18, dummy_input, "quant_model.onnx", verbose=True, opset_version=13)
```
It can generate the desired graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42835
Reviewed By: houseroad
Differential Revision: D26293823
Pulled By: SplitInfinity
fbshipit-source-id: 300498a2e24b7731b12fa2fbdea4e73dde80e7ea
Co-authored-by: Hao Wu <skyw@users.noreply.github.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52151
CUDA 11.2 might not be as performant as we thought so let's downgrade to
something we think is more performant.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D26408314
Pulled By: seemethere
fbshipit-source-id: e2446aa0115e2c2a79718b1fdfd9fccf2072822d
(cherry picked from commit a11650b069729997b002032d70e9793477147851)
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Summary:
Necessary to ensure correct link order, especially if libraries are
linked statically. Otherwise, one might run into:
```
/usr/bin/ld: /usr/local/cuda/lib64/libcublasLt_static.a(libcublasLt_static.a.o): undefined reference to symbol 'cudaStreamWaitEvent@libcudart.so.11.0'
/usr/local/cuda/lib64/libcudart.so: error adding symbols: DSO missing from command line
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52243
Reviewed By: seemethere, ngimel
Differential Revision: D26437159
Pulled By: malfet
fbshipit-source-id: 33b8bb5040bda10537833f3ad737f535488452ea
torch.vmap is a prototype feature and should not be in the stable
binary. This PR:
- Removes the `torch.vmap` API
- Removes the documentation entry for torch.vmap
- Changes the vmap tests to use an internal API instead of torch.vmap.
Test Plan:
- Tested locally (test_torch, test_autograd, test_type_hints, test_vmap), but also wait
for CI.
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50180
Resolves the regression in
https://github.com/pytorch/pytorch/issues/49819 by adding copy over background
stream similar to scatter. For internal use cases, this is gated with an env var that maintains the previous behavior when it is off.
Test Plan: CI
Reviewed By: mrshenli, ngimel
Differential Revision: D25818170
fbshipit-source-id: e50c76c035504b2a44e2be084701cee45c90df75
Summary:
It frequently happens when PyTorch compiled with CUDA support is installed on machine that does not have NVIDIA GPUs.
Fixes https://github.com/pytorch/pytorch/issues/47038
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51806
Reviewed By: ezyang
Differential Revision: D26285827
Pulled By: malfet
fbshipit-source-id: 9fd5e690d0135a2b219c1afa803fb69de9729f5e
Summary:
Move definition of copysign template and specialization for
bfloat16/half types before first use of copysign in that file
Add comment explaining why this is necessary
Fixes https://github.com/pytorch/pytorch/issues/51889
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51900
Reviewed By: walterddr
Differential Revision: D26321741
Pulled By: malfet
fbshipit-source-id: 888858b11d9708fa140fe9c0570cc5a24599205b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51878
`fake_quantize_per_tensor_affine_cachemask` and
`fake_quantize_per_channel_affine_cachemask` are implementation
details of `fake_quantize_per_tensor_affine` and
`fake_quantize_per_channel_affine`, removing the
Python bindings for them since there is no need to
expose them.
Test Plan:
```
python test/test_quantization.py TestFakeQuantize
```
Imported from OSS
Reviewed By: albanD, bugra
Differential Revision: D26314173
fbshipit-source-id: 733c93a3951453e739b6ed46b72fbad2244f6e97
(cherry picked from commit 33afb5f19f4e427f099653139ae45b661b8bc596)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51748
Adding docs for `fake_quantize_per_tensor_affine` and `fake_quantize_per_channel_affine`
functions.
Note: not documenting `fake_quantize_per_tensor_affine_cachemask` and
`fake_quantize_per_channel_affine_cachemask` since they are implementation details
of `fake_quantize_per_tensor_affine` and `fake_quantize_per_channel_affine`,
and do not need to be exposed to the user at the moment.
Test Plan: Build the docs locally on Mac OS, it looks good
Reviewed By: supriyar
Differential Revision: D26270514
Pulled By: vkuzo
fbshipit-source-id: 8e3c9815a12a3427572cb4d34a779e9f5e4facdd
Summary:
Replacing 11.0 with 11.2 in our nightlies.
(am slightly uncertain why the manywheel linux tests worked before we added the GPU driver for 11.2)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51611
Reviewed By: malfet, seemethere, zhangguanheng66
Differential Revision: D26282829
Pulled By: janeyx99
fbshipit-source-id: b15380e5c44a957e6a85e4f5fb9691ab9c6103a5
Summary:
The new profiler API was added in PR#48280. This PR is to add FLOPS
support to the new profiler API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51734
Test Plan:
```python
python test/test_profiler.py -k test_flops
```
Reviewed By: xuzhao9
Differential Revision: D26261851
Pulled By: ilia-cher
fbshipit-source-id: dbeba4c197e6f51a9a8e640e8bb60ec38df87f73
Summary: Moving caffe2_core_gpu_python contbuild to use GPU/RE
Test Plan: CI
Reviewed By: malfet
Differential Revision: D26261826
fbshipit-source-id: a6f8c7bd8368c1cb69499ea0ea7d5add0956a7ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50924
`clamp_min` seems slightly faster than `threshold` (on avx2 cpus)
because it compiles down to vmaxps, rather than vcmpps+vblendv.
I see the biggest perf difference (about 20% faster) with float
tensors at 32k-64k elements. Bigger tensors are more memory bound
although it looks like it might still be a tiny win (2%).
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D26009829
Pulled By: bertmaher
fbshipit-source-id: 7bb1583ffb3ee242e347f59be82e0712c7631f7e
Summary:
Add hardswish_ and hardsigmoid_ activations to enable MobileNetV3.
Also fix binary elementwise ops to work when the first input is being broadcasted rather than the second.
Test Plan:
Test on device:
```
arc focus2 pp-ios
```
Test on mac
```
buck test pp-macos
```
Reviewed By: xta0
Differential Revision: D26241385
fbshipit-source-id: 6ce7269d60d63cf909b75a7f4e18fb17ac2f5d31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51759
Some unit tests actually register a comm hook on other backends like GLOO. Example: `test_ddp_comm_hook_future_passing_cpu`
Therefore, only do the check on `register_builtin_comm_hook`.
Currently DDP communication hook can only be supported on NCCL. Add a check in the registration methods.
ghstack-source-id: 121115814
Test Plan: unit tests.
Reviewed By: pritamdamania87
Differential Revision: D26268581
fbshipit-source-id: c739fa4dca6d320202dc6689d790c2761c834c30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50590
Larger blocking across M dim such as 8 in previous PR is likely
introducing wasted compute on the shapes being benchmarked.
Here we introduced 4x8 blocking of mrxnr. This helps 1) in packing
smaller data for small values of M and 2) for compute kernel it writes
same number of bytes but more contiguously. It is not certain but it
likely helps.
Test Plan:
q8gemm-sparse-test
fully-connected-sparse-test
Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D25925499
fbshipit-source-id: 01c661ceea38bd6ee8321bb85cf1d5da5de4e984
Summary:
Usage explanation will be in the release note runbook.
This allows to generate diffs like:
```
Processing torch.nn
Things that were added:
{'quantizable', 'ChannelShuffle', 'LazyConvTranspose2d', 'LazyConv2d', 'LazyConvTranspose3d', 'LazyConv1d', 'GaussianNLLLoss', 'LazyConv3d', 'PixelUnshuffle', 'UninitializedParameter', 'LazyLinear', 'LazyConvTranspose1d'}
Things that were removed:
set()
```
This can then be shared with module owners along with the commits to help them validate that the namespace changes for their submodule is as expected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51685
Reviewed By: zhangguanheng66
Differential Revision: D26260258
Pulled By: albanD
fbshipit-source-id: 40e40f86314e17246899d01ffa4b2631e93b52f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51683
**Summary**
This commit enables implicit boolean conversion of lists, strings, and
dictionaries in conditional expressions. Like Python, empty lists,
strings and dictionaries evaluate to `False` and their non-empty
counterparts evaluate to `True`. This allows users to write code like
```
torch.jit.script
def fn(l: List[int]):
if l:
...
else:
...
```
This has been requested by some users and would be a good usability
improvement.
**Test Plan**
This commit adds unit tests to `TestList`, `TestDict` and
`test_jit_string.py` to test this new feature.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26264410
Pulled By: SplitInfinity
fbshipit-source-id: b764c18fd766cfc128ea98a02b7c6c3fa49f8632
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50983
There is currently no way to handle/propagate errors with the python-based futures API (they are raised correctly if set with an error, but this is only possible from C++).
This diff allows the Future's `unwrap_func` to be set in python optionally, so users can set futures completed with an exception and the error will throw as expected. This is mostly to support the following use case in the next diff:
```
ret_fut = torch.futures.Future(unwrap_func = lambda python_result: {
# throw exception if needed
if isinstance(python_result, Exception):
throw python_result
})
rpc_fut = rpc.rpc_async(...) # RPC future that times out
# Goal is to propagate RPC error to this future
rpc_fut.add_done_callback(
res => {
# Note that ret_fut.set_result(res.wait()) won't propagate the error
try:
ret_fut.set_result(res.wait())
except Exception as e:
ret_fut.set_result(e)
}
)
```
ghstack-source-id: 121021434
Test Plan:
unittest
```
buck test mode/dev-nosan mode/no-gpu //caffe2/test:futures -- te
st_unwrap --print-passing-details
```
Reviewed By: mrshenli
Differential Revision: D25950304
fbshipit-source-id: 7ee61e98fcd783b3f515706fa141d538e6d2174d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50979
Noticed that the documentation is inconsisntent about the arg needed
in the callback. It appears to require the future, so fix this in the docs.
ghstack-source-id: 121021431
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D25944637
fbshipit-source-id: 0bfcd4040c4a1c245314186d29a0031e634b29c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50978
Noticed that the documentation is not clear that the cbs are invoked
inline if the future is already completed. We should probably document this
behavior.
ghstack-source-id: 121021432
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D25944636
fbshipit-source-id: f4ac133d076ba9a5690fecfa56bde6d614a40191
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50977
Adds a `blocking` flag that can be set to False to make this API return a `Future` to the type. This is to make this function non-blocking, mostly for a future change that will allow `rref.rpc_async()` to be completely non-blocking (it currently calls and waits for this function that issues an RPC in-line).
ghstack-source-id: 121021433
Test Plan: Modified UT
Reviewed By: mrshenli
Differential Revision: D25944582
fbshipit-source-id: e3b48a52af2d4578551a30ba6838927b489b1c03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50589
Adds 1. Input prepacking kernel 2. Compute kernels that processes
prepacked activation.
Hunch is that input prepacking will help with 1. Cache locality and 2.
Avoid a lot of address compute instructions.
Cache locality helps mainly comes from the fact that we are doing mr=8
and nr=4.
mr being 8 likely results in cache line evictions as likely cache
associativity is 4. Laying out transposed activations which are blocked
by mr=8 will lay all the transposed activation in one contiguous block.
Downside is that now we will tranpose all the blocks regardless of them
participating in compute. However it is likely that entire activation
matrix participates in compute for some output block.
Also add benchmark
Test Plan:
q8gemm-sparse-test
fully-connected-test-sparse
Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D25925502
fbshipit-source-id: b2c36419a2c5d23b4a49f25f9ee41cee8397c3be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51706
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50280
As mentioned in gh-43874, this adds a `rounding_mode={'true', 'trunc', 'floor'}`
argument so `torch.div` can be used as a replacement for `floor_divide` during
the transitional period.
I've included dedicated kernels for truncated and floor division which
aren't strictly necessary for float, but do perform significantly better (~2x) than
doing true division followed by a separate rounding kernel.
Note: I introduce new overloads for `aten::div` instead of just adding a default
`rounding_mode` because various JIT passes rely on the exact operator schema.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D26123271
Pulled By: mruberry
fbshipit-source-id: 51a83717602114597ec9c4d946e35a392eb01d46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51572
Modifications in remove_inplace_ops_for_onnx pass and remove_inplace_ops pass to better handle binary inplace ops
* Handles special case of binary inplace ops, where the first input node has a lower type precedence than the second input node.
* When the inplace node is converted to a regular op, this information is lost and the resulting type is based on type precedence, just like regular ops. To avoid this loss of information, we add a cast node before the input node with the higher data type precedence, so that both the input types are the same.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26203117
Pulled By: SplitInfinity
fbshipit-source-id: f018b503701b9067dba053c2764c3b92ef1abc38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51524
* def unsafe_chunk() support and test in ops13.
* Use _unsqueeze_helper insteadof Unsqueeze operator
* Cast the splits into long.
* Change the test to a fixed dimension.
* Update test_pytorch_onnx_onnxruntime.py
* Disable test_loop_with_list for opset 13.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26203123
Pulled By: SplitInfinity
fbshipit-source-id: b273aeff8339faa0e8e9f1fcfbf877d1b703209f
Co-authored-by: Negin Raoof <neginmr@utexas.edu>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51521
* Add loop & if node to the list of nodes that could produce sequence type output.
* Switch from `[]` to `at()` to avoid segfault of out of range access.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26203112
Pulled By: SplitInfinity
fbshipit-source-id: e990eeed933124b195be0be159271e33fb485063
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51520
Previous insertBefore approach might end-up inserting clone node in inner sub-blocks, while then the node being used later at other outside call sites.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26203124
Pulled By: SplitInfinity
fbshipit-source-id: 999511e901ad1087f360bb689fcdfc3743c78aa4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51518
* enable remaining test in opset13
* add comments for error version test info
* fix comments:opset12 unbind problem
* add ignore[no-redef]
* fix format
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26203122
Pulled By: SplitInfinity
fbshipit-source-id: e7d95bd2ce13f79f11965be82f640379cd55ff0f
Co-authored-by: hwangdeyu <deyhuang@qq.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51517
Fix get/set attributes when getting/setting a model parameter.
This PR also fixes inplace ops in If blocks.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26203116
Pulled By: SplitInfinity
fbshipit-source-id: bed6ee6dd92b5b43febc8c584a6872290f8fe33f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51514
Update constant-folding of Gather operator so it also includes cases where rank of indices input is 0.
Currently it only support cases where rank of indices is 1.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26191323
Pulled By: SplitInfinity
fbshipit-source-id: 7edcbd8835b0248fefb908aca394f5cca5eae29e
Summary:
Currently it's passed in a dict but might be worth considering whether we want to support other methods of passing it in (like a list corresponding to the positional args).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51609
Reviewed By: zou3519
Differential Revision: D26224464
Pulled By: Chillee
fbshipit-source-id: 305769db1a6e5fdcfb9e7dcacfdf153acd057a5a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/51349
The memory leak happens when 1) `create_graph` is True AND 2) detect anomaly mode is on. When a backward node's constructor is called during backward, the current evaluating node is assigned as a "parent" of the created node. The code that assigns the parent encounters the below issue:
`functionToPyObject(parent_node)` returns a new PyObject (with refcount 1) or if PyObject already exists, increments its refcount by 1. However [PyDict_SetItem](1b55b65638/Objects/dictobject.c (L1532)) calls into [insertdict](https://github.com/python/cpython/blob/v3.8.1/Objects/dictobject.c#L1034) which increments refcount again. This means that when dict is destroyed, the refcount of the PyObject is at least one. This keeps `parent_node` (the backward function) alive, which then keeps the saved tensor alive.
Similar calls in the codebase to `functionToPyObject` won't require Py_DECREF if it is then passed into a tuple (instead of dict), because the analogous PyTuple_SetItem call does not increment refcount.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51610
Reviewed By: albanD
Differential Revision: D26240336
Pulled By: soulitzer
fbshipit-source-id: 2854528f66fab9dbce448f8a7ba732ce386a7310
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51052
Ensure that shadow modules are inserted only for quantized modules in a model. Removes redundant module insertion.
ghstack-source-id: 121041113
Test Plan: buck test caffe2/test:quantization -- 'test_compare_model_stub_partial \(quantization\.test_numeric_suite\.TestEagerModeNumericSuite\)'
Reviewed By: vkuzo
Differential Revision: D26054016
fbshipit-source-id: 73fc2fd2f0239b0363f358c80e34566d06a0c7cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51666
This ensures the modules will get properly unloaded when all references
to them die
Test Plan: Imported from OSS
Reviewed By: Lilyjjo
Differential Revision: D26232574
Pulled By: suo
fbshipit-source-id: a9889965aa35ba2f6cbbfbdd13e02357cc706cab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51590
This PR backports a subset of Jiakai's changes from
https://github.com/pytorch/pytorch/pull/51554 that adds support
for at::cpu in non-structured kernels.
The unusual bits:
- Need to add a new forward inference rule for doing conversions
of const optional<Tensor>& to const Tensor&
- Need to give the wrapper functions a prefix so that the call to
wrapper is not ambiguous
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D26209871
Pulled By: ezyang
fbshipit-source-id: 8162686039675ab92a2af7a14f6b18941f8944df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51585
Some payoff from the stack of refactors. When I initially landed
at::cpu, Brian asked me why I couldn't just separate the anonymous
and namespaced definitions. Well, it used to be annoying. Now it's
not annoying anymore, so go ahead and split them up.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D26209873
Pulled By: ezyang
fbshipit-source-id: 63057d22acfaa0c17229947d9e65ec1193e360ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51583
There are no substantive changes in this PR. The cluster of structured
helper methods is now split off into its own class. To make sure all of
the original closure was available, I subclassed RegisterDispatchKey and
passed it all on; the only new thing closed over is the structured
functions group being processed. I also renamed all the methods to
remove structured_ from their names as it is now redundant.
Most of the benefit is being able to remove a level of indentation
from gen_one.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D26209872
Pulled By: ezyang
fbshipit-source-id: 76c11410a24968d4f3d8a2bbc9392251a7439e6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51508
No substantive changes. The codegen for this file was getting a
bit long so I moved it off into tools.codegen.dest submodule (I
wanted to do tools.codegen.gen but that conflicts with the existing
module; oy vey!) To do this I had to move some other functions around
so that they were more generally accessible. Otherwise
self-explanatory.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D26187856
Pulled By: ezyang
fbshipit-source-id: fd3784571d03d01c4acb7ca589fcde4492526408
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51500
I'm going to add some new Target types shortly, so having tighter
types for the individual unions will make it clearer which ones
are valid.
This is also the first use of typing_extensions in the codegen,
and I want to make sure it works.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D26187854
Pulled By: ezyang
fbshipit-source-id: 6a9842f19b3f243b90b210597934db902b816c21
Summary:
As discussed with suo , having it in `torch._C.XX` means that it automatically gets added to `torch.XX` which is unfortunate. Making it `torch._C._XX` means that it won't be added to `torch.`.
Let me know if that approach to hide it is not good and we can update that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51690
Reviewed By: gchanan
Differential Revision: D26243207
Pulled By: albanD
fbshipit-source-id: 3eb91a96635e90a6b98df799e3a732833dd280d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51421
Mark memory events that did not happen within an operator context
explicitly in the profiler output.
Test Plan: python test/test_profiler.py -k test_memory_profiler
Reviewed By: ngimel
Differential Revision: D26166518
Pulled By: ilia-cher
fbshipit-source-id: 3c14d3ac25a7137733ea7cc65f0eb48693a98f5e
Summary:
In profiler, pass operators' callstack to kineto and dump them into chrome tracing file.
The kineto side update is merged [here](66a4cad380)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51565
Reviewed By: malfet
Differential Revision: D26219324
Pulled By: ilia-cher
fbshipit-source-id: 96ac818012336602368647ff7b75048070f63b28
Summary:
Previously we might have gotten segfaults and all, now it raises an exception.
Thread safety hasn't been an objective.
I have a followup to expand the Python interface for the API.
Fixes https://github.com/pytorch/pytorch/issues/49969.
wanchaol
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50326
Reviewed By: pbelevich
Differential Revision: D26096234
Pulled By: gmagogsfm
fbshipit-source-id: 5425772002eb4deb3830ed51eaa3964f22505840
Summary:
Add some much needed documentation on the Timer callgrind output format, and expand what is shown on the website.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51664
Reviewed By: tugsbayasgalan
Differential Revision: D26246675
Pulled By: robieta
fbshipit-source-id: 7a07ff35cae07bd2da111029242a5dc8de21403c
Summary:
Uses cmake's `configure_file()` macro to generate a new `torch/csrc/api/include/torch/version.h` header with `TORCH_VERSION_{MAJOR,MINOR,PATCH}` \#defines from an input file `torch/csrc/api/include/torch/version.h.in`.
For Bazel builds, this is accomplished with `header_template_rule()`.
For Buck builds, this is accomplished with `fb_native.genrule()`.
Fixes https://github.com/pytorch/pytorch/issues/44365
<img width="1229" alt="Screen Shot 2021-01-05 at 3 19 24 PM" src="https://user-images.githubusercontent.com/75754324/103809279-3fd80380-5027-11eb-9039-fd23922cebd5.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50073
Reviewed By: glaringlee
Differential Revision: D25855877
Pulled By: jbschlosser
fbshipit-source-id: 6bb792718c97e2c2dbaa74b7b7b831a4f6938e49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51432
ghstack-source-id: 120976584
torchbind is a convenient way to include custom class to both python and torchscript. CREATE_OBJECT is used to create an object of custom class.
CREATE_OBJECT was not supported by lite interpreter. The major reason was that for custom class directly defined in Python, there's no language parser in lite interpreter. It's still the case. However, for torchbind classes that are defined in C++, a python/torchscript parser is not needed.
This diff is to support the case of torchbind custom classes.
1. The class type can be resolved at import level.
2. If the class is not the supported torchbind class, an error message is provided at export stage. Workaround is also suggested.
3. Unit tests. C++: ```LiteInterpreterTest::BuiltinClass``` is added as an end-to-end test on supported class. Python: ```test_unsupported_createobject``` is changed to ```test_unsupported_classtype``` to test unsupported classes.
Test Plan: CI
Reviewed By: raziel
Differential Revision: D26168913
fbshipit-source-id: 74e8b6a12682ad8e9c39afdfd2b605c5f8e65427
Summary: LLVM trunk is at 13 now. I'm relaxing the places that only supports up to 12.
Test Plan: Try Sandcastle staging builds.
Reviewed By: ayermolo
Differential Revision: D26227448
fbshipit-source-id: 0b69a9c135b34db4de94b82ee38d2fb1b328888b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49315
Update the learnable fake-quantization to use c++ and CUDA kernels, and resolve some issues on using it with pytorch DDP.
The updated quantization operator have a different gradient calculation for scale and zero_point when the output is at the endpoints of clamp operation. The updated quantization operator calculates the gradient according to the gradient of the `clamp` function. This behavior is consistent with the gradient calculation for non-learnable fake-quant ops.
ghstack-source-id: 120821868
Test Plan:
# learnable_fake_quantization forward/backward op test
## Unit Test:
`buck test mode/dev-nosan -c fbcode.platform=platform009 //caffe2/test:quantization -- -v TestFakeQuantize`
## Benchmark Test:
`buck run mode/opt //caffe2/benchmarks/operator_benchmark/pt:quantization_test -- --operators FakeQuantizePerTensorOpBenchmark`
`buck run mode/opt //caffe2/benchmarks/operator_benchmark/pt:quantization_test -- --operators FakeQuantizePerChannelOpBenchmark`
### In **microseconds** (`1e-6` second),
References: P171624031
input size: [1, 3, 256, 256]
| | C++ Kernel | Non-backprop C++ Kernel |
|---------------------------|---------------|------------|-------------------------|---|
| Per Tensor CPU Forward | 1372.123 | 1365.981 |
| Per Tensor Cuda Forward | 84.586 | 27.205|
| Per Channel CPU Forward | 2306.668 | 2299.991|
| Per Channel Cuda Forward | 154.742 | 135.219 |
| Per Tensor CPU Backward | 2544.617 | 581.268|
| Per Tensor Cuda Backward | 304.529 | 137.335|
| Per Channel CPU Backward | 3328.188 |582.088 |
| Per Channel Cuda Backward | 504.176 | 134.082|
input size: [1, 3, 512, 512]
| | C++ Kernel | Non-backprop C++ Kernel |
|---------------------------|---------------|------------|-------------------------|---|
| Per Tensor CPU Forward | 5426.244 | 5726.440 |
| Per Tensor Cuda Forward | 85.834 | 26.871|
| Per Channel CPU Forward | 9125.913 | 9118.152|
| Per Channel Cuda Forward | 159.599 | 145.117 |
| Per Tensor CPU Backward | 14020.830 | 2214.864|
| Per Tensor Cuda Backward | 285.525 | 131.302|
| Per Channel CPU Backward | 16977.141 |2104.345 |
| Per Channel Cuda Backward | 541.511 | 120.222|
# use learnable_fake_quantization in AI-denoising QAT:
f229412681
Reviewed By: raghuramank100
Differential Revision: D24479735
fbshipit-source-id: 5275596f3ce8200525f4d9d07d0c913afdf8b43a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51532
- Change output of `replace_pattern` to `List[Match]` reflecting the
pattern(s) matched in the original graph
- Ensure that all Callables (not just FunctionType objects) work with
the rewriter
- Fix incorrect matching in degenerate case (`test_subgraph_rewriter_correct_output_replacement`)
- Verify that pattern matching works when pattern and original graph are
the same
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D26193082
Pulled By: ansley
fbshipit-source-id: 7f40c3862012a44adb88f403ade7afc37e50417f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51638
This PR makes the following doc changes:
- Makes it clear to users that they should use vectorize "at their own
risk"
- Makes it clear that vectorize uses the "experimental prototype vmap"
so that when users see error messages related to vmap they will know
where it is coming from.
This PR also:
- makes it so that {jacobian, hessian} call a version of vmap that
doesn't warn the user that they are using an "experimental prototype".
The regular torch.vmap API does warn the user about this. This is to
improve a UX a little because the user already knows from discovering
the flag and reading the docs what they are getting themselves into.
Test Plan:
- Add test that {jacobian, hessian} with vectorize=True don't raise
warnings
Reviewed By: albanD
Differential Revision: D26225402
Pulled By: zou3519
fbshipit-source-id: 1a6db920ecf10597fb2e0c6576f510507d999c34
Summary:
Notes the module is in beta and that the policy for returning optionally computed tensors may change in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51620
Reviewed By: heitorschueroff
Differential Revision: D26220254
Pulled By: mruberry
fbshipit-source-id: edf78fe448d948b43240e138d6d21b780324e41e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51499
I'm going to turn on at::cpu signatures on for all operators; before
I do it I want to make sure I'm at feature parity everywhere.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D26187855
Pulled By: ezyang
fbshipit-source-id: 8fdfd9d843fc98435b1f1df8b475d3184d87dc96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51490
Mutable Tensor ref is a source of endless confusion for kernel writers;
if we're going to make everyone rewrite their kernels, might as well
also get rid of mutable Tensor& while we're at it.
This is a refactor-then-small-update double whammy. The refactor
is to separate tools.codegen.api.structured from api.native for
describing the type signatures of structured kernels (previously,
I was naughtily reusing native for this purpose--now I need it to
behave differently as Tensor). This started off as a copy paste, but
since there are not that many structured kernels so far I could delete
all of the legacy logic from native that didn't make sense (without
having to go out and fix all the use sites all at once).
One more small addition was teaching translate to convert Tensor& to const Tensor&.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D26182413
Pulled By: ezyang
fbshipit-source-id: ed636866add3581179669cf9283f9835fcaddc06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51477
Passing in a full binding is still OK, but if you have less
(e.g., an Expr/CType), that will do too. I'll need this for
some codegen patches I'm doing later.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D26179560
Pulled By: ezyang
fbshipit-source-id: 5730dfb2c91bf5325496e57b0c91eb6823c9194d
Summary:
Add the FLOPS metric computation to the experimental Kineto profiler.
This includes saving necessary extra arguments and compute flops in the C++ code,
and extract the FLOPS value from the Python frontend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51503
Test Plan:
Build PyTorch with USE_KINETO option, then run the unit test:
```python
python test/test_profiler.py -k test_flops
```
Reviewed By: ilia-cher
Differential Revision: D26202711
Pulled By: xuzhao9
fbshipit-source-id: 7dab7c513f454355a220b72859edb3ccbddcb3ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51370
TORCH_CHECK should be used when confirming the correctness of function
arguments like the tag passed to Gloo functions.
ghstack-source-id: 120908449
Test Plan: Sandcastle/CI
Reviewed By: mingzhe09088
Differential Revision: D26152359
fbshipit-source-id: ddffaa6f11393aaedaf0870759dc526d8d4530ee
Summary:
Change `avg_fun -> avg_fn` to match the spelling in the `.py` file.
(`swa_utils.pyi` should match `swa_utils.py`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51608
Reviewed By: glaringlee
Differential Revision: D26224779
Pulled By: zou3519
fbshipit-source-id: 01ff7173ba0a996f1b7a653438acb6b6b4659de6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51594
ExternalCall nodes represent opaque calls to external functions to fill a
tensor (buffer) with values. It could be used to include nodes that are
otherwise not-representable as TE, or whose TE representation is currently too
slow.
To make an external function available in NNC as ExternalCall, one needs to
implement a "bridge" function that would take raw (void*) pointers to the data
along with the arrays containing dimension info. This function would then
internally call the desired external function and make sure the results of the
call are correctly placed in the provided raw data buffers.
The reason the PR was previously reverted was that the LLVM generated
calls to bridge functions were breaking unwind tables. This is now fixed
by requiring bridge functions to never throw and setting the
corresponding attribute in the LLVM generated code.
Differential Revision: D26213882
Test Plan: Imported from OSS
Reviewed By: pbelevich, ngimel
Pulled By: ZolotukhinM
fbshipit-source-id: db954d8338e2d750c2bf0a41e88e38bd494f2945
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51316
Make optim functional API be private until we release with beta
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D26213469
fbshipit-source-id: b0fd001a8362ec1c152250bcd57c7205ed893107
Summary:
This fixes the previous erroring out by adding stricter conditions in cpp_extension.py.
To test, run a split torch_cuda build on Windows with export BUILD_SPLIT_CUDA=ON && python setup.py develop and then run the following test: python test/test_utils.py TestStandaloneCPPJIT.test_load_standalone. It should pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51596
Reviewed By: malfet
Differential Revision: D26213816
Pulled By: janeyx99
fbshipit-source-id: a752ce7f9ab9d73dcf56f952bed2f2e040614443
Summary:
Update logic in MAYBE_SUDO check. Assumption was incorrect that if pip
was installed as user then sudo is needed. pip could be installed as
root and run as root. Assumption was initially pip was root and user was
non root.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50223
Reviewed By: H-Huang
Differential Revision: D26212127
Pulled By: walterddr
fbshipit-source-id: 20b316606b6c210dc705a972c13088fa3d9bfddd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51126
BucketBatch:
Get a chunk of data as a bucket, and sort the bucket by the specified key, then batching.
If sort key is not specified, directly use batchIterableDS..
1. Implement BucketBatch for bucket sampler
2. Improve BatchDS tests
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D26209890
Pulled By: ejguan
fbshipit-source-id: 8519e2e49da158b3fe32913c8f3cadfa6f3ff1fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50457
The code to infer function schema from a C++ function relies on templates and code expansion. This uses valuable binary size. We can avoid inferring the schema from the C++ function type (arguments, name, return value) in case that the function implementation is being added to the dispatcher via `m.impl`. In this case, it is assumed that we have a schema registered already. Adding an implementation via `m.def` still triggers schema inferrence.
In addition, we don't do schema schema checks on mobile, so the schema is not needed in the first place.
ghstack-source-id: 120915259
Test Plan:
Auto-unit tests succeed.
### Size test: igios
```
D25853094-V1 (https://www.internalfb.com/intern/diff/D25853094/?dest_number=119632217)
igios: Succeeded
Change in Download Size for arm64 + 3x assets variation: -21.8 KiB
Change in Uncompressed Size for arm64 + 3x assets variation: -45.5 KiB
Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:261049318687117@base/bsb:261049318687117@diff/
```
### Size test: fbios
```
D25853094-V1 (https://www.internalfb.com/intern/diff/D25853094/?dest_number=119632217)
fbios: Succeeded
Change in Download Size for arm64 + 3x assets variation: -27.2 KiB
Change in Uncompressed Size for arm64 + 3x assets variation: -80.1 KiB
Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:454289062251865@base/bsb:454289062251865@diff/
```
Reviewed By: smessmer
Differential Revision: D25853094
fbshipit-source-id: e138d9dff7561d424bfb732f3a5898466f018f60
Summary:
On all non-Windows platforms we should use 'posix_prefix' schema to discover location of Python.h header
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51586
Reviewed By: ezyang
Differential Revision: D26208684
Pulled By: malfet
fbshipit-source-id: bafa6d79de42231629960c642d535f1fcf7a427f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50587
This diff introduces two kernesl. One is to pretransform A to do block
wise transforms.
And then the kernel that directly works on top pretransformed weights.
Test Plan:
./build/local/q8gemm-sparse-test
./build/local/fully-connected-sparse-test
Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D25925504
fbshipit-source-id: 9b02819405ce587f20e675b154895dc39ecd1bad
Summary:
There has a description error in quantization.rst, fixed it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50187
Reviewed By: mrshenli
Differential Revision: D25895294
Pulled By: soumith
fbshipit-source-id: c0b2e7ba3fadfc0977ab2d4d4e9ed4f93694cedd
Summary:
Implements `np.diff` for single order differences only:
- method and function variants for `diff` and function variant for `diff_out`
- supports out variant, but not in-place since shape changes
- adds OpInfo entry, and test in `test_torch`
- automatic autograd because we are using the `Math` dispatch
_Update: we only support Tensors for prepend and append in this PR. See discussion below and comments for more details._
Currently there is a quirk in the c++ API based on how this is implemented: it is not possible to specify scalar prepend and appends without also specifying all 4 arguments.
That is because the goal is to match NumPy's diff signature of `diff(int n=1, int dim=-1, Union[Scalar, Tensor] prepend=None, Union[Scalar, Tensor] append)=None` where all arguments are optional, positional and in the correct order.
There are a couple blockers. One is c++ ambiguity. This prevents us from simply doing `diff(int n=1, int dim=-1, Scalar? prepend=None, Tensor? append=None)` etc for all combinations of {Tensor, Scalar} x {Tensor, Scalar}.
Why not have append, prepend not have default args and then write out the whole power set of {Tensor, Scalar, omitted} x {Tensor, Scalar, omitted} you might ask. Aside from having to write 18 overloads, this is actually illegal because arguments with defaults must come after arguments without defaults. This would mean having to write `diff(prepend, append, n, dim)` which is not desired. Finally writing out the entire power set of all arguments n, dim, prepend, append is out of the question because that would actually involve 2 * 2 * 3 * 3 = 36 combinations. And if we include the out variant, that would be 72 overloads!
With this in mind, the current way this is implemented is actually to still do `diff(int n=1, int dim=-1, Scalar? prepend=None, Tensor? append=None)`. But also make use of `cpp_no_default_args`. The idea is to only have one of the 4 {Tensor, Scalar} x {Tensor, Scalar} provide default arguments for the c++ api, and add `cpp_no_default_args` for the remaining 3 overloads. With this, Python api works as expected, but some calls such as `diff(prepend=1)` won't work on c++ api.
We can optionally add 18 more overloads that cover the {dim, n, no-args} x {scalar-tensor, tensor-scalar, scalar-scalar} x {out, non-out} cases for c++ api. _[edit: counting is hard - just realized this number is still wrong. We should try to count the cases we do cover instead and subtract that from the total: (2 * 2 * 3 * 3) - (3 + 2^4) = 17. 3 comes from the 3 of 4 combinations of {tensor, scalar}^2 that we declare to be `cpp_no_default_args`, and the one remaining case that has default arguments has covers 2^4 cases. So actual count is 34 additional overloads to support all possible calls]_
_[edit: thanks to https://github.com/pytorch/pytorch/issues/50767 hacky_wrapper is no longer necessary; it is removed in the latest commit]_
hacky_wrapper was also necessary here because `Tensor?` will cause dispatch to look for the `const optional<Tensor>&` schema but also generate a `const Tensor&` declaration in Functions.h. hacky_wrapper allows us to define our function as `const Tensor&` but wraps it in optional for us, so this avoids both the errors while linking and loading.
_[edit: rewrote the above to improve clarity and correct the fact that we actually need 18 more overloads (26 total), not 18 in total to complete the c++ api]_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50569
Reviewed By: H-Huang
Differential Revision: D26176105
Pulled By: soulitzer
fbshipit-source-id: cd8e77cc2de1117c876cd71c29b312887daca33f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50783
Compiling currently shows:
```
Jan 13 16:46:28 In file included from ../aten/src/ATen/native/ForeachOpsKernels.cpp:2:
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:28:21: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:44:21: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:149:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:164:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:183:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:198:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:150:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(add);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:74:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:150:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(add);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:84:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:151:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(sub);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:74:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:151:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(sub);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:84:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:158:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(add);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:158:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(add);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:159:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(sub);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:159:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(sub);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:160:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(mul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:160:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(mul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:161:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(div);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:161:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(div);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:163:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(mul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:53:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:163:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(mul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:63:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:164:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(div);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:53:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:164:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(div);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:63:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:195:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcdiv);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:115:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:195:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcdiv);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:125:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:196:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcmul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:115:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:196:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcmul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:125:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:198:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcdiv);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:135:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:198:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcdiv);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:145:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:199:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcmul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:135:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:199:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcmul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:145:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) {
```
this diff fixes that
Test Plan: Sandcastle tests
Reviewed By: xush6528
Differential Revision: D25935046
fbshipit-source-id: 9a042367410b3c1ffd27d9f957a623f1bae07d20
Summary:
Clang from XCode does not support `-fopenmp` option, no need to try to compile with it.
Infer whether OpenMP is supported by checking _OPENMP define.
Also, use clang compiler if host app was compiled with clang rather than gcc.
Fix few range loop warnings and add static_asserts that range loop variables are raw pointers.
This changes makes fuser tests on OS X a bit faster.
Before:
```
% python3 test_jit.py -v TestScript.test_batchnorm_fuser_cpu
Fail to import hypothesis in common_utils, tests are not derandomized
CUDA not available, skipping tests
test_batchnorm_fuser_cpu (__main__.TestScript) ... clang: error: unsupported option '-fopenmp'
clang: error: unsupported option '-fopenmp'
warning: pytorch jit fuser failed to compile with openmp, trying without it...
ok
----------------------------------------------------------------------
Ran 1 test in 0.468s
OK
```
After:
```
% python3 test_jit.py -v TestScript.test_batchnorm_fuser_cpu
Fail to import hypothesis in common_utils, tests are not derandomized
CUDA not available, skipping tests
test_batchnorm_fuser_cpu (__main__.TestScript) ... ok
----------------------------------------------------------------------
Ran 1 test in 0.435s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51504
Reviewed By: smessmer
Differential Revision: D26186875
Pulled By: malfet
fbshipit-source-id: 930b3bcf543fdfad0f493d687072aaaf5f9e2bfc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51496
A previous change added the possibility of more functions being generated when bundled inputs are attached. Want to preserve those here in optimize_for_mobile
ghstack-source-id: 120862718
Test Plan:
Created a dummy model. Augment several methods with bundled inputs. Call optimize for mobile. Verified the functions are still there.
Discovered a weird interaction between freeze_module and bundled inputs. If the user does something like
inputs =[<inputs>]
augment_many_model_functions_with_bundled_inputs(
model,
inputs={
model.forward : inputs,
model.foo : inputs,
}
)
to attach their bundled inputs, freeze_module within optimize_for_mobile will error out. Instead the user would need to do something like
inputs =[<inputs>]
inputs2 =[<inputs>] # Nominally the same as the the inputs above
augment_many_model_functions_with_bundled_inputs(
model,
inputs={
model.forward : inputs,
model.foo : inputs2,
}
)
Reviewed By: dhruvbird
Differential Revision: D26005708
fbshipit-source-id: 3e908c0f7092a57da9039fbc395aee6bf9dd2b20
Summary:
These tests are failing for ROCm 4.0/4.0.1 release. Disable the tests until they are fixed.
- TestCuda.test_cudnn_multiple_threads_same_device
- TestCudaFuser.test_reduction
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51510
Reviewed By: H-Huang
Differential Revision: D26205179
Pulled By: seemethere
fbshipit-source-id: 0c3d29989d711deab8b5046b458c772a1543d8ed
Summary:
- Makes it possible to use non-sharded optimizer checkpoints (as long as the model/param groups are the same, of course)
- Makes it possible to save with a given world size, and load with another world size
- Use Torch Distributed built-in broadcast object list instead of a ad-hoc version
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50956
Reviewed By: malfet
Differential Revision: D26113953
Pulled By: blefaudeux
fbshipit-source-id: 030bfeee2c34c2d987590d45dc8efe05515f2e5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51578https://github.com/pytorch/pytorch/pull/49710 introduced an edge case in which
drawing a single sample resulted in ignoring the `dtype` arg to `draw`. This
fixes this and adds a unit test to cover this behavior.
Test Plan: Unit tests
Reviewed By: danielrjiang
Differential Revision: D26204393
fbshipit-source-id: 441a44dc035002e7bbe6b662bf6d1af0e2cd88f4
Summary:
Add a tensorboard_trace_handler to output tracing files and formalize the file name for tensorboard plugin.
As discussed in https://github.com/pytorch/pytorch/pull/49231
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50875
Reviewed By: H-Huang
Differential Revision: D26098493
Pulled By: ilia-cher
fbshipit-source-id: 906ea118682f8bff412e76ca3f391bebab23b0ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51360
Invariant should be satisfied by call sites of allocator
ensuring that the device type makes sense.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: swolchok
Differential Revision: D26170202
Pulled By: ezyang
fbshipit-source-id: f23681f34187c0d3da794f7a8c869ea8da88365d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51358
BackendSelect is expected to enforce this invariant.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: swolchok
Differential Revision: D26149502
Pulled By: ezyang
fbshipit-source-id: f53ab66e8324b729a4057b376fe3d60b14daf2fb
Summary:
Improve the flops computation formula of aten::conv2d operator to support stride, pad, dilation, and groups arguments.
This diff also fixes the following issues:
- Apply a factor of 2 to aten::mm because output accounts for multiplication and addition.
- Fix incorrect names of scalar operators to aten::mul and aten::add.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51377
Test Plan:
```python
python test/test_profiler.py
```
Reviewed By: jspark1105
Differential Revision: D26165223
Pulled By: xuzhao9
fbshipit-source-id: 2c5f0155c47af2e6a19332fd6ed73ace47fa072a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51568
The default behavior of inspect.getfile doesn't work on classes imported
from PackageImporter, because it returns the following.
sys.modules[kls.__module__].__file__
Looking in `sys.modules` is hard-coded behavior. So, patch it to first
check a similar registry of PackageImported modules we maintain.
Test Plan: Imported from OSS
Reviewed By: yf225
Differential Revision: D26201236
Pulled By: suo
fbshipit-source-id: aaf5d7ee8ca0155619c8185e64f70a30152ac567
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51340
**Summary**
`toIValue` assumes that any value passed for an argument of type
`torch.device` is a valid device object, even when it is not. This can
lead to device type arguments of functions being assigned incorrect
values (see #51098).
This commit adds an explicit check that the passed in object is indeed a
`torch.device` using `THPDevice_Check` and only then does is it
converted to an `IValue`. Since implicit conversion from strings to
devices is generally allowed, if `THPDevice_Check` fails, it is assumed
that the object is a string and an `IValue` containing a `c10::Device`
containing the passed in string is returned.
**Test Plan**
This commit adds a unit test to `test_jit.py` to test that invalid
strings passed as devices are not longer silently accepted.
**Fixes**
This commit fixes#51098.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26187190
Pulled By: SplitInfinity
fbshipit-source-id: 48c990203431da30f9f09381cbec8218d763325b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51153
Enabled bundled inputs for all public functions that the user wants in a torchscript module. An important caveat here is that you cant add bundled inputs to functions that were in the nn.module but weren't caught in the scripting/tracing process that brought the model to torchscript.
Old Api is exactly the same. Still only works on forward, return types the same, etc.
-----------New API-------------
Attachment of inputs:
***augment_model_with_bundled_inputs*** : works the same as before but added the option to specify an info dictionary.
***augment_many_model_functions_with_bundled_inputs*** : Similar to the above function but allows the user to specify a Dict[Callable, List[<inputs>]] (mapping function references to the bundled inputs for that function) to attach bundled inputs to many functions
Consumption of inputs:
***get_all_bundled_inputs_for_<function_name>()*** : Works exactly like get_all_bundled_inputs does, but can be used for functions other then forward if you know ahead of time what they are called, and if they have bundled inputs.
***get_bundled_inputs_functions_and_info()*** : This is easily the hackiest function. Returns a Dict['str', 'str'] mapping function_names to get_all_bundled_inputs_for_<function_name>. A user can then execute the functions specified in the values with something like
all_info = model.get_bundled_inputs_functions_and_info()
for func_name in all_info.keys():
input_func_name = all_info[func_name]['get_inputs_function_name'][0]
func_to_run = getattr(loaded, input_func_name)
The reason its done this way is because torchscript doesn't support 'Any' type yet meaning I can't return the bundled inputs directly because they could be different types for each function. Torchscript also doesn't support callable so I can't return a function reference directly either.
ghstack-source-id: 120768561
Test Plan:
Got a model into torchscript using the available methods that I'm aware of (tracing, scripting, old scripting method). Not really sure how tracing brings in functions that arent in the forward call path though. Attached bundled inputs and info to them successfully. Changes to TorchTest.py on all but the last version of this diff (where it will be/is removed for land) illustrate what I did to test.
Created and ran unit test
Reviewed By: dreiss
Differential Revision: D25931961
fbshipit-source-id: 36e87c9a585554a83a932e4dcf07d1f91a32f046
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49756
## Background
Fix applied here is to remove the grad enabled check from `collect_next_edges`, unconditionally returning the actual collected edges. This pushes the responsibility for determining whether the function should be called without grad mode to its call-sites. With this update, `collect_next_edges` will no longer incorrectly return an empty list, which caused the problem described in the issue. Three call-sites depended on this behavior and have been updated.
Beyond bad printing side effects, this fix addresses the more general issue of accessing `grad_fn` with grad mode disabled after an in-place operation on a view. The included test verifies this without the use of print.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51364
Test Plan:
```
python test/test_autograd.py TestAutogradDeviceTypeCPU.test_inplace_view_then_no_grad_cpu
```
Reviewed By: zou3519
Differential Revision: D26190451
Pulled By: jbschlosser
fbshipit-source-id: 9b004a393463f8bd4ac0690e5e53c07a609f87f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51354
Re-created from https://github.com/pytorch/pytorch/pull/51301 because of issues with ghstack.
This PR is part of a larger effort to ensure torch.linalg documentation is consistent (see #50287).
Updated torch.slogdet documentation to add a deprecation message in favor of torch.linalg.slogdet.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D26148679
Pulled By: heitorschueroff
fbshipit-source-id: 4d9f3386d9ba6dc735a4d1e86cfcd88eaba3cbcc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51353
Re-created from https://github.com/pytorch/pytorch/pull/51300 because of issues with ghstack.
This PR is part of a larger effort to ensure torch.linalg documentation is consistent (see https://github.com/pytorch/pytorch/issues/50287).
Updated torch.linalg.slogdet to include notes about cross-device synchronization, backend routines used and fix signature missing out argument.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D26148678
Pulled By: heitorschueroff
fbshipit-source-id: 40f6340226ecb72e4ec347c5606012f31f5877fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51427
A user reported that `start_PowerSGD_iter` failed when it's set as 1. This is because allocating memory for error tensors somehow overlap with bucket rebuilding process at iteration 1.
Check `start_PowerSGD_iter > 1` instead of `start_PowerSGD_iter >= 1`.
Also add a unit test of `test_invalid_powerSGD_state` and some guidance on tuning PowerSGD configs.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 120834126
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_invalid_powerSGD_state
Reviewed By: rohan-varma
Differential Revision: D26166897
fbshipit-source-id: 34d5b64bb3dd43acb61d792626c70e6c8bb44a5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51475
ExternalCall nodes represent opaque calls to external functions to fill a
tensor (buffer) with values. It could be used to include nodes that are
otherwise not-representable as TE, or whose TE representation is currently too
slow.
To make an external function available in NNC as ExternalCall, one needs to
implement a "bridge" function that would take raw (void*) pointers to the data
along with the arrays containing dimension info. This function would then
internally call the desired external function and make sure the results of the
call are correctly placed in the provided raw data buffers.
Test Plan: Imported from OSS
Reviewed By: pbelevich, Chillee
Differential Revision: D26179083
Pulled By: ZolotukhinM
fbshipit-source-id: 9e44de098ae94d25772cf5e2659d539fa6f3f659
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50229
`fastmod -m 'cast(<((at|c10)::)?\w+Type>\(\)\s*)->' 'castRaw${1}->'` Presuming it builds, this is a safe change: the
result of `cast()` wasn't being saved anywhere, so we didn't need
it, so we can use a raw pointer instead of a new `shared_ptr`.
ghstack-source-id: 120769170
Test Plan: CI
Reviewed By: SplitInfinity
Differential Revision: D25837494
fbshipit-source-id: 46319100dc0dfc78f6d2b45148207f83481f2ada
Summary:
BUILD_SPLIT_CUDA needs to be exported to true in order for cpp_extensions.py to work properly--currently disabling to make tree green
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51533
Reviewed By: pbelevich
Differential Revision: D26194055
Pulled By: janeyx99
fbshipit-source-id: 08d3cc7e6ba57011dddbf27f96ef5acb648b6b9a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/48831.
- CI image is updated to build hipMAGMA from source and set env MAGMA_HOME.
- CMake is updated to separate different requirements for CUDA versus ROCm MAGMA.
- Some unit tests that become enabled with MAGMA are currently skipped for ROCm due to failures. Fixing these failures will be follow-on work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51238
Reviewed By: ngimel
Differential Revision: D26184918
Pulled By: malfet
fbshipit-source-id: ada632f1ae7b413e8cae6543fe931dcd46985821
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51307
Using -ftime-trace shows that this roughly halves time spent compile/optimizing this function in an optimized build of RegisterCPU.cpp (savings of about 1 second).
ghstack-source-id: 120697493
Test Plan: manual build with -ftime-trace as above; sketch of directions at https://fb.workplace.com/groups/894363187646754/permalink/1153321361750934/ , except that I extracted a compiler invocation for RegisterCPU.cpp by injecting a syntax error and running buck build with -v 3 so that I could rebuild and measure just the one file quickly.
Reviewed By: ezyang
Differential Revision: D26135978
fbshipit-source-id: 756499fbcc8d3b169bae5a463f63caecb79f7fcd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51293
It looks like this header did not need ivalue.h at all.
ghstack-source-id: 120697488
Test Plan: CI to ensure correctness
Reviewed By: ezyang
Differential Revision: D26128288
fbshipit-source-id: a24a7e49b9d623fb182bdfaf286972739497e770
Summary:
Because of the size of our `libtorch_cuda.so`, linking with other hefty binaries presents a problem where 32bit relocation markers are too small and end up overflowing. This PR attempts to break up `torch_cuda` into `torch_cuda_cu` and `torch_cuda_cpp`.
`torch_cuda_cu`: all the files previously in `Caffe2_GPU_SRCS` that are
* pure `.cu` files in `aten`match
* all the BLAS files
* all the THC files, except for THCAllocator.cpp, THCCachingHostAllocator.cpp and THCGeneral.cpp
* all files in`detail`
* LegacyDefinitions.cpp and LegacyTHFunctionsCUDA.cpp
* Register*CUDA.cpp
* CUDAHooks.cpp
* CUDASolver.cpp
* TensorShapeCUDA.cpp
`torch_cuda_cpp`: all other files in `Caffe2_GPU_SRCS`
Accordingly, TORCH_CUDA_API and TORCH_CUDA_BUILD_MAIN_LIB usages are getting split as well to TORCH_CUDA_CU_API and TORCH_CUDA_CPP_API.
To test this locally, you can run `export BUILD_SPLIT_CUDA=ON && python setup.py develop`. In your `build/lib` folder, you should find binaries for both `torch_cuda_cpp` and `torch_cuda_cu`. To see that the SPLIT_CUDA option was toggled, you can grep the Summary of running cmake and make sure `Split CUDA` is ON.
This build option is tested on CI for CUDA 11.1 builds (linux for now, but windows soon).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49050
Reviewed By: walterddr
Differential Revision: D26114310
Pulled By: janeyx99
fbshipit-source-id: 0180f2519abb5a9cdde16a6fb7dd3171cff687a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48863
Support default arguments when invoking a module via PyTorch Lite (`mobile::Module`).
Test Plan:
buck test mode/dbg //caffe2/test/cpp/jit:jit -- LiteInterpreterTest.MethodInvocation
buck test mode/dbg caffe2/test:mobile -- test_method_calls_with_optional_arg
Reviewed By: iseeyuan
Differential Revision: D25896212
fbshipit-source-id: 6d7e7fd5f3244a88bd44889024d81ad2e678ffa5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51389
This should reduce code size when STRIP_ERROR_MESSAGES is defined by allowing callers of TORCH_CHECK to avoid creating `std::string`s.
ghstack-source-id: 120692772
Test Plan: Measure code size of STRIP_ERROR_MESSAGES builds
Reviewed By: ezyang
Differential Revision: D25891476
fbshipit-source-id: 34eef5af7464da6534989443859e2765887c243c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51460
This PR is part of a larger effort to ensure torch.linalg documentation is consistent (see #50287).
* #51459 [doc] Fix linalg.cholesky doc consistency issues
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D26176130
Pulled By: heitorschueroff
fbshipit-source-id: cc89575db69cbfd5f87d970a2e71deb6522a35b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51459
This PR is part of a larger effort to ensure torch.linalg documentation is consistent (see #50287).
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D26176131
Pulled By: heitorschueroff
fbshipit-source-id: 2ad88a339e6dff044965e8bf29dd8c852afecb34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51270
Similar to #50973, allow the batched version to run vanilla allreduce for the first K iterations.
This may be useful if the batched version can be applied to some use cases where the accuracy requirement is not very strict.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 120725858
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
baseline: f248001754
batched PowerSGD: f246960752
The training time was reduced from 54m48s to 30m33s, and the accuracy is approximately the same: 44.21 vs 44.35
Reviewed By: rohan-varma
Differential Revision: D26077709
fbshipit-source-id: 6afeefad7a3fbdd7da2cbffb56dfbad855a96cb5
Summary:
This is the initial skeleton for C++ codegen, it includes generations for Allocate and Free.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51070
Test Plan: New unit tests are added to `test_cpp_codegen.cpp`.
Reviewed By: ZolotukhinM
Differential Revision: D26061818
Pulled By: cheng-chang
fbshipit-source-id: b5256b2dcee6b2583ba73b6c9684994dbe7cdc1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51269
This saves about 10% of the compile time of Functions.cpp. Found using clang-9's `-ftime-trace` feature + ClangBuildAnalyzer.
Test Plan:
Compared -ftime-trace + ClangBuildAnalyzer output.
Before: P167884397
After: P167888502
Note that time spent generating assertSignatureIsCorrect is way down, though it's still kind of slow.
Reviewed By: ezyang
Differential Revision: D26121814
fbshipit-source-id: 949a85d8939c02e4fb5ac1adc35905ed34414724
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51247
See code comment for explanation.
This measures neutral compared to the previous diff with `perf stat` when running on a
benchmark that calls empty in a loop. I think that we should commit it
anyway because:
1) I have previously seen it make a difference when applied earlier in
the stack.
2) This makes sense both on principle and via inspecting output
assembly: we avoid having to touch the boxed kernel at all (usually)
and instead use the unboxed kernel for both the validity check in
`OperatorEntry::lookup` and the actual `KernelFunction::call`.
ghstack-source-id: 120697497
Test Plan: Aforementioned perf measurement
Reviewed By: ezyang
Differential Revision: D26113650
fbshipit-source-id: 8448c4ed764d477f63eb7c0f6dd87b1fc0228b73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51245
Splitting this out from #51164 (D26069629) to allow it to
land separately; I'm sure this is a good idea but I'm less sure about
#51164.
ghstack-source-id: 120697499
Test Plan:
double-check effect on empty benchmark with perf stat;
didn't move
Reviweers: ezyang, messmer
Reviewed By: ezyang
Differential Revision: D26112627
fbshipit-source-id: 50d4418d351527bcedd5ccdc49106bc642699870
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51163
The Dispatcher seems to have been in a precarious local
maximum: I tried to make several different changes to parameter
passing and ended up with regressions due to reduced inlining that
swamped any gains I might have gotten from the parameter passing
changes.
This diff reduces the amount of inline code on the fast path. It
should both reduce code size and provide a platform for making further
improvements to the dispatcher code.
It is a slight performance regression, but it unblocked the following
two diffs (which seem to get us back where we were) from landing.
ghstack-source-id: 120693163
Test Plan:
CI, framework overhead benchmarks to check the size of the
regression
Compared timing for empty framework overhead benchmark before/after.
Build command: `buck build mode/no-gpu //caffe2/caffe2/fb/high_perf_models/pytorch/benchmark_framework_overheads:cpp_benchmark mode/opt-clang --show-output`
Run with `numactl -m 0 -C 3 path/to/cpp_benchmark -op empty -niter 100`
Before:
```
I0126 16:02:04.373075 2135872 bench.cpp:139] Mean 0.266272
I0126 16:02:04.373106 2135872 bench.cpp:140] Median 0.266347
I0126 16:02:04.373111 2135872 bench.cpp:141] Min 0.263585
I0126 16:02:04.373117 2135872 bench.cpp:142] stddev 0.0021264
I0126 16:02:04.373131 2135872 bench.cpp:143] stddev / mean 0.00798581
```
After:
```
I0126 16:02:30.377992 2137048 bench.cpp:139] Mean 0.27579
I0126 16:02:30.378023 2137048 bench.cpp:140] Median 0.275281
I0126 16:02:30.378029 2137048 bench.cpp:141] Min 0.270617
I0126 16:02:30.378034 2137048 bench.cpp:142] stddev 0.00308287
I0126 16:02:30.378044 2137048 bench.cpp:143] stddev / mean 0.0111783
```
Yes, it's a regression, but I compared D26069629 stacked on this diff vs not:
With this diff:
```
I0126 16:02:50.662864 2137574 bench.cpp:139] Mean 0.268645
I0126 16:02:50.662891 2137574 bench.cpp:140] Median 0.267485
I0126 16:02:50.662896 2137574 bench.cpp:141] Min 0.266485
I0126 16:02:50.662901 2137574 bench.cpp:142] stddev 0.00219359
I0126 16:02:50.662915 2137574 bench.cpp:143] stddev / mean 0.00816537
```
Without:
```
I0126 20:40:27.815824 3240699 bench.cpp:139] Mean 0.270755
I0126 20:40:27.815860 3240699 bench.cpp:140] Median 0.268998
I0126 20:40:27.815866 3240699 bench.cpp:141] Min 0.268306
I0126 20:40:27.815873 3240699 bench.cpp:142] stddev 0.00260365
I0126 20:40:27.815886 3240699 bench.cpp:143] stddev / mean 0.00961624
```
So we do seem to have accomplished something w.r.t. not overwhelming the inliner.
Reviewed By: ezyang
Differential Revision: D26091377
fbshipit-source-id: c9b7f4e187059fa15452b7c75fc29816022b92b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51312
Follow up to D24690094 (4a870f6518) exposing the api in python. Created matching unit test.
ghstack-source-id: 120611452
Test Plan: Ran unit test
Reviewed By: dhruvbird
Differential Revision: D26112765
fbshipit-source-id: ffe3bb97de0a4f08b31719b4b47dcebd7d2fd42a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51049
This diff makes it OK to query has_storage() on all TensorImpls. I added debug assertions that storage_ is indeed never set on them, which is required for this to be correct.
ghstack-source-id: 120714380
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D26008498
fbshipit-source-id: b3f55f0b57b04636d13b09aa55bb720c6529542c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51048
There doesn't seem to be any reason to prohibit accessing the always-zero storage_offset of those TensorImpls that prohibit set_storage_offset.
ghstack-source-id: 120714379
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D26008499
fbshipit-source-id: cd92ac0afdebbd5cf8f04df141843635113b6444
Summary:
Performs the update that was suggested in https://github.com/pytorch/pytorch/issues/41489
Adjust the functionality to largely match that pf the scipy companion PR https://github.com/scipy/scipy/pull/10844/, including
- a new `draw_base2` method
- include zero as the first point in the (unscrambled) Sobol sequence
The scipy PR is also quite opinionated if the `draw` method doesn't get called with a base 2 number (for which the resulting sequence has nice properties, see the scipy PR for a comprehensive discussion of this).
Note that this update is a **breaking change** in the sense that sequences generated with the same parameters after as before will not be identical! They will have the same (better, arguably) distributional properties, but calling the engine with the same seed will result in different numbers in the sequence.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49710
Test Plan:
```
from torch.quasirandom import SobolEngine
sobol = SobolEngine(3)
sobol.draw(4)
sobol = SobolEngine(4, scramble=True)
sobol.draw(5)
sobol = SobolEngine(4, scramble=True)
sobol.draw_base2(2)
```
Reviewed By: malfet
Differential Revision: D25657233
Pulled By: Balandat
fbshipit-source-id: 9df50a14631092b176cc692b6024aa62a639ef61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51341
Adds tests for objects that contain CPU/GPU tensors to ensure that
they can also be serialized/deserialized appropriately.
ghstack-source-id: 120718120
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D26144100
fbshipit-source-id: f1a8ccb9741bb5372cb7809cb43cbe43bf47d517
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50625
Make API signatures consistent and provide default argument similar to
the tensor collectives.
ghstack-source-id: 120718121
Test Plan: CI
Reviewed By: wanchaol
Differential Revision: D25932012
fbshipit-source-id: d16267e236a65ac9d55e19e2178f9d9267b08a20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51342
There is a subtle bug with the MemoryPlanner with regard to view ops with out variant.
```
def forward(self, a: Tensor, shape: List[int]):
b = a.reshape(shape)
return b + b
```
In this case, if we replace reshape with the out variant, b would be managed by the MemoryPlanner and the storage of its output would have been set to nullptr right after inference by the MemoryPlanner if opts.cleanup_activations is true. Because b is a view of a, the storage of a is also set to nullptr, and this violates the API which promises that a is const.
To fix this bug, I changed the MemoryPlanner so that it puts b in the unmanaged part.
Test Plan:
Add unit test to enforce the constness of inputs
```
buck test //caffe2/benchmarks/static_runtime:static_runtime_cpptest
```
Reviewed By: ajyu
Differential Revision: D26144203
fbshipit-source-id: 2dbacccf7685d0fe0f0b1195166e0510b2069fe3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51066
backend name of a processgroup created using distributed_c10d python API is tracked, but there is no good way to track name of a processgroup created using processGroup c++ API. In some cases, knowing backend name of a processGroup is useful, e,g., log the backend name, or write some codes that have dependency on the known backend.
ghstack-source-id: 120628432
Test Plan: unit tests
Reviewed By: pritamdamania87
Differential Revision: D26059769
fbshipit-source-id: 6584c6695c5c3570137dc98c16e06cbe4b7f5503
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51314
updating the doc of DistributedOptimizer to include TorchScript enablement information
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26156032
Pulled By: wanchaol
fbshipit-source-id: 1f3841f55918a5c2ed531cf6aeeb3f6e3a09a6a8
Summary:
Reference: https://github.com/pytorch/pytorch/issues/33152
Changes
* Enable complex support for masked_scatter
* Enable half support for masked_scatter CPU
* Enable complex autograd support for masked_scatter CPU and masked_select (both CPU and CUDA).
**Note**:
Complex Support for masked_scatter CUDA is disabled as it depends on `masked_fill` which is yet to be ported to ATen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51281
Reviewed By: ailzhang
Differential Revision: D26127561
Pulled By: anjali411
fbshipit-source-id: 6284926b934942213c5dfc24b5bcc8538d0231af
Summary:
Fixes #{issue number}
Resubmitting a new PR as the older one got reverted due to problems in test_optim.py.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51227
Reviewed By: ezyang
Differential Revision: D26142505
Pulled By: ailzhang
fbshipit-source-id: a2ab5d85630aac2d2ce17652ba19c11ea668a6a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51365
We have a pretty big backlog of PRs when it comes to checking for stale and the action only supports processing 30 PRs at a given time.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D26153785
Pulled By: seemethere
fbshipit-source-id: 585b36068683e04cf4e2cc59013482f143ec30a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51072
AT_ASSERTM is deprecated and should be replaced by either TORCH_CHECK or
TORCH_INTERNAL_ASSERT, depending on the situation.
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D26074364
Pulled By: ezyang
fbshipit-source-id: 742e28afe49e0a546c252a0fad487f93410d0cb5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50843
AT_ASSERTM is deprecated and should be replaced by either TORCH_CHECK or
TORCH_INTERNAL_ASSERT, depending on the situation.
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D26074365
Pulled By: ezyang
fbshipit-source-id: 46e13588fad4e24828f3cc99635e9cb2223a6c2c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51329
Currently the test_qbatch_norm_relu is containing too many examples and causing timeout. Splitting them for now to fix the timeout issue
Test Plan: buck test caffe2/test:quantization
Reviewed By: supriyar
Differential Revision: D26141037
fbshipit-source-id: da877efa78924a252a35c2b83407869ebb8c48b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51236
The problem we currently have with tracing is that GPU models can't load on devvm CPU machines. Here's why:
1. The Metal GPU ops don't exist so the validation that checks for missing ops kicks in and prevents loading
2. Even if the check for missing ops is commented out, the actual model contents can't be succssfully loaded (see t83364623 for details)
Hence, to work around these problems and allow tracing to detect GPU models, and skip actual tracing for these (as discussed in the meeting 2 weeks ago and based on recommendations from raziel, iseeyuan, and xta0), we're adding code to detect these GPU models based on the set of operators that show up in the file `extra/mobile_info.json`.
The code then skips tracing, and picks up the root operators from the model itself.
The diff below this one will be removed before landing since we don't want to check in the model - I've kept it here in case anyone wants to patch this diff in and run the command on their devvm locally.
ghstack-source-id: 120638092
Test Plan:
See {P168657729} for a successful run of tracing on a GPU model (person segmentation tier-0, v1001) provided by xta0
Also ran `buck test //xplat/pytorch_models/build/...` successfully.
Reviewed By: ljk53
Differential Revision: D26109526
fbshipit-source-id: 6119b0b59af8aae8b1feca0b8bc29f47a57a1a67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51246
Using sleef is sometimes slower than libm (I haven't debugged why).
The easy solution is to not use sleef in those cases. With this diff, plus the
prior one to use sleef period, we've sped up every unary op:
ghstack-source-id: 120614087
Test Plan: `buck run mode/opt -c python.package_style=inplace //caffe2/benchmarks/cpp/tensorexpr:bench_ops`
Reviewed By: ZolotukhinM
Differential Revision: D26113672
fbshipit-source-id: 6b731ac935b3652c8b3e3f4a5d2baa39ff31323a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51190
We want to be able to call fast vectorized functions from sleef inside
the jit fuser, but only when they're supported by the host processor. Enabling
this feature has two parts:
1. Record the addresses of the symbols, assuming they're defined. Sleef only
defines vectorized functions if AVX is enabled, so we need to define __AVX__ to
get access to those symbols. We don't actually need to compile anything with
AVX; the symbols just have to be present.
2. Before emitting a call to sleef, check if the host processor actually has
AVX. LLVM makes this easy since we can just check the target feature string
for "+avx".
ghstack-source-id: 120614086
Test Plan:
```
buck run mode -c python.package_style=inplace //caffe2/benchmarks/cpp/tensorexpr:bench_ops
```
shows a significant speedup on most math functions (esp sigmoid, which goes
from 13% of ATen speed to parity).
Reviewed By: navahgar
Differential Revision: D26096170
fbshipit-source-id: b7268a50d73f8dc03b4db11cc38b8402387eed2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51187
Instead of relying on #ifdefs, we want to use sleef if its symbols are
available. This diff adds the mechanism to do that check using LLVM's symbol
lookup.
This diff by itself is a no-op, because sleef isn't properly being exposed to
LLVM yet (the `#ifdef __AVX__` checks are always false, because torch/jit isn't
built with `-mavx`). The next diff will properly expose the symbols, and
perform run time checks.
ghstack-source-id: 120614091
Test Plan: `buck test //caffe2/test/cpp/tensorexpr:`
Reviewed By: Krovatkin
Differential Revision: D26096206
fbshipit-source-id: 3f2b37500276e8bf50a167ecf8aeeb295d7ec232
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51186
Just a bit of drive-by cleanup; the wrapper class should be the same
for all builds so let's not conditionally compile it for no reason.
ghstack-source-id: 120614088
Test Plan: buck build
Reviewed By: navahgar
Differential Revision: D26096205
fbshipit-source-id: 1e4cb682614fae0e889ba35fb1edb489fb99158e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51125
The big pile of X-macros used for emitting (possibly vectorized)
intrinsics makes it **really** difficult to change that code in any systematic
way (which I'm about to do in a later diff).
We can factor most of what the macro does into a fairly simple function. There
are still macros but they're just a bunch of case/call helper/break
boilerplate.
ghstack-source-id: 120614089
Test Plan: `buck test mode/opt -c python.package_style=inplace //caffe2/benchmarks/cpp/tensorexpr:bench_ops`
Reviewed By: ZolotukhinM
Differential Revision: D26078384
fbshipit-source-id: 843548033f73d88c5d9a031c285b92f73be21390
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51259
Store the FQN of the module that is using the packed weights (the quantized op)
In the case of fusion we update the scope mapping to store the module path of the fused node.
Test Plan:
python test/test_quantization.py test_packed_weight_fused_op
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26117964
fbshipit-source-id: 9d929997baafb1c91063dd9786a451b0040ae461
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51265
This PR is the cleanup after #51159. High level, we make the new
definition of fake_quant per channel be the definition used by autograd, but keep the old
function around as a thin wrapper to keep the user facing API the same.
In detail:
1. point fake_quantize_per_channel_affine's implementation to be fake_quantize_per_channel_affine_cachemask
2. delete the fake_quantize_per_channel_affine backward, autograd will automatically use the cachemask backward
3. delete all the fake_quantize_per_channel_affine kernels, since they are no longer used by anything
Test Plan:
```
python test/test_quantization.py TestFakeQuantize
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26120957
fbshipit-source-id: 264426435fabd925decf6d1f0aa79275977ea29b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51255
This is the same as #50561, but for per-channel fake_quant.
TODO before land write up better
Memory and performance impact (MobileNetV2): TODO
Performance impact (microbenchmarks): https://gist.github.com/vkuzo/fbe1968d2bbb79b3f6dd776309fbcffc
* forward pass on cpu: 512ms -> 750ms (+46%)
* forward pass on cuda: 99ms -> 128ms (+30%)
* note: the overall performance impact to training jobs should be minimal, because this is used for weights, and relative importance of fq is dominated by fq'ing the activations
* note: we can optimize the perf in a future PR by reading once and writing twice
Test Plan:
```
python test/test_quantization.py TestFakeQuantize.test_forward_per_channel_cachemask_cpu
python test/test_quantization.py TestFakeQuantize.test_forward_per_channel_cachemask_cuda
python test/test_quantization.py TestFakeQuantize.test_backward_per_channel_cachemask_cpu
python test/test_quantization.py TestFakeQuantize.test_backward_per_channel_cachemask_cuda
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26117721
fbshipit-source-id: 798b59316dff8188a1d0948e69adf9e5509e414c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50985
Explicitly specify the dtype of error tensor when it is initialized by zeros.
Previously if the dtype of input tensor is FP16, the error tensor is still created in FP32, although later it will be assigned by another FP16 tensor (`input_tensor_cp` - `input_tensor`).
This change will make the dtype of error tensor look more clear.
Additionally, also explicitly specify the dtype if rank-1 tensor buffer is empty.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 120377786
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_DistributedDataParallel_powerSGD_ddp_comm_hook
Reviewed By: rohan-varma
Differential Revision: D26034988
fbshipit-source-id: e0d323d0b77c6a2478cdbe8b31a1946ffd1a07da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50981
Since vanilla allreduce will to be applied in the first few iterations, bucket rebuilding process will not affect caching per-variable tensors.
Previously the cached tensors used for error feedback and warm-up need to be rebuilt later, because their corresponding input tensors' shape will be changed after the bucket rebuild process.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 120617971
Test Plan: real run
Reviewed By: rohan-varma
Differential Revision: D26034418
fbshipit-source-id: e8744431c7f3142d75b77b60110e6861c2ff5c14
Summary:
Speeds up clone of pytorch.github.io in CI/CD - currently takes ~7 minutes each run.
Locally these are the results: 3.73 seconds vs 611.87 seconds.
With depth 1:
```
$ time git clone https://github.com/pytorch/pytorch.github.io -b site --depth 1
...
3.73s user 2.97s system 23% cpu 28.679 total
```
Without:
```
$ time git clone https://github.com/pytorch/pytorch.github.io -b site
...
611.87s user 66.16s system 96% cpu 11:41.99 total
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48115
Reviewed By: mrshenli
Differential Revision: D25107867
Pulled By: ranman
fbshipit-source-id: b6131b51df53b7f71d9b4905181182699c0c6c09
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51306
Title wasn't rendering correctly so let's just remove it altogether, it
shouldn't matter that much in the long run
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D26134907
Pulled By: seemethere
fbshipit-source-id: 54485cb66fb57f549255f9e7bcfb39b51fe69776
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51218Fixes#51144.
Context
=======
Users have complained about warning spam from batched gradient
computation. This warning spam happens because warnings in C++ don't
correctly get turned into Python warnings when those warnings arise from
the autograd engine.
To work around that, this PR adds a mechanism to toggle vmap warnings.
By default, the vmap fallback will not warn when it is invoked. However,
by using `torch._C._debug_only_display_vmap_fallback_warnings(enabled)`,
one can toggle the existence of vmap fallback warnings.
This API is meant to be a private, debug-only API. The goal is to be
able to non-intrusively collect feedback from users to improve
performance on their workloads.
What this PR does
=================
This PR adds an option to toggle vmap warnings. The mechanism is
toggling a bool in ATen's global context.
There are some other minor changes:
- This PR adds a more detailed explanation of performance cliffs to the
autograd.functional.{jacobian, hessian} documentation
- A lot of the vmap tests in `test_vmap.py` rely on the fallback warning
to test the presence of the fallback. In test_vmap, I added a context
manager to toggle on the fallback warning while testing.
Alternatives
============
I listed a number of alternatives in #51144. My favorite one is having a new
"performance warnings mode" (this is currently a WIP by some folks on
the team). This PR is to mitigate the problem of warning spam before
a "performance warnings mode" gets shipped into PyTorch
Concerns
========
I am concerned that we are advertising a private API
(`torch._C._debug_only_display_vmap_fallback_warnings(enabled)`) in the
PyTorch documentation. However, I hope the naming makes it clear to
users that they should not rely on this API (and I don't think they have
any reason to rely on the API).
Test Plan
=========
Added tests in `test_vmap.py` to check:
- by default, the fallback does not warn
- we can toggle whether the fallback warns or not
Test Plan: Imported from OSS
Reviewed By: pbelevich, anjali411
Differential Revision: D26126419
Pulled By: zou3519
fbshipit-source-id: 95a97f9b40dc7334f6335a112fcdc85dc03dcc73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51298
newlines weren't being respected so just add them through the `<br>` html
tag.
Also changes the wording for open source ones to designate that a
maintainer may be needed to unstale a particular PR.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D26131126
Pulled By: seemethere
fbshipit-source-id: 465bfc0ba4dc16a7a90e0c03c33d551184e35f5b
Summary:
Follow up to https://github.com/pytorch/pytorch/issues/50746
I accidentally missed the `ord=-inf` case in the OpInfo for `torch.linalg.norm` when I wrote it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51233
Reviewed By: malfet
Differential Revision: D26117160
Pulled By: anjali411
fbshipit-source-id: af921c1d8004783612b3a477ae2025a82860ff4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50860
Since fairscale.nn.Pipe still uses 'balance' and 'devices' parameters,
other frameworks like fairseq still use these parameters. As a result, the
`convert_to_balance` method is a nice utility to use for migrating to PyTorch
Pipe without changing a lot of code in other frameworks.
In addition to this I've renamed the method to be more illustrative of what it
does and also allowed an optional devices parameter.
ghstack-source-id: 120430775
Test Plan:
1) waitforbuildbot
2) Tested with fairseq
Reviewed By: SciPioneer
Differential Revision: D25987273
fbshipit-source-id: dccd42cf1a74b08c876090d3a10a94911cc46dd8
Summary:
^
Currently, `alloc_block`'s error handling has a couple (imo) minor flaws. It might clear the error state even if the error had nothing to do with memory allocation. It might also clear the error state even if it didn't attempt a cudaMalloc, meaning it might clear an error state that came from some completely unrelated earlier cuda call.
The diffs and comments are the best explanation of my preferred (new) error-checking policy.
The diffs add very little work to the common (successful, allocation satisfied by existing block) hot path. Most of the additional logic occurs in `alloc_block`, which is a slow path anyway (it tries cudaMalloc).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51158
Reviewed By: malfet, heitorschueroff
Differential Revision: D26101515
Pulled By: ezyang
fbshipit-source-id: 6b447f1770974a04450376afd9726be87af83c48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51175
gives a suggestion about how to deal with immutable args/kwargs list
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D26093478
Pulled By: zdevito
fbshipit-source-id: 832631c125561c3b343539e887c047f185060252
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51237
Stales pull requests at 150 days and then will close them at 180 days
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: stonks
Reviewed By: yns88
Differential Revision: D26112086
Pulled By: seemethere
fbshipit-source-id: c6b3865aa5cde3415b6dd6622c308895a16e805f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51171
Following up on previous PR, this PR makes scale and zero_point for quantize_per_tensor to be
registered as buffers in the module.
Currently the dtype is still stored as attr (not registered as buffer) since we can only register tensor types.
Test Plan:
python test/test_quantization.py test_qparams_buffers
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26092964
fbshipit-source-id: a54d914db7863402f2b5a3ba2c8ce8b27c18b47b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51166
Currently scale and zero_point values are stored as constant values in the graph.
This prevents these values from being updated in the graph and also does not enable saving
these values to state_dict
After this PR we store scale/zero_point values for quantized ops as buffers in the root module
and createe get_attr nodes for them in the graph.
We also use the FQN of the module where the quantized ops are present to name these attributes so
that they can be uniquely identified and mapped to quantized ops.
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_qparams_buffers
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26092965
fbshipit-source-id: b549b2d3dccb45c5d38415ce95a09c26f5bd590b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51086
Previously we only supported getting scope for call_module and custom qconfig dict for call_module.
This PR extends the Scope class to record the scope for all node types.
For call_function qconfig if module_name is specified it takes precedence over function qconfig.
Test Plan:
python test/test_quantization.py test_qconfig_for_call_func
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26077602
fbshipit-source-id: 99cdcdedde2280e51812db300e17d4e6d8f477d2
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 228f060ccc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51203
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D26099684
Pulled By: yns88
fbshipit-source-id: 0ff985e9d4914d0d00120f96d0f5ba77371f005c
Summary:
CUDA TK >= 11.1 provides ptxjitcompiler that emits SASS instead of PTX.
1. This gives better backward-compatibility that allows future TK to work with older driver, which might not necessarily be able to load generated PTX through JIT compile and would error out at runtime;
https://docs.nvidia.com/deploy/cuda-compatibility/#using-ptx
2. Meanwhile, SASS doesn't provide good future compatibility, so for unsupported arch, we fallback to PTX to support future device.
https://docs.nvidia.com/deploy/cuda-compatibility/index.html#cubin-compatibility
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50319
Reviewed By: malfet
Differential Revision: D26114475
Pulled By: ngimel
fbshipit-source-id: 046e9e7b3312d910f499572608a0bc1fe53feef5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51249
- Add out variant for reshape and flatten. reshape and flatten only create tensor views when it can. In cases where it can't, it does a copy. The out variant reuses the TensorImpl for both cases. The difference is that the TensorImpl is a view in the first case, but a normal TensorImpl in the second case.
- Create a separate registry for the view ops with out variants. Because Tensor views can't participate in memory reuse (memonger), we need to track these ops separately.
- The MemoryPlanner does not track the StorageImpl of tensor views because they don't own the storage, however, in cases where reshape does not create a view, the MemoryPlanner does manage the output tensor.
Reviewed By: ajyu
Differential Revision: D25992202
fbshipit-source-id: dadd63b78088c129e491d78abaf8b33d8303ca0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51115
Add enum type for dispatch key. Prepare to implement the DispatchTable
computation logic in python for static dispatch.
Verified byte-for-byte compatibility of the codegen output.
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D26077430
Pulled By: ljk53
fbshipit-source-id: 86e74f3eb32266f31622a2ff6350b91668c8ff42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51248
Fix bug raised in https://github.com/pytorch/pytorch/issues/50980 by adding a dtype check back to bmm_out_or_baddbmm_.
Test Plan:
```
buck test //caffe2/test:linalg
buck test //caffe2/aten:math_kernel_test
```
Reviewed By: ngimel
Differential Revision: D26113575
fbshipit-source-id: 0d6e03eae70822f8ceeffefd915aee01030304ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50870
**Summary**
Module attributes whose types cannot be determined based on annotations
or inference based on their values at script time are added to the
concrete type of the corresponding module as "failed attributes". Any
attempt to access them in scripted code produces an error with a message
explaining that the attribute could not be contributed to a
corresponding attribute on the TorchScript module. However, this error
is not more specific than that.
This commit modifies `infer_type` in `_recursive.py` so that it returns
`c10::InferredType` instead, which allows more information about typing
failures to be communicated to the caller through the `reason()` method
on this class. This information is appended to the hint added to the
module concrete type for failed attributes.
**Testing**
This commit adds a unit test to `test_module_containers.py` that checks
that extra information is provided about the reason for the failure
when a module attribute consisting of a list of `torch.nn.Module` fails to convert.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26091472
Pulled By: SplitInfinity
fbshipit-source-id: fcad6588b937520f250587f3d9e005662eb9af0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51159
This PR is the cleanup after #50561. High level, we make the new
definition of fake_quant be the definition used by autograd, but keep the old
function around as a thin wrapper to keep the user facing API the same.
In detail:
1. point `fake_quantize_per_tensor_affine`'s implementation to be `fake_quantize_per_tensor_affine_cachemask`
2. delete the `fake_quantize_per_tensor_affine` backward, autograd will automatically use the cachemask backward
3. delete all the `fake_quantize_per_tensor_affine` kernels, since they are no longer used by anything
Test Plan:
```
python test/test_quantization.py TestFakeQuantize
```
performance testing was done in the previous PR.
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26090869
fbshipit-source-id: fda042881f77a993a9d15dafabea7cfaf9dc7c9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50561
Not for review yet, a bunch of TODOs need finalizing.
tl;dr; add an alternative implementation of `fake_quantize` which saves
a ask during the forward pass and uses it to calculate the backward.
There are two benefits:
1. the backward function no longer needs the input Tensor, and it can be
gc'ed earlier by autograd. On MobileNetV2, this reduces QAT overhead
by ~15% (TODO: link, and absolute numbers). We add an additional mask Tensor
to pass around, but its size is 4x smaller than the input tensor. A
future optimization would be to pack the mask bitwise and unpack in the
backward.
2. the computation of `qval` can be done only once in the forward and
reused in the backward. No perf change observed, TODO verify with better
matrics.
TODO: describe in more detail
Test Plan:
OSS / torchvision / MobileNetV2
```
python references/classification/train_quantization.py
--print-freq 1
--data-path /data/local/packages/ai-group.imagenet-256-smallest-side/prod/
--output-dir ~/nfs/pytorch_vision_tests/
--backend qnnpack
--epochs 5
TODO paste results here
```
TODO more
Imported from OSS
Reviewed By: ngimel
Differential Revision: D25918519
fbshipit-source-id: ec544ca063f984de0f765bf833f205c99d6c18b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50955
Preserve name of parameters for ONNX.
Looks like output->copyMetadata(input) API is giving the same debugName to the output. So the name of the original input is changed. This update avoid the name change by just copying the type.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26050880
Pulled By: SplitInfinity
fbshipit-source-id: 8b04e41e6df7f33c5c9c873fb323c21462fc125b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50954
* Replace optional parameters of Resize with placeholder for ops13.
* Use common methods to handle different versions.
* Correct flake8 issue.
* Update per comments.
* Add something to trigger CI again.
* Trigger another round of CI.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26050882
Pulled By: SplitInfinity
fbshipit-source-id: aea6205a1ba4a0621fe1ac9e0c7d94b92b6d8f21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50911
Need to replace dtype of export created scalars from float to double. (In torch implicit conversion logic, python numbers are double)
Test case skipped in CI due to that current CI job env does not have CUDA support.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26050889
Pulled By: SplitInfinity
fbshipit-source-id: 1fdde23a68d4793e6b9a82840acc213e5c3aa760
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50910
Fixing pytorch/vision#3251 (PR #49410 triggers the torch vision test build failure, on three tests test_faster_rcnn, test_mask_rcnn, test_keypoint_rcnn. )
The offending PR is fine on pytorch UT, because the torchvision and pytorch test has a gap when we merge them - we are using different test API on two sides, therefore causing some discrepancy.
This PR bridge the gap for the above three tests, and disable _jit_pass_onnx_fold_if pass until it gets fixed.
Allow _jit_pass_onnx_fold_if only when dynamic_axes is None.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26050886
Pulled By: SplitInfinity
fbshipit-source-id: b765ffe30914261866dcc761f0d0999fd16169e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50906
In opset 13, squeeze/unsqueeze is updated to take axes as input, instead of attribute.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26050883
Pulled By: SplitInfinity
fbshipit-source-id: 7b5faf0e016d476bc75cbf2bfee6918d77e8aecd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50905
Adds an additional run of onnx shape inference after constant folding, since initializer may have changed and affected shape inference.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D26050881
Pulled By: SplitInfinity
fbshipit-source-id: 9e5d69c52b647133cd3a0781988e2ad1d1a9c09d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51124
Original commit changeset: 1c7133627da2
Test Plan: Test locally with interpreter_test and on CI
Reviewed By: suo
Differential Revision: D26077905
fbshipit-source-id: fae83bf9822d79e9a9b5641bc5191a7f3fdea78d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50995
This change makes 'Tensor' a thin wrapper over 'Buf' and 'Stmt', and
merges it with recently introduced 'CompoundTensor'. A statement for the
tensor is either passed directly to the Tensor constructor (akin to
'CompoundTensor'), or is built immediately in constructor.
LoopNest is no longer responsible for constructing statements from
tensors - it simply stitches already constructed statements contained in
Tensors. This has a side effect that now we cannot construct several
loopnests from the same tensors - we need to explicitly clone statements
if we want to do that. A special copy constructor was added to LoopNest
to make it more convenient (note: this only affects tests, we don't
usually create multiple loopnests in other places).
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D26038223
Pulled By: ZolotukhinM
fbshipit-source-id: 27a2e5900437cfb0c151e8f89815edec53608e17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50994
Eventually, 'Tensor' will be fully responsible for its 'Stmt' and moving
this method to it is one step in that direction.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D26038222
Pulled By: ZolotukhinM
fbshipit-source-id: 0549f0ae6b46a93ff7608a22e79faa5115eef661
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50993
This is the first step to make 'Tensor` a thin wrapper over 'Buf' and
'Stmt', which will be finished in subsequent PRs. This change also
allows to remove 'buf_initializers_' from 'LoopNest', making it "less
stateful".
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D26038224
Pulled By: ZolotukhinM
fbshipit-source-id: f418816e54c62f291fa45812901487394e9b95b5
Summary:
The attributes in `dir(mod)` may not be valid, this will throw error when calling `getattr`.
Use `hasattr` to test if it is valid.
Here is an example:
```python
class A:
def __init__(self, x):
if x:
self._attr = 1
property
def val(self):
return getattr(self, '_attr')
a = A(False)
print('val' in dir(a))
print(hasattr(a, 'val'))
b = A(True)
print('val' in dir(b))
print(hasattr(b, 'val'))
```
And the outputs:
```
True
False
True
True
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50680
Reviewed By: malfet
Differential Revision: D26103975
Pulled By: eellison
fbshipit-source-id: 67a799afe7d726153c91654d483937c5e198ba94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51057
Caffe2 has an
[optimization](f8eefbdf7a/caffe2/operators/batch_matmul_op.h (L192))
for the case where the batch size is 1 that uses the underlying `gemm`
instead of `gemm_batched` BLAS function. This diff tries to port that
optimization to `baddbmm_mkl`.
Note that I have very little linear algebra background and am just
going off existing code and cblas API documentation, so please
review without assuming I know what I'm doing with the math itself.
ghstack-source-id: 120342923
Reviewed By: hlu1
Differential Revision: D26056613
fbshipit-source-id: feef80344b96601fc2bd0a2e8c8f6b57510d7856
Summary:
Similar with Optimizer.step(), profile.next_step() occurs every iteration and calls at the end of each iteration. So it's better to make them same naming style.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51032
Reviewed By: heitorschueroff
Differential Revision: D26097847
Pulled By: ilia-cher
fbshipit-source-id: ea2e5c8e865d99f90b004ec7797271217efeeb68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51180
This fast path still did a refcount bump because it copied the inner intrusive_ptr to the stack. Now it's moved.
ghstack-source-id: 120460258
Test Plan:
1) profile empty benchmark & inspect assembly to verify move
2) run framework overhead benchmarks
Reviewed By: bhosmer
Differential Revision: D26094951
fbshipit-source-id: b2e09f9ad885cb633402885ca1e61a370723f6b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44859
TensorPipe's `set_device_map` option was applied during the forward
pass. However, if we ran the backward pass for the graph we would not
automatically pick up the reverse device mapping.
As a result, users had to specify both forward and backward device mapping
which is very tedious to do.
In this PR, I've added this functionality such that TensorPipe automatically
picks up the reverse device mapping during the backward pass. This is done by
storing the appropriate device mapping in the "recv" autograd function for
distributed autograd.
#Closes: https://github.com/pytorch/pytorch/issues/44170
ghstack-source-id: 119950842
Test Plan:
1) waitforbuildbot
2) Unit test added.
Reviewed By: mrshenli
Differential Revision: D23751975
fbshipit-source-id: 2717d0ef5bde3db029a6172d98aad95734d52140
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50760
The SHM transport uses shared-memory-backed ringbuffers to transfer small payloads between processes on the same machine.
It was disabled in v1.6 due to a CMake mishap but we've since realized that it also doesn't work that well in docker and other setups. Enabling it here to see whether CircleCI fails.
ghstack-source-id: 120470890
Test Plan: Exported three times to CircleCI with tests consistently passing
Reviewed By: mrshenli
Differential Revision: D23814828
fbshipit-source-id: f355cb6515776debad536924de4f4d3fbb05a874
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51168
Adds types to function I/O for numeric suite. This is for readability
and static type checking with mypy.
Test Plan:
```
mypy torch/quantization/
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D26092454
fbshipit-source-id: d37cf61e4d9604f4bc550b392f55fb59165f7624
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49824
## Background
When creating a view of a view, there was a possibility that the new view would be less restrictive than the previous view, incorrectly sidestepping the error that should be thrown when using in-place operations on the new view.
The fix addresses this by propagating `CreationMeta` from the previous view to the new view. Currently, the old view's `creation_meta` is only propagated when the new view's `creation_meta == CreationMeta::DEFAULT`. This ensures that the new view is not less restrictive than the previous view wrt. allowing in-place operations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51061
Test Plan:
```
python test/test_autograd.py TestAutogradDeviceTypeCPU.test_inplace_view_of_multiple_output_view_cpu
python test/test_autograd.py TestAutogradDeviceTypeCUDA.test_inplace_view_of_multiple_output_view_cuda
python test/test_autograd.py TestAutogradDeviceTypeCPU.test_inplace_multiple_output_view_of_view_cpu
python test/test_autograd.py TestAutogradDeviceTypeCUDA.test_inplace_multiple_output_view_of_view_cuda
```
Reviewed By: heitorschueroff
Differential Revision: D26076434
Pulled By: jbschlosser
fbshipit-source-id: c47f0ddcef9b8449427b671aff9ad08edca70fcd
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50330
- Encapsulate the `make html` call and capture the stdout/stderr with a `tee` command
- If the buld fails, print out the `WARNING:` lines of the build log and finish up with a message
I tried it out on my branch, but did not write a test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50356
Reviewed By: ezyang
Differential Revision: D26101762
Pulled By: brianjo
fbshipit-source-id: ba2b704d3244ef5139ca9026c5250537bf45734f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50915Fixes#50584
Add a vectorize flag to torch.autograd.functional.jacobian and
torch.autograd.functional.hessian (default: False). Under the hood, the
vectorize flag uses vmap as the backend to compute the jacobian and
hessian, respectively, providing speedups to users.
Test Plan:
- I updated all of the jacobian and hessian tests to also use
vectorized=True
- I added some simple sanity check tests that check e.g. jacobian with
vectorized=False vs
jacobian with vectorized=True.
- The mechanism for vectorized=True goes through batched gradient
computation. We have separate tests for those (see other PRs in this
stack).
Reviewed By: heitorschueroff
Differential Revision: D26057674
Pulled By: zou3519
fbshipit-source-id: a8ae7ca0d2028ffb478abd1b377f5b49ee39e4a1
Summary:
A tiny PR to update the links in the lefthand navbar under Libraries. The canonical link for vision and text is `https://pytorch.org/vision/stable` and `https://pytorch.org/text/stable` respectively. The link without the `/stable` works via a redirect, this is cleaner.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51103
Reviewed By: izdeby
Differential Revision: D26079760
Pulled By: heitorschueroff
fbshipit-source-id: df1fa64d7895831f4e6242445bae02c1faa5e4dc
Summary:
Fixes #{issue number}
This is not really a new issue, just a proposed minor fix to a recent previous issue (now closed) https://github.com/pytorch/pytorch/issues/50640 which was a fix for https://github.com/pytorch/pytorch/issues/50439.
That fix added inlining for vec_signed (and others) but in one case the return was accidentally omitted. This results in a build error:
``` from �[01m�[K../aten/src/ATen/cpu/vec256/vec256.h:19�[m�[K,
from �[01m�[Katen/src/ATen/native/cpu/FillKernel.cpp.VSX.cpp:3�[m�[K:
�[01m�[K../aten/src/ATen/cpu/vec256/vsx/vsx_helpers.h:�[m�[K In function ‘�[01m�[Kvint32 vec_signed(const vfloat32&)�[m�[K’:
�[01m�[K../aten/src/ATen/cpu/vec256/vsx/vsx_helpers.h:33:1:�[m�[K �[01;31m�[Kerror: �[m�[Kno return statement in function returning non-void [�[01;31m�[K-Werror=return-type�[m�[K]
```
I've confirmed that the error disappears after this one-line fix. (Note: There is another issue encountered later in the build unrelated to this particular fix, as I noted in a separate comment in the original issue. I'm trying to make some sense of that one, but in any event it would be a subject for another issue/PR).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51116
Reviewed By: heitorschueroff
Differential Revision: D26078213
Pulled By: malfet
fbshipit-source-id: 59b2ee19138fa1b8d8ec1d35ca4a5ef0a67bc123
Summary:
On Ampere GPU, matmuls are computed by default with TF32 when the dtype is `torch.float`: https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices, which results in reduced precision in results. However, linear algebra usually need higher precision, therefore lots of tests in `test_linalg.py` are failing on Ampere GPU because of precision issue.
To fix this issue:
- Most linear algebra methods, except for matmuls, should add `NoTF32Guard`
- Expected results in unit tests should compute matmuls using numpy instead of pytorch cuda.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50453
Reviewed By: glaringlee
Differential Revision: D26023005
Pulled By: ngimel
fbshipit-source-id: f0ea533494fee322b07925565b57e3b0db2570c5
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50378.
Additionally, this has some minor fixes:
- [x] Fix mean for half-cauchy to return `inf` instead of `nan`.
- [x] Fix constraints/support for the relaxed categorical distribution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51053
Reviewed By: heitorschueroff
Differential Revision: D26077966
Pulled By: neerajprad
fbshipit-source-id: ca0213baa9bbdbc661aebbb901ab5e7fded38a5f
Summary:
as in title
resolves D25791248 (069602e028)
Test Plan: buck test //caffe2/aten:vitals
Reviewed By: EscapeZero, malfet
Differential Revision: D26090442
fbshipit-source-id: 07937f246ec0a6eb338d21208ada61758237ae42
Summary:
In order to enable FC int8 quantization in P2C2, we are trying to run the caffe2 op Int8FCPackWeight in the model transformation pipeline.
The net is being generated from the python side, and passed back into C++ and run here: https://fburl.com/diffusion/3zt1mp03, with these dependencies included: https://fburl.com/diffusion/rdjtdtcf
However, when the net is executed, it errors out with:
```
Cannot create operator of type 'Int8FCPackWeight' on the device 'CPU'
```
This diff attempts to fix this issue.
Test Plan:
To reproduce, just this test without
```
buck test //aiplatform/modelstore/transformation/tests:pyper_to_caffe2_dispatcher_test
```
Reviewed By: jspark1105
Differential Revision: D25965167
fbshipit-source-id: a7414669abb8731177c14e8792de58f400970732
Summary:
Fixes https://github.com/pytorch/pytorch/issues/3307
Previously, `self.grad` was not ~cloned~ deepcopied to the returned tensor in `deepcopy`. Added a test and an implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50663
Reviewed By: heitorschueroff
Differential Revision: D26074811
Pulled By: albanD
fbshipit-source-id: 536dad36415f1d03714b4ce57453f406ad802b8c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50695.
Rather than maintain a LICENSE_BUNDLED.txt by hand, this build it out of the subrepos.
I ~copied and adapted the sdist handling from Numpy~ added a separate file, so the LICENSE.txt file of the repo remains in pristine condition and the GitHub website still recognizes it. If we modify the file, the website will no longer recognize the license.
This is not enough, since the license in the ~wheel~ wheel and sdist is not modified. Numpy has a [separate step](https://github.com/MacPython/numpy-wheels/blob/master/patch_code.sh) when preparing the wheel to concatenate the licenses. I am not sure where/if the [conda-forge numpy-feedstock](https://github.com/conda-forge/numpy-feedstock/) also fixes up the license.
~Should~ I ~commit~ commited the artifact to the repo and ~add~ added a test that reproducing the file is consistent.
Edit: now the file is part of the repo.
Edit: rework the mention of sdist. After this is merged another PR is needed to make the sdist and wheel ship the proper merged license.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50745
Reviewed By: seemethere, heitorschueroff
Differential Revision: D26074974
Pulled By: walterddr
fbshipit-source-id: bacd5d6870e9dbb419a31a3e3d2fdde286ff2c94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51047
If the environment variable `TORCH_VITAL` is set to a non-zero length string, the vitals a dumped at program end.
The API is very similar to google's logging
Test Plan: buck test //caffe2/aten:vitals
Reviewed By: bitfort
Differential Revision: D25791248
fbshipit-source-id: 0b40da7d22c31d2c4b2094f0dcb1229a35338ac2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50630
Add a warning log to distributed optimizer, to warn user the optimizer
is created without TorchScript support.
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D25932777
Pulled By: wanchaol
fbshipit-source-id: 8db3b98bdd27fc04c5a3b8d910b028c0c37f138d
Summary:
Closes https://github.com/pytorch/pytorch/issues/50513 by resolving all four checkboxes. If this PR is merged, I will also modify one or both of the following wiki pages to add instructions on how to use this `mypy` wrapper for VS Code editor integration:
- [Guide for adding type annotations to PyTorch](https://github.com/pytorch/pytorch/wiki/Guide-for-adding-type-annotations-to-PyTorch)
- [Lint as you type](https://github.com/pytorch/pytorch/wiki/Lint-as-you-type)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50826
Test Plan:
Unit tests for globbing function:
```
python test/test_testing.py TestMypyWrapper -v
```
Manual checks:
- Uninstall `mypy` and run `python test/test_type_hints.py` to verify that it still works when `mypy` is absent.
- Reinstall `mypy` and run `python test/test_type_hints.py` to verify that this didn't break the `TestTypeHints` suite.
- Run `python test/test_type_hints.py` again (should finish quickly) to verify that this didn't break `mypy` caching.
- Run `torch/testing/_internal/mypy_wrapper.py` on a few Python files in this repo to verify that it doesn't give any additional warnings when the `TestTypeHints` suite passes. Some examples (compare with the behavior of just running `mypy` on these files):
```sh
torch/testing/_internal/mypy_wrapper.py $PWD/README.md
torch/testing/_internal/mypy_wrapper.py $PWD/tools/fast_nvcc/fast_nvcc.py
torch/testing/_internal/mypy_wrapper.py $PWD/test/test_type_hints.py
torch/testing/_internal/mypy_wrapper.py $PWD/torch/random.py
torch/testing/_internal/mypy_wrapper.py $PWD/torch/testing/_internal/mypy_wrapper.py
```
- Remove type hints from `torch.testing._internal.mypy_wrapper` and verify that running `mypy_wrapper.py` on that file gives type errors.
- Remove the path to `mypy_wrapper.py` from the `files` setting in `mypy-strict.ini` and verify that running it again on itself no longer gives type errors.
- Add `test/test_type_hints.py` to the `files` setting in `mypy-strict.ini` and verify that running the `mypy` wrapper on it again now gives type errors.
- Change a return type in `torch/random.py` and verify that running the `mypy` wrapper on it again now gives type errors.
- Add the suggested JSON from the docstring of `torch.testing._internal.mypy_wrapper.main` to your `.vscode/settings.json` and verify that VS Code gives the same results (inline, while editing any Python file in the repo) as running the `mypy` wrapper on the command line, in all the above cases.
Reviewed By: walterddr
Differential Revision: D26049052
Pulled By: samestep
fbshipit-source-id: 0b35162fc78976452b5ea20d4ab63937b3c7695d
Summary:
`ResolutionCallback` returns `py::object` (i.e. `Any`) rather than `py::function` (i.e. `Callable`)
Discovered while debugging test failures after updating pybind11
This also makes resolution code slightly faster, as it eliminates casts from object to function and back for every `py::object obj = rcb_(name);` statement.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51089
Reviewed By: jamesr66a
Differential Revision: D26069295
Pulled By: malfet
fbshipit-source-id: 6876caf9b4653c8dc8e568aefb6778895decea05
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: f463e0ebfc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50946
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D26018916
fbshipit-source-id: dc8aaa98d4e002e972d5c6783f2351c29f7db239
Summary:
Removed skipCUDAIfRocm to re-enable tests for
ROCM platform.
Initially, Only 4799 cases were being run.
Out of those, 882 cases were being skipped.
After removing skipCUDAIfRocm from two places
in test_ops.py, now more than 8000 cases are
being executed, out of which only 282 cases
are bing skipped, which are FFT related tests.
Signed-off-by: Arindam Roy <rarindam@gmail.com>
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50500
Reviewed By: albanD
Differential Revision: D25920303
Pulled By: mrshenli
fbshipit-source-id: b2d17b7e2d1de4f9fdd6f1660fb4cad5841edaa0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50744
This PR adds a `check_batched_grad=True` option to CriterionTest and
turns it on by default for all CriterionTest-generated tests
Test Plan: - run tests
Reviewed By: ejguan
Differential Revision: D25997676
Pulled By: zou3519
fbshipit-source-id: cc730731e6fae2bddc01bc93800fd0e3de28b32d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50973
This can extend the original PowerSGD method to a hybrid approach: vanilla allreduce + PowerSGD. This can help further improve the accuracy, at the cost of a lower speedup.
Also add more comments on the fields in `PowerSGDState`.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 120257202
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_DistributedDataParallel_powerSGD_ddp_comm_hook
Reviewed By: rohan-varma
Differential Revision: D26031478
fbshipit-source-id: d72e70bb28ba018f53223c2a4345306980b3084e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51051
Disable input pointer caching on ios. We are seeing some issues with this on some ios devices.
Test Plan:
FB:
Test this in of IG with BT effect.
Reviewed By: IvanKobzarev, AshkanAliabadi
Differential Revision: D25984429
fbshipit-source-id: f6ceef606994b22de9cdd9752115b3481cd7bd96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51043
This PR makes `fast_nvcc` stop at failing commands, rather than continuing on to run commands that would otherwise run after those commands. It is still possible for `fast_nvcc` to run more commands than `nvcc` would run if there's no dependency between them, but this should still help to reduce noise from failing `fast_nvcc` runs.
Test Plan: Unfortunately the test suite for this script is FB-internal. It would probably be a good idea to move it into the PyTorch GitHub repo, but I'm not entirely sure how to do so, since I don't believe we currently have a good place to put tests for things in `tools`.
Reviewed By: malfet
Differential Revision: D26007788
fbshipit-source-id: 8fe1e7d020a29d32d08fe55fb59229af5cdfbcaa
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50496
Fixes https://github.com/pytorch/pytorch/issues/34859
Fixes https://github.com/pytorch/pytorch/issues/21596
This fixes many bugs involving `TransformedDistribution` and `ComposeTransform` when the component transforms changed their event shapes. Part of the fix is to introduce an `IndependentTransform` analogous to `distributions.Independent` and `constraints.independent`, and to introduce methods `Transform.forward_shape()` and `.inverse_shape()`. I have followed fehiepsi's suggestion and replaced `.input_event_dim` -> `.domain.event_dim` and `.output_event_dim` -> `.codomain.event_dim`. This allows us to deprecate `.event_dim` as an attribute.
## Summary of changes
- Fixes `TransformDistribution` and `ComposeTransform` shape errors.
- Fixes a behavior bug in `LogisticNormal`.
- Fixes `kl_divergence(TransformedDistribution, TransformedDistribution)`
- Adds methods `Transform.forward_shape()`, `.inverse_shape()` which are required for correct shape computations in `TransformedDistribution` and `ComposeTransform`.
- Adds an `IndependentTransform`.
- Adds a `ReshapeTransform` which is invaluable in testing shape logic in `ComposeTransform` and `TransformedDistribution` and which will be used by stefanwebb flowtorch.
- Fixes incorrect default values in `constraints.dependent.event_dim`.
- Documents the `.event_dim` and `.is_discrete` attributes.
## Changes planned for follow-up PRs
- Memoize `constraints.dependent_property` as we do with `lazy_property`, since we now consult those properties much more often.
## Tested
- [x] added a test for `Dist.support` vs `Dist(**params).support` to ensure static and dynamic attributes agree.
- [x] refactoring is covered by existing tests
- [x] add test cases for `ReshapedTransform`
- [x] add a test for `TransformedDistribution` on a wide grid of input shapes
- [x] added a regression test for https://github.com/pytorch/pytorch/issues/34859
cc fehiepsi feynmanliang stefanwebb
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50581
Reviewed By: ezyang, glaringlee, jpchen
Differential Revision: D26024247
Pulled By: neerajprad
fbshipit-source-id: f0b9a296f780ff49659b132409e11a29985dde9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50622
1. Define a DDPLoggingData struct that is the placeholder for all the ddp related logging fields
2. Put the DDPLoggingData struct in the C10 directory so that it can be easily imported by c10 and torch files
3. Expose get_ddp_logging_data() method in python so that users can get the logging data and dump in their applications
4. Unit test tested the logging data can be set and got as expected
5. Follow up will add more logging fields such as perf stats, internal states, env variables and etc
ghstack-source-id: 120275870
Test Plan: unit tests
Reviewed By: SciPioneer
Differential Revision: D25930527
fbshipit-source-id: 290c200161019c58e28eed9a5a2a7a8153113f99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50458
libinterpreter.so contains a frozen python distribution including
torch-python bindings.
Freezing refers to serializing bytecode of python standard library modules as
well as the torch python library and embedding them in the library code. This
library can then be dlopened multiple times in one process context, each
interpreter having its own python state and GIL. In addition, each python
environment is sealed off from the filesystem and can only import the frozen
modules included in the distribution.
This change relies on newly added frozenpython, a cpython 3.8.6 fork built for this purpose. Frozenpython provides libpython3.8-frozen.a which
contains frozen bytecode and object code for the python standard library.
Building on top of frozen python, the frozen torch-python bindings are added in
this diff, providing each embedded interpreter with a copy of the torch
bindings. Each interpreter is intended to share one instance of libtorch and
the underlying tensor libraries.
Known issues
- Autograd is not expected to work with the embedded interpreter currently, as it manages
its own python interactions and needs to coordinate with the duplicated python
states in each of the interpreters.
- Distributed and cuda stuff is disabled in libinterpreter.so build, needs to be revisited
- __file__ is not supported in the context of embedded python since there are no
files for the underlying library modules.
using __file__
- __version__ is not properly supported in the embedded torch-python, just a
workaround for now
Test Plan: tested locally and on CI with cmake and buck builds running torch::deploy interpreter_test
Reviewed By: ailzhang
Differential Revision: D25850783
fbshipit-source-id: a4656377caff25b73913daae7ae2f88bcab8fd88
Summary:
**BC-breaking note:**
torch.svd() added support for complex inputs in PyTorch 1.7, but was not documented as doing so. The complex "V" tensor returned was actually the complex conjugate of what's expected. This PR fixes the discrepancy.
This will silently break all users of torch.svd() with complex inputs.
**Original PR Summary:**
This PR resolves https://github.com/pytorch/pytorch/issues/45821.
The problem was that when introducing the support of complex inputs for `torch.svd` it was overlooked that LAPACK/MAGMA returns the conjugate transpose of V matrix, not just the transpose of V. So `torch.svd` was silently returning U, S, V.conj() instead of U, S, V.
Behavior of `torch.linalg.pinv`, `torch.pinverse` and `torch.linalg.svd` (they depend on `torch.svd`) is not changed in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51012
Reviewed By: bdhirsh
Differential Revision: D26047593
Pulled By: albanD
fbshipit-source-id: d1e08dbc3aab9ce1150a95806ef3b5da98b5d3ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50868
Ensures that `FakeQuantize` respects device affinity when loading from
state_dict, and knows how to resize scale and zero_point values
(which is necessary for FQ classes wrapping per channel observers).
This is same as https://github.com/pytorch/pytorch/pull/44537, but for
`FakeQuantize`.
Test Plan:
```
python test/test_quantization.py TestObserver.test_state_dict_respects_device_affinity
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25991570
fbshipit-source-id: 1193a6cd350bddabd625aafa0682e2e101223bb1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50791
Add a dedicated pipeline parallelism doc page explaining the APIs and
the overall value of the module.
ghstack-source-id: 120257168
Test Plan:
1) View locally
2) waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D25967981
fbshipit-source-id: b607b788703173a5fa4e3526471140506171632b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50957
MAGMA has an off-by-one error in their batched cholesky implementation which is causing illegal memory access for certain inputs. The workaround implemented in this PR is to pad the input to MAGMA with 1 extra element.
**Benchmark**
Ran the script below for both before and after my PR and got similar results.
*Script*
```
import torch
from torch.utils import benchmark
DTYPE = torch.float32
BATCHSIZE = 512 * 512
MATRIXSIZE = 16
a = torch.eye(MATRIXSIZE, device='cuda', dtype=DTYPE)
t0 = benchmark.Timer(
stmt='torch.cholesky(a)',
globals={'a': a},
label='Single'
)
t1 = benchmark.Timer(
stmt='torch.cholesky(a)',
globals={'a': a.expand(BATCHSIZE, -1, -1)},
label='Batched'
)
print(t0.timeit(100))
print(t1.timeit(100))
```
*Results before*
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7faf9bc63400>
Single
2.08 ms
1 measurement, 100 runs , 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7faf9bc63400>
Batched
7.68 ms
1 measurement, 100 runs , 1 thread
```
*Results after*
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7faf9bc63400>
Single
2.10 ms
1 measurement, 100 runs , 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7faf9bc63400>
Batched
7.56 ms
1 measurement, 100 runs , 1 thread
```
Fixes https://github.com/pytorch/pytorch/issues/41394, https://github.com/pytorch/pytorch/issues/26996, https://github.com/pytorch/pytorch/issues/48996
See also https://github.com/pytorch/pytorch/issues/42666, https://github.com/pytorch/pytorch/pull/26789
TODO
---
- [x] Benchmark to check for perf regressions
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D26050978
Pulled By: heitorschueroff
fbshipit-source-id: 7a5ba7e34c9d74b58568b2a0c631cc6d7ba63f86
Summary:
- Resolves ngimel's review comments in https://github.com/pytorch/pytorch/pull/49109
- Move `ConvolutionArgs` from `ConvShared.h` to `Conv_v7.cpp`, because cuDNN v8 uses different descriptors therefore will not share the same `ConvolutionArgs`.
- Refactor the `ConvolutionParams` (the hash key for benchmark):
- Remove `input_stride`
- Add `input_dim`
- Add `memory_format`
- Make `repro_from_args` to take `ConvolutionParams` instead of `ConvolutionArgs` as arguments so that it can be shared for v7 and v8
- Rename some `layout` to `memory_format`. `layout` should be sparse/strided and `memory_format` should be contiguous/channels_last. They are different things.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50827
Reviewed By: bdhirsh
Differential Revision: D26048274
Pulled By: ezyang
fbshipit-source-id: f71aa02d90ffa581c17ab05b171759904b311517
Summary:
The test is flaky on ROCM when deadline is set to 1 second. This is affecting builds as it is failing randomly.
Disabling for now.
Signed-off-by: Arindam Roy <rarindam@gmail.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50964
Reviewed By: houseroad
Differential Revision: D26049370
Pulled By: BIT-silence
fbshipit-source-id: 22337590a8896ad75f1281e56fbbeae897f5c3b2
Summary:
This simplifies our handling and allows passing CompilationUnits from Python to C++ defined functions via PyBind easily.
Discussed on Slack with SplitInfinity
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50614
Reviewed By: anjali411
Differential Revision: D25938005
Pulled By: SplitInfinity
fbshipit-source-id: 94aadf0c063ddfef7ca9ea17bfa998d8e7b367ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50794
Original commit changeset: b4a7948088c0
There are some subtle extra tweaks on top of the original. I can unbundle them, but I've opted to keep it with the port because it's the easiest way to make sure the changes are exercised.
* There's a bugfix in the codegen to test if a dispatch key is structured *before* short circuiting because the dispatch key was missing in the table. This accounts for mixed structured-nonstructured situations where the dispatch table is present, but the relevant structured key isn't (because the dispatch table only exists to register, e.g., QuantizedCPU)
* Dispatch tables for functions which delegate to structured kernels don't have Math entries from generated for them.
* It's now illegal to specify a structured dispatch key in a delegated structured kernel (it will be ignored!) add is now fixed to follow this
* There are some extra sanity checks for NativeFunctions validation
* Finally, unlike the original PR, I switched the .vec variant of upsample_nearest2d to also be DefaultBackend, bringing it inline with upsample_nearest1d.
ghstack-source-id: 120038038
Test Plan:
```
buck test mode/dev //coreai/tiefenrausch:python_tests -- --exact 'coreai/tiefenrausch:python_tests - test_can_run_local_async_inference_cpu (coreai.tiefenrausch.tests.python_test.TiefenrauschPY)' --run-disabled
```
Reviewed By: ngimel
Differential Revision: D25962873
fbshipit-source-id: d29a9c97f15151db3066ae5efe7a0701e6dc05a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50817
Replace some longs with int64_t. Thanks Tom Heaven for contributing
this patch.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D25975915
Pulled By: ezyang
fbshipit-source-id: c1061a85f80ad17fa4fb313da797bc6d5ba203c2
Summary:
Relate to https://github.com/pytorch/pytorch/issues/50483.
Everything except ONNX, detectron and release notes tests are moved to use common_utils.run_tests() to ensure CI reports XML correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50923
Reviewed By: samestep
Differential Revision: D26027621
Pulled By: walterddr
fbshipit-source-id: b04c03f10d1fe96181b720c4c3868e86e4c6281a
Summary:
Follow up to https://github.com/pytorch/pytorch/issues/50435
I have confirmed this works by running
```
pytest test_ops.py -k test_fn_gradgrad_fft`
```
with normally and with `PYTORCH_TEST_WITH_SLOW=1 PYTORCH_TEST_SKIP_FAST=1`. In the first case all tests are skipped, in the second they all run as they should.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50501
Reviewed By: ezyang
Differential Revision: D25956416
Pulled By: mruberry
fbshipit-source-id: c896a8cec5f19b8ffb9b168835f3743b6986dad7
Summary:
Do it by removing extraneous header dependencies.
None of the at::vec256 primitive depend on notion of Tensor, therefore none of the headers that vec256 depends on should include <ATen/Tensor.h>
Implicity test it be removing c10 and tensor dependency when building `vec256_test_all_types`
Split affine_quantizer into affine_quantizer_base (that contains methods operating on raw types) and affine_quantizer (which contains Tensor specific methods)
Fixes https://github.com/pytorch/pytorch/issues/50567
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50708
Reviewed By: walterddr
Differential Revision: D25949168
Pulled By: malfet
fbshipit-source-id: c3323be7252865a52c7d94026a5a39b494e44efb
Summary:
Pull Request resolved: https://github.com/pytorch/glow/pull/5257
- Add RescaleQuantized parallelization support to graph opts' parallelization code
- On NNPI, mirror Rescale parallelization for FC/Relus that come before it
- Sink Reshapes below Quantize and ConvertTo
- Remove unnecessary ConvertTo when following a Dequantize (i.e. just change the elem kind of the Dequantize instead)
Test Plan: Added unit tests
Reviewed By: hyuen, mjanderson09
Differential Revision: D25947824
fbshipit-source-id: 771abd36a1bc7270bf1f901d1ec6cb6d78e9fd1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50321
Quantization team reported that when there are two empty tensors are replicated among ranks, the two empty tensors start to share storage after resizing.
The root cause is unflatten_dense_tensor unflattened the empty tensor as view of flat tensor and thus share storage with other tensors.
This PR is trying to avoid unflatten the empty tensor as view of flat tensor so that empty tensor will not share storage with other tensors.
Test Plan: unit test
Reviewed By: pritamdamania87
Differential Revision: D25859503
fbshipit-source-id: 5b760b31af6ed2b66bb22954cba8d1514f389cca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50851
Improves upon the previous unittest to ensure allreduce_hook results in the same gradients as vanilla allreduce in DDP.
ghstack-source-id: 120229103
Test Plan:
buck build mode/dev-nosan //caffe2/test/distributed:distributed_nccl_fork --keep-going
BACKEND=nccl WORLD_SIZE=2 ~/fbcode/buck-out/dev/gen/caffe2/test/distributed/distributed_nccl_fork#binary.par -r test_ddp_hook_parity
Reviewed By: SciPioneer
Differential Revision: D25963654
fbshipit-source-id: d55eee0aee9cf1da52aa0c4ba1066718aa8fd9a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50932
After the change to split `_load_for_mobile()` into multiple methods, one which takes in the `extra_files` map, and one which doesn't, we can change the implementation of the `deserialize()` method with different overloads as well. Suggested by raziel on D25968216 (bb909d27d5).
ghstack-source-id: 120185089
Test Plan: Build/Sandcastle.
Reviewed By: JacobSzwejbka
Differential Revision: D26014084
fbshipit-source-id: 914142137346a6246def1acf38a3204dd4c4f52f
Summary:
`philox_engine_inputs()` is deprecated. Callers should refactor to use `philox_cuda_state()`, and afaik all call sites in aten have already been refactored, but in the meantime on behalf of other consumers (ie extensions, possibly some lingering call sites in jit), `philox_engine_inputs` should handle the increment the same way `philox_cuda_state` does.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50916
Reviewed By: mrshenli
Differential Revision: D26022618
Pulled By: ngimel
fbshipit-source-id: 17178ad099ddc17d3596b9508ae4dce729b44f57
Summary:
Also, get rid of MSVC specific `_USE_MATH_DEFINES`
Test at compile time that c10::pi<double> == M_PI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50819
Reviewed By: albanD
Differential Revision: D25976330
Pulled By: malfet
fbshipit-source-id: 8f3ddfd58a5aa4bd382da64ad6ecc679706d1284
Summary:
This contains some improvements and refactoring to how patching is done in `torch.fx.symbolic_trace`.
1) Functions from `math.*` are now supported without needing to call `torch.fx.wrap()`. `wrap()` actually errors on some of these function because they are written in C and don't have `__code__` requiring use of the string version. `math` usage is relatively common, for example [BERT uses math.sqrt here](6f79061bd1/torchbenchmark/models/BERT_pytorch/bert_pytorch/model/attention/single.py (L16)). Both `math.sqrt()` and `from math import sqrt` (copying to module namespace) are supported. When modules are called FX now searches the module's global scope to find methods to patch.
2) [Guarded behind `env FX_PATCH_GETITEM=1`] Fixes a failed trace of [PositionalEmbedding from BERT](6f79061bd1/torchbenchmark/models/BERT_pytorch/bert_pytorch/model/embedding/position.py (L24)), which failed to trace with the error `TypeError: slice indices must be integers or None or have an __index__ method` (a Proxy() is getting passed into `Tensor.__getitem__`). See https://github.com/pytorch/pytorch/issues/50710 for why this is disabled by default.
3) Support for automatically wrapping methods that may have been copied to a different module scope via an import like `from foo import wrapped_function`. This also isn't exposed in `torch.fx.wrap`, but is used to implement `math.*` support.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50793
Test Plan: Added unittests to check each feature
Reviewed By: jamesr66a
Differential Revision: D25999788
Pulled By: jansel
fbshipit-source-id: f1ce11a69b7d97f26c9e2741c6acf9c513a84467
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50949
When converting RPC Message into Python objects, we were not using
a CUDAFuture for the chained Future. As a result, the streams are
not synchronized when calling `rpc_async(...).wait()`. This commit
uses `Future::then` API to create the chained Future, which will
be creating a CUDAFuture if the existing Future is a CUDA one.
fixes#50881fixes#50839
Test Plan: Imported from OSS
Reviewed By: pritamdamania87
Differential Revision: D26020458
Pulled By: mrshenli
fbshipit-source-id: 25195fbc10b99f4c401ec3ed7a382128464b5f08
Summary:
This PR adds a simple debugging helper which exports the AliasDb state as a [GraphViz](http://www.graphviz.org/) graph definition. The generated files can be viewed with any Graphviz viewer (including online based, for example http://viz-js.com)
Usage:
1. Call `AliasDb::dumpToGraphvizFile()` from a debugger. Using gdb for example:
`call aliasDb_->dumpToGraphvizFile("alias.dot")`
2. Add explicit calls to `AliasDb::dumpToGraphvizFile()`, which returns `true` if it succeeds.
An example output file is attached: [example.zip](https://github.com/pytorch/pytorch/files/5805840/example.zip)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50452
Reviewed By: ngimel
Differential Revision: D25980222
Pulled By: eellison
fbshipit-source-id: 47805a0a81ce73c6ba859340d37b9a806f9000d5
Summary:
Closes https://github.com/pytorch/pytorch/issues/50513 by resolving the first three checkboxes. If this PR is merged, I will also modify one or both of the following wiki pages to add instructions on how to use this `mypy` wrapper for VS Code editor integration:
- [Guide for adding type annotations to PyTorch](https://github.com/pytorch/pytorch/wiki/Guide-for-adding-type-annotations-to-PyTorch)
- [Lint as you type](https://github.com/pytorch/pytorch/wiki/Lint-as-you-type)
The test plan below is fairly manual, so let me know if I should add more automated tests to this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50826
Test Plan:
Unit tests for globbing function:
```
python test/test_testing.py TestMypyWrapper -v
```
Manual checks:
- Uninstall `mypy` and run `python test/test_type_hints.py` to verify that it still works when `mypy` is absent.
- Reinstall `mypy` and run `python test/test_type_hints.py` to verify that this didn't break the `TestTypeHints` suite.
- Run `python test/test_type_hints.py` again (should finish quickly) to verify that this didn't break `mypy` caching.
- Run `torch/testing/_internal/mypy_wrapper.py` on a few Python files in this repo to verify that it doesn't give any additional warnings when the `TestTypeHints` suite passes. Some examples (compare with the behavior of just running `mypy` on these files):
```sh
torch/testing/_internal/mypy_wrapper.py README.md
torch/testing/_internal/mypy_wrapper.py tools/fast_nvcc/fast_nvcc.py
torch/testing/_internal/mypy_wrapper.py test/test_type_hints.py
torch/testing/_internal/mypy_wrapper.py torch/random.py
torch/testing/_internal/mypy_wrapper.py torch/testing/_internal/mypy_wrapper.py
```
- Remove type hints from `torch.testing._internal.mypy_wrapper` and verify that running `mypy_wrapper.py` on that file gives type errors.
- Remove the path to `mypy_wrapper.py` from the `files` setting in `mypy-strict.ini` and verify that running it again on itself no longer gives type errors.
- Add `test/test_type_hints.py` to the `files` setting in `mypy-strict.ini` and verify that running the `mypy` wrapper on it again now gives type errors.
- Remove type hints from `torch/random.py` and verify that running the `mypy` wrapper on it again now gives type errors.
- Add the suggested JSON from the docstring of `torch.testing._internal.mypy_wrapper.main` to your `.vscode/settings.json` and verify that VS Code gives the same results (inline, while editing any Python file in the repo) as running the `mypy` wrapper on the command line, in all the above cases.
Reviewed By: glaringlee, walterddr
Differential Revision: D25977352
Pulled By: samestep
fbshipit-source-id: 4b3a5e8a9071fcad65a19f193bf3dc7dc3ba1b96
Summary:
We added this option in https://github.com/pytorch/pytorch/pull/48248, but it would be good to document it somewhere as well, hence adding it to this contributing doc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50861
Reviewed By: mrshenli
Differential Revision: D26014505
Pulled By: rohan-varma
fbshipit-source-id: c1321679f01dd52038131ff571362ad36884510a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49505
I have a problem which is that static runtime needs a way to bypass
dispatch and call into kernels directly. Previously, it used
native:: bindings to do this; but these bindings no longer exist
for structured kernels! Enter at::cpu: a namespace of exactly
at:: compatible functions that assume all of their arguments are
CPU and non-autograd! The header looks like this:
```
namespace at {
namespace cpu {
CAFFE2_API Tensor & add_out(Tensor & out, const Tensor & self, const Tensor & other, Scalar alpha=1);
CAFFE2_API Tensor add(const Tensor & self, const Tensor & other, Scalar alpha=1);
CAFFE2_API Tensor & add_(Tensor & self, const Tensor & other, Scalar alpha=1);
CAFFE2_API Tensor & upsample_nearest1d_out(Tensor & out, const Tensor & self, IntArrayRef output_size, c10::optional<double> scales=c10::nullopt);
CAFFE2_API Tensor upsample_nearest1d(const Tensor & self, IntArrayRef output_size, c10::optional<double> scales=c10::nullopt);
CAFFE2_API Tensor & upsample_nearest1d_backward_out(Tensor & grad_input, const Tensor & grad_output, IntArrayRef output_size, IntArrayRef input_size, c10::optional<double> scales=c10::nullopt);
CAFFE2_API Tensor upsample_nearest1d_backward(const Tensor & grad_output, IntArrayRef output_size, IntArrayRef input_size, c10::optional<double> scales=c10::nullopt);
}}
```
This slows down static runtime because these are not the "allow
resize of nonzero tensor" variant binding (unlike the ones I had manually
written). We can restore this: it's a matter of adding codegen smarts to
do this, but I haven't done it just yet since it's marginally more
complicated.
In principle, non-structured kernels could get this treatment too.
But, like an evil mastermind, I'm withholding it from this patch, as an extra
carrot to get people to migrate to structured muahahahaha.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D25616105
Pulled By: ezyang
fbshipit-source-id: 84955ae09d0b373ca1ed05e0e4e0074a18d1a0b5
Summary:
Cant think of a reason not .gitignore test-reports folder. this can be helpful when
1. running `python test/test*.py` from github root directory since it creates the folder at root.
2. CI test report path generated by `torch/testing/_internal/common_utils.py` creates the folder in the same path where the test python file locates.
Creating a PR to make sure CI is happy. this is also needed by https://github.com/pytorch/pytorch/issues/50923
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50952
Reviewed By: samestep
Differential Revision: D26022436
Pulled By: walterddr
fbshipit-source-id: 83e6296de802bd1754b802b8c70502c317f078c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50832
Please see the previous diff in this stack for the motivation to do so. This makes the same change but for the non-mobile codebase.
ghstack-source-id: 120184012
Test Plan: Sandcastle + Build
Reviewed By: raziel, iseeyuan
Differential Revision: D25979986
fbshipit-source-id: 7708f4f6a50cb16d7a23651e5655144d277d0a4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50593
There are no equivalent to torch.FloatTensor, torch.cuda.FloatTensor for complex
types. So `get_gpu_type` and `get_cpu_type` are broken for complex tensors.
Also found a few places that explicitly cast inputs to floating point types,
which would drop the imaginary component before running the test.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D25954050
Pulled By: mruberry
fbshipit-source-id: 1fa8e5af233aa095c839d5e2f860564baaf92aef
Summary:
This is a benchmarking tooling to work with sparse tensors. To implement this, we extended PR `benchmarking util` [https://github.com/pytorch/pytorch/issues/38338](https://github.com/pytorch/pytorch/pull/38338) for sparse tensors. In order to extend the proposed utility library the **FuzzedTensor** class was extended by creating the new **FuzzedSparseTensor** class. In addition two new operator classes were added, the `UnaryOpSparseFuzzer` and `BinaryOpSparseFuzzer`.
The class `FuzzedSparseTensor` adds new input parameters to the constructor:
1. `sparse_dim`: The number of sparse dimensions in a sparse tensor.
2. `nnz`: Number of non-zero elements in the sparse tensor.
3. `density`: The density of the sparse tensor.
4. `coalesced`: As we know the sparse tensor format permits coalesced/uncoalesced sparse tensors.
and removes `probability_contiguous`, `max_allocation_bytes`, `roll_parameter`, `tensor_constructor` as they are dense-tensors related parameters.
In addition, I've extended the `torch.utils.benchmark.examples` to work with the new classes `FuzzedSparseTensor`, `UnaryOpSparseFuzzer` and `BinaryOpSparseFuzzer`.
Hopefully, this tooling and these examples will help to make other benchmarks in other PRs. Looking forward to your thoughts and feedback. cc robieta, mruberry, ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48397
Reviewed By: ejguan
Differential Revision: D26008137
Pulled By: mruberry
fbshipit-source-id: 2f37811c7c3eaa3494a0f2500e519267f2186dfb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50279
This allows different sample inputs to have different behavior for the same
operator. For example, `div(..., rounding_mode='true')` will promote but other
rounding modes don't. The current boolean flag is too restrictive to allow this.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D25950011
Pulled By: mruberry
fbshipit-source-id: 7e82b82bedc626b2b6970d92d5b25676183ec384
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50288
torch::deploy will bundle the objects contained in libtorch-python together with frozenpython into a shared library. Therefore, the libtorch-python objs can't bring with them a dependency on system python.
Buck TARGETS are added throughout the caffe2 tree to make available objects or headers that will be needed by torch::deploy but would have brought unsuitable dependencies if accessed using existing targets.
CMakeLists are modified to separate a torch-python-objs object library which lets torch::deploy compile these objs with the same compile flags as libttorch_python used, but without some of the link-time dependencies such as python.
CudaIPCTypes is moved from libtorch_python to libtorch_cuda because it is really not a python binding, and it statically registers a cuda_ipc_callback which would be duplicated if included in each copy of torch::deploy.
Test Plan: no new functionality, just ensure existing tests continue to pass
Reviewed By: malfet
Differential Revision: D25850785
fbshipit-source-id: b0b81c050cbee04e9de96888f8a09d29238a9db8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50838
Similar to `torch.save` and `torch.jit.save`, accept a IO-like object
instead of just a file.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D25982719
Pulled By: suo
fbshipit-source-id: 42f3665932bbaa6897215002d116df6338edae50
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50739
This does not turn on batched grad testing for autogenerated NewModuleTest
tests and CriterionTest tests. Those are coming later.
Test Plan: - run tests
Reviewed By: ejguan
Differential Revision: D25997677
Pulled By: zou3519
fbshipit-source-id: b4b2d68e0f99c3d573faf237e1e531d0b3fced40
Summary:
This not only specifies the data types of these NaNs, but also indicate
that the function isn't signaling anything unusual.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50412
Reviewed By: mrshenli
Differential Revision: D25899828
Pulled By: ezyang
fbshipit-source-id: a8ded10954ad08cba3098aa473c6b77f2e03dc93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50795
There's [a post](https://fb.workplace.com/groups/2148543255442743/permalink/2583012411995823/) about a customer having to pass in `-Wno-global-constructors` to disable warnings related to calling constructors for global objects. This is related to the initialization of `default_extra_files_mobile` in `import.h`.
It requires end users to pass in the compiler flag, since the definition is now in code (.cpp files) that they will be compiling.
In addition, it makes the API for `_load_for_mobile` non-re-entrant (i.e. can not be safely used concurrently from multiple threads without the caller taking a mutex/lock) if the `extra_files_mobile` argument is not explicitly passed in.
Instead, a better option would be to create different overloads; one which requires all 3 parameters, and one that can work with 1-2. This solves the problem without creating a static variable.
ghstack-source-id: 120127083
Test Plan: Build Lite Interpreter and sandcastle.
Reviewed By: raziel
Differential Revision: D25968216
fbshipit-source-id: fbd80dfcafb8ef7231aca301445c4a2ca9a08995
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50769
There were a couple new of these lines added in the last couple of days but they're not necessary anymore.
This PR removes them and also adds an assertion to make sure we don't add any more.
ghstack-source-id: 120133715
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D25961316
fbshipit-source-id: e2befc5b6215b42decb2acedcacfb50734857e2f
Summary:
Sub-step of my attempt to split up the torch_cuda library, as it is huge. Please look at https://github.com/pytorch/pytorch/issues/49050 for details on the split and which files are in which target.
This PR introduces two new macros for Windows DLL purposes, TORCH_CUDA_CPP_API and TORCH_CUDA_CU_API. Both are defined as TORCH_CUDA_API for the time being.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50627
Reviewed By: mruberry
Differential Revision: D25955441
Pulled By: janeyx99
fbshipit-source-id: ff226026833b8fb2fb7c77df6f2d6c824f006869
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50644
The dispatcher is a very hot code path; not inlining
`Dispatcher::singleton()` was hurting perf.
Test Plan:
Profiled our internal empty() benchmark. `perf stat` shows
about a 1.7% reduction in cycles spent; the benchmark's timing itself
shows a small reduction.
Reviewed By: dzhulgakov, bhosmer
Differential Revision: D25935275
fbshipit-source-id: a328f8ac8ea479bbe5c6ddb80f98838ae6058bbd
Summary:
Addresses https://github.com/pytorch/pytorch/issues/50496
This fixes a number of inconsistencies in torch.distributions.constraints as used for parameters and supports of probability distributions.
- Adds a `constraints.independent` and replaces `real_vector` with `independent(real, 1)`. (this pattern has long been used in Pyro)
- Adds an `.event_dim` attribute to all constraints.
- Tests that `constraint.check(data)` has the correct shape. (Previously the shapes were incorrect).
- Adds machinery to set static `.is_discrete` and `.event_dim` for `constraints.dependent`.
- Fixes constraints for a number of distributions.
## Tested
- added a new check to the constraints tests
- added a new check for `.event_dim`
cc fehiepsi feynmanliang stefanwebb
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50547
Reviewed By: VitalyFedyunin
Differential Revision: D25918330
Pulled By: neerajprad
fbshipit-source-id: a648c3de3e8704f70f445c0f1c39f2593c8c74db
Summary:
We do a lot of resize_({0}) to force `out` operators to properly
resize their results, and `resize_` does a fair bit of extraneous work
(e.g. trip through dispatch, checks for memory_format and named tensors, etc.).
If we strip it down to the bare minimum it's just setting the sizes to 0, so
lets do that directly.
Test Plan:
Perf results suggest maybe a 1% win:
```
batch 20: P163138256 (large win, 1.7%, mostly in fb_fc_out)
batch 1: P163139591 (smaller win, 0.88%, mostly in resize_)
```
Reviewed By: swolchok
Differential Revision: D25932595
fbshipit-source-id: d306a0a15c0e1be12fde4a7f149e3ed35665e3c0
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: ee15f7a7c5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50895
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: ejguan
Differential Revision: D26001623
fbshipit-source-id: 680d182ba5a6ce1d9cb2467136e8b27fe8266d0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50862
add all missing kernal launch check for all cu and cuh files under caffe2/caffe2/utils
Test Plan:
building
```buck build //caffe2/caffe2:``` gives no error
Tests all pass
```buck test //caffe2/caffe2:```
check using the check to ensure there is no show under
`fbcode/caffe2/caffe2/utils`
the PR on github shows all tests are passed https://github.com/pytorch/pytorch/actions/runs/500036434
Reviewed By: r-barnes
Differential Revision: D25987367
fbshipit-source-id: 52add63a14f2da855c784ab24468f64056c93836
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50818
This PR does two things:
1. Add batched grad testing to OpInfo
2. Improve the error message from `gradcheck` if batched gradient
computation fails to include suggestions for workarounds.
To add batched grad testing to OpInfo, this PR:
- adds new `check_batched_grad=True` and `check_batched_gradgrad=True`
attributes to OpInfo. These are True by default because we expect most
operators to support batched gradient computation.
- If `check_batched_grad=True`, then `test_fn_grad` invokes gradcheck
with `check_batched_grad=True`.
- If `check_batched_gradgrad=True`, then `test_fn_gradgradgrad` invokes
gradgradcheck with `check_batched_grad=True`.
The improved gradcheck error message looks like the following when an
exception is thrown while computing batched gradients:
https://gist.github.com/zou3519/5a0f46f908ba036259ca5e3752fd642f
Future
- Sometime in the not-near future, we will separate out "batched grad
testing" from "gradcheck" for the purposes of OpInfo to make the
testing more granular and also so that we can test that the vmap
fallback doesn't get invoked (currently batched gradient testing only
tests that the output values are correct).
Test Plan: - run tests `pytest test/test_ops.py -v -k "Gradients"`
Reviewed By: ejguan
Differential Revision: D25997703
Pulled By: zou3519
fbshipit-source-id: 6d2d444d6348ae6cdc24c32c6c0622bd67b9eb7b
Summary:
We were implementing it using ifThenElse, which creates conditional
branches that complicate llvm's vectorization. Using CompareSelect directly
yields clean vectorized code with nothing but vmovups and vmaxps.
Test Plan: Trivial benchmark shows 33% speedup on large tensors (256k elements).
Reviewed By: eellison
Differential Revision: D25986637
fbshipit-source-id: 72dd7776924f73c036d46dca30dff22404d86b82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50193
* Supports aten, native reference implementation, and NNC TE implementations.
* Support functionality checks against aten, in addition to performance checks.
Test plans:
* After enable "BUILD_TENSOREXPR_BENCHMARK" in CMakeLists.txt,
* bin/tensorexpr_bench --benchmark_filter=Reduce1D
Measurements:
On a Broadwell E5-2686 CPU,
Reduce1D/Torch/16777216 5638547 ns 5638444 ns 119 BYTES=11.902G/s
Reduce1D/Naive/16777216 19308235 ns 19308184 ns 36 BYTES=3.47567G/s
Reduce1D/NativeRfactor/16777216 8433348 ns 8433038 ns 85 BYTES=7.95785G/s
Reduce1D/NativeVector/16777216 5608836 ns 5608727 ns 124 BYTES=11.9651G/s
Reduce1D/NativeTiled/16777216 5550233 ns 5550221 ns 126 BYTES=12.0912G/s
Reduce1D/TeNaive/16777216 21451047 ns 21450752 ns 33 BYTES=3.12851G/s
Reduce1D/TeSplitTail/16777216 23701732 ns 23701229 ns 30 BYTES=2.83145G/s
Reduce1D/TeSplitMask/16777216 23683589 ns 23682978 ns 30 BYTES=2.83363G/s
Reduce1D/TeRfactorV2/16777216 5378019 ns 5377909 ns 131 BYTES=12.4786G/s
Result summary:
* The single-threaded performance with NNC TeRfactorV2 matches and exceeds Aten and avx2 naive counterpart.
Follow-up items:
* rfactor does not work well with split
* We don't have a multi-threaded implementation yet.
* Missing "parallel" scheduling primitive, which is not different from what we need for pointwise ops.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D25821880
Pulled By: zheng-xq
fbshipit-source-id: 8df3f40d1eed8749c8edcaacae5f0544dbf6bed3
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 9f84778d47
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50807
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D25973473
fbshipit-source-id: 62a9808a6ce5e6c4b51fdf272b687118a8c116b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50283
Realize that for the layerwise compression, the previous warm-start implementation only skips memory allocations, but does not skip filling random values for Qs.
Also fix the unit test in distributed_test.py. Previously the process group was not created correctly, and not communication occurred in the test_DistributedDataParallel_powerSGD_ddp_comm_hook.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 120101220
Test Plan:
Verified the fix by adding added some loggings locally.
Also verified no NE diff on Ads 1x.
Reviewed By: rohan-varma
Differential Revision: D25846222
fbshipit-source-id: 1ebeeb55ceba64d4d904ea6ac1bb42b1b2241520
Summary:
Adds a link to existing instructions in CONTRIBUTING.md, so those instructions are more visible to contributors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50841
Reviewed By: samestep
Differential Revision: D25983089
Pulled By: janeyx99
fbshipit-source-id: 0b777ec760765153c607515ab09441dd0cfddf3c
Summary:
This PR addresses [a two-year-old TODO in `test/test_type_hints.py`](12942ea52b/test/test_type_hints.py (L21-L22)) by replacing most of the body of our custom `get_examples_from_docstring` function with [a function from Python's built-in `doctest.DocTestParser` class](https://docs.python.org/3/library/doctest.html#doctest.DocTestParser.get_examples). This mostly made the parser more strict, catching a few errors in existing doctests:
- missing `...` in multiline statements
- missing space after `>>>`
- unmatched closing parenthesis
Also, as shown by [the resulting diff of the untracked `test/generated_type_hints_smoketest.py` file](https://pastebin.com/vC5Wz6M0) (also linked from the test plan below), this introduces a few incidental changes as well:
- standalone comments are no longer preserved
- indentation is now visually correct
- [`example_torch_promote_types`](4da9ceb743/torch/_torch_docs.py (L6753-L6772)) is now present
- an example called `example_torch_tensor___array_priority__` is added, although I can't tell where it comes from
- the last nine lines of code from [`example_torch_tensor_align_as`](5d45140d68/torch/_tensor_docs.py (L386-L431)) are now present
- the previously-misformatted third line from [`example_torch_tensor_stride`](5d45140d68/torch/_tensor_docs.py (L3508-L3532)) is now present
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50596
Test Plan:
Checkout the base commit, typecheck the doctests, and save the generated file:
```
$ python test/test_type_hints.py TestTypeHints.test_doc_examples
$ cp test/generated_type_hints_smoketest.py /tmp
```
Then checkout this PR, do the same thing, and compare:
```
$ python test/test_type_hints.py TestTypeHints.test_doc_examples
$ git diff --no-index {/tmp,test}/generated_type_hints_smoketest.py
```
The test should succeed, and the diff should match [this paste](https://pastebin.com/vC5Wz6M0).
Reviewed By: walterddr
Differential Revision: D25926245
Pulled By: samestep
fbshipit-source-id: 23bc379ff438420e556263c19582dba06d8e42ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50742
Fixed the other usage of `BaseCType('const ...&)` on #49138.
Checked byte-for-byte compatibility of the codegen output.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D25955565
Pulled By: ljk53
fbshipit-source-id: 83ebd6b039892b805444867ed97a6e2fa6e72225
Summary:
In https://github.com/pytorch/pytorch/issues/42514, NCCL `alltoall_single` is already added. This PR adds NCCL `alltoall`.
The difference between `alltoall_single` and `alltoall` is: `alltoall_single` works on a single tensor and send/receive slices of that tensor, while `alltoall` works on a list of tensor, and send/receive tensors in that list.
cc: ptrblck ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44374
Reviewed By: zhangguanheng66, mrshenli
Differential Revision: D24455427
Pulled By: srinivas212
fbshipit-source-id: 42fdebdd14f8340098e2c34ef645bd40603552b1
Summary:
Implement the first stage of ZeRO, sharding of the optimizer state, as described in [this blog post](https://www.microsoft.com/en-us/research/blog/zero-2-deepspeed-shattering-barriers-of-deep-learning-speed-scale/) and [this paper](https://arxiv.org/abs/1910.02054). This implementation is completely independent from the [DeepSpeed](https://github.com/microsoft/DeepSpeed) framework, and aims at providing ZeRO-compliant building blocks within the PyTorch scheme of things.
This works by:
- acting as a wrapper to a pytorch optimizer. ZeROptimizer does not optimize anything by itself, it only shards optimizers for distributed jobs
- each rank distributes parameters according to a given partitioning scheme (could be updated), and owns the update of a given shard only
- the .step() is called on each rank as expected, the fact that the optimizer actually works on a shard of the model is not visible from the outside
- when the update is completed, each rank broadcasts the updated model shard to all the other ranks
This can be used with DDP, although some communications are wasted in that case (gradients are all-reduced to all ranks). This implementation was initially developed in [Fairscale](https://github.com/facebookresearch/fairscale), and can also be used with an optimized DDP which only reduces to the relevant ranks. More context on ZeRO and PyTorch can be found in [this RFC](https://github.com/pytorch/pytorch/issues/42849)
The API with respect to loading and saving the state is a known pain point and should probably be discussed an updated. Other possible follow ups include integrating more closely to a [modularized DDP](https://github.com/pytorch/pytorch/issues/37002), [making the checkpoints partition-agnostic](https://github.com/facebookresearch/fairscale/issues/164), [exposing a gradient clipping option](https://github.com/facebookresearch/fairscale/issues/98) and making sure that mixed precision states are properly handled.
original authors include msbaines, min-xu-ai and myself
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46750
Reviewed By: mruberry
Differential Revision: D25958918
Pulled By: blefaudeux
fbshipit-source-id: 14280f2fd90cf251eee8ef9ac0f1fa6025ae9c50
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50766
This header breaks certain builds since it causes PyTorch to depend
on gtest.
ghstack-source-id: 119991167
Test Plan: waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D25960810
fbshipit-source-id: ceaaad499f6f363ef35c6623475ae8f191d86171
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50748
Adds support for Linear + BatchNorm1d fusion to quantization.
This is a redo of dreiss's https://github.com/pytorch/pytorch/pull/37467, faster
to copy-paste it than rebase and deal with conflicts.
Test Plan:
```
python test/test_quantization.py TestFusion.test_fusion_linear_bn_eval
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D25957432
fbshipit-source-id: 24e5b760f70186aa953ef65ab0182770e89495e4
Summary: Previously, binary elementwise kernels such as add, sub, and mul were implemented with custom shaders. However, MPSCNN has kernels for these operations for iOS >=11.3. Update these ops to use MPSCNN kernels instead of shader implementations.
Test Plan:
Test on device:
`arc focus2 pp-ios`
Test on mac
`buck test pp-macos`
Reviewed By: xta0
Differential Revision: D25953986
fbshipit-source-id: 3acac3fa7dbe70f92572c21c0f0cfcdedfcdcf23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50385
We no longer use this flag internally, and it's not referenced externally either, so let's clean up.
ghstack-source-id: 119676743
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D25852220
fbshipit-source-id: a4427edff6cbb241340f9f6ae6db4e74832949c2
Summary:
`test_dispatch.py` has many asserts about the error message. When running with `TORCH_SHOW_CPP_STACKTRACES=1`, the error message is different from when `TORCH_SHOW_CPP_STACKTRACES=0`, which makes many tests in `test_dispatch.py` fail. This PR fixes these failures when running with `TORCH_SHOW_CPP_STACKTRACES=1`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50509
Reviewed By: ngimel
Differential Revision: D25956853
Pulled By: ezyang
fbshipit-source-id: 3b3696742a7dfb8f52f23a364838ec96945c5662
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50773
Moves the sha check for version generation to the else clause
since it was causing issues for users building pytorch when the .git
directory was not present and PYTORCH_BUILD_VERSION was already set
Test Plan:
CI
Closes https://github.com/pytorch/pytorch/issues/50730
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Reviewed By: janeyx99
Differential Revision: D25963486
Pulled By: seemethere
fbshipit-source-id: ce1b315f878d074f2ffb6b658d59cbd13150f27f
Summary:
… library builds, as it is already set in shared library builds from the target that was imported from Caffe2.
This was identified on Windows builds when PyTorch was built in shared Release mode, and a testapp was built with RelWithDebInfo in CMake.
The problem appeared to be that because IMPORTED_LOCATION (in TorchConfig.cmake) and IMPORTED_LOCATION_RELEASE were both set (in Caffe2Targets.cmake), there occurred some confusion in the build as to what was correct. The symptoms are the error:
ninja: error: 'torch-NOTFOUND', needed by 'test_pytorch.exe', missing and no known rule to make it
in a noddy consuming test application.
Fixes https://github.com/pytorch/pytorch/issues/48724
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49173
Reviewed By: malfet
Differential Revision: D25974151
Pulled By: ezyang
fbshipit-source-id: 3454c0d29cbbe7a37608beedaae3efbb624b0479
Summary:
Add a new device type 'XPU' ('xpu' for lower case) to PyTorch. Changes are needed for code related to device model and kernel dispatch, e.g. DeviceType, Backend and DispatchKey etc.
https://github.com/pytorch/pytorch/issues/48246
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49786
Reviewed By: mrshenli
Differential Revision: D25893962
Pulled By: ezyang
fbshipit-source-id: 7ff0a316ee34cf0ed6fc7ead08ecdeb7df4b0052
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50649
**Summary**
Tutorials, documentation and comments are not consistent with the file
extension they use for JIT archives. This commit modifies certain
instances of `*.pth` in `torch.jit.save` calls with `*.pt`.
**Test Plan**
Continuous integration.
**Fixes**
This commit fixes#49660.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D25961628
Pulled By: SplitInfinity
fbshipit-source-id: a40c97954adc7c255569fcec1f389aa78f026d47
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50706
Add a default CPU implementation for quantized embedding lookup operators.
This should enable the ops to execute on mobile as well where we don't have fbgemm.
Test Plan:
python test/test_quantization.py
and CI tests
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D25956842
fbshipit-source-id: 07694888e5e1423b496af1a51494a49558e82152
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50194
**Summary**
`ClassType::repr_str()` prints out only the name of a `ClassType`, which
is not always enough to disambiguate it. In some situations, two
`ClassTypes` are compared and do not match despite having identical
names because they are in separate compilation units. In such cases, the
error message can seem nonsensical (e.g. `expected type T but found type
T`). This commit modifies `ClassType::repr_str()` so that it prints out
the address of the type's compilation unit to make these messages less
puzzling (e.g. `expected type T (0x239023) but found type T (0x230223)`).
**Test Plan**
This commit adds a unit test, `ClassTypeTest.IdenticalTypesDifferentCus`
that reproduces this situation.
**Fixes**
This commit fixes#46212.
Test Plan: Imported from OSS
Reviewed By: tugsbayasgalan
Differential Revision: D25933082
Pulled By: SplitInfinity
fbshipit-source-id: ec71b6728be816edd6a9c2b2d5075ead98d8bc88
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50767
The native signature for optional tensor arguments wrongly produced "Tensor" instead of "optional<Tensor>". We didn't notice this because all internal ops currently use hacky_wrapper, and for hacky_wrapper, "Tensor" is correct.
This PR fixes that and ports one op (batch_norm) to not use hacky_wrapper anymore as a proof of fix.
ghstack-source-id: 120017543
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D25960941
fbshipit-source-id: ca6fe133109b5d85cff52390792cf552f12d9590
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 6c8ed2e6f7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50765
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: mrshenli
Differential Revision: D25960813
fbshipit-source-id: 80b4e48ef04f22f750a2eb049f5f7114715c0a1e
Summary:
Bugs:
1) would introduce -I* in compile commands
2) wouldn't hipify source code directly in build_dir, only one level down or more
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50703
Reviewed By: mrshenli
Differential Revision: D25949070
Pulled By: ngimel
fbshipit-source-id: 018c2a056b68019a922e20e5db2eb8435ad147fe
Summary:
draft enable fast_nvcc.
* cleaned up some non-standard usages
* added fall-back to wrap_nvcc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49773
Test Plan:
Configuration to enable fast nvcc:
- install and enable `ccache` but delete `.ccache/` folder before each build.
- `TORCH_CUDA_ARCH_LIST=6.0;6.1;6.2;7.0;7.5`
- Toggling `USE_FAST_NVCC=ON/OFF` cmake config and run `cmake --build` to verify the build time.
Initial statistic for a full compilation:
* `cmake --build . -- -j $(nproc)`:
- fast NVCC
```
real 48m55.706s
user 1559m14.218s
sys 318m41.138s
```
- normal NVCC:
```
real 43m38.723s
user 1470m28.131s
sys 90m46.879s
```
* `cmake --build . -- -j $(nproc/4)`:
- fast NVCC:
```
real 53m44.173s
user 1130m18.323s
sys 71m32.385s
```
- normal NVCC:
```
real 81m53.768s
user 858m45.402s
sys 61m15.539s
```
* Conclusion: fast NVCC doesn't provide too much gain when compiler is set to use full CPU utilization, in fact it is **even worse** because of the thread switcing.
initial statistic for partial recompile (edit .cu files)
* `cmake --build . -- -j $(nproc)`
- fast NVCC:
```
[2021-01-13 18:10:24] [ 86%] Building NVCC (Device) object caffe2/CMakeFiles/torch_cuda.dir/__/aten/src/ATen/native/cuda/torch_cuda_generated_BinaryMiscOpsKernels.cu.o
[2021-01-13 18:11:08] [ 86%] Linking CXX shared library ../lib/libtorch_cuda.so
```
- normal NVCC:
```
[2021-01-13 17:35:40] [ 86%] Building NVCC (Device) object caffe2/CMakeFiles/torch_cuda.dir/__/aten/src/ATen/native/cuda/torch_cuda_generated_BinaryMiscOpsKernels.cu.o
[2021-01-13 17:38:08] [ 86%] Linking CXX shared library ../lib/libtorch_cuda.so
```
* Conclusion: Effective compilation time for single CU file modification reduced from from 2min30sec to only 40sec when compiling multiple architecture. This shows **4X** gain in speed up using fast NVCC -- reaching the theoretical limit of 5X when compiling 5 gencode architecture at the same time.
Follow up PRs:
- should have better fallback mechanism to detect whether a build is supported by fast_nvcc or not instead of dryruning then fail with fallback.
- performance measurement instrumentation to measure what's the total compile time vs the parallel tasks critical path time.
- figure out why `-j $(nproc)` gives significant sys overhead (`sys 318m41.138s` vs `sys 90m46.879s`) over normal nvcc, guess this is context switching, but not exactly sure
Reviewed By: malfet
Differential Revision: D25692758
Pulled By: walterddr
fbshipit-source-id: c244d07b9b71f146e972b6b3682ca792b38c4457
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50414
If the index that is supplied from python is an integral type, it converts everything to int64_t which is traced correctly.
Test Plan:
new test case
Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D25930773
fbshipit-source-id: a3dfeb49df1394c5c8bea0de46038d2c549a0dc6
Summary:
`torch.fx.wrap()` could not be used as a decorator as the docstring claimed because it returned None.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50677
Test Plan: Added `test_wrapped_via_decorator` which used to fail with `'NoneType' object is not callable` and now passes
Reviewed By: jamesr66a
Differential Revision: D25949313
Pulled By: jansel
fbshipit-source-id: 02d0f9adeed812f58ec94c94dd4adc43578f21ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50580
Due to what looked like a bug in CUDA, TensorPipe was sometimes failing to auto-detect the device of a CUDA pointer. A workaround, on the PyTorch side, was to always initialize a CUDA context on device 0. Now that TensorPipe has fixed that we can undo the workaround.
Reviewed By: mrshenli
Differential Revision: D25952929
fbshipit-source-id: 57a5f73241f7371661855c767e44a64ca3b84a74
Summary:
Using `insert` instead of `append` to add torch root directory to `sys.path`, to fix `ModuleNotFoundError: No module named 'tools.codegen'`, as mentioned in https://github.com/pytorch/pytorch/issues/47553
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50353
Reviewed By: mrshenli
Differential Revision: D25893827
Pulled By: ezyang
fbshipit-source-id: 841e28898fee5502495f3890801b49d9b442f9d6
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/50733
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: beauby
Differential Revision: D25954026
fbshipit-source-id: 44d21768379b301144518aafc9c68147db49d931
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50615
The method tests for some of the ops have been ported to the new OpInfo based tests. This PR removes those op names from `complex_list` in `test_autograd.py`
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D25931268
Pulled By: anjali411
fbshipit-source-id: 4d08626431c61c34cdca18044933e4f5b9b25232
Summary:
This PR helps with https://github.com/pytorch/pytorch/issues/50513 by reducing the complexity of our `mypy` test suite and making it easier to reproduce on the command line. Previously, to reproduce how `mypy` was actually run on tracked source files (ignoring the doctest typechecking) in CI, you technically needed to run 9 different commands with various arguments:
```
$ mypy --cache-dir=.mypy_cache/normal --check-untyped-defs --follow-imports silent
$ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/module_list.py
$ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/namedtuple.py
$ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/opt_size.py
$ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/size.py
$ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/tensor_copy.py
$ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/torch_cuda_random.py
$ mypy --cache-dir=.mypy_cache/examples --follow-imports silent --check-untyped-defs test/type_hint_tests/torch_optim.py
$ mypy --cache-dir=.mypy_cache/strict --config mypy-strict.ini
```
Now you only have to run 2 much simpler commands:
```
$ mypy
$ mypy --config mypy-strict.ini
```
One reason this is useful is because it will make it easier to integrate PyTorch's `mypy` setup into editors (remaining work on this to be done in a followup PR).
Also, as shown in the test plan, this also reduces the time it takes to run `test/test_type_hints.py` incrementally, by reducing the number of times `mypy` is invoked while still checking the same set of files with the same configs.
(Because this PR merges `test_type_hint_examples` (added in https://github.com/pytorch/pytorch/issues/34595) into `test_run_mypy` (added in https://github.com/pytorch/pytorch/issues/36584), I've added some people involved in those PRs as reviewers, in case there's a specific reason they weren't combined in the first place.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50631
Test Plan:
Run this twice (the first time is to warm the cache):
```
$ python test/test_type_hints.py -v
```
- *Before:*
```
test_doc_examples (__main__.TestTypeHints)
Run documentation examples through mypy. ... ok
test_run_mypy (__main__.TestTypeHints)
Runs mypy over all files specified in mypy.ini ... ok
test_run_mypy_strict (__main__.TestTypeHints)
Runs mypy over all files specified in mypy-strict.ini ... ok
test_type_hint_examples (__main__.TestTypeHints)
Runs mypy over all the test examples present in ... ok
----------------------------------------------------------------------
Ran 4 tests in 5.090s
OK
```
You can also just run `mypy` to see how many files it checks:
```
$ mypy --cache-dir=.mypy_cache/normal --check-untyped-defs --follow-imports silent
Success: no issues found in 1192 source files
```
- *After:*
```
test_doc_examples (__main__.TestTypeHints)
Run documentation examples through mypy. ... ok
test_run_mypy (__main__.TestTypeHints)
Runs mypy over all files specified in mypy.ini ... ok
test_run_mypy_strict (__main__.TestTypeHints)
Runs mypy over all files specified in mypy-strict.ini ... ok
----------------------------------------------------------------------
Ran 3 tests in 2.404s
OK
```
Now `mypy` checks 7 more files, which is the number in `test/type_hint_tests`:
```
$ mypy
Success: no issues found in 1199 source files
```
Reviewed By: zou3519
Differential Revision: D25932660
Pulled By: samestep
fbshipit-source-id: 26c6f00f338e7b44954e5ed89522ce24e2fdc5f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48719
Attempt to break this PR (https://github.com/pytorch/pytorch/pull/33019) into two parts. As per our discussion with eellison, the first part is to make sure our aten::slice operator take optional parameters for begin/step/end. This will help with refactoring ir_emitter.cpp for genering handling for list and slice striding. Once this PR merged, we will submit a second PR with compiler change.
Test Plan:
None for this PR, but new tests will be added for the second part.
Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D25929902
fbshipit-source-id: 5385df04e6d61ded0699b09bbfec6691396b56c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33884
Mitigates https://github.com/pytorch/pytorch/issues/5261.
It's not possible for us to support cudnn RNN double backwards due to
limitations in the cudnn API. This PR makes it so that we raise an error
message if users try to get the double backward on a cudnn RNN; in the
error message we suggest using the non-cudnn RNN.
Test Plan: - added some tests to check the error message
Reviewed By: albanD
Differential Revision: D20143544
Pulled By: zou3519
fbshipit-source-id: c2e49b3d8bdb9b34b561f006150e4c7551a78fac
Summary:
This PR adds `torch.linalg.slogdet`.
Changes compared to the original torch.slogdet:
- Complex input now works as in NumPy
- Added out= variant (allocates temporary and makes a copy for now)
- Updated `slogdet_backward` to work with complex input
Ref. https://github.com/pytorch/pytorch/issues/42666
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49194
Reviewed By: VitalyFedyunin
Differential Revision: D25916959
Pulled By: mruberry
fbshipit-source-id: cf9be8c5c044870200dcce38be48cd0d10e61a48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50592
This adds a `check_batched_grad=False` option to gradcheck and gradgradcheck.
It defaults to False because gradcheck is a public API and I don't want
to break any existing non-pytorch users of gradcheck.
This:
- runs grad twice with two grad outputs, a & b
- runs a vmapped grad with torch.stack([a, b])
- compares the results of the above against each other.
Furthermore:
- `check_batched_grad=True` is set to be the default for
gradcheck/gradgradcheck inside of test_autograd.py. This is done by
reassigning to the gradcheck object inside test_autograd
- I manually added `check_batched_grad=False` to gradcheck instances
that don't support batched grad.
- I added a denylist for operations that don't support batched grad.
Question:
- Should we have a testing only gradcheck (e.g.,
torch.testing.gradcheck) that has different defaults from our public
API, torch.autograd.gradcheck?
Future:
- The future plan for this is to repeat the above for test_nn.py (the
autogenerated test will require a denylist)
- Finally, we can repeat the above for all pytorch test files that use
gradcheck.
Test Plan: - run tests
Reviewed By: albanD
Differential Revision: D25925942
Pulled By: zou3519
fbshipit-source-id: 4803c389953469d0bacb285774c895009059522f
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: eabfe52867
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50684
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D25944553
fbshipit-source-id: e2bbcc48472cd79df89d87a0e61dcffa783c659d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50611
Removed the unused old-style code to prevent it from being used.
Added all autograd/gen_pyi sources to mypy-strict.ini config.
Confirmed byte-for-byte compatible with the old codegen:
```
Run it before and after this PR:
.jenkins/pytorch/codegen-test.sh <baseline_output_dir>
.jenkins/pytorch/codegen-test.sh <test_output_dir>
Then run diff to compare the generated files:
diff -Naur <baseline_output_dir> <test_output_dir>
```
Confirmed clean mypy-strict run:
```
mypy --config mypy-strict.ini
```
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D25929730
Pulled By: ljk53
fbshipit-source-id: 1fc94436fd4a6b9b368ee0736e99bfb3c01d38ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50711
As title, missed a few of these.
Test Plan: Imported from OSS
Reviewed By: yf225
Differential Revision: D25949363
Pulled By: suo
fbshipit-source-id: 197743fe7097d2ac894421a99c072696c3b8cd70
Summary:
Fixes #{[24991](https://github.com/pytorch/pytorch/issues/24991)}
I used a value of 0.75 as suggested in the forums by Thomas: https://discuss.pytorch.org/t/calculate-gain-tanh/20854/6
I verified that the value keeps the gradient stable for a 100-layer network.
Code to reproduce (from [jpeg729](https://discuss.pytorch.org/t/calculate-gain-tanh/20854/4)):
```python
import torch
import torch.nn.functional as F
import sys
a = torch.randn(1000,1000, requires_grad=True)
b = a
print (f"in: {a.std().item():.4f}")
for i in range(100):
l = torch.nn.Linear(1000,1000, bias=False)
torch.nn.init.xavier_normal_(l.weight, torch.nn.init.calculate_gain("selu"))
b = getattr(F, 'selu')(l(b))
if i % 10 == 0:
print (f"out: {b.std().item():.4f}", end=" ")
a.grad = None
b.sum().backward(retain_graph=True)
print (f"grad: {a.grad.abs().mean().item():.4f}")
```
Output:
```
in: 1.0008
out: 0.7968 grad: 0.6509
out: 0.3127 grad: 0.2760
out: 0.2404 grad: 0.2337
out: 0.2062 grad: 0.2039
out: 0.2056 grad: 0.1795
out: 0.2044 grad: 0.1977
out: 0.2005 grad: 0.2045
out: 0.2042 grad: 0.2273
out: 0.1944 grad: 0.2034
out: 0.2085 grad: 0.2464
```
I included the necessary documentation change, and it passes the _test_calculate_gain_nonlinear_ unittest.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50664
Reviewed By: mruberry
Differential Revision: D25942217
Pulled By: ngimel
fbshipit-source-id: 29ff1be25713484fa7c516df71b12fdaecfb9af8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50564
When an RPC was sent, the associated future was stored in two maps:
pendingResponseMessage_ and timeoutMap_. Once the response was received, the
entry was only removed from pendingResponseMessage_ and not timeoutMap_. The
pollTimedoudRpcs method then eventually removed the entry from timeoutMap_
after the time out duration had passed.
Although, in scenarios where there is a large timeout and a large number of
RPCs being used, it is very easy for the timeoutMap_ to grow without any
bounds. This was discovered in https://github.com/pytorch/pytorch/issues/50522.
To fix this issue, I've added some code to cleanup timeoutMap_ as well once we
receive a response.
ghstack-source-id: 119925182
Test Plan:
1) Unit test added.
2) Tested with repro in https://github.com/pytorch/pytorch/issues/50522
#Closes: https://github.com/pytorch/pytorch/issues/50522
Reviewed By: mrshenli
Differential Revision: D25919650
fbshipit-source-id: a0a42647e706d598fce2ca2c92963e540b9d9dbb
Summary:
- Related with https://github.com/pytorch/pytorch/issues/44937
- Use `resize_output` instead of `resize_as`
- Tuning the `native_functions.yaml`, move the inplace variant `pow_` next to the other `pow` entries
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46830
Reviewed By: mrshenli
Differential Revision: D24567702
Pulled By: anjali411
fbshipit-source-id: a352422c9d4e356574dbfdf21fb57f7ca7c6075d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50632
I'll port the following method tests in follow-up PRs:
`'baddbmm', 'addbmm', 'addmv', 'addr'`
After the tests are ported to OpInfo based tests, it would also be much easier to add tests with complex alpha and beta values.
Edit- it seems like it's hard to port the broadcasting variant tests because one ends up skipping `test_inplace_grad` and `test_variant_consistency_eager` even for the case when inputs are not required to be broadcasted.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D25947471
Pulled By: anjali411
fbshipit-source-id: 9faa7f1fd55a1269bad282adac2b39d19bfa4591
Summary:
Fixes https://github.com/pytorch/pytorch/issues/42588
The contiguity check used to be for memory format suggested by `grad_output->suggest_memory_format()`, but an invariant guaranteed by derivatives.yaml is `input->suggest_memory_format()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50659
Reviewed By: mruberry
Differential Revision: D25938921
Pulled By: ngimel
fbshipit-source-id: a945bfef6ce3d91b17e7ff96babe89ffd508939a
Summary:
- Do not generate inline comments on PRs
- Increase number of signals to wait until generating a comment to 5 (2 for codecov configs, 2 for onnx and 1 for windows_test1)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50601
Reviewed By: albanD
Differential Revision: D25928920
Pulled By: malfet
fbshipit-source-id: 8a4ff70024c948cb65a4bdf31d269080d2cff945
Summary: Fix build with llvm-trunk. With D25877605 (cb37709bee), we need to explicitly include `llvm/Support/Host.h` in `llvm_jit.cpp`.
Test Plan: `buck build mode/opt-clang -j 56 sigrid/predictor/v2:sigrid_remote_predictor -c cxx.extra_cxxflags="-Wforce-no-error" -c cxx.modules=False -c cxx.use_default_autofdo_profile=False`
Reviewed By: bertmaher
Differential Revision: D25920968
fbshipit-source-id: 4b80d5072907f50d01e8fbef41cda8a89dd66a96
Summary:
Building on top of the work of anjali411 (https://github.com/pytorch/pytorch/issues/46640)
Things added in this PR:
1. Modify backward and double-backward formulas
2. Add complex support for `new module tests` and criterion tests (and add complex tests for L1)
3. Modify some existing tests to support complex
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49912
Reviewed By: zhangguanheng66
Differential Revision: D25853036
Pulled By: soulitzer
fbshipit-source-id: df619f1b71c450ab2818eb17804e0c55990aa8ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50499
Adds a timeout API to the following functions:
```
rref.rpc_sync()
rref.rpc_async()
rref.remote()
```
so that RPCs initiated by these proxy calls can be appropriately timed out similar to the regular RPC APIs. Timeouts are supported in the following use cases:
1. rpc.remote finishes in time and successfully, but function run by rref.rpc_async() is slow and times out. Timeout error will be raised
2. rref.rpc_async() function is fast, but rpc.remote() is slow/hanging. Then when rref.rpc_async() is called, it will still timeout with the passed in timeout (and won't block for the rpc.remote() to succeed, which is what happens currently). Although, the timeout will occur during the future creation itself (and not the wait) since it calls `rref._get_type` which blocks. We can consider making this nonblocking by modifying rref._get_type to return a future, although that is likely a larger change.
Test Plan: Added UT
Reviewed By: wanchaol
Differential Revision: D25897495
fbshipit-source-id: f9ad5b8f75121f50537677056a5ab16cf262847e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50498
This change is mostly needed for the next diff in this stack, where
rref._get_type() is called in the rpc_async/rpc_sync RRef proxy function and
can block indefinitely if there is no timeout. It will also be useful to have a
timeout argument when we publicize this API to keep it consistent with other
RPC APIs.
ghstack-source-id: 119859767
Test Plan: Added UT
Reviewed By: pritamdamania87
Differential Revision: D25897588
fbshipit-source-id: 2e84aaf7e4faecf80005c78ee2ac8710f387503e
Summary:
torch.logspace doesn't seem to have explained how integers are handled.
Add some clarification and some test when dtype is integral.
The CUDA implementation is also updated to be consistent with CPU implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47647
Reviewed By: gchanan
Differential Revision: D25843351
Pulled By: walterddr
fbshipit-source-id: 45237574d04c56992c18766667ff1ed71be77ac3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46414
For loops are often written with mismatched data types which causes silent type and sign coercion in the absence of integer conversion warnings. Getting around this in templated code requires convoluted patterns such as
```
for(auto i=decltype(var){0};i<var;i++)
```
with this diff we can instead write
```
for(const auto i = c10::irange(var))
```
Note that this loop is type-safe and const-safe.
The function introduced here (`c10::irange`) allows for type-safety and const-ness within for loops, which prevents the accidental truncation or modification of integers and other types, improving code safety.
Test Plan:
```
buck test //caffe2/c10:c10_test_0
```
Reviewed By: ngimel
Differential Revision: D24334732
fbshipit-source-id: fec5ebda3643ec5589f7ea3a8e7bbea4432ed771
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50505
Even with +u set for the the conda install it still seems to fail out
with an unbound variable error. Let's try and give it a default value
instead.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D25913692
Pulled By: seemethere
fbshipit-source-id: 4b898f56bff25c7523f10b4933ea6cd17a57df80
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 161500fb09
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50572
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D25920888
fbshipit-source-id: fa73ba50a2d9429ea1e0beaac6edc2fd8d3ce244
Summary:
Handle sequence output shape and type inference.
This PR fixes value type of sequence outputs. Prior to this, all model sequence type outputs were unfolded for ONNX models.
This PR also enable shape inference for sequence outputs to represent the dynamic shape of these values.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46542
Reviewed By: ezyang
Differential Revision: D24924236
Pulled By: bzinodev
fbshipit-source-id: 506e70a38cfe31069191d7f40fc6375239c6aafe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49698
Reincarnation of #47620 by jamesr66a.
It's just an initial bunch of things that we're exposing to python, more
is expected to come in future. Some things can probably be done better,
but I'm putting this out anyway, since some other people were interested
in using and/or developing this.
Differential Revision: D25668694
Test Plan: Imported from OSS
Reviewed By: bertmaher
Pulled By: ZolotukhinM
fbshipit-source-id: fb0fd1b31e851ef9ab724686b9ac2d172fa4905a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50541
I found the current phrasing to be confusing
Test Plan: N/A
Reviewed By: ngimel
Differential Revision: D25909205
fbshipit-source-id: 483151d01848ab41d57b3f3b3775ef69f1451dcf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50518
That new feature allows to bisect the pass easily by hard-stopping it
after a given number of hits.
Test Plan: Imported from OSS
Reviewed By: tugsbayasgalan
Differential Revision: D25908597
Pulled By: ZolotukhinM
fbshipit-source-id: 8ee547989078c7b1747a4b02ce6e71027cb3055f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50486
Compiling currently gives:
```
an 13 16:46:39 In file included from ../aten/src/ATen/native/TensorShape.cpp:12:
Jan 13 16:46:39 ../aten/src/ATen/native/Resize.h:37:24: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 if (new_size_bytes > self->storage().nbytes()) {
Jan 13 16:46:39 ~~~~~~~~~~~~~~ ^ ~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:32:24: warning: comparison of integers of different signs: 'size_t' (aka 'unsigned long') and 'int64_t' (aka 'long long') [-Wsign-compare]
Jan 13 16:46:39 for (size_t i = 0; i < shape_tensor.numel(); ++i) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:122:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 for (int64_t i = 0; i < tensors.size(); i++) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:162:21: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 for (int i = 0; i < tensors.size(); i++) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:300:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 for (int64_t i = 0; i < s1.size(); ++i) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:807:21: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 TORCH_CHECK(dim < self_sizes.size());
Jan 13 16:46:39 ~~~ ^ ~~~~~~~~~~~~~~~~~
Jan 13 16:46:39 ../c10/util/Exception.h:361:31: note: expanded from macro 'TORCH_CHECK'
Jan 13 16:46:39 if (C10_UNLIKELY_OR_CONST(!(cond))) { \
Jan 13 16:46:39 ^~~~
Jan 13 16:46:39 ../c10/util/Exception.h:244:47: note: expanded from macro 'C10_UNLIKELY_OR_CONST'
Jan 13 16:46:39 #define C10_UNLIKELY_OR_CONST(e) C10_UNLIKELY(e)
Jan 13 16:46:39 ^
Jan 13 16:46:39 ../c10/macros/Macros.h:173:65: note: expanded from macro 'C10_UNLIKELY'
Jan 13 16:46:39 #define C10_UNLIKELY(expr) (__builtin_expect(static_cast<bool>(expr), 0))
Jan 13 16:46:39 ^~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:855:24: warning: comparison of integers of different signs: 'size_t' (aka 'unsigned long') and 'const int64_t' (aka 'const long long') [-Wsign-compare]
Jan 13 16:46:39 for (size_t i = 0; i < num_blocks; ++i) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:2055:23: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 for (int i = 0; i < vec.size(); i++) {
Jan 13 16:46:39 ~ ^ ~~~~~~~~~~
Jan 13 16:46:39 ../aten/src/ATen/native/TensorShape.cpp:2100:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:39 for (int64_t i = 0; i < src.size(); ++i) {
```
This fixes issues with loop iteration variable types
Test Plan: Sandcastle tests
Reviewed By: xush6528
Differential Revision: D25901799
fbshipit-source-id: c68d9ab93ab0142b5057ce4ca9e75c620a1425f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50482
Compiling currently shows:
```
Jan 13 16:46:28 In file included from ../aten/src/ATen/native/ForeachOpsKernels.cpp:2:
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:28:21: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:44:21: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:149:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:164:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:183:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachUtils.h:198:25: warning: comparison of integers of different signs: 'int64_t' (aka 'long long') and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 for (int64_t i = 0; i < tensors1.size(); i++) {
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:150:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(add);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:74:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:150:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(add);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:84:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:151:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(sub);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:74:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:151:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST_ALPHA(sub);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:84:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST_ALPHA'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:158:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(add);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:158:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(add);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:159:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(sub);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:159:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(sub);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:160:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(mul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:160:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(mul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:161:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(div);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:31:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:161:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_SCALARLIST(div);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:40:21: note: expanded from macro 'FOREACH_BINARY_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < tensors.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:163:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(mul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:53:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:163:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(mul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:63:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:164:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(div);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:53:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:164:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_BINARY_OP_LIST(div);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:63:21: note: expanded from macro 'FOREACH_BINARY_OP_LIST'
Jan 13 16:46:28 for (int i = 0; i < tensors1.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:195:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcdiv);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:115:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:195:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcdiv);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:125:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:196:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcmul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:115:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:196:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALAR(addcmul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:125:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALAR'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:198:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcdiv);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:135:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:198:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcdiv);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:145:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:199:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcmul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:135:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) { \
Jan 13 16:46:28 ~ ^ ~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:199:1: warning: comparison of integers of different signs: 'int' and 'size_t' (aka 'unsigned long') [-Wsign-compare]
Jan 13 16:46:28 FOREACH_POINTWISE_OP_SCALARLIST(addcmul);
Jan 13 16:46:28 ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Jan 13 16:46:28 ../aten/src/ATen/native/ForeachOpsKernels.cpp:145:21: note: expanded from macro 'FOREACH_POINTWISE_OP_SCALARLIST'
Jan 13 16:46:28 for (int i = 0; i < input.size(); i++) {
```
this diff fixes that
Test Plan: Sandcastle tests
Reviewed By: xush6528
Differential Revision: D25901744
fbshipit-source-id: 2cb665358a103d85e07c690d73b3f4a557d4c135
Summary:
Addresses one of the speed points in https://github.com/pytorch/pytorch/issues/50513 by making the `TestTypeHints` suite much faster when run incrementally. Also fixes an issue (at least on 5834438090a1b3206347e30968e48f44251a53a1) where running that suite repeatedly results in a failure every other run (see the test plan below).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50539
Test Plan:
First clear your [`mypy` cache](https://mypy.readthedocs.io/en/stable/command_line.html#incremental-mode):
```
$ rm -r .mypy_cache
```
Then run this twice:
```
$ python test/test_type_hints.py
```
- *Before:*
```
....
----------------------------------------------------------------------
Ran 4 tests in 212.340s
OK
```
```
.F..
======================================================================
FAIL: test_run_mypy (__main__.TestTypeHints)
Runs mypy over all files specified in mypy.ini
----------------------------------------------------------------------
Traceback (most recent call last):
File "test/test_type_hints.py", line 214, in test_run_mypy
self.fail(f"mypy failed: {stdout} {stderr}")
AssertionError: mypy failed: torch/quantization/fx/quantize.py:138: error: "Tensor" not callable [operator]
Found 1 error in 1 file (checked 1189 source files)
----------------------------------------------------------------------
Ran 4 tests in 199.331s
FAILED (failures=1)
```
- *After:*
```
....
----------------------------------------------------------------------
Ran 4 tests in 212.815s
OK
```
```
....
----------------------------------------------------------------------
Ran 4 tests in 5.491s
OK
```
Reviewed By: xuzhao9
Differential Revision: D25912363
Pulled By: samestep
fbshipit-source-id: dac38c890399193699c57b6c9fa8df06a88aee5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50543
Original commit changeset: 2d2f07f79986
Was part of a stack that got reverted. This is just a benchmark.
ghstack-source-id: 119825594
Test Plan: CI
Reviewed By: navahgar
Differential Revision: D25912439
fbshipit-source-id: 5d9ca45810fff8931a3cfbd03965e11050180676
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44418
This commit uses TensorPipe's cuda_ipc channel to conduct
cross-process same-machine GPU-to-GPU communication. On the sender
side, `TensorPipeAgent` grabs a stream to each device used by the
message, let these streams wait for current streams, and passes
the streams to TensorPipe `CudaBuffer`. On the receiver side, it
also grabs a stream for each device used in the message, and uses
these streams to receive tensors and run user functions. After that,
these streams are then used for sending the response back to the
sender. When receiving the response, the sender will grab a new set
of streams and use them for TensorPipe's `CudaBuffer`.
If device maps are provided, `TensorPipeAgent::send` will return a
derived class of `CUDAFuture`, which is specifically tailored for
RPC Messages.
TODOs:
1. Enable sending CUDA RPC to the same process.
2. Add a custom CUDA stream pool.
3. When TensorPipe addressed the error for `cudaPointerGetAttributes()`,
remove `cuda:0` context initialization code in `backend_registry.py`.
4. When TensorPipe can detect availability of peer access, enable all
tests on platforms without peer access.
Differential Revision: D23626207
Test Plan: Imported from OSS
Reviewed By: lw
Pulled By: mrshenli
fbshipit-source-id: d30e89e8a98bc44b8d237807b84e78475c2763f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50490
Right now CPU tests are skipped because it always failed in checking 'torch.cuda.device_count() < int(self.world_size)',
enable CPU tests back by checking device count only when cuda is available
Test Plan: unit tests, CPU tests are not skipped with this diff
Reviewed By: rohan-varma
Differential Revision: D25901980
fbshipit-source-id: e6e8afe217604c5f5b3784096509240703813d94
Summary:
Addresses one of the documentation points in https://github.com/pytorch/pytorch/issues/50513 by making it easier to find our `mypy` wiki page. Also updates the `CONTRIBUTING.md` table of contents and removes some trailing whitespace.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50540
Reviewed By: janeyx99
Differential Revision: D25912366
Pulled By: samestep
fbshipit-source-id: b305f974700a9d9ebedc0c2cb75c92e72d84882a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50521
Original commit changeset: 9731ec1e0c1d
Test Plan:
- run `arc focus2 -b pp-ios //xplat/arfx/tracking/segmentation:segmentationApple -a ModelRunner --force-with-bad-commit `
- build via Xcode, run it on an iOS device
- Click "Person Segmentation"
- Crash observed without the diff patched, and the segmentation image is able to be loaded with this diff patched
Reviewed By: husthyc
Differential Revision: D25908493
fbshipit-source-id: eef072a8a3434b932cfd0646ee78159f72be5536
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49120
This adds a `check_batched_grad=False` option to gradcheck and gradgradcheck.
It defaults to False because gradcheck is a public API and I don't want
to break any existing non-pytorch users of gradcheck.
This:
- runs grad twice with two grad outputs, a & b
- runs a vmapped grad with torch.stack([a, b])
- compares the results of the above against each other.
Furthermore:
- `check_batched_grad=True` is set to be the default for
gradcheck/gradgradcheck inside of test_autograd.py. This is done by
reassigning to the gradcheck object inside test_autograd
- I manually added `check_batched_grad=False` to gradcheck instances
that don't support batched grad.
- I added a denylist for operations that don't support batched grad.
Question:
- Should we have a testing only gradcheck (e.g.,
torch.testing.gradcheck) that has different defaults from our public
API, torch.autograd.gradcheck?
Future:
- The future plan for this is to repeat the above for test_nn.py (the
autogenerated test will require a denylist)
- Finally, we can repeat the above for all pytorch test files that use
gradcheck.
Test Plan: - run tests
Reviewed By: albanD
Differential Revision: D25563542
Pulled By: zou3519
fbshipit-source-id: 125dea554abefcef0cb7b487d5400cd50b77c52c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49726
Just cleaned up the unnecessary `ModuleAttributeError`
BC-breaking note:
`ModuleAttributeError` was added in the previous unsuccessful [PR](https://github.com/pytorch/pytorch/pull/49879) and removed here. If a user catches `ModuleAttributeError` specifically, this will no longer work. They should catch `AttributeError` instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50298
Reviewed By: mrshenli
Differential Revision: D25907620
Pulled By: jbschlosser
fbshipit-source-id: cdfa6b1ea76ff080cd243287c10a9d749a3f3d0a
Summary:
**Expected**: When I run `torch.distributions.HalfCauchy(torch.tensor(1.0), validate_args=True).log_prob(-1)`, I expect a `ValueErro` because that is the behavior of other distributions (e.g. Beta, Bernoulli).
**Actual**: No run-time error is thrown, but a `-inf` log prob is returned.
Fixes https://github.com/pytorch/pytorch/issues/50404
---
This change is [<img src="https://reviewable.io/review_button.svg" height="34" align="absmiddle" alt="Reviewable"/>](https://reviewable.io/reviews/pytorch/pytorch/50403)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50403
Reviewed By: mrshenli
Differential Revision: D25907131
Pulled By: neerajprad
fbshipit-source-id: ceb63537e5850809c8b32cf9db0c99043f381edf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50520
**Summary**
The new version of `clang-format` for linux64 that was uploaded to S3
earlier this week was dynamically linked to fbcode's custom platform.
A new binary has been uploaded that statically links against `libgcc`
and `libstdc++`, which seems to have fixed this issue. Ideally, all
libraries would be statically linked.
**Test Plan**
`clang-format` workflow passes on this PR and output shows that it
successfully downloaded, verified and ran.
```
Created directory /home/runner/work/pytorch/pytorch/.clang-format-bin for clang-format binary
Downloading clang-format to /home/runner/work/pytorch/pytorch/.clang-format-bin
Reference Hash: 9073602de1c4e1748f2feea5a0782417b20e3043
Actual Hash: 9073602de1c4e1748f2feea5a0782417b20e3043
Using clang-format located at /home/runner/work/pytorch/pytorch/.clang-format-bin/clang-format
no modified files to format
```
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D25908868
Pulled By: SplitInfinity
fbshipit-source-id: 5667fc5546e5ed0bbf9f36570935d245eb26629b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50049
Rationale and implementation immortalized in a big comment in
`torch/package/mangling.md`.
This change also allows imported modules to be TorchScripted
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D25758625
Pulled By: suo
fbshipit-source-id: 77a99dd2024c76716cfa6e59c3855ed590efda8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50228
`fastmod -m 'expect(<((at|c10)::)?\w+Type>\(\)\s*)->'
'expectRef${1}.'`
Presuming it builds, this is a safe change: the result of `expect()`
wasn't being saved anywhere, so we didn't need it, so we can take a
reference instead of a new `shared_ptr`.
ghstack-source-id: 119782961
Test Plan: CI
Reviewed By: SplitInfinity
Differential Revision: D25837374
fbshipit-source-id: 86757b70b1520e3dbaa141001e7976400cdd3b08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50395
There's no need for these to be `std::function`.
ghstack-source-id: 119684828
Test Plan: CI
Reviewed By: hlu1
Differential Revision: D25874187
fbshipit-source-id: e9fa3fbc0dca1219ed13904ca704670ce24f7cc3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50301
I'm not sure why this is virtual. We don't seem to override it anywhere, and GitHub code search doesn't turn up anything either.
ghstack-source-id: 119622058
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D25856434
fbshipit-source-id: a95a8d738b109b34f2aadf8db5d4b733d679344f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50290
This was reverted because it landed after D24772023 (b73c018598), which
changed the implementation of `dim()`, without rebasing on top of it,
and thus broke the build.
ghstack-source-id: 119608505
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D25852810
fbshipit-source-id: 9735a095d539a3a6dc530b7b3bb758d4872d05a8
Summary:
Similar to https://github.com/pytorch/pytorch/issues/48201, this PR excludes a file that is auto-generated by [`test/test_type_hints.py`](5834438090/test/test_type_hints.py (L109-L111)), which doesn't happen to be run before the Flake8 check is done in CI. Also, because the `exclude` list in `.flake8` has gotten fairly long, this PR splits it across multiple lines.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50497
Test Plan:
Run this in your shell:
```sh
python test/test_type_hints.py TestTypeHints.test_doc_examples
flake8
```
- _Before:_ `flake8` prints [these 169 false positives](https://pastebin.com/qPJY24g8) and returns exit code 1
- _After:_ `flake8` prints no output and returns exit code 0
Reviewed By: mrshenli
Differential Revision: D25903177
Pulled By: samestep
fbshipit-source-id: 21f757ac8bfa626bb56ece2ecc55668912b71234
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50318
We can skip the dispatcher and go to the device-specific
`at::native::empty_strided` implementation.
Also, unpacking the TensorOptions struct at kernel launch time actually takes a
bit of work, since the optionals are encoded in a bitfield. Do this upfront
and use the optionals directly at runtime.
ghstack-source-id: 119735738
Test Plan:
Before:
```
-------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------
FusedOverhead 2143 ns 2142 ns 332946
UnfusedOverhead 2277 ns 2276 ns 315130
```
After:
```
-------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------
FusedOverhead 2175 ns 2173 ns 321877
UnfusedOverhead 2394 ns 2394 ns 307360
```
(The noise in the baseline makes this really hard to read, it seemed to be
about 3-5% faster in my local testing)
Reviewed By: eellison
Differential Revision: D25859132
fbshipit-source-id: 8753289339e365f78c790bee076026cd649b8509
Summary:
The `TestOpInfoCUDA.test_unsupported_dtypes_addmm_cuda_bfloat16` in `test_ops.py` is failing on ampere. This is because addmm is supported on Ampere, but the test is asserting that it is not supported.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50440
Reviewed By: mrshenli
Differential Revision: D25893326
Pulled By: ngimel
fbshipit-source-id: afeec25fdd76e7336d84eb53ea36319ade1ab421
Summary:
fix https://github.com/pytorch/pytorch/issues/50448.
This replaces all `test/*.py` files with run_tests(). This PR does not address test files in the subdirectories because they seems unrelated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50451
Reviewed By: janeyx99
Differential Revision: D25899924
Pulled By: walterddr
fbshipit-source-id: f7c861f0096624b2791ad6ef6a16b1c4895cce71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50393
Exponential Moving Average
Usage:
add ema_options in adagrad optimizer. For details, plz refer to the test workflow setting.
if ema_end == -1, it means ema will never end.
Test Plan:
buck test caffe2/caffe2/fb/optimizers:ema_op_optimizer_test
buck test caffe2/caffe2/fb/optimizers:ema_op_test
f240459719
Differential Revision: D25416056
fbshipit-source-id: a25e676a364969e3be2bc47750011c812fc3a62f
Summary:
* remove some cases of single characters in
character classes--these can incur the overhead
of a character class with none of the benefits
of a multi-character character class
* for more details, see Chapter 6 of:
Friedl, Jeffrey. Mastering Regular Expressions. 3rd ed.,
O’Reilly Media, 2009.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50294
Reviewed By: zhangguanheng66
Differential Revision: D25870912
Pulled By: malfet
fbshipit-source-id: 9be5be9ed11fd49876213f0be8121b24739f1c13
Summary:
Since version 1.6, oneDNN has provided limited support for AArch64 builds.
This minor change is to detect an AArch64 CPU and permit the use of
`USE_MKLDNN` in that case.
Build flags for oneDNN are also modified accordingly.
Note: oneDNN on AArch64, by default, will use oneDNN's reference C++ kernels.
These are not optimised for AArch64, but oneDNN v1.7 onwards provides support
for a limited set of primitives based Arm Compute Library.
See: https://github.com/oneapi-src/oneDNN/pull/795
and: https://github.com/oneapi-src/oneDNN/pull/820
for more details. Support for ACL-based oneDNN primitives in PyTorch
will require some further modification,
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50400
Reviewed By: izdeby
Differential Revision: D25886589
Pulled By: malfet
fbshipit-source-id: 2c81277a28ad4528c2d2211381e7c6692d952bc1
Summary:
Fixes https://github.com/pytorch/pytorch/issues/21737
With this fix, TORCH_LIBRARIES variable can provide all nessesary static libraries build from pytorch repo.
User program (if do static build) now can just link with ${TORCH_LIBRARIES} + MKL + cuda runtime.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49458
Reviewed By: mrshenli
Differential Revision: D25895354
Pulled By: malfet
fbshipit-source-id: 8ff47d14ae1f90036522654d4354256ed5151e5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48668
Combine tests for `fmod` and `remainder`.
## BC-breaking Note:
In order to make `remainder` operator have type promotion, we have to introduce BC breaking.
### 1.7.1:
In the case where the second argument is a python number, the result is casted to the dtype of the first argument.
```python
>>> torch.remainder(x, 1.2)
tensor([0, 0, 0, 0, 0], dtype=torch.int32)
```
### This PR:
In the case where the second argument is a python number, the dtype of result is determined by type promotion of both inputs.
```python
>>> torch.remainder(x, 1.2)
tensor([1.0000, 0.8000, 0.6000, 0.4000, 0.2000])
```
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D25869136
Pulled By: ejguan
fbshipit-source-id: 8e5e87eec605a15060f715952de140f25644008c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48278
Remove various lines from tests due to no type promotion introduced from #47323
## BC-breaking Note:
In order to make `fmod` operator have type promotion, we have to introduce BC breaking.
### 1.7.1:
In the case where the second argument is a python number, the result is casted to the dtype of the first argument.
```python
>>> torch.fmod(x, 1.2)
tensor([0, 0, 0, 0, 0], dtype=torch.int32)
```
### Prior PR:
Check the BC-breaking note of #47323
### This PR:
In the case where the second argument is a python number, the dtype of result is determined by type promotion of both inputs.
```python
>>> torch.fmod(x, 1.2)
tensor([1.0000, 0.8000, 0.6000, 0.4000, 0.2000])
```
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D25869137
Pulled By: ejguan
fbshipit-source-id: bce763926731e095b75daf2e934bff7c03ff0832
Summary:
And unrelying torch._C._cuda_canDeviceAccessPeer, which is a wrapper around cudaDeviceCanAccessPeer
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50446
Reviewed By: mrshenli
Differential Revision: D25890405
Pulled By: malfet
fbshipit-source-id: ef09405f115bbe73ba301d608d56cd8f8453201b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50455
Certain systems only print logging messages for ERROR/WARN and the
error message that the watchdog is timing out a particular operation is pretty
important.
As a result, changing its level to ERROR instead of INFO.
ghstack-source-id: 119761029
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D25894795
fbshipit-source-id: 259b16c13f6cdf9cb1956602d15784b92aa53f17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49502
It broke the OSS CI the last time I landed it, mostly cuda tests and python bindings.
Similar to permute_out, add the out variant of `aten::narrow` (slice in c2) which does an actual copy. `aten::narrow` creates a view, however, an copy is incurred when we call `input.contiguous` in the ops that follow `aten::narrow`, in `concat_add_mul_replacenan_clip`, `casted_batch_one_hot_lengths`, and `batch_box_cox`.
{F351263599}
Test Plan:
Unit test:
```
buck test //caffe2/aten:math_kernel_test
buck test //caffe2/test:sparse -- test_narrow
```
Benchmark with the adindexer model:
```
bs = 1 is neutral
Before:
I1214 21:32:51.919239 3285258 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.0886948. Iters per second: 11274.6
After:
I1214 21:32:52.492352 3285277 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.0888019. Iters per second: 11261
bs = 20 shows more gains probably because the tensors are bigger and therefore the cost of copying is higher
Before:
I1214 21:20:19.702445 3227229 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.527563. Iters per second: 1895.51
After:
I1214 21:20:20.370173 3227307 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.508734. Iters per second: 1965.67
```
Reviewed By: ajyu
Differential Revision: D25596290
fbshipit-source-id: da2f5a78a763895f2518c6298778ccc4d569462c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50390
Currently, there is a massive switch/case statement that is generated in the `InternedStrings::string()` method to speed up Symbol -> string conversion without taking a lock (mutex). The relative call rate of this on mobile is insignificant, so unlikely to have any material impact on runtime even if the lookups happen under a lock. Plus, parallelism is almost absent on mobile, which is where locks/mutexes cause the most problem (taking a mutex without contention is usually very fast and just adds a memory barrier iirc).
The only impact that caching interned strings has is avoiding taking a lock when interned strings are looked up. They are not looked up very often during training, and based on basic testing, they don't seem to be looked up much during inference either.
During training, the following strings were looked up at test startup:
```
prim::profile
prim::profile_ivalue
prim::profile_optional
prim::FusionGroup
prim::TypeCheck
prim::FallbackGraph
prim::ChunkSizes
prim::ConstantChunk
prim::tolist
prim::FusedConcat
prim::DifferentiableGraph
prim::MMBatchSide
prim::TensorExprGroup
```
Command used to trigger training: `buck test fbsource//xplat/papaya/client/executor/torch/store/transform/feature/test:test`
During inference, the only symbol that was looked up was `tolist`.
ghstack-source-id: 119679831
Test Plan:
See the summary above + sandcastle tests.
### Size test: fbios
```
D25861786-V1 (https://www.internalfb.com/intern/diff/D25861786/?dest_number=119641372)
fbios: Succeeded
Change in Download Size for arm64 + 3x assets variation: -13.9 KiB
Change in Uncompressed Size for arm64 + 3x assets variation: -41.7 KiB
Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:747386759232352@base/bsb:747386759232352@diff/
```
### Size test: igios
```
D25861786-V1 (https://www.internalfb.com/intern/diff/D25861786/?dest_number=119641372)
igios: Succeeded
Change in Download Size for arm64 + 3x assets variation: -16.6 KiB
Change in Uncompressed Size for arm64 + 3x assets variation: -42.0 KiB
Mbex Comparison: https://our.intern.facebook.com/intern/mbex/bsb:213166470538954@base/bsb:213166470538954@diff/
```
Reviewed By: iseeyuan
Differential Revision: D25861786
fbshipit-source-id: 34a55d693edc41537300f628877a64723694f8f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50406
We were creating different TMs in PytorchLLVMJIT and LLVMCodeGen; the
one in LLVMCodeGen had the right target-specific options to generate fast AVX2
code (with FMAs, vbroadcastss, etc.), and that's what was showing up in the
debug output, but the LLVMJIT TM was the one that actually generated runtime
code, and it was slow.
ghstack-source-id: 119700110
Test Plan:
```
buck run mode/opt //caffe2/benchmarks/fb/tensorexpr:tensorexpr_bench
```
With this diff NNC is getting at least somewhat (5%) close to Pytorch with MKL,
for at least this one small-ish test case"
```
Run on (24 X 2394.67 MHz CPU s)
2021-01-11 15:57:27
----------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
----------------------------------------------------------------------------------------------------
Gemm/Torch/128/128/128 65302 ns 65289 ns 10734 GFLOPS=64.2423G/s
Gemm/TensorExprTile4x16VecUnroll/128/128/128 68602 ns 68599 ns 10256 GFLOPS=61.1421G/s
```
Reviewed By: bwasti
Differential Revision: D25877605
fbshipit-source-id: cd293bac94d025511f348eab5c9b8b16bf6505ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50304
Does not include any functional changes -- purely for fixing minor typos in the `fuser_method_mappings.py`
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25857248
Pulled By: z-a-f
fbshipit-source-id: 3f9b864b18bda8096e7cd52922dc21be64278887
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50297
Current implementation has a potential bug: if a user modifies the quantization mappings returned by the getters, the changes will propagate.
For example, the bug will manifest itself if the user does the following:
```
my_mapping = get_default_static_quant_module_mappings()
my_mapping[nn.Linear] = UserLinearImplementation
model_A = convert(model_A, mapping=my_mapping)
default_mapping = get_default_static_quant_module_mappings()
model_B = convert(model_B, mapping=default_mapping)
```
In that case the `model_B` will be quantized with with the modified mapping.
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D25855753
Pulled By: z-a-f
fbshipit-source-id: 0149a0c07a965024ba7d1084e89157a9c8fa1192
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: ac98f40758
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50441
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: mrshenli
Differential Revision: D25888666
fbshipit-source-id: fd447f81462f476c62aed0e43830a710f60187e1
Summary:
This PR fixes two local issue for me:
1. Assert failure when passing `None` to `Optional[Tensor]` input that requires gradient in autodiff
2. Wrong vjp mapping on inputs when `requires_grad` flag changes on inputs stack.
This PR is to support autodiff on layer_norm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49430
Reviewed By: izdeby
Differential Revision: D25886211
Pulled By: eellison
fbshipit-source-id: 075af35a4a9c0b911838f25146f859897f9a07a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50115
There is no way this is performant and we are trying to minimize the usage of scalar_to_tensor(..., device) since it is an anti-pattern, see https://github.com/pytorch/pytorch/issues/49758.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D25790331
Pulled By: gchanan
fbshipit-source-id: 89d6f016dfd76197541b0fd8da4a462876dbf844
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50238
Added `C10_CUDA_KERNEL_LAUNCH_CHECK();` after all kernel launches in caffe2/caffe2/utils/math
Test Plan:
```
buck build //caffe2/caffe2
```
{F356531214}
files in caffe2/caffe2/utils/math no longer show up when running
```
python3 caffe2/torch/testing/check_kernel_launches.py
```
Reviewed By: r-barnes
Differential Revision: D25773299
fbshipit-source-id: 28d67b4b9f57f1fa1e8699e43e9202bad4d42c5f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50222
This PR adds a pass which runs a set of optimizations to be done after freezing. Currently this encompasses Conv-BN folding, Conv->Add/Sub/Mul/Div folding and i'm also planning on adding dropout removal.
I would like some feedback on the API. torch.jit.freeze is technically in \~prototype\~ phase so we have some leeway around making changes. I think in the majority of cases, the user is going to want to freeze their model, and then run in inference. I would prefer if the optimization was opt-out instead of opt-in. All internal/framework use cases of freezing all use `freeze_module`, not the python API, so this shouldn't break anything.
I have separated out the optimization pass as a separate API to make things potentially modular, even though I suspect that is an unlikely case. In a future PR i would like to add a `torch::jit::freeze` which follows the same api as `torch.jit.freeze` intended for C++ use, and runs the optimizations.
Test Plan: Imported from OSS
Reviewed By: tugsbayasgalan
Differential Revision: D25856264
Pulled By: eellison
fbshipit-source-id: 56be1f12cfc459b4c4421d4dfdedff8b9ac77112
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50075
Adds Conv - Add/Sub/Mul/Div fusion for frozen models. This helps cover models like torchvision maskrcnn, which use a hand-rolled batchnorm implementation: 90645ccd0e/torchvision/ops/misc.py (L45).
I haven't tested results yet but I would expect a somewhat similar speed up as conv-bn fusion (maybe a little less).
Test Plan: Imported from OSS
Reviewed By: tugsbayasgalan
Differential Revision: D25856265
Pulled By: eellison
fbshipit-source-id: 2c36fb831a841936fe4446ed440185f59110bf68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50074
Adds Conv-BN fusion for models that have been frozen. I haven't explicitly tested perf yet but it should be equivalent to the results from Chillee's PR [here](https://github.com/pytorch/pytorch/pull/476570) and [here](https://github.com/pytorch/pytorch/pull/47657#issuecomment-725752765). Click on the PR for details but it's a good speed up.
In a later PR in the stack I plan on making this optimization on by default as part of `torch.jit.freeze`. I will also in a later PR add a peephole so that there is not conv->batchnorm2d doesn't generate a conditional checking # dims.
Zino was working on freezing and left the team, so not really sure who should be reviewing this, but I dont care too much so long as I get a review �
Test Plan: Imported from OSS
Reviewed By: tugsbayasgalan
Differential Revision: D25856261
Pulled By: eellison
fbshipit-source-id: da58c4ad97506a09a5c3a15e41aa92bdd7e9a197
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50176
UndefinedTensorImpl was the only type that overrode this, and IIUC we don't need to do it.
ghstack-source-id: 119609531
Test Plan: CI, internal benchmarks
Reviewed By: ezyang
Differential Revision: D25817370
fbshipit-source-id: 985a99dcea2e0daee3ca3fc315445b978f3bf680
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50249
Add a few new patterns for `ConcatAddMulReplaceNanClip`
Reviewed By: houseroad
Differential Revision: D25843126
fbshipit-source-id: d4987c716cf085f2198234651a2214591d8aacc0
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50064
**PROBLEM:**
In issue https://github.com/pytorch/pytorch/issues/36377, min/max functions were disabled for complex inputs (via dtype checks).
However, min/max kernels are still being compiled and dispatched for complex.
**FIX:**
The aforementioned dispatch has been disabled & we now rely on errors produced
by dispatch macro to not run those ops on complex, instead of doing redundant dtype checks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50347
Reviewed By: zhangguanheng66
Differential Revision: D25870385
Pulled By: anjali411
fbshipit-source-id: 921541d421c509b7a945ac75f53718cd44e77df1
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49034
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49035
Test Plan:
Imported from GitHub, without a `Test Plan:` line.
Force rebased to deal with merge conflicts
Reviewed By: zhangguanheng66
Differential Revision: D25767065
Pulled By: walterddr
fbshipit-source-id: ffb904e449f137825824e3f43f3775a55e9b011b
Summary:
This PR adds `torch.linalg.pinv`.
Changes compared to the original `torch.pinverse`:
* New kwarg "hermitian": with `hermitian=True` eigendecomposition is used instead of singular value decomposition.
* `rcond` argument can now be a `Tensor` of appropriate shape to apply matrix-wise clipping of singular values.
* Added `out=` variant (allocates temporary and makes a copy for now)
Ref. https://github.com/pytorch/pytorch/issues/42666
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48399
Reviewed By: zhangguanheng66
Differential Revision: D25869572
Pulled By: mruberry
fbshipit-source-id: 0f330a91d24ba4e4375f648a448b27594e00dead
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49982
The method flip_check_errors was being called in cuda file which had a condition to throw an exception for when dims size is <=0 changed that to <0 and added seperate condition for when equal to zero to return from the method... the return was needed because after this point the method was performing check expecting a non-zero size dims ...
Also removed the comment/condition written to point to the issue
mruberry kshitij12345 please review this once
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50325
Reviewed By: zhangguanheng66
Differential Revision: D25869559
Pulled By: mruberry
fbshipit-source-id: a831df9f602c60cadcf9f886ae001ad08b137481
Summary:
All these Unary operators have been an entry in OpInfo DB.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50096
Reviewed By: zhangguanheng66
Differential Revision: D25870048
Pulled By: mruberry
fbshipit-source-id: b64e06d5b9ab5a03a202cda8c22fdb7e4ae8adf8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50133
`find_unused_parameters=True` is only needed when the model has unused parameters that are not known at model definition time or differ due to control flow.
Unfortunately, many DDP users pass this flag in as `True` even when they do not need it, sometimes as a precaution to mitigate possible errors that may be raised (such as the error we raise with not using all outputs).While this is a larger issue to be fixed in DDP, it would also be useful to warn once if we did not detect unused parameters.
The downside of this is that in the case of flow control models where the first iteration doesn't have unused params but the rest do, this would be a false warning. However, I think the warning's value exceeds this downside.
ghstack-source-id: 119707101
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D25411118
fbshipit-source-id: 9f4a18ad8f45e364eae79b575cb1a9eaea45a86c
Summary:
Apply sebpop patch to correctly inform optimizing compiler about side-effect of missing neon restrictions
Allow vec256_float_neon to be used even if compiled by gcc-7
Fixes https://github.com/pytorch/pytorch/issues/47098
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50389
Reviewed By: walterddr
Differential Revision: D25872875
Pulled By: malfet
fbshipit-source-id: 1fc5dfe68fbdbbb9bfa79ce4be2666257877e85f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50312
Integrate the operator tests to the MacOS playground app, so that we can run them on Sandcastle
ghstack-source-id: 119693035
Test Plan:
- `buck test pp-macos`
- Sandcastle tests
Reviewed By: AshkanAliabadi
Differential Revision: D25778981
fbshipit-source-id: 8b5770dfddba0ca19f662894757b2dff66df87e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50310
Swapping the stride value is OK if the output tensor's storage stays in-contiguous. However, when we copy the result back to CPU, we expect to see a contiguous tensor.
```
>>> x = torch.rand(2,3)
>>> x.stride()
(3, 1)
>>> y = x.t()
>>> y.stride()
(1, 3)
>>> z = y.contiguous()
>>> z.stride()
(2, 1)
```
ghstack-source-id: 119692581
Test Plan: Sandcastle CI
Reviewed By: AshkanAliabadi
Differential Revision: D25823665
fbshipit-source-id: 61667c03d1d4dd8692b76444676cc393f808cec8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49908
As described in https://github.com/pytorch/pytorch/issues/49891, DDP +
Pipe doesn't work with find_unused_parameters.
This PR adds a simple fix to enable this functionality. This only currently
works for Pipe within a single host and needs to be re-worked once we support
cross host Pipe.
ghstack-source-id: 119573413
Test Plan:
1) unit tests added.
2) waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D25719922
fbshipit-source-id: 948bcc758d96f6b3c591182f1ec631830db1b15c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50114
In this case, the function only dispatches on cpu anyway.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D25790155
Pulled By: gchanan
fbshipit-source-id: 799dc9a3a38328a531ced9e85ad2b4655533e86a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50309
Previously, in order to unblock the dogfooding, we did some hacks to calculate the strides for the output tensor. Now it's time to fix that.
ghstack-source-id: 119673688
Test Plan:
1. Sandcastle CI
2. Person segmentation results
Reviewed By: AshkanAliabadi
Differential Revision: D25821766
fbshipit-source-id: 8c067f55a232b7f102a64b9035ef54c72ebab4d4
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: bc5ac93c56
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50369
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: mrshenli
Differential Revision: D25867976
Pulled By: lw
fbshipit-source-id: 5274aa424e3215b200dcb2c02f342270241dd77d
Summary:
After we merged https://github.com/pytorch/pytorch/pull/48743, we noticed that some existing code that subclasses `torch.Distribution` started throwing `NotImplemenedError` since the constraints required for validation checks were not implemented.
```sh
File "torch/distributions/distribution.py", line 40, in __init__
for param, constraint in self.arg_constraints.items():
File "torch/distributions/distribution.py", line 92, in arg_constraints
raise NotImplementedError
```
This PR throws a UserWarning for such cases instead and gives a better warning message.
cc. Balandat
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50302
Reviewed By: Balandat, xuzhao9
Differential Revision: D25857315
Pulled By: neerajprad
fbshipit-source-id: 0ff9f81aad97a0a184735b1fe3a5d42025c8bcdf
Summary:
Because I have a hard time finding this tutorial every time I need it. So I'm sure other people have the same issue :D
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50374
Reviewed By: zhangguanheng66
Differential Revision: D25872173
Pulled By: albanD
fbshipit-source-id: f34f719606e58487baf03c73dcbd255017601a09
Summary:
Now that we support CUDA 11 we can remove support for CUDA 9.2
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50388
Reviewed By: zhangguanheng66
Differential Revision: D25872955
Pulled By: seemethere
fbshipit-source-id: 1c10bcc8f4abbc1af1b3180b4cf4a9ea9c7104f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50399
**Summary**
This commit updates the expected hashes of the `clang-format` binaries
downloaded from S3. These binaries themselves have been updated due to
having been updated inside fbcode.
**Test Plan**
Uploaded new binaries to S3, deleted `.clang-format-bin` and ran
`clang_format_all.py`.
Test Plan: Imported from OSS
Reviewed By: seemethere
Differential Revision: D25875184
Pulled By: SplitInfinity
fbshipit-source-id: da483735de1b5f1dab7b070f91848ec5741f00b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50255
**Summary**
TorchScript classes are copied attribute-by-attribute from a py::object into
a `jit::Object` in `toIValue`, which is called when copying objects from
Python into TorchScript. However, if an attribute of the class cannot be
converted, the error thrown is a standard pybind error that is hard to
act on.
This commit adds code to `toIValue` to convert each attribute to an
`IValue` inside a try-catch block, throwing a `cast_error` containing
the name of the attribute and the target type if the conversion fails.
**Test Plan**
This commit adds a unit test to `test_class_type.py`
based on the code in the issue that commit fixes.
**Fixes**
This commit fixes#46341.
Test Plan: Imported from OSS
Reviewed By: pbelevich, tugsbayasgalan
Differential Revision: D25854183
Pulled By: SplitInfinity
fbshipit-source-id: 69d6e49cce9144af4236b8639d8010a20b7030c0
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47671
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49272
Test Plan:
```
x = torch.tensor([-2, -1, 0, 1, 2], dtype=torch.float32, requires_grad=True)
y = torch.nn.functional.elu_(x.clone(), alpha=-2)
grads = torch.tensor(torch.ones_like(y))
y.backward(grads)
```
```
RuntimeError: In-place elu backward calculation is triggered with a negative slope which is not supported.
This is caused by calling in-place forward function with a negative slope, please call out-of-place
version instead.
```
Reviewed By: albanD
Differential Revision: D25569839
Pulled By: H-Huang
fbshipit-source-id: e3c6c0c2c810261566c10c0cc184fd81b280c650
Summary:
Immediately-upstreamable part of https://github.com/pytorch/pytorch/pull/50148.
This PR fixes what I'm fairly sure is a subtle bug with custom `Philox` class usage in jitted kernels. `Philox` [constructors in kernels](68a6e46379/torch/csrc/jit/codegen/cuda/codegen.cpp (L102)) take the cuda rng generator's current offset. The Philox constructor then carries out [`offset/4`](74c055b240/torch/csrc/jit/codegen/cuda/runtime/random_numbers.cu (L13)) (a uint64_t division) to compute its internal offset in its virtual Philox bitstream of 128-bit chunks. In other words, it assumes the incoming offset is a multiple of 4. But (in current code) that's not guaranteed. For example, the increments used by [these eager kernels](74c055b240/aten/src/ATen/native/cuda/Distributions.cu (L171-L216)) could easily make offset not divisible by 4.
I figured the easiest fix was to round all incoming increments up to the nearest multiple of 4 in CUDAGeneratorImpl itself.
Another option would be to round the current offset up to the next multiple of 4 at the jit point of use. But that would be a jit-specific offset jump, so jit rng kernels wouldn't have a prayer of being bitwise accurate with eager rng kernels that used non-multiple-of-4 offsets. Restricting the offset to multiples of 4 for everyone at least gives jit rng the chance to match eager rng. (Of course, there are still many other ways the numerics could diverge, like if a jit kernel launches a different number of threads than an eager kernel, or assigns threads to data elements differently.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50169
Reviewed By: mruberry
Differential Revision: D25857934
Pulled By: ngimel
fbshipit-source-id: 43a75e2d0c8565651b0f12a5694c744fd86ece99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50173
Previously we did not set the qconfig for call_method node correctly since it requires us to know
the scope (module path of the module whose forward graph contains the node) of the node. This
PR modifies the QuantizationTracer to record the scope information and build a map from call_method
Node to module path, which will be used when we construct qconfig_map
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_qconfig_for_call_method
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D25818132
fbshipit-source-id: ee9c5830f324d24d7cf67e5cd2bf1f6e0e46add8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50367
This had already been done by mrshenli on Friday (#50236, D25847892 (f9f758e349)) but over the weekend Facebook's internal clang-format version got updated and this changed the format, hence we need to re-apply it. Note that this update also affected the JIT files, which are the other module enrolled in clang-format (see 8530c65e25, D25849205 (8530c65e25)).
ghstack-source-id: 119656866
Test Plan: Shouldn't include functional changes. In any case, there's CI.
Reviewed By: mrshenli
Differential Revision: D25867720
fbshipit-source-id: 3723abc6c35831d7a8ac31f74baf24c963c98b9d
Summary:
_resubmission of gh-49654, which was reverted due to a cross-merge conflict_
This caught one incorrect annotation in `cpp_extension.load`.
xref gh-16574.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50278
Reviewed By: walterddr
Differential Revision: D25865278
Pulled By: ezyang
fbshipit-source-id: 25489191628af5cf9468136db36f5a0f72d9d54d
Summary:
As per title.
CC IvanYashchuk (unfortunately I cannot add you as a reviewer for some reason).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50109
Reviewed By: gchanan
Differential Revision: D25828536
Pulled By: albanD
fbshipit-source-id: 3791c3dd4f5c2a2917eac62e6527ecd1edcb400d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48965
This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API.
Test Plan: Existing unit tests. Benchmarks are in #48966
Reviewed By: ezyang
Differential Revision: D25590732
Pulled By: robieta
fbshipit-source-id: 6bd74788f06cdd673f3a2db898143d18c577eb42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48964
Stop importing overrides within methods now that the circular dependency is gone, and also organize the imports while I'm at it because they're a jumbled mess.
Test Plan: Existing unit tests. Benchmarks are in #48966
Reviewed By: ngimel
Differential Revision: D25590730
Pulled By: robieta
fbshipit-source-id: 4fa929ce8ff548500f3e55d0475f3f22c1fccc04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48963
This PR makes the binding code treat `Parameter` the same way as `Tensor`, unlike all other `Tensor` subclasses. This does change the semantics of `THPVariable_CheckExact`, but it isn't used much and it seemed to make sense for the half dozen or so places that it is used.
Test Plan: Existing unit tests. Benchmarks are in #48966
Reviewed By: ezyang
Differential Revision: D25590733
Pulled By: robieta
fbshipit-source-id: 060ecaded27b26e4b756898eabb9a94966fc9840
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50248
make the FileStore path also use TorchScript when it's needed.
Test Plan: wait for sandcastle.
Reviewed By: zzzwen
Differential Revision: D25842651
fbshipit-source-id: dec941e895a33ffde42c877afcaf64b5aecbe098
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 03e0711889
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50267
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: gchanan
Differential Revision: D25848309
Pulled By: mrshenli
fbshipit-source-id: c77adbad73c5b3b4b7d4e79953a797621dc11e5c
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/50271
Test Plan:
new python test case
Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D25853916
fbshipit-source-id: adc31e11331a97d08b5bc3f535f185da268554d1
Summary:
This PR adds `torch.linalg.inv` for NumPy compatibility.
`linalg_inv_out` uses in-place operations on provided `result` tensor.
I modified `apply_inverse` to accept tensor of Int instead of std::vector, that way we can write a function similar to `linalg_inv_out` but removing the error checks and device memory synchronization.
I fixed `lda` (leading dimension parameter which is max(1, n)) in many places to handle 0x0 matrices correctly.
Zero batch dimensions are also working and tested.
Ref https://github.com/pytorch/pytorch/issues/42666
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48261
Reviewed By: gchanan
Differential Revision: D25849590
Pulled By: mruberry
fbshipit-source-id: cfee6f1daf7daccbe4612ec68f94db328f327651
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/49916
Test Plan:
1. Build pytorch locally. `MACOSX_DEPLOYMENT_TARGET=10.9 CC=clang CXX=clang++ USE_CUDA=0 DEBUG=1 MAX_JOBS=16 python setup.py develop`
2. Run `python save_lite.py`
```
import torch
# ~/Documents/pytorch/data/dog.jpg
model = torch.hub.load('pytorch/vision:v0.6.0', 'shufflenet_v2_x1_0', pretrained=True)
model.eval()
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
import pathlib
import tempfile
import torch.utils.mobile_optimizer
input_image = Image.open('~/Documents/pytorch/data/dog.jpg')
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
print(torch.nn.functional.softmax(output[0], dim=0))
traced = torch.jit.trace(model, input_batch)
sum(p.numel() * p.element_size() for p in traced.parameters())
tf = pathlib.Path('~/Documents/pytorch/data/data/example_debug_map_with_tensorkey.ptl')
torch.jit.save(traced, tf.name)
print(pathlib.Path(tf.name).stat().st_size)
traced._save_for_lite_interpreter(tf.name)
print(pathlib.Path(tf.name).stat().st_size)
print(tf.name)
```
3. Run `python test_lite.py`
```
import torch
from torch.jit.mobile import _load_for_lite_interpreter
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open('~/Documents/pytorch/data/dog.jpg')
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
reload_lite_model = _load_for_lite_interpreter('~/Documents/pytorch/experiment/example_debug_map_with_tensorkey.ptl')
with torch.no_grad():
output_lite = reload_lite_model(input_batch)
# Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
print(output_lite[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
print(torch.nn.functional.softmax(output_lite[0], dim=0))
```
4. Compare the result with pytorch in master and pytorch built locally with this change, and see the same output.
5. The model size was 16.1 MB and becomes 12.9 with this change.
Imported from OSS
Reviewed By: kimishpatel, iseeyuan
Differential Revision: D25731596
Pulled By: cccclai
fbshipit-source-id: 9731ec1e0c1d5dc76cfa374d2ad3d5bb10990cf0
Summary:
This adds guarding for DifferentiableGraph nodes in order to not depend on
Also bailing out on required gradients for the CUDA fuser.
Fixes https://github.com/pytorch/pytorch/issues/49299
I still need to look into a handful of failing tests, but maybe it can be a discussion basis.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49433
Reviewed By: ngimel
Differential Revision: D25681374
Pulled By: Krovatkin
fbshipit-source-id: 8e7be53a335c845560436c0cceeb5e154c9cf296
Summary:
This PR is a step towards enabling cross compilation from x86_64 to arm64.
The following has been added:
1. When cross compilation is detected, compile a local universal fatfile to use as protoc.
2. For the simple compile check in MiscCheck.cmake, make sure to compile the small snippet as a universal binary in order to run the check.
**Test plan:**
Kick off a minimal build on a mac intel machine with the macOS 11 SDK with this command:
```
CMAKE_OSX_ARCHITECTURES=arm64 USE_MKLDNN=OFF USE_QNNPACK=OFF USE_PYTORCH_QNNPACK=OFF BUILD_TEST=OFF USE_NNPACK=OFF python setup.py install
```
(If you run the above command before this change, or without macOS 11 SDK set up, it will fail.)
Then check the platform of the built binaries using this command:
```
lipo -info build/lib/libfmt.a
```
Output:
- Before this PR, running a regular build via `python setup.py install` (instead of using the flags listed above):
```
Non-fat file: build/lib/libfmt.a is architecture: x86_64
```
- Using this PR:
```
Non-fat file: build/lib/libfmt.a is architecture: arm64
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50243
Reviewed By: malfet
Differential Revision: D25849955
Pulled By: janeyx99
fbshipit-source-id: e9853709a7279916f66aa4c4e054dfecced3adb1
Summary:
Currentlt classmethods are compiled the same way as methods - the first argument is self.
Adding a fake statement to assign the first argument to the class.
This is kind of hacky, but that's all it takes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49967
Reviewed By: gchanan
Differential Revision: D25841378
Pulled By: ppwwyyxx
fbshipit-source-id: 0f3657b4c9d5d2181d658f9bade9bafc72de33d8
Summary:
These unused variables were identified by [pyflakes](https://pypi.org/project/pyflakes/). They can be safely removed to simplify the code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50181
Reviewed By: gchanan
Differential Revision: D25844270
fbshipit-source-id: 0e648ffe8c6db6daf56788a13ba89806923cbb76
Summary:
BC-breaking note:
This PR changes the behavior of the any and all functions to always return a bool tensor. Previously these functions were only defined on bool and uint8 tensors, and when called on uint8 tensors they would also return a uint8 tensor. (When called on a bool tensor they would return a bool tensor.)
PR summary:
https://github.com/pytorch/pytorch/pull/44790#issuecomment-725596687
Fixes 2 and 3
Also Fixes https://github.com/pytorch/pytorch/issues/48352
Changes
* Output dtype is always `bool` (consistent with numpy) **BC Breaking (Previously used to match the input dtype**)
* Uses vectorized version for all dtypes on CPU
* Enables test for complex
* Update doc for `torch.all` and `torch.any`
TODO
* [x] Update docs
* [x] Benchmark
* [x] Raise issue on XLA
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47878
Reviewed By: albanD
Differential Revision: D25714324
Pulled By: mruberry
fbshipit-source-id: a87345f725297524242d69402dfe53060521ea5d
Summary:
Apply a little bit of defensive programming: `type->cast<TensorType>()` returns an optional pointer so dereferencing it can lead to a hard crash.
Fixes SIGSEGV reported in https://github.com/pytorch/pytorch/issues/49959
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50237
Reviewed By: walterddr
Differential Revision: D25839675
Pulled By: malfet
fbshipit-source-id: 403d6df5e2392dd6adc308b1de48057f2f9d77ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50105
There should be no functional change here.
A couple of reasons here:
1) This function is generally an anti-pattern (https://github.com/pytorch/pytorch/issues/49758) and it is good to minimize its usage in the code base.
2) pow itself has a fair amount of smarts like not broadcasting scalar/tensor combinations and we should defer to it.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D25786172
Pulled By: gchanan
fbshipit-source-id: 89de03aa0b900ce011a62911224a5441f15e331a
Summary:
This is related to https://github.com/pytorch/pytorch/issues/42666 .
I am opening this PR to have the opportunity to discuss things.
First, we need to consider the differences between `torch.svd` and `numpy.linalg.svd`:
1. `torch.svd` takes `some=True`, while `numpy.linalg.svd` takes `full_matrices=True`, which is effectively the opposite (and with the opposite default, too!)
2. `torch.svd` returns `(U, S, V)`, while `numpy.linalg.svd` returns `(U, S, VT)` (i.e., V transposed).
3. `torch.svd` always returns a 3-tuple; `numpy.linalg.svd` returns only `S` in case `compute_uv==False`
4. `numpy.linalg.svd` also takes an optional `hermitian=False` argument.
I think that the plan is to eventually deprecate `torch.svd` in favor of `torch.linalg.svd`, so this PR does the following:
1. Rename/adapt the old `svd` C++ functions into `linalg_svd`: in particular, now `linalg_svd` takes `full_matrices` and returns `VT`
2. Re-implement the old C++ interface on top of the new (by negating `full_matrices` and transposing `VT`).
3. The C++ version of `linalg_svd` *always* returns a 3-tuple (we can't do anything else). So, there is a python wrapper which manually calls `torch._C._linalg.linalg_svd` to tweak the return value in case `compute_uv==False`.
Currently, `linalg_svd_backward` is broken because it has not been adapted yet after the `V ==> VT` change, but before continuing and spending more time on it I wanted to make sure that the general approach is fine.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45562
Reviewed By: H-Huang
Differential Revision: D25803557
Pulled By: mruberry
fbshipit-source-id: 4966f314a0ba2ee391bab5cda4563e16275ce91f
Summary:
This solves a race condition where the worker thread might
see a partially initialized graph_task
Fixes https://github.com/pytorch/pytorch/issues/49652
I don't know how to reliably trigger the race so I didn't add any test. But the rocm build flakyness (it just happens to race more often on rocm builds) should disappear after this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50164
Reviewed By: zou3519
Differential Revision: D25824954
Pulled By: albanD
fbshipit-source-id: 6a3391753cb2afd2ab415d3fb2071a837cc565bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50131
Noticed that in the internal diff for
https://github.com/pytorch/pytorch/pull/49069 there was a clang-tidy warning to
use emplace instead of push_back. This can save us a copy as it eliminates the
unnecessary in-place construction
ghstack-source-id: 119560979
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D25800134
fbshipit-source-id: 243e57318f5d6e43de524d4e5409893febe6164c
Summary:
Excludes sm_86 GPU devices from using cuDNN persistent RNN.
This is because there are some hard-to-detect edge cases that will throw exceptions with cudnn 8.0.5 on Nvidia A40 GPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49534
Reviewed By: mruberry
Differential Revision: D25632378
Pulled By: mrshenli
fbshipit-source-id: cbe78236d85d4d0c2e4ca63a3fc2c4e2de662d9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47508
This moves SizesAndStrides to a specialized representation
that is 5 words smaller in the common case of tensor rank 5 or less.
ghstack-source-id: 119313560
Test Plan:
SizesAndStridesTest added in previous diff passes under
ASAN + UBSAN.
Run framework overhead benchmarks. Looks more or less neutral.
Reviewed By: ezyang
Differential Revision: D24772023
fbshipit-source-id: 0a75fd6c2daabb0769e2f803e80e2d6831871316
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47507
This introduces a new SizesAndStrides class as a helper for
TensorImpl, in preparation for changing its representation.
ghstack-source-id: 119313559
Test Plan:
Added new automated tests as well.
Run framework overhead benchmarks. Results seem to be neutral-ish.
Reviewed By: ezyang
Differential Revision: D24762557
fbshipit-source-id: 6cc0ede52d0a126549fb51eecef92af41c3e1a98
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49906
This commit modifies RPC Message to inherit from `torch::CustomClassHolder`,
and wraps a Message in an IValue in `RpcAgent::send()`.
Test Plan: Imported from OSS
Reviewed By: lw
Differential Revision: D25719518
Pulled By: mrshenli
fbshipit-source-id: 694e40021e49e396da1620a2f81226522341550b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49770
Seems like the performance cost of making this commonly-called method virtual isn't worth having use of undefined tensors crash a bit earlier (they'll still fail to dispatch).
ghstack-source-id: 119528065
Test Plan: framework overhead benchmarks
Reviewed By: ezyang
Differential Revision: D25687465
fbshipit-source-id: 89aabce165a594be401979c04236114a6f527b59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49767
I'm told that the base implementation should work fine. Let's validate that in an intermediate diff before removing it.
ghstack-source-id: 119528066
Test Plan: CI
Reviewed By: ezyang, bhosmer
Differential Revision: D25686830
fbshipit-source-id: f931394d3de6df7f6c5c68fe8ab711d90d3b12fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49766
Devirtualizing this seems like a decent performance improvement on
internal benchmarks.
The *reason* this is a performance improvement is twofold:
1) virtual calls are a bit slower than regular calls
2) virtual functions in `TensorImpl` can't be inlined
Test Plan: internal benchmark
Reviewed By: hlu1
Differential Revision: D25602321
fbshipit-source-id: d61556456ccfd7f10c6ebdc3a52263b438a2aef1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48378
This commit adds support for accepting custom importance scores to use for pruning mask computation, rather than only using the parameter.
This is useful if one wants to prune based on scores from different technique such as activations, gradients, weighted scoring of parameters, etc.
An alternative to the above approach would be pass the custom mask to the already available interface. However, the ability to accept importance scores is easier it can leverage the mask computation logic that has already been baked in.
In addition, the commit also makes some minor lint fixes.
Test Plan:
* Unit tests
* Circle CI
Differential Revision: D24997355
fbshipit-source-id: 30797897977b57d3e3bc197987da20e88febb1fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50124
This patch makes `list_element_from` avoid extra `IValue`
move/copies for `List<IValue>` by just forwarding the reference
argument.
We take advantage of this in `listConstruct` by using `push_back`
(which hits the `ListElementFrom` path) instead of `
ghstack-source-id: 119478962
Test Plan:
Inspected generated assembly for vararg_functions.cpp in
optimized build. Rather than a call to `vector::emplace_back` and an extra
move, `vector::push_back` gets inlined.
Reviewed By: ezyang
Differential Revision: D25794277
fbshipit-source-id: 2354d8c08e0a0d6be2db3f0d0d6c90c3a455d8bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49965
Without this checking the type of the quantized tensor using `type` would throw an error.
After this PR running the `type(qx)`, where `qx` is a quantized tensor would show something like `torch.quantized.QUInt8`.
Test Plan: Not needed -- this is just a string description for the quantized tensors
Differential Revision: D25731594
Reviewed By: ezyang
Pulled By: z-a-f
fbshipit-source-id: 942fdf89a1c50895249989c7203f2e7cc00df4c6
Summary:
The aim is being able to inspect a container image and determine immediately
which version of pytorch it contains.
Closes https://github.com/pytorch/pytorch/issues/48324
Signed-off-by: Felix Abecassis <fabecassis@nvidia.com>
seemethere PTAL.
As you requested in https://github.com/pytorch/pytorch/issues/48324#issuecomment-754237156, I'm submitting the patch. But I could only do limited testing as I'm not sure these Makefile/Dockerfile are used for pushing the Docker Hub images (since the Makefile tags the image with a `v` prefix for the version, as in: `pytorch:v1.7.1`, but Docker Hub images don't have this prefix).
Also on the master branch we currently have the following:
```
$ git describe --tags
v1.4.0a0-11171-g68a6e46379
```
So it's a little off, but it behaves as expected on the `release/1.7` branch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50154
Reviewed By: walterddr
Differential Revision: D25828491
Pulled By: seemethere
fbshipit-source-id: 500ec96cb5f5da1321610002d5e3678f4b0b94b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49964
`torch.nn.modules.linear._LinearWithBias` is only used in the transformers, and is completely identical to the `torch.nn.Linear`.
This PR creates a mapping so that this module would be treated the same as the Linear.
Test Plan:
```
python test/test_quantization.py TestDynamicQuantizedModule TestStaticQuantizedModule
```
Differential Revision: D25731589
Reviewed By: jerryzh168
Pulled By: z-a-f
fbshipit-source-id: 1b2697014e250e97d3010cdb542f9d130b71fbc3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50165
There are currently 17 types, so this used to stretch across 3 cache lines and now it fits in one. All the types in question seem to be way under 255 bytes in size anyway.
ghstack-source-id: 119485090
Test Plan: CI, profiled internal benchmarks
Reviewed By: smessmer
Differential Revision: D25813574
fbshipit-source-id: c342d4f12a7b035503e1483b8301f68d98f3c503
Summary:
**PROBLEM DESCRIPTION:**
GitHub issue 46391 suggests that compiler warnings pertaining to _floating-point value does not fit in required integral type_ might cause some confusion.
These compiler-warnings arise during compilation of the templated function `uniform_int()`. The warnings are misleading because they arise from the way the compiler compiles templated functions, but the if-else statements in the function obviate the possibilities that the warnings describe. So, the purpose of a fix would only be to fix the compiler warnings, and not to fix any sort of a bug.
**FIX DESCRIPTION:**
[EDITED, after inputs from malfet]: In the function `uniform_int()`, the if-else conditions pertaining to types `double` & `float` can be removed, and then an overloaded specialized function can be added for floating-point types. The current version of the function can be specialized to not have its return type as a floating point type.
An unrelated observation is that the if-else condition pertaining to the type `double` (line 57 in the original code) was redundant, as line 61 in the original code covered it (`std::is_floating_point<T>::value` would also have been true for the type `double`).
Fixes https://github.com/pytorch/pytorch/issues/46391
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49914
Reviewed By: H-Huang
Differential Revision: D25808037
Pulled By: malfet
fbshipit-source-id: 3f94c4bca877f09720b0d6efa5e1788554aba074
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50132
When running mypy command using `dmypy run`, it creates a status file.
This PR adds the file to the ignore list.
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D25834504
Pulled By: z-a-f
fbshipit-source-id: 6c5a8edd6d8eaf61983e3ca80e798e02d78e38ce
Summary:
This pull fix #{42271} by manually specify template data type of `tensor<template>.item()` in `aten/src/THC/generic/THCTensorMasked.cu`.
Changes in submodules are not expected since I have pulled the latest submodules from the Pytorch master branch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50141
Reviewed By: zou3519
Differential Revision: D25826104
Pulled By: ezyang
fbshipit-source-id: 80527a14786b36e4e520fdecc932e257d2520f89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50050
Every node will now own its outputs.
I don't expect any big improvements perf-wise from this diff, the only eliminated code is from deallocate_registers
Largely, this is to enable more optimizations going forward.
Test Plan:
buck test mode/dev //caffe2/benchmarks/static_runtime:static_runtime_cpptest
buck test //caffe2/test:static_runtime
Reviewed By: hlu1
Differential Revision: D25571181
fbshipit-source-id: 91fcfbd5cd968af963ba89c45656997650ca6d18
Summary:
ATT
Next step:
1. integrate with dper flow.
2. Support in bento after diff is pushed to prod.
Test Plan:
buck run mode/opt-clang sigrid/predictor/scripts:check_accelerator_unsupported_ops -- --model_entity_id=232891739
I0106 17:08:36.425796 1238141 pybind_state.cc:531] Unsupported ops: Fused8BitRowwiseQuantizedToFloat
Reviewed By: khabinov
Differential Revision: D25818253
fbshipit-source-id: 8d8556b0400c1747f154b0517352f1685f1aa8b1
Summary:
Hi, I changed error messages so that they correspond to the actual implementation.
Acording to the implementation, half of kernel size is valid as padding size.
This is minor but an example that the padding size is exactly equal to the half of kernel size,
Input: 5 x 5
Kernel: 4 x 4
Stride: 4
Padding: 2
==> Output: 2 x 2
You don't get the error in the above case, like following:
```python
import torch
import torch.nn as nn
# no error
input = torch.randn(1, 1, 5, 5)
pool = nn.MaxPool2d(4, 4, padding=2)
print(pool(input).shape)
# >>> torch.Size([1, 1, 2, 2])
```
You get the error when you set the padding size larger then half of kernel size like:
```python
# it raises error
input = torch.randn(1, 1, 5, 5)
pool = nn.MaxPool2d(4, 4, padding=3)
print(pool(input).shape)
```
The error message is:
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-43-2b09d1c5d79a> in <module>()
1 input = torch.randn(1, 1, 5, 5)
2 pool = nn.MaxPool2d(4, 4, padding=3)
----> 3 print(pool(input).shape)
3 frames
/usr/local/lib/python3.6/dist-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
584 stride = torch.jit.annotate(List[int], [])
585 return torch.max_pool2d(
--> 586 input, kernel_size, stride, padding, dilation, ceil_mode)
587
588 max_pool2d = boolean_dispatch(
RuntimeError: pad should be smaller than half of kernel size, but got padW = 3, padH = 3, kW = 4, kH = 4
```
Thanks in advance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50135
Reviewed By: hl475
Differential Revision: D25815337
Pulled By: H-Huang
fbshipit-source-id: 98142296fa6e6849d2e1407d2c1d4e3c2f83076d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50151
**Summary**
This commit adds a graph transformation pass that merges several matrix
multiplications that use the same RHS operand into one large matrix
multiplication. The LHS operands from all of the smaller matrix multiplications
are concatenated together and used as an input in the large matrix multiply,
and the result is split in order to obtain the same products as the original
set of matrix multiplications.
**Test Plan**
This commit adds a simple unit test with two matrix multiplications that share
the same RHS operand.
`python test/test_fx_experimental.py -k merge_matmul -v`
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D25809409
Pulled By: SplitInfinity
fbshipit-source-id: fb55c044a54dea9f07b71aa60d44b7a8f3966ed0
Summary:
## Rationale
While most of the `torch.Generator` properties and methods are implemented as a thin wrapper of the corresponding `at::Generator` methods, `torch.Generator.get_state()` and `torch.Generator.set_state()` are implemented in legacy Torch code and are not dispatched through the `c10::GeneratorImpl` interface. This is not structured well and makes implementing generators for new backends (e.g. `XLAGeneratorImpl` for the XLA backend) inconvenient. As such, this pull request seeks to move these generator state APIs to c10 and ATen.
## What is being refactored?
* Interfaces
- Added `c10::GeneratorImpl::set_state` and `c10::GeneratorImpl::state` for getting and setting the internal state of a random number generator.
- `at::Generator::set_state` and `at::Generator::state` wraps the above-mentioned APIs, as it's basically a PIMPL.
- Added helper function `at::detail::check_rng_state` for checking the validity of new RNG state tensor.
* CPU Generator
- Renamed and moved `THTensor_(setRNGState)` and `THTensor_(getRNGState)` to `CPUGeneratorImpl::set_state` and `CPUGenerator::state`.
- Renamed and moved `THGeneratorState` and `THGeneratorStateNew` to `CPUGeneratorStateLegacy` and `CPUGeneratorState`.
* CUDA Generator
- Renamed and moved `THCRandom_setRNGState` and `THCRandom_getRNGState` to `CUDAGeneratorImpl::set_state` and `CUDAGeneratorImpl::state`.
* PyTorch Bindings
- `THPGenerator_setState` and `THPGenerator_getState` now simply forward to `at::Generator::set_state` and `at::Generator::state`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49589
Reviewed By: H-Huang
Differential Revision: D25785774
Pulled By: pbelevich
fbshipit-source-id: 8ed79209c4ffb1a0ae8b19952ac8871ac9e0255f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49801
Per "https://fb.workplace.com/groups/e/permalink/3320810064641820/" we can no longer use the terms "whitelist" and "blacklist", and editing any file containing them results in a critical error signal. Let's embrace the change.
This diff changes "blacklist" to "blocklist" in a number of non-interface contexts (interfaces would require more extensive testing and might interfere with reading stored data, so those are deferred until later).
Test Plan: Sandcastle
Reviewed By: xush6528
Differential Revision: D25686949
fbshipit-source-id: e07de4d228674ae61559719cbe4717f8044778d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50061
These are more efficient than creating an extra `shared_ptr`
when you just want to access the casted value.
ghstack-source-id: 119325644
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D25766630
fbshipit-source-id: 46f11f70333b44714cab708a4850922ab7486793
Summary:
I am submitting this PR on behalf of Janne Hellsten(nurpax) from NVIDIA, for the convenience of CLA. Thanks Janne a lot for the contribution!
This fixes the bug when running `
./tools/nightly.py checkout -b my-nightly-branch` on windows. Before this fix, this command gets the following error on Windows.
```
ERROR:root:Fatal exception
Traceback (most recent call last):
File "./tools/nightly.py", line 166, in logging_manager
yield root_logger
File "./tools/nightly.py", line 644, in main
install(
File "./tools/nightly.py", line 552, in install
spdir = _site_packages(pytdir.name, platform)
File "./tools/nightly.py", line 325, in _site_packages
os.path.join(pytdir.name, "Lib", "site-packages")
NameError: name 'pytdir' is not defined
log file: d:\pytorch\nightly\log\2020-12-11_16h10m14s_6867a21e-3c0e-11eb-878e-04ed3363a33e\nightly.log
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49274
Reviewed By: H-Huang
Differential Revision: D25808156
Pulled By: malfet
fbshipit-source-id: 00778016366ab771fc3fb152710c7849210640fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50162
Adds an option to not run the build workflow when the `run_build`
parameter is set to false
Should reduce the amount of double workflows that are run by
pytorch-probot
Uses functionality introduced in https://github.com/pytorch/pytorch-probot/pull/18
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: yns88
Differential Revision: D25812971
Pulled By: seemethere
fbshipit-source-id: 4832170f6abcabe3f385f47a663d148b0cfe2a28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49763
This was reverted because it landed in a stack together with
D25542799 (9ce1df079f), which really was broken.
ghstack-source-id: 119063016
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D25685959
fbshipit-source-id: 514d8076eac67c760f119cfebc2ae3d0ddcd4e04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49613
Just following a TODO in the code base...
ghstack-source-id: 119450484
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25644597
fbshipit-source-id: 26f5fa6af480929d0468b0de3ab103813e40d78b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49259
Since `use_c10_dispatcher: full` is now the default, we can remove all those pesky lines mentioning it. Only the `use_c10_dispatcher: hacky_wrapper_for_legacy_signatures` lines are left.
ghstack-source-id: 119450485
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25506526
fbshipit-source-id: 8053618120c0b52ff7c73cacb34bec7eb38f8fe0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49251
Since all ops are c10-full and use templated unboxing now, we don't need to codegenerate any unboxing logic anymore.
Since this codegen was the only code using setManuallyBoxedKernel, we can also remove that functionality from KernelFunction, OperatorEntry and Dispatcher.
ghstack-source-id: 119450486
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25502865
fbshipit-source-id: 49d009df159fda4be41bd02457d4427e6e638c10
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49220
Since all ops are c10-full, we can remove .impl_UNBOXED now.
This also removes the ability of KernelFunction or CppFunction to store unboxedOnly kernels.
ghstack-source-id: 119450489
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25490225
fbshipit-source-id: 32de9d591e6a842fe18abc82541580647e9cfdad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49164
This PR removes the logic paths in codegen that were responsible for handling non-c10-full ops.
This only goes through our basic codegen. It does not simplify C++ code yet and it does not remove the codegen for generated unboxing wrappers yet.
ghstack-source-id: 119450487
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25462977
fbshipit-source-id: 7e70d14bea96948f5056d98125f3e6ba6bd78285
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49996
According to section 5.2.1 of Snapdragon Profiler User Guide
(https://developer.qualcomm.com/qfile/30580/snapdragon_profiler_user_guide_reva.pdf)
OpenGL ES, Vulkan, and OpenCL apps must include
android.permission.INTERNET in the app's AndroidManifest.xml to enable
API tracing and GPU metrics.
Test Plan: Imported from OSS
Reviewed By: SS-JIA
Differential Revision: D25809555
Pulled By: AshkanAliabadi
fbshipit-source-id: c4d88a7ea98d9166efbc4157df7d822d99ba0df9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49486
Remove code for Python 3.5 and lower.
There's more that can be removed/modernised, but sticking mainly to redundant version checks here, to keep the diff/PR smaller.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46579
Reviewed By: zou3519
Differential Revision: D24453571
Pulled By: ezyang
fbshipit-source-id: c2cfcf05d6c5f65df64d89c331692c9aec09248e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49279
Now that the YAML files for tracing based selective build optionally have the information regarding the selected kernel function dtypes, we can start generating constexpr selection code in the include file (`selected_mobile_ops.h`) to make the inclusion of code for specific dtypes selective based on compile time decisions.
The way this is done is that if we detect that the code for a specific dtype should not be in the binary, we add an exception (throw) statement just before the method is called (see the first diff in this dtack) and allow the compiler to optimize away the rest of the function's body. This has the advantage of allowing the compiler to know the lambda's return type (since it's inferred from the `return` statements in the body of the method, and if we compile out all the cases, then the compiler won't know the return type and it will result in a compilation error).
The generated `<ATen/selected_mobile_ops.h>` is being used (included) in `Dispatch.h`. In case `XPLAT_MOBILE_BUILD` is not defined, then we should include code for all kernel dtypes (non-selective build).
When merging, we need to handle the case of both older and newer (tracing based) operator lists. If we detect any operator that includes all overloads, it indicates that an old style operator list is part of the build, and we need to `include_all_kernel_dtypes` for this build.
ghstack-source-id: 119439497
Test Plan:
For Segmentation v220, here is one of the intermediate generated YAML files (selected_operators.yaml): {P154480509}
and here is the generated `selected_mobile_ops.h` file: {P159808798}
Here is the `selected_mobile_ops.h` file for lite_predictor (which includes all ops and all dtypes): {P159806443}
Continuous build for ~8 checked-in models validates that the selection code works as expected when we build based on dtype selection.
Reviewed By: iseeyuan
Differential Revision: D25388949
fbshipit-source-id: 1c182a4831a7f94f7b152f02dbd3bc01c0d22443
Summary:
There is an internal user who is experiencing a bug with masked_fill. While I am almost certain this corresponds to an old pytorch version with the bug, the model that is breaking is important and time-sensitive and we are covering all bases to try to get it to work again.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50147
Reviewed By: nhsoukai
Differential Revision: D25806541
Pulled By: eellison
fbshipit-source-id: 131bd71b5db9717a8a9cb97973d0b4f0e96455d6
Summary:
Adding `torch::cuda::synchronize()` to libtorch. Note that the implementation here adds a new method to the `CUDAHooksInterface`. An alternative that was suggested to me is to add a method to the `DeviceGuard` interface.
Fixes https://github.com/pytorch/pytorch/issues/47722
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50072
Reviewed By: H-Huang
Differential Revision: D25804342
Pulled By: jbschlosser
fbshipit-source-id: 45aa61d7c6fbfd3178caf2eb5ec053d6c01b5a43
Summary:
Uses the Python standard library 2to3 script to convert a number of Python 2 files to Python 3. This facilitates code maintenance such as dropping unused imports in D25500422.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49351
Test Plan: Standard sandcastle tests
Reviewed By: xush6528
Differential Revision: D25499576
fbshipit-source-id: 0c44718ac734771ce0758b1cb30676cc3d76ac10
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49498
In the near future, I want to code generate some functions that are
visible externally to this compilation unit. I cannot easily do this
if all the codegen code is wrapped in a global anonymous namespace,
so push the namespace in.
Registration has to stay in an anonymous namespace to avoid name conflicts.
This could also have been solved by making the wrapper functions have
more unique names but I didn't do this in the end.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD, smessmer
Differential Revision: D25616104
Pulled By: ezyang
fbshipit-source-id: 323c0dda05a081502aab702f359a08dfac8c41a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48868
Building on the previous diff, we can make `toTensor()` return a
`const Tensor&`, which should make it easier to avoid reference
counting.
ghstack-source-id: 119327372
Test Plan: internal benchmarks.
Reviewed By: bwasti
Differential Revision: D25325379
fbshipit-source-id: ca699632901691bcee432f595f75b0a4416d55dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48824
Enables following diff, which will make toTensor() return
`const Tensor&` and allow callers to avoid refcounting overhead.
ghstack-source-id: 119327370
Test Plan:
ivalue_test
Internal benchmark to ensure perf parity. Some interesting steps
during the debugging process:
- First version was about a 5% regression
- Directly implementing move construction instead of using swap
lowered the regression to 2-3%
- Directly implementing move assign was maybe an 0.5% improvement
- Adding C10_ALWAYS_INLINE on move assign got our regression to
negligible
- Fixing toTensor() to actually be correct regressed us again, but
omitting the explicit dtor call as exhaustively spelled out in a
comment fixed it.
Reviewed By: bwasti
Differential Revision: D25324617
fbshipit-source-id: 7518c1c67f6f2661f151b43310aaddf4fb6e511a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49718
Improving test coverage in preparation for updating the
implementation of IValue.
ghstack-source-id: 119327373
Test Plan: ivalue_test
Reviewed By: hlu1
Differential Revision: D25674605
fbshipit-source-id: 37a82bb135f75ec52d2d8bd929c4329e8dcc4d25
Summary:
These unused variables were identified by [pyflakes](https://pypi.org/project/pyflakes/). They can be safely removed to simplify the code and possibly improve performance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50100
Reviewed By: ezyang
Differential Revision: D25797764
Pulled By: smessmer
fbshipit-source-id: ced341aee692f429d2dcc3a4ef5c46c8ee99cabb
Summary:
The command used here is essentially `where cl.exe`. By using `system()` we will not be able to find cl.exe unless we are using VS Developer Prompt, which makes `activate()` meaningless. Change `system()` to `run()` fixes this.
Found during https://github.com/pytorch/pytorch/issues/49781.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50085
Reviewed By: smessmer
Differential Revision: D25782054
Pulled By: ezyang
fbshipit-source-id: e8e3cac903a73f3bd78def667ebe0e93201814c8
Summary:
Refiled duplicate of https://github.com/pytorch/pytorch/issues/31341 which was reverted in commit 63964175b52197a75e03b73c59bd2573df66b398.
This PR enables RCCL support when building Gloo as part of PyTorch for ROCm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34683
Reviewed By: glaringlee
Differential Revision: D25540578
Pulled By: ezyang
fbshipit-source-id: fcb02e5745d62e1b7d2e02048160e9e7a4b4df2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49762
This was reverted because it landed in a stack together with
D25542799 (9ce1df079f), which really was broken.
ghstack-source-id: 119326870
Test Plan: CI
Reviewed By: maratsubkhankulov
Differential Revision: D25685905
fbshipit-source-id: f4ec9e114993f988d4af380677331c72dfe41c44
Summary:
The [offset calculation](e3c56ddde6/aten/src/ATen/native/cuda/Dropout.cu (L328)) (which gives an estimated ceiling on the most 32-bit values in the philox sequence any thread in the launch will use) uses the hardcoded UNROLL value of 4, and assumes the hungriest threads can use every value (.x, .y, .z, and .w) their curand_uniform4 calls provide. However, the way fused_dropout_kernel_vec is currently written, that assumption isn't true in the VEC=2 case: Each iteration of the `grid x VEC` stride loop, each thread calls curand_uniform4 once, uses rand.x and rand.y, and discards rand.z and rand.w. This means (I _think_) curand_uniform4 may be called twice as many times per thread in the VEC=2 case as for the VEC=4 case or the fully unrolled code path, which means the offset calculation (which is a good estimate for the latter two cases) is probably wrong for the `fused_dropout_kernel_vec<..., /*VEC=*/2>` code path.
The present PR inserts some value-reuse in fused_dropout_kernel_vec to align the number of times curand_uniform4 is called for launches with the same totalElements in the VEC=2 and VEC=4 cases. The diff should
- make the offset calculation valid for all code paths
- provide a very small perf boost by reducing the number of curand_uniform4 calls in the VEC=2 path
- ~~make results bitwise accurate for all code paths~~ nvm, tensor elements are assigned to threads differently in the unrolled, VEC 2 and VEC 4 cases, so we're screwed here no matter what.
ngimel what do you think?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50110
Reviewed By: smessmer
Differential Revision: D25790121
Pulled By: ngimel
fbshipit-source-id: f8f533ad997268c6f323cf4d225de547144247a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50058
This PR adds the support for {input/output}_quantized_idxs for standalone module.
if input_quantized_idxs = [] and output_quantized_idxs = [], the standalone module will be expecting float
input and produce float output, and will quantize the input and dequantize output internally
if input_quantized_idxs = [0] and otuput_qiuantized_idxs = [0], the standalone module will be expecting quantized
input and produce quantized output, the input will be quantized in the parent module, and output will be dequantized
in the parent module as well, this is similar to current quantized modules like nn.quantized.Conv2d
For more details, please see the test case
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_standalone_module
Imported from OSS
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D25768910
fbshipit-source-id: 96c21a3456cf192c8f1400afa4e86273ee69197b
Summary:
Based on ngimel's (Thank you!) feedback, cpu half was only accidental, so I'm removing it.
This lets us ditch the old codepath for without replacement in favour of the new, better one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50063
Reviewed By: mruberry
Differential Revision: D25772449
Pulled By: ngimel
fbshipit-source-id: 608729c32237de4ee6d1acf7e316a6e878dac7f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50120
This commit adds a graph transformation pass that merges several matrix
multiplications that use the same RHS operand into one large matrix
multiplication. The LHS operands from all of the smaller matrix multiplications
are concatenated together and used as an input in the large matrix multiply,
and the result is split in order to obtain the same products as the original
set of matrix multiplications.
Test Plan:
This commit adds a simple unit test with two matrix multiplications that share
the same RHS operand.
`buck test //caffe2/test:fx_experimental`
Reviewed By: jamesr66a
Differential Revision: D25239967
fbshipit-source-id: fb99ad25b7d83ff876da6d19dc4abd112d13001e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49761
This was reverted because it landed in a stack together with
D25542799 (9ce1df079f), which really was broken.
ghstack-source-id: 119361027
Test Plan: CI
Reviewed By: bwasti
Differential Revision: D25685855
fbshipit-source-id: b51f67ebe667199d15bfc6f8f131a6f1ab1b0352
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49760
This was reverted because it landed in a stack together with
D25542799 (9ce1df079f), which really was broken.
ghstack-source-id: 119361028
Test Plan: CI
Reviewed By: bwasti
Differential Revision: D25685789
fbshipit-source-id: 41e5abb4ff30acaa6f33f9c806acd652a6dd9646
Summary:
Ref https://github.com/pytorch/pytorch/issues/42175
This adds out argument support to all functions in the `torch.fft` namespace except for `fftshift` and `ifftshift` because they rely on `at::roll` which doesn't have an out argument version.
Note that there's no general way to do the transforms directly into the output since both cufft and mkl-fft only support single batch dimensions. At a minimum, the output may need to be re-strided which I don't think is expected from `out` arguments normally. So, on cpu this just copies the result into the out tensor. On cuda, the normalization is changed to call `at::mul_out` instead of an inplace multiply.
If it's desirable, I could add a special case to transform into the output when `out.numel() == 0` since there's no expectation to preserve the strides in that case anyway. But that would lead to the slightly odd situation where `out` having the correct shape follows a different code path from `out.resize_(0)`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49335
Reviewed By: mrshenli
Differential Revision: D25756635
Pulled By: mruberry
fbshipit-source-id: d29843f024942443c8857139a2abdde09affd7d6
Summary: The remaining operator registrations that are not marked as selective. The size save is -12.2 KB for igios and -14 KB for fbios.
Test Plan: CI
Reviewed By: dhruvbird
Differential Revision: D25742543
fbshipit-source-id: 3e58789d36d216a52340c00b53e2f783ea2c9414
Summary:
When continuing the deprecation process for stft it was made to throw an error when `use_complex` was not explicitly set by the user. Unfortunately this PR missed a model relying on the historic stft functionality. Before re-enabling the error we'll need to write an upgrader for that model.
This PR turns the error back into a warning to allow that model to continue running as before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50102
Reviewed By: ngimel
Differential Revision: D25784325
Pulled By: mruberry
fbshipit-source-id: 825fb38af39b423ce11b376ad3c4a8b21c410b95
Summary:
Implements very simple changes suggested in the short discussion of the issue. Updated documentation to inform user that creation of tensor with memory mapped read only numpy arrays will probably cause a crash of the program. The displayed warning message was also updated to contain the information about issues concerning the use of a memory mapped read only numpy array. Closes https://github.com/pytorch/pytorch/issues/46741.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49516
Reviewed By: mrshenli
Differential Revision: D25746115
Pulled By: mruberry
fbshipit-source-id: 3e534a8f2bc1f083a2835440d324bd6f30798ad4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49242
Fixes https://github.com/pytorch/pytorch/issues/45072
As discussed with zdevito gchanan cpuhrsch and suo, this change allows developers to create custom preparations for their modules before scripting. This is done by adding a `__prepare_scriptable__` method to a module which returns the prepared scriptable module out-of-place. It does not expand the API surface for end users.
Prior art by jamesr66a: https://github.com/pytorch/pytorch/pull/42244
Test Plan: Imported from OSS
Reviewed By: dongreenberg
Differential Revision: D25500303
fbshipit-source-id: d3ec9005de27d8882fc29d02f0d08acd2a5c6b2c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49735
This is the final wave of autograd codegen data model migration.
After this PR:
- autograd codegen no longer depends on Declarations.yaml;
- autograd codegen sources are fully type annotated and pass mypy-strict check;
To avoid potential merge conflicts with other pending PRs, some structural
changes are intentionally avoided, e.g. didn't move inner methods out, didn't
change all inner methods to avoid reading outer function's variables, and etc.
Confirmed byte-for-byte compatible with the old codegen:
```
Run it before and after this PR:
.jenkins/pytorch/codegen-test.sh <baseline_output_dir>
.jenkins/pytorch/codegen-test.sh <test_output_dir>
Then run diff to compare the generated files:
diff -Naur <baseline_output_dir> <test_output_dir>
```
Confirmed clean mypy-strict run:
```
mypy --config mypy-strict.ini
```
Test Plan: Imported from OSS
Reviewed By: ezyang, bhosmer
Differential Revision: D25678879
Pulled By: ljk53
fbshipit-source-id: ba6e2eb6b9fb744208f7f79a922d933fcc3bde9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49497
Noticed this thing spending relatively most of its time in
malloc in perf. Optimize for typical tensor sizes.
ghstack-source-id: 119318388
Test Plan:
perf profile internal benchmark; saw inferUnsqueezeGeometry
go from 0.30% exclusive 0.47% inclusive to 0.11% exclusive 0.16%
inclusive.
Differential Revision: D25596549
fbshipit-source-id: 3bbd2031645a4b9fe6f49a77d41db46826d0f632
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47123
Follows https://github.com/pyro-ppl/pyro/pull/2701
This turns on `Distribution` validation by default. The motivation is to favor beginners by providing helpful error messages. Advanced users focused on speed can disable validation by calling
```py
torch.distributions.Distribution.set_default_validate_args(False)
```
or by disabling individual distribution validation via `MyDistribution(..., validate_args=False)`.
In practice I have found many beginners forget or do not know about validation. Therefore I have [enabled it by default](https://github.com/pyro-ppl/pyro/pull/2701) in Pyro. I believe PyTorch could also benefit from this change. Indeed validation caught a number of bugs in `.icdf()` methods, in tests, and in PPL benchmarks, all of which have been fixed in this PR.
## Release concerns
- This may slightly slow down some models. Concerned users may disable validation.
- This may cause new `ValueErrors` in models that rely on unsupported behavior, e.g. `Categorical.log_prob()` applied to continuous-valued tensors (only {0,1}-valued tensors are supported).
We should clearly note this change in release notes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48743
Reviewed By: heitorschueroff
Differential Revision: D25304247
Pulled By: neerajprad
fbshipit-source-id: 8d50f28441321ae691f848c55f71aa80cb356b41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49233
As the comments on line 160, say we should suppress this overly aggressive warning with MSVC:
```
caffe2\tensorbody.h_ovrsource#header-mode-symlink-tree-only,headers\aten\core\tensorbody.h(1223): warning C4522: 'at::Tensor': multiple assignment operators specified
```
However, in order to remove the warning, the closing brace of the class must be between the`#pragma warning` push and its corresponding pop. Move the pop down to ensure that.
Test Plan: Built locally using clang for Windows without buck cache, confirmed the warning resolved
Reviewed By: bhosmer
Differential Revision: D25422447
fbshipit-source-id: c1e1c66fb8513af5f9d4e3c1dc48d0070c4a1f84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49930
Certain store implementations don't work well when we use get() and
add() on the same key. To avoid this issue, we only use add() in the store
based barrier. The buggy store implementations can't be properly fixed due to
legacy reasons.
Test Plan:
1) unit tests.
2) waitforbuildbot
Reviewed By: osalpekar
Differential Revision: D25725386
fbshipit-source-id: 1535e2629914de7f78847b730f8764f92cde67e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49983
We have observed very rare flakiness in some profiling tests recently,
i.e.: . However, we were not able to reproduce these even with thousands of
runs on the CI machines where the failure was originally reported. As a result,
relaxing these tests and re-enabling them to reduce failure rates.
ghstack-source-id: 119352019
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D25739416
fbshipit-source-id: 4dbb6b30f20d3af94ba39f4a7ccf4fb055e440bc
Summary:
For a multi GPU node, rank and corresponding GPU mapping can be different.
Provide optional parameter to specify the GPU device number for the
allreduce operation in barrier function.
Add test cases to validate barrier device_ids.
Signed-off-by: Jagadish Krishnamoorthy <jagdish.krishna@gmail.com>
Fixes https://github.com/pytorch/pytorch/issues/48110
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49069
Reviewed By: mrshenli
Differential Revision: D25658528
Pulled By: rohan-varma
fbshipit-source-id: 418198b6224c8c1fd95993b80c072a8ff8f02eec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49990
**Summary**
This commit removes the forward-compatibility gate for buffer metadata
serialization. It was introduced to allow versions of fbcode
binaries statically linked against older versions of PyTorch (without
buffer metadata in JIT) to deserialize archives produced by new versions
of PyTorch. Enough time has probably passed that these old binaries
don't exist anymore, so it should be safe to remove the gate.
**Test Plan**
Internal tests.
Test Plan: Imported from OSS
Reviewed By: xw285cornell
Differential Revision: D25743199
Pulled By: SplitInfinity
fbshipit-source-id: 58d82ab4362270b309956826e36c8bf9d620f081
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49813https://github.com/pytorch/pytorch/issues/49739 reports a crash
where removing forward hooks results in a
```
RuntimeError: OrderedDict mutated during iteration
```
Unfortunately I cannot repro this inside the PyTorch module, but the issue
author has a good point and and we should not mutate the dict inside
of the iteration.
Test Plan:
```
// test plan from https://github.com/pytorch/pytorch/pull/46871 which
// originally added this
python test/test_quantization.py TestEagerModeQATOps
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25698725
fbshipit-source-id: 13069d0d5017a84038c8f7be439a3ed537938ac6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49802
Currently `torch.allclose` is not supported with quantized inputs.
Throw a nice error message instead of a cryptic one.
Test Plan:
```
torch.allclose(x_fp32, y_fp32)
torch.allclose(x_int8, y_int8)
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D25693538
fbshipit-source-id: 8958628433adfca3ae6ce215f3e3ec3c5e29994c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49899
Per channel weights observer in conv transpose is not supported yet. Adding an
error message which fails instantly instead of making the user wait until after
calibration/training finishes.
Test Plan:
```
python test/test_quantization.py TestPostTrainingStatic.test_convtranspose_per_channel_fails_early
python test/test_quantization.py TestQuantizeFx.test_convtranspose_per_channel_fails_early
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25717151
fbshipit-source-id: 093e5979030ec185e3e0d56c45d7ce7338bf94b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49800
Ensures that having a Tensor with 0 elements does not crash observers.
Note: it's illegal to pass Tensors with 0 elements to reductions such
as min and max, so we gate this out before the logic hits min/max.
This should not be hit often in practice, but it's coming up
during debugging of some RCNN models with test inputs.
Test Plan:
```
python test/test_quantization.py TestObserver.test_zero_numel
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25693230
fbshipit-source-id: d737559697c98bd923356edacba895835060bb38
Summary:
Improves one annotation for `augment_model_with_bundled_inputs`
Also add a comment to not work on caffe2 type annotations, that's not worth the effort - those ignores can stay as they are.
xref gh-16574
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49658
Reviewed By: heitorschueroff
Differential Revision: D25757721
Pulled By: ezyang
fbshipit-source-id: 44c396d8da9ef3f41b97f9c46a528f0431c4b463
Summary:
https://github.com/pytorch/pytorch/issues/48675 had some typos in indices computations so that results for trilinear interpolation where height is not equal to width were wrong. This PR fixes it.
cc xwang233
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50084
Reviewed By: BIT-silence
Differential Revision: D25777083
Pulled By: ngimel
fbshipit-source-id: 71be545628735fe875b7ea30bf6a09df4f2fae5c
Summary: (Note: this ignores all push blocking failures!)
Test Plan: unit tests
Differential Revision: D25775357
fbshipit-source-id: 0ae3c59181bc123d763ed9c0d05c536998ae5ca0
Summary:
This appears to have been a copy-paste error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49951
Reviewed By: mrshenli
Differential Revision: D25757099
Pulled By: zou3519
fbshipit-source-id: e47cc3b0694645bd0025326bfe45852ef0266adf
Summary: Use `llvm::CodeGenFileType` for llvm-10+
Test Plan: local build
Reviewed By: asuhan
Differential Revision: D25694990
fbshipit-source-id: c35d973ef2669929715a94da5dd46e4a0457c4e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49931
This fixes#49932. The `maybe_return_annotation` was not being passed by reference, so it was never getting modified.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D25725582
Pulled By: esqu1
fbshipit-source-id: 4136ff169a269d6b98f0b8e14d95d19e7c7cfa71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49552
This PR:
1. Migrates independent autograd test for `hstack`, `dstack`, `vstack`, `movedim`, `moveaxis` from `test_autograd.py` to the new `OpInfo` based tests.
2. Migrates autograd test for `gather`, `index_select` from the method_tests to the new `OpInfo` based tests.
2. Enables complex backward for `stack, gather, index_select, index_add_` and adds tests for complex autograd for all the above mentioned ops.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D25682511
Pulled By: anjali411
fbshipit-source-id: 5d8f89db4a9ec340ab99a6196987d44a23e2c6c6
Summary:
introduce a flag to disable aten::cat in TE
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49579
Reviewed By: eellison
Differential Revision: D25763758
Pulled By: Krovatkin
fbshipit-source-id: c4f4a8220964813202369a3383057e77e7f10cb0
Summary:
Based on existing implementation of var_mean, values of dim have to be sequential and start with zero. The formats listed below are cause scenarios with incompatible dimension for the Sub node.
-> dim[1, 2]
-> dim[0, 2]
-> dim[2, 0]
The changes in this PR allow such formats to be supported in var_mean
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48949
Reviewed By: houseroad
Differential Revision: D25540272
Pulled By: SplitInfinity
fbshipit-source-id: 59813a77ff076d138655cc8c17953358f62cf137
Summary:
For the added UT and existing UTs, this code is independent and ready for review.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48734
Reviewed By: izdeby
Differential Revision: D25502677
Pulled By: bzinodev
fbshipit-source-id: 788b4eaa5e5e8b5df1fb4956fbd25928127bb199
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49495
Compiling PyTorch currently generates a large number of warnings like this:
```
caffe2/aten/src/ATen/core/builtin_function.h(105): warning: statement is unreachable
```
The offending code
```
std::string pretty_print_schema() const override {
TORCH_INTERNAL_ASSERT(false);
return "";
}
```
has an unreachable return which prevents a "no return" warning.
We resolve the situation by using NVCC's pragma system to suppress this warning within this function.
Test Plan:
The warning appears when running:
```
buck build mode/dev-nosan //caffe2/torch/fb/sparsenn:test
```
As well as a number of other build commands.
Reviewed By: ngimel
Differential Revision: D25546542
fbshipit-source-id: 71cddd4fdb5fd16022a6d7b2daf0e6d55e6e90e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49926
While investigating https://github.com/pytorch/pytorch/issues/49758, I changed the xlogy kernel to use the recommended wrapped_scaler_tensor pattern instead of moving the scalar to the GPU as a tensor.
While this doesn't avoid a synchronization (there is no synchronization in the move, as its done via fill), this does significantly speed up the GPU kernel (almost ~50%, benchmark in PR comments).
From looking at the nvprof output, it looks like this code path avoids broadcasting. Aside: this seems unnecessary, as there is nothing special from the point-of-view of broadcasting whether the Tensor
is ()-sized or marked as a wrapped_scalar. Still, this is a useful change to make as we avoid extra kernel launches and dispatches to create and fill the tensor.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D25724215
Pulled By: gchanan
fbshipit-source-id: 4adcd5d8b3297502672ffeafc77e8af80592f460
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49490
No reason to let people to do the legacy thing for the brand new kernel.
This simplifies the codegen. I have to port the two structured kernels
to this new format.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D25595406
Pulled By: ezyang
fbshipit-source-id: b5931873379afdd0f3b00a012e0066af05de0a69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49489
Previously, it was done at a use site, but that meant other use
sites don't get the right logic. Pushing it in makes sure everyone
gets it.
I also fixed one case of confusion where defn() was used to define a decl().
If you want to define a declaration with no defaults, say no_default().decl()
which is more direct and will give us code reviewers a clue if you should
have pushed this logic in.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D25595407
Pulled By: ezyang
fbshipit-source-id: 89c664f0ed4d95699794a0d3123d54d0f7e4cba4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49348
This is a redux of #45666 post refactor, based off of
d534f7d4c5
Credit goes to peterbell10 for the implementation.
Fixes#43945.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D25594004
Pulled By: ezyang
fbshipit-source-id: c8eb876bb3348308d6dc8ba7bf091a2a3389450f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49341
I noticed that #49097 was using manual_kernel_registration incorrectly,
so this diff tightens up the testing so that:
1. We don't generate useless wrapper functions when manual_kernel_registration
is on (it's not going to be registered, so it does nothing).
2. manual_kernel_registration shouldn't affect generation of functions in
Functions.h; if you need to stop bindings, use manual_cpp_binding
3. Structured and manual_kernel_registration are a hard error
4. We raise an error if you set dispatch and manual_kernel_registration at the
same time.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D25594003
Pulled By: ezyang
fbshipit-source-id: 655b10e9befdfd8bc95f1631b2f48f995a31a59a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50053
For some reason conda likes to re-activate the conda environment when attempting this install
which means that a deactivate is run and some variables might not exist when that happens,
namely CONDA_MKL_INTERFACE_LAYER_BACKUP from libblas so let's just ignore unbound variables when
it comes to the conda installation commands
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D25760737
Pulled By: seemethere
fbshipit-source-id: 9e7720eb8a4f8028dbaa7bcfc304e5c1ca73ad08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49619
This is a minimal-change PR that enforces that all operators are c10-full by making it the default.
This does not clean up any code yet, that will happen in PRs stacked on top. But this PR already ensures
that there are no non-c10-full ops left and there will be no non-c10-full ops introduced anymore.
ghstack-source-id: 119269182
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D25650198
fbshipit-source-id: efc53e884cb53193bf58a4834bf148453e689ea1
Summary:
We recently (https://github.com/pytorch/pytorch/issues/7582) dropped magma v1 support, but we were still including the legacy compatibility headers and using functions only provided by them.
This changes the includes to the new magma_v2 header and fixes the triangular solve functions to use the v2-style magma_queue-using API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49978
Reviewed By: mrshenli
Differential Revision: D25752499
Pulled By: ngimel
fbshipit-source-id: 26d916bc5ce63978b341aefb072af228f140637d
Summary:
It is now running for forks, and generates a lot of failure message to owner of forks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49934
Reviewed By: mruberry
Differential Revision: D25739552
Pulled By: seemethere
fbshipit-source-id: 0f9cc430316c0a5e9972de3cdd06d225528c81c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49138
See for details: https://fb.quip.com/QRtJAin66lPN
We need to model optional types explicitly, mostly for schema inference. So we cannot pass a `Tensor?[]` as `ArrayRef<Tensor>`, instead we need to pass it as an optional type. This PR changes it to `torch::List<c10::optional<Tensor>>`. It also makes the ops c10-full that were blocked by this.
## Backwards Compatibility
- This should not break the Python API because the representation in Python is the same and python_arg_parser just transforms the python list into a `List<optional<Tensor>>` instead of into a `List<Tensor>`.
- This should not break serialized models because there's some logic that allows loading a serialized `List<Tensor>` as `List<optional<Tensor>>`, see https://github.com/pytorch/pytorch/pull/49138/files#diff-9315f5dd045f47114c677174dcaa2f982721233eee1aa19068a42ff3ef775315R57
- This will break backwards compatibility for the C++ API. There is no implicit conversion from `ArrayRef<Tensor>` (which was the old argument type) to `List<optional<Tensor>>`. One common call pattern is `tensor.index({indices_tensor})`, where indices_tensor is another `Tensor`, and that will continue working because the `{}` initializer_list constructor for `List<optional<Tensor>>` can take `Tensor` elements that are implicitly converted to `optional<Tensor>`, but another common call pattern was `tensor.index(indices_tensor)`, where previously, the `Tensor` got implicitly converted to an `ArrayRef<Tensor>`, and to implicitly convert `Tensor -> optional<Tensor> -> List<optional<Tensor>>` would be two implicit conversions. C++ doesn't allow chaining. two implicit conversions. So those call sites have to be rewritten to `tensor.index({indices_tensor})`.
ghstack-source-id: 119269131
Test Plan:
## Benchmarks (C++ instruction counts):
### Forward
#### Script
```py
from torch.utils.benchmark import Timer
counts = Timer(
stmt="""
auto t = {{op call to measure}};
""",
setup="""
using namespace torch::indexing;
auto x = torch::ones({4, 4, 4});
""",
language="cpp",
).collect_callgrind(number=1_000)
print(counts)
```
#### Results
| Op call |before |after |delta | |
|------------------------------------------------------------------------|---------|--------|-------|------|
|x[0] = 1 |11566015 |11566015|0 |0.00% |
|x.index({0}) |6807019 |6801019 |-6000 |-0.09%|
|x.index({0, 0}) |13529019 |13557019|28000 |0.21% |
|x.index({0, 0, 0}) |10677004 |10692004|15000 |0.14% |
|x.index({"..."}) |5512015 |5506015 |-6000 |-0.11%|
|x.index({Slice(None, None, None)}) |6866016 |6936016 |70000 |1.02% |
|x.index({None}) |8554015 |8548015 |-6000 |-0.07%|
|x.index({false}) |22400000 |22744000|344000 |1.54% |
|x.index({true}) |27624088 |27264393|-359695|-1.30%|
|x.index({"...", 0, true, Slice(1, None, 2), torch::tensor({1, 2})})|123472000|123463306|-8694|-0.01%|
### Autograd
#### Script
```py
from torch.utils.benchmark import Timer
counts = Timer(
stmt="""
auto t = {{op call to measure}};
""",
setup="""
using namespace torch::indexing;
auto x = torch::ones({4, 4, 4}, torch::requires_grad());
""",
language="cpp",
).collect_callgrind(number=1_000)
print(counts)
```
Note: the script measures the **forward** path of an op call with autograd enabled (i.e. calls into VariableType). It does not measure the backward path.
#### Results
| Op call |before |after |delta | |
|------------------------------------------------------------------------|---------|--------|-------|------|
|x.index({0}) |14839019|14833019|-6000| 0.00% |
|x.index({0, 0}) |28342019|28370019|28000| 0.00% |
|x.index({0, 0, 0}) |24434004|24449004|15000| 0.00% |
|x.index({"..."}) |12773015|12767015|-6000| 0.00% |
|x.index({Slice(None, None, None)}) |14837016|14907016|70000| 0.47% |
|x.index({None}) |15926015|15920015|-6000| 0.00% |
|x.index({false}) |36958000|37477000|519000| 1.40% |
|x.index({true}) |41971408|42426094|454686| 1.08% |
|x.index({"...", 0, true, Slice(1, None, 2), torch::tensor({1, 2})}) |168184392|164545682|-3638710| -2.16% |
Reviewed By: bhosmer
Differential Revision: D25454632
fbshipit-source-id: 28ab0cffbbdbdff1c40b4130ca62ee72f981b76d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49994
Revert preserving memory format in qconv op because it is negatively affecting performance, will revert revert after fixing all issues
Test Plan: pytest fbcode/caffe2/test/quantization/test_quantized_op.py
Reviewed By: kimishpatel
Differential Revision: D25731279
fbshipit-source-id: 908dbb127210a93b27ada7ccdfa531177edf679a
Summary:
All pretty minor. I avoided renaming `class DestructableMock` to `class DestructibleMock` and similar such symbol renames (in this PR).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49815
Reviewed By: VitalyFedyunin
Differential Revision: D25734507
Pulled By: mruberry
fbshipit-source-id: bbe8874a99d047e9d9814bf92ea8c036a5c6a3fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49905
There's size regression in model delivery in D25682312. Only the model version numbers are used. However, the dependency of the entire c10 (128 KB) is pulled in.
This diff is to decouple the version numbers to a separate header file, versions.h. Other targets referring to version numbers only can have deps of ```caffe2:version_headers```.
ghstack-source-id: 119161467
Test Plan: CI
Reviewed By: xcheng16, guangyfb
Differential Revision: D25716601
fbshipit-source-id: 07634bcf46eacfefa4aa75f2e4c9b9ee30c6929d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49671
- Introduces the `torch.nn.quantizable` namespace
- Adds the `torch.nn.quantizable.LSTM` module
The point of the `quantizable` namespace is to segregate the purely quantized modules with the modules that could be quantized through a normal quantization flow, but are not using the quantized kernels explicitly.
That means the quantizable modules are functionally and numerically equivalent to the FP ones and can be used instead of the FP ones without any loss.
The main difference between the `torch.nn.LSTM` and the `torch.nn.quantizable.LSTM` is that the former one does not support observation for the linear layers, because all the computation is internal to the `aten` namespace.
The `torch.nn.quantizable.LSTM`, however, uses explicit linear layers that can be observed for further quantization.
Test Plan: Imported from OSS
Differential Revision: D25663870
Reviewed By: vkuzo
Pulled By: z-a-f
fbshipit-source-id: 70ff5463bd759b9a7922571a5712d3409dfdfa06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49902
Adds a common errors section, and details the two errors
we see often on the discuss forums, with recommended solutions.
Test Plan: build the docs on Mac OS, the new section renders correctly.
Reviewed By: supriyar
Differential Revision: D25718195
Pulled By: vkuzo
fbshipit-source-id: c5ef2b24831d18d57bbafdb82d26d8fbf3a90781
Summary:
The first commit fixes the `MultiheadAttention` docstrings, which are causing a cryptic KaTeX crash.
The second commit fixes many documentation issues in `torch/_torch_docs.py`, and closes gh-43667 (missing "Keyword arguments" headers). It also fixes a weird duplicate docstring for `torch.argmin`; there's more of these, it looks like they were written based on whether the C++ implementation has an overload. That makes little sense to a Python user though, and the content is simply duplicate.
The `Shape:` heading for https://pytorch.org/docs/master/generated/torch.nn.MultiheadAttention.html looked bad, here's what it looks like with this PR:
<img width="475" alt="image" src="https://user-images.githubusercontent.com/98330/102797488-09a44e00-43b0-11eb-8788-acdf4e936f2f.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49684
Reviewed By: ngimel
Differential Revision: D25730909
Pulled By: mruberry
fbshipit-source-id: d25bcf8caf928e7e8e918017d119de12e10a46e9
Summary:
Remove `THPWrapper` from PyTorch C code since it is not used anymore and because we have dropped Python 2 compatibility, its usage can be replaced by capsule objects (`PyCapsule_New`, `PyCapsule_CheckExact`, `PyCapsule_GetPointer` and `PyCapsule_GetDestructor`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49871
Reviewed By: mruberry
Differential Revision: D25715038
Pulled By: albanD
fbshipit-source-id: cc3b6f967bbe0dc42c692adf76dff4e4b667fdd5
Summary:
=======
This PR addresses the following:
* Adds JIT support for CUDA Streams
* Adds JIT support for CUDA Events
* Adds JIT support for CUDA Stream context manager
Testing:
======
python test/test_jit.py -v TestCUDA
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48020
Reviewed By: navahgar
Differential Revision: D25725749
Pulled By: nikithamalgifb
fbshipit-source-id: b0addeb49630f8f0c430ed7badeca43bb9d2535c
Summary:
Previously header files from jit/tensorexpr were not copied, this PR should enable copying.
This will allow other OSS projects like Glow to used TE.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49933
Reviewed By: Krovatkin, mruberry
Differential Revision: D25725927
Pulled By: protonu
fbshipit-source-id: 9d5a0586e9b73111230cacf044cd7e8f5c600ce9
Summary:
I am opening this PR early to have a place to discuss design issues.
The biggest difference between `torch.qr` and `numpy.linalg.qr` is that the former `torch.qr` takes a boolean parameter `some=True`, while the latter takes a string parameter `mode='reduced'` which can be one of the following:
`reduced`
this is completely equivalent to `some=True`, and both are the default.
`complete`
this is completely equivalent to `some=False`.
`r`
this returns only `r` instead of a tuple `(r, q)`. We have already decided that we don't want different return types depending on the parameters, so I propose to return `(r, empty_tensor)` instead. I **think** that in this mode it will be impossible to implement the backward pass, so we should raise an appropriate error in that case.
`raw`
in this mode, it returns `(h, tau)` instead of `(q, r)`. Internally, `h` and `tau` are obtained by calling lapack's `dgeqrf` and are later used to compute the actual values of `(q, r)`. The numpy docs suggest that these might be useful to call other lapack functions, but at the moment none of them is exposed by numpy and I don't know how often it is used in the real world.
I suppose the implementing the backward pass need attention to: the most straightforward solution is to use `(h, tau)` to compute `(q, r)` and then use the normal logic for `qr_backward`, but there might be faster alternatives.
`full`, `f`
alias for `reduced`, deprecated since numpy 1.8.0
`economic`, `e`
similar to `raw but it returns only `h` instead of `(h, tau). Deprecated since numpy 1.8.0
To summarize:
* `reduce`, `complete` and `r` are straightforward to implement.
* `raw` needs a bit of extra care, but I don't know how much high priority it is: since it is used rarely, we might want to not support it right now and maybe implement it in the future?
* I think we should just leave `full` and `economic` out, and possibly add a note to the docs explaining what you need to use instead
/cc mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47764
Reviewed By: ngimel
Differential Revision: D25708870
Pulled By: mruberry
fbshipit-source-id: c25c70a23a02ec4322430d636542041e766ebe1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49740
1. Separates the module and functional linear test cases.
2. Combines the test case which tests for linear bias observation into
the main linear test case, as requested in
https://github.com/pytorch/pytorch/pull/49628.
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps.test_linear_module
python test/test_quantization.py TestQuantizeFxOps.test_linear_functional
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25681272
fbshipit-source-id: 0ed0ebd5afb8cdb938b530f7dbfbd79798eb9318
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49717
Quantization of `ConvTranpose{n}d` is supported in Eager mode. This PR
adds the support for FX graph mode.
Note: this currenlty only works in `qnnpack` because per-channel weights
are not supported by quantized conv transpose. In a future PR we should throw
an error when someone tries to quantize a ConvTranspose model with per-channel
weight observers until this is fixed.
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps.test_conv_transpose_1d
python test/test_quantization.py TestQuantizeFxOps.test_conv_transpose_2d
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25674636
fbshipit-source-id: b6948156123ed55db77e6337bea10db956215ae6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49627
There was a bug in the test that was hidden by the `If eager mode doesn't support a dtype/op/device combo` try / catch, so cuda wasn't being tested � The fix is just to rename `aten::masked_fill` to `aten_masked_fill`.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D25696409
Pulled By: eellison
fbshipit-source-id: 83de1f5a194df54fe317b0035d4a6c1aed1d19a0
Summary:
This is follow up on https://github.com/pytorch/pytorch/issues/49799.
* uses `torch.cuda.synchronize()` to validate CUDA assert instead of inspecting error message.
* remove non CUDA tests.
hopefully can reproduce why slow_tests fails but not normal test. since the test still runs for >1min.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49869
Reviewed By: mruberry
Differential Revision: D25714385
Pulled By: walterddr
fbshipit-source-id: 04f8ccb50d8c9ee42826a216c49baf90285b247f
Summary:
**BC-breaking Note:**
This PR updates PyTorch's digamma function to be consistent with SciPy's special.digamma function. This changes the result of the digamma function on the nonpositive integers, where the gamma function is not defined. Since the gamma function is undefined at these points, the (typical) derivative of the logarithm of the gamma function is also undefined at these points, and for negative integers this PR updates digamma to return NaN. For zero, however, it returns -inf to be consistent with SciPy.
Interestingly, SciPy made a similar change, which was noticed by at least one user: https://github.com/scipy/scipy/issues/9663#issue-396587679.
SciPy's returning of negative infinity at zero is intentional:
59347ae8b8/scipy/special/cephes/psi.c (L163)
This change is consistent with the C++ standard for the gamma function:
https://en.cppreference.com/w/cpp/numeric/math/tgamma
**PR Summary:**
Reference https://github.com/pytorch/pytorch/issues/42515
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48302
Reviewed By: ngimel
Differential Revision: D25664087
Pulled By: mruberry
fbshipit-source-id: 1168e81e218bf9fe5b849db0e07e7b22e590cf73
Summary: When the FC output min max range is very small, we want to enforce a cutoff on the scale parameter to better generalize for future values that could fall beyond the original range.
Test Plan:
More analysis about the output distributions can be found in N425166
An example workflow using fp16 min clipping is f240972205
Reviewed By: jspark1105
Differential Revision: D25681249
fbshipit-source-id: c4dfbd3ee823886afed06e6c2eccfc29d612f7e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49754
This PR adds the support for {input/output}_quantized_idxs for standalone module.
if input_quantized_idxs = [] and output_quantized_idxs = [], the standalone module will be expecting float
input and produce float output, and will quantize the input and dequantize output internally
if input_quantized_idxs = [0] and otuput_qiuantized_idxs = [0], the standalone module will be expecting quantized
input and produce quantized output, the input will be quantized in the parent module, and output will be dequantized
in the parent module as well, this is similar to current quantized modules like nn.quantized.Conv2d
For more details, please see the test case
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_standalone_module
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D25684692
fbshipit-source-id: 900360e01c0e35b26fe85f4a887dc1fd6f7bfb66
Summary:
this is a reland of https://github.com/pytorch/pytorch/issues/49527.
fixed slow test not running properly in py36 because capture_output is introduced in py37.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49799
Reviewed By: janeyx99
Differential Revision: D25692616
Pulled By: walterddr
fbshipit-source-id: 9c5352220d632ec8d7464e5f162ffb468a0f30df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49803
Per "https://fb.workplace.com/groups/e/permalink/3320810064641820/" we can no longer use the terms "whitelist" and "blacklist", and editing any file containing them results in a critical error signal. Let's embrace the change.
This diff changes "blacklist" to "blocklist" in a number of non-interface contexts (interfaces would require more extensive testing and might interfere with reading stored data, so those are deferred until later).
Test Plan: Sandcastle
Reviewed By: vkuzo
Differential Revision: D25686924
fbshipit-source-id: 117de2ca43a0ea21b6e465cf5082e605e42adbf6
Summary:
This PR adds `torch.linalg.inv` for NumPy compatibility.
`linalg_inv_out` uses in-place operations on provided `result` tensor.
I modified `apply_inverse` to accept tensor of Int instead of std::vector, that way we can write a function similar to `linalg_inv_out` but removing the error checks and device memory synchronization.
I fixed `lda` (leading dimension parameter which is max(1, n)) in many places to handle 0x0 matrices correctly.
Zero batch dimensions are also working and tested.
Ref https://github.com/pytorch/pytorch/issues/42666
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48261
Reviewed By: ngimel
Differential Revision: D25690129
Pulled By: mruberry
fbshipit-source-id: edb2d03721f22168c42ded8458513cb23dfdc712
Summary:
* qconv used to return NHWC no matter the input format
* this change returns NCHW format if the input was NCHW
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49533
Test Plan:
pytest test/quantization/test_quantized_op.py::\
TestQuantizedConv::test_qconv2d_preserve_mem_format
Fixes https://github.com/pytorch/pytorch/issues/47295
Reviewed By: kimishpatel
Differential Revision: D25609205
Pulled By: axitkhurana
fbshipit-source-id: 83f8ca4a1496a8a4612fc3da082d727ead257ce7
Summary:
This PR adds instructions on what to do if one committed into a PR branch w/o having a pre-commit hook enabled and having CI report flake8 errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49345
Reviewed By: cpuhrsch
Differential Revision: D25683167
Pulled By: soumith
fbshipit-source-id: 3c45c866e1636c116d2cacec438d62c860e6b854
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49711
`torch.cuda.synchronize` uses the current device by default. Explicitly specify this device for better readability.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 119017654
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_DistributedDataParallel_powerSGD_ddp_comm_hook
Reviewed By: rohan-varma
Differential Revision: D25672267
fbshipit-source-id: 62a2266727a2ea76175f3c438daf20951091c771
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49719
We find there are multiple use cases for standalone module, one use case requires standalone module
to produce a module that takes float Tensor as input and outputs a float Tensor, the other needs to
produce a modulee that takes quantized Tensor as input and outputs a quantized Tensor.
This is similar to `quantized_input_idxs` and `quantized_output_idxs` so we want to nest
prepare_custom_config_dict in the standalone module configuration, for maximum flxibility we also
include qconfig_dict for stand alone module as well in case user needs to have special qconfig_dict for
the standalone module in the future.
Changed from
```python
prepare_custom_config_dict =
{
"standalone_module_name": ["standalone_module"],
"standalone_module_class": [StandaloneModule]
}
```
to
```python
prepare_custom_config_dict =
{
"standalone_module_name": [("standalone_module", qconfig_dict1, prepare_custom_config_dict1)],
"standalone_module_class": [(StandaloneModule, qconfig_dict2, prepare_custom_config_dict2)]
}
```
The entries in the config are:
1. name/module_class
2. optional qconfig_dict, when it is None, we'll use {"": qconfig} where qconfig is the one from parent qconfig_dict
3. optional prepare_custom_config_dict, when it is None, we'll use default value of prepare_custom_config_dict for prepare API (None)
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_standalone_module
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D25675704
fbshipit-source-id: 0889f519a3e55a7a677f0e2db4db9a18d87a93d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49709
Since wait() has already been called in the return statements of the precursor callbacks, no need to wait again.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 119015237
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_DistributedDataParallel_powerSGD_ddp_comm_hook
Reviewed By: rohan-varma
Differential Revision: D25672068
fbshipit-source-id: da136327db4c4c0e3b846ba8d6885629f1044374
Summary:
**BC-Breaking Note:**
This PR updates PyTorch's angle operator to be consistent with NumPy's. Previously angle would return zero for all floating point values (including NaN). Now angle returns `pi` for negative floating point values, zero for non-negative floating point values, and propagates NaNs.
**PR Summary:**
Reference: https://github.com/pytorch/pytorch/issues/42515
TODO:
* [x] Add BC-Breaking Note (Prev all real numbers returned `0` (even `nan`)) -> Fixed to match the correct behavior of NumPy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49163
Reviewed By: ngimel
Differential Revision: D25681758
Pulled By: mruberry
fbshipit-source-id: 54143fe6bccbae044427ff15d8daaed3596f9685
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49765
Some PyTorch module can have None as submodule, which causes the following error in JIT-tracing:
Repro script:
```
import torch
class TestModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.submod = torch.nn.Linear(3, 4)
self.submod = None
def forward(self, inputs):
return inputs
m = TestModule()
tm = torch.jit.trace(m, torch.tensor(1.))
```
Error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/data/miniconda3/envs/master_nightly/lib/python3.7/site-packages/torch/jit/_trace.py", line 742, in trace
_module_class,
File "/data/miniconda3/envs/master_nightly/lib/python3.7/site-packages/torch/jit/_trace.py", line 928, in trace_module
module = make_module(mod, _module_class, _compilation_unit)
File "/data/miniconda3/envs/master_nightly/lib/python3.7/site-packages/torch/jit/_trace.py", line 560, in make_module
return _module_class(mod, _compilation_unit=_compilation_unit)
File "/data/miniconda3/envs/master_nightly/lib/python3.7/site-packages/torch/jit/_trace.py", line 1039, in __init__
submodule, TracedModule, _compilation_unit=None
File "/data/miniconda3/envs/master_nightly/lib/python3.7/site-packages/torch/jit/_trace.py", line 560, in make_module
return _module_class(mod, _compilation_unit=_compilation_unit)
File "/data/miniconda3/envs/master_nightly/lib/python3.7/site-packages/torch/jit/_trace.py", line 988, in __init__
assert isinstance(orig, torch.nn.Module)
AssertionError
```
This pull request changes the JIT-tracing logic to skip the None submodule when tracing.
Test Plan: `buck test mode/dev //caffe2/test:jit -- test_trace_skip_none_submodule`
Reviewed By: wanchaol
Differential Revision: D25670948
fbshipit-source-id: 468f42f5ddbb8fd3de06d0bc224dc67bd7172358
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49688
Adds more types on FX quantize convert, fixing things as they
are uncovered by mypy.
Test Plan:
```
mypy torch/quantization
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25667231
fbshipit-source-id: 262713c6ccb050a05e3119c0457d0335dde82d25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49628
Ensures that linear bias is not observed in a `F.linear` call. This should
be a small speedup in PTQ, and will change numerics (in a good way) for
QAT if someone is using `F.linear`.
Note: the implementation is slightly more verbose compared to conv
because bias is a keyword argument in Linear.
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps.test_linear_functional_bias_not_observed
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25653532
fbshipit-source-id: c93501bf6b55cbe4a11cfdad6f79313483133a39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49623
(not ready for review)
Ensures that conv bias is not observed in a `F.conv{n}d` call.
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25652856
fbshipit-source-id: 884f87be1948d3e049a557d79bec3c90aec34340
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49019
I marked the test_testing function as slow since it took ~1 minute to finish the subprocess test suite.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49527
Reviewed By: malfet
Differential Revision: D25623219
Pulled By: walterddr
fbshipit-source-id: 1b414623ecce14aace5e0996d5e4768a40e12e06
Summary:
Minor doc fix in clarifying that the input data is rounded not truncated.
CC zasdfgbnm ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49625
Reviewed By: mruberry
Differential Revision: D25668244
Pulled By: ngimel
fbshipit-source-id: ac97e41e0ca296276544f9e9f85b2cf1790d9985
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49380
Couldn't resist removing a class member that is only used in one function.
Reviewed By: yinghai
Differential Revision: D25547366
fbshipit-source-id: 74e61c6a0068566fb7956380862999163e7e94bf
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49214
**BC-Breaking**
Before this PR, `%=` didn't actually do the operation inplace and returned a new tensor.
After this PR, `%=` operation is actually inplace and the modified input tensor is returned.
Before PR,
```python
>>> import torch
>>> a = torch.tensor([11,12,13])
>>> id(a)
139627966219328
>>> a %= 10
>>> id(a)
139627966219264
```
After PR,
```python
>>> import torch
>>> a = torch.tensor([11,12,13])
>>> id(a)
139804702425280
>>> a %= 10
>>> id(a)
139804702425280
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49390
Reviewed By: izdeby
Differential Revision: D25560423
Pulled By: zou3519
fbshipit-source-id: 2b92bfda260582aa4ac22c4025376295e51f854e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49566Fixes#49422.
check_jacobian and gradcheck do roughly the same thing: they both
compute an analytic jacobian and a numeric jacobian and check that
they are equivalent. Furthermore, NewModuleTest will (by default) call
both check_jacobian and gradcheck, leading to some redundant checks that
waste CI resources.
However, there is one subtle difference: `check_jacobian` can handle the
special case where a Module takes in dense inputs and dense parameters
but returns sparse gradients, but that is not something gradcheck can
handle. This is only used in the tests for nn.Embedding and
nn.EmbeddingBag.
This PR does the following:
- have NewModuleTest call gradcheck instead of check_jacobian by default
- add a new "has_sparse_gradients" flag to NewModuleTest. These are True
for the nn.Embedding and nn.EmbeddingBag sparse gradient tests. If
`has_sparse_gradients` is True, then we call check_jacobian, otherwise,
we call gradcheck.
- Kills the "jacobian_input" flag. This flag was used to tell
NewModuleTest to not attempt to compute the jacobian for the inputs to
the module. This is only desireable if the input to the module isn't
differentiable and was only set in the case of nn.Embedding /
nn.EmbeddingBag that take a LongTensor input. `gradcheck` handles these
automatically by not checking gradients for non-differentiable inputs.
Test Plan:
- Code reading
- run test_nn.py
Reviewed By: albanD
Differential Revision: D25622929
Pulled By: zou3519
fbshipit-source-id: 8d831ada98b6a95d63f087ea9bce1b574c996a22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49451
Reuse the low-rank tensors P(s) and Q(s) from the previous iteration if possible.
This can give a better compression performance in terms of both accuracy and speed.
Also add a unit test for batched PowerSGD to test_c10d.py.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 119014132
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_DistributedDataParallel_powerSGD_ddp_comm_hook
Reviewed By: rohan-varma
Differential Revision: D25583086
fbshipit-source-id: a757df3c4cfcc0ead4647f7de2f43198f1e063ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49721
As a refactor effort of per-app selective build, we are decoupling ATen/native from the rest of aten (D25413998).
All symbols of ATen/native could only be referenced through dispatcher (https://github.com/pytorch/pytorch/issues/48684).
This diff is to decouple the native reference recently introduced for sparse tensors.
ghstack-source-id: 119028080
Test Plan: CI
Reviewed By: dhruvbird, ngimel
Differential Revision: D25675711
fbshipit-source-id: 381cbb3b361ee41b002055399d4996a9ca21377c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49506
- Get rid of expensive stuff like `TensorArg`, `checkBackend`, `checkSize`, and `TensorAccessor`.
- Add `checkDim` that does not require creating a `TensorArg` which incurs a refcount bump
- Avoid unnecessary calls to `torch.select`, which goes through the dispatcher in the cases we care about, with mat1 and mat2 not permuted or permuted with dims = [0, 2, 1]. The pt version of bmm supports crazy cases like when the inputs are permuted with dims = [1, 2, 0], which is uncommon in SparseNNs.
Test Plan:
Unit test:
```
buck test //caffe2/test:linalg
```
Benchmark with the adindexer model:
```
Before:
I1216 14:02:24.155516 2595800 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.0847197. Iters per second: 11803.6
After:
I1216 14:02:26.583878 2595939 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.082051. Iters per second: 12187.5
```
Reviewed By: bwasti
Differential Revision: D25577574
fbshipit-source-id: 8aba69b950e7b4d9d1b14ba837931695a908c068
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49549
Somehow `mypy torch/quantization` got broken in the past couple of days:
https://gist.github.com/vkuzo/07af454246f0a68e6fa8929beeec7e0d
. I didn't see any relevant PRs other than
https://github.com/pytorch/pytorch/pull/47725, which doesn't seem
related. The error doesn't seem real, as the arguments to
`_cudnn_rnn_flatten_weight` seem correct. For now,
ignoring the failure so we have a clean `mypy` run on
`torch/quantization`.
Test Plan:
```
mypy torch/quantization
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25616972
fbshipit-source-id: 46c207fe1565ec949c0b1f57d6cd0c93f627e6bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49697
Mostly mechanical move. This refactoring helps to hide unnecessary
details from the SimpleIREval interface and make it more similar to a
pure 'codegen'.
Test Plan: Imported from OSS
Reviewed By: nickgg
Differential Revision: D25668696
Pulled By: ZolotukhinM
fbshipit-source-id: 423247bfcdfa88403e8ec92152f00110bb9da19c
Summary:
THC_API and THC_CLASS were leftover macros from before the consolidation of caffe2, aten, and torch. Now that they're combined, these are misleading and should just be TORCH_CUDA_API. The only file I manually edited was `THCGeneral.h.in`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49690
Reviewed By: malfet
Differential Revision: D25667982
Pulled By: janeyx99
fbshipit-source-id: 2fdf7912b2a0537b7c25e1fed21cc301fa59d57f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49052
The TCPStore example with 4 arguments was working because the datetime value was being implicitly converted to a bool. Modified the pybind definition and updated documentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49685
Test Plan:
```
import torch.distributed as dist
from datetime import timedelta
dist.TCPStore("127.0.0.1", 0, True, timedelta(seconds=30))
```
Now fails with
```
TypeError: __init__(): incompatible constructor arguments. The following argument types are supported:
1. torch._C._distributed_c10d.TCPStore(host_name: str, port: int, world_size: int, is_master: bool, timeout: datetime.timedelta = datetime.timedelta(seconds=300))
Invoked with: '127.0.0.1', 0, True, datetime.timedelta(seconds=30)
```
Reviewed By: mrshenli, ngimel
Differential Revision: D25668021
Pulled By: H-Huang
fbshipit-source-id: ce40b8648d0a414f0255666fbc680f1a66fae090
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49694
The store based barrier introduced in
https://github.com/pytorch/pytorch/pull/49419 broke for certain store types.
This is a quick fix to resolve the issues for other store types.
ghstack-source-id: 119006874
Test Plan: 1) waitforbuildbot
Reviewed By: ppwwyyxx, rohan-varma
Differential Revision: D25668404
fbshipit-source-id: 751fb8b229ad6f50ee9c50f63a70de5a91c9eda5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49568
We have some inference use cases where the expected output of a module is of the form `{"key": (t1, t1)}` and are currently jit tracing the modules until we can reach jit script compatibility.
Test Plan: buck test mode/dev caffe2/test:jit -- 'test_trace_returning_complex_dict'
Reviewed By: houseroad
Differential Revision: D25624152
fbshipit-source-id: 5adef0e3c9d54cd31ad5fece4ac6530d541fd673
Summary:
GCD should always return positive integers. When negative values are used, we hit a corner case that results in an infinite recursion during simplification.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49379
Reviewed By: ezyang
Differential Revision: D25597115
Pulled By: navahgar
fbshipit-source-id: b0e8ac07ee50a5eb775c032628d4840df7424927
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49691
Quite a few stale items, let's make the list short.
Test Plan: oss ci
Reviewed By: hl475
Differential Revision: D25667464
fbshipit-source-id: cff1be8b5e0068470b3f621acf6bf4fbd414233e
Summary:
minor changes to block codegen to handle new inlining in NNC.
For Block code generation we need to delay inlining before collecting dimension data about the tensors.
We need to collect the dimension of the tensor before they were flattened. We don't have this information after the inlining pass, so for Block we run inling after we have collected this data using `CreateBufferMap` analysis.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47687
Reviewed By: ZolotukhinM
Differential Revision: D24864869
Pulled By: protonu
fbshipit-source-id: 9574c0599f7d959a1cf0eb49d4e3e541cbe9b1d3
Summary:
Used to temporarily change working directory, but restore it even if exception is raised
Use it in test_type_hints and during code coverage collection
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49657
Reviewed By: walterddr
Differential Revision: D25660543
Pulled By: malfet
fbshipit-source-id: 77f08d57e4b60b95daa4068d0dacf7c25f978526
Summary:
Related https://github.com/pytorch/pytorch/issues/38349
Implement NumPy-like function `torch.broadcast_to` to broadcast the input tensor to a new shape.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48997
Reviewed By: anjali411, ngimel
Differential Revision: D25663937
Pulled By: mruberry
fbshipit-source-id: 0415c03f92f02684983f412666d0a44515b99373
Summary:
Makes two changes in NNC for intermediate buffer allocations:
1. Flattens dimensions of buffers allocated in LoopNest::prepareForCodegen() to match their flattened usages.
2. Adds support for tracking memory dependencies of Alloc/Free to the MemDependencyChecker, which will allow us to check safety of accesses to intermediate buffers (coming in a future diff).
I didn't add any new tests as the mem dependency checker tests already cover it pretty well, particularly the GEMM test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49554
Reviewed By: VitalyFedyunin
Differential Revision: D25643133
Pulled By: nickgg
fbshipit-source-id: 66be3054eb36f0a4279d0c36562e63aa2dae371c
Summary:
This small PR fixes a one character typo in the docstring for `DataLoader`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49437
Reviewed By: ngimel
Differential Revision: D25665971
Pulled By: mrshenli
fbshipit-source-id: b60f975f1e3bf0bb8f88e39f490f716c602f087e
Summary:
Very small PR to fix a typo.
### Description
Fixed 1 typo in the documentation of `torch/utils/tensorboard/writer.py` (replaced "_should in_" by "_should be in_")
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49648
Reviewed By: ngimel
Differential Revision: D25665831
Pulled By: mrshenli
fbshipit-source-id: a4e733515603bb9313c1267fdf2cfcc2bc2773c6
Summary:
This PR adds `torch.linalg.solve`.
`linalg_solve_out` uses in-place operations on the provided result tensor.
I modified `apply_solve` to accept tensor of Int instead of std::vector, that way we can write a function similar to `linalg_solve_out` but removing the error checks and device memory synchronization.
In comparison to `torch.solve` this routine accepts 1-dimensional tensors and batches of 1-dim tensors for the right-hand-side term. `torch.solve` requires it to be at least 2-dimensional.
Ref. https://github.com/pytorch/pytorch/issues/42666
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48456
Reviewed By: izdeby
Differential Revision: D25562222
Pulled By: mruberry
fbshipit-source-id: a9355c029e2442c2e448b6309511919631f9e43b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49574
Adds support for additional Eigen Utils for custom type defs.
Reviewed By: linbinyu
Differential Revision: D25624556
fbshipit-source-id: 0ffa90aaf8cbf1d08825e95156fb40d966ca7042
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49435
Previously the assertion that prevents illegal memory access is because of the torch.any that returns a boolean value, which initiates a data transfer from the device to the host and forces a synchronization.
An explicit synchronization is more to the point.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 118664204
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_DistributedDataParallel_powerSGD_ddp_comm_hook
Reviewed By: rohan-varma
Differential Revision: D25573484
fbshipit-source-id: 516d0d502da2863b516c15332702335ee662f072
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49418
Add error feedback to the original implementation of PowerSGD.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 118670930
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_DistributedDataParallel_powerSGD_ddp_comm_hook
Reviewed By: rohan-varma
Differential Revision: D25555538
fbshipit-source-id: c01145cc9acf574a4c6aa337dbbba0ba7d9350b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49022
**BC-breaking note**:
Previously torch.stft took an optional `return_complex` parameter that indicated whether the output would be a floating point tensor or a complex tensor. By default `return_complex` was False to be consistent with the previous behavior of torch.stft. This PR changes this behavior so `return_complex` is a required argument.
**PR Summary**:
* **#49022 stft: Change require_complex warning to an error**
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D25658906
Pulled By: mruberry
fbshipit-source-id: 11932d1102e93f8c7bd3d2d0b2a607fd5036ec5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49639
Resubmit #49417 with a fix for distributed_test.
The previous submission broke a multi-gpu test that runs on 4 GPUs. Since this test only runs on master, couldn't detect it before the submission.
The real diff is:
4ca1014bb5
This time I have verified that the previous failed test `pytorch_linux_xenial_cuda10_2_cudnn7_py3_multigpu_test` could pass after creating a PR (#49651) from a separate branch:
https://app.circleci.com/pipelines/github/pytorch/pytorch/253644/workflows/c1c02b70-0877-40e6-8b4c-61f60f6b70ed/jobs/9768079
ghstack-source-id: 118969912
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_DistributedDataParallel_powerSGD_ddp_comm_hook、
Reviewed By: mrshenli
Differential Revision: D25654961
fbshipit-source-id: 2a45c8ceb9bdb54ff7309a8b66ec87e913e0150e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48840
The CUDAFuture class needs to inspect the values it contains in order to extract its tensors (in fact, the DataPtrs backing those). These are needed first to determine what CUDA devices back those tensors, so that an event for each such device can be recorded; and later to record these DataPtrs with the CUDA caching allocator if they are used in other streams.
This became complicated when Python was added to the mix, because to inspect a Python object we need to acquire the GIL, but we couldn't do so from code that was supposed to also work in C++-only mode. The solution was for users to provide a custom way to extract DataPtrs, so that the PythonFutureWrapper could install such a custom Python-aware one. This was the DataPtr extractor.
In https://github.com/pytorch/pytorch/pull/48502 a different suggestion was proposed. At its root, it consists in adding support for IValues of type PyObject to the visit() and getSubValues() methods. In order to deal with the GIL, we do this through a virtual method: PyObjectHolder, which is the base class, is available also in C++-only mode, and thus defines this method but leaves it unimplemented; ConcretePyObjectHolder, which is the subclass, is only included in Python mode, and thus it can implement that method, acquire the GIL, and do what it's supposed to.
In my opinion, this approach is just brilliant! Thank wanchaol for proposing it! It hides the complexity of dealing with Python inside getSubValues(), where it can be done properly, thus simplifying enormously the CUDAFuture and the PythonFutureWrapper classes.
ghstack-source-id: 118704935
Test Plan: Unit tests
Reviewed By: wanchaol
Differential Revision: D25334355
fbshipit-source-id: 3f1d3bf6e6e8505a114c877fb9a6fcc3f68d91d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49170
Added an extra step to **always** preserve the bundled inputs methods if they are present in the input module.
Also added a check to see if all the methods in the `preseved_methods` exist. If not, we will now throw an exception. This can hopefully stop hard-to-debug inputs from getting into downstream functions.
~~Add an optional argument `preserve_bundled_inputs_methods=False` to the `optimize_for_mobile` function. If set to be True, the function will now add three additional functions related with bundled inputs to be preserved: `get_all_bundled_inputs`, `get_num_bundled_inputs` and `run_on_bundled_input`.~~
Test Plan:
`buck test mode/dev //caffe2/test:mobile -- 'test_preserve_bundled_inputs_methods \(test_mobile_optimizer\.TestOptimizer\)'`
or
`buck test caffe2/test:mobile` to run some other related tests as well.
Reviewed By: dhruvbird
Differential Revision: D25463719
fbshipit-source-id: 6670dfd59bcaf54b56019c1a43db04b288481b6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49621
This adds support to configure qconfig for a call_method, e.g. x.chunk, this will help workaround
a problem in our internal model.
TODO: since call_method is also a string and we flatten the qconfig, might need to resolve namespace conflict between
call_method and module_name
TODO: Add scope support to set the qconfig for call_method correctly with original qconfig
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D25651828
fbshipit-source-id: 82d66b121d37c8274fd481b6a2e9f9b54c5ca73d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48638
Polishing up some of the docs for the main `Pipe` class and its
`forward` method.
ghstack-source-id: 118820804
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D25237705
fbshipit-source-id: ba3d8737b90a80024c827c0887fc56f14bf678b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49417
The existing implementation applies PowerSGD to a batch of flattened tensors, which is a coarse-grained compression. This hook now is renamed as "batched_powerSGD_hook".
Now implement the original implementation in the paper, which applies PowerSGD to each per-parameter tensor. This is a layerwise fine-grained compression. Although this original implementation is slower, it is expected to achieve a higher accuracy, especially when the shapes of per-param tensors cannot be aligned.
Also add a test in distributed_test.py.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 118921275
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:distributed_nccl_fork -- test_DistributedDataParallel_powerSGD_ddp_comm_hook
Reviewed By: rohan-varma
Differential Revision: D25511543
fbshipit-source-id: 19ef188bc2d4c7406443c8fa233c1f2c2f27d93c
Summary:
Instead of calling coverage frontend import coverage module and call combine() and html_report()
Fixes https://github.com/pytorch/pytorch/issues/49596 by not using a strict mode when combining those reports
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49615
Reviewed By: seemethere
Differential Revision: D25645196
Pulled By: malfet
fbshipit-source-id: be55b5c23a3569a331cbdf3f86d8c89bc27d5fe1
Summary:
This PR currently just modifies the `test/print_test_stats.py` script (run in the `pytorch_linux_test` job) so that now it uploads test times to the new `ossci-metrics` S3 bucket (rather than just to Scribe) if passed the `--upload-to-s3` parameter.
The next step is to add an additional step to that `pytorch_linux_test` job which checks if it's being run on a PR, and if so, finds the `master` commit to compare against (similar to what's done in the now-unused `.jenkins/pytorch/short-perf-test-{c,g}pu.sh` scripts) and adds test time info to the Dr CI comment if the PR is significantly different from the base revision.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49190
Test Plan:
An "integration test" would be to just look in [the `ossci-metrics` S3 bucket](https://s3.console.aws.amazon.com/s3/buckets/ossci-metrics) to confirm that the CI run(s) for this PR did indeed upload their test time data successfully.
To test this locally, first make sure you have all the packages you need, such as these:
```
$ conda install -c anaconda boto3
$ conda install -c conda-forge unittest-xml-reporting
```
Then run whatever tests you want; these are the ones I used for my local smoke test, for no particular reason:
```
$ python test/test_spectral_ops.py --save-xml=/tmp/reports/spectral_ops
```
Once the tests finish, run the script to upload their times to S3:
```
$ CIRCLE_SHA1="$(git rev-parse HEAD)" CIRCLE_JOB=foo test/print_test_stats.py --upload-to-s3 /tmp/reports/spectral_ops
```
Now check that they uploaded successfully:
```
$ aws s3 cp "s3://ossci-metrics/test_time/$(git rev-parse HEAD)/foo/" /tmp/reports --recursive
```
And that it's a valid `*.json.bz2` file:
```
$ bzip2 -kdc /tmp/reports/*Z.json.bz2 | jq . | head -n21
{
"build_pr": null,
"build_tag": null,
"build_sha1": "e46f43621b910bc2f18dd33c08f5af18a542d5ed",
"build_branch": null,
"build_job": "foo",
"build_workflow_id": null,
"total_seconds": 0.9640000000000003,
"suites": {
"TestFFTCPU": {
"total_seconds": 0.9640000000000003,
"cases": [
{
"name": "test_fft_invalid_dtypes_cpu",
"seconds": 0.022,
"errored": false,
"failed": false,
"skipped": false
},
{
"name": "test_istft_throws_cpu",
```
Reviewed By: walterddr, malfet
Differential Revision: D25618035
Pulled By: samestep
fbshipit-source-id: 4d8013859a38a49e5bba700c5134951ca1a9d8b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49306
This allows you to mock out everything except for specific patterns while
still correctly externing the python standard library. This makes it less
likely that you will need to override require_module.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D25526212
Pulled By: zdevito
fbshipit-source-id: 7339f4c7f12af883496f79de95e57d452bb32dc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48470
Adding a unit test to test this works as expected. Although, this
doesn't work with other checkpointing modes of the pipe and checkpoint=never
needs to be set for this to work.
ghstack-source-id: 118820806
Test Plan: waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D25182668
fbshipit-source-id: 85e69e338bf388c132a303ad93e29ec2cc4a0ed8
Summary:
========
Fixes #{42915}
This commit adds support for Bitwise Shorthands in TorchScript, i.e : |=,&=,^=,<<=,>>=,**=
Testing:
======
This commit also adds test for the above fix in test_jit.py
The test can be invoked by
pytest -k augassign test/test_jit.py
Here is a snapshot of the testing:
<img width="1238" alt="image" src="https://user-images.githubusercontent.com/70345919/93105141-8f9f5300-f663-11ea-836b-3b52da6d2be5.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44621
Reviewed By: mrshenli
Differential Revision: D23906344
Pulled By: nikithamalgifb
fbshipit-source-id: 4c93a7430a625f698b163609ccec15e51417d564
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48280
Adding new API for the kineto profiler that supports enable predicate
function
Test Plan: unit test
Reviewed By: ngimel
Differential Revision: D25142220
Pulled By: ilia-cher
fbshipit-source-id: c57fa42855895075328733d7379eaf3dc1743d14
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49385
Currently, the API to export operator lists accepts a `torch::jit::Module` object, and spits out an operator list. The operator list is practically used only for mobile. This is not ideal because the set of root operators may change by the time the model is subsequently optmized and exported for mobile.
What we need to to instead is glean the list of operators from the mobile model itself (`bytecode.pkl` specifically), and expose that instead.
Also updated the logic in `converter`.
### Before this change:
1. Get operator List from Torch Script Model
2. Convert to bytecode mobile model
### After this change:
1. Convert to bytecode mobile model
2. Use this converted mobile model to get the list of operators for each method on the model
ghstack-source-id: 118796752
Test Plan:
Added a unit test in `test_lite_interpreter.cpp` to ensure that all model referenced operators show up in the exported operator list. Also make `test_lite_interpreter.cpp` runnable from `xplat/caffe2/BUCK` since this is where the production code will be built from.
Verified that the list of operators produced before and after this change for an example model (segmentation) are the same.
{P147863234}
Also verified that the operator lists for BI-Xray model is different (we have been having problems with missing operators for this one): {P154903132}
Reviewed By: iseeyuan
Differential Revision: D24690094
fbshipit-source-id: 0426a6ef90456a811010cfe337c415882ae2deff
Summary:
Since caffe2 and torch have been consolidated, CAFFE2_API should be merged with TORCH_API. Addresses a TODO.
Manually edited some references of the removed `CAFFE2_API`:
* `CONTRIBUTING.md`
* `caffe2/proto/CMakeLists.txt`
* `cmake/ProtoBuf.cmake`
* `c10/macros/Export.h`
* `torch/csrc/WindowsTorchApiMacro.h`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49496
Reviewed By: malfet, samestep
Differential Revision: D25600726
Pulled By: janeyx99
fbshipit-source-id: 7e068d959e397ac183c097d7e9a9afeca5ddd782
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49591
A bunch of these tests are marked flaky, and have been since time immemorial. (Read: as far back as Buck will build.) However closer inspection reveals that they fail if and only if run on a GPU worker. What seems to be going on is that there are more jobs than GPUs, so the contention causes waits which registers as timeouts on the test.
This diff is kind of hacky, but it basically just drops deadlines if a GPU is present. Because Caffe2 is going away I'm not too terribly concerned about a beautiful solution, but we may as well keep some test coverage if it's easy.
CC Sebastian, Ilia, Min, and Hongzheng who also have tasks for what seems to be the same flakiness.
Test Plan: Turn the tests back on and see if they fall over. (The failure repros reliably on an OnDemand GPU and is fixed by this change, so it's not really just a hail Mary.)
Reviewed By: ngimel
Differential Revision: D25632981
fbshipit-source-id: 43dcce416fea916ba91f891e9e5b59b2c11cca1a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/598
This is BC-breaking as we now explicitly don't call the hook when there are not Tensors at the top level of the output.
This feature was not working anyways as the returned grad_input/grad_output were wrong (not respecting the output structure and wrong inputs for multi-Node Module).
This is also BC-breaking as we now report the correct gradients for `nn.Module`s that contain multiple autograd `Node`s while we use to return bad results before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46163
Reviewed By: ailzhang, mruberry
Differential Revision: D24894180
Pulled By: albanD
fbshipit-source-id: e1b5d193d2818eb2f51e2a2722c7405c8bd13c2b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49482
Motivation
==========
Batching rules always invoke newLogicalToPhysical at the very end to turn
a physical tensor into a logical BatchedTensor (an example is below):
```
Tensor select_backward_batching_rule(const Tensor& grad, IntArrayRef input_sizes, int64_t dim, int64_t index) {
auto grad_physical = MultiBatchVmapTransform::logicalToPhysical(grad);
auto grad_input = at::zeros(grad_physical.getPhysicalShape(input_sizes), grad.options());
auto physical_dim = getGradInputPhysicalDim(dim, input_sizes, grad_physical.numBatchDims());
grad_input.select(physical_dim, index).copy_(grad_physical.tensor());
return grad_physical.newLogicalFromPhysical(grad_input);
}
```
However, albanD noted that this function is confusing and ambiguous
because it's unclear which physical tensor is being turned into the logical
(in this case, grad_physical is a VmapPhysicalView, but we're really transforming
grad_input and returning it).
https://github.com/pytorch/pytorch/pull/44505#discussion_r487144018
I didn't want to make too many changes to the batching rule API because
I think we'll change it even more in the future, but this PR attempts to
remove the ambiguity by applying one of the suggestions in
https://github.com/pytorch/pytorch/pull/44505#discussion_r487144018
This PR
=======
The diagnosis of the problem is that we were conflating
"VmapPhysicalView", which maps logical attributes on a Tensor (like
dimension and shape) to physical attributes, with the reverse
physical-to-logical map. This PR creates a new VmapPhysicalToLogicalMap
object that handles the latter.
Instead of calling `grad_physical.newLogicalFromPhysical(grad_input)`,
an author of batching rules should now retrieve the VmapPhysicalToLogicalMap
object and apply it to their physical input. So the above code becomes:
```
grad_physical.getPhysicalToLogicalMap().apply(grad_input)
```
I've also moved VmapPhysicalView::makeLogicalFromPhysicalListInplace
to VmapPhysicalToLogicalMap::applyInplace.
Test Plan
=========
wait for tests
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D25592645
Pulled By: zou3519
fbshipit-source-id: 9c6ede9901ec6b70e5763193064658a8f91e6d48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49357
This is a follow-up fix for PR #48679, where the previous PR
adds support for integer inputs to aten::abs by promoting integers to
float and then demote the result back to integers. This PR supports
integer inputs to aten::abs more efficiently in the SimpleIREvaluator
by allowing implementing integer inputs for kAbs (renamed from kFabs).
- Rename kFabs to kAbs
- Add support for integer input to kAbs in SimpleIREvalator (note that:
llvm_codegen and cuda_codegen already supports integer inputs to kAbs)
Test Plan:
- `PYTORCH_TENSOREXPR_DONT_USE_LLVM=1 python test/test_jit_fuser_te.py
TestTEFuser.test_unary_ops`
- `python test/test_jit_fuser_te.py TestTEFuser.test_unary_ops`
Imported from OSS
Reviewed By: eellison
Differential Revision: D25545791
fbshipit-source-id: e52f51a352d149f66ce8341fb3beb479be08a230
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49201
This unblocks kineto profiler for 1.8 release.
This PR supercedes https://github.com/pytorch/pytorch/pull/48391
Note: this will somewhat increase the size of linux server binaries, bc
we add libkineto.a and libcupti_static.a:
-rw-r--r-- 1 jenkins jenkins 1107502 Dec 10 21:16 build/lib/libkineto.a
-rw-r--r-- 1 root root 13699658 Nov 13 2019 /usr/local/cuda/lib64/libcupti_static.a
Test Plan:
CI
https://github.com/pytorch/pytorch/pull/48391
Imported from OSS
Reviewed By: ngimel
Differential Revision: D25480770
fbshipit-source-id: 037cd774f5547d9918d6055ef5cc952a54e48e4c
Summary:
Clear static variable at the end of the test to ensure test passes after re-runs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49581
Test Plan:
`./bin/test_api "--gtest_filter=CustomAutogradTest.ReentrantPriority" --gtest_repeat=50`
Before the change all subsequent runs of the test failed with
```
../test/cpp/api/autograd.cpp:681: Failure
Expected equality of these values:
order.size()
Which is: 310
10
```
Reviewed By: mrshenli
Differential Revision: D25632374
Pulled By: malfet
fbshipit-source-id: 4814d22b5dff15e1b38a0187e51070771fd58370
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49419
As described in https://github.com/pytorch/pytorch/issues/48110, the
newly introduced `barrier()` in `init_process_group` messes up NCCL
communicator state since it uses a bunch of default devices to perform an
allreduce which simulates a barrier(). As a ressult, subsequent NCCL operations
might not behave as expected.
ghstack-source-id: 118861776
Test Plan:
1) unit test added.
2) waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D25566550
fbshipit-source-id: ab083b67b634d7c515f4945deb228f959b27c936
Summary:
These are redundant with the functional variant checks and can be very costly, as some grad and gradgrad testing takes minutes to run per variant. Maybe in the future we'll add them back for operations with divergent method implementations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49576
Reviewed By: albanD, ngimel
Differential Revision: D25631691
Pulled By: mruberry
fbshipit-source-id: 247f750979d9dafab2454cdbfa992a2aa6da724a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49517
We should add concrete type info for Tensor List case as well.
Test Plan: ci
Reviewed By: qizzzh
Differential Revision: D25599223
fbshipit-source-id: 3614e9ec25fc963a8d6a0bd641735fcca6c87032
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49571
Disable nested namespace check since OSS standard is
```
set(CMAKE_CXX_STANDARD 14)
```
and its currently causing confusion on clang-tidy internally such as D25214452
Test Plan: clang-tidy
Reviewed By: xuzhao9
Differential Revision: D25626392
fbshipit-source-id: 1fb472c89ebe9b83718ae27f2c1d77b8b2412b5e
Summary:
I was exhausted with needing to hunt down zombies when working with ddp launcher, so this PR solves the various zombie issues.
This PR addresses 2 distinct zombie scenarios caused by ddp launch.py:
1. When the main process is killed, the child processes aren't killed and continue running
2. When any of the children processes dies (e.g. OOM), the rest of the children and the parent remain running, but really are stuck
To solve these problems this PR switches from `wait` to `poll` and uses signal handlers.
The main problem with `wait()` was that it's not async, and I was having a 2nd process OOM, and the code was stuck waiting for the first process to finish which will not happen since the first process is blocking now waiting for the 2nd process - a sort of deadlock. My 2nd card is smaller than the first one, so it occasionally OOMs.
Using `asyncio` would probably be the cleanest solution, but as it's relatively new in python, perhaps polling is good enough.
I wrote this little script to reproduce 2 problematic scenarios and a normal running setup, it does 3 different things according to the `--mode` arg
- `oom` - causes the 2nd process to exit prematurely emulating OOM
- `clean-finish` - just exit normally in both processes
- `False` (lack of arg) just keep on running - emulating multiple normally running processes
```
# oom.py
import argparse
from time import sleep
import sys
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=False, type=int)
parser.add_argument("--mode", default=False, type=str)
args, _ = parser.parse_known_args()
print(f"{args.local_rank} is starting")
sleep(3)
if args.mode == "oom":
# emulate OOM in 2nd card
if args.local_rank == 1:
raise RuntimeError("OOM")
if args.mode == "clean-finish":
sleep(1)
print(f"{args.local_rank} is cleanly finishing")
sys.exit(0)
while (True):
# emulate long running process
print(f"{args.local_rank} is running")
sleep(1)
if __name__ == "__main__":
main()
```
Let's begin:
### 1. Normal execution
```
python -m torch.distributed.launch --nproc_per_node=2 ./oom.py --mode=clean-finish
```
All the processes exit upon completion - I won't bother pasting the log here - just testing that my code didn't break the normal running
### 2. OOM
```
python -m torch.distributed.launch --nproc_per_node=2 ./oom.py --mode=oom
```
```
POLLING FOR 17547
POLLING FOR 17548
0
0 is starting
1
1 is starting
POLLING FOR 17547
POLLING FOR 17548
POLLING FOR 17548
POLLING FOR 17547
POLLING FOR 17547
POLLING FOR 17548
0 is running
Traceback (most recent call last):
File "./oom.py", line 33, in <module>
main()
File "./oom.py", line 20, in main
raise RuntimeError("OOM")
RuntimeError: OOM
POLLING FOR 17548
process 17548 is no more
Killing subprocess 17547
Killing subprocess 17548
Traceback (most recent call last):
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/distributed/launch.py", line 341, in <module>
main()
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/distributed/launch.py", line 327, in main
sigkill_handler(signal.SIGTERM, None) # not coming back
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/distributed/launch.py", line 301, in sigkill_handler
raise subprocess.CalledProcessError(returncode=last_return_code, cmd=cmd)
subprocess.CalledProcessError: Command '['/home/stas/anaconda3/envs/main-38/bin/python', '-u', './oom.py', '--local_rank=1', '--mode=oom']' returned non-zero exit status 1.
```
All processes exited and the trace was printed
### 3. Exit on SIGINT/SIGTERM
If I started a process and then realized I made a mistake I want to be able to kill it cleanly and if any sub-processes have already been spawned I want them to be killed too. Here the sighandler takes care of trapping the SIGTERM/SIGINT.
```
python -m torch.distributed.launch --nproc_per_node=2 ./oom.py
```
Here the processes emulate a long normal run.
So let's Ctrl-C the process as soon as it started and see:
```
POLLING FOR 18749
POLLING FOR 18750
0
0 is starting
1
1 is starting
POLLING FOR 18749
POLLING FOR 18750
POLLING FOR 18750
POLLING FOR 18749
POLLING FOR 18749
POLLING FOR 18750
0 is running
1 is running
POLLING FOR 18750
POLLING FOR 18749
0 is running
1 is running
^CTraceback (most recent call last):
Killing subprocess 18749
Traceback (most recent call last):
File "./oom.py", line 33, in <module>
File "./oom.py", line 33, in <module>
Killing subprocess 18750
Parent got kill signal=SIGINT, exiting
```
all processes got killed
--------------------------------
So this covered the 2 problematic cases and 1 normal case
Notes:
- we could probably switch to `sleep(3)` - `1` is probably too fast
- all the debug prints will be removed once you are happy - I left them so that it's easier for you to test that my PR does the right thing.
Thank you!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49305
Reviewed By: izdeby
Differential Revision: D25565617
Pulled By: rohan-varma
fbshipit-source-id: 1ea864113f283d4daac5eef1131c8d745aae4c99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49557
Updating the PyTorch docs to reflect that FileStore now supported the
num_keys API. Also included a note to describe the behavior of the API.
Test Plan: build and rendered docs.
Reviewed By: jiayisuse
Differential Revision: D25619000
fbshipit-source-id: 6c660d7ceb32d1d61024df8394aff3fcd0b752c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49556
Implemented the missing Store functionality (specifically numKeys) in the FileStore.
Test Plan: Added both C++ and Python tests to verify functionality.
Reviewed By: jiayisuse
Differential Revision: D25619001
fbshipit-source-id: 9146d0da9e0903622be3035880f619bbb2cc3891
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49428
Previously dequantstub will be swapped with nn.quantized.DeQuantize regardless of qconfig
reason is we skipped attaching qconfig for DeQuantStub to avoid adding fake quantize module to it
but the correct fix is to skip it in insert observers, this PR fixes the issue.
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D25569991
fbshipit-source-id: d44a08c6e64c7a49509687dc389b57de1cbb878c
Summary:
This is a fast log implementations
benchmark:
```
buck run mode/opt //caffe2/benchmarks/cpp/tensorexpr:tensorexpr_bench -c 'fbcode.caffe2_gpu_type=none'
```
Test Plan: buck test mode/no-gpu //caffe2/test/cpp/tensorexpr:tensorexpr -- *.fastLogFloat
Reviewed By: bertmaher
Differential Revision: D25445815
fbshipit-source-id: 20696eacd12a55e797f606f4a6dbbd94c9652888
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49072
As per the title, we should enable these tests for Gloo when run on GPU and the profiler is enabled with `use_cuda=True`. Enabling ProcessGroupNCCL profiling test to work with `use_cuda=True` is being tracked in https://github.com/pytorch/pytorch/issues/48987.
ghstack-source-id: 118789003
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D25388986
fbshipit-source-id: 664d922ac2e10c77299daebdc6d3c92bb70eb56e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49470https://github.com/pytorch/pytorch/pull/48625 changes the default contiguous settings for `TensorImpl` causing the Vulkan backend to crash. Therefore, add argument that can set `is_non_overlapping_and_dense_` back to false for `OpaqueTensorImpl` constructor.
Test Plan: Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D25592826
Pulled By: SS-JIA
fbshipit-source-id: e5d9de9a733875cb00c0546a3bc3271e5c6e23a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49009
As per the title, we should generally not have exception swalling and
this commit makes it so that if there is a true error in JIT operator
resolution, it is propagated back to the RPC callee and we don't silently
swallow any other exceptions that may happen. Swallowing the exceptions
previously resulted in hard to debug issues such as unexpected ops showing up
in profiler, and flaky tests which were fixed by
https://github.com/pytorch/pytorch/pull/41287
Added a unittest that validates the error that comes from `jit/pybind_utils.h`.
ghstack-source-id: 118794661
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D25392905
fbshipit-source-id: 6f93251635740bcf902824548b2bc6f9249be5f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49402
In cases of NCCLAllReduce operations there could be non-trivial overhead for
launching cooperative kernels (especially in case of async execution of
different parts of the model). This diff is reviving this operator to make it
possible to fuse multiple operations into a single kernel.
Test Plan:
Unit-test.
Used in a later diff.
Reviewed By: xianjiec
Differential Revision: D25531206
fbshipit-source-id: 64b1c161233a726f9e2868f1059316e42a8ea1fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49463
set_quantizer_ takes a ConstQuantizerPtr argument, which is neither supported by JIT nor by c10.
Also, it doesn't get dispatched (CPU and CUDA have the same implementation) and it is excluded from python bindings generation.
So there is no real reason why this needs to be in native_functions.yaml
Removing it unblocks the migration to c10-fullness since this is an op that would have been hard to migrate. See https://fb.quip.com/QRtJAin66lPN
ghstack-source-id: 118710663
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25587763
fbshipit-source-id: 8fab921f4c256c128d48d82dac731f04ec9bad92
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49362
**Summary:**
This PR fixes the issue where invalid annotation types are used for a dictionary.
Unsupported assertion message is generated for all invalid annotations
**Test Case**:
python test/test_jit.py TestJit.test_dict_invalid_annotations
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49425
Reviewed By: navahgar
Differential Revision: D25601578
Pulled By: nikithamalgifb
fbshipit-source-id: 91633e3d0891bdcb5402f044a74d02fe352ecd6f
Summary:
This PR is to change the `aten::native_layer_norm` and `aten::native_layer_norm_backward` signature to match `torch.layer_norm` definition. The current definition doesn't provide enough information to the PyTorch JIT to fuse layer_norm during training.
`native_layer_norm(X, gamma, beta, M, N, eps)` =>
`native_layer_norm(input, normalized_shape, weight, bias, eps)`
`native_layer_norm_backward(dY, X, mean, rstd, gamma, M, N, grad_input_mask)` =>
`native_layer_norm_backward(dY, input, normalized_shape, mean, rstd, weight, bias, grad_input_mask)`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48971
Reviewed By: izdeby
Differential Revision: D25574070
Pulled By: ngimel
fbshipit-source-id: 23e2804295a95bda3f1ca6b41a1e4c5a3d4d31b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49420
Before: if an output was marked as quantized, it could actually not
be quantized, if the previous node was not quantized.
After: if an output was marked as quantized, it will be quantized
regardless of the quantization status of the previous node.
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps.test_quant_output_always_observed
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25566834
fbshipit-source-id: 84755a1605fd3847edd03a7887ab9f635498c05c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49382
Fixes an edge case. If the input to the graph is quantized and the
first node does not need activation observation, makes sure that
the observer is not inserted.
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps.test_int8_input_no_unnecessary_fq
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25551041
fbshipit-source-id: a6cba235c63ca7f6856e4128af7c1dc7fa0085ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49239
Context: the existing implementation of `quantized_input_idxs` is convert-only.
Therefore, observers are inserted between the input and the first
quantized node. This is a problem during QAT, because the initial
input is a fake_quant, and it starts with scale=1 and zp=0. This does
not match the quantization parameters of the graph input, which can
lead to incorrect numerics.
Fix: do not insert observer for a quantized input.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25499486
fbshipit-source-id: 303b49cc9d95a9fd06fef3b0859c08be34e19d8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49238
Moves the `input_quantized_idxs` and `output_quantized_idxs` options
from the convert config to the prepare config. This is done because
these operations are related to placing observers, which is numerics
changing during QAT.
The next PR will adjust the behavior of `input_quantized_idxs` in
prepare in QAT to prevent placing a fake_quant at the input if the
input is marked quantized. Placing a fake_quant there can lead to
numerical inaccuracies during calibration, as it would start with
scale=1 and zp=0, which may be different from the quantization
parameters of the incoming quantized input.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25498762
fbshipit-source-id: 17ace8f803542155652b310e5539e1882ebaadc6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49213
Changes behavior of Eager mode quantization to remove observation after add_scalar/mul_scalar.
This is not used, and it removes one difference between Eager and FX modes.
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps.test_quantized_add_qat
python test/test_quantization.py TestQuantizeFxOps.test_quantized_mul_qat
python test/test_quantization.py TestQuantizationAwareTraining.test_add_scalar_uses_input_qparams
python test/test_quantization.py TestQuantizationAwareTraining.test_mul_scalar_uses_input_qparams
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25486276
fbshipit-source-id: 34a5d6ce0d08739319ec0f8b197cfc1309d71040
Summary:
tldr: current version of `is_ninja_available` of `torch/utils/cpp_extension.py` fails to run in the recent incarnations of pip w/ new build isolation feature which is now a default. This PR fixes this problem.
The full story follows:
--------------------------
Currently trying to build https://github.com/facebookresearch/fairscale/ which builds cuda extensions fails with the recent pip versions. The build is failing to perform `is_ninja_available`, which runs a simple subprocess to run `ninja --version` but does it with some /dev/null stream override which seems to break with the new pip versions. Currently I have `pip==20.3.3`. The recent pip performs build isolation which first fetches all dependencies to somewhere under /tmp/pip-install-xyz and then builds the package.
If I build:
```
pip install fairscale --no-build-isolation
```
everything works.
When building normally (i.e. without `--no-build-isolation`), the failure is a long long trace,
<details>
<summary>Full log</summary>
<pre>
pip install fairscale
Collecting fairscale
Downloading fairscale-0.1.1.tar.gz (83 kB)
|████████████████████████████████| 83 kB 562 kB/s
Installing build dependencies ... done
Getting requirements to build wheel ... error
ERROR: Command errored out with exit status 1:
command: /home/stas/anaconda3/envs/main-38/bin/python /home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pip/_vendor/pep517/_in_process.py get_requires_for_build_wheel /tmp/tmpjvw00c7v
cwd: /tmp/pip-install-1wq9f8fp/fairscale_347f218384a64f24b8d5ce846641213e
Complete output (55 lines):
running egg_info
writing fairscale.egg-info/PKG-INFO
writing dependency_links to fairscale.egg-info/dependency_links.txt
writing requirements to fairscale.egg-info/requires.txt
writing top-level names to fairscale.egg-info/top_level.txt
Traceback (most recent call last):
File "/home/stas/anaconda3/envs/main-38/bin/ninja", line 5, in <module>
from ninja import ninja
ModuleNotFoundError: No module named 'ninja'
Traceback (most recent call last):
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pip/_vendor/pep517/_in_process.py", line 280, in <module>
main()
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pip/_vendor/pep517/_in_process.py", line 263, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pip/_vendor/pep517/_in_process.py", line 114, in get_requires_for_build_wheel
return hook(config_settings)
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/setuptools/build_meta.py", line 149, in get_requires_for_build_wheel
return self._get_build_requires(
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/setuptools/build_meta.py", line 130, in _get_build_requires
self.run_setup()
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/setuptools/build_meta.py", line 145, in run_setup
exec(compile(code, __file__, 'exec'), locals())
File "setup.py", line 56, in <module>
setuptools.setup(
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/setuptools/__init__.py", line 153, in setup
return distutils.core.setup(**attrs)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/distutils/core.py", line 148, in setup
dist.run_commands()
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/setuptools/command/egg_info.py", line 298, in run
self.find_sources()
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/setuptools/command/egg_info.py", line 305, in find_sources
mm.run()
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/setuptools/command/egg_info.py", line 536, in run
self.add_defaults()
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/setuptools/command/egg_info.py", line 572, in add_defaults
sdist.add_defaults(self)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/distutils/command/sdist.py", line 228, in add_defaults
self._add_defaults_ext()
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/distutils/command/sdist.py", line 311, in _add_defaults_ext
build_ext = self.get_finalized_command('build_ext')
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/distutils/cmd.py", line 298, in get_finalized_command
cmd_obj = self.distribution.get_command_obj(command, create)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/distutils/dist.py", line 858, in get_command_obj
cmd_obj = self.command_obj[command] = klass(self)
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 351, in __init__
if not is_ninja_available():
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 1310, in is_ninja_available
subprocess.check_call('ninja --version'.split(), stdout=devnull)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/subprocess.py", line 364, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['ninja', '--version']' returned non-zero exit status 1.
----------------------------------------
ERROR: Command errored out with exit status 1: /home/stas/anaconda3/envs/main-38/bin/python /home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/pip/_vendor/pep517/_in_process.py get_requires_for_build_wheel /tmp/tmpjvw00c7v Check the logs for full command output.
</pre>
</details>
and the middle of it is what we want:
```
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 351, in __init__
if not is_ninja_available():
File "/tmp/pip-build-env-a5x2icen/overlay/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 1310, in is_ninja_available
subprocess.check_call('ninja --version'.split(), stdout=devnull)
File "/home/stas/anaconda3/envs/main-38/lib/python3.8/subprocess.py", line 364, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['ninja', '--version']' returned non-zero exit status 1.
```
For some reason pytorch fails to run this simple code:
```
# torch/utils/cpp_extension.py
def is_ninja_available():
r'''
Returns ``True`` if the `ninja <https://ninja-build.org/>`_ build system is
available on the system, ``False`` otherwise.
'''
with open(os.devnull, 'wb') as devnull:
try:
subprocess.check_call('ninja --version'.split(), stdout=devnull)
except OSError:
return False
else:
return True
```
I suspect that pip does something to `os.devnull` and that's why it fails.
This PR proposes a simpler code which doesn't rely on anything but `subprocess.check_output`:
```
def is_ninja_available():
r'''
Returns ``True`` if the `ninja <https://ninja-build.org/>`_ build system is
available on the system, ``False`` otherwise.
'''
try:
subprocess.check_output('ninja --version'.split())
except Exception:
return False
else:
return True
```
which doesn't use `os.devnull` and performs the same function. There could be a whole bunch of different exceptions there I think, so I went for the generic one - we don't care why it failed, since this function's only purpose is to suggest whether ninja can be used or not.
Let's check
```
python -c "import torch.utils.cpp_extension; print(torch.utils.cpp_extension.is_ninja_available())"
True
```
Look ma - no std noise to take care of. (i.e. no need for /dev/null).
I was editing the installed environment-wide `cpp_extension.py` file directly, so didn't need to tweak `PYTHONPATH` - I made sure to replace `'ninja --version'.` with something that should fail and I did get `False` for the above command line.
I next did a somewhat elaborate cheat to re-package an already existing binary wheel with this corrected version of `cpp_extension.py`, rather than building from source:
```
mkdir /tmp/pytorch-local-channel
cd /tmp/pytorch-local-channel
# get the latest nightly wheel
wget https://download.pytorch.org/whl/nightly/cu110/torch-1.8.0.dev20201215%2Bcu110-cp38-cp38-linux_x86_64.whl
# unpack it
unzip torch-1.8.0.dev20201215+cu110-cp38-cp38-linux_x86_64.whl
# edit torch/utils/cpp_extension.py to fix the python code with the new version as in this PR
emacs torch/utils/cpp_extension.py &
# pack the files back
zip -r torch-1.8.0.dev20201215+cu110-cp38-cp38-linux_x86_64.whl caffe2 torch torch-1.8.0.dev20201215+cu110.dist-info
```
Now I tell pip to use my local channel, plus `--pre` for it to pick up the pre-release as an acceptable wheel
```
# install using this local channel
git clone https://github.com/facebookresearch/fairscale/
cd fairscale
pip install -v --disable-pip-version-check -e . -f file:///tmp/pytorch-local-channel --pre
```
and voila all works.
```
[...]
Successfully installed fairscale
```
I noticed a whole bunch of ninja not found errors in the log, which I think is the same problem with other parts of the build system packages which also use this old check copied all over various projects and build tools, and which the recent pip breaks.
```
writing manifest file '/tmp/pip-modern-metadata-_nsdesbq/fairscale.egg-info/SOURCES.txt'
Traceback (most recent call last):
File "/home/stas/anaconda3/envs/main-38/bin/ninja", line 5, in <module>
from ninja import ninja
ModuleNotFoundError: No module named 'ninja'
[...]
/tmp/pip-build-env-fqflyevr/overlay/lib/python3.8/site-packages/torch/utils/cpp_extension.py:364: UserWarning: Attempted to use ninja as the BuildExtension backend but we could not find ninja.. Falling back to using the slow distutils backend.
warnings.warn(msg.format('we could not find ninja.'))
```
but these don't prevent from the build completing and installing.
I suppose these need to be identified and reported to various other projects, but that's another story.
The new pip does something to `os.devnull` I think which breaks any code relying on it - I haven't tried to figure out what happens to that stream object, but this PR which removes its usage solves the problem.
Also do notice that:
```
git clone https://github.com/facebookresearch/fairscale/
cd fairscale
python setup.py bdist_wheel
pip install dist/fairscale-0.1.1-cp38-cp38-linux_x86_64.whl
```
works too. So it is really a pip issue.
Apologies if the notes are too many, I tried to give the complete picture and probably other projects will need those details as well.
Thank you for reading.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49443
Reviewed By: mruberry
Differential Revision: D25592109
Pulled By: ezyang
fbshipit-source-id: bfce4420c28b614ead48e9686f4153c6e0fbe8b7
Summary:
I am submitting this PR on behalf of Janne Hellsten(nurpax) from NVIDIA, for the convenience of CLA. Thanks Janne a lot for the contribution!
Currently, the ninja build decides whether to rebuild a .cu file or not pretty randomly. And there are actually two issues:
First, the arch list in the building command is ordered randomly. When the order changes, it will unconditionally rebuild regardless of the timestamp.
Second, the header files are not included in the dependency list, so if the header file changes, it is possible that ninja will not rebuild.
This PR fixes both issues. The fix for the second issue requires nvcc >= 10.2. nvcc < 10.2 can still build CUDA extension as it used to be, but it will be unable to see the changes in header files.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49344
Reviewed By: glaringlee
Differential Revision: D25540157
Pulled By: ezyang
fbshipit-source-id: 197541690d7f25e3ac5ebe3188beb1f131a4c51f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/48114
Before:
```
>>> torch.empty(2 * 10 ** 20)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: empty(): argument 'size' must be tuple of ints, but found element of type int at pos 1
```
After fix:
```
>>> torch.empty(2 * 10 ** 20)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: Overflow when unpacking long
```
Unclear whether we need a separate test for this case, I can add one if it's necessary...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48250
Reviewed By: linbinyu
Differential Revision: D25105217
Pulled By: ezyang
fbshipit-source-id: a5aa7c0266945c8125210a2fd34ce4b6ba940c92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49510
Adding old style operators with out arguments will break XLA. This prevents that. See for background: https://fb.workplace.com/groups/pytorch.dev/permalink/809934446251704/
This is a temporary change that will prevent this breakage for the next couple of days until the problem is resolved for good.
It will be deleted in https://github.com/pytorch/pytorch/pull/49164 then.
ghstack-source-id: 118756437
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D25599112
fbshipit-source-id: 6b0ca4da4b55da8aab9d1b332cd9f68e7602301e
Summary:
In https://github.com/pytorch/pytorch/pull/48967/ we enabled output buffer inlining, which results in duplicate computation if one output depends on another. This was done to fix correctness for CUDA, but is not needed for correctness for CPU and results in perf slowdown.
The output buffer inlining solution for CUDA is intended to be an interim solution because it does not work with reductions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49488
Reviewed By: ezyang
Differential Revision: D25596071
Pulled By: eellison
fbshipit-source-id: bc3d987645da5ce3c603b4abac3586b169656cfd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49122
cpparguments_exprs has induced a lot of head scratching in many recent PRs for how to structure the code in a good way. This PR eliminates the old algorithm for an entirely new algorithm inspired by logic programming. The net result is shorter, cleaner and should be more robust to future changes.
This PR is a bit of a whopper. Here is the order to review it.
- tools/codegen/api/types.py
- Deleted CppArgument, CppArgumentPackIface (and subclasses), CppExpr, DispatcherExpr, DispatcherArgument, NativeExpr, NativeArgument, MetaArgument. All things previously called XArgument are now Binding. All things previously called XExpr are now Expr. I deleted the `__str__` implementation on Binding and fixed all call sites not to use it. On Binding, I renamed `str_no_default` and `str_default` to `defn` and `decl` for better symmetry with the corresponding signature concepts, although I'm open to naming them back to their original versions.
- Obviously, things are less type safe without the class distinctions. So I introduce a new ADT called CType. CType represents the *semantic C++ type* of a binding: it is both the C++ type (e.g., `const Tensor&`) as well as the argument name that specifies what the binding denotes (e.g., `other`). Every binding now records its CType. The key observation here is that you don't actually care if a given expression is from the cpp or dispatcher or native API; what you care is having enough information to know what the expression means, so you can use it appropriately. CType has this information. For the most part, ArgNames are just the string names of the arguments as you see them in JIT schema, but there is one case (`possibly_redundant_memory_format`) where we encode a little extra information. Unlike the plain strings we previously used to represent C++ types, CType have a little bit of structure around optional and references, because the translation code needs to work around these concepts.
- I took the opportunity to kill all of the private fields like `_arguments` and `_returns_type` (since the argument types don't make sense anymore). Everything is computed for you on the fly. If this is a perf problem in codegen we can start using `cached_property` decorator.
- All of the heavy lifting in CppSignature.argument_packs has been moved to the cpp module. We'll head over there next. Similarly, all of the exprs methods are now calling translate, the new functionality which we haven't gotten to yet
- tools/codegen/api/cpp.py
- We refactor all of the type computation functions to return CType instead of str. Because CTypes need to know the denotation, there is a new `binds: ArgName` argument to most functions that provides the denotation, so we can slot it in. (An alternative would have been to construct CTypes without denotations and then fill them in post-facto, but I didn't do it this way. One downside is there are some places where I need a CType without denotation, so I fill these in with `__placeholder__` whenever this happens).
- `argument` and `arguments` are now extremely simple. There is no more Pack business, just produce one or more Bindings. The one thing of note is that when both a `memory_format` and `options` are in scope, we label the memory format as `possibly_redundant_memory_format`. This will be used in translation
- tools/codegen/api/dispatcher.py and tools/codegen/api/native.py - same deal as cpp.py. One thing is that `cpparguments_exprs` is deleted; that is in the translator
- tools/codegen/api/translate.py - the translator! It uses a very simple backwards deduction engine to work out how to fill in the arguments of functions. There are comments in the file that explain how it works.
- Everything else: just some small call site tweaks for places when I changed API.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D25455887
Pulled By: ezyang
fbshipit-source-id: 90dc58d420d4cc49281aa8647987c69f3ed42fa6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49412
FLAGS_disable_variable_dispatch had to go, but it looks like the only user was some benchmarks anyway.
ghstack-source-id: 118669590
Test Plan:
Small (order of 0.1% improvement) on Internal benchmarks. Wait for
GitHub CI since this was reverted before due to CI break
Reviewed By: ezyang
Differential Revision: D25547962
fbshipit-source-id: 58424b1da230fdc5d27349af762126a5512fce43
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49371
As with previous diff, .sizes() is strictly more efficient.
ghstack-source-id: 118627223
Test Plan: internal benchmark
Differential Revision: D25546409
fbshipit-source-id: 196034716b6e11efda1ec8cb1e0fce7732d73eb4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49368
The former is faster because it doesn't allow negative indexing (which we don't use).
ghstack-source-id: 118624598
Test Plan: internal benchmark
Reviewed By: hlu1
Differential Revision: D25545777
fbshipit-source-id: b2714fac95c801fd735fac25b238b4a79b012993
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49364
We had a local `Tensor` when we only needed a `const Tensor&`.
ghstack-source-id: 118624595
Test Plan: Internal benchmark.
Reviewed By: hlu1
Differential Revision: D25544731
fbshipit-source-id: 7b9656d0371ab65a6313cb0ad4aa1df707884c1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49359
This should be both slightly more efficient (1 less TLS guard
check in at::shouldRunRecordFunction) and definitely more correct
(CoinflipTLS is now saved whenever RecordFunctionTLS is saved), fixing
a bad merge that left RecordFunctionTLS::tries_left dead.
ghstack-source-id: 118624402
Test Plan: Review, CI
Reviewed By: hlu1
Differential Revision: D25542799
fbshipit-source-id: 310f9fd157101f659cea13c331b2a0ee6db2db88
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48863
Support default arguments when invoking a module via PyTorch Lite (`mobile::Module`).
Test Plan:
buck test mode/dbg //caffe2/test/cpp/jit:jit -- LiteInterpreterTest.MethodInvocation
buck test mode/dbg caffe2/test:mobile -- test_method_calls_with_optional_arg
Reviewed By: raziel, iseeyuan
Differential Revision: D25152559
fbshipit-source-id: bbf52f1fbdbfbc6f8fa8b65ab524b1cd4648f9c0
Summary:
One of the links for ramp up tasks wasn't showing any results and the other was only RPC results. Instead of this, I just changed it to one link that has `pt_distributed_rampup` which seems reasonable as the developer will be able to see both RPC and distributed tasks.
Also added test command for DDP tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49141
Reviewed By: ezyang
Differential Revision: D25597560
Pulled By: rohan-varma
fbshipit-source-id: 85d7d2964a19ea69fe149c017cf88dff835b164a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49146
Add support for Storage arguments to IValue and the JIT typing system, and make ops that were blocked on that c10-full.
ghstack-source-id: 118710665
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25456799
fbshipit-source-id: da14f125af352de5fcf05a83a69ad5a69d5a3b45
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49467
Credit to beauby for the Bazel fixes.
Test Plan: Export and run on CI
Reviewed By: beauby
Differential Revision: D25588027
fbshipit-source-id: efe1c543eb7438ca05254de67cf8b5cee625119a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49119
I don't know how the accumulate_grad code gets hit via calling
autograd.grad, so I went through all places in accumulate_grad
that are definitely impossible to vmap through and changed them.
To support this:
- I added vmap support for Tensor::strides(). It returns the strides
that correspond to the public dimensions of the tensor (not the ones
being vmapped over).
- Changed an instance of empty_strided to new_empty_strided.
- Replaced an in-place operation in accumulate_grad.h
Test Plan:
- added a test for calling strides() inside of vmap
- added tests that exercise all of the accumulate_grad code path.
NB: I don't know why these tests exercise the code paths, but I've
verified that they do via gdb.
Suggestions for some saner test cases are very welcome.
Reviewed By: izdeby
Differential Revision: D25563543
Pulled By: zou3519
fbshipit-source-id: 05ac6c549ebd447416e6a07c263a16c90b2ef510
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49118
I need this in the next stack up. It seems useful to have as a helper
function.
Test Plan: - run tests
Reviewed By: izdeby
Differential Revision: D25563546
Pulled By: zou3519
fbshipit-source-id: a4031fdc4b2373cc230ba3c66738d91dcade96e2
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46213
I didn't yet update the documentation, will add those change soon. A few other things that I didn't do, but want to clarify if I maybe should.
1. I didn't expose projections in c++ API: torch/csrc/api/src/nn/modules/rnn.cpp. Let me know if this is desirable and I will add those changes.
2. I didn't expose projections in "lstm_cell" function and "_thnn_differentiable_lstm_cell_backward" functions from aten/src/ATen/native/RNN.cpp. As far as I understand, they are not needed for nn.LSTM CPU execution. For lstm_cell, projections don't bring any real benefit, since if cell is used separately, it can be easily added in Python. For "_thnn_differentiable_lstm_cell_backward", I'm actually not sure where exactly that function is used, so I also disabled projections there for now. Please let me know if I should change that.
3. I added check that projections are not supported for quantized LSTMs to quantized_lstm_<data/input> functions. But I didn't add any checks to LSTMCell code. It seems that since I disabled projections in "lstm_cell" function, they should also not be available for quantized models through any other API than quantized_lstm_<data/input>. Please let me know if I'm not correct and I will add checks to other places.
4. Projections are not supported for CuDNN versions < 7.1.2. Should I add the check for CuDNN version and disable projections in that case? If so, what will be the best way to do that?
5. Currently I added projection weight as the last weight, so the layout is "w_ih, w_hh, b_ih, b_hh, w_hr". This breaks the assumption that biases come after weights and thus I had to add additional if-s in various places. Alternative way would be to have "w_ih, w_hh, w_hr, b_ih, b_hh" layout, in which case the assumption will be true. But in that case I will need to split the loop in get_parameters function from aten/src/ATen/native/cudnn/RNN.cpp. And in some cases, I will still need to add an "undefined" tensor in the 3rd position, because we get all 5 weights from CuDNN most of the time. So I'm not sure which way is better. Let me know if you think I should change to the weights-then-biases layout.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47725
Reviewed By: zou3519
Differential Revision: D25449794
Pulled By: ngimel
fbshipit-source-id: fe6ce59e481d1f5fd861a8ff7fa13d1affcedb0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49167
Building with clang and a fair warning level can result in hundreds of lines of compiler output of the form:
```
caffe2\gen_aten_libtorch\autograd\generated\VariableType_1.cpp(2279,8): warning: unused variable '_any_requires_grad' [-Wunused-variable]
auto _any_requires_grad = compute_requires_grad( self );
^
caffe2\gen_aten_libtorch\autograd\generated\VariableType_1.cpp(2461,8): warning: unused variable '_any_requires_grad' [-Wunused-variable]
auto _any_requires_grad = compute_requires_grad( grad_output, self );
^
caffe2\gen_aten_libtorch\autograd\generated\VariableType_1.cpp(2677,8): warning: unused variable '_any_requires_grad' [-Wunused-variable]
auto _any_requires_grad = compute_requires_grad( self );
^
...
```
This happens when requires_derivative == False. Let's mark `_any_requires_grad` as potentially unused. If this were C++17 we would use `[[maybe_unused]]` but to retain compatibility with C++11 we just mark it with `(void)`.
Test Plan: CI + locally built
Reviewed By: ezyang
Differential Revision: D25421548
fbshipit-source-id: c56279a184b1c616e8717a19ee8fad60f36f37d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49189
This reverts commit d307601365c3b848072b8b8381208aedc1a0aca5 and fixes the bug with diagonals and ellipsis combined.
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D25540722
Pulled By: heitorschueroff
fbshipit-source-id: 86d0c9a7dcfda600b546457dad102af2ff33e353
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49130
The Python Store API docs had some typos, where boolean value were
lower case, which is incorrect Python syntax. This diff fixes those typos.
Test Plan: Built and Rendered Docs
Reviewed By: mrshenli
Differential Revision: D25411492
fbshipit-source-id: fdbf1e6b8f81e9589e638286946cad68eb7c9252
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49131
Users frequently assume the correct range of ranks is 1 ...
`world_size`. This PR udpates the docs to indicate that the correct rank range
users should specify is 0 ... `world_size` - 1.
Test Plan: Rendering and Building Docs
Reviewed By: mrshenli
Differential Revision: D25410532
fbshipit-source-id: fe0f17a4369b533dc98543204a38b8558e68497a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49442
When moving Aten/native to app level, symbols from native/quantized may sit in a target away from some of its call sites. As a result, there are linking errors of missing symbols of instantiations of PackedConvWeight::prepack. The solution is to instantiate PackedConvWeight in the same compilation unit. It's similar to D24941989 (fe6bb2d287).
ghstack-source-id: 118676374
Test Plan: CI
Reviewed By: dhruvbird
Differential Revision: D25576703
fbshipit-source-id: d6e3d11d51d8172ab8487ce44ec8c042889f0f11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48944
This is a stack PR for webdataset prototype. I am trying to make each stack a separate dataset.
To make the implementation simple, each dataset will only support the basic functionality.
- [x] ListDirFilesDataset
- [x] LoadFilesFromDiskIterableDataset
- [x] ReadFilesFromTarIterableDataset
- [x] ReadFilesFromZipIterableDataset
- [x] RoutedDecoderIterableDataset
Test Plan: Imported from OSS
Reviewed By: izdeby
Differential Revision: D25541277
Pulled By: glaringlee
fbshipit-source-id: 9e738f6973493f6be1d5cc1feb7a91513fa5807c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49355
List's move ctor is a little bit more expensive than you might expect, but we can easily avoid it.
ghstack-source-id: 118624596
Test Plan: Roughly 1% improvement on internal benchmark.
Reviewed By: hlu1
Differential Revision: D25542190
fbshipit-source-id: 08532642c7d1f1604e16c8ebefd1ed3e56f7c919
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49088
We had special case logic to support `int[]?` and `double[]?` but nothing for `DimnameList[]?`.
This PR generalizes the logic to support optional lists so it should now work with all types.
It also enables c10-fullness for ops that were blocked by this.
Note that using these arguments in a signature was always and still is expensive because the whole list needs to be copied.
We should probably consider alternatives in the future like for example using `torch::List` instead of `ArrayRef`, that could work without copying the list.
ghstack-source-id: 118660071
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25423901
fbshipit-source-id: dec58dc29f3bb4cbd89e2b95c42da204a9da2e0a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49083
We have some (but very few) ops that take optional out arguments `Tensor(a!)? out`.
This PR makes them non-optional mandatory arguments and enables c10-fullness for them.
There is only a very small number of ops affected by this.
Putting this up for discussion.
Alternatives considered:
If we keep them optional, we run into lots of issues in the dispatcher. We have to decide what the dispatcher calling convention for this argument type should be.
1) If we keep passing them in as `Tensor&` arguments and return them as `tuple<Tensor&, Tensor&, Tensor&>`, so basically same as currently, then the schema inference check will say "Your kernel function got inferred to have a `Tensor` argument but your native_functions.yaml declaration says `Tensor?`. This is a mismatch, you made an error". We could potentially disable that check, but that would open the door for real mistakes to not be reported anymore in the future. This sounds bad.
2) If we change them to a type that schema inference could differentiate from `Tensor`, say we pass them in as `const optional<Tensor>&` and return them as `tuple<const optional<Tensor>&, const optional<Tensor>&, const optional<Tensor>&>`, then our boxing logic fails because it can't recognize those as out overloads anymore and shortcut the return value as it is doing right now. We might be able to rewrite the boxing logic, but that could be difficult and could easily develop into a rabbit hole of having to clean up `Tensor&` references throughout the system where we use them.
Furthermore, having optional out arguments in C++ doesn't really make sense. the C++ API puts them to the front of the argument list, so you can't omit them anyways when calling an op.
You would be able to omit them when calling from Python with out kwargs, but not sure if we want that discrepancy between the c++ and python API.
ghstack-source-id: 118660075
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25422197
fbshipit-source-id: 3cb25c5a3d93f9eb960d70ca014bae485be9f058
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49449
Similar to permute_out, add the out variant of `aten::narrow` (slice in c2) which does an actual copy. `aten::narrow` creates a view, however, an copy is incurred when we call `input.contiguous` in the ops that follow `aten::narrow`, in `concat_add_mul_replacenan_clip`, `casted_batch_one_hot_lengths`, and `batch_box_cox`.
{F351263599}
Test Plan:
Unit test:
```
buck test //caffe2/aten:native_test
```
Benchmark with the adindexer model:
```
bs = 1 is neutral
Before:
I1214 21:32:51.919239 3285258 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.0886948. Iters per second: 11274.6
After:
I1214 21:32:52.492352 3285277 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.0888019. Iters per second: 11261
bs = 20 shows more gains probably because the tensors are bigger and therefore the cost of copying is higher
Before:
I1214 21:20:19.702445 3227229 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.527563. Iters per second: 1895.51
After:
I1214 21:20:20.370173 3227307 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.508734. Iters per second: 1965.67
```
Reviewed By: bwasti
Differential Revision: D25554109
fbshipit-source-id: 6bae62e6ce3456ff71559b635cc012fdcd1fdd0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49373
Unescaping the string in RPC error message to provide better error msg
Test Plan: CI
Reviewed By: xush6528
Differential Revision: D25511730
fbshipit-source-id: 054f46d5ffbcb1350012362a023fafb1fe57fca1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49346
This is less ambitious redo of
https://github.com/pytorch/pytorch/pull/49129/.
We make the
```
xq_slice = xq[:, [0], :, :]
```
indexing syntax work if `xq` is a quantized Tensor. For now, we are
making the code not crash, with an in efficient `dq -> index -> q`
implementation. A future PR can optimize performance by removing
the unnecessary memory copies (which will require some non-trivial
changes to TensorIterator).
Test Plan:
```
python test/test_quantization.py TestQuantizedOps.test_advanced_indexing
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25539365
fbshipit-source-id: 98485875aaaf5743e1a940e170258057691be4fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49447
Adding an out variant for `permute`. It's better than fixing the copy inside contiguous because 1) we can leverage the c2 math library, 2) contiguous creates a tensor inside the function which isn't managed by the MemoryPlanner in StaticRuntime
Test Plan:
Benchmark:
```
After:
I1214 12:35:32.218775 991920 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.0902339. Iters per second: 11082.3
Before:
I1214 12:35:43.368770 992620 PyTorchPredictorBenchLib.cpp:209] PyTorch run finished. Milliseconds per iter: 0.0961521. Iters per second: 10400.2
```
Reviewed By: yinghai
Differential Revision: D25541666
fbshipit-source-id: 013ed0d4080cd01de4d3e1b031ab51e5032e6651
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47462, but not completely.
Update breathe to the latest version to get fixes for the "Unable to resolve..." issues. There are still some build errors, but much fewer than before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49407
Reviewed By: izdeby
Differential Revision: D25562163
Pulled By: glaringlee
fbshipit-source-id: 91bfd9e9ac70723816309f489022d72853f5fdc5
Summary:
Since NCCL is an optional CUDA dependency, remove nccl.cpp from the core filelist
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49429
Reviewed By: nikithamalgifb
Differential Revision: D25569883
Pulled By: malfet
fbshipit-source-id: 61371a4c6b0438e4e0a7f094975b9a9f9ffa4032
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49408
Nearly every non-test callsite doesn't need to capture any variables anyway, and this saves 48 bytes per callback.
ghstack-source-id: 118665808
Test Plan:
Wait for GitHub CI since we had C++14-specific issues with
this one in previous PR https://github.com/pytorch/pytorch/pull/48629
Reviewed By: malfet
Differential Revision: D25563207
fbshipit-source-id: 6a2831205917d465f8248ca37429ba2428d5626d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49322
In some cases async execution might loose dependencies (Alias like ops) or produce suboptimal scheduling when there is an option which parts to schedule first. Example of the later behavior can happen in ModelParallel training where copy can get lower priority compared to the rest of the execution on the given GPU, which will caused other GPUs to starve.
This operator allows to address these issues by introducing extra explicit dependencies between ops.
Test Plan:
Unit-test/
E2E testing in the future diffs.
Reviewed By: xianjiec
Differential Revision: D24933471
fbshipit-source-id: 1668994c7856d73926cde022378a99e1e8db3567
Summary:
Adding a flag torch_jit_disable_warning_prints to optimize interpreter performance by suppressing (potentially large amount) of warnings.warn.
This is to work around TorchScript's warning behavior mismatch with Python. Python by default triggers a warning once per location but TorchScript doesn't support it. This causes same warning to trigger and print once per inference run, hurting performance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49313
Reviewed By: SplitInfinity
Differential Revision: D25534274
Pulled By: gmagogsfm
fbshipit-source-id: eaeb57a335c3e6c7eb259671645db05d781e80a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49424
As per conversation in this [comment](https://www.internalfb.com/intern/diff/D25541113 (e2510a0b60)/?dest_fbid=393026838623691&transaction_id=3818008671564312) on D25541113 (e2510a0b60), although THError does more than just log any errors associated cuda kernel launches, we're going to go ahead and replace it with C10_CUDA_KERNEL_LAUNCH_CHECK, so as to be consistent throughout the code base.
Standardization FTW.
This commit is purposefully sent in as a single file change so it can be easily reverted if it introduces a regression.
Test Plan:
Checked that the code still builds with
```
buck build //caffe2/aten:ATen-cu
```
Also ran basic aten tests
```
buck test //caffe2/aten:atest
```
Reviewed By: r-barnes
Differential Revision: D25567863
fbshipit-source-id: 1093bfe2b6ca6b9a3bfb79dcdc5d713f6025eb77
Summary:
BC-breaking note:
This PR changes the behavior of the any and all functions to always return a bool tensor. Previously these functions were only defined on bool and uint8 tensors, and when called on uint8 tensors they would also return a uint8 tensor. (When called on a bool tensor they would return a bool tensor.)
PR summary:
https://github.com/pytorch/pytorch/pull/44790#issuecomment-725596687
Fixes 2 and 3
Also Fixes https://github.com/pytorch/pytorch/issues/48352
Changes
* Output dtype is always `bool` (consistent with numpy) **BC Breaking (Previously used to match the input dtype**)
* Uses vectorized version for all dtypes on CPU
* Enables test for complex
* Update doc for `torch.all` and `torch.any`
TODO
* [x] Update docs
* [x] Benchmark
* [x] Raise issue on XLA
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47878
Reviewed By: H-Huang
Differential Revision: D25421263
Pulled By: mruberry
fbshipit-source-id: c6c681ef94004d2bcc787be61a72aa059b333e69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49340
This refines the fusion group to include on certain types of operations. We cannot safely handle "canRunNatively" types and the memonger pass causes regressions on some internal models, so it was disabled (to be revisited with proper memory optimization once Tensor pools are implemented)
Test Plan:
```
buck test mode/no-gpu caffe2/test:static_runtime
buck test //caffe2/benchmarks/static_runtime:static_runtime_cpptest
```
Reviewed By: ZolotukhinM
Differential Revision: D25520105
fbshipit-source-id: add61d103e4f8b4615f5402e760893ef759a60a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49396
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49271
Two things:
1. These throw exceptions in their constructor, which causes a segfault (*), so
move the exceptions to ::make.
2. They technically support FP types but the rules are complicated so let's not
bother.
(*) The reason for the segfault: all Exprs including these inherit from
KernelScopedObject, whose constructor adds the object to a list for destruction
at the end of the containing KernelArena's lifetime. But if the derived-class
constructor throws, the object is deleted even though it's still in the
KernelArena's list. So when the KernelArena is itself deleted, it double-frees
the pointer and dies. I've also fixed And, Or, and Xor in this diff.
ghstack-source-id: 118594998
Test Plan: `buck test //caffe2/test:jit`
Reviewed By: bwasti
Differential Revision: D25512052
fbshipit-source-id: 42670b3be0cc1600dc5cda6811f7f270a2c88bba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49013
I don't know why this works. I know, this is never a good way to start a PR description :P
I know that Generator is a dispatch relevant argument when called from an unboxed API and is ignored
for dispatch purposes when called from a boxed API. This should break something, but maybe we don't
have test cases for that.
We likely need to align the unboxed and boxed dispatch behavior before landing this.
The best solution would be to make Generator not dispatch relevant in unboxing. But that might be a bigger change.
An acceptable solution could be to make Generator dispatch relevant in boxing, but that needs perf measurements.
This PR needs further discussion.
ghstack-source-id: 118619230
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D25394998
fbshipit-source-id: f695c659ee6e3738f74cdf0af1a514ac0c30ebff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49012
For some reason we apply default arguments to the functions in at::native too. So when an out overload had default arguments,
we couldn't move the out argument to the end because of those default arguments preceding it.
This PR fixes that and makes out overloads with default arguments c10-full
ghstack-source-id: 118619222
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25394605
fbshipit-source-id: 2ed1c3ce0d04a548e3141df2dca517756428fe15
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49007
Some ops had manual registrations, e.g. in VmapModeRegistrations and those manual registrations had to be changed too when making the op c10-full.
This PR makes those ops c10-full and fixes the manual registrations.
ghstack-source-id: 118619231
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25392591
fbshipit-source-id: f4124c0547594879646cb1778357f857ea951132
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49006
There was an issue in the unboxing logic with ops returning multiple out arguments.
This PR fixes that and makes those ops c10 full.
Additionally, it makes some ops c10 full that slipped through the cracks before.
ghstack-source-id: 118619224
(Note: this ignores all push blocking failures!)
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D25392592
fbshipit-source-id: 6947304f34c5658fc12dc6608a21aff7bc4491e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49197
Compiling currently gives a number of these warnings:
```
caffe2/c10/util/TypeCast.h(27): warning: calling a constexpr __host__ function from a __host__ __device__ function is not allowed. The experimental flag '--expt-relaxed-constexpr' can be used to allow this.
detected during:
instantiation of "decltype(auto) c10::maybe_real<true, src_t>::apply(src_t) [with src_t=c10::complex<double>]"
(57): here
instantiation of "uint8_t c10::static_cast_with_inter_type<uint8_t, src_t>::apply(src_t) [with src_t=c10::complex<double>]"
(157): here
instantiation of "To c10::convert<To,From>(From) [with To=uint8_t, From=c10::complex<double>]"
(169): here
instantiation of "To c10::checked_convert<To,From>(From, const char *) [with To=uint8_t, From=c10::complex<double>]"
caffe2/c10/co
```
Here we fix this by adding `C10_HOST_DEVICE` to the offending function.
Test Plan:
Compiling
```
buck build mode/dev-nosan -c=python.package_style=inplace dper3/dper3_models/experimental/pytorch/ads:ads_model_generation_script
```
shows this warning.
We rely on sandcastle for testing here.
Reviewed By: xw285cornell
Differential Revision: D25440771
fbshipit-source-id: 876c412eb06e8837978061cc4793abda42fac821
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49343
at::cuda::CUDAEvent is "lazy" and only creates an event when it's first recorded. Until then, at::cuda::CUDAEvent is empty. If we use at::cuda::CUDAEvent::query() this is taken into account (an empty event is always ready), but WorkNCCL extracts the raw cudaEvent_t value from at::cuda::CUDAEvent and calls cudaEventQuery manually and doesn't check this. This could cause a failure.
It's unclear if this is ever supposed to happen, but we're seeing that failure, and we want to sort it out in order to see if there's something "deeper" going on.
ghstack-source-id: 118532806
Test Plan: Unit tests
Reviewed By: SciPioneer
Differential Revision: D25537844
fbshipit-source-id: 506319f4742e1c0a02aa75ecc01112ea3be42d8f
Summary:
Credit to beauby for the Bazel fixes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49232
Test Plan: Export and run on CI
Reviewed By: beauby
Differential Revision: D25494735
fbshipit-source-id: 3d6f326ca49dcd28d0d19cb561818c3c2904cb55
Summary:
`check_kernel_launches.py` currently gives a false positive in instances such as:
```
735: <<<smallIndexGrid, smallIndexBlock, 0, stream>>>( \
736: outInfo, selfInfo, indicesInfo, \
737: outSelectDim, selfSelectDim, static_cast<TYPE>(sliceSize), \
738: selfSelectDimSize); \
739: C10_CUDA_KERNEL_LAUNCH_CHECK();
```
because the newlines after the last `\` are not consumed by the regex. This fixes that.
In addition, the regex is modified to provide greater context for the start of the kernel launch. This changes the context from:
```
157: (
158: size, X_strides, Y_dims, X, Y);
```
to
```
157: <<<M, CAFFE_CUDA_NUM_THREADS, 0, context->cuda_stream()>>>(
158: size, X_strides, Y_dims, X, Y);
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49365
Test Plan:
```
buck test //caffe2/test:kernel_launch_checks -- --print-passing-details
```
Reviewed By: aakshintala
Differential Revision: D25545402
Pulled By: r-barnes
fbshipit-source-id: 76feac6a002187239853752b892f4517722a77bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49374
After the assertion is added, the NaN error on certain trainings disappears.
It seems that the real error is caused by the underlying illegal memory access. This is a temporary workaround.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 118572471
Test Plan:
Real run on Ads 10X model: scripts/wayi/mast_prof_gradient_compression.sh POWER_SGD 8
To reproduce the error, just comment out the assertion.
Reviewed By: rohan-varma
Differential Revision: D25548299
fbshipit-source-id: 039af7d94a27e0f47ef647c6163fd0e5064951d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48629
Nearly every non-test callsite doesn't need to capture any variables anyway, and this saves 48 bytes per callback.
ghstack-source-id: 118568240
Test Plan: CI
Reviewed By: dhruvbird
Differential Revision: D25135415
fbshipit-source-id: 5e92dc79da6473ed15d1e381a21ed315879168f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48620
In preparation for storing bare function pointer (8 bytes)
instead of std::function (32 bytes).
ghstack-source-id: 118568242
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D25132183
fbshipit-source-id: 3790cfb5d98479a46cf665b14eb0041a872c13da
Summary:
No issue opened for this (that I can see) and it was a fairly small change, so just opening this PR directly!
The docstring for `torch.load` had some of parameter descriptions including typos like ``:meth`readline` `` instead of``:meth:`readline` ``. This PR corrects that :)
<img width="811" alt="image" src="https://user-images.githubusercontent.com/30357972/102128240-7fa33500-3e45-11eb-8f54-ce5ca7bba96c.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49350
Reviewed By: glaringlee
Differential Revision: D25543041
Pulled By: mrshenli
fbshipit-source-id: 10db04d58dd5b07777bdd51d3fcb3c45dea4c84b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49247
uint8's expose all kind of corner cases in type promotion. As an example, consider:
```
>>> torch.tensor([1], dtype=torch.uint8).lt(-1)
tensor([True])
>>> torch.tensor([1], dtype=torch.uint8).lt(torch.tensor(-1))
tensor([True])
>>> torch.tensor([1], dtype=torch.uint8).lt(torch.tensor([-1]))
tensor([False])
```
the difference is how promotions involving scalars (or 0-dim tensors, which are treated like scalars) are prioritized compared to tensor dtypes.
Per eellison, the order is something like:
1. Tensor FP types
2. Scalar FP types
3. Tensor Int types
4. Scalar Int types
The logic for this is here: c73e97033a/aten/src/ATen/native/TypeProperties.cpp (L93)
AFAICT the effects are mainly visible for the unsigned byte type (the only unsigned type, besides bool) since the others degrade more or less gracefully.
It's hard to re-use this logic as is in TensorIterator/TypeProperties, and it's complicated enough that it's not worth re-implementing in TE unless there's evidence that it matters for real models.
ghstack-source-id: 118555597
Test Plan: `buck test //caffe2/test:jit`
Reviewed By: eellison
Differential Revision: D25489035
fbshipit-source-id: db3ab84286d472fd8a247aeb7b36c441293aad85
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49358
Added the header file (`c10/cuda/CUDAException.h`) where the `C10_CUDA_KERNEL_LAUNCH_CHECK` is defined as needed to files under `caffe2/aten/THC`, and then added `C10_CUDA_KERNEL_LAUNCH_CHECK()` calls after each kernel launch. In some cases, removed some extraneous ErrorChecks
Test Plan:
Checked that the code still builds with
```
buck build //caffe2/aten:ATen-cu
```
Also ran basic aten tests
```
buck test //caffe2/aten:atest
```
Reviewed By: r-barnes
Differential Revision: D25541113
fbshipit-source-id: df1a50e14d291a86b24ca1746ac27fa586f9757c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49187
Expands the implementation of PixelShuffle to support any number of batch dimensions
Test Plan: `buck test caffe2/test:nn -- test_pixel_shuffle`
Reviewed By: mruberry
Differential Revision: D25399058
fbshipit-source-id: ab0a7f593b276cafc9ebb46a177e2c1dce56d0de
Summary:
This replaces the narrow character set APIs with the wide character set ones in `THAllocator.cpp`. This fixes the potential crashes caused by passing non-ASCII characters in `torch::from_file` on Windows.
See: https://github.com/pytorch/pytorch/issues/47422
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47905
Reviewed By: zhangguanheng66
Differential Revision: D25399146
Pulled By: ezyang
fbshipit-source-id: 0a183b65de171c48ed1718fa71e773224eaf196f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/44530
As explained in the issue description, CatTransform does not work with event_dim > 0.
This PR fixes this. If this gets approved I am hoping to do the same for StackTransform as well.
fritzo Can you take a look at this ?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49111
Reviewed By: neerajprad
Differential Revision: D25526005
Pulled By: ezyang
fbshipit-source-id: e14430093f550d5e0da7a311f9cd44796807830f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49269
Added C10_CUDA_KERNEL_LAUNCH_CHECK(); after all kernel launches in caffe2/aten/src/ATen/native/cuda.
Several files in the directory still trigger the check_kernel_launches.py tool. These are false positives as the tool doesn't seem to be parsing MACROS correctly.
Normalization.cuh <- This file is also highlighted by the check_kernel_launches.py tool, but the highlighted regions are device code where exception handling isn't allowed.
Test Plan:
Check that the code still builds with
```
buck build //caffe2/aten:ATen-cu
```
https://pxl.cl/1tLRB
Also ran
```
buck test //caffe2/aten:atest
```
https://pxl.cl/1tLSw
Reviewed By: r-barnes
Differential Revision: D25487597
fbshipit-source-id: 7a6689534f7ff85a5d2262831bf6918f1fe0b745
Summary:
In the case people are confused how to make sure ccache is working, I added another sentence in the documentation for how to check that the symlinks are correctly set up in addition to waiting for 2 clean builds of PyTorch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49337
Reviewed By: walterddr
Differential Revision: D25535659
Pulled By: janeyx99
fbshipit-source-id: 435696255f517c074dd0d9f96534d22b60f795b2
Summary:
One unintended side effect of moving type annotations inline was that those annotations now show up in signatures in the html docs. This is more confusing and ugly than it is helpful. An example for `MaxPool1d`:

This makes the docs readable again. The parameter descriptions often already have type information, and there will be many cases where the type annotations will make little sense to the user (e.g., returning typevar T, long unions).
Change to `MaxPool1d` example:

Note that once we can build the docs with Sphinx 3 (which is far off right now), we have two options to make better use of the extra type info in the annotations (some of which is useful):
- `autodoc_type_aliases`, so we can leave things like large unions unevaluated to keep things readable
- `autodoc_typehints = 'description'`, which moves the annotations into the parameter descriptions.
Another, more labour-intensive option, is what vadimkantorov suggested in gh-44964: show annotations on hover. Could also be done with some foldout, or other optional way to make things visible. Would be nice, but requires a Sphinx contribution or plugin first.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49294
Reviewed By: glaringlee
Differential Revision: D25535272
Pulled By: ezyang
fbshipit-source-id: 5017abfea941a7ae8c4595a0d2bdf8ae8965f0c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49264
FLAGS_disable_variable_dispatch had to go, but it looks like the only user was some benchmarks anyway.
ghstack-source-id: 118480532
Test Plan: Small (order of 0.1% improvement) on Internal benchmarks
Reviewed By: smessmer
Differential Revision: D25489030
fbshipit-source-id: 63147bae783e7a45391dd70d86730e48d3e0cafc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48916
optimize adaptive average pool2d forward path
optimize adaptive average pool2d backward path
remove unused headers
minor change
minor change
rename the header; add adaptive max pooling in future.
minor change
loosen adapative_pool2d test on nhwc to both device cuda and cpu
minor change
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D25399469
Pulled By: VitalyFedyunin
fbshipit-source-id: 86f9fda35194f21144bd4667b778c861c05a5bac
Summary:
For `Vec256<bfloat16>::blendv()` operator to work correctly, float32 -nan (0xfffffffff) must be converted to bfloat16 -nan (0xffff).
But cvtfp32_bf16 converts -nan to nan (0x7fc0)
TODO: Fix float32 +-nan conversion: i.e. float32 nan (0x7fffffff) must be converted to bfloat16 (0x7fff) nan
Closes https://github.com/pytorch/pytorch/issues/41238
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41280
Reviewed By: mruberry
Differential Revision: D23311585
Pulled By: malfet
fbshipit-source-id: 79499ce19f1ec3f6c954a874f1cd47f4ece6bdb5
Summary:
- Add the link to the original paper (Attention is All You Need)
- Fix indentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48775
Reviewed By: H-Huang
Differential Revision: D25465914
Pulled By: heitorschueroff
fbshipit-source-id: bbc296ec1523326e323587023c126e820e90ad8d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49263
Now it is smaller and calls to an out-of-line function in
case of failure.
ghstack-source-id: 118480531
Test Plan:
1) Inspect perf profile of internal benchmark, much less
time spent in (for example) `c10::impl::getDeviceImpl`, which calls
TORCH_CHECK and should be inlined
2) Internal benchmarks
Reviewed By: smessmer
Differential Revision: D25481308
fbshipit-source-id: 0121ada779ca2518ca717f75920420957b3bb1aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49262
This uses the newly-added native_cpp_binding feature to avoid
dispatcher overhead for `size()` and `stride()`.
ghstack-source-id: 118480533
Test Plan: CI
Reviewed By: bwasti
Differential Revision: D25446275
fbshipit-source-id: 1215eaa530d5aa3d501f89da8c99d0a487d8c1b6
Summary:
Fixes formatting error that was preventing a bulleted list from being displayed properly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49136
Reviewed By: zou3519
Differential Revision: D25493130
Pulled By: mruberry
fbshipit-source-id: 7fc21e0e2cfa9465a60d2d43b805164316375f01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48443
Add a constant folding pass in FX:
- Iterate over an input graph and tag what nodes are fully constant, i.e. either `get_attr` nodes, or nodes with all inputs that are either `get_attr` or constant
- Use `model_transform.split_by_tags()` to split the graph into two
- Look for the `output` node in the constant graph to get names of attrs that will be folded
- Iterate over the non-constant graph and replace placeholders that are using the same name as the attrs with a `get_attr` as well as a dummy attr on the module
- Return these two graphs in a new `FoldedGraphModule`, which is a normal GraphModule but also stores the constant graph on the side along with a `run_folding()` method that will run const folding and update the dummy parameters with the actual folded parameters
Test Plan: Added a couple tests
Reviewed By: 842974287
Differential Revision: D25033996
fbshipit-source-id: 589c036751ea91bb8155d9be98af7dbc0552ea19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48767
As part of investigating
https://github.com/pytorch/pytorch/issues/48464, I realized some weird
inconsistency in how we use `_default_pg` and `group.WORLD`. `group.WORLD`
apparently was an `object()` and never changed despite `_default_pg` changing.
In this sense, `group.WORLD` was being used a constant to refer to the default
pg, but wasn't of type PG at all. In fact the passed in group is also compared
via `==` to `group.WORLD` in many places, and it just worked since the default
argument was `group.WORLD`.
To clean this up, I got rid of `_default_pg` completely and instead used
`group.WORLD` as the default pg throughout the codebase. This also fixes the
documentation issues mentioned in
https://github.com/pytorch/pytorch/issues/48464.
#Closes: https://github.com/pytorch/pytorch/issues/48464
ghstack-source-id: 118459779
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D25292893
fbshipit-source-id: 9a1703c71610aee2591683ab60b010332e05e412
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48467
The current API's forward method only accepted a Tensor or a Tuple of
Tensors, making this more generic by accepting any Sequence of Tensors.
ghstack-source-id: 118436340
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D25181944
fbshipit-source-id: 4db251dad52c01abc69f3d327788f2e4289e6c9d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49255
- Replace `size(dim)` with `sizes()[dim]` because `sizes()` does not go through the dispatcher and is marginally better.
- Remove unnecessary `size(dim)` and `sizes()` calls by saving the return value of `sizes()` to a temporary var.
Reviewed By: radkris-git
Differential Revision: D25488129
fbshipit-source-id: 4039e0609df20d5888666a71ad93b15e9a2182c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49148
Instead of defining our own variants. I'm pretty sure this fixes a bug too, in that Bfloat16 wasn't being considered FP. Otoh, I don't think it's possible to create TEs with Bfloat so...
ghstack-source-id: 118415314
Test Plan: `buck test //caffe2/test:jit`
Reviewed By: robieta
Differential Revision: D25456767
fbshipit-source-id: bd5822114b76c4fde82f566308909bd2a55f4f21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49147
D25456366 adds Dtype::is_signed (which is backed by c10::isSignedType), so use that instead of this one-off.
ghstack-source-id: 118415315
Test Plan:
```
buck test //caffe2/test{:jit,:tensorexpr,/cpp/tensorexpr:tensorexpr}
```
Reviewed By: robieta
Differential Revision: D25456683
fbshipit-source-id: 428f1e8bff21ea05730690226a44984995c4c138
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49143
Riddle me this, batman: how could `torch.clamp(torch.tensor([0], dtype=torch.uint8), -10, 10)` equal `10`? The answer: the min/max args are first cast to the dtype of the input, giving min=246 and max 10. Then you have to apply Min and Max in the right order: `Min(Max(in, min), max)`. Differ in any way and you're doomed. Hooray.
This PR makes TE match eager mode for this operator, plus fixes a major facepalm in the llvm min/max codegen where we were always generating signed comparisons.
ghstack-source-id: 118415318
Test Plan: `buck test //caffe2/test:{jit,tensorexpr}`
Reviewed By: robieta
Differential Revision: D25456366
fbshipit-source-id: dde3c26c2134bdbe803227601fa3d23eaac750fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49117
Try to resolve part of the github issue of https://github.com/pytorch/pytorch/issues/48684 . It essentially calls the same functionality inside at::native::zeros().
After this diff, all references to aten::native symbols are removed.
ghstack-source-id: 118261305
Test Plan: CI
Reviewed By: dhruvbird
Differential Revision: D25444940
fbshipit-source-id: 7f782680daa3aedd1b7301cb08576da2ec70c188
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49246
Previously the comment on matrix_approximation_rank was in PowerSGD_hook function. Now move it into PowerSGDState, because the function arg is already moved to this state as an attribute.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 118414247
Test Plan: N/A
Reviewed By: rohan-varma
Differential Revision: D25501091
fbshipit-source-id: 701e3109a9a3f2a5f9d18d5bf6d0a266518ee8ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48865
If DistributedSampler was provided an invalid rank (ex:
https://discuss.pytorch.org/t/distributed-datasets-on-multi-machines/105113),
it failed with a cryptic assertion failure.
To fix this issue, I've added an additional check to DistributedSampler to
validate we provide a valid rank.
ghstack-source-id: 117906769
Test Plan:
1) waitforbuildbot
2) Unit test added.
Reviewed By: malfet
Differential Revision: D25344945
fbshipit-source-id: 7685e00c8b2c200efbd2949fb32ee32ea7232a08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49184
Adds BitCasting to NNC. This will enable fast approximation algorithms implemented directly in TensorExpressions
Test Plan: buck test mode/no-gpu //caffe2/test/cpp/tensorexpr:tensorexpr
Reviewed By: bertmaher
Differential Revision: D25466476
fbshipit-source-id: f063ab29ba7bab2dcce463e499f2d4a16bdc1f0e
Summary:
inlines `has` function for DispatchKeySet, that is frequently used in TensorImpl in calls such as `is_sparse`, `is_cuda` etc.
This increases `empty` instruction count (1853228 -> 1937428) without appreciable effect on runtime, and noticeably reduces instruction counts for `copy_` and friends that have to rely on `is_sparse`, `is_cuda` and the like a lot to decide which path to take (3269114 -> 2634114).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49191
Reviewed By: H-Huang
Differential Revision: D25483011
Pulled By: ngimel
fbshipit-source-id: 2f3ab83e2c836a726b9284ffc50d6ecf3701aada
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49210
The RPC tests use multiple gpus in some cases (ex: DDP + RPC and Pipe
+ DDP). We should enable multigpu tests for this purpose.
ghstack-source-id: 118366595
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D25485506
fbshipit-source-id: eabbf442471ebc700b5986bc751879b9cf72b752
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47829
As per proposal in https://github.com/pytorch/pytorch/issues/44827,
the API needs to return an RRef to support inter-host pipelining.
For now, we just return a local RRef and only support pipeline on a single
host. But having this change in the API upfront ensures we don't make any BC
breaking changes later.
ghstack-source-id: 118366784
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D24914022
fbshipit-source-id: e711e7d12efa45645f752f0e5e776a3d845f3ef5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48981
1) It was copying the entire hash table every time.
2) We don't need to do a hash lookup at all.
ghstack-source-id: 118164406
Reviewed By: dzhulgakov
Differential Revision: D25385543
fbshipit-source-id: 6be95c742d6713345c51859ce36a7791a9e2e3f0
Summary:
Updated `qr_backward` to work correctly for complex-valued inputs.
Added `torch.qr` to list of complex tests.
The previous implementation for real-valued differentiation used equation 42 from https://arxiv.org/abs/1001.1654
The current implementation is a bit simpler but the result for the real-valued input case is the same and all tests still pass.
Derivation of complex-valued QR differentiation https://giggleliu.github.io/2019/04/02/einsumbp.html
Ref. https://github.com/pytorch/pytorch/issues/33152
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48489
Reviewed By: bdhirsh
Differential Revision: D25272344
Pulled By: albanD
fbshipit-source-id: b53c1fca1683f4aee5f4d5ce3cab9e559170e7cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48211
Our empty benchmark makes this call unconditionally. If
MemoryFormat::Contiguous is indeed a common case (or if workloads are
likely to use a consistent-ish memory format), then I'd expect
checking first to be a win.
ghstack-source-id: 118224990
Test Plan:
Profiled empty benchmark with perf, saw time spent in empty_tensor_restride go down.
Ran framework overhead benchmarks. ~7% win on empty(), 0.5-1.5% regression on InPlace, ~2% win on OutOfPlace. Seems like both the In/Out of place ones are likely to be noise because they don't exercise empty?
Reviewed By: bhosmer
Differential Revision: D24914706
fbshipit-source-id: 916771b335143f9b4ec9fae0d8118222ab6e8659
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49057
Now that all of the byte-for-byte hacks are removed in the pyi codegen, there's no reason for the codegen to group pyi signature overloads together. I updated the logic in `gen_pyi` that computes signatures (`generate_type_hints()` and _generate_named_tuples()`) to operate per individual `PythonSignatureGroup`
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D25410849
Pulled By: bdhirsh
fbshipit-source-id: 8c190035d7bfc06ed192468efbe7d902922ad1fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49056
This is another byte-for-byte compatibility hack. I'm now sorting pyi signature overloads (previously the codegen did not).
Mostly put this in a separate PR just to more easily reason about the diff in the codegen output.
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D25410846
Pulled By: bdhirsh
fbshipit-source-id: 06e5c32edbce610dd12ec7499014b41b23c646bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49055
Removed the majority of the TODO hacks that I added to the original pyi PR to maintain byte-for-byte compatibility.
I left a few of the divergences between pyi deprecated vs. native signatures, since (a) they're smaller and (b) it might make more sense to kill the deprecated functions at some point entirely.
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D25410847
Pulled By: bdhirsh
fbshipit-source-id: cf07cdda92f7492cd83d363cbb810e3810f6b8c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49054
These are some followups from the first pyi codegen PR. Still maintaining byte-for-byte compatibility in this one.
- Separated `argument_str() with a pyi flag into two functions, `argument_str()` and `argument_str_pyi()`
- Added a notes section for pyi at the top of `python.py`
- Added a `Python Interface` section that I moved the free-standing pyi functions to
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D25410848
Pulled By: bdhirsh
fbshipit-source-id: db83a80af900c32b5e32d67ce27767f6e7c2adfb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49244
see https://fb.quip.com/ceEdANd5iVsO
RegisterMkldnnCPU kernels incorrectly used makeUnboxedOnly() calls to register add_.Tensor kernels. This is because the codegen incorrectly thought they're not c10-full.
This PR fixes that.
ghstack-source-id: 118411117
Test Plan: After this PR, RegisterMkldnnCPU doesn't contain the makeUnboxedOnly() calls anymore.
Reviewed By: ezyang
Differential Revision: D25500246
fbshipit-source-id: 8a8c2be9c4f4a5ce7eaae94257c2f8cbd176e92e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48607
This change builds on top of
https://github.com/pytorch/pytorch/pull/46865
further exposing the async interface to `torch::jit::Method`.
added unit test for new `run_async`
Test Plan: `buck test caffe2/test/cpp/jit/...`
Reviewed By: dzhulgakov
Differential Revision: D25219726
fbshipit-source-id: 89743c82a0baa1affe0254c1e2dbf873de8e5c76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48660
We used to support tuple slicing without any step size before, but this PR extends this feature to support arbitrary step size. We do this by manually reconstructing a new tuple in the IR instead of relying on TupleSlice prim.
Test Plan:
python tests
Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D25359336
fbshipit-source-id: 28cde536f28dd8a00607814b2900765e177f0ed7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48826
This change updates various macros to pass in the kernel tag string (`const char*`) into the macro that sets up the `case` statement for the dtype switch. This macro already receives the dtype (enum) which we also need.
There are 2 phases we need to build out for the `dtype` tracing to work:
1. Recording Phase
2. Conditional Compilation Phase
For this most part, this change is trying to focus on [1] (The Recording Phase) and sets up a new `RecordScope` enum value to track kernel dtypes. This code is compiled in only if a specific macro is defined (since this is an **extremely** hot code path, and even the slightest regression here can cause tremendous slow down overall).
I have only added a skeleton of the phase [2] (Conditional Compilation Phase) and there is a no-op `constexpr` method that selects every dtype in the kernel implementation. In subsequent diffs, this will be updated to point to a code-generated function based on the result of tracing the models that were requested.
ghstack-source-id: 118336675
Test Plan: See the next few diff in the stack for the application of this change to both record triggered dtypes (in kernel functions) as well as select dtype specific portions of kernel functions.
Reviewed By: ezyang
Differential Revision: D24220926
fbshipit-source-id: d7dbf21c7dcc6ce981d0fd4dcb62ca829fe3f69d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49014
We extracted a generic and reusable CUDAFuture class from FutureNCCL, but we had left FutureNCCL around, as a subclass of CUDAFuture, in order to deal with some peculiarity of ProcessGroupNCCL, namely that the future would be completed right away when constructed and that its CUDA events would be _shared_ with the ones of the WorkNCCL. This required some "hacks" in CUDAFuture itself (protected members, fields wrapped in shared_ptrs, ...).
My understanding is that creating CUDA events is a rather cheap operation. That would mean that we could afford to record _twice_ the events after each NCCL call, once for the WorkNCCL and once for the future. By doing so, we can use the CUDAFuture class directly and revert all its hacks.
ghstack-source-id: 118391217
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25355272
fbshipit-source-id: 3a2a0891724928221ff0f08600675d2f5990e674
Summary:
This PR adds `tools/fast_nvcc/fast_nvcc.py`, a mostly-transparent wrapper over `nvcc` that parallelizes compilation of CUDA files when building for multiple architectures at once.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48934
Test Plan: Currently this script isn't actually used in PyTorch OSS. Coming soon!
Reviewed By: walterddr
Differential Revision: D25286030
Pulled By: samestep
fbshipit-source-id: 971a404cf57f5694dea899a27338520d25191706
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48789
CUDAFuture aims to "capture" the current state of CUDA-related stuff when the future is marked complete (e.g., by looking at current streams and recording events on them) and then "replicate" a similar state when users synchronize with the result of the future (by synchronizing the current streams with these events).
However, one "contextual" aspect of CUDA that we weren't capturing/replicating was the current device. This diff tries to fix that. I must mention that we can only do this for callbacks, while we cannot do it for the wait() method. I don't know if such a discrepancy between the two actually makes the overall behavior _worse_. I'd love to hear people's opinions on this.
ghstack-source-id: 118081338
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25210335
fbshipit-source-id: 1d1a3f80b1cc42e5114bc88554ed50617f1aaa90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48983
Expose an API for users to retrieve the RRef for the underlying module.
This would be useful if users would like to run custom code on the remote end for the nn.Module.
Original PR issue: RemoteModule enhancements #40550
ghstack-source-id: 118378601
Test Plan: buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- RemoteModule
Reviewed By: pritamdamania87
Differential Revision: D25386042
fbshipit-source-id: 2dff33e8d5c9770be464eacf0b26c3e82f49a943
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49174
We've seen this happening when libtorch is loaded repeatedly on macOS. Tbh I'm not sure I understand why this happens; why do we re-construct these static objects but re-use the static registry itself? But it's fairly straightforward to just overwrite the factory method and no harm in doing so.
ghstack-source-id: 118306581
Test Plan: compile
Reviewed By: ZolotukhinM
Differential Revision: D25466642
fbshipit-source-id: 4c456a57407f23fa0c9f4e74975ed1186e790c74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48911
This enables us to use hacky_wrapper_for_legacy_signatures for ops with out arguments so they can use templated unboxing logic without having to be rewritten.
This only actually enables it for one op as a proof of concept. There will be a separate PR enabling it for more ops.
ghstack-source-id: 118379659
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D25363336
fbshipit-source-id: da075d2cc58814f886a25d52652511dbbe990cec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49092
Functions which specify manual_cpp_binding don't automatically
get C++ bindings generated for them in TensorBody.h or
Functions.h. This lets end users manually define the bindings
themselves, which may be helpful if there is a way to
short circuit the dispatcher entirely. contiguous() is switched
to use this mechanism.
Although manual_cpp_binding suggests that we don't generate the
binding at all, it is often the case that there is some "fast
path", but when this path is not satisfied, we should go back
to the slow dispatch. So we still generate a fallback method/function
which the user-defined binding can call into in case that we
have to go slowpath.
The correctness conditions for bindings manually written in this
way are subtle. Here are the ones I can think of off the top
of my head:
- Whatever condition is tested in the C++ body, must ALSO be
tested again in the native:: implementation on the other
side of the dispatcher. This is because you are NOT GUARANTEED
to hit the native:: implementation through the C++ binding,
you may go straight to the implementation via a boxed call.
- If a binding is written in this way, it is only safe to
skip dispatch if you would have returned the same tensor as
before. In any situation you would return a fresh tensor,
you MUST go to the slow path, because you need to actually
get to the autograd kernel.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D25428440
Pulled By: swolchok
fbshipit-source-id: 6e71767cb8d1086d56cd827c1d2d56cac8f6f5fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49199
This should save us an extra round of dispatch for resize_,
resize_as_, detach_, and copy_, at the cost of disabling profiling and
tracing. I'm told that static runtime has its own per-op profiling and
we don't need tracing.
ghstack-source-id: 118348314
Test Plan:
Code review to confirm lack of need for profiling &
tracing, and that there isn't a different switch we should be using
instead.
Internal benchmarks -- seeing 11-12% improvement in overall runtime
Reviewed By: hlu1
Differential Revision: D25476819
fbshipit-source-id: 71e2c919b386b25c41084e2e4a54fe765a4f8f22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48946
Move recordFunctionEndCallback to after the blocking portion of launching the NCCL kernel, and remove addCallback since it runs the lambda inline anyways, and triggers unnecessary CUDA stream logic. If we want CUDA operations such as NCCL kernels accurately profiled, we should use the profiler with use_cuda=True. However, we are currently debugging a deadlock for the use_cuda=True case, fix is being tracked in #48987.
To ensure that the tests are no longer flaky, submitted this PR to ci-all: #48947 and ran the test a bunch of times ssh'd into the CI machine.
ghstack-source-id: 118330130
Test Plan: Ci
Reviewed By: mrzzd
Differential Revision: D25368322
fbshipit-source-id: 7d17036248a3dcd855e58addc383bba64d6bc391
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49066
This PR tweaks mock_module and extern_module. They are now renamed
mock and extern, and now only edit the package when a module matching
the pattern specified is required through dependency analysis.
save_extern_module and save_mock_module are added to explicitly modify
the package, but should not be needed by most users of the API unless they
are overriding require_package.
mock and extern now use bazel-style glob matching rules
(https://docs.bazel.build/versions/master/be/functions.html#glob).
i.e. `torch.**` matches `torch` and `torch.bar` but not `torchvision`.
mock and extern also now take an exclude list to filter out packages
that should not apply to the action.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D25413935
Pulled By: zdevito
fbshipit-source-id: 5c06b417bee94ac8e72c13985b5ec42fcbe00817
Summary:
Adds the CompoundTensor, a specialisation of the NNC Tensor which allows arbitrary production statements. This will allow lowering of aten ops into specific NNC IR patterns (which don't need to be functional) - allowing us to shortcut to the optimized form of common patterns.
This is part 1 of trying to clean up the lowering of aten::cat so it is easier to optimize.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48750
Reviewed By: tugsbayasgalan
Differential Revision: D25433517
Pulled By: nickgg
fbshipit-source-id: de13c4719f8f87619ab254e5f324f13b5be1c9da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49043
Previously, this function had nontrivial algorithmic content,
but after #48195, this was just a swiss army knife for pasting
together arguments while maintaining structure. I added some
more properties for Arguments for convenient access in this way,
and then inlined the implementation of group_arguments into all of its call
sites, simplifying whenever contextual. This might be controversial, but I
think the resulting code is easier to understand.
You may notice that there is some modest code duplication between
dispatcher.cpparguments_exprs and CppSignature.argument_packs.
This is a known problem and I will be attempting to fix it in
a follow up PR.
Confirmed to be byte-for-byte compatible.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D25455885
Pulled By: ezyang
fbshipit-source-id: 8fbe066e8c3cb7ee8adb5b87296ec5bd7b49e01f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49042
I want the names positional and kwarg_only to give the unflat
representation (e.g., preserving TensorOptionsArguments in the
returned Union). So I regret my original naming choice when
I moved grouping to model. This renames them to have flat_ prefix
and also adds a flat_non_out argument for cases where you just
want to look at non-out arguments.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D25455884
Pulled By: ezyang
fbshipit-source-id: f923f8881267a3e3e8e9521519412f7cc25034fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48679
This addresses the remaining problem reported in issue #48053
Data type supports for aten kernels in SimpleIREvaluator are not
consistent w/ aten::native library implementation. In SimpleIREvaluator,
- only float/double are supported on aten::abs (integral types and half
are missing)
- only float/double are supported on aten::frac (half are missing)
It is also not clear from kernel.cpp source code what are the expected
input data types for an aten kernel, leading to potential missing data
type issues down the road.
This commit addresses both issues in a limited way by
- Added type promotion ops from half/integral input types to float
- Added a skeleton support for some type checking for aten kernels,
currently, only check for valid data types for frac and abs to limit
the scope of the change; but the utility function can be used for
consistently adding type checking for all aten functions
Known limitations:
- abs support for integral types can be made more effective by invoking
std::abs for integral tensors (currently kFabs maps to std::fabs).
Since that change is a bit more involved (e.g., changing IntrinsicsOp
kFabs to kAbs and other code generators accordingly), will leave it to
another issue
- other aten kernels may need similar type checking and some scrutiny
on the use of promoteToFloat to detect invalid data types early on.
That is also left for another issue
Test Plan:
test_jit_fuser_te.test_unary_ops
Imported from OSS
Reviewed By: asuhan
Differential Revision: D25344839
fbshipit-source-id: 95aca04c99b947dc20f11e4b3bae002f0ae37044
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49127
Small change, but useful: it means that double-clicking the line lets
you copy the url easily
Test Plan: Imported from OSS
Reviewed By: zdevito
Differential Revision: D25450408
Pulled By: suo
fbshipit-source-id: 8b13b971b444187a8de59c89cc8f60206035b2ad
Summary:
should fixes https://github.com/pytorch/pytorch/issues/48879.
To test the effect of the messages: make test break, such as add `self.assertEqual(1, 2, "user_msg")` to any test
* Before:
```
AssertionError: False is not true : user_msg
```
* After
```
AssertionError: False is not true : Scalars failed to compare as equal! Comparing 1 and 2 gives a difference of 1, but the allowed difference with rtol=0 and atol=0 is only 0!
user_msg;
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48935
Reviewed By: samestep
Differential Revision: D25382153
Pulled By: walterddr
fbshipit-source-id: 95633a9f664f4b05a28801786b12a10bd21ff431
Summary:
Use `UL` suffix supported by all C99 compatible compilers instead of `__AARCH64_UINT64_C`, which is a gcc specific extension
Before the change this check would have failed as follows with a bug-free clang compiler with the following errors:
```
$ clang has_vst1.c
has_vst1.c:5:41: warning: implicit declaration of function '__AARCH64_UINT64_C' is invalid in C99 [-Wimplicit-function-declaration]
v.val[0] = vcombine_f32 (vcreate_f32 (__AARCH64_UINT64_C (0)), vcreate_f32 (__AARCH64_UINT64_C (0)));
^
has_vst1.c:5:79: warning: implicit declaration of function '__AARCH64_UINT64_C' is invalid in C99 [-Wimplicit-function-declaration]
v.val[0] = vcombine_f32 (vcreate_f32 (__AARCH64_UINT64_C (0)), vcreate_f32 (__AARCH64_UINT64_C (0)));
^
has_vst1.c:6:41: warning: implicit declaration of function '__AARCH64_UINT64_C' is invalid in C99 [-Wimplicit-function-declaration]
v.val[1] = vcombine_f32 (vcreate_f32 (__AARCH64_UINT64_C (0)), vcreate_f32 (__AARCH64_UINT64_C (0)));
^
has_vst1.c:6:79: warning: implicit declaration of function '__AARCH64_UINT64_C' is invalid in C99 [-Wimplicit-function-declaration]
v.val[1] = vcombine_f32 (vcreate_f32 (__AARCH64_UINT64_C (0)), vcreate_f32 (__AARCH64_UINT64_C (0)));
^
4 warnings generated.
/tmp/has_vst1-b1e162.o: In function `main':
has_vst1.c:(.text+0x30): undefined reference to `__AARCH64_UINT64_C'
```
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49182
Reviewed By: walterddr
Differential Revision: D25471994
Pulled By: malfet
fbshipit-source-id: 0129a6f7aabc46aa117ef719d3a211449cb410f1
Summary:
### Pytorch Vec256 ppc64le support
implemented types:
- double
- float
- int16
- int32
- int64
- qint32
- qint8
- quint8
- complex_float
- complex_double
Notes:
All basic vector operations are implemented:
There are a few problems:
- minimum maximum nan propagation for ppc64le is missing and was not checked
- complex multiplication, division, sqrt, abs are implemented as PyTorch x86. they can overflow and have precision problems than std ones. That's why they were either excluded or tested in smaller domain range
- precisions of the implemented float math functions
~~Besides, I added CPU_CAPABILITY for power. but as because of quantization errors for DEFAULT I had to undef and use vsx for DEFAULT too~~
#### Details
##### Supported math functions
+ plus sign means vectorized, - minus sign means missing, (implementation notes are added inside braces)
(notes). Example: -(both ) means it was also missing on x86 side
g( func_name) means vectorization is using func_name
sleef - redirected to the Sleef
unsupported
function_name | float | double | complex float | complex double
|-- | -- | -- | -- | --|
acos | sleef | sleef | f(asin) | f(asin)
asin | sleef | sleef | +(pytorch impl) | +(pytorch impl)
atan | sleef | sleef | f(log) | f(log)
atan2 | sleef | sleef | unsupported | unsupported
cos | +((ppc64le:avx_mathfun) ) | sleef | -(both) | -(both)
cosh | f(exp) | -(both) | -(both) |
erf | sleef | sleef | unsupported | unsupported
erfc | sleef | sleef | unsupported | unsupported
erfinv | - (both) | - (both) | unsupported | unsupported
exp | + | sleef | - (x86:f()) | - (x86:f())
expm1 | f(exp) | sleef | unsupported | unsupported
lgamma | sleef | sleef | |
log | + | sleef | -(both) | -(both)
log10 | f(log) | sleef | f(log) | f(log)
log1p | f(log) | sleef | unsupported | unsupported
log2 | f(log) | sleef | f(log) | f(log)
pow | + f(exp) | sleef | -(both) | -(both)
sin | +((ppc64le:avx_mathfun) ) | sleef | -(both) | -(both)
sinh | f(exp) | sleef | -(both) | -(both)
tan | sleef | sleef | -(both) | -(both)
tanh | f(exp) | sleef | -(both) | -(both)
hypot | sleef | sleef | -(both) | -(both)
nextafter | sleef | sleef | -(both) | -(both)
fmod | sleef | sleef | -(both) | -(both)
[Vec256 Test cases Pr https://github.com/pytorch/pytorch/issues/42685](https://github.com/pytorch/pytorch/pull/42685)
Current list:
- [x] Blends
- [x] Memory: UnAlignedLoadStore
- [x] Arithmetics: Plus,Minu,Multiplication,Division
- [x] Bitwise: BitAnd, BitOr, BitXor
- [x] Comparison: Equal, NotEqual, Greater, Less, GreaterEqual, LessEqual
- [x] MinMax: Minimum, Maximum, ClampMin, ClampMax, Clamp
- [x] SignManipulation: Absolute, Negate
- [x] Interleave: Interleave, DeInterleave
- [x] Rounding: Round, Ceil, Floor, Trunc
- [x] Mask: ZeroMask
- [x] SqrtAndReciprocal: Sqrt, RSqrt, Reciprocal
- [x] Trigonometric: Sin, Cos, Tan
- [x] Hyperbolic: Tanh, Sinh, Cosh
- [x] InverseTrigonometric: Asin, ACos, ATan, ATan2
- [x] Logarithm: Log, Log2, Log10, Log1p
- [x] Exponents: Exp, Expm1
- [x] ErrorFunctions: Erf, Erfc, Erfinv
- [x] Pow: Pow
- [x] LGamma: LGamma
- [x] Quantization: quantize, dequantize, requantize_from_int
- [x] Quantization: widening_subtract, relu, relu6
Missing:
- [ ] Constructors, initializations
- [ ] Conversion , Cast
- [ ] Additional: imag, conj, angle (note: imag and conj only checked for float complex)
#### Notes on tests and testing framework
- some math functions are tested within domain range
- mostly testing framework randomly tests against std implementation within the domain or within the implementation domain for some math functions.
- some functions are tested against the local version. ~~For example, std::round and vector version of round differs. so it was tested against the local version~~
- round was tested against pytorch at::native::round_impl. ~~for double type on **Vsx vec_round failed for (even)+0 .5 values**~~ . it was solved by using vec_rint
- ~~**complex types are not tested**~~ **After enabling complex testing due to precision and domain some of the complex functions failed for vsx and x86 avx as well. I will either test it against local implementation or check within the accepted domain**
- ~~quantizations are not tested~~ Added tests for quantizing, dequantize, requantize_from_int, relu, relu6, widening_subtract functions
- the testing framework should be improved further
- ~~For now `-DBUILD_MOBILE_TEST=ON `will be used for Vec256Test too~~
Vec256 Test cases will be built for each CPU_CAPABILITY
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41541
Reviewed By: zhangguanheng66
Differential Revision: D23922049
Pulled By: VitalyFedyunin
fbshipit-source-id: bca25110afccecbb362cea57c705f3ce02f26098
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49053
**Summary**
`BufferPolicy::valid` uses `!typ->is_parameter(i)` to check if an
attribute is a buffer or not; it should use `type->is_buffer(i)` instead.
**Test Plan**
It is difficult to write an additional test that would have failed before this
commit because the two booleans `is_parameter` and `is_buffer` are never set
to `true` at the same time.
**Fixes**
This commit fixes#48746.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D25434956
Pulled By: SplitInfinity
fbshipit-source-id: ff2229058abbafed0b67d7b26254d406e5f7b074
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49079
BackendSelect kernels have been changed to be written the new way, so this hacky_wrapper here isn't needed anymore.
This PR is not expected to change perf or anything, just simplify the code a bit. The hacky_wrapper here was a no-op and not creating any actual wrappers
because it short-cirtuits to not create a wrapper when there is no wrapper needed.
ghstack-source-id: 118318436
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D25421633
fbshipit-source-id: 7a6125613f465dabed155dd892c8be6af5c617cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47793
This migrates aten::div.out to be c10-full (without hacky wrapper) and fixes everything that needed to be fixed to make it work.
This is a prerequisite step to making out ops c10-full. Diffs stacked on top of this will introduce a hacky_wrapper for out ops and use it to make more ops c10-full.
ghstack-source-id: 118318433
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D24901944
fbshipit-source-id: e477cb41675e477808c76af01706508beee44752
Summary:
The args parameter of ONNX export is changed to better support optional arguments such that args is represented as:
args (tuple of arguments or torch.Tensor, a dictionary consisting of named arguments (optional)):
a dictionary to specify the input to the corresponding named parameter:
- KEY: str, named parameter
- VALUE: corresponding input
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47367
Reviewed By: H-Huang
Differential Revision: D25432691
Pulled By: bzinodev
fbshipit-source-id: 9d4cba73cbf7bef256351f181f9ac5434b77eee8
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49064 by using raw strings
I removed `# noqa: W605` because that's the "invalid escape sequence" check: https://www.flake8rules.com/rules/W605.html
I wrote a quick test to make sure the strings are the same before and after this PR. This block should print `True` (it does for me).
```
convolution_notes1 = \
{"groups_note": r"""* :attr:`groups` controls the connections between inputs and outputs.
:attr:`in_channels` and :attr:`out_channels` must both be divisible by
:attr:`groups`. For example,
* At groups=1, all inputs are convolved to all outputs.
* At groups=2, the operation becomes equivalent to having two conv
layers side by side, each seeing half the input channels
and producing half the output channels, and both subsequently
concatenated.
* At groups= :attr:`in_channels`, each input channel is convolved with
its own set of filters (of size
:math:`\frac{\text{out\_channels}}{\text{in\_channels}}`).""",
"depthwise_separable_note": r"""When `groups == in_channels` and `out_channels == K * in_channels`,
where `K` is a positive integer, this operation is also known as a "depthwise convolution".
In other words, for an input of size :math:`(N, C_{in}, L_{in})`,
a depthwise convolution with a depthwise multiplier `K` can be performed with the arguments
:math:`(C_\text{in}=C_\text{in}, C_\text{out}=C_\text{in} \times \text{K}, ..., \text{groups}=C_\text{in})`."""} # noqa: B950
convolution_notes2 = \
{"groups_note": """* :attr:`groups` controls the connections between inputs and outputs.
:attr:`in_channels` and :attr:`out_channels` must both be divisible by
:attr:`groups`. For example,
* At groups=1, all inputs are convolved to all outputs.
* At groups=2, the operation becomes equivalent to having two conv
layers side by side, each seeing half the input channels
and producing half the output channels, and both subsequently
concatenated.
* At groups= :attr:`in_channels`, each input channel is convolved with
its own set of filters (of size
:math:`\\frac{\\text{out\_channels}}{\\text{in\_channels}}`).""", # noqa: W605
"depthwise_separable_note": """When `groups == in_channels` and `out_channels == K * in_channels`,
where `K` is a positive integer, this operation is also known as a "depthwise convolution".
In other words, for an input of size :math:`(N, C_{in}, L_{in})`,
a depthwise convolution with a depthwise multiplier `K` can be performed with the arguments
:math:`(C_\\text{in}=C_\\text{in}, C_\\text{out}=C_\\text{in} \\times \\text{K}, ..., \\text{groups}=C_\\text{in})`."""} # noqa: W605,B950
print(convolution_notes1 == convolution_notes2)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49065
Reviewed By: agolynski
Differential Revision: D25464507
Pulled By: H-Huang
fbshipit-source-id: 88a65a24e3cc29774af25e09823257b2136550fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48264
Preserves the strided representation of NNC Tensor outputs by transforming them into the right layout at the end of the kernel.
Fix for https://github.com/pytorch/pytorch/issues/45604
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D25286213
Pulled By: eellison
fbshipit-source-id: 64d94ac463741e2568a1c9d44174e15ea26e511f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48263
The inferred type is only used once in `getInferred` and is confusing next to the other parameters. It has nothing to do with runtime values, it just means the type was inferred in type-checking. There are a bunch of parameters and overloads of Tensor instantiation as is.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D25286211
Pulled By: eellison
fbshipit-source-id: 3dfc44ab7ff4fbf0ef286ae8716a4afac646804b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47814
Previously, we would bail completely if a node had a constant tensor input. This PR adds support for this case by lifting the constant out of the fusion graph after we've done fusion. It might be nice to add support for Tensor Constants in NNC itself, but it looked kind of tricky and this is an easy enough temporary solution.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D25286215
Pulled By: eellison
fbshipit-source-id: 9ff67f92f5a2d43fd3ca087569898666525ca8cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47813
We have some code paths that at kernel invocation seem to handle dynamic sizes, but I'm not sure how well it works because we have other parts of our code base that assume that tenso shapes are always fully specified. https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/tensorexpr/kernel.cpp#L1572
As with some other PRs in the stack, I think it would be good to remove the features that aren't on/actively being worked on while they are not used.
I initially did this PR to try to speed up perf. I couldn't observe too much of a speed up, so we can decide to keep drop this PR if we want.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D25286212
Pulled By: eellison
fbshipit-source-id: 4ae66e0af88d649dd4e592bc78686538c2fdbaeb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47812
Previously we were checking the environment every kernel invocation for `tensorExprFuserEnabled`, which checks the environment for `PYTORCH_TENSOREXPR`. This is only a dev-exposed API, so I think it is fine to only check once when the kernel is initialized. The `disable_optimization` flag which is user-exposed more or less covers the same functionality.
For fun, some benchmarking. I compared scripted before and after of
```
def foo(x, y):
return x + y
```
for x, y = torch.tensor([1]). I also removed the prim::TypeCheck node to better
isolate the kernel (I cheated). Here is gist: https://gist.github.com/eellison/39f3bc368f5bd1f25ded4827feecd15e
Without Changes Run 1:
no fusion: sum 6.416894399004377 min: 0.6101883250012179 median 0.6412974080012646
with fusion: sum 6.437897570998757 min: 0.6350401220006461 median 0.6446951820034883
Without Changes Run2:
no fusion: sum 6.601341788002173 min: 0.6292048720024468 median 0.6642187059987918
with fusion: sum 6.734651455997664 min: 0.6365462899993872 median 0.6755226659988693
With Changes Run1:
no fusion: sum 6.097717430002376 min: 0.5977709550024883 median 0.613631643998815
with fusion: sum 6.1299369639964425 min: 0.5857932209983119 median 0.6159247440009494
With Changes Run2:
no fusion: sum 6.5672018059995025 min: 0.6245676209982776 median 0.6386050750006689
with fusion: sum 6.489086147994385 min: 0.6236886289989343 median 0.6535737619997235
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D25286210
fbshipit-source-id: a18b4918a7f7bed8a39112ae04b678e79026d39b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47810
`bindSymbolicShapes` wasn't checking device or dtype at all, so it wasn't correct. It also isn't being used anywhere (num_profiles is always 1 and we don't use symbolic shapes). We shouldn't have it on until we are actually using symoblic shapes.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D25286214
Pulled By: eellison
fbshipit-source-id: 10fb175d0c75bd0159fb63aafc3b59cc5fd6c5af
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/48098
Test Plan:
Imported from OSS
***
make duplicate def() calls an error in the dispatcher. Updating all fb operators to use the new dispatcher registration API
Reviewed By: ezyang
Differential Revision: D25056089
Pulled By: bdhirsh
fbshipit-source-id: 8d7e381f16498a69cd20e6955d69acdc9a1d2791
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49175
As title
ghstack-source-id: 118306312
Test Plan: CI
Reviewed By: xta0
Differential Revision: D25466577
fbshipit-source-id: 67a521947db3744695f0ab5f421483ab96d8ed9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49176
Bump up the cocoapods version
ghstack-source-id: 118305636
Test Plan: CI
Reviewed By: xta0
Differential Revision: D25466321
fbshipit-source-id: 916adc514c5edc8971445da893362a160cfc092b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49145
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49105
(1) Add a safety check `C10_CUDA_KERNEL_LAUNCH_CHECK()` after each kernel launch. This diff only changes the files inside the directory /fbsource/fbcode/caffe2/modules/, /fbsource/fbcode/caffe2/fb/, /fbsource/fbcode/caffe2/test/.
(2) Get rid of old check `AT_CUDA_CHECK(cudaGetLastError())` when necessary.
Test Plan:
Test build:
```
buck build mode/dev-nosan //caffe2/modules/detectron:
buck test mode/dev-nosan //caffe2/modules/detectron:
buck build mode/dev-nosan //caffe2/torch/fb/:
buck test mode/dev-nosan //caffe2/torch/fb/:
```
To check for launches without checks:
```
python3 caffe2/torch/testing/check_kernel_launches.py
```
Make sure none of the updated files are in the returned list.
Reviewed By: r-barnes
Differential Revision: D25452852
fbshipit-source-id: d6657edab612c9e0fa99b29c68460be8b1a20064
Summary:
**BC-breaking note:**
Previously, when given a complex input, `torch.linalg.norm` and `torch.norm` would return a complex output. `torch.linalg.cond` would sometimes return a complex output and sometimes return a real output when given a complex input, depending on its `p` argument. This PR changes this behavior to match `numpy.linalg.norm` and `numpy.linalg.cond`, so that a complex input will result in the downgraded real number type, consistent with NumPy.
**PR Summary:**
The following cases were previously unsupported for complex inputs, and this commit adds support:
- Frobenius norm
- Norm order 2 (vector and matrix)
- CUDA vector norm
Part of https://github.com/pytorch/pytorch/issues/47833
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48284
Reviewed By: H-Huang
Differential Revision: D25420880
Pulled By: mruberry
fbshipit-source-id: 11f6a2f3cad57d66476d30921c3f6ab8f3cd4017
Summary:
Fix https://github.com/pytorch/pytorch/issues/48523
Related https://github.com/pytorch/pytorch/issues/38349
**BC-breaking Note:**
This PR updates PyTorch's quantile function to add additional interpolation methods `lower`, `higher`, `nearest`, and `midpoint`, and these interpolation methods are currently supported by NumPy.
New parameter `interpolation` is added to the signature for both `torch.quantile` and `torch.nanquantile` functions.
- `quantile(input, q, dim=None, interpolation='linear', keepdim=False, *, out=None) -> Tensor`
- `nanquantile(input, q, dim=None, interpolation='linear', keepdim=False, *, out=None) -> Tensor`
Function signatures followed the NumPy-like style for the moment, keeping `out` at the end to be consistent with PyTorch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48711
Reviewed By: H-Huang
Differential Revision: D25428587
Pulled By: heitorschueroff
fbshipit-source-id: e98d24f6a651d302eb94f4ff4da18e38bdbf0124
Summary:
cuDNN v7 API has been deprecated, so we need to migrate to cuDNN v8 API. The v8 API does not exist on cuDNN 7, so there will be a long time both API should exist.
This is step 0 of adding cuDNN v8 API. There is no real code change in this PR. It just copy-pastes existing code. The original `Conv.cpp` is split into `ConvPlaceholders.cpp`, `ConvShared.cpp`, `ConvShared.h`, `Conv_v7.cpp`, `Conv_v8.cpp`. Currently `Conv_v8.cpp` is empty, and will be filled in the future.
The `ConvPlaceholders.cpp` contains placeholder implementation of cudnn convolution when cudnn is not enabled. These operators only raise errors and do no real computation. This file also contains deprecated operators. These operators are implemented using current operators.
The `ConvShared.cpp` and `ConvShared.h` contains code that will be shared by the v7 and v8 API, these include the definition of struct `ConvolutionParams` and `ConvolutionArgs`. As well as ATen exposed API like `cudnn_convolution` and intermediate `cudnn_convolution_forward`. These exposed functions will call raw API like `raw_cudnn_convolution_forward_out` in `Conv_v7.cpp` or `Conv_v8.cpp` for the real implementation.
The `Conv_v7.cpp`, `Conv_v8.cpp` contains the implementation of raw APIs, and are different for v7 and v8.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49109
Reviewed By: H-Huang
Differential Revision: D25463783
Pulled By: ezyang
fbshipit-source-id: 1c80de8e5d94d97a61e45687f6193e8ff5481e3e
Summary: Adds BitCasting to NNC. This will enable fast approximation algorithms implemented directly in TensorExpressions
Test Plan: buck test mode/no-gpu //caffe2/test/cpp/tensorexpr:tensorexpr
Reviewed By: bertmaher
Differential Revision: D25441716
fbshipit-source-id: c97b871697bc5931d09cda4a9cb0a81bb420f4e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48761
Targeting one of the items in https://github.com/pytorch/pytorch/issues/48684. For performance purpose we don't use at::scalar_tensor. Since scalar_tensor_static is available for CPU we could use it at least for CPU. One uncertainty is the CUDA performance. But there's no fast path for CUDA under native::scalar_tensor either, I assume the perf on CUDA may not be affected.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D25410975
Pulled By: iseeyuan
fbshipit-source-id: 160d21ffeefc9a2e8f00a55043144eebcada2aac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48788
CUDAFuture needs to inspect the value it contains in order to first determine what devices its tensors reside on (so that it can record events on those devices), and then to record these tensors with the caching allocator when they are used in other streams. Extracting data ptrs can become somewhat expensive (especially if we resort to using the pickler to do that), hence it's probably a good idea to cache the result the first time we compute it.
ghstack-source-id: 118180023
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25303486
fbshipit-source-id: 5c541640f6d19249dfb5489ba5e8fad2502836fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48506
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
FutureNCCL is now a general-purpose type-agnostic multi-device class, so in this commit I extract it from ProcessGroupNCCL to make it available for wider use (notably by the RPC module). We'll call this new class CUDAFuture. We'll keep FutureNCCL as a subclass of CUDAFuture to deal with some NCCL peculiarity, namely the fact that the future becomes complete immediately upon creation. We can clean this up for good once we're done merging Future and Work.
I'm not exactly sure of where to put CUDAFuture. It needs to be available to both c10d and RPC (which lives under torch/csrc). If I figured CMake out correctly (and that's a big if) I think c10d can only depend on ATen (I'll maybe add a comment with how I tracked that down). Hence we cannot put CUDAFuture in torch/csrc. On the other hand, RPC currently depends on c10d, because RPC agents use ProcessGroups internally, so it would be "ok" to put CUDAFuture in c10d. However, we want to get rid of ProcessGroups in RPC, and at that point RPC should in principle not depend on c10d. In that case, the only shared dep between the two that I see is ATen itself.
While I'm a bit wary of putting it right in ATen, I think it might actually make sense. CUDAFuture is intended to be a general-purpose component that can be reused in all settings and is not particularly tied to c10d or RPC. Moreover, ATen already contains ivalue::Future, and it contains a lot of CUDA helpers, so CUDAFuture definitely belongs to the "closure" of what's already there.
ghstack-source-id: 118180030
Test Plan: Unit tests?
Reviewed By: wanchaol
Differential Revision: D25180532
fbshipit-source-id: 697f655240dbdd3be22a568d5102ab27691f86d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48505
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
FutureNCCL isn't just adding CUDA support to ivalue::Future, it's also reimplementing a lot of the latter's logic (by overriding plenty of its methods). That's brittle, as whenever a new method is added to ivalue::Future there's a risk of forgetting to add it to FutureNCCL, and in such a case calling this method on FutureNCCL would defer to the base class and give inconsistent results (e.g., future not being completed when it actually is). This _is already happening_, for example with the waitAndThrow or hasError, which are not implemented by FutureNCCL. In addition, this creates duplication between the two classes, which could lead to inconsistencies of behavior, bugs, missing features, ...
The best solution would be to keep the core future logic in ivalue::Future, and have _only_ the CUDA additions in FutureNCCL. That's what we're going to do, in two steps. In the previous commit, I split the CUDA features into separate hooks, which are called by FutureNCCL's other methods. In this commit, I'm removing these latter methods, and invoke the hooks directly from ivalue::Future.
ghstack-source-id: 118180032
Test Plan: Unit tests
Reviewed By: wanchaol
Differential Revision: D25180535
fbshipit-source-id: 19181fe133152044eb677062a9e31e5e4ad3c03c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48504
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
FutureNCCL isn't just adding CUDA support to ivalue::Future, it's also reimplementing a lot of the latter's logic (by overriding plenty of its methods). That's brittle, as whenever a new method is added to ivalue::Future there's a risk of forgetting to add it to FutureNCCL, and in such a case calling this method on FutureNCCL would defer to the base class and give inconsistent results (e.g., future not being completed when it actually is). This _is already happening_, for example with the waitAndThrow or hasError, which are not implemented by FutureNCCL. In addition, this creates duplication between the two classes, which could lead to inconsistencies of behavior, bugs, missing features, ...
The best solution would be to keep the core future logic in ivalue::Future, and have _only_ the CUDA additions in FutureNCCL. That's what we're going to do, in two steps. In this commit, I'll split the CUDA features into separate hooks, which are called by FutureNCCL's other methods. In the next commit, I'll remove these latter methods, and invoke the hooks directly from ivalue::Future.
ghstack-source-id: 118180025
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25180534
fbshipit-source-id: 7b3cd374aee78f6c07104daec793c4d248404c61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48502
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
FutureNCCL restricted the values to be tensors, or (singleton) lists of tensors, or Python object that could be converted to either of those types. We need a CUDA future that can handle more generic types though.
The main challenge is extracting all DataPtrs from an arbitrary object. I think I found some ways of doing so, but I'd like some JIT experts to look into this and tell me if there are better ways. I'll add inline comments for where their input would be appreciated.
ghstack-source-id: 118180026
Test Plan: Unit tests (I should probably add new ones)
Reviewed By: wanchaol
Differential Revision: D25177562
fbshipit-source-id: 1ef18e67bf44543c70abb4ca152f1610dea4e533
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48501
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
FutureNCCL stores a set of devices (on which the tensors in the data reside) and a CUDA event for each of those devices. In fact, each event instance also already contains the device it belongs to, which means we can avoid storing that information separately (with the risk that it'll be mismatched and/or inaccurate).
ghstack-source-id: 118180024
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25177554
fbshipit-source-id: 64667c176efc2a7dafe99457a1fbba5d142cb06c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48500
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
After the previous changes, this is now much simpler than it sounds. For the most part it just consists in repeating some operations multiple times, once for device (e.g., recording and blocking on events). Funnily, we already had a vector of events, even though we only ever stored one element in it (this probably comes from the fact that this is shared with WorkNCCL, which can hold more than one event). Here, we now also store a vector of device indices.
Perhaps the only non-trivial part of this is that now, for "follow-up" Futures (for callbacks), we can't know in advance which device the result will be on so we must determine it dynamically when we receive the result, by inspecting it. That's also easier than it sound because we already have a dataptr extractor.
ghstack-source-id: 118180022
Test Plan: Unit tests (I should probably add new ones)
Reviewed By: mrshenli
Differential Revision: D25177556
fbshipit-source-id: 41ef39ec0dc458e341aa1564f2b9f2b573d7fa9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48563
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
The CUDA caching allocator requires us to register all streams in which a DataPtr is used. We already do so when we invoke a callback, for which we obtain streams from the ATen pool. However, we didn't do so when the user waits for the Future and then uses the results in their current streams. This was probably fine in most cases, because the outputs of the NCCL ops (which is the tensors we're dealing with here) were user-provided, and thus already registered in some user streams, but in principle the user could use different streams when waiting than the ones they used to create the tensors. (If they use the same streams, registering becomes a no-op). But, more importantly, this change will help us turn FutureNCCL into a more general-purpose class as for example in RPC the tensors of the result are allocated by PyTorch itself and thus we need to record their usage on the user's streams with the caching allocator.
ghstack-source-id: 118180033
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25210338
fbshipit-source-id: e0a4ba157653b74dd84cf5665c992ccce2dea188
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48503
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
My impression is that one property of the upstream Future class is that once .wait() returns, or once a callback is invoked, then .completed() should return True. This was not the case for FutureNCCL because .wait() would return immediately, and callbacks would be invoked inline, but .completed() could return False if the CUDA async operations hadn't completed yet.
That was odd and confusing. Since there are other ways for users to check the status of CUDA operations (if they really need, and typically I don't think it's so common), perhaps it's best to avoid checking the status of CUDA events in .completed().
ghstack-source-id: 118180028
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25180531
fbshipit-source-id: e1207f6b91f010f278923cc5fec1190d0fcdab30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48499
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
We can merge and "hide" a whole bunch of CUDA-related logic if we store and record the CUDA events that correspond to the completion of a FutureNCCL when we call markCompleted (rather than splitting it between the constructor, the `then` method, and a wrapper around the callback).
A more concrete reason for this change is that soon I'll add support for multi-device, and in that case we can't necessarily know in advance which devices a value will be on until we get that value (and we don't want to record an event on all devices as then we might "over-synchronize").
To me, this also makes more conceptual sense: the moment when we store a value on the future, which is the "signal" that the future is now ready, should also be time at which we record the events needed to synchronize with that value. Though this may just be personal preference.
ghstack-source-id: 118180034
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25177557
fbshipit-source-id: 53d4bcdfb89fa0d11bb7b1b94db5d652edeb3b7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48498
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
FutureNCCL has a dedicated CUDA stream that it sets as current when running callbacks. This stream is initialized by the ProcessGroupNCCL by extracting it from the global ATen pool.
In order to decouple FutureNCCL from that specific ProcessGroup and make it more generic, in this commit we make FutureNCCL extract a fresh stream from the ATen pool each time it needs one.
This introduces a functional change, because it removes the implicit synchronization and ordering between the callbacks of a same Future. In fact, such an ordering is hard to guarantee in the general case as, for example, a user could attach a new callback just after the future becomes completed, and thus that callback would be run inline, immediately, out-of-order wrt the other callbacks. (There are ways to "fix" this but they are complicated). NCCL got around this because its futures are already marked complete when they're returned, but in fact it could also run into issues if multiple threads were adding callbacks simultaneously.
Note that it remains still possible to enforce ordering between callbacks, but one must now do so explicitly. Namely, instead of this:
```
fut.then(cb1)
fut.then(cb2)
```
one must now do:
```
fut.then(cb1).then(cb2)
```
ghstack-source-id: 118180029
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25177559
fbshipit-source-id: 4d4e73ea7bda0ea65066548109b9ea6d5b465599
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48497
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
When we record the events to mark a "follow-up" future complete (for a callback), we used to record them onto the dedicated stream, but that streams is the current stream at that time, so instead we could just record them onto the current stream. This introduces no functional differences. The reason I'm adding such an additional layer of indirection is so that the dedicated stream is only referenced inside the `addCallback` method, which will later allow us to more easily change how that stream works.
ghstack-source-id: 118180035
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25177553
fbshipit-source-id: c6373eddd34bd399df09fd4861915bf98fd50681
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48496
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
There are two ways to add a callback to a Future: `then` and `addCallback` (with the former deferring to the latter). FutureNCCL only "patched" `then`, which caused `addCallback` to be unsupported. By patching `addCallback`, on the other hand, we cover both.
The high-level goal of this change though is to remove all CUDA-specific stuff from `then`, and move it to either `markCompleted` or to a wrapper around the callback. This will take a few more steps to achieve.
ghstack-source-id: 118180031
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25177558
fbshipit-source-id: ee0ad24eb2e56494c353db700319858ef9dcf32b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48562
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
In this commit I'm adding a few asserts to the constructors of FutureNCCL to make sure that what's passed in is what we expect (fun fact: until two commits ago that wasn't the case, as we were passed some empty events).
I'm also making the second constructor private, as it's only supposed to be used by the then() method.
ghstack-source-id: 118180036
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25210333
fbshipit-source-id: d2eacf0f7de5cc763e3cdd1ae5fd521fd2eec317
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48495
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
PythonFutureWrapper needs to provide a GIL-aware way to extract tensors from an IValue of type PyObject. Since this was only used by FutureNCCL it was guarded by #ifdef USE_C10D_NCCL. However, we will need to use it with CUDA-aware futures other than the NCCL one. This might have been achieved simply by replacing USE_C10D_NCCL with USE_CUDA, but I wanted to clean this up better.
We're dealing with two independent dimensions: C++-vs-Python and CPU-vs-CUDA. To make the code more modular, the two dimensions should be dealt with by orthogonal solutions: the user setting a custom callback to handle Python, and the subclass being CUDA-aware. Mixing these two axes makes it more complicated.
Another reason for changing how this works is that later on, when we'll introduce multi-device support, we'll need to extract dataptrs for other reasons too (rather than just recording streams with the caching allocator), namely to inspect the value to determine which devices it resides on.
ghstack-source-id: 118180038
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25177560
fbshipit-source-id: 3a424610c1ea191e8371ffee0a26d62639895884
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48561
This commit is part of a stack that reworks FutureNCCL in order to extract a generic CUDA-aware Future subclass. The stack deliberately breaks up this transition into elementary changes, to make it easier to verify that the behavior is preserved (or to highlight how it gets changed).
---
WorkNCCL allows to extract a FutureNCCL through getFuture(). There is one instance of this method being called by ProcessGroupNCCL itself, in order to attach a callback to it. This was happening _before_ the work was actually launched, however FutureNCCL does _always_ invoke its callbacks immediately inline. The events that the FutureNCCL was using hadn't been recorded yet, thus blocking on them was a no-op. Moreover, the function that was being called was installed by the generic ProcessGroup superclass, which is not CUDA-aware, and thus probably didn't make any use of the CUDA events or streams.
383abf1f0c/torch/lib/c10d/ProcessGroup.cpp (L66)
In short: I believe that creating a FutureNCCL and attaching a callback was equivalent to just invoking that function directly, without any CUDA-specific thing. I'm thus converting the code to do just that, in order to simplify it.
Note that, given the comment, I don't think this was the original intention of that code. It seems that the function was intended to be run once the work finished. However, I am not familiar with this code, and I don't want to introduce any functional changes.
ghstack-source-id: 118180037
Test Plan: Unit tests
Reviewed By: mrshenli
Differential Revision: D25210337
fbshipit-source-id: 54033c814ac77641cbbe79b4d01686dfc2b45495
Summary:
Added an extra step to **always** preserve the bundled inputs methods if they are present in the input module.
Also added a check to see if all the methods in the `preseved_methods` exist. If not, we will now throw an exception. This can hopefully stop hard-to-debug inputs from getting into downstream functions.
~~Add an optional argument `preserve_bundled_inputs_methods=False` to the `optimize_for_mobile` function. If set to be True, the function will now add three additional functions related with bundled inputs to be preserved: `get_all_bundled_inputs`, `get_num_bundled_inputs` and `run_on_bundled_input`.~~
Test Plan:
`buck test mode/dev //caffe2/test:mobile -- 'test_preserve_bundled_inputs_methods \(test_mobile_optimizer\.TestOptimizer\)'`
or
`buck test caffe2/test:mobile` to run some other related tests as well.
Reviewed By: dhruvbird
Differential Revision: D25433268
fbshipit-source-id: 0bf9b4afe64b79ed1684a3db4c0baea40ed3cdd5
Summary: Adding support to gen qparams to quantize a tensor from min and max thresholds of a tensor
Test Plan:
```
buck test mode/opt caffe2/caffe2/quantization/server:int8_gen_quant_params_min_max_test
```
```
Started reporting to test run: https://our.intern.facebook.com/intern/testinfra/testrun/5629499573509506
✓ ListingSuccess: caffe2/caffe2/quantization/server:int8_gen_quant_params_min_max_test - main (2.522)
✓ Pass: caffe2/caffe2/quantization/server:int8_gen_quant_params_min_max_test - test_int8_gen_quant_params_min_max_op (caffe2.caffe2.quantization.server.int8_gen_quant_params_min_max_test.TestInt8GenQuantParamsMinMaxOperator) (1.977)
Summary
Pass: 1
ListingSuccess: 1
```
Reviewed By: hx89
Differential Revision: D24485985
fbshipit-source-id: 18dee193f7895295d85d31dc013570e5d5d97357
Summary:
Adds a new optimization method to LoopNest which eliminates stores that do not contribute to any output. It's unlikely any of the lowerings of aten operators produce these stores yet, but this creates some wiggle room for transformations in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49030
Reviewed By: tugsbayasgalan
Differential Revision: D25434538
Pulled By: nickgg
fbshipit-source-id: fa1ead82e6f7440cc783c6116b23d0b7a5b5db4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48877
Setting `Storage` in the TensorImpl ctor only to set it again in
`copy_tensor_metadata` wastes one refcount bump.
ghstack-source-id: 117937872
Test Plan:
internal benchmark. compared results with perf, saw 0.15%
reduction in percent of total time spent in
`TensorImpl::shallow_copy_and_detach`.
Reviewed By: bhosmer
Differential Revision: D25353529
fbshipit-source-id: e85d3a139ccd44cbd059c14edb19b22b962881a9
Summary:
Add a `version_info` similar to `sys.version_info` for being able to make version tests. Example generated `version.py`:
```
__version__ = '1.8.0a0'
version_info = (1, 8, 0, 'a0')
# or version_info = (1, 8, 0, 'a0', 'deadbeef') if you're in a Git checkout
debug = False
cuda = None
git_version = '671ee71ad4b6f507218d1cad278a8e743780b716'
hip = None
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48414
Reviewed By: zhangguanheng66
Differential Revision: D25416620
Pulled By: malfet
fbshipit-source-id: 20b561a0c76ac0b16ff92f4bd43f8b724971e444
Summary:
Currently this folder isn't covered by continuous build and ideally, it should be covered.
I've made everything that is actually used build, but there are test failures (commented out). Specifically:
### Build Failures
1. [Resolved] Vulkan stuff doesn't build because codegen doesn't generate files that Vulkan expects.
2. [Resolved] Vulkan relies in Android dev environment being set up, which doesn't exist on sandcastle machines. I think the resolution should be to restrict Vulkan stuff to the ANDROID platform, but will let AshkanAliabadi (who is the expect on all things Vulkan) provide the appropriate resoltion.
3. [Resolved] Older caffe2 stuff didn't have the deps set up correctly for zlib.
4. [Resolved] Some Papaya stuff didn't have the QPL deps set up correctly.
5. [Resolved] Some tests include cuda, which isn't available on xplat PyTorch Mobile.
6. [Resolved] Missing NNPACK dep on platforms other than ANDROID and MACOS.
7. [Resolved] Maskrcnn binary missing header includes.
8. [Resolved] Braces around scalar initializers in Vulkan Tests.
9. [Resolved] Incorrect header `<vulkan/vulkan.h>` and incorrect BUCK glob path to include it - seems like some completely different header was being included by libvulkan-stub.
### Test Failures
1. [Resolved] Memory Leak on exit in multiple (all?) QNNPACK tests.
2. [Unresolved] Lite Trainer test doesn't explicitly specify dep on input `.ptl` file, resulting in the file not being found in the test when the test attempts to open it.
3. [Resolved] Heap Use after free errors in old caffe2 tests.
4. [Resolved] Heap buffer overflow errors in old caffe2 tests.
5. [Unresolved] Something related to an overload of `at::Tensor` accepting C2 Tensor not being found (new PyTorch test I think).
Everything marked `[Unresolved]` above results in stuff that is commented out so that it isn't triggered. It is already currently broken, so it doesn't represent a regression - merely an explicit indication of the fact that it's broken.
Everything marked `[Resolved]` above means that it was fixed to function as intended based on my understanding of the intent.
Test Plan: Sandcastle.
Reviewed By: iseeyuan
Differential Revision: D25093853
fbshipit-source-id: e0dda4f3d852ef158cd088ae2cfd44019ade1573
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48718
This PR rewrites structured kernels to do the class-based mechanism (instead of defining a meta and impl function, they are methods on a class), and adds enough customizability on the class to support TensorIterator. To show it works, add is made a structured kernel. Don't forget to check https://github.com/pytorch/rfcs/pull/9 for a mostly up-to-date high level description of what's going on here.
High level structure of this PR (the order you should review files):
* TensorMeta.h - TensorMeta is deleted entirely; instead, meta functions will call `set_output` to allocate/resize their outputs. MetaBase gets a new `maybe_get_output` virtual method for retrieving the (possibly non-existent) output tensor in a meta function; this makes it easier to do special promotion behavior, e.g., as in TensorIterator.
* TensorIterator.cpp - Two major changes: first, we add TensorIteratorBase::set_output, which is a "light" version of TensorIterator::set_output; it sets up the internal data structures in TensorIterator, but it doesn't do allocation (that is assumed to have been handled by the structured kernels framework). The control flow here is someone will call the subclassed set_output, which will allocate output, and then we will call the parent class (TensorIteratorBase) to populate the fields in TensorIterator so that other TensorIterator phases can keep track of it. Second, we add some tests for meta tensors, and skip parts of TensorIterator which are not necessary when data is not available.
* tools/codegen/model.py - One new field in native_functions.yaml, structured_inherits. This lets you override the parent class of a structured meta class; normally it's MetaBase, but you can make it point at TensorIteratorBase instead for TensorIterator based kernels
* tools/codegen/gen.py - Now generate all of the classes we promised. It's kind of hairy because this is the first draft. Check the RFC for what the output looks like, and then follow the logic here. There are some complications: I need to continue to generate old style wrapper functions even if an operator is structured, because SparseCPU/SparseCUDA/etc won't actually use structured kernels to start. The most complicated code generation is the instantiation of `set_output`, which by in large replicates the logic in `TensorIterator::set_output`. This will continue to live in codegen for the forseeable future as we would like to specialize this logic per device.
* aten/src/ATen/native/UpSampleNearest1d.cpp - The previous structured kernel is ported to the new format. The changes are very modest.
* aten/src/ATen/native/BinaryOps.cpp - Add is ported to structured.
TODO:
* Work out an appropriate entry point for static runtime, since native:: function stubs no longer are generated
* Refactor TensorIteratorConfig construction into helper functions, like before
* Make Tensor-Scalar addition structured to fix perf regression
* Fix `verify_api_visibility.cpp`
* Refactor tools/codegen/gen.py for clarity
* Figure out why header changes resulted in undefined reference to `at::Tensor::operator[](long) const`
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D25278031
Pulled By: ezyang
fbshipit-source-id: 57c43a6e5df21929b68964d485995fbbae4d1f7b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45964
Indexing operators e.g. `scatter`/`gather` use tensor restriding so the `TensorIterator` built in overlap checking needs to be disabled. This adds the missing overlap checks for these operators.
In addition, some indexing operators don't work will with `MemOverlapStatus::FULL` which is explicitly allowed by `assert_no_partial_overlap`. So, I've introduced `assert_no_overlap` that will raise an error on partial _or_ full overlap.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48651
Reviewed By: zhangguanheng66
Differential Revision: D25401047
Pulled By: ngimel
fbshipit-source-id: 53abb41ac63c4283f3f1b10a0abb037169f20b89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49074
Try to resolve part of the github issue of https://github.com/pytorch/pytorch/issues/48684 . ```aten::native::empty()``` is referenced in TensorIndexing.h. However, the definition of ```aten::native::empty()``` is nothing but checks and eventually calling ```at::empty()```.
In this diff, ```at::empty()``` is directly used to avoid the reference to native symbols.
ghstack-source-id: 118165999
Test Plan: CI
Reviewed By: dhruvbird
Differential Revision: D25417854
fbshipit-source-id: 7e4af411ae63642c8470e78cf8553400dc9a16c9
Summary:
I already migrated the majority of fbcode ops to the new registration API, but there are a few stragglers (mostly new files that were created in the last two weeks).
The goal is mostly to stamp out as much of the legacy registration API usage as possible, so that people only see the new API when they look around the code for examples of how to register their own ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48954
ghstack-source-id: 118140663
Test Plan: Ran buck targets for each file that I migrated
Reviewed By: ezyang
Differential Revision: D25380422
fbshipit-source-id: 268139a1d7b9ef14c07befdf9e5a31f15b96a48c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48989
1. Pass shape hints at model export time.
2. A bit of logging to show if passed shape hints are loaded by OnnxifiOp.
From jfix71:
> for AOT we skip onnxifi on the predictor side. We do onnxifi at model export time
Test Plan:
Temporarily added extra logging to verify that we use passed shape hints for AOT scenario. Here are the test results:
1. AOT model generation https://fburl.com/paste/1dtxrdsr shows that pybind_state.cc is called.
2. Running predictor service https://fburl.com/paste/d4qcizya with more logging in onnxifi_op.cc D25344546 shows that we use provided shape hints instead of doing shape inference every time.
Reviewed By: jfix71
Differential Revision: D25344546
fbshipit-source-id: 799ca4baea23ed4d81d89d00cb3a52a1cbf69a44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49105
(1) Add a safety check `C10_CUDA_KERNEL_LAUNCH_CHECK()` after each kernel launch. This diff only changes the files inside the directory /fbsource/fbcode/caffe2/modules/, /fbsource/fbcode/caffe2/fb/, /fbsource/fbcode/caffe2/test/.
(2) Get rid of old check `AT_CUDA_CHECK(cudaGetLastError())` when necessary.
Test Plan:
Test build:
```
buck build //caffe2/modules/detectron:
buck build //caffe2/torch/fb/:
```
To check for launches without checks:
```
python3 caffe2/torch/testing/check_kernel_launches.py
```
Make sure none of the updated files are in the returned list.
Reviewed By: r-barnes
Differential Revision: D25325039
fbshipit-source-id: 2043d6e63c7d029c35576d3101c18247ffe92f01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48872
Using NCCL communicators concurrently is not safe and this is
documented in NCCL docs.
However, this is not documented in PyTorch and we should add documentation for
ProcessGroupNCCL so that users are aware of this limitation.
ghstack-source-id: 118148014
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D25351778
fbshipit-source-id: f7f448dc834c47cc1244f821362f5437dd17ce77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49060
TE contains a fast tanh/sigmoid implementation that may be slightly less precise than the eager implementation (I measured 1 ulp in some test cases). We disabled it by default using an #ifdef but that may be too conservative. Adding a gflag allows more testing without recompilation.
ghstack-source-id: 118140487
Test Plan: `buck test //caffe2/test:jit`
Reviewed By: eellison
Differential Revision: D25406421
fbshipit-source-id: 252b64091edfff878d2585e77b0a6896aa096ea5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49059
We'd like to be able to change these defaults without rebuilding the library.
ghstack-source-id: 118140486
Test Plan: `buck build //caffe2/test:jit`
Reviewed By: eellison
Differential Revision: D25405568
fbshipit-source-id: 5d0561a64127adc44753e48d3b6c7f560c8b5820
Summary:
`isCompleteTensor()` only returns true when both scalar type and shape is present. All dimensions in the shape must be static. This high requirement is unnecessary for many use cases such as when only rank or scalar type needs to be known.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48162
Reviewed By: malfet
Differential Revision: D25340823
Pulled By: bzinodev
fbshipit-source-id: 1fef61f44918f4339dd6654fb725b18cd58d99cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49068
TH folder has some kernal implementations referenced by ATen/native. It goes with ATen/native in the follow-up diff for per-app selective build. ATen/Context.cpp stays in the lib level and should not reference to symbols in TH directly.
It's a simple change in this diff, as ```getTHDefaultAllocator()``` did nothing but returns ```c10::GetCPUAllocator()```. Use ```c10::GetCPUAllocator()``` instead of going extra route through ```getTHDefaultAllocator()```.
ghstack-source-id: 118151905
Test Plan: CI
Reviewed By: dhruvbird
Differential Revision: D24147914
fbshipit-source-id: 37efb43adc9b491c365df0910234fa6a8a34ec25
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47330
Add support for DataParallel complex tensors by handling them as `torch.view_as_real` for `broadcast_coalesced`, `scatter` and `gather`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48686
Reviewed By: osalpekar
Differential Revision: D25261533
Pulled By: sidneyfletcher
fbshipit-source-id: 3a25e05deee43e053f40d1068fc5c7867cfa9686
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48625
The default TensorImpl is contiguous. Therefore, it is non-overlapping and dense per refresh_contiguous().
ghstack-source-id: 118035410
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D25232196
fbshipit-source-id: 1968d9ed444f2ad5414a78d0b11e5d3030e3109d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47441
To give user more information about python level functions in profiler traces, we propose to instrument on the following functions:
```
_BaseDataLoaderIter.__next__
Optimizer.step
Optimizer.zero_grad
```
Because the record_function already uses if (!active) to check whether the profiler is enabled, so we don't explicitly call torch.autograd._profiler_enabled() before each instrument.
Acknowledgement: nbcsm, guotuofeng, gunandrose4u , guyang3532 , mszhanyi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47655
Reviewed By: smessmer
Differential Revision: D24960386
Pulled By: ilia-cher
fbshipit-source-id: 2eb655789e2e2f506e1b8f95ad3d470c83281102
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48939
Add numerical test for fx graph mode for resnet base, comparing with eager mode
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D25375342
fbshipit-source-id: 08f49b88daede47d44ee2ea96a02999fea246cb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48993
I don't see any reasons that we need to call contiguous on the embedding tables. They should not exist in the first place. The indices and lengths/offsets are actually generated in the model, but they're most likely generated by SigridTransform -> ClipRanges -> GatherRanges -> SigridHash (sometimes) and none of these ops produce non-contiguous tensors. It should be fine to enforce tensor.is_contiguous().
Reviewed By: radkris-git
Differential Revision: D25266756
fbshipit-source-id: f15ecb67281c9ef0c7ac6637f439e538e77e30a2
Summary:
This is a follow up PR of https://github.com/pytorch/pytorch/issues/48463
> Rather than requiring that users write import numbers and then use numbers.Float etc., this PEP proposes a straightforward shortcut that is almost as effective: when an argument is annotated as having type float, an argument of type int is acceptable; similar, for an argument annotated as having type complex, arguments of type float or int are acceptable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48584
Reviewed By: zhangguanheng66
Differential Revision: D25411080
Pulled By: malfet
fbshipit-source-id: e00dc1e9e6e46a8cfae77da4f2cf159c0c2b9bcc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49027
For cat followed by linear since the output of cat is not quanitzed, we didnt quantize the linear
This checks the uses of the cat op to insert observers
Test Plan:
python test/test_quantization.py TestQuantizeJitOps.test_cat_linear
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25403412
fbshipit-source-id: 5875db259bf75f08ce672ce341a67005ed2f8a04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47935
Fetch the parameters that are needed for lowering from nn.Module to fx.node for leaf_modules.
Test Plan: A test `test_fetch` is added to test_fx_experimental.py.
Reviewed By: jfix71
Differential Revision: D24957142
fbshipit-source-id: a349bb718bbcb7f543a49f235e071a079da638b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48876
**Summary**
This commit adds support for `del` statements with multiple targets.
Targets are deleted left-to-right just like Python.
**Test Plan**
This commit updates the `TestBuiltins.test_del_multiple_operands` unit
test to actually test that multiple deletion works instead of asserting
that an error is thrown.
**Fixes**
This commit fixes#48635.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D25386285
Pulled By: SplitInfinity
fbshipit-source-id: c0fbd8206cf98b2bd1b695d0b778589d58965a74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48906
As titled, removing some code which is no longer
needed after refactors.
Test Plan:
CI
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25363079
fbshipit-source-id: 9e4bcf63f4f1c2a2d3fb734688ba593d72495349
Summary:
Currently CUDAExtension assumes that all cards are of the same type on the same machine and builds the extension with compute capability of the 0th card. This breaks later at runtime if the machine has cards of different types.
Specifically resulting in:
```
RuntimeError: CUDA error: no kernel image is available for execution on the device
```
when the cards of the types that weren't compiled for are used. (and the error is far from telling what the problem is to the uninitiated)
My current setup is:
```
$ CUDA_VISIBLE_DEVICES=0 python -c "import torch; print(torch.cuda.get_device_capability())"
(8, 6)
$ CUDA_VISIBLE_DEVICES=1 python -c "import torch; print(torch.cuda.get_device_capability())"
(6, 1)
```
but the extension was getting built with `-gencode=arch=compute_80,code=sm_80`.
This PR:
* [x] introduces a loop over all visible at build time devices to ensure the extension will run on all of them (it sorts the new list generated by the loop, so that the output is easier to debug should a card with lower capacity come last)
* [x] adds `+PTX` to the last entry of ccs derived from local cards (`if not _arch_list:`) to support other archs
* [x] adds a digest of my conversation with ptrblck on slack in the form of docs which hopefully can help others know which archs to support, how to override defaults, when and how to add PTX, etc.
Please kindly review that my prose is clear and easy to understand.
ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48891
Reviewed By: ngimel
Differential Revision: D25358285
Pulled By: ezyang
fbshipit-source-id: 8160f3adebffbc8e592ddfcc3adf153a9dc91557
Summary:
add a unit test to test the situation where a node is too large to fit into any device
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48938
Reviewed By: zhangguanheng66
Differential Revision: D25402967
Pulled By: scottxu0730
fbshipit-source-id: a2e2a3dc70d139fa678865ef03e67fa57eff4a1d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48991
Add native impl of `aten::narrow` to skip dispatcher, because `aten::narrow` calls `aten::slice` in its implementation, here we reduce the dispatcher overhead by two-fold by calling the native impl of `aten::slice`.
Reviewed By: bwasti
Differential Revision: D25387119
fbshipit-source-id: c020da2556a35bc57a8a2e21fa45dd491ea516a0
Summary:
This PR moves the list of Flake8 requirements/versions out of `.github/workflows/lint.yml` and into its own file `requirements-flake8.txt`. After (if) this PR is merged, I'll modify the Flake8 installation instructions on [the "Lint as you type" wiki page](https://github.com/pytorch/pytorch/wiki/Lint-as-you-type) (and its internal counterpart) to just say to install from that new file, rather than linking to the GitHub Actions YAML file and/or giving a command with a set of packages to install that keeps becoming out-of-date.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49032
Test Plan:
Either look at CI, or run locally using [act](https://github.com/nektos/act):
```sh
act -P ubuntu-latest=nektos/act-environments-ubuntu:18.04 -j flake8-py3
```
Reviewed By: janeyx99
Differential Revision: D25404037
Pulled By: samestep
fbshipit-source-id: ba4d1e17172a7808435df06cba8298b2b91bb27c
Summary:
These files refer to https://travis-ci.org/github/zdevito/ATen and https://github.com/zdevito/ATen which were last updated in 2018 and 2019 respectively. According to zdevito:
> yeah, all of that stuff can be deleted
> was from a time when ATen was a separate repo from pytorch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49028
Reviewed By: zdevito
Differential Revision: D25401810
Pulled By: samestep
fbshipit-source-id: a8eea7382f91e1aee6f45552645e6d53825fe5a7
Summary:
As a follow up to https://github.com/pytorch/pytorch/issues/48041, this adds the `LKJCholesky` distribution that samples the Cholesky factor of positive definite correlation matrices.
This also relaxes the check on `tril_matrix_to_vec` so that it works for 2x2 matrices with `diag=-2`.
cc. fehiepsi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48798
Reviewed By: zhangguanheng66
Differential Revision: D25364635
Pulled By: neerajprad
fbshipit-source-id: 4abf8d83086b0ad45c5096760114a2c57e555602
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48616
This adds a couple of _out variants and then registers them to the registry.
I also added the concept of "canReuse{Input,Output}" so that we can annotate tensors that are not optimizable (specifically, non-float tensors).
In the future we can change this (with this D25062301)
after removing `RecordFunction`, we see these results
```
BS=20
---
caffe2: 0.651617 ~ 0.666354
static runtime: 0.753481
pytorch: 0.866658
BS=1
---
caffe2: 0.0858684 ~ 0.08633
static runtime: 0.209897
pytorch: 0.232694
```
Test Plan: standard internal test of ads model against caffe2 reference (see the scripts in this quip: https://fb.quip.com/ztERAYjuzdlr)
Reviewed By: hlu1
Differential Revision: D25066823
fbshipit-source-id: 25ca181c62209a4c4304f7fe73832b13e314df80
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47792
For operators with out arguments, VariableType previously called the out overload of the C++ API because that's all we had.
We introduced a faithful C++ API that takes out arguments in schema-order in D24835252 and this PR changes VariableType to use that API instead.
Note that this only applies to c10-full ops. Non-c10-full ops still call the unfaithful API. There aren't any c10-full out ops at the moment.
So this PR can only be tested and evaluated together with PRs on top that make ops with out arguments c10-full.
ghstack-source-id: 118068088
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D24901945
fbshipit-source-id: a99db7e4d96fcc421f9664504f87df68fe1c482f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47712
This adds a faithful API for ops with out arguments, as described in https://docs.google.com/document/d/1h7nBibRwkRLQ8rsPhfALlwWR0QbkdQm30u4ZBwmaps8/edit# .
After this, an op will generate the following overloads for the C++ API:
```cpp
// Generated from the aten::abs operator (NOT from aten::abs.out)
Tensor at::abs(Tensor& self)
// Generated from the aten::abs.out operator
Tensor& at::abs(Tensor& self, Tensor& out)
Tensor& at::abs_out(Tensor& out, Tensor& self)
```
This is an important step towards making those ops c10-full (it allows VariableType, XLA and other backends to ignore reordering and just call through with the same argument order), but this does not make any of those ops c10-full yet.
It enables the faithful API independent from c10-fullness. That means the API is more consistent with the same API for all ops and making an op c10-full in the future will not trigger future C++ API changes.
ghstack-source-id: 118068091
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D24835252
fbshipit-source-id: dedfabd07140fc8347bbf16ff219aad3b20f2870
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47711
Seems we generated the declaration but the definition only for c10-full ops. We should also generate the definition for non-c10-full ops.
This makes future migrations of ops from non-c10-full to c10-full have a lower impact on the C++ API.
ghstack-source-id: 118064755
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D24835006
fbshipit-source-id: 8f5c3c0ffcdc9b479ca3785d57da16db508795f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46727
This adds kernel launch safety checks to a number of kernels. See D24309971 (353e7f940f) for context.
Test Plan: The existing pre-commit test rigs are used.
Reviewed By: ngimel
Differential Revision: D24334303
fbshipit-source-id: b6433f6be109fc8dbe789e91f3cbfbc31fd15951
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48893
This simplifies some code which is written in an interesting way. It may be that this was intentional, but I don't recognize the pattern being used.
Test Plan: N/A - Sandcastle
Reviewed By: igorsugak
Differential Revision: D25358283
fbshipit-source-id: 19bcf01cbb117843e08df0237e6a03ea77958078
Summary:
Adds an extra make variable 'EXTRA_DOCKER_BUILD_FLAGS' that allows us to
add extra docker build flags to the docker build command.
Example:
make -f docker.Makefile EXTRA_DOCKER_BUILD_FLAGS=--no-cache devel-image
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48942
Reviewed By: walterddr
Differential Revision: D25376288
Pulled By: seemethere
fbshipit-source-id: 9cf2c2a5e01d505fa54447604ecd653dcbdd42e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48902
Previously if the dtype of input gradients is FP16, matrix multiplications will fail, because the created low-rank tensors P and Q use FP32 dtype.
Now let the dtype of P and Q be the same as the input tensor.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 117962078
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
Reviewed By: rohan-varma
Differential Revision: D25362071
fbshipit-source-id: e68753ff23bb480605b02891e128202ed0f8a587
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48799
Python's IMPORT_FROM bytecode will bypass the import infrastructure
when a packaging being loaded as part of a cirular dependency is being
accessed from the module _before_ that package has finished loading
and is installed on the module. Since we cannot override the lookup
on sys.modules, this PR pre-emptively does the module assignment before
running the submodules initialization code.
Note: this appears to work, but it is not clear to me why python doesn't
do this by default. It is possible that the logic for creating modules
is flexible enough in generic python that this interception between creating
the module and running its code is not always possible.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D25312467
Pulled By: zdevito
fbshipit-source-id: 6fe3132af29364ccb2b3cabdd2b847d0a09eb515
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43932
Adds some basic examples to the documentation for each of the newly added
object-based collectibves.
ghstack-source-id: 117965966
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D23441838
fbshipit-source-id: 91344612952cfcaa71f08ccf2a2c9ed162ca9c89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48909
Adds these new APIs to the documentation
ghstack-source-id: 117965961
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D25363279
fbshipit-source-id: af6889d377f7b5f50a1a77a36ab2f700e5040150
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48754
The goal of this PR is to kill Declarations.yaml in the pyi codegen, in favor of native_functions + the existing python object model.
**High-level design**
Since the python signatures used by the `python_arg_parser` are “supposed” to resemble the corresponding pyi type hint signatures, I re-used the existing python object model that Jiakai defined in `tools/codegen/api/python.py`. This means that the pyi codegen now reads `native_functions.yaml`, parses it into a bunch of `PythonSignatureGroup` objects, and emits corresponding method + function variants of type-hint signatures for each one, respectively into `__init__.pyi` and `_VariableFunctions.pyi`.
What makes this uglier is that pyi and the python arg parser have a number of differences in how they’re emitted. I expressed that through a `pyi` flag on the `PythonSignature` dataclass, that tells it whether or not to print itself as a pyi vs. arg_parser signature.
One thing worth noting is how pyi generates signatures differently for native / deprecated op signatures.
For native ops:
- The pyi codegen fuses functional and out variants of each op into a single signature with an optional `out` argument. Ops without an `out` variant just get an ordinary functional signature.
- Some ops that fit certain criteria also get a second “varargs” signature - basically ops with a single positional argument of type List[int].
For deprecated signatures:
- Functional and out variants are not fused - they each get their own signature entry
- There are no varargs signatures
This is currently implemented through the `signature_str()` and `signature_str_vararg()` methods on the `PythonSignature`/`PythonSignatureDeprecated` classes. `signature_str()` knows how to print itself with/without out arguments, differently for native/deprecated ops. `signature_str_vararg()` optionally returns a vararg variant of the signature if one exists.
**Calling out the gap between python_arg_parser vs. pyi**
The two formats are notably different, so I don’t think we can expect to unify them completely. That said, I encountered a number of differences in the pyi codegen that looked wrong- I tried to call them out in the PR, to be removed later. Just as an example, looking at the `svd` signature in the python_arg_parser vs. the pyi type hint:
python_arg_parser
```
Static PythonArgParser parser({
“svd(Tensor input, bool some=True, bool compute_uv=True, *, TensorList[3] out=None”,
}, /*traceable=*/true);
```
Pyi
```
def svd(input: Tensor, some: _bool=True, compute_uv: _bool=True, *, out: Optional[Tensor]=None) -> namedtuple_U_S_V: …
```
The two have obvious syntactic differences that we probably don’t plan on changing: the python_arg_parser doesn’t include `def` or return types, and it includes the type hint before the variable name. But the type of `out` in pyi is probably wrong, since `svd` has multiple output params. I tried to clearly call out any instances of the pyi codegen diverging in a way that looks buggy, so we can clean it up in a later PR (see the comments for details).
Another particularly ugly “bug” that I kept in to maintain byte-for-byte compatibility is the fact that the pyi codegen groups operator overloads together. It turns out that the only reason it does this (as far as I can tell) is because is tacks on an out argument to signatures that don’t have one, if ANY overloads of that op have an out variant.
E.g. consider the pyi type hints generated for `nanmedian` in `_VF.pyi`:
```
overload
def nanmedian(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ...
overload
def nanmedian(input: Tensor, dim: _int, keepdim: _bool=False, *, out: Optional[Tensor]=None) -> namedtuple_values_indices: ...
overload
def nanmedian(input: Tensor, dim: Union[str, ellipsis, None], keepdim: _bool=False, *, out: Optional[Tensor]=None) -> namedtuple_values_indices: ...
```
And the corresponding native_functions.yaml entries:
```
- func: nanmedian(Tensor self) -> Tensor
- func: nanmedian.dim(Tensor self, int dim, bool keepdim=False) -> (Tensor values, Tensor indices)
- func: nanmedian.dim_values(Tensor self, int dim, bool keepdim=False, *, Tensor(a!) values, Tensor(b!) indices) -> (Tensor(a!) values, Tensor(b!) indices)
- func: nanmedian.names_dim(Tensor self, Dimname dim, bool keepdim=False) -> (Tensor values, Tensor indices)
- func: nanmedian.names_dim_values(Tensor self, Dimname dim, bool keepdim=False, *, Tensor(a!) values, Tensor(b!) indices) -> (Tensor(a!) values, Tensor(b!)
```
Signature 2 corresponds to entries 2 and 3 in native_functions, and Signature 3 corresponds to entries 4 and 5. But signature 1 has an optional out argument, even though entry 1 in native_functions.yaml has no out variant.
I’d like to delete that logic in a later PR- that will also have the added benefit no longer requiring to group overloads together in the pyi codegen. We can just operate independently on each PythonSignatureGroup.
**More detailed accounting of the changes**
Per file:
gen_python_functions.py
- `load_signatures()` can now skip deprecated signatures. Needed because pyi only includes deprecated functions, and skips their method variants (maybe we should add them in…?)
- Moved `namedtuple_fieldnames` into python.cpp
- `group_overloads()` can now opt to not sort the overloads (needed for byte-for-byte compact, pyi doesn’t sort for some reason)
Python.py:
- Gave `PythonSignature`and `PythonSignatureDeprecated` a `pyi` flag that tells it whether or not to print itself in pyi vs. python_arg_parser format
- Added a `PythonReturns` dataclass , which is now a member of PythonSignature. It is only used by pyi. I found this useful because python returns need to know how to deal with named tuple returns properly. I also moved `namedtuple_fieldnames` into this file from gen_python_functions
gen_pyi.py
- Merged `get_py_torch_functions` and `get_py_variable_methods` into a single function, since they’re very similar
- Lifted out all of the pyi type hint type-mapping mess and dropped it into python.py. This required updating the mapping to deal with NativeFunction objects instead of the outputs of Declarations.yaml (this was most of the logic in `type_to_python`, `arg_to_type_hint`, and `generate_type_hints`). `generate_type_hints` is now a small orchestration function that gathers the different signatures for each PythonSignatureGroup.
- NamedTuples are now generated by calling `PythonReturn.named_tuple()` (in `generate_named_tuples()`), rather than appending to a global list
A lot of hardcoded pyi signatures still live in `gen_pyi.py`. I didn’t look to closely into whether or not any of that can be removed as part of this PR.
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D25343802
Pulled By: bdhirsh
fbshipit-source-id: f73e99e1afef934ff41e4aca3dabf34273459a52
Summary: Add more error message in ComputeBinaryBroadcastForwardDims
Test Plan:
buck test mode/opt caffe2/caffe2/python/operator_test:gather_ranges_op_test
buck test mode/opt caffe2/caffe2/python/operator_test:reduce_ops_test
buck test mode/opt caffe2/caffe2/python/operator_test:elementwise_ops_test
Reviewed By: BIT-silence
Differential Revision: D24949525
fbshipit-source-id: 762d913a6615a6394072f5bebbcb5cc36f0b8603
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48802
Current torch::jit::load API only supports unique_ptr ReadAdaptInterface input, but for some cases, torch::jit::load may not be the only consumer of the reader adapter. This diff enables an overload of torch::jit::load to load shared_ptr PyTorchStreamReader.
Reviewed By: malfet, houseroad
Differential Revision: D25241904
fbshipit-source-id: aa403bac9ed820cc0e94342aebfe524a1d5bf913
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47860
This PR makes torch.einsum compatible with numpy.einsum except for the sublist input option as requested here https://github.com/pytorch/pytorch/issues/21412. It also fixed 2 performance issues linked below and adds a check for reducing to torch.dot instead of torch.bmm which is faster in some cases.
fixes#45854, #37628, #30194, #15671fixes#41467 with benchmark below
```python
import torch
from torch.utils.benchmark import Timer
a = torch.randn(10000, 100, 101, device='cuda')
b = torch.randn(10000, 101, 3, device='cuda')
c = torch.randn(10000, 100, 1, device='cuda')
d = torch.randn(10000, 100, 1, 3, device='cuda')
print(Timer(
stmt='torch.einsum("bij,bjf->bif", a, b)',
globals={'a': a, 'b': b}
).blocked_autorange())
print()
print(Timer(
stmt='torch.einsum("bic,bicf->bif", c, d)',
globals={'c': c, 'd': d}
).blocked_autorange())
```
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7fa37c413850>
torch.einsum("bij,bjf->bif", a, b)
Median: 4.53 ms
IQR: 0.00 ms (4.53 to 4.53)
45 measurements, 1 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7fa37c413700>
torch.einsum("bic,bicf->bif", c, d)
Median: 63.86 us
IQR: 1.52 us (63.22 to 64.73)
4 measurements, 1000 runs per measurement, 1 thread
```
fixes#32591 with benchmark below
```python
import torch
from torch.utils.benchmark import Timer
a = torch.rand(1, 1, 16, 2, 16, 2, 16, 2, 2, 2, 2, device="cuda")
b = torch.rand(729, 1, 1, 2, 1, 2, 1, 2, 2, 2, 2, device="cuda")
print(Timer(
stmt='(a * b).sum(dim = (-3, -2, -1))',
globals={'a': a, 'b': b}
).blocked_autorange())
print()
print(Timer(
stmt='torch.einsum("...ijk, ...ijk -> ...", a, b)',
globals={'a': a, 'b': b}
).blocked_autorange())
```
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7efe0de28850>
(a * b).sum(dim = (-3, -2, -1))
Median: 17.86 ms
2 measurements, 10 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7efe0de286a0>
torch.einsum("...ijk, ...ijk -> ...", a, b)
Median: 296.11 us
IQR: 1.38 us (295.42 to 296.81)
662 measurements, 1 runs per measurement, 1 thread
```
TODO
- [x] add support for ellipsis broadcasting
- [x] fix corner case issues with sumproduct_pair
- [x] update docs and add more comments
- [x] add tests for error cases
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D24923679
Pulled By: heitorschueroff
fbshipit-source-id: 47e48822cd67bbcdadbdfc5ffa25ee8ba4c9620a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48867
Previously the key of error_dict is the hashcode of tensor. Now replaced with bucket index.
Bucket index can have a few advantages over the hashcode of tensor.
1) Error dict in the state never removes any key. If the bucket rebuild process occurs frequently, the size of error dict can increase. For now, such rebuild process is infrequent, so it is probably fine.
2) Integer index has a better readability than hashcode, and it can facilitate debugging.
If the user wants to debug the tensor values, usually only a specific bucket needs to be targeted. It's easy to specify such condition (e..g, bucket_index = 0), but it's hard to specify a hashcode in advance, as it can only be determined at runtime.
Note that sometimes the buckets can be rebuilt in the forward pass. In this case, the shape of the bucket with the same index will not be consistent with the one in the previous iteration, and hence the error tensor will be re--initialized as a zero tensor of the new shape. Therefore, `and state.error_dict[bucket_index].shape[0] == padded_total_length` is added to the condition of applying the local error from the previous iteration.
Deleted the arg type of `dist._GradBucket` in powerSGD_hook.py, because somehow test_run_mypy - TestTypeHints failed:
AssertionError: mypy failed: torch/distributed/algorithms/ddp_comm_hooks/powerSGD_hook.py:128: error: "_GradBucket" has no attribute "get_index" [attr-defined]
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 117951402
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
Reviewed By: rohan-varma
Differential Revision: D25346347
fbshipit-source-id: 8348aa103002ec1c69e3ae759504b431140b3b0d
Summary:
`torch.cholesky_solve` now works for complex inputs on GPU.
I moved the existing tests to `test_linalg.py` and modified them to test complex and float32 dtypes.
Differentiation also works correctly with complex inputs now.
Ref. https://github.com/pytorch/pytorch/issues/33152
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47047
Reviewed By: ngimel
Differential Revision: D24730020
Pulled By: mruberry
fbshipit-source-id: 95402da5789c56e5a682019790985207fa28fa1f
Summary:
Now that Lilyjjo's [stack of OpInfo updates](https://github.com/pytorch/pytorch/pull/48627) is landed, we can port method_test entries to OpInfos. This PR doesn't port any method_test entries, but it removes redundant entries. These entries previously tested both multi-dim and zero-dim tensors, so a new zero-dim tensor input is added to UnaryUfuncInfo's sample inputs.
To recap, this PR:
- removes method_test() entries that are redundant with OpInfo entries
- adds a new sample input to unary ufunc OpInfos that tests them on 0d tensors
cc kshitij12345 as an fyi. Going forward we should have a goal of not only porting all the MathTestMeta objects to use the OpInfo pattern but also all the current method_test entries. For each entry the function needs to be added as an OpInfo and the inputs need to be added as sample inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48828
Reviewed By: malfet
Differential Revision: D25336071
Pulled By: mruberry
fbshipit-source-id: 6b3f6c347195233d6b8ad57e2be68fd772663d9b
Summary:
+ Add ArgMin support to Caffe2 to PyTorch converter
+ Using hypothesis to parameterize different conditions for test
Test Plan: buck test //caffe2/torch/fb/model_transform/c2_convert:c2_pt_converter_test
Reviewed By: houseroad
Differential Revision: D25016203
fbshipit-source-id: 94489fcf1ed3183ec96f9796a5b4fb348fbde5bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48851
Adding typing to improve readability.
Note: this uncovered a few missing return statements, we should
fix that before landing.
Test Plan:
```
mypy torch/quantization/
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25338644
fbshipit-source-id: 0ac4405db05fdd2737bc3415217bc1937c2db684
Summary:
add a unit test for the situation where devices have no enough memory
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48858
Reviewed By: malfet, gcatron
Differential Revision: D25341254
Pulled By: scottxu0730
fbshipit-source-id: c0524c22717b6c8afd67f5b0ad0f1851b973e4b7
Summary:
Ref https://github.com/pytorch/pytorch/issues/42175
This removes the 4 deprecated spectral functions: `torch.{fft,rfft,ifft,irfft}`. `torch.fft` is also now imported by by default.
The actual `at::native` functions are still used in `torch.stft` so can't be full removed yet. But will once https://github.com/pytorch/pytorch/issues/47601 has been merged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48594
Reviewed By: heitorschueroff
Differential Revision: D25298929
Pulled By: mruberry
fbshipit-source-id: e36737fe8192fcd16f7e6310f8b49de478e63bf0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48757
Add an index field to GradBucekt, so error_dict is keyed by this index instead of the hashcode of input tensor. The replacement will be done in a separate diff, as the definition of this new method somehow couldn't be recognized in the OSS version.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 117939208
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
Reviewed By: rohan-varma
Differential Revision: D25288496
fbshipit-source-id: 6f71977809690a0367e408bd59601ee62c9c03ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48286
RecordFunction initialization is a hot path. shouldRun often does little enough work that the function prologue takes a significant proportion of its time. So, this diff forces it to be inline.
ghstack-source-id: 117892387
Test Plan: FB-internal benchmarks
Reviewed By: ezyang
Differential Revision: D25108879
fbshipit-source-id: 7121413e714c5ca22c8bf10c1d2535a878c15aec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43930Closes#23232. As part of addressing #23232, this PR adds support for scatter_object_list which is an API to scatter arbitrary picklable objects to all the other ranks.
The implementation approach follows a similar approach as https://github.com/pytorch/pytorch/pull/42189. The result of the `scatter` is stored as the first element of `scatter_object_output_list`, and the src rank is expected to provide an input list `scatter_object_input_list` which contains the objects to scatter.
Note that this API requires 1 broadcast and 2 scatters. This is because we must communicate the maximum object size to be scattered, which only the src rank knows about. After that, we also need to communicate the objects themselves as well as the true sizes of the object.
Note that the API is designed to match the tensor-based collectives other than supporting async_op. For now, it is a blocking call. If we see demand to support async_op, we will have to make more progress on merging work/future to support this.
It only works for Gloo because NCCL doesn't support scatter.
ghstack-source-id: 117904065
Reviewed By: mrshenli
Differential Revision: D23430686
fbshipit-source-id: f033b89cd82dadd194f2b036312a98423449c26b
Summary:
This diff enables JIT serialization of `ProcessGroup`, including both base `ProcessGroup` class and derived classes like `ProcessGroupNCCL`.
If a `ProcessGroup` is created via high-level APIs like `dist_c10d.frontend().new_process_group_helper()`, they are automatically serializable. If a `ProcessGroup` is created via its derived class TorchBind APIs like `dist_c10d.ProcessGroupNCCL()`, then it has to be given a name and registered with `dist_c10d.frontend().register_process_group_name` to be uniquely identifiable and serializable.
* Fixed a minor bug in new dist_c10d frontend which fails to check whether a process group is used or not
* Fixed an issue where `test_jit_c10d.py` wasn't really run due to a configuration bug. Now tests are run as a slow test (need ci-all/* branch)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48544
Reviewed By: wanchaol
Differential Revision: D25298309
Pulled By: gmagogsfm
fbshipit-source-id: ed27ce37373c88277dc0c78704c48d4c19d46d46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48681
This should reduce reference counting traffic when creating views.
The code duplication here is unfortunate and I'm open to suggestions on how to reduce it. It's especially regrettable that we create a footgun for subclasses of TensorImpl: they can accidentally override only one of the two overloads and get confusing behavior.
ghstack-source-id: 117896685
Test Plan: internal benchmarks
Reviewed By: ezyang
Differential Revision: D25259741
fbshipit-source-id: 55f99b16b50f9791fdab85cbc81d7cd14e31c4cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48680
It seems a bit long to put into the header (and is virtual anyway).
ghstack-source-id: 117894350
Test Plan: CI
Reviewed By: bhosmer
Differential Revision: D25259848
fbshipit-source-id: e3eed1f2483fc3c1ff51459159bf3bfed9d6f363
Summary:
What this does is that given a `FxModule foo`, you can call `foo.to_folder('foo_folder', 'Foo')` and dump the current FX module into runnable Python code.
That is
```
foo = <fxModule>
foo = foo.to_folder('bar', 'Foo')
from bar import Foo
foo2 = Foo()
forall x, foo2(x) == Foo(x)
```
This has several use cases, largely lifted from jamesr66a's doc here: https://fb.quip.com/U6KHAFaP2cWa (FB-internal).
1. As we apply more heavy-weight function transformations with FX, figuring out what's going on can be quite a difficult experience. In particular, things that can typically be used for debugging (like `print` or `import pdb; pdb.set_trace()`) no longer work. This is particularly necessary if you're using a FX transform like `grad` or `vmap. With this, you simply open up the dumped file, and add `print`/`pdb` statements wherever you'd like.
2. This also provides an immense amount of user control. Some potential use-cases:
- Let's say an existing FX transform has some bug, or generates suboptimal code. Instead of needing to modify that FX transform, writing another FX pass that fixes the suboptimal code, or simply giving up on FX, they can workaround it by simply modifying the resulting code themselves.
- This allows users to check in their FX modules into source control.
- You could even imagine using this as part of some code-gen type workflow, where you write a function, `vmap` it to get the function you actually want, and then simply copy the output of the `vmap` function without needing FX at all in the final code.
An example:
```python
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
self.W = torch.nn.Parameter(torch.randn(2))
self.linear = nn.Linear(2, 2)
self.attr = torch.randn(2)
self.attr2 = torch.randn(2)
def forward(self, x):
return self.linear(self.W + (self.attr + self.attr2) + x)
mod = fx.symbolic_trace(Test())
mod.to_folder('foo', 'Foo')
```
results in
```python
import torch
class Foo(torch.nn.Module):
def __init__(self):
super().__init__()
state_dict = torch.load('foo/state_dict.pt')
self.linear = torch.load('foo/linear.pt') # Linear(in_features=2, out_features=2, bias=True)
self.__tensor_constant0 = state_dict['__tensor_constant0']
self.W = torch.nn.Parameter(state_dict['W'])
def forward(self, x):
w = self.W
tensor_constant0 = self.__tensor_constant0
add_1 = w + tensor_constant0
add_2 = add_1 + x
linear_1 = self.linear(add_2)
return linear_1
```
Some current issues:
1. How do you actually ... save things like modules or parameters? I don't think FX is in the business of tracking initializations and such. Thus, the only way I see to do it is to dump the parameters/modules as blobs, and then load them in the generated initialization. This is a somewhat subpar user experience, and perhaps prevents it from being in some use cases (ie: you would need to check in the blobs into source control to save the model).
2. Currently, the only "atomic" modules we have are those in `torch.nn`. However, if we want to allow flexibility in this, and for example, allow "atomic" modules that are user-defined, then it's not clear how to allow those to be dumped in a way that we can then load elsewhere.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47544
Reviewed By: jamesr66a
Differential Revision: D25232917
Pulled By: Chillee
fbshipit-source-id: fd2b61a5f40e614fc94256a2957ed1d57fcf5492
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48829
The first line was a run-on.
ghstack-source-id: 117845927
Test Plan: visual inspection
Reviewed By: ZolotukhinM
Differential Revision: D25326136
fbshipit-source-id: 3f46ad20aee5ed523b64d852d382eb06f4d60369
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48700
fmod and remainder on int tensors will raise ZeroDivisionError if their divisors are 0. I don't think we should try to generate code that raises exceptions. If at some point we really wanted to fuse these, I might lean towards calling a C++ helper function from the generated code.
ghstack-source-id: 117845642
Test Plan: `buck test //caffe2/test:jit -- test_binary_ops`
Reviewed By: eellison
Differential Revision: D25265792
fbshipit-source-id: 0be56ba3feafa1dbf3c37f6bb8c1550cb6891e6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48732
add support for ScriptObject as attributes in symbolic trace.
Test Plan: OSS CI
Reviewed By: jamesr66a
Differential Revision: D25116185
fbshipit-source-id: c61993c84279fcb3c91f1d44fb952a8d80d0e552
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48762
In distributed inference, we want to use a new type info to pass some information to operators. add a new key to threadLocalDebugInfo to unblock the development.
Test Plan: Only add a new key. Should have not effect on current build.
Reviewed By: dzhulgakov
Differential Revision: D25291242
fbshipit-source-id: c71565ff7a38cc514d7cd65246c7d5f6b2ce3b8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48861
`std::function` already has an empty state; no need to wrap
it in `c10::Optional`.
ghstack-source-id: 117891382
Reviewed By: hlu1
Differential Revision: D25296912
fbshipit-source-id: 8291bcf11735d49db17415b5de915591ee65f781
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48240
Adds the support for converting the SparseLengthsSum4BitRowwiseSparse operator from caffe2 to pytorch as a part of c2_pt_converter
Test Plan:
Added a unit tested
buck test //caffe2/torch/fb/model_transform/c2_convert:c2_pt_converter_test
Tests Passed :
https://our.intern.facebook.com/intern/testinfra/testrun/2251799856412296
Reviewed By: houseroad
Differential Revision: D25067833
fbshipit-source-id: 45cbc331ca35bee27e083714e65a1e87a2a2d2e0
Summary:
Calling torch.distributed.irecv(src=None) fails with "The global rank None is not part of the group". This change calls recv_anysource if src is None. Tested locally with MPI backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47137
Reviewed By: heitorschueroff
Differential Revision: D25292656
fbshipit-source-id: beb018ba0b676924aeaabeb4a4d6acf96e4a1926
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46405, https://github.com/pytorch/pytorch/issues/43352
I updated the docstring in the local file (function level comments). Do I also need to edit somewhere else or recompile docstrings?
Also, though I didn't change any types here, how is typing (for IDE type checking) documentation generated / used)?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46813
Reviewed By: ezyang
Differential Revision: D24923112
Pulled By: vincentqb
fbshipit-source-id: be7818e0d4593bfc5d74023b9c361ac2a538589a
Summary: Adds support for additional Eigen Utils for custom type defs.
Reviewed By: vkuzo
Differential Revision: D23898398
fbshipit-source-id: fb5f6d6ed8a56e6244f4f0cb419140b365ff7a82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48346
Onnxifi now accepts output shape info for all possible batch sizes. This is used to avoid doing shape inference inside `OnnxifiOp::extractOutputBatchSizes()`.
FB:
In this diff we try to pre-calculate output shapes for all possible batch sizes inside `PredictorContainer` where we supposedly have enough data to do so. This data is then passed down to OnnxifiOp.
Here is the dependency graph that I built manually trying to understand the entire flow.
https://pxl.cl/1rQRv
Test Plan:
Strobelight data https://fburl.com/strobelight/jlhhgt21 shows that `OnnxifiOp::RunOnDevice()` now takes only 2.17% of CPU instead of ~20% CPU with the current implementation.
Also, the current implementation takes dozens of milliseconds according to ipiszy:
> After adding more logs, I found each shapeinference call actually takes 40~50ms.
I also added added time measurements temporarily for `OnnxifiOp::extractOutputBatchSizes()`. New impenentation typically consumes 1 to 4 microseconds, and, when data for current bs is not present yet in `output_reshape_info_`, it takes 20-40 microseconds which is still much better than the current implementation.
AF canary https://www.internalfb.com/intern/ads/canary/431357944274985799
AI canary https://www.internalfb.com/intern/ads/canary/431365503038313840
Verifying using test tier https://pxl.cl/1sZ4S
Reviewed By: yinghai, ipiszy
Differential Revision: D25047110
fbshipit-source-id: 872dc1578a1e8e7c3ade5f5e2711e77ba290a671
Summary:
Copying myself from the code comments:
A value can be profiled with differently typed uses.
This can occur from:
- having a use which is not executed, so the type will be
TensorType::get()
- control-flow that depends on tensor type:
if x.size() == 2 op(x) else op(x)
- mutation of the value on a field represented in the tensor type
op(x); x.resize_([...]); op(x)
The most common case today with num_profiles = 1 is from the first case. Here we can just ignore non-profiled uses, and choose any of the profiled uses. Because we guard all tensor types in the runtime, even if we set a Value to have a profiled type from one use and then execute a use with a different profiled type, we will still be correct. In the future we could consider unifying the types of uses, or adding a type refinement node so uses can have the correct corresponding type.
Fix for https://github.com/pytorch/pytorch/issues/48043 I think there's probably too much context required for that to be a good bootcamp task...
There was an observed missed fusion opportunity in detectron2 because of this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48689
Reviewed By: ngimel
Differential Revision: D25278791
Pulled By: eellison
fbshipit-source-id: 443e5e1254446a31cc895a275b5f1ac3798c327f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48339
Closes https://github.com/pytorch/pytorch/issues/48294https://github.com/pytorch/pytorch/pull/48293 added creation and transfer of ScriptModule over RPC in python, but it did not work with ScriptModule.
This PR makes the above work with ScriptModule as per a discussion with mrshenli:
1) We remove the `hasattr()` check and just let Python throw the exception as it would when accessing the py function with `getattr`
2) We condition on `issubclass(type, ScriptModule)` when checking if it is wrapped with async_function, because `ScriptModule` does not have getattr implemented (this is because ScriptModule forward/function is not a python function, it is a torchscript specific function):
```
torch/jit/_script.py", line 229, in __get__
return self.__getattr__("forward") # type: ignore
AttributeError: '_CachedForward' object has no attribute '__getattr__'
```
ghstack-source-id: 117631795
Test Plan: Modified ut
Reviewed By: wanchaol
Differential Revision: D25134423
fbshipit-source-id: 918ca88891c7b0531325f046b61f28947575cff0
Summary:
Add a ROCm 3.10 docker image for CI. Keep the 3.9 image and remove the 3.8 image. Plan is to keep two ROCm versions at a time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48791
Reviewed By: janeyx99
Differential Revision: D25307102
Pulled By: walterddr
fbshipit-source-id: 88371aafd07db7c5d0dd210759bb7c3aac1f0187
Summary:
Add missing types for bitwise_ops in `SimpleIREvaluator`
This is the first part of fixes for issue https://github.com/pytorch/pytorch/issues/48053.
- Original implementation of bitwise_ops supports only int operands, the
fix all support for integral types supported by the IR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48179
Test Plan: `python test/test_jit_fuser_te.py TestTEFuser.test_bitwise_ops`
Reviewed By: ZolotukhinM
Differential Revision: D25126944
Pulled By: penguinwu
fbshipit-source-id: 04dc7fc00c93b2bf1bd9f9cd09f7252357840b85
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48823
deadline=None is not good because
Sandcastle tests will return success for tests timeout (default flag), and we cannot efficiently detect broken tests if there is any.
In addition, the return signal for timeout is 64, which is same as skip test.
Test Plan: Sandcastle, and run tests on card
Reviewed By: hyuen
Differential Revision: D25318184
fbshipit-source-id: de1b55a259edb2452fb51ba4c598ab8cca9e76b7
Summary:
When converting a model that uses `torch.chunk`, it does not work when we have a dynamic input axes, because `Split` split attr is static for opset 11. Therefore, we convert it using `Slice` (support opset 11+). This PR also handles the cases that the input axes cannot be divided by the number of outputs. Pytorch works a way that fit the first (n-1) outputs for the same dim, and remaining for the last one. Added UT for it.
The existing code on `sequence` `split` cannot be leveraged here, because `start`, `end` of `Slice` are static there, but dynamic here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48176
Reviewed By: bdhirsh
Differential Revision: D25274862
Pulled By: bzinodev
fbshipit-source-id: 7d213a7605ad128aca133c057d6dd86c65cc6de9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48792
Adds some more typehints throughout quantization/fx/quantize.py,
to help with readability.
Test Plan:
```
mypy torch/quantization/fx/quantize.py
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25306683
fbshipit-source-id: fc38b885a2cb5bf2c6d23b6305658704c6eb7811
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48774
Adds some more typehints throughout `quantization/fx/quantize.py`.
More are needed, ran out of time for now, we can continue in
future PRs.
Test Plan:
```
mypy torch/quantization/fx/quantize.py
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25295836
fbshipit-source-id: 4029aa8ea5b07ce9a57e4be6a66314d7a4e19585
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48773
Makes util functions in `_prepare` have no side effects,
all dependencies are now in arguments.
Note: arg names are added in order as they appeared in function
code. It's not the most readable, but the lowest risk. This can
be cleaned up in future PRs if needed.
```
python test/test_quantization.py TestQuantizeFx
```
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25295839
fbshipit-source-id: 60c687f6b64924473f969541c8703118e4f7d16e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48772
Makes util functions in `_generate_qconfig_map` have no side
effects, all dependencies are now in arguments.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25295837
fbshipit-source-id: 49399abef626234e34bb5ec8c6d870da3c1760e7
Summary:
These files are generated by MSVC when building with debug symbols `REL_WITH_DEB_INFO=1`:
```
PS C:\Users\Xiang Gao\source\repos\pytorch> git status
On branch master
Your branch is up to date with 'origin/master'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
torch/lib/asmjit.pdb
torch/lib/c10.pdb
torch/lib/c10_cuda.pdb
torch/lib/caffe2_detectron_ops_gpu.pdb
torch/lib/caffe2_module_test_dynamic.pdb
torch/lib/caffe2_observers.pdb
torch/lib/fbgemm.pdb
torch/lib/shm.pdb
torch/lib/torch_cpu.pdb
torch/lib/torch_cuda.pdb
nothing added to commit but untracked files present (use "git add" to track)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47963
Reviewed By: heitorschueroff
Differential Revision: D25311564
Pulled By: malfet
fbshipit-source-id: 1a7125f3c6ff296b4bb0975ee97b59c23586b1cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48741
**Summary**
This commit fixes a bug in the handling of `ast.Subscript` inside
`get_annotation_str`. `annotation.value` (which contains the AST node
representing the container name) should also be processed using
`get_annotation_str`.
**Test Plan**
This commit adds a unit test to `TestClassType` based on the test case
from the issue that reported this bug.
**Fixes**
This commit fixes#47570.
Test Plan: Imported from OSS
Reviewed By: ppwwyyxx
Differential Revision: D25286013
Pulled By: SplitInfinity
fbshipit-source-id: 61a9e5dc16d9f87b80578f78d537f91332093e52
Summary:
Bump oneDNN (mkl-dnn) to 1.7 for bug fixes and performance optimizations
- Fixes https://github.com/pytorch/pytorch/issues/42115. Fixed build issue on Windows for the case when oneDNN is built as submodule
- Fixes https://github.com/pytorch/pytorch/issues/45746. Fixed segmentation fault for convolution weight gradient on systems with Intel AVX512 support
This PR also contains a few changes in ideep for follow-up update (not enabled in current PR yet):
- Performance improvements for the CPU path of Convolution
- Channel-last support
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47853
Reviewed By: bdhirsh
Differential Revision: D25275268
Pulled By: VitalyFedyunin
fbshipit-source-id: 75a589d57e3d19a7f23272a67045ad7494f1bdbe
Summary:
Add a new function, torch.cuda.set_per_process_memory_fraction(fraction, device), to torch.cuda. Related: https://github.com/pytorch/pytorch/issues/18626
The fraction (float type, from 0 to 1) is used to limit memory of cashing allocator on GPU device . One can set it on any visible GPU. The allowed memory equals total memory * fraction. It will raise an OOM error when try to apply GPU memory more than the allowed value. This function is similar to Tensorflow's per_process_gpu_memory_fraction
Note, this setting is just limit the cashing allocator in one process. If you are using multiprocess, you need to put this setting in to the subprocess to limit its GPU memory, because subprocess could have its own allocator.
## usage
In some cases, one needs to split a GPU device as two parts. Can set limitation before GPU memory using.
Eg. device: 0, each part takes half memory, the code as follows:
```
torch.cuda.set_per_process_memory_fraction(0.5, 0)
```
There is an example to show what it is.
```python
import torch
torch.cuda.set_per_process_memory_fraction(0.5, 0)
torch.cuda.empty_cache()
total_memory = torch.cuda.get_device_properties(0).total_memory
# less than 0.5 will be ok:
tmp_tensor = torch.empty(int(total_memory * 0.499), dtype=torch.int8, device='cuda')
del tmp_tensordel tmp_tensor
torch.cuda.empty_cache()
# this allocation will raise a OOM:
torch.empty(total_memory // 2, dtype=torch.int8, device='cuda')
"""
It raises an error as follows:
RuntimeError: CUDA out of memory. Tried to allocate 5.59 GiB (GPU 0; 11.17 GiB total capacity; 0 bytes already allocated; 10.91 GiB free; 5.59 GiB allowed; 0 bytes reserved in total by PyTorch)
"""
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48172
Reviewed By: bdhirsh
Differential Revision: D25275381
Pulled By: VitalyFedyunin
fbshipit-source-id: d8e7af31902c2eb795d416b57011cc8a22891b8f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48749
this change reverts D25179863 (55e225a2dc) because in 1.0.0.14 this behavior got
reintroduced
we believe this was already working pre 1.0.0.9, then intel regressed which is
why we had to remove this quantization section, and in 1.0.0.14 they fixed it
Test Plan:
we tested ctr_instagram_5x which now passes with bitwise matching
hl475 will test the top6 models and if they match, we will use this point
to lock any further changes in the future
Reviewed By: venkatacrc
Differential Revision: D25283605
fbshipit-source-id: 33aa9af008c113d4d61e3461a44932b502bf42ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47665
Re-enabled the pass to remove outputs from fusion that is only used by aten::size;
Added size computation for reduction op via new operator prim::ReductionSizes;
Test Plan: Imported from OSS
Reviewed By: navahgar, jamesr66a
Differential Revision: D25254675
Pulled By: Krovatkin
fbshipit-source-id: e9a057b0287ed0ac93b415647fd8e5e836ba9856
Summary:
Onnx op Gather index need be int32 or int64. However, we don't have this Cast in our converter.
Therefore, it fails the following UT (for opset 11+)
`seq_length.type().scalarType()` is None, so `_arange_cast_helper()` cannot treat it as all integral, then it will cast all to float. Then this float value will be used as Gather index, hence it throws error in ORT about float type index.
The fix is that we need cast Gather index type to Long if it is not int/long.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47653
Reviewed By: heitorschueroff
Differential Revision: D25298056
Pulled By: mruberry
fbshipit-source-id: 05e3a70ccfd74612233c63ec5bb78e060b211909
Summary:
Enable TcpStore for DDP on Windows platform, in order to improve running DDP cross machines performance.
Related RFC is https://github.com/pytorch/pytorch/issues/47659
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47749
Reviewed By: bdhirsh
Differential Revision: D25220401
Pulled By: mrshenli
fbshipit-source-id: da4b46b42296e666fa7d8ec8040093de7443a529
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48728
Mostly removing unnecessary includes so that TensorIterator.h can be
included from NativeFunctions.h without causing cycles. There some
cases where I moved code around so that I didn't have to pull in other
unnecessary stuff.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D25278030
Pulled By: ezyang
fbshipit-source-id: 5f6b95a6bc734e452e9bd7bee8fe5278f5e45be2
Summary:
This adds a transform to convert a real vector of (D * (D-1))/2 dimension into the cholesky factor of a D x D correlation matrix. This follows the implementation in [NumPyro](https://github.com/pyro-ppl/numpyro/blob/master/numpyro/distributions/transforms.py) by fehiepsi. This is needed for the LKJDistribution which will be added in a subsequent PR.
Also in line with the ongoing effort to refactor distributions test, this moves the transforms test into its own file that uses pytest with parametrized fixtures.
For review:
fehiepsi - could you help review the math?
fritzo - do you have any suggestions for what to do about the event dimension (more details are in the comment below)?
ezyang - could you review the changes in `run_test.py`? Instead of a separate `PYTEST_TESTS`, I have clubbed these tests in `USE_PYTEST_LIST` to avoid duplicate logic. The only difference is that we do not anymore check if pytest is not installed and exclude the tests in the list. I figured that if existing tests are already using pytest, this should not matter.
TODOs (probably not all can be satisfied at the same time):
- [x] Use operations that are JIT friendly, i.e. the transform works with different sized input under JIT.
- [x] Resolve test failures - currently `arange(scalar_tensor)` fails on certain backends but this is needed for JIT. Maybe we should only support same sized tensor under JIT?
- [x] Add tests to check that the transform gives correct gradients and is in agreement with the `log_det_jacobian`.
- [x] Add `input_event_dim` and `output_event_dim` to `CorrCholeskyTransform`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48041
Reviewed By: zhangguanheng66
Differential Revision: D25262505
Pulled By: neerajprad
fbshipit-source-id: 5a57e1c19d8230b53592437590b9169bdf2f71e9
Summary:
Fixes https://github.com/pytorch/pytorch/issues/43837
This adds a `torch.broadcast_shapes()` function similar to Pyro's [broadcast_shape()](7c2c22c10d/pyro/distributions/util.py (L151)) and JAX's [lax.broadcast_shapes()](https://jax.readthedocs.io/en/test-docs/_modules/jax/lax/lax.html). This helper is useful e.g. in multivariate distributions that are parameterized by multiple tensors and we want to `torch.broadcast_tensors()` but the parameter tensors have different "event shape" (e.g. mean vectors and covariance matrices). This helper is already heavily used in Pyro's distribution codebase, and we would like to start using it in `torch.distributions`.
- [x] refactor `MultivariateNormal`'s expansion logic to use `torch.broadcast_shapes()`
- [x] add unit tests for `torch.broadcast_shapes()`
- [x] add docs
cc neerajprad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43935
Reviewed By: bdhirsh
Differential Revision: D25275213
Pulled By: neerajprad
fbshipit-source-id: 1011fdd597d0a7a4ef744ebc359bbb3c3be2aadc
Summary:
Convert the NVFUSER's runtime CUDA sources (under `.../jit/codegen/cuda/runtime`) to string literals, then include the headers with the generated literals.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48283
Reviewed By: mrshenli
Differential Revision: D25163362
Pulled By: ngimel
fbshipit-source-id: 4e6c181688ddea78ce6f3c754fee62fa6df16641
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48671
Standalone module might be called separately so it's better to use float
as interface.
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D25256184
fbshipit-source-id: e209492a180ce1f81f31c8d6057956a74bad20b1
Summary:
Fixes https://github.com/pytorch/pytorch/issues/48049
Root cause of the issue explained [here](https://github.com/pytorch/pytorch/issues/48049#issuecomment-736701769).
This PR implements albanD's suggestion to add the `!t.is_view()` check and disable autocast caching for views of tensors.
The added test checks for an increase in memory usage by comparing the initially allocated memory with the memory after 3 iterations using a single `nn.Linear` layer in a `no_grad` and `autocast` context.
After this PR the memory usage in the original issue doesn't grow anymore and yields:
```python
autocast: True
0: 0MB (peak 1165MB)
1: 0MB (peak 1264MB)
2: 0MB (peak 1265MB)
3: 0MB (peak 1265MB)
4: 0MB (peak 1265MB)
5: 0MB (peak 1265MB)
6: 0MB (peak 1265MB)
7: 0MB (peak 1265MB)
8: 0MB (peak 1265MB)
9: 0MB (peak 1265MB)
```
CC ngimel mcarilli
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48696
Reviewed By: bdhirsh
Differential Revision: D25276231
Pulled By: ngimel
fbshipit-source-id: e2571e9f166c0a6f6f569b0c28e8b9ca34132743
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48627
Several changes to the OpInfo testing suite:
- Changed test_ops.py to support sample.inputs that are longer than a single element
- Changed OpInfo class to use custom sample_input generator functions, changed UnaryUfuncInfo to use new format
- Added mvp addmm op to operator database to test out sample.inputs with a length greater than a single element
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D25234178
Pulled By: Lilyjjo
fbshipit-source-id: cca2c60af7e6deb849a1cc3770c04ed88865016c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47695
The method_tests from common_methods_invoations.py are being migrated into a new OpInfo class-based testing framework. The work in this commit pulls out the functions embedded in the old method_tests logic and places them in a location that both the old method_tests and OpInfo tests can use
Specifically: created torch/testing/_internal/common_jit.py from functions and methods in torch/testing/_internal/jit_utils.py and test/test_jit.py. Also created new intermediate class JitCommonTestCase to house moved methods. Also slightly modified jit_metaprogramming_utils.py to work for OpInfo tests
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D25212437
Pulled By: Lilyjjo
fbshipit-source-id: 97bc52c95d776d567750e7478fac722da30f4985
Summary:
On A100, cuDNN persistent RNN algo doesn't work quite well when batch size is not a multiple of 8, so we need to disable it.
Related: https://github.com/pytorch/pytorch/pull/43165
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48070
Reviewed By: bdhirsh
Differential Revision: D25283953
Pulled By: ngimel
fbshipit-source-id: d7f33b1f43e2e3c46dc89ae046779175f6992569
Summary:
[Refiled version of earlier PR https://github.com/pytorch/pytorch/issues/45451]
This PR revamps the hipify module in PyTorch to overcome a long list of shortcomings in the original implementation. However, these improvements are applied only when using hipify to build PyTorch extensions, not for PyTorch or Caffe2 itself.
Correspondingly, changes are made to cpp_extension.py to match these improvements.
The list of improvements to hipify is as follows:
1. Hipify files in the same directory as the original file, unless there's a "cuda" subdirectory in the original file path, in which case the hipified file will be in the corresponding file path with "hip" subdirectory instead of "cuda".
2. Never hipify the file in-place if changes are introduced due to hipification i.e. always ensure the hipified file either resides in a different folder or has a different filename compared to the original file.
3. Prevent re-hipification of already hipified files. This avoids creation of unnecessary "hip/hip" etc. subdirectories and additional files which have no actual use.
4. Do not write out hipified versions of files if they are identical to the original file. This results in a cleaner output directory, with minimal number of hipified files created.
5. Update header rewrite logic so that it accounts for the previous improvement.
6. Update header rewrite logic so it respects the rules for finding header files depending on whether "" or <> is used.
7. Return a dictionary of mappings of original file paths to hipified file paths from hipify function.
8. Introduce a version for hipify module to allow extensions to contain back-compatible code that targets a specific point in PyTorch where the hipify functionality changed.
9. Update cuda_to_hip_mappings.py to account for the ROCm component subdirectories inside /opt/rocm/include. This also results in cleanup of the Caffe2_HIP_INCLUDE path to remove unnecessary additions to the include path.
The list of changes to cpp_extension.py is as follows:
1. Call hipify when building a CUDAExtension for ROCm.
2. Prune the list of source files to CUDAExtension to include only the hipified versions of any source files in the list (if both original and hipified versions of the source file are in the list)
3. Add subdirectories of /opt/rocm/include to the include path for extensions, so that ROCm headers for subcomponent libraries are found automatically
cc jeffdaily sunway513 ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48715
Reviewed By: bdhirsh
Differential Revision: D25272824
Pulled By: ezyang
fbshipit-source-id: 8bba68b27e41ca742781e1c4d7b07c6f985f040e
Summary:
They removed the specific function in Python 3.9 so we should just
remake the function here and use our own instead of relying on hidden
functions from the stdlib
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Fixes https://github.com/pytorch/pytorch/issues/48617
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48618
Reviewed By: samestep
Differential Revision: D25230281
Pulled By: seemethere
fbshipit-source-id: 57216af40a4ae4dc8bafcf40d2eb3ba793b9b6e2
Summary:
Add reparameterization support to the `OneHotCategorical` distribution. Samples are reparameterized based on the straight-through gradient estimator, which is proposed in the paper [Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation](https://arxiv.org/abs/1308.3432).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46610
Reviewed By: neerajprad
Differential Revision: D25272883
Pulled By: ezyang
fbshipit-source-id: 8364408fe108a29620694caeac377a06f0dcdd84
Summary:
It has been deprecated for a while and was finally removed in 20.3
Followup after https://github.com/pytorch/pytorch/pull/48722
Fixes ONNX build failures after docker image update
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48742
Reviewed By: walterddr
Differential Revision: D25282017
Pulled By: malfet
fbshipit-source-id: 1dfa4eb57398f979107ca1544aafbc6d7b5e68a4
Summary:
Fixes https://github.com/pytorch/pytorch/issues/48200
CUDA 11.0 only supports < sm_80 (https://docs.nvidia.com/cuda/archive/11.0/nvrtc/#group__options)
Note: NVRTC documentation is not a reliable source to query supported architecture. Rule of thumb is that nvrtc supports the same set of arch for nvcc, so the best way to query that is something like `nvcc -h | grep -o "compute_[0-9][0-9]" | sort | uniq`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48455
Reviewed By: zhangguanheng66
Differential Revision: D25255529
Pulled By: ngimel
fbshipit-source-id: e84cf51ab50519b4c97dad063cc43c9194942bb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47457
This fixes two issues.
1. lite interpreter record_function is intended to be used only for root op
profiling. At the moment if RECORD_FUNCTION is enabled via Dispatcher then it
logs not just root ops but all ops.
2. Because interpreter sets op index that later gets picked up elsewhere
(decoupled design), op index that is set in lite interpreter ends up getting
used by all the record function calls not just root op. Thus we dont really get
correct per op profiling. This diff also fixes this issue.
Reviewed By: ilia-cher
Differential Revision: D24763689
fbshipit-source-id: 6c1f8bcaec9fb5ebacb2743a5dcf7090ceb176b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48178
I migrated all call sites that used the legacy dispatcher registration API (RegisterOperators()) to use the new API (TORCH_LIBRARY...). I found all call-sites by running `fbgs RegisterOperators()`. This includes several places, including other OSS code (nestedtensor, torchtext, torchvision). A few things to call out:
For simple ops that only had one registered kernel without a dispatch key, I replaced them with:
```
TORCH_LIBRARY_FRAGMENT(ns, m) {
m.def("opName", fn_name);
}
```
For ops that registered to a specific dispatch key / had multiple kernels registered, I registered the common kernel (math/cpu) directly inside a `TORCH_LIBRARY_FRAGMENT` block, and registered any additional kernels from other files (e.g. cuda) in a separate `TORCH_LIBRARY_IMPL` block.
```
// cpu file
TORCH_LIBRARY_FRAGMENT(ns, m) {
m.def("opName(schema_inputs) -> schema_outputs");
m.impl("opName", torch::dispatch(c10::DispatchKey::CPU, TORCH_FN(cpu_kernel)));
}
// cuda file
TORCH_LIBRARY_IMPL(ns, CUDA, m) {
m.impl("opName", torch::dispatch(c10::DispatchKey::CUDA, TORCH_FN(cuda_kernel)));
}
```
Special cases:
I found a few ops that used a (legacy) `CPUTensorId`/`CUDATensorId` dispatch key. Updated those to use CPU/CUDA- this seems safe because the keys are aliased to one another in `DispatchKey.h`
There were a handful of ops that registered a functor (function class) to the legacy API. As far as I could tell we don't allow this case in the new API, mainly because you can accomplish the same thing more cleanly with lambdas. Rather than delete the class I wrote a wrapper function on top of the class, which I passed to the new API.
There were a handful of ops that were registered only to a CUDA dispatch key. I put them inside a TORCH_LIBRARY_FRAGMENT block, and used a `def()` and `impl()` call like in case two above.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D25056090
Pulled By: bdhirsh
fbshipit-source-id: 8f868b45f545e5da2f21924046e786850eba70d9
Summary:
The PR adds a feature to disable atomics in rocblas calls thereby making the output deterministic when it is expected in pyTorch. This mode of rocBLAS can be exercised using the global setting `torch.set_deterministic(True)`
cc: ezyang jeffdaily sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48654
Reviewed By: bdhirsh
Differential Revision: D25272296
Pulled By: ezyang
fbshipit-source-id: 70400572b0ab37c6db52636584de0ae61bb5270a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48661
Previously _conv_forward will add self.bias to the result, so bias is added twice in qat ConvBn module
this PR added a bias argument to _conv_forward and _conv_forward is called with zero bias
in ConvBn module
fixes: https://github.com/pytorch/pytorch/issues/48514
Test Plan:
Imported from OSS
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D25249175
fbshipit-source-id: 4536c7545d3dcd7e8ea254368ffb7cf15118d78c
Summary:
This fix allows the calibration function to take in more than one positional argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48537
Reviewed By: zhangguanheng66
Differential Revision: D25255764
Pulled By: jerryzh168
fbshipit-source-id: 3ce20dbed95fd26664a186bd4a992ab406bba827
Summary:
In 3.9, `ast.Index` and `ast.ExtSlice` are deprecated, so:
- `ast.parse('img[3]', model='eval')` evaluates to
`Expression(body=Subscript(value=Name(id='img'), slice=Constant(value=3)))` by 3.9,
but was previously evaluated to `Expression(body=Subscript(value=Name(id='img'), slice=Index(value=Num(n=3))))`
- and `ast.parse('img[..., 10:20]', mode='eval')` is evaluated to
`
Subscript(value=Name(id='img'),slice=Tuple(elts=[Constant(value=Ellipsis),Slice(lower=Constant(value=10), upper=Constant(value=20))]))
`
, but was evaluated to
`
Subscript(value=Name(id='img'), slice=ExtSlice(dims=[Index(value=Ellipsis()), Slice(lower=Num(n=10), upper=Num(n=20), step=None)]))
`
Fixes https://github.com/pytorch/pytorch/issues/48674
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48676
Reviewed By: seemethere, gmagogsfm
Differential Revision: D25261323
Pulled By: malfet
fbshipit-source-id: cc818ecc596a062ed5f1a1d11d3fdf0f22bf7f4a
Summary:
"--build <dir>" flag has been deprecated for a while and finally removed in pip-20.3
Before this PR is applied, every change to docker images would result in ONNX failures
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48722
Reviewed By: janeyx99
Differential Revision: D25274020
Pulled By: malfet
fbshipit-source-id: 9e0f9daba58ceeec5474d649d1b22bfeca91d7bc
Summary:
Relanding https://github.com/pytorch/pytorch/pull/46862
There was an issue with the simultaneous merge of two slightly conflicting PRs.
This PR adds `torch.lu_solve` for complex inputs both on CPU and GPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48028
Reviewed By: linbinyu
Differential Revision: D25003700
Pulled By: zou3519
fbshipit-source-id: 24cd1babe9ccdbaa4e2ed23f08a9153d40d0f0cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48687
Only one header needed to be updated to now include NativeFunctions.h
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D25261845
Pulled By: ezyang
fbshipit-source-id: de778b5e014c812c52a307841827193ce823afcc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48683
I want to delete NativeFunctions.h from Functions.h header. To do this I must remove all references to native:: However; I also must avoid trampling over iseeyuan's work of making ATen compilable without reference to ATen_cpu. In this particular case, I fix the Functions.h problem by moving it to a cpp file, and removing the native:: short-circuit (ostensibly there for performances). This also fixes a hypothetical correctness bug where these would not dispatch properly if the underlying functions no longer uniformly used a single native:: implementation.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D25261843
Pulled By: ezyang
fbshipit-source-id: 05ca6555fbf1062f9b22d868c8cb88fdf8e4c24b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48659
Detailed RFC at
https://github.com/pytorch/rfcs/blob/rfc-0005/RFC-0005-structured-kernel-definitions.md#handling-tensoriterator
What this diff does:
* Refactor allocation of outputs in TensorIterator into a call to a single function TensorIterator::set_output. This nicely centralizes restriding logic and mostly eliminates the need for a separate named tensor propagation pass. The one exception is for inplace operations (`add_`), where previously we never actually call `set_output` when we determine resizing is not necessary; there's an extra propagate names in `allocate_or_resize_outputs` to handle this case (I audited all other `set_output` sites and found that we always hit this path in that situation). Although hypothetically this could cause problems for structured kernels (which require a `set_output` call in all cases), this codepath is irrelevant for structured kernels as a TensorIterator will never be constructed with an explicit out argument (remember, structured kernels handle out/functional/inplace variants). There's also a tricky case in `compute_types`; check the comments there for more details.
* Split TensorIterator into a TensorIteratorBase, which contains most of the logic but doesn't define `set_output`. A decent chunk of the diff is just the mechanical rename of TensorIterator to TensorIteratorBase. However, there are a few cases where we create fresh TensorIterator objects from another TensorIterator. In those cases, we always construct a fresh TensorIterator (rather than preserving the subclass of TensorIteratorBase that induced this construction). This makes sense, because a structured function class will contain metadata that isn't relevant for these downstream uses. This is done by *intentionally* permitting object slicing with the `TensorIterator(const TensorIteratorBase&)` constructor.
* Introduce a new `MetaBase` class which contains the canonical virtual method definition for `set_output`. This will allow structured classes to make use of it directly without going through TensorIterator (not in this PR).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D25261844
Pulled By: ezyang
fbshipit-source-id: 34a9830cccbc07eaaf7c4f75114cd00953e3db7d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48195
The general approach is to change Arguments, splitting `positional`, `kwarg_only` and `out`, into `pre_self_positional`, `self_arg`, `post_self_positional`, and `pre_tensor_options_kwarg_only`, `tensor_options` and `post_tensor_options_kwarg_only`. The splits are as you'd expect: we extract out the self argument and the tensor options arguments, and record the other arguments that came before and after. To do this, we move the logic in `group_arguments` to the parsing process.
Some fuzz in the process:
* I renamed `ThisArgument` to `SelfArgument`, since we don't actually use the terminology "this" outside of C++ (and the model is Python biased)
* I kept the `group_arguments` function, which now just reads out the arguments from the structured model in the correct order. In the long term, we should get rid of this function entirely, but for now I kept it as is to reduce churn.
* I decided to arbitrarily say that when self is missing, everything goes in "post-self", but when tensor options is missing, everything goes in "pre-tensor-options". This was based on where you typically find the argument in question: self is usually at front (so most args are after it), while tensor options are typically at the end (so most args go before it).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zhangguanheng66
Differential Revision: D25231166
Pulled By: ezyang
fbshipit-source-id: 25d77ad8319c4ce0bba4ad82e451bf536ef823ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48182
I'm planning to add a bunch more argument fields following
https://github.com/pytorch/pytorch/pull/45890#discussion_r503646917 and
it will be a lot more convenient if the arguments get to live
in their own dedicated struct. Type checker will tell you if
I've done it wrong. No change to output.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D25057897
Pulled By: ezyang
fbshipit-source-id: dd377181dad6ab0c894d19d83408b7812775a691
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48116
If you port kernels to be structured, you get Meta kernels automatically
generated for you. This is one payoff of structured kernels.
Code generation was mercifully really simple, although at risk of
"swiss cheese" syndrome: there's two new conditionals in the codegen
to tweak behavior when generating for meta keys. It's not too bad
right now but there's a risk of things getting out of hand. One
way to rationalize the logic here would be to transmit "TensorMeta-ness"
inside the TensorOptions (so tensor_from_meta can deal with it); then
the "Meta" kernel magic would literally just be generating empty
out_impls to call after all the scaffolding is done. But I didn't
do this because it seemed like it would be more annoying short term.
Also had to teach resize_ to work on meta tensors, since we use them
to implement the out kernels.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer, ailzhang
Differential Revision: D25056640
Pulled By: ezyang
fbshipit-source-id: f8fcfa0dbb58a94d9b4196748f56e155f83b1521
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48670
Support an optional error feedback for PowerSGD -- storing the difference (i.e., the local error caused by compression) between the input gradient (adjusted by the existing error) and the gradient after decompression, and reinserting it at the next iteration.
Still need to add an index field to GradBucket as the key of error_dict. This is because the current key, input tensor of the bucket, can change across steps, as the buckets may be rebuilt in forward pass in order to save peak memory usage.
This is halfway of error feedback. Plan to add the new index field in a separate PR.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 117636492
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
Reviewed By: rohan-varma
Differential Revision: D25240290
fbshipit-source-id: 5b6e11e711caccfb8984ac2767dd107dbf4c9b3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48672
When a user specifies `pruned_weights = True`, compressed_indices_mapping = {0}, it means they have not pruned the weights. In this case, we need to go through non-sparse kernels for embedding bag lookup.
Test Plan:
buck test //caffe2/test:quantization
https://www.internalfb.com/intern/testinfra/testconsole/testrun/3377699760676256/
Reviewed By: radkris-git
Differential Revision: D25252904
fbshipit-source-id: 3a97dfd41ec8113d61135f02d9f534df3419e81f
Summary:
This PR adds `torch.linalg.matrix_rank`.
Changes compared to the original `torch.matrix_rank`:
- input with the complex dtype is supported
- batched input is supported
- "symmetric" kwarg renamed to "hermitian"
Should I update the documentation for `torch.matrix_rank`?
For the input with no elements (for example 0×0 matrix), the current implementation is divergent from NumPy. NumPy stumbles on not defined max for such input, here I chose to return appropriately sized tensor of zeros. I think that's mathematically a correct thing to do.
Ref https://github.com/pytorch/pytorch/issues/42666.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48206
Reviewed By: albanD
Differential Revision: D25211965
Pulled By: mruberry
fbshipit-source-id: ae87227150ab2cffa07f37b4a3ab228788701837
Summary: Adds support for Eigen Utils for custom type defs.
Reviewed By: vkuzo
Differential Revision: D23753697
fbshipit-source-id: de1cfb1c8176a08dd418364f2fce003344fe25bb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45215
Still need to resolve a few mypy issues before a review. In special, there is an error which I don't know how to solve, see:
```python
torch/onnx/utils.py:437: error: Name 'is_originally_training' is not defined [name-defined]
if training is None or training == TrainingMode.EVAL or (training == TrainingMode.PRESERVE and not is_originally_training):
```
`is_originally_training` is used but never defined/imported on [`torch/onnx/utils.py`](ab5cc97fb0/torch/onnx/utils.py (L437)),
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45258
Reviewed By: zhangguanheng66
Differential Revision: D25254920
Pulled By: ezyang
fbshipit-source-id: dc9dc036da43dd56b23bd6141e3ab92e1a16e3b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48615
Convert the macro from `TORCH_CUDA_KERNEL_LAUNCH_CHECK` to `C10_CUDA_KERNEL_LAUNCH_CHECK`, since it is now accessible through c10, not just torch.
Test Plan:
```
buck build //caffe2/caffe2:caffe2_cu
buck build //caffe2/aten:ATen-cu
buck test //caffe2/test:kernel_launch_checks -- --print-passing-details
```
Reviewed By: jianyuh
Differential Revision: D25228727
fbshipit-source-id: 9c65feb3d0ea3fbd31f1dcaecdb88ef0534f9121
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48248
We have found a few bugs where initializing/de-initializing/re-initializing RPC, and using RPC along with process groups does not work as expected, usually under TCP/env initialization (which is used over `file` which is the init that we use in our test in multi-machine scenarios).
Due to this motivation, this PR adds an environment variable `RPC_INIT_WITH_TCP` that allows us to run any RPC test with TCP initialization.
To avoid port collisions, we use `common.find_free_port()`.
ghstack-source-id: 117553039
Test Plan: CI
Reviewed By: lw
Differential Revision: D25085458
fbshipit-source-id: b5dbef2ff8ae88fa5bc1bb85a9e0fe077dbb552c
Summary:
Fixes a pointless comparison against zero warning that arises for some scalar types
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48272
Test Plan:
Arises with
```
xbuck test mode/dev-nosan //caffe2/torch/fb/sparsenn:gpu_test -- test_prior_correction_calibration_prediction_binary
```
Fixes issues raised by https://github.com/pytorch/pytorch/issues/47876 - `std::is_signed` was a poor choice `std::is_unsigned` is a better choice. Surprisingly, the two are non-reciprocal.
Reviewed By: zhangguanheng66
Differential Revision: D25256251
Pulled By: r-barnes
fbshipit-source-id: 31665f5b0bc7eebee7456b85c37c5bce3f738bea
Summary:
In PyTorch 1.5, when running `torch.cuda.reset_peak_memory_stats()` on a machine where `torch.cuda.is_available() is False`, I would get:
```
AssertionError:
Found no NVIDIA driver on your system. Please check that you
have an NVIDIA GPU and installed a driver from
http://www.nvidia.com/Download/index.aspx
```
In PyTorch 1.7, the same gets me a worse error (and a user warning about missing NVIDIA drivers if you look for it):
```
...
File "/opt/conda/lib/python3.7/site-packages/torch/_utils.py", line 440, in _get_device_attr
if device_type.lower() == "cuda":
AttributeError: 'NoneType' object has no attribute 'lower'
```
The formerly raised AssertionError is depended on by libraries like pytorch_memlab: ec9a72fc30/pytorch_memlab/line_profiler/line_profiler.py (L90)
It would be pretty gross if pytorch_memlab had to change that to catch an AttributeError.
With this patch, we get a more sensible:
```
...
File "/opt/conda/lib/python3.7/site-packages/torch/cuda/memory.py", line 209, in reset_peak_memory_stats
return torch._C._cuda_resetPeakMemoryStats(device)
RuntimeError: invalid argument to reset_peak_memory_stats
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48406
Reviewed By: mrshenli
Differential Revision: D25205630
Pulled By: ngimel
fbshipit-source-id: 7c505a6500d730f3a2da348020e2a7a5e1306dcb
Summary:
many newly added build settings are not saved in torch.__config__. adding them to the mix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48380
Reviewed By: samestep
Differential Revision: D25161951
Pulled By: walterddr
fbshipit-source-id: 1d3dee033c93f2d1a7e2a6bcaf88aedafeac8d31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46827
TensorPipe RPC agent uses JIT pickler/unpickler to serialize/deserialize
tensors. Instead of saving tensors to a file, the agent can directly
invoke `cudaMemcpy` to copy tensors from the sender to the receiver
before calling into JIT unpickler. As a result, before unpickling,
the agent might already have allocated tensors and need to pass
them to the JIT unpickler. Currently, this is done by providing a
`read_record` lambda to unpickler for CPU tensors, but this is
no longer sufficient for zero-copy CUDA tensors, as the unpickler
always allocate the tensor on CPU.
To address the above problem, this commit introduces a `use_storage_device`
flag to unpickler ctor. When this flag is set, the unpickler will
use the device from the `DataPtr` returned by the `read_record`
lambda to override the pickled device information and therefore
achieves zero-copy.
Test Plan: Imported from OSS
Reviewed By: wanchaol
Differential Revision: D24533218
Pulled By: mrshenli
fbshipit-source-id: 35acd33fcfb11b1c724f855048cfd7b2991f8903
Summary:
For the same reason that ubuntu builds need conda cmake to find mkl.
CC jaglinux
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48035
Reviewed By: zhangguanheng66
Differential Revision: D25246723
Pulled By: malfet
fbshipit-source-id: 9dac130eecd2f76764d8027b888404c87e7a954a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47550
I saw over 5% time spent in RecordFunction's ctor during one
of our framework overhead benchmarks in `perf`. Inspecting assembly,
it looks like we just create a lot of RecordFunctions and the
constructor has to initialize a relatively large number of member
variables.
This diff takes advantage of the observation that RecordFunction does
nothing most of the time by moving its state onto the heap and only
allocating it if needed. It does add the requirement that profiling is
actually active to use RecordFunction accessors, which I hope won't be
a problem.
ghstack-source-id: 117498489
Test Plan: Run framework overhead benchmarks. Savings ranging from 3% (InPlace_ndim_1) to 7.5% (empty_ndim_3) wall time.
Reviewed By: ilia-cher
Differential Revision: D24812213
fbshipit-source-id: 823a1e2ca573d9a8d7c5b7bb3972987faaacd11a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48274
The std::function-ness of it was used only for tests. (std::function is huge at 32 bytes, and not particularly efficient.)
ghstack-source-id: 117498491
Test Plan: CI
Reviewed By: dzhulgakov
Differential Revision: D25102077
fbshipit-source-id: fd941ddf32235a9659a1a17609c27cc5cb446a54
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48663
enable the flag inside the test
Test Plan:
GLOW_NNPI=1 USE_INF_API=1 buck-out/opt/gen/caffe2/caffe2/contrib/fakelowp/test/test_fc_nnpi_fp16nnpi#binary.par
buck test -c glow.nnpi_use_inf_api=true mode/opt //caffe2/caffe2/contrib/fakelowp/test:test_fc_nnpi_fp16nnpi
Reviewed By: hl475
Differential Revision: D25249575
fbshipit-source-id: bb0a64859fa8e70eeea458376998142f37361525
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48432
As per our design in https://github.com/pytorch/pytorch/issues/44827,
changign the API such that the user places modules on appropriate devices
instead of having a `balance` and `devices` parameter that decides this.
This design allows us to use RemoteModule in the future.
ghstack-source-id: 117491992
ghstack-source-id: 117491992
Test Plan: waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D25172970
fbshipit-source-id: 61ea37720b92021596f69788e45265ac9cd41746
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47871
- FuzzedTensor now supports complex data types
- Compare no longer calls min on empty ranges when a table has empty cells
* **#47871 Fix complex tensors and missing data in benchmark utility**
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D25237500
Pulled By: robieta
fbshipit-source-id: 76248647313d4d81590a68297a5f6768fa7d3d82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48624
Before this PR, there was an assumption that all graph inputs
and outputs are in floating point, with some exceptions for
`standalone_module`.
This PR adds an option to specify either inputs or outputs
as being quantized.
This is useful for incremental migrations of models using Eager mode.
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25231833
fbshipit-source-id: 9f9da17be72b614c4c334f5c588458b3e726ed17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48347
Add a safety check `TORCH_CUDA_KERNEL_LAUNCH_CHECK()` after each kernel launch. This only includes changes to `//caffe2/caffe2/sgd`. Specifically these files did not have any kernel launch checks before.
Files changed were determined by running `python3 caffe2/torch/testing/check_kernel_launches.py`.
Other directories will be done in seperate diffs.
Test Plan:
Check build status
```
buck build //caffe2/caffe2:caffe2_cu
```
- https://www.internalfb.com/intern/buck/build/5cb3185e-b481-4f83-9c3a-260827dde5ef
Running
```
python3 caffe2/torch/testing/check_kernel_launches.py
```
results in no files within this subdirectory (as of now)
- P150434759
Reviewed By: jianyuh
Differential Revision: D24868557
fbshipit-source-id: 1ad02260bcc9d13710bfd577c8d93be52595845c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46983.
The solution is based of two components:
1. The introduction of the `_initialized` attribute. This will be used during ParameterList/Dict creation methods `__init__` (introduced in https://github.com/pytorch/pytorch/issues/47772) and `__setstate__` to not trigger warnings when setting general `Module` attributes.
2. The introduction of the `not hasattr(self, key)` check to avoid triggering warnings when changing general `Module` attributes such as `.training` during the `train()` and `eval()` methods.
Tests related to the fix are added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48315
Reviewed By: mrshenli
Differential Revision: D25130217
Pulled By: albanD
fbshipit-source-id: 79e2abf1eab616f5de74f75f370c2fe149bed4cb
Summary:
Onnx op Gather index need be int32 or int64. However, we don't have this Cast in our converter.
Therefore, it fails the following UT (for opset 11+)
`seq_length.type().scalarType()` is None, so `_arange_cast_helper()` cannot treat it as all integral, then it will cast all to float. Then this float value will be used as Gather index, hence it throws error in ORT about float type index.
The fix is that we need cast Gather index type to Long if it is not int/long.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47653
Reviewed By: ejguan
Differential Revision: D25097324
Pulled By: bzinodev
fbshipit-source-id: 42da1412d1b972d4d82c17fb525879c2575820c9
Summary:
Support exporting with `as_tuple = true`
Example:
`torch.nonzero(x, as_tuple=True)`
This is the same as
`torch.unbind(torch.nonzero(x), 1)`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47421
Reviewed By: malfet
Differential Revision: D24870760
Pulled By: bzinodev
fbshipit-source-id: 06ca1e7ecf95fbf7c28eebce800df958c83264c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48426
Tests are run on the intersection of the dtypes requested and the types that are
supported by the operator (or are _not_ if `unsupported_dtypes_only` is used).
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D25205835
Pulled By: mruberry
fbshipit-source-id: 2c6318a1a3dc9836af7361f32caf9df28d8a792b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48593
Previously _conv_forward will add self.bias to the result, so bias is added twice in qat ConvBn module
this PR added a bias argument to _conv_forward and _conv_forward is called with zero bias
in ConvBn module
fixes: https://github.com/pytorch/pytorch/issues/48514
Test Plan: Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D25222215
fbshipit-source-id: 90c0ab79835b6d09622dcfec9de4139881a60746
Summary:
This PR add supports on AOT based partition. Given each node and its corresponding partition id, generate the partition, submodules and dag
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48336
Reviewed By: gcatron
Differential Revision: D25226899
Pulled By: scottxu0730
fbshipit-source-id: 8afab234afae67c6fd48e958a42b614f730a61d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48507
Previously the random seed is the length of input tensor, which is not guaranteed to be the different for different batches. Now initialize a random generator in PowerSGD state, and use this generator to create a random seed to randomize the low-rank tensor Q at every step.
Therefore, the initial tensor Q should be the same across all the replicas at the same step, but different at different steps.
'torch.manual_seed' is used in the same way as https://github.com/epfml/powersgd/blob/master/gradient_reducers.py#L675
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 117483639
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d --
test_powerSGD_ddp_comm_hook_nccl_grad_is_view
Also checked the initial Qs and input random seeds of torch.manual_seed() of different ranks for a few steps in real runs.
Example logs:
Exactly same random seed of different ranks at the same step on two nodes, and the random seed varies at each step.
{F346971916}
Reviewed By: rohan-varma
Differential Revision: D25191589
fbshipit-source-id: f7f17df3ad2075ecae1a2a56ca082160f7c5fcfc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47960
Audited this code path after seeing it in profiling. Found some issues:
- Multiple lookups in std::map can be avoided by using `std::map::insert`. It's really a find-or-insert, which is what this code wanted anyway.
- Some unnecessary copying of arguments that could be moved from
- We can move from shared_ptrs that are going out of scope anyway
ghstack-source-id: 116914902
Test Plan: Please advise, as I'm new to this code. Does it have test coverage? Is there a way I can easily measure the performance impact of this change?
Reviewed By: Krovatkin
Differential Revision: D24971041
fbshipit-source-id: 881a45f8958854be0e95fba659e0b64bd341501e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48340
This changes the context managed classes from using a decorator to define them to using inheritance. Inheritance allows the python static type checking to work correctly.
```
context.define_context()
class Bar(object): ...
context.define_context(allow_default=True)
class Foo(object): ...
```
becomes
```
class Foo(context.Managed): ...
class Bar(context.DefaultManaged): ...
```
Behavior differences:
* arg_name has been removed since it's not used anywhere
* classes need to call `super()` in `__enter__/__exit__` methods if they override (none do)
This also defines a context.pyi file to add types for python3. python2 support should not be affected
Test Plan:
ci
buck test //caffe2/caffe2/python:context_test //caffe2/caffe2/python:checkpoint_test
Reviewed By: dongyuzheng
Differential Revision: D25133469
fbshipit-source-id: 16368bf723eeb6ce3308d6827f5ac5e955b4e29a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48623
The error introduced by fast sigmoid/tanh seems to accumulate in a way that's detectable in a macro-benchmark (unfortunately I don't have the model demonstrating it in a format that can be publically committed).
ghstack-source-id: 117496822
Test Plan: Tbh not sure how to test this since I'm not super well-versed in numerics. I can verify it fixes a model divergence locally.
Reviewed By: navahgar
Differential Revision: D25230376
fbshipit-source-id: c404a0439f190359b72ad65b3f42369c53cae340
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48407
T79817692: Fused8BitRowwiseQuantizedToFloat operator support for c2_pt_converter.
Also refactored some repeated code from the existing test functions. (Initial commit only has refactoring.)
Test Plan: buck test //caffe2/torch/fb/model_transform/c2_convert:c2_pt_converter_test
Reviewed By: bugra
Differential Revision: D25069936
fbshipit-source-id: 72f6a845a1b4639b9542c6b230c8cd74b06bc5a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48313
Previous prepacking method would cause stored data to be lost whenever data is flushed during a `.cpu()` call. I updated the weight/bias prepacking to use the same method from `conv2d` in order to avoid this.
Test Plan: Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D25125405
Pulled By: SS-JIA
fbshipit-source-id: 2533994d522d90824fc25ee78c54016cfd0f3253
Summary:
Improves support for rocgdb when setting DEBUG=1 and building for ROCm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46717
Reviewed By: mrshenli
Differential Revision: D25171544
Pulled By: malfet
fbshipit-source-id: b4699ba2277dcb89f07efb86f7153fae82a80dc3
Summary:
I found a number of spelling & grammatical mistakes in the repository. Previously I had these fixes submitted individually, but I saw that a single word change was apparently too small for a PR to be merged. Hopefully this new PR has a sufficient number of changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48592
Reviewed By: ejguan
Differential Revision: D25224216
Pulled By: mrshenli
fbshipit-source-id: 2af3db2aee486563efd0dffc4e8f777306a73e44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48161
- Register BlackBoxPredictor AllocationArenaPool as CPUCachingAllocator
- Use the AllocationArenaPool in both BlackBoxPredictor and StaticRuntime
Test Plan:
```
buck run //caffe2/caffe2/fb/predictor:black_box_predictor_test
buck run //caffe2/caffe2/fb/predictor:pytorch_predictor_test
```
AF canary:
https://www.internalfb.com/intern/ads/canary/431021257540238874/
Reviewed By: dzhulgakov
Differential Revision: D24977611
fbshipit-source-id: 33ba596b43c1e558c3ab237a0feeae93565b2d35
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48404
On bento this is printing a lot of msgs like (see N408483 if you're an internal user)
```
W1123 120952.322 schema.py:811] Scalar should be considered immutable. Only call Scalar.set() on newly created Scalar with unsafe=True. This will become an error soon.
```
And it's ignoring the log level I set at global level. Removing this line unless this is super important.
Test Plan: build a local dper package and verify
Differential Revision: D25163808
fbshipit-source-id: 338d01c82b4e67269328bbeafc088987c4cbac75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48308
The original regex that I added didn't correctly match namespaces that started with an underscore (e.g. `_test`), which caused a master-only test to fail.
The only change from the previous commit is that I updated the regex like so:
before: `^.*TORCH_LIBRARY_IMPL_init_([^_]+)_([^_]+)_[0-9]+(\(.*)?$`
after: `^.*TORCH_LIBRARY_IMPL_init_([_]*[^_]+)_([^_]+)_[0-9]+(\(.*)?$`
I added in a `[_]*` to the beginning of the namespace capture. I did the same for the `_FRAGMENT` regex.
Verified that running `ANALYZE_TEST=1 tools/code_analyzer/build.sh` (as the master-only test does) produces no diff in the output.
Fixing regex pattern to allow for underscores at the beginning of the
namespace
This reverts commit 3c936ecd3c68f395dad01f42935f20ed8068da02.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D25123295
Pulled By: bdhirsh
fbshipit-source-id: 54bd1e3f0c8e28145e736142ad62a18806bb9672
Summary:
Test should verify, that all listed conditions throw, not just the first one
Refactor duplicated constants
Use `self.assertTrue()` instead of suppressing flake8 `B015: Pointless Comparison` warning
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48597
Reviewed By: mruberry
Differential Revision: D25222734
Pulled By: malfet
fbshipit-source-id: 7854f755a84f23a1a52dc74402582e34d69ff984
Summary:
Creates multiple new test suites to have fewer tests in test_torch.py, consistent with previous test suite creation like test_unary_ufuncs.py and test_linalg.py.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47356
Reviewed By: ngimel
Differential Revision: D25202268
Pulled By: mruberry
fbshipit-source-id: 75fde3ca76545d1b32b86d432a5cb7a5ba8f5bb6
Summary:
Otherwise, this test will appear flaky for ROCm even though it is a generic PyTorch issue.
CC albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48405
Reviewed By: mrshenli
Differential Revision: D25183473
Pulled By: ngimel
fbshipit-source-id: 0fa19b5497a713cc6c5d251598e57cc7068604be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48481
we removed deadlines thinking that was the cause for the timeout of
the int8 test, but turns out that the int8 tests were failing because of a
legitimate bug and this was masked as a timeout
Now that the bug has been fixed, the tests are failing because it takes more
than 10s to run the test, this is an option we used to override
https://www.internalfb.com/intern/testinfra/diagnostics/2533274833752501.562949971168104.1606367728/
Test Plan: reran the test manually
Reviewed By: venkatacrc
Differential Revision: D25184573
fbshipit-source-id: 0b1b2eaa690472e80b9b0991618da8d792aeb42b
Summary:
The doc string let suppose that `quint8` is for singed 8 bit values.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48418
Reviewed By: ngimel
Differential Revision: D25181705
Pulled By: mrshenli
fbshipit-source-id: 70e151b6279fef75505f80a7b0cd50032b4f1008
Summary:
Quiet errors from flake8. Only a couple of code changes for deprecated Python syntax from before 2.4. The rest is just adding noqa markers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48453
Reviewed By: mruberry
Differential Revision: D25181871
Pulled By: ngimel
fbshipit-source-id: f8d7298aae783b1bce2a46827b088fc390970641
Summary:
Adding Unary Ufunc Test entry for `erf` variants.
We use scipy functions for reference implementation.
We can later update the tests once these functions will update integer input to float.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47155
Reviewed By: ngimel
Differential Revision: D25176654
Pulled By: mruberry
fbshipit-source-id: cb08efed1468b27650cec4f87a9a34e999ebd810
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48357
Cleans up the long lines in `torch/quantization/fx/quantize.py`
to fit the 80 character limit, so it's easier to read and looks
better on FB's tools.
In the future we can consider adding a linter for this.
Test Plan:
CI
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25140833
fbshipit-source-id: 78605d58eda0184eb82f510baec26685a34870e2
Summary:
The approach is to simply reuse `torch.repeat` but adding one more functionality to tile, which is to prepend 1's to reps arrays if there are more dimensions to the tensors than the reps given in input. Thus for a tensor of shape (64, 3, 24, 24) and reps of (2, 2) will become (1, 1, 2, 2), which is what NumPy does.
I've encountered some instability with the test on my end, where I could get a random failure of the test (due to, sometimes, random value of `self.dim()`, and sometimes, segfaults). I'd appreciate any feedback on the test or an explanation for this instability so I can this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47974
Reviewed By: ngimel
Differential Revision: D25148963
Pulled By: mruberry
fbshipit-source-id: bf63b72c6fe3d3998a682822e669666f7cc97c58
Summary:
This PR adds `torch.linalg.eigh`, and `torch.linalg.eigvalsh` for NumPy compatibility.
The current `torch.symeig` uses (on CPU) a different LAPACK routine than NumPy (`syev` vs `syevd`). Even though it shouldn't matter in practice, `torch.linalg.eigh` uses `syevd` (as NumPy does).
Ref https://github.com/pytorch/pytorch/issues/42666
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45526
Reviewed By: gchanan
Differential Revision: D25022659
Pulled By: mruberry
fbshipit-source-id: 3676b77a121c4b5abdb712ad06702ac4944e900a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48343
Annotates the 4 class variables on `Quantizer` with real types,
fixing the small things uncovered by this along the way.
Test Plan:
```
mypy torch/quantization/
python test/test_quantization.py TestQuantizeFx
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D25136212
fbshipit-source-id: 6ee556c291c395bd8d8765a99f10793ca738086f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48331
Enables mypy to not ignore type errors in FX quantization files. Fixes the easy
typing errors inline, and comments out the harder errors to be fixed at a later time.
After this PR, mypy runs without errors on `torch/quantization`.
Test Plan:
```
> mypy torch/quantization/
Success: no issues found in 25 source files
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D25133348
fbshipit-source-id: 0568ef9405b292b80b3857eae300450108843e80
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48348
To support the features like error feedback, warm start, PowerSGD comm hook needs to maintain a state besides process group. Currently this state only includes a process group and a matrix approximation rank config.
This diff is a pure refactoring. Plan to add more state fields later.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 117305280
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_powerSGD_ddp_comm_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d --
test_powerSGD_ddp_comm_hook_nccl_grad_is_view
Reviewed By: rohan-varma
Differential Revision: D25137962
fbshipit-source-id: cd72b8b01e20f80a92c7577d22f2c96e9eebdc52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48326
The PR introduces a set of 'cuda-only' ops into `isSupported` function.
It is done to disable `pow` lowering on CPU where it's tricky to support
integer versions.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D25129211
Pulled By: ZolotukhinM
fbshipit-source-id: c62ae466e1d9ba9b3020519aadaa2a7fe7942d84
Summary:
Fixes error introduced in https://github.com/pytorch/pytorch/pull/47657
`node.target` can be either a str or a callable, but this is checked in the pattern matching portion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48359
Reviewed By: ilia-cher
Differential Revision: D25141885
Pulled By: Chillee
fbshipit-source-id: 94365a5a3dd351652ea7337077cd0e71b6ffe203
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48322
Disable old fuser internally. I would like to find where we are inadvertently setting the old fuser, but in the meantime I would like to land a diff that I know will 100% cause it not to be run, and verify that it fixes the issue.
Test Plan: sandcastle
Reviewed By: ZolotukhinM
Differential Revision: D25126202
fbshipit-source-id: 5a4d0742f5f829e536f50e7ede1256c94dd05232
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48192
This is to allow producing a backend independent quantized module
since some backend don't have packed weight for linear
Test Plan:
test_quantized_module.py
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D25061645
fbshipit-source-id: a65535e53f35af4f2926af0ee330fdaae6dae996
Summary:
Separate PR to add Kineto submodule, mirrors the one I used
in my stack (45887)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48332
Reviewed By: gdankel
Differential Revision: D25139969
Pulled By: ilia-cher
fbshipit-source-id: b9ca2be5f15647655eeb4b2fbf4c82f84eee3dd8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48255
There's effort to move aten::native files to app level. After this effort, the operators and their kernels in aten::native can be selectively built per app.
There are some direct reference to at::native symbols in jit/runtime/static/ops.cpp. Those symbols are missing if their implementations are moved up to app level in Android.
Files in jit/runtime/static folder belongs to full-jit and should not be built from mobile. However, since Federated Learning is still using full-jit in fb4a, The current solution is to exclude those files from mobile torch_core target.
ghstack-source-id: 117123663
Test Plan: CI
Reviewed By: dhruvbird
Differential Revision: D24822690
fbshipit-source-id: c599b10f35e8d42bd4ca272da1a0cddf88ad7c37
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48293
This PR enables a `ScriptModule` to be created on a remote worker, retrieve it to current device, and run methods on it remotely.
In order to do this, we define custom pickling for `ScriptModule` in our `InternalRPCPickler`. The pickling basically uses torch.save and torch.load to save/recover the ScriptModule.
We test that we can create and retrieve a ScriptModule with rpc_sync, and create RRef to ScriptModule with rpc.remote. We can also run remote methods on the rref and transfer it to current worker.
Although we can run methods remotely on the RRef to ScriptModule, this does not currently work with RRef helper, filed to track that.
ghstack-source-id: 117275954
Test Plan: CI
Reviewed By: wanchaol
Differential Revision: D25107773
fbshipit-source-id: daadccf7bd25fe576110ee6e0dba6ed2bcd3e7f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48290
`scalar_t` here is expanded from nested macros to be an input value and
`upper_bound` is templated upon it. Whatever it gives back is unconditionally
cast to a `double` via the fact that it is always passed to
`binary_kernel_reduce_vec` which has a `double` as the fourth argument.
Change it here to be an explicit `static_cast<double>` to do what the compiler
was implicitly doing.
Test Plan: this is an error with -Werror in llvm11. This allows it to build
Reviewed By: ezyang
Differential Revision: D25111258
fbshipit-source-id: 6837afec52821f1f57b8c8f2df2d0eb3fc9b58bd
Summary:
Some interesting stuff going on. All benchmarks are tested with both my implementation as well as the current quantized fuser.
For these benchmarks, things like using MKLDNN/FBGEMM make a big differene.
## Manual compilation (everything turned off)
In the small case, things look good
```
non-fused: 1.174886703491211
fused: 0.7494957447052002
```
However, for `torchvision.resnet18`, we see
```
non-fused: 1.2272708415985107
fused: 3.7183213233947754
```
This is because Conv (no bias) -> Batch Norm is actually faster than Conv (bias) if you don't have any libraries...
## Nightly (CPU)
```
Toy
non-fused: 0.45807552337646484
fused: 0.34779977798461914
resnet18
non-fused: 0.14216232299804688
fused: 0.13438796997070312
resnet50
non-fused: 0.2999534606933594
fused: 0.29364800453186035
densenet161
non-fused: 0.6558926105499268
fused: 0.6190280914306641
inception_v3
non-fused: 1.2804391384124756
fused: 1.181272029876709
```
with MKLDNN.
We see a small performance gain across the board, with more significant performance gains for smaller models.
## Nightly (CUDA)
```
M
non-fused: 1.2220964431762695
fused: 1.0833759307861328
resnet18
non-fused: 0.09721899032592773
fused: 0.09089207649230957
resnet50
non-fused: 0.2053072452545166
fused: 0.19138741493225098
densenet161
non-fused: 0.6830024719238281
fused: 0.660109281539917
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47657
Reviewed By: eellison
Differential Revision: D25127546
Pulled By: Chillee
fbshipit-source-id: ecdf682038def046045fcc09faf9aeb6c459b5e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48234
This was copying the iterator varaible instead of taking a reference.
Fix the trivial error here.
Test Plan:
clang11 catches this and throws a warning that we promote with
-Werror. This change fixes the error.
Reviewed By: smeenai
Differential Revision: D24970929
fbshipit-source-id: 335a1b53276467987bc27fa41326803e01e70c01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48232
This was not the correct type that's being generated via the begin()
function and thus a new object was being created and attempted to take a
reference to. Instead just take a reference to whatever the range-based loop
generates.
Test Plan: This fixes a build error from a new warnign in llvm11
Reviewed By: smeenai
Differential Revision: D24970920
fbshipit-source-id: f125dca900f7550eee505b4f94781b6637533be0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48277
We move `TORCH_CUDA_KERNEL_LAUNCH_CHECK` from `//caffe2/aten/src/ATen/cuda/Exceptions.h` to `//caffe2/c10/cuda/CUDAException.h`.
The primary reason is for allowing us to use this MACRO in other subdirectories of //caffe2, not just in ATen. Refer to D24309971 (353e7f940f) for context.
An example of this use case is D24868557, where we add these checks to `//caffe2/caffe2/sgd`.
Also, this should not affect current files, because `Exceptions.h` includes `CUDAException.h`.
Test Plan:
```
buck build //caffe2/aten:ATen-cu
```
- https://fburl.com/buck/oq3rxbir
Also wait for sandcastle tests.
Reviewed By: ngimel
Differential Revision: D25101720
fbshipit-source-id: e2b05b39ff1413a21e64949e26ca24c8f7d0400f
Summary:
This PR aims to reduce the import overhead and symbol noises from the `windows.h` headers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48009
Reviewed By: gchanan
Differential Revision: D25045840
Pulled By: ezyang
fbshipit-source-id: 01fda70f433ba2dd0cd2d7cd676ab6ffe9d98b90
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46703
Previously, we would compile one side of an if-statement if it was a type-based expression we could statically resolve. I think it's reasonable to extend this metacompilation to booleans that are constant at compile time. There have been some instances where i've recommended unintuitive workarounds due to not having this behavior.
This is also possibly needed if we add boolean literals to schema declarations, which is a feature that might be needed to cleanup our `boolean_dispatch` mechanism.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46721
Reviewed By: ppwwyyxx
Differential Revision: D25008862
Pulled By: eellison
fbshipit-source-id: 5bc60a18f1021c010cb6abbeb5399c669fe04312
Summary: is_external_input doesn't check if the lookup tables are valid. Calling .Proto() should invalidate all lookup tables and have them rebuilt on call to any methods depending on them. This adds this check to is_external_input.
Test Plan: internal unit tests
Reviewed By: dzhulgakov, esqu1
Differential Revision: D25100464
fbshipit-source-id: d792dec7e5aa9ffeafda88350e05cb757f4c4831
Summary:
Addresses step 1 of https://github.com/pytorch/pytorch/issues/46564
Took processing logic for each case in request_callback_no_python.cpp and put it in a dedicated function.
cc: izdeby
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47816
Reviewed By: izdeby
Differential Revision: D25090207
Pulled By: H-Huang
fbshipit-source-id: bfa38e38db02e077d859125739aaede90ba492e7
Summary:
Adds ldexp operator for https://github.com/pytorch/pytorch/issues/38349
I'm not entirely sure the changes to `NamedRegistrations.cpp` were needed but I saw other operators in there so I added it.
Normally the ldexp operator is used along with the frexp to construct and deconstruct floating point values. This is useful for performing operations on either the mantissa and exponent portions of floating point values.
Sleef, std math.h, and cuda support both ldexp and frexp but not for all data types. I wasn't able to figure out how to get the iterators to play nicely with a vectorized kernel so I have left this with just the normal CPU kernel for now.
This is the first operator I'm adding so please review with an eye for errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45370
Reviewed By: mruberry
Differential Revision: D24333516
Pulled By: ranman
fbshipit-source-id: 2df78088f00aa9789aae1124eda399771e120d3f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47313
This PR implements `torch.addr` function using `TensorIterator` with `cpu_kernel_vec` and `gpu_kernel`.
It helps reduce memory usage, improve performance, and fix the bug when `beta` or `alpha` is a complex number.
Todo
- [x] benchmarking `torch.addr` for the change of this PR, as well as the legacy TH implementation used in PyTorch 1.6.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47664
Reviewed By: zhangguanheng66
Differential Revision: D25059693
Pulled By: ngimel
fbshipit-source-id: 20a90824aa4cb2240e81a9f17a9e2f16ae6e3437
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48226
this test is timing out, I am removing the deadline argument to see if
things improve
Test Plan:
ran locally
https://fburl.com/p41ocvrs
Reviewed By: venkatacrc
Differential Revision: D25067867
fbshipit-source-id: 80065553e0bd9883ea80e70a6748de1012e0d4e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48249
Introduced autograd related data models at tools.codegen.api.autograd.
Migrated load_derivatives.py to produce the new data models from derivatives.yaml.
It has clean mypy-strict result.
Changed both gen_autograd_functions.py and gen_variable_type.py to consume
the new data model.
Added type annotations to gen_autograd_functions.py - it has clean mypy-strict
result except for the .gen_autograd import (so haven't added it to the strict
config in this PR).
To limit the scope of the PR, gen_variable_type.py is not refactored, and the
main structure of load_derivatives.py / gen_autograd_functions.py is kept. We
only make necessary changes to make it work.
Confirmed byte-for-byte compatible with the old codegen:
```
Run it before and after this PR:
.jenkins/pytorch/codegen-test.sh <baseline_output_dir>
.jenkins/pytorch/codegen-test.sh <test_output_dir>
Then run diff to compare the generated files:
diff -Naur <baseline_output_dir> <test_output_dir>
```
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D25086561
Pulled By: ljk53
fbshipit-source-id: 1f43ab0931d9814c24683b9a48ca497c5fc3d729
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48221
load-acquire, acquire-release increment and decrement. (We
need acquire-release increment to make unique() and use_count()
reliable.) Note that this doesn't make a difference on x86, but we
should expect it to improve things on ARM and ARM64.
ghstack-source-id: 117065956
Test Plan: Careful review :)
Reviewed By: ezyang
Differential Revision: D24708209
fbshipit-source-id: 5e574115eee5c0a65047b638c5f9b1ec0124d04d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47734
**Summary**
This commit allows `torch.device` to be resolved properly when used in
class types that are recursively scripted. This is accomplished by augmenting
the resolution callback used during recursively class scripting to include
the type annotations used on class method declarations.
Classes that are not explicitly annotated with `torch.jit.script` are
implicitly scripted during the compilation of a function or class method
that uses them. One key difference between this method of class type
compilation and explicit scripting is that the former uses a resolution callback
that can only resolve variables that class methods close over (see
`_jit_internal.createResolutionCallbackForClassMethods`). This does
not include type annotations and default arguments. This means that
builtin types like `torch.Tensor` and `torch.device` cannot be resolved
using the resolution callback. This issue does not arise when explicitly
scripting classes because the resolution callback for that code path is
constructed from scope of the class definition
(see `_jit_internal.createResolutionCallbackFromFrame`). `torch.Tensor`
and `torch.device` are almost always present in that scope, usually from
`import`ing `torch`.
**Test Plan**
This commit adds a new unit test to `TestClassType`,
`test_recursive_script_builtin_type_resolution`.
**Fixes**
This commit closes#47405.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D24995374
Pulled By: SplitInfinity
fbshipit-source-id: db68212634cacf81cfaeda8095a1fe5105fa73b7
Summary:
Add TorchBind-binding for ProcessGroup class.
Currently there are a few limitation of TorchBind that prevents us from fully matching existing PyBind-binding of ProcessGroup:
- TorchBind doesn't support method overloading. Current PyBind binding uses overloading extensively to provide flexible API, but TorchBind (and TorchScript ClassType behind it) doesn't yet support it. Therefore, we can provide at most one version of API under each name.
- TorchBind doesn't support C++ enums yet. This prevents us from making real uses of XXXOptions, which is widely used in many APIs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47907
Reviewed By: wanchaol
Differential Revision: D24945814
Pulled By: gmagogsfm
fbshipit-source-id: e103d448849ea838c10414068c3e4795db91ab1c
Summary:
The scale variable needs to be a scalar, otherwise it will report the following error: "RuntimeError: Cannot input a tensor of dimension other than 0 as a scalar argument"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48265
Test Plan: Tested locally and the error disappeared.
Reviewed By: zhizhengwu
Differential Revision: D25105423
Pulled By: jerryzh168
fbshipit-source-id: 2a0df24cf7e40278a950bffe6e0a9552f99da1d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48253
Explained why a hand-crafted orthogonalize function is used instead of `torch.qr`.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 117132622
Test Plan: N/A
Reviewed By: rohan-varma
Differential Revision: D25088607
fbshipit-source-id: ebc228afcb4737bb8529e7143ea170086730520e
Summary:
This is a partition search based on Kernighan-Lin algorithm. First, the graph is partitioned using size_based_partition, then nodes from different partitions are swapped until the cost reaches minimum.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48197
Reviewed By: gcatron
Differential Revision: D25097065
Pulled By: scottxu0730
fbshipit-source-id: 3a11286bf4e5a712ab2848b92d0b98cd3d6a89be
Summary:
Addresses https://github.com/pytorch/pytorch/issues/47145
Adds a new MessageTypeFlags enum so that checking for certain properties (e.g. isResponse, isRequest) can be done with a BITWISE AND instead of checking for each MessageType enum individually.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48143
Reviewed By: mrshenli
Differential Revision: D25091008
Pulled By: H-Huang
fbshipit-source-id: 56a823747748633c1ef3fa07817ca0f08c7399a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48231
Noticed that these tests were being skipped with NCCL backend, but
there doesn't appear to be a valid reason to. Enabled these tests and verify
that they pass with 500 stress runs.
ghstack-source-id: 117085209
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D25079030
fbshipit-source-id: 8204288ffbd387375a1a86fe8c07243cfd855549
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48252
Moved to a shared place so that gen_variable_type.py can reuse it.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D25087808
Pulled By: ljk53
fbshipit-source-id: 1f32e506956fc4eb08734cfde0add47b3e666bd9
Summary:
Inspired by https://github.com/pytorch/pytorch/issues/47993, this fixes the import error in `collect_env.py` with older version of PyTorch when `torch.version` does not have `hip` property.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48076
Reviewed By: seemethere, xuzhao9
Differential Revision: D25024352
Pulled By: samestep
fbshipit-source-id: 7dff9d2ab80b0bd25f9ca035d8660f38419cdeca
Summary:
Adds a standalone script which can be used to test different BLAS libraries. Right now I've deliberately kept it limited (only a couple BLAS libs and only GEMM and GEMV). It's easy enough to expand later.
CC ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47058
Reviewed By: zhangguanheng66
Differential Revision: D25078946
Pulled By: robieta
fbshipit-source-id: b5f7f7ec289d59c16c5370b7a6636c10a496b3ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48256
`PackedConvWeightsQnnp<2>::prepack` is referenced by both `quantized::conv_prepack` and fbgemm.cpp. Since `quantized::conv_prepack` is in the same compilation unit as the class template it was fine. However, if we make operator registration selective, the reference from `quantized::conv_prepack` is gone. The reference from fbgemm.cpp is in another compilation unit and there is link error.
To avoid the link error, instantiate the symbol in the cpp file. It should also work to move all implementations to .h file, but to keep the existing code structure and to avoid (small chance of) code bloat, the implementations are kept as is.
ghstack-source-id: 117123564
Test Plan:
CI
buck build //fbandroid/apps/oculus/assistant:assistant_arm64_debug
Reviewed By: dhruvbird
Differential Revision: D24941989
fbshipit-source-id: adc96d0e55c89529fb71a43352aa68a1088a62a2
Summary:
Currently when I run `flake8` locally I get [a bunch of extraneous warnings](https://pastebin.com/DMQevCtC) because the docs build puts a `pytorch-sphinx-theme` dir into `docs/cpp/src`. Those warnings don't show up in CI because the CI lint job doesn't generate that dir. This PR adds that to the Flake8 `exclude` list, similar to how `docs/src` is already present in that list.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48201
Reviewed By: walterddr, zhangguanheng66
Differential Revision: D25069130
Pulled By: samestep
fbshipit-source-id: 2fda9e813f54092398525b7fc97d0a8f7f835ca6
Summary:
xref gh-46927 to the 1.7 release branch
This backports a fix to the script to push docs to pytorch/pytorch.github.io. Specifically, it pushes to the correct directory when a tag is created here. This issue became apparent in the 1.7 release cycle and should be backported to here.
Along the way, fix the canonical link to the pytorch/audio documentation now that they use subdirectories for the versions, xref pytorch/audio#992. This saves a redirect.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47349
Reviewed By: zhangguanheng66
Differential Revision: D25073752
Pulled By: seemethere
fbshipit-source-id: c778c94a05f1c3e916217bb184f69107e7d2c098
Summary:
Previously it was only possible to pass up to one [verbosity level](https://adamj.eu/tech/2019/10/03/my-most-used-pytest-commandline-flags/) to `pytest` when running a test via `test/run_test.py`. Presumably that behavior was never added because `unittest` [doesn't do anything extra](https://stackoverflow.com/a/1322648/5044950) when given more than one `--verbose` flag. This PR removes that limitation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48204
Test Plan:
Make a dummy `pytest`-style file `test/test_foo.py`:
```py
def test_bar():
assert 'hello\n' * 10 == 'hello\n' * 20
```
Then add `'test_foo'` to both `TESTS` and `USE_PYTEST_LIST` in `test/run_test.py`, and run this command:
```sh
test/run_test.py -vvi test_foo
```
Reviewed By: walterddr
Differential Revision: D25069147
Pulled By: samestep
fbshipit-source-id: 2765ee78d18cc84ea0e262520838993f9e9ee04f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48057
This PR fixes batched grad computation for:
- binary_cross_entropy (i.e., vmap through binary_cross_entropy_double_backward)
- symeig (i.e. vmap through symeig_backward)
It was previously impossible to vmap through those functions because
they use in-place operations in a vmap-incompatible way.
See note at
233192be73/aten/src/ATen/BatchedFallback.cpp (L117-L122)
for what it means for an in-place operation to be vmap-incompatible.
This PR adds a check: if the in-place operations in e.g. symeig are
vmap-incompatible and we are inside of a vmap, then we do the
out-of-place variant of the operation. Ditto for binary_cross_entropy.
This is to avoid code duplication: the alternative would be to register
the backward formula as an operator and change just those lines to be
out-of-place!
This PR also adds some general guidelines for what to do if an in-place
operation is vmap-incompatible.
General guidelines
------------------
If an in-place operation used in a backward formula is vmap-incompatible,
then as developers we have the following options:
- If the in-place operation directly followed the creation of a tensor with
a factory function like at::zeros(...), we should replace the factory with a
corresponding grad.new_zeros(...) call. The grad.new_zeros(...) call
propagates the batch dims to the resulting tensor.
For example:
Before: at::zeros(input.sizes(), grad.options()).copy_(grad)
After: grad.new_zeros(input.sizes()).copy_(grad)
- If the in-place operation followed some sequence of operations, if the
we want to be able to vmap over the backward formula as-is (this is
usually the case for simple (<15loc) backward formulas), then use
inplace_is_vmap_compatible to guard the operation. For example:
c = a * b
Before: c.mul_(grad)
After: c = inplace_is_vmap_compatible(c, grad) ? c.mul_(grad) : c * grad
- If we don't want to vmap directly over the backward formula (e.g., if the
backward formula is too complicated or has a lot of vmap-incompatible
operations, then register the backward formula as an operator and eventually
write a batching rule for it.
Test Plan
---------
New tests
Test Plan: Imported from OSS
Reviewed By: zhangguanheng66
Differential Revision: D25069525
Pulled By: zou3519
fbshipit-source-id: e0dfeb5a812f35b7579fc6ecf7252bf31ce0d790
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48060
Implement a PowerSGD variant that applies to a batched flattened tensor with zero paddings.
This version does not require handling 1D tensors and multi-dimenionsal tensors in the input separately, and hence it does not need to create two asyncrhonous future chains.
Potential optimizations:
1) Consider FP16 compression throughout PowerSGD.
2) Warm start and save one matrix multiplication per ieration.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 117105938
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_default_ddp_comm_hooks_nccl
Reviewed By: jiayisuse
Differential Revision: D24843692
fbshipit-source-id: f44200b1fd6e12e829fc543d21ab7ae086769561
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47391
Current Numeric Suite will fail if it's collecting for multiple inputs and each input is of not same size. This fix adds support for varying size input in numeric suite.
ghstack-source-id: 117058862
Test Plan:
buck test mode/dev caffe2/test:quantization -- 'test_shadow_logger'
buck test mode/dev caffe2/test:quantization -- 'test_output_logger'
buck test mode/dev caffe2/test:quantization -- 'test_compare_weights_lstm_dynamic'
buck test mode/dev caffe2/test:quantization -- 'test_compare_model_stub_lstm_dynamic'
buck test mode/dev caffe2/test:quantization -- 'test_compare_model_outputs_lstm_dynamic'
buck test mode/dev caffe2/test:quantization -- 'test_compare_weights_conv_static'
buck test mode/dev caffe2/test:quantization -- 'test_compare_weights_linear_static'
buck test mode/dev caffe2/test:quantization -- 'test_compare_weights_linear_dynamic'
buck test mode/dev caffe2/test:quantization -- 'test_compare_model_stub_conv_static'
buck test mode/dev caffe2/test:quantization -- 'test_compare_model_stub_linear_static'
buck test mode/dev caffe2/test:quantization -- 'test_compare_model_stub_submodule_static'
buck test mode/dev caffe2/test:quantization -- 'test_compare_model_stub_functional_static'
buck test mode/dev caffe2/test:quantization -- 'test_compare_model_stub_linear_dynamic'
buck test mode/dev caffe2/test:quantization -- 'test_compare_model_outputs_conv_static'
buck test mode/dev caffe2/test:quantization -- 'test_compare_model_outputs_linear_static'
buck test mode/dev caffe2/test:quantization -- 'test_compare_model_outputs_functional_static'
buck test mode/dev caffe2/test:quantization -- 'test_compare_model_outputs_linear_dynami
Reviewed By: hx89
Differential Revision: D24662271
fbshipit-source-id: 6908169ee448cbb8f33beedbd26104633632896a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48213
it was completely broken unless rhs was a constant.
Test Plan: new unit test in test_jit_fuser_te.py
Reviewed By: eellison
Differential Revision: D25071639
fbshipit-source-id: ef1010a9fd551db646b83adfaa961648a5c388ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47796
`ThreadLocalDebugInfo::get()` is a hot function. For example, it is called by `DefaultCPUAllocator::allocate()`. Most callers do not even bother to keep the returned `shared_ptr` around, proving that they have no lifetime issues currently. For the rest, it appears that the only way that the returned pointer could become invalid is if they then called a function that swapped out `ThreadLocalDebugInfo` using `ThreadLocalStateGuard`. There are very few such paths, and it doesn't look like any current callers of `ThreadLocalDebugInfo::get()` needed a `shared_ptr` at all.
ghstack-source-id: 116979577
Test Plan:
1) reviewers to double-check audit of safety
2) run framework overhead benchmarks
Reviewed By: dzhulgakov
Differential Revision: D24902978
fbshipit-source-id: d684737cc2568534cac7cd3fb8d623b971c2fd28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48008
### Motivation
The idea is to quantize the weights during model exporting and dequantize them when performing setstate in runtime. To replicate exactly what caffe2 did, only 10 conv layers were quantized.
Since the code here is restricted to the unet model, I created a custom prepacking context to do the graph rewriting and registering custom ops.
To run on iOS/MacOS, we need to link `unet_metal_prepack` explicitly.
- buck build //xplat/caffe2/fb/custom_ops/unet_metal_prepack:unet_metal_prepackApple
- buck build //xplat/caffe2/fb/custom_ops/unet_metal_prepack:unet_metal_prepackAppleMac
On the server side, the `unet_metal_prepack.cpp` needs to be compiled into the `aten_cpu` in order to do the graph-rewrite via optimize_for_mobile. However, since we don't want to ship it to the production, some local hacks were made to make this happen. More details can be found in the following diffs.
### Results
-rw-r--r-- 1 taox staff 1.1M Nov 10 22:15 seg_init_net.pb
-rw-r--r-- 1 taox staff 1.1M Nov 10 22:15 seg_predict_net.pb
Note since we quantize the weights, some precision loss are expected, but overall good.
### ARD
- Person seg - v229
- Hair seg - v105
ghstack-source-id: 117019547
Test Plan:
### Video eval results from macos
{F345324969}
Differential Revision: D24881316
fbshipit-source-id: b67811d6d06de82130f4c22392cc961c9dda7559
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48113
Fix is simple: just treat Meta as a backend covered by AutogradOther.
This semantically makes sense, since meta kernels are just like regular
CPU/CUDA kernels, they just don't do any compute.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zhangguanheng66
Differential Revision: D25056641
Pulled By: ezyang
fbshipit-source-id: 7b68911982352b3e0ee8616b38cd9c70bd58a740
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47023
DeviceType pretty clearly only needs 1 byte. DeviceIndex only needs 1 byte given that machines don't have anywhere near 255 GPUs in them as far as I know.
ghstack-source-id: 116901430
Test Plan: Existing tests, added assertion to catch if my assumption about DeviceIndex is incorrect
Reviewed By: dzhulgakov
Differential Revision: D24605460
fbshipit-source-id: 7c9a89027fcf8eebd623b7cdbf6302162c981cd2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48069
also renamed float_qparam_dynamic_qconfig to float_qparam_weight_only_qconfig
It's not used in user code yet so we only need to update the tests.
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D25010175
fbshipit-source-id: caa3eaa5358a8bc5c808bf5f64e6ebff3e0b61e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47549
In preparation for moving state onto the heap.
ghstack-source-id: 117027862
Test Plan: CI
Reviewed By: ilia-cher
Differential Revision: D24812214
fbshipit-source-id: 1455c2782b66f6a59c4d45ba58e1c4c92402a323
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47959
Taking a shared_ptr by value incurs refcounting overhead and should only be done if the callee needs to take ownership. Otherwise, `const T&` is more efficient. (Specifically, you will have to do an atomic decrement when the argument is destroyed and probably an atomic increment as well. Passing by `const T&` also takes one less register than passing `std::shared_ptr<T>`, but that's less important.)
This diff fixes just this one function, but I'd be happy to audit & fix this whole file in future diffs. Thoughts?
ghstack-source-id: 116914899
Test Plan: build ATen-cpu
Reviewed By: Krovatkin
Differential Revision: D24970954
fbshipit-source-id: 6bdb4b710a94b8baf4ad63418fb38136134e0ef3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48185
In a scenario where we have Caffe2 wrapped into a dynamic library, we were running into the memory corruption crash at program termination:
"corrupted size vs. prev_size in fastbins"
Turns out the crash occurs in glog's logging.cc, which is not thread-safe and has to initialize a static hostname string when flushing. If this ends up happening on multiple threads simultaneously, this can lead to a memory corruption.
```
==1533667== Invalid free() / delete / delete[] / realloc()
==1533667== at 0xA3976BB: operator delete(void*, unsigned long) (vg_replace_malloc.c:595)
==1533667== by 0x37E36AE: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::~basic_string() (basic_string.h:647)
==1533667== by 0xAD87 (97b9712aed)F6B: __run_exit_handlers (in /usr/lib64/libc-2.28.so)
==1533667== by 0xAD8809 (153e2e96d4)F: exit (in /usr/lib64/libc-2.28.so)
==1533667== by 0xAD71799: (below main) (in /usr/lib64/libc-2.28.so)
==1533667== Address 0x165cd720 is 0 bytes inside a block of size 31 free'd
==1533667== at 0xA3976BB: operator delete(void*, unsigned long) (vg_replace_malloc.c:595)
==1533667== by 0x37E36AE: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::~basic_string() (basic_string.h:647)
==1533667== by 0xAD87 (97b9712aed)F6B: __run_exit_handlers (in /usr/lib64/libc-2.28.so)
==1533667== by 0xAD8809 (153e2e96d4)F: exit (in /usr/lib64/libc-2.28.so)
==1533667== by 0xAD71799: (below main) (in /usr/lib64/libc-2.28.so)
==1533667== Block was alloc'd at
==1533667== at 0xA39641F: operator new(unsigned long) (vg_replace_malloc.c:344)
==1533667== by 0x37F4E18: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:317)
==1533667== by 0x37F4F2E: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:466)
==1533667== by 0x5170344: GetHostName(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >*) (logging.cc:227)
==1533667== by 0x51702D4 (fc7f026980): google::LogDestination::hostname[abi:cxx11]() (logging.cc:555)
==1533667== by 0x5173789: google::(anonymous namespace)::LogFileObject::Write(bool, long, char const*, int) (logging.cc:1072)
==1533667== by 0x51746DF: google::LogDestination::LogToAllLogfiles(int, long, char const*, unsigned long) (logging.cc:773)
==1533667== by 0x5170BDC: google::LogMessage::SendToLog() (logging.cc:1386)
==1533667== by 0x5171236: google::LogMessage::Flush() (logging.cc:1305)
==1533667== by 0x517114D: google::LogMessage::~LogMessage() (logging.cc:1264)
==1533667== by 0x108DC840: caffe2::ReinitializeTensor(caffe2::Tensor*, c10::ArrayRef<long>, c10::TensorOptions) (tensor.cc:0)
==1533667== by 0x103BBED0: caffe2::int8::Int8GivenTensorFillOp::RunOnDevice() (int8_given_tensor_fill_op.h:29)
==1533667==
```
There doesn't seem to be an obvious easy solution here. The logging API being used by c10 is fundamentally not thread-safe, at least when it uses glog. Glog does have a threadsafe API (raw_logging), but this doesn't seem to be used by c10 right now. I suspect other callers are not running into this crash because:
- They have other libraries using glog in their module, so the static variable in glog gets initialized before getting into a race condition
- They don't use int8 network in a glog context, thus avoiding this problematic log statement
An alternative fix would be to correctly initialize the dtype of the int8 tensor, which is currently always uninitialized, making the log statement always trigger for int8 networks. Initializing the int8 tensor correctly in tensor_int8.h is proving to be challenging though, at least without knowledge of Caffe2's codebase. And even then, it wouldn't fix the issue for all use cases.
Test Plan: Ran my app with valgrind, I no longer get the crash and valgrind doesn't complain about a memory corruption anymore
Reviewed By: thyu, qizzzh
Differential Revision: D25040725
fbshipit-source-id: 1392a97ccf9b4c9ade1ea713610ee44a1578ae7d
Summary:
It seems that the machinery to handle comparison method in C rather than Python already exists, unless I'm missing something. (There is a wrapper for `TypeError_to_NotImplemented_`, and Python code gen handles `__torch_function__` which are the two things `_wrap_type_error_to_not_implemented` is doing) The performance change is quite stark:
```
import torch
from torch.utils.benchmark import Timer
global_dict = {
"x": torch.ones((2, 2)),
"y_scalar": torch.ones((1,)),
"y_tensor": torch.ones((2, 1)),
}
for stmt in ("x == 1", "x == y_scalar", "x == y_tensor"):
print(Timer(stmt, globals=global_dict).blocked_autorange(min_run_time=5), "\n")
```
### Before:
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7f3d1289dc10>
x == 1
Median: 12.86 us
IQR: 0.65 us (12.55 to 13.20)
387 measurements, 1000 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7f3d1289d1d0>
x == y_scalar
Median: 6.03 us
IQR: 0.33 us (5.91 to 6.24)
820 measurements, 1000 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7f3d2b9e2050>
x == y_tensor
Median: 6.34 us
IQR: 0.33 us (6.16 to 6.49)
790 measurements, 1000 runs per measurement, 1 thread
```
### After:
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7fbdba2a16d0>
x == 1
Median: 6.88 us
IQR: 0.40 us (6.74 to 7.14)
716 measurements, 1000 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7fbdd2e07ed0>
x == y_scalar
Median: 2.98 us
IQR: 0.19 us (2.89 to 3.08)
167 measurements, 10000 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7fbdd33e4510>
x == y_tensor
Median: 3.03 us
IQR: 0.13 us (2.97 to 3.10)
154 measurements, 10000 runs per measurement, 1 thread
```
There's still a fair bit of work left. Equivalent NumPy is about 6x faster than the new overhead, and PyTorch 0.4 is about 1.25 us across the board. (No scalar cliff.) But it's a start.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48018
Reviewed By: gchanan
Differential Revision: D25026257
Pulled By: robieta
fbshipit-source-id: 093b06a1277df25b4b7cc0d4e585b558937b10a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47977
Avoid calling CppSignatureGroup api - python signature shouldn't depend on
cpp signature. Still use cpp.group_arguments() to group TensorOptions.
Confirmed byte-for-byte compatible with the old codegen:
```
Run it before and after this PR:
.jenkins/pytorch/codegen-test.sh <baseline_output_dir>
.jenkins/pytorch/codegen-test.sh <test_output_dir>
Then run diff to compare the generated files:
diff -Naur <baseline_output_dir> <test_output_dir>
```
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D24976334
Pulled By: ljk53
fbshipit-source-id: 5df5a7bbfd2b8cb460153e5bea4d91e65f716390
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47976
Confirmed byte-for-byte compatible with the old codegen:
```
Run it before and after this PR:
.jenkins/pytorch/codegen-test.sh <baseline_output_dir>
.jenkins/pytorch/codegen-test.sh <test_output_dir>
Then run diff to compare the generated files:
diff -Naur <baseline_output_dir> <test_output_dir>
```
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D24976273
Pulled By: ljk53
fbshipit-source-id: 6f8f20d18db20c3115808bfac0a8b8ad83dcf64c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48160
We no longer use the custom c++ test infra anyways, so move to pure
gtest.
Fixes#45703
ghstack-source-id: 116977283
Test Plan: `buck test //caffe2/test/cpp/tensorexpr`
Reviewed By: navahgar, nickgg
Differential Revision: D25046618
fbshipit-source-id: da34183d87465f410379048148c28e1623618553
Summary:
Reference https://github.com/pytorch/pytorch/issues/38349
Delegates to `torch.transpose` (not sure what is the best way to alias)
TODO:
* [x] Add test
* [x] Add documentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46041
Reviewed By: gchanan
Differential Revision: D25022816
Pulled By: mruberry
fbshipit-source-id: c80223d081cef84f523ef9b23fbedeb2f8c1efc5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48061
This results in a ~6% improvement on DeepAndWide model and would improve
other models as well.
Before the change:
```
393[ms]
458[ms]
413[ms]
390[ms]
430[ms]
399[ms]
426[ms]
392[ms]
428[ms]
399[ms]
```
After the change:
```
396[ms]
375[ms]
396[ms]
392[ms]
370[ms]
402[ms]
395[ms]
409[ms]
366[ms]
388[ms]
```
Differential Revision: D25006357
Test Plan: Imported from OSS
Reviewed By: suo
Pulled By: ZolotukhinM
fbshipit-source-id: c9cdc6354c42962b14207db31cf2580a4e2430b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48129
It looks like all test failures in distributed_test have to do with
profiling, so disabling them in this PR (by setting `expect_event=False`
always), so that the distributed profiling tests don't run.
Created https://github.com/pytorch/pytorch/issues/48127 to track the fix.
Will verify with CI all that re-enabling distributed tests passes as expected.
ghstack-source-id: 116938304
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D25034888
fbshipit-source-id: c10bad3ca2425a2f2cde82232001dafcca152d1c
Summary:
Now when https://github.com/pytorch/pytorch/pull/42553 is merged we can delete a bit of code from the tests and enable some of the skipped complex tests.
Unfortunately, `test_pinverse_complex_xfailed` and `test_symeig_complex_xfailed` had bugs and it wasn't caught automatically that these tests xpass. Need to be careful next time with `unittest.expectedFailure`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47910
Reviewed By: zhangguanheng66
Differential Revision: D25052130
Pulled By: mruberry
fbshipit-source-id: 29512995c024b882f9cb78b7bede77733d5762d0
Summary:
This PR revamps the hipify module in PyTorch to overcome a long list of shortcomings in the original implementation. However, these improvements are applied only when using hipify to build PyTorch extensions, **not for PyTorch or Caffe2 itself**.
Correspondingly, changes are made to `cpp_extension.py` to match these improvements.
The list of improvements to hipify is as follows:
1. Hipify files in the same directory as the original file, unless there's a "cuda" subdirectory in the original file path, in which case the hipified file will be in the corresponding file path with "hip" subdirectory instead of "cuda".
2. Never hipify the file in-place if changes are introduced due to hipification i.e. always ensure the hipified file either resides in a different folder or has a different filename compared to the original file.
3. Prevent re-hipification of already hipified files. This avoids creation of unnecessary "hip/hip" etc. subdirectories and additional files which have no actual use.
4. Do not write out hipified versions of files if they are identical to the original file. This results in a cleaner output directory, with minimal number of hipified files created.
5. Update header rewrite logic so that it accounts for the previous improvement.
6. Update header rewrite logic so it respects the rules for finding header files depending on whether `""` or `<>` is used.
7. Return a dictionary of mappings of original file paths to hipified file paths from `hipify` function.
8. Introduce a version for hipify module to allow extensions to contain back-compatible code that targets a specific point in PyTorch where the hipify functionality changed.
9. Update `cuda_to_hip_mappings.py` to account for the ROCm component subdirectories inside `/opt/rocm/include`. This also results in cleanup of the `Caffe2_HIP_INCLUDE` path to remove unnecessary additions to the include path.
The list of changes to `cpp_extension.py` is as follows:
1. Call `hipify` when building a CUDAExtension for ROCm.
2. Prune the list of source files to CUDAExtension to include only the hipified versions of any source files in the list (if both original and hipified versions of the source file are in the list)
3. Add subdirectories of /opt/rocm/include to the include path for extensions, so that ROCm headers for subcomponent libraries are found automatically
cc jeffdaily sunway513 hgaspar lcskrishna ashishfarmer
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45451
Reviewed By: ezyang
Differential Revision: D24924736
Pulled By: malfet
fbshipit-source-id: 4af42b8ff4f21c3782dedb8719b8f9f86b34bd2d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47979
For MHA module, it is preferred to use the combined weight branch as much as possible when query/key/value are same (in case of same values by `torch.equal` or exactly same object by `is` ops). This PR will enable the faster branch when a single object with `nan` is passed to MHA.
For the background knowledge
```
import torch
a = torch.tensor([float('NaN'), 1, float('NaN'), 2, 3])
print(a is a) # True
print(torch.equal(a, a)) # False
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48126
Reviewed By: gchanan
Differential Revision: D25042082
Pulled By: zhangguanheng66
fbshipit-source-id: 6bb17a520e176ddbb326ddf30ee091a84fcbbf27
Summary:
For ROCm, the CI images serve both the CI jobs as well as public releases. Without removing the sccache wrappers, end users are forced to use sccache. Our users have encountered sccache bugs when using our PyTorch images, so we choose to remove them after the CI build completes. Further, runtime compilation of MIOpen kernels still experiences errors due to sccache.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47947
Reviewed By: gchanan
Differential Revision: D24994031
Pulled By: malfet
fbshipit-source-id: 65c57ae98e28fc0ce79f754b792d504148c7fcd6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48042
Moving scalar test to a separate method so the XLA team can continue to test for the other cases without failing. Requested here https://github.com/pytorch/xla/issues/2620#issuecomment-725696108
Test Plan: Imported from OSS
Reviewed By: zhangguanheng66
Differential Revision: D25055677
Pulled By: heitorschueroff
fbshipit-source-id: 5da66bac78ea197821fee0b9b8a213ff2dc19c67
Summary:
When building libtorch with CUDA installed in some unconventional
location, CMake files rely on some environment variables to set cmake
variable, in particular NVTOOLSEXT_PATH environment variable is used to
set NVTOOLEXT_HOME in cmake/public/cuda.cmake. Later when consuming
such build using the generated cmake finder TorchConfig.cmake, another
convention is used which feels rather inconsistent, relying on a
completly new environment variable NVTOOLEXT_HOME, although the former
way is still in place, cmake/public/cuda.cmake being transitively called
via Caffe2Config.cmake, which is called by TorchConfig.cmake
Fixes https://github.com/pytorch/pytorch/issues/48032
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48012
Reviewed By: gchanan
Differential Revision: D25031260
Pulled By: ezyang
fbshipit-source-id: 0d6ab8ba9f52dd10be418b1a92b0f53c889f3f2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48168
TensorPipe deduplicated a set of error (which existed both under the ::transport and the ::channel namespaces). The old names were kept as aliases but we should migrate to the new ones.
ghstack-source-id: 116989010
Test Plan: CI
Reviewed By: beauby
Differential Revision: D25051218
fbshipit-source-id: caef27f1a0ff0e6f0b8b09fa92d6f79641c1e17a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48150
With D24767322, the remaining ops without out_ variant are pretty much the sparsenn specific ops, which are a bit trickier to add.
Test Plan:
```
buck run //caffe2/test:static_runtime
buck run //caffe2/benchmarks/static_runtime:static_runtime_cpptest
buck run //caffe2/caffe2/fb/predictor:pytorch_predictor_test
buck-out/opt/gen/caffe2/caffe2/fb/predictor/ptvsc2_predictor_bench \
--pred_net=/home/hlu/ads/adindexer/adindexer_ctr_mobilefeed/pt/merge/precomputation_merge_net.pb \
--c2_inputs=/home/hlu/ads/adindexer/adindexer_ctr_mobilefeed/pt/merge/c2_inputs_precomputation_bs1.pb \
--c2_weights=/home/hlu/ads/adindexer/adindexer_ctr_mobilefeed/pt/merge/c2_weights_precomputation.pb \
--scripted_model=/home/hlu/ads/adindexer/adindexer_ctr_mobilefeed/pt/merge/traced_precomputation_partial_dper_fixes.pt \
--pt_inputs=/home/hlu/ads/adindexer/adindexer_ctr_mobilefeed/pt/merge/container_precomputation_bs1.pt \
--iters=1 --warmup_iters=1 --num_threads=1 --pt_enable_static_runtime=true \
--pt_cleanup_activations=true --pt_enable_out_variant=true \
--eps 1e-2
```
Reviewed By: bwasti
Differential Revision: D25016076
fbshipit-source-id: 59a7948d4cca60182b6755217571128c2fc51f4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47965
**Summary**
This commit fixes `FunctionSchema::isSubtypeOf` so that the subtyping rule it
implements for `FunctionSchema` instances is contravariant in argument
types and covariant in return type. At present, the rule is covariant in
argument types and contravariant in return type, which is not correct.
A brief but not rigourous explanation follows. Suppose there are two
`FunctionSchema`s, `M = (x: T) -> R` and `N = (x: U) -> S`. For `M <= N`
to be true (i.e. that `M` is a subtype of `N`), it must be true that `U
<= T` and `R <= S`. This generalizes to functions with multiple
arguments.
**Test Plan**
This commit extends `TestModuleInterface.test_module_interface_subtype`
with two new tests cases that test the contravariance of argument types
and covariance of return types in determining whether a `Module`
implements an interface type.
Test Plan: Imported from OSS
Reviewed By: qizzzh
Differential Revision: D24970883
fbshipit-source-id: 2e4bda079c7062806c105ffcc14a28796b063525
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45277
Implements structured kernels as per https://github.com/pytorch/rfcs/pull/9 and ports upsample_nearest1d to use the framework.
The general structure of this diff:
- Define a new syntax for specifying structured kernels in `native_functions.yaml`. You put `structured: True` on the `out` function (that's what you implement) and `structured_delegate: foo.out` on the functional/inplace variants to define them in terms of the `out` function. There's a bunch of new consistency checking to see if you've done this right, though the error messages are of varying quality. This is most of what's going on in tools.codegen.model
- NativeFunctionGroup turns into StructuredNativeFunctions. Previously I thought that maybe we would use this grouping mechanism for both structured and unstructured kernels, but it turned out that Jiakai needed to make his own grouping structure. So now I've specialized it for structured kernels, which also means I get to add a bunch of invariants, like requiring structured kernels to have both a functional and an out variant. This is the lower bundle of changes in tools.codegen.model
- When you make an out kernel structured, this induces us to generate a new meta function signature for you to write shape checking and output allocation code. The signatures of these is defined by `tools.codegen.api.meta` and generated into `MetaFunctions.h`. Coverage here is very bare bones and will be driven by actual operators we port as we go.
- The meaty part of code generation is what we do when we have some grouped StructuredNativeFunctions. We continue to generate a wrapper per function type, but they're are a bit different as the call your meta functions, and make reference to the actual implementations in out.
- Then there's a port of `upsample_nearest1d`; easiest to review by just looking at what the final code looks like.
Missing pieces:
- Stride calculation in TensorMeta
- Sufficient sanity checking for inplace/out variants
- Enough rope to make TensorIterator work
This PR improves instruction counts on `upsample_nearest1d` because it eliminates an extra redispatch. Testing `at::upsample_nearest1d(x, {10});`
* Functional: before 1314105, after 1150705
* Out: before 915705, after 838405
These numbers may be jittered up to +-16400 (which is the difference when I tested against an unaffected operator `at::upsample_linear1d`), though that may also because unrelated changes affected all operators globally.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D24253555
Test Plan: Imported from OSS
Reviewed By: smessmer
Pulled By: ezyang
fbshipit-source-id: 4ef58dd911991060f13576864c8171f9cc614456
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48062
When Embedding/EmbeddingBag are configured with static quant we'll skip inserting observer for
them in the graph and keep the op unchanged and print a warning.
This also aligns with eager mode behavior as well.
We'll enforce this behavior for other ops that only supports dynamic/weight_only quant but not static quant as well.
We used a global variable `DEFAULT_NOT_OBSERVED_QUANTIZE_HANDLER`, this is not exposed to user right now,
we can add that later if needed.
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D25007537
fbshipit-source-id: 6ab9e025269b44bbfd0d6dd5bb9f95fe3ca9dead
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47635
Add macosx support for metal. The supported os version is 10.13 and above.
ghstack-source-id: 116845318
Test Plan:
1. Sandcastle Tests
2. CircleCI Jobs
3. In the next diff, we'll run the person segmentation model inside a macos app
Reviewed By: dreiss
Differential Revision: D24825088
fbshipit-source-id: 10d7976c953e765599002dc42d7f8d248d7c9846
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47768
This stores the next ID for a given NextName(prefix, output_id) so repeated calls to NextName are significantly faster. This accounts for ~65% of time spent for large models.
Test Plan:
buck test //caffe2/caffe2/python/...
will launch canary job before landing to ensure no regressions + confirm speedup
Reviewed By: dzhulgakov
Differential Revision: D24876961
fbshipit-source-id: 668d73060d800513bc72d7cd405a47d15c4acc34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48085
We were treating it as a binary operator, which implies shape
broadcasting, even though the second arg is thrown away aside from the type.
Treating it as a unary is the proper approach.
ghstack-source-id: 116873680
Test Plan: new unit test
Reviewed By: ZolotukhinM
Differential Revision: D25017585
fbshipit-source-id: 0cfa89683c9bfd4fbb132617c74b47b268d7f368
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48084
as title
ghstack-source-id: 116870328
Test Plan: new unit test
Reviewed By: Krovatkin
Differential Revision: D25017489
fbshipit-source-id: 0d1998fccad6f509db04b6c67a4e4e4093d96751
Summary:
Fixes an internally reported issue in the tensorexpr fuser when using FP16 on Cuda. The HalfChecker analysis to determine if we need to define the Half type searches the IR for expressions that use Half. If one of the parameters is of type Half but it (or any other Half expr) are not used in the IR we'll return a false negative. Fix this by adding the parameter list to the HalfChecker.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48068
Reviewed By: ZolotukhinM
Differential Revision: D25009680
Pulled By: nickgg
fbshipit-source-id: 24fddef06821f130db3d3f45d6d041c7f34a6ab0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48038
nn.ReLU works for both float and quantized input, we don't want to define an nn.quantized.ReLU
that does the same thing as nn.ReLU, similarly for nn.quantized.functional.relu
this also removes the numerical inconsistency for models quantizes nn.ReLU independently in qat mode
Test Plan:
Imported from OSS
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D25000462
fbshipit-source-id: e3609a3ae4a3476a42f61276619033054194a0d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47876
Fixes a pointless comparison against zero warning that arises for some scalar types
Test Plan:
Arises with
```
buck test mode/dev-nosan //caffe2/torch/fb/sparsenn:gpu_test -- test_prior_correction_calibration_prediction_binary
```
Reviewed By: ngimel
Differential Revision: D24925955
fbshipit-source-id: 56bcf32aeb164b078d537dd5d7c28a52bd7b66de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47531
This is part of a stack of PRs that fixes mypy typing errors in the torch.distributed.* directory.
Test Plan:
python test_type_hints.py -v TestTypeHints.test_run_mypy
Imported from OSS
Reviewed By: walterddr
Differential Revision: D24952499
fbshipit-source-id: b193171e28c2211a71d28a544fa44770bf938a1e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48063
The TE fuser does not know how to construct a list of Tensors.
Test Plan: new unit test
Reviewed By: eellison
Differential Revision: D25007234
fbshipit-source-id: 1a8ffdf5ffecb39a727357799ed32df8f53150d6
Summary:
Pull Request resolved: https://github.com/pytorch/glow/pull/5062
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45556
User defined classes can be used as constants. This is useful when freezing and removing the module from the graph.
Test Plan: waitforsadcastle
Reviewed By: eellison
Differential Revision: D23994974
fbshipit-source-id: 5b4a5c91158aa7f22df39d71f2658afce1d29317
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48034
The Tensor case is one of the most common and the existing check can be
made faster. This results in a ~21% improvement on DeepAndWide model and
would improve other models as well.
Before the change:
```
505[ms]
491[ms]
514[ms]
538[ms]
514[ms]
554[ms]
556[ms]
512[ms]
516[ms]
527[ms]
```
After the change:
```
406[ms]
394[ms]
414[ms]
423[ms]
449[ms]
397[ms]
410[ms]
389[ms]
395[ms]
414[ms]
```
Differential Revision: D24999486
Test Plan: Imported from OSS
Reviewed By: zdevito
Pulled By: ZolotukhinM
fbshipit-source-id: 7139a3a38f9c44e8ea793afe2fc662ff51cc0460
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48021
Extending operator schema check for simple memonger to dag memonger as well. As part of this a fix is being made to handle inplace ops (having at least one output name same as input blob). Earlier all the output blobs from ops were being treated as shareable but it failed assertion of external input blobs with the same name not allowed to share.
Test Plan: Added corresponding unit tests
Reviewed By: hlu1
Differential Revision: D24968862
fbshipit-source-id: b6679a388a82b0d68f65ade64b85560354aaa3ef
Summary:
This PR fixes the add_node and remove_node in partition class and also add a unit test for node manipulation in partition
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48016
Reviewed By: gcatron
Differential Revision: D24996368
Pulled By: scottxu0730
fbshipit-source-id: 0ddffd5ed3f95e5285fffcaee8c4b671929b4df3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47322
Updating all call-sites of the legacy dispatcher registration API in fbcode to the new API.
I migrated all call sites that used the legacy dispatcher registration API (RegisterOperators()) to use the new API (TORCH_LIBRARY...). I found all call-sites by running `fbgs RegisterOperators()`. This includes several places, including other OSS code (nestedtensor, torchtext, torchvision). A few things to call out:
For simple ops that only had one registered kernel without a dispatch key, I replaced them with:
```
TORCH_LIBRARY_FRAGMENT(ns, m) {
m.def("opName", fn_name);
}
```
For ops that registered to a specific dispatch key / had multiple kernels registered, I registered the common kernel (math/cpu) directly inside a `TORCH_LIBRARY_FRAGMENT` block, and registered any additional kernels from other files (e.g. cuda) in a separate `TORCH_LIBRARY_IMPL` block.
```
// cpu file
TORCH_LIBRARY_FRAGMENT(ns, m) {
m.def("opName(schema_inputs) -> schema_outputs");
m.impl("opName", torch::dispatch(c10::DispatchKey::CPU, TORCH_FN(cpu_kernel)));
}
// cuda file
TORCH_LIBRARY_IMPL(ns, CUDA, m) {
m.impl("opName", torch::dispatch(c10::DispatchKey::CUDA, TORCH_FN(cuda_kernel)));
}
```
Special cases:
I found a few ops that used a (legacy) `CPUTensorId`/`CUDATensorId` dispatch key. Updated those to use CPU/CUDA- this seems safe because the keys are aliased to one another in `DispatchKey.h`
There were a handful of ops that registered a functor (function class) to the legacy API. As far as I could tell we don't allow this case in the new API, mainly because you can accomplish the same thing more cleanly with lambdas. Rather than delete the class I wrote a wrapper function on top of the class, which I passed to the new API.
There were a handful of ops that were registered only to a CUDA dispatch key. I put them inside a TORCH_LIBRARY_FRAGMENT block, and used a `def()` and `impl()` call like in case two above.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D24714803
Pulled By: bdhirsh
fbshipit-source-id: c809aad8a698db3fd0d832f117f833e997b159e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47613
This is to test some more cancellation edge cases that were missing before. It passes under the current code.
Test Plan: buck test mode/opt caffe2/caffe2:caffe2_test_cpu -- PlanExecutorTest --stress-runs 10
Reviewed By: dahsh
Differential Revision: D24836956
fbshipit-source-id: 3b00dc081cbf4f26e7756d597099636edb49d256
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47851
Since the definitions of these functions in `native_functions.yaml` has special dispatch, we were already generating the proper `NotImplemented` behavior for these functions but we were wrongfully setting that gradient of all of the outputs.
Added entries in `derivatives.yaml` to allow us to specify which outpus are differentiable or not.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47930
Reviewed By: smessmer
Differential Revision: D24960667
Pulled By: albanD
fbshipit-source-id: 19e5bb3029cf0d020b31e2fa264b3a03dd86ec10
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47973
Currently torch.Assert is not scriptable, which makes it not very useful for production code. According to jamesr66a , moving this to c++ op land will help with scriptability. This PR implements the change.
Note: with the current code the Assert is scriptable but the Assert is a no-op after being scripted. Would love suggestions on how to address that (can be in future PR).
Test Plan:
```
python test/test_utils.py TestAssert.test_assert_scriptable
python test/test_utils.py TestAssert.test_assert_true
python test/test_fx.py TestFX.test_symbolic_trace_assert
```
Reviewed By: supriyar
Differential Revision: D24974299
Pulled By: vkuzo
fbshipit-source-id: 20d4f4d8ac20d76eee122f2cdcdcdcaf1cda3afe
Summary:
Add support for ReduceOp in the Vectorizer, which allows vectorization of reductions. Only non-reduce axes can be vectorized currently, we'd need either automatically pulling out the RHS of reductions (better as a separate transform, I think) or special handling of vector reduce in the LLVM codegen (tricky, maybe not useful?) to make vectorizing reduce axes work.
There was a disabled LLVM test for this case which I reenabled with a bit of massaging, and added a few more.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47924
Reviewed By: bertmaher
Differential Revision: D24963464
Pulled By: nickgg
fbshipit-source-id: 91d91e9e2696555ab5690b154984b1ce48359d51
Summary:
`CIRCLE_PR_NUMBER` is not always set during CI.
This is to extract PR NUMBER from BRANCH info in order to launch additional CI jobs.
Should allow tag:`ci/binaries` and `ci/all` worked on forked PRs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47969
Reviewed By: janeyx99
Differential Revision: D24991790
Pulled By: walterddr
fbshipit-source-id: 3ca30752135d54236a9abf0610eb89946852d45a
Summary:
Fix https://github.com/pytorch/pytorch/issues/46242
This ensures that the `check_inplace()` run the proper checks even if the Tensor that is being modified inplace does not requires gradient. As the Tensor written into it might require gradient and will make this inplace modification actually differentiable.
This contains:
- Codegen changes to tell `check_inplace()` if the inplace will be differentiable
- Changes in `handle_view_on_rebase` to work properly even when called for an input that does not require gradients (which was assumed to be true before)
- Corresponding tests (both warnings and the error raise internal assert errors without this fix)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46296
Reviewed By: ezyang
Differential Revision: D24903770
Pulled By: albanD
fbshipit-source-id: 74e65dad3d2e3b9f762cbb7b39f92f19d9a0b094
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47952
We don't actually generate a TE kernel so no need to use the
arena-allocation guard.
Test Plan:
```
buck test //caffe2/test/cpp/tensorexpr -- FuserPass
```
Reviewed By: ZolotukhinM
Differential Revision: D24967107
fbshipit-source-id: 302f65b2fcff704079e8b51b942b7b3baff95585
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47896
Per title
ghstack-source-id: 116710141
Test Plan: CI
Reviewed By: osalpekar
Differential Revision: D24943323
fbshipit-source-id: 7bf33ce3a021b9750b65e0c08f602c465cd81d28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47818
This is another relatively small codegen.
Ideally we should CppSignature.decl() to generate the c++ function declaration.
We didn't because it needs to add 'at::' to the types defined in ATen namespace.
E.g.:
- standard declaration:
```
Tensor eye(int64_t n, int64_t m, const TensorOptions & options={})
```
- expected:
```
at::Tensor eye(int64_t n, int64_t m, const at::TensorOptions & options = {})
```
Kept the hacky fully_qualified_type() method to keep compatibility with old codegen.
We could clean up by:
- Using these types in torch namespace - but this is a user facing header file,
not sure if it will cause problem;
- Update cpp.argument_type() method to take optional namespace argument;
Confirmed byte-for-byte compatible with the old codegen:
```
Run it before and after this PR:
.jenkins/pytorch/codegen-test.sh <baseline_output_dir>
.jenkins/pytorch/codegen-test.sh <test_output_dir>
Then run diff to compare the generated files:
diff -Naur <baseline_output_dir> <test_output_dir>
```
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D24909478
Pulled By: ljk53
fbshipit-source-id: a0ceaa60cc765c526908fee39f151cd7ed5ec923
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47746
- Removed the integration hack in gen_python_functions.py. It now directly
loads native_functions.yaml. All dependencies on Declarations.yaml
have been removed / moved to elsewhere.
- Rewrote the deprecated.yaml parsing logic to work with new data model directly.
Confirmed byte-for-byte compatible with the old codegen:
```
Run it before and after this PR:
.jenkins/pytorch/codegen-test.sh <baseline_output_dir>
.jenkins/pytorch/codegen-test.sh <test_output_dir>
Then run diff to compare the generated files:
diff -Naur <baseline_output_dir> <test_output_dir>
```
Differential Revision: D24885067
Test Plan: Imported from OSS
Reviewed By: bhosmer
Pulled By: ljk53
fbshipit-source-id: 8e906b7dd36a64395087bd290f6f54596485ceb4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47745
This is a relatively small codegen. Reintroduced 'simple_type' to preserve
old codegen output.
It depends on some methods defined in gen_python_functions.py - next PR will
clean up the remaining Declarations.yaml methods in gen_python_functions.py.
Confirmed byte-for-byte compatible with the old codegen:
```
Run it before and after this PR:
.jenkins/pytorch/codegen-test.sh <baseline_output_dir>
.jenkins/pytorch/codegen-test.sh <test_output_dir>
Then run diff to compare the generated files:
diff -Naur <baseline_output_dir> <test_output_dir>
```
Differential Revision: D24885068
Test Plan: Imported from OSS
Reviewed By: ezyang
Pulled By: ljk53
fbshipit-source-id: c0fbd726bcc450c3c7fe232c23e5b31779d0b65f
Summary:
Change Partitioner.py file name to partitioner.py
Change GraphManipulation.py file name to graph_manipulation.py
Move test_replace_target_nodes_with() to test_fx_experimental.py
Remove the unnecessary argument in size_based_partition() in Partitioner class
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47914
Reviewed By: gcatron
Differential Revision: D24956653
Pulled By: scottxu0730
fbshipit-source-id: 25b65be7dc7d64e90ffdc59cf394446fee83c3e6
Summary:
If world_size is lesser than or equal to number of GPU's available
then the rank can be directly mapped to corresponding GPU.
This fixes the issue referenced in https://github.com/pytorch/pytorch/issues/45435 and https://github.com/pytorch/pytorch/issues/47629
For world_size = 3 and number of GPU's = 8, the rank to GPU mapping
will be 0,2,4. This is due to the introduction of barrier,
(refer PR https://github.com/pytorch/pytorch/issues/45181)
the tensors in barrier is mapped to cuda0,1,2 and the tensors in the
actual test cases are mapped to cuda0,2,4 resulting in different streams and
leading to timeout. This issue is specific to default process group.
Issue is not observed in new process group since the streams are created again
after the initial barrier call.
This patch maps the rank to corresponding GPU's when the world_size is
less than or equal to the number of GPU's, in this case 0,1,2
Note: The barrier function in distributed_c10d.py should include new parameter
to specify the tensor or rank to GPU mapping. In that case, this patch will be
redundant but harmless since the tests can specify the tensors with appropriate
GPU rankings.
Fixes https://github.com/pytorch/pytorch/issues/47629
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47898
Reviewed By: smessmer
Differential Revision: D24956021
Pulled By: rohan-varma
fbshipit-source-id: a88257f22a7991ba36566329766c106d3360bb4e
Summary:
I think these can be safely removed since the min version of supported Python is now 3.6
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47822
Reviewed By: smessmer
Differential Revision: D24954936
Pulled By: ezyang
fbshipit-source-id: 5d4b2aeb78fc97d7ee4abaf5fb2aae21bf765e8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47246
We crash the process in NCCL Async Error Handling if the collective
has been running for greater than some set timeout. This PR introduces more
information about the rank and duration the collective ran.
ghstack-source-id: 116676182
Test Plan: Run desync tests and flow.
Reviewed By: pritamdamania87
Differential Revision: D24695126
fbshipit-source-id: 61ae46477065a1a451dc46fb29c3ac0073ca531b
Summary:
Fix for https://github.com/pytorch/pytorch/issues/46122
For `Any`, we infer the type of the ivalue to set the ivalue's type tag. When we saw a Tensor, we would use a specialized Tensor type, so when `Dict[str, Tensor]` was passed in as any `Any` arg it would be inferred as `Dict[str, Float(2, 2, 2, 2)]` which breaks runtime `isinstance` checking.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46130
Reviewed By: glaringlee
Differential Revision: D24261447
Pulled By: eellison
fbshipit-source-id: 8a2bb26ce5b6c56c8dcd8db79e420f4b5ed83ed5
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 9b0131179f
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47929
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: smessmer
Differential Revision: D24957361
fbshipit-source-id: 72fe80a784f10ddca52ee99fcf67cf6448a93012
Summary: D24747035 (1478e5ec2a) removes the entry point of `nnq.functional.relu`. Adjust op benchmark to `torch.nn.ReLU` accordingly.
Test Plan: buck run caffe2/benchmarks/operator_benchmark/pt:qactivation_test -- --use_jit --iterations 1 --warmup_iterations 1
Reviewed By: mingzhe09088
Differential Revision: D24961625
fbshipit-source-id: 5ed0ec7fa6d8cfefc8e7fc8324cf9a2a3e59de90
Summary:
Inside a container, the user is often root. We should allow this use case so that people can easily run `run_test.py` insider a container
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43794
Reviewed By: ezyang
Differential Revision: D24904469
Pulled By: malfet
fbshipit-source-id: f96cb9dda3e7bd18b29801cde4c5b0616c750016
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47076
Pull Request resolved: https://github.com/pytorch/glow/pull/5038
Eliminate double casting in glow when submitting fp16 per sample weights
Test Plan:
buck test glow/glow/torch_glow/tests:embedding_bag_test
Due to dependency conflicts between glow and caffe2, the test has been reverted from this diff, and landed separately
Reviewed By: allwu
Differential Revision: D24421367
fbshipit-source-id: eb3615144a2cad3d593543428dfdec165ad301df
Summary:
* Enable ONNX shape inference by default.
* ONNX could potentially set inferred shape in output instead of value_infos, checking both to be sure.
* Small fix in symbol_map to avoid overlooking dup symbols.
* Fix scalar_type_analysis to be consistent with PyTorch scalar type promotion logic.
* Correctly handle None dim_param from ONNX inferred shape.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46629
Reviewed By: ailzhang
Differential Revision: D24900171
Pulled By: bzinodev
fbshipit-source-id: 83d37fb9daf83a2c5969d8383e4c8aac986c35fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47926
Given that we're soon enabling async error handling in PET, we should make the behavior explicit when users have set NCCL_BLOCKING_WAIT in their own code while also using PET. This PR essentially gives blocking wait precedence (for now). This way the blast radius of the PET change is smaller, while we continue working with blocking wait users and discussing whether moving to async error handling may be a good fit.
ghstack-source-id: 116553583
Test Plan: Simple FBL run/CI
Reviewed By: jiayisuse
Differential Revision: D24928149
fbshipit-source-id: d42c038ad44607feb3d46dd65925237c564ff7a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47718
Distributed Inference splits a predict net into multiple parts, part0 being the main part which contains ops to make remote calls to other parts. part0 predict net may contain AsyncIf ops to optimize rpc call usage. AsyncIf ops have internal nets which may refer to memongered blobs. This change handles AsyncIf ops to update internal nets to refer to memongered blobs.
As part of this change, I am also updating dag memonger traversal to always start from root op, i.e. ops with 0 in degree. Earlier logic will start traversing ops based on input head blobs and if one of the head inputs is getting used in a non-root op which gets visited before its parent, the traversal will throwing assertion error here: https://fburl.com/diffusion/ob110s9z . Almost for all the distributed inference part0 nets, it was throwing this assertion error.
Test Plan: Added corresponding tests in memonger_test.py . Could not find unit tests in c++ version of memonger.
Reviewed By: hlu1
Differential Revision: D24872010
fbshipit-source-id: 1dc99b2fb52b2bc692fa4fc0aff6b7e4c5e4f5b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46454
we stopped syncing this folder to fbcode, and it's not been used. AIbench will use the ones in xplat.
Test Plan: zbgs fbcode/caffe2/mode/ find nothing
Reviewed By: xta0
Differential Revision: D24356743
fbshipit-source-id: 7e70a2181a49b8ff3f87e5be3b8c808135f4c527
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47731
**Summary**
This commit modifies `ScriptTypeParser::parseTypeFromExpr` so that
string literal type annotations are resolved using
`Resolver::resolveType`. At present, they are parsed in
`parseBaseTypeName`, which inadvertently allows any key from
`string_to_type_lut` to be used as a string literal type annotation.
**Test Plan**
Existing unit tests (most notably
`TestClassType.test_self_referential_method` which tests the main
feature, self-referential class type annotations, that make use of
string literal type annotations).
**Fixes**
This commit fixes#47570.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D24934717
Pulled By: SplitInfinity
fbshipit-source-id: b915b2c08272566b63b3cf5ff4a07ad43bdc381a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47884
We need to know output types of everything in a fusion group to ensure
that we generate correctly-typed tensors. We were incorrectly starting a
fusion group with an unknown-typed output.
Test Plan:
New unit tests:
```
buck test //caffe2/test:jit //caffe2/test/cpp/tensorexpr:tensorexpr
```
Reviewed By: eellison
Differential Revision: D24932786
fbshipit-source-id: 83978a951f32c1207bbc3555a7d3bd94fe4e70fb
Summary:
This is a second attempt at 8304c25c67, since the first attempt did not work as shown by b05f3571fe and c59015f21d. This time the idea is to directly embed the commit hash itself into the generated command that is fed to `docker exec`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47922
Reviewed By: zou3519
Differential Revision: D24953734
Pulled By: samestep
fbshipit-source-id: 35b14d1266ef039e8c1bdf3648275af812a2e57b
Summary:
In the cost_aware_partition, check the circular dependency in try_combining_partitions. Also fix the calculate of communication time between partitions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47856
Reviewed By: gcatron
Differential Revision: D24926591
Pulled By: scottxu0730
fbshipit-source-id: c634608675ac14b13b2370a727e4fb05e1bb94f0
Summary:
`torch.lu_solve` now works for complex inputs both on CPU and GPU.
I moved the existing tests to `test_linalg.py` and modified them to test complex dtypes, but I didn't modify/improve the body of the tests.
Ref. https://github.com/pytorch/pytorch/issues/33152
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46862
Reviewed By: nikithamalgifb
Differential Revision: D24543682
Pulled By: anjali411
fbshipit-source-id: 165bde39ef95cafebf976c5ba4b487297efe8433
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47634
Follow up on d16r's diff - D24710102. Make the function inline in order to get rid of the compiler checking `-Werror,-Wunused-function`.
ghstack-source-id: 116607200
Test Plan:
1. Sandcastle Tests
2. CircleCI jobs
Reviewed By: d16r
Differential Revision: D24824637
fbshipit-source-id: c17e219b384b91ac4620aa23112a6cda1200a605
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47706
**Summary**
This commit fixes `FunctionSchema::isSubtypeOf` so that the subtyping rule it
implements for `FunctionSchema` instances is contravariant in argument
types and covariant in return type. At present, the rule is covariant in
argument types and contravariant in return type, which is not correct.
A brief but not rigourous explanation follows. Suppose there are two
`FunctionSchema`s, `M = (x: T) -> R` and `N = (x: U) -> S`. For `M <= N`
to be true (i.e. that `M` is a subtype of `N`), it must be true that `U
<= T` and `R <= S`. This generalizes to functions with multiple
arguments.
**Test Plan**
This commit extends `TestModuleInterface.test_module_interface_subtype`
with two new tests cases that test the contravariance of argument types
and covariance of return types in determining whether a `Module`
implements an interface type.
**Fixes**
This commit closes#47631.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb
Differential Revision: D24934099
Pulled By: SplitInfinity
fbshipit-source-id: bd07e7b47d2a3a56d676f2f572de09fb18ececd8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47791
`debug_info` is `thread_local` and this function is a leaf, so nobody else could free it out from under us. Regular pointer should be fine.
ghstack-source-id: 116456975
Test Plan: Run framework overhead benchmarks
Reviewed By: bhosmer
Differential Revision: D24901749
fbshipit-source-id: c01a60b609fd08e5200264d8e98d356e2c78cf28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47399
Currently torch.Assert is not scriptable, which makes it not very useful for production code. According to jamesr66a , moving this to c++ op land will help with scriptability. This PR implements the change.
Note: with the current code the Assert is scriptable but the Assert is a no-op after being scripted. Would love suggestions on how to address that (can be in future PR).
Test Plan:
```
python test/test_utils.py TestAssert.test_assert_scriptable
python test/test_utils.py TestAssert.test_assert_true
python test/test_fx.py TestFX.test_symbolic_trace_assert
```
Imported from OSS
Reviewed By: eellison
Differential Revision: D24740727
fbshipit-source-id: c7888e769c921408a3020ca8332f4dae33f2bc0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47763
Changing the name due to the discussion in
https://github.com/pytorch/pytorch/pull/47399.
Test Plan:
```
python test/test_utils.py TestAssert.test_assert_true
python test/test_fx.py TestFX.test_symbolic_trace_assert
python test/test_fx_experimental.py
```
Imported from OSS
Reviewed By: ezyang
Differential Revision: D24891767
fbshipit-source-id: 01c7a5acd83bf9c962751552780930c242134dd2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47834
We can determine if (as is likely) there are no outstanding
weak references without bothering to decrement the
count. `std::shared_ptr` does this same optimization in libc++:
229db36474/libcxx/src/memory.cpp (L69-L107)
ghstack-source-id: 116576326
Test Plan:
Saw time spent in TensorImpl::release_resources drop in
local profiling of empty benchmark
Run framework overhead benchmarks. 9-10% savings on OutOfPlace, small single digit savings on empty, essentially none on InPlace.
Reviewed By: bhosmer
Differential Revision: D24914763
fbshipit-source-id: 19b03f960e32123bc72f7edce63fa1d18c3c143f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47890
As titled. In order to fix issue when running `chunk_test`, `split_test`, `qobserver` , `sort in qunary` in jit mode, because the output of `chunk_op` is a list of tensors which can not be handled by the current `_consume_op`
Test Plan:
OSS:
python3 -m benchmark_all_test --iterations 1 --warmup_iterations 1 --use_jit
Reviewed By: mingzhe09088
Differential Revision: D24774105
fbshipit-source-id: 210a0345b8526ebf3c24f4d0794e20b2ff6cef3d
Summary:
Fixed test:
- `test_is_nonzero`, this is asserting exact match, which is flaky when `TORCH_SHOW_CPP_STACKTRACES=1`, I changed this to non-exact assert
- `test_pinverse` TF32
- `test_symeig` TF32
- `test_triangular_solve_batched_many_batches_cpu_float64` precision on CPU BLAS
- `test_qr` TF32, as well as the tensor factory forgets a `dtype=dtype`
- `test_lu` TF32
- `ConvTranspose2d` TF32
- `Conv3d_1x1x1_no_bias` TF32
- `Transformer*` TF32
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46941
Reviewed By: heitorschueroff
Differential Revision: D24852725
Pulled By: mruberry
fbshipit-source-id: ccd4740cc643476178d81059d1c78da34e5082ed
Summary: Added the MatMul operator for caffe2
Test Plan: buck test //caffe2/torch/fb/model_transform/c2_convert:c2_pt_converter_test
Reviewed By: bugra
Differential Revision: D24920937
fbshipit-source-id: 7ba09ba0439cb9bd15d6a41fd8ff1a86d8d11437
Summary:
This PR is a bug fix.
As UT shows, for multiple-dimensional tensors, the current conversion for _len returns the total number of the tensors. But it should return the first dimension length, as pytorch _len defines.
Need `Squeeze` op at the end to ensure it outputs a scalar value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47538
Reviewed By: malfet
Differential Revision: D24870717
Pulled By: bzinodev
fbshipit-source-id: c53c745baa6d2fb7cc1de55a19bd2eedb2ad5272
Summary:
Refactors the ReduceOp node to remove the last remaining deferred functionality: completing the interaction between the accumulator buffer and the body. This fixes two issues with reductions:
1. Nodes inside the interaction could not be visited or modified, meaning we could generate bad code when the interaction was complex.
2. The accumulator load was created at expansion time and so could not be modified in some ways (ie. vectorization couldn't act on these loads).
This simplifies reduction logic quite a bit, but theres a bit more involved in the rfactor transform.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47709
Reviewed By: ZolotukhinM
Differential Revision: D24904220
Pulled By: nickgg
fbshipit-source-id: 159e5fd967d2d1f8697cfa96ce1bb5fc44920a40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47767
This diff implements the functionality of running benchmark on mobile on top of operator_benchmark framework. It does so through a few steps:
1. create a scripted module from existing benchmark case.
2. run mobile specific optimization pass on the scripted module
3. run the scripted module on AiBench by calling its Python API
A small change in the way of writing a benchmark case is introduced so that both local and mobile run can share the same interface. The change is about having inputs as arguments of the `forward` function, so that mobile optimization pass can be run successfully (otherwise everything will be optimized away by constant propagation).
Test Plan:
## local op_bench run
buck run caffe2/benchmarks/operator_benchmark:benchmark_all_test -- --iterations 1 --warmup_iterations 1
buck run caffe2/benchmarks/operator_benchmark:benchmark_all_test -- --iterations 1 --warmup_iterations 1 --use_jit
Exceptions: `py_module` op in `FakeQuantizePerTensorBaseOpBenchmark` and `FakeQuantizePerChannelBaseOpBenchmark` under JIT mode. These tests also failed in the base version
```
RuntimeError:
Module 'FakeQuantizePerChannelOpBenchmark' has no attribute 'op_func' (This function exists as an attribute on the Python module, but we failed to compile it to a TorchScript function.
The error stack is reproduced here:
Python builtin <built-in method apply of FunctionMeta object at 0x619000c652a0> is currently not supported in Torchscript:
File "/data/users/wangyang19/fbsource/fbcode/buck-out/dev/gen/caffe2/benchmarks/operator_benchmark/pt/quantization_test#link-tree/quantization_test.py", line 260
quant_min: int, quant_max: int
):
return _LearnableFakeQuantizePerChannelOp.apply(input, scale, zero_point, axis, quant_min, quant_max, 1.0)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
:
File "/data/users/wangyang19/fbsource/fbcode/buck-out/dev/gen/caffe2/benchmarks/operator_benchmark/pt/quantization_test#link-tree/quantization_test.py", line 313
axis: int, quant_min: int, quant_max: int
):
return self.op_func(input, scale, zero_point, axis, quant_min, quant_max)
~~~~~~~~~~~~ <--- HERE
```
`_consume_op` typing mismatch: chunk, split, qobserver, sort in qunary. These will be fixed in D24774105
## OSS test
python3 -m benchmark_all_test --iterations 1 --warmup_iterations 1 --use_jit
python3 -m benchmark_all_test --iterations 1 --warmup_iterations 1
## saved module graph
```
module __torch__.mobile_benchmark_utils.OpBenchmarkMobile {
parameters {
}
attributes {
training = True
num_iters = 1
benchmark = <__torch__.pt.add_test.___torch_mangle_4.AddBenchmark object at 0x6070001b8b50>
}
methods {
method forward {
graph(%self : __torch__.mobile_benchmark_utils.OpBenchmarkMobile):
%12 : None = prim::Constant() # /data/users/wangyang19/fbsource/fbcode/buck-out/dev/gen/caffe2/benchmarks/operator_benchmark/fb/pt/mobile/benchmark_all_test_fbcode#link-tree/mobile_benchmark_utils.py:9:4
%4 : bool = prim::Constant[value=1]() # /data/users/wangyang19/fbsource/fbcode/buck-out/dev/gen/caffe2/benchmarks/operator_benchmark/fb/pt/mobile/benchmark_all_test_fbcode#link-tree/mobile_benchmark_utils.py:10:8
%1 : int = prim::GetAttr[name="num_iters"](%self)
= prim::Loop(%1, %4) # /data/users/wangyang19/fbsource/fbcode/buck-out/dev/gen/caffe2/benchmarks/operator_benchmark/fb/pt/mobile/benchmark_all_test_fbcode#link-tree/mobile_benchmark_utils.py:10:8
block0(%i : int):
%6 : __torch__.pt.add_test.___torch_mangle_4.AddBenchmark = prim::GetAttr[name="benchmark"](%self)
%7 : __torch__.pt.add_test.___torch_mangle_4.AddBenchmark = prim::GetAttr[name="benchmark"](%self)
%self.inputs_tuple : (Float(1, 1, 1, strides=[1, 1, 1], requires_grad=0, device=cpu), Float(1, 1, 1, strides=[1, 1, 1], requires_grad=0, device=cpu)) = prim::Constant[value=({0.48884}, {0.809042})]()
%9 : Tensor, %10 : Tensor = prim::TupleUnpack(%self.inputs_tuple)
%23 : int = prim::Constant[value=1]()
%24 : Tensor = aten::add(%9, %10, %23) # /data/users/wangyang19/fbsource/fbcode/buck-out/dev/gen/caffe2/benchmarks/operator_benchmark/fb/pt/mobile/benchmark_all_test_fbcode#link-tree/pt/add_test.py:39:15
-> (%4)
return (%12)
}
}
submodules {
module __torch__.pt.add_test.___torch_mangle_4.AddBenchmark {
parameters {
}
attributes {
mobile_optimized = True
}
methods {
method forward {
graph(%self : __torch__.pt.add_test.___torch_mangle_4.AddBenchmark,
%input_one.1 : Tensor,
%input_two.1 : Tensor):
%3 : int = prim::Constant[value=1]()
%4 : Tensor = aten::add(%input_one.1, %input_two.1, %3) # /data/users/wangyang19/fbsource/fbcode/buck-out/dev/gen/caffe2/benchmarks/operator_benchmark/fb/pt/mobile/benchmark_all_test_fbcode#link-tree/pt/add_test.py:39:15
return (%4)
}
method get_inputs {
graph(%self : __torch__.pt.add_test.___torch_mangle_4.AddBenchmark):
%self.inputs_tuple : (Float(1, 1, 1, strides=[1, 1, 1], requires_grad=0, device=cpu), Float(1, 1, 1, strides=[1, 1, 1], requires_grad=0, device=cpu)) = prim::Constant[value=({0.48884}, {0.809042})]()
return (%self.inputs_tuple)
}
}
submodules {
}
}
}
}
```
Reviewed By: kimishpatel
Differential Revision: D24322214
fbshipit-source-id: 335317eca4f40c4083883eb41dc47caf25cbdfd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46092
Make empty c10-full without using hacky-wrapper, i.e. port the kernel to the new style signature.
This PR also changes the signature of some helpers called by empty to the new style.
ghstack-source-id: 116544203
(Note: this ignores all push blocking failures!)
Test Plan:
vs prev diff (outdated, before c10::optional fix): https://www.internalfb.com/intern/fblearner/details/224735103/
after c10::optional fix:
https://www.internalfb.com/intern/fblearner/details/231391773/
Also, after the c10::optional fix, the instruction counting benchmark shows a 2% regression for calling empty from Python. We decided this is acceptable and decided against landing D24425836 which would fix the regression.
Reviewed By: ezyang
Differential Revision: D24219944
fbshipit-source-id: e554096e90ce438c75b679131c3151ff8e5c5d50
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46804
As per our design in https://github.com/pytorch/pytorch/issues/44827,
changign the API such that the user places modules on appropriate devices
instead of having a `balance` and `devices` parameter that decides this.
This design allows us to use RemoteModule in the future.
ghstack-source-id: 116479842
Test Plan: waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D24524219
fbshipit-source-id: 9973172c2bb7636572cdc37ce06bf8368638a463
Summary:
Currently ([example](https://github.com/pytorch/pytorch/runs/1381883195)), ShellCheck is run on `*.sh` files in `.jenkins/pytorch`, but it uses a three-and-a-half-year-old version, and doesn't fail the lint job despite yielding many warnings. This PR does the following:
- update ShellCheck to v0.7.1 (and generally make it always use the latest `"stable"` release), to get more warnings and also enable the directory-wide directives that were introduced in v0.7.0 (see the next bullet)
- move the rule exclusions list from a variable in `.jenkins/run-shellcheck.sh` to a [declarative file](https://github.com/koalaman/shellcheck/issues/725#issuecomment-469102071) `.jenkins/pytorch/.shellcheckrc`, so now editor integrations such as [vscode-shellcheck](https://github.com/timonwong/vscode-shellcheck) give the same warnings as the CLI script
- fix all ShellCheck warnings in `.jenkins/pytorch`
- remove the suppression of ShellCheck's return value, so now it will fail the lint job if new warnings are introduced
---
While working on this, I was confused because I was getting fairly different results from running ShellCheck locally versus what I saw in the CI logs, and also different results among the laptop and devservers I was using. Part of this was due to different versions of ShellCheck, but there were even differences within the same version. For instance, this command should reproduce the results in CI by using (almost) exactly the same environment:
```bash
act -P ubuntu-latest=nektos/act-environments-ubuntu:18.04 -j quick-checks \
| sed '1,/Run Shellcheck Jenkins scripts/d;/Success - Shellcheck Jenkins scripts/,$d' \
| cut -c25-
```
But the various warnings were being displayed in different orders, so it was hard to tell at a glance whether I was getting the same result set or not. However, piping the results into this ShellCheck-output-sorting Python script showed that they were in fact the same:
```python
import fileinput
items = ''.join(fileinput.input()).split('\n\n')
print(''.join(sorted(f'\n{item.strip()}\n\n' for item in items)), end='')
```
Note that while the above little script worked for the old version (v0.4.6) that was previously being used in CI, it is a bit brittle, and will not give great results in more recent ShellCheck versions (since they give more different kinds of output besides just a list of warnings).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47786
Reviewed By: seemethere
Differential Revision: D24900522
Pulled By: samestep
fbshipit-source-id: 92d66e1d5d28a77de5a4274411598cdd28b7d436
Summary:
This PR replaces the current auto-generated commit messages like pytorch/pytorch.github.io@fb217ab34a (currently includes no information) and pytorch/cppdocs@7efd67e8f1 (currently includes only a timestamp, which is redundant since it's a Git commit) with more descriptive ones that specify the pytorch/pytorch commit they originated from. This information would be useful for debugging issues such as https://github.com/pytorch/pytorch/issues/47462.
GitHub will also [autolink](https://docs.github.com/en/free-pro-team@latest/github/writing-on-github/autolinked-references-and-urls#commit-shas) these new messages (similar to ezyang/pytorch-ci-hud@bc25ae770d), and so they will now also mostly follow Git commit message conventions by starting with a capital letter, using the imperative voice, and (at least in the autolink-rendered form on GitHub, although not in the raw text) staying under 50 characters.
**Question for reviewers:** Will my `export CIRCLE_SHA1="$CIRCLE_SHA1"` work here? Is it necessary?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47694
Reviewed By: walterddr
Differential Revision: D24868240
Pulled By: samestep
fbshipit-source-id: 4907341e7b57ed6818ab550dc1ec423f2c2450c1
Summary:
NNC lowering of aten::pow assumes that the types of the exponent is either float or int cast to to float, which doesn't work great with double (or half for that matter).
Fixes https://github.com/pytorch/pytorch/issues/47304
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47795
Reviewed By: ZolotukhinM
Differential Revision: D24904201
Pulled By: nickgg
fbshipit-source-id: 43c3ea704399ebb36c33cd222db16c60e5b7ada5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47643
Updating the docs to indicate the `num_keys` and `delete_key` APIs are now supported by the HashStore (not just TCPStore).
ghstack-source-id: 116459958
Test Plan: CI
Reviewed By: jiayisuse, mrshenli
Differential Revision: D24633570
fbshipit-source-id: 549479dd99f9ec6decbfffcb74b9792403d05ba2
Summary: As title
Test Plan:
- Circle CI
- Sandcastle
Reviewed By: husthyc
Differential Revision: D24915370
fbshipit-source-id: fe05ac37a25c804695a13fb5a7eabbc60442a102
Summary:
Adds a helper function to Bounds Inference / Memory Analaysis infrastructure which returns the kind of hazard found between two Stmts (e.g. Blocks or Loops). E.g.
```
for (int i = 0; i < 10; ++i) {
A[x] = i * 2;
}
for (int j = 0; j < 10; ++j) {
B[x] = A[x] / 2;
}
```
The two loops have a `ReadAfterWrite` hazard, while in this example:
```
for (int i = 0; i < 10; ++i) {
A[x] = i * 2;
}
for (int j = 0; j < 10; ++j) {
A[x] = B[x] / 2;
}
```
The loops have a `WriteAfterWrite` hazard.
This isn't 100% of what we need for loop fusion, for example we don't check the strides of the loop to see if they match.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47684
Reviewed By: malfet
Differential Revision: D24873587
Pulled By: nickgg
fbshipit-source-id: 991149e5942e769612298ada855687469a219d62
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47374
A few small fixes needed to enable unary op cpu testing. If reviewers would prefer I split them up let me know.
Test Plan: Imported from OSS
Reviewed By: ansley
Differential Revision: D24805248
Pulled By: eellison
fbshipit-source-id: c2cfe2e3319a633e64da3366e68f5bf21d390cb7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46951
If e.g. we're casting from torch.int -> torch.bool, previously we would just truncate from int32 -> i8. Since torch.bool has 8 bits but only uses one of them, we need to makes sure that one bit is set.
Test Plan: Imported from OSS
Reviewed By: ansley
Differential Revision: D24805253
Pulled By: eellison
fbshipit-source-id: af3aa323f10820d189827eb51037adfa7d80fed9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46950
Make sure that we're fusing in a fuse tests, and refactor to more concise API to check if fusions have happened.
Test Plan: Imported from OSS
Reviewed By: ansley
Differential Revision: D24805250
Pulled By: eellison
fbshipit-source-id: f898008a64b74e761bb5fe85f91b3cdf2dbdf878
Summary:
When printing doubles, we don't do anything to distinguish intregal doubles (ie, 1 or 2) from ints. Added decoration of these doubles with `.0` if they are integral (i.e. DoubleImm(1) will print as `1.0`).
This is an issue specifically on Cuda where some intrinsics do not have type coercion. Added a test which covers this case (without the fix it tries to look up pow(double, int) which doesn't exist).
Fixes https://github.com/pytorch/pytorch/issues/47304
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47799
Reviewed By: ZolotukhinM
Differential Revision: D24904185
Pulled By: nickgg
fbshipit-source-id: baa38726966c94ee50473cc046b9ded5c4e748f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47415
nn.ReLU works for both float and quantized input, we don't want to define an nn.quantized.ReLU
that does the same thing as nn.ReLU, similarly for nn.quantized.functional.relu
this also removes the numerical inconsistency for models quantizes nn.ReLU independently in qat mode
Test Plan: Imported from OSS
Reviewed By: z-a-f
Differential Revision: D24747035
fbshipit-source-id: b8fdf13e513a0d5f0c4c6c9835635bdf9fdc2769
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47797
NCCL p2p tests had hang issues before, the reason is that there were some unexpected context switches. For example, process 1 which is supposed to only use GPU1 could use GPU0 as a result of missing explicitly setting device.
ghstack-source-id: 116461969
Test Plan: waitforsandcastle
Reviewed By: jiayisuse
Differential Revision: D24863808
fbshipit-source-id: 92bd3a4874be8334210c7c8ee6363648893c963e
Summary:
For tracing successfully, we need write pytorch model in torch way. So we add instructions with examples here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46961
Reviewed By: ailzhang
Differential Revision: D24900040
Pulled By: bzinodev
fbshipit-source-id: b375b533396b11dbc9656fa61e84a3f92f352e4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47011
smessmer has complained about how it is difficult to find generated
code. Well hopefully this diffs helps a bit with that.
There are three components to this refactor:
- Rename TypeDerived (CPUType) to RegisterDispatchKey (RegisterCPU).
The 'Type' nomenclature is vestigial and I think Register says
what these files do a lot more clearly. I also got rid of
the CPUType namespace; everything just goes in anonymous
namespace now, less moving parts this way.
- Give Math and DefaultBackend their own files (RegisterMath and
RegisterDefaultBackend)
- Restructure code generation so that schema definition is done
completely separately from RegisterDispatchKey
I decided to name the files RegisterCPU rather than the old convention
BackendSelectRegister, because it seems better to me if these
files clump together in an alphabetical listing rather than being
spread out everywhere. There are a few manual registration files
which should probably get similar renaming.
I also did a little garden cleaning about how we identify if a
dispatch key is a cuda key or a generic key (previously called
KEYWORD_ALL_BACKENDS but I like my naming better).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D24600806
Test Plan: Imported from OSS
Reviewed By: smessmer
Pulled By: ezyang
fbshipit-source-id: c1b510dd7515bd95e3ad25b8edf961b2fb30a25a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42553
Ports `torch.bmm` and `torch.baddbmm` from TH to ATen, as well as adds support for complex dtypes. Also removes dead TH code for Level 2 functions.
Closes#24539
Test Plan: Imported from OSS
Reviewed By: ansley
Differential Revision: D24893511
Pulled By: anjali411
fbshipit-source-id: 0eba3f2aec99c48b3018a5264ee7789279cfab58
Summary:
This test started failing when ROCm CI moved to 3.9. Skip until triage is complete.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47809
Reviewed By: seemethere
Differential Revision: D24906319
Pulled By: walterddr
fbshipit-source-id: 0c425f3b21190cfbc5e0d1c3f477d834af40f0ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47766
The operator now supports accepting 2D indices as inputs.
For embedding operators, we set the default offsets in the op since the FBGEMM kernel expects it to be set
Output shape depends on the shape if the indices.
For embedding_bag operator, if indices is 2D (B, N) then offsets should be set to None by user. In this case
the input is interpreted as B bags each of fixed length N. Output shape is still 2-D in this case.
Test Plan:
python test/test_quantization.py TestQuantizedEmbeddingOps.test_embedding_bag_2d_indices
python test/test_quantization.py TestQuantizedEmbeddingOps.test_embedding_2d_indices
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D24895048
fbshipit-source-id: 2020910e1d85ed8673eedee2e504611ba260d801
Summary:
[WIP]This PR adds cost_aware_partition method in Partitioner class. The method partitions the fx graph module based on the latency of the whole graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47673
Reviewed By: gcatron
Differential Revision: D24896685
Pulled By: scottxu0730
fbshipit-source-id: 1b1651fe82ce56554f99d68da116e585c74099ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47394
This is a preliminary refactor for the next diff that will add an
additional flag to control whether we throw a StopIteration or not. We
basically move the flags for ddp uneven inputs to a simple class.
ghstack-source-id: 116428177
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D24739509
fbshipit-source-id: 96bf41bd1c02dd27e68f6f37d08e22f33129b319
Summary:
gcc-7.4.x or older fails to compile XNNPACK in debug mode with internal compiler error
Workaround this in a build script by pasing -O1 optimisation flag to XNNPACK if compiled on older compilers
Fixes https://github.com/pytorch/pytorch/issues/47292
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47805
Reviewed By: seemethere
Differential Revision: D24905758
Pulled By: malfet
fbshipit-source-id: 93f4e3b3b5c10b69734627c50e36b2eb544699c8
Summary:
`torch.triangular_solve` now works for complex inputs on GPU.
I moved the existing tests to `test_linalg.py` and modified them to test complex and float32 dtypes.
Ref. https://github.com/pytorch/pytorch/issues/33152
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46916
Reviewed By: navahgar, agolynski
Differential Revision: D24706647
Pulled By: anjali411
fbshipit-source-id: fe780eac93d2ae1b2549539bb385e5fac25213b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46541
When weights are prepacked XNNPACK packs the weights in a separate memory. After that original weights are not needed for inference. Having those weights lying around increase memory footprint, so we would like to remove the original weights once prepacking is done.
Test Plan: buck test //caffe2/aten:mobile_memory_cleanup
Reviewed By: kimishpatel
Differential Revision: D24280928
fbshipit-source-id: 90ffc53b1eabdc545a3ccffcd17fa3137d500cbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47198
Fixes:
```xplat/caffe2/aten/src/ATen/native/xnnpack/OpContext.h:77:10: error: 'run' overrides a member function but is not marked 'override' [-Werror,-Winconsistent-missing-override]
Tensor run(const Tensor& input);```
Test Plan: CI tests
Reviewed By: kimishpatel
Differential Revision: D24678573
fbshipit-source-id: 244769cc36d3c1126973a67441aa2d06d2b83b9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47775
When serializing graphs, we check every node for named types referenced,
so that we can register them as dependencies. We were skipping this
check for the graph inputs themselves. Since types used at input are
almost always used somewhere in the graph, we never noticed this gap
until a user reported an issue with NamedTuples.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D24896289
Pulled By: suo
fbshipit-source-id: 4ce76816cb7997a7b65e7cea152ea52ed8f27276
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47644
Minor Update to the init_process_group docs.
ghstack-source-id: 116441798
Test Plan: CI
Reviewed By: jiayisuse, mrshenli
Differential Revision: D24633432
fbshipit-source-id: fbd38dab464ee156d119f9f0b22ffd0e416c4fd7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47100
Profiling with Linux `perf` shows that we spend at least 1% of our time doing this increment in our framework overhead benchmark. Here's the inline function breakdown for empty_cpu, which takes 6.91% of the total time:
```
- at::native::empty_cpu
- 1.91% at::detail::make_tensor<c10::TensorImpl, c10::intrusive_ptr<c10::StorageImpl, c10::detail::intrusive_target_default_null_type<c10::StorageImpl> >, c10::DispatchKey, caffe2::TypeMeta&> (inlined)
- 0.98% c10::make_intrusive<c10::TensorImpl, c10::detail::intrusive_target_default_null_type<c10::TensorImpl>, c10::intrusive_ptr<c10::StorageImpl, c10::detail::intrusive_target_default_null_type<c10::StorageImpl> >, c10::DispatchKey, caffe2::TypeMeta&> (inlined
0.97% c10::intrusive_ptr<c10::TensorImpl, c10::detail::intrusive_target_default_null_type<c10::TensorImpl> >::make<c10::intrusive_ptr<c10::StorageImpl, c10::detail::intrusive_target_default_null_type<c10::StorageImpl> >, c10::DispatchKey, caffe2::TypeMeta&>
0.84% intrusive_ptr<c10::TensorImpl, c10::detail::intrusive_target_default_null_type<c10::TensorImpl> > (inlined) - 1.44% c10::make_intrusive<c10::StorageImpl, c10::detail::intrusive_target_default_null_type<c10::StorageImpl>, c10::StorageImpl::use_byte_size_t, long&, c10::DataPtr, c10::Allocator*&, bool> (inlined)
- 1.44% c10::intrusive_ptr<c10::StorageImpl, c10::detail::intrusive_target_default_null_type<c10::StorageImpl> >::make<c10::StorageImpl::use_byte_size_t, long&, c10::DataPtr, c10::Allocator*&, bool> (inlined)
1.02% std::__atomic_base<unsigned long>::operator++ (inlined)
- 0.80% ~DataPtr (inlined)
~UniqueVoidPtr (inlined)
~unique_ptr (inlined)
- 0.78% c10::TensorOptions::memory_format (inlined)
- c10::TensorOptions::set_memory_format (inlined)
- c10::optional<c10::MemoryFormat>::operator bool (inlined)
c10::optional<c10::MemoryFormat>::initialized (inlined)
```
This change comes with a caveat: if we have constructors where `this` escapes to another thread before returning, we cannot make this assumption, because that other thread may have called `intrusive_ptr::make` already. I chose to just mandate that `instrusive_ptr_target`s's ctors hand back exclusive ownership of `this`, which seems like a reasonable requirement for a ctor anyway. If that turns out to be unacceptable, we could provide an opt-out from this optimization via a traits struct or similar template metaprogramming shenanigan.
ghstack-source-id: 116368592
Test Plan: Run framework overhead benchmark. Results look promising, ranging from a tiny regression (? presumably noise) on the InPlace benchmark, 2.5% - 4% on OutOfPlace, to 9% on the empty benchmarks and 10-12% on the view benchmarks.
Reviewed By: ezyang
Differential Revision: D24606531
fbshipit-source-id: 1cf022063dab71cd1538535c72c4844d8dd7bb25
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: eb55572e55
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47605
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jianyuh
Differential Revision: D24833658
Pulled By: heitorschueroff
fbshipit-source-id: 7a577c75d244a58d94c249c0e50992078a3b62cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47636
Previously:
```
terminate called after throwing an instance of 'c10::Error'
what(): *cpp_signature == cpp_signature_->signature INTERNAL ASSERT FAILED at "caffe2/aten/src/ATen/core/dispatch/OperatorEntry.cpp":92, please report a bug to PyTorch. Tried to register a kernel (registered at buck-out/dev/gen/caffe2/generate-code/autograd/generated/TraceType_2.cpp:9847) for operator aten::div.out (registered at buck-out/dev/gen/caffe2/aten/gen_aten=TypeDefault.cpp/TypeDefault.cpp:3541) for dispatch key Tracer, but the C++ function signature at::Tensor& (at::Tensor const&, at::Tensor const&, at::Tensor&) mismatched with a previous kernel (registered at buck-out/dev/gen/caffe2/aten/gen_aten=CPUType.cpp/CPUType.cpp:2166) that had the signature at::Tensor& (at::Tensor&, at::Tensor const&, at::Tensor const&)
```
Now:
```
terminate called after throwing an instance of 'c10::Error'
what(): *cpp_signature == cpp_signature_->signature INTERNAL ASSERT FAILED at "caffe2/aten/src/ATen/core/dispatch/OperatorEntry.cpp":96, please report a bug to PyTorch.
Mismatch in kernel C++ signatures
operator: aten::div.out(Tensor self, Tensor other, *, Tensor(a!) out) -> (Tensor(a!))
registered at buck-out/dev/gen/caffe2/aten/gen_aten=TypeDefault.cpp/TypeDefault.cpp:3541
kernel 1: at::Tensor& (at::Tensor&, at::Tensor const&, at::Tensor const&)
dispatch key: CPU
registered at buck-out/dev/gen/caffe2/aten/gen_aten=CPUType.cpp/CPUType.cpp:2166
kernel 2: at::Tensor& (at::Tensor const&, at::Tensor const&, at::Tensor&)
dispatch key: Tracer
registered at buck-out/dev/gen/caffe2/generate-code/autograd/generated/TraceType_2.cpp:9847
```
Previously:
```
W1109 13:38:52.464170 1644302 OperatorEntry.cpp:117] Warning: Registering a kernel (registered at caffe2/torch/csrc/autograd/VariableTypeManual.cpp:310) for operator aten::_backward (registered at buck-out/dev/gen/caffe2/aten/gen_aten=TypeDefault.cpp/TypeDefault.cpp:3549) for dispatch key Autograd that overwrote a previously registered kernel (registered at caffe2/torch/csrc/autograd/VariableTypeManual.cpp:310) with the same dispatch key for the same operator. (function registerKernel)
```
Now:
```
W1109 13:49:40.501817 1698959 OperatorEntry.cpp:118] Warning: Overriding a previously registered kernel for the same operator and the same dispatch key
operator: aten::_backward(Tensor self, Tensor[] inputs, Tensor? gradient=None, bool? retain_graph=None, bool create_graph=False) -> ()
registered at buck-out/dev/gen/caffe2/aten/gen_aten=TypeDefault.cpp/TypeDefault.cpp:3549
dispatch key: Autograd
previous kernel: registered at caffe2/torch/csrc/autograd/VariableTypeManual.cpp:310
new kernel: registered at caffe2/torch/csrc/autograd/VariableTypeManual.cpp:310 (function registerKernel)
```
Previously:
```
terminate called after throwing an instance of 'c10::Error'
what(): In registration for dummy_library::dummy_op: expected schema of operator to be "dummy_library::dummy_op(Tensor a) -> (Tensor)" (registered at caffe2/torch/csrc/autograd/VariableTypeManual.cpp:298), but got inferred schema "(Tensor _0) -> ()" (registered at caffe2/torch/csrc/autograd/VariableTypeManual.cpp:298). The number of returns is different. 1 vs 0
```
Now:
```
terminate called after throwing an instance of 'c10::Error'
what(): Inferred operator schema for a C++ kernel function doesn't match the expected function schema.
operator: dummy_library::dummy_op
expected schema: dummy_library::dummy_op(Tensor a) -> (Tensor)
registered at caffe2/torch/csrc/autograd/VariableTypeManual.cpp:298
inferred schema: (Tensor _0) -> ()
registered at caffe2/torch/csrc/autograd/VariableTypeManual.cpp:298
reason: The number of returns is different. 1 vs 0
````
Previously:
```
terminate called after throwing an instance of 'c10::Error'
what(): !cpp_signature_.has_value() || (CppSignature::make<FuncType>() == cpp_signature_->signature) INTERNAL ASSERT FAILED at "caffe2/aten/src/ATen/core/dispatch/OperatorEntry.h":170, please report a bug to PyTorch. Tried to access operator _test::dummy with a wrong signature. Accessed with void (at::Tensor, long) but the operator was registered with void (at::Tensor) (schema: registered by RegisterOperators, kernel: registered by RegisterOperators) This likely happened in a call to OperatorHandle::typed<Return (Args...)>(). Please make sure that the function signature matches the signature in the operator registration call.
```
Now:
```
terminate called after throwing an instance of 'c10::Error'
what(): !cpp_signature_.has_value() || (CppSignature::make<FuncType>() == cpp_signature_->signature) INTERNAL ASSERT FAILED at "caffe2/aten/src/ATen/core/dispatch/OperatorEntry.h":169, please report a bug to PyTorch.
Tried to access or call an operator with a wrong signature.
operator: _test::dummy(Tensor dummy) -> ()
registered by RegisterOperators
correct signature: void (at::Tensor)
registered by RegisterOperators
accessed/called as: void (at::Tensor, long)
This likely happened in a call to OperatorHandle::typed<Return (Args...)>(). Please make sure that the function signature matches the signature in the operator registration call.
```
ghstack-source-id: 116359052
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D24846523
fbshipit-source-id: 0ce7d487b725bfbdf2261e36027cb34ef50c1fea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47632
This one is fun because we have to be careful not to squeeze out any of
the batch dims (it is the dims of the per-example tensor that are being squeezed).
Test Plan: - new tests
Reviewed By: anjali411
Differential Revision: D24859022
Pulled By: zou3519
fbshipit-source-id: 8adbd80963081efb683f62ea074a286a10da288f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47628
Pytorch has a special case where scalar_tensor.transpose(0, 0) works and
returns the scalar tensor. If the following happens:
```py
>>> x = torch.randn(B0) # the per-examples are all scalars
>>> vmap(lambda x: x.transpose(0, 0), x)
```
then we replicate this behavior
Test Plan: - new tests
Reviewed By: anjali411
Differential Revision: D24843658
Pulled By: zou3519
fbshipit-source-id: e33834122652473e34a18ca1cecf98e8a3b84bc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47625
kwargs is {} most of the time so this PR makes it optional. Note that it
is bad practice for {} to be a default argument; we work around this by
using None as the default and handling it accordingly.
Test Plan
- `pytest test/test_vmap.py -v`
Test Plan: Imported from OSS
Reviewed By: Chillee
Differential Revision: D24842571
Pulled By: zou3519
fbshipit-source-id: a46b0c6d5240addbe3b231b8268cdc67708fa9e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47621
Followup to #47365.
is_contiguous on BatchedTensorImpl is implemented as:
- Whenever one creates a BatchedTensorImpl, we cache the strides of the
per-examples, just like how we cache the sizes of the per-examples.
- With the cached strides, we use TensorImpl::refresh_contiguous() to
compute if the tensor is contiguous or not.
- is_contiguous checks the `is_contiguous_` flag that
refresh_contiguous() populates.
Both contiguous and is_contiguous only support torch.contiguous_format.
I'm not sure what the semantics should be for other memory formats; they
are also rank dependent (e.g., channels_last tensor must have 4
dimensions) which makes this a bit tricky.
Test Plan: - new tests
Reviewed By: Chillee, anjali411
Differential Revision: D24840975
Pulled By: zou3519
fbshipit-source-id: 4d86dbf11e2eec45f3f08300ae3f2d79615bb99d
Summary:
Cases with bool inputs to index_put nodes were handled for tracing purposes. This PR adds support for similar situations in scripting
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46866
Reviewed By: malfet
Differential Revision: D24870818
Pulled By: bzinodev
fbshipit-source-id: 2d75ca6f5f4b79d8c5ace337633c5aed3bdc4be7
Summary: To support min/max/mean/std, SummarizeOp need to skip size checking (similar to the LpNorm error mentioned above) and accept multiple types
Test Plan:
unit test:
`buck test //caffe2/caffe2/fb/tensorboard/tests:tensorboard_accumulate_histogram_op_test`
https://our.intern.facebook.com/intern/testinfra/testrun/1407375057859572
`buck test //caffe2/caffe2/fb/tensorboard/tests:tensorboard_accumulate_histogram_op_test --stress-runs 1000`
https://our.intern.facebook.com/intern/testinfra/testrun/2533274832166362
Reviewed By: cryptopic
Differential Revision: D24605507
fbshipit-source-id: fa08372d7c9970083c38abd432d4c86e84fb10e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47008
bhosmer has been complaining about how it is difficult to distinguish
between local variables and closed over variables in the higher order
functions. Well, closures and objects do basically the same thing, so
just convert all these HOFs into objects.
The decoder ring:
- Higher order function => Constructor for object
- Access to closed over variable => Access to member variable on object
- with_native_function => method_with_native_function (because it's
hard writing decorators that work for both functions and methods)
I didn't even have to change indentation (much).
When there is no need for closed over variables (a few functions), I
kept them as plain old functions, no need for an object with no
members.
While I was at it, I also deleted the kwargs, since the types are
enough to prevent mistakes.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D24600805
Pulled By: ezyang
fbshipit-source-id: 7e3ce8cb2446e3788f934ddcc17f7da6e9299511
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46998
It's not using any TypeDefault symbols directly; running
CI to see if it was being included for other headers.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D24621920
Pulled By: ezyang
fbshipit-source-id: f868e5412ff3e5a616c3fc38110f203ca545eed5
Summary:
For some of the end to end flow projects, we will need the capabilities to read module information during model validation or model publishing.
Creating this model_reader.py for utilities for model content reading, this diff we included the following functionalities:
1. read the model bytecode version;
2. check if a model is lite PyTorch script module;
3. check if a model is PyTorch script module.
This diff is recreated from the reverted diff: D24655999 (7f056e99dd).
Test Plan:
```
[xcheng16@devvm1099]/data/users/xcheng16/fbsource/fbcode% buck test //caffe2/torch/fb/mobile/tests:mobile_model_reader_tests
Action graph will be rebuilt because files have been added or removed.
Parsing buck files: finished in 10.4 sec
Creating action graph: finished in 22.2 sec
Building: finished in 01:29.1 min (100%) 10619/10619 jobs, 1145 updated
Total time: 02:01.8 min
More details at https://www.internalfb.com/intern/buck/build/f962dfad-76f9-457a-aca3-768ce20f0c31
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: 172633f6-6b5b-49e9-a632-b4efa083a001
Trace available for this run at /tmp/tpx-20201109-165156.109798/trace.log
Started reporting to test run: https://our.intern.facebook.com/intern/testinfra/testrun/3940649712677511
✓ ListingSuccess: caffe2/torch/fb/mobile/tests:mobile_model_reader_tests - main (18.229)
✓ Pass: caffe2/torch/fb/mobile/tests:mobile_model_reader_tests - test_is_pytorch_lite_module (caffe2.torch.fb.mobile.tests.test_model_reader.TestModelLoader) (8.975)
✓ Pass: caffe2/torch/fb/mobile/tests:mobile_model_reader_tests - test_is_pytorch_script_module (caffe2.torch.fb.mobile.tests.test_model_reader.TestModelLoader) (9.136)
✓ Pass: caffe2/torch/fb/mobile/tests:mobile_model_reader_tests - test_read_module_bytecode_version (caffe2.torch.fb.mobile.tests.test_model_reader.TestModelLoader) (9.152)
Summary
Pass: 3
ListingSuccess: 1
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/3940649712677511
```
Reviewed By: husthyc
Differential Revision: D24848563
fbshipit-source-id: ab3371e111206a4bb4d07715c3314596cdc38d2c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46398
This PR makes torch.einsum compatible with numpy.einsum except for the sublist input option as requested here https://github.com/pytorch/pytorch/issues/21412. It also fixed 2 performance issues linked below and adds a check for reducing to torch.dot instead of torch.bmm which is faster in some cases.
fixes#45854, #37628, #30194, #15671fixes#41467 with benchmark below
```python
import torch
from torch.utils.benchmark import Timer
a = torch.randn(10000, 100, 101, device='cuda')
b = torch.randn(10000, 101, 3, device='cuda')
c = torch.randn(10000, 100, 1, device='cuda')
d = torch.randn(10000, 100, 1, 3, device='cuda')
print(Timer(
stmt='torch.einsum("bij,bjf->bif", a, b)',
globals={'a': a, 'b': b}
).blocked_autorange())
print()
print(Timer(
stmt='torch.einsum("bic,bicf->bif", c, d)',
globals={'c': c, 'd': d}
).blocked_autorange())
```
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7fa37c413850>
torch.einsum("bij,bjf->bif", a, b)
Median: 4.53 ms
IQR: 0.00 ms (4.53 to 4.53)
45 measurements, 1 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7fa37c413700>
torch.einsum("bic,bicf->bif", c, d)
Median: 63.86 us
IQR: 1.52 us (63.22 to 64.73)
4 measurements, 1000 runs per measurement, 1 thread
```
fixes#32591 with benchmark below
```python
import torch
from torch.utils.benchmark import Timer
a = torch.rand(1, 1, 16, 2, 16, 2, 16, 2, 2, 2, 2, device="cuda")
b = torch.rand(729, 1, 1, 2, 1, 2, 1, 2, 2, 2, 2, device="cuda")
print(Timer(
stmt='(a * b).sum(dim = (-3, -2, -1))',
globals={'a': a, 'b': b}
).blocked_autorange())
print()
print(Timer(
stmt='torch.einsum("...ijk, ...ijk -> ...", a, b)',
globals={'a': a, 'b': b}
).blocked_autorange())
```
```
<torch.utils.benchmark.utils.common.Measurement object at 0x7efe0de28850>
(a * b).sum(dim = (-3, -2, -1))
Median: 17.86 ms
2 measurements, 10 runs per measurement, 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7efe0de286a0>
torch.einsum("...ijk, ...ijk -> ...", a, b)
Median: 296.11 us
IQR: 1.38 us (295.42 to 296.81)
662 measurements, 1 runs per measurement, 1 thread
```
TODO
- [x] add support for ellipsis broadcasting
- [x] fix corner case issues with sumproduct_pair
- [x] update docs and add more comments
- [x] add tests for error cases
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D24860367
Pulled By: heitorschueroff
fbshipit-source-id: 31110ee598fd598a43acccf07929b67daee160f9
Summary:
Currently the max `src_column_width` is hardcoded to 75 which might not be sufficient for modules with long file names. This PR exposes `max_src_column_width` as a changeable parameter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46257
Reviewed By: malfet
Differential Revision: D24280834
Pulled By: yf225
fbshipit-source-id: 8a90a433c6257ff2d2d79f67a944450fdf5dd494
Summary:
Export as `onnx::MatMul` if possible since it has less constraint. Resolves issue with exporting `weight_norm` in scripting that fails onnx shape inference with `onnx::Gemm` in unreachable `if` subgraph.
Updates skipped tests list.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46570
Reviewed By: ngimel
Differential Revision: D24657480
Pulled By: bzinodev
fbshipit-source-id: 08d47cc9fc01c4a73a9d78c964fef102d12cc21c
Summary:
This change adds the arch settings for caffe2 builds, fixes some typos,
and clarifies that this setting applies to both CircleCI and Jenkins.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47683
Reviewed By: zou3519
Differential Revision: D24864034
Pulled By: malfet
fbshipit-source-id: 304b8a8e5c929ddaeb9c399f6219783a1369d842
Summary:
Previously did not considered the case were optional `m` is not provided in `torch.eye(n, m)`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47016
Reviewed By: ejguan
Differential Revision: D24735916
Pulled By: bzinodev
fbshipit-source-id: ec9b410fc59f27d77d4ae40cb38a67537abb3cd8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47470
Reland of https://github.com/pytorch/pytorch/pull/47206, which was reverted due to failing multigpu tests.
The fix to make multigpu tests work is to compare against `torch.tensor([world_size, 0])`, not hardcode `torch.tensor([2, 0]` which assumes a world size of 2.
Original commit description:
As discussed offline with pritamdamania87, add testing to ensure per-iteration and rank-dependent control flow works as expected in DDP with find_unused_parameters=True.
ghstack-source-id: 115993934
ghstack-source-id: 115993934
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D24767893
fbshipit-source-id: 7d7a2449270eb3e72b5061694e897166e16f9bbc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45092
Adding two operators
1. at::float_to_half -> Converts FP32 tensor to FP16 tensor
2. at::half_to_float -> Converts FP16 tensor to FP32 tensor.
These operators internally use the kernel provided by FBGeMM. Both C2 and PT will use the same FBGeMM kernel underneath.
Test Plan:
buck test //caffe2/test:torch -- .*test_half_tensor.*
Run benchmark locally using
```
buck run //caffe2/benchmarks/operator_benchmark/pt:tensor_to_test
```
AI Bench results are pending. I expect that not to finish as we have large queue with jobs pending for 2+ days.
Benchmark for 512x512 tensor with FbGeMM implementation
```
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: FloatToHalfTensorConversionBenchmark
# Mode: Eager
# Name: FloatToHalfTensorConversionBenchmark_M512_N512_cpu
# Input: M: 512, N: 512, device: cpu
Forward Execution Time (us) : 1246.332
# Benchmarking PyTorch: HalfToFloatTensorConversionBenchmark
# Mode: Eager
# Name: HalfToFloatTensorConversionBenchmark_M512_N512_cpu
# Input: M: 512, N: 512, device: cpu
Forward Execution Time (us) : 1734.304
```
Benchmark for 512x512 tensor trunk with no FbGeMM integration.
```
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: FloatToHalfTensorConversionBenchmark
# Mode: Eager
# Name: FloatToHalfTensorConversionBenchmark_M512_N512_cpu
# Input: M: 512, N: 512, device: cpu
Forward Execution Time (us) : 169045.724
# Benchmarking PyTorch: HalfToFloatTensorConversionBenchmark
# Mode: Eager
# Name: HalfToFloatTensorConversionBenchmark_M512_N512_cpu
# Input: M: 512, N: 512, device: cpu
Forward Execution Time (us) : 152382.494
```
Reviewed By: ngimel
Differential Revision: D23824869
fbshipit-source-id: ef044459b6c8c6e5ddded72080204c6a0ab4582c
Summary:
This PR tries to make building the docs less confusing for new contributors:
- `npm` is discouraged on devservers for Facebook employees, so I added another way to install `katex`
- the path to `check-doxygen.sh` was wrong, so I fixed it
- while generating the CPP docs, it created two new folders that weren't ignored by Git, so I added those to `.gitignore`
- I wasn't able to get the SSH tunnel to work, so I added instructions to use `scp` as an alternative
I'm not entirely sure how the `docs/cpp/source/{html,latex}/` directories were created since I haven't been able to reproduce them.
I also think that it would be better to use the SSH tunnel since `scp` is so much slower, but I just wasn't able to figure it out; I followed the instructions from `CONTRIBUTING.md` and then ran a [Python `http.server`](https://docs.python.org/3/library/http.server.html) on my devserver:
```bash
python -m http.server 8000 --bind 127.0.0.1 --directory build/html
```
but my browser failed to connect and my (local) terminal printed error messages (presumably from the SSH command).
If anyone knows how to properly set up the SSH tunnel and HTTP server, I add those more detailed instructions to `CONTRIBUTING.md` and remove the `scp` instructions from this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47539
Reviewed By: malfet
Differential Revision: D24806833
Pulled By: samestep
fbshipit-source-id: 456691018a76efadde28fa5eb783b0895582e72d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/31136
This PR:
1. moves several installations to Docker from `test.sh` for both PyTorch and Caffe2
2. removes version fixing for numba and llvmlite as the issue linked has been resolved
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47451
Reviewed By: walterddr
Differential Revision: D24791350
Pulled By: janeyx99
fbshipit-source-id: bf36cd419e30d9e02622ad7c7049fbc724c89579
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47586
relanding PR of https://github.com/pytorch/pytorch/pull/44492, and add
additional Capsule related wrapping to ensure we still have the correct
type in pybind11 to resolve Capsule as torch._C.CapsuleType
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D24822519
Pulled By: wanchaol
fbshipit-source-id: eaaea446fb54b56ed3b0d04c31481c64096e9459
Summary:
To ensure the frozen models produced from traced models are not
over-optimized, clear shape info in the frozen model
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47511
Reviewed By: eellison
Differential Revision: D24792849
Pulled By: bzinodev
fbshipit-source-id: 5dc7c4d713a113c23d59cabf5541b3c58b075b43
Summary:
Distributed Inference splits a predict net into multiple parts, part0 being the main part which contains ops to make remote calls to other parts. part0 predict net may contain AsyncIf ops to optimize rpc call usage. AsyncIf ops have internal nets which may refer to memongered blobs. This change handles AsyncIf ops to update internal nets to refer to memongered blobs. Here is one reference part0 predict net with AsyncIf ops: https://www.internalfb.com/intern/paste/P145812115/
As part of this change, I am also updating dag memonger traversal to always start from root op, i.e. ops with 0 in degree. Earlier logic will start traversing ops based on input head blobs and if one of the head inputs is getting used in a non-root op which gets visited before its parent, the traversal will throwing assertion error here: https://fburl.com/diffusion/ob110s9z . Almost for all the distributed inference part0 nets, it was throwing this assertion error.
Reviewed By: hlu1
Differential Revision: D24346771
fbshipit-source-id: ad2dd2e63f3e822ad172682f6d63f8474492255d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45072
As discussed with zdevito gchanan cpuhrsch and suo, this change allows developers to create custom preparations for their modules before scripting. This is done by adding a `__prepare_scriptable__` method to a module which returns the prepared scriptable module out-of-place. It does not expand the API surface for end users.
Prior art by jamesr66a: https://github.com/pytorch/pytorch/pull/42244
cc: zhangguanheng66
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45645
Reviewed By: dongreenberg, ngimel
Differential Revision: D24039990
Pulled By: zhangguanheng66
fbshipit-source-id: 4ddff2d353124af9c2ef22db037df7e3d26efe65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47514
Previosuly the scale and zero_point were returned on the CPU even if
the input tensor was on the GPU.
This is because `copy_()` doesn't respect the device when copying over the tensor.
Also fixed a bug where we were always setting the device to 'cuda' (irrespective of the device id)
in the calculate_qparams function
Test Plan:
python test/test_quantization.py TestObserver.test_observer_qparams_respects_device_affinity
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D24800495
fbshipit-source-id: d7a76c59569842ed69029d0eb4fa9df63f87e28c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47305
Fixes https://github.com/pytorch/pytorch/issues/47127.
Ideally this would just use diag and sum (as the CUDA implementation does), but that seems to have performance problems, which I'll link in the github PR.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D24729627
Pulled By: gchanan
fbshipit-source-id: 151b786b53e7b958f0929c803dbf8e95981c6884
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47227
Motivation
----------
We would like to compute batched gradients for view+inplace operations.
This most notably shows up in internal implementation of operations.
For example, many view backward functions (SelectBackward, DiagonalBackward)
are implemented with view+inplace, so to support vectorized hessian
computation for e.g. torch.select and torch.diagonal we would need a
way to handle or workaround view+inplace.
Approach
--------
view+inplace creates a CopySlices node and transmute view backward nodes
into an AsStrided node. For example,
```
leaf = torch.randn(4, 5, requires_grad=True)
base = leaf * leaf
view = base[0]
view.cos_()
```
base.grad_fn is CopySlices and view.grad_fn is AsStridedBackward.
To support vmap over CopySlices and AsStridedBackward:
- We use `new_empty_strided` instead of `empty_strided` in CopySlices
so that the batch dims get propagated
- We use `new_zeros` inside AsStridedBackward so that the batch dims get
propagated.
Test Plan
---------
- New tests. When we get closer to having most operations support batched
grad computation via vmap, I'd like to add it as an option to gradcheck
and turn it on for our tests.
Test Plan: Imported from OSS
Reviewed By: kwanmacher, glaringlee
Differential Revision: D24741687
Pulled By: zou3519
fbshipit-source-id: 8210064f782a0a7a193752029a4340e505ffb5d8
Summary:
Fix an issue with the TensorExpr lowering of aten::remainder with integral inputs. We were always lowering to fmod and never to Mod.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47611
Reviewed By: bertmaher, heitorschueroff
Differential Revision: D24846929
Pulled By: nickgg
fbshipit-source-id: adac4322ced5761a11a8e914debc9abe09cf5637
Summary:
Refactors NNC bounds inference to use the dependency analysis added in https://github.com/pytorch/pytorch/issues/46952. This ends up being a pretty good simplification because we no longer need the complicated bound merging code that we used to determine contiguous ranges. There were no usages of that code and the memory dependency analyzer is closer to what we want for those use cases anyway.
Added tests for a few cases uncovered by the existing bounds inference test - much of the coverage for this feature is in tests of it's uses: rfactor, computeAt and cacheAccesses.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47450
Reviewed By: heitorschueroff
Differential Revision: D24834458
Pulled By: nickgg
fbshipit-source-id: f93e40b09c0745dcc46c7e34359db594436d04f0
Summary:
Added a convenience function that allows users to load models without DP/DDP from a DP/DDP state dict.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45643
Reviewed By: rohan-varma
Differential Revision: D24574649
fbshipit-source-id: 17d29ab16ae24a30890168fa84da6c63650e61e9
Summary:
This PR moves some helper functions out of Partitioner class. It will make Partitioner class cleaner and make these helper functions easier to use in the future
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47515
Reviewed By: gcatron, heitorschueroff
Differential Revision: D24844751
Pulled By: scottxu0730
fbshipit-source-id: 04397d0ce995cf96943df0a2b9265a521177b4de
Summary:
Sorry for my previous inaccurate [PR](https://github.com/pytorch/pytorch/pull/42471#issue-462329192 ).
Here are some toy code to illustrate my point:
* non-DistributedDataParallel version
```python
import torch
if __name__ == "__main__":
torch.manual_seed(0)
inp = torch.randn(1,16)
inp = torch.cat([inp, inp], dim=0)
model = torch.nn.Linear(16, 2)
loss_func = torch.nn.CrossEntropyLoss()
opti = torch.optim.SGD(model.parameters(), lr=0.001)
opti.zero_grad()
loss = loss_func(model(inp), torch.tensor([0, 0]))
loss.backward()
opti.step()
print("grad:", model.weight.grad)
print("updated weight:\n", model.weight)
```
* DistributedDataParallel version
```python
import os
import torch
import torch.nn as nn
import torch.distributed as dist
from torch.multiprocessing import Process
def run(rank, size):
torch.manual_seed(0)
x = torch.randn(1,16)
model = torch.nn.Linear(16, 2)
model = torch.nn.parallel.DistributedDataParallel(model)
loss_func = torch.nn.CrossEntropyLoss()
opti = torch.optim.SGD(model.parameters(), lr=0.001)
opti.zero_grad()
y = model(x)
label = torch.tensor([0])
loss = loss_func(y, label)
loss.backward()
opti.step()
if rank == 0:
print("grad:", model.module.weight.grad)
print("updated weight:\n", model.module.weight)
def init_process(rank, size, fn, backend="gloo"):
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
if __name__ == "__main__":
size = 2
process = []
for rank in range(size):
p = Process(target=init_process, args=(rank, size, run))
p.start()
process.append(p)
for p in process:
p.join()
```
Both of these two pieces of code have the same output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47156
Reviewed By: mruberry
Differential Revision: D24675199
Pulled By: mrshenli
fbshipit-source-id: 1238a63350a32a824b4b8c0018dc80454ea502bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47541
The profiler has guided us to `schema.py`. Since these `Field`s are used everywhere and in huge quantities, we can easily make some optimizations system wide by adding `__slots__`.
From StackOverflow, benefits include:
* faster attribute access.
* space savings in memory.
Read more: https://stackoverflow.com/a/28059785/
Reviewed By: dzhulgakov
Differential Revision: D24771078
fbshipit-source-id: 13f6064d367440069767131a433c820eabfe931b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47626
`caffe2/test:cuda` was safeguarded by a GPU availability check however most of the mixed CPU/GPU tests aren't.
Use `TEST_WITH_*SAN` flags to safeguard test discovery for CUDA tests.
Test Plan: sandcastle
Reviewed By: janeyx99
Differential Revision: D24842333
fbshipit-source-id: 5e264344a0b7b98cd229e5bf73c17433751598ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47542
The previous way of doing `Field.__init__(self, [])` is just wrong. Switching to Python2 compatible way: `super(ObjectName, self).__init__(...)`
Reviewed By: dzhulgakov
Differential Revision: D24771077
fbshipit-source-id: d6798c72090c0264b6c583602cae441a1b14587c
Summary:
Still depending on rank of original tensor being known. i.e.
```python
x[i, j, k] = y # rank of x must be known at export time
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46571
Reviewed By: mrshenli
Differential Revision: D24657502
Pulled By: bzinodev
fbshipit-source-id: 6ec87edb67be06e34526225e701954fcfc5606c8
Summary:
Related: https://github.com/pytorch/pytorch/issues/33090
I just realized that I haven't updated the docs of `torch.eig` when implementing the backward.
Here's the PR updating the docs about the grad of `torch.eig`.
cc albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47598
Reviewed By: heitorschueroff
Differential Revision: D24829373
Pulled By: albanD
fbshipit-source-id: 89963ce66b2933e6c34e2efc93ad0f2c3dd28c68
Summary:
- rand/randn: the type signature of int[] is different in scripting, thus failing the check.
- where: scripting produces dynamic cases which are supported by `unbind` export of higher opsets.
- test_list_pass: this test fails when using new scripting api, should be fixed by https://github.com/pytorch/pytorch/issues/45369
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45793
Reviewed By: mrshenli
Differential Revision: D24566096
Pulled By: bzinodev
fbshipit-source-id: 6fe0925c66dee342106d71c9cbc3c95cabe639f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47365
I wanted to avoid defining vmap behavior over contiguous_format for as
long as possible. This is potentially ambiguous, consider the following:
```
>>> x = torch.randn(3, B0, 5)
>>> y = vmap(lambda x: x.clone(torch.contiguous_format), in_dims=1,
out_dims=1)(x)
>>> y[:,0].is_contiguous() # ??
```
There are two possible ways to interpret this operation (if we choose to
allow it to succeed):
1. Each per-sample becomes contiguous, so y[:,0] is contiguous.
2. The output of vmap is contiguous (so y is contiguous, but y[:,0] is
not)
(1) makes more sense because vmap operates on a per-sample level.
This makes sense when combined with the vmap fallback:
- there are places in the codebase where we perform .contiguous() and
then pass the result to an operator `op` that only accepts contiguous
inputs.
- If we vmap over such code and don't have a batching rule implemented for
`op`, then we want the per-samples to be contiguous so that
when `op` goes through the vmap fallback, it receives contiguous
per-samples.
(1) is the approach we've selected for this PR.
Motivation
----------
To vmap over CopySlices, we have to vmap over a clone(contiguous_format)
call:
e4bc785dd5/torch/csrc/autograd/functions/tensor.cpp (L93)
Alternatives
------------
- Implementing (2) is difficult in the current design because vmap is
allowed to move batch dimensions to the front of the tensor. We would
need some global information about the in_dims and out_dims passed to
vmap.
- We could also error out if someone calls clone(contiguous_format) and
the batch dims are not at the front. This would resolve the ambiguity at
the cost of limiting what vmap can do.
Future Work
-----------
- Add to a "vmap gotchas" page the behavior of contiguous_format.
- Implement is_contiguous, Tensor.contiguous() with the same semantics.
Those currently error out.
Test Plan
---------
- new tests
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D24741683
Pulled By: zou3519
fbshipit-source-id: 3ef5ded1b646855f41d39dcefe81129176de8a70
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47364
This PR adds a batching rule for as_strided. `as_strided` is a really weird
operation and I hope that users don't use it very much.
Motivation
----------
The motivation for adding a batching rule for as_strided is for
batched gradient computation.
AsStridedBackward appears in PyTorch when handling view+in-place
operations and calls `as_strided`. AsStridedBackward calls as_strided on
a fresh tensor with storage_offset equal to 0. We would like to be able
to vmap through the backward graph of view+in-place operations to
for batched gradient computation, especially because internally we have
a number of functions that are implemented as a view+in-place.
Alternatives
------------
If we think that as_strided is too crazy to have a batching rule, we
could either:
- have a flag that controls the autograd view+in-place
behavior
- require that the input tensor's storage offset must be equal to 0
to make it easier to reason about.
I think the batching rule makes sense, so I didn't pursue the
alternatives.
The batching rule
-----------------
```
y = vmap(lambda x: x.as_strided(sizes, strides, offset))(xs)
```
The result of the above should be "equivalent" to:
- Assume that each x has storage offset equal to xs.storage_offset()
(call that S).
- Calling as_strided with (sizes, sizes, offset + x[i].storage_offset() - S) on each x.
More concretely,
this returns a view on `xs`, such that each y[i] has:
- sizes: `sizes`
- strides: `strides`
- storage_offset: offset + i * x.stride(batch_dim)
Why the behavior can be weird
-----------------------------
The behavior of the batching rule may be different from actually running
as_strided in a for-loop because `as_strided` takes in `offset` as a
"absolute offset". As an example, consider
```
>>> x = torch.tensor([0., 1., 2., 3., 4.])
>>> z = [x[i].as_strided([1], [1], 0) for i in range(5)]
```
Each z[i] is actually the same view on x (z[i] == torch.tensor([0.]))!
However, we consider the above for-loop comprehension to be a user error:
a user should have written the following if they wanted to use as_strided
in a per-sample way:
```
>>> z = [x[i].as_strided([1], [1], 0 + x[i].storage_offset()) for i in range(5)]
```
Test Plan
---------
- Added some tests that compare vmap+as_strided to vmap+(the equivalent operator)
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D24741685
Pulled By: zou3519
fbshipit-source-id: c1429caff43bfa33661a80bffc0daf2c0eea5564
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47540
In FB's hybrid llvm 7/8 flavor, we (read: I) forgot to register
intrinsics. It was... a bit annoying to figure out how to do this, and I'm
sure it could be done more efficiently by someone who isn't just cargo-culting
the API from KaleidoscopeJIT. Anyways.
There are kind of 3 independent changes here but they're a bit annoying to separate out, so:
0. (trivial) Add the correct #defines to the internal build to run test_llvm.
1. (easy) add an assertSuccess function to convert llvm::Errors into
`TORCH_INTERNAL_ASSERT`s, for better/easier debugging.
2. (medium) Factor out the gigantic register-all-the-things function into a
helper so we can call it from both the LLVM and LLVM-FB constructors.
3. (hard) Fix the symbol resolver in llvm-fb to do a lookup using the
ExecutionSession. This is the bit I don't really understand; it feels like the
CompileLayer lookup should find these symbols but it doesn't. Whatever.
Test Plan: `buck test //caffe2/test/cpp/tensorexpr:tensorexpr`
Reviewed By: asuhan
Differential Revision: D24807361
fbshipit-source-id: 8bb0d632dff6a065963ed14a600614cd21fbb095
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47537
When a module only appears in a type constructor List[torch.Tensor],
it previously didn't get added to the list of used modules. This fixes it
by introspecting on the type constructor.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D24806317
Pulled By: zdevito
fbshipit-source-id: 263391af71e1f2156cbefaab95b9818c6b9aaae1
Summary:
checks sizes of sparse tensors when comparing them in assertEqual.
Removes additional checks in safeCoalesce, safeCoalesce should not be a test for `.coalesce()` function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47148
Reviewed By: mruberry
Differential Revision: D24823127
Pulled By: ngimel
fbshipit-source-id: 9303a6ff74aa3c9d9207803d05c0be2325fe392a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47226
The batching rule is a little weird because it's not immediately obvious
what the strides of the result should be. If
tensor.new_empty_strided(size, stride) is called inside vmap and
`tensor` is being vmapped over, the result is a physical tensor with:
- size `[batch_shape] + size`
- strides `[S0, S1, ..., Sn] + stride` such that the
S0...Sn are part of a contiguous subspace and Sn is equal to the size of
the storage of `torch.empty_strided(size, stride)`.
I refactored some of the logic that computes the storage size for
`torch.empty_strided(size, stride)` into a helper function
`native::storage_size_for` and use it in the batching rule.
Test Plan: - New tests in test/test_vmap.py
Reviewed By: ejguan
Differential Revision: D24741690
Pulled By: zou3519
fbshipit-source-id: f09b5578e923470d456d50348d86687a03b598d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47225
Summary
-------
This PR implements Tensor.new_empty_strided. Many of our torch.* factory
functions have a corresponding new_* method (e.g., torch.empty and
torch.new_empty), but there is no corresponding method to
torch.empty_strided. This PR adds one.
Motivation
----------
The real motivation behind this is for vmap to be able to work through
CopySlices. CopySlices shows up a lot in double backwards because a lot
of view functions have backward formulas that perform view+inplace.
e0fd590ec9/torch/csrc/autograd/functions/tensor.cpp (L78-L106)
To support vmap through CopySlices, the approach in this stack is to:
- add `Tensor.new_empty_strided` and replace `empty_strided` in
CopySlices with that so that we can propagate batch information.
- Make some slight modifications to AsStridedBackward (and add
as_strided batching rule)
Please let me know if it would be better if I squashed everything related to
supporting vmap over CopySlices together into a single big PR.
Test Plan
---------
- New tests.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D24741688
Pulled By: zou3519
fbshipit-source-id: b688047d2eb3f92998896373b2e9d87caf2c4c39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47530
`Net.AddExternalInput` should raise if there are duplicate names. The previous code would only raise if the addition of duplicates was in separate calls, but not if it was in the same call.
Test Plan:
Added two new regression tests
```
✓ Pass: caffe2/caffe2/python:core_test - testSetInputRecordWithBlobs (caffe2.caffe2.python.core_test.TestExternalInputs) (9.622)
✓ Pass: caffe2/caffe2/python:core_test - testAddExternalInputShouldRaiseIfDuplicate (caffe2.caffe2.python.core_test.TestExternalInputs) (9.639)
✓ Pass: caffe2/caffe2/python:core_test - testSetInputRecordWithoutBlobs (caffe2.caffe2.python.core_test.TestExternalInputs) (9.883)
✓ Pass: caffe2/caffe2/python:core_test - testAddExternalInputShouldRaiseIfDuplicateInSameCall (caffe2.caffe2.python.core_test.TestExternalInputs) (10.153)
```
Test trained 2 models. No issues
f230755456
f230754926
Reviewed By: dzhulgakov
Differential Revision: D24763586
fbshipit-source-id: c87088441d76f7198f8b07508b2607aec13521ed
Summary:
`__ROOT__` ops are only used in full-jit. To make size compact, disable using it in inference. Since FL is still in fill-jit, keep it for training only.
It saves -17 KB for fbios.
TODO: when FL is migrated to lite_trainer, remove `__ROOT__` to save size in training too.
Test Plan: CI
Reviewed By: dhruvbird
Differential Revision: D24686838
fbshipit-source-id: 15214cebb9d8defa3fdac3aa0d73884b352aa753
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46978
Refactored and added type annotations to the most part of the file.
Some top-level codegen functions are called by other codegen scripts.
Will migrate them in subsequent PRs.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D24589210
Pulled By: ljk53
fbshipit-source-id: e0c7e5b3672b41983f321400c2e2330d1462e76e
Summary:
I have been asked several times how to toggle this flag on libtorch. I think it would be good to mention it in the docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47331
Reviewed By: glaringlee
Differential Revision: D24777576
Pulled By: mruberry
fbshipit-source-id: cc2a338c477bb57e0bb74b8960c47fde99665e41
Summary:
The current `_var_mean` implementation cannot ensure non-negative for variance, because it is actually `E(X^2)-(E(X))^2`: numerically when the dimension number is large and X is close to 0, it can have negative numbers (like our UT shows). The new implementation is `(E(X-E(X))^2)`, it ensures non-negative because the expectation of square is non-negative for sure.
The UT passes for the new implementation (but fails for the existing one). So it is good to go.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47240
Reviewed By: ejguan
Differential Revision: D24735729
Pulled By: bzinodev
fbshipit-source-id: 136f448dd16622b2b46f40cdf6cb2fccf357c48d
Summary:
inside IValue.h, we previously printed -0.0 as 0.0. Therefore, it was causing some inconsistency when using -0.0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47081
Test Plan:
A new test case inside test_jit that divides a tensor by -0. and checks if it outputs -inf for all modes.
Fixes https://github.com/pytorch/pytorch/issues/46848
Reviewed By: mrshenli
Differential Revision: D24688572
Pulled By: gmagogsfm
fbshipit-source-id: 01a9d3f782e0711dd10bf24e6f3aa62eee72c895
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47425
Extra files can be exported in lite interpreter model, but it could not be loaded. This PR is to add the capability to load extra files from lite interpreter model. Because extra_files is a default argument, it should not affect the existing usage of _load_for_mobile. It's a simple assembly or a generic unordered_map. No additional dependency should be introduced and the size overhead should be small (to be tested).
Test Plan: Imported from OSS
Reviewed By: kwanmacher
Differential Revision: D24770266
Pulled By: iseeyuan
fbshipit-source-id: 7e8bd301ce734dbbf36ae56c9decb045aeb801ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47468
**Summary:** QuantizePerChannel4d and QuantizePerChannel4dChannelsLast have issues with flakiness on both ARM and x86 builds.
The flakiness stems from two sources:
1. The rounding strategy used by quantization for half values is to round the number to the nearest even integer (e.g. `4.5->4`, `5.5 -> 6`, `6.5->6`; however the above tests are incorrect by expecting the values to be rounded away from zero.
2. On ARM devices, `quantize_val_arm` calculates `zero_point + round(val / scale)` which behaves differently from `quantize_val`, which calculates `zero_point + round(val * (1.0f/scale))`. This small distinction leaves enough room for the floating point arithmetic errors to change rounding behavior (e.g. `3 / .24 = 12.5` whereas `3 * (1.0f / .24) = 12.500001`).
**Test Plan:**
For local builds:
```
python setup.py develop
./build/bin/quantized_test --gtest_filter='TestQTensor.QuantizePerChannel4d*' --gtest_repeat=10000 | grep FAILURE
```
For ARM Neon:
```
BUILD_MOBILE_BENCHMARK=1 BUILD_MOBILE_TEST=1 ANDROID_DEBUG_SYMBOLS=1 BUILD_PYTORCH_MOBILE=1 ANDROID_ABI="armeabi-v7a with NEON" ./scripts/build_android.sh -DANDROID_CCACHE=$(which ccache) -DBUILD_BINARY=ON
adb push ./build/bin/quantized_test /data/local/tmp
adb shell "/data/local/tmp/quantized_test --gtest_filter='TestQTensor.QuantizePerChannel4d*' --gtest_repeat=1000 | grep FAILURE"
```
For ARM64:
```
BUILD_MOBILE_BENCHMARK=1 BUILD_MOBILE_TEST=1 ANDROID_DEBUG_SYMBOLS=1 BUILD_PYTORCH_MOBILE=1 ANDROID_ABI=arm64-v8a ./scripts/build_android.sh -DANDROID_CCACHE=$(which ccache) -DBUILD_BINARY=ON
adb push ./build/bin/quantized_test /data/local/tmp
adb shell "/data/local/tmp/quantized_test --gtest_filter='TestQTensor.QuantizePerChannel4d*' --gtest_repeat=1000 | grep FAILURE"
```
**Reviewers:**
**Subscribers:**
**Tasks:** T79019469
**Tags:**
Test Plan: Imported from OSS
Reviewed By: kimishpatel
Differential Revision: D24769889
Pulled By: AJLiu
fbshipit-source-id: 417e7339bac70df5b9f630a1e286fad435e49240
Summary:
Original commit changeset: b9796e15074d
have weird issue happening with custom class + recursive scripting, unland this first to figure out more details
Test Plan: wait for sandcastle
Reviewed By: zhangguanheng66
Differential Revision: D24780498
fbshipit-source-id: 99a937a26908897556d3bd9f1b2b39f494836fe6
Summary:
This diff adds support for `log_softmax` op in NNC.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47409
Reviewed By: ejguan
Differential Revision: D24750203
Pulled By: navahgar
fbshipit-source-id: c4dacc7f62f9df65ae467f0d578ea03d3698273d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47512
I deleted the last line of `__init__` -- `self._field_offsets.append(offset)` -- and the unittests didn't fail.
So this diff is to improve test coverage.
Test Plan:
```
✓ Pass: caffe2/caffe2/python:schema_test - testInitShouldSetEmptyParent (caffe2.caffe2.python.schema_test.TestField) (8.225)
✓ Pass: caffe2/caffe2/python:schema_test - testInitShouldSetFieldOffsetsIfNoChildren (caffe2.caffe2.python.schema_test.TestField) (8.339)
✓ Pass: caffe2/caffe2/python:schema_test - testInitShouldSetFieldOffsets (caffe2.caffe2.python.schema_test.TestField) (8.381)
```
Reviewed By: dzhulgakov
Differential Revision: D24767188
fbshipit-source-id: b6ce8cc96ecc61768b55360e0238f7317a2f18ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47464
```
ValueError: Unknown type annotation: 'typing.Sequence[torch.Tensor]' at File "xxx.py", line 223
images = [x["image"].to(self.device) for x in batched_inputs]
images = [(x - self.pixel_mean) / self.pixel_std for x in images]
images = ImageList.from_tensors(images, self.backbone.size_divisibility)
~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
return images
```
Otherwise have no clue where the error is.
Test Plan: sandcastle
Reviewed By: glaringlee
Differential Revision: D24764886
fbshipit-source-id: abd5734394e53b20baa6473134896e3a2b178662
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47475
This improves the core.Net cloning/init performance by quite a bit. It makes set_input_record run in linear time instead of O(n) by checking the external_input map instead of regenerating the external inputs each time and then iterating over it.
Test Plan: unit tests + canary runs
Reviewed By: dzhulgakov
Differential Revision: D24765346
fbshipit-source-id: 92d9f6dec158512bd50513b78675174686f0f411
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47474
After enabling GPU/Re, some issues were specific to those runs
Test Plan:
```
buck test -c test.external_runner=tpx mode/opt //caffe2/test:torch_cuda -- --use-remote-execution --force-tpx --run-disabled
```
Reviewed By: malfet, janeyx99
Differential Revision: D24771578
fbshipit-source-id: 1ada79dae12c8cb6f795a0d261c60f038eee2dfb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/40869
Resubmit of https://github.com/pytorch/pytorch/pull/33818.
Adds support for `list()` by desugaring it to a list comprehension.
Last time I landed this it made one of the tests slow, and got unlanded. I think that's bc the previous PR changed the emission of `list()` on a list input or a str input to a list comprehension, which is the more general way of emitting `list()`, but also a little bit slower. I updated this version to emit to the builtin operators for these two case. Hopefully it can land without being reverted this time...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42382
Reviewed By: navahgar
Differential Revision: D24767674
Pulled By: eellison
fbshipit-source-id: a1aa3d104499226b28f47c3698386d365809c23c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47158
1. Test the default Python comm hook implementations ALLREDUCE and FP16_COMPRESS, besides an ad-hoc all-reduce implementation.
2. Typo fix.
3. Reformat default_hooks.py.
4. Publish register_comm_hook API for DDP module (This should be done in a separate diff, but got merged unintentionally.)
The new style can be used for testing any new comm hook like PowerSGD easily.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 116012600
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_default_ddp_comm_hooks_nccl
Reviewed By: rohan-varma
Differential Revision: D24669639
fbshipit-source-id: 048c87084234edc2398f0ea6f01f2f083a707939
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47465
This results in a ~10% improvement on a DeepAndWide model:
10 runs of a benchmark before the change:
```
1.480785621330142
1.430812582373619
1.3845220785588026
1.4510653037577868
1.4827174227684736
1.3679781593382359
1.4239587392657995
1.5069784726947546
1.3988622818142176
1.4533461946994066
```
10 runs of the same benchmark after the change:
```
1.3221493270248175
1.3624659553170204
1.3415213637053967
1.3560577500611544
1.3064174111932516
1.2934542261064053
1.379274770617485
1.3850531745702028
1.26725466363132
1.3738237638026476
```
Link to benchmark: https://gist.github.com/ZolotukhinM/2308732eabb47685c6f7786e5a13b3d1
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D24767247
Pulled By: ZolotukhinM
fbshipit-source-id: a77e89fdfb54286e6463533c86b3a4ba606ca1c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46780
This is in prototype status, but pretty functional. There are two major
parts.
- Model converter. This is a pure Python component that consumes a
model in TorchScript format, converts the operations into NNAPI
semantics, and serializes the model in a custom format. It then wraps
the result in a new TorchScript model that can invoke NNAPI under the
hood.
- Runtime. This is a TorchBind object that deserializes the model and
sends the result to NNAPI. This is fairly simple since the serialized
format is basically just a list of NNAPI calls to make, so most of the
code is spent on bounds checking.
A few notes on the design.
- Currently, all tensor sizes need to be fixed, and those fixed sizes
are burned directly into the serialized model. This will probably
need to change. NNAPI supports variable-sized tensors, but the
important hardware backends do not. However, we're seeing use cases
crop up where the input size is not known until around the time that
the model is loaded (for example, it might depend on the camera aspect
ratio). I think the proper fix here is to remove the code in the
converter that eagerly calculates the sizes of the intermediate
tensors and replace it with a code generator that will generate some
TorchScript code that will perform those calculations at model load
time. This way, we will be able to support models that have
variable-sized inputs while still only showing fixed-sized operands to
NNAPI.
- The important hardware backends want operands to be in NHWC order, but
PyTorch natively represents all tensors and NCHW. The strategy for
this is to keep NCHW during most of the conversion process, but track
and additional value per operand representing the "dimension order".
The dimension order gets propagated through convolutions and pointwise
ops. When we're ready to serialize the model, we reorder the
dimensions for "channels last" operands to NHWC.
Test Plan:
Some local testing with FB prod models. I'll need to add some examples
and automated tests.
Reviewed By: iseeyuan
Differential Revision: D24574040
Pulled By: dreiss
fbshipit-source-id: 6adc8571b234877ee3666ec0c0de24da35c38a1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47466
- Add kernel launch check `TORCH_CUDA_KERNEL_LAUNCH_CHECK()` (D24309971 (353e7f940f)) to several files in aten/src/ATen/native/cuda
- Get rid of old check `AT_CUDA_CHECK(cudaGetLastError())` in these same files
Test Plan:
Test build:
```
buck build //caffe2/aten:ATen-cu
```
To check for launches without checks:
```
python3 caffe2/torch/testing/check_kernel_launches.py
```
Make sure none of the updated files are in the returned list:
{F343234608}
Reviewed By: r-barnes
Differential Revision: D24724947
fbshipit-source-id: a7c7d3c70ed8fb5dfd69997b50f9c838f8651791
Summary:
Take 2 of this fix, I removed the repro from the issue which is a bit flaky due to parallelism. It broke on Windows but isn't specific to Windows or this fix, I think. I'll make sure all the tests pass this time (cc zou3519).
Fixes an issue where fp16 scalars created by the registerizer could be referenced as floats - causing invalid conversions which would crash in the NVRTX compile. I also noticed that we were inserting patterns like float(half(float(X))) and added a pass to collapse those down inside the CudaHalfScalarRewriter.
Fixes https://github.com/pytorch/pytorch/issues/47138
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47448
Reviewed By: glaringlee
Differential Revision: D24765070
Pulled By: nickgg
fbshipit-source-id: 5297e647534d53657bef81f4798e8aa6a93d1fbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47223
This PR enables batched gradient computation for advanced indexing.
Previously, the backward formula was writing parts of the grad tensori
in-place to zeros_like(self). Since grad is a BatchedTensor and self is
not a BatchedTensor, this is not possible.
To solve the problem, we instead create a new tensor with
`grad.new_zeros` and then write to that in-place. This new tensor will
have the same batchedness as the `grad` tensor.
To prevent regressions (the autograd codegen special cases zeros_like
to avoid saving the `self` tensor for backward), we teach the autograd
codegen how to save `self.options()`.
Test Plan:
- new tests
- run old indexing tests
Reviewed By: ejguan
Differential Revision: D24741684
Pulled By: zou3519
fbshipit-source-id: e267999dc079f4fe58c3f0bdf5c263f1879dca92
Summary:
add get_device_to_partitions_mapping function in the Partitioner class to make size_based_partition more modular and organized. This function will also be used in the future cost_aware_partition
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47361
Reviewed By: gcatron
Differential Revision: D24760911
Pulled By: scottxu0730
fbshipit-source-id: 8cdda51b9a1145f9d13ebabbb98b4d9df5ebb6cd
Summary:
`torch.inverse` now works for complex inputs on GPU.
Test cases with complex matrices are xfailed for now. For example, batched matmul does not work with complex yet.
Ref. https://github.com/pytorch/pytorch/issues/33152
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45034
Reviewed By: zou3519
Differential Revision: D24730264
Pulled By: anjali411
fbshipit-source-id: b9c94ec463012913c117278a884adeee96ea02aa
Summary:
The `docker-pytorch-linux-xenial-py3.6-gcc4.8` job is not used for any builds anymore. This PR removes it from CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47446
Reviewed By: seemethere, samestep
Differential Revision: D24759876
Pulled By: janeyx99
fbshipit-source-id: e7d420fc2c6c7ffa43001d83b449e9ef3070e902
Summary:
Currently, code like
```
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
self.W = torch.nn.Parameter(torch.randn(5))
def forward(self, x):
return torch.dot(self.W, x)
mod = Test()
print(fx.symbolic_trace(Test())(5))
```
gives an error like the below, which does not show the actual code that throws the error.
```
Traceback (most recent call last):
File "t.py", line 20, in <module>
print(fx.symbolic_trace(Test())(5))
File "/home/chilli/fb/pytorch/torch/nn/modules/module.py", line 744, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/chilli/fb/pytorch/torch/fx/graph_module.py", line 191, in debug_forward
return src_forward(self, *args, **kwargs)
File "<eval_with_key_0>", line 5, in forward
TypeError: dot(): argument 'tensor' (position 2) must be Tensor, not int
```
This is particularly annoying when your function has already been transformed several times.
So, the really annoying thing is that the error clearly has the requisite information in `exception.__traceback__` - it just isn't printing it.
I think the right way of doing this is simply replacing `sys.excepthook`. This appears to be the standard way to modify exception messages.
**Scratch the below**
The 2 methods in the PR right now are:
1. Just prepend the final part of the traceback to the beginning of your error message. Looks like
```
Traceback (most recent call last):
File "t.py", line 20, in <module>
print(fx.symbolic_trace(Test())(5))
File "/home/chilli/fb/pytorch/torch/nn/modules/module.py", line 744, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/chilli/fb/pytorch/torch/fx/graph_module.py", line 197, in debug_forward
raise e
File "/home/chilli/fb/pytorch/torch/fx/graph_module.py", line 192, in debug_forward
return src_forward(self, *args, **kwargs)
File "<eval_with_key_0>", line 5, in forward
TypeError: File "<eval_with_key_0>", line 5, in forward
dot_1 = torch.dot(w, x)
dot(): argument 'tensor' (position 2) must be Tensor, not int
```
2. Use the `from exception` feature in Python. Looks like
```
Traceback (most recent call last):
File "/home/chilli/fb/pytorch/torch/fx/graph_module.py", line 192, in debug_forward
return src_forward(self, *args, **kwargs)
File "<eval_with_key_0>", line 5, in forward
TypeError: File "<eval_with_key_0>", line 5, in forward
dot_1 = torch.dot(w, x)
dot(): argument 'tensor' (position 2) must be Tensor, not int
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "t.py", line 20, in <module>
print(fx.symbolic_trace(Test())(5))
File "/home/chilli/fb/pytorch/torch/nn/modules/module.py", line 744, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/chilli/fb/pytorch/torch/fx/graph_module.py", line 197, in debug_forward
raise Exception(last_tb) from e
Exception: File "<eval_with_key_0>", line 5, in forward
dot_1 = torch.dot(w, x)
```
I think the first one looks better, but it's pretty hacky since we're shoving the traceback in the message.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47108
Reviewed By: jamesr66a
Differential Revision: D24751019
Pulled By: Chillee
fbshipit-source-id: 83e6ed0165f98632a77c73de75504fd6263fff40
Summary:
Update pass that handles prim::ListUnpack in peephole file, so that it also covers the case when input to the node is of ListType.
Fixes https://github.com/pytorch/pytorch/issues/45816
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46264
Reviewed By: mrshenli
Differential Revision: D24566070
Pulled By: bzinodev
fbshipit-source-id: 32555487054f6a7fe02cc17c66bcbe81ddf9623e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47423
Since the dtype of this fake_quant is `quint8`, the output range should be
from 0 to 255. Fixing. This should address the numerical inaccuracies with
sigmoid and hardsigmoid with `FixedQParamsFakeQuantize` attached compared
to their quantized counterparts.
In a future PR, might be safer to also make the activation functions
using `FixedQParamsFakeQuantize` to explicitly specify their expected
output range and zero_point. Leaving that for later, as this bugfix
should be landed urgently.
Test Plan:
Manual script which gives low SQNR before this PR and high SQNR after
this PR: https://gist.github.com/vkuzo/9906bae29223da72b10d6b6aafadba42https://github.com/pytorch/pytorch/pull/47376, which can be landed after
this, adds a proper test.
Imported from OSS
Reviewed By: ayush29feb, jerryzh168
Differential Revision: D24751497
fbshipit-source-id: 4c32e22a30116caaceeedb4cd47146d066054a89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47414
This improves the build time of this file by 10x on my machine (~12 minutes to ~1 minute).
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D24746458
Pulled By: gchanan
fbshipit-source-id: cdef801199d4fdc2bbd740fe1b771285b1d71319
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47189
PyTorch has a special case where sum(scalar_tensor, dim=0) does not fail
and instead returns a new copy of the original scalar_tensor. If we
end up vmapping over per-example scalar tensors, e.g.,
```
>>> x = torch.randn(B0) # the per-examples are all scalars
>>> vmap(partial(torch.sum, dim=0), x)
```
then we should replicate the behavior of sum(scalar_tensor, dim=0) by
returning a clone of the input tensor.
This PR also adds a batching rule for clone(Tensor, MemoryFormat). The
batching rule:
- unwraps the BatchedTensor, calls clone(), and rewraps the
BatchedTensor if MemoryFormat is torch.preserve_format (which is the
default).
- errors out with an NYI for all other memory formats, including
torch.contiguous_format. There are some weird semantics for memory
layouts with vmap that I need to go and figure out. Those are noted in
the comments for `clone_batching_rule`
Test Plan: - new tests
Reviewed By: ejguan
Differential Revision: D24741689
Pulled By: zou3519
fbshipit-source-id: e640344b4e4aa8c0d2dbacc5c49901f4c33c6613
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47410
This is a copy-paste except for:
1) The code is put in an anonymous namespace
1) The static declarations on functions (in the now-anonymous namespace) are removed
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D24745597
Pulled By: gchanan
fbshipit-source-id: 049b6bb10845cd8d7961b533782f582b3db25248
Summary:
First commit contains the initial code from Richard's branch.
Second commit are the changes that I made during the writing process
Third commit is the update to support category/topic pair for each commit
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47360
Reviewed By: ejguan
Differential Revision: D24741003
Pulled By: albanD
fbshipit-source-id: d0fcc6765968dc1732d8a515688d11372c7e653d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47329
Supports pruned weights along with mapping for the compressed indices
Test Plan:
python test/test_quantization.py TestQuantizedEmbeddingOps
Imported from OSS
Reviewed By: qizzzh
Differential Revision: D24719909
fbshipit-source-id: f998f4039e84bbe1886e492a3bff6aa5f56b6b0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47328
Extend tests to cover case for pruned weights with mapping table.
Support for 8-bits sparse lookup to follow
Test Plan:
python test/test_quantization.py TestQuantizedEmbeddingOps
Imported from OSS
Reviewed By: qizzzh
Differential Revision: D24719910
fbshipit-source-id: d31db6304f446104ee8c7b10b902accd2919a513
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47015
c10::optional has non-trivial copy and move operations always. This change specializes it for 32-bit scalars so that it has trivial copy and move operations in that case. Ideally, we would instead rely on P0602 "variant and optional should propagate copy/move triviality" and use `std::optional` (or implement that functionality ourselves). We can't use `std::optional` because we are stuck with C++14. Implementing the full P0602 ourselves would add even more complexity. We could do it, but this should be a helpful first step.
ghstack-source-id: 115886743
Test Plan:
Collect Callgrind instruction counts for `torch.empty(())`. Data:
Make empty c10-ful (https://github.com/pytorch/pytorch/pull/46092):
```
<torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7ffaed1128e0>
torch.empty(())
All Noisy symbols removed
Instructions: 648005 632899
Baseline: 4144 3736
100 runs per measurement, 1 thread
```
This diff atop #46092:
```
<torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f943f1dc8e0>
torch.empty(())
All Noisy symbols removed
Instructions: 602347 591005
Baseline: 4106 3736
100 runs per measurement, 1 thread
```
(6.6% improvement vs #46092)
Pass optionals by const reference (https://github.com/pytorch/pytorch/pull/46598)
```
<torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f1abb3988e0>
torch.empty(())
All Noisy symbols removed
Instructions: 601349 590005
Baseline: 4162 3736
100 runs per measurement, 1 thread
```
(6.8% improvement vs #46092)
This diff atop #46598 (i.e., both together)
```
<torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f9577c22850>
torch.empty(())
All Noisy symbols removed
Instructions: 596095 582451
Baseline: 4162 3736
100 runs per measurement, 1 thread
Warning: PyTorch was not built with debug symbols.
Source information may be limited. Rebuild with
REL_WITH_DEB_INFO=1 for more detailed results.
```
(another 1.3% savings!)
#46598 outperformed this change slightly, and combining the two leads to further benefits. I guess we should do both! (Though I still don't understand why passing optionals that should fit in a register by const reference would help...)
Reviewed By: smessmer
Differential Revision: D24552280
fbshipit-source-id: 4d93bfcffafebd8c01559398513fa6b9db959d11
Summary:
Adds a new piece of infrastructure to the NNC fused-kernel generation compiler, which builds a dependency graph of the reads and writes to memory regions in a kernel.
It can be used to generate graphs like this from the GEMM benchmark (not this only represents memory hierarchy not compute hierarchy):

Or to answer questions like this:
```
Tensor* c = Compute(...);
Tensor* d = Compute(...);
LoopNest loop({d});
MemDependencyChecker analyzer;
loop.root_stmt()->accept(analyzer);
if (analyzer.dependsDirectly(loop.getLoopStmtsFor(d)[0], loop.getLoopStmtsFor(c)[0]) {
// do something, maybe computeInline
}
```
Or this:
```
Tensor* d = Compute(...);
LoopNest loop({d});
MemDependencyChecker analyzer(loop.getInputs(), loop.getOutputs());
const Buf* output = d->buf();
for (const Buf* input : inputs) {
if (!analyzer.dependsIndirectly(output, input)) {
// signal that this input is unused
}
}
```
This is a monster of a diff, and I apologize. I've tested it as well as possible for now, but it's not hooked up to anything yet so should not affect any current usages of the NNC fuser.
**How it works:**
Similar to the registerizer, the MemDependencyChecker walks the IR aggregating memory accesses into scopes, then merges those scopes into their parent scope and tracks which writes are responsible for the last write to a particular region of memory, adding dependency links where that region is used.
This relies on a bunch of math on symbolic contiguous regions which I've pulled out into its own file (bounds_overlap.h/cpp). Sometimes this wont be able to infer dependence with 100% accuracy but I think it should always be conservative and occaisionally add false positives but I'm aware of no false negatives.
The hardest part of the analysis is determining when a Load inside a For loop depends on a Store that is lower in the IR from a previous iteration of the loop. This depends on a whole bunch of factors, including whether or not we should consider loop iteration order. The analyzer comes with configuration of this setting. For example this loop:
```
for (int i = 0; i < 10; ++i) {
A[x] = B[x] + 1;
}
```
has no inter loop dependence, since each iteration uses a distinct slice of both A and B. But this one:
```
for (int i = 0; i < 10; ++i) {
A[0] = A[0] + B[x];
}
```
Has a self loop dependence between the Load and the Store of A. This applies to many cases that are not reductions as well. In this example:
```
for (int i =0; i < 10; ++i) {
A[x] = A[x+1] + x;
}
```
Whether or not it has self-loop dependence depends on if we are assuming the execution order is fixed (or whether this loop could later be parallelized). If the read from `A[x+1]` always comes before the write to that same region then it has no dependence.
The analyzer can correctly handle dynamic shapes, but we may need more test coverage of real world usages of dynamic shapes. I unit test some simple and pathological cases, but coverage could be better.
**Next Steps:**
Since the PR was already so big I didn't actually hook it up anywhere, but I had planned on rewriting bounds inference based on the dependency graph. Will do that next.
There are few gaps in this code which could be filled in later if we need it:
* Upgrading the bound math to work with write strides, which will reduce false positive dependencies.
* Better handling of Conditions, reducing false positive dependencies when a range is written in both branches of a Cond.
* Support for AtomicAdd node added in Cuda codegen.
**Testing:**
See new unit tests, I've tried to be verbose about what is being tested. I ran the python tests but there shouldn't be any way for this work to affect them yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46952
Reviewed By: ejguan
Differential Revision: D24730346
Pulled By: nickgg
fbshipit-source-id: 654c67c71e9880495afd3ae0efc142e95d5190df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46993
Introducing benchmark that combines Distributed Data Parallelism with Distributed Model Parallelism. The benchmark measures distributed training iteration time. The number of trainer nodes and parameter servers are configurable. The default setup has 8 trainers, 1 master node and 8 parameter servers.
The training process is executed as follows:
1) The master creates embedding tables on each of the 8 Parameter Servers and holds an RRef to it.
2) The master, then kicks off the training loop on the 8 trainers and passes the embedding table RRef to the trainers.
3) The trainers create a `HybridModel` which performs embedding lookups in all 8 Parameter Servers using the embedding table RRef provided by the master and then executes the FC layer which is wrapped and replicated via DDP (DistributedDataParallel).
4) The trainer executes the forward pass of the model and uses the loss to
execute the backward pass using Distributed Autograd.
5) As part of the backward pass, the gradients for the FC layer are computed
first and synced to all trainers via allreduce in DDP.
6) Next, Distributed Autograd propagates the gradients to the parameter servers,
where the gradients for the embedding table are updated.
7) Finally, the Distributed Optimizer is used to update all parameters.
Test Plan:
waitforbuildbot
Benchmark output:
---------- Info ---------
* PyTorch version: 1.7.0
* CUDA version: 9.2.0
---------- nvidia-smi topo -m ---------
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity
GPU0 X NV2 NV1 NV2 NV1 NODE NODE NODE 0-19,40-59
GPU1 NV2 X NV2 NV1 NODE NV1 NODE NODE 0-19,40-59
GPU2 NV1 NV2 X NV1 NODE NODE NV2 NODE 0-19,40-59
GPU3 NV2 NV1 NV1 X NODE NODE NODE NV2 0-19,40-59
GPU4 NV1 NODE NODE NODE X NV2 NV1 NV2 0-19,40-59
GPU5 NODE NV1 NODE NODE NV2 X NV2 NV1 0-19,40-59
GPU6 NODE NODE NV2 NODE NV1 NV2 X NV1 0-19,40-59
GPU7 NODE NODE NODE NV2 NV2 NV1 NV1 X 0-19,40-59
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe switches (without traversing the PCIe Host Bridge)
PIX = Connection traversing a single PCIe switch
NV# = Connection traversing a bonded set of # NVLinks
------------------ PyTorch Distributed Benchmark (DDP and RPC) ---------------------
sec/iter ex/sec sec/iter ex/sec sec/iter ex/sec sec/iter ex/sec
Trainer0: p50: 0.376s 185/s p75: 0.384s 182/s p90: 0.390s 179/s p95: 0.396s 176/s
Trainer1: p50: 0.377s 204/s p75: 0.384s 200/s p90: 0.389s 197/s p95: 0.393s 195/s
Trainer2: p50: 0.377s 175/s p75: 0.384s 172/s p90: 0.390s 169/s p95: 0.395s 166/s
Trainer3: p50: 0.377s 161/s p75: 0.384s 158/s p90: 0.390s 156/s p95: 0.393s 155/s
Trainer4: p50: 0.377s 172/s p75: 0.383s 169/s p90: 0.389s 166/s p95: 0.395s 164/s
Trainer5: p50: 0.377s 180/s p75: 0.383s 177/s p90: 0.389s 174/s p95: 0.395s 172/s
Trainer6: p50: 0.377s 204/s p75: 0.384s 200/s p90: 0.390s 197/s p95: 0.394s 195/s
Trainer7: p50: 0.377s 185/s p75: 0.384s 182/s p90: 0.389s 179/s p95: 0.394s 177/s
All: p50: 0.377s 1470/s p75: 0.384s 1443/s p90: 0.390s 1421/s p95: 0.396s 1398/s
Reviewed By: pritamdamania87
Differential Revision: D24409230
fbshipit-source-id: 61de31dd4b69914198cb4becc2e616b17d47ef1a
Summary:
This PR adds the support to calculate the cost of a partitioned graph partition by partition based on the node cost. In a partitioned graph, top partitions (partitions without parents) are collected as the starting points, then use DFS to find the critical path among all partitions in the graph
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47280
Reviewed By: gcatron
Differential Revision: D24735932
Pulled By: scottxu0730
fbshipit-source-id: 96653a8208554d2c3624e6c8718628f7c13e320b
Summary:
By default, TorchScript execution is single threaded and uses the caller's thread pool. For the use case of distributed inference, we hope there is a way to customize the behavior where the interpreter in torch script can be executed in other places. This diff allows an explicit taskLauncher for torchscript interpreter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46865
Test Plan:
unit test is passed.
fbshipit-source-id: 1d7b003926c0d1f8facc53206efb960cff8897ac
Fixes #{issue number}
Reviewed By: houseroad
Differential Revision: D24616102
Pulled By: garroud
fbshipit-source-id: 79202b62f92d0b0baf72e4bf7aa3f05e0da91d59
Summary:
Moved all torch specific checks under `if TORCH_AVAILABLE` block
Embed gpu_info dict back into SystemEnv constructor creation and deduplicate some code between HIP and CUDA cases
Fixes https://github.com/pytorch/pytorch/issues/47397
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47398
Reviewed By: walterddr
Differential Revision: D24740421
Pulled By: malfet
fbshipit-source-id: d0a1fe5b428617cb1a9d027324d24d7371c68d64
Summary:
Fixes an issue where fp16 scalars created by the registerizer could be referenced as floats - causing invalid conversions which would crash in the NVRTX compile. I also noticed that we were inserting patterns like `float(half(float(X)))` and added a pass to collapse those down inside the CudaHalfScalarRewriter.
Fixes https://github.com/pytorch/pytorch/issues/47138
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47229
Reviewed By: agolynski
Differential Revision: D24706475
Pulled By: nickgg
fbshipit-source-id: 9df72bbbf203353009e98b9cce7ab735efff8b21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47206
As discussed offline with pritamdamania87, add testing to ensure per-iteration and rank-dependent control flow works as expected in DDP with `find_unused_parameters=True`.
ghstack-source-id: 115854944
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D24659901
fbshipit-source-id: 17fc2b3ebba9cef2dd01d2877bad5702174b9767
Summary:
This would be the case when package is build for local development rather than for installation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47390
Reviewed By: janeyx99
Differential Revision: D24738416
Pulled By: malfet
fbshipit-source-id: 22bd676bc46e5d50a09539c969ce56d37cfe5952
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47014
Some tests are better than zero tests.
ghstack-source-id: 115769678
Test Plan: Run new tests, passes
Reviewed By: smessmer
Differential Revision: D24558649
fbshipit-source-id: 50b8872f4f15c9a6e1f39b945124a31b57dd61d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47013
It was getting used in client code, and it's not part of `std::optional`.
ghstack-source-id: 115769682
Test Plan: Existing tests
Reviewed By: smessmer
Differential Revision: D24547710
fbshipit-source-id: a24e0fd03aba1cd996c85b12bb5dcdb3e7af46b5
Summary:
freeze was temporarily renamed to _freeze in a reorg, and then removed from doc [here](https://github.com/pytorch/pytorch/pull/43473). add it back to docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47120
Reviewed By: suo
Differential Revision: D24650712
Pulled By: eellison
fbshipit-source-id: 399e31586b8093de66937ba1266007ee291f509e
Summary:
Complex-valued named tensors do not support backpropagation currently. This is due to `tools/autograd/gen_variable_type.py` not containing `alias` in `GRADIENT_IMPLEMENTED_FOR_COMPLEX` which is required to constructed named tensors.
This fixes https://github.com/pytorch/pytorch/issues/47157. Also removed a duplicate `cholesky` in the list and added a test in `test_autograd.py`.
Apologies, this is a duplicate of https://github.com/pytorch/pytorch/issues/47181 as I accidently removed my pytorch fork.
cc: zou3519 anjali411
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47289
Reviewed By: agolynski
Differential Revision: D24706571
Pulled By: zou3519
fbshipit-source-id: 2cc48ce38eb180183c5b4ce2f8f4eef8bcac0316
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47252
For now, just use the CPU to reshape.
Test Plan: Imported from OSS
Reviewed By: IvanKobzarev
Differential Revision: D24733906
Pulled By: SS-JIA
fbshipit-source-id: df0e4c0f21379cb2533a1717300b2f7275936e55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47203
1. Create a new field in BucketReplica to store sizes info for each variable.
2. Export sizes list, along with lengths and offsets to GradBuceket.
These fields are needed for PowerSGD.
Original PR issue: Investigate Applying PowerSGD to Communication Hook for Gradient Compression #47202
ghstack-source-id: 115875194
Test Plan: Checked the field values from log.
Reviewed By: rohan-varma
Differential Revision: D24644137
fbshipit-source-id: bcec0daf0d02cbf25389bfd9be90df1e6fd8fc56
Summary:
Currently, no test reports are uploaded to CI because the paths for the `onnx` runs are incorrect. This PR attempts to change that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47315
Reviewed By: malfet
Differential Revision: D24727607
Pulled By: janeyx99
fbshipit-source-id: f6d91698fdb15a39e01ef812032d4cd30621f864
Summary:
**BC-breaking Note:**
This PR disallows passing in a generator of a different device than the tensor being created during `randperm` execution. For example, the following code which used to work no longer works.
```
> torch.randperm(3, device='cuda', generator=torch.Generator(device='cpu'))
tensor([0, 1, 2], device='cuda:0')
```
It now errors:
```
> torch.randperm(3, device='cuda', generator=torch.Generator(device='cpu'))
RuntimeError: Expected a 'cuda:0' generator device but found 'cpu'
```
**PR Summary:**
Fixes https://github.com/pytorch/pytorch/issues/44714
Also added + ran tests to ensure this functionality.
Disclaimer: More work needs to be done with regards to small cuda tensors when a generator is specified, look at the issue thread for more details.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47022
Reviewed By: samestep
Differential Revision: D24608237
Pulled By: janeyx99
fbshipit-source-id: b83c47219c7816d93f938f7ce86dc8857513961b
Summary:
Our tests do not test these folders (as they shouldn't), and their inclusion in codecov obfuscates our coverage metrics.
We ask codecov to ignore these folders when calculating our coverage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47310
Reviewed By: walterddr
Differential Revision: D24711775
Pulled By: janeyx99
fbshipit-source-id: 6095bb5e8d52202c7930114d2f357163d2271022
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46896
The idea of the memory model is quite similar to that of BlackBoxPredictor, however, it's more complicated in pt due to 1) tensor views that share storage with storage refcount bumps but with different TensorImpls, 2) tensors sharing the same TensorImpl and the same storage, but with no refcount bump of the StorageImpl, 3) data types such as TensorList and Tuples that have Tensors in them, 4) need to support non-out/out variant mix while we move the aten ops to out variants.
As a result, I have to make the following adjustments:
1) remove tensors in output Tuples from internal blob list;
2) for memory allocation/deallocation, get candidate Tensors from the outputs of ops with out variant, extract StorageImpls from the Tensors, dedup, and remove output tensor StorageImpls, and get the final list of blobs for memory planning;
3) during the clean_up_memory pass, clean up memory held by the StorageImpls as well as Tensors/Lists/Tuples in IValues that don't participate in memory planning to reduce overall memory usage
Risk:
PyTorch team is planning to deprecate the current resize_outout api, which we do rely on. This is a pretty big risk.
https://www.internalfb.com/intern/diffusion/FBS/browsefile/master/fbcode/caffe2/aten/src/ATen/native/Resize.cpp?commit=6457b329847607553d34e788a3a7092f41f38895&lines=9-23
Test Plan:
```
buck test //caffe2/test:static_runtime
buck test //caffe2/benchmarks/static_runtime:static_runtime_cpptest
buck test //caffe2/caffe2/fb/predictor:pytorch_predictor_test
```
Benchmarks:
```
MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 numactl -m 0 -C 13 \
buck-out/opt/gen/caffe2/caffe2/fb/predictor/ptvsc2_predictor_bench \
--scripted_model=/home/hlu/ads/adindexer/adindexer_ctr_mobilefeed/pt/merge/traced_precomputation.pt \
--pt_inputs=/home/hlu/ads/adindexer/adindexer_ctr_mobilefeed/pt/merge/container_precomputation_bs1.pt \
--iters=1000 --warmup_iters=10000 --num_threads=1 --pt_enable_static_runtime=true \
--pt_cleanup_activations=true --pt_enable_out_variant=false
```
|pt_cleanup_activations |pt_enable_out_variant |old ms/iter |new ms/iter |
|--- |--- |--- |--- |
|0 |0 |0.31873 |0.30228 |
|0 |1 |0.30018 |0.29184 |
|1 |0 |0.35246 |0.31895 |
|1 |1 |0.35742 |0.30417 |
Reviewed By: bwasti, raziel
Differential Revision: D24471854
fbshipit-source-id: 4ac37dca7d2a0c362120a7f02fd3995460c9a55c
Summary:
* This is a pre-step to build c10d into libtorch
* Includes a minor cleanup in c10d/CMakeLists.txt
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47309
Reviewed By: wanchaol
Differential Revision: D24711768
Pulled By: gmagogsfm
fbshipit-source-id: 6f9e0a6a73c30f5ac7dafde9082efcc4b725dde1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46758
It's in general helpful to support int32 indices and offsets, especially when such tensors are large and need to be transferred to accelerator backends. Since it may not be very useful to support the combination of int32 indices and int64 offsets, here we enforce that these two must have the same type.
Test Plan: unit tests
Reviewed By: ngimel
Differential Revision: D24470808
fbshipit-source-id: 94b8a1d0b7fc9fe3d128247aa042c04d7c227f0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47306
Expose SparseLengthsSum8BitRowwiseSparse to PyTorch, since pt's 8bit embedding doesn't support pruning yet.
It's temporary solution to unblock the QRT test, not best for performance.
Test Plan: ci
Reviewed By: ashishenoyp
Differential Revision: D24709524
fbshipit-source-id: 725dfc9d803e4a555dd71fa5ab75dc175e671563
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47270
This is almost same as #46959, except that in caffe2/torch/nn/parallel/distributed.py, BuiltinCommHookType should be imported conditionally, only when dist.is_available(). Otherwise, this Python enum type defined in caffe2/torch/scrc/distributed/c10d/init.cpp cannot be imported. See https://github.com/pytorch/pytorch/issues/47153
I tried to follow another enum type enum type ReduceOp defined in the same file, but did not work, because the C++ enum class is defined torch/lib/c10d library, but BuiltinCommHookType is defined in torch/csrc/distributed library. These two libraries are compiled in two different ways.
To avoid adding typing to distributed package, which can be a new project, I simply removed the arg type of BuiltinCommHookType in this file.
To review the diff on top of #46959, compare V1 vs Latest:
https://www.internalfb.com/diff/D24700959?src_version_fbid=270445741055617
Main Changes in V1 (#46959):
1. Implemented the Pybind part.
2. In the reducer, once the builtin_comm_hook_type is set, a c++ comm hook instance will be created in Reducer::autograd_hook.
3. Added unit tests for the builit-in comm hooks.
Original PR issue: C++ DDP Communication Hook https://github.com/pytorch/pytorch/issues/46348
ghstack-source-id: 115783237
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_builtin_ddp_comm_hooks_nccl
//arvr/projects/eye_tracking/Masquerade:python_test
USE_DISTRIBUTED=0 USE_GLOO=0 BUILD_TEST=0 USE_CUDA=1 USE_MKLDNN=0 DEBUG=0 python setup.py install
Reviewed By: mrshenli
Differential Revision: D24700959
fbshipit-source-id: 69f303a48ae275aa856e6e9b50e12ad8602e1c7a
Summary:
This diff enables inlining for all non-output buffers, including the intermediate buffers that are created as part of an op. However, the buffers that correspond to reductions will not be inlined.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47258
Reviewed By: anjali411
Differential Revision: D24707015
Pulled By: navahgar
fbshipit-source-id: ad8b03e38497600cd69980424db6d586bf93db74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47254
CUDA codegen used a static global counter for picking names for
functions, but the functions only need to be unique in the scope of the
given codegen. This PR fixes that.
Differential Revision: D24698271
Test Plan: Imported from OSS
Reviewed By: bertmaher
Pulled By: ZolotukhinM
fbshipit-source-id: 516c0087b86b35bbb6ea7c71bb0ed9c3daaca2b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47253
The function simply goes over all aten nodes in the graph and
concatenates their names, truncating the final name to a given length.
Differential Revision: D24698272
Test Plan: Imported from OSS
Reviewed By: bertmaher
Pulled By: ZolotukhinM
fbshipit-source-id: d6e50194ca5faf0cb61f25af83247b5e40f202e4
Summary:
Fix https://github.com/pytorch/pytorch/issues/44601
I added bicubic grid sampler in both cpu and cuda side, but haven't in AVX2
There is a [colab notebook](https://colab.research.google.com/drive/1mIh6TLLj5WWM_NcmKDRvY5Gltbb781oU?usp=sharing) show some test results. The notebook use bilinear for test, since I could only use distributed version of pytorch in it. You could just download it and modify the `mode_torch=bicubic` to show the results.
There are some duplicate code about getting and setting values, since the helper function used in bilinear at first clip the coordinate beyond boundary, and then get or set the value. However, in bicubic, there are more points should be consider. I could refactor that part after making sure the overall calculation are correct.
Thanks
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44780
Reviewed By: mrshenli
Differential Revision: D24681114
Pulled By: mruberry
fbshipit-source-id: d39c8715e2093a5a5906cb0ef040d62bde578567
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47244
This is an event-logging based update that should allow us to collect high-quality data about how many times the NCCL Async Error Handling mechanism is triggered. This logs an event called `ProcessGroupNCCL.WorkNCCL.handleNCCLGuard`, which is recorded as an entry in the `scuba_caffe2_pytorch_usage_stats` Scuba table. This Scuba entry will also contain metadata like workflow status, entitlement, hostnames, and workflow names, which will give us insight into what workloads/domains and machines are benefiting from async error handling. It also contains the Flow Run ID, which can be used as a join key with the `fblearner_workflow_run_status` scuba table for additional information like final error message, etc. We can easily quantify the number of times the async handling code was triggered by querying the `scuba_caffe2_pytorch_usage_stats` table.
As a demonstration, I ran the following workflow with this diff patched: f229675892
Since the workflow above causes a desync, the `handleNCCLGuard` event is logged in scuba soon. See here for the filtered table: https://www.fburl.com/scuba/scuba_caffe2_pytorch_usage_stats/tmp1uvio
As you can see, there are 4 entries. The workflow above uses 3 GPUs, 2 of which run into the desync scenario and are crashed using async error handling. We make this fail twice before succeeding the 3rd time, hence 4 entries.
ghstack-source-id: 115708632
Test Plan: Did a quick demo as described above. Scuba entries with the logs can be found here: https://www.fburl.com/scuba/scuba_caffe2_pytorch_usage_stats/tmp1uvio
Reviewed By: jiayisuse
Differential Revision: D24688739
fbshipit-source-id: 7532dfeebc53e291fbe10d28a6e50df6324455b1
Summary:
As typing.NoReturn is used in the codebase
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47314
Reviewed By: seemethere
Differential Revision: D24712847
Pulled By: malfet
fbshipit-source-id: f0692d408316d630bc11f1ee881b695437fb47d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47300
**Summary**
This commit augments the module interface subtyping check that is done
before the emission of the `prim::ModuleDictIndex` operator so that the
error message that is printed if the subtyping check fails provides more
information on which methods do not match.
**Test Plan**
Existing unit tests for `prim::ModuleDictIndex`. Compilation of `ModWithWrongAnnotation` now produces this error:
```
Attribute module is not of annotated type __torch__.jit.test_module_containers.ModuleInterface: Method on class '__torch__.jit.test_module_containers.DoesNotImplementInterface' (1) is not compatible with interface '__torch__.jit.test_module_containers.ModuleInterface' (2)
(1) forward(__torch__.jit.test_module_containers.DoesNotImplementInterface self, Tensor inp) -> ((Tensor, Tensor))
(2) forward(InterfaceType<ModuleInterface> self, Any inp) -> (Any)
:
```
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D24709538
Pulled By: SplitInfinity
fbshipit-source-id: 6b6cb75e4b2b12b08576a5530b4b90cbcad9b6e5
Summary:
libiomp runtime is the only external dependency OS X package has if compiled with MKL
Copy it to the stage directory from one of the available rpathes
And remove all absolute rpathes, since project shoudl have none
Fixes https://github.com/pytorch/pytorch/issues/38607
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47262
Reviewed By: walterddr
Differential Revision: D24705094
Pulled By: malfet
fbshipit-source-id: 9f588a3ec3c6c836c8986d858fb53df815a506c8
Summary:
This PR adds a function for calculating the Kronecker product of tensors.
The implementation is based on `at::tensordot` with permutations and reshape.
Tests pass.
TODO:
- [x] Add more test cases
- [x] Write documentation
- [x] Add entry `common_methods_invokations.py`
Ref. https://github.com/pytorch/pytorch/issues/42666
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45358
Reviewed By: mrshenli
Differential Revision: D24680755
Pulled By: mruberry
fbshipit-source-id: b1f8694589349986c3abfda3dc1971584932b3fa
Summary:
This PR moves combine_partitions_based_on_size and find_partition_to_combine_based_on_size to sparse_nn_partition since they are both only used by sparse_nn_partition
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47283
Reviewed By: gcatron
Differential Revision: D24707864
Pulled By: scottxu0730
fbshipit-source-id: 183fe945e477e16301d7f489103287eb9d8a30af
Summary:
This behavior was changed by side effect by https://github.com/pytorch/pytorch/pull/41984
Update the doc to reflect the actual behavior of the function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46937
Reviewed By: mruberry
Differential Revision: D24682750
Pulled By: albanD
fbshipit-source-id: 89b94b61f54dbcfc6a6988d7e7d361bd24ee4964
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 8eb6dcb23e
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47263
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: malfet
Differential Revision: D24701113
fbshipit-source-id: 92ab4ae93c4d0753ee3d6590e5616fc8cd6082a0
Summary:
Fixes deprecated use of the HIP_PLATFORM env var. This env var is no longer needed to be set explicitly. Instead, HIP_PLATFORM is automatically detected by hipcc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47241
Reviewed By: mruberry
Differential Revision: D24699982
Pulled By: ngimel
fbshipit-source-id: 9cd2f32e7c0c8d662832b0cbbc2988835a45961a
Summary:
asan testing diff is absurd right now, moving some heftier tests to be in shard2 (test_nn and test_quantization)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47290
Reviewed By: malfet
Differential Revision: D24706877
Pulled By: janeyx99
fbshipit-source-id: 35069d1e425857f85775f9be76501d6a158e0376
Summary:
Also remove MAX_JOBS constraint, since OOM warning was about nvcc rather than clang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47277
Reviewed By: walterddr
Differential Revision: D24705180
Pulled By: malfet
fbshipit-source-id: 25fd0161de3f7e14a2a4db86cbea8357cdc69e06
Summary:
`std::vector<bool>` can not return values by reference, since they are stored as bit fields
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47279
Reviewed By: glaringlee
Differential Revision: D24705188
Pulled By: malfet
fbshipit-source-id: 96e71cc4b9881f92af3b4a508d397deab6d68174
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47102
Since the current mobile end to end workflow involves using `optmize_for_mobile` in python, the goal here is to be able to use `optmize_for_mobile(m, backend="metal")` in fbcode.
ghstack-source-id: 115749752
Test Plan:
1. Be able to export models for metal (see the next diff)
2. Make sure the change won't break the OSS workflow
3. Make sure the change won't break on the mobile bulild.
Reviewed By: xcheng16
Differential Revision: D24644422
fbshipit-source-id: bd77e22f0799533a96d048207932055fd051a67e
Summary:
CC: gchanan jspisak seemethere
I previewed the docs and they look reasonable. Let me know if I missed anything.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46880
Reviewed By: seemethere, izdeby
Differential Revision: D24551503
Pulled By: robieta
fbshipit-source-id: 627f73d3dd4d8f089777bca8653702735632b9fc
Summary:
This adds a dedicated dispatch key for the [nestedtensor project](https://github.com/pytorch/nestedtensor).
- [ ] Since this isn't a device or a backend, does this need further updates in other places other than DispatchKey.h?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44668
Reviewed By: zhangguanheng66, ailzhang
Differential Revision: D23998801
Pulled By: cpuhrsch
fbshipit-source-id: 133b5a9a04c4f61c27c0728832da09e4b38a5939
Summary:
This PR adds node-by-node cost function. Given a partition of nodes, get_latency_of_one_partition function will find the critical path in the partition and return its latency. A test unit is also provided. In the test unit, a graph module is partitioned into two partitions and the latency of each partition is tested.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47009
Reviewed By: gcatron
Differential Revision: D24692542
Pulled By: scottxu0730
fbshipit-source-id: 64c20954d842507be0d1afa2516d88f705e11224
Summary:
I don't think this method is used anywhere, so I don't know how to test it. But the diff should justify itself.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43841
Reviewed By: mruberry
Differential Revision: D24696505
Pulled By: anjali411
fbshipit-source-id: f2a249ae2e078b16fa11941a048b7d093e60241b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46018
Currently on mobile devices quantize_tensor has a vectorized implementation
using ARM intrinsics; however quantize_tensor_per_channel does not.
Test Plan:
Build for ARM Neon
```
BUILD_MOBILE_BENCHMARK=1 BUILD_MOBILE_TEST=1 ANDROID_DEBUG_SYMBOLS=1 BUILD_PYTORCH_MOBILE=1 ANDROID_ABI="armeabi-v7a with NEON" ./scripts/build_android.sh -DANDROID_CCACHE=$(which ccache) -DBUILD_BINARY=ON
```
Build for ARM64
```
BUILD_MOBILE_BENCHMARK=1 BUILD_MOBILE_TEST=1 ANDROID_DEBUG_SYMBOLS=1 BUILD_PYTORCH_MOBILE=1 ANDROID_ABI=arm64-v8a ./scripts/build_android.sh -DANDROID_CCACHE=$(which ccache) -DBUILD_BINARY=ON
```
Then run the benchmark binary over adb shell. Note that by android cpu is not frequency locked by default and can lead to noisy benchmark results, but this can be changed by running the following for every cpu.
```
adb shell "echo userspace > /sys/devices/system/cpu/${cpu}/cpufreq/scaling_governor"
adb shell "echo '2000000' > /sys/devices/system/cpu/${cpu}/cpufreq/scaling_setspeed"
adb push build_android/bin/quantize_per_channel /data/local/tmp/
adb shell "/data/local/tmp/quantize_per_channel"
```
Resulting benchmarks are located [here](https://gist.github.com/AJLiu/d1711bb6a5e93b3338eca2c14c8aec9f)
Google spreadsheet comparing results [here](https://docs.google.com/spreadsheets/d/1Ky-rEu2CqOqex2a84b67hB1VLAlfEDgAN2ZXe8IlGF8/edit?usp=sharing)
Reviewed By: kimishpatel
Differential Revision: D24286528
fbshipit-source-id: 5481dcbbff8345a2c0d6cc9b7d7f8075fbff03b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47211
The attribute is getting shadowed by the default one set on all modules,
and the __setattr__ on the TracedModule object prevents setting it correctly.
import torch
inp = torch.zeros(1, 3, 224, 224)
model = torch.hub.load('pytorch/vision:v0.6.0', 'mobilenet_v2', pretrained=True)
model.eval()
print(model.training)
with torch.no_grad():
traced = torch.jit.trace(model, inp)
print(traced.training)
traced.eval()
print(traced.training)
traced.training = False
print(traced.training)
torch.jit.freeze(traced)
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D24686690
Pulled By: zdevito
fbshipit-source-id: 9c1678dc68e9bf83176e9f5a20fa8f6bff5d69a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46017
Currently on mobile only per tensor quantization is optimized for mobile using ARM intrinsics. This benchmark is
dded to help gauge performance improvement on mobile after performing the same optimizations for per channel quantization.
Test Plan:
Build for ARM Neon
```
BUILD_MOBILE_BENCHMARK=1 BUILD_MOBILE_TEST=1 ANDROID_DEBUG_SYMBOLS=1 BUILD_PYTORCH_MOBILE=1 ANDROID_ABI="armeabi-v7a with NEON" ./scripts/build_android.sh -DANDROID_CCACHE=$(which ccache) -DBUILD_BINARY=ON
```
Build for ARM64
```
BUILD_MOBILE_BENCHMARK=1 BUILD_MOBILE_TEST=1 ANDROID_DEBUG_SYMBOLS=1 BUILD_PYTORCH_MOBILE=1 ANDROID_ABI=arm64-v8a ./scripts/build_android.sh -DANDROID_CCACHE=$(which ccache) -DBUILD_BINARY=ON
```
Then run the benchmark binary over adb shell. Note that by android cpu is not frequency locked by default and can lead to noisy benchmark results, but this can be changed by running the following for every cpu.
```
adb shell "echo userspace > /sys/devices/system/cpu/${cpu}/cpufreq/scaling_governor"
adb shell "echo '2000000' > /sys/devices/system/cpu/${cpu}/cpufreq/scaling_setspeed"
adb push build_android/bin/quantize_per_channel /data/local/tmp/
adb shell "/data/local/tmp/quantize_per_channel"
```
Reviewed By: kimishpatel
Differential Revision: D24286488
fbshipit-source-id: 1e7942f0bb3d9d1fe172409d522be9f351a485bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47144
Change `optional` to `c10::optional` to avoid conflicting with `std::optional` in files that happen to include both.
Test Plan: contbuild
Reviewed By: yinghai
Differential Revision: D24662515
fbshipit-source-id: 1e72fbc791d585e797a7239305ab5e3f82ddfec9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47068
Filter the dtype config before performing the quantization in linear
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D24627907
fbshipit-source-id: 162fa47b3fcf6648049f8bc0438e41ee97ac19e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46596
1. Added `conj` method for scalar similar to numpy.
2. Updates backward formulas for add and sub to work correctly for R -> C cases and for the case when alpha is complex.
3. Enabled complex backward for nonzero (no formula update needed).
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D24529227
Pulled By: anjali411
fbshipit-source-id: da871309a6decf5a4ab5c561d5ab35fc66b5273d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47126
Context
-------
This PR is a rebase of shihongzhi's https://github.com/pytorch/pytorch/pull/35360.
I forgot to merge it back when it was submitted so I rebased it and ran new benchmarks on it.
Benchmarks
----------
TL;DR: The op has more overhead than the TH version but for larger shapes the overhead disappears.
```
import torch
shapes = [
[1, 1],
[100, 100],
[1000, 1000],
[10000, 10000],
[100000, 100000],
]
for shape in shapes:
x = torch.ones(shape)
%timeit x.trace()
Before:
1.83 µs ± 42.4 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
1.98 µs ± 48.2 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
3.19 µs ± 10.7 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
85.2 µs ± 700 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
1.23 ms ± 4.34 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
After:
2.16 µs ± 325 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
2.08 µs ± 275 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
4.45 µs ± 19.2 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
81.8 µs ± 766 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
1.27 ms ± 6.75 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Future work
-----------
Things that can be done after this PR:
- add complex tensor support
- Fix the type promotion discrepancy between CPU and CUDA
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D24683259
Pulled By: zou3519
fbshipit-source-id: f92b566ad0d58b72663ab64899d209c96edb78eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47125
We didn't actually have any tests for torch.trace. The tests expose a
discrepancy between the behavior of torch.trace on CPU and CUDA that
I'll file an issue for.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D24683260
Pulled By: zou3519
fbshipit-source-id: 71dd3af62bc98c6b9b0ba2bf2923cb6d44daa640
Summary:
This diff enables inlining producers into reductions. It also guards against inlining reductions themselves.
Prior to this diff, if there was a reduction in the loopnest, no inlining was happening. After this change, we will inline all non-output buffers that do not correspond to a reduction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47020
Reviewed By: albanD
Differential Revision: D24644346
Pulled By: navahgar
fbshipit-source-id: ad234a6877b65be2457b734cbb7f3a1800baa6a5
Summary:
This is a followup to the C++ anomaly detection mode, implementing the guard.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47164
Reviewed By: mruberry
Differential Revision: D24682574
Pulled By: albanD
fbshipit-source-id: b2224a56bf6eca0b90b8e10ec049cbcd5af9d108
Summary:
This PR attempts to remove unneeded installations of `pip` among other packages in `install_base.sh` since these very same packages are already installed elsewhere (for example in `install_conda.sh`).
In the process, I found some old `TRAVIS_PYTHON_VERSION` references that are no longer needed, so I removed all references that need `install_travis_python.sh`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47209
Reviewed By: mruberry
Differential Revision: D24690079
Pulled By: janeyx99
fbshipit-source-id: f8fef4cda9832c868595d4745d811fc7d42df34d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46373
As noted in https://github.com/pytorch/pytorch/issues/46373, there needs to be a flag passed into the engine that indicates whether it was executed through the backward api or grad api. Tentatively named the flag `accumulate_grad` since functionally, backward api accumulates grad into .grad while grad api captures the grad and returns it.
Moving changes not necessary to the python api (cpp, torchscript) to a new PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46855
Reviewed By: ngimel
Differential Revision: D24649054
Pulled By: soulitzer
fbshipit-source-id: 6925d5a67d583eeb781fc7cfaec807c410e1fc65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46835
We make explicit a couple of previously implicit down/narrowing conversions. This fixes a couple of compiler warnings.
Test Plan: Standard pre-commit test rig.
Reviewed By: ngimel
Differential Revision: D24481427
fbshipit-source-id: 8c9b0215a662ccdef8e2ba3df5f78ef110071f7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46885
There seem to be a lot of situations where users are running into problems with missing operators (these users are mostly within FB for now since the mobile focus is currently on internal use cases). To avoid wasting their time, we would very much like to point them in a more actionable direction. This diff attempts to do just that.
Please find additional context at: https://fb.workplace.com/groups/894363187646754/permalink/1081939438889127/
Previous message:
```
Could not run 'aten::less_equal.Scalar' with arguments from the 'CPU' backend.
```
New message:
```
Could not run 'aten::less_equal.Scalar' with arguments from the 'CPU' backend.
This could be because the operator doesn't exist for this backend, or was
omited during the selective/custom build process (if using custom build).
If you are a Facebook employee using PyTorch on mobile, please visit
https://fburl.com/ptmfixes for possible resolutions.
```
ghstack-source-id: 115691682
Test Plan: Sandcastle
Reviewed By: ezyang
Differential Revision: D24552243
fbshipit-source-id: fb78b1ab2c1fa0e1faf5537cbf0575256391f081
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47207
Add a safety check TORCH_CUDA_KERNEL_LAUNCH_CHECK() after each kernel launch. This diff only chnges the files inside the directory fbcode/caffe2/aten/src/ATen/native/cuda/. Will create similar DIFFS per directory.
Test Plan:
Run test with:
```
buck build //caffe2/aten:ATen-cu
```
Results:
```
[fjponce@30644.od ~/fbcode (c32bce1c)]$ buck build //caffe2/aten:ATen-cu
Building: finished in 0.8 sec (100%) 1/1 jobs, 0 updated
Total time: 1.0 sec
More details at https://www.internalfb.com/intern/buck/build/c8d463e5-2d8b-4566-97f0-2d355eda8f2d
[fjponce@30644.od ~/fbcode (b78b1f2d)]$
```
The files does not appear anymore in the list when executing python script
https://www.internalfb.com/intern/paste/P147803236/
Reviewed By: r-barnes
Differential Revision: D24685062
fbshipit-source-id: 6ef7989d28b6629752d98dc36dd4a92c2507204c
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 5b7566f412
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47190
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D24682770
fbshipit-source-id: da11d6039c3e158444253d3c6237e3ee71d5afb5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45716
**Summary**
This commit enables indexing into `ModuleDict` using a non-literal
index if the `ModuleDict` is annotated with `Dict[str, X]`, where `X` is
a module interface type. These annotations must be expressed using a
class attribute named `__annotations__`, which is a `Dict[str, Type]`
where the keys are the names of module attributes and the values are
their types.
The approach taken by this commit is that these annotations are stored
as "hints" along with the corresponding module attributes in the
`ConcreteSubmoduleTypeBuilder` instance for each module (which might be
a `ModuleDict`). These hints are passed into the `ModuleValue` that is
created for desugaring operations on submodules so that indexing into a
`ModuleDict` can be emitted as a getitem op into a dict emitted into the
graph that represents the `ModuleDict`.
**Test Plan**
This commit adds unit tests to `TestModuleContainers` to test this
feature (`test_typed_module_dict`).
Differential Revision: D24070606
Test Plan: Imported from OSS
Reviewed By: ansley
Pulled By: SplitInfinity
fbshipit-source-id: 6019a7242d53d68fbfc1aa5a49df6cfc0507b992
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46959
1. Implemented the Pybind part.
2. In the reducer, once the builtin_comm_hook_type is set, a c++ comm hook instance will be created in Reducer::autograd_hook.
3. Added unit tests for the builit-in comm hooks.
Original PR issue: C++ DDP Communication Hook https://github.com/pytorch/pytorch/issues/46348
ghstack-source-id: 115629230
Test Plan: buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_builtin_ddp_comm_hooks_nccl
Reviewed By: pritamdamania87
Differential Revision: D24471910
fbshipit-source-id: f96b752298549ea2067e2568189f1b394abcd99a
Summary:
For some of the end to end flow projects, we will need the capabilities to read module information during model validation or model publishing.
Creating this model_reader.py for utilities for model content reading, this diff we included the following functionalities:
1. read the model bytecode version;
2. check if a model is lite PyTorch script module;
3. check if a model is PyTorch script module.
Test Plan:
```
[xcheng16@devvm1099]/data/users/xcheng16/fbsource/fbcode% buck test pytorch_mobile/utils/tests:mobile_model_reader_tests
Processing filesystem changes: finished in 1.5 sec
Parsing buck files: finished in 1.6 sec
Building: finished in 4.9 sec (100%) 9249/43504 jobs, 2 updated
Total time: 6.5 sec
More details at https://www.internalfb.com/intern/buck/build/6d0e2c23-d86d-4248-811f-31cb1aa7eab3
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: 2ffccd62-ece5-44b5-8350-3a292243fad9
Trace available for this run at /tmp/tpx-20201030-122220.664763/trace.log
Started reporting to test run: https://our.intern.facebook.com/intern/testinfra/testrun/3940649711969390
✓ ListingSuccess: pytorch_mobile/utils/tests:mobile_model_reader_tests - main (10.234)
✓ Pass: pytorch_mobile/utils/tests:mobile_model_reader_tests - test_is_pytorch_lite_module (pytorch_mobile.utils.tests.test_model_reader.TestModelLoader) (7.039)
✓ Pass: pytorch_mobile/utils/tests:mobile_model_reader_tests - test_is_pytorch_script_module (pytorch_mobile.utils.tests.test_model_reader.TestModelLoader) (7.205)
✓ Pass: pytorch_mobile/utils/tests:mobile_model_reader_tests - test_read_module_bytecode_version (pytorch_mobile.utils.tests.test_model_reader.TestModelLoader) (7.223)
Summary
Pass: 3
ListingSuccess: 1
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/3940649711969390
Reviewed By: husthyc
Differential Revision: D24655999
fbshipit-source-id: 5095ca158d89231fb17285d445548f91ddb89bab
Summary:
Fixes a TODO. This PR moves `pip_install unittest-xml-reporting coverage pytest` to the base Ubuntu docker instead of running that installation during every test.
This should save some time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47082
Reviewed By: samestep
Differential Revision: D24634393
Pulled By: janeyx99
fbshipit-source-id: 3b980890409eafef9b006b9e03ad7f3e9017529e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46274
We crash the process in NCCL Async Error Handling if the collective
has been running for greater than some set timeout. This PR logs more
information about the rank and duration the collective ran before throwing an exception.
ghstack-source-id: 115614622
Test Plan:
Run desync tests and flow. Here are the Flow runs showing the right messages: f225031389
f225032004
Reviewed By: jiayisuse
Differential Revision: D24200144
fbshipit-source-id: 02d48f13352aed40a4476768c123d5cebbedc8e0
Summary:
While using `torch.utils.data.TensorDataset`, if sizes of tensors mismatch, there's now a proper error message.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46905
Reviewed By: ngimel
Differential Revision: D24565712
Pulled By: mrshenli
fbshipit-source-id: 98cdf189591c2a7a1b693627cc8464e8f553d9ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47085
Both in train and eval mode
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D24632457
fbshipit-source-id: 486aee4e073fb87e9da46a344e8dc77e848a60cf
Summary:
In order to enable C++ code coverage for tests, we need to build pytorch with the correct coverage flags. This PR should introduce a build that allows coverage tests to stem from a specific coverage build.
This PR does the following:
1. Adds a new build to `*-coverage_*` build with the correct `--coverage` flag for C++ coverage
2. Calls `lcov` at the end of testing to capture C++ coverage results
3. Pushes C++ results along with Python results
4. Shards the coverage test to not take ~4hrs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46656
Reviewed By: walterddr
Differential Revision: D24636213
Pulled By: janeyx99
fbshipit-source-id: 362a1a2a20c069ba0a7931669194dac53ac81133
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46558
This PR fixes a bug with how pooling output shape was computed.
## BC Breaking Notes
Previously, a bug in the pooling code allowed a sliding window to be entirely off bounds. Now, sliding windows must start inside the input or left padding (not right padding, see https://github.com/pytorch/pytorch/issues/46929) and may only go off-bounds if ceil_mode=True.
fixes#45357
TODO
- [x] Ensure existing tests are checking for the correct output size
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D24633372
Pulled By: heitorschueroff
fbshipit-source-id: 55925243a53df5d6131a1983076f11cab7516d6b
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 39d5addbff
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47071
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: albanD
Differential Revision: D24628407
fbshipit-source-id: 9b636f66b92e5853cafd521e704996ebc2faa954
Summary:
Add `last_n_window_collector` as C2 supports and PyTorch currently does not have this operator: https://www.internalfb.com/intern/diffusion/FBS/browsefile/master/fbcode/caffe2/caffe2/operators/last_n_window_collector.cc?lines=139
## Problem that we are solving
This operator works on multiple pieces of data and collects last `n` element that has been seen.
If you have the following pieces of data that has been passed around:
```
[1, 2, 3, 4]
[5, 6, 7]
[8, 9, 10, 11]
```
for 3 times and the number of collector is given to be 6. The expected result is:
```
[6, 7, 8, 9, 10, 11]
```
What this means is that, almost like we need a FIFO(First in First Out) mechanism where as we are passing this data through the collector, we will be pushing some other data at the end.
In this particular example, in the first pass(the data is `[1, 2, 3, 4]`) , we hold `[1, 2, 3, 4]` in the queue as our queue size is 6.
In the second pass(the data is `[5, 6, 7]`), we hold `[2, 3, 4, 5, 6, 7]` in the queue and since 1 is inserted the last, it will drop due to the size limitation of the queue.
In the third pass(the data is `[8, 9, 10, 11]`), we hold `[6, 7, 8, 9, 10, 11]` in the queue and `2,3,4,5` are dropped due the the size of the queue.
For multidimension case, when we have the following data:
```
[[1, 2], [2, 3], [3, 4], [4, 5]]
[[5, 6], [6, 7], [7, 8]]
[[8, 9], [9, 10], [10, 11], [11, 12]]
```
and our queue size is 6.
In the first pass, we will have ` [[1, 2], [2, 3], [3, 4], [4, 5]]`
In the second pass, we will have `[2, 3], [3, 4], [4, 5]] [[5, 6], [6, 7], [7, 8]]`
In the third pass, we will have `[6, 7], [7, 8]] [[8, 9], [9, 10], [10, 11], [11, 12]]`
### The implementation
I am using FIFO queue in Python which is in the collections library. This accepts `maxlen` argument which can be used to set the size of the queue.
I am using last n indices of the tensor through list indices and in this operator, I am not doing copy.
In the test plan, I have both single dimension tensors as well as multi-dimension tensors.
### Benchmark
I used various different configurations and added a benchmark test. PyTorch implementation is much master than Caffe2 implementation:
#### CPU Benchmark
```
torch_response.median
0.00019254473969340324
caffe_response.median
0.00030233583599794657
```
#### GPU Benchmark
```
torch_response.mean
0.000081007429903838786
caffe_response.mean
0.00010279081099724863
```
Test Plan:
### For CPU:
```
buck test //caffe2/torch/fb/sparsenn:test
```
### For GPU:
- Used an on-demand machine and did the following commands:
```
jf get D24435544
buck test mode/opt //caffe2/torch/fb/sparsenn:test
```
https://www.internalfb.com/intern/testinfra/testconsole/testrun/4222124688138052/
Reviewed By: dzhulgakov, radkris-git
Differential Revision: D24435544
fbshipit-source-id: 8193b4746b20f2a4920fd4d41271341045cdcee1
Summary:
Placeholders and constants in the partition are counted twice when combining two partitions. This PR fixes it by adding add_node function into Partition class. A unit test is also updated to test if the partition size is correct
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47083
Reviewed By: gcatron
Differential Revision: D24634368
Pulled By: scottxu0730
fbshipit-source-id: ab408f29da4fbf729fd9741dcb3bdb3076dc30c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43613
**Summary**
This commit adds a helper/utility to faciliate the selective lowering of
specific submodules within a module hierarchy to a JIT backend. The reason
that this is needed is that lowering a submodule of a scripted
module to a backend after the module has been scripted requires
adjusting its JIT type.
**Test Plan**
This commit refactors `NestedModuleTest` in `jit/test_backends.py` to
use this new selective lowering API.
**Fixes**
This commit fixes ##41432.
Test Plan: Imported from OSS
Reviewed By: mortzur
Differential Revision: D23339855
Pulled By: SplitInfinity
fbshipit-source-id: d9e69aa502febbe04fd41558c70d219729252be9
Summary:
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **https://github.com/pytorch/pytorch/issues/47019 Split comm hooks into python-dependent hooks and others**
This is needed because we plan to move most of c10d C++ implementation into `libtorch_*.so`, which can not have Python dependencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47019
Reviewed By: albanD
Differential Revision: D24614129
Pulled By: gmagogsfm
fbshipit-source-id: 3f32586b932a2fe6a7b01a3800f000e66e9786bb
Summary:
I know the `aten/src/ATen/core/CMakeLists.txt` link is now correct because that file was deleted in 061ed739c17028fe907737b52f50a495ab5b4617:
```
$ git log --full-history -- aten/src/ATen/core/CMakeLists.txt | head -n 1
commit 061ed739c17028fe907737b52f50a495ab5b4617
$ git show 061ed739c17028fe907737b52f50a495ab5b4617^ | head -n 1
commit f99a693cd9ff7a9b5fdc71357dac66b8192786d3
```
But I can't tell what the `tools/cpp_build/torch/CMakeLists.txt` link is supposed to be, because that file (indeed, its entire parent directory) doesn't seem to have ever existed:
```
$ git log --full-history -- tools/cpp_build/torch
```
(The output of the above command is empty.) So I saw that the grandparent directory was deleted in 130881f0e37cdedc0e90f6c9ed84957aee6c80ef:
```
$ git log --full-history -- tools/cpp_build | head -n 1
commit 130881f0e37cdedc0e90f6c9ed84957aee6c80ef
$ git show 130881f0e37cdedc0e90f6c9ed84957aee6c80ef^ | head -n 1
commit c6facc2aaa5a568756e971a9d2b7f2af282dff39
```
And looking at [the history of that directory](c6facc2aaa/tools/cpp_build), I see that some of the last commits touch `torch/CMakeLists.txt`, so I'm just using that here and hoping it's correct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47066
Reviewed By: albanD, seemethere
Differential Revision: D24628980
Pulled By: samestep
fbshipit-source-id: 0fe8887e323593ef1676c34d4b920aeeaebd8550
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47032
these are not top level apis, not supposed to be called directly by user.
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D24610602
fbshipit-source-id: c5510f06b05499387d70f23508470b676aea582c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46805
The current implementation goes with slow path if there is zero tensor in the list. This is inefficient. Use the fast path for torch.cat even if there are empty tensors. This wastes one thread block for the empty tensor, but still much better than the slow path.
Test Plan: CI + sandcastle
Reviewed By: ngimel
Differential Revision: D24524441
fbshipit-source-id: 529c8af51ecf8374621deee3a9d16cacbd214741
Summary:
Possibly fixes https://github.com/pytorch/pytorch/issues/46764.
Computing number of tensor elements in many cases is written as
```
int64_t numel = std::accumulate(oldshape.begin(), oldshape.end(), 1,
std::multiplies<int64_t>());
```
This computes the product with the type of `1` literal, which is `int`. When there's more than INT_MAX elements, result overflows. In https://github.com/pytorch/pytorch/issues/46746, the tensor that was sent to reshape had 256^4 elements, and that was computed as `0`, so reshape was not done correctly.
I've audited usages of std::accumulate and changed them to use int64_t as `init` type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46997
Reviewed By: albanD
Differential Revision: D24624654
Pulled By: ngimel
fbshipit-source-id: 3d9c5e6355531a9df6b10500eec140e020aac77e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46967
Tests under `tests/distributed/_pipeline/sync` use pytest and
specifying the `-f` option for such tests as follows: `python test/run_test.py
-i distributed/_pipeline/sync/skip/test_api -- -f` doesn't work.
The equivalent option for pytest is `-x`. To resolve this issue, I've updated
`run_test.py` to replace `-f` with `-x` for pytest tests.
More details in https://github.com/pytorch/pytorch/issues/46782
#Closes: https://github.com/pytorch/pytorch/issues/46782
ghstack-source-id: 115440558
Test Plan:
1) waitforbuildbot
2) `python test/run_test.py -i distributed/_pipeline/sync/skip/test_api -- -f`
Reviewed By: malfet
Differential Revision: D24584556
fbshipit-source-id: bd87f5b4953504e5659fe72fc8615e126e5490ff
Summary:
Recently the ort-nightly has become unstable and causing issues with CI tests. Switching to release package for now for stability, until the situation is improved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46595
Reviewed By: houseroad
Differential Revision: D24566175
Pulled By: bzinodev
fbshipit-source-id: dcf36e976daeeb17465df88f28bc9673eebbb7b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47002
There was no good reason for TypeDerived.h (CPUType.h) codegen
to exist after static dispatch was deleted, and now that we
have Math alias key TypeDefault.h header is not needed either.
Sorry to anyone who was using these out of tree.
I didn't entirely delete TypeDefault.h as it has a use in
a file that I can't conveniently compile test locally. Will
kill it entirely in a follow up.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D24596583
Pulled By: ezyang
fbshipit-source-id: b5095d3509098ff74f836c5d0c272db0b2d226aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47000
There is a new invariant that emit_body is only ever called when
strategy is 'use_derived', which means we can delete a bunch of code.
This removes the last use of TypeXXX.h headers.
Note that this change makes sense, as the TypeDefault entries are
registered as Math entries, which means they automatically populate
Autograd (and we no longer have to register them ourselves). Ailing
did all the hard work, this is just the payoff.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D24596584
Pulled By: ezyang
fbshipit-source-id: 6fa754b5f16e75cf2dcbf437887c0fdfda5e44b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46991
This change is motivated by a problem bdhirsh observed which is
that in internal builds that include both SchemaRegister.cpp
and TypeDefault.cpp, some operators have their schemas defined
multiple times. Instead of dumping schema registrations in
multiple files, it seems better to just toggle how many schemas
we write into TypeDefault.cpp.
ljk53 observes that technically SchemaRegister.cpp is only needed by
full-JIT frontend, and not by light interpreter (to resolve schema
lookups). However, in practice, the registration file seems to be
unconditionally loaded. This change will make it harder to do the
optimization where we drop schemas in the light interpreter, but you
probably want to architect this differently (similar to per-op
registrations, DON'T do any registrations in ATen, and then write out
the schema registrations in a separate library.)
I took this opportunity to also simplify the TypeDefault generation
logic by reworking things so that we only ever call with None argument
when registering. Soon, we should be able to just split these
files up entirely.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D24593704
Pulled By: ezyang
fbshipit-source-id: f01ea22a3999493da77b6e254d188da0ce9adf2f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46970
Now that catchall declarations are reinterpreted as registrations to
dispatch key Math, we can now simplify code generation logic by directly
generating to Math, and bypasing logic for catchall. This also helps
avoid bugs where we incorrectly classify some kernels as Math and others
as not, even though they get registered in the same way.
Bill of changes:
- Give Math its own unique TORCH_LIBRARY_IMPL
- Make it so NativeFunction.dispatch is always non-None. Simplify
downstream conditionals accordingly
- When parsing NativeFunction, fill in missing dispatch with a
singleton Math entry (pointing to the cpp.name!)
One thing that is a little big about this change is a lot of kernels
which previously didn't report as "math" now report as math. I picked
a setting for these booleans that made sense to me, but I'm not sure
if e.g. XLA will handle it 100% correctly.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D24592391
Pulled By: ezyang
fbshipit-source-id: 2e3355f19f9525698864312418df08411f30a85d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46938
It turns out that after https://github.com/pytorch/pytorch/pull/42194
landed we no longer actually generate any registrations into this
file. That means it's completely unnecessary.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: IvanKobzarev
Differential Revision: D24573518
Pulled By: ezyang
fbshipit-source-id: b41ada9e394b780f037f5977596a36b896b5648c
Summary:
Enables the use of NoneType arguments to inputs tuple in the export API
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45792
Reviewed By: heitorschueroff
Differential Revision: D24312784
Pulled By: bzinodev
fbshipit-source-id: 1717e856b56062add371af7dc09cdd9c7b5646da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46755
As reported in https://github.com/pytorch/pytorch/issues/41324, there is a bug in DDP when `find_unused_parameters=True` and 2 or more parameters share the same gradient accumulator.
In the reducer, we currently keep a mapping of grad accumulator to index and populate it with map[accumulator] = index, but this overwrites indices when the accumulator is the same. To fix this, switch the mapping values to a vector of indices to hold all such indices that share the same accumulator.
ghstack-source-id: 115453567
Test Plan: Added UT
Reviewed By: pritamdamania87
Differential Revision: D24497388
fbshipit-source-id: d32dfa9c5cd0b7a8df13c7873d5d28917b766640
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46469
There are some "fast_pass" function calls, where the symbols in `ATen/native` are directly referenced from outside of native at linking stage. This PR is to decouple one of the fast pass from native, while keeping the same functionality. `scalar_to_tensor` is included through `ATen/ATen.h`, which could be referenced by any cpp file including this header.
ghstack-source-id: 114485740
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D24361863
fbshipit-source-id: 28d658688687b6cde286a6e6933ab33a4b3cf9ec
Summary:
Related https://github.com/pytorch/pytorch/issues/38349
This PR implements `column_stack` as the composite ops of `torch.reshape` and `torch.hstack`, and makes `row_stack` as the alias of `torch.vstack`.
Todo
- [x] docs
- [x] alias pattern for `row_stack`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46313
Reviewed By: ngimel
Differential Revision: D24585471
Pulled By: mruberry
fbshipit-source-id: 62fc0ffd43d051dc3ecf386a3e9c0b89086c1d1c
Summary:
If there is no annotation given, we want to show users that the type is inferred
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46969
Test Plan:
Added a new test case that throws an error with the expected error message
Fixes https://github.com/pytorch/pytorch/issues/46326
Reviewed By: ZolotukhinM
Differential Revision: D24614450
Pulled By: gmagogsfm
fbshipit-source-id: dec555a53bfaa9cdefd3b21b5142f5e522847504
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46985.
Can someone comment on whether the "Run flake8" step should fail if `flake8` produces errors? This PR makes sure the errors are still shown, but [the job linked from the issue](https://github.com/pytorch/pytorch/runs/1320258832) also shows that the failure of that step seems to have caused the "Add annotations" step not to run.
Is this what we want, or should I instead revert back to the `--exit-zero` behavior (in this case by just removing the `-o pipefail` from this PR) that we had before https://github.com/pytorch/pytorch/issues/46740? And if the latter, then (how) should I modify this `flake8-py3` job to make sure it fails when `flake8` fails (assuming it didn't already do that?)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46990
Reviewed By: VitalyFedyunin
Differential Revision: D24593573
Pulled By: samestep
fbshipit-source-id: 361392846de9fadda1c87d2046cf8d26861524ca
Summary:
The FullyConnectedDNNLowPOp::Y_int32_ vectors consume between 1GB and 2GB on one of FB's larger applications. By adding tracing I noticed that the number of elements in each instance oscillates wildy over time. As the buffer backing a vector can only be extended in a resize operation, this means there is wasted memory space. So as a simple optimization, I added code to right-size the buffer backing the vector when the number of elements is less than half the vector capacity at that point; this doesn't affect the existing elements.
There is of course a memory/cpu tradeoff here - with the change we are doing more mallocs and frees. I added tracing to measure how many times we grow or shrink per second: it's about 100 per second on average, which is not a great deal.
Test Plan:
Memory growth impact: over 24 hours and after the startup period, the memory consumed by this code grows from 0.85GB to 1.20GB vs 0.95GB to 1.75GB in the baseline. [ source: https://fburl.com/scuba/heap_profiles/wm47kpfe ]
https://pxl.cl/1pHlJ
Reviewed By: jspark1105
Differential Revision: D24592098
fbshipit-source-id: 7892b35f24e42403653a74a1a9d06cbc7ee866b9
Summary:
Updates mul_scalar shader to support the new Vulkan API, and adds a new op for it using the new API.
Also adds an in-place version for the op.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47021
Test Plan:
Unit test included. To build & run:
```
BUILD_CUSTOM_PROTOBUF=OFF \
BUILD_TEST=ON \
USE_EIGEN_FOR_BLAS=OFF \
USE_FBGEMM=OFF \
USE_MKLDNN=OFF \
USE_NNPACK=OFF \
USE_NUMPY=OFF \
USE_OBSERVERS=OFF \
USE_PYTORCH_QNNPACK=OFF \
USE_QNNPACK=OFF \
USE_VULKAN=ON \
USE_VULKAN_API=ON \
USE_VULKAN_SHADERC_RUNTIME=ON \
USE_VULKAN_WRAPPER=OFF \
MACOSX_DEPLOYMENT_TARGET=10.9 CC=clang CXX=clang++ python3 setup.py develop --cmake && ./build/bin/vulkan_api_test
```
Reviewed By: AshkanAliabadi
Differential Revision: D24624729
Pulled By: SS-JIA
fbshipit-source-id: 97e76e4060307a9a24311ac51dca8812e4471249
Summary:
Preserve PYBIND11 (63ce3fbde8) configuration options in `torch._C._PYBIND11 (63ce3fbde8)_COMPILER_TYPE` and use them when building extensions
Also, use f-strings in `torch.utils.cpp_extension`
"Fixes" https://github.com/pytorch/pytorch/issues/46367
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46415
Reviewed By: VitalyFedyunin
Differential Revision: D24605949
Pulled By: malfet
fbshipit-source-id: 87340f2ed5308266a46ef8f0317316227dab9d4d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/41768
The fault was that a NULL `tau` would get passed to LAPACK function. This PR fixes that by checking whether the `tau` contains 0 elements at the beginning of the function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46700
Reviewed By: albanD
Differential Revision: D24616427
Pulled By: mruberry
fbshipit-source-id: 92e8f1489b113c0ceeca6e54dea8b810a51a63c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46833
Implicit integer conversions are causing compiler warnings. Since in this case the logs make it pretty clear that the `unsigned` types won't overflow despite 64-bit inputs, we fix the issue by making the downconversion explicit.
Test Plan: Standard test rig.
Reviewed By: malfet
Differential Revision: D24481377
fbshipit-source-id: 4422538286d8ed2beb65065544016fd430394ff8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46850
So far, in the error messages when kernel signatures mismatched, we showed the location where the second kernel came from,
but we didn't show the location of the first kernel. This PR now shows the location of both.
ghstack-source-id: 115468616
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D24540368
fbshipit-source-id: 3b4474062879d17f9bb7870ad3814343edc1b755
Summary:
This PR disables the test_softmax and test_softmax_results in test_nn.py that were enabled in https://github.com/pytorch/pytorch/issues/46363. The softmax tests are causing failure on gfx906 machines. Disabling those until we root cause and fix them on 906.
cc: jeffdaily ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46793
Reviewed By: izdeby
Differential Revision: D24539211
Pulled By: ezyang
fbshipit-source-id: 633cb9dc497ad6359af85b85a711c4549d772b2a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46590
This operator is very similar to LengthsToRanges but doesn't pack the offsets next to the original lengths.
Reviewed By: yf225
Differential Revision: D24419746
fbshipit-source-id: aa8b014588bb22eced324853c545f8684086c4e4
Summary: I was reading/looking into how LocalSession works and realized that the workspace type being passed around was the bound function on TaskGroup instead of the actual type. This meant that all workspaces for localsession would always be global, because they'd never match the private workspace type.
Test Plan: <not sure, could use some suggestions>
Reviewed By: cryptopic
Differential Revision: D24458428
fbshipit-source-id: 0f87874babe9c1ddff25b5363b443f9ca37e03c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47035
Chillee thought the `from math import inf, nan` string at the top of `.code` was annoying so here's an alternative way to do it by putting those values in `globals` before we `exec`
Test Plan: Imported from OSS
Reviewed By: dzhulgakov
Differential Revision: D24611278
Pulled By: jamesr66a
fbshipit-source-id: c25ef89e649bdd3e79fe91aea945a30fa7106961
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46773
Changed the constructor of RemoteModule to accept a `remote_device` arg in the following format:
"<workername>/<device>" (e.g., "trainer0/cpu", "ps0/cuda:0")
This arg merges the original `on` and `device` arg.
Original PR issue: RemoteDevice Format #46554
ghstack-source-id: 115448051
Test Plan: buck test mode/dev-nosan caffe2/test/distributed/rpc:process_group_agent -- RemoteModule
Reviewed By: pritamdamania87
Differential Revision: D24482562
fbshipit-source-id: 5acfc73772576a4b674df27625bf560b8f8e67c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44266
If PyTorchStreamWriter is writing to a file in a non-existing path, it throws an exception. In unwinding the destructor calls writeEndOfFile() and throws again. To avoid this double-exception, a check and throw is added in the constructor. In such case the destructor will not be called and the exception can go through the unwinding.
Test Plan: python test/test_jit.py TestSaveLoad.test_save_nonexit_file
Reviewed By: dreiss
Differential Revision: D23560770
Pulled By: iseeyuan
fbshipit-source-id: 51b24403500bdab3578c7fd5e017780467a5d06a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46401
Broader context about selective/custom build available at https://fb.quip.com/2oEzAR5MKqbD and https://fb.workplace.com/groups/pytorch.mobile.team/permalink/735794523641956/
Basically, we want to be able to trace full operator names (with overload name). The current observer infra picks up the operator name from the schema, which doesn't seem to include the overload name. To ensure consistency with the existing uses and to accomodate the new use-case, this diff adds a new overload to accept an `OperatorHandle` object, and the code in `before()` eagerly resolves it to an `OperatorName` object (which can be cached in a member variable) as well as a string (view) operator-name which has the same semantics as before.
Why do we pass in an `OperatorHandle` but then resolve it to an `OperatorName`? This might come across as a strange design choice (and it is), but it is grounded in practicality.
It is not reasonable to cache an `OperatorHandle` object but caching an `OperatorName` object is reasonable since it holds all the data itself.
An initial version of this change was trying to test this change in the `xplat` repo, which didn't work. Thanks to ilia-cher for pointing out that the dispatcher observing mechanism is disabled under a compile time flag (macro) for xplat.
ghstack-source-id: 114360747
Test Plan:
`buck test fbcode/caffe2/fb/test:record_function_test` succeeds. Also replicated this test in OSS in the file `test_misc.cpp` where the rest of the `RecordFunction` subsystem is being tested.
Ran benchmark as reqiested by ilia-cher
{P146511280}
Reviewed By: ilia-cher
Differential Revision: D24315241
fbshipit-source-id: 239f3081e6aa2e26c3021a7dd61f328b723b03d9
Summary:
Plus two minor fixes to `torch/csrc/Module.cpp`:
- Use iterator of type `Py_ssize_t` for array indexing in `THPModule_initNames`
- Fix clang-tidy warning of unneeded defaultGenerator copy by capturing it as `const auto&`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47025
Reviewed By: samestep
Differential Revision: D24605907
Pulled By: malfet
fbshipit-source-id: c276567d320758fa8b6f4bd64ff46d2ea5d40eff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46977
Clean up a few TODOs in the new python binding codegen.
Get rid of the _simple_type() hack and the uses of cpp_type_str.
Now python argument type strings and PythonArgParser unpacking methods
are directly generated from the original Type model.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D24589209
Pulled By: ljk53
fbshipit-source-id: b2a6c3911d58eae49c031d319c8ea6f804e2cfde
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46976
Technically, it's not semantic preserving, e.g.: emition of
'requires_grad' is no longer gated by 'has_tensor_return' - there is no
guarantee that is_like_or_new_function should all have tensor return.
But the output is identical so there might be some invariant - could
also add assertion to fail loudly when it's broken.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D24589211
Pulled By: ljk53
fbshipit-source-id: 47c7e43b080e4e67a526fde1a8a53aae99df4432
Summary:
WIP: add support for different memory sizes on size_based_partition, so the size_based_partition could support different logical devices with different memory sizes. Compared to the original size_based_partition, the new one also supports partition to logical device mapping. Multiple partitions can be mapped into one device if the memory size is allowed. A test unit test_different_size_partition is also added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46919
Reviewed By: gcatron, VitalyFedyunin
Differential Revision: D24603511
Pulled By: scottxu0730
fbshipit-source-id: 1ba37338ae054ad846b425fbb7e631d3b6c500b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46955
Initially we were thinking of adding a `invalidate_quantized_float_parameters` option to free the memory
of quantized floating parameters, but it turns out we will do module swap just like in eager mode for the modules
that are quantized, so the old floating point module will not be referenced after quantization. therefore this feature
is only needed for functionals, since most people are using quantization with modules we may not need this.
we'll revisit after we find there is a need for this.
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D24579400
fbshipit-source-id: fbb0e567405dc0604a2089fc001573affdade986
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46834
`next` is set to `-1`, presumably to avoid an "undefined variable" warning. However, Setting `next=-1` gives a signed-to-unsigned warning. In practice, the `-1` wraps around to `size_t::max`. So we set this to `size_t::max` from the get go to avoid all warnings.
Test Plan: Standard pre-commit test rig.
Reviewed By: xw285cornell
Differential Revision: D24481068
fbshipit-source-id: 58b8a1b027a129fc4994c8593838a82b3991be22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46897
These APIs implicitly assumed that gpu for rank == rank index, but
that is not necessarily true. For example, the first GPU could be used for a
different purpose and rank 0 could use GPU 1, rank 1 uses GPU 2, etc. Thus, we
mandate that the user specify the device to use via `torch.cuda.set_device()`
before making calls to this API. This expectation should be okay since we
clearly document it, and we expect the user to set this for
DistributedDataParallel as well.
Also adds/tidies up some documentation.
ghstack-source-id: 115359633
Test Plan: Modified unittests
Reviewed By: divchenko
Differential Revision: D24556177
fbshipit-source-id: 7e826007241eba0fde3019180066ed56faf3c0ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46686
I was trying to page this code back in after a while and some things
stuck out as unnecessarily confusing.
1. Improve documentation of closures and fork stuff to be more accurate
to how we use them today.
2. Change `prim::LocalVariableScope` to `prim::ListComprehension`. It is
only ever used for a list comprehensions, and in general the nodes
emitted by `ir_emitter` should correspond to concrete operations or
language features rather than semantic constraints.
3. Change the somewhat mysterious "inputs" and "attributes" argument
names throughout the codebase to be the more obvious "args" and "kwargs"
that they generally represent (I think "inputs" and "attributes" come
from the AST naming).
Test Plan: Imported from OSS
Reviewed By: navahgar, jamesr66a
Differential Revision: D24464197
Pulled By: suo
fbshipit-source-id: 1f4b1475b58b5690a0b204e705caceff969533b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46957
Possibly due to use of large tensor in hypothesis. Reducing the size to see if it helps
Test Plan:
python test/test_quantization.py TestRecordHistogramObserver.test_histogram_observer_against_reference
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D24580137
fbshipit-source-id: f44ab059796fba97cccb12353c13803bf49214a1
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/46779
Test Plan: Used it in some notebooks.
Reviewed By: suo
Differential Revision: D24574005
Pulled By: dreiss
fbshipit-source-id: 78ba7a2bdb859fef5633212b73c7a3eb2cfbc380
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46839
Interval midpoint calculations can overflow (integers). This fixes such an instance.
Test Plan: Standard test rig.
Reviewed By: drdarshan
Differential Revision: D24392545
fbshipit-source-id: 84c81802165bb8084e2d54c9f3755f39143a5b00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46837
Formerly `static_cast<StreamId>(bits)` and `static_cast<DeviceIndex>(bits)` were and-ed against `ull` types resulting in an integer promotion which later raised a warning in downcasting passes to `Stream` and `Device`.
Moving the `&` operation inside the cast results in two `uint64_t` being operated on and then cast to the correct type, eliminating the warning.
Test Plan: Standard pre-commit test rig.
Reviewed By: malfet
Differential Revision: D24481292
fbshipit-source-id: a8bcbde631054c26ca8c98fbed275254dd359dd0
Summary:
Caffe2 and Torch currently does not have a consistent mechanism for determining if a kernel has launched successfully. The result is difficult-to-detect or silent errors. This diff provides functionality to fix that. Subsequent diffs on the stack fix the identified issues.
Kernel launch errors may arise if invalid launch parameters (number of blocks, number of threads, shared memory, or stream id) are specified incorrectly for the hardware or for other reasons. Interestingly, unless these launch errors are specifically checked for CUDA will silently fail and return garbage answers which can affect downstream computation. Therefore, catching launch errors is important.
Launches are currently checked by placing
```
AT_CUDA_CHECK(cudaGetLastError());
```
somewhere below the kernel launch. This is bad for two reasons.
1. The check may be performed at a site distant to the kernel launch, making debugging difficult.
2. The separation of the launch from the check means that it is difficult for humans and static analyzers to determine whether the check has taken place.
This diff defines a macro:
```
#define TORCH_CUDA_KERNEL_LAUNCH_CHECK() AT_CUDA_CHECK(cudaGetLastError())
```
which clearly indicates the check.
This diff also introduces a new test which analyzes code to identify kernel launches and determines whether the line immediately following the launch contains `TORCH_CUDA_KERNEL_LAUNCH_CHECK();`.
A search of the Caffe2 codebase identifies 104 instances of `AT_CUDA_CHECK(cudaGetLastError());` while the foregoing test identifies 1,467 launches which are not paired with a check. Visual inspection indicates that few of these are false positives, highlighting the need for some sort of static analysis system.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46474
Test Plan:
The new test is run with:
```
buck test //caffe2/test:kernel_launch_checks -- --print-passing-details
```
And should be launched automatically with the other land tests. (TODO: Is it?)
The test is currently set up only to provide warnings but can later be adjusted to require checks.
Otherwise, I rely on the existing test frameworks to ensure that changes resulting from reorganizing existing launch checks don't cause regressions.
Reviewed By: ngimel
Differential Revision: D24309971
Pulled By: r-barnes
fbshipit-source-id: 0dc97984a408138ad06ff2bca86ad17ef2fdf0b6
Summary:
All other system call failures in `THMapAllocator` constructor are considered failures, but this one, for some reason was not
Fixes https://github.com/pytorch/pytorch/issues/46651
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46934
Reviewed By: walterddr, seemethere
Differential Revision: D24572657
Pulled By: malfet
fbshipit-source-id: 0a2b6ce78d5484190536bc4949fc4697d6387ab8
Summary:
Hello there 👋
I do believe there is some typo in the typing of the `bool` argument of `_ConvNd`constructor.
The typing of the attribute is correct, but the constructor argument, while being the same way, is not the value that will be assigned to `self.bias`.
This PR simply corrects that.
Any feedback is welcome!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46828
Reviewed By: izdeby
Differential Revision: D24550435
Pulled By: ezyang
fbshipit-source-id: ab10f1a5b29a912cb23fc321a51e78b04a8391e3
Summary:
`graph` is automatically cached even when the underlying graph changes -- this PR hardcodes a fix to that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46960
Reviewed By: mrshenli
Differential Revision: D24582185
Pulled By: bwasti
fbshipit-source-id: 16aeeba251830886c92751dd5c9bda8699d62803
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46701
Provide 2 built-in implementations of C++ comm hook.
Original PR issue: C++ DDP Communication Hook https://github.com/pytorch/pytorch/issues/46348
ghstack-source-id: 115319061
Test Plan: waitforbuildbot
Reviewed By: pritamdamania87
Differential Revision: D24382504
fbshipit-source-id: 1c1ef56620f91ab37a1707c5589f1d0eb4455bb3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46566
Only provides an interface. Some built-in implementations will be provided in a follow-up commit.
Original PR issue: C++ DDP Communication Hook https://github.com/pytorch/pytorch/issues/46348
ghstack-source-id: 115319038
Test Plan: waitforbuildbot
Reviewed By: pritamdamania87
Differential Revision: D24379460
fbshipit-source-id: 8382dc4185c7c01d0ac5b3498e1bead785bccec5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46786
Previously we only support static quant, this PR added support for other types of quantization.
Note qat is actually orthogonal to these quant types, this is referring to the convert step where we
convert the observed module to a quantized module.
for qat, user will provide a CustomModule -> FakeQuantizedCustomModule in prepare_custom_config_dict
and FakeQuantizedCustomModule -> static/dynamic/weight_only quantized CustomModule in convert_custom_config_dict.
Test Plan: Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D24514701
fbshipit-source-id: 2918be422dd76093d67a6df560aaaf949b7f338c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46751
Currently we assume the first input for add/mul is node (Tensor), but it might not be the case
Test Plan:
python test/test_quantization.py TestQuantizeFxOps.test_quantized_add
python test/test_quantization.py TestQuantizeFxOps.test_quantized_mul
python test/test_quantization.py TestQuantizeFxOps.test_quantized_add_relu
python test/test_quantization.py TestQuantizeFxOps.test_quantized_mul_relu
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D24494456
fbshipit-source-id: ef5e23ba60eb22a57771791f4934306b25c27c01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46772
When running `buck run caffe2/benchmarks/operator_benchmark/pt:qactivation_test -- --use_jit`, I encountered the following error P146518683. The error was traced down to the fact that `torch.allclose` does not work with quantized tensors (the error was triggered by this particular multiplication https://fburl.com/diffusion/8vw647o6 since native mul can not work with a float scalar and a quantized tensor.)
Minimum example to reproduce:
```(Pdb) input = torch.ones(5)
(Pdb) aa = torch.quantize_per_tensor(input, scale=1.0, zero_point=0, dtype=torch.quint8)
(Pdb) bb = torch.quantize_per_tensor(input, scale=1.0, zero_point=0, dtype=torch.quint8)
(Pdb) torch.allclose(aa, bb)
Comparison exception: promoteTypes with quantized numbers is not handled yet; figure out what the correct rules should be, offending types: QUInt8 Float
```
Here the proposed fix is to compare quantized tensors strictly within `_compare_tensors_internal`.
The other two possible fixes are:
1. convert quantized tensors to float tensors first before sending them to `torch.allclose`
2. change `torch.allclose` to handle quantized tensor.
Test Plan: buck run caffe2/benchmarks/operator_benchmark/pt:qactivation_test -- --use_jit
Reviewed By: kimishpatel
Differential Revision: D24506723
fbshipit-source-id: 6426ea2a88854b4fb89abef0edd2b49921283796
Summary:
We've been seeing a lot of Hypothesis timeouts and from profiling a few of the failing tests one of the contributing factors is really slow grad checker. In short, it launches the whole op for each of the input elements so the overall complexity is O(numel^2) at least.
This applies a very unscientific hack to just run grad check on the first and last few elements. It's not ideal, but it's better than flaky tests. One can still explicitly opt in with the env var.
Reviewed By: malfet
Differential Revision: D23336220
fbshipit-source-id: f04d8d43c6aa1590c2f3e72fc7ccc6aa674e49d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46895
Bug: models after the FX graph mode quant prepare step lost information,
such as the extra attributes defined in `Quantizer.save_state`,
if the user performed `copy.deepcopy` on them. The information was lost
because `GraphModule` does not copy attributes which are not present on
`nn.Module` by default.
Fix: define a custom `__deepcopy__` method on observed models and
whitelist the attributes we care about.
This is needed because users sometimes run `copy.deepcopy` on their
models during non-quantization related preparations, and we should make
sure that quantization related state survives these calls.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_deepcopy
python test/test_quantization.py TestQuantizeFx.test_standalone_module
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D24556035
fbshipit-source-id: f7a6b28b6d2225fa6189016f967f175f6733b124
Summary:
We already link g++ and gcc to the correct version, but we do not do that for gcov, which is needed for coverage.
This PR adds a link for gcov as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46928
Reviewed By: malfet
Differential Revision: D24569240
Pulled By: janeyx99
fbshipit-source-id: 4be012bff21ddae0c81339665b58324777b9304f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46935
Bump up the cocoapods version
ghstack-source-id: 115283786
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: xta0
Differential Revision: D24572715
fbshipit-source-id: 41ffcd43512dc7d4e94af887fb5dfeab703d7602
Summary:
It is incorrect to assume that a newly recorded event will immediately query as False.
This test is flaky on ROCm due to this incorrect assumption.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46857
Reviewed By: albanD
Differential Revision: D24565581
Pulled By: mrshenli
fbshipit-source-id: 0e9ba02cf52554957b29dbeaa5093696dc914b67
Summary:
Also, be a bit future-proof in support version list
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46921
Reviewed By: seemethere
Differential Revision: D24568733
Pulled By: malfet
fbshipit-source-id: ae34f8da1ed39b80dc34db0b06e4ef142104a3ff
Summary:
WIP: This PR adds sparse_nn_partition into Partitioner class. It includes logical device assignment for all dag nodes. The basic idea is to do size_based_partition separately for embedding nodes and non-embedding nodes. A test unit is also added in test_fx_experimental.py.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46390
Reviewed By: gcatron
Differential Revision: D24555415
Pulled By: scottxu0730
fbshipit-source-id: 8772af946d5226883759a02a1c827cfdfce66097
Summary:
This is the second attempt at replacing flatten tensors with flatten loops in `TensorExprKernel::generateStmt`. The first attempt (https://github.com/pytorch/pytorch/pull/46539) resulted in a build failure due to an exception that gets thrown during inline.
The reason for the build failure was because there was an inline step, which was supposed to happen on the unflattened tensors. This was necessary earlier because for every flattened tensor there was an unflattened tensor which had to be inlined. That is no longer necessary since we do not have 2 tensors (flattened and unflattened) now. Removed this inline.
Checked python and cpp tests on CPU as well as CUDA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46737
Reviewed By: anjali411, izdeby
Differential Revision: D24534529
Pulled By: navahgar
fbshipit-source-id: 8b131a6be076fe94ed369550d9f54d3879fdfefd
Summary:
Pull Request resolved: https://github.com/pytorch/glow/pull/5029
Support single element tuples in to_backend
Test Plan: new unit test for to_glow
Reviewed By: andrewmillspaugh
Differential Revision: D24539869
fbshipit-source-id: fb385a7448167b2b948e70f6af081bcf78f338dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46795
add fburl link to the error message of missing ops so user can debug themselves.
Test Plan: fburl.com/missing_ops
Reviewed By: iseeyuan
Differential Revision: D24519992
fbshipit-source-id: d2d16db7e9d9c84ce2c4600532eb253c30b31971
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46007
When owner released the object, target will become null and illegal to
access refcount_ again. This PR fixes this and return null in that case.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D24374846
Pulled By: wanchaol
fbshipit-source-id: 741074f59c0904a4d60b7bde956cad2d0925be4e
Summary:
findAlgorithm should return if and only if a suitable algorithm is found.
The default algorithm is not guaranteed to have been cached.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46852
Reviewed By: izdeby
Differential Revision: D24546748
Pulled By: bhosmer
fbshipit-source-id: 171137b377193e0825769b61d42a05016f02c34c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46838
`SCALAR_TYPE` may be unused in some contexts where the macro is used. We use the standard `(void)var` trick to suppress the compiler warning in these instances.
Test Plan: Standard pre-commit tests.
Reviewed By: jerryzh168
Differential Revision: D24481142
fbshipit-source-id: 4fcde669cc279b8863443d49c51edaee69f4d7bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46512
1. Merge 1-line PythonCommHook constructor into the header for simplicity.
2. Move the implementation of PythonCommHook destructor from the header file to cpp file.
3. Rename processFuture method as parseHookResult for readability.
4. Simplify some comments.
Original PR issue: C++ DDP Communication Hook https://github.com/pytorch/pytorch/issues/46348
ghstack-source-id: 115161086
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_comm_hook_allreduce_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_comm_hook_sparse_gradients
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_comm_hook_allreduce_with_then_hook_nccl
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_comm_hook_future_passing_gpu_gloo
Reviewed By: jiayisuse
Differential Revision: D24374282
fbshipit-source-id: c8dbdd764bca5b3fa247708f1218cb5ff3e321bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46568
This PR adds support for an RRef.backward() API. This would be useful
in applications like pipeline parallelism as described here:
https://github.com/pytorch/pytorch/issues/44827
This PR only adds support for local RRefs, remote RRef support will be added in
a follow up PR.
ghstack-source-id: 115100729
Test Plan:
1) unit tests.
2) waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D24406311
fbshipit-source-id: fb0b4e185d9721bf57f4dea9847e0aaa66b3e513
Summary:
Looks like this op is never tested for the support of different dtypes?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45155
Reviewed By: zou3519
Differential Revision: D24438839
Pulled By: ngimel
fbshipit-source-id: 103ff609e11811a0705d04520c2b97c456b623ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46846
Previously, this would crash with a floating point error. If the user vmaps
over a dimension of size 0, ideally we would return a tensor with a
batch dim of size 0 and the correct output shape. However, this isn't
possible without a shape-checking API. This PR changes the vmap fallback
to error out gracefully if it sees vmap occuring over a dimension of
size 0.
If we want to support vmapping over dimension of size 0 for a specific
op, then the guidance is to implement a batching rule for that op that
handles 0-sized dims.
Test Plan: - new test
Reviewed By: ezyang
Differential Revision: D24539315
Pulled By: zou3519
fbshipit-source-id: a19c049b46512d77c084cfee145720de8971f658
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46856
Add reference to NCCL_ASYNC_ERROR_HANDLING in the pytorch docs,
similar to how NCCL_BLOCKING_WAIT is curently described.
ghstack-source-id: 115186877
Test Plan: CI, verifying docs change
Reviewed By: jiayisuse
Differential Revision: D24541822
fbshipit-source-id: a0b3e843bc6392d2787a4bb270118f2dfda5f4ec
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/41807
Test Plan: Make sure ci tests pass, including newly written test
Reviewed By: mrshenli
Differential Revision: D22640839
Pulled By: osandoval-fb
fbshipit-source-id: 3ff98d8e8c6e6d08575e307f05b5e159442d7216
Summary:
This is a tiny PR for two minor fixes:
1. Added `torch._C._jit_set_texpr_fuser_enabled(False)` to enable shape inference on nv fuser runs.
2. Renamed dynamic benchmark module names to avoid multiple matching. i.e. `simple_element` with `dynamic_simple_element`. I guess it'd be much easier if the pattern matching was based on `startswith`. Would be happy to update that if agreed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46778
Reviewed By: zhangguanheng66
Differential Revision: D24516911
Pulled By: bertmaher
fbshipit-source-id: 839f9a3e058f9d7aca17b2e6eb8b558e0e48e8f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46543
Add error messages and workaround for RET failure of containers with a torch class type.
- Error case condition
1) ins.op == RET
2) input_type == TypeKind::ListType or TypeKind::DictType
3) Any(input_type's element type) == TypeKind::ClassType
ghstack-source-id: 114618426
Test Plan:
buck test mode/dev caffe2/test:mobile -- 'test'
Summary
Pass: 13
ListingSuccess: 1
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/7318349417617713
Reviewed By: iseeyuan
Differential Revision: D24388483
fbshipit-source-id: 7d30f6684a999054d0163e691422797cb818bb6a
Summary:
According to [this issue](https://github.com/linux-test-project/lcov/issues/58), LCOV 1.14 and below are not compatible with GCC9 when gathering coverage.
Instead of installing `lcov` with `apt-get`, which installs version 1.13, this PR would install v1.15 from source onto the ubuntu Docker images.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46847
Reviewed By: seemethere
Differential Revision: D24540444
Pulled By: janeyx99
fbshipit-source-id: 0ac2a37241d94cdd8fea2fded7984c495a64cedc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46769
Value to be hashed is `int64_t`, but hash is `int`. This results in a downconversion which throws out bits which would otherwise be hashed.
Test Plan: Standard pre-commit test rig
Reviewed By: malfet
Differential Revision: D24480962
fbshipit-source-id: 497b1d8bc3f6d2119a6ba16e6ae92911bd34b916
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46771
`std::ceil` returns a `float` which is cast to `size_t` by the `max` operation.
We convert to `int64_t` to suppress the warning while matching the type of `newDims[0]`.
Since the types match, we don't need an explicit template type for `max`. This allows `max` to take `int64_t` as its values, matching the type of `newCapacity`.
Test Plan: Standard pre-commit test rig.
Reviewed By: malfet
Differential Revision: D24481684
fbshipit-source-id: aed7cabc1e9d395b2662cb633f3ace19c279ab4c
Summary: `sizeof` returns an unsigned, so comparison against `-1` is a warning. This fixes that.
Test Plan: Standard pre-commit test rig.
Reviewed By: bhosmer
Differential Revision: D24506390
fbshipit-source-id: cdb2887d319c6730a90b9f8d74a248527dd6c2ab
Summary:
With this PR, users can optionally provide a "doc_string" to describe a class or its method. doc_string for TorchBind classes and methods are stored as `doc_string` properties in `Function` and `ScriptClass`. These `dos_string` properties are then exposed in Python layer via PyBind for doc generation.
Fixes https://github.com/pytorch/pytorch/issues/46047
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46576
Reviewed By: wanchaol
Differential Revision: D24440636
Pulled By: gmagogsfm
fbshipit-source-id: bfa9b270a6c2d8bc769a88fad6be939cc6310412
Summary:
It used to be that TorchScript only supported hashing of `int`, `float` and `str`. This PR adds hashing for many other types including `Tuple`, `bool`, `device` by implementing generic hashing on IValue.
* Tensor hashing follows eager behavior, which is identity-based (hash according to pointer address rather than tensor content).
Fixes https://github.com/pytorch/pytorch/issues/44038
This is based on suo's https://github.com/pytorch/pytorch/issues/44047, with some cleaning, more tests and fixing BC check issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46441
Reviewed By: robieta
Differential Revision: D24440713
Pulled By: gmagogsfm
fbshipit-source-id: 851f413f99b6f65084b551383ad21e558e7cabeb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46346
Allow user to provide additional fusion/quant patterns for fx graph mode
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D24317437
fbshipit-source-id: 719927cce50c74dffa4f848bd5c98995c944a26a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46674
Summary
-------
This adds batched gradient support (i.e., vmap through the gradient
formulas) for Tensor.max(), Tensor.min(), Tensor.median()
that have evenly_distribute_backward as their backward formula.
Previously, the plan was to register incompatible gradient formulas as
backward operators (see #44052). However, it turns out that we can just use
`new_zeros` to get around some incompatible gradient formulas (see next
section for discussion).
Context: the vmap+inplace problem
---------------------------------
A lot of backwards functions are incompatible with BatchedTensor due to
using in-place operations. Sometimes we can allow the in-place
operations, but other times we can't. For example, consider select_backward:
```
Tensor select_backward(const Tensor& grad, IntArrayRef input_sizes,
int64_t dim, int64_t index) {
auto grad_input = at::zeros(input_sizes, grad.options());
grad_input.select(dim, index).copy_(grad);
return grad_input;
}
```
and consider the following code:
```
x = torch.randn(5, requires_grad=True)
def select_grad(v):
torch.autograd.grad(x[0], x, v)
vs = torch.randn(B0)
batched_grads = vmap(select_grad)(vs)
```
For the batched gradient use case, grad is a BatchedTensor.
The physical version of grad has size (B0,).
However, select_backward creates a grad_input of shape (5), and
tries to copy grad to a slice of it.
Up until now, the proposal to handle this has been to register these
backward formulas as operators so that vmap doesn’t actually see the
`copy_` calls (see #44052). However, it turns out we can actually just
use `new_zeros` to construct a new Tensor that has the same
"batched-ness" as grad:
```
auto grad_input = grad.new_zeros(input_sizes);
grad_input.select(dim, index).copy_(grad);
```
We should use this for simple backward functions. For more complicated
backward functions where this solution doesn't work, we should register
those as operators.
Alternatives
------------
Option 2: Register `evenly_distribute_backward` as an operator and have the
vmap fallback run it in a loop.
- This requires more LOC changes.
- Furthermore, we'd have to write an efficient batching rule for
`evenly_distribute_backward` in the future.
- If we use `new_zeros` instead, we don't need to write an efficient
batching rule for `evenly_distribute_backward` as long as the
constituents of `evenly_distributed_backward` have efficient batching rules.
Option 3: Have factory functions perform differently if they are called
inside vmap.
- For example, `at::zeros(3, 5)` could return a Tensor of shape
`(B0, B1, 3, 5)` if we are vmapping over two dimensions with size B0 and B1.
This requires maintaining some global and/or thread-local state about
the size of the dims being vmapped over which can be tricky.
And more...
Future
------
- I will undo some of the work I’ve done in the past to move backward
functions to being operators (#44052, #44408). The simpler backward
functions (like select backward) can just use Tensor.new_zeros.
I apologize for the thrashing.
- Include a NOTE about the vmap+inplace problem somewhere in the
codebase. I don't have a good idea of where to put it at the moment.
Test Plan
---------
- New tests
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D24456781
Pulled By: zou3519
fbshipit-source-id: 9c6c8ee2cb1a4e25afd779bdf0bdf5ab76b9bc20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46671
Previously, the vmap fallback would choke whenever it saw an undefined
tensor. For each sample in a batch, the fallback runs an operator
and then stacks together outputs to get the actual output.
Undefined tensors can occur as outputs while computing batched gradients
with vmap.
This PR updates the vmap fallback to handle undefined tensors which can
appear in backward formulas:
- if for each sample in a batch the output was undefined, then the vmap
fallback returns an undefined tensor
- if for each sample in a batch the output is defined, then the vmap
fallback stacks together the defined tensors
- if for some samples in a batch the output is defined/undefined, then
we error out.
Test Plan: - new tests
Reviewed By: ezyang
Differential Revision: D24454909
Pulled By: zou3519
fbshipit-source-id: d225382fd17881f23c9833323b68834cfef351f3
Summary:
When run with `--continue-through-error`, the script ends with the following error:
```
Traceback (most recent call last):
File "run_test.py", line 745, in <module>
main()
File "run_test.py", line 741, in main
print_to_stderr(message)
NameError: name 'message' is not defined
make: *** [macos-compat] Error 1
```
This PR just changes `message` to `err`, which is the intended variable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46777
Reviewed By: seemethere
Differential Revision: D24510460
Pulled By: janeyx99
fbshipit-source-id: be1124b6fc72b178d62acc168d0cbc74962de52b
Summary:
Currently circle doesn't report workflow ID as one of the dimensions
This causes statistics for some failed/rerun CircleCI job to report overlapping results.
Fixing it by adding workflow ID tag
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46725
Reviewed By: seemethere, zhangguanheng66
Differential Revision: D24505006
Pulled By: walterddr
fbshipit-source-id: cc65bb8ebc0787e443a42584dfb0d2224e824e7d
Summary:
Closes https://github.com/pytorch/pytorch/issues/7134. This request is to add an option to log the subprocess output (each subprocess is training a network with DDP) to a file instead of the default stdout.
The reason for this is that if we have N processes all writing to stdout, it'll be hard to decipher the output, and it would be cleaner to log these to separate files.
To support this, we add an optional argument `--logdir` set the subprocess stdout to be the a file of the format "node_rank_{}_local_rank_{}" in the logging directory. With this enabled, none of the training processes output to the parent process stdout, and instead write to the aformentioned file. If a user accidently passes in something that's not a directory, we fallback to ignoring this argument.
Tested by taking a training script at https://gist.github.com/rohan-varma/2ff1d6051440d2c18e96fe57904b55d9 and running `python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 --master_addr="127.0.0.1" --master_port="29500" --logdir test_logdir train.py`. This results in a directory `test_logdir` with files "node_0_local_rank_0" and "node_0_local_rank_1" being created with the training process stdout.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33193
Reviewed By: gchanan
Differential Revision: D24496013
Pulled By: rohan-varma
fbshipit-source-id: 1d3264cba242290d43db736073e841bbb5cb9e68
Summary: Similar to If operator, AsyncIf also contains nets in args. It needs the same handling.
Test Plan:
New unit test test_control_op_remap
`buck test caffe2/caffe2/python:core_test`
Also it worked end to end in prototype of dist bulk eval workflow f226680903
Reviewed By: yyetim
Differential Revision: D24451775
fbshipit-source-id: 50594e2ab9bb457329ed8da7b035f7409461b5f6
Summary:
As per title. Limitations: only for batches of squared full-rank matrices.
CC albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46284
Reviewed By: zou3519
Differential Revision: D24448266
Pulled By: albanD
fbshipit-source-id: d98215166268553a648af6bdec5a32ad601b7814
Summary:
We need an object to hold the ownership of allocated memory in the scope, instead of directly using the raw pointer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46605
Reviewed By: zou3519
Differential Revision: D24453548
Pulled By: ezyang
fbshipit-source-id: d29e5a69afa6c0d9e519849910e04524667d0a26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46730
A narrowing conversion on `last_idx` raises a compiler warning. This fixes that.
Test Plan: Standard pre-commit test rig.
Reviewed By: EscapeZero
Differential Revision: D24481497
fbshipit-source-id: f3e913b586738add59c422c3cf65035d87fc9e34
Summary:
Small quality-of-life improvement to NVTX Python bindings, that we're using internally and that would be useful to other folks using NVTX annotations via PyTorch. (And my first potential PyTorch contribution.)
Instead of needing to be careful with try/finally to make sure all your range_push'es are range_pop'ed:
```
nvtx.range_push("Some event")
try:
# Code here...
finally:
nvtx.range_pop()
```
you can simply do:
```
with nvtx.range("Some event"):
# Code here...
```
or even use it as a decorator:
```
class MyModel(nn.Module):
# Other methods here...
nvtx.range("MyModel.forward()")
def forward(self, *input):
# Forward pass code here...
```
A couple small open questions:
1. I also added the ability to call `msg.format()` inside `range()`, with the intention that, if there is nothing listening to NVTX events, we should skip the string formatting, to lower the overhead in that case. If you like that idea, I could add the actual "skip string formatting if nobody is listening to events" parts. We can also just leave it as is. Or I can remove that if you folks don't like it. (In the first two cases, should we add that to `range_push()` and `mark()` too?) Just let me know which one it is, and I'll update the pull request.
2. I don't think there are many places for bugs to hide in that function, but I can certainly add a quick test, if you folks want.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42925
Reviewed By: gchanan
Differential Revision: D24476977
Pulled By: ezyang
fbshipit-source-id: 874882818d958e167e624052e42d52fae3c4abf1
Summary:
This pull request enables the following tests on ROCm:
* TestCuda.test_tiny_half_norm_
* TestNNDeviceTypeCUDA.test_softmax_cuda_float16
* TestNNDeviceTypeCUDA.test_softmax_cuda_float32
* TestNNDeviceTypeCUDA.test_softmax_results_cuda_float16
* TestNNDeviceTypeCUDA.test_softmax_results_cuda_float32
The earlier failures, because of which the tests were skipped, were because of a precision issue for FP16 compute on MI25 hardware with ROCm 3.7 and older. The fix was delivered in the compiler in ROCm 3.8.
The pull request fixes https://github.com/pytorch/pytorch/issues/37493
cc: jeffdaily ezyang malfet mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46363
Reviewed By: heitorschueroff
Differential Revision: D24325639
Pulled By: ezyang
fbshipit-source-id: a7dbb238cf38c04b6592baad40b4d71725a358c9
Summary:
[Previously](https://github.com/pytorch/pytorch/runs/1293724033) Flake8 was run using `flake8-mypy`, which didn't change the actual lint output, and undesirably resulted in this noisy message being printed many times:
```
/opt/hostedtoolcache/Python/3.9.0/x64/lib/python3.9/site-packages is in the MYPYPATH. Please remove it.
See https://mypy.readthedocs.io/en/latest/running_mypy.html#how-mypy-handles-imports for more info
```
Since `mypy` is already run in other test scripts, this PR simply removes it from the Flake8 setup. This PR also removes the `--exit-zero` flag from Flake8, because currently Flake8 gives no error output, so it would be valuable to know if it ever does happen to return error output.
(This doesn't strike me as a perfect solution since now it's a bit harder to reproduce the Flake8 behavior when running locally with `flake8-mypy` installed, but it's the easiest way to fix it in CI specifically.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46740
Reviewed By: janeyx99
Differential Revision: D24487904
Pulled By: samestep
fbshipit-source-id: d534fdeb18e32d3bc61406462c1cf955080a688f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46645
### Summary
The IOS_VERSION should be renamed to XCODE_VERSION
### Test
- CircleCI
Test Plan: Imported from OSS
Reviewed By: seemethere, linbinyu
Differential Revision: D24459598
Pulled By: xta0
fbshipit-source-id: 9dcba973cc57aa44f8fd4151daf5d89c8da61c67
Summary:
For similar reasons as documented in the `[Sync Streams]` note. For a current example, `ProcessGroupNCCL::allgather` must also call `recordStream` and does so already.
The output tensor is created on the default stream (by the application). NCCL/RCCL internally uses another stream (i.e., ncclStream). If we do not record the output tensor on the ncclStream, there is a chance that the output tensor might be deallocated while NCCL/RCCL is using it.
The application is not aware of the ncclStream since it's internal to ProcessGroupNCCL. So, the application cannot record the output tensor on the ncclStream.
Patch originally developed by sarunyap.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46603
Reviewed By: srinivas212
Differential Revision: D24458530
fbshipit-source-id: b02e74d1c3a176ea1b9bbdd7dc671b221fcadaef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46345
Allow user to add more fusion mappings
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D24317439
fbshipit-source-id: 3b144bbc305e41efbdf3e9fb25dbbeaad9e86c6a
Summary:
Close https://github.com/pytorch/pytorch/issues/31690
I have verified the functionality of ConvTranspose2d (with this PR) on roughly 32,000 random shapes on V100, A100, using cuDNN 8.0.4 and CUDA 11.1. The 32,000 shapes contain 4x8,000 of (fp16, fp32) x (nchw, nhwc) each.
The random shapes are sampled from
```jsonc
{
"batch_size": {"low": 1, "high": 8},
"in_channels": {"low": 16, "high": 128},
"out_channels": {"low": 16, "high": 128},
"height": {"low": 16, "high": 224},
"stride": {"set": [[1, 1], [2, 2]]},
"padding": {"set": [[0, 0]]},
"output_padding": {"set": [[0, 0], [1, 1], [0, 1], [1, 0]]},
"kernel_size": {"set": [[3, 3], [1, 1], [1, 3], [3, 1], [2, 2]]},
"dilation": {"set": [[1, 1]]},
"deterministic": {"set": [true, false]},
"benchmark": {"set": [true, false]},
"allow_tf32": {"set": [true, false]},
"groups": {"set": [1, IN_CHANNELS]}
}
```
- Input `width` is the same as `height`.
- `groups` can be either 1, or the same as `in_channels` (grouped convolution). When `groups` is 1, `out_channels` is random; when `groups` is the same as `in_channels`, `out_channels` is also the same as `in_channels`
All of the checked shapes can be found in csv files here https://github.com/xwang233/code-snippet/tree/master/convtranspose2d-dilation/functionality-check-cudnn8.0.4.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46290
Reviewed By: mruberry
Differential Revision: D24422091
Pulled By: ngimel
fbshipit-source-id: 9f0120f2995ae1575c0502f1b2742390d7937b24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46134
Make sure in-place ops stay in-place after SsaRewrite. This seems to break the premise of SSA, but it's necessary to ensure correctness. Note here we only preserve the inplace ops that enforce inplace. Ops like `Relu` don't enforce inplace, they allow inplace.
(Note: this ignores all push blocking failures!)
Reviewed By: yinghai
Differential Revision: D24234957
fbshipit-source-id: 274bd3ad6227fce6a98e615aad7e57cd2696aec3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46560
Follow-up for D24236604 (16c52d918b).
For nets that pass the schema check, memonger actually makes sure to preserve the inplaceness of operators if they are already inplace. So we can safely enable it for correct input nets.
(Note: this ignores all push blocking failures!)
Differential Revision: D24402482
fbshipit-source-id: a7e95cb0e3eb87adeac79b9b69eef207957b0bd5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46669
Make `Graph`'s deepcopy behavior iterative rather than recursive. This prevents stack overflow issues with very large `Graph`s
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D24455120
Pulled By: jamesr66a
fbshipit-source-id: 5c37db5acabe313b9a7a464bebe2a82c59e4e2e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46606
Note that new_empty uses `m.impl_UNBOXED` because the operator doesn't
go through the c10 dispatcher due to #43572.
Test Plan: - new tests
Reviewed By: ezyang
Differential Revision: D24428106
Pulled By: zou3519
fbshipit-source-id: 5e10f87a967fb27c9c3065f3d5b577db61aeb20e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46694
For the op with parameters (e.g. conv), the jit mode run currently will raise an error of
`RuntimeError: Cannot insert a Tensor that requires grad as a constant. Consider making it a parameter or input, or detaching the gradient`. After consulting https://www.fburl.com/vtkys6ug, decided to turn-off gradient for the parameters in the forward run. If we want op with parameters to work in backward with jit mode, probably needs to turn `TorchBenchmarkBase` into a sub-class of `nn.Module`
Test Plan: ./buck-out/gen/caffe2/benchmarks/operator_benchmark/pt/conv_test.par --use_jit
Reviewed By: mingzhe09088
Differential Revision: D24451206
fbshipit-source-id: 784eb60ca155b0152d745c92f6d0ce6b2c9014c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44090
This is an initial commit pulling in the torchgpipe fork at
https://github.com/facebookresearch/fairscale.
The purpose of this commit is to just pull in the code and ensure all tests and
builds work fine. We will slowly modify this to match our intended API
mentioned in https://fb.quip.com/txurAV3zIFox#RPZACAfAKMq. Follow up PRs would
address further changes needed on top of the initial commit..
We're pulling the code into the `torch.distributed._pipeline.sync` package. The
package is private on purpose since there is a lot of work (ex: docs, API
changes etc.) that needs to go in before we can actually officially support
this.
ghstack-source-id: 114864254
Test Plan:
1) waitforbuildbot
2) Ran all tests on my devgpu
Reviewed By: mrshenli
Differential Revision: D23493316
fbshipit-source-id: fe3c8b7dadeeb86abdc00e8a8652491b0b16743a
Summary:
Follow-up of https://github.com/pytorch/pytorch/issues/46461 with a similar goal
Makes them more readable and possibly faster. Care has to be taken because `map` applies the function immediately while `(x for x in xs)` is a generator expression which gets evaluated later. This is a benefit in some cases where it is not required to actually create the list of values in memory (e.g. when passing to `tuple` or `extend` or `join`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46462
Reviewed By: zou3519
Differential Revision: D24422343
Pulled By: ezyang
fbshipit-source-id: 252e33499c92ac0b15238f2df32681dbbda2b237
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46372
Currently, in `_run_function`, we catch an exception from the python
function which is run, and report it back to the master. However in some large
scale training jobs, it would be valuable to also log the error on the trainer
itself for faster debugging.
Test Plan: Added unittest.
Reviewed By: pritamdamania87
Differential Revision: D24324578
fbshipit-source-id: 88460d7599ea69d2c38fd9c10eb6471f7edd4100
Summary:
I got confused while locally running some of the `quick-checks` lints (still confused by `.jenkins/run-shellcheck.sh` but that's a separate matter) so I'm adding a comment to the "Ensure C++ source files are not executable" step in case someone in the future tries it and gets confused like I did.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46698
Reviewed By: walterddr
Differential Revision: D24470718
Pulled By: samestep
fbshipit-source-id: baacd8f414aa41b9b7b7aac765d938f21085eac5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46666
Interval midpoint calculations can overflow (integers) this diff fixes such an instance.
Test Plan: Standard test rig
Reviewed By: xw285cornell
Differential Revision: D23997893
fbshipit-source-id: 788c1181031e0b71d3efb6f7090fbd4ba2aa3f86
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46304
In the case that a single process operates only on one GPU, we can
avoid this scatter and instead replace it with a recursive version of `to`
which transfers the input tensors to the correct device.
The implementation of `_recursive_to` is modeled after `scatter` in https://github.com/pytorch/pytorch/blob/master/torch/nn/parallel/scatter_gather.py, in order to keep parity with the previous conventions (i.e. custom types not having their tensors moved).
ghstack-source-id: 114896677
Test Plan: Added unittest, and CI
Reviewed By: pritamdamania87
Differential Revision: D24296377
fbshipit-source-id: 536242da05ecabfcd36dffe14168b1f2cf58ca1d
Summary: benchmakr_caffe2 is broken, due to some refactoring which change from eager test generation to register only.
Test Plan:
`buck run caffe2/benchmarks/operator_benchmark/c2:add_test`
```
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking Caffe2: add
WARNING: Logging before InitGoogleLogging() is written to STDERR
W1021 08:07:06.350742 390665 init.h:137] Caffe2 GlobalInit should be run before any other API calls.
# Name: add_M8_N16_K32_dtypeint
# Input: M: 8, N: 16, K: 32, dtype: int
Forward Execution Time (us) : 652.748
# Benchmarking Caffe2: add
# Name: add_M16_N16_K64_dtypefloat
# Input: M: 16, N: 16, K: 64, dtype: float
Forward Execution Time (us) : 63.570
# Benchmarking Caffe2: add
# Name: add_M64_N64_K128_dtypeint
# Input: M: 64, N: 64, K: 128, dtype: in
```
Reviewed By: qizzzh
Differential Revision: D24448374
fbshipit-source-id: 850fd375d194c20c385ea4433aea13066c7476e6
Summary:
References https://github.com/pytorch/pytorch/issues/42515
> Enable integer -> float unary type promotion for ops like sin
Will follow-up for other such Ops once this PR is merged.
cc: mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45733
Reviewed By: zou3519
Differential Revision: D24431194
Pulled By: mruberry
fbshipit-source-id: db600bc5de0e535b538d2aa301c3526b7c75ed17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45318
When calling `then()` from WorkNCCL, record the input data pointers in futureNCCLCallbackStream_ before the execution of the input callback.
Note that the recording cannot be directly added to the lambda used by addCallback in ProcessGroupNCCL.hpp. This is because the type of future value in that context is pyobject rather than TensorList, but a type casting will require pybind and introduce Python dependency, which should not be allowed in c10d library.
I have considered creating a util function in a separate file to support this type casting, and then placing it under torch/csrc directory where python dependency is allowed. However, torch/csrc has a dependency on c10d, so this will create a circular dependency.
Finally, a `record_stream_cb_` member is added to FutureNCCL, and the default value is nullptr. A default `record_stream_cb_` implementation is added to `PythonFutureWrapper,` where Python dependency is allowed.
In addition, a few lines are reformatted by lint.
caffe2/torch/csrc/distributed/c10d/init.cpp is only reformatted.
#Closes: https://github.com/pytorch/pytorch/issues/44203
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- ProcessGroupNCCLTest
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_accumulate_gradients_no_sync_allreduce_with_then_hook
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_ddp_comm_hook_allreduce_with_then_hook_nccl
Reviewed By: pritamdamania87
Differential Revision: D23910257
fbshipit-source-id: 66920746c41f3a27a3689f22e2a2d9709d0faa15
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46501
Gradients in this method will not be modified.
ghstack-source-id: 114851646
Test Plan: waitforbuildbot
Reviewed By: pritamdamania87
Differential Revision: D24374300
fbshipit-source-id: a2941891008f9f197a5234b50260218932d2d37d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46601
* except excluded tests and magic methods.
https://github.com/pytorch/pytorch/issues/38731
Previously, we'd only do run these tests for inplace operations. Since this is a lot more tests, fixed these issues that came up when running them -
- Updated schema of conj() to reflect existing behaviour.
- Updated deepEquals method in check_alias_annotation.cpp to re-use the overloaded == operator. Previous implementation did not cover all types of IValues.
- Corrected the order inputs are passed in during autograd testing of 'view' & 'reshape'.
- Subbed out atn::ger with the func its aliased to, atn::outer, for testing. The alias annotation checking code doesn't handle aliased operators properly.
ghstack-source-id: 114830903
Test Plan: Ran all tests in test:jit and verified they pass.
Reviewed By: eellison
Differential Revision: D24424955
fbshipit-source-id: 382d7e2585911b81b1573f21fff1d54a5e9a2054
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46657
This is used to simulate fake quantize operation for ops with fixed quantization parameters
e.g. hardsigmoid
Test Plan:
Imported from OSS
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D24451406
fbshipit-source-id: 26cc140c00f12bdec9a8f9dc880f4c425f4d4074
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46679
Current way of import configs will have runtime error when a single benchmark is launched directly with buck(e.g. `/buck-out/gen/caffe2/benchmarks/operator_benchmark/pt/conv_test.par`). The diff fixed that issue.
ghstack-source-id: 114857978
Test Plan: waitforsandcastle
Reviewed By: vkuzo
Differential Revision: D24459631
fbshipit-source-id: 29df17e66962a8604dbb7b8b9106713c3c19bed5
Summary:
I am adding documentation for building the C++-only libtorch.so without invoking Python in the build and install process. This works on my Ubuntu 20.04 system and is designed to be operating system agnostic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44196
Reviewed By: zou3519
Differential Revision: D24421066
Pulled By: malfet
fbshipit-source-id: e77c222703353ff7f7383fb88f7bce705f88b7bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46572
When `num_samples == 0`, grid becomes zero. Although CUDA just silently proceeds, `cudaGetLastError()` will complain about the `Error: invalid configuration argument`. So it's actually failing in some future places that becomes really hard to debug.
Reviewed By: jianyuh
Differential Revision: D24409874
fbshipit-source-id: ca54de13b1ab48204bbad265e3f55b56b94a1a2f
Summary:
Added a workaround for the cases when NVCC tries to compile the object for sm_30 GPU compute capability to avoid the error message telling that `__ldg` intrinsic is not defined.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46535
Reviewed By: zou3519
Differential Revision: D24422445
Pulled By: ezyang
fbshipit-source-id: 66e8eb1cbe42d848cfff46d78720d72100e628f8
Summary:
There's some code which uses `six.PY3`, similar to:
```python
if six.PY3:
print("Python 3+ code")
else:
print "Python 2 code"
```
Where:
```python
PY3 = sys.version_info[0] == 3
```
When run on Python 4, this will run the Python 2 code! Instead, use `six.PY2` and avoid `six.PY3`.
---
Similarly, there's some `sys.version_info[0] == 3` checks, better done as `sys.version_info[0] >= 3`.
---
Also, it's better to avoid comparing the `sys.version` string, as it makes assumptions that each version component is exactly one character long, which will break in Python 3.10:
```pycon
>>> sys.version
'3.8.1 (v3.8.1:1b293b6006, Dec 18 2019, 14:08:53) \n[Clang 6.0 (clang-600.0.57)]'
>>> sys.version < "3.3"
False
>>> fake_v3_10 = '3.10.1 (v3.8.1:1b293b6006, Dec 18 2019, 14:08:53) \n[Clang 6.0 (clang-600.0.57)]'
>>> fake_v3_10 < "3.3"
True
```
---
Finally, I think the intention here is to skip when the Python version is < 3.6:
```python
unittest.skipIf(sys.version_info[0] < 3 and sys.version_info[1] < 6, "dict not ordered")
```
However, it will really skip for Python 0.0-0.5, 1.0-1.5 and 2.0-2.5. It's best to compare to the `sys.version_info` tuple and not `sys.version_info[1]`:
```python
unittest.skipIf(sys.version_info < (3, 6), "dict not ordered")
```
---
Found using https://github.com/asottile/flake8-2020:
```console
$ pip install -U flake8-2020
$ flake8 --select YTT
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32389
Reviewed By: zou3519
Differential Revision: D24424662
Pulled By: ezyang
fbshipit-source-id: 1266c4dbcc8ae4d2e2e9b1d7357cba854562177c
Summary:
Fixes issues when building certain PyTorch extensions where the cpp files do NOT compile if flags such as `__HIP_NO_HALF_CONVERSIONS__` are defined.
cc jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46273
Reviewed By: zou3519
Differential Revision: D24422463
Pulled By: ezyang
fbshipit-source-id: 7a43d1f7d59c95589963532ef3bd3c68cb8262be
Summary:
This PR makes it possible to cast the parameters of nn.Module to complex dtypes.
The following code works with the proposed changes.
```python
In [1]: import torch
In [2]: lin = torch.nn.Linear(5, 1).to(torch.complex64)
In [3]: lin(torch.zeros(3, 5, dtype=torch.complex64))
Out[3]:
tensor([[-0.1739+0.j],
[-0.1739+0.j],
[-0.1739+0.j]], grad_fn=<AddmmBackward>)
```
Fixes https://github.com/pytorch/pytorch/issues/43477.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44788
Reviewed By: zou3519
Differential Revision: D24307225
Pulled By: anjali411
fbshipit-source-id: dacc4f5c8c9a99303f74d1f5d807cd657b3b69b5
Summary:
Resolves one item in https://github.com/pytorch/pytorch/issues/46321
This PR sets up DistExamplesTest which will be used as the class to implement future tests for examples. This class is run as part of CI tests. It also creates a dist_examples folder and includes the [batch server example](https://github.com/pytorch/examples/blob/master/distributed/rpc/batch/parameter_server.py) which is slightly modified to allow to be tested.
Run test:
pytest test/distributed/rpc/test_tensorpipe_agent.py -k test_batch_updating_parameter_server -vs
pytest test/distributed/rpc/test_process_group_agent.py -k test_batch_updating_parameter_server -vs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46510
Reviewed By: mrshenli
Differential Revision: D24379296
Pulled By: H-Huang
fbshipit-source-id: 1c102041e338b022b7a659a51894422addc0e06f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46249
This saves 15kb binary size on ios and increases binary size on android x86 for 30kb. It also reduces size a bit for android arm. I've talked to Martin and we should land this since Android binary size is much less important because of Voltron.
ghstack-source-id: 114177627
Test Plan: bsb
Reviewed By: ezyang
Differential Revision: D23057150
fbshipit-source-id: 43bd62901b81daf08ed96de561d711357689178f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46573
Original commit changeset: 7dd709b585f8
ghstack-source-id: 114730143
Test Plan: Verified on circleci that previously broken test is fixed.
Reviewed By: zdevito
Differential Revision: D24413096
fbshipit-source-id: 439568c631c4556b8ed6af20fcaa4b1375e554cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46046
*_like functions are used in pytorch to create a new tensor with the same shape of the input tensor. But we don’t always preserve the layout permutation of the tensor. Current behavior is that, for a dense and non-overlapping tensor, its layout permutation is preserved. For eg. passing a channel last contiguous tensor t with ‘shape/stride’ (2, 4, 3, 2)/(24, 1, 8, 4) to empty_like(t) function will create a new tensor with exactly the same ‘shape/stride’ as the input tensor t. However, if the input tensor is non-dense or has overlap, we simply create a contiguous tensor based on input tensor’s shape, so the tensor layout permutation is lost.
This PR preserves the layout permutation for non-dense or overlapping tensor. The strides propagation rule that used in this PR is exactly the same as what is being used in TensorIterator. The behavior changes are listed below:
| code | old | new |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------|------------------------------------------------------|
| #strided tensors<br>a=torch.randn(2,3,8)[:,:,::2].permute(2,0,1)<br>print(a.stride())<br>print(a.exp().stride())<br>print((a+a).stride())<br>out = torch.empty(0)<br>torch.add(a,a,out=out)<br>print(out.stride()) | (2, 24, 8) <br>(6, 3, 1) <br>(1, 12, 4) <br>(6, 3, 1) | (2, 24, 8)<br>(1, 12, 4)<br>(1, 12, 4)<br>(1, 12, 4) |
| #memory dense tensors<br>a=torch.randn(3,1,1).as_strided((3,1,1), (1,3,3))<br>print(a.stride(), (a+torch.randn(1)).stride())<br>a=torch.randn(2,3,4).permute(2,0,1)<br>print(a.stride())<br>print(a.exp().stride())<br>print((a+a).stride())<br>out = torch.empty(0)<br>torch.add(a,a,out=out)<br>print(out.stride()) | (1, 3, 3) (1, 1, 1)<br>(1, 12, 4)<br>(6, 3, 1)<br>(1, 12, 4)<br>(6, 3, 1) | (1, 3, 3) (1, 3, 3)<br>(1, 12, 4)<br>(1, 12, 4)<br>(1, 12, 4)<br>(1, 12, 4) |
This is to solve the non-dense tensor layout problem in #45505
TODO:
- [x] Fix all the BC broken test cases in pytorch
- [ ] Investigate if any fb internal tests are broken
This change will cover all kinds of non-dense tensors.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D24288970
Pulled By: glaringlee
fbshipit-source-id: 320fd4e0d1a810a12abfb1441472298c983a368d
Summary: It creates cpu overload issues when openmp gets enabled and OMP_NUM_THREADS=1 is not set.
Test Plan: buck test //caffe2/caffe2/quantization/server:quantize_dnnlowp_op_test
Reviewed By: jspark1105
Differential Revision: D24437305
fbshipit-source-id: 426209fc33ce0d4680c478f584716837ee62cb5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46356
Adding the flag `-Werror=cast-function-type` to ensure we don't allow
any invalid casts (ex: PyCFunction casts).
For more details see: https://github.com/pytorch/pytorch/issues/45419
ghstack-source-id: 114632980
Test Plan: waitforbuildbot
Reviewed By: albanD
Differential Revision: D24319759
fbshipit-source-id: 26ce4650c220e8e9dd3550245f214c7e6c21a5dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45538
This is used to simulate fake quantize operation for ops with fixed quantization parameters
e.g. hardsigmoid
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D24004795
fbshipit-source-id: fc4797f80842daacd3b3584c5b72035774634edd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46337
We plan to pass around the mappings instead of using global registration api to keep
the mappings local to the transformations user is performing
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D24317436
fbshipit-source-id: 81569b88f05eeeaa9595447e482a12827aeb961f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46227
Follow up from https://github.com/pytorch/pytorch/issues/45419, in
this PR I've removed as many PyCFunction casts as I could from the codebase.
The only ones I didn't remove were the ones with `METH_VARARGS | METH_KEYWORDS`
which have 3 parameters instead of 2 and had to be casted. Example: `
{"copy_", (PyCFunction)(void(*)(void))THPStorage_(copy_), METH_VARARGS |
METH_KEYWORDS, nullptr},`
ghstack-source-id: 114632704
Test Plan: waitforbuildbot
Reviewed By: albanD
Differential Revision: D24269435
fbshipit-source-id: 025cfd43a9a2a3e59f6b2951c1a78749193d77cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46219
- Refactor StaticRuntime and group common data structures, the jit graph, and the script module into a separate struct `InferenceModule`:
```
struct InferenceModule {
explicit InferenceModule(const torch::jit::Module& m);
explicit InferenceModule(std::shared_ptr<torch::jit::Graph> g);
torch::jit::Module module;
std::shared_ptr<torch::jit::Graph> graph;
std::unique_ptr<c10::FunctionSchema> schema;
std::unordered_map<Value*, size_t> value_to_reg;
std::vector<size_t> input_regs; // inputs to the graph
std::vector<size_t> output_regs; // outputs of the graph
std::vector<size_t> internals;
};
```
which is stored in the PyTorchPredictor, as well as the static runtime, and shared across threads. Then this is what's left inside the Static Runtime:
```
mutable std::vector<IValue> reg_;
// The nodes we need to run
std::vector<ProcessedNode> nodes_;
```
`reg_` holds all the weights and activations, which is different across threads during running. `nodes_` holds the op nodes and input/output registers, and is the same across threads for now. We could potentially put other stateful data structures in it, so I kept it inside the static runtime. It could be easily moved into the `InferenceModule` if we decide not to anything else into `ProcessedNode`.
- Added StaticRuntimeOptions so we can toggle certain optimizations on/off, for testing and benchmarking. `cleanup_activations` is an example.
- Integration with PyTorchPredictor. Added a lockfree stack in the PyTorchPredictor to hold all the static runtime instances. Benchmark shows that the `push` and `pop` combo takes about 80 ns, which is quite acceptable.
This diff focuses on threading model only. Benchmarks will be separate.
Reviewed By: bwasti
Differential Revision: D24237078
fbshipit-source-id: fd0d6347f02b4526ac17dec1f731db48424bade1
Summary:
Simplifies some parts of build.sh and removes old references in the code to non-existent trusty images.
There are other parts of the code where trusty is referenced for travis (most of them in third party directories) and I did not touch those. https://github.com/pytorch/pytorch/search?q=trusty
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46594
Reviewed By: seemethere
Differential Revision: D24426796
Pulled By: janeyx99
fbshipit-source-id: 428c52893d2d35c1ddd1fd2e65a4b6575f260492
Summary:
This diff changes `TensorExprKernel::generateStmt` to use flatten loops instead of flatten tensors.
Checked all tests on CPU as well as CUDA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46539
Reviewed By: nickgg
Differential Revision: D24395956
Pulled By: navahgar
fbshipit-source-id: f3792903f2069bda37b571c9f0a840e6fb02f189
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 23cb1db72b
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46578
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: YazhiGao
Differential Revision: D24415308
fbshipit-source-id: c353dcf86cfd833a571a509930a17d09277a73e4
Summary:
Instead of installing Open MPI for build and test jobs with environment *-xenial-cuda*, install Open MPI into the relevant Docker images. This would save time and remove duplication in our scripts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46569
Reviewed By: walterddr
Differential Revision: D24409534
Pulled By: janeyx99
fbshipit-source-id: 6152f2f5daf63744d907dd234bc12d2a5ec58f3d
Summary:
The `IN_CIRCLECI` variable is a misnomer since the flag really indicates when we enable XML reporting because we want to run the test in CI. Since this doesn't necessarily mean CircleCI in particular, IN_CI is more accurate and general.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46567
Reviewed By: walterddr
Differential Revision: D24407642
Pulled By: janeyx99
fbshipit-source-id: 5e141a0571b914310a174a58ac0fde58e9521c6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46289
Previously, vmap had the restriction that any Tensors in the inputs must
not be a part of a nested python collection. This PR relaxes that
restriction. We can also do the same thing for vmap outputs, but I'll
leave that for future work
The mechanism behind vmap is to convert any Tensor inputs (that have
been specified via in_dims) into BatchedTensor. Using a pytree
implementation, that logic becomes:
- flatten inputs
- broadcast in_dims to inputs and unflatten it
- use the flat inputs and flat in_dims to construct BatchedTensors
- unflatten the BatchedTensors into the same structure as the original
inputs.
- Send the unflattened BatchedTensors into the desired function.
Performance
-----------
Some benchmarking using
```
import torch
def foo(a, b, c, d):
return a, b, c, d
x = torch.randn(2, 3)
foo_vmap = torch.vmap(foo)
%timeit foo_vmap(x, x, x, x)
```
shows a slowdown from 15us to 25us on my machine. The 10us overhead is
not a lot, especially since our vmap implementation is a "prototype". We
can work around the performance in the future by either moving part of
the pytree implementation into C++ or depending on a library that has a
performant pytree implementation.
Test Plan
---------
- New tests, also updated old tests.
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D24392892
Pulled By: zou3519
fbshipit-source-id: 072b21dcc6065ab43cfd341e84a01a5cc8ec3daf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46288
This "broadcasts" `pytree` to have the same structure as `spec`
and then flattens it.
I find it hard to describe what that does in words, so here's an example:
- Broadcasting 1 to have the same structure as [0, [0, 0]] would
return [1, [1, 1]]. Further flattening it gives us [1, 1, 1].
- Broadcasting [1, 2] to have the same structure as [0, [0, 0]] would
return [1, [2, 2]]. Further flattening it gives us [1, 2, 2].
What is this used for?
----------------------
The next PR up in the stack uses this helper function to allow vmap to
accept nested data structures. `vmap(fn, in_dims)(*inputs)` allows the
user to specify in_dims with a tree structure that is a sub-graph of
that of `inputs` (where both contain the root of the tree).
For example, one can do `vmap(fn, in_dims=0)(x, y, z)`. `in_dims` is 0
and inputs is (x, y, z). We would like to broadcast in_dims up to the
structure of inputs to get (0, 0, 0).
Another example, is `vmap(fn, in_dims=(0, 1))(x, [y, z])`. `in_dims` is
(0, 1) and inputs is (x, [y, z]). We would like to broadcast in_dims up
to the structure of inputs to get (0, [1, 1]); this value of in_dims is
used to say "let's vmap over dim 0 for x and dim 1 for y and z".
Test Plan
---------
New tests.
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D24392891
Pulled By: zou3519
fbshipit-source-id: 6f494d8b6359582f1b4ab6b8dd6a956d8bfe8ed4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46287
This adds a lightweight `pytree` implementation that is similar to and
inspired by JAX pytrees, tensorflow.nest, deepmind/tree,
TorchBeast's TensorNest, etc.
A *pytree* is Python nested data structure. It is a tree in the sense
that nodes are Python collections (e.g., list, tuple, dict) and the leaves
are Python values. Furthermore, a pytree should not contain reference
cycles.
This PR:
- adds support for flattening and unflattening nested Python list/dict/tuples
Context: nested Tensor inputs for vmap
--------------------------------------
Right now, vmap is restricted to taking in flat lists of tensors. This
is because vmap needs to be able to convert every tensor in the input
that is being vmapped over into a BatchedTensor.
With a pytree library, we can simply flatten the input data structure
(returning the leaves), map all of the Tensors in the flat input to
BatchedTensors, and unflatten the flat list of BatchedTensors into a new
input. Or equivalently, with a `tree_map` function, we can map a nested
python data structure containing Tensors into one containing
BatchedTensors.
Future work
-----------
In some future PRs, we'll add nested input support for vmap. The
prerequisites for that are:
- a `broadcast_to(small, big)` that broadcasts `small` up to `big`.
This is for handling the in_dims to vmap: the in_dims structure must
be compatible with the structure of the inputs.
Test Plan
---------
- New tests in test/test_pytree.py
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D24392890
Pulled By: zou3519
fbshipit-source-id: 7daf7430c5a38354e7d203a72882bd7a9b24cfb1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46057
The code analyser (that uses LLVM and runs in the OSS PyTorch git repo) already produces a YAML file which contains base operator names and the operators that they depend on. Currently, this operator dependency graph is converted into a python dictionary to be imported in BUCK and used there. However, it is mostly fed into other executables by serializing the JSON and the consumer pieces this JSON together by concatenating each argument together. This seems unnecessary. Instead, this diff retains the original YAML file and makes all consumers consume that same YAML file.
ghstack-source-id: 114641582
Test Plan: Build Lite Predictor + sandcastle.
Reviewed By: iseeyuan
Differential Revision: D24186303
fbshipit-source-id: eecf41bf673d90b960c3efe7a1271249f0a4867f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46308
This PR adds a hand optimized version of DeepAndWide model with the goal
of estimating overheads of static runtime. While static runtime is
currently much faster than the existing JIT interpreter, it would be
useful to understand how close we are to an absolutely 0-overhead
system. Currently, this "ideal" implementation is 2x faster than the
static runtime on batchsize=1.
Full benchmark results:
```
Running build/bin/static_runtime_bench
Run on (24 X 2394.71 MHz CPU s)
CPU Caches:
L1 Data 32K (x24)
L1 Instruction 32K (x24)
L2 Unified 4096K (x24)
L3 Unified 16384K (x24)
------------------------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------------------------
BM_deep_wide_base/1 59518 ns 59500 ns 10909
BM_deep_wide_base/8 74635 ns 74632 ns 9317
BM_deep_wide_base/20 82186 ns 82147 ns 9119
BM_deep_wide_fast/1 13851 ns 13851 ns 49825 << new
BM_deep_wide_fast/8 22497 ns 22497 ns 32089 << new
BM_deep_wide_fast/20 23868 ns 23841 ns 31184 << new
BM_deep_wide_jit_graph_executor/1 62786 ns 62786 ns 10835
BM_deep_wide_jit_graph_executor/8 76730 ns 76718 ns 7529
BM_deep_wide_jit_graph_executor/20 78886 ns 78883 ns 8769
BM_deep_wide_jit_profiling_executor/1 69504 ns 69490 ns 10309
BM_deep_wide_jit_profiling_executor/8 75718 ns 75715 ns 9199
BM_deep_wide_jit_profiling_executor/20 75364 ns 75364 ns 9010
BM_deep_wide_static/1 40324 ns 40318 ns 17232
BM_deep_wide_static/8 50327 ns 50319 ns 13335
BM_deep_wide_static/20 53075 ns 53071 ns 12855
BM_deep_wide_static_threaded/threads:8 6258 ns 49873 ns 14008
```
PS: The implementation could probably be optimized even more.
Differential Revision: D24300702
Test Plan: Imported from OSS
Reviewed By: dzhulgakov
Pulled By: ZolotukhinM
fbshipit-source-id: 7870bdef127c39d11bcaa4f03a60eb80a46be58e
Summary:
Adds new rules to the NNC IRSimplifier to take care of the following cases:
* Comparisons which are symbolic but have a constant difference. E.g. this is most useful in cases like `if (x > x + 4) ...` which we can now eliminate.
* Simplification of `Mod` nodes, including simple rules such as `0 % x` and `x % 1`, but also factorization of both sides to find common symbolic multiples. E.g. `(x * y) % x` can be cancelled out to `0`.
See tests for many more examples!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46412
Reviewed By: navahgar
Differential Revision: D24396151
Pulled By: nickgg
fbshipit-source-id: abb954dc930867d62010dcbcd8a4701430733715
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46298
Allow user to specify a list of qualified names for non traceable submodule
or type of the non traceable submodule
See quantize_fx.py for api
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D24294210
fbshipit-source-id: eb1e309065e3dfbf31e63507aaed73587f0dae29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46244
- What does the generated binding code do?
The Python binding codegen produces code that takes the input list of
PyObjects, finds the matching ATen C++ function using PythonArgParser,
converts the PyObjects into C++ types and calls the ATen C++ function:
```
+--------+ parsing +------------------------+ binding +-----------------------+
| PyObjs | ---------> | PythonArgParser Output | ---------> | Cpp Function Dispatch |
+--------+ +------------------------+ +-----------------------+
```
- Are Python arguments 1-1 mapped to C++ arguments?
Python arguments might be reordered, packed, unpacked when binding to
C++ arguments, as illustrated below:
```
// Binding - Reorder & Packing
// aten::empty.names(int[] size, *, Dimname[]? names, ScalarType? dtype=None, Layout? layout=None,
Device? device=None, bool? pin_memory=None, MemoryFormat? memory_format=None) -> Tensor
Python Args Cpp Args
-----------------------------------------------------------
0: size size
1: names names
2: memory_format -------+
3: dtype -----+-|--> options
4: layout / |
5: device / +--> memory_format
6: pin_memory /
7: requires_grad -+
// Binding - Unpacking
// aten::max.names_dim(Tensor self, Dimname dim, bool keepdim=False) -> (Tensor values, Tensor indices)
Python Args Cpp Args
-----------------------------------------------------------
+----> max
/-----> max_values
0: input / self
1: dim / dim
2: keepdim / keepdim
3: out -----+
```
- Why do we want to rewrite the python binding codegen?
The old codegen takes Declarations.yaml as input. It doesn't distinguish
between Python arguments and C++ arguments - they are all mixed together
as a bag of non-typed dict objects. Different methods process these arg
objects and add new attributes for various different purposes. It's not so
obvious to figure out the semantics of these attributes. The complicated
binding logic happens implicitly and scatteredly.
```
+--------------------+
| Native Functions |
+--------------------+
|
|
v
+--------------------+
| Cpp Signatures |
+--------------------+
|
|
v
+--------------------+
| Declarations.yaml |
+--------------------+
| +-------------------------------------+
| +-------> | PythonArgParser Schema |
| | +-------------------------------------+
| | .
| | .
v | .
+--------------------+ +-------------------------------------+
| NonTyped Args Objs | --> | PythonArgParser -> Cpp Args Binding |
+--------------------+ +-------------------------------------+
| .
| .
| .
| +-------------------------------------+
+-------> | Cpp Function Dispatch |
+-------------------------------------+
```
This PR leverages the new immutable data models introduced in the new
aten codegen. It introduces dedicated data models for python schema.
This way, we can not only avoid subtle Declaration.yaml conversions but
also decouple the generation of python schema, python to c++ binding and
c++ function call.
The ultimate state will be like the following diagram:
```
+-------------------+ +-------------------------------------+
+-------> | Python Signatures | --> | PythonArgParser Schema |
| +-------------------+ +-------------------------------------+
| | .
| | .
| | .
+------------------+ | +-------------------------------------+
| Native Functions | +-------> | PythonArgParser -> Cpp Args Binding |
+------------------+ | +-------------------------------------+
| | .
| | .
| | .
| +-------------------+ +-------------------------------------+
+-------> | Cpp Signatures | --> | Cpp Function Dispatch |
+-------------------+ +-------------------------------------+
```
This PR has migrated the core binding logic from
tools/autograd/gen_python_functions.py to tools/codegen/api/python.py.
It produces the byte-for-byte same results (tested with #46243).
Will migrate the rest of gen_python_functions.py in subsequent PRs.
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D24388874
Pulled By: ljk53
fbshipit-source-id: f88b6df4e917cf90d868a2bbae2d5ffb680d1841
Summary: Interval midpoint calculations can overflow (integers). This fixes such an instance.
Test Plan: Standard test rigs.
Reviewed By: iseeyuan
Differential Revision: D24392608
fbshipit-source-id: 0face1133d99cea342abbf8884b14262d50b0826
Summary:
1. Added CudaFusionGuard as the custom TypeCheck for nvfuser; enabled dynamic shape support with profiling executor;
2. dropped support for legacy fuser;
3. re-enabled nvfuser tests;
4. added registration for profiling record to allow profiling on user specified nodes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46452
Reviewed By: zou3519, anjali411
Differential Revision: D24364642
Pulled By: ngimel
fbshipit-source-id: daf53a9a6b6636e1ede420a3a6d0397d4a8b450b
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: f20d61e119
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46443
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: dskhudia
Differential Revision: D24355446
fbshipit-source-id: dc2900367d5de37e67efa963cb2c417e29fe7a88
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46493
This will allow us to override tow following methods of Tracer:
-- get_module_qualified_name: to find qualified name of a module. In default implementation, it looks for module in registered modules and from there it gets to the name, but in some scenarios, the module being called could not be the exact same module that was registered.
-- create_args_for_root: This allows to create and pass custom structured input (like dictionary with specific keys) to the main module, rather than pure proxy objects. This will also allows us to let proxy objects only represent tensors when they are passed to modules.
ghstack-source-id: 114609258
Test Plan: Unit tests passed
Reviewed By: zdevito, bradleyhd
Differential Revision: D24269034
fbshipit-source-id: d7b67f2349dd516b6f7678e41601d6899403d9de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46504
As titled, so we can start seeing who is using this.
Test Plan: CI
Reviewed By: hx89
Differential Revision: D24375254
fbshipit-source-id: ff7b5560d0a6a175cecbf546eefc910759296dbb
Summary:
Retake on https://github.com/pytorch/pytorch/issues/40493 after all the feedback from albanD
This PR implements the generic Lazy mechanism and a sample `LazyLinear` layer with the `UninitializedParameter`.
The main differences with the previous PR are two;
Now `torch.nn.Module` remains untouched.
We don't require an explicit initialization or a dummy forward pass before starting the training or inference of the actual module. Making this much simpler to use from the user side.
As we discussed offline, there was the suggestion of not using a mixin, but changing the `__class__` attribute of `LazyLinear` to become `Linear` once it's completely initialized. While this can be useful, by the time being we need `LazyLinear` to be a `torch.nn.Module` subclass since there are many checks that rely on the modules being instances of `torch.nn.Module`.
This can cause problems when we create complex modules such as
```
class MyNetwork(torch.nn.Module):
def __init__(self):
super(MyNetwork, self).__init__()
self.conv = torch.nn.Conv2d(20, 4, 2)
self.linear = torch.nn.LazyLinear(10)
def forward(self, x):
y = self.conv(x).clamp(min=0)
return self.linear(y)
```
Here, when the __setattr__ function is called at the time LazyLinear is registered, it won't be added to the child modules of `MyNetwork`, so we have to manually do it later, but currently there is no way to do such thing as we can't access the parent module from LazyLinear once it becomes the Linear module. (We can add a workaround to this if needed).
TODO:
Add convolutions once the design is OK
Fix docstrings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44538
Reviewed By: ngimel
Differential Revision: D24162854
Pulled By: albanD
fbshipit-source-id: 6d58dfe5d43bfb05b6ee506e266db3cf4b885f0c
Summary:
According to https://app.circleci.com/pipelines/github/pytorch/pytorch/228154/workflows/31951076-b633-4391-bd0d-b2953c940876/jobs/8290059
TestFFTCUDA.test_fftn_backward_cuda_complex128 takes 242 seconds to finish, where most of the time spent checking 2nd gradient
Refactor common part of test_fft_backward and test_fftn_backward into _fft_grad_check_helper
Introduce `slowAwareTest` decorator
Split test into fast and slow parts by checking 2nd degree gradient only during the slow part
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46509
Reviewed By: walterddr
Differential Revision: D24378901
Pulled By: malfet
fbshipit-source-id: 606670c2078480219905f63b9b278b835e760a66
Summary:
Refactor foreach APIs to use overloads in case of scalar list inputs.
Tested via unit tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45673
Reviewed By: heitorschueroff
Differential Revision: D24053424
Pulled By: izdeby
fbshipit-source-id: 35976cc50b4acfe228a32ed26cede579d5621cde
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45722
This diff does a bunch of things:
1. Introduces some abstractions as detailed in https://fb.quip.com/2oEzAR5MKqbD to help with selective build related codegen in multiple files.
2. Adds helper methods to combine operators, debug info, operator lists, etc...
3. Currently, the selective build machinery querying `op_registration_whitelist` directly at various places in the code. `op_registration_whitelist` is a list of allowed operator names (without overload name). We want to move to a world where the overload names are also included so that we can be more selective about which operators we include. To that effect, it makes sense to hide the checking logic in a separate abstraction and have the build use that abstraction instead of putting all this selective build specific logic in the code-generator itself. This change is attempting to do just that.
4. Updates generate_code, unboxing-wrapper codegen, and autograd codegen to accept the operator selector paradigm as opposed to a selected operator list.
5. Update `tools/code_analyzer/gen_op_registration_allowlist.py` to expose providing an actual structured operator dependency graph in addition to a serialized string.
There are a bunch of structural changes as well:
1. `root_op_list.yaml` and `combined_op_list.yaml` are now actual YAML files (not a space separated list of operator names)
2. `generate_code.py` accepts only paths to operator list YAML files (both old style as well as new style) and not list of operator names on the command line as arguments
3. `gen.py` optionally also accepts a custom build related operators YAML path (this file has information about which operators to register in the generated library).
ghstack-source-id: 114578753
(Note: this ignores all push blocking failures!)
Test Plan:
`buck test caffe2/test:selective_build`
Generated YAML files after the change:
{P143981979}
{P143982025}
{P143982056}
Ensure that the generated files are same before and after the change:
```
[dhruvbird@devvm2490 /tmp/TypeDefault.cpp] find -name "*.cpp" | xargs md5sum
d72c3d125baa7b77e4c5581bbc7110d2 ./after_change/gen_aten/TypeDefault.cpp
42353036c83ebc7620a7159235b9647f ./after_change/lite_predictor_lib_aten/TypeDefault.cpp
d72c3d125baa7b77e4c5581bbc7110d2 ./before_change/gen_aten/TypeDefault.cpp
42353036c83ebc7620a7159235b9647f ./before_change/lite_predictor_lib_aten/TypeDefault.cpp
```
`VariableTypes_N.cpp` are generated the same both before and after the change:
```
[dhruvbird@devvm2490 /tmp/VariableType] find -name "*.cpp" | xargs -n 1 md5sum | sort
3be89f63fd098291f01935077a60b677 ./after/VariableType_2.cpp
3be89f63fd098291f01935077a60b677 ./before/VariableType_2.cpp
40a3e59d64e9dbe86024cf314f127fd6 ./after/VariableType_4.cpp
40a3e59d64e9dbe86024cf314f127fd6 ./before/VariableType_4.cpp
a4911699ceda3c3a430f08c64e8243fd ./after/VariableType_1.cpp
a4911699ceda3c3a430f08c64e8243fd ./before/VariableType_1.cpp
ca9aa611fcb2a573a8cba4e269468c99 ./after/VariableType_0.cpp
ca9aa611fcb2a573a8cba4e269468c99 ./before/VariableType_0.cpp
e18f639ed23d802dc4a31cdba40df570 ./after/VariableType_3.cpp
e18f639ed23d802dc4a31cdba40df570 ./before/VariableType_3.cpp
```
Reviewed By: ljk53
Differential Revision: D23837010
fbshipit-source-id: ad06b1756af5be25baa39fd801dfdf09bc565442
Summary:
Do not post comments if there are no changes in coverage and post only diff stats
Partially addresses an issue raised in https://github.com/pytorch/pytorch/issues/44187
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46499
Reviewed By: walterddr
Differential Revision: D24373480
Pulled By: malfet
fbshipit-source-id: a49d7e661507ad98d5222c119b2f3f3550c1a949
Summary:
`getGraphExecutorOptimize` mandates we don't do any optimizations beyond what's required to run graphs. In this scenario, we don't want to do any profiling as profiling information will not be used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46479
Reviewed By: ZolotukhinM
Differential Revision: D24368292
Pulled By: Krovatkin
fbshipit-source-id: a2c7618d459efca9cb0700c4d64d829b352792a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45164
This PR implements `fft2`, `ifft2`, `rfft2` and `irfft2`. These are the last functions required for `torch.fft` to match `numpy.fft`. If you look at either NumPy or SciPy you'll see that the 2-dimensional variants are identical to `*fftn` in every way, except for the default value of `axes`. In fact you can even use `fft2` to do general n-dimensional transforms.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D24363639
Pulled By: mruberry
fbshipit-source-id: 95191b51a0f0b8e8e301b2c20672ed4304d02a57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46384
Currently, the optimize_for_mobile binary only works on macOS, which is not very convenient to use. This diff introduces a new buck target that separates out the objective-c code. The goal here is to be able to export models for metal on linux machines.
ghstack-source-id: 114499418
Test Plan:
- set `enable_mpscnn` to 1 in pt_defs.bzl
- buck build //xplat/caffe2:optimize_for_mobile --show-full-output
- ./optimize_for_mobile --model="./model.pt" --backend="metal"
- CI
```
[taox@devvm2780.vll0 ~/mobilenetv2] ./optimize_for_mobile --model="./model.pt" --backend="metal"
pt_operator_library(
name = "old_op_library",
ops = [
"aten::Int.Tensor",
"aten::_convolution.deprecated",
"aten::adaptive_avg_pool2d",
"aten::add.Tensor",
"aten::addmm",
"aten::batch_norm",
"aten::dropout",
"aten::hardtanh_",
"aten::reshape",
"aten::size.int",
"aten::t",
"prim::NumToTensor.Scalar",
],
)
find output:
%411 : Tensor = aten::addmm(%self.classifier.1.bias, %input0.1, %694, %26, %26) # /Users/taox/anaconda/lib/python3.7/site-packages/torch/nn/functional.py:1674:0
insert: %817 : Tensor = metal::copy_to_host(%411)
pt_operator_library(
name = "new_op_library",
ops = [
"aten::adaptive_avg_pool2d",
"aten::add.Tensor",
"aten::addmm",
"aten::reshape",
"aten::size.int",
"metal::copy_to_host",
"metal_prepack::conv2d_run",
],
)
```
Reviewed By: linbinyu
Differential Revision: D24322017
fbshipit-source-id: 2b8062b069659bfec78ca4f9f9a5bb9dfbd693d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46383
The old `USE_METAL` is actually being used by Caffe2. Here we introduce a new macro to enable metal in pytorch.
ghstack-source-id: 114499392
Test Plan:
- Circle CI
- The Person Segmentation model works
Reviewed By: linbinyu
Differential Revision: D24322018
fbshipit-source-id: 4e5548afba426b49f314366d89b18ba0c7e745ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46455
After this PR(https://github.com/pytorch/pytorch/pull/46236 ) landed, the `aten::copy_` can no longer be dispatched to Metal kernels.
ghstack-source-id: 114499399
Test Plan:
- Sandcastle CI
- Circle CI
Reviewed By: IvanKobzarev, ailzhang
Differential Revision: D24356769
fbshipit-source-id: 8660ca5be663fdc8985d9eb710ddaadbb43b0ddd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46498
The name of the first arg "ddp_model" is misleading, because it is actually the reducer of DDP model rather than entire model.
This method is called in the file caffe2/torch/nn/parallel/distributed.py:
`dist._register_comm_hook(self.reducer, state, hook)`
ghstack-source-id: 114531188
(Note: this ignores all push blocking failures!)
Test Plan: waitforbuildbot
Reviewed By: pritamdamania87
Differential Revision: D24372827
fbshipit-source-id: dacb5a59e87400d93a2f35da43560a591ebc5499
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43987
This replaces the caffe2 CPU random number (std::mt19937) with at::mt19937 which is the one currently used in pytorch. The ATen RNG is 10x faster than the std one and appears to be more robust given bugs in the std (https://fburl.com/diffusion/uhro7lqb)
For large embedding tables (10GB+) we see UniformFillOp taking upwards of 10 minutes as we're bottlenecked on the single threaded RNG. Swapping to at::mt19937 cuts that time to 10% of the current.
Test Plan: Ran all relevant tests + CI. This doesn't introduce new features (+ is a core change) so existing tests+CI should be sufficient to catch regressions.
Reviewed By: dzhulgakov
Differential Revision: D23219710
fbshipit-source-id: bd16ed6415b2933e047bcb283a013d47fb395814
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45858
When cloning a module that has __setstate__, __getstate__ methods.
We need to load these methods to initialize these modules.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D24116524
Pulled By: bzinodev
fbshipit-source-id: a5111638e2dc903781f6468838c000850d1f9a74
Summary:
This hack was introduced in 2018 and should be able to b removed now. Previously, all Docker images removed NCCL installation to allow some distributed tests to pass: https://github.com/pytorch/pytorch/issues/5877
This should no longer be the case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46495
Reviewed By: malfet
Differential Revision: D24372198
Pulled By: janeyx99
fbshipit-source-id: 6285db77734367f0b8dd363bfd6e9f61a0b58084
Summary:
Instead of installing NCCL for every build and test job with environment `*-xenial-cuda10.1-*`, install NCCL into the Docker image. This would save time and remove duplication in our scripts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46476
Reviewed By: ailzhang
Differential Revision: D24369397
Pulled By: janeyx99
fbshipit-source-id: c107aac9845024d2621eb967ca83c5fc8127a950
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46424
Currently if an exception occurs in a reporter thread the process is killed via std::terminate. This adds support for handling the reporter exception if FLAGS_caffe2_handle_executor_threads_exceptions is set to true.
Test Plan: buck test mode/opt -c python.package_style=inplace //caffe2/caffe2/python:hypothesis_test //caffe2/caffe2:caffe2_test_cpu -- --stress-runs 100
Reviewed By: dahsh
Differential Revision: D24345027
fbshipit-source-id: 0659495c9e27680ebae41fe5a3cf26ce2f455cb3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45193
This change makes it possible to subclass the tracer to add additional
behavior when you know something about the shape of the Proxy objects,
by overriding the defaults for how the tracer tries to make something iterable,
looks for keys for **kwargs, or tries to convert to a boolean.
An example test shows how this can be used to tag inputs with shapes.
It can also be used combined with create_node to do type propagation during
tracing to fullfil requests like iter.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D24258993
Pulled By: zdevito
fbshipit-source-id: 6ece686bec292e51707bbc7860a1003d0c1321e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46051
Creates a subroutine for aborting timed out collectives. This should help modularize the ncclCommWatchdog a bit, since it is growing too large.
ghstack-source-id: 114398496
Test Plan:
Successful Flow Run:
f225037915
f217609101
Reviewed By: jiayisuse
Differential Revision: D23607535
fbshipit-source-id: 0b1c9483bcd3a41847fc8c0bf6b22cdba01fb1e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46445
Fix an instance in which a truncated integer prevents downstream type safety checks.
Test Plan: I'm not sure what's appropriate here.
Reviewed By: albanD
Differential Revision: D24339292
fbshipit-source-id: 15748ec64446344ff1a8344005385906d3484d7c
Summary:
As per title. LU decomposition is used for computing determinants, and I need this functionality to implement the matrix square root. Next PR on my list is to enable `torch.det` on CUDA with complex input.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45898
Reviewed By: heitorschueroff
Differential Revision: D24306951
Pulled By: anjali411
fbshipit-source-id: 168f578fe65ae1b978617a66741aa27e72b2172b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45989
This test was failing internally for the Thrift-based RPC agent, since
it has a different error regex. Use `self.get_timeout_error_regex` which gets
the timeout error string for each backend to fix this.
ghstack-source-id: 114463458
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D24170394
fbshipit-source-id: 9b30945e3e30f36472268d042173f8175ad88098
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46457
Wanted to see if using CopyMatrix specialized for float that uses mkl_somatcopy can be faster but it wasn't. Still want to check in benchmark that can be used later.
Test Plan: .
Reviewed By: dskhudia
Differential Revision: D24345901
fbshipit-source-id: d3e68dbb560e3138fda11c55789cd41bc0715c6d
Summary:
In assertValidDevice() compare device index to `caching_allocator.device_allocator` rather than to `device_no`
Fixes potential crashes when caching allocator is accessed before being initialized, for example by calling something like:
`python -c "import torch;print(torch.cuda.memory_stats(0))"`
Fixes https://github.com/pytorch/pytorch/issues/46437
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46439
Reviewed By: ngimel
Differential Revision: D24350717
Pulled By: malfet
fbshipit-source-id: 714e6e74f7c2367a9830b0292478270192f07a7f
Summary:
As a step to enable C++ code coverage in PyTorch, we want to install `lcov` in the Docker image so that lcov is available to use later on in the process. `lcov` is now installed in all non-rocm non-cuda ubuntu images.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46404
Reviewed By: seemethere
Differential Revision: D24343450
Pulled By: janeyx99
fbshipit-source-id: 3fdab0c0f78c004488e115505740620417f76646
Summary:
Related to https://github.com/pytorch/pytorch/issues/44592
This PR is to fix the deprecated warnings for the nan_to_num function.
Below is the warning message when building the latest code.
```
../aten/src/ATen/native/UnaryOps.cpp: In function ‘at::Tensor& at::native::nan_to_num_out(at::Tensor&,
const at::Tensor&, c10::optional<double>, c10::optional<double>, c10::optional<double>)’:
../aten/src/ATen/native/UnaryOps.cpp:397:45: warning: ‘bool c10::isIntegralType(c10::ScalarType)’
is deprecated: isIntegralType is deprecated.
Please use the overload with 'includeBool' parameter instead. [-Wdeprecated-declarations]
if (c10::isIntegralType(self.scalar_type())) {
```
The deprecated warning is defined in `ScalarType.h`.
d790ec6de0/c10/core/ScalarType.h (L255-L260)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46309
Reviewed By: mrshenli
Differential Revision: D24310248
Pulled By: heitorschueroff
fbshipit-source-id: 0f9f2ad304eb5a2da9d2b415343f2fc9029037af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46449
modifies `ComputeEqualizationScale` to have a single output `S`
Test Plan:
```
buck test caffe2/caffe2/quantization/server:compute_equalization_scale_test
```
plus e2e tests
Reviewed By: hx89
Differential Revision: D23946768
fbshipit-source-id: 137c2d7a58bb858db411248606a5784b8066ab23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46347
Added the named tuple's error messages & workarounds when it returns from a function of a class in Pytorch Mobile.
To identify the error cases (returning NamedTuple type), I used the following coditions:
1) ins.op == RET (for returing)
2) type->kind() == TypeKind::TupleType (for pruning non-tuple types)
3) type->cast<TupleType>().name() (for pruning Tuple type)
- I could use the type's str (str() or repr_str()) directly, but I used whether it has the "name" attribute. Please give the comment for this.
[Information of Tuple and NamedTuple types]
1. Tuple
type->str(): (int, int)
type->repr_str(): Tuple[int, int]
type->kind(): TypeKind::TupleType # different with other types
type()->cast<NamedType>(): True
type()->cast<NamedType>()>name(): False # different with NamedTuple
2. NamedTuple
type->str(): __torch__.myNamedTuple
type->repr_str(): __torch__.myNamedTuple
type->kind(): TypeKind::TupleType # different with other types
type()->cast<NamedType>(): True
type->cast<TupleType>().name() = True # different with Tuple
(From the next diff, I will handle the other error cases: 1) returning List<module class>, Dict<module class> and 2) accessing Module class's member functions)
ghstack-source-id: 114361762
Test Plan:
[Added test results]
buck test mode/dev caffe2/test:mobile -- 'test_unsupported_return'
Summary
Pass: 2
ListingSuccess: 1
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/7036874440497926
[Whole test results]
buck test mode/dev caffe2/test:mobile -- 'test'
Summary
Pass: 11
ListingSuccess: 1
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/4503599664074084
Reviewed By: iseeyuan
Differential Revision: D24291962
fbshipit-source-id: a1a9e24e41a5f1e067738f59f1eae34d07cba31a
Summary:
This PR just adds more polish to the benchmark utils:
1) `common.py`, `timer.py`, and `valgrind_wrapper/timer_interface.py` are now MyPy strict compliant. (except for three violations due to external deps.) Compare and Fuzzer will be covered in a future PR.
2) `CallgrindStats` now uses `TaskSpec` rather than accepting the individual fields which brings it closer to `Measurement`.
3) Some `__repr__` logic has been moved into `TaskSpec` (which `Measurement` and `CallgrindStats` use in their own `__repr__`s) for a more unified feel and less horrible f-string hacking, and the repr's have been given a cleanup pass.
4) `Tuple[FunctionCount, ...]` has been formalized as the `FunctionCounts` class, which has a much nicer `__repr__` than just the raw tuple, as well as some convenience methods (`__add__`, `__sub__`, `filter`, `transform`) for easier DIY stat exploration. (I find myself using the latter two a lot now.) My personal experience is that manipulating `FunctionCounts` is massively more pleasant than the raw tuples of `FunctionCount`. (Though it's still possible to get at the raw data if you want.)
5) Better support for multi-line `stmt` and `setup`.
6) Compare now also supports rowwise coloring, which is often the more natural layout for A/B testing.
7) Limited support for `globals` in `collect_callgrind`. This should make it easier to benchmark JIT models. (CC ZolotukhinM)
8) More unit tests, including extensive tests for the Callgrind stats manipulation APIs.
9) Mitigate issue with `MKL_THREADING_LAYER` when run in Jupyter. (https://github.com/pytorch/pytorch/issues/37377)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46023
Test Plan: changes should be covered by existing and new unit tests.
Reviewed By: navahgar, malfet
Differential Revision: D24313911
Pulled By: robieta
fbshipit-source-id: 835d4b5cde336fb7ff0adef3c0fd614d64df0f77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46191
This PR adds a fallback for in-place operators to vmap. We define an
in-place operator to be an operator that operators in-place on its first
argument and returns the first argument.
The "iteration over batch" logic is mostly copied from the out-of-place
vmap fallback. I wanted to try to not copy this but the iteration logic
is pretty entangled with the rest of the logic; one alternative was to
use if/else statements inside batchedTensorForLoopFallback but then
there are ~3-4 different sites where we would need that.
When in-place operations are not possible
=========================================
Sometimes, an in-place operation inside of vmap is not possible. For
example, `vmap(Tensor.add_, (None, 0))(torch.rand(3), torch.rand(B0, 3))`
is not possible because the tensor being written to in-place has size
[3] and the other tensor has size [B0, 3].
We detect if this is the case and error out inside the in-place
fallback.
Test Plan
=========
Added some new tests to `test_vmap.py`.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D24335240
Pulled By: zou3519
fbshipit-source-id: 1f60346059040dc226f0aeb80a64d9458208fd3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46190
Moved `createLevelsBitset` to BatchedTensorImpl.h and renamed it to
`createVmapLevelsBitset`. I moved it there because I want to use it in
another file in a future diff.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D24335241
Pulled By: zou3519
fbshipit-source-id: 1c225a00b6da9c69dc7fbc61516bf7257298355c
Summary: Add operator benchmark for 4bit/8bit embedding lookups in `aibench`.
Test Plan:
```
buck build //caffe2/benchmarks/operator_benchmark/pt:qembedding_bag_lookups_test
aibench-cli adhoc -c 'buck run //caffe2/benchmarks/operator_benchmark/pt:qembedding_bag_lookups_test'
````
The run was successful in aibench: https://www.internalfb.com/intern/aibench/details/738300474https://www.internalfb.com/intern/aibench/details/346463246
Reviewed By: radkris-git
Differential Revision: D24268413
fbshipit-source-id: 7fb4ff75da47f8f327edab562c5d29bb69e00b8d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46037
I now isolated the special case to be only between cuda tensor bases and cpu tensor exponents. My previous fix was not a complete fix--it fixed some stuff but broke others. The current fix is a more complete fix:
```
In [1]: import torch
In [2]: a=torch.randn(3)
In [3]: b=torch.tensor(2, device="cuda")
In [4]: torch.pow(a,b) #should not work and throws exception now!
In [5]: a=torch.tensor(3, device="cuda")
In [6]: b=torch.tensor(2)
In [7]: torch.pow(a,b) #should work, and now does
In [8]: a=torch.randn(3, device="cuda")
In [9]: torch.pow(a,b) # yeah, that one is fixed and still works
```
To add a test case to reflect the change, I had to modify the existing setup a little bit. I think it is an improvement but would appreciate any tips on how to make it better!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46320
Reviewed By: malfet
Differential Revision: D24306610
Pulled By: janeyx99
fbshipit-source-id: cc74c61373d1adc2892a7a31226f38895b83066a
Summary: as title
Test Plan:
run ai bench
buck run aibench:run_bench -- -b aibench/specifications/models/caffe2/squeezenet/squeezenet.json --remote --devices s9f
INFO 2020-10-15 12:24:21 everstore.py: 177: Everstore: Try internal upload
INFO 2020-10-15 12:24:21 subprocess_with_logger.py: 56: Running: clowder put --fbtype=24665 /tmp/aibenchj5w4craj/build.sh
INFO 2020-10-15 12:24:25 subprocess_with_logger.py: 39: Process Succeeded: clowder put --fbtype=24665 /tmp/aibenchj5w4craj/build.sh
INFO 2020-10-15 12:24:25 everstore.py: 185: Uploading /tmp/aibenchj5w4craj/build.sh
everstore handle: GIxbhAQoAOdQNqwCAEam42Z-pfQrbllgAAAP
url:
INFO 2020-10-15 12:24:25 run_remote.py: 182: program: //everstore/GIxbhAQoAOdQNqwCAEam42Z-pfQrbllgAAAP/build.sh
INFO 2020-10-15 12:24:25 everstore.py: 177: Everstore: Try internal upload
INFO 2020-10-15 12:24:25 subprocess_with_logger.py: 56: Running: clowder put --fbtype=24665 /tmp/aibenchj5w4craj/program
INFO 2020-10-15 12:24:32 subprocess_with_logger.py: 39: Process Succeeded: clowder put --fbtype=24665 /tmp/aibenchj5w4craj/program
INFO 2020-10-15 12:24:32 everstore.py: 185: Uploading /tmp/aibenchj5w4craj/program
everstore handle: GICWmAA66cD0qNMCAJh4vKJzTU8-bllgAAAP
url:
INFO 2020-10-15 12:24:32 run_remote.py: 182: program: //everstore/GICWmAA66cD0qNMCAJh4vKJzTU8-bllgAAAP/program
Scuba => https://fburl.com/scuba/caffe2_benchmarking/w6tvinl0
Job status for SM-G960F-8.0.0-26 (sm-g960f-26,galaxy-s9f,s9f) is changed to CLAIMED
Job status for SM-G960F-8.0.0-26 (sm-g960f-26,galaxy-s9f,s9f) is changed to RUNNING
Job status for SM-G960F-8.0.0-26 (sm-g960f-26,galaxy-s9f,s9f) is changed to DONE
ID:0 NET latency: 82192.9
You can find more info via https://our.intern.facebook.com/intern/aibench/details/915762192256210
Reviewed By: smeenai
Differential Revision: D24340103
fbshipit-source-id: cea15bc866361b397b4e1b001e609eb7e9f9aa47
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: abc56f644d
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46395
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: malfet
Differential Revision: D24333846
fbshipit-source-id: 307bbb7e857cd9e472d03374d3d3941128d807b5
Summary:
This PR adds support for complex-valued input for `torch.pinverse`.
Fixed cuda SVD implementation to return singular values with real dtype.
Fixes https://github.com/pytorch/pytorch/issues/45385.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45819
Reviewed By: heitorschueroff
Differential Revision: D24306539
Pulled By: anjali411
fbshipit-source-id: 2fe19bc630de528e0643132689e1bc5ffeaa162a
Summary:
Those files are never directly built, only included in other files.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46335
Reviewed By: albanD
Differential Revision: D24316737
Pulled By: gchanan
fbshipit-source-id: 67bb95e7f4450e3bbd0cd54f15fde9b6ff177479
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42845
- In server builds, always allow the compiler to inline the kernel into the unboxing wrapper, i.e. optimize for perf.
- In mobile builds, never inline the kernel into the unboxing wrapper, i.e. optimize for binary size.
Note that this only applies for registration API calls where we can actually inline it, i.e. calls with `TORCH_FN` or some of the old API calls.
Registrations that give the registration API a runtime function pointer can't inline and won't do so on server either.
Note also that in server builds, all we do is **allow** the compiler to inline. We don't force inlining.
ghstack-source-id: 114177591
Test Plan:
waitforsandcastle
https://www.internalfb.com/intern/fblearner/details/225217260/
Reviewed By: ezyang
Differential Revision: D23045772
fbshipit-source-id: f74fd600eaa3f5cfdf0da47ea080801a03db7917
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46327
### Summary
Update the COMPILE_TIME_MAX_DEVICE_TYPES to 12 as we landed a new Metal backend.
### Test Plan
- Circle CI
Test Plan: Imported from OSS
Reviewed By: IvanKobzarev
Differential Revision: D24309189
Pulled By: xta0
fbshipit-source-id: eec076b7e4fc94bab11840318821aa554447e541
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45940
**Summary**
In `try_ann_to_type`, if an annotation has an attribute named
`__torch_script_class__`, it is assumed to be a TorchScript class that
has already been scripted. However, if it is a class that extends
another class, this code path causes a crash because it looks up the
JIT type for the class by name in the compilation unit. This JIT type
obviously cannot exist because inheritance is not supported.
This commit fixes this by looking up the qualified name of a class
in torch.jit._state._script_class in order to ascertain whether it has
already been scripted (instead of looking for a `__torch_script_class__`
attribute on the class object.
**Test Plan**
This commit adds a unit test consisting of the code sample from the
issue that reported this problem.
**Fixes**
This commit fixes#45860.
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D24310027
Pulled By: SplitInfinity
fbshipit-source-id: 9f8225f3316fd50738d98e3544bf5562b16425b6
Summary:
This diff restores previous behavior of silently allow overflowing when inserting instructions. The behavior was changed recently in https://github.com/pytorch/pytorch/issues/45382. But it started to break some existing use cases that haver overflow problems.
Restoring original behavior but throw a warning to to unblock existing use cases where overflowing happens.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46369
Reviewed By: kwanmacher, wanchaol, fbhuba
Differential Revision: D24324345
Pulled By: gmagogsfm
fbshipit-source-id: 1c0fac421d4de38f070e21059bbdc1b788575bdf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45993
Some bug exposed via updated test and validation code.
Also enabled this test to be run on CI instead of just mobile only test.
Test Plan:
cpu_profiling_allocator_test
Imported from OSS
Reviewed By: dzhulgakov
Differential Revision: D24172599
fbshipit-source-id: da0d2e1d1dec87b476bf39a1c2a2ffa0e4b5df66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45934https://pytorch.org/docs/stable/checkpoint.html pytorch checkpoint requires all input to the function being checkpointed to requires_grad, but this assumption is not necessarily try. consider the following two examples
```
output = MultiheadedMaskedAtten(input, mask)
output = LSTM(input, seq_length)
```
both length and mask are tensors that won't requires grad, currently if you try to checkpoint torch.autograd.backward will complain
```
File "/mnt/xarfuse/uid-124297/7d159c34-seed-nspid4026531836-ns-4026531840/torch/autograd/function.py
", line 87, in apply
return self._forward_cls.backward(self, *args)
File "/mnt/xarfuse/uid-124297/7d159c34-seed-nspid4026531836-ns-4026531840/torch/utils/checkpoint.py"
, line 99, in backward
torch.autograd.backward(outputs, args)
File "/mnt/xarfuse/uid-124297/7d159c34-seed-nspid4026531836-ns-4026531840/torch/autograd/__init__.py
", line 132, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: element 1 of tensors does not require grad and does not have a grad_fn
```
this diff allows skipping the non-grad-requiring tensor when running autograd.backward.
added documentation for this feature as well.
Test Plan: added unit test to make sure partial tensor grads can be used in checkpoint().
Differential Revision: D24094764
fbshipit-source-id: 6557e8e74132d5a392526adc7b57b6998609ed12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46074
I found 2 instances where the NAME parameter passed in to the dispatch macros is not a C++ string (constant) (i.e. double quoted compile time string).
In one instance it is a single quoted multi-character constant (I don't know what this resolves to in practice), and in the other instance, it is an unquoted identified generated as a result of concatenating 2 identifiers using the `##` operator.
In addition, I found 2 instances where the `NAME` of the tag passed in is not a constant character array, but an `std::string` variable instead. I am changing it to a constant character array with the same name as the variable name (earlier). For the purposes of any code using this data, eveything remains the same since the code was string-izing the value anyway using `#NAME` so it would get the name of the variable and not the contents.
ghstack-source-id: 113928208
Test Plan: I have a commit (not part of this change set) that attempts to print the `NAME` argument passed in to the various dispatch macros to be able to do some analysis. These weren't expanding correctly for the uses cases that are fixed in this diff.
Reviewed By: ezyang
Differential Revision: D24211393
fbshipit-source-id: 28953d9f859315b371a60ae34b19671720209c99
Summary:
import print_function to make setup.py invoked by Python2 print human readable error:
```
% python2 setup.py
Python 2 has reached end-of-life and is no longer supported by PyTorch.
```
Also, remove `future` from the list of the PyTorch package install dependencies
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46317
Reviewed By: walterddr, bugra
Differential Revision: D24305004
Pulled By: malfet
fbshipit-source-id: 9181186170562384dd2c0e6a8ff0b1e93508f221
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46325
Otherwise, mutating them would make the uses/users lists inaccurate.
You can still mutate the node by assigning a new value to .args or .kwargs
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D24308672
Pulled By: zdevito
fbshipit-source-id: a5305e1d82668b36e46876c3bc517f6f1d03dd78
Summary:
Fixes https://github.com/pytorch/pytorch/issues/40362
The new `three_phase` option provides a way of constructing schedules according to the scheme recommended in [Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates](https://arxiv.org/abs/1708.07120).
Note that this change maintains backwards compatibility, and as a result the default behaviour of OneCycleLR remains quite counter-intuitive.
vincentqb
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42715
Reviewed By: heitorschueroff
Differential Revision: D24289744
Pulled By: vincentqb
fbshipit-source-id: e4aad87880716bb14613c0aa8631e43b04a93e5c
Summary:
Only under static axes does opset 9 supports no-op squeeze when dim is not 1.
Updating the test case where it was setting dynamic axes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45369
Reviewed By: anjali411
Differential Revision: D24280180
Pulled By: bzinodev
fbshipit-source-id: d7cda88ab338a1c41a68052831dcebe739a3843c
Summary:
Even when dim is None, there are cases when flatten can be exported.
Also enable test_densenet in scripting mode
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45632
Reviewed By: VitalyFedyunin
Differential Revision: D24116994
Pulled By: bzinodev
fbshipit-source-id: 76da6c073ddf79bba64397fd56b592de850034c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46045
PG NCCL functionality differs based on certain binary environment
variables such as NCCL_BLOCKING_WAIT and NCCL_ASYNC_ERROR_HANDLING. Previously
we had separate helper function to parse these env vars and set class variables
accordingly. This PR introduces a general purpose function for this purpose.
ghstack-source-id: 114209823
Test Plan:
Ran the following flow with NCCL_BLOCKING_WAIT set, and ensured the
ProcessGroup constructor set blcokingWait_ to true: f223454701
Reviewed By: jiayisuse
Differential Revision: D24173982
fbshipit-source-id: b84db2dda29fcf5d163ce8860e8499d5070f8818
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46049
Adding support for the deleteKey API in the c10d HashStore.
ghstack-source-id: 113874207
Test Plan:
Added C++ tests to check whether deleteKey function works, and
whether it returns an exception for attempting to delete non-existing keys.
Reviewed By: jiayisuse
Differential Revision: D24067657
fbshipit-source-id: 4c58dab407c6ffe209585ca91aa430850261b29e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46048
This PR adds support for the getNumKeys API for the HashStore
ghstack-source-id: 113874241
Test Plan: Added C++ tests for the HashStore::getNumKeys
Reviewed By: jiayisuse
Differential Revision: D24067658
fbshipit-source-id: 2db70a90f0ab8ddf0ff03cedda59b45ec987af07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46292
since it is not needed
Test Plan: Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D24290815
fbshipit-source-id: 5cc24a305dbdfee5de3419dc83a9c3794d949300
Summary:
When the input to an indexing operation is a boolean, for example array[True] = value,
the subsequent index_put node formed needs to be converted to masked_scatter/masked_fill node based on the type of val the indexing node is equated. If that value is just a single scalar, then we use the masked_fill functionality and if value is a tensor of appropriate size, we use the masked_scatter functionality.
Fixes https://github.com/pytorch/pytorch/issues/34054
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45584
Reviewed By: VitalyFedyunin
Differential Revision: D24116921
Pulled By: bzinodev
fbshipit-source-id: ebd66e06d62e15f0d49c8191d9997f55edfa520e
Summary:
The `i` variable in `Line 272` may cause ambiguity in understanding. I think it should be named as `epoch` variable.
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45944
Reviewed By: agolynski
Differential Revision: D24219486
Pulled By: vincentqb
fbshipit-source-id: 2af0408594613e82a1a1b63971650cabde2b576e
Summary:
Reopen the PR: https://github.com/pytorch/pytorch/pull/45837
This PR add a new feature for Partitioner() class called size_based_partition. Given a list of devices with the same memory size, this function could distribute graph nodes into different devices. To implement this feature, several help functions are created in Partitioner.py and GraphManipulation.py.
An unit test is also added in test/test_fx_experimental.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46282
Reviewed By: gcatron
Differential Revision: D24288470
Pulled By: scottxu0730
fbshipit-source-id: e81b1e0c56e34f61e497d868882126216eba7538
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46121
Otherwise, mutating them would make the uses/users lists inaccurate.
You can still mutate the node by assigning a new value to .args or .kwargs
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D24232288
Pulled By: zdevito
fbshipit-source-id: c95b1a73ae55ad9bdb922ca960c8f744ff732100
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45950
A pain point for debugging failed training jobs due to NCCL errors has
been understanding the source of the error, since NCCL does not itself report
too many details (usually just "unhandled {system, cuda, internal} error").
In this PR, we add some basic debug information about what went wrong. The information is collected by grepping the NCCL codebase for when these errors are thrown. For example, `ncclSystemError` is what is thrown when system calls such as malloc or munmap fail.
Tested by forcing `result = ncclSystemError` in the macro. The new error
message looks like:
```RuntimeError: NCCL error in:
caffe2/torch/lib/c10d/ProcessGroupNCCL.cpp:759, unhandled system error, NCCL
version 2.7.3
ncclSystemError: System call (socket, malloc, munmap, etc) failed.
```
The last line is what we have added to the message.
In the future, we will also evaluate setting NCCL_DEBUG=WARN, by which NCCL
provides more details about errors sa well.
ghstack-source-id: 114219288
Test Plan: CI
Reviewed By: mingzhe09088
Differential Revision: D24155894
fbshipit-source-id: 10810ddf94d6f8cd4989ddb3436ddc702533e1e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45942
We only need to keep track of this for traversing the autograd graph
when find_unused_parameters=True. Without that, we populate and keep this
mapping in memory, which occupies sizeof(pointer) * number of grad accumulators
of extra memory.
ghstack-source-id: 114219289
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D24154407
fbshipit-source-id: 220d723e262f36590a03a3fd2dab47cbfdb87d40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46221
The RPC framework only allowed sending RPCs based on provided
WorkerInfo or name. When using RPC with DDP, sometimes it might just be easier
to refer to everything in terms of ranks since DDP doesn't support names yet.
As a result, support a `to` parameter in the RPC APIs which allow for
specifying a rank as well would be helpful.
ghstack-source-id: 114207172
Test Plan:
1) waitforbuildbot
2) Unit Tests
Reviewed By: mrshenli
Differential Revision: D24264989
fbshipit-source-id: 5edf5d92e2bd2f213471dfe7c74eebfa9efc9f70
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46174
Want to separate the real changes in this file from noisy reformatting changes, so check in this reformatting first.
Test Plan: N/A
Reviewed By: pritamdamania87
Differential Revision: D24246841
fbshipit-source-id: 50bb671b0a2feab38acaa4fc171608e379fc92e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46265
tl;dr - we must remove tensor-related logging from the
WorkNCCL::operator<< function, otherwise printing the work objects tracked in
the workMetaList_ will cause segfaults.
The Work objects we track in the workMetaList for the NCCL Async Error
Handling mechanism don't have any `outputs_`. As described in the workEnqueue
function, destructing the output tensors calls into autograd_meta, which
happens in the user thread, but our system destructs work objects in the
workCleanupThread, so this could lead to a deadlock scenario. We avoid this
problem by not tracking the tensors in the work objects in the workMetaList
(it's called work meta list because these work objects only track the metadata
and not the actual tensors), so when the WorkNCCL::operator<< function tried to
log tensor shapes for work objects from the watchdog thread, the async error
handling mechanism hanged (in the desync test) or segfaulted (in the desync
flow). This PR removes the tensor-related logging from the operator<< function.
ghstack-source-id: 114192929
Test Plan: Verified that this fixes the desync test and desync flow.
Reviewed By: jiayisuse
Differential Revision: D24268204
fbshipit-source-id: 20ccb8800aa3d71a48bfa3cbb65e07ead42cd0dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46116
Ideally I would just use one of the existing preprocessor flags such as `FBCODE_CAFFE2`, but this implies a whole bunch of other things elsewhere, so it is not really a solution for ovrsource.
Test Plan: CI green, we are able to disable it internally with `-DNVALGRIND`
Reviewed By: malfet
Differential Revision: D24227360
fbshipit-source-id: 24a3b393cf46d6a16acca0a9ec52610d4bb8704f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45872
`VariableType_N.cpp` is generated in a sharded manner to speed up compilationt time. Same for `generated_unboxing_wrappers_N.cpp`. However, `VariableTypeEverything.cpp` exists, but `generated_unboxing_wrappers_everything.cpp` does not. These files have all the registration/implementation code in them for easier debugging of codegen logic.
This diff adds `generated_unboxing_wrappers_everything.cpp`.
ghstack-source-id: 113606771
Test Plan: Build + CI
Reviewed By: iseeyuan
Differential Revision: D24124405
fbshipit-source-id: 1f6c938105e17cd4b14502978483a1b178c777dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45551
The FP16 version of SparseNormalize op in Caffe2 is missing. This Diff adds FP16 support to unblock MC process of adding FP16 to Dper3.
Check https://fb.quip.com/L0T2AXGwUY3n#EReACAeifk3 .
One question is whether the pure FP16 Sparse Normalized op will affect the accuracy? Maybe we should do it in FP32 domain.
ghstack-source-id: 114184398
Test Plan:
```
buck run mode/opt //caffe2/caffe2/python/operator_test:sparse_normalize_test
```
```
buck run mode/opt -c python.package_style=inplace mode/no-gpu //caffe2/caffe2/python/benchmarks:sparse_normalize_benchmark -- --fp16
```
Reviewed By: jspark1105
Differential Revision: D24005618
fbshipit-source-id: 8b918ec4063fdaafa444779b95206ba2b7b38537
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45878
Support int32 as indices and offsets for embedding_bag_byte|4bit_rowwise_offsets, to avoid costly casting operators such as `aten::to`.
Currently we don't make the assumption that indices and offsets should be the same type, which should not be a problem since downstream fbgemm supports either cases.
Test Plan:
```
buck test mode/dev caffe2/test:quantization -- --stress-runs 100 test_embedding_bag
```
Reviewed By: radkris-git
Differential Revision: D23854367
fbshipit-source-id: 6758a4252b36a7fe2890f37d38d66f20651e850e
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: a570f94657
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46271
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D24285369
fbshipit-source-id: a5928251ec8386891d31d2f88193aa97e4ad715f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46250
Previously the type of GetAttr nodes was getting set incorrectly and wasn't matching the module type
Test Plan:
Existing quantization tests
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D24279872
fbshipit-source-id: 2b2e3027f6e9ad8ba9e9b7937bd5cc5daaf6e17c
Summary:
As reported in https://github.com/pytorch/pytorch/issues/46020, something seems to go wrong with the storage._write_file method used with a BytesIO and a GPU buffer.
Given that we were going to create the intermediate buffer (currently via BytesIO) anyway, we might as well use storage.cpu() to move the storage to the CPU. This appears to work better.
This is a hot fix, further investigation is highly desirable. In particular, I don't have a reproducing test to show.
Fixes https://github.com/pytorch/pytorch/issues/46020
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46028
Reviewed By: bdhirsh
Differential Revision: D24194370
Pulled By: gchanan
fbshipit-source-id: 99d463c4accb4f1764dfee42d7dc98e7040e9ed3
Summary:
The android publish snapshot job was failing since it wasn't utilizing
the new docker tagging system
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46266
Reviewed By: walterddr
Differential Revision: D24282375
Pulled By: seemethere
fbshipit-source-id: 58e6ca80bda0b81b09f8614b9ccec764a2f26b49
Summary:
In response to https://github.com/pytorch/pytorch/issues/11578. This is a test run to see if CI (and other internal systems) works fine with pytest style tests.
- Creates a separate `distributions` directory within `test`.
- For testing, this rewrites the `constraint` tests as parameterized tests in pytest. I don't plan to convert any other tests to pytest style, but only expose this option for adding new tests, if required.
If this is a success, we can move `EXAMPLES` in `test_distributions` into a separate file that can be imported by both pytest and unittest style tests. cc. fritzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45648
Reviewed By: ezyang, colesbury
Differential Revision: D24080248
Pulled By: neerajprad
fbshipit-source-id: 1f2e7d169c3c291a3051d0cece17851560fe9ea9
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46037
I'm not sure this is the most performant solution, but this works:
torch.pow(cuda_tensor, 5) should work and worked before.
torch.pow(cuda_tensor, torch.tensor(5)), should work **and works now!**
torch.pow(cuda_tensor, torch.tensor((5,))), should NOT work and complain the tensors are on different devices and indeed continues to complain.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46185
Reviewed By: glaringlee, malfet
Differential Revision: D24257687
Pulled By: janeyx99
fbshipit-source-id: 2daf235d62ec5886d7c153da05445c2ec71dec98
Summary:
The record_stream method was hard coded for CUDA device. Define the record_stream in the native_functions.yaml to enable the dynamic dispatch to different end device.
Fixes https://github.com/pytorch/pytorch/issues/36556
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44301
Reviewed By: glaringlee
Differential Revision: D23763954
Pulled By: ezyang
fbshipit-source-id: e6d24f5e7892b56101fa858a6cad2abc5cdc4293
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45990
In #45890 we introduced the concept of a CppSignature, which bundled
up all of the information necessary to declare a C++ signature for
the cpp API. This PR introduces analogous concepts for dispatcher
and native: DispatcherSignature and NativeSignature.
The three interfaces are not particularly well coupled right now,
but they do have some duck typing coincidences:
- defn() which renders the C++ definition "bool f(int x)"
- decl() which renders the C++ declaration "bool f(int x = 2)"
- type() which renders the C++ function type "bool(int)"
Maybe at some point we'll introduce a Protocol, or a supertype.
Many other methods (like arguments()) have varying types. These
signatures also have some helper methods that forward back to real
implementations in the api modules. Something to think about is
whether or not we should attempt to reduce boilerplate here or
not; I'm not too sure about it yet.
The net effect is we get to reduce the number of variables we
have to explicitly write out in the codegen, since now these are all
bundled together into a signature. Something extra special happens
in BackendSelect, where we now dynamically select between dispatcher_sig
and native_sig as "how" the backend select is implemented.
A little bit of extra cleanup:
- Some places where we previously advertised Sequence, we now advertise
a more informative Tuple.
- defn() may take an optional positional parameter overriding the entire
name, or a kwarg-only prefix parameter to just add a prefix to the
name.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D24223100
Pulled By: ezyang
fbshipit-source-id: f985eced08af4a60ba9641d125d0f260f8cda9eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45975
I reordered declarations in the faithful API reimplementation to
make sure the diffs lined up nicely; they're not necessary now.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D24223102
Pulled By: ezyang
fbshipit-source-id: 77c6ae40c9a3dac36bc184dd6647d6857c63a50c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45974
The term "legacy dispatcher" caused a bunch of confusion between
me and Sebastian when discussing what the intended semantics of
legacy dispatcher argument is. Legacy dispatcher argument implies
that you ought NOT to use it when you have use_c10_dispatcher: full;
but that's not really what's going on; legacy dispatcher API describes
the API that you write native:: functions (NativeFunctions.h) to.
Renaming it here makes this more clear.
I applied these seds:
```
git grep -l 'legacy_dispatcher' | xargs sed -i 's/legacy_dispatcher/native/g'
git grep -l 'legacydispatcher' | xargs sed -i 's/legacydispatcher/native/g'
git grep -l 'LegacyDispatcher' | xargs sed -i 's/LegacyDispatcher/Native/g'
```
and also grepped for "legacy" in tools/codegen and fixed documentation.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D24223101
Pulled By: ezyang
fbshipit-source-id: d1913b8b823b3b95e4546881bc0e876acfa881eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45918
This groups together related native functions (functional, inplace, out)
into a single group. It's not used by anything but Jiakai said this
would be useful for his stuff so I'm putting it in immediately.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D24163526
Pulled By: ezyang
fbshipit-source-id: 9979b0fe9249c78e4a64a50c5ed0e2ab99f499b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45890
This rewrite is as per my comments at https://github.com/pytorch/pytorch/pull/44087#issuecomment-701664506
I did the rewrite by reverting #44087 and then reimplementing it on top.
You may find it easier to review by diffing against master with only #44087
reverted.
There are two main ideas.
First, we now factor cpp argument processing into two phases operating
on three representations of data:
1. `FunctionSchema` - this is the source from native_functions.yaml
2. `Union[Argument, ThisArgument, TensorOptionsArgument]` - this is
the arguments after doing some basic semantic analysis to group
them (for TensorOptions) or identify the this argument (if this
is a method). There is only ever one of these per functions.
3. `Union[CppArgument, CppThisArgument, CppTensorOptionsArgument]` -
this is the arguments after we've elaborated them to C++. There
may be multiple of these per actual C++ signature.
You can think of (2) as common processing, whereas (3) bakes in specific
assumptions about whether or not you have a faithful or non-faithful
signature.
Second, we now have CppSignature and CppSignatureGroup representing
the *total* public C++ API signature. So those dataclasses are what
know how to render definitions/declarations, and you no longer have
to manually type it out in the Functions/TensorMethods codegen.
Here is an exhaustive accounting of the changes.
tools.codegen.api.types
- CppSignature and CppSignatureGroup got moved to tools.codegen.api.types
- Add new CppThisArgument and CppTensorOptionsArguments (modeled off
of ThisArgument and TensorOptionsArguments) so that we can retain
high level semantic structure even after elaborating terms with C++
API information. Once this is done, we can refine
CppArgument.argument to no longer contain a ThisArgument (ThisArgument
is always translated to CppThisArgument. Note that this doesn't
apply to TensorOptionsArguments, as those may be expanded or not
expanded, and so you could get a single CppArgument for 'options')
- Add no_default() functional mutator to easily remove default arguments
from CppArgument and friends
- Add an explicit_arguments() method to CppArgument and friends to
extract (flat) argument list that must be explicitly written in the signature.
This is everything except (Cpp)ThisArgument, and is also convenient
when you don't care about the extra structure of
CppTensorOptionsArguments
tools.codegen.api.cpp
- group_arguments is back, and it doesn't send things directly to a
CppSignatureGroup; instead, it moves us from representation (1) to (2)
(perhaps it should live in model). Here I changed my mind from my
PR comment; I discovered it was not necessary to do classification at
grouping time, and it was simpler and easier to do it later.
- argument got split into argument_not_this/argument/argument_faithful.
argument and argument_faithful are obvious enough what they do,
and I needed argument_not_this as a more refined version of argument
so that I could get the types to work out on TensorOptionsArguments
tools.codegen.api.dispatcher
- Here we start seeing the payoff. The old version of this code had a
"scatter" mode and a "gather" mode. We don't need that anymore:
cppargument_exprs is 100% type-directed via the passed in cpp
arguments. I am able to write the functions without any reference
to use_c10_dispatcher
tools.codegen.gen
- Instead of having exprs_str and types_str functions, I moved these to
live directly on CppSignature, since it seemed pretty logical.
- The actual codegen for TensorMethods/Functions is greatly simplified,
since (1) all of the heavy lifting is now happening in
CppSignature(Group) construction, and (2) I don't need to proxy one
way or another, the new dispatcher translation code is able to handle
both cases no problem. There is a little faffing about with ordering
to reduce the old and new diff which could be removed afterwards.
Here are codegen diffs. For use_c10_dispatcher: full:
```
+// aten::_cudnn_init_dropout_state(float dropout, bool train, int dropout_seed, *, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False) -> Tensor
Tensor _cudnn_init_dropout_state(double dropout, bool train, int64_t dropout_seed, const TensorOptions & options) {
- return _cudnn_init_dropout_state(dropout, train, dropout_seed, optTypeMetaToScalarType(options.dtype_opt()), options.layout_opt(), options.device_opt(), options.pinned_memory_opt());
+ static auto op = c10::Dispatcher::singleton()
+ .findSchemaOrThrow("aten::_cudnn_init_dropout_state", "")
+ .typed<Tensor (double, bool, int64_t, c10::optional<ScalarType>, c10::optional<Layout>, c10::optional<Device>, c10::optional<bool>)>();
+ return op.call(dropout, train, dropout_seed, optTypeMetaToScalarType(options.dtype_opt()), options.layout_opt(), options.device_opt(), options.pinned_memory_opt());
}
```
Otherwise:
```
+// aten::empty_meta(int[] size, *, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=None, MemoryFormat? memory_format=None) -> Tensor
Tensor empty_meta(IntArrayRef size, c10::optional<ScalarType> dtype, c10::optional<Layout> layout, c10::optional<Device> device, c10::optional<bool> pin_memory, c10::optional<MemoryFormat> memory_format) {
- return empty_meta(size, TensorOptions().dtype(dtype).layout(layout).device(device).pinned_memory(pin_memory), memory_format);
+ static auto op = c10::Dispatcher::singleton()
+ .findSchemaOrThrow("aten::empty_meta", "")
+ .typed<Tensor (IntArrayRef, const TensorOptions &, c10::optional<MemoryFormat>)>();
+ return op.call(size, TensorOptions().dtype(dtype).layout(layout).device(device).pinned_memory(pin_memory), memory_format);
}
```
Things that I probably did not get right:
- The Union[Argument, TensorOptionsArguments, ThisArgument] and
the Cpp variants are starting to get a little unwieldy. Not sure if
this means I should add a supertype (or at the very least an
alias); in some cases I do purposely omit one of these from the Union
- Code may not necessarily live in the most logical files. There isn't
very much rhyme or reason to it.
- The fields on CppSignature. They're not very well constrained and
it will be better if people don't use them directly.
- Disambiguation. We should do this properly in #44087 and we don't
need special logic for deleting defaulting for faithful signatures;
there is a more general story here.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D24144035
Pulled By: ezyang
fbshipit-source-id: a185f8bf9df8b44ca5718a7a44dac23cefd11c0a
Summary:
Fix the DistributedDataParallelSingleProcessTest to work around a limitation in DistributedDataParallel where the batch_size needs to evenly divide by the number of GPUs used
See https://github.com/pytorch/pytorch/issues/46175
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46186
Reviewed By: bdhirsh
Differential Revision: D24264664
Pulled By: mrshenli
fbshipit-source-id: 6cfd6d29e97f3e3420391d03b7f1a8ad49d75f48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46112
### Summary
This PR adds the support of running torchscript models on iOS GPU via Metal (Inference only). The feature is currently in prototype state, API changes are expected. The tutorial and the documents will be added once it goes to beta.
allow-large-files
- Users API
```
auto module = torch::jit::load(model);
module.eval();
at::Tensor input = at::ones({1,3,224,224}, at::ScalarType::Float).metal();
auto output = module.forward({input}).toTensor().cpu();
```
- Supported Models
- Person Segmentation v106 (FB Internal)
- Mobilenetv2
- Supported Operators
- aten::conv2d
- aten::addmm
- aten::add.Tensor
- aten::sub.Tensor
- aten::mul.Tensor
- aten::relu
- aten::hardtanh
- aten::hardtanh_
- aten::sigmoid
- aten::max_pool2d
- aten::adaptive_avg_pool2d
- aten::reshape
- aten::t
- aten::view
- aten::log_softmax.int
- aten::upsample_nearest2d.vec
- Supported Devices
- Apple A9 and above
- iOS 10.2 and above
- CMake scripts
- `IOS_ARCH=arm64 ./scripts/build_ios.sh -DUSE_METAL=ON`
### Test Plan
- Circle CI
ghstack-source-id: 114155638
Test Plan:
1. Sandcastle CI
2. Circle CI
Reviewed By: dreiss
Differential Revision: D23236555
fbshipit-source-id: 98ffc48b837e308bc678c37a9a5fd8ae72d11625
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45920
See docs for new way of defining custom modules
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D24145856
fbshipit-source-id: 488673fba503e39e8e303ed5a776fe36899ea4e3
Summary:
Kill jit_simple test config because it was no different than a regular diff config
Fix pattern matching in test.sh for `jit_legacy` config, as it was expecting `legacy_jit`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46230
Reviewed By: walterddr
Differential Revision: D24270144
Pulled By: malfet
fbshipit-source-id: 2e00dba288af1f1e904334b952033aa21062927a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45708
This makes it possible to define reasonable semantics for what happens
when a node in the list is deleted. In particular the iteration over nodes
will continue at the node that was after the deleted node _when it was deleted_.
If the new node is also deleted, we skip it and, continue to the node after it.
Eventually we either reach a node still in the list or we reach the end of the list.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D24089516
Pulled By: zdevito
fbshipit-source-id: d01312d11fe381c8d910a83a08582a2219f47dda
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46078
The peak memory usage of ddp comm hook has increased due to an extra copy of gradient tensors. To reduce the memory usage, decompress the fp16 tensor in place of the tensor stored in the the gradient bucket.
#Closes: https://github.com/pytorch/pytorch/issues/45968
ghstack-source-id: 113996453
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed:c10d -- test_accumulate_gradients_no_sync_allreduce_hook
Also verified the decrease in memory consumption with some toy modeling exmaples.
Reviewed By: pritamdamania87
Differential Revision: D24178118
fbshipit-source-id: 453d0b52930809bd836172936b77abd69610237a
Summary:
Fixes two bugs reported by https://github.com/pytorch/pytorch/issues/45953 in the NNC Cuda codegen which could break when using Half floats:
1. The Registerizer will generate new scalars with the type of the load being replaced, and doesn't have Cuda specific logic to avoid using the half type. I've added a quick mutator to coerce these to float, similar to the existing load casting rules.
2. We're not handling explicit casts to Half inserted by the user (in the report the user being the JIT). Addressing this by replacing these with casts to Float since thats the type we do Half math in.
Fixes https://github.com/pytorch/pytorch/issues/45953.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46129
Reviewed By: glaringlee
Differential Revision: D24253639
Pulled By: nickgg
fbshipit-source-id: 3fef826eab00355c81edcfabb1030332cae595ac
Summary:
Removed test_tensorexpr from the JIT-EXECUTOR exclude list.
CI will now run those tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46188
Reviewed By: glaringlee
Differential Revision: D24255433
Pulled By: janeyx99
fbshipit-source-id: f18e5b41d49b439407c1c24ef6190ef68bc809bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46110
## Motivation
* `Cancel` is now added to `OperatorBase` and `NetBase` (https://github.com/pytorch/pytorch/pull/44145).
* We need a test to cover and exhibit that we can cancel stuck net and propagate error with plan executor.
## Summary
* Added PlanExecutorTest `ErrorPlanWithCancellableStuckNet` for plan executor.
* Set cancelCount to zero at the beginning of tests to avoid global state be carried over in some test environment.
Test Plan:
## Unit Test Added
```
buck test caffe2/caffe2:caffe2_test_cpu -- PlanExecutorTest
buck test caffe2/caffe2:caffe2_test_cpu -- PlanExecutorTest --stress-runs 1000
```
Reviewed By: d4l3k
Differential Revision: D24226577
fbshipit-source-id: c834383bfe6ab50747975c229eb42a363eed3458
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46036
Previously, this function didn't do error-bounds checking on the GetItem (GET_ITEM) calls, which led to issues like https://github.com/pytorch/pytorch/issues/46020.
A better solution would be to use pybind, but given writing the file is going to dominate bounds checking, this is strictly better.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D24228370
Pulled By: gchanan
fbshipit-source-id: f5d0a3d21ff12b4380beefe1e9954fa81ea2f567
Summary:
Some internal tests were sporadically failing for https://github.com/pytorch/pytorch/pull/45648. The cause of this is a bug in `Binomial.__init__` that references the lazy `logits` attribute and sets it when not needed. This cleans up the `is_scalar` logic too which isn't needed given that `broadcast_all` will convert `Number` to a `tensor`.
The reason for the flakiness is the mutation of the params dict by the first test, which is fixed by doing a shallow copy. It will be better to convert this into a pytest parameterized test once https://github.com/pytorch/pytorch/pull/45648 is merged.
cc. fritzo, ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46055
Reviewed By: agolynski
Differential Revision: D24221151
Pulled By: neerajprad
fbshipit-source-id: 15aae90a692ee6aed729c9f1d2d1b1388170a3c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45742
Add a new flag to native_functions.yaml: `use_c10_dispatcher: hacky_wrapper_for_legacy_signatures`
and the codegen only wraps kernels in the aforementioned wrapper if that flag is set.
Apart from that, `use_c10_dispatcher: hacky_wrapper_for_legacy_signatures` is equivalent to `full`,
i.e. it has full boxing and unboxing support.
This greatly reduces the number of ops we apply the hacky_wrapper to, i.e. all ops marked as `use_c10_dispatcher: full` don't have it anymore.
ghstack-source-id: 113982139
Test Plan:
waitforsandcastle
vs fbcode:
https://www.internalfb.com/intern/fblearner/details/214511705/
vs base diff:
https://www.internalfb.com/intern/fblearner/details/214693207/
Reviewed By: ezyang
Differential Revision: D23328718
fbshipit-source-id: be120579477b3a05f26ca5f75025bfac37617620
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45838
`ARCH_OPT_FLAGS` was the old name of `MKLDNN_ARCH_OPT_FLAGS`, which has been renamed in [this commit](2a011ff02e (diff-a0abcbf647ed740b80615fb5b1614a44L97)), but not updated in pytorch.
As its default value will be set to sse4.1, some kernels are going to fail on the legacy arch that does not support SSE4.1. This patch was to make this flag effective.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46082
Reviewed By: glaringlee
Differential Revision: D24252149
Pulled By: agolynski
fbshipit-source-id: 7079deed373d664763c5888feb28795e5235caa8
Summary: Added OpSchema::NeedsAllInputShapes wrapper around the TensorInferenceFunction to fix exception when referencing the dim array when the input shape was unknown. There may be other operators that could use a similar change, these are just the ones that was causing InferShapesAndTypes throw an exception for my examples.
Test Plan: Tested with notebook n352716
Differential Revision: D23745442
fbshipit-source-id: d63eddea47d7ba595e73c4693d34c790f3a329cc
Summary: I think this preprocessor check is incorrect. The fused multiply-add (FMA) instructions are not part of AVX2.
Test Plan: CI
Reviewed By: jspark1105
Differential Revision: D24237836
fbshipit-source-id: 44f9b9179918332eb85ac087827726300f56224e
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: da05c8db75
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46151
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D24239896
fbshipit-source-id: 78ff9c100e39ef9a429eafd11a4c158dabd5cb15
Summary:
* Removes incorrect statement that "the vector norm will be applied to the last dimension".
* More clearly describe each different combination of `p`, `ord`, and input size.
* Moves norm tests from `test/test_torch.py` to `test/test_linalg.py`
* Adds test ensuring that `p='fro'` and `p=2` give same results for mutually valid inputs
Fixes https://github.com/pytorch/pytorch/issues/41388
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42696
Reviewed By: bwasti
Differential Revision: D23876862
Pulled By: mruberry
fbshipit-source-id: 36f33ccb6706d5fe13f6acf3de8ae14d7fbdff85
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46124
We want to make sure we can actually fuse kernels within a fairly
tight time budget. So here's a quick benchmark of codegen for a simple
pointwise activation function (swish). I kept all the intermediate tensors
separate to force TE to actually do inlining.
Test Plan:
```
buck run mode/opt //caffe2/benchmarks/cpp/tensorexpr:tensorexpr_bench
```
I've only run in debug mode so results aren't super meaningful, but even in
that mode it's 18ms for compilation, 15 of which are in llvm.
Update, opt build mode:
```
----------------------------------------------------------------------------
Benchmark Time CPU Iterations
----------------------------------------------------------------------------
BM_CompileSwish 5123276 ns 5119846 ns 148
BM_CompileSwishLLVMOnly 4754361 ns 4753701 ns 160
```
Reviewed By: asuhan
Differential Revision: D24232801
fbshipit-source-id: d58a8b7f79bcd9244c49366af7a693e09f24bf76
Summary:
This PR modifies `benchmarks/tensorexpr`. It follows up[ https://github.com/pytorch/pytorch/issues/44101](https://github.com/pytorch/pytorch/pull/44101) and further supports characterizing fusers with dynamic shape benchmarks. Dynamic shape condition models the use case when the input tensor shape changes in each call to the graph.
Changes include:
Added an auxiliary class `DynamicShape `that provides a simple API for enabling dynamic shapes in existing test cases, example can be found with `DynamicSimpleElementBench`
Created new bench_cls: `DynamicSimpleElementBench`, `DynamicReduce2DInnerBench`, `DynamicReduce2DOuterBench`, and `DynamicLSTM`. They are all dynamic shaped versions of existing benchmarks and examples of enabling dynamic shape with `DynamicShape`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46107
Reviewed By: glaringlee
Differential Revision: D24229400
Pulled By: bertmaher
fbshipit-source-id: 889fece5ea87d0f6f6374d31dbe11b1cd1380683
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46059
These files are not generated sources, and they also already exist in another variable in the same file (`libtorch_extra_sources`).
Test Plan: CI green
Reviewed By: malfet
Differential Revision: D24203450
fbshipit-source-id: 0c9e12cd1a292c5484961876d4fa7f2341a3165b
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 75ea7ce6f8
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46125
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D24233275
fbshipit-source-id: 526c44aba92e622c6b46c17b467e146303a77b57
Summary: Adding a new flag shape_is_set to the structs for shape inference on in-place op to prevent duplicated inference.
Test Plan:
buck test mode/opt-clang caffe2/caffe2/opt:bound_shape_inference_test
buck test mode/opt-clang caffe2/caffe2/fb/opt:shape_info_utils_test
Reviewed By: ChunliF
Differential Revision: D24134767
fbshipit-source-id: 5142e749fd6d1b1092a45425ff7b417a8086f215
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46077
Some of QNNPACK quantized kernels were not handling NHWC correctly,
the data written respected the input format but the memory flag
was always set to contiguous. This PR
1. adds testing for NHWC for qnnpack activations
2. fixes those activations which did not set the memory format on the output
Test Plan:
```
python test/test_quantization.py TestQuantizedOps.test_qhardsigmoid
python test/test_quantization.py TestQuantizedOps.test_leaky_relu
python test/test_quantization.py TestQuantizedOps.test_hardswish
python test/test_quantization.py TestQNNPackOps.test_qnnpack_tanh
python test/test_quantization.py TestQNNPackOps.test_qnnpack_sigmoid
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D24213257
fbshipit-source-id: 764fb588a8d8a0a6e6e4d86285904cdbab26d487
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44988
The new NCCL async error handling feature throws an exception from the
workCleanup Thread if one of the NCCL operations encounters an error or times
out. This PR adds an error log to make it more clear to the user why the
training process crashed.
ghstack-source-id: 114002493
Test Plan:
Verified that we see this error message when running with the desync
test.
Reviewed By: pritamdamania87
Differential Revision: D23794801
fbshipit-source-id: 16a44ce51f01531062167fb762a8553221363698
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46095
Adds logging on usage of public quantization APIs. This only works in FB codebase
and is a no-op in OSS.
Test Plan: The test plan is fb-only
Reviewed By: raghuramank100
Differential Revision: D24220817
fbshipit-source-id: a2cc957b5a077a70c318242f4a245426e48f75e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46067
In our store tests, we expect there to be an exception when we call
get on a recently-deleted key. Unforunately, the store waits for the timeout
period for the key to be set before throwing, which causes the tests to idel
wait for 5+ minutes. This PR decreases the timeouts before this set call so
these tests run faster.
ghstack-source-id: 113917315
Test Plan: Ran both the Python and C++ tests.
Reviewed By: pritamdamania87
Differential Revision: D24208617
fbshipit-source-id: c536e59ee305e0c01c44198a3b1a2247b8672af2
Summary:
Fixes a crash bug in the IRSimplifier when the LHS is a Term (e.g. 2x) and the RHS is a Polynomial (e.g. 2x+1).
This case crashes 100% of the time so I guess it's not very common in models we've been benchmarking.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46108
Reviewed By: agolynski
Differential Revision: D24226593
Pulled By: nickgg
fbshipit-source-id: ef454c855ff472febaeba16ec34891df932723c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45994
Send/Recv tests were disabled because of the https://github.com/pytorch/pytorch/issues/42517. With that issue fixed, this diff enables those tests.
ghstack-source-id: 113970569
Test Plan: waitforsandcastle
Reviewed By: jiayisuse
Differential Revision: D24172484
fbshipit-source-id: 7492ee2e9bf88840c0d0086003ce8e99995aeb91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45174
Introduce different types of exceptions that map to different failures
of torch.multiprocessing.spawn. The change introduces three different exception types:
ProcessRaisedException - occurs when the process initiated by spawn raises an exception
ProcessExitedException - occurs when the process initiated by spawn exits
The following logic will allow frameworks that use mp.spawn to categorize failures.
This can be helpful for tracking metrics and enhancing logs.
Test Plan: Imported from OSS
Reviewed By: taohe
Differential Revision: D23889400
Pulled By: tierex
fbshipit-source-id: 8849624c616230a6a81158c52ce0c18beb437330
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46010
When training jobs running with NCCL fail sometimes it is hard to
debug the reason of the failure and our logging doesn't provide enough
information at times to narrow down the issue.
To improve the debugging experience, I've enhanced our logging to add a lot
more information about what the ProcessGroup is doing under the hood.
#Closes: https://github.com/pytorch/pytorch/issues/45310
Sample output:
```
> I1002 15:18:48.539551 1822062 ProcessGroupNCCL.cpp:528] [Rank 2] NCCL watchdog thread started!
> I1002 15:18:48.539533 1821946 ProcessGroupNCCL.cpp:492] [Rank 2] ProcessGroupNCCL initialized with following options:
> NCCL_ASYNC_ERROR_HANDLING: 0
> NCCL_BLOCKING_WAIT: 1
> TIMEOUT(ms): 1000
> USE_HIGH_PRIORITY_STREAM: 0
> I1002 15:18:51.080338 1822035 ProcessGroupNCCL.cpp:530] [Rank 1] NCCL watchdog thread terminated normally
> I1002 15:18:52.161218 1821930 ProcessGroupNCCL.cpp:385] [Rank 0] Wrote aborted communicator id to store: NCCLABORTEDCOMM:a0e17500002836080c8384c50000000100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
> I1002 15:18:52.161238 1821930 ProcessGroupNCCL.cpp:388] [Rank 0] Caught collective operation timeout for work: WorkNCCL(OpType=ALLREDUCE, TensorShape=[10], Timeout(ms)=1000)
> I1002 15:18:52.162120 1821957 ProcessGroupNCCL.cpp:530] [Rank 0] NCCL watchdog thread terminated normally
> I1002 15:18:58.539937 1822062 ProcessGroupNCCL.cpp:649] [Rank 2] Found key in store: NCCLABORTEDCOMM:a0e17500002836080c8384c50000000100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000, from rank: 0, aborting appropriate communicators
> I1002 15:19:34.740937 1822062 ProcessGroupNCCL.cpp:662] [Rank 2] Aborted communicators for key in store: NCCLABORTEDCOMM:a0e17500002836080c8384c50000000100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
> I1002 15:19:34.741678 1822062 ProcessGroupNCCL.cpp:530] [Rank 2] NCCL watchdog thread terminated normally
```
ghstack-source-id: 113961408
Test Plan: waitforbuildbot
Reviewed By: osalpekar
Differential Revision: D24183463
fbshipit-source-id: cb09c1fb3739972294e7edde4aae331477621c67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46075
Removes these from public docs for now as we are still
iterating/formalizing these APIs. Will add them back once they are part of a
PyTorch release.
ghstack-source-id: 113928700
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D24211510
fbshipit-source-id: 3e36ff6990cf8e6ef72b6e524322ae06f9097aa2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45933
Occasionally users run DDP with models with unused params, in this
case we would like to surface an error message telling them to run with
find_unused_params=True. However, a recent change to rebuild_buckets logic (https://github.com/pytorch/pytorch/pull/44798) made
it so that we raise a size mismatch error when this happens, but the
information about unused parameters is likely to be more useful and likely to
be the most common case of failure. Prefer raising this error over the
subsequent size mismatch errors.
ghstack-source-id: 113914759
Test Plan: Added unittest
Reviewed By: mrshenli
Differential Revision: D24151256
fbshipit-source-id: 5d349a988b4aac7d3e0ef7b3cd84dfdcbe9db675
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 974d2b41e7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46079
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D24213375
fbshipit-source-id: b80786490079f9f56a90e10fbb476d0963cf2abc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46080
temp removal of ErrorPlanWithCancellableStuckNet, will fill out more
Test Plan:
```
buck test caffe2/caffe2:caffe2_test_cpu -- PlanExecutorTest
```
remove a test
Reviewed By: fegin
Differential Revision: D24213971
fbshipit-source-id: e6e600bad00b45c726311193b4b3238f1700526e
Summary:
`TCPStoreTest.test_numkeys_delkeys` takes 5+ min (mostly in idle wait for socket timeout)
`TestDataLoader.test_proper_exit` and `TestDataLoaderPersistentWorkers.test_proper_exit` take 2.5 min each
`TestXNNPACKConv1dTransformPass.test_conv1d_with_relu_fc` takes 2 min to finish
Add option to skip reporting test classes that run for less than a second to `print_test_stats.py` and speed up `TestTorchDeviceTypeCUDA.test_matmul_45724_cuda`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46068
Reviewed By: mruberry
Differential Revision: D24208660
Pulled By: malfet
fbshipit-source-id: 780e0d8be4f0cf69ea28de79e423291a1f3349b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45319
## Motivation
* `Cancel` is now added to `OperatorBase` and `NetBase` (https://github.com/pytorch/pytorch/pull/44145)
* We need a test to cover and exhibit that we can cancel stuck net and propagate error with plan executor.
## Summary
* Added `ErrorPlanWithCancellableStuckNet` for plan executor.
* We set a plan with two nets: one stuck net with blocking operator that never returns, and one with error
net with error op that throws, and tested it throw and cancel.
Test Plan:
## Unit Test added
```
buck test caffe2/caffe2:caffe2_test_cpu -- PlanExecutorTest
buck test caffe2/caffe2:caffe2_test_cpu -- PlanExecutorTest --stress-runs 100
```
```
Summary
Pass: 400
ListingSuccess: 2
```
Reviewed By: d4l3k
Differential Revision: D23920548
fbshipit-source-id: feff41f73698bd6ea9b744f920e0fece4ee44438
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45926
torch/csrc/cuda/nccl.cpp is compiled as part of torch_cuda library and thus by calling this function from ProcessGroupNCCCL.cpp it avoids linking 2nd instance of libnccl.a into torch_python
Fixes similiar issue as https://github.com/pytorch/pytorch/issues/42517
ghstack-source-id: 113910530
Test Plan: waitforsandcastle
Reviewed By: jiayisuse
Differential Revision: D24147802
fbshipit-source-id: d8901fdb31bdc22ddca2364f8050844639a1beb3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45873
This diff adds support for sending/receiving to/from self. It also fixed a bug when p2p operations are not used by all processes.
ghstack-source-id: 113910526
Test Plan: waitforsandcastle
Reviewed By: jiayisuse
Differential Revision: D24124413
fbshipit-source-id: edccb830757ac64f569e7908fec8cb2b43cd098d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45783
After the previous device maps commits, `pipeWrite` might throw. In
this case, if we increment active calls before `pipeWrite` on the
caller, that active call won't be decremented properly when `pipeWrite`
throws. As a result, `shutdown` can silently timeout. I noticed this
as some tests take more than 60s to finish.
This commit extract the tensor device checking logic out of pipeWrite,
and make sure the error is thrown before the active call count is
incremented.
Differential Revision: D24094803
Test Plan: Imported from OSS
Reviewed By: mruberry
Pulled By: mrshenli
fbshipit-source-id: d30316bb23d2afd3ba4f5540c3bd94a2ac10969b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45919
As discussed with JIT team, we'll run symbolic trace in quantization functions
prepare_fx now takes orginal pytorch model (torch.nn.Module) instead of `GraphModule` as input
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D24145857
fbshipit-source-id: 2b7a4ca525a7a8c23a26af54ef594c6a951e4024
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46003
sparse is confusing because itt is used in training for sparse gradients
Test Plan: Imported from OSS
Reviewed By: radkris-git, qizzzh
Differential Revision: D24178248
fbshipit-source-id: 0a2b595f3873d33b2ce25839b6eee31d2bfd3b0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45997
The current sparse field using in the float module is for sparse gradients, which is not applicable
to inference. The sparse field in the quantizd ops denotes pruned weights.
Test Plan:
python test/test_quantization.py TestQuantizeDynamicJitOps.test_embedding_bag
Imported from OSS
Reviewed By: qizzzh
Differential Revision: D24176543
fbshipit-source-id: a05b4ff949e0375462ae411947f68076e1b460d2
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45558
This assertion failure is caused by the incorrect implementation of ``aten::set_grad_enabled`` in [torch/csrc/jit/runtime/register_special_ops.cpp](https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/runtime/register_special_ops.cpp#L436). The current implementation is:
```cpp
Operator(
"aten::set_grad_enabled(bool val) -> ()",
[](Stack* stack) {
torch::GradMode::set_enabled(pop(stack).toBool());
push(stack, IValue());
},
aliasAnalysisConservative()),
```
which push a ``None`` on to the evaluation stack after calling ``set_enabled``. But according to the signature, the behavior is incorrect as the signature says this function won't return a value. I guess the original author might be confused by the behavior of Python, which pushes a ``None`` on to the evaluation stack when the function definition does not end with a return statement with an explicit result value.
If ``aten::set_grad_enabled`` pushes a ``None`` on to the evaluation stack, each time it's called, the evaluation stack will accumulate an extra ``None``. In our case, ``with torch.no_grad():`` will cause ``aten::set_grad_enabled`` to be called twice, so when the ``forward`` method finishes, the evaluation stack will be ``[None, None, Tensor]``. But the return statement of ``GraphFunction::operator()`` in [torch/csrc/jit/api/function_impl.cpp](https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/api/function_impl.cpp#L51) is ``return stack.front();`` which will try to extract a tensor out of a ``None`` thus causes the assertion failure.
The solution is simple, just remove the push in the implementation of ``aten::set_grad_enabled``.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45559
Reviewed By: albanD
Differential Revision: D24142153
Pulled By: SplitInfinity
fbshipit-source-id: 75aad0e38bd912a437f7e1a1ee89ab4445e35b5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45981
This is a recommit of previously reverted D20850851 (3fbddb92b1).
TL;DR - combining condition_variables and atomics is a bad idea
https://stackoverflow.com/questions/49622713/c17-atomics-and-condition-variable-deadlock
This also adds some ifdefs to disable the death test for mobile, xplat and tsan builds since forking doesn't play nicely with them.
Test Plan:
buck test mode/opt //caffe2/caffe2/python:hypothesis_test -- --stress-runs 1000 test_atomic_iter_with_concurrent_steps --timeout 120
buck test mode/opt //caffe2/caffe2/python:hypothesis_test -- --stress-runs 100
buck test mode/opt caffe2/caffe2:caffe2_test_cpu -- PlanExecutorTest --stress-runs 100
no timeouts https://www.internalfb.com/intern/testinfra/testconsole/testrun/7036874440059883/
will ensure no timeouts in OSS
Reviewed By: walterddr, dahsh
Differential Revision: D24165505
fbshipit-source-id: 17cd23bfbcd9c2826a4067a387023d5186353196
Summary:
Adds a new transform to the NNC compiler, which adds support for buffer access caching. All accesses within a provided scope are redirected to a cache which is initialized or written back as necessary at the boundaries of that scope. For TVM fans, this is essentially a combination of cache_reads and cache_writes. E.g. it can do this kind of thing:
Before:
```
for (int i = 0; i < 64; i++) {
for (int j = 0; j < 64; j++) {
A[i, j] = i * j;
}
}
for (int i_1 = 0; i_1 < 20; i_1++) {
for (int j_1 = 0; j_1 < 10; j_1++) {
B[i_1, j_1] = (A(i_1 + 30, j_1 + 40)) + (A(i_1 + 31, j_1 + 41));
}
```
After `cacheAccesses(A->buf(), "A_local", j_loop);`
```
for (int i = 0; i < 64; i++) {
for (int j = 0; j < 64; j++) {
A[i, j] = i * j;
}
}
for (int i_1 = 0; i_1 < 20; i_1++) {
for (int i_2 = 0; i_2 < 2; i_2++) {
for (int j_1 = 0; j_1 < 11; j_1++) {
A_local[i_2, j_1] = A[(i_2 + i_1) + 30, j_1 + 40];
}
}
for (int j_2 = 0; j_2 < 10; j_2++) {
B[i_1, j_2] = (A_local[1, j_2 + 1]) + (A_local[0, j_2]);
}
}
```
Or this reduction:
```
for (int l1 = 0; l1 < 4; l1++) {
sum[l1] = 0.f;
for (int n1_1 = 0; n1_1 < 3; n1_1++) {
for (int m1_1 = 0; m1_1 < 2; m1_1++) {
sum[l1] = (sum[l1]) + (scale[(6 * l1 + 2 * n1_1) + m1_1]);
}
}
}
```
After `l.cacheAccesses(d->buf(), "d_local", n_loop);`:
```
for (int l1 = 0; l1 < 4; l1++) {
Allocate(d_local, float, {1});
sum[l1] = 0.f;
d_local[0] = 0.f;
for (int n1_1 = 0; n1_1 < 3; n1_1++) {
for (int m1_1 = 0; m1_1 < 2; m1_1++) {
d_local[0] = (d_local[0]) + (scale[(6 * l1 + 2 * n1_1) + m1_1]);
}
}
sum[l1] = (sum[l1]) + (d_local[0]);
Free(d_local);
}
```
I had originally planned to write `cacheReads` and `cacheWrites` wrappers so we could use them just like their TVM cousins, but they just ended up being big masses of checking that reads or writes weren't present. Didn't feel too useful so I removed them, but let me know.
This is based on bounds inference and inherits a few bugs present in that functionality, which I will address in a followup.
While working on this I realized that it overlaps heavily with `computeAt`: which is really just `cacheReads` + `computeInline`. I'm considering refactoring computeAt to be a wrapper around those two transforms. ZolotukhinM opinions on this?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45869
Reviewed By: mruberry
Differential Revision: D24195276
Pulled By: nickgg
fbshipit-source-id: 36a58ae265f346903187ebc4923637b628048155
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46043
As title, this is necessary for some internal linter thing
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D24197316
Pulled By: suo
fbshipit-source-id: 07e69fd6ce1937a0caa5838d6995eeed1be5162d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45791
Most of the lowering for log1p and lgamma already existed, add JIT integration.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D24169536
Pulled By: eellison
fbshipit-source-id: a009c77a3471f3b5d378bad5de6d8e0880e9da3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45790
Making sure that more tests invoke a run with a Fusion Group.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D24169534
Pulled By: eellison
fbshipit-source-id: a2666df53fbb12c64571e960f59dbe94df2437e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45789
Making sure that more tests invoke a run with a Fusion Group.
Test Plan: Imported from OSS
Reviewed By: Krovatkin
Differential Revision: D24169535
Pulled By: eellison
fbshipit-source-id: 54d7af434772ba52144b12d15d32ae30460c0c3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45788
We were only running the traced graph once, which would not yet have been fused at that point. We should run for num_profiled_runs + 1, and also assert that all nodes in the graph were fused.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D24169537
Pulled By: eellison
fbshipit-source-id: 8499bb1a5bd9d2221b1f1c54d6352558cf07ba9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45847
Original PR here https://github.com/pytorch/pytorch/pull/45084. Created this one because I was having problems with ghstack.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D24136629
Pulled By: heitorschueroff
fbshipit-source-id: dd7c7540a33f6a19e1ad70ba2479d5de44abbdf9
Summary:
This enables the cuda fuser on ROCm and enables tests for them.
Part of this patch is based on work of Rohith Nallamaddi, thank you.
Errors are my own, of course.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45965
Reviewed By: seemethere
Differential Revision: D24170457
Pulled By: walterddr
fbshipit-source-id: 3dd25b3501a41d2f00acba3ce8642ce51c49c9a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45892
Previously we were using hashtable (`std::unordered_map` in OSS, `folly::F14FastMap` in fb) for workspace, a container for all the IValues in the graph. Hashtable based lookups can be expensive. This diff replaces the hashtable with `std::vector` and extra bookkeepings are introduced to keep track of the indices of graph inputs/outputs in `StaticRuntime` and op inputs/outputs in `ProcessedNode`.
Reviewed By: dzhulgakov
Differential Revision: D24098763
fbshipit-source-id: 337f835ee144985029b5fa2ab98f9bcc5e3606b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45853
The method name in README is not consistent with actual implementation.
Reviewed By: qizzzh
Differential Revision: D24114849
fbshipit-source-id: d979e324c768708e99b8cc5b87e261f17c22a883
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45908
As per subj, existing logging does not explain the cause of the error
Test Plan: unit tests pass.
Reviewed By: SplitInfinity
Differential Revision: D23609965
fbshipit-source-id: 818965176f7193c62035e3d2f0547bb525fea0fb
Summary:
Many of our functions contain same warnings about results reproducibility. Make them use common template.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45748
Reviewed By: colesbury
Differential Revision: D24089114
Pulled By: ngimel
fbshipit-source-id: e6aa4ce6082f6e0f4ce2713c2bf1864ee1c3712a
Summary:
The primary HTE configuration (for `HTE@clang-tidy` project) is stored at the parent config `~/fbsource/fbcode.clang-tidy`. The diff enables inheretence of that configuration.
Note: `facebook-hte-` checks will not be used until switch to HTE2clang-tidy be made.
Note: `clang-diagnostic-*` will start work. As result clang warning messages can be dublicated: one time from HTE and another time from clang-diagnostic
Test Plan: N/A
Reviewed By: wfarner
Differential Revision: D24099167
fbshipit-source-id: 2e092fe678ad3e53a4cef301ce1cb737cf8401e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45948
No functionality changes expected, it's just a preparation for further
changes in the LoopNest interface.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D24156000
Pulled By: ZolotukhinM
fbshipit-source-id: f95ab07aac0aba128bc4ed5376a3251ac9c31c06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45946
Also, make these functions static - they are not using anything from
`LoopNest` and can be applied to any `Stmt`.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D24156002
Pulled By: ZolotukhinM
fbshipit-source-id: 1c7d205f85a2a1684e07eb836af662f10d0a50fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45936
`Tensor` has been a view into a `Function` that was supposed to be used
for a more general case when we have multiple computations over the same
domain (aka multiple output functions). We have never got to a point
where we need this and now have other ideas in mind on how to support
this case if need be. For now, let's just nuke `Function` to reduce the
overall system complexity.
The change should not affect any existing behavior.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D24153214
Pulled By: ZolotukhinM
fbshipit-source-id: 26d5f11db5d661ff5e1135f4a49eff1c6d4c1bd5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45952
Pull Request resolved: https://github.com/pytorch/glow/pull/4967
When glow compilation meets with nonrecoverable fatal error (hardware is busted), we would like to throw a special exception other than the normal caffe2::EnforceNotMet so that we can signal the upper layer application to handle it differently.
Test Plan: Manually code some error and add LOG(FATAL) in the special exception path and wait for application to fatal.
Reviewed By: ipiszy
Differential Revision: D24156792
fbshipit-source-id: 4ae21bb0d36c89eac331fc52dd4682826b3ea180
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45979
For some reason, sometime we cannot write out the debug files. This shouldn't block the whole service. Hence, we opt in to error out instead of throw error.
Test Plan: Run net_runner test at `/` and observe error being printed out but the test passes.
Reviewed By: ipiszy
Differential Revision: D24165081
fbshipit-source-id: a4e1d0479d54d741e615e3a00b3003f512394fd4
Summary:
Ref https://github.com/pytorch/pytorch/issues/42175
As already noted in the `torch.fft` `gradcheck` tests, `gradcheck` isn't fully working for complex types yet and the function inputs need to be real. A similar workaround for `gradgradcheck` works, viewing the complex outputs as real before returning them makes `gradgradcheck` pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46004
Reviewed By: ngimel
Differential Revision: D24187000
Pulled By: mruberry
fbshipit-source-id: 33c2986b07bac282dff1bd4f2109beb70e47bf79
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45900
Use `torch:cuda::nccl:all2all` from `ProcesGroupNCCL.cpp`
Fixes https://github.com/pytorch/pytorch/issues/42517
Here is a NCCL dependency graph:
```
libnccl.a --> libtorch_cuda.so ---> libtorch_python.so
| ^
| |
--------> libc10d.a -----------------
```
When static library is linked into a dynamic library or an executable, linker is removes all unused/duplicate symbols from that library, unless `-whole-archive` option is used. Before https://github.com/pytorch/pytorch/pull/42514 all nccl call made from `ProcessGroupNCCL.cpp` were also made from `torch/csrc/cuda/nccl.cpp`, which is compiled as part of `libtorch_cuda.so`
But adding `ncclSend`|`ncclRecv` to ProcesGroupNCCL.cpp forced linker to embed those into `libtorch_python.so`, which also resulted in linking other dependent symbols into the library.
This PR adds `nccl[Send|Recv]` call to `torch_cuda.so` by implementing `all2all` in `torch_cuda` and thus avoids double linking the static library.
More involved, but prone solution, would be to use wrappers exported in `torch::cuda::nccl` namespace, instead of making direct NCCL API calls.
Test Plan: Imported from OSS
Reviewed By: mingzhe09088
Differential Revision: D24138011
Pulled By: malfet
fbshipit-source-id: 33305197fc7d8707b7fd3a66b543f7733b9241a1
Summary:
cpu implementation of `torch.symeig` uses `[zc]heev`, but MAGMA only have `d`-suffixed flavors of those functions
Fixes https://github.com/pytorch/pytorch/issues/45922
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46002
Reviewed By: walterddr
Differential Revision: D24177730
Pulled By: malfet
fbshipit-source-id: 0e9aeb60a83f8a4b8ac2a86288721bd362b6040b
Summary:
This test is changed one day before the landing of the tf32 tests PR, therefore the fix for this is not included in that PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45492
Reviewed By: ezyang
Differential Revision: D24101876
Pulled By: ngimel
fbshipit-source-id: cb3615b2fb8acf17abe54cd18b1faec26582d6b6
Summary:
This is a rewrite of the Registerizer, supporting scalar replacement in *vastly* more situations. As a refresher, the registerizer does this:
Before:
``` A[0] = 0;
for (int x = 0; x < 10; x++) {
A[0] = (A[0]) + x;
}
```
After:
```
int A_ = 0;
for (int x = 0; x < 10; x++) {
A_ = x + A_;
}
A[0] = A_;
```
Which can greatly reduce the number of accesses to main memory in a kernel. There are cases where doing this gets complicated, and the existing implementation bails out whenever encountering multiple partial overlaps of the same buffer, or conditional accesses under any circumstances. This makes it much less useful in the presence of complex (ie. real world not example) kernels. This new version should work optimally in almost all cases (I have a few minor follow ups).
I tested this version extensively, and found quite a few bugs in the original implementation I'd prefer not to back port fixes for - so I'm in favor of landing this even if we don't immediately see a perf win. I believe the killer app for this kind of optimization is fused reductions and we haven't enabled many examples of that yet.
It is safe to move two accesses of the same Tensor element to a local scalar Var if between all usages of the element there are no other Loads or Stores that may refer to it. In the comments I refer to this as overlapping the access, or "cutting" the existing AccessInfo. In the case where a candidate for registerization is cut, it may be possible to finalize the access early by writing it back to the Tensor and then create a new scalar variable after the overlapping access is complete. We will attempt to do this when it saves memory accesses.
There are a few cases that make this more challenging:
- For: Loops change the number of real usages of a buffer by the loop extent, but only if we can pull the definition and finalization of the scalar variable out of the loop block. For loops often create accesses which are conditional on a loop var and will overlap large ranges of elements.
E.g. Before:
```
A[0] = 2;
for (int x1 = 0; x1 < 10; x1++) {
A[0] = (A[0]) + x1;
}
for (int x2 = 1; x2 < 10; x2++) {
A[x2] = A[x2 - 1];
}
for (int x3 = 0; x3 < 10; x3++) {
A[0] = (A[0]) + x3;
}
```
After:
```
int A_1 = 2;
for (int x1 = 0; x1 < 10; x1++) {
A_1 = A_1 + x1;
}
A[0] = A_1;
for (int x2 = 1; x2 < 10; x2++) {
A[x2] = A[x2 - 1];
}
int A_2 = A[0];
for (int x3 = 0; x3 < 10; x3++) {
A_2 = A_2 + x3;
}
A[0] = A_2;
```
- Cond: Conditions complicate lifting scalars out of internal scopes. Generally we cannot lift an access outside of a conditional scope unless there is already a reference to that same access at the higher scope, since we don't know if the condition was guarding an array access not safe at the higher scope. In the comments I refer to this as the condition "hiding" the access, and the outer access "unhiding" it.
E.g. this example:
```
if (x<5 ? 1 : 0) {
A[x] = (A[x]) + 1;
}
A[x] = (A[x]) + 1;
if (x>5 ? 1 : 0) {
A[x] = (A[x]) + 1;
}
```
The A[x] access can be registerized due to the unconditional access between the two conditions:
```
int A_1 = A[x];
if (x<5 ? 1 : 0) {
A_1 = A_1 + 1;
}
A_1 = A_1 + 1;
if (x>5 ? 1 : 0) {
A_1 = A_1 + 1;
}
A[x] = A_1;
```
But this example has no accesses that can be registerized:
```
if (x<5 ? 1 : 0) {
A[x] = (A[x]) + 1;
}
if (x>5 ? 1 : 0) {
A[x] = (A[x]) + 1;
}
```
- IfThenElse: Same situation as Cond, except since IfThenElse is an Expr rather than a Stmt we cannot insert the scalar definition or finalizer within the conditional scope. Accesses inside an IfThenElse can be safely combined with external accesses but cannot exist completely within.
E.g in this example the `B[x]` cannot be registerized as there is no safe place to define it.
```
A[x] = IfThenElse(x<3 ? 1 : 0, (B[x]) + (B[x]), B[x]);
```
But the equivalent kernel using Cond can be registerized:
```
if (x<3 ? 1 : 0) {
float B_1 = B[x];
A[x] = B_1 + B_1;
} else {
A[x] = B[x];
}
```
- Let: Accesses dependent on local variables via Let Stmts, or loop vars, cannot be raised outside of the scope of the dependent var.
E.g. no accesses in this example can be registerized:
```
for (int x = 0; x < 10; x++) {
int y = 30;
A[y] = x + (A[y]);
}
```
But they can in this example:
```
int y = 30;
for (int x = 0; x < 10; x++) {
A[y] = x + (A[y]);
}
```
**Testing**
The majority of this PR is tests, over 3k lines of them, because there are many different rules to consider and they can interact together more or less arbitrarily. I'd greatly appreciate any ideas for situations we could encounter that are not covered by the tests.
**Performance**
Still working on it, will update. In many FastRRNS sub kernels this diff reduces the number of total calls to Store or Load by 4x, but since those kernels use Concat very heavily (meaning a lot of branches) the actual number encountered by any particular thread on GPU is reduced only slightly. Overall perf improved by a very small amount.
Reductions is where this optimization should really shine, and in particular the more complex the kernel gets (with extra fusions, etc) the better this version of the registerizer should do compared the existing version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45574
Reviewed By: albanD
Differential Revision: D24151517
Pulled By: nickgg
fbshipit-source-id: 9f0b2d98cc213eeea3fda16fee3d144d49fd79ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45992
Created a template version of AddFakeFp16 to take both float and int inputs.
Test Plan: notebook with local bento kernel: N369049
Reviewed By: amylittleyang
Differential Revision: D24169720
fbshipit-source-id: 679de391224f65f6c5b3ca890eb0d157f09712f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45929
We were checking `and` when we should have been checking `or`.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D24148804
Pulled By: eellison
fbshipit-source-id: 9c394ea10ac91a588169d934b1e3208512c71b9d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45857
Fix for https://github.com/pytorch/pytorch/issues/45627
Op was calling `insert` instead of `insert_or_assign`, so it wouldn't overwrite an existing key.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D24148805
Pulled By: eellison
fbshipit-source-id: bf39c71d5d928890b82cff1a9a0985dc47c1ffac
Summary:
This PR fixes a bug when torch is used with pyspark, by converting namedtuples in `torch.utils.data._utils.worker` into classes.
Before this PR, creating an IterableDataset and then running `list(torch.utils.data.DataLoader(MyIterableDataset(...), num_workers=2)))` will not terminate, if pyspark is also being used. This is because pyspark hijacks namedtuples to make them pickleable ([see here](https://github.com/apache/spark/blob/master/python/pyspark/serializers.py#L370)). So `_IterableDatasetStopIteration` would be modified, and then the check at [this line in dataloader.py](5472426b9f/torch/utils/data/dataloader.py (L1072)) is never true.
Converting the namedtuples to classes avoids this hijack and allows the iteration to correctly stop when signaled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45870
Reviewed By: ngimel
Differential Revision: D24162748
Pulled By: albanD
fbshipit-source-id: 52f009784500fa594b2bbd15a8b2e486e00c37fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45986
Recurrent networks have subnets that are not well supported by `RemoveOpsByType`. Here we exclude recurrent networks by adding the same check as in memonger.
Test Plan:
```
buck test //caffe2/caffe2/fb/predictor:black_box_predictor_test
```
AdIndexer canary for sanity check:
https://www.internalfb.com/intern/ads/canary/430059485214766620
Differential Revision: D24167284
fbshipit-source-id: fa90d1c1f34af334a599d879af09d4c0bf7c27bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45780
When training jobs running with NCCL fail sometimes it is hard to
debug the reason of the failure and our logging doesn't provide enough
information at times to narrow down the issue.
To improve the debugging experience, I've enhanced our logging to add a lot
more information about what the ProcessGroup is doing under the hood.
#Closes: https://github.com/pytorch/pytorch/issues/45310
Sample output:
```
> I1002 15:18:48.539551 1822062 ProcessGroupNCCL.cpp:528] [Rank 2] NCCL watchdog thread started!
> I1002 15:18:48.539533 1821946 ProcessGroupNCCL.cpp:492] [Rank 2] ProcessGroupNCCL initialized with following options:
> NCCL_ASYNC_ERROR_HANDLING: 0
> NCCL_BLOCKING_WAIT: 1
> TIMEOUT(ms): 1000
> USE_HIGH_PRIORITY_STREAM: 0
> I1002 15:18:51.080338 1822035 ProcessGroupNCCL.cpp:530] [Rank 1] NCCL watchdog thread terminated normally
> I1002 15:18:52.161218 1821930 ProcessGroupNCCL.cpp:385] [Rank 0] Wrote aborted communicator id to store: NCCLABORTEDCOMM:a0e17500002836080c8384c50000000100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
> I1002 15:18:52.161238 1821930 ProcessGroupNCCL.cpp:388] [Rank 0] Caught collective operation timeout for work: WorkNCCL(OpType=ALLREDUCE, TensorShape=[10], Timeout(ms)=1000)
> I1002 15:18:52.162120 1821957 ProcessGroupNCCL.cpp:530] [Rank 0] NCCL watchdog thread terminated normally
> I1002 15:18:58.539937 1822062 ProcessGroupNCCL.cpp:649] [Rank 2] Found key in store: NCCLABORTEDCOMM:a0e17500002836080c8384c50000000100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000, from rank: 0, aborting appropriate communicators
> I1002 15:19:34.740937 1822062 ProcessGroupNCCL.cpp:662] [Rank 2] Aborted communicators for key in store: NCCLABORTEDCOMM:a0e17500002836080c8384c50000000100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
> I1002 15:19:34.741678 1822062 ProcessGroupNCCL.cpp:530] [Rank 2] NCCL watchdog thread terminated normally
```
ghstack-source-id: 113731163
Test Plan: waitforbuildbot
Reviewed By: osalpekar
Differential Revision: D24093032
fbshipit-source-id: 240b03562f8ccccc3d872538f5e331df598ceca7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45941
This adds CLI options to the `test/print_test_stats.py` script for specifying how many of the longest tests should be printed. It also makes the following incidental changes:
- The script now has a `--help` option to describe its usage.
- The number of longest tests being shown is now displayed as a number, rather than in words.
- The median time is now displayed with the label `median_time` instead of `mean_time`, is calculated using `statistics.median` instead of raw indexing and bit shifting, and is displayed even when there are only two tests in a class.
Test Plan: Imported from OSS
Reviewed By: walterddr, seemethere
Differential Revision: D24154491
Pulled By: samestep
fbshipit-source-id: 9fa402bf0fa56badd505f87f289ac9cca1862d6b
Summary:
splits up all the cuda linux tests into 2 shards to decrease total test runtime
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45972
Reviewed By: malfet
Differential Revision: D24163521
Pulled By: janeyx99
fbshipit-source-id: da6e88eb4305192fb287c4458c31199bf62354c0
Summary:
Currently, a GraphRoot instance doesn't have an associated stream. Streaming backward synchronization logic assumes the instance ran on the default stream, and tells consumer ops to sync with the default stream. If the gradient the GraphRoot instance passes to consumer backward ops was populated on a non-default stream, we have a race condition.
The race condition can exist even if the user doesn't give a manually populated gradient:
```python
with torch.cuda.stream(side_stream):
# loss.backward() implicitly synthesizes a one-element 1.0 tensor on side_stream
# GraphRoot passes it to consumers, but consumers first sync on default stream, not side_stream.
loss.backward()
# Internally to backward(), streaming-backward logic takes over, stuff executes on the same stream it ran on in forward,
# and the side_stream context is irrelevant. GraphRoot's interaction with its first consumer(s) is the spot where
# the side_stream context causes a problem.
```
This PR fixes the race condition by associating a GraphRoot instance, at construction time, with the current stream(s) on the device(s) of the grads it will pass to consumers. (i think this relies on GraphRoot executing in the main thread, before backward thread(s) fork, because the grads were populated on the main thread.)
The test demonstrates the race condition. It fails reliably without the PR's GraphRoot diffs and passes with the GraphRoot diffs.
With the GraphRoot diffs, manually populating an incoming-gradient arg for `backward` (or `torch.autograd.grad`) and the actual call to `autograd.backward` will have the same stream-semantics relationship as any other pair of ops:
```python
# implicit population is safe
with torch.cuda.stream(side_stream):
loss.backward()
# explicit population in side stream then backward in side stream is safe
with torch.cuda.stream(side_stream):
kickoff_grad = torch.ones_like(loss)
loss.backward(gradient=kickoff_grad)
# explicit population in one stream then backward kickoff in another stream
# is NOT safe, even with this PR's diffs, but that unsafety is consistent with
# stream-semantics relationship of any pair of ops
kickoff_grad = torch.ones_like(loss)
with torch.cuda.stream(side_stream):
loss.backward(gradient=kickoff_grad)
# Safe, as you'd expect for any pair of ops
kickoff_grad = torch.ones_like(loss)
side_stream.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(side_stream):
loss.backward(gradient=kickoff_grad)
```
This PR also adds the last three examples above to cuda docs and references them from autograd docstrings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45787
Reviewed By: nairbv
Differential Revision: D24138376
Pulled By: albanD
fbshipit-source-id: bc4cd9390f9f0358633db530b1b09f9c1080d2a3
Summary:
Fixes #{issue number}
This makes the command line shorter.
Also updates `randomtemp` in which the previous version has a limitation that the length of the argument cannot exceed 260.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45842
Reviewed By: albanD
Differential Revision: D24137088
Pulled By: ezyang
fbshipit-source-id: f0b4240735306e302eb3887f54a2b7af83c9f5dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45686
This uses an online graphviz viewer. The code is simpler, and
since it embeds all the data in the url you can just click the url
from your terminal.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D24059157
Pulled By: zdevito
fbshipit-source-id: 94d755cc2986c4226180b09ba36f8d040dda47cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45665Fixes#43944
Note that the codegen doesn't use a proper parser so, in the same way as with lists, the string `, ` cannot appear in defaults or it will be interpreted as a splitting point between arguments.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D24141835
Pulled By: ezyang
fbshipit-source-id: 578127861fd2504917f4486c44100491a2c40343
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45752
Use the torch.quint4x2 dtype to create 4-bit packed tensors in the previous PR.
These packed tensors can be directly consumed by the operator.
Serialization of the packed tensors is supported using torchbind custom class.
Module support will follow in a later PR.
Test Plan:
python test/test_quantization.py TestEmbeddingBagOps
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D24120996
fbshipit-source-id: 2639353b3343ebc69e058b5ba237d3fc56728e1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45639
`StaticRuntime::run_individual` is to mimic the caffe2 operator benchmark `SimpleNet::TEST_Benchmark`, so we can accurate information on the operator breakdown. We found that the PyTorch AutogradProfiler adds a lot of overhead to small models, such as the adindexer precomputation_merge net, 100% for batch_size 1, 33% for batch_size 20. This implementation adds very little overhead, as shown in the test plan.
Test Plan: Test results are fb internal only.
Reviewed By: yinghai, dzhulgakov
Differential Revision: D24012088
fbshipit-source-id: f32eb420aace93e2de421a15e4209fce6a3d90f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45262
**Summary**
This commit adds an API for ignoring arbitrary module attributes during
scripting. A class attribute named `ignored_attributes` containing names
of attributes to ignore can be added to the class of the instance being
scripted. Attributes ignored in this fashion cannot be used in
`forward`, methods used by `forward` or by `exported` methods. They
are, however, copied to the `RecursiveScriptModule` wrapper and can be
used by `ignored` methods and regular Python code.
**Test Plan**
This commit adds unit tests to `TestScriptPy3` to test this new API.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23971882
Pulled By: SplitInfinity
fbshipit-source-id: 8c81fb415fde7b78aa2f87e5d83a477e876a7cc3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45875
Adds a googlebenchmark harness for perf testing programs generated by
tensorexpr, sans any pytorch wrappings (for python-level benchmarks of
tensorexpr, see benchmarks/tensorexpr).
Currently there's a harness for gemm that sets up the problem using torch (and
also measures the perf of a torch::mm to give a baseline).
Right now there's just an unoptimized implementation that is expected to be not
very fast. More optimized versions are coming.
Sample output from my dev box:
```
Run on (48 X 2501 MHz CPU s)
CPU Caches:
L1 Data 32K (x24)
L1 Instruction 32K (x24)
L2 Unified 256K (x24)
L3 Unified 30720K (x2)
--------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
--------------------------------------------------------------------------------------------
Gemm/Torch/128/128/128 73405 ns 73403 ns 8614 GFLOPS=57.1411G/s
Gemm/TensorExprNoopt/128/128/128 3073003 ns 3072808 ns 229 GFLOPS=1.36497G/s
```
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D24142403
Pulled By: bertmaher
fbshipit-source-id: 3354aaa56868a43a553acd1ad9a192f28d8e3597
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45714
Hit the problem when writing a test like following:
```
class M(...):
def forward(self, x):
x = x.some_op()
return x
```
we need to know the scope of `x` to figure out the qconfig for `x`
Test Plan: Imported from OSS
Reviewed By: z-a-f
Differential Revision: D24069959
fbshipit-source-id: 95ac8963c802ebce5d0e54d55f5ebb42085ca8a6
Summary:
**BC-breaking note**
For ease of exposition let a_min be the value of the "min" argument to clamp, and a_max be the value of the "max" argument to clamp.
This PR changes the behavior of torch.clamp to always compute min(max(a, a_min), a_max). torch.clamp currently computes this in its vectorized CPU specializations:
78b95b6204/aten/src/ATen/cpu/vec256/vec256_double.h (L304)
but in other places it clamps differently:
78b95b6204/aten/src/ATen/cpu/vec256/vec256_base.h (L624)78b95b6204/aten/src/ATen/native/cuda/UnaryOpsKernel.cu (L160)
These implementations are the same when a_min < a_max, but divergent when a_min > a_max. This divergence is easily triggered:
```
t = torch.arange(200).to(torch.float)
torch.clamp(t, 4, 2)[0]
: tensor(2.)
torch.clamp(t.cuda(), 4, 2)[0]
: tensor(4., device='cuda:0')
torch.clamp(torch.tensor(0), 4, 2)
: tensor(4)
```
This PR makes the behavior consistent with NumPy's clip. C++'s std::clamp's behavior is undefined when a_min > a_max, but Clang's std::clamp will return 10 in this case (although the program, per the above comment, is in error). Python has no standard clamp implementation.
**PR Summary**
Fixes discrepancy between AVX, CUDA, and base vector implementation for clamp, such that all implementations are consistent and use min(max_vec, max(min_vec, x) formula, thus making it equivalent to numpy.clip in all implementations.
The same fix as in https://github.com/pytorch/pytorch/issues/32587 but isolated to the kernel change only, so that the internal team can benchmark.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43288
Reviewed By: colesbury
Differential Revision: D24079453
Pulled By: mruberry
fbshipit-source-id: 67f30d2f2c86bbd3e87080b32f00e8fb131a53f7
Summary:
Between September 25 and September 27, approximately half an hour was added to the running time of `pytorch_linux_xenial_cuda10_2_cudnn7_py3_gcc7_test`. Judging from the CircleCI data, it looks like the majority of the new time was added by the following PRs:
- https://github.com/pytorch/pytorch/issues/44550
- https://github.com/pytorch/pytorch/issues/45298
I'm not sure what to do about https://github.com/pytorch/pytorch/issues/44550, but it looks like https://github.com/pytorch/pytorch/issues/45298 increased the `N` for `TestForeach` from just 20 to include both 30 and 300. This PR would remove the 300, decreasing the test time by a couple orders of magnitude (at least when running it on my devserver), from over ten minutes to just a few seconds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45785
Reviewed By: malfet
Differential Revision: D24094782
Pulled By: samestep
fbshipit-source-id: 2476cee9d513b2b07bc384de751e08d0e5d8b5e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45297
If we have two concurrent substeps and one of them throws an exception and the other is blocking, we'll currently hang. This waits up to 1 minute for it to complete before terminating the process.
Test Plan: buck test caffe2/caffe2:caffe2_test_cpu -- PlanExecutorTest --stress-runs 100
Reviewed By: dahsh
Differential Revision: D20850851
fbshipit-source-id: 330503775d8062a34645ba55fe38e6770de5e3c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45712
Eager mode will still be able to use functional leaky relu, but it will be less accurate than
LeakyReLU module.
FX graph mode will support both leaky relu functional and module
Test Plan: Imported from OSS
Reviewed By: z-a-f
Differential Revision: D24069961
fbshipit-source-id: 8d91c3c50c0bcd068ba3072378ebb4da9549be3b
Summary:
This PR patches the ReplicationPad modules in `torch.nn` to be compatible with 0-dim batch sizes.
EDIT: this is part of the work on gh-12013 (make all nn layers accept empty batch size)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39137
Reviewed By: albanD
Differential Revision: D24131386
Pulled By: ngimel
fbshipit-source-id: 3d93057cbe14d72571943c8979d5937e4bbf743a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45899
Use function polymorphism to avoid repeated casts
I.e. instead of using `NCCL_CHECK(from_nccl_result(` add variant of the function that takes `ncclResult_t` as input argument
Add non-pointer variant of `to_nccl_comm` to avoid `*to_nccl_comm(&comm)` pattern
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D24138012
Pulled By: malfet
fbshipit-source-id: 7f62a03e108cbe455910e86e894afdd1c27e8ff1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45702https://github.com/pytorch/pytorch/issues/45593
Previously quantized leaky_relu does not require observation and just inherits
the quantization parameters from input, but that does not work very well in qat
This PR added a quantized::leaky_relu that has observation for output and it will
become the default leaky_relu that our quantization tools produce (eager/graph mode)
Test Plan: Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D24067681
fbshipit-source-id: d216738344363794b82bd3d75c8587a4b9415bca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45850
In TSAN mode most xnnpack integration tests seem to be failing. Reason for
failure is not entirely clear. It is not clear if this is spurious.
Test Plan: python test/test_xnnpack_integration.py
Reviewed By: xcheng16
Differential Revision: D24113885
fbshipit-source-id: dc3de3ad3d4bf0210ad67211383dbe0e842b09dd
Summary:
When attempting to install PyTorch locally on my Macbook, I had some difficulty running the setup steps and understanding what I was really doing. I've added some clarifications and summarized some debugging steps about `python setup.py develop` to lower the barrier of entrance for new contributors.
I'm seeking a lot of review here since I am not sure if what I wrote is entirely the most useful or accurate. Thank you!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45903
Reviewed By: albanD
Differential Revision: D24140343
Pulled By: janeyx99
fbshipit-source-id: a5e40d1bc804945ae7db2b95ab18cf7fe169e68a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43951
AllocationPlan: Stores the sequence of allocations, their sizes
and liftime of the allocations. Along with this
it also stores the total size of a single memory
blob, total_size, required to satisfy all the allocations.
It also stores the offsets in the blob, of size
total_size, corresponding to each allocation.
Thus allocation plan contains:
- allocation sizes
- allocation lifetimes
- allocation offsets
- total size
AllocationPlaner: Takes a pointer to the allocation plan and fills
it ups with plan, i.e. sizes, lifetimes, offsets,
total size.
This is done via WithProfileAllocationsGuard which
takes in AllocationPlan* and constructs
AllocationPlanner* and set the thread local
allocation_planner to it.
MobileCPUAllocator profiles allocations via
allocation_planner.
In WithValidateAllocationsGuard, allocations profiled
in the allocation plan are validated.
CPUProfilingAllocator:
Application owns CPUProfilingAllocator
Using WithProfilingAllocatorGuard, it passes both CPUProfilingAllocator
and AllocationPlan created earlier. Then CPUProfilingAllocator will
manage allocations and frees according to the plan. Allocations that
are not managed by CPUProfilingAllocator will be routed through
c10::alloc_cpu, c10::free_cpu.
Test Plan:
cpu_profiling_allocator_test on mobile.
Imported from OSS
Reviewed By: dreiss
Differential Revision: D23451019
fbshipit-source-id: 98bf1dbcfa8fcfb83d505ac01095e84a3f5b778d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45773
Changes the function schema's backward compatibility check to be stricter to comply with C++ API backwards compatibility capabilities.
ghstack-source-id: 113537304
Test Plan:
Updated and added tests to test_function_schema.py
Browsed through several commits to native_functions.yaml and derivatives.yaml and I don't see instances where new arguments where not already being appended.
Reviewed By: dzhulgakov
Differential Revision: D24089751
fbshipit-source-id: a21f407cdc750906d3326e3ea27928b8aa732804
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45485
Essentially this is the problem reported by ezyang: https://fb.workplace.com/groups/llvm.gcc/permalink/4053565044692080. There are two proposed fixes:
* https://github.com/pytorch/pytorch/pull/44883: this doesn't work because it fails some static assert at runtime
```
caffe2/c10/core/TensorOptions.h:553:1: error: static_assert failed due to requirement 'sizeof(c10::TensorOptions) <= sizeof(long) * 2' "TensorOptions must fit in 128-bits"
static_assert( sizeof(TensorOptions) <= sizeof(int64_t) * 2,
^
```
* https://github.com/pytorch/pytorch/pull/44885: to be tested
This diff is a temp hack to work around the problem. W/o this patch:
```
volatile size_t device_type = static_cast<size_t>(type);
auto p = device_guard_impl_registry[device_type].load();
C10_LOG_FIRST_N(WARNING, 10) << "XDW-fail: " << cntr << ", Device type: " << type << ", type cast: " << device_type << ", guard: " << p;
// output
XDW-fail: 1129, Device type: cuda, type cast: 65537, guard: 0
```
Another workaround is D23788441, which changes -O3 to -O2. So this seems to be a miscompilation for nvcc or the host compiler.
Reviewed By: ezyang
Differential Revision: D23972356
fbshipit-source-id: ab91fbbfccb6389052de216f95cf9a8265445aea
Summary:
Clarified that the `Categorical` distribution will actually accept input of any arbitrary tensor shape, not just 1D and 2D tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45804
Reviewed By: dzhulgakov
Differential Revision: D24125415
Pulled By: VitalyFedyunin
fbshipit-source-id: 5fa1f07911bd85e172199b28d79763428db3a0f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45867
In most cases the lock ordering was hold a lock in local autograd and
then hold a lock in DistAutogradContext.
In case of `set_exception_without_signal` the lock order was in reverse and as
a result we saw potential deadlock issues in our TSAN tests. To fix this, I
removed the lock and instead just used std::atomic exchange.
In addition to this, I fixed TestE2E to ensure that we use the appropriate
timeout.
TestE2EProcessGroup was flaky for these two reasons and now is fixed.
ghstack-source-id: 113592709
Test Plan: waitforbuildbot.
Reviewed By: albanD
Differential Revision: D24120962
fbshipit-source-id: 12447b84ceae772b91e9a183c90d1e6340f44e66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44922
For NCCL send/recv operations, we will create NCCL communicator on demand following the same design as how it's currently done for collective operations.
ghstack-source-id: 113592757
Test Plan: to add
Reviewed By: pritamdamania87
Differential Revision: D23773726
fbshipit-source-id: 0d47c29d670ddc07f7181e8485af0e02e2c9cfaf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44921
This diff adds support for Process Group point-to-point operations on NCCL backend based on ncclSend/ncclRecv. See https://github.com/pytorch/pytorch/issues/43995 for more context.
ghstack-source-id: 113592785
Test Plan: unittest
Reviewed By: jiayisuse
Differential Revision: D23709848
fbshipit-source-id: cdf38050379ecbb10450f3394631317b41163258
Summary:
Instead of dynamically loading `caffe2_nvrtc`, lazyNVRTC provides the same functionality by binding all the hooks to lazy bind implementation, very similar to the shared library jump tables:
On the first call, each function from the list tries to get a global handle to the respective shared library and replace itself with the dynamically resolved symbol, using the following template:
```
auto fn = reinterpret_cast<decltype(&NAME)>(getCUDALibrary().sym(C10_SYMBOLIZE(NAME)));
if (!fn)
throw std::runtime_error("Can't get" ## NAME);
lazyNVRTC.NAME = fn;
return fn(...)
```
Fixes https://github.com/pytorch/pytorch/issues/31985
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45674
Reviewed By: ezyang
Differential Revision: D24073946
Pulled By: malfet
fbshipit-source-id: 1479a75e5200e14df003144625a859d312885874
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45763
**Summary**
This commit updates the documentation for `EmbeddingBag` to say that for
bags of constant length with no per-sample weights, the class is
equivalent to `Embedding` followed by `torch.sum(dim=1)`. The current
docs say `dim=0` and this is readily falsifiable.
**Test Plan**
1) Tried `Embedding` + `sum` with `dim`=0,1 in interpreter and compared
to `EmbeddingBag`
```
>>> import torch
>>> weights = torch.nn.Parameter(torch.randn(10, 3))
>>> e = torch.nn.Embedding(10, 3)
>>> eb = torch.nn.EmbeddingBag(10, 3, mode="sum")
>>> e.weight = weights
>>> eb.weight = weights
# Use 2D inputs because we are trying to test the case in which bags have constant length
>>> inputs = torch.LongTensor([[4,1,2,7],[5,6,0,3]])
>>> eb(inputs)
tensor([[-2.5497, -0.1556, -0.5166],
[ 2.2528, -0.3627, 2.5822]], grad_fn=<EmbeddingBagBackward>)
>>> torch.sum(e(inputs), dim=0)
tensor([[ 1.6181, -0.8739, 0.8168],
[ 0.0295, 2.3274, 1.2558],
[-0.7958, -0.4228, 0.5961],
[-1.1487, -1.5490, -0.6031]], grad_fn=<SumBackward1>)
>>> torch.sum(e(inputs), dim=1)
tensor([[-2.5497, -0.1556, -0.5166],
[ 2.2528, -0.3627, 2.5822]], grad_fn=<SumBackward1>)
```
So clearly `torch.sum` with `dim=0` is not correct here.
2) Built docs and viewed in browser.
*Before*
<img width="882" alt="Captura de Pantalla 2020-10-02 a la(s) 12 26 20 p m" src="https://user-images.githubusercontent.com/4392003/94963035-557be100-04ac-11eb-986c-088965ac3050.png">
*After*
<img width="901" alt="Captura de Pantalla 2020-10-05 a la(s) 11 26 51 a m" src="https://user-images.githubusercontent.com/4392003/95117732-ea294d80-06fd-11eb-9d6b-9b4e6c805cd0.png">
**Fixes**
This commit closes#43197.
Test Plan: Imported from OSS
Reviewed By: ansley
Differential Revision: D24118206
Pulled By: SplitInfinity
fbshipit-source-id: cd0d6b5db33e415d8e04ba04f2c7074dcecf3eee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45471
Intead of assuming that 'torch' is the only module used by generated code,
use the qualified names of builtin functions to generate import statements
for all builtins. This allows user-captured functions to also get code generated correctly.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D23978696
Pulled By: zdevito
fbshipit-source-id: ecbff150e3de38532531cdadbfe4965468f29a38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45766
As per subj, making KeyError message more verbose.
Test Plan:
Verified that breakage can be successfully investigated with verbose error message
unit tests
Reviewed By: esqu1
Differential Revision: D24080362
fbshipit-source-id: f4e22a78809e5cff65a69780d5cbbc1e8b11b2e5
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: fe9164007c
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45713
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: VitalyFedyunin
Differential Revision: D24069807
fbshipit-source-id: 4670725be42368bdf6e29a3746c89514c5f4ee1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45862
Bump up the cocoapods version
ghstack-source-id: 113585513
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: xta0
Differential Revision: D24119158
fbshipit-source-id: e689b69628dcf802084e67c5ea627220cafcc575
Summary:
Move duplicated code for computing LRWork array dimention form CPU/CUDA implementation of apply_svd into LinearAlgebraUtils
Reduce common multiplication factor from 7 to 5, which according to the documentation should be sufficient for LAPACK-3.6+
From 122506cd8b/SRC/cgesdd.f (L186)
```
RWORK is REAL array, dimension (MAX(1,LRWORK))
Let mx = max(M,N) and mn = min(M,N).
If JOBZ = 'N', LRWORK >= 5*mn (LAPACK <= 3.6 needs 7*mn);
else if mx >> mn, LRWORK >= 5*mn*mn + 5*mn;
else LRWORK >= max( 5*mn*mn + 5*mn,
2*mx*mn + 2*mn*mn + mn ).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45812
Reviewed By: walterddr
Differential Revision: D24100836
Pulled By: malfet
fbshipit-source-id: 0ca86aed25077c91cf60086ed301298381d5f628
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45844
Someone pointed out that dataclasses were actually added to the python
stdlib in 3.7 and not 3.8, so bumping down the dependency on dataclasses
from 3.8 -> 3.7 makes sense here
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr, malfet
Differential Revision: D24113367
Pulled By: seemethere
fbshipit-source-id: 03d2d93f7d966d48a30a8e2545fd07dfe63b4fb3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45642
Prior to https://github.com/pytorch/pytorch/pull/45181, initializing a
NCCL process group would work even if no GPUs were present. Although, now since
init_process_group calls `barrier()` this would fail.
In general the problem was that we could initialize ProcessGroupNCCL without
GPUs and then if we called a method like `barrier()` the process would crash
since we do % numGPUs resulting in division by zero.
ghstack-source-id: 113490343
Test Plan: waitforbuildbot
Reviewed By: osalpekar
Differential Revision: D24038839
fbshipit-source-id: a1f1db52cabcfb83e06c1a11ae9744afbf03f8dc
Summary:
Rename jobs for testing GraphExecutor configurations to something a little bit more sensical.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45715
Reviewed By: ezyang, anjali411
Differential Revision: D24114344
Pulled By: Krovatkin
fbshipit-source-id: 89e5f54aaebd88f8c5878e060e983c6f1f41b9bb
Summary: This diff adds a string equality checking operator.
Test Plan: Unit tests
Differential Revision: D24042344
fbshipit-source-id: c8997c6130e3438f2ae95dae69f76978e2e95527
Summary:
The torchbind tests didn't work be cause somehow we missed the rename of caffe2_gpu to torch_... (hip for us) in https://github.com/pytorch/pytorch/issues/20774 (merged 2019-06-13, oops) and still tried to link against it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45426
Reviewed By: VitalyFedyunin
Differential Revision: D24112439
Pulled By: walterddr
fbshipit-source-id: a66a574e63714728183399c543d2dafbd6c028f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45776
Splitting out backend and custom class registration into their own library is
not currently implemented in fbcode, so detect that we are running tests in
fbcode and disable those tests.
Test Plan: buck test mode/no-gpu mode/dev caffe2/test:jit
Reviewed By: smessmer
Differential Revision: D24085871
fbshipit-source-id: 1fcc0547880bc4be59428e2810b6a7f6e50ef798
Summary:
* Add a pass at end of runCleanupPasses to annotate `aten::warn` so that each has its unique id
* Enhanced interpreter so that it tracks which `aten::warn` has been executed before and skip them
* Improved insertInstruction so that it correctly checks for overflow
Fixes https://github.com/pytorch/pytorch/issues/45108
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45382
Reviewed By: mrshenli
Differential Revision: D24060677
Pulled By: gmagogsfm
fbshipit-source-id: 9221bc55b9ce36b374bdf614da3fe47496b481c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45649
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44275
* This Diff applies WarpReduce optimization for dedup version of RowWiseSparseAdagrad fused op. Basically we can achieve ~1.33x performance improvement with this Diff.
* Port the way from D23948802 to find the num_dup
* fix the likely bug about fp16 in the dedup kernel
Reviewed By: jianyuh
Differential Revision: D23561994
fbshipit-source-id: 1a633fcdc924593063a67f9ce0d36eadb19a7efb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45726
FB has an old internal platform that uses some random llvm version
that looks sort of like llvm 7. I've guarded that with the appropriate
LLVM_VERSION_PATCH.
I've also swapped out some of our uses of ThreadSafeModule/ThreadSafeContext
for the variants without ThreadSafe in the name. As far as I can tell we
weren't using the bundled locks anyways, but I'm like 85% sure this is OK since
we compile under the Torch JIT lock anyways.
Test Plan: unit tests
Reviewed By: ZolotukhinM, asuhan
Differential Revision: D24072697
fbshipit-source-id: 7f56b9f3cbe5e6d54416acdf73876338df69ddb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44220
Closes https://github.com/pytorch/pytorch/issues/44009
Currently if a dataloader returns objects created with a
collections.namedtuple, this will incorrectly be cast to a tuple. As a result, if we have data of these types, there can be runtime errors during the forward pass if the module is expecting a named tuple.
Fix this in
`scatter_gather.py` to resolve the issue reported in
https://github.com/pytorch/pytorch/issues/44009
ghstack-source-id: 113423287
Test Plan: CI
Reviewed By: colesbury
Differential Revision: D23536752
fbshipit-source-id: 3838e60162f29ebe424e83e474c4350ae838180b
Summary:
Originally introduced in https://github.com/pytorch/pytorch/issues/45023. When I was doing test in the original PR, it was a Conv3d, so this problem was not discovered.
Arrays in `ConvolutionParams` have a fixed length of 3 or 5. This is because `max_dim` is set as a constexpr of 3, regardless of Conv2d or Conv3d. The current code will make some error message be weird. See below in the comments.
9201c37d02/aten/src/ATen/native/cudnn/Conv.cpp (L212-L226)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45729
Reviewed By: mruberry
Differential Revision: D24081542
Pulled By: ngimel
fbshipit-source-id: 141f8946f4d0db63a723131775731272abeaa6ab
Summary:
Added a sharding option to run_test.py to enable users to run a subset of the many tests. The new `--shard` argument takes in two integer values, `x` and `y`, where the larger value would denote the number of shards and the smaller value would denote which shard to run.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45583
Reviewed By: malfet
Differential Revision: D24083469
Pulled By: janeyx99
fbshipit-source-id: 1777bd7822c95b3bf37079deff9381c6f8eaf4cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45543
This PR adds documentation for the c10d Store to the public docs. Previously these docs were missing although we exposed a lightly-used (but potentially useful) Python API for our distributed key-value store.
ghstack-source-id: 113409195
Test Plan: Will verify screenshots by building the docs.
Reviewed By: pritamdamania87
Differential Revision: D24005598
fbshipit-source-id: 45c3600e7c3f220710e99a0483a9ce921d75d044
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45464
Usage of Symbols to find arguments requires one to generate a nonsense symbol for inputs which don't already have one. The intention of symbols appears to be something of an internalized string, but the namespace component doesn't apply to an argument. In order to access the arguments by name without adding new symbols, versions of those functions with std::string input was added. These can be proved valid based on the existing codepath. Additionally, a hasNamedInput convenience function was added to remove the necessity of a try/catch block in user code.
The primary motivation is to be able to easily handle the variable number of arguments in glow, so that the arange op may be implemented.
Reviewed By: eellison
Differential Revision: D23972315
fbshipit-source-id: 3e0b41910cf07e916186f1506281fb221725a91b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45744
Tag me as reviewer
Test Plan: na
Reviewed By: jiayisuse
Differential Revision: D23881569
fbshipit-source-id: 8452fa60fe3d017ae1f0da26c0ce476f2b9c170c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44158
Previously, the C++ API only supported calling ops with a gathered TensorOptions object. So even if the VariableKernel took scattered arguments,
it had to re-gather them to call into the C++ API. But a diff stacked below this one introduced a scattered API for the C++ frontend.
This reaps the benefits and makes sure that if the Variable kernel gets scattered arguments (i.e. it's a c10-full op), then it passes those on without regathering
ghstack-source-id: 113355690
Test Plan:
vs master: https://www.internalfb.com/intern/fblearner/details/216342597/
vs prev diff: https://www.internalfb.com/intern/fblearner/details/216342688/
Reviewed By: ezyang
Differential Revision: D23512538
fbshipit-source-id: 8ee6c1cc99443a2141db85072fd6dbc52b4d77fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44087
Each op taking a TensorOptions argument now has an additional overload in the C++ frontend where it takes scattered ScalarType, Layout, Device, bool instead of one TensorOptions argument.
If it is a c10-full op, then the scattered version calls into the dispatcher and the gathered version is a proxy calling into the scattered version.
If it is a non-c10-full op, then the gathered version calls into the dispatcher and the scattered version is a proxy calling into the gathered version.
This should minimize the amount of gathering and scattering needed.
This PR is also a prerequisite to remove the re-gathering of arguments that is currently happening in VariableKernel. Currently, VariableKernels gather arguments into a TensorOptions object
to call into the C++ API. In a PR stacked on top of this, VariableKernel will just directly call into the scattered C++ API introduced here and avoid the gathering step.
ghstack-source-id: 113355689
Test Plan:
waitforsandcastle
vs master: https://www.internalfb.com/intern/fblearner/details/216169815/
vs previous diff: https://www.internalfb.com/intern/fblearner/details/216169957/
Reviewed By: ezyang
Differential Revision: D23492188
fbshipit-source-id: 3e84c467545ad9371e98e09075a311bd18411c5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45594
Adds support for Per-channel quantization using float qparams for 4-bit dtype
We use the new dispatch mechanism and use existing quantize/dequantize kernels to pack the
4-bit data depending on the bit_width.
Size of 4-bit quantized tensor is half that of 8-bit quantized tensor.
Test Plan:
python test/test_quantization.py TestQuantizedTensor.test_quantize_per_channel_sub_byte
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D24025595
fbshipit-source-id: dd9d0557de585dd4aaf5f138959c3523a29fb759
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44678
This is a prototype PR that introduces 4 bit qtensors. The new dtype added for this is c10::quint4x2
The underlying storage for this is still uint8_t, so we pack 2 4-bit values in a byte while quantizing it.
This change uses most of the existing scaffolding for qtensor storage. We allocate storage
based on the dtype before creating a new qtensor.
It also adds a dispatch mechanism for this dtype so we can use this to get the bitwidth, qmin and qmax info
while quantizing and packing the qtensor (when we add 2-bit qtensor)
Kernels that use this dtype should be aware of the packing format.
Test Plan:
Locally tested
```
x = torch.ones((100, 100), dtype=torch.float)
qx_8bit = torch.quantize_per_tensor(x, scale=1.0, zero_point=2, dtype=torch.quint8)
qx = torch.quantize_per_tensor(x, scale=1.0, zero_point=2, dtype=torch.quint4x2)
torch.save(x, "temp.p")
print('Size float (B):', os.path.getsize("temp.p"))
os.remove('temp.p')
torch.save(qx_8bit, "temp.p")
print('Size quantized 8bit(B):', os.path.getsize("temp.p"))
os.remove('temp.p')
torch.save(qx, "temp.p")
print('Size quantized 4bit(B):', os.path.getsize("temp.p"))
os.remove('temp.p')
```
Size float (B): 40760
Size quantized 8bit(B): 10808
Size quantized 4bit(B): 5816
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D23993134
fbshipit-source-id: 073bf262f9680416150ba78ed2d932032275946d
Summary:
This modifies the default bailout depth to 20 which gives us a reasonable performance in benchmarks we considered (fastrnns, maskrcnn, hub/benchmark, etc)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45710
Reviewed By: robieta
Differential Revision: D24071861
Pulled By: Krovatkin
fbshipit-source-id: 472aacc136f37297b21f577750c1d60683a6c81e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45693
**Summary**
This commit updates the docstring for
`torch.distributions.NegativeBinomial` to better match actual behaviour.
In particular, the parameter currently documented as probability of
success is actually probability of failure.
**Test Plan**
1) Ran the code from the issue to make sure this is still an issue (it
is)
2) `make html` and viewed the docs in a browser.
*Before*
<img width="879" alt="Captura de Pantalla 2020-10-01 a la(s) 1 35 28 p m" src="https://user-images.githubusercontent.com/4392003/94864456-db3a5680-03f0-11eb-977e-3bab0fb9c206.png">
*After*
<img width="877" alt="Captura de Pantalla 2020-10-01 a la(s) 2 12 24 p m" src="https://user-images.githubusercontent.com/4392003/94864478-e42b2800-03f0-11eb-965a-51493ca27c80.png">
**Fixes**
This commit closes#42449.
Test Plan: Imported from OSS
Reviewed By: robieta
Differential Revision: D24071048
Pulled By: SplitInfinity
fbshipit-source-id: d345b4de721475dbe26233e368af62eb57a47970
Summary:
This fixes MIOpen runtime compilation since it passes quoted arguments to the clang compiler. This change also makes the sccache wrapper scripts consistent with the nvcc wrapper.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45582
Reviewed By: seemethere, izdeby
Differential Revision: D24034477
Pulled By: malfet
fbshipit-source-id: 1964bac1e693b238e8efe9c046a39be64571e9df
Summary:
Adds a CUDA job on Windows for the jit legacy executor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45612
Reviewed By: mrshenli
Differential Revision: D24042196
Pulled By: Krovatkin
fbshipit-source-id: 35c79c53ed569d221e79376c108bc864900ef49e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45651
### Summary
1. Update the iOS developer certificates. The new expiration date is 10/01/2021.
2. Restore the iOS arm64 jobs and the nightly.
### Test Plan
The following CI jobs succeed
- ci/circleci: pytorch_ios_11_2_1_arm64_build
- ci/circleci: pytorch_ios_11_2_1_arm64_custom_build
- ci/circleci: pytorch_ios_11_2_1_x86_64_build
Test Plan: Imported from OSS
Reviewed By: husthyc
Differential Revision: D24065648
Pulled By: xta0
fbshipit-source-id: 758f41de8296fdfbd3cfad87e9445c2acafd5f94
Summary:
We are trying to build libtorch statically (BUILD_SHARED_LIBS=OFF) then link it into a DLL. Our setup hits the infinite loop mentioned [here](54c05fa34e/torch/csrc/autograd/engine.cpp (L228)) because we build with `BUILD_SHARED_LIBS=OFF` but still link it all into a DLL at the end of the day.
This PR fixes the issue by changing the condition to guard on which windows runtime the build links against using the `CAFFE2_USE_MSVC_STATIC_RUNTIME` flag. `CAFFE2_USE_MSVC_STATIC_RUNTIME` defaults to ON when `BUILD_SHARED_LIBS=OFF`, so backwards compatibility is maintained.
I'm not entirely confident I understand the subtleties of the windows runtime versus linking setup, but this setup works for us and should not affect the existing builds.
Fixes https://github.com/pytorch/pytorch/issues/44470
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43532
Reviewed By: mrshenli
Differential Revision: D24053767
Pulled By: albanD
fbshipit-source-id: 1127fefe5104d302a4fc083106d4e9f48e50add8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45672
This PR merges all quantization mode and will only expose the following top level functions:
```
prepare_fx
prepare_qat_fx
convert_fx
```
Test Plan:
Imported from OSS
Imported from OSS
Reviewed By: z-a-f
Differential Revision: D24053439
fbshipit-source-id: 03d545e26a36bc22a73349061b751eeb35171e64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45610
Also add to the usual documentation places that this option exists.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D24058199
Pulled By: suo
fbshipit-source-id: 81574fbd042f47587e2c7820c726fac0f68af2a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45611
dataclasses was made a standard library item in 3.8
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D24031740
Pulled By: seemethere
fbshipit-source-id: 15bdf1fe0d8de9b8ba7912e4a651f06b18d516ee
Summary: `__repr__` calling self.tasks() ends up marking the instance as "used", which doesn't seem appropriate. I was debugging a value being passed around and then ran into `Cannot add Task to an already used TaskGroup.` because the value had been logged once.
Test Plan:
Added a unit test -- didn't see a clean public method to test it, but I'm happy to add one if that makes sense.
Will wait for sandcastle to trigger everything else; I'm not at all familiar with this code so any other recommendations would be great!
Reviewed By: cryptopic
Differential Revision: D23541198
fbshipit-source-id: 5d1ec674a1ddaedf113140133b90e0da6afa7270
Summary:
WIP: This PR is working in progress for the partition of fx graph module. _class partitioner_ generates partitions for the graph module. _class partition_ is a partition node in the partitions.
_Partitioner()_ : create a partitioner
_partition_graph(self, fx_module: GraphModule, devices: List[str]) -> None_:
use fx graph module and devices as the input and create partition_ids for each node inside the graph module
_dump_partition_DAG(self) -> None_:
print out the information about each partition, including its id, its backend type (what type of device this partition uses), all the nodes included in this partition, its parent partitions, children partitions, input nodes, and output nodes.
So far, only a single partition is considered, which means there is only one device with unlimited memory.
A test unit call _test_find_single_partition()_ is added to test if all nodes in the graph are marked for the only partition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45429
Reviewed By: izdeby
Differential Revision: D24026268
Pulled By: scottxu0730
fbshipit-source-id: 119d506f33049a59b54ad993670f4ba5d8e15b0b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/42855. Previously, back quotes weren't rendering correctly in
equations. This is because we were quoting things like `'mean'`. In
order to backquote properly in latex in text-mode, the back-quote needs
to be written as a back-tick.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45662
Test Plan:
- built docs locally and viewed the changes.
For NLLLoss (which is not the original module mentioned in the issue, but it has the same problem), we can see how the back quotes now render properly:

Reviewed By: glaringlee
Differential Revision: D24049880
Pulled By: zou3519
fbshipit-source-id: 61a1257994144549eb8f29f19d639aea962dfec0
Summary:
This PR adds support for complex-valued input for `torch.symeig`.
TODO:
- [ ] complex cuda tests raise `RuntimeError: _th_bmm_out not supported on CUDAType for ComplexFloat`
Update: Added xfailing tests for complex dtypes on CUDA. Once support for complex `bmm` is added these tests will work.
Fixes https://github.com/pytorch/pytorch/issues/45061.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45121
Reviewed By: mrshenli
Differential Revision: D24049649
Pulled By: anjali411
fbshipit-source-id: 2cd11f0e47d37c6ad96ec786762f2da57f25dac5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45131
These make it easier to group native functions together and determine
what kind of native function it is (inplace/out/functional). Currently
they are not used but they may be useful for tools.autograd porters.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zhangguanheng66
Differential Revision: D23872526
Pulled By: ezyang
fbshipit-source-id: 1d6e429ab9a1f0fdb764be4228c5bca4dce8f24e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45127
I thought I was being clever by using Sequence, which doesn't commit to
List or Tuple, but forces read-onlyness in the type system. However,
there is runtime implication to using List or Tuple: Lists can't be
hashed, but Tuples can be! This is important because I shortly want
to group by FunctionSchema, and to do this I need FunctionSchema to
be hashable. Switch everything to Tuple for true immutability.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D23872527
Pulled By: ezyang
fbshipit-source-id: 5c8fae1c50a5ae47b4167543646d94ddcafff8c3
Summary:
Amp gradient unscaling is a great use case for multi tensor apply (in fact it's the first case I wrote it for). This PR adds an MTA unscale+infcheck functor. Really excited to have it for `torch.cuda.amp`. izdeby your interface was clean and straightforward to use, great work!
Labeled as bc-breaking because the native_functions.yaml exposure of unscale+infcheck changes from [`_amp_non_finite_check_and_unscale_` to `_amp_foreach_non_finite_check_and_unscale_`]( https://github.com/pytorch/pytorch/pull/44778/files#diff-f1e4b2c15de770d978d0eb77b53a4077L6289-L6293).
The PR also modifies Unary/Binary/Pointwise Functors to
- do ops' internal math in FP32 for FP16 or bfloat16 inputs, which improves precision ([and throughput, on some architectures!](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#arithmetic-instructions)) and has no downside for the ops we care about.
- accept an instantiated op functor rather than an op functor template (`template<class> class Op`). This allows calling code to pass lambdas.
Open question: As written now, the PR has MTA Functors take care of pre- and post-casting FP16/bfloat16 inputs to FP32 before running the ops. However, alternatively, the pre- and post-math casting could be deferred/written into the ops themselves, which gives them a bit more control. I can easily rewrite it that way if you prefer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44778
Reviewed By: gchanan
Differential Revision: D23944102
Pulled By: izdeby
fbshipit-source-id: 22b25ccad5f69b413c77afe8733fa9cacc8e766d
Summary:
This PR removes redundant profiling jobs since after the switch PE (https://github.com/pytorch/pytorch/pull/45396) will be now running by default.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45397
Reviewed By: zhangguanheng66
Differential Revision: D23966890
Pulled By: Krovatkin
fbshipit-source-id: ef184ca5fcf079580fa139b6653f8d9a6124050e
Summary:
* Support propagating `dim_param` in ONNX by encoding as `ShapeSymbol` in `SymbolicShape` of outputs. If export is called with `dynamic_axes` provided, shape inference will start with these axes set as dynamic.
* Add new test file `test_pytorch_onnx_shape_inference.py`, reusing all test cases from `test_pytorch_onnx_onnxruntime.py`, but focus on validating shape for all nodes in graph. Currently this is not enabled in the CI, since there are still quite some existing issues and corner cases to fix. The test is default to run only at opset 12.
* Bug fixes, such as div, _len, and peephole.cpp passes for PackPadded, and LogSoftmaxCrossEntropy.
* This PR depends on existing PR such as 44332.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44920
Reviewed By: eellison
Differential Revision: D23958398
Pulled By: bzinodev
fbshipit-source-id: 00479d9bd19c867d526769a15ba97ec16d56e51d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45292
This PR merges all quantization mode and will only expose the following top level functions:
```
prepare_fx
prepare_qat_fx
convert_fx
```
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23913105
fbshipit-source-id: 4e335286d6de225839daf51d1df54322d52d68e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45343
Current default dynamic quant observer is not correct since we don't accumulate
min/max and we don't need to calculate qparams.
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D23933995
fbshipit-source-id: 3ff497c9f5f74c687e8e343ab9948d05ccbba09b
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/45586
Test Plan: The unit test has been softened to be less platform sensitive.
Reviewed By: mruberry
Differential Revision: D24025415
Pulled By: robieta
fbshipit-source-id: ee986933b984e736cf1525e1297de6b21ac1f0cf
Summary:
This is an attempt at refactoring `torch.distributed` implementation. Goal is to push Python layer's global states (like _default_pg) to C++ layer such that `torch.distributed` becomes more TorchScript friendly.
This PR adds the skeleton of C++ implementation, at the moment it is not included in any build (and won't be until method implementations are filled in). If you see any test failures related, feel free to revert.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45547
Reviewed By: izdeby
Differential Revision: D24024213
Pulled By: gmagogsfm
fbshipit-source-id: 2762767f63ebef43bf58e17f9447d53cf119f05f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45585
I discovered this bug when I was trying to print the graph to a file. Turns out I had to close the file, but flushing should be a good safeguard in case other users forget.
Test Plan:
Tested with and without flushing.
with P144064292
without P144064767
Reviewed By: mortzur
Differential Revision: D24023819
fbshipit-source-id: 39574b3615feb28e5b5939664c04ddfb1257706a
Summary:
This commit updates `.github/workflows/jit_triage.yml` to use the new `oncall: jit` tag instead of the old `jit` tag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45613
Reviewed By: izdeby
Differential Revision: D24032388
Pulled By: SplitInfinity
fbshipit-source-id: 6631a596b2f80bdb322caa74adaf0dc2cb146350
Summary: The current `median` calculation in the bucketize binary search is done in a way which is well-known to produce overflow issues ([link](https://en.wikipedia.org/wiki/Binary_search_algorithm#Implementation_issues)). This diff fixes the calculation so that overflows do not occur.
Test Plan:
Standard commit tests.
Also can test with:
```
#include <cassert>
#include <iostream>
#include <cstdint>
int32_t mp1(int32_t a, int32_t b){
return (a+b)/2;
}
int32_t mp2(int32_t a, int32_t b){
return a+(b-a)/2;
}
int main(){
int32_t low=-1;
for(int32_t high=1;high<10000;high++){
if(mp1(low,high)!=mp2(low,high)){
std::cout<<"Ahhhh!"<<std::endl;
}
}
}
```
Reviewed By: drdarshan
Differential Revision: D23993920
fbshipit-source-id: 6b4567515552092de5876de6cab77df27c9cf61d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45474
When batchnorm affine is set to false, weight and bias is set to None, which is not supported in this case. Added a fix to set weights to 1 and bias to 0 if they are not set.
Test Plan: Add unit test for testing fusing conv, batchnorm where batchnorm is in affine=False mode.
Reviewed By: z-a-f
Differential Revision: D23977080
fbshipit-source-id: 2782be626dc67553f3d27d8f8b1ddc7dea022c2a
Summary:
Export of embedding bag with dynamic list of offsets.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44693
Reviewed By: malfet
Differential Revision: D23831980
Pulled By: bzinodev
fbshipit-source-id: 3eaff1a0f20d1bcfb8039e518d78c491be381e1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45377
This PR adds a C++ implementation of the TripletMarginWithDistanceLoss, for which the Python implementation was introduced in PR #43680. It's based on PR #44072, but I'm resubmitting this to unlink it from Phabricator.
Test Plan: Imported from OSS
Reviewed By: izdeby
Differential Revision: D24003973
fbshipit-source-id: 2d9ada7260a6f27425ff2fdbbf623dad0fb79405
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44826
As described in https://github.com/pytorch/pytorch/issues/43690, there
is a need for DDP to be able to ignore certain parameters in the module (not
install allreduce hooks) for certain use cases. `find_unused_parameters` is
sufficient from a correctness perspective, but we can get better performance
with this upfront list if users know which params are unused, since we won't
have to traverse the autograd graph every iteration.
To enable this, we add a field `parameters_to_ignore` to DDP init and don't
pass in that parameter to reducer if that parameter is in the given list.
ghstack-source-id: 113210109
Test Plan: Added unittest
Reviewed By: xw285cornell, mrshenli
Differential Revision: D23740639
fbshipit-source-id: a0411712a8b0b809b9c9e6da04bef2b955ba5314
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45530
Returning double values requires special handling as a return type for aten functions.
Instead return tensors where the type is preserved in the tensor dtype
Test Plan:
python test/test_quantization.py TestQuantizedTensor.test_choose_qparams_optimized
Imported from OSS
Reviewed By: dskhudia
Differential Revision: D24001134
fbshipit-source-id: bec6b17242f4740ab5674be06e0fc30c35eb0379
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45512
This diff addresses https://github.com/pytorch/pytorch/issues/41443.
It is a clone of D23205313 which could not be imported from GitHub
for strange reasons.
Test Plan: Continuous integration.
Reviewed By: AshkanAliabadi
Differential Revision: D23967322
fbshipit-source-id: 744eb92de7cb5f0bc9540ed6a994f9e6dce8919a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45461
This PR disables autograd for all C -> C, R -> C functions which are not included in the whitelist `GRADIENT_IMPLEMENTED_FOR_COMPLEX`. In practice, there will be a RuntimeError during forward computation when the outputs are differentiable:
```
>>> x=torch.randn(4, 4, requires_grad=True, dtype=torch.cdouble)
>>> x.pow(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: pow does not support automatic differentiation for outputs with complex dtype.
```
The implicit assumption here is that all the C -> R functions have correct backward definitions. So before merging this PR, the following functions must be tested and verified to have correct backward definitions:
`torch.abs` (updated in #39955 ), `torch.angle`, `torch.norm`, `torch.irfft`, `torch.istft`.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D23998156
Pulled By: anjali411
fbshipit-source-id: 370eb07fe56ac84dd8e2233ef7bf3a3eb8aeb179
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45532
- updated documentation
- explicitly not supporting negative values for beta (previously the
result was incorrect)
- Removing default value for beta in the backwards function, since it's
only used internally by autograd (as per convention)
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D24002415
Pulled By: bdhirsh
fbshipit-source-id: 980c141019ec2d437b771ee11fc1cec4b1fcfb48
Summary:
This PR allows Timer to collect deterministic instruction counts for (some) snippets. Because of the intrusive nature of Valgrind (effectively replacing the CPU with an emulated one) we have to perform our measurements in a separate process. This PR writes a `.py` file containing the Timer's `setup` and `stmt`, and executes it within a `valgrind` subprocess along with a plethora of checks and error handling. There is still a bit of jitter around the edges due to the Python glue that I'm using, but the PyTorch signal is quite good and thus this provides a low friction way of getting signal. I considered using JIT as an alternative, but:
A) Python specific overheads (e.g. parsing) are important
B) JIT might do rewrites which would complicate measurement.
Consider the following bit of code, related to https://github.com/pytorch/pytorch/issues/44484:
```
from torch.utils._benchmark import Timer
counts = Timer(
"x.backward()",
setup="x = torch.ones((1,)) + torch.ones((1,), requires_grad=True)"
).collect_callgrind()
for c, fn in counts[:20]:
print(f"{c:>12} {fn}")
```
```
812800 ???:_dl_update_slotinfo
355600 ???:update_get_addr
308300 work/Python/ceval.c:_PyEval_EvalFrameDefault'2
304800 ???:__tls_get_addr
196059 ???:_int_free
152400 ???:__tls_get_addr_slow
138400 build/../c10/core/ScalarType.h:c10::typeMetaToScalarType(caffe2::TypeMeta)
126526 work/Objects/dictobject.c:_PyDict_LoadGlobal
114268 ???:malloc
101400 work/Objects/unicodeobject.c:PyUnicode_FromFormatV
85900 work/Python/ceval.c:_PyEval_EvalFrameDefault
79946 work/Objects/typeobject.c:_PyType_Lookup
72000 build/../c10/core/Device.h:c10::Device::validate()
70000 /usr/include/c++/8/bits/stl_vector.h:std::vector<at::Tensor, std::allocator<at::Tensor> >::~vector()
66400 work/Objects/object.c:_PyObject_GenericGetAttrWithDict
63000 ???:pthread_mutex_lock
61200 work/Objects/dictobject.c:PyDict_GetItem
59800 ???:free
58400 work/Objects/tupleobject.c:tupledealloc
56707 work/Objects/dictobject.c:lookdict_unicode_nodummy
```
Moreover, if we backport this PR to 1.6 (just copy the `_benchmarks` folder) and load those counts as `counts_1_6`, then we can easily diff them:
```
print(f"Head instructions: {sum(c for c, _ in counts)}")
print(f"1.6 instructions: {sum(c for c, _ in counts_1_6)}")
count_dict = {fn: c for c, fn in counts}
for c, fn in counts_1_6:
_ = count_dict.setdefault(fn, 0)
count_dict[fn] -= c
count_diffs = sorted([(c, fn) for fn, c in count_dict.items()], reverse=True)
for c, fn in count_diffs[:15] + [["", "..."]] + count_diffs[-15:]:
print(f"{c:>8} {fn}")
```
```
Head instructions: 7609547
1.6 instructions: 6059648
169600 ???:_dl_update_slotinfo
101400 work/Objects/unicodeobject.c:PyUnicode_FromFormatV
74200 ???:update_get_addr
63600 ???:__tls_get_addr
46800 work/Python/ceval.c:_PyEval_EvalFrameDefault
33512 work/Objects/dictobject.c:_PyDict_LoadGlobal
31800 ???:__tls_get_addr_slow
31700 build/../aten/src/ATen/record_function.cpp:at::RecordFunction::RecordFunction(at::RecordScope)
28300 build/../torch/csrc/utils/python_arg_parser.cpp:torch::FunctionSignature::parse(_object*, _object*, _object*, _object**, bool)
27800 work/Objects/object.c:_PyObject_GenericGetAttrWithDict
27401 work/Objects/dictobject.c:lookdict_unicode_nodummy
24115 work/Objects/typeobject.c:_PyType_Lookup
24080 ???:_int_free
21700 work/Objects/dictobject.c:PyDict_GetItemWithError
20700 work/Objects/dictobject.c:PyDict_GetItem
...
-3200 build/../c10/util/SmallVector.h:at::TensorIterator::binary_op(at::Tensor&, at::Tensor const&, at::Tensor const&, bool)
-3400 build/../aten/src/ATen/native/TensorIterator.cpp:at::TensorIterator::resize_outputs(at::TensorIteratorConfig const&)
-3500 /usr/include/c++/8/x86_64-redhat-linux/bits/gthr-default.h:std::unique_lock<std::mutex>::unlock()
-3700 build/../torch/csrc/utils/python_arg_parser.cpp:torch::PythonArgParser::raw_parse(_object*, _object*, _object**)
-4207 work/Objects/obmalloc.c:PyMem_Calloc
-4500 /usr/include/c++/8/bits/stl_vector.h:std::vector<at::Tensor, std::allocator<at::Tensor> >::~vector()
-4800 build/../torch/csrc/autograd/generated/VariableType_2.cpp:torch::autograd::VariableType::add__Tensor(at::Tensor&, at::Tensor const&, c10::Scalar)
-5000 build/../c10/core/impl/LocalDispatchKeySet.cpp:c10::impl::ExcludeDispatchKeyGuard::ExcludeDispatchKeyGuard(c10::DispatchKey)
-5300 work/Objects/listobject.c:PyList_New
-5400 build/../torch/csrc/utils/python_arg_parser.cpp:torch::FunctionParameter::check(_object*, std::vector<pybind11::handle, std::allocator<pybind11::handle> >&)
-5600 /usr/include/c++/8/bits/std_mutex.h:std::unique_lock<std::mutex>::unlock()
-6231 work/Objects/obmalloc.c:PyMem_Free
-6300 work/Objects/listobject.c:list_repeat
-11200 work/Objects/listobject.c:list_dealloc
-28900 build/../torch/csrc/utils/python_arg_parser.cpp:torch::FunctionSignature::parse(_object*, _object*, _object**, bool)
```
Remaining TODOs:
* Include a timer in the generated script for cuda sync.
* Add valgrind to CircleCI machines and add a unit test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44717
Reviewed By: soumith
Differential Revision: D24010742
Pulled By: robieta
fbshipit-source-id: df6bc765f8efce7193893edba186cd62b4b23623
Summary:
Originally proposed at https://github.com/pytorch/pytorch/issues/44473#issuecomment-690670989 by colesbury .
This PR adds the functionality to print relevant tensor shapes and convolution parameters along with the stack trace once a cuDNN exception is thrown.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45023
Reviewed By: gchanan
Differential Revision: D23932661
Pulled By: ezyang
fbshipit-source-id: 5f5f570df6583271049dfc916fac36695f415331
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45482
Working on some models that need these ops on lite interpreter.
Test Plan: locally build and load/run the TS model without problem.
Reviewed By: iseeyuan
Differential Revision: D23906581
fbshipit-source-id: 01b9de2af2046296165892b837bc14a7e5d59b4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45520
With this change `Load`s and `Store`s no longer accept `Placeholder`s in
their constructor and `::make` functions and can only be built with
`Buf`.
`Placeholder` gets its own `store`, `load`, `storeWithMask`, and
`loadWithMask` method for more convenient construction.
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D23998789
Pulled By: ZolotukhinM
fbshipit-source-id: 3fe018e00c1529a563553b2b215f403b34aea912
Summary:
This might be an alternative to reverting https://github.com/pytorch/pytorch/issues/45396 .
The obvious rough edge is that I'm not really seeing the work group limits that TensorExpr produces.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45506
Reviewed By: zhangguanheng66
Differential Revision: D23991410
Pulled By: Krovatkin
fbshipit-source-id: 11d3fc4600e4bffb1d1192c6b8dd2fe22c1e064e
Summary:
This PR adds a new GraphManipulation library for operating on the GraphModule nodes.
It also adds an implementation of replace_target_nodes_with, which replaces all nodes in the GraphModule or a specific op/target with a new specified op/target. An example use of this function would be replacing a generic operator with an optimized operator for specific sizes and shapes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44775
Reviewed By: jamesr66a
Differential Revision: D23874561
Pulled By: gcatron
fbshipit-source-id: e1497cd11e0bbbf1fabdf137d65c746248998e0b
Summary:
In coordination with jlin27.
This PR is meant to build documentation when the repo is tagged. For instance, tagging the repo with 1.7.0rc1 will push that commit's documentation to pytorch/pytorch.github.io/docs/1.7.
Subsequently tagging 1.7.0rc2 will override the 1.7 docs, as will 1.7.0, and 1.7.1. I think this is as it should be: there should be one, latest, version for the 1.7 docs. This can be tweaked differently if desired.
There is probably work that needs to be done to adjust the [versions.html](https://pytorch.org/docs/versions.html) to add the new tag?
Is there a way to test the tagging side of this without breaking the production documentation?
As an aside, the documentation is being built via the `pytorch_linux_xenial_py3_6_gcc5_4_build` image. Some projects are starting to move on from python3.6 since [it is in security-only support mode](https://devguide.python.org/#status-of-python-branches), no new binaries are being released.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45204
Reviewed By: zhangguanheng66
Differential Revision: D23996800
Pulled By: seemethere
fbshipit-source-id: a94a080348a47738c1de5832ab37b2b0d57d2d57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45364
Plus add some more comments about the usage, limitations and cons.
Test Plan: Build and run benchmark binary.
Reviewed By: gchanan
Differential Revision: D23944193
fbshipit-source-id: 30d4f4991d2185a0ab768d94c846d73730fc0835
Summary:
Per feedback in the recent design review. Also tweaks the documentation to clarify what "deterministic" means and adds a test for the behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45410
Reviewed By: ngimel
Differential Revision: D23974988
Pulled By: mruberry
fbshipit-source-id: e48307da9c90418fc6834fbd67b963ba2fe0ba9d
Summary:
Updated `cholesky_backward` to work correctly for complex input.
Note that the current implementation gives the conjugate of what JAX would return. anjali411 is that correct thing to do?
Ref. https://github.com/pytorch/pytorch/issues/44895
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45267
Reviewed By: bwasti
Differential Revision: D23975269
Pulled By: anjali411
fbshipit-source-id: 9908b0bb53c411e5ad24027ff570c4f0abd451e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45488
model_name logging was broken, issue is from the recent change of assigning the method name into the module name, this diff is fixing it.
ghstack-source-id: 113103942
Test Plan:
made sure that now the model_name is logged from module_->name().
verified with one model which does not contain the model metadata, and the model_name field is logged as below:
09-28 21:59:30.065 11530 12034 W module.cpp: TESTINGTESTING run() module = __torch__.Model
09-28 21:59:30.065 11530 12034 W module.cpp: TESTINGTESTING metadata does not have model_name assigning to __torch__.Model
09-28 21:59:30.066 11530 12034 W MobileModuleQPLObserver.cpp: TESTINGTESTING onEnterRunMethod log model_name = __torch__.Model
09-28 21:59:30.066 11530 12034 W MobileModuleQPLObserver.cpp: TESTINGTESTING onEnterRunMethod log method_name = labels
09-28 21:59:30.068 11530 12034 W MobileModuleQPLObserver.cpp: TESTINGTESTING onExitRunMethod()
Reviewed By: linbinyu
Differential Revision: D23984165
fbshipit-source-id: 5b00f50ea82106b695c2cee14029cb3b2e02e2c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45261
**Summary**
This commit enables `unused` syntax for ignoring
properties. Inoring properties is more intuitive with this feature enabled.
`ignore` is not supported because class type properties cannot be
executed in Python (because they exist only as TorchScript types) like
an `ignored` function and module properties that cannot be scripted
are not added to the `ScriptModule` wrapper so that they
may execute in Python.
**Test Plan**
This commit updates the existing unit tests for class type and module
properties to test properties ignored using `unused`.
Test Plan: Imported from OSS
Reviewed By: navahgar, Krovatkin, mannatsingh
Differential Revision: D23971881
Pulled By: SplitInfinity
fbshipit-source-id: 8d3cc1bbede7753d6b6f416619e4660c56311d33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45479
Add a top level boolean attribute to the model called mobile_optimized that is set to true if it is optimized.
Test Plan: buck test //caffe2/test:mobile passes
Reviewed By: kimishpatel
Differential Revision: D23956728
fbshipit-source-id: 79c5931702208b871454319ca2ab8633596b1eb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45083
This PR just reorders the methods in Sorting.cpp placing related methods next to each other.
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D23908817
Pulled By: heitorschueroff
fbshipit-source-id: 1dd7b693b5135fddf5dff12303474e85ce0c2f83
Summary:
Fix `torch._C._autocast_*_nesting` declarations in __init__.pyi
Fix iterable constructor logic: not every iterable can be constructed using `type(val)(val)` trick, for example it would not work for `val=range(10)` although `isinstance(val, Iterable)` is True
Change optional resolution logic to meet mypy expectations
Fixes https://github.com/pytorch/pytorch/issues/45436
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45480
Reviewed By: walterddr
Differential Revision: D23982822
Pulled By: malfet
fbshipit-source-id: 6418a28d04ece1b2427dcde4b71effb67856a872
Summary:
This PR makes the deprecation warnings for existing fft functions more prominent and makes the torch.stft deprecation warning consistent with our current deprecation planning.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45409
Reviewed By: ngimel
Differential Revision: D23974975
Pulled By: mruberry
fbshipit-source-id: b90d8276095122ac3542ab625cb49b991379c1f8
Summary:
This avoids unnecessary memory allocations in `view_as_complex` and `view_as_real`. I construct the new tensor directly with the existing storage to avoid creating a new storage object and also use `DimVector`s to avoid allocating for the sizes and strides. Overall, this saves about 2 us of overhead from `torch.fft.fft` which currently has to call `view_as_real` and `view_as_complex` for every call.
I've used this simple benchmark to measure the overhead:
```python
In [1]: import torch
...: a = torch.rand(1, 2)
...: ac = torch.view_as_complex(a)
...: %timeit torch.view_as_real(ac)
...: %timeit torch.view_as_complex(a)
...: %timeit ac.real
```
Results before:
```
2.5 µs ± 62.4 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
2.22 µs ± 36 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
4.17 µs ± 8.76 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
```
and after:
```
1.83 µs ± 9.26 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
1.57 µs ± 7.17 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
3.47 µs ± 34.4 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44908
Reviewed By: agolynski
Differential Revision: D23793479
Pulled By: anjali411
fbshipit-source-id: 64b9cad70e3ec10891310cbfa8c0bdaa1d72885b
Summary:
PR opened just to run the CI tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44465
Reviewed By: ngimel
Differential Revision: D23907565
Pulled By: mruberry
fbshipit-source-id: 620661667877f1e9a2bab17d19988e2dc986fc0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44846
The save function traverses the model state dict to pick out the observer stats
load function traverse the module hierarchy to load the state dict into module attributes depending on observer type
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_save_observer_state_dict
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D23746821
fbshipit-source-id: 05c571b62949a2833602d736a81924d77e7ade55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45390
Tensor objects should always refer to their Function's bufs. Currently
we never create a Tensor with a buffer different than of its function,
but having it in two places seems incorrect and dangerous.
Differential Revision: D23952865
Test Plan: Imported from OSS
Reviewed By: nickgg
Pulled By: ZolotukhinM
fbshipit-source-id: e63fc26d7078427514649d9ce973b74ea635a94a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45388
Classes defined in these files are closely related, so it is reasonable
to have them all in one file. The change is purely a code move.
Differential Revision: D23952867
Test Plan: Imported from OSS
Reviewed By: nickgg
Pulled By: ZolotukhinM
fbshipit-source-id: 12cfaa968bdfc4dff00509e34310a497c7b59155
Summary:
In profiler, cuda did not report self time, so for composite functions there was no way to determine which function is really taking time. In addition, "total cuda time" reported was frequently more than total wallclock time. This PR adds "self CUDA time" in profiler, and computes total cuda time based on self cuda time, similar to how it's done for CPU. Also, slight formatting changes to make table more compact. Before:
```
-------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls
-------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
aten::matmul 0.17% 890.805us 99.05% 523.401ms 5.234ms 49.91% 791.184ms 7.912ms 100
aten::mm 98.09% 518.336ms 98.88% 522.511ms 5.225ms 49.89% 790.885ms 7.909ms 100
aten::t 0.29% 1.530ms 0.49% 2.588ms 25.882us 0.07% 1.058ms 10.576us 100
aten::view 0.46% 2.448ms 0.46% 2.448ms 12.238us 0.06% 918.936us 4.595us 200
aten::transpose 0.13% 707.204us 0.20% 1.058ms 10.581us 0.03% 457.802us 4.578us 100
aten::empty 0.14% 716.056us 0.14% 716.056us 7.161us 0.01% 185.694us 1.857us 100
aten::as_strided 0.07% 350.935us 0.07% 350.935us 3.509us 0.01% 156.380us 1.564us 100
aten::stride 0.65% 3.458ms 0.65% 3.458ms 11.527us 0.03% 441.258us 1.471us 300
-------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Self CPU time total: 528.437ms
CUDA time total: 1.585s
Recorded timeit time: 789.0814 ms
```
Note recorded timeit time (with proper cuda syncs) is 2 times smaller than "CUDA time total" reported by profiler
After
```
-------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
-------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
aten::matmul 0.15% 802.716us 99.06% 523.548ms 5.235ms 302.451us 0.04% 791.151ms 7.912ms 100
aten::mm 98.20% 519.007ms 98.91% 522.745ms 5.227ms 790.225ms 99.63% 790.848ms 7.908ms 100
aten::t 0.27% 1.406ms 0.49% 2.578ms 25.783us 604.964us 0.08% 1.066ms 10.662us 100
aten::view 0.45% 2.371ms 0.45% 2.371ms 11.856us 926.281us 0.12% 926.281us 4.631us 200
aten::transpose 0.15% 783.462us 0.22% 1.173ms 11.727us 310.016us 0.04% 461.282us 4.613us 100
aten::empty 0.11% 591.603us 0.11% 591.603us 5.916us 176.566us 0.02% 176.566us 1.766us 100
aten::as_strided 0.07% 389.270us 0.07% 389.270us 3.893us 151.266us 0.02% 151.266us 1.513us 100
aten::stride 0.60% 3.147ms 0.60% 3.147ms 10.489us 446.451us 0.06% 446.451us 1.488us 300
-------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 528.498ms
CUDA time total: 793.143ms
Recorded timeit time: 788.9832 ms
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45209
Reviewed By: zou3519
Differential Revision: D23925491
Pulled By: ngimel
fbshipit-source-id: 7f9c49238d116bfd2db9db3e8943355c953a77d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44970
Right now, when RecordFunction is not active (usual case),
we do two TLS accesses (check for thread local callbacks, and check for
thread local boolean).
Experimenting with reducing number of TLS accesses in RecordFunction
constructor.
Test Plan: record_function_benchmark
Reviewed By: dzhulgakov
Differential Revision: D23791165
Pulled By: ilia-cher
fbshipit-source-id: 6137ce4bface46f540ece325df9864fdde50e0a4
Summary:
To support abnormal detection for test time spike
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45457
Reviewed By: malfet
Differential Revision: D23975628
Pulled By: walterddr
fbshipit-source-id: f28d0f12559070004d637d5bde83289f029b15b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45069
`torch.abs` is a `C -> R` function for complex input. Following the general semantics in torch, the in-place version of abs should be disabled for complex input.
Test Plan: Imported from OSS
Reviewed By: glaringlee, malfet
Differential Revision: D23818397
Pulled By: anjali411
fbshipit-source-id: b23b8d0981c53ba0557018824d42ed37ec13d4e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45233
**Summary**
This commit modifies `TestClassType.test_properties` to check that
properties on class types can be ignored with the same syntax as
ignoring properties on `Modules`.
**Test Plan**
`python test/test_jit.py TestClassType.test_properties`
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D23971885
Pulled By: SplitInfinity
fbshipit-source-id: f2228f61fe26dff219024668cc0444a2baa8834c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45232
**Summary**
This commit updates the TorchScript language reference to include
documentation on recently-added TorchScript enums. It also removed
`torch.no_grad` from the list of known unsupported `torch` modules and
classes because it is now supported.
**Test Plan**
Continuous integration.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D23971884
Pulled By: SplitInfinity
fbshipit-source-id: 5e2c164ed59bc0926b11201106952cff86e9356e
Summary:
Inline pytorch into wrapper, which is especially helpful in combination
with dead code elimination to reduce IR size and compilation times when
a lot of parameters are unused.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45445
Test Plan: CI
Reviewed By: ZolotukhinM
Differential Revision: D23969009
Pulled By: asuhan
fbshipit-source-id: a21509d07e4c130b6aa6eae5236bb64db2748a3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43612
**Summary**
This commit modifies the `torch._C._jit_to_backend` function so that it
accepts `ScriptModules` as inputs. It already returns `ScriptModules`
(as opposed to C++ modules), so this makes sense and makes the API more
intuitive.
**Test Plan**
Continuous integration, which includes unit tests and out-of-tree tests
for custom backends.
**Fixes**
This commit fixes#41432.
Test Plan: Imported from OSS
Reviewed By: suo, jamesr66a
Differential Revision: D23339854
Pulled By: SplitInfinity
fbshipit-source-id: 08ecef729c4e1e6bddf3f483276947fc3559ea88
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45280
Performance is the same on CPU and on CUDA is only 1-1.05x slower. This change is necessary for the future nan ops including nan(min|max|median)
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D23908796
Pulled By: heitorschueroff
fbshipit-source-id: c2b57acbe924cfa59fbd85216811f29f4af05088
Summary:
Stumbled upon a little gem in the audio conversion for `SummaryWriter.add_audio()`: two Python `for` loops to convert a float array to little-endian int16 samples. On my machine, this took 35 seconds for a 30-second 22.05 kHz excerpt. The same can be done directly in numpy in 1.65 milliseconds. (No offense, I'm glad that the functionality was there!)
Would also be ready to extend this to support stereo waveforms, or should this become a separate PR?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44201
Reviewed By: J0Nreynolds
Differential Revision: D23831002
Pulled By: edward-io
fbshipit-source-id: 5c8f1ac7823d1ed41b53c4f97ab9a7bac33ea94b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45214
When in verbose mode the package exporter will produce an html visualization
of dependencies of a module to make it easier to trim out unneeded code,
or debug inclusion of things that cannot be exported.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D23873525
Pulled By: zdevito
fbshipit-source-id: 6801991573d8dd5ab8c284e09572b36a35e1e5a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45402
Previous diffs in this stack implemented the getNumKeys and deleteKey
APIs in the c10d Store as well as added tests at the C++ layer. This diff adds
tests at the Python level in test_c10d.py
ghstack-source-id: 112997161
Test Plan: Running these new python tests as well as previous C++ tests
Reviewed By: mrshenli
Differential Revision: D23955729
fbshipit-source-id: c7e0af7c884de2d488320e2a1d94aec801a782e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45401
Added a DeleteKey API for the TCP Store
ghstack-source-id: 112997162
Test Plan:
Modified the existing get/set test to use delete. verified that the
correct keys were deleted and that the numKeys API returned the right values
Reviewed By: mrshenli
Differential Revision: D23955730
fbshipit-source-id: 5c9f82be34ff4521c59f56f8d9c1abf775c67f9f
Summary: As title.
Test Plan:
FBL job without this diff failed:
f221545832
Error message:
```
NonRetryableException: AssertionError: Label is missing in training stage for HistogramBinningCalibration
```
FBL job with canary package built in this diff is running without failure:
f221650379
Reviewed By: chenshouyuan
Differential Revision: D23959508
fbshipit-source-id: c077230de29f7abfd092c84747eaabda0b532bcc
Summary:
Recent changes to the seq_num correlation behavior in profiler (PR https://github.com/pytorch/pytorch/issues/42565) has changed the behavior for emit_nvtx(record_shapes=True) which doesn't print the name of the operator properly.
Created PR to dump out the name in roctx traces, irrespective of the sequence number assigned only for ROCm.
cc: jeffdaily sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45229
Reviewed By: zou3519
Differential Revision: D23932902
Pulled By: albanD
fbshipit-source-id: c782667ff002b70b51f1cc921afd1b1ac533b39d
Summary:
This PR cleans up some of the rough edges around `Timer` and `Compare`
* Moves `Measurement` to be dataclass based
* Adds a bunch of type annotations. MyPy is now happy.
* Allows missing entries in `Compare`. This is one of the biggest usability issues with `Compare` right now, both from an API perspective and because the current failure mode is really unpleasant.
* Greatly expands the testing of `Compare`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45361
Test Plan: Changes to Timer are covered under existing tests, changes to `Compare` are covered by the expanded `test_compare` method.
Reviewed By: bwasti
Differential Revision: D23966816
Pulled By: robieta
fbshipit-source-id: 826969f73b42f72fa35f4de3c64d0988b61474cd
Summary:
Export of view op with dynamic input shape is broken when using tensors with a 0-dim.
This fix removes symbolic use of static input size to fix this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43558
Reviewed By: ailzhang
Differential Revision: D23965090
Pulled By: bzinodev
fbshipit-source-id: 628e9d7ee5d53375f25052340ca6feabf7ba7c53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45291
It's not necessary, you can just check if the dtype is integral.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23911963
Pulled By: gchanan
fbshipit-source-id: 230139e1651eb76226f4095e31068dded30e03e8
Summary: Adding support for type double to caffe2 MeanOp and MeanGradientOp.
Test Plan:
All tests passed.
Example FBL job failed without this diff:
f221169563
Error message:
```
c10::Error: [enforce fail at mean_op.h:72] . Mean operator only supports 32-bit float, but input was of type double (Error from operator:
input: "dpsgd_8/Copy_3" input: "dpsgd_8/Copy_4" output: "dpsgd_8/Mean_2" name: "" type: "Mean" device_option { device_type: 0 device_id: 0 })
```
Example FBL job is running without failure with the canary package built from this diff:
f221468723
Reviewed By: chenshouyuan
Differential Revision: D23956222
fbshipit-source-id: 6c81bbc390d812ae0ac235e7d025141c8402def1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45294
While tracking down a recent memory corruption bug we found that
cuda-memcheck wasn't finding the bad accesses, and ngimel pointed out that
it's because we use a caching allocator so a lot of "out of bounds" accesses
land in a valid slab.
This PR adds a runtime knob (`PYTORCH_NO_CUDA_MEMORY_CACHING`) that, when set,
bypasses the caching allocator's caching logic so that allocations go straight
to cudaMalloc. This way, cuda-memcheck will actually work.
Test Plan:
Insert some memory errors and run a test under cuda-memcheck;
observe that cuda-memcheck flags an error where expected.
Specifically I removed the output-masking logic here:
https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/tensorexpr/cuda_codegen.cpp#L819-L826
And ran:
```
PYTORCH_NO_CUDA_MEMORY_CACHING=1 cuda-memcheck pytest -k test_superslomo test_jit_fuser_te.py
```
Reviewed By: ngimel
Differential Revision: D23964734
Pulled By: bertmaher
fbshipit-source-id: 04efd11e8aff037b9edde80c70585cb820ee6e39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45433
Primarily in order to pick up the fix landed in https://github.com/pytorch/tensorpipe/pull/225 which fixes the handling of scopes in link-local IPv6 addresses, which was reported by a user.
Test Plan: The specific upstream change is covered by new unit tests. The submodule update will be validated by the PyTorch CI.
Reviewed By: beauby
Differential Revision: D23962289
fbshipit-source-id: 4ed762fc19c4aeb1398d1337d61b3188c4c228be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45438
Adds torchelastic (as well as its dependencies) to the official docker
images
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: tierex
Differential Revision: D23963787
Pulled By: seemethere
fbshipit-source-id: 54ebb4b9c50699e543f264975dadf99badf55753
Summary:
As per title. Fixes [#{38948}](https://github.com/pytorch/pytorch/issues/38948). Therein you can find some blueprints for the algorithm being used in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43002
Reviewed By: zou3519
Differential Revision: D23931326
Pulled By: albanD
fbshipit-source-id: e6994af70d94145f974ef87aa5cea166d6deff1e
Summary:
Changes the deprecation of norm to a docs deprecation, since PyTorch components still rely on norm and some behavior, like automatically flattening tensors, may need to be ported to torch.linalg.norm. The documentation is also updated to clarify that torch.norm and torch.linalg.norm are distinct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45415
Reviewed By: ngimel
Differential Revision: D23958252
Pulled By: mruberry
fbshipit-source-id: fd54e807c59a2655453a6bcd9f4073cb2c12e8ac
Summary:
Fix a couple of issues with scripting inplace indexing in prepare_inplace_ops_for_onnx pass.
1- Tracing index copy (such as cases lik x[1:3] = data) already applies broadcasting on rhs if needed. The broadcasting node (aten::expand) is missing in scripting cases.
2- Inplace indexing with ellipsis (aten::copy_) is replaced with aten::index_put and then handled with slice+select in this pass.
Support for negative indices for this op added.
Shape inference is also enabled for scripting tests using new JIT API.
A few more tests are enabled for scripting.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44351
Reviewed By: ezyang
Differential Revision: D23880267
Pulled By: bzinodev
fbshipit-source-id: 78b33444633eb7ae0fbabc7415e3b16001f5207f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45143
This PR prevents freezing cleaning up a submodule when user requests to
preserve a submodule.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23844969
Pulled By: bzinodev
fbshipit-source-id: 80e6db3fc12460d62e634ea0336ae2a3551c2151
Summary:
in ONNX NegativeLogLikelihoodLoss specification, ignore_index is optional without default value.
therefore, when convert nll op to ONNX, we need to set ignore_index attribute even if it is not specified (e.g. ignore_index=-100).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44816
Reviewed By: ezyang
Differential Revision: D23880354
Pulled By: bzinodev
fbshipit-source-id: d0bdd58d0a4507ed9ce37133e68533fe6d1bdf2b
Summary:
Optimize export_onnx api to reduce string and model proto exchange in export.cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44332
Reviewed By: bwasti, eellison
Differential Revision: D23880129
Pulled By: bzinodev
fbshipit-source-id: 1d216d8f710f356cbba2334fb21ea15a89dd16fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44419
Closes https://github.com/pytorch/pytorch/issues/39969
This PR adds support for propagation of input shapes over the wire when the profiler is invoked with `record_shapes=True` over RPC. Previously, we did not respect this argument.
This is done by saving the shapes as an ivalue list and recovering it as the type expected (`std::vector<std::vector<int>>` on the client). Test is added to ensure that remote ops have the same `input_shapes` as if the op were run locally.
ghstack-source-id: 112977899
Reviewed By: pritamdamania87
Differential Revision: D23591274
fbshipit-source-id: 7cf3b2e8df26935ead9d70e534fc2c872ccd6958
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44967
When enabling profiler on server, if it is a different machine it may
not have CUDA while caller does. In this case, we would crash but now we
fallback to CPU and log a warning.
ghstack-source-id: 112977906
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D23790729
fbshipit-source-id: dc6eba172b7e666842d54553f52a6b9d5f0a5362
Summary: Currently GetSingleArgument is overflowing since it's expecting an int instead of an int64 when using a 1cycle (hill policy) annealing schedule
Test Plan:
unittest
buck test caffe2/caffe2/python/operator_test:learning_rate_op_test
Differential Revision: D23938169
fbshipit-source-id: 20d65df800d7a0f1dd9520705af31f63ae716463
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45223
Previous diffs in this stack implemented the getNumKeys and deleteKey
APIs in the c10d Store as well as added tests at the C++ layer. This diff adds
tests at the Python level in test_c10d.py
ghstack-source-id: 112939763
Test Plan: Ensured these new python tests as well as previous C++ tests pass
Reviewed By: jiayisuse
Differential Revision: D23878455
fbshipit-source-id: 0a17ecf66b28d46438a77346e5bf36414e05e25c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43963
Added a DeleteKey API for the TCP Store
ghstack-source-id: 112939762
Test Plan:
Modified the existing get/set test to use delete. verified that the
correct keys were deleted and that the numKeys API returned the right values
Reviewed By: jiayisuse
Differential Revision: D23009117
fbshipit-source-id: 1a0d95b43d79e665a69b2befbaa059b2b50a1f66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43962
TCPStore needs a getNumKeys API for our logging needs.
ghstack-source-id: 112939761
Test Plan: Adding tests to C++ Store Tests
Reviewed By: pritamdamania87
Differential Revision: D22985085
fbshipit-source-id: 8a0d286fbd6fd314dcc997bae3aad0e62b51af83
Summary:
This PR adds get_all_users_of function. The function returns all the users of a specific node. A test unit is also added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45216
Reviewed By: ezyang
Differential Revision: D23883572
Pulled By: scottxu0730
fbshipit-source-id: 3eb68a411c3c6db39ed2506c9cb7bb7337520ee4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45306
Adds details to the main quantization doc on how specifically
users can skip or customize quantization of layers.
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23917034
Pulled By: vkuzo
fbshipit-source-id: ccf71ce4300c1946b2ab63d1f35a07691fd7a2af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45305
Adds an explanatation for reduce_range to the main quantization
doc page.
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23916669
Pulled By: vkuzo
fbshipit-source-id: ef93fb774cb15741cd92889f114f6ab76c39f051
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45135
The previous quantization summary had steps on what to do for
dynamic, static, QAT. This PR moves these steps to comments in the
example code, so it is more clear how to accomplish the steps.
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23842456
Pulled By: vkuzo
fbshipit-source-id: db2399e51e9ae33c8a1ac610e3d7dbdb648742b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45093
This adds a tl;dr; style summary of the quantization API
to the documentation. Hopefully this will make this easier
for new folks to learn how to use quantization.
This is not meant to be all-encompassing. Future PRs
can improve the documentation further.
Test Plan:
1. build the doc as specified in https://github.com/pytorch/pytorch#building-the-documentation
2. inspect the quantization page in Chrome, format looks good
Reviewed By: jerryzh168
Differential Revision: D23828257
Pulled By: vkuzo
fbshipit-source-id: 9311ee3f394cd83af0aeafb6e2fcdc3e0321fa38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45221
This PR introduces a distributed functional optimizer, so that
distributed optimizer can reuse the functional optimizer APIs and
maintain their own states. This could enable the torchscript compatible
functional optimizer when using distributed optimizer, helps getting rid
of GIL and improve overall performance of training, especially distributed
model parallel training
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D23935256
Pulled By: wanchaol
fbshipit-source-id: 59b6d77ff4693ab24a6e1cbb6740bcf614cc624a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44715
We have provided a nice and intuitive API in Python. But in the context of large scale distributed training (e.g. Distributed Model Parallel), users often want to use multithreaded training instead of multiprocess training as it provides better resource utilization and efficiency.
This PR introduces functional optimizer concept (that is similar to the concept of `nn.functional`), we split optimizer into two parts: 1. optimizer state management 2. optimizer computation. We expose the computation part as a separate functional API that is available to be used by internal and OSS developers, the caller of the functional API will maintain their own states in order to directly calls the functional API. While maintaining the end user API be the same, the functional API is TorchScript friendly, and could be used by the distributed optimizer to speed up the training without GIL.
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D23935258
Pulled By: wanchaol
fbshipit-source-id: d2a5228439edb3bc64f7771af2bb9e891847136a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45353
Temporarily removing this feature, will add this back after branch cut.
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D23939865
Pulled By: mrshenli
fbshipit-source-id: 7dceaffea6b9a16512b5ba6036da73e7f8f83a8e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44433
Not entirely sure why, but changing the type of beta from `float` to `double in autocast_mode.cpp and FunctionsManual.h fixes my compiler errors, failing instead at link time
fixing some type errors, updated fn signature in a few more files
removing my usage of Scalar, making beta a double everywhere instead
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D23636720
Pulled By: bdhirsh
fbshipit-source-id: caea2a1f8dd72b3b5fd1d72dd886b2fcd690af6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45181
`init_process_group` and `new_group` update a bunch of global
variables after initializing the actual process group. As a result, there is a
race that after initializing the process group on say rank 0, if we immediately
check the default process group on rank 1 (say via RPC), we might actually get
an error since rank 1 hasn't yet updated its _default_pg variable.
To resolve this issue, I've added barrier() at the end of both of these calls.
This ensures that once these calls return we are guaranteed about correct
initialization on all ranks.
Since these calls are usually done mostly during initialization, it should be
fine to add the overhead of a barrier() here.
#Closes: https://github.com/pytorch/pytorch/issues/40434, https://github.com/pytorch/pytorch/issues/40378
ghstack-source-id: 112923112
Test Plan:
Reproduced the failures in
https://github.com/pytorch/pytorch/issues/40434 and
https://github.com/pytorch/pytorch/issues/40378 and verified that this PR fixes
the issue.
Reviewed By: mrshenli
Differential Revision: D23858025
fbshipit-source-id: c4d5e46c2157981caf3ba1525dec5310dcbc1830
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45356
In this PR, I'm adding a warning to the PG backend mentioning it would
be deprecated in the future. In addition to this I removed the warning from the
TP backend that it is a beta feature.
ghstack-source-id: 112940501
Test Plan: waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D23940144
fbshipit-source-id: d44054aa1e4ef61004a40bbe0ec45ff07829aad4
Summary:
This should get the builds green again
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45354
Reviewed By: zhangguanheng66
Differential Revision: D23939615
Pulled By: bwasti
fbshipit-source-id: e93b11bc9592205e52330bb15928603b0aea21ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45188
This is a symbolically traceable alternative to Python's `assert`.
It should be useful to allow people who want to use FX to also
be able to assert things.
A bunch of TODO(before) land are inline - would love thoughts
on where is the best place for this code to live, and what this
function should be called (since `assert` is reserved).
Test Plan:
```
python test/test_fx.py TestFX.test_symbolic_trace_assert
```
Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D23861567
fbshipit-source-id: d9d6b9556140faccc0290eba1fabea401d7850de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44923
This ensures that RPC profiling works in single-threaded server
scenarios and that we won't make the assumption that we'll have multiple
threads when working on this code. For example, this assumption resulted in a
bug in the previous diff (which was fixed)
ghstack-source-id: 112868469
Test Plan: CI
Reviewed By: lw
Differential Revision: D23691304
fbshipit-source-id: b17d34ade823794cbe949b70a5ab35723d974203
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44664
Closes https://github.com/pytorch/pytorch/issues/39971. This PR adds support for functions decorated with `rpc.functions.async_execution` to be profiled over RPC as builtins, jit functions, and blocking python UDFs currently can be. The reasoning for this is to provide complete feature support in terms of RPC profiling and the various types of functions users can run.
To enable this, the PR below this enables calling `disableProfiler()` safely from another thread. We use that functionality to defer disabling the profiler on the server until the future corresponding to the RPC request completes (rather than only the blocking `processRPC` call as was done previously). Since when the future completes we've kicked off the async function and the future corresponding to it has completed, we are able to capture any RPCs the function would have called and the actual work done on the other node.
For example, if the following async function is ran on a server over RPC:
```
def slow_add(x, y):
time.sleep(1)
return torch.add(x, y)
rpc.functions.async_execution
def slow_async_add(to, x, y):
return rpc.rpc_async(to, slow_add, args=(x, y))
```
we expect to see the original RPC profiled, the nested RPC profiled, and the actual torch.add() work. All of these events should be recorded with the correct node id. Here is an example profiling output:
```
------------------------------------------------------------------------------------------------------------------------- --------------- --------------- --------------- --------
------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg Number of Calls Node ID
------------------------------------------------------------------------------------------------------------------------- --------------- --------------- --------------- --------
------- --------------- --------------- --------------- rpc_async#slow_async_add(worker1 -> worker2) 0.00% 0.000us 0 1.012s
1.012s 1 1
aten::empty 7.02% 11.519us 7.02% 11.519us 11.519us 1 1
rpc_async#slow_async_add(worker1 -> worker2)#remote_op: rpc_async#slow_add(worker2 -> worker3) 0.00% 0.000us 0 1.006s
1.006s 1 2 rpc_async#slow_async_add(worker1 -> worker2)#remote_op: aten::empty 7.21% 11.843us 7.21% 11.843us
11.843us 1 2
rpc_async#slow_async_add(worker1 -> worker2)#remote_op: rpc_async#slow_add(worker2 -> worker3)#remote_op: aten::add 71.94% 118.107us 85.77% 140.802us 140.802us 1 3
rpc_async#slow_async_add(worker1 -> worker2)#remote_op: rpc_async#slow_add(worker2 -> worker3)#remote_op: aten::empty 13.82% 22.695us 13.82% 22.695us
22.695us 1 3 ------------------------------------------------------------------------------------------------------------------------- --------------- --------------- --------------- --------
------- --------------- --------------- ---------------
Self CPU time total: 164.164us
```
This PR also moves a bunch of the profiling logic to `rpc/utils.cpp` to declutter `request_callback` code.
ghstack-source-id: 112868470
Test Plan:
```
rvarm1@devbig978:fbcode (52dd34f6)$ buck test mode/no-gpu mode/dev-nosan //caffe2/test/distributed/rpc:process_group_agent -- test_rpc_profiling_async_function --print-passing-details --stress-runs 1
```
Reviewed By: mrshenli
Differential Revision: D23638387
fbshipit-source-id: eedb6d48173a4ecd41d70a9c64048920bd4807c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45264
Context for why we are porting to gtest in: https://github.com/pytorch/pytorch/pull/45018.
This PR completes the process of porting and removes unused files/macros.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D23901392
Pulled By: suo
fbshipit-source-id: 89526890e1a49462f3f77718f4ee273c5bc578ba
Summary:
The Cuda HalfChecker casts up all loads and stores of Half to Float, so we do math in Float on the device. It didn't cast up HalfImmediate (ie. constants) so they could insert mixed-size ops. Fix is to do that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45213
Reviewed By: ezyang
Differential Revision: D23885287
Pulled By: nickgg
fbshipit-source-id: 912991d85cc06ebb282625cfa5080d7525c8eba9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45257
Currently we inline fork-wait calls when we insert observers for quantization
In the case where fork and wait are in different subgraphs, inlining the fork-wait calls
only gets rid of the fork. This leaves the aten::wait call in the graph with a torch.Tensor as input,
which is currently not supported.
To avoid this we check to make sure input to all wait calls in the graph is of type Future[tensor]
in the cleanup phase
Test Plan:
python test/test_quantization.py TestQuantizeJitPasses.test_quantize_fork_wait
Imported from OSS
Reviewed By: qizzzh
Differential Revision: D23895412
fbshipit-source-id: 3c58c6be7d7e7904eb6684085832ac21f827a399
Summary:
I noticed while working on https://github.com/pytorch/pytorch/issues/45163 that edits to python files in the `tools/codegen/api/` directory wouldn't trigger rebuilds. This tells CMake about all of the dependencies, so rebuilds are triggered automatically.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45275
Reviewed By: zou3519
Differential Revision: D23922805
Pulled By: ezyang
fbshipit-source-id: 0fbf2b6a9b2346c31b9b0384e5ad5e0eb0f70e9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44071
Previously, tracing re-gathered ScalarType, Layout, Device, bool into a TensorOptions object and called `tracer::addInput()` on the gathered TensorOptions argument. `tracer::addInput()` then scattered them again and added the individual scattered arguments to the traced graph. This PR avoids the extraneous gathering and re-scattering step and calls `tracer::addInput()` on the individual arguments directly. This avoid the perf hit for an unnecessary gathering step.
This applies to both c10-full and non-c10-full ops. In the case of c10-full ops, the tracing kernels takes scattered arguments and we can directly pass them to `tracer::addInput()`. In the case of non-c10-full ops, the kernel takes a `TensorOptions` argument but we still call `tracer::addInput()` on the scattered arguments.
ghstack-source-id: 112825793
Test Plan:
waitforsandcastle
vs master: https://www.internalfb.com/intern/fblearner/details/216129483/
vs previous diff: https://www.internalfb.com/intern/fblearner/details/216170069/
Reviewed By: ezyang
Differential Revision: D23486638
fbshipit-source-id: e0b53e6673cef8d7f94158e718301eee261e5d22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44062
Previously, BackendSelect kernels were still written in the legacy way, i.e. they took one TensorOptions argument instead of scattered dtype, layout, device, pin_memory, and they used hacky_wrapper to be callable. This caused a re-wrapping step. Calling into a BackencSelect kernel required taking the individual scattered arguments, packing them into a TensorOptions, and the kernel itself then gathered them again for redispatch.
Now with this PR, BackendSelect kernels are written in the new way and no hacky_wrapper or rewrapping is needed for them.
ghstack-source-id: 112825789
Test Plan:
vs master: https://www.internalfb.com/intern/fblearner/details/216117032/
vs previous diff: https://www.internalfb.com/intern/fblearner/details/216170194/
Reviewed By: ezyang
Differential Revision: D23484192
fbshipit-source-id: e8fb49c4692404b6b775d18548b990c4cdddbada
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44005
Previously, VariableType and TraceType kernels were still written in the legacy way, i.e. they took one TensorOptions argument instead of scattered dtype, layout, device, pin_memory, and they used hacky_wrapper to be callable.
Now with this PR, variable and tracing kernels are written in the new way and no hacky_wrapper is needed for them.
ghstack-source-id: 112825791
Test Plan:
waitforsandcastle
https://www.internalfb.com/intern/fblearner/details/215954270/
Reviewed By: ezyang
Differential Revision: D23466042
fbshipit-source-id: bde730a9e3bb4cb80ad484417be1ebecbdc2d377
Summary:
A lot of changes are in this update, some highlights:
- Added Doxygen config file
- Split the fusion IR (higher level TE like IR) from kernel IR (lower level CUDA like IR)
- Improved latency with dynamic shape handling for the fusion logic
- Prevent recompilation for pointwise + reduction fusions when not needed
- Improvements to inner dimension reduction performance
- Added input -> kernel + kernel launch parameters cache, added eviction policy
- Added reduction fusions with multiple outputs (still single reduction stage)
- Fixed code generation bugs for symbolic tiled GEMM example
- Added thread predicates to prevent shared memory form being loaded multiple times
- Improved sync threads placements with shared memory and removed read before write race
- Fixes to FP16 reduction fusions where output would come back as FP32
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45218
Reviewed By: ezyang
Differential Revision: D23905183
Pulled By: soumith
fbshipit-source-id: 12f5ad4cbe03e9a25043bccb89e372f8579e2a79
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45317
Eager mode quantization depends on the presence of the `config`
model attribute. Currently converting a model to use `SyncBatchNorm`
removes the qconfig - fixing this. This is important if a BN is not
fused to anything during quantization convert.
Test Plan:
```
python test/test_quantization.py TestDistributed.test_syncbn_preserves_qconfig
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23922072
fbshipit-source-id: cc1bc25c8e5243abb924c6889f78cf65a81be158
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45134
Per-Op-Registration was a mechanism used for mobile selective build v0. Since then, a new dispathing mechanism has been built for PyTorch, and this code path isn't used any more. Remove it to simplify understanding/updating the code-generator's code-flow.
ghstack-source-id: 112723942
Test Plan: `buck build` and sandcastle.
Reviewed By: ezyang
Differential Revision: D23806632
fbshipit-source-id: d93cd324650c541d9bfc8eeff2ddb2833b988ecc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45284
This is the 2nd batch of the change described in #45010.
In this batch we relaxed some filters to cover more 'backend specific' ops:
* ops that not call any 'Tensor::is_xxx()' method OR only call
'Tensor::is_cuda()' - we are adding CUDA dispatch key anyway;
* ops that call other ATen ops but ARE differentiable - differentiability
is a fuzzy indicator of not being 'composite';
Inherited other filters from the 1st batch:
* These ops don't already have dispatch section in native_functions.yaml;
* These ops call one or more DispatchStub (thus "backend specific");
Differential Revision: D23909901
Test Plan: Imported from OSS
Reviewed By: ailzhang
Pulled By: ljk53
fbshipit-source-id: 3b31e176324b6ac814acee0b0f80d18443bd81a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44430
log metadata even when model loading is failed
Test Plan: {F331550976}
Reviewed By: husthyc
Differential Revision: D23577711
fbshipit-source-id: 0504e75625f377269f1e5df0f1ebe34b8e564c4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45315
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45314
in D23858329 (721cfbf842), we put PriorCorrectionCalibrationPrediction unit test in OSS file which causes test failure issue in public trunk.
this diff moves it to FB only test file.
Test Plan:
```
buck test //caffe2/caffe2/python/operator_test:torch_integration_test -- test_gather_ranges_to_dense_op
buck test //caffe2/caffe2/fb/python/operator_test:torch_integration_test -- test_prior_correct_calibration_prediction_op
```
all pass.
Reviewed By: houseroad
Differential Revision: D23899012
fbshipit-source-id: 1ed97d8702e2765991e6caf5695d4c49353dae82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45162
This test was flaky because it was not able to validate that the
overall record_function's CPU times are greater than the sum of its children.
It turns out that this is a general bug in the profiler that can be reproduced
without RPC, see https://github.com/pytorch/pytorch/issues/45160. Hence,
removing this from the test and replacing it by just validating the expected
children.
Ran the test 1000 times and they all passed.
ghstack-source-id: 112632327
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D23851854
fbshipit-source-id: 5d9023acd17800a6668ba4849659d8cc902b8d6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44972
Previously, our fusion strategy would be:
- start at the end of the block, find a fusable node
- iteratively try to merge inputs into the fusion group, sorted topologically
This strategy works pretty well, but has the possibility of missing fusion groups. See my attached test case for an example where we wouldn't find all possible fusion groups. bertmaher found an example of a missed fusion groups in one of our rnn examples (jit_premul) that caused a regression from the legacy fuser.
Here, I'm updating our fusion strategy to be the same as our other fusion passes - create_autodiff_subgraphs, and graph_fuser.cpp.
The basic strategy is:
- iterate until you find a fusible node
- try to merge the nodes inputs, whenever a succesful merge occurs restart at the beginning of the nodes inputs
- after you've exhausted a node, continue searching the block for fusion opportunities from the node
- continue doing this on the block until we go through an iteration without an succesful merges
Since we create the fusion groups once, and only re-specialize within the fusion groups, we should be running this very infrequently (only re-triggers when we fail undefinedness specializations). Also bc it's the same algorithm as the existing fuser it is unlikely to cause a regression.
Test Plan: Imported from OSS
Reviewed By: Krovatkin, robieta
Differential Revision: D23821581
Pulled By: eellison
fbshipit-source-id: e513d1ef719120dadb0bfafc7a14f4254cd806ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44238
Refactor create_autodiff_subgraphs to use the same updating of output aliasing properties logic as tensorexpr fuser, and factor that out to a common function in subgraph utils.
Test Plan: Imported from OSS
Reviewed By: Krovatkin, robieta
Differential Revision: D23871565
Pulled By: eellison
fbshipit-source-id: 72df253b16baf8e4aabf3d68b103b29e6a54d44c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45096
Add operator to compute the equalization scale. This will be used in the integration of equalization into dper int8 fixed quant scheme quantization flow.
Design docs:
https://fb.quip.com/bb7SAGBxPGNChttps://fb.quip.com/PDAOAsgoLfRr
Test Plan: buck test caffe2/caffe2/quantization/server:compute_equalization_scale_test
Reviewed By: jspark1105
Differential Revision: D23779870
fbshipit-source-id: 5e6a8c220935a142ecf8e61100a8c71932afa8d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45178
## Motivation
* To be able to make C2 ops cancellable so we can safely exit.
* Some C2 operators are now blocking thus being non-cancellable. If an error
occurs we need to be able to safely stop all net execution so we can throw
the exception to the caller.
## Summary
* Adds a hypothesis test for queue ops cancellation.
Test Plan:
## Unit test added to verify that queue ops propagate errors
```
buck test caffe2/caffe2/python:hypothesis_test
buck test caffe2/caffe2/python:hypothesis_test -- test_safe_dequeue_blob__raises_exception_when_hang --stress-runs 1000
```
```
Summary
Pass: 1000
ListingSuccess: 1
```
Reviewed By: d4l3k
Differential Revision: D23847576
fbshipit-source-id: 2fc351e1ee13ea8b32d976216d2d01dfb6fcc1ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45177
## Motivation
* To be able to make C2 ops cancellable so we can safely exit.
* Some C2 operators are now blocking thus being non-cancellable. If an error
occurs we need to be able to safely stop all net execution so we can throw
the exception to the caller.
## Summary
* When an error occurs in a net or it got cancelled, running ops will have the
`Cancel` method called.
This diff adds `Cancel` method to the `SafeEnqueueBlobsOp`
and `SafeDequeueBlobsOp` to have the call queue->close() to force all the
blocking ops to return.
* Adds unit test that verified the error propagation.
Test Plan:
## Unit test added to verify that queue ops propagate errors
```
buck test caffe2/caffe2/python:hypothesis_test -- test_safe_dequeue_blob__raises_exception_when_hang --stress-runs 1000
```
```
Summary
Pass: 1000
ListingSuccess: 1
```
Reviewed By: d4l3k
Differential Revision: D23846967
fbshipit-source-id: c7ddd63259e033ed0bed9df8e1b315f87bf59394
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44643
This method is not used anywhere else.
Also formatted the file.
Test Plan: buck test caffe2/test/distributed/algorithms/ddp_comm_hooks:test_ddp_hooks
Reviewed By: pritamdamania87
Differential Revision: D23675945
fbshipit-source-id: 2d04f94589a20913e46b8d71e6a39b70940c1461
Summary:
Modify contbuild to disable sanitizers, add option to run "cuda" test using TPX RE
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: walterddr, cspanda
Differential Revision: D23854578
fbshipit-source-id: 327d7cc3655c17034a6a7bc78f69967403290623
Summary:
- The thresholds of some tests are bumped up. Depending on the random generator, sometimes these tests fail with things like 0.0059 is not smaller than 0.005. I ran `test_nn.py` and `test_torch.py` for 10+ times to check these are no longer flaky.
- Add `tf32_on_and_off` to new `matrix_exp` tests.
- Disable TF32 on test suites other than `test_nn.py` and `test_torch.py`
cc: ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44240
Reviewed By: mruberry
Differential Revision: D23882498
Pulled By: ngimel
fbshipit-source-id: 44a9ec08802c93a2efaf4e01d7487222478b6df8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45238
Adds a warning when there is much higher than expected amount of
discrepancy of inputs across different processes when running with uneven
inputs. This is because a skew in the thousands can reduce performance a
nontrivial amount as shown in benchmarks, and it was proposed to add this
warning as a result. Tested by running the tests so the threshold is hit and
observing the output.
ghstack-source-id: 112773552
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D23719270
fbshipit-source-id: 306264f62c1de65e733696a912bdb6e9376d5622
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45144
Moves prim ops from C10 back to JIT.
These were originally moved to C10 from JIT in D19237648 (f362cd510d)
ghstack-source-id: 112775781
Test Plan:
buck test //caffe2/test/cpp/jit:jit
https://pxl.cl/1l22N
buck test adsatlas/gavel/lib/ata_processor/tests:ata_processor_test
https://pxl.cl/1lBxD
Reviewed By: iseeyuan
Differential Revision: D23697598
fbshipit-source-id: 36d1eb8c346e9b161ba6af537a218440a9bafd27
Summary:
I noticed that the recently introduced adaptive_autorange tests occasionally timeout CI, and I've been meaning to improve the Timer tests for a while. This PR allows unit tests to swap the measurement portion of `Timer` with a deterministic mock so we can thoroughly test behavior without having to worry about flaky CI measurements. It also means that the tests can be much more detailed and still finish very quickly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45173
Test Plan: You're lookin' at it.
Reviewed By: ezyang
Differential Revision: D23873548
Pulled By: robieta
fbshipit-source-id: 26113e5cea0cbf46909b9bf5e90c878c29e87e88
Summary:
In this PR:
1) Added binary operations with ScalarLists.
2) Fixed _foreach_div(...) bug in native_functions
3) Covered all possible cases with scalars and scalar lists in tests
4) [minor] fixed bug in native_functions by adding "use_c10_dispatcher: full" to all _foreach functions
tested via unit tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44743
Reviewed By: bwasti, malfet
Differential Revision: D23753711
Pulled By: izdeby
fbshipit-source-id: bf3e8c54bc07867e8f6e82b5d3d35ff8e99b5a0a
Summary:
For integral types, isnan is meaningless. Provide specializations for
maximum and minimum which don't call it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44984
Test Plan: python test/test_jit_fuser_te.py -k TestTEFuser.test_minmax_int_ops
Reviewed By: ezyang
Differential Revision: D23885259
Pulled By: asuhan
fbshipit-source-id: 2e6da2c43c0ed18f0b648a2383d510894c574437
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44550
Part of the `torch.fft` work (gh-42175).
This adds n-dimensional transforms: `fftn`, `ifftn`, `rfftn` and `irfftn`.
This is aiming for correctness first, with the implementation on top of the existing `_fft_with_size` restrictions. I plan to follow up later with a more efficient rewrite that makes `_fft_with_size` work with arbitrary numbers of dimensions.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D23846032
Pulled By: mruberry
fbshipit-source-id: e6950aa8be438ec5cb95fb10bd7b8bc9ffb7d824
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45235
This is so that users know that the profiler works as expected with
RPC and they can learn how to use it to profile RPC-based workloads.
ghstack-source-id: 112773748
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D23777888
fbshipit-source-id: 4805be9b949c8c7929182f291a6524c3c6a725c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45149
The choose_qparams_optimized calculates the the optimized qparams.
It uses a greedy approach to nudge the min and max and calculate the l2 norm
and tries to minimize the quant error by doing `torch.norm(x-fake_quant(x,s,z))`
Test Plan: Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D23848060
fbshipit-source-id: c6c57c9bb07664c3f1c87dd7664543e09f634aee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45231
There are two operators:
`PriorCorrectionCalibrationPrediction` and `GatherRangesToDense` is not supported in PT which makes GLOW cannot work.
To unblock, we first try to use C2->PT conversion. In the long-term, we need to implement PT custom ops.
This diff does this conversion to unblock current project.
Test Plan:
Run unit test. the Test input is from current DPER example.
All pass.
```buck test //caffe2/caffe2/python/operator_test:torch_integration_test -- test_prior_correct_calibration_prediction_op --print-passing-details
> c2 reference output
> [0.14285715 0.27272728 0.39130434 0.5 ]
> PT converted output
> tensor([0.1429, 0.2727, 0.3913, 0.5000])
buck test //caffe2/caffe2/python/operator_test:torch_integration_test -- test_gather_ranges_to_dense_op --print-passing-details
c2 reference output
> [array([[6, 5, 4, 3], [0, 0, 0, 0]], dtype=int64)]
> PT converted output
> [tensor([[6, 5, 4, 3], [0, 0, 0, 0]])]
```
Reviewed By: allwu, qizzzh
Differential Revision: D23858329
fbshipit-source-id: ed37118ca7f09e1cd0ad1fdec3d37f66dce60dd9
Summary:
There is a module called `2to3` which you can target for future specifically to remove these, the directory of `caffe2` has the most redundant imports:
```2to3 -f future -w caffe2```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45033
Reviewed By: seemethere
Differential Revision: D23808648
Pulled By: bugra
fbshipit-source-id: 38971900f0fe43ab44a9168e57f2307580d36a38
Summary:
We need to check if dtypes differ in scalar type or lanes to decide between
Cast and Broadcast.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45179
Test Plan: test_tensorexpr --gtest_filter=TensorExprTest.SimplifyBroadcastTermExpander
Reviewed By: bwasti
Differential Revision: D23873316
Pulled By: asuhan
fbshipit-source-id: ca141be67e10c2b6c5f2ff9c11e42dcfc62ac620
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44835
This is for feature parity with fx graph mode quantization
Test Plan: Imported from OSS
Reviewed By: z-a-f
Differential Revision: D23745086
fbshipit-source-id: ae2fc86129f9896d5a9039b73006a4da15821307
Summary:
Arithmetic operations on Bool aren't fully supported in the evaluator. Moreover,
such semantics can be implemented by the client code through insertion of
explicit casts to widen and narrow to the desired types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44677
Test Plan:
test_tensorexpr --gtest_filter=TensorExprTest.ExprDisallowBoolArithmetic
python test/test_jit_fuser_te.py
Reviewed By: agolynski
Differential Revision: D23801412
Pulled By: asuhan
fbshipit-source-id: fff5284e3a216655dbf5a9a64d1cb1efda271a36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43872
This PR allows the recursive scripting to have a separate
submodule_stubs_fn to create its submodule with specific user provided
rules.
Fixes https://github.com/pytorch/pytorch/issues/43729
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D23430176
Pulled By: wanchaol
fbshipit-source-id: 20530d7891ac3345b36f1ed813dc9c650b28d27a
Summary:
When doing a splitWithMask we only mask if the loop extent is not cleanly divide by the split factor. However, the logic does not simplify so any nontrivial loop extents will always cause a mask to be added, e.g. if the loop had been previously split. Unlike splitWithTail, the masks added by splitWithMask are always overhead and we don't have the analysis to optimize them out if they are unnecessary, so it's good to avoid inserting them if we can.
The fix is just to simplify the loop extents before doing the extent calculation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45141
Reviewed By: ezyang
Differential Revision: D23869170
Pulled By: nickgg
fbshipit-source-id: 44686fd7b802965ca4f5097b0172a41cf837a1f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44856
Support following format of qconfig_dict
```python
qconfig_dict = {
# optional, global config
"": qconfig?,
# optional, used for module and function types
# could also be split into module_types and function_types if we prefer
"object_type": [
(nn.Conv2d, qconfig?),
(F.add, qconfig?),
...,
],
# optional, used for module names
"module_name": [
("foo.bar", qconfig?)
...,
],
# optional, matched in order, first match takes precedence
"module_name_regex": [
("foo.*bar.*conv[0-9]+", qconfig?)
...,
]
# priority (in increasing order): global, object_type, module_name_regex, module_name
# qconfig == None means fusion and quantization should be skipped for anything
# matching the rule
}
```
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23751304
fbshipit-source-id: 5b98f4f823502b12ae2150c93019c7b229c49c50
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44684
The ad-hoc quantization benchmarking script in D23689062 recently highlighted that quantized ops were surprisingly slow after the introduction of support for custom ops in torch.fx in D23203204 (f15e27265f).
Using strobelight, it's immediately clear that up to 66% of samples were seen in `c10::get_backtrace`, which is descends from `torch::is_tensor_and_apppend_overloaded -> torch::check_has_torch_function -> torch::PyTorch_LookupSpecial -> PyObject_HasAttrString -> PyObject_GetAttrString`.
I'm no expert by any means so please correct any/all misinterpretation, but it appears that:
- `check_has_torch_function` only needs to return a bool
- `PyTorch_LookupSpecial` should return `NULL` if a matching method is not found on the object
- in the impl of `PyTorch_LookupSpecial` the return value from `PyObject_HasAttrString` only serves as a bool to return early, but ultimately ends up invoking `PyObject_GetAttrString`, which raises, spawning the generation of a backtrace
- `PyObject_FastGetAttrString` returns `NULL` (stolen ref to an empty py::object if the if/else if isn't hit) if the method is not found, anyway, so it could be used singularly instead of invoking both `GetAttrString` and `FastGetAttrString`
- D23203204 (f15e27265f) compounded (but maybe not directly caused) the problem by increasing the number of invocations
so, removing it in this diff and seeing how many things break :)
before:
strobelight: see internal section
output from D23689062 script:
```
$ ./buck-out/gen/scripts/v/test_pt_quant_perf.par
Sequential(
(0): Quantize(scale=tensor([0.0241]), zero_point=tensor([60]), dtype=torch.quint8)
(1): QuantizedLinear(in_features=4, out_features=4, scale=0.017489388585090637, zero_point=68, qscheme=torch.per_tensor_affine)
(2): DeQuantize()
)
fp 0.010896682739257812
q 0.11908197402954102
```
after:
strobelight: see internal section
output from D23689062 script:
```
$ ./buck-out/gen/scripts/v/test_pt_quant_perf.par
Sequential(
(0): Quantize(scale=tensor([0.0247]), zero_point=tensor([46]), dtype=torch.quint8)
(1): QuantizedLinear(in_features=4, out_features=4, scale=0.012683945707976818, zero_point=41, qscheme=torch.per_tensor_affine)
(2): DeQuantize()
)
fp 0.011141300201416016
q 0.022639036178588867
```
which roughly restores original performance seen in P142370729
UPDATE: 9/22 mode/opt benchmarks
```
buck run //scripts/x:test_pt_quant_perf mode/opt
Sequential(
(0): Quantize(scale=tensor([0.0263]), zero_point=tensor([82]), dtype=torch.quint8)
(1): QuantizedLinear(in_features=4, out_features=4, scale=0.021224206313490868, zero_point=50, qscheme=torch.per_tensor_affine)
(2): DeQuantize()
)
fp 0.002968311309814453
q 0.5138928890228271
```
with patch:
```
buck run //scripts/x:test_pt_quant_perf mode/opt
Sequential(
(0): Quantize(scale=tensor([0.0323]), zero_point=tensor([70]), dtype=torch.quint8)
(1): QuantizedLinear(in_features=4, out_features=4, scale=0.017184294760227203, zero_point=61, qscheme=torch.per_tensor_affine)
(2): DeQuantize()
)
fp 0.0026655197143554688
q 0.0064449310302734375
```
Reviewed By: ezyang
Differential Revision: D23697334
fbshipit-source-id: f756d744688615e01c94bf5c48c425747458fb33
Summary:
Although PyTorch already supports CUDA 11, the Dockerfile still relies on CUDA 10. This pull request upgrades all the necessary versions such that recent NVIDIA GPUs like A100 can be used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45071
Reviewed By: ezyang
Differential Revision: D23873224
Pulled By: seemethere
fbshipit-source-id: 822c25f183dcc3b4c5b780c00cd37744d34c6e00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43790
Interface calls were not handled properly when they are used in fork
subgraph. This PR fixes this issue.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23402039
Pulled By: bzinodev
fbshipit-source-id: 41adc5ee7d942250e732e243ab30e356d78d9bf7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45159
By default, pybind11 binds void* to be capsules. After a lot of
Googling, I have concluded that this is not actually useful:
you can't actually create a capsule from Python land, and our
data_ptr() function returns an int, which means that the
function is effectively unusable. It didn't help that we had no
tests exercising it.
I've replaced the void* with uintptr_t, so that we now accept int
(and you can pass data_ptr() in directly). I'm not sure if we
should make these functions accept ctypes types; unfortunately,
pybind11 doesn't seem to have any easy way to do this.
Fixes#43006
Also added cudaHostUnregister which was requested.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: lw
Differential Revision: D23849731
Pulled By: ezyang
fbshipit-source-id: 8a79986f3aa9546abbd2a6a5828329ae90fd298f
Summary:
This is a small developer quality of life improvement. I commonly try to run some snippet of python as I'm working on a PR and forget that I've cd-d into the local clone to run some git commands, resulting in annoying failures like:
`ImportError: cannot import name 'default_generator' from 'torch._C' (unknown location)`
This actually took a non-trivial amount of time to figure out the first time I hit it, and even now it's annoying because it happens just infrequently enough to not sit high in the mental cache.
This PR adds a check to `torch/__init__.py` and warns if `import torch` is likely resolving to the wrong thing:
```
WARNING:root:You appear to be importing PyTorch from a clone of the git repo:
/data/users/taylorrobie/repos/pytorch
This will prevent `import torch` from resolving to the PyTorch install
(instead it will try to load /data/users/taylorrobie/repos/pytorch/torch/__init__.py)
and will generally lead to other failures such as a failure to load C extensions.
```
so that the soon to follow internal import failure makes some sense. I elected to make this a warning rather than an exception because I'm not 100% sure that it's **always** wrong. (e.g. weird `PYTHONPATH` or `importlib` corner cases.)
EDIT: There are now separate cases for `cwd` vs. `PYTHONPATH`, and failure is an `ImportError`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39995
Reviewed By: malfet
Differential Revision: D23817209
Pulled By: robieta
fbshipit-source-id: d9ac567acb22d9c8c567a8565a7af65ac624dbf7
Summary:
This prevents DrCI from misidentifying test failures for the compilation failures, such as:
```
/var/lib/jenkins/workspace/build/CMakeFiles/CMakeTmp/CheckSymbolExists.c:8:19: error: use of undeclared identifier \'strtod_l\'
return ((int*)(&strtod_l))[argc];
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45183
Reviewed By: ezyang
Differential Revision: D23859267
Pulled By: malfet
fbshipit-source-id: 283d9bd2ab712f23239b72f3758d121e2d026fb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44983
`_all_gather` was converted from `_wait_all_workers` and inherited its
5 seconds fixed timeout. As `_all_gather` meant to support a broader
set of use cases, the timeout configuration should be more flexible.
This PR makes `rpc._all_gather` use the global default RPC timeout.
Test Plan: Imported from OSS
Reviewed By: pritamdamania87
Differential Revision: D23794383
Pulled By: mrshenli
fbshipit-source-id: 382f52c375f0f25c032c5abfc910f72baf4c5ad9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44960
Since we have templated selective build, it should be safe to move the operators to prim so that they can be selectively built in mobile
Test Plan: CI
Reviewed By: linbinyu
Differential Revision: D23772025
fbshipit-source-id: 52cebae76e4df5a6b2b51f2cd82f06f75e2e45d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45065
To preserve backwards compatibility with applications that were passing in some ProcessGroupRpcBackendOptions but were not explicitly setting backend=BackendType.PROCESS_GROUP, we're here now inferring the backend type from the options if only the latter ones are passed. If neither are passed, we'll default to TensorPipe, as before this change.
ghstack-source-id: 112586258
Test Plan: Added new unit tests.
Reviewed By: pritamdamania87
Differential Revision: D23814289
fbshipit-source-id: f4be7919e0817a4f539a50ab12216dc3178cb752
Summary:
combineMultilane used the wrong order when ramp was on the left hand side,
which matters for subtract.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45157
Test Plan: test_tensorexpr --gtest_filter=TensorExprTest.SimplifyRampSubBroadcast
Reviewed By: ailzhang
Differential Revision: D23851751
Pulled By: asuhan
fbshipit-source-id: 864d1611e88769fb43327ef226bb3310017bf858
Summary:
Otherwise, invoking something like `python -c "import torch._C;print(torch._C.ListType(None))"` will result in SIGSEGV
Discovered while trying to create a torch script for function with the following type annotation `Tuple[int, Ellipsis] -> None`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44958
Reviewed By: suo
Differential Revision: D23799906
Pulled By: malfet
fbshipit-source-id: 916a243007d13ed3e7a5b282dd712da3d66e3bf7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45015
torch.package allows you to write packages of code, pickled python data, and
arbitrary binary and text resources into a self-contained package.
torch.package.PackageExporter writes the packages and
torch.package.PackageImporter reads them.
The importers can load this code in a hermetic way, such that code is loaded
from the package rather than the normal python import system. This allows
for the packaging of PyTorch model code and data so that it can be run
on a server or used in the future for transfer learning.
The code contained in packages is copied file-by-file from the original
source when it is created, and the file format is a specially organized
zip file. Future users of the package can unzip the package, and edit the code
in order to perform custom modifications to it.
The importer for packages ensures that code in the module can only be loaded from
within the package, except for modules explicitly listed as external using :method:`extern_module`.
The file `extern_modules` in the zip archive lists all the modules that a package externally depends on.
This prevents "implicit" dependencies where the package runs locally because it is importing
a locally-installed package, but then fails when the package is copied to another machine.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D23824337
Pulled By: zdevito
fbshipit-source-id: 1247c34ba9b656f9db68a83e31f2a0fbe3bea6bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44655
Since `toHere()` does not execute operations over RPC and simply
transfers the value to the local node, we don't need to enable the profiler
remotely for this message. This causes unnecessary overhead and is not needed.
Since `toHere` is a blocking call, we already profile the call on the local node using `RECORD_USER_SCOPE`, so this does not change the expected profiler results (validated by ensuring all remote profiling tests pass).
ghstack-source-id: 112605610
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D23641466
fbshipit-source-id: 109d9eb10bd7fe76122b2026aaf1c7893ad10588
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44653
This changes the profiler per a discussion with ilia-cher offline that enables `disableProfiler()` event consolidation logic to be called from different threads (i.e. threads where the profiler was not explicitly enabled). This is needed to support the functionality enabled by D23638387 where we defer profiling event collection until executing an async callback that can execute on a different thread, to support RPC async function profiling.
This is done by introducing 2 flags `cleanupTLSState` and `consolidate` which controls whether we should clean up thread local settings (we don't do this when calling `disableProfiler()` on non-main threads) and whether we should consolidate all profiled events. Backwards compatiblity is ensured since both options are true by default.
Added a test in `test_misc.cpp` to test this.
ghstack-source-id: 112605620
Reviewed By: mrshenli
Differential Revision: D23638499
fbshipit-source-id: f5bbb0d41ef883c5e5870bc27e086b8b8908f46b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44646
Per a discussion with ilia-cher, this is not needed anymore and
removing it would make some future changes to support async RPC profiling
easier. Tested by ensuring profiling tests in `test_autograd.py` still pass.
ghstack-source-id: 112605618
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D23683998
fbshipit-source-id: 4e49a439509884fe04d922553890ae353e3331ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45098
**Summary**
This commit adds support for default arguments in methods of class
types. Similar to how default arguments are supported for regular
script functions and methods on scripted modules, default values are
retrieved from the definition of a TorchScript class in Python as Python
objects, converted to IValues, and then attached to the schemas of
already compiled class methods.
**Test Plan**
This commit adds a set of new tests to TestClassType to test default
arguments.
**Fixes**
This commit fixes#42562.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D23844769
Pulled By: SplitInfinity
fbshipit-source-id: ceedff7703bf9ede8bd07b3abcb44a0f654936bd
Summary:
This flag simply allows users to get fusion groups that will *eventually* have shapes (such that `getOperation` is a valid).
This is useful for doing early analysis and compiling just in time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44401
Reviewed By: ZolotukhinM
Differential Revision: D23656140
Pulled By: bwasti
fbshipit-source-id: 9a26c202752399d1932ad7d69f21c88081ffc1e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45110
A recent change in DSNN quantizes the ad embedding to 8 bits. Ad embeddings are part of the inputs to the DSNN merge net. To correctly pass shape hints of input tensors including quantized ad embeddings, we need to be able to annotate the data types in shape hints.
A bit on the corner cases, if type is omitted or not a valid type, e.g., white spaces, instead of throwing an exception, I decided to return the default type, float.
Test Plan:
```
buck test caffe2/caffe2/fb/opt:shape_info_utils_test
```
Reviewed By: yinghai
Differential Revision: D23834091
fbshipit-source-id: 5e072144a7a7ff4b5126b618062dfc4041851dd3
Summary:
The ATen/native/cuda headers were copied to torch/include, but then not included in the final package. Further, add ATen/native/hip headers to the installation, as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45097
Reviewed By: mruberry
Differential Revision: D23831006
Pulled By: malfet
fbshipit-source-id: ab527928185faaa912fd8cab208733a9b11a097b
Summary:
NVIDIA GPUs are binary compatible within major compute capability revision
This would prevent: "GeForce RTX 3080 with CUDA capability sm_86 is not compatible with the current PyTorch installation." messages from appearing, since CUDA-11 do not support code generation for sm_85.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45130
Reviewed By: ngimel
Differential Revision: D23841556
Pulled By: malfet
fbshipit-source-id: bcfc9e8da63dfe62cdec06909b6c049aaed6a18a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44766
There might be modules that are not symbolically traceable, e.g. LSTM (since it has
input dependent control flows), to support quantization in these cases, user will provide
the corresponding observed and quantized version of the custom module, the observed
custom module with observers already inserted in the module and the quantized version will
have the corresponding ops quantized. And use
```
from torch.quantization import register_observed_custom_module_mapping
from torch.quantization import register_quantized_custom_module_mapping
register_observed_custom_module_mapping(CustomModule, ObservedCustomModule)
register_quantized_custom_module_mapping(CustomModule, QuantizedCustomModule)
```
to register the custom module mappings, we'll also need to define a custom delegate class
for symbolic trace in order to prevent the custom module from being traced:
```python
class CustomDelegate(DefaultDelegate):
def is_leaf_module(self, m):
return (m.__module__.startswith('torch.nn') and
not isinstance(m, torch.nn.Sequential)) or \
isinstance(m, CustomModule)
m = symbolic_trace(original_m, delegate_class=CustomDelegate)
```
Test Plan: Imported from OSS
Reviewed By: z-a-f
Differential Revision: D23723455
fbshipit-source-id: 50d666e29b94cbcbea5fb6bcc73b00cff87eb77a
Summary:
This is a sub-task for addressing: https://github.com/pytorch/pytorch/issues/42969. We re-enable type check for `autocast_test_lists `.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45107
Test Plan:
`python test/test_type_hints.py` passed:
```
(pytorch) bash-5.0$ with-proxy python test/test_type_hints.py
....
----------------------------------------------------------------------
Ran 4 tests in 103.871s
OK
```
Reviewed By: walterddr
Differential Revision: D23842884
Pulled By: Hangjun
fbshipit-source-id: a39f3810e3abebc6b4c1cb996b06312f6d42ffd6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45106
**Summary**
This commit fixes `WithTest.test_with_exceptions`. It's been running
in regular Python this whole time; none of the functions created and
invoked for the test were scripted. Fortunately, the tests still pass
after being fixed.
**Test Plan**
Ran unit tests + continuous integration.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D23848206
Pulled By: SplitInfinity
fbshipit-source-id: fd975ee34db9441ef4e4a4abf2fb21298166bbaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45153
xcode 9 is being deprectated within circleci infra so we should get
everything else on a more recent version of xcode
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D23852774
Pulled By: seemethere
fbshipit-source-id: c02e162f1993d408de439fee21b340e9640e5a24
Summary:
Fixes a subtask of https://github.com/pytorch/pytorch/issues/42969
Tested the following and no warnings were seen.
python test/test_type_hints.py
....
----------------------------------------------------------------------
Ran 4 tests in 180.759s
OK
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44971
Reviewed By: walterddr
Differential Revision: D23822274
Pulled By: visweshfb
fbshipit-source-id: e3485021e348ee0a8508a9d128f04bad721795ef
Summary:
Previously, `prim::EnumValue` is serialized to `ops.prim.EnumValue`, which doesn't have the right implementation to refine return type. This diff correctly serializes it to enum.value, thus fixing the issue.
Fixes https://github.com/pytorch/pytorch/issues/44892
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44891
Reviewed By: malfet
Differential Revision: D23818962
Pulled By: gmagogsfm
fbshipit-source-id: 6edfdf9c4b932176b08abc69284a916cab10081b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43680
As discussed [here](https://github.com/pytorch/pytorch/issues/43342),
adding in a Python-only implementation of the triplet-margin loss that takes a
custom distance function. Still discussing whether this is necessary to add to
PyTorch Core.
Test Plan:
python test/run_tests.py
Imported from OSS
Reviewed By: albanD
Differential Revision: D23363898
fbshipit-source-id: 1cafc05abecdbe7812b41deaa1e50ea11239d0cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39111
In our present alias analysis, we consider any Value that enter another container as entering the heap, and thus aliasing all other heap values of the same type. There are a number of advantages to this approach:
- it is not to hard to maintain the aliasDb implementation
- it is much easier from an op schema perspective - there are many composite list ops registered internally and externally that would be tricky to register and get right if we did something more complicated
- It limits the size of the AliasDb, because a container of size 10 only contains a single memory dag element instead of 10 elements.
The downside is that we have are unable to handle the simple and extremely common case of a list of tensors being used in an ATen op.
In an example like:
```
def foo(input):
x = torch.tensor([1, 2, 3, 4])
y = [x, x]
input.add_(1)
return torch.cat(y)
```
we will consider x to be written to. any write to any wildcard element (an element that enters a tuple, an element that is taken from a list) will mark x as written to. This can be limiting for our ability to create a functional subset and fuse graphs - as a result, 4 of TorchVision classification models could not be functionalized.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D23828003
Pulled By: eellison
fbshipit-source-id: 9109fcb6f2ca20ca897cae71683530285da9d537
Summary:
Change from self to self._class_() in _DecoratorManager to ensure a new object is every time a function is called recursively
Fixes https://github.com/pytorch/pytorch/issues/44531
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44633
Reviewed By: agolynski
Differential Revision: D23783601
Pulled By: albanD
fbshipit-source-id: a818664dee7bdb061a40ede27ef99e9546fc80bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44639
As title; this will unblock migration of several modules that need learning rate functionality.
Test Plan:
```
buck test //dper3/dper3/modules/low_level_modules/tests:learning_rate_test
```
Reviewed By: yf225
Differential Revision: D23681733
fbshipit-source-id: 1d98cb35bf6a4ff0718c9cb6abf22401980b523c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39955
resolves https://github.com/pytorch/pytorch/issues/36323 by adding `torch.sgn` for complex tensors.
`torch.sgn` returns `x/abs(x)` for `x != 0` and returns `0 + 0j` for `x==0`
This PR doesn't test the correctness of the gradients. It will be done as a part of auditing all the ops in future once we decide the autograd behavior (JAX vs TF) and add gradchek.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D23460526
Pulled By: anjali411
fbshipit-source-id: 70fc4e14e4d66196e27cf188e0422a335fc42f92
Summary:
We currently are fetching an allreduced tensor from Python in C++ in, where we are storing the resulting tensor in a struct's parameter. This PR removes extra tensor paratemeter in the function parameter and fetch from a single place.
Fixes https://github.com/pytorch/pytorch/issues/43960
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44914
Reviewed By: rohan-varma
Differential Revision: D23798888
Pulled By: bugra
fbshipit-source-id: ad1b8c31c15e3758a57b17218bbb9dc1f61f1577
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45010
The motivation of this change is to differentiate "backend specific" ops
and "generic" ops.
"backend specific" ops are those invoking backend specific kernels thus
only able to run on certain backends, e.g.: CPU, CUDA.
"generic" ops are those not *directly* invoking backend specific kernels.
They are usually calling other "backend specific" ops to get things
done. Thus, they are also referred to as "composite" ops, or "math" ops
(because they are usually pure C++ code constructed from math formula).
The other way to see the difference is that: we have to implement new
kernels for the "backend specific" ops if we want to run these ops on a
new backend. In contrast, "generic"/"composite" ops can run on the new
backend if we've added support for all the "backend specific" ops to
which they delegate their work.
Historically we didn't make a deliberate effort to always populate
supported backends to the "dispatch" section for all the "backend specific"
ops in native_functions.yaml. So now there are many ops which don't have
"dispatch" section but are actually "backend specific" ops. Majority
of them are calling "DispatchStub" kernels, which usually only support
CPU/CUDA (via TensorIterator) or QuantizedCPU/CUDA.
The ultimate goal is to be able to differentiate these two types of ops
by looking at the "dispatch" section in native_functions.yaml.
This PR leveraged the analysis script on #44963 to populate missing
dispatch keys for a set of "backend specific" ops. As the initial step,
we only deal with the simplest case:
* These ops don't already have dispatch section in native_functions.yaml;
* These ops call one or more DispatchStub (thus "backend specific");
* These ops don't call any other aten ops - except for some common
ones almost every op calls via framework, e.g. calling aten::eq via
Dispatcher::checkSchemaCompatibility. Calling other nontrivial aten
ops is a sign of being "composite", so we don't want to deal with this
case now;
* These ops don't call Tensor::is_quantized() / Tensor::is_sparse() / etc.
Some ops call thse Tensor::is_XXX() methods to dispatch to quantized /
sparse kernels internally. We don't deal with this case now.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D23803951
Pulled By: ljk53
fbshipit-source-id: aaced7c34427d1ede72380af4513508df366ea16
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44936
need to provide max sequence size and max element size instead of
total
added a check that onnxifi was succesful
Test Plan: sls tests
Reviewed By: yinghai
Differential Revision: D23779437
fbshipit-source-id: 5048d6536ca00f0a3b0b057c4e2cf6584b1329d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45088Fixes#45082
Found a few problems while working on #44983
1. We deliberately swallow RPC timeouts during shutdown, as we haven't
found a good way to handle those. When we convert `_wait_all_workers`
into `_all_gather`, the same logic was inherited. However, as
`_all_gather` meant to be used in more general scenarios, we should
no longer keep silent about errors. This commit let the error throw
in `_all_gather` and also let `shutdown()` to catch them and log.
2. After fixing (1), I found that `UnpickledPythonCall` needs to
acquire GIL on destruction, and this can lead to deadlock when used
in conjuction with `ProcessGroup`. Because `ProcessGroup` ctor is a
synchronization point which holds GIL. In `init_rpc`, followers
(`rank != 0`) can exit before the leader (`rank == 0`). If the two
happens together, we could get a) on a follower, it exits `init_rpc`
after running `_broadcast_to_followers` and before the reaching dtor
of `UnpickledPythonCall`. Then it runs the ctor of `ProcessGroup`,
which holds the GIL and wait for the leader to join. However, the
leader is waiting for the response from `_broadcast_to_followers`,
which is blocked by the dtor of `UnpickledPythonCall`. And hence
the deadlock. This commit drops the GIL in `ProcessGroup` ctor.
3. After fixing (2), I found that `TensorPipe` backend
nondeterministically fails with `test_local_shutdown`, due to a
similar reason as (2), but this time it is that `shutdown()` on a
follower runs before the leader finishes `init_rpc`. This commit
adds a join for `TensorPipe` backend `init_rpc` after `_all_gather`.
The 3rd one should be able to solve the 2nd one as well. But since
I didn't see a reason to hold GIL during `ProcessGroup` ctor, I
made that change too.
Test Plan: Imported from OSS
Reviewed By: pritamdamania87
Differential Revision: D23825592
Pulled By: mrshenli
fbshipit-source-id: 94920f2ad357746a6b8e4ffaa380dd56a7310976
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44912
This is to add vec256 test into linux CI system.
The whole test will last 50 to 70 seconds.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D23772923
Pulled By: glaringlee
fbshipit-source-id: ef929b53f3ea7894abcd9510a8e0389979cab4a2
Summary:
int8_t is not vectorized in vec256_int.h. This PR adds vectorization for
int8_t. As pointed out in https://github.com/pytorch/pytorch/issues/43033, this is an important type for vectorization because
a lot of images are loaded in this data type.
Related issue: https://github.com/pytorch/pytorch/issues/43033
Benchmark (Debian Buster, Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz, Turbo off, Release build):
```python
import timeit
dtype = 'torch.int8'
for op in ('+', '-'):
for n, t in [(10_000, 200000),
(100_000, 20000)]:
print(f'a {op} b, numel() == {n} for {t} times, dtype={dtype}')
print(timeit.timeit(f'c = a {op} b', setup=f'import torch; a = torch.arange(1, {n}, dtype={dtype}); b = torch.arange({n}, 1, -1, dtype={dtype})', number=t))
```
Results:
Before:
```
a + b, numel() == 10000 for 200000 times, dtype=torch.int8
1.2223373489978258
a + b, numel() == 100000 for 20000 times, dtype=torch.int8
0.6108450189931318
a - b, numel() == 10000 for 200000 times, dtype=torch.int8
1.256775538000511
a - b, numel() == 100000 for 20000 times, dtype=torch.int8
0.6101213909860235
```
After:
```
a + b, numel() == 10000 for 200000 times, dtype=torch.int8
0.5713336059998255
a + b, numel() == 100000 for 20000 times, dtype=torch.int8
0.39169703199877404
a - b, numel() == 10000 for 200000 times, dtype=torch.int8
0.5838428330025636
a - b, numel() == 100000 for 20000 times, dtype=torch.int8
0.37486923701362684
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44759
Reviewed By: malfet
Differential Revision: D23786383
Pulled By: glaringlee
fbshipit-source-id: 67f5bcd344c0b5014bacbc876143231fca156713
Summary:
This would force jit.script to raise an error if someone tries to mutate tuple
```
Tuple[int, int] does not support subscripted assignment:
File "/home/nshulga/test/tupleassignment.py", line 9
torch.jit.script
def foo(x: Tuple[int, int]) -> int:
x[-1] = x[0] + 1
~~~~~ <--- HERE
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44929
Reviewed By: suo
Differential Revision: D23777668
Pulled By: malfet
fbshipit-source-id: 8efaa4167354ffb4930ccb3e702736a3209151b6
Summary:
This PR was originally authored by slayton58. I steal his implementation and added some tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44986
Reviewed By: mruberry
Differential Revision: D23806039
Pulled By: ngimel
fbshipit-source-id: 305d66029b426d8039fab3c3e011faf2bf87aead
Summary:
Fixes https://github.com/pytorch/pytorch/issues/43622
- Moves the model loading part of `torch.hub.load()` into a new `torch.hub.load_local()` function that takes in a path to a local directory that contains a `hubconf.py` instead of a repo name.
- Refactors `torch.hub.load()` so that it now calls `torch.hub.load_local()` after downloading and extracting the repo.
- Updates `torch.hub` docs to include the new function + minor fixes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44204
Reviewed By: malfet
Differential Revision: D23817429
Pulled By: ailzhang
fbshipit-source-id: 788fd83c87a94f487b558715b2809d346ead02b2
Summary:
This PR introduces a (Const)StridedRandomAccessor, a [random access iterator](https://en.cppreference.com/w/cpp/named_req/RandomAccessIterator) over a strided array, and a CompositeRandomAccessor, a random access iterator over two random access iterators.
The main motivation is to be able to use a handful of operations from STL and thrust in numerous dim-apply types of algorithms and eliminate unnecessary buffer allocations. Plus more advanced algorithms are going to be available with C++17.
Porting `sort` provides a hands-on example of how these iterators could be used.
Fixes [https://github.com/pytorch/pytorch/issues/24770](https://github.com/pytorch/pytorch/issues/24770).
Some benchmarks:
```python
from IPython import get_ipython
torch.manual_seed(13)
ipython = get_ipython()
sizes = [
[10000, 10000],
[1000, 1000, 100]
]
for size in sizes:
t = torch.randn(*size)
dims = len(size)
print(f"Tensor of size {size}")
for dim in range(dims):
print(f"sort for dim={dim}")
print("float:")
ipython.magic("timeit t.sort(dim)")
print()
```
#### Master
```
Tensor of size [10000, 10000]
sort for dim=0
float:
10.7 s ± 201 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
sort for dim=1
float:
6.27 s ± 50.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Tensor of size [1000, 1000, 100]
sort for dim=0
float:
7.21 s ± 23.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
sort for dim=1
float:
6.1 s ± 21.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
sort for dim=2
float:
3.58 s ± 27 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
#### This PR
```
Tensor of size [10000, 10000]
sort for dim=0
float:
10.5 s ± 209 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
sort for dim=1
float:
6.16 s ± 28.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Tensor of size [1000, 1000, 100]
sort for dim=0
float:
5.94 s ± 60.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
sort for dim=1
float:
5.1 s ± 11.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
sort for dim=2
float:
3.43 s ± 8.52 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
As you can see, the legacy sorting routine is actually quite efficient. The performance gain is likely due to the improved reduction with TensorIterator.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39744
Reviewed By: malfet
Differential Revision: D23796486
Pulled By: glaringlee
fbshipit-source-id: 7bddad10dfbc0a0e5cad7ced155d6c7964e8702c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45017
this is the default indexing folder for clangd 11.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D23817619
Pulled By: suo
fbshipit-source-id: 6a60136e591b2fec3d432ac5343cb76ac0934502
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45018
Now that https://github.com/pytorch/pytorch/pull/44795 has landed, we
can convert the bulk of our cpp tests to use gtest APIs. Eventually
we'll want to get rid of our weird harness for cpp tests entirely in
favor of using regular gtest everywhere. This PR demonstrates some of
the benefits of this approach:
1. You don't need to register your test twice (once to define it, once
in tests.h).
2. Consequently, it's easier to have many individual test cases.
Failures can be reported independently (rather than having huge
functions to test entire modules.
3. Some nicer testing APIs, notably test fixtures.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D23802297
Pulled By: suo
fbshipit-source-id: 774255da7716294ac573747dcd5e106e5fe3ac8f
Summary:
Including commits to fix Windows CI failure of enable distributed training on Windows PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45025
Reviewed By: beauby
Differential Revision: D23807995
Pulled By: mrshenli
fbshipit-source-id: a2f4c1684927ca66d7d3e9920ecb588fb4386f7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45014
Pull Request resolved: https://github.com/pytorch/tensorpipe/pull/219
Pull Request resolved: https://github.com/pytorch/tensorpipe/pull/212
+ Introduce buffer.h defining the buffer struct(s). The `CpuBuffer`
struct is always defined, while the `CudaBuffer` struct is defined
only when `TENSORPIPE_SUPPORTS_CUDA` is true.
+ Update all channels to take a `CpuBuffer` or `CudaBuffer` for
`send`/`recv` rather than a raw pointer and a length.
+ Make the base `Channel`/`Context` classes templated on `TBuffer`,
effectively creating two channel hierarchies (one for CPU channels,
one for CUDA channels).
+ Update the Pipe and the generic channel tests to use the new API. So
far, generic channel tests are CPU only, and tests for the CUDA IPC
channel are (temporarily) disabled. A subsequent PR will take care of
refactoring tests so that generic tests work for CUDA channels. An
other PR will add support for CUDA tensors in the Pipe.
Differential Revision: D23598033
Test Plan: Imported from OSS
Reviewed By: lw
Pulled By: beauby
fbshipit-source-id: 1d6c3f91e288420858835cd5e7962e8da051b44b
Summary:
A previous fix for masking Cuda dimensions (https://github.com/pytorch/pytorch/issues/44733) changed the behaviour of inserting thread synchronization barriers in the Cuda CodeGen, causing the CudaSharedMemReduce_1 to be flaky and ultimately disabled.
The issue is working out where these barriers must be inserted - solving this optimally is very hard, and I think not possible without dependency analysis we don't have, so I've changed our logic to be quite pessimistic. We'll insert barriers before and after any blocks that have thread dimensions masked (even between blocks that have no data dependencies). This should be correct, but it's an area we could improve performance. To address this somewhat I've added a simplifier pass that removes obviously unnecessary syncThreads.
To avoid this test being flaky again, I've added a check against the generated code to ensure there is a syncThread in the right place.
Also fixed a couple of non-functional but clarity issues in the generated code: fixed the missing newline after Stores in the CudaPrinter, and prevented the PrioritizeLoad mutator from pulling out loads contained within simple Let statements (such as those produced by the Registerizer).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44909
Reviewed By: agolynski
Differential Revision: D23800565
Pulled By: nickgg
fbshipit-source-id: bddef1f40d8d461da965685f01d00b468d8a2c2f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44894
Looks like we added double backwards support but only turned on the ModuleTests.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23762544
Pulled By: gchanan
fbshipit-source-id: b5cef579608dd71f3de245c4ba92e49216ce8a5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43208
This PR adds gradcheck for complex. The logic used for complex gradcheck is described in Section 3.5.3 here: https://arxiv.org/pdf/1701.00392.pdf
More concretely, this PR introduces the following changes:
1. Updates get_numerical_jacobian to take as input a scalar value for vector (v). Adds gradcheck logic for C -> C, C-> R, R -> C. For R -> C functions, only the real value of gradient is propagated.
2. Adds backward definition for `torch.complex` and also adds a test to verify the definition added.
3. Updates backward for `mul`, `sin`, `cos`, `sinh`, `cosh`.
4. Adds tests for all `torch.real`, `torch.imag`, `torch.view_as_real`, `torch.view_as_complex`, `torch.conj`.
Follow up tasks:
1. Add more thorough tests for R -> C cases. Specifically, add R->C test variants for functions. for e.g., `torch.mul(complex_tensor, real_tensor)`
2. Add back commented test in `common_methods_invocation.py`.
3. Add more special case checking for complex gradcheck to make debugging easier.
4. Update complex autograd note.
5. disable complex autograd for operators not tested for complex.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D23655088
Pulled By: anjali411
fbshipit-source-id: caa75e09864b5f6ead0f988f6368dce64cf15deb
Summary:
These alias are consistent with NumPy. Note that C++'s naming would be different (std::multiplies and std::divides), and that PyTorch's existing names (mul and div) are consistent with Python's dunders.
This also improves the instructions for adding an alias to clarify that dispatch keys should be removed when copying native_function.yaml entries to create the alias entries.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44463
Reviewed By: ngimel
Differential Revision: D23670782
Pulled By: mruberry
fbshipit-source-id: 9f1bdf8ff447abc624ff9e9be7ac600f98340ac4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44956
Makes buffer shapes for HistogramObserver have the
same shapes in uninitialized versus initialized states.
This is useful because the detectron2 checkpointer assumes
that these states will stay the same, so it removes the
need for manual hacks around the shapes changing.
Test Plan:
```
python test/test_quantization.py TestObserver.test_histogram_observer_consistent_buffer_shape
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D23785382
fbshipit-source-id: 1a83fd4f39b244b00747c368d5d305a07d877c92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44861
We were redefining things like ASSERT_EQ to take a _VA_ARGS_ parameter, so compiling these files with gtest (instead of pytorch's custom python-based cpp test infra) fails.
Test Plan: buck build //caffe2/test/cpp/tensorexpr
Reviewed By: asuhan
Differential Revision: D23711293
fbshipit-source-id: 8af14fa7c1f1e8169d14bb64515771f7bc3089e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44889
This HACK doesn't seem to be necessary any more - there is no 'real'
type in generated Declarations.yaml file.
Verified by comparing generated code before/after.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D23761624
Pulled By: ljk53
fbshipit-source-id: de996f04d77eebea3fb9297dd90a8ebeb07647bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44934
Fix build errors when using clang to build cuda sources:
```
In file included from aten/src/ATen/native/cuda/DistributionBernoulli.cu:4:
In file included from aten/src/ATen/cuda/CUDAApplyUtils.cuh:5:
caffe2/aten/src/THC/THCAtomics.cuh:321:1: error: control reaches end of non-void function [-Werror,-Wreturn-type]
}
^
1 error generated when compiling for sm_70.
In file included from aten/src/ATen/native/cuda/DistributionBernoulli.cu:4:
In file included from aten/src/ATen/cuda/CUDAApplyUtils.cuh:5:
caffe2/aten/src/THC/THCAtomics.cuh:321:1: error: control reaches end of non-void function [-Werror,-Wreturn-type]
}
^
1 error generated when compiling for sm_60.
In file included from aten/src/ATen/native/cuda/DistributionBernoulli.cu:4:
In file included from aten/src/ATen/cuda/CUDAApplyUtils.cuh:5:
caffe2/aten/src/THC/THCAtomics.cuh:321:1: error: control reaches end of non-void function [-Werror,-Wreturn-type]
}
^
1 error generated when compiling for sm_52.
```
Test Plan: CI
Reviewed By: ngimel
Differential Revision: D23775266
fbshipit-source-id: 141e6624e2da870a8c50ff9f71fcf0717222fb17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44795
Today, we build our cpp tests twice, once as a standalone gtest binary,
and once linked in `libtorch_python` so we can call them from
`test_jit.py`.
This is convenient (it means that `test_jit.py` is a single entry point
for all our tests), but has a few drawbacks:
1. We can't actually use the gtest APIs, since we don't link gtest into
`libtorch_python`. We're stuck with the subset that we want to write
polyfills for, and an awkward registration scheme where you have to
write a test then include it in `tests.h`).
2. More seriously, we register custom operators and classes in these
tests. In a world where we may be linking many `libtorch_python`s, this
has a tendency to cause errors with `libtorch`.
So now, only tests that explicitly require cooperation with Python are
built into `libtorch_python`. The rest are built into
`build/bin/test_jit`.
There are tests which require that we define custom classes and
operators. In these cases, I've built thm into separate `.so`s that we
call `torch.ops.load_library()` on.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity, ZolotukhinM
Differential Revision: D23735520
Pulled By: suo
fbshipit-source-id: d146bf4e7eb908afa6f96b394e4d395d63ad72ff
Summary:
Adds a pass to the IR Simplifier which fuses together the bodies of Cond statements which have identical conditions. e.g.
```
if (i < 10) {
do_thing_1;
} else {
do_thing_2;
}
if (i < 10) {
do_thing_3;
}
```
is transformed into:
```
if (i < 10) {
do_thing_1;
do_thing_3;
} else {
do_thing_2;
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44886
Reviewed By: glaringlee
Differential Revision: D23768565
Pulled By: nickgg
fbshipit-source-id: 3fe40d91e82bdfff8dcb8c56a02a4fd579c070df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44699
Original commit changeset: 3b1ec928e3db
Previous revert (D23698861) was on the wrong diff stack. Backing out the revert.
Test Plan: Passed unit tests and previously landed.
Reviewed By: mruberry
Differential Revision: D23702258
fbshipit-source-id: 5c3e197bca412f454db5a7e86251ec85faf621c1
Summary:
Moved description of tool and changes in function name
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44124
Reviewed By: albanD
Differential Revision: D23674618
Pulled By: bzinodev
fbshipit-source-id: 5db0bb14fc106fc96358b1e0590f08e975388c6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44254
Add a device parameter to RemoteModule, so it can be placed on any device
and not just CPU.
Original PR issue: RemoteModule enhancements #40550
Test Plan: buck test test/distributed/rpc:process_group_agent -- RemoteModule
Reviewed By: pritamdamania87
Differential Revision: D23483803
fbshipit-source-id: 4918583c15c6a38a255ccbf12c9168660ab7f6db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44786
This predates gradcheck and gradcheck does the same and more.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23731902
Pulled By: gchanan
fbshipit-source-id: 425fd30e943194f63a663708bada8960265b8f05
Summary:
Ref https://github.com/pytorch/pytorch/issues/42175, fixes https://github.com/pytorch/pytorch/issues/34797
This adds complex support to `torch.stft` and `torch.istft`. Note that there are really two issues with complex here: complex signals, and returning complex tensors.
## Complex signals and windows
`stft` currently assumes all signals are real and uses `rfft` with `onesided=True` by default. Similarly, `istft` always takes a complex fourier series and uses `irfft` to return real signals.
For `stft`, I now allow complex inputs and windows by calling the full `fft` if either are complex. If the user gives `onesided=True` and the signal is complex, then this doesn't work and raises an error instead. For `istft`, there's no way to automatically know what to do when `onesided=False` because that could either be a redundant representation of a real signal or a complex signal. So there, the user needs to pass the argument `return_complex=True` in order to use `ifft` and get a complex result back.
## stft returning complex tensors
The other issue is that `stft` returns a complex result, represented as a `(... X 2)` real tensor. I think ideally we want this to return proper complex tensors but to preserver BC I've had to add a `return_complex` argument to manage this transition. `return_complex` defaults to false for real inputs to preserve BC but defaults to True for complex inputs where there is no BC to consider.
In order to `return_complex` by default everywhere without a sudden BC-breaking change, a simple transition plan could be:
1. introduce `return_complex`, defaulted to false when BC is an issue but giving a warning. (this PR)
2. raise an error in cases where `return_complex` defaults to false, making it a required argument.
3. change `return_complex` default to true in all cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43886
Reviewed By: glaringlee
Differential Revision: D23760174
Pulled By: mruberry
fbshipit-source-id: 2fec4404f5d980ddd6bdd941a63852a555eb9147
Summary:
Fix https://discuss.pytorch.org/t/illegal-memory-access-when-i-use-groupnorm/95800
`dX` is a Tensor, comparing `dX` with `nullptr` was wrong.
cc BIT-silence who wrote the kernel.
The test couldn't pass with `rtol=0` and `x.requires_grad=True`, so I have to update that to `1e-5`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44863
Reviewed By: mruberry
Differential Revision: D23754101
Pulled By: BIT-silence
fbshipit-source-id: 2eb0134dd489480e5ae7113a7d7b84629104cd49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44345
As part of enhancing profiler support for RPC, when executing TorchScript functions over RPC, we would like to be able to support user-defined profiling scopes created by `with record_function(...)`.
Since after https://github.com/pytorch/pytorch/pull/34705, we support `with` statements in TorchScript, this PR adds support for `with torch.autograd.profiler.record_function` to be used within TorchScript.
This can be accomplished via the following without this PR:
```
torch.opts.profiler._record_function_enter(...)
# Script code, such as forward pass
torch.opts.profiler._record_function_exit(....)
```
This is a bit hacky and it would be much cleaner to use the context manager now that we support `with` statements. Also, `_record_function_` type operators are internal operators that are subject to change, this change will help avoid BC issues in the future.
Tested with `python test/test_jit.py TestWith.test_with_record_function -v`
ghstack-source-id: 112320645
Test Plan:
Repro instructions:
1) Change `def script_add_ones_return_any(x) -> Any` to `def script_add_ones_return_any(x) -> Tensor` in `jit/rpc_test.py`
2) `buck test mode/dev-nosan //caffe2/test/distributed/rpc:process_group_agent -- test_record_function_on_caller_rpc_async --print-passing-details`
3) The function which ideally should accept `Future[Any]` is `def _call_end_callbacks_on_future` in `autograd/profiler.py`.
python test/test_jit.py TestWith.test_with_foo -v
Reviewed By: pritamdamania87
Differential Revision: D23332074
fbshipit-source-id: 61b0078578e8b23bfad5eeec3b0b146b6b35a870
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44798
[test all]
Update for relanding: in ddp.join(), moved _rebuild_buckets from end of backward to beginning of forward as well.
Part of relanding PR #41954, this refactoring is to move rebuild_buckets call from end of first iteration to beginning of second iteration
ghstack-source-id: 112279261
ghstack-source-id: 112279261
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D23735185
fbshipit-source-id: c26e0efeecb3511640120faa1122a2c856cd694e
Summary:
Fixes the `true_divide` symbolic to cast tensors correctly.
The logic depends on knowing input types at export time, which is a known gap for exporting scripted modules. On that end we are improving exporter by enabling ONNX shape inference https://github.com/pytorch/pytorch/issues/40628, and starting to increase coverage for scripting support.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43991
Reviewed By: mruberry
Differential Revision: D23674614
Pulled By: bzinodev
fbshipit-source-id: 1b1b85340eef641f664a14c4888781389c886a8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44840
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44762
Move CostInferenceForFCGradient to fc_inference.cc/h to be used in multiple .cc files.
Test Plan: CI
Reviewed By: qizzzh
Differential Revision: D23714877
fbshipit-source-id: d27f33e270a93b0e053f2af592dc4a24e35526cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44000
This wasn't documented, so add a doc saying all ranks are used when
ranks=None
ghstack-source-id: 111206308
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D23465034
fbshipit-source-id: 4c51f37ffcba3d58ffa5a0adcd5457e0c5676a5d
Summary:
* Implement tuple sort by traversing contained IValue types and generate a lambda function as comparator for sort.
* Tuple, class objects can now arbitrarily nest within each other and still be sortable
Fixes https://github.com/pytorch/pytorch/issues/43219
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43448
Reviewed By: eellison
Differential Revision: D23352273
Pulled By: gmagogsfm
fbshipit-source-id: b6efa8d00e112178de8256da3deebdba7d06c0e1
Summary:
Fixes https://github.com/pytorch/pytorch/issues/43699
- Changed the order of `TORCH_CHECK` and `if (options.layout() == kSparse && self.is_sparse())`
inside `empty_like` method.
- [x] Added tests
EDIT:
More details on that and why we can not take zeros_like approach.
Python code :
```python
res = torch.zeros_like(input_coalesced, memory_format=torch.preserve_format)
```
is routed to
```c++
// TensorFactories.cpp
Tensor zeros_like(
const Tensor& self,
const TensorOptions& options,
c10::optional<c10::MemoryFormat> optional_memory_format) {
if (options.layout() == kSparse && self.is_sparse()) {
auto res = at::empty({0}, options); // to be resized
res.sparse_resize_and_clear_(
self.sizes(), self.sparse_dim(), self.dense_dim());
return res;
}
auto result = at::empty_like(self, options, optional_memory_format);
return result.zero_();
}
```
and passed to `if (options.layout() == kSparse && self.is_sparse())`
When we call in Python
```python
res = torch.empty_like(input_coalesced, memory_format=torch.preserve_format)
```
it is routed to
```c++
Tensor empty_like(
const Tensor& self,
const TensorOptions& options_,
c10::optional<c10::MemoryFormat> optional_memory_format) {
TORCH_CHECK(
!(options_.has_memory_format() && optional_memory_format.has_value()),
"Cannot set memory_format both in TensorOptions and explicit argument; please delete "
"the redundant setter.");
TensorOptions options =
self.options()
.merge_in(options_)
.merge_in(TensorOptions().memory_format(optional_memory_format));
TORCH_CHECK(
!(options.layout() != kStrided &&
optional_memory_format.has_value()),
"memory format option is only supported by strided tensors");
if (options.layout() == kSparse && self.is_sparse()) {
auto result = at::empty({0}, options); // to be resized
result.sparse_resize_and_clear_(
self.sizes(), self.sparse_dim(), self.dense_dim());
return result;
}
```
cc pearu
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44058
Reviewed By: albanD
Differential Revision: D23672494
Pulled By: mruberry
fbshipit-source-id: af232274dd2b516dd6e875fc986e3090fa285658
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44773
The model is created and prepared using fx APIs and then scripted for training.
In order to test QAT on scriptmodel we need to be able to disable/enable fake_quant
and observer modules on it.
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_qat_and_script
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23741354
fbshipit-source-id: 3fee7aa9b049d9901313b977710f4dc1c4501532
Summary:
[test all]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44330
Part of relanding PR #41954, this refactor is to seperate intialize_bucket_views and populate_bucket_views_out, as they are doing different things and called by different callsites as well
ghstack-source-id: 112257271
Test Plan: unit tests
Reviewed By: mrshenli
Differential Revision: D23583347
fbshipit-source-id: a5f2041b2c4f2c2b5faba1af834c7143eaade938
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44729
Switches our MAX_JOBS from a hardcoded value to a more dynamic value so
that we can always utilize all of the core that are available to us
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D23759643
Pulled By: seemethere
fbshipit-source-id: ad26480cb0359c988ae6f994e26a09f601b728e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44745
Much like CriterionTest, NewCriterionTest these are outdated formulations and we should just use the new one.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23717808
Pulled By: gchanan
fbshipit-source-id: eb91982eef23452456044381334bfc9a5bbd837e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44393
torch.quantile now correctly propagates nan and implemented torch.nanquantile similar to numpy.nanquantile.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23649613
Pulled By: heitorschueroff
fbshipit-source-id: 5201d076745ae1237cedc7631c28cf446be99936
Summary:
Fixes https://github.com/pytorch/pytorch/issues/33394 .
This PR does two things:
1. Implement CUDA scatter reductions with revamped GPU atomic operations.
2. Remove support for divide and subtract for CPU reduction as was discussed with ngimel .
I've also updated the docs to reflect the existence of only multiply and add.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41977
Reviewed By: mruberry
Differential Revision: D23748888
Pulled By: ngimel
fbshipit-source-id: ea643c0da03c9058e433de96db02b503514c4e9c
Summary:
buck build has -Wall for downcasts - need to add safe_downcast<int32_t> everywhere
BUCK build changes for aten_vulkan to include vulkan_wrapper lib
Test Plan: The next diff with segmentation demo works fine
Reviewed By: dreiss
Differential Revision: D23739445
fbshipit-source-id: b22a30e1493c4174c35075a68586defb0fccd2af
Summary:
Enabled type checking in common_distributed by using tensors of ints
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44821
Test Plan: Run python test/test_type_hints.py, errors are no longer ingnored by mypy.ini
Reviewed By: walterddr
Differential Revision: D23747466
Pulled By: alanadakotashine
fbshipit-source-id: 820fd502d7ff715728470fbef0be90ae7f128dd6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44570
**Summary**
This commit improves subtype checking for futures so that
`Future[T]` is considered to be a subtype of `Future[U]` if `U` is a
subtype of `V`.
**Test Plan**
This commit adds a test case to `test_async.py` that tests this.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23660588
Pulled By: SplitInfinity
fbshipit-source-id: b606137c91379debab91b9f41057f7b1605757c5
Summary:
Adds a new optimization to the IRSimplifier which changes this pattern:
```
for ...
if ...
do thing;
```
into:
```
if ...
for ...
do thing;
```
Which should be almost strictly better.
There are many cases where this isn't safe to do, hence tests. Most obviously when the condition depends on something modified within the loop.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44764
Reviewed By: mruberry
Differential Revision: D23734463
Pulled By: nickgg
fbshipit-source-id: 51617e837de96b354fb702d0090ac65ddc523d36
Summary:
### Java, CPP
Introducing additional parameter `device` to LiteModuleLoader to specify device on which the `forward` will work.
On the java side this is enum that contains CPU and VULKAN, passing as jint to jni side and storing it as a member field on the same level as module.
On pytorch_jni_lite.cpp - for all input tensors converting them to vulkan.
On pytorch_jni_common.cpp (also goes to OSS) - if result Tensor is not cpu - call cpu. (Not Cpu at the moment is only Vulkan).
### BUCK
Introducing `pytorch_jni_lite_with_vulkan` target, that depends on `pytorch_jni_lite_with_vulkan` and adds `aten_vulkan`
In that case `pytorch_jni_lite_with_vulkan` can be used along with `pytorch_jni_lite_with_vulkan`.
Test Plan:
After the following diff with aidemo segmentation:
```
buck install -r aidemos-android
```
{F296224521}
Reviewed By: dreiss
Differential Revision: D23198335
fbshipit-source-id: 95328924e398901d76718c4d828f96e112dfa1b0
Summary:
## Motivation
* To be able to make C2 ops cancellable so we can safely exit.
* Some C2 operators are now blocking thus being non-cancellable. If an error
occurs we need to be able to safely stop all net execution so we can throw
the exception to the caller.
* When an error occurs in a net or it got cancelled, running ops will have the
`Cancel` method called.
* This diff adds `Cancel` method to the `SafeEnqueueBlobsOp`
and `SafeDequeueBlobsOp` to have the call queue->close() to force all the
blocking ops to return.
* Adds unit test that verified the error propagation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44495
Test Plan:
## Unit Test added to verify that queue ops propagate errors
```
buck test caffe2/caffe2/python:hypothesis_test
```
Reviewed By: dzhulgakov
Differential Revision: D23236088
Pulled By: dahsh
fbshipit-source-id: daa90d9ee32483fb51195e269a52cf5987bb0a5a
Summary:
PyObject_IsSubclass may set python live exception bit if given object is not a class. `IsNamedTuple` is currently using it incorrectly, which may trip all following python operations in debug-build python. Normal release-build python is not affected because `assert` is no-op in release-build.
Fixes https://github.com/pytorch/pytorch/issues/43577
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44769
Reviewed By: jamesr66a
Differential Revision: D23725584
Pulled By: gmagogsfm
fbshipit-source-id: 2dabd4f8667a045d5bf75813500876c6fd81542b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44586
**Summary**
This commit disallows plain `Optional` type annotations without
any contained types both in type comments and in-line as
Python3-style type annotations.
**Test Plan**
This commit adds a unit test for these two situations.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D23721517
Pulled By: SplitInfinity
fbshipit-source-id: ead411e94aa0ccce227af74eb0341e2a5331370a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43796
This diff adds an option for the process group NCCL backend to pick high priority cuda streams.
Test Plan: waitforsandcastle
Reviewed By: jiayisuse
Differential Revision: D23404286
fbshipit-source-id: b79ae097b7cd945a26e8ba1dd13ad3147ac790eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44577
I would like to to move this to cmake so that I can depend on it
happening from other parts of the build.
This PR pulls out the logic for determining the version string and
writing the version file into its own module. `setup.py` still receives
the version string and uses it as before, but now the code for writing
out `torch/version.py` lives in a custom command in torch/CMakeLists.txt
I noticed a small inconsistency in how version info is populated.
`TORCH_BUILD_VERSION` is populated from `setup.py` at configuration
time, while `torch/version.py` is written at build time. So if, e.g. you
configured cmake on a certain git rev, then built it in on another, the
two versions would be inconsistent.
This does not appear to matter, so I opted to preserve the existing
behavior.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23734781
Pulled By: suo
fbshipit-source-id: 4002c9ec8058503dc0550f8eece2256bc98c03a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44585
**Summary**
This commit disallows plain `Tuple` type annotations without any
contained types both in type comments and in-line as Python3-style
type annotations.
**Test Plan**
This commit adds a unit test for these two situations.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D23721515
Pulled By: SplitInfinity
fbshipit-source-id: e11c77a4fac0b81cd535c37a31b9f4129c276592
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44584
**Summary**
This commit extends the work done in #38130 and disallows plain
Python3-style `List` type annotations.
**Test Plan**
This commit extends `TestList.test_no_element_type_annotation` to the
Python3-style type annotation.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D23721514
Pulled By: SplitInfinity
fbshipit-source-id: 48957868286f44ab6d5bf5e1bf97f0a4ebf955df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44334
**Summary**
This commit detects and prohibits the case in which `typing.Dict` is
used as an annotation without type arguments (i.e. `typing.Dict[K, V]`).
At present, `typing.Dict` is always assumed to have two arguments, and
when it is used without them, `typing.Dict.__args__` is nonempty and
contains some `typing.TypeVar` instances, which have no JIT type equivalent.
Consequently, trying to convert `typing.Dict` to a JIT type results in
a `c10::DictType` with `nullptr` for its key and value types, which can cause
a segmentation fault.
This is fixed by returning a `DictType` from
`jit.annotations.try_ann_to_type` only if the key and value types are converted
successfully to a JIT type and returning `None` otherwise.
**Test Plan**
This commit adds a unit test to `TestDict` that tests the plain `Dict`
annotations throw an error.
**Fixes**
This commit closes#43530.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D23610766
Pulled By: SplitInfinity
fbshipit-source-id: 036b10eff6e3206e0da3131cfb4997d8189c4fec
Summary:
Unifies a number of partial solutions to the thread and block dimension extent masking, including the NoThreadIdxWriter and my last fix https://github.com/pytorch/pytorch/issues/44325. The NoThreadIdxWriter is gone in favour of tracking the current loop extents and masking any statements that have a lower rank than the launch parameters in any Block or Thread dimension, which handles both the "no" and "smaller" axis binding cases.
For example it will transform the following:
```
for i in 0..10 // blockIdx.x
for j in 0..10 // threadIdx.x
do thing(i, j);
for k in 0..5 // threadIdx.x
do other thing(i, k);
```
Into:
```
do thing(blockIdx.x, threadIdx.x);
if (threadIdx.x < 5) {
do other thing(blockIdx.x, threadIdx.x);
}
```
And handle the case where statements are not bound by any axis, eg.
```
do outer thing;
for i in 0..10 // blockIdx.x
for j in 0..10 // threadIdx.x
do thing(i, j);
do other thing(i);
```
will become:
```
if (blockIdx.x < 1) {
if (threadIdx.x < 1) {
do outer thing;
}
}
syncthreads();
do thing(blockIdx.x, threadIdx.x);
syncthreads();
if (threadIdx.x < 1) {
do other thing(blockIdx.x);
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44733
Reviewed By: mruberry
Differential Revision: D23736878
Pulled By: nickgg
fbshipit-source-id: 52d08626ae8043d53eb937843466874d479a6768
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44819
[12:39 AM] Cherckez, Tal
please review the following patch.
should address these issues that our validation team found:
A) test_op_nnpi_fp16: hypothesis to trigger max_example*max_example.
B) batchnorm: batchNorm has derived from unit test which doesnt have setting required for hypothesis. hence default value as 100 getting set.
Test Plan:
buck test //caffe2/caffe2/contrib/fakelowp/test/...
https://our.intern.facebook.com/intern/testinfra/testrun/5910974543950859
Reviewed By: hyuen
Differential Revision: D23740970
fbshipit-source-id: 16fcc49f7bf84a5d7342786f671cd0b4e0fc87d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44703
The description of this public function should be in the header file.
Also fix some typos.
Test Plan: N/A.
Reviewed By: pritamdamania87
Differential Revision: D23703661
fbshipit-source-id: 24ae63de9498e321b31dfb2efadb44183c6370df
Summary:
Make `gcs_cuda_only` and `gcs_gpu_only` return empty device lists if CUDA/GPU(CUDA or RocM) not available
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44578
Reviewed By: walterddr
Differential Revision: D23664227
Pulled By: malfet
fbshipit-source-id: 176b5d964c0b02b8379777cd9a38698c11818690
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44649
To unblock #43208, which adds "is_complex" checks to backward formulas
that are being tested for batched gradient support with vmap.
Test Plan: - `pytest test/test_vmap.py -v`
Reviewed By: anjali411
Differential Revision: D23685356
Pulled By: zou3519
fbshipit-source-id: 29e41a9296336f6d1008e3040cade4c643bf5ebf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44663
The new API returns the type of the data object referenced by this
`RRef`. On the owner, this is same as `type(rref.local_value())`.
On a user, this will trigger an RPC to fetch the `type` object from
the owner. After this function is run once, the `type` object is
cached by the `RRef`, and subsequent invocations no longer trigger
RPC.
closes#33210
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D23691990
Pulled By: mrshenli
fbshipit-source-id: a2d87cd601a691dd75164b6bcd7315245e9cf6bd
Summary:
[Tests for Vec256 classes https://github.com/pytorch/pytorch/issues/15676](https://github.com/pytorch/pytorch/issues/15676)
Testing
Current list:
- [x] Blends
- [x] Memory: UnAlignedLoadStore
- [x] Arithmetics: Plus,Minu,Multiplication,Division
- [x] Bitwise: BitAnd, BitOr, BitXor
- [x] Comparison: Equal, NotEqual, Greater, Less, GreaterEqual, LessEqual
- [x] MinMax: Minimum, Maximum, ClampMin, ClampMax, Clamp
- [x] SignManipulation: Absolute, Negate
- [x] Interleave: Interleave, DeInterleave
- [x] Rounding: Round, Ceil, Floor, Trunc
- [x] Mask: ZeroMask
- [x] SqrtAndReciprocal: Sqrt, RSqrt, Reciprocal
- [x] Trigonometric: Sin, Cos, Tan
- [x] Hyperbolic: Tanh, Sinh, Cosh
- [x] InverseTrigonometric: Asin, ACos, ATan, ATan2
- [x] Logarithm: Log, Log2, Log10, Log1p
- [x] Exponents: Exp, Expm1
- [x] ErrorFunctions: Erf, Erfc, Erfinv
- [x] Pow: Pow
- [x] LGamma: LGamma
- [x] Quantization: quantize, dequantize, requantize_from_int
- [x] Quantization: widening_subtract, relu, relu6
Missing:
- [ ] Constructors, initializations
- [ ] Conversion , Cast
- [ ] Additional: imag, conj, angle (note: imag and conj only checked for float complex)
#### Notes on tests and testing framework
- some math functions are tested within domain range
- mostly testing framework randomly tests against std implementation within the domain or within the implementation domain for some math functions.
- some functions are tested against the local version. ~~For example, std::round and vector version of round differs. so it was tested against the local version~~
- round was tested against pytorch at::native::round_impl. ~~for double type on **Vsx vec_round failed for (even)+0 .5 values**~~ . it was solved by using vec_rint
- ~~**complex types are not tested**~~ **After enabling complex testing due to precision and domain some of the complex functions failed for vsx and x86 avx as well. I will either test it against local implementation or check within the accepted domain**
- ~~quantizations are not tested~~ Added tests for quantizing, dequantize, requantize_from_int, relu, relu6, widening_subtract functions
- the testing framework should be improved further
- ~~For now `-DBUILD_MOBILE_TEST=ON `will be used for Vec256Test too~~
Vec256 Test cases will be built for each CPU_CAPABILITY
Fixes: https://github.com/pytorch/pytorch/issues/15676
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42685
Reviewed By: malfet
Differential Revision: D23034406
Pulled By: glaringlee
fbshipit-source-id: d1bf03acdfa271c88744c5d0235eeb8b77288ef8
Summary:
per title. If `beta=0` and slow path was taken, `nan` and `inf` in the result were not masked as is the case with other linear algebra functions. Similarly, since `mv` is implemented as `addmv` with `beta=0`, wrong results were sometimes produced for `mv` slow path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44681
Reviewed By: mruberry
Differential Revision: D23708653
Pulled By: ngimel
fbshipit-source-id: e2d5d3e6f69b194eb29b327e1c6f70035f3b231c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44702
Original commit changeset: c6bd6d277aca
This diff caused windows build to fail due to a compiler bug in VS2019 (lambda capture constant int value). This back out works around the issue with explicit capture of const int value.
Test Plan: Tested and previously landed.
Reviewed By: mruberry
Differential Revision: D23703215
fbshipit-source-id: f9ef23be97540bc9cf78a855295fb8c69f360459
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44763
The file had separate rules for RPC and DDP/c10d, consolidated all of
it together and placed all the distributed rules together.
ghstack-source-id: 112140871
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D23721162
fbshipit-source-id: d41c757eb1615376d442bd6b2802909624bd1d3f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44439
Adds a test to ddp_under_dist_autograd_test to enusre that that uneven
inputs join() API works properly when DDP + RPC is combined. We test that when
running in outside DDP mode (DDP applied to whole hybrid module) we can
correctly process uneven inputs across different trainers.
ghstack-source-id: 112156980
Test Plan: CI
Reviewed By: albanD
Differential Revision: D23612409
fbshipit-source-id: f1e328c096822042daaba263aa8747a9c7e89de7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44749
Ensure fx module is scriptable after calling prepare_qat on it
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_qat_and_script
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23718380
fbshipit-source-id: abf63ffb21e707f7def8f6c88246877f5aded58c
Summary:
The subclass sets "self.last_epoch" when this is set in the parent class's init function. Why would we need to set last_epoch twice? I think calling "super" resets last_epoch anyway, so I am not sure why we would want to include this in the subclass. Am I missing something?
For the record, I am just a Pytorch enthusiast. I hope my question isn't totally silly.
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44613
Reviewed By: albanD
Differential Revision: D23691770
Pulled By: mrshenli
fbshipit-source-id: 080d9acda86e1a2bfaafe2c6fcb8fc1544f8cf8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44566
The Delegate objects were confusing. They were suppose to be a way to
configure how tracing works, but in some cases they appeared necessary
for consturcting graphs, which was not true. This makes the organization
clearer by removing Delgate and moving its functionality into a Tracer class,
similar to how pickle has a Pickler class.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D23683177
Pulled By: zdevito
fbshipit-source-id: 7605a34e65dfac9a487c0bada39a23ca1327ab00
Summary:
Modified files in `benchmarks/tensorexpr` to add support for NVIDIA's Fuser for the jit compiler.
This support has some modifications besides adding an option to support the NVIDIA fuser:
* Adds FP16 Datatype support
* Fixes SOL/Algo calculations to generally use the data type instead of being fixed to 4 bytes
* Adds IR printing and kernel printing knobs
* Adds a knob `input_iter` to create ranges of inputs currently only for reductions
* Adds further reduction support for Inner and Outer dimension reductions that are compatible with the `input_iter` knob.
* Added `simple_element`, `reduce2d_inner`, and `reduce2d_outer` to isolate performance on elementwise and reduction operations in the most minimal fashion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44101
Reviewed By: ngimel
Differential Revision: D23713658
Pulled By: bertmaher
fbshipit-source-id: d6b83cfab559aefe107c23b3c0f2df9923b3adc1
Summary:
There's an annoying O(N^2) in module export logic that makes saving some of the models (if they have many classes) take eternity.
I'm not super familiar with this code to properly untangle the deps and make it a pure hash lookup. So I just added a side lookup table for raw pointers. It's still quadratic, but it's O(num_classes^2) instead of O(num_classes * num_references) which already gives huge savings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44589
Test Plan:
Tested with one of the offending models - just loading a saving a Torchscript file:
```
Before:
load 1.9239683151245117
save 165.74712467193604
After:
load 1.9409027099609375
save 1.4711427688598633
```
Reviewed By: suo
Differential Revision: D23675278
Pulled By: dzhulgakov
fbshipit-source-id: 8f3fa7730941085ea20d9255b49a149ac1bf64fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44540
Support output type to be fp16 for UniformFill
Reviewed By: jianyuh
Differential Revision: D23558030
fbshipit-source-id: 53a5b2c92cfe78cd11f55e6ee498e1bd682fe4a1
Summary:
This is a reup https://github.com/pytorch/pytorch/issues/43885 with an extra commit which should fix the bugs that caused it to be reverted. Read that for general context.
The issue here was that we were still using the side maps `tensor_to_stmt_` and `stmt_to_tensor_` which get invalidated by any transform of the IR (rather than just any transform that isn't computeInline). I added a comment about this but didn't actually address our usages of it.
I've removed these maps and changed the `getLoopBodyFor` and `getLoopStatementsFor` helpers to search the root stmt directly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44231
Reviewed By: albanD
Differential Revision: D23689688
Pulled By: nickgg
fbshipit-source-id: 1c6009a880f8c0cebf2300fd06b5cc9322bffbf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44654
Previously we weren't creating a fallback graph as intended in specialize autograd zero, so if a Tensor failed one of our undefinedness checks we would run the backward normally without reprofiling & optimizing.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D23691764
Pulled By: eellison
fbshipit-source-id: 10c6fa79518c84a6f5ef2bfbd9ea10843af751eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44089
Add support of fp16 as input type in SparseLengthSum/Mean caffe2 operator
Reviewed By: xianjiec
Differential Revision: D23436877
fbshipit-source-id: 02fbef2fde17d4b0abea9ca5d17a36aa989f98a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44656
All this time, test_vmap wasn't running in the CI. Fortunately all the
tests pass locally for me. h/t to anjali411 for pointing this out.
Test Plan: - Wait for CI
Reviewed By: anjali411
Differential Revision: D23689355
Pulled By: zou3519
fbshipit-source-id: 543c3e6aed0af77bfd6ea7a7549337f8230e3d32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44651
Adds pruning for our anaconda channels (pytorch-nightly, pytorch-test)
into our CI pipeline so that it gets run on a more consistent basis.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D23692851
Pulled By: seemethere
fbshipit-source-id: fa69b506b73805bf2ffbde75d221aef1ee3f753e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44326
Part of relanding PR #41954, this refactoring is to move rebuild_buckets call from end of first iteration to beginning of second iteration
ghstack-source-id: 112011490
Test Plan: unit tests
Reviewed By: mrshenli
Differential Revision: D23583017
fbshipit-source-id: ef67f79437a820d9b5699b651803622418499a83
Summary:
- Bump oneDNN (mkl-dnn) to 1.6 for bug fixes
- Fixes https://github.com/pytorch/pytorch/issues/42446. RuntimeError: label is redefined for convolutions with large filter size on Intel AVX512
- Implemented workaround for internal compiler error when building oneDNN with Microsoft Visual Studio 2019 (https://github.com/pytorch/pytorch/pull/43169)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44706
Reviewed By: ngimel
Differential Revision: D23705967
Pulled By: albanD
fbshipit-source-id: 65e8fecc52a76c9f3324403a8b60ffa8a8948bc6
Summary:
For https://github.com/pytorch/pytorch/issues/44206 and https://github.com/pytorch/pytorch/issues/42218, I'd like to update trilinear interpolate backward and grid_sample backward to use `fastAtomicAdd`.
As a prelude, I spotted a UB risk in `fastAtomicAdd`. I think existing code incurs a misaligned `__half2` atomicAdd when `index` is odd and `tensor` is not 32-bit aligned (`index % 2 == 1` and `(reinterpret_cast<std::uintptr_t>(tensor) % sizeof(__half2) == 1`). In this case we think we're `!low_bit` and go down the `!low_bit` code path, but in fact we are `low_bit`. It appears the original [fastAtomicAdd PR](https://github.com/pytorch/pytorch/pull/21879#discussion_r295040377)'s discussion did not consider that case explicitly.
I wanted to push my tentative fix for discussion ASAP. jjsjann123 and mkolod as original authors of `fastAtomicAdd`. (I'm also curious why we need to `reinterpret_cast<std::uintptr_t>(tensor...` for the address modding, but that's minor.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44642
Reviewed By: mruberry
Differential Revision: D23699820
Pulled By: ngimel
fbshipit-source-id: 0db57150715ebb45e6a1fb36897e46f00d61defd
Summary:
This PR adds dilation to _ConvTransposeNd._output_padding method and tests using a bunch of different sized inputs.
Fixes https://github.com/pytorch/pytorch/issues/14272
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43793
Reviewed By: zou3519
Differential Revision: D23493313
Pulled By: ezyang
fbshipit-source-id: bca605c428cbf3a97d3d24316d8d7fde4bddb307
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42390
**Summary**
This commit extends support for properties to include
ScriptModules.
**Test Plan**
This commit adds a unit test that has a ScriptModule with
a user-defined property.
`python test/test_jit_py3.py TestScriptPy3.test_module_properties`
Test Plan: Imported from OSS
Reviewed By: eellison, mannatsingh
Differential Revision: D22880298
Pulled By: SplitInfinity
fbshipit-source-id: 74f6cb80f716084339e2151ca25092b6341a1560
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44645
Moved CallbackManager as a nested class of RecordFunction to allow private access to the call handles and context without exposing them publicly. It still hides the singleton instance of the CallbackManager inside record_function.cpp.
Test Plan: Unit tests.
Reviewed By: ilia-cher
Differential Revision: D23494065
fbshipit-source-id: 416d5bf6c9426e112877fbd233a6f4dff7bef455
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44252
Add tracing to DPP client. Because DPP requests are async, we need to be able to start a trace event in one thread and potentially end in a different thread. RecordFunction and LibgpumonObserver previously assume each trace event starts and finishes in the same thread. So they use a thread local context to track enter and exit call backs. Async events breaks this assumption. This change attaches the event context to the RecordFunction object so we do not need to use thread local context.
Test Plan:
Tested with dpp perf test and able to collect trace.
{F307824044}
Reviewed By: ilia-cher
Differential Revision: D23323486
fbshipit-source-id: 4b6ca6c0e32028fb38a476cd1f44c17a001fc03b
Summary:
We were hitting an assert error when you passed in an empty `List[List[int]]` - this fixes that error by not recursing into 0-element tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44652
Reviewed By: ZolotukhinM
Differential Revision: D23688247
Pulled By: eellison
fbshipit-source-id: d48ea24893044fae96bc39f76c0f1f9726eaf4c7
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 1d710393d5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44647
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: dskhudia
Differential Revision: D23684528
fbshipit-source-id: 316ff2e448707a6e5a83248c9b22e58118bc8741
Summary:
This PR:
- updates div to perform true division
- makes torch.true_divide an alias of torch.div
This follows on work in previous PyTorch releases that first deprecated div performing "integer" or "floor" division, then prevented it by throwing a runtime error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42907
Reviewed By: ngimel
Differential Revision: D23622114
Pulled By: mruberry
fbshipit-source-id: 414c7e3c1a662a6c3c731ad99cc942507d843927
Summary:
* Support sequence type (de)serialization, enables onnx shape inference on sequence nodes.
* Fix shape inference with block input/output: e.g. Loop and If nodes.
* Fix bugs in symbolic discovered by coverage of onnx shape inference.
* Improve debuggability: added more jit logs. For simplicity, the default log level, when jit log is enabled, will not dump ir graphs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43929
Reviewed By: albanD
Differential Revision: D23674604
Pulled By: bzinodev
fbshipit-source-id: ab6aacb16d0e3b9a4708845bce27c6d65e567ba7
Summary:
When caller / callee pairs are inserted into the mapping, verify that
the arity of the buffer access is consistent with its declared rank.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44561
Test Plan: CI, test_tensorexpr --gtest_filter=TensorExprTest.DetectInlineRankMismatch
Reviewed By: albanD
Differential Revision: D23684342
Pulled By: asuhan
fbshipit-source-id: dd3a0cdd4c2492853fa68381468e0ec037136cab
Summary:
Fixes https://github.com/pytorch/pytorch/issues/43389.
This PR replaces the old ELU formula from the docs that yields wrong results for negative alphas with the new one that fixes the issue and relies on the cases notation which makes the formula more straightforward.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43764
Reviewed By: ailzhang
Differential Revision: D23425532
Pulled By: albanD
fbshipit-source-id: d0931996e5667897d926ba4fc7a8cc66e8a66837
Summary:
Improve simplification of nested Min and Max patterns.
Specifically, handles the following pattern simplications:
* `Max(A, Max(A, Const)) => Max(A, Const)`
* `Max(Min(A, B), Min(A, C)) => Min(A, Max(B, C))`
* `Max(Const, Max(A, OtherConst) => Max(A, Max(Const, OtherConst))`
- This case can have an arbitrarily long chain of Max ops. For example: `Max(5, Max(x, Max(y, Max(z, 8)))) => Max(Max(Max(x, 8), y), z)`
Similarly, for the case of Min as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44142
Reviewed By: albanD
Differential Revision: D23644486
Pulled By: navahgar
fbshipit-source-id: 42bd241e6c2af820566744c8494e5dee172107f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44562
Add a note that torch.median returns the smaller of the two middle elements for even-sized input and refer user to torch.quantile for the mean of the middle values.
fixes https://github.com/pytorch/pytorch/issues/39520
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23657208
Pulled By: heitorschueroff
fbshipit-source-id: 2747aa652d1e7f10229d9299b089295aeae092c2
Summary:
We run remove profile nodes and specialize types before batch_mm, so we cannot run peepholes on the type information of tensors since these properties have not been guarded to be guaranteed to be correct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44565
Reviewed By: albanD
Differential Revision: D23661538
Pulled By: eellison
fbshipit-source-id: 0dd23a65714f047f49b4db4ec582b21870925fe1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44622
Remove an extra empty line in the warning comments.Remove an extra empty line.
Test Plan: N/A
Reviewed By: rohan-varma
Differential Revision: D23674070
fbshipit-source-id: 4ee570590c66a72fb808e9ee034fb773b833efcd
Summary:
This adds HIP version info to the `collect_env.py` output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44106
Reviewed By: VitalyFedyunin
Differential Revision: D23652341
Pulled By: zou3519
fbshipit-source-id: a1f5bce8da7ad27a1277a95885934293d0fd43c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44442
I noticed lock contention on startup as lookupByLiteral() was
calling registerPendingOperators() - some calls were holding the
lock for 10+ ms, as operators were being registered.
canonicalSchemaString() was using ostreamstring, which isn't typically
particularly fast (partly because of c++ spec locale requirements).
If we repalce with regular c++ string appends, it's somewhat faster
(which isn't hard when comparing with stringstream; albeit a bit
more codegen)
Over the first minute or so, this cuts out 1.4 seconds under the
OperatorRegistry lock (as part of registerPendingOperators) in the
first couple minutes of run time (mostly front-loaded) when running
sync sgd.
As an example, before:
registerPendingOperators 12688 usec for 2449 operators
After:
registerPendingOperators 6853 usec for 2449 operators
ghstack-source-id: 111862971
Test Plan: buck test mode/dev-nosan caffe2/test/cpp/...
Reviewed By: ailzhang
Differential Revision: D23614515
fbshipit-source-id: e712f9dac5bca0b1876e11fb8f0850402f03873a
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 0725301da5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44581
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: dskhudia, VitalyFedyunin
Differential Revision: D23665173
fbshipit-source-id: 03cee22335eef0517e561827795bbe2036942ea0
Summary:
Fixes https://github.com/pytorch/pytorch/issues/44219
Rebasing https://github.com/pytorch/pytorch/pull/44288 and fixing the git history.
This allows users to bencmark code without having to specify how long to run the benchmark. It runs the benchmark until the variance (IQR / Median) is low enough that we can be confident in the measurement.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44607
Test Plan: There are unit tests, and we manually tested using Examples posted in git.
Reviewed By: robieta
Differential Revision: D23671208
Pulled By: bitfort
fbshipit-source-id: d63184290b88b26fb81c2452e1ae701c7d513d12
Summary:
This fixes a `katex` error I was getting trying to build the docs:
```
ParseError: KaTeX parse error: Undefined control sequence: \0 at position 55: …gin{cases}
```
This failure was introduced in https://github.com/pytorch/pytorch/issues/42523.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44481
Reviewed By: colesbury
Differential Revision: D23627700
Pulled By: mruberry
fbshipit-source-id: 9cc09c687a7d9349da79a0ac87d6c962c9cfbe2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44337
Add a new run_method to mobile Module which is variadic (takes any number of arguments) to match full jit.
ghstack-source-id: 111909068
Test Plan: Added new unit test to test_jit test suite
Reviewed By: linbinyu, ann-ss
Differential Revision: D23585763
fbshipit-source-id: 007cf852290f03615b78c35aa6f7a21287ccff9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44588
1) SOURCE_DUMP crashes when invoked on a backward graph since
`prim::GradOf` nodes can't be printed as sources (they don't have
schema).
2) Dumping graph each time we execute an optimized plan produces lots of
output in tests where we run the graph multiple times (e.g.
benchmarks). Outputting that on the least level of verbosity seems
like an overkill.
3) Duplicated log statement is removed.
Differential Revision: D23666812
Test Plan: Imported from OSS
Reviewed By: bertmaher
Pulled By: ZolotukhinM
fbshipit-source-id: b9a30e34fd39c85f3e13c3f1e3594e157e1c130f
Summary:
**BC-breaking note**
This change is BC-breaking for C++ callers of linspace and logspace if they were providing a steps argument that could not be converted to an optional.
**PR note**
This PR deprecates calling linspace and logspace wihout setting steps explicitly by:
- updating the documentation to warn that not setting steps is deprecated
- warning (once) when linspace and logspace are called without steps being specified
A test for this behavior is added to test_tensor_creation_ops. The warning only appears once per process, however, so the test would pass even if no warning were thrown. Ideally there would be a mechanism to force all warnings, include those from TORCH_WARN_ONCE, to trigger.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43860
Reviewed By: izdeby
Differential Revision: D23498980
Pulled By: mruberry
fbshipit-source-id: c48d7a58896714d184cb6ff2a48e964243fafc90
Summary: As title; this will unblock migration of several modules that need learning rate functionality.
Test Plan:
```
buck test //dper3/dper3/modules/low_level_modules/tests:learning_rate_test
```
WIP: need to add more learning rate tests for the different policies
Reviewed By: yf225
Differential Revision: D23584071
fbshipit-source-id: f6656531b1caba38c3e3a7d6e16d9591563391e2
Summary:
Adding snpe dependencies to caffe2_benchmark so that this can benchmark SNPE models on portal devices.
Also need to change ndk_libcxx to gnustl till snpe is updated to work with ndk.
Test Plan: Tested on top of the stack.
Reviewed By: linbinyu
Differential Revision: D23569397
fbshipit-source-id: a6281832804ed4fbb5a8406f436caeae1ff4fd2b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44340
Changed the constructor of GradBucket to pass the input by const
reference and hence avoided unnecessary explicit move semantics. Since
previously the declaration and definition are separated, passing the input
tensor vector by value looks quite bizarre.
Test Plan: buck test caffe2/torch/lib/c10d:ProcessGroupGlooTest
Reviewed By: pritamdamania87
Differential Revision: D23569939
fbshipit-source-id: db761d42e76bf938089a0b38e98e76a05bcf4162
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44339
Moved the inline implementations of GradBucket class to the header for
succinctness and readability. This coding style is also consistent with
reducer.h under the same directory.
Test Plan: buck test caffe2/torch/lib/c10d:ProcessGroupGlooTest
Reviewed By: pritamdamania87
Differential Revision: D23569701
fbshipit-source-id: 237d9e2c5f63a6bcac829d0fcb4a5ba3bede75e5
Summary:
Follow up to https://github.com/pytorch/pytorch/pull/36404
Adding prim::device and prim::dtype to list of skipped peepholes when we run inlining. In the long term another fix may not be to encode shape / dtype info on the traced graph, because it is not guaranteed to be correct. This is blocked by ONNX currently.
Partial fix for https://github.com/pytorch/pytorch/issues/43134
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43363
Reviewed By: glaringlee
Differential Revision: D23383987
Pulled By: eellison
fbshipit-source-id: 2e9c5160d39d690046bd9904be979d58af8d3a20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44564
Before this change we sometimes inlined autodiff subgraph containing
fusion groups. This happened because we didn't look for 'unsupported'
nodes recursively (maybe we should), but fusion groups were inside
if-nodes.
The problem was detected by bertmaher in 'LearningToPaint' benchmark
investigation where this bug caused us to keep constantly hitting
fallback paths of the graph.
Test Plan: Imported from OSS
Reviewed By: bwasti
Differential Revision: D23657049
Pulled By: ZolotukhinM
fbshipit-source-id: 7c853424f6dce4b5c344d6cd9c467ee04a8f167e
Summary:
Fix an issue where loops of different sizes are bound to the same Cuda dimension / metavar.
Coming soon more info and tests...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44325
Reviewed By: colesbury
Differential Revision: D23628859
Pulled By: nickgg
fbshipit-source-id: 3621850a4cc38a790b62ad168d32e7a0e2462fad
Summary:
CentOS 8 on AArch64 has vld1_* intrinsics but lacks vst1q_f32_x2 one.
This patch checks for it and handle it separately to vld1_* ones.
Fixes https://github.com/pytorch/pytorch/issues/44198
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44199
Reviewed By: seemethere
Differential Revision: D23641273
Pulled By: malfet
fbshipit-source-id: c2053c8e0427705eaeeeb82ec030925bff22623a
Summary:
According to [documentation](https://github.com/pytorch/pytorch/blob/master/tools/setup_helpers/cmake.py#L265), only options starts with `BUILD_` / `USE_` / `CMAKE_` in `CMakeLists.txt` can be imported by environment variables.
---
This diff is originally intended to enable `c++` source coverage with `CircleCI` and `codecov.io`, but we will finish it in the future. You can find the related information in the diff history. Following is the originally procedur:
Based on [this pull request](1bda5e480c), life becomes much easier for this time.
1.in `build.sh`
- Enable coverage builld option for c++
- `apt-get install lcov`
2.in `test.sh`
- run `lcov`
3.in `pytorch-job-specs.yml`
- copy coverage.info to `test/` folder and upload it to codecov.io
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43999
Test Plan: Test on github
Reviewed By: malfet
Differential Revision: D23464656
Pulled By: scintiller
fbshipit-source-id: b2365691f04681d25ba5c00293fbcafe8e8e0745
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44568
By `lcov`, we can generate beautiful html. It's better than current file report and line report. Therefore in oss gcc, remove `export` code and `file/line level report` code, only use the html report.
But in clang, since such tool is not available, we will still use file-report and line-report generated by ourself.
Test Plan:
Test in docker ubuntu machine.
## Mesurement
1. After running `atest`, it takes about 15 mins to collect code coverage and genrate the report.
```
# gcc code coverage
python oss_coverage.py --run-only=atest
```
## Presentation
**The html result looks like:**
*Top Level:*
{F328330856}
*File Level:*
{F328336709}
Reviewed By: malfet
Differential Revision: D23550784
fbshipit-source-id: 1fff050e7f7d1cc8e86a6a200fd8db04b47f5f3e
Summary: Some tests like `test_dataloader.py` are not able to run under `clang` in oss, because it generates too large intermediate files (~40G) that can't be merged by `llvm`. Skip them when user doesn't specify the `--run-only` option
Test Plan: Test locally. But still, not recomend user to run `clang` coverage in default mode, because it takes too much space.
Reviewed By: malfet
Differential Revision: D23549829
fbshipit-source-id: 0737e6e9dcbe3f38de00580ee6007906e743e52f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44066
Add STL Input iterator to DispatchKeySet:
* Iterator is able to iterate from first not undefined DispatchKey
to NumDispatchKeys.
* Iterator is invalidated once underlying DispatchKeySet is invalidated
Note see http://www.cplusplus.com/reference/iterator/ for comparisons of
different iterators.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D23611405
Pulled By: linux-jedi
fbshipit-source-id: 131b287d60226a1d67a6ee0f88571f8c4d29f9c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44494
These tests check (most) operations that are useful for bayesian logistic
regression (BLR) models. Said operators are basically those found in the
log_prob functions of Distributions objects. This PR is not a general,
structured solution for testing batched gradients (see "Alternative
solution" for that), but I wanted to test a small subset of operations
to confirm that the BLR use case works.
There will be follow-up PRs implementing support for some missing
operations for the BLR use case.
Alternative solution
=====================
Ideally, and in the future, I want to autogenerate tests from
common_method_invocations and delete all of the manual tests
introduced by this PR. However, if we were to do this now,
we would need to store the following additional metadata somewhere:
- operator name, supports_batched_grad, allow_vmap_fallback_usage
We could store that metadata as a separate table from
common_method_invocations, or add two columns to
common_method_invocations. Either way that seems like a lot of work and
the situation will get better once vmap supports batched gradients for
all operators (on the fallback path).
I am neutral between performing the alternative approach now v.s. just
manually writing out some tests for these operations, so I picked the
easier approach. Please let me know if you think it would be better to
pursue the alternative approach now.
Test Plan: - `pytest test/test_vmap.py -v -k "BatchedGrad"`
Reviewed By: anjali411
Differential Revision: D23650408
Pulled By: zou3519
fbshipit-source-id: 2f26c7ad4655318a020bdaab5c767cd3956ea5eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43043
This add the support for rpc_sync in TorchScript in a way similar to
rpc_async
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D23252039
Pulled By: wanchaol
fbshipit-source-id: 8a05329cb8a24079b2863178b73087d47273914c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44537
Originally, the `min_val`, `max_val`, `min_vals`, `max_vals`
attributes of observers were Tensors but not buffers. They had custom
state_dict save/load code to ensure their state was saved.
At some point, these attributes became buffers, and the custom
save/load code remained. This introduced a subtle bug:
* create model A, move it to a device (cpu/cuda) and save its state_dict
* create model B, load its state dict.
* `min_val|min_vals|max_val|max_vals` would always be loaded to model A's device, even if the rest of model B was on a different device
* the above is inconsistent with how save/load on different devices is expected to work (see https://pytorch.org/tutorials/beginner/saving_loading_models.html#saving-loading-model-across-devices)
In practice, the case people would sometimes hit is:
* model A is on CPU, state dict is saved
* model B is created and moved to GPU, state_dict from model A is loaded
* assertions throw when operations are attempted across different devices
This PR fixes the behavior by removing the custom save/load where
possible and letting the default `nn.Module` save/load code handle
device assignment. We special case `PerChannelMinMaxObserver` and its
children to allow for loading buffers or different size, which is
normal.
There are some followups to also enable this for HistogramObserver
and FakeQuantize, which can be done in separate PRs due to higher
complexity.
Test Plan:
```
python test/test_quantization.py TestObserver.test_state_dict_respects_device_affinity
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D23644493
fbshipit-source-id: 0dbb6aa309ad569a91a663b9ee7e44644080032e
Summary:
Solves `the '-j' option requires a positive integer argument` error on some systems when MAX_JOBS is not defined
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44557
Reviewed By: vkuzo
Differential Revision: D23653511
Pulled By: malfet
fbshipit-source-id: 7d86fb7fb6c946c34afdc81bf2c3168a74d00a1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44145
## Motivation
* To be able to make C2 ops cancellable so we can safely exit.
* Some C2 operators are now blocking thus being non-cancellable. If an error
occurs we need to be able to safely stop all net execution so we can throw
the exception to the caller.
## Summary
* Adds `NetBase::Cancel()` to NetBase which iterates over the entire list of
operators and call Cancel.
* Cancel on all ops was added to Net since there's nothing Asyc specific about it.
* `AsyncSchedulingNet` calls parent Cancel.
* To preserve backwards compatibility, `AsyncSchedulingNet`'s Cancel still calls
`CancelAndFinishAsyncTasks` .
* Adds `Cancel()` to `OperatorBase`.
Reviewed By: dzhulgakov
Differential Revision: D23279202
fbshipit-source-id: e1bb0ff04a4e1393f935dbcac7c78c0baf728550
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44486
SmoothL1Loss had a completely different (and incorrect, see #43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the SmoothL1Loss CriterionTests to verify that the target derivative is checked.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23630699
Pulled By: gchanan
fbshipit-source-id: 0f94d1a928002122d6b6875182867618e713a917
Summary:
Add new transforms `sliceHead` and `sliceTail` to `LoopNest`, for example:
Before transformation:
```
for x in 0..10:
A[x] = x*2
```
After `sliceHead(x, 4)`:
```
for x in 0..4:
A[x] = x*2
for x in 4..10:
A[x] = x*2
```
After `sliceTail(x, 1)`:
```
for x in 0..4:
A[x] = x*2
for x in 4..9:
A[x] = x*2
for x in 9..10:
A[x] = x*2
```
`sliceHead(x, 10)` and `sliceTail(x, 10)` is no-op.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43854
Test Plan: Tests are added in `test_loopnest.cpp`, the tests cover the basic transformations, and also tests the combination with other transformations such as `splitWithTail`.
Reviewed By: nickgg
Differential Revision: D23417366
Pulled By: cheng-chang
fbshipit-source-id: 06c6348285f2bafb4be3286d1642bfbe1ea499bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44235
Removes nonvariadic run_method() from mobile Module entirely (to be later replaced by a variadic version). All use cases should have been migrated to use get_method() and Method::operator() in D23436351
ghstack-source-id: 111848220
Test Plan: CI
Reviewed By: iseeyuan
Differential Revision: D23484577
fbshipit-source-id: 602fcde61e13047a34915b509da048b9550103b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44202
In preparation for changing mobile run_method() to be variadic, this diff:
* Implements get_method() for mobile Module, which is similar to find_method but expects the method to exist.
* Replaces calls to the current nonvariadic implementation of run_method() by calling get_method() and then invoking the operator() overload on Method objects.
ghstack-source-id: 111848222
Test Plan: CI, and all the unit tests which currently contain run_method that are being changed.
Reviewed By: iseeyuan
Differential Revision: D23436351
fbshipit-source-id: 4655ed7182d8b6f111645d69798465879b67a577
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43025
- Use new overloads that better reflect the arguments to interpolate.
- More uniform interface for upsample ops allows simplifying the Python code.
- Also reorder overloads in native_functions.yaml to give them priority.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37177
ghstack-source-id: 106938111
Test Plan:
test_nn has pretty good coverage.
Relying on CI for ONNX, etc.
Didn't test FC because this change is *not* forward compatible.
To ensure backwards compatibility, I ran this code before this change
```python
def test_func(arg):
interp = torch.nn.functional.interpolate
with_size = interp(arg, size=(16,16))
with_scale = interp(arg, scale_factor=[2.1, 2.2], recompute_scale_factor=False)
with_compute = interp(arg, scale_factor=[2.1, 2.2])
return (with_size, with_scale, with_compute)
traced_func = torch.jit.trace(test_func, torch.randn(1,1,1,1))
sample = torch.randn(1, 3, 7, 7)
output = traced_func(sample)
assert not torch.allclose(output[1], output[2])
torch.jit.save(traced_func, "model.pt")
torch.save((sample, output), "data.pt")
```
then this code after this change
```python
model = torch.jit.load("model.pt")
sample, golden = torch.load("data.pt")
result = model(sample)
for r, g in zip(result, golden):
assert torch.allclose(r, g)
```
Reviewed By: AshkanAliabadi
Differential Revision: D21209991
fbshipit-source-id: 5b2ebb7c3ed76947361fe532d1dbdd6faa3544c8
Summary: I think these were missed due to a code landing race condition.
Test Plan: Fixes CUDA tests with PR 43025 applied.
Reviewed By: iseeyuan, AshkanAliabadi
Differential Revision: D23639566
fbshipit-source-id: 1322d7708e246b075a66588e7e54f4e12092477f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44471
L1Loss had a completely different (and incorrect, see #43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the L1Loss CriterionTests to verify that the target derivative is checked.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23626008
Pulled By: gchanan
fbshipit-source-id: 2828be16b56b8dabe114962223d71b0e9a85f0f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44500
Some user models are using those operators. Unblock them while keep the ops selective.
Test Plan: CI
Reviewed By: linbinyu
Differential Revision: D23634769
fbshipit-source-id: 55841d1b07136b6a27b6a39342f321638dc508cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44525
Since `TEST_SKIPS` is a global multiprocessing.manager, this was causing
issues when one test would fail and make the rest of the tests fail during
setup due to networking errors.
See the failed CI job: https://app.circleci.com/pipelines/github/pytorch/pytorch/212491/workflows/0450151d-ca09-4cf6-863d-272de6ed917f/jobs/7389065 for an example, where `test_ddp_backward` failed but then caused the rest of the tests to fail at the line `test_skips.update(TEST_SKIPS)`.
To fix this issue, at the end of every test we revert `TEST_SKIPS` back to a regular dict, and redo the conversion to a `mulitiprocessing.Manager` in the next test, which prevents these errors.
ghstack-source-id: 111844724
Test Plan: CI
Reviewed By: malfet
Differential Revision: D23641618
fbshipit-source-id: 27ce823968ece9804bb4dda898ffac43ef732b89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44437
MSELoss had a completely different (and incorrect, see https://github.com/pytorch/pytorch/issues/43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the MSELoss CriterionTests to verify that the target derivative is checked.
TODO:
1) do we still need check_criterion_jacobian when we run grad/gradgrad checks?
2) ensure the Module tests check when target.requires_grad
3) do we actually test when reduction='none' and reduction='mean'?
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23612166
Pulled By: gchanan
fbshipit-source-id: 4f74d38d8a81063c74e002e07fbb7837b2172a10
Summary:
Fixes a bug in the NNC registerizer for Cuda where it would hoist reads out of a conditional context when trying to cache them. As a quick fix, prevent scalar replacement if a usage is within a condition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44223
Reviewed By: gchanan
Differential Revision: D23551247
Pulled By: nickgg
fbshipit-source-id: 17a7bf2be4c8c3dd8a9ab7997dce9aea200c3685
Summary:
Previously we were not removing profiling nodes in graphs that required grad and contained diff graphs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44420
Reviewed By: bertmaher
Differential Revision: D23607482
Pulled By: eellison
fbshipit-source-id: af095f3ed8bb3c5d09610f38cc7d1481cbbd2613
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44493
This function allows to execute a graph exactly as it is, without going
through a graph executor which would run passes on the graph before
interpreting it. I found this feature extremely helpful when I worked on
a stress-testing script to shake out bugs from the TE fuser: I needed to
execute a very specific set of passes on a graph and nothing else, and
then execute exactly it.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D23632505
Pulled By: ZolotukhinM
fbshipit-source-id: ea81fc838933743e2057312d3156b77284d832ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44411
This basically aborts errored NCCL communicators if either blocking
wait or async error handling is enabled. Otherwise we may abort nccl
communicators where neither are enabled, and this may result in subsequent GPU
operations using corrupted data.
ghstack-source-id: 111839264
Test Plan: Succesful Flow run: f217591683
Reviewed By: jiayisuse
Differential Revision: D23605382
fbshipit-source-id: 6c16f9626362be3b0ce2feaf0979b2dff97ce61b
Summary:
`stdbuf` affects not only the process it launches, but all of its subprocessed, which have a very negative effects on the IPC communication between nvcc and c++ preprocessor, which results in 2x slowdown, for example:
```
$ time /usr/local/cuda/bin/nvcc /pytorch/aten/src/THC/generated/THCTensorMathPointwiseByte.cu -c ...
real 0m34.623s
user 0m31.736s
sys 0m2.825s
```
but
```
time stdbuf -i0 -o0 -e0 /usr/local/cuda/bin/nvcc /pytorch/aten/src/THC/generated/THCTensorMathPointwiseByte.cu -c ...
real 1m14.113s
user 0m37.989s
sys 0m36.104s
```
because OS spends lots of time transferring preprocessed source back to nvcc byte by byte, as requested via stdbuf call
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44532
Reviewed By: ngimel
Differential Revision: D23643411
Pulled By: malfet
fbshipit-source-id: 9fdaf8b8a49574e6b281f68a5dd9ba9d33464dff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44410
See #44052 for context. One of the cumprod_backward overloads was unused
so I just deleted it.
Test Plan: - `pytest test/test_autograd.py -v`
Reviewed By: mrshenli
Differential Revision: D23605503
Pulled By: zou3519
fbshipit-source-id: f9c5b595e62d2d6e71f26580ba96df15cc9de4f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44427
Closes https://github.com/pytorch/pytorch/issues/44425
DDP join API currently does not work properly with `model.no_sync()`, see https://github.com/pytorch/pytorch/issues/44425 for details. This PR fixes the problem via the approach mentioned in the issue, namely scheduling an allreduce that tells joined ranks whether to sync in the backwards pass or not. Tests are added for skipping gradient synchronization for various `sync_interval`s.
ghstack-source-id: 111786479
Reviewed By: pritamdamania87
Differential Revision: D23609070
fbshipit-source-id: e8716b7881f8eee95e3e3499283e716bd3d7fe76
Summary:
Noticed this bug in `torch.movedim` (https://github.com/pytorch/pytorch/issues/41480). [`std::unique`](https://en.cppreference.com/w/cpp/algorithm/unique) only guarantees uniqueness for _sorted_ inputs. The current check lets through non-unique values when they aren't adjacent to each other in the list, e.g. `(0, 1, 0)` wouldn't raise an exception and instead the algorithm fails later with an internal assert.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44307
Reviewed By: mrshenli
Differential Revision: D23598311
Pulled By: zou3519
fbshipit-source-id: fd6cc43877c42bb243cfa85341c564b6c758a1bf
Summary:
This PR fixes three OpInfo-related bugs and moves some functions from TestTorchMathOps to be tested using the OpInfo pattern. The bugs are:
- A skip test path in test_ops.py incorrectly formatted its string argument
- Decorating the tests in common_device_type.py was incorrectly always applying decorators to the original test, not the op-specific variant of the test. This could cause the same decorator to be applied multiple times, overriding past applications.
- make_tensor was incorrectly constructing tensors in some cases
The functions moved are:
- asin
- asinh
- sinh
- acosh
- tan
- atan
- atanh
- tanh
- log
- log10
- log1p
- log2
In a follow-up PR more or all of the remaining functions in TestTorchMathOps will be refactored as OpInfo-based tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44277
Reviewed By: mrshenli, ngimel
Differential Revision: D23617361
Pulled By: mruberry
fbshipit-source-id: edb292947769967de9383f6a84eb327f027509e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44224
The purpose of this file is to help developers on PT distributed get
upto speed on the code structure and layout for PT Distributed.
ghstack-source-id: 111644842
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D23548377
fbshipit-source-id: 561d5b8e257642de172def8fdcc1311fae20690b
Summary:
To help with further typing, move dynamically added native contributions from `torch.autograd` to `torch._C._autograd`
Fix invalid error handling pattern in
89ac30afb8/torch/csrc/autograd/init.cpp (L13-L15)
`PyImport_ImportModule` already raises Python exception and nullptr should be returned to properly propagate the to Python runtime.
And all native methods/types in `torch/autograd/__init.py` after `torch._C._init_autograd()` has been called
Use f-strings instead of `.format` in test_type_hints.py
Fixes https://github.com/pytorch/pytorch/issues/44450
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44451
Reviewed By: ezyang
Differential Revision: D23618261
Pulled By: malfet
fbshipit-source-id: fa5f739d7cff8410641128b55b810318c5f636ae
Summary:
Previously the specialized types were copied over to the fallback function, although the tensors in the fallback type were not of that type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44434
Reviewed By: SplitInfinity
Differential Revision: D23611943
Pulled By: eellison
fbshipit-source-id: 2ea88a97529409f6c5c4c1f59a14b623524933de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43651
This is a forward compatibility follow-up to
https://github.com/pytorch/pytorch/pull/43086/. We switch the
conv serialization to output the v2 format instead of the v1 format.
The plan is to land this 1 - 2 weeks after the base PR.
Test Plan:
```
python test/test_quantization.py TestSerialization.test_conv2d_graph_v2
python test/test_quantization.py TestSerialization.test_conv2d_nobias_graph_v2
```
Imported from OSS
Reviewed By: z-a-f
Differential Revision: D23355480
fbshipit-source-id: 4cb04ed8b90a0e3e452297a411d641a15f6e625f
Summary:
cuda builds using clang error out when building caffe2 due to an incorrect std::move
This does not fix all known errors, but it's a step in the right direction.
Differential Revision: D23626667
fbshipit-source-id: 7d9df886129f671ec430a166dd22e4af470afe1e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44347
Cloned from Pull Request resolved: https://github.com/pytorch/pytorch/pull/44097, because the original author Sinan has completed the internship and now is unable to submit this diff.
As johnsonpaul mentioned in D23277575 (7d517cf96f). It looks like all processes were allocating memory on GPU-ID=0.
I was able to reproduce it by running `test_ddp_comm_hook_allreduce_with_then_hook_nccl` unit test of `test_c10d.py` and running `nvidia-smi` while test was running. The issue was reproduced as:
```
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 3132563 C python 777MiB |
| 0 3132564 C python 775MiB |
| 4 3132564 C python 473MiB |
+-----------------------------------------------------------------------------+
```
I realized that as we initialize ProcessGroupNCCL both processes were initially allocating memory on GPU 0.
We later also realized that I forgot `isHighPriority` input of `getStreamFromPool` and `futureNCCLCallbackStreams_.push_back(std::make_shared<at::cuda::CUDAStream>(at::cuda::getStreamFromPool(device_index)));` was just creating a vector of GPU 0 streams. As i changed `at::cuda::getStreamFromPool(device_index)` to `at::cuda::getStreamFromPool(false, device_index)`. `nvidia-smi` looked like:
```
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 673925 C python 771MiB |
| 0 673926 C python 771MiB |
| 1 673925 C python 771MiB |
| 1 673926 C python 771MiB |
| 2 673925 C python 771MiB |
| 2 673926 C python 771MiB |
| 3 673925 C python 771MiB |
| 3 673926 C python 771MiB |
| 4 673925 C python 771MiB |
| 4 673926 C python 771MiB |
| 5 673925 C python 771MiB |
| 5 673926 C python 771MiB |
| 6 673925 C python 771MiB |
| 6 673926 C python 771MiB |
| 7 673925 C python 707MiB |
| 7 673926 C python 623MiB |
+-----------------------------------------------------------------------------+
```
This confirms that we were just getting GPU 0 streams for the callback. I think this does not explain the `fp16_compress` stability issue, because we were able to reproduce that even without any then callback and just calling copy from fp32 to fp16 before allreduce. However, this can explain other issues where `allreduce` was not on par with `no_hook`. I'll run some additional simulations with this diff.
I tried to to replace `getStreamFromPool` by `getDefaultCUDAStream(deviceIndex)` and it wasn't causing additional memory usage. In this diff, I temporarily solved the issue by just initializing null pointers for each device in the constructor and setting the callback stream for corresponding devices inside `ProcessGroupNCCL::getNCCLComm`. After the fix it looks like the memory issue was resolved:
```
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 2513142 C python 745MiB |
| 4 2513144 C python 747MiB |
+-----------------------------------------------------------------------------+
```
I could use a dictionary instead of a vector for `futureNCCLCallbackStreams_`, but since number of devices is fixed, I think it isn't necessary. Please let me know what you think in the comments.
ghstack-source-id: 111485483
Test Plan:
`test_c10d.py` and some perf tests. Also check `nvidia-smi` while running tests to validate memory looks okay.
This diff also fixes the regression in HPC tests as we register a hook:
{F322730175}
See https://fb.quip.com/IGuaAbD8 (474fdd7e2d)bnvy for details.
Reviewed By: pritamdamania87
Differential Revision: D23495436
fbshipit-source-id: ad08e1d94343252224595d7c8a279fe75e244822
Summary:
This PR fixes unexpected `SystemError` when warnings are emitted and warning filters are set.
## Current behavior
```
$ python -Werror
>>> import torch
>>> torch.range(1, 3)
UserWarning: torch.range is deprecated in favor of torch.arange and will be removed in 0.5. Note that arange generates values in [start; end), not [start; end].
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
SystemError: <built-in method range of type object at 0x7f38c7703a60> returned a result with an error set
```
## Expected behavior
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UserWarning: torch.range is deprecated and will be removed in a future release because its behavior is inconsistent with Python's range builtin. Instead, use torch.arange, which produces values in [start, end).
```
## Note
Python exception must be raised if `PyErr_WarnEx` returns `-1` ([python docs](https://docs.python.org/3/c-api/exceptions.html#issuing-warnings)). This PR fixes warnings raised in the following code:
```py
import torch
torch.range(1, 3)
torch.autograd.Variable().volatile
torch.autograd.Variable().volatile = True
torch.tensor(torch.tensor([]))
torch.tensor([]).new_tensor(torch.tensor([]))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44371
Reviewed By: mrshenli
Differential Revision: D23598410
Pulled By: albanD
fbshipit-source-id: 2fbcb13fe4025dbebaf1fd837d4c8e0944e05010
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44398
These end up executing the same tests, so no reason to have them separate.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D23600855
Pulled By: gchanan
fbshipit-source-id: 0952492771498bf813f1bf8e1d7c8dce574ec965
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43958
There is not any difference between these tests (I'm merging them), so let's merge them in the JIT as well.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D23452337
Pulled By: gchanan
fbshipit-source-id: e6d13cdb164205eec3dbb7cdcd0052b02c961778
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44381
Perhaps this was necessary when the test was originally introduced, but it's difficult to figure out what is actually tested. And I don't think we actually use NotImplementedErorrs.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D23598646
Pulled By: gchanan
fbshipit-source-id: aa18154bfc4969cca22323e61683a301198823be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44406
this fix makes fakelowp identical to hw
- mask out the floating point number with 0x7fff so we are always dealing
with positive numbers
- dsp implementation is correct, ice-ref suffers from this same problem
Test Plan: - tested with test_fusions.py, can't enable the test until the fix in ice-ref appears
Reviewed By: venkatacrc
Differential Revision: D23603878
fbshipit-source-id: a72d93a4bc811f98d1b5e82ddb204be028addfeb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44440
`aten-op.cc` takes a long time to compile due to the large generated constructor. For each case, the `std::function` constructor and the initialization functions are inlined, producing a huge amount of intermediate code that takes a long time to optimize, given that many compiler optimization passes are superlinear in the function size.
This diff moves each case to a separate function, so that each one is cheap to optimize, and the constructor is just a large jump table, which is easy to optimize.
Reviewed By: dzhulgakov
Differential Revision: D23593741
fbshipit-source-id: 1ce7a31cda10d9b0c9d799716ea312a291dc0d36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44226
**Summary**
At present, the `share_types` argument to `create_script_module` is used
to decide whether to reuse a previously created type for a top-level
module that has not yet been compiled. However, that setting does not apply
to the compilation of submodules of the top-level module; types are
still reused if possible.
This commit modifies `create_script_module` so that the `share_types`
flag is honoured during submodule compilation as well.
**Test Plan**
This commit adds a unit test to `TestTypeSharing` that checks that
submodule types are not shared or reused when `share_types` is set to
`False`.
**Fixes**
This commit fixes#43605.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23602371
Pulled By: SplitInfinity
fbshipit-source-id: b909b8b6abbe3b4cb9be8319ac263ade90e83bd3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44352
**Summary**
This commit adds support for `del` with class instances. If a class
implements `__delitem__`, then `del class_instance[key]` is syntactic
sugar for `class_instance.__delitem__[key]`.
**Test Plan**
This commit adds a unit test to TestClassTypes to test this feature.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23603102
Pulled By: SplitInfinity
fbshipit-source-id: 28ad26ddc9a693a58a6c48a0e853a1c7cf5c9fd6
Summary:
Expose the interface of `nesterov` of SGD Optimizer from caffe2 to dper.
dper sgd optimizer (https://fburl.com/diffusion/chpobg0h) has referred to NAG sgdoptimizer in caffe2: https://fburl.com/diffusion/uat2lnan. So just need to add the parameter 'nesterov' in dper sgd optimizer.
Analysis of run resutls: N345540.
- train_ne increases as momentum (m) decreases.
- for m=0.95, 0.9: eval_ne is lower with NAG than production (no NAG, m = 0.95).
- for m=0.99: eval_ne with or without NAG is higher than production. It indicates larger variance in validation and overfit in training (lower train_ne).
Test Plan:
1. unit tests:
`buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test -- test_sgd_without_nesterov`
`buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test -- test_sgd_with_nesterov`
.
1. build dper front end package: `flow-cli canary ads.dper3.workflows.sparse_nn.train --mode opt --entitlement ads_global --run-as-secure-group team_ads_ml_ranking`. The build result (refreshed) is here https://www.internalfb.com/intern/buck/build/2a368b55-d94b-45c1-8617-2753fbce994b. Flow package version is ads_dper3.canary:856b545cc6b249c0bd328f845adeb0d2.
.
2. To build dper back end package: `flow-cli canary dper.workflows.dper3.train --mode opt --entitlement ads_global --run-as-secure-group team_ads_ml_ranking`. The build result (refreshed) is here: https://www.internalfb.com/intern/buck/build/70fa91cd-bf6e-4a08-8a4d-41e41a77fb52. Flow package version is aml.dper2.canary:84123a34be914dfe86b1ffd9925869de.
.
3. Compare prod with NAG-enabled runs:
a) refreshed prod run (m=0.95): f213877098
NAG enabled run (m=0.95): f213887113
.
b) prod run (m=0.9): f214065288
NAG enabled run (m=0.9): f214066319
.
c) prod run (m=0.99): f214065804
NAG enabled run (m=0.99): f214066725
.
d) change date type of nestrov to `bool` and launched a validation run
NAG enabled (m=0.95): f214500597
Reviewed By: ustctf
Differential Revision: D23152229
fbshipit-source-id: 61703ef6b4e72277f4c73171640fb8afc6d31f3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44043
To invoke `cancel` from the net instance in Python, we expose it through pybind state.
Reviewed By: dzhulgakov
Differential Revision: D23249660
fbshipit-source-id: 45a1e9062dca811746fcf2e5e42199da8f76bb54
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43384
Much like the FileStoreTests, the HashStoreTests were also run in a single blob and threw exceptions upon failure. This modularizes the test by separating each function into separate gtest test cases.
ghstack-source-id: 111690834
Test Plan: Confirmed that the tests pass on devvm.
Reviewed By: jiayisuse
Differential Revision: D23257579
fbshipit-source-id: 7e821f0e9ee74c8b815f06facddfdb7dc2724294
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43383
FileStore Test currently has a large blob of tests that throw
exceptions upon failure. This PR modularizes each test so they can run
independently, and migrates the framework to gtest.
ghstack-source-id: 111690831
Test Plan: Confirmed tests pass on devvm
Reviewed By: jiayisuse
Differential Revision: D22879473
fbshipit-source-id: 6fa5468e594a53c9a6b972757068dfc41645703e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43382
StoreTestCommon defines standard helper functions that are used by all of our Store tests. These helpers currently throw exceptions upon failure, this PR changes them to use gtest assertions instead.
ghstack-source-id: 111690833
Test Plan: Tested the 2 PR's above this on devvm
Reviewed By: jiayisuse
Differential Revision: D22828156
fbshipit-source-id: 9e116cf2904e05ac0342a441e483501e00aad3dd
Summary:
Follow up to https://github.com/pytorch/pytorch/pull/41946/, to suggest enumerating a module as an alternative if a user tries indexing into a modulelist/sequential with a non-integer literal
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43361
Reviewed By: mrshenli
Differential Revision: D23602388
Pulled By: eellison
fbshipit-source-id: 51fa28d5bc45720529b3d45e92d367ee6c9e3316
Summary: Exporting the Bucketize operator on CUDA. Also adding unit test.
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/sparsenn:gpu_test -- test_bucketize
Differential Revision: D23581321
fbshipit-source-id: 7f21862984c04d840410b8718db93006f526938a
Summary:
Do not add gencode flags to NVCC_FLAGS twice: First time they are added in `cmake/public/cuda.cmake` no need to do it again in `cmake/Dependencies.cmake`
Copy `additional_unittest_args` before appending local options to it in `run_test()` method
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44414
Reviewed By: seemethere
Differential Revision: D23605733
Pulled By: malfet
fbshipit-source-id: 782a0da61650356a978a892fb03c66cb1a1ea26b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44382
This is to fix a typo that introduced in #44032.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D23601316
Pulled By: glaringlee
fbshipit-source-id: 17d6de5900443ea46c7a6ee9c7614fe6f2d92890
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44400
This diff does the identical thing as D23549149 (398409f072) does. A fix included for OSS CI: pytorch_windows_vs2019_py36_cuda10.1_test1
ghstack-source-id: 111679745
Test Plan:
- CI
- OSS CI
Reviewed By: xcheng16
Differential Revision: D23601050
fbshipit-source-id: 8ebdcd8fdc5865078889b54b0baeb397a90ddc40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44163
In this PR, we introduce a new environment variable
(NCCL_ASYNC_ERROR_HANDLING), which guards the asynchronous error handling
feature. We intend to eventually turn this feature on by default for all users,
but this is a temporary solution so the change in behavior from hanging to
crashing is not the default for users all of a sudden.
ghstack-source-id: 111637788
Test Plan:
CI/Sandcastle. We will turn on this env var by default in
torchelastic and HPC trainer soon.
Reviewed By: jiayisuse
Differential Revision: D23517895
fbshipit-source-id: e7cd244b2ddf2dc0800ff7df33c73a6f00b63dcc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41054
**This Commit:**
ProcessGroupNCCL destructor now blocks until all WorkNCCL objects have either been aborted or completed and removed from the work vector.
**This Stack:**
The purpose of this stack is to fix the hanging behavior observed in when using PyTorch DDP training with NCCL. In various situations (desynchronization, high GPU utilization, etc.), NCCL collectives may hang due to waiting on an unresponsive worker. This stack detects such hanging behavior and aborts timed-out collectives by throwing a user-visible exception, all with minimal perf regression. Training can then be restarted from a previous checkpoint with something like torchelastic.
ghstack-source-id: 111614314
Test Plan:
1. **DDP Sanity Check**: First we have a sanity check based on the PyTorch DDP benchmark. This verifies that the baseline DDP training with NCCL for standard CU workloads works well (esp. with standard models like Resnet50 and BERT). Here is a sample Flow: f213293473
1. **HPC Performance Benchmarks**: This stack has undergone thorough testing and profiling on the Training Cluster with varying number of nodes. This introduces 1-1.5% QPS regression only (~200-400 QPS regression for 8-64 GPUs).
1. **HPC Accuracy Benchmarks**: We've confirmed NE parity with the existing NCCL/DDP stack without this change.
1. **Kernel-Specific Benchmarks**: We have profiled other approaches for this system (such as cudaStreamAddCallback) and performed microbenchmarks to confirm the current solution is optimal.
1. **Sandcastle/CI**: Apart from the recently fixed ProcessGroupNCCL tests, we will also introduce a new test for desynchronization scenarios.
Reviewed By: jiayisuse
Differential Revision: D22054298
fbshipit-source-id: 2b95a4430a4c9e9348611fd9cbcb476096183c06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41053
**This Commit:**
Some minor refactoring - added helper to check if `WorkNCCL` objects have timed out. Adding a new finish function to ProcessGroupNCCL::WorkNCCL that avoids notifying CV and uses `lock_guard`. Also renaming the timeoutCVMutex mutex to be more descriptive.
**This Stack:**
The purpose of this stack is to fix the hanging behavior observed in when using PyTorch DDP training with NCCL. In various situations (desynchronization, high GPU utilization, etc.), NCCL collectives may hang due to waiting on an unresponsive worker. This stack detects such hanging behavior and aborts timed-out collectives by throwing a user-visible exception, all with minimal perf regression. Training can then be restarted from a previous checkpoint with something like torchelastic.
ghstack-source-id: 111614315
Test Plan: See D22054298 for verification of correctness and performance
Reviewed By: jiayisuse
Differential Revision: D21943520
fbshipit-source-id: b27ee329f0da6465857204ee9d87953ed6072cbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41052
**This Commit:**
Watchdog Thread checks for error-ed or timed out `WorkNCCL` objects and aborts all associated NCCL Communicators. For now, we also process these aborted communicators as with the existing Watchdog logic (by adding them to abortedCommIds and writing aborted communicator ids to the store.)
**This Stack:**
The purpose of this stack is to fix the hanging behavior observed in when using PyTorch DDP training with NCCL. In various situations (desynchronization, high GPU utilization, etc.), NCCL collectives may hang due to waiting on an unresponsive worker. This stack detects such hanging behavior and aborts timed-out collectives by throwing a user-visible exception, all with minimal perf regression. Training can then be restarted from a previous checkpoint with something like torchelastic.
ghstack-source-id: 111614313
Test Plan: See D22054298 for verification of correctness and performance
Reviewed By: jiayisuse
Differential Revision: D21943151
fbshipit-source-id: 337bfcb8af7542c451f1e4b3dcdfc5870bdec453
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41051
**This Commit:**
In the workCleanupThread, we process completion and exception handling for workNCCL objects corresponding to collective calls that have either completed GPU Execution, or have already thrown an exception. This way, we throw an exception from the workCleanupThread for failed GPU operations. This approach replaces the previous (and lower performance) approach of enqueuing a callback on the CUDA stream to process failures.
**This Stack:**
The purpose of this stack is to fix the hanging behavior observed in when using PyTorch DDP training with NCCL. In various situations (desynchronization, high GPU utilization, etc.), NCCL collectives may hang due to waiting on an unresponsive worker. This stack detects such hanging behavior and aborts timed-out collectives by throwing a user-visible exception, all with minimal perf regression. Training can then be restarted from a previous checkpoint with something like torchelastic.
ghstack-source-id: 111614319
Test Plan: See D22054298 for verification of correctness and performance
Reviewed By: jiayisuse
Differential Revision: D21938498
fbshipit-source-id: df598365031ff210afba57e0c7be865e3323ca07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41050
**This Commit:**
We introduce a workVector to track live workNCCL objects corresponding to collective operations. Further, we introduce a workCleanupLoop, which busy-polls the vector of workNCCL objects and removes them upon completion.
**This Stack:**
The purpose of this stack is to fix the hanging behavior observed in when using PyTorch DDP training with NCCL. In various situations (desynchronization, high GPU utilization, etc.), NCCL collectives may hang due to waiting on an unresponsive worker. This stack detects such hanging behavior and aborts timed-out collectives by throwing a user-visible exception, all with minimal perf regression. Training can then be restarted from a previous checkpoint with something like torchelastic.
Test Plan: See D22054298 for verification of correctness and performance
Reviewed By: jiayisuse
Differential Revision: D21916637
fbshipit-source-id: f8cadaab0071aaad1c4e31f9b089aa23cba0cfbe
Summary:
Helpful for later analysis on the build time trends
Also, same .whl files out of regular linux build job
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44390
Reviewed By: walterddr
Differential Revision: D23602049
Pulled By: malfet
fbshipit-source-id: 4d55c9aa2d161a7998ad991a3da0436da83f70ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44331
[10:22 AM] Cherckez, Tal
summary of issues(just to have a clear list):
* std::clamp forces the user to use c++17
* using setting without given fails the test
* avoid using max_examples for tests
(Note: this ignores all push blocking failures!)
Test Plan: https://www.internalfb.com/intern/testinfra/testconsole/testrun/6192449509073222/
Reviewed By: hyuen
Differential Revision: D23581440
fbshipit-source-id: fe9fbc341f8fca02352f531cc622fc1035d0300c
Summary:
This should prevent torch_python from linking the entire cudnn library statically just to query its version
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44402
Reviewed By: seemethere
Differential Revision: D23602720
Pulled By: malfet
fbshipit-source-id: 185b15b789bd48b1df178120801d140ea54ba569
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42488
Currently, ProcessGroupGloo tests do not emit logs if the test was
skipped due CUDA not being available/not enough CUDA devices. This PR clarifies
the reason for skipping through these logs.
ghstack-source-id: 111638111
Test Plan: tested on devvm and devgpu
Reviewed By: jiayisuse
Differential Revision: D22879396
fbshipit-source-id: d483ca46b5e22ed986521262c11a1c6dbfbe7efd
Summary:
This PR fixes three OpInfo-related bugs and moves some functions from TestTorchMathOps to be tested using the OpInfo pattern. The bugs are:
- A skip test path in test_ops.py incorrectly formatted its string argument
- Decorating the tests in common_device_type.py was incorrectly always applying decorators to the original test, not the op-specific variant of the test. This could cause the same decorator to be applied multiple times, overriding past applications.
- make_tensor was incorrectly constructing tensors in some cases
The functions moved are:
- asin
- asinh
- sinh
- acosh
- tan
- atan
- atanh
- tanh
- log
- log10
- log1p
- log2
In a follow-up PR more or all of the remaining functions in TestTorchMathOps will be refactored as OpInfo-based tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44277
Reviewed By: ngimel
Differential Revision: D23568330
Pulled By: mruberry
fbshipit-source-id: 03e69fccdbfd560217c34ce4e9a5f20e10d05a5e
Summary:
This can be taken from the system in which case it is not used from the submodule. Hence the check here limits the usage unnecessarily
ccing malfet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44278
Reviewed By: malfet
Differential Revision: D23568552
Pulled By: ezyang
fbshipit-source-id: 7fd2613251567f649b12eca0b1fe7663db9cb58d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44315
I find it more intuitive to dump the optimized graph if we have one;
when I first saw the unoptimized graph being dumped I thought we had failed to
apply any optimizations.
Test Plan: Observe output by hand
Reviewed By: Lilyjjo
Differential Revision: D23578813
Pulled By: bertmaher
fbshipit-source-id: e2161189fb0e1cd53aae980a153aea610871662a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44162
This diff exports Node::isBefore/isAfter method to PythonAPI.
Test Plan: Tested locally. Please let me know if there is a set of unit tests to be passed.
Reviewed By: soumith
Differential Revision: D23514448
fbshipit-source-id: 7ef709b036370217ffebef52fd93fbd68c464e89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42932
Follow up from https://github.com/pytorch/pytorch/pull/41769, rename `test_distributed` to `test_distributed_fork` to make it explicit that it forks.
New command to run test:
`python test/run_test.py -i distributed/test_distributed_fork -v`
ghstack-source-id: 111632568
Test Plan: `python test/run_test.py -i distributed/test_distributed_fork -v`
Reviewed By: izdeby
Differential Revision: D23072201
fbshipit-source-id: 48581688b6c5193a309e803c3de38e70be980872
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41769
Currently the tests in `test_distributed` only work with the `fork` mode multiprocessing, this PR introduces support for `spawn` mode multiprocessing as well (while keeping the `fork` mode intact).
Motivations for the change:
1) Spawn multiprocessing is the default on MacOS, so it better emulates how MacOS users would use distributed
2) With python 3.8+, spawn is the default on linux, so we should have test coverage for this
3) PT multiprocessing suggests using spawn/forkserver over fork, for sharing cuda tensors: https://pytorch.org/docs/stable/multiprocessing.html
4) Spawn is better supported with respect to certain sanitizers such as TSAN, so adding this sanitizer coverage may help us uncover issues.
How it is done:
1) Move `test_distributed` tests in `_DistTestBase` class to a shared file `distributed_test` (similar to how the RPC tests are structured)
2) For `Barrier`, refactor the setup of temp directories, as the current version did not work with spawn, each process would get a different randomly generated directory and thus would write to different barriers.
3) Add all the relevant builds to run internally and in OSS.
Running test_distributed with spawn mode in OSS can be done with:
`python test/run_test.py -i distributed/test_distributed_spawn -v`
Reviewed By: izdeby
Differential Revision: D22408023
fbshipit-source-id: e206be16961fd80438f995e221f18139d7e6d2a9
Summary:
1) Ports nonzero from THC to ATen
2) replaces most thrust uses with cub, to avoid synchronization and to improve performance. There is still one necessary synchronization point, communicating number of nonzero elements from GPU to CPU
3) slightly changes algorithm, now we first compute the number of nonzeros, and then allocate correct-sized output, instead of allocating full-sized output as was done before, to account for possibly all elements being non-zero
4) unfortunately, since the last transforms are still done with thrust, 2) is slightly beside the point, however it is a step towards a future without thrust
4) hard limits the number of elements in the input tensor to MAX_INT. Previous implementation allocated a Long tensor with the size ndim*nelements, so that would be at least 16 GB for a tensor with MAX_INT elements. It is reasonable to say that larger tensors could not be used anyway.
Benchmarking is done for tensors with approximately half non-zeros
<details><summary>Benchmarking script</summary>
<p>
```
import torch
from torch.utils._benchmark import Timer
from torch.utils._benchmark import Compare
import sys
device = "cuda"
results = []
for numel in (1024 * 128,):#, 1024 * 1024, 1024 * 1024 * 128):
inp = torch.randint(2, (numel,), device="cuda", dtype=torch.float)
for ndim in range(2,3):#(1,4):
if ndim == 1:
shape = (numel,)
elif ndim == 2:
shape = (1024, numel // 1024)
else:
shape = (1024, 128, numel // 1024 // 128)
inp = inp.reshape(shape)
repeats = 3
timer = Timer(stmt="torch.nonzero(inp, as_tuple=False)", label="Nonzero", sub_label=f"number of elts {numel}",
description = f"ndim {ndim}", globals=globals())
for i in range(repeats):
results.append(timer.blocked_autorange())
print(f"\rnumel {numel} ndim {ndim}", end="")
sys.stdout.flush()
comparison = Compare(results)
comparison.print()
```
</p>
</details>
### Results
Before:
```
[--------------------------- Nonzero ---------------------------]
| ndim 1 | ndim 2 | ndim 3
1 threads: ------------------------------------------------------
number of elts 131072 | 55.2 | 71.7 | 90.5
number of elts 1048576 | 113.2 | 250.7 | 497.0
number of elts 134217728 | 8353.7 | 23809.2 | 54602.3
Times are in microseconds (us).
```
After:
```
[-------------------------- Nonzero --------------------------]
| ndim 1 | ndim 2 | ndim 3
1 threads: ----------------------------------------------------
number of elts 131072 | 48.6 | 79.1 | 90.2
number of elts 1048576 | 64.7 | 134.2 | 161.1
number of elts 134217728 | 3748.8 | 7881.3 | 9953.7
Times are in microseconds (us).
```
There's a real regression for smallish 2D tensor due to added work of computing number of nonzero elements, however, for other sizes there are significant gains, and there are drastically lower memory requirements. Perf gains would be even larger for tensors with fewer nonzeros.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44259
Reviewed By: izdeby
Differential Revision: D23581955
Pulled By: ngimel
fbshipit-source-id: 0b99a767fd60d674003d83f0848dc550d7a363dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44217
Move the tests to static ones as well
Test Plan:
python test/test_quantization.py TestStaticQuantizedModule.test_embedding_bag_api
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D23547386
fbshipit-source-id: 41f81c31e1613098ecf6a7eff601c7dcd4b09c76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44208
Add quantized module in static quantization namespace. Embedding
quantization requires only weights to be quantized so it is static.
Internally it calls the embedding_bag_byte op with the offsets set corresponding to the
indices.
Future PR will move EmbeddingBag quantization from dynamic to static as well.
Test Plan:
python test/test_quantization.py test_embedding_api
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23547384
fbshipit-source-id: eddc6fb144b4a771060e7bab5853656ccb4443f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42735
We use reduced precision only for embedding table (not for momentum) in RowWiseSparseAdagrad
Test Plan: .
Reviewed By: jianyuh
Differential Revision: D23003939
fbshipit-source-id: 062290d94b160100bc4c2f48b797833819f8e88a
Summary:
Fixes a bug where FP16 values could be incorrectly cast to a half type that doesn't have a cast operator by inserting the cuda specific cast to float during handling of the Cast node, not as a wrapper around printing Loads and Stores. Two main changes: the HalfChecker now inserts the casts to float explicitly in the IR, and the PrioritizeLoad mutator now consumes both Loads and a Cast which immediately preceded a load.
Tested with test_jit_fuser_te.py and test_tensorexpr.py, plus C++ tests obv.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44209
Reviewed By: izdeby
Differential Revision: D23575577
Pulled By: nickgg
fbshipit-source-id: 808605aeb2af812758f96f9fdc11b07e08053b46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44042
Missed one case last time
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23479345
fbshipit-source-id: 30e6713120c494e9fab5584de4df9b25bec83d32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43890
1. auto-detect `CXX` default compiler type in oss, and `clang` as default compiler type in fbcode (because auto-detecting will say `gcc` is the default compiler on devserver).
2. change `compiler type` from str `"CLANG" "GCC"` to enum type
3. rename function `get_cov_type` to `detect_compiler_type`
4. auto-set the default pytorch folder for users in oss
Test Plan:
on devserver:
```
buck run :coverage //caffe2/c10:
```
on oss:
```
python oss_coverage.py --run-only=atest
```
Reviewed By: malfet
Differential Revision: D23420034
fbshipit-source-id: c0ea88188578bb1343a286f2090eb8a74cdf3982
Summary:
When the backward ops execute via the autograd engine evaluate_function(), the fn.release_variables() is called to release the SavedVariables. For the eager mode ops, this releases the saved inputs that was required for backward grad function. However, with TorchScript, we get a DifferentableGraph and the DifferentiableGraphBackward() doesn't implement a release_variables(). This leads to the SavedVariables to be alive longer. Implement release_variables() for DifferentiableGraphBackward to release these SavedVariables early.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42994
Reviewed By: izdeby
Differential Revision: D23503172
Pulled By: albanD
fbshipit-source-id: d87127498cfa72883ae6bb31d0e6c7056c4c36d4
Summary:
This test is failing consistently on linux-bionic-rocm3.7-py3.6-test2. Relevant log snippet:
```
03:43:11 FAIL: test_addcmul_cuda_float16 (__main__.TestForeachCUDA)
03:43:11 ----------------------------------------------------------------------
03:43:11 Traceback (most recent call last):
03:43:11 File "/var/lib/jenkins/.local/lib/python3.6/site-packages/torch/testing/_internal/common_utils.py", line 818, in wrapper
03:43:11 method(*args, **kwargs)
03:43:11 File "/var/lib/jenkins/.local/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 258, in instantiated_test
03:43:11 result = test(self, *args)
03:43:11 File "test_foreach.py", line 83, in test_addcmul
03:43:11 self._test_pointwise_op(device, dtype, torch._foreach_addcmul, torch._foreach_addcmul_, torch.addcmul)
03:43:11 File "test_foreach.py", line 58, in _test_pointwise_op
03:43:11 self.assertEqual(tensors, expected)
03:43:11 File "/var/lib/jenkins/.local/lib/python3.6/site-packages/torch/testing/_internal/common_utils.py", line 1153, in assertEqual
03:43:11 exact_dtype=exact_dtype, exact_device=exact_device)
03:43:11 File "/var/lib/jenkins/.local/lib/python3.6/site-packages/torch/testing/_internal/common_utils.py", line 1127, in assertEqual
03:43:11 self.assertTrue(result, msg=msg)
03:43:11 AssertionError: False is not true : Tensors failed to compare as equal! With rtol=0.001 and atol=1e-05, found 10 element(s) (out of 400) whose difference(s) exceeded the margin of error (including 0 nan comparisons). The greatest difference was 0.00048828125 (-0.46484375 vs. -0.46533203125), which occurred at index (11, 18).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44304
Reviewed By: malfet, izdeby
Differential Revision: D23578316
Pulled By: mruberry
fbshipit-source-id: 558eecf42677383e7deaa4961e12ef990ffbe28c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44149
Thanks Christian Puhrsch for reporting.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: izdeby
Differential Revision: D23574739
Pulled By: ezyang
fbshipit-source-id: 8c9d0d78e6970139e0103cd1e0004b743e3c7f9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44233
**Summary**
By default, scripting tries to share concrete and JIT types across
compilations. However, this can lead to incorrect results if a module
extends `torch.jit.ScriptModule`, and injects instance variables into
methods defined using `define`.
This commit detects when this has happened and disables type sharing
for the compilation of the module that uses `define` in `__init__`.
**Test Plan**
This commit adds a test to TestTypeSharing that tests this scenario.
**Fixes**
This commit fixes#43580.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23553870
Pulled By: SplitInfinity
fbshipit-source-id: d756e87fcf239befa0012998ce29eeb25728d3e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44312
This test is failing now when running on card. Let's disable it while Intel is investigating the issue.
Test Plan: Sandcastle
Reviewed By: hyuen
Differential Revision: D23577475
fbshipit-source-id: 84f957c69ed75e0e0f563858b8b8ad7a2158da4e
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: d5ace7ca70
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44177
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: dskhudia
Differential Revision: D23533561
fbshipit-source-id: 9e580f8dbfb83e57bebc28f8e459caa0c5fc7317
Summary: Exports the operator to PyTorch, to be made into a low-level module.
Test Plan:
```
buck test //caffe2/caffe2/python/operator_test:torch_integration_test -- test_learning_rate
```
Reviewed By: yf225
Differential Revision: D23545582
fbshipit-source-id: 6b6d9aa6a47b2802ccef0f87c1263c6cc2d2fdf6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42537
[First PR: Add private API to support tensor lists: _foreach_add(TensorList tensors, Scalar scalar)](https://github.com/pytorch/pytorch/pull/41554).
**Motivation**
[GitHub issue](https://github.com/pytorch/pytorch/issues/38655)
Current PyTorch optimizer implementations are not efficient in cases when we work with a lot of small feature tensors. Starting a lot of kernels slows down the whole process. We need to reduce the number of kernels that we start.
As an example, we should be looking at [NVIDIAs Apex](https://github.com/NVIDIA/apex).
In order to track progress, we will pick PyTorchs DCGAN model with Adam optimizer and once the optimizer is reimplemented with tensor lists, benchmark the model performance against original model version, Apexs version with original Adam optimizer and it’s FusedAdam optimizer.
**Current API restrictions**
- List can't be empty (will fixed in upcoming PRs).
- All tensors in the list must have the same dtype, device and size.
**Broadcasting**
At this point we don't support broadcasting.
**What is 'Fast' and 'Slow' route**
In particular cases, we cant process an op with a fast list CUDA kernel. Still, we can do with a regular for-loop where the op will be applied to each tensor individually through the dispatch mechanisms. There are a few checks that decide whether the op will be performed via a 'fast' or 'slow' path.
To go the fast route,
- All tensors must have strided layout
- All tensors must be dense and not have overlapping memory
- The resulting tensor type must be the same.
----------------
**In this PR**
Adding APIs:
```
torch._foreach_exp(TensorList tl1)
torch._foreach_exp_(TensorList tl1)
torch._foreach_sqrt(TensorList tl1)
torch._foreach_sqrt_(TensorList tl1)
```
**Tests**
Tested via unit tests
**TODO**
1. Properly handle empty lists
2. Properly handle bool tensors
**Plan for the next PRs**
1. APIs
- Pointwise Ops
2. Complete tasks from TODO
3. Rewrite PyTorch optimizers to use for-each operators for performance gains.
Test Plan: Imported from OSS
Reviewed By: cpuhrsch
Differential Revision: D23331889
Pulled By: izdeby
fbshipit-source-id: 8b04673b8412957472ed56361954ca3884eb9376
Summary:
Check return code of `nvcc --version` and if it's not zero, print warning and mark CUDA as not found.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44236
Test Plan: Run `CUDA_NVCC_EXECUTABLE=/foo/bar cmake ../`
Reviewed By: ezyang
Differential Revision: D23552336
Pulled By: malfet
fbshipit-source-id: cf9387140a8cdbc8dab12fcc4bfaf55ae8e6a502
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44270
The previous PR (#44212) was reverted since I didn't update the
`upload_scribe.py` script and it was looking for 'executor_and_fuser'
field in the json which now is replaced with two separate fields:
'executor' and 'fuser'.
Differential Revision: D23561500
Test Plan: Imported from OSS
Reviewed By: ngimel
Pulled By: ZolotukhinM
fbshipit-source-id: 7fe86d34afa488a0e43d5ea2aaa7bc382337f470
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42536
[First PR: Add private API to support tensor lists: _foreach_add(TensorList tensors, Scalar scalar)](https://github.com/pytorch/pytorch/pull/41554).
**Motivation**
[GitHub issue](https://github.com/pytorch/pytorch/issues/38655)
Current PyTorch optimizer implementations are not efficient in cases when we work with a lot of small feature tensors. Starting a lot of kernels slows down the whole process. We need to reduce the number of kernels that we start.
As an example, we should be looking at [NVIDIAs Apex](https://github.com/NVIDIA/apex).
In order to track progress, we will pick PyTorchs DCGAN model with Adam optimizer and once the optimizer is reimplemented with tensor lists, benchmark the model performance against original model version, Apexs version with original Adam optimizer and it’s FusedAdam optimizer.
**Current API restrictions**
- List can't be empty (will fixed in upcoming PRs).
- All tensors in the list must have the same dtype, device and size.
**Broadcasting**
At this point we don't support broadcasting.
**What is 'Fast' and 'Slow' route**
In particular cases, we cant process an op with a fast list CUDA kernel. Still, we can do with a regular for-loop where the op will be applied to each tensor individually through the dispatch mechanisms. There are a few checks that decide whether the op will be performed via a 'fast' or 'slow' path.
To go the fast route,
- All tensors must have strided layout
- All tensors must be dense and not have overlapping memory
- The resulting tensor type must be the same.
----------------
**In this PR**
Adding APIs:
```
torch._foreach_sub(TensorList tl1, TensorList tl2)
torch._foreach_sub_(TensorList self, TensorList tl2)
torch._foreach_mul(TensorList tl1, TensorList tl2)
torch._foreach_mul_(TensorList self, TensorList tl2)
torch._foreach_div(TensorList tl1, TensorList tl2)
torch._foreach_div_(TensorList self, TensorList tl2)
torch._foreach_sub(TensorList tl1, Scalar scalar)
torch._foreach_sub_(TensorList self, Scalar scalar)
torch._foreach_mul(TensorList tl1, Scalar scalar)
torch._foreach_mul_(TensorList self, Scalar scalar)
torch._foreach_div(TensorList tl1, Scalar scalar)
torch._foreach_div(TensorList self, Scalar scalar)
```
**Tests**
Tested via unit tests
**TODO**
1. Properly handle empty lists
2. Properly handle bool tensors
**Plan for the next PRs**
1. APIs
- Unary Ops for list
- Pointwise Ops
2. Complete tasks from TODO
3. Rewrite PyTorch optimizers to use for-each operators for performance gains.
Test Plan: Imported from OSS
Reviewed By: cpuhrsch
Differential Revision: D23331891
Pulled By: izdeby
fbshipit-source-id: 18c5937287e33e825b2e391e41864dd64e226f19
Summary:
Adding a calibration module called histogram binning:
Divide the prediction range (e.g., [0, 1]) into B bins. In each bin, use two parameters to store the number of positive examples and the number of examples that fall into this bucket. So we basically have a histogram for the model prediction.
As a result, for each bin, we have a statistical value for the real CTR (num_pos / num_example). We use this statistical value as the final calibrated prediction if the pre-cali prediction falls into the corresponding bin.
In this way, the predictions within each bin should be well-calibrated if we have sufficient examples. That is, we have a fine-grained calibrated model by this calibration module.
Theoretically, this calibration layer can fix any uncalibrated model or prediction if we have sufficient bins and examples. It provides the potential to use any kind of training weight allocation to our training data, without worrying about the calibration issue.
Test Plan:
buck test dper3/dper3/modules/calibration/tests:calibration_test -- test_histogram_binning_calibration
buck test dper3/dper3_models/ads_ranking/tests:model_paradigm_e2e_tests -- test_sparse_nn_histogram_binning_calibration
All tests passed.
Example workflows:
f215431958
{F326445092}
f215445048
{F326445223}
Reviewed By: chenshouyuan
Differential Revision: D23356450
fbshipit-source-id: c691b66c51ef33908c17575ce12e5bee5fb325ff
Summary:
When var and std are called without args (other than unbiased) they currently call into TH or THC. This PR:
- Removes the THC var_all and std_all functions and updates CUDA var and std to use the ATen reduction
- Fixes var's docs, which listed its arguments in the incorrect order
- Adds new tests comparing var and std with their NumPy counterparts
Performance appears to have improved as a result of this change. I ran experiments on 1D tensors, 1D tensors with every other element viewed ([::2]), 2D tensors and 2D transposed tensors. Some notable datapoints:
- torch.randn((8000, 8000))
- var measured 0.0022215843200683594s on CUDA before the change
- var measured 0.0020322799682617188s on CUDA after the change
- torch.randn((8000, 8000)).T
- var measured .015128850936889648 on CUDA before the change
- var measured 0.001912832260131836 on CUDA after the change
- torch.randn(8000 ** 2)
- std measured 0.11031460762023926 on CUDA before the change
- std measured 0.0017833709716796875 on CUDA after the change
Timings for var and std are, as expected, similar.
On the CPU, however, the performance change from making the analogous update was more complicated, and ngimel and I decided not to remove CPU var_all and std_all. ngimel wrote the following script that showcases how single-threaded CPU inference would suffer from this change:
```
import torch
import numpy as np
from torch.utils._benchmark import Timer
from torch.utils._benchmark import Compare
import sys
base = 8
multiplier = 1
def stdfn(a):
meanv = a.mean()
ac = a-meanv
return torch.sqrt(((ac*ac).sum())/a.numel())
results = []
num_threads=1
for _ in range(7):
size = base*multiplier
input = torch.randn(size)
tasks = [("torch.var(input)", "torch_var"),
("torch.var(input, dim=0)", "torch_var0"),
("stdfn(input)", "stdfn"),
("torch.sum(input, dim=0)", "torch_sum0")
]
timers = [Timer(stmt=stmt, num_threads=num_threads, label="Index", sub_label=f"{size}",
description=label, globals=globals()) for stmt, label in tasks]
repeats = 3
for i, timer in enumerate(timers * repeats):
results.append(
timer.blocked_autorange()
)
print(f"\r{i + 1} / {len(timers) * repeats}", end="")
sys.stdout.flush()
multiplier *=10
print()
comparison = Compare(results)
comparison.print()
```
The TH timings using this script on my devfair are:
```
[------------------------------ Index ------------------------------]
| torch_var | torch_var0 | stdfn | torch_sum0
1 threads: ----------------------------------------------------------
8 | 16.0 | 5.6 | 40.9 | 5.0
80 | 15.9 | 6.1 | 41.6 | 4.9
800 | 16.7 | 12.0 | 42.3 | 5.0
8000 | 27.2 | 72.7 | 51.5 | 6.2
80000 | 129.0 | 715.0 | 133.0 | 18.0
800000 | 1099.8 | 6961.2 | 842.0 | 112.6
8000000 | 11879.8 | 68948.5 | 20138.4 | 1750.3
```
and the ATen timings are:
```
[------------------------------ Index ------------------------------]
| torch_var | torch_var0 | stdfn | torch_sum0
1 threads: ----------------------------------------------------------
8 | 4.3 | 5.4 | 41.4 | 5.4
80 | 4.9 | 5.7 | 42.6 | 5.4
800 | 10.7 | 11.7 | 43.3 | 5.5
8000 | 69.3 | 72.2 | 52.8 | 6.6
80000 | 679.1 | 676.3 | 129.5 | 18.1
800000 | 6770.8 | 6728.8 | 819.8 | 109.7
8000000 | 65928.2 | 65538.7 | 19408.7 | 1699.4
```
which demonstrates that performance is analogous to calling the existing var and std with `dim=0` on a 1D tensor. This would be a significant performance hit. Another simple script shows the performance is mixed when using multiple threads, too:
```
import torch
import time
# Benchmarking var and std, 1D with varying sizes
base = 8
multiplier = 1
op = torch.var
reps = 1000
for _ in range(7):
size = base * multiplier
t = torch.randn(size)
elapsed = 0
for _ in range(reps):
start = time.time()
op(t)
end = time.time()
elapsed += end - start
multiplier *= 10
print("Size: ", size)
print("Avg. elapsed time: ", elapsed / reps)
```
```
var cpu TH vs ATen timings
Size: 8
Avg. elapsed time: 1.7853736877441406e-05 vs 4.9788951873779295e-06 (ATen wins)
Size: 80
Avg. elapsed time: 1.7803430557250977e-05 vs 6.156444549560547e-06 (ATen wins)
Size: 800
Avg. elapsed time: 1.8569469451904296e-05 vs 1.2302875518798827e-05 (ATen wins)
Size: 8000
Avg. elapsed time: 2.8756141662597655e-05 vs. 6.97789192199707e-05 (TH wins)
Size: 80000
Avg. elapsed time: 0.00026622867584228516 vs. 0.0002447957992553711 (ATen wins)
Size: 800000
Avg. elapsed time: 0.0010556647777557374 vs 0.00030616092681884767 (ATen wins)
Size: 8000000
Avg. elapsed time: 0.009990205764770508 vs 0.002938544034957886 (ATen wins)
std cpu TH vs ATen timings
Size: 8
Avg. elapsed time: 1.6681909561157225e-05 vs. 4.659652709960938e-06 (ATen wins)
Size: 80
Avg. elapsed time: 1.699185371398926e-05 vs. 5.431413650512695e-06 (ATen wins)
Size: 800
Avg. elapsed time: 1.768803596496582e-05 vs. 1.1279821395874023e-05 (ATen wins)
Size: 8000
Avg. elapsed time: 2.7791500091552735e-05 vs 7.031106948852539e-05 (TH wins)
Size: 80000
Avg. elapsed time: 0.00018650460243225096 vs 0.00024368906021118164 (TH wins)
Size: 800000
Avg. elapsed time: 0.0010522041320800782 vs 0.0003039860725402832 (ATen wins)
Size: 8000000
Avg. elapsed time: 0.009976618766784668 vs. 0.0029211788177490234 (ATen wins)
```
These results show the TH solution still performs better than the ATen solution with default threading for some sizes.
It seems like removing CPU var_all and std_all will require an improvement in ATen reductions. https://github.com/pytorch/pytorch/issues/40570 has been updated with this information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43858
Reviewed By: zou3519
Differential Revision: D23498981
Pulled By: mruberry
fbshipit-source-id: 34bee046c4872d11c3f2ffa1b5beee8968b22050
Summary:
This PR adds the following aliaes:
- not_equal for torch.ne
- greater for torch.gt
- greater_equal for torch.ge
- less for torch.lt
- less_equal for torch.le
This aliases are consistent with NumPy's naming for these functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43870
Reviewed By: zou3519
Differential Revision: D23498975
Pulled By: mruberry
fbshipit-source-id: 78560df98c9f7747e804a420c1e53fd1dd225002
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44132
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43985
Added
```
def(detail::SelectiveStr<true>, ...)
impl(detail::SelectiveStr<true>, ...)
```
in torch/library, which can also be used for other templated selective registration.
Size saves for this diff:
fbios-pika: 78 KB
igios: 87 KB
Test Plan: Imported from OSS
Reviewed By: ljk53, smessmer
Differential Revision: D23459774
Pulled By: iseeyuan
fbshipit-source-id: 86d34cfe8e3f852602f203db06f23fa99af2c018
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44048
Inline the fork-wait calls to make sure we can see the ops to be quantized in the main graph
Also fix the InlineForkWait JIT pass to account for the case where the aten::wait call isn't present in the main graph
and we return future tensor from subgraph
Example
```
graph(%self.1 : __torch__.dper3.core.interop.___torch_mangle_6325.DperModuleWrapper,
%argument_1.1 : Tensor,
%argument_2.1 : Tensor):
%3 : Future[Tensor[]] = prim::fork_0(%self.1, %argument_1.1, %argument_2.1) # :0:0
return (%3)
with prim::fork_0 = graph(%self.1 : __torch__.dper3.core.interop.___torch_mangle_5396.DperModuleWrapper,
%argument_1.1 : Tensor,
%argument_2.1 : Tensor):
%3 : __torch__.dper3.core.interop.___torch_mangle_6330.DperModuleWrapper = prim::GetAttr[name="x"](%self.1)
%4 : __torch__.dper3.core.interop.___torch_mangle_5397.DperModuleWrapper = prim::GetAttr[name="y"](%self.1)
%5 : __torch__.dper3.core.interop.___torch_mangle_6327.DperModuleWrapper = prim::GetAttr[name="z"](%4)
%6 : Tensor = prim::CallMethod[name="forward"](%5, %argument_1.1, %argument_2.1) # :0:0
%7 : None = prim::CallMethod[name="forward"](%3, %6) # :0:0
%8 : Tensor[] = prim::ListConstruct(%6)
return (%8)
```
Test Plan:
python test/test_quantization.py test_interface_with_fork
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23481003
fbshipit-source-id: 2e756be73c248319da38e053f021888b40593032
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44008
embedding_bag requires only quantization of weights (no dynamic quantization of inputs)
So the type of quantization is essentially static (without calibration)
This will enable pyper to do fc and embedding_bag quantization using the same API call
Test Plan:
python test/test_quantization.py test_embedding_bag
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23467019
fbshipit-source-id: 41a61a17ee34bcb737ba5b4e19fb7a576d4aeaf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43989
When we trace the model it produces aten::embedding_bag node in the graph,
Add necessary passes in graph mode to help support quantizing it as well
Test Plan:
python test/test_quantization.py TestQuantizeDynamicJitOps.test_embedding_bag
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23460485
fbshipit-source-id: 328c5e1816cfebb10ba951113f657665b6d17575
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44137
We only insert guards on Tensor types, so we rely on the output
of a node being uniquely determined by its input types.
bail if any non-Tensor input affects the output type
and cannot be reasoned about statically
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23543602
Pulled By: eellison
fbshipit-source-id: abd6fe0b1fd7fe6fc251694d4cd442b19c032dd7
Summary:
- test beta=0, self=nan
- test transposes
- fixes broadcasting of addmv
- not supporting tf32 yet, will do it in future PR together with other testing fixes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43980
Reviewed By: mruberry
Differential Revision: D23507559
Pulled By: ngimel
fbshipit-source-id: 14ee39d1a0e13b9482932bede3fccb61fe6d086d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44125
In `Quantizer._prepare`, `observed` was used for two different variables
with different types. Making the names a bit cleaner and removing the
name conflict.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: dskhudia
Differential Revision: D23504109
fbshipit-source-id: 0f73eac3d6dd5f72ad5574a4d47d33808a70174a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44165
Allows convolutions to be quantized if `torch.cudnn.backends.benchmark`
flag was set.
Not for land yet, just testing.
Test Plan:
in the gist below, the resulting graph now has quantized convolutions
https://gist.github.com/vkuzo/622213cb12faa0996b6700b08d6ab2f0
Imported from OSS
Reviewed By: supriyar
Differential Revision: D23518775
fbshipit-source-id: 294f678c6afbd3feeb89b7a6655bc66ac9f8bfbc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44227
As title
ghstack-source-id: 111490242
Test Plan: CI
Reviewed By: xcheng16
Differential Revision: D23549149
fbshipit-source-id: fad742a8d4e6f844f83495514cd60ff2bf0d5bcb
Summary:
Update repeat op so that the inputs to sizes argument can a mixture of dynamic and constant inputs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43430
Reviewed By: houseroad
Differential Revision: D23494257
Pulled By: bzinodev
fbshipit-source-id: 90c5e90e4f73e98f3a9d5c8772850e72cecdf0d4
Summary: Integrate aot flow with model exporter.
Test Plan:
buck test dper3/dper3_backend/delivery/tests:dper3_model_export_test
replayer test see D23407733
Reviewed By: ipiszy
Differential Revision: D23313689
fbshipit-source-id: 39ae8d578ed28ddd6510db959b65974a5ff62888
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43906
This method returns a list of RRefs of remote parameters that can be fed into the DistributedOptimizer.
Original PR issue: RemoteModule enhancements #40550
Test Plan: buck test caffe2/test/distributed/rpc:process_group_agent -- RemoteModule
Reviewed By: rohan-varma
Differential Revision: D23399586
fbshipit-source-id: 4b0f1ccf2e47c8a9e4f79cb2c8668f3cdbdff820
Summary: Disable unroll hints when COMPILING_FOR_MIN_SIZE is on. We were seeing hundreds of errors in the build because the optimization was not being performed.
Test Plan: Smoke builds
Differential Revision: D23513255
fbshipit-source-id: 87da2fdc3c1146e8ffcacf14a49d5151d313f367
Summary:
Duplicate of https://github.com/pytorch/pytorch/issues/41413
This PR initiates the process of updating the torchsciprt backend interface used by ONNX exporter.
Replace jit lower graph pass by freeze module pass
Enable ScriptModule tests for ONNX operator tests (ORT backend) and model tests by default.
Replace jit remove_inplace_ops pass with remove_mutation and consolidation all passes for handling inplace ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43791
Reviewed By: houseroad
Differential Revision: D23421872
Pulled By: bzinodev
fbshipit-source-id: a98710c45ee905748ec58385e2a232de2486331b
Summary: Fix the potential divide by zero error in CostInferenceForRowWiseSparseAdagrad, when n has zero elements
Test Plan:
Ran buck test caffe2/caffe2/python/operator_test:adagrad_test
Result: https://our.intern.facebook.com/intern/testinfra/testrun/562950122086369
Reviewed By: idning
Differential Revision: D23520763
fbshipit-source-id: 191345bd24f5179a9dbdb41c6784eab102cfe89c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44092
instead submodules and weights are installed directly on the
graph_module by transferring the original modules. This makes it more
likely that scripting will succeed (since we no longer have submodules
that are not used in the trace). It also prevents layered transforms
from having to special case handling of the `root` module. GraphModules
can now be re-traced as part of the input to other transforms.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D23504210
Pulled By: zdevito
fbshipit-source-id: f79e5c4cbfc52eb0ffb5d6ed89b37ce35a7dc467
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44148
Automatically remove the build_code_analyzer folder each time build.sh is run
ghstack-source-id: 111458413
Test Plan:
Run build.sh with different options and compare the outputs (should be different).
Ex:
`ANALYZE_TORCH=1 DEPLOY=1 BASE_OPS_FILE=/path/to/baseops MOBILE_BUILD_FLAGS='-DBUILD_MOBILE_AUTOGRAD=OFF' tools/code_analyzer/build.sh `
should produce a shorter file than
`ANALYZE_TORCH=1 DEPLOY=1 BASE_OPS_FILE=/path/to/baseops MOBILE_BUILD_FLAGS='-DBUILD_MOBILE_AUTOGRAD=ON' tools/code_analyzer/build.sh`
Reviewed By: iseeyuan
Differential Revision: D23503886
fbshipit-source-id: 9b95d4365540da0bd2d27760e1315caed5f44eec
Summary:
Because those jobs are running in Docker2XLarge+ container that has 20 cores
Unfortunately `nproc` returns number of cores available on the host rather than number of cores available to container
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44168
Reviewed By: walterddr, ngimel
Differential Revision: D23539558
Pulled By: malfet
fbshipit-source-id: 3df858722e153a8fcbe8ef6370b1a9c1993ada5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44052
Summary
=======
This PR registers the following backwards functions as operators:
- slice_backward
- select_backward
- gather_backward
- index_select_backward (the backward function for index_select)
- select_index_backward (prevously known as index_select_backward, but is actually the backward function for max.dim, min.dim, etc)
In the future, I'd like to register more backward functions as operators
so that we can write batching rules for the backward functions. Batching
rules for backward functions makes it so that we can compute batched
gradients.
Motivation
==========
The rationale behind this PR is that a lot of backwards functions (27 in total)
are incompatible with BatchedTensor due to using in-place operations.
Sometimes we can allow the in-place operations, but other times we can't.
For example, consider select_backward:
```
Tensor select_backward(const Tensor& grad, IntArrayRef input_sizes, int64_t dim, int64_t index) {
auto grad_input = at::zeros(input_sizes, grad.options());
grad_input.select(dim, index).copy_(grad);
return grad_input;
}
```
and consider the following code:
```
x = torch.randn(5, requires_grad=True)
def select_grad(v):
torch.autograd.grad(x[0], x, v)
vs = torch.randn(B0)
batched_grads = vmap(select_grad)(vs)
```
For the batched gradient use case, `grad` is a BatchedTensor.
The physical version of `grad` has size `(B0,)`.
However, select_backward creates a `grad_input` of shape `(5)`, and
tries to copy `grad` to a slice of it.
Other approaches
================
I've considered the following:
- register select_backward as an operator (this PR)
- have a branch inside select_backward for if `grad` is batched.
- this is OK, but what if we have more tensor extensions that want to override this?
- modify select_backward to work with BatchedTensor, by creating a new operator for the "select + copy_ behavior".
- select + copy_ isn't used elsewhere in derivative formulas so this doesn't seem useful
Test Plan
=========
- `pytest test/test_autograd.py -v`
- Registering backward functions may impact performance. I benchmarked
select_backward to see if registering it as an operator led to any noticable
performance overheads: https://gist.github.com/zou3519/56d6cb53775649047b0e66de6f0007dc.
The TL;DR is that the overhead is pretty minimal.
Test Plan: Imported from OSS
Reviewed By: ezyang, fbhuba
Differential Revision: D23481183
Pulled By: zou3519
fbshipit-source-id: 125af62eb95824626dc83d06bbc513262ee27350
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40785
The main goal of this change is to support creating Tensors specifying blob in NHWC (ChannelsLast) format.
ChannelsLast is supported only for 4-dim tensors, this is enforced on LibTorch side, I have not added asserts on java side in case that this limitation will be changed in future and not to have double asserts.
Additional changes in `aten/src/ATen/templates/Functions.h`:
`from_blob` creates `at::empty({0}, options)` tensor first and sets it Storage with sizes and strides afterwards.
But as ChannelsLast is only for 4-dim tensors - it fails on that creation, as dim==1.
I've added `zero_sizes()` function that returns `{0, 0, 0, 0}` for ChannelsLast and ChannelsLast3d.
Test Plan: Imported from OSS
Reviewed By: dreiss
Differential Revision: D22396244
Pulled By: IvanKobzarev
fbshipit-source-id: 02582d748a554e0f859aefe71cd2c1e321fb8979
Summary:
A rework of `computeInline` which makes it work a bit better, particularly when combined with other transformations. Previously we stored Functions that were inlined and then deferred the actual inlining of the function body until prepareForCodgen was called. This has an issue when transformations are applied to the LoopNest: the function body can be different from what appears in the root_stmt and result in inlining that a) fails, b) reverses other transformations or c) a weird unpredictable combination of the two.
This PR changes that behaviour so that the inlining occurs in the root stmt immediately, which means it reflects any previous transformations and any future transformations have a true view of the internal IR. It also has the benefit that inspecting the root statement gives an accurate view of it without needing to call prepareForCodgen. I also removed the difference between `computeInline` and `computeInlineWithRand` and we handle calls to `rand()` in all branches.
This is a rework of https://github.com/pytorch/pytorch/issues/38696, with the agreed changes from ZolotukhinM and zheng-xq: we should only inline if the dimensions are trivial (ie. they are vars not exprs).
This PR is mostly tests, and I fixed a bunch of bugs I found along the way. Partial list:
* When inlining an expression involving rand, we would create random vars equal to the dimensionality of the enclosing Tensor not the produced Tensor - meaning we'd use an incorrect value if the inlined tensor was smaller. E.g: `X[i] = rand(); A[i, j] = X[i]` would produce a tensor where `A[0, 0] != A[0, 1]`. This is fixed by inserting the Let binding of the random variable at the correct loop body.
* When inlining we'd replace all calls to `rand()` rather than just those present in the Tensor being inlined.
* `rand()` was treated symbolically by the simplifier and we would aggregate or cancel calls to `rand()`. Have fixed the hasher to hash all calls to `rand()` distinctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43885
Reviewed By: gmagogsfm
Differential Revision: D23503636
Pulled By: nickgg
fbshipit-source-id: cdbdc902b7a14d269911d978a74a1c11eab004fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44139
Also, make sure that we're checking that condition when we're starting a
new fusion group, not only when we merge a node into an existing fusion
group. Oh, and one more: add a test checking that we're rejecting graphs
with unspecified shapes.
Differential Revision: D23507510
Test Plan: Imported from OSS
Reviewed By: bertmaher
Pulled By: ZolotukhinM
fbshipit-source-id: 9c268825ac785671d7c90faf2aff2a3e5985ac5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44115
Fixes device affinity in the FX prepare pass for QAT. Before this PR, observers
were always created on CPU. After this PR, observers are created on the
same device as the rest of the model. This will enable QAT prepare to
work regardless of whether users move the model to cuda before or after
calling this pass.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_qat_prepare_device_affinity
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D23502291
fbshipit-source-id: ec4ed20c21748a56a25e3395b35ab8640d71b5a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43298
IR emitter uses `ModuleValue` to represent ScriptModules and emit IR for
attribute access, submodule access, etc.
`ModuleValue` relies on two pieces of information, the JIT type of the
module, and the `ConcreteModuleType`, which encapsulates Python-only
information about the module.
ScriptModules loaded from a package used to create a dummy
ConcreteModuleType without any info in it. This led to divergences in
behavior during compilation.
This PR makes the two ways of constructing a ConcreteModuleType equivalent,
modulo any py-only information (which, by definition, is never present in
packaged files anyway).
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23228738
Pulled By: suo
fbshipit-source-id: f6a660f42272640ca1a1bb8c4ee7edfa2d1b07cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43284
The IR emitter looks for attributes on modules like:
1. Check the JIT type for the attribute
2. Check the originating Python class, in order to fulfill requests for, e.g. static methods or ignored methods.
In the case where you do:
```
inner_module = torch.jit.load("inner.pt")
wrapped = Wrapper(inner_module) # wrap the loaded ScriptModule in an nn.Module
torch.jit.script(wrapped)
```
The IR emitter may check for attributes on `inner_module`. There is no
originating Python class for `inner_module`, since it was directly
compiled from the serialized format.
Due to a bug in the code, we don't guard for this case an a segfault
results if the wrapper asks for an undefined attribute. The lookup in
this case looks like:
1. Check the JIT type for the attribute (not there!)
2. Check the originating Python class (this is a nullptr! segfault!)
This PR guards this case and properly just raises an attribute missing
compiler error instead of segfaulting.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23224337
Pulled By: suo
fbshipit-source-id: 0cf3060c427f2253286f76f646765ec37b9c4c49
Summary:
Some tests for alias analysis.
The first aliases at the module level and the second at the input level.
Please let me know if there are other alias situations!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44110
Reviewed By: nickgg
Differential Revision: D23509473
Pulled By: bwasti
fbshipit-source-id: fbfe71a1d40152c8fbbd8d631f0a54589b791c34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44083
Match on the complete schema of a node instead of its node kind when deciding to fuse it. Previously we matched on node kind, which could fail with something like `aten::add(int, int)` and if a new overload was added to an op without corresponding NNC support we would fuse it.
Follow ups are:
- bail when an output tensor type isnt uniquely determined by the input types (e.g. aten::add and the second input could be either a float or an int)
- remove NNC lowering for _tanh_backward & _sigmoid_backward
- Validate that we support all of the overloads here. I optimistically added ops that included Tensors, it's possible that we do not support every overload here. This isn't a regression, and this PR is at least improving our failures in that regard.
I can do any of these as part of this PR if desired, but there are a number of failures people have run into that this PR fixes so I think it would be good to land this sooner than later.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D23503704
Pulled By: eellison
fbshipit-source-id: 3ce971fb1bc3a7f1cbaa38f1ed853e2db3d67c18
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43965
As part of a larger effort to unify the API between the lite interpreter and full JIT:
- implement torch::jit::mobile::Method, a proxy for torch::jit::mobile::Function
- add support for overloaded operator() to mobile Method and Function
- mobile find_method now returns a c10::optional<Method> (so signature matches full jit)
- moves some implementation of Function from module.cpp to function.cpp
ghstack-source-id: 111161942
Test Plan: CI
Reviewed By: iseeyuan
Differential Revision: D23330762
fbshipit-source-id: bf0ba0d711d9566c92af31772057ecd35983ee6d
Summary:
Polishes DDP join api docstrings and makes a few minor cosmetic changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43973
Reviewed By: zou3519
Differential Revision: D23467238
Pulled By: rohan-varma
fbshipit-source-id: faf0ee56585fca5cc16f6891ea88032336b3be56
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44036
Running replaceAtenConvolution on older traced model wont work as
_convolution signature has changed and replaceAtenConvolution was
changed to account for that.
But we did not preserve the old behavior during that. This change
restores the old behavior while keeing the new one.
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23476775
fbshipit-source-id: 73a0c2b7387f2a8d82a8d26070d0059972126836
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44035
change
Also added test so as to capture such cases for future.
Test Plan:
python test/test_xnnpack_integration.py
Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D23476773
fbshipit-source-id: a62c4429351c909245106a70b4c60b1bacffa817
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44060
Right now it skips grad checks as well.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D23484018
Pulled By: gchanan
fbshipit-source-id: 24a8f1af41f9918aaa62bc3cd78b139b2f8de1e1
Summary:
Bucketize returns integers, currently this triggers an internal assert, so we apply the mechanism for this case (also used for argmax etc.).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44102
Reviewed By: zou3519
Differential Revision: D23500048
Pulled By: albanD
fbshipit-source-id: fdd869cd1feead6616b532b3e188bd5512adedea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44054
**Summary**
This commit improves the error message that is printed when an
`Optional` type annotation with an unsupported contained type is
encountered. At present, the `Optional` is printed as-is, and
`Optional[T]` is syntatic sugar for `Union[T, None]`, so that is what
shows up in the error message and can be confusing. This commit modifies
the error message so that it prints `T` instead of `Union[T, None]`.
**Test Plan**
Continuous integration.
Example of old message:
```
AssertionError: Unsupported annotation typing.Union[typing.List, NoneType] could not be resolved.
```
Example of new message:
```
AssertionError: Unsupported annotation typing.Union[typing.List, NoneType] could not be resolved because typing.List could not be resolved.
```
**Fixes**
This commit fixes#42859.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D23490365
Pulled By: SplitInfinity
fbshipit-source-id: 2aa9233718e78cf1ba3501ae11f5c6f0089e29cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44078
When PyTorch mobile inference failed and throw exception, if caller catch and not crash the app, we are not able to track all the inference failures.
So we are adding native soft error reporting to capture all the failures occurring during module loading and running including both crashing and on-crashing failures. Since c10::Error has good error messaging stack handling (D21202891 (a058e938f9)), we are utilizing it for the error handling and message print out.
ghstack-source-id: 111307080
Test Plan:
Verified that the soft error reporting is sent through module.cpp when operator is missing, make sure a logview mid is generated with stack trace: https://www.internalfb.com/intern/logview/details/facebook_android_softerrors/5dd347d1398c1a9a73c804b20f7c2179/?selected-logview-tab=latest.
Error message with context is logged below:
```
soft_error.cpp [PyTorchMobileInference] : Error occured during model running entry point: Could not run 'aten::embedding' with arguments from the 'CPU' backend. 'aten::embedding' is only available for these backends: [BackendSelect, Named, Autograd, Autocast, Batched, VmapMode].
BackendSelect: fallthrough registered at xplat/caffe2/aten/src/ATen/core/BackendSelectFallbackKernel.cpp:3 [backend fallback]
Named: registered at xplat/caffe2/aten/src/ATen/core/NamedRegistrations.cpp:7 [backend fallback]
Autograd: fallthrough registered at xplat/caffe2/aten/src/ATen/core/VariableFallbackKernel.cpp:31 [backend fallback]
Autocast: fallthrough registered at xplat/caffe2/aten/src/ATen/autocast_mode.cpp:253 [backend fallback]
Batched: registered at xplat/caffe2/aten/src/ATen/BatchingRegistrations.cpp:317 [backend fallback]
VmapMode: fallthrough registered at xplat/caffe2/aten/src/ATen/VmapModeRegistrations.cpp:33 [backend fallback]
Exception raised from reportError at xplat/caffe2/aten/src/ATen/core/dispatch/OperatorEntry.cpp:261 (m
```
Reviewed By: iseeyuan
Differential Revision: D23428636
fbshipit-source-id: 82d5d9c054300dff18d144f264389402d0b55a8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44082
Automated submodule is running into some test failures and I am not sure how can I rebase that.
automated submodule update:
https://github.com/pytorch/pytorch/pull/43817
Test Plan: CI tests
Reviewed By: jianyuh
Differential Revision: D23489240
fbshipit-source-id: a49b01786ebf0a59b719a0abf22398e1eafa90af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43734
Following the additional GH comments on the original PR https://github.com/pytorch/pytorch/pull/43307.
ghstack-source-id: 111327130
Test Plan: Run `python test/distributed/test_c10d.py`
Reviewed By: smessmer
Differential Revision: D23380288
fbshipit-source-id: 4b8889341c57b3701f0efa4edbe1d7bbc2a82ced
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44055
There is no functional change here. Another patch will rename NewCriterionTest to CriterionTest.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D23482572
Pulled By: gchanan
fbshipit-source-id: de364579067e2cc9de7df6767491f8fa3a685de2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44050
We don't actually turn on the CTCLoss tests since they fail, but this allows you to toggle check_forward_only and for the code to actually run.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D23481091
Pulled By: gchanan
fbshipit-source-id: f2a3b0a2dee27341933c5d25f1e37a878b04b9f6
Summary:
This PR adds a new test suite, test_ops.py, designed for generic tests across all operators with OpInfos. It currently has two kinds of tests:
- it validates that the OpInfo has the correct supported dtypes by verifying that unsupported dtypes throw an error and supported dtypes do not
- it runs grad and gradgrad checks on each op and its variants (method and inplace) that has an OpInfo
This is a significant expansion and simplification of the current autogenerated autograd tests, which spend considerable processing their inputs. As an alternative, this PR extends OpInfos with "SampleInputs" that are much easier to use. These sample inputs are analogous to the existing tuples in`method_tests()`.
Future PRs will extend OpInfo-based testing to other uses of `method_tests()`, like test_jit.py, to ensure that new operator tests can be implemented entirely using an OpInfo.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43451
Reviewed By: albanD
Differential Revision: D23481723
Pulled By: mruberry
fbshipit-source-id: 0c2cdeacc1fdaaf8c69bcd060d623fa3db3d6459
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44073
We don't have a proper support on NNC and JIT IR->NNC lowering side for it yet.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D23487905
Pulled By: ZolotukhinM
fbshipit-source-id: da0da7478fc8ce7b455176c95d8fd610c94352c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43961
Currently we're removing prim::profile nodes and embed the type info
directly in the IR right before the fuser, because it is difficult to
fuse in a presence of prim::profile nodes. It turns out that BatchMM has
a similar problem: it doesn't work when there are prim::profile nodes in
the graph. These two passes run next to each other, so we could simply
remove prim::profile nodes slightly earlier: before the BatchMM pass.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23453266
Pulled By: ZolotukhinM
fbshipit-source-id: 92cb50863962109b3c0e0112e56c1f2cb7467ff1
Summary:
- This test is very fast and very important, so it makes no sense in marking it as slowTest
- This test is should also run on CUDA
- This test should check alpha and beta support
- This test should check `out=` support
- manual computation should use list instead of index_put because list is much faster
- precision for TF32 needs to be fixed. Will do it in future PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43831
Reviewed By: ailzhang
Differential Revision: D23435032
Pulled By: ngimel
fbshipit-source-id: d1b8350addf1e2fe180fdf3df243f38d95aa3f5a
Summary:
Move `multigpu`, `noavx` and `slow` test configs to CUDA-10.2, but keep them a master only tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44057
Reviewed By: walterddr, seemethere
Differential Revision: D23482732
Pulled By: malfet
fbshipit-source-id: a6b050701cbc1d8f176ebb302f7f5076a78f1f58
Summary:
I usually get this extra "legacy_conv2d.pt" file in my git "changed files". I found that this is from tests with `download_file`
42c895de4d/test/test_nn.py (L410-L426)
and its definition (see `data_dir` for download output location)
f17d7a5556/torch/testing/_internal/common_utils.py (L1338-L1357)
I assume a file "generated" by test should not be tracked in VCS? Also, if the file is updated on the server, users may still use the old version of it if they have already downloaded that before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43941
Reviewed By: anjali411
Differential Revision: D23451264
Pulled By: ezyang
fbshipit-source-id: 7fcdfb24685a7e483914cc46b3b024df798bf7f7
Summary:
To avoid conflicts, this PR does not remove all imports. More are coming in further PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43808
Reviewed By: wanchaol
Differential Revision: D23436675
Pulled By: ailzhang
fbshipit-source-id: ccc21a1955c244f0804277e9e47e54bfd23455cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43972
It is useful when debugging a bug to disable NNC backend to see whether
the bug is there or in the fuser logic.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23455624
Pulled By: ZolotukhinM
fbshipit-source-id: f7c0452a29b860afc806e2d58acf35aa89afc060
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44001
This is to align with the naming in numpy and in
https://github.com/pytorch/pytorch/pull/43092
Test Plan:
```
python test/test_torch.py TestTorchDeviceTypeCPU.test_aminmax_cpu_float32
python test/test_torch.py TestTorchDeviceTypeCUDA.test_aminmax_cuda_float32
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23465298
fbshipit-source-id: b599035507156cefa53942db05f93242a21c8d06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42894
Continuing the min_max kernel implementation, this PR adds the
CPU path when a dim is specified. Next PR will replicate for CUDA.
Note: after a discussion with ngimel, we are taking the fast path
of calculating the values only and not the indices, since that is what
is needed for quantization, and calculating indices would require support
for reductions on 4 outputs which is additional work. So, the API
doesn't fully match `min.dim` and `max.dim`.
Flexible on the name, let me know if something else is better.
Test Plan:
correctness:
```
python test/test_torch.py TestTorchDeviceTypeCPU.test_minmax_cpu_float32
```
performance: seeing a 49% speedup on a min+max tensor with similar shapes
to what we care about for quantization observers (bench:
https://gist.github.com/vkuzo/b3f24d67060e916128a51777f9b89326). For
other shapes (more dims, different dim sizes, etc), I've noticed a
speedup as low as 20%, but we don't have a good use case to optimize
that so perhaps we can save that for a future PR.
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23086798
fbshipit-source-id: b24ce827d179191c30eccf31ab0b2b76139b0ad5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42868
Adds a CUDA kernel for the _min_max function.
Note: this is a re-submit of https://github.com/pytorch/pytorch/pull/41805,
was faster to resubmit than to ressurect that one. Thanks to durumu
for writing the original implementation!
Future PRs will add index support, docs, and hook this up to observers.
Test Plan:
```
python test/test_torch.py TestTorchDeviceTypeCUDA.test_minmax_cuda_float32
```
Basic benchmarking shows a 50% reduction in time to calculate min + max:
https://gist.github.com/vkuzo/b7dd91196345ad8bce77f2e700f10cf9
TODO
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23057766
fbshipit-source-id: 70644d2471cf5dae0a69343fba614fb486bb0891
Summary: Add cost inference for AdaGrad and RowWiseSparseAdagrad
Test Plan:
Ran `buck test caffe2/caffe2/python/operator_test:adagrad_test`
Result: https://our.intern.facebook.com/intern/testinfra/testrun/5629499567799494
Reviewed By: bwasti
Differential Revision: D23442607
fbshipit-source-id: 67800fb82475696512ad19a43067774247f8b230
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43270
`torch.conj` is a very commonly used operator for complex tensors, but it's mathematically a no op for real tensors. Switching to tensorflow gradients for complex tensors (as discussed in #41857) would involve adding `torch.conj()` to the backward definitions for a lot of operators. In order to preserve autograd performance for real tensors and maintain numpy compatibility for `torch.conj`, this PR updates `torch.conj()` which behaves the same for complex tensors but performs a view/returns `self` tensor for tensors of non-complex dtypes. The documentation states that the returned tensor for a real input shouldn't be mutated. We could perhaps return an immutable tensor for this case in future when that functionality is available (zdevito ezyang ).
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D23460493
Pulled By: anjali411
fbshipit-source-id: 3b3bf0af55423b77ff2d0e29f5d2c160291ae3d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43927
Adds uninitialized placeholders for various state
used throughout the Quantizer object, with documentation
on what they are. No logic change.
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestQuantizeFx
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23439473
fbshipit-source-id: d4ae83331cf20d81a7f974f88664ccddca063ffc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43248
We add the support of __torch_function__ override for C++ custom op. The logic is the same as the other components, like torch.nn.Module.
Refactored some code a little bit to make it reusable.
Test Plan: buck test //caffe2/test:fx -- test_torch_custom_ops
Reviewed By: bradleyhd
Differential Revision: D23203204
fbshipit-source-id: c462a86e407e46c777171da32d7a40860acf061e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42533
[First PR: Add private API to support tensor lists: _foreach_add(TensorList tensors, Scalar scalar)](https://github.com/pytorch/pytorch/pull/41554).
**Motivation**
[GitHub issue](https://github.com/pytorch/pytorch/issues/38655)
Current PyTorch optimizer implementations are not efficient in cases when we work with a lot of small feature tensors. Starting a lot of kernels slows down the whole process. We need to reduce the number of kernels that we start.
As an example, we should be looking at [NVIDIAs Apex](https://github.com/NVIDIA/apex).
In order to track progress, we will pick PyTorchs DCGAN model with Adam optimizer and once the optimizer is reimplemented with tensor lists, benchmark the model performance against original model version, Apexs version with original Adam optimizer and it’s FusedAdam optimizer.
**Current API restrictions**
- List can't be empty (will fixed in upcoming PRs).
- All tensors in the list must have the same dtype, device and size.
**Broadcasting**
At this point we don't support broadcasting.
**What is 'Fast' and 'Slow' route**
In particular cases, we cant process an op with a fast list CUDA kernel. Still, we can do with a regular for-loop where the op will be applied to each tensor individually through the dispatch mechanisms. There are a few checks that decide whether the op will be performed via a 'fast' or 'slow' path.
To go the fast route,
- All tensors must have strided layout
- All tensors must be dense and not have overlapping memory
- The resulting tensor type must be the same.
----------------
**In this PR**
- Adding a `_foreach_add(TensorList tl1, TensorList tl2)` API
- Adding a `_foreach_add_(TensorList tl1, TensorList tl2)` API
**Tests**
Tested via unit tests
**TODO**
1. Properly handle empty lists
**Plan for the next PRs**
1. APIs
- Binary Ops for list with Scalar
- Binary Ops for list with list
- Unary Ops for list
- Pointwise Ops
2. Complete tasks from TODO
3. Rewrite PyTorch optimizers to use for-each operators for performance gains.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D23331894
Pulled By: izdeby
fbshipit-source-id: 876dd1bc82750f609b9e3ba23c8cad94d8d6041c
Summary:
Previously when merging a node without a subgraph, we would merge the node's outputs to the corresponding subgraph values, but when merging a node with a subgraph the node's outputs would be absent in the value mapping. This PR makes it so they are included.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43988
Reviewed By: ZolotukhinM
Differential Revision: D23462116
Pulled By: eellison
fbshipit-source-id: 232c081261e9ae040df0accca34b1b96a5a5af57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43974
We already install devtoolset7 in our docker images for binary builds
and tclsh shouldn't be needed since we're not relying on unbuffer
anymore
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D23462531
Pulled By: seemethere
fbshipit-source-id: 83cbb8b0782054f0b543dab8d11fa6ac57685272
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43711
this makes them available in forward if needed
No change to the file content, just a copy-paste.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D23454146
Pulled By: albanD
fbshipit-source-id: 6269a4aaf02ed53870fadf8b769ac960e49af195
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43914
Renames `matches` function to `is_match`, since there is also
a list named `matches` we are passing around in `Quantizer`,
and would be good to decrease name conflicts.
Test Plan:
```
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23435601
fbshipit-source-id: 394af11e0120cfb07dedc79d5219247330d4dfd6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43910
Adds a debug function to get a representation of all nodes in the
graph, such as
```
name op target args kwargs
x plchdr x () {}
linear_weight gt_prm linear.weight () {}
add_1 cl_fun <bi_fun add> (x, linear_weight) {}
linear_1 cl_mod linear (add_1,) {}
relu_1 cl_meth relu (linear_1,) {}
sum_1 cl_fun <bi_meth sum> (relu_1,) {'dim': -1}
topk_1 cl_fun <bi_meth topk> (sum_1, 3) {}
```
using only Python STL. This is useful for printing internal state of
graphs when working on FX code.
Has some on-by-default logic to shorten things so that node reprs for
toy models and unit tests fit into 80 chars.
Flexible on function name and location, I care more that this is
accessible from both inside PT as well as from debug scripts which
are not checked in.
Test Plan:
see
https://gist.github.com/vkuzo/ed0a50e5d6dc7442668b03bb417bd603 for
example usage
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23435029
fbshipit-source-id: 1a2df797156a19cedd705e9e700ba7098b5a1376
Summary:
MKLDNN linear incorrectly assumes that bias is defined and will fail for no-bias calls.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43703
Reviewed By: glaringlee
Differential Revision: D23373182
Pulled By: bwasti
fbshipit-source-id: 1e817674838a07d237c02eebe235c386cf5b191e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43954
CriterionTest is basically dead -- see https://github.com/pytorch/pytorch/pull/43769 and https://github.com/pytorch/pytorch/pull/43776.
The only exception is the cpp parity test, but the difference there doesn't actually have any effect -- the get_target has unpack=True, but all examples don't require unpacking (I checked).
As a pre-requisite for merging these tests, have the cpp parity test start using the NewCriterionTest.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D23452144
Pulled By: gchanan
fbshipit-source-id: 5dca1eb0878b882c93431d3b0e880b5bb1764522
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43853
Add QPL logging for mobile module's metadata
ghstack-source-id: 111113492
(Note: this ignores all push blocking failures!)
Test Plan:
- CI
- Load the model trained by `mobile_model_util.py`
- Local QPL logger standard output.
{F319012106}
Reviewed By: xcheng16
Differential Revision: D23417304
fbshipit-source-id: 7bc834f39e616be1eccfae698b3bccdf2f7146e5
Summary:
`is_complex_t` is a bad name. For example in std, there are `std::is_same` but not `std::is_same_t`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39906
Reviewed By: mrshenli
Differential Revision: D22665013
Pulled By: anjali411
fbshipit-source-id: 4b71745f5e2ea2d8cf5845d95ada4556c87e040d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43887
As part of addressing #23232, this PR adds support for `broadcast_object_list` which is an API to broadcast arbitrary picklable objects to all the other ranks. This has been a long-requested feature, so would be good for Pytorch to natively support this.
The implementation approach follows a similar approach as https://github.com/pytorch/pytorch/pull/42189. The input is a list of objects to be broadcasted and it is in place, meaning all ranks part of the group will have their input list modified to contain the broadcasted objects from the src rank.
Note that the API is designed to match the tensor-based collectives other than supporting async_op. For now, it is a blocking call. If we see demand to support async_op, we will have to make more progress on merging work/future to support this.
ghstack-source-id: 111180436
Reviewed By: mrshenli
Differential Revision: D23422577
fbshipit-source-id: fa700abb86eff7128dc29129a0823e83caf4ab0e
Summary:
This is the common behavior when one builds PyTorch (or any other CUDA project) using CMake, so it should be held true for Torch CUDA extensions as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43931
Reviewed By: ezyang, seemethere
Differential Revision: D23441793
Pulled By: malfet
fbshipit-source-id: 1af392107a94840331014fda970ef640dc094ae4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43892
Run weight observer in the convert function, so user do not need to run calibration
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23429758
fbshipit-source-id: 5bc222e3b731789ff7a86463c449690a58dffb7b
Summary: Update `README.md` for oss to explain the usage of `--run` `--export` `--summary`
Test Plan: Test locally.
Reviewed By: malfet
Differential Revision: D23431508
fbshipit-source-id: 368b8dd8cd5099f39c7f5bc985203c417bf7af39
Summary:
No need for compatibility wrapper in Python3+ world
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43981
Reviewed By: seemethere
Differential Revision: D23458325
Pulled By: malfet
fbshipit-source-id: 00f822895625f4867c22376fe558c50316f5974d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43893
Update `README.md` in oss, provide more examples, start from the most common use to specified use. Make `README.md` be more friendly and more specific.
Test Plan: `README.md` doesn't need test.
Reviewed By: malfet, seemethere
Differential Revision: D23420203
fbshipit-source-id: 1a4c146393fbcaf2893321e7892740edf5d0c248
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43540
selected_mobile_ops.h is generated at BUCK build time, which contains the whitelist of root operators. It's used for templated selective build when XPLAT_MOBILE_BUILD is defined.
ghstack-source-id: 111014372
Test Plan: CI and BSB
Reviewed By: ljk53
Differential Revision: D22618309
fbshipit-source-id: ddf813904892f99c3f4ae0cd14ce8b27727be5a2
Summary:
This PR needs discussion as it changes the behavior of `DataLoader`. It can be closed if its not considered a good practice.
Currently, the `DataLoader` spawns a new `_BaseDataLoaderIter` object every epoch,
In the case of the multiprocess DataLoader, every epoch the worker processes are re-created and they make a copy of the original `Dataset` object.
If users want to cache data or do some tracking on their datasets, all their data will be wiped out every epoch. Notice that this doesn't happen when the number of workers is 0. giving some inconsistencies with the multiprocess and serial data loaders.
This PR keeps the `_BaseDataLoaderIter` object alive and just resets it within epochs, so the workers remain active and so their own `Dataset` objects. People seem to file issues about this often.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35795
Reviewed By: ailzhang
Differential Revision: D23426612
Pulled By: VitalyFedyunin
fbshipit-source-id: e16950036bae35548cd0cfa78faa06b6c232a2ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43889
1. rename input argunment `interested-folder` to `interest-only` -- be consistent with `run-only`, `coverage-only` and be shorted
Test Plan: Test on devserver and linux docker.
Reviewed By: malfet
Differential Revision: D23417338
fbshipit-source-id: ce9711e75ca3a1c30801ad6bd1a620f3b06819c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43938
resubmit
Test Plan: unit test included
Reviewed By: mruberry
Differential Revision: D23443493
fbshipit-source-id: 7b68f8f7d1be58bee2154e9a498b5b6a09d11670
Summary:
This PR moves `DispatchKey::Autograd` to an alias dispatch key mapping to `AutogradCPU, AutogradCUDA, AutogradXLA, AutogradOther, AutogradPrivate*` keys.
A few things are handled in this PR:
- Update alias dispatch key mapping and precompute dispatchTable logic
- Move `Autograd` key from `always_included` set to TensorImpl constructor.
- Update `dummyTensor` constructor to take `requires_grad` as optional argument so that it's closer to the real application in op_registration_test.
- Use `BackendSelect` key for both backend select before and after autograd layer. (1 liner in backend_select codegen)
A few planned followups ordered by priority:
- [cleanup] Update `test_dispatch.py` to include testing `Autograd`.
- [cleanup] Add Math alias key and move catchAll to Math. (to remove 2.2 in `computeDispatchTableEntryWithDebug`)
- [new feature] Add support for Math in native_functions.yaml
- [cleanup] Add iterator like functionality to DispatchKeySet
- [cleanup/large] Only add Autograd backend keys when tensor requires grad. (cc: ljk53 ?)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43070
Reviewed By: ezyang
Differential Revision: D23281535
Pulled By: ailzhang
fbshipit-source-id: 9ad00b17142e9b83304f63cf599f785500f28f71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43780
The general strategy is:
- unsqueeze the physical inputs enough
- pass the unsqueezed physical inputs to at::matmul
- squeeze any extra dimensions
Test Plan: - `pytest test/test_vmap.py -v`
Reviewed By: ezyang
Differential Revision: D23400842
Pulled By: zou3519
fbshipit-source-id: c550eeb935747c08e3b083609ed307a4374b9096
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43731
After this PR, for each test in TestVmapOperators, TestVmapOperators
tests that the test never invokes the slow vmap fallback path. The
rationale behind this change is that TestVmapOperators is used for
testing batching rules and we want confidence that the batching rules
actually get invoked.
We set this up using a similar mechanism to the CUDA memory leak check:
(bff741a849/torch/testing/_internal/common_utils.py (L506-L511))
This PR also implements the batching rule for `to.dtype_layout`; the new
testing caught that we were testing vmap on `to.dtype_layout` but it
didn't actually have a batching rule implemented!
Test Plan: - New tests in `pytest test/test_vmap.py -v` that test the mechanism.
Reviewed By: ezyang
Differential Revision: D23380729
Pulled By: zou3519
fbshipit-source-id: 6a4b97a7fa7b4e1c5be6ad80d6761e0d5b97bb8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43386Resolves#43178
ghstack-source-id: 111109716
Test Plan: Added checks to existing unit test and ran it on gpu devserver.
Reviewed By: rohan-varma
Differential Revision: D23216393
fbshipit-source-id: fed5e37fbabbd2ac4a9055b20057fffe3c416c0b
Summary:
During scripting, combination of shape (or size()) and slice (e.g x.shape[2:]) produces following error:
slice() missing 1 required positional argument: 'step'
This happens because aten::slice has 2 signatures:
- aten::slice(Tensor self, int dim, int start, int end, int step) -> Tensor
- aten::slice(t[] l, int start, int end, int step) -> t[]
and when a list is passed instead of tensor the 2nd of the two slice signatures is called, and since it has 4 instead of 5 arguments it produces the above exception.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42935
Reviewed By: houseroad
Differential Revision: D23398435
Pulled By: bzinodev
fbshipit-source-id: 4151a8f878c520cea199b265973fb476b17801fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43684
This PR attempts to address #42560 by capturing the appropriate
exception_ptr in the autograd engine and passing it over to the Future.
As part of this change, there is a significant change the Future API where we
now only accept an exception_ptr as part of setError.
For the example in #42560, the exception trace would now look like:
```
> Traceback (most recent call last):
> File "test_autograd.py", line 6914, in test_preserve_backtrace
> Foo.apply(t).sum().backward()
> File "torch/tensor.py", line 214, in backward
> torch.autograd.backward(self, gradient, retain_graph, create_graph)
> File "torch/autograd/__init__.py", line 127, in backward
> allow_unreachable=True) # allow_unreachable flag
> File "torch/autograd/function.py", line 87, in apply
> return self._forward_cls.backward(self, *args)
> File "test_autograd.py", line 6910, in backward
> raise ValueError("something")
> ValueError: something
```
ghstack-source-id: 111109637
Test Plan: waitforbuildbot
Reviewed By: albanD
Differential Revision: D23365408
fbshipit-source-id: 1470c4776ec8053ea92a6ee1663460a3bae6edc5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43902
Trace back from the weight node util we hit getattr, reconstruct the graph module with the traced nodes
and run the graph module to pack the weight. then replace the original chain of ops with the packed weight.
Test Plan:
Imported from OSS
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23432431
fbshipit-source-id: 657f21a8287494f7f87687a9d618ca46376d3aa3
Summary:
`torch.range` still hasn't been removed way after version 0.5. This PR fixes the warning message. Alternatively, we can remove `torch.range`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43569
Reviewed By: ngimel
Differential Revision: D23408233
Pulled By: mruberry
fbshipit-source-id: 86c4f9f018ea5eddaf80b78a3c54dfa41cfc6fa6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43901
Add similar APIs like eager and graph mode on torchscript
- fuse_fx
- quantize_fx (for both post training static and qat)
- quantize_dynamic_fx (for post training dynamic)
- prepare_fx (for both post training static and qat)
- prepare_dynamic_fx (for post training dynamic)
- convert_fx (for all modes)
Test Plan:
Imported from OSS
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23432430
fbshipit-source-id: fc99eb75cbecd6ee7a3aa6c8ec71cd499ff7e3c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43789
Since it's single element.. In some cases we may not be able to resize the
buffers.
Test Plan: unit tests
Reviewed By: supriyar
Differential Revision: D23393108
fbshipit-source-id: 46cd7f73ed42a05093662213978a01ee726433eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43847
It seems to slowdown two fastRNN benchmarks and does not speed up
others.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23416197
Pulled By: ZolotukhinM
fbshipit-source-id: 598144561979e84bcf6bccf9b0ca786f5af18383
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43900
The original code assumed that the versioning if was inserted in the
beginning of the graph while in fact it was inserted in the end. We're
now also not removing `profile_optional` nodes and rely on DCE to clean
it up later (the reason we're not doing it is that deletion could
invalidate the insertion point being used).
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23432175
Pulled By: ZolotukhinM
fbshipit-source-id: 1bf55affaa3f17af1bf71bad3ef64edf71a3e3fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43846
We are looking for tensors that are expected to be undefined (according
to the profile info) and should be checking for them to satisfy the
following condition: "not(have any non-zero)", which is equivalent to
"tensor is all zeros". The issue was that we've been checking tensors
that were expected *not* to be undefined.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23416198
Pulled By: ZolotukhinM
fbshipit-source-id: 71e22f552680f68f2af29f427b7355df9b1a4278
Summary:
- Add `torch._C` bindings from `torch/csrc/autograd/init.cpp`
- Renamed `torch._C.set_grad_enabled` to `torch._C._set_grad_enabled`
so it doesn't conflict with torch.set_grad_enabled anymore
This is a continuation of gh-38201. All I did was resolve merge conflicts and finish the annotation of `_DecoratorContextManager.__call__` that ezyang started in the first commit.
~Reverts commit b5cd3a80bbc, which was only motivated by not having `typing_extensions` available.~ (JIT can't be made to understand `Literal[False]`, so keep as is).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43415
Reviewed By: ngimel
Differential Revision: D23301168
Pulled By: malfet
fbshipit-source-id: cb5290f2e556b4036592655b9fe54564cbb036f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43883
Check the result of GCC coverage in OSS is reasonable and ready to ship.
The amount of executable lines are not the same between `gcc` and `clang` because of the following reasons:
* Lines following are counted in `clang` but not in `gcc`:
1. empty line or line with only “{” or “}”
3. some comments are counted in clang but not in gcc
5. `#define ...` -- not supported by gcc according to official documentation
* Besides, a statement that explains to more than one line will be counted as only one executable line in gcc, but several lines in clang
## Advantage of `gcc` coverage
1. Much faster
- code coverage tool runtime is onle **4 min** (*ammazzzing!!*) by `gcc`, compared to **3 hours!!** by `clang`, to analyze all the tests' artifacts
2. Use less disk
- `Clang`'s artifacts will take as large as 170G, but `GCC` is 980M
Besides, also update `README.md`.
Test Plan:
Compare the result in OSS `clang` and OSS `gcc` with the same command:
```
python oss_coverage.py --run-only atest test_nn.py --interested-folder=aten
```
----
## GCC
**Summary**
> time: 0:15:45
summary percentage: 44.85%
**Report and Log**
[File Coverage Report](P140825162)
[Line Coverage Report](P140825196)
[Log](P140825385)
------
## CLANG
**Summary**
> time: 0:21:35
summary percentage: 44.08%
**Report and Log**
[File Coverage Report](P140825845)
[Line Coverage Report](P140825923)
[Log](P140825950)
----------
# Run all tests
```
# run all tests and get coverage over Pytorch
python oss_coverage.py
```
**Summary**
> time: 1:27:20. ( time to run tests: 1:23:33)
summary percentage: 56.62%
**Report and Log**
[File Coverage Report](P140837175)
[Log](P140837121)
Reviewed By: malfet
Differential Revision: D23416772
fbshipit-source-id: a6810fa4d8199690f10bd0a4f58a42ab2a22182b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43800
1. Move fbcode related coverage code to fb/ folder and add TARGETS so that we can use buck run to run the tool and solved the import probelm.
2. Write `README.md` to give users guidance about the tool
Test Plan:
On devserver:
```
buck run //caffe2/fb/code_coverage/tool:coverage -- //caffe2/c10:
```
More examples in README.md
Reviewed By: malfet
Differential Revision: D23404988
fbshipit-source-id: 4942cd0e0fb7bd28a5e884d9835b93f00adb7b92
Summary:
Python code coverage tests should not rely on target determination as it will negatively impact the coverage score
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43899
Reviewed By: seemethere
Differential Revision: D23432069
Pulled By: malfet
fbshipit-source-id: 341fcadafaab6bd96d33d23973e01f7d421a6593
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42577
Closes https://github.com/pytorch/pytorch/issues/38174. Implements a join-based API to support training with the DDP module in the scenario where different processes have different no. of inputs. The implementation follows the description in https://github.com/pytorch/pytorch/issues/38174. Details are available in the RFC, but as a summary, we make the following changes:
#### Approach
1) Add a context manager `torch.nn.parallel.distributed.join`
2) In the forward pass, we schedule a "present" allreduce where non-joined process contribute 1 and joined processes contribute 0. This lets us keep track of joined processes and know when all procs are joined.
3) When a process depletes its input and exits the context manager, it enters "joining" mode and attempts to "shadow" the collective comm. calls made in the model's forward and backward pass. For example we schedule the same allreduces in the same order as the backward pass, but with zeros
4) We adjust the allreduce division logic to divide by the effective world size (no. of non-joined procs) rather than the absolute world size to maintain correctness.
5) At the end of training, the last joined process is selected to be the "authoritative" model copy
We also make some misc. changes such as adding a `rank` argument to `_distributed_broadcast_coalesced` and exposing some getters/setters on `Reducer` to support the above changes.
#### How is it tested?
We have tests covering the following models/scenarios:
- [x] Simple linear model
- [x] Large convolutional model
- [x] Large model with module buffers that are broadcast in the forward pass (resnet). We verify this with a helper function `will_sync_module_buffers` and ensure this is true for ResNet (due to batchnorm)
- [x] Scenario where a rank calls join() without iterating at all, so without rebuilding buckets (which requires collective comm)
- [x] Model with unused params (with find unused parameters=True)
- [x] Scenarios where different processes iterate for a varying number of different iterations.
- [x] Test consistency in tie-breaking when multiple ranks are the last ones to join
- [x] Test that we divide by the effective world_size (no. of unjoined processes)
#### Performance implications
###### Trunk vs PR patched, 32 GPUs, batch size = 32
P50, forward + backward + optimizer batch latency & total QPS: 0.121 264/s vs 0.121 264/s
P50 backwards only batch latency & total QPS: 0.087 369/s vs 0.087 368/s
###### join(enable=True) vs without join, 32 GPUs, batch size = 32, even inputs
P50, forward + backward + optimizer batch latency & total QPS: 0.120 265/s vs 0.121 264/s
P50 backwards only batch latency & total QPS: 0.088 364/s vs 0.087 368/s
###### join(enable=False) vs without join, 32 GPUs, batch size = 32, even inputs
P50 forward + backward + optimizer batch latency & total QPS: 0.121 264/s vs 0.121 264/s
P50 backwards only batch latency & total QPS: 0.087 368/s vs 0.087 368/s
###### join(enable=True) with uneven inputs (offset = 2000), 32 GPUs, batch size = 32
P50 forward + backward + optimizer batch latency & total QPS: 0.183 174/s vs 0.121 264/s
P50 backwards only batch latency & total QPS: 0.150 213/s vs 0.087 368/s
###### join(enable=True) with uneven inputs ((offset = 2000)), 8 GPUs, batch size = 32
P50 forward + backward + optimizer batch latency & total QPS: 0.104 308/s vs 0.104 308/s
P50 backwards only batch latency & total QPS: 0.070 454/s vs 0.070 459/s
The 2 above uneven inputs benchmark was conducted 32 GPUs and 4 GPUs immediately depleting their inputs and entering "join" mode (i.e. not iterating at all), while the other 28 iterating as normal. It looks like there is a pretty significant perf hit for this case when there are uneven inputs and multi-node training. Strangely, when there is a single node (8 GPUs), this does not reproduce.
#### Limitations
1) This is only implemented for MPSD, not SPMD. Per a discussion with mrshenli we want to encourage the use of MPSD over SPMD for DDP.
2) This does not currently work with SyncBN or custom collective calls made in the model's forward pass. This is because the `join` class only shadows the `broadcast` for buffers in the forward pass, the gradient allreduces in the bwd pass, unused parameters reduction, and (optionally) the rebuild buckets broadcasting in the backwards pass. Supporting this will require additional design thought.
3) Has not been tested with the [DDP comm. hook](https://github.com/pytorch/pytorch/issues/39272) as this feature is still being finalized/in progress. We will add support for this in follow up PRs.
ghstack-source-id: 111033819
Reviewed By: mrshenli
Differential Revision: D22893859
fbshipit-source-id: dd02a7aac6c6cd968db882c62892ee1c48817fbe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43742
We can remove all prim::profiles, update the values to their specialized profiled types, and then later guard the input graphs based on the input types of the fusion group. After that we remove specialized tensor types from the graph. This gets rid of having to update the vmap and removes all of the profile nodes in fusing.
Test Plan: Imported from OSS
Reviewed By: Krovatkin
Differential Revision: D23385206
Pulled By: eellison
fbshipit-source-id: 2c84bd1d1c38df0d7585e523c30f7bd28f399d7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43636
We weren't running inlining in the forward graph of differentiable subgraphs, and we weren't getting rid of all profiles as part of optimization.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D23358804
Pulled By: eellison
fbshipit-source-id: 05ede5fa356a15ca385f899006cb5b35484ef620
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43635
Intern the symbol, no functional changes. Aliasing need to be looked at but this should be done in a separate PR; this PR is just changing the symbol.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23358806
Pulled By: eellison
fbshipit-source-id: f18bcd142a0daf514136f019ae607e4c3f45d9f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43634
Because differentiable graphs detach the gradients of input Tensors, creating and inlining differentiable graphs changes the requires_grad property of tensors in the graph. In the legacy executor, this was not a problem as the Fuser would simply ignore the gradient property because it would be invariant that the LegacyExecutor only passed tensors with grad = False. This is not the case with the profiler, as the Fuser does it's own guarding.
Updating the type also helps with other typechecks, e.g. the ones specializing the backward, and with debugging the graph.
Other possibilities considered were:
- Fuser/Specialize AutogradZero always guards against requires_grad=False regardless of the profiled type
- Re-profile forward execution of differentiable graph
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D23358803
Pulled By: eellison
fbshipit-source-id: b106998accd5d0f718527bc00177de9af5bad5fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43657
We didn't have a test that ensures functions ran over RPC that are being profiled can use `with record_function()` to profile specific blocks in the function execution. This is useful if the user wants certain information about specific blocks in the function ran over RPC composed of many torch ops and some custom logic, for example.
Currently, this will not work if the function is TorchScripted since `with record_function()` is not torchscriptable yet. We can add support for this in future PRs so that torchscript RPC functions can also be profiled like this.
ghstack-source-id: 111033981
Reviewed By: mrshenli
Differential Revision: D23355215
fbshipit-source-id: 318d92e285afebfeeb2a7896b4959412c5c241d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43655
Pure, unadulerated bikeshed. The good stuff.
This makes things more consistent with ScriptModule.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D23401528
Pulled By: suo
fbshipit-source-id: 7dd8396365f118abcd045434acd9348545314f44
Summary:
Insert the registerizer into the Cuda Codegen pass list, to enable scalar replacement and close the gap in simple reduction performance.
First up the good stuff, benchmark before:
```
Column sum Caffe2 NNC Simple Better
(10, 100) 5.7917 9.7037 6.9386 6.0448
(100, 100) 5.9338 14.972 7.1139 6.3254
(100, 10000) 21.453 741.54 145.74 12.555
(1000, 1000) 8.0678 122.75 22.833 9.0778
Row sum Caffe2 NNC Simple Better
(10, 100) 5.4502 7.9661 6.1469 5.5587
(100, 100) 5.7613 13.897 21.49 5.5808
(100, 10000) 21.702 82.398 75.462 22.793
(1000, 1000) 22.527 129 176.51 22.517
```
After:
```
Column sum Caffe2 NNC Simple Better
(10, 100) 6.0458 9.4966 7.1094 6.056
(100, 100) 5.9299 9.1482 7.1693 6.593
(100, 10000) 21.739 121.97 162.63 14.376
(1000, 1000) 9.2374 29.01 26.883 10.127
Row sum Caffe2 NNC Simple Better
(10, 100) 5.9773 8.1792 7.2307 5.8941
(100, 100) 6.1456 9.3155 24.563 5.8163
(100, 10000) 25.384 30.212 88.531 27.185
(1000, 1000) 26.517 32.702 209.31 26.537
```
Speedup about 3-8x depending on the size of the data (increasing with bigger inputs).
The gap between NNC and simple is closed or eliminated - remaining issue appears to be kernel launch overhead. Next up is getting us closer to the _Better_ kernel.
It required a lot of refactoring and bug fixes on the way:
* Refactored flattening of parallelized loops out of the CudaPrinter and into its own stage, so we can transform the graph in the stage between flattening and printing (where registerization occurs).
* Made AtomicAddFuser less pessimistic, it will now recognize that if an Add to a buffer is dependent on all used Block and Thread vars then it has no overlap and does not need to be atomic. This allows registerization to apply to these stores.
* Fixed PrioritizeLoad mutator so that it does not attempt to separate the Store and Load to the same buffer (i.e. reduction case).
* Moved CudaAnalysis earlier in the process, allowing later stages to use the analyzed bufs.
* Fixed a bug in the Registerizer where when adding a default initializer statement it would use the dtype of the underlying var (which is always kHandle) instead of the dtype of the Buf.
* Fixed a bug in the IRMutator where Allocate statements logic was inverted to be replaced only if they did not change.
* Added simplification of simple Division patterns to the IRSimplifier.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42878
Reviewed By: glaringlee
Differential Revision: D23382499
Pulled By: nickgg
fbshipit-source-id: 3640a98fd843723abad9f54e67070d48c96fe949
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43728
Trace back from the weight node util we hit getattr, reconstruct the graph module with the traced nodes
and run the graph module to pack the weight. then replace the original chain of ops with the packed weight.
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23385090
fbshipit-source-id: 11341f0af525a02ecec36f163a9cd35dee3744a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43581
Add similar APIs like eager and graph mode on torchscript
- fuse_fx
- quantize_fx (for both post training static and qat)
- quantize_dynamic_fx (for post training dynamic)
- prepare_fx (for both post training static and qat)
- prepare_dynamic_fx (for post training dynamic)
- convert_fx (for all modes)
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23385091
fbshipit-source-id: b789e54e1a0f3af6b026fd568281984e253e0433
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42629
How to approach reviewing this diff:
- The new codegen itself lives in `tools/codegen`. Start with `gen.py`, then read `model.py` and them the `api/` folder. The comments at the top of the files describe what is going on. The CLI interface of the new codegen is similar to the old one, but (1) it is no longer necessary to explicitly specify cwrap inputs (and now we will error if you do so) and (2) the default settings for source and install dir are much better; to the extent that if you run the codegen from the root source directory as just `python -m tools.codegen.gen`, something reasonable will happen.
- The old codegen is (nearly) entirely deleted; every Python file in `aten/src/ATen` was deleted except for `common_with_cwrap.py`, which now permanently finds its home in `tools/shared/cwrap_common.py` (previously cmake copied the file there), and `code_template.py`, which now lives in `tools/codegen/code_template.py`. We remove the copying logic for `common_with_cwrap.py`.
- All of the inputs to the old codegen are deleted.
- Build rules now have to be adjusted to not refer to files that no longer exist, and to abide by the (slightly modified) CLI.
- LegacyTHFunctions files have been generated and checked in. We expect these to be deleted as these final functions get ported to ATen. The deletion process is straightforward; just delete the functions of the ones you are porting. There are 39 more functions left to port.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D23183978
Pulled By: ezyang
fbshipit-source-id: 6073ba432ad182c7284a97147b05f0574a02f763
Summary:
Fixes https://github.com/pytorch/pytorch/issues/43405.
This pull request adds a feature of printing all tracebacks if a `detect_anomaly` mode detects `nan` in nested backward operations.
The way I did it is by assigning a node as a parent to all nodes it produces during its backward calculation. Then if one of the children produces `nan`, it will print the traceback from the parent and grand parents (if any).
The parent is assigned in `parent_node_` member in `Node` class which is accessible in C++ by function `node->parent()` and in Python by `node.parent_function`.
A node has a parent iff:
1. it is created from a backward operation, and
2. created when anomaly mode and grad mode are both enabled.
An example of this feature:
import torch
def example():
x = torch.tensor(1.0, requires_grad=True)
y = torch.tensor(1e-8, requires_grad=True) # small to induce nan in n-th backward
a = x * y
b = x * y
z1 = a / b # can produce nan in n-th backward as long as https://github.com/pytorch/pytorch/issues/43414 is unsolved
z = z1 * z1
gy , = torch.autograd.grad( z , (y,), create_graph=True)
gy2, = torch.autograd.grad(gy , (y,), create_graph=True)
gy3, = torch.autograd.grad(gy2, (y,), create_graph=True)
gy4, = torch.autograd.grad(gy3, (y,), create_graph=True)
return gy4
with torch.autograd.detect_anomaly():
gy4 = example()
with output:
example.py:16: UserWarning: Anomaly Detection has been enabled. This mode will increase the runtime and should only be enabled for debugging.
with torch.autograd.detect_anomaly():
/home/mfkasim/anaconda2/envs/base3/lib/python3.8/site-packages/torch/autograd/__init__.py:190: UserWarning: Error detected in DivBackward0. Traceback of forward call that caused the error:
File "example.py", line 17, in <module>
gy4 = example()
File "example.py", line 12, in example
gy3, = torch.autograd.grad(gy2, (y,), create_graph=True)
File "/home/mfkasim/anaconda2/envs/base3/lib/python3.8/site-packages/torch/autograd/__init__.py", line 190, in grad
return Variable._execution_engine.run_backward(
(Triggered internally at ../torch/csrc/autograd/python_anomaly_mode.cpp:61.)
return Variable._execution_engine.run_backward(
/home/mfkasim/anaconda2/envs/base3/lib/python3.8/site-packages/torch/autograd/__init__.py:190: UserWarning:
Traceback of forward call that induces the previous calculation:
File "example.py", line 17, in <module>
gy4 = example()
File "example.py", line 11, in example
gy2, = torch.autograd.grad(gy , (y,), create_graph=True)
File "/home/mfkasim/anaconda2/envs/base3/lib/python3.8/site-packages/torch/autograd/__init__.py", line 190, in grad
return Variable._execution_engine.run_backward(
(Triggered internally at ../torch/csrc/autograd/python_anomaly_mode.cpp:65.)
return Variable._execution_engine.run_backward(
/home/mfkasim/anaconda2/envs/base3/lib/python3.8/site-packages/torch/autograd/__init__.py:190: UserWarning:
Traceback of forward call that induces the previous calculation:
File "example.py", line 17, in <module>
gy4 = example()
File "example.py", line 8, in example
z1 = a / b # can produce nan in n-th backward as long as https://github.com/pytorch/pytorch/issues/43414 is unsolved
(Triggered internally at ../torch/csrc/autograd/python_anomaly_mode.cpp:65.)
return Variable._execution_engine.run_backward(
Traceback (most recent call last):
File "example.py", line 17, in <module>
gy4 = example()
File "example.py", line 13, in example
gy4, = torch.autograd.grad(gy3, (y,), create_graph=True)
File "/home/mfkasim/anaconda2/envs/base3/lib/python3.8/site-packages/torch/autograd/__init__.py", line 190, in grad
return Variable._execution_engine.run_backward(
RuntimeError: Function 'DivBackward0' returned nan values in its 1th output.
cc & thanks to albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43626
Reviewed By: malfet
Differential Revision: D23397499
Pulled By: albanD
fbshipit-source-id: aa7435ec2a7f0d23a7a02ab7db751c198faf3b7d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43664
This PR implements the test runner for batched gradient computation with
vmap. It also implements the batching rule for sigmoid_backward and
tests that one can compute batched gradients with sigmoid (and batched
2nd gradients).
Test Plan: - New tests: `python test/test_vmap.py -v`
Reviewed By: ezyang
Differential Revision: D23358555
Pulled By: zou3519
fbshipit-source-id: 7bb05b845a41b638b7cca45a5eff1fbfb542a51f
Summary:
It is often that the conversion from torch operator to onnx operator requires input rank/dtype/shape to be known. Previously, the conversion depends on tracer to provide these info, leaving a gap in conversion of scripted modules.
We are extending the export with support from onnx shape inference. If enabled, onnx shape inference will be called whenever an onnx node is created. This is the first PR introducing the initial look of the feature. More and more cases will be supported following this PR.
* Added pass to run onnx shape inference on a given node. The node has to have namespace `onnx`.
* Moved helper functions from `export.cpp` to a common place for re-use.
* This feature is currently experimental, and can be turned on through flag `onnx_shape_inference` in internal api `torch.onnx._export`.
* Currently skipping ONNX Sequence ops, If/Loop and ConstantOfShape due to limitations. Support will be added in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40628
Reviewed By: mrshenli
Differential Revision: D22709746
Pulled By: bzinodev
fbshipit-source-id: b52aeeae00667e66e0b0c1144022f7af9a8b2948
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43539
Move the two source files out of the base internal mobile library to the app level. Make it ready for app-based selective build. Opensource build should not be affected. The file list change in build_variables.bzl affects internal build only.
ghstack-source-id: 111006135
Test Plan: CI
Reviewed By: ljk53
Differential Revision: D23287661
fbshipit-source-id: 9b2d688544e79e0fca9c84730ef0259952cd8abe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43676
This is one part of https://github.com/pytorch/pytorch/issues/41574 to
ensure we consolidate everything around ivalue::Future.
I've removed the use of torch/csrc/utils/future.h from the autograd engines and
used ivalue::Future instead.
ghstack-source-id: 110895545
Test Plan: waitforbuildbot.
Reviewed By: albanD
Differential Revision: D23362415
fbshipit-source-id: aa109b3f8acf0814d59fc5264a85a8c27ef4bdb6
Summary:
This PR adds API to package unoptimized/fallback blocks as function calls. It's mainly meant to be used by TensorExpressionsFuser and SpecializeAutogradZero passes as both specialize the original graph but would also like to provide a fallback path in case the assumptions under which the graph was specialized do not hold for some inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43274
Reviewed By: malfet
Differential Revision: D23406961
Pulled By: Krovatkin
fbshipit-source-id: ef21fc9ad886953461b09418d02c75c58375490c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43647
Nothing fancy, just a basic implementation of the graph executor without using stack machine.
Reviewed By: bwasti
Differential Revision: D23208413
fbshipit-source-id: e483bb6ad7ba8591bbe1767e669654d82f42c356
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43481
Apply OperatorGenerator for prim and special operator registration. It does not affect the existing build by default. However, if a whitelist of operator exists, only the operators in the whitelist will be registered. It has the potential to save up to 200 KB binary size, depending on the usage.
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D23287251
Pulled By: iseeyuan
fbshipit-source-id: 3ca39fbba645bad8d69e69195f3680e4f6d633c5
Summary:
Fixed grammatical errors and punctuation so that it be can more understandable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43779
Reviewed By: ZolotukhinM
Differential Revision: D23407849
Pulled By: malfet
fbshipit-source-id: 09c064ce68d0f37f8023c2ecae8775fc00541a2c
Summary:
In case we want to store binary files using `ScriptModule.save(..., _extra_files=...)` functionality. With python3 we can just use bytes only and not bother about it.
I had to do a copy-pasta from pybind sources, maybe we should upstream it, but it'd mean adding a bunch of template arguments to `bind_map` which is a bind untidy.
Let me know if there's a better place to park this function (it seems to be the only invocation of `bind_map` so I put it in the same file)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43241
Reviewed By: zdevito
Differential Revision: D23205244
Pulled By: dzhulgakov
fbshipit-source-id: 8f291eb4294945fe1c581c620d48ba2e81b3dd9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43310
In this diff, we prepared some example DDP communication hooks [#40848](https://github.com/pytorch/pytorch/pull/40848):
1\. `allreduce_hook`: This DDP communication hook just calls ``allreduce`` using ``GradBucket`` tensors. Once gradient tensors are aggregated across all workers, its ``then`` callback takes the mean and returns the result. If user registers this hook DDP results is expected to be same as the case where no hook was registered. Hence, this won't change behavior of DDP and user can use this as a reference or modify this hook to log useful information or any other purposes while unaffecting DDP behavior.
2\. `allgather_then_aggregate_hook` Similar to ``allreduce_hook``, this hook first gathers ``GradBucket`` tensors and its ``then`` callback aggregates the gathered gradient tensors and takes mean. Instead of ``allreduce`` this hook uses ``allgather``. Note that with W workers, both the computation and communication time scale as O(W) for allgather compared to O(logW) for allreduce. Therefore, this hook is expected to be much slower than ``allreduce_hook`` although both essentially do the same thing with the gradients.
3\. `fp16_compress_hook` This DDP communication hook implements a simple gradient compression approach that converts ``GradBucket`` tensors whose type is assumed to be ``torch.float32`` to half-precision floating point format (``torch.float16``). It allreduces those ``float16`` gradient tensors. Once compressed gradient tensors are allreduced, its then callback called ``decompress`` converts the aggregated result back to ``float32`` and takes the mean.
4\. `quantization_pertensor_hook` does quantization per tensor and uses the idea in https://pytorch.org/docs/master/generated/torch.quantize_per_tensor.html. Note that we separately send scale and zero_point (two floats per rank) before quantized tensors.
5\. `quantization_perchannel_hook` does quantization per channel similar to https://pytorch.org/docs/master/generated/torch.quantize_per_channel.html. The main motivation is that after the initial QSGD study diff, we realized that for considerably large gradient tensors such as a tensor that contains 6 million floats quantizing dividing it into smaller channels (512 float chunks) and quantizing independently may significantly increase the resolution and result with lower error.
ghstack-source-id: 110923269
Test Plan:
python torch/distributed/algorithms/ddp_comm_hooks/test_ddp_hooks.py
Couldn't download test skip set, leaving all tests enabled...
.....
----------------------------------------------------------------------
Ran 4 tests in 26.724s
OK
Internal testing:
```
buck run mode/dev-nosan //caffe2/test/distributed/algorithms/ddp_comm_hooks:test_ddp_hooks
```
Reviewed By: malfet
Differential Revision: D22937999
fbshipit-source-id: 274452e7932414570999cb978ae77a97eb3fb0ec
Summary:
It's useful if we add additional attributed to nodes in the graph - it's easier to set the attribute on all nodes, even if the value would happen to be None.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43432
Reviewed By: jamesr66a
Differential Revision: D23276433
Pulled By: dzhulgakov
fbshipit-source-id: c69e7cb723bbbb4dba3b508a3d6c0e456fe610df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43447
Two main better-engineering motivations to run all FutureNCCL callbacks on a dedicated stream:
1. Each time a then callback was called, we would get a stream from the pool and run the callback on that stream. If we observe the stream traces using that approach, we would see a lot of streams and debugging would become more complicated. If we have a dedicated stream to run all then callback operations, the trace results will be much cleaner and easier to follow.
2. getStreamFromPool may eventually return the default stream or a stream that is used for other operations. This can cause slowdowns.
Unless then callback takes longer than preceding allreduce, this approach will be as performant as the previous approach.
ghstack-source-id: 110909401
Test Plan:
Perf trace runs to validate the desired behavior:
See the dedicated stream 152 is running the then callback operations:
{F299759342}
I run pytorch.benchmark.main.workflow using resnet50 and 32 GPUs registering allreduce with then hook.
See f213777896 [traces](https://www.internalfb.com/intern/perfdoctor/results?run_id=26197585)
After updates, same observation: see f214890101
Reviewed By: malfet
Differential Revision: D23277575
fbshipit-source-id: 67a89900ed7b70f3daa92505f75049c547d6b4d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43086
This PR changes the format of `ConvPackedParam` in a nearly backwards-compatible way:
* a new format is introduced which has more flexibility and a lower on-disk size
* custom pickle functions are added to `ConvPackedParams` which know how to load the old format
* the custom pickle functions are **not** BC because the output type of `__getstate__` has changed. We expect this to be acceptable as no user flows are actually broken (loading a v1 model with v2 code works), which is why we whitelist the failure.
Test plan (TODO finalize):
```
// adhoc testing of saving v1 and loading in v2: https://gist.github.com/vkuzo/f3616c5de1b3109cb2a1f504feed69be
// test that loading models with v1 conv params format works and leads to the same numerics
python test/test_quantization.py TestSerialization.test_conv2d_graph
python test/test_quantization.py TestSerialization.test_conv2d_nobias_graph
// test that saving and loading models with v2 conv params format works and leads to same numerics
python test/test_quantization.py TestSerialization.test_conv2d_graph_v2
python test/test_quantization.py TestSerialization.test_conv2d_nobias_graph_v2
// TODO before land:
// test numerics for a real model
// test legacy ONNX path
```
Note: this is a newer copy of https://github.com/pytorch/pytorch/pull/40003
Test Plan: Imported from OSS
Reviewed By: dreiss
Differential Revision: D23347832
Pulled By: vkuzo
fbshipit-source-id: 06bbe4666421ebad25dc54004c3b49a481d3cc92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43524
1. adds support for testing BC on data format and numerics for graph mode
quantized modules
2. using the above, adds coverage for quantized conv2d on graph mode
Test Plan:
```
python test/test_quantization.py TestSerialization.test_conv2d_nobias
python test/test_quantization.py TestSerialization.test_conv2d_graph
python test/test_quantization.py TestSerialization.test_conv2d_nobias_graph
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D23335222
fbshipit-source-id: 0c9e93a940bbf6c676c2576eb62fcc725247588b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42531
[First PR: Add private API to support tensor lists: _foreach_add(TensorList tensors, Scalar scalar)](https://github.com/pytorch/pytorch/pull/41554).
**Motivation**
[GitHub issue](https://github.com/pytorch/pytorch/issues/38655)
Current PyTorch optimizer implementations are not efficient in cases when we work with a lot of small feature tensors. Starting a lot of kernels slows down the whole process. We need to reduce the number of kernels that we start.
As an example, we should be looking at [NVIDIAs Apex](https://github.com/NVIDIA/apex).
In order to track progress, we will pick PyTorchs DCGAN model with Adam optimizer and once the optimizer is reimplemented with tensor lists, benchmark the model performance against original model version, Apexs version with original Adam optimizer and it’s FusedAdam optimizer.
**Current API restrictions**
- List can't be empty (will fixed in upcoming PRs).
- All tensors in the list must have the same dtype, device and size.
**Broadcasting**
At this point we don't support broadcasting.
**What is 'Fast' and 'Slow' route**
In particular cases, we cant process an op with a fast list CUDA kernel. Still, we can do with a regular for-loop where the op will be applied to each tensor individually through the dispatch mechanisms. There are a few checks that decide whether the op will be performed via a 'fast' or 'slow' path.
To go the fast route,
- All tensors must have strided layout
- All tensors must be dense and not have overlapping memory
- The resulting tensor type must be the same.
---------------
**In this PR**
- Adding a `std::vector<Tensor> _foreach_add_(TensorList tensors, Scalar scalar)` API
- Resolving some additional comments from previous [PR](https://github.com/pytorch/pytorch/pull/41554).
**Tests**
Tested via unit tests
**TODO**
1. Properly handle empty lists
**Plan for the next PRs**
1. APIs
- Binary Ops for list with Scalar
- Binary Ops for list with list
- Unary Ops for list
- Pointwise Ops
2. Complete tasks from TODO
3. Rewrite PyTorch optimizers to use for-each operators for performance gains.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D23331892
Pulled By: izdeby
fbshipit-source-id: c585b72e1e87f6f273f904f75445618915665c4c
Summary:
Adds two more "missing" NumPy aliases: arctanh and arcsinh, and simplifies the dispatch of other arc* aliases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43762
Reviewed By: ngimel
Differential Revision: D23396370
Pulled By: mruberry
fbshipit-source-id: 43eb0c62536615fed221d460c1dec289526fb23c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43792
This fixes the issue we had with the nightlies not being uploaded
properly, basically what was happening was that `aws s3 cp` doesn't
automatically distinguish between prefixes that are already
"directories" vs a single file with the same name.
This means that if you'd like to upload a file to a "directory" in S3
you need to suffix your destination with a slash.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D23402074
Pulled By: seemethere
fbshipit-source-id: 6085595283fcbbbab0836ccdfe0f8aa2a6abd7c8
Summary:
Add a max/min operator that only return values.
## Some important decision to discuss
| **Question** | **Current State** |
|---------------------------------------|-------------------|
| Expose torch.max_values to python? | No |
| Remove max_values and only keep amax? | Yes |
| Should amax support named tensors? | Not in this PR |
## Numpy compatibility
Reference: https://numpy.org/doc/stable/reference/generated/numpy.amax.html
| Parameter | PyTorch Behavior |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------|
| `axis`: None or int or tuple of ints, optional. Axis or axes along which to operate. By default, flattened input is used. If this is a tuple of ints, the maximum is selected over multiple axes, instead of a single axis or all the axes as before. | Named `dim`, behavior same as `torch.sum` (https://github.com/pytorch/pytorch/issues/29137) |
| `out`: ndarray, optional. Alternative output array in which to place the result. Must be of the same shape and buffer length as the expected output. | Same |
| `keepdims`: bool, optional. If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the input array. | implemented as `keepdim` |
| `initial`: scalar, optional. The minimum value of an output element. Must be present to allow computation on empty slice. | Not implemented in this PR. Better to implement for all reductions in the future. |
| `where`: array_like of bool, optional. Elements to compare for the maximum. | Not implemented in this PR. Better to implement for all reductions in the future. |
**Note from numpy:**
> NaN values are propagated, that is if at least one item is NaN, the corresponding max value will be NaN as well. To ignore NaN values (MATLAB behavior), please use nanmax.
PyTorch has the same behavior
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43092
Reviewed By: ngimel
Differential Revision: D23360705
Pulled By: mruberry
fbshipit-source-id: 5bdeb08a2465836764a5a6fc1a6cc370ae1ec09d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/43732.
Requires importing the fft namespace in the C++ API, just like the Python API does, to avoid clobbering torch::fft the function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43749
Reviewed By: glaringlee
Differential Revision: D23391544
Pulled By: mruberry
fbshipit-source-id: d477d0b6d9a689d5c154ad6c31213a7d96fdf271
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43719
Accidentally this slipped through: with guard did not update the current
context
Test Plan: cpu_caching_allocator_test
Reviewed By: linbinyu
Differential Revision: D23374453
fbshipit-source-id: 1d3ef21cc390d0a8bde98fb1b5c2175b40ab571b
Summary:
1) Manifold raises StorageException when it see's an error: https://fburl.com/diffusion/kit3me8a
2) torch re-raises exception: https://fburl.com/diffusion/zbw9wmpu
Issue here, that in StorageException first argument is bool canRetry while re-raising happens with first argument being str as in all Python exceptions.
Test Plan:
Existing tests should pass. +
```
In [1]: from manifold.clients.python import StorageException
In [2]: getattr(StorageException, "message", None)
Out[2]: <attribute 'message' of 'manifold.blobstore.blobstore.types.StorageException' objects>
In [3]: getattr(Exception, "message", None) is None
Out[3]: True
Reviewed By: haijunz
Differential Revision: D23195514
fbshipit-source-id: baa1667dbba4086db6ec93f009e400611ac9b938
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43233
XNNPack is already being used for the convolution2d operation. Add the
ability for it to be used with transpose convolution.
Test Plan: buck run caffe2/test:xnnpack_integration
Reviewed By: kimishpatel
Differential Revision: D23184249
fbshipit-source-id: 3fa728ce1eaca154d24e60f800d5e946d768c8b7
Summary:
This prevents confusing errors when the interpreter encounters some
syntax errors in the middle.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42870
Reviewed By: albanD
Differential Revision: D23269265
Pulled By: ezyang
fbshipit-source-id: 61f62cbe294078ad4a909fa87aa93abd08c26344
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43705
This was causing fb-internal flakiness. I'm surprised that the ASAN
builds don't catch this behavior.
The problem is that dereferencing the end() pointer of a vector is
undefined behavior. This PR fixes one callsite where BatchedFallback
dereferences the end() pointer and adds an assert to make sure another
callsite doesn't do that.
Test Plan:
- Make sure all tests pass (`pytest test/test_vmap.py -v`)
- It's hard to write a new test for this because most of the time this
doesn't cause a crash. It really depends on what lives at the end()
pointer.
Reviewed By: ezyang
Differential Revision: D23373352
Pulled By: zou3519
fbshipit-source-id: 61ea0be80dc006f6d4e73f2c5badd75096f63e56
Summary:
Move `code_coverage_tool` from `experimental` folder to `caffe2/tools` folder.
Not sure if the fb related code is something we don't want to share with the oss. Can reviewers please help me check with `fbcode_coverage.py` and files in `fbcode/` folder?
Test Plan: Test locally
Reviewed By: malfet
Differential Revision: D23379383
fbshipit-source-id: f6782389ebb1b147eaf6d3664b5955db79d24ff3
Summary:
These started failing since **https://github.com/pytorch/pytorch/pull/43633** for indecipherable reasons; temporarily disable. The errors on the PRs were
```
Downloading workspace layers
workflows/workspaces/3ca9ca71-7449-4ae1-bb7b-b7612629cc62/0/8607ba99-5ced-473b-b60a-0025b48739a6/0/105.tar.gz - 8.4 MB
Applying workspace layers
8607ba99-5ced-473b-b60a-0025b48739a6
```
which is not too helpful...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43750
Reviewed By: ZolotukhinM
Differential Revision: D23388060
Pulled By: eellison
fbshipit-source-id: 96afa0160ec948049f3e194787a0a7ddbeb5124a
Summary:
`torch.scatter` allows `src` to be of different type when `src` is a scalar. This requires a an explicit cast op to be inserted in the ONNX graph because ONNX `ScatterElements` does not allow different types. This PR updates the export of `torch.scatter` with this logic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43440
Reviewed By: hl475
Differential Revision: D23352317
Pulled By: houseroad
fbshipit-source-id: c9eeddeebb67fc3c40ad01def134799ef2b4dea6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41371
**Summary**
This commit enables the use of `torch.no_grad()` in a with item of a
with statement within JIT. Note that the use of this context manager as
a decorator is not supported.
**Test Plan**
This commit adds a test case to the existing with statements tests for
`torch.no_grad()`.
**Fixes**
This commit fixes#40259.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D22649519
Pulled By: SplitInfinity
fbshipit-source-id: 7fa675d04835377666dfd0ca4e6bc393dc541ab9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42708
Add rowwise prune pytorch op.
This operator introduces sparsity to the 'weights' matrix with the help
of the importance indicator 'mask'.
A row is considered important and not pruned if the mask value for that
particular row is 1(True) and not important otherwise.
Test Plan:
buck test caffe2/torch/fb/sparsenn:test -- rowwise_prune
buck test caffe2/test:pruning
Reviewed By: supriyar
Differential Revision: D22849432
fbshipit-source-id: 456f4f77c04158cdc3830b2e69de541c7272a46d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43564
Static dispatch was originally introduced for mobile selective build.
Since we have added selective build support for dynamic dispatch and
tested it in FB production for months, we can deprecate static dispatch
to reduce the complexity of the codebase.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D23324452
Pulled By: ljk53
fbshipit-source-id: d2970257616a8c6337f90249076fca1ae93090c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43570
Add the default op dependency graph to the source tree - use it if user runs
custom build in dynamic dispatch mode without providing the graph.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D23326988
Pulled By: ljk53
fbshipit-source-id: 5fefe90ca08bb0ca20284e87b70fe1dba8c66084
Summary:
Suggested by Shoaib Meenai, we should use mode/ndk_libcxx to replace mode/gnustl.
This diff updated all build flags for caffe2 and pytorch in aibench. For easy management, I created two mode files in xplat/caffe2/mode, and delete buckconfig.ptmobile.pep.
Test Plan:
caffe2
```
buck run aibench:run_bench -- -b aibench/specifications/models/caffe2/squeezenet/squeezenet.json --remote --devices s9f
```
https://our.intern.facebook.com/intern/aibench/details/433604719423848
full jit
```
buck run aibench:run_bench -- -b aibench/specifications/models/pytorch/fbnet/fbnet_mobile_inference.json --platform android/full_jit --framework pytorch --remote --devices SM-G960F-8.0.0-26
```
https://our.intern.facebook.com/intern/aibench/details/189359776958060
lite interpreter
```
buck run aibench:run_bench -- -b aibench/specifications/models/pytorch/fbnet/fbnet_mobile_inference.json --platform android --framework pytorch --remote --devices s9f
```
https://our.intern.facebook.com/intern/aibench/details/568178969092066
Reviewed By: smeenai
Differential Revision: D23338089
fbshipit-source-id: 62f4ae2beb004ceaab1f73f4de8ff9e0c152d5ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43633
In the backward graph, _grad_sum_to_size is inserted whenever a possibly broadcasting op is called:"
`"aten::_grad_sum_to_size(Tensor(a) self, int[]? size) -> Tensor(a)"`
If a broadcast occurred, a sum is called, otherwise the second input is None and it is a no-op. Most of the time, it's a no-op (in the fast RNNs benchmark > 90% of the time).
We can get rid of this op by profiling the optionality of the second input. I added `prim::profile_optional` to do this, which counts the number of times it saw a None value and the number of times it saw a value present. When specializing the backward graph, we insert checks for values we profiled as None, and in the optimized block can remove the grad_sum_to_size calls that use those values.
In the future we may revisit this when NNC supports reductions and we want to replace grad_sum_to_size with sums as well, but I think this is worth landing now.
Test Plan: Imported from OSS
Reviewed By: bwasti, ZolotukhinM
Differential Revision: D23358809
Pulled By: eellison
fbshipit-source-id: a30a148ca581370789d57ba082d23cbf7ef2cd4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43632
Specialize the backward graph by guarding on the undefinedness of the input tensors. The graph will look like:
```
ty1, ty2, succesful_checks = prim::TypeCheck(...)
if (succesful_checks)
-> optimized graph
else:
-> fallback graph
```
Specializing on the undefinedness of tensors allows us to clean up the
```
if any_defined(inputs):
outputs = <original_computation>
else:
outputs = autograd zero tensors
```
blocks that make up the backward graph, so that we can fuse the original_computation nodes together.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D23358808
Pulled By: eellison
fbshipit-source-id: f5bb28f78a4a3082ecc688a8fe0345a8a098c091
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43631
I added a new test for just profiler stuff - I don't think the test should go in test_jit.py. Maybe this should just go in test_tensorexpr_fuser, but I'm not really testing tensorexpr stuff either... LMK
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23358810
Pulled By: eellison
fbshipit-source-id: 074238e1b60e4c4a919a052b7a5312b790ad5d82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43630
No functional changes here - just refactoring specialize autograd zero to a class, and standardizing its API to take in a shared_ptr<Graph>
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23358805
Pulled By: eellison
fbshipit-source-id: 42e19ef2e14df66b44592252497a47d03cb07a7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43629
We have a few places where we count the size a block / subgraph - it's nice to have a shared API to ignore operators that are not executed in the optimized graph (will be used when i add a new profiling node in PR ^^)
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23358807
Pulled By: eellison
fbshipit-source-id: 62c745d9025de94bdafd9f748f7c5a8574cace3f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43721
We can combine optimization pass and save_for_mobile together to reduce friction. Since lite interpreter model can also be used in full JIT, I don't think we need the option to save it as full JIT model.
Also
- improved usage message
- print op list before and after optimization pass
Test Plan:
```
buck run //xplat/caffe2:optimize_for_mobile -- --model=/home/linbin/sparkspot.pt
Building: finished in 12.4 sec (100%) 2597/2597 jobs, 2 updated
Total time: 12.5 sec
pt_operator_library(
name = "old_op_library",
ops = [
"aten::_convolution",
"aten::adaptive_avg_pool2d",
"aten::add_.Tensor",
"aten::batch_norm",
"aten::mul.Tensor",
"aten::relu_",
"aten::softplus",
"aten::sub.Tensor",
],
)
pt_operator_library(
name = "new_op_library",
ops = [
"aten::adaptive_avg_pool2d",
"aten::add_.Tensor",
"aten::batch_norm",
"aten::mul.Tensor",
"aten::relu_",
"aten::softplus",
"aten::sub.Tensor",
"prepacked::conv2d_clamp_run",
],
)
The optimized model for lite interpreter was saved to /home/linbin/sparkspot_mobile_optimized.bc
```
```
buck run //xplat/caffe2:optimize_for_mobile -- --model=/home/linbin/sparkspot.pt --backend=vulkan
```
Reviewed By: kimishpatel
Differential Revision: D23363533
fbshipit-source-id: f7fd61aaeda5944de5bf198e7f93cacf8368babd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43653
When nodes are created without an explicit name, a name is generated for
it based on the target. In these cases, we need to avoid shadowing
builtin names. Otherwise, code like:
```
a.foo.bar
```
results in pretty-printed code like:
```
getattr = a.foo
getattr_1 = getattr.bar
```
While this is technically allowed in Python, it's probably a bad idea,
and more importantly is not supported by TorchScript (where `getattr` is
hardcoded).
This PR changes the name generation logic to avoid shadowing all
builtins and langauge keywords. We already do this for PyTorch
built-ins, so just extend that logic. So now the generated code will
look like:
```
getattr_1 = a.foo
getattr_2 = getattr_1.bar
```
Fixes#43522
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D23357420
Pulled By: suo
fbshipit-source-id: 91e9974adc22987eca6007a2af4fb4fe67f192a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43587
Add tests for graph mode quantization on torchvision and make sure it matches
current eager mode quantization
Test Plan:
Imported from OSS
Imported from OSS
Reviewed By: z-a-f
Differential Revision: D23331253
fbshipit-source-id: 0445a44145d99837a2c975684cd0a0b7d965c8f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43456
Introduce the template OperatorGenerator, which returns an optional Operator. It's null if the templated bool value is null.
RegisterOperators() is updated to take the optional Operator. A null will not be registered.
With this update the selective operator registration can be done at compile time. Tests are added to show an operator can be registered if it's in a whitelist and it will not be registered if it's not in the whitelist.
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D23283563
Pulled By: iseeyuan
fbshipit-source-id: 456e0c72b2f335256be800aeabb797bd83bcf0b3
Summary:
To reduce the chance of conflicts, not all ops are fixed. Ops starting with letter `f` will be fixed in separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43583
Reviewed By: ZolotukhinM
Differential Revision: D23330347
Pulled By: mruberry
fbshipit-source-id: 3387cb1e495faebd16fb183039197c6d90972ad4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42259
**Summary**
This commit modifies IR generation to insert explicit cast that cast
each return value to `Any` when a function is annotated as returning `Any`.
This precludes the failure in type unification (see below) that caused
this issue.
Issue #41962 reported that the use of an `Any` return type in
combination with different code paths returning values of different
types causes a segmentation fault. This is because the exit transform
pass tries to unify the different return types, fails, but silently sets
the type of the if node to c10::nullopt. This causes problems later in
shape analysis when that type object is dereferenced.
**Test Plan**
This commit adds a unit test that checks that a function similar to the
one in #41962 can be scripted and executed.
**Fixes**
This commit fixes#41962.
Differential Revision: D22883244
Test Plan: Imported from OSS
Reviewed By: eellison, yf225
Pulled By: SplitInfinity
fbshipit-source-id: 523d002d846239df0222cd07f0d519956e521c5f
Summary:
fmax/fmin propagate the number if one argument is NaN, which doesn't match the eager mode behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43590
Reviewed By: mruberry
Differential Revision: D23338664
Pulled By: bertmaher
fbshipit-source-id: b0316a6f01fcf8946ba77621efa18f339379b2d0
Summary:
Related to https://github.com/pytorch/pytorch/issues/38349
Implement NumPy-like functions `maximum` and `minimum`.
The `maximum` and `minimum` functions compute input tensors element-wise, returning a new array with the element-wise maxima/minima.
If one of the elements being compared is a NaN, then that element is returned, both `maximum` and `minimum` functions do not support complex inputs.
This PR also promotes the overloaded versions of torch.max and torch.min, by re-dispatching binary `torch.max` and `torch.min` to `torch.maximum` and `torch.minimum`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42579
Reviewed By: mrshenli
Differential Revision: D23153081
Pulled By: mruberry
fbshipit-source-id: 803506c912440326d06faa1b71964ec06775eac1
Summary:
Replace `test` with `coverage_test` stage for `pytorch-linux-bionic-py3.8-gcc9` configuration
Add `coverage.xml` to the list of ignored files
Add `codecov.yml` that maps installed pytorch folders back to original locations
Cleanup coverage option utilization in `run_test.py` and adapt it towards combining coverage reports across the runs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43600
Reviewed By: seemethere
Differential Revision: D23351877
Pulled By: malfet
fbshipit-source-id: acf78ae4c8f3e23920a76cce1d50f2821b83eb06
Summary:
These tests are failing on one of my system that does not have lapack
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43566
Reviewed By: ZolotukhinM
Differential Revision: D23325378
Pulled By: mruberry
fbshipit-source-id: 5d795e460df0a2a06b37182d3d4084d8c5c8e751
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43554
Move function implementations in the TensorIteratorConfig Class from TensorIterator.h to TensorIterator.cpp to avoid this issue: https://github.com/pytorch/pytorch/issues/43300
Reviewed By: malfet
Differential Revision: D23319007
fbshipit-source-id: 6cc3474994ea3094a294f795ac6998c572d6fb9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43640
+ added a `self.checkGraphModule` utility function to wrap the common
test assert pattern.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D23356262
Pulled By: suo
fbshipit-source-id: a50626dcb01246d0dbd442204a8db5958cae23ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43559
- remove mkl strided gemm since it was acting weird in some cases, use the plain for loop for gemm for now, it will have performance implications but this closes the gap for the ctr_instagram_5x model
- reproduced the failure scenario of batchmatmul on ctr_instagram_5x by increasing the dimensions of the inputs
- added an option in netrunner to skip bmm if needed
Test Plan:
- net runner passes with ctr_instagram 5x
- bmm unit test repros the discrepancy fixed
Reviewed By: amylittleyang
Differential Revision: D23320857
fbshipit-source-id: 7d5cfb23c1b0d684e1ef766f1c1cd47bb86c9757
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43307
I identified a bug with DDP communication hook while I was trying accuracy benchmarks: I was getting `loss=nan`.
Looks like when we re-`initialize_bucketviews` with the value of `future_work`, as `Reducer::mark_variable_ready_dense` does `bucket_view.copy_(grad)` it wasn't copying the `grads` back to the contents since `bucket_view` wouldn't have any relationship with `contents` after re-intitializing it with something else. As we have multiple iterations, this was causing problems.
I solved this by adding two states for `bucket_view`:
```
// bucket_views_in[i].copy_(grad) and
// grad.copy_(bucket_views_out[i])
// provide convenient ways to move grad data in/out of contents.
std::vector<at::Tensor> bucket_views_in;
std::vector<at::Tensor> bucket_views_out;
```
I included two additional unit tests where we run multiple iterations for better test coverage:
1) `test_accumulate_gradients_no_sync_allreduce_hook`
2) `test_accumulate_gradients_no_sync_allreduce_with_then_hook`.
ghstack-source-id: 110728299
Test Plan:
Run `python test/distributed/test_c10d.py`, some perf&accuracy benchmarks.
New tests:
`test_accumulate_gradients_no_sync_allreduce_hook`
`test_accumulate_gradients_no_sync_allreduce_with_then_hook`
Acc benchmark results look okay:
f214188350
Reviewed By: agolynski
Differential Revision: D23229309
fbshipit-source-id: 329470036cbc05ac12049055828495fdb548a082
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43584
1. add `metadata.pkl` to `.bc` file which includes the model info that we are interested in
2. load `metadata.pkl` as a attribute `unordered_map<string, string>` in the module
ghstack-source-id: 110730013
Test Plan:
- CI
```buck build //xplat/caffe2:jit_module_saving
```
```buck build //xplat/caffe2:torch_mobile_core
```
Reviewed By: xcheng16
Differential Revision: D23330080
fbshipit-source-id: 5d65bd730b4b566730930d3754fa1bf16aa3957e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43247
`torch.cuda.nccl` APIs didn't throw appropriate errors when called
with inputs/outputs that were of the wrong type and it resulted in some cryptic
errors instead.
Adding some error checks with explicit error messages for these APIs.
ghstack-source-id: 110683546
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D23206069
fbshipit-source-id: 8107b39d27f4b7c921aa238ef37c051a9ef4d65b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43573
We recently updated the Stella NLU model in D23307228, and the App started to crash with `Following ops cannot be found:{aten::str, }`.
Test Plan: Verified by installing the assistant-playground app on Android.
Reviewed By: czlx0701
Differential Revision: D23325409
fbshipit-source-id: d670242868774bb0aef4be5c8212bc3a3f2f667c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43591
100 randomized inputs vs 50 doesn't change the balance that much but speed up test runtime
Test Plan: CI
Reviewed By: orionr, seemethere
Differential Revision: D23332393
fbshipit-source-id: 7a8ff9127ee3e045a83658a7a670a844f3862987
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43468
Closes https://github.com/pytorch/pytorch/issues/41378.
https://github.com/pytorch/pytorch/pull/41973 enhanced the skip decorators to
report the right no. of GPUs required, but this information was not passed to
the main process where the message is actually displayed. This PR uses a
`multiprocessing.Manager()` so that the dictionary modification is reflected
correctly in the main process.
ghstack-source-id: 110684228
Test Plan:
With this diff, we can run a test in such as in https://github.com/pytorch/pytorch/pull/42577 that requires 4 GPUs on a 2 GPU machine, and we get the expected message:
```
test_ddp_uneven_inputs_replicated_error (test_distributed.TestDistBackend) ... skipped 'Need at least 4 CUDA devices'
```
Reviewed By: mrshenli
Differential Revision: D23285790
fbshipit-source-id: ac32456ef3d0b1d8f1337a24dba9f342c736ca18
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43182
We should avoid using `deepcopy` on the module because it involves copying the weights.
Comparing the implementation of `c10::ivalue::Object::copy()` vs `c10::ivalue::Object::deepcopy()`, the only difference is `deepcopy` copies the attributes (slots) while `copy` does not.
Reviewed By: bwasti
Differential Revision: D23171770
fbshipit-source-id: 3cd711c6a2a19ea31d1ac1ab2703a0248b5a4ef3
Summary:
Fixes gh-42282
This adds a device-mismatch check to `addmm` on CPU and CUDA. Although it seems like the dispatcher is always selecting the CUDA version here if any of the inputs are on GPU. So in theory the CPU check is unnecessary, but probably better to err on the side of caution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43505
Reviewed By: mruberry
Differential Revision: D23331651
Pulled By: ngimel
fbshipit-source-id: 8eb2f64f13d87e3ca816bacec9d91fe285d83ea0
Summary:
openssh should be installed by either the circleci machines or from the
jenkins workers so we shouldn't need to install it ourselves in order to
get ssh functionality
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43597
Reviewed By: ezyang
Differential Revision: D23333479
Pulled By: seemethere
fbshipit-source-id: 17a1ad0200a9df7d4818ab1ed44c8488ec8888fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43603
We are in the midst of landing a big reword of profiling executor and
benchmarks are expected to fail while we are in the transitional state.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D23334818
Pulled By: ZolotukhinM
fbshipit-source-id: 99ff17c6f8ee18d003f6ee76ff0e719cea68c170
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43173
With this change the fuser starts to generate typechecks for inputs of
fusion group. For each fusion group we generate a typecheck and an if
node: the true block contains the fused subgraph, the false block
contains unoptimized original subgraph.
Differential Revision: D23178230
Test Plan: Imported from OSS
Reviewed By: eellison
Pulled By: ZolotukhinM
fbshipit-source-id: f56e9529613263fb3e6575869fdb49973c7a520b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43235
This functionality is needed when we want to not lose track of
nodes/values as we merge and unmerge them into other nodes. For
instance, if we have a side data structure with some meta information
about values or nodes, this new functionality would allow to keep that
metadata up to date after merging and unmerging nodes.
Differential Revision: D23202648
Test Plan: Imported from OSS
Reviewed By: eellison
Pulled By: ZolotukhinM
fbshipit-source-id: 350d21a5d462454166f8a61b51d833551c49fcc9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43365
We don't have shape inference for them yet.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23253418
Pulled By: ZolotukhinM
fbshipit-source-id: 9c38778b8a616e70f6b2cb5aab03d3c2013b34b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43557
backout the diff that caused some errors in pytext distributed training
Test Plan: Tested by rayhou who verified reverting the diff works
Differential Revision: D23320238
fbshipit-source-id: caa0fe74404059e336cd95fdb41373f58ecf486e
Summary:
Original commit changeset: f368d00f7bae
Back out "[2/3][lite interpreter] add metadata when saving and loading models for mobile"
D23047144 (e37f871e87)
Pull Request: https://github.com/pytorch/pytorch/pull/43516
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: xcheng16
Differential Revision: D23304639
fbshipit-source-id: 970ca3438c1858f8656cbcf831ffee2c4a551110
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43526
Add tests for graph mode quantization on torchvision and make sure it matches
current eager mode quantization
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23306683
fbshipit-source-id: 30d27e225d4557bfc1d9aa462086e416aa9a9c0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43354
Instead of assigning a thread to an input index for repeating that index, we assign a warp to an index. This helps us in avoiding the costly uncoaelesced memory accesses and brach divergence which occur when each thread is repeating the index.
Test Plan: Run trainer to test
Reviewed By: ngimel
Differential Revision: D23230917
fbshipit-source-id: 731e912c844f1d859b0384fcaebafe69cb4ab56a
Summary:
PyTorch uses f-string in its python codes.
Python support for f-string started with version 3.6
Using python version 3.5 or older fails the build with latest release/master.
This patch checks the version of the python used for build and mandates it to be 3.6 or higher.
Signed-off-by: Parichay Kapoor <kparichay@gmail.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43105
Reviewed By: glaringlee
Differential Revision: D23301481
Pulled By: malfet
fbshipit-source-id: e9b4f7bffce7384c8ade3b7d131b10cf58f5e8a0
Summary:
https://github.com/pytorch/pytorch/issues/22990 added a multiprocessing_context argument to DataLoader, but a typo in the test causes the wrong DataLoader class to be used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43343
Reviewed By: glaringlee
Differential Revision: D23299452
Pulled By: malfet
fbshipit-source-id: 9489c48b83bce36f46d350cad902f7ad96e1eec4
Summary:
- `torch._VF` is a hack to work around the lack of support for `torch.functional` in the JIT
- that hack hides `torch._VF` functions from Mypy
- could be worked around by re-introducing a stub file for `torch.functional`, but that's undesirable
- so instead try to make both happy at the same time: the type ignore comments are needed for Mypy, and don't seem to affect the JIT after excluding them from the `get_type_line()` logic
Encountered this issue while trying to make `mypy` run on `torch/functional.py` in gh-43446.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43454
Reviewed By: glaringlee
Differential Revision: D23305579
Pulled By: malfet
fbshipit-source-id: 50e490693c1e53054927b57fd9acc7dca57e88ca
Summary:
Take care of the state of autocast in `parallel_apply`, so there is no need to decorate model implementations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43102
Reviewed By: ngimel
Differential Revision: D23294610
Pulled By: mrshenli
fbshipit-source-id: 0fbe0c79de976c88cadf2ceb3f2de99d9342d762
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43531
It's useful for building some tooling out of tree to manipulate zip files in PyTorch-y way
Test Plan: contbuild
Reviewed By: houseroad
Differential Revision: D23277361
fbshipit-source-id: e15fad20e792d1e41018d32fd48295cfe74bea8c
Summary: per title, makes c2 wrappers safer as contiguity of torch inputs is not guaranteed
Test Plan: covered by existing tests
Reviewed By: dzhulgakov
Differential Revision: D23310137
fbshipit-source-id: 3fe12abc7e394b8762098d032200778018e5b591
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43027
Format db.h and db.cc using the default formatter.
This change was split off of D22705434.
Test Plan: Wait for sandcastle.
Reviewed By: rohithmenon, marksantaniello
Differential Revision: D23113765
fbshipit-source-id: 3f02d55bfb055bda0fcba5122336fa001562d42e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43445
changed the interface for checkGraphModule to make the arguments more explicit
as requested in https://github.com/pytorch/pytorch/pull/43437
Test Plan:
TestQuantizeFx
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23280586
fbshipit-source-id: 5b5859e326d149a5aacb1d15cbeee69667cc9109
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43155
Update the code_analyzer build.sh script to be able to take additional build flags in the mobile build/analysis
Test Plan:
Checkout associated PR or copy contents of build.sh into PyTorch repo (must be run from root of PyTorch repo)
To run with inclusion of autograd dependencies (note BUILD_MOBILE_AUTOGRAD is still an experimental build flag): `ANALYZE_TORCH=1 DEPLOY=1 BASE_OPS_FILE=/path/to/baseopsfile MOBILE_BUILD_FLAGS='-DBUILD_MOBILE_AUTOGRAD=ON' tools/code_analyzer/build.sh`
Reviewed By: ljk53
Differential Revision: D23065754
fbshipit-source-id: d83a7ad62ad366a84725430ed020adf4d56687bd
Summary:
1. add `metadata.pkl` to `.bc` file which includes the model info that we are interested in
2. load `metadata.pkl` as a attribute `unordered_map<string, string>` in the module
Test Plan:
- CI
```buck build //xplat/caffe2:jit_module_saving
```
```buck build //xplat/caffe2:torch_mobile_core
```
Reviewed By: xcheng16
Differential Revision: D23047144
fbshipit-source-id: f368d00f7baef2d3d15f89473cdb146467aa1e0b
Summary:
Reland of the benchmark code that broke the slow tests because the GPU were running out of memory
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43428
Reviewed By: ngimel
Differential Revision: D23296136
Pulled By: albanD
fbshipit-source-id: 0002ae23dc82f401604e33d0905d6b9eedebc851
Summary:
This doesn't fix any reported issue. We validate ROCm PyTorch on ubuntu and centos. For centos, we must modify the test.sh script to let it run on centos.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42197
Reviewed By: ezyang, ngimel
Differential Revision: D23175669
Pulled By: malfet
fbshipit-source-id: 0da435de6fb17d2ca48e924bec90ef61ebbb5042
Summary:
[Re-review tips: nothing changed other than a type in python_ir.cpp to fix a windows build failure]
Adds code printing for enum type
Enhance enum type to include all contained enum names and values
Adds code parsing for enum type in deserialization
Enabled serialization/deserialization test in most TestCases. (With a few dangling issues to be addressed in later PRs to avoid this PR grows too large)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43460
Reviewed By: albanD
Differential Revision: D23284929
Pulled By: gmagogsfm
fbshipit-source-id: e3e81d6106f18b7337ac3ff5cd1eeaff854904f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43362
Batching rules implemented for: addition subtraction division
multiplication.
I refactored the original `mul_batching_rule` into a templated function
so that one can insert arbitrary binary operations into it.
add, sub, rsub, mul, and div all work the same way. However, other
binary operations work slightly differently (I'm still figuring out the
differences and why they're different) so those may need a different
implementation.
Test Plan: - "pytest test/test_vmap.py -v": new tests
Reviewed By: ezyang
Differential Revision: D23252317
Pulled By: zou3519
fbshipit-source-id: 6d36cd837a006a2fd31474469323463c1bd797fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43083
This adds type annotations to all classes, arguments, and returns
for fx. This should make it easier to understand the code, and
encourage users of the library to also write typed code.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D23145853
Pulled By: zdevito
fbshipit-source-id: 648d91df3f9620578c1c51408003cd5152e34514
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43082
Fixes all present errors in mypy. Does not try to add annotations everywhere.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D23145854
Pulled By: zdevito
fbshipit-source-id: 18e483ed605e89ed8125971e84da1a83128765b7
Summary:
Separate user embeddings and ad embeddings in blobsOrder. New order:
1. meta_net_def
2. preload_blobs
3. user_embeddings (embeddings in remote request only net)
4. ad_embeddings (embeddings in remote other net)
Add a field requestOnlyEmbeddings in meta_net_def to record user_embeddings.
This is for flash verification.
Test Plan:
buck test dper3/dper3_backend/delivery/tests:blob_reorder_test
Run a flow with canary package f211282476
Check the net: n326826, request_only_embeddings are recorded as expected
Reviewed By: ipiszy
Differential Revision: D23008305
fbshipit-source-id: 9360ba3d078f205832821005e8f151b8314f0cf2
Summary:
As part of our continued refactoring of test_torch.py, this takes tests for tensor creation ops like torch.eye, torch.randint, and torch.ones_like and puts them in test_tensor_creation_ops.py. There hare three test classes in the new test suite: TestTensorCreation, TestRandomTensorCreation, TestLikeTensorCreation. TestViewOps and tests for construction of tensors from NumPy arrays have been left in test_torch.py. These might be refactored separately into test_view_ops.py and test_numpy_interop.py in the future.
Most of the tests ported from test_torch.py were left as is or received a signature change to make them nominally "device generic." Future work will need to review test coverage and update the tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43104
Reviewed By: ngimel
Differential Revision: D23280358
Pulled By: mruberry
fbshipit-source-id: 469325dd1a734509dd478cc7fe0413e276ffb192
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42840
By caching input/output pointers and input parameters we enable the use
of caching allocator and check if we get the same input/output pointers.
If so we skip setup steps.
Test Plan:
python test/test_xnnpack_integration.py
Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D23044585
fbshipit-source-id: ac676cff77f264d8ccfd792d1a540c76816d5359
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42178
This otherwise introduces unnecessary calls to contiguous in the rest of
the network, where certain ops want channels last format.
Test Plan:
Quantization tests.
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D22796479
fbshipit-source-id: f1ada1c2eeed84991b9b195120699b943ef6e421
Summary:
Optimize exported graph to export slice nodes for aten::split when the number of split outputs are fixed. Previously under some cases these are exported as onnx::SplitToSequence, which is dynamic in tensor output count.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42744
Reviewed By: houseroad
Differential Revision: D23172465
Pulled By: bzinodev
fbshipit-source-id: 11e432b4ac1351f17e48356c16dc46f877fdf7da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43239
This is an incremental step as part of the process to migrate caffe2 random number generator off of std::mt19937 and to instead use at::mt19937+at::CPUGeneratorImpl. The ATen variants are much more performant (10x faster).
This adds a way to get the CPUContext RandSeed for tail use cases that require a std::mt19937 and borrow the CPUContext one.
Test Plan: This isn't used anywhere within the caffe2 codebase. Compile should be sufficient.
Reviewed By: dzhulgakov
Differential Revision: D23203280
fbshipit-source-id: 595c1cb447290604ee3ef61d5b5fc079b61a4e14
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42008
With caching allocator we have increased the likelihood of getting the
same input pointer. With that we can cache qnnpack operator and input
pointer and check if the input pointer is the same. If so we can skip
setup step.
Test Plan:
Ran one of the quantized models to observe
1. No pagefaults due to indirection buffer reallocation.
2. Much less time spent in indirection buffer population.
Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D22726973
fbshipit-source-id: 2dd2a6a6ecf1b5cfa7dde65e384b36a6eab052d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42007
zero buffer and indirection pointers are allocatoed on every iterations.
With this refactor we create op once for qnnpackconv struct and keep
repopulating indirection pointer as necessary.
For deconv moved much of op creation outside so that we can avoid creating and
destroying ops every time.
Test Plan:
CI quantization tests.
deconvolution-test
Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D22726972
fbshipit-source-id: 07c03a4e90b397c36aae537ef7c0b7d81d4adc1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42006
This PR introduces a simple CPU caching allocator. This is specifically
intended for mobile use cases and for inference. There is nothing
specific to the implementation that can prevent it from other use cases,
however its simplicity may not be suitable everywhere.
It simply tracks allocation by sizes and relies on deterministic
repeatable behavior where allocation of same sizes are made on every
inference.
Thus after the first allocation when the pointer is returned, instead of
returning it to system, allocator caches it for subsequent use.
Memory is freed automatically at the end of the process, or it can be
explicitly freed.
This is enabled at the moment in DefaultMobileCPUAllocator only.
Test Plan:
android test: cpu_caching_allocator_test
Imported from OSS
Reviewed By: dreiss
Differential Revision: D22726976
fbshipit-source-id: 9a38b1ce34059d5653040a1c3d035bfc97609e6c
Summary:
This patch allows to freeze model that utilizes interfaces. Freezing works
under the user assumption that the interfase module dones not aliases with
any value used in the model.
To enable freezing of such modules, added an extra pramater:
torch._C._freeze_module(module, ignoreInterfaces = True)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41860
Reviewed By: eellison
Differential Revision: D22670566
Pulled By: bzinodev
fbshipit-source-id: 41197a724bc2dca2e8495a0924c224dc569f62a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42963
* Adds code printing for enum type
* Enhance enum type to include all contained enum names and values
* Adds code parsing for enum type in deserialization
* Enabled serialization/deserialization test in most TestCases. (With a few dangling issues to be addressed in later PRs to avoid this PR grows too large)
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D23223281
Pulled By: gmagogsfm
fbshipit-source-id: 716d1866b7770dfb7bd8515548cfe7dc4c4585f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43355
There seem to be some bugs where we cannot guarantees that blobs in `PARAMETERS_BLOB_TYPE_FULLY_REMOTE_REQUEST_ONLY` and `PARAMETERS_BLOB_TYPE_DISAGG_ACC_REMOTE_OTHER` are disjoint. Hence we need to walk around this.
Also make the msg more informative.
Test Plan:
```
flow-cli test-locally --mode opt dper.workflows.evaluation.eval_workflow --parameters-file=/mnt/shared/yinghai/v0_ctr_mbl_feed_1120_onnx.json
```
Reviewed By: ehsanardestani
Differential Revision: D23141538
fbshipit-source-id: 8e311f8fc0e40eff6eb2c778213f78592e6bf079
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42413
When a default argument is added, it does not break backward compatibility (BC) for full-jit, but does break BC for mobile bytecode. For example, https://github.com/pytorch/pytorch/pull/40737. To make bytecode BC in this case, we
1. Introduce kMinSupportedBytecodeVersion. The loaded model version should be between kMinSupportedBytecodeVersion and kProducedBytecodeVersion.
2. If an operator is updated, and we can handle BC, bump the kProducedBytecodeVersion (for example, from 3 to 4).
3. If model version is at the older version of the operator, add an adapter function at loading. For the added default arg, we push this default arg to stack before calling the actual operator function.
Test Plan: Imported from OSS
Reviewed By: xcheng16
Differential Revision: D22898314
Pulled By: iseeyuan
fbshipit-source-id: 90d339f8e1365f4bb178db8db7c147390173372b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43372
So that adding more binary op tests are easier
Test Plan: Imported from OSS
Reviewed By: z-a-f
Differential Revision: D23257046
fbshipit-source-id: 661acd4c38abdc892c9db8493b569226b13e0d0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43293
'docker run' has the capability to use a file for environment variables,
we should prefer to use that instead of having it be sourced per command
in the docker container.
Also opens the door for cutting down on the total number of commands we
need to echo into a script to then execute as a 'docker exec' command.
Plus side of this approach is that the BASH_ENV is persisted through all
of the steps so there's no need to do any exports / worry about
environment variables not persisting through jobs.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D23227059
Pulled By: seemethere
fbshipit-source-id: be425aa21b420b9c6e96df8b2177f508ee641a20
Summary:
This diff normalizes for-loops that have non 0 loop starts to always start from 0. Given a for-loop, this normalization changes the loop start to be 0 and adjusts the loop end and all accesses to the index variable within the loop body appropriately.
This diff also adds tests for several cases of normalization and also tests normalization in conjunction with `splitwithTail` transformation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43179
Reviewed By: nickgg
Differential Revision: D23220534
Pulled By: navahgar
fbshipit-source-id: 64be0c72e4dbc76906084f7089dea81ae07d6020
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43090
To match the floating point module
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23167518
fbshipit-source-id: 29db596e10731be4cfed7efd18f33a0b3dbd0ca7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43088
Create quantized module that the user can use to perform embedding bag quantization
The module uses the EmbeddingPackedParams to store the weights which can be serialized /deserialized
using TorchBind custom classes (C++ get/setstate code)
Following PR will add support for `from_float` to convert from float to quantized module
Test Plan:
python test/test_quantization.py TestDynamicQuantizedModule.test_embedding_bag_api
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23167519
fbshipit-source-id: 029d7bb44debf78c4ef08bfebf267580ed94d033
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43317
Previous version was returning the path with a prefix so subsequent `getRecord` would fail.
There's only one place in PyTorch codebase that uses this function (introduced in https://github.com/pytorch/pytorch/pull/29339 ) and it's unlikely that anyone else is using it - it's not a public API anyway.
Test Plan: unittest
Reviewed By: houseroad
Differential Revision: D23235241
fbshipit-source-id: 6f7363e6981623aa96320f5e39c54e65d716240b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43242
This causes "std::isnan" to produce confusing error messages (std::std has not been declared).
Instead, simply let isnan be exposed in the global namespace.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D23214374
Pulled By: ezyang
fbshipit-source-id: 9615116a980340e36376a20f2e546e4d36839d4b
Summary:
They were likely copied from some macro definition, but they do not
belong to macro definitions here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43318
Reviewed By: pbelevich
Differential Revision: D23241526
Pulled By: mrshenli
fbshipit-source-id: e0b5eddfde2c882bb67f56d84ee79281cc5fc941
Summary:
This PR:
- ports the tests in TestTorchMathOps to test_unary_ufuncs.py
- removes duplicative tests for the tested unary ufuncs from test_torch.py
- adds a new test, test_reference_numerics, that validates the behavior of our unary ufuncs vs. reference implementations on empty, scalar, 1D, and 2D tensors that are contiguous, discontiguous, and that contain extremal values, for every dtype the unary ufunc supports
- adds support for skipping tests by regex, this behavior is used to make the test suite pass on Windows, MacOS, and ROCm builds, which have a variety of issues, and on Linux builds (see https://github.com/pytorch/pytorch/issues/42952)
- adds a new OpInfo helper, `supports_dtype`, to facilitate test writing
- extends unary ufunc op info to include reference, domain, and extremal value handling information
- adds OpInfos for `torch.acos` and `torch.sin`
These improvements reveal that our testing has been incomplete on several systems, especially with larger float values and complex values, and several TODOs have been added for follow-up investigations. Luckily when writing tests that cover many ops we can afford to spend additional time crafting the tests and ensuring coverage.
Follow-up PRs will:
- refactor TestTorchMathOps into test_unary_ufuncs.py
- continue porting tests from test_torch.py to test_unary_ufuncs.py (where appropriate)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42965
Reviewed By: pbelevich
Differential Revision: D23238083
Pulled By: mruberry
fbshipit-source-id: c6be317551453aaebae9d144f4ef472f0b3d08eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43286
We need to use this in graph mode quantization on fx
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23221734
fbshipit-source-id: 7c3c3840ce5bdc185b962e081aff1618f4c58e85
Summary:
These were added accidentally (probably by an IDE) during a refactor.
These files have always been Open Source.
Test Plan: CI
Reviewed By: xcheng16
Differential Revision: D23250761
fbshipit-source-id: 4974430c0e28dd3269424d38edb36f4f71508157
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39401
This uses the technique proposed by smessmer in D16451848 to selectively
register operators without codegen. See the Note inside for more
details.
This PR has feature parity with the old selective build apparatus:
it can whitelist schema def()s, impl()s, and on a per dispatch key
basis. It has expanded dispatch key whitelisting, whereas previously
manually written registrations were not whitelisted at all. (This
means we may be dropping dispatch keys where we weren't previously!)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D21905593
Pulled By: ezyang
fbshipit-source-id: d4870f800c66be5ce57ec173c9b6e14a52c4a48b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43341
This is to remove the empty pretty_print() since it overrides the impl within Module base which is not as designed here.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D23244616
Pulled By: glaringlee
fbshipit-source-id: 94b8dfd3697dfc450f53b3b4eee6e9c13cafba7b
Summary:
Add ComplexHalf case to toValueType, which fixes the logic how view_as_real and view_as_complex slices complex tensor to the floating point one, as it is used to generate tensor of random complex values, see:
018b4d7abb/aten/src/ATen/native/DistributionTemplates.h (L200)
Also add ability to convert python complex object to `c10::complex<at::Half>`
Add `torch.half` and `torch.complex32` to the list of `test_randn` dtypes
Fixes https://github.com/pytorch/pytorch/issues/43143
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43279
Reviewed By: mrshenli
Differential Revision: D23230296
Pulled By: malfet
fbshipit-source-id: b4bb66c4c81dd867e72ab7c4563d73f6a4d80a44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43175
This PR added graph mode quantization on fx: https://github.com/pytorch/pytorch/pull/42741
Currently it matches eager mode quantization for torchvision with static/dynamic/qat
ddp/synbn test is still wip
Test Plan:
python test/test_quantization.py TestQuantizeFx
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23178602
fbshipit-source-id: 8e7e0322846fbda2cfa79ad188abd7235326f879
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43218
Previously, `vmap(lambda x: x * 0.1)(torch.ones(3))` would return a
float64 tensor(!!). This is because there is a subtle bug in the
batching rule: the batching rule receives:
- A batched tensor for x
- a scalar tensor: tensor(0.1, dtype=torch.float64).
The batching rule decides to expand the scalar tensor to be the same
size as x and then multiplies the two tensors, promoting the output to
be a float64 tensor. However, this isn't correct: we should treat the
scalar tensor like a scalar tensor. When adding a FloatTensor to a
Double scalar tensor, we don't promote the type usually.
Another example of a bug this PR fixes is the following:
`vmap(torch.mul)(torch.ones(3), torch.ones(3, dtype=torch.float64))`
Multiplying a scalar float tensor with a scalar double tensor produces a
float tensor, but the above produced a float64 before this PR due to
mistakingly type-promoting the tensors.
Test Plan:
- new test: `pytest test/test_vmap.py -v`
- I refactored some tests a bit.
Reviewed By: cpuhrsch
Differential Revision: D23195418
Pulled By: zou3519
fbshipit-source-id: 33b7da841e55b47352405839f1f9445c4e0bc721
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43154
Adds the build flag `BUILD_MOBILE_AUTOGRAD` which toggles whether autograd files should be included for a PyTorch mobile build (default off).
ghstack-source-id: 110369406
Test Plan: CI
Reviewed By: ljk53
Differential Revision: D23061913
fbshipit-source-id: bc3d6683ab17f158990d83e4fae0a011d5adeca1
Summary:
Fixes https://github.com/pytorch/pytorch/issues/41314 among other things.
This PR streamlines layout propagation logic in TensorIterator and removes almost all cases of channels-last hardcoding. The new rules and changes are as follows:
1) behavior of undefined `output` and defined output of the wrong (e.g. 0) size is always the same (before this PR the behavior was divergent)
2) in obvious cases (unary operation on memory-dense tensors, binary operations on memory-dense tensors with the same layout) strides are propagated (before propagation was inconsistent) (see footnote)
3) in other cases the output permutation is obtained as inverse permutation of sorting inputs by strides. Sorting is done with comparator obeying the following rules: strides of broadcasted dimensions are set to 0, and 0 compares equal to anything. Strides of not-broadcasted dimensions (including dimensions of size `1`) participate in sorting. Precedence is given to the first input, in case of a tie in the first input, first the corresponding dimensions are considered, and if that does not indicate that swap is needed, strides of the same dimension in subsequent inputs are considered. See changes in `reorder_dimensions` and `compute_strides`. Note that first inspecting dimensions of the first input allows us to better recover it's permutation (and we select this behavior because it more reliably propagates channels-last strides) but in some rare cases could result in worse traversal order for the second tensor.
These rules are enough to recover previously hard-coded behavior related to channels last, so all existing tests are passing.
In general, these rules will produce intuitive results, and in most cases permutation of the full size input (in case of broadcasted operation) will be recovered, or permutation of the first input (in case of same sized inputs) will be recovered, including cases with trivial (1) dimensions. As an example of the latter, the following tensor
```
x=torch.randn(2,1,3).permute(1,0,2)
```
will produce output with the same stride (3,3,1) in binary operations with 1d tensor. Another example is a tensor of size N1H1 that has strides `H,H,1,1` when contiguous and `H, 1, 1, 1` when channels-last. The output retains these strides in binary operations when another 1d tensor is broadcasted on this one.
Footnote: for ambiguous cases where all inputs are memory dense and have the same physical layout that nevertheless can correspond to different permutations, such as e.g. NC11-sized physically contiguous tensors, regular contiguous tensor is returned, and thus permutation information of the input is lost (so for NC11 channels-last input had the strides `C, 1, C, C`, but output will have the strides `C, 1, 1, 1`). This behavior is unchanged from before and consistent with numpy, but it still makes sense to change it. The blocker for doing it currently is performance of `empty_strided`. Once we make it on par with `empty` we should be able to propagate layouts in these cases. For now, to not slow down common contiguous case, we default to contiguous.
The table below shows how in some cases current behavior loses permutation/stride information, whereas new behavior propagates permutation.
| code | old | new |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------|------------------------------------------------------|
| #strided tensors<br>a=torch.randn(2,3,8)[:,:,::2].permute(2,0,1)<br>print(a.stride())<br>print(a.exp().stride())<br>print((a+a).stride())<br>out = torch.empty(0)<br>torch.add(a,a,out=out)<br>print(out.stride()) | (2, 24, 8) <br>(6, 3, 1) <br>(1, 12, 4) <br>(6, 3, 1) | (2, 24, 8)<br>(1, 12, 4)<br>(1, 12, 4)<br>(1, 12, 4) |
| #memory dense tensors<br>a=torch.randn(3,1,1).as_strided((3,1,1), (1,3,3))<br>print(a.stride(), (a+torch.randn(1)).stride())<br>a=torch.randn(2,3,4).permute(2,0,1)<br>print(a.stride())<br>print(a.exp().stride())<br>print((a+a).stride())<br>out = torch.empty(0)<br>torch.add(a,a,out=out)<br>print(out.stride()) | (1, 3, 3) (1, 1, 1)<br>(1, 12, 4)<br>(6, 3, 1)<br>(1, 12, 4)<br>(6, 3, 1) | (1, 3, 3) (1, 3, 3)<br>(1, 12, 4)<br>(1, 12, 4)<br>(1, 12, 4)<br>(1, 12, 4) |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42922
Reviewed By: ezyang
Differential Revision: D23148204
Pulled By: ngimel
fbshipit-source-id: 670fb6188c7288e506e5ee488a0e11efc8442d1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43277
Docker added native support for GPUs with the release of 19.03 and
CircleCI's infrastructure is all on Docker 19.03 as of now.
This also removes all references to `nvidia-docker` in the `.circleci` fodler.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D23217570
Pulled By: seemethere
fbshipit-source-id: af297c7e82bf264252f8ead10d1a154354b24689
Summary:
Globs don't get expanded if you quote them in a bash script...
apparently.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43297
Reviewed By: malfet
Differential Revision: D23227626
Pulled By: seemethere
fbshipit-source-id: d124025cfcaacbfb68167a062ca487c08f7f6bc9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43272
Was missing kwarg-onlyness.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D23215506
Pulled By: ezyang
fbshipit-source-id: 2c282c9a534fa8ea1825c31a24cb2441f0d6b234
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43205
A number of tests that forward to `TestLoadSaveBase.load_save` are all marked as flaky due to them regularly taking much longer to start up than hypothesis' default timeout of 200ms. This diff fixes the problem by removing the timeout for `load_save`. This is alright as these tests aren't meant to be testing the performance of these operators.
I would set the deadline to 60s if I could however it appears the that caffe2 github CI uses a different version of hypothesis that doesn't allow using `dateutil.timedelta` so instead of trying to figure out an approach that works on both I've just removed the deadline time.
I've also tagged all existing tasks WRT these failures.
Differential Revision: D23175752
fbshipit-source-id: 324f9ff034df1ac4874797f04f50067149a6ba48
Summary:
According to the correlation analysis, CUDA-10.1 vs CUDA-11 test failures are quite dependent on each other
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43234
Reviewed By: ezyang, seemethere
Differential Revision: D23204289
Pulled By: malfet
fbshipit-source-id: c53c5f87e55f2dabbb6735a0566c314c204ebc69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42869
We realized that when we invoke a simple callback that divides the tensors by `world_size` after `allreduce`, the performance was almost 50% lower in terms of QPS compared to the case where a simple `allreduce` hook is used with no `then` callback.
The main problem was as we call `work.wait()` before invoking `then` callback, we were synchronizing `work`'s stream with the default PyTorch stream inside [`runHook`](https://github.com/pytorch/pytorch/blob/master/torch/csrc/distributed/c10d/reducer.cpp#L609) and stalling the backward computation.
In that PR, we ensure that FutureNCCL's `then` callback is not stalling the backward computation. Assuming single-process single-device, `FutureNCCL` gets a new stream from device's pool using `at::cuda::getStreamFromPool` to run `callback` and before invoking the `callback` inline it synchronizes `WorkNCCL`'s stream by callback's stream not the default stream.
ghstack-source-id: 110208431
Test Plan: Run performance benchmark tests to validate performance issue is resolved. Also, `python test/distributed/test_c10d.py` to avoid any odd issues.
Reviewed By: pritamdamania87
Differential Revision: D23055807
fbshipit-source-id: 60e50993f1ed97497514eac5cb1018579ed2a4c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40084
This is just a nit diff (got merge conflict) while writing some unit-tests.
This move was nit as part of D21628596 (655f1ea176).
Test Plan: buck test test:quantization -- test_qlinear_legacy
Reviewed By: supriyar
Differential Revision: D22065463
fbshipit-source-id: 96ceaa53355349af7157f38b3a6366c550eeec6f
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 685149bbc0
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43251
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: YazhiGao
Differential Revision: D23207016
fbshipit-source-id: 54e13b246bb5189260ed11316ddf3d26d52c6b24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43206
The batching rule is the same as the unary pointwise batching rules:
given a BatchedTensor, we unwrap it, call Tensor.to, and then re-wrap
it.
Test Plan: - `pytest test/test_vmap.py -v -k`
Reviewed By: ezyang
Differential Revision: D23189053
Pulled By: zou3519
fbshipit-source-id: 51b4e41b1cd34bd082082ec4fff3c643002edbaf
Summary:
Should fix binary build issue on Windows, and promptly error out if images are updated to a different version of VC++
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43220
Reviewed By: ezyang
Differential Revision: D23198530
Pulled By: malfet
fbshipit-source-id: 0c80361ad7dcfb7aaffccc306b7d741671bedc11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43217
Dataclasses is part of standard library in Python 3.7 and there
is a backport for it in Python 3.6. Our code generation will
start using it, so add it to the default library set.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D23214028
Pulled By: ezyang
fbshipit-source-id: a2ae20b9fa8f0b22966ae48506d4ddea203e7459
Summary:
Pull Request resolved: https://github.com/pytorch/glow/pull/4812
if no compilation options are passed, default to c-step
fixed the FC and batchmatmul implementations to match C-step
fixed the fakelowp map calling to make sure we use the fp32 substitution of operators
updated the accumulator test to make it pass with fp32
Test Plan:
fakelowp tests
glow/test/numerics
net_runner
Reviewed By: jfix71
Differential Revision: D23086534
fbshipit-source-id: 3fbb8c4055bb190becb39ce8cdff6671f8558734
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43077
2 Bit Embedding weight conversion operation is quite similar to
4 bit embedding weight conversion.
The diff contains both the
1. 2bit packing op `embedding_bag_2bit_prepack`.
2. 2bit unpacking op `embedding_bag_2bit_unpack`.
Comments about the op are inline with the op definition.
Test Plan: buck test caffe2/test:quantization -- test_embedding_bag_2bit_unpack
Reviewed By: supriyar
Differential Revision: D23143262
fbshipit-source-id: fd8877f049ac1f7eb4bc580e588dc95f8b1edef0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43156
- supports_named_tensor no longer does anything, so I have removed
it. I'm guessing these were cargo culted from some old occurrences
of it in native_functions.yaml
- comma, not period, in variants
In my upcoming codegen rewrite, there will be strict error checking
for these cases (indeed, that is how I found these problems), so
I do not add error testing here.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D23183977
Pulled By: ezyang
fbshipit-source-id: a47d342152badfb8aea248a819ad94fd93dd6ab2
Summary:
This relaxes the assumption that test.sh will be run in the CI environment by the CI user.
CC ezyang xw285cornell sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43236
Reviewed By: colesbury
Differential Revision: D23205981
Pulled By: ezyang
fbshipit-source-id: 302743cb03c9e9c6bfcdd478a6cd920b536dc29b
Summary:
Make CUDA-10.1 configs build-only, as CUDA-10.1 and CUDA-10.2 test matrix is almost identical, and now, since CUDA-11 is out perhaps it's time to stop testing CUDA-10.1.
Make CUDA-9.2+GCC_5.4 an important (i.e. running on PR) build only config, because of the big overlap between CUDA-9.2-GCC7 and CUDA-9.2-GCC5.4 test coverage.
Make CUDA-11 libtorch tests important rather that CUDA-10.2.
As result of the change, every PR will be built against CUDA-9.2, CUDA-10.2 and CUDA-11 and tested against CUDA-10.2
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43240
Reviewed By: ezyang
Differential Revision: D23205129
Pulled By: malfet
fbshipit-source-id: 70932e8b2167cce9fd621115c8bf24b1c81ed621
Summary:
Most of the fixes is the same old enum-is-not-hasheable error
In manager.cpp use std::unordered_map::emplace rather than `insert` to avoid error triggered by missed copy elision
This regression was introduced by https://github.com/pytorch/pytorch/pull/43129
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43223
Reviewed By: albanD, seemethere
Differential Revision: D23198330
Pulled By: malfet
fbshipit-source-id: 576082f7a4454dd29182892c9c4e0b51a967d456
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43097
Boolean arguments weren't promoted, so if you tried to write a comparison with
types such as `Tensor(Bool) == Int` you'd fail typechecking inside the TE
engine.
Test Plan: Imported from OSS
Reviewed By: protonu, zheng-xq
Differential Revision: D23167926
Pulled By: bertmaher
fbshipit-source-id: 47091a815d5ae521637142a5c390e8a51a776906
Summary:
Fixes https://github.com/pytorch/pytorch/issues/42884
I did some additional research and considering the first few lines of the docs (`Creates a criterion that measures the loss given inputs x1, x2, two 1D mini-batch Tensors, and a label 1D mini-batch tensor y (containing 1 or -1`) and the provided tests, this loss should be used primarily with 1-D tensors. More advanced users (that may use this loss in non-standard ways) can easily check the source and see that the definition accepts inputs/targets of arbitrary dimension as long as they match in shape or are broadcastable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43131
Reviewed By: colesbury
Differential Revision: D23192011
Pulled By: mrshenli
fbshipit-source-id: c412c28daf9845c0142ea33b35d4287e5b65fbb9
Summary:
Should close https://github.com/pytorch/pytorch/issues/36428.
The cudnn RNN API expects weights to occupy a flat buffer in memory with a particular layout. This PR implements a "speed of light" fix: [`_cudnn_rnn_cast_reflatten`](https://github.com/pytorch/pytorch/pull/42385/files#diff-9ef93b6a4fb5a06a37c562b83737ac6aR327) (the autocast wrapper assigned to `_cudnn_rnn`) copies weights to the right slices of a flat FP16 buffer with a single read/write per weight (as opposed to casting them to FP16 individually then reflattening the individual FP16 weights, which would require 2 read/writes per weight).
It isn't pretty but IMO it doesn't make rnn bindings much more tortuous than they already are.
The [test](https://github.com/pytorch/pytorch/pull/42385/files#diff-e68a7bc6ba14f212e5e7eb3727394b40R2683) tries a forward under autocast and a backward for the full cross product of RNN options and input/weight/hidden dtypes. As for all FP16list autocast tests, forward output and backward grads are checked against a control where inputs (including RNN module weights in this case) are precasted to FP16 on the python side.
Not sure who to ask for review, tagging ezyang and ngimel because Ed wrote this file (almost 2 years ago) and Natalia did the most recent major [surgery](https://github.com/pytorch/pytorch/pull/12600).
Side quests discovered:
- Should we update [persistent RNN heuristics](dbdd28207c/aten/src/ATen/native/cudnn/RNN.cpp (L584)) to include compute capability 8.0? Could be another PR but seems easy enough to include.
- Many (maybe all?!) the raw cudnn API calls in [RNN.cpp](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/RNN.cpp) are deprecated in cudnn 8. I don't mind taking the AI to update them since my mental cache is full of rnn stuff, but that would be a substantial separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42385
Reviewed By: zhangguanheng66
Differential Revision: D23077782
Pulled By: ezyang
fbshipit-source-id: a2afb1bdab33ba0442879a703df13dc87f03ec2e
Summary:
I think you want to push rewrapped `rets`, not `args`, back to the stack.
Doesn't matter for test purposes because tests only check if/when fallbacks were called, they don't check outputs for correctness. But it avoids reader confusion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42990
Reviewed By: mrshenli
Differential Revision: D23168277
Pulled By: ezyang
fbshipit-source-id: 2559f0707acdca2e3deac09006bc66ce3c788ea3
Summary:
A small change that adds a docstring that can be found with
`getattr(nn.Module, nn.Module.forward.__name__, None).__doc__`
Fixes https://github.com/pytorch/pytorch/issues/43057
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43063
Reviewed By: mrshenli
Differential Revision: D23161782
Pulled By: ezyang
fbshipit-source-id: 95456f858e2b6a0e41ae551ea4ec2e78dd35ee3f
Summary:
The changes are minor.
1. Add back the external links so that readers can find out more about external tools on how to accelerate PyTorch.
2. Fix typo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43100
Reviewed By: colesbury
Differential Revision: D23192251
Pulled By: mrshenli
fbshipit-source-id: dde54b7942ebff5bbe3d58ad95744c6d95fe60fe
Summary:
Fixes https://github.com/pytorch/pytorch/issues/39968
tested with `TORCH_CUDA_ARCH_LIST='3.5 5.2 6.0 6.1 7.0 7.5 8.0+PTX'`, before this PR, it was failing, and with this PR, the build succeed.
With `TORCH_CUDA_ARCH_LIST='7.0 7.5 8.0+PTX'`, `libtorch_cuda.so` with symbols changes from 2.9GB -> 2.2GB
cc: ptrblck mcarilli jjsjann123
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43074
Reviewed By: mrshenli
Differential Revision: D23176095
Pulled By: malfet
fbshipit-source-id: 7b3e6d049fc080e519f21e80df05ef68e7bea57e
Summary:
Had a bunch of merged commits that shouldn't have been there, reverted them to prevent conflicts. Lots of new features, highlights listed below.
**Overall:**
- Enables pointwise fusion, single (but N-D) broadcast -- pointwise fusion, single (but N-D) broadcast -- pointwise -- single (but N-D) reduction fusion.
**Integration:**
- Separate "magic scheduler" logic that takes a fusion and generates code generator schedule
- Reduction fusion scheduling with heuristics closely matching eagermode (unrolling supported, but no vectorize support)
- 2-Stage caching mechanism, one on contiguity, device, type, and operations, the other one is input size->reduction heuristic
**Code Generation:**
- More generic support in code generation for computeAt
- Full rework of loop nest generation and Indexing to more generically handle broadcast operations
- Code generator has automatic kernel launch configuration (including automatic allocation of grid reduction buffers)
- Symbolic (runtime) tilling on grid/block dimensions is supported
- Simplified index generation based on user-defined input contiguity
- Automatic broadcast support (similar to numpy/pytorch semantics)
- Support for compile time constant shared memory buffers
- Parallelized broadcast support (i.e. block reduction -> block broadcast support)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43129
Reviewed By: mrshenli
Differential Revision: D23162207
Pulled By: soumith
fbshipit-source-id: 16deee4074c64de877eed7c271d6a359927111b2
Summary:
The ONNX spec for the Squeeze operator:
> Remove single-dimensional entries from the shape of a tensor. Takes a parameter axes with a list of axes to squeeze. If axes is not provided, all the single dimensions will be removed from the shape. If an axis is selected with shape entry not equal to one, an error is raised.
Currently, as explained in issue https://github.com/pytorch/pytorch/issues/36796, it is possible to export such a model to ONNX, and this results in an exception from ONNX runtime.
Fixes https://github.com/pytorch/pytorch/issues/36796.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38476
Reviewed By: hl475
Differential Revision: D22158024
Pulled By: houseroad
fbshipit-source-id: bed625f3c626eabcbfb2ea83ec2f992963defa19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43151
Using `torch.all` instead of `torch.sum` and length check.
It's unclear whether the increase in perf (~5% for small inputs) is
real, but should be a net benefit, especially for larger channel inputs.
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23170426
fbshipit-source-id: ee5c25eb93cee1430661128ac9458a9c525df8e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43150
The current logic was expensive because it created tensors on CUDA.
Switching to clamp since it can work without needing to create tensors.
Test Plan:
benchmarks
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23170427
fbshipit-source-id: 6fe3a728e737aca9f6c2c4d518c6376738577e21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43149
This value doesn't change, making it a buffer to only pay
the cost of creating a tensor once.
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23170428
fbshipit-source-id: 6b963951a573efcc5b5a57649c814590b448dd72
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42956
In preparation for observer perf improvement, cleans up the
micro benchmarks:
* disable CUDA for histogram observers (it's too slow)
* add larger shapes for better representation of real workloads
Test Plan:
```
cd benchmarks/operator_benchmark
python -m pt.qobserver_test
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D23093996
fbshipit-source-id: 5dc477c9bd5490d79d85ff8537270cd25aca221a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42511
DistEngine currently only has a single thread to execute GPU to CPU
continuations as part of the backward pass. This would be a significant
performance bottleneck in cases where we have such continuations and would like
to execute these using all CPU cores.
To alleviate this in this PR, we have the single thread in DistEngine only
dequeue work from the global queue, but then hand off execution of that work to
the c10 threadpool where we call "execute_graph_task_until_ready_queue_empty".
For more context please see:
https://github.com/pytorch/pytorch/issues/40255#issuecomment-663298062.
ghstack-source-id: 109997718
Test Plan: waitforbuildbot
Reviewed By: albanD
Differential Revision: D22917579
fbshipit-source-id: c634b6c97f3051f071fd7b994333e6ecb8c54155
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43093
without this it's hard to tell which module is going wrong
Test Plan:
```
> TypeError:
> 'numpy.int64' object in attribute 'Linear.in_features' is not a valid constant.
> Valid constants are:
> 1. a nn.ModuleList
> 2. a value of type {bool, float, int, str, NoneType, torch.device, torch.layout, torch.dtype}
> 3. a list or tuple of (2)
```
Reviewed By: eellison
Differential Revision: D23148516
fbshipit-source-id: b86296cdeb7b47c9fd69b5cfa479914c58ef02e6
Summary:
This PR:
- Adds a method variant to movedim
- Fixes the movedim docs so it will actually appear in the documentation
- Fixes three view doc links which were broken
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43122
Reviewed By: ngimel
Differential Revision: D23166222
Pulled By: mruberry
fbshipit-source-id: 14971585072bbc04b5366d4cc146574839e79cdb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43059
This PR implements batching rules for some unary ops. In particular, it
implements the batching rules for the unary ops that take a single
tensor as input (and nothing else).
The batching rule for a unary op is:
(1) grab the physical tensor straight out of the BatchedTensor
(2) call the unary op
(3) rewrap the physical tensor in a BatchedTensor
Test Plan: - new tests `pytest test/test_vmap.py -v -k "Operators"`
Reviewed By: ezyang
Differential Revision: D23132277
Pulled By: zou3519
fbshipit-source-id: 24b9d7535338207531d767155cdefd2c373ada77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43028
There was a bug where we always tried to grab the `__name__` attribute of
the function passed in by the user. Not all Callables have the
`__name__` attribute, an example being a Callable produced by
functools.partial.
This PR modifies the error-checking code to use `repr` if `__name__` is
not available. Furthermore, it moves the "get the name of this function"
functionality to the actual error sites as an optimization so we don't
spend time trying to compute `__repr__` for the Callable if there is no
error.
Test Plan: - `pytest test/test_vmap.py -v`, added new tests.
Reviewed By: yf225
Differential Revision: D23130235
Pulled By: zou3519
fbshipit-source-id: 937f3640cc4d759bf6fa38b600161f5387a54dcf
Summary:
LLVM builds took a large amount of time and bogged down docker builds in
general. Since we build it the same for everything let's just copy it
from a pre-built image instead of building it from source every time.
Builds are defined in https://github.com/pytorch/builder/pull/491
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43038
Reviewed By: malfet
Differential Revision: D23119513
Pulled By: seemethere
fbshipit-source-id: f44324439d45d97065246caad07c848e261a1ab6
Summary:
Since OpenMP is not available on some platforms, or might be disabled by user, set default `ATEN_THREADING` based on USE_OPENMP and USE_TBB options
Fixes https://github.com/pytorch/pytorch/issues/43036
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43067
Reviewed By: houseroad
Differential Revision: D23138856
Pulled By: malfet
fbshipit-source-id: cc8f9ee59a5559baeb3f19bf461abbc08043b71c
Summary:
During cleanup phase, calling recordReferencedAttrs would record
the attributes which are referenced and hence kept.
However, if you have two instances of the same type which are preserved
through freezing process, as the added testcase shows, then during
recording the attributes which are referenced, we iterate through the
type INSTANCES that we have seen so far and record those ones.
Thus if we have another instance of the same type, we will just look at
the first instance in the list, and record that instances.
This PR fixes that by traversing the getattr chains and getting the
actual instance of the getattr output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42457
Test Plan:
python test/test_jit.py TestFreezing
Fixes #{issue number}
Reviewed By: gchanan
Differential Revision: D23106921
Pulled By: kimishpatel
fbshipit-source-id: ffff52876938f8a1fedc69b8b24a3872ea66103b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43069
The transformer c++ impl need to put TransformerEncoderLayer/DecoderLayer and TransformerEncoder/TransformerDecoder in different header since TransformerEncoder/Decoder's options class need TransformerEncoderLayer/DecoderLayer as input parameter. Split header files to avoid cycle includsion.
Test Plan: Imported from OSS
Reviewed By: yf225
Differential Revision: D23139437
Pulled By: glaringlee
fbshipit-source-id: 3c752ed7702ba18a9742e4d47d049e62d2813de0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42880
Enable switching between and checking for training and eval mode for torch::jit::mobile::Module using train(), eval(), and is_training(), like exists for torch::jit::Module.
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D23063006
Pulled By: ann-ss
fbshipit-source-id: b79002148c46146b6e961cbef8aaf738bbd53cb2
Summary:
This adds the torch.arccosh alias and updates alias testing to validate the consistency of the aliased and original operations. The alias testing is also updated to run on CPU and CUDA, which revealed a memory leak when tracing (see https://github.com/pytorch/pytorch/issues/43119).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43107
Reviewed By: ngimel
Differential Revision: D23156472
Pulled By: mruberry
fbshipit-source-id: 6155fac7954fcc49b95e7c72ed917c85e0eabfcd
Summary:
This changes profiled types from being represented as:
`%23 : Float(4:256, 256:1, requires_grad=0, device=cpu) = prim::profile(%0)`
->
`%23 : Tensor = prim::profile[profiled_type=Float(4:256, 256:1, requires_grad=0, device=cpu)](%0)`
Previously, by representing the profiled type in the IR directly it was very easy for optimizations to accidentally use profiled types without inserting the proper guards that would ensure that the specialized type would be seen.
It would be a nice follow up to extend this to prim::Guard as well, however we have short term plans to get rid of prim::Guard.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43035
Reviewed By: ZolotukhinM
Differential Revision: D23120226
Pulled By: eellison
fbshipit-source-id: c78d7904edf314dd65d1a343f2c3a947cb721b32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42822
These ops arent supported with NCCL backend and used to silently error.
We disabled them as part of addressing https://github.com/pytorch/pytorch/issues/41362, so
document that here.
ghstack-source-id: 109957761
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D23023046
fbshipit-source-id: 45d69028012e0b6590c827d54b35c66cd17e7270
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42637
This commit enables sending non-CPU tensors through RPC using
TensorPipe backend. Users can configure device mappings by calling
set_map_location on `TensorPipeRpcBackendOptions`. Internally,
the `init_rpc` API verifies the correctness of device mappings. It
will shutdown RPC if the check failed, or proceed and pass global
mappings to `TensorPipeAgent` if the check was successful. For serde,
we added a device indices field to TensorPipe read and write buffers,
which should be either empty (all tensors must be on CPU) or match
the tensors in order and number in the RPC message. This commit
does not yet avoid zero-copy, the tensor is always moved to CPU
on the sender and then moved to the specified device on the receiver.
Test Plan: Imported from OSS
Reviewed By: izdeby
Differential Revision: D23011572
Pulled By: mrshenli
fbshipit-source-id: 62b617eed91237d4e9926bc8551db78b822a1187
Summary:
Add "asan" node to a `CONFIG_TREE_DATA` rather than hardcoded that non-xla clang-5 is ASAN
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43048
Reviewed By: houseroad
Differential Revision: D23126296
Pulled By: malfet
fbshipit-source-id: 22f02067bb2f5435a0e963a6c722b9c115ccfea4
Summary:
https://github.com/pytorch/pytorch/issues/40980
I have a few questions during implementing Polygamma function...
so, I made PR prior to complete it.
1. some code blocks brought from cephes library(and I did too)
```
/*
* The following function comes with the following copyright notice.
* It has been released under the BSD license.
*
* Cephes Math Library Release 2.8: June, 2000
* Copyright 1984, 1987, 1992, 2000 by Stephen L. Moshier
*/
```
is it okay for me to use cephes code with this same copyright notice(already in the Pytorch codebases)
2. There is no linting in internal Aten library. (as far as I know, I read https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md)
How do I'm sure my code will follow appropriate guidelines of this library..?
3. Actually, there's a digamma, trigamma function already
digamma is needed, however, trigamma function becomes redundant if polygamma function is added.
it is okay for trigamma to be there or should be removed?
btw, CPU version works fine with 3-rd order polygamma(it's what we need to play with variational inference with beta/gamma distribution) now and I'm going to finish GPU version soon.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42499
Reviewed By: gchanan
Differential Revision: D23110016
Pulled By: albanD
fbshipit-source-id: 246f4c2b755a99d9e18a15fcd1a24e3df5e0b53e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42991
Have Node both be a record of the operator in the graph, and the
way we _build_ the graph made it difficult to keep the IR datastructure
separate from the proxying logic in the build.
Among other issues this means that typos when using nodes would add
things to the graph:
```
for node in graph.nodes:
node.grph # does not error, returns an node.Attribute object!
```
This separates the builder into a Proxy object. Graph/Node no longer
need to understand `delegate` objects since they are now just pure IR.
This separates the `symbolic_trace` (proxy.py/symbolic_trace.py) from
the IR (node.py, graph.py).
This also allows us to add `create_arg` to the delegate object,
allowing the customization of how aggregate arguments are handled
when converting to a graph.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D23099786
Pulled By: zdevito
fbshipit-source-id: 6f207a8c237e5eb2f326b63b0d702c3ebcb254e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42881
This enables serialization/de-serialization of embedding packed params using getstate/setstate calls.
Added version number to deal with changes to serialization formats in future.
This can be extended in the future to support 4-bit/2-bit once we add support for that.
Test Plan:
python test/test_quantization.py TestQuantizedEmbeddingBag
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23070634
fbshipit-source-id: 2ca322ab998184c728be6836f9fd12cec98b2660
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42762
Use a prepack function that accepts qtensor as an input. The output is a byte tensor with packed data.
This is currently implemented only for 8-bit. In the future once we add 4-bit support this function will be extended to support that too.
Note -In the following change I will add TorchBind support for this to support serialization of packed weights.
Test Plan:
python test/test_quantization.py TestQuantizedEmbeddingBag
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23070632
fbshipit-source-id: 502aa1302dffec1298cdf52832c9e2e5b69e44a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42927
added fp16 fusion to net transforms
refactored the transforms as well as glow_transform to get out of opt/custom so that the OSS builds passed
Test Plan: added net runner tests for this
Reviewed By: yinghai
Differential Revision: D23080881
fbshipit-source-id: ee6451811fedfd07c6560c178229854bca29301f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42389
**Summary**
This commit adds support for properties to TorchScript classes,
specifically for getters and setters. They are implemented essentially
as pointers to the methods that the corresponding decorators decorate,
which are treated like regular class methods. Deleters for properties
are considered to be out of scope (and probably useless for TorchScript
anyway).
**Test Plan**
This commit adds a unit test for a class with a property that has both
getter and setter and one that has only a getter.
`python test/test_jit.py TestClassType.test_properties`
Test Plan: Imported from OSS
Reviewed By: eellison, ppwwyyxx
Differential Revision: D22880232
Pulled By: SplitInfinity
fbshipit-source-id: 4828640f4234cb3b0d4f3da4872a75fbf519e5b0
Summary:
No type annotations can be added to the script, as it still have to be Python-2 compliant.
Make changes to avoid variable type redefinition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43062
Reviewed By: zou3519
Differential Revision: D23132991
Pulled By: malfet
fbshipit-source-id: 360c02e564398f555273e5889a99f834a5467059
Summary:
Fixes https://github.com/pytorch/pytorch/issues/42153
As [documented](https://docs.nvidia.com/cuda/curand/device-api-overview.html) (search for `curand_uniform` on the page), `curand_uniform` returns "from 0.0 to 1.0, where 1.0 is included and 0.0 is excluded." These endpoints are different than the CPU equivalent, and makes the calculation in the PR fail when the value is 1.0.
The test from the issue is added, it failed for me consistently before the PR even though I cut the number of samples by 10.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42702
Reviewed By: gchanan
Differential Revision: D23107451
Pulled By: ngimel
fbshipit-source-id: 3575d5b8cd5668e74b5edbecd95154b51aa485a1
Summary:
Closes gh-42998
The issue is marked for 1.6.1, if there's anything I need to do for a backport please tell me what that is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43053
Reviewed By: izdeby
Differential Revision: D23131708
Pulled By: malfet
fbshipit-source-id: 2744bacce6bdf6ae463c17411b672f09707e0887
Summary:
Fixes https://github.com/pytorch/pytorch/issues/42860
The `__cuda_array_interface__` tensor specification is missing the appropriate datatypes for the newly merged complex64 and complex128 tensors. This PR addresses this issue by casting:
* `torch.complex64` to 'c8'
* `torch.complex128` to 'c16'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42918
Reviewed By: izdeby
Differential Revision: D23130219
Pulled By: anjali411
fbshipit-source-id: 5f8ee8446a71cad2f28811afdeae3a263a31ad11
Summary:
**`torch.nn.Hardsigmoid`** and **`torch.nn.Hardswish`** classes currently do not support `inplace` operations as it uses `torch.nn.functional.hardsigmoid` and `torch.nn.functional.hardswish` functions with their default inplace argument which is `False`.
So, I added `inplace` argument for `torch.nn.Hardsigmoid` and `torch.nn.Hardswish` classes so that forward operation can be done inplace as well while using these layers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42346
Reviewed By: izdeby
Differential Revision: D23108487
Pulled By: albanD
fbshipit-source-id: 0767334fa10e5ecc06fada2d6469f3ee1cacd957
Summary:
test_e2e_tensorpipe depends on ProcessGroupGloo, therefore it could not be tested with Gloo disabled
Otherwise, it re-introduces https://github.com/pytorch/pytorch/issues/42776
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43041
Reviewed By: lw
Differential Revision: D23122101
Pulled By: malfet
fbshipit-source-id: a8a088b6522a3bc888238ede5c2d589b83c6ea94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43037
In the previous version of mish_op.cc, the output would be 'nan' for large inputs. We re-write mish_op.cc to solve this problem.
Test Plan:
Unit test
buck test //dper3/dper3/modules/tests:core_modules_test -- test_linear_compress_embedding_with_attention_with_activation_mish
{F284052906}
buck test mode/opt //dper3/dper3_models/ads_ranking/tests:model_paradigm_e2e_tests -- test_sparse_nn_with_mish
{F284224158}
## Workflow
f212113434
{F285281318}
Differential Revision: D23102644
fbshipit-source-id: 98f1ea82f8c8e05b655047b4520c600fc1a826f4
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 29d5eb9f3c
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42834
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D23040145
fbshipit-source-id: 1d7209ea1910419b7837703122b8a4c76380ca4a
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/42133
Test Plan:
We save a module with module debugging information as follows.
```
import torch
m = torch.jit.load('./detect.pt')
# Save module without debug info
m._save_for_lite_interpreter('./detect.bc')
# Save module with debug info
m._save_for_lite_interpreter('./detect.bc', _save_debug_info_in_bytecode=True)
```
Size of the file without module debugging information: 4.508 MB
Size of the file with module debugging information: 4.512 MB
Reviewed By: kimishpatel
Differential Revision: D22803740
Pulled By: taivu1998
fbshipit-source-id: c82ea62498fde36a1cfc5b073e2cea510d3b7edb
Summary:
1. Fix illegal memory access issue for SplitByLengths operator in the CUDA context.
2. Add support to scaling lengths vector for SplitByLengths operator.
3. Add support to test SplitByLengths operator in the CUDA context.
Example for SplitByLengths operator processing scaling lengths vector:
value vector A = [1, 2, 3, 4, 5, 6]
length vector B = [1, 2]
after execution of SplitByLengths operator,
the output should be [1,2] and [3,4,5,6]
Test Plan: buck test mode/dev-nosan caffe2/caffe2/python/operator_test:concat_split_op_test
Reviewed By: kennyhorror
Differential Revision: D23079841
fbshipit-source-id: 3700e7f2ee0a5a2791850071fdc16e5b054f8400
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42938
1. Structure the logic in a more straight-forward way: instead of magic
tricks with node iterators in a block we now have a function that
tries to create a fusion group starting from a given node (and pull
everything it can into it).
2. The order in which we're pulling nodes into a fusion group is now
more apparent.
3. The new pass structure automatically allows us to support fusion
groups of size=1.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D23084409
Pulled By: ZolotukhinM
fbshipit-source-id: d59fc00c06af39a8e1345a4aed8d829494db084c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42602
In this diff, clearer semantics and namings for are introduced by splitting the original `init_dynamic_qrange` into 2 separate `Optional[int]` types `qmin` and `qmax` to avoid the confusion of the parameters with dynamic quantization.
The `qmin` and `qmax` parameters allow customers to specify their own customary quantization range and enables specific use cases for lower bit quantization.
Test Plan:
To assert the correctness and compatibility of the changes with existing observers, on a devvm, execute the following command to run the unit tests:
`buck test //caffe2/test:quantization -- observer`
Reviewed By: vkuzo, raghuramank100
Differential Revision: D22948334
fbshipit-source-id: 275bc8c9b5db4ba76fc2e79ed938376ea4f5a37c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43015
Currently activation_post_process are inserted by default in qat modules, which is not
friendly to automatic quantization tools, this PR removes them.
Test Plan:
Imported from OSS
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D23105059
fbshipit-source-id: 3439ac39e718ffb0390468163bcbffd384802b57
Summary:
This PR whitelists and simplifies graphs to help with development later on. Key to note in this PR is the use of both a pattern substitution and the registration of custom operators. This will likely be one of the main optimization types done in this folder.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43024
Reviewed By: hlu1
Differential Revision: D23114262
Pulled By: bwasti
fbshipit-source-id: e25aa3564dcc8a2b48cfd1561b3ee2a4780ae462
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42723
This PR is addressing https://github.com/pytorch/pytorch/issues/39340
and allows users to initialize RPC again after shutdown. Major changes in the
PR include:
1. Change to DistAutogradContainer to support this.
2. Ensure PythonRpcHandler is reinitialized appropriately.
3. Use PrefixStore in RPC initialization to ensure each new `init_rpc` uses a
different prefix.
ghstack-source-id: 109805368
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D22993909
fbshipit-source-id: 9f1c1e0a58b58b97125f41090601e967f96f70c6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/40829
This is cross-platform but I have only tried it on linux, personally. Also, I am not fully certain of the usage pattern, so if there are any additional features / adjustments / tests that you want me to add, please just let me know!
CC ezyang rgommers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42635
Reviewed By: zhangguanheng66
Differential Revision: D23078663
Pulled By: ezyang
fbshipit-source-id: 5c8c8abebd1d462409c22dc4301afcd8080922bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43014
changing this behavior mimics the behavior of the hold hypothesis
testing library
Test Plan: ran all tests on devserver
Reviewed By: hl475
Differential Revision: D23085949
fbshipit-source-id: 433fdfbb04b6a609b738eb7c319365049a49579b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43018
In this diff, a fix is added where the original non-learnable fake quantize is provided with trainable scale and zero point, whereas the requires_grad for both parameters should be completely disabled.
Test Plan:
Use the following command to execute the benchmark test:
`buck test mode/dev-nosan pt:quantization_test`
Reviewed By: vkuzo
Differential Revision: D23107846
fbshipit-source-id: d2213983295f69121e9e6ae37c84d1f37d78ef39
Summary:
Fix typos in torch.utils/_benchmark/README.md
Add empty __init__.py to examples folder to make example invocations from README.md correct
Fixed uniform distribution logic generation when mixval and maxval are None
Fixes https://github.com/pytorch/pytorch/issues/42984
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42960
Reviewed By: seemethere
Differential Revision: D23095399
Pulled By: malfet
fbshipit-source-id: 0546ce7299b157d9a1f8634340024b10c4b7e7de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42946
There are 3 options for the executor and fuser and some of them aren't
super interesting so I've combined the options into a single parameter, but
made it fairly easy to expand the set if there are other configs we might care
about.
Test Plan:
Benchmark it
Imported from OSS
Reviewed By: zheng-xq
Differential Revision: D23090177
fbshipit-source-id: bd93a93c3fc64e5a4a847d1ce7f42ce0600a586e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42612
Add a new Quantizer that supports an input zero point (bias) that can be float.
The quantization equation in this case is
Xq = (Xf - bias) * inv_scale, where bias is float zero_point value
We start with per-row implementation and can extend to per-tensor in the future, if necessary
Test Plan:
python test/test_quantization.py TestQuantizedTensor
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D22960142
fbshipit-source-id: ca9ab6c5b45115d3dcb1c4358897093594313706
Summary:
When working on the Cuda Codegen, I found that running the IRSimplifier before generating code lead to test fails. This was due to a bug in Round+Mod simplification (e.g. (x / y * y) + (x % y) => x) to do with the order in which the terms appeared. After fixing it and writing a few tests around those cases, I found another bug in simplification of the same pattern and have fixed it (with some more test coverage).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42934
Reviewed By: zhangguanheng66
Differential Revision: D23085548
Pulled By: nickgg
fbshipit-source-id: e780967dcaa7a5fda9f6d7d19a6b7e7b4e94374b
Summary:
A simple differentiable abstraction to allow testing of full training graphs.
Included in this 1st PR is an example of trivial differentiation.
If approved, I can add a full MLP and demonstrate convergence using purely NNC (for performance testing) in the next PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42548
Reviewed By: ZolotukhinM
Differential Revision: D23057920
Pulled By: bwasti
fbshipit-source-id: 4a239852c5479bf6bd20094c6c35f066a81a832e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42924
offsets is an optional paramter in the python module currently. So we update the operator to follow suit
in order to avoid bad optional access
Test Plan:
python test/test_quantization.py TestQuantizeDynamicJitOps.test_embedding_bag
Imported from OSS
Reviewed By: radkris-git
Differential Revision: D23081152
fbshipit-source-id: 847b58f826f5a18e8d4978fc4afc6f3a96dc4230
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42343
Currently activation_post_process are inserted by default in qat modules, which is not
friendly to automatic quantization tools, this PR removes them.
Test Plan: Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D22856816
fbshipit-source-id: 988a43bce46a992b38fd0d469929f89e5b046131
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42841
There is nothing using those APIs anymore. While we still have ops that require an unboxedOnly implementation (i.e. that aren't c10-full yet), those are all already migrated to the new op registration API and use `.impl_UNBOXED()`.
ghstack-source-id: 109693705
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D23045335
fbshipit-source-id: d8e15cea1888262135e0d1d94c515d8a01bddc45
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42712
Previously, operators taking Tensor& as arguments or returning it couldn't be c10-full because the unboxing logic didn't support it.
This adds temporary support for that. We're planning to remove this again later, but for now we need it to make those ops c10-full.
See https://docs.google.com/document/d/19thMVO10yMZA_dQRoB7H9nTPw_ldLjUADGjpvDmH0TQ for the full plan.
This PR also makes some ops c10-full that now can be.
ghstack-source-id: 109693706
Test Plan: unit tests
Reviewed By: bhosmer
Differential Revision: D22989242
fbshipit-source-id: 1bd97e5fa2b90b0860784da4eb772660ca2db5a3
Summary:
A small clarity improvement to the cuda init docstring
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42923
Reviewed By: zhangguanheng66
Differential Revision: D23080693
Pulled By: mrshenli
fbshipit-source-id: aad5ed9276af3b872c1def76c6175ee30104ccb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42563
Moved logic for non-named unflatten from python nn module to aten/native to be reused by the nn module later. Fixed some inconsistencies with doc and code logic.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D23030301
Pulled By: heitorschueroff
fbshipit-source-id: 7c804ed0baa5fca960a990211b8994b3efa7c415
Summary:
The premise of this approach is that a small subset of neural networks are well represented by a data flow graph. The README contains more information.
The name is subject to change, but I thought it was a cute reference to fire.
suo let me know if you'd prefer this in a different spot. Since it lowers a JIT'd module directly I assumed the JIT folder would be appropriate. There is no exposed Python interface yet (but is mocked up in `test_accelerant.py`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42753
Reviewed By: zou3519
Differential Revision: D23043771
Pulled By: bwasti
fbshipit-source-id: 5353731e3aae31c08b5b49820815da98113eb551
Summary:
Introducing `//xplat/caffe2:aten_vulkan` target which contains pytorch Vulkan backend and its ops.
`//xplat/caffe2:aten_vulkan` depends on ` //xplat/caffe2:aten_cpu`
Just inclusion it to linking registers Vulkan Backend and its ops.
**Code generation:**
1. `VulkanType.h`, `VulkanType.cpp`
Tensor Types for Vulkan backend are generated by `//xplat/caffe2:gen_aten_vulkan` which runs aten code generation (`aten/src/ATen/gen.py`) with `--vulkan` argument.
2. Shaders compilation
`//xplat/caffe2:gen_aten_vulkan_spv` genrule runs `//xplat/caffe2:gen_aten_vulkan_spv_bin` which is a wrapper on `aten/src/ATen/native/vulkan/gen_spv.py`
GLSL files are listed in `aten/src/ATen/native/vulkan/glsl/*` and to compile them `glslc` (glsl compiler) is required.
`glslc` is in opensource https://github.com/google/shaderc , that also has a few dependencies on other libraries, that porting this build to BUCK will take significant amount of time.
To use `glslc` in BUCK introducing
dotslash `xplat/caffe2/fb/vulkan/dotslash/glslc` which is stored on manifold the latest prebuilt binaries of `glslc` from ANDROID_NDK for linux, macos and windows.
Not using it from ANDROID_NDK directly allows to update it without dependency on ndk.
Test Plan:
Building aten_vulkan target:
```
buck build //xplat/caffe2:aten_vulkan
```
Building vulkan_test that contains vulkan unittests for android:
```
buck build //xplat/caffe2:pt_vulkan_test_binAndroid#android-armv7
```
And running it on the device with vulkan support.
Reviewed By: iseeyuan
Differential Revision: D22770299
fbshipit-source-id: 843af8df226d4b5395b8e480eb47b233d57201df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42876
Previously, the error messages were pretty bad. This PR adds nice
error messages for the following cases:
- user attempts to call .backward() inside vmap for any reason
whatsoever
- user attempts to call autograd.grad(outputs, inputs, grad_outputs),
where outputs or inputs is being vmapped over (so they are
BatchedTensors).
The case we do support is calling autograd.grad(outputs, inputs,
grad_outputs) where `grad_outputs` is being vmapped over. This is the
case for batched gradient support (e.g., user passes in a batched
grad_output).
Test Plan: - new tests: `pytest test/test_vmap.py -v`
Reviewed By: ezyang
Differential Revision: D23059836
Pulled By: zou3519
fbshipit-source-id: 2fd4e3fd93f558e67e2f0941b18f0d00d8ab439f
Summary:
As name suggests, this function should always return a writable path
Call `mkdtemp` to create temp folder if path is not writable
This fixes `TestNN.test_conv_backcompat` if PyTorch is installed in non-writable location
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42895
Reviewed By: dzhulgakov
Differential Revision: D23070320
Pulled By: malfet
fbshipit-source-id: ed6a681d46346696a0de7e71f0b21cba852a964e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42691
fix quantization of FC bias to match nnpi
quantize biases to fp16
Test Plan: improved the unit test to have input tensors in fp32
Reviewed By: tracelogfb
Differential Revision: D22941521
fbshipit-source-id: 00afb70610f8a149110344d52595c39e3fc988ab
Summary:
This PR aims at improving `LayerNorm` performance on CPU for both forward and backward.
Results on Xeon 6248:
1. single socket inference **1.14x** improvement
2. single core inference **1.77x** improvement
3. single socket training **6.27x** improvement
The fine tuning of GPT2 on WikiTest2 dataset time per iteration on dual socket reduced from **4.69s/it** to **3.16s/it**, **1.48x** improvement.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35750
Reviewed By: zhangguanheng66
Differential Revision: D20810026
Pulled By: glaringlee
fbshipit-source-id: c5801bd76eb944f2e46c2fe4991d9ad4f40495c3
Summary:
This is a follow-up PR for https://github.com/pytorch/pytorch/issues/37091, fixing some of the quirks of that PR as that one was landed early to avoid merge conflicts.
This PR addresses the following action items:
- [x] Use error-handling macros instead of a `try`-`catch`.
- [x] Renamed and added comments to clarify the use of `HANDLED_FUNCTIONS_WRAPPERS` in tests. `HANDLED_FUNCTIONS_NAMESPACES` was already removed in the last PR as we had a way to test for methods.
This PR does NOT address the following action item, as it proved to be difficult:
- [ ] Define `__module__` for whole API.
Single-line repro-er for why this is hard:
```python
>>> torch.Tensor.grad.__get__.__module__ = "torch.Tensor.grad"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'method-wrapper' object has no attribute '__module__'
```
Explanation: Methods defined in C/properties don't always have a `__dict__` attribute or a mutable `__module__` slot for us to modify.
The documentation action items were addressed in the following commit, with the additional future task of adding the rendered RFCs to the documentation: 552ba37c05
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42806
Reviewed By: smessmer
Differential Revision: D23031501
Pulled By: ezyang
fbshipit-source-id: b781c97f7840b8838ede50a0017b4327f96bc98a
Summary:
Addresses some comments that were left unaddressed after PR https://github.com/pytorch/pytorch/issues/41377 was merged:
* Use `check_output` instead of `Popen` to run each subprocess sequentially
* Use f-strings rather than old python format string style
* Provide environment variables to subprocess through the `env` kwarg
* Check for correct error behavior inside the subprocess, and raise another error if incorrect. Then the main process fails the test if any error is raised
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42627
Reviewed By: malfet
Differential Revision: D22969231
Pulled By: ezyang
fbshipit-source-id: 38d5f3f0d641c1590a93541a5e14d90c2e20acec
Summary:
During cleanup phase, calling recordReferencedAttrs would record
the attributes which are referenced and hence kept.
However, if you have two instances of the same type which are preserved
through freezing process, as the added testcase shows, then during
recording the attributes which are referenced, we iterate through the
type INSTANCES that we have seen so far and record those ones.
Thus if we have another instance of the same type, we will just look at
the first instance in the list, and record that instances.
This PR fixes that by traversing the getattr chains and getting the
actual instance of the getattr output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42457
Test Plan:
python test/test_jit.py TestFreezing
Fixes #{issue number}
Reviewed By: zou3519
Differential Revision: D22898051
Pulled By: kimishpatel
fbshipit-source-id: 8b1d80f0eb40ab99244f931d4a1fdb28290a4683
Summary:
This PR:
- updates test_op_normalization.py, which verifies that aliases are correctly translated in the JIT
- adds torch.linalg.det as an alias for torch.det
- moves the torch.linalg.outer alias to torch.outer (to be consistent with NumPy)
The torch.linalg.outer alias was put the linalg namespace erroneously as a placeholder since it's a "linear algebra op" according to NumPy but is actually still in the main NumPy namespace.
The updates to test_op_normalization are necessary. Previously it was using method_tests to generate tests, and method_tests assumes test suites using it also use the device generic framework, which test_op_normalization did not. For example, some ops require decorators like `skipCPUIfNoLapack`, which only works in device generic test classes. Moving test_op_normalization to the device generic framework also lets these tests run on CPU and CUDA.
Continued reliance on method_tests() is excessive since the test suite is only interested in testing aliasing, and a simpler and more readable `AliasInfo` class is used for the required information. An example impedance mismatch between method_tests and the new tests, for example, was how to handle ops in namespaces like torch.linalg.det. In the future this information will likely be folded into a common 'OpInfo' registry in the test suite.
The actual tests performed are similar to what they were previously: a scripted and traced version of the op is run and the test verifies that both graphs do not contain the alias name and do contain the aliased name.
The guidance for adding an alias has been updated accordingly.
cc mattip
Note:
ngimel suggests:
- deprecating and then removing the `torch.ger` name
- reviewing the implementation of `torch.outer`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42802
Reviewed By: zou3519
Differential Revision: D23059883
Pulled By: mruberry
fbshipit-source-id: 11321c2a7fb283a6e7c0d8899849ad7476be42d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42576
Previously we have qconfig propagate list and we only attach qconfig for modules
in the list, this works when everything is quantized in the form of module.
but now we are expanding quantization for functional/torch ops, we'll need to attach qconfig
to all modules
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D22939453
fbshipit-source-id: 7d6a1f73ff9bfe461b3afc75aa266fcc8f7db517
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42769
Some of the quantized add and mul can have the same name
Test Plan: Imported from OSS
Reviewed By: supriyar
Differential Revision: D23054822
fbshipit-source-id: c1300f3f0f046eaf0cf767d03b957835e22cfb4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42871
old version of hypothesis.testing was not enforcing deadlines
after the library got updated, default deadline=200ms, but even with 1s or
more, tests are flaky. Changing deadline to non-enforced which is the same
behavior as the old version
Test Plan: tested fakelowp/tests
Reviewed By: hl475
Differential Revision: D23059033
fbshipit-source-id: 79b6aec39a2714ca5d62420c15ca9c2c1e7a8883
Summary:
aten::sorted.str output type was incorrectly set to bool[] due to a copy-paste error. This PR fixes it.
Fixes https://fburl.com/0rv8amz7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42853
Reviewed By: yf225
Differential Revision: D23054907
Pulled By: gmagogsfm
fbshipit-source-id: a62968c90f0301d4a5546e6262cb9315401a9729
Summary: I found out that without exporting to public format IDEEP transpose operator in the middle of convolution net produces incorrect results (probably reading some out-of-bound memory). Exporting to public format might not be the most efficient solution, but at least it ensures correct behavior.
Test Plan: Running ConvFusion followed by transpose should give identical results on CPU and IDEEP
Reviewed By: bwasti
Differential Revision: D22970872
fbshipit-source-id: 1ddca16233e3d7d35a367c93e72d70632d28e1ef
Summary:
They are double, but they are supposed to be of accscalar_t or a faster type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42846
Reviewed By: zou3519
Differential Revision: D23049405
Pulled By: mruberry
fbshipit-source-id: 29bb5d5419dc7556b02768f0ff96dfc28676f257
Summary:
This PR adds:
- an "OpInfo" class in common_method_invocations that can contain useful information about an operator, like what dtypes it supports
- a more specialized "UnaryUfuncInfo" class designed to help test the unary ufuncs
- the `ops` decorator, which can generate test variants from lists of OpInfos
- test_unary_ufuncs.py, a new test suite stub that shows how the `ops` decorator and operator information can be used to improve the thoroughness of our testing
The single test in test_unary_ufuncs.py simply ensures that the dtypes associated with a unary ufunc operator in its OpInfo entry are correct. Writing a test like this previously, however, would have required manually constructing test-specific operator information and writing a custom test generator. The `ops` decorator and a common place to put operator information make writing tests like this easier and allows what would have been test-specific information to be reused.
The `ops` decorator extends and composes with the existing device generic test framework, allowing its decorators to be reused. For example, the `onlyOnCPUAndCUDA` decorator works with the new `ops` decorator. This should keep the tests readable and consistent.
Future PRs will likely:
- continue refactoring the too large test_torch.py into more verticals (unary ufuncs, binary ufuncs, reductions...)
- add more operator information to common_method_invocations.py
- refactor tests for unary ufuncs into test_unary_ufunc
Examples of possible future extensions are [here](616747e50d), where an example unary ufunc test is added, and [here](d0b624f110), where example autograd tests are added. Both tests leverage the operator info in common_method_invocations to simplify testing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41662
Reviewed By: ngimel
Differential Revision: D23048416
Pulled By: mruberry
fbshipit-source-id: ecce279ac8767f742150d45854404921a6855f2c
Summary:
Adds a new optimization pass, the Registerizer, which looks for common Stores and Loads to a single item in a buffer and replaces them with a local temporary scalar which is cheaper to write.
For example it can replace:
```
A[0] = 0;
for (int x = 0; x < 10; x++) {
A[0] = (A[0]) + x;
}
```
with:
```
int A_ = 0;
for (int x = 0; x < 10; x++) {
A_ = x + A_;
}
A[0] = A_;
```
This is particularly useful on GPUs when parallelizing, since after replacing loops with metavars we have a lot of accesses like this. Early tests of simple reductions on a V100 indicates this can speed them up by ~5x.
This diff got a bit unwieldy with the integration code so that will come in a follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42606
Reviewed By: bertmaher
Differential Revision: D22970969
Pulled By: nickgg
fbshipit-source-id: 831fd213f486968624b9a4899a331ea9aeb40180
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42767
Same as previous PR, forcing the qlinear benchmark to follow the fp one
Test Plan:
```
cd benchmarks/operator_benchmark
python -m pt.linear_test
python -m pt.qlinear_test
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23013937
fbshipit-source-id: fffaa7cfbfb63cea41883fd4d70cd3f08120aaf8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42761
Makes the qconv benchmark follow the conv benchmark exactly. This way
it will be easy to compare q vs fp with the same settings.
Test Plan:
```
cd benchmarks/operator_benchmark
python -m pt.qconv_test
python -m pt.conv_test
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23012533
fbshipit-source-id: af30ee585389395569a6322f5210828432963077
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42837
Originally we use
```
list(APPEND CMAKE_C_FLAGS -fprofile-instr-generate -fcoverage-mapping)
list(APPEND CMAKE_CXX_FLAGS -fprofile-instr-generate -fcoverage-mapping)
```
But when compile project on mac with Coverage On, it has the error:
`clang: error: no input files
/bin/sh: -fprofile-instr-generate: command not found
/bin/sh: -fcoverage-mapping: command not found`
The reason behind it, is `list(APPEND CMAKE_CXX_FLAGS` will add an additional `;` to the variable. This means, if we do `list(APPEND foo a)` and then `list(APPEND foo b)`, then `foo` will be `a;b` -- with the additional `;`. Since we have `CMAKE_CXX_FLAGS` defined before in the `CMakeList.txt`, we can only use `set(...)` here
After changing it to
```
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fprofile-instr-generate -fcoverage-mapping")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fprofile-instr-generate -fcoverage-mapping")
```
Test successufully in local mac machine.
Test Plan: Test locally on mac machine
Reviewed By: malfet
Differential Revision: D23043057
fbshipit-source-id: ff6f4891b35b7f005861ee2f8e4c550c997fe961
Summary:
fixes https://github.com/pytorch/pytorch/issues/39566
`typing.Final` is a thing since python 3.8, and on python 3.8, `typing_extensions.Final` is an alias of `typing.Final`, therefore, `ann.__module__ == 'typing_extensions'` will become False when using 3.8 and `typing_extensions` is installed.
~~I don't know why the test is skipped, seems like due to historical reason when python 2.7 was still a thing?~~ Edit: I know now, the `Final` for `<3.7` don't have `__origin__`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39568
Reviewed By: smessmer
Differential Revision: D23043388
Pulled By: malfet
fbshipit-source-id: cc87a9e4e38090d784e9cea630e1c543897a1697
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42810
In this diff, the original backward pass implementation is sped up by merging the 3 iterations computing dX, dScale, and dZeroPoint separately. In this case, a native loop is directly used on a byte-wise level (referenced by `strides`). In addition, vectorization is used such that scale and zero point are expanded to share the same shape and the element-wise corresponding values to X along the channel axis.
In the benchmark test on the operators, for an input of shape `3x3x256x256`, we have observed the following improvement in performance:
**Speedup from python operator**: ~10x
**Speedup from original learnable kernel**: ~5.4x
**Speedup from non-backprop kernel**: ~1.8x
Test Plan:
To assert correctness of the new kernel, on a devvm, enter the command
`buck test //caffe2/test:quantization -- learnable_backward_per_channel`
To benchmark the operators, on a devvm, enter the command
1. Set the kernel size to 3x3x256x256 or a reasonable input size.
2. Run `buck test //caffe2/benchmarks/operator_benchmark/pt:quantization_test`
3. The relevant outputs for CPU are as follows:
```
# Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark
# Mode: Eager
# Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cpu_op_typepy_module
# Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: py_module
Backward Execution Time (us) : 989024.686
# Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark
# Mode: Eager
# Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cpu_op_typelearnable_kernel
# Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: learnable_kernel
Backward Execution Time (us) : 95654.079
# Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark
# Mode: Eager
# Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cpu_op_typeoriginal_kernel
# Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: original_kernel
Backward Execution Time (us) : 176948.970
```
4. The relevant outputs for GPU are as follows:
The relevant outputs are as follows
**Pre-optimization**:
```
# Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark
# Mode: Eager
# Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typepy_module
# Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: py_module
Backward Execution Time (us) : 6795.173
# Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark
# Mode: Eager
# Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typelearnable_kernel
# Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: learnable_kernel
Backward Execution Time (us) : 4321.351
# Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark
# Mode: Eager
# Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typeoriginal_kernel
# Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: original_kernel
Backward Execution Time (us) : 1052.066
```
**Post-optimization**:
```
# Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark
# Mode: Eager
# Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typepy_module
# Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: py_module
Backward Execution Time (us) : 6737.106
# Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark
# Mode: Eager
# Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typelearnable_kernel
# Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: learnable_kernel
Backward Execution Time (us) : 2112.484
# Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark
# Mode: Eager
# Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typeoriginal_kernel
# Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: original_kernel
Backward Execution Time (us) : 1078.79
Reviewed By: vkuzo
Differential Revision: D22946853
fbshipit-source-id: 1a01284641480282b3f57907cc7908d68c68decd
Summary:
Previously, `at::native::embedding` implicitly assumed that the `weight` argument would be 1-D or greater. Given a 0-D tensor, it would segfault. This change makes it throw a RuntimeError instead.
Fixes https://github.com/pytorch/pytorch/issues/41780
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42550
Reviewed By: smessmer
Differential Revision: D23040744
Pulled By: albanD
fbshipit-source-id: d3d315850a5ee2d2b6fcc0bdb30db2b76ffffb01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42617
While we figure out the random plan, I want to initially disable
support for random operations. This is because there is an ambiguity in
what randomness means. For example,
```
tensor = torch.zeros(B0, 1)
vmap(lambda t: t.normal_())(tensor)
```
in the above example, should tensor[0] and tensor[1] be equal (i.e.,
use the same random seed), or should they be different?
The mechanism for disabling random support is as follows:
- We add a new dispatch key called VmapMode
- Whenever we're inside vmap, we enable VmapMode for all tensors.
This is done via at::VmapMode::increment_nesting and
at::VmapMode::decrement_nesting.
- DispatchKey::VmapMode's fallback kernel is the fallthrough kernel.
- We register kernels that raise errors for all random functions on
DispatchKey::VmapMode. This way, whenever someone calls a random
function on any tensor (not just BatchedTensors) inside of a vmap block,
an error gets thrown.
Test Plan: - pytest test/test_vmap.py -v -k "Operators"
Reviewed By: ezyang
Differential Revision: D22954840
Pulled By: zou3519
fbshipit-source-id: cb8d71062d4087e10cbf408f74b1a9dff81a226d
Summary:
Added a new option in AutogradContext to tell autograd to not materialize output grad tensors, that is, don't expand undefined/None tensors into tensors full of zeros before passing them as input to the backward function.
This PR is the second part that closes https://github.com/pytorch/pytorch/issues/41359. The first PR is https://github.com/pytorch/pytorch/pull/41490.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41821
Reviewed By: albanD
Differential Revision: D22693163
Pulled By: heitorschueroff
fbshipit-source-id: a8d060405a17ab1280a8506a06a2bbd85cb86461
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42763
add the fp16 fusions as net transforms:
-layernorm fused with mul+add
-swish int8
Test Plan: added unit test, ran flows
Reviewed By: yinghai
Differential Revision: D23002043
fbshipit-source-id: f0b13d51d68c240b05d2a237a7fb8273e996328b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42706
Different backends accept different type of length to, like MPI_Alltoallv, nccSend/Recv(), gloo::alltoallv(). So to make computeLengthsAndOffsets() template
Test Plan:
Sandcastle
CI
HPC: ./trainer_cmd.sh -p 16 -n 8 -d nccl
Reviewed By: osalpekar
Differential Revision: D22961459
fbshipit-source-id: 45ec271f8271b96f2dba76cd9dce3e678bcfb625
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42750
All of these tests fail under TSAN since we fork in a multithreaded
environment.
ghstack-source-id: 109566396
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D23007746
fbshipit-source-id: 65571607522b790280363882d61bfac8a52007a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42700
I was about to use `isBatched` somewhere not in the files used to
implement vmap but then realized how silly that sounds due to
ambiguity. This PR renames some of the BatchedTensor APIs to make a bit
more sense to onlookers.
- isBatched(Tensor) -> isBatchedTensor(Tensor)
- unsafeGetBatched(Tensor) -> unsafeGetBatchedImpl(Tensor)
- maybeGetBatched(Tensor) -> maybeGetBatchedImpl(Tensor)
Test Plan: - build Pytorch, run tests.
Reviewed By: ezyang
Differential Revision: D22985868
Pulled By: zou3519
fbshipit-source-id: b8ed9925aabffe98085bcf5c81d22cd1da026f46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42628
This PR extends the BatchedTensor fallback to support operators with
multiple Tensor returns. If an operator has multiple returns, we stack
shards of each return to create the full outputs.
Test Plan:
- `pytest test/test_vmap.py -v`. Added a new test for an operator with
multiple returns (torch.var_mean).
Reviewed By: izdeby
Differential Revision: D22957095
Pulled By: zou3519
fbshipit-source-id: 5c0ec3bf51283cc4493b432bcfed1acf5509e662
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42725
This diff changes pt_defs.bzl to pt_defs.py, so that it can be included as python source file.
The reason is if we remove base ops, pt_defs.bzl becomes too big (8k lines) and we cannot pass its content to gen_oplist (python library). The easy solution is to change it to a python source file so that it can be used in gen_oplist.
Test Plan: sandcastle
Reviewed By: ljk53, iseeyuan
Differential Revision: D22968258
fbshipit-source-id: d720fe2e684d9a2bf5bd6115b6e6f9b812473f12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42400
mcarilli spotted that in the original DDP communication hook design described in [39272](https://github.com/pytorch/pytorch/issues/39272), the hooks receive grads that are already predivided by world size.
It makes sense to skip the divide completely if hook registered. The hook is meant for the user to completely override DDP communication. For example, if the user would like to implement something like GossipGrad, always dividing by the world_size would not be a good idea.
We also included a warning in the register_comm_hook API as:
> GradBucket bucket's tensors will not be predivided by world_size. User is responsible to divide by the world_size in case of operations like allreduce.
ghstack-source-id: 109548696
**Update:** We discovered and fixed a bug with the sparse tensors case. See new unit test called `test_ddp_comm_hook_sparse_gradients` and changes in `reducer.cpp`.
Test Plan: python test/distributed/test_c10d.py and perf benchmark tests.
Reviewed By: ezyang
Differential Revision: D22883905
fbshipit-source-id: 3277323fe9bd7eb6e638b7ef0535cab1fc72f89e
Summary:
`torch.scatter` supports two overloads – one where `src` input tensor is same size as the `index` tensor input, and second, where `src` is a scalar. Currrently, ONNX exporter only supports the first overload. This PR adds export support for the second overload of `torch.scatter`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42765
Reviewed By: hl475
Differential Revision: D23025189
Pulled By: houseroad
fbshipit-source-id: 5c2a3f3ce3b2d69661a227df8a8e0ed7c1858dbf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42766
**Summary**
Some python tests are missing in `caffe2/test/TARGETS`, add them to be more comprehension.
According to [run_test.py](https://github.com/pytorch/pytorch/blob/master/test/run_test.py#L125), some tests are slower. Slow tests are added as independent targets and others are put together into one `others` target. The reason is because we want to reduce overhead, especially for code covarge collection. Tests in one target can be run as a bundle, and then coverage can be collected together. Typically coverage collection procedure is time-expensive, so this helps us save time.
Test Plan:
Run all the new test targets locally in dev server and record the time they cost.
**Statistics**
```
# jit target
real 33m7.694s
user 653m1.181s
sys 58m14.160s
--------- Compare to Initial Jit Target runtime: ----------------
real 32m13.057s
user 613m52.843s
sys 54m58.678s
```
```
# others target
real 9m2.920s
user 164m21.927s
sys 12m54.840s
```
```
# serialization target
real 4m21.090s
user 23m33.501s
sys 1m53.308s
```
```
# tensorexpr
real 11m28.187s
user 33m36.420s
sys 1m15.925s
```
```
# type target
real 3m36.197s
user 51m47.912s
sys 4m14.149s
```
Reviewed By: malfet
Differential Revision: D22979219
fbshipit-source-id: 12a30839bb76a64871359bc024e4bff670c5ca8b
Summary:
Add centos Dockerfile and support to circleci docker builds, and allow generic image names to be parsed by build.sh, so both hardcoded images and custom images can be built.
Currently only adds a ROCm centos Dockerfile.
CC ezyang xw285cornell sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41255
Reviewed By: mrshenli
Differential Revision: D23003218
Pulled By: malfet
fbshipit-source-id: 562c53533e7fb9637dc2e81edb06b2242afff477
Summary:
Not sure what happened, but possibly I landed a PR on PyTorch which updated the TensorPipe submodule to a commit hash of a *PR* of TensorPipe. Now that the latter PR has been merged though that same commit has a different hash. The commit referenced by PyTorch, therefore, has become orphaned. This is causing some issues.
Hence here I am updating the commit, which however does not change a single line of code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42789
Reviewed By: houseroad
Differential Revision: D23023238
Pulled By: lw
fbshipit-source-id: ca2dcf6b7e07ab64fb37e280a3dd7478479f87fd
Summary:
Always promote type casts for comparison operators, regardless if the input is tensor or scalar. Unlike arithmetic operators, where scalars are implicitly cast to the same type as tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37787
Reviewed By: hl475
Differential Revision: D21440585
Pulled By: houseroad
fbshipit-source-id: fb5c78933760f1d1388b921e14d73a2cb982b92f
Summary:
Per title. Also updates our guidance for adding aliases to clarify interned_string and method_test requirements. The alias is tested by extending test_clamp to also test clip.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42770
Reviewed By: ngimel
Differential Revision: D23020655
Pulled By: mruberry
fbshipit-source-id: f1d8e751de9ac5f21a4f95d241b193730f07b5dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42740
Adds a pass to hoist conv packed params to root module.
The benefit is that if there is nothing else in the conv module,
subsequent passes will delete it, which will reduce module size.
For context, freezing does not handle this because conv packed
params is a custom object.
Test Plan:
```
PYTORCH_JIT_LOG_LEVEL=">hoist_conv_packed_params.cpp" python test/test_mobile_optimizer.py TestOptimizer.test_hoist_conv_packed_params
```
Imported from OSS
Reviewed By: kimishpatel
Differential Revision: D23005961
fbshipit-source-id: 31ab1f5c42a627cb74629566483cdc91f3770a94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42739
This is a test case which fails with ASAN on at the module freezing
step.
Test Plan:
```
USE_ASAN=1 USE_CUDA=0 python setup.py develop
LD_PRELOAD=/usr/lib64/libasan.so.4 python test/test_mobile_optimizer.py TestOptimizer.test_optimize_for_mobile_asan
// output tail: https://gist.github.com/vkuzo/7a0018b9e10ffe64dab0ac7381479f23
```
Imported from OSS
Reviewed By: kimishpatel
Differential Revision: D23005962
fbshipit-source-id: b7d4492e989af7c2e22197c16150812bd2dda7cc
Summary:
add a fuse path for deq->swish->quant
update swish fake op interface to take arguments accordingly
Test Plan:
net_runner passes
unit tests need to be updated
Reviewed By: venkatacrc
Differential Revision: D22962064
fbshipit-source-id: cef79768db3c8af926fca58193d459d671321f80
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42619
Added missing entries to `DispatchKey::toString()` and reordered to match declaration order in `DispatchKey.h`
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D22963407
Pulled By: bhosmer
fbshipit-source-id: 34a012135599f497c308ba90ea6e8117e85c74ac
Summary:
This function was always expecting to return a `size_t` value
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42454
Reviewed By: ezyang
Differential Revision: D22993168
Pulled By: ailzhang
fbshipit-source-id: 044df8ce17983f04681bda8c30cd742920ef7b1e
Summary:
Backout D22800959 (f30ac66e79). This one is causing the timeout (machine stuck) issues for dedup kernels. Reverting it make the unit test pass. Still need to investigate why this is the culprit...
Original commit changeset: 641d52a51070
Test Plan:
```
buck test mode/dev-nosan //caffe2/caffe2/fb/net_transforms/tests:fuse_sparse_ops_test -- 'test_fuse_sparse_adagrad_with_sparse_lengths_sum_gradient \(caffe2\.caffe2\.fb\.net_transforms\.tests\.fuse_sparse_ops_test\.TestFuseSparseOps\)' --print-passing-details
```
Reviewed By: jspark1105
Differential Revision: D23008389
fbshipit-source-id: 4f1b9a41c78eaa5541d57b9d8aa12401e1d495f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42714
Change two unit tests for the lite trainer to register two instances/objects of the same submodule type instead of the same submodule object twice.
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D22990736
Pulled By: ann-ss
fbshipit-source-id: 2bf56b5cc438b5a5fc3db90d3f30c5c431d3ae77
Summary:
This diff adds FakeQuantizeWithBackward. This works the same way as the regular FakeQuantize module, allowing QAT to occur in the forward pass, except it has an additional quantize_backward parameter. When quantize_backward is enabled, the gradients are fake quantized as well (dynamically, using hard-coded values). This allows the user to see whether there would be a significant loss of accuracy if the gradients were quantized in their model.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40532
Test Plan: The relevant test for this can be run using `python test/test_quantization.py TestQATBackward.test_forward_and_backward`
Reviewed By: supriyar
Differential Revision: D22217029
Pulled By: durumu
fbshipit-source-id: 7055a2cdafcf022f1ea11c3442721ae146d2b3f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42694
The old implementation allowed calling SmallVector constructor and operator= for any type without restrictions,
but then failed with a compiler error when the type wasn't a collection.
Instead, we should only use it if Container follows a container concept and just not match the constructor otherwise.
This fixes an issue kimishpatel was running into.
ghstack-source-id: 109370513
Test Plan: unit tests
Reviewed By: kimishpatel, ezyang
Differential Revision: D22983020
fbshipit-source-id: c31264f5c393762d822f3d64dd2a8e3279d8da44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42756
Similar to ELU, CELU was also broken in the quantized benchmark, fixing.
Test Plan:
```
cd benchmarks/operator_benchmark
python -m pt.qactivation_test
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D23010863
fbshipit-source-id: 203e63f9cff760af6809f6f345b0d222dc1e9e1b
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: a989b99279
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42713
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: amylittleyang
Differential Revision: D22990108
Pulled By: jspark1105
fbshipit-source-id: 3252a0f5ad9546221ef2fe908ce6b896252e1887
Summary: Add Python type annotations for the `caffe2.distributed.python` module.
Test Plan: Will check sandcastle results.
Reviewed By: jeffdunn
Differential Revision: D22994012
fbshipit-source-id: 30565cc41dd05b5fbc639ae994dfe2ddd9e56cb1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42611
**Summary**
This commit modifies the Python frontend to ignore static functions on
Torchscript classes when compiling them. They are currently included
along with methods, which causes the first argument of the
staticfunction to be unconditionally inferred to be of the type of the
class it belongs to (regardless of how it is annotated or whether it is
annotated at all). This can lead to compilation errors depending on
how that argument is used in the body of the function.
Static functions are instead imported and scripted as if they were
standalone functions.
**Test Plan**
This commit augments the unit test for static methods in `test_class_types.py`
to test that static functions can call each other and the class
constructor.
**Fixes**
This commit fixes#39308.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D22958163
Pulled By: SplitInfinity
fbshipit-source-id: 45c3c372792299e6e5288e1dbb727291e977a2af
Summary:
I noticed that `TensorIteratorDynamicCasting.h` defines a helper meta-function `CPPTypeToScalarType` which does exactly the same thing as the `c10::CppTypeToScalarType` meta-function I added in gh-40927. No need for two identical definitions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42640
Reviewed By: malfet
Differential Revision: D22969708
Pulled By: ezyang
fbshipit-source-id: 8303c7f4a75ae248f393a4811ae9d2bcacab44ff
Summary:
Awhile back when commonizing the Let and LetStmt nodes, I ended up removing both and adding a separate VarBinding section the Block. At the time I couldn't find a counter example, but I found it today: Local Vars and Allocations dependencies may go in either direction and so we need to support interleaving of those statements.
So, I've removed all the VarBinding logic and reimplemented Let statements. ZolotukhinM I think you get to say "I told you so". No new tests, existing tests should cover this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42634
Reviewed By: mruberry
Differential Revision: D22969771
Pulled By: nickgg
fbshipit-source-id: a46c5193357902d0f59bf30ab103fe123b1503f1
Summary:
This PR adds the `torch.linalg` namespace as part of our continued effort to be more compatible with NumPy. The namespace is tested by adding a single function, `torch.linalg.outer`, and testing it in a new test suite, test_linalg.py. It follows the same pattern that https://github.com/pytorch/pytorch/pull/41911, which added the `torch.fft` namespace, did.
Future PRs will likely:
- add more functions to torch.linalg
- expand the testing done in test_linalg.py, including legacy functions, like torch.ger
- deprecate existing linalg functions outside of `torch.linalg` in preference to the new namespace
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42664
Reviewed By: ngimel
Differential Revision: D22991019
Pulled By: mruberry
fbshipit-source-id: 39258d9b116a916817b3588f160b141f956e5d0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42383
Test Plan - Updated existing tests to run for complex dtypes as well.
Also added tests for `torch.addmm`, `torch.badmm`
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D22960339
Pulled By: anjali411
fbshipit-source-id: 0805f21caaa40f6e671cefb65cef83a980328b7d
Summary:
If argumenets in set_target_properties are not separated by whitespace, cmake raises a warning:
```
CMake Warning (dev) at cmake/public/cuda.cmake:269:
Syntax Warning in cmake code at column 54
Argument not separated from preceding token by whitespace.
```
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42707
Reviewed By: ailzhang
Differential Revision: D22988055
Pulled By: malfet
fbshipit-source-id: c3744f23b383d603788cd36f89a8286a46b6c00f
Summary:
Pull Request resolved: https://github.com/pytorch/glow/pull/4787
Resurrect ONNX as a backend through onnxifiGlow (was killed as part of D16215878). Then look for the `use_glow_aot` argument in the Onnxifi op. If it's there and true, then we override whatever `backend_id` is set and use the ONNX backend.
Reviewed By: yinghai, rdzhabarov
Differential Revision: D22762123
fbshipit-source-id: abb4c3458261f8b7eeae3016dda5359fa85672f0
Summary:
This PR canonicalizes our (current) pattern for adding aliases to PyTorch. That pattern is:
- Copy the original functions native_functions.yaml entry, but replace the original function's name with their own.
- Implement the corresponding functions and have them redispatch to the original function.
- Add docstrings to the new functions that reference the original function.
- Update the alias_map in torch/csrc/jit/passes/normalize_ops.cpp.
- Update the op_alias_mappings in torch/testing/_internal/jit_utils.py.
- Add a test validating the alias's behavior is the same as the original function's.
An alternative pattern would be to use Python and C++ language features to alias ops directly. For example in Python:
```
torch.absolute = torch.abs
```
Let the pattern in this PR be the "native function" pattern, and the alternative pattern be the "language pattern." There are pros/cons to both approaches:
**Pros of the "Language Pattern"**
- torch.absolute is torch.abs.
- no (or very little) overhead for calling the alias.
- no native_functions.yaml redundancy or possibility of "drift" between the original function's entries and the alias's.
**Cons of the "Language Pattern"**
- requires manually adding doc entries
- requires updating Python alias and C++ alias lists
- requires hand writing alias methods on Tensor (technically this should require a C++ test to validate)
- no single list of all PyTorch ops -- have to check native_functions.yaml and one of the separate alias lists
**Pros of the "Native Function" pattern**
- alias declarations stay in native_functions.yaml
- doc entries are written as normal
**Cons of the "Native Function" pattern**
- aliases redispatch to the original functions
- torch.absolute is not torch.abs (requires writing test to validate behavior)
- possibility of drift between original's and alias's native_functions.yaml entries
While either approach is reasonable, I suggest the "native function" pattern since it preserves "native_functions.yaml" as a source of truth and minimizes the number of alias lists that need to be maintained. In the future, entries in native_functions.yaml may support an "alias" argument and replace whatever pattern we choose now.
Ops that are likely to use aliasing are:
- div (divide, true_divide)
- mul (multiply)
- bucketize (digitize)
- cat (concatenate)
- clamp (clip)
- conj (conjugate)
- rad2deg (degrees)
- trunc (fix)
- neg (negative)
- deg2rad (radians)
- round (rint)
- acos (arccos)
- acosh (arcosh)
- asin (arcsin)
- asinh (arcsinh)
- atan (arctan)
- atan2 (arctan2)
- atanh (arctanh)
- bartlett_window (bartlett)
- hamming_window (hamming)
- hann_window (hanning)
- bitwise_not (invert)
- gt (greater)
- ge (greater_equal)
- lt (less)
- le (less_equal)
- ne (not_equal)
- ger (outer)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42586
Reviewed By: ngimel
Differential Revision: D22991086
Pulled By: mruberry
fbshipit-source-id: d6ac96512d095b261ed2f304d7dddd38cf45e7b0
Summary: Put user embedding before ads embedding in blobReorder, for flash verification reason.
Test Plan:
```
buck run mode/opt-clang -c python.package_style=inplace sigrid/predictor/scripts:enable_large_model_loading -- --model_path_src="/home/$USER/models/" --model_path_dst="/home/$USER/models_modified/" --model_file_name="182560549_0.predictor"
```
https://www.internalfb.com/intern/anp/view/?id=320921 to check blobsOrder
Reviewed By: yinghai
Differential Revision: D22964332
fbshipit-source-id: 78b4861476a3c889a5ff62492939f717c307a8d2
Summary:
[5/N] Implement Enum JIT support
Implement Enum class iteration
Add aten.ne for EnumType
Supported:
Enum-typed function arguments
using Enum type and comparing them
Support getting name/value attrs of enums
Using Enum value as constant
Support Enum-typed return values
Support iterating through Enum class (enum value list)
TODO:
Support serialization and deserialization
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42661
Reviewed By: SplitInfinity
Differential Revision: D22977364
Pulled By: gmagogsfm
fbshipit-source-id: 1a0216f91d296119e34cc292791f9aef1095b5a8
Summary:
in `_jit_pass_onnx`, symbolic functions are called for each node for conversion. However, there are nodes that cannot be converted without additional context. For example, the number of outputs from split (and whether it is static or dynamic) is unknown until the point where it is unpacked by listUnpack node. This pass does a preprocess, and prepares the nodes such that enough context can be received by the symbolic function.
* After preprocessing, `_jit_pass_onnx` should have enough context to produce valid ONNX nodes, instead of half baked nodes that replies on fixes from later postpasses.
* `_jit_pass_onnx_peephole` should be a pass that does ONNX specific optimizations instead of ONNX specific fixes.
* Producing more valid ONNX nodes in `_jit_pass_onnx` enables better utilization of the ONNX shape inference https://github.com/pytorch/pytorch/issues/40628.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41832
Reviewed By: ZolotukhinM
Differential Revision: D22968334
Pulled By: bzinodev
fbshipit-source-id: 8226f03c5b29968e8197d242ca8e620c6e1d42a5
Summary:
`torch.where` supports `ByteTensor` and `BoolTensor` types for the first input argument (`condition` predicate). Currently, ONNX exporter assumes that the first argument is `BoolTensor`. This PR updates the export for `torch.where` to correctly support export when first argument is a `ByteTensor`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42264
Reviewed By: houseroad
Differential Revision: D22968473
Pulled By: bzinodev
fbshipit-source-id: 7306388c8446ef3faeb86dc89d72d1f72c1c2314
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42565
After recent changes to the record function we record more
ranges in profiler output and also keep emitting sequence numbers for
all ranges.
Sequence numbers are used by external tools to correlate forward
and autograd ranges and with many ranges having the same sequence number
it becomes impossible to do this.
This PR ensures that we set sequence numbers only for the top-level
ranges and only in case when autograd is enabled.
Test Plan:
nvprof -fo trace.nvvp --profile-from-start off python test_script.py
test_script
https://gist.github.com/ilia-cher/2baffdd98951ee2a5f2da56a04fe15d0
then examining ranges in nvvp
Reviewed By: ngimel
Differential Revision: D22938828
Pulled By: ilia-cher
fbshipit-source-id: 9a5a076706a6043dfa669375da916a1708d12c19
Summary:
Test takes 5 min to finish and 5 min to spin up the environment, so it doesn't make much sense to keep it as separate config
Limit those tests to be run only when `USE_CUDA` environment variable is set to tru
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42650
Reviewed By: ailzhang
Differential Revision: D22967817
Pulled By: malfet
fbshipit-source-id: c6c26df140059491e7ff53ee9cbbc93433d2f36f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/41656
For the CPU version, this is a regression introduced in https://github.com/pytorch/pytorch/issues/10980 which vectorized the `grid_sampler_2d` implementation. It uses the AVX2 gather intrinsic which for `float` requires 32-bit indexing to match the number of floats in the AVX register. There is also an `i64gather_ps` variant but this only utilizes half of the vector width so would be expected to give worse performance in the more likely case where 32-bit indexing is acceptable. So, I've left the optimised AVX version as-is and reinstated the old non-vectorized version as a fallback.
For the CUDA version, this operation has never supported 32-bit indexing so this isn't a regression. I've templated the kernel on index type and added 64-bit variants. Although I gather in some places a simple `TORCH_CHECK(canUse32BitIndexMath(...))` is used instead. So, there is a decision to be made here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41923
Reviewed By: glaringlee
Differential Revision: D22925931
Pulled By: zou3519
fbshipit-source-id: 920816107aae26360c5e7f4e9c729fa9057268bb
Summary:
Per title. ROCm CI doesn't have MKL so this adds a couple missing test annotations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42701
Reviewed By: ngimel
Differential Revision: D22986273
Pulled By: mruberry
fbshipit-source-id: efa717e2e3771562e9e82d1f914e251918e96f64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42688
Both the profiling executor and the legacy executor have the debug
loggin now.
Ideally, if we had a pass manager, this could be done as a part of it,
but since we have none, I had to insert the debug statements manually.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D22981675
Pulled By: ZolotukhinM
fbshipit-source-id: 22b8789e860aa90d5802fc72a4113b22c6fc4da5
Summary:
Previous when inferring Int8FC, we failed to carry over the scale and zero point properly.
Also fixed int8 FC weight data type to be int8 instead of uint8 as that's what C2 actually uses.
Test Plan: Use net_runner to lower a single Int8Dequantize op. Previous scale and bias would always be 1 and 0. Now the proper value is set.
Reviewed By: yinghai
Differential Revision: D22912186
fbshipit-source-id: a6620c3493e492bdda91da73775bfc9117db12d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42263
Allow a way to get a reference to the stored string in a `List<optional<string>>` without having to copy the string.
This for example improves perf of the map_lookup op by 3x.
ghstack-source-id: 109162026
Test Plan: unit tests
Reviewed By: ezyang
Differential Revision: D22830381
fbshipit-source-id: e6af2bc8cebd6e68794eb18daf183979bc6297ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42189
Rehash of https://github.com/pytorch/pytorch/pull/28811, which was several months old.
As part of addressing https://github.com/pytorch/pytorch/issues/23232, this PR adds support for the following APIs:
`allgather_object` and `gather_object` to support gather/allgather of generic, pickable Python objects. This has been a long-requested feature so PyTorch should provide these helpers built-in.
The methodology is what is proposed in the original issue:
1) Pickle object to ByteTensor using torch.save
2) Comm. tensor sizes
3) Copy local ByteTensor into a tensor of maximal size
4) Call tensor-based collectives on the result of (3)
5) Unpickle back into object using torch.load
Note that the API is designed to match other than supporting `async_op`. For now, it is a blocking call. If we see demand to support `async_op`, we will have to make more progress on merging work/future to support this.
If this is a suitable approach, we can support `scatter`, `broadcast` in follow up PRs.
ghstack-source-id: 109322433
Reviewed By: mrshenli
Differential Revision: D22785387
fbshipit-source-id: a265a44ec0aa3aaffc3c6966023400495904c7d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40719
This is a follow up patch to turn on this feature in order to handle breaking
forward compatibility.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D22457952
Pulled By: bzinodev
fbshipit-source-id: fac0dfed8b8b5fa2d52d342ee8cf06742959b3c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42656
Thing change will allow us to more freely experiment with pass pipelines
in the profiling executor without affecting passes in the legacy
executor. Also, it somewhat helps to keep all passes in one place to be
able to tell what's going on.
Currently this change should not affect any behavior as I copied the
passes exactly as they've been invoked before, but we will probably want
to change these pipelines in a near future.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D22971050
Pulled By: ZolotukhinM
fbshipit-source-id: f5bb60783a553c7b51c5343eec7f8fe40037ff99
Summary:
Run fastrnns benchmark using pytest-benchmark infra, then parse its json format and upload to scribe.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42030
Reviewed By: malfet
Differential Revision: D22970270
Pulled By: wconstab
fbshipit-source-id: 87da9b7ddf741da14b80d20779771d19123be3c5
Summary:
This diff NVMifies the NE Eval Flow.
- It defines a `LoadNVM` operator which either
- receives a list of nvm blobs, or
- extracts the blobs that could be NVMified from the model.
- dumps NVMified blobs into NVM
- and deallocates from DRAM
- NVMify the Eval net on dper and C2 backend
Specific NVMOp for SLS is pushed through different diffs.
Test Plan: flow-cli test-locally dper.workflows.evaluation.eval_workflow --parameters-file=/mnt/public/ehsaardestani/temp/small_model.json 2>&1 | tee log
Reviewed By: yinghai, amylittleyang
Differential Revision: D22469973
fbshipit-source-id: ed8379ad404e96d04ac05e580176d3aca984575b
Summary:
Because 2.7.3 has some bug on GA100 which is fixed in 2.7.6
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42645
Reviewed By: malfet
Differential Revision: D22977280
Pulled By: mrshenli
fbshipit-source-id: 74779eff90d7d660a988ff33659f3a2237ca7e29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42522
Main changes:
- Consolidated CMake files to have a single entry point, rather than having a specialized one for PyTorch.
- Changed the way the preprocessor flags are provided, and changed their name.
There were a few instances in PyTorch's CMake files where we were directly adding TensorPipe's source directory as an include path, which however doesn't contain the auto-generated header we now added. We fix that by adding the `tensorpipe` CMake target as a dependency, so that the include paths defined by TensorPipe are used, which contain that auto-generated header. So instead we link those targets to the tensorpipe target in order for them to pick up the correct include directories.
I'm turning off SHM and CMA for now because they have never been covered by the CI. I'll enable them in a separate PR so that if they turn out to be flaky we can revert that change without reverting this one.
Test Plan: CI
Reviewed By: malfet
Differential Revision: D22959472
fbshipit-source-id: 1959a41c4a66ef78bf0f3bd5e3964969a2a1bf67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42521
PyTorch's usage of TensorPipe is entirely wrapped within the RPC agent, which means we only need access to TensorPipe within the implementation (the .cpp file) and not in the interface (the .h file). We were however including the TensorPipe headers from the public PyTorch headers, which meant that PyTorch's downstream users had to have the TensorPipe include directories for that to work. By forward-declaring the symbols we need in the PyTorch header, and then including the TensorPipe header in the PyTorch implementation, we avoid "leaking" the dependency on TensorPipe, thus effectively keeping it private.
Test Plan: Imported from OSS
Reviewed By: beauby
Differential Revision: D22944238
Pulled By: lw
fbshipit-source-id: 2b12d59bd5beeaa439e50f9088a792c9d9bae9e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42570
ProfiledType doesn't do anything and is not used atm, removing
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D22938664
Pulled By: ilia-cher
fbshipit-source-id: 037c512938028f44258b702bbcde3f8c144f4aa0
Summary:
This PR creates a new namespace, torch.fft (torch::fft) and puts a single function, fft, in it. This function is analogous to is a simplified version of NumPy's [numpy.fft.fft](https://numpy.org/doc/1.18/reference/generated/numpy.fft.fft.html?highlight=fft#numpy.fft.fft) that accepts no optional arguments. It is intended to demonstrate how to add and document functions in the namespace, and is not intended to deprecate the existing torch.fft function.
Adding this namespace was complicated by the existence of the torch.fft function in Python. Creating a torch.fft Python module makes this name ambiguous: does it refer to a function or module? If the JIT didn't exist, a solution to this problem would have been to make torch.fft refer to a callable class that mimicked both the function and module. The JIT, however, cannot understand this pattern. As a workaround it's required to explicitly `import torch.fft` to access the torch.fft.fft function in Python:
```
import torch.fft
t = torch.randn(128, dtype=torch.cdouble)
torch.fft.fft(t)
```
See https://github.com/pytorch/pytorch/issues/42175 for future work. Another possible future PR is to get the JIT to understand torch.fft as a callable class so it need not be imported explicitly to be used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41911
Reviewed By: glaringlee
Differential Revision: D22941894
Pulled By: mruberry
fbshipit-source-id: c8e0b44cbe90d21e998ca3832cf3a533f28dbe8d
Summary:
This PR introduces a variant of `gpu_kernel` for functions that return multiple values with `thrust::tuple`.
With this I simplified `prelu_cuda_backward_share_weights_kernel`.
### Why using `thrust::tuple`?
Because `std::tuple` does not support `operator=` on device code which makes the implementation complicated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37969
Reviewed By: paulshaoyuqiao
Differential Revision: D22868670
Pulled By: ngimel
fbshipit-source-id: eda0a29ac0347ad544b24bf60e3d809a7db1a929
Summary:
Unroll a loop with constant boundaries, replacing it with multiple
instances of the loop body. For example:
```
for x in 0..3:
A[x] = x*2
```
becomes:
```
A[0] = 0
A[1] = 2
A[2] = 4
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42465
Test Plan: `test_tensorexpr` unit tests.
Reviewed By: agolynski
Differential Revision: D22914418
Pulled By: asuhan
fbshipit-source-id: 72ca10d7c0b1ac7f9a3688ac872bd94a1c53dc51
Summary:
According to pytorch/rfcs#3
From the goals in the RFC:
1. Support subclassing `torch.Tensor` in Python (done here)
2. Preserve `torch.Tensor` subclasses when calling `torch` functions on them (done here)
3. Use the PyTorch API with `torch.Tensor`-like objects that are _not_ `torch.Tensor`
subclasses (done in https://github.com/pytorch/pytorch/issues/30730)
4. Preserve `torch.Tensor` subclasses when calling `torch.Tensor` methods. (done here)
5. Propagating subclass instances correctly also with operators, using
views/slices/indexing/etc. (done here)
6. Preserve subclass attributes when using methods or views/slices/indexing. (done here)
7. A way to insert code that operates on both functions and methods uniformly
(so we can write a single function that overrides all operators). (done here)
8. The ability to give external libraries a way to also define
functions/methods that follow the `__torch_function__` protocol. (will be addressed in a separate PR)
This PR makes the following changes:
1. Adds the `self` argument to the arg parser.
2. Dispatches on `self` as well if `self` is not `nullptr`.
3. Adds a `torch._C.DisableTorchFunction` context manager to disable `__torch_function__`.
4. Adds a `torch::torch_function_enabled()` and `torch._C._torch_function_enabled()` to check the state of `__torch_function__`.
5. Dispatches all `torch._C.TensorBase` and `torch.Tensor` methods via `__torch_function__`.
TODO:
- [x] Sequence Methods
- [x] Docs
- [x] Tests
Closes https://github.com/pytorch/pytorch/issues/28361
Benchmarks in https://github.com/pytorch/pytorch/pull/37091#issuecomment-633657778
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37091
Reviewed By: ngimel
Differential Revision: D22765678
Pulled By: ezyang
fbshipit-source-id: 53f8aa17ddb8b1108c0997f6a7aa13cb5be73de0
Summary:
Enforce counter value to double type in rowwise_counter.
**Context:**
The existing implementation is using float type for counter value. But due to the precision limit of a floating number [1], we observed that the counter value can't increment beyond 16777216.0 (i.e., the max value is 16777216.0) in our earlier experiments. We decide to enforce double type to avoid this issue.
[1] https://stackoverflow.com/questions/12596695/why-does-a-float-variable-stop-incrementing-at-16777216-in-c
Test Plan:
op test
```
ruixliu@devvm1997:~/fbsource/fbcode/caffe2/caffe2/python/operator_test(f0b0b48c)$ buck test :rowwise_counter_test
Trace available for this run at /tmp/testpilot.20200728-083200.729292.log
TestPilot test runner for Facebook. See https://fburl.com/testpilot for details.
Testpilot build revision cd2638f1f47250eac058b8c36561760027d16add fbpkg f88726c8ebde4ba288e1172a348c7f46 at Mon Jul 27 18:11:43 2020 by twsvcscm from /usr/local/fbprojects/packages/testinfra.testpilot/887/t.par
Discovering tests
Running 1 test
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/7881299364977047
✓ caffe2/caffe2/python/operator_test:rowwise_counter_test - test_rowwise_counter (caffe2.caffe2.python.operator_test.rowwise_counter_test.TestRowWiseCounter) 0.265 1/1 (passed)
✓ caffe2/caffe2/python/operator_test:rowwise_counter_test - main 14.414 (passed)
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/7881299364977047
Summary (total time 18.51s):
PASS: 2
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
```
optimizer test
```
ruixliu@devvm1997:~/fbsource/fbcode/caffe2/caffe2/python(7d66fbb9)$ buck test :optimizer_test
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/7036874434841896
Summary (total time 64.87s):
PASS: 48
FAIL: 0
SKIP: 24
caffe2/caffe2/python:optimizer_test - testGPUDense (caffe2.caffe2.python.optimizer_test.TestMomentumSgd)
caffe2/caffe2/python:optimizer_test - testGPUDense (caffe2.caffe2.python.optimizer_test.TestGFtrl)
caffe2/caffe2/python:optimizer_test - test_caffe2_cpu_vs_numpy (caffe2.caffe2.python.optimizer_test.TestYellowFin)
caffe2/caffe2/python:optimizer_test - testGPUDense (caffe2.caffe2.python.optimizer_test.TestSparseRAdam)
caffe2/caffe2/python:optimizer_test - testGPUDense (caffe2.caffe2.python.optimizer_test.TestRowWiseAdagradWithCounter)
caffe2/caffe2/python:optimizer_test - testGPUDense (caffe2.caffe2.python.optimizer_test.TestAdagrad)
caffe2/caffe2/python:optimizer_test - test_caffe2_gpu_vs_numpy (caffe2.caffe2.python.optimizer_test.TestYellowFin)
caffe2/caffe2/python:optimizer_test - testDense (caffe2.caffe2.python.optimizer_test.TestRowWiseAdagrad)
caffe2/caffe2/python:optimizer_test - testGPUDense (caffe2.caffe2.python.optimizer_test.TestFtrl)
caffe2/caffe2/python:optimizer_test - testSparse (caffe2.caffe2.python.optimizer_test.TestRmsProp)
...and 14 more not shown...
FATAL: 0
TIMEOUT: 0
OMIT: 0
```
param download test
```
ruixliu@devvm1997:~/fbsource/fbcode/caffe2/caffe2/fb/net_transforms/tests(7ef20a38)$ sudo buck test :param_download_test
Finished test run: Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/6473924481526935
```
e2e flow:
f208394929
f207991149
f207967273
ANP notebook to check the counter value loaded from the flows
https://fburl.com/anp/5fdcbnoi
screenshot of the loaded counter (note that counter max is larger than 16777216.0)
{F250926501}
Reviewed By: ellie-wen
Differential Revision: D22711514
fbshipit-source-id: 426fed7415270aa3f276dda8141907534734337f
Summary:
Make function from method
Since _forward_unimplemented is defined within the nn.Module class,
pylint (correctly) complains about not implementing this method in subclasses.
Fixes https://github.com/pytorch/pytorch/issues/42305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42356
Reviewed By: mruberry
Differential Revision: D22867255
Pulled By: ezyang
fbshipit-source-id: ccf3e45e359d927e010791fadf70b2ef231ddb0b
Summary:
This should fix CUDA-11 on Windows build issue
`defined` is not a function, and so it can not be used in macro substitution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42643
Reviewed By: pbelevich, xw285cornell
Differential Revision: D22963420
Pulled By: malfet
fbshipit-source-id: cccf7db0d03cd62b655beeb154db9e628aa749f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41934
The model exported from online training workflow with int8 quantization contains FCs with 4 inputs. The extra input is the quant_param blob. This diff is to adjust the bound_shape_inferencer and int8 op schema to get shape info for the quant_param input.
Test Plan:
```
buck test caffe2/caffe2/opt:bound_shape_inference_test
```
Reviewed By: yinghai
Differential Revision: D22683554
fbshipit-source-id: 684d1433212a528120aba1c37d27e26b6a31b403
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42491
Hooks up quantized batchnorm_1d to the quantized_bn kernel. Eager mode
hookup will be in a future PR, and graph mode should work after this PR.
Note: currently the implementation is ~2x slower on the benchmark than q_batch_norm2d
because we convert back to contiguous memory format at the end, since
channels_last is only defined for rank >= 4. If further optimization is
needed, that can be a separate PR (will need the NHWC folks to see if
there is a workaround). Meanwhile, having this is better than not having anything.
Context: There have been both internal and external requests for various
quantized BN1d use cases.
Test Plan:
```
python test/test_quantization.py TestQuantizedOps.test_batch_norm_1d_2d_3d
python test/test_quantization.py TestQuantizedOps.test_batch_norm_1d_2d_3d_relu
python test/test_quantization.py TestQuantizeJitOps.test_qbatch_norm
// performance:
// https://gist.github.com/vkuzo/73a07c0f24c05f5804990d9ebfaecf5e
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D22926254
fbshipit-source-id: 2780e6a81cd13a7455f6ab6e5118c22850a97a12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41603
Pull Request resolved: https://github.com/pytorch/glow/pull/4704
Previously in the glow onnxifi path, when an error is encountered, we log it to stderr then just return ONNXIFI_STATUS_INTERNAL_ERROR to C2. C2 then does CAFFE2_ENFORCE_EQUAL(return_code, ONNXIFI_STATUS_SUCCESS). The error message that eventually went to the user is something like
[enforce fail at onnxifi_op.cc:545] eventStatus == ONNXIFI_STATUS_SUCCESS. 1030 vs 0
This diff adds plumbing to get human readable error message out of glow into C2.
Test Plan:
Run ads replayer. Overload it with traffic. Now the error message sent back to the client used to be
E0707 00:57:45.697196 3709559 Caffe2DisaggAcceleratorTask.cpp:493] During running REMOTE_OTHER net: [enforce fail at onnxifi_op.cc:545] eventStatus == ONNXIFI_STATUS_SUCCESS. 1030 vs 0 (Error from operator:....
Now it's
```
E0707 16:46:48.366263 1532943 Client.cpp:966] Exception when calling caffe2_run_disagg_accelerator on remote predictor for model 190081310_0 : apache::thrift::TApplicationException: c10::Error: [enforce fail at onnxifi_op.cc:556] .
Error code: RUNTIME_REQUEST_REFUSED
Error message: The number of allowed queued requests has been exceeded. queued requests: 100 allowed requests: 100
Error return stack:
glow/glow/lib/Runtime/HostManager/HostManager.cpp:673
glow/glow/lib/Onnxifi/HostMana (Error from operator:...
```
Reviewed By: gcatron, yinghai
Differential Revision: D22416857
fbshipit-source-id: 564bc7644d9666eb660725c2dca5637affae9b73
Summary:
Refactor comnon pattern of (torch.cuda.version and [int(x) for x in torch.cuda.version.split(".")] >= [a, b]) into `_get_torch_cuda_version()` function
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42626
Reviewed By: seemethere
Differential Revision: D22956149
Pulled By: malfet
fbshipit-source-id: 897c55965e53b477cd20f69e8da15d90489035de
Summary: this breaks if we cut the net at certain int8 ops boundary.
Test Plan: with net_runner to lower a single Int8Quantize op. It used to break. Now it works.
Reviewed By: yinghai
Differential Revision: D22912178
fbshipit-source-id: ca306068c9768df84c1cfa8b34226a1330e19912
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42528
It seems it was an oversight that they weren't run. This allows to simplify our auto-generation logic as now all test suites are run in both modes.
ghstack-source-id: 109229969
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D22922151
fbshipit-source-id: 0766a6970c927efb04eee4894b73d4bcaf60b97f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40823
Summary of the entire stack:
--
This diff is part of an attempt to refactor the RPC tests. They currently suffer from several problems:
- Several ways to specify the agent to use: there exists one "generic" fixture that uses the global variable TEST_CONFIG to look up the agent name, and is used for process group and Thrift, and then there are separate fixtures for the flaky agent and the TensorPipe one.
- These two ways lead to having two separate decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which must both be specified, making it unclear what the effect of each of them is and what happens if only one is given.
- Thrift must override the TEST_CONFIG global variable before any other import (in order for the `requires_process_group_agent` decorator to work correctly) and for that it must use a "trap" file, which makes it even harder to track which agent is being used, and which is specific to Buck, and thus cannot be used in OSS by other agents.
- Even if the TensorPipe fixture doesn't use TEST_CONFIG, it still needs to set it to the right value for other parts of the code to work. (This is done in `dist_init`).
- There are a few functions in dist_utils.py that return some properties of the agent (e.g., a regexp to match against the error it returns in case of shutdown). These functions are effectively chained if/elses on the various agents, which has the effect of "leaking" some part of the Thrift agent into OSS.
- Each test suite (RPC, dist autograd/dist optimizer, their JIT versions, remote module, ...) must be run on each agent (or almost; the faulty one is an exception) in both fork and spawn mode. Each of these combinations is a separate file, which leads to a proliferation of scripts.
- There is no "master list" of what combinations make sense and should be run. Therefore it has happened that when adding new tests or new agents we forgot to enroll them into the right tests. (TensorPipe is still missing a few tests, it turns out).
- All of these tiny "entry point" files contain almost the same duplicated boilerplate. This makes it very easy to get the wrong content into one of them due to a bad copy-paste.
This refactoring aims to address these problems by:
- Avoiding global state, defaults/override, traps, if/elses, ... and have a single way to specify the agent, based on an abstract base class and several concrete subclasses which can be "mixed in" to any test suite.
- Instead of enabling/disabling tests using decorators, the tests that are specific to a certain agent are now in a separate class (which is a subclass of the "generic" test suite) so that they are only picked up by the agent they apply to.
- Instead of having one separate entry point script for each combination, it uses one entry point for each agent, and in that script it provides a list of all the test suites it wants to run on that agent. And it does that by trying to deduplicate the boilerplate as much as possible. (In fact, the various agent-suite combinations could be grouped in any way, not necessarily by agent as I did here).
It provides further advantages:
- It puts all the agents on equal standing, by not having any of them be the default, making it thus easier to migrate from process group to TensorPipe.
- It will make it easier to add more versions of the TensorPipe tests (e.g., one that disables the same-machine backends in order to test the TCP-based ones) without a further duplication of entry points, of boilerplate, ...
Summary of this commit
--
As it is now easier to spot that the TensorPipe agent wasn't being run on some test suite, we fix that. We keep this change for last so that if those tests turn out to be flaky and must be reverted this won't affect the rest of the stack.
ghstack-source-id: 109229469
Test Plan: Sandcastle and CircleCI
Reviewed By: pritamdamania87
Differential Revision: D22309432
fbshipit-source-id: c433a6a49a7b6737e0df4cd953f3dfde290f20b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40822
Summary of the entire stack:
--
This diff is part of an attempt to refactor the RPC tests. They currently suffer from several problems:
- Several ways to specify the agent to use: there exists one "generic" fixture that uses the global variable TEST_CONFIG to look up the agent name, and is used for process group and Thrift, and then there are separate fixtures for the flaky agent and the TensorPipe one.
- These two ways lead to having two separate decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which must both be specified, making it unclear what the effect of each of them is and what happens if only one is given.
- Thrift must override the TEST_CONFIG global variable before any other import (in order for the `requires_process_group_agent` decorator to work correctly) and for that it must use a "trap" file, which makes it even harder to track which agent is being used, and which is specific to Buck, and thus cannot be used in OSS by other agents.
- Even if the TensorPipe fixture doesn't use TEST_CONFIG, it still needs to set it to the right value for other parts of the code to work. (This is done in `dist_init`).
- There are a few functions in dist_utils.py that return some properties of the agent (e.g., a regexp to match against the error it returns in case of shutdown). These functions are effectively chained if/elses on the various agents, which has the effect of "leaking" some part of the Thrift agent into OSS.
- Each test suite (RPC, dist autograd/dist optimizer, their JIT versions, remote module, ...) must be run on each agent (or almost; the faulty one is an exception) in both fork and spawn mode. Each of these combinations is a separate file, which leads to a proliferation of scripts.
- There is no "master list" of what combinations make sense and should be run. Therefore it has happened that when adding new tests or new agents we forgot to enroll them into the right tests. (TensorPipe is still missing a few tests, it turns out).
- All of these tiny "entry point" files contain almost the same duplicated boilerplate. This makes it very easy to get the wrong content into one of them due to a bad copy-paste.
This refactoring aims to address these problems by:
- Avoiding global state, defaults/override, traps, if/elses, ... and have a single way to specify the agent, based on an abstract base class and several concrete subclasses which can be "mixed in" to any test suite.
- Instead of enabling/disabling tests using decorators, the tests that are specific to a certain agent are now in a separate class (which is a subclass of the "generic" test suite) so that they are only picked up by the agent they apply to.
- Instead of having one separate entry point script for each combination, it uses one entry point for each agent, and in that script it provides a list of all the test suites it wants to run on that agent. And it does that by trying to deduplicate the boilerplate as much as possible. (In fact, the various agent-suite combinations could be grouped in any way, not necessarily by agent as I did here).
It provides further advantages:
- It puts all the agents on equal standing, by not having any of them be the default, making it thus easier to migrate from process group to TensorPipe.
- It will make it easier to add more versions of the TensorPipe tests (e.g., one that disables the same-machine backends in order to test the TCP-based ones) without a further duplication of entry points, of boilerplate, ...
Summary of this commit
--
This is the last step of removing TEST_CONFIG. As there was no one left using it, there is really not much to it.
ghstack-source-id: 109229471
Test Plan: Sandcastle and CircleCI
Reviewed By: pritamdamania87
Differential Revision: D22307778
fbshipit-source-id: 0d9498d9367eec671e0a964ce693015f73c5638c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40821
Summary of the entire stack:
--
This diff is part of an attempt to refactor the RPC tests. They currently suffer from several problems:
- Several ways to specify the agent to use: there exists one "generic" fixture that uses the global variable TEST_CONFIG to look up the agent name, and is used for process group and Thrift, and then there are separate fixtures for the flaky agent and the TensorPipe one.
- These two ways lead to having two separate decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which must both be specified, making it unclear what the effect of each of them is and what happens if only one is given.
- Thrift must override the TEST_CONFIG global variable before any other import (in order for the `requires_process_group_agent` decorator to work correctly) and for that it must use a "trap" file, which makes it even harder to track which agent is being used, and which is specific to Buck, and thus cannot be used in OSS by other agents.
- Even if the TensorPipe fixture doesn't use TEST_CONFIG, it still needs to set it to the right value for other parts of the code to work. (This is done in `dist_init`).
- There are a few functions in dist_utils.py that return some properties of the agent (e.g., a regexp to match against the error it returns in case of shutdown). These functions are effectively chained if/elses on the various agents, which has the effect of "leaking" some part of the Thrift agent into OSS.
- Each test suite (RPC, dist autograd/dist optimizer, their JIT versions, remote module, ...) must be run on each agent (or almost; the faulty one is an exception) in both fork and spawn mode. Each of these combinations is a separate file, which leads to a proliferation of scripts.
- There is no "master list" of what combinations make sense and should be run. Therefore it has happened that when adding new tests or new agents we forgot to enroll them into the right tests. (TensorPipe is still missing a few tests, it turns out).
- All of these tiny "entry point" files contain almost the same duplicated boilerplate. This makes it very easy to get the wrong content into one of them due to a bad copy-paste.
This refactoring aims to address these problems by:
- Avoiding global state, defaults/override, traps, if/elses, ... and have a single way to specify the agent, based on an abstract base class and several concrete subclasses which can be "mixed in" to any test suite.
- Instead of enabling/disabling tests using decorators, the tests that are specific to a certain agent are now in a separate class (which is a subclass of the "generic" test suite) so that they are only picked up by the agent they apply to.
- Instead of having one separate entry point script for each combination, it uses one entry point for each agent, and in that script it provides a list of all the test suites it wants to run on that agent. And it does that by trying to deduplicate the boilerplate as much as possible. (In fact, the various agent-suite combinations could be grouped in any way, not necessarily by agent as I did here).
It provides further advantages:
- It puts all the agents on equal standing, by not having any of them be the default, making it thus easier to migrate from process group to TensorPipe.
- It will make it easier to add more versions of the TensorPipe tests (e.g., one that disables the same-machine backends in order to test the TCP-based ones) without a further duplication of entry points, of boilerplate, ...
Summary of this commit
--
This change continues the work towards removing TEST_CONFIG, by taking a few functions that were accepting the agent name (as obtained from TEST_CONFIG) and then did a bunch of if/elses on it, and replace them by new abstract methods on the fixtures, so that these functions become "decentralized".
ghstack-source-id: 109229472
Test Plan: Sandcastle and CircleCI
Reviewed By: pritamdamania87
Differential Revision: D22307776
fbshipit-source-id: 9e1f6edca79aacf0bcf9d83d50ce9e0d2beec0dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40820
Summary of the entire stack:
--
This diff is part of an attempt to refactor the RPC tests. They currently suffer from several problems:
- Several ways to specify the agent to use: there exists one "generic" fixture that uses the global variable TEST_CONFIG to look up the agent name, and is used for process group and Thrift, and then there are separate fixtures for the flaky agent and the TensorPipe one.
- These two ways lead to having two separate decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which must both be specified, making it unclear what the effect of each of them is and what happens if only one is given.
- Thrift must override the TEST_CONFIG global variable before any other import (in order for the `requires_process_group_agent` decorator to work correctly) and for that it must use a "trap" file, which makes it even harder to track which agent is being used, and which is specific to Buck, and thus cannot be used in OSS by other agents.
- Even if the TensorPipe fixture doesn't use TEST_CONFIG, it still needs to set it to the right value for other parts of the code to work. (This is done in `dist_init`).
- There are a few functions in dist_utils.py that return some properties of the agent (e.g., a regexp to match against the error it returns in case of shutdown). These functions are effectively chained if/elses on the various agents, which has the effect of "leaking" some part of the Thrift agent into OSS.
- Each test suite (RPC, dist autograd/dist optimizer, their JIT versions, remote module, ...) must be run on each agent (or almost; the faulty one is an exception) in both fork and spawn mode. Each of these combinations is a separate file, which leads to a proliferation of scripts.
- There is no "master list" of what combinations make sense and should be run. Therefore it has happened that when adding new tests or new agents we forgot to enroll them into the right tests. (TensorPipe is still missing a few tests, it turns out).
- All of these tiny "entry point" files contain almost the same duplicated boilerplate. This makes it very easy to get the wrong content into one of them due to a bad copy-paste.
This refactoring aims to address these problems by:
- Avoiding global state, defaults/override, traps, if/elses, ... and have a single way to specify the agent, based on an abstract base class and several concrete subclasses which can be "mixed in" to any test suite.
- Instead of enabling/disabling tests using decorators, the tests that are specific to a certain agent are now in a separate class (which is a subclass of the "generic" test suite) so that they are only picked up by the agent they apply to.
- Instead of having one separate entry point script for each combination, it uses one entry point for each agent, and in that script it provides a list of all the test suites it wants to run on that agent. And it does that by trying to deduplicate the boilerplate as much as possible. (In fact, the various agent-suite combinations could be grouped in any way, not necessarily by agent as I did here).
It provides further advantages:
- It puts all the agents on equal standing, by not having any of them be the default, making it thus easier to migrate from process group to TensorPipe.
- It will make it easier to add more versions of the TensorPipe tests (e.g., one that disables the same-machine backends in order to test the TCP-based ones) without a further duplication of entry points, of boilerplate, ...
Summary of this commit
--
Now that no one is using the generic fixture anymore (i.e., the fixture that looks up the agent's name in the global TEST_CONFIG) we can make it abstract, i.e., have its methods become no-ops and add decorators that will require all subclasses to provide new implementations of those methods. This is a first step towards removing TEST_CONFIG.
ghstack-source-id: 109229475
Test Plan: Sandcastle and CircleCI
Reviewed By: pritamdamania87
Differential Revision: D22307777
fbshipit-source-id: e52abd915c37894933545eebdfdca3ecb9559926
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40819
Summary of the entire stack:
--
This diff is part of an attempt to refactor the RPC tests. They currently suffer from several problems:
- Several ways to specify the agent to use: there exists one "generic" fixture that uses the global variable TEST_CONFIG to look up the agent name, and is used for process group and Thrift, and then there are separate fixtures for the flaky agent and the TensorPipe one.
- These two ways lead to having two separate decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which must both be specified, making it unclear what the effect of each of them is and what happens if only one is given.
- Thrift must override the TEST_CONFIG global variable before any other import (in order for the `requires_process_group_agent` decorator to work correctly) and for that it must use a "trap" file, which makes it even harder to track which agent is being used, and which is specific to Buck, and thus cannot be used in OSS by other agents.
- Even if the TensorPipe fixture doesn't use TEST_CONFIG, it still needs to set it to the right value for other parts of the code to work. (This is done in `dist_init`).
- There are a few functions in dist_utils.py that return some properties of the agent (e.g., a regexp to match against the error it returns in case of shutdown). These functions are effectively chained if/elses on the various agents, which has the effect of "leaking" some part of the Thrift agent into OSS.
- Each test suite (RPC, dist autograd/dist optimizer, their JIT versions, remote module, ...) must be run on each agent (or almost; the faulty one is an exception) in both fork and spawn mode. Each of these combinations is a separate file, which leads to a proliferation of scripts.
- There is no "master list" of what combinations make sense and should be run. Therefore it has happened that when adding new tests or new agents we forgot to enroll them into the right tests. (TensorPipe is still missing a few tests, it turns out).
- All of these tiny "entry point" files contain almost the same duplicated boilerplate. This makes it very easy to get the wrong content into one of them due to a bad copy-paste.
This refactoring aims to address these problems by:
- Avoiding global state, defaults/override, traps, if/elses, ... and have a single way to specify the agent, based on an abstract base class and several concrete subclasses which can be "mixed in" to any test suite.
- Instead of enabling/disabling tests using decorators, the tests that are specific to a certain agent are now in a separate class (which is a subclass of the "generic" test suite) so that they are only picked up by the agent they apply to.
- Instead of having one separate entry point script for each combination, it uses one entry point for each agent, and in that script it provides a list of all the test suites it wants to run on that agent. And it does that by trying to deduplicate the boilerplate as much as possible. (In fact, the various agent-suite combinations could be grouped in any way, not necessarily by agent as I did here).
It provides further advantages:
- It puts all the agents on equal standing, by not having any of them be the default, making it thus easier to migrate from process group to TensorPipe.
- It will make it easier to add more versions of the TensorPipe tests (e.g., one that disables the same-machine backends in order to test the TCP-based ones) without a further duplication of entry points, of boilerplate, ...
Summary of this commit
--
This diff removes the two decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which were used to skip tests. They were only used to prevent the TensorPipe agent from running tests that were using the process group agent's options. The converse (preventing the PG agent from using the TP options) is achieved by having those tests live in a `TensorPipeAgentRpcTest` class. So here we're doing the same for process group, by moving those tests to a `ProcessGroupAgentRpcTest` class.
ghstack-source-id: 109229473
Test Plan: Sandcastle and CircleCI
Reviewed By: pritamdamania87
Differential Revision: D22283179
fbshipit-source-id: b9315f9fd67f35e88fe1843faa161fc53a4133c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40818
Summary of the entire stack:
--
This diff is part of an attempt to refactor the RPC tests. They currently suffer from several problems:
- Several ways to specify the agent to use: there exists one "generic" fixture that uses the global variable TEST_CONFIG to look up the agent name, and is used for process group and Thrift, and then there are separate fixtures for the flaky agent and the TensorPipe one.
- These two ways lead to having two separate decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which must both be specified, making it unclear what the effect of each of them is and what happens if only one is given.
- Thrift must override the TEST_CONFIG global variable before any other import (in order for the `requires_process_group_agent` decorator to work correctly) and for that it must use a "trap" file, which makes it even harder to track which agent is being used, and which is specific to Buck, and thus cannot be used in OSS by other agents.
- Even if the TensorPipe fixture doesn't use TEST_CONFIG, it still needs to set it to the right value for other parts of the code to work. (This is done in `dist_init`).
- There are a few functions in dist_utils.py that return some properties of the agent (e.g., a regexp to match against the error it returns in case of shutdown). These functions are effectively chained if/elses on the various agents, which has the effect of "leaking" some part of the Thrift agent into OSS.
- Each test suite (RPC, dist autograd/dist optimizer, their JIT versions, remote module, ...) must be run on each agent (or almost; the faulty one is an exception) in both fork and spawn mode. Each of these combinations is a separate file, which leads to a proliferation of scripts.
- There is no "master list" of what combinations make sense and should be run. Therefore it has happened that when adding new tests or new agents we forgot to enroll them into the right tests. (TensorPipe is still missing a few tests, it turns out).
- All of these tiny "entry point" files contain almost the same duplicated boilerplate. This makes it very easy to get the wrong content into one of them due to a bad copy-paste.
This refactoring aims to address these problems by:
- Avoiding global state, defaults/override, traps, if/elses, ... and have a single way to specify the agent, based on an abstract base class and several concrete subclasses which can be "mixed in" to any test suite.
- Instead of enabling/disabling tests using decorators, the tests that are specific to a certain agent are now in a separate class (which is a subclass of the "generic" test suite) so that they are only picked up by the agent they apply to.
- Instead of having one separate entry point script for each combination, it uses one entry point for each agent, and in that script it provides a list of all the test suites it wants to run on that agent. And it does that by trying to deduplicate the boilerplate as much as possible. (In fact, the various agent-suite combinations could be grouped in any way, not necessarily by agent as I did here).
It provides further advantages:
- It puts all the agents on equal standing, by not having any of them be the default, making it thus easier to migrate from process group to TensorPipe.
- It will make it easier to add more versions of the TensorPipe tests (e.g., one that disables the same-machine backends in order to test the TCP-based ones) without a further duplication of entry points, of boilerplate, ...
Summary of this commit
--
This diff does the changes described above for the process group agent. It defines a fixture for it (instead of using the generic fixture in its default behavior) and then merges all the entry points into a single script. Note that after this change there won't be anymore a "vanilla" RPC test: all test scripts now specify what agent they are using. This puts all agents on equal standing.
ghstack-source-id: 109229474
Test Plan: Sandcastle and CircleCI
Reviewed By: pritamdamania87
Differential Revision: D22283182
fbshipit-source-id: 7e3626bbbf37d88b892077a03725f0598576b370
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40817
Summary of the entire stack:
--
This diff is part of an attempt to refactor the RPC tests. They currently suffer from several problems:
- Several ways to specify the agent to use: there exists one "generic" fixture that uses the global variable TEST_CONFIG to look up the agent name, and is used for process group and Thrift, and then there are separate fixtures for the flaky agent and the TensorPipe one.
- These two ways lead to having two separate decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which must both be specified, making it unclear what the effect of each of them is and what happens if only one is given.
- Thrift must override the TEST_CONFIG global variable before any other import (in order for the `requires_process_group_agent` decorator to work correctly) and for that it must use a "trap" file, which makes it even harder to track which agent is being used, and which is specific to Buck, and thus cannot be used in OSS by other agents.
- Even if the TensorPipe fixture doesn't use TEST_CONFIG, it still needs to set it to the right value for other parts of the code to work. (This is done in `dist_init`).
- There are a few functions in dist_utils.py that return some properties of the agent (e.g., a regexp to match against the error it returns in case of shutdown). These functions are effectively chained if/elses on the various agents, which has the effect of "leaking" some part of the Thrift agent into OSS.
- Each test suite (RPC, dist autograd/dist optimizer, their JIT versions, remote module, ...) must be run on each agent (or almost; the faulty one is an exception) in both fork and spawn mode. Each of these combinations is a separate file, which leads to a proliferation of scripts.
- There is no "master list" of what combinations make sense and should be run. Therefore it has happened that when adding new tests or new agents we forgot to enroll them into the right tests. (TensorPipe is still missing a few tests, it turns out).
- All of these tiny "entry point" files contain almost the same duplicated boilerplate. This makes it very easy to get the wrong content into one of them due to a bad copy-paste.
This refactoring aims to address these problems by:
- Avoiding global state, defaults/override, traps, if/elses, ... and have a single way to specify the agent, based on an abstract base class and several concrete subclasses which can be "mixed in" to any test suite.
- Instead of enabling/disabling tests using decorators, the tests that are specific to a certain agent are now in a separate class (which is a subclass of the "generic" test suite) so that they are only picked up by the agent they apply to.
- Instead of having one separate entry point script for each combination, it uses one entry point for each agent, and in that script it provides a list of all the test suites it wants to run on that agent. And it does that by trying to deduplicate the boilerplate as much as possible. (In fact, the various agent-suite combinations could be grouped in any way, not necessarily by agent as I did here).
It provides further advantages:
- It puts all the agents on equal standing, by not having any of them be the default, making it thus easier to migrate from process group to TensorPipe.
- It will make it easier to add more versions of the TensorPipe tests (e.g., one that disables the same-machine backends in order to test the TCP-based ones) without a further duplication of entry points, of boilerplate, ...
Summary of this commit
--
This diff does the changes described above for the faulty agent, which is its own strange beast. It merges all the test entry points (i.e., the combinations of agent, suite and fork/spawn) into a single file. It also modifies the test suites that are intended to be run only on the faulty agent, which used to inherit from its fixture, to inherit from the generic fixture, as they will be mixed in with the faulty fixture at the very end, inside the entry point script.
ghstack-source-id: 109229477
Test Plan: Sandcastle and CircleCI
Reviewed By: pritamdamania87
Differential Revision: D22283178
fbshipit-source-id: 72659efe6652dac8450473642a578933030f2c74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40816
Summary of the entire stack:
--
This diff is part of an attempt to refactor the RPC tests. They currently suffer from several problems:
- Several ways to specify the agent to use: there exists one "generic" fixture that uses the global variable TEST_CONFIG to look up the agent name, and is used for process group and Thrift, and then there are separate fixtures for the flaky agent and the TensorPipe one.
- These two ways lead to having two separate decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which must both be specified, making it unclear what the effect of each of them is and what happens if only one is given.
- Thrift must override the TEST_CONFIG global variable before any other import (in order for the `requires_process_group_agent` decorator to work correctly) and for that it must use a "trap" file, which makes it even harder to track which agent is being used, and which is specific to Buck, and thus cannot be used in OSS by other agents.
- Even if the TensorPipe fixture doesn't use TEST_CONFIG, it still needs to set it to the right value for other parts of the code to work. (This is done in `dist_init`).
- There are a few functions in dist_utils.py that return some properties of the agent (e.g., a regexp to match against the error it returns in case of shutdown). These functions are effectively chained if/elses on the various agents, which has the effect of "leaking" some part of the Thrift agent into OSS.
- Each test suite (RPC, dist autograd/dist optimizer, their JIT versions, remote module, ...) must be run on each agent (or almost; the faulty one is an exception) in both fork and spawn mode. Each of these combinations is a separate file, which leads to a proliferation of scripts.
- There is no "master list" of what combinations make sense and should be run. Therefore it has happened that when adding new tests or new agents we forgot to enroll them into the right tests. (TensorPipe is still missing a few tests, it turns out).
- All of these tiny "entry point" files contain almost the same duplicated boilerplate. This makes it very easy to get the wrong content into one of them due to a bad copy-paste.
This refactoring aims to address these problems by:
- Avoiding global state, defaults/override, traps, if/elses, ... and have a single way to specify the agent, based on an abstract base class and several concrete subclasses which can be "mixed in" to any test suite.
- Instead of enabling/disabling tests using decorators, the tests that are specific to a certain agent are now in a separate class (which is a subclass of the "generic" test suite) so that they are only picked up by the agent they apply to.
- Instead of having one separate entry point script for each combination, it uses one entry point for each agent, and in that script it provides a list of all the test suites it wants to run on that agent. And it does that by trying to deduplicate the boilerplate as much as possible. (In fact, the various agent-suite combinations could be grouped in any way, not necessarily by agent as I did here).
It provides further advantages:
- It puts all the agents on equal standing, by not having any of them be the default, making it thus easier to migrate from process group to TensorPipe.
- It will make it easier to add more versions of the TensorPipe tests (e.g., one that disables the same-machine backends in order to test the TCP-based ones) without a further duplication of entry points, of boilerplate, ...
Summary of this commit
--
This diff does the changes described above for the TensorPipe agent. It fixes its fixture (making it inherit from the generic fixture) and merges all the entry point scripts into a single one, so that it's easier to have a clear overview of all the test suites which we run on TensorPipe (you'll notice that many are missing: the JIT ones, the remote module one, ...).
ghstack-source-id: 109229476
Test Plan: Sandcastle and CircleCI
Reviewed By: pritamdamania87
Differential Revision: D22283180
fbshipit-source-id: d5e9f9f4e6d4bfd6fbcae7ae56eed63d2567a02f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42567
Before this change we didn't expand arguments, and thus in an expr
`sigmoid(sigmoid(x))` only the outer call was expanded.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D22936177
Pulled By: ZolotukhinM
fbshipit-source-id: 9c05dc96561225bab9a90a407d7bcf9a89b078a1
Summary:
For CUDA >= 10.2, the `CUBLAS_WORKSPACE_CONFIG` environment variable must be set to either `:4096:8` or `:16:8` to ensure deterministic CUDA stream usage. This PR adds some logic inside `torch.set_deterministic()` to raise an error if this environment variable is not set properly and CUDA >= 10.2.
Issue https://github.com/pytorch/pytorch/issues/15359
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41377
Reviewed By: malfet
Differential Revision: D22758459
Pulled By: ezyang
fbshipit-source-id: 4b96f1e9abf85d94ba79140fd927bbd0c05c4522
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42322
Our current type checking rules are rather lax, and for
example don't force users to make sure they annotate all functions
with types. For code generation code, it would be better to force
100% typing. This PR introduces a new mypy configuration
mypy-strict.ini which applies rules from --strict. We extend
test_type_hints.py to test for this case. It only covers
code_template.py, which I have made strict clean in this PR.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D22846120
Pulled By: ezyang
fbshipit-source-id: 8d253829223bfa0d811b6add53b7bc2d3a4356b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42591
We don't support lowering with 2-input Int8Quantize and 4-input Int8FC. Just do a conversion to absorb the quantization params into the op itself.
Test Plan:
```
buck test caffe2/caffe2/quantization/server:quantize_dnnlowp_op_test
```
Reviewed By: benjibc
Differential Revision: D22942673
fbshipit-source-id: a392ba2afdfa39c05c5adcb6c4dc5f814c95e449
Summary:
1. Fix illegal memory access issue for SplitByLengths operator in the CUDA context.
2. Add support to scaling lengths vector for SplitByLengths operator.
3. Add support to test SplitByLengths operator in the CUDA context.
Example for SplitByLengths operator processing scaling lengths vector:
value vector A = [1, 2, 3, 4, 5, 6]
length vector B = [1, 2]
after execution of SplitByLengths operator,
the output should be [1,2] and [3,4,5,6]
Test Plan: buck test mode/dev-nosan caffe2/caffe2/python/operator_test:concat_split_op_test
Reviewed By: kennyhorror
Differential Revision: D22780307
fbshipit-source-id: c5ca60ae16b24032cedfa045a421503b713daa6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42249
Main change is to bring Caffe2's superior error messages for cuda initialization into c10 and use them in all code paths.
Basic logic:
| Case | Call to device_count() | init_cuda, e.g. allocating tensor |
| -- | -- | -- |
| all good | non-zero | just works |
| no gpus | 0, no warning | throw exception with good message |
| driver issues | 0, produce warning | throw exception with good message |
| out of memory with ASAN | 0, produce warning| throw exception with ASAN message |
Previously, the error thrown from init_cuda was very generic and the ASAN warning (if any) was buried in the logs.
Other clean up changes:
* cache device_count() always in a static variable
* move all asan macros in c10
Test Plan:
Hard to unittest because of build modes. Verified manually that the behavior from the table above holds by running the following script in different modes (ASAN/no-ASAN, CUDA_VISIBLE_DEVICES=):
```
print('before import')
import torch
print('after import')
print('devices: ', torch.cuda.device_count())
x = torch.tensor([1,2,3])
print('tensor creation')
x = x.cuda()
print('moved to cuda')
```
Reviewed By: ngimel
Differential Revision: D22824329
fbshipit-source-id: 5314007313a3897fc955b02f8b21b661ae35fdf5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42569
We do not need to allocate buffers for Vulkan Tensors if they are not the forward input or output.
Removing allocate_storage() for outputs of operations by default, their image representation will have the result.
Allocating buffer only if it was requested for the operations (For some ops like concatenate, transpose) or copy to host.
`VulkanTensor.image()` if buffer was not allocated - just allocates texture skipping copy from buffer to texture.
As allocate storage was before for all operations - we are saving buffer allocation and buffer_to_image call.
MobilNetV2 on my Pixel4:
```
flame:/data/local/tmp $ ./speed_benchmark_torch --model=mnfp32-vopt.pt --input_type=float --input_dims=1,3,224,224 --warmup=3 --iter=20 --vulkan=true
Starting benchmark.
Running warmup runs.
Main runs.
Main run finished. Microseconds per iter: 305818. Iters per second: 3.26991
Segmentation fault
```
```
139|flame:/data/local/tmp $ ./speed_benchmark_torch_noas --model=mnfp32-vopt.pt --input_type=float --input_dims=1,3,224,224 --warmup=3 --iter=20 --vulkan=true
Starting benchmark.
Running warmup runs.
Main runs.
Main run finished. Microseconds per iter: 236768. Iters per second: 4.22355
Segmentation fault
```
Test Plan: Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D22946552
Pulled By: IvanKobzarev
fbshipit-source-id: ac0743bb316847632a22cf9aafb8938e50b2fb7b
Summary:
This PR removes manual registration in aten/native codebase.
And it separates manual device/catchall kernel registration from manual VariableType kernel registration.
The first one remains as manual_kernel_registration in native_functions.yaml.
The second one is moved to tools/ codegen.
Difference in generated TypeDefault.cpp: https://gist.github.com/ailzhang/897ef9fdf0c834279cd358febba07734
No difference in generated VariableType_X.cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42386
Reviewed By: agolynski
Differential Revision: D22915649
Pulled By: ailzhang
fbshipit-source-id: ce93784b9b081234f05f3343e8de3c7a704a5783
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 4abc34af1a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42584
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: dskhudia
Differential Revision: D22941475
fbshipit-source-id: 29863cad7f77939edb44d337918693879b35cfaa
Summary:
This PR intends to fix https://github.com/pytorch/pytorch/issues/32983.
The initial (one-line) diff causes statically linked cudnn symbols in `libtorch_cuda.so` to have local linkage (such that they shouldn't be visible to external libraries during dynamic linking at load time), at least in my source build on Ubuntu 20.04.
Procedure I used to verify:
```
export USE_STATIC_CUDNN=ON
python3 setup.py install
...
```
then
```
mcarilli@mcarilli-desktop:~/Desktop/mcarilli_github/pytorch/torch/lib$ nm libtorch_cuda.so | grep cudnnCreate
00000000031ff540 t cudnnCreate
00000000031fbe70 t cudnnCreateActivationDescriptor
```
Before the diff they were marked with capital `T`s indicating external linkage.
Caveats:
- The fix is gcc-specific afaik. I have no idea how to enable it for Windows or other compilers.
- Hiding the cudnn symbols will break external C++ applications that rely on linking `libtorch.so` to supply cudnn symbol definitions. IMO this is "off menu" usage so I don't think it's a major concern. Hiding the symbols _won't_ break applications that call cudnn indirectly through torch functions, which IMO is the "on menu" way.
- I know _very little_ about the build system. The diff's intent is to add a link option that applies to any Pytorch `.so`s that statically link cudnn, and does so on Linux only. I'm blindly following soumith 's recommendation https://github.com/pytorch/pytorch/issues/32983#issuecomment-662056151, and post-checking the built libs (I also added `set(CMAKE_VERBOSE_MAKEFILE ON)` to the top-level CMakeLists.txt at one point to confirm `-Wl,--exclude-libs,libcudnn_static.a` was picked up by the command that linked `libtorch_cuda.so`).
- https://github.com/pytorch/pytorch/issues/32983 (which used a Pytorch 1.4 binary build) complained about `libtorch.so`, not `libtorch_cuda.so`:
```
nvpohanh@ubuntu:~$ nm /usr/local/lib/python3.5/dist-packages/torch/lib/libtorch.so | grep ' cudnnCreate'
000000000f479c30 T cudnnCreate
000000000f475ff0 T cudnnCreateActivationDescriptor
```
In my source build, `libtorch.so` ends up small, containing no cudnn symbols (this is true with or without the PR's diff), which contradicts https://github.com/pytorch/pytorch/issues/32983. Maybe the symbol organization (what goes in `libtorch.so` vs `libtorch_cuda/cpu/whatever.so`) changed since 1.4. Or maybe the symbol organization is different for source vs binary builds, in which case I have no idea if this PR's diff has the same effect for a binary build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41986
Reviewed By: glaringlee
Differential Revision: D22934926
Pulled By: malfet
fbshipit-source-id: 711475834e0f8148f0e5f2fe28fca5f138ef494b
Summary: Current OutputColumnMaxHistogramObserver will output 2048 bins for each column. The file will be extremely large and the dumping time is quite long. However, we only use the min and max finally. This diff enables changing bin_nums by adding an argument. And the default value is set to 16 to reduce dumping overhead. When we need more bins to analyze the results, we only need to change this argument
Test Plan:
buck run caffe2/caffe2/quantization/server:observer_test
{F263843430}
Reviewed By: hx89
Differential Revision: D22918202
fbshipit-source-id: bda34449355b269b24c55802012450ebaa4d280c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42486
**Summary**
This commit fixes a small bug in which `torch.jit.is_tracing()` returns
`torch._C.is_tracing`, the function object, instead of calling the
function and returning the result.
**Test Plan**
Continuous integration?
**Fixes**
This commit fixes#42448.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D22911062
Pulled By: SplitInfinity
fbshipit-source-id: b94eca0c1c65ca6f22acc6c5542af397f2dc37f0
Summary:
Custom layer by `torch.autograd.Function` appears in the lower_tuple as `prim::PythonOp`. Adding this op type to the allowed list to enable lower_tuple pass. This helps with exporting custom layer with tuple outputs.
E.g.
```python
import torch
class CustomFunction(torch.autograd.Function):
staticmethod
def symbolic(g, input):
return g.op('CustomNamespace::Custom', input, outputs=2)
staticmethod
def forward(ctx, input):
return input, input
class Custom(torch.nn.Module):
def forward(self, input):
return CustomFunction.apply(input)
model = Custom()
batch = torch.FloatTensor(1, 3)
torch.onnx.export(model, batch, "test.onnx", verbose=True)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41548
Reviewed By: glaringlee
Differential Revision: D22926143
Pulled By: bzinodev
fbshipit-source-id: ce14d1d3c70a920154a8235d635ab31ddf0c46f3
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 87c378172a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42496
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: dskhudia
Differential Revision: D22911638
fbshipit-source-id: f20c83908b51ff56d8bf1d8b46961f70d023c81a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/42418.
The problem was that the non-contiguous batched matrices were passed to `gemmStridedBatched`.
The following code fails on master and works with the proposed patch:
```python
import torch
x = torch.tensor([[1., 2, 3], [4., 5, 6]], device='cuda:0')
c = torch.as_strided(x, size=[2, 2, 2], stride=[3, 1, 1])
torch.einsum('...ab,...bc->...ac', c, c)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42425
Reviewed By: glaringlee
Differential Revision: D22925266
Pulled By: ngimel
fbshipit-source-id: a72d56d26c7381b7793a047d76bcc5bd45a9602c
Summary:
Add space between double back quotes and left curly bracket
Otherwise doc generation failed with `Inline literal start-string without end-string.`
This regression was introduced by b56db305cf
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42559
Reviewed By: glaringlee
Differential Revision: D22931527
Pulled By: malfet
fbshipit-source-id: 11c04a92dbba48592505f704d77222cf92a81055
Summary:
Initial PR for the Tensor List functionality.
**Motivation**
[GitHub issue](https://github.com/pytorch/pytorch/issues/38655)
Current PyTorch optimizer implementations are not efficient in cases when we work with a lot of small feature tensors. Starting a lot of kernels slows down the whole process. We need to reduce the number of kernels that we start.
As an example, we should be looking at [NVIDIAs Apex](https://github.com/NVIDIA/apex).
In order to track progress, we will pick PyTorchs DCGAN model with Adam optimizer and once the optimizer is reimplemented with tensor lists, benchmark the model performance against original model version, Apexs version with original Adam optimizer and it’s FusedAdam optimizer.
**In this PR**
- Adding `multi_tensor_apply` mechanism which will help to efficiently apply passed functor on a given list of tensors on CUDA.
- Adding a first private API - `std::vector<Tensor> _foreach_add(TensorList tensors, Scalar scalar)`
**Tests**
Tested via unit tests
**Plan for the next PRs**
1. Cover these ops with `multi_tensor_apply` support
- exponent
- division
- mul_
- add_
- addcmul_
- addcdiv_
- Sqrt
2. Rewrite PyTorch optimizers to use for-each operators in order to get performance gains.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41554
Reviewed By: cpuhrsch
Differential Revision: D22829724
Pulled By: izdeby
fbshipit-source-id: 47febdbf7845cf931958a638567b7428a24782b1
Summary:
Was getting an error when attempting to push to master for
pytorch/pytorch.github.io since the main branch on that repository is
actually site and not master.
Get rid of the loop too since the loop wasn't going to work with a
conditional and conditionals on a two variable loop just isn't worth the
readability concerns
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42552
Reviewed By: malfet
Differential Revision: D22929503
Pulled By: seemethere
fbshipit-source-id: acdd26b86718304eac9dcfc81761de0b3e609004
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42211
Helper functions for launching CUDA Sleep and Tensor Value Initialization for the collective test functions.
This is more of a code cleanup fix compared to the previous diffs.
ghstack-source-id: 109097243
Test Plan: working on devGPU and devvm
Reviewed By: jiayisuse
Differential Revision: D22782671
fbshipit-source-id: 7d88f568a4e08feae778669affe69c8d638973db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42209
This PR adds a TearDown function to the testing superclass to ensure that the NCCL_BLOCKING_WAIT environment variable is reset after each test case.
ghstack-source-id: 109097247
Test Plan: Working on devGPU and devvm.
Reviewed By: jiayisuse
Differential Revision: D22782672
fbshipit-source-id: 8f919a96d7112f9f167e90ce3df59886c88f3514
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42208
ProcessGroupNCCLTest is currently written without any testing framework, and all tests are simply called from the main function and throw exceptions upon failure. As a result, it is hard to debug and pinpoint which tests have succeeded/failed.
This PR moves ProcessGroupNCCLTest to gtest with appropriate setup and skipping functionality in the test superclass.
ghstack-source-id: 109097246
Test Plan: Working Correctly on devGPU and devvm.
Reviewed By: jiayisuse
Differential Revision: D22782673
fbshipit-source-id: 85bd407f4534f3d339ddcdd65ef3d2022aeb7064
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42494
Note that we're currently assuming that dtypes of all the arguments and
the return value is the same.
Test Plan: Imported from OSS
Reviewed By: nickgg
Differential Revision: D22910755
Pulled By: ZolotukhinM
fbshipit-source-id: 7f899692065428fbf2ad05d22b4ca39cab788ae5
Summary:
We have code snippet like below in VariableType_X.cpp
```
Tensor __and___Scalar(const Tensor & self, Scalar other) {
auto result = TypeDefault::__and___Scalar(self, other);
return result;
}
TORCH_LIBRARY_IMPL(aten, Autograd, m) {
m.impl("__and__.Scalar",
c10::impl::hacky_wrapper_for_legacy_signatures(TORCH_FN(VariableType::__and___Scalar))
);
```
We already register TypeDefault kernels as catchAll so they're not needed to be wrapped and register to Autograd key in VariableType.cpp. This PR removes the wrapper and registration in VariableType.cpp. (The ones in other files like TracedType.cpp remains the same).
Here's a [diff in generated VariableTypeEverything.cpp](https://gist.github.com/ailzhang/18876edec4dad54e43a1db0c127c5707)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42031
Reviewed By: agolynski
Differential Revision: D22903507
Pulled By: ailzhang
fbshipit-source-id: 04e6672b6c79e079fc0dfd95c409ebca7f9d76fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42514
Add Alltoall and Alltoallv to PT NCCL process group using NCCL Send/Recv.
Reviewed By: mrshenli
Differential Revision: D22917967
fbshipit-source-id: 402f2870915bc237845864a4a27c97df4351d975
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42480
These are grouped together because they all return a tuple of multiple
tensors.
This PR implements batching rules for chunk, split, and unbind. It also
updates the testing logic. Previously, reference_vmap was not able to
handle multiple outputs, now, it does.
Test Plan: - `pytest test/test_vmap.py -v -k "Operators"`
Reviewed By: ezyang
Differential Revision: D22905401
Pulled By: zou3519
fbshipit-source-id: 9963c943d035e9035c866be74dbdf7ab1989f8c4
Summary:
Segfault happens when one tries to deallocate uninitialized generator.
Make `THPGenerator_dealloc` UBSAN-safe by moving implicit cast in the struct definition to reinterpret_cast
Add `TestTorch.test_invalid_generator_raises` that validates that Generator created on invalid device is handled correctly
Fixes https://github.com/pytorch/pytorch/issues/42281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42510
Reviewed By: pbelevich
Differential Revision: D22917469
Pulled By: malfet
fbshipit-source-id: 5eaa68eef10d899ee3e210cb0e1e92f73be75712
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42516
att. We need it for some scripts.
Reviewed By: houseroad
Differential Revision: D22918112
fbshipit-source-id: 8a1696ceeeda67a34114bc57cb52c925711cfb4c
Summary:
* move both under new file `fixup_onnx_controlflow`
* move the fixup to where the ONNX loop/if node is created, as oppose to running the fixup as postpass. This will help with enable onnx shape inference later.
* move `fuseSequenceSplitConcat` to `Peephole`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40943
Reviewed By: mrshenli
Differential Revision: D22709999
Pulled By: bzinodev
fbshipit-source-id: 51d316991d25dc4bb4047a6bb46ad1e2401d3d2d
Summary:
ONNX pass `torch._C._jit_pass_onnx_function_substitution(graph)` inlines the function with the compiled torch graph. But while it removes all connections with the compiled function node (e.g. see below - `%6 : Function = prim::Constant[name="f"]()`), it does not remove the function node itself. For example, if the input graph is:
```
graph(%0 : Long(requires_grad=0, device=cpu),
%1 : Long(requires_grad=0, device=cpu)):
%6 : Function = prim::Constant[name="f"]()
%7 : Tensor = prim::CallFunction(%6, %0, %1)
return (%7)
```
The output graph is:
```
graph(%0 : Long(requires_grad=0, device=cpu),
%1 : Long(requires_grad=0, device=cpu)):
%6 : Function = prim::Constant[name="f"]()
%8 : int = prim::Constant[value=1]()
%z.1 : Tensor = aten::sub(%0, %1, %8) # test/onnx/test_utility_funs.py:790:20
%10 : Tensor = aten::add(%0, %z.1, %8) # test/onnx/test_utility_funs.py:791:23
return (%10)
```
Note that the `%6 : Function = prim::Constant[name="f"]()` has not been removed (though it is not being used).
This PR updates the pass to remove the function node completely. The updated graph looks as follows:
```
graph(%0 : Long(requires_grad=0, device=cpu),
%1 : Long(requires_grad=0, device=cpu)):
%8 : int = prim::Constant[value=1]()
%z.1 : Tensor = aten::sub(%0, %1, %8) # test/onnx/test_utility_funs.py:790:20
%10 : Tensor = aten::add(%0, %z.1, %8) # test/onnx/test_utility_funs.py:791:23
return (%10)
```
A test point has also been added for this scenario.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42146
Reviewed By: VitalyFedyunin
Differential Revision: D22845314
Pulled By: bzinodev
fbshipit-source-id: 81fb351f0a36f47204e5327b60b84d7a91d3bcd9
Summary:
`as_strided` creates a view of an existing tensor with specified `sizes`, `strides`, and `storage_offsets`. This PR supports the export of `as_strided` with static argument `strides`. The following scenarios will not be supported:
* Calling on tensor of dynamic shape, i.e. the tensor shape differs between model runs and different model inputs.
* In-place operations, i.e. updates to the original tensor that are expected to reflect in the `as_strided` output, and vice versa.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41569
Reviewed By: VitalyFedyunin
Differential Revision: D22845295
Pulled By: bzinodev
fbshipit-source-id: 7d1aa88a810e6728688491478dbf029f17ae7201
Summary:
This PR initiates the process of updating the torchsciprt backend interface used by ONNX exporter.
- Replace jit lower graph pass by freeze module pass
- Enable ScriptModule tests for ONNX operator tests (ORT backend) and model tests by default.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41413
Reviewed By: VitalyFedyunin
Differential Revision: D22845258
Pulled By: bzinodev
fbshipit-source-id: d57fd4086f27bd0c3bf5f70af7fd0daa39a2814a
Summary:
Export dynamic torch.eye, i.e. commonly from another tensor, shape for torch.eye is not known at export time.
Static torch.eye where n,m are constants is exported as constant tensor directly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41357
Reviewed By: VitalyFedyunin
Differential Revision: D22845220
Pulled By: bzinodev
fbshipit-source-id: 6e5c331fa28ca542022ea16f9c88c69995a393b2
Summary:
* It originally failed to check for cases where highlight token appears more than once.
* Now it repeated tries to find highlight token if one doesn't seem correctly highlighted until end of error message.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42417
Reviewed By: SplitInfinity
Differential Revision: D22889411
Pulled By: gmagogsfm
fbshipit-source-id: 994835db32849f3d7e98ab7f662bd5c6b8a1662e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42137
This PR implements an SGD optimizer class similar to torch::optim::SGD, but it doesn't inherit from torch::optim::Optimizer, for use on mobile devices (or other lightweight use case).
Adding Martin's comment for visibility: "SGD may be the only optimizer used in near future. If more client optimizers are needed, refactoring the full optim codes and reusing the existing code would be an option."
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D22846514
Pulled By: ann-ss
fbshipit-source-id: f5f46804aa021e7ada7c0cd3f16e24404d10c7eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42492
There's a potential for multiple tags to be created for the same digest
so we should iterate through all potential tags so that we're not
deleting digests that are associated with tags that we actually want.
Also, reduced the number of prints in this script to only the absolutely
necessary prints. (i.e. only the deleted images)
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D22909248
Pulled By: seemethere
fbshipit-source-id: 7f2e540d133485ed6464e413b01ef67aa73df432
Summary:
Segfault happens when one tries to deallocate unintialized generator
Add `TestTorch.test_invalid_generator_raises` that validates that Generator created on invalid device is handled correctly
Fixes https://github.com/pytorch/pytorch/issues/42281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42490
Reviewed By: seemethere
Differential Revision: D22908795
Pulled By: malfet
fbshipit-source-id: c5b6a35db381738c0fc984aa54e5cab5ef2cbb76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42421
Previously, we can only feed shape info from Python with float dtype, and batch based dim type when we do onnxifi from Python. This diff removes this limitation and uses TensorBoundShapes protobuf as a generic shape info struct. This will make the onnxifi interface in Python more flexible.
Reviewed By: ChunliF
Differential Revision: D22889781
fbshipit-source-id: 1a89f3a68c215a0409738c425b4e0d0617d58245
Summary:
This is to unify how output scale calculation is to be done between
fbgemm and qnnpack (servers vs mobile).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41342
Test Plan: Quantization tests.
Reviewed By: vkuzo
Differential Revision: D22506347
Pulled By: kimishpatel
fbshipit-source-id: e14d22f13c6e751cafa3e52617e76ecd9d39dad5
Summary:
`ninputs` variable was always used as a `size_t` but declared as an `int32_t`
Now, some annoying warnings are fixed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42453
Reviewed By: agolynski
Differential Revision: D22898282
Pulled By: mrshenli
fbshipit-source-id: b62d6b07f0bc3717482906df6010d88762ae0ccd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38697
Benchmark (gcc 8.3, Debian Buster, turbo off, Release build, Intel(R)
Xeon(R) E-2136, Parallelization using OpenMP):
```python
import timeit
for dtype in ('torch.double', 'torch.float', 'torch.uint8', 'torch.int8', 'torch.int16', 'torch.int32', 'torch.int64'):
for n, t in [(40_000, 50000),
(400_000, 5000)]:
print(f'torch.arange(0, {n}, dtype={dtype}) for {t} times')
print(timeit.timeit(f'torch.arange(0, {n}, dtype={dtype})', setup=f'import torch', number=t))
```
Before:
```
torch.arange(0, 40000, dtype=torch.double) for 50000 times
1.587841397995362
torch.arange(0, 400000, dtype=torch.double) for 5000 times
0.47885190199303906
torch.arange(0, 40000, dtype=torch.float) for 50000 times
1.5519152240012772
torch.arange(0, 400000, dtype=torch.float) for 5000 times
0.4733216500026174
torch.arange(0, 40000, dtype=torch.uint8) for 50000 times
1.426058754004771
torch.arange(0, 400000, dtype=torch.uint8) for 5000 times
0.43596178699226584
torch.arange(0, 40000, dtype=torch.int8) for 50000 times
1.4289699140063021
torch.arange(0, 400000, dtype=torch.int8) for 5000 times
0.43451592899509706
torch.arange(0, 40000, dtype=torch.int16) for 50000 times
0.5714442400058033
torch.arange(0, 400000, dtype=torch.int16) for 5000 times
0.14837959500437137
torch.arange(0, 40000, dtype=torch.int32) for 50000 times
0.5964003179979045
torch.arange(0, 400000, dtype=torch.int32) for 5000 times
0.15676555599202402
torch.arange(0, 40000, dtype=torch.int64) for 50000 times
0.8390555799996946
torch.arange(0, 400000, dtype=torch.int64) for 5000 times
0.23184613398916554
```
After:
```
torch.arange(0, 40000, dtype=torch.double) for 50000 times
0.6895066159922862
torch.arange(0, 400000, dtype=torch.double) for 5000 times
0.16820953000569716
torch.arange(0, 40000, dtype=torch.float) for 50000 times
1.3640095089940587
torch.arange(0, 400000, dtype=torch.float) for 5000 times
0.39255041000433266
torch.arange(0, 40000, dtype=torch.uint8) for 50000 times
0.3422072059911443
torch.arange(0, 400000, dtype=torch.uint8) for 5000 times
0.0605111670010956
torch.arange(0, 40000, dtype=torch.int8) for 50000 times
0.3449254590086639
torch.arange(0, 400000, dtype=torch.int8) for 5000 times
0.06115841199061833
torch.arange(0, 40000, dtype=torch.int16) for 50000 times
0.7745441729930462
torch.arange(0, 400000, dtype=torch.int16) for 5000 times
0.22106765500211623
torch.arange(0, 40000, dtype=torch.int32) for 50000 times
0.720475220005028
torch.arange(0, 400000, dtype=torch.int32) for 5000 times
0.20230313099455088
torch.arange(0, 40000, dtype=torch.int64) for 50000 times
0.8144655400101328
torch.arange(0, 400000, dtype=torch.int64) for 5000 times
0.23762561299372464
```
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D22291236
Pulled By: VitalyFedyunin
fbshipit-source-id: 134dd08b77b11e631d914b5500ee4285b5d0591e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42276
This commit converts `_wait_all_workers()` to `_all_gather()` by
allowing each worker to provide its own data object. The `_all_gather()`
function blocks and returns the gathered results. This API can be
converted to `rpc.barrier()` latter.
Test Plan: Imported from OSS
Reviewed By: lw
Differential Revision: D22853480
Pulled By: mrshenli
fbshipit-source-id: 9d506813b9fd5b7c144885e2b76a863cbd19466a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42248
Including:
- torch.diagonal
- torch.t
- torch.select
- Tensor.expand_as
- Tensor slicing.
Please let me know in the future if it would be easier to review these
separately (I put five operators into this PR because each
implementation is relatively simple).
Test Plan:
- new tests in `test/test_vmap.py`.
- I would like to have a more structured/automated way of testing but
my previous attempts at making something resulted in something very
complicated.
Reviewed By: ezyang
Differential Revision: D22846273
Pulled By: zou3519
fbshipit-source-id: 8e45ebe11174512110faf1ee0fdc317a25e8b7ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41943
If an operator doesn't have a batching rule implemented then we fallback
to this implementation. The fallback only works on out-of-place operators
that return only tensors with new memory. (e.g., no in-place operators,
no view operations).
The fallback effectively takes all of the BatchedTensors in `stack`,
slices them, and runs `op` on all of the corresponding slices to produce slices
of the outputs. The output slices then get `torch.stack`ed to create the
final returns.
The performance of the fallback is not very good because it introduces
an extra copy from stacking the sliced outputs. Because of this, we prefer
to write batching rules for operators whenever possible.
In the future, I'd like to disable the fallback kernel for random
functions until we have a better random story for vmap. I will probably
add a blocklist of operators to support that.
Test Plan: - `pytest test/test_vmap.py -v`
Reviewed By: ezyang
Differential Revision: D22764103
Pulled By: zou3519
fbshipit-source-id: b235833f7f27e11fb76a8513357ac3ca286a638b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42381
Introduce new tag to support distributed hogwild.
Reviewed By: boryiingsu
Differential Revision: D20484099
fbshipit-source-id: 5973495589e0a7ab185d3867b37437aa747f408a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42397
Since the autograd registration is unified to code-gen, we don't need to keep a manual registration file for mobile.
Remove it to avoid extra maintenance.
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D22883153
Pulled By: iseeyuan
fbshipit-source-id: 6db0bd89369beab9eed6e9a9692dd46f5bd1ff48
Summary:
`abs` doesn't have an signed overload across all compilers, so applying abs on uint8_t can be ambiguous: https://en.cppreference.com/w/cpp/numeric/math/abs
This may cause unexpected issue when the input is uint8 and is greater
than 128. For example, on MSVC, applying `std::abs` on an unsigned char
variable
```c++
#include <cmath>
unsigned char a(unsigned char x) {
return std::abs(x);
}
```
gives the following warning:
warning C4244: 'return': conversion from 'int' to 'unsigned char',
possible loss of data
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42254
Reviewed By: VitalyFedyunin
Differential Revision: D22860505
Pulled By: mruberry
fbshipit-source-id: 0076d327bb6141b2ee94917a1a21c22bd2b7f23a
Summary:
Many ufuncs (mostly unary ufuncs) in NumPy promote integer inputs to float. This typically occurs when the results of the function are not representable as integers.
For example:
```
a = np.array([1, 2, 3], dtype=np.int64)
np.sin(a)
: array([0.84147098, 0.90929743, 0.14112001])
```
In PyTorch we only have one function, `torch.true_divide`, which exhibits this behavior today, and it did it by explicitly pre-casting its inputs to the default (float) scalar type where necessary before calling TensorIterator.
This PR lets TensorIterator understand and implement this behavior directly, and it updates `torch.true_divide` to verify the behavior is properly implemented. This will be convenient when implementing more integer->float promotions later (like with `torch.sin`), and also saves copies on CUDA, where the cast from one dtype to another is fused with the computation.
The mechanism for this change is simple. A new flag, `promote_integer_inputs_to_float_` is added to TensorIteratorConfig, and it requires `promote_integer_inputs_to_float_` be true if it's set. When the new flag is set, after the TensorIterator's "common dtype" (AKA "computation type") is computed it's checked for being an integral (boolean included) type and, if it is, changed to the default (float) scalar type, instead. Only `torch.true_divide` sets this flag (for now).
In the future we'll likely...
- provide helpers (`binary_float_op`, `unary_float_op`) to more easily construct functions that promote int->float instead of requiring they build their own TensorIteratorConfigs.
- update torch.atan2 to use `binary_float_op`
- update many unary ufuncs, like `torch.sin` to use `unary_float_op` and support unary ops having different input and result type (this will also require a small modification to some of the "loops" code)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42359
Reviewed By: ngimel
Differential Revision: D22878394
Pulled By: mruberry
fbshipit-source-id: b8de01e46be859321522da411aed655e2c40e5b9
Summary:
Raise and assert used to have a hard-coded error message "Exception". User provided error message was ignored. This PR adds support to represent user's error message in TorchScript.
This breaks backward compatibility because now we actually need to script the user's error message, which can potentially contain unscriptable expressions. Such programs can break when scripting, but saved models can still continue to work.
Increased an op count in test_mobile_optimizer.py because now we need aten::format to form the actual exception message.
This is built upon an WIP PR: https://github.com/pytorch/pytorch/pull/34112 by driazati
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41907
Reviewed By: ngimel
Differential Revision: D22778301
Pulled By: gmagogsfm
fbshipit-source-id: 2b94f0db4ae9fe70c4cd03f4048e519ea96323ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42380
[Caffe2] Remove explicitly divide by zero in SpatialBN training mode
Test Plan: buck test mode/dev-nosan //caffe2/caffe2/python/operator_test:spatial_bn_op_test
Reviewed By: houseroad
Differential Revision: D22873214
fbshipit-source-id: 70b505391b5db02b45fc46ecd7feb303e50c6280
Summary:
Otherwise numba linking by clang-9 fails with:
```
ld: in /Users/distiller/workspace/miniconda3/lib/python3.7/site-packages/numpy/core/lib/libnpymath.a(npy_math.o), could not parse object file /Users/distiller/workspace/miniconda3/lib/python3.7/site-packages/numpy/core/lib/libnpymath.a(npy_math.o): 'Unknown attribute kind (61) (Producer: 'LLVM10.0.0' Reader: 'LLVM APPLE_1_902.0.39.2_0')', using libLTO version 'LLVM version 9.1.0, (clang-902.0.39.2)' for architecture x86_64
```
Because conda's numpy-1.19.1 is compiled with clang-10
This should fix MacOS regressions in CIrcleCI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42409
Reviewed By: xw285cornell
Differential Revision: D22887683
Pulled By: malfet
fbshipit-source-id: d58ee9bf53772b57c59e18f71151916d4f0a3c7d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/40986.
TensorIterator's test for a CUDA kernel getting too many CPU scalar inputs was too permissive. This update limits the check to not consider outputs and to only be performed if the kernel can support CPU scalars.
A test is added to verify the appropriate error message is thrown in a case where the old error message was thrown previously.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42360
Reviewed By: ngimel
Differential Revision: D22868536
Pulled By: mruberry
fbshipit-source-id: 2bc8227978f8f6c0a197444ff0c607aeb51b0671
Summary:
**BC-Breaking Note:**
BC breaking changes in the case where keepdim=True. Before this change, when calling `torch.norm` with keepdim=True and p='fro' or p=number, leaving all other optional arguments as their default values, the keepdim argument would be ignored. Also, any time `torch.norm` was called with p='nuc', the result would have one fewer dimension than the input, and the dimensions could be out of order depending on which dimensions were being reduced. After the change, for each of these cases, the result has the same number and order of dimensions as the input.
**PR Summary:**
* Fix keepdim behavior
* Throw descriptive errors for unsupported sparse norm args
* Increase unit test coverage for these cases and for complex inputs
These changes were taken from part of PR https://github.com/pytorch/pytorch/issues/40924. That PR is not going to be merged because it overrides `torch.norm`'s interface, which we want to avoid. But these improvements are still useful.
Issue https://github.com/pytorch/pytorch/issues/24802
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41956
Reviewed By: albanD
Differential Revision: D22837455
Pulled By: mruberry
fbshipit-source-id: 509ecabfa63b93737996f48a58c7188b005b7217
Summary:
A heavy refactor of bounds inference to fix some issues and bugs blocking using it to analyze cross thread interactions:
* We were merging all accesses to a Buf into a single bounds info entry, even if they did not overlap. E.g. if we accessed a[0:2] and a[5:6] we would merge that into a bound of a[0:6]. I've changed this behaviour to merge only overlapping bounds.
* We were not separating bounds of different kinds (e.g. Load vs Store) and would merge a Store bounds into a Load bounds, losing the information about what kind of access it was. E.g. this loop would produce bounds: [{Load, 0, 10}] and now produces bounds [{Load, 0, 9}, {Store, 1, 10}]:
```
for i in 1 to 10...
x[i] = x[i-1]
```
* Both ComputeAt and Rfactor relied on the overzealous merging and only used a single entry in the bounds list to determine the bounds of temporary buffers they created, which could result in temporary buffers allocated smaller than accesses to them. I've fixed Rfactor, but *not* ComputeAt - however all ComputeAt tests still pass (may require loop fusion to trigger this issue) - I will come back to it.
Being more precise about bounds is more complex, rather than taking the minimum of starts and maximum of stops we now need to determine if two bounds overlap or are adjacent. There are many edge cases and so I've added a bunch of test coverage of the merging method.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42185
Reviewed By: mruberry
Differential Revision: D22870391
Pulled By: nickgg
fbshipit-source-id: 3ee34fcbf0740a47259defeb44cba783b54d0baa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42202
Currently we used the template in order to be able to take both
`std::vector<ExprHandle>` and `std::vector<VarHandle>`. However,
semantics of this function tells that the only allowed option should be
the former one: we're specifying indices for the tensor access we want
to generate. While it could be convenient to avoid conversion from
vector of vars to a vector of exprs at the callsites, it makes the code
less explicit and thus more difficult to reason about.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D22806429
Pulled By: ZolotukhinM
fbshipit-source-id: 8403af5fe6947c27213050a033e79a09f7075d4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41451
Since TE operates on a limited subset of ops with a well-defined
semantics, we can easily infer shapes of intermediate and output tensors
given shapes of the inputs.
There is a couple of ops that are not yet supported in the shape
inference, once we add them we could relax the shape info requirements
in the TE fuser: currently it requires all values in the fusion group to
have shapes known and we can change it to only inputs.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D22543470
Pulled By: ZolotukhinM
fbshipit-source-id: 256bae921028cb6ec3af91977f12bb870c385f40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42201
Previously, we've been using operators <, >, ==, et al. and relied on
the dtype to be picked automatically. It led to a wrong dtype being
picked for the result, but that choice was overwritten by the type
explicitly specified in JIT IR, which we were lowering. Now we are
moving towards using shape inference instead of relying on all types
being specified in the IR, and that made this issue to immediately pop
up.
Test Plan: Imported from OSS
Reviewed By: Krovatkin
Differential Revision: D22806428
Pulled By: ZolotukhinM
fbshipit-source-id: 89d2726340efa2bb3da45d1603bedc53955e14b9
Summary:
[3/N] Implement Enum JIT support
* Add enum value as constant support
* Add sugared value for EnumClass
Supported:
Enum-typed function arguments
using Enum type and comparing them
Support getting name/value attrs of enums
Using Enum value as constant
TODO:
Add PyThon sugared value for Enum
Support Enum-typed return values
Support serialization and deserialization
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42085
Reviewed By: eellison
Differential Revision: D22758042
Pulled By: gmagogsfm
fbshipit-source-id: 5c6e571686c0b60d7fbad59503f5f94b3b3cd125
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42255
Changes to match Fused Op: Dequantize->Swish->Quantize
* Changes to scale handling
Results showing matching intermediate and final Swish_Int8 Op.
P137389801
Test Plan: test case test_deq_swish_quant_nnpi.py
Reviewed By: hyuen
Differential Revision: D22827499
fbshipit-source-id: b469470ca66f6405ccc89696694af372ce6ce89e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41947
Previously, if an op took an optional `Tensor?` argument, the C++ frontend (i.e. `at::op()` and `Tensor::op()`)
were generated to take `Tensor`. A previous PR (https://github.com/pytorch/pytorch/pull/41610) changed the kernels
to be written with `c10::optional<Tensor>` instead of `Tensor`, but that did not touch the C++ frontend yet.
This PR changes the C++ frontend API to take `c10::optional<Tensor>` instead of `Tensor` as well.
This should be mostly bc conserving. Since `Tensor` implicitly converts to `c10::optional<Tensor>`, any old code
calling an op with a `Tensor` would still work. There are likely corner cases that get broken though.
For example, C++ only ever does *one* implicit conversion. So if you call an op with a non-tensor object
that gets implicitly converted to a `Tensor`, then that previously worked since the API took a `Tensor` and
C++ allows one implicit conversion. Now it wouldn't work anymore because it would require two implicit conversions
(to `Tensor` and then to `c10::optional<Tensor>`) and C++ doesn't do that.
The main reasons for doing this are
- Make the C++ API more sane. Those arguments are optional and that should be visible from the signature.
- Allow easier integration for XLA and Autocast. Those backends generate code to wrap operators and forward
operator arguments to calls to at::op(). After https://github.com/pytorch/pytorch/pull/41610, there was
a mismatch because they had to implement operators with `optional<Tensor>` but call `at::op()` with `Tensor`,
so they had to manually convert between those. After this PR, they can just forward the `optional<Tensor>`
in their call to `at::op()`.
ghstack-source-id: 108873705
Test Plan: unit tests
Reviewed By: bhosmer
Differential Revision: D22704832
fbshipit-source-id: f4c00d457b178fbc124be9e884a538a3653aae1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41610
Previously, operators that have a `Tensor?` (i.e. optional tensor) in their schema implemented it using `Tensor` in C++ and filled in an undefined tensor for the None case.
The c10 operator library, however, expects `Tensor?` to be represented as `optional<Tensor>`, so those operators couldn't be c10-full yet and still had to use codegenerated unboxing instead of templated unboxing.
This PR changes that. It extends the `hacky_wrapper_for_legacy_signatures` to not only take case of TensorOptions, but now also map between signatures taking `Tensor` and `optional<Tensor>`.
For this, it requires an additional template parameter, the expected signature, and it uses that to go argument-by-argument and unwrap any optionals it finds.
ghstack-source-id: 108873701
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D22607879
fbshipit-source-id: 57b2fb01a294b804f82cd55cd70f0ef4a478e14f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42141
Update alias db in-place instead of having to construct alias db from scratch on each change, causing O(n^2) behavior.
Description from https://github.com/pytorch/pytorch/pull/37106 holds pretty well:
"""
Recomputing the aliasdb on every fusion iteration + in every subblock
is hugely expensive. Instead, update it in-place when doing fusion.
The graph fuser pass operates by pushing nodes into a fusion group. So
we start with
`x, y = f(a, b, c)`
and end with:
```
x_out, y_out = prim::fusionGroup(a, b, c)
x_in, y_in = f(a_in, b_in, c_in)
-> x_in, y_in
```
We destroy the x and y Value*s in the process. This operation is
easy to express as an update to the aliasDb--x_out just takes on all
the aliasing information x used to have. In particular, since we know
f and prim::fusionGroup are purely functional, we don't have to mess
with any write information.
"""
The one difficulty here is mapping x, y to x_out, y_out is not trivial in merging nodes into the autodiff subgraph node.
There are a few options:
- attempt to make all subgraph utils & ir cloning logic update a map
- mirror the subgraph utils implementation in create_autodiff_subgraph
- uniquely map x, y and x_in, y_in so you can back out the correspondence.
I went with the third option.
This shouldn't affect the results of the pass at all. LMK if you think there's anything else I should be doing to test, I was thinking about maybe exposing an option to run create autodiff subgraphs without the post processor and check that the alias db was correctly updated.
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D22798377
Pulled By: eellison
fbshipit-source-id: 9a133bcaa3b051c0fb565afb23a3eed56dbe71f9
Summary:
This Diff provides an option for DC++ module to use the squeezed sparse feature embeddings to generate attention weights, with the purpose of reducing the network size to achieve QPS gains. There are 3 squeeze options: sum, max, and mean, along the embedding dimension and are provided for both the attention weights and resnet generation.
Example workflow: f208474456
{F257199459}
Test Plan:
1. Test single ops
buck test dper3/dper3/modules/low_level_modules/tests:single_operators_test -- test_reduce_back_mean
buck test dper3/dper3/modules/low_level_modules/tests:single_operators_test -- test_reduce_back_max
2. Test DC++ module
buck test dper3/dper3/modules/tests:core_modules_test -- test_dc_pp_arch_one_layer_compressed_embeddings_only_squeeze_input
buck test dper3/dper3/modules/tests:core_modules_test -- test_dc_pp_arch_shared_input_squeeze_input
buck test dper3/dper3/modules/tests:core_modules_test -- test_dc_pp_input_compress_embeddings_squeeze_input
3. Test Arch
buck test dper3/dper3_models/ads_ranking/model_impl/sparse_nn/tests:sparse_nn_lib_test -- test_dense_sparse_interaction_compress_dot_arch_dot_compress_pp_squeezed_input
4. e2e test
buck test dper3/dper3_models/ads_ranking/tests:model_paradigm_e2e_tests -- test_sparse_nn_compress_dot_attention_fm_max_fc_size_squeeze_input
Reviewed By: taiqing
Differential Revision: D22825069
fbshipit-source-id: 29269ea22cb47d487a1c92a1f6daae1055f54cfc
Summary:
For mobile custom build, we only generate code for ops that are used by
specific models to reduce binary size.
There multiple places where we apply the op filtering:
- generated_unboxing_wrappers_*.cpp
- autograd/VariableType*.cpp
- c10 op registration (in aten/gen.py)
For c10 op registration, we filter by the main op name - all overloads
that match the main op name part will be kept.
For generated_unboxing_wrappers_*, we filter by the full op name - only
those having exactly the same overload name will be kept.
This PR changes generated_unboxing_wrappers_* and autograd/VariableType*.cpp
codegen to also filter by the main op name.
The reasons are:
- keeping all overloads can have better backward compatibility;
- generated_unboxing_wrappers_* are relatively small as it only contains
thin wrappers for root ops.
- generated_unboxing_wrappers_* will be replaced by c10 op registration
soon anyway.
- autograd/VariableType*.cpp are not included in OSS build.
Why it offers better backward compatibility? #40737 is an example:
It introduced a new `_convolution` overload and renamed the original one
to `_convolution.deprecated`. Before this PR, the model prepared by the
old version PyTorch won't be able to run on the custom mobile build
generated on the PR because `_convolution.deprecated` won't be kept in
the custom build due to full op name matching policy. By relaxing it to
partial matching policy, the mobile custom build CI on the PR can pass.
Will test the size impact for FB production build before landing.
Differential Revision: D22809564
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Pulled By: ljk53
fbshipit-source-id: e2fc017da31f38b9430cc2113f33e6d21a0eaf0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42348
Use the dtype info in placeholderObserver to decide what ops to insert in the graph
In the next PR we can delete NoopObserver
Test Plan:
python test/test_quantization.py
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D22859457
fbshipit-source-id: a5c618f22315534ebd9a2df77b14a0aece196989
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42222
This change adds the necessary passes to perform FP16 dynamic quantization.
We skip inserting observers for activations based on the dtype (torch.float16) and only insert the Fp16Observer for weights
Test Plan:
python test/test_quantization.py TestQuantizeJitOps
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D22849220
fbshipit-source-id: 2c53594ecd2485e9e3dd0b380eceaf7c5ab5fc50
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42221
Adds a new observer that emits a warning if the range of tensor is beyond fp16 range. This will be further used in graph mode quantization to insert the cast to fp16 ops in the graph
Test Plan:
python test/test_quantizaton.py TestObserver.test_fp16_observer
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D22849222
fbshipit-source-id: a301281ce38ba4d4e7a009308400d34a08c113d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42147
Op to check the range of a tensor and clamp the values to fp16 range
This operator will be inserted into the graph in subsequent diffs.
Test Plan:
python test/test_quantization.py TestQuantizedTensor.test_fp16_saturate_op
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D22849221
fbshipit-source-id: 0da3298e179750f6311e3a09596a7b8070509096
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42121
This PR changes the Module API to allow register a module with module
interface type, and therefore allows Module::clone works on the case
where there's a module interface type being shared by two submodules.
interface type will be shared by the new cloned instance in the same
compilation unit bc it only
contains a list of functionSchema, which does not involve any
attributes compared to classType.
fixes https://github.com/pytorch/pytorch/issues/41882
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D22781205
Pulled By: wanchaol
fbshipit-source-id: f97f4b75970f0b434e38b5a1f778eda2c4e5109b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42313
Changes the tests in `ProcessGroupGlooAsyncTest.cpp` to use the Gtest testing framework.
Reviewed By: malfet
Differential Revision: D22821577
fbshipit-source-id: 326b24a334ae84a16434d0d5ef27d16ba4b90d5d
Summary:
`resize_` only requires manual registration to `Autograd` key and its device kernels can safely live together with our normal device dispatch in `native_functions.yaml`.
But currently we do manual registration for `CPU/CUDA` kernels (and leaves no dispatch in native_functions.yaml) which makes `resize_` non-overrideable from backend point of view. While it indeed should dispatch at device level, this caused xla to whitelist `resize_` and register a lowering to XLA key. This PR moves the device dispatch of `resize_` back to `native_functions.yaml` so that it shows up as `abstract` method properly for downstream extensions.
Note that we also do manual registration for `copy_/detach_/resize_as_/etc` in aten but they are slightly different than `resize_` since for them we only register `catchAll` kernels instead of device kernels. I'll need to investigate and send a followup PR for those ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42240
Reviewed By: VitalyFedyunin
Differential Revision: D22846311
Pulled By: ailzhang
fbshipit-source-id: 10b6cf99c4ed3d62fc4e1571f4a2a463d1b88c81
Summary:
See https://github.com/pytorch/pytorch/issues/41027.
This adds a helper to resize output to ATen/native/Resize.* and updates TensorIterator to use it. The helper throws a warning if a tensor with one or more elements needs to be resized. This warning indicates that these resizes will become an error in a future PyTorch release.
There are many functions in PyTorch that will resize their outputs and don't use TensorIterator. For example,
985fd970aa/aten/src/ATen/native/cuda/NaiveConvolutionTranspose2d.cu (L243)
And these functions will need to be updated to use this helper, too. This PR avoids their inclusion since the work is separable, and this should let us focus on the function and its behavior in review. A TODO appears in the code to reflect this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42079
Reviewed By: VitalyFedyunin
Differential Revision: D22846851
Pulled By: mruberry
fbshipit-source-id: d1a413efb97e30853923bce828513ba76e5a495d
Summary:
After being deprecated in 1.5 and throwing a runtime error in 1.6, we can now enable torch.full inferring its dtype when given bool and integer fill values. This PR enables that inference and updates the tests and docs to reflect this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41912
Reviewed By: albanD
Differential Revision: D22836802
Pulled By: mruberry
fbshipit-source-id: 33dfbe4d4067800c418b314b1f60fab8adcab4e7
Summary:
* Make c10::cuda functions regular non-inlined functions
* Add driver_version() and device_synchronize() functions
With this change I don't see anymore direct calls to CUDA API when look at Modules.cpp.obj
FYI malfet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42251
Reviewed By: malfet
Differential Revision: D22826505
Pulled By: ziab
fbshipit-source-id: 8dc2f3e209d3710e2ce78411982a10e8c727573c
Summary: To avoid repeating to() casts for every argument of the function
Test Plan: CI
Reviewed By: malfet
Differential Revision: D22833521
fbshipit-source-id: ae0a8f70339cd6adfeea2f552d35bbcd48b11cf7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42289
`sigmoid_backward` and `fmod` are not covered by neither in `test/cpp/api` nor in `Aten/test`. Add test functions to cover them
Test Plan:
1. Test locally and check new lines are covred
2. CI
Reviewed By: malfet
Differential Revision: D22804912
fbshipit-source-id: ea50ef0ef3dcf3940ac950d74f6f1cb38d8547a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42318
We forgot to update this benchmark when quantized elu's signature
changed to require observation, fixing.
Test Plan:
```
cd benchmarks/operator_benchmark
python -m pt.qactivation_test
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D22845251
fbshipit-source-id: 1443f6f0deac695715b1f2bd47f0f22b96dc72ca
Summary:
Also add __prepare__ method metaclass created by `with_metaclass` to conform with PEP 3115
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42232
Reviewed By: ezyang
Differential Revision: D22816936
Pulled By: malfet
fbshipit-source-id: a47d054b2f061985846d0db6b407f4e5df97b0d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42220
Mobile custom build CI jobs need desktop version libtorch to prepare
models and dump root ops.
Ideally we should use the libtorch built on the PR so that backward
incompatible changes won't break this script - but it will significantly
slow down mobile CI jobs.
This PR changed it to install nightly instead of stable so that we have
an option to temporarily skip mobile CI jobs on BC-breaking PRs until
they are in nightly.
Test Plan: Imported from OSS
Reviewed By: seemethere
Differential Revision: D22810484
Pulled By: ljk53
fbshipit-source-id: eb5f7b762a969d1cfeeac2648816be546bd291b6
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: e04b9ce034
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42302
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: efiks
Differential Revision: D22841424
fbshipit-source-id: 211463b0207da986fc5b451242ae99edf32b9f68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42225
Main changes:
- Consolidated CMake files to have a single entry point, rather than having a specialized one for PyTorch.
- Changed the way the preprocessor flags are provided, and changed their name.
There were a few instances in PyTorch's CMake files where we were directly adding TensorPipe's source directory as an include path, which however doesn't contain the auto-generated header we now added. We fix that by adding the `tensorpipe` CMake target as a dependency, so that the include paths defined by TensorPipe are used, which contain that auto-generated header.
I'm turning off SHM and CMA for now because they have never been covered by the CI. I'll enable them in a separate PR so that if they turn out to be flaky we can revert that change without reverting this one.
Test Plan: CircleCI is all green.
Reviewed By: beauby
Differential Revision: D22812445
fbshipit-source-id: e6d824bb28f5afe75fd765de0430968174f3531f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42286
One more bug to fix. Operators such as If and AsyncIf need special treatment not just in `onnx::SsaRewrite`, but also in `RemoveOpsByType`. The solution needs two steps:
1) add external inputs/outputs of the subnets of If/AsyncIf op to the inputs/outputs of the op
2) if the inputs/outputs of the If/AsyncIf op need to be renamed as a result, the same inputs/outputs of the subnets need to be renamed as well.
I also added unit tests to cover this corner case.
Test Plan:
```
buck test //caffe2/caffe2/fb/predictor:black_box_predictor_test
mkdir /tmp/models
rm -rf /tmp/$USER/snntest
rm -rf /tmp/snntest
buck run mode/opt admarket/lib/ranking/prediction_replayer/snntest_replayer_test/tools:snntest_replay_test -- --serving_paradigm=USER_AD_PRECOMPUTATION_DSNN
```
Differential Revision: D22834028
fbshipit-source-id: c070707316cac694f452a96e5c80255abf4014bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42287
We shouldn't use block_size for thread dimensions in linear_index_weight_offsets_dedup_kernel, since the kernel doesn't iterate the embedding dimensions.
ghstack-source-id: 108834058
Test Plan:
```
buck test mode/dev-nosan //caffe2/caffe2/fb/net_transforms/tests:fuse_sparse_ops_test -- 'test_fuse_sparse_adagrad_with_sparse_lengths_sum_gradient \(caffe2\.caffe2\.fb\.net_transforms\.tests\.fuse_sparse_ops_test\.TestFuseSparseOps\)' --print-passing-details
```
Reviewed By: jspark1105
Differential Revision: D22800959
fbshipit-source-id: 641d52a51070715c04f9fd286e7e22ac62001f61
Summary: function `cross_kernel_scalar` is not covered in `Aten/native/cpu/CrossKernel.cpp`, add tests to cover it
Test Plan:
1. Test locally to check new lines are covered
2. CI
https://pxl.cl/1fZjG
Reviewed By: malfet
Differential Revision: D22834122
fbshipit-source-id: 0d50f3a3e6aee52cb6fdee2b9f5883f542c7b6e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42266
function `lerp_kernel_scalar` and `lerp_kernel_tensor` are not covered in `Aten/native/cpu/LerpKernel.cpp`, add tests to cover them
Test Plan:
1. Test locally to check new lines are covered
2. CI
https://pxl.cl/1fXPd
Reviewed By: malfet
Differential Revision: D22832164
fbshipit-source-id: b1eaabbf8bfa08b4dedc1a468abfdfb619a50e3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42139
A bunch of tests were failing with buck since we would output to
stdout and buck would fail parsing stdout in some cases.
Moving these print statements to stderr fixes this issue.
ghstack-source-id: 108606579
Test Plan: Run the offending unit tests.
Reviewed By: mrshenli
Differential Revision: D22779135
fbshipit-source-id: 789af3b16a03b68a6cb12377ed852e5b5091bbad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42219
Introduce a new extra info that is tagged on the forward net for the operators sharing the same input. The effect is that the auto gen sum of gradient for the input will not follow the tag of the operator tags in the forward net. This allow more flexible device allocation.
Test Plan:
# unit test
`./buck-out/gen/caffe2/caffe2/python/core_gradients_test#binary.par -r testMultiUseInputAutoGenSumDevice`
Reviewed By: xianjiec, boryiingsu
Differential Revision: D22609080
fbshipit-source-id: d558145e5eb36295580a70e1ee3a822504dd439a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41283
in optimizer.zero_grad(), detach_ is useful to avoid memory leak only when grad has grad_fn, so add check to call grad.detach_ only when the grad has grad_fn in zero_grad() function
ghstack-source-id: 108702289
Test Plan: unit test
Reviewed By: mrshenli
Differential Revision: D22487315
fbshipit-source-id: 861909b15c8497f1da57f092d8963d4920c85e38
Summary:
In preparation for creating the new torch.fft namespace and NumPy-like fft functions, as well as supporting our goal of refactoring and reducing the size of test_torch.py, this PR creates a test suite for our spectral ops.
The existing spectral op tests from test_torch.py and test_cuda.py are moved to test_spectral_ops.py and updated to run under the device generic test framework.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42157
Reviewed By: albanD
Differential Revision: D22811096
Pulled By: mruberry
fbshipit-source-id: e5c50f0016ea6bb8b093cd6df2dbcef6db9bb6b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38999
Adds boxing for inplace and outplace kernels, itemizes
remaining unsupported cases, and fails compilation when
new unsupported types are introduced in op signatures.
Test Plan: Imported from OSS
Differential Revision: D21718547
Pulled By: bhosmer
fbshipit-source-id: 03295128b21d1843e86789fb474f38411b26a8b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42151
Previously our Caffe2 SpatialBN op impl was incorrect for computing running_var without unbias coefficent. Actually it should fail the test because the output will be different with CuDNN's output. However, our tests are too weak to find this bug. This diff fix all of them.
Test Plan: buck test mode/dev-nosan //caffe2/caffe2/python/operator_test:spatial_bn_op_test
Reviewed By: houseroad
Differential Revision: D22786127
fbshipit-source-id: db80becb67d60c44faae180c7e4257cb136a266d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41974
In this diff, 2 new sets of benchmark tests are added to the `quantization` benchmark suite where operator-level benchmarking is conducted for the learnable Python operators, the learnable c++ kernels, and the original non-backprop c++ kernels.
Test Plan:
Inside the path `torch/benchmarks/operator_benchmark` (The root directory will be `caffe2` inside `fbcode` if working on a devvm):
- On a devvm, run the command `buck run pt:fake_quantize_learnable_test`
- On a personal laptop, run the command `python3 -m pt.fake_quantize_learnable_test`
Benchmark Results (On devGPU with 0% volatile utilization -- all GPUs are free):
Each sample has dimensions **3x256x256**;
### In **microseconds** (`1e-6` second),
| | Python Module | C++ Kernel | Non-backprop C++ Kernel |
|---------------------------|---------------|------------|-------------------------|
| Per Tensor CPU Forward | 3112.666 | 3270.740 | 3596.864 |
| Per Tensor Cuda Forward | 797.258 | 258.961 | 133.953 |
| Per Channel CPU Forward | 6587.693 | 6931.461 | 6352.417 |
| Per Channel Cuda Forward | 1579.576 | 555.723 | 479.016 |
| Per Tensor CPU Backward | 72278.390 | 22466.648 | 12922.195 |
| Per Tensor Cuda Backward | 6512.280 | 1546.218 | 652.942 |
| Per Channel CPU Backward | 74138.545 | 41212.777 | 14131.576 |
| Per Channel Cuda Backward | 6795.173 | 4321.351 | 1052.066 |
Reviewed By: z-a-f
Differential Revision: D22715683
fbshipit-source-id: 8be528b790663413cbeeabd4f68bbca00be052dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42198
1. add tests to max/min kernel
Test Plan:
1. Run locally to check cover the corresponding code part in BinaryOpsKernel.cpp.
2. CI
Reviewed By: malfet
Differential Revision: D22796019
fbshipit-source-id: 84c8d7df509de453c4ec3c5e38977733b0ef3457
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41969
In this diff, the `_LearnableFakeQuantize` module is extended to provide support for gradient scaling where the gradients for both scale and zero point are multiplied by a constant `g` (in some cases, can help with quicker convergence). In addition, it is also augmented to provide a factory method via `_with_args` such that a partial constructor of the module can be built.
Test Plan:
For correctness of the fake quantizer operators, on a devvm, enter the following command:
```
buck test //caffe2/torch:quantization -- learnable_py_module
```
Reviewed By: z-a-f
Differential Revision: D22715629
fbshipit-source-id: ff8e5764f81ca7264bf9333789f57e0b0cec7a72
Summary:
View ops as outputs of differentiable subgraphs can cause incorrect differentiation. For now, do not include them in the subgraph. This was observed with our autograd tests for MultiheadAttention and nn.Transformer, which currently fail with the legacy executor. This commit fixes those test failures.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42027
Reviewed By: pbelevich
Differential Revision: D22798133
Pulled By: eellison
fbshipit-source-id: 2f6c08953317bbe013933c6faaad20100376c039
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: cad1c21404
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42205
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: dskhudia
Differential Revision: D22806731
Pulled By: efiks
fbshipit-source-id: 779a9f7f00645e7e65f183e2832dc79117eae5fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42215
Specifically on https://github.com/pytorch/pytorch/pull/27477#discussion_r371402079
We would like to supported with include_last=True overall for other reduction types like mean and max. It now causes further code fragmentation in DPER (https://www.internalfb.com/intern/diff/D22794469/).
More details: https://www.internalfb.com/intern/diff/D22794469/?dest_fbid=309597093427021&transaction_id=631457624153457
ghstack-source-id: 108733009
Test Plan:
```
buck test mode/dev-nosan //caffe2/test:nn -- "test_EmbeddingBag_per_sample_weights_and_new_offsets_cpu"
```
```
(base) [jianyuhuang@devbig281.ftw3.facebook.com: ~/fbsource/fbcode/caffe2/test] $ TORCH_SHOW_CPP_STACKTRACES=1 buck test mode/dev-nosan //caffe2/test:
nn -- "test_EmbeddingBag_per_sample_weights_and_new_offsets_cpu" --print-passing-details
Parsing buck files: finished in 1.2 sec
Building: finished in 5.5 sec (100%) 10130/10130 jobs, 2 updated
Total time: 6.7 sec
More details at https://www.internalfb.com/intern/buck/build/dbdc2063-69d8-45cb-9146-308a9e8505ef
First unknown argument: --print-passing-details.
Falling back to TestPilot classic.
Trace available for this run at /tmp/testpilot.20200728-195414.1422748.log
TestPilot test runner for Facebook. See https://fburl.com/testpilot for details.
Testpilot build revision cd2638f1f47250eac058b8c36561760027d16add fbpkg f88726c8ebde4ba288e1172a348c7f46 at Mon Jul 27 18:11:43 2020 by twsvcscm from /usr/local/fbprojects/packages/testinfra.testpilot/887/t.par
Discovering tests
Running 1 test
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/844425097242375
✓ caffe2/test:nn - test_EmbeddingBag_per_sample_weights_and_new_offsets_cpu (test_nn.TestNNDeviceTypeCPU) 0.162 1/1 (passed)
Test output:
> /data/users/jianyuhuang/fbsource/fbcode/buck-out/dev/gen/caffe2/test/nn#binary,link-tree/torch/_utils_internal.py:103: DeprecationWarning: This is a NOOP in python >= 3.7, its just too dangerous with how we write code at facebook. Instead we patch os.fork and multiprocessing which can raise exceptions if a deadlock would happen.
> threadSafeForkRegisterAtFork()
> /usr/local/fbcode/platform007/lib/python3.7/importlib/_bootstrap.py:219: ImportWarning: can't resolve package from __spec__ or __package__, falling back on __name__
and __path__
> return f(*args, **kwds)
> test_EmbeddingBag_per_sample_weights_and_new_offsets_cpu (test_nn.TestNNDeviceTypeCPU) ... Couldn't download test skip set, leaving all tests enabled...
> ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 0.162s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/844425097242375
Summary (total time 5.54s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
Did _not_ run with tpx. See https://fburl.com/tpx for details.
```
Reviewed By: dzhulgakov
Differential Revision: D22801881
fbshipit-source-id: 80a624465727081bb9bf55c28419695a3d79c6e5
Summary:
After being deprecated in 1.5 and throwing a runtime error in 1.6, we can now enable torch.full inferring its dtype when given bool and integer fill values. This PR enables that inference and updates the tests and docs to reflect this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41912
Reviewed By: pbelevich
Differential Revision: D22790718
Pulled By: mruberry
fbshipit-source-id: 8d1eb01574b1977f00bc0696974ac38ffdd40d9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42045
This PR changes the save_data() member functions of torch::jit::mobile::Module which was introduced in #41403 to be the non member function torch::jit::mobile::_save_parameters() (taking a mobile Module as its first argument).
In addition, this PR:
* adds a getter function _ivalue() for the mobile::Module object
* renames torch::jit::mobile::_load_mobile_data() to torch::jit::mobile_load_parameters()
* refactors the import.h header file into import.h and import_data.h
Test Plan: Imported from OSS
Reviewed By: kwanmacher, iseeyuan
Differential Revision: D22766781
Pulled By: ann-ss
fbshipit-source-id: 5cabae31927187753a958feede5e9a28d71d9e92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42149
Some of these tests were flaky since we could kill the process in some
way without cleaning up the ProcessGroup. This resulted in issues where the
FileStore didn't clean up appropriately resulting in other processes in the
group to crash.
Fixed this by explicitly deleting the process_group before we bring a process
down forcibly.
ghstack-source-id: 108629057
Test Plan: waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D22785042
fbshipit-source-id: c31d0f723badbc23b7258e322f75b57e0a1a42cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42143
Replaces the original makeshift error messages in ProcessGroupNCCLTest
with more appropriate ones.
ghstack-source-id: 108711579
Test Plan: Ran the tests on DevGPU
Reviewed By: mrshenli
Differential Revision: D22778505
fbshipit-source-id: 27109874f0b474a74b09f588cf6e7528d2069702
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42192
This PR fixes the complicated skipping logic for ProcessGroupNCCLErrors Tests - it correctly logs the reason for skipping tests when GPUs are not available or the NCCL version is too old.
This is part of a broader effort to improve the testing of the ProcessGroup and Collectives tests.
ghstack-source-id: 108620568
Test Plan: Tested on devGPU and devvm. Tests are run correctly on GPU and skipped on CPU as expected.
Reviewed By: mrshenli
Differential Revision: D22782856
fbshipit-source-id: 6071dfdd9743f45e59295e5cee09e89c8eb299c9
Summary: Sometimes first dim of X in FC is BATCH_OF_FEATURE_MAX instead of BATCH. This caused an issue in f207899183 (when first dim of X is 64 but is set to 1 in inferFC). Change the check from `!= BATCH` to `== UNKNOWN`
Test Plan: unit test
Reviewed By: yinghai
Differential Revision: D22784691
fbshipit-source-id: eb66ba361d6fe75672b13edbac2fbd269a7e7a00
Summary:
And since CUDA-9.2 is incompatible with VS2019, disable CUDA-9.2 for Windows as well
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42144
Reviewed By: pbelevich
Differential Revision: D22794475
Pulled By: malfet
fbshipit-source-id: 24fc980e6fc75240664b9de8a4a63b1153f8d8ee
Summary:
Fixes issue where
- top level fuser's block_ was captured by callback due to [&] capture,
- recursive/nested fusers would compare erroneously to top-level block_ instead of own block_
Closes (https://github.com/pytorch/pytorch/issues/39810)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41560
Reviewed By: Krovatkin
Differential Revision: D22583196
Pulled By: wconstab
fbshipit-source-id: 8f543cd9ea00e116cf3e776ab168cdd9fed69632
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42135
Tested the code analyzer with LLVM 9 & 10 and fixed a couple issues:
- Rename local demangle() which is available as public API since LLVM 9;
- Fix falsely associated op registrations due to the `phi` instruction;
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D22795508
Pulled By: ljk53
fbshipit-source-id: 2d47af088acd3312a7ea5fd9361cdccd48940fe6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41171
DistributedSampler allows data to be split evenly across workers in
DDP, but it has always added additional samples in order for the data to be
evenly split in the case that the # of samples is not evenly divisible by the
number of workers. This can cause issues such as when doing distributed
validation accuracy, where multiple samples could be considered twice.
This PR adds a drop_last option where the tail of the data is dropped such that
the effective dataset size is still evenly divisible across the workers. This
ensures that DDP can train fine (there is no uneven inputs) and each replica
gets an equal number of data indices.
ghstack-source-id: 108617516
Test Plan: Added unittest
Reviewed By: mrshenli
Differential Revision: D22449974
fbshipit-source-id: e3156b751f5262cc66437b9191818b78aee8ddea
Summary:
Found while trying to get RocM Caffe2 CI green
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42168
Reviewed By: seemethere
Differential Revision: D22791879
Pulled By: malfet
fbshipit-source-id: 8f7ef9711bdc5941b2836e4c8943bb95c72ef8af
Summary:
Found while trying to get RocM Caffe2 job green
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42169
Reviewed By: seemethere
Differential Revision: D22791896
Pulled By: malfet
fbshipit-source-id: 9df6233876aec5ead056365499bab970aa7e8bdc
Summary:
I encountered a zero division problem when using LBFGS:
File "/home/yshen/anaconda3/lib/python3.7/site-packages/torch/optim/lbfgs.py", line 118, in _strong_wolfe
bracket[1], bracket_f[1], bracket_gtd[1])
File "/home/yshen/anaconda3/lib/python3.7/site-packages/torch/optim/lbfgs.py", line 21, in _cubic_interpolate
d1 = g1 + g2 - 3 * (f1 - f2) / (x1 - x2)
ZeroDivisionError: float division by zero
My solution is to determine whether "line-search bracket is so small" before calling _cubic_interpolate
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42093
Reviewed By: pbelevich
Differential Revision: D22770667
Pulled By: mrshenli
fbshipit-source-id: f8fdfcbd3fd530235901d255208fef8005bf898c
Summary:
Apply syntax highlighting to the command in `README.md`. This makes `README.md` easier to read.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42065
Reviewed By: pbelevich
Differential Revision: D22753418
Pulled By: mrshenli
fbshipit-source-id: ebfa90fdf60478c34bc8a7284d163e0254cfbe3b
Summary:
xref gh-39002 which handled the reading but not the writing of the onnx expect files, and the last comment in that PR which points out `XXX` was suboptimal.
xref [this comment](https://github.com/pytorch/pytorch/pull/37091#discussion_r456460168) which pointed out the problem.
This PR:
- replaces `XXX` with `CURRENT_VERSION` in the stored files
- ensures that updating the results with the `--accept` flag will maintain the change
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41910
Reviewed By: pbelevich
Differential Revision: D22758671
Pulled By: ezyang
fbshipit-source-id: 47c345c66740edfc8f0fb9ff358047a41e19b554
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41942
This function:
- permutes all batch dims to the front of the tensors
- aligns all the batch dims to the collective levels of all the tensors
- expands all of the batch dims such that they are present in each of
the result tensors
This function is useful for the next diff up on the stack (which is
implementing a fallback kernel for BatchedTensor). It's also useful in
general for implementing batching rules on operators that take in
multiple batch dimensions at the front of each tensor (but we don't have
too many of those in PyTorch).
Test Plan: - `./build/bin/vmap_test`
Reviewed By: ezyang
Differential Revision: D22764104
Pulled By: zou3519
fbshipit-source-id: d42cc8824a1bcf258687de164b7853af52852f53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41941
If we know that the tensor already has the desired aligned size, we
don't need to put in the effort to align it.
Test Plan: - `./build/bin/vmap_test`, `pytest test/test_vmap.py -v`
Reviewed By: albanD
Differential Revision: D22764101
Pulled By: zou3519
fbshipit-source-id: a2ab7ce7b98d405ae905f7fd98db097210bfad65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41940
See title. I marked methods that don't mutate the VmapPhysicalView as
`const`.
Test Plan: - wait for tests
Reviewed By: albanD
Differential Revision: D22764102
Pulled By: zou3519
fbshipit-source-id: 40f957ad61c85f0e5684357562a541a2712b1f38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42118
We toggle trace on with a certain probablility. In the case of 3 inferences with trace on/off/on. We leak the trace from the first inference. Always clean up the trace will fix it.
Test Plan:
predictor
I created a tiny repro here: D22786551
With this fix, this issue is gone.
Reviewed By: gcatron
Differential Revision: D22768382
fbshipit-source-id: 9ee0bbcb2bc5f76107dae385759fe578909a683d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42101
1. Add test fixture `atest class` to store global variables
2. Make `run_binary_ops_test` function generic: can dispose different dtypes and different numbers of parameters
3. add test to `add_kernel`
Test Plan:
Run locally to check cover the corresponding code part in `BinaryOpsKernel.cpp`.
CI
Reviewed By: malfet
Differential Revision: D22760015
fbshipit-source-id: 95b47732f661124615c0856efa827445dd714125
Summary:
the onnxifi path didn't handle the input/output name rewrite for ssa correctly for AsyncIf op. Add support for it.
Also fixed a place where we lose the net type while doing onnxifi transform.
Test Plan: Load 163357582_593 which is a multi feed model that uses AsyncIf. This used to fail with c2 not finding some blobs in workspace. Now it works.
Reviewed By: dhe95
Differential Revision: D21268230
fbshipit-source-id: ce7ec0e952513d0f251df1bfcfb2b0250f51fd94
Summary:
This PR adds a description of `torch.optim.swa_utils` added in https://github.com/pytorch/pytorch/pull/35032 to the docs at `docs/source/optim.rst`. Please let me know what you think!
vincentqb andrewgordonwilson
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41228
Reviewed By: ngimel
Differential Revision: D22609451
Pulled By: vincentqb
fbshipit-source-id: 8dd98102c865ae4a074a601b047072de8cc5a5e3
Summary:
This uses cub for cum* operations, because, unlike thrust, cub is non-synchronizing.
Cub does not support more than `2**31` element tensors out of the box (in fact, due to cub bugs the cutoff point is even smaller)
so to support that I split the tensor into `2**30` element chunks, and modify the first value of the second and subsequent chunks to contain the cumsum result of the previous chunks. Since modification is done inplace on the source tensor, if something goes wrong and we error out before the source tensor is reverted back to its original state, source tensor will be corrupted, but in most cases errors will invalidate the full coda context.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42036
Reviewed By: ajtulloch
Differential Revision: D22749945
Pulled By: ngimel
fbshipit-source-id: 9fc9b54d466df9c8885e79c4f4f8af81e3f224ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42127
This diff renames core_autograd_sources to core_trainer_sources and moves/adds dependencies for the lite trainer in order to build the serializer functionality internally.
ghstack-source-id: 108589416
Test Plan: Manually tested serializer functionality from the internal lite trainer and verified that data is written correctly.
Reviewed By: iseeyuan
Differential Revision: D22738293
fbshipit-source-id: 992beb0c4368b2395f5bd5563fb2bc12ddde39a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42136
Expect was giving weird issues so let's just use netrc since it doesn't
rely on janky expect behavior
Another follow up for: https://github.com/pytorch/pytorch/pull/41964
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: yns88
Differential Revision: D22778940
Pulled By: seemethere
fbshipit-source-id: 1bdf879a5cfbf68a7d2d34b6966c20f95bd0a3b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42037
This is to fix#41951
Test Plan: Imported from OSS
Reviewed By: yf225
Differential Revision: D22764717
Pulled By: glaringlee
fbshipit-source-id: e6da0aeb05a2356f52446e6d5fad391f2cd1cf6f
Summary: we need this op to avoid the splicing of a dense tensor and then use the Mergesinglescaler op
Test Plan: integrated test with dper2
Differential Revision: D22677523
fbshipit-source-id: f4f9a1f06841b0906ec8cbb435482ae0a89e1721
Summary:
This PR fixes an issue in https://github.com/pytorch/pytorch/issues/40967 where duplicate parameters across different parameter groups are not allowed, but duplicates inside the same parameter group are accepted. After this PR, both cases are treated equally and raise `ValueError`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41597
Reviewed By: zou3519
Differential Revision: D22608019
Pulled By: vincentqb
fbshipit-source-id: 6df41dac62b80db042cfefa6e53fb021b49f4399
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39384
Introducing `ComputeUnitFactory` which is responsible for providing `ComputeUnit`s (Shaders),
it caches it, using shader name (glsl file name)+workGroupSize as a cacheKey, just `std::map<string, std::shared_ptr>`
Macro GLSL_SPV changed to have literal name for cache key as a first argument.
All constructors of ComputeUnit are changed to use `ComputeUnitFactory`
Ownership model:
ComputeUnitFactory also owns `vkPipelineCache` that is internal vulkan cache object ( https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/VkPipelineCache.html )
`VContext` (global object) owns ComputeUnitFactory, that owns ComputeUnits, vkPipelineCache, for destruction of them we need valid VkDevice, so it should be destructed before `vkDestryDevice` in `~VContext` => As members of the class will be destructed only after destructor - forcing destruction of ComputeUnitFactory before `vkDestroyDevice`, doing `unique_ptr<ComputeUnitFactory>.reset()`
Test Plan: Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D21962430
Pulled By: IvanKobzarev
fbshipit-source-id: effe60538308805f317c11448b31dbcf670487e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42019
According to benchmarks, this makes IValue::toStringRef() 3-4x as fast.
ghstack-source-id: 108451154
Test Plan: unit tests
Reviewed By: ezyang
Differential Revision: D22731354
fbshipit-source-id: 3ca3822ea7310d8593e38b1d3e6014d6d80963db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42034
In this diff, scale and zero point gradient calculations are updated to correctly reflect the actual backpropagation equation (instead of `dScale * dX`, the near-final output should be `dScale * dY`; the same applies to zero point).
Test Plan:
To execute the unit tests for all affected learnable fake quantize modules and kernels, on a devvm, execute the following command:
`buck test //caffe2/test:quantization -- learnable`
To enable the `cuda` tests, execute the following command:
`buck test mode/dev-nosan //caffe2/test:quantization -- learnable`
Reviewed By: jerryzh168
Differential Revision: D22735668
fbshipit-source-id: 45c1e0fd38cbb2d8d5e60be4711e1e989e9743b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42033
In this diff, the Python `_LearnableFakeQuantize` module is updated where the gradient with respect to the input `x` is actually computed instead of passed through. Argument naming is also updated for better clarity; and unit tests on the `PerTensor` and `PerChannel` operators are added for asserting correctness.
Test Plan:
On a devvm, execute the command:
`buck test //caffe2/test:quantization -- learnable_py_module`
To include `cuda` tests as well, run:
`buck test mode/dev-nosan //caffe2/test:quantization -- learnable_py_module`
Reviewed By: jerryzh168
Differential Revision: D22735580
fbshipit-source-id: 66bea7e9f8cb6422936e653500f917aa597c86de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42032
In this diff, the arguments `dX` within the C++ kernels are named as `dY` for clarity and avoid confusion since it doesn't represent the gradient with respect to the input.
Test Plan:
To test all related fake quantize kernel operators, on a devvm, run the command:
`buck test //caffe2/test:quantization -- learnable`
Reviewed By: z-a-f, jerryzh168
Differential Revision: D22735429
fbshipit-source-id: 9d6d967f08b98a720eca39a4d2280ca8109dcdd6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42114
Remove settings for the logit test case.
(Note: this ignores all push blocking failures!)
Test Plan: test_op_nnpi_fp16.py test case.
Reviewed By: hyuen
Differential Revision: D22766728
fbshipit-source-id: 2fe8404b103c613524cf1beddf1a0eb9068caf8a
Summary:
Current losses in PyTorch only include a (partial) implementation of Huber loss through `smooth l1` based on Fast RCNN - which essentially uses a delta value of 1. Changing/Renaming the [`_smooth_l1_loss()`](3e1859959a/torch/nn/functional.py (L2487)) and refactoring to include delta, enables to use the actual function.
Supplementary to this, I have also made a functional and criterion versions for anyone that wants to set the delta explicitly - based on the functional `smooth_l1_loss()` and the criterion `Smooth_L1_Loss()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37599
Differential Revision: D21559311
Pulled By: vincentqb
fbshipit-source-id: 34b2a5a237462e119920d6f55ba5ab9b8e086a8c
Summary:
xref gh-38010 and gh-38011.
After this PR, there should be only two warnings:
```
pytorch/docs/source/index.rst:65: WARNING: toctree contains reference to nonexisting \
document 'torchvision/index'
WARNING: autodoc: failed to import class 'tensorboard.writer.SummaryWriter' from module \
'torch.utils'; the following exception was raised:
No module named 'tensorboard'
```
If tensorboard and torchvision are prerequisites to building docs, they should be added to the `requirements.txt`.
As for breaking up quantization into smaller pieces: I split out the list of supported operations and the list of modules to separate documents. I think this makes the page flow better, makes it much "lighter" in terms of page cost, and also removes some warnings since the same class names appear in multiple sub-modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41321
Reviewed By: ngimel
Differential Revision: D22753099
Pulled By: mruberry
fbshipit-source-id: d504787fcf1104a0b6e3d1c12747ec53450841da
Summary:
xref gh-38011.
Fixes two warnings when building documentation by
- using the external link to torchvision
- install tensorboard before building documentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41334
Reviewed By: ngimel
Differential Revision: D22753083
Pulled By: mruberry
fbshipit-source-id: 876377e9bd09750437fbfab0378664b85701f827
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41930
As title
ghstack-source-id: 108517079
Test Plan: CI
Reviewed By: jerryzh168
Differential Revision: D22698386
fbshipit-source-id: 4f748c9bae4a0b615aa69c7cc8d8e451e5d26863
Summary:
**BC-Breaking Note**
This PR changes the behavior of the torch.tensor, torch.as_tensor, and sparse constructors. When given a tensor as input and a device is not explicitly specified, these constructors now always infer their device from the tensor. Historically, if the optional dtype kwarg was provided then these constructors would not infer their device from tensor inputs. Additionally, for the sparse ctor a runtime error is now thrown if the indices and values tensors are on different devices and the device kwarg is not specified.
**PR Summary**
This PR's functional change is a single line:
```
auto device = device_opt.has_value() ? *device_opt : (type_inference ? var.device() : at::Device(computeDeviceType(dispatch_key)));
```
=>
```
auto device = device_opt.has_value() ? *device_opt : var.device();
```
in `internal_new_from_data`. This line entangled whether the function was performing type inference with whether it inferred its device from an input tensor, and in practice meant that
```
t = torch.tensor((1, 2, 3), device='cuda')
torch.tensor(t, dtype=torch.float64)
```
would return a tensor on the CPU, not the default CUDA device, while
```
t = torch.tensor((1, 2, 3), device='cuda')
torch.tensor(t)
```
would return a tensor on the device of `t`!
This behavior is niche and odd, but came up while aocsa was fixing https://github.com/pytorch/pytorch/issues/40648.
An additional side affect of this change is that the indices and values tensors given to a sparse constructor must be on the same device, or the sparse ctor must specify the dtype kwarg. The tests in test_sparse.py have been updated to reflect this behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41984
Reviewed By: ngimel
Differential Revision: D22721426
Pulled By: mruberry
fbshipit-source-id: 909645124837fcdf3d339d7db539367209eccd48
Summary:
Resubmit of https://github.com/pytorch/pytorch/issues/41318 pushed to ci-all branch.
Original description:
Closes https://github.com/pytorch/pytorch/issues/24137.
This PR adds support for the torch.bool tensor type to ProcessGroupNCCL. For most types we use the existing mapping, but since bool is not supported as a native ncclDataType_t, we add the following logic:
Map at::kBool to ncclUint8
During reduction (allreduce for example), if the operation is SUM, we instead override to to a MAX, to avoid overflow issues. The rest of the operations work with no changes. In the boolean case, changing sum to max makes no correctness difference since they both function as a bitwise OR.
The reduction logic (for example for reduce/allreduce) is as follows:
sum, max = bitwise or
product, min = bitwise and
Note that this PR doesn't add support for BAND/BOR/BXOR. That is because these reduction ops currently are not supported by NCCL backend, see https://github.com/pytorch/pytorch/issues/41362
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41959
Reviewed By: mrshenli
Differential Revision: D22719665
Pulled By: rohan-varma
fbshipit-source-id: 8bc4194a8d1268589640242277124f277d2ec9f1
Summary:
build_android.sh should check PYTHON environment variable before trying to use default python executable.
Even in that case, try to pick python3 over python2 when available.
Closes https://github.com/pytorch/pytorch/issues/41795
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41927
Reviewed By: seemethere
Differential Revision: D22696850
Pulled By: malfet
fbshipit-source-id: be236c2baf54a1cd111e55ee7743cdc93cb6b9d7
Summary:
[2/N] Implement Enum JIT support
Add prim::EnumName and prim::EnumValue and their lowerings to support getting `name` and `value` attribute of Python enums.
Supported:
Enum-typed function targuments
using Enum type and comparing them
Support getting name/value attrs of enums
TODO:
Add PyThon sugared value for Enum
Support Enum-typed return values
Support enum values of different types in same Enum class
Support serialization and deserialization
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41965
Reviewed By: eellison
Differential Revision: D22714446
Pulled By: gmagogsfm
fbshipit-source-id: db8c4e26b657e7782dbfc2b58a141add1263f76e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41945
This test previously did a thread sleep before launching the allgather operation, and then waited on the work object. Since the sleep was done before the work object was created, it did not affect the allgather call, and thus, did not test work-level timeouts as intended.
I am removing this test for now. In the future we can add this test back, but would need to somehow inject a `cudaSleep` call before the allgather (so the collective operation itself is delayed). This may require overriding the `ProcessGroupNCCL::collective`, so it's a bit more heavy-weight.
In the meantime, we can remove this test - work-level timeouts are still thoroughly tested with Gloo.
ghstack-source-id: 108370178
Test Plan: Ran ProcessGroupNCCL tests on devGPU
Reviewed By: jiayisuse
Differential Revision: D22702291
fbshipit-source-id: a36ac3d83abfab6351c0476046a2f3b04a80c44d
Summary:
Since NCCL makes calls to shm_open/shm_close it must depend on librt on Linux
This should fix `DSO missing from command line` error on some platforms
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41978
Reviewed By: colesbury
Differential Revision: D22721430
Pulled By: malfet
fbshipit-source-id: d2ae08ce9da3979daaae599e677d5e4519b080f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41267
Due to llvm bug and some unsupported intrinsics we could not directly
use intrinsics for implementing aarch32 neon back end for Vec256.
Instead we resort to inline assembly.
Test Plan:
vec256_test run on android phone.
Imported from OSS
Reviewed By: AshkanAliabadi
Differential Revision: D22482196
fbshipit-source-id: 1c22cf67ec352942c465552031e9329550b27b3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41482
This adds a new tag for use with pipeline parallelism.
Test Plan: CI
Reviewed By: heslami
Differential Revision: D22551487
fbshipit-source-id: 90910f458a9bce68f7ef684773322a49aa24494a
Summary:
instead exporting schemas using the current binary being tested, install nightly and export its schemas to use in a back-compat test run by the current binary being tested.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41949
Reviewed By: houseroad
Differential Revision: D22731054
Pulled By: bradleyhd
fbshipit-source-id: 68a7e7637b9be2604c0ffcde2a40dd208057ba72
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41964
Since we're not executing this in a docker container we should go ahead
an install expect explicitly
This is a follow up PR to #41871
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D22736738
Pulled By: seemethere
fbshipit-source-id: a56e19c1ee13c2f6e2750c2483202c1eea3b558a
Summary:
Currently constant pooling runs before const propagation, which can create more constants that need pooling. This can get in the way of serialization/deserialization stability because each time user serializes and deserializes a module, runCleanUpPasses is called upon it. Doing so multiple times would lead to different saved module.
This PR moves constant pooling after const propagation, which may slow down const propagation a little bit, but would otherwise side-step aforementioned problem.
test_constant_insertion in test_jit.py is also updated because after fixing the pass ordering, the number of constants is no longer a constant and it is extremely difficult to get the exact number with the current convoluted test structure. So for now, I changed the test to check only that CSE doesn't change number of "prim::constant" rather than comparing against a known number. Also left a TODO to improve this test.
ConstantPropagation pass is replaced by ConstantPropagationImmutableTypes because the latter is used in runCleanUpPasses. If not replaced, the former would create new CSE opportunities by folding more constants. This voids the purpose of the test case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41891
Reviewed By: colesbury
Differential Revision: D22701540
Pulled By: gmagogsfm
fbshipit-source-id: 8e60dbdcc54a93dac111d81b8d88fb39387224f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41596
We've modified the previous design of `convert_dist_work_to_future` API in the GH Issue [#39272](https://github.com/pytorch/pytorch/issues/39272).
1. Whenever we create a `WorkNCCL` object, create a `Future` associated with `WorkNCCL` and store it with the object.
2. Add an API `c10::intrusive_ptr<c10::ivalue::Future> getFuture()` to `c10d::ProcessGroup::Work`.
3. This API will only be supported by NCCL in the first version, the default implementation will throw UnsupportedOperation.
4. To mark the future associated with WorkNCCL completed, implement a `cudaStreamCallback` function.
`cudaStreamAddCallback` is marked as deprecated. An alternative is `cudaLaunchHostFunc`, but it is supported for CUDA > 10 and may not be deprecated until there's a reasonable alternative available according to [this discussion](https://stackoverflow.com/questions/56448390/how-to-recover-from-cuda-errors-when-using-cudalaunchhostfunc-instead-of-cudastr).
ghstack-source-id: 108409748
Test Plan:
Run old python test/distributed/test_c10d.py.
Some additional tests:
`test_ddp_comm_hook_allreduce_hook_nccl`: This unit test verifies whether a DDP communication hook that just calls allreduce gives the same result result with the case of no hook registered. Without the then callback, the future_value in reducer is no longer a PyObject, and this unit test verifies future_value is properly checked.
`test_ddp_comm_hook_allreduce_then_mult_ten_hook_nccl`: This unit test verifies whether a DDP communication hook that calls allreduce and then multiplies the result by ten gives the expected result.
As of v10:
```
........................s.....s.....................................................s...............................
----------------------------------------------------------------------
Ran 116 tests
OK (skipped=3)
```
`flow-cli` performance validation using a stacked diff where `bucket.work` is completely replaced with `bucket.future_work` in `reducer`. See PR [#41840](https://github.com/pytorch/pytorch/pull/41840) [D22660198](https://www.internalfb.com/intern/diff/D22660198/).
Reviewed By: izdeby
Differential Revision: D22583690
fbshipit-source-id: 8c059745261d68d543eaf21a5700e64826e8d94a
Summary:
Added a logic so that if a prehook is passed into the prepare method during quantization, then the hook will be added as a prehook to all leaf nodes (and modules specified in the non_leaf_module_list).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41863
Test Plan:
Small demo, made simple module then called prepare with prehook parameter set to the numeric suite logger, printed the results to verify its what we wanted
{F245156246}
Reviewed By: jerryzh168
Differential Revision: D22671288
Pulled By: edmundw314
fbshipit-source-id: ce65a00830ff03360a82c0a075b3b6d8cbc4362e
Summary:
fix https://github.com/pytorch/pytorch/issues/40604
Add parameter to Dataloader to configure the per-worker prefetch number.
Before this edit, the prefetch process always prefetch 2 * num_workers data items, this commit help us make this configurable, e.x. you can specify to prefetch 10 * num_workers data items.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41130
Reviewed By: izdeby
Differential Revision: D22705288
Pulled By: albanD
fbshipit-source-id: 2c483fce409735fef1351eb5aa0b033f8e596561
Summary:
so that testing _min_max on the different devices is easier, and min/max operations have better CUDA test coverage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41908
Reviewed By: mruberry
Differential Revision: D22697032
Pulled By: ngimel
fbshipit-source-id: a796638fdbed8cda90a23f7ff4ee167f45530914
Summary:
**Summary**
This commit updates the repository's pull request template to remind contributors to tag the issue that their pull request addresses.
**Fixes**
This commit fixes https://github.com/pytorch/pytorch/issues/35319.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41812
Reviewed By: gmagogsfm
Differential Revision: D22667902
Pulled By: SplitInfinity
fbshipit-source-id: cda5ff7cbbbfeb89c589fd0dfd378bf73a59d77b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41963
the error message of dot(CUDA) was copied from dot(CPU), however, they both are easy to cause confusion
Test Plan: wait for unittests
Reviewed By: ngimel
Differential Revision: D22710822
fbshipit-source-id: 565b51149ff4bee567ef0775e3f8828579565f8a
Summary:
Import __future__ to make `print(*args)` a syntactically correct statement under Python-2
Otherwise, if once accidentally invokes setup.py using Python-2 interpreter they will be greeted by:
```
File "setup.py", line 229
print(*args)
^
SyntaxError: invalid syntax
```
instead of:
```
Python 2 has reached end-of-life and is no longer supported by PyTorch.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41960
Reviewed By: orionr, seemethere
Differential Revision: D22710174
Pulled By: malfet
fbshipit-source-id: ffde3ddd585707ba1d39e57e0c6bc9c4c53f8004
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41612
This change adds preliminary support to quantize the EmbeddingBag operators. We currently support 4-bit and 8-bit quantization+packing of the weights.
To quantize these operators, specify the operator name in the `custom_op_name` field of the NoopObserver. Based on the op name (4bit or 8bit) we call the corresponding quantization functions.
Refer to the testplan for how to invoke the qconfig for the embedding_bag ops.
Future versions of this will support 4-bit and 2-bit qtensors with native support to observe and quantize it.
NB - This version assumes that the weights in the EmbeddingBag Module reside on the same device.
Test Plan:
python test/test_quantization.py TestQuantizeDynamicJitOps.test_embedding_bag
Imported from OSS
Reviewed By: vkuzo, jerryzh168
Differential Revision: D22609342
fbshipit-source-id: 23e33f44a451c26719e6e283e87fbf09b584c0e6
Summary:
I copyed a pruned model after deleteing the derived tensors. In order to be able to reparameter the model, we should check the existence of the tensors here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41913
Reviewed By: izdeby
Differential Revision: D22703248
Pulled By: mrshenli
fbshipit-source-id: f5274d2c634a4c9a038100d8a6e837f132eabd34
Summary:
As explained in https://github.com/pytorch/pytorch/issues/41922 using `if(NOT ${var})" is usually wrong and can lead to issues like https://github.com/pytorch/pytorch/issues/41922 where the condition is wrongly evaluated to FALSE instead of TRUE. Instead the unevaluated variable name should be used in all cases, see the CMake docu for details.
This fixes the `NOT ${var}` cases by using a simple regexp replacement. It seems `pybind11_PREFER_third_party` is the only variable really prone to causing an issue as all others are set. However due to CMake evaluating unquoted strings in `if` conditions as variable names I recommend to never use unquoted `${var}` in an if condition. A similar regexp based replacement could be done on the whole codebase but as that does a lot of changes I didn't include this now. Also `if(${var})` will likely lead to a parser error if `var` is unset instead of a wrong result
Fixes https://github.com/pytorch/pytorch/issues/41922
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41924
Reviewed By: seemethere
Differential Revision: D22700229
Pulled By: mrshenli
fbshipit-source-id: e2b3466039e4312887543c2e988270547a91c439
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41479
Previously we were re-running CSE every time we recursed into a new block, which in turn created a new Alias Db for the whole graph. This was O(# Nodes * # Blocks).
For graphs which don't have any autodiff opportunities, such as Densenet, create_autodiff_subgraphs is now linear in number of nodes. For Densenet this pass was measured at ~.1 seconds.
This pass is still non-linear for models which actually do create autodiff subgraphs, because in the
```
bool any_changed = true;
while (any_changed) {
AliasDb aliasDb(graph_);
any_changed = false;
for (auto it = workblock.end()->reverseIterator();
it != workblock.begin()->reverseIterator();) {
bool changed;
std::tie(it, changed) = scanNode(*it, aliasDb);
any_changed |= changed;
}
}
```
loop we recreate the AliasDb (which is O(N)) every time we merge something and scan node returns. I will make that linear in next PR in the stack.
Test Plan: Imported from OSS
Reviewed By: Krovatkin
Differential Revision: D22600606
Pulled By: eellison
fbshipit-source-id: b08abfde2df474f168104c5b477352362e0b7b16
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41437
[copied from commented code]
the IR has many nodes which can never be reordered around, such as a
prim::Bailout. if a node N is surrounded by two nodes which cannot be
reordered, A and B, then a differentiable subgraph that is created from N
can only contain nodes from [A, B] The nodes from A to B represent one
work block for the subgraph slicer to work on. By creating these up
front, we avoid retraversing the whole graph block any time scanNode
returns, and we can also avoid attempting to create differentiable
subgraphs in work blocks that do not contain a minimum number of differentiable nodes
This improved compilation time of e of densenet (the model with the slowest compilation time we're tracking) from 56s -> 28s, and for mobilenet from 8s -> 6s.
Test Plan: Imported from OSS
Reviewed By: Krovatkin, ZolotukhinM
Differential Revision: D22600607
Pulled By: eellison
fbshipit-source-id: e5ab6ed87bf6820b4e22c86eabafd9d17bf7cedc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41436
Constants are not executed as instructions, we should ignore them when counting subgraph size, as we ignore them in counting block size for loop unrolling.
Test Plan: Imported from OSS
Reviewed By: Krovatkin, ZolotukhinM
Differential Revision: D22600608
Pulled By: eellison
fbshipit-source-id: 9770b21c936144a3d6a1df89cf3be5911095187e
Summary:
Per comment in run_test.py, every test module must have a __main__ entrypoint:
60e2baf5e0/test/run_test.py (L237-L238)
Also disable test_wait_all on Windows, as it fails with an uncaught exception:
```
test_wait_all (__main__.TestFuture) ... Traceback (most recent call last):
File "run_test.py", line 744, in <module>
main()
File "run_test.py", line 733, in main
raise RuntimeError(err)
RuntimeError: test_futures failed!
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41826
Reviewed By: seemethere, izdeby
Differential Revision: D22654899
Pulled By: malfet
fbshipit-source-id: ab7fdd7adce3f32c53034762ae37cf35ce08cafc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41318
Closes https://github.com/pytorch/pytorch/issues/24137.
This PR adds support for the `torch.bool` tensor type to ProcessGroupNCCL. For most types we use the existing mapping, but since `bool` is not supported as a native `ncclDataType_t`, we add the following logic:
1) Map `at::kBool` to `ncclUint8`
2) During reduction (allreduce for example), if the operation is SUM, we instead override to to a MAX, to avoid overflow issues. The rest of the operations work with no changes. In the boolean case, changing sum to max makes no correctness difference since they both function as a bitwise OR.
The reduction logic (for example for reduce/allreduce) is as follows:
sum, max = bitwise or
product, min = bitwise and
Tests are added to ensure that the reductions work as expected.
ghstack-source-id: 108315417
Test Plan: Added unittests
Reviewed By: mrshenli
Differential Revision: D22496604
fbshipit-source-id: a1a15381ec41dc59923591885d40d966886ff556
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41269
The ultimate goal is to move things that are not gated with `if (compute_requires_grad(...))`
or `if (grad_fn)` out from VariableType so that VariableType kernels can be enabled/disabled
based upon `GradMode`. Then we can merge `AutoNonVariableTypeMode` and `NoGradGuard`.
We've moved profiling / tracing logic out from VariableType. One remaining thing that's
not gated with the if-statement is the `increment_version` call.
However, the `gen_variable_type.py` does use bits from `derivatives.yaml` to determine whether
to emit the `increment_version` call. If an output is never going to be differentiable (not based
upon runtime property of the variable but based upon static property, e.g. it's integral type)
then it would never emit the increment_version call.
Hypothetically, increment_version for a tensor can be orthogonal to its differentiability.
This PR is to make the change and test its impact. Making this logical simplification would
allow us to move this out from VariableType to aten codegen.
ghstack-source-id: 108318746
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D22471643
fbshipit-source-id: 3e3a442c7fd851641eb4a9c4f024d1f5438acdb8
Summary:
I'd like to amend the docstring introduced in https://github.com/pytorch/pytorch/issues/41564. It's not rendering correctly on the web, and this should fix it.
cc albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41835
Reviewed By: izdeby
Differential Revision: D22672368
Pulled By: albanD
fbshipit-source-id: f0b03c2b2a4c79b790d54f7c8f2ae28ef9d76a75
Summary:
Move the timing utils to `torch.utils._benchmark`. I couldn't figure out how to get setuptools to pick it up and put it under `torch` unless it is in the `torch` directory. (And I think it has to be for `setup.py develop` anyway.)
I also modified the record function benchmark since `Timer` and `Compare` should always be available now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41506
Reviewed By: ngimel
Differential Revision: D22601460
Pulled By: robieta
fbshipit-source-id: 9cea7ff1dcb0bb6922c15b99dd64833d9631c37b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/19227
This PR adds a regression test for ONNX exports where a module has a sequential that references an Embedding layer
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32598
Reviewed By: izdeby
Differential Revision: D22672790
Pulled By: ezyang
fbshipit-source-id: c88beb29a36b07378c28b0e4546efe887fcbc3be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41895
### Summary
The iOS binary for 1.6.0 has been uploaded to AWS. This PR bumps up the version for cocoapods.
### Test Plan
- Check CI
Test Plan: Imported from OSS
Reviewed By: husthyc
Differential Revision: D22683787
Pulled By: xta0
fbshipit-source-id: bb95b670a7945d823d55e9c65b357765753f295a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41892
Currently the input of batch_norm is considered as dynamically quantizable but it shouldn't be
this PR fixes that
Test Plan:
internal models
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D22681423
fbshipit-source-id: 7f428751de0c4af0a811b9c952e1d01afda42d85
Summary:
They are already owned by `jenkins` user after the build
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41884
Reviewed By: orionr
Differential Revision: D22682441
Pulled By: malfet
fbshipit-source-id: daf99532d300d30a5de591ad03af4597e145fdfc
Summary:
This pull request enables the following tests from test_torch, previously skipped on ROCm:
test_pow_-2_cuda_float32/float64
test_sum_noncontig_cuda_float64
test_conv_transposed_large
The first two tests experienced precision issues on earlier ROCm version, whereas the conv_transposed test was hitting a bug in MIOpen which is fixed with the version shipping with ROCm 3.5
ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41611
Reviewed By: xw285cornell
Differential Revision: D22672690
Pulled By: ezyang
fbshipit-source-id: 5585387c048f301a483c4c0566eb9665555ef874
Summary:
Separates out the docs build from the push and limits when the push
actually happens.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41871
Reviewed By: yns88
Differential Revision: D22673716
Pulled By: seemethere
fbshipit-source-id: fff8b35ba8465dc15832214c4c9ef03ce12faa48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41859
A value can be used multiple times in the same node, we don't really need to assert uses of dequantize == 1
Test Plan: Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D22673525
fbshipit-source-id: 2c4a770e0ddee722ca54e68d310c395e7f418b3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41687
Specifically, this makes a new library (lazy), which can be used from both core
and workspace.
This allows workspace.Createnet to trigger lazy loading of dyndep dependencies.
Test Plan: Added a unit test specifically for workspace.CreateNet
Reviewed By: dzhulgakov
Differential Revision: D22441877
fbshipit-source-id: 3a9d1af9962585d08ea2566c9c85bec7377d39f2
Summary:
Add pass that fuses Conv and Batchnormalization nodes into one node Conv.
This pass is only applied in inference mode (training is None or TrainingMode.Eval).
Since this pass needs access to param_dict it is written outside peephole file where these kind of passes (fusing multiple nodes into one) is usually placed.
This PR also adds wrapper skipIfNoEmbed to skip debug_embed_params test:
Pass that fuses Conv and Batchnorm changes the params of resnet model and parameters of onnx and pytorch model won't match. Since parameters are not matching, debug_embed_params test for test_resnet will fail and that is expected, therefore debug_embed_params test for test_resnet should be skipped.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40547
Reviewed By: gchanan
Differential Revision: D22631687
Pulled By: bzinodev
fbshipit-source-id: fe45812400398a32541e797f727fd8697eb6d8c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41820
Pull Request resolved: https://github.com/pytorch/glow/pull/4721
In order to support int8 quantized tensor as an input to OnnxifiOp, we need to
- Add support to recognize and extract shape meta from int8 tensor at input of OnnxifiOp
- Make a copy of the input data and shift by 128 in Glow if input data is uint8 quantized tensor to get correct result because Glow uses int8 to represent the quantized data regardless.
- Propagate correct quantization parameters to through shape info in C2.
This diff implements the above.
Test Plan:
```
buck test caffe2/caffe2/contrib/fakelowp/test:test_int8_quantnnpi
```
Reviewed By: jackm321
Differential Revision: D22650584
fbshipit-source-id: 5e867f7ec7ce98bb066ec4128ceb7cad321b3392
Summary:
The function torch.cross is a bit confusing, in particular the defaulting of the dim argument.
The default `dim` has been documented as -1 but it is actually `None`. This increases the confusion, in two possible ways depending on how carefully you read the rest. I also add a final warning to the final sentence.
This partially addresses https://github.com/pytorch/pytorch/issues/39310.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41850
Reviewed By: izdeby
Differential Revision: D22664625
Pulled By: albanD
fbshipit-source-id: b8669e026fd01de9e4ec16da1414b9edfaa76bdd
Summary:
Reland PR https://github.com/pytorch/pytorch/issues/40056
A new overload of upsample_linear1d_backward_cuda was added in a recent commit, so I had to add the nondeterministic alert to it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41538
Reviewed By: zou3519
Differential Revision: D22608376
Pulled By: ezyang
fbshipit-source-id: 54a2aa127e069197471f1feede6ad8f8dc6a2f82
Summary:
Fix a bug in SplitWithTail and SplitWithMask where loop_options such as Cuda block/thread bindings are overwritten by the split. This PR fixes this bug by propagating the loop options to the outer loop, which for axis bindings should be equivalent.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40035
Reviewed By: ZolotukhinM
Differential Revision: D22080263
Pulled By: nickgg
fbshipit-source-id: b8a9583fd90f69319fc4bb4db644e91f6ffa8e67
Summary:
closes gh-37584. ~I think I need to do more to generate an image, but the `.circleci/README.md` is vague in the details. The first commit reflows and updates that document a bit, I will continue to update it as the PR progresses :)~ Dropped updating `.circleci/README.md`, will do that in a separate PR once this is merged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38796
Reviewed By: gchanan
Differential Revision: D22627522
Pulled By: ezyang
fbshipit-source-id: 99d5c19e942f15b9fc10f0de425790474a4242ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39984
Add Alltoall and Alltoallv to PT NCCL process group using NCCL Send/Recv.
Reviewed By: jiayisuse
Differential Revision: D20781624
fbshipit-source-id: 109436583ff69a3fea089703d32cfc5a75f973e0
Summary:
With transition to hipclang, the HIP runtime library name was changed. A symlink was added to ease the transition, but is going to be removed. Conditionally set library name based on HIP compiler used. Patch gloo submodule as part of build_amd.py script until its associated fix is available.
CC ezyang xw285cornell sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41813
Reviewed By: zhangguanheng66
Differential Revision: D22660077
Pulled By: xw285cornell
fbshipit-source-id: c538129268d9947535b34523201f655b13c9e0a3
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 139c6f2292
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41814
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: dskhudia
Differential Revision: D22648844
fbshipit-source-id: 4cfa8d83585407f870ea2bdee74e1c1f371082eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41828
This reverts commit fe66bdb498efe912d8b9c437a14efa4295c04fdd.
This also makes a sense to THTensorEvenMoreMath because sumall was removed, see THTensor_wrap.
Test Plan: Imported from OSS
Reviewed By: orionr
Differential Revision: D22657473
Pulled By: malfet
fbshipit-source-id: 95a806cedf1a3f4df91e6a21de1678252b117489
Summary:
The goal is to implement cross layer equalization as described in section 4.1 in this paper: https://arxiv.org/pdf/1906.04721.pdf
Given two adjacent submodules in a trained model, A,B quantization might hurt one of the submodules more than the other. The paper poses the idea that a loss in accuracy from quantizing can be due to a difference in the channel ranges between the two submodules (the output channel range of A can be small, while the input channel range of B can be large). To minimize this source of error, we want to scale the tensors of A,B s.t. their channel ranges are equal (them being equal means no difference in ranges and minimizes this source of error).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41685
Test Plan: Imported from OSS
Reviewed By: z-a-f
Differential Revision: D22630219
Pulled By: edmundw314
fbshipit-source-id: ccc91ba12c10b652d7275222da8b85455b8a7cd5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41558
The problem was due to non-deterministic destruction order of two global static variables: the mutexes used by glog and the RPC agent (which was still set because we didn't call `rpc.shutdown()`). When the TensorPipe RPC agent shuts down some callbacks may fire with an error and thus attempt to log something. If the mutexes have already been destroyed this causes a SIGABRT.
Fixes https://github.com/pytorch/pytorch/issues/41474
ghstack-source-id: 108231453
Test Plan: Verified in https://github.com/pytorch/pytorch/issues/41474.
Reviewed By: fmassa
Differential Revision: D22582779
fbshipit-source-id: 63e34d8a020c4af996ef079cfb7041b2474e27c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41825
Add flag to gate D21374246 (e7a09b4d17) to mitigate mobile size regression.
ghstack-source-id: 108212047
Test Plan: CI
Reviewed By: linbinyu
Differential Revision: D22650708
fbshipit-source-id: ac9318af824ac31f519b7d5b4fe72df892d8d3f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41576
Previously we are assuming CallMethod only happens on module instances,
but it turns out this is not true, this PR fixes this issue.
Test Plan: Imported from OSS
Reviewed By: z-a-f
Differential Revision: D22592789
fbshipit-source-id: 48217626d9ea8e82536f00a296b8f9a471582ebe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41809
Add new unittests to Operator Kernels.
Explicitly announce function type in tests because it can't be inferred.
Test Plan: CI
Reviewed By: malfet
Differential Revision: D22647221
fbshipit-source-id: ef2f0e8c847841e90aa26d028753f23c8c53d6b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41570
For min/max based quantization observers, calculating min and max of a tensor
takes most of the runtime. Since the calculation of min and max is done
on the same tensor, we can speed this up by only reading the tensor
once, and reducing with two outputs.
One question I had is whether we should put this into the quantization
namespace, since the use case is pretty specific.
This PR implements the easier CPU path to get an initial validation.
There is some needed additional work in future PRs, which durumu will
take a look at:
* CUDA kernel and tests
* making this work per channel
* benchmarking on observer
* benchmarking impact on QAT overhead
Test Plan:
```
python test/test_torch.py TestTorch.test_min_and_max
```
quick bench (not representative of real world use case):
https://gist.github.com/vkuzo/7fce61c3456dbc488d432430cafd6eca
```
(pytorch) [vasiliy@devgpu108.ash6 ~/local/pytorch] OMP_NUM_THREADS=1 python ~/nfs/pytorch_scripts/observer_bench.py
tensor(5.0390) tensor(-5.4485) tensor([-5.4485, 5.0390])
min and max separate 11.90243935585022
min and max combined 6.353186368942261
% decrease 0.466228209277153
(pytorch) [vasiliy@devgpu108.ash6 ~/local/pytorch] OMP_NUM_THREADS=4 python ~/nfs/pytorch_scripts/observer_bench.py
tensor(5.5586) tensor(-5.3983) tensor([-5.3983, 5.5586])
min and max separate 3.468616485595703
min and max combined 1.8227086067199707
% decrease 0.4745142294372342
(pytorch) [vasiliy@devgpu108.ash6 ~/local/pytorch] OMP_NUM_THREADS=8 python ~/nfs/pytorch_scripts/observer_bench.py
tensor(5.2146) tensor(-5.2858) tensor([-5.2858, 5.2146])
min and max separate 1.5707778930664062
min and max combined 0.8645427227020264
% decrease 0.4496085496757899
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D22589349
fbshipit-source-id: c2e3f1b8b5c75a23372eb6e4c885f842904528ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41815
**All are minor changes to enable better simulations.**
The constructors of MinMaxObserver, MovingAverageMinMaxObserver, PerChannelMinMaxObserver, and MovingAveragePerChannelMinMaxObserver are augmented so they can utilize the dynamic quantization range support in the _ObserverBase class.
In addition, minor adjustments are made to the enable_static_observation function that allow observer to update parameters but do not fake quantize on the output (for constructing baseline).
Test Plan:
To ensure this modification is still backward compatible with past usages, numerics are verified by running the quantization unit test suite, which contains various observer tests. The following command executes the test suite, which also verifies the observer numerics:
```
buck test //caffe2/test:quantization -- observer
```
Reviewed By: z-a-f
Differential Revision: D22649128
fbshipit-source-id: 32393b706f9b69579dc2f644fb4859924d1f3773
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41806
Generally a good practice not to have tests spew output.
Test Plan:
`build/bin/test_tensorexpr`
Imported from OSS
Reviewed By: zheng-xq
Differential Revision: D22646833
fbshipit-source-id: 444e883307d058fe77e7550d436fa61b7d91a701
Summary:
Auto fuse the output loops of outer Rfactors, so it is in a more convenient format for binding GPU axes.
An example:
```
Tensor* c = Reduce("sum", {}, Sum(), b, {{m, "m"}, {n, "n"}, {k, "k"}});
LoopNest loop({c});
std::vector<For*> loops = loop.getLoopStmtsFor(c);
auto v = loops.at(0)->var();
loop.rfactor(c->body(), v);
```
Before:
```
{
Allocate(tmp_buf, float, {m});
sum[0] = 0.f;
for (int m_1 = 0; m_1 < m; m_1++) {
tmp_buf[m_1] = 0.f;
}
for (int m_1 = 0; m_1 < m; m_1++) {
for (int n = 0; n < n_1; n++) {
for (int k = 0; k < k_1; k++) {
tmp_buf[m_1] = (tmp_buf[m_1]) + (b[((n_1 * m_1) * k_1 + k) + k_1 * n]);
}
}
}
for (int m_1 = 0; m_1 < m; m_1++) {
sum[0] = (sum[0]) + (tmp_buf[m_1]);
}
Free(tmp_buf);
}
```
After:
```
{
sum[0] = 0.f;
for (int m = 0; m < m_1; m++) {
Allocate(tmp_buf, float, {m_1});
tmp_buf[m] = 0.f;
for (int n = 0; n < n_1; n++) {
for (int k = 0; k < k_1; k++) {
tmp_buf[m] = (tmp_buf[m]) + (b[((n_1 * m) * k_1 + k) + k_1 * n]);
}
}
sum[0] = (sum[0]) + (tmp_buf[m]);
Free(tmp_buf);
}
}
```
The existing Rfactor tests cover this case, although I did rename a few for clarity. This change broke the LLVMRFactorVectorizedReduction test because it now does what its intending to (vectorize a loop with a reduction in it) rather than nothing, and since that doesn't work it correctly fails. I've disabled it for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40050
Reviewed By: ZolotukhinM
Differential Revision: D22605639
Pulled By: nickgg
fbshipit-source-id: e359be53ea62d9106901cfbbc42d55d0e300e8e0
Summary: Enforce duplicate op name check on mobile
Test Plan: run full/lite predictor
Reviewed By: iseeyuan
Differential Revision: D22639758
fbshipit-source-id: 2993c4bc1b14c833b273183f4f343ffad62121b3
Summary:
Skipping the test test_streams as it is flaky on rocm.
cc: jeffdaily sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41697
Reviewed By: zhangguanheng66
Differential Revision: D22644600
Pulled By: malfet
fbshipit-source-id: b1b16d496e58a91c44c40d640851fd62a5d7393d
Summary:
This PR implements a feature extension discussed in https://github.com/pytorch/pytorch/issues/41516.
I followed this other PR https://github.com/pytorch/pytorch/issues/22245 to add this other module. While I was at it, I also added `extra_repr()` method in `Flatten` which was missing.
I see there are no unit tests for these modules. Should I add those too? If so, what is the best place I should place these?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41564
Reviewed By: gchanan
Differential Revision: D22636766
Pulled By: albanD
fbshipit-source-id: f9efdefd3ffe7d9af9482087625344af8f990943
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41535
A generalized fake quantization module is built to support lower-bit fake quantization with back propagation on the scale and zero point. The module supports both per tensor and per channel fake quantization.
Test Plan:
Please see diff D22337313 for a related experiment performed on the fake quantizer module.
The `_LearnableFakeQuantize` module supports the following use cases:
- Per Tensor Fake Quantization or Per Channel Fake Quantization
- Static Estimation from Observers or Quantization Parameter Learning through Back Propagation
By default, the module assumes per tensor affine fake quantization. To switch to per channel, during initialization, declare `channel_size` with the appropriate length. To toggle between utilizing static estimation and parameter learning with back propagation, you can invoke the call `enable_param_learning` or `enable_static_estimate`. For more information on the flags that support these operations, please see the doc string of the `_LearnableFakeQuantize` module.
The `_LearnableFakeQuantizer` module relies on 2 operators for its forward and backward paths: `_LearnableFakeQuantizePerTensorOp` and `_LearnableFakeQuantizePerChannelOp`. The backpropagation routine is developed based on the following literature:
- Learned Step Size Quantization: https://openreview.net/pdf?id=rkgO66VKDS
- Trained Quantization Thresholds: https://arxiv.org/pdf/1903.08066.pdf
Reviewed By: z-a-f
Differential Revision: D22573645
fbshipit-source-id: cfd9ece8a959ae31c00d9beb1acf9dfed71a7ea1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41693
Add non zero offset test cases for Quantize and Dequantize Ops.
Test Plan: Added new test case test_int8_non_zero_offset_quantize part of the test_int8_ops_nnpi.py test file.
Reviewed By: hyuen
Differential Revision: D22633796
fbshipit-source-id: be17ee7a0caa6e9bc7b175af539be2e6625ad47a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41376
torch::jit::mobile::Module does not currently support accessing parameters via their attribute names, but torch::jit::Module does. This diff adds an equivalent functionality to mobile::Module.
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D22609142
Pulled By: ann-ss
fbshipit-source-id: 1a5272ff336f99a3c0bb6194c6a6384754f47846
Summary:
## TLDR
Support using NaN default value for missing dense features in RawInputProcessor for DPER2. In preparation for subsequent support for null flag features in compute meta. For train_eval this is already supported in DPER3 and we do not plan to support this in DPER2 train eval.
Differential Revision: D22439142
fbshipit-source-id: 99ae9755bd41a5d5f43bf5a9a2819d64f3883005
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41503
Fix for https://github.com/pytorch/pytorch/issues/41192
We can map fill_ and zero_ to their functional equivalents full_like and zeros_like
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D22629269
Pulled By: eellison
fbshipit-source-id: f1c62684dc55682c0b3845022e0461ec77d07179
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41689
It's annoying not to know which jobs are actually related to docker
builds so let's just add the prefix.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D22631578
Pulled By: seemethere
fbshipit-source-id: ac0cdd983ccc3bebcc360ba479b378d8f0eaa9c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41618
More LayerNorm Vectorization in calcMeanStd function.
Test Plan: test covered in test_layernorm_nnpi_fp16.py
Reviewed By: hyuen
Differential Revision: D22606585
fbshipit-source-id: be773e62f0fc479dbc2d6735f60c2e98441916e9
Summary:
A minor spell check!
I have gone through a dozen of .md files to fix the typos.
zou3519 take a look!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41599
Reviewed By: ezyang
Differential Revision: D22601629
Pulled By: zou3519
fbshipit-source-id: 68d8f77ad18edc1e77874f778b7dadee04b393ef
Summary:
The test loops over `upper` but does not use it effectively running the same test twice which increases test times for no gain.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41583
Reviewed By: soumith, seemethere, izdeby
Differential Revision: D22598475
Pulled By: zou3519
fbshipit-source-id: d100f20143293a116ff3ba08b0f4eaf0cc5a8099
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41113
In this diff, the `ObserverBase` class is augmented with 2 additional optional arguments qmin and qmax. Correspondingly the calculation of qmin and qmax and the related quantization parameters are modified to accommodate this additional flexibility should the number of bits for quantization be lower than 8 (the default value).
Additional logic in the base class `_calculate_qparams` function has also been modified to provide support for dynamic quantization range.
Test Plan:
To ensure this modification is still backward compatible with past usages, numerics are verified by running the quantization unit test suite, which contains various observer tests. The following command executes the test suite, which also verifies the observer numerics:
`buck test //caffe2/test:quantization -- observer`
This modified observer script can be tested within the experiments for lower bit fake quantization. Please see the following diffs for reference.
- Single Fake Quantizer: D22337447
- Single Conv Layer: D22338532
Reviewed By: z-a-f
Differential Revision: D22427134
fbshipit-source-id: f405e633289322078b0f4a417f54b684adff2549
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41621
Per title. In some situation, deviceGuard constructor in mul_kernel_cuda segfaults, so construct deviceGuard conditionally only when first argument is scalar.
This does not root cause why deviceGuard constructor segfaults, so the issue might come back.
Test Plan: pytorch oss CI
Reviewed By: jianyuh
Differential Revision: D22616460
fbshipit-source-id: b91bbe55c6eb0bbe80b8d6a61c41f09288752658
Summary:
* Add EnumType and AnyEnumType as first-class jit type
* Add Enum-typed IValue
* Enhanced aten::eq to support Enum
Supported:
Enum-typed function targuments
using Enum type and comparing them
TODO:
Add PyThon sugared value for Enum
Support getting name/value attrs of enums
Support Enum-typed return values
Support enum values of different types in same Enum class
Support serialization and deserialization
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41390
Reviewed By: eellison
Differential Revision: D22524388
Pulled By: gmagogsfm
fbshipit-source-id: 1627154a64e752d8457cd53270f3d14aea4b1150
Summary:
- Removes outdated language like "BoolTensor"
- Consistently labels keyword arguments, like out
- Uses a more natural string to describe their return type
- A few bonus fixes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41626
Reviewed By: ngimel
Differential Revision: D22617322
Pulled By: mruberry
fbshipit-source-id: 03cc3562b78a07ed30bd1dc7936d7a4f4e31f01d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37587
Lifting RecordFunction up into the dispatcher code
Test Plan: Imported from OSS
Differential Revision: D21374246
fbshipit-source-id: 19f9c1719e6fd3990e451c5bbd771121e91128f7
Summary:
https://github.com/pytorch/pytorch/issues/38349
mruberry
Not entirely sure if all the changes are necessary in how functions are added to Pytorch.
Should it throw an error when called with a non-complex tensor? Numpy allows non-complex arrays in its imag() function which is used in its isreal() function but Pytorch's imag() throws an error for non-complex arrays.
Where does assertONNX() get its expected output to compare to?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41298
Reviewed By: ngimel
Differential Revision: D22610500
Pulled By: mruberry
fbshipit-source-id: 817d61f8b1c3670788b81690636bd41335788439
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41578
A new op aten::gcd(Tensor...) was added while the duplicated op name check was disabled. It's not a prime op, but it has the same name with one prime op aten::gcd(int, int).
It will be safer to enforce all prim ops have overload name, even there is no duplicated name right now. People may add tensor ops without overload name in the future.
This diff added the overload name for all ops defined using "DEFINE_INT_OP".
```
aten::__and__
aten::__or__
aten::__xor__
aten::__lshift__
aten::__rshift__
aten::__round_to_zero_floordiv
aten::gcd
```
Test Plan: run full JIT predictor
Reviewed By: iseeyuan
Differential Revision: D22593689
fbshipit-source-id: b3335d356a774d33450a09d0a43ff947197f9b8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41606
The previous diff (D22220798 (59294fbbb9) and D22220797) was recently reverted (D22492356 (28291d3cf8), D22492355) because of a bug associated with the op AsyncIf. The AsyncIf op has net_defs as args and the SSA rewriting didn't take that into account. It has a special path for the op If, but not for AsyncIf. Several changes I made to fix the bug:
1) Add op AsyncIf to the special path for If op in SSA rewriting
2) clear inputs/outputs of the netdefs that are args in If/AsyncIf ops because they're no longer valid
3) revert renamed inputs/outputs in the arg netdefs that are in the external_outputs in the parent netdef
2) and 3) are existing bugs in the `SsaRewrite` function that were just never exposed before.
The algorithm for `RemoveOpsByType` is the same as in my previous diff D22220798 (59294fbbb9). The only new changes in this diff are in `onnx::SsaRewrite` and a few newly added unit tests.
(Note: this ignores all push blocking failures!)
Reviewed By: yinghai
Differential Revision: D22588652
fbshipit-source-id: ebb68ecd1662ea2bae14d4be8f61a75cd8b7e3e6
Summary:
Leave undefined tensors / None returned from custom backward functions as undefined/None instead of creating a tensor full of zeros. This change improves performance in some cases.
**This is BC-Breaking:** Custom backward functions that return None will now see it potentially being propagated all the way up to AccumulateGrad nodes. Potential impact is that .grad field of leaf tensors as well as the result of autograd.grad may be undefined/None where it used to be a tensor full of zeros. Also, autograd.grad may raise an error, if so, consider using allow_unused=True ([see doc](https://pytorch.org/docs/stable/autograd.html?highlight=autograd%20grad#torch.autograd.grad)) if it applies to your case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41490
Reviewed By: albanD
Differential Revision: D22578241
Pulled By: heitorschueroff
fbshipit-source-id: f4966f4cb520069294f8c5c1691eeea799cc0abe
Summary:
lcm was missing an abs. This adds it plus extends the test for NumPy compliance. Also includes a few doc fixes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41552
Reviewed By: ngimel
Differential Revision: D22580997
Pulled By: mruberry
fbshipit-source-id: 5ce1db56f88df4355427e1b682fcf8877458ff4e
Summary:
Previously we did not link against amdhip64 (roughly equivalent to cudart). Apparently, the recent RTDL_GLOBAL fixes prevent the extensions from finding the symbols needed for launching kernels.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41257
Reviewed By: zou3519
Differential Revision: D22573288
Pulled By: ezyang
fbshipit-source-id: 89f9329b2097df26785e2f67e236d60984d40fdd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40474
These constants are unnecessary since there is an enum, and we can add
the size at the end of the enum and it will be equal to the list size. I
believe that this is the typical pattern used to represent enum sizes.
ghstack-source-id: 107969012
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D22147754
fbshipit-source-id: 7064a897a07f9104da5953c2f87b58179df8ea84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41577
* Remove skipping test
* Use fma_avx_emulation
* Increase test examples to 100
(Note: this ignores all push blocking failures!)
Test Plan: Tests are covered in test_sls_8bit_nnpi.py
Reviewed By: hyuen
Differential Revision: D22585742
fbshipit-source-id: e1f62f47eb10b402b11893ffca7a6786e31daa79
Summary:
Changes in the ROCm runtime have improved hipEventRecord. The events no longer take ~4 usec to execute on the gpu stream, instead they appear instantaneous. If you record two events, with no other activity in between, then they will have the same timestamp and the elapsed duration will be 0.
The profiler uses hip/cuda event pairs to infer gpu execution times. It wraps functions whether they send work to the gpu or not. Functions that send no gpu work will show as having zero duration. Also they will show as running at the same time as neighboring functions. On a trace, all those functions combine into a 'call stack' that can be tens of functions tall (when indeed they should be sequential).
This patch suppresses recording the zero duration 'kernel' events, leaving only the CPU execution part. This means functions that do not use the GPU do not get an entry for how long they were using the GPU, which seams reasonable. This fixes the 'stacking' on traces. It also improves the signal to noise of the GPU trace beyond what was available previously.
This patch will not effect CUDA or legacy ROCm as those are not able to 'execute' eventRecord markers instantaneously.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41540
Reviewed By: zou3519
Differential Revision: D22597207
Pulled By: albanD
fbshipit-source-id: 5e89de2b6d53888db4f9dbcb91a94478cde2f525
Summary:
Before, inverse for division by scalar is calculated in the precision of the non-scalar operands, which can lead to underflow:
```
>>> x = torch.tensor([3388.]).half().to(0)
>>> scale = 524288.0
>>> x.div(scale)
tensor([0.], device='cuda:0', dtype=torch.float16)
>>> x.mul(1. / scale)
tensor([0.0065], device='cuda:0', dtype=torch.float16)
```
This PR makes results of multiplication by inverse and division the same.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41446
Reviewed By: ezyang
Differential Revision: D22542872
Pulled By: ngimel
fbshipit-source-id: b60e3244809573299c2c3030a006487a117606e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41507
These fields have always been a part of tensor types, this change just
makes them serializable through IR dumps.
Test Plan: Imported from OSS
Reviewed By: Krovatkin, ngimel
Differential Revision: D22563661
Pulled By: ZolotukhinM
fbshipit-source-id: f01aaa130b7e0005bf1ff21f65827fc24755b360
Summary:
Implementing the quantile operator similar to [numpy.quantile](https://numpy.org/devdocs/reference/generated/numpy.quantile.html).
For this implementation I'm reducing it to existing torch operators to get free CUDA implementation. It is more efficient to implement multiple quickselect algorithm instead of sorting but this can be addressed in a future PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39417
Reviewed By: mruberry
Differential Revision: D22525217
Pulled By: heitorschueroff
fbshipit-source-id: 27a8bb23feee24fab7f8c228119d19edbb6cea33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41575
Fixes https://github.com/pytorch/pytorch/issues/34294
This updates the C++ argument parser to correctly handle `TensorList` operands. I've also included a number of updates to the testing infrastructure, this is because we're now doing a much more careful job of testing the signatures of aten kernels, using the type information about the arguments as read in from `Declarations.yaml`. The changes to the tests are required because we're now only checking for `__torch_function__` attributes on `Tensor`, `Optional[Tensor]` and elements of `TensorList` operands, whereas before we were checking for `__torch_function__` on all operands, so the relatively simplistic approach the tests were using before -- assuming all positional arguments might be tensors -- doesn't work anymore. I now think that checking for `__torch_function__` on all operands was a mistake in the original design.
The updates to the signatures of the `lambda` functions are to handle this new, more stringent checking of signatures.
I also added override support for `torch.nn.functional.threshold` `torch.nn.functional.layer_norm`, which did not yet have python-level support.
Benchmarks are still WIP.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34725
Reviewed By: mruberry
Differential Revision: D22357738
Pulled By: ezyang
fbshipit-source-id: 0e7f4a58517867b2e3f193a0a8390e2ed294e1f3
Summary:
Assert in OptionalType::create for valid TypePtr to catch all uses, as well as in python resolver to propagate slightly more helpful error message.
Closes https://github.com/pytorch/pytorch/issues/40713.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41509
Reviewed By: suo
Differential Revision: D22563710
Pulled By: wconstab
fbshipit-source-id: ee6314b1694a55c1ba7c8251260ea120be148b17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41464
If input is int8 rowwise quantized, currently we cannot low it to Glow. And previously, we had some error when running with inbatch broadcast. The main issue is that Tile op doesn't support uint8_t type, which is very easily added here. However, this will result in non-ideal situation that we will leave Tile -> Fused8BitRowwiseQuantizedToFloat on host side, which probably hurt the memory bw a lot. Even we later add the support to Fused8BitRowwiseQuantizedToFloat in Glow, it's still not ideal because we are doing redudant compute on identical columns. So the solution here is to swap the order of Fused8BitRowwiseQuantizedToFloat and Tile to make it Tile -> Fused8BitRowwiseQuantizedToFloat. In this way, it will resolve the error we saw immediately. For the short term, we can still run Tile in card. And for longer term, things runs faster on card.
The optimization is a heuristic. If in the net, there isn't such pattern, inbatch broadcast will work as it was before.
(Note: this ignores all push blocking failures!)
Test Plan:
```
buck test caffe2/caffe2/opt/custom:in_batch_broadcast_test
```
Reviewed By: benjibc
Differential Revision: D22544162
fbshipit-source-id: b6dd36a5925a9c8103b80f034e7730a7a085a6ff
Summary:
Delete "nogpu" job since both "AVX" and "AVX2" jobs already act like one
Fix naming problem when NO_AVX_NO_AVX2 job and NO_AVX2 jobs were semantically identical, due to the following logic in test.sh:
```
if [[ "${BUILD_ENVIRONMENT}" == *-NO_AVX-* ]]; then
export ATEN_CPU_CAPABILITY=default
elif [[ "${BUILD_ENVIRONMENT}" == *-NO_AVX2-* ]]; then
export ATEN_CPU_CAPABILITY=avx
fi
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41565
Reviewed By: seemethere
Differential Revision: D22584743
Pulled By: malfet
fbshipit-source-id: 783cce60f35947b5d1e8b93901db36371ef78243
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41343
Currently caffe2.InitOpLibrary does the dll import uniliaterally. Instead if we make a lazy version and use it, then many pieces of code which do not need the caffe2urrenoperators get a lot faster.
One a real test, the import time went from 140s to 68s. 8s.
This also cleans up the algorithm slightly (although it makes a very minimal
difference), by parsing the list of operators once, rather than every time a
new operator is added, since we defer the RefreshCall until after we've
imported all the operators.
The key way we maintain safety, is that as soon as someone does an operation
which requires a operator (or could), we force importing of all available
operators.
Future work could include trying to identify which code is needed for which
operator and only import the needed ones. There may also be wins available by
playing with dlmopen (which opens within a namespace), or seeing if the dl
flags have an impact (I tried this and didn't see an impact, but dlmopen may
make it better).
Note that this was previously landed and reverted. The issue was that if a import failed and raised an exception, the specific library would not be removed from the lazy imports. This caused our tests which had libraries that failed to poison all other tests that ran after it. This has been fixed and a unit test has been added for this case (to help make it obvious what failed).
Test Plan:
I added a new test a lazy_dyndep_test.py (copied from all_compare_test.py).
I'm a little concerned that I don't see any explicit tests for dyndep, but this
should provide decent coverage.
I've added a specific test to handle the poisoning issues mentioned above, which caused the previous version to get reverted.
Differential Revision: D22506369
fbshipit-source-id: 7395df4778e8eb0220630c570360b99a7d60eb83
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/41405
Test Plan:
**Imported from GitHub: all checks have passed**
{F244195355}
**The Intern Builds & Tests have 127 success, 5 no signals, and 1 failure. Double check the failed test log file, the failure is result differences:**
- AssertionError: 0.435608434677124 != 0.4356083869934082
- AssertionError: 0.4393022060394287 != 0.4393021583557129
- AssertionError: 0.44707541465759276 != 0.44707536697387695
These are all very small numerical errors (within 0.0000001).
Reviewed By: malfet
Differential Revision: D22531486
Pulled By: threekindoms
fbshipit-source-id: 21543ec76bb9b502885b5146c8ba5ede719be9ff
Summary:
Add Conf.is_test_stage() method to avoid duplicating state in ['test', 'test1', 'test2'] throughout the code
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41553
Test Plan: Make sure that in modified config.yml ROCM tests jobs are assigned `pytorch/amd-gpu` resource class
Reviewed By: yns88
Differential Revision: D22580471
Pulled By: malfet
fbshipit-source-id: 514555f0c0ac94c807bf837ba209560055335587
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41515
add test in atest.cpp to cover logical_and_kernel, logical_or_kernel and logical_nor_kernel in Aten/native/cpu/BinaryOpsKernel.cpp
https://pxl.cl/1drmV
Test Plan: CI
Reviewed By: malfet
Differential Revision: D22565235
fbshipit-source-id: 7ad9fd8420d7fdd23fd9a703c75da212f72bde2c
Summary:
A small PR fixing some formatting in lcm, gcd, and the serialization note. Adds a note to lcm and gcd explaining behavior that is not always defined.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41526
Reviewed By: ngimel
Differential Revision: D22569341
Pulled By: mruberry
fbshipit-source-id: 5f5ff98c0831f65e82b991ef444a5cee8e3c8b5a
Summary:
Fix https://github.com/pytorch/pytorch/issues/32530
I used the next() function to generate samples one at a time. To compensate replacement=False, I added a variable called "sample_list" to RandomSampler for random permutation.
cc SsnL
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40026
Reviewed By: zhangguanheng66
Differential Revision: D22519869
Pulled By: ezyang
fbshipit-source-id: be65850025864d659a713b3bc461b25d6d0048a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41424
Adding alltoall to Gloo process group
Test Plan:
buck test caffe2/torch/lib/c10d:ProcessGroupGlooTest
Verified on TSC as well D22141532
Reviewed By: osalpekar
Differential Revision: D22451929
fbshipit-source-id: 695c4655c894c85229b16097fa63352ed04523ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41218
This test doesn't assert anything and was accidentally committed as
part of a larger diff a few months ago.
ghstack-source-id: 107882848
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D22469852
fbshipit-source-id: 0baa23da56b08200e16cf66df514566223dd9b15
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41217
Fixes this flaky test. Due to the possibility of callback
finishCreatingOwnerRRef running after request_callback has processed and
created the owner RRef, we could actually end up with 0 owners on the node,
since the callback removes from the owners_ map. In this case, shutdown is fine
since there are no owners. On the other hand, if the callback runs first, there
will be 1 owner which we will delete in shutdown when we detect it has no
forks. So either way, shutdown works fine and we don't need to enforce there to
be 1 owner.
ghstack-source-id: 107883497
Test Plan: Ran the test 500 times with TSAN.
Reviewed By: ezyang
Differential Revision: D22469806
fbshipit-source-id: 02290d6d5922f91a9e2d5ede21d1cf1c4598cb46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41265
This PR adds tests for the Async Work wait-level timeouts that were added in the previous PR
ghstack-source-id: 107835732
Test Plan: New tests are in this diff - Running on local machine and Sandcastle
Reviewed By: jiayisuse
Differential Revision: D22470084
fbshipit-source-id: 5552e384d384962e359c5f665e6572df03b6aa63
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40948
Add work-level timeouts to ProcessGroupGloo. This uses the timeout support in `waitSend` and `waitRecv` functions from Gloo's `unbound_buffer` construct.
ghstack-source-id: 107835738
Test Plan: Tests are in the last PR in this stack
Reviewed By: jiayisuse
Differential Revision: D22173763
fbshipit-source-id: e0493231a23033464708ee2bc0e295d2b087a1c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40947
This PR adds tests for work-level timeouts in WorkNCCL objects. We kick off an allgather operation that waits for 1000ms before actually starting computation. We wait on completion of this allgather op with a timeout of 250ms, expecting the operation to timeout and throw a runtime error.
ghstack-source-id: 107835734
Test Plan: This diff added tests - checking CI/Sandcastle for correctness. These are NCCL tests so they require at least 2 GPUs to run.
Reviewed By: jiayisuse
Differential Revision: D22173101
fbshipit-source-id: 8595e4b67662cef781b20ced0befdcc53d157c39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40946
Adds timeout to ProcessGroupNCCL::wait. Currently, WorkNCCL objects already have a timeout set during ProcessGroupNCCL construction. The new wait function will override the existing timeout with the user-defined timeout if one is provided. Timed out operations result in NCCL communicators being aborted and an exception being thrown.
ghstack-source-id: 107835739
Test Plan: Test added to `ProcessGroupNCCLTest` in the next PR in this stack.
Reviewed By: jiayisuse
Differential Revision: D22127898
fbshipit-source-id: 543964855ac5b41e464b2df4bb6c211ef053e73b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40944
This stack adds Work-level timeout for blocking wait.
This PR just changes the API to accept a default wait arg for the wait function in each ProcessGroup backend. The ProcessGroup superclass correctly waits for the given timeout by changing the CV wait to wait_for.
Closes: https://github.com/pytorch/pytorch/issues/37571
ghstack-source-id: 107835735
Test Plan: Tests in 4th PR in this stack
Reviewed By: jiayisuse
Differential Revision: D22107135
fbshipit-source-id: b38c07cb5e79e6c86c205e580336e7918ed96501
Summary:
The test was always running on the CPU. This actually caused it to throw an error on non-MKL builds, since the CUDA test (which ran on the CPU) tried to execute but the test requires MKL (a requirement only checked for the CPU variant of the test).
Fixes https://github.com/pytorch/pytorch/issues/41402.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41523
Reviewed By: ngimel
Differential Revision: D22569344
Pulled By: mruberry
fbshipit-source-id: e9908c0ed4b5e7b18cc7608879c6213fbf787da2
Summary:
This test function is confusing since our `assertEqual` behavior allows for tolerance to be specified, and this is a redundant mechanism.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41514
Reviewed By: ngimel
Differential Revision: D22569348
Pulled By: mruberry
fbshipit-source-id: 2b2ff8aaa9625a51207941dfee8e07786181fe9f
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 73ea1f5828
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40332
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: gchanan, yns88
Differential Revision: D22150737
fbshipit-source-id: fe7e6787adef9e2fedee5d1a0a1e57bc4760b88c
Summary:
Update the API to access grad in cpp to avoid unexpected thread safety issues.
In particular, with the current API, a check like `t.grad().defined()` is not thread safe.
- This introduces `t.mutable_grad()` that should be used when getting a mutable version of the saved gradient. This function is **not** thread safe.
- The `Tensor& grad()` API is now removed. We could not do a deprecation cycle as most of our call side use non-const Tensors that use the non-const overload. This would lead to most calls hitting the warning. This would be too verbose for all the users.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40887
Reviewed By: ezyang
Differential Revision: D22343932
Pulled By: albanD
fbshipit-source-id: d5eb909bb743bc20caaf2098196e18ca4110c5d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41505
fix the dequantization to match the fixes from quantization
Test Plan:
test is not conclusive, since only comparing emulation with reference collected from Amy's run
running an evaluation workflow at the moment
Reviewed By: venkatacrc
Differential Revision: D22558092
fbshipit-source-id: 3ff00ea15eac76007e194659c3b4949f07ff02a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41494
revert back to the changes from amylittleyang to make quantization work
Test Plan:
ran against a dump from ctr_instagram, and verified that:
-nnpi and fakelowp match bitwise
-nnpi is different at most by 1 vs fbgemm, most likely due to the type of
rounding
Reviewed By: venkatacrc
Differential Revision: D22555276
fbshipit-source-id: 7074521d181f15ef6270985bb71c4b44d25d1c30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41476
deleted this test by default, re-adding it in its own file to make it
more explicit
Test Plan: ran the test
Reviewed By: yinghai
Differential Revision: D22550217
fbshipit-source-id: 758e279b2bab3b23452a3d0ce75fb366f7afb7be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41461
capacity is misleading, and we have many wrong uses internally. Let's rename to nbytes to avoid the confusion in future. Ultimately, we could remove this parameter if possible.
So far I haven't seen any case this capacity is necessary.
Test Plan: oss ci
Differential Revision: D22544189
fbshipit-source-id: f310627f2ab8f4ebb294e0dd5eabc380926991eb
Summary:
Declaring GLOG_ constants in google namespace causes a conflict in C++ project that uses GLOG and links with LibPyTorch compiled without GLOG.
For example, see https://github.com/facebookresearch/ReAgent/issues/288
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41504
Reviewed By: kaiwenw
Differential Revision: D22564308
Pulled By: malfet
fbshipit-source-id: 2167bd2c6124bd14a67cc0a1360521d3c375e3c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41430
To avoid duplication at compile time, modularize the common autograd files used by both mobile and full-jit.
ghstack-source-id: 107742889
Test Plan: CI
Reviewed By: kwanmacher
Differential Revision: D22531358
fbshipit-source-id: 554f10be89b7ed59c9bde13387a0e1b08000c116
Summary:
The contiguity preprocessing was mistakenly removed in
cd48fb503088af2c00884f1619db571fffbcdafa . It causes erroneous output
when the output tensor is not contiguous. Here we restore this
preprocessing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41286
Reviewed By: zou3519
Differential Revision: D22550822
Pulled By: ezyang
fbshipit-source-id: ebad4e2ba83d2d808e3f958d4adc9a5513a95bec
Summary:
Doc update intended to clarify and expand our current serialization behavior, including explaining the difference between torch.save/torch.load, torch.nn.Module.state_dict/torch.nn.Module.load_state_dict, and torch.jit.save/torch.jit.load. Also explains, for the time, when historic serialized Torchscript behavior is preserved and our recommendation for preserving behavior (using the same PyTorch version to consume a model as produced it).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41395
Reviewed By: ngimel
Differential Revision: D22560538
Pulled By: mruberry
fbshipit-source-id: dbc2f1bb92ab61ff2eca4888febc21f7dda76ba1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41429
This diff contains the benchmark test to evaluate the speed of executing the learnable fake quantization operator, both in the forward path and the backward path, with respect to both per tensor and per channel usages.
Test Plan:
Inside the path `torch/benchmarks/operator_benchmark` (The root directory will be `caffe2` inside `fbcode` if working on a devvm):
- On a devvm, run the command `buck run pt:fake_quantize_learnable_test`
- On a personal laptop, run the command `python3 -m pt.fake_quantize_learnable_test`
Benchmark Results (Locally on CPU):
Each sample has dimensions **3x256x256**; Each batch has 16 samples (`N=16`)
- Per Tensor Forward: 0.023688 sec/sample
- Per Tensor Backward: 0.165926 sec/sample
- Per Channel Forward: 0.040432 sec / sample
- Per Channel Backward: 0.173528 sec / sample
Reviewed By: vkuzo
Differential Revision: D22535252
fbshipit-source-id: e8e953ff2de2107c6f2dde4c8d5627bdea67ef7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36893
Adding an end to end test for running a simple training loop in C++
for the distributed RPC framework.
The goal of this change is to enable LeakSanitizer and potentially catch memory
leaks in the Future. Enabling LSAN with python multiprocessing is tricky and we
haven't found a solution for this. As a result, adding a C++ test that triggers
most of the critical codepaths would be good for now.
As an example, this unit test would've caught the memory leak fixed by:
https://github.com/pytorch/pytorch/pull/31030
ghstack-source-id: 107781167
Test Plan:
1) Verify the test catches memory leaks.
2) waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D21112208
fbshipit-source-id: 4eb2a6b409253108f6b6e14352e593d250c7a64d
Summary:
This pulls the following merge requests from CMake upstream:
- https://gitlab.kitware.com/cmake/cmake/-/merge_requests/4979
- https://gitlab.kitware.com/cmake/cmake/-/merge_requests/4991
The above two merge requests improve the Ampere build:
- If `TORCH_CUDA_ARCH_LIST` is not set, it can now automatically pickup 8.0 as its part of its default value
- If `TORCH_CUDA_ARCH_LIST=Ampere`, it no longer fails with `Unknown CUDA Architecture Name Ampere in CUDA_SELECT_NVCC_ARCH_FLAGS`
Codes related to architecture < 3.5 are manually removed because PyTorch no longer supports it.
cc: ngimel ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41133
Reviewed By: malfet
Differential Revision: D22540547
Pulled By: ezyang
fbshipit-source-id: 6e040f4054ef04f18ebb7513497905886a375632
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41262
In this diff, implementation is provided to support the GPU kernel running the learnable fake quantize per tensor kernels.
Test Plan: On a devvm, run `buck test //caffe2/test:quantization -- learnable` to test both the forward and backward for the learnable per tensor fake quantize kernels. The test will test the `cuda` version if a gpu is available.
Reviewed By: vkuzo
Differential Revision: D22478832
fbshipit-source-id: 2731bd8b57bc83416790f6d65ef42d450183873c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41127
In this diff, implementation is provided to support the GPU kernel running the learnable fake quantize per tensor kernels.
Test Plan: On a devvm, run `buck test //caffe2/test:quantization -- learnable` to test both the forward and backward for the learnable per tensor fake quantize kernels. The test will test the `cuda` version if a gpu is available.
Reviewed By: z-a-f
Differential Revision: D22435037
fbshipit-source-id: 515afde13dd224d21fd47fb7cb027ee8d704cbdd
Summary: Adding epsilon input argument to the Logit Op
Test Plan: Added test_logit test case.
Reviewed By: hyuen
Differential Revision: D22537133
fbshipit-source-id: d6f89afd1589fda99f09550a9d1b850cfc0b9ee1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41293
Add new operators that does quantize and packing for 8 bit and 4 bit embedding bag operators.
This is an initial change to help unblock testing. This will be follwed by adding graph mode passes to enable quantization of embedding_bag module
Note to reviewers: Future PRs will replace this op with a separate quantize and pack operator and add support for floating point scale and zero point.
Test Plan:
python test/test_quantization.py TestQuantizedEmbeddingBag
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D22506700
fbshipit-source-id: 090cc85a8f56da417e4b7e45818ea987ae97ca8a
Summary:
Add support for including pytorch via an add_subdirectory()
This requires using PROJECT_* instead of CMAKE_* which refer to
the top-most project including pytorch.
TEST=add_subdirectory() into a pytorch checkout and build.
There are still some hardcoded references to TORCH_SRC_DIR, I will
fix in a follow on commit. For now you can create a symlink to
<pytorch>/torch/ in your project.
Change-Id: Ic2a8aec3b08f64e2c23d9e79db83f14a0a896abc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41387
Reviewed By: zhangguanheng66
Differential Revision: D22539944
Pulled By: ezyang
fbshipit-source-id: b7e9631021938255f0a6ea897a7abb061759093d
Summary:
The test asserts that the stream is "ready" but doesn't wait for the
event to be "executed" which makes it fail on some platforms where the
`query` call occurs "soon enough".
Fixes https://github.com/pytorch/pytorch/issues/38807
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41398
Reviewed By: zhangguanheng66
Differential Revision: D22540012
Pulled By: ezyang
fbshipit-source-id: 6f56d951e48133ce4f6a9a54534298b7d2877c80
Summary:
Related to https://github.com/pytorch/pytorch/issues/41368
These benchmarks support CUDA already so there is no reason for it not to be in the benchmark config.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41438
Reviewed By: zhangguanheng66
Differential Revision: D22540756
Pulled By: ezyang
fbshipit-source-id: 621eceff37377c1ab06ff7483b39fc00dc34bd46
Summary: Adding shape inference for SpraseToDense. Proposal impl of shape inference only works when data_to_infer_dim is given, otherwise SpraseToDense output dimension depends on max value of input tensor
Test Plan:
buck test //caffe2/caffe2/python:sparse_to_dense_test
buck test //caffe2/caffe2/python:hypothesis_test -- test_sparse_to_dense
Dper3 Changes:
f204594813
buck test dper3/dper3_models/ads_ranking/model_impl/sparse_nn/tests:sparse_nn_lib_test
Reviewed By: zhongyx12, ChunliF
Differential Revision: D22479511
fbshipit-source-id: 8983a9baea8853deec53ad6f795c874c3fb93de0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41452
The model exported from online training workflow with int8 quantization contains FCs with 4 inputs. The extra input is the quant_param blob. This diff is to adjust the bound_shape_inferencer to get shape info for the quant_param input.
Test Plan:
```
buck test caffe2/caffe2/opt:bound_shape_inference_test
```
Reviewed By: anurag16
Differential Revision: D22543215
fbshipit-source-id: 0977fca06630e279d47292e6b44f3d8180a767a5
Summary:
1. Support SparseAdagradFusedWithSparseLengthsMeanGradient and RowWiseSparseAdagradFusedWithSparseLengthsMeanGradient on CPU and GPU
2. Add the dedup implementation of fused RowWiseAdagrad op on GPUs for mean pooling
Reviewed By: xianjiec
Differential Revision: D22165603
fbshipit-source-id: 743fa55ed5893c34bc6406ddfbbbb347b88091d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41414
This diff exports replaceAllUsesAfterNodeWith to PythonAPI.
Test Plan: Tested locally. Please let me know if there is a set of unit tests to be passed outside of the default ones triggered by Sandcastle.
Reviewed By: soumith
Differential Revision: D22523211
fbshipit-source-id: 3f075bafa6208ada462abc57d495c15179a6e53d
Summary:
remove layernorm templates and make them float since that's the only variant
minor fixes in logging and testing
Test Plan: ran the test
Reviewed By: venkatacrc
Differential Revision: D22527359
fbshipit-source-id: d6eec362a6e88e1c12fddf820ae629ede13fb2b8
Summary:
BCELoss currently uses different broadcasting semantics than numpy. Since previous versions of PyTorch have thrown a warning in these cases telling the user that input sizes should match, and since the CUDA and CPU results differ when sizes do not match, it makes sense to upgrade the size mismatch warning to an error.
We can consider supporting numpy broadcasting semantics in BCELoss in the future if needed.
Closes https://github.com/pytorch/pytorch/issues/40023
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41426
Reviewed By: zou3519
Differential Revision: D22540841
Pulled By: ezyang
fbshipit-source-id: 6c6d94c78fa0ae30ebe385d05a9e3501a42b3652
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41287
Profiler tests that test profiling with builtin functions and `test_callback_simple` test has been broken for a while. This diff fixes that by preferring c10 ops to non-c10 ops in our operation matching logic.
The result of this is that these ops go through the c10 dispatch and thus have profiling enabled. For `test_callback_simple` this results in the effect that we choose `aten::add.Tensor` over `aten::add.Int` which fixes the type issue.
Test Plan:
Ensured that the tests are no longer flaky by running them a bunch
of times.
Reviewed By: vincentqb
Differential Revision: D22489197
fbshipit-source-id: 8452b93e4d45703453f77d968350c0d32f3f63fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41202
This commit fixes dead stores in JIT surfaced by the Quality Analyzer.
Test Plan: Continuous integration.
Reviewed By: jerryzh168
Differential Revision: D22461492
fbshipit-source-id: c587328f952054fb9449848e90b7d28a20aed4af
Summary: The device attribute in the op benchmark can only include 'cpu' or 'cuda'. So adding a check in this diff.
Test Plan: buck run caffe2/benchmarks/operator_benchmark:benchmark_all_test -- --warmup_iterations 1 --iterations 1
Reviewed By: ngimel
Differential Revision: D22538252
fbshipit-source-id: 3e5af72221fc056b8d867321ad22e35a2557b8c3
Summary: Change the device config in qobserver test to a string to honor --device flag.
Test Plan: buck run caffe2/benchmarks/operator_benchmark/pt:qobserver_test -- --iterations 1 --device cpu
Reviewed By: ngimel
Differential Revision: D22536379
fbshipit-source-id: 8926b2393be1f52f9183f8205959a3ff18e3ed2a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41312
I was hoping that exhale had gotten incremental recompilation
in its latest version, but experimentally this does not seem
to have been the case. Still, I had gotten the whole shebang
to be working on the latest version of these packages, so might
as well land the upgrade. There was one bug in Optional.h that
I had to fix; see the cited bug report.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D22526349
Pulled By: ezyang
fbshipit-source-id: d4169c2f48ebd8dfd8a593cc8cd232224d008ae9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41354
The nightly pipeline has the potential to be flaky and thus the html
pages have the potential not to be updated.
This should actually be done as an automatic lambda job that runs
whenever the S3 bucket updates but this is intermediate step in order to
get there.
Closes https://github.com/pytorch/pytorch/issues/40998
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D22530283
Pulled By: seemethere
fbshipit-source-id: 0d80b7751ede83e6dd466690cc0a0ded68f59c5d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/36403
Copy-paste of the issue description:
* Escape hatch: Introduce unsafe_* version of the three functions above that have the current behavior (outputs not tracked as views). The documentation will explain in detail why they are unsafe and when it is safe to use them. (basically, only the outputs OR the input can be modified inplace but not both. Otherwise, you will get wrong gradients).
* Deprecation: Use the CreationMeta on views to track views created by these three ops and throw warning when any of the views is modified inplace saying that this is deprecated and will raise an error soon. For users that really need to modify these views inplace, they should look at the doc of the unsafe_* version to make sure their usecase is valid:
* If it is not, then pytorch is computing wrong gradients for their use case and they should not do inplace anymore.
* If it is, then they can use the unsafe_* version to keep the current behavior.
* Removal: Use the CreationMeta on view to prevent any inplace on these views (like we do for all other views coming from multi-output Nodes). The users will still be able to use the unsafe_ versions if they really need to do this.
Note about BC-breaking:
- This PR changes the behavior of the regular function by making them return proper views now. This is a modification that the user will be able to see.
- We skip all the view logic for these views and so the code should behave the same as before (except the change in the `._is_view()` value).
- Even though the view logic is not performed, we do raise deprecation warnings for the cases where doing these ops would throw an error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39299
Differential Revision: D22432885
Pulled By: albanD
fbshipit-source-id: 324aef091b32ce69dd067fe9b13a3f17d85d0f12
Summary:
Fixes the overhead reported by ngimel in https://github.com/pytorch/pytorch/pull/40927#issuecomment-657709646
As it turns out, `Tensor.size(n)` has more overhead than `Tensor.sizes()[n]`. Since addmm does a lot of introspection of the input matrix sizes and strides, this added up to a noticeable (~1 us) constant time overhead.
With this change, a 1x1 matmul takes 2.85 us on my machine compared to 2.90 us on pytorch 1.5.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41374
Reviewed By: ailzhang
Differential Revision: D22519924
Pulled By: ngimel
fbshipit-source-id: b29504bee7de79ce42e5e50f91523dde42b073b7
Summary:
nccl tests and parallelize_bmuf_distributed test are failing on rocm3.5.1. Skipping these tests to upgrade the CI to rocm3.5.1
jeffdaily sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41409
Reviewed By: orionr
Differential Revision: D22528928
Pulled By: seemethere
fbshipit-source-id: 928196b7a62a441d391e69f54b278313ecc75d77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41145
**Summary**
This commit adds out-of-source-tree tests for `to_backend`. These tests check
that a Module can be lowered to a backend, exported, loaded (in both
Python and C++) and executed.
**Fixes**
This commit fixes#40067.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D22510076
Pulled By: SplitInfinity
fbshipit-source-id: f65964ef3092a095740f06636ed5b1eb0884492d
Summary:
Closes https://github.com/pytorch/pytorch/issues/36977
This avoid the division by zero that was causing NaNs to appear in the output. `AvgPooling2d` and `AvgPooling3d` both had this issue on CPU and CUDA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41368
Reviewed By: ailzhang
Differential Revision: D22520013
Pulled By: ezyang
fbshipit-source-id: 3ece7829f858f5bc17c2c1d905266ac510f11194
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41270
The Smart Keyboard model for Oculus requires operators previously not in the lite interpreter: aten::exp (for floats), aten::ord, aten::lower, aten::__contains__.str_list, aten::slice.str, aten::strip, aten::split.str, and aten::__getitem__.str.
Test Plan:
Verify smart keyboard model can be used:
Check out next diff in stack and follow test instructions there
Reviewed By: iseeyuan
Differential Revision: D22289812
fbshipit-source-id: df574d5af4d4fafb40f0e209b66a93fe02d83020
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40179
- Pass no-psabi to shut up GCC about # Suppress "The ABI for passing
parameters with 64-byte alignment has changed in GCC 4.6"
- Fix use of deprecated data() accessor (and minor optimization: hoist
accessor out of loop)
- Undeprecate NetDef.num_workers, no one is serious about fixing these
- Suppress warnings about deprecated pthreadpool types
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22234138
Pulled By: ezyang
fbshipit-source-id: 6a1601b6d7551a7e6487a44ae65b19acdcb7b849
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41330
`torch.cuda.check_error` is annotated as taking an `int` as argument but when running `torch.cuda.check_error(34)` one would get:
```
TypeError: cudaGetErrorString(): incompatible function arguments. The following argument types are supported:
1. (arg0: torch._C._cudart.cudaError) -> str
Invoked with: 34
```
Even if one explicitly casted the argument, running `torch.cuda.check_error(torch._C._cudart.cudaError(34))` would give:
```
AttributeError: 'str' object has no attribute 'decode'
```
This PR fixes both issues (thus allowing `check_error` to be called with a un-casted int) and adds a test.
ghstack-source-id: 107628709
Test Plan: Unit tests
Reviewed By: ezyang
Differential Revision: D22500549
fbshipit-source-id: 9170c1e466dd554d471e928b26eb472a712da9e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41198https://github.com/pytorch/pytorch/pull/39611 unified signatures of some ops taking TensorOptions arguments by making them optional.
That has FC implications but only for models writting with a PyTorch version after that version (see explanation in description of that PR).
However, it also changed the default from `pin_memory=False` to `pin_memory=None`, which actually breaks FC for preexisting models too if they're re-exported with a newer PyTorch,
because we materialize default values when exporting. This is bad.
This PR reverts that particular part of https://github.com/pytorch/pytorch/pull/39611 to revert the FC breakage.
ghstack-source-id: 107475024
Test Plan: waitforsandcastle
Reviewed By: bhosmer
Differential Revision: D22461661
fbshipit-source-id: ba2776267c3bba97439df66ecb50be7c1971d20d
Summary: add logit and swish to this list
Test Plan: f203925461
Reviewed By: amylittleyang
Differential Revision: D22506814
fbshipit-source-id: b449e4ea16354cb76915adb01cf317cffb494733
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41297
GH issue: https://github.com/pytorch/pytorch/issues/40105
Add a helper function to DDP to print out all relevant env vars for debugging
Test Plan:
test through unittest, example output:
---
env:RANK=3
env:LOCAL_RANK=N/A
env:WORLD_SIZE=N/A
env:MASTER_PORT=N/A
env:MASTER_ADDR=N/A
env:CUDA_VISIBLE_DEVICES=N/A
env:GLOO_SOCKET_IFNAME=N/A
env:GLOO_DEVICE_TRANSPORT=N/A
env:NCCL_SOCKET_IFNAME=N/A
env:NCCL_BLOCKING_WAIT=N/A
...
---
Reviewed By: mrshenli
Differential Revision: D22490486
fbshipit-source-id: 5dc7d2a18111e5a5a12a1b724d90eda5d35acd1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41195
`BLAS_F2C` is set in `THGeneral.h`.
`sdot` redefined with double return type in the case that `BLAS_F2C` is set and `BLAS_USE_CBLAS_DOT` is not.
Test Plan: CircleCI green, ovrsource green
Reviewed By: malfet
Differential Revision: D22460253
fbshipit-source-id: 75f17b3e47da0ed33fcadc2843a57ad616f27fb5
Summary:
1. While do convert() preserve module's **pre and post forward** hooks
2. While do fusion preserve only module's **pre forward** hooks (because after fusion output no longer the same)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37233
Differential Revision: D22425141
Pulled By: jerryzh168
fbshipit-source-id: e69b81821d507dcd110d2ff3594ba94b9593c8da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41215
To unblock int8 model productization on accelerators, we need the shape and type info for all the blobs after int8 quantization. This diff added shape inference functions for int8 quantization related ops.
Test Plan:
```
buck test caffe2/caffe2/quantization/server:int8_gen_quant_params_test
buck test caffe2/caffe2/quantization/server:fully_connected_dnnlowp_op_test
```
Reviewed By: hx89
Differential Revision: D22467487
fbshipit-source-id: 8298abb0df3457fcb15df81f423f557c1a11f530
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37176
The non-deprecated user-facing interface to these ops (F.interpolate)
has a good interface: output size and scale are both specified as
a scalar or list, and exactly one must be present. These aten ops
have an older, clunkier interface where output size is required and
scales are specified as separate optional scalars per dimension.
This change adds new overloads to the aten ops that match the interface
of interpolate. The plan is to eventually remove the old overloads,
resulting in roughly net-zero code added. I also believe it is possible
to push this interface down further, eliminating multiple optional<double>
arguments, and simplifying the implementations.
The rollout plan is to land this, wait for a reasonable interval for
forwards-compatibility (maybe 1 week?), land the change that updates
interpolate to call these overloads, wait for a reasonable interval
for backwards-compatibility (maybe 6 months?), then remove the old
overloads.
This diff does not add the `.out` variants of the ops because they
are not currently accessible through any user-facing API.
ghstack-source-id: 106938113
Test Plan:
test_nn covers these ops fairly well, so that should prevent this diff
from breaking anything on its own.
test_nn on the next diff in the stack actually uses these new overloads,
so that should validate that they are actually correct.
Differential Revision: D21209989
fbshipit-source-id: 2b74d230401f071364eb05e138cdaa55279cfe91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37175
ghstack-source-id: 106938114
Test Plan: Upcoming diffs use this for upsampling.
Differential Revision: D21209994
fbshipit-source-id: 1a71c07e45e28772a2bbe450b68280dcc0fe2def
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41313
This diff backs out the backout diff. The failure was due to C++ `or`
not being supported in MSVC. This is now replaced with ||
Original commit changeset: fc7f3f8c968d
Test Plan: Existing unit tests, check github CI.
Reviewed By: malfet
Differential Revision: D22494777
fbshipit-source-id: 3271288919dc3a6bfb82508ab9d021edc910ae45
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41268
We also want nvidia runtime packages to get installed when the
BUILD_ENVIRONMENT also includes "*cu*"
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22505885
Pulled By: seemethere
fbshipit-source-id: 4d8e70ed8aed9c6fd1828bc13cf7d5b0f8f50a0a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41305
added a warning message when layernorm under/overflows, which is what
nnpi does, reducing the frequency of the logging to every 1000
Test Plan: compilation
Reviewed By: yinghai
Differential Revision: D22492726
fbshipit-source-id: 9343beeae6e65bf3846c6b3d2edd2a08dac85ed6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41315
We should pass the number of indices but not embedding size in SparseAdagrad fused PyTorch operator
Reviewed By: jianyuh
Differential Revision: D22495422
fbshipit-source-id: ec5d3a5c9547fcd8f95106d912b71888217a5af0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41037
This diff contains the core implementation for the fake quantizer per channel kernel that supports back propagation on the scale and zero point.
Test Plan:
On a devvm, use:
- `buck test //caffe2/test:quantization -- learnable_forward_per_channel`
- `buck test //caffe2/test:quantization -- learnable_backward_per_channel`
Reviewed By: z-a-f
Differential Revision: D22395665
fbshipit-source-id: 280c2405d04adfeda9fb9cfc94d89e8d868e0d41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41029
This diff contains the core implementation for the fake quantizer per tensor kernel that supports back propagation on the scale and zero point.
Test Plan:
On a devvm, use:
- `buck test //caffe2/test:quantization -- learnable_forward_per_tensor`
- `buck test //caffe2/test:quantization -- learnable_backward_per_tensor`
Reviewed By: z-a-f
Differential Revision: D22394145
fbshipit-source-id: f6748b635b86679aa9174a8065e6be5e20a95d81
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41303
the error came from I0710 18:02:48.025024 1780875 NNPIOptions.cpp:49]
[NNPI_LOG][D] [KS] convert_base_kernel_ivp.cpp(524): Output Scale 108240.101562
is out of valid range +-(Min 0.000061 Max 65504.000000)!!!
Seems like the weights we are using are too small, thus generating scaling
factors out of the range of fp16 (>65k). I am tentatively increasing this
factor to a higher value to avoid this. (10x bigger)
Also increased max_examples to 100
Test Plan: ran this test
Reviewed By: yinghai
Differential Revision: D22492481
fbshipit-source-id: c0f9e59b0e70895ab787868ef1d87e6e80106554
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41299
When using `cub::DeviceRadixSort::SortPairs` (https://nvlabs.github.io/cub/structcub_1_1_device_radix_sort.html), the `end_bit` argument, or the most-significant bit index (exclusive) needed for key comparison, should be passed with `int(log2(float(num_rows)) + 1)` instead of `int(log2(float(num_indice)) + 1)`. This is because all the values in indices array are guaranteed to be less than num_rows (hash_size), not num_indices. Thanks ngimel for pointing this point and thanks malfet for quickly fixing the log2() compilation issues.
Note:
An optional bit subrange [begin_bit, end_bit) of differentiating key bits can be specified. This can reduce overall sorting overhead and yield a corresponding performance improvement.
Test Plan:
```
buck test mode/dev-nosan //caffe2/caffe2/fb/net_transforms/tests:fuse_sparse_ops_test -- 'test_fuse_sparse_adagrad_with_sparse_lengths_sum_gradient \(caffe2\.caffe2\.fb\.net_transforms\.tests\.fuse_sparse_ops_test\.TestFuseSparseOps\)' --print-passing-details
```
Reviewed By: malfet
Differential Revision: D22491662
fbshipit-source-id: 4fdabe86244c948af6244f9bd91712844bf1dec1
Summary:
It doesn't do a good job of checking BLAS library capabilities, so hardcode the undef of BLAS_F2C
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41285
Differential Revision: D22489781
Pulled By: malfet
fbshipit-source-id: 13a14f31e08d7f9ded49731e4fd23663bac75cd2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41146
**Summary**
This commit adds support for using `Modules` that have been lowered as
submodules in `ScriptModules`.
**Test Plan**
This commit adds execution and save/load tests to test_backends.py for
backend-lowered submodules.
**Fixes**
This commit fixes#40069.
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D22459543
Pulled By: SplitInfinity
fbshipit-source-id: 02e0c0ccdce26c671ade30a34aca3e99bcdc5ba7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41272
Implicit casting from int to float is resulting in vec256_test build failure
internally. This diff fixes that.
Test Plan: Build vec256_test for android and run it on android phone.
Reviewed By: ljk53, paulshaoyuqiao
Differential Revision: D22484635
fbshipit-source-id: ebb9fc2eccb8261ab01d8266150fc3b05166f1e7
Summary:
# Description
The goal is to reduce the size of the docker image. I checked a few things:
* Docker layer overlaps
* Removing .git folder
* Removing intermediate build artifacts (*.o and *.a)
The only one that gave satisfying result was the 3rd approach, removing *.o and *.a. The final image went from 10 GB to 9.7 GB.
I used Dive (https://github.com/wagoodman/dive) to inspect the Docker image manually.
# Test:
* Check the image size was reduced
* No test failures in CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41207
Test Plan:
* Check the image size was reduced
* No test failures in CI
Differential Revision: D22465221
Pulled By: ssylvain
fbshipit-source-id: 48754259729401e3c08447b0fa0630ca7217cb98
Summary:
Resubmit #40927
Closes https://github.com/pytorch/pytorch/issues/24679, closes https://github.com/pytorch/pytorch/issues/24678
`addbmm` depends on `addmm` so needed to be ported at the same time. I also removed `THTensor_(baddbmm)` which I noticed had already been ported so was just dead code.
After having already written this code, I had to fix merge conflicts with https://github.com/pytorch/pytorch/issues/40354 which revealed there was already an established place for cpu blas routines in ATen. However, the version there doesn't make use of ATen's AVX dispatching so thought I'd wait for comment before migrating this into that style.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40927
Reviewed By: ezyang
Differential Revision: D22468490
Pulled By: ngimel
fbshipit-source-id: f8a22be3216f67629420939455e31a88af20201d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40875
This op uses the given num_bins and a spacing strategy to automatically bin and compute the histogram of given matrices.
Test Plan: Unit tests.
Reviewed By: neha26shah
Differential Revision: D22329069
fbshipit-source-id: 28406b94e284d52d875f73662fc82f93dbc00064
Summary:
Shape is passed to _reshape_to_tensor as a Constant and cannot infer shape of the input when model is exported with dynamic axes set. Instead of a Constant pass output of a subgraph Shape-Slice-Concat to compute the shape for the Reshape node in _reshape_to_tensor function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40418
Reviewed By: hl475
Differential Revision: D22480127
Pulled By: houseroad
fbshipit-source-id: 11853adb6e6914936871db1476916699141de435
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41214
Same as D21032976, add check for duplicated op name in JIT
Test Plan:
run full JIT predictor
also
buck test pytorch-playground
Reviewed By: smessmer
Differential Revision: D22467871
fbshipit-source-id: 9b7a40a217e6c63cca44cad54f9f657b8b207a45
Summary:
some people have been confused by `retain_graph` in the snippet, they thought it was an additional requirement imposed by amp.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41203
Differential Revision: D22463700
Pulled By: ngimel
fbshipit-source-id: e6fc8871be2bf0ecc1794b1c6f5ea99af922bf7e
Summary:
Per title. `lgamma` produces a different result for `-inf` compared to scipy, so there comparison is skipped.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41225
Differential Revision: D22473346
Pulled By: ngimel
fbshipit-source-id: e4ebda1b10e2a061bd4cef38d1d7b5bf0f581790
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40252
As title says.
Test Plan:
python test/test_mobile_optimizer.py
Imported from OSS
Differential Revision: D22126825
fbshipit-source-id: a1880587ba8db9dee0fa450bc463734e4a8693d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39631
Background:
Currently, we cannot send ScriptModule over RPC as an argument.
Otherwise, it would hit the following error:
> _pickle.PickleError: ScriptModules cannot be deepcopied using
> copy.deepcopy or saved using torch.save. Mixed serialization of
> script and non-script modules is not supported. For purely
> script modules use my_script_module.save(<filename>) instead.
Failed attempt:
tried to install `torch.jit.ScriptModule` to RPC's
dispatch table, but it does not work as the dispatch table only
matches exact types and using base type `torch.jit.ScriptModule`
does not work for derived typed.
Current solution:
The current solution exposes `_enable_jit_rref_pickle` and
`_disable_jit_rref_pickle` APIs to toggle the `allowJitRRefPickle`
flag. See `test_pickle_script_module_with_rref` as an example.
Test Plan: Imported from OSS
Differential Revision: D21920870
Pulled By: mrshenli
fbshipit-source-id: 4d58afce5d0b4b81249b383c173488820b1a47d6
Summary:
unique op test failure in caffe2 blocks upgrading CI to rocm3.5.1. Skipping the test to unblock will re-enable after root causing and fixing the issue.
jeffdaily sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41219
Differential Revision: D22471452
Pulled By: xw285cornell
fbshipit-source-id: 9e503c8b37c0a4b92632f77b2f8a90281a9889c3
Summary:
the current quantization rounding function uses fbgemm which
defaults to round to nearest. The current implementation of hw uses round
flush to infinity. Adding such an option to switch the mode of rounding.
Test Plan: ran against test_fc_int8
Reviewed By: venkatacrc
Differential Revision: D22452306
fbshipit-source-id: d2a1fbfc695612fe07caaf84f52669643507cc9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39343
Building on top of previous PR that adds fused add_relu op, this PR adds
a JIT pass to transform input graph to find all fusable instancs of add
+ relu and fuses them.
Test Plan:
python test/test_jit.py TestJit.test_add_relu_fusion
Imported from OSS
Differential Revision: D21822396
fbshipit-source-id: 12c7e8db54c6d70a2402b32cc06c7e305ffbb1be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39342
Many networks such as resnet have adds followed by relu. This op is the
first step in enabling this fused implementation.
Once we have the fused add_relu op, a JIT pass will be written to
replace add + relu patterns with add_relu.
Test Plan:
python test/test_nn.py TestAddRelu
Imported from OSS
Differential Revision: D21822397
fbshipit-source-id: 03df83a3e46ddb48a90c5a6f755227a7e361a0e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39341
This PR introduces neon backend for vec256 class for float datatype.
For now only aarch64 is enabled due to few issues with enabling in
aarch32 bit.
Test Plan:
vec256_test
Imported from OSS
Differential Revision: D21822399
fbshipit-source-id: 3851c4336d93d1c359c85b38cf19904f82bc7b8d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40059
This benchmark is added specifically for mobile to see if compiler is
autovectorizing and thus we have no advantage of neon backend for vec256
for add op.
Test Plan:
CI
Imported from OSS
Differential Revision: D22055146
fbshipit-source-id: 43ba6c4ae57c6f05d84887c2750ce21ae1b0f0b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41200
In short, we messed up. The SHM and CMA backends of TensorPipe are Linux-specific and thus they are guarded by a #ifdef in the agent's code. Due to a mishap with CMake (due the fact that TensorPipe has two CMake files, one for PyTorch and a "standalone" one) we were not correctly propagating some flags and these #ifdefs were always false. This means that these two backends have always been disabled and have thus never been covered by our OSS CI. It would be irresponsible to enable them now in v1.6, so instead we remove any mention of them from the docs.
Note that this is perhaps not as bad as it sounds. These two backends were providing higher performance (latency) when the two endpoints were on the same machine. However, I suspect that most RPC users will only do transfers across machines, for which SHM and CMA wouldn't have played any role.
ghstack-source-id: 107458630
Test Plan: Docs only
Differential Revision: D22462158
fbshipit-source-id: 0d72fea11bcaab6d662184bbe7270529772a5e9b
Summary:
Fixes gh-39007
We replaced actual content with links to generated content in many places to break the documentation into manageable chunks. This caused references like
```
https://pytorch.org/docs/stable/torch.html#torch.flip
```
to become
```
https://pytorch.org/docs/master/generated/torch.flip.html#torch.flip
```
The textual content that was located at the old reference was replaced with a link to the new reference. This PR adds a `<p id="xxx"/p>` reference next to the link, so that the older references from outside tutorials and forums still work: they will bring the user to the link that they can then follow through to see the actual content.
The way this is done is to monkeypatch the sphinx writer method that produces the link. It is ugly but practical, and in my mind not worse than adding javascript to do the same thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39086
Differential Revision: D22462421
Pulled By: jlin27
fbshipit-source-id: b8f913b38c56ebb857c5a07bded6509890900647
Summary:
Add `torch._C._cuda_getArchFlags()` that returns list of architecture `torch_cuda` were compiled with
Add `torch.cuda.get_arch_list()` and `torch.cuda.get_gencode_flags()` methods that returns architecture list and gencode flags PyTorch were compiled with
Print warning if some of GPUs is not compatible with any of the CUBINs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41173
Differential Revision: D22459998
Pulled By: malfet
fbshipit-source-id: 65d40ae29e54a0ba0f3f2da11b821fdb4d452d95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41103
add a CLANG_CODE_COVERAGE option to CMakeList. If the option is ON, add code coverage needed compile flags.
Test Plan:
Clone pytorch source code to local, modified these changes and builded it with `CLANG_CODE_COVERAGE ON` and `BUILD_TESTS ON`. Run a manual test and attach code coverage report.
{F243609020}
Reviewed By: malfet
Differential Revision: D22422513
fbshipit-source-id: 27a31395c31b5b5f4b72523954722771d8f61080
Summary:
Based on discussion with jlucier (https://github.com/pytorch/pytorch/pull/38925#issuecomment-655859195) . `batch_size` change isn't made because data loader only has the notion of `batch_sampler`, not batch size. If `batch_size` dependent sharding is needed, users can still access it from their own code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41175
Differential Revision: D22456525
Pulled By: zou3519
fbshipit-source-id: 5281fcf14807f219de06e32107d5fe7d5b6a8623
Summary:
**Summary**
This commit fixes the JIT triage workflow based on testing done in my
own fork.
**Test Plan**
This commit has been tested against my own fork. This commit is
currently at the tip of my master branch, and if you open an issue in my
fork and label it JIT, it will be added to the Triage Review project in
that fork under the Needs triage column.
*Old issue that is labelled JIT later*
<img width="700" alt="Captura de Pantalla 2020-07-08 a la(s) 6 59 42 p m" src="https://user-images.githubusercontent.com/4392003/86988551-5b805100-c14d-11ea-9de3-072916211f24.png">
*New issue that is opened with the JIT label*
<img width="725" alt="Captura de Pantalla 2020-07-08 a la(s) 6 59 17 p m" src="https://user-images.githubusercontent.com/4392003/86988560-60dd9b80-c14d-11ea-94f0-fac01a0d239b.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41170
Differential Revision: D22460584
Pulled By: SplitInfinity
fbshipit-source-id: 278483cebbaf3b35e5bdde2a541513835b644464
Summary:
This avoids a (currently only) warning of cmake:
```
The dependency target "nccl_external" of target "gloo_cuda" does not exist.
Call Stack (most recent call first):
CMakeLists.txt:411 (include)
```
This will be a real problem once Policy CMP0046 is set which will make this warning be an error
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41180
Differential Revision: D22460623
Pulled By: malfet
fbshipit-source-id: 0222b12b435e5e2fdf2bc85752f95abba1e3d4d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40806
When the input is empty, the operator will crash on "runtime error: division by zero". This has been causing Inference platform server crashes.
Example crash logs:
{P134526683}
Test Plan:
Unit test
See reproducing steps in the Test Plan of D22300135
Reviewed By: houseroad
Differential Revision: D22302089
fbshipit-source-id: aaa5391fddc86483b0f3aba3efa7518e54913635
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41096
The spark spot model had some issues in tensor conversion, see P134598596. It happens when we convert an undefined c10 tensor to caffe2 tensor.
This diff added a null check.
Test Plan: spark spot model runs without problem
Reviewed By: smessmer
Differential Revision: D22330705
fbshipit-source-id: dfe0f29a48019b6611cad3fd8f2ae49e8db5427e
Summary:
When we return to Python from C++ in PyTorch and have warnings and and error, we have the problem of what to do when the warnings throw because we can only throw one error.
Previously, if we had an error, we punted all warnings to the C++ warning handler which would write them to stderr (i.e. system fid 2) or pass them on to glog.
This has drawbacks if an error happened:
- Warnings are not handled through Python even if they don't raise,
- warnings are always printed with no way to suppress this,
- the printing bypasses sys.stderr, so Python modules wanting to
modify this don't work (with the prominent example being Jupyter).
This patch does the following instead:
- Set the warning using standard Python extension mechanisms,
- if Python decides that this warning is an error and we have a
PyTorch error, we print the warning through Python and clear
the error state (from the warning).
This resolves the three drawbacks discussed above, in particular it fixes https://github.com/pytorch/pytorch/issues/37240 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41116
Differential Revision: D22456393
Pulled By: albanD
fbshipit-source-id: c3376735723b092efe67319321a8a993402985c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39488
Currently caffe2.InitOpLibrary does the dll import uniliaterally. Instead if we make a lazy version and use it, then many pieces of code which do not need the caffe2urrenoperators get a lot faster.
One a real test, the import time went from 140s to 68s. 8s.
This also cleans up the algorithm slightly (although it makes a very minimal
difference), by parsing the list of operators once, rather than every time a
new operator is added, since we defer the RefreshCall until after we've
imported all the operators.
The key way we maintain safety, is that as soon as someone does an operation
which requires a operator (or could), we force importing of all available
operators.
Future work could include trying to identify which code is needed for which
operator and only import the needed ones. There may also be wins available by
playing with dlmopen (which opens within a namespace), or seeing if the dl
flags have an impact (I tried this and didn't see an impact, but dlmopen may
make it better).
Test Plan:
I added a new test a lazy_dyndep_test.py (copied from all_compare_test.py).
I'm a little concerned that I don't see any explicit tests for dyndep, but this
should provide decent coverage.
Differential Revision: D21870844
fbshipit-source-id: 3f65fedb65bb48663670349cee5e1d3e22d560ed
Summary:
This is a duplicate of https://github.com/pytorch/pytorch/pull/38362
"This PR completes Interpolate's deprecation process for recomputing the scales values, by updating the default value of the parameter recompute_scale_factor as planned for pytorch 1.6.0.
The warning message is also updated accordingly."
I'm recreating this PR as previous one is not being updated.
cc gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39453
Reviewed By: hl475
Differential Revision: D21955284
Pulled By: houseroad
fbshipit-source-id: 911585d39273a9f8de30d47e88f57562216968d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40718
Currently only constant except tensor must be inlined during serialization.
Tensor are stored in the contant table. This patch generalizes this capability
to any IValue. This is particularly useful for non ASCII string literal that
cannot be inlined.
Test Plan: Imported from OSS
Differential Revision: D22298169
Pulled By: bzinodev
fbshipit-source-id: 88cc59af9cc45e426ca8002175593b9e431f4bac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40326
Adds a helper function `addCallbackWithTLSState` to both
torch/csrc/utils/future.h which is used internally by RPC framework and the JIT
future. Uses this helper function to avoid to pass in TLS state where it is needed for rpc and `record_function_ops.cpp`. For example, the following:
```
at::ThreadLocalState tls_state;
fut->addCallback([tls_state = std::move(tls_state)]() {
at::ThreadLocalStateGuard g(tls_state);
some_cb_that_requires_tls_state();
}
```
becomes
```
fut->addCallbackWithTLSState(some_cb_that_requires_tls_state);
```
ghstack-source-id: 107383961
Test Plan: RPC Tests and added a test in test_misc.cpp
Differential Revision: D22147634
fbshipit-source-id: 46c02337b90ee58ca5a0861e932413c40d06ed4c
Summary:
Noticed while trying to script one of the models which happened to have numpy values as constants. Lacking the numpy prefix in the error message was quite confusing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41024
Differential Revision: D22426399
Pulled By: dzhulgakov
fbshipit-source-id: 06158b75355fac6871e4861f82fc637c2420e370
Summary:
This PR contains the following updates:
1. MIOpen 3D pooling enabled in Caffe2.
2. Refactored the MIOpen pooling code in caffe2.
3. Enabled unit test cases for 3D pooling.
CC: ezyang jeffdaily ashishfarmer
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38260
Differential Revision: D21524754
Pulled By: xw285cornell
fbshipit-source-id: ddfe09dc585cd61e42eee22eff8348d326fd0c3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41136
Running this within CI seems impossible since this script exits out
after one failed test, so let's just add an option that CI can use to
power through these errors.
Should not affect current functionality.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22441694
Pulled By: seemethere
fbshipit-source-id: 7f152fea15af9d47a964062ad43830818de5a109
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41056
**Summary**
This commit adds a new GitHub workflow that automatically adds a card to
the "Need triage" section of the project board for tracking JIT triage
for each new issue that is opened and labelled "jit".
**Test Plan**
???
Test Plan: Imported from OSS
Differential Revision: D22444262
Pulled By: SplitInfinity
fbshipit-source-id: 4e7d384822bffb978468c303322f3e2c04062644
Summary:
Closes https://github.com/pytorch/pytorch/issues/24679, closes https://github.com/pytorch/pytorch/issues/24678
`addbmm` depends on `addmm` so needed to be ported at the same time. I also removed `THTensor_(baddbmm)` which I noticed had already been ported so was just dead code.
After having already written this code, I had to fix merge conflicts with https://github.com/pytorch/pytorch/issues/40354 which revealed there was already an established place for cpu blas routines in ATen. However, the version there doesn't make use of ATen's AVX dispatching so thought I'd wait for comment before migrating this into that style.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40927
Differential Revision: D22418756
Pulled By: ezyang
fbshipit-source-id: 44e7bb5964263d73ae8cc6adc5f6d4e966476ae6
Summary:
This should be in its own file...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41137
Reviewed By: jamesr66a
Differential Revision: D22437922
Pulled By: eellison
fbshipit-source-id: 1b62dde1a4ebac673b5c60aea4f398f734d62501
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39611
A few ops have been taking non-optional ScalarType, Device and Layout. That isn't supported by the hacky wrapper that makes those
kernels work with the c10 operator library. This PR unifies the signatures and makes those ops c10-full.
ghstack-source-id: 107330186
Test Plan: waitforsandcastle
Differential Revision: D21915788
fbshipit-source-id: 39f0e114f2766a3b27b80f93f2c1a95fa23c78d4
Summary:
I noticed this very unusual use of atomics in `at::native::DispatchStub`. The comment asserts that `choose_cpu_impl()` will always return the same value on every thread, yet for some reason it uses a CAS loop to exchange the value instead of a simple store? That makes no sense considering it doesn't even read the exchanged value.
This replaces the CAS loop with a simple store and also improves the non-initializing case to a single atomic load instead of two.
For reference, the `compare_exchange` was added in https://github.com/pytorch/pytorch/issues/32148 and the while loop added in https://github.com/pytorch/pytorch/issues/35794.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40930
Differential Revision: D22438224
Pulled By: ezyang
fbshipit-source-id: d56028ce18c8c5dbabdf366379a0b6aaa41aa391
These jobs didn't really fulfill the intended purpose that they had once
had since the travis python versions were basically locked to 3.7.
Going to go ahead and remove these along with its docker jobs as well
since we don't actively need them anymore.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
ghstack-source-id: cdfc4fc2ae15a0c86d322cc706d383d6bc189fbc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41134
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36439
A proposal of versioning in bytecode, as suggested by dzhulgakov in the internal post: https://fb.workplace.com/groups/pytorch.mobile.work/permalink/590192431851054/
kProducedBytecodeVersion is added. If the model version is not the same as the number in the code, an error will be thrown.
The updated bytecode would look like below. It's a tuple of elements, where the first element is the version number.
```
(3,
('__torch__.m.forward',
(('instructions',
(('STOREN', 1, 2),
('DROPR', 1, 0),
('MOVE', 2, 0),
('OP', 0, 0),
('RET', 0, 0))),
('operators', (('aten::Int', 'Tensor'),)),
('constants', ()),
('types', ()),
('register_size', 2))))
```
Test Plan: Imported from OSS
Differential Revision: D22433532
Pulled By: iseeyuan
fbshipit-source-id: 6d62e4abe679cf91a8e18793268ad8c1d94ce746
Summary:
Per title. This is not used currently in the pytorch codebase, but it is a legitimate usecase, and we have extensions that want to do that and are forced to roll their own atomic implementations for non-standard types. Whether atomic op returns old value or not should not affect performance, compiler is able to generate correct code depending on whether return value is used. https://godbolt.org/z/DBU_UW.
Atomic operations for non-standard integer types (1,2 and 8 byte-width) are left as is, with void return.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41028
Differential Revision: D22425008
Pulled By: ngimel
fbshipit-source-id: ca064edb768a6b290041a599e5b50620bdab7168
Summary:
Fixes https://github.com/pytorch/pytorch/issues/41047.
Some CPU kernel implementations don't call `cast_outputs()`, so when CPU temporaries were created to hold their outputs they weren't copied back to the out parameters correctly. Instead of fixing that issue, for simplicity this PR disables the behavior. The corresponding test in test_type_promotion.py is expanded with more operations to verify that unary ops can no longer have out arguments with different dtypes than their inputs (except in special cases like torch.abs which maps complex inputs to float outputs and torch.deg2rad which is secretly torch.mul).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41097
Differential Revision: D22422352
Pulled By: mruberry
fbshipit-source-id: 8e61d34ef1c9608790b35cf035302fd226fd9421
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40902
See the bottom of this stack for context.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D22360210
Pulled By: suo
fbshipit-source-id: 4275127173a36982ce9ad357aa344435b98e1faf
Summary:
There's a regression in MIOpen in ROCm3.5 that results in failure of autocast tests. Skipping the tests for now and will re-enable once the fixes are in MIOpen.
ezyang jeffdaily sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41088
Differential Revision: D22419823
Pulled By: xw285cornell
fbshipit-source-id: 347fb9a03368172fe0b263d14d27ee0c3efbf4f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41077
This PR is a refactor that moves error messages into their callsites in
`_vmap_internals.py`. Furthermore, because a little bird told me we've
dropped python 3.5 support, this PR adopts f-string syntax to clean up
the string replace logic. Together these changes make the error messages
read better IMO.
Test Plan:
- `python test/test_vmap.py -v`. There exists tests that invoke each of the
error messages.
Differential Revision: D22420473
Pulled By: zou3519
fbshipit-source-id: cfd46b2141ac96f0a62864928a95f8eaa3052f4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41092
added overload name for some full JIT operators and removed some duplicated op registrations
Test Plan:
apply D21032976, then buck run fbsource//xplat/caffe2/fb/pytorch_predictor:predictor
make sure there's no runtime error in operator registration
Reviewed By: iseeyuan
Differential Revision: D22419922
fbshipit-source-id: f651898e75b5bdb8dc03fc00b136689536c51707
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41020
Only support quantization of list append for List[Tensor]
Test Plan: Imported from OSS
Differential Revision: D22420698
fbshipit-source-id: 179677892037e136d90d16230a301620c3111063
Summary: Export logit op to pt for better preproc perf
Test Plan:
unit test
Also tested with model re-generation
Reviewed By: houseroad
Differential Revision: D22324611
fbshipit-source-id: 86accb6b4528e5c818d2c3f8c67926f279d158d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41094
mimic nnpi's quantization operations
removed redundant int8 test
Test Plan: ran FC with sizes up to 5, running bigger sizes
Reviewed By: venkatacrc
Differential Revision: D22420537
fbshipit-source-id: 91211c8a6e4d3d3bec2617b758913b44aa44b1b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40842
**Summary**
This commit adds out-of-source-tree tests for `to_backend`. These tests check
that a Module can be lowered to a backend, exported, loaded (in both
Python and C++) and executed.
**Fixes**
This commit fixes#40067.
Test Plan: Imported from OSS
Differential Revision: D22418731
Pulled By: SplitInfinity
fbshipit-source-id: 621ba4efc1b121fa76c9c7ca377792ac7440d250
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40841
**Summary**
This commit adds support for using `Modules` that have been lowered as
submodules in `ScriptModules`.
**Test Plan**
This commit adds execution and save/load tests to test_backends.py for
backend-lowered submodules.
**Fixes**
This commit fixes#40069.
Test Plan: Imported from OSS
Differential Revision: D22418716
Pulled By: SplitInfinity
fbshipit-source-id: d2b2c6d5d2cf3042a620b3bde7d494f1abe28dc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40840
**Summary**
This commit moves the TestBackend used for the JIT backend
extension to the tests directory. It was temporarily placed
in the source directory while figuring out some details of
the user experience for this feature.
**Test Plan**
`python test/test_jit.py TestBackends`
**Fixes**
This commit fixes#40067.
Test Plan: Imported from OSS
Differential Revision: D22418682
Pulled By: SplitInfinity
fbshipit-source-id: 9356af1341ec4d552a41c2a8929b327bc8b56057
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40839
**Summary**
This commit splits the to_backend API properly into
`libtorch` and `libtorch_python`. The backend interface and all
of the code needed to run a graph on a backend is in
libtorch, and all of the code related to creating a Python binding
for the lowering process is in `libtorch_python`.
**Test Plan**
`python test/test_jit.py TestBackends`
**Fixes**
This commit fixes#40072.
Test Plan: Imported from OSS
Differential Revision: D22418664
Pulled By: SplitInfinity
fbshipit-source-id: b96e0c34ab84e45dff0df68b8409ded57a55ab25
Summary:
[index_put](https://pytorch.org/docs/master/tensors.html#torch.Tensor.index_put) requires src and dst tensors to be the same dtype, so imo it belongs on the promote list when autocast is active (output should be widest dtype among input dtypes).
i also put some other registrations in alphabetical order.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41035
Differential Revision: D22418305
Pulled By: ngimel
fbshipit-source-id: b467cb16ac6c2ba1f9e43531f69a144b17f00b87
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41100
Unit test case for the Int8FC to cover quantization scale errors.
Test Plan: test_int8_ops_nnpi.py test case test_int8_small_input.
Reviewed By: hyuen
Differential Revision: D22422353
fbshipit-source-id: b1c1baadc32751cd7e98e0beca8f0c314d9e5f10
Summary:
Spotted a broken link, and while I was at it, fixed a few little language and formatting nits.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41066
Reviewed By: mruberry
Differential Revision: D22415371
Pulled By: dongreenberg
fbshipit-source-id: 7d11c13235b28a01886063c11a4c5ccb333c0c02
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41085
add the first LUT implementation of swish
Test Plan:
compared against swish lowered as x*sigmoid(x), had to
increase the threshold of error but looks generally right
Reviewed By: venkatacrc
Differential Revision: D22418117
fbshipit-source-id: c75fa496aa7a5356ddc87f1d61650f432e389457
Summary:
Previously it used the default arch set which may or may not coincide with the user's.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40170
Differential Revision: D22400866
Pulled By: xw285cornell
fbshipit-source-id: 222ba684782024fa68f37bf7d4fdab9a2389bdea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37174
ghstack-source-id: 106938112
Test Plan: Upcoming diffs use this for upsampling.
Differential Revision: D21210002
fbshipit-source-id: d6a55ab6420c05a92873a569221b613149aa0daa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37173
This function is only called in one place, so inline it. This eliminates
boilerplate related to overloads and allows for further simplification
of shared logic in later diffs.
All shared local variables have the same names (from closed_over_args),
and no local variables accidentally collide.
ghstack-source-id: 106938108
Test Plan: Existing tests for interpolate.
Differential Revision: D21209995
fbshipit-source-id: acfadf31936296b2aac0833f704764669194b06f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37172
This improves readability by keeping cases with similar behavior close
together. It should also have a very tiny positive impact on perf.
ghstack-source-id: 106938109
Test Plan: Existing tests for interpolate.
Differential Revision: D21209996
fbshipit-source-id: c813e56aa6ba7370b89a2784fcb62cc146005258
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37171
Every one of these branches returns or raises, so there's no need for elif.
This makes it a little easier to reorder and move conditions.
ghstack-source-id: 106938110
Test Plan: Existing test for interpolate.
Differential Revision: D21209992
fbshipit-source-id: 5c517e61ced91464b713f7ccf53349b05e27461c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41060
Exposes a const ref opaque_handle and made copy_tensor_metdata a
protected method. This helps in reusing code in sub classes of OpaqueTensorImpl
Test Plan: waitforbuildbot
Reviewed By: dzhulgakov
Differential Revision: D22406602
fbshipit-source-id: e3b8338099f257da7f6bbff679f1fdb71e5f335a
Summary:
Decouple DataParallel/DistributedDataParallel from CUDA to support more device types.
- Move torch/cuda/comm.py to torch/nn/parallel/comm.py with minor changes for common devices support. Torch.cuda.comm is kept as is for backward compatibility
- Provide common APIs to arbitrary device types without changing existing CUDA APIs in torch.cuda space.
- Replace the torch.cuda calls in DataParellel/DistributedDataParallel with the new APIs.
Related RFC: [https://github.com/pytorch/pytorch/issues/36160](https://github.com/pytorch/pytorch/issues/36160)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38454
Differential Revision: D22051557
Pulled By: mrshenli
fbshipit-source-id: 7842dad0e5d3ca0f6fb760bda49182dcf6653af8
Summary:
solves most of gh-38011 in the framework of solving gh-32703.
These should only be formatting fixes, I did not try to fix grammer and syntax.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41068
Differential Revision: D22411919
Pulled By: zou3519
fbshipit-source-id: 25780316b6da2cfb4028ea8a6f649bb18b746440
Summary:
We need an easy to way to quickly visually grep binary sizes from builds
and then have a way to test out those binaries quickly.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41074
Differential Revision: D22415667
Pulled By: seemethere
fbshipit-source-id: 86386e5390dce6aae26e952a47f9e2a2221d30b5
Summary:
This is to workaround an issue in hipclang wrt templated kernel name arguments to hipLaunchKernelGGL.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41022
Differential Revision: D22404183
Pulled By: ngimel
fbshipit-source-id: 63135ccb9e087f4c8e8663ed383979f7e2c1ba06
Summary:
Currently embedding_bag's CPU kernel queries whether weight.requires_grad() is true. This violates layering of AutoGrad and Op Kernels, causing issues in third-party backends like XLA. See this [issue](https://github.com/pytorch/xla/issues/2215) for more details.
This PR hoists the query of weight.requires_grad() to Python layer, and splits embedding_bag into two separate ops, each corresponding to weight.requires_grad() == true and false.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40557
Reviewed By: ailzhang
Differential Revision: D22327476
Pulled By: gmagogsfm
fbshipit-source-id: c815b3690d676a43098e12164517c5debec90fdc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40837
As ninja has accurate dependency tracking, if there is nothing to do,
then we will very quickly noop. But this is important for correctness:
if a change was made to a header that is not listed explicitly in
the distutils Extension, then distutils will come to the wrong
conclusion about whether or not recompilation is needed (but Ninja
will work it out.)
This caused https://github.com/pytorch/vision/issues/2367
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D22340930
Pulled By: ezyang
fbshipit-source-id: 481b74f6e2cc78159d2a74d413751cf7cf16f592
Summary:
Forward-declare `tensorpipe::Message` class in utils.h
Guard TensorPipe specific methods in utils.cpp with `#ifdef USE_TENSORPIPE`
Pass `USE_TENSORPIPE` as private flag to `torch_cpu` library
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40846
Differential Revision: D22338864
Pulled By: malfet
fbshipit-source-id: 2ea2aea84527ae7480e353afb55951a068b3b980
Summary:
It's a known gcc-5.4 bug that enum class is not hasheable by default, so `std::unordered_map` needs 3rd explicit parameters to compute hash from the type.
Should fix regression caused by https://github.com/pytorch/pytorch/pull/40864
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41055
Differential Revision: D22405478
Pulled By: malfet
fbshipit-source-id: f4bd36bebdc1ad0251ebd1e6cefba866e6605fe6
Summary:
In issue https://github.com/pytorch/pytorch/issues/36997 the user encountered a non-meaningful error message when trying to export the model to ONNX. The Pad operator in opset 9 requires the list of paddings to be constant. This PR tries to improve the error message given to the user when this is not the case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39651
Reviewed By: hl475
Differential Revision: D21992262
Pulled By: houseroad
fbshipit-source-id: b817111c2a40deba85e4c6cdb874c1713312dba1
Summary:
I ran `make linkcheck` using `sphinx.builders.linkcheck` on the documentation and noticed a few links weren't using HTTPS so I quickly updated them all.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40878
Differential Revision: D22404647
Pulled By: ngimel
fbshipit-source-id: 9c9756db59197304023fddc28f252314f6cf4af3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40717
`in_dims` specifies which dimension of the input tensors should be
vmapped over. One can also specify `None` as an `in_dim` for a particular
input to indicate that we do not map over said input.
We implement `in_dims` by creating a BatchedTensor with BatchDim equal
to said `in_dim`. Most of this PR is error checking. `in_dims` must
satisfy the following:
- `in_dim` can be either an int or a Tuple[Optional[int]]. If it is an
int, we use it to mean the `in_dim` for every input.
- If `in_dims` is not-None at some index `idx`, then the input at index
`idx` MUST be a tensor (vmap can only map over tensors).
jax supports something more generalized: their `in_dims` can match the
structure of the `inputs` to the function (i.e., it is a nested python
data structure matching the data structure of `inputs` specifying where
in `inputs` the Tensors to be mapped are and what their map dims should
be). We don't have the infrastruture yet so we only support `int` or a
flat tuple for `in_dims`.
Test Plan: - `pytest test/test_vmap.py -v`
Differential Revision: D22397914
Pulled By: zou3519
fbshipit-source-id: 56d2e14be8b6024e4cde2729eff384da305b4ea3
Summary:
Most time-consuming tests in test_nn (taking about half the time) were gradgradchecks on Conv3d. Reduce their sizes, and, most importantly, run gradgradcheck single-threaded, because that cuts the time of conv3d tests by an order of magnitude, and barely affects other tests.
These changes bring test_nn time down from 1200 s to ~550 s on my machine.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40999
Differential Revision: D22396896
Pulled By: ngimel
fbshipit-source-id: 3b247caceb65d64be54499de1a55de377fdf9506
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40939
Previously, when we would do shape analysis by running the op with representative inputs, we would always set the grad property to false. This led to a wrong static analysis when we would create differentiable subgraphs, and propagate shapes without also propagating requires_grad, and then uninline them.
Test Plan: Imported from OSS
Differential Revision: D22394676
Pulled By: eellison
fbshipit-source-id: 254e6e9f964b40d160befe0e125abe1b7aa2bd5e
Summary:
Original commit changeset: 46c59d849fa8
The original commit is breaking DPER3 release pipeline with the following failures:
https://www.internalfb.com/intern/chronos/jobinstance?jobinstanceid=9007207344413239&smc=chronos_gp_admin_client&offset=0
```
Child workflow f 202599639 failed with error: c10::Error: [enforce fail at operator.cc:76] blob != nullptr. op Save: Encountered a non-existing input blob: feature_preproc/feature_sparse_to_dense/default_float_value
```
https://www.internalfb.com/intern/chronos/jobinstance?jobinstanceid=9007207344855973&smc=chronos_gp_admin_client&offset=0
```
Child workflow f 202629391 failed with error: c10::Error: [enforce fail at operator.cc:76] blob != nullptr. op Save: Encountered a non-existing input blob: tum_preproc/inductive/feature_sparse_to_dense/default_float_value
```
Related UBN tasks: T69529846, T68986110
Test Plan: Build a DPER3 package on top of this commit, and check that DPER3 release test `model_deliverability_test` is passing.
Differential Revision: D22396317
fbshipit-source-id: 92d5b30cc146c005d6159a8d5bfe8973e2c546dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40856
Add a new activation function - Mish: A Self Regularized Non-Monotonic Neural Activation Function https://arxiv.org/abs/1908.08681
Test Plan:
buck test //caffe2/caffe2/python/operator_test:elementwise_ops_test -- 'test_mish'
{F242275183}
Differential Revision: D22158035
fbshipit-source-id: 459c1dd0ac5b515913fc09b5f4cd13dcf095af31
Summary:
This trick should have no effect on performance, but it reduces size of kernels using the template by 10%
For example, sizeof(BinaryMulDivKernel.cu.o) compiled by CUDA-10.1 toolchain for sm_75 before the change was 4.2Mb, after 3.8Mb
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40992
Differential Revision: D22398733
Pulled By: malfet
fbshipit-source-id: 6576f4da00dc5fc2575b2313577f52c6571d5e6f
Summary:
Closes https://github.com/pytorch/pytorch/issues/40560
This adds the equation for the weighted mean to `CrossEntropyLoss`'s docs and the `reduction` argument for `CrossEntropyLoss` and `NLLLoss` no longer describes a non-weighted mean of the outputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40991
Differential Revision: D22395805
Pulled By: ezyang
fbshipit-source-id: a623b6dd2aab17220fe0bf706bd9b62d6ba531fd
Summary:
Have basic reduction fusion working, and have improved code generator to approach performance of eager mode reductions. Coming soon will be pointwise-reduction fusions in a way that should prevent the possibility of hitting regressions. Also working on performant softmax kernels in the code generator which may be our next fusion target.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40864
Reviewed By: ngimel
Differential Revision: D22392877
Pulled By: soumith
fbshipit-source-id: 457448a807d628b1035f6d90bc0abe8a87bf8447
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41004
Tracing has been moved into separate files. Now we can disable it by not compiling the source files for xplat mobile build.
ghstack-source-id: 107158627
Test Plan: CI + build size bot
Reviewed By: iseeyuan
Differential Revision: D22372615
fbshipit-source-id: bf2e2249e401295ff63020a292df119b188fb966
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40903
This PR continues the work of #38467 - decoupling Autograd and Trace for manually registered ops.
ghstack-source-id: 107158638
Test Plan: CI
Differential Revision: D22354804
fbshipit-source-id: f5ea45ade2850296c62707a2a4449d7d67a9f5b5
Summary:
Unbind, which has a special backward with cat, is arguably better than multiple selects, whose backward is creating & adding a bunch of tensors as big as `self`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40884
Reviewed By: pbelevich
Differential Revision: D22363376
Pulled By: zou3519
fbshipit-source-id: 0911cdbb36f9a35d1b95f315d0a2f412424e056d
Summary:
fix https://github.com/pytorch/pytorch/issues/40227
Removed the sorting operation both in ModuleDict class, updated the docstring.
Also remove a sort operation in corresponding unit test, which will lead to unit test fail.
BC Note: Python version after 3.6, the plain dict will preserve the order of keys.
example:
For a python 3.6+ user, if he is initial a ModuleDict instance using plain python dict:
{
"b": torch.nn.MaxPool2d(3),
"a": torch.nn.MaxPool2d(3)
}
, he will get a ModuleDict which preserve the order:
ModuleDict(
(b): MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False)
(a): MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False)
)
For a python 3.5 user, if we maintain the same input, then the output ModuleDict could be:
ModuleDict(
(a): MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False)
(b): MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False)
)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40905
Differential Revision: D22357480
Pulled By: albanD
fbshipit-source-id: 0e2502769647bb64f404978243ca1ebe5346d573
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40807
We pack a lot of logic into `jit/__init__.py`, making it unclear to
developers and users which parts of our API are public vs. internal. This
is one in a series of PRs intended to pull implementation out into
separate files, and leave `__init__.py` as a place to register the
public API.
This PR moves all the tracing-related stuff out, and fixes other spots up
as necessary. Followups will move other core APIs out.
The desired end-state is that we conform to the relevant rules in [PEP 8](https://www.python.org/dev/peps/pep-0008/#public-and-internal-interfaces). In particular:
- Internal implementation goes in modules prefixed by `_`.
- `__init__.py` exposes a public API from these private modules, and nothing more.
- We set `__all__` appropriately to declare our public API.
- All use of JIT-internal functionality outside the JIT are removed (in particular, ONNX is relying on a number internal APIs). Since they will need to be imported explicitly, it will be easier to catch new uses of internal APIs in review.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D22320645
Pulled By: suo
fbshipit-source-id: 0720ea9976240e09837d76695207e89afcc58270
Summary:
Needed maintenance step to avoid running out of disk space on RocM testers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40917
Differential Revision: D22385844
Pulled By: malfet
fbshipit-source-id: b6dc9ba888a2e34c311e9bf3c8b7b98fa1ec5435
Summary:
Define static script implementation of __len__ and __contains__ on any subclass derived from a type such as ModuleList, Sequential, or ModuleDict. Implement getitem for classes derived from ModuleDict.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40789
Reviewed By: eellison
Differential Revision: D22325159
Pulled By: wconstab
fbshipit-source-id: fc1562c29640fe800e13b5a1dd48e595c2c7239b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40931
Fix docstrings for dynamic quantized Linear/LSTM and associated classes
ghstack-source-id: 107064446
Test Plan: Docs show up in correctly
Differential Revision: D22360787
fbshipit-source-id: 8e357e081dc59ee42fd7f12ea5079ce5d0cc9df2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40652
Resolves https://github.com/pytorch/pytorch/issues/40304, but looking for
feedback on whether there is a better approach for this.
In order to profile `rpc_async` calls made within a torchscript function, we
add the profiling logic to `rpcTorchscript` which is the point where the RPC is
dispatched and is called by the jit `rpc_async` operator. We take a somewhat
similar approach to how this is done in the python API. If profiling is
enabled, we call `record_function_enter` which creates a `RecordFunction`
object and runs its starting callbacks. Then, we schedule end callbacks for
this `RecordFunction` to be run when the jit future completes.
One caveat is that `rpcTorchscript` can also be called by rpc_async from a
non-JIT function, in which case the profiling logic lives in Python. We add a
check to ensure that we don't double profile in this case.
ghstack-source-id: 107109485
Test Plan: Added relevant unittests.
Differential Revision: D22270608
fbshipit-source-id: 9f62d1a2a27f9e05772d0bfba47842229f0c24e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40913
Summary of the entire stack:
--
This diff is part of an attempt to refactor the RPC tests. They currently suffer from several problems:
- Several ways to specify the agent to use: there exists one "generic" fixture that uses the global variable TEST_CONFIG to look up the agent name, and is used for process group and Thrift, and then there are separate fixtures for the flaky agent and the TensorPipe one.
- These two ways lead to having two separate decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which must both be specified, making it unclear what the effect of each of them is and what happens if only one is given.
- Thrift must override the TEST_CONFIG global variable before any other import (in order for the `requires_process_group_agent` decorator to work correctly) and for that it must use a "trap" file, which makes it even harder to track which agent is being used, and which is specific to Buck, and thus cannot be used in OSS by other agents.
- Even if the TensorPipe fixture doesn't use TEST_CONFIG, it still needs to set it to the right value for other parts of the code to work. (This is done in `dist_init`).
- There are a few functions in dist_utils.py that return some properties of the agent (e.g., a regexp to match against the error it returns in case of shutdown). These functions are effectively chained if/elses on the various agents, which has the effect of "leaking" some part of the Thrift agent into OSS.
- Each test suite (RPC, dist autograd/dist optimizer, their JIT versions, remote module, ...) must be run on each agent (or almost; the faulty one is an exception) in both fork and spawn mode. Each of these combinations is a separate file, which leads to a proliferation of scripts.
- There is no "master list" of what combinations make sense and should be run. Therefore it has happened that when adding new tests or new agents we forgot to enroll them into the right tests. (TensorPipe is still missing a few tests, it turns out).
- All of these tiny "entry point" files contain almost the same duplicated boilerplate. This makes it very easy to get the wrong content into one of them due to a bad copy-paste.
This refactoring aims to address these problems by:
- Avoiding global state, defaults/override, traps, if/elses, ... and have a single way to specify the agent, based on an abstract base class and several concrete subclasses which can be "mixed in" to any test suite.
- Instead of enabling/disabling tests using decorators, the tests that are specific to a certain agent are now in a separate class (which is a subclass of the "generic" test suite) so that they are only picked up by the agent they apply to.
- Instead of having one separate entry point script for each combination, it uses one entry point for each agent, and in that script it provides a list of all the test suites it wants to run on that agent. And it does that by trying to deduplicate the boilerplate as much as possible. (In fact, the various agent-suite combinations could be grouped in any way, not necessarily by agent as I did here).
It provides further advantages:
- It puts all the agents on equal standing, by not having any of them be the default, making it thus easier to migrate from process group to TensorPipe.
- It will make it easier to add more versions of the TensorPipe tests (e.g., one that disables the same-machine backends in order to test the TCP-based ones) without a further duplication of entry points, of boilerplate, ...
Summary of this commit
--
Once we start merging multiple test suites in a single file (which we'll happen in the next diffs in the stack) the OSX tests on CircleCI start failing due to "too many open files". This indicates a file descriptor leak. I then managed to repro it on Linux too by lowering the limit on open file descriptors (`ulimit -n 500`). Each test method that unittest runs is run on a new instance of the Testcase class. With our multiprocessing wrappers, this instance contains a list of child processes. Even after these processes are terminated, it appears they still hold some open file descriptor (for example a pipe to communicate with the subprocess). It also appears unittest is keeping these Testcase instances alive until the entire suite completes, which I suspect is what leads to this "leak" of file descriptors. Based on that guess, in this diff I am resetting the list of subprocesses during shutdown, and this seems to fix the problem.
ghstack-source-id: 107045908
Test Plan: Sandcastle and CircleCI
Differential Revision: D22356784
fbshipit-source-id: c93bb9db60fde72cae0b0c735a50c17e427580a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40815
Summary of the entire stack:
--
This diff is part of an attempt to refactor the RPC tests. They currently suffer from several problems:
- Several ways to specify the agent to use: there exists one "generic" fixture that uses the global variable TEST_CONFIG to look up the agent name, and is used for process group and Thrift, and then there are separate fixtures for the flaky agent and the TensorPipe one.
- These two ways lead to having two separate decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which must both be specified, making it unclear what the effect of each of them is and what happens if only one is given.
- Thrift must override the TEST_CONFIG global variable before any other import (in order for the `requires_process_group_agent` decorator to work correctly) and for that it must use a "trap" file, which makes it even harder to track which agent is being used, and which is specific to Buck, and thus cannot be used in OSS by other agents.
- Even if the TensorPipe fixture doesn't use TEST_CONFIG, it still needs to set it to the right value for other parts of the code to work. (This is done in `dist_init`).
- There are a few functions in dist_utils.py that return some properties of the agent (e.g., a regexp to match against the error it returns in case of shutdown). These functions are effectively chained if/elses on the various agents, which has the effect of "leaking" some part of the Thrift agent into OSS.
- Each test suite (RPC, dist autograd/dist optimizer, their JIT versions, remote module, ...) must be run on each agent (or almost; the faulty one is an exception) in both fork and spawn mode. Each of these combinations is a separate file, which leads to a proliferation of scripts.
- There is no "master list" of what combinations make sense and should be run. Therefore it has happened that when adding new tests or new agents we forgot to enroll them into the right tests. (TensorPipe is still missing a few tests, it turns out).
- All of these tiny "entry point" files contain almost the same duplicated boilerplate. This makes it very easy to get the wrong content into one of them due to a bad copy-paste.
This refactoring aims to address these problems by:
- Avoiding global state, defaults/override, traps, if/elses, ... and have a single way to specify the agent, based on an abstract base class and several concrete subclasses which can be "mixed in" to any test suite.
- Instead of enabling/disabling tests using decorators, the tests that are specific to a certain agent are now in a separate class (which is a subclass of the "generic" test suite) so that they are only picked up by the agent they apply to.
- Instead of having one separate entry point script for each combination, it uses one entry point for each agent, and in that script it provides a list of all the test suites it wants to run on that agent. And it does that by trying to deduplicate the boilerplate as much as possible. (In fact, the various agent-suite combinations could be grouped in any way, not necessarily by agent as I did here).
It provides further advantages:
- It puts all the agents on equal standing, by not having any of them be the default, making it thus easier to migrate from process group to TensorPipe.
- It will make it easier to add more versions of the TensorPipe tests (e.g., one that disables the same-machine backends in order to test the TCP-based ones) without a further duplication of entry points, of boilerplate, ...
Summary of this commit
--
This prepares the stack by aligning the `ddp_under_dist_autograd` test to the other ones, so that later changes will be more consistent and thus easier to follow. It does so by moving the `skipIf` decorators and the `setUp` methods from the base test suite to the entry point scripts.
ghstack-source-id: 107045911
Test Plan: Sandcastle and CircleCI
Differential Revision: D22287535
fbshipit-source-id: ab0c9eb774b21d81e0ebd3078df958dbb4bfa0c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40814
Summary of the entire stack:
--
This diff is part of an attempt to refactor the RPC tests. They currently suffer from several problems:
- Several ways to specify the agent to use: there exists one "generic" fixture that uses the global variable TEST_CONFIG to look up the agent name, and is used for process group and Thrift, and then there are separate fixtures for the flaky agent and the TensorPipe one.
- These two ways lead to having two separate decorators (`requires_process_group_agent` and `@_skip_if_tensorpipe_agent`) which must both be specified, making it unclear what the effect of each of them is and what happens if only one is given.
- Thrift must override the TEST_CONFIG global variable before any other import (in order for the `requires_process_group_agent` decorator to work correctly) and for that it must use a "trap" file, which makes it even harder to track which agent is being used, and which is specific to Buck, and thus cannot be used in OSS by other agents.
- Even if the TensorPipe fixture doesn't use TEST_CONFIG, it still needs to set it to the right value for other parts of the code to work. (This is done in `dist_init`).
- There are a few functions in dist_utils.py that return some properties of the agent (e.g., a regexp to match against the error it returns in case of shutdown). These functions are effectively chained if/elses on the various agents, which has the effect of "leaking" some part of the Thrift agent into OSS.
- Each test suite (RPC, dist autograd/dist optimizer, their JIT versions, remote module, ...) must be run on each agent (or almost; the faulty one is an exception) in both fork and spawn mode. Each of these combinations is a separate file, which leads to a proliferation of scripts.
- There is no "master list" of what combinations make sense and should be run. Therefore it has happened that when adding new tests or new agents we forgot to enroll them into the right tests. (TensorPipe is still missing a few tests, it turns out).
- All of these tiny "entry point" files contain almost the same duplicated boilerplate. This makes it very easy to get the wrong content into one of them due to a bad copy-paste.
This refactoring aims to address these problems by:
- Avoiding global state, defaults/override, traps, if/elses, ... and have a single way to specify the agent, based on an abstract base class and several concrete subclasses which can be "mixed in" to any test suite.
- Instead of enabling/disabling tests using decorators, the tests that are specific to a certain agent are now in a separate class (which is a subclass of the "generic" test suite) so that they are only picked up by the agent they apply to.
- Instead of having one separate entry point script for each combination, it uses one entry point for each agent, and in that script it provides a list of all the test suites it wants to run on that agent. And it does that by trying to deduplicate the boilerplate as much as possible. (In fact, the various agent-suite combinations could be grouped in any way, not necessarily by agent as I did here).
It provides further advantages:
- It puts all the agents on equal standing, by not having any of them be the default, making it thus easier to migrate from process group to TensorPipe.
- It will make it easier to add more versions of the TensorPipe tests (e.g., one that disables the same-machine backends in order to test the TCP-based ones) without a further duplication of entry points, of boilerplate, ...
Summary of this commit
--
This prepares the stack by simplifying the TensorPipe fixture. A comment says that the TensorPipe fixture cannot subclass the generic fixture class as that would lead to a diamond class hierarchy which Python doesn't support (whereas in fact it does), and therefore it copies over two properties that are defined on the generic fixture. However, each class that uses the TensorPipe fixture also inherits from the generic fixture, so there's no need to redefine those properties. And, in fact, by not redefining it we save ourselves some trouble when the TensorPipe fixture would end up overriding another override.
ghstack-source-id: 107045914
Test Plan: Sandcastle and CircleCI
Differential Revision: D22287533
fbshipit-source-id: 254c38b36ba51c9d852562b166027abacbbd60ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40860
It turns out that the `@_skip_if_tensorpipe_agent` decorator was written in such a way that it accidentally caused the test to become a no-op (and thus always succeed) for all agents. What this means is that all tests wrapped by that decorator were never ever being run, for any agent.
My understanding of the root cause is that the following code:
```
@_skip_if_tensorpipe_agent
def test_foo(self):
self.assertEqual(2 + 2, 4)
```
ended up behaving somewhat like this:
```
def test_foo(self):
def original_test_func(self):
self.assertEqual(2 + 2, 4)
return unittest.skipIf(self.agent == "TENSORPIPE")(original_test_func)
```
which means that the test body of the decorated method was not actually calling the original test method.
This issue probably came from the `@_skip_if_tensorpipe_agent` being copy-pasted from `requires_process_group_agent` (which, however, is not a decorator but rather a decorator *factory*). An unfortunate naming (calling `decorator` what was in fact the wrapped method) then hindered readability and hid the issue.
Note that a couple of tests had become legitimately broken in the meantime and no one had noticed. The breakages have been introduced in #39909 (a.k.a., D22011868 (145df306ae)).
ghstack-source-id: 107045916
Test Plan: Discovered this as part of my refactoring, in D22332611. After fixing the decorator two tests started breaking (for real reasons). After fixing them all is passing.
Differential Revision: D22332611
fbshipit-source-id: f88ca5574675fdb3cd09a9f6da12bf1e25203a14
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40865
1. applied filter for the module types
2. removed the assumption that the conv bn are immediate child of parent module
Test Plan:
python test/test_quantization.py TestQuantizeJitPasses
Imported from OSS
Differential Revision: D22338074
fbshipit-source-id: 64739a5e56c0a74249a1dbc2c8454b88ec32aa9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40743
`aten::append` modifies input inplace and the output is ignored, these ops are not
supported right now, so we'll need to first make `aten::append` non-inplace
by change
```
ignored = aten::append(list, x)
```
to
```
x_list = aten::ListConstruct(x)
result = aten::add(list, x_list)
```
and then quantize the aten::add instead.
Test Plan:
TestQuantizeJitOps.test_general_shape_ops
Imported from OSS
Differential Revision: D22302151
fbshipit-source-id: 931000388e7501e9dd17bec2fad8a96b71a5efc5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40199
Mobile custom selective build has already been covered by `test/mobile/custom_build/build.sh`.
It builds a CLI binary with host-toolchain and runs on host machine to
check correctness of the result.
But that custom build test doesn't cover the android/gradle build part.
And we cannot use it to measure and track the in-APK size of custom
build library.
So this PR adds the selective build test coverage for android NDK build.
Also integrate with the CI to upload the custom build size to scuba.
TODO:
Ideally it should build android/test_app and measure the in-APK size.
But the test_app hasn't been covered by any CI yet and is currently
broken, so build & measure AAR instead (which can be inaccurate as we
plan to pack C++ header files into AAR soon).
Sample result: https://fburl.com/scuba/pytorch_binary_size/skxwb1gh
```
+---------------------+-------------+-------------------+-----------+----------+
| build_mode | arch | lib | Build Num | Size |
+---------------------+-------------+-------------------+-----------+----------+
| custom-build-single | armeabi-v7a | libpytorch_jni.so | 5901579 | 3.68 MiB |
| prebuild | armeabi-v7a | libpytorch_jni.so | 5901014 | 6.23 MiB |
| prebuild | x86_64 | libpytorch_jni.so | 5901014 | 7.67 MiB |
+---------------------+-------------+-------------------+-----------+----------+
```
Test Plan: Imported from OSS
Differential Revision: D22111115
Pulled By: ljk53
fbshipit-source-id: 11d24efbc49a85f851ecd0e481d14123f405b3a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40188
Create a custom command for this task to avoid copy/paste for new build jobs.
Test Plan: Imported from OSS
Differential Revision: D22111114
Pulled By: ljk53
fbshipit-source-id: a7d4d6bbd61ba6b6cbaa137ec7f884736957dc39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40661
Add ser-de to support int8 quantization during online training
Test Plan:
```
buck test caffe2/caffe2/fb/fbgemm:int8_serializer_test
```
Reviewed By: hx89
Differential Revision: D22273292
fbshipit-source-id: 3b1e9c820243acf41044270afce72a262ef92bd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40646
Support double, float, at::Half.
Avoid creating output result on CPU.
Both of two tensors must be on GPU.
Reviewed By: ngimel
Differential Revision: D22258840
fbshipit-source-id: 95f4747477f09b40b1d682cd1f76e4c2ba28c452
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40920
Pytorch depends on this from both C and C++ source files, so unify linking so it's fully fixed.
Test Plan: Build it on Windows
Reviewed By: dreiss, supriyar
Differential Revision: D22348247
fbshipit-source-id: 2933b4804f4725ab1742914656fa367527f8f7e1
Summary: Namespacing the symbol, since it clashes with "the real thing" otherwise.
Test Plan: Sandcastle + build it on windows
Reviewed By: dreiss
Differential Revision: D22348240
fbshipit-source-id: f9c9a7abc97626ba327605cb4749fc5c38a24d35
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40925
normalization operator does not handle empty tensors correctly. This is a fix.
Test Plan: unit tests
Differential Revision: D22330340
fbshipit-source-id: 0bccf925bb768ebb997ed0c88130c5556308087f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40872
Shape hints as its name suggests, is hint. We should use real shape from workspace for the weights.
Reviewed By: ChunliF
Differential Revision: D22337680
fbshipit-source-id: e7a6101fb613ccb332c3e34b1c2cb8c6c47ce79b
Summary:
## TLDR
Support using NaN default value for missing dense features in RawInputProcessor for DPER2. In preparation for subsequent support for null flag features in compute meta. For train_eval this is already supported in DPER3 and we do not plan to support this in DPER2 train eval.
## Overview
Intern project plan to support adding dense flags for missing feature values instead of replacing with zero.
## Project plan :
https://docs.google.com/document/d/1OsPUTjpJycwxWLCue3Tnb1mx0uDC_2KKWvC1Rwpo2NI/edit?usp=sharing
## Code paths:
See https://fb.quip.com/eFXUA0tbDmNw for the call stack for all affected code paths.
Test Plan:
## fblearner flow test
1. `flow-cli clone f197867430 --run-as-secure-group ads_personalization_systems --force-build` to build a ephemeral package and start a fblearner flow run (may fail)
2. Clone the new run and change the secure_group to `XXXX` and entitlement to `default` in the UI
3. Adds explicit_null_min_coverage flag
4. Optionally reduce `max_examples` since we only test pass/fail instead of quality.
5. Submit the run to test the change
Example:
f198538878
## compare output coverages to daiquery runs
1. Randomly select null flag features from compute meta workflow output
2. Look up the feature id in feature metadata using feature name
3. Check against a daiquery sample of coverage to see if the coverage falls within guidelines.
https://www.internalfb.com/intern/daiquery/workspace/275342740223489/192619942076136/
## Sampled features:
GFF_C66_ADS_USER_SUM_84_PAGE_TYPE_RATIO_EVENT_LIKE_IMPRESSION: 15694257
- original feature compute meta coverage: 0.999992
- daiquery feature coverage (10k rows): 0.69588
- null flag compute meta coverage: 0.293409
GFF_R1303_ADS_USER_SUM_7_PAGE_TYPE_COUNTER_CONVERSION: 16051183
- original feature compute meta coverage: 0.949868
- daiquery feature coverage: 0.82241
- null flag compute meta coverage: 0.151687
## Unit tests:
`buck test fblearner/flow/projects/dper/tests/workflows:ads_test`
https://www.internalfb.com/intern/testinfra/testconsole/testrun/6192449504303863/
Differential Revision: D22026450
fbshipit-source-id: 46c59d849fa89253f14dc2b035c4c677cd6e3a4c
Summary:
Move Storage class from __init__.pyi.in to types.py and make it a protocol, since this is not a real class
Expose `PyTorchFileReader` and `PyTorchFileWriter` native classes
Ignore function attributes, as there are yet no good way to type annotate those, see https://github.com/python/mypy/issues/2087
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40862
Differential Revision: D22344743
Pulled By: malfet
fbshipit-source-id: 95cdb6f980ee79383960f306223e170c63df3232
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40885
`TracingState::setValue` associates a concrete IValue in the traced
program with a `Value*` symbolic. Previously, the logic for how
GenericDicts worked was special cased to only work for very simple cases
and silently eat other cases.
This PR generalizes the logic to reflect the same behavior as using
dictionaries on input: whenever we encounter a dictionary in the system,
we completely "burn in" all the keys into the graph, and then
recursively call `setValue` on the associated value.
This has the effect of requiring that any dictionary structure you are
creating in a traced program be of fixed structure, similar to how any
dictionary used as input must be static as well.
Test Plan: Imported from OSS
Differential Revision: D22342490
Pulled By: suo
fbshipit-source-id: 93e610a4895d61d9b8b19c8d2aa4e6d57777eaf6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40649
The original implementation of RemoveOpsByType is pretty buggy and does not remove all instances of the ops that should be removed. It's also quite complicated and hard to modify. I reimplemented it by first converting the graph to its SSA form. The algorithm is quite simple once the graph is in SSA form. It's very similar to constant propagation with a few modifications. The hardest part is to deal with the case of removing an op with the output being an output of the predict net, because that output has to be preserved.
(Note: this ignores all push blocking failures!)
Reviewed By: yinghai, dzhulgakov
Differential Revision: D22220798
fbshipit-source-id: faf6ed5242f1e2f310125d964738c608c6c55c94
Summary:
This PR introduces a warning when user tries to export the model to ONNX in training-amenable mode while constant folding is turned on. We want to warn against any unintentional use because constant folding may fold some parameters that may be intended to be trainable in the exported model.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40546
Reviewed By: hl475
Differential Revision: D22310917
Pulled By: houseroad
fbshipit-source-id: ba83b8e63af7c458b5ecca8ff2ee1c77e2064f90
Summary:
Right now it is used to check whether `math.remainder` exists, which is the case for both Python-3.7 and 3.8
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40868
Differential Revision: D22343454
Pulled By: malfet
fbshipit-source-id: 6b6d4869705b64c4b952309120f92c04ac7e39fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38257
It seems we're doing a runtime type check for custom classes on each operator call if the operator has custom class arguments.
This does not have an effect on operators without custom class arguments, but this is a problem for operators with custom class arguments,
for example operators taking a at::native::xnnpack::Conv2dOpContext argument.
The long term solution would be to move those checks to op registration time instead of doing them at call time,
but as an intermediate fix, we can at least make the check fast by
- Using ska::flat_hash_map instead of std::unordered_map
- Using std::type_index instead of std::string (i.e. avoid calling std::hash on a std::string)
ghstack-source-id: 106805209
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D21507226
fbshipit-source-id: bd120d5574734be843c197673ea4222599fee7cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40876
clang format reducer.cpp
ghstack-source-id: 106980050
Test Plan: unit test
Differential Revision: D22321422
fbshipit-source-id: 54afdff206504c7bbdf2e408928cc32068e15cdc
Summary:
Moving this to a file that can be source by downstream pytorch/xla.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40828
Reviewed By: malfet
Differential Revision: D22339513
Pulled By: ailzhang
fbshipit-source-id: c43b18fa2b7e1e8bb6810a6a43bb7dccd4756238
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40585
This PR aborts incomplete NCCL Communicators in the ProcessGroupNCCL
destructor. This should prevent pending NCCL communicators from blocking other CUDA ops.
ghstack-source-id: 106988073
Test Plan: Sandcastle/ OSS CI
Differential Revision: D22244873
fbshipit-source-id: 4b4fe65e1bd875a50151870f8120498193d7535e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40709
Cast to kHalf and back to kFloat before the linear operator to mimic FP16 quant support
Test Plan:
python test/test_quantization.py test_convert_dynamic_fp16
Imported from OSS
Differential Revision: D22335977
fbshipit-source-id: f964128ec733469672a1ed4cb0d757d0a6c22c3a
Summary:
If virtual function is implemented in header file, it's implementation will be included as a weak symbol to every shared library that includes this header along with all of it's dependencies.
This was one of the reasons why size of libcaffe2_module_test_dynamic.so was 500Kb (AddRelatedBlobInfo implementation pulled a quarter of libprotobuf.a with it)
Combination of this and https://github.com/pytorch/pytorch/issues/40845 reduces size of `libcaffe2_module_test_dynamic.so` from 500kb to 50Kb.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40844
Differential Revision: D22334725
Pulled By: malfet
fbshipit-source-id: 836a4cbb9f344355ddd2512667e77472546616c0
Summary:
… file
This prevents implementation of those functions(as lambdas) to be embedded as weak symbol into every shared library that includes this header.
Combination of this and https://github.com/pytorch/pytorch/pull/40844 reduces size of `libcaffe2_module_test_dynamic.so` from 500kb to 50Kb.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40845
Differential Revision: D22334779
Pulled By: malfet
fbshipit-source-id: 64706918fc2947350a58c0877f294b1b8b085455
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40830Fixes#40725
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22323886
Pulled By: ezyang
fbshipit-source-id: b8a61496923d9f086d4c201024748505ba783238
Summary:
Apologize if this seems trivial, but i'd like to fix them on my way of reading some of the source code. Thanks!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40692
Differential Revision: D22284651
Pulled By: mrshenli
fbshipit-source-id: 4259d1808aa4d15a02cfd486cfb44dd75fdc58f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40758
Currently we flip a coin for each sampled callback each time
we run RecordFunction, this PR is an attempt to skip most of the coin
flips (for the low-probability observers) and keep the distribution
close to the original one
Test Plan:
CI and record_function_benchmark
```
(python_venv) iliacher@devgpu151:~/local/pytorch (reduce_coin_flops)$ ./build/bin/record_function_benchmark
Warmup time: 30108 us.
Time per iteration (1x1): 1496.78 us.
Time per iteration (16x16): 2142.46 us.
Pure RecordFunction runtime of 10000000 iterations 687929 us, number of callback invocations: 978
(python_venv) iliacher@devgpu151:~/local/pytorch (reduce_coin_flops)$ ./build/bin/record_function_benchmark
Warmup time: 19051 us.
Time per iteration (1x1): 1581.89 us.
Time per iteration (16x16): 2195.67 us.
Pure RecordFunction runtime of 10000000 iterations 682402 us, number of callback invocations: 1023
(python_venv) iliacher@devgpu151:~/local/pytorch (reduce_coin_flops)$ ./build/bin/record_function_benchmark
Warmup time: 18715 us.
Time per iteration (1x1): 1566.11 us.
Time per iteration (16x16): 2131.17 us.
Pure RecordFunction runtime of 10000000 iterations 693571 us, number of callback invocations: 963
(python_venv) iliacher@devgpu151:~/local/pytorch (reduce_coin_flops)$
(python_venv) iliacher@devgpu151:~/local/pytorch (reduce_coin_flops)$ ./build/bin/record_function_benchmark
Warmup time: 18814 us.
Time per iteration (1x1): 1536.2 us.
Time per iteration (16x16): 1985.82 us.
Pure RecordFunction runtime of 10000000 iterations 944959 us, number of callback invocations: 1015
(python_venv) iliacher@devgpu151:~/local/pytorch (reduce_coin_flops)$ ./build/bin/record_function_benchmark
Warmup time: 18278 us.
Time per iteration (1x1): 1526.32 us.
Time per iteration (16x16): 2093.77 us.
Pure RecordFunction runtime of 10000000 iterations 985307 us, number of callback invocations: 1013
(python_venv) iliacher@devgpu151:~/local/pytorch (reduce_coin_flops)$ ./build/bin/record_function_benchmark
Warmup time: 18545 us.
Time per iteration (1x1): 1524.65 us.
Time per iteration (16x16): 2080 us.
Pure RecordFunction runtime of 10000000 iterations 952835 us, number of callback invocations: 1048
```
Reviewed By: dzhulgakov
Differential Revision: D22320879
Pulled By: ilia-cher
fbshipit-source-id: 2193f07d2f7625814fe7bc3cc85ba4092fe036bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40792
Fixes https://github.com/pytorch/pytorch/issues/40529.
One followup should be to produce a better error message when a new
dictionary has different keys than the traced input. Right now it
presents as a fairly opaque `KeyError`.
Test Plan: Imported from OSS
Differential Revision: D22311731
Pulled By: suo
fbshipit-source-id: c9fbe0b54cf69daed2f11a191d988568521a3932
Summary:
This directory is opted-in to clang-format but is not format-clean. This blocks continuous formatting from being enabled on fbcode, and causes hassle for other codemods that leave inconsistent formatting. This diff runs clang-format, which is widely used and considered safe.
If you are unhappy with the formatting of a particular block, please *accept this diff* and then in a stacked commit undo the change and wrap that code in `// clang-format off` and `// clang-format on`, or `/* clang-format off */` and `/* clang-format on */`.
drop-conflicts
Test Plan: sandcastleit
Reviewed By: jerryzh168
Differential Revision: D22311706
fbshipit-source-id: 1ca59a82e96156a4a5dfad70ba3e64d44c5e762a
Summary:
Allow np.memmap objects to be processed by default_collate
np.memmap objects has the same behavior as numpy arrays, and the only difference is that they are stored in a binary file on the disk. However, the default_collate function used by PyTorch DataLoader only accepts np.array, and rejects np.memmap by type checking. This commit allows np.memmap objects to be processed by default_collate. In this way, users can use in-disk large arrays with PyTorch DataLoader.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39847
Reviewed By: ezyang
Differential Revision: D22284650
Pulled By: zou3519
fbshipit-source-id: 003e3208a2afd1afc2e4640df14b3446201e00b4
Summary: Use the newly added counter op in sparse adagrad
Reviewed By: chocjy, ellie-wen
Differential Revision: D19221100
fbshipit-source-id: d939d83e3b5b3179f57194be2e8864d0fbbee2c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40727
This unit test doesn't need to initialize a PG, as a result avoiding
initializing a process group.
#Closes: https://github.com/pytorch/pytorch/issues/40292
ghstack-source-id: 106817362
Test Plan: waitforbuildbot
Differential Revision: D22295131
fbshipit-source-id: 5a60e91e4beeb61cc204d24c564106d0215090a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40788
Avoid repeated the same `:gencode[foo/bar]` over and over again
Test Plan: CI
Reviewed By: EscapeZero
Differential Revision: D22271151
fbshipit-source-id: f8db57db4ee0948bcca0c8945fdf30380ba81cae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40802
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22317343
Pulled By: ezyang
fbshipit-source-id: 8a982dd93a28d102dfd63163cd44704e899922e0
Summary:
This is the prototype for the modular utils that we've been discussing. It is admittedly a large PR, but a good fraction of that is documentation and examples. I've trimmed a bit on the edges since we last discussed this design (for instance Timer is no longer Fuzzer aware), but it's mostly the same.
In addition to the library and hermetic examples, I've included `examples.end_to_end` which tests https://github.com/pytorch/pytorch/pull/38061 over a variety of shapes, dtypes, degrees of broadcasting, and layouts. (CC crcrpar) I only did CPU as I'm not set up on a GPU machine yet. [Results from my devserver](https://gist.github.com/robieta/d1a8e1980556dc3f4f021c9f7c3738e2)
Key takeaways:
1) For contiguous Tensors, larger dtypes (fp32 and fp64) and lots of reuse of the mask due to broadcasting, improvements are significant. (Presumably due to better vectorization?)
2) There is an extra ~1.5 us overhead, which dominates small kernels.
3) Cases with lower write intensity (int8, lower mask fraction, etc) or non-contiguous seem to suffer.
Hopefully this demonstrates the proof-of-concept for how this tooling can be used to tune kernels and assess PRs. Looking forward to thoughts and feedback.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38338
Differential Revision: D21551048
Pulled By: robieta
fbshipit-source-id: 6c50e5439a04eac98b8a2355ef731852ba0500db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40513
This PR makes the following changes:
1. Complex Printing now uses print formatting for it's real and imaginary values and they are joined at the end.
2. Adding 1. naturally fixes the printing of complex tensors in sci_mode=True
```
>>> torch.tensor(float('inf')+float('inf')*1j)
tensor(nan+infj)
>>> torch.randn(2000, dtype=torch.cfloat)
tensor([ 0.3015-0.2502j, -1.1102+1.2218j, -0.6324+0.0640j, ...,
-1.0200-0.2302j, 0.6511-0.1889j, -0.1069+0.1702j])
>>> torch.tensor([1e-3, 3+4j, 1e-5j, 1e-2+3j, 5+1e-6j])
tensor([1.0000e-03+0.0000e+00j, 3.0000e+00+4.0000e+00j, 0.0000e+00+1.0000e-05j,
1.0000e-02+3.0000e+00j, 5.0000e+00+1.0000e-06j])
>>> torch.randn(3, dtype=torch.cfloat)
tensor([ 1.0992-0.4459j, 1.1073+0.1202j, -0.2177-0.6342j])
>>> x = torch.tensor([1e2, 1e-2])
>>> torch.set_printoptions(sci_mode=False)
>>> x
tensor([ 100.0000, 0.0100])
>>> x = torch.tensor([1e2, 1e-2j])
>>> x
tensor([100.+0.0000j, 0.+0.0100j])
```
Test Plan: Imported from OSS
Differential Revision: D22309294
Pulled By: anjali411
fbshipit-source-id: 20edf9e28063725aeff39f3a246a2d7f348ff1e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40753
The reference says that this op always returns a 1-D tensor, even if
the input and the mask are 0-D.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D22300354
Pulled By: ZolotukhinM
fbshipit-source-id: f6952989c8facf87d73d00505bf6d41573eff2d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40576
`out_dims` specifies where in the output tensors the vmapped dimension
should appear. We implement this by simply creating a view with the
batch dimension moved to the desired position.
`out_dims` must either:
- be int (use the same value for all outputs)
- be Tuple[int] (so the user specifies one out_dim per output).
(See the vmap docstring for what we advertise out_dims to do).
I also renamed `TestVmap` to `TestVmapAPI` to make it clearer that we
are testing the API here and not specific operators (which will go into
their own test class).
Test Plan: - `pytest test/test_vmap.py -v`
Differential Revision: D22288086
Pulled By: zou3519
fbshipit-source-id: c8666cb1a0e22c54473d8045477e14c2089167cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40575
This provides some more context for the next ~2 PRs that will implement
the `out_dims` and `in_dims` functionality. I will probably add more to
it later (things I think we should add: examples (maybe in a dedicated
docs page), specific examples of things vmap cannot handle).
Test Plan:
- Code reading for now. When we are ready to add vmap to master documentation,
I'll build the docs and fix any formatting problems.
Differential Revision: D22288085
Pulled By: zou3519
fbshipit-source-id: 6e28d7bd524242395160c20270159b4b121d6789
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40728
there are two reasons the test is failing:
1) div by 0
2) result is bigger than fp16 max
for 1) make the divisor some safe number like 1e-3
2) when a combination of random numbers results in their resulting value bigger than 65e3, clip
multiplication is fine because range of random numbers is 0,100 -> result is 0->10000
Test Plan: ran tes_div test
Reviewed By: hl475
Differential Revision: D22295934
fbshipit-source-id: 173f3f2187137d6c1c4d4a505411a27f1c059f1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39763
This is an ask from fluent. For performance reasons, they need a way to get read access to the std::string inside of a torch::List<std::string> without having to copy that string.
Instead of special casing std::string, we decided to give access to the underlying value. The API now looks like:
```cpp
torch::List<std::string> list = ...;
const std::string& str = list[2].toIValueRef().toStringRef();
```
ghstack-source-id: 106806840
Test Plan: unit tests
Reviewed By: ezyang
Differential Revision: D21966183
fbshipit-source-id: 8b80b0244d10215c36b524d1d80844832cf8b69a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40720
Add support for populating domain_discrete field in TensorBoard add_hparams API
Test Plan: Unit test test_hparams_domain_discrete
Reviewed By: edward-io
Differential Revision: D22291347
fbshipit-source-id: 78db9f62661c9fe36cd08d563db0e7021c01428d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37034
c10 takes a Stack* in boxed functions while JIT took Stack&.
c10 doesn't return anything while JIT returns an int which is always zero.
This changes JIT to follow the c10 behavior.
ghstack-source-id: 106834069
Test Plan: unit tests
Differential Revision: D20567950
fbshipit-source-id: 1a7aea291023afc52ae706957e9a5ca576fbb53b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40247
This CI job was bypassed on PR because most part of it has already been
covered by mobile-custom-build-dynamic job that runs on every PR.
However, it can still fail independently because it builds and analyzes
a small test project, e.g.: if people forget to update the registration API
used in the test project.
So this PR changed it to only build and analyze the test project and run
the job on every PR.
Test Plan: Imported from OSS
Differential Revision: D22126044
Pulled By: ljk53
fbshipit-source-id: 6699a200208a65b249bd3a4e43ad72bc07388ce3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40588
Two bugs were preventing this from working. One was a divide by zero
when multithreading was enabled, fixed similarly to the fix for static
quantized linear in the previous commit. The other was computation of
min and max to determine qparams. FBGEMM uses [0,0] for [min,max] of
empty input, do the same.
Test Plan: Added a unit test.
Differential Revision: D22264415
Pulled By: dreiss
fbshipit-source-id: 6ca9cf48107dd998ef4834e5540279a8826bc754
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40587
Previously, this was causing divide-by-zero only in the multithreaded
empty-batch case, while calculating tiling parameters for the threads.
In my opinion, the bug here is using a value that is allowed to be zero
(batch size) for an argument that should not be zero (tile size), so I
fixed the bug by bailing out right before the call to
pthreadpool_compute_4d_tiled.
Test Plan: TestQuantizedOps.test_empty_batch
Differential Revision: D22264414
Pulled By: dreiss
fbshipit-source-id: 9446d5231ff65ef19003686f3989e62f04cf18c9
Summary:
This PR implements gh-33389.
As a result of this PR, users can now specify various reduction modes for scatter operations. Currently, `add`, `subtract`, `multiply` and `divide` have been implemented, and adding new ones is not hard.
While we now allow dynamic runtime selection of reduction modes, the performance is the same as as was the case for the `scatter_add_` method in the master branch. Proof can be seen in the graph below, which compares `scatter_add_` in the master branch (blue) and `scatter_(reduce="add")` from this PR (orange).
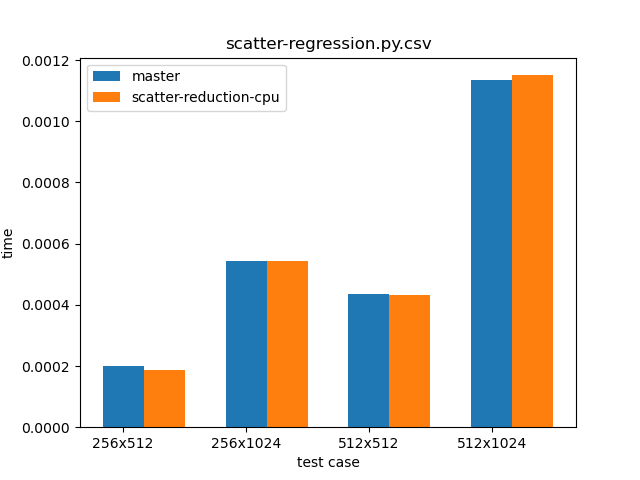
The script used for benchmarking is as follows:
``` python
import os
import sys
import torch
import time
import numpy
from IPython import get_ipython
Ms=256
Ns=512
dim = 0
top_power = 2
ipython = get_ipython()
plot_name = os.path.basename(__file__)
branch = sys.argv[1]
fname = open(plot_name + ".csv", "a+")
for pM in range(top_power):
M = Ms * (2 ** pM)
for pN in range(top_power):
N = Ns * (2 ** pN)
input_one = torch.rand(M, N)
index = torch.tensor(numpy.random.randint(0, M, (M, N)))
res = torch.randn(M, N)
test_case = f"{M}x{N}"
print(test_case)
tobj = ipython.magic("timeit -o res.scatter_(dim, index, input_one, reduce=\"add\")")
fname.write(f"{test_case},{branch},{tobj.average},{tobj.stdev}\n")
fname.close()
```
Additionally, one can see that various reduction modes take almost the same time to execute:
```
op: add
70.6 µs ± 27.3 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
26.1 µs ± 26.5 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
op: subtract
71 µs ± 20.5 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
26.4 µs ± 34.4 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
op: multiply
70.9 µs ± 31.5 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
27.4 µs ± 29.3 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
op: divide
164 µs ± 48.8 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
52.3 µs ± 132 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
Script:
``` python
import torch
import time
import numpy
from IPython import get_ipython
ipython = get_ipython()
nrows = 3000
ncols = 10000
dims = [nrows, ncols]
res = torch.randint(5, 10, dims)
idx1 = torch.randint(dims[0], (1, dims[1])).long()
src1 = torch.randint(5, 10, (1, dims[1]))
idx2 = torch.randint(dims[1], (dims[0], 1)).long()
src2 = torch.randint(5, 10, (dims[0], 1))
for op in ["add", "subtract", "multiply", "divide"]:
print(f"op: {op}")
ipython.magic("timeit res.scatter_(0, idx1, src1, reduce=op)")
ipython.magic("timeit res.scatter_(1, idx2, src2, reduce=op)")
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36447
Differential Revision: D22272631
Pulled By: ngimel
fbshipit-source-id: 3cdb46510f9bb0e135a5c03d6d4aa5de9402ee90
Summary:
Set PYTORCH_ROCM_ARCH to `gfx900;gfx906` if `CIRCLECI` environment variable is defined
Add RocM build test jobs and schedule them on `xlarge` and `amd-gpu` resource classes respectively.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39760
Differential Revision: D22290335
Pulled By: malfet
fbshipit-source-id: 7462f97b262abcacac3e515086ac6236a45626d2
Summary:
By default freeze_module pass, invoked from optimize_for_mobile,
preserves only forward method. There is an option to specify a list of
methods that can be preserved during freeze_module. This PR exposes that
to optimize_for_module pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40629
Test Plan: python test/test_mobile_optimizer.py
Reviewed By: dreiss
Differential Revision: D22260972
Pulled By: kimishpatel
fbshipit-source-id: 452c653269da8bb865acfb58da2d28c23c66e326
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40673
As title. We planed to have lite-interpreter and full-jit co-exist for short-term. To avoid the duplicated symbol and operator registrations in dynamic lib loading, we put the common files in a separate component.
The original source file list names are reserved.
ghstack-source-id: 106757184
Test Plan: CI
Reviewed By: kwanmacher
Differential Revision: D22276185
fbshipit-source-id: 328a8ba9c3d88437da0d30c6e6791087d0df5e2e
Summary: Add support for populating domain_discrete field in TensorBoard add_hparams API
Test Plan: Unit test test_hparams_domain_discrete
Reviewed By: edward-io
Differential Revision: D22227939
fbshipit-source-id: d2f0cd8e5632cbcc578466ff3cd587ee74f847af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40660
Support custom run_name since using timestamp as run_name can be confusing to people
Test Plan:
hp = {"lr": 0.1, "bool_var": True, "string_var": "hi"}
mt = {"accuracy": 0.1}
writer.add_hparams(hp, mt, run_name="run1")
writer.flush()
Reviewed By: edward-io
Differential Revision: D22157749
fbshipit-source-id: 3d4974381e3be3298f3e4c40e3d4bf20e49dfb07
Summary: This reverts a change that was made to fix range loop analysis warning.
Test Plan: CI
Reviewed By: nlutsenko
Differential Revision: D22274461
fbshipit-source-id: dedc3fcaa6e32259460380163758d6c9c9b73211
Summary:
Also modernize the test script itself by using `mypy.api.run` rather than `subprocess.call`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40656
Differential Revision: D22274421
Pulled By: malfet
fbshipit-source-id: 59232d4d37ee01cda56375b84ac1476d16686bfe
Summary:
Remove `skipIfRocm` from most jit tests and enable `RUN_CUDA_HALF` tests for ROCm.
These changes passed more than three rounds of CI testing against the ROCm CI.
CC ezyang xw285cornell sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40447
Differential Revision: D22190711
Pulled By: xw285cornell
fbshipit-source-id: bac44825a2675d247b3abe2ec2f80420a95348a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40624
Previously we didn't clone schema, so the default schema is used, this is
causing issue for some models
Test Plan: Imported from OSS
Differential Revision: D22259519
fbshipit-source-id: e2a393a54cb18f55da0c7152a74ddc22079ac350
Summary:
1. In reducer.cpp, we have a new boolean `find_unused_param_` and its value is set in `Reducer::prepare_for_backward`.
If `!find_unused_param_`, then it avoids `allreduce(local_used_maps_dev_)`.
2. Solves issue [38942](https://github.com/pytorch/pytorch/issues/38942).
3. Fixes incorrect `find_unused_parameters_` passing like checking `outputs.empty()` or `unused_parameters_.empty()`.
ghstack-source-id: 106693089
Test Plan:
1. Run `test/distributed/test_c10d.py` and make sure all tests pass.
2. A new test case `test_find_unused_parameters_when_unused_parameters_empty` is included. Old `reducer.cpp` was failing in that unit test because it was checking `find_unused_parameters_` by `unused_parameters_.empty()`. Current `reducer.cpp` passes this unit test.
3. Two test cases were failing `test_forward_backward_unused_parameters` and `test_forward_backward_optimizer` , because `find_unused_parameter_` of their `reducer` object was not set properly. I fixed that as well.
Imported from OSS
**Output of version 14:**
```
................s.....s...............................................test/distributed/test_c10d.py:1531: UserWarning: Deprecation warning: In a future PyTorch release torch.full will no longer return tensors of floating dtype by default. Instead, a bool fill_value will return a tensor of torch.bool dtype, and an integral fill_value will return a tensor of torch.long dtype. Set the optional `dtype` or `out` arguments to suppress this warning. (Triggered internally at ../aten/src/ATen/native/TensorFactories.cpp:364.)
tensor = torch.full([100, 100], self.rank)
test/distributed/test_c10d.py:1531: UserWarning: Deprecation warning: In a future PyTorch release torch.full will no longer return tensors of floating dtype by default. Instead, a bool fill_value will return a tensor of torch.bool dtype, and an integral fill_value will return a tensor of torch.long dtype. Set the optional `dtype` or `out` arguments to suppress this warning. (Triggered internally at ../aten/src/ATen/native/TensorFactories.cpp:364.)
tensor = torch.full([100, 100], self.rank)
test/distributed/test_c10d.py:1531: UserWarning: Deprecation warning: In a future PyTorch release torch.full will no longer return tensors of floating dtype by default. Instead, a bool fill_value will return a tensor of torch.bool dtype, and an integral fill_value will return a tensor of torch.long dtype. Set the optional `dtype` or `out` arguments to suppress this warning. (Triggered internally at ../aten/src/ATen/native/TensorFactories.cpp:364.)
tensor = torch.full([100, 100], self.rank)
test/distributed/test_c10d.py:1531: UserWarning: Deprecation warning: In a future PyTorch release torch.full will no longer return tensors of floating dtype by default. Instead, a bool fill_value will return a tensor of torch.bool dtype, and an integral fill_value will return a tensor of torch.long dtype. Set the optional `dtype` or `out` arguments to suppress this warning. (Triggered internally at ../aten/src/ATen/native/TensorFactories.cpp:364.)
tensor = torch.full([100, 100], self.rank)
.test/distributed/test_c10d.py:1554: UserWarning: Deprecation warning: In a future PyTorch release torch.full will no longer return tensors of floating dtype by default. Instead, a bool fill_value will return a tensor of torch.bool dtype, and an integral fill_value will return a tensor of torch.long dtype. Set the optional `dtype` or `out` arguments to suppress this warning. (Triggered internally at ../aten/src/ATen/native/TensorFactories.cpp:364.)
self.assertEqual(torch.full([10, 10], self.world_size), tensor)
test/distributed/test_c10d.py:1554: UserWarning: Deprecation warning: In a future PyTorch release torch.full will no longer return tensors of floating dtype by default. Instead, a bool fill_value will return a tensor of torch.bool dtype, and an integral fill_value will return a tensor of torch.long dtype. Set the optional `dtype` or `out` arguments to suppress this warning. (Triggered internally at ../aten/src/ATen/native/TensorFactories.cpp:364.)
self.assertEqual(torch.full([10, 10], self.world_size), tensor)
test/distributed/test_c10d.py:1554: UserWarning: Deprecation warning: In a future PyTorch release torch.full will no longer return tensors of floating dtype by default. Instead, a bool fill_value will return a tensor of torch.bool dtype, and an integral fill_value will return a tensor of torch.long dtype. Set the optional `dtype` or `out` arguments to suppress this warning. (Triggered internally at ../aten/src/ATen/native/TensorFactories.cpp:364.)
self.assertEqual(torch.full([10, 10], self.world_size), tensor)
test/distributed/test_c10d.py:1554: UserWarning: Deprecation warning: In a future PyTorch release torch.full will no longer return tensors of floating dtype by default. Instead, a bool fill_value will return a tensor of torch.bool dtype, and an integral fill_value will return a tensor of torch.long dtype. Set the optional `dtype` or `out` arguments to suppress this warning. (Triggered internally at ../aten/src/ATen/native/TensorFactories.cpp:364.)
self.assertEqual(torch.full([10, 10], self.world_size), tensor)
.....s...............................
----------------------------------------------------------------------
Ran 108 tests in 214.210s
OK (skipped=3)
```
Differential Revision: D22176231
fbshipit-source-id: b5d15f034e13a0915a474737779cc5aa8e068836
Summary:
## TLDR
Support using NaN default value for missing dense features in RawInputProcessor for *DPER2*. In preparation for subsequent support for null flag features in *compute meta*. For train_eval this is already supported in DPER3 and we do not plan to support this in DPER2 train eval.
## Overview
Intern project plan to support adding dense flags for missing feature values instead of replacing with zero.
Project plan :
https://docs.google.com/document/d/1OsPUTjpJycwxWLCue3Tnb1mx0uDC_2KKWvC1Rwpo2NI/edit?usp=sharing
## Code paths:
See https://fb.quip.com/eFXUA0tbDmNw for the call stack for all affected code paths.
Test Plan:
# A. DPER3 blob value inspection
## 1. Build local bento kernel in fbcode folder
`buck build mode/dev-nosan //bento/kernels:bento_kernel_ads_ranking`
## 2. Use kernel `ads_ranking (local)` to print dense feature blob values
n280239
## 2.1 Try `default_dense_value = "0.0"` (default)
```
preproc_6/feature_preproc_6/dper_feature_processor_7/raw_input_proc_7/float_feature_sparse_to_dense_7/float_features [[0. ]
[0. ]
[0. ]
[0. ]
[0. ]
[0. ]
[0. ]
[1. ]
[1.7857143]
[1.7777778]
[1. ]
[0. ]
[0.5625 ]
[0. ]
[0. ]
[0.8 ]
[0. ]
[1. ]
[0.56 ]
[0. ]]
```
## 2.2 Try `default_dense_value = "123"`
```
preproc_2/feature_preproc_2/dper_feature_processor_3/raw_input_proc_3/float_feature_sparse_to_dense_3/float_features [[123. ]
[123. ]
[123. ]
[123. ]
[123. ]
[123. ]
[123. ]
[ 1. ]
[ 1.7857143]
[ 1.7777778]
[ 1. ]
[123. ]
[ 0.5625 ]
[123. ]
[123. ]
[ 0.8 ]
[123. ]
[ 1. ]
[ 0.56 ]
[123. ]]
```
## 2.3 Try `default_dense_value = float("nan")`
```
RuntimeError: [enforce fail at enforce_finite_op.h:40] std::isfinite(input_data[i]). Index 0 is not finite (e.g., NaN, Inf): -nan (Error from operator:
input: "unary_4/logistic_regression_loss_4/average_loss_4/average_loss" name: "" type: "EnforceFinite" device_option { random_seed: 54 })
```
which is expected due to nan input.
# B. Unit test
`buck test fblearner/flow/projects/dper/tests/preprocs:raw_feature_extractor_test`
https://www.internalfb.com/intern/testinfra/testconsole/testrun/5348024586274923/
{F241336814}
Differential Revision: D21961595
fbshipit-source-id: 3dcb153b3c7f42f391584f5e7f52f3d9c76de31f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39459
Update to this PR: this code isn't going to fully solve https://github.com/pytorch/pytorch/issues/37010. The changes required for 37010 is more than this PR initially planned. Instead, this PR switches op registration of rng related tests to use the new API (similar to what was done in #36925)
Test Plan:
1) unit tests
Imported from OSS
Reviewed By: ezyang
Differential Revision: D22264889
fbshipit-source-id: 82488ac6e3b762a756818434e22c2a0f9cb9dd47
Summary:
This replicates the pattern of other "do for luck" commands.
Prep change to add RocM to CircleCI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40631
Differential Revision: D22261707
Pulled By: malfet
fbshipit-source-id: 3dadfa434deab866a8800715f3197e84169cf43e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37055
Sometimes it's okay to bundle a large example input tensor with a model.
Add a utility function to make it easy for users to do that *on purpose*.
Test Plan: Unit test.
Differential Revision: D22264239
Pulled By: dreiss
fbshipit-source-id: 05c6422be1aa926cca850f994ff1ae83c0399119
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36764
This allows bundling inputs that are large uniform buffers in
channels-last memory format.
Test Plan: Unit test.
Differential Revision: D21142660
Pulled By: dreiss
fbshipit-source-id: 31bbea6586d07c1fd0bcad4cb36ed2b8bb88a7e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40611
This commit removes a dead store in `transformWith` of exit_transforms.cpp.
Test Plan: Continuous integration.
Reviewed By: suo
Differential Revision: D22254136
fbshipit-source-id: f68c4625f7be8ae29b3500303211b2299ce5d6f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40614
This update pulls in a oneliner fix, which sets the TCP_NODELAY option on the TCP sockets of the UV transport. This leads to exceptional performance gains in terms of latency, with about a 25x improvement in one simple benchmark. This thus resolves a regression that TensorPipe had compared to the ProcessGroup agent and, in fact, ends up beating it by 2x.
The benchmark I ran is this, with the two endpoints pinned to different cores of the same machine:
```
torch.jit.script
def remote_fn(t: int):
return t
torch.jit.script
def local_fn():
for _ in range(1_000_000):
fut = rpc.rpc_async("rhs", remote_fn, (42,))
fut.wait()
```
And the average round-trip time (one iteration) is:
- TensorPipe with SHM: 97.2 us
- TensorPipe with UV _after the fix_: 205us
- Gloo: 440us
- TensorPipe with UV _before the fix_: 5ms
Test Plan: Ran PyTorch RPC test suite
Differential Revision: D22255393
fbshipit-source-id: 3f6825d03317d10313704c05a9280b3043920507
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40584
Also patch [this github issue](https://github.com/pytorch/pytorch/issues/33124)
involving an illegal assembly instruction in 8x8-dq-aarch64-neon.S.
Test Plan:
Build binaries, copy to shaker, run executables. Also run all
existing caffe tests.
Reviewed By: kimishpatel
Differential Revision: D22240670
fbshipit-source-id: 51960266ce58699fe6830bcf75632b92a122f638
Summary:
Switch windows CPU testers from `windows.xlarge` to `windows.medium` class.
Remove VS 14.16 CUDA build
Only do smoke force-on-cpu tests using VS2019+CUDA10.1 config.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40592
Differential Revision: D22259351
Pulled By: malfet
fbshipit-source-id: f934ff774dfc7d47f12c3da836ca314c12d92208
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/38555
I did an audit of `native_functions.yaml` and found several functions in addition to `reshape` which were not reporting that they could alias:
```
torch.jit.script
def foo(t: torch.Tensor):
new_value = torch.tensor(1, dtype=t.dtype, device=t.device)
t.flatten()[0] = new_value
t.reshape(-1)[1] = new_value
t.view_as(t)[2] = new_value
t.expand_as(t)[3] = new_value
t.reshape_as(t)[4] = new_value
t.contiguous()[5] = new_value
t.detach()[6] = new_value
return t
```
Currently none of the values are assigned after dead code elimination, after this PR all are. (And the JIT output matches that of eager.)
I don't think this needs to be unit tested; presumably the generic machinery already is and this just brings these ops under the same umbrella.
**BC-breaking note**: This updates the native operator schema and the aliasing rules for autograd. JIT passes will no longer incorrectly optimize mutations on graphs containing these ops, and inplace ops on the result of `flatten` will now properly be tracked in Autograd and the proper backward graph will be created.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39794
Differential Revision: D22008358
Pulled By: robieta
fbshipit-source-id: 9d3ff536e58543211e08254a75c6110f2a3b4992
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40512
Fixes https://github.com/pytorch/pytorch/issues/32454
The heart of this diff is changing this:
```
inline const KernelFunction& Dispatcher::dispatch_(const DispatchTable& dispatchTable, DispatchKey dispatchKey) c
nst {
const KernelFunction* backendKernel = dispatchTable.lookup(dispatchKey);
if (nullptr != backendKernel) {
return *backendKernel;
}
const auto& backendFallbackKernel = backendFallbackKernels_[dispatchKey];
if (backendFallbackKernel.isValid()) {
return backendFallbackKernel;
}
const KernelFunction* catchallKernel = dispatchTable.lookupCatchallKernel();
if (C10_LIKELY(nullptr != catchallKernel)) {
return *catchallKernel;
}
reportError(dispatchTable, dispatchKey);
}
```
to this:
```
const KernelFunction& OperatorEntry::lookup(DispatchKey k) const {
const auto& kernel = dispatchTable_[static_cast<uint8_t>(k)];
if (C10_UNLIKELY(!kernel.isValid())) {
reportError(k);
}
return kernel;
}
```
The difference is that instead of checking a bunch of places to find the
right kernel to use for an operator, all of the operators are
precomputed into dispatchTable_ itself (so you don't have to consult
anything else at runtime.) OperatorEntry::computeDispatchTableEntry
contains that computation (which is exactly the same as it was before.)
By doing this, we are able to substantially simplify many runtime
components of dispatch.
The diff is fairly large, as there are also some refactors interspersed
with the substantive change:
- I deleted the DispatchTable abstraction, folding it directly into
OperatorEntry. It might make sense to have some sort of DispatchTable
abstraction (if only to let you do operator[] on DispatchKey without
having to cast it to integers first), but I killed DispatchTable to
avoid having to design a new abstraction; the old abstraction wasn't
appropriate for the new algorithm.
- I renamed OperatorEntry::KernelEntry to AnnotatedKernel, and use it
to store backend fallbacks as well as regular kernel registrations
(this improves error messages when you incorrectly register a backend
fallback twice).
- I moved schema_ and debug_ into an AnnotatedSchema type, to make the
invariant clearer that these are set together, or not at all.
- I moved catch-all kernels out of kernels_ into its own property
(undoing a refactor I did before). The main reason I did this was
because our intended future state is to not have a single catch-all,
but rather possibly multiple catch-alls which fill-in different
portions of the dispatch table. This may change some more in
the future: if we allow registrations for multiple types of
catch alls, we will need a NEW data type (representing bundles
of dispatch keys) which can represent this case, or perhaps
overload DispatchKey to also record these types.
The key changes for precomputation:
- OperatorEntry::updateDispatchTable_ is now updated to fill in the
entry at a DispatchKey, considering both kernels (what it did
before) as well as catch-all and backend fallback. There is also
OperatorEntry::updateDispatchTableFull_ which will update the
entire dispatch table (which is necessary when someone sets a
catch-all kernel). OperatorEntry::computeDispatchTableEntry
holds the canonical algorithm specifying how we decide what
function will handle a dispatch key for the operator.
- Because dispatch table entry computation requires knowledge of
what backend fallbacks are (which is recorded in Dispatcher,
not OperatorEntry), several functions on OperatorEntry now
take Dispatcher as an argument so they can query this information.
- I modified the manual boxing wrapper invariant: previously, kernels
stored in kernels_ did NOT have manual boxing wrappers and this
was maintained by DispatchTable. Now, we just ALWAYS maintain
manual boxing wrappers for all KernelFunctions we store.
- DispatchKeyExtractor is greatly simplified: we only need to maintain
a single per-operator bitmask of what entries are fallthrough
(we don't need the global bitmask anymore).
- Introduced a new debugging 'dumpComputedTable' method, which prints
out the computed dispatch table, and how we computed it to be some way.
This was helpful for debugging cases when the dispatch table and
the canonical metadata were not in sync.
Things that I didn't do but would be worth doing at some point:
- I really wanted to get rid of the C10_UNLIKELY branch for
whether or not the KernelFunction is valid, but it looks like
I cannot easily do this while maintaining good error messages.
In principle, I could always populate a KernelFunction which
errors, but the KernelFunction needs to know what the dispatch
key that is missing is (this is not passed in from the
calling convention). Actually, it might be possible to do
something with functors, but I didn't do it here.
- If we are going to get serious about catchalls for subsets of
operators, we will need to design a new API for them. This diff
is agnostic to this question; we don't change public API at all.
- Precomputation opens up the possibility of subsuming DispatchStub
by querying CPU capability when filling in the dispatch table.
This is not implemented yet. (There is also a mild blocker here,
which is that DispatchStub is also used to share TensorIterator
configuration, and this cannot be directly supported by the
regular Dispatcher.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22236352
Pulled By: ezyang
fbshipit-source-id: d6d90f267078451816b1899afc3f79737b4e128c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40469
- The old testing interface C._dispatch_import was based off the old
c10::import variation, which meant the API lined up in a strange
way with the actual torch/library.h. This diff reduces the
differences by letting you program the Library constructor directly.
- Using this newfound flexibility, we add a test for backend fallbacks
from Python; specifically testing that we disallow registering a
backend fallback twice.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22236351
Pulled By: ezyang
fbshipit-source-id: f8365e3033e9410c7e6eaf9f78aa32e1f7d55833
Summary:
Remove `-std=c++14` flag from `utils.cmake`, since PyTorch C++ API can be invoked by any compiler compliant with C++14 standard or later
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40510
Differential Revision: D22253313
Pulled By: malfet
fbshipit-source-id: ff731525868b251c27928fc98b0724080ead9be2
Summary:
1. Modularize some bzl files to break circular buck load
2. Use query-based on instrumentation_tests
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: kwanmacher
Differential Revision: D22188728
fbshipit-source-id: affbabd333c51c8b1549af6602c6bb79fabb7236
Summary:
std::complex is gone. We are now using c10::complex
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39830
Differential Revision: D22252066
Pulled By: malfet
fbshipit-source-id: cdd5bb03ec66825d82177d609cbcf0738922dba0
Summary:
edit: apparently we hardcode a lot more versions that I would've anticipated.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40519
Differential Revision: D22221280
Pulled By: seemethere
fbshipit-source-id: ba15a910a6755ec08c10f7783ed72b1e06e6b570
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40596
Previously the fusion patterns for {add/mul}_scalar is inconsistent since the op pattern
produces a non-quantized tensor and the op replacement graph produces a quantized tensor
Test Plan: Imported from OSS
Differential Revision: D22251072
fbshipit-source-id: e16eb92cf6611578cca1ed8ebde961f8d0610137
Summary: Adding python test file with image files wit the input image being p.jpg. Test for the quality difference between the raw image and the decoded image
Test Plan:
Parsing buck files: finished in 1.5 sec
Building: finished in 6.4 sec (100%) 10241/10241 jobs, 2 updated
Total time: 8.0 sec
More details at https://www.internalfb.com/intern/buck/build/387cb1c1-2902-4f90-ae9f-83fb6d473487
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: 93e6ef88-ec68-41cb-9de7-7868a14e6d65
Trace available for this run at /tmp/tpx-20200623-055836.283269/trace.log
Started reporting to test run: https://our.intern.facebook.com/intern/testinfra/testrun/4222124679431330
✓ ListingSuccess: caffe2/test:test_bundled_images - main (18.865)
✓ Pass: caffe2/test:test_bundled_images - test_single_tensors (test_bundled_images.TestBundledInputs) (18.060)
✓ Pass: caffe2/test:test_bundled_images - main (18.060)
Summary
Pass: 2
ListingSuccess: 1
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/4222124679431330
Reviewed By: dreiss
Differential Revision: D22046611
fbshipit-source-id: fabc604269a5a4d8a37135ce776200da2794a252
Summary:
Related to https://github.com/pytorch/pytorch/issues/40397
Inspired by ezyang's comment at https://github.com/pytorch/pytorch/issues/40397#issuecomment-648233001, this PR attempts to leverage using `__all__` to explicitly export private functions from `_VariableFunctions.pyi` in order to make `mypy` aware of them after:
```
if False:
from torch._C._VariableFunctions import *
```
The generation of the `__all__` template variable excludes some items from `unsorted_function_hints`, as it seems that those without hints end up not being explicitly included in the `.pyi` file: I leaned on the side of caution and opted for having `__all__` consistent with the definitions inside the file. Additionally, added some pretty-printing to avoid having an extremely long line.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40499
Differential Revision: D22240716
Pulled By: ezyang
fbshipit-source-id: 77718752577a82b1e8715e666a8a2118a9d3a1cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40528
Previously, an assignment like `self.foo : List[int] = []` would ignore
the type hint.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D22222927
Pulled By: suo
fbshipit-source-id: b0af19b87c6fbe0670d06b55f2002a783d00549d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40076
Pull Request resolved: https://github.com/pytorch/glow/pull/4606
[PyPer][quant] Add quantized embedding operators to OSS.
This is the first step in supporting Graph Mode Quantization for EmbeddingBag.
At a high level, the next steps would be
a) Implementation of Embedding prepack/unpack operators,
b) Implementation of torch.nn.quantized.dynamic.EmbeddingBag Module,
c) Implementation of torch.nn.quantized.EmbeddingBag Module,
d) Implementation (modification) of IR passes to support graph quantization of EmbeddingBag module.
More in-depth details regarding each step will be in the follow up diffs. Consider this as an initial diff that moves operators to respective places that's required for us to proceed.
Test Plan: ```buck test mode/no-gpu caffe2/test:quantization -- --stress-runs 100 test_embedding_bag```
Reviewed By: supriyar
Differential Revision: D21949828
fbshipit-source-id: cad5ed0a855db7583bddb1d93e2da398c128024a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40554
Get a sublist of `libtorch_python_cuda_sources` named `libtorch_python_cuda_core_sources`. Use it to replace the list which has the same content in `CMakeList.txt`.
This is a change to make consistency between CMakeList and bazel.
Test Plan: CI
Reviewed By: malfet
Differential Revision: D22223207
fbshipit-source-id: 2bde3c42a0b2d60d689581561075df4ef52ab694
Summary:
This code path is used to read tensor bodies, so we need it to respect
alignment and padding requirements.
Test Plan: Ran an internal test that was failing.
Reviewed By: zdevito
Differential Revision: D22225622
fbshipit-source-id: f2126727f96616366850642045ab9704f3885824
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40518
I overlooked this in the initial vmap frontend api PR. Right now we
want to restrict vmap to taking in functions that only return Tensors.
A function that only return tensors can look like one of the following:
```
def fn1(x):
...
return y
def fn2(x):
...
return y, z
```
fn1 returns a Tensor, while fn2 returns a tuple of Tensors. So we add a
check that the output of the function passed to vmap returns either a
single tensor or a tuple of tensors.
NB: These checks allow passing a function that returns a tuple with a
single-element tensor from vmap. That seems OK to me.
Test Plan: - `python test/test_vmap.py -v`
Differential Revision: D22216166
Pulled By: zou3519
fbshipit-source-id: a92215e9c26f6138db6b10ba81ab0c2c2c030929
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40517
This is necessary for implementing the vmap frontend API's out_dims
functionality.
Test Plan:
- `./build/bin/vmap_test`. The vmap python API can't accept inputs that
aren't integers right now. There are workarounds around that (use a
lambda) but that doesn't look too nice. In the future we'll test all
batching rules in Python.
Differential Revision: D22216168
Pulled By: zou3519
fbshipit-source-id: b6ef552f116fddc433e242c1594059b9d2fe1ce4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40455
These don't need to be implemented right now but are useful later down
the line. I thought I would use these in implementing vmap's `out_dims`
functionality, but it turns out they weren't necessary. Since the code
exists and is useful anyways, I am leaving this PR here.
Test Plan:
- `./build/bin/vmap_test`. We could test this using the vmap frontend API,
but there is the catch that vmap cannot directly take integers right
now (all inputs passed to vmap must be Tensors at the moment). It's
possible to hack around that by declaring lambdas that take in a single
tensor argument, but those don't look nice.
Differential Revision: D22216167
Pulled By: zou3519
fbshipit-source-id: 1a010f5d7784845cca19339d37d6467f5b987c32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40549
Currently we didn't check if %weight_t is produced by `aten::t`, this will fuse some `matmul`/`addmm` that is
not 2d to `aten::linear`, which is incorrect
Test Plan: Imported from OSS
Differential Revision: D22225921
fbshipit-source-id: 9723e82fdbac6d8e1a7ade22f3a9791321ab12b6
Summary: `-Wrange-loop-analysis` is turned on by default for clang 10 (see https://reviews.llvm.org/D73834). This fixes a warning that's found with that.
Test Plan: Build with clang 10 and check there are no `range-loop-analysis` warnings.
Reviewed By: yinghai
Differential Revision: D22207072
fbshipit-source-id: 858ba8a36c653071eab961cb891ce945faf0fa87
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40504
Make CUDA mem liek test not flaky
Test Plan: python test/test_profiler.py
Differential Revision: D22215527
Pulled By: ilia-cher
fbshipit-source-id: 5f1051896342ac50cd3a21ea86ce7487b5f82a19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40533
These ops are required by the demucs denoiser model
Test Plan: build
Reviewed By: kaustubh-kp, linbinyu
Differential Revision: D22216217
fbshipit-source-id: f300ac246fe3a7a6566a70bb89858770af68a90c
Summary:
These were changes that had to be made in the `release/1.6` branch in order to get backups to work.
They should be brought to the master branch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40515
Differential Revision: D22221308
Pulled By: seemethere
fbshipit-source-id: 24e2a0196a8e775fe324a383c8f0c681118b741b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/38716, fixes https://github.com/pytorch/pytorch/issues/37234
This algorithm does the summation along a single axis with multiple "levels" of accumulator, each of which is designed to hold the sum of an order of magnitude more values than the previous.
e.g. if there are 2^16 elements, the first level will hold the sum of 2^4 elements, and so on in increasing powers of 2: 2^4, 2^8, 2^12 and finally 2^16.
This limits the differences in magnitude of the partial results being added together, and so we don't lose accuracy as the axis length increases.
WIP to write a vectorized version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39516
Reviewed By: ezyang
Differential Revision: D22106251
Pulled By: ngimel
fbshipit-source-id: b56de4773292439dbda62b91f44ff37715850ae9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40495
As part of debugging flaky ddp_under_dist_autograd tests, I realized
we were running into the following deadlock.
1) Rank 0 would go into DDP construction, hold GIL and wait for broadcast in
DDP construction.
2) Rank 3 is a little slower and performs an RRef fetch call before the DDP
construction.
3) The RRef fetch call is done on Rank 0 and tries to acquire GIL.
4) We now have a deadlock since Rank 0 is waiting for Rank 3 to enter the
collective and Rank 3 is waiting for Rank 0 to release GIL.
ghstack-source-id: 106534442
Test Plan:
1) Ran ddp_under_dist_autograd 500 times.
2) waitforbuildbot
Differential Revision: D22205180
fbshipit-source-id: 6afd55342e801b9edb9591ff25158a244a8ea66a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40525
Move `USE_CUDNN` define under `USE_CUDA` guard, add `cuda/shared/cudnn.cpp` to filelist if either USE_ROCM or USE_CUDNN is set.
This is a prep change for PyTorch CUDA src filelist unification change.
Test Plan: CI
Differential Revision: D22214899
fbshipit-source-id: b71b32fc603783b41cdef0e7fab2cc9cbe750a4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40424
dictConstruct should preserve the inputs order
Test Plan: Imported from OSS
Differential Revision: D22202690
Pulled By: wanchaol
fbshipit-source-id: c313b531b7fa49e6f3486396d61bfc5d6400cd01
Summary:
https://github.com/pytorch/pytorch/issues/24697
VitalyFedyunin
glaringlee
Test script:
```Python
import timeit
setup_ones = """
import torch
a = torch.ones(({n}, {n}), dtype={dtype})
b = torch.ones(({n}, {n}), dtype={dtype})
"""
for n, t in [(1000, 10000), (2000, 10000)]:
for dtype in ('torch.bool', 'torch.int', 'torch.long', 'torch.bfloat16', 'torch.float', 'torch.double'):
#for dtype in ('torch.bool', 'torch.int', 'torch.long', 'torch.float', 'torch.double'):
print('torch.ones(({n}, {n})) equal for {t} times {dtype}'.format(n=n, t=t, dtype=dtype))
print(timeit.timeit(stmt='torch.equal(a, b)', setup=setup_ones.format(n=n, dtype=dtype), number=t))
setup_rand = """
import torch
a = torch.rand(({n}, {n}), dtype={dtype})
b = a.clone()
"""
for n, t in [(1000, 10000), (2000, 10000)]:
for dtype in ('torch.float', 'torch.double'):
print('torch.rand(({n}, {n})) for {t} times {dtype}'.format(n=n, t=t, dtype=dtype))
print(timeit.timeit(stmt='torch.equal(a, b)', setup=setup_rand.format(n=n, dtype=dtype), number=t))
setup_non_contiguous = """
import torch
a = torch.rand(({n}, {n}), dtype={dtype})
a2 = a[:, 500:]
a3 = a2.clone()
torch.equal(a2, a3)
"""
for n, t in [(1000, 10000), (2000, 10000)]:
for dtype in ('torch.float', 'torch.double'):
print('non_contiguous torch.rand(({n}, {n})) for {t} times {dtype}'.format(n=n, t=t, dtype=dtype))
print(timeit.timeit(stmt='torch.equal(a2, a3)', setup=setup_non_contiguous.format(n=n, dtype=dtype), number=t))
setup_not_equal = """
import torch
a = torch.rand(({n}, {n}), dtype={dtype})
b = torch.rand(({n}, {n}), dtype={dtype})
torch.equal(a, b)
"""
for n, t in [(1000, 10000), (2000, 10000)]:
for dtype in ('torch.float', 'torch.double'):
print('not equal torch.rand(({n}, {n})) for {t} times {dtype}'.format(n=n, t=t, dtype=dtype))
print(timeit.timeit(stmt='torch.equal(a, b)', setup=setup_not_equal.format(n=n, dtype=dtype), number=t))
```
TH
```
torch.ones((1000, 1000)) equal for 10000 times torch.bool
1.8391206220258027
torch.ones((1000, 1000)) equal for 10000 times torch.int
1.8877864250680432
torch.ones((1000, 1000)) equal for 10000 times torch.long
1.938108820002526
torch.ones((1000, 1000)) equal for 10000 times torch.bfloat16
3.184849138953723
torch.ones((1000, 1000)) equal for 10000 times torch.float
1.8825413499725983
torch.ones((1000, 1000)) equal for 10000 times torch.double
2.7266416549682617
torch.ones((2000, 2000)) equal for 10000 times torch.bool
7.227149627986364
torch.ones((2000, 2000)) equal for 10000 times torch.int
7.76215292501729
torch.ones((2000, 2000)) equal for 10000 times torch.long
9.631909006042406
torch.ones((2000, 2000)) equal for 10000 times torch.bfloat16
8.097328286035918
torch.ones((2000, 2000)) equal for 10000 times torch.float
5.5739822529722005
torch.ones((2000, 2000)) equal for 10000 times torch.double
8.444009944912978
torch.rand((1000, 1000)) for 10000 times torch.float
1.168096570065245
torch.rand((1000, 1000)) for 10000 times torch.double
1.6577326939441264
torch.rand((2000, 2000)) for 10000 times torch.float
5.49395391496364
torch.rand((2000, 2000)) for 10000 times torch.double
8.507486199960113
non_contiguous torch.rand((1000, 1000)) for 10000 times torch.float
6.074504268006422
non_contiguous torch.rand((1000, 1000)) for 10000 times torch.double
6.1426916810451075
non_contiguous torch.rand((2000, 2000)) for 10000 times torch.float
37.501055537955835
non_contiguous torch.rand((2000, 2000)) for 10000 times torch.double
44.6880351039581
not equal torch.rand((1000, 1000)) for 10000 times torch.float
0.029356416082009673
not equal torch.rand((1000, 1000)) for 10000 times torch.double
0.025421109050512314
not equal torch.rand((2000, 2000)) for 10000 times torch.float
0.026333761983551085
not equal torch.rand((2000, 2000)) for 10000 times torch.double
0.02748022007290274
```
ATen
```
torch.ones((1000, 1000)) equal for 10000 times torch.bool
0.7961567062884569
torch.ones((1000, 1000)) equal for 10000 times torch.int
0.49172434909269214
torch.ones((1000, 1000)) equal for 10000 times torch.long
0.9459248608909547
torch.ones((1000, 1000)) equal for 10000 times torch.bfloat16
2.0877483217045665
torch.ones((1000, 1000)) equal for 10000 times torch.float
0.606857153121382
torch.ones((1000, 1000)) equal for 10000 times torch.double
1.1388208279386163
torch.ones((2000, 2000)) equal for 10000 times torch.bool
2.0329296849668026
torch.ones((2000, 2000)) equal for 10000 times torch.int
3.534358019940555
torch.ones((2000, 2000)) equal for 10000 times torch.long
8.19841272290796
torch.ones((2000, 2000)) equal for 10000 times torch.bfloat16
6.595649406313896
torch.ones((2000, 2000)) equal for 10000 times torch.float
4.193911510054022
torch.ones((2000, 2000)) equal for 10000 times torch.double
7.931309659034014
torch.rand((1000, 1000)) for 10000 times torch.float
0.8877940969541669
torch.rand((1000, 1000)) for 10000 times torch.double
1.4142901846207678
torch.rand((2000, 2000)) for 10000 times torch.float
4.010025603231043
torch.rand((2000, 2000)) for 10000 times torch.double
8.126411964651197
non_contiguous torch.rand((1000, 1000)) for 10000 times torch.float
0.602473056409508
non_contiguous torch.rand((1000, 1000)) for 10000 times torch.double
0.6784545010887086
non_contiguous torch.rand((2000, 2000)) for 10000 times torch.float
3.0991827426478267
non_contiguous torch.rand((2000, 2000)) for 10000 times torch.double
5.719010795000941
not equal torch.rand((1000, 1000)) for 10000 times torch.float
0.046060710679739714
not equal torch.rand((1000, 1000)) for 10000 times torch.double
0.036034489050507545
not equal torch.rand((2000, 2000)) for 10000 times torch.float
0.03686975734308362
not equal torch.rand((2000, 2000)) for 10000 times torch.double
0.04189508780837059
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33286
Differential Revision: D22211962
Pulled By: glaringlee
fbshipit-source-id: a5c48f328432c1996f28e19bc75cb495fb689f6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40405
This adds a finishAndThrow function that completes the work object,
sets an exception if one is provided by the user, and throws an exception (if
it is already set or passed by the caller). This is now done by grabbing the
lock just once and simplifies the wait functions in ProcessGroupGloo.
ghstack-source-id: 106516114
Test Plan: CI
Differential Revision: D22174890
fbshipit-source-id: ea74702216c4328187c8d193bf39e1fea43847f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40404
Adds docs to the finish function in ProcessGroup::Work. It's better to have some documentation around these functions since we have some PR's with API-changes/optimizations for these work-level functions here and in the subclasses.
ghstack-source-id: 106381736
Test Plan: CI (Docs change only)
Differential Revision: D22174891
fbshipit-source-id: 7901ea3b35caf6f69f37178ca574104d3412de28
Summary:
PyTorch should stop polluting global namespace with symbols such as `ERROR` `WARNING` and `INFO`.
Since `logging_is_not_google_glog.h` is a C++ header, define severity levels in namespace and add `GLOG_` prefix to match an unshortened glog severity levels.
Change `LOG` and `LOG_IF` macros to use prefix + namespaced severity levels.
Closes https://github.com/pytorch/pytorch/issues/40083
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40491
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D22210925
Pulled By: malfet
fbshipit-source-id: 0ec1181a53baa8bca2f526f245e398582304aeab
Summary:
BC NOTE:
This change makes it so modules saved with torch.jit.save in PyTorch 1.6 can be loaded by previous versions of PyTorch unless they use torch.div or (soon) torch.full. It also lets tensors saved using torch.save be loaded by previous versions. So this is the opposite of BC-breaking, but I'm using that label to highlight this issue since we don't have a "BC-improving" label.
PR NOTE:
When an operator's semantics change in PyTorch we want to do two things:
1) Preserve the semantics of older serialized Torchscript programs that use the operator
2) Ensure the new semantics are respected
Historically, this meant writing a Versioned Symbol that would remap older versions of the operator into current PyTorch code (1), and bumping the produced file format version (2). Unfortunately, bumping the produced file format version is a nuclear option for ensuring semantics are respected, since it also prevents older versions of PyTorch from loading anything (even tensors!) from newer versions.
Dynamic versioning addresses the nuclear consequences of bumping the produced file format version by only bumping it when necessary. That is, when an operator with changed semantics is detected in the serialized Torchscript. This will prevent Torchscript programs that use the changed operator from loading on earlier versions of PyTorch, as desired, but will have no impact on programs that don't use the changed operator.
Note that this change is only applicable when using torch.jit.save and torch.jit.load. torch.save pickles the given object using pickle (by default), which saves a function's Python directly.
No new tests for this behavior are added since the existing tests for versioned division in test_save_load already validate that models with div are loaded correctly at version 4.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40279
Reviewed By: dzhulgakov
Differential Revision: D22168291
Pulled By: mruberry
fbshipit-source-id: e71d6380e727e25123c7eedf6d80e5d7f1fe9f95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40115
Closes https://github.com/pytorch/pytorch/issues/37790
Closes https://github.com/pytorch/pytorch/issues/37944
A user may wish to run DDP's forward + backwards step under a non-default CUDA stream such as those created by `with torch.cuda.Stream(stream)`. In this case, the user should be responsible for synchronizing events on this stream with other streams used in the program (per the documentation at https://pytorch.org/docs/stable/notes/cuda.html#cuda-semantics), but currently DDP has a bug which causes DDP under non-default streams to fail.
If a user does the following:
```
model = DDP(...)
loss = model(inptut).sum()
loss.backward()
grad = model.module.weight.grad()
average = dist.all_reduce(grad)
```
There is a chance that `average` and `grad` will not be equal. This is because the CUDA kernels corresponding to the `all_reduce` call may run before `loss.backward()`'s kernels are finished. Specifically, in DDP we copy the allreduced gradients back to the model parameter gradients in an autograd engine callback, but this callback runs on the default stream. Note that this can also be fixed by the application synchronizing on the current stream, although this should not be expected, since the application is not using the current stream at all.
This PR fixes the issue by passing the current stream into DDP's callback.
Tested by adding a UT `test_DistributedDataParallel_non_default_stream` that fails without this PR
ghstack-source-id: 106481208
Differential Revision: D22073353
fbshipit-source-id: 70da9b44e5f546ff8b6d8c42022ecc846dff033e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40494
Resubmit the diff because D22124313 (1ec4337b7d) was reverted due to CI test failures
Added the int8_gen_quant_params.cc to CMakeList.txt to fix the CI failures
Test Plan: buck test caffe2/caffe2/quantization/server:
Reviewed By: hx89
Differential Revision: D22204244
fbshipit-source-id: a2c8b668f199cc5b0c5894086f554f7c459b1ad7
Summary:
Currently, even if USE_OPENMP is turned off, ATEN_THEADING can still use OpenMP. This commit fixes it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40146
Reviewed By: ezyang
Differential Revision: D22208758
Pulled By: pbelevich
fbshipit-source-id: 0866c9bb9b3b5b99d586aed176eb0fbe177efa4a
Summary:
Should close https://github.com/pytorch/pytorch/issues/35810.
I decided to keep sparse handling on the Python side for clarity, although it could be moved to the C++ side (into `_amp_non_finite_check_and_unscale_`) without much trouble.
For non-fp16 sparse grads the logic is simple (call `_amp_non_finite_check_and_unscale_` on `grad._values()`) instead of `grad` itself. At least I hope it's that easy.
For fp16 sparse grads, it's tricker. Sparse tensors can be uncoalesced. From the [Note](https://pytorch.org/docs/master/sparse.html#torch.sparse.FloatTensor):
> Our sparse tensor format permits uncoalesced sparse tensors, where there may be duplicate coordinates in the indices; in this case, the interpretation is that the value at that index is the sum of all duplicate value entries.
An uncoalesced scaled fp16 grad may have values at duplicate coordinates that are all finite but large, such that adding them to make the coalesced version WOULD cause overflows.** If I checked `_values()` on the uncoalesced version, it might not report overflows, but I think it should.
So, if the grad is sparse, fp16, and uncoalesced, I still call `_amp_non_finite_check_and_unscale_` to unscale `grad._values()` in-place, but I also double-check the coalesced version by calling a second `_amp_non_finite_check_and_unscale_` on `grad.coalesce()._values()`. `coalesce()` is out-of-place, so this call doesn't redundantly affect `grad._values()`, but it does have the power to populate the same `found_inf` tensor. The `is_coalesced()` check and `coalesce()` probably aren't great for performance, but if someone needs a giant embedding table in FP16, they're better than nothing and memorywise, they'll only create a copy of nnz gradient values+indices, which is still way better than changing the whole table to FP32.
An `unscale` variant with liberty to create unscaled grads out-of-place, and replace `param.grad` instead of writing through it, could get away with just one `_amp_non_finite_check_and_unscale_`. It could say `coalesced = grad.coalesced()`, do only the stronger `_amp_non_finite_check_and_unscale_` on `coalesced._values()`, and set `param.grad = coalesced`. I could even avoid replacing `param.grad` itself by going one level deeper and setting `param.grad`'s indices and values to `coalesced`'s, but that seems brittle and still isn't truly "in place".
** you could whiteboard an uncoalesced fp32 grad with the same property, but fp32's range is big enough that I don't think it's realistic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36786
Reviewed By: ezyang
Differential Revision: D22202832
Pulled By: ngimel
fbshipit-source-id: b70961a4b6fc3a4c1882f65e7f34874066435735
Summary:
Partial support for slicing of Sequential containers.
- works around missing Sequential slice functionality
by converting to tuple
- only supports iteration of resulting tuple values,
not direct call() on the sliced sequential
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40445
Differential Revision: D22192469
Pulled By: wconstab
fbshipit-source-id: 61c85deda2d58f6e3bea2f1fa1d5d5dde568b9b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40172
This PR introduces the initial vmap frontend API. It has the following
limitations that we can resolve in the future:
- the inputs must be a flat list of tensors
- the outputs must be a flat list of tensors
- in_dims = 0 (so we always vmap over dim 0 of input tensors)
- out_dims = 0 (so the returned tensors have their vmap dim appear at
dim 0)
- Coverage limited to operations that have batching rules implemented
(torch.mul, torch.sum, torch.expand).
There are some other semantic limitations (like not being able to handle
mutation, aside from pytorch operations that perform mutation) that will
be documented in the future.
I wanted to introduce the API before adding a slow fallback for the
coverage so that we can test future batching rules (and coverage) via
the python API to avoid verbosity in C++-land.
The way vmap works is that `vmap(func)(inputs)` wraps all Tensor inputs
to be batched in BatchedTensors, sends those into func, and then unwraps
the output BatchedTensors. Operations on BatchedTensors perform the batched
operations that the user is asking for. When performing nested vmaps,
each nested vmap adds a batch dimension upon entry and removes a batch
dimension on exit.
Coming up in the near future:
- Support for non-zero in_dims and out_dims
- docstring for vmap
- slow fallback for operators that do not have a batching rule
implemented.
Test Plan: - `pytest test/test_vmap.py -v`
Differential Revision: D22102076
Pulled By: zou3519
fbshipit-source-id: b119f0a8a3a3b1717c92dbbd180dfb1618295563
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40171
It checks that all of the bdims in BatchedTensorImpl are sorted in
order of ascending `level`.
Test Plan: - Check that nothing breaks in `./build/bin/vmap_test`
Differential Revision: D22102077
Pulled By: zou3519
fbshipit-source-id: 094b7abc6c65208437f0f51a0d0083091912decc
Summary:
This is just a minor doc fix:
the `MarginRankingLoss` takes 2 input samples `x1` and `x2`, not just `x`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40285
Reviewed By: ezyang
Differential Revision: D22195069
Pulled By: zou3519
fbshipit-source-id: 909f491c94dca329a37216524f4088e9096e0bc6
Summary: [WIP] Logit Fake16 Op
Test Plan: [WIP] Tests will be enabled in test_op_nnpi_fp16.py file.
Reviewed By: hyuen
Differential Revision: D22109329
fbshipit-source-id: fd73850c3ec61375ff5bbf0ef5460868a874fbf3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40475
As title
ghstack-source-id: 106474870
Test Plan: CI
Differential Revision: D22200640
fbshipit-source-id: 1f4c7bbf54be8c4187c9338fefdf14b501597d98
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40324
1) avoid the use of item 2) bypass the im2col for 1x1 conv
Test Plan:
unit test and perf benchmark to show improvement
```
num = 50
N = 1
C = 512
H = 4
W = 4
M = 512
kernel_h = 1
kernel_w = 1
stride_h = 1
stride_w = 1
padding_h = 0
padding_w = 0
X_np = np.random.randn(N, C, H, W).astype(np.float32)
W_np = np.random.randn(M, C, kernel_h, kernel_w).astype(np.float32)
X = torch.from_numpy(X_np)
conv2d_pt = torch.nn.Conv2d(
C, M, (kernel_h, kernel_w), stride=(stride_h, stride_w),
padding=(padding_h, padding_w), groups=1, bias=True)
class ConvNet(torch.nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv2d = conv2d_pt
def forward(self, x):
return self.conv2d(x)
model = ConvNet()
def pt_forward():
# with torch.autograd.profiler.profile(record_shapes=True) as prof:
model(X)
# print(prof.key_averages().table(sort_by="self_cpu_time_total"))
torch._C._set_mkldnn_enabled(False)
t = Timer("pt_forward()", "from __main__ import pt_forward, X")
```
Before the optimization:
pt time = 5.841153813526034
After the optimization:
pt time = 4.513134760782123
Differential Revision: D22149067
fbshipit-source-id: 538d9eea5b729e6c3da79444bde1784bde828876
Summary:
BC-breaking NOTE:
In PyTorch 1.6 bool and integral fill values given to torch.full must set the dtype our out keyword arguments. In prior versions of PyTorch these fill values would return float tensors by default, but in PyTorch 1.7 they will return a bool or long tensor, respectively. The documentation for torch.full has been updated to reflect this.
PR NOTE:
This PR causes torch.full to throw a runtime error when it would have inferred a float dtype by being given a boolean or integer value. A versioned symbol for torch.full is added to preserve the behavior of already serialized Torchscript programs. Existing tests for this behavior being deprecated have been updated to reflect it now being unsupported, and a couple new tests have been added to validate the versioned symbol behavior. The documentation of torch.full has also been updated to reflect this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40364
Differential Revision: D22176640
Pulled By: mruberry
fbshipit-source-id: b20158ebbcb4f6bf269d05a688bcf4f6c853a965
Summary:
1. Use LoadLibraryEx if available
2. Print more info on error
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40365
Differential Revision: D22194974
Pulled By: malfet
fbshipit-source-id: e8309f39d78fd4681de5aa032288882910dff928
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40461
It turned out `:inheried-members:` (see [doc](https://www.sphinx-doc.org/en/master/usage/extensions/autodoc.html#directive-autoclass)) is not really usable.
Because pybind11 generates a docstring that writes `self` as parent class, `rpc.PyRRef`, type.
As a workaround, I am pulling docstrings on parent-class, `PyRRef` class, into subclass, `RRef`. And do surgery on the docstring generated by pybind11.
{F241283111}
ghstack-source-id: 106472496
Test Plan:
buck test mode/dev-nosan //caffe2/test/distributed/rpc/:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc/:rpc_fork && \
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par \
-r test_rref_str
buck build mode/dev-nosan //caffe2/test/distributed/rpc/:rpc_fork && \
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par \
-r test_return_local_rrefs
buck test mode/dev-nosan //caffe2/torch/fb/distributed/model_parallel/tests:test_elastic_averaging -- 'test_elastic_averaging_center \(caffe2\.torch\.fb\.distributed\.model_parallel\.tests\.test_elastic_averaging\.TestElasticAveragingCenter\)'
P134031188
Differential Revision: D7933834
fbshipit-source-id: c03a8a4c9d98888b64492a8caba1591595bfe247
Summary:
This re-applies D21232894 (b9d3869df3) and D22162524, plus updates jni_deps in a few places
to avoid breaking host JNI tests.
Test Plan: `buck test @//fbandroid/mode/server //fbandroid/instrumentation_tests/com/facebook/caffe2:host-test`
Reviewed By: xcheng16
Differential Revision: D22199952
fbshipit-source-id: df13eef39c01738637ae8cf7f581d6ccc88d37d5
Summary:
Currently, torchvision annotates `batched_nms` with `torch.jit.script` so the function gets compiled when it is traced and ONNX will work. Unfortunately, this means we are eagerly compiling batched_nms, which fails if torchvision isn't built with `torchvision.ops.nms`. As a result, torchvision doesn't work on torch hub right now.
`_script_if_tracing` could solve our problem here, but right now it does not correctly interact with recursive compilation. This PR fixes that bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40468
Reviewed By: jamesr66a
Differential Revision: D22195771
Pulled By: eellison
fbshipit-source-id: 83022ca0bab6d389a48a478aec03052c9282d2b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40442
Problem:
Nightly builds do not include libtorch headers as local build.
The reason is that on docker images path is different than local path when building with `scripts/build_pytorch_android.sh`
Solution:
Introducing gradle property to be able to specify it and add its specification to gradle build job and snapshots publishing job which run on the same docker image.
Test:
ci-all jobs check https://github.com/pytorch/pytorch/pull/40443
checking that gradle build will result with headers inside aar
Test Plan: Imported from OSS
Differential Revision: D22190955
Pulled By: IvanKobzarev
fbshipit-source-id: 9379458d8ab024ee991ca205a573c21d649e5f8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37243
*** Why ***
As it stands, we have two thread pool solutions concurrently in use in PyTorch mobile: (1) the open source pthreadpool library under third_party, and (2) Caffe2's implementation of pthreadpool under caffe2/utils/threadpool. Since the primary use-case of the latter has been to act as a drop-in replacement for the third party version so as to enable integration and usage from within NNPACK and QNNPACK, Caffe2's implementation is intentionally written to the exact same interface as the third party version.
The original argument in favor of C2's implementation has been improved performance as a result of using spin locks, as opposed to relinquishing the thread's time slot and putting it to sleep - a less expensive operation up to a point. That seems to have given C2's implementation the upper hand in performance, hence justifying the added maintenance complexity, until the third party version improved in parallel surpassing the efficiency of C2's implementation as I have verified in benchmarks. With that advantage gone, there is no reason to continue using C2's implementation in PyTorch mobile either from the perspective of performance or code hygiene. As a matter of fact, there is considerable performance benefit to be had as a result of using the third party version as it currently stands.
This is a tricky change though, mainly because in order to avoid potential performance regressions, of which I have witnessed none but just in abundance of caution, we have decided to continue using the internal C2's implementation whenever building for Caffe2. Again, this is mainly to avoid potential performance regressions in production C2 use cases even if doing so results in reduced performance as far as I can tell.
So to summarize, today, and as it currently stands, we are using C2's implementation for (1) NNPACK, (2) PyTorch QNNPACK, and (3) ATen parallel_for on mobile builds, while using the third party version of pthreadpool for XNNPACK as XNNPACK does not provide any build options to link against an external implementation unlike NNPACK and QNNPACK do.
The goal of this PR then, is to unify all usage on mobile to the third party implementation both for improved performance and better code hygiene. This applies to PyTorch's use of NNPACK, QNNPACK, XNNPACK, and mobile's implementation of ATen parallel_for, all getting routed to the
exact same third party implementation in this PR.
Considering that NNPACK, QNNPACK, and XNNPACK are not mobile specific, these benefits carry over to non-mobile builds of PyTorch (but not Caffe2) as well. The implementation of ATen parallel_for on non-mobile builds remains unchanged.
*** How ***
This is where things get tricky.
A good deal of the build system complexity in this PR arises from our desire to maintain C2's implementation intact for C2's use.
pthreadpool is a C library with no concept of namespaces, which means two copies of the library cannot exist in the same binary or symbol collision will occur violating ODR. This means that somehow, and based on some condition, we must decide on the choice of a pthreadpool implementation. In practice, this has become more complicated as a result of all the possible combinations that USE_NNPACK, USE_QNNPACK, USE_PYTORCH_QNNPACK, USE_XNNPACK, USE_SYSTEM_XNNPACK, USE_SYSTEM_PTHREADPOOL and other variables can result in. Having said that, I have done my best in this PR to surgically cut through this complexity in a way that minimizes the side effects, considering the significance of the performance we are leaving on the table, yet, as a result of this combinatorial explosion explained above I cannot guarantee that every single combination will work as expected on the first try. I am heavily relying on CI to find any issues as local testing can only go that far.
Having said that, this PR provides a simple non mobile-specific C++ thread pool implementation on top of pthreadpool, namely caffe2::PThreadPool that automatically routes to C2's implementation or the third party version depending on the build configuration. This simplifies the logic at the cost of pushing the complexity to the build scripts. From there on, this thread pool is used in aten parallel_for, and NNPACK and family, again, routing all usage of threading to C2 or third party pthreadpool depending on the build configuration.
When it is all said or done, the layering will look like this:
a) aten::parallel_for, uses
b) caffe2::PThreadPool, which uses
c) pthreadpool C API, which delegates to
c-1) third_party implementation of pthreadpool if that's what the build has requested, and the rabbit hole ends here.
c-2) C2's implementation of pthreadpool if that's what the build has requested, which itself delegates to
c-2-1) caffe2::ThreadPool, and the rabbit hole ends here.
NNPACK, and (PyTorch) QNNPACK directly hook into (c). They never go through (b).
Differential Revision: D21232894
Test Plan: Imported from OSS
Reviewed By: dreiss
Pulled By: AshkanAliabadi
fbshipit-source-id: 8b3de86247fbc3a327e811983e082f9d40081354
Summary:
This file should have been renamed as `complex.h`, but unfortunately, it was named as `complex_type.h` due to a name clash with FBCode. Is this still the case and is it easy to resolve the name clash? Maybe related to the comment at https://github.com/pytorch/pytorch/pull/39834#issuecomment-642950012
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39885
Differential Revision: D22018575
Pulled By: ezyang
fbshipit-source-id: e237ccedbe2b30c31aca028a5b4c8c063087a30f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40184
Whenever requires_tensor is True, it is also the case that abstract
is true. Thus, it is not necessary to specify requires_tensor.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22187353
Pulled By: ezyang
fbshipit-source-id: d665bb69cffe491bd989495020e1ae32340aa9da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40182
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22187354
Pulled By: ezyang
fbshipit-source-id: 875a6a7837981b60830bd7b1c35d2a3802ed7dd7
Summary:
**Summary**
This commit adds an instance method `_reconstruct` that permits users
to reconstruct a `ScriptModule` from a given C++ `Module` instance.
**Testing**
This commit adds a unit test for `_reconstruct`.
**Fixes**
This pull request fixes https://github.com/pytorch/pytorch/issues/33912.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39979
Differential Revision: D22172323
Pulled By: SplitInfinity
fbshipit-source-id: 9aa6551c422a5a324b822a09cd8d7c660f99ca5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40379
The current sum operator doesn't support Long .. hence modify the code
Test Plan: Write a test case
Reviewed By: jspark1105, yinghai
Differential Revision: D21917365
fbshipit-source-id: b37d2c100c70d17d2f89c309e40360ddfab584ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39492
This PR adds use_c10_dispatcher: full to ops taking TensorOptions. To allow this, since the c10 operator library doesn't know about TensorOptions, we need to register the operator kernels as optional<ScalarType>, optional<Device>, optional<Layout>, optional<bool> instead, and also call them this way.
Changes:
Add use_c10_dispatcher: full to those ops
Write hacky_wrapper_for_legacy_signatures which takes an old-style kernel (i.e. one written to take TensorOptions) an creates a wrapper kernel for it that takes the scattered optional<ScalarType>, optional<Device>, optional<Layout>, optional<bool> instead.
Change codegen so that all op registrations are wrapped into hacky_wrapper_for_legacy_signatures. This is added to all ops but is a no-op if the op doesn't take TensorOptions. This allows us in the future to just change a kernel signature from TensorOptions to the scattered version and have it work without having to touch codegen.
Change codegen so that the frontend calls those operators with expanded arguments instead of with a TensorOptions object. This is required because now the kernels are written in this way.
This PR does not remove TensorOptions special cases from codegen, but instead it separates kernels from the codegen/frontend issues. After this, kernels can be worked on separately without having to touch codegen and codegen can be worked on without having to touch kernels.
Codegen diff: P133121032
ghstack-source-id: 106426630
Test Plan: waitforsandcastle
Differential Revision: D21581908
fbshipit-source-id: 6d4a9f526fd70fae40581bf26f3ccf794ce6a89e
Summary:
This is a faster and more idiomatic way of using `itertools.chain`. Instead of computing all the items in the iterable and storing them in memory, they are computed one-by-one and never stored as a huge list. This can save on both runtime and memory space.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40156
Reviewed By: ezyang
Differential Revision: D22189038
Pulled By: vincentqb
fbshipit-source-id: 160b2c27f442686821a6ea541e1f48f4a846c186
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40367
If the tensor has no storage then do not inline as a constant. This
situation when Mkldnn tensors are used.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D22158240
Pulled By: bzinodev
fbshipit-source-id: 8d2879044f2429004983a1242d837367b75a9f2a
2. Run the `regenerate.sh` script in this directory and commit the script changes and the resulting change to `config.yml`.
You'll see a build failure on TravisCI if the scripts don't agree with the checked-in version.
You'll see a build failure on GitHub if the scripts don't agree with the checked-in version.
Motivation
@ -55,7 +55,7 @@ Future direction
See comment [here](https://github.com/pytorch/pytorch/pull/17323#pullrequestreview-206945747):
In contrast with a full recursive tree traversal of configuration dimensions,
> in the future future I think we actually want to decrease our matrix somewhat and have only a few mostly-orthogonal builds that taste as many different features as possible on PRs, plus a more complete suite on every PR and maybe an almost full suite nightly/weekly (we don't have this yet). Specifying PR jobs in the future might be easier to read with an explicit list when we come to this.
> in the future I think we actually want to decrease our matrix somewhat and have only a few mostly-orthogonal builds that taste as many different features as possible on PRs, plus a more complete suite on every PR and maybe an almost full suite nightly/weekly (we don't have this yet). Specifying PR jobs in the future might be easier to read with an explicit list when we come to this.
----------------
----------------
@ -90,7 +90,7 @@ The binaries are built in CircleCI. There are nightly binaries built every night
We have 3 types of binary packages
* pip packages - nightlies are stored on s3 (pip install -f <as3url>). releases are stored in a pip repo (pip install torch) (ask Soumith about this)
* pip packages - nightlies are stored on s3 (pip install -f \<a s3 url\>). releases are stored in a pip repo (pip install torch) (ask Soumith about this)
* conda packages - nightlies and releases are both stored in a conda repo. Nighty packages have a '_nightly' suffix
* libtorch packages - these are zips of all the c++ libraries, header files, and sometimes dependencies. These are c++ only
* shared with dependencies (the only supported option for Windows)
@ -104,16 +104,16 @@ All binaries are built in CircleCI workflows except Windows. There are checked-i
Some quick vocab:
* A\**workflow** is a CircleCI concept; it is a DAG of '**jobs**'. ctrl-f 'workflows' on\https://github.com/pytorch/pytorch/blob/master/.circleci/config.yml to see the workflows.
* A\**workflow** is a CircleCI concept; it is a DAG of '**jobs**'. ctrl-f 'workflows' onhttps://github.com/pytorch/pytorch/blob/master/.circleci/config.yml to see the workflows.
* **jobs** are a sequence of '**steps**'
* **steps** are usually just a bash script or a builtin CircleCI command.* All steps run in new environments, environment variables declared in one script DO NOT persist to following steps*
* **steps** are usually just a bash script or a builtin CircleCI command. *All steps run in new environments, environment variables declared in one script DO NOT persist to following steps*
* CircleCI has a **workspace**, which is essentially a cache between steps of the *same job* in which you can store artifacts between steps.
## How are the workflows structured?
The nightly binaries have 3 workflows. We have one job (actually 3 jobs: build, test, and upload) per binary configuration
@ -144,7 +144,7 @@ The nightly binaries have 3 workflows. We have one job (actually 3 jobs: build,
## How are the jobs structured?
The jobs are in https://github.com/pytorch/pytorch/tree/master/.circleci/verbatim-sources. Jobs are made of multiple steps. There are some shared steps used by all the binaries/smokes. Steps of these jobs are all delegated to scripts in https://github.com/pytorch/pytorch/tree/master/.circleci/scripts .
The jobs are in https://github.com/pytorch/pytorch/tree/master/.circleci/verbatim-sources. Jobs are made of multiple steps. There are some shared steps used by all the binaries/smokes. Steps of these jobs are all delegated to scripts in https://github.com/pytorch/pytorch/tree/master/.circleci/scripts .
* Linux jobs: https://github.com/pytorch/pytorch/blob/master/.circleci/verbatim-sources/linux-binary-build-defaults.yml
* binary_linux_build.sh
@ -178,8 +178,7 @@ CircleCI creates a final yaml file by inlining every <<* segment, so if we were
So, CircleCI has several executor types: macos, machine, and docker are the ones we use. The 'machine' executor gives you two cores on some linux vm. The 'docker' executor gives you considerably more cores (nproc was 32 instead of 2 back when I tried in February). Since the dockers are faster, we try to run everything that we can in dockers. Thus
* linux build jobs use the docker executor. Running them on the docker executor was at least 2x faster than running them on the machine executor
* linux test jobs use the machine executor and spin up their own docker. Why this nonsense? It's cause we run nvidia-docker for our GPU tests; any code that calls into the CUDA runtime needs to be run on nvidia-docker. To run a nvidia-docker you need to install some nvidia packages on the host machine and then call docker with the '—runtime nvidia' argument. CircleCI doesn't support this, so we have to do it ourself.
* This is not just a mere inconvenience. **This blocks all of our linux tests from using more than 2 cores.** But there is nothing that we can do about it, but wait for a fix on circleci's side. Right now, we only run some smoke tests (some simple imports) on the binaries, but this also affects non-binary test jobs.
* linux test jobs use the machine executor in order for them to properly interface with GPUs since docker executors cannot execute with attached GPUs
* linux upload jobs use the machine executor. The upload jobs are so short that it doesn't really matter what they use
* linux smoke test jobs use the machine executor for the same reason as the linux test jobs
@ -205,7 +204,7 @@ TODO: fill in stuff
## Overview
The code that runs the binaries lives in two places, in the normal [github.com/pytorch/pytorch](http://github.com/pytorch/pytorch), but also in [github.com/pytorch/builder](http://github.com/pytorch/builder), which is a repo that defines how all the binaries are built. The relevant code is
The code that runs the binaries lives in two places, in the normal [github.com/pytorch/pytorch](http://github.com/pytorch/pytorch), but also in [github.com/pytorch/builder](http://github.com/pytorch/builder), which is a repo that defines how all the binaries are built. The relevant code is
```
@ -261,7 +260,7 @@ Linux, MacOS and Windows use the same code flow for the conda builds.
Conda packages are built with conda-build, see https://conda.io/projects/conda-build/en/latest/resources/commands/conda-build.html
Basically, you pass `conda build` a build folder (pytorch-nightly/ above) that contains a build script and a meta.yaml. The meta.yaml specifies in what python environment to build the package in, and what dependencies the resulting package should have, and the build script gets called in the env to build the thing.
tldr; on conda-build is
tl;dr on conda-build is
1. Creates a brand new conda environment, based off of deps in the meta.yaml
1. Note that environment variables do not get passed into this build env unless they are specified in the meta.yaml
@ -271,7 +270,7 @@ tldr; on conda-build is
4. Runs some simple import tests (if specified in the meta.yaml)
5. Saves the finished package as a tarball
The build.sh we use is essentially a wrapper around ```python setup.py build``` , but it also manually copies in some of our dependent libraries into the resulting tarball and messes with some rpaths.
The build.sh we use is essentially a wrapper around `python setup.py build`, but it also manually copies in some of our dependent libraries into the resulting tarball and messes with some rpaths.
The entrypoint file `builder/conda/build_conda.sh` is complicated because
@ -356,15 +355,15 @@ The Dockerfiles are available in pytorch/builder, but there is no circleci job o
# How to manually rebuild the binaries
tldr; make a PR that looks like https://github.com/pytorch/pytorch/pull/21159
tl;dr make a PR that looks like https://github.com/pytorch/pytorch/pull/21159
Sometimes we want to push a change to master and then rebuild all of today's binaries after that change. As of May 30, 2019 there isn't a way to manually run a workflow in the UI. You can manually re-run a workflow, but it will use the exact same git commits as the first run and will not include any changes. So we have to make a PR and then force circleci to run the binary workflow instead of the normal tests. The above PR is an example of how to do this; essentially you copy-paste the binarybuilds workflow steps into the default workflow steps. If you need to point the builder repo to a different commit then you'd need to change https://github.com/pytorch/pytorch/blob/master/.circleci/scripts/binary_checkout.sh#L42-L45 to checkout what you want.
## How to test changes to the binaries via .circleci
Writing PRs that test the binaries is annoying, since the default circleci jobs that run on PRs are not the jobs that you want to run. Likely, changes to the binaries will touch something under .circleci/ and require that .circleci/config.yml be regenerated (.circleci/config.yml controls all .circleci behavior, and is generated using ```.circleci/regenerate.sh``` in python 3.7). But you also need to manually hardcode the binary jobs that you want to test into the .circleci/config.yml workflow, so you should actually make at least two commits, one for your changes and one to temporarily hardcode jobs. See https://github.com/pytorch/pytorch/pull/22928 as an example of how to do this.
Writing PRs that test the binaries is annoying, since the default circleci jobs that run on PRs are not the jobs that you want to run. Likely, changes to the binaries will touch something under .circleci/ and require that .circleci/config.yml be regenerated (.circleci/config.yml controls all .circleci behavior, and is generated using `.circleci/regenerate.sh` in python 3.7). But you also need to manually hardcode the binary jobs that you want to test into the .circleci/config.yml workflow, so you should actually make at least two commits, one for your changes and one to temporarily hardcode jobs. See https://github.com/pytorch/pytorch/pull/22928 as an example of how to do this.
@ -409,7 +408,7 @@ The advantage of this flow is that you can make new changes to the base commit a
You can build Linux binaries locally easily using docker.
```
```sh
# Run the docker
# Use the correct docker image, pytorch/conda-cuda used here as an example
#
@ -419,8 +418,6 @@ You can build Linux binaries locally easily using docker.
# in the docker container then you will see path/to/foo/baz on your local
# machine. You could also clone the pytorch and builder repos in the docker.
#
# If you're building a CUDA binary then use `nvidia-docker run` instead, see below.
#
# If you know how, add ccache as a volume too and speed up everything
docker run \
-v your/pytorch/repo:/pytorch \
@ -444,9 +441,7 @@ export DESIRED_CUDA=cpu
**Building CUDA binaries on docker**
To build a CUDA binary you need to use `nvidia-docker run` instead of just `docker run` (or you can manually pass `--runtime=nvidia`). This adds some needed libraries and things to build CUDA stuff.
You can build CUDA binaries on CPU only machines, but you can only run CUDA binaries on CUDA machines. This means that you can build a CUDA binary on a docker on your laptop if you so choose (though it’s gonna take a loong time).
You can build CUDA binaries on CPU only machines, but you can only run CUDA binaries on CUDA machines. This means that you can build a CUDA binary on a docker on your laptop if you so choose (though it’s gonna take a long time).
For Facebook employees, ask about beefy machines that have docker support and use those instead of your laptop; it will be 5x as fast.
@ -456,7 +451,7 @@ There’s no easy way to generate reproducible hermetic MacOS environments. If y
But if you want to try, then I’d recommend
```
```sh
# Create a new terminal
# Clear your LD_LIBRARY_PATH and trim as much out of your PATH as you
(! git grep -I -l $'#include "' -- ./c10 ./aten ./torch/csrc ':(exclude)aten/src/ATen/native/quantized/cpu/qnnpack/**' || (echo "The above files have include with quotes; please convert them to #include <xxxx>"; false))
# note that this next step depends on a clean heckout;
# if you run it locally then it will likely to complain
# about all the generated files in torch/test
- name:Ensure C++ source files are not executable
run:|
(! find . \( -path ./third_party -o -path ./.git -o -path ./torch/bin -o -path ./build \) -prune -o -type f -executable -regextype posix-egrep -not -regex '.+(\.(bash|sh|py|so)|git-pre-commit|git-clang-format)$' -print | grep . || (echo 'The above files have executable permission; please remove their executable permission by using `chmod -x`'; false))
(! find . \( -path ./third_party -o -path ./.git -o -path ./torch/bin -o -path ./build \) -prune -o -type f -executable -regextype posix-egrep -not -regex '.+(\.(bash|sh|py|so)|git-pre-commit|git-clang-format|gradlew)$' -print | grep . || (echo 'The above files have executable permission; please remove their executable permission by using `chmod -x`'; false))
Looks like this PR hasn't been updated in a while so we're going to go ahead and mark this as `Stale`. <br>
Feel free to remove the `Stale` label if you feel this was a mistake. <br>
If you are unable to remove the `Stale` label please contact a maintainer in order to do so. <br>
`Stale` pull requests will automatically be closed 30 days after being marked `Stale` <br>
exempt-pr-labels:"no-stale,high priority"
only-labels:"open source"
days-before-stale:150
days-before-close:180
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
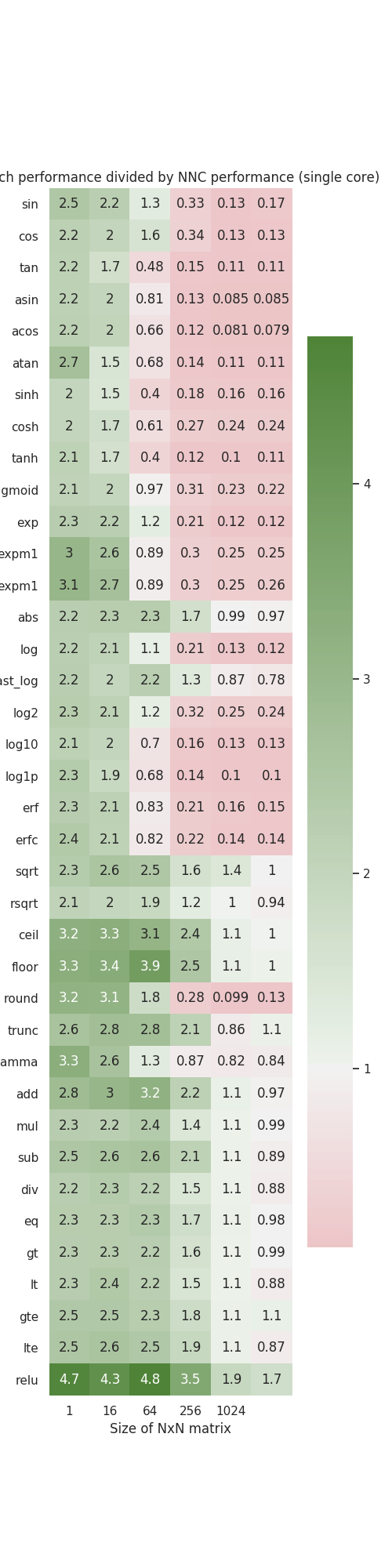{kind=link}
{kind=link}
{kind=link}
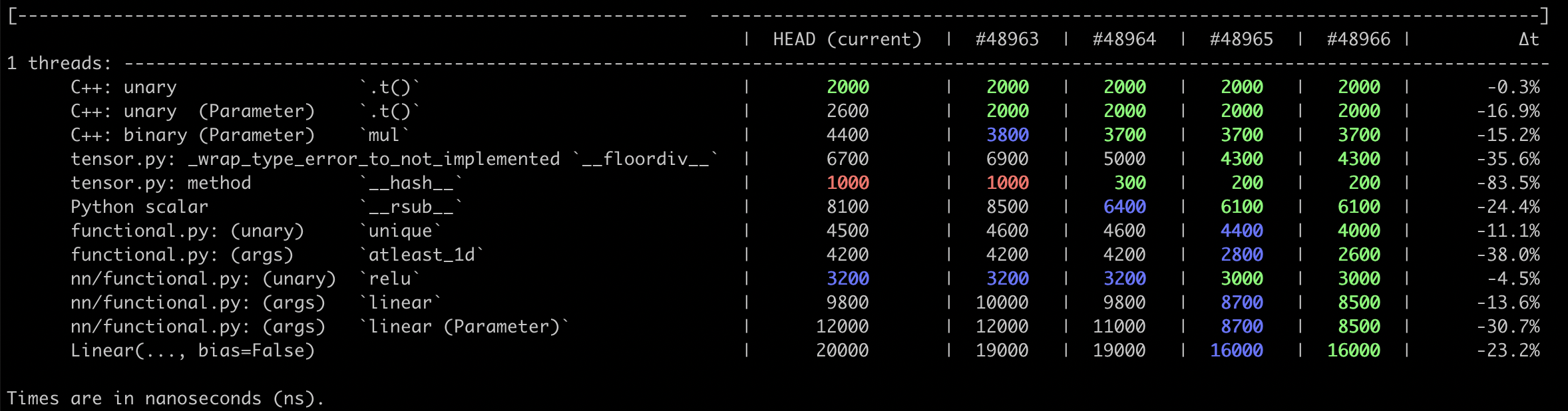{kind=link}
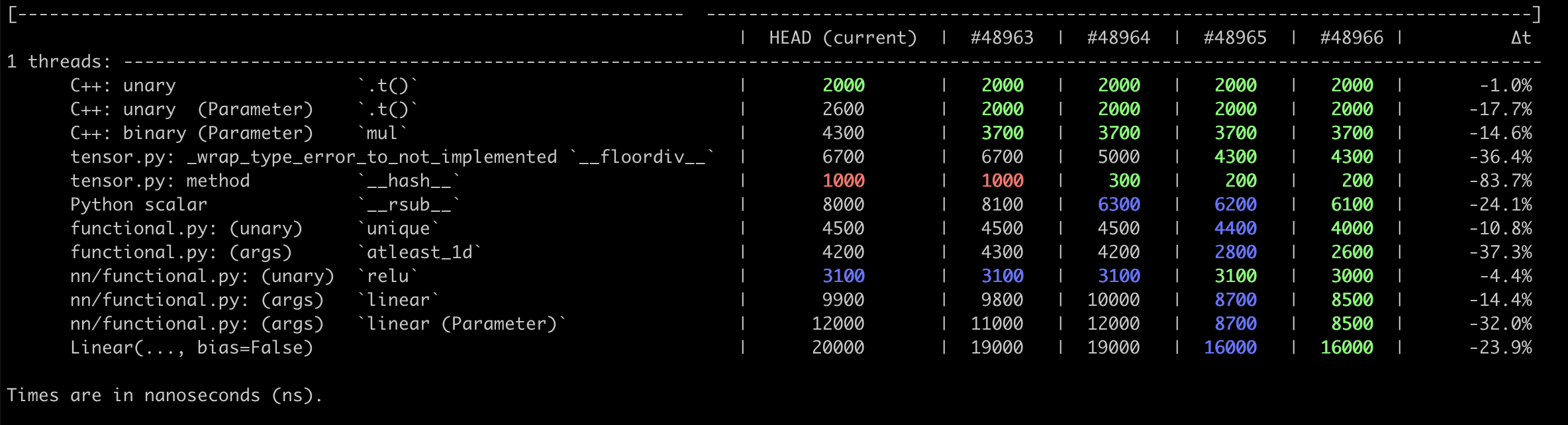{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
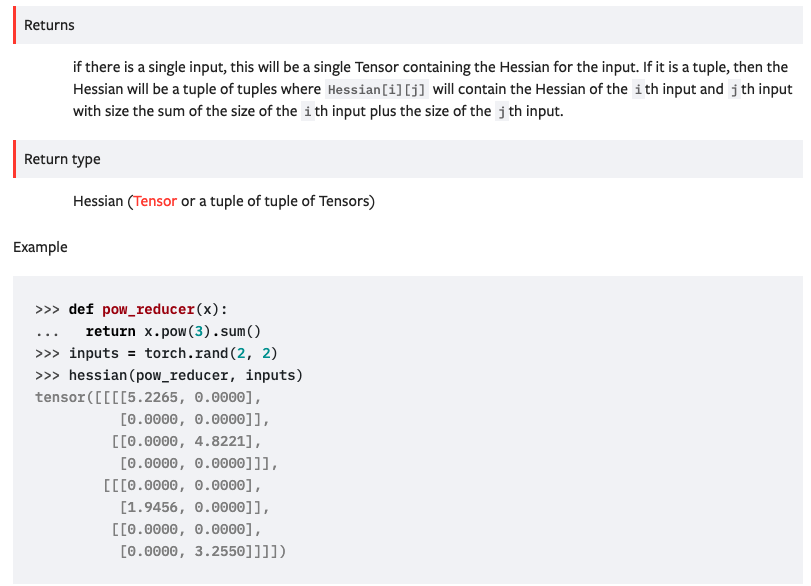{kind=link}
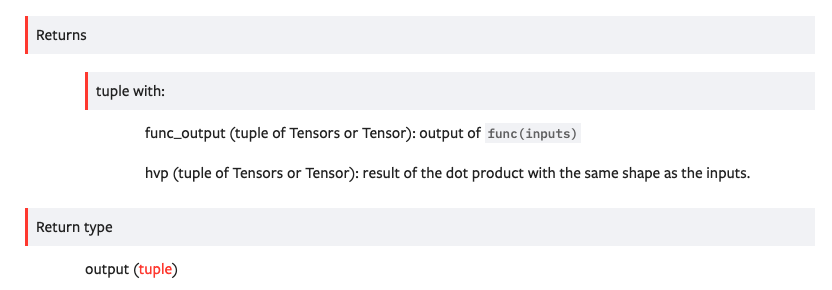{kind=link}
{kind=link}
{kind=link}
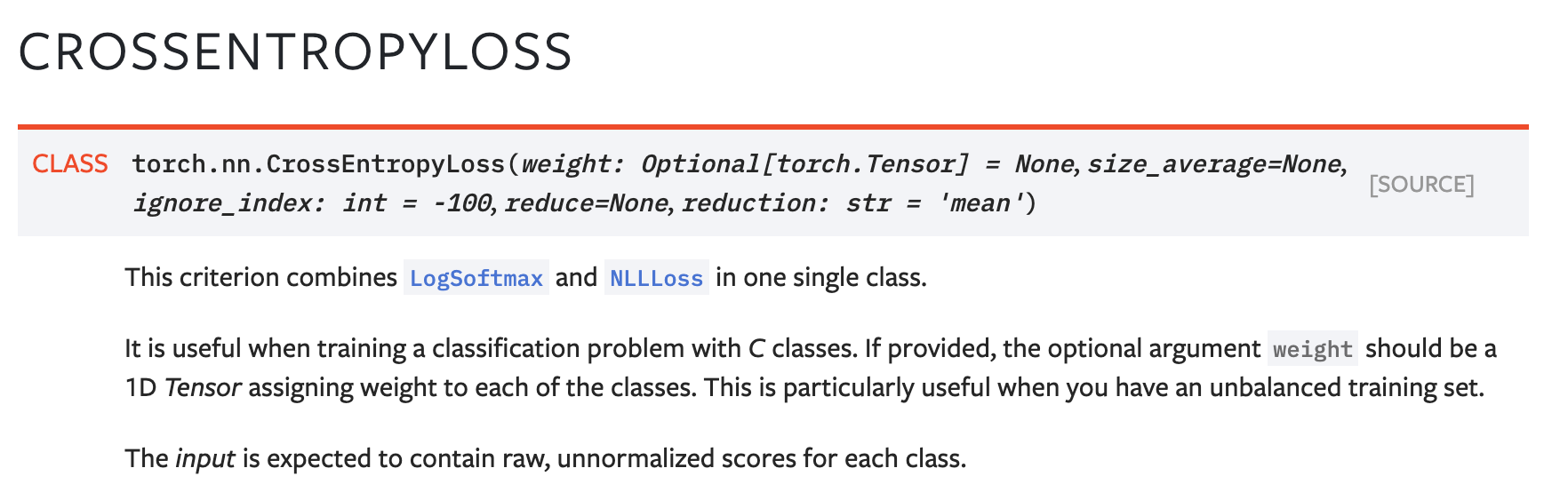{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
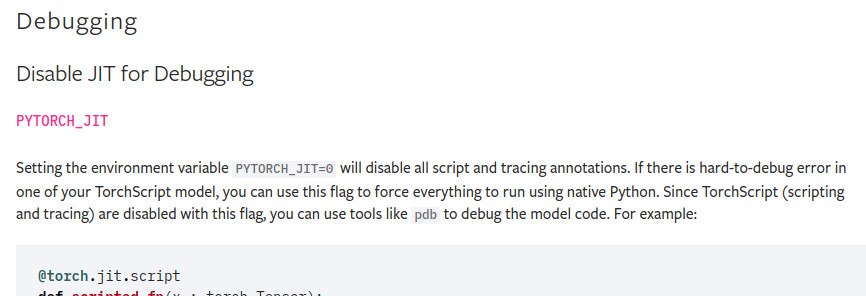{kind=link}
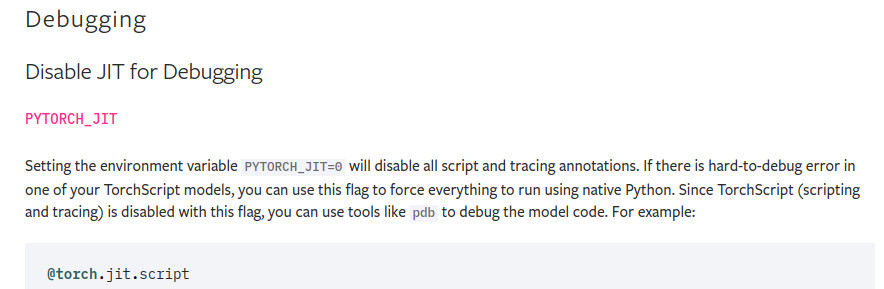{kind=link}
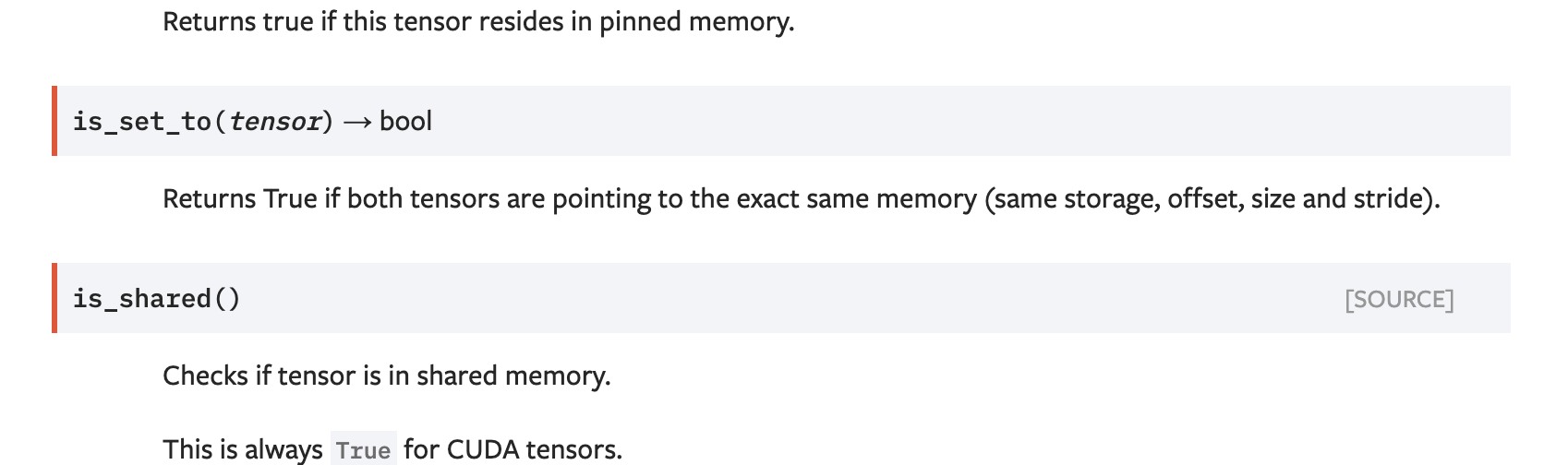{kind=link}
{kind=link}
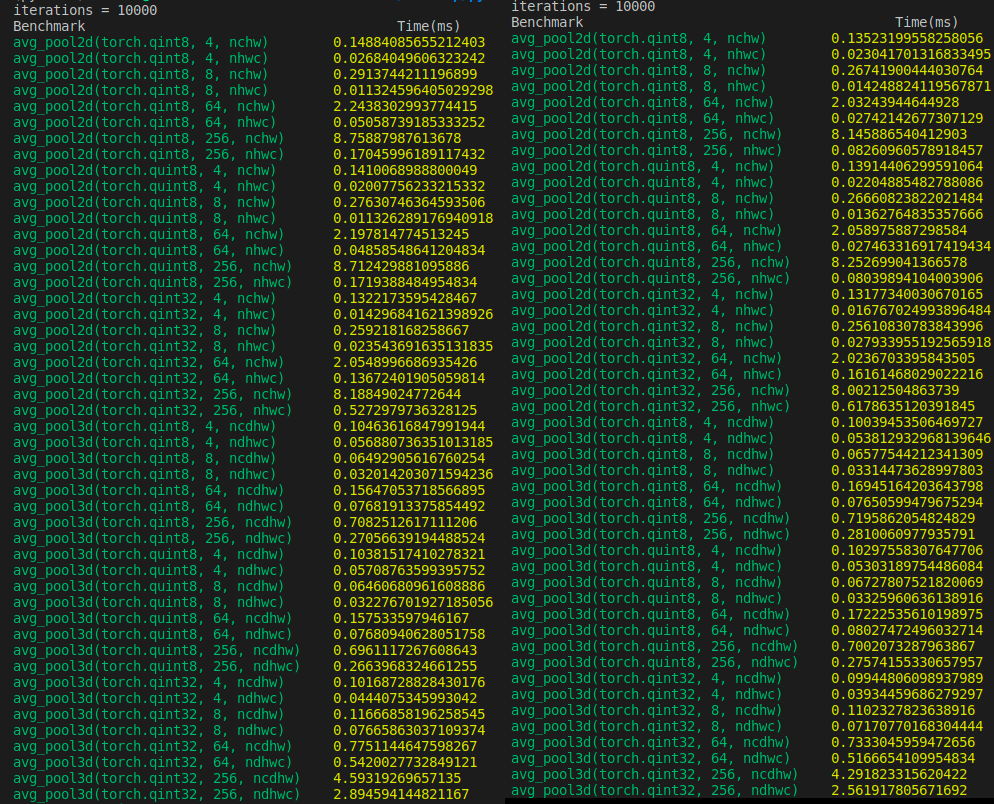{kind=link}
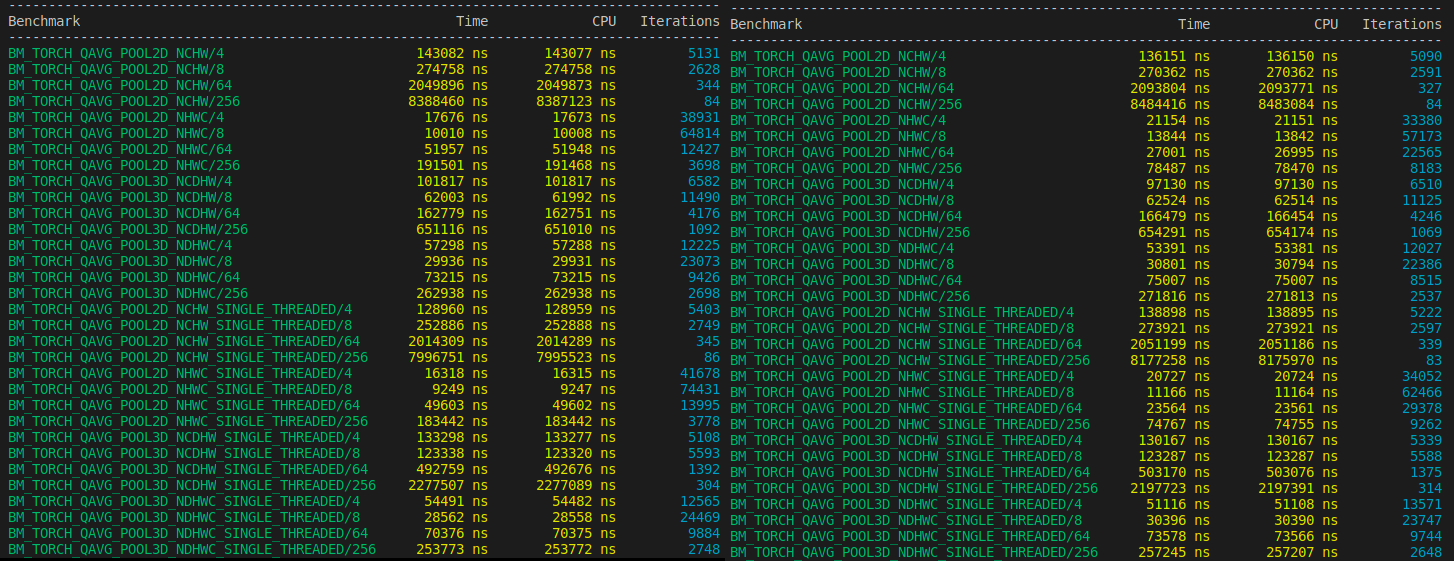{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
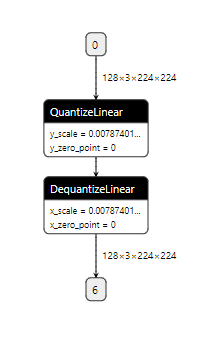{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
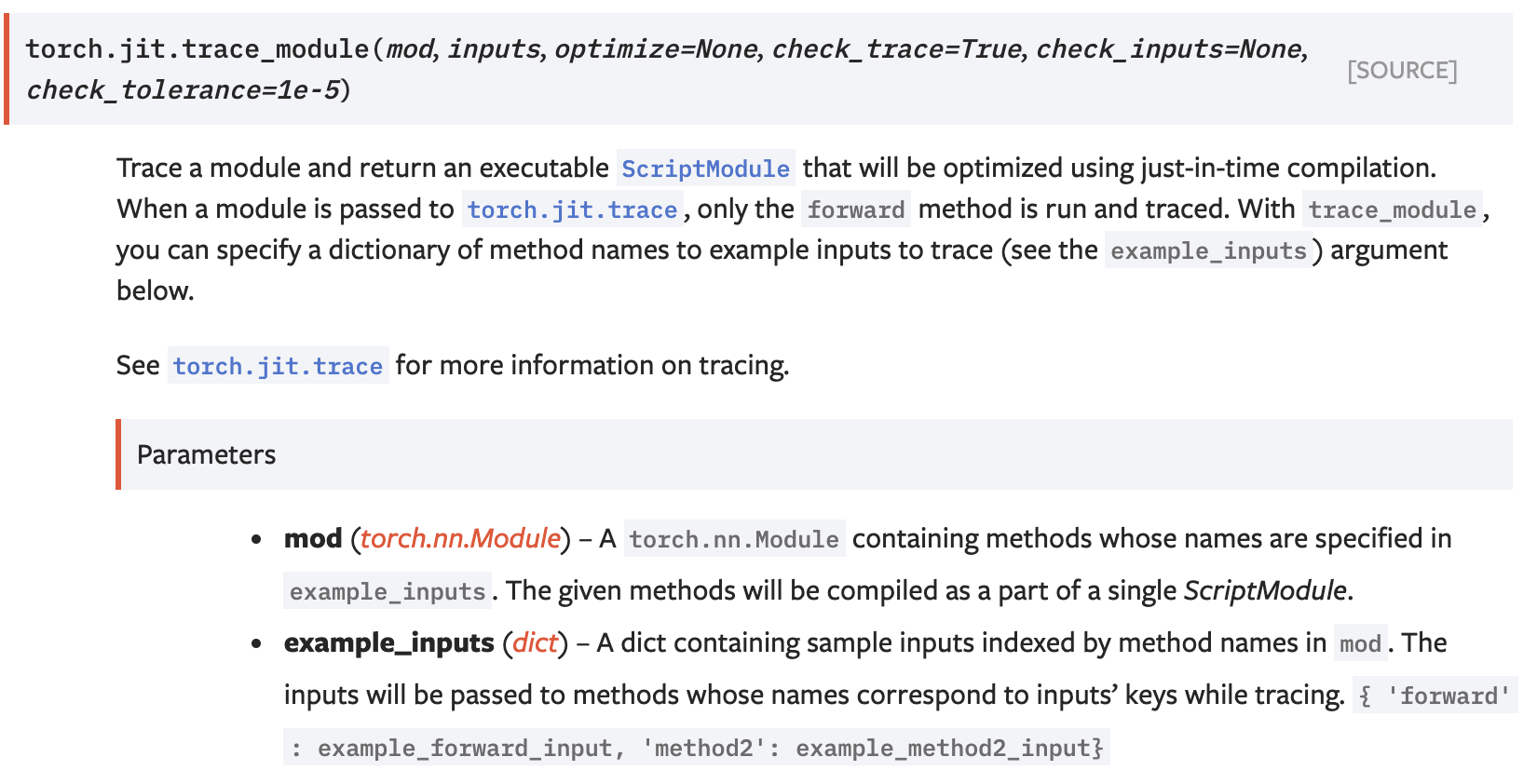{kind=link}
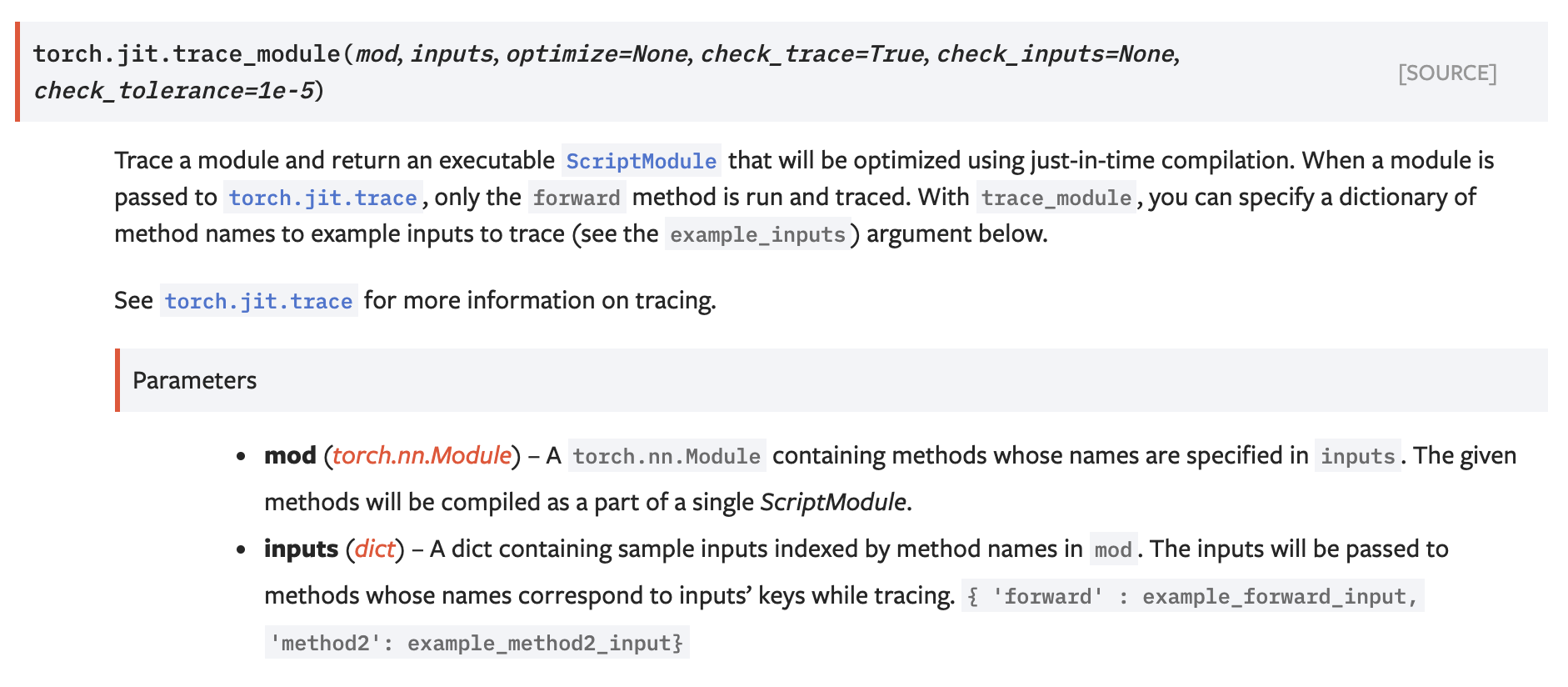{kind=link}